hammer project - answering queries on open data
TRANSCRIPT

ANSWERING QUERIES ON OPENDATA
Pelucchi Mauro
Relatore: Prof. Giuseppe Psaila Correlatore: Prof. Maurizio Pietro Toccù

COSA E’ OPEN DATA?
• Con dati aperti facciamo riferimento alle informazioni raccolte e detenute da Pubbliche Amministrazioni ed Enti Pubblici che vengono messe a disposizione di tutti attraverso internet

HTTP://OPENDEFINITION.ORGLa conoscenza è aperta quando chiunque ha libertà di
accesso, uso, modifica e condivisione ad essa – avendo al massimo
come limite misure che ne preservino la provenienza e l’apertura.
#opendefinition

HTTP://OPENDEFINITION.ORGLa conoscenza è aperta quando chiunque ha libertà di
accesso, uso, modifica e condivisione ad essa – avendo al massimo
come limite misure che ne preservino la provenienza e l’apertura.
#opendefinition
Open Government Open Source Open Access

PERCHÉ FARE OPEN DATA?• TRASPARENZA
• Volontà di rendere pubblica l’azione di governo
• CREAZIONE DI SERVIZI A CITTADINI E IMPRESE
• Creazione di nuovi servizi da parte di enti terzi
• CREAZIONE DI NUOVA ECONOMIA
• Nuovi mercati, nuovi prodotti e nuovi posto di lavoro
• LEVA PER L’INNOVAZIONE

Open Data in Italia

LE CARATTERISTICHE DEGLI OPEN DATA
Non strutturati Varietà di formati
Fonti dati eterogenee
Procedure e strumenti diverse
Varietà di struttura
VolumeDati grezzi

CATENA DEL VALORE
Rilascio dataset
Raccolta e raffinamento
Riuso Open Data
Utilizzo Open Data
dati grezzi dati raffinatinuovi prodotti e nuovi servizi
Enti Pubblici Società specializzate Imprese Cittadini

CATENA DEL VALORE
Rilascio dataset
Raccolta e raffinamento
Riuso Open Data
Utilizzo Open Data
dati grezzi dati raffinatinuovi prodotti e nuovi servizi
Enti Pubblici Società specializzate Imprese Cittadini

Select TITOLOfrom GIORNALE
WhereTITOLO like ‘%BergamoScienza%’
and Anno = 2015

Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015

Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015
TITOLO GIORNALE
BERGAMOSCIENZA 2015

Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015
TITOLO GIORNALE
BERGAMOSCIENZA 2015
Ricerca dei dataset
Catalogo locale
TITOLO GIORNALE
BERGAMOSCIENZA 2015
metadati attributi{

Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015
TITOLO GIORNALE
BERGAMOSCIENZA 2015
Ricerca dei dataset
Catalogo locale
Risultato della ricerca
TITOLO GIORNALE
BERGAMOSCIENZA 2015
metadati attributi{
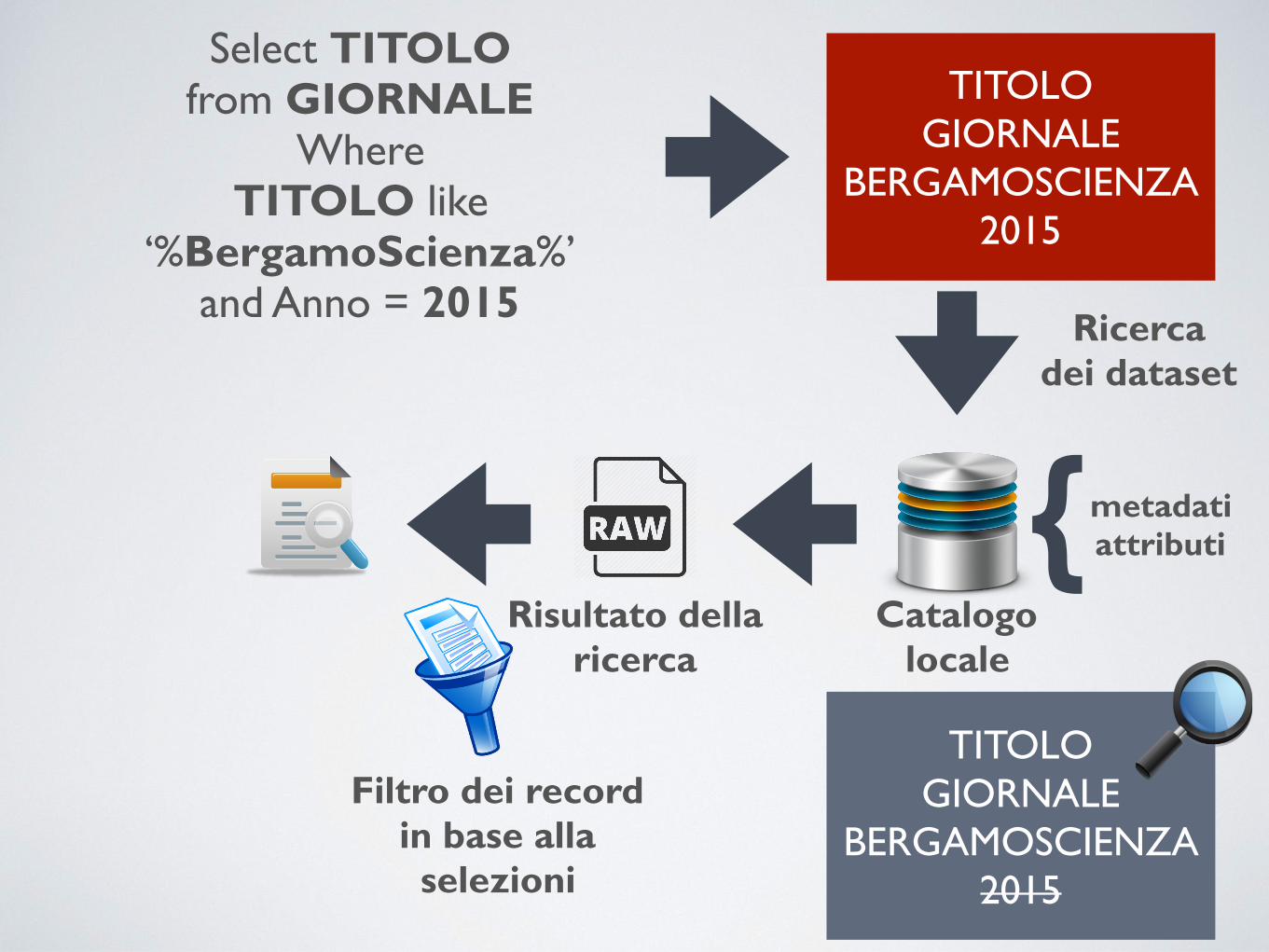
Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015
TITOLO GIORNALE
BERGAMOSCIENZA 2015
Ricerca dei dataset
Catalogo locale
Filtro dei record in base alla selezioni
