gi-edition - subs.emis.de · ulrich greveler,benjamin justus, dennis lohr¨ identifikation von...
TRANSCRIPT

This volume contains the contributions to the 6th Conference of the GI special interest group “Sicherheit, Schutz und Zuverlässigkeit” that took place in Darmstadt on March 7-9, 2012. The main aspects of the conference were secure software development, bio-metrics, e-commerce, reliability and safety, certification, fault-tolerance, formal meth-ods, critical infrastructure protection, cryptography, network security, privacy enhanc-ing techniques, intrusion detection and prevention, and steganography.
ISSN 1617-5468ISBN 978-88579-289-5
Gesellschaft für Informatik e.V. (GI)
publishes this series in order to make available to a broad public recent findings in informatics (i.e. computer science and informa-tion systems), to document conferences that are organized in co-operation with GI and to publish the annual GI Award dissertation.
Broken down into• seminars• proceedings• dissertations• thematicscurrent topics are dealt with from the vantage point of research and development, teaching and further training in theory and practice.The Editorial Committee uses an intensive review process in order to ensure high quality contributions.
The volumes are published in German or English.
Information: http://www.gi.de/service/publikationen/lni/
195
GI-EditionLecture Notes in Informatics
Neeraj Suri, Michael Waidner (Hrsg.)
Sicherheit 2012
Sicherheit, Schutz und Zuverlässigkeit Beiträge der 6. Jahrestagung des Fachbereichs Sicherheit der Gesellschaft für Informatik e.V. (GI)
7.–9. März 2012Darmstadt
Proceedings
Nee
raj S
uri
, Mic
hae
l Wai
dn
er (
Hrs
g.):
Sich
erh
eit
2012



Neeraj Suri, Michael Waidner (Hrsg.)
S I C H E R H E I T 2 0 1 2
Sicherheit, Schutz und Zuverlässigkeit
Konferenzband der 6. Jahrestagung des FachbereichsSicherheit der Gesellschaft für Informatik e.V. (GI)
7.-9. März 2012in Darmstadt
Gesellschaft für Informatik e.V. (GI)

Lecture Notes in Informatics (LNI) - ProceedingsSeries of the Gesellschaft für Informatik (GI)
Volume P-195
ISBN 978-3-88579-289-5ISSN 1617-5468
Volume EditorsProf. Dr. Michael Waidner
Technische Universität DarmstadtSicherheit in der Informationstechnik64293 Darmstadt, GermanyEmail: [email protected]
Prof. Suri Neeraj, Ph. D.Technische Universität DarmstadtZuverlässige Eingebettete Softwaresysteme64289 Darmstadt, GermanyEmail: [email protected]
Series Editorial BoardHeinrich C. Mayr, Alpen-Adria-Universität Klagenfurt, Austria(Chairman, [email protected])Hinrich Bonin, Leuphana Universität Lüneburg, GermanyDieter Fellner, Technische Universität Darmstadt, GermanyUlrich Flegel, Hochschule Offenburg, GermanyUlrich Frank, Universität Duisburg-Essen, GermanyJohann-Christoph Freytag, Humboldt-Universität zu Berlin, GermanyMichael Goedicke, Universität Duisburg-Essen, GermanyRalf Hofestädt, Universität Bielefeld, GermanyMichael Koch, Universität der Bundeswehr München, GermanyAxel Lehmann, Universität der Bundeswehr München, GermanyErnst W. Mayr, Technische Universität München, GermanyThomas Roth-Berghofer, DFKI, GermanySigrid Schubert, Universität Siegen, GermanyMartin Warnke, Leuphana Universität Lüneburg, Germany
DissertationsSteffen Hölldobler, Technische Universität Dresden, GermanySeminarsReinhard Wilhelm, Universität des Saarlandes, GermanyThematicsAndreas Oberweis, Karlsruher Institut für Technologie (KIT), Germany
Gesellschaft für Informatik, Bonn 2012printed by Köllen Druck+Verlag GmbH, Bonn

Vorwort
Die Konferenz “Sicherheit, Schutz und Zuverlassigkeit” SICHERHEIT der Gesellschaft furInformatik e.V. fand 2012 in der sechsten Ausgabe in Darmstadt statt. Sie ist die regelmaßigstattfindende Fachtagung des Fachbereichs “Sicherheit – Schutz und Zuverlassigkeit” derGesellschaft fur Informatik e.V. Die SICHERHEIT bietet einem Publikum aus Forschung,Entwicklung und Anwendung ein Forum zur Diskussion von Herausforderungen, Trends,Techniken und neuesten wissenschaftlichen und industriellen Ergebnissen. Die Tagungdeckt alle Aspekte der Sicherheit informationstechnischer Systeme ab und versucht, aucheine Brucke zwischen den Themen IT Security, Safety und Dependability zu bilden.
Der vorliegende Tagungsband umfasst alle 20 Beitrage des wissenschaftlichen Programms.Diese Beitrage wurden aus insgesamt 51 Einreichungen durch das international besetzte 38-kopfige Programmkomitee ausgewahlt. Traditionsgemaß durften Beitrage in Deutsch undin Englisch eingereicht werden. In diesem Jahr gab es zudem vier eingeladene Sprecher.
Unser Dank gilt allen, die sich mit Zeit und Muhe am Gelingen der Konferenz beteiligthaben. Allen voran zu nennen sind hier die Autorinnen und Autoren, die Mitglieder desProgrammkomitees und die weiteren Gutachter, sowie die Sponsoren der Konferenz. Unserganz besonderer Dank gilt Andrea Puchner und Marco Ghiglieri, die sich ruhig und aus-dauernd um alle Probleme der lokalen Organisation gekummert haben, von der Planungbis zur eigentlichen Durchfuhrung. Unser Dank gilt auch dem Leitungsgremium des GI-Fachbereichs “Sicherheit - Schutz und Zuverlassigkeit”, insbesondere den Mitgliedern derTagungsleitung, Hannes Federrath, Felix C. Freiling und Jorg Schwenk.
Marz 2012 Neeraj Suri, Michael Waidner

Tagungsleitung
• Hannes Federrath (Sprecher des Fachbereichs, Universitat Hamburg)
• Felix C. Freiling (Leiter der Sicherheit 2010, Friedrich-Alexander-Universitat Erlangen-Nurnberg)
• Jorg Schwenk (stellv. Sprecher des Fachbereichs, Ruhr-Universitat Bochum)
• Neeraj Suri (Co-Leiter, Technische Universitat Darmstadt)
• Michael Waidner (Leiter, Technische Universitat Darmstadt und Fraunhofer SIT)
Programmkomitee
• Neeraj Suri (Technische Universitat Darmstadt)
• Michael Waidner (Technische Universitat Darmstadt und Fraunhofer SIT)
• Michael Backes (Universitat des Saarlandes)
• Bernd Becker (Universitat Freiburg)
• Fevzi Belli (Universitat Paderborn)
• Thomas Biege (SUSE Linux Products GmbH)
• Jens Braband (Siemens AG)
• Peter Buchholz (Technische Universitat Dortmund)
• Christoph Busch (Hochschule Darmstadt)
• Christof Fetzer (Technische Universitat Dresden)
• Simone Fischer-Hubner (Karlstad University, Schweden)
• Felix C. Freiling (Friedrich-Alexander-Universitat Erlangen-Nurnberg)
• Sabine Glesner (Technische Universitat Berlin)
• Bernhard Hammerli (Acris GmbH)
• Marit Hansen (Unabhangiges Landeszentrum fur Datenschutz Schleswig-Holstein)
• Thorsten Holz (Ruhr-Universitat Bochum)
• Jorg Kaiser (Otto-von-Guericke-Universitat Magdeburg)
• Gunter Karjoth (IBM Research – Zurich)
• Stefan Katzenbeisser (Technische Universitat Darmstadt)

• Ralf Kusters (Universitat Trier)
• Helmut Kurth (atsec information security)
• Peter Ladkin (Universitat Bielefeld)
• Pavel Laskov (Universitat Tubingen)
• Erik Maehle (Universitat Lubeck)
• Jorn Muller-Quade (Karlsruhe Institut fur Technologie)
• Isabel Munch (BSI - Bundesamt fur Sicherheit in der Informationstechnik)
• Roman Obermaisser (Universitat Siegen)
• Gunther Pernul (Universitat Regensburg)
• Andreas Polze (HPI Universitat Potsdam)
• Kai Rannenberg (Goethe-Universitat Frankfurt am Main)
• Felix Salfner (SAP Innovation Center Potsdam)
• Jorg Schwenk (Ruhr-Universitat Bochum)
• Jean-Pierre Seifert (Technische Universitat Berlin)
• Claus Stark (Citigroup AG)
• Martin Steinebach (Fraunhofer SIT)
• Reinhard von Hanxleden (Christian-Albrechts-Universitat zu Kiel)
• Carsten Willems (Ruhr-Universitat Bochum)
• Sven Wohlgemuth (National Institute of Informatics, Japan)
Zusatzliche Gutachter
• Rafael Accorsi (Universitat Freiburg)
• Gokhan Bal (Goethe-Universitat Frankfurt am Main)
• Zinaida Benenson (Friedrich-Alexander-Universitat Erlangen-Nurnberg)
• Sebastian Biedermann (Technische Universitat Darmstadt)
• Tino Brade (Otto-von-Guericke-Universitat Magdeburg)
• Christian Broser (Universitat Regensburg)

• Andreas Dewald (Universitat Mannheim)
• Sebastian Ertel (Technische Universitat Dresden)
• Linus Feiten (Universitat Freiburg)
• Daniel Fett (Universitat Trier)
• Marco Ghiglieri (Technische Universitat Darmstadt)
• Oliver Gmelch (Universitat Regensburg)
• Tim Grebien (Christian-Albrechts-Universitat zu Kiel)
• Sabri Hassan (Universitat Regensburg)
• Uwe Hentschel (Universitat Potsdam)
• Paula Herber (Technische Universitat Berlin)
• Johannes Hoffmann (Ruhr-Universitat Bochum)
• Ralf Hund (Ruhr-Universitat Bochum)
• Christine Hundt (Technische Universitat Berlin)
• Christian Kahl (Goethe-Universitat Frankfurt am Main)
• Lukas Kalabis (Technische Universitat Darmstadt)
• Matthias Kirchner (Westfalische Wilhelms-Universitat Munster)
• Daniel Kraschewski (Karlsruher Institut fur Technologie)
• Christoph Kruger (Christian-Albrechts-Universitat zu Kiel)
• Marc Kuhrer (Ruhr-Universitat Bochum)
• Andre Martin (Technische Universitat Dresden)
• Christian Moch (Friedrich-Alexander-Universitat Erlangen-Nurnberg)
• Michael Muter (Daimler AG)
• Michael Netter (Universitat Regensburg)
• Christian Neuhaus (HPI Universitat Potsdam)
• Andreas Peter (Technische Universitat Darmstadt)
• Marcel Pockrandt (Technische Universitat Berlin)
• Robert Reicherdt (Technische Universitat Berlin)

• Andreas Reisser (Universitat Regensburg)
• Konrad Rieck (Universitat Gottingen)
• Ahmad Sabouri (Goethe-Universitat Frankfurt am Main)
• Matthias Sauer (Universitat Freiburg)
• Alexander Schacht (HPI Universitat Potsdam)
• Dirk Scheuermann (Fraunhofer SIT)
• Andre Schmitt (Technische Universitat Dresden)
• Christian Schneider (Christian-Albrechts-Universitat zu Kiel)
• Christoph Daniel Schulze (Christian-Albrechts-Universitat zu Kiel)
• Miro Sponemann (Christian-Albrechts-Universitat zu Kiel)
• Christoph Steup (Otto-von-Guericke-Universitat Magdeburg)
• Daniel Stohr (Technische Unversitat Berlin)
• Martin Stopczynski (Technische Universitat Darmstadt)
• Dirk Tetzlaff (Technische Univeristat Berlin)
• Max Tuengerthal (Universitat Trier)
• Fatbardh Veseli (Goethe-Universitat Frankfurt am Main)
• Andreas Vogt (Universitat Trier)
• Michael Weber (Universitat Regensburg)
• Robert Wierschke (HPI Universitat Potsdam)
• Ralf Wimmer (Universitat Freiburg)
• Philipp Winter (Karlstad University, Sweden)
• Lars Wolos (Goethe-Universitat Frankfurt am Main)
• Sebastian Zug (Otto-von-Guericke-Universitat Magdeburg)


Inhaltsverzeichnis
Eingeladene Sprecher
Christian CachinSicherheits-Forschung fur die Cloud - Heisse Luft oder Wolke Sieben? 1
Hinrich VoelckerIT Security – Effiziente Organisation uber Governance hinaus . . . . 2
Jens BrabandSecurity und Safety – das Yin und Yang der Systemsicherheit? . . . . . 3
Volkmar LotzTowards a Secure and Trusted Business Web . . . . . . . . . . . . . . 4
Xuebing ZhouA Practical View of Privacy Preserving Biometric Authentication . . . 6
Benutzbarkeit von IT-Sicherheit I
Zinaida Benenson, Olaf Kroll-Peters, Matthias KruppMentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 7
Jan Zibuschka, Heiko RoßnagelOn Some Conjectures in IT Security: The Case for Viable SecuritySolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25

IT-Forensik
Ulrich Greveler, Benjamin Justus, Dennis LohrIdentifikation von Videoinhalten uber granulare Stromverbrauchsdaten 35
Andreas Dewald, Felix C. Freiling, Thomas Schreck,Michael Spreitzenbarth, Johannes Stuttgen, Stefan Vomel,Carsten WillemsAnalyse und Vergleich von BckR2D2-I und II . . . . . . . . . . . . . . 47
Christian Zimmermann, Michael Spreitzenbarth, Sven Schmitt,Felix C. FreilingForensic Analysis of YAFFS2 . . . . . . . . . . . . . . . . . . . . . . 59
Kryptographie
Christina Brzuska, Ozgur Dagdelen, Marc FischlinTLS, PACE, and EAC: A Cryptographic View at Modern Key ExchangeProtocols . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
Lassaad Cheikhrouhou, Werner Stephan, Ozgur Dagdelen,Marc Fischlin, Markus UllmannMerging the Cryptographic Security Analysis and the Algebraic-LogicSecurity Proof of PACE . . . . . . . . . . . . . . . . . . . . . . . . . 83
Detlef Huhnlein, Dirk Petrautzki, Johannes Schmolz, Tobias Wich,Moritz Horsch, Thomas Wieland, Jan Eichholz, Alexander Wiesmaier,Johannes Braun, Florian Feldmann, Simon Potzernheim, Jorg Schwenk,Christian Kahlo, Andreas Kuhne, Heiko VeitOn the design and implementation of the Open eCard App . . . . . . 95
Sicherheit im Web
Sebastian Lekies, Walter Tighzert, Martin JohnsTowards stateless, client-side driven Cross-Site Request Forgeryprotection for Web applications . . . . . . . . . . . . . . . . . . . . . 111

Karl-Peter Fuchs, Dominik Herrmann, Hannes FederrathgMix: Eine generische Architektur fur Mix-Implementierungen undihre Umsetzung als Open-Source-Framework . . . . . . . . . . . . . 123
Markus Engelberth, Jan Gobel, Christian Schonbein, Felix C. FreilingPyBox - A Python Sandbox . . . . . . . . . . . . . . . . . . . . . . . 137
Dokumenten- und Netzwerksicherheit
Steffen WendzelThe Problem of Traffic Normalization Within a Covert Channel’sNetwork Environment Learning Phase . . . . . . . . . . . . . . . . . 149
Philipp Trinius, Felix C. FreilingFiltern von Spam-Nachrichten mit kontextfreien Grammatiken . . . . 163
Patrick Wolf, Martin SteinebachFixBit-Container: Effizienter Urheberschutz durch Wasserzeichenentlang der Medien-Wertschopfungskette . . . . . . . . . . . . . . . . 175
Benutzbarkeit von IT-Sicherheit II
Michaela Kauer, Thomas Pfeiffer, Melanie Volkamer, Heike Theuerling,Ralph BruderIt is not about the design - it is about the content! Making warningsmore efficient by communicating risks appropriately . . . . . . . . . . 187
Stefan Penninger, Stefan Meier, Hannes FederrathUsability von CAPTCHA-Systemen . . . . . . . . . . . . . . . . . . . 199
Wiebke Menzel, Sven Tuchscheerer, Jana Fruth, Christian Kratzer,Jana DittmannDesignansatz und Evaluation von Kindgerechten Securitywarnungenfur Smartphones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211

Authentisierung und Biometrie
Markus Ullmann, Ralph Breithaupt, Frank Gehring
”On-Card“ User Authentication for Contactless Smart Cards basedon Gesture Recognition . . . . . . . . . . . . . . . . . . . . . . . . . 223
Marcus Quintino Kuhnen, Mario Lischka, Felix Gomez MarmolTriggering IDM Authentication Methods based on Device CapabilitiesInformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
Daniel Hartung, Anika Pflug, Christoph BuschVein Pattern Recognition Using Chain Codes Spatial Information andSkeleton Fusing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245

Sicherheits-Forschung fur die Cloud - Heisse Luft oderWolke Sieben?
Christian Cachin
IBM Research – ZurichSaumerstrasse 4
CH-8803 Ruschlikon, [email protected]
Abstract: Seit dem Erscheinen von Cloud-Computing sind viele neue Bedenken ge-genuber ”Big Brother“ aufgekommen. Dennoch nutzen Privatleute und Firmen heu-te die Cloud, weil sie so praktisch ist - und behalten dabei ein mulmiges Gefuhl imBauch zuruck. Ihre großten Bedenken betreffen die Sicherheit und Zuverlassigkeit vonCloud-Diensten. Da aber langfristige Erfahrungen mit der Cloud bis heute fehlen, sindbeide Großen noch weitgehend Unbekannte.
Besondere Sichtbarkeit erlangen daher Forschungsresultate, die darauf abzielen,die Benutzer und ihre Daten vor Problemen in der Cloud zu schutzen. Diese Arbei-ten sollen Geheimhaltung und Integritat der Daten garantieren und die Zuverlassigkeitder bezogenen Dienste sicherstellen. Dieser Vortrag prasentiert und analysiert eini-ge Trends aus dieser Forschung: erstens, die Verarbeitung von verschlusselten Da-ten durch ”Homomorphic Encryption“, zweitens, die Konsistenz von verteilten Spei-cherdiensten und, drittens, hochverfugbare Systeme, welche auch teilweise von einemGegner unterwandert noch weiterlaufen konnen (sog. ”Byzantine Fault-Tolerant Sys-tems“).

IT Security - Effiziente Organisation uber Governancehinaus
Hinrich Voelcker
Deutsche BankAlfred-Herrhausen-Allee 16-24
D-65670 [email protected]
Abstract: Die Sicherheit der IT-Systeme ist nicht zuletzt durch das breite Interes-se der Medien und Offentlichkeit zu einem ausgesprochen wichtigen Thema jedesWirtschaftunternehmens geworden. Vertraulichkeit, Verfugbarkeit und Integritat derUnternehmens- und Kundendaten ist uberlebenswichtig - gerade in Bezug auf dieReputation. Besonders Banken leben von der Vertrauenswurdigkeit gegenuber ihrenKunden. Wahrend die Regulatoren des Finanzwesens schon immer auf die Einhaltungeines hohen Standards der IT-Sicherheit achteten, richtet sich auch deren Augenmerknoch starker als bisher auf die Sicherheit der IT-Systeme. Ausloser hierfur sind nichtzuletzt die steigende Anzahl und zunehmende Professionalitat von Cyberangriffengegen Unternehmen zu deren Abwehr die Implementierung von ”Game-Changing-Technologies”, wie proaktive Cyber-Intelligence-Losungen, eine immer wichtigereRolle spielt.
Wahrend einzelne Losungen zur IT-Sicherheit auch nur einzelne Probleme undmogliche Schwachstellen adressieren, ist es besonders in einem Großunternehmenwichtig, ein umfassendes Gesamtkonzept zur erfolgreichen Verteidigung vonCyberangriffen zu gestalten und effizient aufzubauen. Voraussetzung fur die Durch-setzung dieses Ziels ist ein zentral aufgestellter IT Security-Bereich mit einer hohenVisibilitat und globalen Verantwortung fur die Sicherheit der IT-Systeme. Diese Orga-nisationsform spiegelt auch den gewachsenen Stellenwert der IT-Sicherheit in Unter-nehmen wieder.

Security und Safety - das Yin und Yang derSystemsicherheit? Beispiel Eisenbahnsignaltechnik
Jens Braband
Siemens AGAckerstraße 22
D-38126 [email protected]
Abstract: Yin und Yang stehen in der chinesischen Philosophie fur Gegensatze, z. B.Krafte oder Prinzipien, in ihrer wechelseitigen Bezogenheit. In diesem Beitrag wirddas Bild von Yin und Yang benutzt, um die Beziehungen zwischen Safety und Secu-rity am Beispiel der Eisenbahnsignaltechnik zu erlautern. Dabei werden sowohl dienormativen Grundlagen als auch typische Anwendungen diskutiert. Insbesondere diein der Eisenbahnsignaltechik verwendeten Referenzarchitekturen sowie die ublicheKategorisierung von Kommunikationssystemen wird erlautert.Es wird ein Ansatz vorgestellt, der es ermoglichen soll, Safety- und Security-Eigen-schaften in der Kommunikationssicherheit soweit moglich zu orthogonalisieren, uminsbesondere auch die Aspekte der Zulassung bzw. Zertifizierung soweit moglich zutrennen. Dabei wird auch verschiedene Ansatze zur Zertifizierung eingegangen undkonkrete Erfahrungen mit der Erstellung eines Schutzprofils nach Common Criteriawerden diskutiert.

Towards a Secure and Trusted Business Web
Volkmar Lotz
SAP Labs France, Security & Trust Research Practice805, Avenue du Dr Maurice Donat
06250 Mougins, [email protected]
Abstract: We currently see a major shift in development, deployment and operationof Enterprise IT systems and business applications. Driven by cost and effectivenessconsiderations, and facilitated by virtual infrastructures (aka the cloud) and serviceorientation, application development is distributed over a variety of entities (ISPs -independent service providers), applications are composed of services from differentISPs, and IT operations is run by independent data and computation centers. Usingthe Internet as fast and ubiquitous communication infrastructure, we see a fabric ofresources, platforms, services and applications emerging forming a number of ecosys-tems that will drive society and business. For this set of ecosystems and facilitatingtechnology and infrastructure, we have coined the term ”Business Web”. Since theBusiness Web is going to be the critical infrastructure underlying business and privatelife, concerns related to security and privacy will inevitably be raised. These concernsare grounded in the open and dynamic nature of the Business Web and its coverage ofall aspects of business including the most sensitive areas like finance, healthcare, per-sonal information etc. The strength of the Business Web lies in information sharing andspontaneous interaction with entities, even if they are previously unknown, and thereis an inherent risk of information being abused and data owners losing control overtheir data in terms of usage, consistency or availability. To mitigate these risk whilebeing able to exploit the benefits of collaboration, one needs to determine with whomthe collaboration takes place, to express which mutual protection needs are to be met,and which controls can be imposed to actually enforce them. In this talk, we focus onthe establishment of trust in services and the complementary support of data-centricservices.
In addition to traditional means based on observation, recommendation, and re-putation which come to their limits upon discovery of new services, rich service de-scriptions including security and privacy related attributes, attested by trusted parties,provide the needed information and form a service identity where the mere name ofthe service would not be meaningful. At the same time, such descriptions can serve asa container for policy information expressing the service’s protection needs, its abili-ties to match consumers’ policies and its governance. Given that the user can expressher policies in a similar, machine-processable way, we are able to match policies anddecide if the service can be safely used.
When considering the complexity of Business Web structures, however, we haveto ensure that the above approach scales to multiple layers of dynamic collaboration.Data are travelling across domains, services and resources, while still being subject totheir owners’ policies. This motivates a data-centric security concept, where policiesare bound to data and travel with them - ßticky policies”. Each processor of the data,even if it cannot be predicted where they will eventually end up, has access to thepolicy information and can handle the data accordingly. Sticky policies allow for the

expression of obligations (like a deletion or retention period) to be met by processingentities. While this concept is theoretically pleasing, it faces practical challenges ofperformance and enforcement asking for further research. We show how a solutionmeeting some of these challenges can be provided on top of a distributed Java platform.
Towards a Secure and Trusted Business Web 5

A Practical View of Privacy Preserving BiometricAuthentication
Xuebing Zhou
Center for Advanced Security Research DarmstadtMornewegstraße 32D-64293 Darmstadt
Abstract: Recently, biometric market is growing rapidly and biometric applicationscan be found in diverse areas such as border control, banking, ID-documents, accesscontrol, etc. However, usage of personal biometric information can harm privacy ofusers and raise problems of cross matching and identity theft. Privacy preserving tech-niques like template protection are an important supplement to biometric systems toprevent abuse of stored biometric information and to improve security of biometricauthentication. This work introduces the concept of biometric privacy preserving tech-niques and shows how to quantify their security and privacy in practice with help of ageneralized evaluation framework. The advantages as well as limitations of the existingmethods are analyzed. Additionally, systematic security considerations are given anda guideline to successfully design privacy preserving techniques for biometric systemsis proposed.

Mentale Modelle der IT-Sicherheit bei der Nutzung mobilerEndgerate
Zinaida BenensonUniversitat Erlangen-Nurnberg
Olaf Kroll-PetersEnBW AG
Matthias KruppUniversitat Mannheim
Abstract: Mobile Endgerate werden immer leistungsfahiger und damit wachst fur dieNutzer auch das Gefahrenpotenzial durch typische IT-Sicherheitsbedrohungen. Ob-wohl die Verantwortung des Benutzers fur die Einhaltung der IT-Sicherheit anerkanntund wissenschaftlich belegt ist, konzentriert sich die Forschung zur IT-Sicherheit immobilen Umfeld meistens auf die technische Seite der Problematik. In dieser Arbeitwird der erste Schritt zur Untersuchung der Rolle der Benutzer in der IT-Sicherheitmobiler Endgerate unternommen, indem anhand von Interviews entsprechende menta-le Modelle erstellt werden. Als mentale Modelle werden Abbildungen der Realitat imBewusstsein des Menschen bezeichnet. Obwohl diese Abbildungen normalerweise un-genau und oft fehlerhaft sind, kann ihre Kenntnis zu Prognosen uber Handlungen vonMenschen verwendet werden. Mentale Modelle der IT-Sicherheit bilden die Grund-lage fur die Bemuhungen der Nutzer (oder fur das Fehlen solcher Bemuhungen), dieIT-Sicherheit ihrer Systeme zu gewahrleisten.
1 Einleitung
Die Anzahl sowie Leistungsfahigkeit mobiler Endgerate nimmt im Verlauf der letzten Jah-re immer starker zu und damit wachst auch die Anzahl der IT-Sicherheitsbedrohungenin diesem Bereich [Jun11, BFH+11]. Auf der einen Seite sind die Anwender techni-schen Bedrohungen wie Malware, das Abhoren der Datenubermittlung und das Ausspahenvon Standortinformationen ausgesetzt. Auf der anderen Seite bestehen auch menschlicheBedrohungen wie Verlust, Diebstahl, Fehlbedienung und Social Engineering. In beidenFallen nehmen Benutzer einen bedeutenden Anteil fur das Umsetzen von IT-Sicherheitmobiler Endgerate ein. Zum Beispiel ist zum Installieren der mobilen Malware meistensnach wie vor die aktive Teilnahme der Benutzer notwendig.
Bisher ist die Rolle der Benutzer in der Sicherheit mobiler Endgerate nicht ausreichendbekannt. In dieser Arbeit unternehmen wir die ersten Schritte zur Feststellung mentalerModelle der IT-Sicherheit bei der Benutzung mobiler Endgerate. Mentale Modelle cha-rakterisieren die individuelle Reprasentation und das Verstandnis von Realitat, beeinflusstdurch Erfahrungen, Empfindungen und Informationen, im Bewusstsein von Menschen.

Im Abschnitt 2 wird zunachst ein Uberblick uber verwandte Arbeiten zu mentalen Model-len der IT-Sicherheit gegeben. Dann wird im Abschnitt 3 unsere Untersuchung zur Ermitt-lung mentaler Modelle der IT-Sicherheit bei der Benutzung mobiler Endgerate vorgestellt.Anschließend werden im Abschnitt 4 die Ergebnisse der Arbeit diskutiert und schließlichim Abschnitt 5 weiterfuhrende Arbeiten vorgeschlagen.
2 Mentale Modelle in der IT-Sicherheit
Erste mentale Modelle fur den Themenkomplex der IT-Sicherheit erstellten Camp et al.[ALC07, Cam09]. Sie unterscheiden funf Metaphern der IT-Sicherheit: physische Sicher-heit (z.B. Schlosser), medizinische Infektionen (Viren), kriminelles Verhalten (Einbre-cher), Kriegsfuhrung und wirtschaftliches Versagen (Schwachstellen in der Software).
Implizite Beschreibungen der mentalen Modelle der IT-Sicherheit finden sich haufig inPublikationen zum Themenkomplex der Mensch-Computer-Interaktion. So fanden Sasseet al. [SBW01] heraus, dass die Kenntnisse der Nutzer nicht ausreichend sind, um diebestehenden Sicherheitsbedrohungen richtig einzuordnen. Norman [Nor09] beobachtet,dass die Anwender sogar die Installation essentieller Sicherheitspatches abgelehnt habenaus Angst etwas Falsches zu installieren. Ihr mentales Modell lautet: ”Installieren neuerSoftware ist gefahrlich“. Haufig sind die Anwender aufgrund fehlender Kenntnisse nichtin der Lage zwischen sicheren und unsicheren Installationsanfragen zu unterscheiden.
Inakkurate mentale Modelle schaffen oft weitere Gefahrenquellen [RHJ+10]. Unter ande-rem erstellen Anwender eigene Regeln im Umgang mit IT-Systemen, wie z.B. nur schein-bar sichere Passworter, die ihnen besser im Gedachtnis bleiben [AS99, FH07, FCB07].
Fur die Anwender ist ihr sicherheitskonformes Handeln eine Kosten-/Nutzen-Kalkula-tion [Her09]. Werden die Kosten als zu hoch wahrgenommen, entsteht die Vorstellung
”Sicherheitsmechanismen sind ein Hindernis, das es zu umgehen gilt“. Nach Ansicht vonLampson [Lam09] hat sich bei vielen Anwendern ein ”Sag OK zu jeglichen Sicherheits-fragen“-Modell entwickelt. Die zunehmende Anzahl von Checkboxen, die eine Ruckmel-dung der Nutzer haben mochten, haben dazu gefuhrt, dass die Anwender herausgefundenhaben, welchen Knopf sie drucken mussen, um ungestort ihrer Arbeit weiter nachgehenzu konnen [SEA+09, KFR10].
Ein weiterer Einflußfaktor auf das Bild der IT-Sicherheit vieler Anwender ist ihr sozialesUmfeld.
Verhalten sich Anwender sicherheitsbewusst, werden sie oft als ”paranoid“ oder ”pedan-tisch“ beschrieben [SBW01, WS01] oder als eine Person, die niemandem vertraut. Da dieAnwender sehr viel Wert darauf legen von ihrem Umfeld akzeptiert zu werden, gehen siesogar so weit offen zuzugeben, dass sie stolz darauf sind, Sicherheitsmechanismen nichtzu verstehen oder nicht zu befolgen [SBW01].
Die obigen Publikationen beschreiben mentale Modelle der Anwender zur IT-Sicherheitder ”klassischen“ Rechnersysteme. Bei der Nutzung mobiler Endgerate fehlen jedoch bis-her mentale Modelle der IT-Sicherheit. Im folgenden Abschnitt wird unser Vorgehen zur
8 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

Erstellung solcher mentalen Modelle sowie die daraus resultierenden Ergebnisse vorge-stellt.
3 Studien zur IT-Sicherheit bei der Nutzung mobiler Endgerate
Ein erster Uberblick uber den Themenkomplex ”Anwender und ihr mobiles Endgerat“wurde durch die Erstellung einer Pilotstudie verschafft. In der Hauptuntersuchung wurdenanschließend mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate er-stellt. Beide Untersuchungen wurden anhand eines Fragebogens als Leitfaden-Interviewsdurchgefuhrt.
3.1 Pilotstudie
In der Pilotstudie wurde die Nutzung mobiler Endgerate betrachtet. Es haben sich zweimentale Grundmodelle bei der Nutzung mobiler Endgerate herauskristallisiert. Zum einengibt es Anwender, die ihr Endgerat nur als konventionelles Telefon-Gerat sehen. Trotzeines deutlich großeren Funktionsumfanges, nutzen sie ihr Gerat fast ausschließlich zumTelefonieren oder Schreiben von Kurznachrichten. Zum anderen gibt es Nutzer, die ihrEndgerat als Smartphone sehen. Bei diesen ubersteigt die tagliche Nutzung deutlich denRahmen konventioneller Telefon-Gerate: sie surfen im Internet, schreiben E-Mails odertauschen sich uber soziale Netzwerke aus. Diese mentalen Grundmodelle (”Telefon“ vs.
”Smartphone“) wurden in der Hauptuntersuchung detaillierter betrachtet.
Weiter konnte in der Pilotstudie festgestellt werden, dass sich Nutzer wenig mit der IT-Sicherheit ihres Endgerats befassen. Sie fuhlen sich oft sicher bei der Nutzung ihres mobi-len Endgerats, ohne sich in den Themenkomplex einzuarbeiten oder eigene Anstrengungenfur IT-Sicherheit im mobilen Umfeld zu unternehmen.
3.2 Hauptuntersuchung
Das Ziel der Hauptuntersuchung war eine detaillierte Beschreibung der Sichtweise derNutzer auf die IT-Sicherheit ihrer mobilen Endgerate.
3.2.1 Hypothesen
Auf Grundlage der Untersuchungen und Ergebnisse der Pilotstudie wurden unter anderemfolgende Hypothesen aufgestellt:
• H1: Benutzer, die ihr Gerat als Smartphone sehen, haben ein großeres Sicherheits-bewusstsein als Benutzer, die ihr Gerat als Telefon sehen.
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 9

• H2: Benutzer, die ihr Gerat als Smartphone sehen, fuhlen sich weniger sicher, alsBenutzer, die ihr Gerat als Telefon sehen.
• H3: Benutzer sehen sich selbst nicht fur die Sicherheit ihrer Gerate verantwortlich.
• H4: Benutzer bringen Probleme bei der Benutzung ihres Endgerats nicht mit IT-Sicherheit in Verbindung.
• H5: Um fur ihre IT-Sicherheit im mobilen Umfeld zu sorgen, ist die Hauptanstren-gung der Benutzer der bewusste Umgang mit dem Gerat.
Die beiden Begriffe ”Sicherheitsbewusstsein“ und ”bewusster Umgang“ werden weiterunten erlautert. Eine ausfuhrliche und vollstandige Beschreibung der Hypothesen und derdazugehorigen Ergebnisse findet sich in Krupp [Kru11].
3.2.2 Versuchsbeschreibung
Um die aufgestellten Hypothesen zu evaluieren, wurden personliche Leitfragen-Interviewsmit 24 Versuchspersonen durchgefuhrt. Das Alter der Befragten lag zwischen 18 und 50Jahren, die Halfte war mannlich und funf waren beruflich im IT-Umfeld tatig.
Die Interviews orientierten sich an einem zweiteiligen Fragebogen (s. Anhang A). DieSchwierigkeit einer aussagekraftigen Evaluation besteht darin, dass sich die Teilnehmerdem Untersuchungsfokus und der Untersuchungssituation nicht bewusst sein durfen, dasie sich sonst anders verhalten als bei einer Entscheidungsfindung im Alltag [RWN02].Daher wurde bei der Erstellung der Fragen darauf geachtet, dass die Teilnehmer zumindestvon Anfang an nicht wussten, dass sie in Bezug auf IT-Sicherheit untersucht wurden.
Im ersten Teil der Interviews stand die Nutzung mobiler Endgerate im Fokus. Hierbei wur-den die Teilnehmer unter anderem zu regelmaßig genutzten Diensten, zu Eigenschaften,die sie mit der Nutzung mobiler Endgerate verbinden, zu Problemen bei deren Nutzungund Kenntnissen zum Schutz mobiler Endgerate befragt. Weiterhin wurde gefragt zu wel-chem Anteil sie sich selbst und die Hersteller von Programmen oder Hardware in derVerantwortung fur die Umsetzung von IT-Sicherheit bei mobilen Endgeraten sehen.
Der zweite Teil des Fragebogens konzentrierte sich auf die Anstrengungen der Befragtenzur Sicherstellung von IT-Sicherheit. Hierbei mussten sie angeben wie groß ihr Interessean der Sicherheit ihres Endgerates ist und welche Anstrengungen sie fur die Umsetzungunternehmen. Ob sie sich bei der Nutzung ihres Endgerats sicher fuhlen und welche Datenihrer Meinung nach auf dem Endgerat bedroht sind. Abschließend wurde eine Frage zueiner erweiterten Sicherheitseinstellung gestellt, um die Selbsteinschatzung der Befragtenbezuglich ihrer Kenntnisse besser einordnen zu konnen.
3.2.3 Evaluierung der Hypothesen
H1: Benutzer, die ihr Gerat als Smartphone sehen, haben ein großeres Sicherheitsbe-wusstsein als Benutzer, die ihr Gerat als Telefon sehen. Unter Sicherheitsbewusstsein
10 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

verstehen wir einen Komplex aus dem Wissen uber die IT-Sicherheit und dem Interesse anIT-Sicherheit. Insgesamt sahen elf Befragte ihr Endgerat als konventionelles Telefon und13 als Smartphone. Sieben der 13 Befragten (54 %), die ihr mobiles Endgerat als Smart-phone sehen, gaben an, dass sie uber gute Kenntnisse zum Schutz mobiler Endgerate ver-fugen wurden (s. Abbildung 1(a)). Funf der Smartphone-Benutzer (38 %) ordneten sichmit Grundkenntnissen ein. Die Halfte dieser Benutzer beantwortete die Kontrollfrage kor-rekt.
(a) Wie schatzen Sie ihr Wissen bezuglich desmoglichen Schutzes ihres mobilen Endgerats ein?
(b) Wie schatzen Sie ihr Interessebezuglich der Sicherheit von mobilenEndgeraten und ihrer Daten ein?
Abbildung 1: Ergebnisse zu Hypothese 1
Bei den 11 Befragten, die ihr Endgerat als Telefon sehen, gaben lediglich vier Befragtean, dass sie mindestens gute Kenntnisse uber den Schutz mobiler Endgerate verfugen. Nureiner dieser Anwender konnte ebenfalls die Kontrollfrage korrekt beantworten.
Zu den insgesamt schlechteren Kenntnissen der Telefon-Anwender kommt hinzu, dassdiese im Allgemeinen kein all zu großes Interesse an der Sicherheit ihres Endgerats haben.Abbildung 1(b) zeigt, dass sechs der elf Befragten nur ein geringes bzw. gar kein Interessean der Sicherheit ihres Endgerats haben.
Bei den Befragten, die ihr Endgerat als Smartphone sehen, ist das Interesse sichtbar starkerausgepragt. Sechs Studienteilnehmer gaben ein mittleres, weitere sechs ein hohes Interessean.
Die Teilnehmer wurden in einer offenen Frage zu ihnen bekannten Bedrohungen im mo-bilen Umfeld befragt. Die Gruppierung der Antworten ergab eine Ubereinstimmung zuden sechs Gruppierungen des ”Malicious Mobile Threats Report 2010/2011“ von Juniper[Jun11]: Abhoren von Datenubermittlungen, Ausnutzung/Fehlverhalten, Erstellung vonBewegungsprofilen/Ortung, Direkte Angriffe, Malware sowie Verlust/Diebstahl.
Korreliert man die Anzahl der genannten Bedrohungsklassen der Anwender mit derenselbst eingeschatzten Kenntnissen, zeigt sich, dass viele Anwender, die sich mit gutenKenntnissen einordneten, mehr Bedrohungen nennen konnten (s. Abbildung 2).
Vergleicht man die Ergebnisse der beiden mentalen Grundmodellen, so wird deutlich, dassdie Smartphone-Anwender mehr Bedrohungen als die Telefon-Anwender nennen konntenund ihre Kenntnisse verhaltnismaßig gut eingeschatzt haben. Hierzu besteht jedoch weite-rer Forschungsbedarf, da die Anzahl der Befragten insgesamt zu gering war.
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 11

Abbildung 2: Anzahl der genannten Bedrohungen in Relation zu den eingeschatzten Kenntnissen
Zusammenfassend zeigen die Ergebnisse, dass Anwender, die ihr mobiles Endgerat alsSmartphone sehen, bessere Kenntnisse zum Schutz und ein großeres Interesse an der Si-cherheit mobiler Endgerate haben. Somit konnte die erste Hypothese belegt werden.
(a) Fuhlen Sie sich bei der Benutzungihres Endgerats sicher?
(b) Welche Daten auf ihrem Endgerat sind ihrerMeinung nach bedroht?
Abbildung 3: Ergebnisse zu Hypothese 2
H2: Benutzer, die ihr Gerat als Smartphone sehen, fuhlen sich weniger sicher, alsBenutzer, die ihr Gerat als Telefon sehen. 17 der 24 Befragten gaben an, dass sie sichbei der Nutzung ihres mobilen Endgerats sicher fuhlen (s. Abbildung 3(a)).
Dies zeigt ein insgesamt hohes Sicherheitsgefuhl der Anwender. Die Betrachtung der bei-den Grundmodelle zeigt, dass sich deutlich weniger Smartphone-Anwender bei der Nut-zung ihres Endgerats sicher fuhlen. Grunde fur die Unsicherheit sind nach Ansicht dieserNutzer die Uberwachung von Datenflussen und das Aufzeichnen von Standortdaten.
Das hohere Sicherheitsempfinden der Telefonanwender fuhrten diese darauf zuruck, dasssie mit ihrem Endgerat nicht ins Internet gehen. Als weitere Grunde gaben sie an, dasssie nicht wichtig genug fur einen Angreifer waren und dass sie keine wichtigen Daten auf
12 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

ihrem Endgerat hatten.
Abbildung 3(b) zeigt, dass nach Ansicht aller Befragten besonders das Adressbuch undTelefonbuch sowie die Standortinformationen auf dem mobilen Endgerat bedroht sind.Die Telefon-Anwender sehen durchschnittlich deutlich weniger Daten auf dem mobilenEndgerat bedroht. Damit kann die zweite Hypothese belegt werden.
H3: Benutzer sehen sich selbst nicht fur die Sicherheit ihrer Gerate verantwortlich.Um herauszufinden bei wem die Befragten die Verantwortung fur die Sicherheit mobilerEndgerate sehen, wurden sie gebeten, den Programmherstellern, Hardwareherstellern undsich selbst einen prozentualen Anteil der Verantwortung zuzuteilen. Es zeigte sich, dassnach Ansicht der Befragten fast die Halfte der Verantwortung auf die Programmherstellerfallt (s. Abbildung 4). Die Hersteller von Hardware und den Benutzer selbst sehen dieBefragten zu jeweils einem Viertel in der Verantwortung.
Abbildung 4: Wer sollte fur die Sicherheit von mobilen Endgeraten verantwortlich sein?
Anwender, die ihr Gerat als Telefon sehen, sehen den Benutzer am wenigsten in der Ver-antwortung fur die Sicherheit. Dagegen sehen die Smartphone-Nutzer die Programmher-steller und den Benutzer zum gleichen Prozentanteil verantwortlich.
Anhand dieser Ergebnisse kann die dritte Hypothese belegt werden, denn die Benutzerzeigen eine deutliche Praferenz dazu, den Programm- und Hardwareherstellern die Verant-wortung fur die Sicherheit ihrer Gerate zu geben. Jedoch sehen insbesondere Smartphone-Anwender einen Teil der Verantwortung bei sich selbst. Inwieweit sie bereit sind, dieseVerantwortung zu ubernehmen, bedarf weiterer Forschung.
H4: Benutzer bringen Probleme bei der Benutzung ihres Endgerats nicht mit IT-Sicherheit in Verbindung. Im Zuge des ersten Teils der Befragung wurden die Teil-nehmer gefragt, ob sie bei der Nutzung ihrer Gerate bisher Probleme hatten. Sieben der24 Befragten gaben ein Problem an. Die geschilderten Probleme ließen sich alle auf dieBedienung bzw. Eigenheiten des Endgerats zuruckfuhren, wie z.B. das Aufhangen bzw.Absturzen des Gerats, eine schlechte Akkulaufzeit, Probleme mit dem Betriebssystem oderein unzureichender Funktionsumfang.
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 13

Als die Teilnehmer im zweiten Teil der Befragung explizit zu sicherheitskritischen Pro-blemen bei der Nutzung mobiler Endgerate befragt wurden, gab ein Teilnehmer an, dasser bisher ein sicherheitskritisches Problem hatte. Durch das versehentliche Klicken einesHyperlinks beim Surfen im Internet sei er in eine Abo-Falle geraten. Bei der allgemeingehaltenen Frage zu Problemen bei der Nutzung gab er dieses Problem jedoch nicht an.
Auch in der Pilotstudie wurde die Beobachtung gemacht, dass mehrere Teilnehmer zwarProbleme bei der Nutzung mit ihrem Endgerat angaben, dabei aber keine Sicherheitspro-bleme erwahnten. Zwei Benutzer gaben auch dort sicherheitskritische Probleme erst dannan, als sie explizit darauf angesprochen wurden.
Somit kann belegt werden, dass die sicherheitskritischne Probleme sich bei der Nutzungmobiler Endgerate nicht in den mentalen Modellen der Anwender verankert haben. Daskonnte damit zusammenhangen, dass die Teilnehmer bisher sehr wenig mit solchen Pro-blemen konfrontiert wurden.
H5: Um fur ihre IT-Sicherheit im mobilen Umfeld zu sorgen, ist die Hauptanstren-gung der Benutzer der bewusste Umgang mit dem Gerat. Die Interviewpartner wur-den gebeten, anhand vorgegebener Sicherheitsvorkehrungen anzugeben, welche Anstren-gungen sie unternehmen, um fur die eigene IT-Sicherheit im mobilen Umfeld zu sorgen.
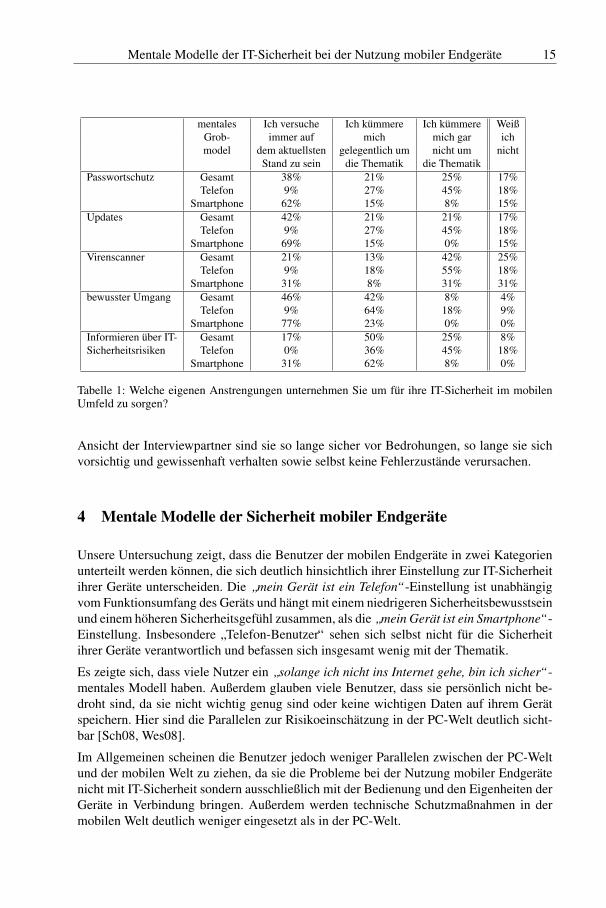
Bewusster Umgang mit dem Gerat ist die popularste Sicherheitsmaßnahme (s. Tabelle 1).Nur 8 % der Befragten gaben an, dass sie sich nie mit dem bewussten Umgang ihres End-gerats auseinandersetzen. Wahrend die Mehrzahl der Smartphone-Anwender versucht im-mer auf einen bewussten Umgang zu achten, gaben 64 % der Telefon-Anwender an, sichgelegentlich darum zu kummern. Unter bewusstem Umgang verstehen die Teilnehmer,dass sie unter anderem bei der Nutzung ihres Endgerats darauf achten, welche Applikatio-nen sie installieren und nutzen und dass sie verantwortungsbewusst im Internet unterwegssind.
Des Weiteren informiert sich nur ein Viertel nicht uber IT-Sicherheitsrisiken. Hierunter istfast die Halfte aller Anwender, die ihr Endgerat als Telefon sehen. Die restlichen Befragteninformieren sich in der Regel gelegentlich uber aktuelle Gefahren.
Technische Sicherheitsmaßnahmen werden seltener eingesetzt. 38 % aller Befragten nut-zen regelmaßig den Passwortschutz auf ihren mobilen Endgeraten und 21 % nutzen ihngelegentlich. Insbesondere fallen die 62 % der Smartphone-Anwender auf, die den Pass-wortschutz regelmaßig einsetzen. Ahnliche Werte gelten fur Updates, Virenscanner sindweniger popular. Im PC-Umfeld dagegen gibt es regelmaßig Studien, die zeigen, dass uber75 % einen Virenscanner auf ihrem PC installiert haben [BIT10, BSI11]. Grunde fur dieseErgebnisse konnten u.a. in den Voreinstellungen der Gerate liegen, wurden in dieser Arbeitjedoch nicht weiter untersucht.
Somit konnte die funfte Hypothese belegt werden. 88 % der Teilnehmer gaben an wenigs-tens gelegentlich auf den bewussten Umgang mit dem mobilen Endgerat zu achten. Nach
14 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate
mentales Ich versuche Ich kummere Ich kummere WeißGrob- immer auf mich mich gar ichmodel dem aktuellsten gelegentlich um nicht um nicht
Stand zu sein die Thematik die ThematikPasswortschutz Gesamt 38% 21% 25% 17%
Telefon 9% 27% 45% 18%Smartphone 62% 15% 8% 15%
Updates Gesamt 42% 21% 21% 17%Telefon 9% 27% 45% 18%
Smartphone 69% 15% 0% 15%Virenscanner Gesamt 21% 13% 42% 25%
Telefon 9% 18% 55% 18%Smartphone 31% 8% 31% 31%
bewusster Umgang Gesamt 46% 42% 8% 4%Telefon 9% 64% 18% 9%
Smartphone 77% 23% 0% 0%Informieren uber IT- Gesamt 17% 50% 25% 8%Sicherheitsrisiken Telefon 0% 36% 45% 18%
Smartphone 31% 62% 8% 0%
Tabelle 1: Welche eigenen Anstrengungen unternehmen Sie um fur ihre IT-Sicherheit im mobilenUmfeld zu sorgen?
Ansicht der Interviewpartner sind sie so lange sicher vor Bedrohungen, so lange sie sichvorsichtig und gewissenhaft verhalten sowie selbst keine Fehlerzustande verursachen.
4 Mentale Modelle der Sicherheit mobiler Endgerate
Unsere Untersuchung zeigt, dass die Benutzer der mobilen Endgerate in zwei Kategorienunterteilt werden konnen, die sich deutlich hinsichtlich ihrer Einstellung zur IT-Sicherheitihrer Gerate unterscheiden. Die ”mein Gerat ist ein Telefon“-Einstellung ist unabhangigvom Funktionsumfang des Gerats und hangt mit einem niedrigeren Sicherheitsbewusstseinund einem hoheren Sicherheitsgefuhl zusammen, als die ”mein Gerat ist ein Smartphone“-Einstellung. Insbesondere ”Telefon-Benutzer“ sehen sich selbst nicht fur die Sicherheitihrer Gerate verantwortlich und befassen sich insgesamt wenig mit der Thematik.
Es zeigte sich, dass viele Nutzer ein ”solange ich nicht ins Internet gehe, bin ich sicher“-mentales Modell haben. Außerdem glauben viele Benutzer, dass sie personlich nicht be-droht sind, da sie nicht wichtig genug sind oder keine wichtigen Daten auf ihrem Geratspeichern. Hier sind die Parallelen zur Risikoeinschatzung in der PC-Welt deutlich sicht-bar [Sch08, Wes08].
Im Allgemeinen scheinen die Benutzer jedoch weniger Parallelen zwischen der PC-Weltund der mobilen Welt zu ziehen, da sie die Probleme bei der Nutzung mobiler Endgeratenicht mit IT-Sicherheit sondern ausschließlich mit der Bedienung und den Eigenheiten derGerate in Verbindung bringen. Außerdem werden technische Schutzmaßnahmen in dermobilen Welt deutlich weniger eingesetzt als in der PC-Welt.
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 15

Zum Schutz im mobilen Umfeld beschranken sich die Anstrengungen zur Zeit fast aus-schließlich auf den bewussten Umgang mit dem Gerat. Die Befragten gaben unter ande-rem an, dass sie sichere Applikationen nutzen, auf unseriose Dienste verzichten und nichtungeachtet jegliche Links anklicken wurden. Zusatzlich hielten sie ihr Datenvolumen soniedrig wie moglich und achten darauf, nicht ungeschutzt uber Verbindungsprotokolle wiebeispielsweise Bluetooth oder WLAN erreichbar zu sein.
Es scheint, dass viele Benutzer ein ”ich werde Gefahren fur mein Gerat auf jeden Fallerkennen konnen“-mentales Modell haben. Ob dieses Modell tatsachlich funktioniert, istzweifelhaft, wenn man Parallelen zur PC-Welt zieht [DTH06, DHC06, SEA+09, RHJ+10].Es ist auch unklar, ob die meisten Anwender noch keine Sicherheitsprobleme mit ihrenEndgeraten hatten oder ob sie solche Probleme noch nicht erkannt haben.
5 Fazit und Weiterfuhrende Arbeiten
Unsere Studie zeigte erste Einblicke darin, wie die Nutzer die Sicherheit ihrer mobilenEndgerate wahrnehmen und wie sie ihre Gerate schutzen.
Obwohl die Nutzer wissen, dass viele Daten auf ihrem mobilen Endgerat bedroht sind,fuhlen sie sich bei der Nutzung zum Großteil sicher. Unternehmen die Befragten eigeneAnstrengungen fur den Schutz im mobilen Umfeld, konzentrieren sich diese haufig auf denbewussten Umgang mit dem Gerat. Anwender mit guten Kenntnissen nehmen zusatzlichzum Schutz technische Sicherheitsvorkehrungen, wie das Nutzen eines Passwortschutzesoder das regelmaßige Installieren von Updates, vor.
Insgesamt ergab unsere erste Untersuchung mehr Fragen als Antworten, so dass weite-rer Forschungsbedarf besteht. Es ist z.B. nicht ausreichend bekannt, wie gut die Selbst-einschatzung der Nutzer zu ihren Sicherheitskenntnissen mit den tatsachlichen Kenntnis-sen korreliert.
Der bewusste Umgang mit dem mobilen Endgerat stellte sich als Hauptanstrengung derNutzer zur Sicherstellung von IT-Sicherheit im mobilen Umfeld dar. Die Nutzer beschrie-ben den bewussten Umgang haufig damit, dass sie keine unseriosen Applikationen instal-lieren, auf ihr Surfverhalten im Internet achten und nicht ungeschutzt uber Kommunika-tionsschnittstellen wie Bluetooth oder WLAN erreichbar sind. Hierbei ist von Interesse,ob die Anwender ein gemeinsames Bild des bewussten Umgangs haben und ob sie auchunsichere Handlungen mit dem bewussten Umgang verbinden. Daruber hinaus stellt sichdie Frage, ob die Anwender tatsachlich uber ausreichend Wissen verfugen, um die Unter-scheidung zwischen sicheren und unsicheren Applikationen, Links und Einstellungen desGerats vornehmen zu konnen.
Ein weiterer Punkt fur zukunftige Untersuchungen ist die Frage, ob die Nutzer unter-schiedliche Sichtweisen auf PCs und auf mobile Endgerate haben. Moderne mobile End-gerate werden immer leistungsfahiger, haben einen immer großeren Funktionsumfang undahneln immer mehr den PCs. Dennoch scheinen die Anwender noch wenige Parallelenzur PC-Welt zu ziehen und schutzen sich im PC-Umfeld in viel starkerem Maße, obwohlimmer mehr Bedrohungen identisch sind.
16 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

Literatur
[ALC07] Farzaneh Asgharpour, Debin Liu und L. Jean Camp. Mental models of security risks.In Proceedings of the 11th International Conference on Financial cryptography and 1stInternational conference on Usable Security, FC’07/USEC’07, Seiten 367–377, Berlin,Heidelberg, 2007. Springer-Verlag.
[AS99] Anne Adams und Martina Angela Sasse. Users are not the enemy. Commun. ACM,42:40–46, December 1999.
[BFH+11] M. Becher, F.C. Freiling, J. Hoffmann, T. Holz, S. Uellenbeck und C. Wolf. MobileSecurity Catching Up? Revealing the Nuts and Bolts of the Security of Mobile Devices.In Security and Privacy (SP), 2011 IEEE Symposium on, Seiten 96–111, may 2011.
[BIT10] BITKOM. Internet-Sicherheit. Studie, Bundesverband Informationswirtschaft, Tele-kommunikation und neue Medien e.V., Februar 2010.
[BSI11] BSI. Mit Sicherheit. BSI Jahresbericht 2010, Bundesamt fur Sicherheit in der Informa-tionstechnik, Juli 2011.
[Cam09] L. J. Camp. Mental models of privacy and security. Technology and Society Magazine,IEEE, 28(3):37–46, Fall 2009.
[DHC06] Julie S. Downs, Mandy B. Holbrook und Lorrie Faith Cranor. Decision strategies andsusceptibility to phishing. In Proceedings of the second symposium on Usable privacyand security, SOUPS ’06, Seiten 79–90, 2006.
[DTH06] Rachna Dhamija, J. D. Tygar und Marti Hearst. Why phishing works. In Proceedingsof the SIGCHI conference on Human Factors in computing systems, CHI ’06, Seiten581–590, 2006.
[FCB07] Alain Forget, Sonia Chiasson und Robert Biddle. Helping users create better passwords:is this the right approach? In Proceedings of the 3rd symposium on Usable privacy andsecurity, SOUPS ’07, Seiten 151–152, 2007.
[FH07] Dinei Florencio und Cormac Herley. A large-scale study of web password habits. InProceedings of the 16th international conference on World Wide Web, WWW ’07, Seiten657–666, 2007.
[Her09] Cormac Herley. So long, and no thanks for the externalities: the rational rejection of se-curity advice by users. In Proceedings of the 2009 workshop on New security paradigmsworkshop, NSPW ’09, Seiten 133–144, 2009.
[Jun11] Juniper Networks. Malicious Mobile Threats Report 2010/2011: An Objective Briefingon the Current Mobile Threat Landscape Based on Juniper Networks Global ThreatCenter Research. Juniper Networks, Inc., 2011.
[KFR10] R. Kainda, I. Flechais und A.W. Roscoe. Security and Usability: Analysis and Evaluati-on. In Availability, Reliability, and Security, 2010. ARES ’10 International Conferenceon, Seiten 275–282, 2010.
[Kru11] Matthias Krupp. Die Verantwortung von Nutzern zur Umsetzung von IT-Sicherheit,Masterarbeit, 2011.
[Lam09] Butler Lampson. Privacy and security: Usable security: how to get it. Commun. ACM,52:25–27, November 2009.
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 17

[Nor09] Donald A. Norman. THE WAY I SEE IT: When security gets in the way. interactions,16:60–63, November 2009.
[RHJ+10] Fahimeh Raja, Kirstie Hawkey, Pooya Jaferian, Konstantin Beznosov und Kellogg S.Booth. It’s too complicated, so i turned it off!: expectations, perceptions, and miscon-ceptions of personal firewalls. In Proceedings of the 3rd ACM workshop on Assurableand usable security configuration, SafeConfig ’10, Seiten 53–62, 2010.
[RWN02] K. Rudolph, G. Warshawsky und L. Numkin. Security Awareness. In M.E. Kabay, Hrsg.,Computer Security Handbook, Kapitel 29. John Wiley & Sons, Inc., Basel, 4. Auflage,2002.
[SBW01] M. A. Sasse, S. Brostoff und D. Weirich. Transforming the ’Weakest Link’ – a Hu-man/Computer Interaction Approach to Usable and Effective Security. BT TechnologyJournal, 19:122–131, July 2001.
[Sch08] Bruce Schneier. The psychology of security. http://www.schneier.com/essay-155.html,Januar 2008.
[SEA+09] Joshua Sunshine, Serge Egelman, Hazim Almuhimedi, Neha Atri und Lorrie Faith Cra-nor. Crying wolf: an empirical study of SSL warning effectiveness. In Proceedings of the18th conference on USENIX security symposium, SSYM’09, Seiten 399–416, Berkeley,CA, USA, 2009. USENIX Association.
[Wes08] Ryan West. The psychology of security. Commun. ACM, 51:34–40, April 2008.
[WS01] Dirk Weirich und Martina Angela Sasse. Pretty good persuasion: a first step towardseffective password security in the real world. In Proceedings of the 2001 workshop onNew security paradigms, NSPW ’01, Seiten 137–143, 2001.
18 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

A Anhang
Fragebogen zur Nutzung von mobilen Endgeraten
Einleitung zum Fragebogen:
Ziel des Fragebogens ist es das Verhalten von Anwendern im Umgang mit mobilen End-geraten (Handys und Smartphones) zu untersuchen.
Der Fragebogen besteht aus zwei Teilen. Der erste Teil besteht aus einigen einleitendenund grundlegenden Fragen zur Nutzung von mobilen Endgeraten. Im zweiten Teil stehtdarauf aufbauend die weitere Nutzung von mobilen Endgeraten im Fokus.
Hinweis zum Datenschutz:
Die Daten werden anonymisiert erhoben und dienen nur zu Forschungszwecken. Der Fra-gebogen ist so konzipiert, dass kein Ruckschluss auf den Befragten moglich ist.
Falls Sie eine Frage nicht beantworten mochten oder konnen, lassen Sie die Antwort ein-fach offen.
Vielen Dank fur ihre Bereitschaft den Fragebogen auszufullen!
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 19

Teil A
1. Ihr Geschlecht:❐ Weiblich ❐ Mannlich
2. Ihr Alter:❐ junger als 21 ❐ 21 - 25❐ 26 - 30 ❐ 31 - 35❐ 36 - 40 ❐ 41 - 45❐ 46 - 50 ❐ 51 - 55❐ 56 - 60 ❐ 61 oder alter
3. Welchen Beruf uben Sie aus? Welche Fachrichtung?
4. Besitzen Sie privat ein mobiles Endgerat (Handy oder Smartphone)?❐ Ja ❐ Nein
5. Spielt das Betriebssystem ihres mobilen Endgerats fur Sie eine relevante Rolle?❐ Ja ❐ Nein
6. Welche Eigenschaften (Spaß, Erreichbarkeit, Streß etc.) verbinden Sie mit der Nut-zung ihres Endgerats?
7. Besitzt ihr Endgerat die Moglichkeit eigenstandig Applikationen zu installieren?❐ Ja ❐ Nein
8. Welche Dienste nehmen Sie privat am meisten in Anspruch?
9. Welche Dienste wunschen Sie sich zusatzlich?
20 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

10. Besitzen Sie neben ihrem privaten mobilen Endgerat auch ein Firmengerat?❐ Ja ❐ Nein
11. Wenn ja, wie unterscheidet sich die Benutzung?
12. Welche der folgenden Programme nutzen Sie? (Mehrfachnennungen sind moglich)privates Endgerat: Firmenendgerat:❐ E-Mail ❐ E-Mail❐ Internet ❐ Internet❐ Geldgeschafte uber Internet, ❐ Geldgeschafte uber Internet,
z.B. Onlinebanking z.B. Onlinebanking❐ Soziale Netzwerke ❐ Soziale Netzwerke❐ Virenscanner ❐ Virenscanner❐ Routenplaner ❐ Routenplaner
13. Hatten Sie bisher Probleme bei der Benutzung ihres Endgerats?❐ Ja ❐ Nein
14. Wenn ja, welche?
15. Wie schatzen Sie ihr Wissen bezuglich des moglichen Schutzes ihres mobilen End-gerates ein?
❐ Sehr gute Kenntnisse ❐ Gute Kenntnisse❐ Grundkenntnisse ❐ Keine Kenntnisse
16. Beurteilen Sie die Wichtigkeit von Benutzbarkeit im Bezug auf IT-Sicherheit auffolgender Skala:
Benutzbarkeit gleich Sicherheitist wichtiger wichtig ist wichtiger
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 21

17. Wer sollte fur die Sicherheit von mobilen Endgeraten verantwortlich sein? (Bitteverteilen Sie insgesamt 100 % auf die drei angegebenen Antwortmoglichkeiten)
• Hersteller von Programmen %• Hersteller von Hardware %• Benutzer %
18. Welche Bedrohungen, speziell bezogen auf mobile Endgerate, kennen Sie?
22 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

Teil B
1. Wie schatzen Sie ihr Interesse bezuglich der Sicherheit von mobilen Endgeraten undihrer Daten ein?
❐ hoch ❐ mittel❐ niedrig ❐ kein
2. Hatten Sie auf Ihrem mobilen Endgerat schon einmal Sicherheitsprobleme?privates Endgerat: Firmenendgerat:❐ Ja ❐ Ja❐ Nein ❐ NeinWenn ja, welche? Wenn ja, welche?
3. Hatten Sie schon einmal Probleme mit sensiblen Daten von sich?❐ Ja ❐ Nein
4. Wenn ja, welche?
5. Fuhlen Sie sich bei der Benutzung ihres Endgerats sicher?❐ Ja ❐ Nein
Begrundung:
6. Welche Daten auf ihrem Endgerat sind ihrer Meinung nach bedroht (Mehrfachnen-nungen sind moglich)?
❐ Adressbuch/Telefonbuch❐ Nachrichteninhalte (SMS/E-Mail)❐ sonstige gespeicherte Informationen (Notizen, etc.)❐ Standortinformationen❐ weitere:
Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate 23

7. Welche eigenen Anstrengungen unternehmen Sie, um fur IT-Sicherheit im mobilenUmfeld zu sorgen (Mehrfachnennungen sind moglich und erwunscht)?
Ich versuche Ich kummere Ich kummere Weißimmer auf mich mich gar ich
dem neuesten gelegentlich um nicht um nichtStand zu sein die Thematik die Thematik
Virenscanner ❐ ❐ ❐ ❐
Passwortschutz ❐ ❐ ❐ ❐
Updates ❐ ❐ ❐ ❐
bewusster Umgang ❐ ❐ ❐ ❐
Verschlusselung ❐ ❐ ❐ ❐
Informieren uber IT-Sicherheitsrisiken ❐ ❐ ❐ ❐
8. Was verstehen Sie unter dem Begriff Remote Wipe?
24 Mentale Modelle der IT-Sicherheit bei der Nutzung mobiler Endgerate

On Some Conjectures in IT Security: The Case for ViableSecurity Solutions
Jan Zibuschka, Heiko Roßnagel
Fraunhofer IAONobelstraße 1270569 Stuttgart
[email protected]@iao.fraunhofer.de
Abstract: Due to the increased utilization of computers and the Internet the impor-tance of IT security has also increased. Naturally the field of IT security has grownsignificantly and has provided many valuable contributions in recent years. Most of thework is concerned with the design of systems offering strong technological security.With regard to behavioural factors, researchers build their work on assumptions abouthuman behaviour that are prevalent in the field of IT security without considering theresults and insights of related disciplines. In this contribution we challenge some ofthese widely held conjectures and offer alternative interpretations based on the resultsof neighbouring disciplines. Based on this analysis, we suggest new directions forthe design of security solutions that support the inclusion of insights from referencedisciplines during the design process.
1 Introduction
Since the series of cyber-attacks in the first half of 2011 against leading, international cor-porations like Sony, Citigroup, Lockheed Martin, Google, and Apple [Pau11], it shouldbe obvious that IT security is more important than ever before. With the increased uti-lization of computers and networks for mission-critical applications in recent years, theirreliability and security has also become essential. As a result the field of IT security hasgrown significantly and has provided many valuable contributions. However, as the recentsuccessful attacks also illustrate, not all of these advances have been utilized in practiceand systems remain vulnerable to attacks that are not very sophisticated. For example, arecent study by SANS Institute lists SQL injections and unpatched known vulnerabilitiesas the predominant threat vectors [DDEK09]. Security technologies that could protectcompanies or users against these attacks do exist. The problem is that these technologiesare often simply not bought, not used or not configured correctly. Therefore, several au-thors have argued that human factors might be the biggest threat to security in practice[Sas03, JEL03]. At the same time, researchers in the IT security field rely on assumptionsabout human behavior to guide both the designs of individual systems, and the directionof the discipline as a whole. Examples include conjectures about how humans form trust

on the internet, theories concerning market failure, and opinions about user awareness andeducation. However, the field of IT security lacks the tools or methods to provide anythingbut anecdotal evidence to support those conjectures. Neighboring disciplines, especiallyinformation systems (IS) and marketing, have amassed a significant amount of knowledgeabout human behavior with regard to factors such as trust, diffusion of innovative systems,and what constitutes a market failure. Those results at times contradict the conjecturesapplied in the security domain. However, this body of kernel theory is seldom applied byresearchers when designing secure systems [SO07]. In this paper, we will challenge someof the most commonly held conjectures from IT security publications, and present alter-native interpretations based on evidence from neighboring disciplines. As this evidencecasts doubt on some of these conjectures, we will further argue that those misconceptionsare at least partially responsible for the missing market success and utilization of securitysolutions. In addition, we will outline a framework for the design of secure systems thatallows collecting and including relevant evidence concerning behavioral aspects duringthe planning and specifically feasibility analysis stages, using the information systems andmarketing fields as reference disciplines. Especially IS has now collected a significantbody of knowledge, especially with regard to the development of innovative yet viablesystems [Nam03].
2 Common Conjectures in IT Security
In this section we present three common conjectures that are prevalent in the field of ITsecurity. We will challenge these widely held beliefs and present alternative theories thatare supported by inputs from kernel theory from the proposed reference disciplines.
2.1 “More Security = More Trust”
One of the most widely held beliefs in IT security is that increasing the security of a sys-tem, and thus its trustworthiness, will eventually also lead to an increase in trust towardsthe system [RIS09, GRSS04, Ran00]. On first glance, this reasoning seems to be quitelogical. A system that is more secure than others should be more trustworthy and there-fore people should trust it more, which in turn should lead to a higher intention to use orbuy the system. However, both trust and intention to use are behavioral aspects, involvinghuman beings, and thus are subject to beliefs and behavior of those involved. Therefore,methods of behavioral science are needed in order to be able to measure whether trust-worthiness of systems translates into trust of users towards the system or their intentionto use it. IT security research does not possess these methods, and cannot provide strongevidence answering the question scientifically. Therefore, researchers in this field shouldconsider the results of related disciples. Trust has been subject of various disciplines, suchas sociology, psychology, and economics. As a result there a many different definitions,which often reflect the disciplinary perspectives, but today most researchers see it as amultidimensional and context-dependent construct [LPF06]. When considering the results
26 On Some Conjectures in IT Security: The Case for Viable Security Solutions

of information systems and economics, we find several research contributions that provideevidence that trust indeed positively affects intention to use or buy, especially in the E-Commerce environment [Gef00]. However, when looking into the relationship betweentechnological trustworthiness and trust, it becomes apparent that the relations are muchmore complicated than a direct implication. Trust is influenced by many different factors.Security technology certainly is one of those factors, but not the only one. McKnight et alconducted a large-scale meta-study on trust formation in electronic commerce, and foundthat the most important influences on trust in an e-commerce site are institutional trust— the trust in the operator of the site — and individuals’ general predisposition to trust[MCK02]. Furthermore, technical measures providing trust through security are domi-nated by user interface issues: a user may distrust even a secure system because it is verycomplicated to use, it appeals less to him visually, or it produces errors during usage.Those influences have an impact that is at least as strong as technical security across alluser groups [LT01]. Even the color of the web site has been identified as a statistical sig-nificant influence on trust [LSR10]. These results cast a serious doubt on the assumptionthat improved security will automatically lead to an increase in trust. Some IT securityresearchers have acknowledged, that trust is a social construct that is mainly influencedby the interacting parties, and is hardly influenced by preventive technologies that the usercannot even observe [And01] and have expressed skepticism whether trust can really bemanaged or influenced by technical means [JKD05]. Consequently, this implies that trustand trustworthiness are separate constructs that are determined by different requirementsand influences. Therefore, they should also be addressed separately during system design.
2.2 “We need to educate the users”
One possible conclusion that may be drawn from the disparity of theoretical trustworthi-ness and actual trust is that users need to be educated, enabling them to identify trustworthysystems. This argument is quite compelling. Once users recognize the technological supe-riority of the more secure product they will naturally choose the better solution. However,several problems arise with regards to this argument. Flinn and Lumsden surveyed users’security knowledge and practices, and specifically the impact of educational measures.They find “that the benefits of modest education may not be as dramatic as we wouldhope” [FL05]. User education is inefficient as the problems associated with security arehighly complex. But even if we assume that user education does work, research in relateddisciplines especially marketing suggests that educating users will not necessarily makethem buy more secure products. When confronted with purchasing decisions users needto make choices regarding different product features and the price of the overall product.The security of the product is only one product feature that will be weighed against otherfeatures and the costs associated with it. Since more secure solutions often also come withhigher costs (including non monetary costs such as reduced performance or high complex-ity) they might not offer the highest consumer surplus to prospective customers, who aregenerally perceived as being careless and unmotivated with regard to security [VCU08].Even when users do exhibit a significant willingness to pay for security, much of this
On Some Conjectures in IT Security: The Case for Viable Security Solutions 27

willingness to pay vanishes if the guaranteed security level is anything less than 100%[MPLK06]. This common underestimation of risks is further reinforced by the tendencyof users to assume that negative events are less likely to happen to them than to othersand that positive events are more likely to happen to them than others [Wei89]. Therefore,educating users about the trustworthiness of products is not sufficient by itself. It has tobe combined with raising the awareness of user about the risks of using unsecure systems.However, given the prominence of the recent security incidents it remains doubtful, thatusers are still unaware of these risks in general. Furthermore, raising awareness aboutspecific risks can even undermine trust in the systems due to privacy and security salience[JAL11]: the mention of security risks may reduce users’ intention to use a service asthey are made aware that breaches are possible. In addition, the users’ criticized securitybehavior can be seen as entirely rational [Her09]: contemporary systems are asking toomuch of users in terms of both cost and complexity and offer too little benefit in return.
2.3 “There is a market failure, and we need regulation”
Many information security practitioners share this assessment, and call for the governmentto intervene and regulate computer security [Lau96, BHRR07]. A common reasoning isthat the problems of security solutions in the market indicate a market failure, caused byincomplete information — a lemon market problem [Ake70], an asymmetric informationdistribution that results in a vicious circle where price is the dominant factor for success,and high quality systems suffer. Of course, we cannot disprove market failure for all secu-rity systems in their specific markets in general here; this has to be discussed for each mar-ket individually. However, we can say that in some cases where regulation has been madebased on observations of market failure have not gone as had been hoped; in analyses fol-lowing the implementation of the regulation, economic factors such as high costs, networkexternalities, unfair incentive distributions and lacking applications have been identifiedas problems e.g. in the case of the German electronic signatures [Roß06]. Speaking of amarket failure of security systems in a sense that regulation was needed might be under-stood as implying that the situation in the market was not Pareto optimal, meaning thatthe situation of the users might be improved by forcing them to use highly secure systems.Vidyaraman et al. [VCU08] proposed to persuade users to improve their security prac-tices by designing systems in a way that would artificially make insecure practices lessdesirable. They warned that there would be a backlash from the users, making the ap-proach of imposing security on the user impractical where practices cannot be enforced byan overarching organization, as users would not adopt a solution threatening disciplinarymeasures to enforce secure practices voluntarily. As we stated in the last section, usersvaluate systems based on a number of factors, including but not limited to security. If theyneed to be forced, this would not be an improvement in the sense of Pareto optimality.We feel, in such cases we need an alternative to calls for regulation that would persuadeusers to use security systems they would not employ by choice. Classical information se-curity aims at developing systems with high complexity (which is a problem with regardsto diffusion [Rog03]) and offering the highest possible level of security (which users can-
28 On Some Conjectures in IT Security: The Case for Viable Security Solutions

not observe [And01]). Under those circumstances, the explanation of market failure mayapply in some cases, i.e. where a lemon market problem is the main hindrance, but all inall is not necessary to explain why security systems often have no success in the market.Our idea, as an alternative to this, is to find methods for a new design process that wouldtake market compliance factors into account early in the system design.
3 Engineering Viable Security Systems
We propose an alternative approach, a stakeholder requirements driven analysis in the veryearly stages of security system design. As Greenwald et al. observe [GORR04], user ac-ceptance is underrepresented in security systems design. While we recognize that securitysystems should offer the highest feasible level of security, we feel this feasibility is limitedby market compliance, as we need to build systems that are not only trustworthy in theory,but also trusted. It is a condition for the design of such systems that all involved stakehold-ers would still voluntarily use them. Where related approaches like Karyda et al.’s ViableInformation Systems [KKK01] are concerned with the question how much security an in-formation system needs to be successful, we consider the design of IT security systems,and ask how to make them more viable from a market compliance perspective. One veryrelevant approach is the viable security model [ZR11], which illustrates important factorsinfluencing the impact of a given security solution on the overall security of deployed infor-mation systems [ZR11], including how market-compliant a security infrastructure needsto be to succeed on the market, and how effective it is in comparison with the currentlydeployed state of the art. Those two aspects mirror the earlier discussion of the trustwor-thiness of effective security systems, and the market compliance reached by creating trustin users. An effective security solution that is not market-compliant will not lead to an in-crease in security in practice, while a solution that is market-compliant but not as least assecure as what is currently deployed might even harm the overall level of security [ZR11].The question of effectiveness is widely discussed in information security and related fieldsof computer science. Technical soundness is the core requirement of information securityresearch in computer science, and the requirement that computer scientists can analyze us-ing the methods of computer science. There have also been quite some efforts to increasethe usability of security systems in recent years [JEL03]. Human-computer interactionexperts have a comprehensive set of methods for designing and evaluating user interfaces[JEL03]. Factors like task-technology-fit have received less attention, but require a veryspecific combination of implemented system and concrete task, which makes them notdirectly applicable to system design. Hevner et al. [HMPR04] recently made the case fordesign science in information systems, where artifacts such as reference architectures ordesign theories are developed and then evaluated using behavioral methods, as a promis-ing vector for research that contributes both to the scientific knowledge base (the researchis rigorous) and to practice (it is also relevant). While this approach brought the informa-tion systems domain, which had been focused on behavioral studies, closer to the subjectsclassically addressed in computer science, we propose a paradigm shift that would bringthe IT security domain closer to IS. While performing an iterative design, as described
On Some Conjectures in IT Security: The Case for Viable Security Solutions 29

by Hevner and usually applied in Software Engineering and security system development,we keep an IT security and computer science perspective, implying direct applicability tothe technical design of such systems, but also regularly evaluate the market complianceof the designs based on reference disciplines such as IS or marketing that have methodsfor assessing market compliance. Hevner et al. [HMPR04] also make a strong argumentfor evidence-based evaluation. Several methods from the field of information systems canbe applied to assess market compliance in the early stages of the design process. Meth-ods such as stakeholder analysis [Pou99] and analyses based on diffusion theory [RZ12]have been applied in the IS field. They are tailored towards qualitative results, but caneasily be applied by engineers as part of the design process, and are capable of digestingnon-monetary impacts of e.g. privacy [Pou99]. Choice-based conjoint analysis from themarketing field [DRC95] offers quantitative results in the form of measuring stakeholders’willingness to pay for several system configurations, but requires expertise for designinga valid survey instrument.
4 Related Work
As mentioned earlier, our approach builds directly on the design science approach byHevner et al. [HMPR04]. An argument that is very similar to ours has also been madeby Fenton et al [FPG94] in the software engineering domain. There, they argue, that a lotof new technologies are developed which claim to lower development effort needed andmake software more readily adaptable or maintainable, without giving a sound evaluation.Fenton et al. argue that more empirically sound evaluation is needed to address this. Therehave been several initiatives in information systems research focussing on the design ofviable, secure information systems. Those include the Viable IS approach by Karyda etal. [KKK01], as well as the approach proposed by Siponen and Baskerville [SB02]. Onthe computer science side, Jurjen’s UMLSec [Jur02] has provided a similar contribution,building on UML. Recently, Heyman et al [HYS+11] have proposed an iterative approachsimilar to the one proposed by Hevner, alternating between requirements and architecture,but lacking Hevner’s focus on evaluation and contribution to theory. There are also a widerrange of security requirements engineering approaches [FGH+09].
5 Conclusion
From our point of view, security systems designs should take into account both technolog-ical trustworthiness and socio-economic trust aspects. We build on findings from referencedisciplines including information systems and marketing, but derive a framework for en-gineering secure systems targeting specifically the IT security domain. To achieve a viablesecurity solution, designers have to make sure that their solution provides an effective se-curity improvement and is compliant with market demands. We listed several methodsthat can be applied to assess market compliance already in the early stages of the design
30 On Some Conjectures in IT Security: The Case for Viable Security Solutions

process. Even though our reference disciplines are influenced by economics, our aim isnot to maximise profit. Neither do we want to attack basic research in the area of security,which is of course needed to provide the underpinnings of a more secure future IT infras-tructure. Our aim is to provide engineers designing security systems with tools enablingthem to increase the practical impact of their solutions by designing solutions that are notonly trustworthy but also trusted, effective as well as market-compliant. We see this asimportant contribution, as earlier work regarding system design has focused on trustwor-thiness/effectiveness, which, as the viable security model illustrates, is only one aspect ofa larger problem. This contribution may also be applicable to field beyond IT security,Fenton et al. [FPG94] make a similar argument for software engineering tools, but wefeel it is of special interest in the case of IT security due to the difficulties of many prod-ucts in the market, said to be due to human factors [Sas03], and the underrepresentationin earlier works. We do not feel this contribution, specifically regarding the details of thedesign process, is final yet. However, we want to once again point to Hevner et al.’s designscience [HMPR04], which provides a very solid meta-framework for a scientific designprocess with evidence-based evaluation concerning human factors.
References
[Ake70] George A. Akerlof. The Market for ”Lemons”: Quality Uncertainty and the MarketMechanism. The Quarterly Journal of Economics, 84(3):488–500, August 1970. Arti-cleType: primary article / Full publication date: Aug., 1970 / Copyright 1970 The MITPress.
[And01] Ross Anderson. Why Information Security is Hard - An Economic Perspective. InComputer Security Applications Conference, pages 358–365, Las Vegas, 2001.
[BHRR07] P. Bramhall, M. Hansen, K. Rannenberg, and T. Roessler. User-Centric Identity Man-agement: New Trends in Standardization and Regulation. IEEE Security & Privacy,5(4):84–87, August 2007.
[DDEK09] R. Dhamankar, M. Dausin, M. Eisenbarth, and J. King. The top cyber security risks.SANS Institute, http://www.sans.org/top-cyber-security-risks/, 2009.
[DRC95] Wayne S. Desarbo, Venkatram Ramaswamy, and Steven H. Cohen. Market segmen-tation with choice-based conjoint analysis. Marketing Letters, 6(2):137–147, March1995.
[FGH+09] Benjamin Fabian, Seda Gurses, Maritta Heisel, Thomas Santen, and Holger Schmidt. Acomparison of security requirements engineering methods. Requirements Engineering,15:7–40, November 2009.
[FL05] S. Flinn and J. Lumsden. User perceptions of privacy and security on the web. In TheThird Annual Conference on Privacy, Security and Trust (PST 2005), 2005.
[FPG94] N. Fenton, S.L. Pfleeger, and R.L. Glass. Science and substance: a challenge to softwareengineers. Software, IEEE, 11(4):86–95, 1994.
[Gef00] D. Gefen. E-commerce: the role of familiarity and trust. Omega, 28(6):725737, 2000.
On Some Conjectures in IT Security: The Case for Viable Security Solutions 31

