heart of the swarmkit: store, topology & object model
TRANSCRIPT

Heart of the SwarmKit
Stephen DayAndrea LuzzardiAaron Lehmann
Docker Distributed Systems Summit, BerlinOctober 2016
v0

Heart of the SwarmKit:Data Model
Stephen DayDocker, Inc.Docker Distributed Systems Summit, BerlinOctober 2016
v0

Stephen DayDocker, Inc.github.com/stevvooe@stevvooe

SwarmKitA new framework by Docker for building orchestration systems.

5
OrchestrationA control system for your cluster
ClusterO
-
Δ StD
D = Desired StateO = OrchestratorC = ClusterSt = State at time tΔ = Operations to converge S to D
https://en.wikipedia.org/wiki/Control_theory

6
ConvergenceA functional view
D = Desired StateO = OrchestratorC = ClusterSt = State at time t
f(D, Sn-1, C) → Sn | min(S-D)
7
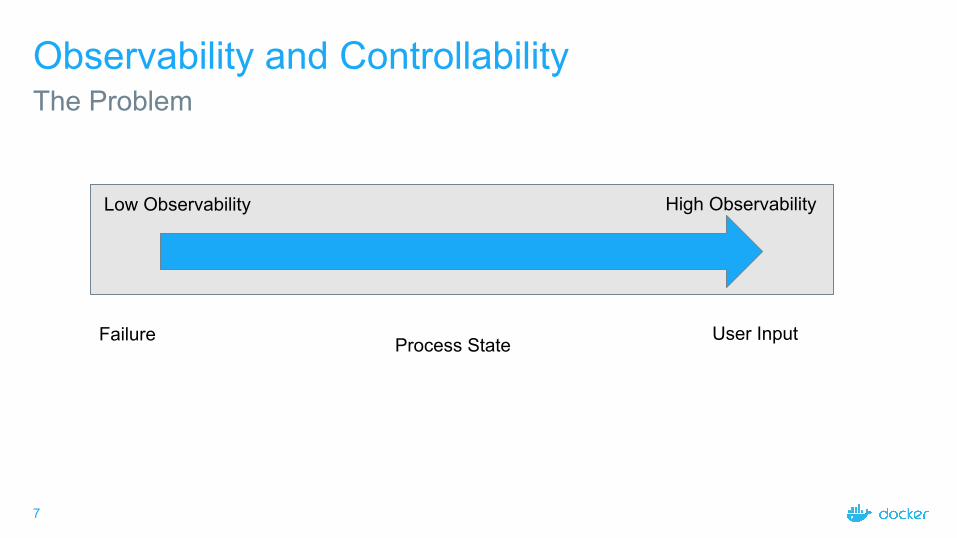
Observability and ControllabilityThe Problem
Low Observability High Observability
Failure Process State User Input

8
Data Model Requirements
- Represent difference in cluster state- Maximize Observability- Support Convergence- Do this while being Extensible and Reliable

Show me your data structures and I’ll show you your orchestration system

10
Services- Express desired state of the cluster- Abstraction to control a set of containers- Enumerates resources, network availability, placement- Leave the details of runtime to container process- Implement these services by distributing processes across a cluster
Node 1 Node 2 Node 3

11
Declarative$ docker network create -d overlay backend 31ue4lvbj4m301i7ef3x8022t
$ docker service create -p 6379:6379 --network backend redis bhk0gw6f0bgrbhmedwt5lful6
$ docker service scale serene_euler=3 serene_euler scaled to 3
$ docker service ls ID NAME REPLICAS IMAGE COMMANDdj0jh3bnojtm serene_euler 3/3 redis

12
ReconciliationSpec → Object
ObjectCurrent State
SpecDesired State

Task Model
Prepare: setup resourcesStart: start the taskWait: wait until task exitsShutdown: stop task, cleanly
Runtime

