gpu programming: escience or engineering? henri bal commit/ msterdam vrije universiteit
TRANSCRIPT

GPU Programming:eScience or Engineering?
Henri Bal
COMMIT/
msterdamVrije Universiteit

Graphics Processing Units
● GPUs and other accelerators take top-500 by storm
● Many application success stories● But GPUs are very difficult to program and
optimize
http://www.nvidia.com/object/tesla-case-studies.html
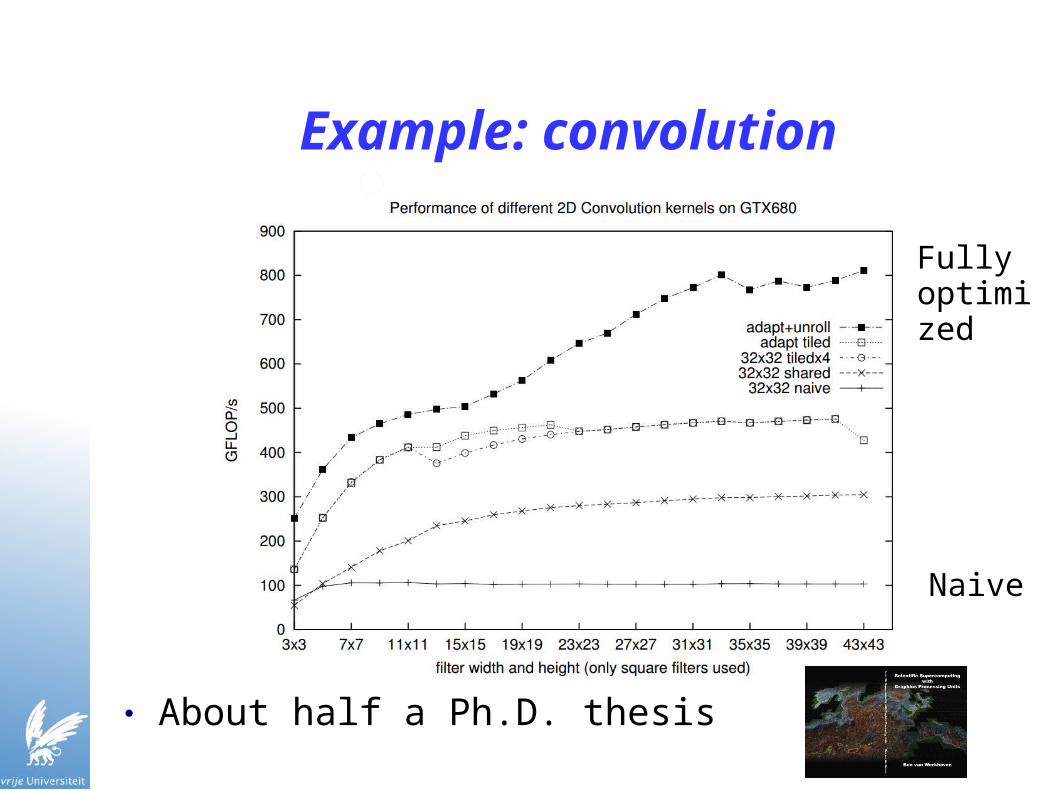
Example: convolution
● About half a Ph.D. thesis
Naive
Fully optimized

Parallel Programming Lab course
● Lab course for MSc students (next to lectures)● CUDA:
● Simple image processing application on 1 node
● MPI: ● Parallel all pairs shortest path algorithms
● CUDA: 11 out of 21 passed (52 %)● MPI: 17 out of 21 passed (80 %)

Questions
● Why are accelerators so difficult to program?● What are the challenges for Computer
Science?● What role do applications play?

