hmm-based arabic handwritten word recognition via zone...
TRANSCRIPT

Chiew, T.K., et al. (Eds.): PGRES 2017, Kuala Lumpur: Eastin Hotel, FCSIT, 2017: pp 63-76
Page | 63
HMM-based Arabic Handwritten word recognition via zone
segmentation
Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak
Faculty of Computer Science and Information Technology, University of Malaya,
Kuala Lumpur, MALAYSIA
Faiz Alotaibi Department of Computer Science and Information Technology,
Universiti Putra Malaysia, Malaysia. e-mail: [email protected]; [email protected], [email protected],
[email protected], [email protected].
ABSTRACT This paper presents a novel approach towards Arabic handwritten word recognition using the zone-wise material. Due to complex nature of the Arabic characters involving issues of overlapping and related issues like touching, the segmentation and recognition is a monotonous main occupation of in Arabic cursive (e.g. Naskha, Riqaa and other comparable scripts written for Holy Quran). To solve the issues of this character segmentation in such cursive, HMM founded on sequence modelling relying on the holistic way. This paper proposes an efficient framework word recognition by segmenting the handwritten word features horizontally into three zones (upper, middle and lower) and then recognise the corresponding zones. The aim of this zone is to minimise the quantity of distinct component classes associated to the total a number of classes in Arabic cursive. As an outcome of this proposed approach is to enhance the recognition performance of the system. The elements of segmentation zone especially in middle zone (baseline), where characters are frequently tender, are recognised using HMM. After the recognition of middle zone, HMM Based in Viterbi forced Alignment is performed to mark the right and left characters in conjoint zones. Next, the residue components, if any, in upper and lower zones are highlighted in a character boundary then the Components are joint with the morphology of the character to achieve the whole word level recognition. Water reservoir- created the main properties that had integrated into the framework to increase the performance of the zone segmentation especially for the upper zone for the character to determine the boundary detection imperfections in segmentation stage. A new sliding window-based feature, named hierarchical Histogram OF-Oriented Gradient (PHOG) is suggested for lower and upper zone recognition. The comparison study with other similar PHOG features and found robust for Arabic handwriting script recognition. An exhaustive experiment is performed of other handwriting using different dataset such IFN / IFNT to evaluate the rate and the recognition performance. The outcome of this experiment, it has been renowned that proposed zone-wise recognition increases accuracy. Keywords: Handwritten word recognition, Hidden Markov Model, Arabic script recognition

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 64
INTRODUCTION The increasing usage of images as a tool for broadcasting information in the last two decades has led to the need for the management and interpretation of image type of data captured by various devices. Moreover, recent development in social media and the Internet has produced an overwhelming stream of data in both structured and unstructured formats (such as images).For illustrating well know approaches, optical character recognition (OCR) [1] is considered as an accepted as well as the standard method, to comprehend and analyse various languages with diverse characteristics and complexities, such as the case in Chinese [2], English [3], and Bangla [4]. Researchers have been able to develop many text recognition systems [3] with high recognition rates such as offline Arabic handwriting and it deals with segmentation characters. The handwriting recognition systems are commonly used to comprehend text from images. Early work began by applying conventional Optical Character Recognition (OCR) techniques, and the results are passed to special search engines to search for words [4]. Unfortunately, the research is still at the early stage and facing many challenges [5]. There are several efforts to address Arabic handwritten word recognition for using certain classifiers such as Support Vector Machines (SVM), HMM and Recurrent Neural Networks (RNN) [6], Transparent Neural Networks [7] and Neural Networks (NN). Mohammad and Sabri introduced a recognition system for Arabic handwriting using a syntactic and structural pattern attributes. The work has attempted different slant angles of various components of single text line where highlighted. Moreover, they invented, “novel design segmentation algorithm which is integrated into the recognition phase” [7].Recognition of cursive handwriting, via different methodologies that are performed using either shape based approach or descriptors-based approach, is highlighted in [5-7]. A combination of genetic propagation and artificial neural network based approaches has been demonstrated to improve the overall accuracy rate of recognition of cursive handwriting [8]. This study aims at proposing new approaches including providing a comprehensive approach deals with challenges of developing Arabic cursive writing recognition systems. The study also explores different approaches applied for segmentation and classification phases. An evaluation of the performance of existing systems is also presented. Issues on the Arabic cursive writing recognition systems are discussed. Most importantly, different steps for achieving a generic Arabic writing recognition system are highlighted. The rest of this paper is structured as follows. Section 2 presents a background on the problem of Arabic cursive writing recognition including the related terminologies, definitions and characteristics of the Arabic language. Section 3 proposed approaches for zone-based word recognition. Section 4 provides a survey on the state-of-the-arts and feature extraction.Section5 presents recognition stage for the proposal model of Arabic character recognitions. Section 6 concludes and provides some directions for future works in this research domain.
LITERATURE REVIEW

