how to submit and run jobs on compute canada hpc systems · 2020-04-29 · hardware connecting...
TRANSCRIPT

Hardware Connecting Environment Transfer Jobs Best practices Summary
How to submit and run jobs on Compute CanadaHPC systems
ALEX [email protected]
4 copy of these slides at http://bit.ly/2D40VML
WestGrid Webinar 2018-Sep-19 1 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
To ask questions
Websteam: email [email protected]
Vidyo: use the GROUP CHAT to ask questions
Please mute your mic unless you have a question
Feel free to ask questions via audio at any time
WestGrid Webinar 2018-Sep-19 2 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Cluster overview
WestGrid Webinar 2018-Sep-19 3 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Compute Canada’s national systemsSince 2016, CC has been renewing its national infrastructure:
Arbutus is an extension to the West Cloud (UVic), in production since Sep. 2016
Cedar (SFU), Graham (Waterloo) are general-purpose clusters, in production since June 2017
Niagara is a large parallel cluster (Toronto), in production since April 2018
One more general-purpose system (Béluga) in Québec, in production in early 2019
WestGrid Webinar 2018-Sep-19 4 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Cedar cedar.computecanada.ca Graham graham.computecanada.capurpose general-purpose cluster for a variety of workloads
specs https://docs.computecanada.ca/wiki/Cedar https://docs.computecanada.ca/wiki/Graham
processor count 58,416 CPUs and 584 GPUs 33,472 CPUs and 320 GPUs
interconnect 100Gbit/s Intel OmniPath, non-blocking to1024 cores
56-100Gb/s Mellanox InfiniBand,non-blocking to 1024 cores
128GB base nodes 576 nodes: 32 cores/node 864 nodes: 32 cores/node
256GB large nodes 128 nodes: 32 cores/node 56 nodes: 32 cores/node
0.5TB bigmem500 24 nodes: 32 cores/node 24 nodes: 32 cores/node
1.5TB bigmem1500 24 nodes: 32 cores/node -
3TB bigmem3000 4 nodes: 32 cores/node 3 nodes: 64 cores/node
128GB GPU base 114 nodes: 24-cores/node, 4 NVIDIA P100Pascal GPUs with 12GB HBM2 memory
160 nodes: 32-cores/node, 2 NVIDIA P100Pascal GPUs with 12GB HBM2 memory
256GB GPU large 32 nodes: 24-cores/node, 4 NVIDIA P100Pascal GPUs with 16GB HBM2 memory
-
192 GB Skylakebase nodes
640 nodes: 48 cores/node (similar to Niagara’s) -
å All nodes have on-node SSD storage
å On Cedar use --constraint={broadwell,skylake} to specify CPU architecture (usually not needed)
WestGrid Webinar 2018-Sep-19 5 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Niagara niagara.computecanada.capurpose for large parallel jobs, ideally ≥1,000 cores with an allocation
specs https://docs.computecanada.ca/wiki/Niagara and https://docs.scinet.utoronto.ca
processor count 60,000 CPUs and no GPUs
interconnect EDR Infiniband (Dragonfly+, completely connected topology, dynamicrouting), 1:1 to 432 nodes, effectively 2:1 beyond that
192GB basenodes
1,500 nodes: 40 cores/node
å No local disk, nodes booting off the network, small RAM filesystem
å All cores are Intel Skylake (2.4 GHz, AVX512)
å Authentication via CC accounts; for now, need to request a SciNet account; long-term regular accessfor all CC account holders
å Scheduling is by node (in multiples of 40-cores)
å Users with an allocation: job sizes up to 1000 nodes and 24 hours max runtime
å Users without an allocation: job sizes up to 20 nodes and 12 hours max runtime
å Maximum number of jobs per user: running 50, queued 150
WestGrid Webinar 2018-Sep-19 6 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Accessing resources: RAS vs. RAC
∼20% of compute cycles available via the Rapid Access Service (RAS)I available to all CC users via default queuesI you can start using it as soon as you have a CC accountI shared pool with resources allocated via “fair share” mechanismI will be sufficient to meet computing needs of many research groups
∼80% of compute cycles allocated via annual Resource Allocation Competitions(RAC)
I apply if you need >50 CPU-years or >10 GPU-yearsI only PIs can apply, allocation per research groupI announcement in the fall of each year via email to all usersI 2018 RAC: 469 applications, success rate (awarded vs. requested) 55.1% for CPUs, 20.5%
for GPUs, 73% for storageI 2019 RAC submission period Sep-27 to Nov-08, start of allocations in early April 2019
WestGrid Webinar 2018-Sep-19 7 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
File systemsDetails at https://docs.computecanada.ca/wiki/Storage_and_file_management
filesystem quotas backed up? purged? performance mounted oncompute nodes?
