florin rusu - ucm facultywebfaculty.ucmerced.edu/frusu/talks/2017-12-ibm-gd-gpu.pdf · florin rusu...
TRANSCRIPT

Stochastic Gradient Descent on Highly-Parallel Architectures: Multi-core CPU or GPU?
Synchronous or Asynchronous?
Florin RusuYujing Ma, Martin Torres (Ph.D. students)
University of California Merced

Machine Learning (ML) Boom
• Two SIGMOD 2017 tutorials

ML SystemsGeneral purpose (databases)
● BIDMach● Bismarck● Cumulon● DeepDive● DimmWitted● GLADE● GraphLab● MADlib● Mahout● MLlib (Mlbase)● SimSQL (BUDS)● SystemML● Vowpal Wabbit● …
Deep learning ● Caffe (con Troll)● CNTK● DL4J● Keras● MXNet● SINGA● TensorFlow● Theano● Torch● …

ML Hardware Accelerators

ML Systems with GPU AccelerationGeneral purpose (databases)
● BIDMach● Bismarck● Cumulon● DeepDive● DimmWitted● GLADE● GraphLab● MADlib● Mahout● MLlib (Mlbase)● SimSQL (BUDS)● SystemML● Vowpal Wabbit● …
Deep learning ● Caffe (con Troll)● CNTK● DL4J● Keras● MXNet● SINGA● TensorFlow● Theano● Torch● …

ML in Databases● It is not so much about deep learning
– Regression (linear, logistic)– Classification (SVM)– Recommendation (LMF)
● Mostly about training– Inside DB, close to data– Over joins or factorized databases– Compressed data, (compressed) large models
● Selection of optimization algorithm and hyper-parameters– BGD vs. SGD vs. SCD

Training for Generalized Linear Models
Logistic Regression (LR)
Support Vector Machines (SVM)
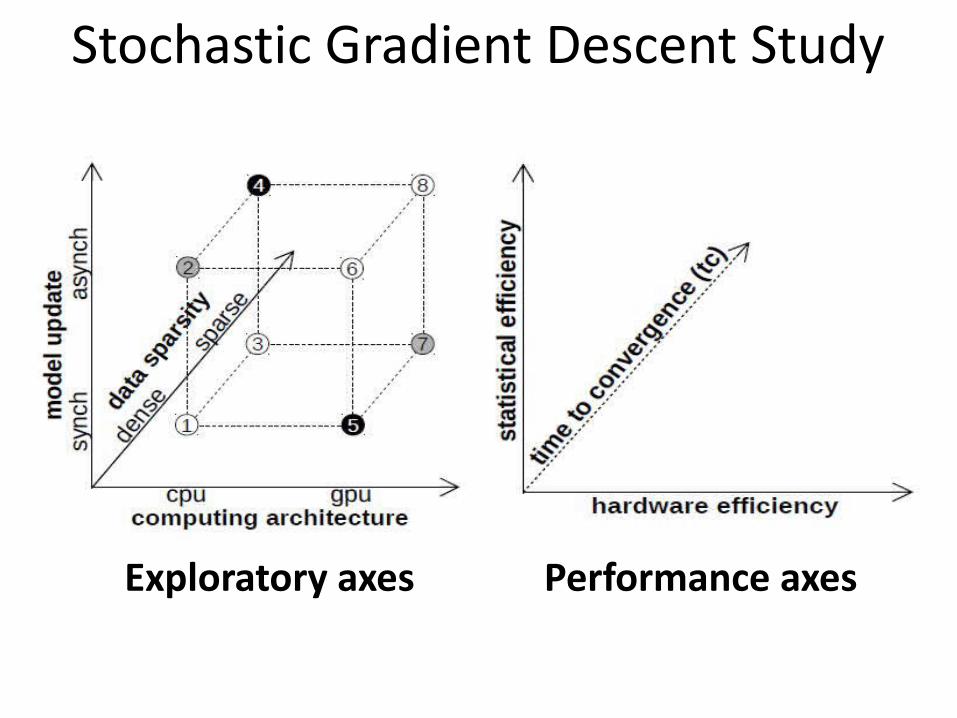
Stochastic Gradient Descent Study
Exploratory axes Performance axes
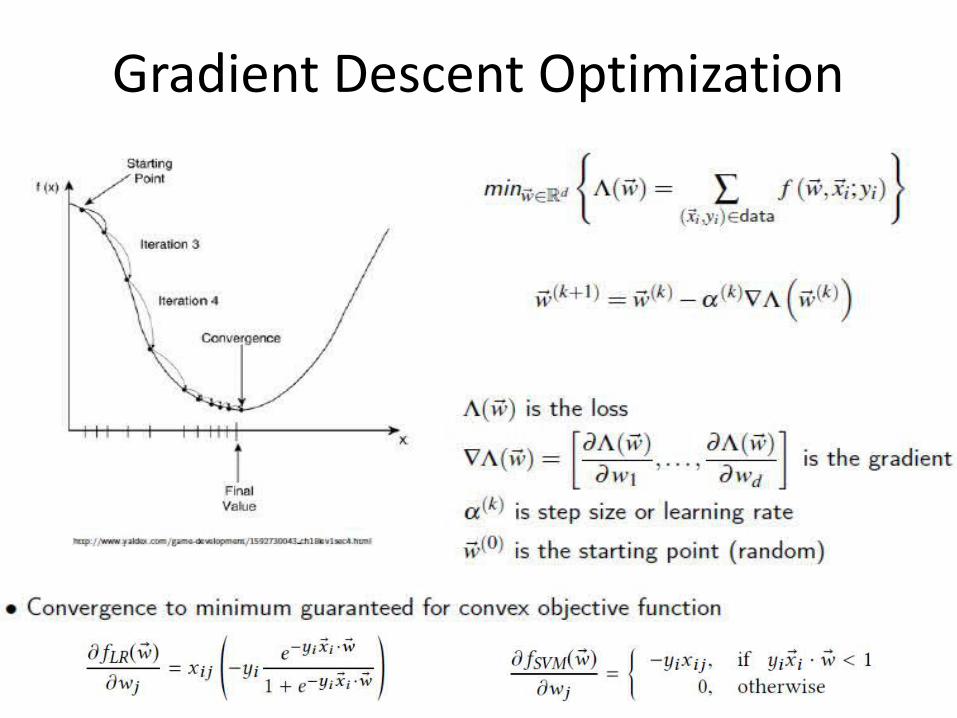
Gradient Descent Optimization