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 65
This section reviews studies that focus on different state-of-the-art techniques and approaches for image segmentation and recognition processes that deal with the Arabic characters. This is to provide a concise summary of the research that has already been done in the field. Segmentation is where sub-methods deals with only pattern image recognition. The approaches applied for Arabic handwriting include overlapping, close characters issues composite character and touching character. Each of these methods deals with Arabic text line, starting with digitisation, noise removal, skew detection, and correction is required in the pre-processing stage. To recognise text in an image, there is high demand for segmentation; the whole text is converted into lines text and then single words. It is then converted into individual characters by performing the vertical, horizontal projection [9]. Unfortunately, research’s is still immature and facing different challenges[10]. For example, developing Arabic OCR systems is a difficult task because of three reasons. Firstly, the Arabic cursive is printed from the right side to left side [3]. Secondly, the Arabic characters have different shapes, which can change according to whether the alphabet shape is connected from the beginning to the middle and from the middle to the end. Lastly, the Arabic script has diverse Arabic fonts on printing machines and recognition systems. This may suggest that a specific approach designed for Arabic writing recognition should be established. A. Arabic Characters Orthography and pronunciation The Arabic language is like the Latin language with alphabets named Hourouf- ) حروف possesses 28 characters), but it has a unique Morphological form. It has its own specific language orthography and morphology of charters. Each character has two to four different shapes, and the selection of shapes depends on connecting characters within several words or sub-words. The shapes correspond to the positions. Namely, the single alphabets that can be changed according to it are connectivity from “the beginning” to” the middle” and from “the middle to the end” (sub-) words and in isolation of (sub-) words. Table 1 shows each single pattern. The shape can be changed according to its sides and attached to its neighbouring sides on each one and is connected to its neighbourhood on each news. Several characters have an initial or middle changing shapes. They are simply written only at the end of (sub-) words. TABLE1: ARABIC ALPHABET AND ITS APPEARANCE IN A DIFFERENT POSITION (BEGINNING – MODEL –AND END):
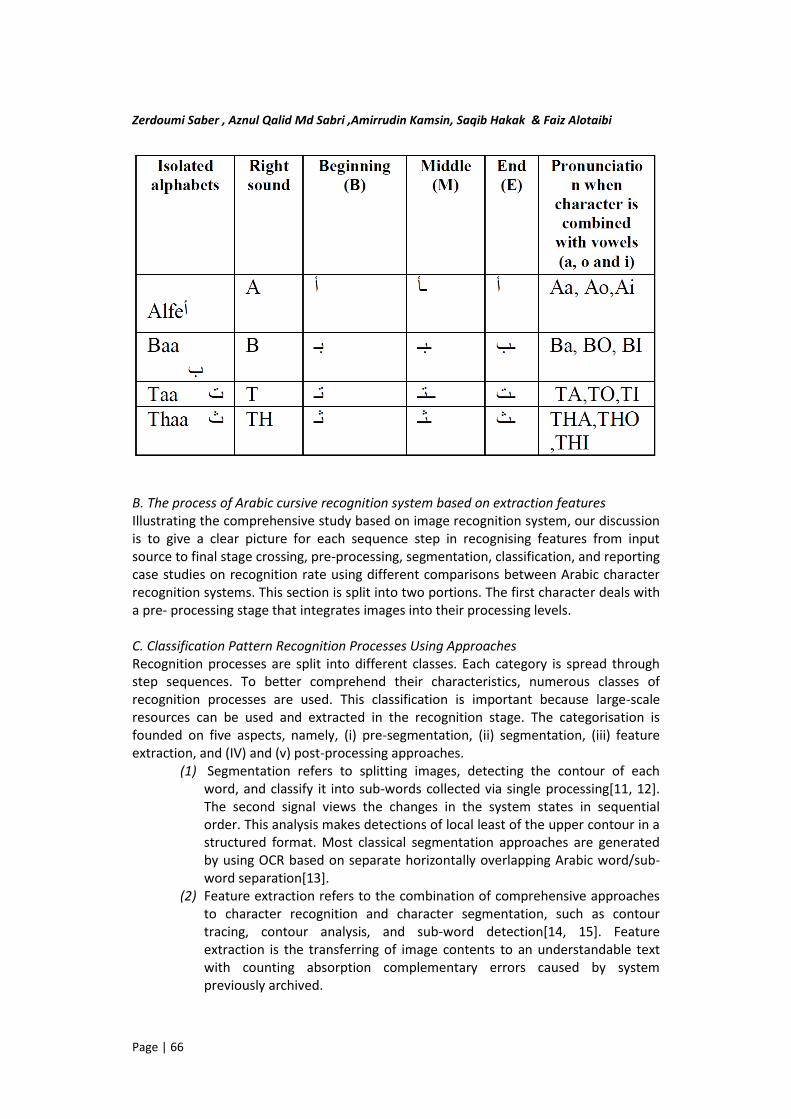
Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 66
B. The process of Arabic cursive recognition system based on extraction features Illustrating the comprehensive study based on image recognition system, our discussion is to give a clear picture for each sequence step in recognising features from input source to final stage crossing, pre-processing, segmentation, classification, and reporting case studies on recognition rate using different comparisons between Arabic character recognition systems. This section is split into two portions. The first character deals with a pre- processing stage that integrates images into their processing levels. C. Classification Pattern Recognition Processes Using Approaches Recognition processes are split into different classes. Each category is spread through step sequences. To better comprehend their characteristics, numerous classes of recognition processes are used. This classification is important because large-scale resources can be used and extracted in the recognition stage. The categorisation is founded on five aspects, namely, (i) pre-segmentation, (ii) segmentation, (iii) feature extraction, and (IV) and (v) post-processing approaches.
(1) Segmentation refers to splitting images, detecting the contour of each word, and classify it into sub-words collected via single processing[11, 12]. The second signal views the changes in the system states in sequential order. This analysis makes detections of local least of the upper contour in a structured format. Most classical segmentation approaches are generated by using OCR based on separate horizontally overlapping Arabic word/sub-word separation[13].
(2) Feature extraction refers to the combination of comprehensive approaches to character recognition and character segmentation, such as contour tracing, contour analysis, and sub-word detection[14, 15]. Feature extraction is the transferring of image contents to an understandable text with counting absorption complementary errors caused by system previously archived.

