generalized minimum spanning tree problem, independent set problem y flexible job shop problem:...
TRANSCRIPT

Generalized Minimum Spanning Tree Problem, Independent Set Problem y
Flexible Job Shop Problem: Implementación de solución mediante
algoritmos genéticos
Alcívar Cevallos Roberth Abel, Contreras Fernández Juan Pablo, Párraga Álava Jorge
Antonio.
(roberth.alcivar, juan.contrerasff, jorge.parraga)@usach.cl
Universidad de Santiago de Chile
Avenida Libertador Bernardo O'Higgins nº 3363. Estación Central. Santiago. Chile

Resumen
Con el objetivo de utilizar algoritmos genéticos en la resolución de los problemas de
optimización conocidos como Generalized Minimum Spanning Tree Problem, Independent
Set Problem y Flexible Job Shop Problem se realizó un reconocimiento de las
particularidades de cada uno de ellos. Al realizar el análisis fue posible modelar el
problema a través de la identificación de una solución inicial factible, función fitness y
operadores de variación; de esta manera se codificó la solución mediante algoritmos
genéticos, y mediante el software matemático MATLAB, siendo imperioso el uso de
instancias para cada uno de los problemas. En seguida, con el código en ejecución, se
definió la población inicial y sus generaciones sucesoras hasta llegar a obtener soluciones
óptimas para cada problema. Se alcanzó 95.28% de eficacia en el primer problema, 62.31%
en el segundo y 82.42% en el tercero. Finalmente se plasman las conclusiones y exponen los
recursos bibliográficos utilizados.
Palabras clave Algoritmos Genéticos, Generalized Minimum Spanning Tree, Independent
Set Problem, Flexible Job Shop.

1
1. Introducción
John Holland desde pequeño, se preguntaba cómo logra la naturaleza, crear seres
cada vez más perfectos (aunque, como se ha visto, esto no es totalmente cierto, o en todo
caso depende de qué entienda uno por perfecto). Lo curioso era que todo se lleva a cabo a
base de interacciones locales entre individuos, y entre estos y lo que les rodea. No sabía la
respuesta, pero tenía una cierta idea de cómo hallarla: tratando de hacer pequeños modelos
de la naturaleza, que tuvieran alguna de sus características, y ver cómo funcionaban, para
luego extrapolar sus conclusiones a la totalidad. En los años 50 entró en contacto con los
primeros ordenadores, donde pudo llevar a cabo algunas de sus ideas, aunque no se encontró
con un ambiente intelectual fértil para propagarlas. Años después aprendió que la evolución
era una forma de adaptación más potente que el simple aprendizaje, y tomó la decisión de
aplicar estas ideas para desarrollar programas bien adaptados para un fin determinado
naciendo así los algoritmos genéticos (AG). [1]
Sin embargo no fue hasta 1989 cuando los AG se hicieron famosos, gracias a
Goldberg, y debido a que la finalidad de estos es la de optimizar cuando las técnicas
tradicionales presentan dificultades. Por ello, los AG se pueden aplicar a numerosos campos,
desde la ingeniería, hasta el modelado económico, social, político o comercial. [2]
Muchos han sido los problemas clásicos que han sido resueltos mediante AG entre
ellos el problema del agente viajero [3] en el paper titulado “Algoritmo genético para el
problema del agente viajero aprovechando las capacidades de GEOQ” mejora las
heurísticas constructivas para la inicialización de la población, e incorpora dos nuevos
operadores de cruzamiento y dos de mutación, mediante un análisis de visibilidad y
proximidad.
De igual modo el problema del coloramiento de vértices [4] fue solucionado en el
trabajo “Implementación de un algoritmo genético paralelo sobre hardware gráfico de
última generación”, de igual manera “Algoritmos genéticos: Aplicación al problema de la
mochila” realizado por [5]. De allí que en este trabajo se pretende utilizar algoritmos

2
genéticos para solucionar los problemas: árbol de cobertura mínimo generalizado, conjunto
independiente de vértices y taller de tareas flexibles.
2. Caracterización del problema
2.1. Problema del Árbol de Cobertura Mínima Generalizado (MSGTP)
El problema del Árbol de Cobertura Mínima consiste en un grafo no dirigido cuyos
nodos son divididos en clúster. Se busca encontrar un árbol de cobertura de costo mínimo
que incluya solo un nodo de cada clúster.
Se trata de un grafo no dirigido multipartito G (V, E) cuyos vértices están dividido en
m subconjuntos {V1, V2, ..., Vm}, con |V| = n, tal que V= V1UV2…UVm; y V1∩Vk = Θ ∀ l, k ∈ {1, … m}, l≠k. G sólo tiene aristas entre vértices de diferentes subgrupos, y se supone que
cada arista tiene un coste negativo asociado. Definimos el problema generalizado árbol de
expansión mínima (GMSTP) como el problema de encontrar un árbol de coste mínimo que
se extiende exactamente un vértice de cada clúster. En la ilustración 1 se aprecia un ejemplo
del (GMSTP) con 5 clúster y 17 vértices. [6]
Ilustración 1. Ejemplo de (GMSTP) con 5 clúster y 17 vértices.

3
2.2. Problema del conjunto independiente de vértices máximo (MISP)
En teoría de grafos, el problema del conjunto independiente o estable es un conjunto
de vértices en un grafo tal que ninguno de sus vértices es adyacente a otro. Es decir, es un
conjunto V de vértices tal que para ningún par de ellos existe alguna arista que los conecten.
En otras palabras, cada arista en el grafo contiene a lo más un vértice en V. El tamaño de un
conjunto independiente es el número de vértices que contiene. [7]
Ilustración 2. Coberturas de vértices (conformadas por los vértices rellenos)
El conjunto independiente máximo corresponde al mayor conjunto independiente
definible sobre un grafo dado. El problema de encontrar un conjunto con estas características
se llama problema del máximo conjunto independiente y es NP-completo.
.
Ilustración 3. Grafo con seis diferentes conjuntos independiente de vértices. (conformadas por los vértices rellenos)

4
2.3. Problema del taller de tareas flexibles (FJSP)
El problema del Job shop flexible (Flexible Job Shop Scheduling Problem: FJSSP) es
considerado como una variante del problema del job shop original. Dado un sistema con un
conjunto de m máquinas, M={M1,...,Mm}, y un conjunto de n trabajos independientes, J =
{J1,...,Jn}. Considerando que cada trabajo está compuesto por una secuencia de operaciones
O{j,1}, O{j,2},...,O{j,h},...,O{j,hj}, cada una de las cuales debe ser procesada en una máquina.
Se dispone de los tiempos de proceso p{i,j,h} de cada operación O{j,h} en cada máquina
factible Mi ∈ M{j,h} ⊆ M, el problema de Job Shop Flexible requiere minimizar el tiempo
de completación de la última operación: el makespan.
Donde:
O{j,h} corresponde a la h-ésima operación del trabajo J j y hj indica el número de
operaciones que requiere el trabajo Jj.
M{j,h} ⊆ M es el conjunto de todas las máquinas en el problema que pueden
procesar la operación O{j,h}.
Cuando todas las operaciones pueden ser procesadas por todas las máquinas,
M{j,h} = M, la flexibilidad del problema es total (T-FJSP). Por el contrario,
cuando al menos una operación O{j,h} no puede ser procesada en todas las
máquinas, es decir M{j,h} ⊂ M, la flexibilidad del problema es parcial (P-FJSP).
Se conoce el tiempo de proceso de cada operación en cada una de las máquinas
donde puede ser procesada. Se denota como p{ i,j,h} el tiempo de proceso de la
operación O{j,h} en la máquina Mi ∈ M{j,h}. No se permite interrumpir las
operaciones cuando han iniciado su proceso, como tampoco se permite que las
máquinas ejecuten más de una operación simultáneamente. Además, se asume
que todos los trabajos y máquinas están disponibles en el instante (tiempo) cero.
Para encontrar el tiempo de completación de la última operación (makespan) es
necesario asignar las operaciones a las máquinas y secuenciar dichas
operaciones, por lo cual la función objetivo del problema se puede expresar
como:
min Cmax = min {maxJj ∈ J CJj}