Stochastic Gradient Descent (SGD)

(Mini-)Batch SGD
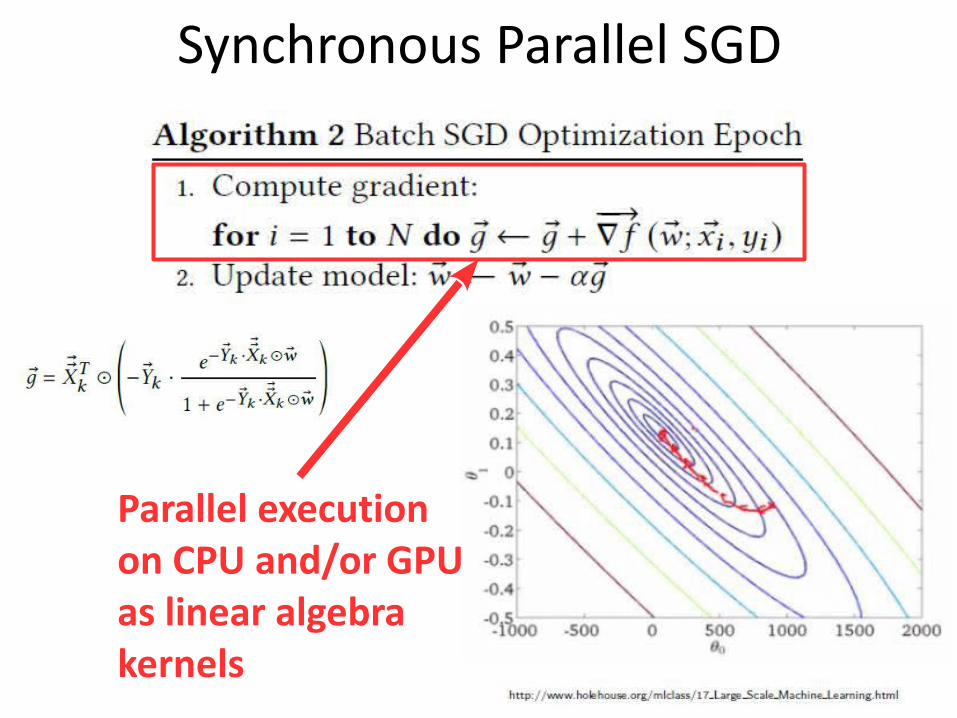
Synchronous Parallel SGD
Parallel execution on CPU and/or GPU as linear algebra kernels
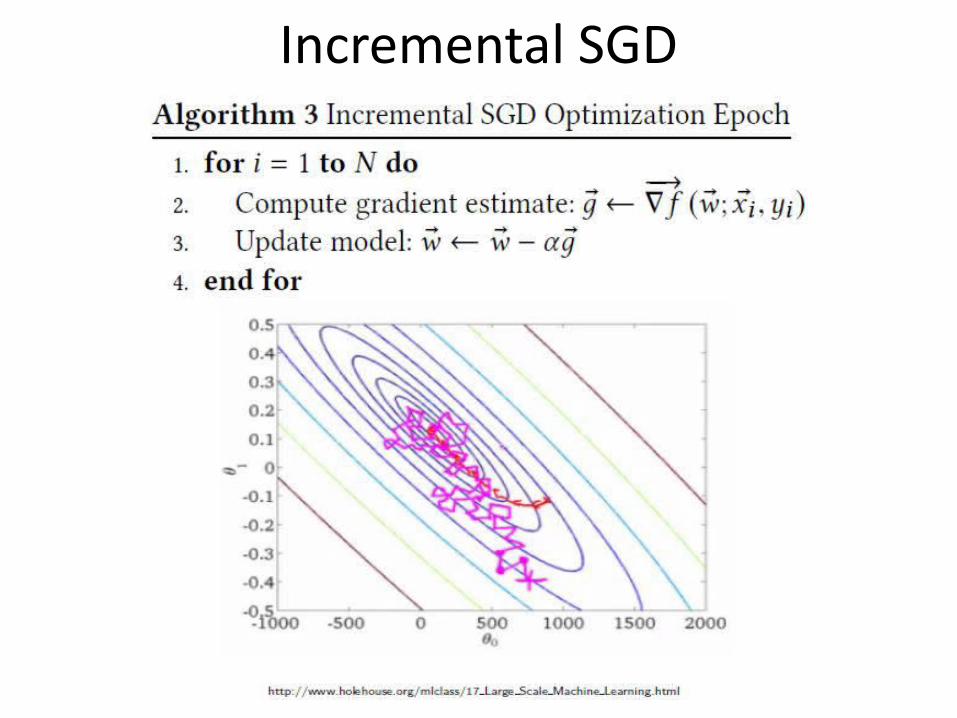
Incremental SGD
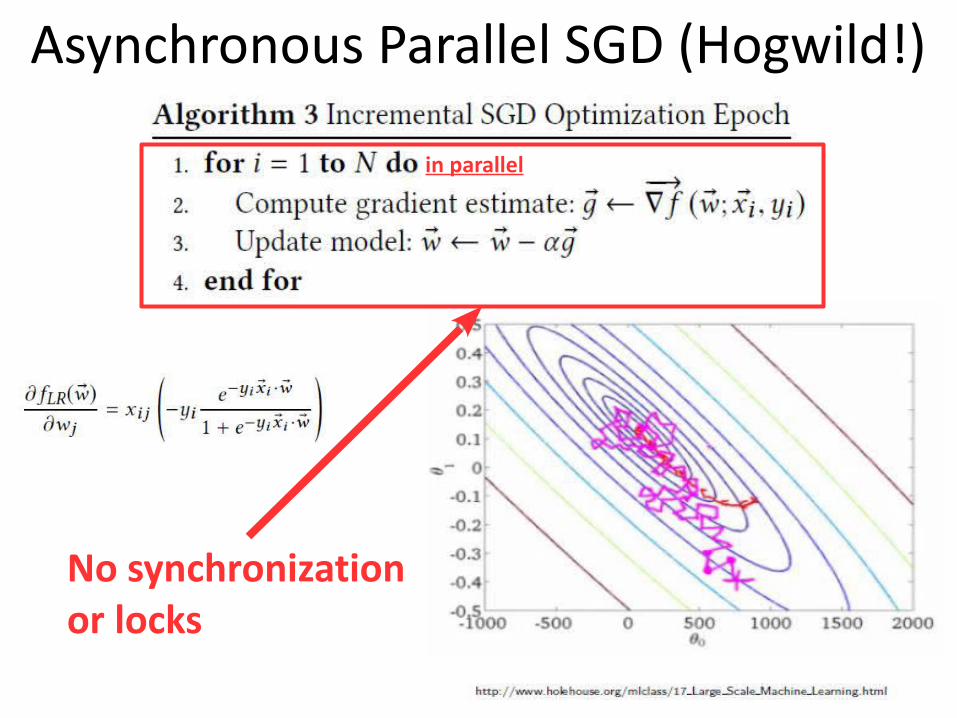
