how early is too early to plan for operational readiness? sadaf alam chief architect and head of hpc...
TRANSCRIPT

How Early is too Early to Plan for Operational Readiness?
Sadaf AlamChief Architect and Head of HPC OperationsSwiss National Supercomputing Centre (CSCS)Switzerland
2014 Smoky Mountains Computational Sciences and Engineering Conference

How Early is too Early to Plan for Operational Readiness? A Proposal for Robust505 List
Sadaf AlamChief Architect and Head of HPC OperationsSwiss National Supercomputing Centre (CSCS)Switzerland
2014 Smoky Mountains Computational Sciences and Engineering Conference
Late Late

2014 Smoky Mountains Computational Sciences and Engineering Conference 3
Outline
CSCS overview: systems,
customers & services
Co-Designed System (Piz
Daint): Early -> Deployment
phases
Future Integrated*
Installations & Proposal for
Robust505 List
© CSCS 2014
* compute, data, visualization, etc.

2014 Smoky Mountains Computational Sciences and Engineering Conference 4© CSCS 2014

2014 Smoky Mountains Computational Sciences and Engineering Conference 5
Computing Systems @ CSCS
© CSCS 2014
and several T&D systems (incl. an IMB IDataPlex M3 with GPU and two dense GPU servers) plus networking and storage infrastructure …
http://www.cscs.ch/computers
User Lab: Cray XC30 with GPU devices
User Lab: Cray XE6
User Lab R&D: Cray XK7 with GPU devices
User Lab: InfiniBand Cluster
User Lab: InfiniBand Cluster
User Lab: SGI AltixUser Lab: Cray XMT
User Lab: InfiniBand Cluster with GPU devicesMeteo Swiss Cray XE6
EPFL Blue Brain Project IBM BG/Q & viz cluster
PASC InfiniBand Cluster
LCG Tier2 InfiniBand Cluster

2014 Smoky Mountains Computational Sciences and Engineering Conference 6
Customers, Users & Operational Responsibilities • Customers & users priorities:
– Robust and sustainable performance for production-level simulations
– Debugging and performance measurement tools to identify and isolate issues (e.g. TAU, Vampir, vendor tools, DDT, Totalview, etc.)
• 24/7 operational support considerations:
– Monitoring for degradation and failures, isolate components as needed (e.g. Ganglia, customized vendor interfaces)
– Quick diagnostics and fixes of known problems– Alerting mechanisms for on-call services (e.g. Nagios)
© CSCS 2014
# Realities of using bleeding edge technologiesTools primarily available for non-accelerated clusters running MPI & OpenMP applications plus processors, memories, NICs, ...

2014 Smoky Mountains Computational Sciences and Engineering Conference 7
Piz Daint: Applications
readiness -> installation
-> operation
© CSCS 2014

8
2009 2010 2011 2012 2013 2014 2015 …
Application Investment & Engagement
Training and workshops
Prototypes & early access parallel systems
HPC installation and operations
High Performance High Productivity Computing (HP2C)
Platform for Advanced Scientific Computing (PASC)
HP2C training program PASC conferences & workshops
GPU nodes in a viz cluster Collaborative projects
Prototypes with accelerator devices
GPU cluster
Cray XK6 Cray XK7
Cray XC30 Cray XC30 (adaptive)
Top500
Green 500
* Timelines & releases are not precise

