gossip algorithms and mixing times alex dimakis based on collaborations with florence benezit,...
TRANSCRIPT

Gossip Algorithms and Mixing Times
Alex Dimakis based on collaborations with
Florence Benezit, Kannan RamchandranAnand Sarwate, Patrick ThiranMartin Vetterli, Martin Wainwright

2
problem: distributed averaging
• Every node has a number (i.e. sensing temperature)
• Every node wants access to global average
• Want a randomized, distributed, localized, algorithm to compute averages.
2 2
3
5
12

3
gossip algorithms for aggregation
• Start with initial measurement as an estimate for the average and update
• Each node interacts with a random neighbor and both compute pairwise average
• Converges to true average• Fundamental building block for
numerous problems (distributed detection, localization, randomized projections for compressive sensing)
• How many messages?
2 2
3
5
2.5
2.5
12
3.75
3.75
7.87
7.87
( Related work: Tsitsiklis, Boyd et al, Alanyali et al. Spanos et al, Sundaram et al., Nedich et al.)

4
Standard gossip
2 2
3
5
12
2.5
2.5
1/2 0 1/2 0 0
0 1 0 0 0
1/2 0 1/2 0 0
0 0 0 1 0
0 0 0 0 1
2235
12
2235
12
x(0)W(1)
=
2.52
2.55
12
2.52
2.55
12
x(1)
x(t)= W(t) x(t-1) = Πt W(t)
x(0)
W(t) iid random matrices

5
How many messages
• ε-averaging time: First time where x(t) is ε-close to the normalized true average with probability greater than 1-ε.
• x(t)= W(t) x(t-1) = Πt W(t) x(0).• Define W= E W(t)
• Theorem: ε-averaging time can be bounded using the spectral gap of W:
€
Tave (n,ε) = supx(0)
inf t : P(|| x(t) − xave
r 1 ||
|| x(0) ||≥ ε) ≤ ε
⎧ ⎨ ⎩
⎫ ⎬ ⎭
€
Tave[n,ε] ≤3log(ε−1)
1− λ 2(W )
(Boyd, Gosh, Prabhakar and Shah, IEEE Trans. On Information Theory, June 2006)
Scaling laws?or how does the number of messages scale if I double my network
Scaling laws?or how does the number of messages scale if I double my network

6
cost of standard gossip
• Depends on graph and the gossip probabilities:
• Complete graph: Tave=Θ(n log1/ε) (Kempe et al. FOCS’03)
• Small World/Expander: Tave=Θ(n logn)
• Random Geometric Graphs: Tave =Θ(n2)
Note that flooding everything everywhere costs Θ(n2) messages

7
random geometric graphs
• Realistic sensor network model (Gupta & Kumar, Penrose):
• Random Geometric Graph G(n,r): n random points, connect if distance<r
• Connectivity threshold:
r
)log
()(n
nnr Θ=

8
• Standard Gossip algorithms require a lot of energy.(For realistic sensor network topologies)
• Why: useful information performs random walks, diffuses slowly• Can we save energy with extra information?
• Idea: gossip in random directions, diffuse faster.
• Assume each node knows its location and locations of 1-hop neighbors.
cost of standard Gossip

9
Random Target Routing: How to find an (almost) random node
• Node picks a random location (=“target”)
• Greedy routing towards the target
• Probability to receive ~ Voronoi cell area

10
Geographic Gossip
• Nodes use random routing to gossip with nodes far away in the network
• Each interaction costs
• But faster mixing• Number of messages
))(
1()
log(
nrO
n
nO =
2
3
2.5
2.5
(D, Sarwate, and Wainwright. IPSN’06, IEEE Trans. on Signal Processing)
€
Tave (n) ~ O(n1.5)

11
Recent related work
• Wenjun, Huaiyu - O(n1.5 log1/ε ) using partial location lifting (L.A.D.A. ISIT’2007)
• Shah, Jung, Shin - O(n1.5 log1/ε) by expander liftings• (related to liftings of Markov chains for faster mixing)• Different target distribution? (say ~1/r2)?
Rabbat (Statistical Signal Processing ’07) showed it still scales like O(n1.5 log1/ε)
• Can n1.5 be improved?

