ザイリンクス wp389 : 28nm プロセスを採用した 7 シリーズ … · virtex®-4 fpga...
TRANSCRIPT

WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 1
© Copyright 2011 Xilinx, Inc. XILINX, the Xilinx logo, Virtex, Spartan, ISE, and other designated brands included herein are trademarks of Xilinx in the UnitedStates and other countries. PCI, PCIe and PCI Express are trademarks of PCI-SIG and used under license. All other trademarks are the property of theirrespective owners.
このホワイ ト ペーパーでは、 TSMC 28nm high-k メ タ
ル ゲート (HKMG)、高性能、低消費電力 (28nm HPL または 28 HPL) プロセスの選択を含め、 ザイ リ ン ク ス
28nm 7 シ リーズ FPGA の消費電力に関する事項につい
てさまざまな観点で論じます。
28 HPL プロセスによって得られる消費電力の利点やザ
イ リ ンクス製品すべてがもたらす有用性だけでなく、 革
新的なアーキテクチャやスタティ ッ ク電力、 ダイナミ ッ
ク電力、および I/O 電力を削減するための機能について
も説明しています。
ホワイ ト ペーパー : 7 シリーズ FPGA
WP389 (v1.1) 2011 年 6 月 13 日
28nm プロセスを採用した7 シリーズ FPGA で消費電力を削減
著者 : Jameel Hussein、 Matt Klein、 Michael Hart

2 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
はじめに
はじめに
FPGA の消費電力は FPGA 選定における重要な要素となっています。絶対的な消費電力、使用可能なパ
フォーマンス、 バッテ リー寿命、 熱課題、 あるいは信頼性のどれを考慮して選択する場合でも、 その中
心であるのが消費電力です。ザイ リ ンクスは、これまで何年にもわたって消費電力削減に注力しており、
Virtex®-4 FPGA の開発ではト リプル オキサイ ドを使用するこ とで、 スタティ ッ ク電力の飛躍的な削減
に成功しました。 さ らに、 Virtex-4 デバイスでは、 FPGA のスタティ ッ ク電力の温度変動をモデル化し
て提供しています (WP221 『スタティ ッ ク電力および現実的なジャンクシ ョ ン温度解析の重要性』 を参
照)。 ザイ リ ンクスは、 プロセスの変更や改善、 アーキテクチャの変更、 電圧スケーリ ング製品、 ソフ ト
ウェアでの消費電力 適化など、 さまざま消費電力削減方法についての検討と実装を継続的に行ってい
ます。
ザイ リ ンクスの 7 シ リーズ FPGA (Artix™-7、 Kintex™-7、 および Virtex-7) では、 スタティ ッ ク電力、
ダイナミ ッ ク電力、 I/O 電力に対する電力削減方法の効果がすべて評価されています。 また、 新しいテ
ク ノ ロジの導入、 製品化までの時間、 パフォーマンス、 ソフ ト ウェア、 ダイ面積への影響などのリ スク
およびそのコス トについての追加調査も実施しています。 このホワイ ト ペーパーでは、ザイ リ ンクスの
新 28nm 7 シ リーズ FPGA の消費電力に関わる事項についてさまざまな観点で論じる と共に、28 HPLプロセスの選択、 すべてのザイ リ ンクス製品における消費電力と有用性の利点、 スタティ ッ ク電力、 ダ
イナミ ッ ク電力、 I/O 電力を削減するための革新的なアーキテクチャや機能についても説明していきま
す。
適切なプロセス技術の選択
ザイ リ ンクスでは、各プロセス ノードにおける製品リ リースに先立って、革新的なプロセス技術の調査
やさまざまなオプシ ョ ンをどのよ うに FPGA アーキテクチャで適合させるかの決定までに数年をかけ
ています。 そして、 その調査ではパフォーマンス、 消費電力、 製造の容易さに重点を置いています。
TSMC は 28nm に対して、 28 LP、 28 HP、 28 HPL の 3 つのプロセスを提供しています。 ザイ リ ンク
ス 7 シ リーズ FPGA での 適な選択は 28 HPL プロセスで、消費電力とパフォーマンスが重要な決定要
素とな り ました (ザイ リ ンクス プレス リ リース、 「ザイ リ ンクス、 高性能かつ低消費電力の 28nm プロ
セスを採用」 を参照)。
ザイ リ ンクスは、7 シ リーズ FPGA の製品決定段階で実現可能なあらゆる 28nm プロセス技術について
検討しました。 そして非常に早い段階で、 FPGAアプリ ケーシ ョ ンにおける HKMG ト ランジスタ技術
の優位性を認識し、 ファウンド リ パートナーと密接に協力して、 この技術の確立と開発を行いました。
HKMG は (40nm および従来の Poly/SiON (ポ リシ リ コン/シ リ コン オキシナイ ト ライ ド )と比較して) パフォーマンスの飛躍的な向上を可能と し、高性能で低価格な FPGA を実現する統一アーキテクチャを採
用する機会を生み出しました。 低消費電力のためのパフォーマンスに関するいくつかの ト レードオフに
よ り、 他社 40nm 製品において報告されているスタティ ッ ク電力の問題を軽減しています。