9
2009 2010 2011 2012 2013 2014 2015 …
Applications development and tuning
Requirements analysis
CUDA 2.x
OpenCL 1.0
CUDA 3.x CUDA 4.x CUDA 5.x CUDA 6.xCUDA 2.x
CUDA 2.xCUDA 2.x
CUDA 3.xCUDA 3.x
CUDA 4.xCUDA 4.x
CUDA 5.x
OpenCL 1.1 OpenCL 1.2 OpenCL 2.0
GPUDirect GPUDirect-RDMA
GPU-enabled MPI & MPS
X86 cluster with C2070, M2050, S1070
iDataPlex clusterM2090
Cray XK6 Cray XK7
Cray XC30 & hybrid XC30
Testbed with Kepler & Xeon Phi
OpenACC 1.0 OpenACC 2.0
* Timelines & releases are not precise
24/7 monitoring & troubleshooting
Tesla Deployment Kit (TDK), NVML & healthmon Ganglia plugins
GPU Deployment Kit (GDK), NVML & healthmon v2
Cray PMDB, Node Health Check & RUR
Custom solutions & integration at CSCS on case-by-case basis
2014 Smoky Mountains Computational Sciences and Engineering Conference 10
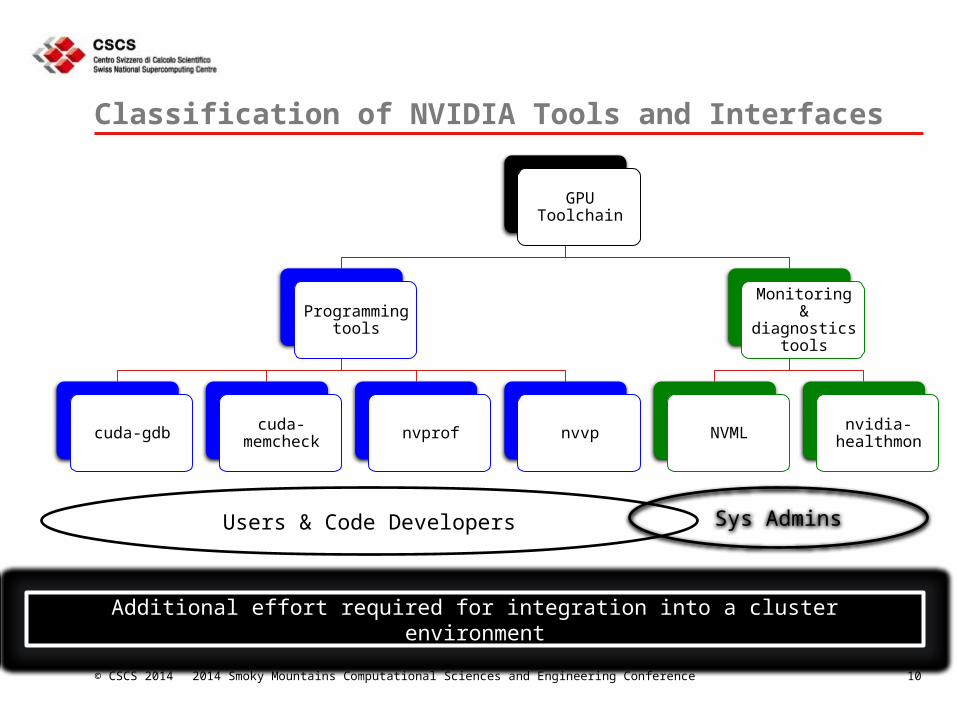
Classification of NVIDIA Tools and Interfaces
GPU Toolchain
Programming tools
cuda-gdb cuda-memcheck nvprof nvvp
Monitoring & diagnostics
tools
NVML nvidia-healthmon
Sys AdminsUsers & Code Developers
© CSCS 2014
Additional effort required for integration into a cluster environment

2014 Smoky Mountains Computational Sciences and Engineering Conference 11
Case Study # 1
• Finding and resolving bugs in the GPU driver
– Intermittent bug appears at scale only, 1K+ GPU devices– Error code can be confused with user programming bugs– Users do not see the error code output, recorded on console logs
– Availability of driver patch– Validation of patch by vendor & OEM
– Driver patch evaluation and regression– Deployment or a driver patch == major intervention
– Verification and resume of operations– … until a new, unknown issue is triggered
© CSCS 2014

2014 Smoky Mountains Computational Sciences and Engineering Conference 12
Case Study 2• Enabling privileged modes for legitimate use cases
© CSCS 2014
Extracted from the NVML reference document
Implemented to support
applications needs
K20X

