hbase archetypes
TRANSCRIPT

‹#›© Cloudera, Inc. All rights reserved.
Matteo Bertozzi |Apache HBase Committer & PMC member
Apache HBase Archetypes
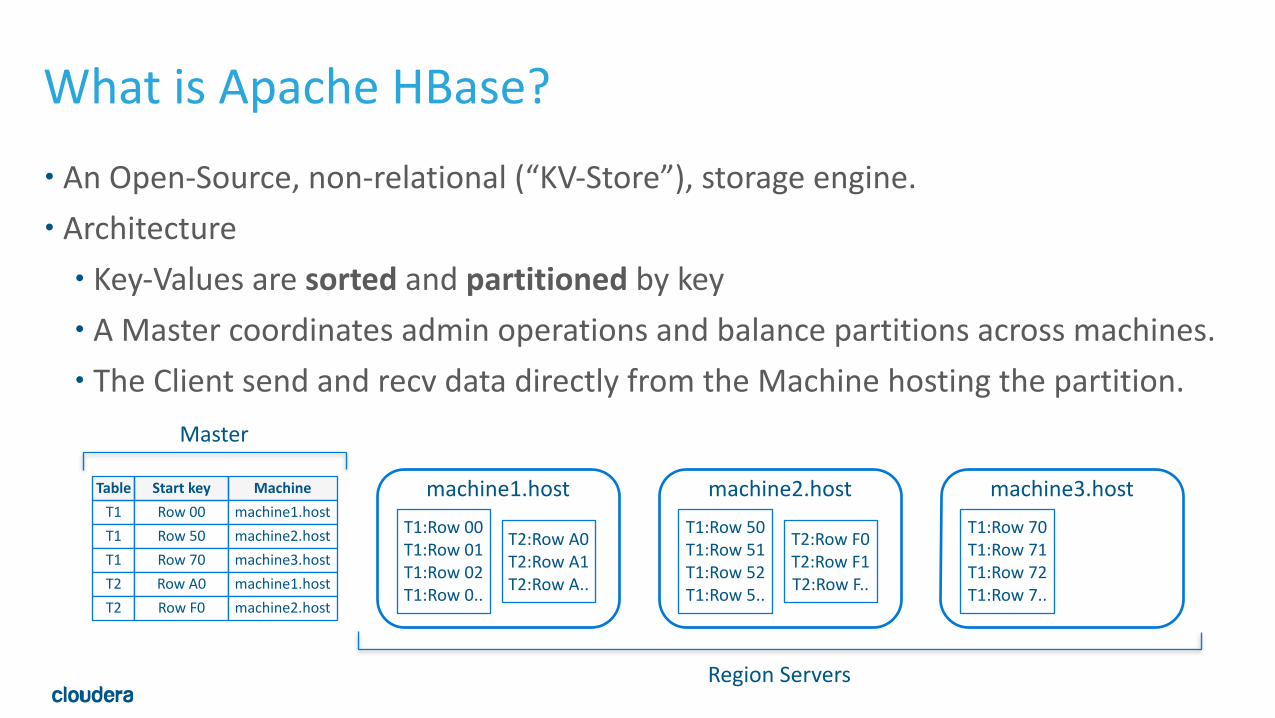
What is Apache HBase?• An Open-‐Source, non-‐relational (“KV-‐Store”), storage engine. • Architecture • Key-‐Values are sorted and partitioned by key • A Master coordinates admin operations and balance partitions across machines. • The Client send and recv data directly from the Machine hosting the partition.
T1T1T1T2T2
Row 00Row 50Row 70Row A0Row F0
Table Start key Machinemachine1.hostmachine2.hostmachine3.hostmachine1.hostmachine2.host
T1:Row 00 T1:Row 01 T1:Row 02 T1:Row 0..
T2:Row A0 T2:Row A1 T2:Row A..
machine1.hostT1:Row 50 T1:Row 51 T1:Row 52 T1:Row 5..
T2:Row F0 T2:Row F1 T2:Row F..
machine2.hostT1:Row 70 T1:Row 71 T1:Row 72 T1:Row 7..
machine3.host
Master
Region Servers
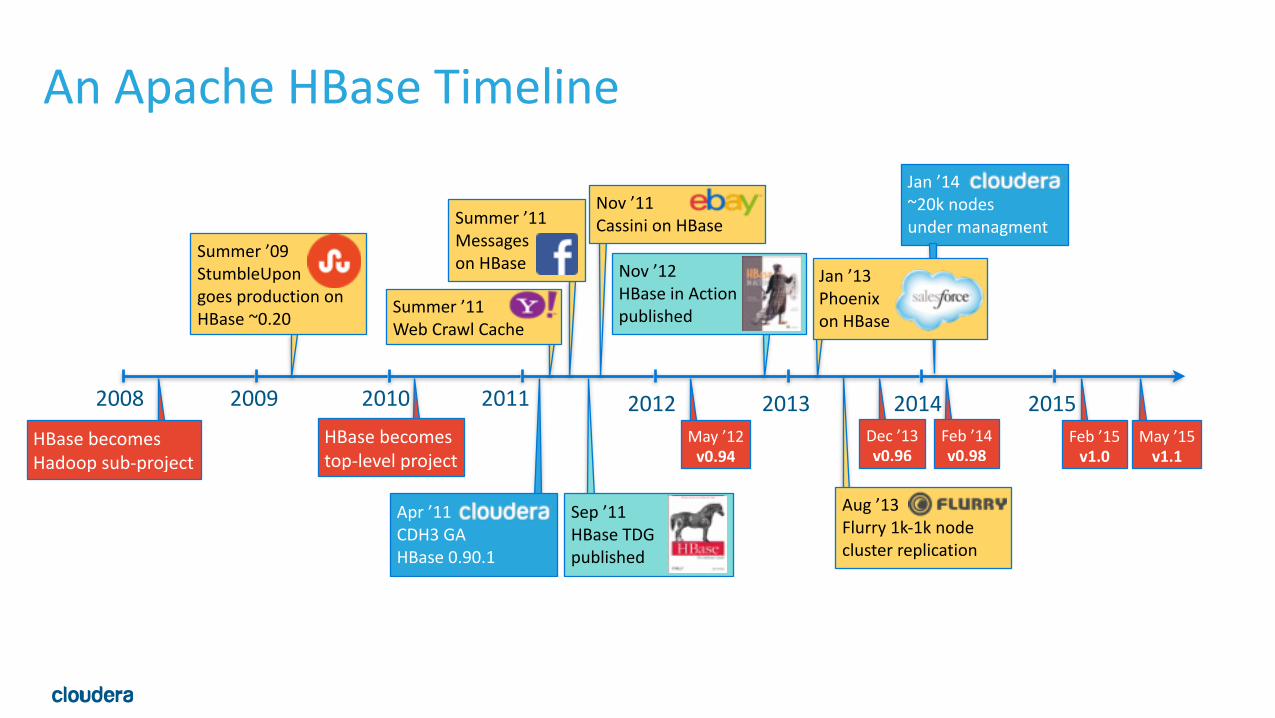
2008 2009 2010 2011 2012 2013 2014 2015
An Apache HBase Timeline
HBase becomes top-‐level project
Jan ’14 ~20k nodes under managment
Feb ’15 v1.0
May ’15 v1.1
Feb ’14 v0.98
May ’12 v0.94
HBase becomes Hadoop sub-‐project
Summer ’09 StumbleUpon goes production on HBase ~0.20
Summer ’11 Web Crawl Cache
Summer ’11 Messages on HBase
Nov ’11 Cassini on HBase
Apr ’11 CDH3 GA HBase 0.90.1
Dec ’13 v0.96
Sep ’11 HBase TDG published
Jan ’13 Phoenix on HBase
Aug ’13 Flurry 1k-‐1k node cluster replication
Nov ’12 HBase in Action published