$HOME 50GB, 5e5 files per user,100GB Niagara
nightly, latestsnapshot
no medium yes
$SCRATCH 20TB Cedar, 100TB Graham,25TB Niagara, 1e6 files per
user except when full
no yes high for largefiles
yes
$PROJECT(long-term disk
storage)
1TB, 5e5 files per user couldbe increased via RAC, Niagara
only via RAC
nightly no medium yes
/nearline(tape archive)
5TB per group via RAC no no medium to low no
/localscratch none no maybe very high local
Wide range of options from high-speed temporary storage to different kinds of long-term storage
Checking disk usage: run quota command (aliased to diskusage_report)
Requesting more storage: small increases via [email protected], large requests via RAC
Niagara only: 256TB $BBUFFER (burst buffer, NVMe SSDs) for low-latency I/O, space must be requested (10TBquota), files should be moved to $SCRATCH at the end of a job
WestGrid Webinar 2018-Sep-19 8 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
How to log into a cluster
WestGrid Webinar 2018-Sep-19 9 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Logging into the systems: SSH client + your CC account
On Mac or Linux in terminal:
$ ssh [email protected] # Cedar login node$ ssh [email protected] # Graham login node$ ssh [email protected] # Niagara login node
On Windows many options:I MobaXTerm https://docs.computecanada.ca/wiki/Connecting_with_MobaXTermI PuTTY https://docs.computecanada.ca/wiki/Connecting_with_PuTTYI if using Chrome browser, from https://chrome.google.com/webstore/category/extensions
install Secure Shell ExtensionI bash from the Windows Subsystem for Linux (WSL) – starting with Windows 10, need to enable developer
mode and then WSL
SSH key pairs are very handy to avoid typing passwordsI implies secure handling of private keys, non-empty passphrasesI https://docs.computecanada.ca/wiki/SSH_KeysI https://docs.computecanada.ca/wiki/Using_SSH_keys_in_Linux
I https://docs.computecanada.ca/wiki/Generating_SSH_keys_in_Windows
GUI connection: X11 forwarding (through ssh -Y), VNC, x2go
Client-server workflow in selected applications, both on login and compute nodes
WestGrid Webinar 2018-Sep-19 10 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Linux command line
All system run Linux (CentOS 7) ⇒ you need to know basic command lineI for very basic introduction, https://hpc-carpentry.github.io/hpc-shellI other online tutorials , e.g. http://bit.ly/2vH3j8vI attend one of our Software Carpentry 3-hour in-person bash sessions
Much typing can be avoided by using bash aliases, functions, ∼/.bashrc, hitting TAB
FILE COMMANDSls directory listingls -alF pass command argumentscd dir change directory to dircd change to homepwd show current directorymkdir dir create a directoryrm file delete filerm -r dir delete directoryrm -f file force remove filerm -rf dir force remove directorycp file target copy file to targetmv file target rename or move file to targetln -s file link create symbolic link to filetouch file create or update file
PATHSrelative vs. absolute pathsmeaning of ∼ . ..