[GORR04] Steven J. Greenwald, Kenneth G. Olthoff, Victor Raskin, and Willibald Ruch. The usernon-acceptance paradigm: INFOSEC’s dirty little secret. In Proceedings of the 2004workshop on New security paradigms, pages 35–43, Nova Scotia, Canada, 2004. ACM.
[GRSS04] Dirk Gunnewig, Kai Rannenberg, Ahmad-Reza Sadeghi, and Christian Stuble. TrustedComputing Platforms: Zur technischen und industriepolitischen Situation und Vorge-hensweise. In Vertrauenswurdige Systemumgebungen, pages 154–162. Verlag Rechtund Wirtschaft, 2004.
[Her09] Cormac Herley. So long, and no thanks for the externalities: the rational rejectionof security advice by users. In Proceedings of the 2009 workshop on New securityparadigms workshop, pages 133–144, Oxford, United Kingdom, 2009. ACM.
[HMPR04] A.R. Hevner, S.T. March, J. Park, and S. Ram. Design Science in Information SystemsResearch. MIS Quarterly, 28(1):75–105, 2004.
[HYS+11] Thomas Heyman, Koen Yskout, Riccardo Scandariato, Holger Schmidt, and Yijun Yu.The Security Twin Peaks. In Ulfar Erlingsson, Roel Wieringa, and Nicola Zannone, edi-tors, Engineering Secure Software and Systems, volume 6542, pages 167–180. SpringerBerlin Heidelberg, Berlin, Heidelberg, 2011.
[JAL11] Leslie K. John, Alessandro Acquisti, and George Loewenstein. Strangers on a Plane:Context-Dependent Willingness to Divulge Sensitive Information. Journal of ConsumerResearch, 37(5):858–873, February 2011.
[JEL03] J. Johnston, J. H. P. Eloff, and L. Labuschagne. Security and human computer inter-faces. Computers & Security, 22(8):675–684, December 2003.
[JKD05] Audun Jsang, Claudia Keser, and Theo Dimitrakos. Can We Manage Trust? In PeterHerrmann, Valerie Issarny, and Simon Shiu, editors, Trust Management, volume 3477,pages 93–107. Springer Berlin Heidelberg, Berlin, Heidelberg, 2005.
[Jur02] Jan Jurjens. UMLsec: Extending UML for Secure Systems Development. In Jean-MarcJezequel, Heinrich Hussmann, and Stephen Cook, editors, UML 2002 The UnifiedModeling Language, volume 2460 of Lecture Notes in Computer Science, pages 1–9.Springer Berlin / Heidelberg, 2002. 10.1007/3-540-45800-X 32.
[KKK01] Maria Karyda, Spyros Kokolakis, and Evangelos Kiountouzis. Redefining informationsystems security: viable information systems. Proceedings of the 16th internationalconference on Information security: Trusted information: the new decade challenge,page 453468, 2001. ACM ID: 510799.
[Lau96] Kenneth C. Laudon. Markets and privacy. Communications of the ACM, 39:92–104,September 1996.
[LPF06] H Lacohee, A Phippen, and S Furnell. Risk and restitution: Assessing how users estab-lish online trust. Computers & Security, 25(7):486–493, October 2006.
[LSR10] S. Lee and V. Srinivasan Rao. Color and store choice in Electronic Commerce: Theexplanatory role of trust. Journal of Electronic Commerce Research, 11(2):110–126,2010.
[LT01] M.K.O. Lee and E. Turban. A trust model for consumer internet shopping. InternationalJournal of electronic commerce, 6(1):7591, 2001.
[MCK02] D. Harrison McKnight, Vivek Choudhury, and Charles Kacmar. Developing and Val-idating Trust Measures for e-Commerce: An Integrative Typology. INFORMATIONSYSTEMS RESEARCH, 13(3):334–359, September 2002.
32 On Some Conjectures in IT Security: The Case for Viable Security Solutions

[MPLK06] Milton L Mueller, Yuri Park, Jongsu Lee, and Tai-Yoo Kim. Digital identity: How usersvalue the attributes of online identifiers. Information Economics and Policy, 18(4):405–422, November 2006.
[Nam03] Satish Nambisan. Information Systems as a Reference Discipline for New ProductDevelopment. MIS Quarterly, 27(1):1–18, March 2003.
[Pau11] Ian Paul. IMF Hacked; No End in Sight to Security Horror Shows, PCWorld.http://bit.ly/jTpgAp, June 2011.
[Pou99] A. Pouloudi. Aspects of the stakeholder concept and their implications for informationsystems development. In System Sciences, 1999. HICSS-32. Proceedings of the 32ndAnnual Hawaii International Conference on, page 7030, 1999.
[Ran00] Kai Rannenberg. Mehrseitige Sicherheit - Schutz fur Unternehmen und ihre Partner imInternet. WIRTSCHAFTSINFORMATIK, 42(6):489–498, 2000.
[RIS09] RISEPTIS. Trust in the Information Society: A Report of the Advisory Board RISEP-TIS. www.think-trust.eu/downloads/public-documents/riseptis-report/download.html,2009.
[Roß06] H. Roßnagel. On Diffusion and Confusion Why Electronic Signatures Have Failed. InTrust and Privacy in Digital Business, pages 71–80. Springer, 2006.
[Rog03] Everett M. Rogers. Diffusion of Innovations, 5th Edition. Free Press, original edition,August 2003.
[RZ12] Heiko Roßnagel and Jan Zibuschka. Assessing Market Compliance of IT Security Solu-tions A Structured Approach Using Diffusion of Innovations Theory. In Strategic andPractical Approaches for Information Security Governance: Technologies and AppliedSolutions. IGI Global, 2012.
[Sas03] Martina Angela Sasse. Computer security: Anatomy of a usability disaster, and a planfor recovery. In Proceedings of CHI 2003 Workshop on HCI and Security Systems,2003.
[SB02] Mikko Siponen and Richard Baskerville. A New Paradigm for Adding Security into isDevelopment Methods. In Jan H. P. Eloff, Les Labuschagne, Rossouw Solms, and Gur-preet Dhillon, editors, Advances in Information Security Management & Small SystemsSecurity, volume 72, pages 99–111. Kluwer Academic Publishers, Boston, 2002.
[SO07] Mikko T. Siponen and Harri Oinas-Kukkonen. A review of information security issuesand respective research contributions. SIGMIS Database, 38(1):6080, February 2007.
[VCU08] S. Vidyaraman, M. Chandrasekaran, and S. Upadhyaya. Position: the user is the enemy.In Proceedings of the 2007 Workshop on New Security Paradigms, pages 75–80, NewHampshire, 2008. ACM.
[Wei89] ND Weinstein. Optimistic biases about personal risks. Science, 246(4935):1232 –1233,December 1989.
[ZR11] Jan Zibuschka and Heiko Roßnagel. A Structured Approach to the Design of ViableSecurity Solutions. In N. Pohlmann, H. Reimer, and W. Schneider, editors, SecuringElectronic Business Processes, pages 246–255. Vieweg, 2011.
On Some Conjectures in IT Security: The Case for Viable Security Solutions 33


Identifikation von Videoinhalten uber granulareStromverbrauchsdaten∗
Ulrich Greveler, Benjamin Justus, Dennis Lohr
Labor fur IT-SicherheitFachhochschule Munster
Stegerwaldstraße 3948565 Steinfurt
{greveler|benjamin.justus|loehr}@fh-muenster.de
Abstract: Sekundenscharfe Ablese-Intervalle bei elektronischen Stromzahlern stelleneinen erheblichen Eingriff in die Privatsphare der Stromkunden dar. Das datenschutz-rechtliche Gebot der Datensparsamkeit und Datenvermeidung steht einer feingranu-laren Messhaufigkeit und der vollstandigen Speicherung der Stromverbrauchsdatenentgegen.
Wir konnen experimentell nachweisen, dass neben der Erkennung von im Haushaltbefindlichen Geraten eine Erkennung des Fernsehprogramms und eine Identifikationdes abgespielten Videoinhalts moglich ist.
Alle Mess- und Testergebnisse wurden zwischen August und November 2011 mit-hilfe eines geeichten und operativen Smart Meters, der alle zwei Sekunden Messwerteaufzeichnet, gewonnen. Die ubertragenen Daten dieses Gerates waren unverschlusseltund nicht signiert.
Keywords. Smart Meter, Data Privacy, Audiovisual Content, Smart Grid
1 Einfuhrung
Bundesweit und auch im europaischen Rahmen ist die Einfuhrung von intelligenten Strom-messgeraten (Smart Metern) geplant, die vorhandene Stromzahler ersetzen sollen. Strom-kunden konnen mithilfe dieser Gerate detaillierte Informationen uber den Stromverbraucherhalten und sind in der Lage, Stromverbraucher zu identifizieren, Ursachen fur hohenVerbrauch zu bestimmen und damit Abhilfe zu schaffen, d. h. insbesondere Stromver-brauchskosten zu senken (Forderung des bewussten Energieverbrauchs).
Fur Stromverkaufer und Netzbetreiber sind granulare Verbrauchsdaten ebenfalls von In-teresse, da diese zu Planungszwecken, Ausfuhrung von Netzoptimierungen, Vorhersagevon Lastspitzen und informierte Beratungen der Kunden herangezogen werden konnen.Die Energieeffizienz- und Energiedienstleistungsrichtlinie (2006/32/EG) sieht individuel-
∗Dieser Beitrag stellt wesentliche Ergebnisse in aktualisierter Form dar, die in einer englischsprachigen Pu-blikation [GJL12] der Autoren veroffentlicht wurden.

le Zahler, die den tatsachlichen Verbrauch und die tatsachliche Nutzungszeit feststellen[Ren11], vor. Mittelfristig ist daher damit zu rechnen, dass sich Smart Meter gegenuberbisherigen Stromzahlern bei Neuverlegungen und dem Austausch alter Zahler durchset-zen.
Aufgrund der Aufzeichnung personenbezogener Verbrauchsdaten durch Smart Meter er-geben sich Anforderungen an Datenschutz und Datensicherheit. Abhangig von der Genau-igkeit der Messung und der zeitlichen Auflosung konnen nach Auswertung der erhobenenDaten Ruckschlusse auf die Verhaltensweisen der sich im Haushalt aufhaltenden Men-schen gezogen werden; die Granularitat heute eingesetzter Gerate sieht Messpunkte imAbstand von einer Stunde, viertelstundlich, minutlich bis hin in den Sekundenbereich vor.
2 Verwandte Arbeiten
Wie von Molina-Markham et al. [AMSF+10] beschrieben wurde, konnen Daten, die ca.viertelstundlich erhoben werden, in einer Weise ausgewertet werden, dass feststellbar ist,wann sich Personen zuhause aufhalten, wann sie dort schlafen und wann sie Mahlzeitenzubereiten. Erhoht man die Granularitat in den Minuten- oder Sekundenbereich, sind auchAussagen moglich, ob das Fruhstuck warm oder kalt zubereitet wurde, wann Wasche ge-waschen oder der Fernseher eingeschaltet wurde - oder ob die Kinder alleine zu Hausewaren.
Bereits vor dem Aufkommen der Smart Meter wurden Forschungsarbeiten zu ”non-intrusiveload monitoring“ (NILM) bekannt. NILM-Methoden [LFL07, Pru02] erlauben die Iden-tifikation einer Vielzahl von Geraten anhand charakteristischer Lastkurven, wodurch dieAktivitaten der im Haushalt befindlichen Personen nachvollziehbar werden [Qui09].
Hinweise auf Datenschutzaspekte in Bezug auf die Einfuhrung von Smart Metern sindTeil der offentlichen Diskussion um den Nutzen und die Risiken der Technologie. [Bo11,AMSF+10, Ren11] Es wurden zudem Gegenmaßnahmen, die den Datenschutz bei derEinfuhrung von Smart Metern starken sollen, vorgeschlagen: Schlusselhinterlegung zuranonymen Authentikation [EK10], Reduktion verraterischer Lastkurven durch Einsatz vonStromspeichern [EKD+10, KDLC11] oder auch anonyme Rechnungsstellung unter Nut-zung eines Zero-Knowledge-Protokolls [AG10]. Die Messung elektromagnetischer Inte-ferenz mit hoher Abtastrate zur Identifikation des Fernsehbildes wurde zeitgleich und un-abhangig zu den von den Autoren durchgefuhrten Experimenten mit Stromzahlern vonEnev et al. [EGKP11] betrachtet; hierbei gelingt eine Identifikation mithilfe neuronalerNetze. Erste Ergebnisse der experimentellen Arbeiten wurden zudem uber die Presse ver-beitet [Bo11].
36 Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten

3 Experimentelle Ergebnisse
Die Untersuchungsergebnisse beziehen sich auf die Fragestellung: Welche Auswertungs-moglichkeiten stehen in der Praxis zur Verfugung und welche Qualitat haben die vontatsachlich im Feld befindlichen geeichten Smart Metern erhobenen Daten? Welche Ruck-schlusse auf personenbezogenes Verhalten konnen erfolgreich gewonnen werden?
3.1 Hardware
Getesteter Smart Meter: Das Gerat wurde von der Firma Discovergy GmbH (Heidelberg)nach Abschluss eines Privatkundenvertrags1 durch einen von der Firma beauftragten Elek-tromeister im August 2011 eingebaut. Das geeichte und verplombte Gerat ersetzte den bis-herigen von der RWE AG verbauten Stromzahler eines privaten Haushaltes in NRW. DerStrombezug erfolgt vor und nach dem Einbau des Smart Meters uber den VersorgungstarifRWE Klassik Strom.
Die Discovergy-Losung verwendet als Modul einen Smart Meter2 der Firma EasyMe-ter GmbH, Bielefeld (Elektronischer 3-Phasen 4-Leiter Zahler Q3D, Messung im zwei-Sekunden-Intervall) und eine selbst entwickelte Losung zur Datenentnahme und Weiter-leitung uber das Internet an einen Server von Discovergy, der dem Stromkunden einenwebbasierten Zugriff auf die erhobenen Stromverbrauchsdaten liefert. In der experimen-tellen Untersuchung werten wir allein die Daten aus, die an Discovergy ubermittelt undgespeichert werden. Alle Mess- und Testergebnisse wurden zwischen August und Novem-ber 2011 gewonnen.
4 Ubertragung der Verbrauchsdaten
Die Ubermittlung der Daten vom Smart Meter zum Discovergy-Server erfolgt uber TCP/IP.Das Gerat wird direkt mit dem heimischen LAN/DSL-Router verbunden und erhalt vondiesem uber DHCP seine IP-Adresse. Entgegen den vertraglichen Angaben erfolgt dieUbertragung jedoch nicht verschlusselt. Die Daten werden in einem textbasierten Formatubertragen, so dass sie ohne weitere Decodierung abgelesen werden konnen. In Abb. 1 isteine solche Ubertragung, die acht Messwerte gemeinsam ubermittelt, dargestellt.
1Der Vertrag enthielt umfangreiche Bestimmungen zum Datenschutz: ”Die Discovergy GmbH speichert diepersonenbezogenen Daten ausschließlich zur Abwicklung der oben aufgefuhrten Zwecke und gibt diese nichtan Dritte weiter, es sei denn, dieses ist zur Abwicklung des Vertrages erforderlich. Derzeit werden Daten anDritte weitergegeben zur Erstellung der Abrechnung, im Bereich des Zahl- und Messwesens sowie zur Daten-aufbereitung in elektronischer Form. [...] Die Ubertragung der Daten im Internet erfolgt verschlusselt.“ Der Abrufder Daten uber die Webschnittstelle war zum Testzeitpunkt nur unverschlusselt moglich, da TLS nicht unterstutztwurde. Die automatisierte Ubertragung vom Smart Meter zum Server erfolgte im Widerspruch zum Vertragstextebenfalls unverschlusselt.
2Ubermittelte Messwerte gemaß Herstellerangaben: Zahlwerksstand (15-stellig in kWh), drei Phasenleis-tungen (7,5-stellig in W), Summenleistung (7,5-stellig in W), Protokoll nach EN62056-21 und EN62056-61.
Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten 37

POST /api/w.html HTTP/1.1Content-Type: application/x-www-form-urlencodedHost:85.214.93.99Content-Length:851
version=0.9&identity= &msg=228601&values=[{"meterdata":"00000285.9823514*kWh","tickdelta":"00000285.9822239*kWh","seconds":"399511319.61"},{"meterdata":"00000285.9824793*kWh","tickdelta":"00000285.9823514*kWh","seconds":"399511321.61"},{"meterdata":"00000285.9826075*kWh","tickdelta":"00000285.9824793*kWh","seconds":"399511323.61"},{"meterdata":"00000285.9827358*kWh","tickdelta":"00000285.9826075*kWh","seconds":"399511325.62"},{"meterdata":"00000285.9828636*kWh","tickdelta":"00000285.9827358*kWh","seconds":"399511327.62"},{"meterdata":"00000285.9829915*kWh","tickdelta":"00000285.9828636*kWh","seconds":"399511329.62"},{"meterdata":"00000285.9831196*kWh","tickdelta":"00000285.9829915*kWh","seconds":"399511331.62"},{"meterdata":"00000285.9832476*kWh","tickdelta":"00000285.9831196*kWh","seconds":"399511333.62"}]&now=399511335.65
Abbildung 1: Kommunikation Zwischen Smart Meter und Server
Es ist zudem unmittelbar zu erkennen, dass die Daten nicht signiert werden. Durch Kennt-nis der ”identity“ (in der Abb. 1 geschwarzt) konnten Daten fur beliebige andere Zahleran den Server ubertragen werden, was zwischenzeitlich demonstriert wurde [BCC11]. DerSmart Meter verfugt jedoch uber eine digitale Anzeige des Stromverbrauchs, so dass Da-ten, die am Zahler abgelesen werden, von einer Verfalschung nicht betroffen sind.
4.1 Auflosung der dem Stromkunden prasentierten Daten
Discovergy stellt einen Web-basierten Zugang zur Visualisierung der Stromverbrauchsda-ten zur Verfugung. Eine typische Darstellung eines Stromverbrauchsprofils kann Abb. 2entnommen werden (Stand: Nov. 2011).
Abbildung 2: Verbrauchsprofil visualisiert vom Anbieter
Eine Analyse des Javascript-Sourcecodes zeigte, dass die Kunden nicht die volle Auflosungihrer gespeicherten Stromverbrauchsdaten einsehen konnen (Messungen erfolgen mit Fre-quenz 0.5s−1). Die Daten werden konsolidiert, indem einzelne Messwerte ausgelassenwerden. Diese Konsolidierung war zum Testzeitpunkt fehlerhaft, weswegen einzelne dar-gestellte Messwerte nicht mit abgerufenen Daten ubereinstimmten. Durch Entwicklungeines eigenen Tools zum Abrufen und zur Darstellung erhielten wir die volle Auflosungund korrekte Daten: Abb. 3 zeigt ein kleines Intervall in voller Auflosung, welches inAbb. 2 (im Teilzeitraum 22.35h-22.50h) enthalten ist.
Genauigkeitsklasse: A, B gemaß EN50470-1
38 Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten

4.2 Identifikation von Geraten
Wir konnten die in der Literatur getroffenen Aussagen [Har92, AMSF+10, Mu10] bestati-gen, dass viele Gerate uber ein charakteristisches Stromprofil erkennbar sind. Insbesonderekonnten wir mithilfe der feingranularen Daten identifizieren: Kuhlschrank, Wasserkocher,Durchlauferhitzer, Gluhbirne, Energiesparlampe, Kaffee-Padmaschine, Herd, Mikrowelle,Ofen, Waschmaschine, Geschirrspuler und TV-Gerat.
5 TV/Film-Detektion
5.1 TV-Geratetechnik
Durch Auswertung des Stromverbrauchs eines im getesteten Privathaushalt vorhande-nen TV-Gerates (Panasonic Viera LCD-TV, HD, 80cm Diag., 130W) konnte nicht nurdie bereits in der Literatur genannte Einschaltzeit [Qui09] identifiziert werden. Es wardaruber hinaus moglich, das eingeschaltete Programm bzw. den abgespielten Film zuidentifizieren, obwohl der eingesetzte Smart Meter den Strom fur den gesamten Vier-Personenhaushalt misst - also nicht direkt mit dem TV-Gerat verbunden wurde - und dieDaten uber den Discovergy-Server abgefragt wurden, d. h. dort in dieser Auflosung zentralgespeichert vorliegen.
5.2 Vorhersage des Stromverbrauchs anhand von Filmdaten
Kernelement unseres Softwaretools zur Identifikation von Inhalten ist eine Funktion, dieden zu erwartenden Stromverbrauch berechnet. Input der Funktion sind Bilddaten, Outputist der Stromverbrauch wie er vom Smart Meter gemessen wird.
Abbildung 3: Bestimmung der minimalen Bildhelligkeit, die zum maximalen Stromverbrauch fuhrt
Ein erster Schritt ist die Messung des Stromverbrauchs fur eine Folge von Grautonenals Teil der Folge schwarz-(RGB-2-2-2)-weiß-schwarz-(RGB-4-4-4)-weiß-schwarz-(RGB-6-6-6). . . , die es erlaubt den minimalen Helligkeitswert zu bestimmen, der den Strom-verbrauch maximiert. Dies geschieht nicht selten bereits bei recht dunklen Bildern (z. B.RGB 32-32-32 fur o. g. LCD TV) und ist abhangig vom Fernseher, Zeitpunkt (der Wertist nicht uber Stunden konstant) und den Benutzereinstellungen. Abb. 3 zeigt die anstei-
Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten 39

gende Stromkurve (zwischen schwarz und weiß) fur obige Bildersequenz. Man kann vonHand abzahlen, dass bei ab RGB-38-38-38 der Stromverbrauch maximal ist. Diesen Wert(minimale Helligkeit fur maximalen Stromverbrauch) bezeichnen wir mit bmin.
Wir konnten anhand des Messergebnisses eine lineare Abhangigkeit annehmen und pro-gnostizierten den Stromverbrauch fur ein 2-Sekunden-Intervall durch den Mittelwert ausder doppelten Anzahl Frames, die in einer Sekunde dargestellt werden (meist sind es 25fps bei Filmproduktionen).
mi :=
{1 falls bi > bmin
bibmin
sonst
ppk :=1
n
n(k+1)−1∑i=nk
mi
brightness
time
powerprediction
time
b pp
Abbildung 4: Stromverbrauch wird anhand von gemittelten Helligkeiten prognostiziert
Wir erhalten damit eine Folge von prognostizierten normalisierten Messwerten fur 2s (k =1), 4s (k = 2), 6s (k = 3), etc., die wir mit dem tatsachlichen Stromverbrauch korrelierenkonnen, um den Inhalt zu identifizieren. Abb. 5 zeigt Ergebnisse dieser Vorgehensweisefur drei Filmausschnitte a funf Minuten. Grun sind vorhergesagte Messwerte, rot sind dieWerte vom Smart Meter: Die Korrelationen nach Pearson betragen 0.94, 0.98 und 0.93.
5.3 Korridor-Algorithmus
Nachdem sich experimentell gezeigt hatte, dass hohe Korrelationen auch dann auftre-ten konnen, wenn die im Stromverbrauchsprofil gesuchte 5-minutige Filmsequenz einemEinschalt- oder Ausschaltvorgang eines beliebigen Gerates ahnelt (z. B. lange helle Szenefolgt auf eine lange dunkle Szene: korreliert stark mit dem Einschalten eines konstantenVerbrauchers, z. B. einer Lampe), haben wir einen Korridor-Algorithmus entworfen, derdiese False Positives eliminiert. Bevor eine Fundstelle identifiziert wird (ab einer Kor-relation von 0.85 gehen wir von einem Treffer aus), werden die Messwerte, die in zweioptimal gewahlten Korridoren mit jeweils 5% Hohe liegen, gezahlt. Uberschreiten dieseeinen Schwellenwert von 50% aller Werte, wird der Treffer eliminiert. Abb. 6 zeigt einentypischen Anwenungsfall, der zur Elimination des Treffers fuhrt.
40 Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten

50
60
70
80
90
100
110
120
130
0 50 100 150 200 250 300
pow
erco
nsum
ptio
n(w
)
time (s)
comsumptionprediction
50
60
70
80
90
100
110
120
130
0 50 100 150 200 250 300
pow
erco
nsum
ptio
n(w
)
time (s)
comsumptionprediction
50
60
70
80
90
100
110
120
130
0 50 100 150 200 250 300
pow
erco
nsum
ptio
n(w
)
time (s)
comsumptionprediction
Abbildung 5: Vorhersage und tatsachlicher Verbrauch: Erste 5 Minuten von Star Trek 11 (oben);Episode 1-1, Star Trek TNG; Body of Lies (unten)
Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten 41

pow
erpr
edic
tion
time
pp
Abbildung 6: Korridor-Algorithmus eliminiert False Positives
5.4 Work-flow
Mithilfe der zuvor genannten Algorithmen konnten wir den Proof-of-Concept einer foren-sischen Software realisieren, der automatisch nach Videoinhalten in den Stromverbrauchs-daten sucht. Wir stellten dazu eine Filmdatenbasis zusammen, die aus den 5-Minuten-Abschnitten von 653 Filmen bzw. Fernsehproduktionen besteht. Der Ablauf des Suchvor-gangs ist in Abb. 7 dargestellt: Jeder zu suchende Film wird in 5-Minuten-Abschnitte un-terteilt und es wird die Helligkeit und daraus der erwartete Stromverbrauch jedes Framesbestimmt. Der Abschnitt wird dann fortlaufend uber die gesamten Stromverbrauchsdatenkorreliert (sliding window). Ab einem Wert von 0.85 wird der Treffer, sofern er nicht dieKorridorbedingung (Ausschlusskriterium) erfullt, ausgegeben.
Ergebnis: Bei dieser Vorgehensweise wird fast die Halfte der gespielten Videosequenzenanhand des Stromverbrauchs identifiziert. Da ein Film (i.d.R. mind. 90 Minuten) uber 18oder mehr Abschnitte verfugt, ist selbst bei Storungen durch andere Verbraucher (z. B.Einschalten eines starken ”rauschenden“ Gerates3 wahrend der Abspielzeit), eine gewisseWahrscheinlichkeit gegeben, mehrere nicht wesentlich beeintrachtigte Abschnitte zu iden-tifizieren. Uber einen Zeitraum von 24h werden jedoch (bei unserer Datenbasis von 653 Vi-deoinhalten) auch ca. 35 falsche Identifizierungen von 5-Minuten-Abschnitten vorgenom-men. Zahlt man jedoch nur solche Treffer, bei denen zwei korrespondierende Abschnit-te desselben Inhaltes gefunden werden (wie im Beispiel von Abb. 7), wurden samtlicheFalse Positives eliminiert. Im Testhaushalt konnten Spielfilminhalte trotz gleichzeitig ak-tiver elektrischer Gerate in allen Fallen anhand mehrerer Abschnitte identifiziert werden4.Aufgezeichnete Fernsehproduktionen, die ein hohes durchgehendes Helligkeitsniveau auf-weisen (bspw. Talkshows), konnen mit LCD-Geraten oft nicht identifiziert werden, da dergeratespezifische Wert bmin zu niedrig ist.
3Verbraucher, die eine konstante Last erzeugen (z. B. Lampen, Standby-Gerate, Hifi), wirken sich auf dieKorrelation nicht storend aus, da diese nur eine Intervallskalierung voraussetzt.
4Hier ist aber zu bemerken, dass Filme im getesteten Haushalt abends konsumiert wurden und zur gleichenZeit kein Herd, Fon oder baugleicher Fernseher benutzt wurde.
42 Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten

< threshold > threshold < threshold
movie tng1chunk 1 at 2103h
movie tng1chunk 3 at 2113h
split into 5-min chunks calculate bmin and correlation foreach match
calculate brightness find best corridors and discard bythreshold
calculate generic power prediction output matches to logfile
find correlation matches on powerprofileiso file from DVD movie
Abbildung 7: Workflow zur Identifikation einer abgespielten DVD
5.5 Weitere TV-Geratemodelle
Die Experimente aus den vorangegangenen Abschnitten wurden mit dem im Testhaushaltbefindlichen LCD-TV5 durchgefuhrt, das uber eine dynamische Hintergrundbeleuchtungverfugt. Um abzuschatzen, inwieweit andere TV-Modelle ahnliche Ruckschlusse erlaubenbzw. ”datenschutzfreundliche“ Stromverbrauchsprofile generieren, haben wir die Tests miteinem weiteren (nicht operativen) Smart Meter desselben Typs fur weitere Gerate im La-bor durchgefuhrt. In Tab. 1 werden Testergebnisse fur unterschiedlichen Videoinhalt auf-gefuhrt. Bei zwei der getesteten Gerate (Hersteller Sony und LG) ist die Watt-Differenzzwischen einem hellen und dunklen Bild zu gering, um Film-Inhalte zu identifizieren (Kor-relation < 0.85).
6 Diskussion
Kurze Ablese-Intervalle bei elektronischen Stromzahlern stellen einen erheblichen Ein-griff in die Privatsphare der Stromkunden dar. Das datenschutzrechtliche Gebot der Daten-sparsamkeit und Datenvermeidung steht einer Messhaufigkeit im Sekundenbereich und dervollstandigen Speicherung des Stromverbrauchs entgegen. Eine regelmaßige oder durchFernabfrage ermoglichte Ubermittlung dieser Daten an Energieversorger oder Netzbetrei-ber sollte nicht nur einer ausdrucklichen Zustimmung aller im Haushalt lebenden Personenunterliegen, die Betroffenen sind auch daruber aufzuklaren, welche Auswertungsmoglich-
5Panasonic Modellnummer TX-L37S10E
Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten 43

Tabelle 1: Getestete TV-GerateHersteller Modellnr.
Technikwattmin wattdiff Korr.
M1aKorr.M2b
Korr.M3c
TV-Seried
Panasonic TX-L37-S10E LCD
∼ 45 ∼ 70.0 0.9599 0.9283 0.9487 <0.85
LG 47LH4000LCD
∼ 65 ∼ 1.5 0.9458 <0.85
<0.85
<0.85
Orion TV32FX-100D LCD
∼ 100 ∼ 3.0 0.8958 0.9402 0.9326 0.8989
Panasonic TX-P50S-20E Plasma
∼ 45 ∼ 160.0 0.8722 0.9510 0.8871 0.8933
Sony KDL46EX-505 LCD
∼ 170 − <0.85
<0.85
<0.85
<0.85
Telefunken Cinevision32 CR tube
∼ 60 ∼ 50.0 0.8833 0.9454 <0.85
0.9283
aFanboys (2008). Regie: Kyle Newman. Erschien: 6. Februar, 2009bDeath Race (2008). Regie: Paul W.S. Anderson. Erschien: 22. November, 2008c2012 (2009). Regie: Roland Emmerich. Erschien: 11. November, 2009dJAG Pilotfolge. Regie: D. P. Bellisario. Erstausstrahlung: 23. September, 1995
keiten sich bei hoher Granularitat der Messdaten ergeben.
Die experimentell festgestellte Tatsache, dass die Daten beim getesteten Anbieter unver-schlusselt und nicht signiert ubertragen werden, stellt einen Verstoß gegen Grundsatze vonDatenschutz und Datensicherheit dar. Diese Tatsache wiegt umso schwerer, da beim getes-teten Anbieter vertraglich zugesichert wurde, dass die Ubertragung verschlusselt erfolgt6.
Die prinzipiell vorhandene Moglichkeit, audiovisuelle Inhalte bzw. das eingestellte Fern-sehprogramm zu identifizieren, fuhrt zu einer neuen Qualitat des Eingriffs in die privateLebensgestaltung. Die in diesem Beitrag durchgefuhrten Tests lassen aufgrund der uber-schaubaren Testdatenbasis (653 Videoinhalte) zwar keine Ruckschlusse zu, inwieweit eineforensische Auswertung der Stromverbrauchsdaten tatsachlich einen ausreichenden Be-weiswert (bspw. zum Nachweis von Verstoßen gegen das Urheberrecht) hatte; die Re-levanz in Bezug auf die Schutzwurdigkeit der granularen Stromverbrauchsdaten ist aberbereits dadurch gegeben, dass unter gunstigen Umstanden eine Identifikation moglich ist.
Literatur
[AG10] A.Rial und G.Danezis. Privacy-Preserving Smart Metering, Technical Report MSR-TR-2010-150. Microsoft Research, 2010.
[AMSF+10] A.Molina-Markham, P. Shenoy, K. Fu, E. Cecchet und D. Irwin. Private Memoirs ofa Smart Meter. In 2nd ACM Workshop on Embedded Sensing Systems for Energy-
6Der Anbieter hat die Sicherheitslucke zwischenzeitlich bestatigt und Abhilfe in naher Zukunft angekundigt.
44 Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten

Efficiency in Buildings (BuildSys 2010), Zurich, Switzerland, November 2010.
[BCC11] D. Bachfeld, D. Carluccio und C.Wegener. Wer hat an der Uhr gedreht? Sicherheit beiintelligenten Stromzahlern. In c’t-Magazin (Heise Verlag), 23/2011, 2011.
[Bo11] M. Bo. Was moderne Stromzahler verraten konnten (Spiegel online). http://www.spiegel.de/netzwelt/netzpolitik/0,1518,787629,00.html,September 2011.
[EGKP11] Enev, Gupta, Kohno und Patel. Televisions, Video Privacy, and Powerline Electroma-gnetic Interference. In Proceedings of the 18th ACM conference on Computer andcommunications security (Oct. 2011). ACM, 2011.
[EK10] C. Efthymiou und G. Kalogridis. Smart Grid Privacy via anonymization of smart me-tering data. In First IEEE International Conference on Smart Grid Communications,SmartGridComm10, 2010.
[EKD+10] C. Efthymiou, G. Kalogridis, S.Z. Denic, T.A. Lewis und R.Cepeda. Privacy for SmartMeters, Towards Undetectable Appliance Load Signatures. In First IEEE Internatio-nal Conference on Smart Grid Communications, SmartGridComm10, 2010.
[GJL12] U. Greveler, B. Justus und D. Loehr. Multimedia Content Identification Through SmartMeter Power Usage Profiles. In 5th International Conference on Computers, Privacyand Data Protection, Brussels. Springer, 2012.
[Har92] G.W. Hart. Nonintrusive appliance load monitoring. Proceedings of the IEEE,80(12):1870–1891, 1992.
[KDLC11] G. Kalogridis, S. Denic, T. Lewis und R. Cepeda. Privacy protection system andmetrics for hiding electrical events. IJSN, 6(1):14–27, 2011.
[LFL07] H. Lam, G. Fung und W. Lee. A Novel Method to Construct a Taxonomy of ElectricalAppliances Based on Load Signatures. In IEEE Transactions on Consumer Electro-nics, 2007.
[Mu10] K. Muller. Gewinnung von Verhaltensprofilen am intelligenten Stromzahler. Daten-schutz und Datensicherheit - DuD, 34:359–364, 2010. 10.1007/s11623-010-0107-2.
[Pru02] A. Prudenzi. A Neuron Nets based procedure for identifying domestic appliancespattern-of-use from energy recording at meter panel. In IEEE Power EngineeringSociety Winter Meeting, 2002.
[Qui09] E.L. Quinn. Privacy and New Energy Infrastructure. Available:http://papers.ssrn.com/sol3/papers.cfm?abstract id=1370731, 2009.
[Ren11] S. Renner. Smart Metering und Datenschutz in Osterreich, Datenschutz und Datensi-cherheit - DuD 2011.
Identifikation von Videoinhalten uber granulare Stromverbrauchsdaten 45


Analyse und Vergleich von BckR2D2-I und II
Andreas Dewald1
, Felix C. Freiling∗2
, Thomas Schreck2
, Michael Spreitzenbarth2
,
Johannes Stuttgen2
, Stefan Vomel2
, und Carsten Willems3
1
Universitat Mannheim2
Friedrich-Alexander Universitat Erlangen-Nurnberg3
Ruhr-Universitat Bochum
Abstract: Im Oktober 2011 erregte die Veroffentlichung von Details uber die inzwischenmeist als BckR2D2 bezeichnete Schadsoftware offentliches Aufsehen. Mitglieder des Cha-os Computer Club e.V. veroffentlichten einen ersten Bericht uber die Funktionsweise desTrojaners, dem weitere Analysen folgten. In dieser Arbeit geben wir einen Uberblickuber die bislang veroffentlichen Einzelberichte und uber die verschiedenen Komponen-ten der Schadsoftware sowie deren Funktionsweise. Hierzu prasentiert diese Arbeit diewesentlichen Ergebnisse einer ausfuhrlichen Analyse aller Komponenten des Trojanersund geht insbesondere auf Unterschiede zwischen den beiden bislang bekannten Varian-ten BckR2D2-I und II ein. Ziel dieser Arbeit ist auch die kritische Uberprufung der vonanderen Autoren getroffenen Aussagen uber die Schadsoftware.
1 Einleitung
Im Laufe des Jahres 2011 wurden verschiedene Versionen der inzwischen als BckR2D2 be-zeichneten Schadsoftware bekannt. Eine erste Analyse wurde Anfang Oktober 2011 durch denChaos Computer Club e.V. (CCC) in Form einer Presseerklarung sowie eines dazugehorigen20-seitigen Berichts veroffentlicht [Cha11d, Cha11b]. In diesem werden einzelne Programm-funktionen und insbesondere der eingesetzte Verschlusselungsmechanismus detailliert darge-stellt. F-Secure, ein bekannter Hersteller von Anti-Viren-Software, berichtete wenige Tagespater in seinem Blog uber einen so genannten Dropper [FS11], welcher den eigentlichenTrojaner installiert. Dieser wurde offenbar bereits im Dezember 2010 beim Onlinedienst Vi-rusTotal1 hochgeladen und beinhaltet eine Installationsroutine zur Einrichtung der verschie-denen Programmkomponenten der Schadsoftware auf einem System. Knapp zwei Wochenspater veroffentlichte der CCC einen Bericht uber die Unterschiede zwischen beiden Varian-ten [Cha11e, Cha11c]. Der Fokus dieser Analyse liegt wiederum auf der Art und Weise desEinsatzes von Verschlusselungstechniken. Eine weitere, kurze Analyse des Droppers stammtvon Tillmann Werner [Wer11]. Diese Analysen, vor allem die des CCC, erregten ein umfang-reiches offentliches Aufsehen. Eine kritische Wurdigung dieser Analysen sowie eine detail-lierte Aufstellung der Quellengenese existiert jedoch bisher noch nicht.
∗Kontaktautor, Kontaktadresse: Am Wolfsmantel 46, 91058 Erlangen, Deutschland.1http://www.virustotal.com/

Ausgangspunkt unserer Arbeit war die von uns als BckR2D2-I bezeichnete Variante der Schad-software. Diese wurde uns von Rechtsanwalt Patrick Schladt zur Verfugung gestellt und stammtvon der Festplatte eines seiner Mandanten. Diese Version wurde bereits 2009 eingesetzt undstellt das bislang alteste den Autoren bekannte Exemplar der Trojaner-Familie dar. Im Oktober2011 veroffentlichten Mitglieder des CCC ebenfalls eine Variante dieses Trojaners [Cha11d],die auf den ersten Blick nicht mit der Version BckR2D2-I ubereinstimmte. Nach eingehen-der Analyse gelangten wir jedoch zu der Einsicht, dass es sich bis auf minimale Modifika-tionen um die gleiche Variante der Schadsoftware handelt. Daher bezeichnen wir diese alsBckR2D2-I’.2 Zusatzlich wurde uns eine Version des Droppers [FS11, Cha11e, Wer11] voneinem Hersteller von Antiviren-Software zur Verfugung gestellt. Wir bezeichnen diese Ver-sion als BckR2D2-II. Abbildung 1 veranschaulicht die Quellengenese, also die Herkunft derunterschiedlichen Versionen der Schadsoftware sowie die der jeweiligen Version zugehorigenKomponenten.
R2D2-I
Schladt CCC Website
R2D2-I'
~
anonymer AV-Hersteller
R2D2-II
Dropper
Remover
Softwarebibliothek
User-Level-Anwendung
32-bit Kernel-Level-TreiberSoftwarebibliothek
64-bit Kernel-Level-Treiber
32-bit Kernel-Level-Treiber
Abbildung 1: Herkunft und Komponenten der unterschiedlichen Versionen von BckR2D2.
Ziel dieser Arbeit ist es, einen unabhangigen Uberblick uber die beiden bislang bekannten,unterschiedlichen Varianten der Schadsoftware zu liefern und einen Vergleich untereinan-der zu ziehen. Ein besonderes Augenmerk gilt hierbei potenziellen Erweiterungen oder Ein-schrankungen des Funktionsumfanges sowie Verbesserungen zwischen den verschiedenenVersionen. Hierzu unterzogen wir beide Varianten der Schadsoftware einer intensiven stati-schen Analyse. In dieser Arbeit werden die wesentlichen Ergebnisse dieser Analyse erlautert.Im Zuge dessen werden insbesondere die in unterschiedlichen Quellen [Cha11b, Cha11e,FS11, Wer11] veroffentlichten Aussagen uber einzelne Varianten der Schadsoftware uber-pruft.
Aufgrund der Seitenlimitierung beschranken sich die Autoren in dieser Arbeit auf die Erlaute-rung der wichtigsten Ergebnisse. Weitere Details werden die Autoren in einem technischen
2So beschreibt der CCC eine Reihe zum Zwecke des Quellenschutzes vorgenommener Anderungen, die zuBckR2D2-I’ fuhrten, auf seiner Webseite [Cha11a].
48 Analyse und Vergleich von BckR2D2-I und II

Bericht [DFS+11] zur Verfugung stellen.
1.1 Gliederung der Arbeit
Die restlichen Abschnitte dieser Arbeit sind wie folgt gegliedert: Abschnitt 2 gibt einen kurzenUberblick uber die einzelnen Komponenten der Schadsoftware. Eine detaillierte Analyse derKomponenten folgt in Abschnitt 3. Wichtige Unterschiede zwischen den beiden Schadsoftwa-reversionen sind in Abschnitt 4 naher erlautert. Eine abschließende kurze Zusammenfassungder Untersuchungsergebnisse ist Gegenstand von Abschnitt 5.
2 Uberblick uber die Komponenten von BckR2D2
Bislang sind insgesamt funf verschiedene Komponenten unterschiedlicher Funktionalitat be-kannt, die der Schadsoftware zuzuordnen sind. Diese Komponenten liegen jedoch ausschließ-lich fur die Variante BckR2D2-II vollstandig vor und sind in dem bereits genannten Drop-per [FS11] enthalten. Fur die altere Variante BckR2D2-I liegt lediglich der 32-bit Kernel-Level-Treiber und die Softwarebibliothek vor. Ein Uberblick uber die betreffenden Ressourcenist mit einer kurzen Beschreibung in Tabelle 1 dargestellt.
Bezeichnung Kurzbeschreibung erlautert in
DropperInstallationsroutine zur Einrichtung deranderen Komponenten Abschnitt 3.1
SoftwarebibliothekBibliothek zur Uberwachung verschie-dener Applikationen Abschnitt 3.2
Kernel-Level-Treiber (32-bit)Treiber zur Bereitstellung privilegier-ter Operationen (benotigt Administra-torrechte)
Abschnitt 3.3
Kernel-Level-Treiber (64-bit )Treiber zur Bereitstellung privilegier-ter Operationen (benotigt Administra-torrechte)
Abschnitt 3.3
User-Level-AnwendungProgramm als bestmoglicher Ersatz furden Kernel-Level-Treiber bei einge-schrankten Benutzerrechten
Abschnitt 3.4
RemoverHilfsprogramm zum Loschen beliebi-ger Dateien Abschnitt 3.5
Tabelle 1: Komponenten der untersuchten Schadsoftware
Neben dem bereits genannten Dropper, der Softwarebibliothek und dem 32-bit Kernel-Level-Treiber existiert weiterhin ein 64-bit Kernel-Level-Treiber sowie eine User-Level-Anwendung,welche die Funktionalitaten des Kernel-Level-Treibers soweit wie moglich ersetzt, falls beider Installation der Schadsoftware keine Administratorprivilegien zur Verfugung stehen. Einso genannter Remover dient zum Loschen von Dateien und zur Verwischung angefallenerSpuren. Tabelle 3 im Anhang enthalt eine Ubersicht uber die Prufsummen und die Dateigroßen
Analyse und Vergleich von BckR2D2-I und II 49

der einzelnen analysierten Komponenten.
3 Analyse der Komponenten
In diesem Abschnitt werden die Ergebnisse der Analyse aller Komponenten der Schadsoftwa-re in Bezug auf ihre Funktion und Implementierung erlautert.
3.1 Dropper
Die verschiedenen Komponenten der Schadsoftware in Variante BckR2D2-II werden mit Hil-fe einer Installationsroutine auf dem Zielsystem eingebracht. Dabei handelt es sich um eineausfuhrbare .exe-Datei. Dieses Installationsprogramm enthalt samtliche Komponenten derSchadsoftware als eingebettete Ressource, die mittels einer dreistelligen Ziffernfolge im Be-reich von 101 bis 118 eindeutig referenziert werden konnen.
Nach Aufruf der Installationsroutine versucht diese zunachst im Windows-Systemverzeich-nis des Rechners eine temporare Datei mit dem Namen ˜pgp˜.tmp anzulegen, um dieSchreibberechtigung fur dieses Verzeichnis zu prufen. Sofern diese Operation erfolgreichdurchgefuhrt werden konnte, wird die temporare Datei anschließend sofort wieder geloschtund eine dynamische Bibliothek mit der internen Ressourcennummer 101 unter dem Namenmfc42ul.dll im besagten Verzeichnis abgelegt. Es handelt sich hierbei um die Software-bibliothek der Schadsoftware, welche in Abschnitt 3.2 erlautert wird.
Wahrscheinlich um die Bibliothek besser vor einer Entdeckung zu schutzen oder den Instal-lationszeitpunkt zu verschleiern, werden die Erstell-, Anderungs- und Zugriffs-Zeitstempelder Datei von der namensahnlichen Bibliothek mfc42.dll ubernommen. Letztere ist legi-timer Bestandteil der Microsoft Foundation Classes (MFC), einer Sammlung von Klassen furdie Softwareentwicklung mit C++, die ublicherweise auf Microsoft Betriebssystemen vorin-stalliert ist [Mic11]. Wenn diese jedoch nicht in Version 4.2 auf dem Zielrechner vorgefun-den werden kann, so erfolgt die Anpassung aller Zeitstempel der Softwarebibliothek auf dasfest codierte Datum 04.08.2004, 12:00 Uhr. Die bloße Betrachtung kurzlich vorgenommenerAnderungen auf dem System fuhrt also nicht zur Aufdeckung der installierten Komponente.Jedoch existiert im NTFS-Dateisystem, welches seit Windows 2000 standardmaßig eingesetztwird, ein weiterer, meist als ctime bezeichneter Zeitstempel, der die letzte Anderung der zu-gehorigen Dateisystem-Datenstruktur angibt [Gar09]. Dieser Zeitstempel ist nicht ohne Wei-teres zur Laufzeit des Systems manipulierbar. Auf Basis dieses Zeitstempels sind daher unterUmstanden dennoch Ruckschlusse auf den eigentlichen Installationszeitpunkt der Schadsoft-ware moglich.
In Abhangigkeit der festgestellten Betriebssystemarchitektur wird im weiteren Verlauf der In-stallation ein 32- oder 64-bit Treiber aus der internen Ressourcentabelle geladen (Ressour-cennummer 102 und 118) und unter dem Namen winsys32.sys im Systemverzeich-nis der Windows-Installation gespeichert. Im nachsten Schritt wird der Treiber mit Hilfe derCreateService-Funktion als SERVICE KERNEL DRIVER (Servicetyp: 0x00000001)mit vollen Rechten und ohne weitere Abhangigkeiten auf dem Computer eingerichtet und
50 Analyse und Vergleich von BckR2D2-I und II

nachfolgend gestartet. Auch hier erfolgt eine Anpassung der Zeitstempel auf die bereits bei derInstallation der Softwarebibliothek genannten Werte. Im Anschluss an diesen Vorgang initiiertdas Installationsprogramm mehrere Code Injection-Operationen und schleust die Softwarebi-bliothek in verschiedene Prozesse ein, namentlich in den Windows-Explorer (Explorer.exe)sowie in zwei Prozesse der VoIP-Software Skype (Skype.exe, SkypePM.exe).
In einem letzten Schritt extrahiert die Routine eine weitere Ressource, die intern unter derNummer 106 abgelegt ist und auf der Festplatte des Zielsystems unter dem Dateinamen˜acrd˜tmp˜.exe in einem temporaren Verzeichnis gespeichert wird. Wie die Autoren inAbschnitt 3.5 darstellen, handelt es sich dabei um ein rudimentares Loschwerkzeug, mit demdas ursprungliche Installationsprogramm nach Abschluss aller Maßnahmen wieder entferntwerden kann.
Sofern die oben aufgefuhrten Dateien nicht im Systemverzeichnis der Windows-Installationerstellt werden konnen, beinhaltet das Installationsprogramm einen alternativen Infektions-weg: Hierbei wird die Softwarebibliothek (Ressourcennummer 101) im Applikationsverzeich-nis des aktiven Benutzers abgelegt und als versteckt markiert.3 Als Ersatz fur den System-treiber, der aufgrund der fehlenden Rechte nicht eingesetzt werden kann, erstellt die Routi-ne zwei versteckte und sich gegenseitig uberwachende Instanzen der User-Level-Anwendungunter dem Namen SkypeLauncher.exe und SkypePM Launcher.exe, die uber denRegistrierungsschlussel HKCU\Software\Microsoft\CurrentVersion\ Run stan-dardmaßig bei jedem Start des Betriebssystems gestartet werden. Wie wir in Abschnitt 3.4naher darstellen werden, sind diese Prozesse fur die Uberwachung einer Vielzahl von Anwen-dungsprogrammen verantwortlich.
3.2 Softwarebibliothek
Die Softwarebibliothek wird in mehrere laufende Prozesse injiziert. (Die hierzu genutztenAnsatze werden in Abschnitt 4.2 naher erlautert, da sie sich in den beiden vorliegenden Va-rianten stark unterscheiden.) In Abhangigkeit des jeweiligen Elternprozesses, in den die Soft-warebibliothek injiziert wurde, weisen die gestarteten Threads unterschiedliche Verhaltens-muster auf. So uberpruft beispielsweise der in den Windows Explorer eingeschleuste Code dieVersion und das Patchlevel des Betriebssystems.
Ein primares Ziel der Softwarebibliothek ist offenbar die Uberwachung der Software Skype.Hierzu registriert sich die Bibliothek uber die offizielle Schnittstelle als Skype-Erweiterung,was dazu fuhrt, dass sie uber eingehende und abgehende Anrufe und Textnachrichten infor-miert wird. Uber die Windows Multi-Media-Library (winmm.dll) wird dann im Falle einesAnrufs der Ton aufgezeichnet, mit dem freien Audiocodec libspeex komprimiert und anden Kontrollserver ubertragen. Der Kontrollserver ist ein System, von welchem der Trojanermogliche Steuerbefehle erhalt bzw. an den er aufgezeichnete Daten versendet.
Um einen Informationsaustausch mit anderen observierten Programmen zu ermoglichen, wer-den benannte Dateimappings verwendet, eine Art von gemeinsamem Speicher (Shared Me-mory) unter Microsoft Windows. Die Namen dieser Mappings beginnen in BckR2D2 stets mitder Zeichenfolge SYS!I[PC|CP]!, gefolgt von einer mehrstelligen Ziffernkombination, im
3Unter Microsoft Windows XP ist das Applikationsverzeichnis eines Benutzers unter C:\Dokumente undEinstellungen\<Benutzername>\Anwendungsdaten zu finden.
Analyse und Vergleich von BckR2D2-I und II 51

Fall des Microsoft Messengers zum Beispiel, 79029. Die Schadsoftware ist ebenfalls in derLage, die gesammelten Informationen uber das Internet an einen Kontrollserver zu senden.Hierzu nimmt ein dedizierter Thread uber den Port 443 Kontakt mit dem Server auf.
Kommando Beschreibung I II
0x02Anfertigung von Bildschirmschnappschussen von aktivenFenstern eines Internetbrowsers x
0x03Erstellung eines dedizierten Threads, der periodische Bild-schirmschnappschusse des kompletten Bildschirms anfertigt x
0x04Entfernung des Kernel-Level-Treibers, Einrichtung derSchadsoftware im Applikationsverzeichnis des Benutzers x x
0x05 Aktualisierung der Schadsoftware uber das Netzwerk x x
0x06Herunterfahren des Systems per ExitWindowsEx()(EWX_SHUTDOWN, EWX_FORCE) x x
0x07Herunterfahren per KeBugCheckEx() (erzeugt einen BlueScreen of Death) x x
0x08 Abfrage der installierten Anwendungen und Programme x
0x09Erstellung eines weiteren Threads, der periodische Bild-schirmschnappschusse anfertigt (Code ahnlich zu Komman-do 0x03)
x
0x0CEntgegennahme mehrerer (unbekannter) Parameter uber dasNetzwerk x x
0x0DAnfertigung von Bildschirmschnappschussen von bestimm-ten Fenstern im Vordergrund, unter anderem auch Internet-browsern (ahnlich zu Kommando 0x02)
x
0x0E Ubertragung und Ausfuhrung einer beliebigen Datei x x0x10 Noch unbekannt x x0x11 Noch unbekannt x x0x12 Null-Ruckgabe x
Tabelle 2: Unterstutzte Kommandos der Schadsoftwarebibliothek in den beiden Trojaner-Varianten (x =Funktionalitat vorhanden)
Der Kontrollserver kann mit Hilfe einer Reihe von Kommandobefehlen den Client zur Durch-fuhrung verschiedener Operationen anweisen. Dazu gehort insbesondere die Anfertigung vonBildschirmschnappschussen, aber auch die Ubertragung und Ausfuhrung beliebiger Dateien.Eine Ubersicht und Beschreibung der in den jeweiligen Versionen implementierten Befehleist in Tabelle 2 aufgefuhrt. Wie aus dieser Tabelle ersichtlich, konnten die Kommandos 0x0C,0x10 und 0x11 bis zum gegenwartigen Zeitpunkt noch nicht vollstandig analysiert werden.
3.3 Kernel-Level-Treiber
Dieser Abschnitt basiert im wesentlichen auf der Analyse von BckR2D2-I. Die beschriebeneFunktionalitat ist auch in BckR2D2-II enthalten, jedoch enthalt BckR2D2-II einige weitereFunktionen, deren Zweck zum gegenwartigen Zeitpunkt unklar ist.
Der Kernel-Level-Treiber bietet zahlreiche Funktionen, um unter Umgehung der im User-
52 Analyse und Vergleich von BckR2D2-I und II

in diverse Prozesse injiziert
Dropper(BckR2D2-II)
Softwarebibliothek
installiert
Kernel-Level-Treiberkommunizieren
installiert
injiziert (BckR2D2-II)
Abbildung 2: Zusammenspiel der Komponenten mit dem Kernel-Level-Treiber.
mode geltenden Sicherheitsmaßnahmen des Betriebssystems Anderungen am System vorzu-nehmen. Des Weiteren ist eine Keylogger-Funktionalitat enthalten, die jedoch bereits in derVersion BckR2D2-I deaktiviert ist. (Der entsprechende Code ist zwar vorhanden, wird jedochaus dem Treiber selbst nicht angesprungen.) Außerdem beinhaltet er zwei weitere Codefrag-mente, die in der vorliegenden Version jedoch nicht weiter referenziert werden. Abbildung 2zeigt eine schematische Ubersicht uber das Zusammenspiel des Kernel-Level-Treibers mitden ubrigen Komponenten. Fur weitere Details zum Kernel-Level-Treiber verweisen wir ausPlatzgrunden auf den technischen Bericht.
3.4 User-Level-Anwendung
Die Anwendung mit der Ressourcen-Nummer 107 dient als Ersatz fur den Kernel-Level-Treiber. So kann die Software auch auf Systemen verwendet werden, bei denen es zum Infek-tionszeitpunkt nicht moglich ist, Administrator-Rechte zu erlangen. Die Anwendung erfulltzwei Aufgaben: Zum einen uberpruft sie periodisch, ob die Installation beschadigt wurde.Wird festgestellt, dass der oben genannte Run-Key aus der Systemregistrierung entfernt oderdas Image der Anwendung von der Festplatte geloscht wurde, generiert sie eine entsprechendeFehlermeldung und kommuniziert diese der Softwarebibliothek. Die zweite Aufgabe ist dasInjizieren der Softwarebibliothek in folgende Prozesse:
• explorer.exe • Skype.exe• SkypePM.exe • msnmsgr.exe• yahoomessenger.exe
In Abbildung 3 ist analog zu Abbildung 2 die Einrichtung der eingesetzen Komponenten beifehlenden Berechtigungen aufgezeigt. Dieses Szenario ist jedoch, ebenso wie der Dropper,nur aus BckR2D2-II bekannt.
Analyse und Vergleich von BckR2D2-I und II 53

in diverse Prozesse injiziert
Dropper(BckR2D2-II)
Softwarebibliothek
installiert installiert
injiziert (BckR2D2-II) User-Level-Anwendung
zwei Instanzen überwachensich gegenseitig
Abbildung 3: Zusammenspiel der Komponenten mit der User-Level-Anwendung.
3.5 Remover
Bei dieser Komponente der Schadsoftware, dem sogenannten Remover, handelt es sich umein einfaches Loschwerkzeug, das beliebige Dateien von der Festplatte des kompromittier-ten Systems entfernen kann. Die zu loschende Datei wird dabei als Kommandozeilenpa-rameter spezifiziert. Der eigentliche Loschvorgang erfolgt uber den Windows-SystemaufrufDeleteFileA(). Diese Funktion uberschreibt die eigentlichen Daten nicht, sodass es prin-zipiell moglich ist, die geloschte Datei wiederherzustellen. Nach Abschluss der Operation, diebei Nichterfolg insgesamt maximal 10 Mal wiederholt wird, vernichtet sich das Werkzeug mitHilfe der MoveFileExA-Funktion beim nachsten Systemstart selbstandig.
4 Vergleich von BckR2D2-I und BckR2D2-II
Im Folgenden stellen wir die beiden Varianten der Schadsoftware BckR2D2 vergleichend ge-genuber und gehen auf die wesentlichen Unterschiede ein. Neben diversen Anderungen in derSoftwarebibliothek wurde in der Version BckR2D2-II auch der Kernel-Level-Treiber wesent-lich erweitert. In dieser Version existiert erstmals neben dem 32-bit Kernel-Level-Treiber aucheine Treiberversion fur 64-bit Windows-Systeme.
4.1 Kernel-Level-Treiber
Der Kernel-Level-Treiber hat in der 32-bit Version von BckR2D2-I eine Große von 5.376 By-tes, in Version BckR2D2-II bereits eine Große von 10.112 Bytes. Anzumerken ist, dass sich dieFunktionen des Treibers zwischen den Varianten BckR2D2-I und BckR2D2-II bezuglich derunterstutzten Routinen und der Kommandokommunikation zur Usermode-Applikation nichtwesentlich verandert haben. In Variante BckR2D2-II wurde der Kernel-Level-Treiber jedochdahingehend erweitert, die Softwarebibliothek in verschiedene Prozesse zu injizieren. Hierzustartet der Treiber einen zusatzlichen Thread, um kontinuierlich die Liste aller laufenden Pro-zesse zu ermitteln und den Schadcode der Softwarebibliothek in die folgenden Anwendungs-
54 Analyse und Vergleich von BckR2D2-I und II

und Kommunikationsprogramme zu injizieren:
• skype.exe • msnmsgr.exe• paltalk.exe • x-lite.exe• voipbuster.exe • simppro.exe• simplite-icq-aim.exe • icqlite.exe• skypepm.exe • firefox.exe• yahoomessenger.exe • explorer.exe• opera.exe • lowratevoip.exe.
Der Kernel-Level-Treiber in BckR2D2-I besitzt diese Funktionalitat nicht. Hier wird das Inji-zieren der Softwarebibliothek anderweitig erreicht (siehe Abschnitt 4.2). Zusatzlich zum 32-bit Treiber besitzt die Variante BckR2D2-II eine 64-bit Version des gleichen Kernel-Level-Treibers. Voraussetzung fur das Laden dieser Treiberversion unter 64-bit Windows-Systemenist die Signierung des Treibers mit einem digitalen Zertifikat. Der 64-bit Kernel-Level-Treiberaus Variante BckR2D2-II wurde hierzu mit einem RSA Zertifikat des fiktiven Ausstellers Goo-se Cert (Fingerprint: e5 44 5e 4a 9c 7d 24 c8 43 f0 c6 69 e2 a8 d3 a178 cf 7f a8) signiert. In unseren Experimenten vertraute ein standardmaßig eingerichte-tes 64-bit Windows 7-System diesem Zertifikat nicht und erforderte die manuelle Bestatigungder Treiberinstallation.
4.2 Softwarebibliothek
Die Softwarebibliothek aus Version BckR2D2-I wurde den Angaben im PE-Header zufol-ge am 07.04.2009, 14:39:10 Uhr, kompiliert. Die Version BckR2D2-II hingegen wurde am06.12.2010 um 16:23:52 Uhr erstellt und ist damit uber 1 1/2 Jahre alter als seine Vorganger-version. Obwohl eine Falschung dieser Angaben leicht moglich ist, schatzen die Autoren einegezielte Manipulation der Daten angesichts lediglich nur marginaler, von der Komponenteangewandter Verschleierungsmaßnahmen als unwahrscheinlich ein.
In der Version BckR2D2-I ist aufgrund der Programmarchitektur davon auszugehen, dass dieSchadsoftware durch Veranderung eines Registrierungsschlussels in alle startenden Prozes-se injiziert wird.4 Da der Dropper fur diese Version nicht vorliegt, ist dies jedoch nicht mitabsoluter Sicherheit festzustellen. Die Software selbst beinhaltet aber keine entsprechendeFunktionalitat, sodass ein externer Eingriff fur den Start zwingend notwendig ist. Wird dieBibliothek in einen Prozess geladen, fuhrt sie initial immer einen Abgleich des Prozesses miteiner Whitelist durch. Nur wenn der Name der Image-Datei in der Liste vorhanden ist, wirddie Bibliothek aktiv. In diesem Falle startet sie mehrere Threads, die Prozess-spezifische Auf-gaben wahrnehmen. Die Prozessnamen in der Whitelist sind im einzelnen:
• skype.exe • skypepm.exe • msnmsgr.exe• x-lite.exe • yahoomessenger.exe• explorer.exe
4Der betreffende Registrierungsschluessel lautet HKLM\Software\Microsoft\WindowsNT\CurrentVersion\Windows\AppInit DLLs und veranlasst das Betriebsystem, alle hier eingetrage-nen Bibliotheken in den Adressraum eines jeden gestarteten Prozesses zu laden.
Analyse und Vergleich von BckR2D2-I und II 55

Die Liste der uberwachten Programme wurde in der Version BckR2D2-II um eine weitereAnwendung, der Video-Chat-Software Paltalk, erweitert (paltalk.exe).
In Version BckR2D2-II wurde ein System mit der IP-Adresse 207.158.22.134 uber denPort 443 als Kontrollserver kontaktiert. Diese IP-Adresse ist laut der lokalen Internetregist-rierungs- und Verwaltungsorganisation RIPE5 dem amerikanischen Unternehmen Web Intel-lects in Columbus, Ohio zugeordnet. In der Version BckR2D2-II wurde dieser Server durcheinen Rechner in Deutschland ersetzt, der unter der IP-Adresse 83.236.140.90 erreichbarist. RIPE hat als Inhaber der IP-Adresse die QSC AG registriert, welche diese wiederum aneinen nicht naher genannten Kunden mit der Bezeichnung QSC-CUSTOMER-5464944-564637 vermietet.
Bei allen untersuchten Varianten von BckR2D2 erfolgte eine Authentifizierung der Schadsoft-ware gegenuber dem Kontrollserver durch Ubermittlung der Zeichenkette C3PO-r2d2-POE,welche auch namensgebend fur die Schadsoftware war. Aus diesem Grund ist es moglich,einen eigenen Kontrollserver zu praparieren und die Kontrolle uber durch BckR2D2 kompro-mittierte Systeme zu erhalten, wie der CCC bereits zeigte [Cha11b]. In Variante BckR2D2-IIwurde das Kommunikationsprotokoll verbessert, indem sowohl beide Richtungen der Kom-munikation verschlusselt werden und eine Authentifizierung beider Kommunikationspartnererforderlich ist. Zur Verschlusselung wird das symmetrische Verfahren AES (Advanced En-cryption Standard) im Electronic Codebook-Verfahren (ECB) verwendet und als kryptogra-phischer Schlussel stets die konstante (hexadezimale) Zeichenfolge 49 03 93 08 19 94 9694 28 93 83 04 68 28 A8 F5 0A B9 94 02 45 81 93 1F BC D7 F3 AD 93 F5 32 93eingesetzt. Die in der Version BckR2D2-II neu implementierte Authentifikation des Serversgegenuber dem Client pruft lediglich, ob vor jedem Kommando vier sequentielle, fest codierteWerte (0x95838568, 0x0B894FAD4, 0x8202840E, 0x83B5F381) ubertragen werden.Der Mechanismus kann deshalb durch einen nicht-authorisierten Angreifer leicht uberwundenwerden. Zur Loschung des Systemtreibers und der Schadbibliothek im Systemverzeichnis desBenutzers sowie zur Einrichtung entsprechender Komponenten im Applikationsverzeichnis(Kommando 0x04, siehe Tabelle 2) ist eine zusatzliche Authentifikationsprufung vorgese-hen. Durch Ubertragung der Ziffernfolgen 0x0DEAF48F7, 0x8474BAFD, 0x0BAAD49F1sowie 0x8472BCF2 kann diese ebenfalls erfolgreich uberwunden werden.
Schließlich unterscheiden sich die beiden Versionen der Softwarebibliothek hinsichtlich ih-res angebotenen Funktionsumfangs: Die Anzahl der Operationen, die vom Kontrollserver aufdem kompromittierten System initiiert werden konnen, wurde in Variante BckR2D2-II im Ver-gleich zu BckR2D2-I von 14 auf 8 reduziert. Die jeweiligen Kommandos wurden jedoch ledig-lich dadurch deaktiviert, indem sie aus der Routine zur Befehlsverarbeitung entfernt wurden.Der entsprechende Code, welcher die Funktionalitat der Kommandos bereitstellt, ist jedochweitherhin in der Bibliothek enthalten.
5 Zusammenfassung
Insgesamt konnten im Rahmen unserer Untersuchung die wesentlichen Ergebnisse der ein-gangs erwahnten Berichte bestatigt werden. Dies betrifft sowohl die Analyse des CCC [Cha11b]hinsichtlich der Funktionalitat und des Einsatzes von Verschlusselungsmechanismen in BckR2D2,
5http://www.ripe.net/
56 Analyse und Vergleich von BckR2D2-I und II

als auch den Vergleich der beiden Versionen der Schadsoftware [Cha11e]. Auch die durchWerner beschriebene Funktionsweise des Droppers [Wer11] ist nach unseren Untersuchun-gen zutreffend.
Literatur
[Cha11a] Chaos Computer Club. Addendum Staatstrojaner. http://www.ccc.de/de/updates/2011/addendum-staatstrojaner, 9. Oktober 2011.
[Cha11b] Chaos Computer Club. Analyse einer Regierungs-Malware. http://www.ccc.de/system/uploads/76/original/staatstrojaner-report23.pdf, 8. Okto-ber 2011.
[Cha11c] Chaos Computer Club. Chaos Computer Club analysiert aktuelle Ver-sion des Staatstrojaner. http://www.ccc.de/de/updates/2011/analysiert-aktueller-staatstrojaner, 26. Oktober 2011.
[Cha11d] Chaos Computer Club. Chaos Computer Club analysiert Staatstrojaner. http://www.ccc.de/de/updates/2011/staatstrojaner, 8. Oktober 2011.
[Cha11e] Chaos Computer Club. ozapftis — Teil 2: Analyse einer Regierungs-Malware. http://www.ccc.de/system/uploads/83/original/staatstrojaner-report42.pdf, 26. Oktober 2011.
[DFS+11] Andreas Dewald, Felix C. Freiling, Thomas Schreck, Michael Spreitzenbarth, JohannesStuttgen, Stefan Vomel und Carsten Willems. Analyse und Vergleich von BckR2D2-I und II.Bericht CS-2011-08, Friedrich-Alexander Universitat Erlangen-Nurnberg, Department Infor-matik, 2011.
[FS11] F-Secure. More Info on German State Backdoor: Case R2D2. http://www.f-secure.com/weblog/archives/00002250.html, 11. Oktober 2011.
[Gar09] Simson L. Garfinkel. Automating Disk Forensic Processing with SleuthKit, XML and Py-thon. In Fourth International IEEE Workshop on Systematic Approaches to Digital ForensicEngineering (SADFE), Seiten 73–84. IEEE Computer Society, 2009.
[Mic11] Microsoft Corporation. MFC Reference. http://msdn.microsoft.com/de-de/library/d06h2x6e.aspx, 2011.
[Wer11] Tillmann Werner. Federal Trojan’s got a “Big Brother”. http://www.securelist.com/en/blog/208193167/Federal_Trojan_s_got_a_Big_Brother, 18. Ok-tober 2011.
Analyse und Vergleich von BckR2D2-I und II 57

A Ubersicht uber Prufsummen und Dateigroßen
Tabelle 3 enthalt eine Ubersicht uber die Prufsummen und die Dateigroßen der einzelnenanalysierten Komponenten.
Bezeichnung Version MD5-Prufsumme Große in BytesDropper BckR2D2-II 309ede406988486bf81e603c514b4b82 643.072Softwarebibliothek BckR2D2-I b5080ea3c9a25f2ebe0fb5431af80c34 364.544
BckR2D2-I’ 930712416770a8d5e6951f3e38548691 360.448BckR2D2-II 934b696cc17a1efc102c0d5633768ca2 356.352
Kernel-Level-Treiber BckR2D2-I d6791f5aa6239d143a22b2a15f627e72 5.376(32-bit) BckR2D2-I’ d6791f5aa6239d143a22b2a15f627e72 5.376
BckR2D2-II 9a8004e2f0093e3fe542fa53bd6ad1b2 10.112Kernel-Level-Treiber(64-bit )
BckR2D2-II cd01256f3051e6465b817fffc97767dd 262.730
User-Level-Anwendung
BckR2D2-II 976dd8be30df45c6fb2b4aaaa9ce9106 155.648
Remover BckR2D2-II 96c56885d0c87b41d0a657a8789779f2 40.960
Tabelle 3: Komponenten der untersuchten Schadsoftware mit ihren zugehorigen Prufsummen und Da-teigroßen
58 Analyse und Vergleich von BckR2D2-I und II

Forensic Analysis of YAFFS2
Christian ZimmermannIIG Telematics
University of Freiburg, Germany
Michael Spreitzenbarth Sven Schmitt Felix C. Freiling∗
Department of Computer ScienceFriedrich-Alexander-University Erlangen-Nuremberg
Abstract: In contrast to traditional file systems designed for hard disks, the file sys-tems used within smartphones and embedded devices have not been fully analyzedfrom a forensic perspective. Many modern smartphones make use of the NAND flashfile system YAFFS2. In this paper we provide an overview of the file system YAFFS2from the viewpoint of digital forensics. We show how garbage collection and wearleveling techniques affect recoverability of deleted and modified files.
1 Introduction
The ubiquitous use of smartphones and other mobile devices in our daily life demandsrobust storage technologies that are both low-cost and well suited for embedded use. Thereare several reasons why hard disks are not at all well suited for embedded use: physicalsize, power consumption and fragile mechanics are just some of the reasons. That is whyother technologies, namely NAND flash, became very popular and are widely used withinmodern embedded devices today. NAND flash chips contain no moving parts and havelow power consumption while being small in size.
However, NAND flash is realized as integrated circuits “on chip” and comes with somelimitations regarding read/write operations that can lead to decreased performance undercertain conditions. Furthermore, flash technology is subject to wear while in use whichmay dramatically shorten the chips’ lifetime. Thus, various specific techniques have beendeveloped to overcome such shortcomings and to enable flash technology to withstanda substantial amount of read/write operations at constant speeds. Classically, these tech-niques are integrated into dedicated controllers that implement and enforce the above men-tioned flash specific algorithms on the hardware level.
From the perspective of digital forensics, hard drives and low-level structures of variousfile systems are rather well studied (see for example Carrier [Car05]). The effects ofNAND technologies on the amount of recoverable data on storage devices, however, ishardly understood today. Since wear leveling techniques tend to “smear” outdated data
∗Contact author. Address: Am Wolfsmantel 46, 91058 Erlangen, Germany.

all over the device, it is often conjectured that digital investigations can profit from thewidespread introduction of NAND flash, because it is harder for criminals to delete filesand cover their traces. However, we are unaware of any related work that has investigatedthis question. Probably this is due to the difficulty of circumventing the controllers ofNAND flash chips.
Another option, however, to implement NAND flash specific behavior is to use specificallydesigned file systems. These file systems are aware of the generic flash limitations and takethese into account on the software level when reading and writing data from and to the chip.Such file systems are much easier to analyze since they implement techniques like wearleveling in software. The most common example of such a file system is YAFFS2, a filesystem used by the popular Android platform, which is “the only file system, under anyoperating system, that has been designed specifically for use with NAND flash” [Man02].YAFFS2 stands for “Yet Another Flash File System 2” and was the standard file systemfor the Android platform until 2010. Allthough since the beginning of 2011 with versionGingerbread (Android 2.3) the platform switched to the EXT4 file system, there are stillmany devices in use running a lower version than 2.3 and thus using YAFFS2. Therefore,insights into the amount and quality of evidence left on YAFFS2 devices is still of majorinterest.
Goal of this paper. In this paper, we give insights into the file system YAFFS2 from aforensic perspective. Next to giving a high level introduction to YAFFS2, our goal is toexplore the possibilities to recover modified and deleted files from YAFFS2 drives. Sincethere is no specific literature on this topic, we reverse engineered [ZSS11] the behaviorof the file system from the source code of the YAFFS2 driver for Debian Linux runningkernel version 2.6.36.
Results. As a result of our analysis, we found out that the movement of data on aYAFFS2 NAND never stops and that obsolete data (that could be recovered) is eventu-ally completely deleted. Thus, a YAFFS2 NAND stays only for a very brief span of timein a state that can be considered a best case scenario regarding recovery of obsolete data.In one of our conducted tests, the block that held a deleted file was finally erased 7 minutesand 53 seconds after the file was deleted. Larger devices have a positive effect on this timefrom a forensic point of view (i.e., they potentially enlarge the time span). Therefore, thechances to recover deleted data after days or weeks, as can be done on classical hard disks[Car05], are not very high in YAFFS2.
Roadmap. We begin by giving a high-level introduction into the concepts and terminol-ogy of YAFFS2 in Section 2. In Section 3 we give insights into the inner workings of itsalgorithms. We construct and experimentally analyze best case scenarios in Section 4 andpresent some results regarding the recovery of files in Section 5. We conclude in Section 6.
60 Forensic Analysis of YAFFS2

2 A Brief Introduction to YAFFS2
Blocks and chunks. YAFFS2 separates storage into several areas of fixed size, calledblocks. Within each block, again there exist several areas of fixed size, but smaller thanthe size of a block. These areas are called chunks. Following the characteristics of NANDflash, a chunk is the smallest amount of data which can be written whereas a block is thesmallest amount of data which can be erased from the flash. Data can only be written to ablock if the corresponding chunk was erased beforehand. A chunk that was just erased iscalled free.
Free and obsolete chunks. Since data can only be written to free chunks, modificationof data is more complicated than on classical hard drives. To modify data, the data mustfirst be read, then be modified in memory and finally be written back to a free chunk.This method is similar to the well known Copy-on-Write method. YAFFS2 writes chunkssequentially and marks all chunks with a sequence number in the flash. That way, anychunk that was associated with the original data will be identified as obsolete although itstill holds the original (now invalid) data.
The existence of obsolete chunks is interesting from a forensic investigator’s point of view:Whenever one or more obsolete chunks exist within a block, the corresponding data willstill be recoverable until the respective block gets garbage collected. After this block getsgarbage collected, all of its obsolete chunks will be turned to free chunks.
Header chunks and data chunks. YAFFS2 distinguishes between header chunks usedto store an object’s name and meta data and data chunks which are used to store an ob-ject’s actual data content [Man10]. The meta data in such a header chunk describes if thecorresponding object is a directory, regular data file, hard link or soft link. In Table 1 thestructure of a regular file with three chunks of data and one header chunk is shown.
Block Chunk Object ID Chunk ID Comment1 0 100 0 Object header chunk for this file1 1 100 1 First chunk of data1 2 100 2 Second chunk of data1 3 100 3 Third chunk of data
Table 1: Structure of a file with one header chunk and three data chunks.
If a file shrinks in size, data chunks become invalid and the corresponding header chunkreceives a special shrink-header marker to indicate this. In Table 2 we show how a deletedfile looks like. In this case chunk number 5 indicates that the file had been deleted andthis chunk receives the shrink-header marker. As we show below, shrink-header markersare important because object headers with this marker are prevented from being deletedby garbage collection [Man10, Sect. 10].
Forensic Analysis of YAFFS2 61

Block Chunk Object ID Chunk ID Comment1 0 100 0 Object header chunk for this file1 1 100 1 First chunk of data1 2 100 2 Second chunk of data1 3 100 3 Third chunk of data1 4 100 0 New object header chunk (unlinked)1 5 100 0 New object header chunk (deleted)
Table 2: Structure of the file from Table 1 after the file had been deleted.
Object ID and Chunk ID. Each object (file, link, folder, etc.) has its own Object ID,thus it is possible to find all chunks belonging to one specific object. A Chunk ID of 0indicates that this chunk holds an object header. A different value indicates that this is adata chunk. The value of the Chunk ID stands for the position of the chunk in the file.If you have a chunk with Chunk ID = 1 it means, that this is the first data chunk of thecorresponding object.
The tnode tree. YAFFS2 keeps a so-called tnode tree in RAM for every object. Thistree is used to provide mapping of object positions to actual chunk positions on a NANDflash memory device. This tree’s nodes are called tnodes [Man10, Sect. 12.6.1].
Checkpoint data. Checkpoint data is written from RAM to a YAFFS2 NAND device onunmounting and contains information about all of a device’s blocks and objects (a subsetof information stored in the tnode tree). It is used to speed up mounting of a YAFFS2NAND device.
The number of blocks needed to store a checkpoint consists of (1) a fixed number ofbytes used for checksums and general information regarding the device and (2) a variablenumber of bytes depending on the number of objects stored on the device and the device’ssize. The variable part of a checkpoint consists of information on blocks, objects andtnodes.
3 Garbage Collection in YAFFS2
In YAFFS2, obsolete chunks can only be turned into free chunks by the process of garbagecollection. Among all of YAFFS2’s characteristics and functionalities, the garbage collec-tion algorithm has the most significant impact on the amount of deleted or modified datathat can be recovered from a NAND. In this section, we describe the different garbage col-lection methods (Section 3.1). An important variant of garbage collection is called blockrefreshing and explained in Section 3.2. Additionally, we describe the impact of shrinkheader markers on garbage collection (Section 3.3). For brevity, detailed references to thesource code of the Linux driver can be found elsewhere [Zim11, ZSS11].
62 Forensic Analysis of YAFFS2

3.1 Garbage Collection Methods
Garbage collection is the process of erasing certain blocks in NAND flash to increasethe overall amount of free blocks. Valid data that exists in blocks selected for garbagecollection will first be copied to another block and thus not be erased.
Garbage Collection can be triggered either from a foreground or a background thread. Thetrigger within a foreground thread is always a write operation to the NAND. Backgroundgarbage collection is not directly triggered by any foreground thread, but executed evenwhen the device is idle. Background garbage collection typically takes place every twoseconds.
Interestingly, the behavior of garbage collection does not primarily depend on a device’sstorage occupancy. Execution rather depends on the current state of blocks regarding theamount of obsolete chunks they hold. Still, every garbage collection can be performedeither aggressively or passively, depending on the device’s storage occupancy. Passivebackground garbage collection only collects blocks with at least half of their chunks beingobsolete and only checks 100 blocks at most when searching a block to garbage collect.Foreground garbage collection is executed passively if one quarter or less of all free chunksare located in free blocks and a block with seven-eighths of its chunks being obsolete canbe found.
If no block of the entire flash qualifies for erasure, oldest dirty garbage collection is ex-ecuted. This type of garbage collection selects the oldest block that features at least oneobsolete chunk. It is executed every time background or foreground garbage collectionhave been skipped (due to the lack of qualifying blocks) 10 or respectively 20 consecutivetimes. Hence, as long as every block of a device has at least half of its chunks filled withvalid data, the only way a block can be garbage collected is through oldest dirty garbagecollection (or its variant called block refreshing explained below).
Aggressive garbage collection occurs if background or foreground garbage collection isperformed and a device does not feature enough free blocks to store checkpoint data.Aggressive garbage collection potentially deletes a higher number of obsolete chunks percycle than passive garbage collection and is triggered if a device features less than a certainthreshold of free blocks, where the threshold depends on the size of the checkpoint data[ZSS11].
Summary from a forensic perspective. The scenario where a maximum of obsoletechunks can be recovered (and therefore the “best” case for a forensic analyst) requires thatduring the whole time of its usage a device features enough free blocks to store checkpointdata and a distribution of obsolete and valid chunks that leads to every block having justmore than half of its chunks being valid. Additionally, enough free blocks must be avail-able to ensure that more than one quarter of all free chunks is located within empty blocks.This results in a behavior in which all blocks are garbage collected as seldom as possibleand still feature a high number of obsolete chunks that potentially contain evidence.
Forensic Analysis of YAFFS2 63