Apache HBase “NASCAR” Slide
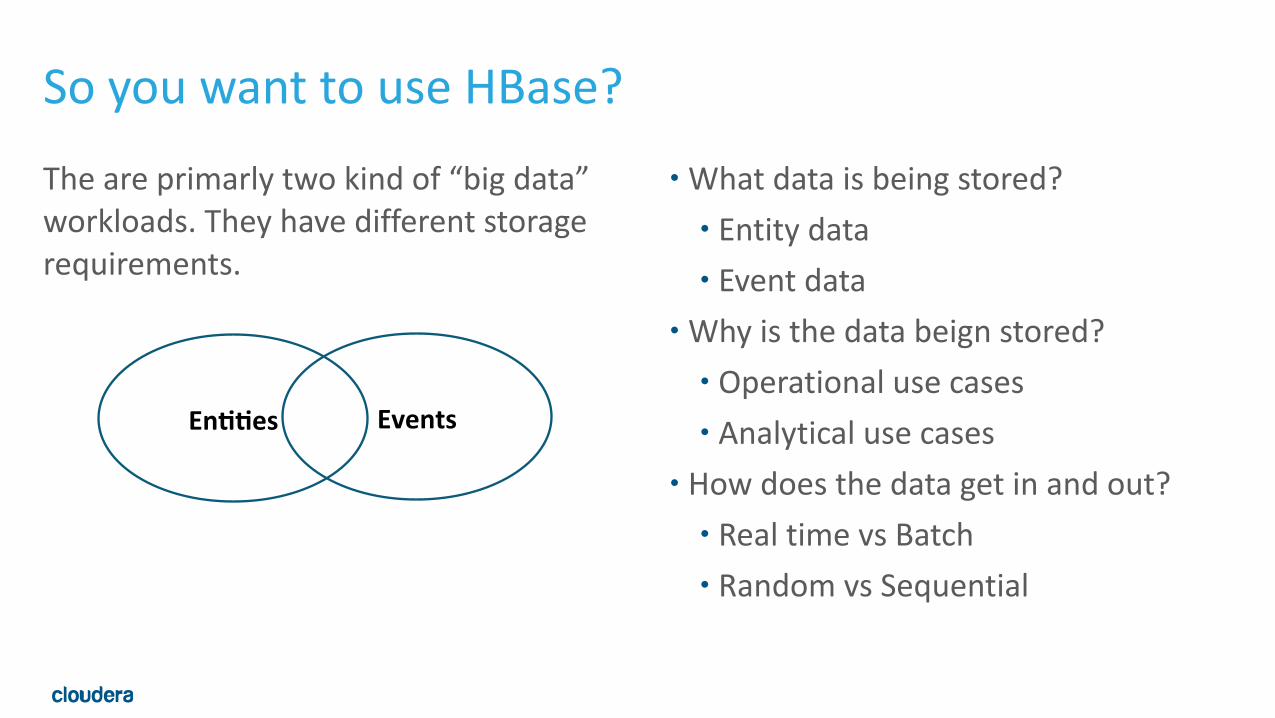
•What data is being stored? • Entity data • Event data
•Why is the data beign stored? • Operational use cases • Analytical use cases
• How does the data get in and out? • Real time vs Batch • Random vs Sequential
The are primarly two kind of “big data” workloads. They have different storage requirements.
So you want to use HBase?
En##es& Events&

Entity Centric Data• Entity data is information about current state • Generally real time reads and writes
• Examples: • Accounts • Users • Geolocation points • Click Counts and Metrics • Current Sensors Reading
• Scales up with # of Humans and # of Machines/Sensors • Billions of distinct entities
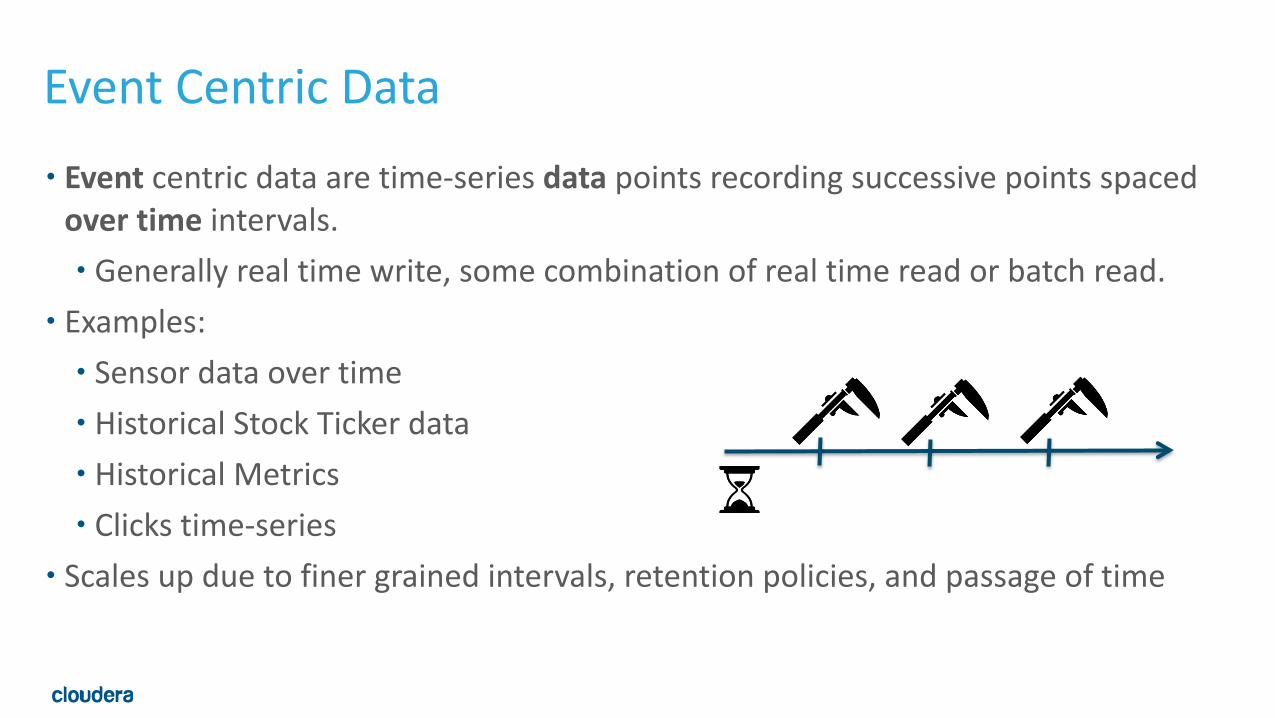
Event Centric Data• Event centric data are time-‐series data points recording successive points spaced over time intervals. • Generally real time write, some combination of real time read or batch read.
• Examples: • Sensor data over time • Historical Stock Ticker data • Historical Metrics • Clicks time-‐series
• Scales up due to finer grained intervals, retention policies, and passage of time

• So what kind of questions are you asking the data? • Entity-‐centric questions • Give me everything about entity E • Give me the most recent event V about entity E • Give me the N most recent events V about entity E • Give me all events V about E between time [t1, t2]
• Event and Time-‐centric Questions • Give me an aggregate on each entity between time [t1, t2] • Give me an aggregate on each time interval for entity E • Find events V that match some other given criteria
Why are you storing the data?