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 67
Classification is the most significant aspect of the Arabic recognition system. It refers to the process of associating a shape with a corresponding character from large values and large datasets with various handwriting types. The following representation is proposed on the basis of the above-mentioned designations and statement in the analysis of image recognition. The image identification system is a set of techniques and approaches depending on their technologies required for each footprint in the flow chart sequence with some addition, such as machine learning largely hidden values from specific datasets that require varied and complex cursive writing.
Fig. 1. Diagram of the four main recognition steps for Arabic recognition systems.
METHODOLOGY (PROPOSED APPROACHES FOR ZONE-BASED WORD RECOGNITION) In this section, we introduce novel zone segmentation founded for Arabic word recognition framework.by performing the hybrid combination of HMM and SVM-based classification for handwritten word recognition. Once accomplishment of the preprocessing errands, the word image is accepted through zone segmentation component. Unlike, classical Arabic handwritten word recognition approaches. By segmenting the words image into 3 main zones to diminish the quantity of basic factors that determine character recognition (discussed in Section 2). After segmenting into zones, recognition of middle zone components is performed using HMM. Upper and lower zone components are predictable using SVM classifier and lastly zone wise consequences are married to obtain the final outcome. The suggested zone-based recognition system performs classical character-wise word recognition method it also validates that the enhancement in zone-segmentation improves the recognition performance. The architecture approaches have been shown in Fig.2 with an Arabic phrase as an example to expound the details of each these main steps are discussed briefly in following subsections.

