ieee transactions on network science and …
TRANSCRIPT

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 1
Spatial-Temporal Conv-sequence Learning withAccident Encoding for Traffic Flow Prediction
Zichuan Liu, Rui Zhang, Member, IEEE, Chen Wang, Senior Member, IEEE,and Hongbo Jiang, Senior Member, IEEE
Abstract—In an intelligent transportation system, the key problem of traffic forecasting is how to extract the periodic temporaldependencies and complex spatial correlation. Current state-of-the-art methods for traffic flow forecasting are based on grapharchitectures and sequence learning models, but they do not fully exploit spatial-temporal dynamic information in the traffic system.Specifically, the temporal dependence of the short-range is diluted by recurrent neural networks, and the existing sequence modelignores local spatial information because the convolution operation uses global average pooling. Besides, there will be some trafficaccidents during the transitions of objects causing congestion in the real world that trigger increased prediction deviation. To overcomethese challenges, we propose the Spatial-Temporal Conv-sequence Learning (STCL), in which a focused temporal block usesunidirectional convolution to effectively capture short-term periodic temporal dependence, and a spatial-temporal fusion module is ableto extract the dependencies of both interactions and decrease the feature dimensions. Moreover, the accidents features impact on localtraffic congestion, and position encoding is employed to detect anomalies in complex traffic situations. We conduct a large number ofexperiments on real-world tasks and verify the effectiveness of our proposed method.
Index Terms—Sequence learning, spatial-temporal, accident, traffic prediction
F
1 INTRODUCTION
W ITH the rapid traffic development and deploymentof intelligent transportation systems (ITSs), traffic
handled by computational intelligence has gained more andmore attention on the road to urbanization. Predicting thetraffic volume in any area of the city has become one ofthe most basic problems in today’s intelligent transportationsystem. Through deriving spatial-temporal patterns fromhistorical data, our target is to calculate the future time traf-fic flow of a certain road or intersection. In order to enablesome transportation agencies such as traffic-police and Uberto better dispatch and navigate vehicles, the key factor is anaccurate volume forecasting model so that we can better pre-allocate resources to meet volume and avoid unnecessaryblockage. Focussing on utilizing real-world transportationdata, some studies incorporated regional similarity featuresas spatial information [1], [2] and added contextual datalike venue, weather and events in the real world to conductprediction [3], [4]. These studies show that the forecastcan be improved by taking various additional factors intoaccount. Moreover, we find that traffic accidents have a
• Z. Liu and R. Zhang are with the Department of Computer Science andTechnology, Wuhan University of Technology, Wuhan, China, 430070.E-mail: [email protected]; [email protected].
• C. Wang is with Internet Technology and Engineering R&D Center(ITEC), School of Electronic Information and Communications, HuazhongUniversity of Science and Technology, Wuhan, China, 430074. E-mail:[email protected].
• H. Jiang is with the Department of Electrical and Computer Engi-neering, Hunan University, Changsha China, 410012. E-mail: [email protected].
Manuscript received X X, 202X; revised X X, 202X. This work was supportedin part by the National Natural Science Foundation of China under GrantsU20A20181, 61872416, 52031009, 62002104 and 62071192; in part by thefund of Hubei Key Laboratory of Transportation Internet of Things underGrants 2018IOT004 and WHUTIOT-2019004.
Fig. 1. The impact of accidents on traffic flow. Dividing a city into gridmaps according to the longitude and latitude, we show the one week’straffic volume in the region (x = 4, y = 9) and the accident data inthis area. Traffic flow represents the number of times that vehicles enterand exit this area, and the asterisk represents the number of accidentsper hour in this area. Circled from the figure, we can lightly see that thefrequent traffic accidents have seriously affected the traffic congestion.
significant impact on congestion in a certain area. Figure1 is a direct reflection of the fluctuation of traffic flow andthe number of accidents in a certain week. It can be seenthat the accident data increases with the increase of travelpeak, which indicates that there is a certain relationshipbetween both that can be mined. Because the traditionalmachine learning [5], [6], [7] is difficult to capture the high-dimensional spatio-temporal characteristics, it is also unableto mine the mutations caused by traffic accidents. Thismotivates us to rethink the traffic prediction problem basedon deep architecture network.
In the past few years, the deep neural network hasachieved notable successes in the prediction of the urbantraffic flow by fitting the traffic volume in a certain period of
arX
iv:2
105.
1047
8v2
[cs
.LG
] 3
0 A
ug 2
021

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 2
time. Huang et al. [8] utilized a Deep Belief Network (DBN)with multitask learning to mine the considerable featuresand Lv et al. [9] employ Stacked Autoencoder for traffic flowforecasting. After that, with Long Short Term Memory net-works (LSTM) widely used in the field of time series, someresearchers [10], [11], [12] use it to mine the relationship oftraffic temporal correlations. These traditional deep learningmethods can achieve a relatively satisfactory result. Never-theless, all of them are mainly aimed at modeling a singlesequence that only considers the time-series dependenceof the transportation network and does not involve spatialinformation. Besides, with the continuation of recursion, thetemporal dependence of the short-term is diluted to lead toerror propagation of surrounding information.
Recently, researchers apply Convolutional Neural Net-works (CNN) and LSTM in traffic prediction tasks in or-der to excavate spatial-temporal features. Zhang et al. [13]recommended that the traffic volume in a city during aperiod of time be regarded as pixel values. When givinga set of historical traffic images, the traffic images of thenext timestamp are predicted by the model, and the CNNis used to model the complex spatial correlation. Yu et al.[14] proposed to apply convolution manipulation for trafficflow and the results were extracted by LSTM network withautoencoder structure to capture sequential dependency indifferent time periods. However, spatial information is eas-ily discarded by the global average pooling layer in CNN,and the short-term temporal dependence is also distortedand not received continuous attention through the long-term dependence of recursive network.Moreover, the inef-ficient recurrent structure like RNN is difficult to meet thelarge-scale traffic flow prediction. Some researchers startedapplied the Self-Attention mechanism [15] to capture theentire traffic flow information via scaled dot-product at-tention. They proposed some spatio-temporal self-attentionmodels [16], [17], [18] to deal with sophisticated and dy-namic feature dependencies simultaneously, which seemsto be the most novel spatial-temporal prediction scheme.Nevertheless, all of the structures asynchronously handlethe dependence relationship that ignores the complex in-teractions and limits the correlation of predictions. It alsorelies on an ambiguous assumption that there are manycongestions and accidents without considering the reality,which in complex traffic situations is extremely critical forprediction. According to the research of Pan et al. [19], [20],we find that when dealing with the temporal and spatialcorrelation, the sudden impact of traffic between locationswill quickly spread to the surroundings, and the state ofa place at a certain moment will affect the state of thesubsequent time. As shown in the event in Figure 2 (a), oncean accident occurs, the local state will remain for a period oftime and will quickly spread to the surrounding areas.
