hadoop installation
TRANSCRIPT

Single node Cluster
Hadoop Installation

Profile
Ankit Desai
Ph.D. Scholar, IET, Ahmedabad University
Education: M. Tech. (C.E.), B. E. (I. T.)
Experience: 8 years (Academic and Research)
Research Interest: IoT, Big Data Analytics,
Machine Learning, Data Mining, Algorithms.
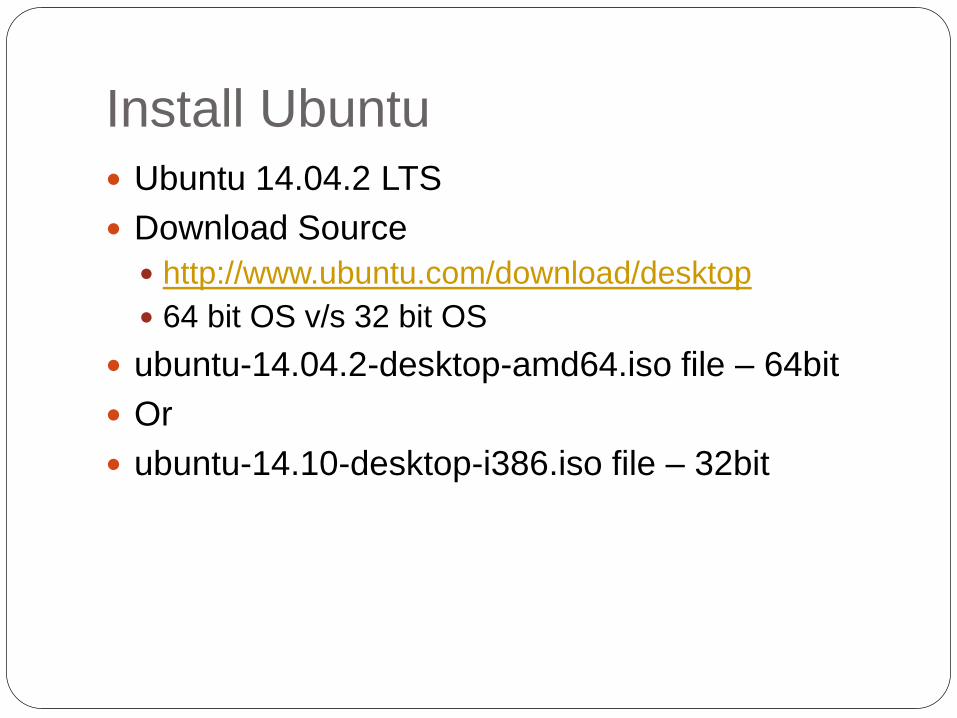
Install Ubuntu
Ubuntu 14.04.2 LTS
Download Source
http://www.ubuntu.com/download/desktop
64 bit OS v/s 32 bit OS
ubuntu-14.04.2-desktop-amd64.iso file – 64bit
Or
ubuntu-14.10-desktop-i386.iso file – 32bit

Download Java
Java 7
http://www.oracle.com/technetwork/java/javase/d
ownloads/jdk7-downloads-1880260.html
Java 6
http://www.oracle.com/technetwork/java/javase/d
ownloads/java-archive-downloads-javase6-
419409.html
x86 or x64 bit as per your computer
configurations
Download:
For 7: jdk-7u75-linux-i586.tar.gz or jdk-7u75-linux-
x64.tar.gz

Cont…
Extract the jdk file
Open the terminal
$cd /user/lib (make new dir java)
$ sudo mkdir java
Move jdk folder from Download to usr/lib/java
$sudo mv jdk1.7.0_67/ /usr/lib/java

Cont…
Goto /usr/lib/java/jdk1.7.0_67/bin
$ sudo update-alternatives –install
“/usr/bin/java” “java”
“/usr/lib/java/jdk1.7.0_67/bin/java” 1
$ sudo update-aternatives –install
“/usr/bin/javac” “javac”
“usr/lib/java/jdk1.7.0_67/bin/javac” 1
$ sudo update-aternatives –install
“/usr/bin/javaws” “javaws”
“usr/lib/java/jdk1.7.0_67/bin/javaws”
1

