google file system report
TRANSCRIPT

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 1/36
BBB EEE SSS eee mmm iii nnn aaa rrr
titled
GG ooooggllee FF iillee SSyysstt eemm
Submitted
BY
Mr Nikhil Bhatia
Supervisor
Prof. Vivaksha Jariwala
2014-2015
Department of Computer EngineeringC. K. PITHAWALLA COLLEGE OF
ENGINEERING AND TECHNOLOGYSURAT

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 2/36
ii
C E R T I F I C A T E
This is to certify that the seminar report entitled Google File System ” ,
submitted by Nikhil Bhatia, bearing Roll No: 120735 in partial fulfillment of
the requirement for the award of the degree of Bachelor of Engineering in
Computer Engineering, at Computer Engineering Department of the C. K.
Pithawalla College of Engineering and Technology, Surat is a record of
his/her own work carried out as part of the coursework for the year 2014-15.
To the best of our knowledge, the matter embodied in the report has not beensubmitted elsewhere for the award of any degree or diploma.
Certified by
_____________Prof. Vivaksha JariwalaAssistant Professor,AddressDepartment of Computer Engineering,C. K. Pithawalla College of Engineering and Technology,Surat 395007India
Head,Department of Computer Engineering,C. K. Pithawalla College of Engineering and Technology,Surat 395007, India

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 3/36
iii
Department of Computer Engineering
C. K. PITHAWALLA COLLEGE OF ENGINEERING AND TECHNOLOGY,SURAT
2014-15)
Approval Sheet
This is to state that the Seminar Report entitled Google File System submitted
by Mr Nikhil Bhatia Admission No: 120090107035 ) is approved for the
award of the degree of Bachelor of Engineering in Computer Engineering.
Board of Examiners Examiners
Guide
Prof. Vivaksha Jariwala
Head, Department of Computer Engineering
Date:6th
Sept’14 Place:CKPCET, Surat

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 4/36
iv
Acknowledgements
I would like to take this opportunity to pay my gratitude to few people who were closely
associated with my dissertation throughout. I would like to thank Prof. Vivaksha Jariwala,
my guide, whose insightful comments and path direction has greatly enhanced the value
that I had kept in my dissertation which otherwise would have not been possible. Her
valuable words will surely be a great help in my professional life as well.
I would also like to thank the University authorities for providing excellent infrastructure
such as world class library with excellent collection of books, providing access to
valuable journals, and IT facilities. I truly feel privileged to be part of this University.
Finally, I want to acknowledge the encouragement and support of my parents without
which it would not be possibl e to be part of this reputed University. It’s truly just beyond
dissertation. I am grateful to them for every bit of contribution in helping me, shaping my
dream.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 5/36
v
Abstract
In the need for a scalable infrastructure supporting storage and processing of
large data sets, Google has developed a number of cluster-based technologies which
include the Google File System. This seminar aims at explaining the key ideas andmechansims deployed in the Google File System and illustrates the architecture and fault
tolerance features implemented.
Google File system is the largest file system in operation. Formally, Google File
System (GFS) is a scalable distributed file system for large distributed data-intensive
applications. It provides fault tolerance while running on inexpensive commodity
hardware, and it delivers high aggregate performance to a large number of clients. The
file system has successfully met Google’s storage needs. It is widely deployed withinGoogle as the storage platform for the generation and processing of data used by their
service as well as research and development efforts that require large data sets.
The entire file system is organized hierarchically in directories and identified by
pathnames. The architecture comprises of a single master, multiple chunk servers and
multiple clients. Files are divided into chunks, which is the key design parameter. Google
File System also uses leases and mutation order in their design to achieve consistency
and atomicity. As of fault tolerance, GFS is highly available, replicas of chunk servers
and master exists.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 6/36
vi
Table of Contents
1.0 INTRODUCTION ............................................................................ 1
1.1 COMPARISON WITH OTHER DISTRIBUTED FILE SYSTEM ...................................... 2
1.2 MOTIVATION BEHIND GFS ................................................................................ 3
2.0 DESIGN OVERVIEW ...................................................................... 4
2.1 ASSUMPTIONS ................................................................................................... 4
2.2 I NTERFACE ....................................................................................................... 5
2.3 ARCHITECTURE ................................................................................................. 5
2.4 SINGLE MATER ................................................................................................. 7
2.5 CHUNK SIZE ..................................................................................................... 8
2.6 METADATA ....................................................................................................... 8
2.6.1 In-Memory Data Structures .......................................................................... 9
2.6.2 Chunk Locations .......................................................................................... 9
2.6.3 Operation Log .............................................................................................. 9
2.7 CONSISTENCY MODEL ..................................................................................... 10
3.0 SYSTEM INTERACTIONS........................................................... 12
3.1 LEASES AND MUTATION ORDER ...................................................................... 12
3.2 DATA FLOW ................................................................................................... 14
3.3 ATOMIC R ECORD APPENDS ............................................................................. 15
3.4 S NAPSHOT ...................................................................................................... 15
4.0 MASTER OPERATION ................................................................ 17
4.1 NAMESPACE MANAGEMENT AND LOCKING ...................................................... 17
4.2 R EPLICA PLACEMENT ...................................................................................... 17
4.3 CREATION , R E-REPLICATION , R EBALANCING ................................................... 18
4.4 GARBAGE COLLECTION ................................................................................... 19
4.5 STALE R EPLICA DETECTION ............................................................................ 19
5.0 FAULT TOLERANCE AND DIAGNOSIS ................................... 21
5.1 HIGH AVAILABILITY ....................................................................................... 21 5.1.1 Fast Recovery ............................................................................................ 21