In order to solve these drawbacks well, a novel modelstructure is proposed by us called Spatial-Temporal Conv-sequence Learning (STCL) to adaptively exploit spatial-temporal dependencies and consider diverse factors thataffect the evolution of traffic flow in an encoder-decoderstructure. In our network, we assemble the causal convo-lution [21] into a novel module called Focused Temporalblock (FT-block), which can focus on capturing the temporaldependencies of short-range and make forward prediction
Fig. 2. (a) Example of ST correlations. The brown lines show the impactof traffic between locations. For instance, in case of a car accident,the traffic congestion could quickly spread to the surrounding areas.And he green line shows the influence on the time dimension. Anevent in a place changes the state at a certain time and affects thestate of subsequent time. (b) The accident encoding we proposed is aposition encoding method. We combine accidents features Ci as localtraffic semantic information and merge accident data into correspondinglocations via position encoding.
with high performance. Then the Spatial-Temporal FusionModule (STFM in short) is applied to extract complex in-teractions from spatio-temporal information. Moreover, tak-ing into account the real traffic conditions, we incorporateaccident data to the corresponding locations by positionencoding in Figure 2 (b). In summary, the contributions inour paper are summarized as follows:
• In STCL, we apply the newly proposed STFM toreplace the global average pooling, which can extractthe dependencies of interactions and decrease thefeature dimension. Simultaneously, we propose theFT-block to focus on capturing short-range temporalinformation with high-performance forward predic-tion.
• The accidents features impact on local traffic con-gestion and position encoding is employed to detectanomalies in complex traffic situations.
• We conduct a large number of experiments to com-pare our model with three typical baselines and sixdifferent methods based on neural network on large-scale real-world datasets. The experimental resultsindicate that our model can excellently outperformother state-of-the-art approaches.
2 RELATED WORK
The problem of traffic prediction, driven by data, has re-ceived widespread attention in recent years. In this section,we briefly discuss the related works of traffic flow predictionbased on deep learning, as shown below.
2.1 Traffic Flow Prediction
The method based on deep learning has shown a superiorability for traffic flow forecasting in recent years. The LSTM[10], [11], [22] based methods demonstrates strong perfor-mance on capturing long-term temporal dependencies, andother studies applied convolution neural network to capturespatial correlation [4], [23] when the deep residual convolu-tional structure [24] was proposed. However, while these

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 3
studies only focus on spatial correlation or temporal depen-dency in their methods, none of them pay close attentionto both aspects simultaneously. Thereupon, Yao et al. [25]proposed a multi-view spatial-temporal network that learnsthe spatial-temporal trajectory similarity by local-CNN andintegrating LSTM for demand prediction, and Wang et al.[26] proposed a transfer learning method based on the com-bination of spatio-temporal information to overcome thescarcity of cross-city geographical data in diverse cities. Intransfer learning and some multi-view methods mentionedabove, divide-and-conquer solves time-space dependencies.Nevertheless, in these studies, the interaction between mul-tiple modules is limited by the way of connection. They alsooverlook the influence of adjacent environmental factors inshort-term prediction.
More recently, several studies in view of road networkssuch as multi-graph convolution network [27] and graphattention [28], applied the graph-based LSTM and CNNstructure to encode the topological network of the roadtraffic and to enhance spatial-temporal correlation. Sim-ilarly, the graph-wavenet [29] was proposed to improvethe forecasting accuracy by embedding each hidden spatialpattern clearly into the graph, but the spatial-temporaldependencies pattern can not be found on the link exceptfor the local nodes. For the multi connected road network,it not only can not well represent the edge information,but also needs a lot of computational resource overheadto spread the node information.Other novel frameworkssuch as Yao et al. [30] introduced the meta-learning usingshort-term data collection to tackle the flow prediction, Liet al. [31] incorporate R-GCN with LSTM and a novel pathembedding method for path in traffic network predictiontask. In these studies, they also overlook the impact of trafficcongestion on traffic flow and what the domain of spatial-temporal correlation dissipates with the depth of networks.
2.2 Sequence-to-sequence Model
With the development of the encoder-decoder structure, thesequence-to-sequence method [32] (seq2seq in short) hasbeen followed with interest in the natural language process-ing field. The processed data is mapped by an encoder intopotential hidden vectors with stacked structure, and thenpropagates and merges into each layer decoder. Hereafter,the decoder forward calculates the data at period t+ 1 thatis dependent on the historical data of 1 : t steps with theencoder’s output in a forward operation.
In several studies, the attention mechanism [15], [33]is also applied to calculate attention weights in seq2seqmodels. The attention mechanism [15] can help the de-coder to attract attention to each timestamp and give cal-culation weight at each step to facilitate better forwardoperation, so as to produce better results. Thereupon, Yaoet al. [34] proposed a standard attention model based onseq2seq with LSTM and local-CNN combination for trafficprediction. Another seq2seq model named spatial-temporaltransformer is also proposed by Xu et al. [35] to improveprediction accuracy.
However, while the self-attention mechanism learns thewhole temporal relations, the short-term time dependencewill be dissipated in the residual layers. Different from the
existing seq2seq methods, convolutional layers are incorpo-rated in our seq2seq method to represent the correlationsof spatial-temporal dependency. The experimental resultsshow that our proposed method outperforms the previousmodels in traffic flow prediction.
3 NOTATIONS AND PRELIMINARIES
In the following section, we deal with and define somenotations then formulate the traffic flow prediction problemformulation based on these notations.
Traffic Variable Definition: We divide the whole cityinto a x × y grid map with r regions (r = x × y), used S ={s1, s2, ..., sr} to denote each area and T = {t1, t2, · · · , tn}to denote the whole time period for historical observations.For the definition of flow, we follow the previous work [34]to define the inflow/outflow regional traffic volume for anarea as the quantity of trips arriving/departing. Specifically,a vehicle or person was in si at ti and appeared in sj attj (si 6= sj , ti ≤ tj) that contributed a value of each si’soutflow and sj ’s inflow. So the overall values of outflow andinflow of si at period t are denoted as V i,tin and V i,tout matrix.Similarly, in order to extract the transition between nodes,we denote Γi,j,tin and Γi,j,tout matrix to indicate transitionsarrive and depart from si to sj in period t. In the followingwe define w to represent two features of input and output.Note that since transitions may span multiple regions andtime steps, we discard transitions that last longer than thethreshold m because they have less impact on the trafficprediction in the next time interval.
