high performance computing - computer and information …cs.iupui.edu/~sfang/cs120/hpc_cs120.pdf ·...
TRANSCRIPT


Content ¡ What is HPC
¡ History of supercomputing
¡ Current supercomputers (Top 500)
¡ Common programming models, tools, and languages
¡ Simple example of matrix multiplication
¡ Software challenges
2

What is HPC ¡ A computer science to use many high-end
computing resources to solve large-scale problems
¡ It involves many technologies: Hardware, architecture, OS, software/tools, energy/heat, performance analysis and measurement, algorithm, compilers, runtimes, and so on ¡ A yardstick to measure a country’s tech level.
¡ Is used to improve our life and competitiveness, to enable innovations; It is the most important weapon to remain in the world leader
¡ Being used in many different areas: medicine to consumer products, energy to aerospace, HIV virus to auto collision, …
3

https://www.youtube.com/watch?v=TGSRvV9u32M
• Used everywhere • Very important to the economy
4 https://www.youtube.com/watch?v=S9YPcPtPsuY&list=FLBuJrSSPIU9LTOZnBU6tVlA&index=13

Understanding Flop/s ¡ How to measure the computing power?
¡ Flop/s: floating point operations per second
¡ A regular desktop: 10 Gflop/s ¡ i.e., 10 billion operations per second
¡ Teraflop/s = 1000 Gflop/s
¡ Petaflop/s = 1000 Tflop/s
¡ Exaflop/s = 1000 Petaflop/s
¡ Top One (in June 2014): Tianhe-2: 33.8 Petaflop/s ¡ If Tianhe-2 calculates for 1 second, ¡ Each person holds one calculator, how long it will take for all people on earth to do
the same work? ¡ 7 billion people
¡ Two months! ¡ 6 seconds à 1 year!
5

Exascale Computing ¡ Climate change:
¡ Sea level rise ¡ Sever weather ¡ Regional climate change ¡ Geologic carbon sequestration
¡ Energy related: ¡ Reducing time and cost of reactor design
and deployment ¡ Improving the efficiency of combustion
energy sources
¡ National Nuclear Security: ¡ Stockpile certification ¡ Predictive scientific challenges ¡ Real-time evaluation of urban nuclear
detonation
6

Simulation Enables Fundamental Advances in Science ¡ Nuclear physics
¡ Quark-gluon plasma & nucleon structure ¡ Fission and fusion reactions
¡ Facility and experimental design ¡ Design of accelerators ¡ Probes of dark energy and dark matter ¡ ITER shot planning and device control
¡ Materials / Chemistry ¡ Predictive multi-scale materials modeling ¡ Effective, commercial, renewable energy
technologies, catalysts and batteries
¡ Life Science ¡ Better biofuels ¡ Sequence to structure to function
ITER ILC
Structure of nucleons
7

Exascale to Arrive in 2020 ¡ How powerful it could be? 30 Tianhe-2 systems
8

Challenge of Energy Cost 9

Proposed Timeline for Exascale Computing (DOE)
10

4 Paradigms and HPC ¡ Historically, the two dominant paradigms for
scientific discovery are: ¡ Theory ¡ Experiment
¡ With progress in computer technology ¡ Vacuum tube -> transistors -> IC -> VLIC ¡ Moore’s Law ¡ Supercomputers are more and more powerful ¡ Simulation emerges as the 3rd paradigm
¡ Today, Big Data emerges as the 4th paradigm ¡ Data -> knowledge
11

¡ The listing of the 500 most powerful computer in the world
¡ Yardstick: Rmax from LINPACK ¡ Ax = b, dense problem
¡ Updated twice every year ¡ SC’## in USA in November (next week in New Orleans) ¡ ISC conference in Germany in June
¡ All data available from www.top500.org
¡ The following Top500-related slides are from Dr. Jack Dongarra at University of Tennessee Knoxville
12