適切なプロセス技術の選択
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 3
統一アーキテクチャ7 シ リーズ FPGA における統一アーキテクチャは、高性能な領域を備えつつ、飛躍的な消費電力削減を
可能とする 28 HPL プロセスをベース と しています。 (HP プロセス と比較して) リーク電流の低い HPLプロセスを採用するこ とで、 FPGA デザインにおける複雑で高コス トのスタティ ッ ク電力の管理が不要
とな り、 予定通りの市場出荷、 新たな製品機能、 しっかり と した設計、 性能強化に集中するこ とが可能
とな り ます。量産かつ高性能な FPGA 全体でアーキテクチャが統一されているこ とは、FPGA 業界でほ
かになく、 次のよ うな利点をもたらします。
• 異なる FPGA デバイス間およびファ ミ リ間の移行が容易
• お客様のコードや IP が再利用可能
• 共通ブロッ ク (ブロ ッ ク RAM、DSP、 I/O、 ク ロ ッキング、相互接続ロジッ ク、 メモ リ インターフェ
イス)
28 HPL プロセスの利点 28 HPL プロセス技術は、 28 HP プロセスで使用される SiGe 埋め込みプロセスに見られる歩留ま りや
リーク問題を回避し、 よ り コス ト効率の良いプロセス ソ リ ューシ ョ ンを提供します。 HPL プロセスの
大規模デザインのマージン (電圧マージン) は、 よ り広い VCC 動作範囲の選択を許容して、 28 HPプロ
セスでは不可能な、 電力/性能の柔軟な組み合わせを可能と します。 28 HPL には次に示すよ うな利点が
あ り ます。
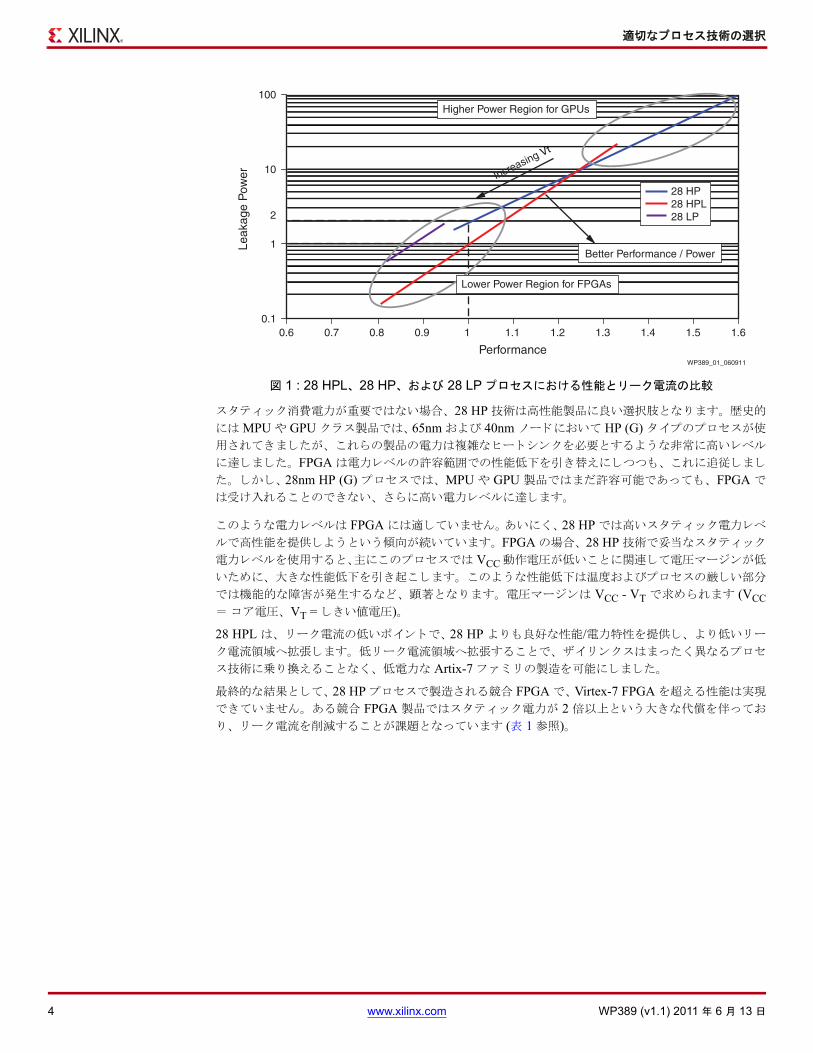
• 高性能モード (VCC = 1.0V) : 28 HPL は FPGA のターゲッ ト性能範囲で、スタティ ッ ク電力を低く
抑えた状態の 28 HP よ り も高い性能を提供します (図 1 参照)。
• 低消費電力モード (VCC = 0.9V) : 28 HPL は 28 HP よ り も 65% 低いスタティ ッ ク電力を実現しま
す。 28 HPL での電圧マージンは Vcc = 0.9V においても、 良好な性能分布を示します (図 1 参照)。
また、 ダイナミ ッ ク電力も この低い電圧によ り ~20% 削減されます。
• Adaptive Voltage Scaling (AVS) または Voltage ID (VID) モード : これらのモードは VCC を制御す
るこ とで電力削減を可能と し、一部のデバイスではさらなる性能向上に活用されています。 VID で
は特にデバイスごとに電圧 ID が格納されています。読み出し可能な電圧 ID は、必要な性能を満足
する 小電圧を示します。
低消費電力モードの優位点は、 28 HPL プロセスにおける電圧マージンによってもたら されています。
4 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
適切なプロセス技術の選択
スタティ ッ ク消費電力が重要ではない場合、 28 HP 技術は高性能製品に良い選択肢とな り ます。 歴史的
には MPU や GPU ク ラス製品では、65nm および 40nm ノードにおいて HP (G) タイプのプロセスが使
用されてきましたが、 これらの製品の電力は複雑なヒート シンクを必要とするよ うな非常に高いレベル
に達しました。 FPGA は電力レベルの許容範囲での性能低下を引き替えにしつつも、 これに追従しまし
た。 しかし、 28nm HP (G) プロセスでは、 MPU や GPU 製品ではまだ許容可能であっても、 FPGA では受け入れるこ とのできない、 さ らに高い電力レベルに達します。
このよ うな電力レベルは FPGA には適していません。あいにく、28 HP では高いスタティ ッ ク電力レベ
ルで高性能を提供しよ う という傾向が続いています。 FPGA の場合、 28 HP 技術で妥当なスタティ ッ ク
電力レベルを使用する と、主にこのプロセスでは VCC 動作電圧が低いこ とに関連して電圧マージンが低
いために、 大きな性能低下を引き起こします。 このよ うな性能低下は温度およびプロセスの厳しい部分
では機能的な障害が発生するなど、 顕著とな り ます。 電圧マージンは VCC - VT で求められます (VCC= コア電圧、 VT = しきい値電圧)。
28 HPL は、 リーク電流の低いポイン トで、 28 HP よ り も良好な性能/電力特性を提供し、 よ り低いリー
ク電流領域へ拡張します。 低リーク電流領域へ拡張するこ とで、 ザイ リ ンクスはまったく異なるプロセ
ス技術に乗り換えるこ とな く、 低電力な Artix-7 ファ ミ リの製造を可能にしました。
終的な結果と して、28 HP プロセスで製造される競合 FPGA で、Virtex-7 FPGA を超える性能は実現
できていません。 ある競合 FPGA 製品ではスタティ ッ ク電力が 2 倍以上という大きな代償を伴ってお
り、 リーク電流を削減するこ とが課題となっています (表 1 参照)。
X-Ref Target - Figure 1
図 1 : 28 HPL、 28 HP、 および 28 LP プロセスにおける性能と リーク電流の比較
100
10
1
2
0.1
Leak
age
Pow
er
0.90.80.70.6 1 1.1 1.2 1.3 1.4 1.5 1.6
WP389_01_060911
Performance
28 HP28 HPL28 LP
Better Performance / Power
Increasing Vt
Higher Power Region for GPUs
Lower Power Region for FPGAs

適切なプロセス技術の選択
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 5
28 HPL ではプロセスのばらつき、 電圧、 および温度へのセンシティビティが、 主に設計マージンが大
き くなったこ とによ り、 28 HPよ り も大き く改善されています。 図 2 に、 28 HPL および 28 HP の各プ
ロセスでの ト ランジスタのしきい値電圧 (V) における電圧マージン対性能を示します。
HPL プロセスでは、このよ うなすべての要素が HP プロセスよ り も容易に電力と性能のターゲッ ト を満
たすのに役立ちます。HP プロセスと HPL プロセスのデバイス上で同じデザインを動作させた場合、前
者の方がずっと早い段階でシステムの温度もし くは電力が上限に到達するでし ょ う。 この周波数マージ
ンは、HPL プロセス とザイ リ ンクスの 適化された ト ランジスタ構成の必然的な結果です。電圧スケー
リ ングは HPLプロセスのも う 1 つの利点で、電力、温度条件が等しい同一デザインの消費電力マージン
を増加させます。 図 3 に、 この概念を図示します。
表 1 : 28 HP における電力削減かつ性能向上のためのプロセス テクニック
Options Other FPGA Vendors 28 HP Process to Reduce Leakage
Xilinx 28 HPL Low Leakage
Low leakage transistors Custom Standard
Low bulk leakage transistors Custom Standard
Judicious use of mixed gatelengths
New
Used by Xilinx since 65 nm (Virtex-5 FPGAs and earlier):
See WP246, Power Consumption in 65 nm FPGAs and WP298, Power Consumption at 40 and 45 nm.
Capacitance 1X 1X
Ability to operate at twodifferent VCC voltages fordifferent power modes
No, due to lack of headroom
Yes
X-Ref Target - Figure 2
図 2 : 28 HPL と 28 HP プロセスにおける性能対電圧マージン
0.8
0.7
0.5
0.6
0.4
Hea
droo
m (
VC
C -
VT) V
olts
0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7
WP389_02_021511
Performance
Less Sensitive to VCC and Process
Unusable Region(Too Leaky)
Increasing V T
28 HP28 HPL
Increasing Headroom

6 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
適切なプロセス技術の選択
7 シ リーズ FPGA の -3 および -2L デバイスには拡張 (E) 温度範囲 (0 ~ 100°C) のオプシ ョ ンがあ り ま
す。 28 HPL プロセスでは設計マージンが確保されているため、 -2LE デバイスは 1.0V または 0.9V で動作可能です。 このホワイ ト ペーパーでは、 これらのデバイスを -2L (1.0V) および -2L (0.9V) と記載
します。 1.0V で動作する -2L デバイスはスピード グレードでは -2I および -2C デバイスと同じ性能を
持ちますが、 スタティ ッ ク電力が大き く削減されています。 また、 0.9V で動作する -2L デバイスも -1Iおよび-1C デバイス とほぼ同等の能力を持ちながら、 スタティ ッ ク電力とダイナミ ッ ク電力が低くなっ
ています。 「改善された電圧スケーリ ング オプシ ョ ン」 を参照してください。
28 HPL プロセスの電圧スケーリ ング デバイスは、HPプロセスのデバイス と比べ、かつてないレベルで
のスタティ ッ ク電力削減を実現します。 図 4 は、 28 HPL と電圧スケーリ ングによって リーク電流がさ
らに削減されるこ とを示しています。
X-Ref Target - Figure 3
図 3 : カスタマー デザインにおける 28nm でのプロセス別の性能マージン
X-Ref Target - Figure 4
図 4 : 28 HP と 28 HPL プロセスのリーク電流
Frequency in MHzWP389_03_060711
Power Headroomfrom 28 HPL Processand Voltage Scaling
Frequency Headroomfrom HPL Process
Additional FrequencyHeadroom fromVoltage Scaling
-2L (0.9V)
28 HP
28 HPL
28 HPL at 0.9V
Power/ThermalLimitP
ower
in W
atts
120%
100%
60%
80%
40%
40%
20%
Rel
ativ
e Le
akag
e P
ower
Nearest 28 nmCompetitor
7 Series Standard 7 Series -2L (0.9V)
WP389_04_060711
28 HP (VCC = 0.85V)
Xilinx 28 HPL (VCC = 1V)
Xilinx 28 HPL (VCC = 0.9V)
50%Lower
65%Lower