Accident Variable Definition: A traffic accident hasa principal impact on traffic congestion within a certainarea. As shown in Figure 1, the traffic volume is stronglyimpacted by the accident. In order to explore the potentialrelationship between both, we also incorporate the historicalaccident data to deal with this task. Additional definitionof accident data as Ci,t to indicate the traffic congestionof si at period t, so constitute tensors C ∈ Rx×y×T×w.The collection and preprocessing of traffic variable data andaccident data are given a minute description in Section 5.1.
Problem Statement: Given the historical volume andtransition data V ∈ Rx×y×T×w and Γ ∈ Rx×y×x×y×T×w,with the traffic accident data C , the traffic flow predictionproblem can be formulated as learning a function fθ thatmaps the inputs to the predicted traffic flows Y at the nexttimestamp:
Y = fθ(V,Γ, C) (1)
where Y ∈ R2r and θ stands for the learnable parameters.
4 MODEL ARCHITECTURE
In this section, Figure 3 shows the architecture of our pro-posed model, which comprehensively considers the role ofspatial-temporal view together. The inputs of the encoderare d-dimensional features represented by spatial-temporalfusion module and the accident data is projected into theencoder. Then the focused temporal block converts it intoa low dimensional features and calculates it forward bysequence to sequence. We will elaborate on the details ofour spatial-temporal fusion module, accident encoding andFT-block in the conv-seq2seq model.

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 4
Fig. 3. The architecture of our proposed Spatial-Temporal Conv-sequence Learning (STCL), which takes traffic flow and transition se-quences as input and outputs sequences of the volume in future time.The accident encoding is added to the initial features of the encoder astraffic congestion, and the custom modules will be specific introducedin the test chapters. During training, The transitions Γi,j,t is put into theencoder to pre-training and the label V i,t at period t is input into thedecoder to calculate the next data Y i,t.
4.1 Spatial-Temporal Fusion Module
Before passing the spatial-temporal sequence into theseq2seq architectures, they usually go through a stack oflocal-CNN [25] to capture the spatial dependence. Sincethe output of CNN cannot be directly used by the seq2seqmodel because of a high dimensionality, most methodsapply global average pooling to decrease the dimension ofthe features, in which the studies [36], [37] show that iseffective in dimension reduction. Nevertheless, we find thatthis localizing ability is not capable of capturing continously,only indicating the attention map of CNNs and activationlayers can capture subtle changes in the traffic transitions.This is because the local CNN may make the same contribu-tion to the ultimate features generated by the global pool indifferent spatial regions.
As shown in Figure 4 (a), we propose that aSpatial-Temporal Fusion Module (STFM) integrates high-dimensional features into low-dimensional features whileretaining important local spatial information to fuse high-dimensional spatial features. When generating historicaltransition input Γiinput, STFM applies a Spatial Poolingblock operating across the m × m spatial dimension likeRoIPooling [38]. Spatial Pooling extracts the domain offeature map ht ∈ Rm×m×w with setting fixed dimensionfrom each spatial information Γi,tinput ∈ Rx×y×w, and thenreshape the features Hi = [h1, h2, · · · , ht] ∈ Rm×m×T×w toM i ∈ RT×(w∗m2), where w′ and w respectively representthe quantity of output and input features. Subsequently,to control the number of output channels and enhanceinteraction between each time step, the M i is input into a
stack of convolutions as:
M ik = f(M i
k−1 ∗W ik + bik), (2)
where ∗ represents the convolutional operation, W ik and bik
are two learnable parameters in the kth convolution layer,and f(·) is an activation function. Finally, we get the featuresM ′i ∈ RT×w′
as the representation for region i.
4.2 Accident EncodingAn accident has a significant impact on the local traffic con-gestion in the identified area, and the centralized treatmenteffect can help to improve the prediction performance moreeffectively. To determine how accidents affect traffic data, weapply map encoding to extract the features of the number ofaccidents and potentially represent traffic congestions. Po-sitional encoding is employed as the positional accident in-formation. In figure 2 (b), accident features cit is representedas a one-hot vector c′it ∈ Rz+λ, where z is the quantityof timestamp intervals. We set the λ = 7 to represent thetraffic accident in a week of this day and the z to representthe index of time interval. Therefore, the accident positionalencoding of cit is embedded to AEi ∈ RT×(z+λ) as:
AEit = f(wit,1 ·ReLU(wit,0c′it + bit,0) + bit,1), (3)
where f(·) is an activation function and wit,0, bit,0, w
it,1, b
it,1
are the learnable parameters in different layers of the net-work. Before fed in the conv-seq2seq model, we concate-nate the M ′ the whole accident encoding matrix AEi ∈RT×(z+λ) as accident features.
4.3 Conv-seq2seq LearningEncoder-decoder: Following Vaswani’s related work [15],we employ the most competitive sequence structures of theencoder-decoder shown in Figure 3. The encoder maps thetransition feature M ′ processed by STFM as input, and thepropagated outputs with the previously predicted volumeV = [v1, v2, ..., vt] are received by the decoder to generatean output yit+1 as the predicted output to represent the nexttime interval, where i is defined as the i-th region in the grid.
The encoder contains ofN = 3 identical encoder-modulethat includes a local self-attention module and a focusedtemporal block designed in section 4.3. The dimension ofeach encoder outputs produced is set to dmodel = 64.Similarly, the decoder is stacked of N = 3 identical block,whose sub-layers are composed of a local self-attention,vanilla-attention module and FT-block. Where the formulaof vanilla attention is similar to that of multi-head attention,it utilizes the hidden states of decoder as target features andthe encoder output as source features.
Focused temporal block: We propose the FT-blockto help the map features to capture short-range temporaldependencies and look around their neighbours. One di-mensional convolution of FT-block is defined as follows:
Outdot =
Di∑di=1
k∑i=1
kerneldidoi ∗ Indit−k/2−1 (4)
where Di, Do stand for the number of input and outputchannels, kernel ∈ Rk×Di×Do is the convolution kernel,Outdot is the convolutional result that learns from In1:Do
t

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 5
Fig. 4. The details about some modules in the model. (a) Spatial-Temporal Fusion Module (STFM). The fed spatial-temporal matrix Γiinput ∈
Rx×y×T×w is a high-dimensional feature converted to a low-dimensional feature Zi ∈ RT×w′. w′ and w respectively represent the quantity of
output and input features. (b) FT-block is an incorporated implementation consists of several branches with two same sizes causal convolutionlayers, where k represents the kernel size of causal convolution. Each causal convolution is followed via a standardization layer and a feedforwardneural network.
and its neighbouring k channels at timestamp t. As shown inFigure 4 (b), the Outdot of the employ convolution operationis not only applied to the input data at time-step t, but alsoto the fusion domain features together. Moreover, FT-blockshould also be able to learn a more robust representationof traffic flow, which is the ability to extract correct STinformation regardless of traffic flow. So we link the outputof different convolution kernel sizes to form a residualstructure to prevent overfitting neighbouring features. Then,each channel is incorporated and passed through the feed-forward network to control dimension dmodel = 64 as thefinal output.
