in adobe reader press f5 to display bookmarks to assist … adobe reader press f5 to display...
TRANSCRIPT


About the CCRP
The Command and Control Research Program (CCRP)has the mission of improving DoD’s understanding ofthe national security implications of the Information Age.Focusing upon improving both the state of the art andthe state of the practice of command and control, theCCRP helps DoD take full advantage of the opportunitiesafforded by emerging technologies. The CCRP pursuesa broad program of research and analysis in informationsuperiority, information operations, command andcontrol theory, and associated operational concepts thatenable us to leverage shared awareness to improve theeffectiveness and efficiency of assigned missions. Animportant aspect of the CCRP program is its ability toserve as a bridge between the operational, technical,analytical, and educational communities. The CCRPprovides leadership for the command and controlresearch community by:
n articulating critical research issues;n working to strengthen command and control
research infrastructure;n sponsoring a series of workshops and symposia;n serving as a clearing house for command and
control related research funding; andn disseminating outreach initiatives that include the
CCRP Publication Series.

This is a continuation in the series of publicationsproduced by the Center for Advanced Concepts andTechnology (ACT), which was created as a “skunkworks” with funding provided by the CCRP underthe auspices of the Assistant Secretary of Defense(C3I). This program has demonstrated theimportance of having a research program focusedon the national security implications of theInformation Age. It develops the theoreticalfoundations to provide DoD with informationsuperiority and highlights the importance of activeoutreach and dissemination initiatives designed toacquaint senior military personnel and civilians withthese emerging issues. The CCRP Publication Seriesis a key element of this effort.
Check our Web site for the latest CCRP activities and publications.
www.dodccrp.org

DoD Command and Control Research ProgramASSISTANT SECRETARY OF DEFENSE (C3I)
&CHIEF INFORMATION OFFICER
Mr. John P. Stenbit
PRINCIPAL DEPUTY ASSISTANT SECRETARY OF DEFENSE (C3I)
Dr. Linton Wells, II
SPECIAL ASSISTANT TO THE ASD(C3I)&
DIRECTOR, RESEARCH AND STRATEGIC PLANNING
Dr. David S. Alberts
Opinions, conclusions, and recommendations expressed or impliedwithin are solely those of the authors. They do not necessarilyrepresent the views of the Department of Defense, or any other U.S.Government agency. Cleared for public release; distribution unlimited.
Portions of this publication may be quoted or reprinted withoutfurther permission, with credit to the DoD Command and ControlResearch Program, Washington, D.C. Courtesy copies of reviewswould be appreciated.
Library of Congress Cataloging-in-Publication DataAlberts, David S. (David Stephen), 1942-Code of best practice for experimentation / David S. Alberts, Richard E. Hayes. p. cm. -- (CCRP publication series)Includes bibliographical references.ISBN 1-893723-07-0 (pbk.)1. Military research—United States—Methodology. I. Hayes, Richard E., 1942- II. Title. III. Series.U393 .A667 2002355’.07’0973--dc21 2002011564
July 2002

Information Age Transformation Series
CODE OF BEST PRACTICE
EXPERIMENTATION

i
Table ofContents
Acknowledgments ............................................. vii
Preface ................................................................. xi
Chapter 1: Introduction ....................................... 1
Chapter 2: Transformation andExperimentation................................................... 7
Chapter 3: Overview of Experimentation ........ 19
Chapter 4: The Logic of ExperimentationCampaigns .......................................................... 41
Chapter 5: Anatomy of an Experiment ............ 61
Chapter 6: Experiment Formulation .............. 127
Chapter 7: Measures and Metrics .................. 155
Chapter 8: Scenarios ....................................... 199
Chapter 9: Data Analysis andCollection Plans ............................................... 223
Chapter 10: Conduct of the Experiment........ 253
Chapter 11: Products....................................... 281
Chapter 12: Model-Based Experiments......... 317

ii
Chapter 13: Adventures in Experimentation:Common Problems and PotentialDisasters .......................................................... 343
Appendix A: Measuring Performance andEffectiveness in the Cognitive Domain........ 367
Appendix B: Measurement Hierarchy........... 387
Appendix C: Overview of Models andSimulations...................................................... 401
Appendix D: Survey......................................... 425
Acronyms ......................................................... 427
Bibliography .................................................... 433
About the Editors ............................................. 435

iii
List of FiguresFigure 2-1. NCW Value Chain .............................. 9
Figure 2-2. Mission Capability Packages ........ 13
Figure 2-3. NCW Maturity Model ....................... 15
Figure 3-1. From Theory to Practice ................ 26
Figure 4-1. Comparison of An Experiment to AnExperimentation Campaign .............................. 44
Figure 4-2. The Experimentation CampaignSpace................................................................... 49
Figure 5-1. Phases of Experiments .................. 62
Figure 5-2. Modeling and Simulations ........... 123
Figure 6-1. Illustrative Initial Descriptive Model:Self-Synchronization Experiment .................. 135
Figure 7-1. Hierarchy of Outcomes ................ 177
Figure 8-1. Scenario Threat Space................. 202
Figure 11-1. Management and DisseminationProducts .......................................................... 283
Figure 11-2. Archival Products ....................... 297
Figure 12-1. Modeling and Simulation inExperimentation............................................... 322

iv
Figure 12-2. Multidisciplinary ModelingTeam .................................................................. 325
Figure 12-3. Sensemaking ConceptualFramework ........................................................ 328
Figure 12-4. Analysis of Model-BasedExperiment Results ......................................... 334
Figure B-1. Hierarchy of ExperimentationMetrics .............................................................. 388
Figure B-2. Measurement Issues – Real-TimeInformation and Knowledge ........................... 390
Figure B-3. Measurement Issues – Expertise,Beliefs, Culture, and Experience.................... 391
Figure B-4. Measurement Issues – IndividualAwareness and Understanding ...................... 392
Figure B-5. Measurement Issues –Collaboration.................................................... 394
Figure B-6. Measurement Issues – SharedAwareness and Understanding ...................... 395
Figure B-7. Measurement Issues –Decisionmaking ............................................... 396
Figure B-8. Measurement Issues – ForceElement Synchronization ................................ 398
Figure B-9. Measurement Issues – Military Task/Mission Effectiveness ..................................... 399

v
Figure B-10. Measurement Issues – PolicyEffectiveness .................................................... 400
Figure C-1. (from Understanding InformationAge Warfare) ..................................................... 406
Figure C-2. Infrastructure to Support Modeling,Simulation, and Experimentation................... 410
Figure C-3. Model Hierarchy ........................... 412
Figure C-4. Illustrative Model Linkage ........... 420

vii
Acknowledgments
This Code of Best Practice would never have beenundertaken if it were not for the inspiration and
support provided to this effort by MG Dean Cash.MG Cash, as the J9 at JFCOM, is responsible forjoint experimentation. Joint experimentation is anawesome responsibility since it is a critical missionthat will directly influence the course of no less thanthe transformation of the DoD and ultimately ourability to meet the challenges of the new century.MG Cash recognized that experimentation was notyet a core competency and that efforts to betterunderstand how experiments should be planned,conducted, and mined for insights were key to thesuccess of his organization’s mission. Driven by adesire not only to record lessons from pastexperimenters but also to ensure the quality of futureones, he requested that the CCRP engage the bestminds we could employ to develop this Code of BestPractice (COBP) for Experimentation.
The COBP is not being published as a definitive work.Much remains to be learned about organizing andconducting experiments of the extraordinary rangeand complexity required by the task of transformation.Rather, this code should be seen for what it is- aninitial effort to pull together important basic ideas andthe myriad lessons learned from previous experimentsand to synthesize this material into a guide for thosewho must conceive, plan, conduct, and analyze theresults of experiments as well as those who must use

viii
the results of experimentation to make decisions aboutthe future of the military.
Many people contributed to this effort. We undertookthe roles of contributing editors, trying to ensure bothcoherence and coverage of key topics. John E. Kirzl,Dr. Dennis K. Leedom, and Dr. Daniel T. Maxwelleach drafted important elements of the volume.Significant and very helpful comments on an earlydraft were received from Dr. Larry Wiener and Dr.Richard Kass. A debt of gratitude is also owed to themembers of the AIAA Technical Committee onInformation and C2 Systems who contributed to aforerunner to the COBP, a study of lessons learnedfrom the first Joint Expeditionary Force Experiment(JEFX). This review was requested of them by thethen J7 MGen Close. Participating with us in the AIAAstudy were John Baird, John Buchheister, Dr. LelandJoe, Kenneth L. Jordan, Dr. Alexander H. Levis, Dr.Russel Richards, RADM Gary Wheatley (ret), andDr. Cindy L. Williams. In some important ways, thisdocument also builds upon the NATO COBP of C2Assessment, a product of an outstandinginternational team. Participating with us in the SAS-026 effort were Dr. Alexander von Baeyer, TimothyBailey, Paul Choinard, Dr. Uwe Dompke, Corneliusd’Huy, Dr. Dean Hartley, Dr. Reiner Huber, DonaldKroening, Dr. Stef Kurstjens, Nicholas Lambert, Dr.Georges Lascar, LtCol (ret) Christian Manac’h,Graham Mathieson, Prof. James Moffat, Lt. OrhunMolyer, Valdur Pille, Mark Sinclair, Mink Spaans, Dr.Stuart Starr, Dr. Swen Stoop, Hans Olav Sundfor,LtCol Klaus Titze, Dr. Andreas Tolk, CorinneWallshein, and John Wilder.

ix
The Information Superiority Working Group (ISWG),a voluntary group of professionals from government,industry, and academia that meets monthly underCCRP leadership to further the state of the art andpractice, also contr ibuted signif icant ideas.Members of the ISWG include Edgar Bates,Dr. Peter Brooks, Dennis Damiens, Hank DeMattia,Greg Giovanis, Dr. Paul Hiniker, Hans Keithley,Dr. Cliff Lieberman, Julia Loughran, Dr. MarkMandeles, Telyvin Murphy, Dan Oertel, Dr. WalterPerry, John Poirier, Dennis Popiela, Steve Shaker,Dr. David Signori, Dr. Ed Smith, Marcy Stahl, ChuckTaylor, Mitzi Wertheim, Dave White, and Dr. LarryWiener.
I would also like to thank Joseph Lewis for editingour rough drafts into a finished product and BerniePineau for designing and producing the graphics,charts, and cover artwork.
Dr. David S. Alberts Dr. Richard E. Hayes

xi
Preface
Experimentation is the lynch pin in the DoD’sstrategy for transformation. Without a properly
focused, well-balanced, rigorously designed, andexpertly conducted program of experimentation,the DoD will not be able to take full advantage ofthe opportunities that Information Age conceptsand technologies offer.
Therefore, experimentation needs to become anew DoD core competency and assume its rightfulplace along side of our already world-class trainingand exercise capabilities. In fact, as we gainexperience and acquire expertise with the designand conduct of experiments and focusedexperimentation campaigns, I expect that the wayin which we think about and conduct training andexercises will become a coherent continuum withinthe overall process of coevolving new missioncapability packages.
This Code of Best Practice was developed to (1)accelerate the process of our becoming more awareof the issues involved in planning, designing, andconducting experiments and using experimentresults, and (2) provide support to individualsand organizations engaged in a variety ofexperimentation activities in support of DoDtransformation.
This initial edition of the Code of Best Practice willevolve over time as we gain more experience andincorporate that experience into new versions of the

xii
Code. We are interested in learning about yourreactions to this Code, your suggestions forimproving the Code, and your experiences withexperimentation. For this purpose, a form has beenprovided in the back of the Code for you.

1
CHAPTER 1
Introduction
Why DoD Experiments?
Experiments of various kinds have begun toproliferate throughout the Department of
Defense (DoD) as interest in transforming thedefense capabilities of the United States hasgrown. DoD transformation is motivated by arecogn i t ion tha t (1 ) the na t iona l secur i t yenv i ronment o f the 21 s t cen tu ry w i l l besignificantly different and as a consequence, theroles and missions the nation will call upon theDoD to undertake will require new competenciesand capabilities, (2) Information Age conceptsand techno log ies p rov ide unpara l le ledoppor tun i t ies to deve lop and employ newoperational concepts that promise to dramaticallyenhance competitive advantage, and (3) theDoD’s business processes will need to adapt toprovide the flexibility and speed necessary tokeep pace with the rapid changes in both ourna t iona l secur i t y and in fo rmat ion - re la tedtechnologies, as well as the organizationaladaptations associated with these advances.

2 Code of Best Practice for Experimentation
Need For a Code of BestPractice
There is growing concern that many of theactivities labeled experiments being conductedby the DoD have been less valuable than theycould have been. That is, their contributions toDoD s t ra teg ies and dec is ions , to thedevelopment of mission capability packages(MCPs), and to the body of knowledge in generalhave been limited by the manner in which theyhave been conceived and conducted. Given theprominent ro le that both jo int and Serviceexper imenta t ion need to p lay in thetransformation of the DoD, it seems reasonableto ask if we can do better. We believe that theanswer is a resounding “yes.”
This Code of Best Practice (COBP) is intendedto (1) increase awareness and understanding ofthe different types of experimentation activitiesthat the DoD needs to employ in order to informthe transformation, (2) articulate a useful set oforganizing principles for the design and conductof experiments and experimentation campaigns,(3) provide both producers of experiments andconsumers of experimentation results with “bestpractice” and lessons learned, (4) provide futureexperimenters with a firm foundation upon whichto build, and (5) promote a degree of scientificr igor and pro fess iona l ism in the DoDexperimentation process.

3Chapter 1
Scope and Focus
This COBP presents a philosophy and broad setof guidelines to be considered by professionalsresponsib le for p lanning and conduct ingexperiments within the DoD, and by policy makerswho must judge the validity of experimentationinsights and incorporate them into defense policyand investment decisions.
The DoD transformation has three dimensions:what we do; how we do it; and how we provisionand prepare. Experimentation activities are andw i l l be f ocused on each o f t hese th reedimensions. This COBP is intended to applyacross all three dimensions, but particularlyupon the second of these dimensions – how wedo it – and uses the precepts and hypothesesof Network Centric Warfare (NCW) to exploreeach o f t he face ts o f expe r imen ta t i on .Additionally, the Code presents examples anddiscussions that highlight why adherence tosound experimentation principles is important.
Organization of the Code
To effectively illuminate the many aspects andstages of experimentation, this Code of BestPractice proceeds from broad to specific topics, aswell as studying the stages of experimentation asthey occur chronologically.
Chapter 2 briefly discusses the need for a DoDtransformation in the context of the military andpolitical agendas at the time of this writing. To support

4 Code of Best Practice for Experimentation
transformation efforts, the need for superiorexperimentation techniques and processes areintroduced. Chapter 3 provides a definition andoverview of experimentation, both as a generalconcept and a DoD process. The three uses ofexperimentation (discovery, hypothesis testing, anddemonstration) are defined and differentiated by theirroles within the DoD.
Chapter 4 explains the need and purpose forexperimentation campaigns, as opposed to focusingonly on individual experiments. Since the purposeof any experiment should be to increase or generateuseful knowledge, it must also be the purpose ofthe experiment to ensure the validity of thatknowledge. Because no individual experiment,regardless of preparation and execution, is immunefrom human error or the effects of unforeseeablevariables, multiple experiments must be conductedto verify results.
In Chapter 5, the anatomy of an experiment is brokendown into phases, stages, and cycles of interaction.By understanding the purpose of each stage of theexperiment (and its relationships to other stages),the experimentation team can conduct a moreprofitable experiment through proper preparation,execution, feedback, and analysis. An incompleteexecution of the experimentation process can onlyresult in an incomplete experiment with weakproducts. Experimentation formulation is discussedin Chapter 6. This begins with a discussion of howto formulate an experimentation issue and proceedsto a short discussion of specific experimentationdesign considerations.

5Chapter 1
Chapter 7, Metrics and Measures, examines theneed for generating and specifying the metrics andmeasures to be used in the data collection process,including the need to ensure that team membersuse identical definitions of terms and metrics.Chapter 8 discusses the importance of properlydesigning and employing a set of scenarios1 thatprovide an opportunity to observe a range of valuesfor the variables of interest.
Chapter 9 discusses the importance of developingand implementing data analysis and data collectionplans, both before and during the conduct of theexperiment to ensure that all needed data areproperly identified, collected, and archived, and thatthey remain available for future use. The actualconduct and execution of the experiment is reviewedin Chapter 10.
The generation of a set of products (as discussedin Chapter 11) is crucial to the dissemination of theexperimentation results to the sponsors and theresearch community. Chapter 12 discusses theuses, benefits, and limitations of modeling andsimulation as a substitute for empirical datacollection. Chapter 13 concludes this Code with adiscussion of the most common failures andobstacles to successful experimentation.
1The American use of the word “scenario” is interchangeablewith the British “usecase.”

7
CHAPTER 2
Transformationand
Experimentation
Transformation and NCW
Our transformational challenge is clear. In thewords of the President, “We must build forces
that draw upon the revolutionary advances in thetechnology of war…one that relies more heavily onstealth, precision, weaponry, and informationtechnologies” (emphasis added). Informationtechnologies have proven to be revolutionary not onlyin the nature of the capabilities being developed inthe “Information Domain”1 and the pace of theseadvances, but also in promoting discontinuouschanges in the way individuals and organizationscreate effects, accomplish their tasks, and realizetheir objectives. The DoD’s Network Centric WarfareReport to Congress2 defines the connection betweenDoD Transformation and Network Centric Warfare:“Network Centric Warfare (NCW) is no less than theembodiment of an Information Age transformation ofthe DoD. It involves a new way of thinking about howwe accomplish our missions, how we organize and

8 Code of Best Practice for Experimentation
interrelate, and how we acquire and field the systemsthat support us… It will involve ways of operatingthat have yet to be conceived, and will employtechnologies yet to be invented... This view of thefuture is supported by accumulating evidence froma wide variety of experiments, exercises, simulations,and analyses.”3
NCW and Experimentation
The report goes on to explain NCW in terms of a setof tenets that are, in essence, a set of linkagehypotheses that provide structure and guidance forthe development of network-centric operationalconcepts. These tenets serve as a useful set oforganizing principles for experimentation. Thus, DoDexperiments should focus on exploring the basictenets of NCW, and developing and maturingnetwork-centric operational concepts based uponthese tenets.
Tenets of NCW
NCW represents a powerful set of warfightingconcepts and associated military capabilities thatallow warfighters to take full advantage of allavailable information and bring all available assetsto bear in a rapid and flexible manner. The fourtenets of NCW are that:
• A robustly networked force improves informationsharing and collaboration;

9Chapter 2
• Information sharing and collaboration enhancethe quality of information and shared situationalawareness;
• Shared situational awareness enables self-synchronization; and
• These, in turn, dramatically increase missioneffectiveness.
Each tenet represents a testable linkage hypothesis.The tenets themselves are linked to form a valuechain as shown in Figure 2-1.
Figure 2-1. NCW Value Chain

10 Code of Best Practice for Experimentation
The Domains of NCW
NCW concepts can only be understood and exploredby focusing on the relationships that take placesimultaneously in and among the physical, information,and cognitive domains.
Physical Domain: The physical domain is thetraditional domain of warfare. It is where strike,protection, and maneuver operations take placeacross the ground, sea, air, and space environments.It is the domain where physical platforms and thecommunications networks that connect them reside.Comparatively, the elements of this domain are theeasiest to “see” and to measure; consequently,combat power has traditionally been measured byeffects in this domain.
Information Domain: The information domain is thedomain where information is created, manipulated,and shared. Moreover, it is the domain where thecommand and control of modern military forces iscommunicated and where a commander’s intent isconveyed. Consequently, it is increasingly theinformation domain that must be protected anddefended to enable a force to generate combat powerin the face of offensive actions taken by an adversary.And, in the all-important battle for informationsuperiority, the information domain is the area ofgreatest sensitivity. System performance relatedmetrics (e.g., bandwidths) have predominated untilrecently, but these are no longer sufficient bythemselves for measuring the quality of information.
Cognitive Domain: The cognitive domain is thedomain of the mind of the warfighter and the

11Chapter 2
warfighter’s supporting populace. This is the domainwhere commander’s intent, doctrine, tactics,techniques, and procedures reside. The intangiblesof leadership, morale, unit cohesion, level of trainingand experience, situation awareness, and publicopinion are elements of this domain. Effects in thisdomain present the greatest challenge with respectto observation and measurement.
A warfighting force that can conduct network-centricoperations can be defined as having the followingcommand and control-related attributes andcapabilities in each of the domains:
Physical Domain
• All elements of the force are robustly networked,achieving secure and seamless connectivity, or
• Sufficient resources are present to dominate thephysical domain using NCW-derived informationadvantage.
Information Domain
• The force has the capability to collect, share,access, and protect information.
• The force has the capability to collaborate,which enables it to improve its informationposition through processes of correlation, fusion,and analysis.
• A force can achieve information advantage overan adversary.

12 Code of Best Practice for Experimentation
Cognitive Domain
• The force is able to develop and share high-quality situation awareness.
• The force is able to develop a sharedknowledge of the commander’s intent.
• The force is able to self-synchronize itsoperations.
Experimentation with the application of network-centric operational concepts should be traceabledirectly to one or more of the linkage hypothesesor to one or more of the attributes and capabilitiesthat define network-centric operations. Thus, therewill need to be experiments that involve attentionto all three of the domains and the interactionsamong them.
Concept-Based, MissionCapability-FocusedExperimentation
NCW involves changes not only in information-related capabilities and flows, but also in the waydecisions and processes are distributed acrossthe force. It has long been understood that, inorder to leverage increases in information-related capabilities, new ways of doing businessare required.
This is not just a matter of getting the most out of newinformation-related capabilities, but these new waysof doing business are needed to avoid potentialorganizational dysfunction. This idea is explored in

13C
hapter 2
Figure 2-2. Mission Capability Packages

14 Code of Best Practice for Experimentation
the book Unintended Consequences of the InformationAge. It addresses the concept of mission capabilitypackages as a framework for dealing with theintroduction of new technology (Figure 2-2).
Thus, the essence of a network-centric capability is acoevolved mission capability package, one thatderives its power from the tenets of NCW. A missioncapability package begins with a concept ofoperations, in this case a network-centric concept ofoperations that includes characteristics from each ofthe domains described above.
Note that NCW applications exist at different levelsof maturity. For example, a less mature applicationmay only seek to share information to improve thequality of information available to the participants;it would not involve changes to process or commandapproach. Conversely, a fully mature network-centric concept would involve collaboration and acommand approach that features self-synchronization. The NCW Report to Congressprovides a maturity model (Figure 2-3) that definesa migrat ion path for the maturing of NCWcapabilities over time and hence, a migration pathfor experimentation.
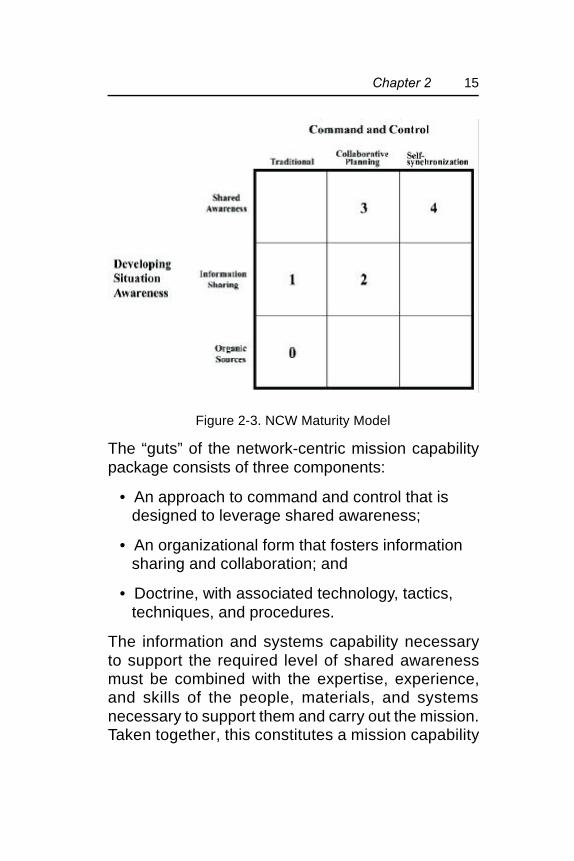
15Chapter 2
Figure 2-3. NCW Maturity Model
The “guts” of the network-centric mission capabilitypackage consists of three components:
• An approach to command and control that isdesigned to leverage shared awareness;
• An organizational form that fosters informationsharing and collaboration; and
• Doctrine, with associated technology, tactics,techniques, and procedures.
The information and systems capability necessaryto support the required level of shared awarenessmust be combined with the expertise, experience,and skills of the people, materials, and systemsnecessary to support them and carry out the mission.Taken together, this constitutes a mission capability

16 Code of Best Practice for Experimentation
package. All of this is required to turn an operationalconcept into a real deployable capability.
The term mission capability package is preferred tothe widely used acronym DOTMLPF (doctrine,organization, training, material, leadership,personnel, and facilities) because it is broader. Amission capability package, or the innovation itrepresents, certainly can impact and must take intoaccount all the elements of DOTMLPF, but it is alsoricher (may have more than one form while underdevelopment) and matures over time as the missioncapability package process is executed. Hence, theinnovation “collaborative work process” may takeseveral different forms depending on the functionbeing performed and may be supported by anevolving set of DOTMLPF elements as it matures.
The objectives of experimentation are therefore todevelop and ref ine innovat ive concepts ofoperation and to coevolve mission capabilitypackages to turn these concepts into realoperational capabilities. One experiment cannotpossibly achieve this objective. Rather it will takea well-orchestrated experimentation campaignconsisting of a series of related activities toaccomplish this. Hence, this COBP treats both howto conduct successful individual experiments andalso how to link them together into successfulcampaigns of experimentation.
1Alberts, David S., John J. Garstka, and Frederick P. Stein.Network Centric Warfare: Developing and Leveraging InformationSuperiority. Second Edition. Washington, DC: CCRP. 1999.

17Chapter 2
2Network Centric Warfare Department of Defense Report toCongress. July 2001.3Ibid. Executive Summary, p. i.

19
CHAPTER 3
Overview ofExperimentation
T he term experimentation arises from theLatin, experiri, which means, “to try.”
Experimentation knowledge differs from other typesof knowledge in that it is always founded uponobservation or experience. In other words,experiments are always empirical. However,measurement alone does not make an experiment.Experiments also involve establishing some level ofcontrol and also manipulating one or more factors ofinterest in order to establish or track cause and effect.A dictionary definition of experiment is a test made“to determine the efficacy of something previouslyuntried,” “to examine the validity of an hypothesis,”or “to demonstrate a known truth.” These threemeanings distinguish the three major roles that DoDorganizations have assigned to experimentation.
Uses of Experiments
Discovery experiments involve introducing novelsystems, concepts, organizational structures,technologies, or other elements to a setting wheretheir use can be observed and catalogued. In theDoD context, the objective is to find out how the

20 Code of Best Practice for Experimentation
innovation is employed and whether it appears tohave military utility. Discovery experiments are similarto the time honored military practice by which newmilitary hardware (aircraft, tanks, etc.) was developedagainst a set of technical specifications (fly faster,turn tighter, shoot farther, etc.), then given to technicaluser communities (typically Service testorganizations or boards) to work out the concepts ofoperation, tactics, techniques, and procedure foreffective employment. For example, when GPS wasa novel concept, one U.S. Marine Corps battalionwas reportedly provided with the capability and givena few days to decide how they might best employ it,then run through the standard 29 Palms exercise tosee both how they used the capability and whatdifference it made. This discovery experiment wasenabled because a body of knowledge existed onhow U.S. Marine Corps battalions performed the 29Palms mission, so the sentry GPS was a manipulationand the 29 Palms setting and U.S.M.C. organizationwere, effectively, controls.
The goals of discovery experiments are to identifypotential military benefits, generate ideas about thebest way for the innovation to be employed, andidentify the conditions under which it can be used(as well as the limiting conditions – situations wherethe benefits may not be available). In a scientificsense, these are “hypothesis generation” efforts.They will typically be employed early in thedevelopment cycle. While these experiments mustbe observed carefully and empirically in order togenerate rich insights and knowledge, they will notordinarily provide enough information (or evidence)to reach a conclusion that is val id (correct

21Chapter 3
understandings of the cause-and-effect or temporalrelationships that are hypothesized) or reliable (canbe recreated in another experimentation setting).They are typically guided by some clearly innovativepropositions (see Chapters 5 and 6) that would beunderstood as hypotheses if there were a body ofexisting knowledge that supported them. Typicaldiscovery experiments lack the degree of controlnecessary to infer cause and effect, and ofteninvolve too few cases or trials to support validstatistical inference.
However, these limitations are not barriers todiscovery experimentation. Most new concepts,ideas, and technologies will benefit from discoveryexperimentation as a way of weeding out ideas thatsimply do not work, forcing the community to askrigorous questions about the benefits being soughtand the dynamics involved in implementing the idea,or specifying the l imit ing condit ions for theinnovation. Good discovery experiments will lay thefoundation for more rigorous types of experimentswhere the hypotheses they generate are subject tomore rigorous assessment and refinement.
Moreover, discovery experiments must be observedin detail if they are to reach their maximum value.For example, one of the earl iest discoveryexperiments looking at Joint Vision 2010 conceptsfound that the subjects altered their workingorganization and process during the event. This wasreported as a major finding. However, no tools orinstruments were in place to record how the playersaltered their processes and structures, so the

22 Code of Best Practice for Experimentation
experiment fell short of specifying precise hypothesesto guide later research and development.
Hypothesis testing experiments are the classic typeused by scholars to advance knowledge by seekingto falsify specific hypotheses (specifically if…thenstatements) or discover their limiting conditions. Theyare also used to test whole theories (systems ofconsistent, related hypotheses that attempt to explainsome domain of knowledge) or observablehypotheses derived from such theories. In a scientificsense, hypothesis testing experiments buildknowledge or refine our understanding of aknowledge domain.
In order to conduct hypothesis testing experiments,the experimenter(s) create a situation in which one ormore factors of interest (dependent variables) can beobserved systematically under conditions that vary thevalues of factors thought to cause change(independent variables) in the factors of interest, whileother potentially relevant factors (control variables)are held constant, either empirically or throughstatistical manipulation. Hence, results fromhypothesis testing experiments are always caveatedwith ceteris paribus, or “all other things being equal.”Both control and manipulation are integral toformulating hypothesis testing experiments.
Hypothesis testing experiments have been employedin a variety of military settings. For example, DARPA’sCommand Post of the Future (CPOF) Program ranan experiment on alternative presentationtechnologies and their impact on the situationawareness of individuals. Similarly, the J-9, JFCOM

23Chapter 3
Experimentation Command ran an experiment onpresentation technologies and their impact onindividual and team situation awareness.
Since the number of independent, dependent, andcontrol variables relevant in the military arena isvery large, considerable thought and care are oftenneeded to conduct valid hypothesis tests. Moreover,no single experiment is likely to do more thanimprove knowledge marginally and help clarify newissues. Hence, sets of related hypothesis testingexperiments are often needed in order to gain usefulknowledge. The planning of sets of relatedexperiments is discussed below under the headingof experimentation campaigns.
Demonstration experiments, in which known truth isrecreated, are analogous to the experimentsconducted in a high school, where students followinstructions that help them prove to themselves thatthe laws of chemistry and physics operate as theunderlying theories predict. DoD equivalent activitiesare technology demonstrations used to showoperational organizations that some innovation can,under carefully orchestrated conditions, improve theefficiency, effectiveness, or speed of a militaryactivity. In such demonstrations, all the technologiesemployed are well-established and the setting(scenario, participants, etc.) is orchestrated to showthat these technologies can be employed efficientlyand effectively under the specified conditions.
Note that demonstration experiments are notintended to generate new knowledge, but rather todisplay existing knowledge to people unfamiliar with

24 Code of Best Practice for Experimentation
it. The reasons for empirical observation change torecording the results reliably and noting theconditions under which the innovations weredemonstrated in demonstration experiments. Failureto capture this information will lead to unrealisticexpectations and inappropriate applications of theinnovations. This has happened more than once inthe DoD when capabilities developed for a specificdemonstration were transferred to a very differentcontext and failed because they had not beenproperly adapted. Some demonstration experimentsinvolve control, but no manipulation.
Experimentation Campaigns
As noted earlier, military operations are too complexand the process of change is too expensive for theU.S. to rely on any single experiment to “prove” thata particular innovation should be adopted or willprovide a well-understood set of military benefits.Indeed, in academic settings, no single experimentis relied on to create new knowledge. Instead,scholars expect that experimentation results will berepeatable and will fit into a pattern of knowledge onrelated topics. Replication is important because itdemonstrates that the experimentation results arenot the product of some particular circumstances(selection of subjects, choice of the experimentationsituation or scenario, bias of the researchers, etc.).Placing the results in the context of other researchand experimentation provides reasons to believe thatthe results are valid and also help to provide linkagesto the causal mechanisms at work.

25Chapter 3
An experimentation campaign is a series of relatedactivities that explore and mature knowledge abouta concept of interest. As illustrated in Figure 3-1,experimentation campaigns use the different typesof experiments in a logical way to move from an ideaor concept to some demonstrated military capability.Hence, experimentation campaigns are organizedways of testing innovations that allow refinement andsupport increased understanding over time.
The initial concept may come from almost anywhere– a technological innovation, a concept of operationsdeveloped to deal with new or emerging threats, acapability that has emerged in civilian practice andappears to have meaningful military application andutility, a commission or study generated to examinea problem, lessons learned from a conflict, anobserved innovation in a foreign force, or any of ahost of other sources.
Ideally, this innovation is understood well enoughto place it in the context of a mission capabilitypackage. For example, a technological innovationmay require new doctrine, organizational structures,training, or other support in order to achieve themilitary utility envisioned for it. In some cases,research into prior experience, applications, orresearch on similar topics may help developmentof the mission capability package needed. Simplyplacing a technological innovation into the contextof existing doctrine, organization, and training fordiscovery experimentation is normally a very weakand inefficient approach for it will not be able toproperly evaluate the potential of the technologicalinnovation. In cases where this has been done, the

26C
ode of Best P
ractice for Experim
entation
Figure 3-1. From Theory to Practice

27Chapter 3
potential value of the innovation has been missedor undervalued.
Discovery Experiments in theContext of an ExperimentationCampaign
Obviously, some discovery experiments will beneeded first to see whether the innovation showsserious potential for military utility and impact. Thesemay involve pure models and computer simulationsto place the new concept in the context of otherfactors, or human-in-the-loop experiments to learnhow people relate to the innovation and choose toemploy it, or war games, or field trials. Whateverformats are chosen should be loosely configured toencourage adaptation and innovation, but shouldalso be carefully observed, recorded, and analyzedto maximize learning. In many cases, these discoveryexperiments will involve surrogate capabilities thatcreate the effect of the innovation, but minimize thecost of the effort.
Perhaps the most famous ini t ial discoveryexperiments were those conducted by the Germansto explore the tactical use of short range radiosbefore World War II. They mimicked a battlespace(using Volkswagens as tanks) in order to learn aboutthe reliability of the radios and the best way toemploy the new communications capabilities andinformation exchanges among the components oftheir force. Similarly, the early U.S. Marine Corpsexperimentation with remotely piloted vehicles(RPVs) during efforts like HUNTER WARRIOR used

28 Code of Best Practice for Experimentation
commercially available vehicles to conduct a varietyof missions, from reconnaissance to resupply. Inboth cases, the users were able to gain a basicunderstanding of the potential uses and limits ofnovel technologies. This prepared them for morerigorous and focused development and testing later.Similarly, the Command Post of the Future programin DARPA has conducted a series of “block party”experiments in which their technologists haveworked together with selected military subject matterexperts (SMEs) to try out new technologies acrossa variety of military contexts, ranging from meetingengagements to urban warfare. An interestingdiscovery experiment was generated by the AirForce in 1994 and 1995 when Lieutenant GeneralEdward Franklin, U.S. Air Force, then head of theU.S. Air Force ESC (Electronic Systems Center) atHanscom Air Force Base, required that all Air Forcecommand and control-related programs set up shopat the end of one of his runways and demonstratetheir capability for interoperability with othersystems funded by the Air Force. A great deal ofdiscovery occurred as program managers andcontractors struggled to meet this requirement.
Note that not all discovery experiments result inenough knowledge gain to support moving to thehypothesis testing level. One major advantage of anexperimentation perspective is that some ideas donot prove sound, at least as presently conceived andunderstood. Hence, Figure 3-1 shows the results ofsome discovery experiments as simply establishingnew research and development priorities. In otherwords, if there was a real opportunity or a realproblem being addressed during the discovery

29Chapter 3
experiment, but the proposed innovation did not lookpromising in the experimentation setting, then somedifferent approach would be needed. This approachmay be a new innovation, some change to anotherelement of the mission capability package, orrecognition of a limiting condition not previouslyunderstood. In many cases, further discoveryexperimentation may also be needed.
Even when an initial discovery experiment issuccessful in suggesting military utility and someway of employing the innovation, more research anddiscovery experimentation will usually be requiredto val idate the ini t ia l f inding, to ref ine theemployment concepts, or to determine theconditions under which the innovation is most likelyto provide significant payoff. At a minimum, theresults of an apparently successful discoveryexperiment needs to be exposed to the widestpossible community, including operators and otherresearchers. This breadth of exposure is an inherentpart of the scientific method being harnessed forexperimentation. It ensures that constructivecriticism will be offered, alternative explanations forthe findings will be explored, and the relatedresearch will be identified. In many cases, it willalso spark other research and experimentationintended to replicate and validate the initial findings.The more important the innovation and the higherthe potential payoff, the greater the community’sinterest and the more l ikely the discoveryexperiment will be replicated or created in asomewhat different domain. All this greatly benefitsthe processes of maturing the concept anddeveloping improved knowledge.

