ibent: chemical entity mentions in patents using chebi
TRANSCRIPT

IBEnt: Chemical Entity Mentions in Patents using ChEBI
Andre Lamurias , Luis F. Campos, and Francisco M. CoutoLaSIGE, Faculdade de Ciências, Universidade de Lisboa, Portugal
BioCreative V.5 Workshop , April 26‐27, 2017
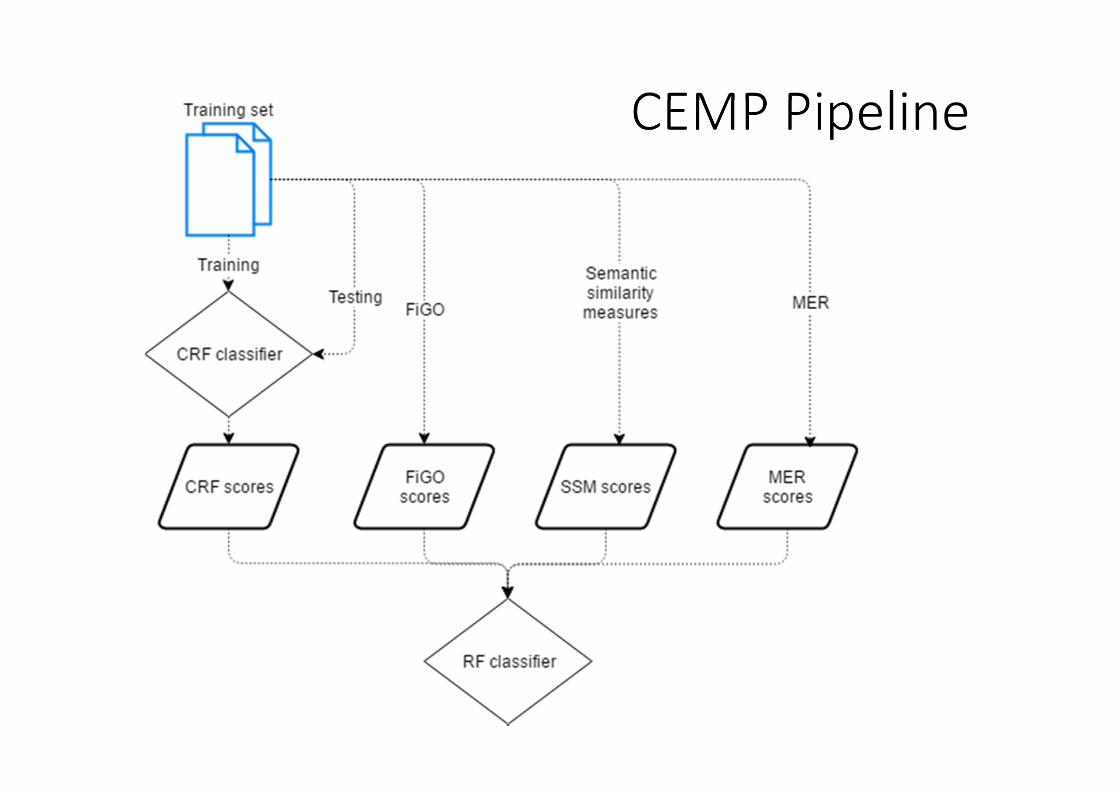
CEMP Pipeline

IBEnt
- IBEnt: in‐house tool to identify entities and relations in text
- Machine learning and ontologies- Integrates Stanford CoreNLP, Genia Sentence splitter, CRFsuite
- Used to participate in text mining competitions
https://github.com/lasigeBioTM/IBEnt

CRF Classifier- Generic features:
- Prefix, suffix, HasNumber, WordCase, Lemma, POS, Word shape
- Current token and window size=‐1/1
Cells exposed to α‐MeDA showed an increase in intracellular glutathione (GSH) levels

Chemical‐specific features:• Periodic table: token is a periodic table element
• “oxygen”, “gold”, “carbon”
• Amino acid: token consists of an amino acid abbreviation
• “ala”, “arg”, “asn”
• Greek letter: token contains at least one Greek letter
CRF Classifier

