i circuiti sommatori - units.it · approccio (se vogliamo, a “reti iterative”), risulta...
TRANSCRIPT

1
I CIRCUITI SOMMATORI
In elettronica digitale, il poter sommare parole di N bits riveste un ruolo fondamentale. Occorrono
pertanto dei circuiti in grado di poter eseguire questa operazione, in maniera più o meno efficiente.
Si riporteranno dunque i passi da seguire (se vogliamo, con approccio “top-down” e sviluppo
“bottom-up”) per realizzare differenti architetture di sommatori.
Volendo realizzare un sommatore di 2 parole di N bits, la prima soluzione che salta in mente è
l’utilizzo di sottoblocchi elementari, collegati in maniera opportuna, ciascuno con il compito di
sommare tre bits: il sottoblocco i-esimo avrà cioè in ingresso il bit i-esimo di una parola, il bit i-
esimo dell’altra, ed il bit di carry generato dal sottoblocco (i-1)-esimo (si assume implicitamente in
posizione i=0 il sottoblocco adibito alla somma dei LSbs delle parole da sommare). Questo
approccio (se vogliamo, a “reti iterative”), risulta abbastanza intuitivo, dal momento che rispecchia
esattamente le operazioni compiute dall’uomo per svolgere, concettualmente in qualunque base di
numerazione, appunto una somma in colonna tra due numeri di N cifre ciascuno. Il sottoblocco in
posizione i=0 non necessiterebbe di alcun carry in ingresso, se considerato come primo stadio di
una catena a sé stante, tuttavia può esserne munito se si pensa a tale rete come un “macro-
sottoblocco” utilizzabile in una cascata più larga, dove ciascun elemento della cascata può essere a
sua volta un sottoblocco od un macro-sottoblocco. Analogamente, il riporto generato dall’ultimo
stadio potrebbe essere ignorato (poiché sarebbe l’(N+1)-esimo bit del risultato), utilizzato come
parte del risultato (se l’architettura finale prevede che il risultato sia in effetti ad N+1 bits),
utilizzato come bit di overflow (se invece l’architettura prevede un risultato di al massimo N bits), o
propagato ad altri sommatori in cascata.
Procedendo nella nostra analisi top-down, risulta a questo punto necessaria la definizione del
sottoblocco elementare, che somma 3 bits. Ma anch’esso può essere scomposto in due ulteriori
“celle”, la prima adibita alla somma di due soli bits (quelli i-esimi delle due parole da sommare,
senza carry in ingresso), la seconda adibita all’aggiunta, alla somma prodotta dalla cella precedente,
del carry in ingresso. Ripercorriamo a questo punto alla rovescia quanto detto finora, costruendo
dapprima le celle elementari, poi i sottoblocchi ed infine il primo tipo di sommatore.
Half-Adder (HA, semisommatore)
Denominato “cella” in precedenza, consente la somma di due bits. Di conseguenza sarà munito di
due ingressi “a linea singola” (A e B, i due bits da sommare), e di due uscite anch’esse ad un bit (S
e C, rispettivamente il risultato della somma ed il riporto da propagare a livello superiore). La sua
costruzione risulta semplice a partire dalla tavola di verità:
A B S C
0 0 0 0
0 1 1 0
1 0 1 0
1 1 0 1
da cui si ricavano le funzioni:

2
Lo schema elettrico del semisommatore risulta quindi:
Full-Adder (FA, sommatore con Carry-In)
Denominato “sottoblocco” in precedenza, estende la funzionalità dell’HA potendo sommare anche
un riporto in ingresso; questo lo rende (contrariamente al precedente) conglobabile all’interno di
una rete combinatoria iterativa per la somma di parole di N bits. Il FA avrà pertanto tre linee
d’ingresso da un bit ciascuna (A, B e Cin), e sempre due linee di uscita (S, Cout). La tavola di verità
risulta essere:
A B Cin S Cout
0 0 0 0 0
0 0 1 1 0
0 1 0 1 0
0 1 1 0 1
1 0 0 1 0
1 0 1 0 1
1 1 0 0 1
1 1 1 1 1
da cui si ricavano:
Una rapida occhiata mostra che S si ottiene con l’XOR tra il carry-in e il bit di somma tra A e B
(S’), mentre Cout si ottiene con un OR tra due bit di riporto (quello tra A e B, che chiamiamo C’, e
quello tra S’ ed il nuovo carry-in, che chiamiamo C). Ovvero il FA, come ci si poteva del resto
aspettare, è ottenibile utilizzando due HA, l’uno che somma A e B (e produce S’ e C’), l’altro che
somma S’ e Cin (e produce S e C). Cout risulta infine C’ + C. Lo schema elettrico risulta pertanto:
S’
C’