FILE COMMANDScommand > file redirect command output to filecommand � file append command output to filemore file page through contents of filecat file print all contents of filehead -n file output the first n lines of filetail -n file output the last n lines of filetail -f file output the contents of file as it grows
PROCESS MANAGEMENTtop display your currently active processesps display all running processeskill pid kill process ID pid
FILE PERMISSIONSchmod -R u+rw,g-rwx,o-rwx file set permissions
ENVIRONMENT VARIABLES AND ALIASESexport VAR=’value’ set a variableecho $VAR print a variablealias ls=’ls -aFh’ set an alias command
SEARCHINGgrep pattern files search for pattern in filescommand | grep pattern example of a pipefind . -name ’*.txt’ | wc -l another pipe
OTHER TOOLSman command show the manual for commandcommand --help get quick help on commanddf -kh . show disk usagedu -kh . show directory space usage
COMPRESSION AND ARCHIVINGtar cvf file.tar files create a tar filetar xvf file.tar extract from file.targzip file compress filegunzip file.gz uncompress file.gz
LOOPSfor i in *tex; do wc -l $i; done loop example
WestGrid Webinar 2018-Sep-19 11 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Editing remote files from the command line
Inside the terminalI nano is the easiest option for novice usersI emacs -nw is available for power usersI vi and vim are also available (for die-hard fans: basic, difficult to use)
Remote graphical emacs not recommendedI you would connect via ssh with an X11 forwarding flag (-X, -Y)
My preferred option: local emacs on my laptop editing remote files via ssh withemacs’s built-in package tramp
I need to add to your ∼/.emacs
(require ’tramp)(setq tramp-default-method "ssh")
I only makes sense with a working ssh-key pairI your private key is your key to the cluster, so don’t share it!I cross-platform (Windows/Linux/Mac)
Same remote editing functionality exists in several other text editorsI Atom (open-source, Windows/Linux/Mac)I Sublime Text (commercial, Windows/Linux/Mac)
WestGrid Webinar 2018-Sep-19 12 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Cluster software environment
WestGrid Webinar 2018-Sep-19 13 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Cluster software environment at a glance
Programming languages: C/C++, Fortran 90, Python, R, Java, Matlab, ChapelI several different versions and flavours for most of theseI for more details see https://docs.computecanada.ca/wiki/Programming_GuideI parallel programming environments in the next slide
Job scheduler: Slurm open-source scheduler and resource manager
Popular software: installed by staff, listed athttps://docs.computecanada.ca/wiki/Available_software
I lower-level, not performance sensitive packages installed via Nix package managerI general packages installed via EasyBuild frameworkI everything located under /cvmfs, loaded via modules (in two slides)
Other softwareI email [email protected] with your request, orI can compile in your own space (feel free to ask staff for help)
WestGrid Webinar 2018-Sep-19 14 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Parallel programming environment
CPU parallel development support: OpenMP (since 1997), MPI (since 1994)I OpenMP is a language extension for C/C++/Fortran provided by compilers, implements shared-memory
parallel programmingI MPI is a library with implementations for C/C++/Fortran/Python/R/etc, designed for distributed-memory
parallel environments, also works for CPU cores with access to common shared memoryI industry standards for the past 20+ years
Chapel is a open-source parallel programming languageI ease-of-use of Python + performance of a traditional compiled languageI combines shared- and distributed-memory models; data and task parallelism for bothI multi-resolution: high-level parallel abstractions + low-level controlsI in my opinion, by far the best language to learn parallel programming ⇒ we teach it as part of HPC
Carpentry, in summer schools and full-day Chapel workshopsI experimental support for GPUsI relative newcomer to HPC, unfortunately still rarely used outside its small/passionate community
GPU parallel development support: CUDA, OpenCL, OpenACC
WestGrid Webinar 2018-Sep-19 15 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Software modules
Use appropriate modules to load centrally-installed software (might have to selectthe right version)$ module avail <name> # search for a module (if listed)$ module spider <name> # search, typically will list more$ module list # show currently loaded modules$ module load moduleName$ module unload moduleName$ module show moduleName # show commands in the module$ module purge # remove currently loaded modules
All associated prerequisite modules will be automatically loaded as wellModules must be loaded before a job using them is submitted
I alternatively, can load a module from the job submission scriptOn Niagara, software was compiled specifically for its architecture
I different selection of modules; optionally can load CC’s software stack forCedar/Graham (compiled for a previous generation of CPUs)