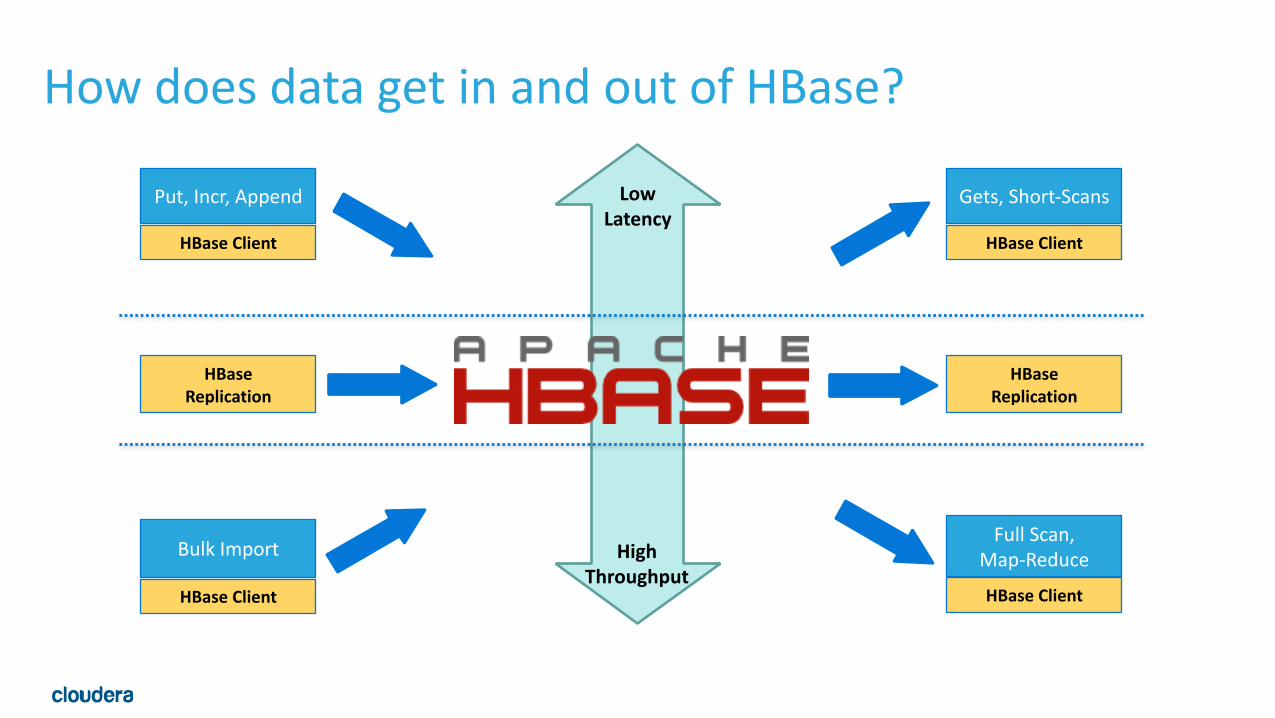
How does data get in and out of HBase?
HBase Client
Put, Incr, Append
HBase Replication
HBase Client
Bulk Import
HBase Client
Gets, Short-‐Scans
HBase Replication
HBase Client
Full Scan, Map-‐Reduce
How does data get in and out of HBase?
HBase Client
HBase Replication
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce

What system is most efficient?• It is all physics • You have a limited I/O budget • Use all your I/O by parallelizing access and read/write sequentially • Choose the system and features thatreduces I/O in general
IOPs/s/disk
Pick the system that is best for your workload!

The physics of Hadoop Storage Systems
Workload HBase HDFS
Low Latency ms, cached min, MR seconds, Impala
Random Read primary index index? small files problem
Short Scan sorted partition
Full Scan live table(MR on snapshots)
MR, Hive, Impala
Random Write log structured not supported
Sequential Write HBase overheadBulk Load
minimal overhead
Updates log structured not supported

The physics of Hadoop Storage Systems
Workload HBase HDFS
Low Latency ms, cached min, MR seconds, Impala
Random Read primary index index? small files problem
Short Scan sorted partition
Full Scan live table(MR on snapshots)
MR, Hive, Impala
Random Write log structured not supported
Sequential Write HBase overheadBulk Load
minimal overhead
Updates log structured not supported

The physics of Hadoop Storage Systems
Workload HBase HDFS
Low Latency ms, cached min, MR seconds, Impala
Random Read primary index index? small files problem
Short Scan sorted partition
Full Scan live table(MR on snapshots)
MR, Hive, Impala
Random Write log structured not supported
Updates log structured not supported
Sequential Write HBase overheadBulk Load
minimal overhead

The ArchetypesHBase Applications

HBase Application use cases
• The Bad • Large Blobs • Naïve RDBMS port • Analytic Archive
• The Maybe • Time series DB • Combined workloads
• The Good • Simple Entities •Messaging Store • Graph Store •Metrics Store
• There are a lot of HBase applications • some successful, some less so • They have common architecture patterns • They have common trade offs
• Archetypes are common architecture patterns • common across multiple use-‐cases • extracted to be repeatable

Archetypes: The GoodsHBase, you are my soul mate.

Archetype: Simple Entities• Purely entity data, no releation between entities • Batch or real-‐time, random writes • Real-‐time, random reads • Could be a well-‐done denormalized RDBMS port •Often from many different sources, with poly-‐structured data
• Schema • Row per entity • Row key: entity ID, or hash of entity ID • Column qualifier: Property / Field, possibly timestamp
• Examples: • Geolocation data • Search index building • Use solr to make text data searchable
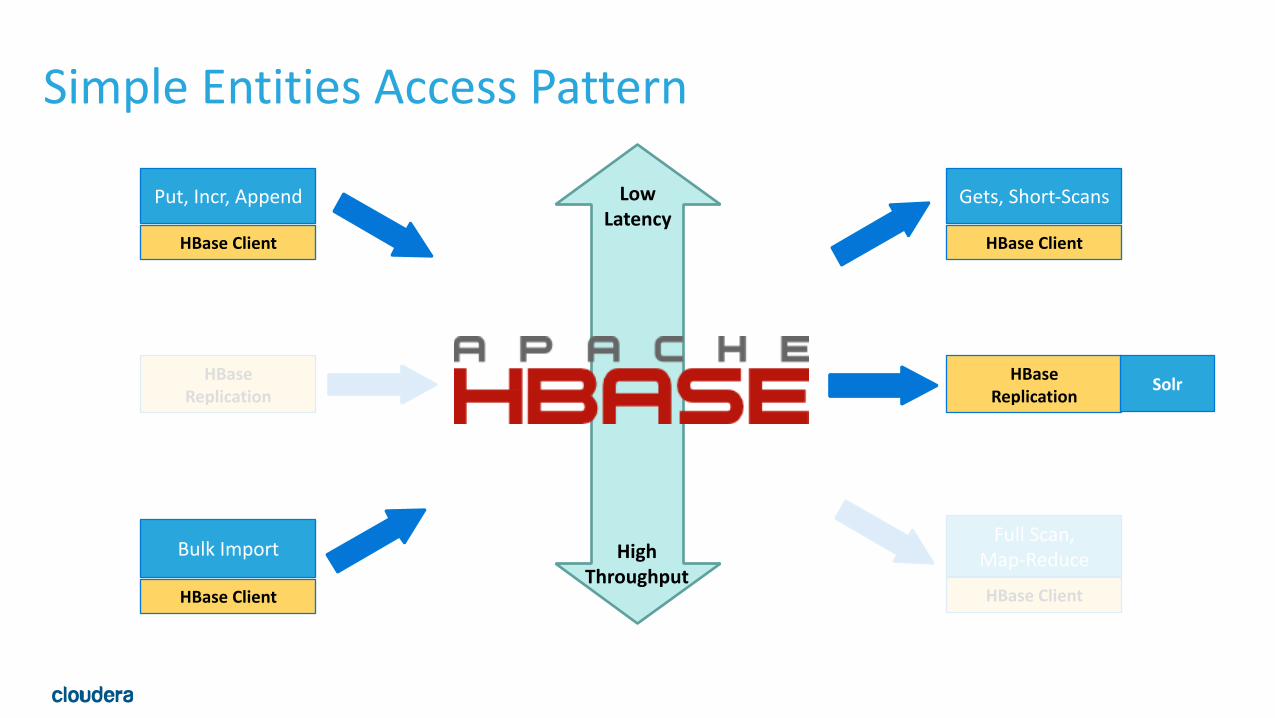
Simple Entities Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce
Solr