Asynchronous Parallel SGD (Hogwild!)
in parallel
No synchronization or locks
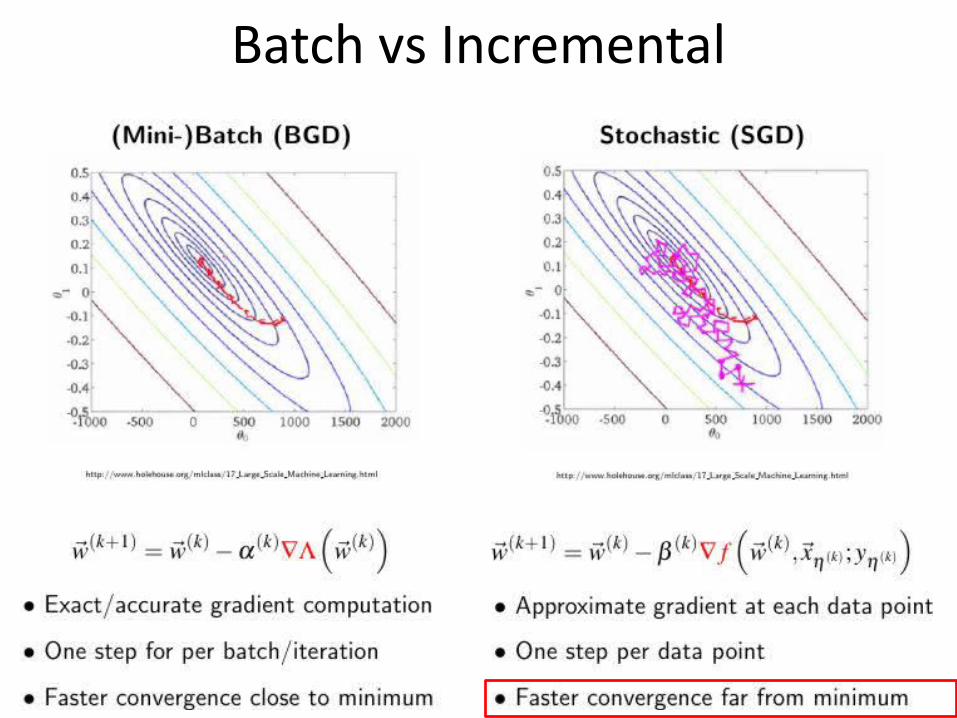
Batch vs Incremental

NUMA CPU Architecture

GPU Architecture

NUMA CPU vs GPU
• CPU: 2 x Intel Xeon E5-2660 (14 cores, 28 threads)• GPU: Tesla K80 (use only one multiprocessor, ~K40)

