fuzzing—orhowtohelpcomputerscopewiththeunexpected fuzzing...
TRANSCRIPT

Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
1
Fuzzing—or how tohelp computers copewith the unexpectedTesting the security of software before implementation can bea hit-and-miss affair, and is unlikely to discover every weakness.Toby Clarke and Jason Crampton explain how the techniqueof fuzzing can help in all stages of testing.

HE PRESENCE OF vulnerabilities in software appli-cations represents a significant risk to thesecurity of individuals, businesses and nationstates. As increasing reliance is placed upon
data and the systems that process and store it,the risk associated with vulnerabilities in softwareapplications increases.
In this article we will examine fuzzing: a specifictype of software security testing which can beused to discover vulnerabilities in software appli-cations.
We will begin by looking at software vulnerabil-ities and security testing in general, before focus-ing on fuzzing. After describing a basic modelof a fuzzer, we will identify and discuss four fun-damental problems that practical fuzzers haveto address. We will then explore three differentapproaches to a key aspect of fuzzer design: fuzztest data generation. Finally, we will examinewhat fuzzing can, and cannot, offer us.
Humans are rather good at coping with theunexpected, but computers, by default, are not.In the early days of computing, programs wereused exclusively by thoughtful, scientific peoplewho were very methodical and precise about
entering data.As computers became more common, a wider
range of people began to interact with computerprograms and data entry errors often led to pro-gram failures. The phrase “syntax error’’ drovemany users to distraction.
Developers tried to defend themselves with therallying cry “Garbage in, garbage out’’, and theage of the Graphical User Interface was usheredin to address the failings of the Command LineInterface (or as a means to contain the damageusers were capable of, depending on your view-point).
However, computers and computer programswere going to have to get a lot better at dealingwith unexpected data, because the wider popula-tion of humans were not only error prone, butsometimes actively malicious. Once computersbecame networked, software had to learn todefend itself.
SOFTWARE VULNERABILITIESSoftware vulnerabilities occur when an applica-tion permits the confidentiality, integrity or avail-
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
2
T

ability of data it processes or stores to be affectedin an unauthorized manner. In other words, a soft-ware vulnerability is a security compromise wait-ing to happen: an attacker can exploit the vulner-ability in order to read or modify the data thesoftware processes, or even take control of thecomputer system on which the applicationresides.
Vulnerabilities can stem from failings at allstages in the life cycle of an application. Thisincludes the software design and implementation(programming) phases of development, thedeployment and operational stages, right throughto the retirement and removal of an application.
Programming defects (’bugs’) are of particularconcern, since they are so common1 that it is usu-ally not economically viable to detect and correctevery bug during the development of an applica-tion.
Instead, bugs are typically rated in terms of therisk they represent, and resources are allocated toaddressing the most critical bugs until an agreed’bug bar’ of acceptable bugs is reached.
While it may be acceptable to release a com-mercial software application with hundreds oreven thousands of known bugs, bugs that havepotential to be exploitable (i.e. vulnerabilities)must be detected and corrected as far as possi-
ble. As well as protecting users and their data,this makes economic sense, since the cost of cor-recting vulnerabilities post-release is far greaterthan doing so pre-release [5].
SOFTWARE SECURITY TESTINGThe objective of software security testing is toidentify the presence of vulnerabilities, so that thedefects that cause them can be addressed. Secu-rity testing methods can be grouped into two keyareas: static and dynamic testing.
� Static testing usually involves analysis of thehigh-level application source code, but can alsobe performed using low-level assembly ’dead list-ings’ if the source is not available.
� Dynamic testing involves testing for vulnera-bilities by analysing the application as it executes;this means that access to the source code is nota requirement. Examples of dynamic softwaresecurity testing include API fault injection, whereerror messages are passed to the application atthe API-level, or run-time permissions auditing,where tools such as Sysinternals Accesschk,WinObj, or Process Explorer2 are used to test theapplication as it executes for inappropriately
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
3