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 7/36
vii
5.1.2 Chunk Replication...................................................................................... 21
5.1.3 Master Replication ..................................................................................... 21
5.2 DATA I NTEGRITY ............................................................................................ 22
5.3 DIAGNOSIS TOOLS .......................................................................................... 22
6.0 ADVANTAGES – DISADVANTAGES ......................................... 24
6.1 ADVANTAGES ................................................................................................. 24
6.2 DISADVANTAGES ............................................................................................ 24
7.0 CONCLUSION & FUTURE WORK ............................................ 26
ENNUMERATIVE BIBLIOGRAPHY ................................................... 27

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 8/36
viii
List of Figures
Fig 1 : GFS Architecture [1]. ....................................................................................... 5
Fig 2 : The chunk servers replicate the data automatically [11]. ................................... 6
Fig 3 : Consistency state of records on different chunk servers [4]. ........................... 10
Fig 4 : Write Control and Data Flow [1]. ................................................................... 13

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 9/36
ix
List of Tables
Table 1 : Comparison between GFS, NFS and AFS ................................................... 2

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 10/36
1
1.0 Introduction
Operating the market- leading internet search engine, Google’s infrastructure faces
unique performance and scalability needs. Although exact numbers have not been leaked
to the public, Google is estimated to run approximately 900,000 servers [5].
Google has designed a unique
distributed file system to meet its huge
storage demand, known as Google File
System (GFS). GFS is designed as a
distributed file system to be run on
clusters up to thousands of machines.
Initially it was built to store data
generated by its large crawling and
indexing system. The files generated by
this system were usually huge.
Maintaining and managing such huge files and data processing demands was a challenge
[8] with the existing file systems which gave rise for designing Google’s ow n file system,
GFS. Another big concern was scalability, which refers to the ease of adding capacity to
the system. A system is scalable if it's easy to increase the system's capacity. The system's
performance shouldn't suffer as it grows [3]. GFS shares many of the same goals as
previous distributed file systems such as performance, scalability, reliability, and
availability [1].
Running on commodity hardware, GFS is not only challenged by managing
distribution, it also has to cope with the increased danger of hardware faults.
Consequently, one of the assumptions made in the design of GFS is to consider disk
faults, machine faults as well as network faults as being the norm rather than the
exception. Ensuring safety of data as well as being able to scale up to thousands of
computers while managing multiple terabytes of data can thus be considered the key
challenges faced by GFS [4].
GFS is designed to accommodate Google’s large cluster requirements without
burdening applications [6]. GFS has been fully customized to suite Google's needs. This
8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 11/36
2
specialization allows the design of the file system to abstain from many compromises
made by other file systems. As an example, a file system targeting general applicability is
expected to be able to efficiently manage files with sizes ranging from very small (i.e.
few bytes) to large (i.e. gigabyte to multi-terabyte) [7]. GFS is only optimized for usage
of large files only with space efficiency being of minor importance. Moreover, GFS files
are commonly modified by appending data, whereas modifications at arbitrary file offsets
are rare. The majority of files can thus, in sharp contrast to other file systems, be
considered as being append-only or even immutable (write once, read many) [4]. Coming
along with being optimized for large files and acting as the basis for large-volume data
processing systems, the design of GFS has been optimized for large streaming reads and
generally favors throughput over latency [2].
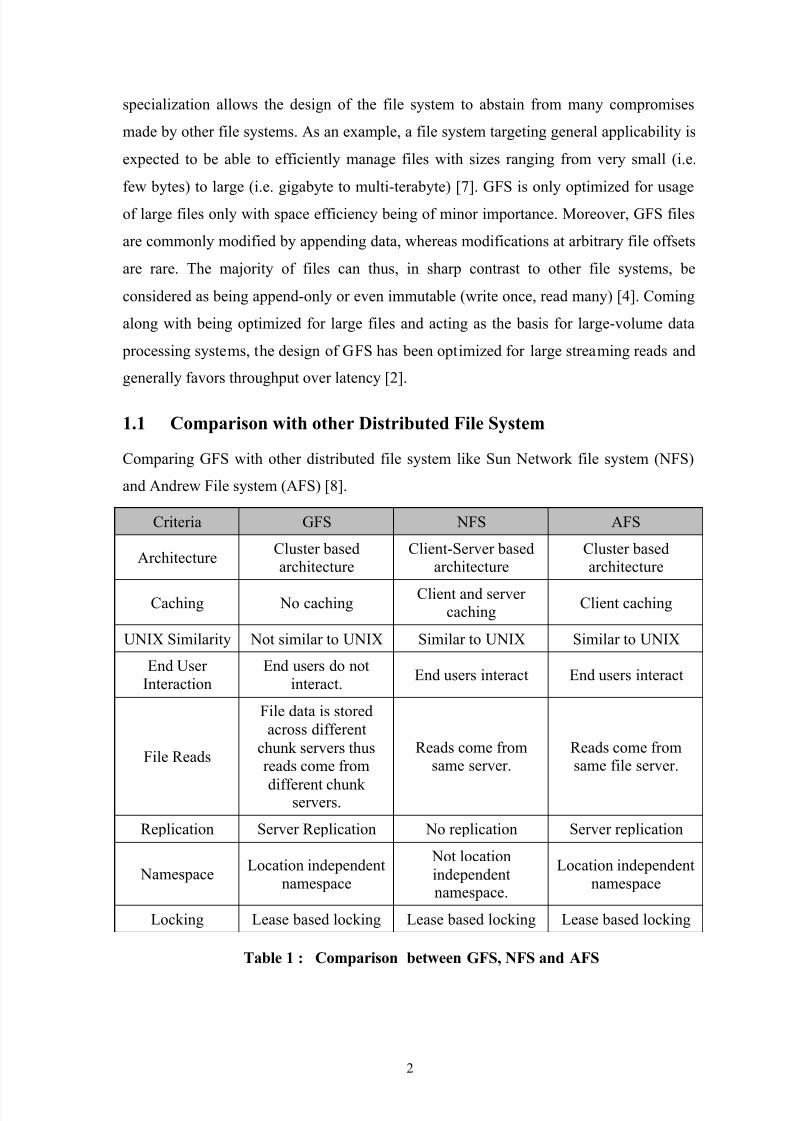
1.1 Comparison with other Distributed File System
Comparing GFS with other distributed file system like Sun Network file system (NFS)
and Andrew File system (AFS) [8].
Criteria GFS NFS AFS
Architecture Cluster basedarchitecture
Client-Server basedarchitecture
Cluster basedarchitecture
Caching No caching Client and servercaching Client caching
UNIX Similarity Not similar to UNIX Similar to UNIX Similar to UNIX
End UserInteraction
End users do notinteract. End users interact End users interact
File Reads
File data is storedacross different
chunk servers thusreads come from
different chunkservers.
Reads come fromsame server.
Reads come fromsame file server.
Replication Server Replication No replication Server replication
Namespace Location independentnamespace
Not locationindependentnamespace.
Location independentnamespace
Locking Lease based locking Lease based locking Lease based locking
Table 1 : Comparison between GFS, NFS and AFS

