frustration-reduced spark: dataframes and the spark time-series library
TRANSCRIPT

Frustration-Reduced Spark
DataFrames and the Spark Time-Series LibraryIlya Ganelin

Why are we here?Spark for quick and easy batch ETL (no streaming)Actually using data frames
Creation Modification Access Transformation
Time Series analysis https://github.com/cloudera/spark-timeseries http://blog.cloudera.com/blog/2015/12/spark-ts-a-new-
library-for-analyzing-time-series-data-with-apache-spark/

Why Spark?Batch/micro-batch processing of large datasetsEasy to use, easy to iterate, wealth of common
industry-standard ML algorithmsSuper fast if properly configuredBridges the gap between the old (SQL, single
machine analytics) and the new (declarative/functional distributed programming)

Why not Spark?Breaks easily with poor usage or improperly
specified configsScaling up to larger datasets 500GB -> TB scale
requires deep understanding of internal configurations, garbage collection tuning, and Spark mechanisms
While there are lots of ML algorithms, a lot of them simply don’t work, don’t work at scale, or have poorly defined interfaces / documentation

ScalaYes, I recommend Scala
Python API is underdeveloped, especially for ML Lib
Java (until Java 8) is a second class citizen as far as convenience vs. Scala
Spark is written in Scala – understanding Scala helps you navigate the source
Can leverage the spark-shell to rapidly prototype new code and constructs
http://www.scala-lang.org/docu/files/ScalaByExample.pdf

Why DataFrames?Iterate on datasets MUCH fasterColumn access is easierData inspection is easiergroupBy, join, are faster due to under-the-hood
optimizationsSome chunks of ML Lib now optimized to use
data frames