Risultato della ricerca
TITOLO GIORNALE
BERGAMOSCIENZA 2015
metadati attributi{
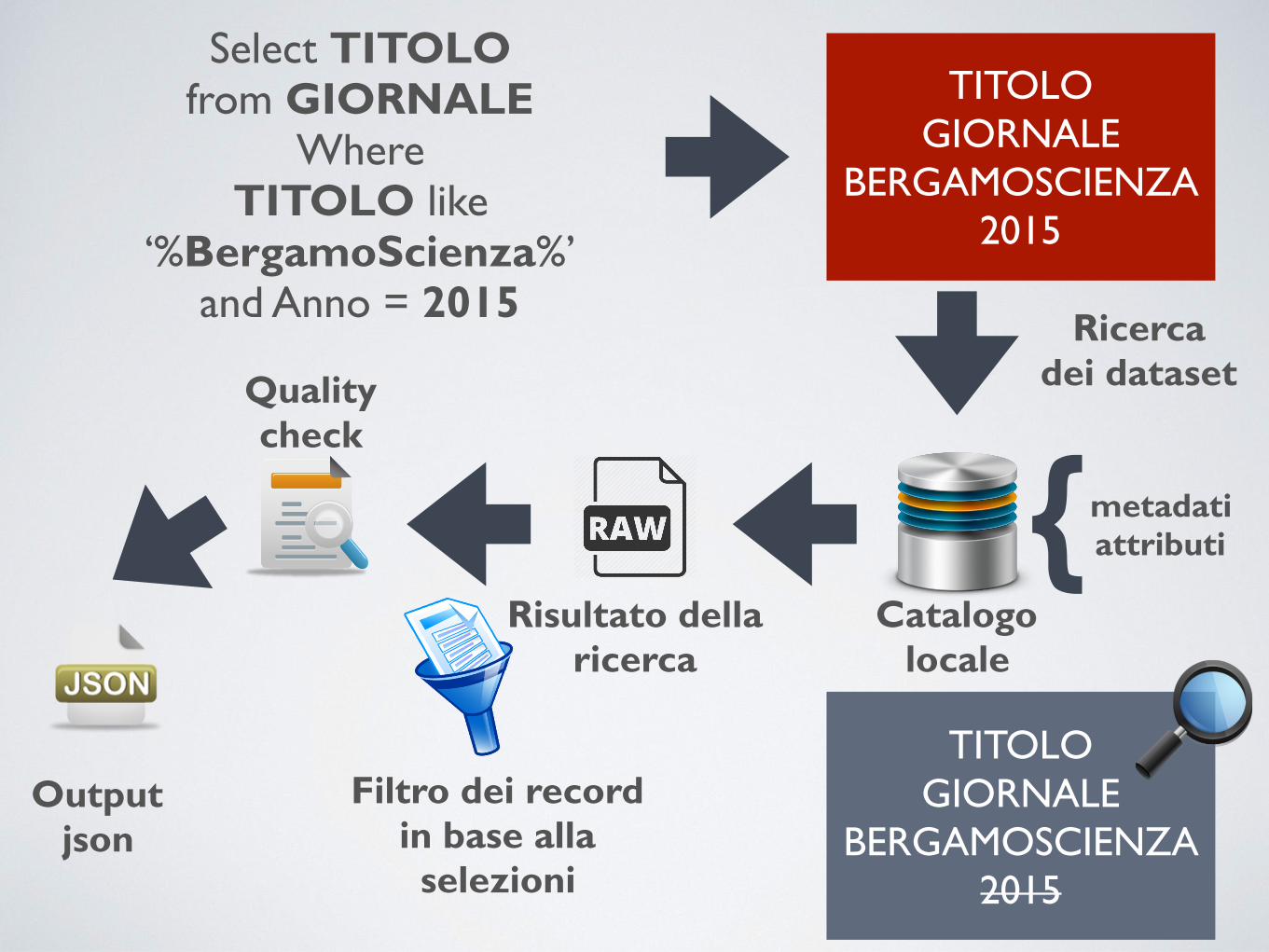
Select TITOLO from GIORNALE
Where TITOLO like
‘%BergamoScienza%’ and Anno = 2015
TITOLO GIORNALE
BERGAMOSCIENZA 2015
Ricerca dei dataset
Catalogo locale
Output json
Filtro dei record in base alla selezioni
Risultato della ricerca
TITOLO GIORNALE
BERGAMOSCIENZA 2015
metadati attributi{
Quality check