適切なプロセス技術の選択
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 7
HP プロセスと LP プロセスHPL プロセスが低価格、高性能、低電力、 そしてファ ミ リ間での簡単な移行を提供する、世界ク ラスの
FPGA ファ ミ リにとって正しい選択であるこ とは明らかです。 ザイ リ ンクスは、 HPL プロセスによ り、
適な電力範囲内で、 2 倍のロジッ ク セルを集積できました。 高集積の 28nm で一層高性能な製品を提
供するこ とで、 マルチコア プロセッサによって CPU の性能が向上するのと同様に、 ユーザーは並列処
理を有効に活用して、同じ熱および電力要件内で 2 倍のデザイン量を持つこ とができるよ うになり ます。
HPL プロセスによってザイ リ ンクスはさ らに、さまざまなコス ト と性能の組み合わせを可能とする統一
アーキテクチャを提供しています。
HP プロセスは 100W 程度で動作する GPU および CPU をターゲッ ト と し、 そのうち 大 40% がリー
ク電力 (~40W) で消費されます。 ダイ サイズは GPU や CPU とほぼ同等ですが、 40W 程度を総電力 ( リーク電力とダイナミ ッ ク電力) の 大値とする FPGA では、 このリーク電力量は許容できません。
FPGA の許容範囲内に HP プロセスでのリーク電力が削減されたと しても、 性能は著し く減少するこ と
にな り、 結果的にそのプロセスは、 同等の性能の HPL プロセスよ り も非常に高価で複雑なものとな り
ます。
LP プロセスは、それほど性能を必要と しないアプリ ケーシ ョ ンをターゲッ ト とする従来の PolySiON プロセスで、 FPGA には不向きです。妥当な性能を得るには、 28 LP は VCC=1.1V で動作させなければな
らず、HKMG 28nm プロセス と比べる と非常に高いダイナミ ッ ク電力になってしまいます。 このプロセ
スは、 性能の低い携帯電話などをターゲッ ト と しています (表 2 参照)。
HPL プロセスの選択は、 FPGA 業界で 28G SerDes を リードするザイ リ ンク スの可能性も拡げます。
Virtex-7 HT FPGA は業界 高のバンド幅 (28G の ト ランシーバーを 16 本、 他社 FPGA ベンダーの 4倍) を提供します。
表 2 : 28nm プロセスの比較
Process Normalized FPGA Speed
Normalized Leakage Current
Technology Features
Targeted Applications
28 LP 87% 250%
Legacy PolySiON:
Complex embeddedSiGe strain
Legacy low performancecell phones
28 HPL 100% 100%HKMG: Simple rotatedsubstrate strain
FPGAs, ASICs, andASSPs
28 HP 100% 220%H K M G : C o m p l e xembedded SiGe strain
GPUs and CPUs

8 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
スタテ ィ ッ ク、 ダイナミ ック、 I/O の電力削減
FPGA に正しい低電力プロセスを決定するには、 おびただしい技術や調査が必要と されます。 しかし、
プロセス レベルでの低電力化が止まるこ とはあ り ません。ザイ リ ンクスは 28nm ノードであらゆる角度
から電力効率を高めるこ とに力を注ぎました。ザイ リ ンクスの電力に対する取り組みは、プロセス改善、
革新的なアーキテクチャ、 電圧スケーリ ング、 ソフ ト ウェアによる 適化など広範囲にわたり ます。 ス
タティ ッ ク、 ダイナミ ッ ク、 あるいは I/O の電力削減率並びに歩留ま り、 インプリ メンテーシ ョ ンに伴
う リ スクや時間などを基準に多数のオプシ ョ ンが評価されました。 さ らにこれまでと同様に、 各電力削
減手法は性能、 コス ト、デザイン フローや全体的なスケジュールへの影響などの点での評価も行いまし
た。数多くの手法が 28nm 7 シ リーズ FPGA に適用され、かつ統一アーキテクチャが採用されたこ とで、
すべての製品ファ ミ リで低電力機能が利用できるよ うになっています。
スタテ ィ ック電力の削減28nm ノードにおけるスタティ ッ ク電力削減の も大きな要素は TSMC からの HPL プロセスで、HP プロセスよ り も電力が 50% 低くなっています。 それに加え、 ザイ リ ンクスは電力を抑えるための総合的
なアプローチをプロセス レベルを超えて行い、 28nm で改善あるいは導入されたスタティ ッ ク電力の低
減機能を多数組み込みました。 (表 3 参照)。表 3 : 7 シリーズ FPGA で使用されているスタテ ィ ック電力削減手法
Reduction Technique Power Savings Reason for Xilinx Choice
Use 28 HPL Process 50% savings compared to HPprocess
Xilinx co-developed thislow-power, high-performanceprocess specifically for FPGAs
Transistor DistributionOptimizations in IntegratedBlocks and Core Logic
40–80% reduction compared toprevious generation, dependingon block, with new highthreshold voltage transistors
Xilinx’s investment at designtime provides great reduction inleakage for customerapplications
Stacked Silicon InterconnectTechnology
Saves 40% static powercompared to monolithic deviceof same density
Offers unprecedented powersavings in the largest devicesever made
Integrated Blocks Up to 90% reduction in staticpower compared to soft-IPimplementations throughreducing the number oftransistors
Selecting a set of commonblocks needed by manycustomers allows Xilinx to offerbetter performance and lowerstatic power. Also, see 表 5 fordynamic power benefits.
Power Gating of Unused Blocks Eliminates up to 100% of blockRAM leakage depending onutilization
Allows customers to powerblocks instead of forcing themto pay a power penalty forblocks they are not using
Partial Reconfiguration 80% static power savings ifseveral sections of logic areswapped in and out of the activedesign
Unique Xilinx benefit; greatstatic power savings

スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 9
最適なト ランジスタ構成Virtex-6 FPGA ( WP298 『40nm および 45 nm における消費電力』参照) で初めて導入されていますが、
すべての 7 シ リーズ FPGA においても ト ランジスタの選択や前世代よ り も優れた ト ランジスタ構成に
よる利点を得ています。 IC 設計者は、 高/標準/低のしきい値電圧およびゲート長、 幅の異なる ト ランジ
スタを使用できます。 各ト ランジスタにはそれ自身のリーク電流と性能の特性があ り ます。 高速な ト ラ
ンジスタ と低速な ト ランジスタのリーク電流差は、15~20 倍にもな り得るこ とに注意するこ とが重要で
す。 可能な限り リーク電流を低くするためにザイ リ ンクスは、 各ブロ ッ クを設計する際に も リーク電
流の低いト ランジスタだけを使用して設計を開始しました。 そして、 ブロ ッ クの性能目標を達成するた
めに必要な部分だけ高速ト ランジスタに移行しました。 この手法は各ブロ ッ クにおける高リーク電流の
ト ランジスタを減少させるために非常に有効で、標準 (Typical) と 大 (Maximum) の間のばらつきを減
らしました。 HPL プロセス と上手く組み合わせるこ とで、 ザイ リ ンクスは前世代と比較して 65% のス
タティ ッ ク電力の削減を実現しています (図 5 参照)。
Voltage Scaling -2L Devices Operated at 0.9V
Static power from leakage isapproximately proportional toVCCINT
3 (i.e., ~30% reductionfor 10% lower VCCINT)
Up front IC design verificationand implementation of processscreen at manufacturing testallows lower power option forusers
Lower VCCAUX Voltage from2.5V to 1.8V
30% savings compared toprevious generation on PLL,IDELAY, and other parts of theI/O block
Significantly reduces expensiveDC power in the FPGA
表 3 : 7 シリーズ FPGA で使用されているスタテ ィ ック電力削減手法 (続き)
Reduction Technique Power Savings Reason for Xilinx Choice
X-Ref Target - Figure 5
図 5 : 7 シリーズ FPGA のコア ロジックでのト ランジスタのタイプ比率
100%
80%
40%
60%
0%
20%Per
cent
age
of T
rans
isto
rs
Regular VT, 33 nmLowest Leakage,
Slowest
Regular VT, 28 nmLow Leakage,
Slow
Low VT, 33 nmHigh Leakage,
Fast
Low VT, 28 nmHighest Leakage,
Fastest
Minimal use of 28 nm Low VT transistors yieldsoptimized performance/power in 7 series FPGAs
40%
50%
9.5% < 0.5%
WP389_06_021511
Transistor Type