3.2 Block Refreshing
YAFFS2’s only explicit wear leveling technique is block refreshing. Block refreshingis performed during the first execution of garbage collection after mounting a YAFFS2NAND flash memory device and every 500 times a block is selected for garbage col-lection. Basically, block refreshing is a variant of garbage collection that does not payattention to the number of obsolete chunks within blocks. Instead, its goal is to move ablock’s contents to another location on the NAND in order to distribute erase operationsevenly. This technique enables the collection of blocks, even if they completely hold validchunks.
Whenever block refreshing is performed, it selects the device’s oldest block for garbagecollection, regardless of the number of obsolete chunks within this block. Thus, if the old-est block does not contain any obsolete chunks, block refreshing does not lead to deletionof data, as all the oldest block’s chunks are copied to the current allocation block.
3.3 Shrink header markers
From a forensic point of view, shrink header markers can play an important role, as a blockcontaining an object header chunk marked with a shrink header marker is disqualified forgarbage collection until it becomes the device’s oldest dirty block. Its contents can remainstored on a device for a comparatively long time without being deleted by YAFFS2’sgarbage collector. We practically evaluate the effects of shrink header markers on therecoverability of obsolete chunks in Section 5.1
4 Best case and worst case scenarios
All data written to a YAFFS2 NAND remains stored on the device until the correspondingblocks are erased during execution of garbage collection. Therefore, recovery of modifiedor deleted files is always a race against YAFFS2’s garbage collector. In the following, thebest case scenario described above is further analyzed for its practical relevance.
4.1 Experimental Setup
All practical evaluations of YAFFS2 discussed in the following were performed on a sim-ulated NAND flash memory device. The simulated NAND featured 512 blocks and eachblock consisted of 64 pages with a size of 2048 bytes. Thus, the device had a storagecapacity of 64 MiB.
YAFFS2 reserves five of the device’s blocks for checkpoint data and uses a chunk sizematching the device’s page size. Hence, a chunk had a size of 2048 bytes. For ev-
64 Forensic Analysis of YAFFS2

ery analysis, we created images of the simulated NAND by use of nanddump from themtd-utils.
4.2 General Considerations
As a result of previous discussions, sooner or later all obsolete chunks present on the deviceare deleted and thus no previous versions of modified files or deleted files exist because ofthe unpreventable oldest dirty garbage collection and block refreshing techniques.
Passive and oldest dirty garbage collection only collect five valid chunks per executionof passive garbage collection. Thus, not every execution of passive garbage collectionnecessarily leads to deletion of a block. In case a block consisting of 64 pages respectivelychunks contains only one obsolete chunk, thirteen executions of passive garbage collectionare necessary before the block gets erased.
Once a block has been selected for garbage collection, YAFFS2 does not need to selectanother block to garbage collect until the current garbage collection block is completelycollected. Hence, as soon as a block has been chosen for oldest dirty garbage collec-tion, every subsequent attempt of background garbage collection leads to collection of thisblock. Given the cycle time of 2 seconds for background garbage collection, even in abest case scenario, a block that features only one obsolete chunk gets erased 24 seconds atmost after it was selected for oldest dirty garbage collection.
4.3 Experiments
To validate our findings about the best case, we created one file of size 124 928 bytes(respectively 61 chunks) on an otherwise empty NAND. Due to writing of one obsoletefile header chunk on creation of a file and writing of a directory header chunk for the rootdirectory of the device, this lead to a completely filled block that featured exactly oneobsolete chunk. As no write operations were performed after creation of the file, passivegarbage collection triggered by a foreground thread was not performed. Additionally,aggressive garbage collection was ruled out due to only one block of the device beingoccupied. As the block only featured one obsolete chunk, regular background garbagecollection was also unable to select the block for garbage collection. Thus, only after tenconsecutive tries of background garbage collection, the block was selected for oldest dirtygarbage collection. Subsequently, the block was garbage collected every two seconds dueto background garbage collection.
In our conducted test, the block containing the file is selected for garbage collection sixseconds after the last chunk of the block has been written. This is because of backgroundgarbage collection attempts before creation of the file making oldest dirty garbage collec-tion necessary.
Forensic Analysis of YAFFS2 65

4.4 Summary
Since garbage collection cannot be prevented completely, all obsolete chunks will even-tually be erased. Therefore, the number of obsolete chunks that can be recovered from aYAFFS2 NAND also depends on the time span between the execution of a file deletion ormodification and a forensic analysis.
Due to block refreshing and oldest dirty garbage collection, chunks on a YAFFS2 NANDare in constant movement. As shown above, the speed of this movement depends to a parton the occupancy of the device’s storage capacity. However, the number and distributionof obsolete chunks on the device and the device’s size have a much greater influence on thespeed of this movement. Passive garbage collection only checks 100 blocks at most whensearching a block to garbage collect. Therefore, it can take longer for a specific block to beselected for garbage collection on a large NAND featuring a high number of blocks thanit would on a smaller NAND.
5 Data Recovery
In the following, we focus on the analysis of best case scenarios regarding recovery ofdeleted files. For other possible scenarios see Zimmermann [Zim11].
5.1 General Considerations
YAFFS2 uses deleted and unlinked header chunks to mark an object as deleted.Hence, an object is (at least partially) recoverable from a YAFFS2 NAND until garbagecollection deletes all of the object’s chunks. Although recovery of a specific deleted filedoes not differ fundamentally from recovery of a specific modified file, one important dif-ference exists. YAFFS2’s deleted header chunk is always marked with a shrink headermarker. In Table 3, a selection of a block’s chunks are depicted. The chunks depictedcontain data of files “fileX” and “fileY”. While “fileX” was modified by changing its lastchunk’s content, “fileY” was deleted. As can be seen, modification of a file leads to writingof new chunks (chunk 4) replacing the chunks containing the now invalid data (chunk 1).However, deletion of a file leads to writing of deleted and unlinked header chunkswith the deleted header chunk being marked with a shrink header marker.
A best case scenario regarding recovery of a delete file is a scenario in which the deletedfile is completely recoverable for the longest time possible. A block containing a chunkmarked with a shrink header marker is disqualified for garbage collection until the blockgets the oldest dirty block. Therefore, in the best case scenario, the file’s deleted headerchunk has to be stored in the same block as all of the file’s chunks in order to protect theblock (and respectively the complete file) with a shrink header marker. As a block con-taining a deleted header chunk can only be garbage collected if it is the device’s oldestblock, it does not need to feature a minimum amount of valid chunks to be disqualified for
66 Forensic Analysis of YAFFS2

Block Chunk Object ID Chunk ID Comment1 0 257 1 fileX: first data chunk1 1 257 2 fileX: second data chunk1 2 257 0 fileX: header chunk1 3 1 0 root directory: header chunk1 4 257 2 fileX: second data chunk (new content)1 5 257 0 fileX: header chunk1 6 258 1 fileY: first data chunk1 7 258 2 fileY: second data chunk1 8 258 0 fileY: header chunk1 9 258 0 fileY: unlinked header chunk1 10 258 0 fileY: deleted header chunk1 11 1 0 root directory: header chunk
Table 3: The results of modification and deletion of a file
garbage collection.
5.2 Experimental Recovery of a Deleted File
We created ten files to fill exactly ten of the device’s blocks with valid chunks. Aftercreation of a stable initial state by the garbage collector by deleting all obsolete chunkscreated during the files’ creation, we performed the following steps on the device:
1. Creation of “fileD” (77 824 bytes, respectively 38 data chunks)
2. Modification of all files on the device except for “fileD”
3. Deletion of “fileD”
To modify the ten initial files we overwrote one data chunk of each file in a way that leadto one obsolete data chunk in each of the ten initially filled blocks. Hence, featuring onlya very small number of obsolete chunks, these blocks complied to the criteria of an overallbest case scenario. However, the block containing the chunks written due to creation of“fileD” did not comply to the criteria of a best case scenario as, after the file’s deletion, itcontained a high number of obsolete chunks.
By analyzing the kernel log entries written by YAFFS2, we could determine that, in ourconducted test, the block that held the file was finally erased seven minutes and 53 secondsafter the file was deleted (see also [Zim11]). The block was selected for garbage collec-tion after background garbage collection was skipped ten consecutive times. However, thereason for that was not, that the block, at that time being the oldest dirty block, was dis-qualified for regular background garbage collection. All attempts of background garbage
Forensic Analysis of YAFFS2 67

collection were skipped because the block was not checked for necessity of garbage col-lection during these attempts. Thus, it was not selected for regular background garbagecollection immediately after it became the only dirty block, although that would have beenpossible. This shows, that obsolete chunks can potentially be recovered for a longer timefrom a larger NAND than from a small NAND as passive garbage collection only checksa subset of all blocks when trying to select a block to garbage collect. Also, an obsoletechunk can be recovered for a longer time, if the NAND is filled to a higher degree andmore blocks have to be garbage collected before the block containing the obsolete chunkin question.
Recovery of chunks that are obsolete due to file modifications differs only slightly fromrecovery of chunks that are obsolete due to file deletions. Modification of a file does notlead to writing of shrink header markers, except the modification creates a hole biggerthan four chunks within the file. Thus, obsolete chunks of a modified file are usually notprotected from garbage collection by a shrink header marker. Nevertheless, in a best casescenario, these chunks are recoverable for almost as long as obsolete chunks of deletedfiles (see also Zimmermann [Zim11] and Zimmermann et al. [ZSS11])).
6 Conclusion
Generally YAFFS2 allows for easy recovery of obsolete data. However, YAFFS2’s garbagecollector ensures that, over time, all obsolete data is erased. The amount of data recov-erable depends on many factors, especially the distribution of valid and obsolete chunkswithin a device’s blocks, the device’s size and occupancy and the amount of time that haspassed between modification or deletion of a file and the device’s disconnection from itspower source.
Acknowledgments
This work has been supported by the Federal Ministry of Education and Research (grant01BY1021 – MobWorm).
References
[Car05] Brian Carrier. File System Forensic Analysis. Addison-Wesley, 2005.
[Man02] Charles Manning. YAFFS: The NAND-specific flash file sys-tem — Introductory Article. http://www.yaffs.net/yaffs-nand-specific-flash-file-system-introductory-article,2002.
68 Forensic Analysis of YAFFS2

[Man10] Charles Manning. How YAFFS works. http://www.yaffs.net/sites/yaffs.net/files/HowYaffsWorks.pdf, 2010.
[Zim11] Christian Zimmermann. Mobile Phone Forensics: Analysis of the An-droid Filesystem (YAFFS2). Master’s thesis, University of Mannheim, 2011.http://www1.informatik.uni-erlangen.de/filepool/thesis/diplomarbeit-2011-zimmermann.pdf
[ZSS11] Christian Zimmermann, Michael Spreitzenbarth, and Sven Schmitt. Reverse Engineer-ing of the Android File System (YAFFS2). Technical Report CS-2011-06, Friedrich-Alexander-University of Erlangen-Nuremberg, 2011.
Forensic Analysis of YAFFS2 69


TLS, PACE, and EAC:A Cryptographic View at Modern Key Exchange Protocols
Christina Brzuska Ozgur Dagdelen Marc FischlinTechnische Universitat Darmstadtwww.cryptoplexity.de
Abstract. To establish a secure channel between two parties common security so-lutions often use a key exchange protocol as a preliminary subroutine to generate ashared key. These solutions include the protocols for secure communication betweena reader and an identity card or passport, called PACE and EAC, and the TLS protocolfor secure web communication. In this work we survey the cryptographic status ofthese protocols and the recent developments in this area.
1 Introduction
A secure channel between two parties is an important cryptographic primitive. It allowsto communicate securely over a public channel by “wrapping” the communication into acryptographically protected layer. The secure channel at foremost provides two securityproperties: confidentiality and authenticity. The former means that no outsider can learnthe payload. In contrast, authenticity ensures integrity of the data, i.e., no adversary caninject or modify data, or even change the order of transmissions.
Most secure channel protocols assume that the two parties already share a common se-cret. Thus, before exchanging the actual data via a secure channel, the two parties firstneed to establish such a shared secret. For this, they usually first run a so-called key ex-change protocol (occasionally also called key agreement protocol) over the public channelto agree on a symmetric key. The security property of the key exchange protocol assuresthat no eavesdropper on the communication can learn the key. Subsequently, the two par-ties use the derived secret to implement the secure channel, usually through (symmetric)encryption for confidentiality, and message authentication for authenticity. This paradigmis widely deployed by a number of practical protocols, amongst which are the prominentTLS protocol and the PACE/EAC protocols on the new German identity card.
In TLS, the key exchange is called handshake, and the channel protocol is named recordlayer. For the identity card, the Password-Authenticated Connection Establishment (PACE)protocol establishes a shared key between the card and the channel protocol is called se-cure messaging. The latter is also used as the channel protocol between the card and aterminal (e.g., a service provider), after the Extended Access Control (EAC) protocol hasbeen executed to generate the key between these two parties.

In this work we survey the recent cryptographic developments for building secure chan-nels, especially for TLS and the German identity card, where we focus on the key exchangestep. To this end we first review the traditional security notions for key exchange and dis-cuss their shortcomings compared to recent approaches. We then discuss the identity cardprotocols and TLS in more detail, and also give a brief overview over the state-of-the-artconcerning their respective channel protocols.
2 Building Secure Channels
We look at secure channel protocols that consist of the key exchange step in which theparties agree upon a shared secret key, and the channel implementation that protects thepayload (as in TLS/SSL, PACE, and EAC). Instead of a monolithic cryptographic analysis,it is often convenient to use a modular approach and to investigate the security of each stepindividually. This, however, requires to recompose the individual protocols and securityproofs to be able to argue about the security of the whole protocol. Towards such a modularanalysis of composed two-stage channel protocols, there are two main approaches: game-based security models and simulation-based security models.
2.1 Game-Based Security Models
In game-based security models one defines security of the task in question as a gameplayed between a challenger and an adversary. The game specifies the moves the adver-sary is allowed (and the way the challenger answers them), i.e., it defines the attack model.Consider, for example, the well established model by Bellare and Rogaway [BR94] for au-thenticated key exchange protocols. There, the adversary may for instance observe severalprotocol executions between honest parties, may modify messages sent between the partiesor inject new messages, or corrupt parties and learn their long-term secret keys.
In addition, a game specifies when the adversary “wins”, i.e., when the adversary breakssecurity. For example, to break a secure channel, the adversary wins if it either breaksauthenticity or confidentiality. For authenticity, the adversary’s goal is to modify the trans-mitted data between two honest parties without being detected. To break confidentiality,the adversary has to learn some non-trivial information about the transmitted data. Accord-ing to such a game-based definition, a scheme is called secure, if all (efficient) adversarieshave only negligible winning advantage.
Game-based Security of Key Agreement. We now provide an (informal) descriptionof the well-established and game-based Bellare-Rogaway security model [BR94] for au-thenticated key agreement. As mentioned above, we therefore need to define the attackmodel and the adversary’s winning condition.
In the attack model, the adversary is mainly a very powerful Dolev-Yao adversary [DY81],
72 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

that is, the adversary fully controls the network and decides when and what messages arereceived by a running session of a user. This, in particular, enables the adversary to seethe messages sent by honest parties, to modify them, change the order of delivery, and toinject new messages. Moreover, after two honest sessions agreed on a key, the adversarymay “reveal” it, which models potential leakage of keys. The adversary can also corruptusers and mount insider attacks, i.e., run arbitrarily many (concurrent) sessions of thekey exchange protocol with honest users. The number of all executed sessions as well astheir scheduling is also chosen by the adversary. In other words, the adversary’s attackcapabilities are very broad, such that any security proof against such adversaries providesstrong guarantees.
We now turn to the adversary’s winning condition. At some point in the game, the ad-versary may pick an (unrevealed) terminated session between two honest users. She thenneeds to prove that she knows at least one bit of information about their session key. Thisis modeled as an indistinguishability game: the adversary is given either the session key ora random string of the same length, and the game challenger asks the adversary to distin-guish between the two cases, i.e., to correctly predict the case with probability significantlygreater than the pure guessing probability 1
2 . Note that a random guess trivially achievesthe success probability 1
2 ; we are thus interested in the adversary’s advantage beyond this.
Game-Based Security for Secure Channels. Krawczyk [Kra01] and Bellare and Nam-prempre [BN00] consider different security levels of the underlying building blocks, mes-sages authentication codes (MACs) and symmetric encryption and ask when their compo-sition yields a secure channel. As there are various ways to compose these two buildingblocks, the theorems do not apply directly to specific real-world protocols such as TLS,where the channel implementation is a stateful algorithm that uses padding, sequence num-bers and a range of different operator modes for the cipher; moreover, error messages areusually not covered by these models. These supposedly minor aspects, however, can im-pact security severely, as shown in Vaudenay [Vau02] and Paterson and Watson [PW08].Therefore, depending on the protocol under consideration, the security models sometimesneed to be tailor-made. We refer to Paterson et al. [PRS11] for a recent state-of-the-artanalysis of the TLS record layer.
2.2 Simulation-Based Security Models
In contrast to game-based security models, simulation-based notions do not specify theadversary’s goal explicitly. Instead, they first define an ideal version of the primitive inquestion such that the ideal version reflects the desired functionality. For example, theideal version of an authenticated channel would faithfully deliver messages, which areinput from the honest sender, to the intended receiver; the adversary could see the message,but not modify it or inject new messages. Authenticity is thus guaranteed by definition.An implementation through a real protocol is then called secure if it is essentially “as goodas” the ideal functionality, even in the presence of an adversary.
TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols 73

More formally, a protocol is secure according to such a simulation-based model if anyattack against the real-world protocol can also been mounted against the ideal primitive.Consequently, as the ideal primitive trivially prevents any kind of attack, there cannot bean attack against the real-world protocol either, as it is indistinguishable from the idealfunctionality. Put differently, the (only trivial) attacks on the ideal functionality give anupper bound for potential attacks on the real protocol. This is usually formalized by sayingthat, for any adversary A against the real protocol, there exists a so-called ideal-modeladversary (aka. the simulator) S which can generate the same output as A when attackingthe real protocol.
Simulation-Based Models for Key Agreement. The ideal functionality for a key agree-ment protocol is a trusted third party that gives a random string to both honest parties. Thelocal output of the parties only consists in this random string. If a protocol is indistin-guishable from this ideal functionality, then the outputs of the protocol look like randomstrings. For a formal description, see Canetti and Krawczyk [CK01] or the full version ofCanetti [Can01].1
Simulation-Based Models for Secure Channels. The ideal version of a secure channelprotocol is a functionality (or trusted third party) to which the sender can securely pass amessage, that the functionality securely delivers to the intended receiver, i.e., the adversaryneither gets to see the message nor to modify it. For a detailed formulation, we refer thereader to the full version of Canetti [Can01].
2.3 Comparison
There are advantages and disadvantages to each of the two approaches. Simulation-basedsecurity usually provides stronger security guarantees than game-based security: if one canbreak security in the game, then one can (in many cases) also make the protocol deviatefrom its ideal specification. Thus, whenever there is a successful adversary in the game-based setting, then there is a successful adversary against the simulation-based security.Taking the logical contra-position this means simulation-based security usually impliesgame-based security.
In addition, simulation-based security turns out to be useful for secure composition. Proto-cols shown to be secure in Canetti’s (simulation-based) universal composition (UC) frame-work [Can01] compose well with other protocols in this framework. In particular, thecompound execution of a UC-secure key agreement protocol with a UC-secure channel isalso secure.
Unfortunately, simulation-based security is sometimes not achievable by real-life proto-cols, or sometimes even by any protocol [CF01]. As far as secure channels and keyagreement are concerned, they cannot be secure against fully adaptive corruptions in the
1While [CK01] give a game-based model, they prove it to be equivalent to a simulation-based one.
74 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

UC model where the adversary decides during executions if and when to corrupt parties[Nie02]2. Moreover, security in the UC framework necessitates the use of global sessionidentifiers, and real-life protocols such as TLS or PACE/EAC usually do not meet thesesyntactical stipulations. We note that a recent work by Kuesters and Tuengerthal [KT11]somewhat alleviates the latter point, but their model still does not overcome the otherproblems with adaptive corruptions and strong simulation requirements.
In contrast, game-based security only asks for a specific security property (such as keyindistinguishability) instead of general “ideal world” indistinguishability. As such, game-based security appears to be sufficient for the task at hand and is also often easier toachieve. The downside of achievable game-based security is that games are either notknown, or provably lack, composition properties. This implies that when analyzing keyexchange protocols and channel protocols separately in games, then their composition isoften not known to be secure.
In conclusion, it is desirable to combine the advantages of both approaches: feasibilityof game-based security and composability of simulation-based security. In the followingsection, we cover the recent progress on composability of game-based security in the areaof key agreement.
2.4 Other Approaches
Simulation-based models and game-based models both consider arbitrary computationallybounded adversaries, usually modeled through Turing machines. In contrast, in the settingof symbolic methods, adversaries can derive symbolic expressions via a restricted set ofso-called derivation rules. In a key exchange protocol, they can inject any message, whichcan be derived via these rules. A session key is called secure if the adversary is unable toderive it via the rules. As this is a weaker requirement than in the computational setting,one often enhances —if possible— a symbolic security analysis by a so-called soundnessresult to obtain the same security guarantees as in the computational setting.
The weaker security guarantees come at the advantage of a simpler (or even automated)analysis such that, in particular, a granular analysis of protocols is feasible, as done for TLSby Fournet et al. [FKS11] and for Kerberos by Backes et al. [BCJ+11]. Note, however,that composition of symbolic analysis is as challenging as in the computational setting,as the derivation rules for the attack model of one protocol might affect the security ofanother protocol which was shown to be secure against a different set of derivation rules.For advances in this regard we refer the reader to the recent work by Cortier et al. [CW11]who prove first composition results for certain classes of derivation systems.
2Canetti and Krawczyk [CK01] claim to achieve full security—towards this purpose, they assume that theparties securely erase their state, which makes state corruption trivial and is, essentially, equivalent to not allowingstate corruption.
TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols 75

3 Compositional Game-Based Models
The idea of looking into game-based security notions which also provide compositionguarantees appears to be a promising venue to overcome the disadvantages of game-basedmodels while keeping their benefits.
3.1 Composition of Bellare-Rogaway Protocols
For key agreement protocols, a recent result by Brzuska et al. [BFWW11] proves thatBR-secure key agreement protocols are generally composable with arbitrary game-basedprotocols, if the key agreement protocol satisfies a notion called “session matching prop-erty”. This property says that a key exchange protocol allows a third party to always iden-tify from the public communication which sessions of which users agreed on the samekey. While BR-secure protocols were always somewhat believed to be composable, theresult in [BFWW11] is the first to show this property formally and to identify a sufficientcondition for this.
Theorem 3.1 (from [BFWW11], informally) Let ke be a key agreement protocol and letπ be an arbitrary symmetric-key protocol that is secure according to some game-basedmodel, then the following holds: if the key agreement protocol is correct, BR-secure, andsatisfies public session matching, then the composed protocol (ke, π) is secure.
We note that the public session matching holds for all common protocols but one can easilydevise examples for which this is not true. Moreover, Brzuska et al. [BFWW11] show thatthe public session matching algorithm is not merely an artefact of their theorem but insteada necessary condition for key exchange protocols to be composable.
Theorem 3.2 (from [BFWW11], informally) If a key agreement protocol ke is compos-able with arbitrary symmetric-key protocols, then ke satisfies the public session matchingrequirement.
One can now conclude that any BR-secure protocol, composed with a secure channelprotocol, automatically provides a secure channel. This holds if each of the componentshas been proven secure in its respective game-based model, and if the mild assumptionabout public session matching holds.
3.2 Compositional Results for TLS/SSL, PACE, and EAC
To protocols such as TLS and PACE/EAC, the composition result for BR-protocols, how-ever, does not immediately apply. The reason is that in the key exchange stage, all theseprotocols use a so-called key confirmation step. In this step both participants authenti-cate the protocol transcript already with the established session key, with the intuition that
76 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

it provides an a-posteriori authentication of the otherwise unauthenticated transmissions.But this means that within the key agreement protocol, in the final protocol messages, thesession key is already used. This, however, violates the security in the BR sense as theestablished key cannot be considered fresh anymore (and is easily distinguishable fromrandom). Consequently, we cannot apply the general composition result for BR-secureprotocols, even though the protocols allow for public session matching.
In the sequel, we present several approaches to deal with the problem. Firstly, as done inthe PACE/EAC proof [BFK09, DF10a], one can add an additional key refresh step to theprotocol and argue that if the protocol satisfies an additional property (namely a differentmessage structure in the key confirmation message than in the actual payload transmis-sion), then the original protocol is secure whenever the modified protocol is secure. Thisapproach is valid whenever the key agreement protocol is used with secure channels, andthe authenticated message in the key confirmation step is distinct from the messages sentover the secure channel.
For TLS, Jager et al. [JKSS11] deal with this problem by mounting a monolithic analysis,i.e., they forgo splitting the TLS protocol into separate phases, and instead analyze thewhole protocol. In another approach, Kusters and Tuengerthal [KT11] cope with the keyconfirmation message via considering ideal functionalities that implement several primi-tives simultaneously. Their model is again simulation-based and thus provides high mod-ularity but also suffers from the aforementioned disadvantages (see Section 2.3).
A recent solution, which even goes beyond the application of secure channels, is a generalgame-based composition framework by Brzuska et al. [BFS+11]. They consider compo-sition of key agreement with arbitrary game-based protocols, without requiring the keyagreement to satisfy BR-security. Instead, they use a form of key usability, a notion firstconsidered by Datta et al. [DDMW06] and formalized in the simulation-based setting in[KT11]. The idea is roughly to invest a bit more work for analyzing the key agreement andto show that it is good for some primitives like symmetric encryption and message authen-tication. By this, one can automatically conclude security of the composition of the keyagreement protocols with any protocol that relies on these primitives, like secure channelsbuilt out of symmetric encryption and message authentication. Using their framework,they give a modular analysis of TLS and provide foundations for such proofs in a generalwhen not only composition with secure channels, but also with other protocols is desirable.
4 TLS: Overview over the Cryptographic Status
The TLS protocol consists of a key agreement step, the handshake protocol and a securechannel, called the record layer. Both protocols have been scrutinized with different goalsand varying strengths of the results. As explained in the previous section, the TLS Hand-shake protocol in its due form (unlike the modified versions considered by Morrissey etal. [MSW10] and by Gajek et al. [GMP+08]) cannot be analyzed in security models thatrequire key indistinguishability. For TLS, only this year several solutions to this problemhave been considered and, noteworthy, appeared concurrently.
TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols 77

For one, Jager et al. [JKSS11] presented a monolithic analysis of the TLS protocol forone choice of the TLS Handshake (among the choices negotiated by the parties duringthe handshake). While monolithic approaches usually suffer from a lack of modularity(entailing poor robustness of the analysis in light of future protocol modifications), theiranalysis, interestingly, does not. Their key ingredient towards modularity is somewhat aspecial case of the composition result by Brzuska et al. [BFWW11]. In particular, theyshow that a truncated version of the TLS Handshake protocol is BR-secure and identify asufficient condition for the TLS Record Layer to be securely composable with the (trun-cated) TLS Handshake. Hence, their analysis can be composed with any formal securityproof for the TLS Record Layer, provided the achieved security level matches the one con-sidered by Jager et al. [JKSS11]. In light of [BFWW11], we can even deduce that theirresult composes in general. Note that this approach is TLS-specific; usually, truncatedversions of protocols, now without key confirmation, become insecure.
Simultaneously, two new frameworks were introduced, as explained in the previous sec-tion, one by Kusters and Tuengerthal [KT11] and one by Brzuska et al. [BFS+11]. Bothallow to analyze the TLS Handshake protocol3. As the model by Kusters and Tuengerthalis simulation-based, it suffers from the aforementioned restrictions on the adversary’s cor-ruption capacities, while, noteworthy, nicely circumventing nuisances of prior simulation-based approaches. The game-based composition framework by Brzuska et al. [BFS+11]fully applies to TLS. They carry out a security proof that, combined with a security prooffor the TLS Record Layer, yields a security analysis of (an abstracted version of) the entireTLS protocol.
Theorem 4.1 (from [BFS+11], informally) The TLS Handshake protocol can be securelycomposed with a secure channel that uses (specific stateful implementations of) MACs andencryption.
The TLS Record Layer is similarly issue of intense research. In [Kra01], Krawczyk ana-lyzes two abstract versions of the TLS record layer. One of them is a general scheme calledMAC-then-ENC whereas the other is more specific. While he proves that MAC-then-ENCdoes not always yield a secure channel, Krawczyk proves it to be a secure channel whenthe encryption is instantiated via a secure cipher in CBC mode. The latter result was inter-preted as a security proof for the TLS Record Layer and the protocol description complied,indeed, with the accepted standard for cryptographic abstraction of protocols.
However, Vaudenay [Vau02] later discovered that some of the dispatched details leaveleverages for attacks. In particular, the process of message padding enables additionalsecurity breaches. In subsequent works, e.g., Paterson and Watson [PW08] as well asMaurer and Tackmann [MT10], the analysis progressively reflected the actual real-worldimplementation, culminating in the recent work by Paterson et al. [PRS11] who analyzethe actual RFC [DA99, DA06]. On the way several attacks were discovered, and the RFCwas modified to prevent those attacks.
We can therefore consider the cryptographic analysis of the TLS protocol as having achievedan acceptable level of rigorousness, showing that the protocol is secure.
3Kusters and Tuengerthal [KT11] actually do not carry out this analysis formally, but convincingly show itsfeasability in their model.
78 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

5 EAC & PACE: Overview over the Cryptographic Status
The Password Authenticated Connection Establishment (PACE), and the Extended AccessControl (EAC) protocol, are deployed in the current electronic ID card in Germany. Theyeach enable the card and the (local) reader resp. the card and the (remote) terminal to sharea secret session key which is used subsequently in the secure messaging protocol.
5.1 Extended Access Control (EAC)
EAC is deployed in two different variants. Here, we focus on the latest version whichis implemented in the German ID card. In EAC, a chip and terminal agree upon a se-cret session key if both parties mutually authenticate first. This is accomplished by twosub-protocols, called Terminal Authentication (TA) and Chip Authentication (CA). First,in the TA phase, the terminal signs in a challenge-response step the card’s challenge un-der a certified key. Subsequently, in the CA step, the chip authenticates itself also via achallenge-response step, but using already the derived session key in a message authenti-cation code instead of a signature, as this ensures deniability for the card. The session keyitself, which is also used for this chip authentication, is derived from a DH key computedbetween the static (certified) key of the card and an ephemeral key of the terminal.
The security analysis of EAC, as a key exchange protocol, in [DF10a] is done in theBellare-Rogaway model, with the hindsight that the key is already used in the key ex-change step for a dedicated message which does not appear in the channel protocol. Theformal analysis thus assumes a key refresh step for which the composition result for BR-key exchange protocols in [BFWW11] applies, noting that one can publicly match session.Alternatively, for the version using the session key already, the result [DF10b] about com-positional properties of key exchange protocols with controlled usage of the key applies.
The security analysis of the channel protocol, called secure messaging, is done in [DF10b].The secure messaging follows an encrypt-then-authenticate method with a counter valuefor each message, with all data like the counter value, the auxiliary information, and themessage carefully aligned to block length. As such it provides a secure channel for ran-domly chosen keys (instead of keys generates through the key exchange protocol).
The entire secure channel, consisting of the EAC key exchange composed with the securemessaging, is analyzed in [DF10b] in a monolithic way, saying that security follows fromthe security of the key exchange protocols and the security of the primitives:
Theorem 5.1 (from [DF10b], informally) The security of the composed protocol, con-sisting of the EAC key exchange protocol with secure messaging, follows from the securityof the EAC key exchange protocol, the security of the encryption scheme, and the unforge-ability of the message authentication code.
TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols 79

5.2 Password-Authenticated Connection Establishment (PACE)
The PACE protocol is deployed between the chip and a reader. In contrast to EAC it doesnot rely on certified public keys, but is password based. That is, the chip and the readershare a low-entropy secret at the outset of the execution. In practice, the card holdertypes in this password at the reader, or in case of machine readable travel documents thepassword is built out of the data in the machine readable zone and obtained by the readerthrough a physical read-out (say, via swiping the passport at the reader).
PACE, as a key exchange protocol, has been analyzed in a version of the BR model, suit-able for the case of password-based protocols. The model is due to Bellare-Pointcheval-Rogaway (BPR model) [BPR00] and takes into account that an adversary could potentiallyguess the low-entropy password in an execution with an honest party. But the model saysthat the adversary should not be able to do more than that. In particular, the adversaryshould only be able to test one password in any active execution (online testing) but mustnot be able to identify a password after eavesdropping a communication (offline testing).
Formally, the model is as the BR model, except that we measure the adversary’s successprobability against the trivial prediction strategy of guessing the right password with prob-ability 1/N (if passwords are chosen uniformly from a set of size N , say, N = 106 for6-digit PINs). This bound is for a single execution and grows to q/N when the adversarycan probe q executions. To be precise, the adversary in q executions should then not beable to be significantly better in distinguishing the genuine key from a random string, thanwith probability q/N . Such a password-based protocol is considered to be optimal.
While the PACE protocol as a key exchange protocol has been shown in [BFK09] to beoptimal, the channel protocol following the PACE step has, to best of our knowledge, notbeen analyzed formally (when composed with PACE). Luckily, since the channel is alsoimplemented by secure messaging, and by the similarity of the BPR model to the BRmodel, the monolithic analysis in [DF10b] for EAC and Secure Messaging immediatelycarries over. Only the security bound for the overall protocol now also contains the weakerbound q/N (plus a negligible term). This, of course, is inevitable for password-basedprotocols:
Theorem 5.2 (adopted from [DF10b], informally) The security of the composed proto-col, consisting of the PACE password-based key exchange protocol with secure messaging,follows from the security of the PACE key exchange protocol, the security of the encryptionscheme, and the unforgeability of the message authentication code.
6 Conclusion
As discussed, research on key exchange protocols is crucial for a wide range of practicalprotocols such as TLS, EAC, and PACE. The latter, however, are often non-trivial to ana-lyze. Fortunately, several new approaches have been developed such that TLS, EAC, andPACE are now shown to be cryptographically sound protocols.
80 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

References
[BCJ+11] Michael Backes, Iliano Cervesato, Aaron D. Jaggard, Andre Scedrov, and Joe-KaiTsay. Cryptographically sound security proofs for basic and public-key Kerberos. Int.J. Inf. Secur., 10:107–134, 2011.
[BFK09] Jens Bender, Marc Fischlin, and Dennis Kugler. Security Analysis of the PACE Key-Agreement Protocol. In ISC 2009, volume 5735 of LNCS, pages 33–48. Springer,2009.
[BFS+11] Christina Brzuska, Marc Fischlin, Nigel P. Smart, Bogdan Warinschi, and Stephen C.Williams. Less is More: Relaxed yet Composable Security Notions for Key Exchange.In submission, 2011.
[BFWW11] Christina Brzuska, Marc Fischlin, Bogdan Warinschi, and Stephen C. Williams. Com-posability of bellare-rogaway key exchange protocols. In CCS 2011, pages 51–62.ACM, 2011.
[BN00] Mihir Bellare and Chanathip Namprempre. Authenticated Encryption: Rela-tions among notions and analysis of the generic composition paradigm. In ASI-ACRYPT 2000, volume 1976 of LNCS, pages 531–545. Springer, 2000.
[BPR00] Mihir Bellare, David Pointcheval, and Phillip Rogaway. Authenticated Key ExchangeSecure against Dictionary Attacks. In EUROCRYPT 2000, volume 1807 of LNCS,pages 139–155. Springer, 2000.
[BR94] Mihir Bellare and Phillip Rogaway. Entity Authentication and Key Distribution. InCRYPTO’93, volume 773 of LNCS, pages 232–249. Springer, 1994.
[Can01] Ran Canetti. Universally Composable Security: A New Paradigm for CryptographicProtocols. In 42nd FOCS, pages 136–145. IEEE Computer Society, 2001.
[CF01] Ran Canetti and Marc Fischlin. Universally Composable Commitments. InCRYPTO 2001, volume 2139 of LNCS, pages 19–40. Springer, 2001.
[CK01] Ran Canetti and Hugo Krawczyk. Analysis of Key-Exchange Protocols and TheirUse for Building Secure Channels. EUROCRYPT 2001, volume 2045 of LNCS, pages453–474. Springer, 2001.
[CW11] Veronique Cortier and Bogdan Warinschi. A composable computational soundnessnotion. In CCS 2011, pages 63–74. ACM, 2011.
[DA99] T. Dierks and C. Allen. The TLS Protocol Version 1.0. In RFC 2246, 1999.
[DA06] T. Dierks and C. Allen. The TLS Protocol Version 1.2. In RFC 4346, 2006.
[DDMW06] Anupam Datta, Ante Derek, John Mitchell, and Bogdan Warinschi. ComputationallySound Compositional Logic for Key Exchange Protocols. In CSFW 2006, pages 321–334. IEEE Computer Society, 2006.
[DF10a] Ozgur Dagdelen and Marc Fischlin. Security Analysis of the Extended Access ControlProtocol for Machine Readable Travel Documents. In ISC 2010, volume 6531 ofLNCS, pages 54–68. Springer, 2010.
[DF10b] Ozgur Dagdelen and Marc Fischlin. Sicherheitsanalyse des EAC-Protokolls. Tech-nical report, Project 826, 2010. http://www.personalausweisportal.de/SharedDocs/Downloads/DE/Studie_Kryptographie_Volltext.pdf?__blob=publicationFile.
TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols 81

[DY81] D. Dolev and A. C. Yao. On the security of public key protocols. In SFCS ’81, pages350–357. IEEE Computer Society, 1981.
[FKS11] Cedric Fournet, Markulf Kohlweiss, and Pierre-Yves Strub. Modular code-based cryp-tographic verification. In CCS 2011, pages 341–350. ACM, 2011.
[GMP+08] Sebastian Gajek, Mark Manulis, Olivier Pereira, Ahmad-Reza Sadeghi, and JorgSchwenk. Universally Composable Security Analysis of TLS. In ProvSec 2008, vol-ume 5324 of LNCS, pages 313–327. Springer, 2008.
[JKSS11] Tibor Jager, Florian Kohlar, Sven Schage, and Jorg Schwenk. A Standard-Model Se-curity Analysis of TLS-DHE. IACR Cryptology ePrint Archive, 2011:219, 2011.
[Kra01] Hugo Krawczyk. The Order of Encryption and Authentication for Protecting Commu-nications (or: How Secure Is SSL?). In CRYPTO 2001, volume 2139 of LNCS, pages310–331. Springer, 2001.
[KT11] Ralf Kusters and Max Tuengerthal. Composition theorems without pre-establishedsession identifiers. In CCS 2011, pages 41–50. ACM, 2011.
[MSW10] Paul Morrissey, Nigel P. Smart, and Bogdan Warinschi. The TLS Handshake Protocol:A Modular Analysis. Journal of Cryptology, 23(2):187–223, 2010.
[MT10] Ueli Maurer and Bjorn Tackmann. On the soundness of authenticate-then-encrypt:formalizing the malleability of symmetric encryption. In CCS 2010, pages 505–515.ACM, 2010.
[Nie02] Jesper Buus Nielsen. Separating Random Oracle Proofs from Complexity TheoreticProofs: The Non-committing Encryption Case. In CRYPTO 2002, volume 2442 ofLNCS, pages 111–126. Springer, 2002.
[PRS11] Kenneth G. Paterson, Thomas Ristenpart, and Thomas Shrimpton. Tag Size DoesMatter: Attacks and Proofs for the TLS Record Protocol. In ASIACRYPT 2011, toappear.
[PW08] Kenneth G. Paterson and Gaven J. Watson. Immunising CBC Mode Against PaddingOracle Attacks: A Formal Security Treatment. In SCN 08, volume 5229 of LNCS,pages 340–357. Springer, 2008.
[Vau02] Serge Vaudenay. Security Flaws Induced by CBC Padding - Applications to SSL,IPSEC, WTLS ... In EUROCRYPT 2002, volume 2332 of LNCS, pages 534–546.Springer, 2002.
82 TLS, PACE, and EAC: A Cryptographic View at Modern Key Exchange Protocols

Merging the Cryptographic Security Analysisand the Algebraic-Logic Security Proof of PACE
Lassaad Cheikhrouhou1, Werner Stephan1,Ozgur Dagdelen2, Marc Fischlin2, Markus Ullmann3
1German Research Center for Artificial Intelligence (DFKI GmbH){lassaad,stephan}@dfki.de
2Technische Universitat [email protected] [email protected]
3Federal Office for Information Security (BSI)[email protected]
Abstract: In this paper we report on recent results about the merge of the cryp-tographic security proof for the Password Authenticated Connection Establishment(PACE), used within the German identity cards, with the algebraic-logic symbolicproof for the same protocol. Both proofs have initially been carried out individually,but have now been combined to get “the best of both worlds”: an automated, error-resistant analysis with strong cryptographic security guarantees.
1 Introduction
The cryptographic protocol PACE (Password Authenticated Connection Establishment) isdesigned by the BSI for the establishment of authenticated radio frequency connectionsbetween contactless cards and readers [UKN+]. PACE is deployed in the German (elec-tronic) identity card and should be used instead of the BAC (Basic Access Control) proto-col in the inspection procedure of machine readable travel documents (ePassports) [EAC].The protocol realizes a password-authenticated Diffie-Hellman (DH) key agreement be-tween an RF-chip and a terminal. A successful run yields a fresh session key that is usedby the reader to establish a secure connection to the RF-chip.
Two Views on the Security: The security of PACE has been analyzed by following twostate-of-the-art approaches. A (symbolic) algebraic-logic security proof of PACE [CS10],in the Dolev-Yao (DY) model has been carried out in the Verification Support Environment(VSE) tool, yielding a machine generated proof of all its security properties. The DYmodel is based on a message algebra given by cryptographic operations and equations.The operations define the syntax of protocol messages while the equations in an abstractway formalize the computations that are necessary for the honest participants to executethe protocol. A subset of these operations is available for the adversary to analyze observedmessages and to synthesize new ones. This attacker model is very powerful with respectto an unrestricted access (of the adversary) to the communication lines. On the other hand,

it limits the abilities of the adversary in attacking cryptography by assuming that exactlythe algebraic (or symbolic) computations can be carried out by the adversary.
Concurrently, a cryptographic security analysis of PACE [BFK09] has been carried outbased on the Bellare Rogaway (BR) security model, yielding a pencil-and-paper proof ofthe confidentiality and authenticity of the session key. The cryptographic proof followsthe common complexity-theoretic approach to show that any security breach of the keyexchange protocol within the security model can be used to refute any of the underlyingassumptions and primitives. Vice versa, if the underlying primitives of the protocol aresecure, then the proof shows – in terms of the complexity of the algorithms and concreteprobabilities – how secure the PACE protocol is. Here, the adversary can be arbitrary(Turing) machines whose abilities to communicate with the system are determined bythe model. Security proofs in the BR model consider strong adversaries who control thenetwork, i.e., eavesdrop, modify and inject messages, and may learn leaked session keysor long-term keys of users.
Merging the Views: In this paper we describe an approach to merge the cryptographicsecurity analysis in [BFK09] and the algebraic-logic security proof in [CS10], aiming ata reliability improvement in the security of PACE. Our merging approach is based on anadequate formalization of the BR model used within PACE that allows us to attributepublic bit strings (values) to symbolic expressions for corresponding applications of thecryptographic functions. Sequences of alternating intruder queries and protocol oracleresponses (BR traces) are attributed this way a symbolic structure that allows us to defineDY computations in the BR model.
The main result is the theorem that symbolic traces of DY computations in the BR modelare equivalent to symbolic traces in the algebraic-logic security proof. Equivalence isdefined wrt. the capabilities and the knowledge of the adversary. This means that thealgebraic-logic security proof of PACE in VSE provides us with a machine generated prooffor the confidentiality of the session key in the BR-model, though for Turing machinesrestricted to DY computations.
Apart from that, our formalization of the BR model for PACE provides us with the formalmeans to define computational problems arbitrary adversary machines are confronted with(relative to the protocol model). The ultimate goal is an axiom-based formal proof ofPACE’s security in the BR model relative to an exhaustive listing of formally definedcomputational problems. In the paper we describe only the formalization of PACE’s BRmodel (Sec. 4) and the equivalence of DY computations both in the BR and the DY model(Sec. 5). Prior to that we introduce PACE (Sec. 2) and we review its cryptographic securityanalysis and its algebraic-logic security proof (Sec. 3).
Related Work about Proof Integrations: Abadi and Rogaway [AR02, AR07] werethe first to aim at bridging the gap between the two views on cryptography, the formalor symbolic view, and the complexity-based or computational view, through linking thetwo worlds explicitly. Their soundness theorem for encryption schemes is accomplishedby mapping symbolic expressions to (probabilistic) cryptographic ensembles. Since thenfurther works aimed at closing the gap between the two worlds in the same spirit (e.g.,[BPW03, IK03, MW04a, MW04b, CLC08]).
84 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

A supportive approach towards linking the cryptographic and the symbolic world is givenby the reactive simulatability (RSIM) framework of Pfitzmann and Waidner [PW00, PW01]and Canetti’s concurrently proposed and similar-in-spirit universal composition (UC) frame-work [Can01]. The idea of the frameworks is to analyze cryptographic protocols in pres-ence of ideal functionalities, similar to idealized primitives in the DY setting. So-calledcomposition theorems then allow to conclude security of the combined protocol when theideal functionalities are replaced by secure sub protocols. Hence, this allows to decomposethe analysis of complex, potentially multi-session protocols into analysis of more handysingle-session sub protocols. A series of soundness results [BPW04, CH06, Pat05, MH07,BU08] for these frameworks shows that any symbolically secure protocol (in a symbolicversion of the RSIM/UC framework) is also secure in the computational framework; oftensuch formal analysis have also been carried out explicitly. However, in order to be securein the RSIM/UC frameworks, protocols need to satisfy very strong security guarantees inthe first place. This rules out numerous protocols, especially quite a number of practicalprotocols. This means that the method is not applicable to a large class of protocols, andit is, in particular, unknown whether it applies to PACE.1
While computer-aided verification of cryptographic protocols is a well-established disci-pline, computer-aided verification of cryptographic proofs (in the computational model)is a quite new approach to combine the benefits of automated, error-free verification andthe flexibility of cryptographic proofs to consider arbitrary adversaries strategies and toreason about the security of a protocol in terms of reduction to primitives (instead of ideal-izing the primitives). There are several approaches to build systems along this line, amongwhich the recently proposed framework EasyCrypt [BGHB11] stands out. Our approachfollows the same idea of verifying game-based proofs for the PACE protocol with the helpof automated tools. Here, we used the available cryptographic proof for PACE [BFK09]and the previous efforts for the formal analysis for PACE in VSE [CS10] to merge thecryptographic reasoning with the symbolic analysis.
2 The PACE Protocol
PACE is a password-based key agreement protocol with mutual entity authentication. Ittakes place between the RF-chip (A) of a contactless smart card and an (inspection) termi-nal (B). After a successful run of PACE, an RF-chip and a terminal share a fresh sessionkey, and the terminal can establish a secure connection to the RF-chip of the smart cardusing the established session key.
We have to point out that a successful PACE protocol run between an RF-chip A and aterminal B is only possible if the terminal has learned the appropriate password pwd(A)of the RF-chip A at the outset, e.g., if the user typed it in at the terminal, or if it is read offthe machine-readable zone in passports. This password pwd(A) is stored on the RF-chipin secure memory and the way it is utilized in PACE guarantees that the chip originates
1Note that the cryptographic analysis of PACE has indeed been carried out in the game-based BPR securitymodel, not in the UC framework.
Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof 85

from the smart card at hand.
2.1 Cryptographic Functions
PACE messages are computed out of passwords, random values (nonces), and basic gen-erators for the underlying elliptic curve group, using the following (abstract) functions:
• enc(·, ·), dec(·, ·) for (symmetric) encryption and decryption, respectively,
• dh(·, ·) for the computation of Diffie-Hellman values, and
• mac(·, ·), gen(·, ·) for the computation of mac values and (fresh) generators, respec-tively.
The algebraic properties that are necessary to run the protocol are expressed by three equa-tions:
• For encryption and decryption we have
dec(m0, enc(m0,m1)) = m1 and enc(m0, dec(m0,m1)) = m1.
The second equation guarantees the absolute indistinguishability of failed and suc-cessful decrypting attempts. This property is necessary to obtain the resistanceagainst offline password testing (see section 3.2).
• For the computation of a common DH key we have
dh(dh(m0,m1),m2) = dh(dh(m0,m2),m1).
2.2 PACE Steps
To run the protocol with an RF-chip A, the terminal B does not only have to learn thepassword pwd(A). It also has to access (in a protocol pre-phase) the domain parametersthat include a static generator g for DH exchange in steps 2+3.
In the description of the protocol steps below we additionally make use of the meta-operator % to separate the sender’s view (the left-hand side of %) from the receiver’sview (the right-hand side of %). Unstructured messages in steps 1-5 below means that thereceiver accepts any message without practically any check. Compare this with steps 6and 7 below. Here, the respective receiver sees a message that can be compared with anexpression determined from the own knowledge (the right-hand side of %).
1. A −→ B : enc(pwd(A), sA) % z
2. B −→ A : dh(g, x1) % X1
3. A −→ B : dh(g, y1) % Y 1
86 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

4. B −→ A : dh(gen(dh(g, dec(pwd(A), z)), dh(Y 1, x1)), x2) % X2
5. A −→ B : dh(gen(dh(g, sA), dh(X1, y1)), y2) % Y 2
6. B −→ A : mac(dh(Y 2, x2), Y 2)% mac(dh(X2, y2), dh(gen(dh(g, sA), dh(X1, y1)), y2))
7. A −→ B : mac(dh(X2, y2), X2)%mac(dh(Y 2, x2), dh(gen(dh(g, dec(pwd(A), z)), dh(Y 1, x1)), x2))
A starts the protocol by sending a nonce sA encrypted with the own password pwd(A)to B. The decryption of this message z by B with the password that B can determinewhile B is connected with A results in sA, provided this password equals pwd(A). Thefirst DH exchange in steps 2+3 establishes a first DH value that is used with sA and thestatic generator g in the computation of a fresh generator for the subsequent DH exchangein steps 4+5. The composition of these parameters by gen guarantees that the resultinggenerator is cryptographically as strong as g and binds this generator with the intermediateof sA to the password pwd(A). Thus, the DH value established in steps 4+5 can bedetermined only by participants that know the password. Its use in steps 6+7 to computethe mac authenticates the sender for the receiver. Each mac can be created only by acommunication partner who has participated in the DH exchange of steps 4+5 after usingthe password.
3 The Cryptographic and Symbolic Security Analyses
3.1 The Cryptographic Proof
The PACE protocol is accompanied by a cryptographic security proof [BFK09]. Thecryptographic proof follows the classical paper-and-pencil approach of defining a securitymodel, describing the adversary’s capabilities and goals, specifying a set of underlyingcryptographic assumptions, and a mathematical proof that the adversary cannot succeedwithin the model under the assumptions.
As for the model, the authors in [BFK09] used the widely-deployed BR model [BR94]for authenticated key exchange (or, to be precise, the variations of Bellare-Pointcheval-Rogaway [BPR00] and of Abdalla et al. [AFP06] for the password-based case).The BRmodel defines a game between the adversary and a challenger oracle in which the pow-erful adversary can: (a) observe interactions between honest participants (i.e., RF-chipsand terminals), (b) inject or modify transmissions in such communications, or even takeover the side of one of the parties, (c) corrupt players, and (d) learn the derived DH keyin executions. We note that the model considers multi-session executions, which may runconcurrently. The adversary’s goal is now to distinguish derived fresh DH keys from in-dependent random strings in so-called test sessions, the idea being that good keys muststill look random to the adversary. The model now demands that the adversary cannot dis-tinguish the two cases, defined within the usual cryptographic notion of having negligibleadvantage over distinguishing the two cases by pure guessing with probability 1
2 .
Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof 87

The cryptographic proof now defines a set of assumptions, such as the hardness of theso-called PACE-DH number-theoretic problem (which is related to the DH problem), thesecurity of the underlying message authentication code, and idealizing the deployed cipherand the hash function as a random oracle. Under these assumptions, it is shown (mathe-matically) that the PACE protocol is secure. The caveat here is that the proof takes intoaccount the fact that the protocol is password-based, i.e., relies on low-entropy secrets,which can, in principle, be guessed by the adversary. The security claim shows that the –trivial and inevitable – on-line guessing of passwords, where the adversary tries to predictthe password and then tests its guess in an execution with an honest party, is (essentially)the best adversarial strategy. In other words, PACE achieves optimal security.
The proof itself is carried out with the common technique of game hopping. That is, onestarts with the actual attack and gradually eliminates success strategies of the adversary ineach game hop, e.g., the ability to forge MACs. In the final game, the adversary provablycannot distinguish the DH keys from random keys anymore. One then accounts for theloss in the adversary’s success probabilities and sums up all the losses for the hops. Thissum gives an upper bound on the adversary’s advantage.
The next theorem states the cryptographic security of the PACE protocol (for more generalcases where the first Diffie-Hellman key exchange is substituted by a canonical protocolMap2Point). It obviously relates the adversary’s characteristics like running time andsuccess probability to the ones for the underlying primitives and assumptions. The theo-rem roughly shows that the best strategy for the adversary (unless it can break one of theprimitives) is to guess the password (with probability 1/N among all passwords) and tomount a test run for this guess. Since there can be in total qe executions the overall successprobability is roughly qe/N .
Theorem 3.1 ([BFK09]) Let Map2Point be canonical and assume that the password ischosen from a dictionary of size N . In the random oracle model and the ideal ciphermodel we have
AdvakePACE(t, Q) ≤ qeN
+ qe · AdvgPACE−DHMap2Point (t∗, N, qh)
+qe · Advforgemac (t∗, 2qe) +2qeN
2 + 8q2eN + qcqemin{q, |Range(H)}
The resources of an adversary are captured by the time t∗ = t + O(Q2) and number oforacle queries Q = (qe, qc, qh) where qe denotes the number of key exchanges, qc thequeries to the cipher oracle and qh the queries to the random oracle. The theorem saysthat the advantage AdvakePACE(t, Q) of any adversary having resources (t∗, Q) breakingthe security of PACE is bounded by the pure guessing strategy qe/N , the advantage offorging a MAC Advforgemac (t∗, 2qe), and the DH related hard problem gPACE-DH, denotedby AdvgPACE−DH
Map2Point (t∗, N, qh) plus some negligible term. In short, an adversary is merelyas successful as blind guessing whenever a secure MAC scheme is used in PACE.
The security reduction of PACE does not consider explicitly the hardness of the (ideal)block cipher. Instead, the security of the underlying block cipher is implicitly captured inthe hardness of gPACE-DH problem and modeled as an ideal cipher.
88 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

3.2 The Algebraic-Logic Proof
The symbolic analysis of PACE has been carried out in the VSE tool, [CS10]. The resultingalgebraic-logic proof handles explicitly the standard security properties (mutual authenti-cation and confidentiality of session keys) and the following three properties, which aretypical for password protocols:
• forward secrecy of session keys, i.e. that a successfully guessed password does nothelp to reveal the session keys that had been generated in previous runs,
• resistance against offline password testing, i.e. that the obtained protocol messagesby an active intruder cannot be exploited offline to determine a correct passwordfrom a given list of candidate passwords, and
• forward secrecy of passwords, i.e. a stronger form of the resistance property wherethe intruder may use disclosed session keys in addition to protocol messages.
We note that these properties are implied by the BR model. They have been verified in theVSE tool where the protocol model consists of a set TPACE of (finite) sequences (traces)tr = 〈e0, . . . , en−1〉 of (protocol-) events. The main events are of the form says(a, b,m)where a protocol participant a sends a (symbolic) message m to some other participant b.
The set TPACE is defined inductively by using predicates (rules) R(tr, e) that describethe conditions for a given trace tr to be extended by a new event e. There is a predicateRi for each line i of the protocol and an additional predicate Rf for the fake case. Wehave Rf (tr, says(spy, b,m)) for an arbitrary participant b iff the intruder (named spy) isable to derive m out of the observable messages in tr. We denote the set of (immediately)observable messages by spies(tr) and the set of derivable messages (from spies(tr)) byDY (spies(tr)). The latter is an extension of spies(tr) given by the reasoning capabilitiesof a DY intruder, i.e. by the application of the functions and the equations in Sec. 2.1.
In this algebraic-logic model, PACE properties are formalized on arbitrary traces fromTPACE and the corresponding machine-proofs are by induction on these event traces.
4 A Symbolic Formalization of the BR-Model
The global structure of the BR model, as depicted in Fig. 1, consists of two components: aPPT adversary machine and the oracle O that reacts on queries from the adversary by sim-ulating steps of a given protocol. The most important query is of the form send(adr,m)where m is a protocol message that has to be answered by a certain participant in a cer-tain session, both given by adr, according to the protocol rules and the execution statewhich is part of the overall oracle state. The response value may depend on the appli-cation of cryptographic primitives where idealized functions are realized by probabilisticchoices of the oracle. The adversary uses these responses to generate subsequent queries
Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof 89

by possibly guessing (sub-) messages and/or performing computations that are not neces-sarily included in the message algebra used in the DY model (see Sec. 2.1). To break theprotocol, after termination of a particular session the adversary has to distinguish thesession key stored in the oracle state from a ran-
Figure 1: The BR Model
dom value with a considerably high probability.The test item is presented by the oracle as a reac-tion to a special query.
In [CSDF10] we formalize the BR model by spec-ifying O as a state transition system and by defin-ing computation trees Comp(O ‖ A), see Fig. 2,generated by the joint execution of the oracle andan arbitrary but fixed adversary A.
Let SO be the set of oracle states, TA be the set of states of the adversary, QA the set ofqueries that can be generated by the adversary, and RO the set of possible responses of theoracle. As mentioned above queries may contain protocol messages to be processed bythe oracle.
Nodes of computation trees are quadruples (s, t, r, p) and (s, t, q, p), where s ∈ SO, t ∈TA, r ∈ RO, and q ∈ QA. The probability p ∈ [0, 1] captures probabilistic choices of Oand A, respectively.
Starting from the initial states s0 ∈ SO and t0 ∈ TA the computation tree grows byalternating transition steps of the adversary A (•→•) and the oracle O (•→•). Steps ofthe adversary depend on the current state t ∈
!!! !!!
!!!
!!!
!!!
!!!
!!!
!!!
!!!
Figure 2: A computation tree Comp(O ‖ A)
TA and the current response r ∈ RO. The stateof the adversary which is not explicitly givencan be thought of (among others) as represent-ing past responses of the oracle. Outcomes ofsteps of the adversary consist of a new statet′ ∈ TA and a query q ∈ QA. Since theadversary is given by a probabilistic machine,there is a finite set (or list) of outcomes, eachequipped with a probability. Similarly, steps ofthe oracle depend on its current internal states ∈ SO and the current query q ∈ QA. Out-comes of computations of the oracle consist ofa new state s′ ∈ SO and a response r ∈ RO. Again, idealized (cryptographic) functionsmodeled by random choices lead to several possible outcomes.
The behavior of the combined system is given by two functions
stepO : SO×QA → (SO×RO×[0, 1])+ and stepA : TA×RO → (TA×QA×[0, 1])∗.
We specify the function stepO for PACE by transition rules that are similar to the rulesR(tr, e) in the inductive definition of the set TPACE of (DY) traces (see Sec. 3.2). Inparticular, we use symbolic expressions to represent the control part of the session states aspart of s ∈ SO. The symbolic expressions are interpreted by an operator . that evaluates
90 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

symbols. For instance, pwd(i) is evaluated to the password (value) π ∈ PWD of the i-th participant acting in role A (i.e. A[i]) and nonce(l) to the l-th nonce (value) randomlychosen from a set RND.
Probabilistic values are generated using the oracle by certain additional state components.For example, the first PACE message is generated by a participant (A[i]) with passwordπ = pwd(i) as follows. We consider all choices for a nonce sA = nonce(l) from theset RND. For each sA we check whether the state component orC(s) ⊆ PWD×RND×RND already contains a triple (π, sA, z) in which case, we generate the response value asenc(π, sA) = z. Otherwise, we consider all choices of z from a set of n possible values(i.e. from a subset of RND given by orC(s)) to obtain z = enc(π, sA) after (π, sA, z)was inserted into orC(s
′). The probability of the alternative transition steps generatedthis way is determined by the the cardinality |RND| and n. Obviously, the same visibleresponse z might lead to different successor states hidden in the oracle. In the controlcomponent of the oracle, we keep enc(pwd(i), nonce(l)) as the last successful step of thissession. In this way, the control states and the responses of the oracle exhibit the samestructure as traces in the symbolic (DY) model.
Computation paths end by situations where A halts, given by an empty image of stepA.
Without further analyzing computation paths in the tree the only knowledge about theprobabilities p in the outcomes of stepA is that their sum is one.
5 Analyzing (BR) Computation Trees
In this section, we describe the analysis of attacks based on computation trees. Attacks aregiven by paths where the final problem is solved, i.e. the adversary distinguishes a sessionkey (by an honest participant) from a random value. Every success computation pathcontains a terminated session by an honest participant where the responses are computedas reaction on send queries generated by the adversary. The messages in these querieshave to be accepted by the honest participant as simulated by the oracle according to theprotocol rules. In general, the adversary has to solve the problem of generating a correctprotocol message by using knowledge obtained from all previously observed responses.The main question is whether there can be an adversary A that is able to solve all theseproblems including the final problem with a considerably high probability.
First we consider the adversary machines that are restricted to DY reasoning. We de-fine this kind of machines relative to computation trees: (a) In a DY-computation treeComp(O ‖ A), the steps of A are deterministic, i.e. every red node may not have morethan a child node. This must not be confused with the fact that there are different strate-gies for adversaries. (b) Each value in a query must be associated a symbolic expressionε ∈ DY (ε), where the list ε contains the symbolic expressions associated to the corre-sponding directly observable (message) values.
The following theorem allows us to exploit the algebraic-logic proof as a VSE proof for thesecurity of PACE (in the BR model) against DY restricted adversary machines. Note thatDY adversaries cannot be removed by complexity considerations, since DY computations
Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof 91

are feasible.
Theorem 5.1 ([CSDF10]) Let Comp(O ‖ A) be a (PACE) DY-computation tree. For alllist ε of the symbolic expressions associated to the public values on a computation path inComp(O ‖ A) there exists a protocol trace tr in the DY model of PACE such that
∀ε : ε ∈ DY (ε) ⇔ ε ∈ DY (spies(tr)).
This theorem is proved by induction on computation paths, [Neu11].
Regarding arbitrary adversary machines, the success to break the protocol shall be tracedback to a complete list of local computation problems that are induced, as explained above,by protocol rules and that fit to the (partly idealized) assumptions on the cryptographicoperations. This is work in progress. Up to now, we identified systematically a list oflocal (sub-) problems that we formally defined owing to notions given by computationtrees, [CSDF10, Neu11]. Each local problem is defined by an input-output relation whichis specified by input computation paths (in Comp(O ‖ A)) and by correct outputs definedrelative to associated states s ∈ SO. Further work will be an axiomatic system that can beused to prove the completeness of the identified problem list.
6 Conclusion
In spite of well-developed frameworks which guarantee soundness of algebraic-logic secu-rity proofs with respect to cryptographic security, their applicability to practical protocolsis quite limited (see Sec. 1). For this reason, two independent security analysis for PACEwere performed, a cryptographic security analysis and an algebraic-logic security proof,to explore PACE by applying state-of-the-art techniques. As the mathematical founda-tions are quite different, i.e., complexity theory versus mathematical logic, both analysesfor PACE existed more or less concurrently at the outset of our merging attempt. Now,the described formalization of the BR-model provides us with a uniform formal frame-work for algebraic-logic and (computational-)cryptographic reasoning. This enables us tomerge the cryptographic security analysis and the algebraic-logic security proof of PACEas described in this paper. We obtained a closed formal security analysis for PACE. Theconsequence is that the proven properties of the PACE protocol in both approaches canbe linked. This enhances the reliability of the cryptographic (pencil-and-paper) proof as itcan be supported by an accurate, formal algebraic-logic verification.
Here, we have only described the merging of a cryptographic security analysis and thealgebraic-logic security proof of the password-based security protocol PACE. However,our approach, formalizing cryptographic analysis methodologies, seems to be much moregeneral and applicable to a broad class of security protocols. This estimation has stimu-lated the project ProtoTo, funded by the German Federal Ministry of Education and Re-search (BMBF), about merges in related cases.
92 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

References
[AFP06] Michel Abdalla, Pierre-Alain Fouque, and David Pointcheval. Password-Based Au-thenticated Key Exchange in the Three-Party Setting. IEE Proceedings — InformationSecurity, 153(1):27–39, March 2006.
[AR02] Martın Abadi and Phillip Rogaway. Reconciling Two Views of Cryptography (TheComputational Soundness of Formal Encryption). Journal of Cryptology, 15(2):103–127, 2002.
[AR07] Martın Abadi and Phillip Rogaway. Reconciling Two Views of Cryptography (TheComputational Soundness of Formal Encryption). Journal of Cryptology, 20(3):395,July 2007.
[BFK09] Jens Bender, Marc Fischlin, and Dennis Kugler. Security Analysis of the PACE Key-Agreement Protocol. In Proceedings of the Information Security Conference (ISC)2009, volume 5735 of Lecture Notes in Computer Science, pages 33–48. Springer-Verlag, 2009.
[BGHB11] Gilles Barthe, Benjamin Gregoire, Sylvain Heraud, and Santiago Zanella Beguelin.Computer-Aided Security Proofs for the Working Cryptographer. In CRYPTO, volume6841 of Lecture Notes in Computer Science, pages 71–90. Springer, 2011.
[BPR00] Mihir Bellare, David Pointcheval, and Phillip Rogaway. Authenticated Key ExchangeSecure against Dictionary Attacks. In Bart Preneel, editor, Advances in Cryptology —Eurocrypt ’00, volume 1807 of Lecture Notes in Computer Science, pages 139+, 2000.
[BPW03] Michael Backes, Birgit Pfitzmann, and Michael Waidner. A Composable CryptographicLibrary with Nested Operations. In Sushil Jajodia, Vijayalakshmi Atluri, and TrentJaeger, editors, ACM CCS 03: 10th Conference on Computer and CommunicationsSecurity, pages 220–230. ACM Press, October 2003.
[BPW04] Michael Backes, Birgit Pfitzmann, and Michael Waidner. A General Composition The-orem for Secure Reactive Systems. In Moni Naor, editor, TCC 2004: 1st Theory ofCryptography Conference, volume 2951 of Lecture Notes in Computer Science, pages336–354. Springer, February 2004.
[BR94] Mihir Bellare and Phillip Rogaway. Entity Authentication and Key Distribution. InDouglas R. Stinson, editor, Advances in Cryptology – CRYPTO’93, volume 773 of Lec-ture Notes in Computer Science, pages 232–249. Springer, August 1994.
[BU08] Michael Backes and Dominique Unruh. Limits of Constructive Security Proofs. In JosefPieprzyk, editor, Advances in Cryptology – ASIACRYPT 2008, volume 5350 of LectureNotes in Computer Science, pages 290–307. Springer, December 2008.
[Can01] Ran Canetti. Universally Composable Security: A New Paradigm for CryptographicProtocols. In 42nd Annual Symposium on Foundations of Computer Science, pages136–145. IEEE Computer Society Press, October 2001.
[CH06] Ran Canetti and Jonathan Herzog. Universally Composable Symbolic Analysis of Mu-tual Authentication and Key-Exchange Protocols. In Shai Halevi and Tal Rabin, editors,TCC 2006: 3rd Theory of Cryptography Conference, volume 3876 of Lecture Notes inComputer Science, pages 380–403. Springer, March 2006.
[CLC08] Hubert Comon-Lundh and Veronique Cortier. Computational soundness of observa-tional equivalence. In Peng Ning, Paul F. Syverson, and Somesh Jha, editors, ACMCCS 08: 15th Conference on Computer and Communications Security, pages 109–118.ACM Press, October 2008.
Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof 93

[CS10] Lassaad Cheikhrouhou and Werner Stephan. Meilensteinreport: Inductive Verificationof PACE. Technical report, Deutsches Forschungszentrum fur Kunstliche IntelligenzGmbH, 2010.
[CSDF10] Lassaad Cheikhrouhou, Werner Stephan, Ozgur Dagdelen, and Marc Fischlin. Meilen-steinreport: Integrating the Cryptographic Security Analysis and the Algebraic-LogicSecurity Proof of PACE. Technical report, Deutsches Forschungszentrum fur KunstlicheIntelligenz GmbH, 2010.
[EAC] Technical Guideline: Advanced Security Mechanisms for Machine Readable TravelDocuments – Extended Access Control (EAC), Password Authenticated ConnectionEstablishment (PACE), and Restricted Identification (RI). Technical Report TR-03110,Version 2.05, Federal Office for Information Security (BSI).
[IK03] Russell Impagliazzo and Bruce M. Kapron. Logics for Reasoning about CryptographicConstructions. In 44th Annual Symposium on Foundations of Computer Science, pages372–383. IEEE Computer Society Press, October 2003.
[MH07] Hirofumi Muratani and Yoshikazu Hanatani. Computationally Sound Symbolic Criteriafor UC-secure Multi-Party Mutual Authentication and Key Exchange Protocols. InIEICE Tech. Rep., volume 106 of ISEC2006-150, pages 59–64, Gunma, March 2007.Thu, Mar 15, 2007 - Fri, Mar 16 : Gunma Univ. (Kiryu Campus) (IT, ISEC, WBS).
[MW04a] Daniele Micciancio and Bogdan Warinschi. Completeness Theorems for the Abadi-Rogaway Language of Encrypted Expressions. Journal of Computer Security, 12(1):99–130, 2004.
[MW04b] Daniele Micciancio and Bogdan Warinschi. Soundness of Formal Encryption in thePresence of Active Adversaries. In Moni Naor, editor, TCC 2004: 1st Theory of Cryp-tography Conference, volume 2951 of Lecture Notes in Computer Science, pages 133–151. Springer, February 2004.
[Neu11] Stephan Rouven Neumann. Integration der kryptographischen Sicherheitsanalyse unddes algebraisch-logischen Sicherheitsbeweises von PACE. Master’s thesis, SaarlandUniversity, Germany, 2011.
[Pat05] A.R. Patil. On symbolic analysis of cryptographic protocols. Massachusetts Institute ofTechnology, Dept. of Electrical Engineering and Computer Science, 2005.
[PW00] Birgit Pfitzmann and Michael Waidner. Composition and Integrity Preservation of Se-cure Reactive Systems. In S. Jajodia and P. Samarati, editors, ACM CCS 00: 7th Confer-ence on Computer and Communications Security, pages 245–254. ACM Press, Novem-ber 2000.
[PW01] Birgit Pfitzmann and Michael Waidner. A Model for Asynchronous Reactive Systemsand its Application to Secure Message Transmission. In IEEE Symposium on Securityand Privacy, pages 184–, 2001.
[UKN+] Markus Ullmann, Dennis Kugler, Heike Neumann, Sebastian Stappert, and VogelerMatthias. Password Authenticated Key Agreement for Contactless Smart Cards. InProceedings of the 4-th Workshop on RFID Security, Budapest 2008, pages 140–161.
94 Merging the Cryptographic Sec. Analysis and the Algebraic-Logic Security Proof

On the design and implementation of the Open eCard App
Detlef Hühnlein1 · Dirk Petrautzki2 · Johannes Schmölz1 · Tobias Wich1
Moritz Horsch1,3 · Thomas Wieland2 · Jan Eichholz4 ·Alexander Wiesmaier5
Johannes Braun3 · Florian Feldmann6 · Simon Potzernheim2 · Jörg Schwenk6Christian Kahlo7 ·Andreas Kühne8 · Heiko Veit8
1 ecsec GmbH, Sudetenstraße 16, 96247 Michelau2Hochschule Coburg, Friedrich-Streib-Straße 2, 96450 Coburg
3Technische Universität Darmstadt, Hochschulstraße 10, 64289 Darmstadt4Giesecke & Devrient GmbH, Prinzregentenstraße 159, 81677 München
5AGT Group (R&D) GmbH, Hilpertstraße 20a, 64295 Darmstadt6Ruhr Universität Bochum, Universitätsstraße 150, 44801 Bochum
7AGETO Innovation GmbH, Winzerlaer Straße 2, 07745 Jena8Trustable Ltd., Kirchröder Str. 70e, 30625 Hannover
Abstract: The paper at hand discusses the design and implementation of the“Open eCard App”, which is a lightweight and open eID client, which integratesmajor international standards. It supports strong authentication and electronicsignatures with numerous common electronic identity cards in desktop as well asmobile environments. The Open eCard App is designed to be as lightweight,usable and modular as possible to support a variety of popular platforms includingAndroid for example. It will be distributed under a suitable open source license andhence may provide an interesting alternative to existing eID clients.
1. Introduction
Against the background of various electronic identity (eID) card projects around theglobe (e.g. in the USA [NIST-PIV], Australia [AGIMO-NSF] and Europe [CEN15480])there have been numerous initiatives in the area of research, development andstandardization of eID cards, smart card middleware components and related services.
The German government, for example, has been issuing a new electronic identity card(“neuer Personalausweis”, nPA) since November 2010, which features moderncryptographic privacy enhanced protocols [BSI-TR3110] and contactless smart cardtechnology [ISO14443]. In order to support the broad adoption of this innovativesecurity technology the German government initiated a 30 million euro subsidy programin which security bundles (“IT-Sicherheitskits”) are provided for German citizen. Thesesecurity bundles comprise a free eID client [AusweisApp] for computers and a free ordiscounted smart card terminal. This eID client was announced to support all majorplatforms, interface devices, and smart cards as specified in the “eCard-API-Framework”[BSI-TR03112], which in turn is based on major international standards such as[ISO24727], [CEN15480] and [OASIS-DSS]. Thus, there have been high expectationswith respect to the real world impact of these developments.

