hpe reference architecture for migration from a ... · hpe reference architecture for migration...
TRANSCRIPT

HPE Reference Architecture for migration from a traditional Hadoop architecture to an HPE Workload and Density Optimized solution Deployed on Hortonworks Data Platform (HDP 2.6)
Reference Architecture

Reference Architecture
Contents Executive summary ................................................................................................................................................................................................................................................................................................................................ 3 Solution overview ..................................................................................................................................................................................................................................................................................................................................... 4 Solution components ............................................................................................................................................................................................................................................................................................................................ 5
Hardware ................................................................................................................................................................................................................................................................................................................................................... 5 Software ..................................................................................................................................................................................................................................................................................................................................................... 7
Best practices and configuration guidance for the solution ............................................................................................................................................................................................................................. 7 Procedures used in the various migration scenarios ........................................................................................................................................................................................................................................ 8 Steps for migration scenarios ............................................................................................................................................................................................................................................................................................. 14
Capacity and sizing ............................................................................................................................................................................................................................................................................................................................ 16 Workload description ................................................................................................................................................................................................................................................................................................................. 16 Analysis and recommendations ....................................................................................................................................................................................................................................................................................... 17
Summary ...................................................................................................................................................................................................................................................................................................................................................... 17 Appendix A: Bill of materials ...................................................................................................................................................................................................................................................................................................... 18 Resources and additional links ................................................................................................................................................................................................................................................................................................ 21

Reference Architecture Page 3
Executive summary As companies grow their big data implementations, they often find themselves deploying multiple clusters to support their business needs. This could be to support different big data environments, such as MapReduce, Spark, NoSQL, etc., rigid workload partitioning for departmental requirements, or simply as a product of multi-generational hardware. These multiple clusters often lead to data duplication and movement of large amounts of data between systems to accomplish the organization’s business requirements.
The HPE Elastic Platform for Big Data Analytics (EPA), is designed as a modular infrastructure to address the need for a scalable multi-tenant platform, by enabling independent scaling of compute and storage while also providing a model which scales compute and storage together through infrastructure building blocks that are optimized for density and workloads.
Hewlett Packard Enterprise supports two different deployment models under this platform:
• HPE Balanced and Density Optimized system (BDO) – Supports conventional Hadoop deployments that scale compute and storage together, with some flexibility in choice of memory, processor, and storage capacity. This is primarily based on the HPE ProLiant DL380 server platform, with density optimized variants using HPE Apollo 4200 server platforms.
• HPE Workload and Density Optimized system (WDO) – Harnesses the power of faster Ethernet networks that enables a building block approach to independently scale compute and storage and lets you consolidate your data and workloads growing at different rates. The HPE WDO system is based on the HPE Apollo 4200 storage block and the HPE Apollo 2000 compute block, and combines them with Hadoop YARN’s features for resource scheduling using containers and labels on the Hortonworks Data Platform to enable a scalable multi-tenant Hadoop platform.
For an in-depth analysis of the Hewlett Packard Enterprise architecture for scalable and shared enterprise analytics platforms, and the benefits of separating compute and storage, review the HPE Elastic Platform for Big Data Analytics technical white paper at, http://h20195.www2.hpe.com/V2/GetDocument.aspx?docname=4AA6-8931ENW.
Organizations that have already invested in balanced symmetric configurations, like the HPE EPA BDO, have the ability to repurpose nodes from the existing deployments into the more elastic platform, the WDO. This can help address scenarios where customers are looking to expand analytics capabilities by growing compute and/or storage capacity independently, without building a new cluster, but rather by adding nodes where needed and changing which Hadoop services are running on the various nodes.
This white paper demonstrates the value of HPE EPA WDO as compared to HPE EPA BDO using performance testing for a mixed workload scenario. The goal of the testing is to showcase the value of moving to HPE EPA WDO from HPE EPA BDO as customers add more workloads and want to leverage a common data pool. Testing was done by running a multi-tenant workload including several benchmarks running MapReduce and Spark applications, along with several query streams running against Hive 2.0’s Low Latency Analytical Processing (LLAP). Results show that the HPE EPA WDO configuration completed 2.0 times the number of test iterations, on the average for each workload, while costing 50% more than the HPE EPA BDO configuration. This gives a relative price/performance comparison of the HPE EPA WDO to be 75% of that of the HPE EPA BDO.
Although similar results may be obtained with different hardware combinations to meet particular business needs, the Hadoop cluster built for the testing in this paper utilized the Apollo 2000 systems with HPE ProLiant XL170r Gen9 servers for compute nodes and the HPE Apollo 4200 Gen9 servers for the storage nodes. This was compared to a Hadoop cluster built on HPE ProLiant DL380 Gen9 servers as worker nodes.
Key point Hortonworks HDP 2.6 and Red Hat® Enterprise Linux® (RHEL) 7.3 were used in this particular testing scenario. However, similar configuration and results can be expected when using other Hadoop distributions such as Cloudera or MapR.
Target audience: This paper is directed toward decision makers, system and solution architects, system administrators and experienced users that are interested in simplifying the transition between more traditional deployments of Hadoop to the more elastic HPE EPA WDO system. An intermediate knowledge of Apache Hadoop is recommended.
Document purpose: The purpose of this document is to describe how to migrate from a traditional Hadoop cluster to the HPE Elastic Platform for Big Data Analytics’ highly scalable HPE EPA WDO system, and how to size the new cluster appropriately based upon current cluster usage.