30 Code of Best Practice for Experimentation
Hypothesis TestingExperiments in the Context ofan Experimentation Campaign
When the discovery experimentation process hasproduced interesting, important, and well-statedhypotheses, the experimentation campaign is readyto move to a hypothesis testing stage. Figure 3-1stresses that this is a complex stage, highlightingthe idea that there will be both preliminary andrefined hypothesis tests as the innovation maturesand becomes better understood.
Technically speaking, no hypothesis is ever proven.The strongest statement that a scientist can make isthat the evidence is consistent with (supports) a givenhypothesis. However, propositions can be disprovedby the discovery of evidence inconsistent with them.To take a simple example, the proposition that theworld is flat was disproved by the observation thatwhen ships sailed away from port, their hullsdisappeared before their sails. However, thatobservation could not prove the world was round. Theidea that the world was curved, but still had an edge,was also consistent with the evidence.
Science therefore uses the very useful concept of anull hypothesis, which is stated as the converse ofthe hypothesis being tested. Experimenters thenattempt to obtain sufficient evidence to disprove thenull hypothesis. This provides supporting evidencefor the original hypothesis, although it does not proveit. For example, in Command Post of the Futureexperimentation with visualization technologies, thehypothesis was that:

31Chapter 3
IF sets of tailored visualizations were presentedto subjects, THEN those subjects would havericher situation awareness than those subjectspresented with standard military maps andsymbols, UNDER THE CONDITIONS THAT thesame underlying information was available tothose creating both types of displays, thesubjects were active duty military officers with atleast 10 years of service, and the subjects’ timeto absorb the material was limited.
This proposition could not be proven, so the moreuseful null hypothesis was crafted:
IF sets of tailored visualizations werepresented to subjects, THEN no improvementwould be observed in the richness of theirsituation awareness than that of subjectspresented with standard military maps andsymbols, UNDER THE CONDITIONS THAT thesame underlying information was available tothose creating both types of displays, thesubjects were active duty military officers withat least 10 years of service, and the subjects’time to absorb the material was limited.
When significant differences were reported, the nullhypothesis was rejected and the evidence was foundto be consistent with the primary hypothesis.Experimentation and research could then move onto replicating the findings with different subjects indifferent experimentation settings, and specifyingwhich elements in the tailored visualization weregenerating which parts of the richer situationawareness. Hence, the experimentation campaign

32 Code of Best Practice for Experimentation
was advanced, but by no means concluded, by thehypothesis testing experiment.
Selecting the hypothesis to be examined in anexperiment is a crucial and sometimes difficult task.The innovation and its expected impact need to bedefined clearly. Moreover, establishing a baseline– how this task is carried out in the absence of theinnovation – is a crucial element. If the hypothesesare not set up for comparative purposes, theexperiment will contribute little to the knowledgedomain. For example, demonstrating that a newcollaborative process can be used to supportmission planning is not very helpful unless thehypothesis is drawn to compare this new processwith an existing one. Failure to establish thebaseline leaves an open question of whether anybenefit is achieved by the innovation.
Several rounds of hypothesis testing experiments areneeded for any reasonably complex or importantmission capability package. The variety of applicablemilitary contexts and the rich variety of humanbehavior and cognition argue for care during thisprocess. Many innovations currently of interest, suchas collaborative work processes and dispersedheadquarters, have so many different applicationsthat they must be studied in a variety of contexts.Others have organizational and cultural implicationsthat must be examined in coalition, interagency, andinternational contexts.
As Figure 3-1 shows, some hypothesis testingexperiments also result in spinning off research anddevelopment issues or helping to establish priorities

33Chapter 3
for them. In other words, some experiments willidentify anomalies that require research, others willsuggest new innovations, and still others will identifymissing elements that must be researched andunderstood before the innovation can beimplemented successfully.
Particularly visible sets of hypothesis testingpropositions are the Limited Objective Experiments(LOEs) being undertaken by J-9, JFCOM. They havescheduled a series of hypothesis testing experimentsfocused on specific elements of their new concepts,having recognized that there are a variety of issuescontained in the innovative concepts they aredeveloping. Their major events, such as MillenniumChallenge ‘02 and Olympic Challenge ‘04, are bothtoo large and complex to effectively determine thecause and effect relationships involved in the largenumber of innovations they encompass. For example,during 2001 they ran LOEs on the value of opensource information, alternative presentationtechnologies, coalition processes, and production oftheir key documents (Operational Net Assessmentsand Effects Tasking Orders). Similarly, the U.S.Navy’s series of Fleet Battle Experiments have eachsought to examine some specific element of NetworkCentric Warfare in order to understand their usesand limits.
Early or preliminary hypothesis testing experimentsoften lead to more than one “spiral” of more refinedhypothesis testing experiments as a fundamentalconcept or idea is placed into different applicationcontexts. This is a natural process that is furtheredby widely reporting the results of the early

34 Code of Best Practice for Experimentation
experiments, thereby attracting the attention of expertsin different application arenas. For example, goodideas arising from the Revolution in Business Affairsare being explored in a variety of DoD arenas, frommilitary medicine and personnel to force deploymentand sustainment. Each of these arenas has differentcultures, experiences, limiting conditions, andorganizational structures, so no single line ofexperimentation is likely to provide satisfactoryknowledge to all of them. Rich innovations can beexpected to generate multiple experimentationcampaigns.
Once an experimentation campaign has refined thecommunity’s understanding of an innovation, itsuses and limits, and the benefits available from it,it is ready to move into the formal acquisition oradoption processes. As Figure 3-1 indicates, awell-crafted campaign, conducted in the contextof a meaningful community discussion, shouldprovide the evidence needed for JROC or otherformal assessment and budgetary support. Thisdoes, however, presuppose high-qual i tyexperiments, widely reported so that the relevantmilitary community understands the results andfindings that indicate military utility.
Demonstration Experimentsin the Context of anExperimentation Campaign
Many innovations fail to attract sufficient support tomove directly into the acquisition or adoptionprocesses. This can occur for a variety of reasons,

35Chapter 3
but often involves inadequate awareness, skepticism,or lack of confidence in the user communities. Facedwith these situations, program managers havesometimes found it valuable to perform demonstrationexperiments, where they can display the value of theirinnovation to operators. Indeed, both TechnologyDemonstrations (TDs) and Advanced ConceptTechnology Demonstrations (ACTDs) have provenincreasingly valuable over the past decade.
To be useful, demonstration experiments must placetechnologies or other innovations into a specificcontext developed in order to demonstrate their utility.They can only be done effectively and efficiently withwell-developed innovations that have been subjectedto enough discovery and hypothesis testingexperimentation to identify the types of military utilityavailable, to define the context within which thosebenefits can be realized, and to identify the otherelements of the mission capabil i ty packagenecessary for successful application. If these criteriaare ignored, the demonstration experiment willquickly degenerate into an ad hoc assembly of itemsoptimized on a very narrow problem, provingunconvincing to the operators for whom it isdesigned, and unable to support more generalapplication after the demonstration.
As noted earlier, demonstration experiments also needto be observed and instrumented so that the benefitsbeing demonstrated are documented and can berecalled after the experiment is over. Failure to capturethe empirical evidence of a successful demonstrationexperiment turns it into simple “show and tell” andprevents carrying the results to audiences that were

36 Code of Best Practice for Experimentation
not present during the event. This may be particularlyimportant if funding support is being sought for theinnovation. Endorsements from senior officers and theirstaffs are valuable, but not persuasive in budgetcontests where every item comes with a cadre ofsupporters, usually from the part of the community thatis perceived as having a vested interest in theinnovation.
Results of a Well-CraftedExperimentation Campaign
Properly designed and executed, experimentationcampaigns generate several useful products. Theseinclude:
• A richly crafted mission capability package thatclearly defines the innovation and the elementsnecessary for its success;
• A set of research results that form a coherentwhole and specify how the innovation should beimplemented, the cause and effect relationshipsat work, the conditions necessary for success,and the types of military benefits that can beanticipated;
• A community of interest that includes researchers,operators, and decisionmakers who understandthe innovation and are in a position to assess itsvalue; and
• Massive reduction in the risks associated withadopting an innovation.

37Chapter 3
An Experimentation Venue isNot an ExperimentationCampaign
Over the past several years, a few mil i taryorganizations have lost sight of the complexity ofconducting experiments and sought to create largeexercises in which a variety of different experimentscan be conducted. These integrated constructs havealmost always been at least partially field exercises,often in the context of major command postexercises. The underlying idea is to generate someefficiencies in terms of the scenarios beingemployed, the missions and tasks assigned, andthe personnel involved. Good examples include theU.S. Air Force series known as JEFX (JointExpeditionary Force Exercise) and the U.S. MarineCorps series of HUNTER exercises. Theseintegrated constructs should be understood to beexperimentation venues because they create anopportunity to conduct a variety of differentexperiments. However, they are not experimentationcampaigns because they typical ly includeexperiments about different domains.
While large experimentation venues do provide theopportunity for a variety of specific experiments, theyalso can present unique challenges. For example,different experiments may be interlocked, with theindependent or intervening variables for oneexperiment (which are deliberately controlled) beingor impacting on the dependent variable for another.Similarly, many of these experimentation venues are,at least in part, training exercises for the forces they

38 Code of Best Practice for Experimentation
field. This can mean that current doctrine andorganization, which may differ substantially fromthose identified in the mission capability package,play a controlling role. It can also limit the availabilityof the experiment subjects for training.
Core Challenges ofExperimentation
The core challenges of good experimentation areno different for the DoD than any other groupseeking to refine and mature a concept or aninnovation. They include:
• Clear specification of the idea;
• Creation of a mission capability package thatarticulates the whole context necessary forsuccess;
• Articulation of the hypotheses underlying theinnovation, including the causal mechanismsperceived to make it work;
• Specification of the benefits anticipated from theinnovation and the conditions under which theycan be anticipated;
• Development of reliable and valid measurementof all elements of the hypotheses such that theycan be controlled and/or observed in theexperimentation setting;
• Design of an experiment or experimentationcampaign that provides unambiguous evidenceof what has been observed;

39Chapter 3
• Creation of an experimentation setting (subjects,scenarios, instrumentation, etc.) that provides foran unbiased assessment of the innovations andhypotheses under study;
• Selection of analytic methods that minimize therisks and uncertainties associated with eachexperiment or experimentation campaign; and
• Creation of a community of interest that cutsacross relevant sets of operators, researchers,and decisionmakers.
Meeting these challenges requires thought, planning,and hard work. The chapters that follow deal withelements of these challenges.

41
CHAPTER 4
The Logic ofExperimentation
Campaigns
Why Campaigns Rather ThanIndividual Experiments?
No single experiment, regardless of how welli t is organized and executed, improves
knowledge enough to support a major goal liketransformation. First, building knowledge requiresreplication. Scientists know that the findings of asingle experiment may be a product of someunknown factor that was not controlled, the impactof biases built into the design, or simply the impactof some random variable unlikely to occur again.Hence, they require replication as a standard forbuilding knowledge.
Second, individual experiments are typically focusedon a narrow set of issues. However, the stakes arevery high in transformation and the experimentationfindings required to pursue it will need to be robust,in other words, they must apply across a wide rangeof situations. While models and simulations can be

42 Code of Best Practice for Experimentation
used to test the limits of individual experiments, theyare neither valid enough nor robust enough inthemselves to explore the range of conditionsrelevant to military operations.
Third, experiments are undertaken on the basis ofexisting knowledge from prior experience, research,and experimentation. In order to understandexperimentation findings fully, they must be placedback into that larger context. When that occurs,alternative interpretations and explanations areoften identified for the findings of the singleexperiment. Hence, new experiments are oftenneeded to help us differentiate between thesecompeting hypotheses before we can claim the“actionable knowledge” needed for transformation.
Fourth, the kind of rich and robust explanations andunderstandings needed to support transformation willalmost inevitably include the unhappy phrase, “itdepends.” In other words, context matters. Hence,individual experiments, which can only look at a smallnumber of different contexts, will need to becalibrated against other experiments and knowledgeto ensure that their limiting conditions are properlyunderstood. This is essential if new knowledge is tobe applied wisely and appropriately.
Fifth, building useful knowledge, particularly in acomplex arena like transformation, often meansbringing together different ideas. Findings fromindividual experiments often need to be broughttogether in later experiments in order to see howrelevant factors interact. Hence, sets of related

43Chapter 4
experiments often yield richer knowledge than theindividual events.
Final ly, individual experiments are l ikely togenerate some unexpected findings. Because theyare unexpected, such findings are both importantand interesting. They may be an indication of newknowledge or new l imi t ing condi t ions.Exper imentat ion campaigns provide theopportunity to explore these novel insights andfindings, as well as their implications and limits, ina more structured setting.
Experimentation CampaignsRequire a Different Mindset
It is a misconception to think of an experimentationcampaign as merely a series of individualexperiments that are strung together. Assummarized in Figure 4-1, campaigns serve abroader scientific and operational purpose andrequire different conceptualization and planning.
An experiment typically involves a single event thatis designed to address a specif ic thread ofinvestigation. For example, experiments conductedby the U.S. Army during the past few years havefocused on assessing the impact of introducingdigital information technology into command andcontrol processes at battalion through corps level.During this same period, separate experimentswere conducted to assess the contributions ofselected maintenance and logist ics enablertechnologies to sustain combat forces. In eachcase, the experiment involved a single thread of

44 Code of Best Practice for Experimentation
investigation. By contrast, an experimentationcampaign involves multiple components (e.g.,l imi ted object ive exper iments, integrat ingexperiments, simulation experiments) conductedover a period of time to address multiple axes ofinvestigation. Each of these axes manipulatessome specific aspect of force capability (e.g.,networking of command and control, precision andagility of weapon systems, reorganization ofsustaining operations) while controlling for others.Taken together, however, these axes ofinvestigation contribute to a broader picture offorce transformation.
Figure 4-1. Comparison of An Experiment to AnExperimentation Campaign
Experimentation campaigns are organized arounda broader framework. Whereas individualexperiments are organized around a set of specific

45Chapter 4
issues or hypotheses, campaigns are structured toaddress broad operational concepts. In the case ofindividual experiments, the specific issues orhypotheses that are under analysis shape everyaspect of experiment planning (e.g., developmentof metrics, scenario, experiment design). Thecareful planning of a multi-year experimentationcampaign must be motivated and shaped byconsistent adherence to broad goals and visionstatements moving toward transformation.
Experiments and experimentation campaigns alsodiffer in terms of their analytic goals. Experimentsare designed to provide objective testing of afocused set of questions (e.g., are communicationbandwidth and connectivity associated withimproved shared awareness and understanding?).As such, the experiment is tailored to provide thebest conditions and methods for testing the specificset of questions. The fundamental planning questionfor an experiment is: “Are we researching this issueor testing this hypothesis in the best, most objectivemanner?” By contrast, campaigns respond to abroader analytic goal. Campaigns are designed toprovide comprehensive insight across a set ofrelated issues. The focus of campaign planning isto ensure that each important aspect of forcecapability is addressed and that no critical issuesare overlooked. As a result, the various axes of theexperimentation campaign employ a range ofconditions and methods for investigating differenttypes of issues. The fundamental planning questionfor an experimentation campaign is: “Are weaddressing all of the important aspects of theproblem?”

46 Code of Best Practice for Experimentation
In terms of decision points, experiments typicallyreflect a single decision to design and executea spec i f i c exper iment . F rom incep t ion tocompletion, attention is focused on achieving asingle, coherent outcome. Experimentat ioncampaigns, on the other hand, contain multipledecision points that provide the opportunity toeither refine alternatives or identify emergingissues. As a result, operational attention canshift from event to event, the nature of theana ly t i ca l ques t ions can evo lve , and theexperimentation objectives can mature over timeas the campaign yields deeper insights into theproblem space. Experimentation campaigns arenot fixed or static programs. Rather, they shouldreflect a degree of adaptibility and innovation toaccommodate learning over time. Campaignplans must be flexible so that subsequent eventsare properly focused to provide for the bestreturn on investment.
Given a number of pract ical and scient i f icconsiderations, experiments are designed tomeasure the impact of a few factors or variableswhile controll ing other influences on systemperformance to the highest degree possible. Inthis manner, causal i ty can be isolated andattributed to a relatively small number of factors.In this sense, experiments best reflect the rootconcept of analysis, the systematic understandingof causes and ef fects . Exper imentat ioncampaigns, by contrast, are designed to assessthe relative importance and impact of manydifferent factors or variables within the problemspace. The objective of the campaign design is

47Chapter 4
to give comprehensive attention to all of theimportant influences on system performance. Inthis sense, experimentation campaigns bestre f lec t the root concept o f synthesis , thesystematic integration of causes and effects intoimproved, actionable knowledge.
S im i la r l y , exper iments bes t ach ieve the i robjectives by tailoring scenarios to provide thebest set of conditions for assessing selectedissues or testing a set of specific hypotheses.Hence , p lann ing a t ten t ion i s focused onidentifying elements of the operational scenariosthat allow for adequate variability to occur amonginput and output measures – an analyt icalrequisite for assessing causality. Dependingupon the nature and focus of the experiment, thescenarios can vary in echelon (e.g., tactical,operational, strategic), level of complexity (e.g.,isolated mil i tary functions, joint operations,effects-based operations), or a few levels ofoutcome measure (e.g., situation awareness,force synchronization, mission effectiveness). Bycontrast, campaigns are not limited to a singlelevel of detail, single level of complexity, or afew levels of outcome measure. Hence, planningattention should be given to addressing al limportant influences on system performancethrough a range of scenarios. In this manner,experimentat ion campaigns offer a greaterposs ib i l i t y o f (1 ) y ie ld ing genera l i zedconclusions, (2) identifying regions of greatestperformance sensitivity, (3) associating the bodyof empirical knowledge with the most l ikelyconditions in the real world, and (4) providing

48 Code of Best Practice for Experimentation
robus t ins igh t in to t rans format ion- re la tedprogramming and policy decisions.
Finally, as compared with individual experiments,experimentation campaigns require a broader andmore consistent set of performance metrics. Abroader set of metr ics is required becausecampaigns typically deal with a more diverse set ofmilitary functions, operational effects, and levels ofsystem outcome, as compared with focusedexperiments. At the same time, however, the set ofmetrics adopted within a campaign must be definedmore consistently from the outset since they are theprincipal mechanism for linking empirical findingsacross different experiments. While developingappropriate metrics for an individual experiment isdifficult enough, the development of metrics for usein an experimentation campaign requires even morethought and skill in order to anticipate how thosemetrics will be employed.
Structure UnderlyingExperimentation Campaigns
As il lustrated in Figure 4-2, there are threeprinciple dimensions underlying campaigns ofexperimentation:
• Maturity of the knowledge contribution – fromdiscovery to hypothesis testing to demonstration;
• Fidelity of experimentation settings – from wargaming to laboratory settings and models toexercises; and

49C
hapter 4
Figure 4-2. The Experimentation Campaign Space

50 Code of Best Practice for Experimentation
• Complexity of the issues included – from simple tocomplex.
The logical structure underlying experimentationcampaigns is always the same – to move along the“campaign vector” shown in Figure 4-2 from thelower left front of the experimentation space towardthe upper right rear. In other words, moving towardmore mature knowledge, in more realistic settings,and involving more complex issues.
Maturity of KnowledgeContribution
This dimension was already described as the threebasic classes of experiments were introduced.Initial work in any knowledge domain is bestundertaken in discovery experiments intended tocreate a basic understanding of the phenomenonof interest. In science terms, this is an effort todescribe what is occurring, classify factors andrelevant behaviors correctly, and hypothesizecause and effect relationships and their limitingcondi t ions. Discovery exper iments can bedesigned based on experience, subject matterexpertise, prior research, or experimentation onsimilar or apparently analogous topics. More thanone discovery experiment is normally needed togenerate the insights and knowledge required tosupport hypothesis testing experiments. Discoveryexperiments should also be used to create, refine,and validate the measurement tools needed in theknowledge domain.

51Chapter 4
Once the hypotheses can be clearly articulated, aseries of hypothesis testing experiments can beused to enrich understanding of the issues understudy. These typically begin with efforts to refinethe hypotheses of interest (in science terms, theset of consistent, interrelated hypotheses that forma theory. However, the term theory is seldom usedwhen dealing with experimentation within the DoDbecause it is understood to convey a sense thatthe knowledge is tentative or impractical. In fact,there is nothing so practical as a good theory andthe set of conditions under which it applies). Theseinitial experiments are typically followed by anumber of in-depth experiments that explorealternative cause-and-effect patterns, sets oflimiting conditions, and temporal dynamics. Mostof the effort necessary to mature knowledge on agiven topic will be consumed in these hypothesistesting experiments.
As hypothesis testing experiments go forward,the relevant measures, tools, and techniquesneeded for successful experimentation are alsorefined and matured. In addition, by circulatingthe results of hypothesis testing experimentswidely, researchers often generate feedback thatenables them to better understand the topicsunder s tudy. Th is mu l t ip l y ing e f fec t onknowledge maturity is vital to rapid progress. Itallows researchers to learn from both otherresearchers and also expert practitioners.
Demonstration experiments, which are educationaldisplays of mature knowledge, should not beundertaken until the science underlying the issues

52 Code of Best Practice for Experimentation
of interest have been largely resolved. They can onlybe done with mature mission capability packages,including technologies, training, organizationalstructures, and leadership. In essence, the underlyingknowledge must be predictive. The cause and effectrelationships hypothesized must be fully understoodand the conditions necessary for success must beknown. Note that demonstration experiments shouldbe few in number and organized primarily to educatepotential users of the innovation and thoseresponsible for deciding (1) whether the innovationshould be adopted and (2) how the innovationshould be resourced. They sometimes also yieldknowledge about how the innovation can beemployed effectively. The greatest danger indemonstration experimentation is attempting it toosoon – when the innovation is immature. Evenweakly resourced demonstration experimentsusing mature innovations are more likely to besuccessful than premature demonstrations.
Experimentation at different levels of maturity alsoyields different products. Discovery experiments areintended to weed out ideas that have little chanceof success and identify promising ideas. Theirproducts include sets of hypotheses for testing,specification of initial limiting conditions or relevantapplication contexts, measurement tools, andresearch and development priorities. Hypothesistesting experiments refine knowledge, sharpendefinitions and measures, clarify relationships,improve understanding of limiting conditions, andgenerate r ich insights. They may also helpstrengthen and focus research and developmentpriorities, particularly in the initial hypothesis testing

53Chapter 4
phase. Well-crafted sets of hypothesis testingexperiments can yield the knowledge needed foracquisition efforts, organizational change, andtraining initiatives. Demonstration experiments areintended to directly support decisions abouttransformation initiatives.
Fidelity of ExperimentationSettings
Mission capability packages and transformationinitiatives must ultimately be implemented in the worldof real military operations. Their origins, however,are cognitive – concepts arising in someone’s mindand developed in dialogue with others. Well-craftedcampaigns of experimentation are structured to movefrom the relatively vague and undisciplined world ofideas and concepts into more and more realisticsettings. In the sense of scientific inquiry, this iscreating increasingly robust tests for the ideas.Transformational innovations will be strong enoughto matter in realistic settings.
When a new subject comes under study, a varietyof unconstrained settings are typically used toformulate the issues and generate preliminaryinsights. These might include lessons learnedreported from the field, brainstorming sessions,subject matter expert elicitation efforts, review ofexisting relevant research and experiments, andworkshops designed to bring together experts fromthe relevant fields. These approaches have beenwidely used by the Joint Staff in developingconcepts like dominant maneuver and precision

54 Code of Best Practice for Experimentation
engagement. They were also used by J-9, JFCOM inorder to generate concepts such as Rapid DecisiveOperations (RDO). While these activities can helpexplore a new topic, they are not experiments becausethey lack the essential empirical dimension.
Placing these ideas into a weakly structuredexperimentation environment, such as a war game,provides the opportunity to collect systematic dataand capture relevant insights. While the free flowof ideas and the opportunity for a variety ofbehaviors makes these loose environments idealfor exploring a problem and generating hypotheses,their inability to be replicated and their low fidelityto real world situations limits their utility.
Experimentation campaigns should move thevenue from these weakly structured settings intothose with more specific and conscious controlsintended to enrich the fidelity of the setting in whichknowledge is gathered. This can be done bymoving into the laboratory or moving into modelsand simulations. In some cases, both can be doneat once.
Moving into a laboratory in order to work in a morerealistic setting may appear counter-intuitive. Themost widely understood purpose of laboratorysettings is to control by screening out many realworld factors. However, laboratory settings are alsoused to focus the experiment setting on factorsbelieved to be important and ensure that their impactis assessed systematically. For example, war gamesintended to examine the effect of differentialinformation on decisionmaking do not normally

55Chapter 4
systematically control for the types of subjects makingdecisions or the decision styles employed, despitethe fact that both of these factors are widely believedto be important. By going into a laboratory settingwhere factors like these can be brought under controlthrough subject selection, research design, andstatistical control procedures, an experimentationcampaign can improve the match between theexperiment and the real world settings where thefindings will be employed.
Similarly, building a model or simulation is always, bydefinition, an abstraction from reality. How then, is therealism of the setting improved if these tools arebrought into play to replace loosely structured wargames? Again, the answer lies in the ability of themodel or simulation to explicitly include factors believedto be important and to exclude the wide variety ofissues not under analysis.
Note also that by using simulation-driven laboratoryexperiments, or human-in-the-loop techniques, bothlaboratory and modeling controls can be used toadd realism and filter out extraneous factors. Thisis the primary approach used by J-9, JFCOM in theirseries of LOEs designed to develop and refineoperational concepts, organizational structures, andwork processes for JointTask Force headquartersin the future.
Laboratories and simulations are, however, far lessrealist ic than the sett ings needed before atransformational innovation should be adopted.Exercises, whether command post (CPX) or fieldtraining exercises (FTX), represent the most realistic

56 Code of Best Practice for Experimentation
settings available for experimentation and should beemployed in the later stages of experimentationcampaigns. However, the realism available inexercises can also be, and has proven in the pastto be, a trap for experimentation. Exercises areexpensive and are typically used to train the forcesinvolved. Even CPX are typically training events forcommanders and their staffs. Training is about howthe force does business today and will do businesstomorrow in real crises or combat. However,transformational innovat ions often involvefundamentally different ways of doing business.These differences may range across all crucialelements – doctrine and associated tactics,techniques, and procedures; force structure andorganization; training and preparation of leadersand staffs; the information systems used; and soforth. Hence, “piggybacking” transformationalexperimentation on exercises intended to train thecurrent force is not a useful strategy.
Therefore, the ideal exercises for creating realisticexperimentation settings will be those designed withthe experimentation in mind. This has been donesuccessfully, primarily when a narrow innovationwas being brought into the nearly current force (forexample, the U.S. Air Force taking training dataabout the impact of Link 16 and comparing with theperformance of those without the innovation) andwhen the experiment was placed into a force createdfor that purpose (as in the Army’s digitizationexperimentation and the Navy’s series of FleetBatt le Experiments). At this wri t ing, jointexperimentation has been hampered by the lack ofthese realistic exercises. ACTDs are an effort in this

57Chapter 4
direction. They represent demonstration experimentsand are supposed to include mature technologies, butthey have not always been transformational. They havetended to focus on technologies without the supportingmission capability packages that transformation willrequire.
Complexity of the IssuesAddressed
This dimension of experimentation campaigns isitself multidimensional. A variety of different factorscan impact the complexity of any one experimentand must, therefore, be considered when campaignsare designed. They are limited only by the richnessof the knowledge domain under study and theimagination of the experimentation team. Theyinclude the:
• Number of subjects;
• Variety of actors (echelons, functions, andrelationship to the U.S.);
• Stability of the operating environment;
• Linkage patterns;
• Information flows;
• Quality of the information;
• Degree of uncertainty; and
• Many other factors.

58 Code of Best Practice for Experimentation
The key here is to recognize that complexity exacts amajor price in experimentation. Campaigns typicallybegin simply, but cannot end there. Over time andacross different experiments, more and more factorswill need to be considered or examined and ruled outbecause they do not have measurable impacts. Atthe same time, allowing too many factors into a givenexperiment will make it very difficult to sort out thecause and effect relationships being observed. Verylarge designs, typically implying large expenditures,are required to deal with a variety of complex factorsin the same experiment. Moreover, the tools tomeasure the impact of a variety of different factors,and keep them distinct enough to analyze them, willbe a challenge in many experimentation campaigns.
Designing ExperimentationCampaigns
While the cube shown in Figure 4-2 shows anexperimentation campaign vector that starts atthe or igin for al l three dimensions, not al lexperimentation campaigns for transformation willbegin at the origin on all dimensions. The key toselecting the starting point is understanding whatis already known and what experimentation hasalready been done.
In studying a new field with little existing knowledge,i t is essent ial to begin at the beginning.Thecampaign will have to be organized aroundsimple discovery experiments in weakly structuredsettings that mature over time as the domain becomesunderstood.

59Chapter 4
For examining an issue that has arisen from real world,military lessons learned and experience, theexperimentation campaign may start in the center ofthe experimentation campaign space. Hypothesistesting in laboratory and simulation settings can beused to rapidly assess the robustness of the conceptand refine its applications, as well as to isolate andidentify areas requiring further research.
Application of a well-understood knowledge arenato the DoD may start even further along, in the regionwhere hypothesis refinement experiments areconducted in relatively high fidelity, complexenvironments. These situations can begin to movetoward demonstration experiments as soon as themain effects in the experiments prove replicable.
As a practical matter, experimentation teamsseeking transformational issues should be lookingfor relatively mature concepts or issues that havebeen developed in other fields. For example, thesearch for business practices that have provensuccessful in high stakes, dynamic arenas was agood idea when looking for advantages arising fromthe introduction of new information technologies.Similarly, the existing body of research into thedynamics at work after natural disasters has provento be a rich source of insight on the crucial topic ofdesigning effective organizations with minimalinfrastructure for a diverse set of stakeholders.
The other practical imperative for experimentationcampaigns is that they must be planned far enoughinto the future to ensure that resources are availableto support them. Given the complexity of conducting

60 Code of Best Practice for Experimentation
any experiment, lead time is essential. Adding thecomplexity required to accumulate knowledge andmature a concept makes it essential that seriousplanning be done. This complexity also means thatplans for campaigns of experiments cannot beimmutable. Learning in early experiments oftenleads to changes in later ones. However, thosechanges can be well within the planning parametersoriginally established, provided the experiments arenot scheduled too close together and a “lock step”mentality is avoided.
Conclusion
No single experiment will be adequate to support atransformation initiative. Hence, experimentationcampaigns should be used to develop matureknowledge and move concepts along towardmission capability packages. These campaigns willchange over time in terms of the knowledge theygenerate, in the realism of the settings in which theytake place, and in their complexity.