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 12/36
3
1.2 Motivation behind GFS
Google file system is a distributed file system built for large distributed data intensive
applications. Initially it was built to store data generated by its large crawling and
indexing system. The files generated by this system were usually huge. Maintaining andmanaging such huge files and data processing demands was a challenge with the existing
file systems [8]. The main objective of the designers was building a highly fault tolerant
system while running inexpensive commodity hardware.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 13/36
4
2.0 Design Overview
2.1 Assumptions
In designing a file system, Google have been guided by some assumptions that offers
both challenges and opportunities [1].
Inexpensive commodity hardware : - The system is built from many inexpensive
commodity components that often fail. It must constantly monitor itself and
detect, tolerate, and recover promptly from component failures on a routine basis
[1].
Large files - Multi-GB : - The system stores a ‘modest’ number of large files.
Google File System expects a few million files, each typically 100 MB or larger in
size. Multi-GB files are the common case and should be managed efficiently.
Small files must be supported, but GFS need not optimize for them [1].
Workloads : - The workloads primarily consist of two kinds of reads: large
streaming reads and small random reads. In large streaming reads, individual
operations typically read hundreds of KBs, more commonly 1 MB or more.
Google File System assumes to have successive operations from the same client
often read through a contiguous region of a file. A small random read typically
reads a few KBs at some arbitrary offset. Performance-conscious applications
often batch and sort their small reads to advance steadily through the file rather
than go back and forth [1].
Write Operations : - Once files are written they are mostly read. Most of the write
operations are of append type [8].
Concurrent append to the same file : - The system must efficiently implement
well-defined semantics for multiple clients that concurrently append to the same
file. The system must efficiently implement well-defined semantics for multiple
clients that concurrently append to the same file. Google’s files are often used as
producer consumer queues or for many-way merging. Hundreds of producers,
running one per machine, will concurrently append to a file. Atomicity with
minimal synchronization overhead is essential. The file may be read later, or a

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 14/36
5
consumer may be reading through the file simultaneously [1].
High sustained throughput & low latency : - High sustained bandwidth and
throughput are more important than low latency [8].
2.2 Interface
In order to meet these goals of high distribution, tolerance to high failure rates,
fast-path appends and huge files the designers provided their own API to the Google File
System [9]. GFS provides a familiar file system interface, though it does not implement a
standard API (application programming interface) such as POSIX (an acronym for
"Portable O perating System Interface" [10]). Files are organized hierarchically in
directories and identified by pathnames [1]. The deviations from POSIX are not extreme.
GFS’s API operations like create, delete, open, close, read and write files.
Moreover, GFS has snapshot and record append operations. Snapshot creates a
copy of a file or a directory tree at low cost. Record append allows multiple clients to
append data to the same file concurrently while guaranteeing the atomicity of each
individual client’s append. It is useful for implementing multi -way merge results and
producer-consumer queues that many clients can simultaneously append [1]. Snapshot
and record append are discussed further in Sections 3.4 and 3.3 respectively.
2.3 Architecture
Fundamentally, GFS is quite simply put together [9]. GFS is a distributed system
to be run on clusters. The architecture relies on a master/slave pattern. Whereas the
master is primarily in charge of managing and monitoring the cluster, all data is stored on
the slave machines, which are referred to as chunkservers , as shown in Figure 1.
Fig 1 : GFS Architecture [1].

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 15/36
6
In order to provide sufficient data safety, all data is replicated to a number of
chunkservers, the default being three, as shown in Figure 2. While the exact replication
algorithms are not fully documented. This way, the risk of losing data in the event of a
failure of an entire rack or even sub-network is mitigated [4].
To implement such distribution in an efficient manner, GFS employs a number of
concepts. First and foremost, files are divided into chunks, each having a fixed size of 64
MB. A file always consists of at least one chunk, although chunks are allowed to contain
a smaller payload than 64 MB. New chunks are automatically allocated in the case of the
file growing. Chunks are not only the unit of management and their role can thus be
roughly compared to blocks in ordinary file systems, they are also the unit of distribution.
Although client code deals with files, files are merely an abstraction provided by
GFS in that a file refers to a sequence of chunks. This abstraction is primarily supported
by the master, which manages the mapping between files and chunks as part of its
metadata [4]. This system metadata also includes the namespace, access control
information, and the current locations of chunks [1]. Chunkservers in turn exclusively
deal with chunks, which are identified by unique numbers. Based on this separation
between files and chunks, GFS gains the flexibility of implementing file replication solely
on the basis of replicating chunks.
As the master server holds the metadata and manages file distribution, it is
involved whenever chunks are to be read, modified or deleted. Also, the metadata
managed by the master has to contain information about each individual chunk. The size
of a chunk (and thus the total number of chunks) is thus a key
Fig 2 : The chunk servers replicate the data automatically [11].