3
Sommatore Ripple-Carry (4-bit)
In questo documento si affronterà la costruzione di sommatori di parole ad N = 8 bits, seppure le
nozioni qui riportate sono facilmente espandibili a parole di lunghezza inferiore o superiore. Poiché,
nel terzo tipo di sommatore che vedremo (Carry-Select), ci ritorneranno utili dei blocchi in grado di
sommare parole di 4 bits, costruiremo dapprima tali blocchi.
Volendo sommare parole di 4 bits, occorreranno 4 FAs, ciascuno che somma i bits i-esimi delle due
parole. Il FA più significativo renderà disponibile l’ultimo riporto (il suo carry-out), mentre il FA
meno significativo potrà essere sostituito da un HA qualora non si preveda la possibilità che il
sommatore complessivo sia utilizzato all’interno di una cascata di sommatori Ripple-Carry. In
questo esempio utilizziamo un FA anche a livello meno significativo, ottenendo un sommatore che
(secondo la terminologia adottata in precedenza) potrebbe costituire un macro-sottoblocco
collegabile in cascata.
Lo schema elettrico del sommatore Ripple-Carry a 4 bits è il seguente:
1. Sommatore Ripple-Carry (8-bit) Facilmente ottenibile collegando in cascata due sommatori Ripple-Carry a 4 bits appena costruiti.
Questa possibilità ci viene direttamente fornita dall’aver previsto un ingresso carry-in nel Ripple-
Carry 4-bit. Lo schema elettrico risulta banale:
Si noti che, anche per il Ripple-Carry 8-bit, è stato previsto l’ingresso Cin. Quindi tale sommatore
potrebbe essere utilizzato per la realizzazione di sommatori per parole di più di 8 bits.
4
2. Sommatore Carry Look-Ahead (8-bit) Il sommatore Ripple-Carry, in teoria estendibile ad un qualsiasi numero di bits, è affetto da un
problema: la lentezza. Ciò è dovuto ai ritardi di propagazione dei riporti sulla catena del carry. Si
prenda ad esempio il Ripple-Carry ad 8 bits appena realizzato, e lo si veda in termini di sottoblocchi
elementari (FAs): il FA più significativo (i=7) è vero che riceverà quasi subito i due bits delle
parole da sommare A7 e B7, tuttavia il risultato della sua somma non potrà essere considerato
attendibile fino a quando a tale FA non giungerà anche il suo Cin, ovvero il riporto prodotto al
settimo stadio. Ovviamente tale riporto dovrà dapprima essere calcolato dal settimo stadio, che non
potrà farlo però fino a quando non avrà ricevuto il Cout prodotto dal sesto stadio, e via discorrendo
lungo la catena di FAs. Di conseguenza l’intero risultato della somma e l’ultimo riporto potranno
essere ritenuti validi solo dopo che ciascun FA avrà calcolato somma e riporto, e quest’operazione
diviene via via più lenta man mano che si procede verso il FA più significativo. I ritardi aumentano
con l’aumentare del numero di FAs, ovvero della lunghezza delle parole da sommare.
È possibile risolvere il problema della lentezza facendo in modo che ogni FA riceva il proprio
carry-in non dal FA precedente, bensì da una rete combinatoria che lo computa. Nasce, da questo
presupposto, il sommatore Carry Look-Ahead, un circuito la cui velocità di calcolo non solo è
estremamente elevata, ma risulta essere indipendente dalla lunghezza delle parole da sommare. Si
compone di due blocchi circuitali: una catena di FAs, che deve realizzare le somme, ed una rete
combinatoria, che deve calcolare i riporti da fornire ai FAs. Nel caso di N = 8 bits, sono necessari 8
FAs, pertanto il circuito complessivo del sommatore Carry Look-Ahead 8-bit risulta:
Le parole da sommare vengono sia cedute ai FAs, sia ad una logica di calcolo dei riporti. Tale
logica si serve dei bits di tali parole per “prevedere” i riporti da fornire a ciascun FA, prima che gli
stadi precedenti li calcolino. Si noti che infatti le uscite Cout dei vari FAs non sono utilizzate in
quest’architettura, mentre gli ingressi Cin prelevano i valori direttamente dalla logica LAC. Il FA
meno significativo chiaramente non ha bisogno di alcuna logica che ne calcoli l’ingresso Cin (esso
coincide con il bit da sommare alle due parole, non necessario ai fini della somma ma utile se si
volesse realizzare una cascata di sommatori, anche di differente architettura). Questo discorso è del
tutto identico a quello visto per il Ripple-Carry, ed anche in questo caso il carry-in del FA meno
significativo può benissimo non essere usato se non occorre (connettendolo a massa, od utilizzando
un HA al primo stadio). Non resta che analizzare la costruzione della logica LAC.
Fermiamo la nostra attenzione sul generico stadio i-esimo, dove per “stadio” intendiamo un singolo
FA con i suoi ingressi (Ai, Bi, Ciin
) e le sue uscite (Si, Ci). Il calcolo del riporto Ci da fornire allo
stadio (i+1)-esimo passa attraverso le due funzioni logiche “Generate” e “Propagate”.

5
Funzione “Generate”
È evidente che, quando entrambi Ai e Bi valgono 1, lo stadio i-esimo dovrà generare il riporto da
propagare allo stadio successivo. Ovvero se Ai = Bi = 1, indipendentemente dal valore di Ciin
(che
influisce solo sul termine Si) Ci deve valere 1. Se poi Ciin
vale 1, Si acquisirà valore 1, altrimenti Si
acquisirà valore 0. La funzione Generate indica pertanto quando lo stadio i-esimo genera esso
stesso il riporto da fornire allo stadio (i+1)-esimo, e vale:
Quando Gi = 1, dev’essere Ci = 1, cioè dev’essere fornito (indipendentemente dal valore di Ciin
) il
riporto allo stadio successivo.
Funzione “Propagate”
Quando Gi = 0, non è detto che non vi sia riporto da propagare allo stadio successivo. Supponiamo
infatti che uno fra Ai e Bi valga 1 (che entrambi valgano uno si può per ora escludere, poiché se così
fosse varrebbe 1 anche la Generate, ed in tal caso Ci può essere messo automaticamente ad 1). In
tale situazione, il riporto da fornire allo stadio (i+1)-esimo coincide con Ciin
. Infatti, se Ciin
vale 1, si
avrebbe Si = 0 e Ci = 1; viceversa, se Ciin
vale 0, si avrebbe Si = 1 e Ci = 0. La funzione Propagate
assume importanza dunque proprio nel caso esaminato, ovvero quando Ai oppure Bi valgono 1.
Essa risulta quindi:
La funzione Propagate segnala quando il riporto prodotto dallo stadio i-esimo non viene generato
da quest’ultimo, bensì da stadi precedenti, ed in tal caso viene propagato dallo stadio i-esimo verso
lo stadio successivo. Quando cioè Pi = 1, la funzione di propagazione è attiva, e dunque lo stadio i-
esimo fornirà come riporto allo stadio (i+1)-esimo quello che riceverà dallo stadio (i-1)-esimo.
Rimane da analizzare il caso in cui entrambi Ai e Bi valgono 0: in questa condizione, entrambe le
funzioni Generate e Propagate valgono 0. Ma questo ha un senso, perché in effetti se entrambi Ai e
Bi sono 0 il riporto Ciin
si esaurisce allo stadio i-esimo, ovvero nessun riporto dev’essere fornito allo
stadio successivo (Ci = 0).
Riassumendo, occorre per Ci un’equazione logica in grado di soddisfare le seguenti:
Ci deve valere 1 quando Gi vale 1;
Ci deve valere Ciin
quando Gi vale 0 e Pi vale 1;
Ci deve valere 0 quando entrambe Gi e Pi valgono 0.
In definitiva risulta:
(ricavabile banalmente dalle condizioni sopra riportate, o comunque mappandole su una tabella di
verità che esprima Ci in funzione di Gi, Pi, Ciin
).
Ricordando a questo punto che Ci è si il carry-out dello stadio i-esimo (da fornire allo stadio (i+1)-
esimo), ma coincide con il carry-in dello stadio (i+1)-esimo, l’espressione sopra può essere riscritta:
Riferendola allo stadio i-esimo, si perviene alla:
Infine, adottando la nomenclatura riportata nello schema circuitale del Carry Look-Ahead:
che determina il carry da fornire in ingresso allo stadio i-esimo.