61
CHAPTER 5
Anatomy of anExperiment
Merely knowing what an experiment is (and isnot) does not make it possible to organize and
conduct a successful experiment. This chapter takesa deeper look into the anatomy of an experiment:the structures, processes, procedures, and productsneeded to make an experiment a success. This isan end-to-end review of an experiment, from itsformulation to the delivery of its products.
Phases of an Experiment
Figure 5-1 shows an overview of the three majorphases in any experiment: pre-experiment, conductof the experiment, and post-experiment. The outputsof the pre-experiment phase provide “what we know”and “what we think” as expressed in the experimentmodel and experiment propositions in hypotheses,and “what we are going to do” as expressed in thedetailed experiment plan. The output of the conductphase is simply the empirical data generated by theexperiment as well as other observations andlessons recorded. The output of the post-experimentphase is a revised model that captures andincorporates what is learned, empirical data that

62C
ode of Best P
ractice for Experim
entation
Figure 5-1. Phases of Experiments

63Chapter 5
others can use, the documentation of supportingexperimentation activities, and other findings andconclusions such as lessons learned.
Unfortunately, there is a misconception that mostof the effort required in successful experimentationoccurs during the actual conduct of the experiment(the most visible part, when subjects are being putthrough their paces or the experimentation modelor simulation is running). In fact, the bulk of theeffort in successful experiments is invested beforethe experiment itself is conducted, in the pre-experiment phase. Moreover, substantial effort isalso required after the experiment is conductedwhen the results are analyzed, understood,extrapolated, documented, and disseminated. Thisweak grasp of the required allocation of effortacross the various elements of the experimentationprocess often creates mischief by mismatchingresources against the work needed to producequality results. Hence, this chapter looks at thewhole process from the perspect ive of theexperimentation team, identifies all of the criticalsteps, discusses their interrelationships, and askswhat must be done in order to achieve success.
While the detailed discussion of each phase thatfollows is largely from the perspective of anhypothesis testing experiment, all of these stepsare a lso needed in both d iscovery anddemonstration experiments. Given the nature ofDoD transformat ion, th is d iscussion alsoemphasizes exper iments involv ing humansubjects. Also, given the formidable problem ofexploring warfare in anything that approaches a

64 Code of Best Practice for Experimentation
realistic setting, a chapter discussing modelingexperiments has also been included.
Pre-Experiment Phase
The objective of the pre-experiment phase is todefine the experiment’s objectives and to developa plan for carrying out the experiment. Experiments,even if they are not explicitly part of a campaign,are not isolated events. There is, of course, anexisting body of knowledge to draw upon, includingthe results of previous research and existing modelsthat attempt to capture some or all of the behaviorsand relationships of interest. There may also havebeen a number of related experiments, includingsome modeling experiments, to draw upon.
Well-run experiments wil l devote signif icantresources to learning what is already known. Thiscan avoid blind alleys, save massive effort later,and allow the use of precious experimentationassets to move the state of knowledge forwardrather than simply rediscover existing knowledge.While termed a literature search in academia, thiseffort involves much more in a realistic militarycontext. First, it means knowing what relevantresearch (including experimentation, historicalresearch, modeling, etc.) has been done andreported in published sources, including sourcessuch as DTIC (Defense Technical InformationCenter). Second, it means an open source searchon the Internet to see what research has been done,but is not carried in the formal journals or has notyet had time to reach them. Since Internet sources

65Chapter 5
are not rated for reliability, this effort must bedisciplined and accompanied by an analysis of theresearch and publication histories of the scholars,teams, and organizations responsible for each item.In addition, lessons learned documents, technicalassessments, and other related materials should begathered and reviewed. Finally, lead researcherswho have worked similar topics should be contacteddirectly to learn about their current work and exploittheir knowledge of the topic. Investment in this initialreview of knowledge often pays high dividends.
Almost all experiments worth doing require amultidisciplinary team. Since efforts normally beginwith only a part of the experimentation team inplace, it is important that care is taken to bring thefull range of expertise and experience needed tobear before settling upon an experimental conceptand developing a plan of action. The types ofexperiments needed to develop transformationalmission capability packages will, in all likelihood,focus at least in part on command concepts,information, cognitive issues, and organizationalbehavior. The reader is referred to the NATO COBPfor C2 Assessment (Section 2-D)1 for a point ofdeparture on the building of an assessment team.That discussion includes the nature of the skillsthat are required.
The pre-experiment phase consists of four majoractivities:
• Formulating the experiment;
• Establishing the experimentation team;

66 Code of Best Practice for Experimentation
• Generating the initial plan for the experiment;and
• Drafting the detailed plan for the experiment.
Formulation of the Experiment
Effective formulation is fundamental to the successof all experiments, but particularly in transformationalexperiments because the issues are complex andinherently involve the many dimensions that form amission capability package. Proper attention toformulation will provide a solid foundation upon whichthe experiment can be built.
A review of the existing body of knowledge andprevious experiments will provide the team with agood idea of what is known and what conjectureshave some apparent merit. The first task informulation is to properly understand the issues thatthe experiment will address and the context in whichthe issues will be addressed. This task involves theexplicit definition of several items, including:
• Propositions, hypotheses, and/or relationshipsto be addressed;
• Assumptions that will be made;
• The identity of the dependent variable(s);
• The identity of the independent variables;
• Which of the independent variables will becontrolled; and

67Chapter 5
• Constraints on the value of the variables for thepurpose of the experiments.
Specific articulation of the problem is really whatthe experiment is all about. The assumptions madeare another important part of the formulation of anexperiment. They determine the scope of theexperiment and clearly identify areas that are notbeing investigated. Making explicit assumptions isvery important in helping one and all to understandand evaluate the empirical data that will result fromthe experimentation and its interpretation. It isalways good practice to clearly articulate all of thekey assumptions made.
The independent variables are the inputs. Takentogether, they frame the experiment space. Theyfocus us on the relationships of interest. Thedependent variables are the outputs or productsof an individual, team, or organization. Theyrepresent the characteristics and behaviors thatare important to the success of military operations.The NCW value chain2 provides a hierarchy ofmeasures, any of which might be the focus of agiven experiment. Given the complexity of NCW-related issues and the military contexts in whichthey will be applied, many of the assumptions willserve to fix the values of some subset of theirrelationships to one another.
The heart of any experiment is in what we attemptto control. Control can be exercised in a number ofways. While the selection of variables to becontrol led is part of the formulat ion of theexperiment, how they are to be controlled is

68 Code of Best Practice for Experimentation
determined in detai l when developing theexperiment plan. The formulation task is completedwith the specification of constraints that will beimposed on the variables. Some of these may be areflection of the assumptions; others are a reflectionof the scope of the experiment, or as a result ofpractical considerations.
There are two major outputs of formulation. First isthe construction of an experimentation model thatcontains the key variables and the relationships(some known, some hypothesized, some the subjectof discovery) between them. Second is thespecification of the relationships of primary interest,the related assumptions, and constraints.
Formulating Discovery Experiments
Discovery experiments, however unstructured theyappear to be, are no exception to the need forcareful formulation. They need to be designedaround clearly articulated questions. For example,“what makes for effective collaboration?” is toovague. A more articulate question would be “howdo differences in group structure, communicationspatterns, work processes, participant intelligence,participant cooperative experiences, and participantexpertise affect the quality of collaboration?” Thesecond version will make it much easier to designfor success, including the crucial issues of what dataneed to be collected and how the data will beanalyzed and exploited. When possible, the subjectof a discovery experiment should also be stated interms of the relevant environment or operatingconstraints that will bound the analysis. For

69Chapter 5
example, determinants for quality collaboration maybe sought at a particular level of command within asingle Service, joint, or coalition context; or aspecific part of the spectrum of conflict (peaceoperations, small scale contingencies, etc.); or usingdifferent types of participants (college students,retired military, active duty military, etc.). Failure tobe explicit about these limiting conditions can leadto inappropriate conclusions about what is alreadyknown, what has been learned during theexperiment, and what related research still needsto be undertaken.
Discovery experiments also require an open-endedarticulation of the issue under study. While allexperimentation teams should be alert to insightsor research results that go beyond the specificissues under study, this is particularly important forthose conducting discovery experiments. The factthat their purpose is exploratory makes it veryunlikely that every factor that will make a differencewill have been clearly articulated in advance.Hence, issue definition must be broad in order toensure broad capture of what unfolds. This will alsohelp to ensure open mindedness while the resultsare reviewed and interpreted.
Formulating Hypothesis Testing Experiments
For hypothesis testing experiments, the product offormulation needs to be expressed as a specifichypothesis or a set of related hypotheses. Unlesssimple “if…then…condition” statements can bearticulated, the research issue cannot be convertedinto falsifiable propositions and the experiment

70 Code of Best Practice for Experimentation
results will not be clear. This includes the nullhypotheses to be tested, the related-assumptionsmade, and the identif ication of the baselinecondition for comparison. A good hypothesisdifferentiates between two or more treatments orsets of independent variables so that the resultswill be interesting and will advance our knowledge,regardless of the outcome. For example, theproposition that “information sharing will improvegroup situation awareness in combat” needs to berestated into a primary hypothesis:
IF information sharing occurs, THEN groupsituation awareness will increase WHEN thesubjects are military professionals working in awarfighting context.
It also needs to be understood to imply the falsifiablenull hypothesis:
IF information sharing occurs, THEN noincrease in group situation awareness will beobserved WHEN the subjects are militaryprofessionals working in a warfighting context.
Equally important, the research team will need toknow how these propositions are anchored in thereal world. That is, when the hypothesis is in facttestable by the experiment, then the experimentformulation will be complete. For example, theexperimentation team will want an applicationcontext in which it makes sense that informationsharing would increase situation awareness. Theyalso want to ensure that the context selected forexperimentation is one where improved situationawareness is believed to be valuable. They may

71Chapter 5
also want to design the experiment so they canalso test hypotheses about the importance of thatshared awareness. The ideal experimentationcontext would have no prior information sharing.However, such conditions are very rare today.Hence, the research team will need to know howmuch occurs today and know how the experimentconditions will ensure that more sharing occurs oncertain topics expected to increase situationawareness. The team also needs to have anunderstanding of what consti tutes situationawareness and how more of it could be recognizedand measured.
Formulating Demonstration Experiments
Demonstration experiments will normally have quitespecific issues – they are set up to show that specificapproaches and/or federations of systems providemilitary utility (effectiveness, efficiency, speed ofprocess) in selected situations or operatingenvironments. These goals can normally be statedas fairly rigorous hypotheses and sets of interrelatedhypotheses. However, even these “simple”demonstration experiments should be set up toidentify novel insights. Any time we task militaryprofessionals to operate in new ways or use newtechnologies we stand a very real chance that theywill innovate or identify new challenges andopportunities. Ignoring that likelihood means a veryreal chance of missing the opportunity to gainvaluable knowledge.

72 Code of Best Practice for Experimentation
Articulating the Initial Experiment Model
One good test of whether the experiment has beenformulated well is to circulate the underlyingconceptual model. This representation shouldshow the dependent variables, independentvariables, the relationships between them, and thelimiting conditions (context, assumptions, andfactors to be controlled) perceived as relevant. Thisinitial model is subject to revision and is unlikelyto be stable, and will later form the basis for atleast part of the analysis to be performed. If itcannot be articulated clearly, the experimentformulation is probably immature.
Establishing theExperimentation Team
As the research issue is c lar i f ied and thehypotheses are articulated, the research leader willbe in a position to establish the experimentationteam. Hopefully, this step is informed by earlyefforts to involve people with a variety of expertise.It may even be completed while the problem isbeing formulated. Experiments are rarely smallefforts, so some help is going to be needed.Expertise will, for example, be required in each ofthe substantive areas identified in the issue andhypothesis articulation. This may mean militarysubject matter experts or operators familiar withthe functions involved (information sharing andsituation awareness in the example above),expert ise in the academic topics involved(experiment design, data analysis, modeling),

73Chapter 5
knowledge of scenario development, and technicalexpertise in generating and instrumenting arealistic experiment environment. At this stage, thecore of the team needs to be brought on board,though others (e.g., observers and the bulk of thehands-on technicians needed to run the detailedscenarios) can be added later.
Initial Experimentation Plan
Following the formulation of the experiment, attentionis focused on developing an initial experimentationplan. The process is iterative because a balanceneeds to be reached between what is desired andwhat is possible. On occasion, the formulation needsto be revised. Perhaps a variable that we wanted tocontrol cannot be realistically controlled. Perhapsimportant new variables will emerge when the initialmodel of the problem is specified.
Two major activities need to be completed in order todevelop the initial experimentation plan:
• Specify the initial research design including thedevelopment of the rough experimentation plan;and
• Simulate the experiment using the experimentalmodel.
Initial Research Design
With the experiment formulated, existing knowledgeexplored, and a preliminary experiment modelarticulated, the experimentation team is in a position

74 Code of Best Practice for Experimentation
to take its first cut at the research design itself. Thisdesign contains several crucial ideas:
• What are the treatments of appropriate ranges ofthe independent variables and how will they beoperationalized?
• How will each of the variables be measured?
• What factors are believed to influence therelationships between the independentvariables, intervening variables, and thedependent variables and the interrelationshipsamong the independent variables?
• How will control be established for thosevariables where it is needed?
• What baseline is being used? Is it pre-established or must it be built into theexperiment?
• How much data (nature and number ofobservations) will be needed to generate clearfindings and how will those data be generated?
• What analytic strategy is appropriate?
Each of these issues could be the subject of a majortext in itself. However, the discussion that followsart iculates some principles that can guideexperimentation teams.
The Variables
This section discusses the nature of the variablesassociated with transformation experiments. Theycan be put into three groups: dependent ,

75Chapter 5
independent, and intervening. First, the dependentvariables, which will form the objective function inthe analysis that accompanies the experiment, mustbe chosen to ensure that they are valid and reliableindicators or measures of the anticipated benefitsfrom the innovation being investigated. Valid meansthat the measures represent all of the concepts understudy. This may well require multiple variables. Forexample, an innovation designed to improvedecisionmaking may well mean that the decisionsare both faster and more likely to be correct.Measuring only part of the concept, for exampledecision speed alone, would make the results of theexperiment misleading. Reliable means that themeasures selected are objective so that the samevalues will be recorded for the same observations.This can be a meaningful challenge when humanbehavior is to be recorded or human observers areemployed. Thinking at this stage needs to extend towhat will need to be observed and recorded and howthat will be done. A more thorough discussion ofdependent variables is included in the chapterdealing with measures of merit and data collection.
Second, the independent variables of interest mustalso be clearly articulated and the process by whichthey will be introduced into the experiment must bethought through. Moving from the concepts of interestin the initial model to the specific treatment to beintroduced often proves challenging. This isparticularly true when the richness of a true missioncapability package must be introduced. Whileacademic researchers will argue that experimentingwith smaller elements will produce clearer findings,military innovation almost always involves a syndrome

76 Code of Best Practice for Experimentation
of factors. For example, analyzing a new technologyrequires analysis of (1) the work process shifts awayfrom current practices to new doctrine crafted to exploitthe technology, (2) changes in the organizationalstructures and information flows required to exploitthe technology fully, and (3) alteration in the roles ofthose employing the technology. Hence, a missioncapability package concept will normally form the basisof the treatments to be assessed. As with theindependent variables, the experimentation teamshould try to avoid partial treatments that include onlysome elements of the mission capability package. Forexample changes that introduce a technology andsupporting work process, but do not alloworganizational changes believed necessary for themto be fully productive, will only show part of thepotential impact from the innovation. They may evengenerate results that lead us in the wrong direction.
The initial experiment design does not requiredetailed articulation of the treatments. It doesrequire understanding of how many there will beand what will be required to support them in theexperiment. However, the development of detailedtreatments can continue until it is time to integratethem into the federation of systems supporting theexperiment and training those who will use them.The Command Post of the Future experiment onrapid visualization makes a good case in point. Theirgoal was to compare new presentation technologieswith existing U.S. Army standard representationsof a land warfare battlespace. In this stage of theprocess, the decision had been made to have twoteams of researchers independently develop novelrepresentations. Hence, the experimentation team

77Chapter 5
could assume that the bundles of technologies andapproaches (different use of shapes, colors, waysto represent movement and the passage of time,selection of different map backgrounds, etc.) wouldbe organized into two treatments, each of whichwould represent a set of new ideas. A third treatmentwas the baseline representing the situationaccording to existing doctrine and practice. This wasadequate for the initial experimentation plan.Indeed, several months would pass and a great dealof preliminary research would be done before theprecise contents of the two innovative treatmentswere determined. However, knowing there were twoinnovations and a baseline was enough informationto permit experiment planners to continue their work.
Identifying the intervening variables, those primarilyof interest because they impact the relationshipbetween the independent and dependent variables,must also be done with care. This is an area whereprior research is particularly beneficial because itwill help the team identify important factors and howthey can be expected to influence the behaviorsobserved in the experiment. If these factors are notunderstood and identified before the experiment, theycan be expected to have a major impact on theexperiment’s results and to confound the team’sefforts to improve knowledge.
The most common intervening factor in DoDexperiments has been the level of training. Againand again, reports have shown that an experimentfailed to ensure that the subjects had adequatetraining on the new technology being introduced andtherefore the experiment’s results were dominated

78 Code of Best Practice for Experimentation
by the learning curve of the subjects. This means, ofcourse, that the full benefits from the innovation werenot achieved and its full potential could not beassessed in the experiment. In many cases, the weaktraining occurred because of a failure to cut offdevelopment of the new technology in time to createhigh quality training programs. The lack of a “goodidea cut-off date” has been cited in numerous post-experiment reports over the last decade as a sourceof problems because the technologies were not readywhen needed and the subjects had inadequate timeto train on them. In other cases, the problem hasbeen too little time allocated to the training process.All too often, training is shoehorned into a fixedschedule rather than given the importance and timeit deserves. The exit criteria from training should besome level of proficiency, not a fixed number of hoursof training. Thus, experimentation teams need toconduct performance-based testing on the subjectsso that all the participants have at least a minimalcapabil ity before the experiment starts. Theexperimentation team can then use statisticalcontrols to analyze the results in ways that factorskill level out of the analysis.
A number of other factors can intervene in manymilitary experiments and will often need attention. Apartial list includes:
• Reliability of the systems being tested and theinfrastructure underlying the experiment;
• The intelligence quotients (IQ) of the subjects;
• The experience of the subjects;

79Chapter 5
• Experience of the subjects working together;
• Physical limitations of the participants relevant tothe research (color blindness for presentationtechnologies, distances from individuals toscreens they are responsible for monitoring,etc.); and
• Learning by the subjects during the experiment.
Note that many of these deal with the natural varietyof the human beings involved. This implies thattesting of participants and research into theirbackgrounds can be used to ensure that they areassigned to treatments so that their individualdifferences are not a confounding factor. In largeexperiments, this is normally done by randomassignment of subjects. At a minimum, the potentialintervening variables need to be measured so thattheir impact can be factored out in the analysis. In asimple example, experimentation with a newcollaboration tool may involve communicationequipment or software that fails during part of theexperiment. The experimentation team needs toanticipate the need to record downtime, to identifythe workstations impacted, and to isolate data thatmay have been impacted so as not to skew theanalysis. Similarly, if, despite random assignment,one team in a collaboration experiment was found tobe composed of individuals with significantly higherIQs than the others, then the experimenters need tobe ready to use statistical analysis to control for thatdifference and ensure that it does not skew theresults. At this stage, the key is to have identifiedthe relevant sources of potential bias and developed

80 Code of Best Practice for Experimentation
a plan to (1) avoid them if possible, (2) test for themduring the experiment, and (3) prevent them fromimpacting the results.
Baseline and Treatments
The initial research design also needs to be veryclear about the manipulations and comparisonsbeing made. Experiments are inherent lycomparative. DoD experiments are conducted inorder to see (1) whether some improvements canbe expected from some innovation or (2) which oftwo or more alternatives will yield the greatestbenefit. Hence, it is often crucial to know how wellthe current practice performs. In other words, somebaseline is needed for comparison. The baseline issometimes available from prior work. For example,the rationale for the innovation may be lessonslearned or requirements analyses that havedocumented current pract ice and found i tinsufficient. The process of time critical targeting,for example, has been documented as inadequatebecause it is too slow to strike many targets ofinterest to the United States. In cases like this, thebaseline exists and change from it can become avery useful objective function. However, theexperimentation team must also make sure that itsexperiment is realistic enough that a fair comparisoncan be made between the real world baseline andthe experiment results.
For many innovations, however, no good baselinedata exists at this stage. For example, the questionof how many errors occur in situation awarenessin Joint Task Force (JTF) operations is important,

81Chapter 5
but documented only sporadically and in verydifferent contexts. Hence, a research team seekingto experiment with tools and processes designedto minimize those errors would need to build abaseline condition (no innovation) into the design.Building it into the experiment plan ensures thatdata on situation awareness are collected in thesame way and under comparable conditions so thatvalid and reliable comparisons can be madebetween treatments including innovations and thebaseline condition.
Sample Size
The initial research plan also needs to take a first cutat the technical issues of how much data are neededand what will be the analytic strategy. These are richtopics and must ultimately be dealt with by havingexperimentation and analysis expertise on the team.However, a few rough guidelines can be offered.
First, experiments should be designed with the lawof large numbers in mind. Most of the parametricstatistics preferred for experimentation do not applyto sets of observations less than 30, thoughmeaningful comparisons can be made between setsof 15, and non-parametric statistics can dealefficiently with as few as a handful of cases. Second,it is necessary to know what is being observed andto maximize the frequency with which it will occurand can be observed. For example, early efforts toexperiment with alternative planning processeswere hampered by the low frequency of planproduction. However, by shifting the unit of analysisfrom the plan to the elements of the plan (missions,

82 Code of Best Practice for Experimentation
assets, schedules, boundaries, and contingencies),the research team multipl ied the number ofobservations dramatically. At the same time, theyalso allowed the analysis to penetrate the problemmore deeply by examining which parts of the planstended to work better or worse under differentscenarios and planning contexts.
The broad analytic strategy can usually be inferredfrom the preliminary model and the finite definitionsof the variables to be observed and manipulated. If,for example, a discovery experiment is looking at howwork processes and new technologies can bemanipulated to increase speed of decisionmaking, theanalytic strategy will be to compare the treatmentswhile capturing the specific processes used and theway the technology is employed. This would implydifference of means tests that compare both thealternative treatments (combinations of workprocesses and technologies consciously built into theexperiment) and those time periods during which novelwork processes, structures, or methods of employingthe technology were reported. The initialexperimentation design would need to ensure acontext in which dozens of decisions were made. Ifonly a handful of decisions occur, the experimentresults will not be rich enough to see patterns in thesubjects’ behavior.
If, by contrast, a hypothesis testing experiment werefocused on the use of alternative collaborationtechnologies, holding work process and structureconstant, the analytic strategy might well be to buildan explanatory model that accounts for all thevariation in the objective function. In this case, the

83Chapter 5
treatment (alternative technology) would ideally beplaced into a multivariate statistical package wherethe influence of intervening variables believed to berelevant could also be considered. This allows theexperimentation team to test propositions aboutfactors such as learning effects within the experimentand differences between subjects and build a richermodel of the way collaboration can be employed indifferent contexts. Here again, however, dozens ofrelevant behaviors (collaboration sessions) will beneeded to ensure rich results.
Rough Experimentation Plan
As the initial research design emerges for theexperiment, the team will need to turn its attentionto the plan necessary to carry it out. Plans,including experimentation plans, always involvefive key elements:
• Missions - what is to be done;
• Assets - which organizations are responsiblefor each task; what resources do they have forthem, and which other organizations willprovide the support for each task;
• Schedules - when the tasks and subtasks are tobe completed and how those efforts will flowover time;
• Boundaries - how the pieces of the effort are tobe kept independent enough for successfulimplementation, but at the same time made intoa coherent whole; and

84 Code of Best Practice for Experimentation
• Contingencies - foreseeable circumstancesunder which missions, assets, schedules orboundaries will need to be changed.
As a practical matter, five specific items must beincluded in the detailed experimentation plan: thefacilities to carry out the research design, thesubjects, the scenarios to drive the experiment, theobservation plan for data collection, and theexperimentation schedule.
Finding the right facilities and fixing the dates for theexperiment, including the rehearsal or pretest, arecore issues. The nature of the experiment largelydefines the facilities required. These include not onlyrooms or hangars in which to conduct the experimenttrials, but also spaces for training and meeting withthe team, meeting rooms for observers, spaces forequipment, spaces where visitors can be briefedwithout disrupting the experiment, and facilities tofeed and house the participants. Facilities alsoinclude the computers and peripherals required andany specialized observation equipment necessary.Security is often an issue, not only for conductingthe experiment, but also for the areas from which itmust be supported. Most useful research andexperimentation facilities are very busy at the timeof this writing. Planning ahead will almost certainlyrequire months of lead time and may well require ayear or more. Facilities are both crucial and complex.A senior member of the experimentation team willnormally be assigned to manage this effort andanother person on the team wil l be givenresponsibility for detailed administrative support.

85Chapter 5
Subjects
Human subjects will be part of the experiment, unlessit is a pure modeling experiment. They must beidentified and arrangements must be made for theirparticipation. This is a very difficult task, but a crucialone because the results of the experiment can onlybe applied with confidence to the populationrepresented by the subjects. Here, again, a fewguidelines can be offered.
Academic experiments typically rely on studentpopulations for their subjects. They do this becausethey are normally trying to research fundamentalhuman issues – how some stimuli are perceived,how individuals behave under di f ferentcircumstances, how small groups function or changetheir work process under specific conditions, andso forth. When they want to understand theperceptions or behaviors of specialized populations(for example, older individuals, professionals whoshare some educational and work experiences, orthose who belong to a working culture such asmedical technicians) the academics must find poolsof subjects representative of those populations.
DoD experimenters face precisely the samechoices. In order to understand the behaviorexpected from mil i tary professionals, eitherindividually or in groups and organizations, subjectstypical of those populations must be used. To takea typical example, those concerned with thetransformation of the military are interested in hownovel tools and techniques will be employed 5 to20 years into the future. Clearly, this cannot be done

86 Code of Best Practice for Experimentation
using college students unless the research focuseson very basic human perceptual issues (whichcolors and shapes are more easily perceived underconditions of distraction and time stress) orprocesses (how should work be allocated betweenhumans and computers with a given level ofinformation processing capability). If the probleminvolves military expertise, then the subjects muststart with that expertise. At the same time, the useof retired personnel as surrogates, or even activeduty senior personnel, will require that they bewilling and able to accept retraining in order to getinto the future mindset necessary for the experiment.Some clever researchers have even employedteams of junior personnel they believed would relatedifferently to their technical innovations than theirsenior counterparts. They are trading off a differentattitude about systems and innovation againstestablished expertise.
The introduction of different pools of subjects (as away of controll ing for some of the expectedintervening variables) will, of course, impact theresearch design. Sufficient numbers of subjects ofeach relevant type and observations on theirbehaviors will be needed to test the hypothesis thatthe subject type did make a difference and moreimportantly, the null hypothesis that the subject typedid not make a difference. The same knowledge canbe gained by building different types of subjects intoan experimentation campaign design by firstconducting the experiment with one pool of subjectsduring one experiment, then trying to replicate theexperiment using a different pool of subjects. Thismay be a useful strategy over t ime, testing

87Chapter 5
propositions with different groups to see how broadlythe innovation is useful. At this writing, DARPA’sFuture Combat System Command and ControlProgram, undertaken in close cooperation with theArmy, has conducted an experiment with a flag officersupported by field grade officers and is planning toreplicate it with company grade officers and cadetsfrom West Point. Their goal is to understand howtheir innovations are employed by capable operatorswith different mixes of training and exposure tomodern computing technologies.
Subjects also need to be unbiased in that they haveno stake in the outcome of the experiment. Forexample, if the experiment is assessing the militaryutility of an innovation, people responsible for thesuccess of that innovation are inappropriatesubjects. Even if they make every effort to beunbiased, there is ample evidence that they will findthat almost impossible. Moreover, using such“contaminated” personnel will raise questions aboutthe experiment results. In demonstrat ionexperiments, of course, such advocates will oftenbe at the core of those applying the innovation. Inthis situation, where the utility of the innovation hasalready been established, their extra motivation toensure that the innovat ion is successful lyimplemented becomes an asset to the effort.
Subjects and teams of subjects also need to be equalin capability and substantive knowledge. In the eventthat some of the subjects have richer knowledge ofthe substance or processes involved in theexperiment, that difference should be fed back intothe experiment design. The design can sometimes

88 Code of Best Practice for Experimentation
be adjusted so that the bias does not impact thetreatments in an unbalanced way (for example, theexperienced subjects can be assigned so they areequally involved in all treatments, so their impact will“wash out” across applications). In any case, the factof a difference in expertise or experience can berecorded and included in the data analysis plan toensure a statistical test is run to detect any impact,measure its influence on the results, and provide acorrection that will prevent misunderstanding ormisinterpretation of the results.
Subjects need to be properly motivated. Whileacademic researchers are typically careful to carryout double-blind experiments so that the subjectsare not aware of the true research issues until aftertheir participation, this is seldom possible with DoDexperiments. Academic experiments also use avariety of incentives to ensure motivation such asgrades for participation and monetary rewards forsuccess are the most common incentives. Theseare not possible in most DoD settings. For example,the justification needed to capture the time of militaryand DoD civilians to participate in experimentsrequires a clear statement of the objectives.Moreover, unless they are given reason to believethat their efforts are contributing to significantefforts, adult professionals of all types, includingmilitary personnel, will not be motivated to put forththe best possible effort. Hence, the general purposeof the experiment should be made clear to thesubjects. Successful DoD transformation, whileavoiding change that does not have military utility,is a widely shared goal and has been shown toprovide strong motivation to active duty military

89Chapter 5
personnel, DoD civilians, reserves, national guardpersonnel, and the contractors who support them.However, these messages must be made clear tothe organizations that are asked to provide subjectsfor experimentation.
In addition, if professional subjects believe they arebeing evaluated, particularly in artificial contexts suchas those needed for experimenting with futureorganizational and doctrinal concepts, they will behesitant to be creative and energetic whenparticipating in the effort. In essence, they will seek toavoid risk. Hence, the experimentation team needs tomake it clear to subjects that they are not the subjectof the experiment and that it is the innovation ormission capability package being assessed, not theperformance of individuals or teams. This messagemust also be conveyed to organizations being askedto provide subjects. Otherwise they may be reluctantto provide subjects or convey a wrong impressionabout the purpose of the experiment.
Subjects must also be available for the entire timerequired. Very often, the type of people needed assubjects are very busy. The more skilled they are,the more demand there will be for their time. Hence,the experimentation team must make the minimumnecessary demands on their time. At the same time,requesting insufficient preparation time for briefing,training, learning doctrine and techniques, andworking in teams, as well as insufficient time todebrief them and gather insights and knowledgedeveloped during their participation undermines theexperiment. Failure to employ the subjects foradequate lengths of time will badly compromise the

90 Code of Best Practice for Experimentation
experiment and may make it impossible to achieveits goals. This has been a very real problem in manyDoD experiments. This has been particularly truewhen the experiments were designed for severalspirals in order to create cumulative knowledge andtrain subjects over time in order to ensure thesuccess of major experimentation venues such asJEFX and Millennium Challenge ‘02. Hence, the timecommitment required for success must be fulfilledand the importance of personnel stability whenrequesting support is very high.
Where are subjects likely to be found? Experiencesuggests several answers.
• Some service organizations designate particularunits to support particular experiments, whileothers identify particular organizations forexperimentation over time.
• Some (i.e., JFCOM) are creating specializedsurrogate organizations populated with retiredmilitary personnel or some mix of active dutyand retired personnel.
• Some experiments are conducted as part ofregular training exercises, either CPX or FTX.As discussed in Chapter 13, this “piggybacking”can be difficult as there is often tension betweenthe training objectives and the experimentobjectives.
• Pools of casual officers awaiting assignment orarriving early for military schools can sometimesbe employed.

91Chapter 5
Efforts to introduce new technologies, not onlyJWIPs and ACTDs, but also CINC and Serviceexperimentation may provide opportunities toexperiment with mission capability packages.
Military schools can sometimes be persuaded to buildrelevant experiments into their curriculum. The NavalPostgraduate School has been particularlysuccessful at this and the War Colleges can providehighly qualified pools of subjects. However, directlinkage to educational goals and incorporation intothe curriculum are usually necessary for militaryschool participation. This typically means long leadtimes for planning.
Reserve and National Guard units can providesubjects for experiments that are relevant to theirmissions. Again, some planning and lead time aretypically necessary.
For issues that deal with human perception, thetraditional sources such as college studentsand people attracted by advertising may beperfectly adequate.
Commands that have an interest in a particularexperiment often must take the lead in making surethat enough subjects with appropriate backgroundscan be made available to ensure successfulexperimentation. Experimentation teams need toinclude military personnel and/or retired militarypersonnel who can help them identify appropriatesources of subjects and communicate thelegitimate needs of the experimentation team tothose organizations.

92 Code of Best Practice for Experimentation
Scenarios
The choice of the scenarios or situations to be usedin an experiment needs to begin as the roughexperiment plan is developed. The NATO Code ofBest Practice for C2 Assessments contains a detaileddiscussion of scenario selection and is recommendedreading for those who need background on thesubject. The key principles include:
• No single scenario will provide the breadthneeded for a successful experiment.
• The model of the problem, with emphasis on thelimiting conditions as well as the independentand dependent variables, should be the driver inscenario selection.
• Scenarios should be designed to exerciseparticular levels of command (tactical,operational, etc.) because the types ofinformation and level of detail needed changewith those levels. At the same time, at leastthree echelons of command (one above theexperimentation focus and one below as well asthe primary echelon under study) will need to berepresented in the scenario to ensure adequaterichness for validity and credibility.
• The experimentation team should seek to definethe “interesting range” across which scenarioscan be spaced to generate a sampling of theproblem under study.
• Scenarios must be given enough depth to becredible to the subjects and to allow meaningfulinterpretation of the results.

93Chapter 5
• Ideal scenarios permit creativity. While scriptingwill be essential to establish the context for anexperiment, free play by both sides will benecessary to achieve the levels of engagementneeded by the participants and meaningful testsof propositions involving human perceptions,behaviors, and decisionmaking.
• Scenarios, particularly in-depth scenariosneeded for testing rich concepts andinnovations, are expensive and time consumingto create. Hence, reuse of scenarios will bewise, provided that it does not compromise theexperimentation goals.
• While approved or accepted scenariosdeveloped on the basis of current militaryguidance should be used when appropriate, theymay not provide an adequate basis forassessing innovations designed for the longerterm future.
Observation/Data Collection
The observation plan – how data will be collectedduring the experiment – should be initiated as part ofthe experiment plan. This involves thinking throughall three classes of variables (independent,dependent, and intervening). The observation planshould emphasize automated collection mechanismsthat are as unobtrusive as possible. A few principlesshould be emphasized:
• No single tool or technique is likely to generateall the data required for a successful experiment.

94 Code of Best Practice for Experimentation
• Observation should be as unobtrusive aspossible.
• Automated collection should be used wheneverpractical. For example, computer systems canreport how they are used and track automatedinteractions.
• Human collectors will be needed when humanperceptions, decisionmaking, or collaborationare used.
• If recording devises are used, the question ofhow their results will be employed costeffectively must be assessed.
• Survey instruments, whether applied to observer/controllers, experiment subjects, senior mentors,or other subject matter experts should be cross-checked by real time observation and empiricaldata.
• Observations should be shielded from theparticipants and from visitors of others outsidethe experimentation team until they have beenvalidated and analyzed.
The key issue in designing an observation plan isaccess. The experimentation team must understandthe physical situation in which data must becollected and ensure that they can be collected. Thismeans both physical access and also enough timeto ensure that survey forms can be completed,interviews conducted, data recorded, and subjectsdebriefed properly.

95Chapter 5
Feasibility Review and Exploratory Modeling
With dates fixed for the actual conduct of theexperiment and a better idea of what is going to bedone, work can begin on the schedule anddeconflicting of the activities of the experimentationteam. Before committing itself to a detailedexperimentation plan, the team should (1) besatisfied that the schedule is feasible, and (2)attempt to develop an executable model orsimulation of the issue or problem under study. Toreview the schedule, a PERT chart can provide asanity check with respect to the interdependenciesamong activities and resources allocation. This isboth a check on the logic underlying the hypothesesof interest and also an opportunity to explore theresearch space and find the “interesting range”where the experiment should focus.
The logic check performed by bui lding anexecutable model is essentially one that ensuresthat the abstract ideas expressed in the hypothesescan be integrated and expressed in a somewhatmore concrete form. The tools for this kind ofmodeling will be simple, employing systemsdynamics, influence networks, IDEF 0, colored petrinets, or similar logics. (See the NATO Code of BestPractice for C2 Assessment for a discussion of thetypes of models and tools that might be considered.)Even so, they wil l require translation of thehypotheses of interest into sets of related valuesand integration of the elements of the analysis intoa coherent theory.

