ii-sdv 2015, 20 - 21 april, in nice
TRANSCRIPT


Why Search – European Patent Convention
2
Information Management`s
Task: Support Search

Introduction – What do we want, where are we?
3
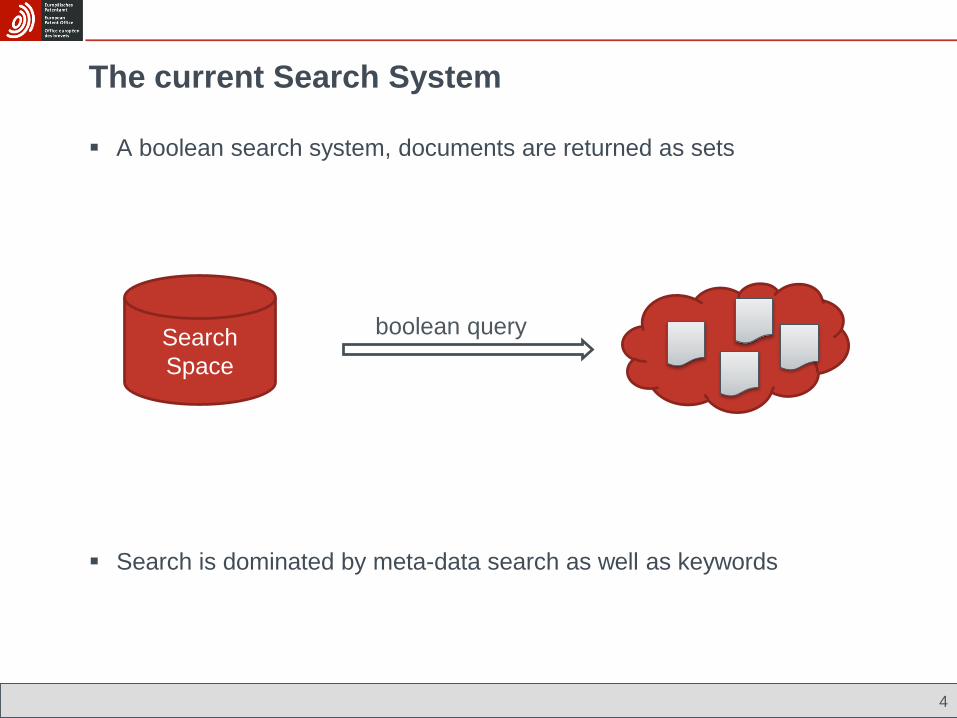
The current Search System
A boolean search system, documents are returned as sets
Search is dominated by meta-data search as well as keywords
4
Search
Space
boolean query

The current Search System
A Lucene elastic search based system, documents are returned as
ranked lists (pilot – fully available but no extensive training)
Moving away from a meta-data dominated search...?
5
Search
Spacek
Lucene query1

Patent Gold Standards
We have “manually” curated search reports for about 40 million simple
patent families
The relevant documents are mentioned in the search report as either
–X(I,N),A,Y,... documents
6
median: 5 citations
in search reports

Citation temporal distribution
50% of all citations are younger than 10 years (2005-now); 80% of all
citations are younger than 20 years; only 5% of citations are older than
1974.
7

Setting up a benchmarking environment
We need to move away from anecdotal evidence to statistically
meaningful facts
TAPAS
8
SEARCH
INDEX
Applications
Method 1 Method 2
MAP:0.4 MAP:0.2
Patent Corpus
1
2
3
4
* Exploiting real queries

Setting up a prototyping environment - KNIME
9
1
2
3
41
1
1
1 2
2
2
33
3
1

Evaluating the results
10

Graph Databases are valid tools - if we have a good
starting document (seed)
11

Graph Databases are valid tools - if we have a good
starting document (seed)
12

Graph Databases are valid tools - if we have a good
starting document (seed)
13

Graph Databases are valid tools - if we have a good
starting document (seed)
14
Again Meta-Data based!