Reference Architecture Page 4
The testing for this paper was performed in July 2017.
Solution overview Customers who already have a significant investment into the HPE EPA BDO system and are experiencing a need for the more elastic and flexible architecture of the HPE EPA WDO system have several choices in how to implement an HPE EPA WDO system. Some of these methods could utilize nodes in their existing configurations to facilitate this migration. This is due to the flexibility of the HPE ProLiant DL380 Gen9 server platform that is used in the HPE EPA BDO system and the openness of the architecture of the HPE EPA WDO system.
There are three main scenarios where customer big data solutions could find that migrating from the HPE EPA BDO architecture to the HPE EPA WDO architecture is a better alternative.
1. Current cluster is demanding more storage capacity, but has plenty of compute resources available for the workloads. When a cluster’s HDFS free space is nearly exhausted and the worker nodes have no more available drive bays to add more disks to, it is time to add more nodes to the cluster. However CPU usage history indicates that the current processing power has plenty of free cycles (idle time), it is time to consider the advantages of adding one or more storage blocks to the cluster in order to increase the HDFS free space at a lower cost per terabyte added.
2. Current cluster is demanding more compute resources, but has plenty of storage resources and capacity for the workloads. When a cluster is consistently running applications utilizing the processors at or near their maximum capacity, it is time to add more nodes to the cluster. However, when HDFS usage history does not indicate that the current disk capacity is require more space to be added, it is time to consider the advantages of adding one or more compute blocks to the cluster in order to increase processing capacity of the cluster without the additional costs of adding unnecessary storage.
3. Multiple clusters are currently duplicating the data used, amongst each other. In a situation where multiple clusters are built and they have a common data set, and a significant portion of time is spent copying and verifying the data is consistent data between the clusters, it is time to consider migrating these multiple clusters into a single cluster which shares storage blocks between them.
For each of these scenarios, this paper will overview the steps to migrate from HPE EPA BDO cluster(s) to an HPE EPA WDO cluster.
The paper will then demonstrate the value of running multiple workloads on a single HPE EPA WDO cluster, through a multi-tenant workload test that exercises three main components of the Hadoop eco system simultaneously. The three components exercised include MapReduce, Spark and Hive services, with multiple workloads running simultaneously for each component.

Reference Architecture Page 5
Solution components Hardware Customers migrating from an HPE EPA BDO solutions will likely already be familiar with the HPE ProLiant DL360 and HPE ProLiant DL380 servers, and/or possibly the HPE Apollo 4200 server which is also used in some HPE EPA BDO configurations. The HPE EPA WDO solutions require a familiarity to the HPE Apollo 2000 and 4000 systems. Please reference the HPE Elastic Platform for Big Data Analytics white paper, which contains detailed information on the various components used in each solution.
In all of the migration scenarios it is assumed that there is already a configuration to migrate from. For the purposes of this white paper, the starting scenario is an HPE EPA BDO solution running Hortonworks HDP 2.6, consisting of 9x HPE ProLiant DL380 Gen9 systems where each node is configured as shown in Figure 1 below.
Figure 1. Starting HPE EPA BDO configuration

Reference Architecture Page 6
In the various migration scenarios it is assumed that either the compute or the storage resources are insufficient for future needs, and as such the above resources are not enough to get the job done. So the final solution will add additional resources beyond the existing BDO cluster defined above. As such the final HPE EPA WDO configuration used in this testing consisted of the components shown in Figure 2.
Figure 2. Final HPE EPA WDO configuration.
The ending solution for our scenario has three additional nodes of compute power (12 vs. 9), moves from 10Gb networking to 25Gb networking and increases the HDFS storage capacity by about 10% (HPE EPA BDO has 405 TB of raw storage, and HPE EPA WDO has 448 TB of raw storage).

Reference Architecture Page 7
Software Hortonworks Data Platform (HDP 2.6) was used for the testing documented in this paper. The concepts and relative performance expectations should be consistent with other Hadoop distributions. The Hadoop features implemented and utilized for this test include:
• HDFS (version 2.7.3) – Hadoop Distributed File System which distributes the data to all the DataNodes.
• YARN (version 2.7.3) – Yet Another Resource Negotiator which distributes the tasks to the NodeManagers.
• Hive (version 2.1.0) – Data warehouse software project build on Hadoop.
– Tez (version 0.7.0) engine
– LLAP or Low Latency Analytical Processing
LLAP combines persistent query servers and optimized in-memory caching that allows Hive to launch queries instantly and avoids unnecessary disk I/O. LLAP brings compute to memory, it caches memory intelligently and it shares this data among all clients, while retaining the ability to scale elastically within a cluster. LLAP has been shown to increase performance dramatically, by running queries up to 7.8 times faster than running Hive on Tez without LLAP features. See the following blog for details: (BI Acceleration: Hortonworks HDP 2.6 HIVE with LLAP - opening up new possibilities in EDW )
• SPARK (version 2.1.0) -- Another fast and general usage-engine for large scale data processing.
Best practices and configuration guidance for the solution The migration process can take a couple of different forms. Either building a completely new HPE EPA WDO system from scratch, thereby freeing up the original HPE EPA BDO system’s hardware for other organizational purposes; or with the addition of the more specialized node(s) from the HPE EPA WDO system suite to meet the growing demand of the storage or compute resource required, repurposing the existing nodes in the configuration. The complete replacement of the configuration with an HPE EPA WDO architecture is a pretty straightforward process. Simply buying a whole new setup, then after setup and configuration transferring the data over from the source Hadoop cluster(s) to the destination cluster. This could be done using a distributed copy utility like Apache Hadoop’s DistCp, which uses MapReduce to effect its distribution, error handling and recovery, and reporting. Even when building an entire new cluster, systems from the original cluster could be repurposed as edge nodes or possibly used in the new cluster in other ways, for example as an archival storage tier or as dedicated compute resources through the use of YARN labels and queues.
Whenever expanding a traditional Hadoop cluster with newer generation servers, this results in a heterogeneous cluster configuration with mixed performance characteristics. This creates challenges because Hadoop assumes a homogeneous environment. For example, speculative execution is a feature of Hadoop where a task that takes longer to finish than expected gets re-executed preemptively on a second node assuming the first may fail. Hadoop's homogeneity assumptions lead to incorrect and often excessive speculative execution in heterogeneous environments, and can even degrade performance below that obtained with speculation disabled. In some experiments, as many as 80% of tasks were speculatively executed. To alleviate this, HPE strongly encourages utilizing YARN labels in cases where the different compute nodes have greatly differing numbers of CPU and memory capabilities to avoid having Hadoop run speculative execution tasks on slower compute nodes. YARN labels are a feature which was introduced in Apache Hadoop 2.6. They were introduced to help manage different workloads and organizations in the same cluster as the business grows. Nodes can be grouped together into partitions by assigning them the same label. This partitioning allows isolation of resources among workloads or organizations.
In the case where you are building a completely new Hadoop cluster with new hardware, the migration stages are pretty straight forward. Going through the management tool for the distribution of your choice. It’s simply a matter of building up the new cluster with all the new host systems. Assigning the proper services to each host as needed. All this can be referenced in the various Big Data Reference Architecture papers found here hpe.com/info/bigdata-ra. Once the cluster is built the data can be migrated to the new cluster using tools similar to Apache Hadoop’s DistCp tool for the HDFS data.
The major difference between HPE EPA BDO architecture’s worker nodes and the HPE EPA WDO compute and storage nodes is that in the HPE EPA BDO each worker node is running both the NodeManager and the DataNode services. Therefore, the migration process from HPE EPA BDO to HPE EPA WDO architecture while repurposing some of the existing HPE EPA BDO worker nodes is a little more complex. No matter which migration scenario, the migration process will go through several procedures.