Moreover, normal convolution is not suitable for thesequence prediction because the decoder should be future-blind in a seq2seq model. Following Oord et al. work [21],causal convolution is employed to split the local featuresinto different orientations: forward and backward. In theencoder, the bidirectional convolution is performed. But inthe decoder, we replaced the CNN layers to causal convolu-tion in Figure 4 (b), only forward fusion can be performedto predict the next time. The formula of causal convolutionis defined as:
Outdot =
Di∑di=1
k∑i=1
kerneldidoi ∗ Indit−k+1 (5)
where kernel ∈ Rk×Di×Do is the convolution kernel andthe features In1:Do
t is changed forward training. Therefore,all the pass features can be blocked by unidirectional causalconvolution.
Local self-attention: Compared with ordinary languagesequence models, the feature space has two additional di-mensions to hold the domain of spatial maps, and a lot oftemporal information is implicit in the overall sequence. Theself-attention module [15] is applied to consider the entiresequence of each position to adopted the periodic temporalfeatures under long-term dependence.
We denote target states Qt = [q1, q2, · · · , qTt] ∈ RTt×dt
and the keys of source states Ks = [k1, k2, · · · , kTs] ∈
RTs×ds , where Ts and ds stand for sequence length andfeature dimension. The scaled dot-product attention is usedas:
Att(Qt,Ks, Vs) = softmax(WtQt(WsKs)
T
√ds
)Vs (6)
where Qt and Ks are the same features of FT-block output,Wt and Ws are learnable parameters.
Moreover, we find that due to the calculated attentionweights, the model is not only complex for the whole inputsequence, but also loses local temporal information for longtime series in our experiments. Therefore, we proposed alocal self-attention block both in our encoder and decoderto capture the fixed range dependencies as:
LA = softmax(WtQt(WsKs)
T ∗Wm√ds
)Vs (7)
where Wm ∈ RTt×Ts is a mask matrix to controlling therange of attention, LA is the output of the local attention.
Since all spatial heads can be computed in parallel, thelearning and inference are computationally efficient. weadopt multi-head attention [15] as a function aggregatingthe results of all subspaces:
Multi_LA = Concat(LA1, · · · , LAu)W o (8)
where W o is learned linear transformation matrix and u isthe number of attention head.
Loss function: STCL is trained by minimizing the lossfunction of mean square error (MSE) between predictedresult maps and truths maps:
L(θ) =
∑ri=1(yi − yi)2
r × ω(9)
where yi and yi represent the i-th traffic flow at the nexttimestamp respectively, θ is the learnable parameter.

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 6
TABLE 1The experimental details of the datasets.
Dataset Taxi-NYC Bike-NYC
Time Span 2016/01/01–2016/02/29 2016/07/01–2016/08/29
Time Interval 15 minutes 15 minutes
Grid map size 10× 20 10× 20
Number of vehicles 24,000+ 8,200+
Loss threshold 10 10
Max flow 928 168
Total records 23 million 3.2 million
5 EXPERIMENT
5.1 Datasets and Preprocessing
The proposed deep architecture model was evaluated totwo largescale public real-world datasets from New YorkCity (NYC), TaxiNYC and BikeNYC. In addition, we addNYC motor vehicle accident data to support our accidentencoding.
TaxiNYC and BikeNYC: All the New York data (NYC)we used included 60 days of traffic records in 2016. Inaddition, each record also includes the positions of thevehicles and the start and end times of the trip. We apply theprevious 45 days, 75% of the data, as the training sets andthe last 15 days as the testing sets. A summary of the twodatasets is shown in Table 1, and particulars of transitionsand volumes preprocessing methods are similar to that ofYao et al [34] that is currently the most common in industryand academia.
Accident Data: Vehicle accident data is collected fromthe New York City Open Data1, and there are about 8,000traffic accident records in New York every month. The datais processed in the same way as above with time slot, xlocation and y location, and the data values are the numberof accidents at each time point in each grid.
5.2 Implementation Details
Before feeding into the network, we first perform z-scorescaling on the data during the training and testing. ForSTFM information, we set the spatial pooling size m = 5,the convolution kernel sizes 5×5, and the number of outputchannels to 256. In our proposed conv-seq2seq model, weset the all convolution kernel sizes 3 × 3 with 64 filters,the dmodel = 64, df = 256, and the dropout rate is setto dprate = 0.1. N of the model stacked and the multi-head attention modulars are set to 3 and 4, respectively. Toschedule the learning rate, we apply the so-called Noamscheme as introduced in [15] with warm-up steps set to4000. We tune the STCL model on the validation set andobserved that using the above hyperparameters achievedthe best performance in both data sets. It takes about sevenhours to experiment with 64 as the batchsize on one machinewith four NVIDIA RTX1080Ti GPUs.
1. https://opendata.cityofnewyork.us/
5.3 Methods for ComparisonIn this subsection, we compare the proposed model withnine discriminative traffic flow forecasting approaches, andanalyze the causes of the results. There are three categoriesof comparison methods that we divide, including: (1) tra-ditional time series prediction models; (2) spatial-temporalfeatures mining deep learning network for traffic flowprediction; (3) some spatial-temporal prediction networkswith multi-view or complex structure. The details of therecompared approaches are described as follows:
• HA: Historical average is a statistical method, whichcan directly calculate the coming traffic flow by aver-aging data of the corresponding period in historicalflow.
• ARIMA [39]: Auto-regressive integrated moving av-erage model is universally known a statistical math-ematical method that usually makes time trend pre-diction by moving average.
• VAR [40]: Vector auto-regression is usually appliedto capture interconnected time-series.
• MLP: Multi-layer perceptron with there fully con-nected layers. The number of hidden units with reluactivation we set are 128, 64 and 32 respectively.
• FC-GRU: FC-GRU is the vanilla version of GRUis a very classic time prediction network, in somecases better than LSTM. We flatten the traffic volumetensor and take it as input into FC-GRU and we setthe number of the hidden unit is 64.