6
La logica LAC deve dunque calcolare i vari riporti facendo uso iterativamente dell’espressione
sopra riportata, ovvero (ricordando che il carry-in del primo FA coincide con il Cin dell’intero
sommatore):
La struttura della logica LAC risulterebbe essere molto semplice se si sfruttassero le funzioni Ci-1in
ai livelli i-esimi. Tuttavia, tali funzioni non possono essere utilizzate, perché darebbero luogo a due
problemi di fondo:
1. sebbene il carry-in del livello i-esimo non dipenda più dal carry-out del livello (i-1)-esimo
(come accadeva nel Ripple-Carry), esso verrebbe a dipendere dal carry-in del livello (i-1)-
esimo, che dev’essere anch’esso calcolato con conseguente perdita di tempo per lo stadio i-
esimo;
2. i livelli di logica coinvolti nella funzione Cyi aumenterebbero di numero all’aumentare del
valore dell’indice i, con conseguente aumento del tempo di calcolo della funzione stessa. Ad
esempio, per N = 8, Cy1 = G0 + P0C0in
, e Cy7 = G6 + P6C6in
; si evince subito che la funzione
Cy7 necessita di maggior tempo di calcolo rispetto alla Cy1, dal momento che la prima deve
attendere il calcolo di C6in
= Cy6 , che a sua volta deve attendere il calcolo di Cy5, che a sua
volta deve attendere il calcolo di Cy4, … .
Entrambi i problemi possono essere risolti al prezzo di aumentare la complessità del circuito: è
sufficiente infatti, a livello i-esimo, non fare uso delle funzioni Ci-1in
fornite dai livelli precedenti,
bensì ricalcolarle tutte. Così facendo si ottengono le seguenti funzioni:
Sono tutte funzioni a due livelli di logica (3, se consideriamo anche il livello singolo delle funzioni
Generate e Propagate), pertanto sono estremamente veloci. Inoltre, le velocità di calcolo delle
funzioni Cyi si equivalgono, ovvero in prima approssimazione calcolare Cy1 richiede lo stesso
tempo necessario per il computo di Cy7 (poiché entrambe Cy1 e Cy7 sono funzioni a 3 livelli).
Tuttavia, la complessità della rete che realizza Cy7 è molto maggiore di quella che realizza Cy1;
infatti, Cy7 (per poter essere a 3 livelli di logica) richiede ben 7 porte AND ad ingressi via via
crescenti (da 2 fino a 8), ed una porta OR da 8 ingressi. La complessità delle reti coinvolte nel
calcolo dei riporti aumenta a dismisura con l’aumentare della lunghezza delle parole da sommare,
ma la velocità computazionale del sommatore Carry Look-Ahead si mantiene elevata ed è
indipendente da tale lunghezza. Ovvero, se vogliamo, il funzionamento è esattamente l’opposto di
quello del sommatore Ripple-Carry, dove all’aumentare di N aumentava la lentezza ma rimaneva
costante la complessità del circuito (peraltro estremamente bassa).
7
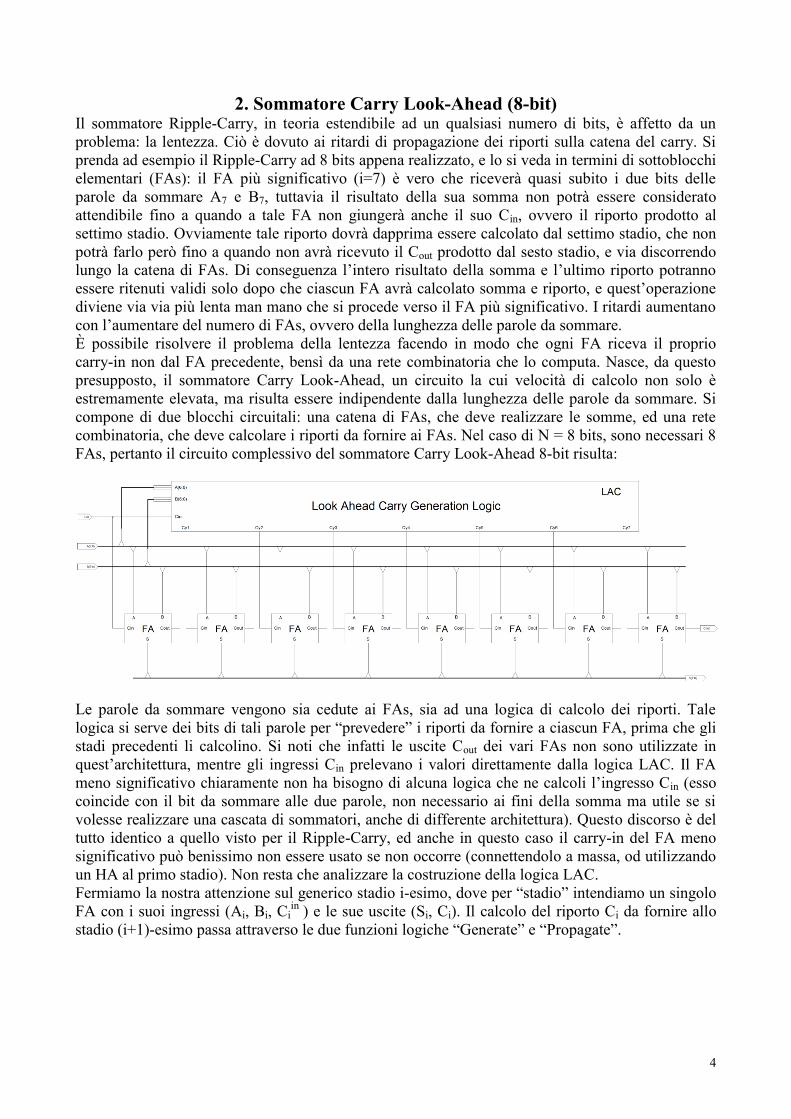
Giusto per dare un esempio, si riporta la rete per il calcolo di Cy1:
quella per il calcolo di Cy7:
G(6)
G(5)
P(6)
G(4)
P(5) P(6) G(3) P(4) P(5) P(6) G(2) P(3) P(4) P(5)
P(6) G(1) P(2) P(3)
P(4) P(5)
P(6) G(0) P(1) P(2) P(3) P(4)
P(5) P(6) P(0) P(1)
P(2) P(3) P(4) P(5) P(6)