10 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
改善された電圧スケーリング オプシ ョ ン
ザイ リ ンクスは、 28 HPL プロセスのマージン増加によるも う 1 つの有効な利点である電圧スケーリ ン
グ オプシ ョ ンを提供しています。 7 シ リーズ FPGA は 1.0V と 0.9V の 2 つのコア電圧で動作させるこ
とが可能です。 これは Virtex-6 と Spartan-6 で初めて導入した消費電力への取り組みと同様です。 1.0Vまたは 0.9V で動作可能なデバイスは、 1.0V でのスピード グレードに基づいて 「-2L」 と位置付けられ
ました。その性能は 1.0V で -2 スピードグレード と等し くで、0.9V では -1 スピード グレード とほぼ同
等ですが、 「L」 は低スタティ ッ ク電力と低電圧で動作可能であるこ とを示しています。 0.9V でデバイ
スの電圧を下げるだけでも~30% のスタティ ッ ク電力が削減されます。電圧を下げるこ とによって性能
も低下してしまいますが、ザイ リ ンクスはこの -2L (0.9V) デバイスをスピードおよび標準デバイスよ り
も厳しいリーク電流の条件で選別しています。 図 6 に示すよ うに、 -2L (0.9V) デバイスになり得る低い
リーク電流および高い性能のデバイスのみを選択しています。この選別手法を用いるこ とで、標準スピー
ドグレードのデバイス と比較してワース ト ケース プロセスで 55% の電力削減を可能と しています (図 7 および表 4 参照)。X-Ref Target - Figure 6
図 6 : 標準デバイスと -2L (0.9V) デバイスのスピード分布
X-Ref Target - Figure 7
図 7 : 標準デバイスと -2L (0.9V) デバイスのリーク電流
Dis
trib
utio
n
Slower Faster
WP389_06_021511
Absolute Speed
Too Leaky
Too Slow
7 Series -1, -2, -3 VCCINT = 1.0V7 Series -1L VCCINT = 0.9VToo Slow/Too Leaky
1.0V0.9V
Leak
age
Slower Faster
WP389_07_021711
Normalized Speed
Maximum
Typical
-30% from Voltage Scaling
2.5
1.751.7
1.2
1.0
0.7
-50%
7 Series -1, -2, -3 VCCINT = 1.0V7 Series -1L VCCINT = 0.9V
Leaky Partsfor -1L

スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 11
PDS (電力分配システム) は、電源が 悪条件下で正常動作し、供給できるこ とを保証するためにワース
ト ケース ( 大) での電力要求に追従する必要があ り ます。 このため、 ザイ リ ンクス はワース ト ケース
プロセスでのスタティ ッ ク電力を削減するための取り組みにも非常に注力しました。
スタ ック ド シリコン インターコネク ト テク ノロジ
ワース ト ケースでのリーク電流は FPGA において深刻な問題になっています。 それは各ト ランジスタ
がリーク要素を持つだけでなく、大規模デバイスでは 1 兆個を超える ト ランジスタが使用されるこ と も
あるためです。 XC7V1500T や XC7V2000T のよ うな大規模な 7 シ リーズ FPGA は、 ザイ リ ンクスの
スタ ッ ク ド シ リ コン インターコネク ト テク ノ ロジを使用して製造されます。 単純に言えば、 このテク
ノ ロジは 1 つの大きなデバイスを作るために複数のダイを用います。 スタ ッ ク ド シ リ コン インターコ
ネク ト テク ノ ロジの利点の 1 つは、 1 つのダイで製造されたほぼ同じサイズのデバイスに比べて、 大
スタティ ッ ク電力が削減できるこ とです (図 8 参照)。
たとえば、1 つのダイで構成された 500K ロジッ ク セルでワース ト ケースのリーク電流が標準的な リー
ク電流に対して 2 倍の場合、 ス タ ッ ク ド シ リ コン インターコネク ト テク ノ ロジを使用していない
1,500K ロジッ ク セルのデバイスのワース ト ケース リーク電流は約 6 倍になり ます。これに対して、ス
タ ッ ク ド シ リ コン インターコネク ト テク ノ ロジを使用し、 かつザイ リ ンクスの低電力手法を適用した
場合は、1,500K ロジッ ク セル デバイスのワース ト ケースのリーク電流は 3.6 倍で、40% 削減されます。
ザイ リ ンクスは 1 つのデバイス内のダイすべてのリーク電流がワース ト ケース とならないよ うにしま
した。ダイの 1 つがワース ト ケースのリーク電流に近い場合は、デバイス内のその他のダイは標準に近
いものを選択します。その結果、同じ集積度の 1 つのダイ と比べる と ワース ト ケースのリーク電流は非
常に小さ くな り ました。
また、 スタ ッ ク ド シ リ コン インターコネク ト テク ノ ロジによって、 I/O インターコネク ト電力の大幅
な削減も可能です。ザイ リ ンクスの SSI デバイス (Virtex-7 1500T および 2000T FPGA など) ではなく、
小さな個々の FPGA で 2M ロジッ ク セルを実現するには、 各デバイスを機能的に必要な帯域幅で接続
するために何万本もの I/O ピンが必要とな り ます。 スタ ッ ク ド シ リ コン インターコネク ト テク ノ ロジ
表 4 : スタテ ィ ック電力、 ダイナミ ック電力、 性能の比較
7 シリーズ FPGAs C-Grade Devices -2LE (1.0V) -2LE (0.9V)
VCCINT 1.0V 1.0V 0.9V
Static Power Nominal –45% –55%
Dynamic Power Nominal Nominal –20%
Performance -1, -2 -2 ~ -1
X-Ref Target - Figure 8
図 8 : Virtex-7 FPGA の最大 (Maximum) プロセスでのスタティ ック電力とロジック セル
Max
imum
Sta
tic P
ower
0 500 1,000 1,500 2,000WP389_08_021711
28 nm FPGA Slice
28 nm FPGA Slice
28 nm FPGA Slice
28 nm FPGA Slice
Stacked Silicon Interconnect Technologywith 28 nm FPGA Slices
Virtex-7 Monolithic FPGA Virtex-7 Multi-Slice FPGA
Extrapolated Virtex-7 Monolith
ic FPGA

12 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
を用いれば、 I/O インターコネク ト電力は I/O と ト ランシーバーで構成した同等のインターフェイスよ
り も 100 倍 (帯域/W) 小さ くな り ます。 信号をオフチップで駆動するのではなく、 すべての接続をオン
チップで構成するこ とによ り、 非常に高速かつ低電力となる、 この劇的な削減が可能となっています (図 9 参照)。
VCCAUX の低電圧化
スタティ ッ ク電力はアーキテクチャ レベルでも削減されました。ザイ リ ンクスは VCCAUX を 2.5V から
1.8V に低減しました。 これによ り、 PLL、 IDELAY、 入出力バッファー、 コンフ ィギュレーシ ョ ン回路
など VCCAUX によって電力供給されるすべてのブロッ クの消費電力が ~30% 抑えられます。
未使用ブロックの電力ゲーティング
これまでの世代のザイ リ ンクス FPGA でも、 未使用のト ランシーバー、 PLL、 DCM、 および I/O の電
力を遮断できました。 これにさらに 7 シ リーズ デバイスでは、未使用ブロ ッ ク RAM への電力ゲーティ
ングが追加されています。
前世代のザイ リ ンクス FPGA を分析したと ころ、 リーク電流の約 30% がブロ ッ ク RAM によるもので
した。 ザイ リ ンク スはこの リーク電流を削減するために積極的に改善に取り組みました。 7 シ リーズ
FPGA では、 デバイス上のすべてのブロ ッ ク RAM ではなく、 そのデザインで使用されているブロ ッ ク
RAM でのみリーク電流が発生します。 ソフ ト ウェアはブロ ッ ク RAM がインスタンスされているか、
されていないかを認識し、 デザインがロード される と きにインスタンスされているブロ ッ ク RAM にの
み電力を供給します。 反対に、 未使用のブロ ッ ク RAM に対しては電力を供給しません (図 10 参照)。
X-Ref Target - Figure 9
図 9 : スタ ック ド シリコン インターコネク ト テク ノロジによる
I/O インターコネク ト電力削減
I/O PerformanceBottlenecks
Large Monolithic FPGA Multiple Die on an Interposer
Xilinx Innovation
WP389_09_021011
X-Ref Target - Figure 10
図 10 : 未使用ブロック RAM の電力ゲーティング
WP389_10_021011
Unused Block RAMPower Savings
Block RAM

スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 13
パーシャル リコンフ ィギュレーシ ョ ンとスタテ ィ ック電力の低減
いくつかの例外 (スタ ッ ク ド シ リ コン インターコネク ト テク ノ ロジを使用したデバイスなど) を除い
て、 スタティ ッ ク電力はデバイスのサイズに直接関係します。 スタティ ッ ク電力を削減する手段の 1 つは、 簡単に言う と小さなデバイスを使う こ とです。 しかし、 これまで多くのデザインは小さなダイに適
合できませんでした。 これが、 Virtex-6 FPGA で主流デザインにおけるパーシャル リ コンフ ィギュレー
シ ョ ンを推進する変化の始ま りでした。そして、 これは 7 シ リーズ FPGA においても継続し、改善され
てきています。 ザイ リ ンクスはすでにパーシャル リ コンフ ィギュレーシ ョ ン技術を持っていましたが、
この機能は 近のソフ ト ウェアの改善によ り、従来よ り も さまざまな FPGA デザインに適用できるもの
とな り ました。 パーシャル リ コンフ ィギュレーシ ョ ンでは、 カスタマーは原則的に FPGA を時分割で
処理させ、 デザインの各部を個別に動作させます。 デザインの全部分が常に必要とはならないため、 よ
り小さなデバイスが使用できます。
また、パーシャル リ コンフ ィギュレーシ ョ ンはスタティ ッ ク電力だけでなく、動作電力を削減できる可
能性も持っています。たとえば、多くのカスタマー デザインは非常に高速で動作しなければなり ません
が、その 高性能が必要と されている時間の割合はとても低いものです。電力を抑えるため、常時 100%高性能なデザインではなく、パーシャル リ コンフ ィギュレーシ ョ ンを使用して低電力バージ ョ ンに置き
換えるこ とが可能です。 その後、 必要なと きに高性能デザインに戻すこ とができます (図 11 参照)。
また、 この原理は I/O 規格に対しても適用可能で、 消費電力の高いインターフェイスが随時必要と され
ない場合に有効です。 LVDS は直流動作であるため、 動作率に関わらず消費電力の高いインターフェイ
スです。こ こでパーシャル リ コンフ ィギュレーシ ョ ンを用いて、 高速が必要のないと きには LVDS から LVCMOS のよ うな消費電力の低い I/O 規格に変更できます。 そして、 再び高速伝送が要求されたと
きに LVDS に戻すこ とが可能です。
パーシャル リ コンフ ィギュレーシ ョ ンに関する詳細は、 WP374 『ISE 12 を使用した Virtex FPGA のパーシャル リ コンフ ィギュレーシ ョ ン』 をご参照ください。
X-Ref Target - Figure 11
図 11 : パーシャル リコンフ ィギュレーシ ョ ンによる機能的な変更とサイズの削減
WP389_11_021011

14 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
ダイナミ ック電力の削減ダイナミ ッ ク電力は、 CV2f (=動作率、 C =容量、 V =電圧、 f =ク ロ ッ ク周波数) で得られます。 ザイ
リ ンクスは 7 シ リーズ FPGA におけるダイナミ ッ ク電力に関わる全要素を検討しました。プロセス ノー
ドが継続的に微細化しているのに伴い、 ダイナミ ッ ク電力の削減は難しい課題となっています。 それに
も関わらずザイ リ ンクスは、多くの改善と新たな機能によって、 7 シ リーズ FPGA においてダイナミ ッ
ク電力をさ らに低減させています (表 5 参照)。
7 シ リーズ FPGA では、 プロセスの微細化をはじめと して、寄生容量および配線容量の削減によってダ
イナミ ッ ク電力が 25% 以上低減されます (図 12 参照)。
28 HPL および製造中のテス ト を通して得られたマージンによ り、 ザイ リ ンクスは設計者へ選択肢を提
供します。設計レベルでは、 -2L (0.9V) 電圧スケーリ ング デバイスを使用するだけで、標準の 7 シ リー
ズ FPGA に比べて 20% の電力を節約できます。
表 5 : 7 シリーズ FPGA におけるダイナミ ック電力の削減
Reduction Technique Power Savings Reason for Xilinx Choice
Smaller Process Approximate linear reduction indynamic power in the core basedon transistor and interconnectshrink
Allows packing more transistorsinto a given area to increasedensity.
On-chip Clock GatingEnhancements
Depends on clock enable dutycycle (10–80% can be achieved)
Offers an excellent opportunity forcustomers and software to reduceclock-tree power.
Integrated Blocks Up to 90% reduction in dynamicpower compared to soft-IPimplementations throughcapacitance reduction by use ofdedicated metal connections andminimum layers of logic
Selecting a set of common blocksneeded by many customers allowsXilinx to offer better performanceand lower dynamic power.Also see表 3 for static power benefits.
ISE Design Tool Automated Intelligent Clock Gating
Up to 30% savings in dynamic power
Takes power reduction beyond any limitations of the silicon and focuses on customer design.
Voltage Scaling -2L (0.9V) devices
Dynamic power is proportional to VCCINT
2 (i.e., 20% reduction for 10% lower VCCINT)
Up front IC design verification and implementation of process screen at manufacturing test allows lower power option for users.
X-Ref Target - Figure 12
図 12 : プロセス微細化による容量とダイナミ ック電力の削減
WP389_12_021411
L
POLY
Transistor
Interconnect
DrainVia
Source
W
Metal Plate

スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 15
FPGA そのもので比較する場合、 コア電圧が低減する と、 常に電圧の二乗の割合でダイナミ ッ ク電力も
削減されます。 しかし、 複数の FPGA を比較する場合は、 一部の FPGA 製造者が提案しているよ うに
単純にコア電圧のみの問題ではあ り ません。ザイ リ ンクス FPGA では、高いコア電圧を使用しているに
も関わらず、 似たよ うな機能を持ついくつかのブロ ッ クで実際、 ダイナミ ッ ク電力がよ り低くになって
います。 これは容量を 小化するために内部でクロ ッ ク ゲーティングなどを使用し、非常に効率の良い
ブロ ッ ク設計が施されているためです。
ザイ リ ンクスはいくつかの方法で容量に対処しています。 アーキテクチャレベルでは、 ザイ リ ンクスの
エンジニアは LUT6 やメモ リサブシステム ブロ ッ クの統合などのよ う な機能的な革新に注力していま
す。 ク ロ ッ ク ゲーティングのよ う な機能、 ク ロ ッ ク ツ リーの電力削減および高ファンアウ トの削減な
ど Virtex-6 FPGA における改善はすべての 7 シ リーズ デバイスに適用されています。 LUT6 は高性能、
小領域、 少配線を継続して提供し、 容量を小さ く、 電力を節約するこ とができます。 7 シ リーズ デバイ
スでは、 PCIe のよ うな統合されたブロ ッ クによって、 ソフ ト IP を実装する場合に比べて、 スタティ ッ
ク電力を 大 90% 下げられるこ とがあ り ます。
周波数はよ くデザイン目標と してかかげられますが、 それを緩和するこ とでダイナミ ッ ク電力を削減す
るこ とが可能です。 多くの場合、 デザインのいくつかの部分は 100% は動作していません。 したがって
設計者は、 ク ロ ッ ク バッファーを使用して、 その部分に接続されるク ロ ッ クを止めるこ とができます。
周波数を 0 に落とすこ とは、 デザインの一部のダイナミ ッ ク消費電力を本質的に抑えます。
動作率はダイナミ ッ ク電力計算式の 後の部分で、 大でどの程度ト グルしているかを示し、 周波数は
ト グルしている速度になり ます。 ザイ リ ンクスはこのダイナミ ッ ク電力計算式の動作率の部分と挑戦す
るためにソフ ト ウェアによる 適化を用います。この 適化は Virtex-6 FPGA で初めて導入したもので
す ( 「ISE デザイン ツールでの自動クロ ッ ク ゲーティング」 を参照)。