5
Un ejemplo de este problema se muestra a continuación.
Ilustración 4. Estructura de asignación del problema de programación de taller de trabajo
3. Materiales y Métodos
3.1. Materiales
Para la exitosa solución del problema fue necesario crear los programas informáticos
que se detallan en el punto 3.2, para el efecto se utilizó MATLAB. En cuanto al hardware,
para el apartado de programación, ejecución de pruebas y validación de resultados, se utilizó
un equipo con Sistema operativo Microsoft Windows 7® en su versión de 64 bits, tipo
notebook Samsung q430, Procesador Intel i5 m520 a 2.4ghz, Memoria ram de 4gb.
3.2. Métodos
Para los tres problemas propuestos el proceso evolutivo seguido se describe en el
algoritmo [8] a continuación:

6
InicioGeneracionInicial()para t 0 hasta N_Individuos hacer
Evaluacion de individuo tfin paraGeneracion 1mientras Generacion <= N_max_Generaciones hacer
para t 0 hasta N_Individuos hacerSelección (Dependiendo de cada problema)Cruzamiento(Dependiendo de cada problema)Mutacion(Dependiendo de cada problema)
fin paramientras t 0 hasta N_Individuos hacer
Evaluacion de individuo tfin mientrassi el mejor individuo es optimo entonces
Terminar AGfin siGenerar nueva población()Generacion Generacion +1
fin mientrasFin
El algoritmo genético usado lo que hace es operar en la modalidad genotipo fenotipo
cuyos pasos son:
1. Generar población inicial de soluciones factibles.
2. Evaluar cada solución según su factibilidad con la función objetivo del
problema.
3. En cada generación se crean y evalúan nuevas soluciones con el uso de
operadores de selección:
a. Selección: Torneo.
b. Cruzamiento: Dependiendo del problema.
c. Mutación: Dependiendo del problema.
4. Los puntos anteriores son repetitivos hasta el momento que se encuentre la
solución optimo o se alcance el máximo número de generaciones.
3.2.1. Problema del Árbol de Cobertura Mínima Generalizado (GMSTP)

7
Para este problema la representación mediante string, función fitness, operadores de
variación y el proceso evolutivo usada por el algoritmo genético fueron basadas en el estudio
realizado por Contreras et al. [8].
3.2.1.1. Representación
Se usará representación entera. El string entero tendrá largo m (total de clústers),
donde cada i-ésimo posición representa a un clúster. Y cada i-ésimo valor corresponde al
vértice seleccionado en el i-ésimo clúster. Este i-ésimo valor puede ir de 1 a c (cantidad
mayor de vértice del clúster).
En el caso que en la i-ésimo posición aparece un valor mayor al total de vértices al
contenido en la posición que representa a ese clúster, se aplica la función MODULO1entre el
i-ésimo valor y total de vértices de ese clúster.
Ilustración 5. Ejemplo de (GMSTP) con 5 clúster y 17 vértices.
Tomando como ejemplo la ilustración 5. El string tendrá largo m=5; y cada posición
tendrá un valor que representa al vértice seleccionado en el i-ésimo clúster, este valor estará
1 Función que devuelve el residuo de una división.

8
entre 1 y c=5. De este modo se muestra un string donde el clúster 1 tiene seleccionado el
vértice 3, clúster 2 el vértice 3, clúster 3 vértice 5, clúster 4 vértice 1, clúster 5 vértice 1.
3 3 5 1 1
Sin embargo, los clúster 2 y 3 presentan vértices que no están disponibles en esos
clúster por lo que se aplica la función modulo. En el caso del clúster 2 (3/2) obteniendo
como residuo 1 y clúster 3 (5/3) residuo 2, por lo que el string quedaría sin problemas de
infactibilidades en sus valores.
3 1 2 1 1
En forma resumida, una solución del problema es un subgrafo T que cumpla dos
condiciones:
1. T es árbol 2. T contiene un y sólo un vértice de cada cluster.
Un cromosoma de nuestro problema será un arreglo de largo igual a la cantidad de
clúster donde, en cada celda, se indicara el número del nodo que se debe tomar del clúster
correspondiente a ese índice de celda. Así estamos trabajando con un cromosoma que puede
ser de números enteros o reales pero al ser codificado en Matlab se tomará únicamente parte
entera, es decir números que se mueven entre 1 y la cantidad de nodos en el clúster.
El cromosoma, por tanto, indica cuales nodos son los seleccionados para configurar
el árbol solución T. Las aristas del árbol T se escogerán como las aristas que resuelvan el
problema del árbol de cobertura mínimo para los nodos seleccionados. Recordamos en este
punto que para resolver el problema del árbol de cobertura de peso mínimo existen
algoritmos polinomiales O(|V|2+|E|) donde V y E corresponden a los vértices y aristas del
grafo respectivamente.

9
3.2.1.2. Función Fitness
La función de fitness se aplica sobre cada string para saber que tan bien se adapta
esta al problema. Notemos que con la codificación elegida se obtienen solo soluciones
factibles por lo tanto no hay necesidad de agregar un término de penalización.
Así, definimos el fitness de un individuo como el peso del árbol de cobertura de peso
mínimo que se puede formar para la configuración de vértices que define este individuo.
3.2.1.3. Generación de población inicial
Para generar la población inicial se crean 1000 individuos de forma aleatoria, según
la cantidad de vértices y aristas que tenga cada una de las instancias.
3.2.1.4. Operadores de Cruzamiento y Mutación
A pesar que teóricamente el string o cromosoma puede ser de números enteros o
reales, en la práctica lo que se hizo fue considerar solo la parte entera aplicando funciones
para ello (propias de matlab), en conjunto con la función módulo explicada en el punto
3.2.1.1. De este modo podremos usar cualquier operador de variación definido para este tipo
de codificación. En este caso usamos cruzamiento 1 Point Crossover y Random Resseting
[9] para la mutación.
3.2.1.5. Parámetros genéticos
Se utilizaron las instancias de 53gil262, 34gr229, 27pr264, 21eil101, 30kroa150,
1pr152, 34gr202europe, 40krob200, 12brazil58, 10att48. Todas tienen un valor óptimo
Min f ( x )=∑e∈E
❑
Ce∗Xe