Why not DataFrames?RDD API is still much better developedGetting data into DataFrames can be clunkyTransforming data inside DataFrames can be
clunkyMany of the algorithms in ML Lib still depend on
RDDs
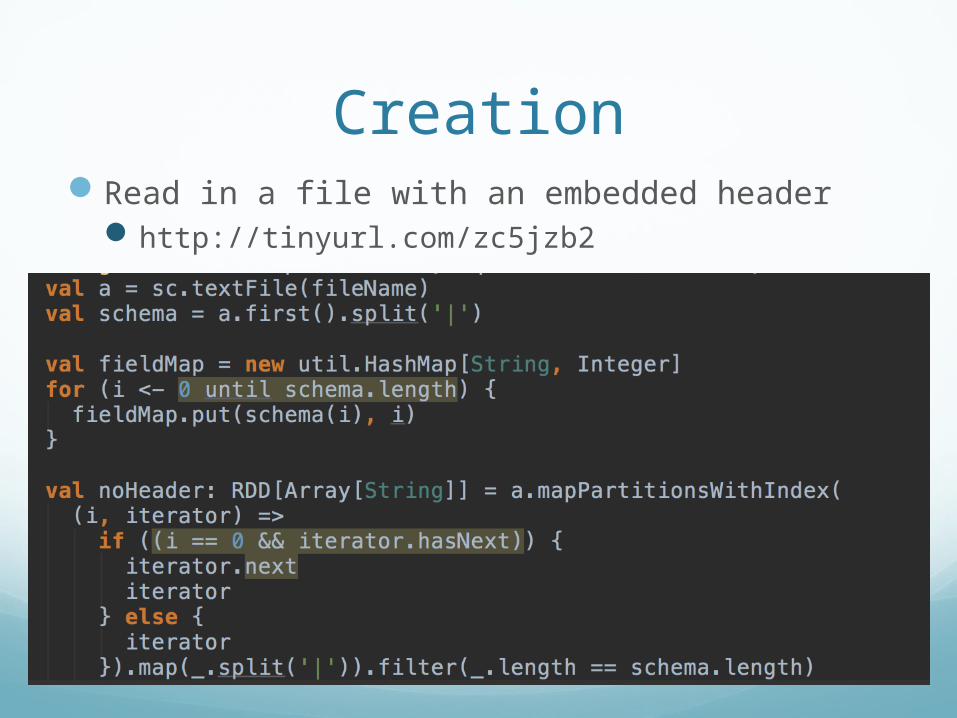
CreationRead in a file with an embedded header
http://tinyurl.com/zc5jzb2
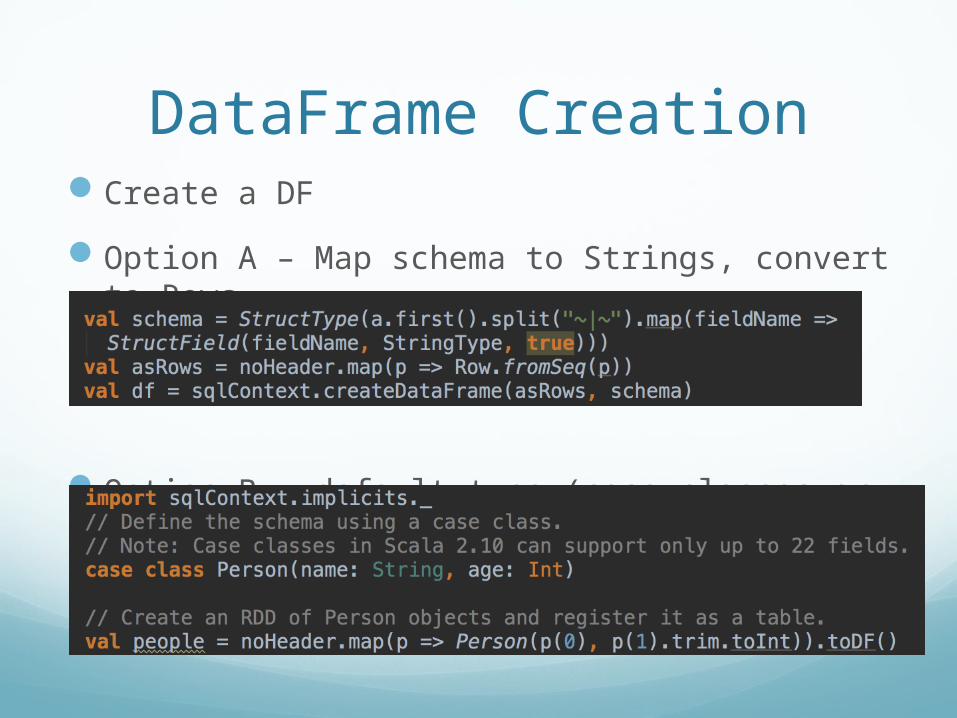
Create a DFOption A – Map schema to Strings, convert to
Rows
Option B – default type (case-classes or tuples)
DataFrame Creation
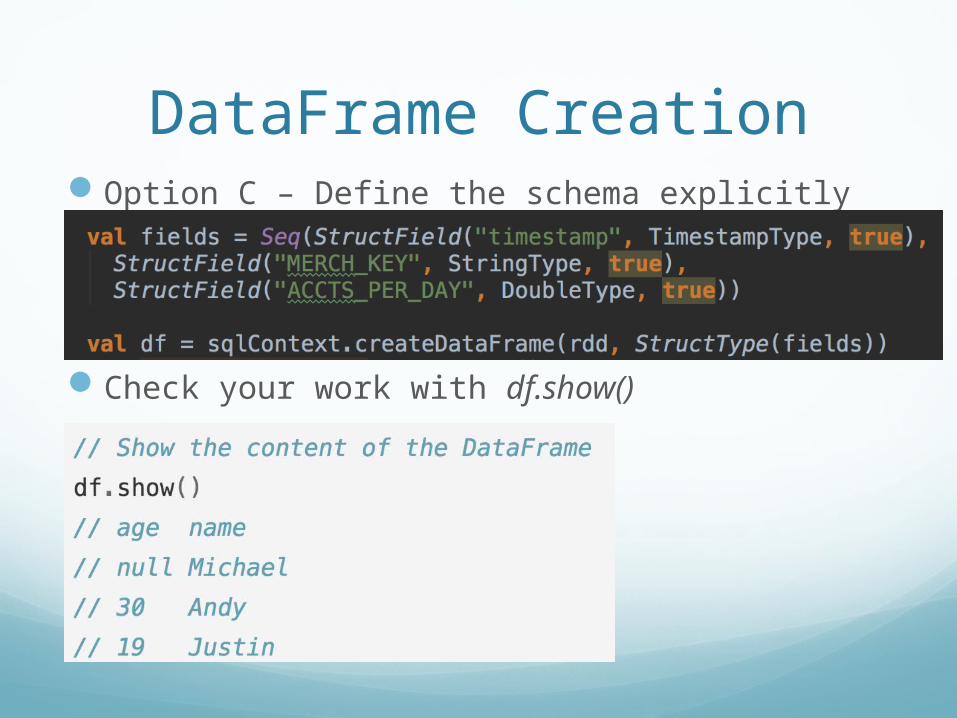
Option C – Define the schema explicitly