16 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
内蔵クロック ゲーティング
内蔵クロ ッ ク ゲーティングは、ダイナミ ッ ク電力削減のための優れた手法を提供します。ク ロ ッ ク ゲー
ティングによ り、 ク ロ ッ ク ド ラ イバーはロジッ クが使用されていないと きに動的に停止されます。 これ
は、ある時間基準で動作/停止する必要がある部分に対して静的に、または 1 ク ロ ッ クサイ クルの精度で
動的に動かすこ とができます。 以前の Virtex および Spartan デバイスには、 デバイス サイズに関わら
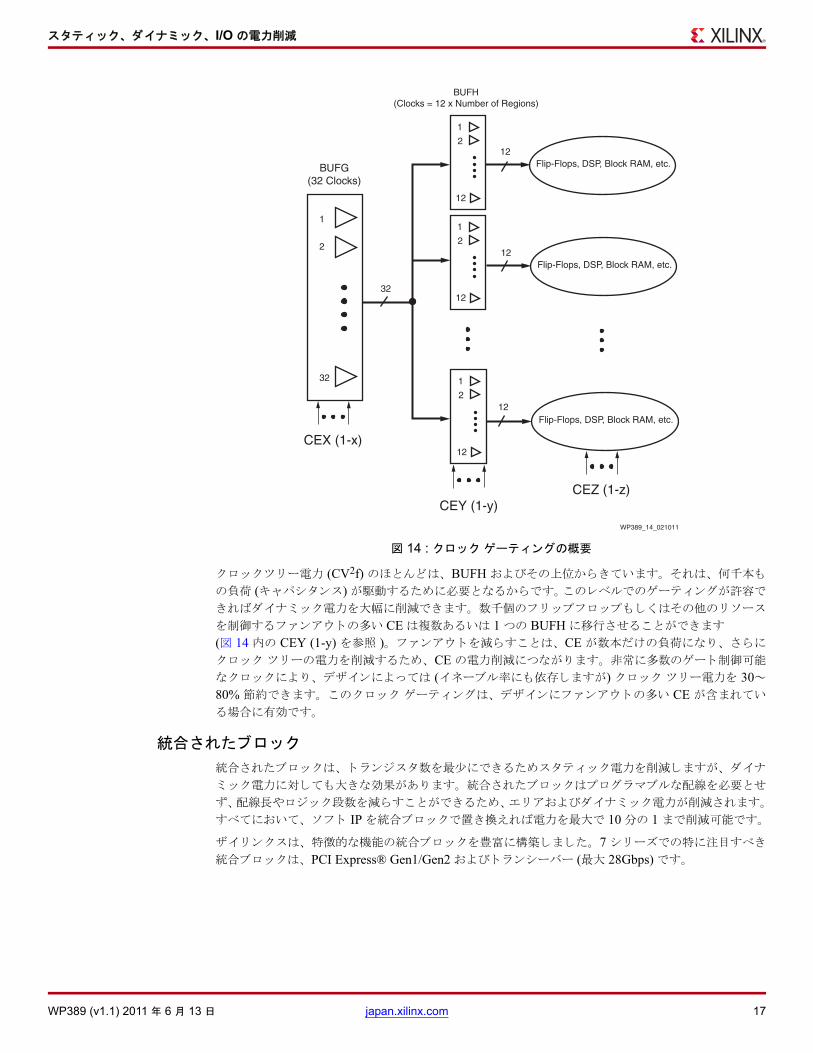
ず、 16~32 個の静的あるいはイネーブル付きのグローバル バッファー (それぞれ BUFG と BUFGCE)があ り ます。図 13 は、多くの世代の FPGA に共通するクロ ッ ク領域と次のレベルの横方向のバッファー
(BUFH) を示しています。 BUFG は割愛していますが、 図 13の中に階層的に存在します。
各 HROW 領域は 32 個のクロ ッ ク バッファーすべてに接続できます。 各 HROW ク ロ ッ ク領域の中に
は選択された 8~12 本のクロ ッ クが BUFH と呼ばれるブロ ッ クを通してバッファーされます。図 14 に示すよ うに、 各 HROW 領域あたり 12 の BUFH を動的あるいは静的にゲート制御できます。 つま り、
固定数のゲート付きクロ ッ ク (16~32 個) ではなく、 Virtex-6 およびすべての 7 シ リーズ FPGA ではデ
バイス サイズによって異なる数のクロ ッ クが使用できます。3 段階の階層レベルのクロ ッ ク ゲーティン
グおよびさまざまなクロ ッ ク イネーブル (CE) を使用したブロ ッ クのイネーブルは電力削減に大きな柔
軟性を与えます。 も大きな 7 シ リーズ FPGA には、 ゲート制御可能なグローバル ク ロ ッ クに加えて、
数百のゲート制御可能な リージ ョナル ク ロ ッ クがあ り ます (図 14 参照)。
X-Ref Target - Figure 13
図 13 : HROW クロック領域と BUFH クロック ド ライバー
WP389_13_021611
Horizontal or HROWClock Regions
BUFH Clock Driver
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 17
ク ロ ッ クツ リー電力 (CV2f) のほとんどは、 BUFH およびその上位からきています。 それは、 何千本も
の負荷 (キャパシタンス) が駆動するために必要となるからです。このレベルでのゲーティングが許容で
きればダイナミ ッ ク電力を大幅に削減できます。 数千個のフ リ ップフロ ップもし くはその他のリ ソース
を制御するファンアウ トの多い CE は複数あるいは 1 つの BUFH に移行させるこ とができます (図 14 内の CEY (1-y) を参照 )。 ファンアウ ト を減らすこ とは、 CE が数本だけの負荷にな り、 さ らに
クロ ッ ク ツ リーの電力を削減するため、 CE の電力削減につながり ます。 非常に多数のゲート制御可能
なクロ ッ クによ り、 デザインによっては (イネーブル率にも依存しますが) ク ロ ッ ク ツ リー電力を 30~80% 節約できます。 このク ロ ッ ク ゲーティングは、 デザインにファンアウ トの多い CE が含まれてい
る場合に有効です。
統合されたブロック
統合されたブロ ッ クは、 ト ランジスタ数を 少にできるためスタティ ッ ク電力を削減しますが、 ダイナ
ミ ッ ク電力に対しても大きな効果があ り ます。 統合されたブロ ッ クはプログラマブルな配線を必要とせ
ず、配線長やロジッ ク段数を減らすこ とができるため、エリ アおよびダイナミ ッ ク電力が削減されます。
すべてにおいて、 ソフ ト IP を統合ブロ ッ クで置き換えれば電力を 大で 10 分の 1 まで削減可能です。
ザイ リ ンクスは、 特徴的な機能の統合ブロッ クを豊富に構築しました。 7 シ リーズでの特に注目すべき
統合ブロ ッ クは、 PCI Express® Gen1/Gen2 およびト ランシーバー ( 大 28Gbps) です。
X-Ref Target - Figure 14
図 14 : クロック ゲーティ ングの概要
BUFG(32 Clocks)
1
2
32
BUFH(Clocks = 12 x Number of Regions)
1
2
12
1
2
12
1
2
12
32
Flip-Flops, DSP, Block RAM, etc.12
12
12
WP389_14_021011
CEX (1-x)
CEY (1-y)CEZ (1-z)
Flip-Flops, DSP, Block RAM, etc.
Flip-Flops, DSP, Block RAM, etc.

18 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
スタテ ィ ック、 ダイナミ ック、 I/O の電力削減
ISE デザイン ツールでの自動クロック ゲーティング
デザイン ツールでの電力 適化の点で、 ザイ リ ンク スは FPGA デザインでダイナ ミ ッ ク電力を 大
30% 削減できる初の自動化、 ファ イン グレーンクロ ッ ク ゲーティング ソ リ ューシ ョ ンを取り入れまし
た。 これは Virtex-6 および Spartan-6 FPGAで初めて導入された重要な機能です。 ザイ リ ンクスの高度
なクロ ッ ク ゲーティングによる 適化は、新たなツールやフローへの追加手順を必要とせず、 さ らに既
存ロジッ クやクロ ッ クに対してデザインの挙動を変えるこ とな く、 デザイン全体に対して自動的に実行
されます。 そしてまた、 ほとんどの場合でタイ ミ ングに影響を与えません。
ISE® Design Suite 12 デザイン ツールのリ リースによ り、 ザイ リ ンクスはデザイン全体 (従来の IP やサードパーティの IP を含む) を解析する革新的なアルゴ リズムを用いて、標準の FPGA デザイン フロー
の配置配線の部分に自動化機能を取り入れました。 ソフ ト ウェアは、各クロ ッ ク サイクルの結果に影響
を与えない、 レジスタに接続される前段のロジッ クを解析して、 7 シ リーズ FPGA が豊富に備える CEを利用します。 ソフ ト ウェアは、図 15 に示したよ うに、必要以上のスイ ッチングを抑制するためのファ
イン グレーン ク ロ ッ ク ゲーティングもし くはロジッ ク ゲーティング信号を生成します。 さ らにフ リ ッ
プフロ ップ レベルでは、CE は対象となる FF の D 入力と Q 出力ではなく、実際にはクロ ッ クをゲート
制御します。 これは CE の性能を上げるだけではなく、 ク ロ ッ クの電力も削減します。 これは Virtex-6FPGA にも言えるこ とですが、 7 シ リーズ FPGA ではさらに改善されています。
高度なクロ ッ ク ゲーティングによる 適化によ り、 専用ブロッ ク RAM (シンプル、 デュアル ポートの
両モードで利用可能) の電力も削減できます。 これらのブロ ッ クは数本のイネーブル、 アレイ イネーブ
ル、 ライ ト イネーブルおよび出力レジスタのク ロ ッ ク イネーブルを備えています。 電力節約のほとん
どはアレイ イネーブルによるものです。そして、 ソフ ト ウェアはデータが書き込みされていないと きや
出力が未使用のと きに電力を削減するための機能を実装します (図 16 を参照)。
7 シ リーズ FPGA においては、 さ らに多くのデザインで電力が一層削減されるよ う ソフ ト ウェアの改善
が続けられています。 WP370 『高度なクロ ッ ク ゲーティングによるスイ ッチ電力の削減』 を参照してく
ださい。
X-Ref Target - Figure 15
図 15 : 高度なクロック ゲーティ ング
X-Ref Target - Figure 16
図 16 : ブロック RAMイネーブルを活用した高度なクロック ゲーティ ングによる最適化
WP389_15_021011
Before
sigPower
ConsumptionPower
Consumption
After
sig
CE
address address
data in
data in
ce
data out data out
Before After
WP389_16_021011
I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 19
I/O の電力削減
I/O の電力は、 総電力の中でも極めて大きな要素の 1 つになってきています。 FPGA の進化によ り、 コ
ア電力は大き く削減されましたが、 I/O 電力はそれほど削減されていません。 メモ リ を集約するよ う な
デザインでは総電力の 50% 程度が I/O によるものです。ザイ リ ンクスは前世代の FPGA で積極的に I/O電力の削減に取り組み、 改善の余地を見ました。 そして、 7 シ リーズ FPGA に電力削減技術を実装しま
した (表 6 参照)。
変更可能なスルーレートやド ライブ能力に加えて、 FPGA 間や低速なメモリ インターフェイスの電力を
大き く減らすこ とができる HSLVDCI のよ うな特別な規格も用意しています。7 シ リーズ FPGA でザイ
リ ンクスは、高速メモ リ インターフェイスでの電力削減に注力しました。 その利点は、 そこでの電力削
減がほかのタイプのインターフェイスにも適用できるこ とです。
すべての 7 シ リーズ デバイスは変更可能なスルーレートやド ライブ能力を兼ね備えています。ザイ リ ン
クスは、 ト ラ イステート制御可能な DCI (デジタル コン ト ロール インピーダンス) も実装しています。
この機能は前世代の FPGA ファ ミ リで提供され、 7 シ リーズでさ らに改善させたもので、 メモ リ イン
ターフェイスに有用です。 DCI は FPGA から メモリへの書き込み動作中の終端電力を除去できるため、
終端電力は読み出し動作時のみ消費されます。場合によっては、およそバス サイクル中の書き込み率の
分だけ、 終端電力を削減可能です。
表 6 : 7 シリーズ FPGA における I/O 電力の削減
Reduction Technique Power Savings Reason for ザイリンクス Choice
Programmable Slew Rate andDrive Strength
Lowers dynamic power in I/Odrive.
Gives the user the ability tochoose various edge rates forsignal integrity vs. I/O dynamicpower.
Lowest slew/power should beused.
3-State DCI Dynamically assertabletermination during memory readremoves termination powerduring memory write.
Eliminates unnecessarytermination power when I/Oinput is not being used.
Stacked Silicon InterconnectTechnology
Saves 100X I/O connectionpower needed to bridge multipledevices together to get anequivalently sized device.
Offers unprecedented powersavings compared to amulti-device equivalent.
HSLVDCI Series Termination 50% input power reduction forFPGA inputs driven byHSLVDCI vs. split terminationplus IODELAY and input bufferpower
Offers users the ability to gain ahigh-performance, single-endedI/O standard and lower powerwithout the need for a paralleltermination.
Programmable IODELAYPower
70% input power reduction vs.high performance.
Offers the ability to selectivelyreduce IODELAY power forsmall reduction in performance.
Programmable ReferenceReceiver Power (HSTL, SSTL,LVDS)
50% input power reduction vs.high performance.
Offers the ability to selectivelyreduce power for the inputreceiver for a small reduction inperformance.
IBUF and DCI TerminationDisable
Eliminates power on IBUF andDCI termination when bus is inIDLE state.
Cuts power when the bus is notin use.The customer only paysfor DC power in I/O duringinputs to the device.