Datasets
sparse
dense

Synchronous SGD Implementation
ViennaCL library kernels● Same API for CPU and GPU● Separate compilation for each
architecture

Synchronous SGD Study
dense
sparse

Synchronous SGD Results

Asynchronous SGD Implementation (Hogwild!)
● NUMA CPU● Extensive study in DimmWitted by Zhang and Re (PVLDB 2014)
● GPU● Novel study
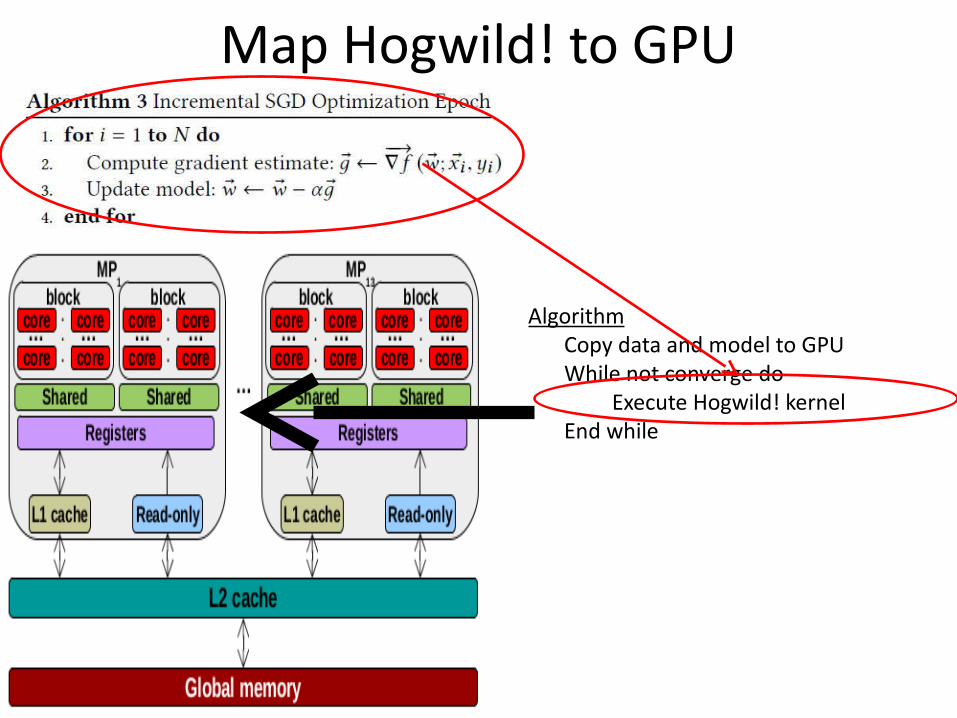
Map Hogwild! to GPU
AlgorithmCopy data and model to GPUWhile not converge do
Execute Hogwild! kernelEnd while

Data Access Pathrow-major round-robin (row-rr)
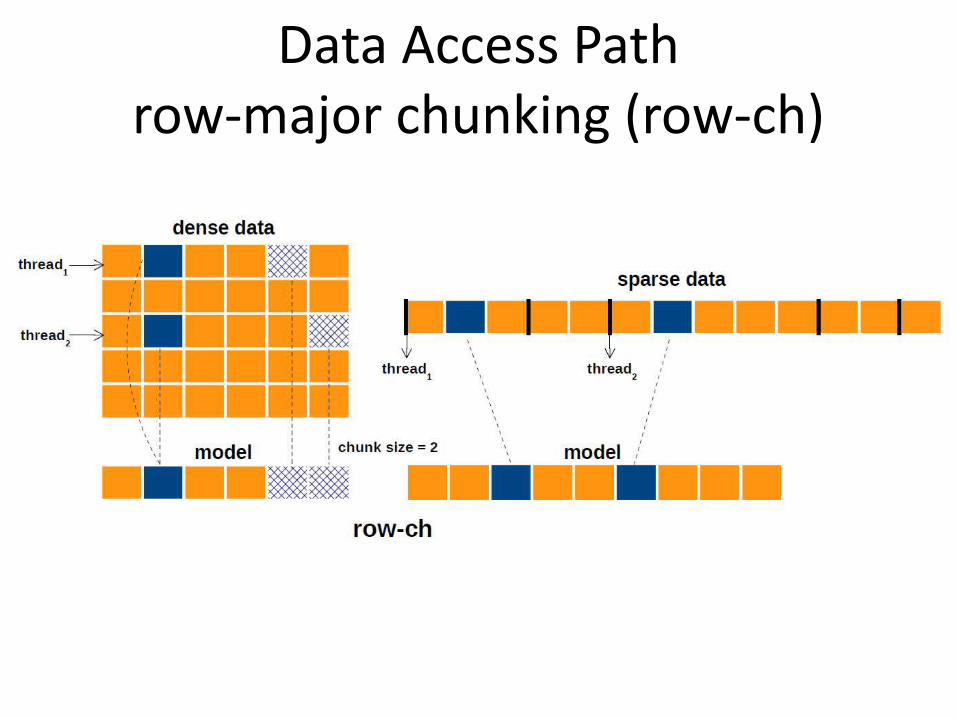
Data Access Pathrow-major chunking (row-ch)
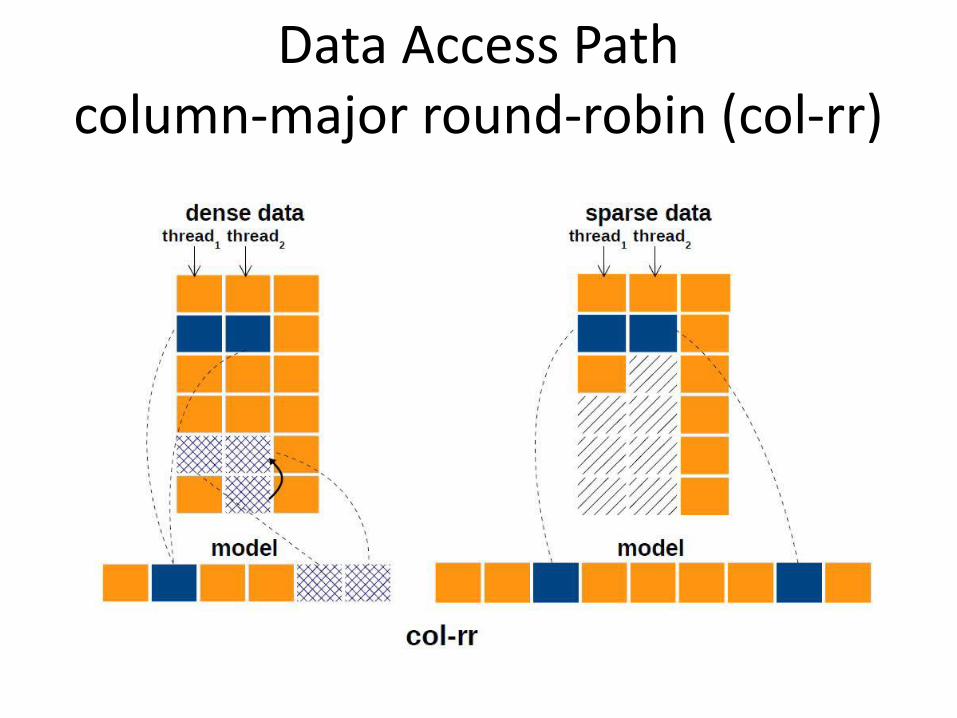
Data Access Pathcolumn-major round-robin (col-rr)