Reference Architecture Page 8
Procedures used in the various migration scenarios Adding new Configuragion Groups to cluster Since the cluster is going to have nodes with different hardware configurations (number of disk drives, amount of memory, etc.), it is a good idea to have Configuration Groups for each Hadoop service where there are nodes with different hardware configurations. The most critical configuration differences between nodes being the following:
HDFS DataNode Settings: dfs.datanode.data.dir: varies based upon number of disks in the node to be used by the HDFS DataNode service.
YARN NodeManager Settings: yarn.nodemanager.resource.memory.mb: varies based upon total memory in the nodes useable by the YARN NodeManager service.
yarn.nodemanager.resource.cpu-vcores: varies based upon total processor cores in the nodes useable by the YARN NodeManager service.
yarn.nodemanager.local-dirs: varies based upon number of disks in each node to be used by YARN NodeManager service for container working directories.
yarn.nodemanager.logs-dirs: varies based upon number of disks in each node to be used by YARN NodeManager service for container log output.
Each Hadoop service has its own Configuration Groups. Which can be accessed by selecting “Manage Config Groups” link on the Configs tab of the service. This is where the various Configuration groups are created and then the cluster hosts can be assigned to their Configuration Group. The Default group is the one to which all hosts are assigned, unless otherwise specified during the HDP installation. Figure 3 shows the Manage HDFS Configuration Groups wizard.
Figure 3. Configuration Group Management for Hadoop HDFS service

Reference Architecture Page 9
Figure 4 demonstrates how Ambari highlights configuration settings where multiple Configuration Groups have different values. This is also where configuration setting changes are made for the various Configuration Groups.
Figure 4. Ambari HDFS view showing multiple settings for different configuration groups (default and ‘Apollo 4200’)
Adding new nodes to cluster 1. For our testing purposes with Ambari this was done with the “Add Host Wizard” found under the Hosts tab, other Hadoop distributions have
a similar function in their management tools. In this wizard enter the new node names in the Target Hosts section, then go through the prompts registering the hosts.
Figure 5: Ambari Add Host Wizard

Reference Architecture Page 10
2. Following the registration process there will be a “Confirm Hosts” page. Here will be found any issues in the registration process for the given hosts. Along with a request to confirm before moving on.
.
Figure 6. Confirm Hosts page of Add Host Wizard
3. In figure 7, place the correct services on the new nodes.
a. Select the NodeManager check box for new nodes that are compute nodes.
b. Select the DataNode check box for new nodes that are storage nodes.
.
Figure 7. Assigning services to new nodes

Reference Architecture Page 11
4. Assign configuration groups to the new hosts, as seen in figure 8. If there are already multiple configuration groups in the cluster then simple select the configuration group that matches the new hosts.
Figure 8. Assigning Configuration groups to the new hosts.
5. Review the configuration before installation.
Figure 9. Review page of Add Host Wizard.