weak access permissions—an example of this isprovided by Cerrudo [3].
Fuzzing is a form of dynamic software testingthat works by submitting malformed input(s) tothe target application to see if it causes an error.If a software application crashes as a result ofreceiving malformed input, the fuzzer has discov-ered a software defect.
Fuzzing can be thought of as a form of softwaresecurity performance testing. There are similari-ties between stress testing—“Can this applicationhandle 1000 simultaneous users?’’—and fuzz test-ing—“Can this application handle a URL with 256characters?’’. Indeed, the first ever fuzzer (appro-priately called fuzz), was developed to test therobustness of UNIX applications [9]. However,when a fuzzer is employed for security testing,the objective is usually not to determine whethera functional requirement is met, but to trigger anddetect software defects so that they may beaddressed.
The term fuzzer may be used to describe a widerange of tools, scripts, applications, and testingframeworks. However, most fuzzers share the fol-lowing features:
� Data generation (creating data to be passedto the target application);
� Data transmission (getting the data to thetarget);
� Target monitoring and logging (observing andrecording the reaction of the target); and
� Automation (reducing, as much as possible,the amount of direct user-interaction required tocarry out the testing regime).
One of the key aspects that differentiatefuzzers is test data generation. But before weexamine this topic, it would be useful to under-stand some of the problems that have shapedfuzzer development.
FOUR FUNDAMENTAL FUZZING PROBLEMSAt least four fundamental fuzzing problems mustbe addressed to produce an effective fuzzer. Thedegree to which a fuzzer addresses these prob-lems will significantly influence its success in dis-covering vulnerabilities.
1. Input Validation. Almost all commercial soft-ware applications incorporate some form of inputvalidation. In order to ensure that test data isprocessed by the application, a fuzzer should
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
4

generate malformed data that can also satisfyvalidation checks if possible. This does not neces-sarily require analysis of the target applicationsource code or design documents: validationchecks may be documented in a network protocolor file format specification.
2. Optimising Program State Coverage. A run-ning program can be thought of as a machinewhich moves through a number of states. Ideally,a fuzzer would ensure that every possible state is‘visited’’ during testing, by programmatically gen-erating and submitting every possible permuta-tion of input (termed the input space) to theapplication under test. Unfortunately, it is infeasi-ble to enumerate the input space of all but themost simple of programs. The best fuzzersattempt to optimise program state coverage,maximizing the number of potential security vul-nerabilities they discover, while reducing testduration.
3. Detecting Errors. It is not enough to triggerfailures: a fuzzer needs to be capable of detectingfailures, otherwise they cannot be reported to theanalyst.
4. Target Recovery.Once the target crashes,
testing must stop until the target has beenreturned to its normal running state. It would bevery useful to automatically return the target toits normal running state as this would allow unat-tended testing to be performed.
Solving the input validation problem involvescreating input that is malformed (in order tocause a crash) while also satisfying any integritychecks that the application may employ to vali-date input such as:
� content length checks as found in many net-work protocols such as Hyper Text Transfer Pro-tocol.
� checks for the presence of static values atspecific locations such as Java’s use of theCAFEBABE ’magic number’.
� self-referential checks such as cyclic redun-dancy checks (CRCs) found in the Portable Net-work Graphic (PNG) image file format.
Most applications employ checks to detectdata corruption, as opposed to active data tam-pering. Such checks can usually be circumventedby making the fuzzer ’aware’ of them. For exam-
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
5