Check your work with df.show()
DataFrame Creation
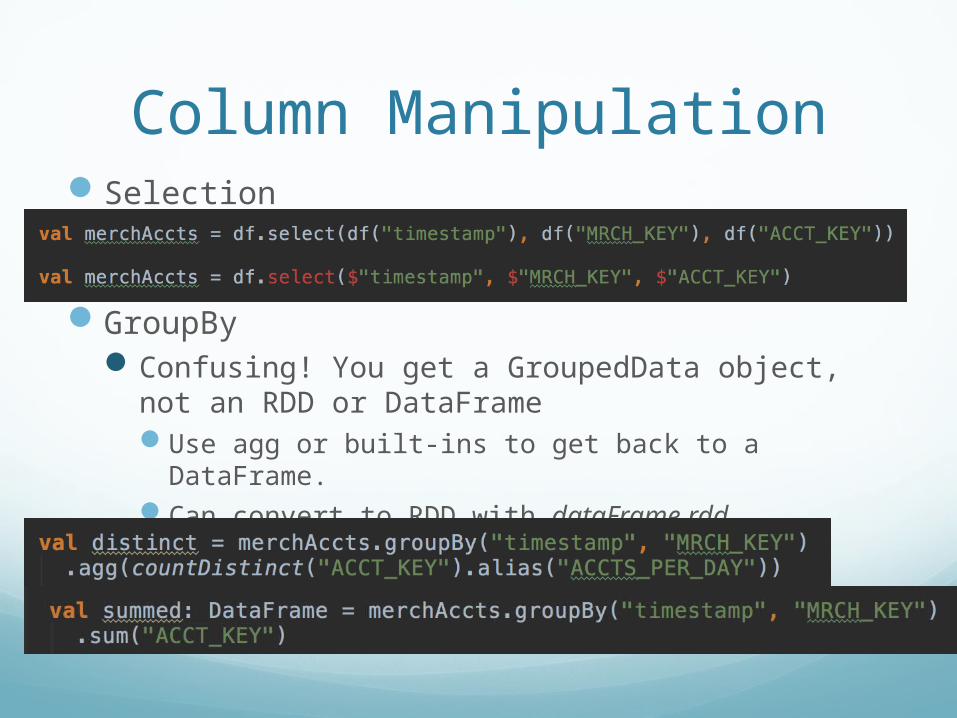
Column ManipulationSelection
GroupByConfusing! You get a GroupedData object, not an
RDD or DataFrameUse agg or built-ins to get back to a DataFrame.Can convert to RDD with dataFrame.rdd
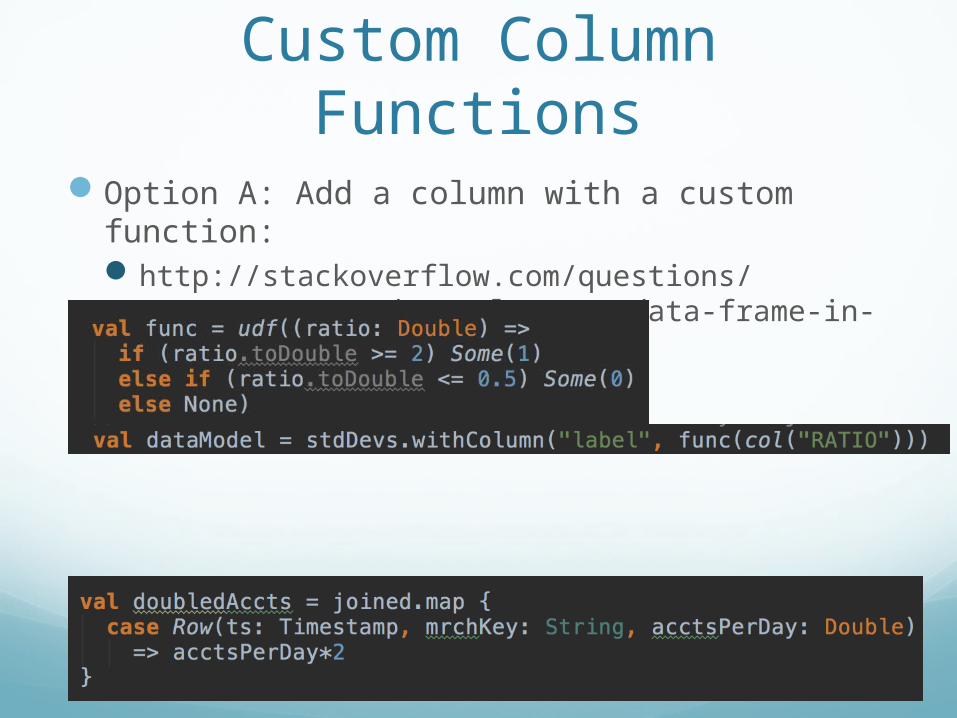
Custom Column FunctionsOption A: Add a column with a custom function:
http://stackoverflow.com/questions/29483498/append-a-column-to-data-frame-in-apache-spark-1-3
Option B: Match the Row, get explicit names (yields RDD, not DataFrame!)