12
Why not average on the path?
• Averaging on the routed path? • The routed packet computes the sum of all the nodes it
visits, and a hop-count. The average is propagated backwards to all the nodes on the path.
12 4 1
2
22 2 2

13
Path averaging is optimal
• Theorem: Geographic gossip with path averaging on G(n, r) requires expected number of messages
Tave=Θ(n log1/ε)
(with high probability over random graphs)
• Optimal number of messages (since averaging n numbers).
• Analysis bounds eigenvalues of a random matrix through the Poincare inequality.
(Benezit, D., Thiran, and Vetterli, Allerton 2007)

14
Proof ingredients: appetizers
• ε-averaging time: First time where x(k) is ε-close to the normalized true average with probability greater than 1-ε.
• x(t)= W(t) x(t-1) = Πt W(t) x(0).• Define W= E W(t)
• The ε-averaging time can be bounded using the spectral gap of W:
⎭⎬⎫
⎩⎨⎧
≤≥−
= εεε )||)0(||
||1)(||(:infsup),(
)0( x
xtxPtnT ave
xave
r
€
Tave (n,ε) ≤3log(ε−1)
1− λ 2(W )

15
Proof ingredients:Poincare inequality
• Capacity of an edge e=(i,j),C(e)=π(i)Pij• Each pair of states x,y has demand D(x,y)=π(x) π(y)• A flow is a way to route D(x,y) units from x to y, for all
pairs.
• Cost of a flow is ρ(f)= maxef(e)/ C(e). Length of a flow is the length of the longest flow-carrying path.
• Poincare inequality:
€
1
1− λ 2(W )≤ ρ( f )l( f )
i j
Diaconis, Strook, Geometric bounds on eigenvalues, Ann. of Applied Probability, 1991
Sinclair, Improved bounds for mixing rates of markov chains and multicommodity flow. STOC’91, Combinatorics, Probability and Computing, volume 1, 1992

16
Proof ingredients: Counting paths
W(i,j)= 1/length of path * Prob(i,j) averaged together)
Key lemma: Typical pairs of nodes i,j are averaged in Ω(n) paths.
W(i,j)=Ω(n1.5) if d(i,j)<= const n0.5

17
Mixing ingredients
• For each pair of nodes (i,j) we construct a flow that does not overload any edge.
• Can be done by going through one intermediate node for each pair i,j
• D(x,y)= 1/n2 , C(e)1/n 1/n1.5=1/n2.5 (for e typical)
• Cost= ρ(f)=n1/2 , (f)=2• Poincare coefficient O( n1/2) • Averaging time O(n1/2), but each averaging round
costs O(n1/2) messages (= typical path length).

gossip and mobility
18

gossip and mobility
19
Refresh:Every node randomly and independently chooses a new site

gossip and mobility
20
•Grid with no mobility Tave=Θ(n2 log1/ε)•Grid with full mobility Tave=Θ(n log1/ε)•What if only horizontal mobility?

gossip and mobility
21
•Grid- horizontal mobility Tave=Θ(n2 log1/ε) (useless)•Bidirectional mobility Tave=Θ(n log1/ε) (as good as full)•Adding m mobile agents: cuts time by m factor
Sarwate,D: The impact of mobility on gossip algorithms (Infocom 2009)

gossip and mobility
22

Open problem: gossip and mobility
23
Random walk: Every node does random walk step on grid.

Open problem: gossip and mobility
24

Open problem: gossip and mobility
25
•The random walk model tends to the refresh model if enough moving steps m are allowed between each gossip step•Conjecture: the convergence is monotonically decreasing in the number m•What is the scaling of messages for m=1 ?•More realistic mobility models (e.g. random waypoint)?
•Gossip algorithms are especially interesting for scenarios with mobility and unknown topology

26
Research directions
• Showed that random path averaging is optimal.• Random path idea can be useful for message
passing/distributed optimization algorithms more generally.
• This scheduling avoids diffusive nature of random walks-spreads spatial information fast.
• Impact of mobility?• Exploiting the physical layer?
• Impact of quantization, message errors?
• Scaling laws for distributed optimization problems?

27
fin

28
Poincare inequality: an example
• Capacity C(e)=π(i)Pij= 1/n 1/2• D(x,y)=π(x) π(y)= 1/n2
• A flow is a way to route D(x,y) units from x to y, for all pairs. (no choice!)
• Cost of a flow is ρ(f)= maxef(e)/ C(e)
• ρ(f)=1 / (1/2n)=2n • Length of a flow is the length of the longest flow-
carrying path. (f)=n• Poincare inequality:
1/n2
€
1
1− λ 2
≤ ρ ( f )l( f ) = 2n2

Statistical inference
t1
t2F
t4
t3
x1
x5
x2
x3
x4
€
p(r x ) =
1
Zψ s(xs)
s∈V
∏ ψ st (xs, x t )(s,t )∈E
∏
12
2
Consider an undirected graphical model with potential functions i , ij
The probability of an observation (x1..5) is
What is the distribution of x5 given some (noisy) observations?

