hahacronym: humorous agents for humorous acronyms
TRANSCRIPT

HAHAcronym: Humorous Agents for
Humorous Acronyms
OLIVIERO STOCK and CARLO STRAPPARAVA
Abstract
HAHAcronym has been the first project concerned with computationalhumor sponsored by the European Commission. The project was meantto establish the potential of computational humor through the demonstrationof a working prototype and an assessment of the state of the art and ofscenarios where humor can add something to existing information technolo-gies. The main goal of HAHAcronym was the realization of an acronymironic re-analyzer and generator as a proof of concept in a focalized butnon-restricted context. In order to implement it, some general tools havebeen developed or adapted for the humorous context. For all tools, particu-lar attention has been put on reusability. A fundamental tool is an incongru-ity detector/generator to detect/generate semantic mismatches between theknown/expected “sentence” meaning and other interpretations, along somespecific dimension.
Keywords: Computational humor; acronyms; natural language processing;WordNet.
Introduction
It is time that Computational Humor is perceived as a field that candeliver something useful. The current dynamics of research support, forgood or for bad, is based on the prospect that the research themes areconducive to practical results in more or less short terms. In the field ofinformation technology, generally there is an especially limited amount ofpatience for the first visible outcome of research activity. Another element
0933–1719/03/0016–0297© Walter de Gruyter
Humor 16–3 (2003), 297–314
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

298 O. Stock and C. Strapparava
for pushing toward some concrete results is, on the other side, that by meansof those constructive experiences we can ourselves become more aware ofproblems and necessities. Besides anything else we believe there are realopportunities out there, which do not always require complete modeling ofhumor processes. We are convinced that deep modeling of humor in all ofits facets is not something for the near future; the phenomena are too com-plex, and humor is one of the most sophisticated forms of human intelli-gence. It is AI-complete: The problem of modeling it is as difficult to solveas the most difficult Artificial Intelligence problems. But some steps canbe followed to achieve results. And when something is realized we can notethat humor has the methodological advantage (unlike, say, computer art) ofleading to more directly falsifiable theories; the resulting humorous artifactscan be tested on human subjects in a rather straightforward manner.
Basically, in order to be successfully humorous, a computational systemshould be able to: recognize situations appropriate for humor, choose a suit-able kind of humor for the situation, generate an appropriately humorousoutput, and, if there is some form of interaction or control, evaluate thefeedback.
And indeed society needs humor, not just for entertainment. In the currentbusiness world, humor is considered to be so important that companies mayhire “humor consultants.” Humor can be used “to criticize without alienat-ing, to defuse tension or anxiety, to introduce new ideas, to bond teams, easerelationships and elicit cooperation” (Binsted 1996).
So, looking at computational humor from an application-oriented pointof view, one assumption is that in future human-machine interaction,humans will demand a naturalness and effectiveness that require the incor-poration of models of possibly all human cognitive capabilities, includingthe handling of humor. There are many practical settings where computa-tional humor will add value. Among them there are: business world applica-tions (such as advertisement, e-commerce, etc.), general computer-mediatedcommunication and human-computer interaction (Morkes et al. 1999),increase in the friendliness of natural language interfaces, and educationaland edutainment systems.
Applications need not necessarily emphasize interactivity. For instancethere are important prospects for humor in automatic information presen-tation. In the Web age, presentations will become more and more flexibleand personalized, and they will require humor contributions for electroniccommerce developments (e.g., product promotion, getting selective atten-tion, help in memorizing names, etc.) more or less as it happened in the worldof broadcast advertisement.
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 299
We are concerned with systems that automatically produce humorousoutput (rather than systems that appreciate humor). Some of the funda-mental competencies are within the range of the state of the art of naturallanguage processing.
In one form or another, humor is most often based on some form ofincongruity. In verbal humor, this means that at some level differentinterpretations of material must be possible (and some not detected beforethe culmination of the humorous process), or various pieces of material mustcause perception of specific forms of opposition. Natural language process-ing research has often dealt with ambiguity in language. A common view isthat ambiguity is an obstacle for deep comprehension. Most current textprocessing systems attempt to reduce the number of possible interpretationsof the sentences, and a failure to do so is seen as a weakness of the system.The potential for ambiguity, however, can be seen as a positive feature ofnatural language. Metaphors, idioms, poetic language and humor use themultiple senses of texts to suggest connections between concepts that cannot,or should not, be stated explicitly. Fluent users of natural language are ableto both use and interpret ambiguities inherent in the language, and verbalhumor is one of the most regular uses of linguistic ambiguity.