2014 Smoky Mountains Computational Sciences and Engineering Conference 13© CSCS 2014
I want root permission
I want root permission
I want root permission
User User
User
14
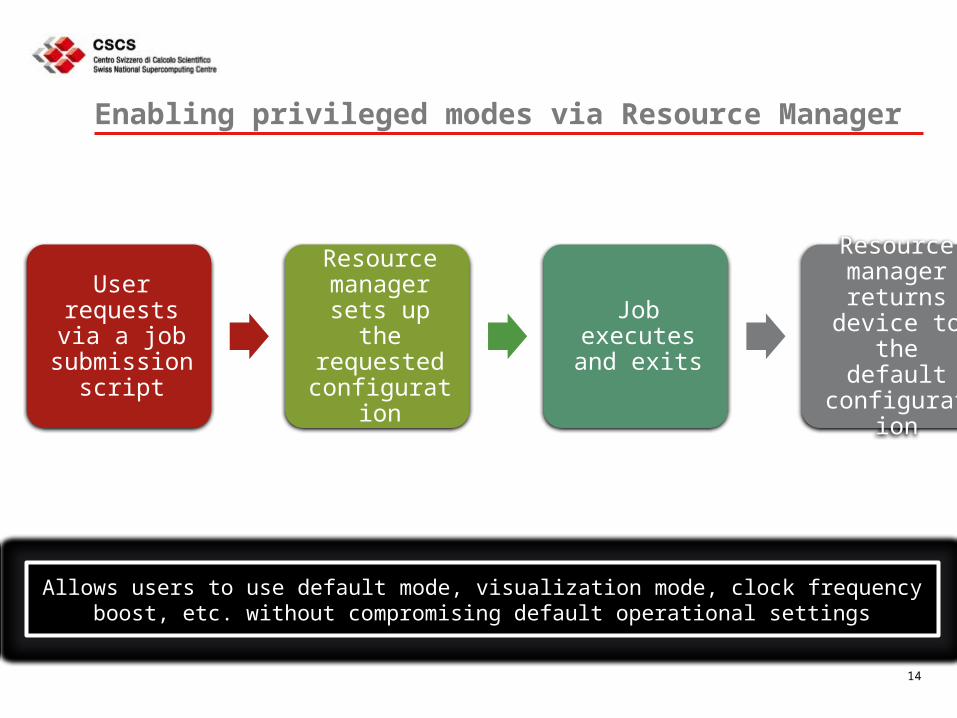
Enabling privileged modes via Resource Manager
User requests via
a job submission
script
Resource manager
sets up the requested
configuration
Job executes and exits
Resource manager returns
device to the default
configuration
Allows users to use default mode, visualization mode, clock frequency boost, etc. without compromising default operational settings

2014 Smoky Mountains Computational Sciences and Engineering Conference 15
Work in Progress
• Monitoring interfaces and diagnostics
– Add as new ones are identified—feedback to vendors– Extending logic to interpret logs– Implementing new alerts
• Early identification of degradation of components
– Partly identified by regression suite– … still alarms are triggered by users
© CSCS 2014
Unintended consequence: Reduction in users productivity and service quality—credibility of service provider

2014 Smoky Mountains Computational Sciences and Engineering Conference 16
Robust505 List—
Incentivizing Operational
Readiness for Vendors &
Service Providers
© CSCS 2014
2014 Smoky Mountains Computational Sciences and Engineering Conference 17
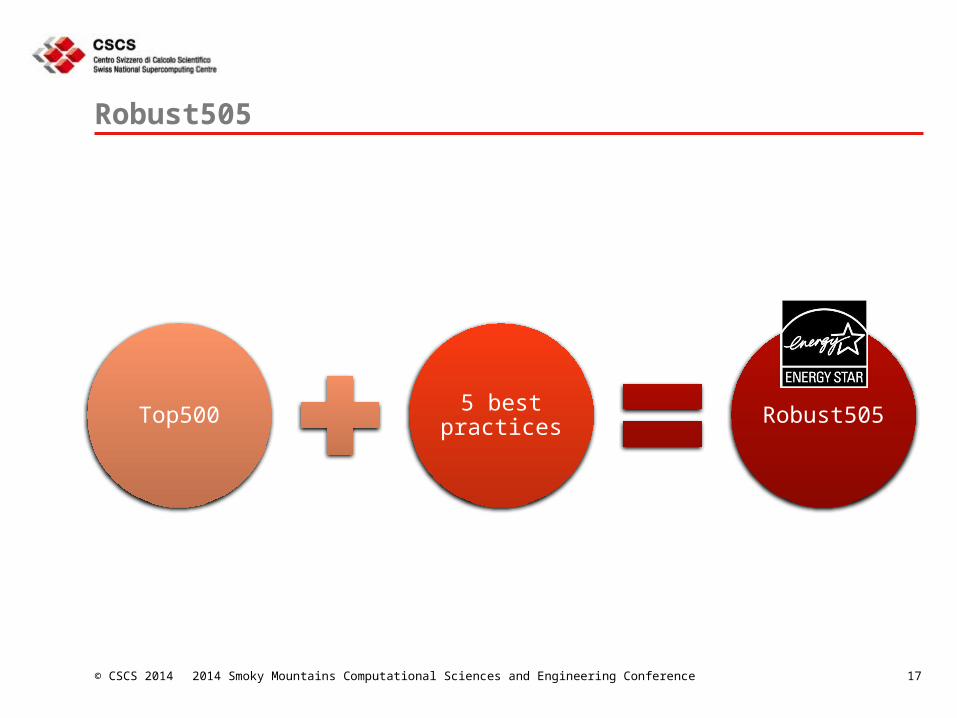
Robust505
Top500 5 best practices Robust505
© CSCS 2014

