hadoop based weblog analysis: a reviewhadoop architecture with hadoop distributed file system...
TRANSCRIPT

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016), pp. 13-30
http://dx.doi.org/10.14257/ijseia.2016.10.6.02
ISSN: 1738-9984 IJSEIA
Copyright ⓒ 2016 SERSC
Hadoop based Weblog Analysis: A Review
Pooja D. Savant1, Debnath Bhattacharyya
2, Tai-hoon Kim
3
1Dept of Information Technology,
Bharati Vidyapeeth Deemed University College of Engineering,
Pune-411043, India 2Department of Computer Science and Engineering,
Vignan’s Institute of Information Technology,
Visakhapatnam-530049, India 3Department of Convergence Security,
Sungshin Women's University,
249-1, Dongseon-dong 3-ga, Seoul, 136-742, Korea
(Corresponding Author)
[email protected], [email protected], [email protected]
Abstract
The growth of websites and the Internet has opened up new research, social,
entertainment, education and business opportunities. With the fast growth of the Internet,
the digital data generated by the websites is becoming so massive that the traditional text
software and relational database technology faces a bottleneck while processing such
massive data and the results generated by these technologies are not satisfactory. Cloud
computing offers a good solution for this problem. Cloud computing is not only capable
of storing such massive data but also capable of processing and analyzing such
voluminous data faster, by making use of distributed storage and distributed computing
technology. A weblog is a group of connected web pages that consists of a log or daily
record of information, particular fields or views which is altered, every now and then, by
owner of site, other websites or by website users. An enterprise weblog analysis system
based on Hadoop architecture with Hadoop Distributed File System (HDFS), Hadoop
MapReduce Software Framework and Pig Latin Language aids the business decision-
making process of the system administrators and helps them to collect and identify the
potential value which is hidden within such huge data generated by the websites. Such a
weblog analysis includes the analysis of an Internet site’s entry log as well as provides
information about the amount of visitors, days of week and rush hours, views, hits, very
often accessed pages, application server traffic trends, performance reports at varying
intervals and statistical reports which indicate the performance of program.
Keywords: Cloud computing, Hadoop Framework, Distributed File System,
MapReduce Software Framework, Pig Latin Language
1. Introduction
The fast development of the Internet has led to increased usage of the Internet in
people's daily life, which has led to accelerated growth of web logs. This has posed
various problems as regards to handling of the weblogs in a timely manner, extracting of
the information required by the people from the massive weblogs generated. A single
computer cannot handle weblog satisfactorily to meet the needs of the people. A Hadoop-
based Weblog Analysis System combines Cloud Computing and Hadoop technology
processes all the gathered logs as well as carries out a distant parallelization study that
solves the difficulties of conventional setups such as simultaneous data handling and

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
14 Copyright ⓒ 2016 SERSC
gathering of data. A Hadoop-based Weblog Analysis System also reduces the congestion
efficiency of computing power as well as depository volume, saves a majority of the
processing time and greatly improves the effectiveness.
Various pitfalls observed in previous weblog analysis systems are as mentioned:
I. The growth of Internet has resulted into a considerable rise in the amount of logs due
to which log processing velocity of existing systems is extremely low.
II. The size of depository is inadequate for the huge logs because of the high escalation
in the quantity of logs everyday and the predefined size of hard disk belonging to the
server [4].
III. It is not possible to execute the collection and analysis of weblogs at the same time.
A Hadoop-based Weblog Analysis System employs a Hadoop cluster system which is
based upon the Cloud Environment. It is able to satisfactorily find a solution for the
problems stated overhead like a lower rate of performing operations, inadequate
depository volume. It can also perform gathering as well as study of the weblogs
simultaneously.
A Hadoop-based Weblog Analysis System is designed and implemented based on the
Hadoop architecture with Hadoop Distributed File System (HDFS), Hadoop MapReduce
Software Framework and Pig Latin Language.
Across the part mentioned below, we briefly discuss historical development about
Hadoop-based Weblog Analysis and also discuss the various steps to perform a Hadoop-
based Weblog Analysis.
1.1. History of Weblog Analysis using Hadoop
As the quick development of internet technology and digital data in recent years is
showing explosive growth, mobile devices and cloud computing environment is
generating huge data logs. Traditional text software’s and relational database technology
has been facing bottleneck and the presented results are not satisfactory. It is an
acknowledged and ongoing problem that the existing systems are incapable to handle
these huge data logs and consequently fails to find out the hidden trends within this huge
data [1].
In today’s world of Internet, analysis of log file is becoming essential for studying a
client’s actions for boosting the promotions as well as purchases. In order to analyze the
log data, we obtain required knowledge from this log data with the help of Web mining.
Log files are being produced extremely quickly with a speed ranging from about 1 to 10
Mb/s for every device. In one day, one data center is able to produce tens of terabytes of
log data. The size of the sets of data is very large. We need a parallel processing system
as well as a dependable data storage mechanism to perform the analysis of such huge
datasets. The Hadoop framework gives us dependable data storage with the help of
Hadoop Distributed File System as well as MapReduce calculating standard that acts as a
parallel operating setup over huge sets of data. A Hadoop distributed file system splits the
initial data as well as provides the initial data fragments across various computers across
HDFS cluster. These machines across the hadoop cluster carry blocks of data which
enables the processing log data in parallel and evaluates the result efficiently. The
superior hadoop methodology is to “Save initially and query afterwards”. Initially,
Hadoop puts entire data over the Hadoop Distributed File System. After this is
completed, Hadoop executes the queries which are in Pig Latin language which enables
to lessen the time for reply and the load against the user setup [2]. Pig is modeled to
blend well within explanatory methodology of SQL as well as the procedure-oriented
map-reduce methodology associated with either the machine-code or an assembly
language which is inflexible, resulting into a large amount of tailor-made consumer

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 15
computer program that proves difficult for managing as well as reutilizing. After being
completely executed, Pig performs the task of compiling Pig Latin in the form of
concrete designs. These concrete designs get implemented across Hadoop. Hadoop is a
publicly accessible, implementation of map-reduce. An Apache-incubator project such as
Pig is open-source and accessible for public usage. Pig drastically lessens the time which
is needed for performing generation as well as implementation related to their data study
activities, in contrast with the time taken when Hadoop is utilized alone. A new
debugging environment is obtained when Hadoop is integrated with Pig which results in
a very high efficiency leading to increased profitability [3].