$ module load CCEnv$ module load StdEnv
WestGrid Webinar 2018-Sep-19 16 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Installed compilers
Intel GNU PGIintel/2016.4 and openmpi/2.1.1 module load gcc/5.4.0 (∗) module load pgi/17.3 (∗)
loaded by defaultC icc mpicc gcc -O2 mpicc pgcc mpicc
Fortran 90 ifort mpifort gfortran -O2 mpifort pgfortran mpifort
C++ icpc mpiCC g++ -O2 mpiCC pgc++ mpiCC
OpenMP flag -qopenmp -fopenmp -mp
(∗) in both cases intel/2016.4 will be unloaded and openmpi/2.1.1 reloaded automatically
mpiXX scripts invoke the right compiler and link your code to the correct MPI libraryuse mpiXX --show to view the commands they use to compile and link
WestGrid Webinar 2018-Sep-19 17 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Other essential tools
File management with gzip and tar
Build automation with make
Version control with git or mercurialI normally taught as a 3-hour Software Carpentry course
Terminal multiplexer with screen or tmuxI share a physical terminal between several interactive shellsI access the same interactive shells from many different terminalsI very useful for persistent sessions, e.g., for compiling large codes
VNC and x2go clients for remote interactive GUI workI on Cedar in $HOME/.vnc/xstartup can switch from twm to mwm/etc. as your default
window managerI can run VNC server on compute nodes
WestGrid Webinar 2018-Sep-19 18 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
PythonDetails at https://docs.computecanada.ca/wiki/Python
Initial setup:
module avail python # several versions availablemodule load python/3.5.4virtualenv bio # install Python tools in your $HOME/biosource ~/bio/bin/activatepip install numpy...
Usual workflow:source ~/bio/bin/activate # load the environmentpython...deactivate
WestGrid Webinar 2018-Sep-19 19 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
R - details at https://docs.computecanada.ca/wiki/R$ module spider r # several versions available$ module load r/3.4.3$ R> install.packages("sp") # install packages from cran.r-project.org; it’ll suggest
# installing into your personal library $HOME/R/$ R CMD INSTALL -l $HOME/myRLibPath package.tgz # install non-CRAN packages
Running R scripts: Rscript script.R
Installing and running Rmpi: see our documentationpbdR (Programming with Big Data in R): high-performance, high-level interfaces toMPI, ZeroMQ, ScaLAPACK, NetCDF4, PAPI, etc. http://r-pbd.orgLaunching multiple serial R calculations via array jobs (details in Scheduling)
I inside the job submission script use something like
Rscript script${SLURM_ARRAY_TASK_ID}.R # multiple scriptsor
export params=${SLURM_ARRAY_TASK_ID} # one script, arrayTaskID passed into the scriptRscript script.R
and then inside script.R:s <- Sys.getenv(’params’)filename <- paste(’/path/to/input’, s, ’.csv’, sep=’’)
WestGrid Webinar 2018-Sep-19 20 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
How to move data
WestGrid Webinar 2018-Sep-19 21 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
File transfer
In Mac/Linux terminal or in Windows MobaXterm you have several good options:
(1) use scp to copy individual files and directories$ scp filename [email protected]:/path/to$ scp [email protected]:/path/to/filename localPath
(2) use rsync to sync files or directories$ flags=’-av --progress --delete’$ rsync $flags localPath/*pattern* [email protected]:/path/to$ rsync $flags [email protected]:/path/to/*pattern* localPath
(3) use sftp for more interactive access$ sftp [email protected]> help
Windows PuTTY uses pscp command for secure file transferNumber of GUI clients for sftp file transfer, e.g.https://filezilla-project.org
WestGrid Webinar 2018-Sep-19 22 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Globus file transferDetails at https://docs.computecanada.ca/wiki/Globus
The CC Globus Portal https://globus.computecanada.ca is a fast, reliable,and secure service for big data transfer (log in with your CC account)
Easy-to-use web interface to automate file transfers between any two endpointsI an endpoint could be a CC system, another supercomputing facility, a campus cluster, a
lab server, a personal laptop (requires Globus Connect Personal app)I runs in the background: initialize transfer and close the browser, it’ll email statusI perfect if you regularly move more than 10GB
Uses GridFTP transfer protocol: much better performance than scp, rsyncI achieves better use of bandwidth with multiple simultaneous TCP streamsI some ISPs and Eduroam might not always play well with the protocol (throttling)
Automatically restarts interrupted transfers, retries failures, checks file integrity,handles recovery from faults
Command-line interface available as wellWestGrid Webinar 2018-Sep-19 23 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Quick scheduling primerand how to submit jobs
figures and some material in this section created by Kamil Marcinkowski
WestGrid Webinar 2018-Sep-19 24 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Why job scheduler?