96 Code of Best Practice for Experimentation
Once the basic concepts have been translated intoan executable model or simulation, it can be runacross the range of plausible values for eachvariable of interest to determine those values andcombinations of values that are worth researchingin detail. Often the extreme values for manyvariables are simply not interesting, or they makeno difference. In some cases, “knees” in the curveswill be found – regions where the rate of change insome variable is altered. These are obviously worthyof detailed exploration.
Detailed Experiment Plan
While the necessary modeling and simulation areoccurring, the experimentation team needs to bedeveloping the detailed plan for the experiment. Thisbuilds on the earlier work done when the facility wasselected, but shifts from relatively abstract issues tothe very concrete problem of how the experiment willactually be conducted. The activities, which includeidentifying the necessary infrastructure, thinkingthrough the controls needed, and developing anintegrated set of data collection and data analysisplans, are typically done in parallel because theyinteract in important ways.
Planning for theExperimentationInfrastructure
Typical infrastructure issues that arise include thenumber and variety of work stations for the subjects,controllers, and observers; the architecture(s) linking

97Chapter 5
them; the equipment needed to automatically collectdata (and other information required by theObservation Plan); the specific simulation(s) neededto drive the experiment and to capture what emergesfrom the subjects’ actions; and the systems neededto support analysis of the results. The level ofclassification for the experiment must also beconsidered when these decisions are made. Theseinfrastructure issues are treated as a bundle becauseinteroperability is a key issue. Failure to link theelements of the experimentation infrastructuretogether will result in a “kluge” of systems that isinefficient, raising the cost of the experiment, andincreasing the likelihood that the experiment will notbe fully successful. A senior member of theexperimentation team normally takes responsibilityfor this element of the plan and its execution.
Controlling the Controllables
Having recognized that significant interveningvariables exist, the experimentation team mustdecide, as part of the detailed planning, how theirinfluences will be controlled. Some factors can behandled directly by the experiment design. This isstrongly preferable if the differences are at thenominal or ordinal level of measurement becausethese types of differences are often difficult tocontrol statistically. If, for example, teams of subjectsare drawn from several nat ions (nominaldifferences) or groups with different levels ofexpertise (typically ordinal differences), theresearch design should provide control for thesefactors by ensuring each type of group is

98 Code of Best Practice for Experimentation
proportionally represented in each treatment. Otherfactors, particularly those for which interval or ratiovalues are readily available, can be controlledstatistically. For example, differences in scores onIQ tests are interval, while differences in years ofrelevant experience are ratio. Both types can becontrolled statistically as long as the number ofsubjects is adequate. This solution is also availablewhen the subjects have taken numerically scoredtests for performance on the systems supporting theexperiment or being evaluated. Some variation inoutcome can be expected based on individualdifferences in aptitudes, skills, or performance, andresearch designs and experiment plans seldomallow perfectly equal distributions of subjects onthese factors. However, the superiority of the controlintroduced through the design will minimize thechances of a confounded experiment and reducedifficulty in detecting and assessing interactiveeffects.
Controlling Exogenous Influences
Visitors, particularly senior visitors, must beunderstood as a potential source of bias in anyexperiment. Their interactions with experimentationsubjects, or even their presence in theexperimentation situation can be expected todistract the subjects and alter their work processes.Hence, a well-designed experiment will includeprovisions for hosting visitors and providing themwith an opportunity to understand the experiment,but will prevent them from impacting the results. Theone-way mirrors built into almost all commercial

99Chapter 5
experimentation and focus group facilities are arecognition of the importance of non-interference.DoD experimentation needs to recognize this realityand make provision to avoid this type of bias. A goodtechnique used in some cases is to videotape all orselected parts of an experimentation session anduse the tape as a way of giving senior visitors arich understanding of the experimentation process.Another is to invite visitors to act as subjects in trialslike those being used. This is usually easy whenindividual subjects, rather than teams, are beingused. However, it requires an experimentationworkstation, drivers, and other support to make itrealistic. Like all such uses of videotape, however,the privacy rights of the participants will need to bepreserved and appropriate permissions obtainedbefore this technique can be used.
Data Collection and Analysis Plan
The final key element of the detailed plan is thedevelopment of an integrated data collection anddata analysis plan. Teams that produce thesedocuments separately almost always find that theyhave problems in analysis and interpretation. A datacollection plan includes all of the variables to becollected, all of the places they are to be collected,all of the means of collection, and all of the placesthat the data will be stored for processing. The mostcommon errors here are failures to provide forcomponent failures (substitute data collectors, spareequipment, etc.), failure to provide collectors withadequate access (terminals, headsets, securityclearances), lack of communication equipment so

100 Code of Best Practice for Experimentation
they can gather data, consult regularly, and flagproblems from their workspaces without the subjectsoverhearing them, and failures to provide adequatestorage (including classified storage). The datacollection plan is an excellent candidate for peerreview because it is crucial and because it needsto be both complete and clear.
The data analysis plan includes whatever processingor data reduction are required to convert what hasbeen collected into a form that can be analyzed in theways desired and the plan of action for that analysis,as well as the interpretation of the results.
Indeed, while experimentation teams collect first andanalyze later, they must reverse that thinking in orderto ensure that collection fully and effectively supportsanalysis. Common errors include failure to recognizethe time and effort necessary to organize raw data(data reduction, structuring of analytic files, etc.),failure to ensure that the qualitative and quantitativeelements of the analysis are integrated and used tocross-check one another, and failure to ensure thatthe analysis looks for insights from the full range ofparticipants (subjects, observers, senior mentors,white cell participants, etc.). The data analysis planshould also include preparations for the use ofmodeling and simulation to examine excursions fromthe original experiment, perform sensitivity analyses,and update and improve the model used to understandthe problem. The data analysis plan is also anexcellent candidate for peer review.

101Chapter 5
Conduct of the Experiment
The development of a detailed experiment plan isessential because of the complexity inherent intransformation experiments. However, just as nomilitary plan ever fully survives contact with theenemy, so no plan for an experiment can ever beimplemented without adjustment, refinement, andaugmentation. In preparing for and conducting anexperiment, three steps are essential:
• Experimentation environment set-up;
• Rehearsal, or pretest; and
• Execution of the experimentation plan.
Experimentation EnvironmentSetup
An experiment requires an artificial environment.This includes all the elements of infrastructureidentified in the experimentation plan includingworkstations for the subjects; simulations or otherdrivers for the scenarios; communications linkagesamong the subjects, controllers, observers, andtechnicians supporting the experiment; databases;and logistics. This is a major effort, particularly forthe technical support personnel. It takes time, oftenfar more than originally estimated, to set theequipment up and check it out. Often the individualsystems work properly, but they have problemsworking together, exchanging information, oraccessing the same data. Integration of even well-tested and reliable system components is a

102 Code of Best Practice for Experimentation
formidable undertaking. Hence, appropriate leadtime is needed to ensure that all the systemsneeded are up, interacting properly, and ready tosupport the experiment. This cannot be doneeffectively at the last moment. Problems that areexperienced with the functionality or the availabilityof the systems impacts the subjects and the natureof the data collected. Thus, given that the properfunctioning of the systems is critical to the successof an experiment, adequate attention, time, andresources need to be allocated to this activity.Experience shows that, in the name of efficiencyand as a false effort at economy, this step issometimes left until the last minute. More than oneexperiment has been undermined because theteam responsible for the facility tried to bring ittogether at the last minute and found they hadglitches that prevented timely and sufficienttraining or initiation of the experiment trials.
In some cases, only a part of the experimentationsetup has been made available for the pretest.For example, only a small subset of subjectworkstations has been used despite the fact thatthe conduct of the experiment called for a muchlarger number. The experimentation team mustmake every effort to ensure that the initial setupis des igned and tes ted in ways that arechallenging enough to ensure that the test is anadequate representation of the environmentrequired for the experiment. Moreover, plans willbe needed to complete and properly test the setupbetween the rehearsal and the conduct of thelarger experiment.

103Chapter 5
Pretest or Rehearsal
Conducting a pretest in which all the myriad elementsrequired for a successful experiment are broughttogether and made to operate successfully is anessential prerequisite for a quality experiment. Inexperimentation, the numerous hidden pitfalls merelyprove that “the devil is in the details,” however, properplanning and careful execution can overcome thesedangers and produce great successes, leavingsponsors and stakeholders proclaiming that “God isin the details!”3 Holding a rehearsal can be expectedto improve every aspect of the experiment, from thesupporting scenario through the data collection andsubsequent analysis. Failure to hold one will almostinevitably mean that some aspects of the effort willneed to be corrected on the fly, greatly decreasingthe likelihood of success.
To be really useful, every aspect of the experimentshould be pretested. All the technical systems tobe used should be brought online – simulationdrivers; workstations for subjects, observers, andcontrollers; the full package of instrumentation; theexperimentation treatments; communicationsdevices; as well as the computers where data willbe captured and stored.
The pretest should be scheduled at least a monthbefore the experiment itself in order to allow time todiagnose the sources of problems, develop effectivesolutions, implement them, and conduct limited teststo make sure that the problems have been resolved.

104 Code of Best Practice for Experimentation
Training
Subjects, observers, control lers, and otherparticipants need to be trained for the pretest.Training should precisely address the skills to beused in the experiment. Moreover, the subjectsbeing trained should be comparable to those whowill participate in the experiment. Full trials shouldbe run (though they may well lack the rigor of thoseto be made during the experiment) in order toenable dialogue between the members of theexperimentation team, the subjects, and thetechnical personnel supporting the rehearsal.Observer training should also be rehearsed anddata taken in order to ensure the training issuccessful and the observers have the tools andaccess they need for a successful effort. Trainingwill also extend to the controllers of the white andred cells to ensure they can play their rolesef fect ively and wi l l not unduly impact thetreatments under study.
Most of the results of the pretest will be obvious, butothers may require some reflection and study. Timeshould be built into the schedule to provide anopportunity to reflect on the results of the pretestand to take corrective action. Because elements ofan experiment are heavily interconnected, changesneeded in one area will often impact or depend uponchanges in other aspects of the experiment. Forexample, learning that the subjects need moretraining on the systems they will use must have animpact on the training schedule and may requiredevelopment of an improved human-computerinterface as well as new training material.

105Chapter 5
Each opportunity to improve the experiment shouldbe fed back into the detailed experiment plan, bothto ensure that the new knowledge is exploited andto ensure that its impact on other aspects of the planare recognized. The detailed experiment planremains an open document, changing in order tomeet new challenges, but also providing a stableoverall structure around which the aspects of theexperiment are organized.
Execution of the Experiment
At this point the reader should certainly recognizethat a lot of effort and thought will have to be putinto getting ready for successful execution andmay recognize the crucial role of those efforts insuccessful experimentation. However, all thathard work and careful thought can also be wastedif the actual conduct of the experiment is notcarried out diligently.
Training of all participants is the last opportunity toidentify and fix problems. It should begin with trainingthe support team that operates the systems and whowill need to respond if there is a problem as well ascapture data about the problem. They will often trainsome of the observers, controllers, or subjects onthe use of technical systems, so this “train the trainer”activity is very important.
As with the pretest, observers and controllers alsoneed to be trained. While they have different roles,the actions they take during an experiment are ofteninterdependent, so they should spend at least someof their training time together. This should include

106 Code of Best Practice for Experimentation
discussions of the objectives of the experiment andhow they will need to work together to preserve itsintegrity. Training also needs to include a clearunderstanding of expected roles and behaviors sothey do not bias or impact the results of theexperiment, as well as ensuring that they canoperate those systems that they will depend uponduring the experiment.
Observer training cannot be accomplishedeffectively in the abstract. Data collectors need tocollect data and be critiqued so their efforts will beproductive. Realistic practical exercises andreliability testing are necessary. Often, part of theobserver training can be combined with thefamiliarization training for subjects and should be ahands-on opportunity to actually collect data undersupervision. This practice also allows the subjectsto become familiar with data collection processesand to raise any questions or concerns they mayhave before the experiment trials begin.
As noted earlier, subject training is particularlyimportant and has proven to be a major problemarea in a number of past DoD experiments.Training must cover an understanding of thepurpose of the experiment, substantive issuesregarding the background or scenar io, theprocesses the subjects will use to perform theirroles, their roles in providing data, as well as thetechnical skills necessary to perform their roles.To preserve the integrity of the experiment,subjects should be able to pass proficiency testsbefore the trials begin. Given the relatively smallnumbers of subjects, subjects that are not properly

107Chapter 5
equipped to perform their assigned tasks createsignificant problems later during the analysisphase. When this type of subject screening is notpractical, scores on those tests can be used as abasis for statistical controls that either mitigate orhopefully prevent differences in proficiency frombiasing experimentation results. Training is also afinal opportunity to ensure that the subjects arehighly motivated. Obtaining subjects who areproperly motivated is achieved initially by subjectselection, but all adults are capable of “turning off”if they believe the activity they are in is not seriousor does not serve a serious purpose. Hence,sessions that inc lude both mot ivat ion andopportunit ies to ask quest ions and providefeedback are very important during training.
The imminent prospect of an experiment tends toconcentrate the mind and bring all the actors,including senior visitors, to the center of the stage.The actual conduct of the experiment is almost ananticlimax when it finally occurs. In theory, thisconduct of the experiment harvests all of the priorwork and thought and will, hopefully, proceedsmoothly. At this point, the major tasks of theexperimentation team are:
• Quality control – ensuring that the experimentthat takes place is the one that was planned anddesigned, with no outside factors intruding inways that undercut the purposes of the effort;
• Data integrity – ensuring that the right data arecollected, that no biases are introduced by the

108 Code of Best Practice for Experimentation
collection, aggregation, storage or datareduction efforts; and
• Debriefing of all the participants to ensure thatqualitative data are collected, issues that mightimpact the data or its interpretation are fullyunderstood, and the insights available fromeveryone (subjects, observers, controllers, andthe support team) are captured while they arefresh.
In fact , however, conduct ing a successfulexperiment often requires practical and intellectualagility. Things frequently go wrong. Systems breakdown, whether they are computer systems,reproduction systems, communication systems, oranything else. People who appeared to havemastered skills or sets of information duringtraining flounder when they are asked to applythem. Participants become il l or unavailablebecause of family concerns or mil i tary dutyimperatives. Schedules prove unrealistic. Seniorvisitors appear unexpectedly and must be madewelcome and given quality information withoutimpacting the experiment. The list goes on and on.In fact, if it were not for all of the effort and thoughtapplied in developing the detailed experiment planand conducting the pretest, problems would simplyoverwhelm the experiment team and cripple theexperiment. Proper contingency planning makesit possible to deal with problems as they arise.
Each and every one of the problems encounteredwill need to be recorded clearly and thoroughly,so that the impact upon the experiment can be

109Chapter 5
tested, and dealt with effectively to achieve asuccessful experiment.
Many of the common problems should have been dealtwith during the pre-experiment phase when theexperiment plan was developed. Robust andredundant systems should have been selected.Refresher training should have been built into theschedule. Reserve talent should have been built intothe observer, controller, and support teams. Extrasubjects should also have been recruited and trainedalong with the main group. Finding useful roles forthese individuals, if they are not needed in the maindesign, is often a test of the creativity of theexperimentation team. Plans for handling seniorvisitors should be in place. In summary, single pointsof failure should be eliminated.
However, Murphy’s Law, that “whatever can gowrong, wil l go wrong,” applies frequently toexperiments of all types. Foreseeing and planningfor every problem that may occur is simply notpossible or practical. The last defense is thedetermination, ingenuity, and hard work of theexperimentation team. Leadership must encouragean attitude that identifies potential problems honestlyand privately (so their potential impact does notunnecessarily impact other parts of the experiment).Issues must be examined promptly when they arise.Best available responses and solutions, which maybe simply tracking the time periods, subjects, ortreatments impacted for later analysis, must beidentif ied and understood by the entireexperimentation team.

110 Code of Best Practice for Experimentation
The raw data collected during an experiment areseldom in exactly the form needed for analysis. Ina sense, the data need to be converted into usefulinformation by being placed in the proper contexts.For example, observer journals may need to beconverted into specific data points about topics ofinterest through a process of selecting relevantevents and coding them according to definitions andcoding rules developed before the experiment.Similarly, raw data recorded automatically about theuse of systems will need to be aggregated by timeperiod, topic, type of user, or other significant controlvariables. These data reduction processes shouldbe completed immediately after the experimentationtrials. Indeed, they can sometimes be initiated whilethe experiment itself is still underway. However, theirquality often depends on having the team thatconducted the experiment available to ensureresolution of ambiguities and understanding of thecircumstances surrounding the data. Failure tocomplete data reduction on the spot using the fullexperimentation team has, in the past, limited thedata and information available for analysis andtherefore reduced the quality of the experiments.
Inexperienced experimenters often assume thatarchiving is only a last minute activity and can bepostponed until after analysis is complete. This is anaive perspective. The raw material generatedduring the experiment may be lost when thesupport ing infrastructure is dismantled orreconfigured to support other efforts. Experiencedresearchers also know that the very process ofanalyzing data can change it. Moreover, databasemanipulation errors are common during analysis.

111Chapter 5
Finally, other research teams, with different datamining tools and analytic purposes may later findthe initial data useful. Hence, archiving both the rawdata and the information created in data reductionshould be seen as an essential part of theexperiment itself. This is consistent with the DoD“post before using” policy to encourage informationsharing or reuse of experimentation data. This isalso an important way of ensuring the integrity ofthe experimentation data. Note that it covers all ofthe crucial artifacts of the experiment:
• Raw and processed data of all sorts, includingbackground information collected on subjectsand survey forms completed during theexperiment;
• Insights offered by experiment participants,particularly during debriefs;
• Lessons learned about the experiment and theexperimentation process; and
• Experimentation materials (simulation drivers,interjections by the control team, briefings orother products developed by the subjects,training materials, databases generated duringexperiment play, etc.).
Post-Experiment Phase
Contrary to popular belief, the experiment is not overwhen the subjects go home and the VIPs leavearmed with a “hot wash” briefing or later with theissuance of a “Quick Look” report. Severalmeaningful steps remain to be taken after the

112 Code of Best Practice for Experimentation
conduct of the experiment in order to ensure itssuccess. These key tasks include:
• Data analysis;
• Integrating experimentation results from differentsources and perspectives;
• Interpretation of the data and informationgathered to generate knowledge;
• Circulation of draft results for comment andconstructive criticism;
• Modeling and simulation to validate and expandfindings;
• Revision of the products to incorporate theresponses to the draft and the new knowledgegenerated by modeling and simulation;
• Archiving experimentation data and materials;and
• Circulating the final products.
All too often, “defeat is snatched from the jaws ofvictory” after an experiment because too little timeand too few resources have been allocated tocomplete these tasks and exploit the empirical datathat has been generated by turning them intocontributions to the body of knowledge. One of themost common problems is the desire for instantresults leading to a hot wash at the end of the conductphase of an experiment, a quick look at the results afew weeks later, and a final report that is a shallowdiscussion of the findings reported in these earlyproducts. This excessive focus and attention given

113Chapter 5
to early deliverables leads to an unhealthyconcentration on the immediately measurable andanecdotal evidence. They are a legacy from trainingexercises where the purpose is prompt feedback ina well-understood problem set. This approval doesnot reflect an understanding of the complexity ofexperimentation. Hence, it undercuts the process ofexperimentation and reduces the impact ofexperimentation on research and developmentprograms. This does not relieve experimentationteams of their obligations to plan experiments thatgenerate results as promptly as is practical, but itdoes speak to the problem of post-experimentationefforts and the need to exploit experiments as muchas possible.
Analysis
The most obvious effort of the post-experiment phaseis analysis. This should be guided by the AnalysisPlan developed as part of the detailed experimentplan. The nature of the tools and processes involvedare discussed in detail inChapter 9. However, a fewguiding principles should be noted here.
First, the ideal analysis plan involves a set ofanalyses, not a single analysis. This is a reflectionof the fact that a variety of different data (subjectbackground, skill proficiency, behavioral data, surveyinformation, insights from debriefings, etc.) must beanalyzed, but also a recognition that differentanalytical tools may be appropriate in order tounderstand the experiment results richly. Theexperimentation team needs to think about the “so

114 Code of Best Practice for Experimentation
what?” of an analysis to make sure that it is necessaryand properly conceived. That is, they need to reflectupon the results of the analysis and the explanationof the results. Would it make sense? Would it becredible? Would the analysis, as envisioned, supportthe purpose of the experiment?
Second, the appropriate set of analyses will varywith the purpose and focus of the experiment.Discovery experiments will require open-endedtools and techniques that allow the analysts toexplore weakly structured problems and unearthpatterns they might not have initially anticipated.Hypothesis testing experiments will require rigoroustools and techniques that permit specific inferencesand allow for statistical control of interveningvariables. These should also be supported byapproaches that allow for discovery of unanticipatedpatterns and exploration of ideas emerging asinsights. Demonstration experiments, on the otherhand, should be primarily supported by analysesthat confirm their underlying postulates. However,even these experiments should not be reduced tomechanical calculations that fail to look for newinsights, new limiting conditions, or novel patterns.
Third, analyses, like experiments, should avoidsingle points of failure. Each analyst or analyticalteam should be required to show their results andexplain them at internal team meetings. Key findingsshould be deliberately replicated, preferably by ananalyst who did not perform the first run. Tests forstatistical bias and technical errors should be used(for example, the impact of outlying cases or otherdistribution problems, the presence of multi-

115Chapter 5
colinearity, or the absence of homoscedasticity) toensure that the results are not an artifact of theanalytical processes chosen.
Finally, items of interest from the experiment outsidethe analysis plan, such as insights coming fromparticipants or anomalies arising from equipmentfailures, should not be ignored. Senior analystsshould work to develop specific approaches, tools,or techniques that allow unanticipated issues andevidence to be understood and exploited to enrichthe results. The NATO Code of Best Practice for C2Assessment includes a rich discussion of analytictools and models. It is recommended reading forthose interested in greater detail.
Integrating ExperimentationResults
The analysis plan will be composed of a variety ofthreads or independent sets of analyses designedto generate knowledge arising from differentelements of the experiment. Sometimes these willbe directly comparable or tightly coupled, as in thestatistical efforts to measure direct effects and thosedesigned to assess the impact of intervening orexogenous variables. Others will be qualitativelydifferent, such as the results from surveys,structured debriefings, and behavioral observations.However, only a single experiment actual lyoccurred. Hence, these different perspectives needto be integrated and used to cross-check oneanother so that the experiment is richly understood.Failure to integrate the data and information arising

116 Code of Best Practice for Experimentation
from the variety of analytic perspectives employedwill lead to a weak understanding of the experimentand may wel l leave unresolved issues orinconsistencies in the analytic results.
Interpretation of the Results
Data and information, even after analyses, do notspeak for themselves. They must be placed in contextbefore they can be understood. The simplest exampleis that analytic results fit into larger frameworks. At afundamental level, they are consistent with,contradict, or help to clarify prior knowledge andresearch. They may also clarify other experimentsin a campaign undertaken to understand issueslarger than those explicitly explored or assessedduring the individual experiment. They may alsoaddress problems, issues, or decisions that areimportant to their sponsors and customers.
Effective reporting of experiments shoulddiscriminate between the f indings and theinterpretation of the findings. In a well-run, successfulexperiment the findings should never be at issue.However, interpretations of these findings will oftenbe an important issue on which knowledgeablepractitioners and researchers may differ. This isparticularly likely when the research results are linkedto important issues or support policy decisions thatmay involve a very different calculus.
Circulation of Draft Results
Experimentation is a research activity. Its goal is arich and comprehensive understanding of the

117Chapter 5
phenomenon under study. All too often, however,experimentation teams and the organizations thattask them act as though these are closely held insideractivities that should not see the light of day untilafter they have been fully analyzed and interpreted.In the worst case, results that are inconsistent withsponsor philosophy or inconsistent with perceivedorganizational interests are not circulated at all.These practices are antithetical to everything weknow about effective research and learning fromexperimentation. Hence experimentation resultsshould always4 be circulated, as early as possible,among those with related interests and knowledge.This includes peer reviewers chosen for their insightsand knowledge, the participants in the experiment,other knowledgeable researchers, and practitioners.
This practice should not be understood to mean thatexperimentation teams should rush their work tobroad publication. The results circulated should bemature and should include the original team’s initialinterpretations of the findings. They should also bemarked “Draft” and should be circulated for theexplicit purpose of soliciting constructive criticismand feedback, both on substance and presentation.This practice will help to create and maintaincommunities of interest on important issues.
Modeling and Simulation to Validate andExpand Findings
While the draft results are being circulated, theexperimentation team should return to its executablemodel of the problem for two different purposes:sensitivity analyses and revision of the experiment

118 Code of Best Practice for Experimentation
model. Sensitivity analyses are primarily used tolearn how robust and how stable the results of theexperiment are in the context of those interveningor exogenous variables identified as important orto examine interactive effects when complexproblems are being researched. Model revisionefforts ask how the initial model might be changedor enriched in order to reflect the results of theexperiment better. In either case, these activitiesare actually part of the overall analyses enabled bythe experiment. They will often impact both the finalproducts of the experiment and any relatedexperimentation campaigns.
Revision of the Products
Feedback on the draft results, modeling andsimulation efforts, as well as reflection anddiscussion within the experimentation team willcome together to support revision of the products.This will typically include some type of annotatedbriefing intended for general audiences, a detailedtechnical report with the data and analyses attachedintended for researchers, and an executivesummary intended for decisionmakers and policymakers and those who expect to implementrecommendations arising from the experiment (withreferences to the more detailed documentation).Keeping these products consistent as the revisionsare made is an important, and sometimeschallenging, task.

119Chapter 5
Archiving and Circulating Dataand Products
Final completion of the experiment includes bothselecting the best vehicles to circulate the resultsand also archiving the experiment’s artifacts sothey can be reviewed or used again. Both areimportant efforts.
Circulating the products can be done in a variety offorms such as traditional paper distribution, e-mailto selected individuals and organizations, posting onWeb sites, offering papers at workshops,conferences, symposia, and publication in journalsor books. The more significant the experiment, themore broadly the team should try to disseminate theproducts. This is true even where the experiment failsto confirm the hypotheses under study. Such findingsare extremely important in advancing knowledge,even though they may be a disappointment to theexperimentation team or its clients.
Archiving is also crucial. Lost data, information, andexperiment support materials are very realimpediments to progress. They deny otherresearchers most of the practical benefit from theexperiment. They also prevent, or make verydifficult, replication of results, one of the keyelements in science. Finally, they result in increasedcosts for later related experiments. Hence, thematerial archived at the end of the experimentshould be inventoried to ensure that it is all present,saved, and available for recall. In addition, analysesand model ing efforts undertaken to betterunderstand the results, or as a result of feedback

120 Code of Best Practice for Experimentation
from the draft products, should also be archived andindexed for recall.
Modeling and Simulation inSupport of Experiments
Models and simulations play important roles in anexperiment. These usually computer-based tools areused to support experimentation with military subjects.Also, there are occasions when the empirical datacollection that is an inherent part of traditionalexperiments can be replaced by models andsimulations. That is when models and simulations arethe generators of empirical data, or more accurately,simulated data. These activities are called model andsimulation experiments.
The use of models or simulations to explore importantissues has been a long tradition in the military insupport of operational planning and other importantanalysis efforts. However, these efforts have notalways been organized as experiments. In manycases, they have simply been efforts to exploreinteractions within a parameterized space. Most suchmodels and simulations are deterministic and amountto an exploration of the consequences of selectedsets of assumptions. Indeed, the application of thesetypes of models is necessary to help identify theinteresting design space for more extensiveexperimentation and for performing sensitivityanalyses over the results of an experiment.
To be an experiment, the effort needs to address theissue of uncertainty with respect to the dependentvariables of interest. Hence, the systematic

121Chapter 5
application of very large, sometimes deterministic,combat models can be thought of as experiments,though they currently are seldom organized that way.Indeed, since the basic purpose of the design of suchmodels is to build a credible representation of combatinteractions, the interactions built into them areusually heavily constrained so that the outputs areunderstandable to the communities they serve. In asense, therefore, these tools are used as a specialtype of demonstration experiment to show that theprocesses under study conform to the assumptionsand expectations of their users.
Increasingly, however, models are being createdthat use simple rule sets to explore interestinginteractions. Such models often employ agents andsets of simple rules to explore behaviors andinteractions among agents seeking to discoveremergent behaviors in complex, nonlinear systems.They can be quite sophisticated (involving fuzzylogic and other advanced tools) or relatively simple.Most of these applications can be understood asdiscovery experiments designed to learn aboutimportant classes of interactions. These models andsimulations can be extended to hypothesis testingexperiments, though only with considerable care arethe nonlinear properties inherent in them willchal lenge both hypothesis formulat ion andinterpretation of results. Nevertheless, they holdgreat promise, particularly because most of themare very fast running and can, therefore, be usedto rapidly explore interesting analytical spaces. Ascomputing power grows over time, this approachmay become more useful and more common.

122 Code of Best Practice for Experimentation
Figure 5-2 shows how modeling and simulationactivities relate to each other within the context oftransformational experimentation in the DoD:
• Pre-experiment research should explore existingmodels and simulations (and their priorapplications), reports of experimentation results,and other documentation. These are keysubjects of study during the knowledge review inorder to formulate the experiment;
• Development of an initial conceptual model tosupport the experiment. This typically staticrepresentation idealizing all the relevantvariables, the relationships between them, andthe context of the experiment is produced duringthe experimentation formulation;
• During the conduct of the experiment, modelsand simulations are used either as (1)experimentation drivers and support tools (in“human in the loop” experiments) or as (2) thedata generation engines (in model-basedexperiments). There are two stages to theprocess of applying models: one is to developthe simulation environment, including thepopulation of data, necessary modeling, andaccomplishing the necessary engineering toensure a simulation environment functions asintended; the second is to conduct theexperiment using the tools;
• After the experimentation data are generated,modeling and simulation are used for sensitivityanalyses and other exploratory efforts; and
123C
hapter 5
Figure 5-2. Modeling and Simulations

124 Code of Best Practice for Experimentation
• A revised model is normally generated to capturethe knowledge/results from the experiment.
There are a few important points to rememberregarding the use of simulations, and other models,in support of experimentation. The first is that theapplication of these tools is not free, either indollars or t ime. But, i t is often a necessaryinvestment to support any significant, well-craftedexperiment. Significant investments in engineeringtraining simulat ions, l ike the Joint TrainingConfederation, to represent new concepts shouldbe preceded by the development of executablemodels. Reasonable investments in upfrontanalysis focused on the experiment can assist infocusing the larger-scale effort, ultimately makingthe effort more efficient.
There is a special case in experimentation calledmodel-based experiments. In these types ofexper iment models, executable computersimulations substitute for human subjects for thepurpose of generating experimentation data. All ofthe principles identified in this chapter hold forthese types of experiments. There are alsoadditional considerations, which are discussed inChapter 12.
1The new NATO COBP for C2 Assessment.2Alberts, et al. “The Network Centric Warfare Value Chain.”Understanding Information Age Warfare. CCRP, 2001. p77.3Ludwig Mies van der Rohe. The New York Times. August 19,1969.

125Chapter 5
4Always is a strong word – but in this case the value of anexperimental activity is directly related into the contributions itmakes to the larger community – and even somewhat flawedexperiments need to be properly documented and circulate sothat others can learn from the experience.

127
CHAPTER 6
ExperimentFormulation
Focus
This chapter and the ones that follow provide amore detailed focus on the specific activities that
the experimentation team must execute. The keysto formulating a successful experiment are exploredhere from three different perspectives:
• Developing the propositions and hypothesesthat will guide the rest of the experimentationdesign process;
• Creating and applying an initial model in orderto define and explore the problem space underanalysis; and
• Key experimentation design considerations,including both the essence of design and howdesigning DoD transformational experimentsdiffers from designing “ideal” experiments froman academic perspective.
This chapter and the others that follow at this level ofdetail are also qualitatively different from those thathave come before in that they use a single example,

128 Code of Best Practice for Experimentation
an experiment in self-synchronization, as a concretecase of each of the topics under discussion.
Propositions and Hypotheses
The topic of formulating the experiment, includingmaking precise statements about the issues underanalysis, was discussed earlier. The key points are(1) specifying the issues under study as preciselyas i s p rac t i ca l regard less o f whether theexperiment will focus on discovery, hypothesistesting, or demonstration of existing knowledge,(2) ensuring that the problem is formulatedcomparat ive ly ( inc lud ing a base l ine whenpossible), and (3) using background research ofwhat is already known so that the statement ofthe problem includes all of the known factors.
Making Better Sets ofPropositions and Hypotheses
A formal statement of the exper imentat ionproblem can be used to make the experimentmore productive (greater knowledge gain fort h e s a m e l e v e l o f e f f o r t ) i f i t i s d o n ethoughtfully. This formal statement should betermed the propositions when the experimenthas a discovery focus because the level ofknowledge is not yet mature enough to statethe problem as formal hypotheses. For bothh y p o t h e s i s t e s t i n g a n d d e m o n s t r a t i o nexperiments, the proper term is hypotheses .Note that both terms are plural. While i t ispossible to design an experiment that focuses

129Chapter 6
on a s ingle re lat ionship between only twovariables, it is almost impossible to identify anont r iv ia l DoD t rans format ion exper imentproblem that does not depend on controllingfor some other factors or intervening variables.Hence, the statement of the problem should beformulated so as to specify the whole issueunder study, not just the specific hypothesesunder detailed analysis. This practice improvesthe experimentation team’s ability to identifyall the elements of the problem and ensureproper controls are in place.
Another useful approach to describing theexperiment problem is selecting the propositions orhypotheses so that any possible outcome providesincreased knowledge. This is the logic underlyingthe pr inciple that useful t ransformationalexperiments are comparative. This means that thereare competing hypotheses. For example, theargument that standing JTF headquarters willenable “better” operational effectiveness impliesthat there are al ternat ive bases for suchheadquarters (ad hoc assembly of tailored JTFheadquarters, for example) that should also beconsidered and compared with the new conceptunder study. If such comparisons are made, thenexperimentation findings would provide importantgains in knowledge if they established that:
• One or the other form is more effective, or
• Each is more effective under specific conditions(for example, ad hoc assembly is better for well-understood operating environments and

130 Code of Best Practice for Experimentation
missions that are primarily military; standing JTFheadquarters are better for more novelenvironments and situations where a broadrange of instruments of national power[economic, political, informational, andhumanitarian as well as military] must beemployed to achieve the desired effects), or
• Neither is more effective than the other in theexperiment.
In other words, the propositions or hypothesesemployed should be organized to create a win-winsituation in terms of maturing the knowledge of thesubject under study.
As noted earlier, all three basic types of experimentshould also be organized so that the participantsare alert to (and can provide) insights about factorsnot understood to be important during the problemformulation stage, but that emerge as significantduring the experiment planning, rehearsal,modeling, conduct, or analysis.
Finally, the actual statements of the propositionsor hypotheses under study should take the formof an integrated set that specify all of the variablesand relationships of interest and make it clearwhat will vary and what will be controlled. Thisexpression of the problem will be modified as theexperimentation team works through the process,but i t needs to be formulated as crisply aspossible, early in the effort.

131Chapter 6
Propositions for an ExploratoryExperiment in Self-Synchronization
Assuming an experimentation team was formed toexamine the issue of how self-synchronizationcould be employed ef fect ively in mi l i taryoperations, it would have to identify and organizethe relevant propositions. Given the relatively weakknowledge today about self-synchronization, theteam would conclude early in its efforts that thisshould be a discovery experiment. The team wouldhave to assemble what has been written on thetopic and would probably convene panels ofsubject matter experts from the military and alsohold a workshop to bring together practitioners,experts from industry, and relevant academicspecialists. That having been done, they mightdevelop the following propositions:
• Effective self-synchronization requires highquality situation awareness.
• Effective self-synchronization requires a highdegree of shared awareness.
• Effective self-synchronization requirescongruent command intent across echelons,functions, and organizations.
• Effective self-synchronization requires highcompetence across all echelons, functions,and organizations.