1.2. Various Steps to Perform a Weblog Analysis using Hadoop
The various steps to perform a Weblog Analysis using Hadoop are as follows:
1.2.1. Data Pre-processing: All the records to be processed are dispersed across the
different Application Servers. The Weblogs spread across various Application Servers
undergo preliminary collation through Linux FTP protocol which is integrated into a log
file [1].
1.2.2. Upload: After the files finish cutting, the designated block size is uploaded into the
HDFS specified directories through various commands [1].
1.2.3. Hadoop processing: The data is not changed after the Weblog file is stored in
HDFS. The system functions are divided into two categories such as batch analysis and
interactive input conditions. The main purpose of batch analysis is to estimate traffic
statistics and conduct multi-dimensional analysis. The main purpose of Interactive
function is to analyze specific business and a specific range [1].
System administrator develops a basic program structure which consists of a shell script
frame:
(i) To receive different parameters according to the functional needs and
(ii) To call the Pig script which loads log and copies the analysis result that is to be
restored across various Linux directories [1].
1.2.4. Analysis: System administrator creates various dimensions analysis reports
according to the results generated such as sales distribution, Application server flow and
data, etc. [1].
2. Literature Review
In this section, we attempt to identify the various indicators derived through Weblog
Analysis and list out various kinds of Web Analytics Software. We also discuss the
Hadoop Framework, Hadoop Distributed File System (HDFS), MapReduce Software
Framework and Pig Programming Language.
2.1. Various Indicators derived through Weblog Analysis
When we perform analysis of a Web log, a server log file is transferred through an
Internet server. Depending upon the amounts that are present inside the log file, the most
prevalent signs such as the amount of web-site access by users as well as the amount
associated with distinct visitors, period of visit as well as final visit, customers who are
authenticated as well as last authenticated web-site access, information about week-days
as well as which are the hours at which the web-site traffic is the heaviest, what are the
domains or countries of the visitors of the host, list of hosts, what are the number of page
views, information about which are the highest viewed, entry, and exit pages, what are

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
16 Copyright ⓒ 2016 SERSC
the types of file used, which OS is used, which browsers are used, which robots are used,
referrer of HTTP, search engines which are used, which are the important group of words
as well as reserved words utilized for identifying the Internet site which is analyzed,
which HTTP errors are identified, information about who is currently visiting the site,
tracking of conversion, time of visit as well as page navigation can be obtained which
enables us to perform analysis of when, how, and by whom an Internet server is accessed.
Results can be produced with the help of log files promptly, or reports can be
generated on demand through a database containing the log files.
2.2. Hadoop
Hadoop is a publicly accessible platform which is utilized with the aim of storing and
extracting an accurate and deep understanding from huge volumes of data. The Apache
Software foundation is responsible for the development of the Hadoop project. The
Apache Software foundation develops open-source software for performing computations
which are dependable, adaptive to increased demands and distributed in nature.
Apache Hadoop is a suite of data and programming code that is used to develop
software programs and applications. It is a platform which enables to perform operations
on the huge sets of data in a distributed manner over clusters of machines utilizing easier
to understand programming standards. It is intended for increasing proportionally from
one server to a large number of computers. Every computer is equally capable in
providing local calculation as well as depository. The Apache Hadoop suite of data and
programming code used to develop software programs and applications is not reliant
upon the physical components of a computer to provide a system that is continuously
operational for a desirably long length of time. The generally available collection of
Hadoop programs and software packages is planned in such a way as to identify and deal
with the breakdowns across application layer which results in a serviceability that is
continuously operational for a desirably long length of time upon the cluster of machines,
with every machine across this cluster equally likely to suffer from failures.
The project contains the modules as mentioned:
a) Hadoop Distributed File System (HDFS)
b) Hadoop MapReduce
c) Pig
2.3. Hadoop Distributed File System (HDFS)
HDFS provides a means for greater rate of processing over the data belonging to a
program. Hadoop File System which was created by utilizing a DFS design is run over
affordable and easy to obtain physical components of a computer. HDFS is different from
other distributed systems due to its great fault-resilient nature and its design which
utilizes cheap hardware.
HDFS carries huge data as well as gives a simpler access mechanism. To save so
much large amount of data, the files are saved throughout numerous computers. The
acquired files are saved in repeating style to save the system against probable failure of
data. HDFS makes programs ready for managing in a parallel manner.
2.3.1. HDFS Architecture: The master-slave architecture is followed by HDFS and it
consists of the elements as shown in Figure 1.

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 17
Figure 1. Architecture of HDFS
Name Node: A Name Node carries metadata for HDFS. The Name Node saves and
maintains information about the position of the files in HDFS. This information
maintained by the Name Node is needed for fetching data spread within the hadoop
cluster across many computers. The Name Node is software that can be run on computer
hardware that is affordable and easy to obtain.
The Namenode system functions as the main server as well as performs jobs as
mentioned:
a) Management of the file system namespace.
b) Regulation of the client’s access to files.
c) Execution of the file or directory setup operations like rename, close, and open.