Tens of thousands of CPUs, many thousands of simultaneous jobs ⇒ need anautomated solution to manage a queue of pending jobs, allocate resources to users,start/stop/monitor jobs ⇒ we use Slurm open-source scheduler/resource manager
I efficiency and utilization: we would like all resources (CPUs, GPUs, memory, disk, bandwidth) tobe all used as much as possible, and minimize gaps in scheduling between jobs
I minimize turnaround for your jobs
Submit jobs to the scheduler when you have a calculation to run; can specify:I walltime: maximum length of time your job will take to runI number of CPU cores, perhaps distribution across nodesI memory (per core or total)I if applicable, number of GPUsI Slurm partition, reservation, software licenses, ...
Your job is automatically started by the scheduler when resources are available
I standard output and error go to file(s)
WestGrid Webinar 2018-Sep-19 25 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Fairshare mechanismAllocation based on your previous usage and your “share” of the cluster
Priority: one per research group (not per user!), ranges from 6 (= high, default)to 0 (= low)
Each group has a share targetI for regular queues: share ∝ the number of group membersI in RAC: share ∝ the awarded allocation (important projects get a larger allocation)
If a research group has used more than its share during a specific interval (typically7-10 days) ⇒ its priority will go down, and vice versa
I the exact formula for computing priority is quite complex and includes some adjustableweights and optionally other factors, e.g., how long a job has been sitting in the queue
I no usage during during the current fairshare interval ⇒ recover back to level 6
Higher priority level can be used to create short-term bursts
Reservations (specific nodes) typically only for special events
WestGrid Webinar 2018-Sep-19 26 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Job packing: simplified view
Consider a cluster with 4 running jobs and 6 newly submitted jobs
Scheduled jobs are arranged in order of their users’ priority, starting from the top of thepriority list (jobs from users with the highest priority)
Consider 2D view: cores and time
In reality a multi-dimensional rectangle to fit on a cluster partition: add memory (3rddimension), perhaps GPUs (4th dimension), and so on, but let’s ignore these for simplicity
WestGrid Webinar 2018-Sep-19 27 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Jobs are scheduled in order of their priority. Highest-priority job may not run first!
Backfill: small lower-priority jobs can run on processors reserved for largerhigher-priority jobs (that are still accumulating resources), if they can completebefore the higher-priority job begins
WestGrid Webinar 2018-Sep-19 28 / 46
Hardware Connecting Environment Transfer Jobs Best practices Summary
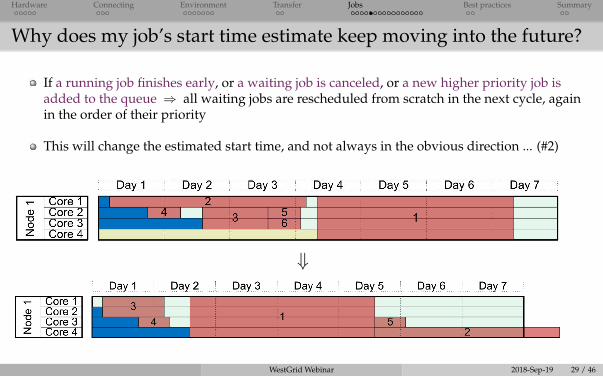
Why does my job’s start time estimate keep moving into the future?