132 Code of Best Practice for Experimentation
• Effective self-synchronization requires a highdegree of trust across command echelons,functions, and organizations.
• All five key factors (high-quality shared situationawareness, congruent command intent,competence, and trust) must be present foreffective self-synchronization.
A l l o f t hese p ropos i t i ons have the samedependen t va r i ab le : e f f ec t i ve se l f -synchronization. Four major causal factors havebeen specified, as has the need for all of themto be present . Hence, each is seen as anecessary yet insufficient condition. Note thata number of potentially intervening factors suchas the leadership style of the commander, theposs ib i l i t y o f cu l tu ra l d i f f e rences ac rosscoal i t ion organizat ions, doctr ine, and pr iortraining have not been identified as specificindependent variables of interest and may needto be (a) subsumed into the variables of interest(i.e., the team might try to include commandstyle as part of trust), (b) inserted into theexpe r imen t ( i . e . , p rov id i ng t r a i n i ng andalternative doctrine to the participants), or (c)controlled during the experiment. Each of thesepotential intervening factors should be clearlyarticulated as an assumption.
Examining these propositions, the experimentationteam should recognize that th is is a hugeexperimentation space. Hence, in our exampleexperiment, they decide to restrict the propositionsunder study to the U.S. and its very close allies

133Chapter 6
(UK, Canada, and Australia) and to crossingechelons and three key functions: information(including intelligence about the adversary and theoperating environment); operations; and logistics,leaving self-synchronization across organizations(inter-agency, broader coalition, etc.) for laterexperimentation. In this way, the team has reducedthe impact of culture by excluding all except theDoD and close coali t ion organizations. Thetemptation to reduce the problem further byexcluding all coalition interactions was avoidedbecause the experimentation team realizes thatclose coalition partners have been part of virtuallyevery operation during the past decade and thatself-synchronization is a crucial element incoal i t ion ef for ts. They have narrowed theapplication range for the experiment to warfightingmissions s ince other types would requireinteragency and broader coalition participation.These types of simplifying and clarifying decisionsare crucial for success.
Initial Models and Their Use
First Descriptive Model
As the process of identifying and articulating theproposi t ions or hypotheses under ly ing theexperiment is being completed, the relevantinformat ion ( independent, intervening, anddependent variables and the relationships betweenthem) should be converted into an initial model.This model will draw from the existing knowledgebeing reviewed and will at first take the form of a

134 Code of Best Practice for Experimentation
static paper model in which variables are identifiedand the types of linkages between them specified.Creation of this initial, heuristic model is anexcellent way to ensure that the experimentationteam has thought the problem through precisely.Very often, ambiguities will be identified, newvariables incorporated, competing propositionsspecified, and differences in emphasis will emergeas this model is developed and perfected. Thisinitial model also becomes the mechanism fornoting where assumptions will be made, whichvariables will be controlled, and which will bemanipulated to answer the key issues underanalysis. The result of this effort is a descriptivemodel of the experiment problem.
Descriptive Model of Self-SynchronizationExample Experiment
The experimentation team building a simpledescriptive model of self-synchronization wouldquickly realize that a number of factors would enterinto the problem. Figure 6-1 illustrates how theymight diagram these factors. Three factors wereultimately seen as direct causes of effective self-synchronization: high-quality shared situationawareness, congruent command intent, and trust.Two of the factors originally identified as directcauses were moved back a layer. Competence wasperceived to be a causal factor of trust, but also toincrease the likelihood of two other second levelfactors: congruent command intent , andempowering leadership. Common perceptual filtersarising from shared knowledge and experience

135C
hapter 6
Figure 6-1. Illustrative Initial Descriptive Model: Self-Synchronization Experiment

136 Code of Best Practice for Experimentation
were seen as key to both high-quality awarenessand shared awareness. High-quality situationawareness was seen as a necessary ingredient forhigh-quality shared situation awareness, whichalso depends on collaborative command andcontrol processes, information availability, andcommon perceptual filters. Empowering leadershipwas also specified as essential to trust, but itand collaborative command and control processeswere not even explicitly recognized in the initialformulat ion. Final ly, shared knowledge andexperience were recognized as keys to trust,competence, and creating common perceptualfilters.
Initial Executable Model
While the initial descriptive model is a very usefulexercise, creation of an executable version will alsohelp the experimentation team in important ways.This model is typically done in some very simpleform using transparent tools. Systems dynamicsmodels, influence diagrams, IDEF 0 models,ACCESS, and similar tools have proven usefulbecause they are easy to use and because therelationships built into them are easy to understand.
Specifying an executable model will help theexperimentation team because it forces them tothink through the experimentation formulation ingreater detai l than is required in either theexperiment formulation process (at the propositionor hypothesis level) or in creating the initial heuristicmodel. For example, specific input parameters must

137Chapter 6
be given values and ranges. Assumptions need tobe translated into parameters. The form ofrelationships between pairs or sets of variables mustbe translated from words into mathematicalfunctions. In other words, greater precision and rigorare required.
The executable model, once developed, can alsobe used to focus the experiment. For example, byexercising this model across the range of plausiblevalues for important independent variables, theexperimentation team can narrow the focus of theexperiment to the interesting range, the set of valuesthat appear to make a meaningful difference in thedependent variables of interest.
Executable Model for the Self-Synchronization Experiment
It is difficult to show an executable model in a paperdocument. In this case the experimentation teamwould use a flexible tool, such as influencediagrams. This would have the advantage offorcing the team to specify operational definitionsfor each of the factors in the initial model, as wellas the set of relationships believed relevant forthe linkages in the model. Such an application,supported by prior research on related topics,would indicate several things important to theexperiment. For example:
• Any value for trust that is not extremely highwould prevent self-synchronization;

138 Code of Best Practice for Experimentation
• Any value for competence that is not extremelyhigh would prevent self-synchronization;
• Any value for quality of information that is nothigh would prevent achieving high-qualitysituation awareness, which would make high-quality shared situation awareness almostimpossible; and
• Any value for system reliability that is not highwill reduce trust and may lead to commandersbeing unwilling to empower their subordinates.
As a consequence of these model findings, thefocus of the experiment should be narrowed andthese factors should be controlled. This impliesthat the underlying quality of the informationavailable during the experiment should be high,though that can include a clear understandingof what is not known and the uncer ta in tysurrounding what is “known” or perceived. It alsoimp l ies tha t the sub jec t poo l needs h ighcompetence in their roles – novices (alone orwith experts) cannot be employed. Moreover, theteams of subjects must either be drawn fromsome existing organizations where trust alreadyexists or put through a training phase duringwhich trust is developed and validated before theexperiment trials begin. Finally, the reliability ofthe supporting information systems will need tobe controlled as a causal factor.

139Chapter 6
Ideal Versus RealTransformationalExperimentation
Focus
The topic of experimentation design is complex andhas been the subject of numerous textbooks.Moreover, the field changes constantly as progressis made in inferential statistics, the mathematics ofnonlinear systems, and the computational poweravailable to researchers. Hence, the single mostimportant consideration for those responsible forexperimentation design, whether single experimentsor campaigns, is to ensure that current expertise isavailable to support the plan. Almost withoutexception, this will mean doctoral level (Ph.D.)training and a decade or more of experience inactually designing and conducting experiments.Moreover, most transformational experimentationwill require experience and expertise in the socialsciences because the human element is so crucial.This expertise is available from a few servingofficers with such training, from the DoD and Servicecivilians in the research establishments, fromfederally funded research and development centers,from industry, and from academia.
This discussion, therefore, focuses on key conceptsand principles that should be understood by all themembers of experimentation teams, as well as bythose who sponsor experimentation and must act onits results. The focus, then, is on understanding thelogic underlying successful experiments and

140 Code of Best Practice for Experimentation
recognizing when that logic is being violated or maycome into question. Bad experiments, which cloakweak or false knowledge in an aura of science, willmake mischief, not music. At a minimum they willslow the process of understanding the impact ofinnovation on transformation (by forcing otherresearch and experimentat ion to learn anddemonstrate that they are wrong) and cost money(by encouraging investments that will not pay off asexpected). At a maximum, bad experiments will leadto flawed mission capability packages that fail in thefield. Hence, everyone involved has a serious qualitycontrol function to accomplish. This section isintended to help the experimentation team and theirsponsors to perform that role. After this discussionof ideal experimentation, the Code looks at someof the imperfect circumstances and conditionsfaced by transformational experimentation effortsand how they can be overcome in the practicalcontext of military analyses.
Ideal Experimentation
The hard sciences, like physics and chemistry, werethe first to rely on experimentation in order todevelop knowledge. The ideal experiment is one inwhich all the possible sources of variation areexcluded except the one of interest. For example,to genuinely determine how fast objects fall requirescreating a vacuum to exclude the effects of airdensity and wind. An experiment that measured thefalling rates for ball bearings and bowling balls inthe open air would conclude that the ball bearingsfell more slowly because of the presence of air

141Chapter 6
resistance and the differences in mass between thetwo objects. This experiment also requires a cleartheory that identifies the causal factors (in this casemass) and limiting conditions (the vacuum).Moreover, a successful experiment also requiresprecise, correct, and reliable measurement of theactive variables (mass, distance, and speed) as wellas the limiting condition (presence of a vacuum orabsence of air). Successful experimentation alsorequires an apparatus that measures speedprecisely and allows the experimentation team toknow exactly when the object starts to fall andexactly when it passes some other known point, aswell as the distance between the start and finish.These two points also need to be far enough apartthat the measurement instruments see enoughdifference to allow inferences about relative speed.
The goal of an experiment is always to advanceknowledge. Because Western, rational sciencealways allows for new insights and knowledge,nothing can ever be perfectly or permanentlyproven. Hence, null hypotheses are used todisprove false knowledge. In the ball bearing/bowling ball experiment, the null hypothesis is thatthese objects will fall at different rates in a vacuum.The two types of objects are called the treatments,which means nothing more than that they are theways that the independent variable is changed. Theterm treatment comes from medical experimentationwhere patients are given alternative medicines orprocedures (including placebos, which serve as abaseline and allow for meaningful comparison) inorder to determine the effectiveness of the differentmedications. Moreover, Western science is inherently

142 Code of Best Practice for Experimentation
skeptical, so experiments must be conducted anumber of times and replicated using differentsubjects, kinds of treatments, methods ofmeasurement, and apparatuses before theirconclusions become accepted.
Later experiments can be used to move from thisideal knowledge to take into account factors thatwere initially excluded. For example, the shapeof the ob jec t was cont ro l led in the in i t ia lexperiment, but would be important for objectsfalling through air. Those designing parachutesneed to understand how manipulating mass andshape can alter the rate of descent. Similarly,those designing bombs or shells would need tounderstand the effects of wind. Therefore, thepurpose of the research will help to determine thecampaign of experimentation. Here again, anumber of different trials will be needed. This isthe functional equivalent of relaxing assumptionsin a model in order to extend our understandingof the phenomenon under study.
Principles of Experimentation
This discussion should help to identify the basicprinciples underlying experimentation. Idealexperimentation manipulates only one independentvariable at a time. Differences of this variable (thetreatments) typically include some baseline (forexample, the placebo in medical research) againstwhich the effectiveness of other treatments can bemeasured.

143Chapter 6
Ideal experimentation observes change in only onedependent variable. This does not mean that onlya single measure is used. If the dependent variablehas more than one important dimension (forexample, both the speed and qual i ty ofdecis ionmaking), a l l should be measured.Similarly, if the measures available are not totallyvalid (do not measure exactly and completely theconcept of the dependent variable), multiplemeasures that provide relevant information aboutdifferent aspects of the dependent variable (calledindicators) may be taken.
Ideal experimentation excludes, or controls for, allrelevant extraneous or intervening variables. If thisis not done, then the changes in the dependentvariable may be due to these factors and not tothe treatment under study. While challenging inphysical experiments, this becomes extremelydifficult when dealing with human subjects, whetherindividuals or teams. When possible, everyextraneous cause must be excluded. When this isnot possible, the effects of extraneous variablesshould be manipulated so that they are “equal”across treatments and trials. For example, whenlarge numbers of people are being used asindividual subjects, they are typically assignedrandomly to the t r ia ls . As a f inal resort ,measurement is made on the possible interveningvariables (for example, molecules of air per cubicfoot in the vacuum, intelligence quotients forindividual subjects, time spent working together forteams) and statistical procedures are used toestimate the relationship between the interveningvariables and the outcomes across treatments.

144 Code of Best Practice for Experimentation
This is possible for all kinds of measures, includingnominal measures such as male/female that haveno direction. However, it is time consuming,complex, and difficult to explain to those withoutscientific training (meaning it can have seriouscredibility problems), so statistical control shouldalways be used as a last resort.
Ideal experimentation involves valid, reliable,precise, and credible measurement of all variables.If the experimentation team cannot perform propermeasurement, the exper iment cannot besuccessful. This cuts across all types of variables:independent, dependent, and intervening. Validmeasurement means measuring exactly what youintend to measure and not some surrogate chosenbecause it is easier to measure. Some complexissues, like quality of collaboration, may have tobe observed indirectly through indicators or by aset of measures, each reflecting some part of theconcept. Reliable means that the same value willbe recorded every time from the same event oractivity. This requires particular attention whenhuman behavior is measured or humans are usedto perform the measurement. Precise means thatthe instruments are calibrated to fine enoughtolerances to detect meaningful differences. It isreally an extension of reliability. If the measuresor measuring instruments being used are soimprecise that they cannot differentiate betweensubstantively different values, the experimentcannot succeed. Credible measurement meansthat the system of measures is understood andrespected by both the research community and the

145Chapter 6
operational community that will be asked to act onthe knowledge generated from the experiment.
Ideal experimentation includes enough data collectionopportunities to support the inferences needed totranslate findings into actionable knowledge.Something that happens once may be suggestive orillustrative, but it is not credible in a scientific sense.For an experiment to be successful, a number ofindependent observations are needed. Independentmeans that the observations are not causally related.For example, in most medical experiments, the numberof individuals participating is the relevant number. Anyfactor in common across the individuals threatens theindependence of the observations. The issue of howmany independent trials are needed is a complextechnical one that depends on (a) how many treatmentsare under study, (b) the number of intervening variablesthat are hypothesized to be relevant and must becontrolled statistically, (c) the level of confidence thatthe experimentation team believes it needs to makemeaningful statements, and (d) the population thatthe experimentation team intends to extend itsfindings to cover. This is a technical issue wherestatistical expertise is essential. However, identifyingpossible threats to the independence of the trials isa task for everyone involved in the experiment.
As a rule of thumb, the basic design for any experimentshould attempt to involve at least 30 independentobservations of any meaningful data category. Forexample, a three-treatment experiment involving twodifferent types of subjects would ideally be designedaround a three-by-two matrix with 30 people in eachcell, or a total of 180 subjects (or observations), 90 of

146 Code of Best Practice for Experimentation
each type of subject. However, if each subject can beused for a single trial in each of the three treatments(thereby controlling for differences between individualsubjects within each of the individual groups), theminimum number of subjects required declines to 60(30 of each subject type). Prudent experimentationdesigners do not, however, plan for the minimumnumber of independent observations. Subjects tendto become ill or miss their appointments. Becausemost inferential statistics allow stronger inferenceswhen the number of independent observations rises,over-designing the numbers needed in an experimentwill both protect an experiment from potential shortfallsand also increase the likelihood of unambiguousfindings. Of course, as the number of independenttrials increases, the greater resources will be neededfor a successful experiment.
A very different approach is often taken whenworking with teams of subjects or organizations.Employing large numbers of teams ororganizations (such as command centers) for anexperiment is difficult and may be impossible. Inthese cases, the groups of subjects should beselected so that they are as typical a populationas possible. In these cases, the focus of theexperiment design becomes the collection ofenough independent observations of relevantbehaviors to achieve the exper imentat ionobjectives. For example, efforts to determine thedeterminants of quality command and control earlyin the 1980s focused on decision cycles duringmilitary exercises. A 1-week Army division or Navyfleet experiment was found to generate about 50major decisions, adequate to support treating them

147Chapter 6
as experiments for purposes of testing hypothesesabout the driving factors for effective command andcontrol. Note that this approach makes it mucheasier to generate meaningful findings from asingle experiment, but requires establishing how“typical” the exercise and the observed commandcenters are of all military decisionmaking. Hence,this work required an experimentation campaignas well as data on the relevant training andexperience of the commanders and staffs involvedin each exercise.
Note also that this approach also assumes thateach event (decision, collaboration session, etc.)being counted as an observation is independentof the others (that is, not influenced by them). Thisis not always true. For example, high-qualitydecisions early in an experiment may mean thatthe team has a better grasp of the situation thanothers making weaker decisions and may alsomean they are under less pressure during laterdecision cycles. Hence, the analysis plan for thistype of experiment will need to include tests forthe independence of observations over time andmake provision for statistical analyses that controlfor this potential “contamination.” Fortunately,these controls are available and used commonlyin the social sciences, biology, and other fieldswhere purely independent observations are hardto obtain.
Ideal experimentat ion generates f indings ,interpretations, and insights. Findings are the datagenerated during the experiment and the directinferences available from those data. They take

148 Code of Best Practice for Experimentation
simple, descriptive form, such as “operational levelcommand centers working familiar problemsrequired an average of 3.5 hours (54 observations)to recognize and react to major changes in thebattlespace, while working on unfamiliar problemsrequired an average of 9.3 hours (49 observations)and this difference was statistically significant(p=.0001).”
Interpretat ions, on the other hand, involveconjectures, which often arise from prior researchor experience. In this case, the experimentationteam might report that the additional decision cycletime required in the unfamiliar situation appearedto occur because the command center appeared totake more time to gather information and to discusswhat it meant. However, unless data were taken onthe time and effort used to gather information anddiscuss what it means, this is not a finding. Indeed,humans have such a strong tendency to find anexplanation for what they observe that they oftendraw wrong conclusions when not challenged toactual ly measure what occurs. Competingexplanations are often offered for observedbehaviors and can only be resolved by furtherexperimentation or consulting research done byothers that focuses on the alternative explanations.For example, another researcher might argue thatthe additional time taken was actually a function ofthe risk aversion of military command centers anda fai lure to recognize the urgency of noveldevelopments in the unfamiliar contexts. Only athorough research effort or a wel l-craftedexperiment will allow resolution of differences in

149Chapter 6
interpretation because the true data or findingstypically support them equally.
Finally, insights are the new thoughts or patterns thatemerge when the experimentation team looks at thefindings or reviews them with outside experts,including the sponsors of the experiment. These maytake the form of new hypotheses (cause and effectrelationships), new limiting conditions (interveningvariables), or even anomalies (data points or patternsthat are inconsistent with the bulk of the evidenceand our current theories and hypotheses). All of theseare valuable, but the anomalies are the mostimportant, because they may be clues to importantnew knowledge. Of course, they may also simply beanomalies – times when subjects behaved in unusualways or low probability events that will not occur oftenenough to be worth attention. Because our level ofknowledge about transformational innovationsremains immature, every experiment is likely toidentify important new insights. Failure to capturethem will impede progress.
Peer review, debate, and discussion are the lifebloodof successful experimentation. While some DoDexperiments involve classified information, many donot. In all cases, experimentation results should becirculated as widely as possible. Science and theability to build actionable knowledge are acceleratedby exposing ideas to review and holding healthydebates about what is known and what has beenlearned. This principle underlies the academic stresson publication in refereed journals – the editors actas a first line of defense against poor work, the

150 Code of Best Practice for Experimentation
reviewers who examine drafts are the second, andthe general readership are a third.
The DoD does not need refereed journals, but it doesneed to tap the breadth and depth of availableexpertise in order to examine transformationalinnovations and the experiments performed toassess them and mature the concepts underlyingthem. Circulation of draft results among respectedcolleagues, briefing across a variety of audiences,presentations at professional meetings, andworkshops to review and build on experiments andexperimentation campaigns are all available toensure peer review, debate, discussions, andalternative explanations. Each of these sources ofconstructive criticism and new insights, however,cost effort and time. These investments need to bebuilt into plans for experimentation.
Transformational experimentation must seek newknowledge, not support for specific ideas. One ofthe attractive features of experimentation is the factthat not all the concepts or ideas put forward willprove useful. The DoD has a tradition of makingeverything a success wherein exercises cannot befailures because that would be a negative indicationof organizational performance and readiness.Assessments of new systems cannot be failuresbecause they represent major investments.Moreover, failed programs imply that those whodeveloped them have not done their jobs well.However, experimentation, particularly successfulexperimentation, means finding out that someconcepts or ideas are better than others, or morecommonly, that two competing ideas or concepts

151Chapter 6
are better than one another under different conditions(in different settings or for dealing with differentproblems). DoD experimentation needs to recognizethis essential principle and not get trapped in a searchfor a single solution to all problems or a premature“shoot off” between competing concepts.
TransformationalExperimentation Realities
Careful reading of the discussion of idealexperimentation clearly shows that this process isrobust. Many of the processes and procedures thathave emerged are designed precisely to enableknowledge gains under difficult circumstances.Robustness comes from anchoring the experimentin existing knowledge, using an open process thatinvolves peer review, developing robust models ofthe phenomenon under study, and using tools andtechniques that allow for cross-checking andquestioning assumptions.
That having been said, every experiment shouldseek to conform as closely as possible tothe ideal experimentation design. However, twomajor real i t ies indicate that transformationexperimentation will differ in two important ways:
• Transformation will not be accomplished bysmall, isolated changes. Transformationalinitiatives will always be rich combinations ofmutually reinforcing changes, such as MCPsthat cut across the DOTMLPF spectrum and gobeyond it to include new ways of thinking aboutwarfare and national policy effectiveness.

152 Code of Best Practice for Experimentation
• The pace of change required for DoDtransformation will not allow for a large numberof sequential experiments designed toauthoritatively explore every nook and cranny ofpossible alternatives.
Fortunately, these two realities and the pressuresthey generate can be managed successfully bythoughtful programs of experimentation and designof individual experiments.
At the conceptual level, t ransformationalinnovations (in this case, MCPs) need to be seenand organized as a single, coherent, holisticphenomenon, not as a patchwork of individual,separable initiatives. Indeed, many of the keychanges involved in transformation will fail orhave very little impact if undertaken in isolation.Business has discovered that adopting advancedinformation technologies without altering theirfundamental ways of doing business (organizations,work processes, etc.) to take full advantage of thenew technology means that only a fraction of thepotential benefits actually occur. The same principleapplies to military innovation and transformation.The elements of an MCP for transformationalexperimentation need to be thought of as asyndrome or an integrated, distinctive pattern ofchanges. Removing any one element means thatthe innovation is a different phenomenon, withdifferent implications.
Hence, experimentation teams concerned withtransformation need to develop full mission capabilitypackages and treat them as coherent wholes when

153Chapter 6
designing experiments. This means that they willlogically form one change, innovation, or treatment.However, the metrics chosen and tracked, as well asthe debriefings of subjects, observers, controllers, andexperiment support personnel will need to be sensitiveto the possibility that some components of thepackage are working better or worse than others, oreven that some components are interfering with oneanother. Hence, the research design and analysis planshould call for analyses that help track performanceof the elements of the innovation.
Besides treating the MCP as a single innovation,experimentation teams also need to rely heavily onthe research conducted by others, both to focus theirexperiments and to help determine how muchconfidence to place in their results. Because MCPswill typically be composed of several differentinitiatives (changes in process, structure, etc.),several different research traditions will normallybe available to help understand the phenomenonunder study and to assist in the interpretationof the experiment findings. Moreover, becauseexperimentation is conducted in a variety of differentDoD organizat ions (Services, CINCs, andAgencies), work on analogous issues and problemswill often be available to help understand what isbeing learned. Interaction and cross-talk betweenthese efforts will provide important knowledge andaccelerate the process of learning. Findings thatare consistent with existing knowledge and otherefforts at experimentation and research in analogoustopics will allow rapid progress. On the other hand,inconsistent findings will be “red flags” indicating

154 Code of Best Practice for Experimentation
more thought, research, and experimentation areneeded promptly on key issues.
Finally, the need to move ahead rapidly and to workin the large leaps implied by MCPs increases thecrucial role of circulating findings widely andsubjecting them to vigorous review and rigorousdebate. The DoD has enormous analytical andoperational talent available, both in the active forceand in the organizations and institutions that supportthat force. While transformational experiments willchallenge conventional wisdom and should not beexpected to quickly build consensus within thenaturally conservative military community, they canbe expected to spark lively debate and seriousdiscussion. Powerful ideas, the kind necessary forsuccessful transformation, will develop strongempirical support from intelligent campaigns ofexperimentation. Understanding that evidence andits implications will require examination from avariety of perspectives.

155
CHAPTER 7
Measures andMetrics
Focus
Experiments are inherently empirical. Whetherfocused on d iscovery, hypothes is , o r
demonstrat ion, experimenting must includecapturing data and organizing i t to providethe basis for analysis on the key issues understudy. Hence, exper iments a lways involvemeasurement. Deciding what to measure andhow to measure i t is a crucial step in anyexperiment. The old saying, “garbage in, garbageout ” sums up the exper imentat ion teammetrics challenge. Unless good decisions aremade in this arena, no amount of analysis orin terpre ta t ion wi l l generate a successfu lexperiment. This chapter begins with some simpledefinitions of the key measures and metricsconcepts , then d iscusses the cr i te r ia foreva luat ing and se lect ing measures for anexperiment, addresses the process of selection,introduces some of the establ ished sets ofmetrics, and concludes with how these principles

156 Code of Best Practice for Experimentation
would apply to the example experiment onself-synchronization.
Definitions
Some standard definitions are less than useful. Forexample, “measurement” is typically defined as“the act of measuring.” However, as in otheraspects of science, some standard language isnecessary. In particular, the terms attribute,measure, metric, and indicator are frequentlytreated as synonymous, when in fact they havedifferent meanings.
Attribute
An attribute is some aspect of an event, situation,person, or object considered important tounderstanding the subject under study. Examplesof interest might include the range of a weaponsystem, the time required to complete a decisioncycle, the number of nodes in a network, or anyother factor considered important in the hypothesesand model of an experimentation problem or issue.
Measure
A measure is a standard by which some attribute ofinterest (extent, dimensions, quantity, etc.) isrecorded. For example, weight (an attribute) can bemeasured in terms of pounds or kilograms; speed(an attribute) can be measured in miles per hour;and time is measured in minutes and seconds.

157Chapter 7
Measures are the specific form the team expects touse when capturing attributes of interest.
Metric
A metric is the application of a measure to twoor more cases or situations. Because experimentsare inherently comparative as well as inherentlyempirical, selection of the metrics is particularlyimportant. These are the ways things will becompared. For example, an experiment abouttime-critical targeting might include the likelihoodof detecting different types of targets, underdifferent conditions, by different types of sensors,and using different fusion tools and techniques.Therefore, one attribute of interest would be thelikelihood of detection. The measure would thenbe the percentage of detections. The metric ofin terest would be the re lat ive probabi l i tyof detection across the syndromes of targettypes, detect ion condit ions, sensor arrays,and approaches to fus ion. Expla in ing andunderstanding these differences in the dependentvariable would be the primary focus of the analysis.
Indicators
Measures and metr ics apply direct ly to theattributes of interest. However, direct measurementis not possible in all situations. For example,almost all experts agree that situation awarenessis an important element in the quality of militarydecis ionmaking. However, awareness is acognit ive phenomenon that implies not onlythat some combat support system has access to a

158 Code of Best Practice for Experimentation
set of facts or that they are displayed at a workstation, but also that the decisionmakers areaware of those facts. In simple terms, the situationawareness that matters occurs “between the ears.”Indicators are indirect measures and metrics. Toassess quality of situation awareness, for example,an experimentation team might create a stimulus(insert a new enemy force into a military situation)and look for a behavioral response (discussion ofthe new threat, planning to counter it, etc.). Theymight also debrief the key people in a commandcenter to see whether they have perceived thenew threat and understand it. The experimentersmight want to use an indirect approach and callfor a situation briefing to see whether this newfactor is included. Regardless of the techniqueused to generate empirical evidence, that evidencewill be indirect and in the form of indicators.
Levels of Measurement
Measurement should always be as precise asis practical. However, understanding the level ofprecision that can be achieved without distortingwhat is being observed and measured is important.Four different levels of measurement are possible:nominal, ordinal, interval, and ratio. The level ofprecision achieved is crucial both for developingan appropriate data analysis plan and also forunderstanding and interpreting findings.
Nominal measurement means that observations canbe assigned to categories, but the categoriesthemselves have no natural order. For example,service training may differ in important ways and

159Chapter 7
may be a factor expected to influence behavior in acommand center experiment. However, there is nonatural order between Army, Navy, Air Force, andMarine backgrounds. The same is true for genderdifferences or differences between officers fromcoalition countries.
Ordinal measurement means that there is a naturalorder between the categories, but the distancesbetween them have no meaning. Operatingenvironments, for example, might be differentiatedin terms of the level of threat and classified aslow, medium, and high. The order between thesewill not change. However, there is no meaningfulmeasure or metric that expresses the size of thedifference between these categories. Similarly, thelevel of expertise typical in a command center mightbe classified as novice, journeyman, or expertdepending on the level of training and experienceof its personnel. The rank order is clear, but thereis no meaningful way to characterize how muchmore expert one group is than another.
Interval measurement occurs when the distancesbetween points on a scale are meaningful (can beadded and subtracted), but they are anchoredarbitrarily (zero has no empirical meaning) andtherefore cannot be multiplied. The most commonexample of an interval measurement scale is theFahrenheit thermometer. The intervals on this scaleare identical and meaningful. Fifty degrees is 10degrees warmer than 40 degrees, which is preciselythe same as the 10-degree difference between 100degrees and 90 degrees. However, 100 degrees isnot twice as hot as 50 degrees. This occurs

160 Code of Best Practice for Experimentation
because zero degrees is not the absence of heat.Similarly, intelligence quotients, which are often usedto differentiate between subjects in experiments, areinterval scales. Someone with an IQ of 150 is nottwice as intelligent as someone with an IQ of 75.
Ratio measurement has both equal level intervalsand also a meaningful anchor point (zero is ameaningful value). Numbers of platforms, timerequired to complete a task, months or years ofexperience, weapons ranges, and a host of otherattributes in the battlespace are legitimate ratiovalues. As a result, measures and metrics for suchattributes can be treated with the most powerfulanalytic tools available. Whenever possible,therefore, experimentation teams will seek ratiolevel measures and metrics.
The level of measurement sought and achievedin designing an experiment is important in twosignificant ways. First, efforts to be overly precisewill lead to bad data. If judgements about thequal i ty o f mi l i ta ry dec is ions can be ra tedconsistently as successful, marginally successful,and failed, ordinal measurement can be achieved.To assign numeric values that imply interval orratio measurement to those ordered categoriesimplies information content that does not exist.This will distort any analysis performed on thedata and will also undercut the credibility of theresearch effort. Second, statistical analysesemploy tools that assume specif ic levels ofmeasurement. Applying techniques that makeassumptions inconsistent with the informationcontent of the data (for example, ratio techniques

161Chapter 7
to ordinal data) is fraught with peril and very likelyto generate misleading results.
Criteria for Measures andMetrics
Select ing speci f ic measures, metr ics, andindicators for an experiment requires explicitcriteria. While long lists are sometimes offered,selection of the empirical evidence to be collectedshould always be based on three fundamentalcriteria: validity, reliability, and credibility. If any ofthese is compromised, the experiment will notsucceed in contributing to the development ofknowledge and understanding, and may contributeto unnecessary confusion.
Validity
Simply stated, validity means that the measures,metrics, and indicators employed actually measurewhat the experimentation team is trying to measure.For example, the likelihood of target detectionunder specif ic circumstances can be validlymeasured by observing the percentage of targetsactually detected. Hence, this is a valid measure.On the other hand, many important concepts aremuch more difficult to measure validly. For example,NATO has been using “normalcy indicators” inBosnia and Kosovo to recognize when the peaceoperations have achieved the goal of stabilizingsocieties and allowing people to go about theirbusiness safely. This implies a decision as to whatattributes of those societies represent “normalcy”

162 Code of Best Practice for Experimentation
and how empirical evidence (marketplace prices,movement of commerce, attendance at school, etc.)can be collected which reflects a return to normall i fe. Similarly, the measurement of situationawareness raises serious validity issues sincethe experimentation team must have a rich andcorrect understanding of what constitutes highquality situation awareness in order to identify validways to measure it. They must develop indicatorsthat reflect what people actually know.
Errors in validity are all too common in DoDexperimentation. For example, many efforts havetried to deal with the “timeliness” of the informationavailable by measuring its latency (how old it isbefore it is available). Age or latency of informationis certainly an interesting and potentially importantattribute, but it is not timeliness. Timeliness can onlybe meaningful in terms of some situation or windowof opportunity. Age of information is not a validmeasure of its timeliness except in the presence ofsome standard. For example, in a time-criticaltargeting issue, a standard of reporting informationno older than 30 minutes might be seen asimportant. In that case, latency of information couldbe converted into the percentage of reports withdata of 30 minutes or less and would be a morevalid measure in the analysis.
Note also, that more than one measure is oftenrequired to achieve validity. If the concept is acomplex one, it may have more than one dimension.The example of improved command and controlinvolving both faster and better decisionmaking hasalready been mentioned. A similar example occurs

163Chapter 7
when flexibility of planning is assessed. A moreflexible plan includes more than one way to achievethe military mission, but it also must include theability to recognize which of these options isavailable and can be executed successfully. Merelyproliferating options is not, by itself, a valid metricfor flexibility.
Reliability
Reliability implies that the same value would bereported on an attribute of interest regardless ofthe observer or the observation method. A metalruler is more reliable that a rubber one, but notperfectly reliable if major temperature changescan be expected between observations. Reliabilityis often an issue when the phenomenon understudy must be inferred indirectly from indicators orwhen human perceptions are involved – whetherperceptions of subjects, observers, or controllers.Reliability is crucial in science. The design of theobservation and data collection systems are largelydriven by efforts to ensure reliability.
When possible, direct reliable measures should beselected. However, reliable measures that lackvalidity are not useful. Modeling and experimentingare commonly criticized for focusing on data thatcan be easily and reliably measured rather thandata that is important – implying that reliability hasbeen chosen over validity. The answer, whenreliability problems are likely, lies in the training ofobservers and collectors and in planning for inter-coder reliability testing. This testing, which needsto occur during training as well as during the conduct

164 Code of Best Practice for Experimentation
of the experiment and related data reduction efforts,is an explicit method for establishing the reliabilityof the collection and measurement schemes.
The experimentation team also needs to thinkthrough the essent ial elements for rel iablemeasurement. As a simple example, a team thatplans to use time-based measures, such as howlong after a scenario injection a command centerrecognizes the event, must be certain to calibratethe clocks and watches being used to recordthe event and its recognition. Similarly, a teaminterested in the percentage of situation awarenesselements that are reported correctly by members ofa watch team must have a simple, reliable standardfor which elements of situation awareness need tobe covered and how the information presented is tobe coded if it is only “partly correct.”
Credibility
Beyond the essential issues of validity and reliability,experimentation also requires measures and metricsthat are credible to their audiences. Credibilitymeans that the measures are believable to thosewho must understand and act on the results,specifically the research and experimentationcommunity, the decisionmakers who must translateexperiment results into policies, programs, andplans of action, as well as the military subjectmatter experts and “operators” who must learn andact on the knowledge generated. In the socialscience literature, credibility with expert audiencesis termed “face validity.” Novel, subtle, or esotericmeasures must be developed and presented in

165Chapter 7
ways that are transparent to all these audiences.Similarly, careless labeling of measures and metricsthat expose them to surface misunderstandingsor criticisms can lose credibility.
The systems and communications communities’ useof the term situation awareness provides a goodexample of measurement that lacks credibility. Inmany cases, they have chosen to use that term torefer to the quality of the information present indisplays and data files. Hence, good situationawareness meant that all the entities of interestwere present in the information system, availablefor presentation, and could be displayed in waysthat distinguished them from one another (armorwould be distinguished from supply convoys, fastmovers from other types of aircraft, warships fromcommercial vessels, etc.). However, the researchcommunity, which understands situation awarenessto be what people know (not what is available tothem from machines), did not find this approach tomeasuring situation awareness credible. Similarly,many military personnel, who understand situationawareness to extend beyond the “who is where”picture to include obvious military developments inthe future (the turning of a flank, an imminentbreakthrough, an urgent need for water, etc.) alsofound this approach lacking.
Need for All Three Criteria
Transformational experimentation teams need topay attention to all three criteria. Lack of validitymeans that the experiment cannot yield meaningfulresults. Lack of reliability means that the data

166 Code of Best Practice for Experimentation
cannot be trusted, so the results should not bebelieved. Lack of credibility means that the resultswill not be believed. Hence, selecting measures andmetrics is a process where the highest possiblestandards must be used.
Process of Measure and MetricSelection
While every experiment will present differentchallenges and opportunities and every team ofexperimenters will need to exercise both creativityand judgement, there are some processes thathave proven useful in the past. These processesshould be a starting point for selecting measuresand metrics.
Anchoring in the Initial Model
The experimentation team will want to anchorits efforts in the initial model, which was developedas a result of their studies of previous researchand their efforts to build meaningful sets ofpropositions and hypotheses. In many cases, thesame variables represented in that model willhave been present in pr ior research andexperimentation. Hence, the measures and metricsemployed in prior efforts can be considered ascandidates. Note that prior work may containsboth good and bad precedents. While the processof accumulating knowledge will benefit if the sameor similar measures can be employed, precedentsshould not be employed at the expense of validity,rel iabi l i ty, or credibil ity. If the measurement

167Chapter 7
approach in prior work appears flawed, thenthe team should take that as an important lessonlearned, not an example to be followed.
The initial model and its first executable form arealso simple sources for the list of concepts thatneed measuring. It should include definitions,though they may be too abstract to employwithout further work to make them operationallymeaningful. This will sometimes be the firsttime that measures are translated into specificmetrics or that the need for more than one metricin order to capture the full concept under analysisis recognized.
Dependent Variables First
Since the dependent variables are the objectivefunctions for the experiment and its analysis,speci fy ing their def ini t ions, measures, andmetrics is the first task. Note that this discussionpresumes that more than one dependentvar iable wi l l be re levant in a lmost a l ltransformational experimentation. This premiseis based on three assumptions. First, mostimportant concepts under ly ing dependentvariables are mult idimensional. The classic“better command and control” composed of morecorrect decisions made more quickly is anexcellent example. Second, layered systems ofdependent variables are often valuable aids tounderstanding and analysis. A classic example isthe MORS approach of layers of measures ofperformance (MOP) for systems (human andmachine) supporting layers of measures of C2

168 Code of Best Practice for Experimentation
effectiveness (MOCE), supporting layers of forceeffectiveness (MOFE), which support layers ofpo l icy ef fect iveness (MOPE). Third, mostdependent variables should be collected acrossat least three echelons of command for diagnosticpurposes. Hence, an analysis intended to testpropositions at the joint task force level shouldat least be informed by data at the componentand CINC levels of command. For example, aneffort to measure “clear and consistent commandintent” in joint task force performance needs to lookup and down at least one echelon and examinecommunications and collaboration across levels inorder to gauge clarity and consistency.
The definitions of each variable of interest needto be reviewed carefully. If the concept is simple,it may have a single, direct measure. For example,decision cycle time can be measured validly,reliably, and credibly by a team that is properlytrained and has access to reliable, calibratedc locks and the re levant command centeract iv i t ies. S imi lar ly, the number of peopleparticipating in a collaboration session can berecorded d i rec t ly, p rov ided that the termpart icipat ion is clearly defined, perhaps asworkstations linked to the session.
In many cases, however, the dependent variablewill be multidimensional. No single attribute willvalidly cover the entire concept. For example, futurecommand and control systems will need to beadaptable. However, that adaptability may involvechanges in structure, part icipation, or workprocesses. Hence, an experimentation team

169Chapter 7
interested in that phenomenon would need a set ofmeasures, not just a single one.
The purposes of specifying the entire measurementsystem for the dependent variable(s) of interestbefore trying to complete the entire set are toensure (a) that the full set is specified when theindependent and intervening variables’ measuresare chosen and (b) the dependent variables arefully independent of them. If the dependentvariables of interest are somehow defined ormeasured in ways that cause them to overlap withthe independent or intervening variables, theexperiment will be confounded and its results willbe confusing at best, and meaningless at worst.
As each measure and metric is considered, theexperimentation team needs to review the simplemantra of “validity, reliability, and credibility.” Thequestion on validity is whether the measure or setof measures selected real ly represents theconcept, the whole concept, and nothing but theconcept under study. The question on reliabilityis whether the same events, situations, attributes,or behaviors will always be recorded and scoredthe same way, regardless of when, where, or bywhom (or by which machine) the data are captured.The issue on credibility is whether the measurewill be accepted by, or can be explained clearly to,the three key audiences: the research andexperimentation community, the decisonmakingcommunity, and the operational community.