• ConvLSTM [41]: Convolutional LSTM is a well-known network to forecast the temporal datas. Weevaluate multiple hyperparameters and choose thebest setting unit is 64 and learning rate is 0.001.
• ST-ResNet [13]: Spatial-Temporal Residual Convolu-tional Network incorporates the closeness, periodicdependence and trend data with external weatherfeatures to forecast the citywide traffic flow withresidual structure.
• DMVST-Net [25]: Deep Multi-View Spatial-Temporal Network, this framework makespredictions through multiple perspectives includingtime modules, spatial modules and external factorslike weather.
• STDN [34]: Spatial-Temporal Dynamic Network im-plemented the prediction of future traffic flow, whichtake the long-term periodic dependence and tempo-ral lagging simultaneously by the attention module.
To test the performance of our proposed model, weevaluated traffic prediction errors using the Root MeanSquare Error (RMSE) and Mean Absolute Error (MAE). Weuse Adam [42] as the optimizer for all baselines, settingthe parameter of Adam β1 = 0.9, β2 = 0.98, ε = 10−9
and using the mirrored strategy for distributed training. ForST-ResNet, DMVST-Net and STDN, the hyperparametersremain as the optimized settings the same introduced bytheir authors. Being STDN trained, it takes about five hoursto experiment on our machine.
During the evaluation and testing, the results in Table2 show that the overall results of compared methods onthe two datasets of the test set. The RMSE and MAE inTaxiNYC are all higher than those of BikeNYC on the

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 7
TABLE 2Quantitative comparison with discriminative baselines of TaxiNYC and BikeNYC, and the results were predicted by RMSE and MAE.
Methods
Datasets TaxiNYC BikeNYC
Inflow(RMSE/MAE) Outflow(RMSE/MAE) Inflow(RMSE/MAE) Outflow(RMSE/MAE)
HA 25.9856 / 17.2775 23.6287 / 14.9653 11.1288 / 7.9088 10.8701 / 7.8254
ARIMA [39] 53.2120 / 33.7210 46.2979 / 34.1989 27.4020 / 23.4436 27.6041 / 23.6154
VAR [40] 41.5135 / 26.9960 39.4129 / 17.3546 16.9276 / 13.7604 16.5867 / 13.6108
MLP 19.0216 / 13.1050 16.0133 / 11.0316 9.5292 / 6.8345 9.1321 / 6.5823
FC-GRU 18.6762 / 12.6428 16.3984 / 11.1141 9.4131 / 6.8256 9.1179 / 6.6041
ConvLSTM [41] 18.6523 / 12.6978 16.1923 / 11.0207 9.3754 / 6.6942 9.2677 / 6.7002
ST-ResNet [13] 18.5457 / 11.2446 16.0472 / 9.8477 9.0788 / 6.7831 8.9774 / 6.6475
DMVST-Net [25] 17.3786 / 10.8742 15.5972 / 9.1285 8.9796 / 6.3568 8.6871 / 6.1473
STDN [34] 16.8271 / 9.7584 15.3281 / 8.7156 8.5764 / 5.8981 7.9934 / 6.1382
STCL w/o AE(ours) 16.6148 / 9.4863 15.4652 / 8.6812 8.3766 / 5.9184 8.0345 / 6.0918
STCL(ours) 16.2752 / 9.1295 14.9671 / 8.2187 7.9184 / 5.8441 7.7815 / 5.8991
methods since traffic volume in TaxiNYC is presented ofa larger magnitude than BikeNYC. For the two data sets,the baseline traditional time series analysis methods have alarge forecast deviations on two metrics. This indicates thatthe traffic flow is enormously affected via the spatial variesin the consecutive time interval, and it is not enough to usemanual feature extraction to mine temporal information.Compared to neural network-based models like MLP, theworse results in basic methods confirm that the complexspatial-temporal dependencies cannot be well captured withsimple regressions. Thus the interdependency among re-gions could be explored to achieve better performances.
TABLE 3Further analysis of the role of the accident module.
Datasets Methodswith acc w/o acc
Inflow Outflow Inflow Outflow
MLP* 19.17 15.91 19.02 16.01
GRU* 18.58 16.15 18.67 16.39
TaxiNYC ConvLSTM* 18.88 15.99 18.65 16.19
STDN* 16.47 15.11 16.83 15.33
STCL(ours) 16.28 14.97 16.61 15.46
MLP* 9.42 9.19 9.52 9.13
GRU* 9.44 9.08 9.41 9.11
BikeNYC ConvLSTM* 9.32 9.16 9.37 9.26
STDN* 8.24 7.78 8.57 7.99
STCL(ours) 7.92 7.78 8.37 8.03
For neural-network-based methods, our method out-performs ConvLSTM and ST-ResNet on both metrics. Thepotential reason is that they did not dig out the potentialtemporal sequential dependency and neighborhood depen-dency. For instance, ST-ResNet focuses on long-range inputinformation through deep residual CNNs, which makesit less efficient in measuring the surrounding correlation.Due to the pooling effect, the smaller grid informationwill be averaged by convolution operation, which results
in low prediction accuracy of most networks with CNNs.Recent work has solved this problem by combining CNNsand LSTMs. Thereupon, DMVST-Net and STDN attempt tosolve the dissipation of spatio-temporal semantics throughmulti-view and long-term attention mechanisms, respec-tively. However, they also face similar problems mentionedabove, without taking into account local semantic changes,such as accidents. Thereupon, the experiment shows that,STCL achieves the best performances on RMSE and MAE,showing 2.65% - 7.51% lower than DMVST-Net and STDN.There are two main reasons: (1) the short-range temporaldependencies receives no extra attention in the dynamicspatial similarity, but STCL takes the whole traffic volumetensor as input, using the FT-block to capture the spatial-temporal information of the field and the multi-head atten-tion mechanism to capture long-term time periods. (2) Localspatial information is discarded because of the applicationof global average pooling in CNN, so we designed STFM tocapture the local spatial information.
Notice that, STCL added accident data as spatial encod-ing features to represent local traffic congestions, signifi-cantly improving the performance of model prediction com-pared to without accident encoding structure. As shown inTable 3, we further analyze the role of accident data in trafficflow prediction through RMSE. The symbol ∗ represents thatwe concatenate accidents as features to traffic features andthe two columns on the right represent whether there is anaccident module. The performance of most of the meth-ods mentioned above has been improved, especially themodel considering spatial dependence. This is because somemodels, such as GRU or MLP, only focus on to historicaltime information but cannot dig out the spatial relationshipand additional local traffic semantic information in externalfeature. However, some models that consider the spatialrelationship after the convolution operation, the dependen-cies in the domain area are transmitted so that the trafficcongestion information can be mined. Compared with otherbaselines, our model has been promoted significantly afterposition encoding. It effectively illustrates that the accidentdata can extract the local semantic information varieties and
IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 8
apply to the traffic flow prediction.