10
conocido. Número máximo de generaciones = 20, probabilidad de cruzamiento= 0.90 y
probabilidad de mutación 0.10 y la selección mediante Tournament2.
3.2.1.6. Codificación
Para encontrar la solución al subproblema del árbol de cubrimiento de peso mínimo y
evaluar la función fitness se utilizó el algoritmo de Kruskal 3 (se van escogiendo las aristas
de menor peso sin formar ciclos hasta conseguir un árbol de peso mínimo), uno de los más
usados para resolver este problema, y cuyo seudocódigo se describe a continuación:
Kruskal (G)E(1)=0, E(2)= todos los Arcos del grafo GMientras E(1) contenga menos de n-1 arcos y E(2)=0 doDe los arcos de E(2) seleccionar el de menor coste-->e(ij)E(2)= E(2) - {e(ij)}
Si V(i), V(j) no están en el mismo árbol entoncesjuntar los árboles de V(i) y de V(j) en uno sóloend Si
end doFin del algoritmo
Así la solución al subproblema, evaluación de la fitness y demás procesos se
realizaron mediante codificación MatLab, de forma que una porción del código muestra en
la ilustración 5:
2 Se escogen aleatoriamente un número T de individuos de la población, y el que tiene puntuación mayor se reproduce, sustituyendo su descendencia al que tiene menor puntuación.3 http://es.wikipedia.org/wiki/Algoritmo_de_Kruskal

11
Ilustración 6. Código en MatLab del Algoritmo Genético para el problema GMSTP
3.2.2. Problema del conjunto independiente de vértices máximo (MISP)
Para este problema la representación mediante string, función fitness, operadores de
variación y el proceso evolutivo usada por el algoritmo genético fueron basadas en el estudio
realizado por Back, T. et al. [10]
3.2.2.1. Representación
Para dar la representación primero es necesario entender la solución matemática
mediante el uso de matriz de incidencia de un grafo G (V, E).

12
V: conjunto de vértices. Donde V= {1 a n}
E: conjunto de aristas. Donde E= {1 a m}
(i,j): Par que representa una arista entre los vértices i, j. Talque la arista ∈ E.
Ai,j: Matriz de adyacencia.
Ai , j={ 1 si A i , j∈ E0 caso contrario
Con la formulación matemática del problema clara, es posible representar el
problema como un string binario (Xi, X,i+1, … , Xn) de largo n (total de vértices). Donde
cada i-ésimo posición representa al vértice i. Si Xi=1 el vértice i está en la solución inicial,
caso contrario no lo está y Xi=0. Este string se multiplicará con la matriz de adyacencia para
obtener la solución candidata.
Es importante indicar que esta representación puede generar soluciones candidatas
infactibles, por ello se aplicará una función de penalidad en el fitness para atacar este
problema.
Por ejemplo, dado el grafo de la ilustración 7, la matriz de adyacencia
correspondiente está dada en la tabla 1. Y un posible string binario para nuestro problema es:
1 0 0 1
Que representa una solución candidata formado por los nodos {1,4}.
Ilustración 7. Grafo no dirigido con 4 nodos y 5 arista para el problema del MIS

13
.
Aijaristas
a b c d e
nodo
s
1 1 0 0 1 02 1 1 0 0 13 0 1 1 1 04 0 0 1 0 1
Tabla 1. Matriz de adyacencia del grafo de la ilustración 7.
3.2.2.2. Función Fitness
En primera instancia se evalúa si la solución inicial (string, vector o cromosoma) es
factible o infactible.
Para ello se realiza una multiplicación de matrices entre la matriz de adyacencia Aij y
el cromosoma (traspuesto) Xj. El resultado de esta operación entregará un vector del mismo
largo que el vector de solución inicial. Tomando como referencia el ejemplo del punto
3.2.2.1 este proceso seria:
1 0 0 1 0 11 1 0 0 1 X 00 1 1 1 0 00 0 1 0 1 1
El mismo devuelve el vector o solución candidata: (en este caso es factible)
1011
Será factible si solo está formado por 0 y 1, es decir que una misma arista ha tocado a lo
más 1 vez a un vértice de la solución candidata.

14
Será infactible si está formado por números diferentes a 0 y 1. En este caso se aplica
penalidad. Para el efecto se cuenta la cantidad de veces que aparecen números
diferentes de 0 y 1, es decir 2 o superiores.
Así la función fitness es:
M ℑ f ( X⃗ )=−∑i=1
n
( X i )+Penalizaci ón
In=Numero de 2 que aparecen en el string resultante.n=nodosm=aristas
f ( x⃗ )=¿
3.2.2.3. Generación de población inicial
La población inicial será realizada de forma aleatoria, generando 2000 vectores o
soluciones iniciales. Luego, también de forma aleatoria, se escoge un vértice (nodo, posición
o gen) de este vector y se eliminan todos sus vecinos que tengan menor fitness, este proceso
se repite hasta que la actual solución no pueda ser mejorada.
3.2.2.4. Operadores de Cruzamiento y Mutación
Por ser un string de representación binaria se usaran operadores de variación
definido para este tipo de codificación. En este caso usamos 1-Point Crossover y mutación
Bitflip Mutation.
Parámetros genéticos
Se utilizaron las instancias de frb30-15-1, frb30-15-2, frb30-15-3, frb30-15-4, frb30-
15-5. El tamaño de población fue de 2000, número máximo de generaciones = 30,

15
probabilidad de cruzamiento= 0.90 y probabilidad de mutación 0.40 y la selección mediante
Tournament4.
3.2.2.5. Codificación
En este caso fue necesario codificar la función de penalidad que se seguiría en las
soluciones infectables además del resto del código como se describe enseguida:
Ilustración 8. Código en MatLab de evaluación función fitness.
Por defecto el toolbox de optimización y algoritmos genéticos de MatLab opera este
tipo de problemas como minimización por ello lo que se hizo fue convertir el problema a
minimización multiplicando por -1.
Con el proceso para aplicar penalidad claro, se expone una porción del código del
algoritmo genético utilizado.
4 Se escogen aleatoriamente un número T de individuos de la población, y el que tiene puntuación mayor se reproduce, sustituyendo su descendencia al que tiene menor puntuación

16
Ilustración 9. Código en MatLab del Algoritmo Genético para el problema GMSTP
3.2.3. Problema del taller de tareas flexibles (FJSP)
Para este problema la representación mediante string, función fitness, operadores de
variación y el proceso evolutivo usada por el algoritmo genético fueron basadas en el estudio
realizado por [11] pero con algunas modificaciones.
3.2.3.1. Representación
M1 M2 M3
O1,1 1 2 1O1,2 X 1 1O1,3 4 3 XO2,1 5 X 2O2,2 X 2 XO2,3 7 5 3
Ilustración 10. Ejemplo de Job Shop Flexible. 2 trabajos 3 máquinas.