170 Code of Best Practice for Experimentation
Dependent and Intervening Variables
Once the proper set of dependent variables isarticulated and any requisite changes made to thehypotheses or propositions under study, theremaining variables should be subjected to thesame process, with one exception. Beyond validity,reliability, and credibility, the other variables needto be examined for independence, both from oneanother and from the set of dependent variablesalready chosen. Where independence is inquestion, the data analysis plan will need to includeempirical tests of the strength of associationbetween the variables of interest. Moreover,provision should be made for analytic techniquesthat can provide statistical processes that cancompensate if independence cannot be achieved.
Feasibility Testing: Data Analysis and DataCollection Planning
As the full set of variables is identif ied andmeasures, metrics, and indicators are selected, theyneed to be organized into a system that will informthe data analysis and data collection plans. Thisprocess raises a number of important practicalconsiderations, including:
• Whether the measures and metrics will yielddata sets ready for analysis on all the issuesunder study;
• Whether the experimentation team has accessto all the data and information necessaryto support the analyses;

171Chapter 7
• Whether the data and information needed canbe captured cost effectively;
• Whether adequate numbers of collectors,recorders (human and machine), and controllersare available;
• Whether the schedule and resources for training,collection, data reduction, inter-coder reliabilitytesting, and archiving are adequate.
In essence, this practical review enables the teamto complete the data analysis and data collectionplans while also forcing the experimenters to thinkthrough their resource requirements.
Established Measures andMetric Systems
While each experiment is different and eachexperimentation team will need to be both creativeand thoughtful about the specific measures andmetrics they choose to employ, there are someestablished frameworks that may be useful,particularly when command and control issuesare central to the research effort. Both the MORScategories of measures and the NATO Code of BestPractice for C2 Assessment have been mentionedearlier and can be used to understand the classicapproaches. However, those classic sources canbe brought up to date and better focused by lookingat some of the more recent applications andapproaches. Those are briefly discussed below,including an assessment of their strengths and

172 Code of Best Practice for Experimentation
weaknesses, as well as references to where moreinformation can be located.
Network Centric Warfare Value Chain
The elements of one established system, theNetwork Centric Warfare value chain, are illustratedin Figure 2-1.1 This approach employs severallayered concepts:
• The beginning point is the quality of theinformation and knowledge available within thecommand and control system.
• Information quality follows the metricsdeveloped more than 20 years ago in theHeadquarters Effectiveness Assessment Tool(HEAT) to track the completeness,correctness, currency, consistency, andprecision of the data items and informationstatements available.
• Knowledge quality here refers to the priorknowledge embedded in the command andcontrol system such as templates foradversary forces, assumptions about entities(ranges, weapons, etc.), and doctrinalassumptions used to infer future adversaryactions (intentions).
• Awareness refers to information andknowledge as they are known by theindividuals using the command and controlsystem. Awareness is always in the cognitivedomain and must be measured using

173Chapter 7
indicators such as survey instruments anddebriefings, or inferred from behavior.
Taken together, information, knowledge, and individualawareness constitute the richness of the contentavailable in the command and control system. Reach,on the other hand, depends on the ability to shareinformation, knowledge, and awareness.
• Shared information and knowledge can bemeasured in almost exactly the same wayas individual information and knowledge(completeness, correctness, currency,consistency, and precision). However, newdimensions must be considered: what fractionsof the relevant command and control systemusers have access, what delays may occur inthat access, how well the total system isinformed (what is known to the members), andhow well the typical (average or median) useris informed.
• Similarly, shared awareness must beunderstood in terms of these four newdimensions, but the indicators will focus onwhat individuals perceive, not what isavailable to them from their systems.
• Shared understanding, which builds in theinformation, knowledge, and awareness todefine relevant cause and effect relationshipsas well as temporal dynamics and puts theminto an operational context that defines thethreats and opportunities relevant to eachactor and their opportunities to influence the

174 Code of Best Practice for Experimentation
military situation, is also an important elementof reach.
The command and control processes supported byreach and richness form a hierarchical ladder thatmoves from decisionmaking in the military contextthrough synchronization and mission or taskeffectiveness to the overarching level of policyeffectiveness.
• Decisionmaking effectiveness has twofundamental components: quality of thedecision process and quality of the decision.
- Quality of the decision process can bemeasured in several ways. These includeissues such as the number and variety ofparticipants, the variety of alternativesconsidered, and the explicitness of thecriteria applied.
- Quality of decision measures oftenincludes the speed with which the decisionis made, but should also include some wayof assessing the decision itself – fastdecisionmaking should not be confused withgood decisionmaking. The quality of militarydecisions is only known in the real worldafter the fact. In experiments, it is commonto use panels of subject matter experts tojudge decision quality, both before and afterthe fact. The key here is to ensureobjectivity – bias due to interpersonalrelationships, service doctrine, or otherfactors should be screened out wheneverpossible. Blind judging can be helpful.

175Chapter 7
• Synchronization is a factor that has long beenappreciated in judging command and controlperformance, but is only now coming to beunderstood well enough to measure in areliable and valid way. Synchronization refersto “purposeful arrangement in time andspace.”2 The fundamental scale that hasemerged is the percentage of the elements orassets of a force that are (a) conflicted(interfering with one another or limiting oneanother’s actions), (b) deconflicted, or (c)synergistic (multiplying the effects of oneanother).
• Measures of mission or task effectiveness,which include classic force effectivenessmeasures (casualty ratios, territorial control,etc.) when classic force or attrition missionsare assigned, form a still higher or morecomprehensive layer of measures. Whenstrategy-to-task structures are used, theyprovide the framework for this class ofmeasure.
• Policy Effectiveness forms the topmost layer inthis framework. As mission complexity hasgrown and purely military activities havebecome subordinate to political, humanitarian,counter-drug, counter-terrorism, counter-insurgency, and peace operations; the need toassess overall success (rather than militarysuccess) has become increasingly important.
The Network Centric Warfare value chain providesa rich source for thinking through the set of metrics

176 Code of Best Practice for Experimentation
relevant to a particular experiment. However, it isonly one such source. Most data collection and dataanalysis plans should consider more than oneapproach and ultimately select a set of measuresand metrics that make unique sense for theirproblem or hypotheses.
Effects-Oriented Measures and Metrics
An Australian team (Seymour et. al.)3 has recentlyintroduced an alternative hierarchical arrangementof measures (Figure 7-1) predicated on theassumption that effects-based operations (EBO) isthe concept that best underlies future militaryoperations. This approach asserts that there are fivecrucial layers:
• Data Superiority (data collected);
• Information Superiority (information quality);
• Knowledge Superiority (situation awareness);
• Decision Superiority (decision quality); and
• Effects Superiority (achieving intent).
Unfortunately, this approach introduces somelanguage that is inconsistent with the NCW usagein the United States and mixes ideas from theNCW work with that of Professor Endsley (2000),but i t is reported intel l igently and providescomparative results as the basis for suggesting anew approach.

177Chapter 7
Figure 7-1. Hierarchy of Outcomes
Headquarters Effectiveness Assessment Tool(HEAT)
The longest surviving approach to measurementof command and control, HEAT, originated 20years ago and has been app l ied to rea lwarfighting cases, exercises, and experiments,and still underlies work at U.S. Joint ForcesCommand and in the NATO Code of Best practicefor C2 Assessments . 4 HEAT organizes thecommand and control process into severalelements and posits a variety of indicators foreach element. The elements considered include:
• Monitoring the battlespace – facts known tothe information system, scored forcompleteness, correctness, currency,consistency, and precision;

178 Code of Best Practice for Experimentation
• Understanding the battlespace – perceptionsand understandings of the battlespace, scoredfor completeness, correctness, time horizon,and consistency;
• Alternatives considered – scored for varietyand number of perspectives;
• Predictions made – scored for variety andnumber, completeness of alternative futuresconsidered;
• Decisions made – not scored, recorded forlater comparison with outcomes formission accomplishment;
• Directives generated – scored for clarity andconsistency with decisions made;
• Reports issued – scored for correctness andconsistency; and
• Queries for information – scored for responserate, response time, and correctness ofresponse.
All HEAT categories are also supported by speedmetrics designed to learn how long the commandand control process steps have taken. Morerecently (in the past 2 years) they have also beensupported by measures focused on the degreeand quality of collaboration in the command andcontrol processes.
Because it has been widely applied, HEAT has alsodemonstrated a couple of principles that allexperimentation teams should bear in mind. First,

179Chapter 7
HEAT experience underscores the importance ofcollecting data at echelons above and below thoseunder detailed study. For example, learningwhether directives or reports were clear can onlybe done by comparing what the authors meant toconvey with what the recipients understood.Second, HEAT applications have made it clearthat data on automated command and controlprocesses can be taken automatically, but thathuman-centric command and control processescan only be captured properly by teams of well-trained human observers. In addition, HEATexperience has made it clear that the perceptionsof observers, controllers, participants, and supportpersonnel will differ (often widely) and may differfrom the empirical evidence. Hence, rich dataanalysis and data collection plans that includeall these perspectives are essential.
Example Application:Self-SynchronizationExperiment
The discovery experiment in self-synchronizationintroduced in the last chapter makes an excellentpractical example for developing measures, metrics,and indicators. The first task is to make a list ofthe variables of interest, which are really theattributes for which measurement is needed. AsFigure 6-1 shows, there were 12 attributes identifiedin the initial descriptive model:
• Effective self-synchronization (the dependentvariable of interest);

180 Code of Best Practice for Experimentation
• High quality shared situation awareness(intervening variable);
• Congruent command intent (interveningvariable);
• Trust (intervening variable);
• Common perceptual filters (interveningvariable);
• High quality situation awareness (interveningvariable);
• Collaborative command and control processes(intervening variable);
• Competence (intervening variable);
• Empowering leadership (intervening variable);
• High quality information (independentvariable);
• Information availability (independent variable);and
• Shared knowledge and experience(independent variable).
All of these variables will need to be understood atthe measure and metric level, whether they are tobe manipulated or controlled in the experiment.Even factors that will be controlled in the experimentdesign wi l l need scales and values so theexperimenters know that these variables haveachieved and maintained those values, and so thatlater experiments (where they may be manipulated)can be informed properly by these results.

181Chapter 7
Dependent Variable:Effective Self-Synchronization
Identification of measures and metrics shouldalways begin with the dependent variable, both toensure that the other variables are defined in waysthat are not confounded with the dependent, andalso to ensure that the focus of the experiment hasbeen properly captured. The project team foundthat little experimentation had been done on thistopic and most of the work on defining the termremained immature. Hence, the experimentationteam focused its first efforts at clear, precisedefinition. The term has at least three elements:“effective,” “synchronization,” and “self.”
Work began with the concept of synchronization.This has been defined as “purposeful arrangementin and across time and space.”5 While helpful, thisdefinition is not operational. It does not tell aresearch team what to look for in order to determinewhether one case is at all “more synchronized”than another.
The most fundamental dimension underlying theconcept emerges from conflicted situations (unitsand activities that interfere with one another, downto and including fratricide) through de-conflictedsituations (boundaries, schedules, and other controlmeasures are used to prevent interference, but unitsand activities therefore function independently andalso constrain one another) to synergistic situationswhere activities and units interact to generateeffects or mission accomplishments greater thanthe linear sum of their parts. This approach has the

182 Code of Best Practice for Experimentation
advantage of including the concept of effectivewithin the meaning of synchronization. Moreover,the experimentation team stressed that synergisticactivities and units are supporting one another,not just working within the same space andtime period. Adopting this approach, theexperimentation team selected two fundamentalmeasures for “effective synchronization:”
• For a given period of time, the percentage ofactivities (missions or tasks) that areconflicted, de-conflicted, and synergistic; and
• For a given period of time, the percentage ofunits whose actions are conflicted, de-conflicted,and synergistic.
These two measures cross-check one another.They also recognize that synchronization occursover time and must be integrated over time to bemeaningful. They will require the ability to identifytasks (as in the concept of strategy to task, butincluding non-military tasks such as informational,political, economic, and social activities that aresignificant in accomplishing the mission) as wellas a consistent definition of unit that applies tothe forces and other organizations involved. Thebasic mathematical formulation of these twometrics is shown below.6

183Chapter 7
S = n-1 Σ Vι ι = 1 Cn
2where,
S = degree of synchronization [-1≤S≤+1]Cn
2 = combination of n things taken 2 at a time
Vι = 1 if the ith pair is in a state of synergy 0 if the ith pair is in a state of neutrality -1 if the ith pair is in a state of interferencen = case number
Knowing what synchronization means helps todefine self-synchronization because it is anessential element of the concept, a necessary yetinsufficient condition. Clearly, synchronization canbe achieved by centralized control. For example,U.S. Air Force Air Tasking Orders (ATO)synchronize a variety of different types of aircraftengaged in a variety of missions and tasks byproviding a centralized mechanism that blends theefforts of all the forces. These “order” types ofmechanisms, as well as directives that focus onspecif ic mil i tary objectives under integratedschedules, discourage many kinds of initiative.7
Classic self-synchronization occurs when leadersand commanders throughout the battlespace areable to generate synergy based on their shared (a)training and experience, (b) understanding of thecommander’s intent, and (c) awareness andunderstanding of the situation.
For example, dur ing the Civi l War and theNapoleonic Wars, commanders often followed the

184 Code of Best Practice for Experimentation
rule that their forces should “march to the soundof the guns,” largely because they seldom hadgood intelligence on where the enemy force waslocated or even where the other friendly forceswere at a given point in time. Hence, this rule ofthumb made it possible for forces to concentratein the presence of an enemy wi thout f i rs testablishing communications or developing a planto integrate their actions.
The experimentation team in this case decidedthat self-synchronization would be recognizedwhen the commander’s mission type orders andthe forces involved could be scored as synergisticin terms of units and activit ies. Hence, theexperimenters incurred an obligation to be ableto capture all directives (from written plansthrough verbal commands and consultationsbetween commanders) in their data collectionp lan, and a lso to create the capabi l i ty todistinguish mission type orders from others.Therefore, part of the ef for t to make sel f -synchronization operational will need to includedeveloping, testing, and revising coding rules thatcan identify mission type orders and count themissions and tasks assigned, as well as the unitsassigned to them.
Independent Variables
The working model of the problem (Figure 6-1)identified only three true independent variables(factors expected to impact the dependentvariable, but not driven by other factors in themodel): information quality, information availability,

185Chapter 7
and shared knowledge and experience. The firsttwo of them, however, were seen as interacting withone another and being mutually reinforcing. Thatis, the quality of the available information wasexpected to be higher if that information could bemade avai lable widely, and the breadth ofavailability was seen as increasing the qualityof the information as the participants shared anddiscussed it. These three factors were seen as soimportant to effective self-synchronization thatthey would need to be assured by the experimentdesign in order to activate the processes that theexperiment would focus on, namely the interactionsbetween the participants.
High quality information is well-defined in the HEATtradition. High quality information is drawn fromthe monitoring function, which is located in theinformation domain and consists of facts and basicinferences about what is and what is becoming,rather than the richer inferences needed to convertthose sets of facts into situation awareness andunderstandings. This perspective was seen asappropriate to the problem under analysis sincethe initial model distinguishes between the qualityof in format ion and the qual i ty of s i tuat ionawareness. The key measures suggested in thispart of the HEAT model are:
• Completeness – information is available aboutall the entities and situations of interest to thedecisionmakers (metrics focus on percentagecomplete);

186 Code of Best Practice for Experimentation
• Correctness – there is no false informationand the uncertainty surrounding thatinformation is explicitly known (metrics focuson percentage correct);
• Currency – the information has no time lag andthe time lags that do exist are known (metricsfocus on latency of information items andpercentage within command standardsestablished for types of information);
• Consistency – there is no difference betweenthe information sets known to different parts ofthe information system (metrics focus onpercentage of items consistent); and
• Precision – whether the information item hasadequate precision for some specificapplication (metrics focus on percentage ofitems within the command standard suchas targeting quality versus adversary posturein the battlespace).
Each of these groups of measures already hasdetailed working definitions in the HEAT system.Moreover, training materials exist from priorapplications. However, every experiment hasunique needs and features, so even these “triedand true” sets of measures were scrubbed indetail to ensure their relevance and focus. Forexample, establishing the command standards forlatency on information of different types requiresassessment. Prior applications had establishedacceptable time-critical targeting latency at 60minutes based on the time required to processthe information, assign assets, and strike the

187Chapter 7
target. However, only a fraction of the relevanttargets were being struck successfully with thisstandard, so the subject matter experts workingwith the experimentation team recommended thisthreshold be reduced to 30 minutes.
Because high quality information was seen as anecessary yet insufficient condition for effectiveself-synchronization, the experimentation teamdecided that its values should be directly controlledin the experiment. They did not, however, want tolose the very real features of uncertainty and alack of precision as factors that the subjects shouldconsider. Hence, they instructed those developingthe experimentation environments (supportingscenario information – see the next chapter) thatcompleteness should be at 80 percent, correctnessat 90 percent, currency within command standardsat 80 percent, consistency at 100 percent forwhat was available (no differences in the underlyingdata sets) for U.S. forces and at 80 percent forcoalition forces, while precision would reflect thecapabilities of the reporting sensors. This lastassumption reflected concerns that the participantswould have prior knowledge of the reliability andcapabilities of the sensor suites in use. Therefore,using artificial values for precision would lead toconfusion and might reduce the credibility of theexperiment in the eyes of some subjects.
Because information quality would vary acrosstime within the boundaries established by theexperimenters, it also had to be recorded so itcould be included in the data analysis plan and itshypothesized impact on other factors assessed

188 Code of Best Practice for Experimentation
statistically. In this case, this meant monitoring thedatabases and injections into them and takingmeasures of central tendency (means, since themetr ics adopted are rat io measures) anddispersion (standard deviations). Ideally, thesewould be tracked continuously, minute by minute.However, given the indirect impact of the qualityof information, the decision was made to recorddata hourly throughout the experiment.
Information availability, also seen as a necessaryyet insuff ic ient condit ion for effect ive self-synchronization, was another factor that theexperimentation team wanted to control, but not atperfect levels. The measure that matters isworkstation access, meaning who can interactwith which parts of the database at any given timeand collaborate with others about the availableinformation. Connectivity was established for thisexperiment at 95 percent, with randomly assignedbreaks ranging from 1 minute to 40 minutes acrosslinkages. Participants were to be given the capabilityto check on outages and ground truth about theirexistence and correct them to within plus or minus30 percent of their length, but only if they inquired.
The experimentat ion team also noted thatinformation availability was a potentially crucialfactor that they were deliberately controlling in thisexperiment, but which was worthy of furtherresearch. Hence, they noted that it should beexplored further, both in their own sensitivityanalyses after the experiment and in laterexperimentation on similar issues.

189Chapter 7
As noted earlier, shared knowledge and experiencewas the final truly independent variable seen as afundamentally necessary yet insufficient conditionfor self-synchronization. This is a very difficult factorto control, but it is also seen as a powerfuldeterminant of other factors in the model, suchas creating common perceptual filters, perceptionsof competence, and willingness of leaders toempower subordinate commanders.
The first inclination of the experimentation teamwas to look for existing military organizations inorder to ensure that their teams of subjects had ahigh level of shared knowledge and experience.However, they soon recognized that (a) such teamswould be difficult to obtain as subjects, (b) existingmilitary teams are impacted by rotation and mayor may not have rich shared knowledge andexperience, and (c) the settings and militarymissions for this experiment may reduce therelevance of the shared knowledge and experienceof existing teams.
The second approach considered was informedby one o f the soc ia l sc ient is ts on theexperimentation team. She pointed out that smallgroups create shared knowledge and experienceas they work on problems and that this processgenerates a set of artifacts that capture theirefforts. This set of artifacts includes specializedlanguage, heuristic approaches to the problemthat increase team productivity, knowledge of oneanother’s expertise and perspectives, as well asroles within the team. Taking this perspective, theexperimenters decided that they would seek to

190 Code of Best Practice for Experimentation
create the shared knowledge and experiencewithin their teams of subjects during training. Thissolution to the problem illustrates the value ofhaving a multidisciplinary team. While they stillfelt a strong need to have military professionalsas subjects, they felt they could, by having thegroups work a series of problems together duringthe training phase of the experiment, create ameaningful level of relevant shared knowledgeand experience. This decision obviously implieda link to subject training, demanding that subjectteams be created as early as possible and trainingwould need to ensure a number and variety ofrelevant problems where those teams would worktogether. The training impact of this decision aboutcontrolling shared knowledge and experience isan excellent example of the close linkage betweenthe elements of an experimentation plan.
However, deciding on an approach to establishingshared knowledge and experience within the teamsof subjects is not the same as creating theappropriate measures and metrics. Regardless ofhow well the training creates opportunities forcreating these factors, the subject teams are likelyto vary in shared knowledge and experience.Moreover, these may change during the experimentas the subjects gain more experience workingtogether. Hence, good definitions and measureswill be needed.
The team noted that knowledge and experienceare partly determined before the teams cometogether for the experiment. Hence, data will beneeded about the individual’s background and

191Chapter 7
t raining. Fortunately, they had access to aquestionnaire developed by the InformationSuperiority Working Group for an experimentconducted at U.S. JFCOM in 2001. 8 Th isinstrument includes the length of professionalmilitary experience, Service, branch, military,and civilian educational background, computerl i teracy, assignments, command experience,command center experience, combat experience,and other factors that might impact performance.However, the new thinking implied by the self-synchronization experiment is focused on howthese background factors can be compared toidentify teams with more or less shared knowledgeand experience. In this case, the team decidedthe questionnaire was adequate for data collection,but noted that the data analysis plan wouldneed to use some clustering techniques tomeasure closeness of prior education, training, andexperience. Multidimensional scaling was therecommended approach, though the number ofteams and indiv iduals involved was alsorecognized as a under-developed factor in theanalysis plan that might lead to different choiceslater in the process.
Another other key issue remained – how tomeasure shared knowledge and experience at theend of training and during the experiment itself.The decision was made to rely on two cross-checking techniques: self-reporting and behavioralobservation. These two very different techniqueswere chosen because th is is a d i f f icu l tmeasurement problem and because neither

192 Code of Best Practice for Experimentation
technique can be assumed to be fully valid orreliable by itself.
The self-reporting instrument focused on eachteam member’s perceptions of what they have incommon with others on the team as well asrelevant differences from them. It also askedabout how close the individual’s perceptionsof the experiment’s situations and approachesto mi l i tary problems are to those of othermembers of the team. This latter section of thequestionnaire was designed to reflect changes inshared knowledge and experience as the groupworked together through training problems andexperiment trials. Provision was also made in theschedule o f the exper iment for fo l low-upinterviews with individual members of the subjectteams to clarify their answers where necessary.
Behavioral observation was planned around thegroups’ creating artifacts such as specializedlanguage, heuristic approaches to problem solving,common ground among team members, etc. Thisentailed training the observers in recognizing theemergence, use, and growth of those artifacts thatindicated increasing shared knowledge andexperience, as well as those behaviors (challenges,miscommunication, etc.) indicating a lack of sharedknowledge and experience. This required anotheradjustment to the training schedule and aninstrument on which to record relevant behaviors.

193Chapter 7
Intervening Variables
The eight other variables being explicitly consideredare intervening variables believed to impact thedependent variable, but also influenced by one ofmore other factors in the conceptual model.
Common Perceptual Filters are a product of sharedknowledge and experience. Hence, the decision wasmade to handle them as part of the questionnaireon that topic. The specific technique selected wasto offer key terms and images from each of theoperational vignettes used to drive the experimentand have the subjects provide their interpretationsof what each means and the relative importance ofeach term or object in the situation. Responses werescored on commonality, not on correctness.
Competence, in the context of this experiment, isreally perception of competence. The assumptionis that superior commanders will be reluctant toempower junior commanders with mission typeorders and responsibility for self-synchronizedact ions unless they perceive those juniorcommanders as competent. Hence, this issue willneed to be addressed with a survey instrument.Again, the decision was made to include issues ofthe competence of other actors on the samequestionnaire used to assess shared knowledgeand experience and common perceptual filters.
Trust is also a perceptual issue and was also addedto the questionnaire. Trust, however, is oftensituational. Hence, several questions were neededto establish levels of trust on different topics suchas (a) willingness and ability to provide complete

194 Code of Best Practice for Experimentation
and correct information, (b) capability to developan independent plan of action, (c) willingness to askfor assistance when needed, and (d) willingness toseize the initiative when appropriate.
Empowering Leadership is difficult to control as itresults not only from the perceptions thatcommanders have of their subordinates, but alsopersonal leadership style. As a consequence, thedecision was made to capture this factor throughbehavioral observation. A rich literature exists onleadership and it was researched to find bothoperational definitions of empowering leadership andalso indicators of that behavior. The key definitionfocuses on the distinction between consultative anddirective approaches. The key indicators focus onthe extent to which the leader seeks prior knowledgeabout and explicit control over decisions that are fullywithin the responsibility of the subordinate, andthe extent to which collaboration and problem solvingbetween subordinate commanders is encouragedand accepted. This subject also needed to beincluded in the training plan for the experiment.
Collaborative Command and Control Processeswere available to the subjects throughout theexperiment, except when their connectivity wasinterrupted (see the discussion of informationavailability), which was recorded for analysis.Hence, the major dif ference is how muchcol laboration each team used. This can bemeasured directly by instrumenting and recordingthe collaboration tool.

195Chapter 7
High Quality Situation Awareness is a difficultconcept in the abstract. Fortunately, an operationalapproach to this issue was developed in theDARPA Command Post of the Future Program,vetted by the Information Superiority WorkingGroup, and applied again within the JFCOM seriesof Limited Objective Experiments. This approachrecognizes that awareness is what people know.I t decomposes the knowledge needed tounderstand a military problem into factors:
• Capability and intentions of own, adversary,and uncommitted forces;
• Missions assigned to those forces as well asconstraints on them;
• Knowledge of the environment (physical,weather, political, economic, social, andother relevant factors such as InternationalOrganizations, NGOs, etc);
• Time and space relationships;
• Uncertainties about the data and informationavailable; and
• Threats and Opportunities for all the actorsinvolved.
In the approach adopted, each of these factors ispre-solved into an ideal solution by subject matterexperts. The subjects complete a questionnaireabout their perceptions of the situation duringselected breaks in the experiments. These answersare then compared with the “school solution”generated earlier. Scores are reported as a

196 Code of Best Practice for Experimentation
percentage of the correct solution, with counts madeof both erroneous perceptions and correct relevantperceptions not in the school solution.
High Quality Shared Situational Awareness canbe inferred by comparing the situation awarenessquestionnaires from the subjects assigned to thesame team. Shared items are those that arecorrect across members of the team. Differentscores can be expected across different pairs sothat scoring should be available in case onemember of a team turns out to have a very differentawareness from the larger team. Incorrect sharedperceptions should also be scored separately asthey are likely to influence the overall performanceof the team.
Congruent Command Intent, the last interveningvariable, can be scored by comparison of thestatements of intent, plans, directives, and ordersgiven at different echelons and across differentunits or functions. The standard for comparison isthe senior commander. However, pair-wisecomparison is the driving metric. In a self-synchronized world, the lower level commandersmay well be making decisions that are consistentwith one another, but are not identical to the originalcommand intent generated at senior levels whendifferent information was available.
Conclusion
The length and complexity of this example illustratesthe difficulty and importance of serious, upfrontwork on measures and metrics. Experiments that

197Chapter 7
fail to invest in these crucial topics are very likelyto fall far short of their goals and purposes. Clarityof definition; validity, reliability, and credibility ofmeasures and metrics; preparation and planning fordata collection and analysis; and training forsubjects, observers, and others supporting theexperiment are all heavily impacted by the qualityof thinking in this crucial arena.
1Alberts, David S., John J. Gartska, Richard E. Hayes, and DavidA. Signori. Understanding Information Age Warfare. Washington,DC: CCRP. 2001. p76.2Understanding Information Age Warfare. p206.3Seymour, Robert, Yi Yue, Anne-Marie Grisogono, and MichaelBonner. “Example of Use of a ‘Knowledge Superiority’ BasedFramework for C4ISR Metrics.” Land Operations DivisionDefence Science and Technology Organisation. 2002.4Headquarters Effectiveness Assessment Tool “HEAT” User’sManual. McLean, VA: Defense Systems, Inc. 1984.5Understanding Information Age Warfare. p206. Note this hasbeen adapted by the ISWG to emphasize “across.”6Understanding Information Age Warfare. p231.7Alberts, David S. and Richard E. Hayes. CommandArrangements for Peace Operations. Washington, DC: NDUPress. 1995.8See Appendix D.