But where do we start with an incoming patent
application?
15
?
Patent
Application

This has been implemented during the last 1-3
years, but
Literature suggest that we are sealed with our parameter optimization
strategies applying classic IR methods
We ignore the huge NPL part of the citations
The problem becomes worse every day (~3000 applications per week)
16

A searcher tries to work around “meaning” by:
Proximity Queries simulate or approximate “meaning”
Assumption: certain distances transport more meaning than others
(e.g. 3w or p) .
We want to ask “Give me all documents that are relevant with regards
to treatment of migraine pain with Aspirin”
But we actually ask “Migraine AND Pain AND Aspirin” or many variants
of that.
Classification is a very strong aid, representing a meaningful relation
<belongs to>
17

What does search actually mean?
Claim 1: A composition comprising a combination of paracetamol
and aspirin for use in the treatment a migraine pain in a human
subject.
Claim 2: A composition according to claim 1 where the composition
further comprises caffeine
18
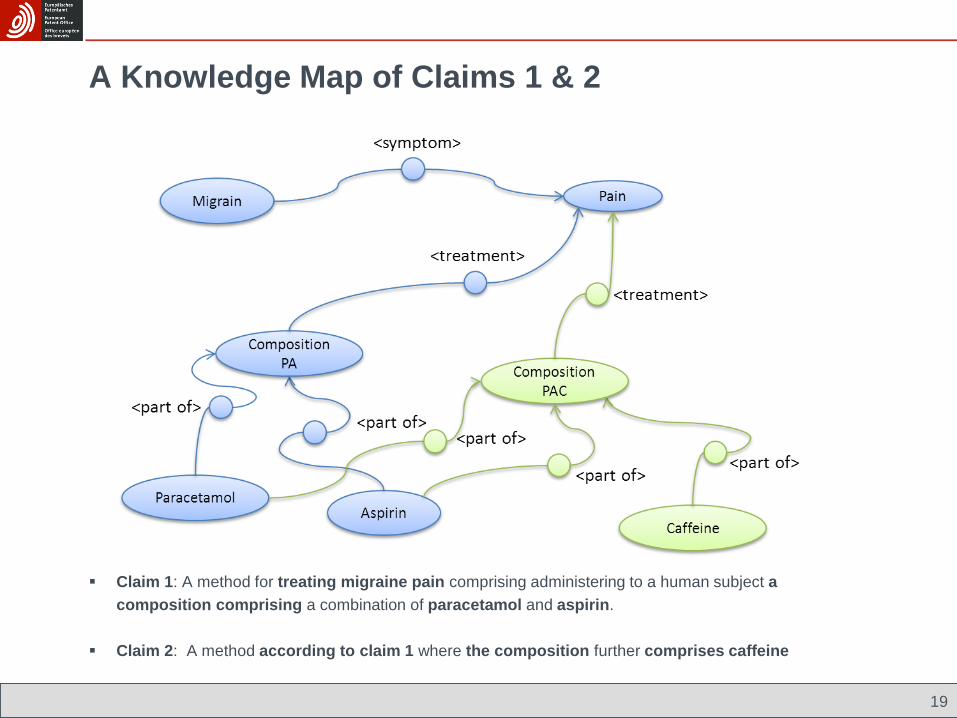
A Knowledge Map of Claims 1 & 2
Claim 1: A method for treating migraine pain comprising administering to a human subject a
composition comprising a combination of paracetamol and aspirin.
Claim 2: A method according to claim 1 where the composition further comprises caffeine
19