Reference Architecture Page 12
6. The Add Host Wizard will now begin to install and start the selected services on the new nodes. After completion of the installation a summary page will be seen.
Removing unwanted services from worker nodes Now that all the nodes have been added to the cluster and configured with the proper services based upon the node type, the next step is to remove any unwanted Hadoop services from the original worker nodes. This involves two steps.
1. Decommissioning the unwanted service(s) on the original worker nodes.
a. Decommission DataNode service from the worker nodes that will become compute nodes. This process is initiated by going to the Hosts tab and selecting the hosts on which you wish to decommission the service. Then select Actions -> Selected Hosts -> the desired service to decommission (either NodeManager or DataNode) -> Decommission (see Figure 10), or by selecting the dropdown arrow next to the DataNode service on the host screen in Ambari and selecting decommission. During the decommissioning process the HDFS data replicas are migrated to other DataNode(s) in the cluster. Wait for the status to change from “decommissioning”. Another indicator is the number of Under Replicated Blocks will be quite large while any DataNode services are being decommissioned.
Figure 10. Decommissioning service from a group of nodes from the Hosts tab.
Reference Architecture Page 13
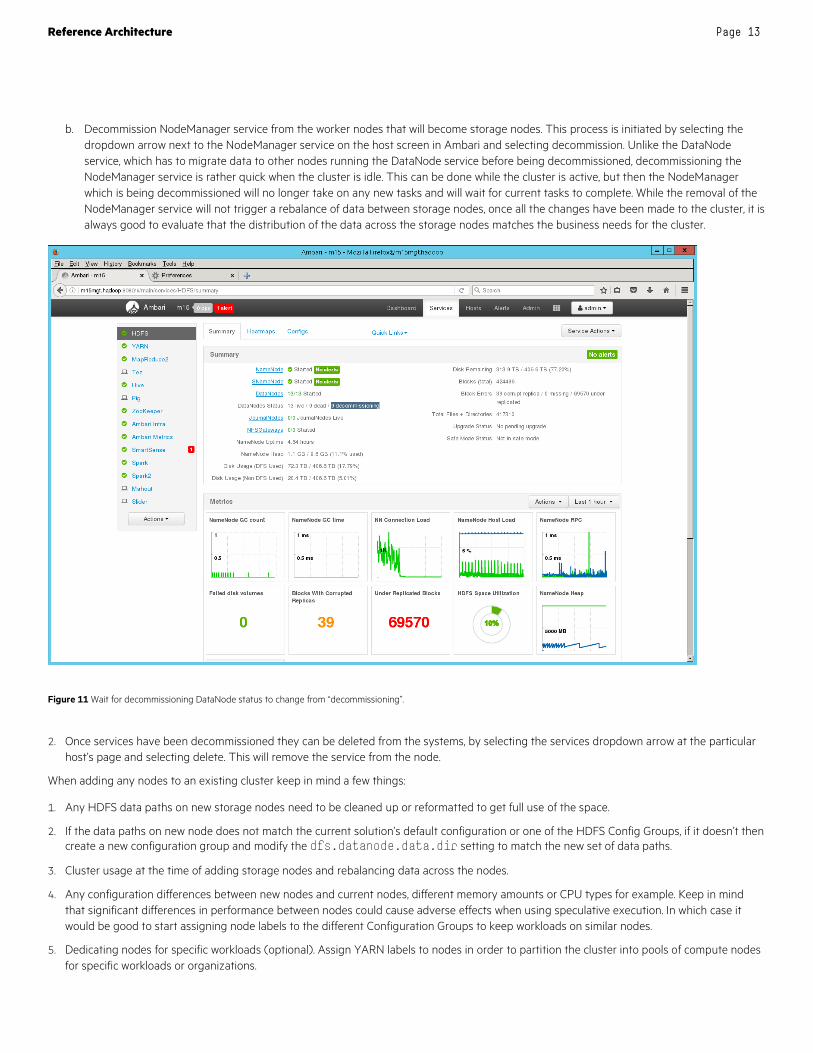
b. Decommission NodeManager service from the worker nodes that will become storage nodes. This process is initiated by selecting the dropdown arrow next to the NodeManager service on the host screen in Ambari and selecting decommission. Unlike the DataNode service, which has to migrate data to other nodes running the DataNode service before being decommissioned, decommissioning the NodeManager service is rather quick when the cluster is idle. This can be done while the cluster is active, but then the NodeManager which is being decommissioned will no longer take on any new tasks and will wait for current tasks to complete. While the removal of the NodeManager service will not trigger a rebalance of data between storage nodes, once all the changes have been made to the cluster, it is always good to evaluate that the distribution of the data across the storage nodes matches the business needs for the cluster.
Figure 11 Wait for decommissioning DataNode status to change from “decommissioning”.
2. Once services have been decommissioned they can be deleted from the systems, by selecting the services dropdown arrow at the particular host’s page and selecting delete. This will remove the service from the node.
When adding any nodes to an existing cluster keep in mind a few things:
1. Any HDFS data paths on new storage nodes need to be cleaned up or reformatted to get full use of the space.
2. If the data paths on new node does not match the current solution’s default configuration or one of the HDFS Config Groups, if it doesn’t then create a new configuration group and modify the dfs.datanode.data.dir setting to match the new set of data paths.
3. Cluster usage at the time of adding storage nodes and rebalancing data across the nodes.
4. Any configuration differences between new nodes and current nodes, different memory amounts or CPU types for example. Keep in mind that significant differences in performance between nodes could cause adverse effects when using speculative execution. In which case it would be good to start assigning node labels to the different Configuration Groups to keep workloads on similar nodes.
5. Dedicating nodes for specific workloads (optional). Assign YARN labels to nodes in order to partition the cluster into pools of compute nodes for specific workloads or organizations.