Cont…
Check java version
$java –version
Set env. Variable JAVA_HOME in .bashrc file
$gedit ~/.bashrc file
In .bashrc file
export
JAVA_HOME=”/usr/lib/java/jdk1.7.0_67”
set PATH=”$PATH:$JAVA_HOME/bin”
export PATH
save & exit
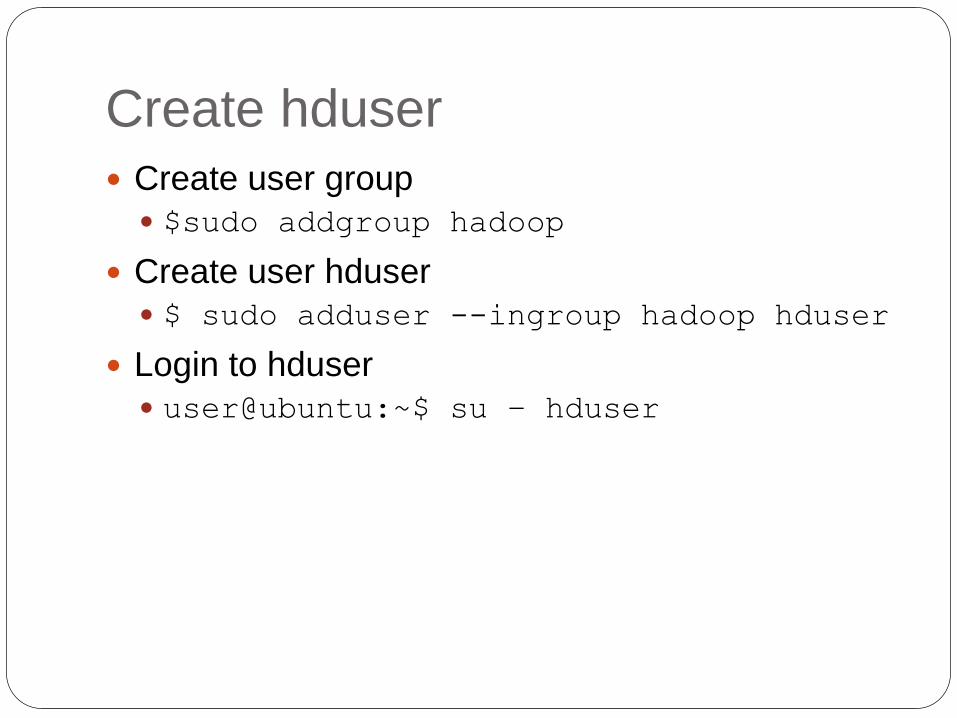
Create hduser
Create user group
$sudo addgroup hadoop
Create user hduser
$ sudo adduser --ingroup hadoop hduser
Login to hduser
user@ubuntu:~$ su – hduser

Working with SSH hduser@ubuntu: ~$ ssh (should give you path of
ssh), if not then type $sudo apt-get install
ssh
hduser@ubuntu: ~$ sshd (should give you path
of sshd), if not then type user@ubuntu:~$ sudo
apt-get install openssh-server
Generate public and private key pair:
hduser@ubuntu:~$ ssh-keygen -t rsa -P “”
hduser@ubuntu:~$ cat
/home/hduser/.ssh/id_rsa.pub >>
/home/hduser /.ssh/authorized_keys
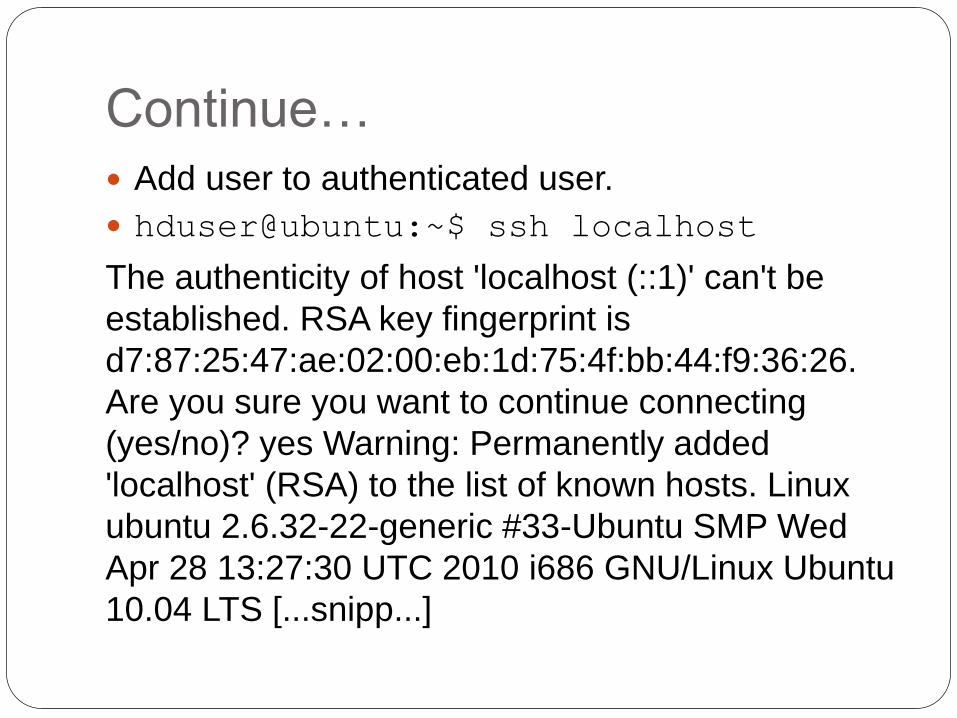
Continue…
Add user to authenticated user.
hduser@ubuntu:~$ ssh localhost
The authenticity of host 'localhost (::1)' can't be
established. RSA key fingerprint is
d7:87:25:47:ae:02:00:eb:1d:75:4f:bb:44:f9:36:26.
Are you sure you want to continue connecting
(yes/no)? yes Warning: Permanently added
'localhost' (RSA) to the list of known hosts. Linux
ubuntu 2.6.32-22-generic #33-Ubuntu SMP Wed
Apr 28 13:27:30 UTC 2010 i686 GNU/Linux Ubuntu
10.04 LTS [...snipp...]