17
Tomando con ejemplo la ilustración tabla 4, donde las columnas representan cada
una de las tres máquinas (M1, M2, M3) y las filas las 2 operaciones que se pueden realizar en
las tres máquinas, por ejemplo: (O1,2= operación 1, maquina 2). Los valores internos
representan el tiempo de los procesos de las operaciones en cada máquina. La X indica que
la maquina no puede realizar la operación.
Con la finalidad de simplificar la solución al problema, se altera la solución
propuesta por [11] y en vez de usar tres vectores, solo se usa un vector S de
secuenciamiento. Para poder detallar el método introduciremos la notación a utilizar
• M = {M1,...,Mm} conjunto de maquinas
• J = {J1,...,Jn} conjunto de trabajos
• hj cantidad de operaciones del trabajo j. j = 1,...,n
• Oj,h h-esima operación del trabajo j. j = 1,...,2, h = 1,...,hj
• Mj,h ⊆ M conjunto de máquinas donde la operación Oj,h puede ser realizada.
• Ti,j,h tiempo que demora en ser procesada la operación Oj,h en la máquina Mi ∈ Mj,h
El vector de secuenciamiento es un vector de largo igual al número total de
operaciones ∑j=1
n
h j que contiene tantos valores j como operaciones tenga el trabajo j, es decir
el cromosoma de secuenciamiento tiene h1 cantidad de 1’s, luego h2 cantidad de 2’s y así
hasta hn cantidad de valores n donde n es la cantidad de trabajos.
Los individuos de nuestra población serán permutaciones o reordenamientos de los
valores de este vector. La interpretación de este cromosoma es que en cada celda aparece
alguno de los trabajos y aparecen tantas veces como operaciones tienen, por lo tanto cada
vez que el trabajo j se hace referencia las operaciones consecutivas en orden de prioridad de
este.

18
De esta forma dada una permutación del vector de secuenciamiento es posible
obtener un vector de operaciones que indica el orden de las operaciones donde además se
respeta la prioridad de esta en cada trabajo.
Lo anterior no resuelve nada acerca del problema de asignación de operaciones a
máquinas. Para atacar este problema hacemos lo siguiente:
Dado un cromosoma de secuenciamiento, generamos un cromosoma de operaciones
(que es una permutación de los números entre 1 y la cantidad total de operaciones). De
izquierda a derecha recorremos el vector de operaciones. Para cada operación O j,h del vector
determinamos Mj,h y elegimos de entre ellas a la máquina que tenga menos carga de trabajo
(en tiempo) y se la asignamos a dicha operación. Finalmente actualizamos la carga de
trabajo de la máquina sumando a su carga el tiempo correspondiente a la operación en esa
máquina.
Así para cada cromosoma de secuenciamiento podemos generar vectores de
ordenamiento y de asignación con los cuales es posible calcular el makespan de la solución.
Notemos que la regla, “asignar a la máquina con menos carga de trabajo” es una
opción escogida por nosotros al atacar el problema. En general puede escogerse cualquier
máquina que esté apta para realizar la operación. Esta regla podría cambiarse por ejemplo
por “asignar a la máquina que demore menos tiempo en realizar la operación”.
3.2.3.2. Función Fitness
Se define la función fitness cuyo propósito es de minimizar el makespan 5, es decir
minimizar la diferencia de tiempo entre el inicio y finalización de una secuencia de trabajo.
El valor del makespan corresponde al tiempo que tarda en terminar de procesar todas sus
operaciones la máquina que más demora.
5 Diferencia entre el inicio y fin de una sequencia de trabajo

19
3.2.3.3. Generación de población inicial
Para generar la población inicial se generan individuos de forma aleatoria. Como
nuestro cromosoma se basa en el vector de secuenciamiento los individuos de la población
inicial son permutaciones del vector de secuenciamiento original ya descritos anteriormente.
A partir de esta permutación es posible obtener un vector de operaciones y luego un vector
de asignación con lo que es posible obtener el makespan de cada individuo
3.2.3.4. Operadores de Cruzamiento y Mutación
Dado que todas las soluciones se codifican como un cromosoma de largo ∑j=1
n
h j
permutaciones del vector de secuenciamiento definido anteriormente basta con utilizar los
operadores clásicos de permutación, en este caso se utilizó cruzamiento mediante PMX.
Para la mutación se usó swap mutation donde se seleccionan aleatoriamente dos
posiciones del cromosoma y se intercambian de forma de mantener siempre cromosomas
factibles.
3.2.3.5. Parámetros genéticos
Se utilizaron las instancias 01a, 02a, 03a, Mk01, Mk02, Mk03, Mk04, Mk05,
Mk06¸Mk07, con un tamaño de población de 200, número generaciones = 50, probabilidad
de cruzamiento= 0.90 y probabilidad de mutación 0.10 y la selección mediante Tournament.
3.2.3.6. Codificación

20
Una vez que se estableció el proceso evolutivo se procedió a codificarlo en MatLab
como se describe a continuación:
Ilustración 11. Código de generación de la población inicial para Job Shop Flexible.
Ilustración 12. Porción de código del algoritmo genético para la solución del Job Shop Flexible Problem.

21
4. Resultados
4.1. Problema del árbol de cobertura mínimo generalizado (GMSTP)
A continuación se presentan los resultados obtenidos para la solución propuesta para
el problema de árbol de cobertura mínimo generalizado:
N° Instancias Datos relevantesÓptimo Conocido
Resultado Algoritmo Genético
Error porcentual
Tiempo (Segundos)
1 53gil262 262 nodos, 53 clúster 887 911 2.70574971 1872 34gr229 229 nodos, 34 clúster 45989 63772 38.6679423 1023 27pr264 264 nodos, 27 clúster 16546 16677 0.79173214 704 21eil101 101 nodos, 21 clúster 204 205 0.49019607 485 30kroa150 150 nodos, 30 clúster 9815 9868 0.53998981 766 31pr152 152 nodos, 31 clúster 39109 39130 0.05369608 83
734gr202europe
202 nodos, 34 clúster 135 150 11.1111111 94
8 40krob200 200 nodos, 40 clúster 11244 11441 1.75204553 1169 12brazil58 58 nodos, 12 clúster 9206 9356 1.62937214 2110 10att48 48 nodos, 10 clúster 10923 10930 0.06408495 18
Promedio 4.720018 80
Tabla 2. Resumen de resultados alcanzados y tiempos de duración del algoritmo genético propuesto.
En la tabla 2 se observa que de las 10 instancias nuestro algoritmo genético tuvo
efectividad superior a 95% en ocho instancias, mientras que en dos casos (instancias 2 y 7)
no fue tan satisfactorio el resultado.
El menor tiempo obtenido fue 18 segundos esto sucedió en la instancia 10, y el
mayor tiempo en la instancia 1 con una duración de 187 segundos. Esta situación es
originada debido la cantidad de nodos y clúster pues mientras más crecen estos parámetros
el algoritmo tiende a resolver el problema en tiempos más altos.