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 68
Figure 2 Top row: Original Arabic script which is unlabelled. Bottom row: Arabic script
with the labelling of upper baseline, baseline and down line of the Arabic cursive. A. Zone segmentation Afterwards rectifying the skew detection and slant flaws, the words were segmented into three zones: upper, lower zones and the main middle zone where most of the alphabet are stands in what named baseline detection. For this purpose, the baseline is very important such as matra in Indic language.the detection reduces the complexity of writing. The detection of Matra-words is not easy always. Hence the detection has the diverse possibility of Matra region. These are explained as follows. B. Baseline detection Server study addressed the printed word recognition[16], one of most interesting is Matra is usually used in and script determine horizontal projections including the main functionality were is detect the direction of baseline. Matra was considered the row with highest peak value pixels. But, unfortunately, due to the nature and freestyle of handwriting, the baseline is hardly a features-perfect straight line which led the curvy and touching characters are broken. To regulate the assessed location of baseline detection, we consider three diverse row information for localising the estimated row in the word image. Side to side, we toke the best one among these three. Primarily row symbolised as R1, which is the maximum peak resolute by projection analysis of the filters in the horizontal direction. Instant row, R2, is row measurement by from depth-points of water reservoirs where the entirety of the squares of the distance between this R1, R2 where for each the depth points were minimum. Min (R12-R22) (1) The last row, R3 were calculated as: As the upper zone of script contain fewer apparatuses comparing with the middle zone, the part below the baseline will be as compressed as that of upper baseline discovery. Therefore, at hand will be a penetrating decline in estimated peak in upper partial of the word features although shifting from below the baseline to above the baseline.Labing of the R3 where a traced decline in projection is observed as the third estimated location (R3) of main raw. Finally, the baseline row has been detected by following rules. These rows are shown in Fig2. 8. where Th¼H/10 is the threshold and H are the height of the word image; H is calculated by taking the mode of height list taken from the top and bottom-most pixels of each column of the word image. We have noticed that the location of baseline row has been efficiently detected with this rule in most of the word
images.

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 69
C. Upper zone segmentation After estimating the baseline detection, we create a window of baseline region (WB) of height 4*Sw keeping the in middle, where generated. Sw is the stroke width noted that the curvilinear baseline resides in WBin more than 98% of the words from experiment dataset.the extracting of the words skeleton where find by high, junction points, curvature points and final points of the skeleton features.These points are noticeable as ‘P’. Currently, finding the links between successive ‘P’s in horizontal direction within WB. Including the condition of line-segment emerges from point ‘P’ and crosses WM, we consider it as a character portion and hence discard it. Only those line segments between ‘P’s which are passed within WM are considered. If more than one pixel is found in a single column we consider the uppermost pixel. In some words, the baseline may be broken and discontinuous. There, we join the two nearest Matra pixels using standard Bresenham algorithm. Next, the modifiers in the upper zone are marked by checking the upper portions of baseline.It is noted that the curvilinear baseline resides in WM in more than 98% of the words from experiment dataset. Next, we extract the skeleton of the word image and find the high curvature points, junction points, and end points of the skeleton image (see Fig. 1). These points are marked as ‘P’. Now, we find the lines between consecutive ‘P’s in the horizontal direction within WM. If a line-segment emerges from point ‘P’ and crosses WM, we consider it as a character portion and hence discard it. Only those line segments between ‘P’s which are passed within WM are considered. If more than one pixel is found in a single column we consider the uppermost pixel. In some words, the baseline may be broken and discontinuous. There, we join the two nearest Matra pixels using standard Bresenham algorithm.Next, the modifiers in the upper zone are marked by checking the upper portions of baseline. D. Lower zone segmentation In our earlier approach [19], to detect the modifiers in the lower zone, we marked the baseline which separated the middle zone from the lower zone by observing a sharp decline in the busy zone in the lower half of the image. This approach may fail sometimes, in the situation, when the baseline that separates the middle zone from the lower zone is difficult to locate. If the letters of the word are irregular in size, or there exist many modifiers in lower zones, then we may not find any sharp decline in projection peak between the middle zone and lower zone of the image. To have an idea we show an example in Fig. 2 where due to complex writing style, the lower zone detection becomes difficult using projection analysis. To overcome this problem we include a shape matching based algorithm for modifier extraction in this paper. To segment the lower zone modifiers, we search for modifiers in the lower half of the image by shape matching. To do so, we find the touching location of modified by skeleton analysis and separate them from the middle zone. If the remainder contour components are coordinated with one of lower zone characters with high corresponding confidence, that part is separated from the middle zone. Let M1 defined as the word futures. The skeleton future of M1 is primarily element acquired and the junction till the end points in skeleton features is distinguished. Let define L1 be the lower half of M1. via connected component (CC) analysis in L1, the mechanisms which are not associated to M1 are distinguished as modifiers. Connection connectivity was mainly charity in CC analysis. The approximately lower portions modifiers container the touching to M1. To isolated these modifiers, the tracing of components skeleton is begun from lower end