However, despite the tremendous political, technical and financial efforts of the Germangovernment the practical situation with respect to the secure, easy and ubiquitous use ofthe different smart cards involved in the German eCard-strategy (cf. [Kowa07] and[HoSt11]) is not yet satisfying. The currently available eID client [AusweisApp], forexample, only supports authentication with the German ID card on selected PC-basedplatforms. Important features such as the support for electronic signature techniques,other smart cards, the Mac OS platform or mobile devices are still lacking. As of today itis not clear whether1 and when those features will be supported.
In order to solve this problem the authors of the paper at hand have started to design andimplement a lightweight alternative, the “Open eCard App”, and will publish its sourceunder a suitable open source license. The present contribution discusses selected aspectsrelated to the design and development of this lightweight eID client.
The remainder of the paper is structured as follows: Section 2 provides an overview ofrelated work. Section 3 summarizes the main functional and non-functional requirementsfor the Open eCard App. Section 4 presents the high level design that has beendeveloped based on the given requirements. Section 5 highlights selected aspects of themodule design and related implementation issues. Section 6 closes the paper with anoutlook on the next steps and future development.
2. Related Work
In addition to the development of the eCard-API-Framework [BSI-TR03112], therespective standards (e.g. [CEN15480], [ISO24727] and [OASIS-DSS]) and the eIDclient [AusweisApp] supported by the German government, there have been variousrelated developments which need to be considered here.
First, there are a few alternative proprietary eID clients (cf. [Ageto-AA] and [bos-Autent]), which support the German ID card, or implement a subset of the eCard-API-Framework (cf. [T7-eCard-QES]).
Furthermore, there have been first academic contributions to enable the use of theGerman ID card on mobile and PC-based platforms.
[EiHü08] discusses the use of [ISO24727] in a mobile environment. In [Hors09],[Kief10], [WHB+11] and [Hors11] an NFC-enabled Java Micro Edition (Java ME)mobile phone is used for mobile authentication with the German ID card. In the[Androsmex] project an Android based NFC-enabled smartphone is used to implementthe Password Authenticated Connection Establishment (PACE) protocol (cf. [BSI-TR3110] and [ICAO-PACE]). In [Petr11] a mobile authentication using the German IDcard is realized on an Android-based Smartphone using a separate mobile smart cardreader. At the University Koblenz-Landau the rosecat project [Jahn11] aims at providingan open source eID client and the [OpenPACE] project at the Humboldt UniversityBerlin aims at providing a cryptographic library which provides support for PACE andparts of the Extended Access Control (EAC) version 2.0 protocol [BSI-TR3110]. Whileboth latter projects have been developed with PCs as primary target in mind, there have
1 As the size of the different versions of [AusweisApp] ranges between 56.3 MB and 97.6 MB, there areserious doubts whether this eID client may ever be available for mobile devices.
96 On the design and implementation of the Open eCard App

been related contributions, which focus on mobile eID scenarios (cf. [Beil10], [Oepe10],[MMO11] and [MOMR11]).
In addition to the projects in Germany, there have been some open eID relateddevelopments in other countries, which are to be considered. The JMRTD project[JMRTD] provides an open source Java implementation of the Machine Readable TravelDocuments (MRTD) standards developed by the International Civil AviationOrganization. For the Belgian eID card there is already a Java library [eidlib], a Javaapplet [eID-Applet] and software for the creation of XML-based signatures [eID-DSS].[VeLa+09] discusses some security and privacy improvements for the Belgian eIDtechnology. With [MOCCA] an open source environment for the Austrian Citizen Cardis available. Recently, an open source middleware for the Portuguese Citizen Card wasintroduced [MEDI11].
For the generation and verification of XML Advanced Electronic Signatures (XAdES)the [OpenXAdES] project provided a C-based library and in [Gonç10] a Java-basedimplementation has been developed. The Sirius project [Sirius-SS] develops an opensource signing server, which supports the interfaces standardized in [OASIS-DSS].
With respect to smart cards, there are already two open source projects [OpenSC] and[OpenSCDP], which aim at providing a platform-independent framework for the use ofsmart cards. While [OpenSC] in particular supports cards with CryptographicInformation Application data according to part 15 of [ISO7816], the [OpenSCDP]project provides scripting based support for the German ID card and the Germanelectronic health card for example. For the Android-platform there is an open sourcesecure element evaluation kit [SEEK4Android], which implements [OpenMobile].
There are various frameworks and components in the area of the Security AssertionMarkup Language (SAML). [OpenSAML] is a platform-independent and open sourcerepresentative of them. The use of eID cards in a SAML-environment has been discussedin [EHS09] and [EHMS10]. Corresponding SAML-profiles have been defined in [BSI-TR03130] and [STORK]. The channel binding presented in Section 3.3.10 of Part 7 of[BSI-TR03112] may be used to prevent man-in-the-middle attacks. Unfortunately, thisapproach is only applicable to cards which feature the Extended Access Control protocolspecified in [BSI-TR3110], such as the German ID card for example. In order to providea secure SAML-binding, which may be used with arbitrary eID cards, the alternativesdiscussed in [SAML-HoK], [GaLiSc08] and [KSJG10] as well as the TLS-channelbinding specified in [RFC5929] may serve as starting points.
For PC-based platforms a trusted computing environment may be realized utilizing aTrusted Platform Module (TPM) and a Trusted Software Stack (TSS). The [jTSS]project provides an open source TSS implementation for the Java Platform. Because theOpen eCard App is required to run also on mobile platforms, particularly Android, it isnecessary to consider the specific security aspects for this platform in more detail.Android specific attacks have for example been shown in [DaDm+10] and there existseveral projects and publications that discuss possible ways to improve the security ofAndroid smartphones (cf. [BDDH+11], [NKZS10], [YZJF11] and [CoNC10]). Toprovide a robust and trustworthy implementation of the mobile eID client it is alsorequired to consider unconventional attack vectors such as discussed in [AGMB+10] and
On the design and implementation of the Open eCard App 97

[WaSt10]. On the other side there will be mobile device platforms, which are offeringenhanced security features like the Trusted Execution Environment (TEE) specified byGlobal Platform [GP-TEE]. The TEE realizes a secure operating system next to thestandard mobile operating system (e.g. Android, iOS, Windows Phone) and hence, canbe utilized to secure the mobile eID client. It offers the possibility to install new trustedapplications in the field, which are completely separated from each other andapplications running outside the trusted execution environment. Trusted applications cansecurely store data, access secure elements, perform cryptographic operations andprotocols and perform secure input and output using the display and keypad of themobile device.
3. Requirements for the Open eCard App
This section contains the main functional and non-functional requirements of thelightweight Open eCard App, where the key words MAY, SHOULD, SHALL andMUST are used as defined in [RFC2119].
R1. Support for all popular platforms
The Open eCard App MUST be designed to support the most popular client platforms.In addition to PCs based on Windows, Linux or Mac OS this in particular includes NFC-enabled mobile devices, which are for example based on [Android]. On the other side –unlike the clients considered in [EiHü08], [Hors09] and [Hors11] – we do not restrictourselves to the limited feature set provided by the Java ME platform, but only requirethat it SHOULD be possible to port our client to such a platform if it turns out to benecessary.
R2. Modularity, open interfaces and extensibility
In order to facilitate the distributed development and portability to different platforms,the Open eCard App MUST consist of suitable modules, which are connected throughopen interfaces. Those modules SHOULD be designed to minimize the effort of creatinga new client application for a specific purpose2. For features, which are expected tochange over time, such as cryptographic and communication protocols, the Open eCardApp SHALL provide suitable extension mechanisms. The basic cryptographicmechanisms SHOULD be provided in form of a standardized cryptographic module toensure implementation independence and interoperability for cryptographic functions oneach supported platform. In particular the Graphical User Interface (GUI), which isexpected to be very platform specific, MUST be clearly separated from the othermodules.
R3. Architecture based on ISO/IEC 24727
The architecture of the Open eCard App SHALL be based on the international secureelement infrastructure standard [ISO24727]. This means in particular that the InterfaceDevice (IFD) API (cf. [ISO24727], part 4) and the Service Access Layer (SAL) API (cf.[ISO24727], part 3) MUST be supported. The IFD Layer SHALL allow to use a widerange of external card terminals, e.g. those based on the PC/SC architecture or
2 As sketched in [BHWH11] the mobile phone based eID client may serve as smart card terminal for a PC-based eID-client or as standalone system for mobile authentication scenarios.
98 On the design and implementation of the Open eCard App

[OpenMobile], and NFC-modules integrated in mobile phones and SHOULD supportTPMs, if present on the platform. The SAL SHALL support arbitrary smart cards, whichare described by a CardInfo file according to Section 9 of [CEN15480]3.
R4. Support for electronic signatures and federated identity management
The Open eCard App SHOULD be able to create advanced electronic signatures instandardized formats (cf. [ETSI-101733], [ETSI-101903] and [ETSI-102778]) using thesupported eID cards and / or suitable server systems.
R5. Support for federated identity management
The Open eCard App SHOULD support federated identity management protocolsaccording to internationally acknowledged standards, such as [SAML(v2.0)] forexample.
R6. Browser integration
The Open eCard App MUST be start- and accessible from within a browser to performan authentication at web-based services.
R7. Secure components
The Open eCard App MUST utilize the security features of the attached components.This includes the usage of the secure input and output facility of an attached reader aswell as the usage of a possibly available secure operating system like the TrustedExecution Environment for mobile devices [GP-TEE].
R8. Security
The Open eCard App MUST be designed in a security aware manner, such that a formalsecurity evaluation, e.g. according to Common Criteria [CC(v3.1)], is possible withmodest additional effort. Furthermore the Open eCard App SHALL use the securityfeatures provided by attached components. This includes the usage of the secure inputand output facility of an attached reader as well as the usage of a possibly availablesecure operating system like the Trusted Execution Environment [GP-TEE] for mobiledevices.
R9. Open source capable
The Open eCard App SHOULD be substantially free of external dependencies. This wayit can be released as open source software under a suitable license and there is no regardto take on rights of third parties.
R10. Transparency
The Open eCard App SHOULD provide information to the user about all the existingconnections (Internet), access to smart card and other actions.
R11. Stability
The released versions of the Open eCard App SHOULD always be stable, i.e. workwithout crashes and undesired behaviour.
3 See http://www.cardinfo.eu for more information about this topic.
On the design and implementation of the Open eCard App 99

R12. High usability and accessible GUI
The design and implementation of a GUI MUST consider platform specific issues tomaximize usability and the GUI SHOULD support accessibility features.
4. High Level Design
Based on previous work (e.g. [BSI-TR03112], [Petr11] and [Hors11]) and therequirements above, the high level design depicted in Figure 1 has been developed. Itenvisages the implementation of the Open eCard App in the Java programminglanguage, making use of the respective architectural concepts. Java is selected mainlybecause it is supported on all target platforms (R1) and allows applications that caneasily be modularized and updated (R2).
Figure 1: High Level Design of the Open eCard App
The main building blocks of the Open eCard App are as follows:
• Interface Device (IFD)
This component implements the IFD interface as specified in part 6 of [BSI-TR03112] and part 4 of [ISO24727]. It also contains the additional interfaces forpassword-based protocols such as PACE (cf. Section 5.1). It provides a generalizedinterface for communication with specific readers and smart cards, to enable theuser to use arbitrary card terminals or smart cards.
100 On the design and implementation of the Open eCard App

• Event Manager
The Event Manager monitors the occurrence of events (e.g. added or removedterminals or cards) and performs the type-recognition of freshly captured cards (cf.Sections 5.3 - 5.4).
• Service Access Layer (SAL)
This module implements the Service Access Layer as specified in part 4 of [BSI-TR03112] and part 3 of [ISO24727]. An important aspect of this component is thatit provides an extension mechanism, which enables the addition of newauthentication protocols in the future without changing other parts of theimplementation.
• Crypto
The crypto module unifies the access to cryptographic functions of the othermodules. Through the use of the Java Cryptography Architecture (JCA) [JCA]interface and the provider architecture offered by it, it is easy to exchange theCryptographic Service Provider (CSP) and hence use the most suitable one for eachplatform. As JCA provider for the presented eID client primarily [BouncyCastle]4,[FlexiProvider] and [IAIK-JCE] come in mind.
• Graphical User Interface (GUI)
The GUI is connected via an abstract interface (cf. Section 5.2) and hence is easilyinterchangeable. This allows providing platform-specific GUI-implementations,while leaving the other modules unchanged.
• Security Assertion Markup Language (SAML)
This component provides support for the SAML Enhanced Client and Proxy (ECP)profile [SAML-ECP], which allows receiving an AuthnRequest via the PAOS-binding [PAOS-v2.0] and starting the eID based authentication procedure with asuitable Identity Provider. Compared to the Web Browser Single Sign-On (SSO)profile used in [BSI-TR03130], the support of the ECP-profile leads to a morestraightforward authentication procedure that is easier to protect.
• Electronic Signatures (eSign)
This component allows to create advanced electronic signatures according to [ETSI-101733], [ETSI-101903] and [ETSI-102778] using the interface defined in part 2 of[BSI-TR03112], which is based on [OASIS-DSS].
• Dispatcher
The dispatcher provides a centralized entry point for the handling of incoming andoutgoing messages. By this centralization, the dispatcher helps to reduce the amountof Java code and the complexity of the Open eCard App.
4 In order to avoid conflicts with the crippled version of Bouncy Castle integrated in Android, it may turn outto be advantageous to use [SpongeCastle] instead.
On the design and implementation of the Open eCard App 101

• Transport
The transport component encapsulates the individual transport protocols settled atvarious transport layers. The layered structure makes it easy to use the protocolsneeded for a specific use case and to add new protocols. In order to support thecurrently available eID servers, the protocol stack will at least allow exchangingPAOS messages, which are bound to HTTP and require TLS and TCP/IP to betransported. However the protocol stack of the eID client is designed to additionallysupport other bindings (e.g. SOAP [SOAP-v1.1]) and alternative protocols such asthe Austrian Security Token Abstraction Layer (STAL) [MOCCA] or the eID appletprotocol used in Belgium [eID-Applet].
• Browser Integration
As the Open eCard App should start automatically (without requiring further actionby the user) on accessing an appropriately prepared website, there has to be amechanism for the browser to launch the application and pass over (connection-)parameters. For this purpose, the eID activation mechanisms specified in part 7 of[BSI-TR03112] and the cryptographic interfaces supported by popular browsers(e.g. [PKCS#11]) are implemented in this module.
5. Selected Aspects of the Module Design and Implementation
This section highlights selected aspects of the design and implementation of the OpeneCard App.
5.1 PACE in IFD Layer
The standardisation of the IFD interface in part 4 of [ISO24727] took place before alldetails of the PACE protocol (see [BSI-TR3110] and [ICAO-PACE]) and thecorresponding card terminals (see [BSI-TR03119] and [PC/SC-PACE]) were specified.Thus PACE-support is currently not yet integrated in the standardized IFD layer andexisting eID clients such as [AusweisApp], [bos-Autent] and [Ageto-AA] seem toimplement PACE on top of the IFD layer. As in this case the Service Access Layerneeds to be aware of the detailed capabilities of the connected card terminal this is notoptimal from an architectural point of view.
To overcome this problem we propose an extension for the IFD API, that contains thetwo commands EstablishChannel and DestroyChannel, which are protocolagnostic generalizations of the EstablishPACEChannel and DestroyPACE-Channel commands defined in [PC/SC-PACE] and (partly) in [BSI-TR03119].
102 On the design and implementation of the Open eCard App

5.2 GUI Interface
As the Graphical User Interface (GUI) needs to be developed in a platform specificmanner, it is necessary to introduce an interface, which decouples the user interface fromthe rest of the eID client. As the Open eCard App shall support a wide range of smartcard terminals with varying capabilities in a homogeneous manner, the GUI needs tocompensate these differences and provide a card- and terminal-specific dialogue toobtain the user consent for a specific transaction. In order to support arbitrary terminalsand eID cards, the GUI interface is defined in an abstract manner. A user dialoguespecification consists of a sequence of steps, which in turn may contain a sequence ofinput and output elements. The input elements allow to mark check boxes, which mayfor example be used to restrict a Certificate Holder Authorization Template (cf. [BSI-TR3110], Annex C.1.5 and C.4), or capture a PIN.
5.3 Event Manager
Events in the IFD layer (e.g. insertion or removal of cards) can be recognized using theWait function of the IFD interface as specified in part 6 of [BSI-TR03112] and in part 4of [ISO24727]. This function returns the state of a monitored terminal, after an event hasoccurred. In order to identify a specific event, the calling component must compare thereceived state with the previous state of the terminal. Thus, every component that makesuse of the Wait function would need to implement this kind of comparison, which is notvery convenient.
To centralize this functionality, we introduce an Event Manager, which monitors theoccurrence of events, triggers the card recognition and distributes the receivedinformation to all components that have registered to it. A component can register forone or more specific events (e.g. insertion of cards) and will be notified if one of themoccurs. Furthermore custom filters can be applied to the Event Manager, in case thepredefined registration options are not sufficient.
5.4 Card Recognition
In order to support the widest possible range of eID cards, the Open eCard App supportsCardInfo structures according to [BSI-TR03112] Part 4, Annex A and [CEN15480]Section 9. For the recognition of the card type it is necessary to construct a decision tree(cf. [BSI-TR03112] Part 4, Figure 5 and [Wich11] Section 5.1.2) using the set ofavailable CardInfo files. While this construction could be performed by an eID clientupon initialization, we propose to perform this construction only once and store theconstructed decision tree in a suitable XML format. As there is no need for the eID clientto perform the construction itself, we propose that a suitable infrastructure component,such as the CardInfo repository (cf. [BSI-TR03112] Part 5), performs the constructionand distributes the compact decision tree.
On the design and implementation of the Open eCard App 103

The Card Recognition module within the Open eCard App (cf. Figure 1) works with therecognition tree and just needs access to the IFD. As soon as a new card is captured anda corresponding event is identified by the Event Manager (cf. Section 5.3), the cardrecognition procedure is performed by connecting the card and walking through therecognition tree until the card type is determined. In the eCard-API layering model, thisrequest to the Card Recognition module is performed by the SAL. However, with theavailability of the Event Manager, the most natural approach is to perform therecognition right after a “card inserted” event and distribute the information with a“card recognised” event afterwards. This information distribution mechanism has theadvantage that not only the SAL, but also other modules which need this kind ofinformation (e.g. the GUI), can act as an event sink, too.
6. Summary
The paper at hand presents the design and selected implementation details of the OpeneCard App. This eID client supports arbitrary smart cards, which are described byCardInfo files and is designed to support PC-based as well as mobile platforms, e.g.based on [Android]. As the Open eCard App is designed to be as lightweight and usableas possible and will be distributed under a suitable open source license, it may providean interesting open alternative to the currently available eID clients such as the[AusweisApp].
104 On the design and implementation of the Open eCard App

7. References
[Ageto-AA] Ageto Innovation GmbH: AGETO AusweisApp,http://www.ageto.de/egovernment/ageto-ausweis-app
[AGIMO-NSF] Australian Government Information Management Office (AGIMO): NationalSmartcard Framework, http://www.finance.gov.au/e-government/security-and-authentication/smartcard-framework.html
[AGMB+10] A. Aviv, K. Gibson, E. Mossop, M. Blaze and J. Smith: Smudge attacks onsmartphone touch screens, WOOT'10 Proceedings of the 4th USENIXconference on offensive technologies,http://www.usenix.org/events/woot10/tech/full_papers/Aviv.pdf
[Android] Google Inc.: Android Website, http://www.android.com/
[Androsmex] T. Senger & al.: Androsmex Project - A mobile smart card explorer forandroid smartphones with NFC capabilities,http://code.google.com/p/androsmex/
[AusweisApp] BSI: Official Portal for the eID-client “AusweisApp”,http://www.ausweisapp.de
[BDDH+11] S. Bugiel, L. Davi, A. Dmitrienko, S. Heuser, A. Sadeghi and B. Shastry:Practical and Lightweight Domain Isolation on Android, Proceedings of the1st ACM CCS Workshop on Security and Privacy in Mobile Devices (SPSM),ACM Press, October 2011, http://www.informatik.tu-darmstadt.de/fileadmin/user_upload/Group_TRUST/PubsPDF/spsm18-bugiel.pdf
[Beil10] K. Beilke: Mobile eCard-API, Humboldt-University, Diploma Thesis, 2010,http://sar.informatik.hu-berlin.de/research/publications/#SAR-PR-2010-12
[BHWH11] J. Braun, M. Horsch, A. Wiesmaier and D. Hühnlein: Mobile Authenticationand Signature (in German), DACH Security 2011, pp. 1-12,http://www.cdc.informatik.tu-darmstadt.de/mona/pubs/201109_DACH11_Mobile_Authentisierung_und_Signatur.pdf
[BouncyCastle] The Legion of the Bouncy Castle: Bouncy Castle API,http://www.bouncycastle.org/
[bos-Autent] bos GmbH & Co. KG: Governikus Autent, http://www.bos-bremen.de/de/governikus_autent/1854605/
[BSI-TR3110] BSI: Advanced Security Mechanism for Machine Readable Travel Documents– Extended Access Control (EAC), Technical Directive of the Federal Officefor Information Security Nr. 03110, BSI TR-03110, Version 2.05,https://www.bsi.bund.de/ContentBSI/Publikationen/TechnischeRichtlinien/tr03110/index_htm.html
[BSI-TR03112] BSI: eCard-API-Framework, Technical Directive of the Federal Office forInformation Security Nr. 03112, BSI TR-03112, Version 1.1,https://www.bsi.bund.de/ContentBSI/Publikationen/TechnischeRichtlinien/tr03112/index_htm.html
On the design and implementation of the Open eCard App 105

[BSI-TR03119] BSI: Requirements for Card Terminals with support for the new German eID-card, in German, Technical Directive of the Federal Office for InformationSecurity Nr. 03119, BSI TR-03119, Version 1.2, 27.03.2011,https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Publikationen/TechnischeRichtlinien/TR03119/BSI-TR-03119_V1_pdf
[BSI-TR03130] BSI: eID-Server, Technical Directive of the Federal Office for InformationSecurity Nr. 03130 (in German), BSI TR-03130, Version 1.4.1,https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Publikationen/TechnischeRichtlinien/TR03130/TR-03130_TR-eID-Server_V1_4_pdf
[CC(v3.1)] CCMB: Common Criteria for Information Technology Security Evaluation,Version 3.1, part 1-3, 2009, http://www.commoncriteriaportal.org/cc/
[CEN15480] CEN: Identification card systems — European Citizen Card, CEN TS 15480(Part 1-4)
[CoNC10] M. Conti1, V. Nguyen and B. Crispo: CRePE - Context-Related PolicyEnforcement for Android, ISC'10 Proceedings of the 13th internationalconference on Information security, Springer, ISBN: 978-3-642-18177-1,http://www.few.vu.nl/~mconti/papers/C16.pdf
[DaDm+10] L. Davi, A. Dmitrienko, A. Sadeghi and M. Winandy: Privilege EscalationAttacks on Android, ISC'10 Proceedings of the 13th international conferenceon Information security, Springer, ISBN: 978-3-642-18177-1,http://www.ei.rub.de/media/trust/veroeffentlichungen/2010/11/13/DDSW2010_Privilege_Escalation_Attacks_on_Android.pdf
[eID-Applet] F. Cornelis & al.: eID-Applet Project, http://code.google.com/p/eid-applet/
[eID-DSS] F. Cornelis & al.: eID Digital Signature Service Project,http://code.google.com/p/eid-dss/
[eidlib] K. Overdulve: eidlib Project, http://code.google.com/p/eidlib/
[EHS09] J. Eichholz, D. Hühnlein and J. Schwenk: SAMLizing the European CitizenCard, in A. Brömme & al. (Ed.), BIOSIG 2009: Biometrics and ElectronicSignatures, GI-Edition Lecture Notes in Informatics (LNI) 155, 2009, pp. 105-117, http://www.ecsec.de/pub/SAMLizing-ECC.pdf
[EHMS10] J. Eichholz, D. Hühnlein, G. Meister and J. Schmölz: New Authenticationconcepts for electronic Identity Tokens, in Proceedings of “ISSE 2010”,Vieweg, 2010, pp. 26-38, http://www.ecsec.de/pub/ISSE2010.pdf
[EiHü08] J. Eichholz and D. Hühnlein: Using ISO/IEC 24727 for mobile devices, inProceedings of Sicherheit 2008, GI, LNI 128, pp. 581-587,http://www.ecsec.de/pub/2008_Sicherheit.pdf
[ETSI-101733] ETSI: CMS Advanced Electronic Signatures (CAdES), ETSI TS 101 733,Version 1.8.1. http://pda.etsi.org/pda/queryform.asp, December 2009
[ETSI-101903] ETSI: Technical Specification XML Advanced Electronic Signatures (XAdES),ETSI TS 101 903, Version 1.4.1, http://pda.etsi.org/pda/queryform.asp, June2009
[ETSI-102778] ETSI: PDF Advanced Electronic Signature Profiles, ETSI TS 102 778, part 1-5, http://pda.etsi.org/pda/queryform.asp, 2009
[FlexiProvider] M. Maurer & al.: Flexiprovider Project, http://www.flexiprovider.de
[GaLiSc08] S. Gajek, L. Liao and J. Schwenk: Stronger TLS Bindings for SAML Assertionsand SAML Artifacts, Proceedings of the 2008 ACM workshop on Secure webservices
106 On the design and implementation of the Open eCard App

[Gonç10] L. Gonçalves: XAdES4j— a Java Library for XadES Signature Services,Master Thesis, Instituto Superior de Engenharia de Lisboa, 2010,http://luisfsgoncalves.files.wordpress.com/2011/01/xades4j.pdf
[GP-TEE] Global Platform: The Trusted Execution Environment: Delivering EnhancedSecurity at a Lower Cost to the Mobile Market, Whitepaper, February 2011,http://www.globalplatform.org/documents/GlobalPlatform_TEE_White_Paper_Feb2011.pdf
[Hors09] M. Horsch: MobilePACE – Password Authenticated Connection Establishmentimplementation on mobile devices, Bachelor Thesis, TU Darmstadt, 2009,http://www.cdc.informatik.tu-darmstadt.de/mona/pubs/200909_BA_MobilePACE.pdf
[Hors11] M. Horsch: MONA - Mobile Authentication with the new German eID-card (inGerman), Master Thesis, TU Darmstadt, 2011, http://www.cdc.informatik.tu-darmstadt.de/mona/pubs/201107_MA_Mobile%20Authentisierung%20mit%20dem%20neuen%20Personalausweis%20(MONA).pdf
[HoSt11] M. Horsch and M. Stopczynski: The German eCard-Strategy, TechnicalReport: TI-11/01, TU Darmstadt, http://www.cdc.informatik.tu-darmstadt.de/reports/reports/the_german_ecard-strategy.pdf
[IAIK-JCE] TU Graz: IAIK Provider for the Java™ Cryptography Extension (IAIK-JCE),http://jce.iaik.tugraz.at/
[ICAO-PACE] ICAO: Supplemental Access Control for Machine Readable TravelDocuments, ICAO Technical Report, Version 1.01, 11.11.2010,http://www2.icao.int/en/MRTD/Downloads/Technical%20Reports/Technical%20Report.pdf
[ISO7816] ISO/IEC: Identification cards – Integrated circuit cards, ISO/IEC 7816 (part1-15)
[ISO14443] ISO/IEC: Contactless integrated circuit cards - Proximity cards, ISO/IEC14443 (Part 1-4)
[ISO24727] ISO/IEC: Identification cards – Integrated circuit cards programminginterfaces, ISO/IEC 24727 (Part 1-5)
[Jahn11] N. Jahn: rosecat - Architecture and Implementation of an Open Source eIDClient, in German, Diploma Thesis, University Koblenz-Landau, 2011,http://kola.opus.hbz-nrw.de/volltexte/2011/672/pdf/Diplomarbeit.pdf
[JCA] Oracle: Java ™ Cryptography Architecture (JCA) Reference Guide,http://download.oracle.com/javase/6/docs/technotes/guides/security/crypto/CryptoSpec.html
[JMRTD] M. Oostdijk & al.: JMRTD Project, http://jmrtd.org/
[jTSS] M. Pirkner, R. Toegl & al.: Trusted Computing for the Java Platform Project,http://sourceforge.net/projects/trustedjava/
[Kief10] F. Kiefer: Efficient Implementation of the PACE and EAC Protocol for mobiledevices, in German, Bachelor Thesis, TU Darmstadt, 2010,http://www.cdc.informatik.tu-darmstadt.de/mona/pubs/201007_BA_Effiziente_Implementierung_des_PACE-_und_EAC_Protokolls_fuer_mobile_Geraete.pdf
On the design and implementation of the Open eCard App 107

[Kowa07] B. Kowalski: The eCard-Strategy of the Federal Government of Germany, inGerman, in BIOSIG 2007: Biometrics and Electronic Signatures, Proceedingsof the Special Interest Group on Biometrics and Electronic Signatures, LNI108, pp. 87–96, 2007, http://subs.emis.de/LNI/Proceedings/Proceedings108/gi-proc-108-008.pdf
[KSJG10] F. Kohlar, J. Schwenk, M. Jensen and S. Gajek: Secure Bindings of SAMLAssertions to TLS Sessions, Proceedings of the Fifth International Conferenceon Availability, Reliability and Security (ARES), 2010
[MEDI11] L. Medinas: The development of the new Free/Opensource Portuguese CitizenCard Middleware, https://codebits.eu/intra/s/proposal/212
[MMO11] W. Müller, F. Morgner and D. Oepen: Mobile scenario for the new German IDcard, in German, in 21st Smartcard-Workshop, 2.-3. Februar 2011, Darmstadt,pp. 179-188, 2011, http://sar.informatik.hu-berlin.de/research/publications/SAR-PR-2011-01/SAR-PR-2011-01.pdf
[MOCCA] MOCCA: Modular Open Citizen Card Architecture Project,http://mocca.egovlabs.gv.at/
[MOMR11] F. Morgner, D. Oepen, W. Müller and J.-P. Redlich: Mobile Reader for thenew German ID card, in German, in 12th German IT-Security Congress,SecuMedia, pp. 227-240, 2011, http://sar.informatik.hu-berlin.de/research/publications/SAR-PR-2011-04/SAR-PR-2011-04.pdf
[NIST-PIV] NIST: About Personal Identity Verification (PIV) of Federal Employees andContractors, http://csrc.nist.gov/groups/SNS/piv/index.html
[NKZS10] M. Nauman , S. Khan , X. Zhang and J. Seifert: Beyond Kernel-level IntegrityMeasurement: Enabling Remote Attestation for the Android Platform, In Trustand Trustworthy Computing, Vol. 6101 (2010),http://profsandhu.com/zhang/pub/trust10-android.pdf
[OASIS-DSS] OASIS: Digital Signature Service Core Protocols, Elements, and Bindings,Version 1.0, OASIS Standard, via http://docs.oasis-open.org/dss/v1.0/oasis-dss-core-spec-v1.0-os.pdf
[Oepe10] D. Oepen: Authentication in the mobile web – on the usability of eID basedauthentication using an NFC based mobile device, in German, DiplomaThesis, Humboldt-University, 2010, http://sar.informatik.hu-berlin.de/research/publications/SAR-PR-2010-11/SAR-PR-2010-11_.pdf
[OpenPACE] F. Morgner & al.: OpenPACE Project - Crypto library for the PACE protocol,http://openpace.sourceforge.net/
[OpenMobile] SIM Card Alliance: Open Mobile API specification, Version 1.2,http://tinyurl.com/ckl7sbt
[OpenSAML] S. Cantor & al.: OpenSAML Project,https://wiki.shibboleth.net/confluence/display/OpenSAML/Home
[OpenSC] M. Paljak & al.: OpenSC Project - tools and libraries for smart card,http://www.opensc-project.org
[OpenSCDP] A. Schwier & al.: OpenSCDP Project - Open Smart Card DevelopmentPlatform, http://www.openscdp.org/
[OpenXAdES] T. Martens & al.: OpenXAdES Project, http://www.openxades.org/
108 On the design and implementation of the Open eCard App

[PAOS-v2.0] Liberty Alliance Project: Liberty Reverse HTTP Binding for SOAPSpecification, Version v2.0, viahttp://www.projectliberty.org/liberty/content/download/909/6303/file/liberty-paos-v2.0.pdf
[PC/SC-PACE] PC/SC Workgroup: Interoperability Specification for ICCs and PersonalComputer Systems - Part 10 IFDs with Secure PIN Entry Capabilities –Amendment 1, 2011,http://www.pcscworkgroup.com/specifications/files/pcsc10_v2.02.08_AMD1.pdf
[Petr11] D. Petrautzki: Security of Authentication Procedures for Mobile Devices, (inGerman), Master Thesis, Hochschule Coburg, 2011
[PKCS#11] RSA Laboratories: PKCS #11 Base Functionality v2.30: Cryptoki – Draft 4,10 July 2009
[RFC2119] S. Bradner: Key words for use in RFCs to Indicate Requirement Levels, IETFRFC 2119, via http://www.ietf.org/rfc/rfc2119.txt
[RFC5929] J. Altman, N. Williams, L. Zhu: Channel Bindings for TLS, IETF RFC 5929,via http://www.ietf.org/rfc/rfc5929.txt
[SAML(v2.0)] S. Cantor, J. Kemp, R. Philpott and E. Maler: Assertions and Protocol for theOASIS Security Assertion Markup Language (SAML) V2.0, OASIS Standard,15.03.2005. http://docs.oasis-open.org/security/saml/v2.0/saml-core-2.0-os.pdf, 2005
[SAML-HoK] N. Klingenstein: SAML V2.0 Holder-of-Key Web Browser SSO Profile, OASISCommittee Draft 02, 05.07.2009. http://www.oasis-open.org/committees/download.php/33239/sstc-saml-holder-of-key-browser-sso-cd-02.pdf, 2009
[SAML-ECP] S. Cantor & al.: SAML V2.0 Enhanced Client or Proxy Profile Version 2.0,Working Draft 02, 19.02.2011, http://www.oasis-open.org/committees/download.php/41209/sstc-saml-ecp-v2.0-wd02.pdf
[SEEK4Android] F. Schäfer & al.: Secure Element Evaluation Kit for the Android platformProject, http://code.google.com/p/seek-for-android/
[Sirius-SS] A. Kühne, H. Veit & al.: Sirius Sign Server Project,http://sourceforge.net/projects/sirius-sign/
[SOAP-v1.1] W3C Note: Simple Object Access Protocol (SOAP) 1.1, 8 May 2000, viahttp://www.w3.org/TR/2000/NOTE-SOAP-20000508
[SpongeCastle] R. Tyley: Sponge Castle Project, https://github.com/rtyley/spongycastle
[STORK] J. Alcalde-Moraño, J. L. Hernández-Ardieta, A. Johnston, D. Martinez, B.Zwattendorfer: STORK Deliverable D5.8.1b – Interface Specification,08.09.2009, https://www.eid-stork.eu/index.php?option=com_processes&Itemid=&act=streamDocument&did=960
[T7-eCard-QES] T7 e.V.: Common PKI – Signature API, in German,http://www.t7ev.org/themen/anwendungsanbieter/common-pki-signatur-api.html
On the design and implementation of the Open eCard App 109

[VeLa+09] P. Verhaeghe, J. Lapon, B. De Decker, V. Naessens and K. Verslype: Securityand privacy improvements for the Belgian eID technology, 2009, Springer,Emerging Challenges for Security, Privacy and Trust vol:297 pages:237-247,4th IFIP International Information Security Conference (SEC) edition:24location:Pafos, Cyprus date:18-20 May 2009, ISBN: 978-3-642-01243-3,https://lirias.kuleuven.be/bitstream/123456789/215296/1/paper.pdf
[WaSt10] Z. Wang, A. Stavrou: Exploiting Smart-Phone USB Connectivity For Fun AndProfit, ACSAC '10, Proceedings of the 26th Annual Computer SecurityApplications Conference, www.cs.gmu.edu/~astavrou/research/acsac10.pdf
[WHB+11] A. Wiesmaier, M. Horsch, J. Braun, F. Kiefer, D. Hühnlein, F. Strenzke and J.Buchmann: An efficient PACE Implementation for mobile Devices, ASIA CCS'11: 6th ACM Symposium on Information, Computer and CommunicationsSecurity, vol. ACM Symposium on Information, Computer andCommunications Security, p. 176-185, ACM, March 2011,https://www.cdc.informatik.tu-darmstadt.de/de/publikations-details/?no_cache=1&pub_id=TUD-CS-2011-0064
[Wich11] T. Wich: Tools for automated utilisation of Smart-Card Descriptions, MasterThesis, Hochschule Coburg, 2011
[YZJF11] Y. Zhou, X. Zhang, X. Jiang and V. Freeh: Taming Information-StealingSmartphone Applications (on Android), 4th International Conference on Trustand Trustworthy Computing, Pittsburgh,http://online.wsj.com/public/resources/documents/TISSA042511.pdf
110 On the design and implementation of the Open eCard App

Towards stateless, client-side driven Cross-Site RequestForgery protection for Web applications
Sebastian Lekies, Walter Tighzert, and Martin JohnsSAP Research
Abstract: Cross-site request forgery (CSRF) is one of the dominant threats in the Webapplication landscape. In this paper, we present a lightweight and stateless protectionmechanism that can be added to an existing application without requiring changesto the application’s code. The key functionality of the approach, which is based onthe double-submit technique, is purely implemented on the client-side. This way fullcoverage of client-side generation of HTTP requests is provided.
1 Introduction
Cross-site Request Forgery (CSRF) is one of the dominant threats in the Web applicationlandscape. It has been rated by the OWASP on place five in their widely regarded “Top TenMost Critical Web Application Security Vulnerabilities” [Ope10a]. CSRF exists due to anunfortunate combination of poor design choices which have been made while evolvingthe Web application paradigm. The fundamental cause being the adding of transparentauthentication tracking using HTTP cookies onto a stateless hypertext medium consistingof HTTP and HTML. For this reason, there is no “easy fix” for CSRF. Instead, the currentpractice is to selectively identify all potential vulnerable interfaces that a Web applicationexposes and protecting them manually within the application logic.
In this paper, we present a lightweight and stateless protection mechanism which can beadded to an application deployment without requiring any changes to the actual applicati-on code. Our approach reliably outfits all legitimate HTTP requests with evidence whichallows the Web server to process these requests securely.
2 Technical background
In this section, we briefly revisit the technical background of Web authentication trackingand how it can be misused by CSRF, before detailing the mechanism of the double-submitcookie protection.

2.1 Web authentication tracking
The HTTP protocol is stateless. For this reason, the application itself has to provide mea-sures to track sessions of users that span more than one request-response pair. The mostcommon approach to do so relies on HTTP cookies: The first time a client connects to aserver, the server generates a random, hard to guess number (the so-called session iden-tifier) and sends it to the client. From now on, the client’s Web browser will attach thiscookie value to all subsequent requests, allowing the server to keep track of the session.
In case the Web application requires authentication, the user will enter his credentials(usually a combination of a username and a password). After validating the provided in-formation, the server upgrades the user’s session context into an authenticated state. Inconsequence, the session identifier is utilized as the user’s authentication token: All fur-ther requests which carry the user’s session identifier will be regarded by the Web serveras being authenticated.
2.2 CSRF
Cross-Site Request Forgery (CSRF) is an attack that consists in tricking the victim to sendan authenticated HTTP request to a target Web server, e.g., via visiting a malicious pagethat creates such a request in the background. In cases that the user is currently in anauthenticated state with the targeted Web site, the browser will automatically attach thesession cookies to such requests, making the server believe that this request is a legitimateone and, thus, may cause state-changing actions on the server-side.
Take for instance the attack illustrated in Fig. 1: First, the victim logs into his online bankaccount (www.bank.com) and doesn’t log out. Afterwards, he navigates to a site underthe control of an attacker (www.attacker.org). Tricking the victim to visit this website canbe done, for instance, by sending an email to the victim promising him nice cat pictures.Unfortunately, the website doesn’t contain only pictures. A GET cross-domain request towww.bank.com is made using an invisible image tag that carries a src-URL pointing to thebank’s server1. As the user didn’t log out, the request is made in his authentication contextas the browser attach the cookies to this request and the money transfer is started. TheSame Origin Policy doesn’t prevent this request to be made, it only prevent the attackerto read the request’s response but the attacker is not interested in the response, only in theaction that has been triggered on the server-side.
2.3 CSRF protection with double-submit cookies
The most common protection against CSRF is to restrict the state changing action requeststo POST requests and the usage of a nonce. When a form is requested, the application
1There are different possibilities to make such cross domain requests: an HTTP GET request can be embeddedin an image tag whereas a POST request can be the result of a FORM created using JavaScript.
112 Towards stateless, client-side driven Cross-Site Request Forgery protection

www.bank.com
Cookie: auth_ok
www.attacker.org
GET transfer.cgi?am=10000&an=3422421
Abbildung 1: CSRF attack
generates a nonce and attach it to the form as a hidden field. When the user submits aform, the nonce is then sent back to the server, which then checks if this nonce is valid.One of the disadvantage of this protection is that the server has to manage all nonces,i.e., the server has to remember each nonce for each form, invalidate the expired one.This can under certain circumstances even lead to a Denial of Service attack, where anattacker successively requests forms, generating for each form a new nonce. With eachnew nonce the available memory of the server is reduced until nothing is left anymoreto store legitimate data. Moreover, this protection can not be easily integrated in a legacyapplication without having to modify the application’s code.
The double-submit cookie method as first described in [ZF08] offers a protection againstCSRF that can be implemented without the need for server-side state. Thereby, the CSRFtoken is submitted twice. Once in the cookie and simultaneously within the actual request.As the cookie is protected by the Same-Origin Policy only same-domain scripts can accessthe cookie and thus write or receive the respective value. Hence, if an identical value isstored within the cookie and the form, the server side can be sure that the request wasconducted by a same-domain resource. As a result, cross-domain resources are not able tocreate a valid requests and therefore CSRF attacks are rendered void.
Nevertheless, this methods still requires some code modifications, as the token attachmentneeds to be conducted within the application’s code. In the next section we present a me-chanism for legacy applications that makes use of the double-submit cookie technique, butwithout the need for code modifications. In order to do so, we implemented a library thatconducts the token attachment completely on the client-side.
3 Protection approach
This section is structured as follows: First we provide an outline of the general architectureof our approach (see Sec. 3.1). Then we explore our client-side framework in depth, cover-ing the aspects of HTML-tag augmentation (Sec. 3.2), dealing with implicit HTTP requestgeneration (Sec. 3.3), handling JavaScript-based HTTP request generation (Sec. 3.4) andcovering server-side redirects (Sec. 3.5).
Towards stateless, client-side driven Cross-Site Request Forgery protection 113

3.1 High-level overview
Our proposed protection mechanism, which is based on the double-submit cookie techni-que (see Sec. 2.3) consists of a client-side and a server-side component:
On the server-side a proxy (in the following called gatekeeper) tracks any incoming requestand validates whether the request carries a valid token according to the double-submitscheme. Additionally, the gatekeeper holds a whitelist of defined entry points for the Webapplication that a client is allowed to call without a valid token. Any request that does notcarry a valid token and is targeted towards a non-whitelisted resource is automatically dis-carded by the gatekeeper2. Besides that, the gatekeeper injects the client-side componentin the form of a JavaScript library into any outgoing response by inserting an HTML scriptelement directly into the beginning of the document’s head section. Therewith, the JavaS-cript library is executed before the HTML rendering takes place or before any other scriptruns. Its duty is to attach the CSRF token according to the double-submit scheme to anyoutgoing request targeted towards the server. Unlike other approaches, such as [JKK06],which rely on server-side rewriting of the delivered HTML, our rewriting method is im-plemented completely on the client-side. This way, we overcome server-side completenessproblems (see Sec. 4.2 for details).
Within a browser multiple different techniques can be leveraged to create state changingHTTP requests. Each of these mechanisms has to ensure that CSRF tokens are attachedto valid requests. Otherwise a valid request would be discarded by the gatekeeper (as itdoes not carry a valid token). Hence, the client-side component needs to implement such atoken attachment mechanism for any of these techniques. In general we are, thereby, ableto distinguish between 4 different possibilities to create valid HTTP requests:
1. Requests that are caused by a user interacting with DOM elements (e.g. ’a’ tags or’form’ elements)
2. Requests that are implicitly generated by HTML tags (e.g. frames, img, script, linktags)
3. Requests that are created by JavaScript’s XMLHttpRequest
4. Redirects triggered by the server
3.2 Requests caused by a user interacting with DOM elements
Traditionally, requests within a Web browser are caused by user interaction, for exam-ple, by clicking on a link or submitting a form. Incorporating tokens into such a requestis straight forward. For the case of ’a’ tags our library simply rewrites the ’href’ attri-bute whenever such a tag is inserted into the document3. For form tags we can app-
2Note: Pictures, JS and CSS files are whitelisted by default3Note: Tags are only rewritten if the URLs point to the webpage’s own server, so that no foreign website is
accidentally able to receive the CSRF token.
114 Towards stateless, client-side driven Cross-Site Request Forgery protection

ly a similar technique, but instead of rewriting the location we register an onSubmithandler that takes care of attaching the token when a form is submitted. This techniqueof rewriting attributes or registering handler function is executed multiple times duringthe runtime of a document. Once, when the page has finished loading4 and once whe-never the DOM is manipulated in some way. Such a manipulation can be caused byseveral different JavaScript functions and DOM attributes such as document.write,document.createElement or .innerHTML. Therefore, our library wraps all thosefunctions and attributes by utilizing the function wrapping techniques described by Maga-zinius et al. [MPS10] . The wrapper functions simply call our rewrite engine whenever theyare invoked i.e. whenever the DOM is manipulated. In that way the rewriting functionalityis applied to the plain HTML elements that were already inserted into the page.
3.3 Implicitly generated Requests caused by HTML tags
Besides requests that are generated by the user, HTML tags are also able to create newrequests implicitly. For example, if a new img, iframe, link or script tag is inserted into adocument the browser immediately creates a new request. As a CSRF protection only hasto protect state changing actions it is not necessary to incorporate protection tokens intoimg, script and link tags as these tags are not supposed to be used for any state changingactivity. Therefore, the gatekeeper on the server-side won’t block any requests targetedtowards pictures, script- or CSS-files not carrying a protection token. Frames, however,could potentially be used to trigger actions in the name of the user, hence, CSRF tokenshave to be incorporated into it somehow. But as the browser fires the corresponding re-quests implicitly our JavaScript library is not able to do a rewriting of the location asdescribed in the previous section (the request is already sent out when our rewriting engi-ne is triggered). One way of overcoming this problem would be to parse the content givento DOM manipulating functions and rewriting iframe tags before inserting them into thepage. This, however, has two major drawbacks. On one hand parsing is prone to errors andimplies a lot of performance overhead and on the other hand we cannot parse the contentduring the initial loading of the Web page as this is completely done by the browser and notby JavaScript functions. Therefore, we would not be able to incorporate CSRF tokens intoiframes that are initially available within an HTML document. Hence we need to utilize adifferent method to overcome this problem.
Figure 2 shows the general setup of our framing approach. Whenever a request towards aprotected resource arrives without a valid token (1), the gatekeeper responds with a 200HTTP status code and delivers a piece of JavaScript code back to the client (2). The codewhich is seen in Listing 1 exploits the properties guaranteed by the Same-Origin Policyin order to detect whether a request was valid or not. The Same-Origin Policy allowsscripting access from one frame to another frame only if both frames run on the samedomain. So if the framed page has access to DOM properties of its parent window it canensure that the website in the parent window runs on the same domain. As a CSRF attackis always conducted across domain boundaries, a request that is conducted cross-domain
4at the onload event
Towards stateless, client-side driven Cross-Site Request Forgery protection 115

hGp://a.netBrowser
IFrame
Proxy1.) Ini"al Request
2.) Framing Code
3.) Validate Framing
4.) Request with Token
5.) Response
hGp://a.net
Abbildung 2: Framing Solution
is very suspicious while a request from the same domain is not suspicious at all. A validrequest is thus caused by a frame that is contained in a page that relies on the same domainwhile an illegitimate request is caused by a frame that is contained on a page running ona different domain. Therewith our Script is able to validate the legitimacy of the requestby accessing the location.host DOM property of its parent window (3). If it is ableto access it (and thus it is running on the same domain), it receives the CSRF token fromthe cookie and triggers a reload of the page, but this time with the token incorporated intothe request. The gatekeeper will recognize the valid token and instead of sending out ourscript again it will forward the request to the protected resource (4) that answers with thedesired response (5).
Listing 1 Frameing code
(function () {"use strict";
try {if (parent.location.host === window.location.host) {
var token = getCookie("CSRFToken");var redirectLoc = attachToken(window.location, token);window.location = redirectLoc;
}} catch (err) {
console.log(err);//parent.location.host was not accessible
}
})();
3.4 Requests created by JavaScript’s XMLHttpRequest
Besides generating requests by inserting HTML elements, JavaScript is also able to in-itiate HTTP requests directly by utilizing the XMLHttpRequest object. Most of themodern JavaScript-based application, such as GMail, make use of this technique in order
116 Towards stateless, client-side driven Cross-Site Request Forgery protection

to communicate asynchronously with a server. Incorporating tokens into this techniques isvery easy. Our library simply wraps the XMLHttpRequest Object and is thus able to fullycontrol any request send via this object (See Listing 2 for a code excerpt). Whenever thewrapper is supposed to send a requests towards the protected server the token is inserted asa GET parameter for GET requests or as a POST parameter for post requests. Therewith,protecting modern AJAX applications is very easy.
Listing 2 XMLHttpWrapper (Excerpt)
(function () {"use strict";var OriginalXMLHttpRequest = window.XMLHttpRequest;
function XHR() {this.originalXHR = new OriginalXMLHttpRequest();
//define getter and setter for variablesObject.defineProperty(this, "readyState", {
get: function () { return this.originalXHR.readyState; },set: function (val) { this.originalXHR.readyState = val; }
});[...]
}
XHR.prototype.open = function (method, url, async, user, password) {var token = getCookie("CSRFToken");this.attachToken(method, url, token);this.originalXHR.open(method, url, async, user, password);
};[...]
function NewXMLHttpRequest() {return new XHR();
}
window.XMLHttpRequest = NewXMLHttpRequest;})();
3.5 Redirects triggered by the server
As the application is not aware of the CSRF protection mechanism, it is possible thatthe application triggers a redirect from one protected resource towards another via 3xxHTTP redirects. In some cases this will cut of the CSRF tokens as the application will notgenerically attach each received parameter to the new redirect location. Hence, the server-side proxy has to take over this task. Whenever a redirect takes place a server respondswith a 3xx status code and the location response header that defines the location towhich the client is supposed to redirect. Therefore, the gatekeeper monitors the HTTPstatus codes for responses to requests that carry valid tokens. If the response contains a
Towards stateless, client-side driven Cross-Site Request Forgery protection 117

3XX status code, the gatekeeper rewrites the location header field and includes thetoken into it.
4 Discussion
4.1 Assessing security coverage and functional aspects
To assess the protection coverage of the approach, we have to verify if the proposedapproach indeed provides the targeted security properties. For this purpose, we rely onprevious work: Our protection approach enforces the model introduced by Kerschbaumin [Ker07]: Only clearly white-listed URLs are allowed to pass the gatekeeper withoutproviding proof that the corresponding HTTP request was generated in the context of in-teracting with the Web application (for this proof we rely on the double-submit value,while [Ker07] utilizes the referer-header, which has been shown by [BJM09] to be in-sufficient). Using the model checker Alloy, [Ker07] provides a formal verification of thesecurity properties of the general approach. In consequence, this reasoning also applies forour technique.
4.2 The advantage of client-side augmentation
As mentioned before, in our approach the altering of the site’s HTML elements is donepurely on client-side within the browser. This has significant advantages over doing soon the server-side both in respect to completeness as well as to performance. To do thisstep on the server-side, the filter of the outgoing HTTP responses would have to completelyparse the response’s HTML content to find all hyperlinks, forms, and other relevant HTMLelements. Already this step is in danger of being incorrect, as the various browser enginesmight interpret the encountered HTML differently from the utilized server-side parsingengine. In addition, and much more serious, are the shortcomings of the server-side whenit comes to JavaScript: In modern Web applications large parts of the displayed HTMLUI are generated dynamically. Some Web2.0 applications do not transmit HTML at all.Such HTML elements are out of reach for server-side code and cannot be outfitted withthe protection value. In contrast, on the client-side the JavaScript component already worksdirectly on the DOM object, hence, no separate parsing step is necessary. And, as describedin Section 3, our technique is capable to handle dynamic HTML generation via functionwrapping.
4.3 Open issues
Direct assignment of window.location via JavaScript: Besides the techniques presen-ted in Section 3, there is one additional way to create HTTP requests within the browser.
118 Towards stateless, client-side driven Cross-Site Request Forgery protection

By assigning a URI to either window.location, document.location or self.location a piece of JavaScript can cause the browser to redirect to the assigned URI.To control these requests it would again be possible to wrap these three location attribu-tes with function wrappers in order to attach the token whenever something is assignedto the .location attribute. Due to security reasons, however, some browsers do notallow the manipulation of the underlying getters and setters of window.location ordocument.location5. Hence, the function wrapping technique cannot be applied tothose attributes. Although, there are some ways to overcome this obstacle, we are not awa-re of an approach that covers the whole browser spectrum. Therefore, our library is notable to cover redirects via window.location/document.location. As a resultthese requests will not carry a CSRF token and thus they will be discarded by the gatekee-per. Hence, applications that are using .location for redirects are not yet supported byour library. In a later version we plan to include a work around for this problem.
RIA elements: Plugin-based RIA applets such as Flash, Silverlight or Java applets arealso able to create HTTP requests within the user’s browser. In order to function with ourCSRF protection these applets need to attach the CSRF token to their requests. Basically,this can be achieved in two different ways. On the one hand these applets could make use ofJavaScript’s XMLHttpRequest object. As this object is wrapped by our function wrapper,tokens will automatically be attached to legitimate requests. However, if an applet uses anative way to create HTTP requests, our JavaScript approach is not able to augment therequest with our token. Therefore, such RIA elements have to build a custom mechanismto attach our token.
4.4 Server-side requirements and supporting legacy applications
The proposed approach has only very limited footprint on the server-side. It can be im-plemented via a lightweight HTTP request filtering mechanism, which is supported by allmajor Web technologies, such as J2EE or PHP. If no such mechanism is offerd by the uti-lized framework, the component can also be implemented in the form of a self-standingserver-side HTTP proxy.
As explained in Section 3, the component itself needs no back channel into the applicationlogic and is completely stateless, due to choosing the double-submit cookie approach.
In consequence, the proposed approach is well suited to add full CSRF protection to exis-ting, potentially vulnerable applications retroactively. To do so, only two application spe-cific steps have to be taken: For one, potential direct access to the JavaScript locationobject have to be identified and directed to the proxy object (see Sec. 4.3). Secondly, fit-ting configuration files have to provided, to whitelist the well-defined entry points into theapplication and the URL paths for the static image and JavaScript data.
5Firefox still allows the manipulation of window.location, while other browsers do not allow it. On the otherhand Safari allows the overwriting of document.location, while other browsers don’t
Towards stateless, client-side driven Cross-Site Request Forgery protection 119

5 Related work
In the past, the field of CSRF-protection has been addressed from two distinct angles: Theapplication (i.e. the server-side) and the user (i.e., the client-side).
Server-side: Server-side protection measures, such as this paper’s approach, aim to se-cure vulnerable applications directly. The most common defense against CSRF attacks ismanual protection via using request nonces, as mentioned in Sec. 2.2. [Ope10b] providesa good overview on the general approach and implementation strategies. In [JKK06] aserver-side mechanism is proposed, that automatically outfits the delivered HTML contentwith protection nonces via server-side filtering. Due to the purely server-side technique, theapproach is unable to handle dynamically generated HTML content and direct JavaScript-based HTTP requests.
As an alternative to checking protection nonces, [BJM09] proposes the introduction ofan origin-HTTP header. This header carries the domain-value of the URL of the Webside from which the request was created. Through checking the value the application canensure, that the received request was created in a legitimate context and not through anattacker controlled Web site. Up to this date, browser support of the origin-header isincomplete, hence, rendering this mechanism unsuitable for general purpose Web sites.
Client-side: In addition to the server-centric protection approach, several client-side tech-niques have been proposed, which provide protection to the user’s of Web applications,even in cases in which the operator of the vulnerable Web application fails to identify orcorrect potential CSRF vulnerabilities. RequestRodeo [JW06] achieves this protection viaidentifying cross-domain requests and subsequent removal of cookie values from theserequests. This way, it is ensured that such request are not interpreted on the server-sidein an authenticated context. CSFire [RDJP11] improves on RequestRodeo’s technique onseveral levels: For one the mechanism is integrated directly into the browser in form of abrowser extension. Furthermore, CSFire utilizes a sophisticated heuristic to identify legi-timate cross-domain requests which are allowed to carry authentication credentials. Thisway support for federated identity management or cross-domain payment processes isgranted. Furthermore, related client-side protection mechanism were proposed by [ZF08]and [Sam11]. Finally, the ABE component of the Firefox extension NoScript [Mao06] canbe configured on a per-site basis to provide RequestRodeo-like protection.
6 Conclusion
In this paper we presented a light-weight transparent CSRF-protection mechanism. Ourapproach can be introduced without requiring any changes of the application code, asthe server-side component is implemented as a reverse HTTP proxy and the client-sidecomponent consists of a single static JavaScript file, which is added to outgoing HTML-content by the proxy. The proposed technique provides full protection for all incomingHTTP requests and is well suited to handle sophisticated client-side functionality, such asAJAX-calls or dynamic DOM manipulation.
120 Towards stateless, client-side driven Cross-Site Request Forgery protection

Literatur
[BJM09] Adam Barth, Collin Jackson und John C. Mitchell. Robust Defenses for Cross-Site Re-quest Forgery. In CCS’09, 2009.
[JKK06] Nenad Jovanovic, Christopher Kruegel und Engin Kirda. Preventing cross site requestforgery attacks. In Proceedings of the IEEE International Conference on Security andPrivacy for Emerging Areas in Communication Networks (Securecomm 2006), 2006.
[JW06] Martin Johns und Justus Winter. RequestRodeo: Client Side Protection against SessionRiding. In Frank Piessens, Hrsg., Proceedings of the OWASP Europe 2006 Conference,refereed papers track, Report CW448, Seiten 5 – 17. Departement Computerwetenschap-pen, Katholieke Universiteit Leuven, May 2006.
[Ker07] Florian Kerschbaum. Simple Cross-Site Attack Prevention. In Proceedings of the 3rdInternational Conference on Security and Privacy in Communication Networks (Secure-Comm’07), 2007.
[Mao06] Giorgio Maone. NoScript Firefox Extension. [software], http://www.noscript.net/whats, 2006.
[MPS10] Jonas Magazinius, Phu H. Phung und David Sands. Safe Wrappers and Sane Policiesfor Self-Protecting JavaScript. In Tuomas Aura, Hrsg., The 15th Nordic Conference inSecure IT Systems, LNCS. Springer Verlag, October 2010. (Selected papers from AppSec2010).
[Ope10a] Open Web Application Project (OWASP). OWASP Top 10 for 2010 (The Top Ten MostCritical Web Application Security Vulnerabilities). [online], http://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project, 2010.
[Ope10b] Open Web Application Security Project. Cross-Site Request Forgery (CSRF) PreventionCheat Sheet. [online], https://www.owasp.org/index.php/Cross-Site_Request_Forgery_(CSRF)_Prevention_Cheat_Sheet, accessed November2011, 2010.
[RDJP11] Philippe De Ryck, Lieven Desmet, Wouter Joosen und Frank Piessens. Automatic andprecise client-side protection against CSRF attacks. In European Symposium on Researchin Computer Security (ESORICS 2011), Jgg. 6879 of LNCS, Seiten 100–116, September2011.
[Sam11] Justin Samuel. Requestpolicy 0.5.20. [software], http://www.requestpolicy.com, 2011.
[ZF08] William Zeller und Edward W. Felten. Cross-Site Request Forgeries: Exploitation andPrevention. Bericht, Princeton University, 2008.
Towards stateless, client-side driven Cross-Site Request Forgery protection 121


gMix: Eine generische Architektur furMix-Implementierungen und ihre Umsetzung als
Open-Source-Framework
Karl-Peter Fuchs, Dominik Herrmann, Hannes Federrath
Universitat Hamburg, Fachbereich InformatikVogt-Kolln-Straße 30, D-22527 Hamburg
{fuchs, herrmann, federrath}@informatik.uni-hamburg.de
Abstract: Mit dem Open-Source-Projekt gMix, einem generischen Framework fur Mi-xe, mochten wir die zukunftige Forschung im Bereich der DatenschutzfreundlichenTechniken fordern, indem wir die Entwicklung und Evaluation von Mix-basiertenSystemen erleichtern. Das Projekt gMix wird ein umfassendes Code-Repository mitkompatiblen und leicht erweiterbaren Mix-Implementierungen zur Verfugung stellen.Dies ermoglicht den Vergleich verschiedener Mix-Varianten unter einheitlichen Be-dingungen und unterstutzt durch leicht zugangliche und verstandliche Losungen auchden Einsatz in der Lehre. Wir stellen eine generische Softwarearchitektur fur Mix-Implementierungen vor, demonstrieren ihre Anwendbarkeit anhand einer konkretenImplementierung und legen dar, wie wir die Architektur in ein Software-Frameworkmit einem Plug-in-Mechanismus zur einfachen Komposition und parallelen Entwick-lung von Implementierungen uberfuhren wollen.
1 Einleitung
Mixe ermoglichen die anonyme Kommunikation in Vermittlungsnetzen. Das Grundprin-zip ist in Abbildung 1 am Beispiel einer sog. Mix-Kaskade dargestellt. Seit dem ur-sprunglichen Vorschlag von David Chaum im Jahr 1981 [Cha81] wurden zahlreiche Mix-Konzepte und -Strategien vorgestellt. Inzwischen wurden Mixe fur verschiedene Anwen-dungsgebiete, z. B. E-Mail [Cha81, Cot95], elektronische Wahlen [Cha81, PIK94, SK95],Location-Based-Services [FJP96] sowie fur die Kommunikation mit Echtzeitanforderun-gen (z. B. ISDN [PPW91], WWW [BFK01, DMS04], DNS [FFHP11]) vorgeschlagen.
In der Praxis haben sich neben den Systemen Mixmaster [Cot95] und Mixminion[DDM03], die den anonymen E-Mail-Versand ermoglichen, bislang lediglich die Anony-misierungssysteme Tor [DMS04], JAP (JonDonym) [BFK01] und I2P etabliert.1 Durchihre konstante Fortentwicklung haben diese Implementierungen eine so hohe Komplexitatund Spezialisierung auf ihren Anwendungsfall erreicht, dass die wesentlichen Grundfunk-
1Die Implementierungen dieser Systeme sind uber die jeweiligen Webseiten unter http://sourceforge.net/projects/mixmaster/, http://mixminion.net/, http://www.torproject.org, http://anon.inf.tu-dresden.de/ und http://www.i2p2.de abrufbar.

Client ServerNutzerMix 1 Mix 2
ServerClientNutzer
Abbildung 1: Nachrichten werden vom Client schichtweise verschlusselt. Die Mixe entschlusselndie Nachricht schrittweise auf dem Weg zum Empfanger. Weitere Details werden in Abschnitt 2erlautert.
tionen eines Mixes nicht mehr leicht nachvollziehbar sind und ihre Eignung als Ausgangs-punkt fur die Entwicklung neuer Systeme (z. B. fur andere Anwendungsfalle) beschranktist. Der JAP-Client besteht beispielsweise derzeit (Dezember 2011) aus uber 700 Java-Klassen.2
In der Theorie gibt es eine Vielzahl an Vorschlagen, fur die keine offentlich verfugbarenoder gar praktisch einsetzbaren Implementierungen existieren (z. B. [PPW91, DG09,KG10, KEB98, DS03a, Ser07, SDS02, DP04, DS03b] oder [WMS08]). Von diesen Vor-schlagen bleibt nur eine verbale oder formale Beschreibung in der jeweiligen akademi-schen Publikation.
Diese Situation hat drei Konsequenzen: Zum einen wird es Wissenschaftlern unnotigschwer gemacht, bereits publizierte Ergebnisse nachzuvollziehen, da die existierendenTechniken dazu von Grund auf neu implementiert werden mussen. Zweitens ist die Hurdezur Implementierung neuer Mix-Techniken unnotig hoch, da immer wieder von neuemLosungen fur Standardprobleme gefunden und implementiert werden mussen. Und drit-tens ist es zum aktuellen Zeitpunkt relativ schwierig, die Vorschlage aus unterschiedlichenVeroffentlichungen miteinander zu vergleichen, da diese mit unterschiedlichen Implemen-tierungen, Laufzeitumgebungen und Experimentierumgebungen realisiert wurden.
Mit dem gMix-Projekt mochten wir dazu beitragen, diese aus unserer Sicht unerwunschtenKonsequenzen zu beheben. Wir verfolgen dabei funf Ziele:
1. Verfugbarkeit eines umfassenden Code-Repository mit kompatiblen, leicht erweiter-baren Mix-Implementierungen,
2. Vereinfachen der Entwicklung neuer, praktisch nutzbarer Mixe,
3. Evaluation existierender und neuer Mix-Techniken unter einheitlichen Bedingun-gen,
4. Unterstutzung der Lehre durch leicht zugangliche und verstandliche Mix-Losungensowie
5. Wissenschaftler dazu zu motivieren, ihre Implementierungen auf Basis von gMix zuentwickeln und somit an der Weiterentwicklung von gMix beizutragen.
Aus diesem Grund haben wir eine offene, generische Architektur entworfen, mit derexistierende und zukunftige Mixe abgebildet werden konnen. Die Architektur bildet die
2Gezahlt wurden alle Klassen, die unter http://anon.inf.tu-dresden.de/develop/doc/jap/ aufgefuhrt sind.
124 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

gemeinsamen Komponenten ab, die fur die Entwicklung praktischer Mix-Implementie-rungen grundsatzlich erforderlich sind. Weiterhin gibt sie den Rahmen fur das Verhal-ten und die Interaktion der Komponenten vor. Basierend auf dieser Architektur habenwir damit begonnen, ein Framework mit einem Plug-in-Mechanismus zu erstellen, dasdie Auswahl verschiedener Implementierungen einzelner Komponenten (z. B. verschiede-ne Ausgabestrategien) erlaubt.3 Das Framework soll es einem Entwickler ermoglichen,einen konkreten Mix aus den verschiedenen Implementierungen zusammenzustellen, oh-ne den Quelltext des Frameworks anpassen zu mussen. Wir sehen dies als Vorausset-zung dafur, verschiedene Implementierungen einfach und unter einheitlichen Bedingun-gen (z. B. wie in [FFHP11] mit einem Netzwerkemulator oder in einem Forschungsnetz-werk wie dem PlanetLab (http://www.planet-lab.org/) in [BSMG11]) testen zu konnen,sowie die Abhangigkeiten bei der parallelen Entwicklung verschiedener Implementierun-gen durch die Open-Source-Community zu minimieren. Neben dem Framework erstellenwir derzeit Referenzimplementierungen fur die bedeutendsten Mix-Techniken.
Das gMix-Projekt ist im Internet unter https://svs.informatik.uni-hamburg.de/gmix/ er-reichbar. Die Quellcodes sind unter der GPLv3 veroffentlicht.
Der Beitrag ist wie folgt aufgebaut: Im Abschnitt 2 stellen wir die gMix-Architektur vor.Anschließend erlautern wir in Abschnitt 3 anhand einer konkreten Implementierung, ei-nem synchron getakteten Kanal-Mix fur stromorientierte Kommunikation, wie die Archi-tektur in der Praxis umgesetzt werden kann. Ausgehend von der Architektur und der kon-kreten Implementierung wird in Abschnitt 4 der geplante Aufbau des gMix-Frameworksskizziert. Abschnitt 5 fasst schließlich die Ergebnisse zusammen.
2 gMix-Architektur
Wir verstehen unter einer Softwarearchitektur analog zu [Bal96], eine ”strukturierte oderhierarchische Anordnung der Systemkomponenten sowie Beschreibung ihrer Beziehun-gen“. Eine detaillierte Beschreibung der verschiedenen Architekturebenen und Sichten(Kontextsicht, Struktursicht, Verhaltenssicht, Abbildungssicht) der gMix-Architektur fin-det sich in [Fuc09]. Im Folgenden beschranken wir uns auf eine allgemeine Beschreibungder Architekturkomponenten und deren grundlegender Interaktion. Weiterhin legen wirdie zentralen Designentscheidungen dar.
3In einem anderen Forschungsgebiet, dem Data-Mining, hat sich die Veroffentlichung eines Frameworksals großer Erfolg herausgestellt. Das Software-Paket WEKA [HFH+09] (http://www.cs.waikato.ac.nz/ml/weka/index.html), das vor fast 20 Jahren veroffentlicht wurde, bietet Zugriff auf eine Vielzahl von Algorithmen undEvaluationstechniken. Es hat die Nutzung von State-of-the-Art-Data-Mining-Techniken erheblich vereinfachtund dazu gefuhrt, dass diese ganz selbstverstandlich heute in vielen Anwendungsfeldern eingesetzt werden.Wegen seiner Einfachheit wird WEKA inzwischen auch an vielen Universitaten im Lehrbetrieb eingesetzt.
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 125

2.1 Herausforderungen
Die wesentliche Herausforderung bei der Entwicklung einer generischen Architektur furMix-basierte Systeme besteht darin, diese einerseits generisch genug zu spezifizieren, sodass eine Vielzahl von Mix-Varianten unterstutzt wird, sie andererseits aber auch so spe-zifisch wie moglich zu entwerfen. Hierzu werden die wesentlichen Aufgaben eines Mixessowie die fur eine praktisch nutzbare Implementierung notigen zusatzlichen und wieder-verwendbaren Artefakte (z. B. Serverfunktionalitat oder Logging) identifiziert, voneinan-der abgegrenzt und in Komponenten gekapselt.
Dementsprechend haben wir eine Vielzahl der bislang vorgeschlagenen Mix-Konzepte(insbesondere verschiedene Ausgabe- und Dummy-Traffic-Strategien sowie Umkodie-rungsschemata) und drei offentlich verfugbare Implementierungen (Tor, JAP, Mixminion)analysiert. Der Architekturentwurf wurde zusatzlich von der prototypischen Implementie-rung verschiedener Mix-Komponenten, darunter auch der in Abschnitt 3 beschriebene Mixsowie der von uns in [FFHP11] vorgestellte DNS-Mix, begleitet und iterativ weiterentwi-ckelt.
Die gMix-Architektur ermoglicht die parallele bidirektionale anonyme Kommunikati-on (Vollduplex), fur nachrichtenorientierte Anwendungen (z. B. E-Mail) sowie fur Da-tenstrome mit Echtzeitanforderungen (Moglichkeit zur Schaltung langlebiger anonymerKanale, z. B. fur WWW-Traffic), unabhangig von der konkreten Realisierung des zu-grundeliegenden Kommunikationskanals, des zur Anonymisierung verwendeten Umko-dierungsschemas oder der Ausgabestrategie.
2.2 Komponenten
Die wesentlichen Softwarekomponenten sind in Abbildung 2 dargestellt und werden imFolgenden kurz skizziert.
Die Komponenten MessageProcessor, OutputStrategy und InputOutputHandler sindfur die Kernfunktion des Mixes (Unverkettbarkeit ein- und ausgehender Nachrichten)zustandig. Die restlichen Komponenten nehmen Hilfsaufgaben wahr.
Die Komponente MessageProcessor setzt das Umkodierungsschema des Mixes um.Dieses soll sicherstellen, dass ein- und ausgehende Nachrichten nicht anhand ihrerBitreprasentation verkettet werden konnen. Aufgaben der Komponente sind folglichdas Ver- bzw. Entschlusseln von Mix-Nachrichten sowie die Durchfuhrung einer Inte-gritatsprufung4 und Wiederholungserkennung5. Fur den Entwurf der Komponente wur-den die Verfahren nach [Cha81, PPW91, Cot95, DDM03, BFK01, Kop06] und [DMS04]analysiert. Die aktuelle Implementierung ist in Abschnitt 3 beschrieben. Derzeit wird das
4Konnen Nachrichten vom Mix unbemerkt verandert werden, kann die Anonymitat der Nutzer aufgehobenwerden [Dai00].
5Wird ein deterministisches Umkodierungsschema eingesetzt, darf jede Nachricht vom Mix nur ein einzigesMal verarbeitet werden. In diesem Fall muss der Mix wiedereingespielte Nachrichten erkennen und verwerfen,wie beispielsweise in [Kop06] beschrieben.
126 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

MixTrafficPort
Mix<<delegate>>
Mix-‐External-‐Informa/on-‐Port
<<delegate>>
<<component>>:OutputStrategy
<<component>>:KeyGenerator
<<component>>:UserDatabase
<<component>>:NetworkClock
<<component>>:Message-‐Processor
<<component>>:Framework
<<component>>:InputOutput-‐Handler
<<component>>:External-‐Informa;onPort
Abbildung 2: Komponentendiagramm
Umkodierungsschema nach [DG09] integriert.
Umkodierte Nachrichten werden vom MessageProcessor an die Komponente Output-Strategy weitergeleitet, die fur die Umsetzung der Ausgabestrategie zustandig ist. Ih-re Aufgabe ist es, durch das gezielte Verzogern und die umsortierte Ausgabe ein-gehender Nachrichten eine Anonymitatsgruppe zu bilden. Ist vorgesehen, dass unterbestimmten Bedingungen bedeutungslose Nachrichten erzeugt oder verworfen werden(Dummy-Traffic-Schema), muss dies ebenfalls in dieser Komponente erfolgen. Realisie-rungsmoglichkeiten fur die Ausgabestrategie und das Dummy-Traffic-Schema sind u. a. in[Cha81, PPW91, Cot95, KEB98, SDS02, DS03b, DP04, Ser07, BL02, DS03a, VHT08,VT08] und [WMS08] beschrieben.
Durch die Komponente OutputStrategy verzogerte Nachrichten werden an den Input-OutputHandler weitergeleitet. Dieser abstrahiert von den Details des zugrundeliegen-den Kommunikationskanals (z. B. einer TCP-Verbindung) und leitet die Nachrichten andie vorgesehenen Empfanger (z. B. andere Mixe oder Server) weiter. Zusatzlich stellt derInputOutputHandler mittels einer Schnittstelle uber den Kommunikationskanal empfan-gene Nachrichten fur den MessageProcessor bereit. Die Ubergabe von Nachrichten anden InputOutputHandler erfolgt asynchron, das Beziehen von Nachrichten mittels einesBenachrichtigungsprinzips (wait-notify). Entsprechend konnen InputOutputHandler, Mes-sageProcessor und OutputStrategy, abgesehen von der Nachrichtenubergabe, unabhangigvoneinander arbeiten. Im Ergebnis konnen parallel zur Umkodierung weitere Nachrichtenempfangen oder versendet werden. Das Umkodieren selbst kann ebenfalls parallelisiertwerden.
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 127

Im Folgenden wird jeweils kurz auf die Hilfskomponenten UserDatabase, ExternalInfor-mationPort, KeyGenerator, NetworkClock und Framework eingegangen.
Die UserDatabase ermoglicht das Speichern von Daten zu einzelnen Nutzern (z. B. ver-bundene Clients) des Mixes. Dies umfasst beispielsweise Daten zu geschalteten anonymenKanalen, wie Kanalkennzeichen [PPW91] und Sitzungsschlussel. Im einfachsten Fall kanndie Realisierung mit einer Hashtabelle erfolgen.
Uber den ExternalInformationPort konnen allgemeine Informationen uber den Mixveroffentlicht werden, z. B. dessen Public Key, seine unterstutzten Protokolle und eine Ver-sionsnummer. Im Falle von JAP wurde diese Komponente mit dem InfoService [BFK01]kommunizieren.
Der KeyGenerator kann zum Erstellen von kryptographischen Sitzungs- oder Langzeit-schlusseln verwendet werden. Da fur einige Mix-Verfahren Zeitstempel benotigt werden,kann uber die Komponente NetworkClock eine synchronisierte Uhr (z. B. uber das Net-work Time Protocol nach RFC 5905) realisiert werden.
Neben grundlegenden Funktionen, wie dem Erstellen von Logdateien und dem Laden vonKonfigurationsdateien sind in der Komponente Framework weitere Funktionen gekapselt.Eine detaillierte Betrachtung erfolgt in Abschnitt 4.
2.3 Grenzen der Generalisierung
Einschrankungen bei der Generalisierung ergeben sich hinsichtlich des Detaillierungs-grades bei der Spezifikation fur bestimmte Datenstrukturen und Nachrichtenformate.Das grundlegende Problem ist, dass sich konkrete Implementierungsmoglichkeiten imDetail stark unterscheiden konnen. Dies macht eine Vereinheitlichung schwer oder garunmoglich. Betroffen sind das Nachrichtenformat sowie die Inhalte der UserDatabaseund des ExternalInformationPort. Ein SG-Mix [KEB98] benotigt beispielsweise exklusivein in das Nachrichtenformat integriertes Zeitfenster, um den Ausgabezeitpunkt von Nach-richten einzugrenzen. Sind der Aufbau eines anonymen Kanals und die eigentliche Nach-richtenubermittlung wie in [PPW91, DMS04] oder [KG10] getrennt, mussen zusatzlichInformationen wie Kanalkennzeichen und Sitzungsschlussel (in der UserDatabase) ge-speichert werden. Kommt ein Umkodierungsschema wie in [Cha81, DDM03] oder [DG09]zum Einsatz, kann hingegen jeder Schlussel sofort nach dem Umkodieren der zugehorigenNachricht (hybrides Kryptosystem) verworfen werden.
Eine weitere Konkretisierung der Architektur lasst sich mit dem Ziel, die Architektur sogenerell wie moglich zu gestalten, nicht vereinbaren. Um dieses Problem zu losen, verwen-den wir abstrakte Datentypen, die nach dem Key-Value-Prinzip arbeiten. Konkrete Werteund Schlussel werden uber eine Enumeration spezifiziert. Entsprechend kann fur konkre-te Implementierungen einer Komponente angegeben werden, welche Werte sie benotigt,d. h. mit welchen Enumerations sie kompatibel ist. Da die Enumeration nur eine abstrakteBeschreibung benotigter Inhalte ist, kann die konkrete Realisierung unterschiedlich erfol-gen. Die Spezifizierung von Abhangigkeiten und das Auflosen von Konflikten sind eineder wesentlichen Aufgaben des Frameworks (vgl. Abschnitt 4).
128 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

3 Fallstudie: Implementierung eines synchron getakteten Mixes
Wir stellen in diesem Abschnitt vor, wie der abstrakte Architekturentwurf in einer kon-kreten Implementierung, einem synchron getakteten Kanal-Mix (d. h. einen Schub-Mixmit konstantem Dummy Traffic aller Teilnehmer) umgesetzt werden kann. Mit dem Mixkonnen duplexfahige anonyme Kanale zur Ubermittlung von Binardaten geschaltet wer-den. Von den zu ubermittelnden Daten selbst und den in diesen Zusammenhang verwende-tet Protokollen wird abstrahiert, um die Implementierung moglichst generisch zu halten.
Dieser Mix besitzt einen hohen Komplexitatsgrad in allen Komponenten (Echtzeitanfor-derung, verschiedene Nachrichtentypen, Anonymisierung von Datenstromen statt nur Ein-zelnachrichten). Es gibt unseres Wissens nach noch keine entsprechende Open-Source-Implementierung.
3.1 Umsetzungsdetails
Als Programmiersprache wird wegen seiner Plattformunabhangigkeit und weiten Verbrei-tung im wissenschaftlichen Bereich und Lehrbetrieb Java eingesetzt. Auf Clientseite kanndie Implementierung wie ein normaler Socket mittels InputStream und OutputStream an-gesprochen werden. Entsprechend ist die Tunnelung anderer Protokolle, z. B. mittels einesHTTP- oder SOCKS-Proxies, sehr einfach realisierbar.
Unsere Implementierung setzt in der Komponente MessageProcessor ein zu JAP undden ISDN-Mixen [PPW91] sehr ahnliches Umkodierungsschema um: Nachrichten wer-den hybrid mit RSA (OAEP-Modus, 2048 bit Schlussellange) und AES (OFB-Modus,128 bit Schlussellange) verschlusselt. Es gibt drei Nachrichtentypen. Kanalaufbaunach-richten zum Schalten anonymer Kanale (Verteilung der Sitzungsschlussel fur AES und In-tegritatsprufung mit HMAC-SHA256). Rein symmetrisch verschlusselte Kanalnachrich-ten zum Ubermitteln von Nutzdaten und Kanalabbaunachrichten zum Auflosen anonymerKanale. Zusatzlich wurde eine Wiederholungserkennung nach dem Vorbild von [Kop06]implementiert. Zum parallelen Umkodieren konnen mehrere Threads gestartet werden.
Die Komponente OutputStrategy wurde als synchroner Schub-Mix implementiert. Ent-sprechend wird von jedem Teilnehmer eine Kanalnachricht (ggf. eine Dummy-Nachricht)erwartet, bevor die Nachrichten gemeinsam und umsortiert ausgegeben werden. Zusatzlichkann eine maximale Wartezeit angegeben werden.
Der InputOutputHandler setzt das in Abschnitt 2 beschriebene asynchrone Benachrich-tigungsprinzip in einer Steuerungsklasse um. Die Steuerungsklasse kann mittels verschie-dener ConnectionHandler an konkrete Protokolle (z. B. TCP oder UDP) und Kommu-nikationsbeziehungen (z. B. Client-Mix, oder Mix-Mix) angepasst werden. Die aktuelleImplementierung setzt aus Performanzgrunden zwischen Mixen und Clients asynchroneEin- und Ausgabe (non-blocking I/O) ein. Zwischen zwei Mixen besteht jeweils nur eineverschlusselte Verbindung, durch welche die Nachrichten aller Clients getunnelt werden(multiplexing). Es kommt jeweils TCP zum Einsatz.
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 129

3.2 Entwicklungs- und Evaluationsumgebung
Verteilte Systeme wie Mixe sind mit herkommlichen Debugging-Werkzeugen nichtvollstandig analysierbar, da Nachrichten im Betrieb mehrere Systeme durchlaufen. Wirhaben eine einfache Testumgebung entwickelt, die die Fehlersuche erheblich erleichternkann (Paket testEnvironment). Neben der Moglichkeit, die Mixe unter realen Bedingun-gen, also auf mehreren Systemen verteilt, manuell zu starten, besteht auch die Option,mehrere Mixe lokal auf einem Entwicklungssystem automatisiert zu starten, ohne sich umKommunikationseinstellungen und die Schlusselverteilung kummern zu mussen.
Nachrichten konnen mit einer eindeutigen ID ausgezeichnet werden, um sie beim Debug-ging uber Systemgrenzen hinweg zu verfolgen. So kann uberpruft werden, ob die Nach-richtenubermittlung zwischen Clients und Mixen fehlerfrei funktioniert.
Weiterhin existiert ein einfacher Last-Generator, der automatisiert nach einer vorge-gebenen Zufallsverteilung Mix-Clients instanziiert und deren Verhalten simuliert. Diesermoglicht es dem Entwickler, das Verhalten der Mixe mit dynamischen Nutzerzahlen undwechselndem Verkehrsaufkommen zu analysieren. Die aktuelle Implementierung ist aufdas Debugging ausgerichtet und hat die Implementierung des synchron getakteten Mixeserheblich erleichtert. Wir arbeiten an einer Erweiterung, die realistische Verkehrsmodel-le unterstutzt und automatisiert die Verzogerung von Nachrichten in den einzelnen Mix-Komponenten erfassen und visualisieren kann. Wir versprechen uns davon die Identifizie-rung von Flaschenhalsen und den vereinfachten empirischen Vergleich von verschiedenenImplementierungen.
4 Erweiterung zum gMix-Framework
Die in Abschnitt 2 dargestellte Architektur kann durch die Spezifizierung notwendigerKomponenten, deren Verhalten und Interaktion die Entwicklungszeit fur neue praktischeMix-Systeme erheblich verkurzen. Es ware jedoch daruber hinaus wunschenswert, uberein umfangreiches Code-Repository mit kompatiblen Implementierungen, die einfach zueinem konkreten Mix zusammengestellt werden konnen, zu verfugen. Idealerweise solltees unterschiedlichen Entwicklern moglich sein, unabhangig voneinander an verschiedenenImplementierungen zu arbeiten und diese ggf. zu veroffentlichen.
Dieses Ziel soll mit Hilfe eines dedizierten Rahmenwerks erreicht werden. Das Frame-work trennt zwischen veranderbarem Quelltext und gleich bleibenden Strukturen. ImFramework konnen folglich jeweils mehrere konkrete Implementierungen fur die ein-zelnen Komponenten erstellt und registriert werden, so lange sie den Architekturvorga-ben genugen. Die Instanziierung und Steuerung (d. h. die Sicherstellung der Einhaltungdes vorgesehenen Kontrollflusses) der gewahlten Komponentenimplementierungen erfolgtdurch das Framework. Veranderungen am Quelltext des Frameworks durch die Entwicklerkonkreter Implementierungen sind nicht vorgesehen.
Die zentralen Herausforderungen bei der Entwicklung dieses Frameworks werden im Fol-genden zusammen mit unseren geplanten Losungsansatzen kurz dargestellt.
130 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

• Es wird ein Plug-in-Mechanismus benotigt, der das Einbinden konkreter Kompo-nentenimplementierungen durch das Framework ermoglicht.
• Es wird ein Mechanismus benotigt, mit dem Abhangigkeiten zwischen Komponen-ten und Nachrichtenformaten abgebildet und erkannt werden konnen.
• Die einfache Komposition verschiedener Implementierungsvarianten zu einem kon-kreten Mix soll ohne Anpassung des Quelltextes moglich sein.
• Mit Hilfe einer Versionsverwaltung fur verschiedene Implementierungsvariantensoll die Nachvollziehbarkeit von durchgefuhrten Evaluationen verbessert werden.
• Die Bereitstellung umfangreicher Dokumentation und Tutorials ist erforderlich, umdie Hurde zur Nutzung des Frameworks zu senken.
Der Plug-in-Mechanismus ist in Abbildung 3 dargestellt. Das Framework enthalt Schnitt-stellendefinitionen fur samtliche (in Abschnitt 2 beschriebene) Komponenten. Zusatzlichverfugt jede Komponente uber eine sogenannte Controller-Klasse, welche die durch diejeweilige Schnittstelle spezifizierte Funktionalitat nach außen (d. h. fur die anderen Kom-ponenten) zur Verfugung stellt. Intern werden Aufrufe an eine konkrete Implementierung(Komponentenimplementierung) weitergeleitet.
Wie aus der Architektur hervorgeht, arbeiten die einzelnen Komponenten nicht vollig au-tonom, sondern sie interagieren. Jede Implementierung muss daher uber Referenzen aufdie anderen Komponenten verfugen. Diese Anforderung setzen wir durch einen geeig-neten objektorientierten Entwurf und ein dreiphasiges Initialisierungskonzept um. JedeKomponentenimplementierung muss von einer abstrakten Implementierungsklasse (Im-plementation) abgeleitet werden, welche Referenzen auf alle Komponenten enthalt. EineKomponente wird nach dem Laden ihrer Klasse durch den Aufruf ihres Konstruktors in-stanziiert (Phase 1). Sobald alle Klassen geladen und alle Referenzen gultig sind, wird derBeginn von Phase 2 durch Aufruf einer Initialisierungsmethode bekannt gegeben. In Pha-se 2 werden Vorbereitungsfunktionen fur die Anonymisierung durchgefuhrt, z. B. konnenSchlussel generiert und ausgetauscht werden, Zufallszahlen erzeugt werden oder ggf. dieverteilte Netzwerkuhr initialisiert werden. Wenn alle Komponenten ihre Initialisierungs-maßnahmen abgeschlossen haben beginnt Phase 3, der eigentliche Mix-Betrieb, in demMix-Nachrichten entgegengenommen und verarbeitet werden.
Die Zusammenstellung der konkreten Komponentenimplementierungen soll nicht imQuelltext ”fest verdrahtet“ werden, um Plug-ins entwickeln zu konnen, ohne den Quelltextdes Frameworks anpassen zu mussen. Um diese Anforderung umzusetzen, greifen wir aufeinen Klassenlader zuruck, der dynamisch zur Laufzeit die konkreten Implementierungenin die Java Virtual Machine ladt. Der Klassenlader wertet Kompatibilitatsinformationen,die fur jedes Plug-in erfasst werden, aus und verhindert dadurch, dass inkompatible Kon-figurationen ausgefuhrt werden. Die Kompatibilitatsinformationen werden vom Autor desPlug-ins spezifiziert und liegen in einer Property-Datei vor. Darin konnen auch weitereLaufzeitparameter (z. B. die Schubgroße bei einem Batch-Mix) definiert werden.
Um die Konfiguration eines Mixes zu vereinfachen, wollen wir eine grafische Oberflacheentwickeln, die eine interaktive Auswahl der zu integrierenden Komponenten erlaubt. Die-
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 131

se soll die Kompatibilitats- und Konfigurationsparameter interpretieren, um den Nutzerbei der Auswahl der zueinanderpassenden Implementierungen zu unterstutzen. Auf derProjektseite ist der Quelltext des ersten Prototypen des Frameworks veroffentlicht. Ne-ben einer rudimentaren Implementierung des Plug-in-Mechanismus sind bereits 14 der in[Cha81, Cot95, KEB98, SDS02, DS03b] und [WMS08] beschriebenen Ausgabestrategienimplementiert. Implementierungen fur die restlichen Komponenten sind in Arbeit.
Name der Komponente Framework
:Klassenlader
Komposi+on derKomponenten
Logging
Referenzen auf alleKomponenten
:Implementa-on
GUI
<<interface>>Schni)stelle der Komponente
Schni)stellendefini+onenaller Komponenten
...
:Controller-‐Klasse<<delegate>>
austauschbare Implemen+erungen
<<delegate>>
:Komponenten-‐implemen+erung
:Hilfsklasse
ParameterKonfigura+onKompa+bilität
Abbildung 3: Plug-in-Mechanismus
5 Zusammenfassung
In diesem Beitrag haben wir eine generische Mix-Architektur vorgestellt. In der Archi-tektur werden die zentralen Funktionen, die von einer praktischen Mix-Implementierungerbracht werden mussen, in einzelnen Komponenten gekapselt. Jede Komponente erfullteine klar abgegrenzte Aufgabe und hat definierte Schnittstellen. Die Architektur reduziertzum einen die Komplexitat fur Entwickler, zum anderen ist sie die Grundlage fur un-tereinander kompatible Implementierungsvarianten. Am Beispiel des synchron getaktetenKanalmixes wurde die grundsatzliche Anwendbarkeit beispielhaft demonstriert.
Architektur und Implementierung sind offentlich zuganglich und erweiterbar. Weiterhinwurde das geplante gMix-Framework, an dem wir derzeit arbeiten, vorgestellt. Es wirdeine weitgehend unabhangige Entwicklung dedizierter Mix-Plug-ins und die Evaluati-on unter einheitlichen Umgebungsbedingungen ermoglichen. Wir hoffen, dass durch dasgMix-Projekt nicht nur die Entwicklung Datenschutzfreundlicher Techniken vorangetrie-ben, sondern vor allem auch deren Uberfuhrung in die Praxis begunstigt wird.
132 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

