generalizing plans to new environments in relational mdps carlos guestrin daphne koller chris...
Post on 18-Dec-2015
218 views
TRANSCRIPT

Generalizing Plans to New Environments in Relational MDPs
Carlos Guestrin
Daphne Koller
Chris Gearhart
Neal KanodiaStanford University

Collaborative Multiagent Planning
Search and rescue Factory management Supply chain Firefighting Network routing Air traffic control
Long-termgoals
Multiple agents
Coordinateddecisions
CollaborativeMultiagentPlanning

peasant
footman
building
Real-time Strategy GamePeasants collect resources and buildFootmen attack enemiesBuildings train peasants and footmen

F’
E’
G’
P’
Structure in Representation: Factored MDP
State Dynamics Decisions Rewards
Peasant
Footman
Enemy
Gold
RComplexity of representation:Exponential in #parents (worst
case)
[Boutilier et al. ‘95]t t+1TimeAPeasant
AFootman P(F’|F,G,AF)
# states exponential# actions exponential
exact solution is intractable

Linear combination of restricted domain functions [Bellman et al. ’63, Tsitsiklis & Van Roy ’96, Koller & Parr ‘99,’00, Guestrin et al. ‘01]
Structured Value Functions
Each hi is status of small part(s) of a complex system: State of footman and enemy Status of barracks Status of barracks and state of footman
Structured V Structured Q
Must find w giving good approximate value function
o
oVV )()(~
xx
o
oQQ~
small #of Ai’s, Xj’s
ihiwV )()( xxoo o
oVi(Footman) Qi(Footman, Gold,
AFootman)
w o
w o
w o

Approximate LP Solution
:subject to
, ax
:minimize x
),( xaQ)(xV
)(xV
One variable wi for each object basis function Polynomial number of LP variables
One constraint for every state and action Exponentially many LP constraints
Efficient LP decomposition [Guestrin+al `01] Functions depend on small sets of variables Polynomial time solution
, ax
[Schweitzer and Seidmann ‘85]
o
)( xo
oVw o
)( xo
oVw o
)( xo
oVw o
),( xa
ooQw o
)( xo
oVw o
),( xa
ooQw o

Summary of Multiagent Algorithm
Model world as factored MDP
Basis functions selection
Factored LP computes value function
hi
w , Qo
offl
ine
on
lin
e
Real worldx a
Coordination graph computes argmaxa
Q(x,a)
[Guestrin et al.,`01,`02]
o
o

Planning Complex Environments
When faced with a complex problem, exploit structure:
For planning For action selection
Given new problem
Replan from scratch: Different MDP New planning problem Huge problems intractable, even with factored LP

Generalizing to New Problems
SolveProblem 1
SolveProblem n
Good solution to
Problem n+1
SolveProblem 2
MDPs are different! Different sets of states, action, reward,
transition, …
Many problems are “similar”

Generalization with Relational MDPs
Avoid need to replan Tackle larger problems
“Similar” domains have similar “types” of objects
Exploit similarities by computing generalizable value functions
RelationalMDP
Generalization

Relational Models and MDPs
Classes: Peasant, Gold, Wood, Barracks,
Footman, Enemy…
Relations Collects, Builds, Trains, Attacks…
Instances Peasant1, Peasant2, Footman1,
Enemy1…
Builds on Probabilistic Relational Models [Koller, Pfeffer ‘98]

Relational MDPs
Very compact representation!Does not depend on # of objects
Enemy
H’ Health
RCount
Footman
H’ Health
AFootman
my_enemy
Class-level transition probabilities depends on: Attributes; Actions; Attributes of
related objects Class-level reward function

World is a Large Factored MDP
Instantiation (world): # instances of each class Links between instances
Well-defined factored MDP
RelationalMDP
Linksbetweenobjects
FactoredMDP
# of objects