Disable IPv6 open /etc/sysctl.conf file with
hduser@ubuntu:~$ sudo gedit /etc/sysctl.conf
You have to reboot your machine in order to make the changes take effect.
You can check whether IPv6 is enabled on your machine with the following command:
$ cat /proc/sys/net/ipv6/conf/all/disable_ipv6
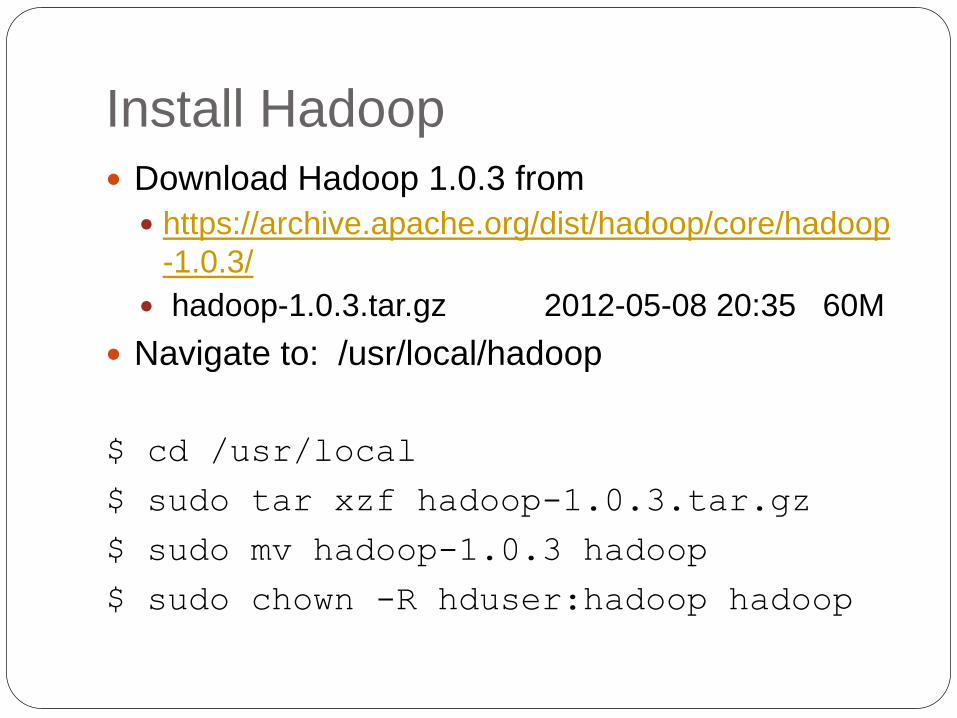
Install Hadoop
Download Hadoop 1.0.3 from
https://archive.apache.org/dist/hadoop/core/hadoop
-1.0.3/
hadoop-1.0.3.tar.gz 2012-05-08 20:35 60M
Navigate to: /usr/local/hadoop
$ cd /usr/local
$ sudo tar xzf hadoop-1.0.3.tar.gz
$ sudo mv hadoop-1.0.3 hadoop
$ sudo chown -R hduser:hadoop hadoop

