feature selection in the independent component subspace for face
TRANSCRIPT

Pattern Recognition Letters 25 (2004) 1377–1388
www.elsevier.com/locate/patrec
Feature selection in the independent component subspacefor face recognition
H.K. Ekenel *, B. Sankur
Department of Electrical and Electronic Engineering, Bogazici University, Bebek 34342, Istanbul, Turkey
Received 2 October 2003; received in revised form 19 March 2004
Available online 11 June 2004
Abstract
This paper addresses the feature selection problem for face recognition in the independent component subspace.
While there exists, at least, energy principle to guide the selection of the principle components, the independent
components (ICs) are devoid of any energy ranking, and must therefore selected based on their discriminatory power.
In addition the independent component features can be selected starting from a much larger pool, or from a combi-
nation pool of ICA and PCA features. Four feature selection schemes have been comparatively assessed, and feature
subsets are tested on a face database constructed from CMU PIE and FERET databases. The discriminatory features
from larger pools are observed to be concentrated around fiduciary spatial details of the nose, the eyes and the facial
contour. Overall, face recognition benefits from the feature selection of ICA or PCA components and from the
combination of ICA and PCA feature pools.
� 2004 Published by Elsevier B.V.
1. Introduction
Face recognition has become one of the most
active research areas of pattern recognition since
the early 1990s. The interest on face recognition
is mainly fueled by the identification require-
ments for access control and for surveillance tasksagainst terrorism. This interest is still increasing,
since face recognition is also seen as an impor-
tant part of next-generation smart environments
(Pentland and Choudhury, 2000).
* Corresponding author. Tel.: +90-212-358-15-00; fax: +90-
212-287-24-65.
E-mail address: [email protected] (H.K. Ekenel).
0167-8655/$ - see front matter � 2004 Published by Elsevier B.V.
doi:10.1016/j.patrec.2004.05.013
Among the plethora of face recognition meth-
ods, the paradigm based on face appearance data,
template-based algorithms and their concomitant
subspace versions, such as PCA and LDA meth-
ods are the most popular (Turk and Pentland,
1991; Belhumeur et al., 1997). Recently a blind
source separation technique, called independentcomponent analysis (ICA) has been adopted
for face recognition as an alternative subspace
method. Face recognition algorithms, however,
encounter several difficulties due to changes of the
face appearances caused by such factors as occlu-
sion, illumination, expression, pose, make-ups
and aging. In fact the subsequent intra-individual
variability of face images can be larger than theinter-individual variability (Gong et al., 2000).

1378 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
One expects to surmount these difficulties, or at
least to mitigate their effect by judicious choice of
features that are insensitive to the variations in the
facial appearance. The purpose of this study is to
explore subsets of ICA and PCA features for face
recognition that increase recognition performance,and that are purportedly robust against expression
variations and differences in illumination. The
feature selection criterion used in PCA-based face
recognition is the eigenvalue variance. On the
other hand the independent components (ICs) are
devoid of any energy/importance ranking, there-
fore relatively high-dimensional feature vectors are
used in face recognition using ICA, i.e., 200dimensions (Baek et al., 2001; Bartlett et al., 1998;
Draper et al., 2003) with respect to PCA. To
handle this problem, proportion of variance (PoV)
has so far been the only feature selection technique
used in the literature on ICA face recognition
(Bartlett et al., 1998; Deniz et al., 2001; Yuen and
Lai, 2002; Havran et al., 2002). Besides using the
feature selection methods based on individualproperties of the features, like proportion of vari-
ance and best individual feature, we also utilize
more sophisticated feature selection schemes that
take into account the combinatorial properties of
the features such as sequential forward selection
and sequential floating forward selection. We as-
sess comparatively these four different feature
selection schemes on the basis of the improvementthey bring in the recognition performance. Fur-
thermore, since the first face recognition architec-
ture of ICA provides local features, we tried to
discover which one of these local features has more
discriminatory power, and thus contributes most
to the person identification.
The paper is organized as follows. In Section 2
we review briefly PCA and ICA techniques. Thefeature selection methods are presented in Section
3. Experimental results are discussed in Section 4
and conclusions are drawn in Section 5.
2. Subspace analysis methods
Face data, as obtained from the raster scanningof the face images, constitutes a very high-dimen-
sional space. However the intrinsic dimensionality
of the face space is known to be much smaller
(Gong et al., 2000), this despite the variations in
expression, pose and lighting. In fact the faces are
believed to be clustered on some low-dimensional
manifolds. The subspace techniques aim to reduce
the inherent excessive dimensionality of scanneddata to make the face recognition algorithms via-
ble and to capture or approximate the underlying
face manifolds. The most widely used subspace
analysis tools are the principal component analysis
(PCA), independent component analysis (ICA),
linear discriminant analysis (LDA) and their non-
linear varieties via kernel tools (Turk and Pent-
land, 1991; Belhumeur et al., 1997; Kim et al.,2002; Yang, 2002; Moghaddam, 2002).