World with 2 Footmen and 2 Enemies
F1.Health
F1.A
F1.H’
E1.Health E1.H’
F2.Health
F2.A
F2.H’
E2.Health E2.H’
R1
R2
Footman1
Enemy1
Enemy2
Footman2

World is a Large Factored MDP
Instantiate world Well-defined factored MDP Use factored LP for planning
We have gained nothing!
RelationalMDP
Linksbetweenobjects
FactoredMDP
# of objects

Class-level Value Functions
F1.Health E1.Health F2.Health E2.Health
Footman1
Enemy1
Enemy2
Footman2
VF1(F1.H, E1.H) VE1(E1.H) VF2(F2.H, E2.H) VE2(E2.H)
V(F1.H, E1.H, F2.H, E2.H) = + + + Units are Interchangeable!VF1 VF2 VF VE1 VE2
VE
At state x, each footman has different contribution to V
Given wC — can instantiate value function for any world
Footman1
Enemy1
Enemy2
Footman2
VF VF VE VE
0
5
10
15
20 F1 alive,E1 aliveF1 alive,E1 deadF1 dead,E1 aliveF1 dead,E1 dead 0
5
10
15
20 F2 alive,E2 aliveF2 alive,E2 deadF2 dead,E2 aliveF2 dead,E2 dead

Computing Class-level VC
:minimize
:subject to
, ax
),( xaQ)(xV
x
)(xV
C Co
oV )(][
x
C Co
oQ ),(][
ax
C Co
oV )(][
x
ax,,
Constraints for each world represented efficient by factored LP
Number of worlds exponential or infinite
w C
w C
w C

Sampling Worlds
Many worlds are similar Sample set I of worlds
, x, a I , x, aSampling

Factored LP-based Generalization
E1 F1
E2 F2
Sample SetI
Class-level
factored LP
0
5
10
15
20 F alive,E aliveF alive,E deadF dead,E aliveF dead,E dead
VF
0
2
4
6
8
10E alive
E deadVE
Gen.
E1 F1
E2 F2
E3 F3
0
5
10
15
20 F1 alive,E1 aliveF1 alive,E1 deadF1 dead,E1 aliveF1 dead,E1 dead
0
2
4
6
8
10 E1 alive
E1dead
0
5
10
15
20 F2 alive,E2 aliveF2 alive,E2 deadF2 dead,E2 aliveF2 dead,E2 dead
0
2
4
6
8
10 E2 alive
E2dead
0
5
10
15
20 F3 alive,E3 aliveF3 alive,E3 deadF3 dead,E3 aliveF3 dead,E3 dead
0
2
4
6
8
10 E3 alive
E3dead
How many samples?

Complexity of Sampling Worlds
NO!
Exponentially many worlds ! need
exponentially many samples?
# objects in a world is unbounded ! must apply LP
decomposition to very large worlds?

(Improved) Theorem
samples
Value function within O() of class-level solution optimized for all worlds,
with prob. at least 1-
Rcmax is the maximum class reward
Sample m small worlds of up to O( ln 1/ ) objects
m =

Learning Subclasses of Objects
1
23
4
23
3
4
510
10
20
30
40
50 GoodFaultyDead
V1
0
10
20
30
40
50 GoodFaultyDeadV2
0
20
40
60 GoodFaultyDead
V1
0
10
20
30
40
50 GoodFaultyDeadV2
Plan for sampled worlds
separately
Objects with similar values
belong to same class
Find regularitiesbetween worlds
Used decision tree regression in experiments

Summary of Generalization Algorithm
Relational MDP model
Class definitions
Factored LP computes class-level value function
C
wC
offl
ine
on
lin
e
Real worldx a
Coordination graph computes argmaxa Q(x,a)
Sampled worlds
I
new world