Data node: A Data node is a component of a computer that is affordable and easy to
obtain that executes the duty of saving HDFS files. A Data node is present for each node
across a hadoop cluster. The Data nodes handle the process of data-storage across HDFS.
They handle the blocks which contain parts of the file at a node. They send the file as
well as block information saved within a particular node and provide reply to the Name
Node for the entire file system operations. Data nodes execute reading and writing
transactions upon file setups, according to user demand. Data nodes carry out the
activities like creating a block, deleting a block, as well as replicating a block as per
Name Node command.
Block: The saving of client data is done inside HDFS files. The file across a file setup
is split into a single or multiple fragments and/or saved over distinct Data nodes. Each of
the file fragments is a Block. A Block is the minimal data quantity which is conducive for
reading and writing by HDFS. By default, 64 MB happens to be the block size. It is
possible to expand it, if we wish to implement a modification while configuring HDFS.
2.3.2. Features of HDFS: Various features of HDFS are given below:
a) Hadoop as well as HDFS, is pertinent for the purpose of implementing distributed
depository and performing distributed operations using a computer hardware that is
affordable and easy to obtain. Both are fault resilient, scalable, and very easy to expand.
b) HDFS is highly configurable. It has a default configuration which is applicable for
more number of installations. The configuration requires tuning only for very large
clusters.

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
18 Copyright ⓒ 2016 SERSC
c) HDFS periodically executes new features and improvements. HDFS includes a few
useful features as File permissions and authentication, Rack awareness which considers
the physical placement of a node during task-planning and providing a depository,
Safemode which is administrative mode with the aim of providing maintenance, fsck
which is a system software for maintenance that helps to identify the nature about state
associated with the file setup, for identifying the files/blocks which are missing, fetchdt
which is a system software for maintenance that enables the fetching of a
DelegationToken and storage of it in a file on the local setup, Rebalancer tool that
performs the task of balancing the cluster when the data is not distributed evenly across
the Data Nodes, post a software upgradation, it is feasible to go back to HDFS condition
prior to the upgradation if unforeseen problems arise through upgrade and rollback and
Secondary Name Node which carries out regular namespace check pointing and enables
to retain volume associated with the file consisting HDFS log of alterations, inside
specific boundaries across Namenode.
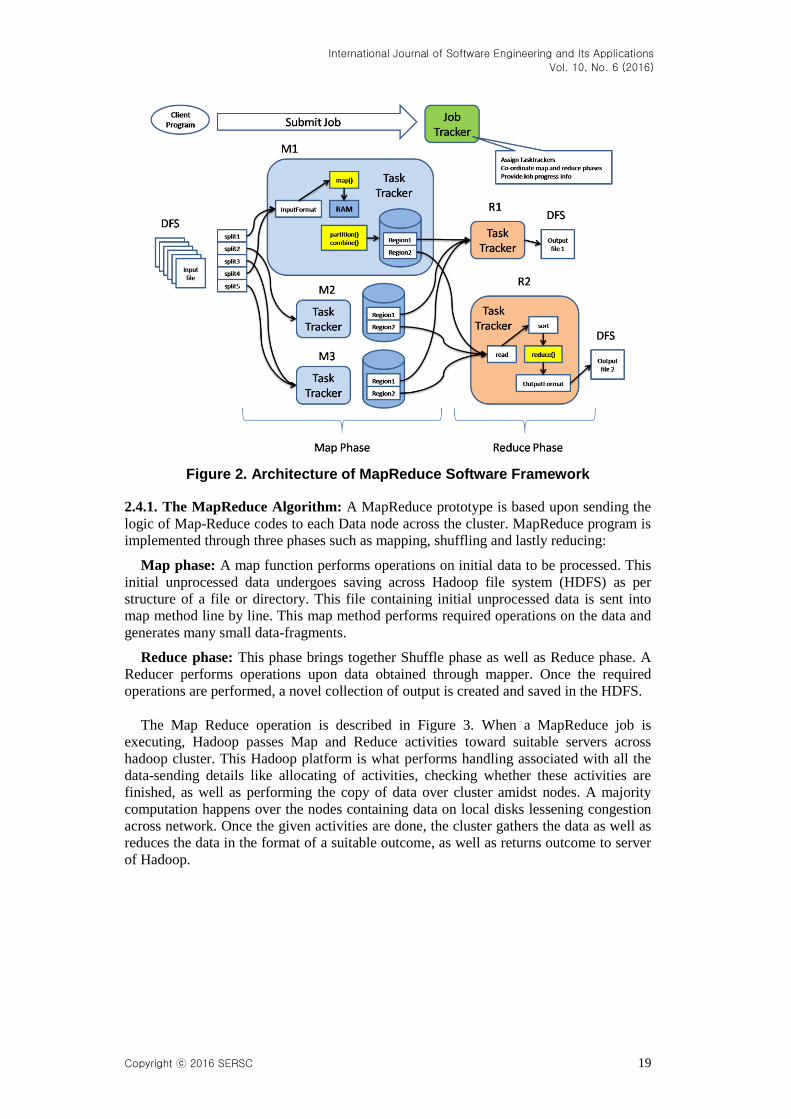
2.4. Hadoop MapReduce
Hadoop MapReduce is a system which is YARN-based for performing the parallel
processing of huge data sets. As described in Figure 2, MapReduce is a framework which
helps us to write applications to process large quantities of data, side-by-side, across huge
clusters of computer components that are affordable and easy to obtain in a dependable
manner. MapReduce is a technique for performing processing as well as a programming
standard that enables distributed processing which has its base in java. A MapReduce
procedure for solving a problem consists of a couple of significant activities, i.e., Map as
well as Reduce. Map accepts a collection of data and transforms it in the form of a
different collection of data, in which distinct constituents are split in the form of tuples
(key and value combinations). After this is done, reduce stage accepts the result derived
through map in the form of an input as well as does the task of combining the key and
value combinations of data into a mini-collection of key and value combinations. The
order of word MapReduce indicates that the reduce stage is executed after the map stage
every single time. A most significant benefit gained by using MapReduce lies in it being
simple to increase proportionally the performing of data operations across the various
processing nodes. As per MapReduce standard, various data handling natives are known
as mappers as well as reducers. Breaking down a data operation performing program in
the form of mappers as well as reducers is not always significant. As soon as a program is
written in the format of MapReduce, scaling the program to execute over a very large
number of devices over a cluster requires simply an alteration within the configuration.