In the sequel, lowercase and uppercase letters
denote scalar values, bold uppercase letters denote
matrices, and bold lowercase letters denote row
vectors.
2.1. Principal component analysis (PCA)
PCA aims to determine a new orthogonal basis
vector set that best reconstructs the face images, in
other words with the smallest mean-square error
for any given subspace dimensionality. These
orthogonal basis vectors, also called eigenfaces,
are the eigenvectors of the covariance matrix of the
face images. The most parsimonious eigenvector
set, say of dimension M , for the face reconstruc-tion problem is chosen as the subset of the M most
energetic eigenvectors, that is the eigenvectors
corresponding to the first M rank ordered eigen-
values.
Consider the K � D-dimensional face data ma-
trix X , where each D-dimensional row corresponds
to the lexicographically ordered pixels of one of
the faces, and where there are K face images. ThePCA method tries to approximate this face space
using an M-dimensional feature vector, that is
using M eigenfaces, where typically M �minðD;KÞ. These M eigenvectors span a face
subspace, such that kXk2 � kXVk2 is minimum,
where V is the D�M-dimensional matrix that
contains orthogonal basis vectors of the face space
in its columns. Once the projection bases V areformed, when a test image xt arrives, it is projected
onto the face subspace to yield the feature vector,

H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388 1379
rt ¼ xtV . The classifier decides for the identity of
the individual, according to a similarity score be-
tween rt and the feature vectors of the individuals
in the database fr1; r2 . . . ; rKg.
2.2. Independent component analysis (ICA)
Independent component analysis is an unsu-
pervised learning method based on high order
statistics. Briefly, ICA is the separation of inde-
pendent sources from their observed linear mix-
tures (Hyvarinen and Oja, 2000). The system
model of ICA is given as
X ¼ AS ð1Þwhere A denotes the mixing matrix, S denotes the
source matrix containing statistically independent
source vectors in its rows and X denotes the data
matrix. In the ICA method, the only information
we possess is the observations, and neither themixing matrix nor the distribution of the sources is
known. Under the assumptions that the sources
are statistically independent and non-Gaussian (at
most one of them can have Gaussian distribution),
we find the unmixing matrix W by maximizing
some measure of independence. In other words, a
separation matrix, W , is estimated, which, under
ideal conditions, is the inverse of the mixingmatrix A.
Y ¼ WX and W ¼ A�1 and Y � S ð2ÞIn the context of face recognition, the use of
ICA features was first proposed in (Bartlett et al.,
1998) and several other studies followed in (Liu
and Wechsler, 1999; Baek et al., 2001; Kwak et al.,
2002; Deniz et al., 2001; Yuen and Lai, 2002; Ding
et al., 2001; Havran et al., 2002; Draper et al.,
2003). In (Bartlett et al., 1998) two different ap-
proaches are presented for face recognition. Inthe first approach (called ICA1 architecture), the
face images are assumed to be a linear mixture
of an unknown set of statistically independent
source images. The source images obtained in this
architecture are spatially local and sparse in nat-
ure. In the second approach (called ICA2 archi-
tecture), the representation (weighting) coefficients
are assumed to be statistically independent. Inthis second architecture, while mixing coefficient
vectors are independent, source images tend to
have global face appearance, as in the case of
PCA. In contrast to the PCA method, where fea-
ture subset selection is based on energy criterion,
the selection of an ICA basis subset is not imme-
diately obvious since the energies of the indepen-dent components cannot be determined. One
typically first trims the minðD;KÞ-dimensional
space to M using a PCA stage, and then proceeds
to extract the ICA components from this M-
dimensional space.
The architecture of ICA1 and that of PCA have
analogous structures, as they are both based on the
statistical properties of the basis images. In ICA1,one tries to find statistically independent basis
images, whereas in PCA one extracts uncorrelated
basis images. ICA2 is based on the statistical
properties of the representation coefficients, thus it
has a different structure with respect to ICA1 and
PCA. In this work, both for a fair comparison
with PCA-based method and to explore the local
face regions that are appropriate for identifica-tion, the first architecture of the ICA is used.