Top One in the Past 20 Years
2
13

November 2013: TOP 10 14

Vendors Share 15

CPUs Share 16

Accelerators (53 Systems) 17
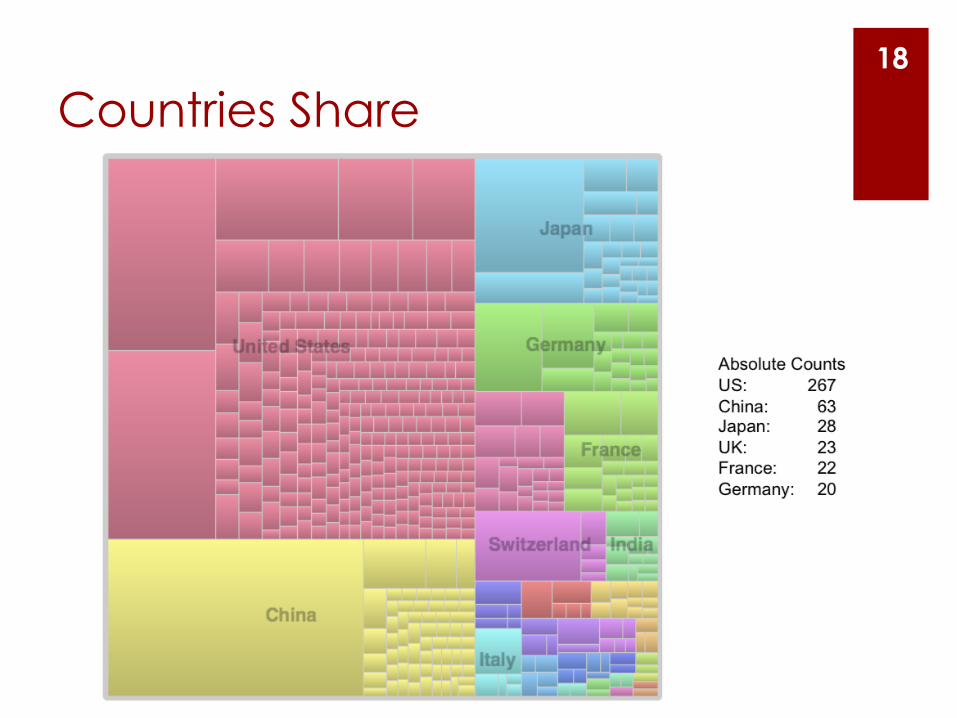
Countries Share 18

Performance Trend in Top500
19

Entering the Muticore Era ¡ Why do we need multicore exactly? ¡ Free lunch of increasing frequencies has ended.
¡ Power Voltage2 x Frequency
¡ Frequency Voltage à Power Frequency3 ∝∝ ∝
20
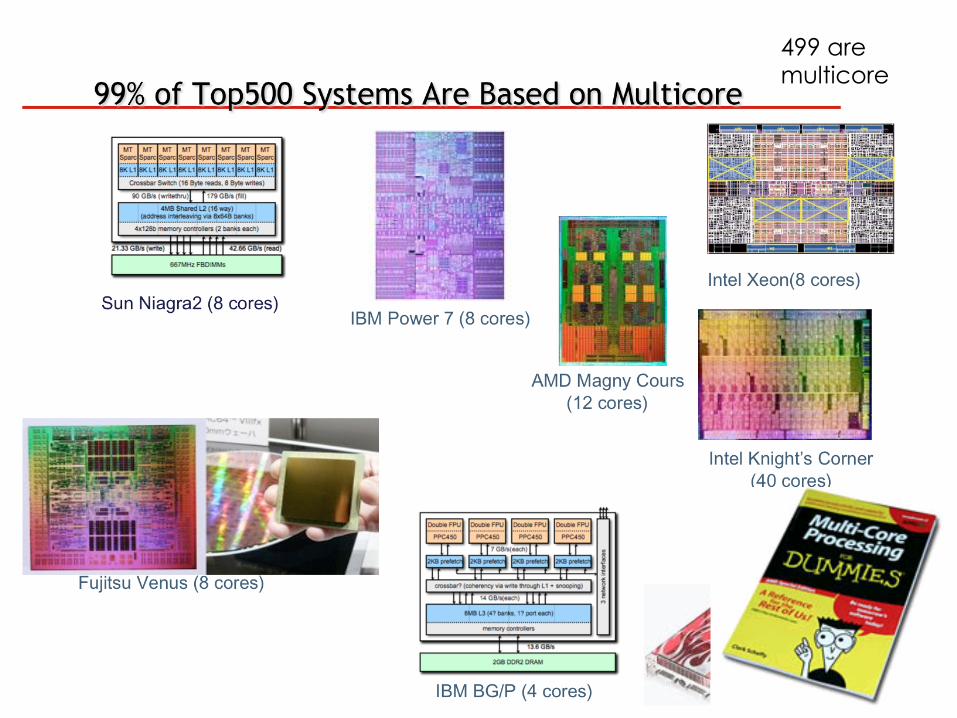
499 are multicore
21