If a running job finishes early, or a waiting job is canceled, or a new higher priority job isadded to the queue ⇒ all waiting jobs are rescheduled from scratch in the next cycle, againin the order of their priority
This will change the estimated start time, and not always in the obvious direction ... (#2)
⇒
WestGrid Webinar 2018-Sep-19 29 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Job billing by core-equivalentGoes into determining your priority
Recall: base nodes have 128GB and 32 cores per node ⇒ effectively 4GB per core
Job billing is by core and memory (via core-equivalents: 4GB = 1 core), whichever islarger
I this is fair: large-memory jobs use more resourcesI a 6GB serial job running for one full day will be billed 36 core-hours
On GPU partitions job billing is by GPU-equivalents (the largest of GPUs / cores /memory)
WestGrid Webinar 2018-Sep-19 30 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Submitting a simple serial job
#!/bin/bashecho This script is running onhostnamesleep 20
$ sbatch [--account=def-razoumov-ac, other flags] simpleScript.sh$ squeue -u yourUsername [-t RUNNING] [-t PENDING] # list your jobs$ scancel jobID # cancel a scheduled or running job$ scancel -u yourUsername # cancel all your jobs
The flag --account=... is needed only if you’ve been added to more than one CPU allocation (RAS/ RAC / reservations)
I used for “billing” purposesI different from your cluster account!
No need to specify the number of cores: one core is the default
Submitting many serial jobs is called “serial farming” (perfect for filling in the parameter space,running Monte Carlo ensembles, etc.)
Common job states: R = running, PD = pending, CG = completing right now, F = failed
WestGrid Webinar 2018-Sep-19 31 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Customising your serial job
$ icc pi.c -o serial$ sbatch [other flags] job_serial.sh$ squeue -u username [-t RUNNING] [-t PENDING] # list all current jobs$ sacct -j jobID [--format=jobid,maxrss,elapsed] # list resources used by
# your completed job
#!/bin/bash#SBATCH --time=00:05:00 # walltime in d-hh:mm or hh:mm:ss format#SBATCH --job-name="quick test"#SBATCH --mem=100 # 100M#SBATCH --account=def-razoumov-ac./serial
The flag --account=... is needed only if you’ve been added to more than one CPU allocation (RAS/ RAC / reservations)
I used for “billing” purposesI different from your cluster account!