2014 Smoky Mountains Computational Sciences and Engineering Conference 18
Proposal & Guidelines• Zero to minimum overhead for making a submission• Metrics (TBD):
– Data collection and reporting for Top500 runs
– Uptime– Failures classification (known vs. unknown)– Self-healing vs. intervention, i.e. unscheduled maintenance
– Known errors database (KEDB)
– Faster workaround & resumption of service to users– Knowledge sharing
– Ganglia and Nagios integration and completeness (main system, ecosystem, file system)
– Best practices from other service providers, e.g. cloud
© CSCS 2014

2014 Smoky Mountains Computational Sciences and Engineering Conference 19
Next Steps
• Form a working group to make a concrete proposal
– Include future requirements for integration of additional services, e.g. big data
• Find volunteers to iron out details
• Explore opportunities to get some leverage thru upcoming deployments, e.g. Trinity and CORAL installations
© CSCS 2014
2014 Smoky Mountains Computational Sciences and Engineering Conference 20
Final Thoughts
© CSCS 2014
Time
Perf
orm
ance
Success
Time
Avera
ge s
low
dow
n f
or
pro
duct
ion
use
rs
Success
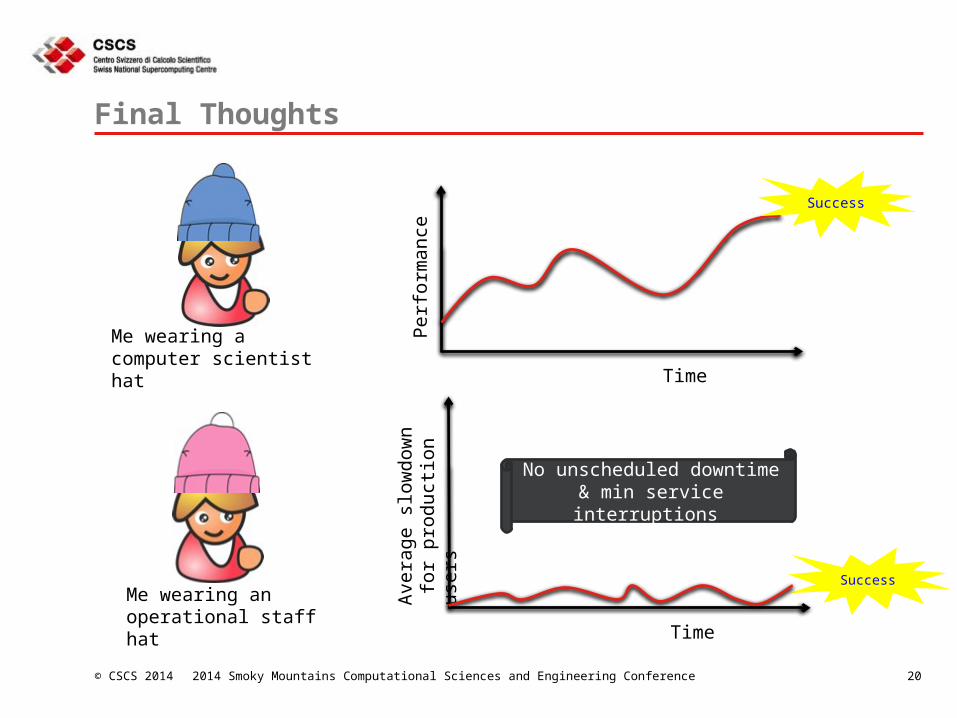
Me wearing a computer scientist hat
Me wearing an operational staff hat
No unscheduled downtime & min service interruptions

2014 Smoky Mountains Computational Sciences and Engineering Conference 21
Thank you
© CSCS 2014