Literatur
[Bal96] Helmut Balzert. Lehrbuch der Software-Technik.: Software-Entwicklung. Lehrbuch derSoftware-Technik. Spektrum, Akad. Verl., 1996.
[BFK01] Oliver Berthold, Hannes Federrath und Stefan Kopsell. Web MIXes: a system for anony-mous and unobservable Internet access. In International workshop on Designing Pri-vacy Enhancing Technologies: Design Issues in Anonymity and Unobservability, Seiten115–129, New York, USA, 2001. Springer-Verlag.
[BL02] Oliver Berthold und Heinrich Langos. Dummy Traffic against Long Term IntersectionAttacks. In Roger Dingledine und Paul F. Syverson, Hrsg., Privacy Enhancing Tech-nologies, Jgg. 2482 of Lecture Notes in Computer Science, Seiten 110–128. Springer,2002.
[BSMG11] Kevin Bauer, Micah Sherr, Damon McCoy und Dirk Grunwald. ExperimenTor: A Test-bed for Safe Realistic Tor Experimentation. In Proceedings of Workshop on CyberSecurity Experimentation and Test (CSET), 2011.
[Cha81] David Chaum. Untraceable electronic mail, return addresses, and digital pseudonyms.Communications of the ACM, 24(2):84–90, 1981.
[Cot95] Lance Cottrell. Mixmaster and remailer attacks. In http://www.obscura.com/ loki/remailer-essay.html, 1995.
[Dai00] Wei Dai. Two attacks against freedom. In http://www.weidai.com/ freedom-attacks.txt,2000.
[DCJW04] Yves Deswarte, Frederic Cuppens, Sushil Jajodia und Lingyu Wang, Hrsg. InformationSecurity Management, Education and Privacy, IFIP 18th World Computer Congress,TC11 19th International Information Security Workshops, 22-27 August 2004, Toulouse,France. Kluwer, 2004.
[DDM03] George Danezis, Roger Dingledine und Nick Mathewson. Mixminion: Design of a TypeIII Anonymous Remailer Protocol. In IEEE Symposium on Security and Privacy, Seiten2–15. IEEE Computer Society, 2003.
[DG09] George Danezis und Ian Goldberg. Sphinx: A Compact and Provably Secure Mix For-mat. In IEEE Symposium on Security and Privacy, Seiten 269–282. IEEE ComputerSociety, 2009.
[DMS04] Roger Dingledine, Nick Mathewson und Paul Syverson. Tor: The Second-GenerationOnion Router. In In Proceedings of the 13th USENIX Security Symposium, Seiten 303–320, 2004.
[DP04] Claudia Dıaz und Bart Preneel. Taxonomy of Mixes and Dummy Traffic. In Deswarteet al. [DCJW04], Seiten 215–230.
[DS03a] George Danezis und Len Sassaman. Heartbeat traffic to counter (n-1) attacks: red-green-black mixes. In Sushil Jajodia, Pierangela Samarati und Paul F. Syverson, Hrsg., WPES,Seiten 89–93. ACM, 2003.
[DS03b] Claudia Dıaz und Andrei Serjantov. Generalising Mixes. In Roger Dingledine, Hrsg.,Privacy Enhancing Technologies, Jgg. 2760 of Lecture Notes in Computer Science, Sei-ten 18–31. Springer, 2003.
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 133

[FFHP11] Hannes Federrath, Karl-Peter Fuchs, Dominik Herrmann und Christopher Piosecny.Privacy-Preserving DNS: Analysis of Broadcast, Range Queries and Mix-Based Protec-tion Methods. In Vijay Atluri und Claudia Dıaz, Hrsg., ESORICS, Jgg. 6879 of LectureNotes in Computer Science, Seiten 665–683. Springer, 2011.
[FJP96] Hannes Federrath, Anja Jerichow und Andreas Pfitzmann. MIXes in Mobile Commu-nication Systems: Location Management with Privacy. In Ross J. Anderson, Hrsg.,Information Hiding, Jgg. 1174 of Lecture Notes in Computer Science, Seiten 121–135.Springer, 1996.
[Fuc09] Karl-Peter Fuchs. Entwicklung einer Softwarearchitektur fur anonymisierende Mixeund Implementierung einer konkreten Mix-Variante. Magisterarbeit, Universitat Re-gensburg, 2009.
[HFH+09] Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann undIan H. Witten. The WEKA data mining software: an update. SIGKDD Explor. Newsl.,11:10–18, November 2009.
[KEB98] Dogan Kesdogan, Jan Egner und Roland Buschkes. Stop-and-Go-MIXes ProvidingProbabilistic Anonymity in an Open System. In David Aucsmith, Hrsg., InformationHiding, Jgg. 1525 of Lecture Notes in Computer Science, Seiten 83–98. Springer, 1998.
[KG10] Aniket Kate und Ian Goldberg. Using Sphinx to Improve Onion Routing Circuit Con-struction. In Radu Sion, Hrsg., Financial Cryptography, Jgg. 6052 of Lecture Notes inComputer Science, Seiten 359–366. Springer, 2010.
[Kop06] Stefan Kopsell. Vergleich der Verfahren zur Verhinderung von Replay-Angriffen derAnonymisierungsdienste AN.ON und Tor. In Jana Dittmann, Hrsg., Sicherheit, Jgg. 77of LNI, Seiten 183–187. GI, 2006.
[PIK94] Choonsik Park, Kazutomo Itoh und Kaoru Kurosawa. Efficient anonymous channeland all/nothing election scheme. In Workshop on the theory and application of cryp-tographic techniques on Advances in cryptology, EUROCRYPT ’93, Seiten 248–259,Secaucus, NJ, USA, 1994. Springer-Verlag New York, Inc.
[PPW91] Andreas Pfitzmann, Birgit Pfitzmann und Michael Waidner. ISDN-MIXes: UntraceableCommunication with Small Bandwidth Overhead. In Wolfgang Effelsberg, Hans Wer-ner Meuer und Gunter Muller, Hrsg., Kommunikation in Verteilten Systemen, Jgg. 267of Informatik-Fachberichte, Seiten 451–463. Springer, 1991.
[SDS02] Andrei Serjantov, Roger Dingledine und Paul F. Syverson. From a Trickle to a Flood:Active Attacks on Several Mix Types. In Fabien A. P. Petitcolas, Hrsg., InformationHiding, Jgg. 2578 of Lecture Notes in Computer Science, Seiten 36–52. Springer, 2002.
[Ser07] Andrei Serjantov. A Fresh Look at the Generalised Mix Framework. In Nikita Borisovund Philippe Golle, Hrsg., Privacy Enhancing Technologies, Jgg. 4776 of Lecture Notesin Computer Science, Seiten 17–29. Springer, 2007.
[SK95] Kazue Sako und Joe Kilian. Receipt-Free Mix-Type Voting Scheme - A Practical Solu-tion to the Implementation of a Voting Booth. In EUROCRYPT, Seiten 393–403, 1995.
[VHT08] Parvathinathan Venkitasubramaniam, Ting He und Lang Tong. Anonymous NetworkingAmidst Eavesdroppers. IEEE Transactions on Information Theory, 54(6):2770–2784,2008.
[VT08] Parvathinathan Venkitasubramaniam und Lang Tong. Anonymous Networking withMinimum Latency in Multihop Networks. In IEEE Symposium on Security and Privacy,Seiten 18–32. IEEE Computer Society, 2008.
134 gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung

[WMS08] Wei Wang, Mehul Motani und Vikram Srinivasan. Dependent link padding algorithmsfor low latency anonymity systems. In Peng Ning, Paul F. Syverson und Somesh Jha,Hrsg., ACM Conference on Computer and Communications Security, Seiten 323–332.ACM, 2008.
gMix: Eine Architektur fur Mix-Implementierungen und ihre Umsetzung 135


PyBox — A Python Sandbox
Markus Engelberth Jan Gobel Christian SchonbeinUniversitat Mannheim
Felix C. Freiling∗
Friedrich-Alexander-Universitat Erlangen-Nurnberg
Abstract: The application of dynamic malware analysis in order to automate the mo-nitoring of malware behavior has become increasingly important. For this purpose,so-called sandboxes are used. They provide the functionality to execute malware in asecure, controlled environment and observe its activities during runtime. While a va-riety of sandbox software, such as the GFI Sandbox (formerly CWSandbox) or the JoeSandbox, is available, most solutions are closed-source. We present the design, im-plementation and evaluation of PyBox, a flexible and open-source sandbox written inPython. The application of a Python based analysis environment offers the opportunityof performing malware analyses on various operating systems as Python is availablefor almost every existing platform.
1 Introduction
The growing amount, variety, and complexity of malicious software (malware) poses ma-jor challenges for today’s IT security specialists. It is often necessary to analyze differenttypes of malware in order to understand and assess the resulting threats. However, sincemanual reverse engineering is time consuming, dynamic malware analysis has become astandard analysis approach in practice. In a dynamic analysis, malware is executed in acontrolled environment and all actions during runtime such as changes in the registry oraccess to the network are recorded. A log file provides the analyst with a first and oftensufficient overview over the basic functionality of the malware.
1.1 Related Work
Several sandbox solutions have been developed for Windows systems in the past. CW-Sandbox [WHF07] is a widely used sandbox tool which is now commercially availableunder the name “GFI Sandbox” [Sof]. While it is possible to use the sandbox over a webinterface as part of a research project [Fri], the sandbox software itself is closed source.The basic idea of CWSandbox is to “hook” specific Windows API calls, i.e., to divert
∗Contact author. Address: Am Wolfsmantel 46, 91058 Erlangen, Germany.

control flow into own code in user mode before executing the original API call.
A tool similar to CWSandbox is Joe Sandbox [joe11]. The primary difference to CW-Sandbox lies in the way how malware is observed. While CWSandbox applies user-modehooking, the behavior engine of Joe Sandbox is implemented as a Windows driver andtherefore runs in kernel mode. So in addition to being able to monitor malware running inkernel mode, it is also much more difficult for malware to detect the analysis environment.Still, Joe Sandbox is also a commercial closed-source system.
While not being commercial, Anubis (formerly known as TTAnalyze) [BMKK06] is asandbox system for research. However, Anubis is not open-source and can only be acces-sed through a web frontend1.
Leder and Plohmann [LP10] developed a user-mode sandbox which is open-source [PL].The idea of their system is to inject an entire Python interpreter into the process to bemonitored. The monitoring functionality is then provided through external Python scripts.In contrast to CWSandbox, this provides more flexibility and a higher degree of configu-rability. The major drawback of this approach is the severe performance overhead that isintroduced.
Another open-source sandbox solution is Cuckoo [Cla10], which is developed by the Ho-neynet Project. Cuckoo is a complete and therefore also rather complex framework formalware analysis including control of virtual machines to execute malicious software on.
1.2 Contribution
In this paper, we describe the design and implementation of an open-source sandbox calledPyBox (Python Sandbox). PyBox combines ideas from existing sandbox systems to createa unique and expandable tool for automated malware analysis:
• PyBox implements user-mode API hooking to monitor the behavior of executedsoftware, i.e., it injects a dynamic-link library (DLL) into created processes in orderto intercept API calls and the according arguments.
• PyBox allows execution control (resume, abort) during runtime.
• PyBox itself uses a programming interface based on Python for improved flexibility.
The main novelty of PyBox compared to existing sandboxes is the fact that it is opensource as well as its flexibility. While comparable closed source software may work wellin business environments, PyBox as an open source product targets to be used in researchas a building block for new malware analysis tools in the future. This way, researcherscan extend PyBox’s functionality and build customized solutions for their special analysistargets or work together to create a more powerful and portable analysis tool. The requiredflexibility is achieved by using Python as programming language for the analysis tool.Due to its easy to understand syntax Python is widely used and available for almost every
1See http://anubis.iseclab.org/.
138 PyBox - A Python Sandbox

platform. Therefore, the interface can be used to analyze targets on various systems byproviding the respective hook libraries. Python also offers the required low-level support tointeract with operating systems as well as integration with the used virtualization software.All this renders Python a perfect choice for our analysis tool. PyBox can be downloadedfrom the PyBox homepage [pyb].
After giving a short background on the techniques used by PyBox in Section 2, we brieflydescribe the design requirements of PyBox in Section 3. We give an overview of the im-plementation in Section 4 and present a brief functional evaluation in Section 5. Section 6concludes the paper.
2 Background
This section provides some general background on techniques used by PyBox.
2.1 Inline API Hooking
Hooking is a concept used to gain control of a program’s execution flow without chan-ging and recompiling its source code. This is achieved by intercepting function calls andredirecting them to infiltrated customized code.
PyBox implements so-called inline API hooking [HB08, Eng07] to monitor software be-havior. The complete process is displayed in Figure 1. Inline hooks directly overwrite thefunction’s code bytes in memory. In particular, only the first few instructions are replacedwith a five byte jump instruction to the actual hook function. The replaced instructions arestored in the trampoline function, which is used as a new entry point to the original APIcall. Within the hook function the logging of information or modification of arguments cantake place before the original API function is executed.
2.2 DLL Injection
In order to make use of hooked API functions within the process space of the softwarethat we want to analyze, we first need to inject code into the target process. The mecha-nism we apply for this purpose is called DLL injection. We instrument the API functionsCreateRemoteThread and LoadLibrary that enable us to create a new thread inthe target process and load a DLL file which in turn installs the hook functions.
PyBox - A Python Sandbox 139

Abbildung 1: Inline hooking [Eng07, p. 33]
3 Design of PyBox
The PyBox analysis environment consists of three major parts: a virtual machine, the ana-lysis tool PyBox.py, and the hook library pbMonitor.dll. Each is described in moredetail in the following paragraphs. A schematic overview of the different parts of PyBoxand their interaction is displayed in Figure 2.
Virtual Machine. Using a virtual machine as a basis for malware analysis guarantees asecure and controlled environment in which the malware can be executed and the originalsystem state can be restored afterwards. Inside the virtual machine we can observe systemactivity of a certain target software during runtime.
Analysis Tool. The analysis tool, called PyBox.py, acts as the hook server. The hookserver is responsible for setup adjustments according to the settings defined in the con-figuration files, target process creation, and hook library injection. During the executionof malicious software, it also receives and processes the log data from the hooked APIfunctions and in the end generates a final behavior report.
Hook Library. The hook library pbMonitor.dll implements the actual hooking andmonitoring functionality. It is responsible for installing the specified hooks, monitoring thesystem calls, and creating log entries, which are then sent to the hook server. Therefore,the hook library and the hook server have to interact with each other very closely by meansof inter-process communication (IPC). This way information exchange between the twoprocesses is straightforward.
The hook library pbMonitor.dll is the only component implemented in Visual C++.
140 PyBox - A Python Sandbox

Abbildung 2: Schematic overview of PyBox analysis process
In this case we have chosen C++ as programming language because Python cannot createDLL files and we have to make much use of various API functions provided by Windows.This requires the use of specific C data structures and is therefore more comfortable toprogram in C++.
4 Implementation Excerpts
Describing the complete implementation of PyBox would be out of the scope of this paper.We therefore focus on a few details only. For more information see Schonbein [Sch11].
4.1 Callbacks and Trampolines
The callback function allows us to execute our own customized code within the addressspace of the target process. Hence, we implement the monitoring functionality here andsend the resulting data to the PyBox analysis tool.
r e t u r n t y p e c a l l i n g c o n v e n t i o n c a l l b a c k f u n c t i o n ( arg1 , . . . , a r g n ){
r e t u r n t y p e s t a t u s ;i n f o = o b t a i n i f o r m a t i o n ( arg1 , . . . , a rgn ) ;i f ( p r e v e n t e x e c u t i o n == f a l s e ){
s t a t u s = t r a m p o l i n e f u n c t i o n ( arg1 , . . . , a r g n ) ;}
PyBox - A Python Sandbox 141

e l s e{
s t a t u s = c u s t o m i z e d r e t u r n v a l u e ;}c r e a t e l o g e n t r y ( i n f o ) ;re turn s t a t u s ;
}
Listing 1: Callback function structure
The basic structure of such a callback function is depicted in Listing 1. The variablesnamed prevent execution and customized return value represent settingsthat have been specified by the user beforehand. The value of prevent executiondetermines whether or not the trampoline function is called in order to execute the originalAPI function. In case it is not called, a custom value is returned. Finally, the functioncreate log entry notifies the analysis environment about the API function that wasexecuted and the arguments that were used.
In order to describe the usage of callback functions in more detail, we present the imple-mentation of a sample callback function in the following. The function NtCreateFile2
is provided by the native API. It is usually called in order to create a new file or to openan existing one. The interface requires eleven arguments that all have to be passed for afunction call. The most important ones are described in the following:
• FileHandle is a pointer to a file handle corresponding to the created or opened file afterthe function has been executed.
• DesiredAccess defines the requested access rights concerning the file.
• ObjectAttributes is a pointer to a structure containing information about the requestedfile such as the file name and its path.
• AllocationSize is an optional pointer to the size of the initial allocation in case a fileis created or overwritten. This pointer can also be NULL implying that no allocation size isspecified.
• FileAttributes contains flags specifying the file’s attributes. Such attributes can forexample mark a file as read-only or hidden.
The corresponding callback function is shown in Listing 2.
16 NTSTATUS NTAPI N t C r e a t e F i l e c a l l b a c k (17 o u t PHANDLE F i l e H a n d l e ,18 i n ACCESS MASK Des i r edAcces s ,19 i n POBJECT ATTRIBUTES O b j e c t A t t r i b u t e s ,20 o u t PIO STATUS BLOCK I o S t a t u s B l o c k ,21 i n o p t PLARGE INTEGER A l l o c a t i o n S i z e ,22 i n ULONG F i l e A t t r i b u t e s ,23 i n ULONG ShareAccess ,24 i n ULONG C r e a t e D i s p o s i t i o n ,25 i n ULONG C r e a t e O p t i o n s ,26 i n o p t PVOID EaBuffe r ,
2http://msdn.microsoft.com/en-us/library/ff566424(v=vs.85).aspx
142 PyBox - A Python Sandbox

27 i n ULONG EaLength28 )29 {30 NTSTATUS s t a t u s ;31 . . .
57 i f ( h o o k s e t t i n g s [ 0 ] . p r e v e n t E x e c u t i o n == FALSE)58 {59 / / C a l l t r a m p o l i n e f u n c t i o n60 s t a t u s = N t C r e a t e F i l e t r a m p o l i n e ( F i l e H a n d l e , Des i r edAcces s ,
O b j e c t A t t r i b u t e s , I o S t a t u s B l o c k , A l l o c a t i o n S i z e , F i l e A t t r i b u t e s ,ShareAccess , C r e a t e D i s p o s i t i o n , C r e a t e O p t i o n s , EaBuf fe r , EaLength ) ;
61 e x e c u t e d = 1 ;62 }63 e l s e64 {65 / / Get c u s t o m i z e d r e t u r n v a l u e66 s t a t u s = (NTSTATUS) h o o k s e t t i n g s [ 0 ] . r e t u r n V a l u e ;67 }68
69 / / C r e a t e l o g e n t r y and r e t u r n70 SOCKET ADDRESS INFO s a i = {0} ;71 c r e a t e L o g ( 0 , o b j e c t , L” ” , ” ” , exec u t e d , Des i r edAcces s , F i l e A t t r i b u t e s ,
ShareAccess , C r e a t e D i s p o s i t i o n , C r e a t e O p t i o n s , s a i , s t a t u s ) ;72 re turn s t a t u s ;73 }
Listing 2: The NtCreateFile callback function
As soon as all required information is gathered, it is determined whether the original APIis to call as well, or if a predefined value should be returned. This check is implemented inline 57. Finally, the callback function returns the value of status (line 72) to the objectthat has called the API function.
An important piece of information that is passed to the createLog function in li-ne 71, is the file path of the target file associated with the API call. All informati-on concerning the target file of a NtCreateFile call can be found in the argumentObjectAttributes. This structure contains the two fields providing the informationwe are looking for: RootDirectory and ObjectName. In order to obtain the comple-te path to a target file, we simply have to combine these two parts. The resulting string isstored in the variable object and finally used to create the associated log entry.
4.2 Detection Prevention
More recent malware samples implement methods to inspect the system environment theyare executed in, to detect analysis software. Since we do not want malware to behavedifferently than on a usual personal computer, we need to avoid easy detection of thePyBox analysis environment.
Possible techniques applied by malware in order to examine the system are to list all run-ning processes or to scan the file system. Often, certain API functions are applied in orderto implement the required detection techniques. In PyBox, we consider two different me-thods. The first method is to use the API function CreateToolhelp32Snapshot in
PyBox - A Python Sandbox 143

order to create a snapshot containing a list of all running processes and to parse this listusing the API functions Process32First and Process32Next. The second methodconsidered is to use the API functions FindFirstFile and FindNextFile in orderto scan the filesystem.
We use the the hooking functionality to intercept these API functions and successfully hidefiles and processes of PyBox. If an object returned by one of the above mentioned APIfunctions belongs to the analysis framework, the corresponding trampoline function willbe called again until it returns an object which does not belong to the analysis frameworkor until there is no more object left in the list to be queried. In this way, PyBox is basicallyinvisible to other processes of the analysis system, in particular to the examined targetprocess, too.
4.3 PyBox Analysis Tool
The PyBox analysis tool is the interface between the hook library and the analyst. It ena-bles the following tasks: configuration management, process creation, library injection,data processing, and report generation.
Abbildung 3: PyBox analysis tool layout
In order to fulfil these tasks, PyBox includes various packages, modules and configurationfiles, as illustrated in Figure 3.
In the upper part of Figure 3, the five packages belonging to the PyBox analysis tool are de-picted. The package setup is responsible for reading the provided configuration files andfor extracting their information. Furthermore, it converts this information into objects thatcan be used by the analysis tool. The package process allows to execute process-relatedoperations such as the creation of the target process. Additionally, it provides requiredprocess-specific information. The DLL injection method is implemented in the packageinjection. The final report generation operations are made available by the packagereport. More precisely, it offers the functionality to process the data received from themonitored process and turn them into a XML-based report. The communication and inter-
144 PyBox - A Python Sandbox

action with the target process is implemented in the package ipc.
The lower part of Figure 3 displays the two configuration files named pybox.cfg andhooks.cfg. The file pybox.cfg defines settings that are required by the analysis fra-mework to work. In particular it contains the path to the hook library, which is injectedinto the target process. In contrast, the file hooks.cfg influences the execution of thehook library inside the target process. More specifically, it defines which hooks to installand, thus, which API functions to monitor.
During the start of the execution of PyBox.py, all hooks are read and mapped to an arrayof C data structures that are present both in the PyBox main application and the hooklibrary. Each hook has a specific identification number by which it can be identified. Oncethe array is created out of the configuration file, the hook library can obtain the array andinstall all specified hooks. More details about logging and the generation of the the XMLreport can be found in Schonbein [Sch11].
5 Evaluation
In order to test the functionality of PyBox, we have tested the analysis environment ex-amining different malware samples. Due to space restrictions, in this section, we presentonly one example. More examples can be found in Schonbein [Sch11].
The malware sample analyzed here can be categorized as back door, trojan horse, or bot.Its common name is “Backdoor.Knocker”. Information about this threat is provided byVirusTotal [Vir], Prevx [Pre], and ThreatExpert [Thr]. ThreatExpert refers to it as Back-door.Knocker. Its purpose is to frequently send information such as the IP address or openports of the infected system to its home server.
During the analysis run of this sample it did not come to an end. Therefore, the analysisprocess terminated the target process after the specified time-out interval of two minutes.
227 <N t C r e a t e F i l e C r e a t e D i s p o s i t i o n =” 0 x00000005 ” C r e a t e O p t i o n s =” 0 x00000064 ”D e s i r e d A c c e s s =” 0 x40110080 ” Execu ted =”YES” F i l e A t t r i b u t e s =” 0
x00000020 ” O b j e c t =” C:\WINDOWS\ sys tem32\ c s s r s s . exe ” Re tu rnVa lue =” 0x00000000 ” Sha reAcce s s =” 0 x00000000 ” Timestamp=” 3115 ” />
228 <N t W r i t e F i l e Execu ted =”YES” Length =” 20928 ” O b j e c t =”WINDOWS\ sys tem32\c s s r s s . exe ” Re tu rnVa lue =” 0 x00000000 ” Timestamp=” 3116 ” />
Listing 3: Extract from the file management section of the malware sample’s analysis report
The first interesting aspect of the behavior report is in line 227 of Listing 3. The file sectiondocuments that the target process has created a file in the Windows system folder andwritten data to it. The file has been named cssrss.exe. These entries also indicatemalicious behavior as the file name is very similar to the file name csrss.exe. Thelatter is the executable of the Client Server Run-Time Subsystem (CSRSS),which is an important part of the Windows operating system. It seems that the analyzedobject is named similar to a system process to hide its presence.
PyBox - A Python Sandbox 145

1211 <NtOpenKey D e s i r e d A c c e s s =” 0 x00000002 ” Execu ted =”YES” O b j e c t =”REGISTRY\MACHINE\SYSTEM\C o n t r o l S e t 0 0 1 \ S e r v i c e s \SharedAccess\ P a r a m e t e r s \F i r e w a l l P o l i c y \ S t a n d a r d P r o f i l e ” Re tu rnVa l ue =” 0 x00000000 ” Timestamp=” 3121 ” />
1212 <NtSetValueKey D e s i r e d A c c e s s =” 0 x00000000 ” Execu ted =”YES” O b j e c t =”REGISTRY\MACHINE\SYSTEM\C o n t r o l S e t 0 0 1 \ S e r v i c e s \SharedAccess\P a r a m e t e r s \ F i r e w a l l P o l i c y \ S t a n d a r d P r o f i l e ” Re tu rnVa l ue =” 0 x00000000” Timestamp=” 3121 ” ValueName=” E n a b l e F i r e w a l l ” ValueType=” 4 ” />
1213 <NtOpenKey D e s i r e d A c c e s s =” 0 x00000002 ” Execu ted =”YES” O b j e c t =”REGISTRY\MACHINE\SYSTEM\C o n t r o l S e t 0 0 1 \ S e r v i c e s \SharedAccess\ P a r a m e t e r s \F i r e w a l l P o l i c y \ S t a n d a r d P r o f i l e \ A u t h o r i z e d A p p l i c a t i o n s \ L i s t ”Re tu rnVa l ue =” 0 x00000000 ” Timestamp=” 3121 ” />
1214 <NtSetValueKey D e s i r e d A c c e s s =” 0 x00000000 ” Execu ted =”YES” O b j e c t =”REGISTRY\MACHINE\SYSTEM\C o n t r o l S e t 0 0 1 \ S e r v i c e s \SharedAccess\P a r a m e t e r s \ F i r e w a l l P o l i c y \ S t a n d a r d P r o f i l e \ A u t h o r i z e d A p p l i c a t i o n s \L i s t ” Re tu rnVa lue =” 0 x00000000 ” Timestamp=” 3122 ” ValueName=” b i n a r y ”
ValueType=” 1 ” />
Listing 4: Extract from the registry section of the malware sample’s analysis report
The behavior report’s registry section also contains many entries, which have to be con-sidered. The process queries various information about system and network services aswell as about the operating system such as the system’s version. One particularly noticea-ble part of the registry section is depicted in Listing 4. The report reveals that the targetprocess uses registry API functions to change the value EnableFirewall (line 1212)and furthermore to add its executable file to the list of authorized applications (line 1214).These entries are clear evidence that the application tries to disable security mechanismsand thus performs malicious behavior unwanted by the system’s user.
6 Conclusion and Future Work
Given the available commercial dynamic analysis tools on the market, PyBox is the firstpublicly available open-source tool which written in a flexible and platform independentprogramming language. This allows PyBox to be easily improved in many ways.
In PyBox we currently only hook native API functions to monitor the behavior of malwaresamples. But different Windows versions often use very different native API functions.Therefore, the hook library has to be extended in order to provide compatibility with va-rious Windows versions.
An approach for extending the functionality of PyBox is to add further hooks to the analy-sis framework in order to monitor more types of activity. Furthermore, the analysis tool’sreport generation can be extended by mapping provided numeric values such as file crea-tion flags to strings that describe the meaning of the activated flags in order to simplifythe interpretation of the report. A third approach is to implement a hook library for otheroperating systems such as Android and thus provide the opportunity to analyze malwaresamples designed to attack mobile devices. In order to provide more flexibility and exten-
146 PyBox - A Python Sandbox

dibility for malware analyses we could incorporate the functionality of a C compiler. Wecould use a special Python script and create the hook library’s code out of existing codefragments according to the configured settings specified by the analyst. Thus, we wouldimplement a modular solution that automatically compiles a separate, customized hooklibrary that can be injected into the remote process to be monitored. In doing so, we wouldhave a more flexible solution, which also considers the performance criterion.
Literatur
[BMKK06] Ulrich Bayer, Andreas Moser, Christopher Krugel und Engin Kirda. Dynamic Analysisof Malicious Code. Journal in Computer Virology, 2(1):67–77, 2006.
[Cla10] Claudio Guarnieri and Dario Fernandes. Cuckoo - Automated Malware Analysis Sys-tem. http://www.cuckoobox.org/, February 2010.
[Eng07] Markus Engelberth. APIoskop: API-Hooking for Intrusion Detec-tion. Diplomarbeit, RWTH Aachen, September 2007. http://www1.informatik.uni-erlangen.de/filepool/thesis/diplomarbeit-2007-engelberth.pdf.
[Fri] Friedrich-Alexander University Erlangen-Nuremberg. Malware Analysis System.http://mwanalysis.org. Retrieved November 2011.
[HB08] Greg Hoglund und James Butler. Rootkits : Subverting the Windows Kernel. Addison-Wesley, 6. edition, 2008.
[joe11] How does Joe Sandbox work?, 2011. http://www.joesecurity.org/products.php?index=3, Retrieved May 2011.
[LP10] Felix Leder und Daniel Plohmann. PyBox — A Python approach to sandboxing. InSebastian Schmerl und Simon Hunke, Hrsg., Proceedings of the Fifth GI SIG SIDARGraduate Workshop on Reactive Security (SPRING), Seite 4. University of Bonn, Juli2010. https://eldorado.tu-dortmund.de/bitstream/2003/27336/1/BookOfAbstracts_Spring5_2010.pdf.
[PL] Daniel Plohmann und Felix Leder. pyboxed — A user-level framework for rootkit-likemonitoring of processes. http://code.google.com/p/pyboxed/. RetrievedNovember 2011.
[Pre] Prevx. Cssrss.exe. http://info.prevx.com/aboutprogramtext.asp?PX5=3E583C9DC0F87CBE51EE002CBE6AE800476D2E00, Retrieved April2011.
[pyb] PyBox – A Python Sandbox. http://www1.informatik.uni-erlangen.de/content/pybox-python-sandbox. Retrieved November 2011.
[Sch11] Christian Schonbein. PyBox - A Python Sandbox. Diploma Thesis, Universityof Mannheim, May 2011. http://www1.informatik.uni-erlangen.de/filepool/thesis/diplomarbeit-2011-schoenbein.pdf.
[Sei09] Justin Seitz. Gray Hat Python: Python Programming for Hackers and Reverse Engi-neers. No Starch Press, San Francisco, CA, USA, 2009.
PyBox - A Python Sandbox 147

[Sof] GFI Software. Malware Analysis with GFI SandBox (formerly CWSandbox). http://www.gfi.com/malware-analysis-tool. Retrieved November 2011.
[Thr] ThreatExpert. ThreatExpert Report: Trojan.Flush.G, Hacktool.Rootkit, Downloader-BIU.sys. http://www.threatexpert.com/report.aspx?md5=3cdb8dc27af1739121b1385f36c40ce9, Retrieved April 2011.
[Vir] VirusTotal. http://www.virustotal.com/file-scan/report.html?id=9e9efb4321ffe9ce9483dc32c37323bada352e2dccc179fcf4ba66dba99fdebf-1233827064, Retrieved April 2011.
[WHF07] Carsten Willems, Thorsten Holz und Felix Freiling. Toward Automated Dynamic Mal-ware Analysis Using CWSandbox. IEEE Security and Privacy, 5:32–39, 2007.
148 PyBox - A Python Sandbox

The Problem of Traffic Normalization Within aCovert Channel’s Network Environment Learning Phase
Steffen WendzelFaculty of Mathematics and Computer Science,University of Hagen, 58084 Hagen, Germany
Abstract: Network covert channels can build cooperating environments within over-lay networks. Peers in such an overlay network can initiate connections with newpeers and can build up new paths within the overlay network. To communicate withnew peers, it is required to determine protocols which can be used between the peers– this process is called the “Network Environment Learning Phase” (NEL Phase). Weshow that the NEL phase itself as well as two similar approaches are affected by trafficnormalization, which leads to a two-army problem. Solutions to overcome this notcompletely solvable problem are presented and analyzed. A proof of concept codewas implemented to verify the approach.
Keywords: network covert storage channel, traffic normalization, active warden
1 Introduction
A covert channel is a communication channel that is not intended for information trans-fer at all [Lam73]. Using network covert channels it is possible to send information ina way prohibited by a security policy [And08, WAM09]. Network covert channels canbe used by both, attackers (e.g. for hidden botnet communication [GP+08, LGC08]) aswell as normal users (e.g. journalists, if they want to keep a low profile when transfer-ring illicit information [ZAB07]). Network storage channels utilize storage attributes ofnetwork protocols while network timing channels modify the timing behavior of networkdata [ZAB07]. We focus on covert storage channels since they (in comparison to coverttiming channels) provide enough space to place a covert channel-internal protocol into thehidden data.
Ways to implement covert channels in TCP/IP network packets and their timings weredescribed by different authors (e.g. [Gir87, Wol89, HS96, Row97, CBS04, Rut04, LLC06,JMS10]). However, such channels occur outside of TCP/IP networks as well, such as insmart grids [LG10], electronic identity cards [Sch10] and business processes [WAM09].A number of means to protect systems against covert channels were also developed (e.g.[Kem83, PK91, Hu91, Fad96, FFPN03, CBS04, BGC05, KMC05]).
Covert channels can contain internal communication protocols [RM08, Stø09], so calledmicro protocols [WK11]. These protocols are located within the hidden data, which isused for both: the micro protocols as well as payload. Micro protocols are used to extend

the capabilities of covert channels by implementing features such as reliability and runtimeprotocol switching.
To enable two communicators to communicate using a covert channel, they need to find acommon cover protocol. A cover protocol is the network protocol (the bits used within anetwork protocol) which is used to place hidden data into. The discovery of informationabout network protocols to use can either be done using a micro protocol as presented in[WK11] or by passive monitoring of traffic [YD+08].
A traffic normalizer is a network gateway with the capaibility to affect the forwarded trafficin a way that prevents malicious communication (e.g. malformed traffic as well as anykind of network-based attacks such as botnet traffic or exploit traffic). Traffic normalizersare also known as packet scrubbers [BP09]. Usually, a traffic normalizer is part of afirewall system [MWJH00] and can decide to drop or forward network traffic. A popularexample of such a combination of a firewall with a traffic normalizer is the pf firewall of theOpenBSD operating system [Ope11]. A similar implementation for the FreeBSD kernelfocuses on the implementation of transport and application layer scrubbing [MWJH00].Additionally to a plain firewall system, a traffic normalizer is able to modify forwardedtraffic [MWJH00]. Therefore, the normalizer can apply rules such as clearing bits of anetwork protocol’s header or setting a header flag that was not set by the packet’s sender[HPK01]. Because of a normalizer’s applied modifications, their implementation in anetwork can result in side-effects, e.g. blocked ICMP types result in the unavailability ofthe related network features of these ICMP types [SN+06].
Traffic normalizers are also referred to as a special type of an active warden. While pas-sive wardens in networks monitor and report events (e.g. for intrusion detection), activewardens are capable of modifying network traffic [SN+06] to prevent steganographic in-formation transfer. Active wardens with active mapping capability reduce the problem ofambiguities in network traffic (i.e. data that can be interpreted in multiple ways [LLC07])by mapping a network and its policies [Sha02]. Afterwards, the mapped information isused by a NIDS to provide unambiguity [LLC07]. Based on the idea of active map-ping and traffic normalization, Lewandowski et. al. presented another technique callednetwork-aware active wardens [LLC07]. Network-aware active wardens have knowledgeabout the network topology and implement a stateful traffic inspection with a focus oncovert channel elimination [LLC06, LLC07].
All these techniques have in common that they drop or modify parts of the network trafficregarding to their configuration. For our purpose, it is required to focus on this commondropping and modification feature. We decided to use only the term normalizer in theremainder because we only deal with the normalization aspect that all three mentionedtechniques (normalizer, active mapper and network-aware active warden) have in common.
This paper contributes to the existing knowledge by presenting and discussing the problemof traffic normalization in a covert channel’s network environment learning phase (NELphase). Within the NEL phase, the covert channel peers try to find out which protocolsthey can use to communicate with each other (e.g. two journalists want to determinehow they can communicate using application layer protocols). Thus, the NEL phase issignificant for establishing a network covert channel. We show that traffic normalization
150 Traffic Normalization within the Network Environment Learning Phase

within the NEL phase results in a two-army problem. We evaluate passive monitoringnot to be capable to solve this problem and present two means to overcome the two-armyproblem. The drawbacks of these results are discussed as well.
The remainder of this paper is organized as follows. Section 2 introduces the problem oftraffic normalization within the NEL phase. Section 3 discusses means to overcome thisproblem and their possible drawbacks while Section 4 highlights the effect of four existingnormalizers on the NEL phase. Section 5 concludes.
2 Related Work and the Problem of NEL-Normalization
Yarochkin et. al. presented the idea of adaptive covert channels, capable of automati-cally determining the network protocols which can be used between two covert channelcommunicators [YD+08]. Their approach filtered out blocked and non-routed networkprotocols within a two-phase communication protocol containing a “network environmentlearning” (NEL) phase as well as a “communication phase”. Within the network envi-ronment learning phase, the covert channel software detects the usable network protocols,while the payload transfer is taking place within the communication phase. Wendzel andKeller extended this approach by introducing goal-dependent protocol sets, i.e., usableprotocols are chosen with different probabilities to optimize a covert channel for goalssuch as providing a high throughput or sending as few data packets as possible to transfera given payload [WK11].
A similar approach by Li and He is based on the idea of autonomic computing [LH11].The authors try to detect survival values for embedded steganographic content in networkpackets, i.e. they evaluate whether hidden data was corrupted within the transmission,or not, and therefore use checksums, transmission rates, and sequence numbers [LH11].However, Li’s and He’s approach requires a previously established connection to evaluatethe results, what is not sufficient if a normalizer is located between sender and receiver,since the two-army problem cannot be solved under such circumstances.
Yarochkin et. al. are focusing on whole network protocols [YD+08]. They detect usablenetwork protocols exchanged between two hosts by monitoring network data. Wendzeland Keller distinguish protocols on a finer scale, e.g. one “protocol” can be to set the “IPID” as well as the “Don’t fragment flag” in IPv4 while another protocol could only use the“Reserved” flag of IPv4 but both “protocols” belong to the same network protocol (IPv4)[WK11]. To prevent confusion, we call the network protocol (or the bits used within anetwork protocol) the “cover protocol” of a covert channel. Using this term, we can referto both approaches at the same time.
Figure 1: Communication between two hosts A and B. Neither A nor B know about the existence ofa normalizer (and its configuration) between them a priori.
Traffic Normalization within the Network Environment Learning Phase 151

All three mentioned methods, Yarochkin et. al., Wendzel and Keller, and Li and He,aim to gain information about usable cover protocols but do not focus on the problem oftraffic normalization. When a traffic normalizer is located between two covert channelsystems which want to exchange information about protocols they can send and receive, anormalizer can drop or modify the exchanged information (Fig. 1). It is also possible thatmore than one normalizer is located on the path between A and B but this does not differfrom a single normalizer in our scenario.
Normalizers usually modify bits (such as they unify the TTL value in IPv4) or clear bits(such as the “Don’t fragment” flag). Implementations like norm [HPK01], the Snort Nor-malizer [Sno11], the netfilter extension ipt scrub [Bar08], or the OpenBSD packet filterscrubbing [Ope11]1 provide more than 80 normalization techniques for IPv4/IPv6, ICMP,TCP, UDP and the most important application layer protocols.
In the given scenario, host A and host B want to exchange information about the cover pro-tocols, i.e. network protocols and the protocol specific bits they can use to communicatewith each other. For example, host A is sending a network packet (e.g. a DNS request) tohost B with the reserved flag set in the IPv4 header: If the normalizer clears the reservedflag (it is zero afterwards), host B cannot determine whether host A did not set the reservedflag or whether a normalizer (B and A are possibly not aware of a normalizer) modified thebit. Alternatively, the normalizer can – like a plain firewall – drop a packet if the reservedflag is set (in that case, host B does not know about the sent packet).
To exchange the information about all usable bits of all cover protocols a covert channelcan support between A and B, it is required to test all bits and protocols in both directions(each received packet must be acknowledged to inform the sender about the successfulsending). Since A cannot know which of his packets will reach B, A depends on the ac-knowledgement of B. If A can successfully send a packet to B, B cannot make sure thatthe response containing the protocol acknowledge information is not getting dropped by anormalizer (since B does not know which bits or protocols will reach A). Since neither Anor B can be sure whether their packets will reach the other system, they are left in an un-informed situation. Hence, the exchange of protocol information between A and B resultsin the two-army problem [Kle78]. The two-army problem cannot be eliminated but the un-certainty of A and B can be reduced by sending multiple (acknowledgement) messages oracknowledgement messages from each side (A acknowledges B acknowledgement, suchas performed by the three-way-handshake of TCP [Pos81]). The next section discussesspecific means for dealing with the two-army problem within the NEL phase.
3 Realizing the NEL Phase in Normalized Environments
If the covert channel software is able to determine a set of non-normalized cover protocols,it will enable the covert channel to communication without problems. Therefore, we definea set of cover protocols P = {x1, ..., xn} (P contains all possible bit areas which can beused within a cover protocol) where, for instance, x1 could represent “sending an IP packet
1Regarding to our investigation, pf supports a number of undocumented normalization features.
152 Traffic Normalization within the Network Environment Learning Phase

with DF flag set”. An element xi ∈ P can contain other elements of P (e.g. x1=“set DFflag” and x2=“set the reserved flag”, x3 = {x1, x2}=“set the reserved flag as well asthe DF flag”). This condition is necessary, since a normalizer can include a rule to drop,modify or clear a packet (respectively bits) if a packet contains both x1 and x2, but doesnot apply the same rule (or no rule) in case of x1 or x2.
Based on this initial specification, we develop two different means for applying the NELphase in normalized environments as well as in environments where A and B cannot besure whether a normalizer is located between them.
The first solution is to use a pre-defined sequence of the elements of P . In comparisonto the passive monitoring approach of Yarochkin et. al., this is an active approach. Wedescribe a disadvantage of the passive approach in Sect. 3.1.
In the first step, A sends an ordered sequence x1, ..., xn to B. The data hidden in xi mustcontain information B can use to identify these as covert data (such as a “magic byte” asin ping tunnel [Stø09] or micro protocol data [WK11]). In case host B receives some ofthese packets, B can assume that A is currently sending the pre-defined packet sequence.Probably, host B will receive a sequence such as x3, x9, x10 (with bit i cleared), x11, x17
(with bits j and k cleared), x19, x20, i.e. some protocols or bit-combinations were blocked(respectively modified) by a normalizer, or got lost. In this case, host B can never becompletely sure that it is currently receiving the packet sequence from A but can use theinformation received to communicate with A in a limited way nevertheless. The completeprocess has to be done vice versa since normalizer rules can be direction-dependent. Af-terwards, A and B will have a set of protocols they can receive from the other peer. A andB assume that the cover protocols of the packets that were received correctly can be usedto send data back to the peer. After this step is completed too, the communication phasecan start.
Since B (respectively A) do not know whether their own packets were received by the peerif the normalizer applies direction-dependent rules, and depend on the acknowledgementinformation from the peer itself, they do not know which cover protocol they can use tosend their acknowledgement. Therefore, this solution results in the two-army problemagain if the normalizer applies direction-dependent rules and has to be considered error-prone.
Figure 2: A and B exchanging protocol information using C.
A second solution (shown in Fig. 2) we want to present is to include a third (but tem-porary) participant C known to A and B. We assume that A and C, as well as B and Calready exchanged the information about usable protocols, i.e. they are able to exchange
Traffic Normalization within the Network Environment Learning Phase 153

information in a way not dropped or cleared, even if a normalizer is present between them.C is not necessarily required to be aware of a covert communication between itself andA or B, i.e. C could be a shared temporary resource such as a Flickr account [BK07]. Cis a temporary solution since A, B (and probably others) can only build a complex covertoverlay network if new paths besides already known paths are created. If A and B wouldtransfer all information between them using C, no new path would be created and C wouldbe a single point of failure if no other connection between A and B exists. Additionally, itis more secure to transfer only information about usable protocols between A and B via Cthan it is to transfer all hidden information itself via C.
In this scenario, C can be used by A to inform B (and vice versa) about packets which A(respectively B) is about to sent. For instance: A sends C the information to tell B that Awill now send an IP packet with DF bit set to B; C will forward the information to B. Awill sent the described packet either after a short waiting time < t to B or after B respondsits waiting state to A (via C). The first method decreases the amount of exchanged datawhile the latter is less error-prone.
If B received the packet, B knows, that the DF flag can be used and was not cleared ordropped. In any case, B reports the reception/the miss of the announced cover protocolcontaining packet. The whole process works in both directions, i.e. A and B can exchangeall required information about usable cover protocols. The temporary system C is notrequired to be a single hop within the overlay network, it can also be a chain of proxies C =P1 → ... → Pn represented as a single system in this second solution. The only differencebetween a single hop called C and a proxy chain called C is the internal forwarding withinthe system. Such forwarding for covert channel proxy chains must be bi-directional andcan be achieved and optimized by known micro protocol means [WK11].
Discussion of the two presented means
While the first scenario (sending a pre-defined sequence) is error-prone, the second sce-nario depends on a third communicator C connected to A and B. A combination of bothscenarios will be a promising approach for further implementations.
A drawback in the second solution exists in case C is aware of covert communication(i.e. not a passive system, such as a Flickr account), since C can manipulate the covertcommunication. For instance, C could drop all protocol information requests from A toB (and vice versa). If A and B are able to exchange cryptographic keys a priori, they cansign messages sent via C to prevent undetected message modifications. However, the useof signatures does not prevent C from actively dropping the messages. Therefore, it isrecommended to use a passive C.
3.1 Improved Protocol Determination Strategies
If a covert channel implementation supports a large amount of cover protocols (or some ar-eas containing many bits), the packet count required to transfer all feasible bit-combinationsthrough the possible normalizer can become high, thus the number of required packets forthe protocol determination can also be high.
154 Traffic Normalization within the Network Environment Learning Phase

For example, if P = {x1, x2, x3} (say each xi is representing one bit of data in this case),it is possible to send each element alone, in combination with another element, or allthree elements at the same time, i.e. there are seven possible combinations. To verify thepossible use of these protocols using strategy #2 (as explained before), it would require 14packets to verify all elements of P and their combinations for the cover protocols betweenA and B (the packets exchanged between A and C as well as between B and C are notincluded in this calculation).
If P contains many elements, the number of required packets can result in raising a highattention due to the abnormal traffic pattern [WK11]. Therefore, it is mandatory to reducethe number of required packets.
A reduction of the necessary network packets for determining the usable cover protocolsbetween A and B can result in a loss of quality in the determined protocol information. Wepresent two reduction strategies, where the first strategy results in a loss of quality whilethe second does not. These strategies are presented since each practical implementationcan profit from them to keep a low profile.
Reduction Strategy 1: If each protocol layer (e.g. the TCP/IP layers) can be scannedindependent of the other layers, the number of possible combinations decreases. For in-stance, if x1 and x2 refer to bits within the IPv4 header, and x3 refers to UDP, there areonly six (instead of eight) combinations left to try. This scan technique has the drawbackthat normalizer rules which depend on multiple layers are not taken into account.
Reduction Strategy 2: If each different covering network protocol on the same networklayer is scanned independent from all other network protocols on the same layer, a loss inthe quality of the resulting information is not possible since different protocols usually donot depend on other protocols on the same layer.2 For instance, if P = {x1, x2} where x1
modifies two bits within the TCP header and x2 modifies one bit within the UDP header,there are only 6 possible bit combinations to verify.
Critique on the passive approach: Another simplification is thinkable but less valu-able for real implementations: Regarding to the passive monitoring approach presentedby Yarochkin et. al. (as discussed in Sect. 2), A could try to use only protocols for thecommunication with B which it can receive on its own network interface. However, theoccurrence of a network protocol on a network interface of A does not necessarily meanthat a normalizer will forward such network packets to A in any case. If, on the other hand,the source address of such a network protocol’s packet does not belong to A’s subnet, it isthe case that such a network protocol is forwarded to the network of A. Such a packet hasprobably passed a normalizer but since there can be more than one normalizer between Aand B, this solution is also error-prone and cannot be recommended for implementations.Of course, one could argue that A could wait for network packets containing the sourceaddress of B’s subnet, but this is only realistic in the case of regular communication be-tween both subnets. Additionally, filter rules can be address-based instead of interface- orsubnet-based, i.e. it is possible that a normalization rule applies for some hosts in B’s (A’s)
2This second rule is mandatory since it is not possible for network packets to contain two different networkprotocols of the same network layer. An exception is to use network tunneling but in network tunneling, a singlenetwork layer also does not really contain two protocols, but a layer can occur multiple times.
Traffic Normalization within the Network Environment Learning Phase 155

subnet but not for all hosts in the subnet. Thus, this approach is only useful for a directcommunication between B and A, and due to that limitation provides no improvement incomparison to the already presented means. However, the passive approach is linked to anumber of drawbacks: It requires additional waiting time and is is not successfully adapt-able to most overlay network situations, since information about the underlay network arenot necessarily available. Mentionable as well, is that a direct third party network dataexchange between A and B, which is required for the monitoring, will usually be rare andwill additionally not necessarily include all elements of P .
3.2 The Problem of Dynamic Routing Environments
Problematic as well is the possibility for traffic to take different routes on the path betweenA and B within the underlay network, where one packet could pass a normalizer and an-other packet does not (or some packets are transferred over different normalizers). Sinceneither A nor B are able to control the routing decisions between them and do not neces-sarily possess knowledge about the underlay network structure, A and B cannot overcomethis situation.
3.3 Proof of Concept Implementation
A proof of concept implementation was developed to run a simulated NEL phase. Acovert channel receiver program (representing B) was built to accept information from atemporary participant (representing C) as shown in strategy #2. The input from C to Bwas scripted by hand and the traffic from A to B was generated using the network packetgenerator scapy (www.secdev.org/projects/scapy/), while the covert receiver software isbased on libpcap (tcpdump.org). Using scapy, we were able to simulate packet loss, perfectpacket transfer and traffic modifications. If packet loss occurs, B assumes that a packetwas filtered. Since uncommon packet occurrences can result in raising a high attention,we cannot recommend to sent such packets multiple times within a small time slice todeal with packet loss. Non-normalized packets obviously result in an uncorrupted NELphase (excluding lost packets). The effect of traffic modifications turned out to producemultiple packets containing the same flag combinations on system B. For instance, if Asends an IPv4 packet containing the DF flag set as well as one packet with an unset DFflag, B will receive two packets with DF=0 if a normalizer clears the DF flag. B mustensure not to accept packets using the same bits as announced by A from other sources,thus B must apply filter rules (e.g. using libpcap filter settings to accept only packets fromA). The covert channel receiver B transfers the information of an useless cover protocolback to A (using C) if such a doubled cover protocol was received. We implemented theacknowledgement transfer to A using a micro protocol as described in [WK11].
156 Traffic Normalization within the Network Environment Learning Phase

4 Effects of Existing Normalizers on the NEL Phase
As discussed in the previous sections, traffic normalizers can drop, modify and clear coverprotocols. Thus, for realizing a covert channel’s NEL phase, it is important to obtainknowledge about the usable cover protocols a priori. By analyzing four normalizers (pfscrubbing, norm, the Linux netfilter/iptables extension ipt scrub, and the Snort normal-izer), we were able to carve out general rules which can be applied to the NEL phase.
Different traffic normalizers contain different capabilities. For instance, Snort and normare able to clear the IPv4 reserved flag, but pf is not. Some capabilities are configuration-dependent, e.g. the handling of the “Don’t Fragment” flag in pf depends on the usage ofthe “no-df” rule in the configuration file. Additionally, the amount of features differs sig-nificantly: While norm supports more than 70 normalization rules, ipt scrub supports only8 of them. Additional differences apply for the amount of supported network protocols.
For the NEL phase, it is useful to define the elements of P by verifying their support withinnormalizers: Elements which are not supported by any or by very few normalizers arelikely to reach their destination within the NEL phase, while elements which are supportedby (almost) any normalizer have a higher probability to get normalized.
We compared the features of the four normalizers and found out that several normaliza-tion capabilities are provided by most of the implementations: IPv4: TTL modification,removing DF flag, reserved bit and options and drop packets with IHL <5 or > 53. IPv6:modify the hop limit, modify or remove optional headers. ICMP modify/drop ICMP type0 and 8. TCP: Clear the reserved bits, drop packets with unusual flag or flag/data com-binations (e.g., SYN=1 and RST=1, SYN=1 and FIN=1, or SYN=1 with payload), dropin case of a small header length. UDP (norm)/HTTP (Snort): Only supported by onenormalizer.
Additionally, we want to provide a general explanation which cover protocols we can calluseful in our scenario. UDP and HTTP are currently only supported by one of the normal-izers, which makes them good choices for bypassing normalizers within the NEL phase.On the other hand, there are network protocols which are not in the scope of any of the nor-malizers, e.g. application layer streaming protocols, frames on the network access layer,or dynamic routing protocols, what makes them good choices for the NEL phase too. Ifsuch protocols are used, it is important to understand that the occurrence of rarely usednetwork protocols can raise the attention of a covert channel [WK11] (e.g. the usage ofIGRP in an OSPF network). Thus, the usefulness of rarely used protocols for the NELphase is low. A passive monitoring can be done to determine the occurrence rates of net-work protocols (but as described in Sect. 3.1, passive monitoring is not recommendable todetect cover protocols). Tab. 1 shows occurrence rates of transport layer network proto-cols within different passive traffic recordings and demonstrates the significant differenceswithin different Ethernet networks. These three traffic recordings where downloaded fromhttp://www.simpleweb.org/wiki/Traces, a website providing a number of tcpdump record-ings (mainly from universities). These different protocol occurrences do not only exist fornetwork protocols but for types of cover protocols as well, as shown in Tab. 2 in case of
3In case of OpenBSD, this is not specified in the manual, but found in a source code analysis for this paper.
Traffic Normalization within the Network Environment Learning Phase 157

Source ARP TCP UDP ICMP IGMPSimpleweb-Loc1 0.02% 77.67% 21.94% 0.25% <0.001%Simpleweb-Loc2 - 92.46% 0.08% 3.20% <0.01%Simpleweb-Loc3 - 68.88% 3.95% 27.12% <0.01%
Table 1: Occurrence rates of different network protocols in three traffic recordings downloaded fromsimpleweb (each source contained between 750.000 and 1.200.000 packets).
Source Type 0 Type 3 Type 8 Type 11Simpleweb-Loc2 2.96% 88.93% 7.97% 0.13%Simpleweb-Loc3 2.24% 0.08% 97.66% 0.02%
Table 2: Relative occurrence rates of ICMP types in three networks.
the different ICMP type values (ICMP is a protocol that is used by popular covert channeltools such as pingtunnel [Stø09]).
To summarize, the presented strategies of Sect. 3 to overcome the normalization withinthe NEL will work, even if a combination of all four normalizers would be present. Thefirst strategy (sending a pre-defined sequence) can only be affected, if a huge part ofthe sequence will be normalized (or if the first packet containing the magic byte will becleared). The solution for this problem is to choose only protocols not supported by thenormalizers. Since none of the normalizers can affect an already working covert channelvia a temporary participant, the second strategy can be applied in any case.
5 Conclusion
In this paper, we have shown that the process of determining possible cover protocolswithin the so called Network Environment Learning (NEL) phase is problematic if a nor-malizer is located on the path between two covert channel peers since it will result in atwo-army problem. We additionally presented two techniques to overcome this not com-pletely solvable problem of one or more possible normalizers which sender and receiverare not aware of, and discussed possible drawbacks of these approaches. We have evalu-ated three existing approaches to be insufficient for this purpose and implemented a proofof concept application to verify our presented approach. Finally, we analyzed four avail-able normalizers to extract information about cover protocols which can be used for theNEL phase without a high probability of getting dropped or modified.
Acknowledgement
I would like to thank Jorg Keller (University of Hagen) for his valuable contributions andguidance. I would also like to thank the anonymous reviewers for their feedback.
158 Traffic Normalization within the Network Environment Learning Phase

References
[And08] R. Anderson. Security Engineering - A Guide to Building Dependable DistributedSystems. Wiley, 2 edition, 2008.
[Bar08] N. Bareil. ipt scrub: scrubbing for Netfilter, May 2008.
[BGC05] V. Berk, A. Giani, and G. Cybenko. Detection of Covert Channel Encoding in Net-work Packet Delays. Technical report, Department of Computer Science - DartmouthCollege, 2005.
[BK07] A. Baliga and J. Kilian. On covert collaboration. In Proceedings of the 9th Workshopon Multimedia & Security, pages 25–34, New York, NY, USA, 2007. ACM.
[BP09] K. Borders and A. Prakash. Quantifying Information Leaks in Outbound Web Traffic.In 30th IEEE Symposium on Security and Privacy, pages 129–140, 2009.
[CBS04] S. Cabuk, C. E. Brodley, and C. Shields. IP covert timing channels: design and detec-tion. In Vijayalakshmi Atluri, Birgit Pfitzmann, and Patrick Drew McDaniel, editors,ACM Conference on Computer and Communications Security, pages 178–187. ACM,2004.
[Fad96] Y. A. H. Fadlalla. Approaches to Resolving Covert Storage Channels in MultilevelSecure Systems. PhD thesis, University of Brunswick, 1996.
[FFPN03] G. Fisk, M. Fisk, C. Papadopoulos, and J. Neil. Eliminating Steganography in InternetTraffic with Active Wardens. In Revised Papers from the 5th International Workshopon Information Hiding, IH ’02, pages 18–35, London, UK, UK, 2003. Springer-Verlag.
[Gir87] C. G. Girling. Covert Channels in LAN’s. IEEE Transactions on Software Engineering,13:292–296, February 1987.
[GP+08] G. Gu, R. Perdisci, et al. BotMiner: Clustering Analysis of Network Traffic forProtocol- and Structure-Independent Botnet Detection. In P. C. van Oorschot, editor,USENIX Security Symposium, pages 139–154. USENIX Association, 2008.
[HPK01] M. Handley, V. Paxson, and C. Kreibich. Network Intrusion Detection: Evasion, TrafficNormalization, and End-to-End Protocol Semantics. In 10th USENIX Security Sympo-sium, volume 10, pages 115–131, 2001.
[HS96] T. G. Handel and M. T. Sandford, II. Hiding Data in the OSI Network Model. InProceedings of the First International Workshop on Information Hiding, pages 23–38,London, UK, 1996. Springer-Verlag.
[Hu91] W.-M. Hu. Reducing Timing Channels with Fuzzy Time. In 1991 Symposium onSecurity and Privacy, IEEE Computer Society, pages 8–20, 1991.
[JMS10] B. Jankowski, W. Mazurczyk, and K. Szczypiorski. Information Hiding Using ImproperFrame Padding. eprint arXiv:1005.1925, 2010.
[Kem83] R. A. Kemmerer. Shared resource matrix methodology: an approach to identifyingstorage and timing channels. ACM Transactions on Computer Systems, 1(3):256–277,1983.
[Kle78] L. Kleinrock. Principles and Lessons in Packet Communications. In Proc. of the IEEE,volume 66, pages 1320–1329, November 1978.
Traffic Normalization within the Network Environment Learning Phase 159

[KMC05] M. H. Kang, I. S. Moskowitz, and S. Chincheck. The Pump: A Decade of Covert Fun.In ACSAC, pages 352–360. IEEE Computer Society, 2005.
[Lam73] B. W. Lampson. A Note on the Confinement Problem. Commun. ACM, 16(10):613–615, 1973.
[LG10] G. Locke and P. D. Gallagher. Guidelines for Smart Grid Cyber Security: Vol. 3,Supportive Analyses and References (NIST Interagency/Internal Report (NISTIR) -7628), 2010.
[LGC08] Z. Li, A. Goyal, and Y. Chen. Honeynet-based Botnet Scan Traffic Analysis. In W. Lee,C. Wang, and D. Dagon, editors, Botnet Detection, volume 36 of Advances in Informa-tion Security, pages 25–44. Springer, 2008.
[LH11] W. Li and G. He. Towards a Protocol for Autonomic Covert Communication. In Proc.8th Conf. on Autonomic and Trusted Computing, pages 106–117, 2011.
[LLC06] N. Lucena, G. Lewandowski, and S. Chapin. Covert Channels in IPv6. In GeorgeDanezis and David Martin, editors, Privacy Enhancing Technologies, volume 3856 ofLecture Notes in Computer Science, pages 147–166. Springer Berlin / Heidelberg, 2006.
[LLC07] G. Lewandowski, N. Lucena, and Steve C. Analyzing Network-Aware Active Wardensin IPv6. In Jan Camenisch, Christian Collberg, Neil Johnson, and Phil Sallee, editors,Information Hiding, volume 4437 of Lecture Notes in Computer Science, pages 58–77.Springer Berlin / Heidelberg, 2007.
[MWJH00] G.R. Malan, D. Watson, F. Jahanian, and P. Howell. Transport and application protocolscrubbing. In Proc. of the INFOCOM 2000. Nineteenth Annual Joint Conference of theIEEE Computer and Communications Societies., pages 1381–1390, 2000.
[Ope11] OpenBSD Project. pf.conf - packet filter configuration file (manual page), July 2011.
[PK91] P. A. Porras and R. A. Kemmerer. Covert Flow Trees: A Technique for Identifying andAnalyzing Covert Storage Channels. In IEEE Symp. on Security and Privacy, pages36–51, 1991.
[Pos81] J. Postel. RFC 793: Transmission Control Protocol. DARPA Internet Programm Proto-col Speicification, September 1981.
[RM08] B. Ray and S. Mishra. A Protocol for Building Secure and Reliable Covert Channel. InLarry Korba, Steve Marsh, and Reihaneh Safavi-Naini, editors, PST, pages 246–253.IEEE, 2008.
[Row97] C. H. Rowland. Covert Channels in the TCP/IP protocol suite. First Monday, 2(5),May 1997.
[Rut04] J. Rutkowska. The implementation of passive covert channels in the linux kernel, 2004.
[Sch10] K. Schmeh. Covert Channels in elektronischen Ausweisen. In Christian Paulsen, editor,Sicherheit in vernetzten Systemen: 17. DFN Workshop. BoD, 2010. (In German).
[Sha02] U. Shankar. Active Mapping: Resisting NIDS Evasion Without Altering Traffic. Tech-nical Report UCB//CSD-2-03-1246, Computer Science Division (EECS) (University ofCalifornia Berkeley), December 2002.
[SN+06] A. Singh, O. Nordstrom, et al. Stateless Model for the Prevention of Malicious Commu-nication Channels. International Journal of Computers and Applications, 28:285–297,2006.
160 Traffic Normalization within the Network Environment Learning Phase

[Sno11] Snort Project. Snort Users Manual 2.9.0, March 2011.
[Stø09] D. Stødle. Ping Tunnel – For those times when everything else is blocked, 2009.
[WAM09] C. Wonnemann, R. Accorsi, and G. Muller. On Information Flow Forensics in BusinessApplication Scenarios. IEEE COMPSAC Workshop on Security, Trust, and Privacy forSoftware Applications, IEEE, 2009.
[WK11] S. Wendzel and J. Keller. Low-attention forwarding for mobile network covert channels.In Proc. of the 12th Conference on Communications and Multimedia Security, pages122–133, 2011.
[Wol89] M. Wolf. Covert channels in LAN protocols. In Thomas Berson and Thomas Beth, ed-itors, Local Area Network Security, volume 396 of Lecture Notes in Computer Science,pages 89–101. Springer Berlin/Heidelberg, 1989.
[YD+08] F. V. Yarochkin, S.-Y. Dai, et al. Towards Adaptive Covert Communication System. InPRDC, pages 153–159. IEEE Computer Society, 2008.
[ZAB07] S. Zander, G. Armitage, and P. Branch. Covert Channels and Countermeasures in Com-puter Network Protocols. IEEE Comm. Magazine, 45(12):136–142, Dec 2007.
Traffic Normalization within the Network Environment Learning Phase 161


Filtern von Spam-Nachrichten mit kontextfreienGrammatiken
Philipp Trinius1 Felix C. Freiling∗2
1 Universitat Mannheim, Deutschland2 Friedrich-Alexander-Universitat Erlangen-Nurnberg
Abstract: Spam wird heute uberwiegend mittels so genannter musterbasierte Spam-Algorithmen uber Botnetze verteilt. Bei musterbasiertem Spam werden die Spam-Nachrichten erst von den Bots aus einem Muster (template) und Fulldaten zusammen-gesetzt. Filteransatze fur musterbasierten Spam versuchten bisher, dieses Muster ausden abgefangenen Nachrichten zu extrahieren und auf regulare Ausdrucke abzubilden.Diese Technik kann aber durch die Umsortierung von Worten oder Zeilen leicht um-gangen werden. Wir schlagen einen neuartigen Filteransatz vor, der auf kontextfreienGrammatiken basiert. Unser Ansatz lernt dabei nicht die Muster sondern die ”Inhalte“der Nachrichten. Das Resultat ist eine Grammatik, die zum Filtern von Nachrichtenaus einer spezifischen Spam-Kampagne verwendet werden kann. Die Filterergebnis-se dieses Ansatzes sind sehr gut: Teilweise erreichen aus einer einzelnen Nachrichterstellte Filter bereits Erkennungsraten von uber 99 Prozent.
1 Einfuhrung
Der uberwiegende Anteil an Spam wird aktuell uber Botnetze versendet. Die verschick-ten Nachrichten werden dabei erst von den Bots selbst, aus vordefinierten Mustern fur dieeinzelnen Spam-Kampagnen und Fulldaten wie Empfanger- und Absenderlisten, zusam-mengesetzt. Die verwendeten Muster bieten hierbei einen Ansatzpunkt fur Kampagnen-spezifische Filter. Bei den bisher veroffentlichen Ansatzen wurde jeweils versucht, dasMuster zu approximieren und zum Filtern der Nachrichten zu verwenden. Dazu werdendie Spambots in sogenannten Sandnets ausgefuhrt und aus den verschickten Nachrichtenwird, uber einen Longest Common Substring (LCS) Algorithmus, das Template berechnet.Die aus den abgegriffenen Nachrichten generierten Filter passen im besten Fall nur aufNachrichten der Kampagne, das heißt, der Filter liefert keine false positives.
Die auf LCS-Berechnungen basierenden proaktiven Filteransatze versuchen, das Templateals regularen Ausdruck darzustellen. Dieser enthalt nur die Teile der Nachrichten, die inallen Nachrichten enthalten sind. Dem Ansatz liegt damit die Annahme zugrunde, dass dasin der Kampagne verwendete Template starr ist und die resultierenden Spam-Nachrichtensich nur an einzelnen Stellen unterscheiden. Sobald das Template nicht nur Ersetzungen,sondern auch Permutationen von Wortern, Satzen, oder auch ganzen Textblocken zulasst,
∗Kontaktautor, Kontaktadresse: Am Wolfsmantel 46,91058 Erlangen, Deutschland.

ist die Beschreibung uber einen regularen Ausdruck nur bedingt moglich. Um die Permuta-tionen in dem extrahierten Muster abzubilden, mussen sehr komplexe regulare Ausdruckekonstruiert werden. Zudem muss immer sichergestellt werden, dass es sich bei den aufge-nommenen Informationen (Varianten) nicht um Fulltexte handelt.
Bisherige Arbeiten. Kreibich et al. [KKL+08] veroffentlichten mit ihrer Studie zumSTORM WORM Botnetz die erste Arbeit, die das Verfahren des musterbasierten Spam furBotnetze im Detail beschreibt. Die Moglichkeit, die von den Bots verwendeten Templatesbedingten Regelmaßigkeiten innerhalb der Nachrichten zum Filtern zu verwenden, wurdeerstmals von Stern [Ste08] erwahnt, dort aber noch nicht umgesetzt.
In der Folge entstanden einige Arbeiten [XYA+08, JMGK09, GHT09], die den von Spam-bots generierten Spam zur Extraktion Kampagnen-spezifischer Informationen heranzuzie-hen. Wahrend Xie et al. [XYA+08] und John et al. [JMGK09] lediglich die in den Nach-richten enthaltenen URLs herauslesen, extrahieren Gobel, Holz und Trinius [GHT09] dasMuster der Kampagne selbst aus den Nachrichten und bilden es in einen regularen Aus-druck ab. Pitsillidis et al. [PLK+10] erweitern den Ansatz von Gobel, Holz und Trinius[GHT09] um Dictionaries fur ausgewahlte, variable Textpassagen, die mit in die regularenFilterausdrucke einfließen.
Ansatz und Ergebnisse. Der von uns vorgestellte Filteransatz lost sich von der starrenBeschreibung des Templates als regularen Ausdruck. Statt das Template aus den abge-griffenen Nachrichten zu extrahieren, wird in unserem Ansatz der Inhalt der innerhalbder Kampagne verschickten Nachrichten gelernt. Aus diesen Daten wird eine kontextfreieGrammatik konstruiert, die zum Filtern von Spam-Nachrichten verwendet werden kann.Hinter diesem Ansatz steht die Annahme, dass Spammern nur eine beschrankte Anzahl anWortern und Satzen zum Beschreiben ihrer Produkte zur Verfugung stehen. Der hier vor-gestellte Ansatz fasst Spam-Nachrichten also weniger als Kette von Zeichen auf sondernals in einer naturlichen Sprache formulierte Texte.
Die Evaluierung der sprachbasierten Filteransatze zeigt, dass sich die Nachrichten mus-terbasierter Spam-Kampagnen aus nur wenigen charakteristischen Wortern und Satzenzusammensetzen. Der Großteil dieser Daten ist in allen Nachrichten einer Kampagne ent-halten und damit schon nach der Analyse einzelner oder weniger Nachrichten bekannt. DerFilteransatz benotigt daher sehr wenige Nachrichten, um sehr effektive Filter fur die ein-zelnen Kampagnen zu berechnen. Fur die zur Evaluierung herangezogenen Spam-Laufekonnten teilweise schon nach dem Lernen einer einzelnen Spam-Nachricht Erkennungsra-ten von uber 99 Prozent erreicht werden. Dieser Beitrag stellt die Ergebnisse in aller Kurzevor. Fur weitere Evaluationen und technische Details sei auf Trinius [Tri11] verwiesen.
Das Dokument gliedert sich wie folgt: Wir stellen zunachst den Systemaufbau zum Ab-greifen und Analysieren der Spam-Nachrichten vor (Abschnitt 2). Anschließend werdenin Abschnitt 3 die Nachteile der auf regularen Ausdrucken basierenden Filter diskutiert.Sie dienen gleichzeitig als Motivation fur den ebenfalls in diesem Abschnitt vorgestellten,auf kontextfreien Grammatiken basierenden Filteransatz. Die Evaluation der auf diesemAnsatz generierten Filter erfolgt in Abschnitt 4. Das Dokument schließt mit einem Aus-
164 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

blick.
2 Systemaufbau
Abbildung 1 zeigt den Aufbau eines um einen lokalen Mail-Server und den Filtergeneratorerweiterten Sandnets. Mit Sandnet bezeichnen wir dabei Analysesysteme, mit deren Hil-fe die Netzwerkkommunikation von Schadprogrammen uberwacht und analysiert werdenkann. Die von dem Schadprogramm zur Laufzeit lokal auf dem Hostsystem ausgefuhrtenOperationen, werden nicht betrachtet. Alle von den Bots verschickten Spam-Nachrichtenwerden an dem zwischen den einzelnen Analysesystemen und dem Internet platziertenGateway auf einen lokalen Mail-Server umgeleitet. Dieser ubergibt die Nachrichten direktan den Filtergenerator, oder speichert sie im Dateisystem ab.
Internet Gateway
lokaler SMTPServerFiltergenerator
Analy
sesy
stem
e
Abbildung 1: Systemaufbau zur Analyse von Spambots.
3 Filtern mit kontextfreien Grammatiken fur E-Mail-Nachrichten
Die auf LCS-Algorithmen und regularen Ausdrucken basierenden Spam-Filter stoßen re-lativ schnell an ihre Grenzen. Schon das Vertauschen von zwei aufeinanderfolgendenWortern in zwei untersuchten Nachrichten fuhrt entweder zu dem Verlust eines der Worte,oder muss uber Oder-Verknupfungen in den regularen Ausdruck abgefangen werden. Die-ses Problem wird bei Permutationen in Listen, oder zwischen ganzen Satzen noch großer.Obwohl sich der ”Inhalt“ der Nachrichten nicht unterscheidet, verlieren die generiertenSpam-Filter an Genauigkeit.
Der in dieser Arbeit vorgestellte Filteransatz lost diese Probleme, indem er eine machtige-
Filtern von Spam-Nachrichten mit kontextfreien Grammatiken 165

re Sprache zur Beschreibung der Spam-Kampagnen einsetzt. Statt das Template der Kam-pagne in einem regularen Ausdruck auszudrucken, kommt eine kontextfreie Grammatikfur E-Mail-Nachrichten zum Einsatz, die um die Kampagnen-spezifischen Informationen,dieses sind die verwendeten Worter und Satze, erweitert wird.
3.1 Grundgrammatik fur E-Mail-Nachrichten
Als Ausgangspunkt fur das Lernen des Spam-Templates verwenden wir die in Listing 1dargestellte Grundgrammatik. Diese besteht aus acht Ableitungsregeln und funf Token.Der NEWMAIL-Token beschreibt dabei die optionale Absender-Zeile vor dem eigentli-chen Header. Ein HEADER-Token passt auf jedes beliebige Feld des Headers, inklusivedem das Feld abschließenden Zeilenumbruch. Dabei werden auch leere oder sich ubermehrere Zeilen erstreckende Felder von genau einem Token abgedeckt. Der NEWLINE-Token stellt einen einzelnen Zeilenumbruch dar und ist notwendig, um den Wechsel zwi-schen dem E-Mail-Header und dem -Body zu erkennen. Der Token ist nur beim Parsendes Headers aktiv. Im Body der Nachricht werden die Zeilenumbruche ignoriert, da siekeinerlei Bedeutung fur die enthaltenen Satze besitzen. Uber den WORD-Token wird jedebeliebige Zeichenfolge abgedeckt und Satzzeichen werden durch den PUNCTUATION-Token dargestellt. Da beim Parsen der Nachrichten die enthaltenen Satze im Vordergrundstehen, mussen die Satzzeichen, die diese voneinander trennen, bewusst verarbeitet wer-den.
spammail : NEWMAIL header NEWLINE body| header NEWLINE body
header : header_fieldsheader_fields : HEADER header_fields
| HEADER| empty
body : sentencessentences : sentences sentences
| sentence sentences| sentence PUNCTUATION
sentence : wordswords : WORD words
| WORD| empty
empty :
Listing 1: Die Ableitungsregeln der Grundgrammatik fur E-Mail-Nachrichten.
Diese einfache Grammatik genugt zwar, um jede E-Mail-Nachricht abzuleiten, ist aberzum Lernen von Inhalten noch zu unprazise. Alle Felder des Headers werden durch einenToken reprasentiert, der nicht zwischen den Bezeichnern und dem Wert des Feldes unter-scheidet. Mogliche Dateianhange – diese werden als base64-codierter Text in den Bodyder Nachricht integriert – werden als Worter gelernt und E-Mail-Adressen und URLs wer-den an den ”Satzzeichen“ zerlegt und ebenfalls wortweise gelernt. Um diese Fehlinterpre-
166 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

tationen zu unterbinden und auch Informationen aus einem Header-Feld extrahieren undlernen zu konnen, sind zusatzliche Token und Grammatikregeln notwendig.
Aus dem Header sind (momentan) lediglich die Felder Subject und Content-Type von In-teresse [GHT09]. Zur Verarbeitung der beiden Felder wird die Grammatik um zwei ent-sprechende Token und die diese einbindenden Grammatikregeln erweitert. Das SUBJECT-Token passt dabei ausschließlich auf den Feldbezeichner. Der Wert des Feldes wird uberdie zusatzliche Grammatikregel als Satz oder Satze, gefolgt von einem NEWLINE-Token,definiert. Der Wert des Subject-Felds wird damit genauso behandelt wie jeder beliebigeSatz aus dem Nachrichten-Body. Da sich das Subject-Feld und Satze des Bodies geradebei Spam-Nachrichten vielfach gegeneinander austauschen lassen, macht eine gesonderteBetrachtung des Subject-Feldes wenig Sinn. Das neue subject-Symbol wird durch dieveranderte Regel zum Ableiten des header-Symbols in die Grammatik integriert.
Der Content-Type ist das zweite interessante Header-Feld. Es wird ausgewertet, um eineventuell enthaltenes Boundary-Attribut auszulesen und zu uberprufen, ob die E-Mail-Nachricht HTML-codiert ist. Anhand der Boundary lassen sich die einzelnen Teile derNachrichten erkennen und voneinander trennen. Wurde ein entsprechender Token ge-funden, wird der Nachrichten-Body beim Ubergang des Lexer vom Header zum Bodywie folgt optimiert: Aus den HTML-codierten Blocken werden alle HTML-Tags entfernt,wobei darin enthaltenen URLs erhalten bleiben. Des Weiteren werden base64-codierteBlocke durch ihren MD5-Hashwert ersetzt. Dadurch wird zum einen verhindert, dassunnotige Worter aus dem ”Multi-Part Header“ oder Dateianhangen gelernt werden undzum anderen konnen die in der Nachricht enthaltenen Dateianhange – als MD5-Hashwert– selbst gelernt werden.
Neben dem Dateianhang kommt den im Nachrichten-Body eventuell enthaltenen E-Mail-Adressen und URLs eine besondere Rolle beim Filtern der Nachrichten zu. Um dieseerkennen zu konnen, wird die Grammatik um zwei Token zum Erkennen von E-Mail-Adressen und URLs erweitert, uber die sich die in den Nachrichten enthaltenen URLs undE-Mail-Adressen wahrend des Parsens lernen lassen.
Die erweiterte Grundgrammatik besitzt neben den hier vorgestellten Erweiterungen nochzusatzliche Token und Regeln, zum Beispiel um Zahlen erkennen zu konnen, auf die andieser Stelle nicht naher eingegangen wird. Insgesamt besteht die erweiterte Grammatikaus 14 Token und 25 Grammatikregeln [Tri11].
3.2 Lernen der Kampagnen-spezifischen Informationen
Der Prototyp zum Parsen, Lernen und anschließenden Filtern von E-Mail-Nachrichten istin PYTHON implementiert und verwendet die von dem Modul PLY [Bea09] bereitgestell-te LEX/YACC-Implementierung. Um das Lernen von neuen Wortern, E-Mail-Adressen,URLs, Dateianhangen und den aus diesen Teilen zusammengesetzten Satzen zu ermogli-chen, wurden selbstmodifizierende Klassen fur den Lexer und Parser implementiert. Diesemodifizieren ihren eigenen Quellcode und sind so in der Lage neue Token und Regelnzu lernen, die nach einem erneuten Import der erweiterten Klassen auch in die, dem Par-
Filtern von Spam-Nachrichten mit kontextfreien Grammatiken 167

ser zugrunde liegende, Grammatik eingehen. Die zu lernenden Informationen werden imFolgenden allgemein als Daten bezeichnet.
In der Regel verschicken Spambots wahrend der Analyse E-Mail-Nachrichten aus ver-schiedenen Spam-Kampagnen [GHT09]. Das heißt, fur die abgefangenen Nachrichtenmussen mehrere Filter (Grammatiken) gelernt werden. Eine alle Kampagnen umfassendeGrammatik ware zu generisch und damit letztlich unbrauchbar. Um alle Kampagnen opti-mal abzudecken, muss daher fur jede abgegriffene E-Mail-Nachricht entschieden werden,welcher Kampagne sie zuzuordnen ist. Dem System sind beim Lernen einer neuen Gram-matik weder die letztlich die Spam-Kampagnen abdeckende Grammatik, noch die zumParsen der verarbeiteten Nachricht notwendigen Token und Regeln bekannt. Somit mussdie Nachricht immer erst vollstandig gelernt werden, bevor entschieden werden kann, obdie Nachricht zu der momentan bearbeiteten Spam-Kampagne gehort.
Der Lernalgorithmus lauft in 5 Schritten ab (siehe Abbildung 2):
1. Von den Basisklassen SpamLexer und SpamParser werden zwei Klassen (Prototy-peLexer und ProtoypeParser) abgeleitet, die die Grundgrammatik definieren.
2. Die erste Nachricht wird dem Datensatz entnommen und dem ParserGeneratorubergeben. Dieser importiert die Klassen PrototypeLexer und ProtoypeParser underzeugt ein Lexer/Parser-Paar. Beim Parsen der Nachricht wird die Grammatik so-lange erweitert, bis die Nachricht fehlerfrei abgeleitet werden kann. Die um die To-ken und Regeln erweiterten Klassen PrototypeLexer und ProtoypeParser definierendie Grammatik grammar1.
3. Anschließend wird die nachste Nachricht dem Datensatz entnommen und die bei-den Prototyp-Klassen werden kopiert. Der ParserGenerator importiert die Kopiender beiden Prototyp-Klassen und erzeugt ein Lexer/Parser-Paar. Die von diesen de-finierte Grammatik wird solange um Token und Regeln erweitert, bis die Nachrichtfehlerfrei verarbeitet werden kann. Die erzeugte Grammatik wird mit grammar2 be-zeichnet.
4. Die beiden Grammatiken grammar1 und grammar2 werden miteinander verglichen.Dabei wird bestimmt, wie viel Prozent der beim Ableiten der Nachricht verwendetenToken und Regeln schon in grammar1 definiert sind (αt, αr) und wie viel Prozentder in grammar1 definierten Token und Regeln beim Parsen angewendet wurden(βt, βr). Unterschreiten alle Werte αt, αr, βt und βr eine Schranke ε, gehort dieNachricht nicht zu der aktuell bearbeiteten Spam-Kampagne und die Nachricht wirdder Liste verworfener Nachrichten hinzugefugt.
Liegt eines der Wertepaare α, β fur die Token oder Regeln uber der Schranke ε,wird die Nachricht als zugehorig eingestuft und die Klassen PrototypeLexer undProtoypeParser werden mit ihren in Schritt 3 erweiterten Kopien uberschrieben.1
Der Algorithmus wird anschließend in Schritt 3 fortgesetzt.1Der optimale Wert fur ε wurde noch nicht bestimmt. Die hier prasentierten Ergebnisse wurden mit ε = 0, 8
generiert. D.h. eine Nachricht wird nur dann als zugehorig eingestuft, wenn entweder mindestens 80% der ingrammar1 enthaltenen Token und Regeln angewendet worden, um die Nachricht abzuleiten, oder falls 80% derin grammar2 enthaltenen Token und Regeln bereits in grammar1 enthalten sind.
168 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

