grammars, constituency and order a grammar describes the legal strings of a language in terms of...
TRANSCRIPT

Grammars, constituency and order
A grammar describes the legal strings of a language in terms of constituency and order.
For example, a grammar for a fragment of English might say that a legal sentence consists of – a noun phrase (subject), – followed by a verb phrase (predicate).
This rule is commonly written as – S → NP VP

Constituents of constituents
The constituents of constituents may be described by other rules.
They would refine, for example, the initial decomposition– [the dog] [chased a cat]
into a complete decomposition – [[the] [dog]] [[chased] [[a] [cat]]]
according to the following rules:

Grammar rules for a fragment of English
S → NP VP NP → Det N VP → V NP N → dog N → cat Det → the Det → a V → chased

Parse trees (derivation trees)
Hierarchical decomposition of sentences are more commonly expressed by special trees, known as parse trees or derivation trees.
For our sample sentence, we would have the parse tree below
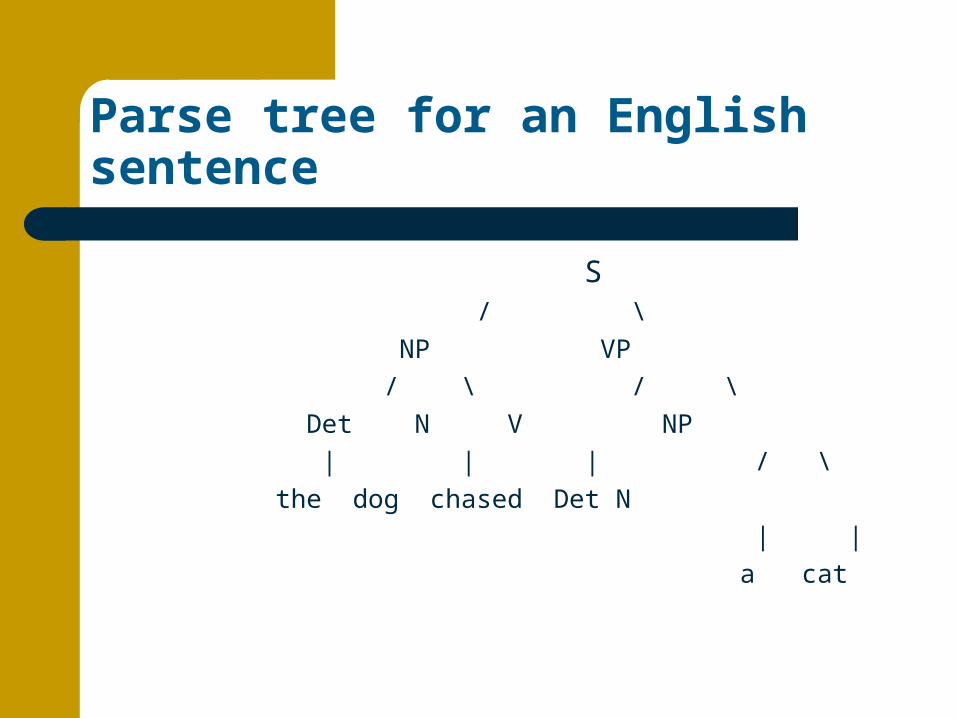
Parse tree for an English sentence
S / \
NP VP
/ \ / \
Det N V NP
| | | / \
the dog chased Det N
| |
a cat

Sentences generated by grammars
The grammar with the rules above would also allow, or generate, sentences like– a dog chased a cat– the dog chased a dog– a cat chased the dog
since parse trees could be constructed for
these sentences.

Context-free grammars (CFGs)
In the example above, the alphabet S consisted of the set of English words.
A grammar also needs to specify symbols aside from S, and rules, so more precisely …

CFGs defined
… a context-free grammar (CFG) consists of – a set T of terminal symbols (analogous to S)– a set V of other variables (or nonterminals)– a start symbol S, which is a member of V– a collection P of rules (or productions), each with
a left-hand side (LHS) from V, and a right-hand side (RHS) from (V U T)*

Context freedom
The notion of context freedom means that any category may be expanded in accordance with the rules no matter where it appears.
So for example, the noun phrases that are legal subjects are the same as those that are legal objects (that is, are NPs in the V → NP rule).

Rules for a CFG for L(0(1+2)*)
– S → 0X– X → – X → YX– Y → 1– Y → 2

CFGs for palindromes
A CFG for even-length palindromes over {0,1}:– S → 0S0 | 1S1
A CFG for odd-length palindromes over {0,1}:– S → 0 | 1 | 0S0 | 1S1
Here we use the common convention allowing several rules with the same LHS to be combined into one, with vertical bars separating the RHSs.

Rules for other 1-variable CFGs
for all palindromes over {0,1}:– S → 0 | 1 | 0S0 | 1S1
for nonempty sequences of balanced parentheses:– S → ( ) | ( S ) | SS
for {0n1n | n ≥ 0}– S → | 0S1
for { x {0,1} | x has as many 0's as 1's}– S → | 0S1 | 1S0 | SS

Parse trees and grammars
A parse tree is legal for a CFG iff it satisfies each correspondence:– root ↔ start symbol– parent node ↔ LHS of a grammar rule– child node ↔ symbol from the RHS of a rule whose LHS is
the parent node– leaf ↔ terminal symbol (or
Also, the ordering of children of a node must match the ordering of the RHS symbols in the corresponding rule.