GPU Gaining Popularity ¡ Why do we need GPU?
¡ Peak FLOPS rates are significantly higher than CPUs. ¡ Higher memory bandwidth (177 GB/s vs 11 GB/s) ¡ Better performance per unit energy (0.2 vs 2 nJ/
Instruction) ¡ Higher computational density
¡ GPU is optimized for throughput
! 4=8DB"#(+*(1'B#&<;EB%&'!!
!
4523(4(6#&7#899%'7(:;%<"(!"#$%&'()*+! ! H!!
!
Q+'!.',/#(!='+0(*!)+'!*0/$.'>,($@!0(!D?#,)0(BH>#0()!$,>,=0?0)@!=')C''(!)+'!PMA!,(*!)+'!OMA!0/!)+,)!)+'!OMA!0/!/>'$0,?0K'*!D#.!$#&>%)'H0()'(/0L'9!+0B+?@!>,.,??'?!$#&>%),)0#(!�!'-,$)?@!C+,)!B.,>+0$/!.'(*'.0(B!0/!,=#%)!�!,(*!)+'.'D#.'!*'/0B('*!/%$+!)+,)!&#.'!).,(/0/)#./!,.'!*'L#)'*!)#!*,),!>.#$'//0(B!.,)+'.!)+,(!*,),!$,$+0(B!,(*!D?#C!$#().#?9!,/!/$+'&,)0$,??@!0??%/).,)'*!=@!T0B%.'!5H43!
!
!
C%7;#"(+F.*( ?="(:65(2"\&B"$(J&#"(?#8'$%$B&#$(B&(28B8(6#&E"$$%'7(
!
I#.'!/>'$0D0$,??@9!)+'!OMA!0/!'/>'$0,??@!C'??H/%0)'*!)#!,**.'//!>.#=?'&/!)+,)!$,(!='!'->.'//'*!,/!*,),H>,.,??'?!$#&>%),)0#(/!�!)+'!/,&'!>.#B.,&!0/!'-'$%)'*!#(!&,(@!*,),!'?'&'()/!0(!>,.,??'?!�!C0)+!+0B+!,.0)+&')0$!0()'(/0)@!�!)+'!.,)0#!#D!,.0)+&')0$!#>'.,)0#(/!)#!&'&#.@!#>'.,)0#(/3!;'$,%/'!)+'!/,&'!>.#B.,&!0/!'-'$%)'*!D#.!',$+!*,),!'?'&'()9!)+'.'!0/!,!?#C'.!.'U%0.'&'()!D#.!/#>+0/)0$,)'*!D?#C!$#().#?9!,(*!='$,%/'!0)!0/!'-'$%)'*!#(!&,(@!*,),!'?'&'()/!,(*!+,/!+0B+!,.0)+&')0$!0()'(/0)@9!)+'!&'&#.@!,$$'//!?,)'($@!$,(!='!+0**'(!C0)+!$,?$%?,)0#(/!0(/)',*!#D!=0B!*,),!$,$+'/3!