Inference in sensor networks through message passing
x1
x9
x7
x4
x8
y1 x2
y2
x5y5 x6
y6
x3
y8

Message passing for sensor networks
• Optimal mappings from nodes to motes are NP-hard.
• There exist graphical models which require routing.
• Theorem: Any graphical model can be modified so that no routing is required.
• Reweighted belief propagation is very robust and practical. (packet drops, node failures, dynamic changes)
(Schiff, Antonelli, D, Chu, and Wainwright. IPSN’07)

Deployment
Motes
A B C
ED F
G H I
1
7
13
25
31
19
• Two space heaters for temperature gradient
• Empirical model to generate potential functions
• Sample at red dots, predict at blue dots

Deployment Results• Estimate temperature as
mean of marginal• Good accuracy
– Within 3 degrees!
Node Actual Temp Mean of Marginal
8 24.5ºC 23.2ºC
11 43.6ºC 41.4ºC
22 27.5ºC 25.3ºC
8 11 22

Simulation results
• Errors in Sensor Readings

Resilience to Communication Failures (simulation results)
• Dead Motes
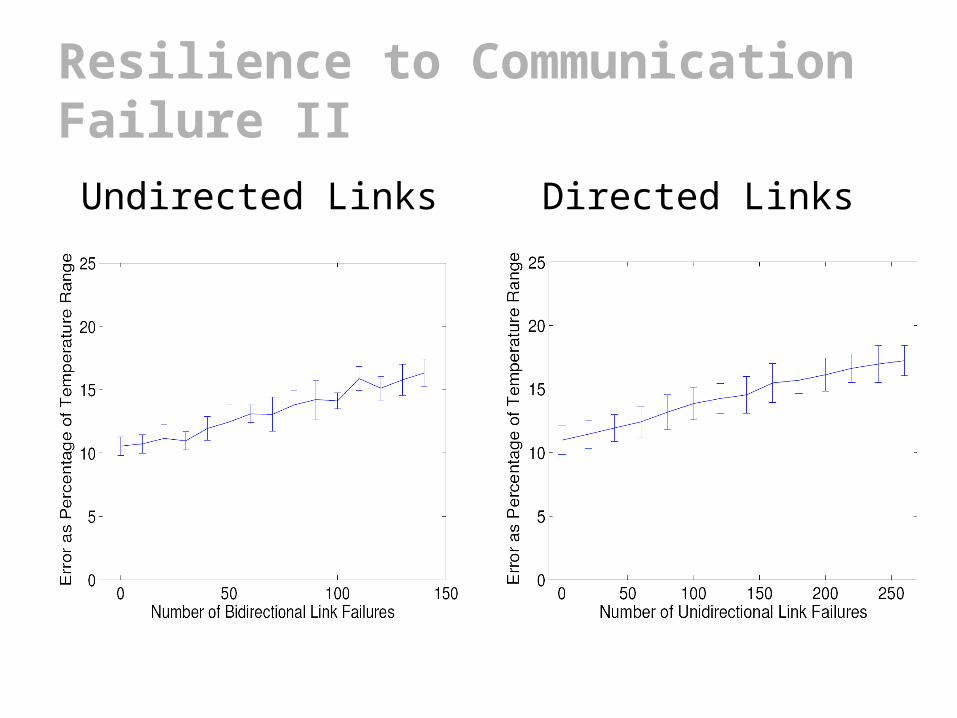
Resilience to Communication Failure II
Undirected Links Directed Links

37
Poincare inequality: an example
• Capacity C(e)=π(i)Pij= 1/n 1/2• D(x,y)=π(x) π(y)= 1/n2
• A flow is a way to route D(x,y) units from x to y, for all pairs. (no choice!)
• Cost of a flow is ρ(f)= maxef(e)/ C(e)
• ρ(f)=1 / (1/2n)=2n • Length of a flow is the length of the longest flow-
carrying path. (f)=n• Poincare inequality:
1/n2
€
1
1− λ 2
≤ ρ ( f )l( f ) = 2n2