Partial parse (derivation) trees
It's convenient to allow representation of the progress of a parse by allowing leaves to be labeled by a nonterminal symbol (and perhaps ignoring the constraint on roots)
In any case, the left to right sequence of leaf labels (ignoring those labeled by ) is called the yield of the parse tree– so the yield is a string of terminals

Notational conventions
Lower case letters are interpreted as for DFAs– those near the beginning of the alphabet represent
terminals; those near the end of the alphabet represent strings
Capital letters represent nonterminals (variables)
Greek letters represent strings of variables and terminals– So a generic rule looks like A →

Derivations and rewrite rules
CFG rules are also rewrite rules. Here the rule S → NP VP would allow rewriting of S as
NP VP We may define generation in terms of derivation from S
by repeated rewriting e.g., we get the legal derivation
S => NP VP => Det N VP => the N VP =>
the dog VP => the dog V NP => the dog chased NP
=> the dog chased Det N => the dog chased a N
=> the dog chased a cat

Leftmost and rightmost derivations
For every parse tree there are unique leftmost and rightmost derivations
The rightmost derivation corresponding to the parse tree above is– S => NP VP => NP V NP => NP V Det N =>
NP V Det cat => NP V a cat => NP chased a cat => Det N chased a cat => Det dog chased a cat => the dog chased a cat

Leftmost and rightmost derivations
All but the simplest parse trees will have other associated derivations besides the leftmost and rightmost.
For every derivation there is a unique associated parse tree.
Def) Using the symbol =>* for the transitive closure of the => relation, then– a sentential form for G is a string from V U T such
that S =>*

Context-free languages (CFLs)
Fact: A CFG G with start symbol S licenses a parse tree for w iff S =>* w
Def) L(G) (the language generated by G) is
{x | G generates x}, or equivalently
{x | G’s start symbol derives x}, or
{x ε T* | x is a sentential form for G}, A language generated by a context-free
grammar is called a context-free language

Ambiguous grammars
Here’s a 1-variable CFG for a subset of algebraic expressions:– E → x | y | E+E | E*E | (E)
Note that this grammar allows multiple parse trees for some strings, like x+y*y.
A grammar with this property is said to be ambiguous.

An unambiguous grammar for algebraic expressions
Rules for an unambiguous grammar for the above language are given below: – E → E + T | T – T → T * F | F – F → x | y | ( E )

Inherent ambiguity
Ambiguity is common in natural languages.– But we don't want it in programming languages!
Often ambiguity can be removed.– i.e., a grammar can be replaced by an unambiguous
one, as seen above
But there are languages for which all grammars are ambiguous.
These languages are said to be inherently ambiguous.

Regular languages and CFLs
We’ve already seen examples of CFLs that aren’t regular languages
But it's fairly easy to show that all regular languages are context-free.
The languages {a}, {}, and have grammars with respective productions– S → a– S → – [no productions]

All regular languages are CFLs
Suppose L1 and L2 have respective start symbols S1 and S2.
Then we may get grammars with start symbol S for their union, for their concatenation, and for L1* by adding the respective productions – S → S1 | S2
– S → S1S2
– S → | S1S2
So all regular languages are CFLs

Grammars for regular languages
Any regular language can be generated by a special type of CFG.
Def) A right-linear grammar is a CFG where the RHS of each rule has the form xB or x, – for x ε T* and B ε V
Fact: Right-linear grammars generate all and only regular languages

Finding a grammar for a regular language
For a DFA M, consider the grammar G with– T = , V = Q and S = q0
– a rule qi → ajqk for each aj move from qi to qk
– a rule qi → aj for each aj move from qi to qk where qk ε F
An easy induction shows that *(q,x) = p iff
q =>* xp– and that *(q,x) = p and p ε F iff q =>* x
So L(G) = L(M)

DFAs for right-linear grammars
Conversely, let G be a right-linear grammar If all strings x on RHSs have length 1, then
the construction above can be reversed– and the proof above still holds
If not, then the construction can be modified by adding extra states as in Linz, pp. 91-2
In either case a DFA can be obtained for L(G)

Regular grammars
Left-linear grammars may be defined by analogy with right-linear grammars– every rule must have a RHS of the form Bx or x
Fact: Left-linear grammars generate all and only regular languages
A CFG is a regular grammar iff it is right-linear or left-linear– so a language has a regular grammar iff it is
regular

Backus-Naur form (BNF)
Grammars for programming languages generally use a variant of our CFG notation called BNF.
In BNF the symbol ::= is used instead of the rightward pointing arrow.
In BNF, terminal symbols may be given in bold face, or nonterminals may be delimited by angle brackets, e.g. – <identifier> ::= <letter> <digits>

Common BNF conventions
The vertical bar convention [ ] brackets
– for optionality (0 or 1 times)
{ } braces– for indefinite repetition (0 or more times)
( ) parentheses– for removing ambiguity, e.g., (a|b)c vs. a | bc

A sample grammar in BNF
– <conditional> ::= – if <test> then <block> [ else <block> ] endif– <block> ::= begin [<statements>] end– <statements> ::= { <statement> }– <test> ::= <var> <op> <var>– <statement> ::= <var> = <var>– <var> ::= x | y– <op> ::= = | /=