",),H>,.,??'?!>.#$'//0(B!&,>/!*,),!'?'&'()/!)#!>,.,??'?!>.#$'//0(B!)+.',*/3!I,(@!,>>?0$,)0#(/!)+,)!>.#$'//!?,.B'!*,),!/')/!$,(!%/'!,!*,),H>,.,??'?!>.#B.,&&0(B!&#*'?!)#!/>''*!%>!)+'!$#&>%),)0#(/3!N(!2"!.'(*'.0(B9!?,.B'!/')/!#D!>0-'?/!,(*!L'.)0$'/!,.'!&,>>'*!)#!>,.,??'?!)+.',*/3!10&0?,.?@9!0&,B'!,(*!&'*0,!>.#$'//0(B!,>>?0$,)0#(/!/%$+!,/!>#/)H>.#$'//0(B!#D!.'(*'.'*!0&,B'/9!L0*'#!'($#*0(B!,(*!*'$#*0(B9!0&,B'!/$,?0(B9!/)'.'#!L0/0#(9!,(*!>,))'.(!.'$#B(0)0#(!$,(!&,>!0&,B'!=?#$J/!,(*!>0-'?/!)#!>,.,??'?!>.#$'//0(B!)+.',*/3!N(!D,$)9!&,(@!,?B#.0)+&/!#%)/0*'!)+'!D0'?*!#D!0&,B'!.'(*'.0(B!,(*!>.#$'//0(B!,.'!,$$'?'.,)'*!=@!*,),H>,.,??'?!>.#$'//0(B9!D.#&!B'('.,?!/0B(,?!>.#$'//0(B!#.!>+@/0$/!/0&%?,)0#(!)#!$#&>%),)0#(,?!D0(,($'!#.!$#&>%),)0#(,?!=0#?#B@3!
+*. 4523�G(8(:"'"#8AF6;#D&$"(68#8AA"A(4&9D;B%'7(3#E=%B"EB;#"(N(!V#L'&='.!46689!VWN"N7!0().#*%$'*!PA"7���,!B'('.,?!>%.>#/'!>,.,??'?!$#&>%)0(B!,.$+0)'$)%.'!�!C0)+!,!('C!>,.,??'?!>.#B.,&&0(B!&#*'?!,(*!0(/).%$)0#(!/')!,.$+0)'$)%.'!�!)+,)!?'L'.,B'/!)+'!>,.,??'?!$#&>%)'!'(B0('!0(!VWN"N7!OMA/!)#!
"$0#'!
BKD!"-,&(-7!
BKD!
BKD!
BKD!
ESB6!
"3D!
ESB6!
!! !!! !!! !!! !!! !!! !!! !!! !
@3D!
! 4=8DB"#(+*(1'B#&<;EB%&'!!
!
4523(4(6#&7#899%'7(:;%<"(!"#$%&'()*+! ! H!!
!
Q+'!.',/#(!='+0(*!)+'!*0/$.'>,($@!0(!D?#,)0(BH>#0()!$,>,=0?0)@!=')C''(!)+'!PMA!,(*!)+'!OMA!0/!)+,)!)+'!OMA!0/!/>'$0,?0K'*!D#.!$#&>%)'H0()'(/0L'9!+0B+?@!>,.,??'?!$#&>%),)0#(!�!'-,$)?@!C+,)!B.,>+0$/!.'(*'.0(B!0/!,=#%)!�!,(*!)+'.'D#.'!*'/0B('*!/%$+!)+,)!&#.'!).,(/0/)#./!,.'!*'L#)'*!)#!*,),!>.#$'//0(B!.,)+'.!)+,(!*,),!$,$+0(B!,(*!D?#C!$#().#?9!,/!/$+'&,)0$,??@!0??%/).,)'*!=@!T0B%.'!5H43!
!
!
C%7;#"(+F.*( ?="(:65(2"\&B"$(J&#"(?#8'$%$B&#$(B&(28B8(6#&E"$$%'7(
!