The work presented here is based on various resources for natural lan-guage processing, adapted for humor. It is a small step but aiming at anappreciable concrete result. It has been developed within the first EuropeanProject devoted to computational humor sponsored by the European Com-mission. A visible result capable of being evaluated was at the basis of thesponsorship. We have proposed a situation that is of practical interest, wheremany components are present but simplified with respect to more complexscenarios. The goal is a system that makes fun (Raskin says profane) ofexisting acronyms, or, starting from concepts provided by the user, producesa new acronym, constrained to be a word of the given language. And, ofcourse, it has to be funny.
HAHAcronym is meant to convince about the potential of computationalhumor, through the demonstration of a working prototype and an assess-ment of the state of the art and of scenarios where humor can add somethingto existing information technologies.
The main goal of HAHAcronym was the realization of an acronymironic re-analyzer and generator as a proof of concept in a focalized butnon-restricted context. In order to implement it some general tools havebeen developed or adapted for the humorous context. For all tools, par-ticular attention has been put on reusability. A fundamental tool is anincongruity detector/generator to detect/generate semantic mismatches
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

300 O. Stock and C. Strapparava
between the known/expected “sentence” meaning and other interpretations,along some specific dimension (i.e., in our case the acronym and its context).
State of the art
So far only very limited effort has been put on building computationalhumor prototypes. Indeed very few working prototypes that processhumorous text and/or simulate humor mechanisms exist. Mostly they areconcerned with rather simple tasks. There has been a considerable amountof research on linguistics of humor and on theories of semantics and prag-matics of humor (Attardo 1994; Attardo and Raskin 1991; Giora and Fein1999; Attardo 2002; Giora 2002); however, most of the work has not beenformal enough to be used directly for computational humor modeling. Aneffort toward formalization of forced reinterpretation jokes has beenpresented by Ritchie (2002).
Within the Artificial Intelligence community, most writing on humor hasbeen speculative (Minsky 1980; Hofstadter et al. 1989). Minsky made somepreliminary remarks about how humor could be viewed from the ArtificialIntelligence/cognitive science perspective, refining Freud’s notion thathumor is a way of bypassing our mental “censors” that control inappro-priate thoughts and feelings. Utsumi (1996) outlines a logical analysis ofirony, but this work has not been implemented. Among other works, DePalma and Weiner (1992) have worked on knowledge representation ofriddles, and Katz (1993) attempted to develop a neural model of humor.Ephratt (1990) has constructed a program that parses a limited range ofambiguous sentences and detects alternative humorous readings. A formal-ization, based on a cognitive approach (the belief-desire-intention model),and distinguishing between real and fictional humor, has been provided byMele (2002).
Probably the most important attempt to create a computational humorprototype is the work of Binsted and Ritchie (1997). They have devised aformal model of the semantic and syntactic regularities underlying some ofthe simplest types of punning riddles. A punning riddle is a question-answerriddle that uses phonological ambiguity. The three main strategies used tocreate phonological ambiguity are syllable substitution, word substitution,and metathesis.
Finally, Jester (Goldberg et al. 2001) is an on-line joke recommendingsystem using collaborative filtering in order to recommend jokes adapted tothe user’s “sense of humor.” It does not implement any linguistic technique
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 301
dealing with humor, rather it uses statistical techniques to recommend jokesbased on the user’s ratings of a set of sample jokes.
Almost all the approaches try to deal with the incongruity theory at vari-ous levels of refinement (Köstler 1964; Raskin 1985; Attardo 1994). Theincongruity theory focuses on the element of surprise. It states that humor iscreated out of a conflict between what is expected and what actually occursin the joke. This accounts for the most obvious features of a large part ofhumor phenomena: ambiguity or double meaning.
Specific workshops concerned with Computational Humor have takenplace in recent years and have drawn together most of the community activein the field. The proceedings of the most comprehensive events are Hulstijnand Nijholt (1996) and Stock, Strapparava, and Nijholt (2002). Ritchie(2001) has published a survey of the state of the art in the field.