In summary, the face recognition algorithm
using ICA1 architecture is as follows:
(i) Prior to ICA, PCA is performed on a train-
ing set and the M eigenvectors, associated
with the largest eigenvalues are selected to
form the matrix V .(ii) The training face images are projected onto
the PCA-based face space and the K �Mmatrix of their representation coefficients,
R ¼ ½r1jr2; . . . ; jrK �T, are obtained:
R ¼ X � V ð3Þ
(iii) An ICA analysis is performed on VT, where
face eigenvectors form the rows of this matrix;
the unmixing matrix, W , reveals the ‘‘ICA
faces’’
S ¼ W � VT ð4Þ
(iv) By using PCA representation coefficients, R,and independent basis images, S, ICA repre-
sentation coefficients of the faces in the train-
ing set, fa1; a2; . . . ; aKg, are calculated asfollows:

1380 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
A ¼ R �W�1 ð5Þ
since VT ¼ W�1 � S, X ¼ R � VT, and
X ¼ R �W�1 � S. When a test image xt ar-
rives, it is projected onto the face subspace
to extract its PCA representation rt ¼ xtV ,
which is then multiplied with the inverse of
the separation matrix to yield the ICA featurevector at ¼ rt �W�1. This vector is compared
vis-�a-vis the feature vectors fa1; a2; . . . ; aKg of
the individuals in the face database.
3. Feature selection techniques
3.1. Rationale for feature selection for PCA/ICA
faces
The main goal of this study is the automatic
selection of the best feature subset for classifica-
tion purposes given a high-dimensional ICA fea-
ture vector. Recall that the feature selection
criterion used in PCA-based face recognition is the
eigenvalue variance. While this criterion yields themost compact set for the reconstruction, it does
not necessarily follow that it is optimal from face
recognition point of view. The ICA methods do
not have such an opportunity of feature selection,
in that the number of ICA features is pre-deter-
mined in the PCA stage of data processing. It is
conjectured that some feature selection scheme
focused on ‘‘recognition’’ rather then on ‘‘recon-struction’’ could augment face classification per-
formance. With this goal in mind, we have not
initially reduced the subspace dimensionality via
PCA to the target feature size, M . Instead we have
reduced the initial dimensionality minðD;KÞ downto an intermediate size M 0, M < M 0 < minðD;KÞ.The judicious choice of M 0, on the one hand,
should make the implementation of the ICAalgorithm viable and avoid overlearning effects
(Bartlett et al., 1998; Liu and Wechsler, 1999). On
the other hand M 0 should allow sufficient freedom
or richness of choice for the feature selection
algorithms to be effective. For example, if the
target feature vector will be 30-dimensional, we do
not effect a minðD;KÞ-to-30 PCA algorithm, but
use, for example, a minðD;KÞ-to-200 PCA reduc-
tion. Following this, the feature selection algo-
rithm proceeds to find the most discriminating
M ¼ 30 ICA features from the intermediate set of
M 0 ¼ 200.
We have comparatively assessed the recogni-
tion performances resulting from different featureselection algorithms, namely, proportion of vari-
ance (PoV), best individual feature (BIF), sequen-
tial forward selection (SFS) and sequential floating
forward selection (SFFS) techniques (Feri et al.,
1994). PoV has so far been the only feature selec-
tion technique used in the literature on ICA face
recognition (Bartlett et al., 1998; Deniz et al., 2001;
Yuen and Lai, 2002; Havran et al., 2002). PoVwould be the best approach if the features’ con-
tributions to the face recognition performance
were independent from each other. BIF is also
based on the same assumption as PoV, the differ-
ence being that, while in PoV the variances of
features are used, in BIF the classification perfor-
mances of the individual features are taken into
consideration. SFS technique is a special case ofthe well known ‘‘plus l ) take away r’’ methods,
and SFFS is an enhanced version of SFS. These
last two techniques search for the best performing
feature set while taking into consideration the
correlation between features.
3.2. Proportion of variance (PoV)
In this technique, for all feature points the ratio
of between-class variance to within-class variance
is calculated and the feature points that have high
ratio are selected. In this context ‘‘class’’ denotes
the ensemble of images belonging to one individ-
ual. Thus the mth feature of the qth face image
ðq ¼ 1; . . . ;QÞ of the kth ðk ¼ 1; . . . ;KÞ individualwill be expressed as fmðk; qÞ. The class mean will beobtained as
�fmðkÞ ¼1
Q
XQq¼1
fmðk; qÞ ð6Þ
while the average of this feature over the database
will be denoted as
f m ¼ 1
KQ
XKk¼1
XQq¼1
fmðk; qÞ ð7Þ

Fig. 1. Sample face images: four images of each of two indi-
viduals with differing illumination effects, expression or acces-
sories.
