ii-sdv 2015, 20 - 21 april, in nice
TRANSCRIPT

Text and Data Mining at CCCSolving the Content Retrieval and Licensing Conundrums for TDM
Dr. Haralambos MarmanisCTO & VP, EngineeringCopyright Clearance Center

Introduction
4/22/20152

Making Copyright Work – CCC and RightsDirect
Rightsholders Content Users
600+ million rights from:
• Publishers
• Authors
• Creators
• 35,000 companies
• Employees worldwide
• Users in 180 countries
• Licensing Solutions
• Rights Management
• Content Delivery
• Copyright Education
4/22/2015

Who Am I?
4/22/20154

What Is Text and Data Mining?
• Automate the extraction of “Entities” from Text
• Find Relationships and Patterns
• Produce hypotheses of interest
• Drive decision making
4/22/20155

Applications
• Biomarker discovery
• Drug repurposing
• Drug safety
• Competitive intelligence
• Sentiment analysis
• …….
4/22/20156

The General Problem & Our Solution Through An Example
4/22/20157

“Drug Discovery” Process
• Goal: Develop new treatments for diseases through hypothesis formation.
• Methodology:
– Keyword/Database Searching
– Review Literature
– Find relationships
– Develop hypothesis
– Test
– Product development
Etc.
4/22/20158

General Overview of the Process
1. Identify a set of resources that are relevant to a particular research objective
2. Analyze and extract information specific to the research objective
3. Develop and explore the various relations between extracted objects of interest
4/22/20159

Data Processing Workflow:Information Retrieval and Knowledge Discovery
4/22/201510 *http://www.jisc.ac.uk/reports/value-and-benefits-of-text-mining
Software Platforms for TDM
Information Retrieval
Knowledge Discovery

Problem: Too Much Research
• 53M Records in Scopus
• 800,000 Journal Articles published per year
4/22/201511

More Problems…
• Many sources of content
• Many formats
• Difficult to obtain full-text in XML
• Difficult to integrate content into TDM software.
• Hard to negotiate and manage licenses and feeds from all publishers.
4/22/201512

The DirectPath Solution
• Speed up time to obtain properly licensed content for text mining
• Discover and download full-text in XML, not just abstracts
• Main corpus includes Subscribed and Not-Subscribed content
• Normalize XML format across many publishers
• Provide a Web UI and RESTful API services
4/22/201513
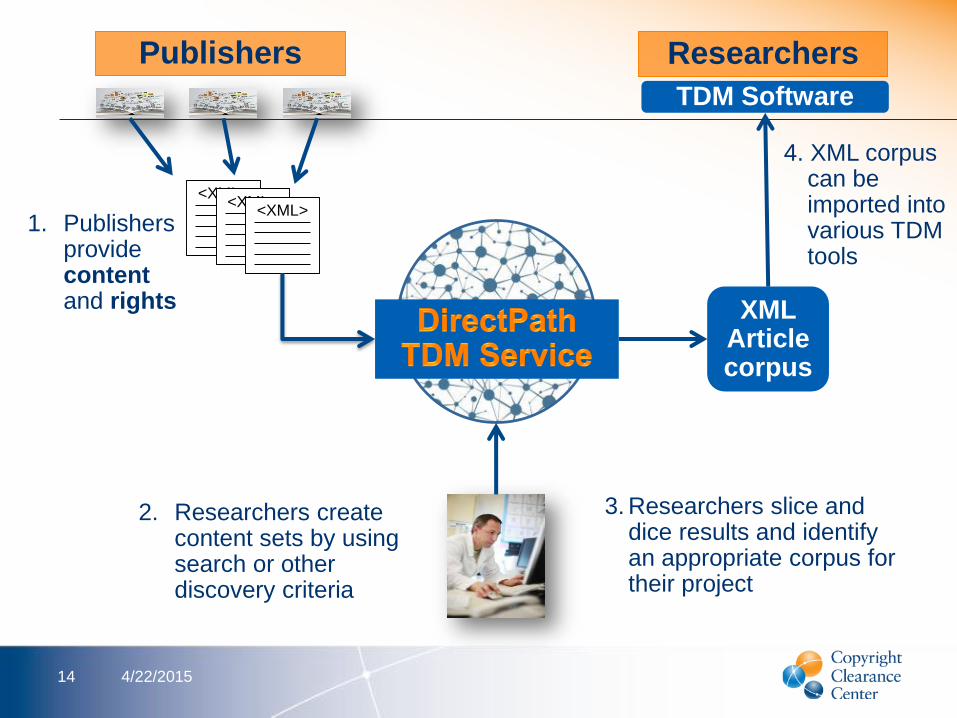
4/22/201514
2. Researchers create content sets by using search or other discovery criteria
XML Article corpus
TDM Software
3. Researchers slice and dice results and identify an appropriate corpus for their project
4. XML corpus can be imported into various TDM tools
1. Publishers provide contentand rights
<XML><XML>
<XML>
Publishers Researchers

Application Walkthrough
4/22/201515

4/22/201516

4/22/201517

4/22/201518

4/22/201519

4/22/201520

4/22/201521

RESTful Services Based on Open Standards
4/22/201522

4/22/201523

Unique Features
• Custom analysis/indexing for each Project
– Custom stop-word lists; synonyms/dictionaries
– Custom analyzers
– The finest granularity at the analysis and indexing level
• Build by design with multilingual support in mind
– Based on Lucene
• Search beyond TFIDF (e.g. document ranking by citation)
• Retrieval beyond Search (e.g. nearest neighbors)
• Cost and Quality Optimization (roadmap/patent pending)
• Integration with text mining tools like Linguamatics I2E
4/22/201524

TDM Product Roadmap
• Augment and Enrich the Inventory
• Workflow Integrations with 3rd Party Support
• Expand and enhance Metadata Normalization
• Introduce Content Metrics for Retrieval
• Cost Optimization
• Information Content Optimization
4/22/201525

Thank You!