The HAHAcronym project
As said before, HAHAcronym has been the first project dedicated to com-putational humor funded by the European Commission. It has been part ofthe Future Emerging Technologies Program within the Information SocietyTechnologies section of the Fifth Framework Program. Partners of theproject were ITC-irst (coordinator) and University of Twente; the latter tookcare of assessing the state of the art. The project benefited from the externalcollaboration of Salvatore Attardo, Rachel Giora, and Franco Mele.
The main goal of the project was the realization of an acronymre-analyzer and generator as a proof of concept in a focalized but non-restricted context. We had to propose something that we could develop in ashort period of time that would be meaningful, well demonstrable, that couldbe evaluated along some pre-decided criteria, and that would be conduciveto a subsequent development in a direction of potential industrial interest. Sofor us it was essential that a) the work could have many components of alarger system, simplified for the current setting; b) we could reuse and adaptexisting relevant linguistic resources; and c) some simple strategies forhumor effects could be experimented with.
The results were submitted to an evaluation by human subjects thatprovided indications for re-use of the semantic tools. Even if the scenario ofthis assessment project is simplified, the tools developed will be reusable forother applications and, in principle, portable to other languages.
Besides the prototype, the project produced an assessment of appliedopportunities in the market, an assessment of the state of the art in the field,
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

302 O. Stock and C. Strapparava
and of what can be done in a short to medium term. The working demonstra-tor is meant to convince about the feasibility and the potential impact of alarger applied project.
Resources and general architecture
Analyzing or generating verbal humor calls for exploitation, adaptation,and elaboration of natural language processing resources, such aslexicons, part-of-speech taggers, parsers, annotation tools, and knowledgerepositories.
One of the purposes of the project was to show that by using “standard”resources (with some extensions and modifications) and suitable linguistictheories of humor (i.e., developing specific algorithms that implement orelaborate theories) it is possible to implement a working prototype. For thatwe have taken advantage of specialized thesauri and repositories and inparticular of WORDNET DOMAINS, an extension developed at ITC-irstof the well-known English WORDNET lexical knowledge base. In WORDNET
DOMAINS, word meanings are annotated with subject field codes (e.g.,MEDICINE, ARCHITECTURE, LITERATURE . . .) providing cross-categorialinformation. WORDNET DOMAINS is organized for multilinguality, and anItalian extension is already available. Other important computational toolsare: a rule database of semantic field oppositions with humorous potential,a parser for analyzing input syntactically and a syntactic generator ofacronyms, and general lexical resources (e.g., acronym grammars, mor-phological analyzers, rhyming dictionaries, proper nouns databases). Thetools resulting from the adaptation will be reusable for other applicationsand are portable straightforwardly to other languages.
WORDNET and WORDNET DOMAINS
WORDNET is a thesaurus for the English language inspired by psy-cholinguistic principles and developed at the Princeton University byGeorge Miller (Miller 1990; Fellbaum 1998). It has been conceived as acomputational resource, therefore improving some of the drawbacks oftraditional dictionaries, such as circularity of definitions and ambiguity ofsense references. Lemmata (about 130,000 for version 1.6) are organizedin synonym classes (about 100,000 synsets). WORDNET can be described asa “lexical matrix” with two dimensions: a dimension for lexical relations,
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 303
that is relations holding among words and therefore language specific, anda dimension for conceptual relations, which hold among senses (the synsets)and that, at least in part, we consider independent from a particular lan-guage. A synset contains all the words by means of which it is possibleto express the synset meaning. For example, the synset {horse, Equus_cab-allus} describes the sense of “horse” as an animal, while the synset {knight,horse} describes the sense of “horse” as a chessman. The main relationspresent in WORDNET are synonymy, antonymy, hyperonymy-hyponymy,meronymy-holonymy, entailment, and troponymy.
Augmenting WORDNET with Domain information. Domains have been usedboth in linguistics (i.e., Semantic Fields) and in lexicography (i.e., SubjectField Codes) to mark technical usages of words. Although this is usefulinformation for sense discrimination, in dictionaries it is typically usedfor a small portion of the lexicon. WORDNET DOMAINS is an attemptto extend the coverage of domain labels within an already existing lexicaldatabase: WORDNET (version 1.6). The synsets have been annotated with atleast one domain label, selected from a set of about 200 labels hierarchicallyorganized (Figure 1 shows a portion of the domain hierarchy).