Such kind of easy scalability allures a large number of programmers to utilize the
MapReduce model.
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 19
Figure 2. Architecture of MapReduce Software Framework
2.4.1. The MapReduce Algorithm: A MapReduce prototype is based upon sending the
logic of Map-Reduce codes to each Data node across the cluster. MapReduce program is
implemented through three phases such as mapping, shuffling and lastly reducing:
Map phase: A map function performs operations on initial data to be processed. This
initial unprocessed data undergoes saving across Hadoop file system (HDFS) as per
structure of a file or directory. This file containing initial unprocessed data is sent into
map method line by line. This map method performs required operations on the data and
generates many small data-fragments.
Reduce phase: This phase brings together Shuffle phase as well as Reduce phase. A
Reducer performs operations upon data obtained through mapper. Once the required
operations are performed, a novel collection of output is created and saved in the HDFS.
The Map Reduce operation is described in Figure 3. When a MapReduce job is
executing, Hadoop passes Map and Reduce activities toward suitable servers across
hadoop cluster. This Hadoop platform is what performs handling associated with all the
data-sending details like allocating of activities, checking whether these activities are
finished, as well as performing the copy of data over cluster amidst nodes. A majority
computation happens over the nodes containing data on local disks lessening congestion
across network. Once the given activities are done, the cluster gathers the data as well as
reduces the data in the format of a suitable outcome, as well as returns outcome to server
of Hadoop.

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
20 Copyright ⓒ 2016 SERSC
Figure 3. Map-Reduce Operation
2.4.2. Inputs as well as Outputs from Java Context: The MapReduce platform
functions over <key, value> combinations, i.e., this platform sees input to a job in the
form of a collection of <key, value> combination as well as creates a collection of <key,
value> combinations which forms desired job output, perceivably belonging to distinct
kinds.
It is essential that the key as well as value classes be acquired in a serialized way by
Hadoop platform. The key as well as value classes can be acquired in a serialized way by
implementing a Writable interface. The key classes are required to implement the
Writable-Comparable interface for making the sort operation easier for the platform.
Input as well as Output kinds of a MapReduce job are (Input) <k1, v1> -> map -> <k2,
v2>-> reduce -> <k3, v3> (Output).
2.4.3. Applications of Map Reduce: The various applications of Map Reduce are as
mentioned below:
Geospatial Query Processing: As technology exhibits an advance in location-reliant
serviceability, a large boost is observed across quantity of geospatial data. Geospatial
queries (nearest neighbor queries as well as reverse most near neighbor queries) utilize a
large number of calculation resources. It is seen that the performing of operations across
geospatial data is made intrinsically parallel [6].
Google Maps utilizes MapReduce for finding the solution of problems such as those
mentioned below:
i. For a specific intersection, identify all the roads connecting to it.
ii. Perform the rendering of tiles in the map.
iii. For a specific address or current location, identify the nearest feature to it.
If we contemplate a search in Google Maps to find the gas stations which are near to
the Arizona State University, the input to a MapReduce program would be a graph
representing a network of nodes with all the marked gas stations. The Map function
would search within a specific radius (say 5 miles) of every gas station as well as mark
the distance to every node. After performing sorting by the key, the Reduce function
would emanate the path and gas station which is nearest to every node. The final output is
a graph which is marked with the gas station nearest to every node as described in Figure
4.

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 21
Figure 4. Search in Google maps using Map-Reduce
Map Reduce for Gridding LIDAR data: Digital Elevation Models are digital or 3D
depiction of the landscape, where every (X, Y) location is depicted with the help of some
distinct amount of elevation. DEMs are mentioned as Digital Terrain Model (DTM) or
Digital Surface Model (DSM). A DEM is able to be depicted in the form of lattice
consisting of squares or in the form of triangular irregular network (TIN). It is able to be
created by remote sensing through satellites or through information regarding the land
elevation that is scrutinized precisely. DEMs can be utilized across a variety of scientific
as well as engineering programs such as creating a hydrologic pattern, terrain study, as
well as framework plan. The rudimentary handling jobs across OpenTopography system
is the production of DEMs with the help of extremely thick (multiple measurements for
each square meter) LIDAR (Light Detection and Ranging) topography data. The usage of
map-reduce for the gridding of LIDAR data is described in Figure 5.
Figure 5. Use of Map-Reduce for Gridding LIDAR Data
The local gridding method uses details regarding altitude through Light Detection and
Ranging measurements consisted inside a circular area of search to calculate altitude of

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
22 Copyright ⓒ 2016 SERSC
every lattice cell. This execution is performed over entire data side-by-side making it the
perfect use case for MapReduce.
During Map stage, input points undergo allocation across respective lattice cells (local
bins), as well as during Reduce stage respective altitudes across every lattice cell get
calculated by the local bins. These reduced outcomes undergo merging, sorting as well as
actual DEM which gets produced by ArcASCII lattice form known as ESRI ASCII grid
format. The Map Reduce implementation for local gridding method in hadoop is depicted
within Figure 6.