FiGO – Finding GO terms• Based on the Information Content of the words• Choose term with highest IC• The term t =“punt binding”• With the synonym “punt activity”
• #punt=1, #binding=4, #activity=8, max=16• IC(“punt”)=‐log(1/16)=4, • IC(“binding”)=‐log(4/16)=2• IC(“activity”)=‐log(8/16)=1• IC(“punt binding”)=4+2=6• IC(“punt activity”)=4+1=5• IC(t)=max{6,5}=6

Semantic Similarity
• “Despite a lack of data regarding their efficacy, both caffeine and doxapram have been recommended for treatment of hypercapnia in equine neonates with central nervous system damage.” (PMID: 18371030)
• The fact that caffeine and doxapram are semantically similar
• both central nervous system stimulants• is an evidence for being correctly identified

Improving chemical entity recognition through h‐index based semantic similarity
A. Lamurias, J. Ferreira, and F. Couto, Improving chemical entity recognition through h‐index based semantic similarity, Journal of Cheminformatics, vol. 7, no. Suppl 1, pp. S13, #20, 2015
8

MER ‐Minimal Named‐Entity Recognizer
- Lexicon‐based matching- Developed for performance- No machine learning, just grep and awk- Minimal dependencies, easily portable- Lexicons: ChEBI, ChEMBL, DrugBank, HDMB