I#.'!/>'$0D0$,??@9!)+'!OMA!0/!'/>'$0,??@!C'??H/%0)'*!)#!,**.'//!>.#=?'&/!)+,)!$,(!='!'->.'//'*!,/!*,),H>,.,??'?!$#&>%),)0#(/!�!)+'!/,&'!>.#B.,&!0/!'-'$%)'*!#(!&,(@!*,),!'?'&'()/!0(!>,.,??'?!�!C0)+!+0B+!,.0)+&')0$!0()'(/0)@!�!)+'!.,)0#!#D!,.0)+&')0$!#>'.,)0#(/!)#!&'&#.@!#>'.,)0#(/3!;'$,%/'!)+'!/,&'!>.#B.,&!0/!'-'$%)'*!D#.!',$+!*,),!'?'&'()9!)+'.'!0/!,!?#C'.!.'U%0.'&'()!D#.!/#>+0/)0$,)'*!D?#C!$#().#?9!,(*!='$,%/'!0)!0/!'-'$%)'*!#(!&,(@!*,),!'?'&'()/!,(*!+,/!+0B+!,.0)+&')0$!0()'(/0)@9!)+'!&'&#.@!,$$'//!?,)'($@!$,(!='!+0**'(!C0)+!$,?$%?,)0#(/!0(/)',*!#D!=0B!*,),!$,$+'/3!
",),H>,.,??'?!>.#$'//0(B!&,>/!*,),!'?'&'()/!)#!>,.,??'?!>.#$'//0(B!)+.',*/3!I,(@!,>>?0$,)0#(/!)+,)!>.#$'//!?,.B'!*,),!/')/!$,(!%/'!,!*,),H>,.,??'?!>.#B.,&&0(B!&#*'?!)#!/>''*!%>!)+'!$#&>%),)0#(/3!N(!2"!.'(*'.0(B9!?,.B'!/')/!#D!>0-'?/!,(*!L'.)0$'/!,.'!&,>>'*!)#!>,.,??'?!)+.',*/3!10&0?,.?@9!0&,B'!,(*!&'*0,!>.#$'//0(B!,>>?0$,)0#(/!/%$+!,/!>#/)H>.#$'//0(B!#D!.'(*'.'*!0&,B'/9!L0*'#!'($#*0(B!,(*!*'$#*0(B9!0&,B'!/$,?0(B9!/)'.'#!L0/0#(9!,(*!>,))'.(!.'$#B(0)0#(!$,(!&,>!0&,B'!=?#$J/!,(*!>0-'?/!)#!>,.,??'?!>.#$'//0(B!)+.',*/3!N(!D,$)9!&,(@!,?B#.0)+&/!#%)/0*'!)+'!D0'?*!#D!0&,B'!.'(*'.0(B!,(*!>.#$'//0(B!,.'!,$$'?'.,)'*!=@!*,),H>,.,??'?!>.#$'//0(B9!D.#&!B'('.,?!/0B(,?!>.#$'//0(B!#.!>+@/0$/!/0&%?,)0#(!)#!$#&>%),)0#(,?!D0(,($'!#.!$#&>%),)0#(,?!=0#?#B@3!
+*. 4523�G(8(:"'"#8AF6;#D&$"(68#8AA"A(4&9D;B%'7(3#E=%B"EB;#"(N(!V#L'&='.!46689!VWN"N7!0().#*%$'*!PA"7���,!B'('.,?!>%.>#/'!>,.,??'?!$#&>%)0(B!,.$+0)'$)%.'!�!C0)+!,!('C!>,.,??'?!>.#B.,&&0(B!&#*'?!,(*!0(/).%$)0#(!/')!,.$+0)'$)%.'!�!)+,)!?'L'.,B'/!)+'!>,.,??'?!$#&>%)'!'(B0('!0(!VWN"N7!OMA/!)#!
"$0#'!
BKD!"-,&(-7!
BKD!
BKD!
BKD!
ESB6!
"3D!
ESB6!
!! !!! !!! !!! !!! !!! !!! !!! !
@3D!
CPU GPU
22