Figure 1. A sketch of the domain hierarchy
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

304 O. Stock and C. Strapparava
We have organized about 250 domain labels in a hierarchy (exploitingDewey Decimal Classification), where each level is made up of codes ofthe same degree of specificity. For example, the second level includesdomain labels, such as BOTANY, LINGUISTICS, HISTORY, SPORT, andRELIGION, while at the third level we can find specialization such asAMERICAN_HISTORY, GRAMMAR, PHONETICS, and TENNIS.
Information brought by domains is complementary to what is alreadypresent in WORDNET. First of all, a domain may include synsets of differentsyntactic categories; for instance, MEDICINE groups together senses fromNouns, such as doctor#1 and hospital#1, and from Verbs, such as oper-ate#7. Second, a domain may include senses from different WORDNET sub-hierarchies (i.e., deriving from different unique “beginners” or fromdifferent “lexicographer files”). For example, SPORT contains sensessuch as athlete#1, deriving from life_form#1, game_equipment#1, fromphysical_object#1, sport#1 from act#2, and playing_field#1, fromlocation#1.
Opposition of semantic fields. On the basis of well recognized propertiesof humor accounted for in many theories (e.g., incongruity, semantic fieldopposition, apparent contradiction, absurdity) we have modeled an inde-pendent structure of domain opposition, such as RELIGION vs. TECHNOL-OGY, SEX vs. RELIGION, etc. We exploit oppositions as a basic resource forthe incongruity generator.
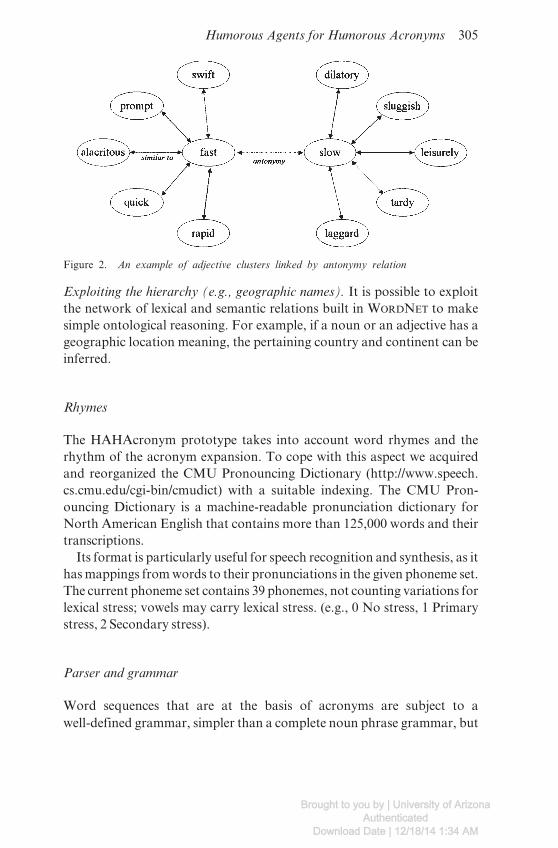
Adjectives and antonymy relations. Adjectives play an important role inmodifying and generating funny acronyms. So we gave them a thoroughanalysis. WORDNET divides adjectives into two categories. Descriptiveadjectives (e.g., big, beautiful, interesting, possible, married) constitute byfar the largest category. The second category is called simply relationaladjectives because they are related by derivation to nouns (i.e., electrical inelectrical engineering is related to noun electricity). To relational adjec-tives, strictly dependent on noun meanings, it is often possible to apply simi-lar strategies as those exploited for nouns. Their semantic organization,though, is entirely different from the other major categories. In fact it is notclear what it would mean to say that one adjective “is a kind of” (ISA) someother adjective. The basic semantic relation among descriptive adjectivesis antonymy. WORDNET proposes also that these kinds of adjectives areorganized in clusters of synsets associated by semantic similarity to a focaladjective. Figure 2 shows clusters of adjectives around the direct antonymsfast/slow.