8
la rete per il calcolo delle funzioni Generate e Propagate:
quindi la struttura interna della logica LAC:
Un’ultima considerazione a proposito del sommatore Carry Look-Ahead può essere fatta a
proposito di una possibile semplificazione delle reti combinatorie che costituiscono i Full Adders.
Tornando infatti alle funzioni Generate e Propagate:
(riferite allo stadio i-esimo), la funzione Gi si era detto indica se lo stadio genera o meno riporto, la
funzione Pi indica se lo stadio propaga o meno il riporto precedente. Ciò equivale a dire che la
funzione Generate vale 1 quando entrambi gli ingressi Ai e Bi del FA valgono 1, e la funzione
Propagate vale 1 quando o l’uno, o l’altro ingresso valgono 1. In realtà la tavola di verità per la
funzione Propagate risulta essere la seguente:
A(6)
B(6) G(6)
A(5)
B(5) G(5)
A(4)
B(4) G(4)
A(3)
B(3) G(3)
A(2)
B(2) G(2)
A(1)
B(1) G(1)
A(0)
B(0) G(0)
A(6)
B(6) P(6)
A(5)
B(5) P(5)
A(4)
B(4) P(4)
A(3)
B(3) P(3)
A(2)
B(2) P(2)
A(1)
B(1) P(1)
A(0)
B(0) P(0)

9
Ai Bi Pi
0 0 0
0 1 1
1 0 1
1 1 -
Notare la dcc nell’ultima riga della tabella: quando cioè entrambi gli ingressi del Full Adder
valgono 1, la funzione Propagate non ha alcuna importanza sul riporto da fornire allo stadio
successivo, in quanto in tali condizioni sarà già la funzione Generate a fornire il riporto, secondo la
formula già vista:
Dunque la funzione Propagate, in virtù della don’t care condition, può anche essere definita come:
non modificando in alcun modo il funzionamento della logica LAC descritta in precedenza. Il
vantaggio nell’utilizzare questa definizione della funzione Propagate risiede nel fatto che la
funzione XOR tra i due ingressi del Full Adder è già presente all’interno del FA stesso, e realizza la
somma dei due bits. Ciò, combinato alla rimozione della circuiteria necessaria al calcolo del riporto
nel FA (inutile, dal momento che i riporti sono calcolati dalla logica LAC), si traduce in una
semplificazione circuitale dei singoli Full Adders impiegati nella costruzione del sommatore:
Notare come la somma dei bits Ai e Bi assuma anche il ruolo della funzione Pi, e come il riporto
generato dal primo HA assuma anche il ruolo della funzione Gi. Entrambi somma e riporto possono
essere utilizzati direttamente all’interno della logica LAC, per il calcolo del riporto da fornire in
ingresso allo stadio successivo, secondo la formula vista in precedenza. La porta OR per il calcolo
del riporto in uscita dal FA è stata rimossa, ed inoltre (non servendo più neanche il bit di riporto in
uscita dal secondo HA) è possibile rimuovere la porta AND del secondo HA che calcola il bit C.
3. Sommatore Carry-Select (8-bit) Abbiamo visto come, se da un lato il sommatore Ripple-Carry è troppo lento per N grande, il
sommatore Carry Look-Ahead è troppo complesso. Il problema della lentezza o complessità può
essere aggirato limitando il numero di bits coinvolti nell’operazione di somma; ciò porrebbe un
vincolo alla massima lunghezza delle parole da sommare, e quindi si rende necessario l’impiego di
altre architetture.