199
CHAPTER 8
Scenarios
What is a Scenario?
T he NATO Code of Best Pract ice for C2Assessment (Revised Edition, 2002) defines the
term scenario as “a description of the area, theenvironment, means, objectives, and events relatedto a conflict or a crisis during a specific timeframesuited for satisfactory study objectives and problemanalysis directives.” That volume also discusses thetopic in considerable detail and is recommendedas a source for those who are new to dealing withthe subject. However, its focus is both broader (alltypes of analysis) and narrower (primarily commandand control, though much of its guidance can beapplied to a range of military analyses) than thefocus here on transformational experimentation.
The same source goes on to argue that scenariosconsist of four primary elements – “a context (e.g.,characterization of a geopolitical situation), theparticipants (e.g., intentions, capabilities, of blue,red, and others), the environment (e.g., natural –weather and manmade – mines), and the evolutionof events in time.” It also notes that “the purpose ofscenarios is to ensure that the analysis is informedby the appropriate range of opportunities to observe

200 Code of Best Practice for Experimentation
the relevant variables and their interrelationships.”This drives home the point that scenarios are tools,not ends in themselves. As such they need to becrafted, selected, or adapted to ensure that theysupport the goals of the experiment.
Scenarios in TransformationExperimentation
Scenarios provide the substantive focus andboundaries for experimentation. This makes thema crucial element in planning for success. Hereinalso reside the core dangers for scenarios inexperimentation. On the one hand, if they are overlyspecific, the experiment may not examine all theimportant propositions or generate data on all therelevant factors and relationships. On the otherhand, if they are too general, the experiment mayfail to generate adequate data and information tosupport genuine analysis and learning.
No Single Scenario
Note that the term scenarios is always used here inthe plural. This reflects a fundamental fact: no singlescenario is likely to be sufficient to support ameaningful experiment. The use of a singlescenario, even one that has been carefully craftedto focus on the key issues in an experiment, invitessuboptimization and narrows the range ofapplicability for the findings. Academic research,which is intended to develop knowledge over longtime periods and therefore focuses primarily onincremental additions to knowledge, can afford

201Chapter 8
this luxury. However, transformational militaryexperimentation cannot. Reliance on a singlescenario means that the resulting knowledge andmodels of what has been observed will be optimizedfor that scenario at the expense of the range of othersituations and missions where the military will beemployed. During the Cold War, when the U.S. wasprimarily focused on the Soviet and Warsaw Pactthreats and had decades to study their orders ofbattle, training, doctrine, and materiel, singlescenario experiments and analyses made somesense. However, their limits became obvious whenAmerican forces had to contend with very differentthreats and missions in Vietnam. Weapons systems,force structure, doctrine, training, and other itemsthat had been optimized for heavy force-on-forcecombat in Europe and Korea were less than idealand had to be altered in fundamental ways.
Defining the Scenario Space
The range of threats and missions relevant totransformational experimentat ion today aredisplayed in Figure 8-1, Scenario Threat Space.1
The vertical axis identifies the sources of threatsfacing the U.S., from classic nation states withmilitary organizations down through non-stateactors (e.g., Palestinians) through organizations(e.g., terrorists, drug cartels, illegal corporateactors) to loosely l inked groups (e.g., anti-globalization demonstrators, ethnic groups inturmoil) to threats that ar ise from naturalphenomenon (e.g., AIDS, hurricanes, earthquakes).
202C
ode of Best P
ractice for Experim
entation
Figure 8-1. Scenario Threat Space

203Chapter 8
The horizontal axis defines the types of controlmechanisms the U.S., and particularly the U.S.military, may have to employ to be effective againstthese very different threats. Military operations areclearly relevant to fighting nation states, butdecl ine in relevance as the threat shif ts tosources that do not have organized military forces.In current terms, defeating Taliban and organizedformations of al-Qaeda forces was a relativelystraightforward military task, but those operationshave ushered in a much more diff icult, andpotentially much longer and more complex, set ofoperations. Other missions today place the militaryin ro les where their pr imary funct ions aremonitoring and providing policing services. Manypeace operat ions, some intervent ions, andhumanitarian assistance missions outside U.S.borders often require this orientation, at leastduring their initial phases. Finally, and perhapsmost important, many missions today require majorefforts in cooperation, not only with nation states(allies, host governments, etc.), but also withinternational organizations, private volunteerorganizations, general populations, and evenmedia organizations.
While some individuals in the military (both U.S.and foreign) would prefer a simpler world in whichthe only task of the armed forces is to “fight and winthe nation’s wars,” this yearning for a “golden age”is illusory. Even at the height of the Cold War, thefirst mission of the U.S. Armed Forces was to determajor conflicts. Today that tradition continues, buthas been expanded into “shaping” the operatingenvironment in ways that seek to prevent or limit

204 Code of Best Practice for Experimentation
overt conflicts and minimize the risks to U.S. lives(including military lives) and property.
As the understanding of effects-based operationsgrows and as it is incorporated into militaryplanning and operations, the capability of militaryorganizations to employ effective communicationsand persuasion to shape the environment andgain cooperation will come into sharper focus.Examination of recent history certainly supportsthe idea that U.S. forces must be able to carry outa wide range of missions and employ a variety ofmeans in order to be effective.
The matrix of threats and control mechanismsmakes is appear that the variety of threat sourcesand ways of carrying out military missions can besegregated neatly. However, the reality is that theyhave become inextricably mixed and connected. TheU.S. Marine Corps concept of a “three block war” inwhich they expect to be engaged in combatoperations in one part of a city, enforcing curfewsand disarming the population close by, whileproviding humanitarian assistance in a third areaof the same metropoli tan area is a graphicportrayal of this reality. The luxury of havingspecialized equipment and different forces foreach type of mission will only occur in sterileposition papers. Realistic thinking about theelements of mission capability packages andDOTMLPF initiatives will have to face this complexreality. Hence, transformational experiments mustnot be based on a single scenario that onlyencourages us to put our heads in the sand andignore crucial threats or critical capabilities.

205Chapter 8
The need for a variety of scenarios has alreadybeen recognized in some parts of theDoD community. For example, the scenariosunderlying the JFCOM series of experimentsleading up to Millennium Challenge ‘02 (UnifiedVision ‘01 and Limited Objective Experiments) werecrafted as a series of vignettes that move from aserious international situation where the U.S. hasclear interests and a range of tools can be used toshape the environment, through a crisis phaserequiring working with other governments inmilitary planning and preparations, to a militaryactions phase, followed by a conflict terminationand regional restoration problem. Similarly, thevisualization tool experiments performed withinDARPA’s CPOF Program used both tactical militaryforce-on-force scenarios and an insurgencysituation where the U.S. role was limited toprotecting U.S. forces, personnel, and facilities aswell as assisting a host government in dealing withthe insurgency. Not surprisingly, these experimentsshowed that new tools and different mindsets wereneeded across the different types of missionsexamined.
Selecting the “Interesting Range”
Each transformation experiment or experimentationcampaign should be aimed at some interesting“range” in the available scenario space. Since therelevant scenarios will have to both focus attentionon the set of variables of interest and also provide arich enough environment to allow variations andbehaviors that have not been foreseen (or fully

206 Code of Best Practice for Experimentation
foreseen), considerable effort is often required toselect the appropriate set of scenarios and vignettes.For example, the threat and mission space definedin Figure 8-1 is probably a good starting point forselecting the strategic and operational context(s) thata given experiment will cover. Once that broadparameter space has been chosen, however; thespecific actors (red, blue, and neutral), operatingenvironment (terrain, weather, and relevant political,social, and cultural contexts), and the driving eventsthat will ensure that the experiment is properlyfocused must also be articulated.
The initial CPOF visualization experiments providea good example. The Program decided that it wouldfocus efforts on two important parts of the missionspace (U.S. operations in support of a weakercoalition partner that had been invaded by amore powerful neighbor, and support to a hostgovernment faced with an active insurgency), andthe experimentation team had to put the otherelements of the scenario in place.
For the high-intensity military operation, thegeopolitical context was organized around a situationthat the U.S. plans for routinely: the invasion of asmall country that cannot defeat the aggressor andrequests U.S. assistance. Environment and terrainwere borrowed from the real world, training centersfor which good map data and real weather data wereavailable. However, because situation awarenesswas one of the experiment variables, the terrainwas expanded to include nearby areas and the mapwas rotated to reduce its familiarity. The friendly andhostile forces were created to represent forces like

207Chapter 8
those the U.S. expects to see. Two very differenttactical situations were selected, located on differentterrain and involving different missions, forcestructures, and driving events. These tacticalsituations had quite different likely futures, threats,and opportunities. The two insurgency scenarioswere located in a real world country with a relativelyweak government and tradition of democracy.Sanctuary was assumed in a neighboring country.The same force structures were used in bothinsurgency cases. Two different patterns of drivingevents were developed, one pointing to a majorinsurgent offensive and the other to “business asusual” rather than any radical initiative by therebels. Since the purpose of the experiment was tofind out which types of visualizations give bettersituation awareness (more correct, more complete,more focused on specific threats/opportunities andactions), this variety in missions, contexts, actors,and driving contexts yielded a rich and useful set ofscenarios focused on the subjects’ ability torapidly and correctly comprehend a variety ofmilitary situations.
Note that this individual experiment did not (and didnot attempt to) cover the entire range of interestingsituations. Rather, i t selected a range withconsiderable variety in context and mission type,leaving some other important types of operation(e.g., peace operations) for later experimentation.Given the resources available, taking on morescenarios and treating them in adequate depthwould have been very difficult.

208 Code of Best Practice for Experimentation
How Much Detail?
The depth of detail needed for a transformationexper iment depends on the focus of theexperiment. Two examples should suffice to makethis clear – scenarios for the major JFCOMexperimentation venues such as Unified Vision ‘01or the Air Force’s JEFX) and the scenarios neededfor a s imple interpersonal exper iment ininformation sharing and shared awareness.
Major experimentation venues involve a variety ofechelons (typically a CINC slice to help drivethe events, a Joint Task Force headquarters,component commands and operating units), avar iety of funct ions ( intel l igence, logist ics,operations, etc.), consideration of host governmentand coalition factors, and development over timefrom pre-crisis to crisis, to military engagementand war termination. These major efforts require acomplex reality and the capacity for the participantsto use the rich set of sources available in the realworld to support their situation awareness anddecisionmaking. Today, these involve organicintelligence, national assets, reach back, outreach,and Internet sources. These experimentationvenues also demand specific scenario materialsto dr ive the var iety of speci f ic d iscovery,hypothesis testing, and demonstration experimentscontained within them. The scenario materialsneeded for these experimentation venues willtypically require a year or more of developmenttime, and a number of person-years of effort. Inmany cases, they will draw from existing (oftenapproved) scenarios in order to minimize the costs

209Chapter 8
and ensure credibility, though ensuring adequateuncertainty and free play to challenge participantsand test key proposi t ions about s i tuat ionawareness, decisionmaking processes, andsynchronization should limit reliance on “canned”scenarios and pre-scripted adversary behaviors.
By contrast, when Thoughtlink sought to researchhow groups exchange information and collaborateto solve problems, they set up a simple set ofscenarios. Every group was given the same problemwithin a game they call “SCUDHUNT.” The problemis to locate Scud missiles in a grid space, very muchlike the old game of Battleship. However, rather thanblind trial and error, each team is given a set ofsensors with different properties (ranges, probabilityof correct detection, probability of false alarms, etc.).Primary decisionmaking is about how to employ thesensors. The behaviors of interest have to do withhow the group shares information and reachesconclusions about the locations of the missiles.Dependent variables include the degree to whicheach group (a) is correct about Scud locations(situation awareness) and (b) agrees on thoselocations (shared situation awareness). The primaryscenario manipulation is simply the locations of theScuds, which can be handled by a random numbergenerator. The experimentation team can obviouslyalso manipulate the characteristics of the sensors,the size of the grid to be searched, the number ofmissiles present, the types of subjects, and thecommunications systems available to them, butthese are controls in the experiment, not scenarios.Note that this set of experiments is designed to learn

210 Code of Best Practice for Experimentation
about human behavior, so the lack of richness inthe scenarios does not impact the experiment itself.
Hence, the level of detail needed for an experimentclearly depends on the purpose of the experiment.Scenarios can be very rich and therefore verydifficult and expensive to develop and support.However, since they are not ends in themselves,scenarios should be limited investments designedonly to faci l i tate the larger experimentationprocess. Indeed, scenarios will almost always beincomplete, and some detail of interest and valueto the subjects will not have been considered whenthe scenarios were built. In these cases the valueof agile, resourceful experimentation teams,including those in the “white” or control cell andthe experiment support team will be demonstrated.Smart teams rely on these resources rather thanattempting to foresee any and all possible issuesand questions.
Driving Data Collection and Analysis
Scenarios must drive the data collection processand ensure that enough data are taken on keyissues to support the data analysis plan. Empiricaldata require appropriate stimuli. For example, if aresearch issue is the speed with which informationcan be transmitted throughout a force, the scenarioneeds to have events in it that should be sentimmediately to all force elements. These arerelatively rare events in the real world. They includenotification that a war has started, reporting thepresence of chemical, biological, or radiologicalweapons in the battlespace, virus alerts and

211Chapter 8
notifications of other types of electronic attacks, andnotification of termination of hostilities. Hence,scenarios where this is an issue would need to haveappropriate stimuli built in at intervals that permittesting of the speed of information distribution.
Analyses of exercises have shown that standardtraining exercises involve about 50 important force-wide decisions per week, based on severalhundred “understandings” or integrated situationassessment conclusions, and tens of thousandsof reports about f r iendly, adversary, orenvironmental developments. Scenarios designedto focus on decisionmaking will need to force thepace of decisions to generate a large enoughnumber to support analysis. Scenarios intendedto illuminate issues about situation awareness willneed to make enough changes in the situation topermit capture of enough meaningfully differentobservations and the time delay involved innoticing and processing such changes.
Adequate variety is also needed in the location wherescenarios deliver stimuli. For example, functionaldistribution is essential if situation awareness anddecisionmaking are to be assessed acrossoperations, intelligence, and logistics. Similarly, allelements of the experimentation command will needto be stimulated to report situation changes and makedecisions if their activities are to be used in theanalysis. A simple, common mistake is to have oneelement of a force remain in reserve, thereforereducing its role and making it difficult to capture dataabout its decisionmaking.

212 Code of Best Practice for Experimentation
Scenario Selection,Adaptation, and Creation
Experimentation teams have their choice ofselecting, adapting, or creating scenarios. Whichapproach they select should depend on the mostefficient and effective way to get the job done.The criteria for scenarios include two of thoseunderlying measures of merit – validity andcredibility. Validity here refers to the ability ofthe scenario to correctly represent all the factorsand relat ionships in the conceptual modelunderlying the experiment. This is often an issueof adequate richness. Credibility (face validity insocial science literature) refers to acceptance bythe professional communities involved in theexperiment – subjects, researchers, and thesupported decisionmakers. Richness is a factorhere, also, but sensitivity to existing professionalknowledge is also important. If these two centralcriteria can be met with an existing set of scenarios,then they should be used. If existing scenarioscan be modified to meet these criteria costeffect ively, that is adequate. However, theexperimentation team must be ready to create someor all the needed scenarios in order to achievevalidity and credibility.
Approved scenarios are often suggested as thesolution because they (a) represent majorinvestments and benefit from established expertise,and (b) support modeling and analyses of a varietyof issues based on a common set of assumptionsand background data. These features make them

213Chapter 8
attractive. However, most approved scenarios aredeveloped by individual Services and lack genuinejoint perspectives. They are also vulnerable to theproblem of familiarity, meaning subjects’ situationawareness and course of action analyses areinformed by prior knowledge. Most importantly,however, approved scenarios build on existingorganizational structures, communications systems,sensors, and doctrine. Since transformationalexperimentation is about new systems and newways of doing business, approved scenarios maybe too constrained to adequately support theseexperiments or experimentation campaigns.
Scenario Selection
Fortunate experimentation teams will be able toselect a scenario and use it without change. Formal,approved scenarios do exist, particularly thosedeveloped by the Services to support cost effectiveevaluation of systems. These should be chosenwhen they offer adequate richness and variety tosupport the experiment’s goals. However,meaningful transformation experimentation cannotbe performed on single scenarios, nor on scenarioswhere adversary behavior is scripted and thereforecannot be impacted by friendly actions. Theconcepts underlying transformation, such asnetwork-centric operations and effects-basedoperations, have, as their fundamental rationale,impacting and altering adversary behavior. Hence,scenarios that assume adversary actions andbehaviors do not provide an adequate basis forexperimenting with them.

214 Code of Best Practice for Experimentation
Given that uncertainty and the ability to developshared situation awareness are often crucialelements in military operations, foreknowledge ofscenarios will be a threat to the validity of manyexperiments. Hence, off-the-shelf scenarios may notbe appropriate in some situations where theirsubstance is a good fit to the experimentation goals.In such cases, serious consideration should be givento scenario adaptation, which builds on the richnessof existing scenarios, but alters key events and actorsin ways that create more uncertainty.
One novel development has been the increasinguse of commercial games for military experimentation.The logic is that commercial gamers have investedin a variety of simulations at levels ranging fromsingle shooters to battles and campaigns. They havealready made a variety of decisions about how totrade off reality with ease of use and have framed arange of open ended decision situations. Use of thesegames, perhaps with additional instrumentation ofthe subjects so their behaviors and decisions can bereadily recorded and analyzed, saves the costs ofscenario adaptation and development. Game costsand equipment costs are also well below thoseneeded for developing and supporting major militarysimulations.
Scenario Adaptation
Adaptation is sometimes a cost effective way to buildon what exists. The goal here is to reuse much ofwhat has already been developed (and hopefullypretested) in another context, but to introduce varietyand uncertainty appropriate to the conceptual model.

215Chapter 8
Adaptation may be needed when existing scenariosare already familiar to the subjects, when the existingscenarios do not include all the factors in theconceptual models, or when the existing scenariosdo not allow enough free play.
The simplest adaptations alter the geopoliticalcontext. This can often force the subjects to behaveas though they have novel constraints anduncertainties. Altering the relevant actors (newmilitary forces or forces from other countries) canalso profoundly impact the situation and subjectbehavior with a relatively modest investment inscenario adaptation. Simple changes in sensors,fusion processes, and communications structures(often needed to move the experiment from today’scontext into the future context needed fortransformational experimentation) can also altera scenario significantly. However, care needs to betaken to ensure that the subjects, particularlymilitary subjects, understand what is different fromtoday’s capabilities and are given reasons to findthose changes reasonable, or at least plausibleenough to be worthy of experimentation. Changesin mission type are perhaps the most importantbecause they allow the experiment to explore theinteresting space more thoroughly. However, theyoften involve the greatest level of effort and maysave little over developing new sets of scenarios.
Adaptation should, whenever possible, be donecollaboratively with those who developed the originalscenarios. It should also be reviewed with expertswho do not participate in the adaptation process. Thisis hard, “pick and shovel” work in which every

216 Code of Best Practice for Experimentation
assumption and every detail needs to be madeexplicit. The most common error is to have theadapted elements of a scenario at a different levelof detail (either more shallow or more detailed) thanthe scenarios being altered. More shallow elementsresult from being in a hurry or inadequately staffed.More detailed elements result from losing sight ofthe instrumental role of scenarios.
A final, increasingly important form of adaptationis the development of federations of modelsthat can be used to drive experiments. Thesefederations allow specialized sub-models of keyprocesses, such as command and control orlogistics, to run in greater detail than the mainmodel driving the scenario. This allows bothdistributed processing (greater efficiency) andmore valid scenario support (greater detail andvariety in key processes). While this remains achallenging technical task (synchronizing thedifferent models is not a trivial problem), it hasproven useful for some experiments.
Scenario Creation
When the problem is fundamental ly humanbehaviors and interactions (as in SCUDHUNT), avery simple set of scenarios may be adequate andthe costs of developing them can be quite modest.This is the primary context where scenario creationwill be the most desirable option. Peer review toensure that the limited scenarios are adequate toexamine the conceptual model of interest is a wisepractice, even in these simple cases.

217Chapter 8
Where complex, realistic military settings are neededmost researchers look for tools, such as DARPA’sSynthetic Theater of War (STOW), that can integratelarge amounts of data about terrain, weather, militaryforces, and contextual variables such as refugees.However, even these tools require major efforts(multiple person-years) to support new scenarios.These tools also typically build in a variety ofinteraction and communication patterns that mayrequire considerable effort to identify and change ifrequired. Hence, they are best used when experienceand expertise in the particular tool is readily availableto the experimentation team.
However, given that transformation is about new andinnovative ways of accomplishing military objectivesand often involve an asymmetric adversary, they will,at times, require the creation of genuinely new,militarily rich scenarios. These are really simulationsthat are designed to allow exploration of theconceptual models under study. The expertise andeffort required here should not be underestimated.Even with the computational power and bandwidthavailable today, this process can be expected totake a couple of years on calendar time and severalperson-years of effort. Expertise in all the relevantdomains (command and control, maneuver, fires,logistics, information operations, intelligence, etc,)as well as technical engineering fields (modeling,simulation, databases, information processing,experiment design) and the sciences that underliethat engineering (physics, weather, behavioralsciences, etc.) will all be required. Moreover, theteam will need to use a collaborative work process

218 Code of Best Practice for Experimentation
that keeps all of these types of expertise andexperience engaged.
As with past efforts at developing new simulationsand models, this process can be expected to be soexpensive that its products will need to be reusable.That criterion, coupled with the need for adequateuncertainty and free play to allow exploration of newconcepts and behaviors, means that such asimulation would ideally be built as a shell thatcan rapidly and easily be fed new material (C2structures, doctrines, terrain, missions, etc.). The keyhere is rapidity. The tool for scenario generation andsupport will need to be modular and flexible. At thesame time, that simulation will need, in its firstinstantiation, to fully represent the experiment it isdesigned to support, both in terms of containing allthe elements of its conceptual model and in terms ofthe depth need to support questions from and actionsby experimentation subjects. At this writing, agent-based models appear to be an attractive alternative,but their ultimate value has not been established.
Example Application:Self-SynchronizationExperiment
Some decisions made in earlier phases constrainedthe self-synchronization experiment. For example,the team had decided that this experiment wouldfocus on warfighting and include only close allies.In addition, because self-synchronization impliesboth cross-echelon and cross-functional activities,

219Chapter 8
the scenarios needed involve multiple levels ofcommand and more than one function.
Examination of existing scenarios showed that theyall assume current doctrine and organizationalfactors, which ruled them out as a basis for a self-synchronization experiment. Even adapting one ofthem was seen as requiring a massive effort,perhaps more than beginning from scratch.
Fortunately, a commercial game had just come onthe market that used the typography and forces ofthe NATO Kosovo campaign, but did not have thepolitical restrictions that limited the early NATOactions. The commercial game also allowedcustomized changes in organizations, sensors, andcommunications systems and was designed formultiple players on the Internet. A limited licensewas purchased for government use and the gamerswho had developed the commercial system wereretained as consultants to help install the game on anetwork that could be used for classified applications.
The geopolitical context was changed so thatNATO’s objective was to first deter war crimes and,if necessary, to defeat hostile forces and occupythe territory of Kosovo. Russia, whose presence andactions contributed uncertainty in the real Kosovosituation, was left in its original role and played bymembers of the control cell. Because of the flexibilityof the game, red forces (which included regularforces and militias) could undertake differentmissions and respond differently to NATO initiatives.All game runs were started with identical situations,as were the pretests and training sessions.

220 Code of Best Practice for Experimentation
However, the subjects were warned that the gamemight take different patterns depending on red’sobjectives and opportunities. Red was given a setof five alternative objectives:
• Offer conventional battle;
• Retreat to difficult terrain and operate asguerrillas;
• Retreat to urban areas and use the civilianpopulations as shields and barriers;
• Seek to divide Kosovo into two regions so thenorthern region would become a part of Bosnia,the southern could become independent, butwould be impoverished; and
• Conduct scorched earth operations whileretreating across the province.
These alternative objectives were randomly assignedto the experiment trials with the rule that no team ofsubjects would encounter the same set of redobjectives twice.
Blue capabilities were advanced to the year 2010,particularly in terms of sensors and communicationssystems. Blue commanders were encouraged, butnot forced, to develop joint mission forces ratherthan rely on traditional component led forceelements. Logistics and logistic constraints usedreal terrain, but lift power from the 2010 timeframe.
Forces on both sides were fixed, as were NATOobjectives. This, plus the reuse of terrain in allscenarios, led the experimentation team to expect

221Chapter 8
learning over time by the subjects, so a statisticaltest for improved performance across trials wasrequired in the data analysis plan.
Conclusion
No single scenario is likely to support meaningfultransformational experimentation. However,scenarios are not ends in themselves. Rather, theyare part of the effort necessary for successfulexperiments. They should be chosen or developedto represent an interesting and important part ofthe problem space under study. The criteria for goodscenarios are that they are valid (cover all theelements of the conceptual model underlying theexperiment richly enough to support the necessaryanalysis) and credible to all those participating andusing the results of the experiment. The scenariosneeded will also have to be coordinated with the datacollection and data analysis plans to ensure that theystimulate an adequate number and variety ofactivities for a successful experiment.
Scenarios can be adopted, adapted, or created. Theapproach chosen should be based on costeffectiveness. Selecting an existing scenariobecause it is inexpensive is wrong if it does notsupport all the important elements of the problemunder study. Adapting existing scenarios will oftenbe attractive. However, the true costs of adaptationcan be very high if the mechanisms in which theyare built are inflexible. Development of newscenarios is most attractive in simple experimentsand least attractive when a realistic military “world”

222 Code of Best Practice for Experimentation
must be built from scratch. Despite the best efforts ofthe modeling and simulation communities, manyof the existing tools lack the flexibility needed forgenuinely transformational experimentation.Commercial games may provide attractive, costeffective scenarios for some experiments.
Peer reviewers and consultants familiar with thescenarios and tools being used are important cross-checks on the quality of the work. No scenarioshould ever be used without a thorough pretest. Theultimate tests for scenarios are validity andcredibility. Valid scenarios reflect all of the factorsseen as important in the conceptual model. Crediblescenarios are acceptable by the researchcommunity, the subjects, and the decisionmakerswho will be informed by the experiment.
1This matrix was initially developed by Randy Pherson, a formerNational Intelligence Officer, and has since been refined by ateam from Evidence Based Research working with the JointStaff and the Decision Support Center in the Office of theSecretary of Defense.

223
CHAPTER 9
Data Analysisand Collection
Plans
Purpose and Focus
B eyond (but interacting with) metrics andscenarios, the experimentation team must
complete explicit plans for the collection andanalysis of data. These two efforts are always tightlylinked because analysis is always limited to thatdata which has been collected. Moreover, trainingfor collectors must ensure that the data from theexperiment are those that the analysts expect andthat unplanned differences (anomalies) are clearlyidentified and recorded so that either (a) theanalysis process can be used to compensate forthem or (b) the contaminated data can be removedfrom the analyses. These two plans are vitalbecause they are at the heart of experimentation –ensuring that valid and reliable data are capturedand that the analyses undertaken address the keyissues in the experiment, as well as that theavailable data and information are fully understoodand exploited, but not misused.

224 Code of Best Practice for Experimentation
Relationship between the DataAnalysis Plan and the DataCollection Plan
Because data collection must be accomplishedbefore data analysis, there is a tendency to think ofthe data collection plan as being developed first.However, the only purpose of a data collection planis to feed a data analysis plan. Hence, the workprocess must begin with positing a data analysisplan – how the research issues will be addressedwith the data generated from the experiment. Ineconomic terms, the data analysis plan acts as thesource of demand. The data collection plan acts asthe source of supply.
Having noted the need to consider the requirementsfor analysis first, the reality is that practical factors(access, minimizing interference, classification, etc.)may limit what can actually be collected in anygiven experiment. Hence, while the data analysisplan should be posited first, the process ofdeveloping the two plans will be iterative. The initialdata requirements from the posited data analysisplan will have to be put into the context of theexperiment setting, the collection means available(pre-experiment, automatic, observer based, SME-based, etc.), and the scenarios being used. Thatprocess will identify challenges, such as data thatare needed or desired but are not available asoriginally conceptualized. That will typically lead tochanges in the analysis plan. In addition, the datacollection planning process may identify needs foranalyses (for example needs for inter-coder

225Chapter 9
reliability tests) not foreseen in the initial dataanalysis plan. This iterative process may continueright through the pretest and even be necessaryin order to overcome anomalies and obstaclesarising during the experiment. However, thefundamental principle driving the process shouldbe clear: the purpose of the data collection planshould be to provide what is needed for theanalysis plan. Losing sight of this principle alwaysleads to the same problem of collecting what iseasy to collect rather than what is needed for asuccessful experiment that contributes to thegrowing body of knowledge.
Final ly, the experimentat ion team needs toremember that neither of these plans is an end ini tsel f . Both are instrumental to the overal lexperiment goals. As such, they are constrained by,and must fit into, the rest of the experimentationplan. The data collection plan must be coordinatedwith the scenarios, the pretest, the training planfor collectors, and the systems used to archive dataand information. The data analysis plan must beorganized for end-to-end application from athorough debugging in the pretest through post-experiment modeling and analysis.
Data Analysis Plans
Analysis is the processing of learning what you wantto know from what you already know or can know.As such, it is a crucial part of any experiment.Experiments are about generating empirical dataand information. Organizing experimentation results

226 Code of Best Practice for Experimentation
and integrating them with existing knowledge togenerate new and valid knowledge and insights isthe analytic challenge.
The data analysis plan takes its shape from theconceptual model underlying the experiment and/or experimentation campaign. The first step is toident i fy the dependent var iables and theirmeasures, then the active independent variablesand their measures, and finally the interveningvariables (including those that are to be controlledin the experiment) and their measures. The specificmeasures are important because they provideinformation about the level of measurement(nominal, ordinal, interval, or ratio) available oneach variable of interest. Those levels ofmeasurement, in turn, help to determine theappropriate analytic techniques to be applied.
The other key factors needed to select theappropriate analytic techniques are the numbersof observations or independent data pointsexpected for each variable. The use of parametrictechniques, for example, assumes that enoughindependent observations will be available in eachexperiment trial to make their use appropriate.Where fewer observat ions are l ikely to beavailable, or the assumption of independencecannot be made properly, non-parametric analysesmay be more appropriate.
Analysis is typically organized into three phases:
• Descriptive analyses of individual variables;
• Bivariate analysis of relationships; and

227Chapter 9
• Multivariate analyses of larger patterns.
These three phases build on one another to providea comprehensive understanding of what has (andhas not) been learned in the experiment.
Descriptive Analysis of Individual Variables
Assuming that the data collection effort has endedwith the tasks of data reduction (converting raw dataand information into the form required for analysis)and data assembly (creation of an integrated dataset, including meta-data that data pedigrees areintact), the first real analytic effort is descriptiveanalysis of each variable of interest (univariateanalyses). These descriptive analyses are performedto (a) identify and correct data anomalies, (b)understand the distribution of each variable, and (c)identify any transformations of those variables withdistributions that may make analysis misleading.
Identification (and correction) of data anomalies issimply a search for those data that appear to beincorrect on the surface. For example, if data from anominal category (such as the military service of asubject) with valid codes of 1 through 4 is found tocontain a value of 7, the value is clearly incorrect.Similarly, if the years of service (ratio variable) isfound to contain an entry of 77 (which is logicallypossible, but highly unlikely to be correct), some formof error is the likely cause. Having found theseanomalous values, the analysis plan will provide thetime and effort necessary to research them in theoriginal records and find the correct values. Sinceall data will have been processed by humans,

228 Code of Best Practice for Experimentation
including such common problem sources askeystroke errors (about 2 percent for uncheckedentries), anomalies are likely to be found in any largedata set.
Those data items that are clearly anomalous andcannot be corrected will need to be excluded fromsubsequent analyses. In any case, the descriptivestatistics will need to be rerun after all the anomalieshave been identified and corrected or removed.
The distributions of each variable will be examinedonce the anomalies have been removed. Thesereviews are a search for variables that may bedistributed in ways that can cause errors in analysis.In a common example, one or more variables maybe “invariant” (have only a single value) or nearlyso (have only a small number of cases that differfrom a single value). Those variables should beremoved from the analysis since they cannotcontribute to differences in the dependent variablesof interest. (Of course, an invariant or nearlyinvariant dependent variable indicates that theexperiment did not manipulate that variable andcannot generate insight or knowledge about itscauses.) Invariant or nearly invariant factors areessentially assumptions of the cases studied andshould be noted as such in the analysis and write-up of the experiment. If they are potentially importantin the underlying conceptual model, they will needto be included in subsequent experiments.
The most common such problem is the discovery ofa small number of outliers (cases that are very distantfrom the bulk of the data). These cases will make

229Chapter 9
the application of simple linear statistics, such asPearson correlations or l inear regression,misleading. They can often be handled bytransforming the variable (for example, using a logconversion that preserves the order of the cases butreduces the effect of the distance betweenobservations) or by creating a new variable thatexcludes the outlying cases (this loses informationby excluding some cases that are clearly differentfrom the main set, but preserves the information fromthe bulk of the cases) or creating a new (dummy)variable that subdivides the cases into theoutliers and the main cases. Obviously, this lasttransformation would also involve examining theoutlying cases in an effort to identify whatdifferentiates this subset from the rest of the data.
This last technique is really a recognition by theanalytic team that the descriptive analysissuggests a bimodal distribution. Examination ofthe distributions is a crucial step since many analytictechniques assume an underlying distribution inthe data. For example, linear regression assumesthat the data are drawn from a single populationthat forms a “normal” distribution characterized byhomoscedasticity (the variance is constant acrossthe range), which may not be true of the data onsome variables in a particular experiment. Findingthat the distributions of some variables do notmeet the assumptions of some particular analytictechniques may cause the analysis team to selectnew techniques or to run more cross-checks (addanalyses or techniques to the original set). Thatlevel of detail is beyond this Code of Best Practice,except to note that statistical expertise is one of the

230 Code of Best Practice for Experimentation
discipl ines that should be available to anyexperimentation team.
When the univariate analyses are complete, the datashould be ready to support more sophisticatedanalyses and the experimentation team shouldunderstand its basic properties (ranges, centraltendency, dispersion, distribution) richly. Thisknowledge is a crucial element in performingintelligent analyses later and interpreting theanalyses well.
Bivariate Analyses of Relationships
While the conceptual model for almost any interestingtransformational experiment will be multivariate,jumping directly to multivariate techniques willoften lead to missing interesting and importantdynamics within the data. Since experimentation isa process of learning, skipping over the bivariaterelationship is inconsistent with the goals of the effort.Moreover, most of the hypotheses that are offeredwill be stated in bivariate terms within the model (IFA, THEN B, under CONDITION C). These bivariaterelationships form the bulk of the testablepropositions under analysis.
There is one exception to this best practice. Onrare occasions, most l ikely during discoveryexperimentation, a team will be dealing with a verylarge number of variables in a knowledge domainthat has not been well-researched or explored. Inthese cases, the best practice is to apply inductivetechniques such as factor analysis or multi-dimensional scaling in order to establish the data

231Chapter 9
structure. This topic is discussed in somewhatmore detail in the section discussing multivariatetechniques. However, in no case should the analyticteam rush into this type of exploratory analysisbefore the univariate, descriptive analyses havebeen completed.
The task of examining bivariate relationships willtypically proceed from the simplest techniques(scatter plots to look for visual patterns) toalgorithmic-based analyses (Chi Square andPeterson correlations, for example). Moreover, theproperties of the data (nominal, ordinal, etc.), numberof observations available, and variable distributionswill combine to indicate the appropriate techniques.These choices should be made by the statisticallyknowledgeable members of the experimentationteam and subject to change or adjustment whenthe descriptive, univariate analyses are performed.
There is a natural order to the bivariate analyses.With current analytic tools, there is no practicalbarrier to running “all against all” bivariate analyses.However, generating massive amounts of computeroutput is very likely to overwhelm the analytic teamand make the process of digesting and interpretingthe analysis (learning what you want to know) muchslower and more difficult than is necessary.Moreover, the seductive approach to “knowingeverything all at once” will also lead to the temptationto select a single set of tools (for example, Pearsoncorrelations) as though all the variables have thesame properties and distributions. The purpose ofthe bivariate analyses is to simplify the problem –reducing the number of variables that must be

232 Code of Best Practice for Experimentation
included and focusing on the data regions whereuseful results are most likely to be found. Hence,the best practice is to decompose the bivariate searchfor relationships into manageable subsets andperform them in a structured order.
In order to identify the relationships between thevarious factors and variables, the order forconducting bivariate analyses is:
1. Dependent variables;
2. Control factors;
3. Control factors and dependent variables;
4. Independent variables;
5. Control factors and independent variables; and
6. Independent variables and dependent variables.
The logic behind this order is simple. First, dependentvariables are supposed to be independent of oneanother. If they are confounded (tend to movetogether across the cases), then they will beassociated with the same causal factors (sets ofindependent and control variables). Stronglycorrelated dependent variables (sharing half ormore of their variance) are essential ly thesame phenomenon and need not be analyzedindependently. They will turn out to have the sameor very similar causes. Two actions are impliedwhen strong correlations are found between twodependent variables: (a) select one of them for fullanalysis (thus saving considerable effort) and (b)

233Chapter 9
revisit the underlying conceptual model becauseit incorrectly distinguishes between two factors thatare closely associated.
Those dependent variables with modest (butsignificant) levels of bivariate correlation should bekept in the analysis, but they should be analyzedseparately. As the analytic process proceeds, theserelationships are likely to emerge as important inbuilding a comprehensive model, suggestingredefinition of the variables, merging them becausethey are different ways of describing the samephenomenon, or splitting them because they revealthe importance of some third causal factor orunderlying condition.
Bivariate relationships between the control factorsshould be determined early in the process becausediscovering strong associations will save time andenergy later. If control factors are confounded, oneor more of them can be removed from the analysis.If they have significant association with oneanother, they may later be found to merge, split, orneed redefinition.
Examining the relationships between controlfactors and the dependent variables is a simple,early cross-check on the effectiveness of theresearch design. The research design is intendedto exclude causal patterns driven by the controlfactors. For example, in an experiment involvingmany subjects, subject experience would typicallybe designed out of the experiment by randomassignment of subjects. If, however, analysisshowed that subject experience was related to

234 Code of Best Practice for Experimentation
performance on one or more dependent variables,the analytic team would know that the design hadbeen unsuccessful and the experience factor wouldneed to be included in the later multivariateanalyses and considered in the process of refiningthe conceptual model. More typically, the bivariateanalysis of relationships between the controlfactors and the dependent variables simplyvalidates the fact that the experiment designworked and that the control factors have no directcausal impact on the data from the experiment.
One major exception that can be expected in manyhuman subject experiments is learning over time andacross trials. Despite the range of tools andtechniques used to ensure that subjects havemastered the experimental technologies, that theyhave established teams and work processes, andthat the tasks assigned to subjects are equallychallenging, human subjects may still learn andimprove performance over time and trials. Hence,the propositions that time and trial are related toperformance must be examined in every humanexperiment (as well as machine experimentswhere efforts have been made to create learningsystems). If significant bivariate patterns are found,their shape and parameters will be needed inorder to apply statistical controls in the later,multivariate analyses.
Examination of bivariate relationships amongindependent variables is important because theyare assumed, in most analyt ic tools, to beunrelated. If they are associated with one another,then analyses involving that pair of variables will

235Chapter 9
be confounded – the same variation in a dependentvariable will be “explained” by more than oneindependent variable. This will yield a statisticalexplanation that is false; it will look artificially strong.
The same approaches already articulated mustbe used when meaningful bivariate association isfound between independent variables – merging,splitting, or removal from the analysis. In addition,when the pattern of association suggests thatseveral independent variables are linked, one ofthem can be selected as a “marker” variable forthe cluster. However, this marker variable shouldbe understood to represent the entire cluster,not just the specific phenomenon it measures.Decisions on merging, splitting, removing, orselecting representative variables will depend onexamining the bivariate scatter plots andconsidering the strength of the association present.They should also be examined for implications forthe conceptual model underlying the experiment.Patterns of association between independentvariables imply that some distinctions made in thatmodel have not been strong enough to show up inthe experiment data.
Bivariate associations between independent andcontrol factors are also signs that the conceptualmodel or the research design may be flawed. Forexample, if a control factor was intended to ensurethat two subsets of scores on independentvariables were examined in the experiment, but anassociat ion was found between them, themultivariate analysis would need to be informedby that fact. If, for example, “hasty decisionmaking”

236 Code of Best Practice for Experimentation
is distinguished from “deliberate decisionmaking”as an intervening variable expected to separatetwo different types of decision processes, butdel iberate decisionmaking was found to beassociated wi th ear ly t r ia ls and hastydecisionmaking with later trials, the researchdesign would have failed to keep the controlvariable “trial” from being confounded with thevariables about decision type. This does notdestroy the validity or utility of the experimentdata, but it does mean that these factors will allneed to be considered together in the multivariateanalyses and that it may not be possible todistinguish the effect of “trial” (which is likely toreflect learning within the experiment) from thetype of decisionmaking process followed.
Finally, with all this prior knowledge in mind, theanalytic team will examine the direct, bivariatehypotheses between the independent anddependent variables. These are true tests of thestrength of association for the direct propositionsof hypotheses posited in the conceptual model.However, they go beyond those propositions in twoimportant ways. First, all possible bivariate pairsare tested in order to allow the analysis team toconsider the possibility that the conceptual modelis not perfect – there may be significant empiricalrelationships that were not originally consideredlikely. This is most likely to be true in earlyexperimentation in a domain. Second, some of thebivariate relationships being explored will alreadybe understood to be confounded in that otherstrong patterns of association have been identifiedearlier in the analysis. In these cases, the analytic

237Chapter 9
team already has insight into some of themultivariate relationships that will be found whenthe data have been fully examined.
Multivariate Analyses
Multivariate analyses are the effort to examine theexperimentation data as a system. The tools andtechniques applied will vary with the number ofvariables being examined, the properties of thosevariables, the number of independent observationsavailable for the analysis, and the state of the artknowledge in the arena under study.
Classic techniques for experimentation are theones that look for simple explanations of thedependent variables. Analysis of variance, multipleregression, and discriminant function analysis(where an ordinal dependent variable is beingexplained) are the most common tools. They haveemerged as common practice because theypermit the user to select different subsets of dataand compare their explanatory power, provideinformation about the degree to which variance inthe dependent variable is explained, and alsoindicate the contribution of each independent orcontrol variable to that explanation.
As noted earlier, some experiments will generate alarge number of variables in knowledge domainswhere little prior work has been done and theunderlying structure of the problem is not well-understood. In these cases, the data analysis planmay well include tools that are inherently deductivesuch as factor analysis or multidimensional scaling.