5. Nachdem der komplette Datensatz einmal durchlaufen ist, ist die Generierung desParsers abgeschlossen. Die die gesuchte Grammatik beschreibenden Prototyp-Klas-sen werden gesichert und stellen die Basis des kontextfreien Filters dar. Anschlie-ßend wird der Algorithmus auf den verworfenen Nachrichten neu gestartet.
Das Lernen einer neuen Grammatik wird immer durch Manipulationen am Quellcode, derdie Grammatik definierenden Klassen, umgesetzt. Das Lernen neuer Daten wird entwedernach dem erfolgreichen Parsen einer Nachricht, oder aus der Fehlerbehandlungsroutineheraus angestoßen: Der erste Fall tritt ein, wenn bei der Verarbeitung der Nachricht einneuer Satz aus noch unbekannten Token geparsed wird. Der Parser kann diesen ohne Feh-ler aus den generischen Token (WORD, UNIT, E-MAIL, etc.) und Regeln (word, words,sentence, etc.) ableiten. Anschließend muss die Erweiterung der Grammatik um neueToken und die dem Satz entsprechende Grammatikregel angestoßen werden. Wenn beimParsen neben unbekannten Token auch bekannte Token innerhalb eines Satzes abgeleitetwerden, tritt hingegen ein Fehler auf. In der Lernphase durfen bekannte Token nur in-nerhalb der definierten Grammatikregeln geparsed werden. Erst diese Einschrankung desParsers macht das Lernen von Modifikationen in bekannten Satzen moglich. Die Fehler-behandlungsroutine untersucht dabei den aktuellen Parserzustand und versucht den Fehleraufzulosen. Die aktuelle Implementierung kann innerhalb eines Satzes einen der folgenden
”Fehler“ abfangen und auflosen, ohne dass das Parsen der Nachricht neu angestoßen wer-den muss: ein zusatzliches Wort, eine Vertauschung zweier aufeinander folgender Worter,ein ausgelassenes Wort und ein ersetztes Wort. Liegt einer dieser Fehler vor, wird die Mo-difikation des Satzes in die Grammatik aufgenommen und der Parser setzt die Bearbeitunghinter dem Satz fort.
3.3 Filtern mit LEX und YACC
Die SpamFilter bekommen die zu filternden Nachrichten und die generierten Prototypenfur den SpamLexer und den SpamParser ubergeben. Wahrend der Lexer unverandert ein-gesetzt werden kann, muss der Parser noch um Grammatikregeln zum Ableiten der ein-zelnen Token erweitert werden. Die zusatzlichen Grammatikregeln sind notwendig, damitsich beim Parsen der Nabchrichten auch unbekannte, aber aus bekannten Wortern beste-hende Satze ableiten lassen.
4 Evaluierung der kontextfreien Spam-Filter
Um die Effektivitat der auf kontextfreien Grammatiken beruhenden Spam-Filter zu eva-luieren, wurden Spam-Laufe aus drei Botnetzen herangezogen, wovon wir die Ergebnisseauf 437 Laufen des STORM-Botnetz hier vorstellen. Ein Spam-Lauf umfasst dabei allevon dem Bot whrend einer Ausfhrung im Sandnet verschickten E-Mail Nachrichten. AlsVergleichswerte wurden die Filterergebnisse der auf regularen Ausdrucken basierendenSpam-Filter [GHT09] verwendet. Basierend auf den Filterergebnissen konnen die beiden
Filtern von Spam-Nachrichten mit kontextfreien Grammatiken 169

Modifikationder Prototypen
Parsen derNachricht
Parsen derNachricht undAnpassung der
Prototypen
Prototyp-Klassender Grammatik
SPAMLexerSPAMParser
grammar
Spam-Nachrichten
Ableiten derGrundgrammatik
VerworfeneNachrichten
FehlerErweitertePrototypen
NächsteNachricht
ErsteNachricht
Testen der Zugehörigkeit:
Berechnung vonα ,α , β , β
Übernahme vongrammar als
grammar
α, β > 𝜖α, β < 𝜖
Parser-Generatorabgeschlossen
Keine Nachrichtmehr vohanden
1
23
4
5
Neustart aufverworfenenNachrichten
1
1
r
grammar2
2
t tr
Abbildung 2: Schematischer Ablauf des Lernens. Die funf Schritte des Algorithmus sind farblichmarkiert.
170 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

Ansatze damit direkt gegenubergestellt und miteinander verglichen werden.
Die Filter wurden jeweils fur Teilmengen der Nachrichten, das heißt, fur jeweils 0,01 Pro-zent, 0,1 Prozent, einem Prozent, 10 Prozent und 100 Prozent der Nachrichten, erzeugtund anschließend zum Filtern der Gesamtdaten verwendet. Dieser Prozess wurde fur je-den Datensatz und jede Kampagne bis zu 10 mal wiederholt, um stabile Ergebnisse zuerhalten.
Der hier vorgestellte Filteransatz ist sehr rechenintensiv. Das stetige Anpassen der Gram-matik wahrend der Lernphase macht die Filtergenerierung langsam und lasst sich nicht par-allelisieren. Deshalb ist es umso wichtiger, dass der Filter-Generierungsprozess nur sehrwenige Nachrichten benotigt, um Filter zu berechnen, die die gesamte Spam-Kampagneabdecken, ohne dabei false-positives zu verursachen. Letzteres wird durch die starke Spe-zifizierung der Spam-Filter auf einzelne Kampagnen sichergestellt. Die Filter bestehen auseiner Kampagnene-spezifischen Grammatik, die die innerhalb der Kampagne verwende-ten Worter und Satze enthalt und Nachrichten auf diese hin untersucht. Jede Nachricht,die von einem Filter als zugehorig klassifiziert wurde, muss sich fehlerfrei mit der spe-zifischen Grammatik ableiten lassen und dabei zu mindestens 80% aus den Kampagnen-spezifischen Wortern und Satzen bestehen oder mindestens 80% aller fur die Kampagnegelernten Worter und Satze enthalten.
Aus dem STORM-Botnetz wurden 437 jeweils 5.000 E-Mail-Nachrichten umfassende Spam-Laufe zur Evaluierung des Filteransatzes herangezogen. Die durchschnittlich uber alle 437Spam-Laufe erreichten Erkennungsraten sind in Tabelle 1 dargestellt. Zusatzlich wurdeein rund 10.000 Nachrichten umfassender Spam-Datensatz herangezogen, um die Filterauf false positives hin zu untersuchen. Der Datensatz wurde jeweils einem Spam-Filter 2
pro Spam-Lauf vorgelegt. Jeder der 437 Filter kategorisierte die Nachrichten dabei alsnicht-zugehorig, d.h., die Filter lieferten auf dem Datensatz keine false positives.
Lerndatensatz Filterergebnisse# E-Mails in % Kampagnen* Erkennungsrate Erkennungsrate
(LexYacc) (RegEx)1 0,01 1 99,7578 % 1,0567 %5 0,1 1 99,5373 % 32,5692 %
50 1,0 1 99,0036 % 92,5036 %500 10 1 99,9997 % 99,9936 %
5000 100 1 100,0000 % 100,0000 %
Tabelle 1: Filterergebnisse fur das STORM-Botnetz. Die Angaben sind Durchschnittswerte uber alle437 Spam-Laufe und die 10 pro Lauf und Teilmenge erzeugten Filter. (* Die Anzahl an Kampagnenbezieht sich jeweils auf einen Spam-Lauf.)
Der Filteransatz liefert mit uber 99 Prozent Erkennungsrate durchweg sehr gute Ergeb-nisse. Schon der auf einer einzigen Nachricht basierende Filter ist gut genug, um dieSpam-Kampagnen zuverlassig zu filtern. Fur die auf regularen Ausrucken basierendenFilter liegt die durchschnittliche Erkennungsrate nach dem Lernen einer Nachricht noch
2Mit den auf 0,01 Prozent der Nachrichten erzeugten Filtern wurden hierbei die am wenigsten genauen Filterherangezogen.
Filtern von Spam-Nachrichten mit kontextfreien Grammatiken 171

bei rund einem Prozent. Erst Filter, die auf 50 Nachrichten basieren, konnen ahnlich hoheErkennungsraten aufweisen, auch wenn der Durchschnitt fur diese Filter mit 92,5 Prozentimmer noch bedeutend schlechter ist.
Aus welchem Grund die Erkennungsrate fur die aus 5 und 50 Nachrichten gelernten Filtergeringer ist, als die der nur auf einer Nachricht basierenden Filter, kann aufgrund dergroßen Anzahl an Filter nicht zweifelsfrei geklart werden. Erste Analysen zeigen, dass dieschlechteren Ergebnisse nicht auf einzelne Ausreißer mit sehr schlechten Erkennungsratenzuruckzufuhren sind, sondern dass viele der Filter leicht schwachere Ergebnisse liefern.Das Gesamtergebnis wird damit von sehr vielen Filtern beeinflusst, was eine detaillierteUntersuchung zusatzlich erschwert.
Die auf einer Grammatik basierenden Filter bestehen, stark vereinfacht, aus gelernten Wor-ten und Satzen. Diese beschreiben, wie die wahrend der Filtergenerierung bearbeiteten E-Mail-Nachrichten aufgebaut sind. Das heißt, der Filter kennt genau die Worter und Satze,die ihm zum Lernen vorgelegt wurden. In Tabelle 2 sind die Anzahl der im Durchschnittvon den Filtern gelernter Worter und Satze aufgelistet.
Lerndatensatz Filterdaten# E-Mails # gelernter Worter # gelernter Satze
1 112,28 23,075 123,83 28,09
50 189,26 65,93500 231,54 98,61
5.000 231,56 98,63
Tabelle 2: Anzahl der im Mittel gelernten Worter und Satze fur die 437 im STORM-Botnetz gene-rierten Spam-Laufe.
Aus den gelernten Daten lasst sich ableiten, dass eine E-Mail-Nachricht der analysiertenSpam-Laufe durchschnittlich aus 112 Wortern und 23 Satzen besteht und dass die in-nerhalb einer Kampagne verschickten Nachrichten zusammen aus rund doppelt so vielenWortern, und fast viermal so vielen Satzen bestehen. Da schon die auf nur einer Nachrichtgenerierten Filter eine Erkennungsrate von uber 99 Prozent aufweisen, muss innerhalb derSpam-Kampagnen jeweils eine Grundmenge von Wortern und Satzen existieren, die in je-der E-Mail-Nachricht einer Kampagne enthalten sind. Die nur langsam steigende Anzahlan Wortern und Satzen weist zudem darauf hin, dass die Nachrichten neben der Grund-menge nur sehr wenige zusatzliche Worter und Satze enthalten. Das Vorhandensein derGrundmenge und die geringe Varianz durch zusatzliche Worter und Satze kommen demauf Grammatiken basierten Filteransatz entgegen und erklaren die fur das STORM-Botnetzerreichten, sehr guten Ergebnisse.
172 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

5 Ausblick
Das Ziel des hier vorgestellten Filteransatzes war es, die Analysemoglichkeiten naturlicherSprache auf Basis von kontextfreien Grammatiken zu untersuchen. Dabei kommen wir zueinem durchaus differenzierten Bild: Wahrend die Erstellung regularer Ausdrucke deutlichschneller ist als das Lernen einer kontextfreien Grammatik, so steigen die Erkennungsra-ten der kontextfreien Filter schneller mit der Zahl der eingegangenen Spam-Nachrichtenals die der regularen Filter. Wenn es also darum geht, mit dem Lernen von nur wenigenNachrichten gute Filterergebnisse zu bekommen, dann bestehen zur Zeit kaum bessereAlternativen zum hier vorgeschlagenen Ansatz.
Auch wenn der vorgestellte Ansatz bereits sehr gute Ergebnisse liefert, reizt die Gram-matik die sich bietenden Moglichkeiten noch lange nicht aus. Beispielsweise ließen sichuber entsprechende Token und Grammatikregeln sprach-spezifische Grammatiken erzeu-gen, die die in einer E-Mail-Nachricht enthaltenen Satze nicht nur als eine Aneinander-reihung von gleichartigen Token definiert, sondern auch den Aufbau der Satze beachtet.Dadurch konnte der Inhalt der Kampagne noch besser erfasst und die erlaubte Varianzgenauer eingestellt werden. Auch aus diesem Blickwinkel macht ein moglicher Ubergangzur machtigeren Klasse der kontext-sensitiven Grammatiken als Basis des Systems ausunserer Sicht vorerst keinen Sinn.
Danksagung
Wir danken Andreas Pitsillidis fur die Bereitstellung seiner Spam-Datensatze und TiloMuller fur seine wertvollen Hinweise zu dieser Arbeit.
Literatur
[Bea09] David M. Beazley. PLY (Python Lex-Yacc), 2009. URL: http://www.dabeaz.com/ply/ply.hmtl.
[GHT09] Jan Gobel, Thorsten Holz und Philipp Trinius. Towards Proactive Spam Filtering. InProceedings of Conference on Detection of Intrusions and Malware & VulnerabilityAssessment (DIMVA), Seiten 38–48, 2009.
[JMGK09] John P. John, Alexander Moshchuk, Steven D. Gribble und Arvind Krishnamurthy. Stu-dying Spamming Botnets Using Botlab. In Proceedings of NSDI’09, 2009.
[KKL+08] Christian Kreibich, Chris Kanich, Kirill Levchenko, Brandon Enright, Geoffrey M. Vo-elker, Vern Paxson und Stefan Savage. On the Spam Campaign Trail. In Proceedings ofLEET’08, 2008.
[PLK+10] A. Pitsillidis, K. Levchenko, C. Kreibich, C. Kanich, G.M. Voelker, V. Paxson, N. Wea-ver und S. Savage. Botnet Judo: Fighting Spam with Itself. In Proceedings of the 17thAnnual Network and Distributed System Security Symposium (NDSS), San Diego, CA,USA, March 2010.
Filtern von Spam-Nachrichten mit kontextfreien Grammatiken 173

[Ste08] Henry Stern. A Survey of Modern Spam Tools. In Proceedings of the 5th Confernecein Email and Anti-Spam, 2008.
[Tri11] Philipp Trinius. Musterbasiertes Filtern von Schadprogrammen und Spam. Dissertation,Universitat Mannheim, 2011.
[XYA+08] Yinglian Xie, Fang Yu, Kannan Achan, Rina Panigrahy, Geoff Hulten und Ivan Osipkov.Spamming Botnets: Signatures and Characteristics. In Proceedings of SIGCOMM’08,2008.
174 Filtern von Spam-Nachrichten mit kontextfreien Grammatiken

FixBit-Container: Effizienter Urheberschutz durchWasserzeichen entlang der Medien-Wertschöpfungskette
Patrick Wolf, Martin Steinebach
Fraunhofer SITRheinstr. 75
64295 [email protected]
Abstract: Beim Einsatz von Transaktionswasserzeichen zum Urheberschutz von di-gitalen Werken wird das zu schützende Werk mit einer Information versehen, die denEmpfänger bzw. den Verteilvorgang (die Transaktion) kennzeichnet. Um eine lücken-lose Sicherheit zu gewährleisten, müsste dies in jedem Schritt der Wertschöpfungskettegeschehen, angefangen beim Rechteinhaber über Aggregatoren und Shops bis hin zumEndkunden. In der Praxis werden Wasserzeichen allerdings meist nur am Ende derWertschöpfungskette eingesetzt, wohl um Mehrfachmarkierungen zu vermeiden. Indieser Arbeit stellen wir den FixBit-Container vor. Dieses für den praktischen Einsatzin Unternehmen entwickelte Prinzip erlaubt mit einem einzigen Markiervorgang unddurch sukzessives Fixieren einzelner Bitpositionen die einzelnen Glieder der Medien-Wertschöpfungskette zu kennzeichnen. Dabei sind einzelnen Kennzeichnungsschrittenahezu so effizient wie ein Kopiervorgang.
1 Einleitung
In dieser Arbeit verfolgen wir einen aus der Praxis heraus motivierten, technisch-organi-satorischen Lösungsansatz beim Einsatz von Transaktionswasserzeichen auf der gesamtenMedien-Wertschöpfungskette – beginnend bei den Rechteinhabern bis hin zu Endkunden.Wissenschaftliche Erkenntnisse fließen mit Erkenntnissen aus der Unternehmenspraxis zu-sammen und münden im Konzept des FixBit-Containers, einer Mischung aus Vorgehens-weise, Formatspezifikation und Arbeitsorganisationsstruktur.
1.1 Ausgangssituation
Transaktionswasserzeichen [SDN02] haben sich als Mittel zum Urheberschutz für alle Ar-ten von Werken – angefangen bei Bild, Audio, Video und mittlerweile auch Ebooks –etabliert. Dabei wird eine Information über den Verbreitungsvorgang, etwa in Form einerTransaktionsnummer, in das zu schützende Werk eingebettet. Die Schutzwirkung beruhtdabei nur zum Teil auf technischen Maßnahmen. Die Tatsache, dass durch die eingebet-

tete Information der Empfänger des Werks zu identifizieren ist, falls das Werk unberech-tigterweise veröffentlicht und gefunden wurde [WS07], wirkt als psychologischer Schutzund verhindert so, dass der Empfänger seinerseits das Werk verbreitet. Bei der Vermark-tung digitaler Werke kommen Transaktionswasserzeichen vor allem im letzten Glied derWertschöpfungskette, beim Verkauf des Werks durch Online-Shops an Endkunden, zumEinsatz [SDN02]. Dabei haben die Online-Shops zunächst nur wenig originäres Interes-se am Schutz der Werke, sondern werden durch Vertriebsverträge zum Schutz der Werkeverpflichtet.
Die Rechteinhaber, die am Anfang der Wertschöpfungskette stehen, können aus nahe-liegenden praktischen Gründen, selbst wenn sie wollten, mit herkömmlichen Methodenkeine mit Transaktionswasserzeichen individuell markierten Werke ausliefern. Sie müss-ten dann für jeden potenziellen Endkunden ein eigenes Werk bereitstellen. Damit könntenzwar analoge und digitale Auslieferung wieder völlig gleich behandelt werden, aber dieVorteile einer digitalen Auslieferung würden nicht zum Tragen kommen. Hinzu kommt,dass zum Urheberschutz durch Transaktionswasserzeichen die Markierung alleine nichtgenügt – sie stellt nur einen passiven Vorgang dar [WSD07]. Als aktiver Teil dient dieSuche nach unberechtigt veröffentlichen Werken im Internet. Die Rechteinhaber könnennatürlich die Online-Shops nicht nur zur Einbettung von Wasserzeichen verpflichten, son-dern auch zu der Suche nach markierten Werken. Zur Suche gehört allerdings auch dasAuslesen der Wasserzeichen und dieses hängt von den jeweiligen technischen Parameterndes Markiervorgangs und insbesondere vom geheimen Schlüssel ab. Diese sind von Shopzu Shop wahrscheinlich unterschiedlich, so dass – selbst wenn man irgendwie die Sucheund das Herunterladen von potenziell markierten Werken koordiniert bekommt – immernoch pro Shop ein aufwändiger separater Auslesevorgang durchgeführt werden muss. Eswäre wesentlich einfacher, wenn Rechteinhaber selbst Suchen nach markierten Werkenbeauftragen könnten.
Natürlich könnten Rechteinhaber die Werke, die sie an die nächsten Glieder der Medien-Wertschöpfungskette (z.B. Aggregatoren) ausliefern, mit Wasserzeichen versehen, um soden Vertriebsweg zu kennzeichnen. Auch im nächsten Schritt könnte das wieder geschehenbis hin zum Endkunden. Dafür wäre aber pro Glied ein Markiervorgang des selben Werksnotwendig. Mehrfachmarkierungen sind zwar möglich [SZ08], aber die wahrgenommeQualität eines markierten Mediums nimmt mit jedem Markierungvorgang höchstens ab.
Der Begriff Wertschöpfungskette ist an dieser Stelle auch irreführend. Es wäre besser voneinem Wertschöpfungsbaum mit den Rechteinhabern als Wurzel zu sprechen, da auf je-der Ebene die Medien an mehrere Empfänger weitergegeben werden. Die Blätter diesesWertschöpfungsbaums bilden dann die Konsumenten und jeder Pfad vom der Wurzel zueinem Blatt ist eine eigene Wertschöpfungskette. Um in jedem Knoten des Baums ei-ne Markierung durchführen zu können, müsste jeweils eine vollständige Integration derWasserzeichenalgorithmen in die jeweiligen Systeme durchgeführt werden, inklusive auf-wändiger technischer Konfiguration. Erschwert wird dies noch zusätzlich dadurch, dassfür Applikationen wie Online-Shops Java die vorherrschende Programmiersprache dar-stellt, für Wasserzeichensoftware aber meist C/C++ verwendet wird. Auch dies stellt keinprinzipielles Hindernis dar [WSZ08], erfordert aber vergleichsweise komplexe Schnittstel-lenarchitekturen.
176 Effizienter Urheberschutz entlang der Medien-Wertschopfungskette

1.2 Herausforderungen
Aus der Ausgangssituation lassen sich folgende konkrete, fachliche Herausforderungenherausarbeiten:
a) Die Rechteinhaber als Wurzel des Wertschöpfungsbaums werden in die Lage versetzt,jeden Weg zu einem Blatt mit Hilfe von Wasserzeichen nachzuvollziehen.
b) Rechteinhaber kontrollieren alleine den Einsatz von Wasserzeichen inklusive derenAuswirkungen auf die wahrgenommene Qualität ([CMB00]) des geschützten Werks.Insbesondere kennen sie alleine die notwendigen technischen Parameter und sind so-mit in der Lage auch nach mit Wasserzeichen markierten Werken zu suchen.
c) Die technischen Auswirkungen auf die Wertschöpfungskette sollen dabei minimal sein– insbesondere sollte das Handhaben der geschützten Werke möglichst in Java erfolgen.
d) Das eingesetzte Verfahren muss (trotzdem) hinreichend effizient sein, so dass ein Ein-satz in Online-Shops technisch sinnvoll ist.
1.3 Struktur der Arbeit und Abgrenzung
Die oben genannten Herausforderungen werden in dieser Arbeit wie folgt angegangen:Zunächst wird in Kapitel 2 als Stand der Technik ein kurzer Abriss über den effizientemEinsatz von Wasserzeichen in Form der sogenannten Containertechnologie gegeben. An-schließend wird der existierende Containeransatz in Kapitel 3 erweitert, so dass er sich aufdie gesamte Wertschöpfungskette ausdehnt. Dabei wird Wert auf tatsächliche praktischeErfahrungen im Unternehmenseinsatz gelegt und die Eigenschaften des FixBit-Contai-ners beschrieben und analysiert. Ergebnis der Arbeit ist schließlich sowohl eine MPEG-ähnliche Formatdefinition wie auch ein Mechanismus zu deren Handhabung.
Es wird dabei bewusst nicht auf konkrete, die Container-Technologie implementierendeWasserzeichenverfahren oder deren (Sicherheits-)Eigenschaften eingegangen. Die Was-serzeichenverfahren werden als kryptologische Primitive angesehen und die Sicherheitdes Gesamtsystems lässt sich voll auf diese Primitive zurückführen, da sich die durchden FixBit-Container markierten Medien nicht von herkömmlich markierten Medien un-terscheiden lassen.
2 Stand der Technik: Containertechnologie
Das Konzept des digitalen Wasserzeichen-Containers stellt eine Lösung für die hohen An-forderungen an die Rechenleistung von Systemen beim Einbetten digitaler Wasserzeichendar [SZC04, WHS08]. Wasserzeichenalgorithmen arbeiten in mehreren Schritten wie Si-gnaltranformationen oder die Berechnung von psycho-perzeptiven Modellen. Die meisten
Effizienter Urheberschutz entlang der Medien-Wertschopfungskette 177

dieser Schritte sind unabhängig von der jeweils einzubettenden Nachricht. Gleichzeitigsind diese Schritte die rechenintesivsten. Die Idee des Wasserzeichencontainers ist es also,den Prozess des Einbettens von Wasserzeichen in zwei Phasen zu unterteilen: Eine Vorbe-reitungshase, die nur einmal durchgeführt wird und in der alle aufwändigen Berechnungenerfolgen und eine Markierungsphase, in der das individuell markierte Werk aus den vorbe-rechneten Teilen zusammengesetzt wird. Abbildung 1 enthält die Phasen beiden (plus dieFixierungsphase aus Abschnitt 3).
2.1 Vorverarbeitungsphase
Für die Vorverarbeitungsphase wird zunächst die Länge der einzubettenden Nachricht fest-gelegt, genauso wie der geheime Wasserzeichen-Schlüssel und alle weiteren technischenParameter.
Für den Container geeignete Wasserzeichennachrichten lassen sich als Folge individuellerBits („0“ und „1“) beschreiben und die jeweiligen zu markierenden Abschnitte des Me-diums („Elementary Units“) müssen unabhängig voneinander markiert werden können.Dies führt dazu, dass für jede Elementary Unit nur eine Version mit einer „0“ und eineVersion mit „1“ erstellt werden muss, um später beliebige Nachrichten zusammenstellenzu können.
Beide Versionen werden dann in einem eigens dafür definierten Containerformat abge-speichert. Das Erzeugen des Containers wird nur ein einziges Mal durchgeführt und ist inetwa so aufwändig wie das zweimalige Markieren des Werks.
2.2 Markierungsphase
Soll nun eine markierte Datei erzeugt werden, ist neben der Containerdatei nur noch dieeinzubettende Wasserzeichen-Information notwendig. Für jedes Bit der Nachricht wird je-weils die vormarkierte Version aus dem Container entnommen und so das individuell mar-kierte Werk erzeugt. Da es sich bei diesem Vorgang im Wesentlichen um einen Lookup-und Kopiervorgang handelt, ist das Erzeugen eines markierten Werks sehr effizient. ZumVergleich: Das individuelle Markieren einer Audiodatei, die im mp3-Format vorliegt, ist inder herkömmlichen Wasserzeichenvariante etwa viermal so schnell, wie die Abspieldauerdes Musikstücks. In der Containervariante ist der gleiche Vorgang – nachdem der Contai-ner vorhanden ist – etwa 3000-mal so schnell wie die Abspieldauer [SZ08].
Die Markierungsphase kann räumlich und zeitlich getrennt von der Vorverarbeitungsphaseausgeführt werden. Insbesondere sind der geheime Schlüssel und die technischen Parame-ter in dieser Phase nicht mehr notwendig.
178 Effizienter Urheberschutz entlang der Medien-Wertschopfungskette

3 FixBit-Container
Die Container-Technologie erlaubt also bereits effizientes Markieren und sogar eine Tren-nung zwischen den wasserzeichentechnologisch komplexen Berechnungen und dem ei-gentlichen Erstellen des markierten Werks. Diese Grundeigenschaften werden für denFixBit-Container konsequent weiter ausgebaut. In diesem Kapitel wird aus Platzgründeneher auf das Prinzip des Containers und den daraus resultierenden Eigenschaften als aufdas konkrete FixBit-Container-Format eingegangen.
3.1 Grundprinzip
Wie wir gesehen haben, kann Herausforderung a), die Nachvollziehbarkeit der genom-menen Wege, befriedigt werden, wenn in jedem Verteilschritt der Wertschöpfungskettejeweils Transaktionswasserzeichen eingebracht werden. Diese Mehrfachmarkierung kannman aber auch als eine einzige Gesamtmarkierung auffassen, in dem die Wasserzeichen-nachrichten der Einzelmarkierung zu einer einzigen Markierung konkatiniert werden. DasProblem ist dann nur noch, dass die einzelnen Teile der Gesamtnachricht zu unterschiedli-chen Zeitpunkten festgelegt werden. Für den FixBit-Container bedienen wir uns der Mög-lichkeit der räumlichen und zeitlichen Trennung, die uns die Container-Technologie bietet.
Die Grundidee ist, dass der FixBit-Container bereits am Anfang der Wertschöpfungsketteerzeugt wird. Damit ist zunächst einmal automatisch Herausforderung b), die Forderungnach der Kontrolle der Wasserzeichenparameter durch die Rechteinhaber, erfüllt. Zusätz-lich wird die Container-Technologie dahingehend erweitert, dass das Ergebnis der Markie-rungsphase nicht unbedingt ein vollständig markiertes Werk sein muss, sondern ein Con-tainer, bei dem nur ein Teil der Nachricht festgelegt wurde. So kann in jedem Schritt derWertschöpfungskette zur Identifizierung des nächsten Glieds immer ein kleiner Teil derNachricht fixiert werden bis schließlich beim letzten Auslieferungsschritt tatsächlich einvollständig markiertes Werk entsteht und nicht mehr ein Container. Abbildung 1 erläutertdies im Detail.
Zur Erinnerung: Das zu markierende Werk besteht aus elementaren Einheiten („Elemen-tary Units“ (EU) [WHS08]), die unabhängig voneinander jeweils mit einem einzelnen Bitmarkiert werden. Daraus entsteht wie bei der herkömmlichen Container-Technologie inder Vorbereitungsphase der Container. Aus einem solchen Container lässt sich jetzt ineiner zusätzlichen Phase („Fixierungsphase“) ein Sub-Container, den eigentlichen FixBit-Container, erzeugen. Dies geschieht, in dem einzelne, aber nicht alle Bits fixiert werdenund zwar einfach durch Löschung des jeweils komplementären Bits. Ergebnis ist ein Con-tainer, in dem nur noch Teile der Nachricht variabel sind – in der Abbildung sind dieersten beiden Bits auf jeweils „1“ fixiert worden. Aus einem FixBit-Container entstehenschließlich analog zur herkömmlichen Container-Technologie markierte Werke.
Das teilweise Festlegen einzelner Bits in der Fixierungsphase kommt einer Teilmarkierunggleich. Damit kann jedes Glied der Wertschöpfungskette nun das nächste Glied identifizie-ren, in dem es für jeden Empfänger andere Bits fixiert. Wird ein markiertes Werk gefunden
Effizienter Urheberschutz entlang der Medien-Wertschopfungskette 179

Abbildung 1: Phasen des FixBit-Containers
und die Nachricht ausgelesen, kann an Hand ihrer Zusammensetzung genau nachvollzogenwerden, welchen Weg das Werk durch die Wertschöpfungskette genommen hat.
Ein Beispiel: Ein Rechteinhaber erstellt ein Container und legt fest, dass die Nachrichteine Länge von 48 Bit haben soll. Er will das Werk an einen Aggregator, seinen eigenenOnline-Shop und an eine Promotion-Agentur verteilen. Um diese drei Empfänger aus-einander zu halten, benötigt er nur 2 Bits der Nachricht. Er erzeugt aus dem Containerdrei FixBit-Container, wobei für den Aggregator die ersten beiden Bits der Nachricht auf„10“, für seinen eigenen Shop auf „11“ und für die Promotion-Agentur auf „01“ fixiert.Dem Online-Shop bleiben damit noch 46 Bit der Nachricht übrig, um kundenindividuelleNachrichten zu erzeugen.
Der Aggregator gibt das Werk nachfolgend an 20 Shops weiter. Dazu fixiert er (20-mal)fünf weitere Bits der Nachricht, so dass den Empfängern jeweils nur noch 41 Bit für ihreNachrichten zur Verfügung stehen. Wird ein markiertes Werk gefunden, kann der Rechte-inhaber an Hand der ersten beiden Bits feststellen, welchen Weg im Wertschöpfungsbaumdas Werk genommen hat. Sind die ersten beiden Bit „10“, so weiß er, dass er sich an denAggregator wenden muss, um mit Hilfe der nächsten fünf Bit herauszufinden, an welchenShop er sich wenden muss, um mit Hilfe der letzten 41 Bit die Identität des Empfängerszu erfahren.
180 Effizienter Urheberschutz entlang der Medien-Wertschopfungskette

3.2 Das FixBit-Container-Format und seine Eigenschaften
Das oben beschriebene FixBit-Container-Prinzip wurde umgesetzt und als Resultat ent-stand ein Container-Format, das ähnlich den MPEG-Standards zwar einen FixBit-Contai-ner beschreibt, sich aber nicht um dessen Erzeugung oder Interpretation kümmert. Durchdie Standardisierung wird erreicht, dass jedes Container-Erzeugungsprogramm spezifischund auf die Bedürfnisse des darunterliegenden Wasserzeichenalgorithmus angepasst ist,aber das Programm zum Erzeugen von individuell markierten Kopien aus Containern, derShuffler, generisch sein kann – so wie MPEG-Dateien von unterschiedlichen Encodernerzeugt, aber alle vom selben Decoder abgespielt werden können. Insbesondere ist derShuffler in Java implementiert und kann so sehr einfach in bestehende Businesssystemeintegriert werden (für eine Geschwindigkeitsauswertung des Shufflers siehe Kapitel 3.3).
Das Format selbst ist ebenfalls an MPEG angelehnt und enthält zu den jeweiligen Unter-einheiten des Werks (System Stream, Elementary Stream, Elementary Unit) Metainforma-tionen in Form von Headern. Im Header einer Elementary Unit findet sich so zum Beispieldie Information, dass die nachfolgende Elementary Unit mit einer „1“ markiert wurde,17554 Byte lang ist und ob sie direkt übernommen werden kann oder aus (Differenz-)Berechnungen aus der vorherigen Elementary Unit hervorgeht1.
Durch diese Vorgehensweise ergeben sich für den FixBit-Container eine Reihe von fürdie Praxis wesentlichen Eigenschaften. Diese stellen auch gleichzeitig Antworten auf dieHerausforderungen c) (minimale Auswirkungen) und d) (Effizienz) dar.
Volle Kontrolle über technische Parameter bei der Container-Erzeugung
Technische Parameter insbesondere der Wasserzeichenschlüssel werden ausschließlich beider Erzeugung des ersten Containers benötigt. Dies versetzt den Erzeuger in die Lage,zum einen direkt die Qualität der markierten Werke sicherzustellen und gleichzeitig sindam Beginn der Wertschöpfungskette somit alle Information vorhanden, um nach mit demContainer erzeugten Werken suchen zu lassen.
Medientyp- und Medienformatunabhängigkeit
Das Container-Format ist sowohl vom Medientyp (Audio, Video, Bild, etc.) des zu schüt-zenden Werks als auch von seinem Medienformat (mp3, PCM, FLAC etc.) unabhängig.
Möglichkeit zur Medienformat-spezifischen Nachbereitung
Trotz der Unabhängigkeit von Medientyp und –format kann es je nach Medienformat not-wendig sein, das erzeugte Werk noch einmal nachbearbeiten zu müssen. Dies ist immerdann notwendig, wenn sich gewisse Eigenschaften des markierten Werks nicht direkt vor-hersehen lassen bzw. sich eine Eigenschaft von zwei unterschiedlich markierten Werken
1Letzteres geschieht, wenn eine Elementary Unit nicht in Gänze im Container abgespeichert wird, sondernals Differenzsignal zum unmarkierten Original
Effizienter Urheberschutz entlang der Medien-Wertschopfungskette 181

unterscheidet (wie etwa die Dateigröße). Die Programme, die Sub-Container und mar-kierte Werke erzeugen, müssen also trotz der Medienformatunabhängigkeit des Container-Formats in der Lage sein, Medienformat-spezifische Funktionalität auszuführen. Dies wirdüber „Plugins“ erreicht, die dynamisch beim Aufruf des Programms mitgeliefert werdenkönnen.
Streamingfähigkeit
In der Wertschöpfungskette gibt es zwei wesentliche Arten der Datenauslieferung: File-basiert und als Stream. Ersteres kommt beim Vertrieb von Einzelwerken in Shops zumEinsatz, letzteres ist vor allem im Broadcastbereich gebräuchlich. Das Container-Formatist so angelegt, dass es auch gestreamt werden kann.
Möglichkeiten der Verschlüsselung
Die einzelnen elementaren Einheiten können auch – wiederum unabhängig voneinander –verschlüsselt werden. Damit integriert das Container-Format auch die Eigenschaften desKrypto-Containers [SK07].
Byte-genauer Zugriff
Das FixBit-Container-Format ist so aufgebaut, dass Byte-genau auf das zu erstellendeWerk zugegriffen werden kann. Dies spielt etwa beim Einsatz von Download-Managern inOnline-Shops eine Rolle, wo mehrere Verbindungen zum markierten Werk geöffnet wer-den, das markierte Werk selbst sich aber nie auf eine Festplatte materialisieren soll. Er-reicht wird diese Genauigkeit durch Angaben der tatsächlichen Größen jeder ElementaryUnit.
3.3 Diskussion
Die Mehrheit der Herausforderungen (a)-c)) ist durch das Design des FixBit-Cotainersbereits erfüllt. Es bleiben allerdings einige Punkte offen, die es zu diskutieren gilt:
Geschwindigkeit
Offen bleibt etwa, ob die Java-Implementation des Shufflers tatsächlich den selben Effizi-enzgrad wie frühere, native Implementierungen des Container-Konzepts erreicht. Hierzuwurden Vergleichstests an Werken verschiedener Größe vorgenommen. Die Werke wurdenauf einem herkömmlichen Desktop-PC jeweils 500 Mal sowohl mit der konventionellenals auch mit der Fix-Bit-Container-Technologie geshuffelt. Wie Abbildung 2 zeigt, wer-den mit den auf Java-basierten Shuffler die Werke ähnlich schnell wie mit dem nativen,konventionellen Shuffler erzeugt – bei kürzeren Stücken sogar schneller und meist mit
182 Effizienter Urheberschutz entlang der Medien-Wertschopfungskette

weniger Schwankungen der Shuffle-Zeiten. Dabei liegen die Datenraten nur etwa 10% bis15% unterhalb der Datenschreibrate der Festplatte.
Abbildung 2: Messung Shuffle-Zeiten diverser Werke bei 500-fachem Shuffling
Prüfsummen und Fehlerkorrektur
Wasserzeichennachrichten werden im Allgemeinen durch Prüfsummen und Fehlerkorrek-tur geschützt [Ber08]. Um während des letztens Shufflens eine Prüfsumme über die Ge-samtnachricht berechnen zu können, ist es notwendig, dass der Shuffler diese vollständigkennt. Sonst müsste jede Teilnachricht mit eigenen Prüfsummen versehen werden, wasdie Kapazität deutlich reduziert. Dazu enthält das Container-Format Angaben, welche Bitsmit welchem Wert fixiert wurden, so dass auch für einen FixBit-Container Prüfsummengenutzt werden können.
Bei Fehlerkorrektur-Verfahren wird dagegen die „Netto“-Nachricht zunächst in eine feh-lerkorrigierender Darstellung („Brutto“) verwandelt und diese eingebettet. Zusätzlich wer-den in der Brutto-Darstellung mehrere Netto-Bits miteinander verknüpft. Dies führt dazu,dass in einem FixBit-Container nicht beliebige Teilnachrichten in Fehler-korrigierenderDarstellung fixiert werden können. Anderseits ist es möglich [Ber08] durch das Hinzu-fügen einzelner weniger Brutto-Bits einen Zustand zu erreichen, in dem ein Teil einer
Effizienter Urheberschutz entlang der Medien-Wertschopfungskette 183

Netto-Nachricht unabhängig von ihren anderen Teilen wird. Dieses Verfahren ist auch aufden FixBit-Container übertragbar.
Koalitionssicherheit und Fingerprinting
Man spricht von einem Koalitionsangriff gegen ein Wasserzeichen, wenn aus Werken mitunterschiedlichen Markierungen ein neues Werk zusammengesetzt wird. Um solchen An-griffen zu begegnen werden sog. Fingerprinting-Codes [SBH+10] eingesetzt. Diese Co-des sind wesentlich länger als herkömmliche Wasserzeichennachrichten und werden soerzeugt, dass aus beliebigen Kombinationen der unterschiedlichen Werke immer mindes-tens eine Version, die an der Angriffskoalition beteiligt war, sicher identifiziert werdenkann.
Beim Einsatz von Fingerprinting-Codes werden nicht einfach beliebige Nachrichten fest-gelegt, sondern die einzelnen Codes (vorab) erzeugt. Insofern lassen sich nicht einfachFixBit-Container und Fingerprinting-Code mischen. Allerdings ist es möglich, die Mengeder Fingerprinting-Codes in Untergruppen übereinstimmender Teile einzuteilen. Auf dieseWeise kann man sicherstellen, dass alle Codes, die an ein Glied der Wertschöpfungsketteweitergereicht werden, gemeinsame gleiche Passagen enthalten. Diese können dann fixiertwerden und agieren so als identifizierende Teilnachrichten.
4 Zusammenfassung und nächste Schritte
In dieser Arbeit haben wir eine praktische Lösung präsentiert, wie Rechteinhaber bereitsan der Wurzel des Medien-Wertschöpfungsbaums Wasserzeichen zum Einsatz bringenkönnen. Der FixBit-Container ist sowohl eine Vorgehensweise wie auch ein standardisier-tes Weitergabeformat für Wasserzeichen, das erlaubt, zur Identifizierung jeder Abzwei-gung des Wertschöpfungsbaums einen Teil der Wasserzeichennachricht als Teilnachrichtzu fixieren. Trotzdem bleibt die Fähigkeit erhalten, an den Blättern des Baums effizientmarkierte Werke zu erhalten.
Rechteinhaber haben nun auf diese Weise sowohl Kontrolle über die Qualität der Markie-rung ihrer Werke und können gleichzeitig die Suche nach ihnen unabhängig vom konkre-ten Auslieferungsweg in die Hand nehmen.
Ein spannender nächster Schritt wird die Entwicklung von Container-Verfahren für nicht-kontinuierliche Medien wie etwa Bilder sein, bei denen sich das zu markierende Mediumnicht einfach in Elementary Units zerlegen lässt wie bei kontinuierlichen Medientypen wieAudio und Video.
Danksagung
Diese Arbeit wurde unterstützt durch CASED (http://www.cased.de/).
184 Effizienter Urheberschutz entlang der Medien-Wertschopfungskette

Literatur
[Ber08] Waldemar Berchthold. Optimierung der Robustheit und Klangqualität digitalerAudio-Wasserzeichen-Verfahren im Kontext von angepassten Vorwärtsfehlerkorrektur-Algorithmen. Diplomarbeit, Hochschule Darmstadt, Fachbereich Mathematik, 2008.
[CMB00] I. J. Cox, M. L. Miller und J. A. Bloom. Watermarking applications and their properties.In Proc. Int Information Technology: Coding and Computing Conf, Seiten 6–10, 2000.
[SBH+10] Marcel Schäfer, Waldemar Berchtold, Margareta Heilmann, Sascha Zmudzinski, MartinSteinebach und Stefan Katzenbeisser. Collusion Secure Fingerprint Watermarking forReal World Applications. In Proceedings of GI Sicherheit 2010, 2010.
[SDN02] Martin Steinebach, Jana Dittmann und Christian Neubauer. Anforderungen an digitaleTransaktionswasserzeichen für den Einsatz im e-Commerce. In Klaus P. Jantke, Wolf-gang S. Wittig und Jörg Herrmann, Hrsg., Von e-Learning bis e-Payment - Das Internetals sicherer Marktplatz, Seiten 209 – 217, Leipzig, September 2002. Akademische Ver-lagsgesellschaft Aka GmbH.
[SK07] Martin Steinebach und M. Kaliszan. Kryptographisch geschützte Wasserzeichencontai-ner. In Patrick Horster, Hrsg., DACH Security 2007, Seiten 370–380, Klagenfurt, 2007.syssec verlag.
[SZ08] Martin Steinebach und Sascha Zmudzinski. Evaluation of robustness and transparen-cy of multiple audio watermark embedding. In E. Delp, P. Wong, J. Dittmann undN. Memon, Hrsg., Security, Steganography, and Watermarking of Multimedia ContentsX, Bellingham, 2008. SPIE and IS&T.
[SZC04] Martin Steinebach, Sascha Zmudzinski und Fan Chen. The digital watermarking con-tainer: secure and efficient embedding. In Proceedings of the 2004 workshop on Mul-timedia and security, MM&Sec ’04, Seiten 199–205, New York, NY, USA, 2004.ACM.
[WHS08] Patrick Wolf, Enrico Hauer und Martin Steinebach. The video watermarking contai-ner: efficient realtime transaction watermarking. In E. Delp, P. Wong, J. Dittmann undN. Memon, Hrsg., Security, Steganography, and Watermarking of Multimedia ContentsX, Bellingham, 2008. SPIE and IS&T.
[WS07] Patrick Wolf und Martin Steinebach. Multimedia Forensics and Security, Kapitel On theNecessity of Finding Content Before Watermark Retrieval: Active Search Strategies forLocalising Watermarked Media on the Internet. IG Global, 2007.
[WSD07] Patrick Wolf, Martin Steinebach und Konstantin Diener. Complementing DRM withdigital watermarking: mark, search, retrieve. Online Information Review, 31(1):10–21,2007.
[WSZ08] Patrick Wolf, Martin Steinebach und Sascha Zmudzinski. Adaptive security for virtualgoods - building an access layer for digital watermarking. In Rüdiger Grimm, Hrsg.,Virtual Goods. 6th International Workshop for Technical, Economic and Legal Aspectsof Business Models for Virtual Goods incorp. the 4th International ODRL Workshop,Poznan, Poland, October 2008.
Effizienter Urheberschutz entlang der Medien-Wertschopfungskette 185


It is not about the design – it is about the content! Makingwarnings more efficient by communicating risks
appropriately
Michaela Kauer1, Thomas Pfeiffer1, Melanie Volkamer2, Heike Theuerling1, and Ralph Bruder11Institute of Ergonomics
Technische Universitat Darmstadt, Petersenstr. 3064287, Darmstadt
2Department of Computer Science; Research Group IT-Security, Usability and SocietyTechnische Universitat Darmstadt, Hochschulstr. 10
64289, Darmstadt
[email protected]; [email protected]; [email protected]@iad.tu-darmstadt.de; [email protected]
Abstract: Most studies in usable security research aim at a quantification of persons,who – depending on the subject – fall for phishing, pass on their password, downloadmalicious software and so on. In contrast, little research is done to identify the reasonsfor such insecure behavior. Within this paper, the result of a laboratory study is pre-sented in which participants were confronted with different certificate warnings. Thosewarnings were presented when the participants tried to access different websites withdifferent criticality (online banking, online shopping, social networks and informationsites). Besides quantitative analyses of participants who were willing to use a websitesdespite the warning, the main focus of this work is to identify reasons for their deci-sion. As a result of our study those risks are identified which were unacceptable formost participants to take and thereby might help to prevent unsecure usage behaviorin the web by rewording warnings according to the perceived risks.
1 Introduction
Many studies in the context of usable security show that users fail to distinguish trust-worthy from non-trustworthy websites [DTH06, TJ07, DHC06, JTS+07]. Consequently,they download viruses, provide personal information to dangerous web services, and fallfor phishing. One reason identified in these studies is that many people are not aware ofsecurity indicators relevant to identify non-trustworthy websites like proper URL and acommunication secured by SSL, ideally based on extended validation certificates. Thesestudies also show that people care more about the content of the webpage like the logoand the quality of the web design than about security indicators. Correspondingly, there isonly a small overlapping between people’s trust indicators and real security indicators.
As this situation is well known, browsers started supporting people in identifying untrust-worthy websites, by displaying warnings, e.g., special phishing warnings and certification

warnings. This is a first progress as the analysis is done automatically and the user is notin charge of it. However, studies [DTH06, ECH08, JSTB07, SDOF07, SEA+09] showedthat people do not understand the content of certification warnings and thus tend to ignorethem. Understanding certification warnings is particularly difficult, because trustworthy(in general less security critical) websites also cause ”invalid” certificate warnings (whichare, e.g., caused by self-signed or expired certificates or the fact that the root certificationauthority is not known to the browser). These warnings can be ignored without any seriousrisk. Research [ECH08, SEA+09] shows that especially people who have often seen cer-tificate warnings on trustworthy websites, where ignoring the warning did not cause anyproblem, tend to ignore these warnings for any website including the untrustworthy ones,which then cause serious problems like losing money.
Bravo-Lillo et al. [BCDK11] developed a mental model of how people understand andreact to security warnings. Within this paper, they found that there are big differences in thebehavior of expert and novice users. Experts analyze security problems before proceeding,whereas novice users think of the consequences afterwards. Overall, the authors foundSSL warnings to be the most confusing warnings. This implicates, that in particular SSLwarnings need to be improved. Therefore, we decided to focus on these warnings.
While most existing studies aim at quantifying persons who fall for different attacks, thiswork aims at identifying reasons for such insecure behavior. Based on these results, im-provements mainly regarding rephrasing warnings are deduced to prevent unsecure behav-ior in the future. We conducted a laboratory study in which participants were confrontedwith different certificate browser warnings when trying to access different websites withdifferent criticality, namely online banking, online shopping, social networks and newswebsites. The participants were asked why they ignored the warning or stopped accessinga corresponding webpage. There was no usability assessment of the warnings. Our mainresult from this study is that people ignoring the warning underestimate the risk and aremore likely to stop accessing web pages when warnings describe personal risks. Thus,based on our results, we recommend using these risk descriptions when rewording (certifi-cation) warnings, while also distinguishing different criticality classes of web pages in thetext of the warning. This idea goes along the lines with those recommendations proposedby Wogalter in ([Wog06], page 6) claiming that warning needs to ”tell exactly what thehazard is, what the consequences are, what to do or not to do”.
This paper is organized in the following way. In Section 2, we’ll discuss related work.Afterwards, we will describe the methodology of the study in Section 3 and propose theresult of the study in Section 4. Section 5 discusses these results and concludes the paperwith an outlook for future work.
2 Related Work
The aspect of user’s perceived consequences when submitting information to a fraudulentwebsite has been studied extensively in the context of phishing attacks [JTS+07, ECH08,SEA+09, DHC07].
188 It is not about the design - it is about the content!

One of the most notable contributions in the area of SSL warnings is by Sunshine et al.[SEA+09]. They conducted an online survey followed by a laboratory study. In the onlinesurvey, they presented three different SSL certificate warnings (unknown issuer, certificateexpired and domain mismatch) within the browser which the participants indicated theywere using at the time. The warnings were displayed on either an anonymous forum or ashopping website (between-subjects) to 409 participants. Among other things they askedtheir participants ”whether they understood what the warnings mean, what they would dowhen confronted with each warning and their beliefs about the consequences of ignor-ing these warnings”. They did not find significant differences between the two websites.However, they did find that users who associated risks related to stolen information (e.g.identity theft, stolen credentials) with the warnings were more likely to heed them. Toverify their findings, Sunshine et al. [SEA+09] conducted a laboratory experiment with100 participants. Each participant completed tasks involving interaction with a library cat-alog and an online banking website (within-subjects) with one of five browsers: Firefox 2,Firefox 3, Internet Explorer 7 (IE7) and another two versions of IE7 with modified warn-ing messages. The first modified warning message was altered visually to appear moresevere and stated ”An attacker is attempting to steal information that you are sending to[domainname]”. The other modified warning first asked the user what kind of website shewas visiting. In case of banks or web shops, the same warning as in the first modifiedversion was displayed. In all other cases, the user was directed to the requested website.In the experiment, significantly fewer participants ignored the redesigned warnings thanthe existing warnings on the banking website. Nine out of eleven participants who heededthe first modified warning mentioned security of their information as the reason for doingso. No other significant effects of warning design were found.
We aim at replicating these findings in Germany with current browser versions as wellas expanding on them by further investigating the risks associated with SSL warningsqualitatively.
3 Methodology
The herein presented study was a laboratory test and took place at the Technische Uni-versitat Darmstadt in Germany. The study consisted of two parts. Part one asked generalquestions on the participants’ online usage behavior and their knowledge of security in-dicators. In part two, participants were instructed that they received an email with a link,which leads them to one out of twelve websites. The mail asked them to log in on the pageand update some of their personal data.
Overall, three independent variables were varied: page type, web browser and warningdisplayed. There were four different kinds of websites: online banking sites, online shop-ping sites, social networks and pure information sites. As in Sunshine et al.’s laboratorystudy [SEA+09], we expect users to react differently to warnings on different kinds ofwebsites. Since Sunshine et al. only found differences in their within-subject study, wepresent different kinds of websites to each subject as well. It was expected that the numberof participants who log in on a website and ignore the warning increases with decreasing
It is not about the design - it is about the content! 189

criticality of the website.
Type and version of the web browser defines the second independent variable. The designof the warning varies significantly between different browser types and versions. Thefollowing four different browsers respectively browser versions were used: FireFox 2,FireFox 4, Internet Explorer 6, and Internet Explorer 9. Those browser types were selectedas they are widely-spread at the time the survey was conducted. The versions were chosento compare current with outdated warning design. Last, the type of certificate warning wasvaried. Three different certificate warnings were used within this study: certificate expired,certification authority unknown and wrong domain name. Figure 1-4 show examples forthe warning ”certification authority unknown” for each browser/version.
Figure 1: Certificate warning ”certification authority unknown” for FireFox 4
Figure 2: Certificate warning ”certification authority unknown” for Internet Explorer 9
Each participant was asked to access four different websites of at least three different kinds.The displayed warnings were in the design of each of the four browser types/versions. The
190 It is not about the design - it is about the content!

Figure 3: Certificate warning ”certification authority unknown” for FireFox 2
warning contained each addressed certificate warning at least once. Participants were ran-domly assigned to the combination of type of website, browser type/version, and contentof warning.
Participants were asked if they would use the website as normally, which included enteringtheir user name and password to log in. In case of the pure information sites, this wouldhave meant getting access to forums or customized information. Additionally, they wereasked to give reasons for their decision. In a second step, each participant was confrontedwith each of these four combinations again and had to answer two questions for each ofthem, namely ”What does the warning mean?” and ”Which risk comes along with thiswarning?”.
4 Results
The results are a combination of quantitative and qualitative data. All calculations on thequantitative data were done with SPSS 19. Qualitative data was quantified by groupingsimilar answers to be able to somehow quantify the prevalence of the different answers.
4.1 Participants
30 participants attended the laboratory study. 14 participants were female. The participantswere aged between 16 and 68 years, with an average of 35.50 years (SD = 15.94). Onethird of the participants stated to use the internet several times a day, 56.7% daily andonly three participants stated to use it between once and four times a week. None of theparticipants stated not to use the internet at all. Participants were asked about their onlineshopping behavior. One participant responded to buy weekly at shops like Amazon, 90%
It is not about the design - it is about the content! 191

Figure 4: Certificate warning ”certification authority unknown” for Internet Explorer 6
of the participants ordered less than once a week and two participants stated that they neveruse online-shopping.
Out of the 30 participants 26.7% stated not to use online banking at all. One third of theparticipants are not active in social networks whereas 16.7% use social networks severaltimes a day. 26.7% participants use social networks at least once a day, 13.3% three to fourtimes a week and 3.3% once a week. 6.7% stated to use social networks less than once aweek. 60% of the participants used Firefox as internet browser, 23.3% used the InternetExplorer. 6.7% used other browsers and 10% did not respond to the question.
The number of 30 participants was chosen because the main focus of this study lies onthe qualitative analysis of the perceived risk. According to Morgan et al. [MFBA01] thissample size is large enough to be likely to reveal at least once any belief held by 10 percentor more of the population.
4.2 Quantitative Reactions to Certificate Warnings
The aim of this section is to quantify the number of people who decided to log in ona website despite the warning. The number of logins is distinguished between browsertype/version (cmp. Table 1), content of warning (cmp. Table 2), and type of website (cmp.Table 3).
With the help of cross tables a χ2 statistic was computed to test if there is an effect of thebrowser type/version, the content of the warning, and the type of website respectively onthe number of participants who would log in on the page despite the warning. The test
192 It is not about the design - it is about the content!

Browser Type/Version Would you log in?Yes No
FireFox 2 10 20FireFox 4 8 22Internet Explorer 6 11 9Internet Explorer 9 9 21
Table 1: Number of participants who decided to log in according to the browser type/version.
Warning Type Would you log in?Yes No
wrong domain name 11 29certificate expired 13 27unknown authentication authority 14 26
Table 2: Number of participants who decided to log in according to the warning type.
Kind of Website Would you log in?Yes No
online banking 2 28online shoping 8 20social network 13 19information site 15 15
Table 3: Number of participants who decided to log in according to type of website.
revealed no significant difference between different browser types/versions (χ = 0.770, df= 3, p = .857). The same holds for the content of the warning (χ = 0.539, df = 2, p =.764). The last independent variable was the type of website on which the certificate warn-ing occurred. Here a χ2 test revealed highly significant differences between the differentwebsite types (χ = 14.636, df = 3, p = .002). Table 3 shows that the number of peoplewho are willing to log in on a certain website despite an occurring warning decreases withincreasing criticality of the deposed data.
4.3 Qualitative Reactions to Certificate Warnings
Within this study qualitative data was collected which is evaluated in this subsection.
Reasons for and against logging in. Besides the decision whether to log in or not ona certain page with a warning, participants were asked to give reasons for their decision.With 30 participants and four pages per participant an overall of 120 reasons were given.Similar reasons were grouped. This led to an overall of 10 different groups of reasonsfor log in and 13 different groups of reasons against log in. Five reasons are present inboth groups, due to the fact that some people decided to log in because of those reasons,
It is not about the design - it is about the content! 193

whereas other participants decided against logging in. Table 4 gives an overview of thereasons combined with the number of participants giving that reason.
a) Reasons for log in Numbertrust in this website 15no personal data existent 6risk unknown/unclear 6interested in content/usage of page 3illusion of inviolability(I am sure nothing will happen/Nothing never happened before) 2warning incomprehensible 2website looks secure 1certificate unknown/invalid 1coping strategies (close site and open again; try again later) 1general caution 1b) Reasons against log in Numbergeneral caution 31personal data existent 10attacks feared 10high risk for banking/websites 7faked website 6warning incomprehensible 5page is insecure 4coping strategies (close site and open again; try again later) 4warning exists 1design of warning 1problems with the content of the page 1certificate unknown/invalid 1risk unknown/unclear 1
Table 4: Number of participants who decided to log in on a website despite the warning (a) or not tolog in on a website (b) separated according to the reason for their decision.
The reason ”trust in this website” which led in majority to a visit of a website despiteshowing a warning was further investigated and divided according to the website for whichthis reason was mentioned. Trust was used as reason to log in on banking sites (oneparticipant), on shopping sites (three participants), in social networks (five participants)and on information sites (six participants) despite the warnings.
Associated Risk. The second part of the qualitative analysis was concerned with thequestion which risk participants associate with ignoring the warnings. Each participanthad to name the risk he would take if he ignored the warning for each warning he waspresented. That made a total 120 named risks. Again, risks were grouped to simplify theevaluation.
A total of eight different risk groups emerged. Those groups and the according number
194 It is not about the design - it is about the content!
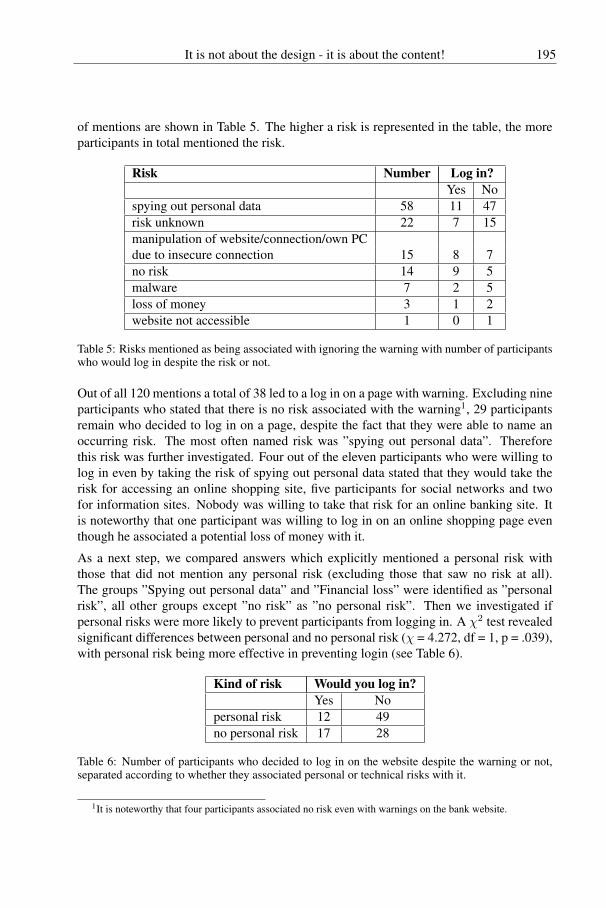
of mentions are shown in Table 5. The higher a risk is represented in the table, the moreparticipants in total mentioned the risk.
Risk Number Log in?Yes No
spying out personal data 58 11 47risk unknown 22 7 15manipulation of website/connection/own PCdue to insecure connection 15 8 7no risk 14 9 5malware 7 2 5loss of money 3 1 2website not accessible 1 0 1
Table 5: Risks mentioned as being associated with ignoring the warning with number of participantswho would log in despite the risk or not.
Out of all 120 mentions a total of 38 led to a log in on a page with warning. Excluding nineparticipants who stated that there is no risk associated with the warning1, 29 participantsremain who decided to log in on a page, despite the fact that they were able to name anoccurring risk. The most often named risk was ”spying out personal data”. Thereforethis risk was further investigated. Four out of the eleven participants who were willing tolog in even by taking the risk of spying out personal data stated that they would take therisk for accessing an online shopping site, five participants for social networks and twofor information sites. Nobody was willing to take that risk for an online banking site. Itis noteworthy that one participant was willing to log in on an online shopping page eventhough he associated a potential loss of money with it.
As a next step, we compared answers which explicitly mentioned a personal risk withthose that did not mention any personal risk (excluding those that saw no risk at all).The groups ”Spying out personal data” and ”Financial loss” were identified as ”personalrisk”, all other groups except ”no risk” as ”no personal risk”. Then we investigated ifpersonal risks were more likely to prevent participants from logging in. A χ2 test revealedsignificant differences between personal and no personal risk (χ = 4.272, df = 1, p = .039),with personal risk being more effective in preventing login (see Table 6).
Kind of risk Would you log in?Yes No
personal risk 12 49no personal risk 17 28
Table 6: Number of participants who decided to log in on the website despite the warning or not,separated according to whether they associated personal or technical risks with it.
1It is noteworthy that four participants associated no risk even with warnings on the bank website.
It is not about the design - it is about the content! 195

5 Discussion
Some of our findings concur with those by Sunshine et al. [SEA+09], while others donot. In both studies, risks associated with ignoring SSL warnings played a key role in thedecision to heed the warning or not. However, Sunshine et al. report no statistical testsfor the correlation between risk perceptions and decisions relating to warnings. Consistentwith their laboratory experiment but in contrast to their online survey, we found significantdifferences in behavior between the different types of websites. This can be explained bythe fact that both our and their lab experiment tested the website type as a within-subjectsfactor whereas it was a between-subjects factor in their survey. Therefore participants wereprobably more aware that there are different kinds of websites and their different securitypreferences were more salient. Since visiting different types of websites in a row is moreakin to usual web browsing behavior than visiting only one kind, we conclude that thisfinding has a higher external validity than the survey finding.
In contrast to Sunshine et al. we found no different reactions to the different kinds ofwarnings. This can be explained by our participant’s lack of knowledge about SSL andrelated warnings, as Sunshine et al. reported much larger differences between reactions tothe different types of warnings for experts than for non-experts.
21 times, participants gave ”risk unknown or unclear” as answer to the question whichrisk is associated with ignoring the warning. Out of these 21 participants six participantsdecided to log-in. This is about a quarter of the participants. It can be assumed that thoseparticipants would not have logged in, if they would have been informed on the risks theywere taking. This leads to the conclusion that the risk should be clearly communicated tothe users.
For the communication of the risk, the wording is essential for the success of the warning,as can be seen in Table 6. Here, nine out of 17 participants who associated the technicalrisk ”Manipulation of website/connection/own PC due to insecure connection” with log-ging in to the website did log in. The communication of the risk should therefore not onlybe formulated in terms of technical risks (e.g. the connection is insecure,) but in terms ofpersonal risks (e.g. therefore, someone might be able to spy out your personal data).
A similar approach is needed for those who enter a website just because of their trust inthe page regardless of warnings (as 15 of our participants did). To inhibit this unsecurebehavior the risks should be clearly named and additionally, it is necessary to communicatethat the look of a page alone is not sufficient to guarantee its trustworthiness.
Furthermore, nine participants were sure that there is no risk associated with the displayedwarnings. Some pointed out that there was no personal data to spy out (on information sitesand social networks), some stated that they are familiar with the warning and until now,nothing had ever happened. This is partly true, because some of the presented warningscome along with low risk. Still, even our information sites had a log-in area, in whichadditional information was provided. To enter this log-in page a password and a username were required. It is alarming that spying out passwords is not perceived as potentialrisks by our participants, especially because many people tend to use the same passwordfor several applications [CVOB06]. Therefore, for a number of participants the theft of a
196 It is not about the design - it is about the content!

password in this application would enable or at least simplify attackers the access to otherapplications used by the same participant. For this reason, it is essential to inform peopleabout possible risks.
Within this study, personal risks (namely spying out personal data and financial loss)were found to be more effective in terms of preventing users from visiting a website de-spite a warning than impersonal risks, like a generalized manipulation of the communi-cation or malware or an unknown risk. This is consistent with a study by Hardee et al.[HWM06] where participants mostly mentioned ”Protecting Information” and ”ProtectingMoney/Property” as the gains from making conservative security decisions. Therefore,”spying out personal data” or ”financial loss” should be mentioned in warning massagesdirectly. We believe that the effectiveness could even be further increased, if it is possibleto make content-sensitive warnings which indicate the kind of data (e.g. banking data) thatwould be spied out on the type of web page that the user tries to access.
6 Conclusion and Outlook
We conducted a study on certificate warnings. A website was shown to the participantswith an according warning. Participants were then asked to either log in or not. After-wards, they were asked to justify their decision. The study revealed the following fouritems: First, the general section on security indicators confirmed that most people are notfamiliar with them. Then, the qualitative part of this research revealed that people are oftennot aware of actual risks. As a third result, we showed that the perceived risk of personaldata being spied out prevented most participants from entering the corresponding website.From this result, we conclude that risks need to be more clearly communicated. The fourthresult of the study allows us to further concretize this statement, as we showed that it ismore effective to communicate personal risks than technical risks. Correspondingly, wecan conclude that personal risk descriptions should be used when rephrasing warnings.
These findings confirm and expand upon the major findings by Sunshine et al. [SEA+09].Building upon our findings we are currently preparing a study that tests newly designedwarnings which incorporate information about the personal consequences of submittingdata to a fraudulent site of a certain kind. We hope that these warnings will be even moreeffective than the ones designed by Sunshine et al., which still remained on an impersonallevel (”An attacker is attempting to steal information”).
7 Acknowledgements
The authors like to thank Tim Protzmann for the conduction of the study and Jurlind Budu-rushi for the formatting. We also thank the reviewers for their constructive feedback.
It is not about the design - it is about the content! 197

References
[BCDK11] Cristian Bravo-Lillo, Lorrie Faith Cranor, Julie S. Downs, and Saranga Komanduri.Bridging the Gap in Computer Security Warnings: A Mental Model Approach. IEEESecurity & Privacy, 9(2):18–26, April 2011.
[CVOB06] Sonia Chiasson, P.C. Van Oorschot, and Robert Biddle. A usability study and critiqueof two password managers. In 15th USENIX Security Symposium, page 1–16, 2006.
[DHC06] Julie S. Downs, Mandy B. Holbrook, and Lorrie Faith Cranor. Decision strategies andsusceptibility to phishing. In Proceedings of the second symposium on Usable privacyand security, SOUPS ’06, page 79–90, New York, NY, USA, 2006. ACM.
[DHC07] Julie S. Downs, Mandy Holbrook, and Lorrie Faith Cranor. Behavioral response tophishing risk. In Proceedings of the anti-phishing working groups 2nd annual eCrimeresearchers summit, eCrime ’07, page 37–44, New York, NY, USA, 2007. ACM.
[DTH06] Rachna Dhamija, J. D. Tygar, and Marti Hearst. Why phishing works. In Proceedingsof the SIGCHI conference on Human Factors in computing systems, CHI ’06, page581–590, New York, NY, USA, 2006. ACM.
[ECH08] Serge Egelman, Lorrie Faith Cranor, and Jason Hong. You’ve been warned: an empiricalstudy of the effectiveness of web browser phishing warnings. In Proceeding of thetwenty-sixth annual SIGCHI conference on Human factors in computing systems, CHI’08, page 1065–1074, New York, NY, USA, 2008. ACM.
[HWM06] Jefferson B. Hardee, Ryan West, and Christopher B. Mayhorn. To download or notto download: an examination of computer security decision making. interactions,13(3):32–37, May 2006.
[JSTB07] Collin Jackson, Daniel R. Simon, Desney S. Tan, and Adam Barth. An Evaluationof Extended Validation and Picture-in-Picture Phishing Attacks. In Sven Dietrich andRachna Dhamija, editors, Financial Cryptography and Data Security, volume 4886,pages 281–293. Springer Berlin Heidelberg, Berlin, Heidelberg, 2007.
[JTS+07] Markus Jakobsson, Alex Tsow, Ankur Shah, Eli Blevis, and Youn-Kyung Lim. Whatinstills trust? a qualitative study of phishing. In Proceedings of the 11th InternationalConference on Financial cryptography and 1st International conference on Usable Se-curity, FC’07/USEC’07, page 356–361, Berlin, Heidelberg, 2007. Springer-Verlag.
[MFBA01] M. Granger Morgan, Baruch Fischhoff, Ann Bostrom, and Cynthia J. Atman. RiskCommunication: A Mental Models Approach. Cambridge University Press, 1 edition,July 2001.
[SDOF07] Stuart E. Schechter, Rachna Dhamija, Andy Ozment, and Ian Fischer. The Emperor’snew security indicators: An evaluation of website authentication and the effect of roleplaying on usability studies. In Proceedings of the 2007 IEEE Symposium on Securityand Privacy, 2007.
[SEA+09] Joshua Sunshine, Serge Egelman, Hazim Almuhimedi, Neha Atri, and Lorrie Faith Cra-nor. Crying wolf: an empirical study of SSL warning effectiveness. In Proceedings ofthe 18th conference on USENIX security symposium, SSYM’09, page 399–416, Berke-ley, CA, USA, 2009. USENIX Association.
[TJ07] Alex Tsow and Markus Jakobsson. Deceit and Deception: A Large User Study ofPhishing. Indiana University. Retrieved September, 9:2007, 2007.
[Wog06] Michael S. Wogalter. Handbook of warnings. Routledge, January 2006.
198 It is not about the design - it is about the content!