Background
● Netherlands eScience Center● Bridge between ICT and applications
● Climate modeling, astronomy,water management, digital forensics, …
● COMMIT: (100 M€) public-private ICT program● http://www.commit-nl.nl/
● Distributed ASCI Supercomputer (DAS)● Testbed for Computer Science (Euro-Par 2014
keynote)
COMMIT/

• Cluster computing• Zoo (1994), Orca
• Wide-area computing• DAS-1 (1997), Albatross
• Grid computing• DAS-2 (2002), Manta, Satin
• eScience & optical grids• DAS-3 (2006), Ibis
• Hybrid computing• DAS-4 (2010), Glasswing, MCL
My background

Background (team)
Ph.D. students● Ben van Werkhoven
● Alessio Sclocco
● Ismail El Hewl
● Pieter Hijma
Staff● Rob van Nieuwpoort
(NLeSC)● Ana Varbanescu (UvA)
Scientific programmers● Rutger Hofman
● Ceriel Jacobs

Agenda
• Application case studies
• Multimedia kernel (convolution)
• Astronomy kernel (dedispersion)
• Climate modelling: optimizing multiple kernels
• Lessons learned: why is GPU programming hard?
• Programming methodologies
• ‘’Stepwise refinement for performance’’ methodology
• Glasswing: MapReduce on accelerators

Application case study 1: Convolution operations
Image I of size Iw by Ih
Filter F of size Fw by Fh
Thread block of size Bw by Bh
Naïve CUDA kernel: 1 thread per output pixel
Does 2 arithmetic operationsand 2 loads (8 bytes)
Arithmetic Intensity (AI) = 0.25

Hierarchy of concurrent threads
GridThread Block 0, 0
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3
Thread Block 0, 1
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3
Thread Block 0, 2
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3
Thread Block 1, 0
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3
Thread Block 1, 1
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3
Thread Block 1, 2
0,0 0,1 0,2 0,3
1,0 1,1 1,2 2,3
2,0 2,1 2,2 2,3

Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Constant Memory
Memory optimizations for tiled convolution
Filter (small) goes into constant memory
Threads within a block cooperatively load entire area they need into a small (e.g. 96KB) shared memory

Tiled convolution
16x16 thread block processing an 11x 7 filter
● Arithmetic Intensity:

Analysis● If filter size increases:
● Arithmetic Intensity increases: ● Kernel shifts from memory-bandwidth bound to compute-
bound
● Amount of shared memory needed increases →fewer thread blocks can run concurrently on each SM

Tiling
● Each thread block computes 1xN tiles in horizontal direction+ Increases amount of work per thread
+ Saves loading overlapping borders
+ Saves redundant instructions
- More shared memory, fewer concurrent thread blocksNo shared memory
bank conflicts

Adaptive tiling
● Tiling factor is selected at runtime depending on the input data and the resource limitations of the device● Highest possible tiling factor that fits within the
shared memory available (depending on filter size)
● Plus loop unrolling, memory banks, search optimal configuration
Ph.D. thesis Ben van Werkhoven,27 Oct. 2014+ FGCS journal, 2014

Lessons learned
● Everything must be in balance to obtain high performance● Subtle interactions between resource limits
● Runtime decision system (adaptive tiling), in combination with standard optimizations● Loop unrolling, memory bank conflicts

Application case study 2:Auto-tuning Dedispersion
● Used for searching pulsars in radio astronomy data
● Pulsar signals get dispersed: lower radio frequencies arrive progressively later● Can be reversed by shifting in time the signal’s
lower frequencies (dedispersion)
Alessio Sclocco et al.: Auto-Tuning Dedispersion for Many-Core Accelerators, IPDPS 2014

Auto-tuning
● Using auto-tuning to find optimal configuration for:● Different many-core platforms
● NVIDIA & AMD GPUs, Intel Xeon Phi
● Different observational scenarios● LOFAR, Apertif
● Different number of Dispersion Measures (DMs)● Represents number of free electrons between source &
receiver● Measure of distance between emitting object & receiver
● Parameters:● Number of threads per sample or DM, thread block
size, number of registers per thread, ….