Orchestrator
14
Task ModelAtomic Scheduling Unit of SwarmKit
ObjectCurrent State
SpecDesired State
Task0 Task1… Taskn Scheduler

Service Spec
message ServiceSpec {
// Task defines the task template this service will spawn.
TaskSpec task = 2 [(gogoproto.nullable) = false];
// UpdateConfig controls the rate and policy of updates.
UpdateConfig update = 6;
// Service endpoint specifies the user provided configuration
// to properly discover and load balance a service.
EndpointSpec endpoint = 8;
}
Protobuf Example

Service Object
message Service {
ServiceSpec spec = 3;
// UpdateStatus contains the status of an update, if one is in
// progress.
UpdateStatus update_status = 5;
// Runtime state of service endpoint. This may be different
// from the spec version because the user may not have entered
// the optional fields like node_port or virtual_ip and it
// could be auto allocated by the system.
Endpoint endpoint = 4;
}
Protobuf Example

Manager
TaskTask
Data Flow
ServiceSpec
TaskSpec
Service
ServiceSpec
TaskSpec
Task
TaskSpec
Worker

Consistency

19
Field Ownership
Only one component of the system can write to a field
Consistency

TaskSpec
message TaskSpec {
oneof runtime {
NetworkAttachmentSpec attachment = 8;
ContainerSpec container = 1;
}
// Resource requirements for the container.
ResourceRequirements resources = 2;
// RestartPolicy specifies what to do when a task fails or finishes.
RestartPolicy restart = 4;
// Placement specifies node selection constraints
Placement placement = 5;
// Networks specifies the list of network attachment
// configurations (which specify the network and per-network
// aliases) that this task spec is bound to.
repeated NetworkAttachmentConfig networks = 7;
}
Protobuf Examples

Task
message Task {
TaskSpec spec = 3;
string service_id = 4;
uint64 slot = 5;
string node_id = 6;
TaskStatus status = 9;
TaskState desired_state = 10;
repeated NetworkAttachment networks = 11;
Endpoint endpoint = 12;
Driver log_driver = 13;
}
Protobuf ExampleOwner
User
Orchestrator
Allocator
Scheduler
Shared

Worker
Pre-Run
Preparing
Manager
Terminal States
Task StateNew Allocated Assigned
Ready Starting
Running
Complete
Shutdown
Failed
Rejected

Field HandoffTask Status
State Owner
< Assigned Manager
>= Assigned Worker

24
Observability and ControllabilityThe Problem
Low Observability High Observability
Failure Process State User Input

25
OrchestrationA control system for your cluster
ClusterO
-
Δ StD
D = Desired StateO = OrchestratorC = ClusterSt = State at time tΔ = Operations to converge S to D
https://en.wikipedia.org/wiki/Control_theory

26
ReconciliationSpec → Object
ObjectCurrent State
SpecDesired State

SwarmKit doesn’t Quit

Heart of the SwarmKit:Topology ManagementSo you’ve got thousands of machines… Now what?
Andrea Luzzardi / [email protected] / @aluzzardiDocker Inc.