ple, where static values are used, the fuzzer isinformed of this (either through a GUI or someform of configuration script) and can then gener-ate test data that includes the required value atthe required location. Where length checks areused, the fuzzer would have to re-calculate theseto ensure they correlate with malformed values.
Solving the program state coverage problemby enumerating all possible program states wouldrequire the generation of every possible combina-tion of input, which is simply infeasible for mod-ern software applications.
Instead, practical fuzzers focus upon trigger-ing errors and thus discovering fault states. Byaccepting that we cannot enumerate the entirestate space of an application, we may constructpractical fuzzers that can complete testing withinreasonable timescales, but we must also acceptthat there can be no assurance that they willdetect all present bugs. In practice then, fuzzingis like fishing for bugs; if you find none, you havelearned nothing. You cannot prove the absenceof bugs via fuzzing.
In fact, all software testing is subject to this lim-itation. The International Software Testing Quali-fications Board states that “Testing reduces theprobability of undiscovered defects remaining in
the software but, even if no defects are found,it is not a proof of correctness.’’ [8]
Most fuzzing is limited to input/output analy-sis, and can be classed as ’black box’ testing,since the internal workings of the target softwareare “invisible’’ to the tester. Extending fuzz testingto include analysis of the internals of the applica-tion (termed white-box fuzzing) provides oppor-tunities to address some of the issues relating toblack-box fuzzing.
Code coverage is one example of a white-boxfuzzing technique that offers feedback aboutfuzzer performance. Code coverage involvesmeasuring the amount of code that is executedduring a complete fuzzing session, and compar-ing this with the total code of the application.
If a fuzzing session results in 10% of the totalcode base being executed, it is obvious that thefuzz test has not been very effective (or a largeproportion of the code is not reachable frominput).
If a fuzzing session results in 100% of the totalcode base being executed, we can say we havesuccessfully traversed all possible code branches,but we can say nothing about what data waspassed to the application at each code branch.Hence, although it can provide some useful feed-back, code coverage does not necessarily provide
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
6

an accurate metric of fuzzer performance.
Solving error detection is achieved using anoracle, a generic term for a software componentthat monitors the target and reports a failure orexception. An oracle may take the form of a sim-ple liveness check, which merely “pings’’ the tar-get to ensure it is responsive, or it may comprisea debugger running on the target that can moni-tor for, and intercept, exceptions, and collectdetailed logging information.
Solving target recoverymay be as simple asautomatically restarting the target applicationbefore each individual test case is passed to it.However, this may be time consuming when mul-tiplied over a large number of test cases. An ele-gant approach is to integrate an oracle into thefuzzer and extend its functionality to allow it torestart the target if an exception occurs. Thisfunctionality is present in the Sulley fuzzingframework.3
Having described some of the requirementsfor effective fuzzing, we will describe threeapproaches to fuzzer test data generation and willexplore how these approaches address the inputvalidation and program state coverage problems.Although we will not cover exception monitoring
or target recovery any further, these subjects arediscussed in the technical report on which thisarticle is based [4, Chapter 7].
FUZZER TEST DATAGENERATIONThe objective of the test data generation aspectof a fuzzer is to induce failures in the target appli-cation. Almost all fuzzers create a large numberof individual ’input buffers’ or test cases, eachone of which will be passed as input to the appli-cation, one at a time.
A number of different data generationapproaches have been adopted, which can begrouped into one of the following classes: ran-dom, (blind) data mutation, and protocol-basedanalysis data generation.
Random data generation involves using a pseu-do-random generator to produce random testcases, minimizing the effort and time required ininitiating testing. However, random generation isthe least effective of the three classes in terms oftriggering bugs.
Using human language as an analogy, if I wereto approach you uttering random vowels and con-sonants at you, you would probably ignore me. Inorder to engage people verbally, I (usually!) shape
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
7