20 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
I/O の電力削減
また、ザイ リ ンクスは HSLVDCI とい う基本的に直列終端の I/O 規格を持っています。これは FPGA 間の接続に有効なだけでなく、 RLDRAM のよ うな外部メモ リの DQ ピンからデータをキャプチャする場
合などにも有効です。 7 シ リーズ デバイスには、 HSTL および SSTL のためのユーザ変更可能な リ ファ
レンス レシーバー電力モード もあ り ます。 そして、 ザイ リ ンクスは 7 シ リーズ デバイスにおいても変
更可能な電力モードを持つ IODELAY ブロッ クを継続的に提供します。これらの 2 つの変更可能な電力
モードは I/O 単位で制御可能であるため、設計者は電力と性能のト レードオフを考慮しながら DC 電力
を削減できます。
メモリ インターフェイスの電力
メモ リ インターフェイスの I/O 電力には 3 つの主要素があ り ます。 1 つは PCB 配線のインピーダンス
整合のための DCI、次に I/O 電圧からコア電圧へのリ ファレンス入力 レシーバー、 後に信号をクロ ッ
クに同期させるための IDELAY です。 これらの要素は相当量の電力を消費します。 Virtex-6 FPGA では、 ト ラ イステート DCI によってメモ リ書き込み動作中は自動的に終端を切り離すこ とで終端電力を
50% 節約できました。 ザイ リ ンクスは高性能モード と比較して 70% 節約可能な リ ファレンス レシー
バーおよび 50% 節約可能な IDELAY の低電力モードを提供します。 これらの機能によ り、 前世代では
同等インターフェイスで消費されていた電力の 50% 以上を節約できます。 7 シ リーズ FPGA でザイ リ
ンクスはその基盤を構築し、 大限の電力削減を行うために各機能の微調整を行っています。
設計面で第一歩と して、 VCCAUX を 2.5V から 1.8V へ下げるこ とで VCCAUX によって電源供給される
すべてのアイテム (IDELAY や入出力バッファーなど) の 30% が節約できます (図 17 参照)。 X-Ref Target - Figure 17
図 17 : VCCAUX の電圧変更
WP389_17_021511
Input
PAD
OBUF
IBUF IOB
Output
VCCO
1.8V 2.5
VCCAUX
VCCAUX 1.8V 2.5

I/O の電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 21
7 シ リーズ FPGA での新しい機能は、動作中に入力バッファーを無効にできるこ とです。 これは動的な
ト ライステート DCI 回路の改良と拡張によって実現しました。 ト ラ イステート DCI 機能は、 メモ リへ
の書き込み動作中に終端が未使用のと きは切り離す、 も し くは無効にする機能から派生したものです。
しかし、 前世代では、 入力バッファーは出力もし くはメモリへの書き込み動作中にも電力を消費してい
ました。 7 シ リーズ FPGA では、 入力バッファーも メモ リへの書き込み動作 (出力) 中に無効にできま
す。これによ り書き込みと読み出しが 50% の比率の場合には、50% の電力削減が可能になり ます (図 18参照)。
X-Ref Target - Figure 18
図 18 : 入力バッファーと DCI 終端の無効化
WP389_18_021011
Tristate
TERMINATION OFF
Input
OBUF
IOBIBUF
IBUF OFF
Output
OE
VCCO
PAD
Memory Write
Tristate
TERMINATION OFF
Input
OBUF
IOBIBUF
IBUF OFF
Output
OE
VCCO
PAD
Memory Read
22 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
I/O の電力削減
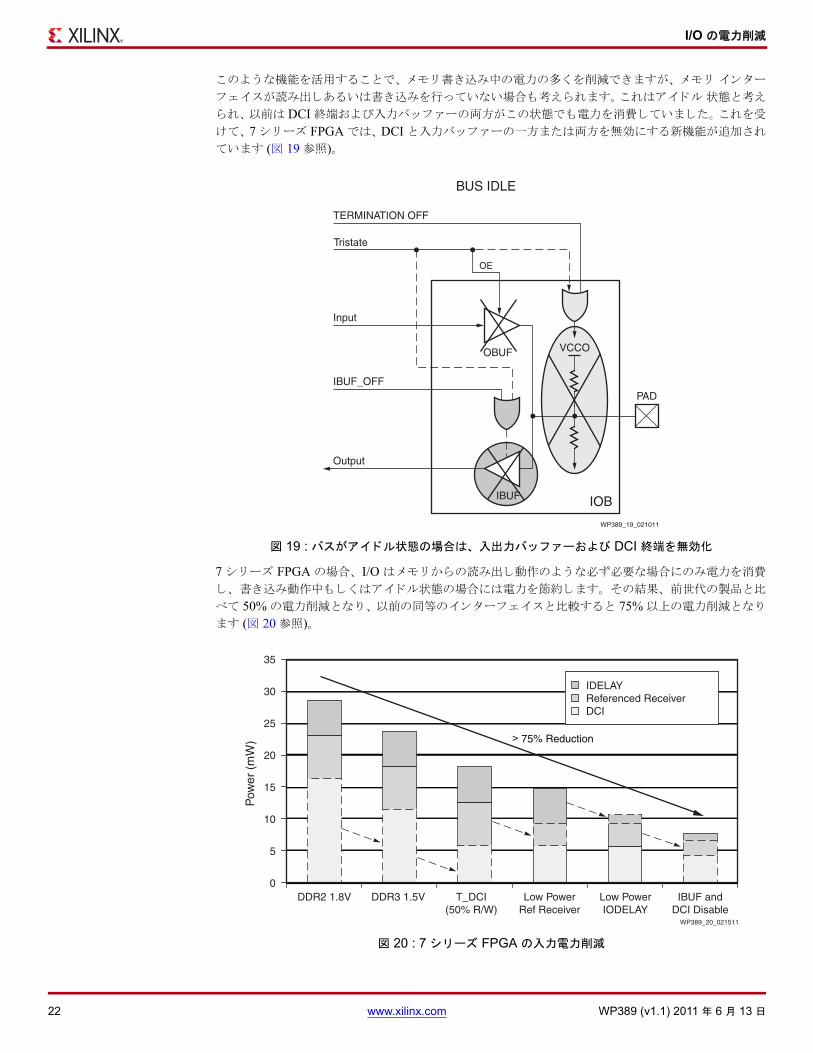
このよ うな機能を活用するこ とで、 メモ リ書き込み中の電力の多くを削減できますが、 メモ リ インター
フェイスが読み出しあるいは書き込みを行っていない場合も考えられます。これはアイ ドル 状態と考え
られ、以前は DCI 終端および入力バッファーの両方がこの状態でも電力を消費していました。 これを受
けて、7 シ リーズ FPGA では、DCI と入力バッファーの一方または両方を無効にする新機能が追加され
ています (図 19 参照)。
7 シ リーズ FPGA の場合、 I/O はメモ リからの読み出し動作のよ うな必ず必要な場合にのみ電力を消費
し、 書き込み動作中もし くはアイ ドル状態の場合には電力を節約します。 その結果、 前世代の製品と比
べて 50% の電力削減となり、以前の同等のインターフェイス と比較する と 75% 以上の電力削減となり
ます (図 20 参照)。
X-Ref Target - Figure 19
図 19 : バスがアイドル状態の場合は、 入出力バッファーおよび DCI 終端を無効化
X-Ref Target - Figure 20
図 20 : 7 シリーズ FPGA の入力電力削減
WP389_19_021011
Tristate
TERMINATION OFF
Input
OBUF
IOBIBUF
IBUF_OFF
Output
VCCO
OE
PAD
BUS IDLE
35
30
25
20
15
10
5
0
Pow
er (
mW
)
DDR2 1.8V DDR3 1.5V T_DCI(50% R/W)
Low PowerRef Receiver
Low PowerIODELAY
IBUF andDCI Disable
WP389_20_021511
> 75% Reduction
IDELAYReferenced ReceiverDCI