Usability von CAPTCHA-Systemen
Stefan Penninger, Stefan MeierUniversitat Regensburg
{stefan.penninger,stefan1.meier}@ur.de
Hannes FederrathUniversitat Hamburg
Abstract: CAPTCHA-Systeme sind weit verbreitete Schutzsysteme, um auf Online-Plattformen menschliche Benutzer von automatischen Bots zu unterscheiden. Dabeikommen verschiedene Varianten zum Einsatz, die sich in Art und Interaktionsmo-dus sowie im Schwierigkeitsgrad der Losung unterscheiden. In der vorliegenden Stu-die werden Kriterien der Benutzbarkeit von CAPTCHA-Systemen aufgestellt. Zudemwerden funf typische CAPTCHA-Implementierungen im Bezug auf ihre Gebrauch-stauglichkeit mit Hilfe einer Benutzerstudie empirisch untersucht. Wahrend sich Math-CAPTCHAs unter den getesteten Alternativen in den zugrunde gelegten Kriterien derBenutzbarkeit uberlegen zeigen, muss unter Einbeziehung von Sicherheitskriterien dasklassische Bild-CAPTCHA nach wie vor als das zuverlassigste Mittel der Mensch-Maschine-Unterscheidung gelten.
1 Motivation
CAPTCHAs sind automatisierte Turing-Tests (Completely Automated Public TuringTest to tell Computers and Humans Apart), welche auf Webseiten verwendet werden,um menschliche Nutzer von automatischen Skripten zu unterscheiden. Dabei handeltes sich um eine Form von Challenge-Response-Tests: Es werden Aufgaben gestellt,die fur den menschlichen Nutzer moglichst einfach zu beantworten sein sollen, sichjedoch nicht effizient durch automatisierte Systeme losen lassen. Alle vorhandenenCAPTCHA-Losungen bieten somit prinzipiell nur Schutz gegen automatisierte Angreifer.Eine typtische Fragestellung ist das Erkennen verfremdeter Schriftzeichen. Diese amhaufigsten auftretenden Vertreter der CAPTCHAs sind die Bild-CAPTCHAs [KZ09][EDHS07]. Durch den Einsatz der Bild-CAPTCHAs auf Seiten wie Facebook, Googleoder eBay gelten diese heute als De-facto-Standard. Die Sicherheitsannahme ist, dassmenschliche Nutzer diese Verfremdung erkennen und auflosen konnen, Texterkennungs-algorithmen daran jedoch scheitern. Fur das Design von CAPTCHAs ist daher immer eineAbwagung zwischen Sicherheit (vor Angriffen) und Erkennbarkeit (durch Menschen)zu treffen. Bei Auftritt der ersten CAPTCHAs Mitte der 1990er Jahre [Nao96] warenangreifende Programme noch wenig leistungsfahig, so dass es bei auch fur Menscheneinfachen Fragestellungen bleiben konnte. Im Laufe der Zeit wurden allerdings die au-tomatisierten Angriffe immer ausgefeilter. Durch diese Fortschritte wurde es notwendig,

die Schwierigkeit des zu losenden Problems zu erhohen. Aktuell ist ein Niveau erreicht,das Menschen bereits vor große Herausforderungen stellt. Der Extremfall unterstreichtdie Notwendigkeit guter Usability von CAPTCHAs: Wenn ein Nutzer ein zur Anmeldungverpflichtendes CAPTCHA nicht zu losen vermag, kann er sein eigentliches Ziel derInteraktion nicht erfullen - etwa die Benutzung einer Webseite. Es ist somit ein fatalerBenutzbarkeitsfehler aufgetreten. CAPTCHAs unterschiedlicher Modi, etwa Bild-, Tonoder Texterkennung, werden in dieser Studie auf ihre Usability getestet. Wir stellenzudem einen Kriterienkatalog vor, der uber die reine Erkennungsrate hinausgeht, welchebereits in anderen Studien (siehe Abschnitt 2) untersucht wurde. Diese Untersuchungbetrachtet Aspekte der Mensch-Maschine-Interaktion bei der Benutzung von CAPTCHAsund beantwortet folgende Fragen:
• Wie lassen sich Usability-Kriterien fur CAPTCHA-Systeme formalisieren?
• Wie gebrauchstauglich sind einzelne CAPTCHAs laut empirischem Nutzertest?
• Welche CAPTCHAs sind im konkreten Anwendungsbereich zu bevorzugen?
2 Sicherheit und Benutzbarkeit von CAPTCHA-Systemen
Aussagen zur Sicherheit einzelner CAPTCHA-Systeme vor Angreifern stehen nichtim Fokus einer Usability-Studie. Um die Auswirkungen der Benutzbarkeitsstudie aufdie Realwelt im Gesamtkontext zu betrachten, stellen wir an dieser Stelle dennochEinschatzungen uber die Sicherheit von CAPTCHAs in der Forschung vor. Ein CAPT-CHA, das sich in der Benutzbarkeit uberlegen zeigt, aber leicht uberwunden werden kann,ist fur die Losung der ursprunglichen Aufgabe ebenso ungeeignet wie ein extrem sicheresCAPTCHA, welches sich vom menschlichen Benutzer nur sehr schwer losen lasst.
Automatisierte Angriffe setzen auf OCR-Systeme (Texterkennungssysteme), Spracher-kennungssysteme oder umfangreiche Bibliotheken bekannter CAPTCHA-Losungen. Bil-ge et al. [BSBK09] untersuchten die CAPTCHA-Systeme bekannter sozialer Netzwerkeund konnten bei ReCAPTCHA (einem CAPTCHA-System von Google) in dessen Bild-CAPTCHA-Version noch Erkennungsraten von 4-7% erreichen. Unter der Annahme, dasspro Tag mehrere hundert Angriffsversuche gestartet werden konnen, gehen sie aus An-greifersicht dennoch von einem Erfolg aus. Wilkins [Wil09] benutze OCR-Technikenund Bilderkennungsverfahren auf ReCAPTCHA und konnte eine Erkennungsrate von17,5% erzielen. Ahmad et al. [AYT11] waren in der Lage, 24,7% der Bild-CAPTCHASvon ReCAPTCHA durch fortgeschrittene Segmentation-Erkennungsmethoden zu losen.Daruber hinaus entwickelten Bursztein et al. [BMM11] eine Moglichkeit, einzelne Bild-CAPTCHA-Systeme mit einer Erfolgsrate zwischen 10% und bis zu 50% zu losen. Tamet al. [TSHVA09] konnten in einem Testsample von Audio-CAPTCHAs eine Erkennungs-rate von 71% erreichen - sie vergleichen das mit der Rate, welche ublicherweise auchvon Menschen bei Audio-CAPTCHAs erreicht wird. Philippe Golle [Gol08] konnte mitHilfe von Klassifizierungsalgorithmen das Quiz-CAPTCHA Asirra in 10,3% der Versu-
200 Usability von CAPTCHA-Systemen

che uberwinden. Hernandez-Castro und Ribagorda [HCR10] untersuchten fortgeschritteneMath-CAPTCHAs und konnten CAPTCHAs selbst aus komplexen mathematischen Auf-gaben in 35% der Falle losen lassen. Einfache Math-CAPTCHAs, welche keinen OCR-Einsatz, einfache Arithmetik und eine Losung im niedrigen zweistelligen Zahlenbereicherwarten, sind daher generell als unsicher anzusehen. Aussagen zur Sicherheit von CAPT-CHAs sind aber auch immer mit der entsprechenden Losungsfahigkeit durch Menschen zuvergleichen. Bursztein et al. [BBF+10] geben eine Aussage uber die Erfolgsraten mensch-licher Nutzer bei verschiedenen CAPTCHA-Implementierungen. Durch einen ”Mechani-cal Turk“-Dienst ließen sie 5.000 CAPTCHAs aus 13 verschiedenen Varianten losen undkamen im Schnitt auf Losungsraten von 71% bei Bild-CAPTCHAs und 31,2% bei Audio-CAPTCHAs. Sie schließen daraus, dass die meisten CAPTCHAs fur Menschen bereitsschwerer zu losen sind als notig. Ahmad et al. [AYT11] benennen als Richtwert fur dieEntwicklung neuer CAPTCHA-Varianten eine Erkennungsrate von mindestens 90% durchMenschen bei maximal 0,01% Erfolg durch automatische Angriffsversuche.
Es kann also keine der unterschiedlichen CAPTCHA-Losungen einen gegenuber anderenVersionen deutlich uberlegenen Schutz bieten. Asirra zeigt sich in der Forschung robus-ter gegen automatisierte Angriffe als die anderen Varianten, gehort aber auch zu den bisjetzt weniger haufig betrachteten Technologien. Bei mehr als 10% erfolgreicher Angriffebei allen CAPTCHA-Varianten kann man von keinem effektiven Schutz gegen massierteautomatische Losungsversuche sprechen.
Im Feld der Usabilityforschung zu CAPTCHA-Systemen untersuchten Chellapilla et al.[CS04] Methoden zur Erhohung des Schwierigkeitsgrades fur die OCR-Erkennung beiBild-CAPTCHAs und deren Auswirkungen auf die Erkennungsleistung von Menschen.Es zeigte sich sowohl beim Einbinden von Stordaten als auch dem Verzerren des Tex-tes ab einem bestimmten Grad ein Einbrechen der Erkennungsleistung von Testpersonen.Baird et al. [BMW05] testeten ebenfalls die Benutzbarkeit von CAPTCHAs beim gleich-zeitigen Einsatz sowohl stark wie auch schwach gestreuter Buchstaben. Nach den Bild-CAPTCHAs werden Audio-CAPTCHAs, also das Erkennen von Worten aus Toneinspie-lungen, laut Yahn und Ahmand [YA08] nachsthaufig eingesetzt. Diese haben theoretischErkennungvorteile bei Personen mit beeintrachtigtem Sehvermogen. Bigham und Caven-der [BC09] zeigten jedoch, dass neben den Verstandnisschwierigkeiten bei den Audio-CAPTCHAs an sich auch ein Benutzbarkeitsproblem hinsichtlich der Player-Schaltflachenbesteht. Abseits der Bild- und Audio-CAPTCHAs gibt es noch Nutzerstudien zu MicrosoftAsirra, welche auf die menschliche Fahigkeit der Bilder-Erkennung und -kategorisierungabzielt. Hier wurde die Erkennungsrate mit 83,4% angegeben [EDHS07]. Kurt AlfredKluever [Klu08] betrachtete Video-CAPTCHAs, welche durch den Einsatz multimodalerAspekte Vorteile versprechen: Es mussen gleichzeitig Bilder und Gerausche vom Benutzerverarbeitet werden. Die Erfolgsrate konnte hier mit 90% angegeben werden.
3 Benutzbarkeitskriterien fur CAPTCHAs
Bislang sind fur die Usability von CAPTCHA-Systemen noch keine umfassenden for-malen Kriterien fur die Gebrauchstauglichkeit von CAPTCHAs definiert. Wir stellen
Usability von CAPTCHA-Systemen 201

Effektivitat Wie hoch ist die Erkennungsrate eines CAPTCHAs? Wieviele Versuche benotigt ein Benutzer im Durchschnitt, umein CAPTCHA zu losen?
Effizienz Wie lange braucht ein Benutzer fur eine richtige Losung imDurchschnitt? Kann das CAPTCHA in weniger als 30 Se-kunden gelost werden? [RL03]
Erlernbarkeit Erkennt ein Benutzer auf den ersten Blick, wie das CAPT-CHA korrekt benutzt wird?
Einpragsamkeit Wie gut kann sich ein Benutzer an ein CAPTCHA-Konzepterinnern?
Zufriedenheit Wie schwierig findet ein Benutzer ein CAPTCHA? Fuhlensich die Benutzer beim Benutzen eines CAPTCHAs wohlund sind sie gewollt ein bestimmtes System zu benutzen?Welches qualitative Feedback geben die Nutzer?
Abbildung 1: Formalisierte Benutzbarkeitskriterien
einen erweiterten Kriterienkatalog der Benutzbarkeit von CAPTCHA-Systemen vor. Indieser Studie interpretieren wir diese Kriterien auf Ebene der jeweiligen CAPTCHA-Anwendung. Usabilityprobleme, die durch die jeweils unterschiedliche Implementierungvon CAPTCHAs in einzelnen Programmen oder Webseiten entstehen, werden daher nichtberucksichtigt. Der reduzierte Interaktionsumfang von CAPTCHAs auf dieser Abstrakti-onsebene spricht fur die Verwendung der ”Anforderungen an die Gebrauchstauglichkeit“nach ISO-Norm 9241-11[ISO98] (Effektivitat, Effizienz und Zufriedenheit), erweitert umJakob Nielsens qualitative Komponenten [Nie93] (Erlernbarkeit, Einpragsamkeit und Feh-lervermeidung) als Basis der Formalisierung. Das Kriterium ”Fehlervermeidung“ inter-pretieren wir in diesem Kriterienkatalog als dem Losungsproblem inherent, und dadurchnicht als Aspekt der Benutzbarkeit von CAPTCHA-Systemen. Fehler bei der Benutzungvon CAPTCHAs sind (auch aufgrund der reduzierten Interaktionsmoglichkeiten) auf dieSchwierigkeit der zu losenden CAPTCHA-Problemstellung zuruckzufuhren. Eine Verein-fachung des CAPTCHA-Problems zur Verbesserung der Gebrauchstauglichkeit wirkt sichnegativ auf die Sicherheit vor automatisierten Angriffen aus, vor denen das CAPTCHAletztendlich schutzen soll. Die quantitative Auspragung der ”Fehlervermeidung“ betrach-ten wir (in Form der Erkennungsrate) in diesem speziellen Kontext als Teilaspekt des Be-nutzbarkeitskriteriums ”Effektivitat“.
Es ergeben sich somit als erweiterten Kriterienkatalog der Benutzbarkeit von CAPTCHA-Systemen die in Abbildung 1 formalisierten Usabilityaspekte.
202 Usability von CAPTCHA-Systemen

GesamtMerkmal AnzahlStudent 25Andere 25Alter Anzahl14-19 620-29 3030-39 240-49 1050-59 2ab 60 0Internetnutzung Anzahlwenig 12normal 26oft 12
Gruppe AndereGruppe AndereAlter Anzahl14-19 520-29 630-39 240-49 1050-59 2ab 60 0Internetnutzung Anzahlwenig 12normal 11oft 2
Gruppe StudentenGruppe StudentenAlter Anzahl14-19 120-29 2430-39 040-49 050-59 0ab 60 0Internetnutzung Anzahlwenig 0normal 15oft 10
Abbildung 2: Demografische Verteilung der Probanden
4 Methodik
Der Benutzertest umfasst 50 Testpersonen. Diese Personengruppe kann in zwei Gruppenunterteilt werden, eine Gruppe mit Studenten der Altersklassen 14-19 sowie 20-29 (Grup-pe ”Studenten“) und eine Gruppe Nichtstudierender mit einer gemischten Altersstruktur(Gruppe ”Andere“). Eine Ubersicht uber die demografische Verteilung der Probanden gibtAbbildung 2.
Alle Teilnehmer waren mit den Grundlagen der PC-Bedienung, sowie den gangigenEingabegeraten Maus und Tastatur vertraut. Die Probanden wurden im Rahmen derMoglichkeiten zufallig ausgewahlt. Alle Teilnehmer nahmen freiwillig und ohne (even-tuell verzerrendes) Anreizsystem am Test teil. Der Test wurde in einer klassischen La-borumgebung durchgefuhrt. Dies bedeutet eine gerauscharme wie optisch ruhige Zone, inder sich die Probanden vollstandig auf die zu untersuchende Aufgabe konzentrieren konn-ten. Der Test beginnt mit der Bearbeitung eines Eingangsfragebogens. Danach werdenin drei Runden zufallig je ein CAPTCHA-System dem Probanden zur Losung vorgelegt.Abschließend erfolgt die Erfassung des Feedbacks des Teilnehmers.
Als quantitative Attribute ergeben sich somit die korrekte Losung des CAPTCHAs(ja/nein), die benotigte Bearbeitungszeit, Notwendigkeit der Hilfefunktion (ja/nein), diejeweilige Runde des Testablaufs (1-3) und die wahrgenommene Schwierigkeit des CAPT-CHAs (funfstufige Likert-Skala).
Unter den moglichen CAPTCHAs musste eine Auswahl getroffen werden, da nicht alleder Systeme die Anforderungen fur diesen Benutzertest erfullen. So wurden rein englisch-sprachige Systeme oder solche, die nicht frei verfugbar waren, aus praktischen Grundennicht berucksichtigt. Dennoch konnte eine ausreichende Heterogenitat in den Interakti-onsmodi der verschiedenen Systeme gewahrleistet bleiben. CaptchaAd [capb] ist eine Im-plementierung, die kurze Videoclips anzeigt, welche Werbung enthalten. Der menschli-che Nutzer kann wahrend und nach Betrachten des Videos eine hierzu passende Frage
Usability von CAPTCHA-Systemen 203

beantworten, z.B. ”Wie hoch ist der Preis des Produktes?“. Google reCAPTCHA Audio(im folgenden ”Audio-CAPTCHA“ genannt) und reCAPTCHA Bild (im folgenden ”Bild-CAPTCHA“) [capd] sind hiermit verglichen klassische Ansatze: Im Audio-CAPTCHAwerden acht Zahlen vorgelesen, die der Nutzer dann uber die Tastatur eingibt, im Bild-CAPTCHA mussen verzerrt dargestellte Worter korrekt erkannt und eingegeben werden.Quiz-CAPTCHAs sind in mehreren Varianten im Einsatz, welche auf unterschiedlicheLosungsstrategien abzielen: Math-CAPTCHAs [capc] erfordern die intellektuelle Losungeiner mathematischen Aufgabe, etwa ”Was ist die Losung aus 8 + 9?“. Microsoft Asirra[capa] hingegen setzt auf die Fahigkeit des Menschen, verschiedene Tiere auf Fotos zu un-terscheiden, in dem Fall Hunde von Katzen - ein Problem, das fur den Menschen einfach zulosen sein sollte, aber ursprunglich schwer automatisierbar war [EDHS07]. In Abbildung 3findet sich eine Darstellung der fur den Nutzertest herangezogenen CAPTCHA-Systeme.
(a) Microsoft Asirra (b) Audio-CAPTCHA
(c) Bild-CAPTCHA (d) CaptchaAd
(e) Math-CAPTCHA
Abbildung 3: Im Nutzertest untersuchte CAPTCHA-Systeme
204 Usability von CAPTCHA-Systemen

5 Auswertung
Die quantifizierbare Messgroße fur Angaben zur Effektivitat ist die Erkennungsrate. Sie istdefiniert als der Anteil positiver Losungen unter allen Versuchen. Das Math-CAPTCHAwurde bei einer Erkennungsrate von 98,67% am besten erkannt. Dem folgte das Bild-CAPTCHA mit 92% Erkenungsrate. Die anderen Systeme Asirra, CaptchaAd und dasAudio-CAPTCHA erreichen 84%, 74% respektive 68,87% in der gesamten Testgruppe.Diese Angaben basieren auf 150 Einzelbeobachtungen je CAPTCHA-Variante. Die Auf-schlusselung der Erkennungsrate zeigt Unterschiede zwischen den Runden sowohl im Ge-samtbild als auch im Vergleich der beiden Teilnehmergruppen. Am wenigsten schwanktdabei Math-CAPTCHA, das bei der Gruppe ”Studenten“ mit einer Erkennungsrate von100% in allen Runden gar keine Veranderung aufweist. Bei der Gruppe ”Andere“ wirdMath-CAPTCHA mit 96% in Runde 1 und 2 sowie 100% in Runde 3 fast so gut erkanntwie in der Gruppe Studenten. Beim Audio-CAPTCHA wird bei einem normierten Kor-relationskoeffizienten von 0,31 und einem p-value von 0,02 beim Chi-Quadrat-Test einleichter Zusammenhang zwischen der Runde und dem entsprechenden Ergebnis erkenn-bar. Mit anderen Worten ist das Audio-CAPTCHA die einzige Losung, die die Anfor-derung der ”Lernforderlichkeit“ im Sinne der Softwareergonomie erfullt: Je haufiger dasCAPTCHA verwendet wird, desto besser werden die Erkennungsraten. Auffallig bei derUntersuchung von Microsoft Asirra ist der Unterschied in der Erkennungsrate zwischender Altersgruppe 50-59 Jahre und den restlichen Altersgruppen. Wahrend die Erkennungs-raten zwischen 80% bei der Gruppe 14-19 und 90% bei der Gruppe 40-49 schwankt, wurdeMicrosoft Asirra von den Teilnehmern der Altersgruppe 50-59 Jahre lediglich in 33% derCAPTCHA-Tests korrekt gelost.
Auch bei der Betrachtung der Effizienz der CAPTCHA-Losung zeigt sich das Math-CAPTCHA als das vorteilhafteste der untersuchten Systeme: Es wurde im Mittel inner-halb von 7,27 Sekunden richtig gelost. Fur eine richtige Losung beim Bild-CAPTCHAbenotigten die Teilnehmer im Durchschnitt mit 17,63 Sekunden knapp 10 Sekundenlanger. Es folgen Microsoft Asirra (25,90 Sekunden), CaptchaAd (29,48 Sekunden)und das Audio-CAPTCHA mit 36,18 Sekunden. Bei den Systemen Math-CAPTCHAund CaptchaAd ist in der Bearbeitungsdauer ein Unterschied zwischen korrekter undfalscher Losung erkennbar. Dieser wird in den beiden Fallen durch einen p-value von0,00 beim Math-CAPTCHA und 0,01 bei CaptchaAd gestutzt. Der Bravis-Pearson-Korrelationskoeffizient im Falle CaptchaAd betragt -0,21. Die Teilnehmer benotigten dem-nach fur einen Fehlversuch langer als fur eine korrekte Losung. Diese Aussage ist auch furdas Math-CAPTCHA zutreffend. Durch den niedrigen p-value ist hierbei aber ohnehin voneiner Abhangigkeit auszugehen. Die Korrelation ist dabei mit einem Korrelationskoeffizi-enten von -0,35 ebenfalls starker als bei CaptchaAd.
Ein Maß fur die Erlernbarkeit von CAPTCHAs ist der Rate der Verwendung der Hil-fefunktionen in den jeweiligen Systemen. Geordnet nach der Haufigkeit des Aufrufensder Hilfefunktion ergibt sich ein anderes Bild als bei der Erkennungsrate. Wahrend dasMath-CAPTCHA die hochste Erkennungsrate aufweist, wird hier auch die Hilfe in 6% derMath-CAPTCHA-Tests in Anspruch genommen. Vor dem Math-CAPTCHA liegt nochCaptchaAd mit 11,33% und Microsoft Asirra mit 6,67%. Beim Audio-CAPTCHA wur-
Usability von CAPTCHA-Systemen 205

de in 4,67% der Tests die Hilfe benutzt und beim Bild-CAPTCHA in 2,67% der Tests.Auch die beiden Gruppen weisen bei der Benutzung der Hilfe Unterschiede auf. Ledig-lich ein Student hat die Hilfe beim Audio-CAPTCHA in Runde 1 in Anspruch genom-men. Ansonsten wird in dieser Gruppe die Hilfe nicht benotigt. Bei der Gruppe ”Andere“wird dementsprechend die Hilfe haufiger in Anspruch genommen, wobei mit zunehmen-der Rundenzahl die Inanspruchnahme der Hilfefunktion abnimmt. Eine Ausnahme bildethier das Bild-CAPTCHA, bei dem in der dritten Runde in 8% der Tests die Hilfe aufge-rufen wurde. Bei CaptchaAd wurde die Hilfe in 22,67% aller Tests der Gruppe ”Andere“benutzt. Bei den Asirra CAPTCHAs wurde die Hilfe in 13,33% der Tests benutzt. 12% derTester in der Gruppe ”Andere“ nutzten beim Math-CAPTCHA die Hilfe sowie 8% beimAudio-CAPTCHA. Beim Bild-CAPTCHA wurde die Hilfe in der Gruppe ”Andere“ nochin 5,33% der Tests benutzt. Aufgrund des hoheren Durchschnittsalters in dieser Gruppeliegt die Vermutung nahe, dass mit zunehmenden Alter des Probanden auch die Verwen-dung der Hilfefunktion zunimmt. Unterstutzt wird diese Aussage durch einen niedrigenp-value von 0,00 und einem normierten Kontingenzkoeffizienten von 0,47 zwischen denMerkmalen ”Alter“ und ”Anzahl der Aufrufe der Hilfefunktion“.
Die Einpragsamkeit eines CAPTCHA-Systems zeigt sich in der benotigten Zeit zumLosen des CAPTCHAs im Zeitverlauf (bzw. nach Anzahl der Runden im Testdurch-lauf). Alle untersuchten Methoden weisen eine Abnahme der zur Losung benotigtenZeit auf. Unterschiede sind vor allem bei Microsoft Asirra, CaptchaAd und Audio-CAPTCHA nachzuweisen. Microsoft Asirra zeigt die hochste (negative) Abhangigkeitzwischen Runde und Losungszeit (Korrelationskoeffizient von -0,40). Darauf folgt dasAudio-CAPTCHA (-0,35) und CaptchaAd (-0,29) und das Math-CAPTCHA (-0,27). BeiBild-CAPTCHAs zeigt sich der geringste Effekt der Wiederholung des CAPTCHAs aufdie Losungsrate. Moglicherweise sind die Benutzer mit dieser Methode bereits so vertraut,dass das Verfahren an sich keine Auswirkungen mehr auf die Losungszeit hat.
Die Zufriedenheit der Probanden mit dem System wurde in den Fragestellungen nach Endedes Tests erfasst. Das Audio-CAPTCHA wurde mit einem Wert von 2,85 als am schwers-ten empfunden, gefolgt von CaptchaAd mit einem Wert von 1,85. Das Bild-CAPTCHAwurde mit 1,72 bewertet. Microsoft Asirra folgt mit einem Wert von 1,44 und das Math-CAPTCHA mit 1,11. Abbildung 4 zeigt die Streuung der Bewertungspunkte. Das Math-CAPTCHA wurde in keinem Einzeltest schwerer als 3 (auf einer Skala von 1-5) emp-funden. Microsoft Asirra wurde uber alle CAPTCHA-Tests nie schwerer als 4 bewertet.Das Bild-CAPTCHA und CaptchaAd wurden im Vergleich zum Audio-CAPTCHA nurin wenigen Fallen als schwer empfunden. Die Bewertungen beim Audio-CAPTCHA sindim Gegensatz zu den anderen Methoden am weitesten gestreut. Außerdem hat das Audio-CAPTCHA auch die hochste Anzahl an schlechten Bewertungen und die wenigsten Pro-banden bewerteten es als leicht losbar.
Die freie Feedbackmoglichkeit am Ende des Tests ermoglichte auch qualitative Aussa-gen zu den einzelnen CAPTCHA-Systemen, die uber die rein quantifizierbaren bzw. diestrukturiert qualifizierbaren Merkmale hinausgeht: Vier Teilnehmer empfanden das Audio-CAPTCHA zu schwer oder nicht verstandlich. Ein weiterer Teilnehmer stufte Audio-CAPTCHAs als zu umstandlich und zu fehleranfallig und deshalb nicht praxistauglichein. Zwei Teilnehmer empfanden die Fragestellungen im CaptchaAd nicht prazise ge-
206 Usability von CAPTCHA-Systemen

Methode
Bewe
rtung
(leicht) 1
2
3
4
(schwer) 5
●
●
●
●
●
●
●
●●
●●●
●
● ●●
●
●
●●
●
●
●
●
●●
●
● ●
●
●
●
●
●●
●●
●
●
●
●
●●●
●
●
●●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●● ●
●
●
● ●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●
●●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●●
●
●
●
●● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
● ●
●●●
●●
●
●
●●●●
●●●
●●
●
●
●
●
●
●
●
●
● ● ●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
● ●
●
●
●
●
●
●
●
●●
●●
●
●● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
Asirra Audio Bild CaptchaAd Math
Abbildung 4: Bewertung der CAPTCHA-Systeme durch die Probanden
nug bzw. wussten nicht, was aus den gegebenen Informationen die korrekte Losung ist.Microsft Asirra wird von zwei Teilnehmern als angenehm und einfach empfunden, einTeilnehmer hingegen fuhlte sich von Asirra genervt. Ein anderer Teilnehmer empfand dasBild-CAPTCHA als zu schwer lesbar. Ein Proband hielt das Math-CAPTCHA fur nichtsicher.
Abbildung 5 zeigt abschließend die unterschiedlichen CAPTCHA-Systeme im Hinblickauf die Erfullung der Usability-Kriterien erweitert um eine qualitative Aussage zurZuganglichkeit (Accessibility).
6 Schlussbemerkungen
Bei der Betrachtung der untersuchten CAPTCHA-Losungen bezuglich ihrer Sicher-heit zeigte sich bereits, dass keine der Losungen ihren jeweiligen Alternativen generelluberlegen war. Asirra wurde in Studien nur in 10% der Angriffsversuche uberwunden,kann allerdings in der Benutzbarkeit nicht uberzeugen. Das Math-CAPTCHA wieder-um ist hinsichtlich der Kriterien der Benutzbarkeit das System, welches die gestell-ten Usability-Anforderungen am besten erfullt. Allerdings bietet es nur Schutz gegensimple Loginversuche. Es zeigt sich am Ende unserer Untersuchungen, dass die be-
Usability von CAPTCHA-Systemen 207

Erlernbarkeit Effektivität Effizienz Einprägsamkeit Zufriedenheit ZugänglichkeitQuiz
Bild
Asirra
CaptchaAd
Audio
✔ ✔ ✔ - ✔ ✔
✔ ✔ ✔ ✔ ✔ O✔ O ✔ - ✔ OO O O - ✔ ×✔ O × - × O
Legende:✔ | Anforderung erfülltO | Anforderung teilweise erfüllt× | Anforderung nicht erfüllt- | keine Aussage möglich
Abbildung 5: Benutzbarkeitsbewertung von CAPTCHA-Systemen
kannten Bild-CAPTCHAs in der Kombination aus Sicherheit und Benutzbarkeit amdeutlichsten uberzeugen konnen. Sie sind nach Asirra das robusteste, und nach denMath-CAPTCHAs das benutzerfreundlichste Verfahren, ohne jedoch die kritischen Ein-schrankungen (schlechte Benutzbarkeit oder fehlende Sicherheit) dieser beiden zu teilen.
Weitere Forschungsansatze liegen in der Betrachtung anderer CAPTCHA-Systeme. Aktu-ell sind Benutzer mit den ublichen Bild-CAPTCHAs deutlich vertrauter als mit bereits vor-handenen, aber weniger haufig eingesetzten Alternativen. In einigem zeitlichen Abstandkonnte sich diese Verzerrung verandert haben. Es konnten im Laufe der Durchfuhrung desNutzertests auch Effekte nachgewiesen werden, die nicht sofort zu erklaren waren. So istetwa noch kein Grund fur die Korrelation aus dem Alter und der erzielten Erkennungsrateklar zu erkennen. Es mag an der allgemein hoheren Computeraffinitat jungerer Menschenliegen. Eine abschließende Untersuchung dieser Hypothese steht aber noch aus.
Es ist aus den beobachteten Fortschritten in den Angriffstechniken auch eine theoreti-sche Grenze fur den Einsatz von CAPTCHAs abzusehen. Sobald deren Erkennungsratenim Mittel diejenigen der menschlichen Nutzer ubersteigen, muss die Mensch-Computer-Unterscheidung auf andere, noch zu ergrundende Arten geschehen. Zur Erhohung vonsowohl Sicherheit als auch Usability sind Fortschritte im Design multimodaler CAPT-CHAs ein naheliegender Ansatz. CaptchaAd zeigte im Test Schwachen sowohl in denBenutzbarkeitskriterien, als auch in der Zuganglichkeit. Allerdings steht ein Nachweis derzusatzlichen Sicherheit multimodaler Systeme noch aus.
Unabhangig vom Konzept des inversen Turing Tests sind auch andere Formen des Nach-weises legitimer Nutzer moglich. Beispielsweise erfordern oder ermoglichen Google undFacebook die Angabe einer Mobilfunknummer, an die eine Textnachricht mit einem Si-cherheitscode gesendet wird. Die Sicherheitsannahme dabei ist, dass der Aufwand zurmassenhaften Generierung von valider mobiler Anschlusse hierbei den erwarteten Nutzenfur Spammer ubersteigt. Diesen Ansatz greift jedoch noch tiefer in die personlichen Datender Nutzer ein. Es bleibt abzuwarten, ob die Sicherheitsbedenken der Anbieter sich gegenden Willen zur Datensparsamkeit der Benutzer durchsetzen.
208 Usability von CAPTCHA-Systemen

Literatur
[AYT11] Salah El Ahmad Ahmad, Jeff Yan und Mohamad Tayara. The Robustness of GoogleCAPTCHAs. Bericht, Newcastle University, 2011.
[BBF+10] Elie Bursztein, Steven Bethard, Celine Fabry, John C. Mitchell und Dan Jurafsky. HowGood Are Humans at Solving CAPTCHAs? A Large Scale Evaluation. In Proceedingsof the 2010 IEEE Symposium on Security and Privacy, SP ’10, Seiten 399–413, Wa-shington, DC, USA, 2010. IEEE Computer Society.
[BC09] Jeffrey P. Bigham und Anna Cavender. Evaluating existing audio CAPTCHAs and aninterface optimized for non-visual use. In Dan R. Olsen Jr., Richard B. Arthur, KenHinckley, Meredith Ringel Morris, Scott E. Hudson und Saul Greenberg, Hrsg., CHI,Seiten 1829–1838. ACM, 2009.
[BMM11] Elie Bursztein, Matthieu Martin und John C. Mitchell. Text-based CAPTCHA Strengt-hs and Weaknessses. ACM CSS ’11, 2011.
[BMW05] Henry S. Baird, Michael A. Moll und Sui-Yu Wang. A Highly Legible CAPTCHAThat Resists Segmentation Attacks. In Henry S. Baird und Daniel P. Lopresti, Hrsg.,HIP, Jgg. 3517 of Lecture Notes in Computer Science, Seiten 27–41. Springer, 2005.
[BSBK09] Leyla Bilge, Thorsten Strufe, Davide Balzarotti und Engin Kirda. All Your ContactsAre Belong To Us: Automated Identity Theft Attacks on Social Networks. WWW 2009Madrid, 2009.
[capa] ASIRRA. Website. http://research.microsoft.com/en-us/um/redmond/projects/asirra/.
[capb] CaptchaAd. Website. http://www.captchaad.com/.
[capc] MathCaptcha. Website. https://github.com/niklas/rails-math-captcha.
[capd] reCAPTCHA: Stop Spam, Read Books. Website. http://www.google.com/recaptcha.
[CS04] Kumar Chellapilla und Patrice Y. Simard. Using Machine Learning to Break VisualHuman Interaction Proofs (HIPs). In NIPS, 2004.
[EDHS07] Jeremy Elson, John R. Douceur, Jon Howell und Jared Saul. Asirra: A CAPTCHA thatExploits Interest-Aligned Manual Image Categorization. In CCS ’07: Proceedings ofthe 14th ACM conference on Computer and communications security, Seiten 366–374.ACM, 2007.
[Gol08] Philippe Golle. Machine learning attacks against the Asirra CAPTCHA. In PengNing, Paul F. Syverson und Somesh Jha, Hrsg., ACM Conference on Computer andCommunications Security, Seiten 535–542. ACM, 2008.
[HCR10] Carlos Javier Hernandez-Castro und Arturo Ribagorda. Pitfalls in CAPTCHA de-sign and implementation: The Math CAPTCHA, a case study. Computer Security,(29):141–157, 2010.
[ISO98] Ergonomic requirements for office work with visual display terminals (VDTs) – Part11: Guidance on usability, 1998. ISO 9241-11:1998 Norm.
[Klu08] Kurt Alfred Kluever. Evaluation the Usability and Security of a Video CAPTCHA.Diplomarbeit, Rochester Institute of Technology, August 2008.
Usability von CAPTCHA-Systemen 209

[KZ09] Kurt Alfred Kluever und Richard Zanibbi. Balancing usability and security in a videoCAPTCHA. In Lorrie Faith Cranor, Hrsg., SOUPS, ACM International ConferenceProceeding Series. ACM, 2009.
[Nao96] Moni Naor. Verification of a human in the loop or Identification via the Turing Test.September 1996.
[Nie93] Jakob Nielsen. Usability Engineering. Academic Press, San Diego, 1993.
[RL03] Yong Rui und Zicheng Liu. ARTiFACIAL: automated reverse turing test using FACI-AL features. In Lawrence A. Rowe, Harrick M. Vin, Thomas Plagemann, Prashant J.Shenoy und John R. Smith, Hrsg., ACM Multimedia, Seiten 295–298. ACM, 2003.
[TSHVA09] Jennifer Tam, Jiri Simsa, Sean Hyde und Luis Von Ahn. Breaking audio CAPTCHAs.Adv. Neu. Inform. Process. Syst., 21:1625–1632, 2009.
[Wil09] Jonathan Wilkins. Strong CAPTCHA Guidelines, December 2009. http://frederic.ple.name/public/documents/captcha.pdf.
[YA08] Jeff Yan und Salah El Ahmad Ahmad. Usability of CAPTCHAs or usability issues inCAPTCHA design. In Lorrie Faith Cranor, Hrsg., SOUPS, ACM International Confe-rence Proceeding Series, Seiten 44–52. ACM, 2008.
210 Usability von CAPTCHA-Systemen

Designansatz und Evaluation von KindgerechtenSecuritywarnungen fur Smartphones
Wiebke Menzel, Sven Tuchscheerer, Jana Fruth, Christian Kratzer, Jana Dittmann
Arbeitsgruppe Multimedia and Security, Institut ITIFakultat fur Informatik
Otto-von-Guericke Universitat Magdeburg Universitatsplatz 239106 Magdeburg
jana.fruth, kraetzer, sven.tuchscheerer, [email protected]@mail.cs.uni-magdeburg.de
Abstract: Dieser Konferenzbeitrag beschreibt die Entwicklung und empirische Vali-dierung eines Designs von Securitywarnungen fur Smartphones fur Kinder im Grund-schulalter (7-10 Jahre). Das Design der Warnmeldungen soll an die Fahig- und Fer-tigkeiten, zum Beispiel visuelle, akustische, taktile Wahrnehmung und Leseleistung,von Kindern im Grundschulalter angepasst sein. Dafur wurden etablierte Designkrite-rien speziell fur Kinder ausgewahlt und darauf aufbauend ein Designansatz entwickelt.Anschließend wurde das entwickelte Design fur Securitywarnungen in einen Prototypuberfuhrt, der eine simulierte Schutzsoftware fur die entwickelten Securitywarnungenprasentierte. Zur empirischen Validierung des Designs wurde eine geeignete Evalua-tionsmethodik gewahlt. Dabei diente als Zielstellung eine ”How good? “ Evaluation,die uberpruft, ob gewunschte Eigenschaften eines Systems bzw. Designs eingehaltenwerden. Fur die Validierung wurden daruber hinaus ein schriftliches Protokoll und einFragebogen erstellt. Schließlich wurde mit dem entwickelten Designansatz auf Grund-lage der gewahlten Evaluationsmethodik mit 13 Grundschulkindern eine Nutzerstudiedurchgefuhrt. Die Auswertung der daraus resultierenden Daten ergab, dass die meistenGrundschulkinder wenig sensibilisiert sind im Bezug auf Sicherheit von Smartphones.Am Ende dieses Beitrages werden Empfehlungen fur die Gestaltung von Securitywar-nungen auf Smartphones fur Kinder und weitere Forschungsvorhaben gegeben.
1 Einleitung
Bisher ist die Nutzung von Virenscannern fur Smartphones - im Unterschied zum Desktop-IT Bereich - wenig verbreitet, obwohl diese aufgrund zunehmender Bedrohungslage wich-tig waren. Laut Bundesamt fur Sicherheit in der Informationstechnik (BSI) wird es zukunftigin großerem Umfang Angriffe auf mobile Endgerate, wie Smartphones, geben [BSI10].Beim Smartphone existieren viele Schnittstellen, wie zum Beispiel Bluetooth, SMS, WLAN,UMTS und somit auch verschiedenste Angriffsmoglichkeiten. Speziell beim Smartphonegeht es unter anderem um die Gefahr des Verlustes bzw. Ausspionierens von personenbe-zogenen Daten, wie Adressbucher und Standortdaten und eines finanziellen Schadens, alsoum den Security-Bereich. Bisherige Securitywarnungen sind vorrangig (teils ausschließ-

lich) fur Standardnutzer gestaltet, wohingegen die Entwicklung nutzerspezifischer Warn-meldungen bisher ein Novum ist. Im Rahmen einer Untersuchung zu SSL-Security War-nungen bei Webbrowsern wurde festgestellt, dass Warnungen, welche den spezielle Kon-text und den Anwender berucksichtigen zu signifikant angemesseneren Reaktionen derUser fuhren [SEA+09]. Dieser Umstand wird dadurch intensiviert, dass jedes zweite Kindim Alter von 6 bis 13 bereits ein eigenes Mobiltelefon besitzt [KIM11]. Die Sattigungsratesteigt mit dem Alter an und daruber hinaus besitzen Kinder bereits Mobiltelefone mit zahl-reichen Funktionen und Schnittstellen, wie z.B. Bluetooth. Aus diesen Grunden soll in die-sem Beitrag ein speziell auf Smartphones abgestimmter nutzerspezifischer Designansatzfur eine Schutzsoftware fur Kinder entwickelt werden.
2 Designansatz von Securitywarnungen zur Darstellung auf Smart-phones fur Kinder
Im Folgenden werden Designkriterien fur Ereignis basierte Securitywarnungen fur Smart-phones fur die Nutzergruppe ”Grundschulkinder“ entwickelt. Zur Auswahl der Designkri-terien wird zwischen optischen, akustischen und haptischen Design unterschieden. Dasakustische und haptische Design soll in Kombination mit dem optischen Design die Len-kung der Aufmerksamkeit auf die Securitywarnung unterstutzen bzw. verstarken. Die Kom-bination der drei Designs wird logisches Design genannt [Bol98].
2.1 Auswahl der Designkriterien
Bei der Gestaltung des visuellen Designs sollen z.B. Denkweisen und Fahigkeiten vonGrundschulkindern mit einbezogen werden. Hierbei ist insbesondere das ”magische undanimistische Denken “ von Kindern interessant [WL02]. Dieses besagt, dass Kinder dazutendieren Gegenstanden und Dingen eine ”Seele “ zuzuordnen. So konnte z.B. ein spre-chendes Smartphone als Charakter bzw. Figur einer Warnung verwendet werden. AufGrundlage einer breiten Recherche zu aktuellen Computerspielen und Kindersendungenab 6 Jahren [kik] im April 2011 konnten weitere Designkriterien erschlossen werden. ImErgebnis dieser Recherche wurden Darstellungen realer Gegenstande, Personen und Sach-verhalte zumeist verfremdet bzw. reduziert, sehr fantasievoll und in 2D oder 2,5D abgebil-det. Seitens der AG Multimedia and Security wurde ein Interview mit dem Experten Prof.Dr. med. Gerhard Jorch, Direktor der Universitatskinderklinik des UniversitatsklinikumMagdeburg, durchgefuhrt. Ein Ergebnis des Interviews ist, dass Kinder schlecht zwischenRealitat und Fiktion unterscheiden konnen. Um Kindern den Unterschied zwischen Rea-litat und digitaler Welt zu verdeutlichen, wird meist eine verfremdete Darstellung auf digi-talen Medien gewahlt. Fur das Design von Securitywarnungen von Smartphones konntenebenfalls Analogien - im Sinne von fiktiven Darstellungen -, wie z.B. die Erschaffungvon Fantasiewesen fur die Securitywarnungen, gewahlt werden. Dieses Designprinzip istKindern aus Computerspielen und Trickfilmen bekannt und es ist an die Erfahrungs- und
212 Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones

Phantasiewelt der Kinder angelehnt. Bei der Typographie, d.h. der Art und Weise, wieText in das Design eingebaut ist, sollten dem Nutzer wichtige Informationen konkret unddirekt mitgeteilt werden [Bol98]. Zu beachten ist die Verwendung von Begriffen, die furKinder verstandlich sind. Außerdem fallt manchen Grundschulkindern das Lesen schwer,so dass der Text kurz, kindgerecht und in angemessener Schriftgroße und auf einheitli-chem Hintergrund zur Erhohung des Kontrastes sein sollte. Daruber hinaus konnte imakustischen Design zusatzlich eine Sprachausgabe zur Unterstutzung integriert werden.Es sollte eine serifenlose Schriftart gewahlt werden, da sich diese besser zum Lesen aufeinem digitalen Display eignet [Jur03]. Zur Darstellung verschiedener Kritikalitatsstufen(siehe Kapitel 2.2) kann, wie bei aktueller Schutzsoftware im Desktop-IT Bereich undSmartphones, eine Farbkodierung genutzt werden. Jedoch sollte ein fur Kinder bekannterZusammenhang, wie z.B. Ampelfarben und nicht z.B. Ein Tacho, genutzt werden. Bei derGestaltung des akustischen Designs konnte wie bereits erwahnt eine Sprachausgabe zumText erfolgen. Des Weiteren kann durch die Wahl eines entsprechenden Warntons, alsoTonhohe, -lange, -wiederholungen, die Securitywarnung unterstutzt bzw. verstarkt wer-den. Eventuell konnte auch ein den Kindern bereits bekannter Ton genutzt werden, wiez.B. der Ton einer Tuba, der u.a. Gefahr signalisiert - wie in der Vertonung von ”Peter undder Wolf “. Jedoch sollte vermieden werden, dass die Securitywarnung von den Kindernnicht ernst genommen bzw. als konsequenzloses Spiel angesehen wird. Beim haptischenDesign spielen insbesondere die Moglichkeiten eines Smartphones eine Rolle. So kann beider Gestaltung das Touchscreendisplay genutzt werden. Dieses ermoglicht eine intuitiveBedienung. Eventuell konnen außerdem weitere Sensoren zur Unterstutzung der Bedie-nung, wie z.B. Lagesensor, genutzt werden [iPhb]. Des Weiteren kann durch Vibrationebenfalls die Aufmerksamkeit auf die Securitywarnung unterstutzt bzw. verstarkt werden.Bei der Wahl der Vibration, also Vibrationsstarke, - Dauer, -wiederholungen, sollte einemogliche Uberforderung des Nutzers beachtet werden. Insgesamt kann beim logischenDesign durch eine geeignete Kombination des optischen, akustischen, haptischen Designsdie Aufmerksamkeit von Grundschulkindern auf die Securitywarnungen gelenkt werden.Dabei kann die Nutzung von multimedialen Signalen den Umgang des Kindes mit der Se-curitywarnung erleichtern. Hierbei ist jedoch eine mogliche Uberforderung durch zu vieleSignale zu vermeiden.
2.2 Bedrohungsskala
Fur das Design der Securitywarnungen ist es sinnvoll eine Bedrohungsskala zu entwer-fen, um zwischen unterschiedlichen Bedrohungslagen differenzieren zu konnen. Es wirdzwischen drei Kritikalitatsstufen unterschieden: Bei Kritikalitatsstufe 0 ist ein gefahrlosesNutzen des Smartphones moglich. Diese Stufe sollte die Standardstufe des Smartphonessein. Die Stufe tritt ein, wenn eine Uberprufung des - als ideal funktionierend angenomme-nen - Schutzprogramms ergibt, dass kein Sicherheitsrisiko besteht bzw. Virus vorhandenist. Bei der Kritikalitatsstufe 1 kann das Smartphone weiter benutzt werden, ist jedochgefahrdet. Dieses tritt dann zu, wenn eine Aktion, die ausgefuhrt werden soll, ein Si-cherheitsrisiko darstellt. Bei Kritikalitatsstufe 1 steht folglich die Handlungsanweisung,
Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones 213

die z.B. eine Infizierung des Smartphones mit einer Schadsoftware verhindert, im Vorder-grund. Bei der hochsten Kritikalitatsstufe 2 besteht ein Sicherheitsrisiko fur Smartphoneund Besitzer. Das Smartphone ist hier zum Beispiel mit einem Virus infiziert, der Datenausspionieren oder das Gerat beschadigen kann. Bei Kritikalitatsstufe 2 sollte das Smart-phone vom Kind ausgeschaltet und den Eltern bzw. einem kompetenten Erwachsenen ge-geben werden.
2.3 Designentwurf
Auf Grundlage der ausgearbeiteten Designkriterien soll nun ein Design fur eventbasierteSecuritywarnungen fur Smartphones fur die Nutzergruppe Grundschulkinder entwickeltwerden. Hierbei wird das visuelle Design in mehrere Komponenten aufgeteilt. Zum einenwurde eine fantasievolle Figur im Zeichentrickstil entwickelt, die sich je nach Kritika-litatsstufe in Farbe und Mimik unterscheidet. Diese Figur warnt und gibt Handlungsan-weisungen uber eine Sprechblase mit einheitlich weißen Hintergrund zur Erhohung desKontrastes. Des Weiteren wird eine serifenlose Schriftart genutzt, um dem Nutzer das Le-sen auf dem digitalen Display zu erleichtern. Je nach Bedrohungsskala ist die Figur Grun(Kritikalitatsstufe 0), Gelb (Kritikalitatsstufe 1) oder Rot (Kritikalitatsstufe 2) gefarbt. DieWahl dieser drei Farben lasst sich auf eine Ampel, die Grundschulkindern bekannt seinsollte, beziehen. Um die Gefahr mit einem - dem Kind - bekannten Symbol zu verdeutli-chen, wird das visuelle Design durch weitere Komponenten erweitert. So wird ein grunesHakchen (Kritikalitatsstufe 0) oder Blaulicht (Kritikalitatsstufe 1 und 2) im Zeichentrick-bzw. Comic-Stil verwendet. Dieses befindet sich in einer Sprechblase, die uber der Figurabgebildet ist. Um das optische Design der Securitywarnung zu vervollstandigen, wird dieFigur mit Textblase und Symbolen in eine Warnmeldungsbox, die dem gangigen iPhone-Oberflachen-Design entspricht, eingefugt. Innerhalb der Warnmeldungen gibt es mehre-re Interaktionsmoglichkeiten mit dem Button ”Warum? “ zum Anzeigen einer genauerenErlauterung zur Warnmeldung, dem Button ”Weiter“ zum Anzeigen der nachsten Ansichteiner Warnmeldung und dem Button ”OK“ zur Kenntnisnahme und zum Schließen derWarnmeldung. Die Securitywarnung ist in zwei Ansichten unterteilt (siehe Abb. 1). Beider ersten Ansicht erscheint die Figur, die ”Achtung! “ sagt. Beim Klicken auf den Button
”Weiter“ erscheint die zweite Ansicht der Warnmeldung, in der die Figur mogliche Hand-lungsweisen naher erlautert. Mit Klick auf den ”OK“-Button schließt sich die Warnmel-dung. Mit Klick auf den ”Warum? “-Button erscheint eine genaue Erlauterung der Gefahrund warum dem Nutzer die entsprechende Handlungsanweisung gegeben wurde. Durchdie zwei Ansichten lasst sich die Konzentration der Kinder besser auf die Warnmeldunglenken. Die Aufmerksamkeit wird so vom aktuellen Benutzungsszenario auf die Securi-tywarnung gelenkt und die Securitywarnung lasst sich nicht beim ersten Klick schließen.Stattdessen wird das Kind durch die erste Securitywarnung aus dem Geschehen gefuhrtund erhalt nach dem Klicken auf ”Weiter“ nahere Informationen. So ist es auch moglichbei der zweiten Ansicht der Securitywarnung mehr Textinformationen einzubauen.
Die ”Warum? “-Ansicht der Securitywarnung soll ahnlich wie die anderen Securitywar-nungen aufgebaut sein. Hier ist die Figur eine neutrale Informationsauskunft. Als neutrale
214 Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones

Abbildung 1: Aufbau der Securitywarnung: Kritikalitatsstufe 2
Farbung wurde weiß gewahlt. Das Weiß soll darstellen, dass die Figur nicht weiß, ob Ge-fahr droht oder nicht bzw. nur informiert. Das akustische Design besteht aus einem kurzenStandard-Warnton [Sad]. Dieser soll betonen, dass es sich bei der Securitywarnung z.B.nicht um ein Spiel handelt. Ein Ton aus einer Comicserie konnte zu einem zu sehr spiele-rischen Umgang fuhren. Der Ton wird je nach Kritikalitatsstufe einmalig oder zweimaligbeim Erscheinen der Securitywarnung abgespielt werden. Das akustische Design kommtnicht zum Einsatz, wenn beim Smartphone der Ton deaktiviert ist. Das haptische Designbesteht aus dem Bedienen des Touchscreendisplays und je nach Kritikalitatsstufe aus einerkurzen und zum Teil wiederholten Vibration des Smartphones beim Erscheinen der Securi-tywarnung. Die Vibration wird nicht verwendet, wenn beim Smartphone diese Funktiona-litat deaktiviert ist. Das logische Design, also die Kombination aus optischen, akustischenund haptischen Design, ist je nach Kritikalitatsstufe verschieden. Die moglichen Kombi-nationen konnen so anhand der Kritikalitatsstufe ausgewahlt werden und so die einzelnenKritikalitatsstufen unterstutzen. Die einzelnen Kritikalitatsstufen sind im logischen De-sign voneinander abgegrenzt und zeigen den Kindern die Pragnanz der Securitywarnung.Dabei wird aber eine mogliche Uberforderung durch zu viele Signale vermieden und derEinsatz von Ton in Kombination mit Vibration lediglich bei der hochsten Kritikalitatsstufeangewandt.
Wenn der Ton deaktiviert ist, soll das fehlende akustische Design durch ein zusatzlichesVibrationssignal ausgeglichen werden. So gibt es in diesem Fall bei Kritikalitatsstufe 1zusatzlich eine kurze einmalige Vibration. Bei Kritikalitatsstufe 2 gibt es, wenn der Tondeaktiviert ist eine zweimalige Vibration. Bei Deaktivierung der Vibration des Smartpho-nes bleibt das zweimalige Abspielen des Warntons bei Kritikalitatsstufe 2. Sollten sowohl
Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones 215

Abbildung 2: Logisches Design der Securitywarnungen nach Kritikalitatsstufen, Ton und Vibrationaktiviert
Ton als auch Vibration deaktiviert sein, besteht die Warnmeldung ausschließlich aus demoptischen Design. Im Folgenden wird bei der prototypischen Implementierung (siehe Ka-pitel 3.1) und der damit verbunden Nutzerstudie (siehe Kapitel 3.2) die Aktivierung vonTon und Vibration als Voraussetzung angesehen.
3 Evaluation des Designansatzes
Evaluationsziel ist die ist die Entwicklung nutzerspezifischer Smartphone- Securitywar-nungen fur Grundschulkinder. Die Evaluation soll also uberprufen, ob das - in Kapitel 2 -entwickelte Design zu den Bedurfnissen und Voraussetzungen der Zielgruppe passt. Dabeidient als Zielstellung eine ”How good? “ Evaluation, die uberpruft, ob gewunschte Eigen-schaften eines Systems bzw. Designs eingehalten werden. Die ”How good? “ Evaluationwird der summativen Evaluation zugeordnet, die auf die globale Bewertung der Softwareabzielt und den gewunschten mit dem erreichten Zustand vergleicht. Um die Zielstellungspater durch eine Evaluation uberprufen zu konnen, wurden Forschungsfragen, die in derAuswertung (siehe Kapitel 3.3) beantwortet werden, aufgestellt. Daruber hinaus werdenEvaluationswerkzeuge (siehe Kapitel 3.1) benotigt, um bei einer selbst durchgefuhrtenNutzerstudie (siehe Kapitel 3.2) die Zielstellung, also die aufgestellten Forschungsfragen,zu uberprufen.
3.1 Evaluationswerkzeuge
Bei den Evaluationswerkzeugen wird im Folgenden zwischen technischen und nichttech-nischen Werkzeugen unterschieden. Als technisches Werkzeug wird ein Prototyp ange-sehen, der die Moglichkeit bietet, wahrend einer Nutzerstudie die entwickelten Security-
216 Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones

warnungen anzuzeigen. Der Prototyp besteht aus zwei Programmen. Zum einen aus demHauptprogramm zur Anzeige der entwickelten Securitywarnungen, das die Probanden be-dienen. Zum anderen aus einem Kontrollprogramm, mit dem Warnmeldungen uber Blue-tooth im Hauptprogramm angezeigt werden konnen. Wahrend der Nutzerstudie bedientder Proband das Testgerat, ein iPhone 3G [iPha], mit dem Hauptprogramm, wahrend einHelfer, fur den Probanden nicht sichtbar, ein zweites iPhone mit dem Kontrollprogrammbedient. So ist es moglich ein Schutzprogramm, das den Nutzer mittels Securitywarnungenwarnt, zu simulieren. Das Hauptprogramm besteht aus einem implementierten Mal-Spiel.Dieses soll den Probanden eine Aufgabe wahrend der Versuchsdurchfuhrung geben unddient somit als Anwendungskontext zur Anzeige der Securitywarnungen. Im Kontrollpro-gramm, das uber Bluetooth im Hauptprogramm Securitywarnungen anzeigen lassen kann,gibt es je Securitywarnung einen Button. Um zu verhindern, dass das Spiel unbeabsichtigtvom Probanden beendet wird, ist beim entsprechenden Testgerat die Menutaste mit einemStuck Pappe verdeckt, sowie mit einem schwarzen Klebeband uberklebt. Die Ausschalt-taste ist ebenfalls unauffallig mit schwarzem Klebeband verdeckt. Die Verhinderung einesunbeabsichtigten Beenden des Programms ist notig, da sonst die Verbindung zwischenHauptprogramm und Kontrollprogramm unterbrochen werden wurde. Das wurde den Ver-such ungewollt vorzeitig beenden. Des Weiteren werden mit dem Prototypen Messdaten,die Ruckschlusse auf die Handhabung der Probanden mit den entwickelten Securitywar-nungen zulassen, erfasst und in ein Logfile gespeichert. Das nicht-technische Werkzeugbesteht aus mehreren Komponenten. Zum einen werden wahrend der Nutzerstudie dieProbanden bei der Ausfuhrung der Aufgabe und Interaktion mit dem Prototyp beobachtet.Diese Beobachtungen werden in einem schriftlichen Protokoll, das der Versuchsleiter derNutzerstudie anfertigt, festgehalten. Des Weiteren wird die Methode des lauten Denkenseingesetzt, um die Gedanken und Gefuhle des Probanden wahrend des Versuchs zu er-fahren und ebenfalls schriftlich protokolliert. Eine Uberforderung des Protokollanten wirdvermeiden, in dem ein vorgefertigtes, strukturiertes Protokoll verwendet wird. Schließlichwird als weiteres nicht-technisches Werkzeug im Anschluss an jeden Versuch mit demPrototypen ein - speziell fur Kinder entwickelter - Fragebogen, der die Beurteilung durchdie Probanden aufzeigt, verwendet. Der Fragebogen soll speziell auf die Bedurfnisse vonGrundschulkindern abgestimmt sein, also nicht zu lang und in einer geeigneten Schritt-große, um die Konzentration aufrecht zu erhalten. Verwendet werden sollten ebenfallsviele Bilder und Symbolik, wie z.B. Smileys, um zu motivieren und Text zu vermeiden.Fragearten des Fragebogens sind z.B. Bewertungsfragen, offene Fragen und Kontrollfra-gen. Die Kinder werden beim Ausfullen des Fragebogens durch einen Helfer unterstutzt.Der Helfer liest die Fragen vor und setzt die Antwortkreuze bzw. schreibt bei offenen Fra-gen die Antwort des Probanden auf. So wird das Lesen und Ausfullen des Fragebogenszusatzlich erleichtert, da dieses v.a. Grundschulkindern teilweise noch schwer fallt.
3.2 Durchfuhrung der Nutzerstudie
Die Evaluation wurde im Rahmen einer Nutzerstudie an einer Grundschule in Magdeburgdurchgefuhrt. Es gab die Moglichkeit den Versuch im Rahmen der Computer- Arbeitsge-
Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones 217

meinschaft (AG) der 1. Klasse oder der 3. Klasse durchzufuhren. Da die AG der 1. Klassenur aus Madchen bestand, fiel die Entscheidung auf die gemischte AG der 3. Klasse. Sokonnten mogliche Unterschiede zwischen Jungen und Madchen mit in die Auswertungeneinfließen. Des Weiteren findet der Unterricht der ausgewahlten 3. Klasse mit Tablet-PCsund einem digitalem Whiteboard statt. Es wurde also vermutet, dass die Kinder eine ge-wisse Erfahrung im Umgang mit Computern und Technik haben. Insgesamt 13 Kinder,darunter 8 Jungen und 5 Madchen, der AG der 3. Klasse nahmen an dem Versuch teil. DieKinder waren im Alter von 8 bis 9 Jahren und alle deutsche Muttersprachler. Vorberei-tend wurde eine Einverstandniserklarung mit einem Begleitschreiben der Schulleitung andie Eltern gegeben und sich der Klasse vorgestellt. Dabei wurde den Kindern erklart, dassihre Hilfe benotigt wird und sie ein Programm auf dem iPhone testen sollen. Es wurdenicht erwahnt, dass es beim dem Test um Warnmeldungen geht, um eine Beeinflussungzu verhindern. Der Versuch wurde an drei aufeinanderfolgenden Tagen mit jeweils 4 bis5 Kindern einzeln durchgefuhrt. Der Versuch bestand aus drei Phasen Einfuhrung, Bedie-nung des Prototypen und Fragebogen. Fur die Einfuhrung waren etwa funf Minuten, furden Versuch funfzehn Minuten und fur das Ausfullen des Fragebogens funfzehn Minu-ten geplant. Insgesamt sollte die Lange des Versuchs eine Schulstunde (ca. 45 min.) nichtuberschreiten, um die Konzentration der Kinder nicht zu uberbeanspruchen.
3.3 Auswertung
Die Auswertung soll klaren, ob die nutzerspezifischen Smartphone-Securitywarnungen furGrundschulkinder angemessen konzipiert sind. Dafur wurden verschiedene Forschungs-fragen untersucht. Zum Einen sollte geklart werden, wie verstandlich die - speziell furGrundschulkinder entwickelten - Securitywarnungen sind. Zur Beantwortung dieser For-schungsfrage muss das Konstrukt ”Verstandlichkeit der Warnmeldung“ operationalisiertwerden. Zur Operationalisierung werden folgende 3 Instrumente herangezogen: Reaktion(angemessene und unangemessene Reaktion erfasst im Protokoll und Logfile), Interpre-tation der Warnmeldung aus Sicht des Kindes (erfasst im Fragebogen), Haufigkeit derNutzung des ”Warum? “-Buttons (erfasst im Logfile). Fur jede angezeigte Warnmeldungwurden die drei Instrumente ausgewertet. Interessant war hierbei die Diskrepanz zwischenInterpretation und Reaktion beim Warnen bzw. Installieren eines infizierten Updates. Sointerpretierten die meisten Kinder die Warnmeldung zwar richtig, die Halfte der Kin-der handelte aber unangemessen (installierten das infizierte Update). Dies konnte, nebendem Verstandnis der Warnmeldung, auch an weiteren Faktoren liegen. Mogliche Ursachender unangemessenen Reaktionen konnten Unsicherheit der Kinder, der Aufforderungscha-rakter des Update-Hinweises und mangelndes Bewusstsein bezuglich IT-Sicherheit aufSmartphones sein. Bei zwei weiteren Warnmeldungen: Angriff uber Bluetooth (angemes-sene Reaktion ist Deaktivieren des Bluetooth) und uber das Senden einer infizierten Dateian das Smartphone (angemessene Reaktion ist das Blockieren dieser Datei) gab es eben-falls interessante Ergebnisse. So reagierten die meisten (92 bzw. 100 Prozent) Kinder an-gemessen. Jedoch ergab die Interpretation im Fragebogen und die Methode des LautenDenkens (erfasst im Protokoll), dass die Mehrheit der Kinder die Warnmeldungen nicht
218 Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones

verstanden hat. So gab es eine intuitiv richtige Reaktion auf die Warnmeldungen trotz derfehlenden oder fehlerhaften Interpretation. Des Weiteren wurde untersucht, wie anspre-chend das gewahlte Design der Securitywarnungen fur Grundschulkinder gestaltet ist. DieEvaluation des Designs wurde mithilfe des Fragebogens durchgefuhrt. Insgesamt beurteil-ten 9 Kinder (69 Prozent) die Warnmeldung und die Comic-Figur auf einer Skala von 1(sehr gut) bis 6 (ungenugend) als sehr gut. Beim Text bewerteten alle Kinder die Schritt-große, sowie 11 Kinder (83 Prozent) die Textlange als angemessen. Die meisten Kinderempfanden die verwendeten Worter verstandlich. Jedoch hatten einige Kinder wahrend desVersuchs Verstandnisprobleme mit englischen Begriffen, wie ”Update“ oder ”Bluetooth“.Insgesamt kann daraus geschlussfolgert werden, dass der Text vom Inhalt, in Schrittgroßeund Textlange ansprechend gestaltet wurde. Jedoch sollte auf englische Begriffe verzichtetwerden. Daruber hinaus sollte geklart werden, wie Zeit und Reihenfolge der Prasentationvon Securitywarnungen die Reaktion der Probanden beeinflussen. Mithilfe des Logfiles,indem gespeichert wurde wie lange eine Warnmeldung geoffnet war und des schriftli-chen Protokolls in dem eine Vermutung, ob eine Warnmeldung gelesen wurde, vermerktwurde, kann geschatzt werden ob eine Warnmeldung gelesen wurde oder nicht. Vergleichtman diese Schatzung mit der zeitlichen Abfolge der Warnmeldungen, ergibt sich eine Ten-denz, dass mit fortschreitender Versuchszeit die Wahrscheinlichkeit fur das Durchlesen derWarnmeldung abnimmt (siehe Abb. 3). Dieses konnte an einer Gewohnung an die Warn-meldung, dem Habituationseffekt, liegen und deckt sich mit der Nutzung des ”Warum?“-Buttons, die ebenfalls mit der Zeit nachlasst.
Abbildung 3: Einfluss der Versuchszeit auf das Leseverhalten aller Warnmeldungen
Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones 219

4 Fazit
Die Nutzerstudie mit anschließender Evaluation lasst darauf schließen, dass die erarbei-teten Designkriterien gut gewahlt sind. So kann die Empfehlung ausgesprochen werden,dass das Design im Comic- bzw. Zeichentrickstil, unterstutzt durch - fur Grundschulkinder- bekannte Symbole und mit altersgerechtem Textinhalten, gestaltet wird. Wobei der Textkeine englischen Begriffe enthalten sollte. Die Nutzung einer Comic- bzw. Zeichentrick-Figur, die uber Text in einer Sprechblase mit den Grundschulkindern ”spricht“, ist alsofur das Design von Securitywarnungen fur Smartphones fur Grundschulkinder geeignet.Auch kann eine Farbkodierung entsprechend einer Ampel (grun, gelb, rot) genutzt wer-den. Die Evaluation hat gezeigt, dass Grundschulkinder die entsprechend gefarbte Figurmit der Warnmeldung in Verbindung bringen, die sie als erstes gesehen haben. Eventuellkonnte dies genutzt werden, indem zum Beispiel verschiedene Figuren bzw. Charaktereentwickelt werden, die jeweils eine bestimmte Bedrohung reprasentieren. Dieses mussteallerdings in weiteren Nutzerstudien evaluiert werden. Die Evaluationsergebnisse lassenvermuten, dass die meisten Grundschulkinder wenig sensibilisiert im Bezug auf Sicher-heit von Smartphones sind. Dem konnte entgegengewirkt werden, indem im Unterrichtoder zum Beispiel in Computer-AGs der Schulen Sicherheitsaspekte und Bedrohungenerlautert werden. Daruber hinaus konnten entsprechende Tutorial-Programme zum spiele-rischen Lernen im Kontext von Security- Ereignissen und die Reaktion darauf entwickeltwerden. Des Weiteren sollten Handlungsmoglichkeiten an die Eltern ubertragen werden.So konnte, wenn ein Kind ein Update installieren will oder das Smartphone aufgrund einesVirus ausgeschaltet werden sollte, eine SMS oder eMail an die Eltern geschickt werden.Den Eltern wurde so die Moglichkeit gegeben aus der Ferne dem Update zuzustimmenbzw. das Smartphone auszuschalten. Bei weiterer Entwicklung von Securitywarnungensollten die unterschiedlichen Einstellungsmoglichkeiten von Smartphones (Ton bzw. Vi-bration deaktivieren) mit implementiert werden. Daruber hinaus konnten unterschiedli-che Modi fur verschiedene Altersstufen bzw. Erfahrungen der Kinder entwickelt werden.Zu betonen ist, dass die Nutzerstudie nur mit einer kleinen Testgruppe von 13 Grund-schulkindern im Alter von acht bis neun Jahren durchgefuhrt wurde. Somit ist die Aus-sagekraftigkeit aufgrund der Große der Testgruppe und der geringen Altersdifferenz derProbanden eingeschrankt. Es ist also zu empfehlen die Testergebnisse, die auf fur Grund-schulkinder angemessen entwickelte Designkriterien schließen lassen, mit einer großerenTestgruppe mit großerer Altersspanne zu uberprufen.
5 Acknowledgements
Die Arbeit von Dr. Sven Tuchscheerer ist Teil des ViERforES II Projektes, welches vomDeutschen Ministerium fur Bildung und Forschung (BMBF) finanziert wird. Teile dieserArbeit entstanden im Rahmen der Bachelorarbeit von Wiebke Menzel im Sommersemester2011 an der Otto-von-Guericke-Universitat Magdeburg (FIN/ITI/AMSL).
220 Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones

Literatur
[Bol98] D. Boles. Vorlesungsskript Mulimedia-Systeme, 12 1998. Letzter Aufruf: 20.04.2011.
[BSI10] Bundesamt fur Sicherheit in der Informationstechnik. Jahresbericht 2010, 2010. LetzterAufruf: 29.09.2011.
[iPha] Webseite Heise.de. Technische Daten iPhone 3G. Letzter Aufruf: 28.07.2011.
[iPhb] Webseite Apple.com. Technische Daten iPhone 4. Letzter Aufruf: 28.07.2011.
[Jur03] S. Jurgens. Evaluation von world-wide-web basierten Benutzungsschnittstellen fur Kin-der. Diplomarbeit, Fachbereich Informatik, Universitat Hamburg, September 2003.
[kik] Webseite KIKA.de. Aktuelles Fernsehprogramm. Letzter Aufruf: 20.04.2011.
[KIM11] KIM-Studie 2010 - Kinder + Medien, Computer + Internet - Basisuntersuchung zumMedienumgang 6- bis 13-Jahriger in Deutschland. Februar 2011. Letzter Aufruf:29.09.2011.
[Sad] Quellecode zu ”Das große iPhone Enwicklerbuch: Rezepte fur Anwendungsprogram-mierung mit dem iPhone SDK“ von Erica Sadun. Letzter Aufruf: 28.08.2011.
[SEA+09] Joshua Sunshine, Serge Egelman, Hazim Almuhimedi, Neha Atri und Lorrie Faith Cra-nor. Crying wolf: an empirical study of SSL warning effectiveness. In Proceedings of the18th conference on USENIX security symposium, SSYM’09, Seiten 399–416, Berkeley,CA, USA, 2009. USENIX Association.
[WL02] S. Wink und K. Lindner. Kids und Computerspiele: Eine padagogische Herausforde-rung. Logophon, 2002. ISBN: 3-922514-83-9.
Designansatz und Evaluation von Kindgerechten Warnungen fur Smartphones 221


“On-Card” User Authentication for Contactless SmartCards based on Gesture Recognition
Markus Ullmann1 2, Ralph Breithaupt1, Frank Gehring1
1 Federal Office for Information Security53133 Bonn
www.bsi.bund.de{markus.ullmann, ralph.breithaupt, frank.gehring}@bsi.bund.de
2 University of Applied Sciences Bonn-Rhine-Siegwww.h-brs.de
Abstract: Smart cards are widely used for security purposes. To protect smart cardsagainst misuse an authentication process (e.g. entering a pin or password) is necessary.Due to missing input interfaces “on-card”, an external terminal is required to input thepassword. Unfortunately the required external hardware (e.g. keypads, etc.) opens upnew security issues by being vulnerable against attacks like side channel, forgery &tampering, man in the middle, eavesdropping and others. An elegant solution for suchproblems is an authentication process “on-card” without the need for external devices.This paper presents a new class of contactless, ISO 14443 compliant smart cards whichare equipped with a multipurpose user input interface as 2D gesture recognition sensortogether with an optical feedback component. This offers new “on-card” authentica-tion, card configuration and even front end interface capabilities. We will describe thebasics of the general hardware design and discuss the gesture recognition process.
1 Introduction
Today, smart cards are primary used as security token. To avoid misuse of the smart cardsit is common to implement an user authentication. For this biometrics or passwords areused. If the capturing of the biometric information or the passwords for user verificationtakes place on an external terminal the verification data has to be transfered to the cardusing an authenticated and secured communication channel. Even in this case skimmingof the verification data on an external terminal is a considerable security issue. Skimmingof the verification data can be principally avoided if the password is directly captured on aninput component of the smart card itself. Here, we describe a first contactless smart cardprototype with an input interface. This contactless card is equipped with an ISO 14443interface, a security controller (here smartMX [NXPb]) and in addition with a capacitive2D gesture sensor for the collection of human gestures “on-card” as well as an opticalcomponent to provide necessary feedback to the user.
The idea to integrate human input and output devices in smart cards is not quite new. In[Ull07] smart cards with an integrated display are introduced. Also [J. 09] suggested an

ID-card with a display component. Moreover, smart cards with an input interface havebeen discussed, see [VIS08] or [UV10]. The last one suggested key button componentsfor the acknowledgement of transactions on-card. [VIS08] presented the integration of anumber key pad. Novel is the integration of a gesture input component in combinationwith a feedback component, as described in this paper.
Here, we propose to use gestures “on-card” mainly for cardholder verification.
A gesture is a movement with time behaviour. A good distinction of gestures is given in[WH99] by Wu and Huang. They distinguish
1. gestures for human communication
2. gestures for human conversation
3. gestures for human interaction with virtual objects and
4. gestures used in user interfaces for the control of systems
Here, we mean gestures of the last type. First of all in a 2D scenario, a gesture can forma number and can be collected and processed on-card. But we show, that gestures are notrestricted to numbers or characters. From a theoretical perspective only the constructionof the sensor restricts the diversity of useable gestures for user authentication.
The rest of the paper is organized as follows: Section 2 starts with a description of re-lated work. A common usage of gestures is for the control of game consoles, smartphonesand touch panels. In this section known usages of gestures for human authentication arepresented. Section 3 presents the principal construction of the contactless card with a ca-pacitve gesture input component and its properties as basis for gesture recognition. Basisfor the technical presentation in this section is a first prototype which is build in cooper-ation with NXP based on requirements of the authors. The next section 4 describes the“on-card” human authentication process. In the following section 5 a brief security analy-sis is given. Finally, section 6 summarizes the findings of this paper and gives an outlineof open security issues regarding gesture authentication.
2 Related Work
Within the last 3 decades a wide variety of 2D gesture recognition algorithms have been de-veloped for many different applications on mobile devices like online handwriting recog-nition, symbolic textural input or intuitive device control. To date, it became the es-tablished usage concept for devices with touch panels, especially for smartphones, see[Pal11], [App]. As the next step current research and development activities focus on 3D-gestures recognition based on camera systems, acceleration sensors and others not only asa user interface for game consoles but as a new paradigm for human machine-interactionin general.
Gestures as authentication mechanisms were published first in [PPA04]. Patel et al. sug-gested a gesture-based authentication scheme for untrusted public terminals. Farella et al.
224 On-Card User Authentication for Smart Cards based on Gesture Recognition

proposed gestures as personal verification system for PDAs. They used biometric signa-tures based on tri-axial accelerometers integrated in the PDA, see [FOBR06]. In [KYJ+10]Ketabdar et al. proposed 3D signature gestures for user authentication of mobile phones.At last Chong et al. [CM09] discussed discrete gestures as alternative to alphanumericalcharacters in passwords, first. But they neither published a concrete alphabet nor did theypresent an entropy calculation.
A good overview of character recognization can be found in [Cha90] and [Cha98]. Asegmentation algorithm for the isolation of strokes is decribed in [MB99], [Don09] andan interesting contour feature algorithm in [Ver03]. [Thi97] specified a character recog-nition procedure which combines segmentation-based and segmentation-free recognitionmethods. [YMS+99] addresses the usage of additional velocity features for characterrecognition.
3 Hardware Concept for “On-Card” Authentication with Gesture Recog-nition
Although 2D gesture recognition is an integral part of millions of smartphones, it is stillvery challenging to develop and integrate the necessary hard- and software into a con-tactless card. Due to the general application requirements, the standardized form factorand the limited resources of a contactless card, all additional components and features aresubject to the following constraints:
• low power: The available power by field induction for all components on our pro-totype is about 50 - 70 mW.
• low profile: In order to meet the ISO-standard for the maximum thickness of a cardall components should be far less than 0.3 mm in height.
• mechanically robust: The cards still have to meet the standardized requirements formechanical flexibility and robustness. This means the whole card has to be robustagainst bending and torsion as well as dirt and splash water.
• low computing capability: Although the performance per Watt ratio and the avail-able memory of suitable microcontrollers are continuously increasing the computingcapability will always be at the very low end of the spectrum. Therefore active powermanagement as well as algorithm efficiency are essential for all software concepts.
Since our approach does not use any external hardware except the simple card reader, theproposed “on card” interface must provide all the components needed for a functional,reliable and intuitively controllable mode of operation. Desirably the operating conceptshould be as publicly acceptable as possible. Therefore we do not only need a gestureinput sensor but also a distinctive optical feedback component to inform the user about thecurrent state of the card and the success of the gesture recognition process in particular.Figure 1 depicts the necessary smart card components. In the following we describe the
On-Card User Authentication for Smart Cards based on Gesture Recognition 225

Figure 1: Configuration of our prototype smart card for “on card” authentication with the additionof a 2D touch sensor and two different optical feedback components: a 10 digits/14 segment displayand a 3x3 LED-matrix incorporated within the touch sensor area.
solution we have developed in our feasibility study that resulted in a working functionalprototype.
3.1 Construction of a 2D Gesture Sensor
In our study we found that the easiest and most reliable way to implement a 2D “on-card”gesture input sensor is the use of a capacitive touch matrix (see figure 2 and [Har]) printedon the inlay PCB (printed circuit board) of the contactless card. With an array of 4 x4 sensor pads we achieved a sensor area of 40 x 40 mm. By using an adaptation of a“center of mass” algorithm we can calculate the position of a finger-sensor contact witha resolution of around 6 - 7 bit (so between 64 and 128 distinguishable positions for eachaxis or about 80 dpi). With a sampling time per position estimate of 16 - 30 ms we supporta minimal overall speed of 0.7 characters per second for complex characters (e.g. 1.5 s toenter a “Z” or a “8”, consisting of 48 - 64 detected position samples). With fewer samplesper character higher speeds are possible.
3.2 Gesture Recognition Processing
Our prototype system is based on a standard smartMX ISO 14443 compliant communi-cation & security controller with a JavaCard2.2-operating system. However, for positiondata acquisition, filtering and the gesture recognition we needed a more flexible process-ing unit and added an Arm Cortex M0 controller [ARM11](running at 6 - 12 MHz). Thisultra low power processor has proven capable enough to recognize even complex, time
226 On-Card User Authentication for Smart Cards based on Gesture Recognition

Figure 2: Cut-away view of the layout of our prototype card. On the top layer the user can see thedisplay and the outline of the touch sensor area in combination with the 3x3 LED-matrix. On theinlay there is the draft of the printed capacitive touch sensor with holes for the back-side mountedLEDs.
dependant gestures without a noticeable delay and a feasible first detection rate of ∼ 90%(numbers and characters).
This solution can support a wide variety of the different known 2D gesture recognitionalgorithms (all the pixel-, vector- and sensor histogram based approaches mentioned insection 2) as long as they have low to moderate requirements for computational power andmemory capacity.
3.3 Optical Feedback Components
Developing display components that meet the above mentioned requirements for contact-less cards is still a topic of current research and development. In order to provide differentsolutions for the requirements of various application scenarios regarding the potential forfeedback information and cost constraints, we implemented two different concepts for op-tical user feedback.
3.3.1 Segment EInk-Display
As a very comfortable feedback component we used a 10 character, 14 segment per char-acter EInk-display [Ein11]. With this display type a very high level of user interaction ispossible: all standard characters and numbers as well as simple symbols can be shown asrequests or as feedback to the user. With such a device even an application with a complexmenu structure is possible in witch the user can navigate by using simple control gestures.Unfortunately those displays are still a little slow, relatively expensive and can not display
On-Card User Authentication for Smart Cards based on Gesture Recognition 227

Figure 3: Example for a four digits password authentication process based on number recognitionwith direct feedback provided by the display and the LED matrix
all possible gestures. Apart from the used EInk-technology there are current developmentsthat provide very cheap printable segmented displays as well as different matrix displaytypes that are suitable for the future generation of contactless cards.
3.3.2 LED Matrix
A very flexible and also a relatively inexpensive way to give gesture related feedback to theuser is a LED matrix embedded in the touch sensor area, see figure 2. Even with a minimalset of 3 x 3 LEDs (or similar/maybe printable illumination techniques) it is possible toreenact the entered user gesture, display a randomly generated gesture set to the user orgive simple position feedback while entering a gesture for a surprisingly large number ofdifferent gestures: all numbers and characters and even more symbols can be displayed asa sequence of 9 illuminated spots. If a matrix of 5 x 5 or more can be implemented, thenumber of displayable gestures increase dramatically. Additional single LEDs can also beused as fixed feedback components such as status or error signals.
4 “On-Card” Authentication
4.1 Password Authentication
An authentication procedure based on gestures is very easy to learn and similar to a normalpassword verification process. Precondition is that a contactless card and the card holder
228 On-Card User Authentication for Smart Cards based on Gesture Recognition

share a secret password. This password is chosen at random during the personalisation ofthe card and securely issued to the card holder. During a verification of the card holderhe has to input his password. Now, the user has to input the sequence of corresspondinggestures for each digit of the password, see figure 3. Therefore the user is guided by thecard itself. After each gesture input, collection and digit recognition a short feedback isgiven to the user according the detection of a known digit. After a complete gesture inputthe inserted password is compared with the reference password stored on the card. In caseof a full correlation the user authentication is successful which can be shown to the useron the display or as a specific symbol on the LED matrix.
4.2 Gesture Alphabet
Beyond the recognition of digits gesture collection components permit the collection andrecognition of arbitrary graphical inputs. The use of shared secret graphical gesturesis briefly suggested as alternative to the usage of passwords. Gestures are proposed toimprove password usebility. Graphical passwords exploit the picture superiority effect[DNW76]. Cognitive studies have shown that people can recognize graphical informationmuch better then alphanumerical [CM09]. Here, we pick up this cognitive human property.
Gesture alphabet means, that a set of basic gestures is defined similar to numbers or char-acters. In that case an individual authentication gesture consists of a sequence of elementsof the gesture alphabet just like passwords which consists of a sequence of numerical oralphanumerical characters. Figure 4 gives only a notion of possible elements of a gesturealphabet. Obviously, the set of gesture elements is much larger then the quantity of al-panumerical characters. So, the entropy of one element of the gesture alphabet is muchhigher in contrast to an element of the set of alphanumerical characters. One benefit is apossible reduction of the password length without loss of security, if a gesture alphabetis used instead of digits or alphanumerical characters. A further benefit of using secretgestures instead of numbers or characters is that the human capacity of remembering themis much better compared to numbers respective characters, as mentioned before.
In principal, gesture authentication can be done either on basis of a defined gesture alpha-bet as describe before or on individual complex gestures with high entropy. But a precisedefinition and descrition as well as an entropy consideration is not subject of this paper.
Although gestures are well known in smartphones current users of smart cards are notfamiliar with this kind of mechanism to date.
An authentication procedure is very easy and similar to a normal password verificationprocess. Now, precondition is that a contactless card and the card holder share a secretgesture. This gesture is chosen at random during the personalisation of the card and se-curely issued to the card holder. During the verification of the card holder he has to inputthe secret gesture at the gesture collection component. Next, the recogniced current gestureand the stored reference gesture are compared. In case of correlation the authentication issuccessful
On-Card User Authentication for Smart Cards based on Gesture Recognition 229

Figure 4: Examples for possible gestures on a 3 x 3 matrix. Various shapes for numbers and charac-ters are possible as well as control gestures, free-formed gestures, dotted gestures and every combi-nation of all of them
4.3 Examplary Number Insertion Process
Here, we describe a password insertion process of a password consisting of four digits,e.g. “9137”. Due to the number insertion based on gestures following situation can occur:
1. inserted digit is recognized correctly (correct recognition)
2. no digit is recognized (alikeness value of the collected gesture to each registeredreference digit is too low)
3. false digit recognition (false recognition)
Now, in contrast to the use of a pin-pad, false number recognition of an inserted numberis possible. We regard false recognition in our usage concept. In addition to digit ges-ture recognition a control gesture is defined. Here, only a horizontal stroke is specified.A human stroke gesture indicates an erasure of the last input digit. Figure 3 illustrates apassword insertion process. Here, two numbers was already recognized and covered (pic-tured as“-” and “-” in the display). Just the currently recognized gesture input is shown(“3”) by the card for a very short time. This is a necessary feedback to the user to interactif the gesture recognition of the card was not correct. In this case the user has to performa horizontal stroke to erase the last digit. If no stroke is inserted after a number recogni-tion within the time interval Δt the next digit input is requested. When the last digit ofthe password is recognized the password verification process is performed and the user isinformed of the failure or success of the password authentication.
230 On-Card User Authentication for Smart Cards based on Gesture Recognition

5 Brief Security Analysis
Here, we observe only an external attacker. So, invasive attacks of smart cards are excludedas well as side channel analysis of the number insertion on the capacitive sensor element.
5.1 Password Skimming
Today, password skimming on external terminals is a known attack for smart cards asdecribed in section 1. Insertion of passwords on-card, as proposed in this paper, prohibitsthis attack in general. But the use of gestures for the insertion of numbers raise the problemof recognition errors in contrast to the use of a key pad.
5.2 Gesture Attack
As mentioned in section 4.3, following situations can occur during a number insertion andrecognition procedure:
1. inserted digit is recognized correctly (correct recognition)
2. no digit is recognized (alikeness value of the collected gesture to each registeredreference number is too low)
3. false digit recognition (false recognition)
In principle, comparable to other defective inputs, like biometrics, false number recogni-tion is not completely avoidable. We cover this false number recognition with a feedbackconcept, as described in section 4.3. The smart cards react to each individual number in-sertion with a short feedback of the recognized number to the user. This is essential for agenuine card holder to verify that the smart card has performed a correct number recog-nition. A password verification itself is only performed after a complete insertion of apassword and not after each number insertion.
The requirement for the feedback concept is, that a false digit recognition may not allowan active attacker, who is in possession of a contactless card, to reduce the available pass-word space for an active online brute force attack of the password. We recommend that acard responds to a digit insertion with a feedback to the user without discharging any in-formation concerning the right password. That is the case if the card is in possession of anattacker, too. But a verification of the password is performed not until the whole passwordis inserted. So, an attacker can not take an advantage of a false number recognition.
On-Card User Authentication for Smart Cards based on Gesture Recognition 231

5.3 Distant Gesture Insertion
One attack method which is not yet completely investigated is the input of the passwordfrom a distance, known as pocket attack. Our smart card is equipped with a capacitivegesture input component. A finger touch of the sensor component effects a local capacitymodification which is sensed and exploited by the card. The sensor component measuresonly the described effect. In general it can not distinguish whether the capacity modifica-tion is achieved by a touch of a human finger or in a different way. A pocket attack denotesthat a contactless smart card is activated by an attacker terminal (e.g. example in a publicbus) whereas the smart card is in a users pocket and the attacker performs gesture insertionattempts. We assume that a correct password insertion is not likely. But any distance ges-ture insertion can be used to enforce wrong password verifications and disable the smartcard anyhow.
To hinder that kind of attack an additional user interaction phase randomly chosen bythe card and shown in the feedback component to the user has to be performed prior tothe password insertion. This operation can be understood as an explicite “switch-on” ofa contactless card. An attacker can not see the chosen random gesture displayed on thefeedback component. If this gesture is not inserted during a defined time interval Δt thecard is moved in a configured short sleep mode.
Here we have to point out, that an activation of a contactless card according ISO 14443is only possible within a very restricted distance between the terminal and the contact-less card, see [NXPa]. Moreover, an activation is a precondition for a gesture collectionanyway.
5.4 Latent Finger Marks
Every touch of a finger on a plane surface usually leaves latent finger prints, every swipemovement leaves tracks that can be easily made visible by an attacker to determine the lastperformed gesture. So, the described effect can appear on our cards as well. As a possiblecountermeasure we could use surface materials that repel finger marks. This techniquecan reduce this effect. Alternatively, the user should perform a swiping gesture after eachpassword insertion.
6 Conclusion
Here, we propose to enhance contactless smart cards with a 2D gesture collection com-ponent. This component is used for the insertion and recognition of human inputs. Firstof all, this component can be used for the input of digits performed as gesture. From asecurity perspective, this component can be used for human password insertion and cardholder verification on-card. Our concept prevents user to input passwords for card holderverification on external terminals. We conclude, that this technology avoids skimming of
232 On-Card User Authentication for Smart Cards based on Gesture Recognition

passwords on external input devices.
Moreover, we showed briefly that gestures as such can be used for authentication pur-poses. Here, we have only given a brief introduction to gesture authentication based onnumber gestures. But we showed that this component allows arbitrary gestures for authen-tication purposes. Only the recognition accuracy of sensor elements in combination withthe recognition algorithms restrict the complexity and number of useable gestures. Here, anew research area is arising. This includes social studies regarding the human capacity forremembering gesture based secrets and the consumer acceptance of gesture authenticationon smart cards.
As a consequence of our brief security analysis further detailed technical examinationshave to be performed by analyzing the real attack potential of side channel analysis anddistant gesture insertion.
7 Acknowledgement
We thank our colleague Christian Wieschebrink for his valuable remarks.
References
[App] Apple Computer Inc. A portable communication device with multi-touch input whichdetects one or more multi-touch contacts and motions and performs one or more oper-ations on an object based on the one or more multi-touch contacts and/or motions. USpatent, US 2007/152984.
[ARM11] ARM11. Cortex-M0 Processor, 2011. http://www.arm.com/products/processors/cortex-m/cortex-m0.php.
[Cha90] Charles C. Tappert, Ching Y. Suen and Toru Wakahara. The State of the Art in On-LineHandwriting Recognition. IEEE Transaction on Pattern Analysis and Machine Intelli-gence, 12(8), August 1990.
[Cha98] Charles C. Tappert, Ching Y. Suen and Toru Wakahara. Online handwriting recognition,a survey. In Proceedings of the 9th International Conference on Pattern Recognition,volume 2, pages 1123 – 1132, August 1998.
[CM09] Ming Ki Chong and Gary Marsden. Exploring the Use of Discrete Gestures for Au-thentication. In INTERACT 2009, International Federation for Information Processing,August 2009.
[DNW76] U.D. Reed D.L. Nelson and J.R. Walling. Picture Superiority Effect. Joural of Experi-mental Psychology: Human Learning and Memory 2, pages 523 – 528, 1976.
[Don09] Don Willems, Ralph Niels, Marcel van Gerven and Louis Vuurpijl. Iconic and multi-stroke gesture recognition. Pattern Recognition, 42(12):3303 – 3312, February 2009.
[FOBR06] Elisabetta Farell, Sile O’Modhrain, Luca Benini, and Bruno Ricco. Gesture Signaturefor Ambient Intelligence Applications: A Feature Study. In Pervasive 2006, May 2006.
On-Card User Authentication for Smart Cards based on Gesture Recognition 233