sounds into words that they recognise andarrange those words into a sequence that givesthem meaning; I obey lexical rules (use the rightwords) and grammatical rules (put the words inthe right order).
Modern software applications often apply
lexical and grammatical rules to determinewhether input will be processed or rejected.Ideally, fuzzer test data should conform to lexicaland grammatical rules to a degree sufficient to beaccepted into the application, but should also vio-late either the same rules or cause some violationof the program logic, in both cases triggering afailure.
Random data generation is highly inefficient
since it cannot account for lexical or grammaticalrules applied to input, nor can it apply any intelli-gence in terms of triggering failures. That doesnot mean that random generation fuzzing doesnot work: many bugs have been discovered thisway. However, this is arguably the least effectivemethod of test data generation, since a large ratioof test cases will likely be rejected by the targetapplication.
Data mutation brings together two importanttechniques: data capture and selective mutation.Valid input is captured and used as a means toquickly and easily define well-formed input.The captured data or mutation template is thenselectively mutated so the test data producedcontains much of the structure present in validinput.
For example, returning to our human languageanalogy, we might capture the valid introductorysentence “Can you talk?’’ and mutate it into “Canyou walk?’’.
In this way, we start out with a well-formedinput that will likely be accepted by the target,and we can then selectively mutate it, creatingboundary cases where input validation routinesstruggle to differentiate between valid and invalidinput.
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
8
“Random generation fuzzingis arguably the least effectivemethod of test data genera-tion, since a large ratio of testcases will be rejected by thetarget application.”

For example, if we are fuzz testing a web server,we might start with a valid HTTP GET requestsuch as:
GET /index.html HTTP/1.1
Malformed requests could then be generated atthe text level by simply replacing each characterof the input string with, say, the ’_’ underscorecharacter:
_ET /index.html HTTP/1.1G_T /index.html HTTP/1.1GE_ /index.html HTTP/1.1GET_/index.html HTTP/1.1
This is a form of ’blind’ fuzzing, since no knowl-edge of the protocol is required. By replaying andprogramatically altering an input buffer, we cancreate near-valid data, which has a number ofbenefits. Firstly, the efficiency is improved as thenumber of test cases which are rejected due tothe program’s inability to parse the input is great-ly reduced compared to random data creation.Secondly, we can target specific aspects of inputhandling because we isolate specific aspects ofinput and mutate them.
In general, software application input invariably
consists of a number of distinct data elementswhich are often processed by different parts ofthe application each using distinct techniques toparse the input.
When a web server processes an HTTP requestsuch as the one above, it will probably separate itinto three elements: ’GET’ (the method), ’index.html’ (the resource) and ’HTTP/1.1’ (the proto-col), each processed by a different routine. Byselectively mutating a valid request we can pro-duce test data with the potential to target specificprocessing routines. However, this is achievedwithout any awareness of the protocol.
Blind data mutation often fails to achieve goodcode coverage for a number of reasons. One flawis that it is limited to mutating the captured data.If we capture and mutate an HTTP GET requestin order to fuzz a web server, what about otherrequests such as POST, TRACE, HEAD and soon?
One solution is to capture multiple data sam-ples and create multiple mutation templates, butwhile each new template has the potential toincrease code coverage, it may increase testduration significantly.
Data mutation is a significant improvementover random fuzzing, since it can (albeit ’blindly’)account for lexical and grammatical rules.
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
9
However, this ’blind’ approach cannot accountfor checks over input data such as hashes orCRCs.
Protocol analysis-based data generation isbased on the fact that application input dataoften conforms to a protocol of some sort. A’protocol aware’ fuzzer can be created by defining
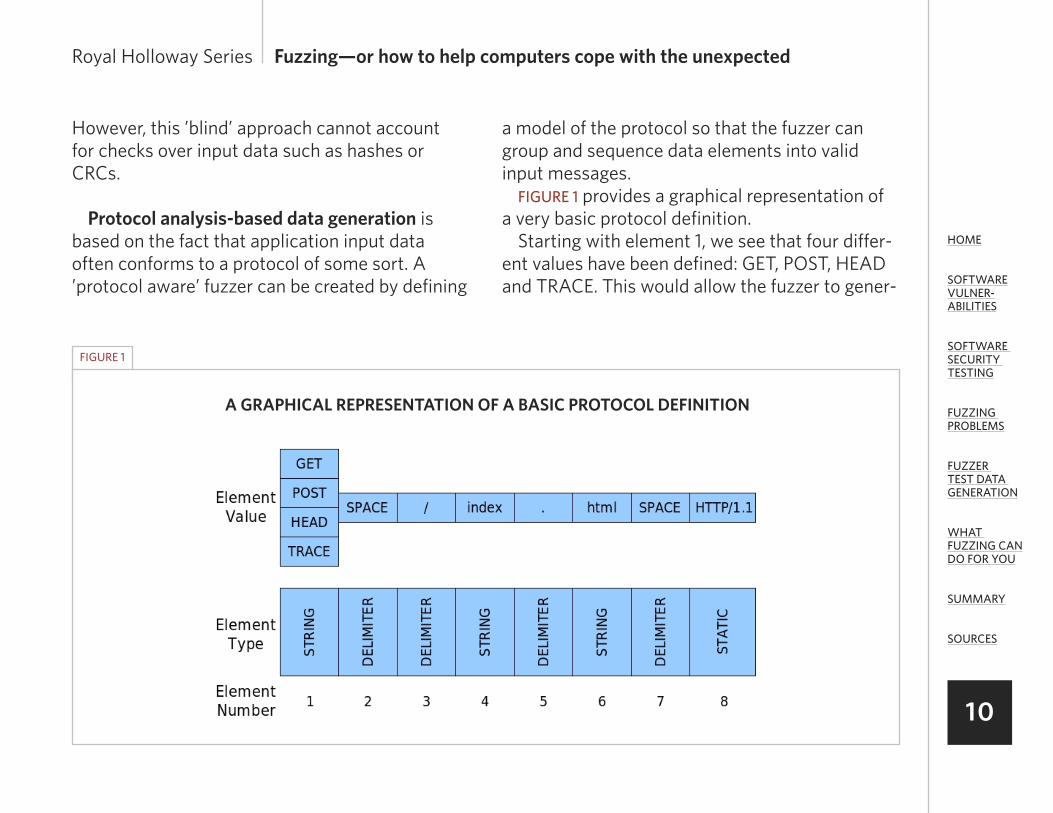
a model of the protocol so that the fuzzer cangroup and sequence data elements into validinput messages.FIGURE 1 provides a graphical representation of
a very basic protocol definition.Starting with element 1, we see that four differ-
ent values have been defined: GET, POST, HEADand TRACE. This would allow the fuzzer to gener-
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
10
FIGURE 1
AGRAPHICAL REPRESENTATIONOF A BASIC PROTOCOL DEFINITION