Reference Architecture Page 14
Steps for migration scenarios Current cluster demanding more storage capacity, but has plenty of compute resources There are several steps to the migration to HPE EPA WDO in the scenario where the current cluster is requiring an increase in storage capacity or throughput. The main decision that needs to be made before taking these steps is whether to keep the current nodes as worker nodes (i.e. running both NodeManager and DataNode services on them) or convert them to being compute nodes, as this will dictate the number of Apollo 4200 storage nodes needed.
1. Add sufficient Apollo 4200 storage nodes to the cluster to meet the storage requirements. Guidance on configuration and quantity of Apollo 4200 nodes can be found using the HPE EPA Sizing Tool.
2. Create an Apollo 4200 storage node configuration group to manage Hadoop HDFS configuration differences for Apollo 4200 storage nodes from the current worker nodes.
3. Do not add any Hadoop compute services to the Apollo 4200 storage nodes. The HDFS DataNode service is required for it to be a storage node, plus (optionally) any monitoring services such as the HST Agent (SmartSense) and Metrics Monitor (Ambari Metrics) services.
4. Remove the DataNode service from any of the current worker nodes that will be designated as compute only nodes. This is done by first decommissioning the DataNode service from the worker node. Then removing the DataNode service from the nodes.
5. Rebalance the I/O across all the DataNodes according to the needs of the new cluster. HDFS Rebalancer will rebalance the Data on nodes that have different amounts of data.
a. On each DataNode the default placement policy is round robin approach with all disks, if it is desired to take into account available space on each disk, then change:
dfs.datanode.fsdataset.volume.choosing.policy=org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
b. Verify that the following parameters to make sure they are set to desired levels of balanced behavior:
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold (default is 10737418240). This setting controls how much DataNode volumes are allowed to differ in bytes of free space before they are considered imbalanced. If all volumes’ free space are within this range of each other, the volumes will still be chosen in round robin fashion using all entries in the dfs.datanode.data.dir setting.
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction (default is 0.75). This setting controls what percentage of new block allocations will be sent to volumes with more available space than others.
c. Introduce HDFS Tiering and separate the different nodes to specific tiers (ARCHIVE, SSD, DISK, etc.).
d. Hadoop version 2.3 introduced HDFS tiering capabilities. This allows the administrator to dedicate certain HDFS data volumes for different workloads or organizational purposes. This is utilized in a three-step process. The first step is to assign a storage type to each storage location listed in assigning storage types the entries in the dfs.datanode.data.dir setting. This setting currently can be ARCHIVE, DISK, SSD, or RAM_DISK, the default being DISK if nothing is listed. The second step is to assign storage policies to HDFS directories that require specific storage requirements. The default storage policy will use all storage directories available in a round robin fashion. Other possible policy settings are shown in Table 1. The third step is to use the mover migration tool to move any existing data in the volume to the appropriate storage types for the policy setting for the given directory. This tool will try to move the replicas within the same node whenever possible, but if that is not possible then it will copy the block replicas to another node over the network.
Table 1. HDFS Storage tiering policy definitions
Policy Name Block Placement (n replicas) Fallback storages for creation Fallback storages for replication
Lazy_Persist RAM_DISK: 1, Disk: n-1 DISK DISK
ALL_SSD SSD: n DISK DISK
One_SSD SSD: 1, DISK: n-1 SSD, DISK SSD_DISK
Hot DISK: n <none> ARCHIVE
Warm Disk: 1, ARCHIVE: n-1 ARCHIVE, DISK ARCHIVE, DISK
Cole ARCHIVE: n <none> <none>

Reference Architecture Page 15
Current cluster is demanding more compute capacity, but has plenty of storage resources Key decisions to be made in the migration scenario where the current cluster is running out of compute capacity, but does not require more storage throughput or capacity include determining:
• Whether or not to convert the current worker nodes to storage nodes.
• Whether or not to introduce YARN labels and queues to dedicate nodes to specific workloads.
• If the network bandwidth on the current worker nodes sufficient to provide the data to the additional compute nodes.
1. If needed increase the network bandwidth by adding network ports and bonding them or upgrading the network cards and switches
2. Add sufficient Apollo 2000 Systems with HPE ProLiant XL170r Servers as compute nodes. HPE EPA Sizing Tool can be used to help determine quantity of Apollo 2000’s needed.
3. Do not and any Hadoop storage services (HDFS DataNode) to the new compute nodes.
4. Add YARN labels and queues to the Hadoop configuration to isolate workloads on specific compute nodes as desired.
Consolidating multiple clusters into single cluster Key decisions to be made in the migration scenario where consolidating multiple clusters into single HPE EPA WDO cluster include:
• The roles that the systems in the current clusters will have in the consolidated cluster.
• The roles that will require new resources that don’t exist in the current clusters.
• Introduction of new features such as HDFS Tiering and YARN labels.
• Determining the required network bandwidth for the consolidated cluster’s DataNodes to provide data to its compute nodes.
1. Determine which current cluster to use as the base cluster. It is probably best to use the cluster that has the most data as the base cluster as this would require less copying of data between the clusters.
2. Upgrade network throughput for nodes, by adding network ports to current bonds, or by upgrading network cards and switches as needed.
3. Make config groups for the Hadoop services that will have multiple types of nodes in the consolidated cluster.
4. Add sufficient Apollo 4200 Servers as DataNodes to base cluster to hold existing data from all clusters. (Introducing any HDFS tiering storage types and policies at this time).
5. Copy the data from the other clusters over using distcp or some other data ingesting mechanism.
6. Add the nodes from the other clusters, assigning them the roles determined earlier.
7. Rebalance the I/O across all the DataNodes according to the needs of the new cluster.
a. HDFS Rebalancer will rebalance the Data on nodes that have different amounts of data. On each DataNode the default placement policy is round robin approach with all disks, if it is desired to take into account available space on each disk, then change:
dfs.datanode.fsdataset.volume.choosing.policy=org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy
b. Verify the following parameters to make sure they are set to desired levels of balanced behavior:
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold (default is 10737418240).
This setting controls how much DataNode volumes are allowed to differ in bytes of free space before they are considered imbalanced. If all volumes’ free space are within this range of each other, the volumes will still be chosen in round robin fashion.
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction (default is 0.75). This setting controls what percentage of new block allocations will be sent to volumes with more available space than others.
8. Implement any HDFS tiering as needed to dedicate workloads to specific HDFS volumes as desired.
9. Implement any YARN labels and queues to isolate workloads to specific compute nodes as desired.