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM
Humorous Agents for Humorous Acronyms 305
Exploiting the hierarchy (e.g., geographic names). It is possible to exploitthe network of lexical and semantic relations built in WORDNET to makesimple ontological reasoning. For example, if a noun or an adjective has ageographic location meaning, the pertaining country and continent can beinferred.
Rhymes
The HAHAcronym prototype takes into account word rhymes and therhythm of the acronym expansion. To cope with this aspect we acquiredand reorganized the CMU Pronouncing Dictionary (http://www.speech.cs.cmu.edu/cgi-bin/cmudict) with a suitable indexing. The CMU Pron-ouncing Dictionary is a machine-readable pronunciation dictionary forNorth American English that contains more than 125,000 words and theirtranscriptions.
Its format is particularly useful for speech recognition and synthesis, as ithas mappings from words to their pronunciations in the given phoneme set.The current phoneme set contains 39 phonemes, not counting variations forlexical stress; vowels may carry lexical stress. (e.g., 0 No stress, 1 Primarystress, 2 Secondary stress).
Parser and grammar
Word sequences that are at the basis of acronyms are subject to awell-defined grammar, simpler than a complete noun phrase grammar, but
Figure 2. An example of adjective clusters linked by antonymy relation
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

306 O. Stock and C. Strapparava
complex enough to require a nontrivial analyzer. We have decided to use awell established nondeterministic parsing technique (ATN-based parsing).Ordinarily, an ATN parser has three components: the ATN itself, whichrepresents the grammar in the form of a network, an interpreter for travers-ing it, and a dictionary (possibly integrated with a morphological analyzer).As obvious at this point, for the third component we use WORDNET, inte-grated with an ad-hoc morphological analyzer. As far as the interpreter isconcerned, we developed an ATN compiler that translates ATNs directlyinto Lisp code (i.e., Lisp augmented with nondeterministic constructs).Figure 3 sketches a portion of the acronym grammar.
Even if for the generation part we do not traverse the grammar, we exploitit as the source for syntactic constraints, which are also present.
A-semantic dictionary
The A-semantic dictionary is a collection of hyperbolic, epistemic, anddeontic adjectives or adverbs. This is a last resource, which sometimescan be useful in the generation of new acronyms. Some examples ofthese kinds of words are: abnormally, abstrusely, adorably, exceptionally,exorbitantly, exponentially, extraordinarily, voraciously, weirdly, and
Figure 3. A simplified grammar
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 307
wonderfully. This resource is hand-made, using various dictionaries asinformation sources.
Other important lexical resources are: a euphemism dictionary, a propernoun dictionary, and lists of typical foreign words commonly used in thelanguage with some strong connotation.
Implementation
To get an ironic or “profaning” re-analysis of a given acronym, the systemfollows various steps and strategies. The main elements of the algorithm canbe schematized as follows:
– acronym parsing and construction of a logical form;– choice of what to keep unchanged (typically the head of the highest
ranking NP) and what to modify (e.g., the adjectives);– look for possible substitutions;– exploitation of semantic field oppositions;– granting phonological analogy: While keeping the constraint on the
initial letters of the words, the overall rhyme and rhythm should bepreserved (the modified acronym should sound similar to the original asmuch as possible);
– exploitation of WORDNET antonymy clustering for adjectives;– use of the A-semantic dictionary as a last resource.
Figures 4 and 5 show a sketch of the architecture and an example of thesystem strategies.
Figure 4. Acronyms Reanalysis: a sketch of the demonstrator architecture
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

308 O. Stock and C. Strapparava
In our system, making fun of existing acronyms amounts to an ironicalrewriting, desecrating them with some unexpectedly contrasting, butotherwise consistent sounding expansion.
As far as acronym generation is concerned, the problem is more complex.To make the task more difficult we constrain resulting acronyms to be wordsof the dictionary (APPLE would be good, IBM would not). The system takesas input concepts (actually synsets, possibly the result of some other process,for instance sentence interpretation) and some minimal structural indica-tion, such as the semantic head. The primary strategy of the system isto consider as potential acronyms words that are in ironic relation withthe input concepts. By definition acronyms have to satisfy constraints — toinclude the initial letters of some lexical realization of the input wordssynsets, granting that the sequence of initials satisfy the overall acronymsyntax. In this primary strategy, the ironic reasoning comes mainly at thelevel of acronym choice in the lexicon and in the selection of the fillers ofthe open slots in the acronym.