What is the Δ of Prior Art and the Application?
Δ
20
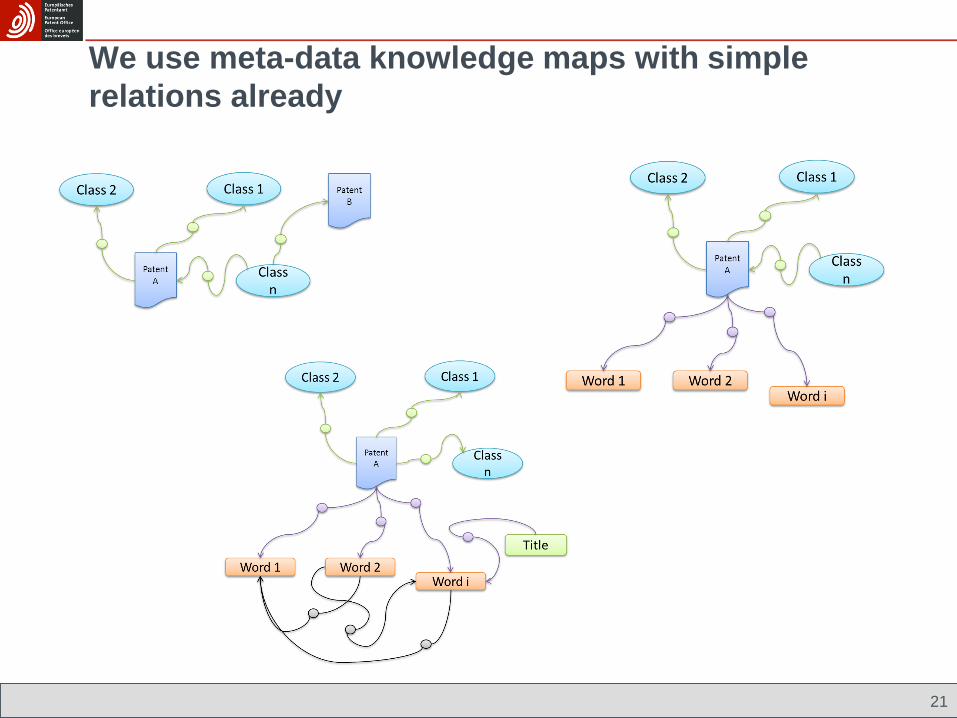
We use meta-data knowledge maps with simple
relations already
21

Moving towards real knowledge maps
Normalized Annotations are one step towards semantic search
connecting mentions in patents with normalized entities
Good coverage for biomedical domains
Lack of good terminologies for everything else
22

Approaches do exist
23

Patents have multi-modal information content: Images
Images
– Chemical Formulas
– Flow Diagrams
– Circuits
– Technical Drawings
24
Google Image Search
25

Image Search
26
Search
Space
Query
State of the art
Image processing
Filtering and
Visualisation

Image Search using S&K prototype
27
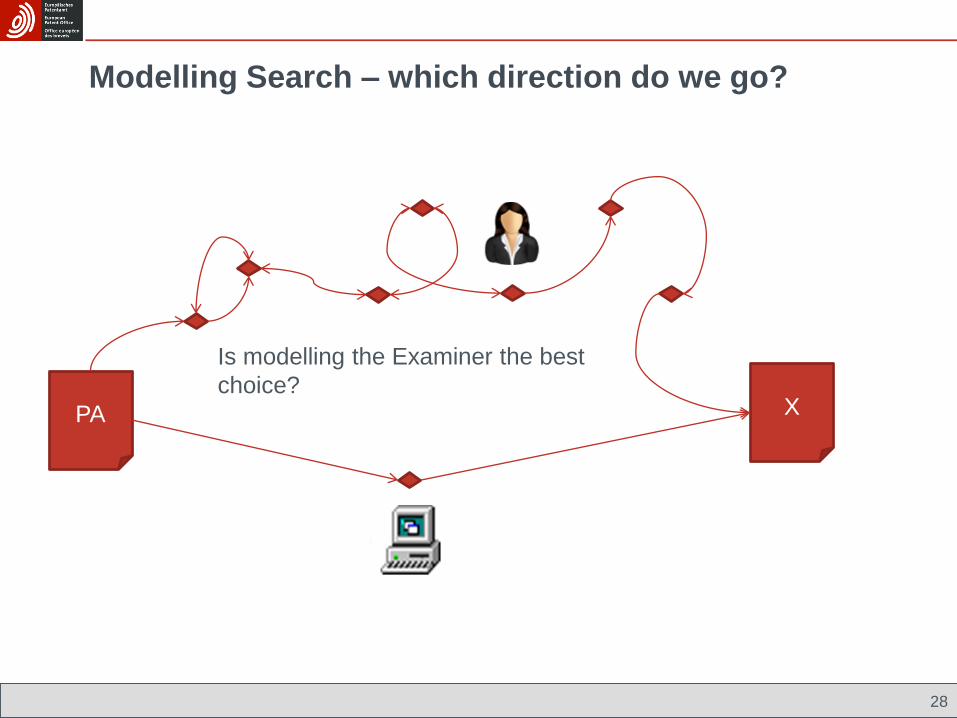
Modelling Search – which direction do we go?
28
PA X
Is modelling the Examiner the best
choice?

