gpu computing architectures -...
TRANSCRIPT

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU Computing Architectures10th Summer School in Statistics for Astronomers
Pierre-Yves Taunay
Research Computing and Cyberinfrastructure224A Computer Building
The Pennsylvania State UniversityUniversity Park
June 2014
1 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Introduction
2 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Objectives
1. (Re)discover GPUs2. Reasons for GPU computing3. Review GPU architectures4. Example(s)
3 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Reminders
I Thread: Sequence of instructions to be executed on a coreI SIMD: Single Instruction Multiple Data
4 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU
I GPU: Graphics Processing UnitI Dedicated to graphicsI Highly parallel architectureI Better at that than CPUs
5 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPGPU – what
I GPGPU: General Purpose computing on GPUI Took off with introduction of CUDA in 2006I CUDA: Compute Unified Device Architecture
↪→ Hardware and software model for NVIDIA GPUsI Alternative: OpenCL
6 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPGPU – where
I Everywhere !↪→ Finance↪→ Computational Engineering↪→ Numerical Methods↪→ Defense↪→ Computational Chemistry↪→ Astrophysics↪→ ...
7 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPGPU – whyI Previous session: expensive machines to solve larger problems
fasterI GPUs: do that at a fraction of the cost !
Hardware Flops (DP) Power (W) Price (k$)2 Ivybridge EX
(2×15 cores 2.8 GHz; 0.672 TFlops 310 8.4–13.78 DP ops/cycle)
K40 GPU 1.43 TFlops 235 3–4GTX Titan Black 1.7 TFlops 250 1
Table: K40 GPU vs. GTX Titan Black vs. dual socket server withIvybridge EX
I Can use a gamer’s card (e.g. GTX) to do calculations↪→ Titan Black – $1k
8 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPGPU – why
Great ! Let’s ditch the CPU, then.I Not so fast !I CPUs are great at serialI Still needed for other opsI Share load CPU/GPUI Amdahl’s law
9 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPGPU – how
I Different approaches throughout the yearsI Used to be C only
C, C++, Python, Fortran, Haskell, IDL, Java, Julia, LUA,Mathematica, MATLAB, .NET, Perl, Ruby, R