For example, giving as input “fast” and “CPU,” we get static, torpid,dormant. (Note that the complete synset for “CPU” is {processor#3,CPU#1, central_processing_unit#1, mainframe#2}. So we can use in theacronym expansion a synonym of “CPU.” The same happens for “fast”).Once we have an acronym proposal, a syntactic skeleton has to be filled toget a correct noun phrase.
For example given in input “fast” and “CPU,” the system selectsTORPID with the possible syntactic skeleton:
< adv >T < adj > O Rapid Processor < prep > < adj > I < noun > Dor
< adj > T < adj > O Rapid Processor < prep > < noun > I < noun > D
where “rapid” and “processor” are synonyms respectively of “fast” and“CPU” and the notation < Part_of_Speech > Letter means a word ofthe Part_of_Speech type with Letter as initial. Then the system fills thissyntactic skeleton with strategies similar to those described for re-analysis.
Figure 5. An example of acronym reanalysis
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 309
Examples and preliminary evaluation
Some examples of acronym re-analysis are reported below. As far as seman-tic field opposition is concerned, we have slightly tuned the system towardthe domains FOOD, RELIGION, and SEX. For each example, we report theoriginal acronym, the re-analysis, and some comments about the strategiesfollowed by the system.
ACM— Association for Computing MachineryLAssociation for Confusing MachineryThe acronym expansion is simple. The system keeps all the heads (thehead of the whole NP and the head of the PP) and works on the adjective,preserving the rhyme and using the A-semantic dictionary.
CCTT — Close Combat Tactical Trainer (Army second generation virtualtrainer)LCold Combat Theological TrainerThis is an example of two changes: antonym-based strategy for the firstadjective and semantic opposition found in the RELIGION domain thatmodifies “Tactical” into “Theological.”
CHI — Computer Human InterfaceLComputer Harry_Truman InterfaceAn unexpected result, mainly achieved exploiting rhyme.
DMSO — Defense Modeling and Simulation OfficeLDefense Meat_eating and Salivation OfficeThe two modifications are coherent within the FOOD semantic fields. Ingeneral the system can choose either to keep coherence among modifica-tions or to exploit contrast, picking them from different “opposite” semanticfields, as in the following example:
IST — Institute for Simulation and TrainingLInstitute for Sexual_abstention and Thanksgiving
FCCSET — Federal Coordinating Committee for Science, Engineering, andTechnologyLFemoral Coordinating Committee for Sword_dance Earring andTheologyThis example shows how too many modifications can produce a re-analysisthat does not resemble the original acronym at all, with poor irony effect.We have now introduced a threshold regarding the number of modifications
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

310 O. Stock and C. Strapparava
that can be crossed only if the overall potential modifications value isconsidered very high by the system.
Testing the humorous quality of texts or other verbal results is not an easytask. There have been relevant studies though, such as (Ruch 1996; Köhlerand Ruch 1996). For HAHAcronym, an evaluation was conducted bySalvatore Attardo at Youngstown State University, with a group of about 40university students. The students had to choose among five levels of amuse-ment (from very_funny to not_funny). The results were very encouraging.None of the re-analyses proposed to the students was rejected as completelynon-humorous. More than 50 percent were considered good enough.
The evaluation was organized as follows:Acronym humorous re-analysis, given an existing acronym
– number of panel members: 20;– method: for every re-analysis, each panelist gives from 1 to 5 (max)
points (100 pts. is the maximum score given 20 testers);– number of experiments: 40;– success threshold: in 60 percent of the given acronyms, a re-analysis
must have a score that exceeds 55/100;
the results are to be differentially compared with the score obtained by ran-domly generated (but syntactically correct) data obtained by the basicmachinery after having disengaged the specific resources and heuristics.65 percent of acronyms must have a more humorous evaluation with thefull machinery.As far as the evaluation of acronym creation from scratch (i.e., from a set ofconcepts) is concerned, the methodology was the following.
– number of panel members: 20;– method: for every acronym generation, each panelist gives from 1 to 5
(max) points (100 pts. is the maximum score given 20 testers);– number of experiments: 30.