H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388 1381
The ratio of between-class variance to within-class
variance for the mth feature point in the feature
vector is calculated as
rm ¼ rbetween;m
rwithin;m
¼PK
k¼1
��fmðkÞ � f m
�2PK
k¼1
PQq¼1 ðfmðk; qÞ � �fmðkÞÞ2
ð8Þ
This measure reveals out whether a change in fa-
cial appearance corresponds to a change in the mthfeature point or not. Thus we rank the featuresaccording to their rm ratio where frðmÞ is the mthranking feature, and select the highest ranking
M features, ffrð1Þ; frð2Þ; . . . ; frðM�1Þ; frðMÞg.
3.3. Best individual feature (BIF)
In this technique, classification performance of
each feature point is calculated separately, that is,on individual basis, and the features giving rise to
highest correct recognition rate are selected. Let Pmbe the classification performance of the mth fea-
ture point, that is, Pm is the probability of correct
detection using solely feature fm. Then the feature
points are ordered according to their individual
classification performances Pm and the first Mones, having highest Pm values, are selected.
3.4. Sequential forward selection (SFS)
In the SFS method, features are selected suc-cessively by adding the locally best feature point,
the feature point that provides the highest incre-
mental discriminatory information, to the existing
feature subset. The SFS technique starts as the
BIF by identifying the first feature that has the
highest discrimination power. It proceeds, how-
ever, by adding sequentially to the selected subset,
those features that contribute most to the classifi-cation performance on top of the already selected
ones. Thus, from a single initial BIF feature, the
SFS subset grows to a pair, to a triple. . .till anM-fold subset is found.
3.5. Sequential floating forward selection (SFFS)
SFFS is similar to the SFS in adding features tothe subset; however, in addition, it goes through
cleansing periods, in that features are removed
systematically so long as the performance im-
proves after pruning. Note that the performance of
the pruned subset is compared with that of a
previous one with the same population. This
stratagem helps to avoid the nesting effect, whichresults when one is stuck with a suboptimal subset.
4. Results and discussion
4.1. Experimental setup
We have used a face database constructed withimages chosen from CMU PIE and FERET da-
tabases (Phillips et al., 2000; Sim et al., 2002). In
our experiment set, there are 214 individuals each
having four different frontal face images, making a
total of 856 images. 584 out of the 856 images are
chosen randomly from the FERET database, fafb
image set. These FERET-based images mainly
differ in expression. The remaining 272 imagesderive from the CMU PIE database, which con-
tain variations in illumination. All the face images
are aligned with respect to the manually detected
eye coordinates, scaled to 60 · 50 pixels resolution
and histogram equalized. For each individual in
the set, two of their images that contain normal
facial expression and have frontal illumination are
used for training, and the remaining two imagesthat contain alternative facial expressions and
illumination from left and right sides are used for
testing purposes (Fig. 1).
1382 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
Feature vectors are extracted via independent
component analysis and principal component
analysis schemes. The FastICA algorithm (Hyvari-
nen and Oja, 2000) is used to perform independent
component analysis. In either case we extracted 200-
dimensional feature vectors, that is, the original3000-dimensional image feature vectors consisting
of raw pixel values were reduced to, respectively,
200 PCA features conserving 96.46% of the energy
and 200 ICA features. Any further feature selection
was carried on these intermediate sets of 200.
We used the nearest-neighborhood classifier in
our feature selection study. We opted for the
nearest-neighbor method, as it is a powerful non-parametric classifier without any costly training
stage since otherwise one needs to re-design the
classifier repetitively for each selected feature
subsets. Finally we evaluated comparatively three
different distance metrics, namely, the L1 norm,
the L2 norm, and the normalized correlation