10 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Upcoming
I CPU vs. GPUI GPU computing architectureI Execution modelI GPU memory architectureI Example
11 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
CPU vs GPU
12 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
CPU, GPU
CPU – hostI Multiple cores e.g. 15/CPU - quad-socket: 60 coresI Run 1 thread / coreI Heavy threads
GPU – deviceI NVIDIA card: 32 threads minimum
↪→ 32 threads = 1 warpI 2048 threads run actively on a streaming multiprocessor
(SMX)I 15 SMX on a card → 30k+ concurrent threadsI Lightweight threads
13 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
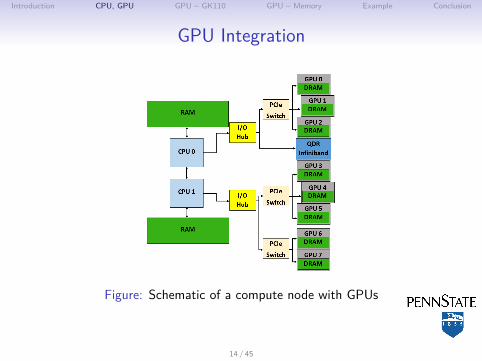
GPU Integration
Figure: Schematic of a compute node with GPUs
14 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU IntegrationA word on memory spaces
I CPU and GPU: distinct memoriesI Remark: CUDA 6 – Unified Memory
15 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Summary
I Many more lightweight threads on GPUI GPU is a PCIe card → transfer rates !I GPU and CPU: not same memory
16 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU ArchitectureGK110
17 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GK110 – at large
18 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
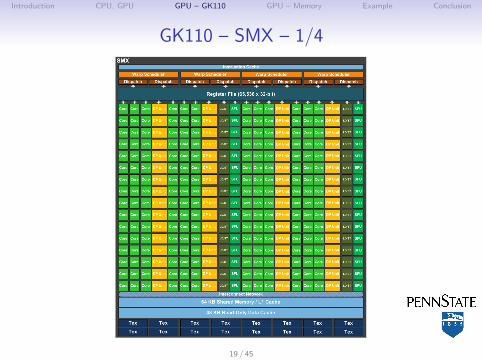
GK110 – SMX – 1/4
19 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GK110 – SMX – 2/4
I 4 warp schedulersI Bunch of execution units:
↪→ 192 CUDA cores↪→ 64 double prec. (DP) units↪→ 32 load/store (LD) units↪→ 32 Special Function Units (SFU)
I L1 cache / Shared memoryI Texture memoryI Registers for threads
20 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
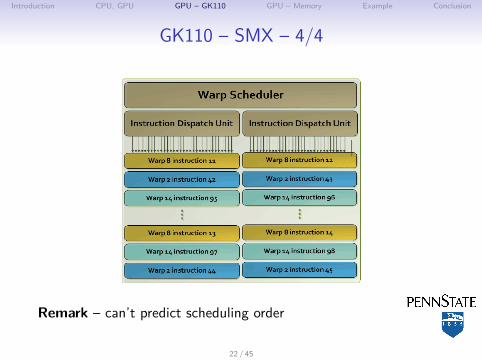
GK110 – SMX – 3/4
WarpsI 32 threadsI Scheduled through warp schedulersI Warp execute the exact same instructions – SIMD
SMXI Schedulers select four warpsI Issues one instruction from each warp to a group of cores /
LD-ST units / SFUI Instructions can be dual issued, including DP
21 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GK110 – SMX – 4/4
Remark – can’t predict scheduling order
22 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Summary
I GPU has multiple SMX that execute thread instructionsI Scheduling through “warp schedulers”