It is good practice to put all flags into a job script (and not the command line)Could specify number of other flags
WestGrid Webinar 2018-Sep-19 32 / 46
Hardware Connecting Environment Transfer Jobs Best practices Summary
Submitting array jobs
Job arrays are a handy tool for submitting many serial jobs that have the same executable and mightdiffer only by the input they are receiving through a file
Job arrays are preferred as they don’t require as much computation by the scheduling system toschedule, since they are evaluated as a group instead of individually
In the example below we want to run 30 times the executable “myprogram” that requires an input file;these files are called input1.dat, input2.dat, ..., input30.dat, respectively
$ sbatch [other flags] job_array.sh
#!/bin/bash#SBATCH --array=1-30 # 30 jobs#SBATCH --job-name=myprog # single job name for the array#SBATCH --time=02:00:00 # maximum walltime per job#SBATCH --mem=100 # maximum 100M per job#SBATCH --account=def-razoumov-ac#SBATCH --output=myprog%A%a.out # standard output#SBATCH --error=myprog%A%a.err # standard error# in the previous two lines %A" is replaced by jobID and "%a" with the array index./myprogram input$SLURM_ARRAY_TASK_ID.dat
WestGrid Webinar 2018-Sep-19 33 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Submitting OpenMP or threaded jobs
$ icc -qopenmp sharedPi.c -o openmp$ sbatch [other flags] job_openmp.sh$ squeue -u username [-t RUNNING] [-t PENDING] # list all current jobs$ sacct -j jobID [--format=jobid,maxrss,elapsed] # list resources used by
# your completed job
#!/bin/bash#SBATCH --cpus-per-task=4 # number of cores#SBATCH --time=0-00:05 # walltime in d-hh:mm or hh:mm:ss format#SBATCH --mem=100 # 100M for the whole job (all threads)#SBATCH --account=def-razoumov-acexport OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK # passed to the programecho running on $SLURM_CPUS_PER_TASK cores./openmp
All threads are part of the same process, share same memory address spaceOpenMP is one of the easiest methods of parallel programmingScaling only to a single node
WestGrid Webinar 2018-Sep-19 34 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Submitting MPI jobs
$ mpicc distributedPi.c -o mpi$ sbatch [other flags] job_mpi.sh$ squeue -u username [-t RUNNING] [-t PENDING] # list all current jobs$ sacct -j jobID [--format=jobid,maxrss,elapsed] # list resources used by
# your completed job
#!/bin/bash#SBATCH --ntasks=4 # number of MPI processes#SBATCH --time=0-00:05 # walltime in d-hh:mm or hh:mm:ss format#SBATCH --mem-per-cpu=100 # in MB#SBATCH --account=def-razoumov-acsrun ./mpi # or mpirun
Distributed memory: each process uses its own memory address spaceCommunication via messagesMore difficult to write MPI-parallel code than OpenMPCan scale to much larger number of processors, across many nodes
WestGrid Webinar 2018-Sep-19 35 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Scheduler: submitting GPU jobs
#!/bin/bash#SBATCH --nodes=3 # number of nodes#SBATCH --gres=gpu:1 # GPUs per node#SBATCH --mem=4000M # memory per node#SBATCH --time=0-05:00 # walltime in d-hh:mm or hh:mm:ss format#SBATCH --output=%N-%j.out # %N for node name, %j for jobID#SBATCH --account=def-razoumov-acsrun ./gpu_program
WestGrid Webinar 2018-Sep-19 36 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Scheduler: interactive jobs
$ salloc --time=1:0:0 --ntasks=2 # submit a 2-core interactive job for 1h$ echo $SLURM_... # can check out Slurm environment variables$ ./serial # this would be a waste: we have allocated 2 cores$ srun ./mpi # run an MPI code, could also use mpirun/mpiexec$ exit # terminate the job
Should automatically go to one of the Slurm interactive partitions
$ sinfo -a | grep interac
Useful for debugging or for any interactive work, e.g., GUI visualizationI interactive CPU-based ParaView client-server visualization on Cedar and Grahamhttps://docs.computecanada.ca/wiki/Visualization
I we use salloc in our hands-on Chapel course
Make sure to only run the job on the processors assigned to your job – this willhappen automatically if you use srun, but not if you just ssh from the headnode
WestGrid Webinar 2018-Sep-19 37 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Slurm jobs and memory
It is very important to specify memory correctly!
If you don’t ask for enough, and your job uses more, your job will be killed
If you ask for too much, it will take a much longer time to schedule a job, and youwill be wasting resources
If you ask for more memory than is available on the cluster your job will never run;the scheduling system will not stop you from submitting such a job or even warnyou
I always ask for slightly less than total memory on a node as some memory is used for theOS, and your job will not start until enough memory is available
Can use either #SBATCH --mem=4000 or #SBATCH --mem-per-cpu=2000
What’s the best way to find your code’s memory usage?
WestGrid Webinar 2018-Sep-19 38 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Slurm jobs and memory (cont.)