10
Un buon compromesso tra lunghezza delle parole e ritardo dell’operazione (se cerchiamo di limitare
la lentezza di un sommatore Ripple-Carry) è raggiunto dal sommatore “Carry-Select”. Esso riduce
la lentezza di calcolo spezzando le parole di N bits in 2 parole più piccole (della dimensione M =
N/2), e fa uso complessivamente di tre sommatori Ripple-Carry ad M bits. Ciascun sottosommatore
risulta a questo punto più semplice (poiché dovrà sommare parole di lunghezza inferiore) e più
veloce (il ritardo del carry si propaga attraverso N/2 bits), ma come svantaggio si dovrà utilizzare
un sommatore in più rispetto a quelli strettamente necessari.
Infatti, non facendo uso di un terzo Ripple-Carry, gli altri due sarebbero comunque vincolati l’un
l’altro, nel senso che il sommatore per i MSbs dovrebbe aspettare il Cout prodotto dal sommatore per
i LSbs. L’aggiunta invece di un terzo Ripple-Carry permette l’elaborazione parallela dei MSbs e dei
LSbs, secondo questo criterio:
un Ripple-Carry viene utilizzato per sommare i LSbs, producendo i LSbs della somma ed un
riporto C che dovrà essere tenuto in considerazione al livello successivo;
un Ripple-Carry viene utilizzato per sommare, contemporaneamente al precedente, i MSbs
nell’ipotesi che C valga 0;
un Ripple-Carry viene utilizzato per sommare, contemporaneamente ai precedenti, i MSbs
nell’ipotesi che C valga 1;
occorre infine una sorta di “multiplexer vettoriale” che, in base al valore di C, scelga se
fornire come MSbs della somma e come ultimo riporto i bits prodotti dal secondo o dal terzo
Ripple-Carry.
Va precisato che i sottosommatori di cui si avvale il Carry-Select non devono essere
necessariamente dei Ripple-Carry. Nel caso siano tali, il Carry-Select riduce il problema della
lentezza, piuttosto che della complessità della rete. Nel caso invece che i sottosommatori siano
Carry Look-Ahead, il Carry-Select riduce il problema della complessità di ciascuno di essi,
piuttosto che la loro lentezza (già molto ridotta da come sono realizzati).
In questo documento si utilizzano 3 sommatori Ripple-Carry 4-bit per realizzare il sommatore
Carry-Select 8-bit. Risulta banale riprogettare il Carry-Select facendo uso dei sommatori Carry
Look-Ahead, che tuttavia devono essere ricostruiti per sommare parole di M = N / 2 = 4 bits.
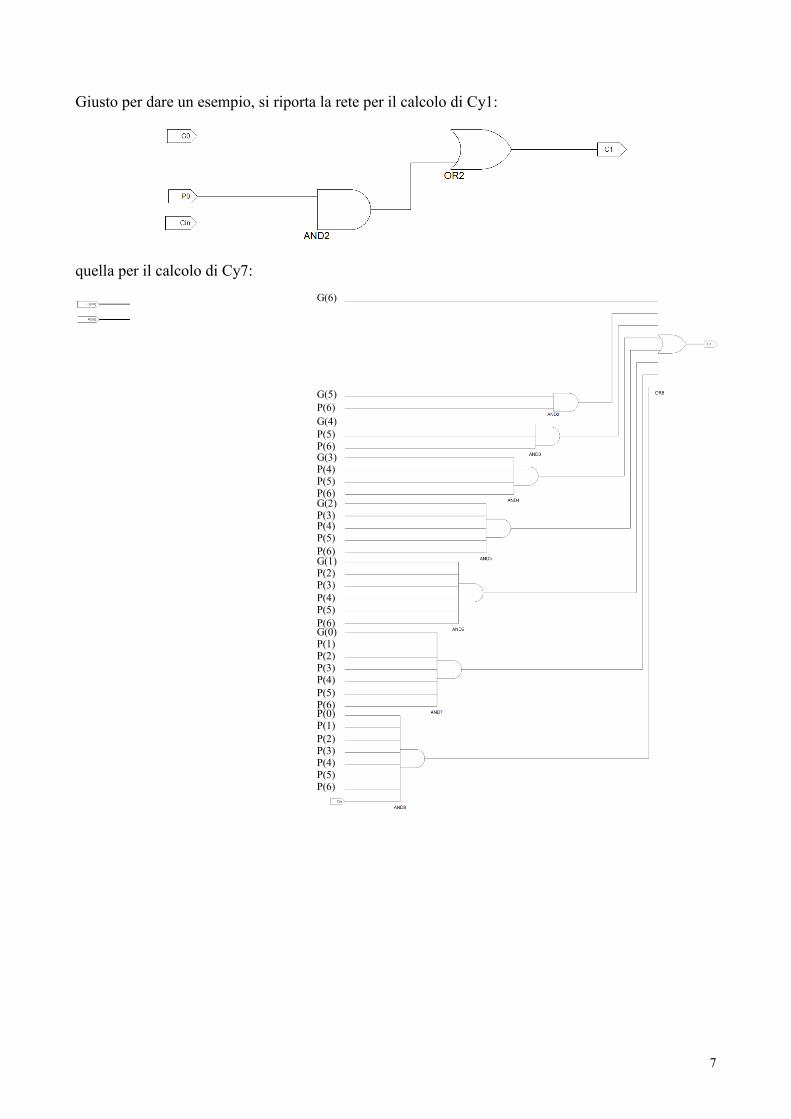
Il multiplexer vettoriale
Tutti i comuni multiplexers sono di tipo “scalare”, ovvero fanno uso di n bits di selezione per poter
connettere con l’unica linea di uscita una tra le 2n linee d’ingresso. Il nostro problema invece
richiede un multiplexer con un singolo ingresso di selezione, ma che metta in comunicazione 5 tra
le 10 linee d’ingresso con le 5 linee d’uscita.
Ovvero possiamo vedere il nostro multiplexer come un dispositivo a due buses di ingresso
(ciascuno di 5 linee, i 4 MSbs prodotti dal rispettivo Ripple-Carry ed il corrispondente carry-out),
ed a singolo bus di uscita (anch’esso di 5 linee, per fornire il risultato della selezione compiuta
dall’omonimo ingresso), cioè un multiplexer 2x1 vettoriale. Esso può essere realizzato collegando
opportunamente 5 multiplexers scalari 2x1, ciascuno che selezioni un singolo bit da uno o dall’altro
Ripple-Carry, a seconda del valore dell’ingresso di selezione (a comune con tutti i multiplexers).
11
Lo schema elettrico risulta:
e quindi il sommatore Carry-Select risulta così implementato:
4. Sommatore Xilinx Nel corso di Elettronica 2 si utilizzerà il “Field Programmable Gate Array” (FPGA) della casa
Xilinx. Si tratta brevemente di un circuito programmabile, ovvero di un chip la cui funzione può
essere programmata elettricamente da PC; in parole povere, il circuito che si vuole realizzare può
essere “scritto” all’interno dell’FPGA. La progettazione di un circuito ed il suo download su FPGA
richiedono specifico software, generalmente (ma non necessariamente) sviluppato e fornito dai
costruttori dell’FPGA stesso.

12
L’ambiente di sviluppo della Xilinx dispone di parecchi componenti circuitali già realizzati ed
ottimizzati per fornire il massimo delle prestazioni; tali componenti sono organizzati in librerie, e
tra essi vi sono anche alcuni tipi di sommatori. Ciascun componente (sommatori inclusi) può essere
esplorato a livello RTL (Register Transfer Level, in breve “livello circuitale”), e ciò ci ha permesso
di dare un’occhiata su come sia realizzato il sommatore “ADD8” (che somma cioè sempre due
parole di 8 bits).
Fondamentalmente è anch’esso ottenuto per rete iterativa, di cui se ne riporta l’ultima cella
elementare (la “most significant”):
Una prima parte della rete risulta ovvia: A e B vengono sommati per mezzo della solita porta XOR,
quindi il risultato viene sommato (tramite un’altra porta XOR) al carry-in. L’uscita di questa
seconda porta è quindi il bit di somma. Per quanto riguarda il riporto Cout, esso viene scelto tra il
carry-in ed A, in base al risultato della somma tra A e B. Si perviene alla seguente tabella di verità
per il riporto Cout:
A B XOR(A,B) Cin Cout
0 0 0 0 0
0 0 0 1 0
0 1 1 0 0
0 1 1 1 1
1 0 1 0 0
1 0 1 1 1
1 1 0 0 1
1 1 0 1 1
Come si può quindi verificare, il multiplexer CY così collegato realizza correttamente la funzione
Cout. Spendiamo ancora due parole a proposito di questa architettura: si potrebbe obiettare sul fatto
della sua velocità, dal momento che il riporto Cout dev’essere calcolato (come avviene nel Ripple-
Carry) in base ai valori di A, B e Cin, prima di poter essere propagato alle celle superiori. Tuttavia,
contrariamente al Ripple-Carry il riporto viene propagato da un multiplexer CY, residente nel
blocco “Carry & Control” di ogni CLB (Configurable Logic Block) all’interno dell’FPGA: ovvero i
multiplexers CY sono stati concepiti apposta per avere la funzione di propagazione del riporto, sono
dedicati a svolgere questo lavoro e quindi sono estremamente veloci. Ecco dunque da cosa deriva la
velocità dell’intero sommatore: è vero che i riporti si propagano da cella a cella, ma il tempo
necessario alla propagazione è molto basso.
Un’ultima parola a proposito dell’uscita OFL (Overflow): essa può essere ignorata nel caso si
decidesse di interpretare le parole in formato Unsigned. Tuttavia il sommatore della Xilinx ammette
anche il formato Signed, ed in tale formato non è sempre vero che si verifichi superamento dei
limiti se Cout diventa 1.
B A
Cin
S