Figure 6. Map-Reduce Implementation of Local Gridding Method in Hadoop
Number of URL Access Frequency: A map method performs the processing of logs
of web page demands as well as generates outcomes <URL, 1>. A reduce method
performs task of adding to each other all the amounts for identical URL and emanates a
<URL, total count> combination [7].
Reverse Web-Link Graph: Map method generates outcomes <target, source>
combinations associated with every link towards a destination URL, identified in a
webpage called as "source". Reduce method performs concatenations upon the list of
entire base URLs connected with a specific destination URL and emanates the
combination: <target, list (source)> [7].
Term-Vector for each Host: The term vector sums up the highest significant words
which occur within a single document or a collection of documents, in the form of a list

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 23
of <word, frequency> combinations. Map method emanates a <hostname, term vector>
combination that associated with every input document (in which the name of host is
obtained from the document URL). Reduce method is sent entire every-document term
vectors associated with specific host. The Reduce method performs the addition of the
received term vectors collectively; getting rid of rare terms, as well as emanates
afterwards a concluding <hostname, term vector> combination [7].
Inverted Index: Map method examines every document, as well as emanates chain
associated with <word, document ID> combinations. Reduce method takes entire
collection of such combinations associated with specific word, performs sorting of the
respective document IDs and emanates a <word, list (document ID)> combination. A
collection of entire collection of outcome combinations takes the format of an easy to
understand inverted index. Reinforcing such a calculation to retain a trace about the word
locations is a simple task [7].
2.5. Pig Programming Language
Pig is a high-level data-flow language as well as an implementation framework for
performing parallel computation. Apache Pig provides an abstraction over MapReduce. It
is a tool or platform which is utilized to perform the analysis of huge data-sets depicting
them as data flows. Pig is utilized along with Hadoop; we can implement all the data
manipulation operations in Hadoop with the usage of Apache Pig. Pig offers a language
which is closer to human languages called as Pig Latin which enables us to write the data
analysis programs independent of a particular type of computer. This language bestows
different operators utilizing which the programmers can develop their own functions for
the purpose of reading, writing as well as processing of the data. Programmers need to
write scripts using Pig Latin language to perform the analysis of data with the usage of
Apache Pig. All these scripts are intrinsically transformed into Map and Reduce tasks.
Apache Pig has a component which is called as Pig Engine, takes the Pig Latin scripts as
input as well as transforms those scripts into MapReduce jobs.
2.5.1. Need for Apache Pig: The programmers, who are not proficient at Java, generally
underwent a lot of strife while working with Hadoop, particularly during the execution of
any MapReduce tasks. Apache Pig is a blessing for all such programmers. With the usage
of Pig Latin, programmers can execute the MapReduce tasks in a simple manner without
the need to type complex codes in Java. Apache Pig utilizes a multi-query methodology,
which lessens the length of codes. For example, an operation that would need us to type
200 lines of code (LoC) in Java can be completed in a simple manner by typing as few as
only 10 LoC in Apache Pig. Apache Pig lessens the time required for development by
almost 16 times. Pig Latin language is similar to SQL language. It is also very simple to
grasp Apache Pig once we are acquainted with SQL. Apache Pig bestows numerous
built-in operators that assist the implementation of data operations such joins, filters,
ordering, etc. Apache Pig gives us nested data types such as tuples, bags as well as maps
that are absent in MapReduce.
2.5.2. Architecture for Apache Pig: The language utilized to perform the analysis of
data in Hadoop using Apache Pig is called as Pig Latin. Pig Latin language is closer to
human languages for writing programs to process data independent of a computer-type,
which gives us a rich set of data types as well as operators to implement different data
operations. Programmers utilize Pig to execute a specific task. Programmers have to
write a Pig script utilizing the Pig Latin language, and implement them with the help of
any of the implementation methods (Grunt Shell, UDFs, as well as Embedded). After
implementation, these scripts will undergo a range of conversions enforced by the Pig
Framework, to generate the expected output. Intrinsically, Apache Pig transforms these

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
24 Copyright ⓒ 2016 SERSC
scripts into a range of MapReduce jobs, which, in turn, makes the programmer’s job very
simple.
The architecture of Apache Pig is described in Figure 7.
Figure 7. Architecture of Apache Pig
2.5.3. Components of Apache Pig: As shown in Figure.7, there are different constituents
in the Apache Pig framework.
The major constituents of Apache Pig are as mentioned:
Parser: At the beginning, the Pig Scripts are managed by the Parser. It inspects the
syntax of the script, performs type checking, as well as other different checks. The output
of the parser will be a DAG (directed acyclic graph), which depicts the Pig Latin
statements as well as logical operators. In the DAG, the logical operators of the script are
depicted as the nodes and the data flows are depicted as the edges.
Optimizer: The logical plan (DAG) is sent to the logical optimizer, which performs
the logical optimizations like projection and pushdown.
Compiler: The compiler performs the compilation of a reasonable design which is
optimized in the form of a range of MapReduce jobs.
Execution engine: MapReduce jobs are then given to Hadoop in a sorted form. These
MapReduce jobs are then implemented on Hadoop generating the required results.
2.5.4. Applications of Apache Pig: Apache Pig is utilized by data scientists for
implementing the tasks that include processing for a specific purpose as well as fast
prototyping.
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 25
Apache Pig is utilized to implement the tasks as mentioned:
a) Processing of large sources of data like web logs.
b) Performing the processing of data for search platforms.
c) Processing of the data loads that are time-sensitive.
3. Results and Comparisons
In this section we list out and compare various functions, advantages and limitations of
Hadoop Distributed File System (HDFS) in Table 1, MapReduce Software Framework in
Table 2 and Pig Programming Language in Table 3. We also list out the comparison
between Apache Pig and SQL in Table 4 as well as the comparison between Apache Pig
and MapReduce in Table 5.