Push vs Pull Model

30
Push vs PullPush Pull
Manager
Worker
ZooKeeper
3 - Payload
1 - Register
2 - Discover Manager
Worker
Registration &Payload
31
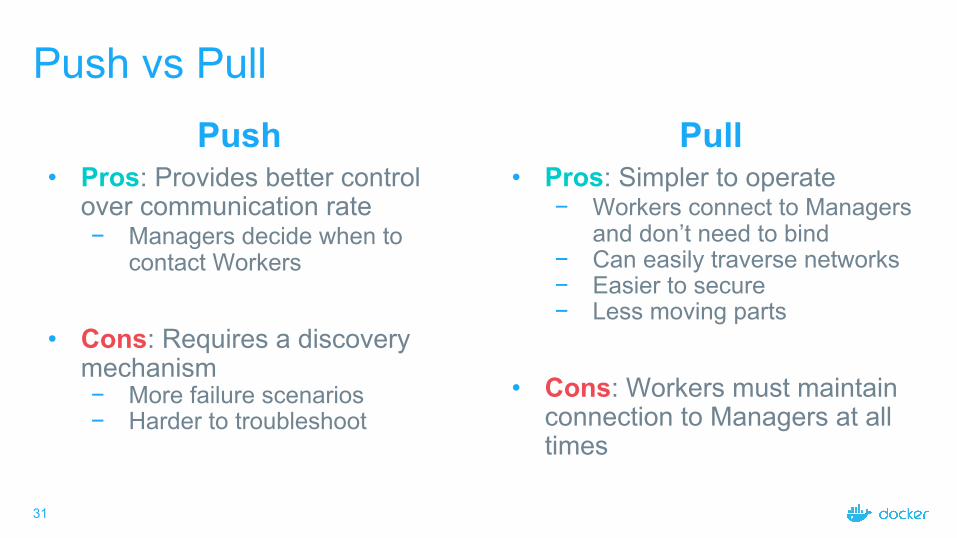
Push vs PullPush
• Pros: Provides better control over communication rate− Managers decide when to
contact Workers
• Cons: Requires a discovery mechanism− More failure scenarios− Harder to troubleshoot
Pull• Pros: Simpler to operate
− Workers connect to Managers and don’t need to bind
− Can easily traverse networks− Easier to secure− Less moving parts
• Cons: Workers must maintain connection to Managers at all times

32
Push vs Pull• SwarmKit adopted the Pull model• Favored operational simplicity• Engineered solutions to provide rate control in pull mode

Rate ControlControlling communication rate in a Pull model

34
Rate Control: Heartbeats• Manager dictates heartbeat rate to
Workers• Rate is Configurable• Managers agree on same Rate by
Consensus (Raft)• Managers add jitter so pings are spread
over time (avoid bursts)
Manager
Worker
Ping? Pong!Ping me back in 5.2 seconds

35
Rate Control: Workloads• Worker opens a gRPC stream to
receive workloads• Manager can send data whenever it
wants to• Manager will send data in batches• Changes are buffered and sent in
batches of 100 or every 100 ms, whichever occurs first
• Adds little delay (at most 100ms) but drastically reduces amount of communication
Manager
Worker
Give me work to do
100ms - [Batch of 12 ]200ms - [Batch of 26 ]300ms - [Batch of 32 ]340ms - [Batch of 100]360ms - [Batch of 100]460ms - [Batch of 42 ]560ms - [Batch of 23 ]

ReplicationRunning multiple managers for high availability

37
Replication
Manager Manager Manager
Worker
Leader FollowerFollower • Worker can connect to any Manager
• Followers will forward traffic to the Leader

38
Replication
Manager Manager Manager
Worker
Leader FollowerFollower • Followers multiplex all workers to the Leader using a single connection
• Backed by gRPC channels (HTTP/2 streams)
• Reduces Leader networking load by spreading the connections evenly
Worker Worker
Example: On a cluster with 10,000 workers and 5 managers, each will only have to handle about 2,000 connections. Each follower will forward its 2,000 workers using a single socket to the leader.
39
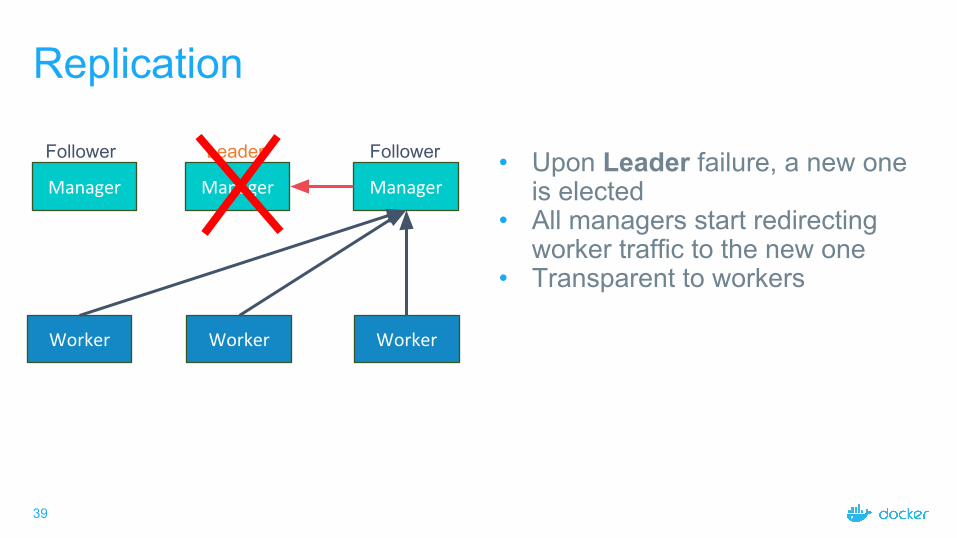
Replication
Manager Manager Manager
Worker
Leader FollowerFollower • Upon Leader failure, a new one is elected
• All managers start redirecting worker traffic to the new one
• Transparent to workers
Worker Worker

