hfodd for leadership class computers n. schunck, j. mcdonnell, hai ah nam
TRANSCRIPT

HFODD for Leadership Class Computers
N. Schunck, J. McDonnell, Hai Ah Nam
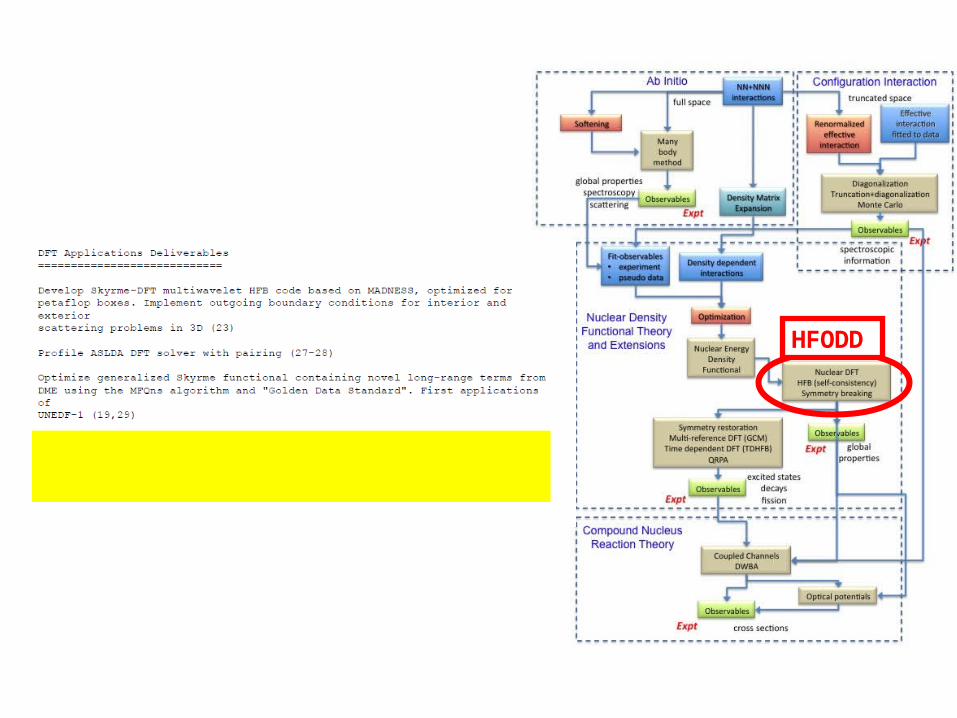
HFODD

DFT AND HPC COMPUTINGHFODD for Leadership Class Computers

Classes of DFT solvers
Resources needed for a “standard HFB” calculation
Configuration space: Expansion of the solutions on a basis (HO)• Fast and amenable to beyond mean-field extensions• Truncation effects: source of divergences/renormalization issues• Wrong asymptotic unless different bases are used (WS, PTG, Gamow, etc.)
Coordinate-space: Direct integration of the HFB equations• Accurate: provide “exact” result• Slow and CPU/memory intensive for 2D-3D geometries
1D 2D 3D
R-space 1 min, 1 core 5 h, 70 cores -
HO basis - 2 min, 1 core 5 h, 1 core

Why High Performance Computing?
Large-scale DFT Static: fission, shape coexistence, etc. – compute > 100k different
configurations Dynamics: restoration of broken symmetries, correlations, time-dependent
problems – combine > 100k configurations Optimization of extended functionals on larger sets of experimental data
g.s. of even nucleus can be computed in a matter of minutes on a standard laptop: why bother with supercomputing?
Core of DFT: Global theory which averages out individual degrees of freedom
Treatment of correlations ? ~100 keV level precision ? Extrapolability ?
From light nuclei to neutron stars Rich physics Fast and reliable

Computational Challenges for DFT• Self-consistency = iterative process:
– Not naturally prone to parallelization (suggests: lots of thinking…)– Computational cost :
(number of iterations) × (cost of one iteration) O(everything else)
• Cost of symmetry breaking: triaxiality, reflection asymmetry, time-reversal invariance– Large dense matrices (LAPACK) constructed and diagonalized many
times – size of the order of (2,000 x 2,000) – (10,000 x 10,000) (suggests: message passing)
– Many long loops (suggests: threading)
• Finite-range forces/non-local functionals: exact Coulomb, Yukawa-, Gogny-like– Many nested loops (suggests: threading)– Precision issues

HFODD• Solve HFB equations in the deformed, Cartesian HO basis• Breaks all symmetries (if needed)• Zero-range and finite-range forces coded• Additional features: cranking, angular momentum projection, etc.• Technicalities:
– Fortran 77, Fortran 90– BLAS, LAPACK– I/O with standard input/output + a few files
Redde Caesari quae sunt Caesaris

OPTIMIZATIONSHFODD for Leadership Class Computers

Loop reordering• Fortran: matrices are stored in memory column-wise
elements must be accessed first by column index, then by row index (good stride)
• Cost of bad stride growsquickly with number of indexes and dimensions
do k = 1, N do j = 1, N do i = 1, N
do i = 1, N do j = 1, N do k = 1, N
Ex.: Accessing Mijk
Time of 10 HF iterations as function of the model space(Skyrme SLy4, 208Pn, HF, exact Coulomb exchange)