ate GET, POST, HEAD and TRACE requests,extending code coverage by satisfying lexical andgrammatical rules.
Element 1 has been defined as being a stringtype. The fuzzer can use this information toreplace the element with a range of mutation ele-ments that are specifically aimed at triggering
bugs in string handling routines.Element 2 has been defined as a delimiter type.
In general, fuzzers do not fuzz all elements simul-taneously but selectively fuzz each element indi-vidually while replaying valid values for the rest ofthe elements. In this way a fuzzed element is fol-lowed by the correct delimiter, increasing the like-
lihood that it will be processed. The fuzzer canalso replace this element with mutation elementsthat are known to cause problems with delimiters.
Element 8 has been defined as a static type.This element will not be fuzzed, reducing thenumber of test iterations.
Only a few element types are present in ourexample, but many more could be used to definedata types such as integers, signed integers, char-acters, bits, etc.
This block-based approach can be extended toinclude elements that describe aspects of otherelements, allowing valid CRCs or hashes to becalculated for input buffers. Content lengthdescriptors and element size descriptors are fea-tured in many protocols, and can also be con-structed and deployed within a block-basedapproach.
SPIKE4 is an excellent example of a block-based fuzzer framework (its creator, Dave Aitel,has also produced numerous valuable articlesand presentations on fuzzing including [1] and[2]). My favourite fuzzer development frameworkSulley5 also applies a block-based approach toprotocol definition.
A fuzzer that has a protocol definition can iden-tify individual data elements and their types, andapply intelligence to triggering faults. This is often
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
11
“This block-based approachcan be extended to includeelements that describeaspects of other elements,allowing valid CRCs or hashesto be calculated for inputbuffers.”