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 16/36
7
figure influencing the amount of data and interactions the master has to handle. Choosing
64 MB as chunk size can be considered a trade-off between trying to limit resource usage
and master interactions on the one hand and accepting an increased degree of internal
fragmentation on the other hand. In order to safeguard against disk corruption,
chunkservers have to verify the integrity of data before it is being delivered to a client by
using checksums [4].
GFS is implemented as user mode components running on the Linux operating
system. As such, it exclusively aims at providing a distributed file system while leaving
the task of managing disks (i.e. the role of a file system in the context of operating
systems) to the Linux file systems. Based on this separation, chunkservers store each
chunk as a file in the Linux file system.
2.4 Single Mater
Having a single master vastly simplifies GFS’s design and enables the mast er to
make sophisticated chunk placement and replication decisions using global knowledge.
However, GFS minimizes its involvement in reads and writes so that it does not become a
bottleneck. Clients never read and write file data through the master. Instead, a client asks
the master which chunkservers it should contact. It caches this information for a limited
time and interacts with the chunkservers directly for many subsequent operations [1] .
Consider the interactions for a simple read with reference to Figure 1. First, using
the fixed chunks size, the client translates the file name and byte offset specified by the
application into a chunk index within the file. Then, it sends the master a request
containing the file name and chunk index. The master replies with the corresponding
chunk handle and locations of the replicas. The client caches this information using the
file name and chunk index as the key. The client then sends a request to one of the
replicas, most likely the closest one. The request specifies the chunk handle and a byte
range within that chunk. Further reads of the same chunk require no more client-master
interaction until the cached information expires or the file is reopened. In fact, the client
typically asks for multiple chunks in the same request and the master can also include the
information for chunks immediately following those requested. This extra information
sidesteps several future client-master interactions at practically no extra cost.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 17/36
8
2.5 Chunk Size
It is notable that due to the comparatively large size of a chunk and the fact that
the metadata of a chunk is as small as 64 bytes, the master server is able to hold all meta
data in memory, which not only simplifies data structures and algorithms but also ensuresgood performance. Each chunk replica is stored as a plain Linux file on a chunkservers
and is extended only as needed. Lazy space allocation avoids wasting space due to
internal fragmentation, perhaps the greatest objection against such a large chunk size.
A large chunk siz e offers several important advantages. First, it reduces clients’
need to interact with the master because reads and writes on the same chunk require only
one initial request to the master for chunk location information. The reduction is
especially signifi cant for GFS’s workloads because applications mostly read and writelarge files sequentially. Even for small random reads, the client can comfortably cache all
the chunk location information for a multi-TB working set. Second, since on a large
chunk, a client is more likely to perform many operations on a given chunk, it can reduce
network overhead by keeping a persistent TCP connection to the chunkserver over an
extended period of time. Third, it reduces the size of the metadata stored on the master
[1].
On the other hand, a large chunk size, even with lazy space allocation, has itsdisadvantages. A small file consists of a small number of chunks, perhaps just one. The
chunkservers storing those chunks may become hot spots if many clients are accessing
the same file [1].
2.6 Metadata
The master stores three major types of metadata: the file and chunk namespaces, the
mapping from files to chunks, and the locations of each chunk’s replicas. All metadata is
kept in the master’s memory. The first two types (namespa ces and file-to-chunk mapping)
are also kept persistent by logging mutations to an operation log stored on the master’s
local disk and replicated on remote machines. Using a log allows us to update the master
state simply, reliably, and without risking inconsistencies in the event of a master crash.
The master does not store chunk location information persistently. Instead, it asks each
chunkserver about its chunks at master startup and whenever a chunkserver joins the
cluster.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 18/36
9
2.6.1 In-Memory Data Structures
Since metadata is stored in memory, master operations are fast. Furthermore, it is
easy and efficient for the master to periodically scan through its entire state in the
background. This periodic scanning is used to implement chunk garbage collection, re-replication in the presence of chunkserver failures, and chunk migration to balance load
and disk space usage across chunkservers.
One potential concern for this memory-only approach is that the number of
chunks and hence the capacity of the whole system is limited by how much memory the
master has. This is not a serious limitation in practice. The master maintains less than 64
bytes of metadata for each 64 MB chunk. Most chunks are full because most files contain
many chunks, only the last of which may be partially filled. Similarly, the file namespacedata typically requires less than 64 bytes per file because it stores file names compactly
using prefix compression.
If necessary to support even larger file systems, the cost of adding extra memory
to the master is a small price to pay for the simplicity, reliability, performance, and
flexibility that GFS gains by storing the metadata in memory [1].
2.6.2 Chunk Locations
The master does not keep a persistent record of which chunkservers have a replica of a
given chunk. It simply polls chunkservers for that information at startup. The master can
keep itself up-to-date thereafter because it controls all chunk placement and monitors
chunkserver status with regular HeartBeat messages [1].
2.6.3 Operation Log
To provide safety of metadata in case of a crash, all changes made by the master is
written (using a write-through technique) to the operations log [4]. The operation log
contains a historical record of critical metadata changes [1]. It is central to GFS. Not only
is it the only persistent record of metadata, but it also serves as a logical time line that
defines the order of concurrent operations. Files and chunks, as well as their versions, are
all uniquely and eternally identified by the logical times at which they were created [1].
If the master should fail its operation can be recovered by a back-up master which
can simply replay the log to get to the same state. However, this can be very slow,
especially if the cluster has been alive for a long time and the log is very long. To help