Auto-tuning: number of threads per thread block
LOFAR
Apertif

Histogram of achieved GFLOP/s
● 396 configurations, the winner is an outlier

Lessons learned
● Auto-tuning allows algorithms to adapt to different platforms and scenarios
● Auto-tuning has large impact on dedispersion● Guessing a good configuration without auto-
tuning is difficult

Application case study 3:Global Climate Modeling
● Understand future local sea level changes● Needs high-resolution simulations● Combine two approaches:
● Distributed computing (multiple resources)● GPUs
COMMIT/

Distributed Computing
● Use Ibis to couple different simulation models● Land, ice, ocean, atmosphere
● Wide-area optimizations similar to Albatross project(16 years ago), like hierarchical load balancing

Enlighten Your Research Global award
EMERALD (UK)
KRAKEN (USA)
STAMPEDE (USA)
SUPERMUC (GER)
#7
#10
10G
10G
CARTESIUS (NLD)
10G

GPU Computing● Offload expensive kernels for Parallel Ocean
Program (POP) from CPU to GPU● Many different kernels, fairly easy to port to GPUs● Execution time becomes virtually 0
● New bottleneck: moving data between CPU & GPU
CPU hostmemor
y
GPU devicememory
Host
Device
PCI Express link

Different methods for CPU-GPU communication
● Memory copies (explicit)● No overlap with GPU computation
● Device-mapped host memory (implicit)● Allows fine-grained overlap between computation
and communication in either direction
● CUDA Streams or OpenCL command-queues● Allows overlap between computation and
communication in different streams
● Any combination of the above

Problem
● Problem:● Which method will be most efficient for a given
GPU kernel? Implementing all can be a large effort
● Solution:● Create a performance model that identifies the
best implementation:● What implementation strategy for overlapping
computation and communication is best for my program?
Ben van Werkhoven, Jason Maassen, Frank Seinstra & Henri Bal: Performance models for CPU-GPU data transfers, CCGrid2014(nominated for best-paper-award)

MOVIE

Example result
Measured Model

Different GPUs (state kernel)

Different GPUs (buoydiff)

Comes with spreadsheet

Lessons learned
● PCIe transfers can have a large performance impact for applications with many small kernels
● Several methods for transferring data and overlapping computation & communication exist
● Performance modelling helps to select the best mechanism

Why is GPU programming hard?
● Mapping algorithm to architecture is difficult, especially as the architecture is difficult:● Many levels of parallelism● Limited resources (registers, shared memory)
● Less of everything than CPU (except parallelism), especially per thread, makes problem-partitioning difficult
● Everything must be in balance to obtain performance

Why is GPU programming hard?
● Many crucial high-impact optimizations needed:● Data reuse
● Use shared memory efficiently● Limited by #registers per thread, shared memory per
thread block
● Memory access patterns● Shared memory bank conflicts, global memory coalescing
● Instruction stream optimization● Control flow divergence, loop unrolling
● Moving data to/from the GPU● PCIe transfers

Why is GPU programming hard?
● Portability● Optimizations are architecture-dependent, and the
architectures change frequently● Optimizations are often input dependent
● Finding the right parameters settings is difficult● Need better performance models
● Like Roofline and our I/O model

Why is GPU programming hard?
● Bottom line: tension between● control over hardware to achieve performance● higher abstraction level to ease programming
● Programmers need understandable performance
● Old problem in Computer Science,but now in extreme form
(1989)

Agenda
• Application case studies
• Multimedia kernel (convolution)
• Astronomy kernel (dedispersion)
• Climate modelling: optimizing multiple kernels
• Lessons learned: why is GPU programming hard?
• Programming methodologies
• ‘’Stepwise refinement for performance’’ methodology
• Glasswing: MapReduce on accelerators

Programming methodology: stepwise refinement for
performance
● Methodology:● Programmers can work on multiple levels of
abstraction● Integrate hardware descriptions into programming
model● Performance feedback from compiler, based on
hardware description and kernel● Cooperation between compiler and programmer
P. Hijma et al., Stepwise-refinement for Performance: a methodology for many-core programming,” Concurrency and Computation: Practice and Experience (accepted)

MCL: Many-Core Levels
● MCL program is an algorithm mapped to hardware
● Start at a suitable abstraction level ● E.g. idealized accelerator, NVIDIA Kepler GPU,
Xeon Phi
● MCL compiler guides programmer which optimizations to apply on given abstraction level or to move to deeper levels

MCL ecosystem

Convolution example

Compiler feedback

Performance(GTX480, 9×9 filters)
380 GFLOPS
MCL:302 GFLOPS
Compiler +

Performance evaluation
Compared to known, fully optimized versions(* measured on a C2050, ** using a different input).