13
Più precisamente, indicando con C il riporto Cout e con C’ il riporto dalla penultima all’ultima
colonna, si verifica overflow quando valgono 1 C oppure C’, mentre non si verifica se valgono
entrambi 0 o entrambi 1. Infatti la rete sopra riportata svolge proprio questa operazione nel calcolo
del bit OFL. OFL segnala anche l’errore di underflow, e dev’essere letto al posto di Cout nel caso si
lavorasse con parole Signed.
Sommatori sincroni
Tutti i sommatori finora riportati sono da intendere come “asincroni”, ovvero una qualsiasi
variazione degli ingressi si riflette “istantaneamente” sull’uscita (l’istantaneità è relativa al
funzionamento comportamentale dei sommatori; è ovvio che, nella pratica, la variazione dell’uscita
avverrà con certo ritardo rispetto alla corrispondente variazione degli ingressi che l’ha generata).
Ma molto gettonati risultano essere i circuiti sincroni, ovvero che lavorano (leggono gli ingressi,
cambiano stato, aggiornano le uscite, …) in specifici istanti di tempo, scanditi da un segnale di
temporizzazione (clock). In tali circuiti risulta evidente che, se occorrono sommatori, sono da
impiegare sommatori sincroni, ovvero che anch’essi aggiornano l’uscita non a seguito di una
variazione dell’ingresso, ma in seguito al valore assunto dall’ingresso in corrispondenza all’istante
di clock. La realizzazione di un sommatore sincrono, a partire da una qualsiasi delle 4 architetture
sopra proposte, può essere compiuta banalmente, campionando i valori degli ingressi e delle uscite
in corrispondenza agli istanti di clock (per mezzo di flip-flops sincroni Delay). Ad esempio,
utilizzando un sommatore Carry Look-Ahead:

14
(i flip-flops in uscita non sono necessari, ma risultano utili qualora si vogliano collegare altri circuiti
sincroni in cascata al sommatore). Un circuito di questo tipo fa si che, all’arrivo di un fronte di
clock:
i flip-flops d’uscita propaghino il valore assunto dall’uscita del sommatore;
i flip-flops d’ingresso propaghino al sommatore il valore assunto dagli ingressi;
il sommatore computi la somma dei nuovi ingressi e la presenti ai flip-flops d’uscita, che la
propagheranno al ciclo successivo.
L’uscita cioè (a causa dei flip-flops in uscita) risulta ritardata di un ciclo: al ciclo (i+1)-esimo sarà
disponibile la somma degli ingressi campionati al ciclo i-esimo.
La velocità di un sommatore sincrono non viene più espressa in termini di “tempo di calcolo (in
sec)”, bensì in termini di massima frequenza di clock a cui è possibile utilizzare il sommatore.
Ovvero lo scopo di un sommatore sincrono è quello di fornire una somma ad ogni ciclo di clock, ma
ciò è fattibile solo mentre la frequenza di clock si mantiene entro certi limiti. A frequenze eccessive,
i ritardi introdotti dalle reti combinatorie cominceranno a far sentire la loro influenza, facendo sì che
le somme, presentate ad ogni ciclo, non siano più attendibili.
Ovviamente, sommatori asincroni veloci (cioè con una rete combinatoria complessa ma veloce, ad
esempio il Carry Look-Ahead) impiegano poco tempo per realizzare una somma, quindi per i
corrispondenti sommatori sincroni la frequenza di clock può essere spinta a valori elevati; viceversa
per i sommatori asincroni lenti.
Sottrattori
È possibile realizzare anche circuiti che forniscono in uscita il risultato della sottrazione tra gli
ingressi (sempre parole di N bits). Essi possono essere sviluppati di nuovo secondo differenti
architetture, la più semplice delle quali prevede (come nel sommatore Ripple-Carry) una cascata di
blocchi elementari in grado ciascuno di effettuare la sottrazione di 3 bits.
Si definiscono dunque:
HS, Half-Subtractor, circuito elementare in grado di effettuare la differenza fra due bits.
Esso vuole come ingressi i due bits da sottrarre, e produce in uscita il risultato della
differenza nonché il prestito, da richiedere al rango superiore.
FS, Full-Subtractor, blocco circuitale che permette la differenza di tre bits: i due delle due
parole da sommare, ed il prestito richiesto dal rango inferiore. Le uscite prodotte sono
nuovamente la differenza, ed un nuovo prestito.
Tramite il FS è possibile costruire banalmente una sorta di “Sottrattore Ripple-Borrow”, in grado di
realizzare (seppure in maniera lenta) sottrazioni tra parole di N bits.
A causa della “poca maneggevolezza” che si ha con i prestiti, si preferisce tuttavia utilizzare dei
sommatori anche per realizzare sottrazioni, piuttosto che costruire circuiti dedicati, utilizzando la
notazione complementata. In tal modo, non è necessario implementare doppia circuiteria (quella
adibita alle somme, e quella adibita alle differenze) in quei dispositivi che, fra le altre cose, devono
poter essere in grado di sommare e sottrarre (ad esempio, i microprocessori).
La notazione complementata prevede in pratica l’utilizzo di parole Signed, ovvero parole che al
proprio interno contengono anche il segno del valore numerico che rappresentano. In tal modo, non
c’è più bisogno di sottrattori, dal momento che una sottrazione può essere vista come la somma tra
due grandezze Signed, una di segno positivo ed una di segno negativo. Inoltre, sfruttando questa
notazione risulta poi possibile effettuare somme tra due grandezze negative, o positive, o la prima
negativa e la seconda positiva.