22
En promedio nuestra solución presenta un error porcentual de 4.72%, es decir
nuestro algoritmo se acerca al optimo en el 95.28% de los casos.
Para entender en detalle los resultados por instancias se realizaron graficas de curvas
de convergencia:
Ilustración 13. Gráfica de curva de convergencia instancia 1.
Para la instancia 1, es evidente que el fitness para la población inicia es alto, en
promedio inicio con un valor superior a 1150 pero paulatinamente disminuía hasta llegar a la
generación 20 donde el mejor valor alcanzado fue 911. Y en promedio 939.60

23
Ilustración 14. Gráfica de curva de convergencia instancia 2.
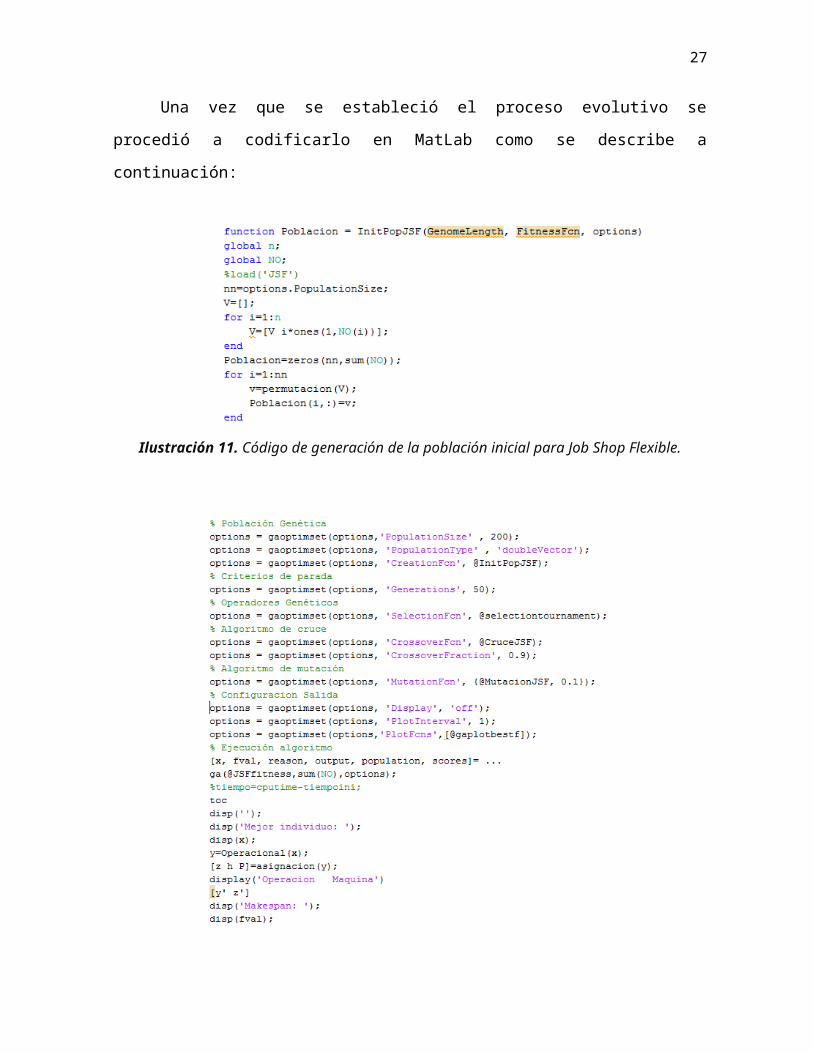
Para la instancia 2, sucede algo similar a la 1, aunque en este caso desde la
generación 14 se estabiliza el valor del fitness quedando finalmente como mejor 63772.
Ilustración 15. Gráfica de curva de convergencia instancia 3.
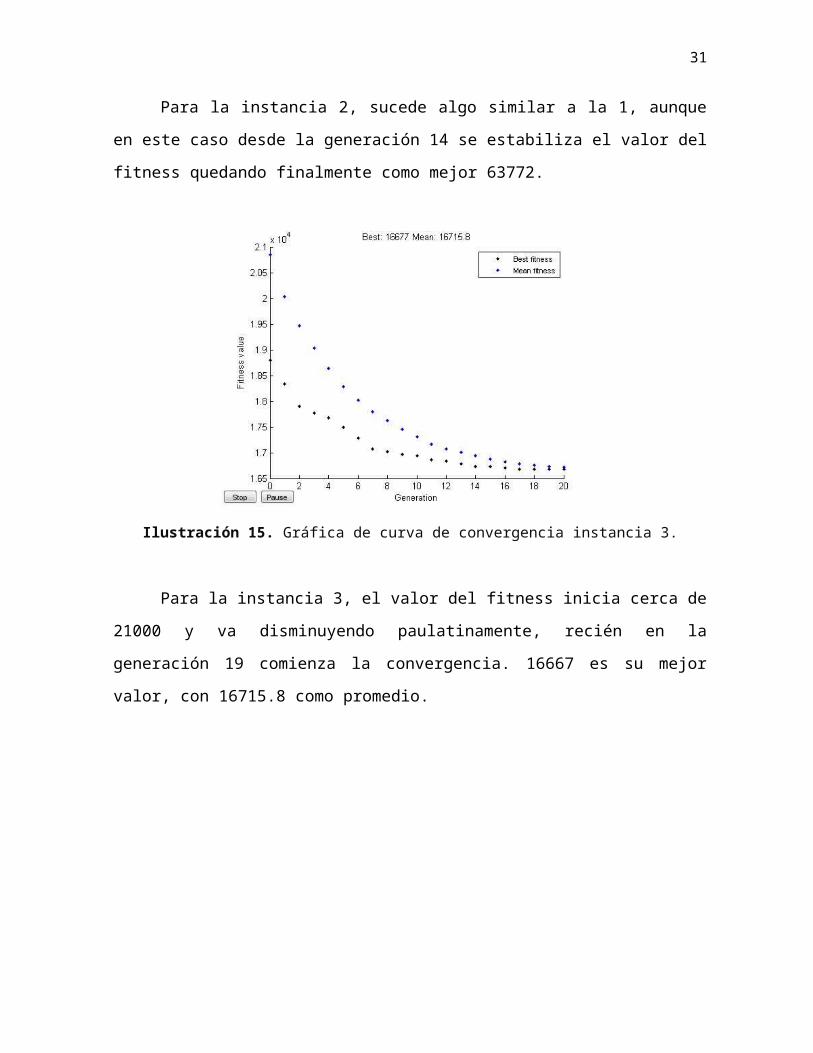
Para la instancia 3, el valor del fitness inicia cerca de 21000 y va disminuyendo
paulatinamente, recién en la generación 19 comienza la convergencia. 16667 es su mejor
valor, con 16715.8 como promedio.

24
Ilustración 16. Gráfica de curva de convergencia instancia 4.
La instancia 4, inicia su proceso de estabilización de función fitness a partir de la generación
14, llegando a la generación 20 con un promedio de 205.48 y con el mejor valor fitness alcanzado de
205.
Ilustración 17. Gráfica de curva de convergencia instancia 5.
En la instancia 5, similarmente a lo que paso con la instancia 3, el valor del fitness no
llega a converger hasta el final de la generación 20, con el valor mejor alcanzado de 9868.