achieved by deploying a database of distinctclasses of known-bad data buffers (which couldbe termed mutation elements) and enabling thefuzzer to target individual element types withtype-specific attacks.6
Protocol-based fuzzing is able to bring togethera protocol definition and a database of known-bad buffers in order to create test data that islikely to result in a high degree of code coverageand have a high probability of triggering faults.Block-based fuzzing frameworks can be used toconstruct protocol-based fuzzers.
WHAT FUZZING CANDO FOR YOUNow that we have described what a fuzzer isand how it works, let’s take a brief look at whatfuzzing has to offer us:
NO REQUIREMENT FOR SOURCE CODE. What ifyou wanted to assess and compare the securitystance of three different closed-source softwareproducts? You could ask for evidence of softwaredevelopment quality assurance, or examine thehistory of vulnerabilities in each vendor’s prod-ucts (although it could be argued that the moremistakes a vendor makes, the more the vendorlearns about secure software development).
Fuzzing, like all forms of run-time testing, offersa means to discover flaws in software applica-tions without access to the source code.
VIOLATION OF ASSUMPTIONS/SCOPE LIMITA-TION. What if, as a developer, an external compo-nent you are relying upon has a defect? What ifyour application exposes a vulnerable aspect of athird party driver or the operating system itself?What if, as a tester, your scope is limited?
One benefit of not having access to informationabout the inner workings of an application is thatthe test cannot be influenced by this information.There is always a risk that the scope of testingwill be restricted based on misplaced trust; anexample of this would be reviewing the sourcecode of an application, but failing to review thesource code of third party drivers or even the hostOperating System itself.
Such scope limitation is usually impossible toachieve when fuzz testing. In fact, the behaviourof an application undergoing fuzz testing is highlyunpredictable; this is why fuzzing should never beperformed in a live, production environment.
The unpredictability of fuzzing, and the factthat it tests the application and the environmentit executes in, prevents misplaced assumptionsand scope restriction; fuzzing is capable of dis-
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
12

covering bugs in an application and any code itinteracts with.
FUZZING IDENTIFIES REACHABLE BUGS ONLYAND PROVIDES PROOF OF CONCEPT CODE. Allsecurity testing methods (static or dynamic) aresubject to false positives; they discover bugs thatappear to be a security vulnerability, but are infact not exploitable.
One class of false positives are potential vulner-abilities that can’t be triggered by input, andhence are not exploitable. An example of an suchan ’unreachable’ vulnerably would be a call to avulnerable function that is present in the programcode, but can never be executed.
Because fuzzing works by sending malformedinput, it cannot discover unreachable bugs, savingthe analyst the effort of assessing each potentialvulnerability for reachability. Fuzzing is perhapsunique among security testing methods in thisaspect of its behaviour.
Additionally, since fuzzing reports the specificinput buffer that triggered a given bug (usually byidentifying the test case that caused the crash),fuzzers provide demonstrable, repeatable evi-dence of a defect—a crude form of proof of con-cept code.
Here’s a look at what Fuzzing cannot offer:
FUZZING PROVIDES NO ASSURANCE. No testingtechnique can provide concrete assurance. How-ever, fuzzing may be more likely to miss bugsthan other testing techniques. A fuzzer may fail totrigger the relevant program state, it may fail tosubmit data sufficient to trigger a bug, and it mayfail to detect a triggered bug.
Fuzzing can be used to discover bugs, not toprovide assurance of their absence.
FUZZING IDENTIFIES BUGS, NOT SECURITYVULNERABILITIES. All dynamic testing, includingfuzzing, aims to identify bugs. However, not allbugs are vulnerabilities. Skilled analysis of bugsdiscovered using fuzz testing is usually requiredin order to determine whether a bug is exploit-able, and rate the associated risk. An exampleapproach to ranking bugs discovered usingfuzzing is provided by Howard and Lipner [7].
SUMMARYWe have seen that fuzz testing provides amethod for discovering vulnerabilities by trigger-ing software defects using malformed input(s) asthe application executes. We have described fourfundamental problems that a fuzzer shouldaddress, and we have explored three different
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
13