https://github.com/lasigeBioTM/MER
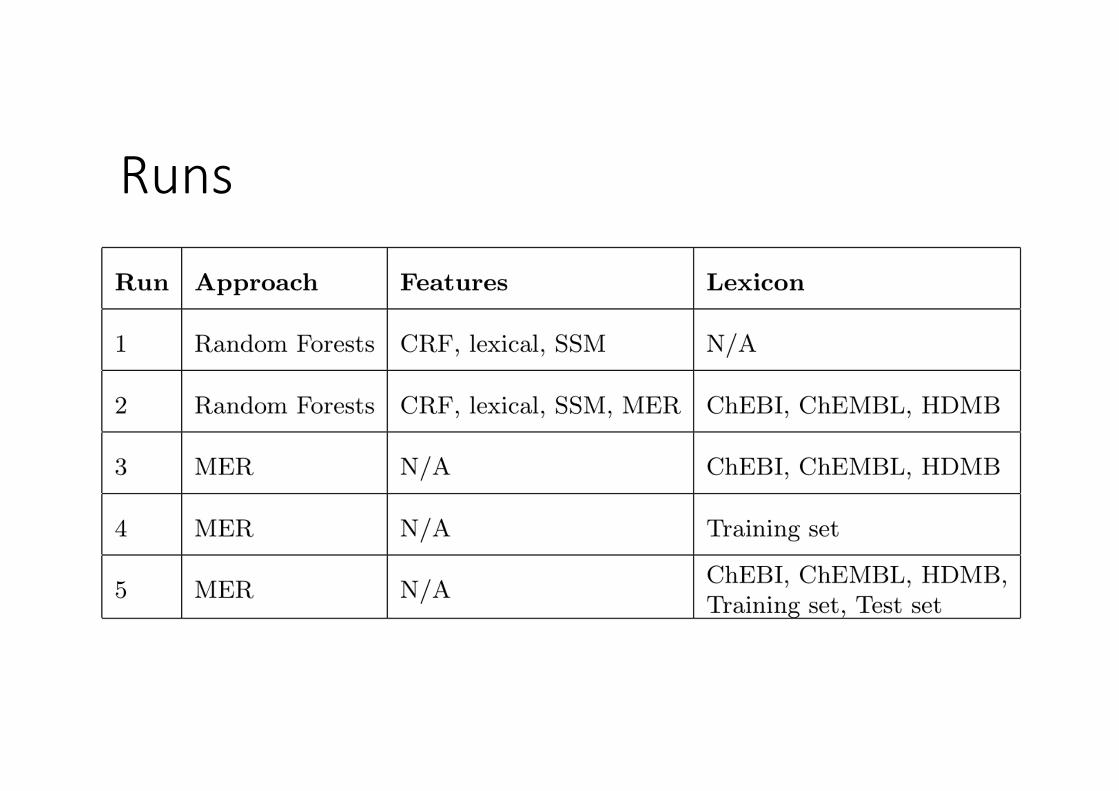
Runs
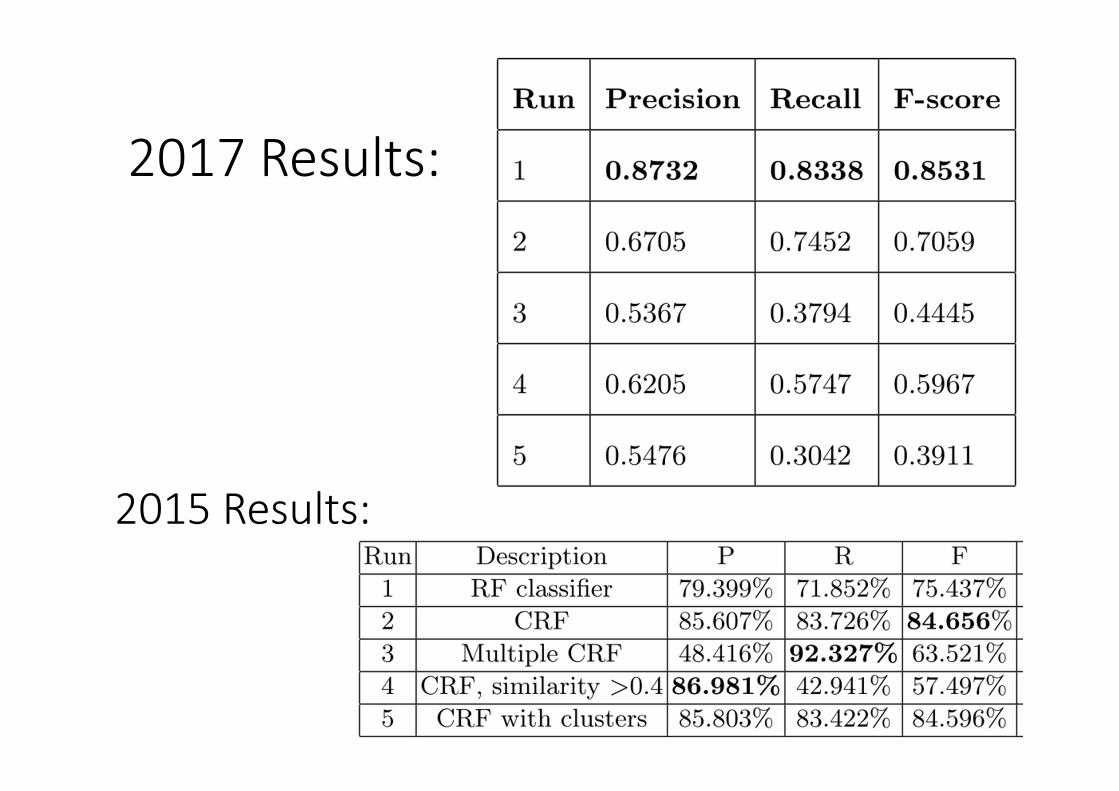
2017 Results:
2015 Results:

Issues identified post‐submission
• Runs using MER (2, 3 and 4) were affected by bugs identified only after submitting results
• Run 5 contained a bug that affected the results more severely:
• Entity identified by more than one lexicon were excluded!• High impact on the recall which should have been higher than Run 4
• We still have to determine what caused Run 2 to have worse results than Run 1

Closing remarks- Trade‐off between machine learning and rule‐based system- Best run (F‐score: 0.8531) used machine learning and semantic similarity
- 43% recall in 2015 using semantic similarity- This edition 83% recall and increasing precision
- Problems with MER- Was still in development at the time of submission- It was developed for performance not accuracy

Future Work- Lexicon matching could be improved: add abbreviation, synonyms and variations to lexicons
- Use more data to train CRF classifier than Random Forests classifier
- Links:- https://github.com/lasigeBioTM/IBEnt- https://github.com/lasigeBioTM/MER- http://labs.fc.ul.pt/mer/