Cont… hadoop-env.sh
Write line:
export JAVA_HOME=”/usr/lib/java/jdk1.7.0_67”
export HADOOP_HOME_WARN_SUPPRESS=”TRUE”
Edit ~/.bashrc
Add following
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=”/usr/lib/java/jdk1.7.0_67”
set PATH=”$PATH:$JAVA_HOME/bin”
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
lzohead () {
hadoop fs -cat $1 | lzop -dc | head -1000 | less
}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH

Cont…
conf/*-site.xml
Create dir /app/hadoop/tmp
$ sudo mkdir -p /app/hadoop/tmp
$ sudo chown hduser:hadoop
/app/hadoop/tmp
# ...and if you want to tighten up
security, chmod from 755 to 750...
$ sudo chmod 750 /app/hadoop/tmp

Conf files
Add the following snippets between the <configuration>
... </configuration> tags in the respective configuration
XML file.

conf/core-site.xml<property>
<name>hadoop.tmp.dir</name><value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.
</description>
</property>
<property>
<name>fs.default.name</name><value>hdfs://localhost:54310</value><description>The name of the default file system. A
URI whose scheme and authority determine the FileSystemimplementation. The uri's scheme determines the configproperty (fs.SCHEME.impl) naming the FileSystemimplementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
</description>
</property>

conf/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The host and port that the
MapReduce job tracker runs at. If "local", then jobs
are run in-process as a single map and reduce
task.
</description>
</property>

conf/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication. The
actual number of replications can be specified
when the file is created. The default is used if
replication is not specified in create time.
</description>
</property>

Done.
How to start? How to work?

