genómica - bioinfo2.ugr.es · universidad de granada • genómica estructural - su objetivo es...
TRANSCRIPT

http://bioinfo2.ugr.es/genomica Universidad de Granada
Genómica Grado en Bioquímica
José L. Oliver ([email protected]) Carmelo Ruiz Rejón ([email protected])
Michael Hackenberg ([email protected]) Guillermo Barturen ([email protected])
http://bioinfo2.ugr.es/genomica

http://bioinfo2.ugr.es/genomica Universidad de Granada
Thomas H. Roderick(1986) • GENOMICA: Su objetivo es mapear y secuenciar el genoma
• La Genética se ocuparía de los genes y la genómica de los genomas
Pero ambas se ocupan del estudio de la herencia y la variación de los organismos, que es el objetivo original de la Genética

http://bioinfo2.ugr.es/genomica Universidad de Granada
• Genómica estructural - Su objetivo es generar y analizar la secuencia y las propiedades conformacionales de genes y proteínas
• Genómica funcional - Trata de asignar función a cada una de las secuencias generadas por los proyectos genoma
• Genómica computacional - Desarrolla el software y las bases de datos necesarias para el almacenamiento, recuperación y análisis de los datos genómicos: secuencias primarias de genes y proteínas, estructuras tridimensionales, perfiles de expresión, etc.
• Genómica evolutiva - Se ocupa del origen y evolución de los genomas. Estudia por tanto la evolución del tamaño y la complejidad de los genomas, los mecanismos de duplicación genómica, la transferencia horizontal de genes, la evolución concertada, etc.

http://bioinfo2.ugr.es/genomica Universidad de Granada
El Proyecto Genoma Humano
Sus objetivos fueron: • Identificar los aprox. 20.000-25.000 genes en el genoma humano
• Determinar la secuencia de los 3.2 Gbp de nucleótidos que componen el
genoma haploide y almacenar esta información en bases de datos
• Mejorar el software para analizar estos datos
• Transferencia de tecnología al sector privado
• Abordar los aspectos éticos, legales y sociales (ELSI) que pudiera provocar el proyecto

http://bioinfo2.ugr.es/genomica Universidad de Granada
El Proyecto Genoma Humano • Fue una iniciativa internacional lanzada en la década de los 90
del pasado siglo para mapear y secuenciar el conjunto de genes del ser humano (genoma)
• Completado en 2003 con la publicación de la secuencia de referencia del genoma humano

Secuenciación masiva
SOLID Sequencing by Ligation (SBL)
454 Pyrosequencing (PS)
Illumina Reversible Termination (RT)
http://bioinfo2.ugr.es/genomica Universidad de Granada

Secuenciación masiva
SANGER SECUENCIACIÓN MASIVA
Di-deoxy terminator
Roche 454 GS FLX (PS)
Illumina HiSeq 2000 (RT) SOLID V4 (SBL)
Salida por proceso 1.6 Mb 600 Mb 200 GB 100 GB
Tiempo/Proceso 1h 10 h 9 d 11 d Longitud media “reads” 800 pbs 400 pb 100 pb 75 pb
Salida por día 38.4 Mb 1.44 GB 22.2 GB 9 GB
Usos frecuentes - Secuenciación de novo Captura de exones
Resecuenciación Captura de exones Metagenómica
Resecuenciación Captura de exones Metagenómica
http://bioinfo2.ugr.es/genomica Universidad de Granada

http://bioinfo2.ugr.es/genomica Universidad de Granada

Secuenciación masiva
APLICACIONES
Re-secuenciación Regulación Epigenómica
• SNVs y CNVs • Inserciones y
deleciones
• Expresión génica • ARNs pequeños
• Metilación del ADN • Histonas • TFBSs
Imágenes extraídas de Schweiger, 2010. http://bioinfo2.ugr.es/genomica Universidad de Granada