15
La notazione complementata
In rappresentazione Unsigned, l’utilizzo di N = 8 bits permette la definizione di numeri compresi
nel range 0..255. Sfruttando un bit degli 8 per esprimere il segno della grandezza, il range dei
numeri esprimibili ovviamente si modifica (ma non la quantità dei numeri, sempre pari a 256). In
notazione complementata (con ad esempio N = 8), le grandezze positive hanno a disposizione 7
bits, pertanto variano tra 0 e 127; le grandezze negative invece dispongono sempre di 7 bits,
pertanto possono spaziare su 128 diversi valori (il range dei numeri negativi risulta quindi -128..-1).
Resta da definire come esprimere le grandezze positive, e come quelle negative. Le grandezze
positive prevedono il bit di segno posto a 0, ed i restanti 7 bits coincidono con la rappresentazione
binaria del numero positivo da rappresentare. Le grandezze negative invece prevedono il bit di
segno posto ad 1, ed i restanti 7 bits esprimono il complemento a 2 del modulo del numero negativo
da rappresentare. Le somme compiute tra grandezze positive e negative producono risultati ancora
in notazione complementata, risultati che sono attendibili purché si mantengano le grandezze da
sommare ed il risultato entro i limiti previsti per i bits a disposizione.
Complemento a 2 e rete di conversione Il complemento a 2 di un numero binario si ottiene aggiungendo 1 al complemento ad 1 del
medesimo; l’ottenimento del complemento ad 1 consiste semplicemente nel negare ciascun bit
costituente il numero di partenza. Da queste due considerazioni si ottiene una regola mnemonica
molto semplice per l’ottenimento del complemento a 2: è sufficiente negare tutti i bits del numero,
fino all’ultimo 1 che si incontra. Tale 1 ed i successivi bits li si copiano uguali. Ad esempio,
lavorando con 8 bits (dei quali il primo è per il segno), il complemento a 2 del numero:
001 1010 (+36) risulta:
110 0110 (CPL2(36)).
Volendo in effetti impiegare il complemento a 2 per rappresentare il numero negativo, occorre porre
ad 1 il bit di segno, ottenendo:
1 110 0110 (-36)
Questa regola formale ci permette di ottenere, in maniera relativamente semplice, una possibile rete
combinatoria adibita alla conversione tra grandezze “standard” e grandezze in notazione
complementata.
Ovvero: si supponga di avere un sistema che tratti grandezze Unsigned. Tale sistema lavori con 8
bits per rappresentare le grandezze, ed utilizzi un bit aggiuntivo per esprimerne il segno (pur non
facendo uso della notazione complementata). Nel caso esso avesse bisogno di eseguire somme e
sottrazioni, occorrerebbero circuiti sommatori e circuiti sottrattori, opportunamente pilotati dai bits
di segno delle varie grandezze. Ciò che ci si prefigge di fare è invece realizzare una rete in grado di
convertire le grandezze negative in complemento a 2, e fornire tali grandezze a soli circuiti
sommatori, quindi eventualmente riconvertire il risultato in formato Unsigned. Un approccio molto
semplice potrebbe essere il seguente:

16
Ciascuna grandezza (8 bits) viene lasciata passare inalterata (sul ramo di sinistra), e convertita in
complemento a 2 (sul ramo di destra). In base al bit di segno detenuto dalla grandezza, un
multiplexer decide se fornire all’esterno la parola inalterata (era positiva), o quella complementata
(era negativa). La parola in uscita sarà composta da 8 bits, in aggiunta al bit di segno (che,
nell’ipotesi che anche nel sistema originario assuma significato “+” se vale 0 e “-“ se vale 1, può
essere lasciato inalterato). Notare che si continua quindi a lavorare (dopo la conversione) con parole
di 9 bits complessivi, quindi non c’è da eseguire alcun controllo sui limiti degli ingressi.
L’uscita così ottenuta può a questo punto rappresentare una parola d’ingresso di un sommatore, il
cui altro operando sarà l’uscita ottenuta da una rete identica a quella sopra riportata. Infine, una
ulteriore rete del tutto uguale può eventualmente essere utilizzata all’uscita del sommatore, per
riportare il risultato della somma in notazione Unsigned (nella quale la somma operata avrebbe
potuto anche significare una sottrazione).
Il multiplexer è nuovamente un multiplexer vettoriale, pertanto per la sua costruzione si rimanda a
quanto già visto in precedenza. Non resta che realizzare la rete che, dato un numero binario di 8
bits, ne realizza il complemento a 2.
Ricordando la regola mnemonica enunciata in precedenza, possiamo pensare ad una rete
combinatoria iterativa, la cui cella elementare risulta:
Cj
Uj
Sj
Iji
Ijo

17
dove:
Uj: ingresso primario, rappresenta il j-esimo bit della parola da convertire (chiamiamola
parola “Unsigned”, ma è del tutto indifferente, dal momento che il complemento a 2 del
complemento a 2 di una parola fornisce la parola stessa);
Iji: ingresso secondario, ricevuto dalla cella meno significativa adiacente. Consente di far
sapere alla cella Cj se vi sono bits “1” a livello meno significativo (e quindi se Cj deve o
meno invertire il bit corrente della parola U);
Ijo: uscita secondaria, propagata alla cella più significativa adiacente. Consente di far sapere
alla cella Cj+1 se essa dovrà invertire o meno il bit Uj+1;
Sj: uscita primaria, rappresenta il j-esimo bit della parola convertita (chiamiamola “Signed”,
ma di nuovo è del tutto indifferente).
Nell’approccio a reti iterative, è necessario costruire una macchina sequenziale che rappresenta la
cella elementare; di tale macchina si individua lo stato attuale negli ingressi secondari, e lo stato
futuro nelle uscite secondarie, mentre ingressi ed uscite primarie coincidono rispettivamente con
ingressi ed uscite della macchina sequenziale. Perveniamo dunque al seguente grafo degli stati
(secondo Mealy):
Lo stato A rappresenta la condizione per la quale (procedendo “la scansione” della parola U dal bit
meno significativo al bit più significativo) non è ancora stato raggiunto il primo 1. In tale stato,
pertanto, l’uscita deve coincidere con l’ingresso (ovvero il bit Sj deve coincidere con il bit Uj). Nel
momento in cui arriva l’ingresso Uj = 1, tuttavia, la macchina deve segnalare che il primo 1 è stato
raggiunto, portandosi nello stato B. Da esso, la macchina evolverà negando l’ingresso (ovvero Sj =
NOT(Uj)).
La tavola di Huffman risulta:
Stato\Ingresso Uj
0 1
A A/0 B/1
B B/1 B/0
Codificando lo stato A con (Iji = ) 0 e lo stato B con (Ij
i = ) 1, si perviene alla tavola di verità della
singola cella:
Iji
Uj Ijo
Sj
0 0 0 0
0 1 1 1
1 0 1 1
1 1 1 0
da cui le equazioni:
A B 0/0
1/1
0/1
1/0