Formatting the HDFS filesystem
via the NameNodehduser@ubuntu:~$ /usr/local/hadoop/bin/hadoopnamenode –format
10/05/08 16:59:56 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNodeSTARTUP_MSG: host = ubuntu/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010 ************************************************************/ 10/05/08 16:59:56 INFO namenode.FSNamesystem: fsOwner=hduser,hadoop 10/05/08 16:59:56 INFO namenode.FSNamesystem: supergroup=supergroup 10/05/08 16:59:56 INFO namenode.FSNamesystem: isPermissionEnabled=true 10/05/08 16:59:56 INFO common.Storage: Image file of size 96 saved in 0 seconds. 10/05/08 16:59:57 INFO common.Storage: Storage directory .../hadoop-hduser/dfs/name has been successfully formatted. 10/05/08 16:59:57 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1 ************************************************************/
hduser@ubuntu:/usr/local/hadoop$
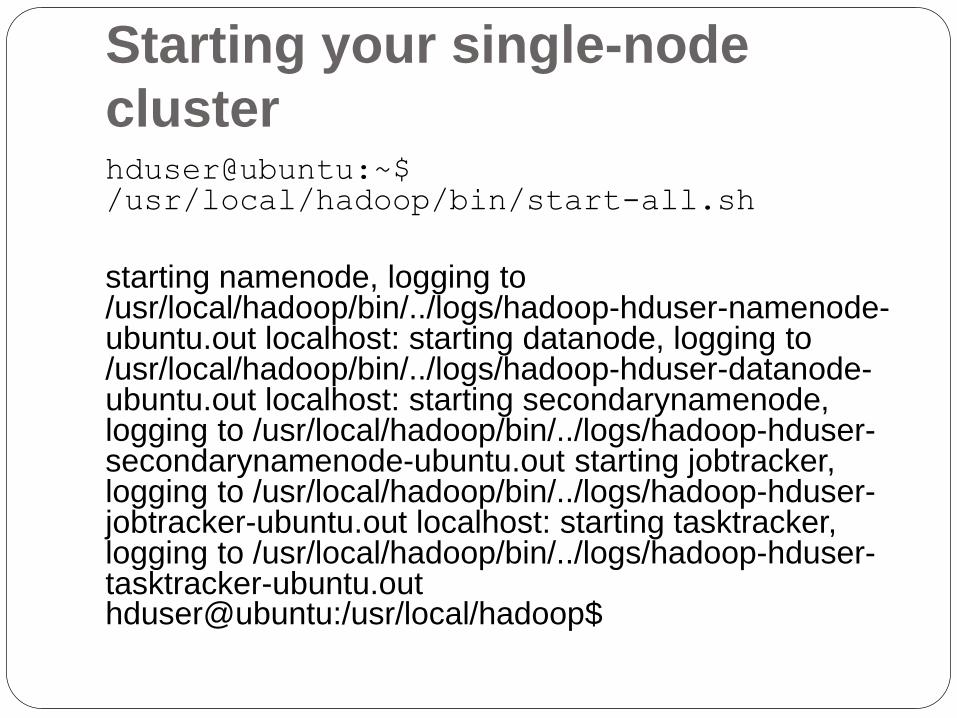
Starting your single-node
clusterhduser@ubuntu:~$ /usr/local/hadoop/bin/start-all.sh
starting namenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-namenode-ubuntu.out localhost: starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-datanode-ubuntu.out localhost: starting secondarynamenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-secondarynamenode-ubuntu.out starting jobtracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-jobtracker-ubuntu.out localhost: starting tasktracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-tasktracker-ubuntu.outhduser@ubuntu:/usr/local/hadoop$
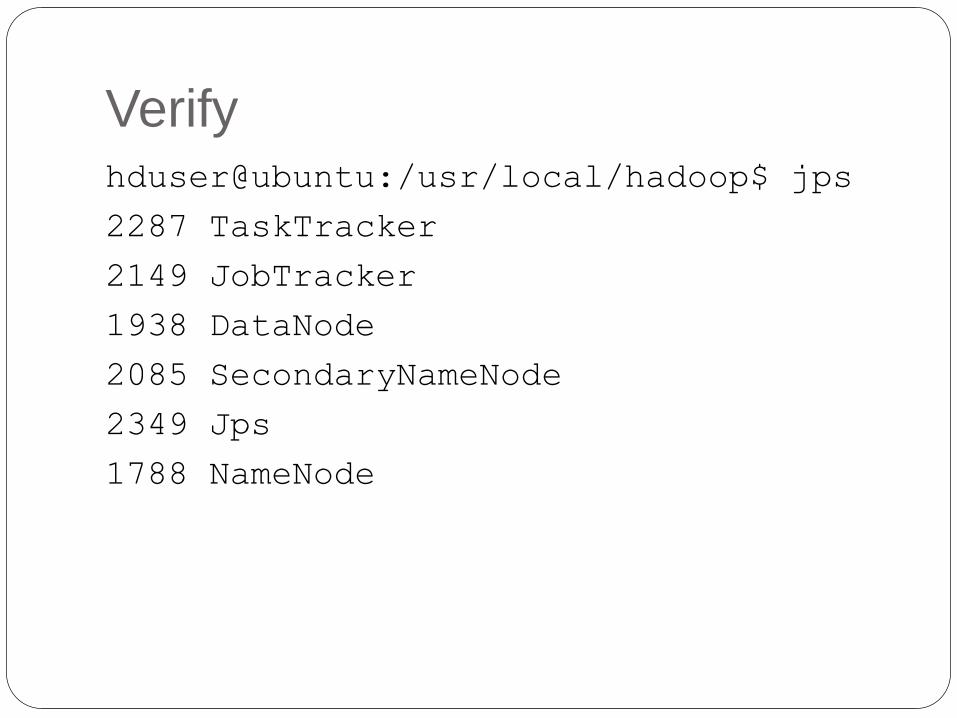
Verifyhduser@ubuntu:/usr/local/hadoop$ jps
2287 TaskTracker
2149 JobTracker
1938 DataNode
2085 SecondaryNameNode
2349 Jps
1788 NameNode

Stopping your single-node
clusterhduser@ubuntu:~$
/usr/local/hadoop/bin/stop-all.sh
hduser@ubuntu:/usr/local/hadoop$
bin/stop-all.sh
stopping jobtracker
localhost: stopping tasktracker
stopping namenode
localhost: stopping datanode
localhost: stopping secondarynamenode
hduser@ubuntu:/usr/local/hadoop$