http://bioinfo2.ugr.es/genomica Universidad de Granada
El proyecto 1000 Genomas pretende la caracterización de la variación genética en el genoma humano
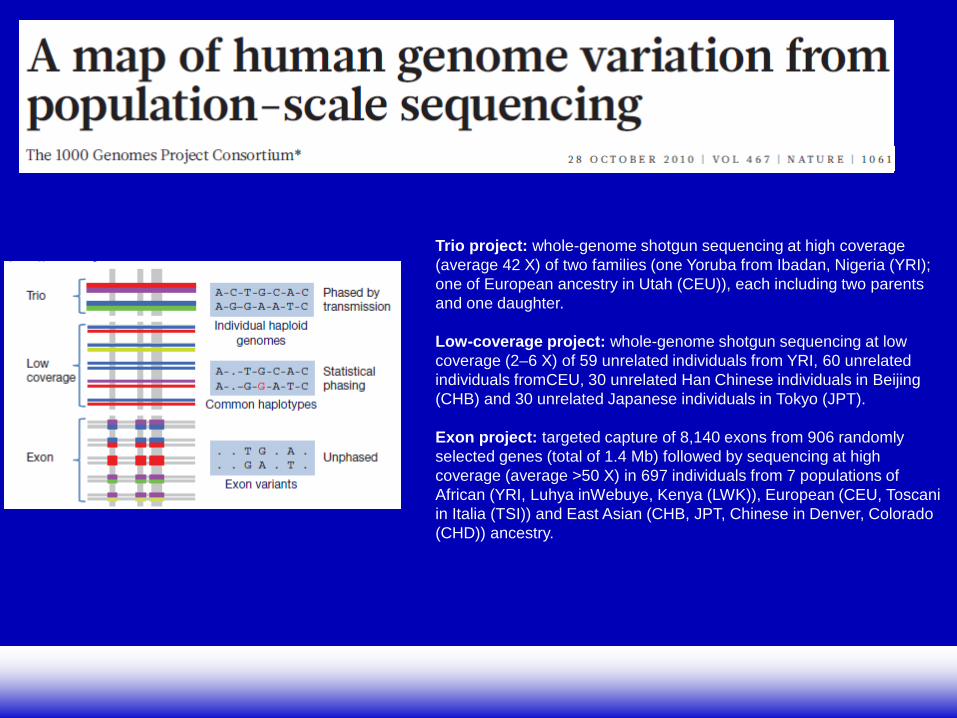
Trio project: whole-genome shotgun sequencing at high coverage (average 42 X) of two families (one Yoruba from Ibadan, Nigeria (YRI); one of European ancestry in Utah (CEU)), each including two parents and one daughter. Low-coverage project: whole-genome shotgun sequencing at low coverage (2–6 X) of 59 unrelated individuals from YRI, 60 unrelated individuals fromCEU, 30 unrelated Han Chinese individuals in Beijing (CHB) and 30 unrelated Japanese individuals in Tokyo (JPT). Exon project: targeted capture of 8,140 exons from 906 randomly selected genes (total of 1.4 Mb) followed by sequencing at high coverage (average >50 X) in 697 individuals from 7 populations of African (YRI, Luhya inWebuye, Kenya (LWK)), European (CEU, Toscani in Italia (TSI)) and East Asian (CHB, JPT, Chinese in Denver, Colorado (CHD)) ancestry.



http://bioinfo2.ugr.es/genomica Universidad de Granada
• La ‘Encyclopedia of DNA Elements’ (ENCODE) surge de una colaboración internacional iniciada en 2003 y financiada por el ‘National Human Genome Research Institute’ (NHGRI).
• El objetivo de ENCODE es elaborar un catálogo
exhaustivo de todos los elementos funcionales en el genoma humano, incluyendo tanto ARNs como proteínas, asi como aquellos elementos reguladores que controlan el tipo celular y el momento del desarrollo en que un gen es activo.
• La cuestión es: la suma de los exones de los aprox. 21.000 genes humanos no llegan al 2% del genoma ¿para que sirve el 98% restante? ¿es ADN basura?
El proyecto ENCODE