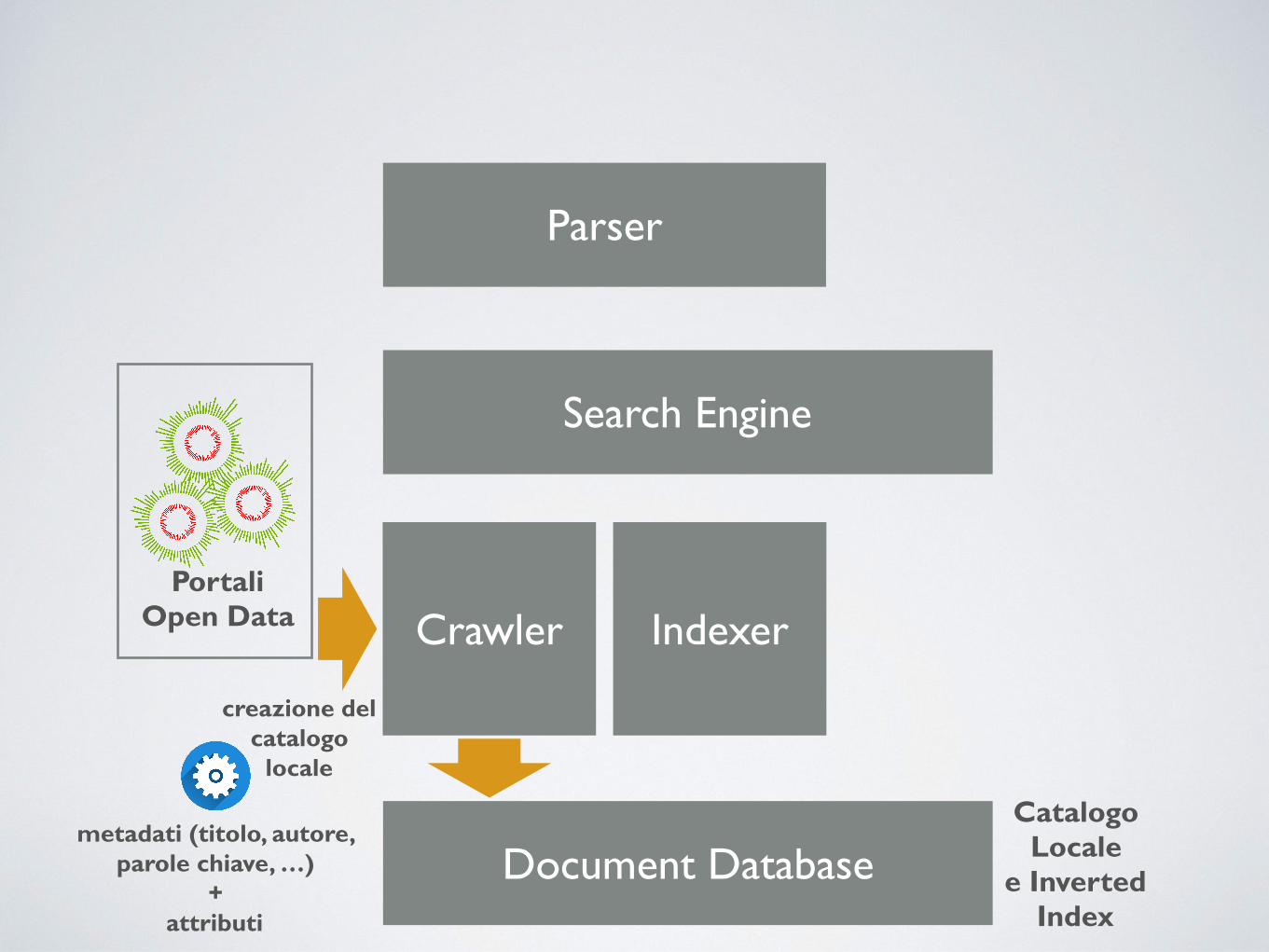
Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Catalogo Locale
e Inverted Index
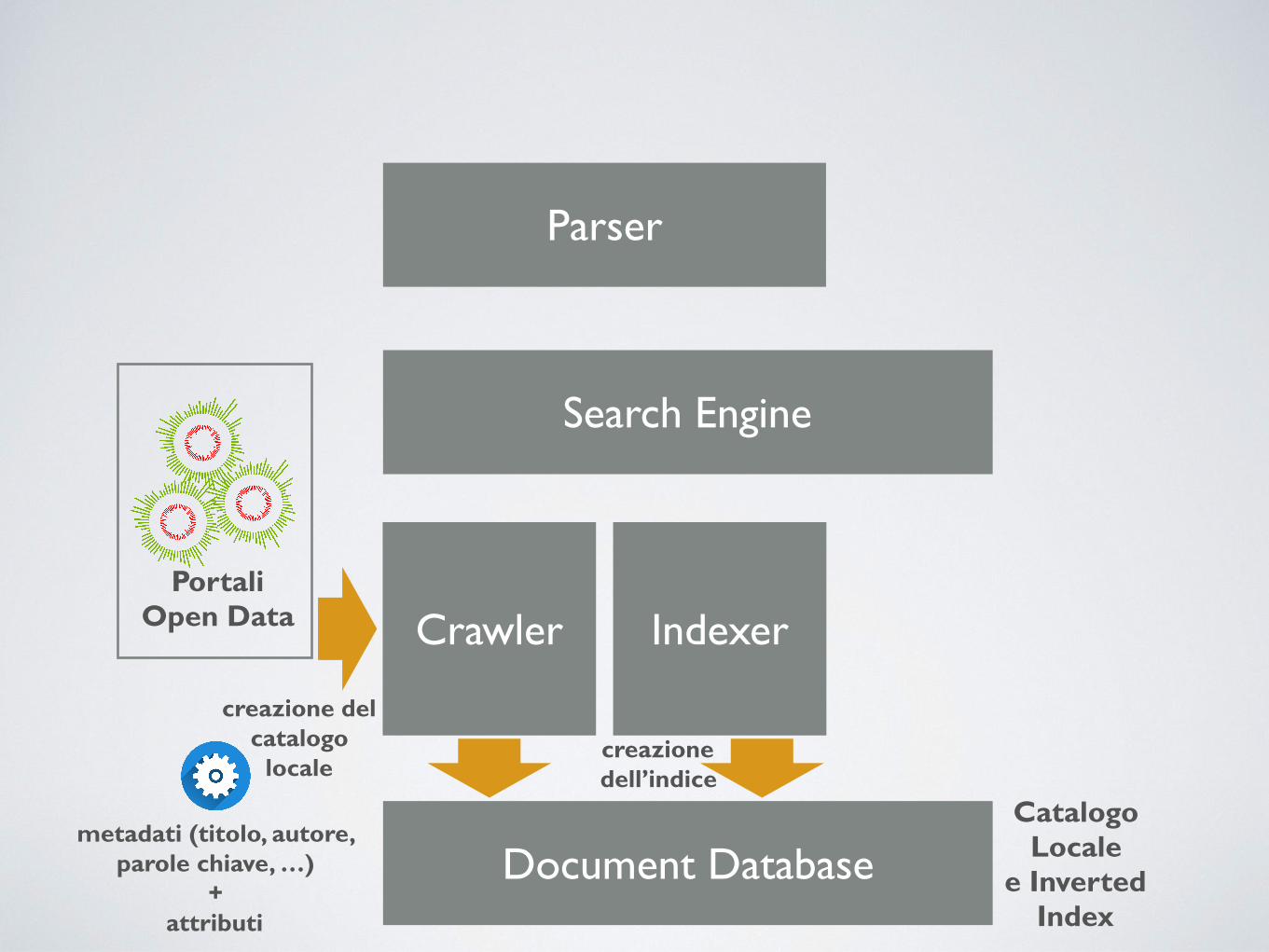
Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
creazione del catalogo
locale
Catalogo Locale
e Inverted Index
metadati (titolo, autore, parole chiave, …)
+ attributi
Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
metadati (titolo, autore, parole chiave, …)
+ attributi

Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Query.json
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
metadati (titolo, autore, parole chiave, …)
+ attributi

Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Query.json
ricerca sull’indice invertito
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
metadati (titolo, autore, parole chiave, …)
+ attributi

Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Query.json
download
ricerca sull’indice invertito
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
metadati (titolo, autore, parole chiave, …)
+ attributi

Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Query.json
download
ricerca sull’indice invertito
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
selezione dei record
metadati (titolo, autore, parole chiave, …)
+ attributi

Parser
Document Database
Crawler
Search Engine
IndexerPortali
Open Data
Query.json
download
ricerca sull’indice invertito
processo di
data quality
creazione del catalogo
localecreazione dell’indice
Catalogo Locale
e Inverted Index
selezione dei record
metadati (titolo, autore, parole chiave, …)
+ attributi

{ "select": [
{ "column": { "instance": "giornale", “label":"titolo"}} ],
"from": [
“giornale" ],
"where": [ {"condition": {
"instance1": “giornale", "label1": "titolo",
"operator": “like", "value": "BERGAMOSCIENZA",
"logicalOperator": "and"
}}, {"condition": {
"instance1": “giornale", "label1": “anno",
"operator": “eq", "value": "2015",
"logicalOperator": "and"
}}]
}
Interoperability
IL LINGUAGGIO
Semplice
Open
Compatto
Estendibile

{ "select": [
{ "column": { "instance": "giornale", “label":"titolo"}} ],
"from": [
“giornale" ],
"where": [ {"condition": {
"instance1": “giornale", "label1": "titolo",
"operator": “like", "value": "BERGAMOSCIENZA",
"logicalOperator": "and"
}}, {"condition": {
"instance1": “giornale", "label1": “anno",
"operator": “eq", "value": "2015",
"logicalOperator": "and"
}}]
}
InteroperabilityInteroperability
IL LINGUAGGIO
Semplice
Open
Compatto
Estendibile

I TERMINI CHIAVESelect TITOLO
from GIORNALE Where
TITOLO like ‘%BergamoScienza%’ and Anno = 2015
Informatività = Quantità di informazione - la capacità di informare propria di un testo
Rappresentatività = Capacità di essere rappresentativi - la probabilità che la ricerca del termine restituisca documenti interessanti per il dominio

IL CATALOGO LOCALE
dati.regionelombardia.itdati.regionetoscana.it
dati.trentino.it…
Read/import data
source
Input split Mapping Shuffling/Reducing Final