Hadoop Web Interfaces
http://localhost:50070/ – web UI of the
NameNode daemon
http://localhost:50030/ – web UI of the JobTracker
daemon
http://localhost:50060/ – web UI of the
TaskTracker daemon
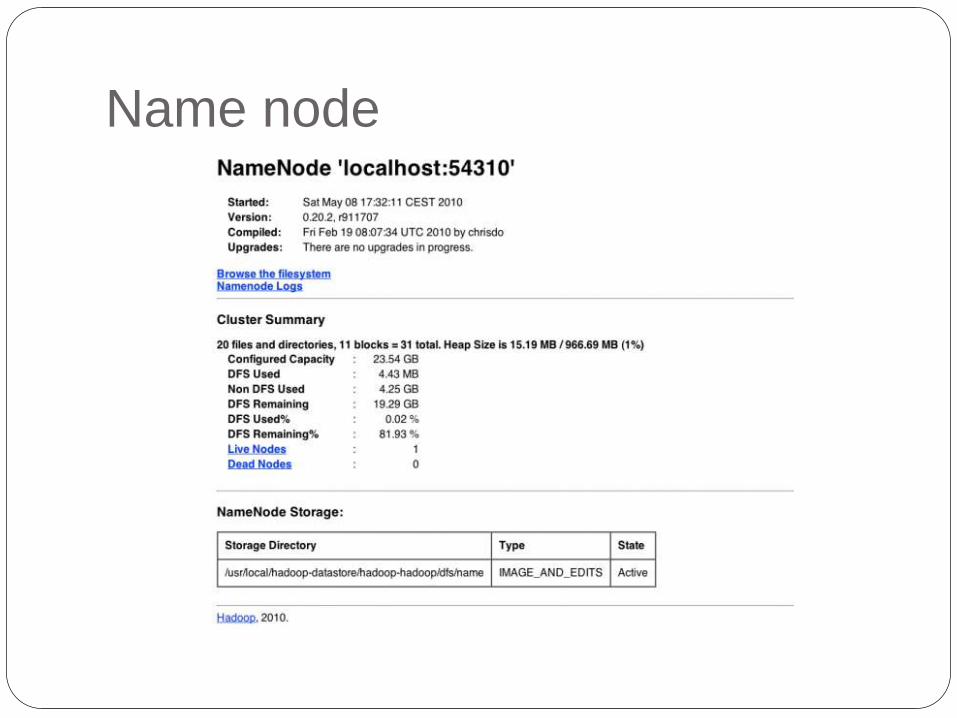
Name node

Job Tracker
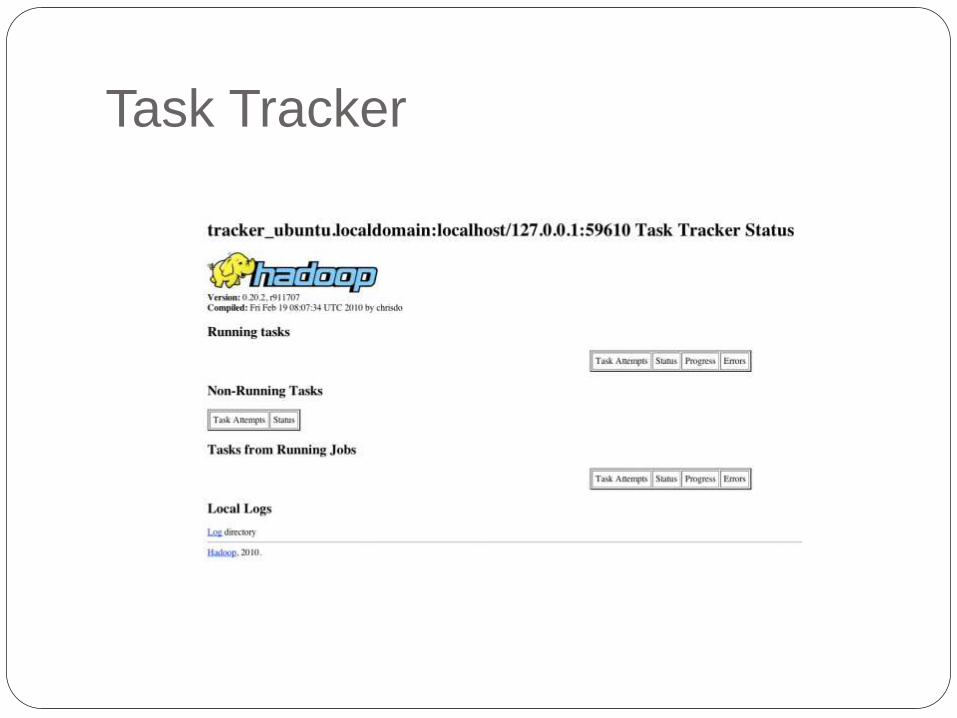
Task Tracker

References
1. http://www.michael-noll.com/tutorials/running-
hadoop-on-ubuntu-linux-single-node-cluster/
2. http://www.tutorialspoint.com/hadoop/hadoop_e
nviornment_setup.htm

Multi-node Cluster
Hadoop Installation

Making single node cluster
Marge two single node cluster in to multi-node
cluster.
One will become designated master
Will also work as slave (will store and process the data as
well)
Pseudo distributed cluster
Another will become slave only

Prerequisites
Configuring single-node clusters first
Copy the Ubuntu install folder and paste it.
(Replication of the same VM)
Make sure your ubuntu system uses DHCP
settings/ reasonably considerable settings for
network setup.