25
Ilustración 18. Gráfica de curva de convergencia instancia 6.
En este caso (ilustración 18) la estabilización de la función fitness se logra a partir de
la generación 16, alcanzado el mejor valor que fue 39130, muy similar al promedio del
fitness para esta instancia que es 39258.
Ilustración 19. Gráfica de curva de convergencia instancia 7.
En la instancia 7 la variación del fitness desde la población inicial hasta la
generación 20 fue muy baja, de hecho desde la generación 12 se ven signos de
estabilización. El mejor fitness fue 150, prácticamente igual al del promedio que fue 150.21

26
Ilustración 20. Gráfica de curva de convergencia instancia 8.
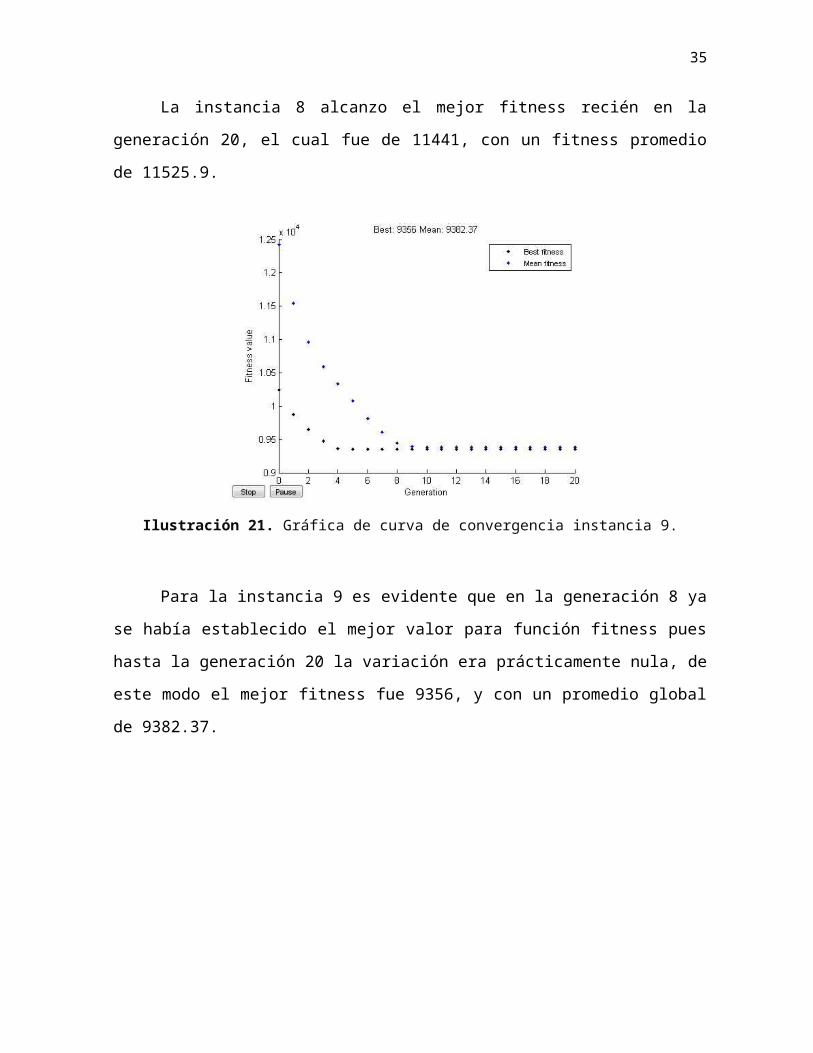
La instancia 8 alcanzo el mejor fitness recién en la generación 20, el cual fue de
11441, con un fitness promedio de 11525.9.
Ilustración 21. Gráfica de curva de convergencia instancia 9.
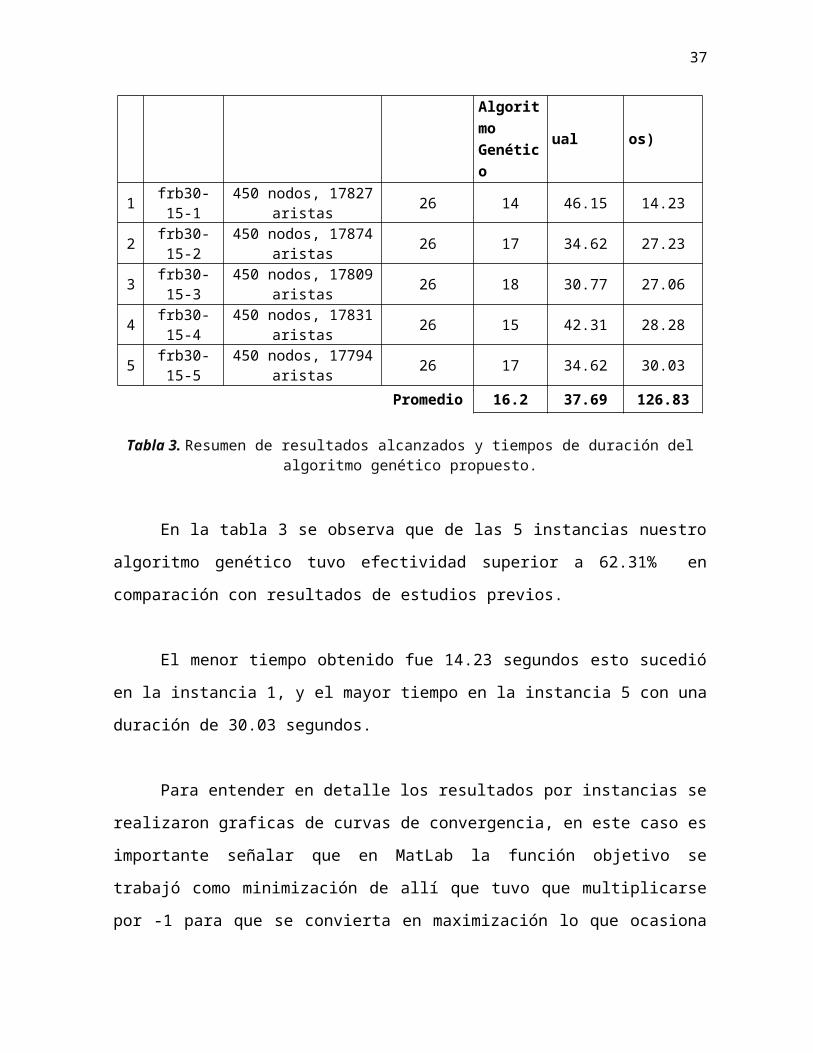
Para la instancia 9 es evidente que en la generación 8 ya se había establecido el
mejor valor para función fitness pues hasta la generación 20 la variación era prácticamente
nula, de este modo el mejor fitness fue 9356, y con un promedio global de 9382.37.
27
Ilustración 22. Gráfica de curva de convergencia instancia 10.
Al igual que sucedió con la instancia 9, la instancia 10 a partir de la generación 8 ya
había establecido el mejor valor para función fitness pues hasta la generación 20 la variación
era prácticamente nula. El mejor fitness fue 10930, y con un promedio global de 10973.2.
4.2. Problema del conjunto independiente de vértices máximo (MISP)
A continuación se presentan los resultados obtenidos mediante el algoritmo
propuesto para el problema del máximo conjunto independiente de vértice:
N°
Instancias Datos relevantesÓptimo Conocido [12]
Resultado Algoritmo Genético
Error porcentual
Tiempo (Segundos)
1 frb30-15-1 450 nodos, 17827 aristas 26 14 46.15 14.232 frb30-15-2 450 nodos, 17874 aristas 26 17 34.62 27.233 frb30-15-3 450 nodos, 17809 aristas 26 18 30.77 27.064 frb30-15-4 450 nodos, 17831 aristas 26 15 42.31 28.285 frb30-15-5 450 nodos, 17794 aristas 26 17 34.62 30.03
Promedio 16.2 37.69 126.83