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 19/36
10
with this issue, the master’s state is periodically serialized to disk and then replicated so
that on recovery a master may load the checkpoint into memory, replay any subsequent
operations in the log, and be available again very quickly. All metadata is held by the
master in main memory – this avoids latency problems caused by disk writes, as well as
making scanning the entire chunk space (e.g. for garbage collection) very efficient [9].
Check pointing the master state is distinct from the second unusual operation that
GFS supports, snapshot [9]. The master recovers its file system state by replaying the
operation log. To minimize startup time, GFS keeps the log small [1]. To limit the size of
the log and thus also the time required to replay the log, snapshots of the metadata are
taken periodically and written to disk. After a crash, the latest snapshot is applied and the
operation log is replayed, which – as all modifications since the last snapshot have been
logged before having being applied to the in-memory structures – yields the same state as
existed before the crash [4].
2.7 Consistency Model
Retrying a failed append request increases the likelihood of a successful operation
outcome, yet it has an impact on the consistency of the data stored. In fact, if a record
append operation succeeds on all but one replica and is then successfully retried, the
chunks on all servers where the operation has succeeded initially will now contain a
duplicate record. Similarly, the chunk on the server that initially was unable to perform
the modification now contains one record that has to be considered garbage, followed by
a successfully written new record, as illustrated by record B in Figure 3
Fig 3 : Consistency state of records on different chunk servers [4].
In order not to have these effects influence the correctness of the results generated by
applications, GFS specifies a special, relaxed consistency model that su pports Google’s
highly distributed applications well but remains relatively simple and efficient to

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 20/36
11
implement.
GFS classifies a file region, i.e. a part of a chunk, as being in one of three states:
Consistent . A region is consistent if all clients see the same data.
Defined . A region is defined with respect to a change if it is consistent and all
clients see the change in its entirety.
Inconsistent . A region is inconsistent if it is not consistent.
Based on this classification, the situation discussed above yields the first record of
record B in an inconsistent state, whereas the second record is considered defined.
Consistent but not defined regions can occur as a result of concurrent successful
modifications on overlapping parts of a file. As a consequence, GFS requires clients to
correctly cope with file regions being in any of these three states. One of the mechanisms
clients can employ to attain this is to include a unique identifier in each record, so that
duplicates can be identified easily. Furthermore, records can be written in a format
allowing proper self-validation.
The relaxed nature of the consistency model used by GFS and the requirement
that client code has to cooperate emphasizes the fact that GFS is indeed a highly
specialized file system neither intended nor immediately applicable for general use
outside Google.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 21/36
12
3.0 System Interactions
GFS is a system that minimizes the master’s involvement in all operations. With that
background, how the client, master, and chunkservers interact to implement data
mutations, atomic record append, and snapshot are described as under [1].
3.1 Leases and Mutation Order
A mutation is an operation that changes the contents or metadata of a chunk such
as a write or an append operation. Each mutation is perform ed at all the chunk’s replicas.
To maintain a consistent mutation order across replicas. The master grants a chunk lease
to one of the replicas, called primary. The primary chooses serial order for all mutations
to the chunk. All replicas follow this order when applying mutations. Thus, the global
mutation order is defined first by the lease grant order chosen by the master, and within a
lease by the serial numbers assigned by the primary [1]. Particularly, Use of leases to
maintain consistent mutation order [12].
A lease has an initial timeout of 60 seconds, thus a leas can be considered as a
lock that has an expiration time. However, as long as the chunk is being mutated, the primary can request and typically receive extensions from the master indefinitely. These
extension requests and grants are piggybacked on the HeartBeat messages regularly
exchanged between the master and all chunkservers. The master may sometimes try to
revoke a lease before it expires (e.g., when the master wants to disable mutations on a file
that is being renamed). Even if the master loses communication with a primary, it can
safely grant a new lease to another replica after the old lease expires [1].
Figure 4, illustrates the process of control flow of a write through these numberedsteps.
1. The client asks the master which chunkserver holds the current lease for the chunk
and the locations of the other replicas. If no one has a lease, the master grants one
to a replica it chooses (not shown).
2. The master replies with the identity of the primary and the locations of the other(secondary) replicas. The client caches this data for future mutations. It needs to

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 22/36
13
Fig 4 : Write Control and Data Flow [1].
contact the master again only when the primary becomes unreachable or replies
that it no longer holds a lease.
3. The client pushes the data to all the replicas. Data is pushed linearly along a chain
of chunkservers in a pipelined fashion. e.g., Client Sec. A Primary Sec.
B. Once a chunkserver receives some data, it starts forwarding immediately
4. Once all the replicas have acknowledged receiving the data, the client sends a
write request to the primary. The request identifies the data pushed earlier to all ofthe replicas. The primary assigns consecutive serial numbers to all the mutations it
receives, possibly from multiple clients, which provides the necessary
serialization. It applies the mutation to its own local state in serial number order.
5. The primary forwards the write request to all secondary replicas. Each secondary
replica applies mutations in the same serial number order assigned by the primary.
6. The secondaries all reply to the primary indicating that they have completed the
operation.
7. The primary replies to the client. Any errors encountered at any of the replicas are
reported to the client. In case of errors, the write may have succeeded at the
primary and an arbitrary subset of the secondary replicas. (If it had failed at the
primary, it would not have been assigned a serial number and forwarded.) The
client request is considered to have failed, and the modified region is left in an
inconsistent state. GFS’s client code handles such errors by retrying the failed
mutation. It will make a few attempts at steps (3) through (7) before falling back