IL CATALOGO LOCALE
dati.regionelombardia.itdati.regionetoscana.it
dati.trentino.it…
dati.regionelombardia.it
dati.regionetoscana.it
dati.trentino.it
Read/import data
source
Input split Mapping Shuffling/Reducing Final

IL CATALOGO LOCALE
dati.regionelombardia.itdati.regionetoscana.it
dati.trentino.it…
dati.regionelombardia.it
dati.regionetoscana.it
dati.trentino.it
Read/import data
source
Input splitElenco comuni della
Lombardia
Aree Wifi a Milano
…
Dati inquinamento Toscana
Anagrafe scuola Toscana
…
Anagrafe scuole Trento
Musei Trento
…
Mapping Shuffling/Reducing Final

IL CATALOGO LOCALE
dati.regionelombardia.itdati.regionetoscana.it
dati.trentino.it…
dati.regionelombardia.it
dati.regionetoscana.it
dati.trentino.it
Read/import data
source
Input splitElenco comuni della
Lombardia
Aree Wifi a Milano
…
Dati inquinamento Toscana
Anagrafe scuola Toscana
…
Anagrafe scuole Trento
Musei Trento
…
Mapping Shuffling/Reducing
Elenco comuni della Lombardia
Aree Wifi a Milano
…
Dati inquinamento Toscana
Anagrafe scuola Toscana
…
Anagrafe scuole Trento
Musei Trento
…
Final

IL CATALOGO LOCALE
dati.regionelombardia.itdati.regionetoscana.it
dati.trentino.it…
dati.regionelombardia.it
dati.regionetoscana.it
dati.trentino.it
Read/import data
source
Input splitElenco comuni della
Lombardia
Aree Wifi a Milano
…
Dati inquinamento Toscana
Anagrafe scuola Toscana
…
Anagrafe scuole Trento
Musei Trento
…
Mapping Shuffling/Reducing
Elenco comuni della Lombardia
Aree Wifi a Milano
…
Dati inquinamento Toscana
Anagrafe scuola Toscana
…
Anagrafe scuole Trento
Musei Trento
…
Final
Catalogo locale