5.4 Hyperparameters Analysis
To demonstrate the impact of various hyperparameters,we also evaluated different hyper parameter settings tomeasure the corresponding performance on the TaxiNYCdataset. Adjusted our model parameters on the validationset, we observed that dmodel = 64, df = 256, dprate = 0.1,mh = 4, N = 3 achieve the best results in both datasetsin the above experiments, it takes around seven hoursfor TaxiNYC and five hours for BikeNYC with 64 as thebatchsize. In Table 4, we record the experimental resultsof adjusting various parameters by RMSE with the controlvariable method, where the blank space represents the sameparameters as STCL.
TABLE 4Influence of different super parameters on the prediction results.
dmodel df dprate N Inflow/Outflow
dmodel
32 17.35/16.13128 16.41/15.57256 16.33/14.97
df128 16.62/15.34512 16.26/15.02
dprate0.05 17.14/15.670.2 16.97/15.78
N2 16.75/15.274 16.34/15.01
STCL 64 256 0.1 3 16.28/14.97
As shown in the table, the influence of different param-eters on the model is similar. The larger the model willcontain more parameters, the training time will also increaseexponentially and the easier it is to overfit. Due to thedifferent random numbers, some swings will be generatedin each experiment. In order to stabilize the model, weadopted the baseline parameters as the final experimentalresults to prevent the model from overfitting.
5.5 Component Analysis
To better understand the impact of components on theSTCL, we also make a controlled variable experiment aboutspatial temporal fusion module and FT-block in our method:
• multi-head attention: In this variant, we remove allredundant structures, just input the data into themulti attention mechanism and decode the sequenceby using the total concatenation layer.
• w/o STFM: For this variant, we only remove theSTFM module and feed the transition features Γi intoConv-seq2seq Learning after processing.
• local CNN: We replace the module with local CNNthat is proposed to extract local spatial features pro-posed by Zhang et al [13].
• w/o FT-block: Feed the extracted periodic featuresdirectly into the multi-head attention mechanism.
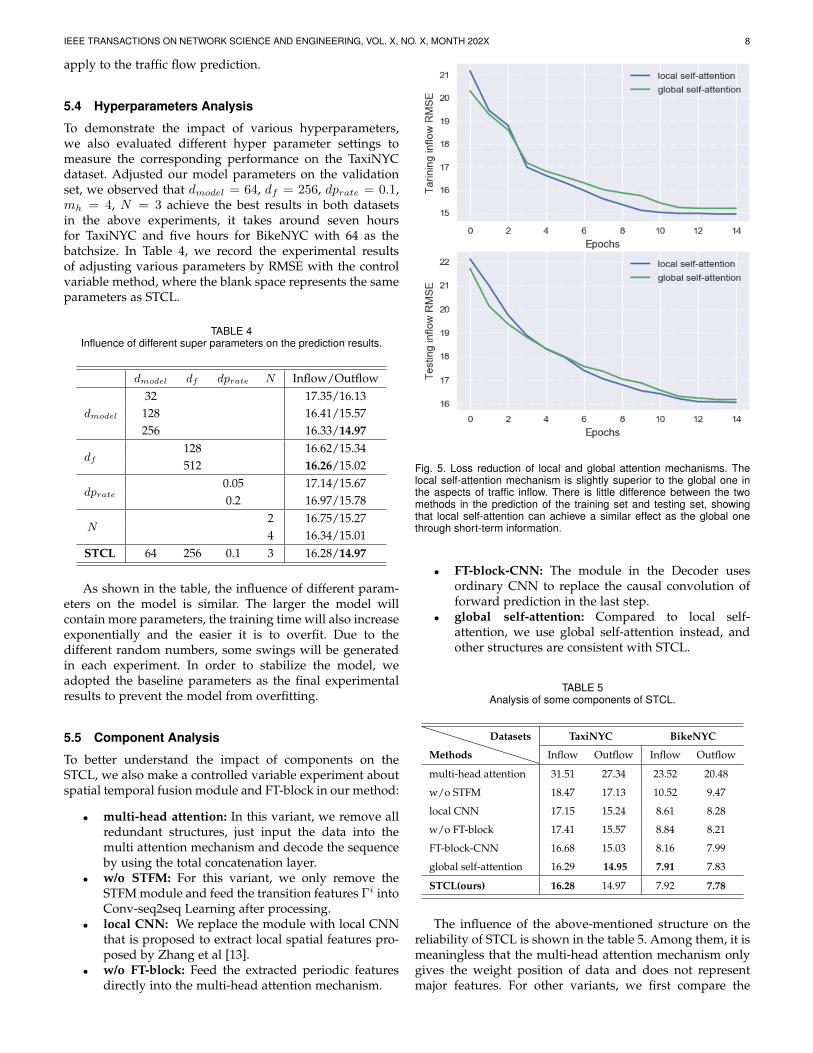
Fig. 5. Loss reduction of local and global attention mechanisms. Thelocal self-attention mechanism is slightly superior to the global one inthe aspects of traffic inflow. There is little difference between the twomethods in the prediction of the training set and testing set, showingthat local self-attention can achieve a similar effect as the global onethrough short-term information.
• FT-block-CNN: The module in the Decoder usesordinary CNN to replace the causal convolution offorward prediction in the last step.
• global self-attention: Compared to local self-attention, we use global self-attention instead, andother structures are consistent with STCL.
TABLE 5Analysis of some components of STCL.
Methods
Datasets TaxiNYC BikeNYC
Inflow Outflow Inflow Outflow
multi-head attention 31.51 27.34 23.52 20.48
w/o STFM 18.47 17.13 10.52 9.47
local CNN 17.15 15.24 8.61 8.28
w/o FT-block 17.41 15.57 8.84 8.21
FT-block-CNN 16.68 15.03 8.16 7.99
global self-attention 16.29 14.95 7.91 7.83
STCL(ours) 16.28 14.97 7.92 7.78
The influence of the above-mentioned structure on thereliability of STCL is shown in the table 5. Among them, it ismeaningless that the multi-head attention mechanism onlygives the weight position of data and does not representmajor features. For other variants, we first compare the

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 9
Fig. 6. Flow matrix at the latest timestamp on two datasets. Comparisonbetween the truth inflow/outflow matrix and the predicted flow of thelatest timestamp. On the right is the residual matrix of subtracting twomatrices, which can directly see the prediction accuracy in differentregions.
model without STFM and next replace the module withlocal CNN [13]. The results show that STFM is slightlybetter than local CNN in extracting spatial dependenciesand it is important to have a dynamic spatial module featureextraction to predict traffic flow. This is because withoutthe effect of the pooling layer, STFM can better capture thedynamic dependence of space. Similarly, we will experimentafter removing the FT-block and replacing the causal convo-lution in the FT-block with bidirectional convolution layers(CNN layers). The results show that STCL is 1.59%-7.70%lower than changing and without the FT-block. Becauseafter we add the causal convolution for forward prediction,the module will pay more attention to the traffic at the nextmoment rather than the global temporal.