Experimental Results
SysAdmin problem
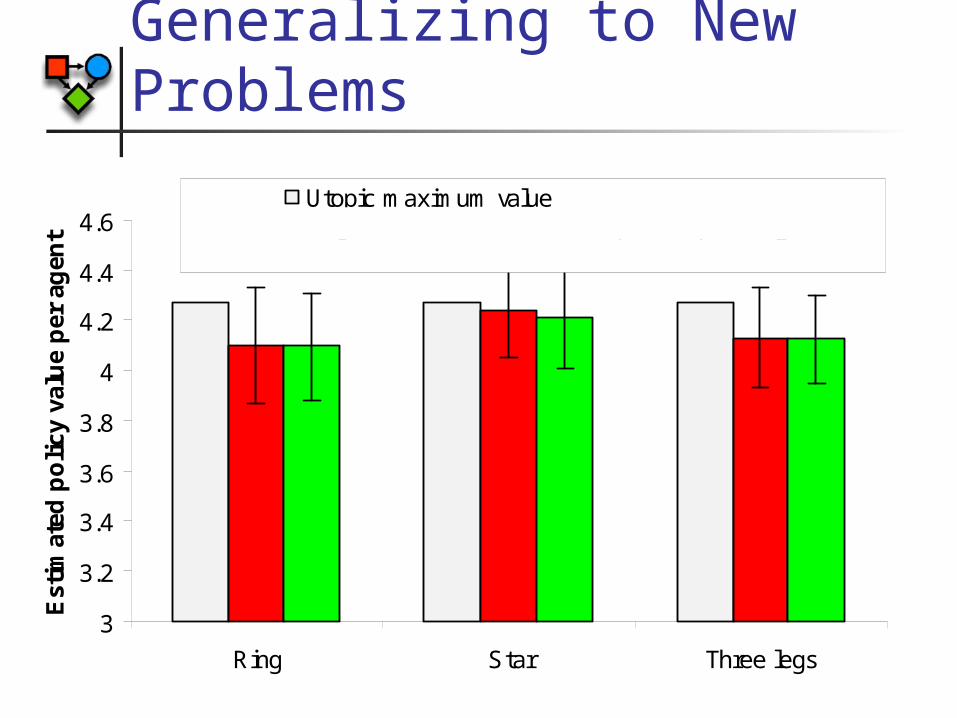
Generalizing to New Problems
3
3.2
3.4
3.6
3.8
4
4.2
4.4
4.6
Ring Star Three legs
Est
imat
ed p
oli
cy v
alu
e p
er a
gen
t
Utopic maximum valueObject-based value with complete replanningClass-based value function - no replanning

Classes of Objects Discovered
Learned 3 classes
Server
Intermediate
Intermediate
Intermediate
Leaf
LeafLeaf

Learning Classes of Objects
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Ring Star Three legs
Max
-no
rm e
rro
r o
f va
lue
fun
ctio
n
No class learning
Learnt classes

Strategic
Tactical

Strategic 2x2
Relational MDP model
2 Peasants, 2 Footmen, Enemy, Gold, Wood,
Barracks~1 million state/action pairs
Factored LP computes value function
Qo
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)

Strategic 9x3
Relational MDP model
9 Peasants, 3 Footmen, Enemy, Gold, Wood,
Barracks
Factored LP computes value function
Qo
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)
~3 trillion state/action pairs
grows exponentially in #
agents

Strategic - Generalization
Relational MDP model
2 Peasants, 2 Footmen, Enemy, Gold, Wood,
Barracks~1 million state/action pairs
Factored LP computes class-level value function
wC
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)
9 Peasants, 3 Footmen, Enemy, Gold, Wood,
Barracks~3 trillion state/action pairs
instantiated Q-functionsgrow polynomially in #
agents

Tactical
Planned in 3 Footmen versus 3 Enemies
Generalized to 4 Footmen versus 4 Enemies
3 vs. 3 4 vs. 4
Generalize

Conclusions Relational MDP representation Class-level value function Efficient linear program optimizes over
sampled environments: Theorem: polynomial sample complexity
generalizes from small to large problems Learning subclass definitions
Generalization of value functions to new worlds: Avoid replanning Tackle larger worlds