40
Replication
Manager Manager Manager
Worker
Follower FollowerLeader • Upon Leader failure, a new one is elected
• All managers start redirecting worker traffic to the new one
• Transparent to workers
Worker Worker

41
Replication
Manager 3
Manager 1
Manager 2
Worker
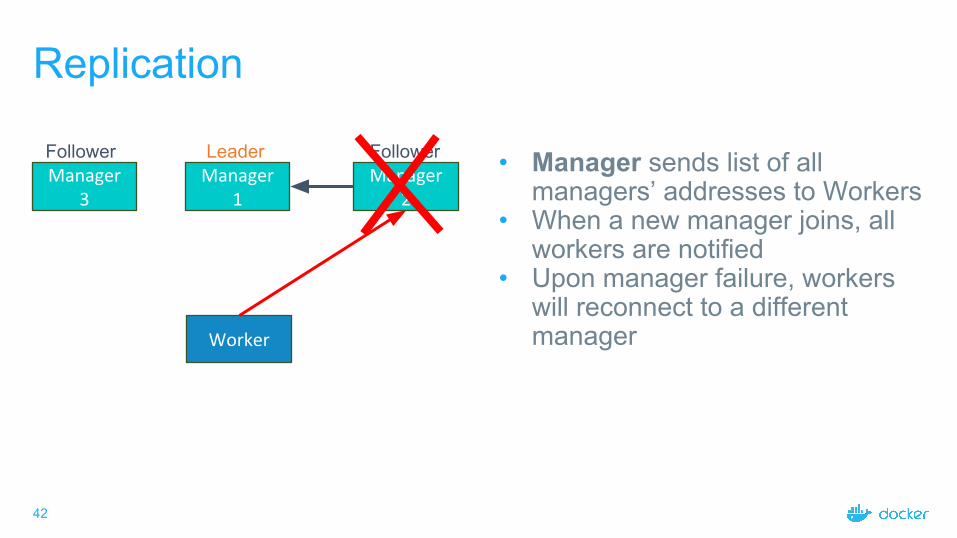
Leader FollowerFollower • Manager sends list of all managers’ addresses to Workers
• When a new manager joins, all workers are notified
• Upon manager failure, workers will reconnect to a different manager
- Manager 1 Addr- Manager 2 Addr- Manager 3 Addr
42
Replication
Manager 3
Manager 1
Manager 2
Worker
Leader FollowerFollower • Manager sends list of all managers’ addresses to Workers
• When a new manager joins, all workers are notified
• Upon manager failure, workers will reconnect to a different manager

43
Replication
Manager 3
Manager 1
Manager 2
Worker
Leader FollowerFollower • Manager sends list of all managers’ addresses to Workers
• When a new manager joins, all workers are notified
• Upon manager failure, workers will reconnect to a different manager
Reconnect to random manager