28
Tabla 3. Resumen de resultados alcanzados y tiempos de duración del algoritmo genético propuesto.
En la tabla 3 se observa que de las 5 instancias nuestro algoritmo genético tuvo
efectividad superior a 62.31% en comparación con resultados de estudios previos.
El menor tiempo obtenido fue 14.23 segundos esto sucedió en la instancia 1, y el
mayor tiempo en la instancia 5 con una duración de 30.03 segundos.
Para entender en detalle los resultados por instancias se realizaron graficas de curvas
de convergencia, en este caso es importante señalar que en MatLab la función objetivo se
trabajó como minimización de allí que tuvo que multiplicarse por -1 para que se convierta en
maximización lo que ocasiona que las soluciones factibles se encuentren en coordenadas con
signo (-) negativo.
Ilustración 23. Gráfica de curva de convergencia instancia 1.
Para la instancia 1, en la población inicial se presentan varias soluciones infactibles
de modo que la aplicación de penalidad de apoco fue ayudando a solucionar este problema,
es así que finalmente la mejor cantidad posibles de vértices en el conjunto independiente
(solución factible) fue 14, pero en promedio a penas 5.16.

29
Ilustración 24. Gráfica de curva de convergencia instancia 2.
En la instancia 2 la situación fue similar, las soluciones inicialmente fueron en alto
grado infactibles pero de a poco se fueron alcanzando mejoras hasta la generación 30, donde
se obtuvo el mejor valor que fue 17, y en promedio para esta instancia se tuvo 7.36.
Ilustración 25. Gráfica de curva de convergencia instancia 3.

30
Ilustración 26. Gráfica de curva de convergencia instancia 4.
Ilustración 27. Gráfica de curva de convergencia instancia 5.
En las instancias restantes, es decir; 3, 4 y 5, la situación fue similar los mejores
resultados estuvieron entre 15 y 18, con promedios entre 4 y 7.
Es evidente que la poca variación de cuanto a soluciones factibles e infactibles se da
porque en todas las instancias presentaban la misma cantidad de nodos, y a penas existían
mínimas variaciones en la cantidad de aristas.
31
4.3. Problema del Taller de Tareas Flexibles (FJSP)
A continuación se presentan los resultados obtenidos para la solución propuesta para
el problema de árbol de cobertura mínimo generalizado:
En la tabla 4 se observa que de las 10 instancias nuestro algoritmo genético tuvo
efectividad del 100% en cuatro instancias, más de 97% en dos casos y 75% en otras dos y
apenas en 1 instancia no fue tan satisfactorio el resultado pues solo se alcanzó efectividad de
7%. En promedio la efectividad del AG fue 82.42%.
El menor tiempo obtenido fue 15.59 segundos esto sucedió en la instancia 1, y el
mayor tiempo en la instancia 1 con una duración de 105.45 segundos. En promedio con las
instancias usadas nuestro AG tarda en resolver el problema del JSF69.22 segundos.
N° Instancias Datos relevantesÓptimo Conocido
Resultado Algoritmo Genético
Error porcentual
Tiempo (Segundos)
1 Mk0110 trabajos, 6 máquinas, 1 operaciones.
36 36 0 15.59
2 Mk0210 trabajos, 6 máquinas, 3.5 operaciones.
24 31 29.166666 33.67
3 Mk0315 trabajos, 8 máquinas, 3 operaciones.
204 204 0 82.84
4 Mk0415 trabajos, 8 máquinas, 2 operaciones.
48 60 25 47.48
5 Mk0515 trabajos, 4 máquinas, 1.5 operaciones.
168 173 2.9761904 58.89
6 Mk0610 trabajos, 15 máquinas, 3 operaciones.
33 64 93.939393 88.21
7 Mk0720 trabajos, 5 máquinas, 3 operaciones.
133 166 24.812030 54.13
8 Dauzere 01a10 trabajos, 5 máquinas, 1 operaciones.
2505 2505 0 103.78
9 Dauzere 02a 10 trabajos, 5 máquinas, 2228 2229 0.0448833 105.45

32
1 operaciones.
10 Dauzere 03a10 trabajos, 5 máquinas, 1 operaciones.
2228 2228 0 102.19
Promedio 17.58 69.22
Tabla 4. Resumen de resultados alcanzados y tiempos de duración del algoritmo genético propuesto.
Para entender en detalle los resultados por instancias se realizaron graficas de curvas
de convergencia:
Ilustración 28. Gráfica de curva de convergencia instancia 1.
Para la instancia 1 (ilustración 28), es evidente que el fitness para la población inicia
es alto, en promedio inicio con un valor de 38, y en cada generación iba cambiando, aunque
en poca intensidad pues finalmente el mejor valor alcanzado fue 36. Y en promedio 36.96

33
Ilustración 29. Gráfica de curva de convergencia instancia 2.
En la ilustración 29, se observa el comportamiento de la instancia 2, claramente a
partir de la generación 5 se alcanza el mejor valor que es 31, que coincide con el valor
optimo conocido para esta instancia.
Ilustración 30. Gráfica de curva de convergencia instancia 3.
Para la instancia 3, los valores son pocos cambiantes de hecho a partir de la
generación 10 estos parecen ser iguales. Así el mejor valor en este caso fue 204 con un
promedio muy parecido de 205.56.

34
Ilustración 31. Gráfica de curva de convergencia instancia 4.
En la ilustración 31, se observa que el fitness parte de un valor alto, pero a partir de
la generación 5 comienza su estabilidad obteniendo un promedio de 62.40 y el mejor valor
60.
Ilustración 32. Gráfica de curva de convergencia instancia 5.
En la instancia 5 los mejores valores para cada generación son muy constantes, en
general hasta la generación 12 se mantiene en 177, luego hasta la generación 30 toma un
valor de 176, pasa hasta la generación 35 con 175, disminuye luego hasta 174 en la
35
generación 48, y de allí llega a su mejor valor 173 en las dos ultima generaciones. El
promedio es 178.03
Ilustración 33. Gráfica de curva de convergencia instancia 6.
En la ilustración 33, se observa el comportamiento de la instancia 6, claramente no
existe convergencia, de hecho el mejor valor es 64 y promedio 72.81, los cuales se
encuentran muy lejanos al óptimo conocido. (ver tabla 3).
Ilustración 34. Gráfica de curva de convergencia instancia 7.