Current work on MCL:Heterogeneous many-core
clusters● New GPUs become available frequently, but
older-generation GPUs often still are fast enough● Clusters become heterogeneous and contain
different types of accelerators
● VU DAS-4 cluster:● NVIDIA GTX480 GPUs (22)● NVIDIA K20 GPUs (8)● Intel Xeon Phi (2)● NVIDIA C2050 (2), Titan, GTX680 GPU● AMD HD7970 GPU

Cashmere
● Integration MCL + Satin divide-and-conquer system
● Satin [ACM TOPLAS 2010] does:● Load-balancing (cluster-aware random work-
stealing)● Latency hiding
● MCL allows kernels to be written and optimized for each type of hardware
● Cashmere does integration, application logic, mapping, and load balancing for multiple GPUs/node

Cashmere skeleton

Kernel performance (GFLOP/s)

K-Means on a homogeneous GTX480
cluster
scalability absolute performance

Heterogeneous performance
Homogeneous:efficiency on 16 GTX480 Heterogeneous:efficiency over total combined hardware

Lessons learned
● MCL● Enables us to develop many optimized many-core
kernels● Key: stepwise refinement + multiple abstraction
levels
● Cashmere ● High performance and automatic load balancing
even when the many-core devices differ widely● Efficiency >90% in 3 out of 4 applications in
heterogeneous executions

Agenda
• Application case studies
• Multimedia kernel (convolution)
• Astronomy kernel (dedispersion)
• Climate modelling: optimizing multiple kernels
• Lessons learned: why is GPU programming hard?
• Programming methodologies
• ‘’Stepwise refinement for performance’’ methodology
• Glasswing: MapReduce on accelerators

Other approaches that deal with performance vs
abstraction● Domain specific languages● Patterns, skeletons, frameworks● Berkeley Dwarfs

Glasswing: Rethinking MapReduce
● Use accelerators (OpenCL) as mainstream feature
● Massive out-of-core data sets● Scale vertically & horizontally● Maintain MapReduce abstraction
Ismail El Helw, Rutger Hofman, Henri Bal [HPDC’2014, SC’2014]

Glasswing Pipeline
● Overlaps computation, communication & disk access
● Supports multiple buffering levels

GPU optimizations
● Glasswing framework does:● Memory management● Some shared memory optimizations ● Data movement, data staging
● Programmer:● Focusses on the map and reduce kernels (using
OpenCL)● Can do kernel optimizations if needed
● Coalescing, memory banks, etc.

Glasswing vs. Hadoop64-node CPU Infiniband
cluster

Glasswing vs. Hadoop16-Node GTX480 GPU
Cluster

Performance K-Means
Hadoop
GlasswingGPU
GlasswingCPU
GPMRcompute

Compute Device Comparison

Lessons learned
● Scalable MapReduce framework combining coarse-grained and fine-grained parallelism
● Handles out-of-core data, sticks with MapReduce model
● Overlaps kernel executions with memory transfers, network communication and disk access
● Outperforms Hadoop by 1.2 – 4x on CPUs and20 – 30x on GPUs

Discussion
● eScience applications help us to● Understand the complexity of GPU programming● Validate our ideas and software● Give inspiration for new CS research
● Applications do need performance of GPUs● Next in line: SKA, digital forensics, water
management …
● GPU programming and optimization is too time-consuming for real applications

Discussion
● Dealing with performance● GPU programs need many complex optimizations
to obtain high performance● Auto-tuning, performance modelling, machine
learning, compiler-based reasoning
● How to deal with the tension between abstraction-level and control?● New programming methodologies that allow a
choice● Frameworks that do separation of concerns