44
Replication
• gRPC handles connection management− Exponential backoff, reconnection jitter, …− Avoids flooding managers on failover− Connections evenly spread across Managers
• Manager Weights− Allows Manager prioritization / de-prioritization− Gracefully remove Manager from rotation

PresenceScalable presence in a distributed environment

46
Presence• Leader commits Worker state (Up vs Down) into Raft
− Propagates to all managers− Recoverable in case of leader re-election
• Heartbeat TTLs kept in Leader memory− Too expensive to store “last ping time” in Raft
• Every ping would result in a quorum write− Leader keeps worker<->TTL in a heap (time.AfterFunc)− Upon leader failover workers are given a grace period to reconnect
• Workers considered Unknown until they reconnect• If they do they move back to Up• If they don’t they move to Down

Heart of the SwarmKit: Distributed Data StoreAaron LehmannDocker
What we store
● State of the cluster● User-defined configuration● Organized into objects:
○ Cluster○ Node○ Service○ Task○ Network○ etc...
48

Why embed the distributed data store?
● Ease of setup● Fewer round trips● Can maintain local indices
49

In-memory data structures
● Objects are protocol buffers messages● go-memdb used as in-memory database:
https://github.com/hashicorp/go-memdb● Underlying data structure: radix trees
50

Radix trees for indexing
Hel
Hello Helpful
Wo
World Work Word
Wor Won
51
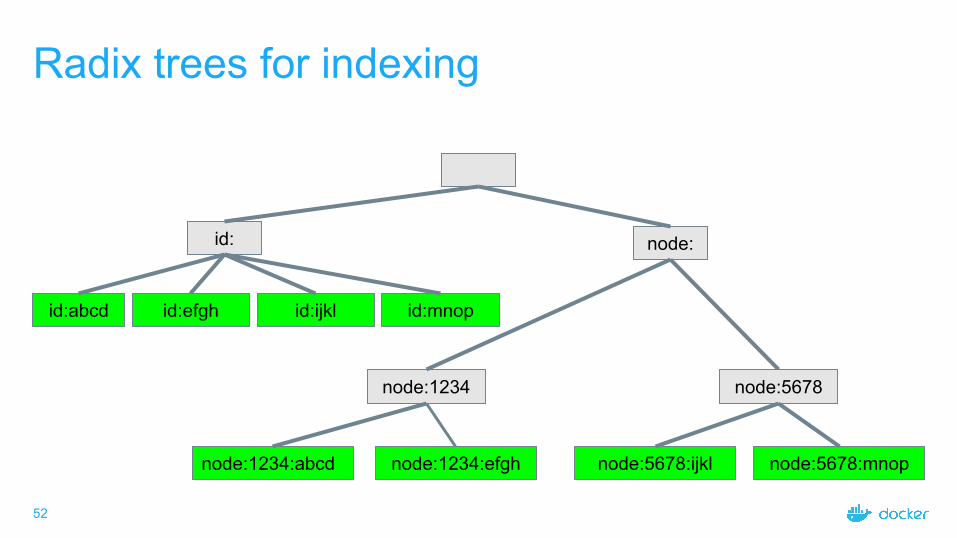
Radix trees for indexing
id:
id:abcd id:efgh
node:
node:1234:abcd node:1234:efgh node:5678:ijkl
node:1234
node:5678:mnop
node:5678
id:ijkl id:mnop
52

Lightweight in-memory snapshots
id:
id:abcd id:efgh id:ijkl id:mnop
Edges are actually pointers
53

Lightweight in-memory snapshots
id:
id:abcd id:efgh id:ijkl id:mnop id:qrst
54

Lightweight in-memory snapshots
id:
id:abcd id:efgh id:ijkl id:mnop id:qrst
55

Lightweight in-memory snapshots
id:
id:abcd id:efgh id:ijkl id:mnop id:qrst
56

Transactions
● We provide a transactional interface to read or write data in the store● Read transactions are just atomic snapshots● Write transaction:
○ Take a snapshot○ Make changes○ Replace tree root with modified tree’s root (atomic pointer swap)
● Only one write transaction allowed at once● Commit of write transaction blocks until changes are committed to Raft
57