18
La cella elementare risulta dunque:
L’ingresso Iji al contorno dev’essere ovviamente posto a massa, quanto all’uscita al contorno Ij
o,
può tranquillamente essere ignorata. La rete conclusiva che realizza il complemento a 2
dell’ingresso (per parole di 8 bits) è dunque:
In alternativa, è possibile costruire una rete che non abbia bisogno di alcun multiplexer, ovvero una
rete che accetta grandezze Unsigned (siano esse positive o negative), e che lascia passare inalterate
quelle positive complementando invece quelle negative. L’ottenimento di una rete del genere può
essere realizzato estendendo la tabella di verità della cella elementare: il bit di segno della parola
d’ingresso dovrà essere letto da tutte le celle della rete iterativa che andiamo a progettare, pertanto
dovrà esserne un ingresso globale. Quando tale ingresso vale 1, ciascuna cella si comporta come
costruita in precedenza, ovvero nega il bit Uj d’ingresso solo se, a livello meno significativo, vi è la
presenza di un bit 1. Nel caso invece il bit di segno valga 0, le celle devono far passare inalterati i
bits Uj; in tal caso, non risulta neppure necessario valutare lo stato attuale o quello futuro, dal
momento che non occorre discriminare la presenza o l’assenza di bits a 1 meno significativi. La
nuova tavola di verità della cella elementare è quindi:
SignI Iji
Uj Ijo
Sj
0 0 0 - 0
0 0 1 - 1
0 1 0 - 0
0 1 1 - 1
1 0 0 0 0
1 0 1 1 1
1 1 0 1 1
1 1 1 1 0

19
Quando il bit di segno vale 0, l’uscita Sj copia l’ingresso Uj, e poiché Sj assume entrambi i valori 0
ed 1 in corrispondenza ad entrambi i valori di Iji, ne conseguirà che Sj non dipende da Ij
i, come
desiderato: l’uscita non dipende dallo stato attuale. Inoltre, non siamo interessati (proprio grazie
all’indipendenza dell’uscita dallo stato attuale) al valore assunto dallo stato futuro, che quindi
poniamo a d.c.c. per cercare di semplificare la rete combinatoria. Quando invece SignI = 1, si adotta
la stessa tavola di verità vista in precedenza. Le funzioni che si ricavano sono:
Ijo
Sj
SignI\IjiUj 00 01 11 10 SignI\Ij
iUj 00 01 11 10
0 - - - - 0 0 1 1 0
1 0 1 1 1 1 0 1 0 1
ovvero:
Dalle espressioni si possono notare tutti i discorsi fatti in precedenza: se SignI = 0, Sj si riduce a Uj
(e non dipende nemmeno da Iji), in caso contrario Sj assume la stessa espressione vista per la prima
versione della rete (quella con il multiplexer); ciò permette di affermare (essendo anche Ijo identica)
che, se SignI = 1, la rete si comporta come nella prima versione. Questa seconda rete ci permette di
rimuovere il multiplexer, pagando come unico prezzo l’aggiunta di una porta AND in più per ogni
cella. Questo risulta accettabile, dal momento che con molta probabilità il multiplexer richiedeva
ben più porte.
In definitiva, la rete con cui dev’essere filtrata ciascuna parola d’ingresso del sommatore (e con cui
può eventualmente esserne filtrata anche l’uscita) è:
Si noti infine che il numero “0”, se specificato con SignI = 1, viene ad essere convertito in “-256”.
Di conseguenza, è necessario far sì che tale numero sia sempre codificato con SignI = 0; la
configurazione d’uscita “-256” sarà inoltre inutilizzata, dal momento che le parole d’ingresso sono
espresse con 8 bits (e quindi arrivano ad un massimo di ±255).
Overflow ed Underflow
Si ricorda infine che, nell’utilizzare sommatori che trattano parole Signed, non è possibile fare
riferimento al bit Cout in uscita dal sommatore per rilevare errori di superamento dei limiti. Occorre
valutare invece il bit di overflow; si rimanda a tal proposito a quanto detto durante la trattazione del
sommatore implementato dalla Xilinx per i propri FPGAs.

20
5. Sommatore Binario Concludiamo questo documento trattando un tipo di sommatore concettualmente diverso da quelli
visti finora. Esso può essere visto come l’estensione del Full-Adder, ovvero se i sommatori Ripple-
Carry, Carry-Select e Carry Look-Ahead permettono somme di due parole di N bits, il sommatore
binario permette la somma di N parole a singolo bit, ovvero di N bits (è dunque un’estensione del
FA, che permetteva la somma di 3 soli bits). Anche l’ottenimento di un sommatore del genere può
essere effettuato banalmente da considerazioni analoghe a quelle fatte parlando del sommatore
Ripple-Carry: quando un essere umano deve sommare N parole a singola cifra (indipendentemente
dalla base del sistema di numerazione), in genere somma dapprima le N cifre trascurando i riporti
(che vengono annotati). Il risultato sarà necessariamente una cifra (non avendo preso in
considerazione i riporti), quella meno significativa della somma. Il passo successivo consiste
nell’iterare il procedimento, sommando i riporti annotati in precedenza. Questo calcolo potrebbe
generare (oltre che la cifra successiva del risultato) ulteriori riporti, da annotare e poi da sommare,
… .
Un sommatore binario per 8 bits può dunque essere ottenuto collegando opportunamente una
cascata di FAs (o, eventualmente, di HAs, del tutto indifferente):
Si noti come sarebbe stato possibile utilizzare al livello 2 un FA ed un HA, al livello 3 un solo HA,
ed il livello 4 non sarebbe a questo punto stato necessario.
Tuttavia si è preferito usare questo schema per mettere in evidenza un particolare fatto: utilizzando
HAs dove converrebbe utilizzare dei FAs, inevitabilmente si ottiene una rete che, apparentemente,
richiede un maggior numero di livelli. Si dimostra però che, da un certo livello in poi, i riporti sono
tutti nulli, dunque non serve completare la catena.
Livello 1 Livello 2 Livello 3 Livello 4

21
Prendendo in considerazione l’esempio sopra riportato, si nota infatti la presenza di un quinto bit
del risultato, ovvero il riporto prodotto dall’ultimo HA. Ma è evidente che questo bit non occorre, se
si pensa che il massimo valore di uscita che dovrà emettere il sommatore sarà la somma di 8 bits ad
1 (ovvero 8 = 10002): occorrono al più 4 bits per esprimere il risultato, quindi questo riporto sarà in
effetti sempre nullo. Molti più livelli sarebbero stati necessari se si fossero utilizzati HAs anche al
primo livello; di nuovo, dal livello dopo il quarto bit del risultato, si potrebbe non completare la
rete.
Un sommatore binario rappresenta la via più semplice per implementare funzioni simmetriche, di
difficile (spesso impossibile) semplificazione se si lavora nel campo dell’algebra booleana.