The success threshold was set as follows: In 45 percent of the sets of inputconcepts, provided there is a solution, a generated acronym will have a scorethat exceeds 55/100.
Both the reanalysis module and the generation module were found to besuccessful according to the criteria spelled out above. Moreover the rean-alysis data were found to be significantly better than randomly generatedsimilar data. Table 1 shows a summary of the evaluation results:
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 311
Prospects and conclusions
The acronym re-analyzer is completed, and one of the main concerns isthe ranking of possible re-analyses so that the ones that are supposed to bethe funniest appear at the top. The system is flexible, and novel strategiescan be added. Ranking a priori is easy: It is based on a combination ofvalues attributed by hand to the various strategies. Ranking a posterioriis much more difficult and involves some initial steps in modeling humorappreciation.
The generator is completed, even if it has some constraints on the numberof concepts submitted for a single input.
The implementation is in Allegro Common Lisp, and the system could beeasily integrated within a number of hosting applications.
We consider this as a first step of a set of possible developments ofpractical impact.
Some possible applied scenarios:
(a) educational software for children, based on the idea of machine ass-isted humor generation, thus helping children explore word-meanings(for a work in this direction, see also McKay 2002);
(b) a system that uses humor as a means to promote products and to get theuser’s attention in an electronic commerce environment;
(c) an appealing names generator for products and merchandise (e.g.,goods, commodities, pharmaceutical products, etc.).
If there are doubts about the possible practical utility of a system like this, letus just consider the case of European Project proposals. The first field of theproposal is for the name that must be an acronym. When a proposal is pre-pared, the energy of the most senior scientists involved in the consortiumgoes to finding a good acronym. Being funny is a plus. A very conservativeestimate is that on average, to prepare a proposal may require a couple ofperson-months. For choosing the name, we think it is fair to say that it may
Table 1.
Acronyms % > 55 Success threshold %
Generation 52.87 45Reanalysis 69.81 60Random 7.69
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

312 O. Stock and C. Strapparava
take two person-days of the best senior scientists. Every year, the number ofproposals submitted to the European Commission is more than 10.000. So,at minimum 20.000 days are spent on (if possible, funny) acronyms, i.e.,some 100 person-years are consumed of the most senior personnel involved:the cost can be estimated at more than 10 million euro (around $10 million).A computational humor system resulting from this prototype would costmuch less . . .
ITC-irst, Istituto per la Ricerca Scientifica e Tecnologica
Note
Correspondence address: [email protected]; [email protected]
References
Attardo, Salvatore1994 Linguistic Theory of Humor. Berlin/New York: Mouton de Gruyter.2002 Formalizing Humor Theory. In Stock, Oliviero, Carlo Strapparava, and
Anton Nijholt (eds.), Proceedings of the The April Fools’ Day Workshopon Computational Humour, April 15–16, 2002, Trento, Italy. Enschede:University of Twente, 1–10.
Attardo, Salvatore, and Victor Raskin1991 Script theory revis(it)ed: Joke similarity and joke representation model.
Humor: International Journal of Humor Research 4(3), 293–347.Binsted, Kim
1996 Machine humour: An implemented model of puns. Ph.D. diss, Universityof Edinburgh.
Binsted, Kim, and Graeme Ritchie1997 Computational rules for punning riddles. Humor: International Journal of
Humor Research 10(1), 25–76.De Palma, Paul, and Judith Weiner
1992 Riddles: accessibility and knowledge representation. In Proceedings ofthe 15th International Conference on Computational Linguistics (COLING-92), vol. 4. Nantes, 1121–1125.
Ephratt, Michal1990 What’s in a joke. In Golumbic, M. (ed.), Advances in AI: Natural
Language and Knowledge Based Systems. Heidelberg: Springer Verlag,406–450.
Fellbaum, Christiane1998 WordNet. An Electronic Lexical Database. Cambridge: The MIT Press.
Freud, Sigmund1905 Der Witz und seine Beziehung zum Unbewussten. Leipzig/Vienna: Deutike.
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

Humorous Agents for Humorous Acronyms 313
Giora, Rachel2002 Optimal innovation and pleasure. In Stock, Oliviero, Carlo Strapparava,
and Anton Nijholt (eds.), Proceedings of the The April Fools’ Day Work-shop on Computational Humour (TWLT 20), April 15–16, 2002, Trento,Italy. Enschede: University of Twente, 11–28.