coefficient, defined as follows:
L1 : d ¼XMj¼1
jftraining;j � ftest;jj ð9Þ
L2 : d ¼XMj¼1
jftraining;j
� ftest;jj2
!1=2
ð10Þ
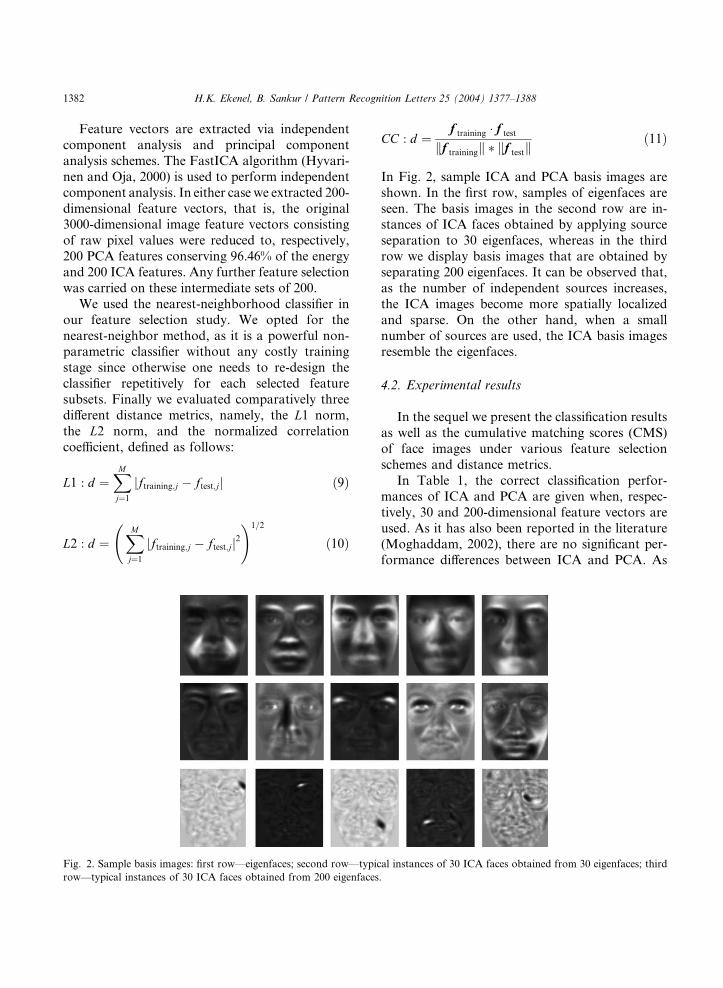
Fig. 2. Sample basis images: first row––eigenfaces; second row––typic
row––typical instances of 30 ICA faces obtained from 200 eigenfaces
CC : d ¼f training � f test
kf trainingk � kf testkð11Þ
In Fig. 2, sample ICA and PCA basis images are
shown. In the first row, samples of eigenfaces are
seen. The basis images in the second row are in-stances of ICA faces obtained by applying source
separation to 30 eigenfaces, whereas in the third
row we display basis images that are obtained by
separating 200 eigenfaces. It can be observed that,
as the number of independent sources increases,
the ICA images become more spatially localized
and sparse. On the other hand, when a small
number of sources are used, the ICA basis imagesresemble the eigenfaces.
4.2. Experimental results
In the sequel we present the classification results
as well as the cumulative matching scores (CMS)
of face images under various feature selection
schemes and distance metrics.
In Table 1, the correct classification perfor-
mances of ICA and PCA are given when, respec-
tively, 30 and 200-dimensional feature vectors are
used. As it has also been reported in the literature(Moghaddam, 2002), there are no significant per-
formance differences between ICA and PCA. As
al instances of 30 ICA faces obtained from 30 eigenfaces; third
.

Table 1
Correct classification performance of ICA and PCA
L1 L2 CC
ICA-30 75.47 74.30 73.60
PCA-30 74.77 74.30 73.60
ICA-200 80.61 79.67 78.50
PCA-200 81.07 79.67 78.50
H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388 1383
one should expect, the correct recognition rategradually increases with the increase in the
dimension of the feature vector. For both feature
sets, the L1 norm gives the best results; hence the
L1 distance metric is taken into consideration
while performing feature selection. Recall that in
this experiment the most energetic 30 (200) PCA
components were selected as feature sets, and that
the ICA features were simply obtained by furtherprocessing these PCA components via the Fast-
ICA algorithm. The rationale for this choice is
explicated in Fig. 3 on the basis of the relative
Fig. 3. Energy percentage accounted by the eigenfaces.
Table 2
Performance results of the feature selection techniques, when the initi
combined case
Feature selection method PCA-30/200 I
PoV 74.30 7
BIF 74.07 7
SFS 77.34 8
SFFS 78.74 8
energy accounted for by the chosen number of
eigenfaces.
To prove the conjecture that a judiciously se-
lected subset from the individual feature sets or
from the merged set of both ICA and PCA faces
can yield better performance, we carried the fol-lowing experiments. In the first experiment, we
selected subsets of 30 features out of the initial
set of 200, individually for the PCA and ICA
cases using various selection algorithms. In the
second experiment, we merged the two sets to
constitute a superset of 400 dimensions (200
PCA+200 ICA) and then proceeded to select the
subset of 30 features from this augmented featureset. Note that before merging of the two feature
sets, they were rendered commensurate by vari-
ance normalization of the ICA and PCA feature
vectors. In Table 2, the performance values of
the selected feature subsets are shown. Sequential
selection methods perform better than the PoV
and BIF methods. The reason can be attributed to
the fact that, in classification, the class-condi-tional features are not independent. Therefore
combinatorial feature selection proves to be more
effective than selecting them based only upon
their individual performances. In other words,
selecting the feature points that have high indi-
vidual classification performances does not imply
the best subset for classification. For example, in
Fig. 4, the ratio of between-class variance towithin-class variance is shown. Although ICA
coefficients have higher ratio as compared to those
of PCA coefficients, this does not necessarily imply
higher classification performance when considered
jointly as can be observed from Table 2. These
results show that the correct combination of the
feature points in the selected subset is more
important than any selection based on individualproperties.