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 23/36
14
to a retry from the beginning of the write.
If a write by the application is large or straddles a chunk boundary, GFS client
code breaks it down into multiple write operations. They all follow the control flowdescribed above but may be interleaved with and overwritten by concurrent operations
from other clients. Therefore, the shared file region may end up containing fragments
from different clients, although the replicas will be identical because the individual
operations are completed successfully in the same order on all replicas. This leaves the
file region in consistent but undefined state as noted in Section 2.7.
3.2 Data Flow
GFS decouples the flow of data from the flow of control to use the network
efficiently. While control flows from the client to the primary and then to all secondaries,
data is pushed linearly along a carefully picked chain of chunkservers in a pipelined
fashion. Main goals of GFS are to fully utilize each machine’s network bandwidth, avoid
network bottlenecks and high-latency links, and minimize the latency to push through all
the data.
To fully utilize each machine’s network bandwidth, the data is pushed linearly
along a chain of chunkservers rather than distributed in some other topology (e.g., tree).
Thus, each machine’s full outbound bandwidth is used to transfer the data as fast as
possible rather than divided among multiple recipients. To avoid network bottlenecks and
high-latency links (e.g., inter-switch links are often both) as much as possible, each
machine forwards the data to the “closest” machine in the network topology that has not
received it. Suppose the client is pushing data to chunkservers C1 through C4. It sends the
data to the closest chunkserver, say C1. C1 forwards it to the closest chunkserver C2
through C4 closest to C1, say C2. Similarly, C2 forwards it to C3 or C4, whichever is
closer to C2, and so on. GFS’s network topology is simple enough that “distances” can be
accurately estimated from IP addresses [1].
Finally, GFS minimizes latency by pipelining the data transfer over TCP
connections. Once a chunkserver receives some data, it starts forwarding immediately.
Pipelining is especially helpful to us because GFS uses a switched network with full-
duplex links. Sending the data immediately does not reduce the receive rate.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 24/36
15
3.3 Atomic Record Appends
GFS provides an atomic append operation called record append. In a traditional
write, the client specifies the offset at which data is to be written. Concurrent writes to the
same region are not serializable: the region may end up containing data fragments frommultiple clients. In a record append, however, the client specifies only the data. GFS
appends it to the file at least once atomically (i.e., as one continuous sequence of bytes) at
an offset of GFS’s choosing and returns that offset to the client. Record append is heavily
used by Google’s distributed applications in which many clients on different machines
append to the same file concurrently [1].
Record append is a kind of mutation and follows the control flow in Section 3.1
with only a little extra logic at the primary [1]. Client pushes write data to all locations i.e.replicas then after, Primary checks if record fits in specified chunk, if record doesn ’t fit,
then the primary:
Pads the chunk
Tell secondaries to do the same
And informs the client
Client then retries to append with the next chunk.
If record fits, then the primary:
Appends the record
Tells secondaries to do the same
Receives responses from secondaries
And sends final response to the client
3.4 Snapshot
The snapshot operation makes a copy of a file or a directory tree (the “source”)
almost instantaneously, while minimizing any interruptions of ongoing mutations. Users
use it to quickly create branch copies of huge data sets (and often copies of those copies,
recursively) [1]. GFS follows following steps for performing snapshot requests:
1. A client issues a snapshot request for source files [13].
2. The master receives a snapshot request, it first revokes any outstanding leases on
the chunks in the files it is about to snapshot. This ensures that any subsequentwrites to these chunks will require an interaction with the master to find the lease

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 25/36
16
older. This will give the master an opportunity to create a new copy of the chunk
first [1].
3. After the leases have been revoked or have expired, the master logs the operation
to disk.4. It then applies this log record to its in-memory state by duplicating the metadata
for the source file or directory tree. The newly created snapshot files point to the
same chunks as the source files.
5. The first time a client wants to write to a chunk C after the snapshot operation, it
sends a request to the master to find the current lease holder.
6. The master notices that the reference count for chunk C is greater than one.
7. It defers replying to the client request and instead picks a new chunk handle C’. It
then asks each chunkserver that has a current replica of C to create a new chunk
called C’. By creating the new chunk on the s ame chunkservers as the original,
GFS ensures that the data can be copied locally, not over the network.
From this point, request handling is no different from that for any chunk: the
master grants one of the replicas a lease on the new chunk C’ and repli es to the client,
which can write the chunk normally, not knowing that it has just been created from an
existing chunk.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 26/36
17
4.0 Master Operation
The master executes all namespace operations. In addition, it manages chunk replicas
throughout the system: it makes placement decisions, creates new chunks and hence
replicas, and coordinates various system-wide activities to keep chunks fully replicated,
to balance load across all the chunkservers, and to reclaim unused storage [1].
4.1 Namespace Management and Locking
Many master operations can take a long time: for example, a snapshot operation
has to revoke chunkserver leases on all chunks covered by the snapshot. But Google
wasn’t interested to delay other master operations while they are running. Therefore, they
allowed multiple operations to be active and use locks over regions of the namespace to
ensure proper serialization.
Unlike many traditional file systems, GFS does not have a per-directory data
structure that lists all the files in that directory. Nor does it support aliases for the same
file or directory (i.e, hard or symbolic links in Unix terms). GFS logically represents its
namespace as a lookup table mapping full pathnames to metadata. With prefixcompression, this table can be efficiently represented in memory. Each node in the
namespace tree (either an absolute file name or an absolute directory name) has an
associated read-write lock.
One nice property of this locking scheme is that it allows concurrent mutations in
the same directory. For example, multiple file creations can be executed concurrently in
the same directory: each acquires a read lock on the directory name and a write lock on
the file name. The read lock on the directory name suffices to prevent the directory from being deleted, renamed, or snapshotted. The write locks on file names serialize attempts
to create a file with the same name twice [1].
4.2 Replica Placement
A GFS cluster is highly distributed at more levels than one. It typically has
hundreds of chunkservers spread across many machine racks. These chunkservers in turn
may be accessed from hundreds of clients from the same or different racks.Communication between two machines on different racks may cross one or more network