Change Host-names
Change hostnames of each systems
Login to each system using hduser@ubuntu$ and
open file /etc/hosts
Find system’s ipv4 address using command ifconfig
Make and entry of ip address and host name of
master and slave both on both systems as follows.
Command:
sudo gedit /etc/hosts

Also change
/etc/hostname
On master
master
On slave
slave
To take its effect run:
Run sudo /etc/init.d/hostname restart or sudoservice hostname restart

Verification
Exit the terminal atleast once to see the effects:
From:
hduser@ubuntu$
To:
hduser@master$ on master side
hduser@slave$ on slave side

SSH access
Distribute the SSH public key of hduser@master
Command:
hduser@master:~$ ssh-copy-id -i
$HOME/.ssh/id_rsa.pub hduser@slave
Above cmd will copy id_rsa.pub on hduser@slave

SSH Login So, connecting from master to master…
Command:
hduser@master:~$ ssh master
Sample output:
hduser@master:~$ ssh master The authenticity of host 'master (192.168.0.1)' can't be established. RSA key fingerprint is 3b:21:b3:c0:21:5c:7c:54:2f:1e:2d:96:79:eb:7f:95. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'master' (RSA) to the list of known hosts. Linux master 2.6.20-16-386 #2 Thu Jun 7 20:16:13 UTC 2007 i686 ...
hduser@master:~$

SSH Login
…and from master to slave.
Command:
hduser@master:~$ ssh slave
Sample output:
The authenticity of host 'slave (192.168.0.2)' can't
be established. RSA key fingerprint is
74:d7:61:86:db:86:8f:31:90:9c:68:b0:13:88:52:72.
Are you sure you want to continue connecting
(yes/no)? yes Warning: Permanently added 'slave'
(RSA) to the list of known hosts. Ubuntu 10.04 ...
hduser@slave:~$
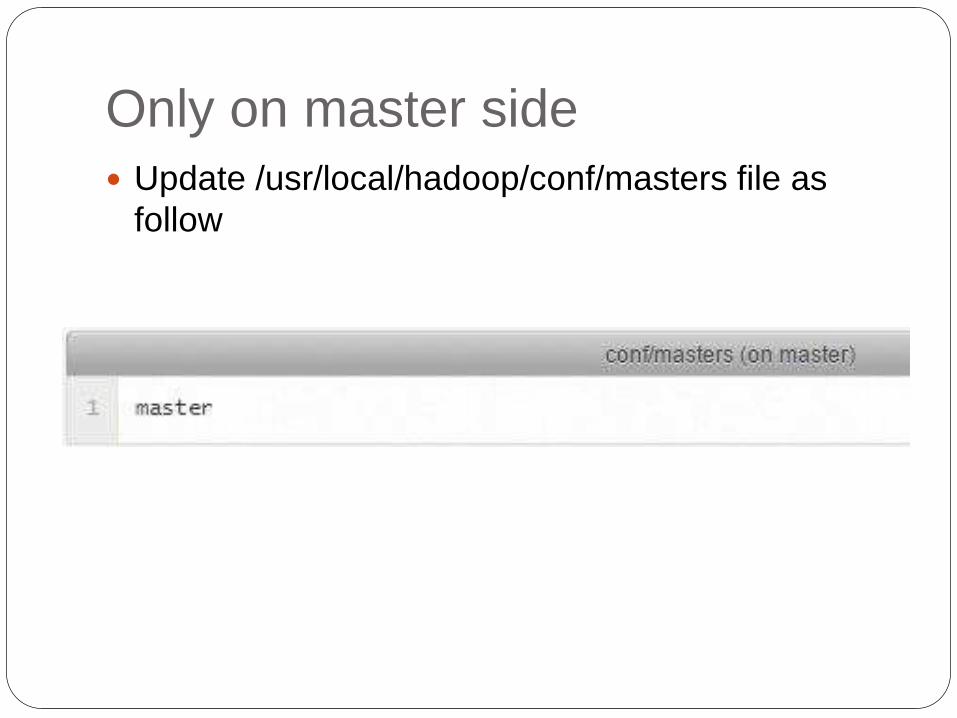
Only on master side
Update /usr/local/hadoop/conf/masters file as
follow
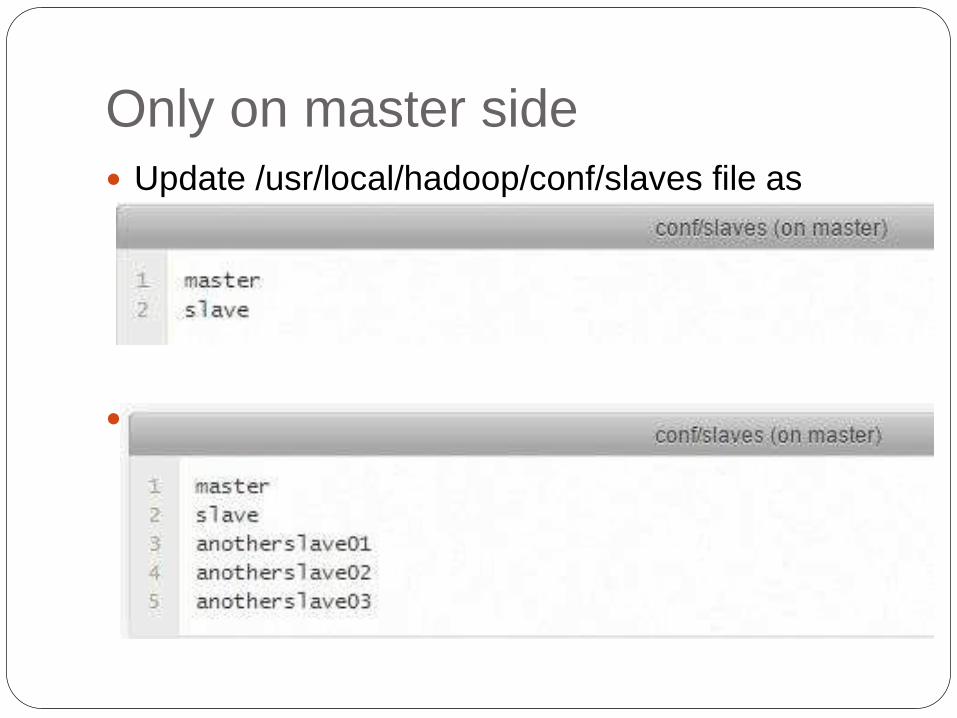
Only on master side
Update /usr/local/hadoop/conf/slaves file as
follow
If you have more than one slaves then…