al feature set is reduced from 200 to 30. From 400 to 30 in the
CA-30/200 Combined 30/400
1.73 72.90
5.93 71.73
0.84 79.67
3.64 86.68
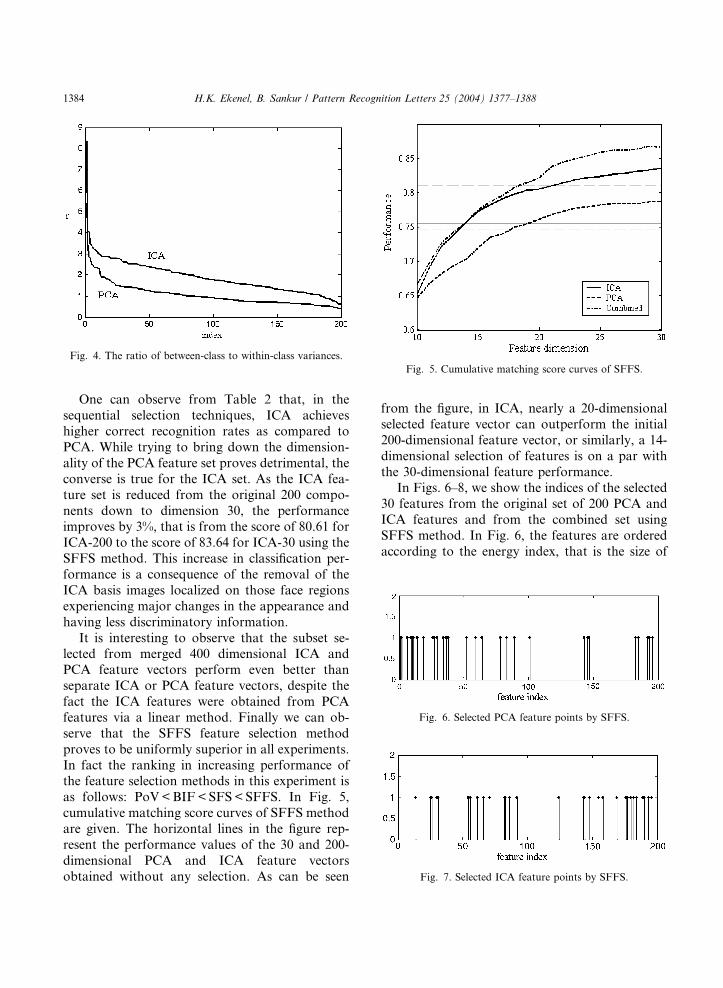
Fig. 4. The ratio of between-class to within-class variances.
Fig. 5. Cumulative matching score curves of SFFS.
Fig. 6. Selected PCA feature points by SFFS.
Fig. 7. Selected ICA feature points by SFFS.
1384 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
One can observe from Table 2 that, in the
sequential selection techniques, ICA achieves
higher correct recognition rates as compared to
PCA. While trying to bring down the dimension-
ality of the PCA feature set proves detrimental, the
converse is true for the ICA set. As the ICA fea-
ture set is reduced from the original 200 compo-
nents down to dimension 30, the performanceimproves by 3%, that is from the score of 80.61 for
ICA-200 to the score of 83.64 for ICA-30 using the
SFFS method. This increase in classification per-
formance is a consequence of the removal of the
ICA basis images localized on those face regions
experiencing major changes in the appearance and
having less discriminatory information.
It is interesting to observe that the subset se-lected from merged 400 dimensional ICA and
PCA feature vectors perform even better than
separate ICA or PCA feature vectors, despite the
fact the ICA features were obtained from PCA
features via a linear method. Finally we can ob-
serve that the SFFS feature selection method
proves to be uniformly superior in all experiments.
In fact the ranking in increasing performance ofthe feature selection methods in this experiment is
as follows: PoV<BIF<SFS<SFFS. In Fig. 5,
cumulative matching score curves of SFFS method
are given. The horizontal lines in the figure rep-
resent the performance values of the 30 and 200-
dimensional PCA and ICA feature vectors
obtained without any selection. As can be seen
from the figure, in ICA, nearly a 20-dimensional
selected feature vector can outperform the initial
200-dimensional feature vector, or similarly, a 14-
dimensional selection of features is on a par with
the 30-dimensional feature performance.In Figs. 6–8, we show the indices of the selected
30 features from the original set of 200 PCA and
ICA features and from the combined set using
SFFS method. In Fig. 6, the features are ordered
according to the energy index, that is the size of

Fig. 8. Selected feature points from the combined set by SFFS:
note that the first 200 indices refer to the ICA features, and the
second set of features, with indices from 201 to 400 refer to the
PCA features.