The width of attention in the sequence model has a greatinfluence on the distribution of attention weight. Therefore,we do an experiment to train a Conv-seq2seq model withglobal multi-headed attention, whose the input sequenceand other parts of the model are the same as those of SCTL.During the training process, we replace the weights beyondthe selection range with zero, and only keep the requiredweights to limit the effective width of attention weights.Experimental results show that local self-attention is betterthan global one in Figure 5. Although the initial loss oflocal self-attention is higher, its loss decreases faster andits running time is about 40 minutes faster than the globalone in TaxiNYC. Moreover, in the test data, the performanceof local self-attention has been improved slightly. This il-lustrates that the local attention mechanism is effective inthe prediction of short-term dynamic dependence, whilelong-term time series may variate and appear non periodic.Eventually, the performance is best when all components arecombined. As shown in Figure 6, most regions have highprediction accuracy, indicating that this model has a highperformance in traffic flow prediction.
6 CONCLUSION AND OUTLOOK
In our work, spatial-temporal conv-sequence learning isproposed to improve short-term temporal dependencies by
FT-block and to sufficiently extract the utilization of domainspatial-temporal information via STFM. In particular, wehave introduced traffic accident data for application withaccident encoding to explore the impact on regional trafficcongestions. The results indicate that our proposed methodhas superior performance of prediction on both TaxiNYCand BikeNYC datasets compared with other state-of-the-artmodels. But the potential problem is that our model willcause noise and error propagation in long-term prediction.In the future, we will focus on using semantic track infor-mation with the Point of Interest (POI) in each area andachieving accurate future traffic via retrieving nontrivialinformation.
REFERENCES
[1] J. Zheng and L. M. Ni, “Time-dependent trajectory regression onroad networks via multi-task learning,” in Proceedings of the AAAIConference on Artificial Intelligence, 2013.
[2] D. Deng, C. Shahabi, U. Demiryurek, L. Zhu, R. Yu, and Y. Liu,“Latent space model for road networks to predict time-varyingtraffic,” in Proceedings of the 22nd ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining, 2016, pp. 1525–1534.
[3] B. Pan, U. Demiryurek, and C. Shahabi, “Utilizing real-worldtransportation data for accurate traffic prediction,” in 2012 IEEE12th International Conference on Data Mining. IEEE, 2012, pp. 595–604.
[4] J. Zhang, Y. Zheng, D. Qi, R. Li, and X. Yi, “Dnn-based predictionmodel for spatio-temporal data,” in Proceedings of the 24th ACMSIGSPATIAL International Conference on Advances in GeographicInformation Systems, 2016, pp. 1–4.
[5] X. Li, G. Pan, Z. Wu, G. Qi, S. Li, D. Zhang, W. Zhang, and Z. Wang,“Prediction of urban human mobility using large-scale taxi tracesand its applications,” Frontiers of Computer Science, vol. 6, no. 1, pp.111–121, 2012.
[6] L. Moreira-Matias, J. Gama, M. Ferreira, J. Mendes-Moreira, andL. Damas, “Predicting taxi–passenger demand using stream-ing data,” IEEE Transactions on Intelligent Transportation Systems,vol. 14, no. 3, pp. 1393–1402, 2013.
[7] S. Shekhar and B. M. Williams, “Adaptive seasonal time seriesmodels for forecasting short-term traffic flow,” Transportation Re-search Record, vol. 2024, no. 1, pp. 116–125, 2007.
[8] W. Huang, G. Song, H. Hong, and K. Xie, “Deep architecturefor traffic flow prediction: deep belief networks with multitasklearning,” IEEE Transactions on Intelligent Transportation Systems,vol. 15, no. 5, pp. 2191–2201, 2014.
[9] Y. Lv, Y. Duan, W. Kang, Z. Li, and F.-Y. Wang, “Traffic flow predic-tion with big data: a deep learning approach,” IEEE Transactions onIntelligent Transportation Systems, vol. 16, no. 2, pp. 865–873, 2014.
[10] Z. Cui, R. Ke, Z. Pu, and Y. Wang, “Deep bidirectional andunidirectional lstm recurrent neural network for network-widetraffic speed prediction,” arXiv preprint arXiv:1801.02143, 2018.
[11] X. Ma, Z. Tao, Y. Wang, H. Yu, and Y. Wang, “Long short-termmemory neural network for traffic speed prediction using remotemicrowave sensor data,” Transportation Research Part C: EmergingTechnologies, vol. 54, pp. 187–197, 2015.
[12] X. Song, H. Kanasugi, and R. Shibasaki, “Deeptransport: Predic-tion and simulation of human mobility and transportation modeat a citywide level,” in Proceedings of the Twenty-Fifth InternationalJoint Conference on Artificial Intelligence, 2016, pp. 2618–2624.
[13] J. Zhang, Y. Zheng, and D. Qi, “Deep spatio-temporal residualnetworks for citywide crowd flows prediction,” in Proceedings ofthe AAAI Conference on Artificial Intelligence, 2017.
[14] R. Yu, Y. Li, C. Shahabi, U. Demiryurek, and Y. Liu, “Deep learn-ing: A generic approach for extreme condition traffic forecasting,”in Proceedings of the 2017 SIAM international Conference on DataMining. SIAM, 2017, pp. 777–785.
[15] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inProceedings of the Advances in Neural Information Processing Systems,2017, pp. 5998–6008.
[16] H. Lin, W. Jia, Y. Sun, and Y. You, “Spatial-temporal self-attentionnetwork for flow prediction,” arXiv preprint arXiv:1912.07663, 2019.

IEEE TRANSACTIONS ON NETWORK SCIENCE AND ENGINEERING, VOL. X, NO. X, MONTH 202X 10
[17] H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena, “Self-attention generative adversarial networks,” in International Con-ference on Machine Learning, 2019, pp. 7354–7363.
[18] H. Lin, W. Jia, Y. You, and Y. Sun, “Interpretable crowd flowprediction with spatial-temporal self-attention,” arXiv preprintarXiv:2002.09693, 2020.