approaches to generating test data. Finally, wehave suggested some of the benefits and draw-backs of fuzzing.
Regarding the comparison of fuzzing withsource code analysis: it has been argued thatsource code review provides more assurance [11],and also that fuzzing finds bugs that static testingcannot [10]. I would argue that the two are com-plementary; that both offer unique methods todiscover vulnerabilities, and that neither shouldbe neglected.
The author would like to think that this articlemay encourage more IT professionals to considerhow they might take advantage of fuzz testing,and to do so with a clear idea of its limitations aswell as its benefits. I welcome any feedback, andinvite readers to comment on any aspect of thispaper. �
ABOUT THE AUTHORS
Toby Clarke is a security consultantproviding penetration testing services withinKPMG's IT Advisory Practice
Dr. Jason Crampton is a reader ininformation security at Royal Holloway, Univer-sity of London, with research interests in accesscontrol. He teaches the course in ComputerSecurity on the M.Sc. in Information Securityat Royal Holloway.
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
14

Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
15
SOURCES:
1One estimate suggests that even when software development is subject to strict Quality Assurance controls, 5 bugsmay be present per 1000 lines of code [6].
2http://technet.microsoft.com/en-us/sysinternals/default.aspx
3http://www.fuzzing.org/
4http://www.immunityinc.com/resources-freesoftware.shtml
5http://www.fuzzing.org/
6A detailed examination of a selection of the attack buffers employed by the SPIKE fuzzing framework (created by DaveAitel) is included in Appendix B3 of [4].

REFERENCES:
[1] Dave Aitel. The advantages of block-based protocol analysis for security testing, 2002.
[2] Dave Aitel. MSRPC fuzzing with SPIKE 2006. On-line article, August 2006.
[3] Cesar Cerrudo. Practical 10 minute security audit Oracle case. On-line article. Argeniss Information Security, Presenta-tion at Black Hat DC 2007.
[4] Toby Clarke. Fuzzing for software vulnerability discovery. Technical Report RHUL-MA-2009-4, Information SecurityGroup, Royal Holloway, University of London, 2008.
[5] Erwin Erkinger. Software reliability in the aerospace industry—how safe and reliable software can be achieved. 23rdChaos Communication Congress presentation, 2006.
[6] Greg Hoglund and Gary McGraw. Exploiting Software: How to Break Code. Pearson Higher Education, 2004.
[7] Michael Howard and Steve Lipner. The Security Development Lifecycle. Microsoft Press, Redmond, WA, USA, 2006.
[8] Thomas Maller, Rex Black, Sigrid Eldh, Dorothy Graham, Klaus Olsen, Maaret Pyhajarvi, Geoff Thompson, Erik van Veen-dendal, and Debra Friedenberg. Certified tester—Foundation level syllabus. On-line article, April 2007.
[9] Barton P. Miller, Louis Fredriksen, and Bryan So. An empirical study of the reliability of UNIX utilities. Communications ofthe ACM, 33(12):32-44, 1990.
[10] David Thiel. Exposing vulnerabilities in media software. Black Hat conference presentation, BlackHat EU 2008.
[11] JacobWest. How I learned to stop fuzzing and find more bugs. Defcon conference presentation, August 2007.
Royal Holloway Series Fuzzing—or how to help computers cope with the unexpected
HOME
SOFTWAREVULNER-ABILITIES
SOFTWARESECURITYTESTING
FUZZINGPROBLEMS
FUZZERTEST DATAGENERATION
WHATFUZZING CANDO FOR YOU
SUMMARY
SOURCES
16