Parallel Programming Models ¡ On shared-memory systems:
¡ Multithreaded programming ¡ Pthread, OpenMP
¡ On Distributed-memory systems: ¡ MPI
¡ On GPU accelerators: ¡ Nvidia: CUDA ¡ AMD: OpenCL
¡ If the machine is distributed, has both multicore CPUs and GPUs, then what to do? ¡ Mixed all the 3 programming models: MPI/Pthread/
CUDA!
CPU
Multicore Host System
DDR3 RAMs
GPU Device Memory
GPU Device Memory
GPU Device Memory
CPU
I/O Hub
I/O Hub
DDR3 RAMs
Infiniband QPI
QPI
QPI
QPI
PCIe x16
PCIe x16
PCIe x16
PCIe x8
23

Shared-memory Parallel Programming ¡ OpenMP
¡ A portable API that supports shared-memory parallel programming on many platforms
¡ Set of compiler directives and an API for C, C++, FORTRAN
¡ You need to identify parallel regions – blocks of code, that can run in parallel
¡ You can modify a sequential code easily.
24

Shared-memory Parallel Programming
¡ Pthread
¡ POSIX standard for thread creation and synchronization
¡ It is a specification, not implementation ¡ could be a user-level or kernel-
level library
¡ Available on most Unix OSes (Linux, Mac OS, Solaris)
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*thrd_routine) (void *), void *arg); • Create a new thread in the calling process • The new thread will execute the thrd_routine
function • You can also pass a void* arg argument to
the thread.
25

MPI Programming Model
¡ Message-passing interface (MPI)
¡ Standard (specification) ¡ Many implementations: mpich, openmpi, intel…
¡ Would be OK even if each vendor provides its own implementation
¡ Support two types of operations ¡ Point-to-point ¡ Collective: e.g., broadcast, all_gather
¡ New Features: remote memory, parallel I/O, dynamic processes, threads, etc.
26

An Example of Point-to-point MPI
¡ Send/Receive (from P0 to P1)
¡ Datatype ¡ Basic for heterogeneity ¡ Derived for non-contiguous
¡ Contexts ¡ Message safety for libraries
¡ Buffering ¡ Robustness and correctness
A(10) B(20)
MPI_Send( A, 10, MPI_DOUBLE, 1, …) MPI_Recv( B, 20, MPI_DOUBLE, 0, … )
27

CUDA (Compute Unified Device Architecture)
• Architecture and programming model, introduced in NVIDIA in 2007
• Enables GPUs to execute programs written in C.
• Within C programs, call “kernel” routines that are executed on GPU.
• CUDA syntax extension to C routine as a Kernel.
• Easy to learn although to get highest performance requires understanding of hardware architecture
28

CUDA Programming Paradigm ¡ There are 3 key abstractions:
¡ A hierarchy of thread groups
¡ Shared memories
¡ Barrier synchronization
¡ Kernel code: a sequential function for one thread, designed to be executed by many threads
¡ Thread block: a set of concurrent threads that execute the same kernel
¡ Grid: a set of thread blocks, which execute in parallel (kernel A à kernel B à kernel C)
29

Host
Kernel 1
Kernel 2
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(0, 1)
Block(1, 1)
Grid 2
Courtesy: NDVIA
Figure 3.2. An Example of CUDA Thread Organization.
Block (1, 1)
Thread(0,1,0)
Thread(1,1,0)
Thread(2,1,0)
Thread(3,1,0)
Thread(0,0,0)
Thread(1,0,0)
Thread(2,0,0)
Thread(3,0,0)
(0,0,1) (1,0,1) (2,0,1) (3,0,1)
30

Simple Processing Flow
1. Copy input data from CPU memory to GPU memory
2. Load GPU program and execute, caching data on chip for performance
3. Copy results from GPU memory to CPU memory
PCI Bus
1
2
3
31

Hello World! with Device Code
__global__ void mykernel(void) { } int main(void) { mykernel<<<1,1>>>(); printf("Hello World!\n"); return 0; }
§ CUDA C/C++ keyword __global__ indicates a function that: runs on the device, called from host
§ mykernel<<<1,1>>>():Triple angle brackets mark a call from host to device code, called “kernel launch”
32

Software Optimizations (Take DGEMM as Example)
¡ Matrix multiplication C = A x B
¡ “Double-precision General Matrix Multiplication”
/* ijk */ for (i=0; i<n; i++) { for (j=0; j<n; j++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum; } }
A B C
(i,*)
(*,j) (i,j)
Inner loop:
Column- wise
Row-wise Fixed
33