Enrichment and
AnnotationsNatural Language
Processing
Topic ModellingInformation Extraction
Knowledge Bases
Visualisation
Techniques
Workflow Management
Information Retrieval
Modelling the Search
Process
Knowledge Organisation
Systems
Technologies that can guide us
29
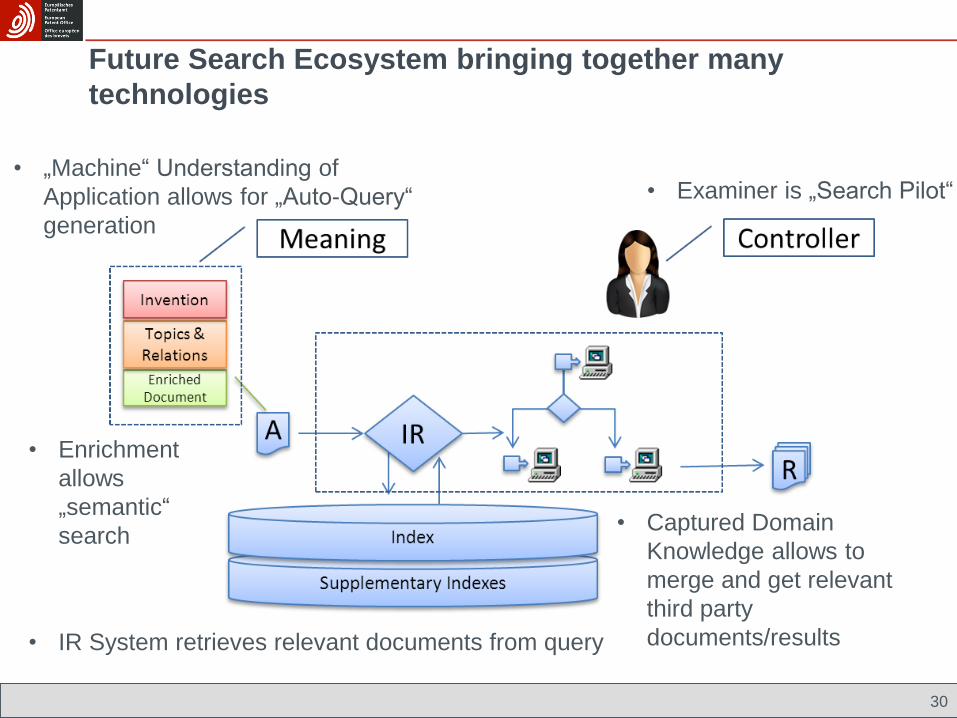
Future Search Ecosystem bringing together many
technologies
• Captured Domain
Knowledge allows to
merge and get relevant
third party
documents/results
• „Machine“ Understanding of
Application allows for „Auto-Query“
generation
• IR System retrieves relevant documents from query
• Enrichment
allows
„semantic“
search
• Examiner is „Search Pilot“
30