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 27/36
18
switches. Additionally, bandwidth into or out of a rack may be less than the aggregate
bandwidth of all the machines within the rack. Multi-level distribution presents a unique
challenge to distribute data for scalability, reliability, and availability.
The chunk replica placement policy serves two purposes: Maximize data reliability and availability.
Maximize network bandwidth utilization.
GFS also spreads chunk replicas across racks. This ensures that some replicas of a chunk
will survive and remain available even if an entire rack is damaged or offline (for
example, due to failure of a shared resource like a network switch or power circuit) [1].
4.3
Creation, Re-replication, RebalancingChunk replicas are created for three reasons: chunk creation, re-replication, and
rebalancing.
When the master creates a chunk, it chooses where to place the initially empty
replicas. It considers several factors.
Place new replicas on chunkservers with below-average disk usage [12]
(For equalization of space [13]).
Limit number of recent creations on each chunkservers [12].
And must have servers across racks.
The master re-replicates a chunk as soon as the number of available replicas falls
below a user-specified goal [1]. This could happen for various reasons: Chunkserver dies,
is removed, is unavailable, etc. Disk fails, is disabled, etc. Chunk is corrupted or the
replication goal is increased. Each chunk that needs to be re-replicated is prioritized based
on several factors [12], as under
How far is it from the goal [12]?
Live files vs. deleted files [12].
Blocking client [12].
Placement policy is similar to chunk creation. Master limits number of cloning per
chunkserver and cluster-wide to minimize impact to client traffic [12].
Finally, the master rebalances replicas periodically: it examines the current replica
distribution and moves replicas for better disks pace and load balancing. Also through this process, the master gradually fills up a new chunkserver [1].

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 28/36
19
4.4 Garbage Collection
After a file is deleted, GFS does not immediately reclaim the available physical storage. It
does so only lazily during regular garbage collection at both the file and chunk levels [1].
Mechanism that garbage collection follows, is as under File deletion logged by master [13].
File renamed to a hidden name with deletion timestamp [13].
Master regularly deletes files older than 3 days (configurable) [13].
Until then, hidden file can be read and undeleted [13].
When a hidden file is removed, its in-memory metadata is erased [13].
Orphaned chunks identified, corresponding metadata erased [13].
Safety against accidental irreversible deletion [13].
4.5 Stale Replica Detection
Chunk replicas may become stale if a chunkserver fails and misses mutations to the chunk
while it is down. For each chunk, the master maintains a chunk version number to
distinguish between up-to-date and stale replicas [1].
Whenever the master grants a new lease on a chunk, it increases the chunkv ersionnumber and informs the up-to date replicas. The master and these replicas all record the
new version number in their persistent state. This occurs before any client is notified and
therefore before it can start writing to the chunk. If another replica is currently
unavailable, its chunk version number will not be advanced. The master will detect that
his chunkserver has a stale replica when the chunkserver restarts and reports its set of
chunks and their associated version numbers. If the master sees a version number greater
than the one in its records, the master assumes that it failed when granting the lease and
so takes the higher version to be up-to-date [1].
The master removes stale replicas in its regular garbage collection. Before that, it
effectively considers a stale replica not to exist at all when it replies to client requests for
chunk information [1]. The master removes stale replicas in its regular garbage collection.
Before that, it effectively considers a stale replica not to exist at all when it replies to
client requests for chunk information. As another safeguard, the master includes the
chunk version number when it informs clients which chunkserver holds a lease on a
chunk or when it instructs a chunkserver to read the chunk from another chunkserver in a

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 29/36
20
cloning operation. The client or the chunkserver verifies the version number when it
performs the operation so that it is always accessing up-to-date data.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 30/36
21
5.0 Fault Tolerance and Diagnosis
One of GFS’s greatest challenges in designing the system is dealing with frequent
component failures. The quality and quantity of components together make these
problems more the norm than the exception: GFS cannot completely trust the machines,
nor it can completely trust the disks. Component failures can result in an unavailable
system or, worse, corrupted data. How GFS meets these challenges and the tools that it
has built into the system to diagnose problems when they inevitably occur are discussed
as under.
5.1 High Availability
Among hundreds of servers in a GFS cluster, some are bound to be unavailable at any
given time. GFS keeps the overall system highly available with two simple yet effective
strategies: fast recovery and replication [1].
5.1.1 Fast Recovery
Master and chunkservers have to restore their state and start in seconds no matter howthey terminated [13].
5.1.2 Chunk Replication
Chunk is replicated on multiple chunkservers on different racks. Users can specify
different replication levels for different parts of the file namespace. The default is three.
The master clones existing replicas as needed to keep each chunk fully replicated as
chunkservers go offline or detect corrupted replicas through checksum verification.
5.1.3 Master Replication
The master state is replicated for reliability. Its operation log and checkpoints are
replicated on multiple machines [1]. One master remains in charge of all mutations and
background activities. If it fails, start instantly. If its machine or disk fails, monitoring
infrastructure outside GFS starts a new master process elsewhere with the replicated
operation log. Clients use only the canonical name of the master (e.g. gfs-test).
Mo reover, “shadow” masters provide read -only access to the file system even