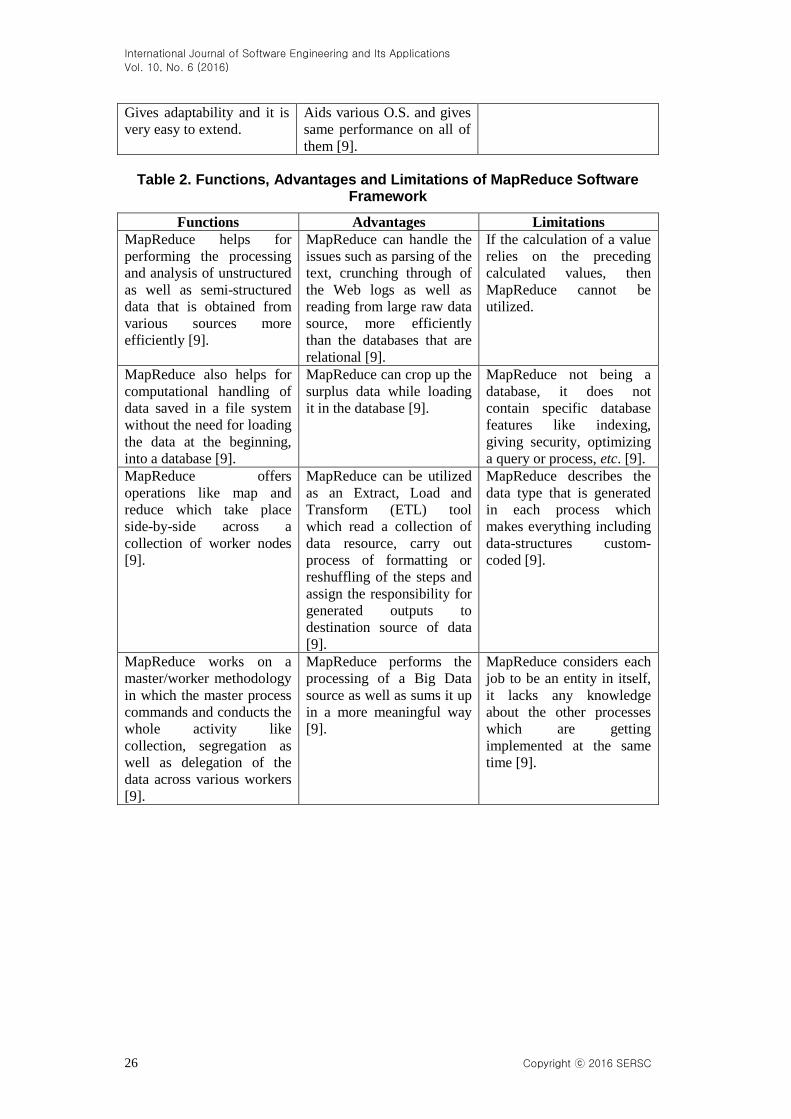
Table 1. Functions, Advantages and Limitations of Hadoop Distributed File System
Functions Advantages Limitations
Maintains transaction logs
to monitor each operation
and execute the efficient
auditing and data recovery,
if something does not go
right [9].
Appropriate for distributed
storage and for performing
processing.
Programs that require
access to data with less
time-interval between
stimulation and response,
i.e., in the tens of milli-
seconds series, do not work
properly with HDFS [10].
Utilizes an efficient error-
detection technique like
validation of checksum for
the verifying the content of
a file [9].
Hadoop also bestows the
command-interface so that
it is feasible to
communicate with HDFS.
For HDFS files, there is no
provisioning for more than
one writer or for performing
alterations across random
displacements in any file
[10].
Maintains the copies of
data blocks that are
replicated to avert
corruption of a file due to
server failure [9].
The built-in servers of
Name Node and Data node
enable the users to inspect
easily the cluster status in a
very simple manner.
HDFS contains a re-
balancer service which
performs the balancing of
data load across the Data
nodes [9].
Gives streaming approach
to data of a file system.
The replication factor can
be reduced or raised
through configuration
settings that permit the
failure of node without data
loss.
Gives file permissions as
well as authentication.
The block placement of
HDFS utilizes rack-
awareness for fault-
tolerance through the
placement of one block
replica on a distinct rack.
Permits data replication that
provides flexibility to data
in the event of an
unforeseen disaster or
corruption of any data
location contents [9].
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
26 Copyright ⓒ 2016 SERSC
Gives adaptability and it is
very easy to extend.
Aids various O.S. and gives
same performance on all of
them [9].