[Har] Harald Philipp. Detailed descriptions of a 2D capacitive sensor. e.g. US patent, US2005/0041018 A1.
[J. 09] J. Fischer, F. Fritze, M. Tietke and M. Paeschke. Prospects and Callenges for ID Docu-ments with Integrated Display. In Proceedings of Printed Electronics Europe Conference,2009.
[KYJ+10] Hamed Ketabdur, Kamel A. Yuksel, Amirhossein Jahnbekam, Mehram Roshandel, andDaria Skripko. MagiSign: User Identification/Authentication. In UBICOMM 2010, TheFourth International Conference on Mobile Ubiquitous Computing, Systems, Servicesand Technologies, October 2010.
[MB99] Blumenstein M. and Verma B. A new segmentation algorithm for handwritten wordrecognition . In IEEE, International Joint Conference on Neural Networks (IJCNN ’99),1999.
[NXPa] NXP Semiconductor. ISO/IEC 14443 Eavesdropping and Activation Distance, 13,56MHz Proximity Smart Cards, Application Note. Rev. 1.01, Januar 2008.
[NXPb] NXP Semiconductor. SmartMX, Smart Card Security Controller, online available at.http://www.nxp.com/products.
[Pal11] PalmSource Inc. Multiple pen stroke character set and handwriting recognition systemwith immediate response, 2011. US patent, US6493464, issued December 10, 2002.
[PPA04] Shwetak N. Patel, Jeffrey S. Pierce, and Gregory D. Abowd. A Gesture-based Authen-tication Scheme for Untrusted Public Terminals. In UIST ’04 Proceedings of the 17thannual ACM symposium on User interface software and technology, October 2004.
[Thi97] Thien M., Matthias Zimmermann and Horst Bunke. Off-Line Handwritten NumericalString Recognition By Combining Segmentation-Based And Segmentation-Free Meth-ods. Pattern Recognition, 31(3):257–272, April 1997.
[Ull07] Markus Ullmann. Flexible Visual Display Unit as Security Enforcing Component forContactless Smart Card Systems. In Firth International EURASIP Workshop on RFIDTechnology (RFID 2007), pages 87–90, 2007.
[UV10] Markus Ullmann and Matthias Vogeler. Contactless Security Token - Enhanced Securityby Using New Hardware Features in Cryptographic Based Security Mechanisms -. InAhmad-Reza Sadeghi and David Naccache, editor, Towards Hardware-Intrinsic Security.Springer, 2010.
[Ver03] Brijesh Verma. A Contour Code Feature Based Segmentation For Handwriting Recogni-tion. In Proceedings of the Seventh International Conference on Document Analysis andRecognition (ICDAR 2003), 2003.
[VIS08] VISA International. One-Time Code Card, online available at, 2008. http://www.inside-it.ch.
[WH99] Y. Wu and T.S. HuANG. Vision-based Gesture Recognition: A review. In Gesture-BasedCommunication in Human-Computer Interactions, pages 103–115, 1999.
[YMS+99] Ho-Sub Yoon, Byung-Woo Min, Jung Soh, Young-Iae Bae, and Hyun Seung Yang.Human computer interface for gesture-based editing system. In Proceedings of the Inter-national Conference on Image Analysis and Processing), pages 969 – 974, 1999.
234 On-Card User Authentication for Smart Cards based on Gesture Recognition

Triggering IDM Authentication Methods based on DeviceCapabilities Information∗
Marcus Quintino Kuhnen1, Mario Lischka2, and Felix Gomez Marmol3
[email protected] Group (R&D) GmbH, Darmstadt Germany, [email protected]
3NEC Laboratories Europe, Heidelberg Germany, [email protected]
Abstract: Identity management systems are a reality today in the Internet. Singlesign-on (SSO) systems allow users to authenticate once in the system and interact withdifferent services providers without the need for creating new accounts. However,most identity management systems only support a simple authentication mechanism,which most of the cases is based on login and password, with its well known associatedvulnerabilities like phishing attacks, for instance. In order to mitigate those drawbacksand improve the overall security of the system, we propose an enhancement of SSOsystems which allows the identity providers to dynamically choose the best authenti-cation method (e.g. fingerprint, digital certificates, smart cards, etc) being applied tothe user based on the users’ device capabilities and context information.
1 Introduction
Nowadays, fixed and mobile networks are converging and thus a new wave of servicesare being offered to the users. As a side effect, the amount of information that a user hasto manage is being steadily growing. In particular for each new service a new account iscreated and crucial personal and financial information have to be shared many times.Along the past years, various Identity Management (IdM) systems have been developedand deployed. Their technology should enable the user to easily interact with diverseservices that are being offered today, especially at the e-Commerce scope.
Users of an IdM system do not need to have a login and password for each Web Servicethey want to access when single sign-on is supported. Using this identity model, theservice provider just needs to have a trust relationship with the IdM system [GMKMP11].In this way, the authentication and authorization for the usage of the service can be alwaysmediated by the IdM system.
However, although IdM systems make things look easier from the users’ and serviceproviders’ perspective, there is a major drawback. A user-centric SSO system usuallyassumes that all data related to the user’s credentials has to be stored centralized in onesingle repository, therefore opening the doors to several types of attacks. Hence, if the
∗This paper is based on the authors work while being employed at NEC Laboratories Europe

user is victim of a phishing attack [JJJM07], for instance, the attacker will not steal onlyone password, but rather an agglomerate of private user’s data, therefore giving him ac-cess to all the user’s service accounts. In [WDRJ10] authors show that users prefer thoseauthentication methods which are better known, even when they might not be as secure asother choices. [Bri08] shows that new methods of authentication like smart cards, finger-print biometrics and converged cards have been evaluated. It also underscores the strategicvalue of solutions that can effectively deploy and manage multiple authentication methods.Thus, strong authentication and its different methods is an unquestionable feature that IdMsystems should support.
Consequently, in this paper we present an enhancement of IdM systems that enables Iden-tity Providers (IdP) with the ability of dynamically choosing the best authentication mech-anism by detecting the capabilities of the device the user is utilizing for authenticatingherself, as shown in Figure 1. These devices ranges from desktop computer and laptopsover tabloid PCs to smart phones.
Figure 1: Scenario description
The remainder of this paper is organized as follows: Section 2 describes some of thecurrent related works in this field. In Section 3 we present a use case where to apply oursolution. An overview of such solution is introduced in Section 4 and a more detaileddescription in Section 5. The application to the aforementioned use case is presented insection 6. We conclude with some final remarks in Section 7.
2 State of the Art
In current Identity Management systems such as those based on SAML, OpenID or frame-works like SASL [MZ06], the service provider specifies the authentication methods whichthe identity provider should use to authenticate the user according to its predefined poli-cies and level of assurance [BDP06]. Usually, this authentication method is indicatedas a specific authentication class. For example, the SAML core specification [OAS05a]indicates that such authentication classes enable the authentication authority and relying
236 Triggering IDM Authentication Methods based on Device Capabilities

party to come to an agreement on what are the acceptable authentication classes by givingthem a framework for negotiation [OAS05b]. In a similar manner, an extension to theOpenID protocol called OpenID Provider Authentication Policy Extension has been pro-posed [Ope07]. Nevertheless, these frameworks do not consider a further communicationwith the user equipment that could have a decisive role in the process. Moreoever, they donot provide a mechanism to adapt from weak to strong authentication depending on con-text information available, such as devices capabilities of the user and internal knowledgeabout the user (e.g. additional communication channels, list of previously provided tokens,etc.). The same is true for the service providers: they do not interact with the user in orderto choose the most appropriated method for authentication. Therefore, the choice of anauthentication method of current state of the art systems does not consider the context anddevices of the user.
Some authentication mechanisims for mobile phones have been examined in [Vap10] re-garding their resistence against certain threats. In [DSBL10] authentication and paymentmethods via web browsers are presented which utilizes QR codes that are read and anal-ysed by a smart phone, which does the final steps. In [EFJr09] presents the criteria forthe evaluation of authentication schemes in IMS, which include security, user-friendlinessand simplicity. However, the specific authentication methods provided through the phonehardware have not been taken into account.
3 Use Case
In order to highlight the importance of a dynamic authentication method considering thedevice capabilities of the user in order to trigger dynamically different authentication meth-ods, let’s consider the following scenario: A user wishing to access a service providercould have the different types of hardware capabilities to provide authentication creden-tials, e.g., finger print, ability to send SMS messages.
Based on the current state of the art [OAS05b, Ope07], a service provider prompting theuser for an authentication procedure would request for a fixed procedure based solely onits authentication policies. However, the end user might be equipped with a finger printdevice on her laptop or her mobile phone. Such devices actually allow a much more secureauthentication than login and password mechanisms, since the user is able to access theservice using her mobile phone and use additional mechanisms, e.g. SMS, for sendingtheir credentials. Alternatively, the user’s finger print could be used for authentication.
Therefore, if the service provider would have this information, it could enable a muchmore flexible mechanim to match service providers authentication policies regarding thelevel of service assurance, and what can be offered by the capabilities of the user’s devices.
Triggering IDM Authentication Methods based on Device Capabilities 237

4 Solution overview and architecture
Regarding the authentication of their users in a federated environment, the service providers(SP) interests are two-fold: one the one hand they want authentication methods in placewhich match their security needs; one the other hand the user should be able to use theirservice from a wide range of devices.
Figure 2 shows the extended authentication protocol which is utilizing the well-knownsingle-sign on pattern extended by the additional step 4, 5 and 6. Once the user equipment(UE) interacts with the IdP, the UE sends its device capabilities based on the IDP devicecapabilities request.(step 4 and 5). Based on the requirements provided by the SP in steps2 and 3 the IdP chooses the best matching authentication method (step 6) and sends thecorresponding reply to the UE (step 7). Assuming a successful authentication (step 8), theUE is then redirected to the SP with a corresponding assertion on the identity includingthe authentication method used.
Figure 2: Discovering Device Capabilities
In order to provide the necessary capablities we propose that an additional plugin is de-ployed at the UE. This signed browser plugin accesses the hardware of the device andissues the response with the device capabilities information. This plugin should, in addi-tion, enable the triggering of the right authentication method among the ones provided bythe particular device.
The decision on which authentication method is the most appropriate is controlled throughXACML policies [OAS09]. We choose this policy language since it allows us to directlyretrieve information from XML files which encode the capabilities. Moreove, it has a highexpressiveness regarding the conditions which have to be fulfilled to choose a method. Dueto the extensions in version 3, obligations provide a flexible method to trigger additionalfunctions such as authentication methods or redirects.
238 Triggering IDM Authentication Methods based on Device Capabilities

5 Solution details
In this section we will present the details of our approach regarding the encoding of thedevice capabilities, the determination of the authentication algorithm through XACMLmechanisms, and an analysis of potential threats.
5.1 Description of the device capabilities
As we already presented in [KKS+09], a device can describe its capabilities using theComposite Capabilities/Preference Profiles (CC/PP) based User Agent Profile (UAprof [Ope06])standard. This standard defines six categories of device capabilities: hardware, softwareplatform, browser user agent, Network, WAP and Push characteristics. A snapshot of thisdocument can be observed in listing 1.
Listing 1: Capability Description1 <rdf:RDF2 <rdf:Description rdf:ID="DeviceProfile" ... >3 <ccpp:component ... >4 <rdf:Description rdf:ID="HardwarePlatform" ... >5 <rdf:type rdf:resource="http://www.openmobilealliance.org/tech/
profiles/UAPROF/ccppschema-20021212#HardwarePlatform"/>6 <prf:Keyboard>yes</prf:Keyboard>7 <prf:Camera>yes</prf:Camera>8 ...9 <rdf:AuthenticationSupport>
10 <rdf:bag>11 <rdf:li>FingerPrint</rdf:li>12 <rdf:li>Smart Card</rdf:li>13 <rdf:li>Digital Certificate</rdf:li>14 <rdf:li>OTP</rdf:li>15 </rdf:bag>16 </rdf:AuthenticationSupport> ... </rdf:Description>17 </ccpp:component> ... </rdf:Description> </rdf:RDF>
Since this is a mature specification, we can rely on it for analyzing the devices’ capabilities.Moreover, we propose to enhance the RDF based device capabilities description using thenew bag <rdf:AuthenticationSupport> element, which can be further extendedto any number of authentication types. While a standardized list as the one in [OAS05b]might be used, instead of the free text in the example listing 1, additional new methodshave to be known between the UE plugin and the IdP.
This information, together with the mechanism to be described in section 5.2, can provideIdM systems with a more enhanced authentication method by allowing to personalize theauthentication process, based on users’ device and authentication capabilities.
According to the proposed extension points in SAML standard protocol we embed theRDF document in a SAML response, in reply to a SAML request issued by the IdP to theuser about her device capabilities.
Triggering IDM Authentication Methods based on Device Capabilities 239

5.2 XACML mechanism and Controlling the authentication method
The second aspect is related to the XACML policy engine [OAS09] of the Identity Provider.Based on the mechanisms of the XACML language, the selection of the authenticationmethod is based on the device’s capability descriptions shown in previous section. Thisway the best authentication mechanism available for the needs of the service provider onthe type of device that the user is currently using is selected and applied.
The policy decision point (PDP) receives a detailed request which contains all the in-formation necessary to make a decision. While we argued in [HKK+09] that the wholecapability list would be too large to be included in each request (which in that approachwas quite frequent on a number of SIP events) in this solution the situation is different,since the decision has to be made only when the user has to be authenticated at the firsttime, or a re-authentication is required due to an expiration, major-context switch, or ahigher level of authentication security is required.
Thus, instead of requesting an attribute utilized in a policy each time via the policy infor-mation point (PIP), we include the capability list in the request. According to the standard,the element ResourceContent allows the inclusion of an XML document in the re-quest sent to the decision engine. The element AttributeSelector enables the editorof a policy to refer to specific values in the XML document via XPATH expressions.
Besides the capability descriptions of the user’s device, the request contains the attributesshown in table 1, where xs-adc is just a prefix to ensure unique names. While theserviceProvider will be assigned to the access–subject category of XACML3, theother attributes are in the resource category.
AttributeID Descriptionxs-adc:serviceProvider the requesting service provider, who triggers the selectionxs-adc:authenticationLevel the level of security targeted for authenticationxs-adc:assumedUserID the identity to be authenticated, if available beforehand
Table 1: Attributes used in XACML request
In addition to the actual effect of an XACML policy (“Permit” or “Deny”), more detailedactions could be defined by adding obligations (one of the extensions of the latest XACMLversion 3) to policy sets, policies and rules. The main idea is that the obligations shouldtrigger the most appropriated authentication method according to the user’s device capa-bilities and level of assurance requested by the Service Provider. However, if such level ofassurance cannot be met by matching the device capabilities and the level of assurance, therule mechanism could express that the user should be automatically redirected to anotherIdentity Provider in the federation that can apply the requested level of assurance.
We assume that the request for authentication will be permitted in case a potential authen-tication method is available. In case no authentication method is available at the IdP whichis controlled through these policies, then the request is denied (although a redirection to adifferent IdP is additionally possible).
In addition to the permit or deny decision, the authentication method which should be
240 Triggering IDM Authentication Methods based on Device Capabilities

used has to be provided to the policy enforcement point (PEP). This is done by includingan obligation in the XACML response. We assume two types of obligations:authenticate(method) and redirect(URI, method).
The first obligation contains a unique identifier for the method to be used. The secondobligation included in the XACML response is used in case the user gets a “Deny”, inorder to forward the authentication request to another Identity Provider which is known tobe able to authenticate the user with the specific method. In case the second parameter isleft empty, then the other Identity Provider has to decide on its own which method shouldbe used.
5.3 Threats Analysis
The proposed extensions enables the user entity to influence the authentication methodchoosen by the identity provider. At a first glance this might be a new security threat incase the user entity got corrupted or the communication is unsecure. In the first case onehas to observe that the list of capabilities is always matched with the one provided by theSP, and the SP specifies what is the minimal authentication method to be used1. Thus acorrupted UE might indicate that it is only capabable to provide a very weak authenticationmethod, but if this is not acceptable, the whole authentication process will fail. Regardingcommunication security and a potential man-in-the-middle attack in order to manipulatethe capapbilities of a device, the plugin could generate a public key pair which will beused to sign its list of capabilities2.
Deploying a plugin software for the UE in a secure and trustworthy way is out of the scopeof this paper. One has to observe that the software would be (in-) directly be provided bythe IdP, to which the user has a stronger (trust) relationship, compared to other serviceproviders. Although this also implies a trustworthy PKI to be in place which has addi-tional challenges and threats, we see this as one of the preconditions not only for a securesoftware distribution in the future.
6 Application to a Use Case
As described in section 3, we could imagine a service provider requiring an authenticationmethod which is highly secure. Since the user is currently requesting the service throughher laptop a finger print reader as well as a camera providing a life picture of the userare available. Thus, the related request contains the service provider, the authenticationlevel and the device capabilities. The excerpt of a policy shown in listing 2 ensures that,depending on the available capabilities, the finger print reader is chosen, if present. If not,
1Additional signatures may ensure that no alteration is possible.2As this could be done offline, even a weak device could precompute the signature and send the signed list
without any delays
Triggering IDM Authentication Methods based on Device Capabilities 241

the OneTimePassword Token (“OTP”) authentication method is chosen3.
The rule combining algorithm first applicable (see line 1) ensures that the first match willdetermine the decision and the obligation of the rule which have to be fulfilled. The targetsection of the policy (line 2) ensures this policy is only evaluated based on a request issuedby service provider YourBank for the authentication with level3. Other service providerswill be handled by different policies. Narrowing the target of a policy ensures a betterperformance by avoiding more costly function calls used in the conditions.
Listing 2: XACML Policy1 <Policy xmlns="urn:oasis:names:tc:xacml:3.0:core:schema:wd-17"
RuleCombiningAlgId="...:rule-combining-algorithm:first-applicable" ....>2 <Target> <AnyOf> <AllOf>3 <Match MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">4 <AttributeValue DataType="...#string">YourBank</AttributeValue>5 <AttributeDesignator MustBePresent="false"
Category="urn:oasis:names:tc:xacml:1.0:subject-category:access-subject"AttributeId="xs-adc:serviceProvider" DataType="...#string"/></Match>
6 <Match MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">7 <AttributeValue DataType="...#string">level3</AttributeValue>8 <AttributeDesignator MustBePresent="false"
Category="urn:oasis:names:tc:xacml:3.0:attribute-category:resource"AttributeId="xs-adc:authenticationLeve" DataType="...#string"/></Match> </AllOf> </AnyOf> </Target>
9 <Rule Effect="Permit"... > <Target /> <Condition>10 <Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:string-is-in">11 <AttributeSelector
Category="urn:oasis:names:tc:xacml:3.0:attribute-category:resource"Path="ccpp:component/AuthenticationSupport/text()"DataType="...#string"/>
12 <AttributeValue DataType="...#string">FingerPrint</AttributeValue> </Apply> ...</Condition>
13 <ObligationExpressions>14 <ObligationExpression ObligationId="xs-adc:authentication" FulfillOn="Permit">15 <AttributeAssignmentExpression AttributeId="xs-adc:methode">16 <AttributeValue DataType="...#string">FingerReader</AttributeValue>17 </AttributeAssignmentExpression>18 </ObligationExpression> </ObligationExpressions> </Rule>19 <Rule Effect="Deny"... > <Target/> <Condition/>20 <ObligationExpressions>21 <ObligationExpression ObligationId="xs-adc:redirect" FulfillOn="Deny">22 <AttributeAssignmentExpression AttributeId="xs-adc:URI">23 <AttributeValue DataType="...#string">SecondaryIdP</AttributeValue>24 </AttributeAssignmentExpression>25 <AttributeAssignmentExpression AttributeId="xs-adc:methode">26 <AttributeValue DataType="...#string"></AttributeValue>27 </AttributeAssignmentExpression> </ObligationExpression> </ObligationExpressions>28 </Rule> </Policy>
The retrieval of the supported authentication method from the request could not be donein the target section of XACML. Thus, the bag rdf:AuthenticationSupport isselected with an XPATH expression (line 11) in the condition of the rule.
3The handling of the OneTimePassword Token (“OTP”) is not shown for simplicity.
242 Triggering IDM Authentication Methods based on Device Capabilities

The function string-is-in (line 10) checks whether the string FingerPrint is containedin the selected bag. If this condition (and potential additional ones like time constraints,etc) holds, then the related obligation (line 14) will be evaluated and returned. The methodindicated in the obligation will then be executed as step 8 in Figure 2.
The final rule (line 19) of the example policy in listing 2 ensures that the request is deniedand forwarded to another identity provider due to the obligation in line 21.
This example gives a first impression on how XACML could be used to determine theauthentication method to be used. More complex conditions like time constrains (thedesktop could not be used outside of the office hours), or checking for failed accesses, forinstance, could be easily added to the specific condition elements.
7 Conclusions
IdM systems are widely spread nowadays in the Internet due to their numerous advantagesfor both end users and service providers. One of those nice facilities is the SSO feature,allowing users to be authenticated once while having access to different services.
Yet, many web services today use the username and password as authentication method,with its known risks, like the phising attack, for instance. As a consequence an attackerobtaining the username and password of a victim will get access to several services.
But more secure authentication mechanisms like fingerprint, smart cards or digital certifi-cates are a reality too. Hence, in the paper at hand we have proposed to enhance the IdMsystems in order to dynamically choose the most appropriate authentication mechanism,based on the capabilities of the device the user is employing to authenticate herself, froma well-defined list of available authentication methods.
Our approach entails that the IdPs have to find out which are the authentication capabilitiesof the device through whom the user is requesting the service. To do so, a request is sentto the user equipment, who replies with a response, containing such capabilities describedusing the RDF language, e.g as an extension of the SAML protocol. Then, the decisionon which authentication mechanism should be finally used is taken by means of XACMLpolicies, avoiding the threat that an undermined user client is triggering only weak authen-tication methods. Depending on the application scenarios registration of the devices andtheir capabilities will allow the IdP to detect spoofed messages.
Our solution applies well known current technologies and it is therefore easy to implementand deploy. We are convinced that this solution will contribute to increase the overallsecurity in the authentication processes taking place within the IdM systems in the Internettoday.
Triggering IDM Authentication Methods based on Device Capabilities 243

References
[BDP06] William E. Burr, Donna F. Dodson, and W. Timothy Polk. Information Security.NIST, April 2006.
[Bri08] Derek E. Brink. Strong User Authentication Best-in-Class Performance at AssuringIdentities. Technical report, Abeerdeen Group, 2008.
[DSBL10] Ben Dodson, Debangsu Sengupta, Dan Boneh, and M.S. Lam. Secure, consumer-friendly web authentication and payments with a phone. In Proceedings of the SecondInternational ICST Conference on Mobile Computing, Applications, and Services(MobiCASE), 2010.
[EFJr09] Charlott Eliasson, Markus Fiedler, and Ivar Jø rstad. A Criteria-Based EvaluationFramework for Authentication Schemes in IMS. 2009 International Conference onAvailability, Reliability and Security, pages 865–869, 2009.
[GMKMP11] Felix Gomez Marmol, Marcus Q. Kuhnen, and Gregorio Martınez Perez. EnhancingOpenID through a Reputation Framework. In Autonomic and Trusted Computing,LNCS 6906, pages 1–18. 8th International Conference, ATC 2011, Springer, sep2011.
[HKK+09] Johannes Haeussler, Daniel Kraft, Marcus Kuhnen, Mario Lischka, and JochenBauknecht. Policy-based Real-time Decision-Making for Personalized Service De-livery. In IEEE International Symposium on Policies for Distributed Systems andNetworks, pages 53–59, London, UK, July, 20–22 2009. IEEE.
[JJJM07] Tom N. Jagatic, Nathaniel A. Johnson, Markus Jakobsson, and Filippo Menczer. So-cial phishing. Communications of the ACM, 50:94–100, 2007.
[KKS+09] Marcus Q. Kuhnen, Daniel Kraft, Anett Schulke, Jochen Bauknecht, Johannes Haus-sler, and Mario Lischka. Personalization-based optimization of real-time service de-livery in a multi-device environment. In WCNC, pages 3029–3034, 2009.
[MZ06] A. Melnikov and K. Zeilenga. Simple Authentication and Security Layer (SASL).RFC 4422 (Standard Tracks), June 2006.
[OAS05a] OASIS. Assertions and Protocols for the OASIS Security Assertion Markup Language(SAML) V2.0, 2005.
[OAS05b] OASIS. Authentication Context for the OASIS Security Assertion Markup Langugage(SAML) V2.0, 2005.
[OAS09] OASIS. eXtensible Access Control Markup Language (XACML) Version 3.0, April2009. Comittee Draft 1.
[Ope06] Open Mobile Alliance. User Agent Profile, February 2006. OMA-TS-UAProf-V2 020060206-A.
[Ope07] OpenID. OpenID Provider Authentication Policy Extension 1.0, 2007. Draft 7.
[Vap10] Anna Vapen. Security Levels for Web Authentication Using Mobile Phones. InSimone Fischer-Hubner, Penny Duquenoy, Marit Hansen, Ronald Leenes, andGe Zhang, editors, Privacy and Identity Management for Life, pages 130–143.Springer Berlin / Heidelberg, 2010.
[WDRJ10] Catherine S. Weir, Gary Douglas, Tim Richardson, and Mervyn Jack. Usable se-curity: User preferences for authentication methods in eBanking and the effects ofexperience. Interact. Comput., 22:153–164, May 2010.
244 Triggering IDM Authentication Methods based on Device Capabilities

Vein Pattern Recognition Using Chain Codes, SpatialInformation and Skeleton Fusing
Daniel HartungNorwegian Information Security Laboratory (NISlab)
Høgskolen i Gjøvik, Teknologivn. 22, 2815 Gjøvik, [email protected]
Anika PflugUniversity of Applied Sciences Darmstadt - CASED, Haardtring 100,
64295 Darmstadt, [email protected]
Christoph BuschNorwegian Information Security Laboratory (NISlab)
Høgskolen i Gjøvik, Teknologivn. 22, 2815 Gjøvik, [email protected]
Abstract: Vein patterns are a unique attribute of each individual and can therefore beused as a biometric characteristic. Exploiting the specific near infrared light absorptionproperties of blood, the vein capture procedure is convenient and allows contact-lesssensors. We propose a new chain code based feature encoding method, using spacialand orientation properties of vein patterns. The proposed comparison method has beenevaluated in a series of different experiments in single and multi-reference scenarioson different vein image databases. The experiments show a competitive or higher bio-metric performance compared to a selection of minutiae-based comparison methodsand other point-to-point comparison algorithms.
1 Introduction
Intended to be a robust approach for liveness detection in fingerprint and hand geome-try systems, vein recognition evolved to an independent biometric modality over the lastdecade. Classically the capturing process can be categorized as a near or a far infraredapproach. Vein recognition systems based on the near infrared approach are exploitingdifferences in the light absorption properties of the de-oxygenated blood flowing in subcu-taneous blood vessels and the surrounding tissue. Veins become visible, as seen in figure1, as dark tubular structures. They absorb higher quantities of the near infrared light, thatis commonly emitted by LEDs of the sensor, than the tissue. Alternatively in the far in-frared approach the heat radiation of the body can be measured: the temperature gradientbetween the blood vessels carrying the warm blood and the tissue can be measured in thisspectrum.
Vein scanners work contact-less, hence they are considered to be more hygienic than sys-

(a) (b)
Figure 1: Finger / wrist vein samples images from: (a) GUC45; (b) UC3M database.
tems requiring direct physical contact.
Vein patterns evolve during the embryonic vasculogenesis, hence their final structure ismostly influenced by random factors [EYM+05]. Even though scientific research aboutthe uniqueness of vein patterns is sparse, many sources state that vein patterns are uniqueamong individuals. Because the network of blood vessels is located underneath the skin,a person’s individual vein pattern is hard to forge. Furthermore, it is expected, that theposition of veins is constant over a whole lifetime [DRC06]. Offering the same user con-venience as fingerprints while being highly secure against forging, vein recognition hasbeen applied in various fields of authentication and access control during the last yearssuch as ATMs or airports.
Still vein recognition faces challenges: limitations in capturing in vivo images from theinside of the body, as well as ambient sunlight, temperature and varying skin propertieslike the pigmentation, or the thickness influence the image quality. As a result of all thesefactors the raw images can have a low contrast, contain strong noise and a non-uniformbrightness. Sophisticated algorithms for the preprocessing like contrast enhancement andsegmentation as well as the final feature extraction and comparison are necessary to handlethe variations and the noise. In this paper we contribute a new chain code based featureextraction method and investigate its performance in combination with fusion techniquesof image skeletons. The fusion aims at enhancing the biometric performance and therobustness against noise induced by errors during the preprocessing phase. Our approachis compared with minutiae-based feature extraction and a state-of-the-art holistic directcomparison approach.
After giving an overview over previously done work in section 2, we introduce two tech-niques for skeleton fusion at feature level. We introduce our chain code based featureextraction method in section 4 and present our experimental setup as well as the results insections 5 and 6. Finally conclusions and future work can be found in section 7.
2 Related Work
Since the first suggestion of using the blood vessel network as a biometric characteris-tic was made, a large number of different techniques for extracting and comparing vein
246 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

patterns have been proposed. In [KK09] and [WZYZ06] Principal Component Analysis(PCA) is used for classification of vein patterns. Another statistical approach is presentedby Xueyan et al. [XS08], who use moment invariants as descriptors for the layout of bloodvessels in vein images.
Hartung et al. [HOXB11] apply spectral minutiae to vein pattern recognition. In theapproach, which has originally been developed for feature representation in fingerprintimages [XV08], the coordinates of minutiae points are transformed into the frequencydomain and mapped in a polar-logarithmic grid. This representation is translations andscale invariant; rotations become translations. For comparison the spectra are shifted andcompared at a correlation basis (SMLFR). Instead of comparing the minutiae locationsWang et al. computes the distances between all minutiae for feature extraction [WZYZ06].
In [WLC07] the bifurcation points of vein patterns are interpreted as endpoints of line seg-ments. The line segments are then compared separately to each other and the similarity oftwo vein patterns is expressed by the line segment Hausdorff distance. in a later approachWang et al. propose to apply the modified Hausdorff distance (MHD) to vein minutiae in[WLC08], where a perfect discrimination of the far infrared data could be achieved.
In the approach proposed by Chen et al. two comparison algorithms are proposed [CLW09].The goal is to make direct comparison algorithms more robust against rotation. Thereforefirst an algorithm called Similarity-based mix-matching is proposed (SMM), which com-pares segmented images and image skeletons with each other. Because the segmented ver-sion of an image is more tolerant to outliers, the approach tolerates small rotations. Theyalso propose a modified version of ICP where the registration error is used as a similaritymeasure.
In 2003 Miura et al. have proposed a method called repeated line tracking, which tracksthe course of veins by tracking dark structures in the images from randomly chosen startingpoints [MNM04]. Yang et al. present a modified version of repeated line tracking whichuses the information gathered during line following for deriving a probability map forvein location [YXL09]. Miura et al. [MNM07] outline another algorithm for vein patternextraction, which exploits local differences in brightness. The algorithm is based on theassumptions, that veins are thick, dark tubular structures and detect local minimums ofgrey values.
3 Skeleton Fusing
In our approach skeletal images are the basis for feature extraction. Because of noiseand poor contrast, these skeletons will differ, even though they are generated from thesame biometric source. In order to improve their reliability and hence the reliability of theextracted features, we propose two different approaches for fusing multiple skeletons intoa single one.
Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing 247

(a) (b) (c)
Figure 2: Fusion based on unification (GUC45 samples) using n = 3 input skeletons: (a) super-imposed structure Suni1 ; (b) disk-shape structuring element dilated structure Suni2 ; (c) final unifiedskeleton Suni.
(a) (b) (c)
Figure 3: Fusion based on intersection (GUC45 samples) with n = 5 input skeletons and thresholdt = 3: (a) dilated density structure S int2 ; (b) S int3 (threshold t applied to segment S int2 ); (c) finalintersection skeleton S int.
3.1 Unified Skeleton
The first approach takes n input skeletons from the same biometric source and computes aunified skeleton based on the input. In a first step, all input skeletons Si(x, y) are alignedwith each other using the Iterative Closest Points algorithm (ICP) [RL01] and then super-imposed to a common structure Suni (Fig. 2(a)):
Suni1(x, y) = ∪ni=1Si(x, y) (1)
The registered input skeletons are fused by dilating the superimposed binary image Suni1
with a disk-shaped structuring element (Fig. 2(b)) to get Suni2 . Afterwards the fast march-ing skeletonization algorithm [TvW02] is applied to the dilated image in order to createthe unified skeleton Suni (Fig. 2(c)).
3.2 Intersected Skeleton
The second proposed algorithm creates an intersected skeleton, which possesses only thosefeatures which occur in at least t of the n input skeletons. An example for skeleton inter-section with n = 5 input skeletons is illustrated in Figure 3. The intersected skeletonin Figure 3 consists of the lines which occur in at least three of the five input skeletons(t = 3).
Similarly to the unification approach, the input skeletons Si need to be aligned to eachother. Afterwards each of the n input skeletons is dilated with a disk-shaped structuringelement, creating binary structures Sint1 . These dilated skeletons are then added up to forma common unified density structure called Sint2 .
248 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

Sint2(x, y) =n∑
i=1
Sint1i (x, y) (2)
Sint2 contains values between 0 and n at each location (x, y). The interpretation: Sint2(x, y)represents the number of skeletons that are classified as veins in location (x, y) for the in-put skeletons – all input skeletons have a pixel that is classified as vein in case of Sint2 = nand none if it is equal to 0.
Now a threshold value t with 1 ≤ t ≤ n is applied to Sint2 resulting in Sint3 . In this stepall pixels which at least occur t times in the input skeletons are kept, all other pixels areset to zero.
Sint3(x, y) =
{1 if Sint2 ≥ t0 else (3)
Finally the fast marching skeletonization is applied [TvW02], which results in the inter-sected skeleton Sint.
4 Chain Code Comparison
Similarities between two image skeletons can be determined by measuring the relativepositions of the skeleton lines as well as their relative orientation. Two lines, which areparallel should be considered to be more similar than two non-parallel skeleton lines. Theproposed feature extraction uses the position of each pixel on a skeleton line in combina-tion with its local orientation reflected by the chain code value. Thus the algorithm findsassociated points between the probe and the reference skeleton and measures it parallelism.
4.1 Preliminaries and Assignment
However before chain code values can be assigned to an image skeleton, some preliminar-ies have to be met. In a first step the probe and the reference skeleton have to be alignedwith each other. As for skeleton fusion, we used ICP for skeleton alignment. Moreoverall points where veins split up (bifurcations) have to be removed from the image skeletonin order to avoid ambiguities. These points are extracted with a fast convolution method[OHBL11] resulting in separated line elements.
To make sure all chain codes refer to a common starting point, a reading direction hasto be defined. In our work, the chain code feature extraction module iterates over eachpixel (x, y) of the skeleton starting from the bottom left corner of each line element andends at the top right corner. Chain codes extracted from the same shape with differentcoordinates will be identical. Each skeleton pixel is assigned a chain code value accordingto the relative position of its successor, which is equivalent to the next skeleton pixel hit
Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing 249

when moving along the reading direction (see Figure 4). All skeletons are defined as8-connected structures.
4.2 Comparison
After the chain code assignment for the reference and the probe, the similarity betweentwo aligned chain codes C and C ′ can be calculated. The algorithm tries to find pairs ofassociated points in the reference and the probe. All skeleton points of the reference areused for the comparison in the following way: a search direction is defined for a skeletonpixel at (x, y) of the reference. It is orthogonal to the direction of the local orientationwhich is approximated by the chain code value stored at the examined point.
Starting from the same position (x, y) in the probe, the search for associated pixels stops ifeither an associated point could be found in the search direction or if the maximum searchdepth dmax is exceeded. When a pair of associated skeleton points has been found, theirsimilarity is calculated based on their euclidean distance d and the chain code differencec, where (x, y) and (x′, y′) are the coordinates of the two associated points and C(x, y)and C ′(x′, y′) are their chain code values.
d =√
|x− x′|2 + |y − y′|2, and (4)
c = |C(x, y)− C ′(x′, y′)|2 (5)
The local error E at point (x, y) is then calculated as follows:
E(x, y) =d+ c
Emax,with (6)
Emax = dmax + cmax (7)
The values for dmax and cmax denote the maximum search depth and the maximum pos-sible difference between two chain code values. Following Equation 5 and the schemesketched in Figure 4, cmax = 82 = 64. The local error is stored at position (x, y) in anerror map E, which has the same size as the input images.
The assignment of associated points is not commutative and therefore the order of thetwo input skeletons leads to different results(probe/reference). Starting with the referenceskeleton and searching for an associated pixel in the probe skeleton, a different pixel paircan be identified as the other way around. This is handled by computing two error mapsE1 and E2. E1 contains all local errors calculated by using C as reference and C ′ as probeskeleton and E2 contains all local error using C ′ as probe and C as reference, respectively.The total error map Etotal is the sum of local errors for each point in the skeleton imagesand is computed as follows:
Etotal(x, y) = E1(x, y) + E2(x, y) (8)
250 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

5C
79
31(x, y+1) (x+1, y+1)
(x+1, y)
(x+1, y-1)(x, y-1)
(x, y)
X
Y
(a)
3
3
5 3
3
1
3
5 7
5 ...
... 35
3
3
3
7
5 ...
...
C
C (b)
Figure 4: Chain code extraction scheme and search procedure for finding associated pixels.
Similarly the error map for the maximum possible error Elimbetween the current imagepair E1 and E2 is the sum of the maximum error values at each pixel in the skeletonimages.
Elim(x, y) = E1max(x, y) + E2max(x, y) (9)
Finally the normalized similarity score of the comparison is defined as:
Score = 1−∑
x
∑y Etotal(x, y)∑
x
∑y Elim(x, y)
(10)
An example of how a point pair can be found by using the local chain code value is shownin Figure 4(b). The algorithm starts at the boldly bordered point in C and searches inorthogonal direction for a corresponding point in C ′. After two mated points have beenidentified, their local error, which is a value between 0 (no error) and 2 (maximum error)is calculated. The global distance measure between all points in C and C ′ is, as statedbefore, the weighted sum of all local errors.
5 Experimental setup
The influence of using different feature extraction and comparison strategies including theproposed chain code based algorithm was measured using the Equal Error Rate (EER).Further, the influence of the proposed skeleton fusion techniques is quantified during thesimulations.
Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing 251

5.1 Datasets
In the experiments two different vein databases were used. In both cases the imageswere captured with a CCD-camera and illuminated with NIR light at a wavelength of850nm. The GUC45 dataset contains finger vein images from 45 data subjects collectedat Gjøvik University College in Norway over a long period of time. Each finger, includ-ing the thumbs, was captured two times during each of the 12 sessions, which results in10800 unique vein images in total. The image from GUC45 suffer from low contrast andhigh noise, which makes it hard for any algorithm to extract stable skeletons and henceto achieve a low error rate on this data. However this fact makes the images particularlyinteresting for research purposes as it allows for exploring the limitations of any algorithmfor feature extraction and comparison.
The second database, called UC3M, consists of wrist vein images, which were collectedas described in [PJUA+10]. The focus of this experiment was to evaluate the effect ofdifferent illumination intensities on the visibility of veins. For each of the 29 users, 6images were taken for each hand under three different illumination settings. This resultsinto 348 images in total.
5.2 Preprocessing
The preprocessing stage consists of three steps, namely image enhancement, segmentationand skeletonization. During image enhancement, noise should be removed and at thesame time image contrast should be enhanced. In order to meet both criteria, differentmethods are combined. In a first step, the vein images are enhanced with adaptive non-local means as proposed by Struc and Pavesic [SP08] followed by non-linear diffusion fornoise suppressing and edge enhancement [wei01].
The image enhancement step is followed by a segmentation step. In order to evaluate, ifthere is an image segmentation method, which is particularly suitable for segmenting veinimages, three different segmentation methods have been benchmarked. The first of thesemethods is Otsu’s histogram-based segmentation [Ots79]. Additionally the active contoursalgorithm proposed by Chan and Vese [CV01] and the multi-scale filter method by Frangiet al. [FNVV98] have been tested on the vein images.
Preprocessing is concluded by the skeletonization approach proposed by Telea and vanWijk [TvW02]. The advantage of this method is the built-in skeleton pruning, whichallows cutting off small, noisy branches of the image skeleton.
5.3 Feature Extraction & Setup
All experiments were conducted on the basis of a modular vein verification system imple-mented in MATLAB. The benchmark system allows for arbitrary combinations of different
252 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

(a) (b)
Figure 5: (ROC curves for (a) selection of feature extraction algorithms and (b) Fused Union con-figuration, different finger samples from GUC45 dataset. Finger indices are assigned according tothe ISO-standard [ISO05] with indices 1 until 5 for the right hand fingers in indices 6 until 10 forthe left hand fingers, where counting always starts from the thumbs.
preprocessing, feature extraction and comparison modules. We evaluated the performanceof spectral minutiae (SMLFR) as proposed in [HOXB11], Similarity-based Mix-Matching(SMM) [CLW09] and the performance of chain code comparison on single references andfused skeletons. In all experiments using fusion techniques, the fused skeleton served asthe reference image and a skeleton extracted from one vein image was used as the probeimage.
6 Results
In our experiments, the segmentation algorithms came to slightly different performanceresults, but had a minor effect on the overall system’s performance. The measured per-formance difference between the different segmentation algorithms is less than 2% pointsin terms of the EER. The main difference between the evaluated segmentation approacheswas in terms of computation time, however the approach by Frangi and Niessen performedslightly better on the UC3M dataset.
In contrast to the preprocessing step, the impact of the feature extraction and comparisonmethod is significant. We evaluated the performance of spectral minutiae (SMLFR) asproposed in [HOXB11], Similarity-based Mix-Matching (SMM) [CLW09] and the per-formance of chain code comparison on single references and fused skeletons. Table 1summarized the performance measures for each of the datasets. The results for GUC45were obtained using Otsu’s segmentation algorithm, whereas the EER measures on UC3Mare based on Frangi and Niessen’s filter-based approach.
As stated before, the images in GUC45 have a particularly low contrast and therefore can-
Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing 253

Comparison Algorithm GUC45 UC3M
Chain Codes 28.72 1.38Fused Union 24.67 0.63Fused Intersect t=2, n=3 34.19 0.69Fused Intersect t=3, n=5 32.85 NAFused Intersect t=5, n=7 34.30 NASMM 27.84 1.38SMLFR 40.25 5.90
Table 1: Benchmark results (EER in %) for finger vein (GUC45) and wrist images (U3CM). NA:not possible due to limited number of samples per source.
not be expected to give good biometric performance. However, GUC45 is a challengefor all tested algorithms. In addition, it also contains multiple samples per subject. Theresults of the different feature extraction and comparison approaches on GUC45 are sum-marized in Figure 5. The best performance could be achieved with chain code comparisonusing unified skeletons as reference samples and skeletons derived from only one imageas probes. This configuration was named Fused Union and with an EER of 24.67% it out-performed all other configurations including SMM, but also single reference chain codecomparison. This shows that already a simple skeleton fusing approach like the proposedone, enhances the quality of image skeletons and improves the system performance signif-icantly.
Further investigations on the performance of Fused Union for each finger on GUC45showed, that the fingers of the left hand performed better than the right hand fingers (seeFigure 5(b)). In our experiments, the highest error rate was measured with images fromthe thumbs (Fingers indices 1 and 6). The EER of configurations using intersected skele-tons gets higher the more input skeletons are used. A reason for this could be that unstableskeletons have only few intersecting parts, which results in fused skeletons with low com-plexity. Less details however mean less distinctive power and results in increasing errorrates.
For the UC3M dataset an excellent biometric performance could be measured without theskeleton fusion techniques proposed. SMM and the chain code algorithm perform at thesame level (around 1% EER). Skeleton fusion could reduce the EER to 0.63%, whereasskeleton intersection with n = 3 and t = 2 yielded in a slightly higher EER of 0.69%.
7 Conclusion and Future Work
The proposed chain code algorithm as well as the state of the art SMM algorithm performvery similar on the chosen datasets, it seems the quality of the images is a limiting factorhere. Only a multi-reference approach could further improve the results.
Even though the proposed comparison on Fused Union skeletons showed promising re-
254 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

sults, the algorithm’s time wise performance is not impressive compared to other featureextraction and comparison algorithms. Future work focuses on reducing the required com-puting time by replacing the pixel-based chain code extraction with a convolution-basedapproach and by selecting less reference points for skeleton registration and comparison.Further improvements could also be made by using a different error functions to make itless sensitive to single outliers and more sensitive to mismatching line segments. More-over, additional simulations on different vein datasets will also show the feasibility of theapproach for different vein modalities.
In summary the combination of spacial information and chain codes proved to be an in-teresting new technique, which combines the robustness and simplicity of holistic com-parison methods with information about the local orientation of vein patterns. On theselection of vein data, chain code comparison performed competitive to state of the artholistic methods like SMM and superior to minutiae-based comparison (SMLFR). It canbe easily extended to a multi-reference scenario: on the proposed Fused Union skeletonsthe performance is superior to the other algorithms.
References
[CLW09] Haifen Chen, Guanming Lu, and Rui Wang. A New Palm Vein Method Based on ICPAlgorithm. In International Conference on Informaion Systems, November 2009.
[CV01] Tony F. Chan and Luminiatia Vese. Active Contours Without Edges. IEEE Transactionson Image processing, 10(2):266–277, February 2001.
[DRC06] Reza Derakhshani, Arun Ross, and Simona Crihalmeanu. A New Biometric Modal-ity Using Concunctival Vasculature. In Proceedings of Artificial Neural Networks inEngineering, November 2006.
[EYM+05] Anne Eichmann, Li Yuan, Delphine Moyon, Ferdinand Lenoble, Luc Pardanaud, andChinstiane Breant. Vascular Development: From Precursor Cells to Branched Arterialand Venous Networks. International Journal of Developmental Biology, 49:259–267,2005.
[FNVV98] Ro F. Frangi, Wiro J. Niessen, Koen L. Vincken, and Max A. Viergever. MultiscaleVessel Enhancement Filtering. In Medical Image Computing and Computer-AssistedInterventation, pages 130–137. Springer-Verlag, 1998.
[HOXB11] Daniel Hartung, Martin Aastrup Olsen, Haiyun Xu, and Christoph Busch. SpectralMinutiae for Vein Pattern Recognition. In The IEEE International Joint Conference onBiometrics (IJCB), 2011.
[ISO05] ISO/IEC 19795-1:2006 Information Technology Biometric Data Interchange Formats- Part 2: Finger Minutiae Data, March 2005.
[KK09] Maleika Heenaye-Mamode Khan and Naushad Mamode Khan. Feature Extraction ofDorsal hand- Vein Pattern Using a Fast Modified PCA Algorithm Based on CholeskyDecomposition and Lanczos Technique. International Journal of Mathematical andComputer Sciences, 5(4):230–234, 2009.
Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing 255

[MNM04] Naoto Miura, Akio Nagasaka, and Takafumi Miyatake. Feature Extraction of Finger-vein Patterns Based on Repeated Line Tracking and its Application to Personal Identi-fication. Machine Vision and Applications, 15:194–203, Juli 2004.
[MNM07] Naoto Miura, Akio Nagasaka, and Takafumi Miyatake. Extraction of Finger-Vein Pat-terns Using Maximum Curvatire Points in Image Profiles. IEICE - Transactions onInformation and Systems, E90-D(8):1185–1194, August 2007.
[OHBL11] Martin Aastrup Olsen, Daniel Hartung, Christoph Busch, and Rasmus Larsen. Con-volution Approach for Feature Detection in Topological Skeletons Obtained from Vas-cular Patterns. In IEEE Symposium Series on Computational Intelligence 2011, Apr2011.
[Ots79] Nobuyuki Otsu. A Threshold Selection Method from Grey-Level Histograms. Systems,Man and Cybernetics, IEEE Transactions, 9:62–66, January 1979.
[PJUA+10] Suarez Pascual, J.E., Uriarte-Antonio, J., Sanchez-Reillo, R., and M.G. Lorenz. Captur-ing Hand or Wrist Vein Images for Biometric Authentication Using Low-Cost Devices.In Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), 2010Sixth International Conference on, pages 318 –322, october 2010.
[RL01] Szymon Rusinkiewicz and Marc Levoy. Efficient Variants of the ICP Algorithm. Tech-nical report, Stanford University, 2001.
[SP08] Vitomir Struc and Nikola Pavesic. Illumination Invariant Face Recognition by Non-local Smoothing. In Proceedings of the BIOID Multicomm, September 2008.
[TvW02] Alexandru Telea and Jarke J. van Wijk. An Augmented Fast Marching Method forComputing Skeletons and Centerlines. In Joint Eurographics - IEEE TCVG Symposiumon vizalization, 2002.
[wei01] Applications of Nonlinear Diffusion in Image Processing and Computer Vision, volumeVol. LXX. Acta Math. Univ. Comenianae, 2001.
[WLC07] L. Wang, G. Leedhm, and S.-Y. Cho. Infrared imaging of Hand Vein Patterns forBiometric Purposes. IET computer vision, 1(3):113–122, 2007.
[WLC08] Lingyu Wang, Graham Leedham, and David Siu-Yeung Cho. Minutiae feature analysisfor infrared hand vein pattern biometrics. Pattern Recognition, 41(3):920 – 929, 2008.Part Special issue: Feature Generation and Machine Learning for Robust MultimodalBiometrics.
[WZYZ06] Kejun Wang, Yan Zhang, Zhi Yuan, and Dayan Zhuang. Hand Vein Recognition Basedon Multi Supplemental Features of Multi-Classifier Fusion Detection. In InternationalConference on Mechatronics and Automation, June 2006.
[XS08] Li Xueyan and Guo Shuxu. Pattern Recognition Techniques: Technology and Applica-tions, chapter The Fourth Biometric, page 626 ff. I-Tech, 2008.
[XV08] Hauyun Xu and Raymond N.J. Veldhius. Spectral Minutae: A Fixed-length Represen-tation of a Minutae Set. In IEEE Computer Society Conference on Computer Visionand Pattern Recognition Workshops, pages 1–6, 2008.
[YXL09] Wenming Yang, Xiang Xu, and Quingmin Liao. Personal Authentication Unsing FingerVein Patterns and Finger-Dorsa Texture Fusion. In MM ’09 Proceedings of the 17thACM international conference on Multimedia, 2009.
256 Vein Recognition Using Chain Codes, Spatial Information and Skeleton Fusing

P-1 GregorEngels,AndreasOberweis,AlbertZündorf(Hrsg.):Modellierung2001.
P-2 MikhailGodlevsky,HeinrichC.Mayr(Hrsg.):InformationSystemsTechnologyanditsApplications,ISTA’2001.
P-3 AnaM.Moreno,ReindP.vandeRiet(Hrsg.):ApplicationsofNaturalLan-guagetoInformationSystems,NLDB’2001.
P-4 H.Wörn,J.Mühling,C.Vahl,H.-P.Meinzer(Hrsg.):Rechner-undsensor-gestützteChirurgie;WorkshopdesSFB414.
P-5 AndySchürr(Hg.):OMER–Object-OrientedModelingofEmbeddedReal-TimeSystems.
P-6 Hans-JürgenAppelrath,RolfBeyer,UweMarquardt,HeinrichC.Mayr,ClaudiaSteinberger(Hrsg.):UnternehmenHoch-schule,UH’2001.
P-7 AndyEvans,RobertFrance,AnaMoreira,BernhardRumpe(Hrsg.):PracticalUML-BasedRigorousDevelopmentMethods–CounteringorIntegratingtheextremists,pUML’2001.
P-8 ReinhardKeil-Slawik,JohannesMagen-heim(Hrsg.):InformatikunterrichtundMedienbildung,INFOS’2001.
P-9 JanvonKnop,WilhelmHaverkamp(Hrsg.):InnovativeAnwendungeninKommunikationsnetzen,15.DFNArbeits-tagung.
P-10 MirjamMinor,SteffenStaab(Hrsg.):1stGermanWorkshoponExperienceMan-agement:SharingExperiencesabouttheSharingExperience.
P-11 MichaelWeber,FrankKargl(Hrsg.):MobileAd-HocNetzwerke,WMAN2002.
P-12 MartinGlinz,GüntherMüller-Luschnat(Hrsg.):Modellierung2002.
P-13 JanvonKnop,PeterSchirmbacherandViljanMahni_(Hrsg.):TheChangingUniversities–TheRoleofTechnology.
P-14 RobertTolksdorf,RainerEckstein(Hrsg.):XML-TechnologienfürdasSe-manticWeb–XSW2002.
P-15 Hans-BerndBludau,AndreasKoop(Hrsg.):MobileComputinginMedicine.
P-16 J.FelixHampe,GerhardSchwabe(Hrsg.):MobileandCollaborativeBusi-ness2002.
P-17 JanvonKnop,WilhelmHaverkamp(Hrsg.):ZukunftderNetze–DieVerletz-barkeitmeistern,16.DFNArbeitstagung.
P-18 ElmarJ.Sinz,MarkusPlaha(Hrsg.):ModellierungbetrieblicherInformations-systeme–MobIS2002.
P-19 SigridSchubert,BerndReusch,NorbertJesse(Hrsg.):Informatikbewegt–Infor-matik2002–32.JahrestagungderGesell-schaftfürInformatike.V.(GI)30.Sept.-3.Okt.2002inDortmund.
P-20 SigridSchubert,BerndReusch,NorbertJesse(Hrsg.):Informatikbewegt–Infor-matik2002–32.JahrestagungderGesell-schaftfürInformatike.V.(GI)30.Sept.-3.Okt.2002inDortmund(Ergänzungs-band).
P-21 JörgDesel,MathiasWeske(Hrsg.):Promise2002:ProzessorientierteMetho-denundWerkzeugefürdieEntwicklungvonInformationssystemen.
P-22 SigridSchubert,JohannesMagenheim,PeterHubwieser,TorstenBrinda(Hrsg.):Forschungsbeiträgezur“DidaktikderInformatik”–Theorie,Praxis,Evaluation.
P-23 ThorstenSpitta,JensBorchers,HarryM.Sneed(Hrsg.):SoftwareManagement2002–FortschrittdurchBeständigkeit
P-24 RainerEckstein,RobertTolksdorf(Hrsg.):XMIDX2003–XML-TechnologienfürMiddleware–Middle-warefürXML-Anwendungen
P-25 KeyPousttchi,KlausTurowski(Hrsg.):MobileCommerce–AnwendungenundPerspektiven–3.WorkshopMobileCommerce,UniversitätAugsburg,04.02.2003
P-26 GerhardWeikum,HaraldSchöning,ErhardRahm(Hrsg.):BTW2003:Daten-banksystemefürBusiness,TechnologieundWeb
P-27 MichaelKroll,Hans-GerdLipinski,KayMelzer(Hrsg.):MobilesComputinginderMedizin
P-28 UlrichReimer,AndreasAbecker,SteffenStaab,GerdStumme(Hrsg.):WM2003:ProfessionellesWissensmanagement–Er-fahrungenundVisionen
P-29 AntjeDüsterhöft,BernhardThalheim(Eds.):NLDB’2003:NaturalLanguageProcessingandInformationSystems
P-30 MikhailGodlevsky,StephenLiddle,HeinrichC.Mayr(Eds.):InformationSystemsTechnologyanditsApplications
P-31 ArslanBrömme,ChristophBusch(Eds.):BIOSIG2003:BiometricsandElectronicSignatures
GI-Edition Lecture Notes in Informatics

P-32 PeterHubwieser(Hrsg.):InformatischeFachkonzepteimUnterricht–INFOS2003
P-33 AndreasGeyer-Schulz,AlfredTaudes(Hrsg.):Informationswirtschaft:EinSektormitZukunft
P-34 KlausDittrich,WolfgangKönig,AndreasOberweis,KaiRannenberg,WolfgangWahlster(Hrsg.):Informatik2003–InnovativeInformatikanwendungen(Band1)
P-35 KlausDittrich,WolfgangKönig,AndreasOberweis,KaiRannenberg,WolfgangWahlster(Hrsg.):Informatik2003–InnovativeInformatikanwendungen(Band2)
P-36 RüdigerGrimm,HubertB.Keller,KaiRannenberg(Hrsg.):Informatik2003–MitSicherheitInformatik
P-37 ArndtBode,JörgDesel,SabineRath-mayer,MartinWessner(Hrsg.):DeLFI2003:e-LearningFachtagungInformatik
P-38 E.J.Sinz,M.Plaha,P.Neckel(Hrsg.):ModellierungbetrieblicherInformations-systeme–MobIS2003
P-39 JensNedon,SandraFrings,OliverGöbel(Hrsg.):IT-IncidentManagement&IT-Forensics–IMF2003
P-40 MichaelRebstock(Hrsg.):ModellierungbetrieblicherInformationssysteme–Mo-bIS2004
P-41 UweBrinkschulte,JürgenBecker,Diet-marFey,Karl-ErwinGroßpietsch,Chris-tianHochberger,ErikMaehle,ThomasRunkler(Edts.):ARCS2004–OrganicandPervasiveComputing
P-42 KeyPousttchi,KlausTurowski(Hrsg.):MobileEconomy–TransaktionenundProzesse,AnwendungenundDienste
P-43 BirgittaKönig-Ries,MichaelKlein,PhilippObreiter(Hrsg.):Persistance,Scalability,Transactions–DatabaseMe-chanismsforMobileApplications
P-44 JanvonKnop,WilhelmHaverkamp,EikeJessen(Hrsg.):Security,E-Learning.E-Services
P-45 BernhardRumpe,WofgangHesse(Hrsg.):Modellierung2004
P-46 UlrichFlegel,MichaelMeier(Hrsg.):DetectionofIntrusionsofMalware&VulnerabilityAssessment
P-47 AlexanderProsser,RobertKrimmer(Hrsg.):ElectronicVotinginEurope–Technology,Law,PoliticsandSociety
P-48 AnatolyDoroshenko,TerryHalpin,StephenW.Liddle,HeinrichC.Mayr(Hrsg.):InformationSystemsTechnologyanditsApplications
P-49 G.Schiefer,P.Wagner,M.Morgenstern,U.Rickert(Hrsg.):IntegrationundDaten-sicherheit–Anforderungen,KonflikteundPerspektiven
P-50 PeterDadam,ManfredReichert(Hrsg.):INFORMATIK2004–Informatikver-bindet(Band1)Beiträgeder34.Jahresta-gungderGesellschaftfürInformatike.V.(GI),20.-24.September2004inUlm
P-51 PeterDadam,ManfredReichert(Hrsg.):INFORMATIK2004–Informatikver-bindet(Band2)Beiträgeder34.Jahresta-gungderGesellschaftfürInformatike.V.(GI),20.-24.September2004inUlm
P-52 GregorEngels,SilkeSeehusen(Hrsg.):DELFI2004–Tagungsbandder2.e-LearningFachtagungInformatik
P-53 RobertGiegerich,JensStoye(Hrsg.):GermanConferenceonBioinformatics–GCB2004
P-54 JensBorchers,RalfKneuper(Hrsg.):Softwaremanagement2004–OutsourcingundIntegration
P-55 JanvonKnop,WilhelmHaverkamp,EikeJessen(Hrsg.):E-ScienceundGridAd-hoc-NetzeMedienintegration
P-56 FernandFeltz,AndreasOberweis,BenoitOtjacques(Hrsg.):EMISA2004–Infor-mationssystemeimE-BusinessundE-Government
P-57 KlausTurowski(Hrsg.):Architekturen,Komponenten,Anwendungen
P-58 SamiBeydeda,VolkerGruhn,JohannesMayer,RalfReussner,FranzSchweiggert(Hrsg.):TestingofComponent-BasedSystemsandSoftwareQuality
P-59 J.FelixHampe,FranzLehner,KeyPousttchi,KaiRanneberg,KlausTurowski(Hrsg.):MobileBusiness–Processes,Platforms,Payments
P-60 SteffenFriedrich(Hrsg.):Unterrichtskon-zeptefürinforrmatischeBildung
P-61 PaulMüller,ReinhardGotzhein,JensB.Schmitt(Hrsg.):Kommunikationinver-teiltenSystemen
P-62 Federrath,Hannes(Hrsg.):„Sicherheit2005“–Sicherheit–SchutzundZuver-lässigkeit
P-63 RolandKaschek,HeinrichC.Mayr,StephenLiddle(Hrsg.):InformationSys-tems–TechnologyandistApplications

P-64 PeterLiggesmeyer,KlausPohl,MichaelGoedicke(Hrsg.):SoftwareEngineering2005
P-65 GottfriedVossen,FrankLeymann,PeterLockemann,WolffriedStucky(Hrsg.):DatenbanksystemeinBusiness,Techno-logieundWeb
P-66 JörgM.Haake,UlrikeLucke,DjamshidTavangarian(Hrsg.):DeLFI2005:3.deutschee-LearningFachtagungInfor-matik
P-67 ArminB.Cremers,RainerManthey,PeterMartini,VolkerSteinhage(Hrsg.):INFORMATIK2005–InformatikLIVE(Band1)
P-68 ArminB.Cremers,RainerManthey,PeterMartini,VolkerSteinhage(Hrsg.):INFORMATIK2005–InformatikLIVE(Band2)
P-69 RobertHirschfeld,RyszardKowalcyk,AndreasPolze,MatthiasWeske(Hrsg.):NODe2005,GSEM2005
P-70 KlausTurowski,Johannes-MariaZaha(Hrsg.):Component-orientedEnterpriseApplication(COAE2005)
P-71 AndrewTorda,StefanKurz,MatthiasRarey(Hrsg.):GermanConferenceonBioinformatics2005
P-72 KlausP.Jantke,Klaus-PeterFähnrich,WolfgangS.Wittig(Hrsg.):MarktplatzInternet:Vone-Learningbise-Payment
P-73 JanvonKnop,WilhelmHaverkamp,EikeJessen(Hrsg.):“HeuteschondasMorgensehen“
P-74 ChristopherWolf,StefanLucks,Po-WahYau(Hrsg.):WEWoRC2005–WesternEuropeanWorkshoponResearchinCryptology
P-75 JörgDesel,UlrichFrank(Hrsg.):Enter-priseModellingandInformationSystemsArchitecture
P-76 ThomasKirste,BirgittaKönig-Riess,KeyPousttchi,KlausTurowski(Hrsg.):Mo-bileInformationssysteme–Potentiale,Hindernisse,Einsatz
P-77 JanaDittmann(Hrsg.):SICHERHEIT2006
P-78 K.-O.Wenkel,P.Wagner,M.Morgens-tern,K.Luzi,P.Eisermann(Hrsg.):Land-undErnährungswirtschaftimWandel
P-79 BettinaBiel,MatthiasBook,VolkerGruhn(Hrsg.):Softwareengineering2006
P-80 MareikeSchoop,ChristianHuemer,MichaelRebstock,MartinBichler(Hrsg.):Service-OrientedElectronicCommerce
P-81 WolfgangKarl,JürgenBecker,Karl-ErwinGroßpietsch,ChristianHochberger,ErikMaehle(Hrsg.):ARCS´06
P-82 HeinrichC.Mayr,RuthBreu(Hrsg.):Modellierung2006
P-83 DanielHuson,OliverKohlbacher,AndreiLupas,KayNieseltandAndreasZell(eds.):GermanConferenceonBioinfor-matics
P-84 DimitrisKaragiannis,HeinrichC.Mayr,(Hrsg.):InformationSystemsTechnologyanditsApplications
P-85 WitoldAbramowicz,HeinrichC.Mayr,(Hrsg.):BusinessInformationSystems
P-86 RobertKrimmer(Ed.):ElectronicVoting2006
P-87 MaxMühlhäuser,GuidoRößling,RalfSteinmetz(Hrsg.):DELFI2006:4.e-LearningFachtagungInformatik
P-88 RobertHirschfeld,AndreasPolze,RyszardKowalczyk(Hrsg.):NODe2006,GSEM2006
P-90 JoachimSchelp,RobertWinter,UlrichFrank,BodoRieger,KlausTurowski(Hrsg.):Integration,InformationslogistikundArchitektur
P-91 HenrikStormer,AndreasMeier,MichaelSchumacher(Eds.):EuropeanConferenceoneHealth2006
P-92 FernandFeltz,BenoîtOtjacques,AndreasOberweis,NicolasPoussing(Eds.):AIM2006
P-93 ChristianHochberger,RüdigerLiskowsky(Eds.):INFORMATIK2006–InformatikfürMenschen,Band1
P-94 ChristianHochberger,RüdigerLiskowsky(Eds.):INFORMATIK2006–InformatikfürMenschen,Band2
P-95 MatthiasWeske,MarkusNüttgens(Eds.):EMISA2005:Methoden,KonzepteundTechnologienfürdieEntwicklungvondienstbasiertenInformationssystemen
P-96 SaartjeBrockmans,JürgenJung,YorkSure(Eds.):Meta-ModellingandOntolo-gies
P-97 OliverGöbel,DirkSchadt,SandraFrings,HardoHase,DetlefGünther,JensNedon(Eds.):IT-IncidentMangament&IT-Forensics–IMF2006

P-98 HansBrandt-Pook,WernerSimonsmeierundThorstenSpitta(Hrsg.):BeratunginderSoftwareentwicklung–Modelle,Methoden,BestPractices
P-99 AndreasSchwill,CarstenSchulte,MarcoThomas(Hrsg.):DidaktikderInformatik
P-100 PeterForbrig,GünterSiegel,MarkusSchneider(Hrsg.):HDI2006:Hochschul-didaktikderInformatik
P-101 StefanBöttinger,LudwigTheuvsen,SusanneRank,MarliesMorgenstern(Hrsg.):AgrarinformatikimSpannungsfeldzwischenRegionalisierungundglobalenWertschöpfungsketten
P-102 OttoSpaniol(Eds.):MobileServicesandPersonalizedEnvironments
P-103 AlfonsKemper,HaraldSchöning,ThomasRose,MatthiasJarke,ThomasSeidl,ChristophQuix,ChristophBrochhaus(Hrsg.):DatenbanksystemeinBusiness,TechnologieundWeb(BTW2007)
P-104 BirgittaKönig-Ries,FranzLehner,RainerMalaka,CanTürker(Hrsg.)MMS2007:MobilitätundmobileInformationssysteme
P-105 Wolf-GideonBleek,JörgRaasch,HeinzZüllighoven(Hrsg.)SoftwareEngineering2007
P-106 Wolf-GideonBleek,HenningSchwentner,HeinzZüllighoven(Hrsg.)SoftwareEngineering2007–BeiträgezudenWorkshops
P-107 HeinrichC.Mayr,DimitrisKaragiannis(eds.)InformationSystemsTechnologyanditsApplications
P-108 ArslanBrömme,ChristophBusch,DetlefHühnlein(eds.)BIOSIG2007:BiometricsandElectronicSignatures
P-109 RainerKoschke,OttheinHerzog,Karl-HeinzRödiger,MarcRonthaler(Hrsg.)INFORMATIK2007InformatiktrifftLogistikBand1
P-110 RainerKoschke,OttheinHerzog,Karl-HeinzRödiger,MarcRonthaler(Hrsg.)INFORMATIK2007InformatiktrifftLogistikBand2
P-111 ChristianEibl,JohannesMagenheim,SigridSchubert,MartinWessner(Hrsg.)DeLFI2007:5.e-LearningFachtagungInformatik
P-112 SigridSchubert(Hrsg.)DidaktikderInformatikinTheorieundPraxis
P-113 SörenAuer,ChristianBizer,ClaudiaMüller,AnnaV.Zhdanova(Eds.)TheSocialSemanticWeb2007Proceedingsofthe1stConferenceonSocialSemanticWeb(CSSW)
P-114 SandraFrings,OliverGöbel,DetlefGünther,HardoG.Hase,JensNedon,DirkSchadt,ArslanBrömme(Eds.)IMF2007IT-incidentmanagement&IT-forensicsProceedingsofthe3rdInternationalConferenceonIT-IncidentManagement&IT-Forensics
P-115 ClaudiaFalter,AlexanderSchliep,JoachimSelbig,MartinVingronandDirkWalther(Eds.)GermanconferenceonbioinformaticsGCB2007
P-116 WitoldAbramowicz,LeszekMaciszek(Eds.)BusinessProcessandServicesComputing1stInternationalWorkingConferenceonBusinessProcessandServicesComputingBPSC2007
P-117 RyszardKowalczyk(Ed.)GridserviceengineeringandmanegementThe4thInternationalConferenceonGridServiceEngineeringandManagementGSEM2007
P-118 AndreasHein,WilfriedThoben,Hans-JürgenAppelrath,PeterJensch(Eds.)EuropeanConferenceonehealth2007
P-119 ManfredReichert,StefanStrecker,KlausTurowski(Eds.)EnterpriseModellingandInformationSystemsArchitecturesConceptsandApplications
P-120 AdamPawlak,KurtSandkuhl,WojciechCholewa,LeandroSoaresIndrusiak(Eds.)CoordinationofCollaborativeEngineering-StateoftheArtandFutureChallenges
P-121 KorbinianHerrmann,BerndBruegge(Hrsg.)SoftwareEngineering2008FachtagungdesGI-FachbereichsSoftwaretechnik
P-122 WalidMaalej,BerndBruegge(Hrsg.)SoftwareEngineering2008-WorkshopbandFachtagungdesGI-FachbereichsSoftwaretechnik

P-123 MichaelH.Breitner,MartinBreunig,ElgarFleisch,LeyPousttchi,KlausTurowski(Hrsg.)MobileundUbiquitäreInformationssysteme–Technologien,Prozesse,MarktfähigkeitProceedingszur3.KonferenzMobileundUbiquitäreInformationssysteme(MMS2008)
P-124 WolfgangE.Nagel,RolfHoffmann,AndreasKoch(Eds.)9thWorkshoponParallelSystemsandAlgorithms(PASA)WorkshopoftheGI/ITGSpecielInterestGroupsPARSandPARVA
P-125 RolfA.E.Müller,Hans-H.Sundermeier,LudwigTheuvsen,StephanieSchütze,MarliesMorgenstern(Hrsg.)Unternehmens-IT:FührungsinstrumentoderVerwaltungsbürdeReferateder28.GILJahrestagung
P-126 RainerGimnich,UweKaiser,JochenQuante,AndreasWinter(Hrsg.)10thWorkshopSoftwareReengineering(WSR2008)
P-127 ThomasKühne,WolfgangReisig,FriedrichSteimann(Hrsg.)Modellierung2008
P-128 AmmarAlkassar,JörgSiekmann(Hrsg.)Sicherheit2008Sicherheit,SchutzundZuverlässigkeitBeiträgeder4.JahrestagungdesFachbereichsSicherheitderGesellschaftfürInformatike.V.(GI)2.-4.April2008Saarbrücken,Germany
P-129 WolfgangHesse,AndreasOberweis(Eds.)Sigsand-Europe2008ProceedingsoftheThirdAISSIGSANDEuropeanSymposiumonAnalysis,Design,UseandSocietalImpactofInformationSystems
P-130 PaulMüller,BernhardNeumair,GabiDreoRodosek(Hrsg.)1.DFN-ForumKommunikations-technologienBeiträgederFachtagung
P-131 RobertKrimmer,RüdigerGrimm(Eds.)3rdInternationalConferenceonElectronicVoting2008Co-organizedbyCouncilofEurope,GesellschaftfürInformatikandE-Voting.CC
P-132 SilkeSeehusen,UlrikeLucke,StefanFischer(Hrsg.)DeLFI2008:Die6.e-LearningFachtagungInformatik
P-133 Heinz-GerdHegering,AxelLehmann,HansJürgenOhlbach,ChristianScheideler(Hrsg.)INFORMATIK2008BeherrschbareSysteme–dankInformatikBand1
P-134 Heinz-GerdHegering,AxelLehmann,HansJürgenOhlbach,ChristianScheideler(Hrsg.)INFORMATIK2008BeherrschbareSysteme–dankInformatikBand2
P-135 TorstenBrinda,MichaelFothe,PeterHubwieser,KirstenSchlüter(Hrsg.)DidaktikderInformatik–AktuelleForschungsergebnisse
P-136 AndreasBeyer,MichaelSchroeder(Eds.)GermanConferenceonBioinformaticsGCB2008
P-137 ArslanBrömme,ChristophBusch,DetlefHühnlein(Eds.)BIOSIG2008:BiometricsandElectronicSignatures
P-138 BarbaraDinter,RobertWinter,PeterChamoni,NorbertGronau,KlausTurowski(Hrsg.)SynergiendurchIntegrationundInformationslogistikProceedingszurDW2008
P-139 GeorgHerzwurm,MartinMikusz(Hrsg.)IndustrialisierungdesSoftware-ManagementsFachtagungdesGI-FachausschussesManagementderAnwendungsentwick-lungund-wartungimFachbereichWirtschaftsinformatik
P-140 OliverGöbel,SandraFrings,DetlefGünther,JensNedon,DirkSchadt(Eds.)IMF2008-ITIncidentManagement&ITForensics
P-141 PeterLoos,MarkusNüttgens,KlausTurowski,DirkWerth(Hrsg.)ModellierungbetrieblicherInformations-systeme(MobIS2008)ModellierungzwischenSOAundComplianceManagement
P-142 R.Bill,P.Korduan,L.Theuvsen,M.Morgenstern(Hrsg.)AnforderungenandieAgrarinformatikdurchGlobalisierungundKlimaveränderung
P-143 PeterLiggesmeyer,GregorEngels,JürgenMünch,JörgDörr,NormanRiegel(Hrsg.)SoftwareEngineering2009FachtagungdesGI-FachbereichsSoftwaretechnik

P-144 Johann-ChristophFreytag,ThomasRuf,WolfgangLehner,GottfriedVossen(Hrsg.)DatenbanksystemeinBusiness,TechnologieundWeb(BTW)
P-145 KnutHinkelmann,HolgerWache(Eds.)WM2009:5thConferenceonProfessionalKnowledgeManagement
P-146 MarkusBick,MartinBreunig,HagenHöpfner(Hrsg.)MobileundUbiquitäreInformationssysteme–Entwicklung,ImplementierungundAnwendung4.KonferenzMobileundUbiquitäreInformationssysteme(MMS2009)
P-147 WitoldAbramowicz,LeszekMaciaszek,RyszardKowalczyk,AndreasSpeck(Eds.)BusinessProcess,ServicesComputingandIntelligentServiceManagementBPSC2009·ISM2009·YRW-MBP2009
P-148 ChristianErfurth,GeraldEichler,VolkmarSchau(Eds.)9thInternationalConferenceonInnovativeInternetCommunitySystemsI2CS2009
P-149 PaulMüller,BernhardNeumair,GabiDreoRodosek(Hrsg.)2.DFN-ForumKommunikationstechnologienBeiträgederFachtagung
P-150 JürgenMünch,PeterLiggesmeyer(Hrsg.)SoftwareEngineering2009-Workshopband
P-151 ArminHeinzl,PeterDadam,StefanKirn,PeterLockemann(Eds.)PRIMIUMProcessInnovationforEnterpriseSoftware
P-152 JanMendling,StefanieRinderle-Ma, WernerEsswein(Eds.) EnterpriseModellingandInformation
SystemsArchitectures Proceedingsofthe3rdInt‘lWorkshop
EMISA2009
P-153 AndreasSchwill,NicolasApostolopoulos(Hrsg.)LernenimDigitalenZeitalterDeLFI2009–Die7.E-LearningFachtagungInformatik
P-154 StefanFischer,ErikMaehleRüdigerReischuk(Hrsg.)INFORMATIK2009ImFocusdasLeben
P-155 ArslanBrömme,ChristophBusch,DetlefHühnlein(Eds.)BIOSIG2009:BiometricsandElectronicSignaturesProceedingsoftheSpecialInterestGrouponBiometricsandElectronicSignatures
P-156 BernhardKoerber(Hrsg.)ZukunftbrauchtHerkunft25Jahre»INFOS–InformatikundSchule«
P-157 IvoGrosse,SteffenNeumann,StefanPosch,FalkSchreiber,PeterStadler(Eds.)GermanConferenceonBioinformatics2009
P-158 W.Claupein,L.Theuvsen,A.Kämpf,M.Morgenstern(Hrsg.)PrecisionAgricultureReloaded–InformationsgestützteLandwirtschaft
P-159 GregorEngels,MarkusLuckey,WilhelmSchäfer(Hrsg.)SoftwareEngineering2010
P-160 GregorEngels,MarkusLuckey,AlexanderPretschner,RalfReussner(Hrsg.)SoftwareEngineering2010–Workshopband(inkl.Doktorandensymposium)
P-161 GregorEngels,DimitrisKaragiannisHeinrichC.Mayr(Hrsg.)Modellierung2010
P-162 MariaA.Wimmer,UweBrinkhoff,SiegfriedKaiser,DagmarLück-Schneider,ErichSchweighofer,AndreasWiebe(Hrsg.)VernetzteITfüreineneffektivenStaatGemeinsameFachtagungVerwaltungsinformatik(FTVI)undFachtagungRechtsinformatik(FTRI)2010
P-163 MarkusBick,StefanEulgem,ElgarFleisch,J.FelixHampe,BirgittaKönig-Ries,FranzLehner,KeyPousttchi,KaiRannenberg(Hrsg.)MobileundUbiquitäreInformationssystemeTechnologien,AnwendungenundDienstezurUnterstützungvonmobilerKollaboration
P-164 ArslanBrömme,ChristophBusch(Eds.)BIOSIG2010:BiometricsandElectronicSignaturesProceedingsoftheSpecialInterestGrouponBiometricsandElectronicSignatures

P-165 GeraldEichler,PeterKropf,UlrikeLechner,PhayungMeesad,HerwigUnger(Eds.)10thInternationalConferenceonInnovativeInternetCommunitySystems(I2CS)–JubileeEdition2010–
P-166 PaulMüller,BernhardNeumair,GabiDreoRodosek(Hrsg.)3.DFN-ForumKommunikationstechnologienBeiträgederFachtagung
P-167 RobertKrimmer,RüdigerGrimm(Eds.)4thInternationalConferenceonElectronicVoting2010co-organizedbytheCouncilofEurope,GesellschaftfürInformatikandE-Voting.CC
P-168 IraDiethelm,ChristinaDörge,ClaudiaHildebrandt,CarstenSchulte(Hrsg.)DidaktikderInformatikMöglichkeitenempirischerForschungsmethodenundPerspektivenderFachdidaktik
P-169 MichaelKerres,NadineOjstersekUlrikSchroeder,UlrichHoppe(Hrsg.)DeLFI2010-8.TagungderFachgruppeE-LearningderGesellschaftfürInformatike.V.
P-170 FelixC.Freiling(Hrsg.)Sicherheit2010Sicherheit,SchutzundZuverlässigkeit
P-171 WernerEsswein,KlausTurowski,MartinJuhrisch(Hrsg.)ModellierungbetrieblicherInformationssysteme(MobIS2010)ModellgestütztesManagement
P-172 StefanKlink,AgnesKoschmiderMarcoMevius,AndreasOberweis(Hrsg.)EMISA2010EinflussfaktorenaufdieEntwicklungflexibler,integrierterInformationssystemeBeiträgedesWorkshopsderGI-FachgruppeEMISA(EntwicklungsmethodenfürInfor-mationssystemeundderenAnwendung)
P-173 DietmarSchomburg,AndreasGrote(Eds.)GermanConferenceonBioinformatics2010
P-174 ArslanBrömme,TorstenEymann,DetlefHühnlein,HeikoRoßnagel,PaulSchmücker(Hrsg.)perspeGKtive2010Workshop„InnovativeundsichereInformationstechnologiefürdasGesundheitswesenvonmorgen“
P-175 Klaus-PeterFähnrich,BogdanFranczyk(Hrsg.)INFORMATIK2010ServiceScience–NeuePerspektivenfürdieInformatikBand1
P-176 Klaus-PeterFähnrich,BogdanFranczyk(Hrsg.)INFORMATIK2010ServiceScience–NeuePerspektivenfürdieInformatikBand2
P-177 WitoldAbramowicz,RainerAlt,Klaus-PeterFähnrich,BogdanFranczyk,LeszekA.Maciaszek(Eds.)INFORMATIK2010BusinessProcessandServiceScience–ProceedingsofISSSandBPSC
P-178 WolframPietsch,BenediktKrams(Hrsg.) VomProjektzumProdukt FachtagungdesGI-
FachausschussesManagementderAnwendungsentwicklungund-wartungimFachbereichWirtschafts-informatik(WI-MAW),Aachen,2010
P-179 StefanGruner,BernhardRumpe(Eds.)FM+AM`2010SecondInternationalWorkshoponFormalMethodsandAgileMethods
P-180 TheoHärder,WolfgangLehner,BernhardMitschang,HaraldSchöning,HolgerSchwarz(Hrsg.)DatenbanksystemefürBusiness,TechnologieundWeb(BTW)14.FachtagungdesGI-Fachbereichs„DatenbankenundInformationssysteme“(DBIS)
P-181 MichaelClasen,OttoSchätzel,BrigitteTheuvsen(Hrsg.)QualitätundEffizienzdurchinformationsgestützteLandwirtschaft,Fokus:ModerneWeinwirtschaft
P-182 RonaldMaier(Hrsg.)6thConferenceonProfessionalKnowledgeManagementFromKnowledgetoAction
P-183 RalfReussner,MatthiasGrund,AndreasOberweis,WalterTichy(Hrsg.)SoftwareEngineering2011FachtagungdesGI-FachbereichsSoftwaretechnik
P-184 RalfReussner,AlexanderPretschner,StefanJähnichen(Hrsg.)SoftwareEngineering2011Workshopband(inkl.Doktorandensymposium)

P-185 HagenHöpfner,GüntherSpecht,ThomasRitz,ChristianBunse(Hrsg.)MMS2011:MobileundubiquitäreInformationssystemeProceedingszur6.KonferenzMobileundUbiquitäreInformationssysteme(MMS2011)
P-186 GeraldEichler,AxelKüpper,VolkmarSchau,HacèneFouchal,HerwigUnger(Eds.)11thInternationalConferenceonInnovativeInternetCommunitySystems(I2CS)
P-187 PaulMüller,BernhardNeumair,GabiDreoRodosek(Hrsg.)4.DFN-ForumKommunikations-technologien,BeiträgederFachtagung20.Junibis21.Juni2011Bonn
P-188 HolgerRohland,AndreaKienle,SteffenFriedrich(Hrsg.)DeLFI2011–Die9.e-LearningFachtagungInformatikderGesellschaftfürInformatike.V.5.–8.September2011,Dresden
P-189 Thomas,Marco(Hrsg.)InformatikinBildungundBerufINFOS201114.GI-FachtagungInformatikundSchule
P-190 MarkusNüttgens,OliverThomas,BarbaraWeber(Eds.)EnterpriseModellingandInformationSystemsArchitectures(EMISA2011)
P-191 ArslanBrömme,ChristophBusch(Eds.)BIOSIG2011InternationalConferenceoftheBiometricsSpecialInterestGroup
P-192 Hans-UlrichHeiß,PeterPepper,HolgerSchlingloff,JörgSchneider(Hrsg.)INFORMATIK2011InformatikschafftCommunities
P-193 WolfgangLehner,GuntherPiller(Hrsg.)IMDM2011
P-194 M.Clasen,G.Fröhlich,H.Bernhardt,K.Hildebrand,B.Theuvsen(Hrsg.)InformationstechnologiefüreinenachhaltigeLandbewirtschaftungFokusForstwirtschaft
P-195 NeerajSuri,MichaelWaidner(Hrsg.)Sicherheit2012Sicherheit,SchutzundZuverlässigkeitBeiträgeder6.JahrestagungdesFachbereichsSicherheitderGesellschaftfürInformatike.V.(GI)
P-198 StefanJähnichen,AxelKüpper,SahinAlbayrak(Hrsg.)SoftwareEngineering2012FachtagungdesGI-FachbereichsSoftwaretechnik
Thetitlescanbepurchasedat:
Köllen Druck + Verlag GmbHErnst-Robert-Curtius-Str.14·D-53117BonnFax:+49(0)228/9898222E-Mail:[email protected]