Archetype: Messaging Store•Messaging Data: • Realtime random writes: EMail, SMS, MMS, IM • Realtime random updates: Msg read, starred, moved, deleted • Reading of top-‐N entries, sorted by time • Records are of varying size • Some time series, but mostly random read/write
• Schema • Row: user/feed/inbox • Row-‐Key: UID or UID + time • Column Qualifier: time or conversation id + time
• Examples • Facebook Messages, Xiaomi Messages • Telco SMS/MMS services • Feeds like tumblr, pinterest
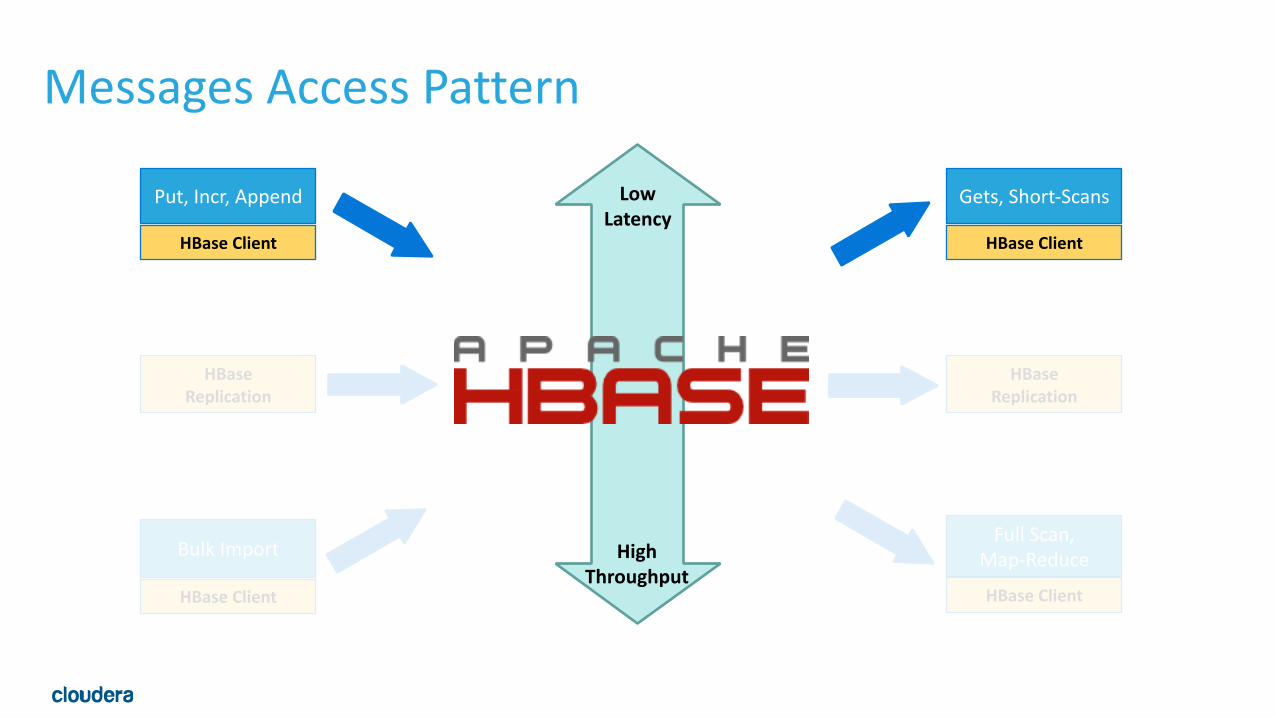
Messages Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce

Facebook Messages -‐ Statistics
Source: HBaseCon 2012 - Anshuman Singh

Archetype: Graph Data•Graph Data: All entities and relations •Batch or Realtime, random writes •Batch or Realtime, random reads • Its an entity with relation edges
• Schema •Row: Node •Row-‐Key: Node ID •Column Qualifier: Edge ID, or property:values
• Examples •Web Caches -‐ Yahoo!, Trend Micro • Titan Graph DB with HBase storage backend • Sessionization (financial transactions, click streams, network traffic) • Government (connect the bad guy)
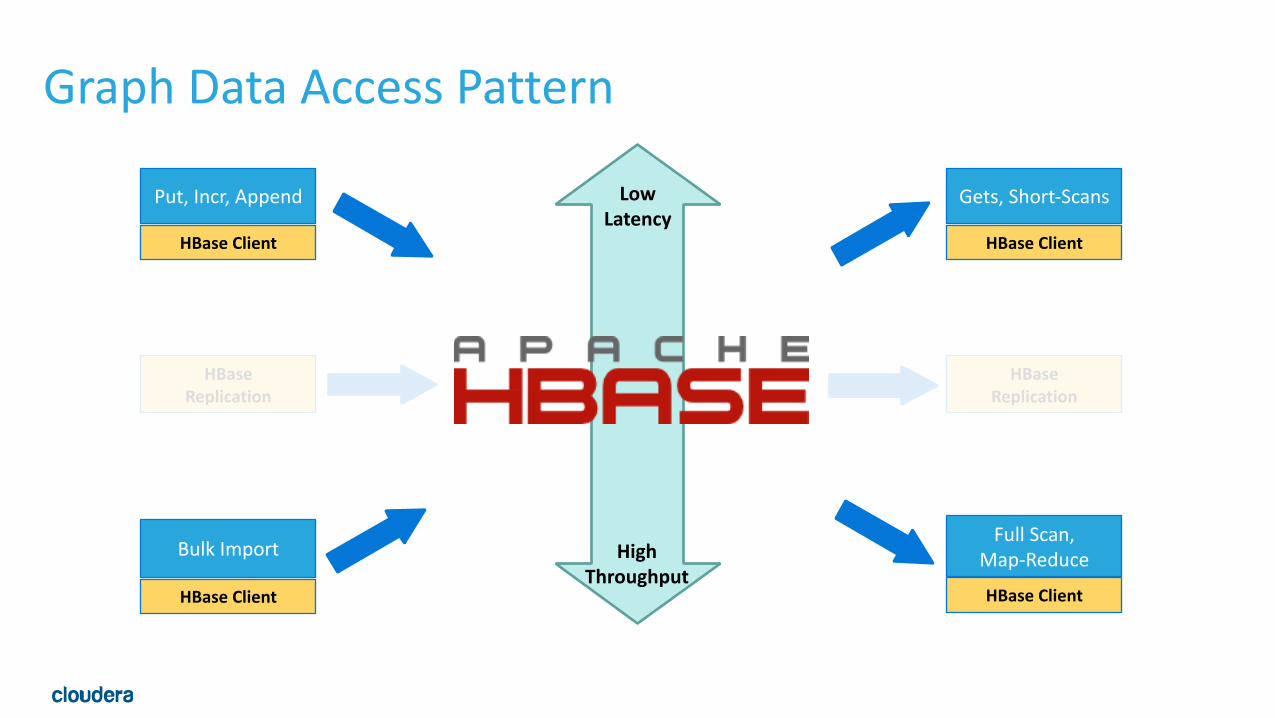
Graph Data Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce

Archetype: Metrics• Frequently updated metrics • Increments • Roll ups generated by MR and bulk loaded to HBase
• Schema • Row: Entity for a time period • Row key: entity-‐<yymmddhh> (granular time) • Column Qualifier: Property -‐> Count
• Examples • Campaign Impression/Click counts (Ad tech) • Sensor data (Energy, Manufacturing, Auto)
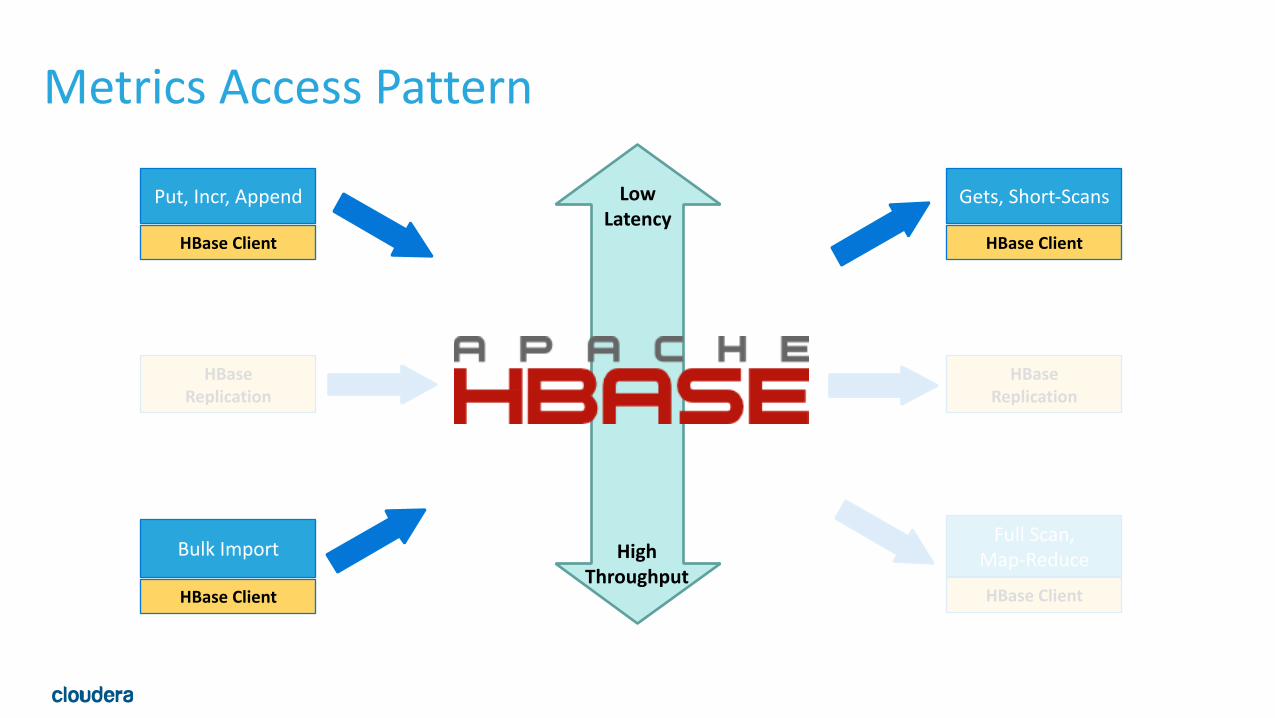
Metrics Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce
Archetypes: The BadThese are not the droids you are looking for