http://bioinfo2.ugr.es/genomica Universidad de Granada
Algunas de las técnicas utilizadas en ENCODE RNA-seq. Aislamiento y secuenciación masiva de ARN CAGE. Captura y secuenciación masiva de los ‘caps’ metilados en los extremos 5’ del ARN. Estos ‘caps’ suelen formarse en los sitios de inicio de la transcripción RNA-PET. Captura simultánea de ARNs con caps metilados y cola de poly-A, es decir ARNs completos, seguida de la secuenciación de un trozo en cada extremo. ChIP-seq. Inmunoprecipitación de las proteínas unidas a la cromatina y secuenciación de las secuencias de ADN asociadas. Se suelen usar anticuerpos frente a factores de transcripción, proteínas no-histonas que se unen a la cromatina, o bien histonas modificadas por metilación, acetilación, etc.

http://bioinfo2.ugr.es/genomica Universidad de Granada
DNase-seq. La enzima DNasa I corta preferencialmente regiones de la cromatina unidas a proteínas no-histonas y que corresponden a regiones de ‘cromatina abierta’. Los puntos de corte se secuencian, obteniéndose así un listado de sitios hipersensibles a DNasa I que corresponden a sitios de cromatina activa. FAIRE-seq. (Formaldehyde assisted isolation of regulatory elements). Permite aislar regiones genómicas libres de nucleosomas. RRBS (Reduced representation bisulphite sequencing). El tratamiento del ADN con bisulfito convierte las citosinas no-metiladas en uracilo, mientras que no afecta a las citosinas metiladas. Se usan enzimas de restricción que cortan alrededor de los dinucleótidos CpG, con lo que se limita el análisis a aquellas regiones ricas en CpG (islas CpG).

http://bioinfo2.ugr.es/genomica Universidad de Granada

http://bioinfo2.ugr.es/genomica Universidad de Granada

http://bioinfo2.ugr.es/genomica Universidad de Granada
Principales hallazgos de ENCODE La mayor parte del genoma (80.4%) es funcional: se puede asociar con al menos una función en alguno de los 147 tipos celulares analizados. Puesto que puede haber hasta 2.000 tipos celulares, este porcentaje podría llegar a ser mucho más alto! Los elementos específicos de primates están sometidos a selección natural deben ser funcionales Se han descubierto 399.124 enhancers y 70.292 promotores Muchas de los elementos funcionales encontrados se localizan en las regiones no-codificadoras de proteínas (fuera de los genes) Los SNPs asociados con enfermedades mediante GWAS abundan en las regiones no-codificadoras y residen en zonas funcionales identificadas por ENCODE. Muchas enfermedades se asocian con un determinado factor de transcripción que varía entre tipos celulares.

http://bioinfo2.ugr.es/genomica Universidad de Granada
• Bases de datos públicas en línea: EBI, NCBI
• El software se ejecuta en servidores remotos de acceso público:
• Formularios Web: Copiar/pegar datos Resultados
• Ventajas:
• Datos actualizados on-line
• Acceso a software profesional permanentemente actualizado por sus propios autores
• No tendremos que instalar ningún programa ni base de datos en nuestra máquina local, todo lo haremos a través de un navegador web
• Podremos acceder a las prácticas del curso desde cualquier ordenador (Windows, Linux, Mac…) con acceso a Internet
Los programas y bases de datos que utilizaremos funcionan en servidores web:

http://bioinfo2.ugr.es/genomica Universidad de Granada
Seminarios • A lo largo del curso, cada alumno desarrollará un seminario sobre algún
tema fijado por el profesor. El objetivo que se persigue es iniciar al alumno en las técnicas de análisis genómico, así como en el manejo de las correspondientes bases de datos.
• Se valorará especialmente el grado de iniciativa a la hora de planear y
desarrollar el trabajo y deberá exponerse oralmente.
• Este tipo de actividad aúna una serie de tareas fundamentales en la formación universitaria (búsqueda de información, análisis, síntesis, expresión escrita y expresión oral) que son de todo punto imprescindibles en la universidad actual.