H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388 1385
their eigenvalue. In Fig. 7, the ordering is what
results from the ICA algorithm, after the PCAreduction stage. Finally note that in Fig. 8, the
ICA and PCA features are juxtaposed in a single
graph, such that the first 200 indices correspond to
the ICA features and the last 200 indices corre-
spond to the PCA features. Contrary to the com-
mon practice of selecting the most energetic PCA
features, as can be observed in Fig. 6, only two
Fig. 9. Selected ICA faces with SFFS method from
thirds of the PCA feature are from the first 100
points. This shows that some of the less energetic
PCA coefficients, which are normally discarded for
image representation and compression, may still
contain valuable discriminatory information. The
selected ICA features are spread more evenly overthe index range. Finally, it is interesting to observe
that the number of selected feature indices from
PCA and ICA feature pools are approximately
equal.
In Fig. 9, the selected ICA features are pre-
sented. One notices that these features are char-
acterized by sparse regions localized around the
eyes, on the face contours and at the nose. One caninterpret these regions in the selected ICA com-
ponents as being less sensitive to the variations in
the facial appearance and at the same time to
contain more discriminatory information. These
findings confirm the results of a recent study on
optimal Gabor kernel location selection (Gokberk
et al., 2003). Another observation from Fig. 9 is
that, these basis images resemble the receptor fields
a training set of normal face appearances.

Fig. 10. Samples of misclassified face images. First image in the
pair is the test image; second image in each pair is the matched
training image.
1386 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
obtained in local feature analysis (LFA) (Penev
and Atick, 1996).
4.3. Discussion of the results
The rationale to resort to a feature selectionscheme was to improve the face recognition per-
formance and to mitigate the effects of intra-vari-
ation. We investigated the source of the attained
improvement (compare for example, ICA-30 per-
formances in Tables 1 and 2). Some of the face
image, which were erroneously classified without
feature selection in ICA, but were then correctly
labeled after feature selection are shown in Fig. 10,in pairs side by side the test image and erroneously
matched training image. As can be seen from these
face pairs, their appearances are very similar and
the individuals can be discriminated by only a
careful consideration of the local face regions.
Appropriate selection of the ICA basis images
provides the utilization of this valuable local dis-
criminatory information.
Fig. 11. Selected ICA faces with SFFS method from a training
A desirable aspect of the proposed scheme
should be the robustness from one face database to
another. In other words, one would like to
encounter the same or very similar subset of fea-
set of faces with expression and illumination variations.

H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388 1387
tures, as one switches from one face database to
another one. To validate the usefulness of the
features we have selected, we perform ICA on a
different training set. We swap the images in the
test set with those in the training set. Thus, in this
new arrangement, the face images in the trainingset contain differences in expression and variations
in illumination, and the face images in the test set
contain normal facial expression and have frontal
illumination. The independent components that
correspond to the selected ICA feature points with
SFFS method are presented in Fig. 11. As can be
observed from Fig. 11, again the ICA basis images
that localize on the eye region, outlines of faceand nose are selected.
5. Conclusions
In this study we have explored feature selection
techniques on ICA and PCA bases for face rec-
ognition. Feature selection techniques are war-
ranted especially for ICA features since these are
devoid of any importance ranking based on energy
content as the PCA components. The study was
carried out on a face database that contains bothfacial expression and illumination variations. Four
different feature selection techniques were used
comparatively and the sequential floating forward
selection method was observed to be uniformly
superior in all cases, in that the maximum correct
classification rate was obtained with its feature
subset.
The major conclusion from this study was thatthe feature selection applied on ICA features def-
initely improves the recognition performance by
8.17%. Furthermore, if the features are selected
from the augmented pool of both ICA and PCA
features, the performance improvement becomes
11.21%. In other words, it pays to select ICA/PCA
features subset from a larger set of them, rather
than deciding a priori for the dimensionality of thefinal feature subset. Indeed, instead of selecting
features on the basis of the first M most energetic
PCA components or their ICA versions, it was
more beneficial to search for the subset resulting in
the best possible classification performance from a
larger pool. It is interesting to note that even the
PCA features benefited from this approach, when
30 of them were selected from the set of 200 via the
SFFS algorithm instead simply selecting the first
most energetic ones, as is commonly done in the
literature.