23 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Execution model
24 / 45
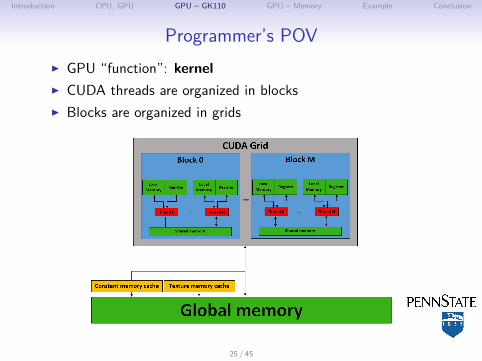
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Programmer’s POVI GPU “function”: kernelI CUDA threads are organized in blocksI Blocks are organized in grids
25 / 45
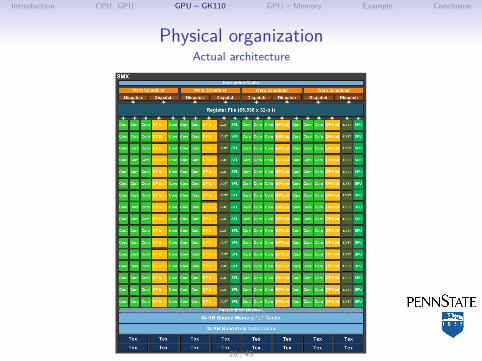
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Physical organizationActual architecture
26 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
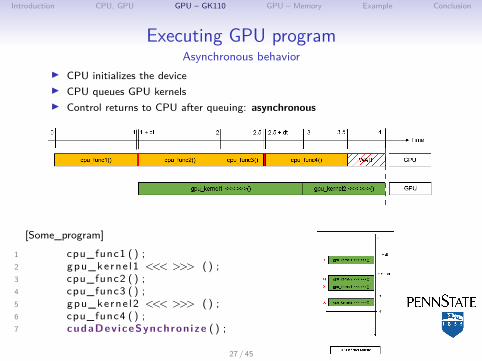
Executing GPU programAsynchronous behavior
I CPU initializes the deviceI CPU queues GPU kernelsI Control returns to CPU after queuing: asynchronous
[Some_program]
1 cpu_func1 ( ) ;2 gpu_kerne l1 <<< >>> () ;3 cpu_func2 ( ) ;4 cpu_func3 ( ) ;5 gpu_kerne l2 <<< >>> () ;6 cpu_func4 ( ) ;7 cudaDev iceSynchron ize ( ) ;
27 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Summary
I Programmer’s POV: kernel, grid, blocks, threadsI GPU execution is asynchronous with CPU
28 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU ArchitectureMemory
29 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
GPU DRAM
I LimitedI 5 GBI K40: 12 GB
30 / 45
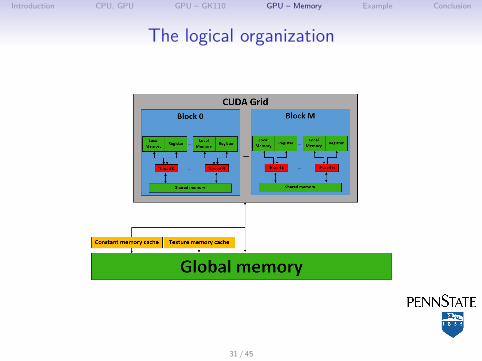
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
The logical organization
31 / 45
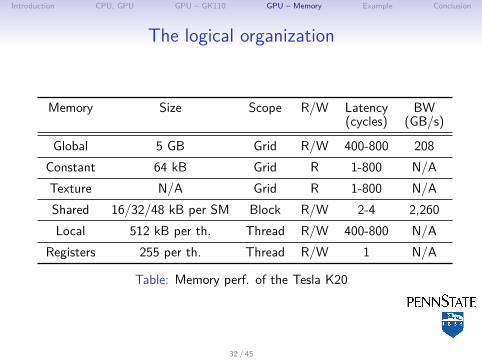
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
The logical organization
Memory Size Scope R/W Latency BW(cycles) (GB/s)
Global 5 GB Grid R/W 400-800 208Constant 64 kB Grid R 1-800 N/ATexture N/A Grid R 1-800 N/AShared 16/32/48 kB per SM Block R/W 2-4 2,260Local 512 kB per th. Thread R/W 400-800 N/A
Registers 255 per th. Thread R/W 1 N/A
Table: Memory perf. of the Tesla K20
32 / 45
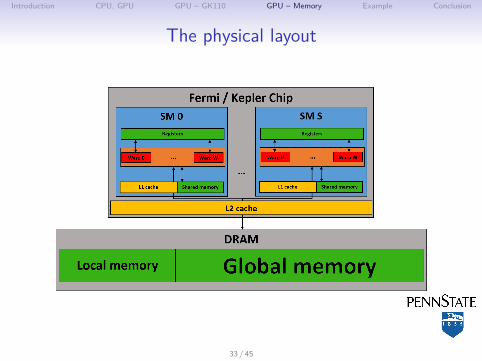
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
The physical layout
33 / 45
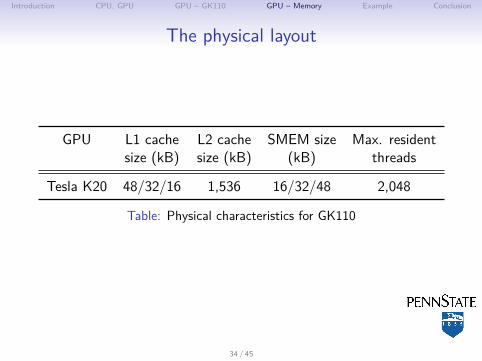
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
The physical layout
GPU L1 cache L2 cache SMEM size Max. residentsize (kB) size (kB) (kB) threads
Tesla K20 48/32/16 1,536 16/32/48 2,048
Table: Physical characteristics for GK110
34 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Summary
I GPU memory is limitedI Different memory and caches perf.