36
Para la instancia 7, al igual que en la 6, no se da una convergencia, pero a pesar de
ello los valores 166 (el mejor) y 189.32 (promedio) durante las 50 generaciones no están tan
alejados del optimo conocido 133 (ver tabla 3).
Ilustración 35. Gráfica de curva de convergencia instancia 8.
Es evidente que en la instancia 8 los mejores valores son constantes en 2505 durante
las 50 generaciones, mientras que el promedio comienza cercano a los 2565 y a partir de la
quinta generación se mantiene en torno al 2520, dando finalmente un promedio de 2523.
Ilustración 36. Gráfica de curva de convergencia instancia 9.
37
En la instancia 9 tampoco se da convergencia durante las 50 generaciones, pese a ello
los mejores valores de cada generación a partir de la décima, tienden a ser constantes a 2229
es decir a penas a un punto de diferencia del óptimo conocido 2228 (tabla 1)
Ilustración 37. Gráfica de curva de convergencia instancia 10.
Finalmente la instancia 10 tampoco se observa la convergencia durante las 50
generaciones, pese a ello los mejores valores de cada generación a partir de la quinta,
tienden son constantes en 2228 justamente el valor del optimo conocido (tabla 1).
5. Discusión
En la actualidad muchos son los trabajos que se han realizado sobre algoritmos
genéticos, uno estos titulado “Un efectivo algoritmo genético para el problema del árbol de
cobertura mínimo generalizado” [8] aplica un algoritmo genético paralelo de tipo genotipo-
fenotipo para resolver dicho problema, sus resultados muestran una tasa de error de apenas
0,033% sin embargo, existen diferencias notorias con nuestro trabajo pues, ellos utilizan el
algoritmo Prim para la generación del árbol de cobertura mínimo de los vértices mientras en
nuestro trabajo se usó el algoritmo Kruskal para la misma actividad. Además el tipo y
cantidad de instancias fue diferente pues usaron 21 instancias de tipo clúster centering y

38
nosotros solo 10 instancias. A pesar de la diferencia en el número de instancias nuestro
trabajo obtuvo tasas de error en promedio inferior al 5% por lo que nuestra solución también
se encuentra en porcentajes altamente confiables.
Por otro lado en “An Evolutionary Heuristic for the Maximal Independent Set
Problem” [10] se encuentran similitudes con el trabajo realizado pues ellos también generan
de forma aleatoria la oblación inicial, y aplican de igual manera una penalidad a la función
fitness, sin embargo utilizan como tamaño de población 50 y como operador de cruzamiento
de dos puntos, todos estos factores influyen en que este trabajo presente una efectividad
superior al 99% mientras que en nuestro estudio solo el 63% aproximadamente, sin embargo
es evidente que esta diferencia se da también porque ellos usaron 10 instancias y cada una de
ellas con vértices y aristas muy distintas. Por lo que para efectos prácticos nuestros 63%
también es un resultado adecuado.
Finalmente, en el estudio “Un algoritmo genético para el problema de Job Shop
Flexible” [11] también resuelven el problema de nuestro trabajo, la diferencia principal es
que este caso ellos usaron tres vectores para la representación del problemas mientras que
nosotros solo uno. En promedio para la instancias usadas [13] obtienen una efectividad de
83.56% muy similar a la obtenida por nuestro algoritmo que fue 82.42%. Los tiempos
computacionales no pueden ser comparados pues ellos usaron una cantidad entre 1000 y
3000 generaciones extremamente superior a la nuestra que fue de 50.
6. Conclusiones
Al finalizar el presente estudio se llega a las siguientes conclusiones:
Este estudio propone algoritmos genéticos para resolver los problemas del
árbol de cobertura mínimo generalizado (GMSTP), conjunto independiente
de vértices (MISP) y taller de tareas flexibles problema de Job Shop Flexible
(FJSP).

39
Para el GMSTP se logró resolver el problema en un tiempo computacional
razonable y obteniendo 95.28% que es un valor similar comparado con las
mejores algoritmos existente en la literatura.
El MISP fue resuelto de tal forma que en promedio, y para la instancias de
pruebas, es posible tener como máximo 18 nodos en el conjunto
independiente, lo que representa un 62.31% de efectividad en relación a otros
resultados alcanzados en el mismo problema, porcentaje aceptable sobre todo
por el hecho de que también se aceptan soluciones infactibles aunque gracias
a la penalidad que se aplicó no se afectó el desempeño de los resultados.
En cuanto al FJSP nuestro algoritmo genético resolvió el problema con una
tasa de efectividad de 82.42% un porcentaje similar a las mejores soluciones
conocidas, a pesar que en general estas utilizan tres vectores (operaciones,
maquinas, trabajos) para la representación y varios operadores de
cruzamiento y mutación; mientras que en nuestro estudio solo se usó uno/a en
ambos situaciones.
Todos estos estudios evidencian las ventajas de utilizar algoritmos genéticos
(AG) para resolver problemas de optimización, pero sobre todo; se muestra
como a través de diferentes representaciones, operadores o configuración de
parámetros, los AG hacen que los distintos problemas sean resueltos con
resultados de efectividad y tiempo bastante similares a otras soluciones
propuestas a nivel mundial por varios autores.

40
7. Bibliografía
[1] J. J. Merelo, "Informática evolutiva: Algoritmos Genéticos," 07 04 2014. [Online].
[2] J. L. Galindo and A. Carnicero, "Optimización mediante algoritmos genéticos: Aplicación al diseño de celosías," Anales de Mecánica y Electricidad, vol. LXXX, no. V, pp. 40-50, 2003.
[3] A. Vásquez, "Algoritmo genético para el problema del agente viajero," Serie Científica de la Universidad de las Ciencias Informáticas, vol. 5, no. 8, 2012.
[4] J. Pedraz and C. Córdoba, "Implementación de un algoritmo genético paralelo sobre hardware gráfico de última generación," e-Prints Complutense, 2005.
[5] J. Sánchez and J. Turrado, "Algoritmos genéticos: Aplicación al problema de la mochila," 2008.
[6] C. Ferreira, L. Satoru, V. Parada and E. Uchoa, "A GRASP-based approach to the generalized minimum spanning tree problem," Expert Systems with Applications, vol. 39, pp. 3526-3536, 2012.
[7] C. Carcamo, "Problema de la cobertura de vértices," 2011.
[8] C. Contreras, C. Rey, G. Gatica and V. Parada, "Un efectivo algoritmo genético para el problema del árbol de cobertura mínimo generalizado," X Optima VI RED-M, 2013.
[9] A. Eiben and J. Smith, Introduction to Evolutionary Computing, 1998.
[10] T. Back and S. Khuri, "An Evolutionary Heuristic for the Maximun Independent Set Problem," IEEE World Congress on Computational Intelligence., 1994.
[11] R. Medina, L. Pradenas and V. Parada, "Un algoritmo genético para el problema de Job Shop Flexible," Ingeniare. Revista Chilena de Ingeniería, vol. 19, no. 1, pp. 53-61, 2011.
[12] S. Balaji, "A New Effective Local Search Heuristic for the Maximum clique problem," International Journal of Mathematical, Computational Science and Engineering, vol. 7, no. 5, pp. 22-28, 2013.
[13] P. Brandimarte, "Routing and scheduling in a flexible job shop by tabu search," Annals of Operations Research, vol. 41, no. 1-4, pp. 157-183, 1993.
[14] J. Osorio and T. Motoa, "Modelo Jerárquico para el Job Shop Flexible," XIII International Conference on Industrial Engineering and Operation Management, 2007.
[15] M. Hifi, "A Genetic algorith based heurisitc for solving the weighted maximum independent set and some equivalent problems," Journal of the Operational Research Society, vol. 48, pp. 612-622, 1997.
[16] D. Andrade, M. Resende and R. Werneck, "Fast Local Search for the Maximum," pp. 220-234.