Reference Architecture Page 16
Capacity and sizing There are two main concerns with capacity planning for determining the number of storage nodes required:
1. The overall capacity for the data storage.
2. The overall I/O throughput required to bring the data to compute nodes.
Keep in mind that with the HPE EPA WDO solution for Hadoop there are no local reads and writes. Every read and write to HDFS is going remotely. Therefore the total I/O throughput capacity of a storage node is limited by both the number of disk spindles in the node and the network bandwidth. So when sizing your storage nodes keep in mind the network throughput of the chosen network infrastructure, whether it be 10, 25, 40, or 100 Gb/second. As well as the I/O throughput for each spindle.
In raw capacity the Apollo 4200 Gen9 system is capable of holding a very large amount of storage. Having 28 drive bays each of which could have a capacity of up to 10TB, so the system could have up to 280TB in a single system. For determining the number of storage nodes needed besides raw capacity of the node, the other concern is the throughput that a node can generate. This will be dictated by the number of disk spindles and the number and speed of network ports. For example, if the average throughput of a disk drive is 100MB/s, then a single 10Gb/s network would be saturated by 10 disk drives, and dual 10Gb/s link would be saturated with 20 disk drives. Since the Apollo 4200 system can utilize up to 28 disk drives, to not have a network bottleneck the system will need to have a network pipe > 25Gb/s (25Gb ≈ 3125 MB/s)..
Compute node calculations are more workload dependent. This storage related work for the average Big Data workload consumes approximately 20% of the worker node processor capabilities. This allows for the number of compute nodes in the HPE EPA WDO to be 80% of the number of worker nodes in the HPE EPA BDO configuration to accomplish the same work. Since there are 9 worker nodes in the example HPE EPA BDO configuration, this would equate to either 7 or 8 nodes in the HPE EPA WDO configuration.
Much of this information is built into the HPE EPA Sizing Tool.
Workload description To stress the Hadoop cluster a test was designed that would represent multiple workloads running simultaneously. With the exception of the Hive/LLAP queries, the workloads listed below come from the HiBench suite. While the HiBench suite normally runs each workload one at a time, the scripts were modified such that all workloads are running simultaneously. The workloads exercised various components of the Hadoop ecosystem. Namely, MapReduce, SPARK, and Hive with LLAP. The tests that exercised these functions are the following:
MapReduce workloads • TeraSort (terasort): TeraSort is a standard benchmark created by Jim Gray. Its input data is generated by Hadoop TeraGen example program.
• Pi (pi): This workload estimates the value of pi using a quasi-Monte Carlo method, and is provided by the Hadoop examples. A purely computational application that uses very little network or I/O.
• GZip/GUnZip (gzip): This workload goes through iterations of compression and decompression of data files takes a set of input files and alternately compresses them and decompresses them using GZip algorithm. The data source for this benchmark is generated by the Hadoop TeraGen example program.
SPARK workloads • Naive Bayesian Classification (bayes): This workload benchmarks Naïve Bayesian (a popular classification algorithm for knowledge discovery
and data mining) classification implemented in Spark-MLLib examples. This workload uses the automatically generated documents whose words follow the Zipfian distribution. The dictionary used for text generation is also from the default Linux file /usr/share/dict/linux.words.
• WordCount (wordcount): This workload is a Spark application that counts the occurrences of each word in the input data.
• PageRank: This workload benchmarks PageRank algorithm implemented in Spark-MLLib/Hadoop, a search engine ranking benchmark, included in Pegasus 2.0 examples. The data source is generated from Web data whose hyperlinks follow the Zipfian distribution.
HIVE/LLAP • Using a decision support system model for a retail product supplier with a database size of approximately 10 TB.
• 20 queries run in each stream.
• 1 query stream per compute or worker node in cluster. All streams running simultaneously.
• To avoid having all the streams performing the same queries at the same time, the order of the 20 queries were randomized for each stream prior to starting the test.
Reference Architecture Page 17
Any data needed by each of the tests was generated before the 3 hour measurement period began. All of these tests were running in parallel and managed by the YARN ResourceManager. The performance runs were done over a 3 hour period and then counted only the number of iterations of each test that were fully completed before the end test time stamp.
In both the HPE EPA BDO and HPE EPA WDO configurations, the LLAP configuration was made to have a number of daemons equal to the number of NodeManagers running in the cluster (9 in HPE EPA BDO solution and 12 in HPE EPA WDO solution) along with 1/3 of the total memory and processors allocated to YARN for each NodeManager, leaving the rest of the memory and processors for YARN to control for the MapReduce and Spark jobs.
Analysis and recommendations Through the testing done, it has been determined that an HPE EPA WDO configuration running on Apollo 2000 systems with 8x HPE ProLiant XL170r is slightly better than the same workload running on an HPE EPA BDO solution running on 9x DL380 Gen9 Servers. As a result of testing, the comparable amount of work done on an HPE EPA WDO solution with 12x HPE ProLiant XL170r Gen9 servers as compute nodes and 4x Apollo 4200 servers running as storage nodes (both solutions had 3x DL380 Gen9 servers for Management and Head nodes.), the HPE EPA WDO solution finished on average about 2.0 times the number of test iterations for each test as measured during a 3 hour period. The cost of the HPE EPA WDO solution is 1.5 times the cost of the HPE EPA BDO system. This yields a relative price/performance number of 75% for HPE EPA WDO compared to HPE EPA BDO.
Table 2. Comparison of HPE EPA BDO and HPE EPA WDO solutions running parallel workloads for 3 hours.
Since the HPE ProLiant XL170r Gen9 and the HPE ProLiant DL380 Gen9 systems were configured with the same amount of memory and processing capabilities the different workloads were spread evenly across all worker nodes or compute nodes in the cluster. If desired, the system architect could introduce YARN node labels and queues to dedicate specific nodes to specific workloads and thereby introduce more customized nodes for each workload, possibly saving on memory and/or processor costs on nodes dedicated to workloads that are less memory and processor intensive.
Similarly, the system architect could reintroduce some of the HPE EPA BDO worker nodes as specialized storage nodes dedicated to different HDFS storage tiers. For instance the nodes could be repopulated with SSDs or large capacity disk drives and be classified in HDFS as an SSD or ARCHIVE storage type.
Summary HPE Workload and Density Optimized system (HPE EPA WDO) enables a building block approach to independently scale compute and storage and lets you consolidate your data and workloads growing at different rates. This system couples compute and storage blocks with Hadoop features for resource scheduling using containers and labels on the Hortonworks Data Platform to enable a scalable multi-tenant Hadoop platform. With the test results achieved for this white paper, Hewlett Packard Enterprise demonstrates the value of HPE EPA WDO when running multiple workloads simultaneously. By completing 2.0 times the number of test iterations, on the average for each workload, while costing 50% more than the HPE EPA BDO configuration, the HPE EPA WDO has a relative price/performance comparison point of 75% of that of the HPE EPA BDO.
Whether due to unequal growth in compute and storage needs of an existing cluster, or the consolidation of multiple clusters, organizations can migrate to an HPE EPA WDO configuration frequently repurposing nodes from the existing deployments. This can help address scenarios where customers are looking to expand analytics capabilities by growing compute and/or storage capacity independently, without building a new
Workload Iterations Completed for HPE EPA BDO Iterations Completed for HPE EPA WDO HPE EPA WDO Times Higher than HPE EPA BDO
GZip/GUnZip 9 17 1.9
Pi 24 59 2.5
Spark Bayes 28 77 2.8
Spark PageRank 5 10 2.0
Spark WordCount 22 37 1.7
Terasort 14 24 1.7
Queries 524 707 1.3
Average for Workloads 2.0