Data Access Pathcolumn-major chunking (col-ch)
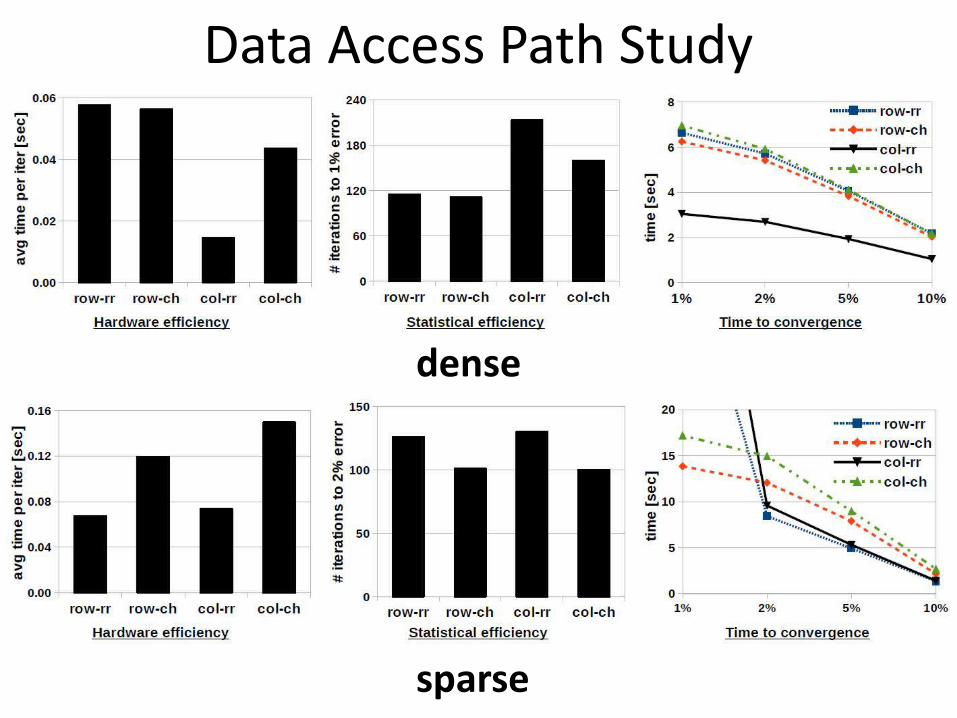
Data Access Path Study
dense
sparse