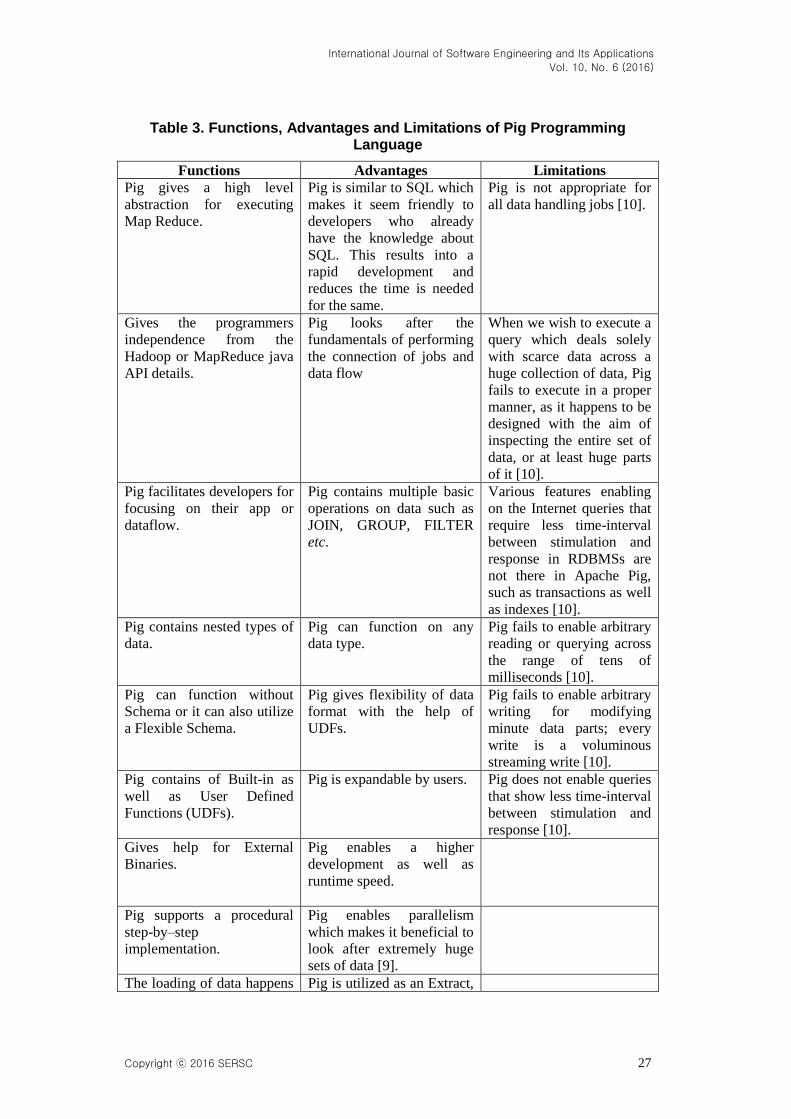
Table 2. Functions, Advantages and Limitations of MapReduce Software Framework
Functions Advantages Limitations
MapReduce helps for
performing the processing
and analysis of unstructured
as well as semi-structured
data that is obtained from
various sources more
efficiently [9].
MapReduce can handle the
issues such as parsing of the
text, crunching through of
the Web logs as well as
reading from large raw data
source, more efficiently
than the databases that are
relational [9].
If the calculation of a value
relies on the preceding
calculated values, then
MapReduce cannot be
utilized.
MapReduce also helps for
computational handling of
data saved in a file system
without the need for loading
the data at the beginning,
into a database [9].
MapReduce can crop up the
surplus data while loading
it in the database [9].
MapReduce not being a
database, it does not
contain specific database
features like indexing,
giving security, optimizing
a query or process, etc. [9].
MapReduce offers
operations like map and
reduce which take place
side-by-side across a
collection of worker nodes
[9].
MapReduce can be utilized
as an Extract, Load and
Transform (ETL) tool
which read a collection of
data resource, carry out
process of formatting or
reshuffling of the steps and
assign the responsibility for
generated outputs to
destination source of data
[9].
MapReduce describes the
data type that is generated
in each process which
makes everything including
data-structures custom-
coded [9].
MapReduce works on a
master/worker methodology
in which the master process
commands and conducts the
whole activity like
collection, segregation as
well as delegation of the
data across various workers
[9].
MapReduce performs the
processing of a Big Data
source as well as sums it up
in a more meaningful way
[9].
MapReduce considers each
job to be an entity in itself,
it lacks any knowledge
about the other processes
which are getting
implemented at the same
time [9].
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 27
Table 3. Functions, Advantages and Limitations of Pig Programming Language
Functions Advantages Limitations
Pig gives a high level
abstraction for executing
Map Reduce.
Pig is similar to SQL which
makes it seem friendly to
developers who already
have the knowledge about
SQL. This results into a
rapid development and
reduces the time is needed
for the same.
Pig is not appropriate for
all data handling jobs [10].
Gives the programmers
independence from the
Hadoop or MapReduce java
API details.
Pig looks after the
fundamentals of performing
the connection of jobs and
data flow
When we wish to execute a
query which deals solely
with scarce data across a
huge collection of data, Pig
fails to execute in a proper
manner, as it happens to be
designed with the aim of
inspecting the entire set of
data, or at least huge parts
of it [10].
Pig facilitates developers for
focusing on their app or
dataflow.
Pig contains multiple basic
operations on data such as
JOIN, GROUP, FILTER
etc.
Various features enabling
on the Internet queries that
require less time-interval
between stimulation and
response in RDBMSs are
not there in Apache Pig,
such as transactions as well
as indexes [10].
Pig contains nested types of
data.
Pig can function on any
data type.
Pig fails to enable arbitrary
reading or querying across
the range of tens of
milliseconds [10].
Pig can function without
Schema or it can also utilize
a Flexible Schema.
Pig gives flexibility of data
format with the help of
UDFs.
Pig fails to enable arbitrary
writing for modifying
minute data parts; every
write is a voluminous
streaming write [10].
Pig contains of Built-in as
well as User Defined
Functions (UDFs).
Pig is expandable by users. Pig does not enable queries
that show less time-interval
between stimulation and
response [10].
Gives help for External
Binaries.
Pig enables a higher
development as well as
runtime speed.
Pig supports a procedural
step-by–step
implementation.
Pig enables parallelism
which makes it beneficial to
look after extremely huge
sets of data [9].
The loading of data happens Pig is utilized as an Extract,
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
28 Copyright ⓒ 2016 SERSC
in Pig before the mapper
runs, for this, Pig bestows a
split operation with the help
of which the input can be
divided into parts that are
individually carried out by
every mapper [10].
Load, and Transform (ETL)
tool for Hadoop due to
which Hadoop becomes
more accessible as well as
user-friendly for non-
technical persons [9].
Pig is designed for
performing the batch-
processing of data [10].