Row ManipulationFilter
Range:
Equality:
Column functions

JoinsOption A (inner join)
Option B (explicit)
Join types: “inner”, “outer”, “left_outer”, “right_outer”, “leftsemi”
DataFrame joins benefit from Tungsten optimizations

Null HandlingBuilt in support for handling nulls in data frames.Drop, fill, replace https://spark.apache.org/docs/1.6.0/api/java/
org/apache/spark/sql/DataFrameNaFunctions.html

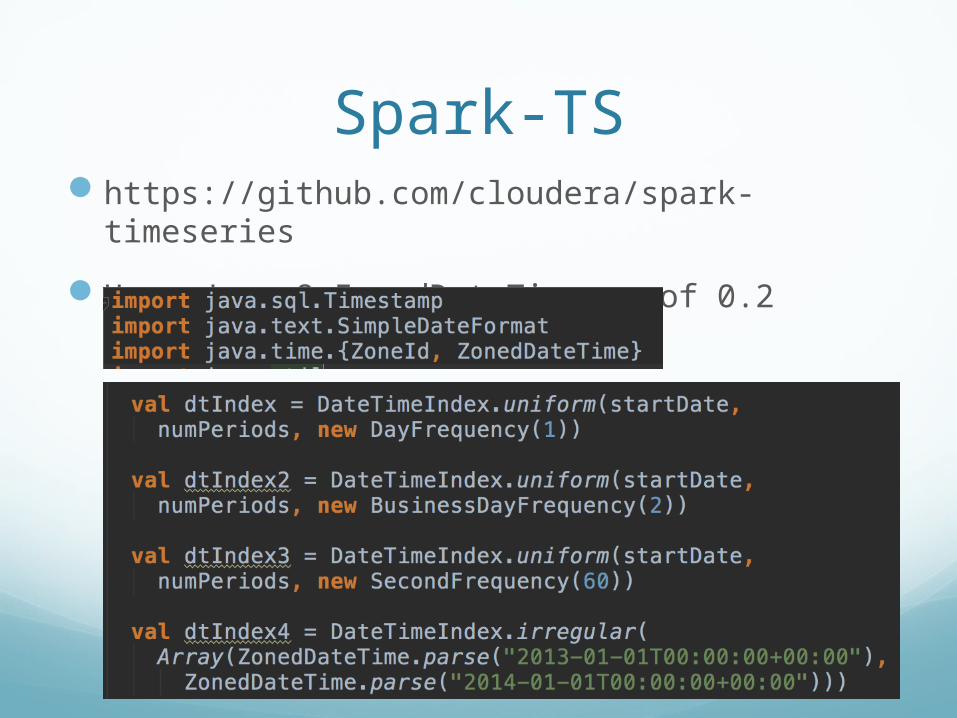
Spark-TShttps://github.com/cloudera/spark-timeseriesUses Java 8 ZonedDateTime as of 0.2 release:
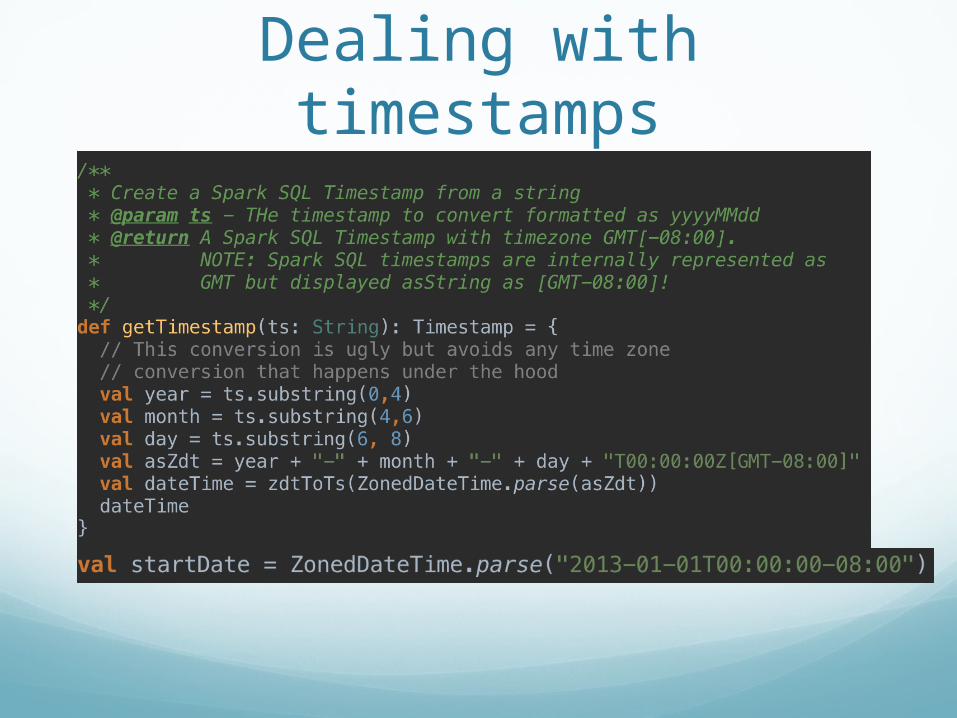
Dealing with timestamps

