group communication robbert van renesse cs614 – tuesday feb 20, 2001
Post on 21-Dec-2015
216 views
TRANSCRIPT

Group Communication
Robbert van RenesseCS614 – Tuesday Feb 20,
2001

Distr. programming is hard
• True concurrency• No shared memory• No locks• Host failures & recoveries• Network failures
• Too many scenarios to wrap your brain around
• Coordination hard to achieve

Kinds of Distributed Apps
• Replicated Services• Parallel Computing• Factory Floor Control• Management Services• Cluster Services• Distributed Games• …

Commonality
• Each requires coordination between distributed, possibly flaky components over a possibly flaky network
• Each involves a dynamic group of processes communicating with one another

Basic operations
• JoinGroup(“group”, event-handler)– Events:
• Point-to-Point and multicast messages• Member Join and Leave (Crash) events
• SendP2P(“group”, member-id, message)
• Multicast(“group”, message)• LeaveGroup(“group”)

Programming Example
Main(){
char buf [ BUF_SIZE ];
group = JoinGroup(“chat”, EventHandler);
while (read(buf) != EOF) {
Multicast(group, buf);
}
}

Programming Example, cont’d
EventHandler(event){
switch (event.type) {
case VIEW: printf(“New view: %v”, event.view); break;
case DATA: printf(“%s: %s”, event.source, event.data);
}
}

What can go wrong?
• Message M gets delivered to X but not to Y– Lack of agreement on delivery
• M1 gets delivered before M2 at X, but the other way around at Y– Lack of order on delivery
• X thinks Z is up, while Y thinks Z is down– Lack of agreement on membership
lack of coordination programmer has to consider many
scenarios

Example 1: Replicated Service
• Updates are multicast• Lack of agreement on delivery of
messages can cause an update to be applied to only some of the replicas
• Lack of order on delivery of messages can cause updates to be applied in different orders at different replicas

Example 2: Parallel Computation
• Membership Partitioning of task• Lack of agreement on membership
Different processes partition the task differently Too little or too much work is done

Making life easier
• Reduce the number of possible scenarios by supporting network protocols that guarantee– Agreement of message delivery– Order of message delivery– Agreement of membership updates– Order of membership updates
• Results in fewer things to think about

Some Terminology
• Group: a set of processes• Member: a process in the group• View: a uniquely identified set of members
as seen by one or more group members– View should approach reachable set of
members– Members install new views over time– Each installed view of a group member always
includes itself– A member never installs the same view twice

Events
• A group member observes the following events:– Join()– Leave()– Crash()– View-Change(view)– Send-Multicast(msg)– Receive-Multicast(msg, sender)(We ignore multiple groups and point-to-point
traffic for the rest of today)
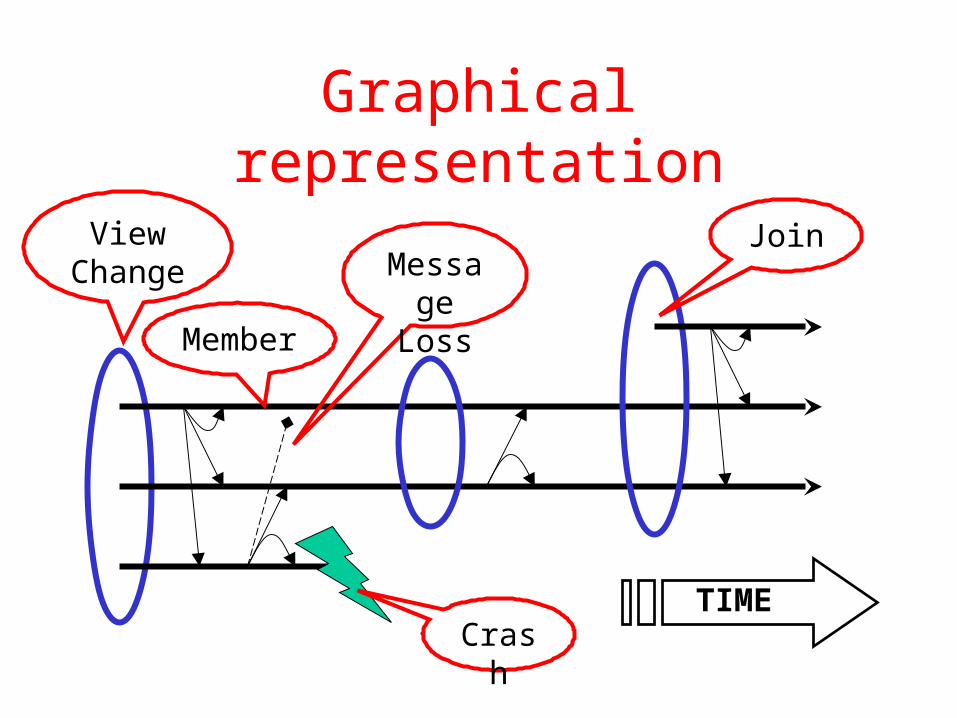
Graphical representation
Message
Loss
Crash
JoinView Change
TIME
Member