↪→ Optimization points
35 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
ExampleLikelihood calculation
36 / 45
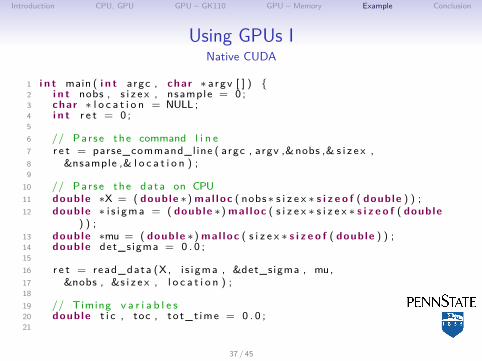
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Using GPUs INative CUDA
1 i n t main ( i n t argc , char ∗ a rgv [ ] ) {2 i n t nobs , s i z e x , nsample = 0 ;3 char ∗ l o c a t i o n = NULL ;4 i n t r e t = 0 ;56 // Parse the command l i n e7 r e t = parse_command_line ( argc , argv ,&nobs ,& s i z e x ,8 &nsample ,& l o c a t i o n ) ;9
10 // Parse the data on CPU11 double ∗X = ( double ∗) mal loc ( nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;12 double ∗ i s i gma = ( double ∗) mal loc ( s i z e x ∗ s i z e x ∗ s i z e o f ( double
) ) ;13 double ∗mu = ( double ∗) mal loc ( s i z e x ∗ s i z e o f ( double ) ) ;14 double det_sigma = 0 . 0 ;1516 r e t = read_data (X, i s i gma , &det_sigma , mu,17 &nobs , &s i z e x , l o c a t i o n ) ;1819 // Timing v a r i a b l e s20 double t i c , toc , to t_t ime = 0 . 0 ;21
37 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
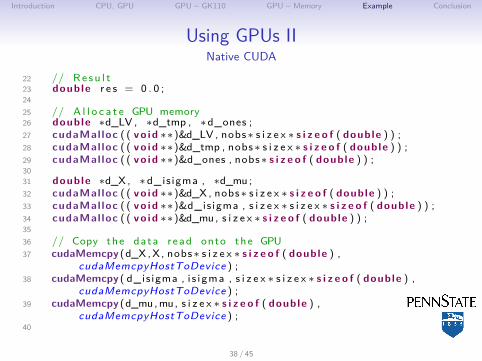
Using GPUs IINative CUDA
22 // Re su l t23 double r e s = 0 . 0 ;2425 // A l l o c a t e GPU memory26 double ∗d_LV , ∗d_tmp , ∗d_ones ;27 cudaMal loc ( ( vo id ∗∗)&d_LV , nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;28 cudaMal loc ( ( vo id ∗∗)&d_tmp , nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;29 cudaMal loc ( ( vo id ∗∗)&d_ones , nobs∗ s i z e o f ( double ) ) ;3031 double ∗d_X , ∗d_is igma , ∗d_mu ;32 cudaMal loc ( ( vo id ∗∗)&d_X , nobs∗ s i z e x ∗ s i z e o f ( double ) ) ;33 cudaMal loc ( ( vo id ∗∗)&d_is igma , s i z e x ∗ s i z e x ∗ s i z e o f ( double ) ) ;34 cudaMal loc ( ( vo id ∗∗)&d_mu, s i z e x ∗ s i z e o f ( double ) ) ;3536 // Copy the data read onto the GPU37 cudaMemcpy (d_X ,X, nobs∗ s i z e x ∗ s i z e o f ( double ) ,
cudaMemcpyHostToDevice ) ;38 cudaMemcpy ( d_is igma , i s i gma , s i z e x ∗ s i z e x ∗ s i z e o f ( double ) ,
cudaMemcpyHostToDevice ) ;39 cudaMemcpy (d_mu,mu, s i z e x ∗ s i z e o f ( double ) ,
cudaMemcpyHostToDevice ) ;40
38 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
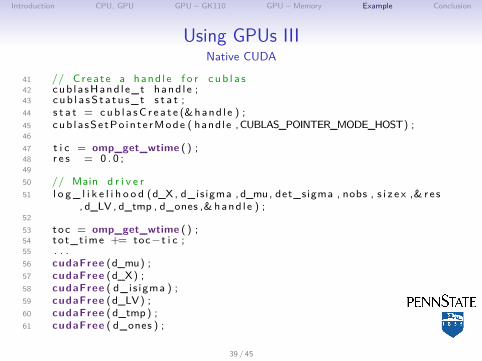
Using GPUs IIINative CUDA