Optimized Matrix Multiply ! Unrolled(C(code(1 #include <x86intrin.h> 2 #define UNROLL (4) 3 4 void dgemm (int n, double* A, double* B, double* C) 5 { 6 for ( int i = 0; i < n; i+=UNROLL*4 ) 7 for ( int j = 0; j < n; j++ ) { 8 __m256d c[4]; 9 for ( int x = 0; x < UNROLL; x++ ) //can do it manually! 10 c[x] = _mm256_load_pd(C+i+x*4+j*n); 11 12 for( int k = 0; k < n; k++ ) 13 { 14 __m256d b = _mm256_broadcast_sd(B+k+j*n); 15 for (int x = 0; x < UNROLL; x++) 16 c[x] = _mm256_add_pd(c[x], 17 _mm256_mul_pd(_mm256_load_pd(A+n*k+x*4+i), b)); 18 } 19 20 for ( int x = 0; x < UNROLL; x++ ) 21 _mm256_store_pd(C+i+x*4+j*n, c[x]); 22 } 23 }
34
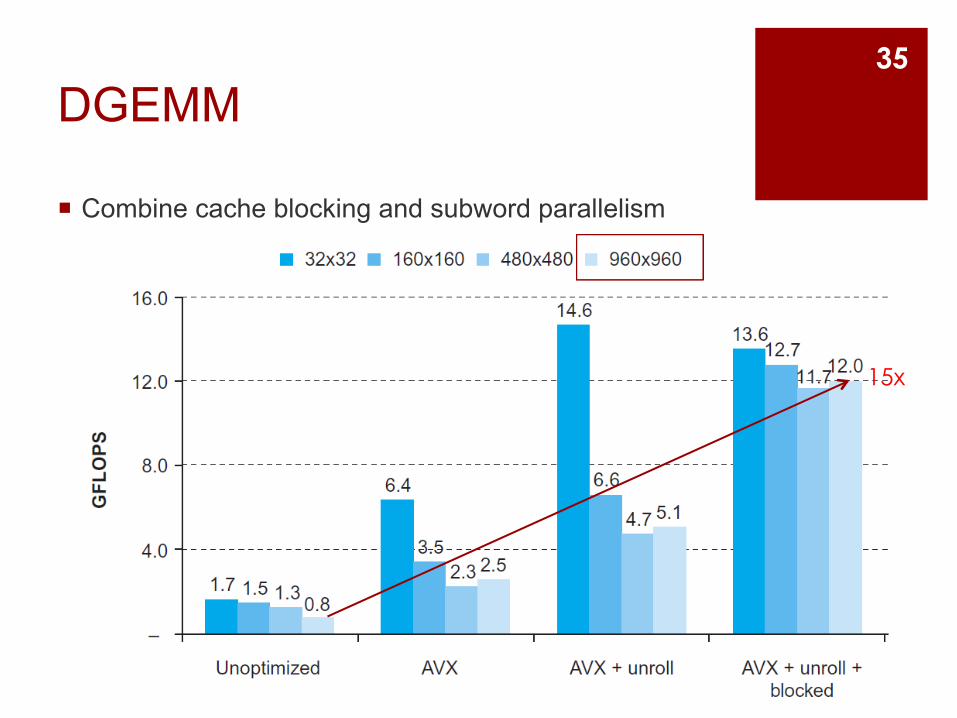
DGEMM
¡ Combine cache blocking and subword parallelism
15x
35

New Software Challenges ¡ Another disruptive technology
¡ Barriers ¡ Design did not anticipate exponential growth in
parallelism ¡ #components and MTBF change the game
¡ Technical focus area involved ¡ System hardware scalability ¡ System software scalability ¡ Application scalability
¡ Technical gap to close ¡ 1000X improvement in system software scaling ¡ 100X improvement in system software reliability
¡ New wisdom ¡ Data movement is expensive ¡ Flop/s is cheap
36

Critical Issues in Future New Software ¡ Synchronization-reducing algorithms
¡ Break Fork-Join model
¡ Communication-reducing algorithms ¡ Use methods which have lower bound on
communication
¡ Mixed-precision methods ¡ 2x speed of ops and 2x speed for data movement
¡ Autotuning ¡ Today’s machines are too complicated, build “smarts”
into software to adapt to the hardware
¡ Fault resilient algorithms ¡ Implement algorithms that can recover from failures/bit
flips
¡ Reproducibility of results ¡ Today we can’t guarantee this. We understand the
issues, but some of our “colleagues” have a hard time with this.
37

HPC Lab at IUPUI ¡ Ongoing Research Projects
¡ 1) Parallel matrix problem solvers ¡ CPU bound
¡ 2) Scalable CFD LBM-IB methods for life sciences ¡ memory bound and I/O intensive
¡ 3) Integrating Big Compute with Big Data with new enabling technologies ¡ To couple computation-intensive applications with
data-intensive analysis efficiently
¡ Big Data? We tackle them as extreme-scale applications of HPC
¡ If you have the need for speed, desire to solve the largest problem in the world, HPC may be your future research area
38
An interesting CFD simulation (10/30/14): https://www.youtube.com/watch?v=ZlH60lm3mz0