Traces and Properties
• Trace: history of events– E.g.: X sends msg4, Y receives msg3, X
gets view3, Y receives msg4, X gets view3, …
• Property: predicate on potential traces– E.g.: Messages are delivered in the order
they were sent– E.g.: Messages sent are eventually
delivered to all correct processes

Protocols
• Properties are implemented by protocols• Each protocol is a layer of software• Syntax the same for each layer:
– Join(), Send-Multicast(), …– Snap together like Lego blocks
• Semantics different:– Unreliable Reliable– Unordered Ordered– …
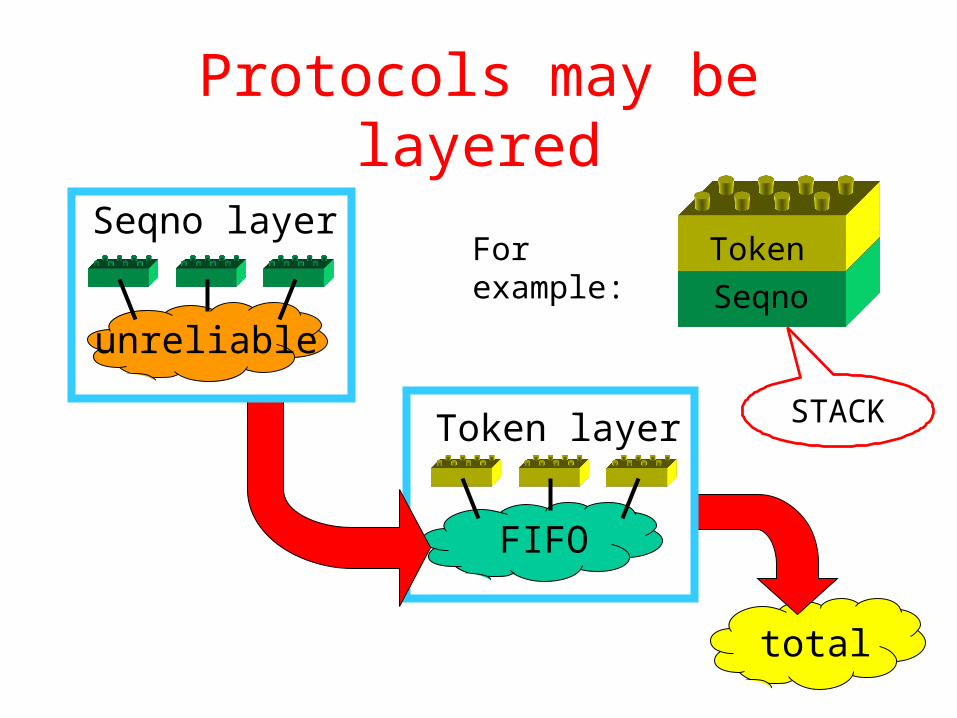
Protocols may be layered
Seqno layer
FIFO
total
unreliable
Token layer
For example: Seqno
Token
STACK