Transaction example: Read
dataStore.View(func(tx store.ReadTx) {
tasks, err = store.FindTasks(tx, store.ByServiceID(serviceID))
if err == nil {
for _, t := range tasks {
fmt.Println(t.ID)
}
}
})
58

Transaction example: Write
err := dataStore.Update(func(tx store.Tx) error {
t := store.GetTask(tx, "id1")
if t == nil {
return errors.New("task not found")
}
t.DesiredState = api.TaskStateRunning
return store.UpdateTask(tx, t)
})
59

Watches
● Code can register to receive specific creation, update, or deletion events on a Go channel
● Selectors on particular fields in the objects● Currently an internal feature, will expose through API in the future
60

Watches
watch, cancelWatch = state.Watch(
r.store.WatchQueue(),
state.EventUpdateTask{
Task: &api.Task{ID: oldTask.ID, Status: api.TaskStatus{State: api.TaskStateRunning}},
Checks: []state.TaskCheckFunc{state.TaskCheckID, state.TaskCheckStateGreaterThan},
},
...
61

Watches state.EventUpdateNode{
Node: &api.Node{ID: oldTask.NodeID, Status: api.NodeStatus{State: api.NodeStatus_DOWN}},
Checks: []state.NodeCheckFunc{state.NodeCheckID, state.NodeCheckState},
},
state.EventDeleteNode{
Node: &api.Node{ID: oldTask.NodeID},
Checks: []state.NodeCheckFunc{state.NodeCheckID},
},
})62

Replication
● Only Raft leader does writes● During write transaction, log every change as well as updating the radix
tree● The transaction log is serialized and replicated through Raft● Since our internal types are protobuf types, serialization is very easy● Followers replay the log entries into radix tree
63

Sequencer
● Every object in the store has a Version field● Version stores the Raft index when the object was last updated● Updates must provide a base Version; are rejected if it is out of date● Similar to CAS● Also exposed through API calls that change objects in the store
64

65
Versioned UpdatesConsistency
service := getCurrentService()
spec := service.Spec
spec.Image = "my.serv/myimage:mytag"
update(spec, service.Version)

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.3.0...
Version = 189
Original object:
66

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.3.0...
Version = 189
Service ABC
SpecReplicas = 4Image = registry:2.4.0...
Version = 189
Update request: Original object:
67

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.3.0...
Version = 189
Original object:
Service ABC
SpecReplicas = 4Image = registry:2.4.0...
Version = 189
Update request:
68

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.4.0...
Version = 190
Updated object:
69

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.4.0...
Version = 190
Service ABC
SpecReplicas = 5Image = registry:2.3.0...
Version = 189
Update request: Updated object:
70

Sequencer
Service ABC
SpecReplicas = 4Image = registry:2.4.0...
Version = 190
Service ABC
SpecReplicas = 5Image = registry:2.3.0...
Version = 189
Update request: Updated object:
71

Write batching
● Every write transaction involves a Raft round trip to get consensus● Costly to do many transactions, but want to limit the size of writes to
Raft● Batch primitive lets the store automatically split a group of changes
across multiple writes to Raft
72

Write batching_, err = d.store.Batch(func(batch *store.Batch) error {
for _, n := range nodes {
err := batch.Update(func(tx store.Tx) error {
node := store.GetNode(tx, n.ID)
node.Status = api.NodeStatus{
State: api.NodeStatus_UNKNOWN,
Message: `Node moved to "unknown" state`,
}
return store.UpdateNode(tx, node)
}
}
return nil
}73
Future work
● Multi-valued indices● Watch API● Version control?
74

THANK YOU