Second best way: use Slurm command to estimate your completed code’s memoryusage
$ sacct -j jobID [--format=jobid,maxrss,elapsed]# list resources used by a completed job
Use the measured value with a bit of a cushion, maybe 15-20%
Be aware of the discrete polling nature of Slurm’s measurementsI sampling at equal time intervals might not always catch spikes in memory usageI sometimes you’ll see that your running process is killed by the Linux kernel (via
kernel’s cgroups https://en.wikipedia.org/wiki/Cgroups) since it has exceeded itsmemory limit but Slurm did not poll the process at the right time to see the spike inusage that caused the kernel to kill the process, and reports lower memory usage
I sometimes sacct output in the memory field will be empty, as Slurm has not had timeto poll the job (job ran too fast)
WestGrid Webinar 2018-Sep-19 39 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Why is my job not running?
In no particular order:
(1) Other jobs have greater priority
(2) There is a problem with the job / resources are not available
I resources do not exist on the cluster?I did not allow for OS memory (whole-node runs)?
(3) The job is blocked
I disk quota / other policy violation?I dependency not met?
(4) There is a problem with the scheduling system or clusterI most frequent: someone just submitted 10,000 jobs via a script, then cancelled them, then
resubmitted them, rendering Slurm unresponsive for a while, even if resources areavailable for your job right now
WestGrid Webinar 2018-Sep-19 40 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Best practices
WestGrid Webinar 2018-Sep-19 41 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Best practices: computing
Production runs: only on compute nodes via the schedulerI do not run anything intensive on login nodes or directly on compute nodes
Only request resources (memory, running time) neededI with a bit of a cushion, maybe 115-120% of the measured valuesI use Slurm command to estimate your completed code’s memory usage
Test before scalingI small tests Ok on login nodesI larger tests on “interactive” nodes (requested with salloc)I test parallel scaling (frequently big surprises!)
For faster turnaround for larger jobs, request whole nodes (--nodes=...) and shortruntimes (--time=...)
I by-node jobs can run on the “entire cluster” partitions, as opposed to smaller partitions for longerand “by-core” jobs
Do not run unoptimized codes (use compilation flags -O2 or -O3 if needed)
Be smart in your programming language choice, use precompiled libraries
WestGrid Webinar 2018-Sep-19 42 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Best practices: file systems
Filesystems in CC are a shared resource and should be used responsibly!
Do not store millions of small filesI organize your code’s outputI use tar or even better dar (http://dar.linux.free.fr, supports indexing, differential
archives, encryption)
Do not store large data as ASCII (anything bigger than a few MB): waste of diskspace and bandwidth
I use a binary formatI use scientific data formats (NetCDF, HDF5, etc.): portability, headers, binary, compression, parallelI compress your files
Use the right filesystemLearn and use parallel I/OIf searching inside a file, might want to read it firstHave a backup planRegularly clean up your data in $SCRATCH, $PROJECT, possibly archive elsewhere
WestGrid Webinar 2018-Sep-19 43 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
Summary
WestGrid Webinar 2018-Sep-19 44 / 46
Hardware Connecting Environment Transfer Jobs Best practices Summary
Documentation and getting help
Official documentation https://docs.computecanada.ca/wikiI https://docs.computecanada.ca/wiki/Niagara_QuickstartI https://docs.computecanada.ca/wiki/Running_jobs
WestGrid training materialshttps://westgrid.github.io/trainingMaterials
Compute Canada Getting started videos http://bit.ly/2sxGO33
Compute Canada YouTube channel http://bit.ly/2ws0JDC
Email [email protected] (goes to the ticketing system)I try to include your full name, CC username, institution, the cluster name, copy and
paste as much detail as you can (error messages, jobID, job script, software version)
Please get to know your local supportI difficult problems are best dealt face-to-faceI might be best for new users
WestGrid Webinar 2018-Sep-19 45 / 46

Hardware Connecting Environment Transfer Jobs Best practices Summary
WestGrid workshops this fallUp-to-date schedule at https://westgrid.github.io/trainingMaterials
WestGrid Webinar 2018-Sep-19 46 / 46