Current HBase weak spots• HBase’s architecture can handle a lot • Engineering tradeoffs optimize for some usecases and against others • HBase can still do things it is not optimal for • However, other systems are fundamentally more efficient for some workloads
•We’ve seen folks forcing apps into HBase • If there is only one workloads on the data, consider another system • if there is a mixed workload, some cases become “maybes”
Just because it is not good today, doesn’t mean it can’t be better tomorrow!

Bad Archetype: Large Blob Store• Saving large objects > 3MB per cell • Schema • Normal entity pattern, but with some columns with large cells
• Examples • Raw photo or video storage in HBase • Large frequently updated structs as a single cell
• Problems: •Write amplification when reoptimizing data for read (compactions on large unchanging data) •Write amplification when large structs are rewritten to update subfields(cells are atomic, and HBase must rewrite an entire cell)
• NOTE: Medium Binary Object (MOB) support coming (lots of 100KB-‐10MB cells)

Bad Archetype: Naïve RDBMS port• A Naïve port of an RDBMS into HBase, directly copying the schema • Schema •Many tables, just like an RDBMS schema • Row-‐Key: primary key or auto-‐incrementing key, like RDBMS schema • Column Qualifiers: field names •Manually do joins, or secondary indexes (not consistent)
• Solution: • HBase is not a SQL Database • No multi-‐region/multi-‐table in HBase transaction (yet) • No built in join support. Must denormalize your schema to use HBase

Bad Archetype: Analytic archive• Store purely chronological data, partitioned by time • Real time writes, chronological time as primary index • Column-‐centric aggregations over all rows • Bulk reads out, generally for generating periodic reports
• Schema • Row-‐Key: date + xxx or salt + date + xxx • Column Qualifiers: properties with data or counters
• Example •Machine logs organized by date (causes write hotspotting) • Full fidelity clickstream organized by date (as opposed to campaign)

Bad Archetype: Analytic archive Problems• HBase not-‐optimal as primary use case •Will get crushed by frequent full table scans •Will get crushed by large compactions •Will get crushed by write-‐side region hot spotting
• Solution • Store in HDFS. Use Parquet columnar data storage + Hive/Impala • Build rollups in HDFS+MR. store and serve rollups in HBase

Archetypes: The MaybeAnd this is crazy | But here’s my data | serve it, maybe!

The Maybe’s• For some applications, doing it right gets complicated.
•More sophisticated or nuanced cases • Require considering these questions: •When do you choose HBase vs HDFS storage for time series data? • Are there times where bad archetypes are ok?

Time Series: in HBase or HDFS?• Time Series I/O Pattern Physics: • Read: collocate related data (Make reads cheap and fast) •Writes: Spread writes out as much as possible (Maximize write throughput)
• HBase: Tension between these goals • Spreading writes spreads dat amaking reads inefficient • Colocating on write causes hotspots, underutilizes resources by limiting write throughput.
• HDFS: The sweet spots • Sequential writes and sequential read • Just write more files in date-‐dirs; physically spreads writes but logically groups data • Reads for time centric queries: just read files in date-‐dir

Time Series: data flow• Ingest • Flume or similar direct tool via app
• HDFS for historical • No real time serving • Batch queries and generate rollups in Hive/MR • Faster queries in Impala
• HBase for recent • Serve individual events • Serve pre-‐computed aggregates

Maybe Archetype: Entity Time Series• Full fidelity historical record of metrics • Random write to event data, random read specific event or aggregate data
• Schema • Row-‐Key: entity-‐timestamp or hash(entity)-‐timestamp. possibly with a salt added after entity. • Column Qualifier: granular timestamp -‐> value •Use custom aggregation to consolidate old data •Use TTL’s to bound and age off old data
• Examples: • OpenTSDB is a system on HBase that handles this for numeric values
• Lazily aggregates cells for better performance • Facebook Insights, ODS
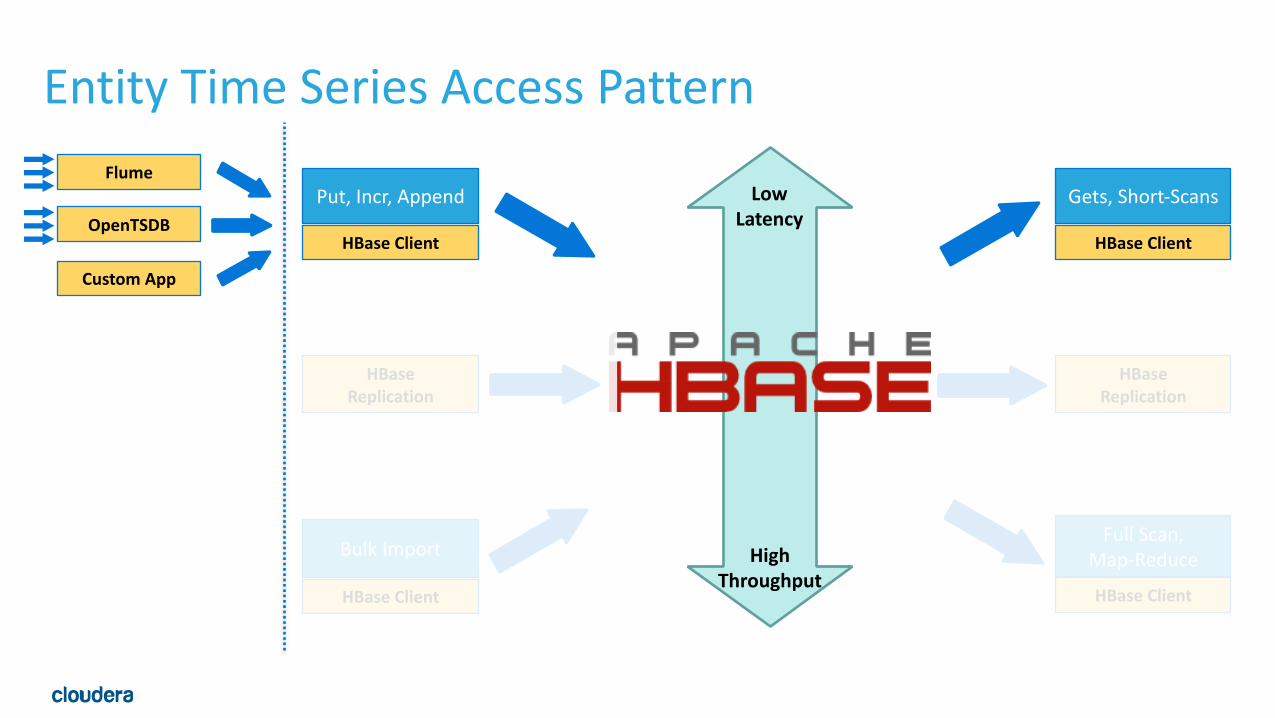
Entity Time Series Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce
Flume
OpenTSDB
Custom App