Model Replicationkernel/thread/example
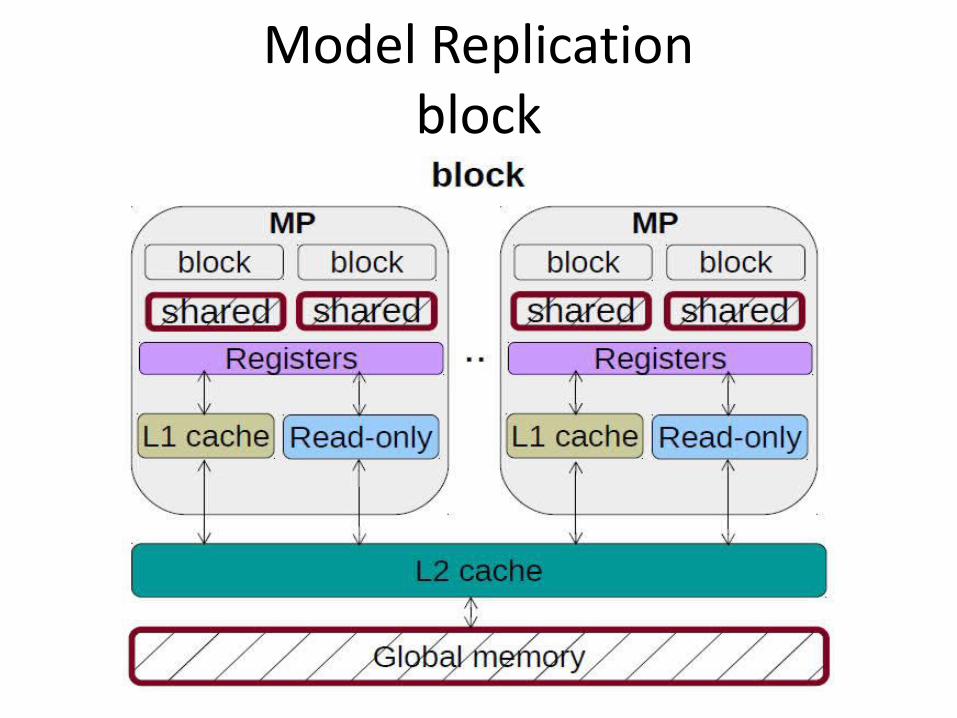
Model Replicationblock

Model Replication Study
dense
sparse

Data Replicationround-robin
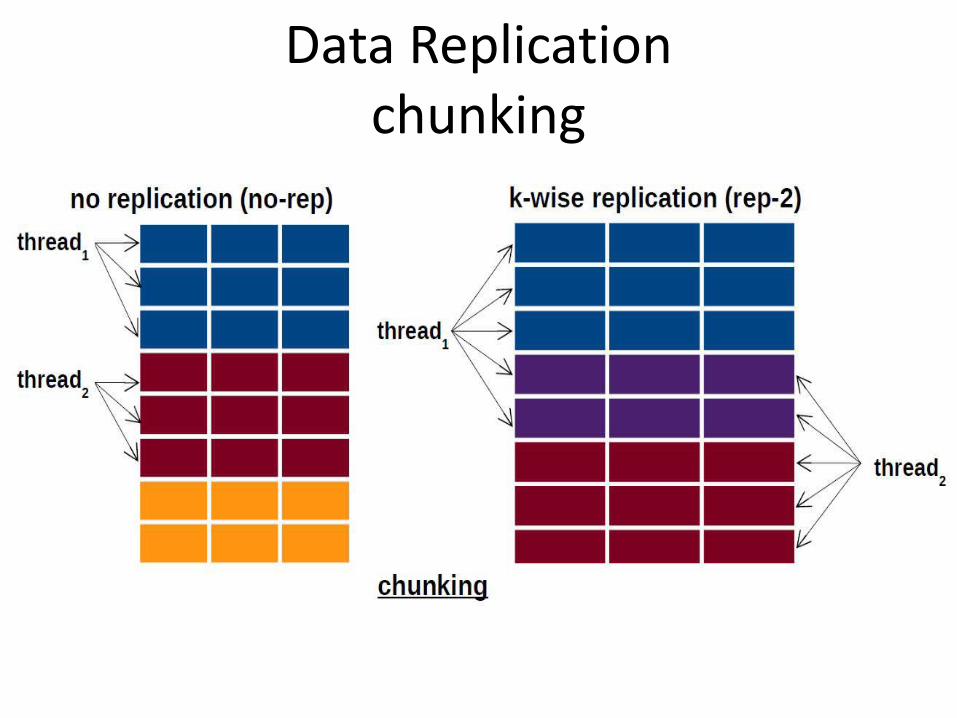
Data Replicationchunking
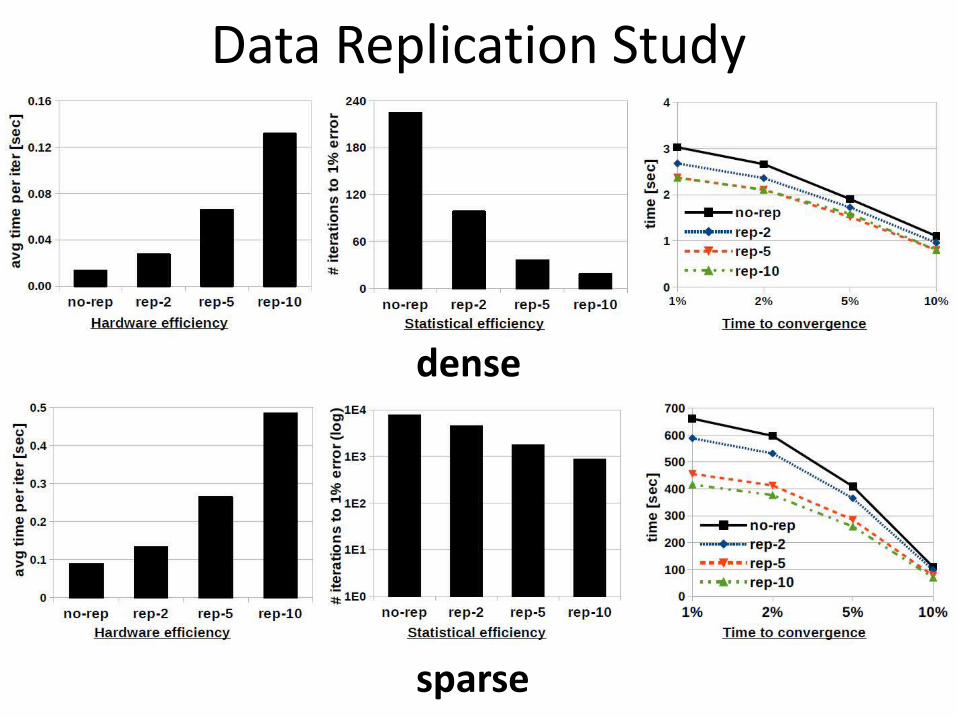
Data Replication Study
dense
sparse
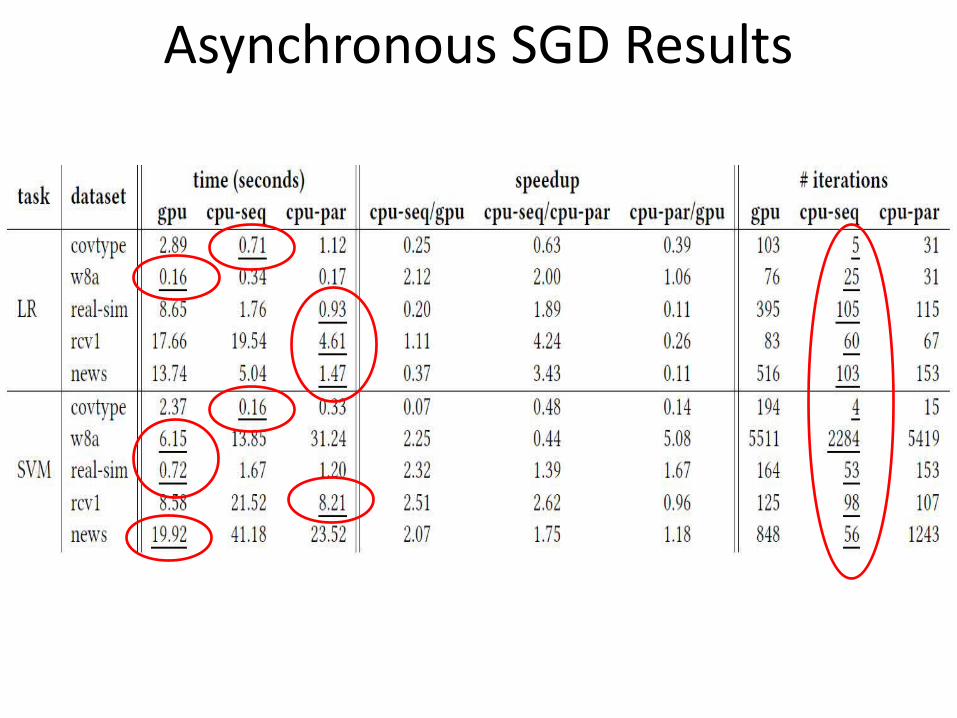
Asynchronous SGD Results