Reference Architecture Page 18
cluster, but rather by adding nodes where needed and changing which Hadoop services are running on the nodes. This migration process enables organizations to transition to the HPE EPA WDO which may reduce the data center footprint, and operating costs, while optimizing resource usage and more efficiently manage the exploding growth of big data.
Appendix A: Bill of materials The BOMs outlined in the following tables below are based upon the HPE EPA WDO system single rack reference architecture with the following key components:
• One HPE EPA control block
• Three HPE EPA Apollo 2000 compute blocks
• Four HPE EPA Apollo 4200 storage blocks
• One HPE EPA WDO Network block (using two HPE FlexFabric 5950 Switches which is 1U 32-port 100GbE QSFP28 Switch in the IRF instead of the FlexFabric 5940 switches)
• HPE EPA Rack block
• Software Licenses
Note Part numbers are at time of publication/testing and subject to change. The bill of materials does not include complete support options or other rack and power requirements. If you have questions regarding ordering, please consult with your HPE Reseller or HPE Sales Representative for more details. hpe.com/us/en/services/consulting.html
Table A-1. Bill of materials for an HPE EPA Control block which consists of three servers, one as a Management node and two as Head Nodes. There was one of these blocks in the final HPE EPA WDO configuration.
Qty Part Number Description
3 755258-B21 HPE DL360 Gen9 8SFF CTO Server
6 720620-B21 HPE 1400w fs Plat Pl Ht Plg Pwr Spply Kit
3 818176-L21 HPE DL360 Gen9 E5-2640v4 FIO Kit
3 818176-B21 HPE DL360 Gen9 E5-2640v4 Kit
3 764642-B21 HPE DL360 Gen9 2P LP PCIe Slot CPU2 Kit
24 836220-B21 HPE 16GB 2Rx4 PC4-2400T-R Kit
3 817749-B21 HPE Eth 10/25Gb 2P 640FLR-SFP28 Adptr
3 749974-B21 HPE Smart Array P440ar/2G FIO Controller
24 785069-B21 HPE 900GB 12G SAS 10K 2.6in SC ENT HDD
3 764757-B21 HPE DL360-Gen9 Loc Disc Svc Ear Kit
3 734807-B21 HPE 1U SFF Easy Install Rail Kit
6 SG508A HPE C13-C14 4.5ft Sgl Data Special
6 AF595A HPE 3.0M, Blue, CAT6 STP, Cable Data
3 764646-B21 HPE DL360 Gen9 Serial Cable
3 764636-B21 HPE DL360 Gen9 SFF Sys Insght Dsply Kit
6 JL295A HPE X240 25G SFP28 to SFP28 3m DAC
3 U7AL9E HPE 3Y FC 24x7 DL360 Gen9 SVC