Maybe Archetype: Hybrid Entity Time Series
• Essentially a combo of Metric Archetype and Entity Time Serieswith bulk loads of rollups via HDFS • Land data in HDFS and HBase • Keep all data in HDFS for future use • Aggregate in HDFS and write to HBase •HBase can do some aggregates too (counters) • Keep serve-‐able data in HBase •Use TTL to discard old values from HBase
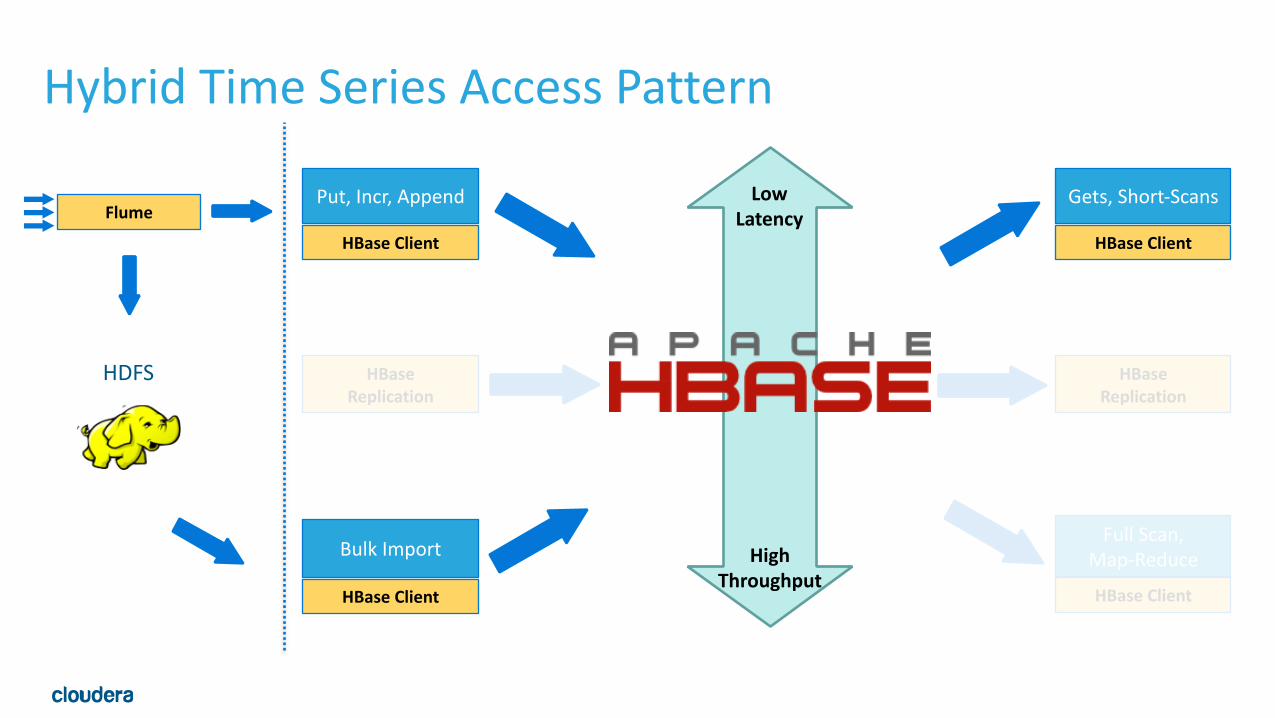
Hybrid Time Series Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce
Flume
HDFS

Meta Archetype: Combined workloads
• In this cases, the use of HBase depends on workload
• Cases where we have multiple workloads styles •Many cases we want to do multiple thing with the same data • Primary use case (real time, random access) • Secondary use case (analytical) • Pick for your primary,here’s some patterns on how to do your secondary.
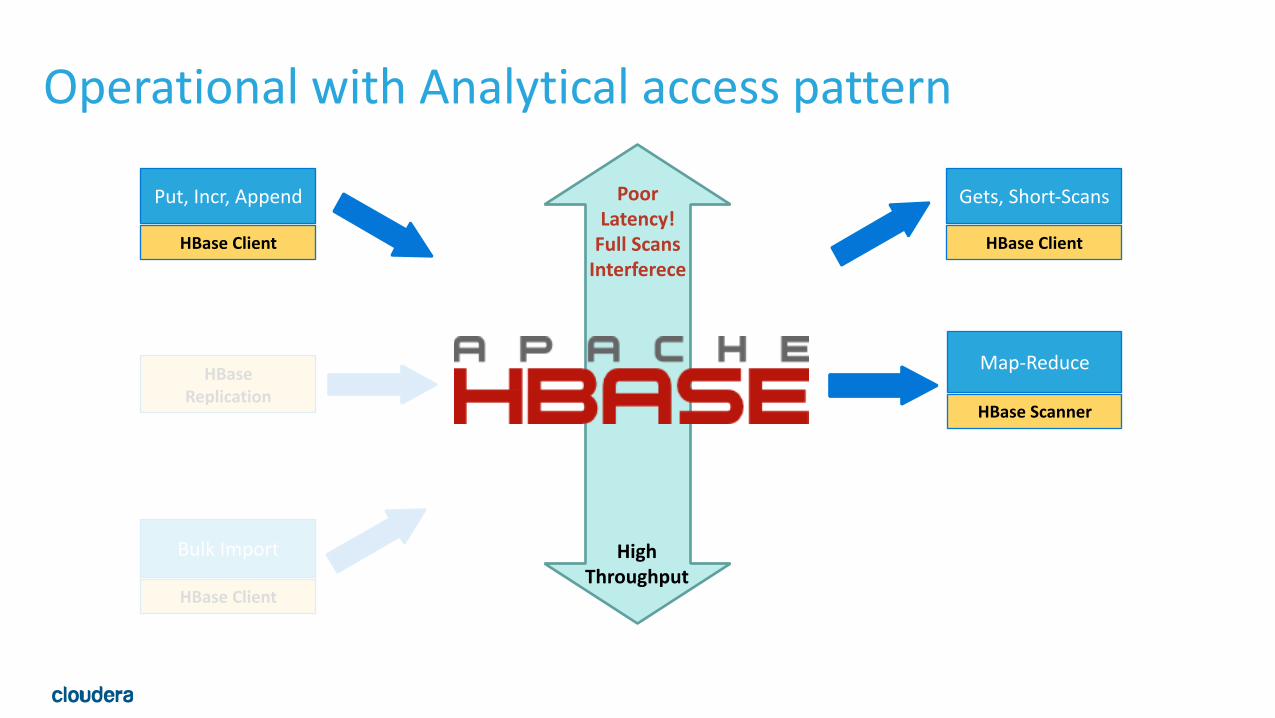
Operational with Analytical access pattern
HBase Client
HBase Client
HBase Client
HBase Scanner
Poor Latency! Full Scans Interferece
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Map-‐Reduce
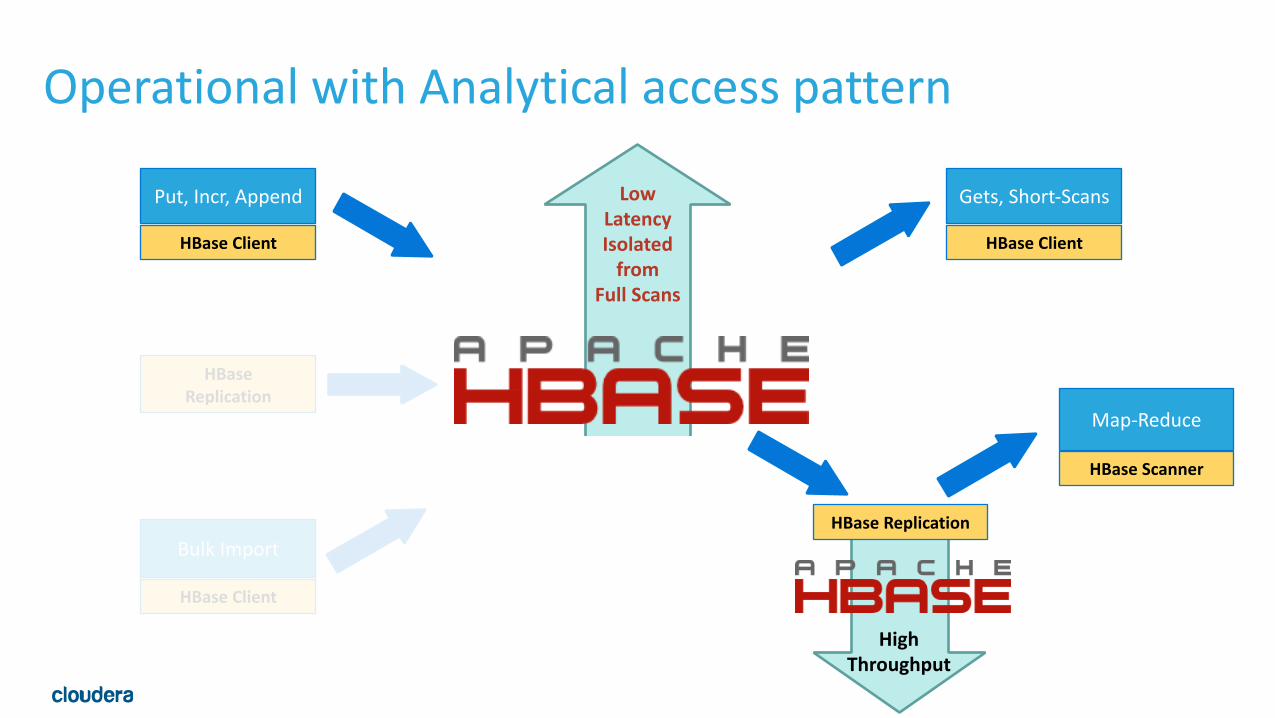
Operational with Analytical access pattern
HBase Client
HBase Client
HBase Scanner
Low Latency Isolated from
Full Scans
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Map-‐Reduce
High Throughput
HBase Replication
HBase Client
Gets, Short-‐Scans