For example: Reliability
• Property: A message that is sent is eventually delivered to all correct processes
• Protocol: ack/timeout/retransmission

For example: Total Order
• Property: if two processes deliver the same two messages, they deliver them in the same order
• Protocol: centralized sequencer, or rotating token, or …

Other examples
Property Protocol
FIFO order Sequence number
Bound on resource use Flow Control
Confidentiality Encryption
Integrity Checksum
Consensus on Membership
Membership
Failures are detected Heartbeat
… …

Dependencies
• Total ordering protocols typically depend on reliable delivery:
layer ordering protocol on top of reliability protocol

Toolkits here at Cornell
• Horus and Ensemble are both protocol stack toolkits, each supplying dozens of protocol layers for group communication
• Plug’n’play allows applications to choose just those protocols that they require, rather one-size-fits-all
• Good performance and flexibility

Typical protocol stack
TOTAL ORDERING
MEMBERSHIP
FLOW CONTROL
RETRANSMISSION
CHECKSUM
UDP/IP

Each layer adds header

Extreme example app:Replicated State Machine
• Model of replicated service:– Each replica is a state machine– Initial state is the same– They receive the same update
messages– They receive them in the same order
keeps replicas in the same state
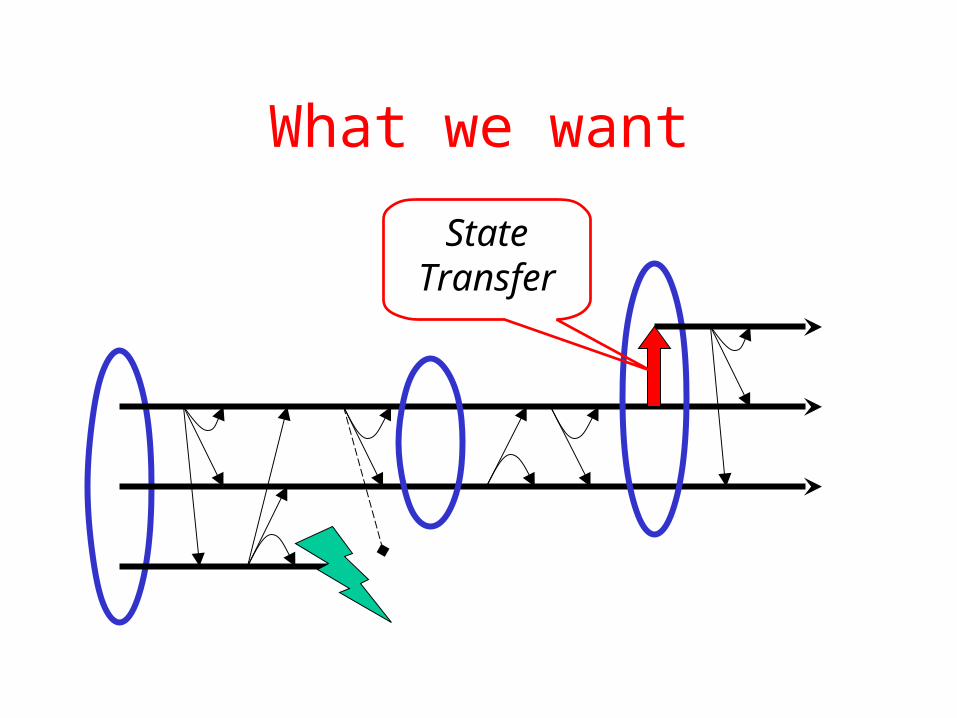
What we want
State Transfer
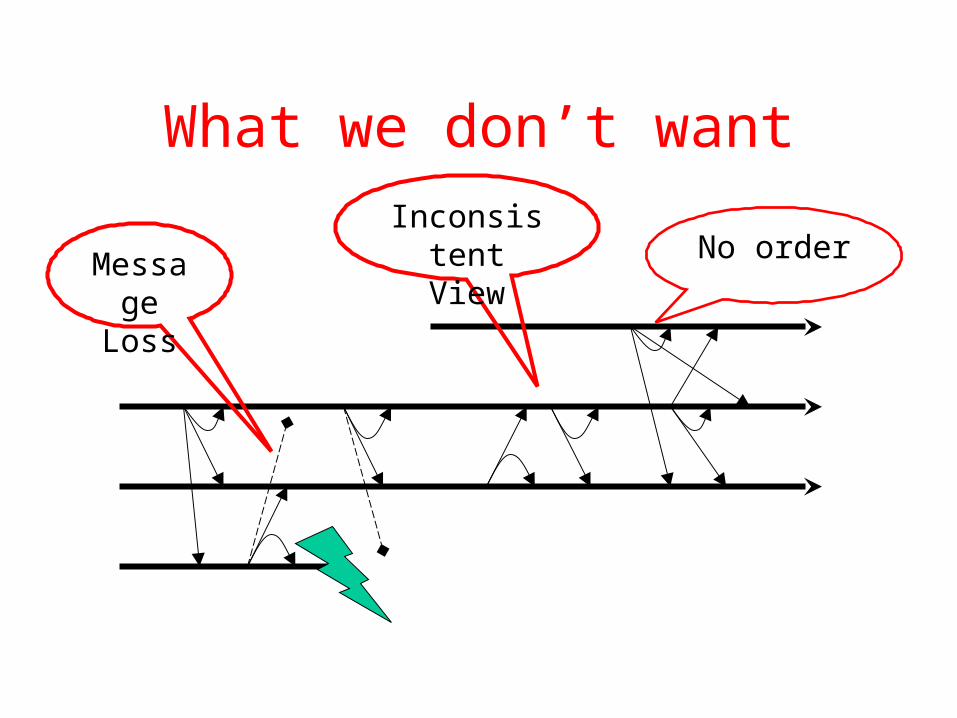
What we don’t want
No orderMessage
Loss
Inconsistent View