GPU Hogwild! Summary

Comparison with TF and BIDMach (LR)
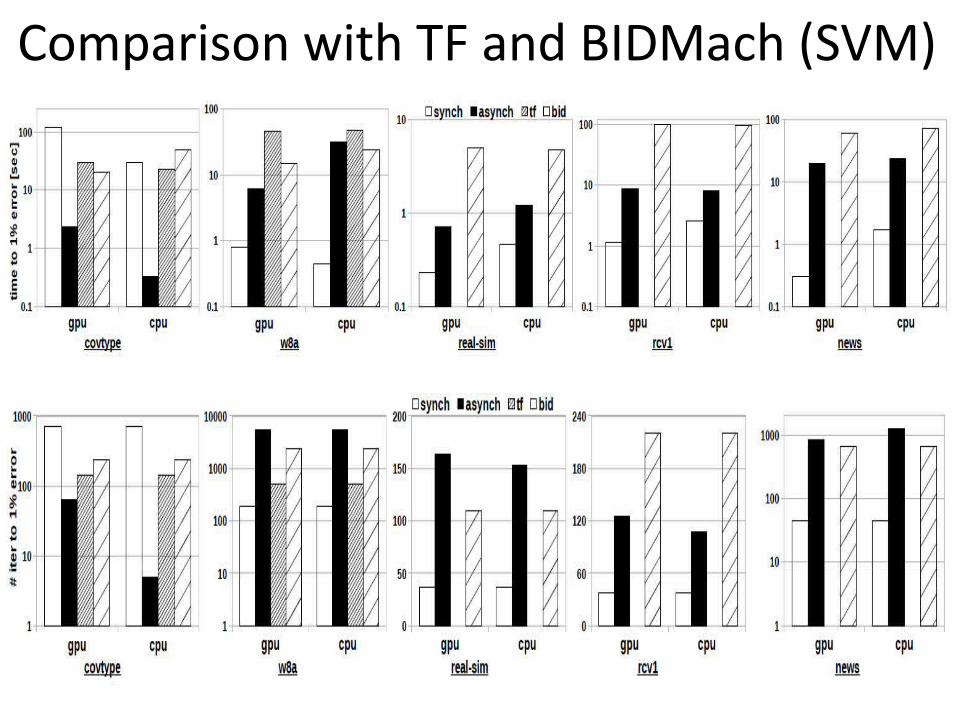
Comparison with TF and BIDMach (SVM)