Threading (OpenMP)• OpenMP designed to auto-
matically parallelize loops• Ex: calculation of density
matrix in HO basis
• Solutions:– Thread it with OpenMP– When possible, replace all
such manual linear algebra with BLAS/LAPACK calls (threaded version exist)
do j = 1, N do i = 1, N do = 1, N
Time of 10 HFB iterations as function of the number of threads (Jaguar Cray XT5 – Skyrme SLy4, 152Dy, HFB, 14 full shells)

Parallel Performance (MPI)
Time of 10 HFB iterations as function of the cores(Jaguar Cray XT5, no threads – Skyrme SLy4, 152Dy, HFB, 14 full shells)
• DFT = naturally parallel • 1 core = 1 configuration
(only if ‘all’ fits into core)• HFODD characteristics
− Very little communication overhead
− Lots of I/O per processor (specific to that processor): 3 ASCII files/core
• Scalability limited by:− File system performance− Usability of the results
(handling of thousands of files)
• ADIOS library being implemented

ScaLAPACK
• Multi-threading: more memory/core available• How about scalability of diagonalization for large model spaces?• ScaLAPACK successfully implemented for simplex-breaking HFB
calculations (J. McDonnell)• Current issues:
– Needs detailed profiling as no speed-up is observed: bottleneck?– Problem size adequate?
M
M
M
M
Nshell 14 18 22 26
N 680 1330 2300 3654
4N 2720 5320 9200 14616
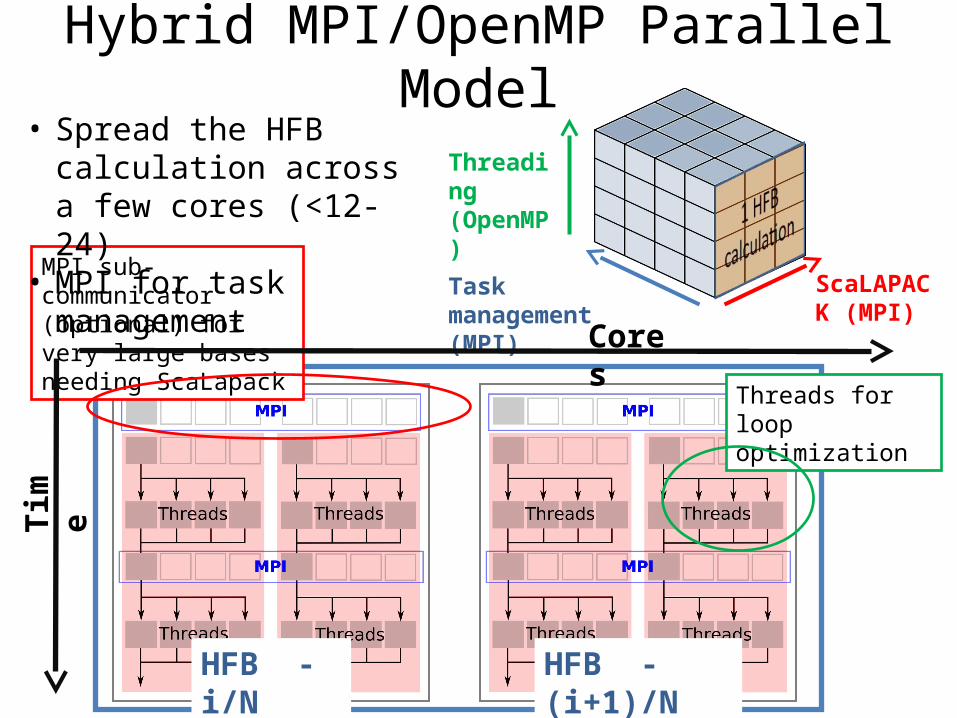
Hybrid MPI/OpenMP Parallel Model
Threads for loop optimization
MPI sub-communicator (optional) for very large bases needing ScaLapack
ScaLAPACK (MPI)
Threading(OpenMP)
Task management (MPI)
• Spread the HFB calculation across a few cores (<12-24)
• MPI for task management
Tim
e
HFB - i/N HFB - (i+1)/N
Cores

Conclusions• DFT codes are naturally parallel and can easily scale to 1 M
processors or more• High-precision applications of DFT are time- and memory-
consuming computations need for fine-grain parallelization• HFODD benefits from HPC techniques and code examination
– Loop-reordering give N ≫1 speed-up (Coulomb exchange: N ~ 3, Gogny force, N ~ 8)
– Multi-threading gives extra factor > 2 (only a few routines have been upgraded)
– ScaLAPACK implemented: very large bases (Nshell > 25) can now be used (Ex.: near scission)
• Scaling only average on standard Jaguar file system because of un-optimized I/O

Year 4 – 5 Roadmap• Year 4– More OpenMP, debugging of ScaLAPACK routine– First tests of ADIOS library (at scale)– First development of a prototype python visualization
interface– Tests of large-scale, I/O-briddled, multi-constrained
calculations
• Year 5– Full implementation of ADIOS– Set up framework for automatic restart (at scale)
• SVN repository (ask Mario for account)http://www.massexplorer.org/svn/HFODDSVN/trunk