MR over Table Snapshots (0.98+)• Previously Map-‐Reduce jobs over HBase required online full table scan • Take a snapshot and run MR job over snapshot files • Doesn’t use HBase client(or any RPC against the RSs) • Avoid affecting HBase caches • 3-‐5x perf boost. • Still requires more IOPs than HDFS raw files
map map map map map map map map
reduce reduce reduce
map map map map map map map map
reduce reduce reduce
snapshot
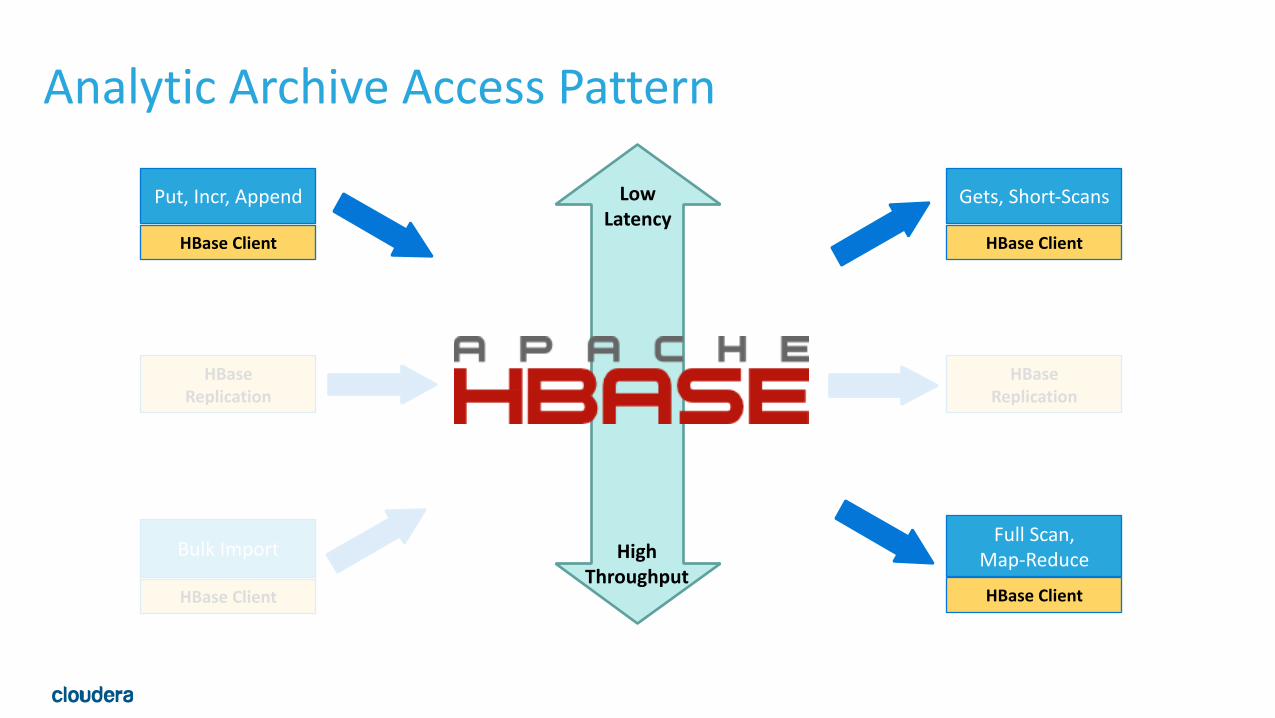
Analytic Archive Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
High Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Full Scan, Map-‐Reduce
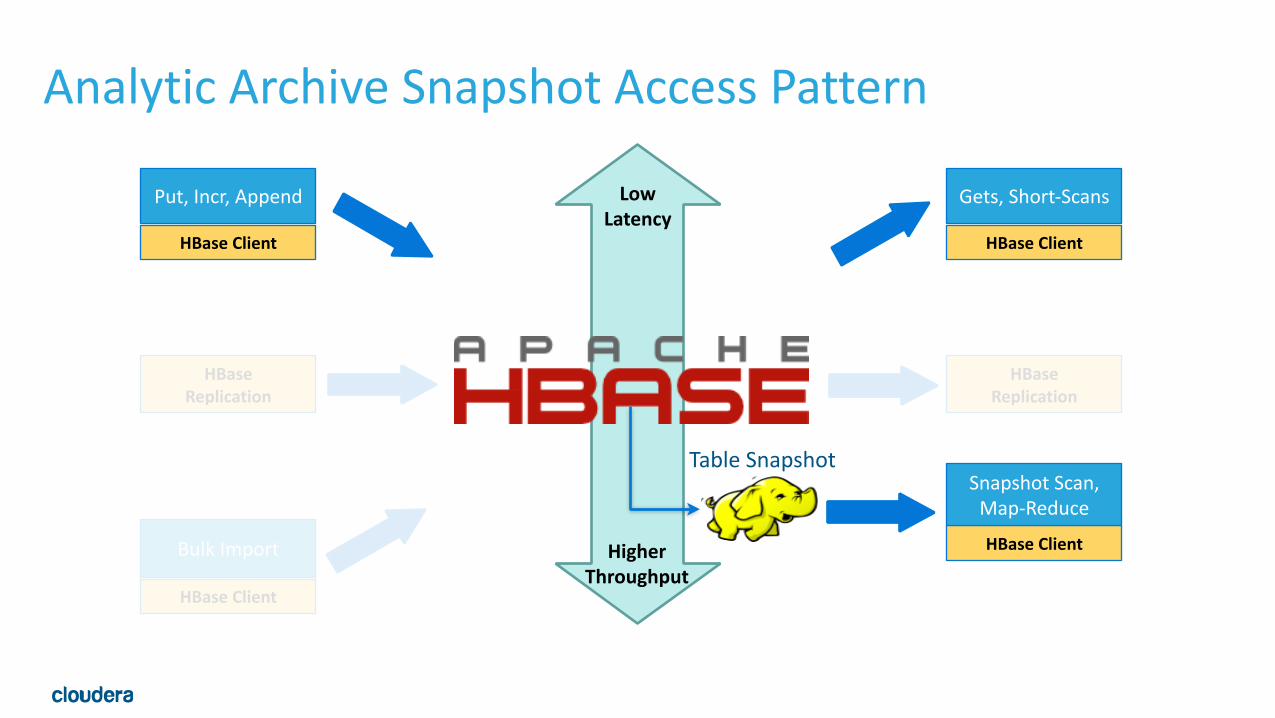
Analytic Archive Snapshot Access Pattern
HBase Client
HBase Client
HBase Client
HBase Replication
HBase Client
Low Latency
Higher Throughput
HBase Replication
Put, Incr, Append
Bulk Import
Gets, Short-‐Scans
Snapshot Scan, Map-‐Reduce
Table Snapshot
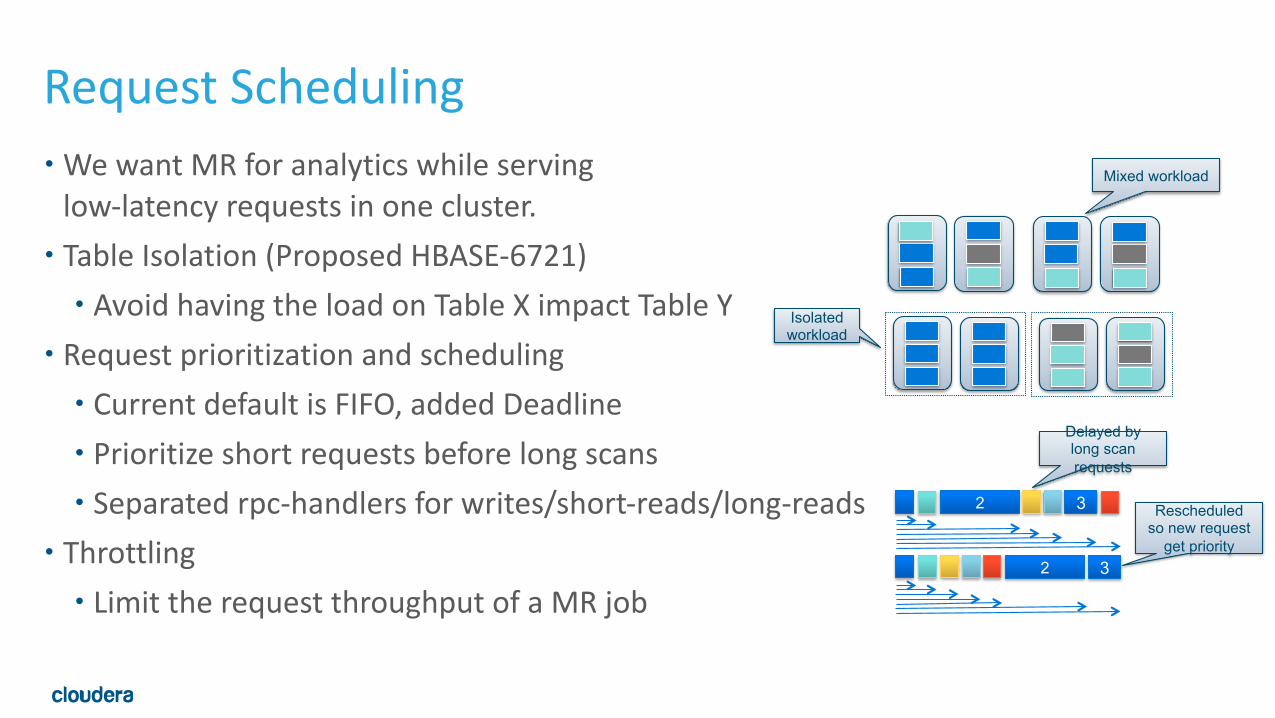
Request Scheduling• We want MR for analytics while servinglow-‐latency requests in one cluster. • Table Isolation (Proposed HBASE-‐6721) • Avoid having the load on Table X impact Table Y
• Request prioritization and scheduling • Current default is FIFO, added Deadline • Prioritize short requests before long scans • Separated rpc-‐handlers for writes/short-‐reads/long-‐reads
• Throttling • Limit the request throughput of a MR job
1 1 2 1 1 3 1
1 1 2 1 1 3 1
Delayed by long scan requests
Rescheduled so new request
get priority
Mixed workload
Isolated workload