Reference Architecture Page 19
Table A-2. Bill of materials for an HPE EPA Apollo 2000 compute block. There were 3 of these blocks used in the final HPE EPA WDO configuration.
Qty Part Number Description
1 798153-B21 HPE Apollo r2600 24SFF CTO chassis
4 798155-B21 HPE ProLiant XL170r Gen9 CTO Svr
2 720620-B21 HPE 1400 FS Plat Ht Plug Power Supply Kit
4 850314-L21 HPE XL170r Gen9 E5-2680v4 FIO Kit
4 798178-B21 HPE XL170r/190r LP PCIex16 L Riser Kit
4 798180-B21 HPE XL170r FLOM x8 R Riser Kit
4 850314-B21 HPE XL170r Gen9 E5-2680v4 Kit
64 836220-B21 HPE 16GB 2Rx4 PC4-2400T-R Kit
4 817749-B21 HPE Eth 10/25Gb 2P 640FLR-SFP28 Adptr
8 872348-B21 HPE 960GB SATA 6G MU 2.5in SC DS SSD
4 844540-B21 HPE XL170r Gen9 NGFF 120Gx2 Riser Drive
4 800060-B21 HPE XL170r Mini-SAS B140 Cbl Kit
2 800059-B21 HPE ProLiant XL170r Gen9 FAN-module Kit
1 740713-B21 HPE t2500 Strap Shipping Bracket
4 798192-B21 HPE XL170r/190r Dedicated NIC IM Board Kit
4 AF595A HPE 3.0M, Blue, CAT6 STP, Cable Data
1 822731-B21 HPE 2U Shelf-Mount Adjustable Rail Kit
8 JL295A HPE X240 25G SFP28 to SFP28 3m DAC
4 U8AW0E HPE 3y FC 24x7 Apollo 2000 SVC
Table A-3. Bill of materials for an HPE EPA Apollo 4200 storage block. There were 4 of these blocks used in the in the final HPE EPA WDO configuration.
Qty Part Number Description
1 808027-B21 HPE Apollo 4200 Gen9 24LFF CTO Svr
2 720620-B21 HPE 1400 FS Plat Ht Plug Power Supply Kit
1 830736-L21 HPE Apollo 4200 Gen9 E5-2660v4 FIO Kit
1 806562-B21 HPE Apollo 4200 Gen9 Redundant Fan Kit
1 830736-B21 HPE Apollo 4200 Gen9 E5-2660v4 Kit
8 836220-B21 HPE 16GB 2Rx4 PC4-2400T-R Kit
1 817749-B21 HPE Eth 10/25Gb 2P 640FLR-SFP28 Adptr
1 806563-B21 HPE Apollo 4200 G9 LFF Rear HDD Cge Kit
28 861683-B21 HPE 4TB 6G SATA 7.2K 3.5in MDL LP HDD
1 878783-B21 HPE Universal SATA HH M.2 Kit
2 875488-B21 HPE 240GB SATA MU M.2 2280 DS SSD
1 822731-B21 HPE 2U Shelf-Mount Adjustable Rail Kit
2 AF595A HPE 3.0M, Blue, CAT6 STP, Cable Data
1 813546-B21 HPE SAS Controller Mode for Rear Storage
1 806565-B21 HPE Apollo 4200 Gen9 IM Card Kit
2 JL295A HPE X240 25G SFP28 to SFP28 3m DAC
1 U8MH3E HPE 3Y FC 24x7 Apollo 4200 SVC

Reference Architecture Page 20
Table A-4. Bill of materials for the HPE EPA WDO network block used in the final HPE EPA WDO configuration.
Qty Part Number Description
2 JH402A HPE FF 5950 48SFP28 8QSFP28 Switch
2 845406-B21 HPE 100Gb QSFP28 to QSFP28 3m DAC Cable
4 JC680A HPE 58x0AF 650W AC Power Supply
10 JH389A HPE X712 Bck(pwr)-Frt(prt) HV2 Fan Tray
2 JL271A HPE X240 100G QSFP28 1m DAC Cable
1 JG510A HPE 5900AF-48G-4XG-2QSFP+ Switch
2 JC680A-B2B JmpCbl-NA/JP/TW
2 JC682A HPE 58x)AF Bck(pwr)-Frt(ports) Fan Tray
2 H5YQ7E HPE 3Y FC 24x7 FF48SFP28 8QSFP28 SwtcSVC
Table A-5. Bill of materials for the HPE EPA Rack block used in the final HPE EPA WDO configuration.
Qty Part Number Description
1 BW904A HPE 42U 600x1075mm Enterprise Shock Rack
1 BW946A HPE 42U Location Discovery Kit
1 BW930A HPE Air Flow Optimization Kit
1 TK817A HPE CS Rack Side Panel 1075mm Kit
1 TK816A HPE CS Rack Light Kit
1 TK815A HPE CS Rack Door Branding Kit
1 BW891A HPE Rack Grounding Kit
4 AF520A HPE Intelligent Mod PDU 24a Na/Jpn Core
6 AF547A HPE 5xC13 Intlgnt PDU Ext Bars G2 Kit
2 C7536A HPE Ethernet 14ft CAT5e RJ45 M/M Cable
Table A-6.Software Licenses (HPE iLO, HPE Insight CMU, RHEL O/S, and Hadoop for 3 years) needed for the final HPE EPA WDO configuration.
Qty Part Number Description
19 BD506A HPE iLO Adv incl 3yr TSU Flex Lic
19 BD476AAE HPE Insight CMU 3yr 24x7 Flex E-LTU
15 JP408AAE HDP Entpl 4N/50TB Rw Strg 1yr 24x7 E-LTU
19 G3J30AAE RHEL Svr 2 Sckt/2 Gst 3yr 24x7 E-LTU

Reference Architecture Page 21
Sign up for updates
© Copyright 2017 Hewlett Packard Enterprise Development LP. The information contained herein is subject to change without notice. The only warranties for Hewlett Packard Enterprise products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Hewlett Packard Enterprise shall not be liable for technical or editorial errors or omissions contained herein.
Red Hat and Red Hat Enterprise Linux Certified are trademarks of Red Hat, Inc. in the United States and other countries. Linux is the registered trademark of Linus Torvalds in the U.S. and other countries.
a00027171enw, October 2017
Resources and additional links HPE Reference Architectures, hpe.com/info/ra
HPE Hadoop Reference Architectures, hpe.com/info/bigdata-ra
HPE Servers, hpe.com/servers
HPE Storage, hpe.com/storage
HPE Networking, hpe.com/networking
HPE Technology Consulting Services, hpe.com/us/en/services/consulting.html
HPE EPA Sizing, https://www.hpe.com/h20195/v2/GetDocument.aspx?docname=a00005868enw
HPE Elastic Platform for Big Data Analytics, http://h20195.www2.hpe.com/V2/GetDocument.aspx?docname=4AA6-8931ENW
To help us improve our documents, please provide feedback at hpe.com/contact/feedback.