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 70
points. The sensitivity overdue tracing is that typically, all lower modifiers obligate to one end point in lower half of the word, without exception of the modifier which doesn’t require junction point. In the case of, the junction point is always a part of a loop. If the loop is found, we continue the tracing to detect the next junction point for segmentation. If more than one endpoint is found in a column the lowermost of it is considered in segmentation analysis. After segmentation, given an image portion, we compute the recognition confidence using SVM classifier to obtain the corresponding class label.
Fig. 2. The flowchart represents the proposal segmentation approaches to from upper and lower
portion of the Arabic.
FEATURE EXTRACTION The feature extraction is considered the important part of recognition system in this proposed algorithm, the middle zone considered as the elementary portion in Arabic word region someplace characters are often touching with each other.By performing the Hidden Markov Model (HMM) via stochastic sequential classifier for determining

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 71
touching components within this zone. On behalf of the HMM-based middle zone recognition, the developing of an efficient Feature Extraction Technique PHOG exhausting delivers resolution HOG features [17].To perform the efficacy of the frame where it demands to implement four different state-of-the-art methods and compared their performances. In previous work [18], where the Local Gradient Histogram (LGH) used for recognising the feature in extraction stage .in this section, the study take in consideration delivers features, mostly, profile feature, GABOR image and G-PHOG image ( a mixture of Gabor and PHOG) in lieu of middle zone or baseline recognition. These features are momentarily described by giving clear vision below. A. PHOG feature: PHOG is defined as the spatial shape for describing the main compound which stretches the feature of the accusation image by spatial arrangement and into local shape, including the gradient orientation for apiece hierarchical resolution arrangement. To perform feature extraction the via sliding window, it demands to split the features into individuals cells at several hierarchical level. The grid has 4N*4N individual cells at N different solution type (i.e. N¼0, 1, 2…). Histogram of gradient orientation take the competition one of each pixel and turning into from these single cells where is quantized into L bins. For single bin indicates a specific octant where is located in the angular radial zone. The merge of all feature vectors at each hierarchical resolution that provides the last PHOG descriptor. L-vector at level zero represents the L-bins of the histogram at that level. At any individual level, it has Lx4N 4Ndimensional feature vector where N is the hierarchical resolution level (i.e. N¼0, 1, 2…). So, the final PHOG descriptor consists of L PN N ¼ ¼ K 0 4Ndimensional feature vector, where K is the limiting hierarchical level. In our implementation, we have limited the level (N) to2 and we considered 8 bins (360°/45°) of angular information. So we obtained (1 8)þ(4 8)þ(16 8)¼(8þ32þ128)¼168 dimensional feature vector for individual sliding window position RECOGNITION The recognition of Middle zone via Hidden Markov Model was extracted for each of upper feature descriptors by sliding window then apply HMM whole word recognition. The feature vector sequence is treated using left-to-right continuous density HMMs[19].One of the important features of HMM is the competence to model sequential dependencies. An HMM can be defined by initial state probabilities π, state transition matrix A¼ [aij], i, j ¼ 1, 2,…, N, where aij signifies the evolution probability from the state I to state j, where the output probability bj(OK) displayed with incessant output probability density function. The concentration function is written as bj(x), where x embodies k dimensional feature vector. A detached Gaussian mixture model (GMM) is definite for each state provided a model. Properly, the output probability density of state j is defined as:

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 72
for the observation, the state is defined as the weight of Gaussian component coefficient of k state to j.For a prototypical λ, if O is an observation sequence O¼ (O1; O2,.., OT) which is expected to have been produced by a formal sequence Q¼(Q1, Q2,…, QT), of dimension T, where the observations probability or likelihood estimates by the follows function:
𝑃(𝑂,𝑄│λ)=Σ_𝑄𝜋𝑞1𝑏𝑞1(𝑂1)Π𝐴𝑇−1𝑞𝑏𝑞(𝑂𝑡)𝑇 (3)
π q1 is the preliminary probability of state when comes to the training phase, the texts of the middle zone of the word images unruffled with the feature vector arrangements are used in order to train the character models. The recognition is performed using the Viterbi algorithm. For the HMM implementation, we used the HTK toolkit[20].The parameters like, numbers of Gaussian Mixture and state are fixed according to validation data. Next resizing the images to 150 150, PHOG feature of vector length 168 is extracted from upper and lower zone modifiers[21]. PHOG feature is measured as it on condition that better result in the experiment. Following, Support Vector Machine (SVM) classifier [22]has been used to classify these components. SVM classifier has been selected here as it has effectively been useful in a widespread diversity of classification problems [23]. Given a training database of M data. Combination of zone-wise recognition results. In this section, the facts of the combination and modified alignment through the middle zone results are explored. For calculating approximately the boundaries of the characters in the middle zone of a word, Viterbi Forced Alignment [24]has been performed in the baseline. By the entrenched preparation of FA, the optimal boundaries of the characters of the baseline are found. After obtaining the character boundaries in the middle zone, the particular boundaries are extended in the upper and lower zones to assistant characters contemporary in lower and upper with the association of the main middle zones characters. This is one hypothesis for characters segmentation and amalgamation of an assumed word. Likewise, we make N such hypothesis using N-best Viterbi list obtained from middle zone of the word. The score to generate a hypothesis is calculated based on the recognition results of middle zone. For a given word image (X), its score is calculated based on a lexicon (W) of the middle zone characters and it is the posterior P(W|X). Using logarithm in Bayes’ rule we get. log𝑝(𝑊𝑋)log𝑝𝑊−log𝑝𝑥 (4)

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 73
From these scores, N-best hypothesis is chosen. Now among these N-best choices, the best hypothesis is chosen combining upper and lower zone information discussed as follows. After computing the zone-wise recognition results (upper and lower zone modifiers are recognised by SVM and middle zone characters by HMM of a word (X) and recognised character labels are obtained) the labels of upper and lower zones are associated with labels of middle zone. The association of character labels can be considered as a path-search problem to find the best matching word where each character label will be used only once. In our framework, the association is performed as follows. Let, the recognition labels of middle zone characters are CM_1, CM_2 CM_N where N is the number of characters obtained in middle zone. Also, let the recognition labels of upper zone characters and lower see the algorithm below.

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 74
CONCLUSION This paper presents a novel approach towards Arabic handwritten word recognition using the zone-wise material. Due to complex nature of the Arabic characters involving issues of overlapping and related issues like touching, the segmentation and recognition is a monotonous main occupation of in Arabic cursive (e.g. Nashua, Riqaa and other comparable scripts written for Holy Quran). To solve the issues of this character segmentation in such cursive, HMM founded on sequence modelling relying on the holistic way. This paper also proposes an efficient framework word recognition by segmenting the handwritten word features horizontally into three zones (upper, middle and lower) and then recognise the corresponding zones. The aim of this zone is to minimise the quantity of distinct component classes associated to the total a number of classes in Arabic cursive. As an outcome of this proposed approach is to enhance the recognition performance of the system. The elements of segmentation zone especially in middle zone (baseline), where characters are frequently tender, are recognised using HMM. After the recognition of middle zone, HMM Based in Viterbi forced Alignment is performed to mark the right and left characters in conjoint zones. Next, the residue components, if any, in upper and lower zones are highlighted in a character boundary then the Components are joint with the morphology of the character to achieve the whole word level recognition. Water reservoir- created the main properties that had integrated into the framework to increase the performance of the zone segmentation especially for the upper zone for the character to determine the boundary detection imperfections in segmentation stage. A new sliding window-based feature, named Pyramid Histogram OF-Oriented Gradient (PHOG) is suggested for lower and upper zone recognition. The comparison study with other similar PHOG features and found robust for Arabic handwriting script recognition. An exhaustive experiment is performed of other handwriting using different dataset such IFN / IFNT to evaluate the rate and the recognition performance. The outcome of this experiment, it has been renowned that proposed zone-wise recognition increases accuracy with respect to the traditional way of Indic word recognition.
REFERENCES
[1] Srihari, S.N., A. Shekhawat, and S.W. Lam, Optical character recognition (OCR). 2003. [2] Du, J. and Q. Huo, A discriminative linear regression approach to adaptation of multi-
prototype based classifiers and its applications for Chinese OCR. Pattern Recognition, 2013. 46(8): p. 2313-2322.
[3] Patil, V. and S. Shimpi, Handwritten English character recognition using a neural network. Elixir Comput Sci Eng, 2011. 41: p. 5587-5591.
[4] Bag, S., G. Harit, and P. Bhowmick, Recognition of Bangla compound characters using structural decomposition. Pattern Recognition, 2014. 47(3): p. 1187-1201.
[5] Aouadi, N., S. Amiri, and A.K. Echi, Segmentation of Connected Components in Arabic Handwritten Documents. Procedia Technology, 2013. 10: p. 738-746.
[6] Supriana, I. and A. Nasution, Arabic Character Recognition System Development. Procedia Technology, 2013. 11: p. 334-341.
[7] Chherawala, Y. and M. Cheriet, Arabic word descriptor for handwritten word indexing and lexicon reduction. Pattern Recognition, 2014. 47(10): p. 3477-3486.