When the ICA features are selected from alarger initial set, we observe that the resulting
features are more localized, as the sharp dark or
bright spots in Figs. 9 and 11 indicate. In fact, not
surprisingly the majority of these local accents are
around the eyes and nose, as well as close to the
facial contours.
References
Baek, K., Draper, B.A., Beveridge, J.R., She, K., 2001. PCA vs.
ICA: A comparison on the FERET data set. In: Internat.
Conf. on Computer Vision, Pattern Recognition and Image
Processing, North Carolina.
Bartlett, M.S., Lades, H.M., Sejnowski, T.J., 1998. Independent
component representations for face recognition. In: Conf.
on Human Vision and Electronic Imaging III, San Jose,
California.
Belhumeur, P.N., Hespanha, J.P., Kriegman, D.J., 1997.
Eigenfaces vs. fisherfaces: Recognition using class specific
linear projection. IEEE Trans. Pattern Anal. Machine
Intell. 19 (7), 711–720.
Deniz, O., Castrillon, M., Hernandez, M., 2001. Face recogni-
tion using independent component analysis and support
vector machines. In: Third Internat. Conf. on Audio and
Video Based Biometric Person Authentication, Sweden.
Ding, P., Kang, X., Zhang, L., 2001. Personal recognition using
ICA. In: Eighth Internat. Conf. on Neural Information
Processing, China.
Draper, B.A., Baek, K., Bartlett, M.S., Beveridge, J.R., 2003.
Recognizing faces with PCA and ICA. Computer Vision
and Image Understanding 91 (1–2), 115–137.
Feri, F.J., Pudil, P., Hatef, M., Kittler, J., 1994. Comparative
study of techniques for large-scale feature selection. In:
Pattern Recognition in Practice IV. Elsevier, pp. 403–
413.
Gokberk, B., Irfanoglu, M.O., Akarun, L., Alpaydın, E., 2003.
Optimal Gabor kernel location selection for face recogni-
tion. In: Internat. Conf. on Image Processing, Spain.
Gong, S., McKenna, S.J., Psarrou, A., 2000. Dynamic vision:
From images to face recognition. Imperial College Press.
Havran, C., Hupet, L., Czyz, J., Lee, J., Vandendorpe, L.,
Verleysen, M., 2002. Independent component analysis for
face authentication. In: KES’2002 Proc., Italy, pp. 1207–
1211.
Hyvarinen, A., Oja, E., 2000. Independent component analysis:
Algorithms and applications. Neural Networks 13 (4–5),
411–430.

1388 H.K. Ekenel, B. Sankur / Pattern Recognition Letters 25 (2004) 1377–1388
Kim, K.I., Jung, K., Kim, H.J., 2002. Face recognition using
kernel principal component analysis. IEEE Signal Process.
Lett. 9 (2), 40–42.
Kwak, N., Choi, C., Ahuja, N., 2002. Face recognition using
feature extraction based on independent component anal-
ysis. In: Internat. Conf. on Image Processing, Rochester.
Liu, C., Wechsler, H., 1999. Comparative assessment of
independent component analysis (ICA) for face recognition.
In: Second Internat. Conf. on Audio and Video Based
Biometric Person Authentication, Washington, DC.
Moghaddam, B., 2002. Principal manifolds and probabilistic
subspaces for visual recognition. IEEE Trans. Pattern Anal.
Machine Intell. 24 (6), 780–788.
Penev, P., Atick, J., 1996. Local feature analysis: A general
statistical theory for object representation. Network: Com-
putation in Neural Systems 7 (3), 477–500.
Pentland, A., Choudhury, T., 2000. Face recognition for smart
environments. IEEE Computer 33 (2), 50–55.
Phillips, P.J., Moon, H., Rizvi, S.A., Rauss, P.J., 2000. The
FERET evaluation methodology for face-recognition algo-
rithms. IEEE Trans. Pattern Anal. Machine Intell. 22 (10),
1090–1104.
Sim, T., Baker, S., Bsat, M., 2002. The CMU pose, illumina-
tion, and expression (PIE) database. In: Proc. IEEE
Internat. Conf. on Automatic Face and Gesture Recogni-
tion, Washington, DC.
Turk, M., Pentland, A., 1991. Eigenfaces for recognition.
J. Cognitive Sci. 3 (1), 71–86.
Yang, M.H., 2002. Kernel eigenfaces vs. kernel fisherfaces: Face
recognition using kernel methods. In: Fifth IEEE Internat.
Conf. on Automatic Face and Gesture Recognition, Wash-
ington, DC.
Yuen, P.C., Lai, J.H., 2002. Face representation using inde-
pendent component analysis. Pattern Recognition 35 (6),
1247–1257.