Why Spark TS?Each row of the TimeSeriesRDD is a keyed
vector of doubles (indexed by your time index)Easily and efficiently slice data-sets by time:
Generate statistics on the data:

Why Spark TS?Feature generation
Moving averages over timeOutlier detection (e.g. daily activity > 2 std-dev
from moving average)Constant time lookups in RDD by time vs.
default O(m), where m is the partition size

What doesn’t work?Cannot have overlapping entries per time index, e.g.
data with identical date time (e.g. same day for DayFrequency)
If time zones are not aligned in your data, data may not show up in the RDD
Limited input format: must be built from two columns => Key (K) and a Double
Documentation/Examples not up to date with v0.20.2 version => There will be bugs
But it’s open source! Go fix them

How do I use it?Download the binary (version 0.2 with
dependencies)http://tinyurl.com/z6oo823
Add it as a jar dependency when launching Spark:spark-shell --jars sparkts-0.2.0-SNAPSHOT-jar-with-
dependencies_ilya_0.3.jar

What else?Save your work => Write completed datasets to
fileWork on small data first, then go to big dataCreate test data to capture edge casesLMGTFY

By popular demand:screen spark-shell --driver-memory 100g \--num-executors 60 \--executor-cores 5 \--master yarn-client \--conf "spark.executor.memory=20g” \--conf "spark.io.compression.codec=lz4" \--conf "spark.shuffle.consolidateFiles=true" \--conf "spark.dynamicAllocation.enabled=false" \--conf "spark.shuffle.manager=tungsten-sort" \--conf "spark.akka.frameSize=1028" \--conf "spark.executor.extraJavaOptions=-Xss256k -XX:MaxPermSize=128m -XX:PermSize=96m -XX:MaxTenuringThreshold=2 -XX:SurvivorRatio=6 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC \-XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AggressiveOpts -XX:+UseCompressedOops"

Any Spark on YARNE.g. Deploy Spark 1.6 on CDH 5.4Download your Spark binary to the cluster and untar In $SPARK_HOME/conf/spark-env.sh:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/conf This tells Spark where Hadoop is deployed, this also gives it the
link it needs to run on YARNexport SPARK_DIST_CLASSPATH=$(/usr/bin/hadoop
classpath) This defines the location of the Hadoop binaries used at run
time

References http://spark.apache.org/docs/latest/programming-guide.html http://spark.apache.org/docs/latest/sql-programming-
guide.html http://tinyurl.com/leqek2d (Working With Spark, by Ilya
Ganelin) http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apa
che-spark-jobs-part-1/ (by Sandy Ryza)
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/ (by Sandy Ryza)
http://www.slideshare.net/ilganeli/frustrationreduced-spark-dataframes-and-the-spark-timeseries-library