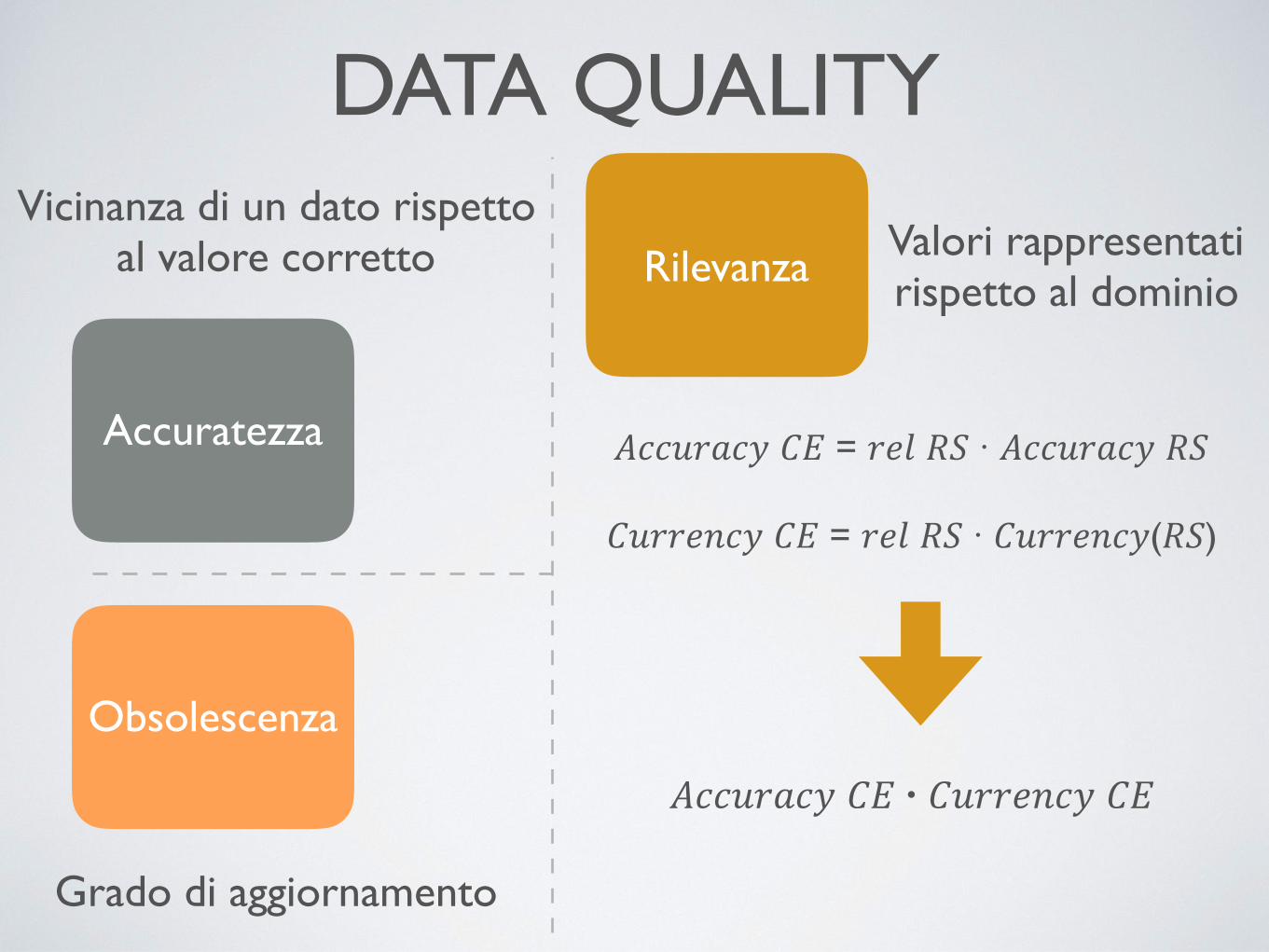
DATA QUALITY
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 𝐶𝐸 · 𝐶𝑢𝑟𝑟𝑒𝑛𝑐𝑦 𝐶𝐸
DATA QUALITY
Accuratezza
Obsolescenza
Vicinanza di un dato rispetto al valore corretto
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 𝐶𝐸 = 𝑟𝑒𝑙 𝑅𝑆 · 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 𝑅𝑆
𝐶𝑢𝑟𝑟𝑒𝑛𝑐𝑦 𝐶𝐸 = 𝑟𝑒𝑙 𝑅𝑆 · 𝐶𝑢𝑟𝑟𝑒𝑛𝑐𝑦(𝑅𝑆)
Grado di aggiornamento
Rilevanza Valori rappresentati rispetto al dominio

PROVE SPERIMENTALIAMBITO SOCIALE
AMBITO ECONOMICO
AMBITO AMBIENTALE
Agriturismi, musei, alberghi, sport, BG
Lombardia, Cened, Biomassa, Polizia, Auto
Cened, Censimento, 2011, Bergamo
44 documenti
19031 record
20 minuti
53 documenti
32759 record
15 minuti
64 documenti
8404 record
7 minuti
Google Cloud Platform 3 nodi Apache Hadoop (totale 9 core, 9 GB) 2 nodi MongoDb (6 core, 6 GB / primary + replica)
Catalogo: 7 sorgenti - 3306 documenti 4851 termini

Un linguaggio per interrogare dati non strutturati
Un algoritmo per la creazione ed il mantenimento di un catalogo locale di
Open Data da fonti eterogenee
Creazione di un Inverted Index
Un algoritmo per estrarre dati strutturati da dati non strutturati partendo da un catalogo locale
Processo di data quality Indice di consistenza
k-level per l’estrazione dei termini chiave
Ontologie e tesauri per migliorare l’indice
Integrazione di altre fonti (es.: Istat) e
applicazioni in ambito BigData
Aggregazioni eordinamenti

LA VISUALIZZAZIONERapidità e affidabilità
delle analisi ad hoc
Ottimizzazione del processo decisionale
Più collaborazione e condivisione
delle informazioni
Più funzionalità self service per gli utenti finali
Incremento del ROI
Risparmio di tempo
Meno pressione
sull’It
20 %43 %
77 %
34 %
15 %36 %
41 %
www.sas.com/italy
CITIZEN DATA SCIENTISTS
Citizen data scientists: people on the business side that may have some data skills, possibly from a math or even
social science degree and putting them to work exploring and analyzing data.
Gartner 2015 Hype Cycle

Per maggior informazioni:
GitHub - https://github.com/HammerProject
http://www.hammer-project.com
Grazie