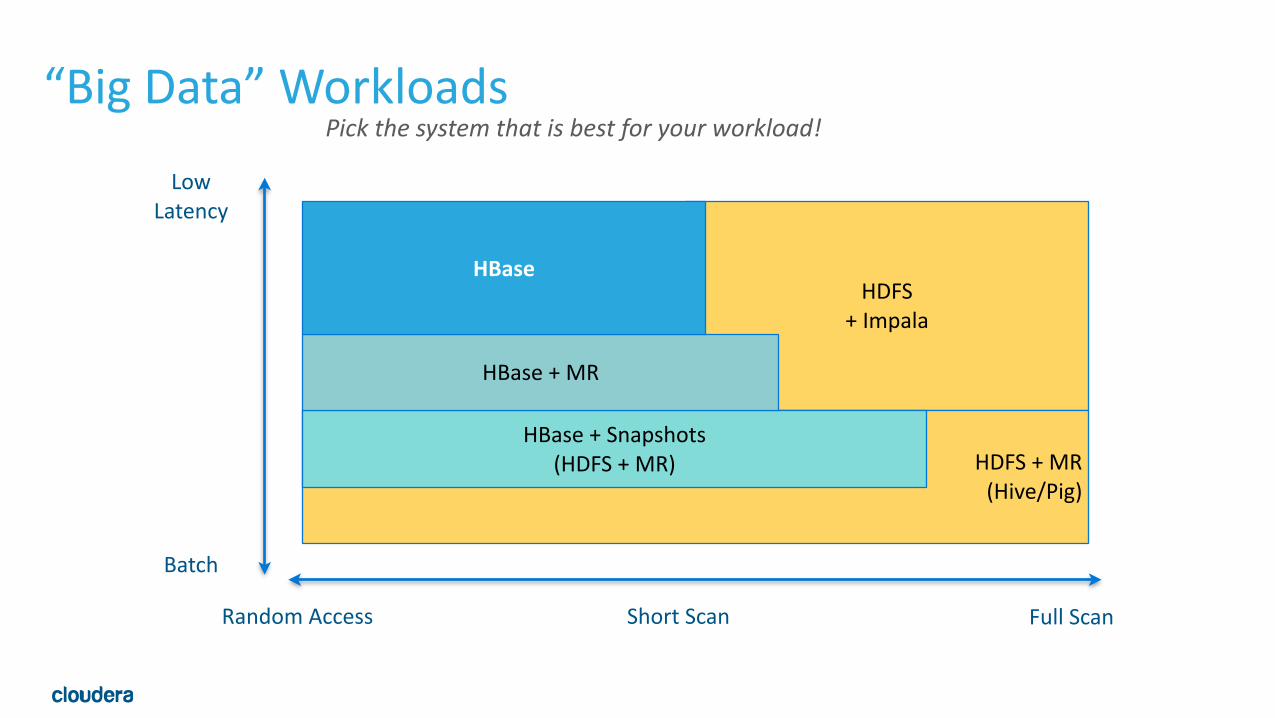
ConclusionsPick the system that is best for your workload!

HBase is evolving to be an Operational Database• Excels at consistent row-‐centric operations • Dev efforts aimed at using all machine resources efficiently,reducing MTTR and improving latency predictability. • Projects built on HBase that enable secondary indexing and multi-‐row transactions • Apache Phoenix and others provide a SQL skin for simplified application development • Evolution towards OLTP workloads
• Analytic workloads? • Can be done but will be beaten by direct HDFS + MR/Spark/Impala
HDFS + Impala
“Big Data” Workloads
Low Latency
Batch
Random Access Full ScanShort Scan
HDFS + MR (Hive/Pig)
HBase + Snapshots (HDFS + MR)
HBase + MR
HBase
Pick the system that is best for your workload!

Thank youQ&A