[19] Z. Pan, Y. Liang, W. Wang, Y. Yu, Y. Zheng, and J. Zhang, “Urbantraffic prediction from spatio-temporal data using deep metalearning,” in Proceedings of the 25th ACM SIGKDD InternationalConference on Knowledge Discovery & Data Mining, 2019, pp. 1720–1730.
[20] Z. Pan, W. Zhang, Y. Liang, W. Zhang, Y. Yu, J. Zhang, andY. Zheng, “Spatio-temporal meta learning for urban traffic predic-tion,” IEEE Transactions on Knowledge and Data Engineering, 2020.
[21] A. V. D. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals,A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu,“Wavenet: A generative model for raw audio,” 2016.
[22] S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
[23] J. Zhang, Y. Zheng, and D. Qi, “Deep spatio-temporal residualnetworks for citywide crowd flows prediction,” arXiv preprintarXiv:1610.00081, 2016.
[24] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learningfor image recognition,” in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2016, pp. 770–778.
[25] H. Yao, F. Wu, J. Ke, X. Tang, Y. Jia, S. Lu, P. Gong, J. Ye, andZ. Li, “Deep multi-view spatial-temporal network for taxi demandprediction,” in Proceedings of the AAAI Conference on ArtificialIntelligence, 2018.
[26] L. Wang, X. Geng, X. Ma, F. Liu, and Q. Yang, “Cross-city trans-fer learning for deep spatio-temporal prediction,” arXiv preprintarXiv:1802.00386, 2018.
[27] X. Geng, Y. Li, L. Wang, L. Zhang, Q. Yang, J. Ye, and Y. Liu,“Spatiotemporal multi-graph convolution network for ride-hailingdemand forecasting,” in Proceedings of the AAAI Conference onArtificial Intelligence, vol. 33, 2019, pp. 3656–3663.
[28] C. Zhang, J. James, and Y. Liu, “Spatial-temporal graph attentionnetworks: A deep learning approach for traffic forecasting,” IEEEAccess, vol. 7, pp. 166 246–166 256, 2019.
[29] Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graphwavenet for deep spatial-temporal graph modeling,” arXiv preprintarXiv:1906.00121, 2019.
[30] H. Yao, Y. Liu, Y. Wei, X. Tang, and Z. Li, “Learning from multiplecities: A meta-learning approach for spatial-temporal prediction,”in Proceedings of the World Wide Web Conference, 2019, pp. 2181–2191.
[31] J. Li, Z. Han, H. Cheng, J. Su, P. Wang, J. Zhang, and L. Pan,“Predicting path failure in time-evolving graphs,” in Proceedingsof the 25th ACM SIGKDD International Conference on KnowledgeDiscovery & Data Mining, 2019, pp. 1279–1289.
[32] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequencelearning with neural networks,” in Proceedings of the Advances inNeural Information Processing Systems, 2014, pp. 3104–3112.
[33] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine trans-lation by jointly learning to align and translate,” arXiv preprintarXiv:1409.0473, 2014.
[34] H. Yao, X. Tang, H. Wei, G. Zheng, and Z. Li, “Revisiting spatial-temporal similarity: A deep learning framework for traffic predic-tion,” in Proceedings of the AAAI Conference on Artificial Intelligence,vol. 33, 2019, pp. 5668–5675.
[35] M. Xu, W. Dai, C. Liu, X. Gao, W. Lin, G.-J. Qi, and H. Xiong,“Spatial-temporal transformer networks for traffic flow forecast-ing,” arXiv preprint arXiv:2001.02908, 2020.
[36] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba,“Learning deep features for discriminative localization,” in Pro-ceedings of the IEEE Conference on Computer Vision and PatternRecognition, 2016, pp. 2921–2929.
[37] W. Liu, A. Rabinovich, and A. C. Berg, “Parsenet: Looking widerto see better,” arXiv preprint arXiv:1506.04579, 2015.
[38] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid poolingin deep convolutional networks for visual recognition,” IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 37,no. 9, pp. 1904–1916, 2015.
[39] G. E. Box, G. M. Jenkins, G. C. Reinsel, and G. M. Ljung, Time seriesanalysis: forecasting and control. John Wiley & Sons, 2015.
[40] H. Lütkepohl, New introduction to multiple time series analysis.Springer Science & Business Media, 2005.
[41] S. Xingjian, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.-c.Woo, “Convolutional lstm network: A machine learning approachfor precipitation nowcasting,” in Proceedings of the Advances inNeural Information Processing Systems, 2015, pp. 802–810.
[42] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza-tion,” arXiv preprint arXiv:1412.6980, 2014.
Zichuan Liu is currently studying toward theB.S. degree at the School of Computer Scienceand Technology, Wuhan University of Technol-ogy, China. His research interests include butare not limited to deep learning and data mining,with a particular focus on spatial-temporal datamining. He often participates in some kagglecompetitions and won Data Science Bowl stu-dent award in 2020.
Rui Zhang is an Associate Professor in Schoolof Computer Science and Technology at WuhanUniversity of Technology, China. She receivedthe M.S. degree and Ph.D. degree in ComputerScience from Huazhong University of Scienceand Technology, China. From 2013 to 2014, shewas a Visiting Scholar with the College of Com-puting, Georgia Institute of Technology, USA.Her research interests include machine learning,network analysis and mobile computing.
Chen Wang (S’10-M’13-SM’19) received theB.S. and Ph.D. degrees from the Department ofAutomation, Wuhan University, China, in 2008and 2013, respectively. From 2013 to 2017, hewas a postdoctoral research fellow in the Net-worked and Communication Systems ResearchLab, Huazhong University of Science and Tech-nology, China. Thereafter, he joined the faculty ofHuazhong University of Science and Technologywhere he is currently an associate professor.His research interests are in the broad areas of
Internet of Things, data mining and mobile computing, with a recentfocus on privacy issues in wireless and mobile systems. He is a seniormember of IEEE and ACM.
Hongbo Jiang (M’08-SM’15) is now a full Pro-fessor in the College of Computer Science andElectronic Engineering, Hunan University. Heever was a Professor at Huazhong University ofScience and Technology. He received his Ph.D.from Case Western Reserve University in 2008.His research concerns computer networking, es-pecially algorithms and protocols for wirelessand mobile networks. He is serving as the editorfor IEEE/ACM Transactions on Networking, theassociate editor for IEEE Transactions on Mobile
Computing, ACM Transactions on Sensor Networks, IEEE Transactionson Network Science and Engineering, IEEE Transactions on IntelligentTransportation Systems, and the associate technical editor for IEEECommunications Magazine. He is a senior member of the IEEE.