Giora, Rachel, and Ofer Fein1999 Irony: Context and salience. Metaphor and Symbol 14: 241–257.
Goldberg, Ken, Theresa Roeder, Dhruv Gupta, and Chris Perkins2001 Eigentaste: A constant time collaborative filtering algorithm. Information
Retrieval 4(2), 133–151.Hofstadter, Douglas, Liane Gabora, Victor Raskin, and Salvatore Attardo
1989 Synopsis of the workshop on humor and cognition. Humor: InternationalJournal of Humor Research 2(4), 293–347.
Hultijn, Joris, and Anton Nijholt1996 Automatic Interpretation and Generation of Verbal Humor. In Hultijn,
Joris, and Anton Nijholt (eds.), Proceedings of the International Workshopon Computational Humour (TWLT 12). Enschede: University of Twente.
Katz, Bruce1993 A neural resolution of the incongruity and incongruity-resolution theories
of humor. Connection Science 5(1), 59–75.Köhler, Gabriele, and Willibald Ruch
1996 Sources of variance in current sense of humor inventories: How muchsubstance, how much method variance? Humor: International Journal ofHumor Research 9 (3/4). (Special issue: Measurement approaches to thesense of humor), 363–397.
Köstler, Arthur1964 The act of creation. London: Hutchinson.
McKay, Justin2002 Generation of Idiom-based Witticisms to Aid Second Language Learning.
In Stock, Oliviero, Carlo Strapparava, and Anton Nijholt (eds.), Proceed-ings of the The April Fools’ Day Workshop on Computational Humour(TWLT 20), April 15–16, 2002, Trento, Italy. Enschede: University ofTwente, 77–88.
Mele, Francesco2002 Real and fictional ridicule. A cognitive approach for models of humour. In
Stock, Oliviero, Carlo Strapparava, and Anton Nijholt (eds.), Proceedingsof the The April Fools’ Day Workshop on Computational Humour (TWLT20), April 15–16, 2002, Trento, Italy. Enschede: University of Twente,89–100.
Miller, George1990 An on-line lexical database. International Journal of Lexicography 13(4),
235–312.Minsky, Marvin
1980 Jokes and the logic of the cognitive unconscious. Technical report, MITArtificial Intelligence Laboratory. AI memo 603.
Morkes, John, Hadyn Kernal, and Clifford Nass1999 Effects of humor in task-oriented human-computer interaction and
computer-mediated communication: A direct test of SRCT theory.Human-Computer Interaction 14, 395–435.
Raskin, Victor1985 Semantic Mechanisms of Humor. Dordrecht/Boston/Lancaster: Reidel.
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM

314 O. Stock and C. Strapparava
Ritchie, Graeme2001 Current Directions in Computational Humour. Artificial Intelligence
Review 16(2), 119–135.2002 The structure of forced interpretation jokes. In Stock, Oliviero, Carlo
Strapparava, and Anton Nijholt (eds.), Proceedings of the The April Fools’Day Workshop on Computational Humour (TWLT 20), April 15–16,2002, Trento, Italy. Enschede: University of Twente, 47–56.
Ruch, Willibald1996 Measurement approaches to the sense of humor. Humor: International
Journal of Humor Research 9 (3/4). (Special issue.)Stock, Oliviero
1996 Password swordfish: Verbal humor in the interface. In Hulstijn, Joris, andAnton Nijholt (eds.), Proceedings of the International Workshop onComputational Humour (TWLT 12). Enschede: University of Twente,1–8.
Stock, Oliviero, Carlo Strapparava, and Anton Nijholt (eds.)2002 Proceedings of the The April Fools’ Day Workshop on Computational
Humour (TWLT 20) April 15–16, 2002, Trento, Italy. Enschede:University of Twente.
Utsumi, Akira1996 Implicit display theory of verbal irony: Towards a computational theory
of irony. In Hulstijn, Joris, and Anton Nijholt (eds.), Proceedings of Inter-national Workshop on Computational Humour (TWLT 12). Enschede:University of Twente, 29–38.
Brought to you by | University of ArizonaAuthenticated
Download Date | 12/18/14 1:34 AM