What we need:Virtual Synchrony
• Introduced by Ken Birman / Isis project
• Agreement and Ordering of messages• State Transfer• Failure Detection• Discovery of New Members • Consensus on views

Example: replicated integer
int X;
Main(){
Join(EventHandler);
for (;;) {
client := receive(ClientRequest);
switch (ClientRequest.type) {
case ReadInt: reply(client, X);
case WriteInt: multicast(ClientRequest.value);
}
}
}

Example cont’d
EventHandler(event){
switch (event.type) {
case View: /* nothing */ break;
case Update: X := event.value; break;
case GetState: return X;
case PutState: X := event.state; break;
}
}

What is a correct process?
• Many properties talk about correct processes, but what is one?
• Process X calls process Y correct if– Y is currently in X’s view– Y will be in X’s next view
correctness relative to views!

Reliability revisited
• A message sent by X in view V is delivered to all correct members (from X’s perspective), and possibly to some incorrect members in V as well…
• If you don’t want the latter part, there’s something called “uniform” or “safe” delivery, which is a much more expensive property.

View Consensus
• A message can only be delivered to members in one and the same view.
requires members to agree on views.
• Also, a member cannot receive messages sent in a different view than its current view.

Failure Detection
• A crashed or unavailable member is eventually removed from views.
guarantees some form of progress• (without this, every member would
be correct, resulting in infinite blocking while the reliability protocol tries to deliver messages to faulty members.

Message Orderings
• Several orderings are optional:– Unordered– FIFO: messages from the same
sender delivered in the order they were sent
– Causal: message delivery respects Lamport’s causality relation
– Total: as before

View Ordering
• Total:– If two processes both deliver V1 and
V2, they do so in the same order
• Without it, the definition of correctness would not make much sense…

Why is all this good?
• The number of possible scenarios has been reduced significantly
• Between two views, you can pretend there is no message loss, and members do not crash
• State Transfer is usually a very easy way to deal with Joins/Recoveries

Useful for lots of stuff
• Replication• Leader election: who’s going to be
responsible for some external event– Primary back-up
• Partitioning work: consensus on views allows parallel computations to split up the work
• Distributed Games: consensus on participants’ views on the virtual world