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 31/36
22
when the primary master is down. They are shadows, not mirrors, in that they may lag the
primary slightly, typically fractions of a second. They enhance read availability for files
that are not being actively mutated or applications that do not mind getting slightly stale
results [1].
To keep itself informed, a shadow master reads a replica of the growing operation
log and applies the same sequence of changes to its data structures exactly as the primary
does. Like the primary, it polls chunkservers at startup to locate chunk replicas and
exchanges frequent handshake messages with them to monitor their status. It depends on
the primary master only for replica location updates resulting from the primary’s
decisions to create and delete replicas [1].
5.2 Data Integrity
Each chunkserver uses check summing to detect corruption of stored data. Given
that a GFS cluster often has thousands of disks on hundreds of machines, it regularly
experiences disk failures that cause data corruption or loss on both the read and write
paths [1]. It is impractical to compare replicas across chunkservers to detect corruption as
divergent replicas may be legal. A chunk is broken up into 64 KB blocks. Each has a
corresponding 32 bit checksum. Like other metadata, checksums are kept in memory and
stored persistently with logging, separate from user data.
For reads, the chunkserver verifies the checksum of data blocks that overlap the
read range before returning any data to the requester, whether a client or another
chunkserver. Therefore chunkservers will not propagate corruptions to other machines. If
a block does not match the recorded checksum, the chunkserver returns an error to the
requestor and reports the mismatch to the master. In response, the requestor will read
from other replicas, while the master will clone the chunk from another replica. After a
valid new replica is in place, the master instructs the chunkserver that reported the
mismatch to delete its replica [1].
5.3 Diagnosis Tools
Extensive and detailed diagnostic logging has helped immeasurably in problem
isolation, debugging, and performance analysis, while incurring only a minimal cost.
Without logs, it is hard to understand transient, non-repeatable interactions between
machines. GFS servers generate diagnostic logs that record many significant events. The

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 32/36
23
performance impact of logging is minimal (and far outweighed by the benefits) because
these logs are written sequentially and asynchronously.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 33/36
24
6.0 Advantages – Disadvantages
6.1 Advantages
Very high availability and fault tolerance through replication: a) Chunk and
master replication and b) Chunk and master recovery.
Simple and efficient centralized design with a single master. Delivers good
performance for what it was designed for i.e. large sequential reads.
Concurrent writes to the same file region are not serializable. Thus replicas might
have duplicates but there is no interleaving of records. To ensure data integrity
each chunkserver verifies integrity of its own copy using checksums.
Read operations span at least a few 64KB blocks therefore the check summing
costs reduces.
Batch operations like writing to operation log, garbage collection help increase the
bandwidth.
Atomic append operations ensures no synchronization is needed at client end.
No caching eliminates cache coherence issues.
Decoupling of flow of data from flow of control allows to use network efficiently.
Orphaned chunks are automatically collected using garbage collection.
GFS master constantly monitors each chunkserver through heartbeat messages.
6.2 Disadvantages
Special purpose design is a limitation when applying to general purpose design.
Many of their design decisions will be inefficient in case of smaller files:
Small files will have small number of chunks even one. This can lead to
chunk servers storing these files to become hot spots in case of many client
requests.
Also if there are many such small files the master involvement will
increase and can lead to a potential bottleneck. Having a single master
node can become an issue.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 34/36
25
Since a relaxed consistency model is used clients have to perform consistency
checks on their own.
Performance might degrade if the numbers of writers and random writes are more.
Master memory is a limited. The whole system is tailored according to workloads present in Google. GFS as
well as applications are adjusted and tuned as necessary since both are controlled
by Google.
No reasoning is provided for the choice of standard chunk size (64MB).

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 35/36
26
7.0 Conclusion & Future work
Google File System describes some fairly interesting technology. GFS has a fairly
clean and apparently efficient design. Google File System demonstrates how to support
large-scale processing workloads on commodity hardware-
Designed to tolerate frequent component failures.
Uniform logical namespace.
Optimize for huge files that are mostly appended and read.
Feel free to relax and extend FS interface as required.
Relaxed consistency model.
Go for simple solutions (e.g., single master, garbage collection).
GFS has successfully met Google’s storage needs and is widely used within Google as the
storage platform for research and development as well as production data processing. It is
an important tool that enables Google to continue to innovate and attack problems on the
scale of the entire web.

8/11/2019 Google File System Report
http://slidepdf.com/reader/full/google-file-system-report 36/36
Ennumerative Bibliography
[1] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung , “The Google FileSystem ”. Pages 1-10.
[2] R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao , “Comparative analysis of GoogleFile System and Hadoop Distributed File System”, In : ‘ International Journal of
Advanced Trends in Computer Science and Engine ering, Vol. 3’ , No.1, Pages : 553 – 558.
[3] ‘HowStuffWorks: “Google File System Basics”’, available athttp://computer.howstuffworks.com/internet/basics/google-file-system1.htm
[4] Johannes Passing , “The Google File System and its application in MapReduce ”, Pages
1-8.[5] ‘Report: Google Uses About 900,000 Servers ’, available athttp://www.datacenterknowledge.com/archives/2011/08/01/report-google-uses-about-900000-servers/
[6] ‘What is Google File System (GFS)? – Definiti on from Techopedia’, available athttp://www.techopedia.com/definition/26906/google-file-system-gfs
[7] R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao , “Comparative analysis of GoogleFile System and Hadoop Distributed File System”, Pages 1 &2.
[8] ‘Google File System’, available at http://kaushiki-gfs.blogspot.in/?view=classic[9] ‘The Google File System : The paper trail’, available at http://the-paper-trail.org/blog/the-google-file-system/
[10] ‘POSIX. 1 FAQ’ , available at http://www.opengroup.org/austin/papers/ posix_faq.html
[11] ‘Google File SystemGFS – Google File System – Wikipedia’, available athttp://en.wikipedia.org/wiki/Google_File_System#mediaviewer/File:GoogleFileSystemGFS.svg
[12] Mauro Fruet , “Distributed File Systems ”, In : ‘ University of Trento – Italy2011/12/19 ’, Pages 13 -20.
[13] Ping Yeh , “Cloud Computing and Mobile Platforms ”, Page.21 -27.