ト ランシーバーの電力削減
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 23
ト ランシーバーの電力削減
7 シ リーズ FPGA のト ランシーバーは、高性能と低ジッタを共に実現するよ う 適化されており、低消
費電力動作用の機能を備えています。 各ファ ミ リの ト ランシーバーは次のとおりです。
• Artix-7 FPGA GTP : 大 6.6Gb/s
• Kintex-7 FPGA GTX : 大 12.5Gb/s
• Virtex-7 FPGA GTH および GTZ : それぞれ 大 13.1Gb/s および 28Gb/s
それぞれのト ランシーバーには、 設計者がその動作を柔軟にカスタマイズし、 消費電力と性能のバラン
スを調整できるよ うにする機能があ り ます。
7 シ リーズの GTP および GTH ト ランシーバーのアーキテクチャは再設計されており、 Spartan-6 LXTと Virtex-6 HXT FPGA それぞれの GTP および GTH ト ラ ンシーバーと比較する と、 総消費電力が
>60% 削減されています。
Artix-7 ファ ミ リに搭載されている GTP ト ランシーバーは 大 6.6Gb/s のデータ レート をサポート し、
コス ト と消費電力を重視するアプリ ケーシ ョ ンにおいて、 も低い消費電力を実現するよ う 適化され
ています。 1 つの GTP クワ ッ ドにある 4 つのト ランシーバーを 3.125Gb/s の同一レートで動作させた
場合の PMA の消費電力はたった 80mW です。
Virtex-7 XT および HT デバイスが備える GTH ト ランシーバーは、400G のライン カードなどチャネル
数が非常に多く、かつ高性能なアプリ ケーシ ョ ンにおける消費電力を低減するよ う 適化されています。
低ジ ッ タ LC タ ン ク と共有 PLL を使用し、 1 つの GTH ク ワ ッ ド にある 4 つの ト ラ ンシーバーを
12.5Gb/s の同一レー ト で動作させた場合の PMA の消費電力は 148mW です。 さ らに、 Virtex-7 HTFPGA の GTZ ト ランシーバーは 28Gb/s のデータレートで、 チャネルあた り 250mW の消費電力であ
りながら、 十分きれいなデータ アイを実現します。
7 シ リーズ ト ランシーバーのアーキテクチャには、LC タンクの電力を抑えた状態で、各ト ランシーバー
のリ ング オシレーターを使用できる高い柔軟性があ り ます。 また、 LC タンク と リ ング オシレーターの
両方を使用するこ とで、1 つのト ランシーバーの TX と RX それぞれを異なるスピード /プロ ト コルで動
作させるこ とができます。 つま り、 1 つのクワ ッ ドで複数のレートの ト ランシーバーを混在させて使用
するこ とが可能です。
表 7 で説明している手法を用いて ト ランシーバー全体の消費電力を低減させるこ とができます。
表 7 : 7 シリーズ FPGA における ト ランシーバーの消費電力の削減
Reduction Technique Power Savings Reason for Xilinx Choice
Bypassable DFE Turns off the decision feedbackequalizer (DFE) circuitry whennot needed and uses the linearequalizer. The linear equalizer ismuch lower power than the DFEbecause of lower RX gain andminimal circuity. This is theLow Power Mode (LPM) of thereceiver.
Many non-backplaneapplications do not need DFE,which burns extra power, soXilinx gives designers a choicewhen servicing otherapplications.
Power Efficient Mode Source all four transceivers’high-speed clocks from one LCtank in a quad since ringoscillators of the quad arepowered down.For RX, the CDR can pull inplesiochronous differences.
Reduces power for multi-laneprotocols when all fourtransceivers of a quad arerunning at the same rate ordivision of that rate by 1, 2, 4, or8.
Separate AVCC and AVTT perQuad
Static power from unusedtransceivers is saved.
Offers the user the opportunityto remove power if sometransceivers will never be used.

24 www.xilinx.com WP389 (v1.1) 2011 年 6 月 13 日
まとめ
まとめ
ザイ リ ンクスは、 7 シ リーズ FPGA において FPGA とシステムに対する電力削減に総体的に取り
組み、 飛躍的な電力削減に成功しました。 7 シ リーズ FPGA は 大 50% の総電力削減を提供しま
す。 そして、 それは 大 (ワース ト ケース) プロセスで前世代の同じ大きさのデバイス と比較した
場合においても大幅な電力削減をもたらします (図 21 参照)。 新しい I/O 機能、 ならびにクロ ッ ク
と ロジッ ク ゲーティングを実現する進化したソフ ト ウェアを利用するこ とによ り、さ らに電力を削
減するこ とが可能です。 ザイ リ ンクスは業界で も総電力の低い FPGA を提供しています。
改訂履歴
次の表に、 この文書の改訂履歴を示します。
Notice of DisclaimerThe information disclosed to you hereunder (the “Information”) is provided “AS-IS” with no warranty ofany kind, express or implied.Xilinx does not assume any liability arising from your use of theInformation.You are responsible for obtaining any rights you may require for your use of thisInformation.Xilinx reserves the right to make changes, at any time, to the Information without notice andat its sole discretion.Xilinx assumes no obligation to correct any errors contained in the Information or toadvise you of any corrections or updates.Xilinx expressly disclaims any liability in connection withtechnical support or assistance that may be provided to you in connection with the Information.XILINXMAKES NO OTHER WARRANTIES, WHETHER EXPRESS, IMPLIED, OR STATUTORY,REGARDING THE INFORMATION, INCLUDING ANY WARRANTIES OF MERCHANTABILITY,FITNESS FOR A PARTICULAR PURPOSE, OR NONINFRINGEMENT OF THIRD-PARTYRIGHTS.
X-Ref Target - Figure 21
図 21 : ザイリンクス 7 シリーズ FPGA における総体的な電力削減への取り組み
Xilinx 40 nm
I/O Power
I/O Power
Dynamic Power
Dynamic Power
Maximum StaticPower
Maximum Static Power
Typical StaticPower
100
90
80
70
60
50
40
30
20
10
0
Nor
mal
ized
Tot
al P
ower
(%
)
Xilinx 28 nm
Up to 50%LowerPower
Increase UsablePerformanceand Capacity
Or
WP389_21_021511
–30%
–25%
–65%
日付 バージョ ン 内容
2011/02/24 1.0 初版リ リース
2011/06/13 1.1 文書全体で 1L デバイスを -2L (0.9V) に変更。 図 1、 図 3、 図 7 の更
新。表 3 および表 5 の更新。表 4 および表 7の追加。「改善された電圧
スケーリ ング オプシ ョ ン」、「7 シ リーズ FPGA におけるダイナミ ッ ク
電力の削減」 の更新。 「 ト ランシーバーの電力削減」 の追加。

Notice of Disclaimer
WP389 (v1.1) 2011 年 6 月 13 日 japan.xilinx.com 25
本資料は英語版 (v1.1) を翻訳したもので、 内容に相違が生じる場合には原文を優先します。
資料によっては英語版の更新に対応していないものがあ り ます。
日本語版は参考用と してご使用の上、 新情報につきましては、 必ず 新英語版をご参照ください。