HMM-based Arabic Handwritten word recognition via zone segmentation
Page | 75
[8] Garg, A. and R. Bajaj, Facial expression recognition & classification using hybridization of ICA, GA, and Neural Network for Human-Computer Interaction. Journal of Network Communications and Emerging Technologies (JNCET) www. jncet. org, 2015. 2(1).
[9] Mozaffari, S., et al., Two-stage lexicon reduction for offline Arabic handwritten word recognition. International Journal of Pattern Recognition and Artificial Intelligence, 2008. 22(07): p. 1323-1341.
[10] Saber, S., et al. Performance Evaluation of Arabic Optical Character Recognition Engines for Noisy Inputs. in The 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), November 28-30, 2015, Beni Suef, Egypt. 2016. Springer.
[11] Olivier, G., et al. Segmentation and coding of Arabic handwritten words. in Pattern Recognition, 1996., Proceedings of the 13th International Conference on. 1996. IEEE.
[12] Alginahi, Y.M., A survey on Arabic character segmentation. International Journal on Document Analysis and Recognition (IJDAR), 2013. 16(2): p. 105-126.
[13] Cheung, A., M. Bennamoun, and N.W. Bergmann, An Arabic optical character recognition system using recognition-based segmentation. Pattern recognition, 2001. 34(2): p. 215-233.
[14] Kavianifar, M. and A. Amin. Preprocessing and structural feature extraction for a multi-fonts Arabic/Persian OCR. in Document Analysis and Recognition, 1999. ICDAR'99. Proceedings of the Fifth International Conference on. 1999. IEEE.
[15] Azmi, A.N., D. Nasien, and S.M. Shamsuddin, A review on handwritten character and numeral recognition for Roman, Arabic, Chinese and Indian scripts. arXiv preprint arXiv:1308.4902, 2013.
[16] Obaidullah, S.M., et al., Separating Indic Scripts with matra for effective handwritten script identification in multi-script documents. International Journal of Pattern Recognition and Artificial Intelligence, 2016.
[17] Dhall, A., et al. Emotion recognition using PHOG and LPQ features. in Automatic Face & Gesture Recognition and Workshops (FG 2011), 2011 IEEE International Conference on. 2011. IEEE.
[18] Rodrıguez, J.A. and F. Perronnin. Local gradient histogram features for word spotting in unconstrained handwritten documents. in Int. Conf. on Frontiers in Handwriting Recognition. 2008.
[19] Meng, S., et al., Unsupervised Learning of Continuous Density HMM for Variable-Length Spoken Unit Discovery. IEICE TRANSACTIONS on Information and Systems, 2016. 99(1): p. 296-299.
[20] Yuan, J. and M. Liberman, Speaker identification on the SCOTUS corpus. Journal of the Acoustical Society of America, 2008. 123(5): p. 3878.
[21] Sun, B., et al. Combining multimodal features with hierarchical classifier fusion for emotion recognition in the wild. in Proceedings of the 16th International Conference on Multimodal Interaction. 2014. ACM.
[22] Tong, S. and D. Koller, Support vector machine active learning with applications to text classification. Journal of machine learning research, 2001. 2(Nov): p. 45-66.
[23] Schilmiller, A., et al., Mass spectrometry screening reveals widespread diversity in trichome specialized metabolites of tomato chromosomal substitution lines. The Plant Journal, 2010. 62(3): p. 391-403.

Zerdoumi Saber , Aznul Qalid Md Sabri ,Amirrudin Kamsin, Saqib Hakak & Faiz Alotaibi
Page | 76
[24] Kraljevski, I., Z.-H. Tan, and M.P. Bissiri. Comparison of Forced-Alignment Speech Recognition and Humans for Generating Reference VAD. in Sixteenth Annual Conference of the International Speech Communication Association. 2015.