The high level of
abstraction of Apache Pig
results into a higher degree
of execution independence.
Pig Latin functions as a data
flow programming
language.
Pig has the capability to
perform the processing
across terabytes of data
very easily, through the
issuing of a half-dozen Pig
Latin lines through the
console.
Pig gives commands to
communicate with the
Hadoop file-systems which
are extremely useful for
manipulating the data
around, prior to processing
as well as post processing.
This is performed using Pig
as well as MapReduce and
commands related to utility.
With the utilization of the
Pig Latin language, the
programmers can execute
the MapReduce tasks in a
very simple manner,
without the need to type
complex codes in Java.
Apache Pig utilizes a multi-
query methodology, which
lessens the length of codes.
For example, an operation
that would need the
developers to type 200 lines
of code (LoC) in Java can
be completed in a very
simple manner, by typing as
few as only 10 LoC in
Apache Pig. Apache Pig
lessens the development
time by almost 16 times.
International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
Copyright ⓒ 2016 SERSC 29
Table 4. Comparison between Apache Pig and sql
Apache Pig SQL
Pig Latin behaves as a procedural language. SQL behaves as a declarative language.
The schema is available as a choice in
Apache Pig. We are able to store data
without designing a schema (values are
stored as $01, $02 etc.)
Schema is compulsory in SQL.
Apache Pig gives a data model that is nested
relational.
The data model which is utilized in SQL
is flat relational.
Apache Pig gives a confined opportunity for
Query optimization.
SQL gives infinite opportunity for query
optimization.
Table 5. Comparison between Apache Pig and MapReduce
Apache Pig MapReduce
Apache Pig behaves as a data flow
language.
MapReduce behaves as a data processing
archetype.
Apache Pig acts as a high level language. MapReduce acts as a low level as well as
an inflexible language.
Executing a Join operation in Apache Pig is
extremely easy.
It is very problematic in MapReduce to
execute a Join operation between the sets
of data.
Any amateur programmer with a
fundamental knowledge of SQL can
function efficiently with Apache Pig.
Experience in Java is mandatory to
implement MapReduce.
Apache Pig utilizes a multi-query
methodology, which lessens the length of
the codes to a higher degree.
MapReduce will need almost 20 times
more the number of lines to implement a
similar task.
There is no requirement for performing the
compilation. Upon implementation, each
Apache Pig operator is transformed
intrinsically into a MapReduce job.
The compilation process of MapReduce
jobs is long.
4. Conclusion
The execution of Weblog analysis system based on Hadoop indicates that the
distributed architecture of Hadoop deems it appropriate for handling large files [1].
Hadoop gives a better performance than shell commands, when the file-size is above
512MB [1]. Being a high-level programming language, Pig bestows many functions for
performing the analysis of data to fulfill the varying requirements of system analysis [1].
5. Future Scope
The cloud computing research is progressing extremely fast to put together Cloud
Computing with Hadoop architecture containing Hadoop Distributed File System
(HDFS), Hadoop MapReduce Software Framework as well as the Pig Latin Language to
expose novel trends for performing more productive as well as more quick collection,
storage and analysis of huge weblogs produced by a huge number of Internet users on a
daily basis. We hope to see better requirement analysis of logs and a better performance
by such a Weblog Analysis System based on Hadoop that gives a reference for doing
performance-tuning that enables us to foretell the future trend of a system.

International Journal of Software Engineering and Its Applications
Vol. 10, No. 6 (2016)
30 Copyright ⓒ 2016 SERSC
References
[1] C. H. Wang, C. T. Tsai, C. C. Fan and S. M. Yuan, “A Hadoop-based Weblog Analysis System”,
International Conference on Ubi-Media Computing and Workshops (UMEDIA), Ulaanbaatar,
Mongolia, (2014) July 12-14, pp. 72 – 77.
[2] S. Narkhede and T. Baraskar, “HMR Log Analyzer: Analyze Web Application Logs Over Hadoop
Mapreduce”, International Journal of UbiComp (IJU), vol. 4, no. 3, (2013) July, pp. 41-51.
[3] C. Olston, B. Reed, U. Srivastava, R. Kumar and A. Tumkins, “Pig Latin: A Not-So-Foreign Language
for Data-Processing”, SIGMOD -2008, Vancouver, Canada, (2008) June 9-12, pp. 1099-1110.
[4] Y. Q. Wei, G. G. Zhou, D. Xu and Y. Chen, “Design of the Web Log Analysis System Based on
Hadoop”, Advanced Materials Research, vol. 926-930, (2014) May, pp. 2474-2477.
[5] http://www.dbms2.com/2009/10/10/enterprises-using-hadoo/
[6] A. Akdogan, U. Demiryurek, F. Banaei-Kashani and C. Shahabi, “Voronoi-Based Geospatial Query
Processing with MapReduce”, International Conference on Cloud Computing Technology and Science
(CloudCom), Indianapolis, IN, (2010) Nov. 30 - Dec. 3, pp. 9-16.
[7] J. Dean and S. Ghemawat, “MapReduce: simplified data processing on large clusters”, ACM
Conference on Symposium, on Opearting Systems Design & Implementation, vol. 6, (2004) December
6, pp. 10.
[8] Z. Ma and L. Gu, “The limitation of MapReduce: A probing case and a lightweight solution”,
International Conference on Cloud Computing, GRIDs, and Virtualization, (2010), pp. 68-73.
[9] D. T. Editorial Services, in Big Data (Covers Hadoop 2, MapReduce, Hive, YARN, Pig, R and Data
Visualization) Black Book, dreamtech Press Publishers, New Delhi (2015).
[10] T. White, in Hadoop: The Definitive Guide, Third Edition, O’Reilly Media, Inc. Publishers, United
States of America (2012).