Stochastic Gradient Descent Study
Exploratory axes Performance axes
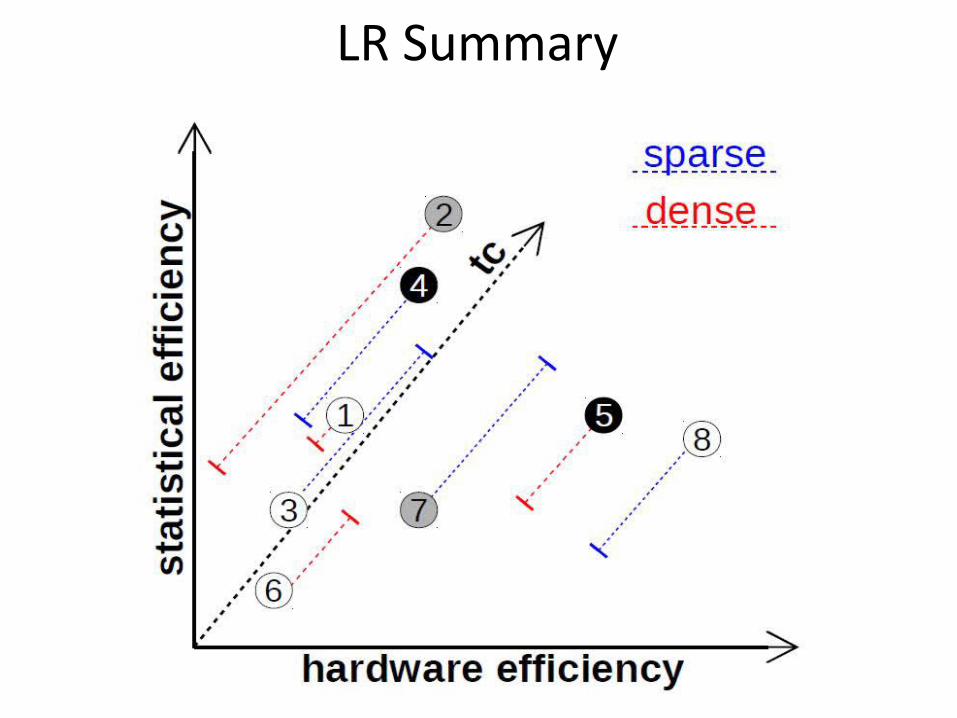
LR Summary
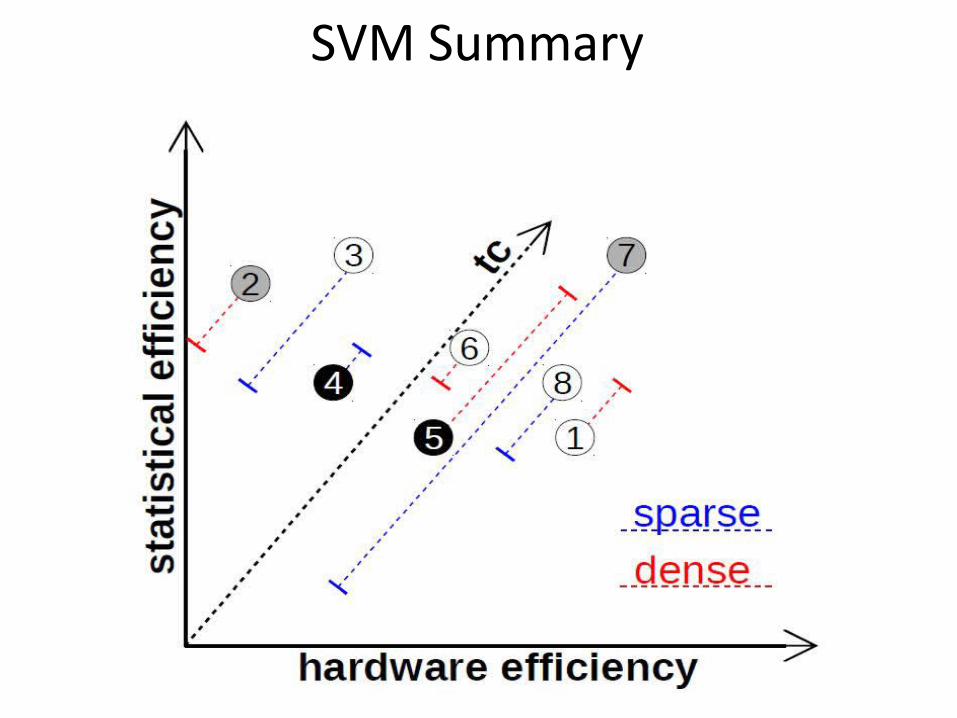
SVM Summary

Conclusions● The optimal configuration for a task is dependent on all the
exploratory axes
● Parallelization is always beneficial
– except for asynchronous SGD on low-dimensional models
● The performance of synchronous SGD on GPU is driven by the gradient formula and the quality of the linear algebra kernels
– ViennaCL kernels for sparse data are optimal for SVM● Efficient asynchronous SGD on GPU requires dense high-
dimensional models and sparse updates
– only w8a satisfies this property

Thank you.
Questions ???