conf/core-site.xml (ALL
machines)<property>
<name>fs.default.name</name>
<value>hdfs://master:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystemimplementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri'sauthority is used to
determine the host, port, etc. for a filesystem.</description>
</property>

conf/mapred-site.xml (ALL machines)
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
<description>The host and port that the
MapReduce job tracker runs
at. If "local", then jobs are run in-process as a
single map
and reduce task.
</description>
</property>

conf/hdfs-site.xml (ALL
machines)
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication.
The actual number of replications can be specified
when the file is created.
The default is used if replication is not specified in
create time.
</description>
</property>

Run name-node format (critical)
hduser@master:/usr/local/hadoop$ bin/hadoopnamenode -format
... INFO dfs.Storage: Storage directory
/app/hadoop/tmp/dfs/name has been successfully
formatted.
hduser@master:/usr/local/hadoop$

Start multi-node Clusterhduser@master:/usr/local/hadoop$ bin/hadoop/start-all.shstarting namenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-namenode-master.out
slave: Ubuntu 10.xx
slave: starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-datanode-slave.out
master: starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-datanode-master.out
master: starting secondarynamenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-secondarynamenode-master.out
hduser@master:/usr/local/hadoop$

Common Errors After some duration… shutdown of Datanode
automatically… Fix
1. Restart Hadoop
2. Go to /app/hadoop/tmp/dfs/name/current
3. Open VERSION (i.e. by vim VERSION)
4. Record namespaceID
5. Go to /app/hadoop/tmp/dfs/data/current
6. Open VERSION (i.e. by vim VERSION)
7. Replace the namespaceID with the namespaceIDyou recorded in step 4.

Common Errors
$HADOOP_HOME is deprecated.
Fix
Try setting
export HADOOP_HOME_WARN_SUPPRESS="TRUE" in
my conf/hadoop-env.sh file
Enjoy Hadooping!!!