41 // Crea te a hand l e f o r c ub l a s42 cub la sHand l e_t hand l e ;43 cub l a sS t a t u s_ t s t a t ;44 s t a t = cub l a sC r e a t e (&hand l e ) ;45 cub l a sSe tPo in t e rMode ( handle ,CUBLAS_POINTER_MODE_HOST) ;4647 t i c = omp_get_wtime ( ) ;48 r e s = 0 . 0 ;4950 // Main d r i v e r51 l o g _ l i k e l i h o o d (d_X , d_is igma , d_mu, det_sigma , nobs , s i z e x ,& re s
, d_LV , d_tmp , d_ones ,& hand l e ) ;5253 toc = omp_get_wtime ( ) ;54 tot_t ime += toc−t i c ;55 . . .56 cudaFree (d_mu) ;57 cudaFree (d_X) ;58 cudaFree ( d_is igma ) ;59 cudaFree (d_LV) ;60 cudaFree (d_tmp) ;61 cudaFree ( d_ones ) ;
39 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Using GPUs IVNative CUDA
6263 f r e e (X) ;64 f r e e ( i s i gma ) ;65 f r e e (mu) ;66 f r e e ( l o c a t i o n ) ;6768 r e t u r n EXIT_SUCCESS ;69 }
40 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
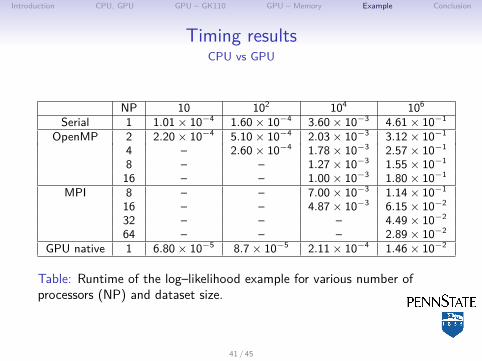
Timing resultsCPU vs GPU
NP 10 102 104 106Serial 1 1.01 × 10−4 1.60 × 10−4 3.60 × 10−3 4.61 × 10−1
OpenMP 2 2.20 × 10−4 5.10 × 10−4 2.03 × 10−3 3.12 × 10−1
4 – 2.60 × 10−4 1.78 × 10−3 2.57 × 10−1
8 – – 1.27 × 10−3 1.55 × 10−1
16 – – 1.00 × 10−3 1.80 × 10−1
MPI 8 – – 7.00 × 10−3 1.14 × 10−1
16 – – 4.87 × 10−3 6.15 × 10−2
32 – – – 4.49 × 10−2
64 – – – 2.89 × 10−2
GPU native 1 6.80 × 10−5 8.7 × 10−5 2.11 × 10−4 1.46 × 10−2
Table: Runtime of the log–likelihood example for various number ofprocessors (NP) and dataset size.
41 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Conclusion
42 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Conclusion
I GPUs are great at parallel tasks↪→ Large amount of lightweight threads↪→ Inherent parallel architecture w/ SMX, warp schedulers
I Programmer’s POV↪→ Kernels, grids, blocks, threads↪→ Asynchronous execution (mostly)↪→ Can’t access CPU mem.↪→ Limited memory: large optimization target
I Multiple languages for GPU programming
43 / 45

Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Want to learn more about GPU programming ?
Online resourcesI CUDA: http://www.nvidia.com/object/cuda_home_new.htmlI OpenCL: https://www.khronos.org/opencl/
MOOCI Coursera: Intro to heterogeneous computing – Wen-Mei HwuI Udacity: Intro to parallel programming – NVIDIA
BooksI Programming Massively Parallel Processors – David B. Kirk,
Wen-mei W. HwuI CUDA By Example – Jason Sanders, Edward KandrotI Numerical Computations with GPUs – Volodymyr Kindratenko
44 / 45
Introduction CPU, GPU GPU – GK110 GPU – Memory Example Conclusion
Questions ?
45 / 45