238 Code of Best Practice for Experimentation
This type of analysis is tricky because the toolssearch for clusters of variables on a purely statisticalbasis. Hence, the analytic team will need to examinethe clusters carefully and label them in ways thatreflect their rich contents, but do not oversimplifythe patterns observed. For example, the dependentvariables can “load” anywhere in the data structure.If they cluster together, they may be confounded. If,however, they each load on a different cluster, thenthe other variables in those clusters will tend toindicate the set of causes relevant to each dependentvariable. If, however, one or more of the dependentvariables remain distant from any of the identifiedclusters, the data is unlikely to provide a statisticallysound explanation for them.
Another type of inductive analysis that might beconsidered is the development of a learning modelusing techniques like neural networks. These toolsbuild an explanation by finding efficient paths throughsets of cases. They can be helpful in creating newinsights into poorly understood domains. However,they do not generally provide the statistical insightnecessary to weight factors or the knowledgestructure needed to sort out the roles of interveningvariables from independent variables. As with theclustering techniques, neural nets also require verycareful interpretation because they are not based ona theoretical structure (other than the selection ofthe set of variables to be included) and thereforecan generate explanations with little or no validity.
The results of applying inductive techniques shouldnot, generally, be the last step in the multivariateanalysis of any experiment. These results tend to be

239Chapter 9
suggestive rather than definitive. Consequently, theyare most properly used as a way to find underlyingpatterns or structures in the knowledge domain.Armed with this information, the analytic team willthen be able to use more traditional techniques togenerate an efficient explanation that can be usedto assess the propositions or hypotheses underexamination. In some cases, the inductive tools willsuggest very different sets of hypotheses andrequire major revision of the underlying conceptualmodel. Where the experiment is in a knowledgedomain with little prior work, this may indicate agenuine breakthrough. However, where substantialprior work exists, a careful examination of theemergent (new) model is best practice. In such cases,the experiment is more likely to have explored aunique subset of the phenomenon under study,rather than to have found a genuinely revolutionarycausal pattern. In any case, the more traditionalanalysis should demonstrate the relative strength ofthe evidence for the new pattern versus the existingrelevant literature.
Linkages from the Data Analysis Plan
The data analysis plan should be consciously linkedto three other elements of the experiment. First andforemost, it needs to be linked to the data collectionplan. That mechanism is used to ensure that thedata required for analysis are generated, captured,and organized for analysis. It is the filter throughwhich the scenarios, subjects, and experimentationenvironment are organized to ensure that theanalytic plan can be supported. Changes in the

240 Code of Best Practice for Experimentation
experiment that alter the availability of data willappear as changes in the data collection plan andits outputs. They will need to be fed back into thedata analysis plan iteratively to ensure the integrityof the experiment.
The data analysis plan will also be linked to any planfor post-experiment modeling, whether designed assensitivity analyses or as ways to extrapolate fromthe experiment to larger areas of application. Theresults of the analyses become drivers for suchmodels, providing both the relevant scope of thoseefforts (identifying variables for inclusion andspecifying the ranges across which they should beexplored) and also providing empirical parametersfor those models. Post-experiment modeling mayalso generate new data streams that can beproductively fed back into the overall analysis tobroaden its reach or strengthen its findings.
Finally, the data analysis plan will result in thematerial necessary to revisit, revise, and perhapsextend the conceptual model underlying theexperiment. This is the crucial, final step in theanalytic process. The statistical results are not anend in themselves. The goal of the experiment isalways better knowledge in the domain underanalysis. The explicit revision of that model andart iculat ion of the strength of the evidenceunderlying it is the f inal analytic step. Thistranslation of the analysis into findings that areclearly articulated, including statements about thedegree of uncertainty remaining and other researchthat should be undertaken, is the final step in

241Chapter 9
analysis. Time and effort for this task must be builtinto the data analysis plan.
Data Collection Plans
As noted earlier, the data collection plan includes allthe variables to be collected, all the places wherethey are to be collected, all the means of collection,and all the places the data will be stored forprocessing. This needs to be a major document,incorporating both the broad philosophy being usedand also the details necessary for implementation.High quality data collection plans also specify thesupport required, the training needed, the proficiencystandards to be met, the approach to quality control,how the data will be archived to ensure its integrity,and the processes by which data sets will be reducedfrom their raw form to create the variable setsenvisioned by the data analysis plan and assembledfor efficient analysis. While it is a major document,this plan is not an end in itself, but rather a means toensure the data collection process is organized forsuccess and understood by all those who need tosupport the effort.
Creation of a data collection plan can be thought ofas a sequential task, although it will prove to be aniterative one because it is closely linked to the goalsof the experiment, the data collection plan, thescenario, the physical spaces available for theexperiment, the systems being employed to supportthe experiment, the subjects, and a host of otherfactors that are likely to change from the initialconcept stage through the pretest phase.

242 Code of Best Practice for Experimentation
The key “steps” include:
• Specifying the variables to be collected;
• Identifying the collection mechanism for eachvariable;
• Ensuring access for collecting each variable;
• Specifying the number of observations neededfor each variable and checking to ensure theyare expected to be generated;
• Identifying the training required to ensure qualitydata collection;
• Specifying the mechanisms to ensure datacapture and archiving; and
• Defining the processes needed for datareduction and assembly.
However, this work sequence is only one keyperspective. Looking at data collection plans throughthe lens of the different types of collection mechanismsthat can be employed may yield a more practicaland useful set of insights. The types of collectionmechanisms used in typical experiments include:
• Automated collection;
• Recording for later reduction;
• Surveys;
• Subject testing; and
• Human observation.

243Chapter 9
Each of these approaches has particular uses,strengths, weaknesses, and factors that need to beconsidered when they are employed.
Automated Collection
Automated collection has become more and moreimportant as the information systems have becomemore and more fundamental to military functions.C4ISR (command, control, communications,computers, intelligence, surveillance, andreconnaissance) functions in particular areincreasingly automated and supported by automatedsystems. As military functions become automated,they are increasingly easy to monitor, but only if plansand preparations are made to capture all of theneeded data.
Planning for automated collection requires expertisein the systems being used as well as the variables tobe collected. Typical collection foci include systemload, workstation load, availabil i ty (system,application, and workstation), and usage (system,application, and workstation), as well as capture andcomparison of “ground truth” with what is availablewithin the systems and from the individuals (theirperceptions and situational awareness).
The tasks that need planning include when andwhere these items will be captured, how that canbe done without impacting the functionality of thesystems (either the operator’s systems or thosebeing used to drive the experiment), how the clockson all these different data capture efforts will besynchronized to faci l i tate comparisons and

244 Code of Best Practice for Experimentation
analyses, how the meta-data tags will be attachedto facilitate data reduction and analysis, and wherethe data will be archived. Because data capture isbest done within the systems and federations ofsystems being used, the earlier these requirementsare identified, the better.
Finally, someone on the experimentation teamneeds to be assigned as the leader to work with thesystems analysts and programmers to ensure thatthey understand the plan and that they have the timeand resources needed to support the experiment. Amilestone plan, built into the engineering plan neededto bring together all the necessary systems to supportthe experiment, is best practice and will help ensurethat the automated data capture process is asuccessful effort.
Recording for Later Data Reduction
Experimentation teams worry about their collectionprocesses intruding and causing different behaviorsor results. Moreover, human observers are notalways available in enough numbers (or are notphysically able) to be everywhere. Finally, humanobservers are able to abstract only a certain levelof meaning or amount of data – they must choosewhat to pay attention to and what to record. As aresult, experimenters often prefer to captureverbatim recordings (audio or visual). At this writing(2002), collaborations are becoming an importantelement in military work processes and have provendifficult to monitor effectively, so they are oftenrecorded for later analysis.

245Chapter 9
This approach is not a panacea – even the bestrecording setups do not capture all of the nuancesof communications in a command center or militaryoperation. Moreover, recordings often requiremassive amounts of time and effort to review andreduce to data that can be analyzed. Finally, somepast efforts have been plagued by the difficulty ofcapturing everything, resulting in capturing only oneside of some conversations, people stepping out ofrange of cameras and microphones when they aremaking decisions, and technical problems with therecording equipment itself.
Experimentation teams engaged in recording needto plan very carefully and ensure that the systemsare both fully pretested and also backed up robustly.Key decisions include:
• Whether audio recordings will suffice or video isneeded;
• Whether to record everything or only selectedmaterials (including decisions about sampling);
• Creating meta-data to tag the recordings,including how individuals will be identified,including their roles;
• Introducing the topic of recording to the subjects,obtaining appropriate permissions and ensuringprivacy protection;
• Positioning and testing the recording equipment;
• Provisioning for equipment failures (backup,anomaly recording, etc.);

246 Code of Best Practice for Experimentation
• Training those operating the system andarchiving the products;
• Ttraining and testing those responsible for datareduction and coding (discussed in more detailin the section below on human observers); and
• Ensuring adequate facilities and time for datareduction and archiving.
Unless these efforts are properly planned,experimenters will find themselves with incompleteor incomprehensible materials or mounds ofmaterial they cannot process. This area is one whereappropriate expertise on the team and thoroughpretesting (both of collection and data reduction) areessential for success.
Surveys
Survey instruments are popular tools because theyallow the experimentation team to collect data in aform that is easy to review. They are used in severaldifferent ways in transformational experiments. First,they can be used to gather data about the subjects’backgrounds and experience. This is typically donebefore the experiment (perhaps as part of subjectselection) or as an early part of the process used tointroduce the subjects to the experiment. The earlierthis is accomplished, the easier it will be for theexperimentation team to use the data to assignsubjects to teams and treatments and to create adata file so that the attributes of the subjects can beused as part of the analysis effort. Subjects arealso often surveyed during the experiment to gathertheir perceptions of the systems and processes they

247Chapter 9
are employing, their knowledge of and attitudestoward other subjects or teams of subjects, theirperceptions and insights about the substance of theexperiment (for example, their situation awareness),and their ideas about how the systems and workprocesses might be improved.
Others on the experimentation team are alsosurveyed in many transformation efforts. Subjectmatter experts and controllers, for example, oftenrecord their perceptions and insights about howthe subjects are performing and how the systemsand processes they are employing (a) are workingand (b) can be improved. Those supporting theexperiment (systems analysts, researcher leaders,etc.) are also surveyed to take advantage of theirperspectives. Finally, observers may be asked to usesurvey formats to report what they are seeing.
Surveys can be a “tender trap” in several ways, sothey require careful development, pre-test, andmonitoring. First, any survey tends to skew theagenda to focus attention on the items included.Hence, it is best practice to include some open-endeditems at the end that ask for reflection (for example,“Are there important topics we have failed to askyou about?”). Second, surveys demand time.Planning for the experiment needs to make certainthat all respondents are given adequate time tocomplete the surveys properly. The time required canonly be estimated realistically by using pretests inwhich the respondents are as similar to those beingused in the experiment as possible. (The classicerror here is to have members of the experimentationteam, who are familiar with the issues and understand

248 Code of Best Practice for Experimentation
what is meant by each of the questions “stand-in” forthe subjects.)
Surveys must also be pretested because the wordingof each item is important and will be subject tointerpretation or misunderstanding. Poorly wordedor ambiguous questions will not result in qualitydata. At the same time, in order to accumulateknowledge across experiments, every effort shouldbe made to identify and use common questions.Expertise in questionnaire design is one elementneeded on teams that plan to use surveys.
Surveys also impact respondent behaviors. Forexample, a survey that asks respondents to describethe military situation and provides them with atemplate (What is the key terrain? What areadversary intentions? and so forth) will lead subjectsto focus on items that they may have beenoverlooking in the scenario and to look for thoseitems in later trials. Hence, such structured questionsshould (a) be chosen to represent “common sense”or training items for the experiment and (b) beintroduced to the subjects during their training. Pastexperience has shown that the “learning behavior”resulting from these structured items can beminimized by ensuring that the subjects are familiarwith them before the experiment begins.
Planners should remember that surveys also creatework for those doing data reduction and assembly.The more structured the survey data is, the less effortis necessary. For example, simple Lickert scales onwhich respondents merely check a space or pointon a line to indicate their answers provide precise

249Chapter 9
data that can be machine read. Of course, theassumption behind these instruments is that theyare not ambiguous and that enough scale points arerelated to precise statements that differentrespondents will be able to answer consistently. Thiscan be a subject for the pretest phase. Lickert scalesusually need to be labeled at their end points andcenters in order to generate consistent responses.For example, an eleven point scale to respond tothe question “How much do you believe your teammates trust your judgment?” might have its zero pointlabeled, “Not At All,” its high end point labeled“Completely” and its mid-point labeled, “Somewhat.”When surveys are designed and pretested, the datacollection plan must include adequate time tocomplete them as well as adequate time for datareduction and archiving.
Not everyone will need to complete every survey.For small experiments, however, everyone who isinvolved in relevant activities should be surveyed –the data analysis plan will have to deal with the entirepopulation. For larger efforts, some sampling maybe wise, both to reduce the effort needed to processthe data and also to ensure that all of the keyperspectives are richly represented.
Subject Testing
Subjects may be tested for proficiency or othercharacteristics. Proficiency tests are used when theresults of the experiment are expected to depend, atleast in part, on the particular skills of the individualsor teams participating. In other words, if proficiencyis a control or is being used to assign subjects in

250 Code of Best Practice for Experimentation
order to control it out of the experiment, testing willbe needed. Proficiency tests require pretestingunless they are already established and normalized.Subjects should generally not be told their scoresuntil after the experiment. This prevents a variety ofanomalous behaviors (bragging, becomingdiscouraged, etc.) that can damage the experiment.
Tests for characteristics (IQ, leadership style, etc.)should, if at all possible, be selected from those thathave been developed, validated, and normalized onlarge populations. This is much less work thancreating new instruments and procedures, andprovides credibility to the work. Planning for thesetypes of tests needs to include having professionalsadminister them as well as a clear statement tothe subjects about what is being assessed, why it isneeded, and also how their privacy is beingprotected. Human subject data needs carefulmanagement and should be divorced from theindividuals’ names throughout its processing. Subjecttesting also needs to be included in the pretestso that possible problems with introducing theassessments, administering them, and managingthe resulting data are all worked out in detail.
Human Observation
Despite progress in automation, many militaryactivities remain human. Hence, whether byreviewing recordings or direct observation, humanswill be needed to capture behaviors and interactionsat the heart of many experiments. Some of theprinciples for human observers were discussed inChapter 5. The discussion here focuses on planning

251Chapter 9
strategies so that those observers will be effectiveand successful.
Observer selection is a key. They should have bothan appropriate substantive background and skills ortraining as observers. If they are to go on location,they need to “fit in,” so they are not a distraction.Observer positioning is a second key issue. Theobservers must be located where they can gatherthe material they have been assigned. At the sametime, they should be as unobtrusive as possible.Observer training is also crucial. They must haveenough training and proficiency testing to ensurethat they know what to capture and will be able tocapture it reliably. As noted earlier, they shouldparticipate in both pretest efforts and the trainingefforts for the subjects, but all of that should comeafter they have already mastered their tasks andpassed basic proficiency tests. Planners also needto build in redundancy. Extra time must be availablefor extended training if some of the observers findtheir tasks difficult. Extra observers also need to beavailable. They can be assigned quality control rolesfor the periods when they are not needed. Theprocedures for establishing and checking inter-coderreliability are also very important. Coders will tendto “drift” as they gain experience and encountersome types of situations more than others will.Cross-checking and (when needed) review trainingcan be used to counter this tendency and maintainthe consistency of coding across individuals.
Scheduling is most likely to be problematic for theobservers. Early selection is very helpful. Read-ahead material can be used for familiarization and

252 Code of Best Practice for Experimentation
allow better use of face-to-face times. Observersshould be organized into teams as early as ispractical so that they have an opportunity to workwith one another. Time for training and proficiencytesting must be generous. Inter-coder reliabilitytests should be built into the schedule. Shift routinesduring the experiment should be designed with thefact that observers must be alert. Ideal shifts are 8hours long, since most observers will have tospend some time organizing, taking transitionbriefings when they first come on, and debriefingafter their shifts. If longer shifts are necessary,physically fit observers must be recruited and strictschedules used to ensure that they get adequaterest. Finally, time for observers to review their notesand create coded data must be generously provided.Failure to do this will mean that the investment inhuman observers generates results that fall shortof the experimentation goals.

253
CHAPTER 10
Conduct of theExperiment
Purpose
Shakespeare tells us, “There’s many a slip twixtcup and lip.” Having planned and prepared
for the experiment does not guarantee success.The team still needs to pay close attention whenthe time comes to execute the plan. Just as nomilitary plan survives first contact with the enemy,no experiment plan survives real-world environmentand conditions despite the most rigorous planning.One should expect to encounter problems thatcan adversely impact the quality of the data beingcollected. This chapter reviews the steps necessaryto reap the benefits of the hard work that has goneinto conceptualizing and planning transformationalexperiments.
Pretest
Scope
The pretest should be viewed as a dress rehearsalfor all the elements of the experiment. While it will

254 Code of Best Practice for Experimentation
be on a smaller scale and will not involve thesame quanti t ies of equipment, subjects,observers, and instrumentation as will be usedfor the experiment itself, it must be sufficientlyrobust to exercise all of the relevant proceduresand processes. The size, type (discovery,hypothesis test ing, or demonstrat ion), andcomplexity of the experiment will determine thesupport infrastructure required. This infrastructurewill generally include workstations, a simulatedenvironment, communications networks, controllers,observers, technical support personnel, databases,and logistical support. Sufficient time must beprovided to fully inspect the systems to ensurethat they are operating satisfactorily, not only ina stand-alone mode, but also as a “system ofsystems.” That is, to ensure that they areappropriately interoperable. Additionally, thesystems must be tested with the experimentaltools running on them. While the number of subjectsand the number of test runs will normally beconsiderably less than for the actual experiment,system tests must stress the system to (or evenbeyond1) the level anticipated for the experiment.There are numerous instances where collaborationexperiments failed because the system wassatisfactorily tested with n nodes during the pretest,but failed during the experiment where xn nodeswere required to operate simultaneously.
In addition to the experimentation infrastructure,elements of the experiment itself need to betested. This is accomplished by conducting a mini-experiment that mimics the actual experiment. Thedata collection plan for the pretest should be

255Chapter 10
designed to provide all the same data as thatdesired for the experiment. The scenario(s) shouldbe the same as those that are to be used during theexperiment. This allows the experiment designerto determine whether the required stimuli areprovided to the subjects in the manner intendedand that they contain those elements necessary toproduce the required range of responses fromthe subjects. The subjects chosen for the pretestshould exhibit characteristics similar to the thoseof the subjects chosen for the experiment. Theyshould have the same levels of expertise andexperience. If the experiment subjects are tooperate as teams, the subjects for pretest shouldbe similarly organized. The closer the pretestsubjects match the experiment subjects, the morethe pretest data will be representative of data to becollected during the experiment.
Due to the need for observers/controllers to mimicthose for the experiment, their ability to collect therequired data and exercise the proper degree ofcontrol must be ascertained. Finally, the collectedpretest data must be reduced and analyzed asit would be for the experiment. Conducting thepretest in this manner ensures that:
• The subjects are capable of performing theirassigned tasks and that they have sufficienttime to complete their tasks;
• The observers/controllers can collect andreduce the required data;
• The necessary analyses can be performed onthe data; and

256 Code of Best Practice for Experimentation
• The experiment can be conducted in theallotted time.
Schedule
The pretest should be scheduled sufficiently inadvance of the experiment to permit remedial actionto be taken. The timing will depend on the size andcomplexity of the experiment. However, one monthwould appear to be the minimum time required.Allowing more time than this minimum reducesrisk further. This needs to include sufficient timeto allow analysis of both the data and the conductof the pretest. The analysis of the pretest needsto investigate not only what went right and wrong,but also possible remedial actions and their impacton the conduct of the experiment. Finally, theremust be time allotted to conduct focused retestingof the areas where remedial action was required.
Training
The pretest also includes a test of the trainingprogram. The training program for the pretest (1)provides actual training for the pretest participantsand (2) is a trial of the actual training program. Thetraining program, which is discussed in more detailbelow, should provide answers to three basicquestions regarding the experiment:
• Does the training provide the subjectssufficient familiarity with the equipment andexercise procedures that this does not becomean issue for analysis (e.g., subjects spent an

257Chapter 10
inordinate amount of time figuring out how touse the equipment)?
• Does the training provide the observerssufficient familiarity with the data collectionmethodology to allow them to competentlycollect the required data (observation,recorded data, survey results, etc.)?
• Do the processes specified in the datacollection and data analysis plans work so theright data can be captured and the rightanalyses executed?
Revisions to Detailed Experimentation Plan
Unless this is an experiment like no other, it willbe necessary to make revisions to the experimentplan based on what is learned in the pretest. Inthe majority of cases these will be minor procedurechanges that can be accomplished without theneed for further testing. However, if the degreeof change required is major or if the changesare complex, it may be necessary to conduct afollow-on pilot test that focuses on the revisedelements. This is a far better use of resources thanattempting the main experiment without a firm ideaof how it will unfold or confidence that it willfocus on the issues under study.

258 Code of Best Practice for Experimentation
Pre-Experiment DataCollection
Process
While the main data collection effort occurs duringthe actual conduct of the experiment, substantialdata can be collected before the experimentcommences. For those experiments that employsubjects, useful data includes backgroundinformation such as level of expertise, schoolsattended, relevant military experience, etc. Thesedata will be used to determine the effect, if any,on the results caused by differences betweenthe subjects’ backgrounds. If the experimentanalysis plan includes comparisons with pastevents, baseline data should be assembled andplaced in the analytical database prior to theconduct of the experiment. Other data that can becollected includes screen captures for prescriptedevents, input stimuli, and databases that willnot change during the experiment (e.g., friendly andadversary OOB).
Archiving
Unfortunately, as with data collected during theexperiment execution, some of the pre-experimentdata may be disposed of within a short time afterthe completion of the experiment. The experimentand its immediate aftermath will be an extremelybusy period for the data collection team. It is likelythat if pre-experiment data is not archived priorto the experiment, they may become lost in the

259Chapter 10
process. These data should be archived in boththeir raw and processed forms. The copies placedin the analysis database will be manipulated andare much more likely to be corrupted or destroyedduring analysis. Hence, having the original dataarchived ensures its availability to other researchteams and also permits the analytic team for thisexperiment to go back and verify initial values orinitiate novel analyses to explore interesting orimportant insights.
Data Integrity and Privacy Protection
Data integrity means that not only the reduced data,but also the raw data, should be archived. Thisallows a link to be made from the raw data to theeventual conclusions and recommendations.Privacy protection is an important element thatcannot be overlooked. It is imperative that thesubjects understand that they are not beingevaluated (the systems, doctrines, organizationalinnovations, under study are being assessed, notthe subjects) and that no links will be made fromindividual participants to scores and/or results. Notonly must they understand this, but they mustalso be confident that this is true. Failure to instillthis confidence can result in distorted results.
Training
Training plays a significant role in the success ofan experiment. A well-conceived and executedtraining program will provide the support team, theobservers/controllers, and the subjects with a

260 Code of Best Practice for Experimentation
strong foundation that will enhance their participationin the experiment.
Observers/Controllers
Most data collection/observation goes well beyondsimple instrumented collection of data. Commandand control experiments generally rely on intelligentdata observers/col lectors that must applyjudgements in collecting and coding the data. It istherefore imperative that they understand why theexperiment is being conducted, the underlyingtheory that explains the hypotheses and metrics,and the context in which the experiment isbeing conducted. I t is therefore absolutelynecessary that the observers/controllers have afundamental understanding of the theory underlyingthe methodology for confirming or not confirmingthe hypotheses. This foundation will enable theobservers and controllers to make the correctjudgements, such as where an observedphenomenon fits into the data collection plan,what data elements are satisfied by this observation,and how the data should be coded. Effectiveinstruction in this area will improve measurementreliability and enhance the construct validity.
The training program should focus on techniquesfor observation in accordance with the experimentplan regarding how the data is to be collected(observation, survey, questionnaire, instrumentation)and where it is to be collected. The observers/controllers are presented with an overview of thescenario and major events so they know when toexpect certain data elements. The program of

261Chapter 10
instruction then focuses on practicing the skillslearned during the training program. This is bestaccomplished by providing vignettes in which theobservers/controllers (with guidance) observesituations similar to what they will be exposed toduring the experiment and record and code thedata. Discussion should follow each vignette withthe “school solution” provided. In addition toindependent practice, observers/controllers shouldbe present and playing their assigned roles duringsubject training. This gives them further practicalexperience and also helps to familiarize thesubjects with the experimentation process.
Proficiency tests are used to determine if theobservers/controllers have been sufficiently trainedto collect the required data. After the lesson portionof the training program, the observers/controllersshould be given a proficiency test. The test shouldinclude (1) a written exam to test their knowledgeof the fundamentals and (2) a practical exam totest their ability to capture and code data correctly.The results of the written exam should be evaluatedprior to proceeding with the practical exam. Thiswill ensure that the observers/controllers havemastered the fundamentals of the program. Ifnecessary, a review session should be conducted.For the practical exam, once again the observers/controllers should be placed in vignette situations.This time, however, they will not be receivingguidance, but will be on their own. They will berequired to make observations and code the dataas if they were observing the actual experiment.Their observations will be evaluated and, again, ifnecessary, a review session will be conducted.
262 Code of Best Practice for Experimentation
Peer feedback and teaching one another shouldbe encouraged as these practices help build strongobservation teams.
Note that the schedule for the training programneeds to have these review sessions built in. Bestpractice assumes that these sessions will beneeded. The price of not reserving time for themcan be high, impacting the morale of theparticipants, the demands placed on the trainers,and the quality of the data collected.
Inter-coder reliability tests are necessary becausethe evaluation of command and control frequentlyrequires judgements on the part of the observers/control lers. To preserve the integrity of theexperiment, it is essential that the observationsby different observers result in the same datacoded the same way by all data collectors, or, ifthere are differences that can be controlled for,that statistical controls be employed to mitigatethose differences.
Subjects
Many C2 exper iments wi l l l ike ly involvecomparisons with a current or baseline systemusing military or ex-military subjects. Unless thesubjects are wel l - t ra ined in the t reatmentsystem being evaluated, the baseline system willhave the distinct advantage over a system that isnot familiar to the subject. Without proper training,subjects are liable to expend an inordinate amountof energy just mastering the workings of the newsystem. Subjects who find themselves frustrated

263Chapter 10
by the new systems and processes they are tryingto employ will not focus creatively and productivelyon the substantive tasks they have been assigned.
The subjects will require training on operating thesystems, both the underlying infrastructure and thesystem(s) under consideration. They need tounderstand how they interface with the system,what tasks it performs, and how it performs them.The subjects also need to understand how thesystem uses underlying data, what operationsit performs on the data to get what results, howit displays the data, and the sources of thosedata. Training is best accomplished by providingan overview followed by hands-on training. Thetraining should culminate (as with the observers/controllers) with a proficiency test that demonstratesfamiliarity with the system. Depending on thecomplexity of the system(s), hands-on trainingalone has proven in the past to take a week ormore. Not all subjects proceed at the same paceand some may require more time. As noted earlier,perhaps more DoD experiments have failed toachieve their goals because of inadequately trainedsubjects than for any other single cause.
Whether as part of a team or as a single player,each of the subjects will be playing a role. As such,the subjects need to understand the duties andfunctions associated with their roles. They alsoneed to understand the processes they are tofollow in performing their tasks. Training for rolesand processes should also incorporate dry runsusing the systems and infrastructure employed inthe experiment.

264 Code of Best Practice for Experimentation
If the training described above were to be carriedout sequentially, the training program would beunacceptably lengthy, not to mention disjointed.An integrated, synchronized training program isrequired to ensure that the parts fit together. Theexperiment director must ensure that theinfrastructure and systems are operating for thetraining to proceed. Initial training of observersand the training of the subjects should proceedsimultaneously and separately. Once the experimentdirector is satisf ied that the observers andsubjects are ready, the final segment of the trainingcan proceed. In this segment, the subjects runthrough a vignette with the observers/collectorstaking data. This will give the observers/collectors afeel for how events will unfold during the experimentand uncover any areas of the training requiringfurther emphasis.
Working with Observers andControllers
Observers/controllers can make or break anexperiment. Adequate training does not ensuresuccess. Attention needs to be paid to howobservers/controllers are employed and managed.
Non-interference
Observers generally perform one of two roles. Theyare either silent observers recording what ishappening or they administer questionnaires and/orsurveys. In either case, they should not engageparticipants in conversation, offer opinions, or in

265Chapter 10
any way interfere with the conduct of the experiment.If asked questions, they should answer only tothe extent of explaining what it is they are doing,explaining why they are there, or clarifyingquestions for the subjects. Only if they are dual-acting in the role of controllers may they answersubstantive questions or offer items of substanceconcerning experiment conduct.
Shift Planning
Unlike machines, observers become fatigued. An8-hour shift with suitable breaks is close to the limitthat an observer can remain on station whileproducing acceptable data. If the experiment isto run longer (e.g., 24 hours per day), shifts willhave to be planned. This will require building intime for shift hand-off which needs to be plannedso that data is not lost during the hand-off.Observer shift planning should be on a differentschedule from the shift changes of the experiment’ssubjects. This enables observers to observe theshift change processes and information exchangesamong the subjects.
Coverage Philosophy
Deciding what data to collect and analyze generallyinvolves tradeoffs between cost and resources,and how comprehensive one needs the effort to be.If the experiment involves observation of singlesubjects conducting multiple runs at a smallnumber of stations, the data collection can be verycomprehensive with one observer at each stationbeing able to observe all that goes on. Observing

266 Code of Best Practice for Experimentation
groups interacting with other groups, or a large-scale event involving large numbers of participants,however, is much more demanding. In thesecases, the resources necessary to cover everysubject and every interaction are prohibitivelyexpensive. Even if the data could be capturedthrough instrumentation, the resources required fordata reduct ion and analysis could proveunrealistically demanding.
Therefore, decisions on how observers areallocated to subjects/tasks need to be based onwhat data are necessary to collect in order toachieve the experiment objectives. This mayinclude decisions to sample some kinds of data orto favor collection of some types over others.This will all be part of the data collection plan.However, the observers will need to know whattheir observations should comprise in great detail.If this is not clear, they may drown in data andmiss crucial data because they are focused onrelatively unimportant, but easily collected items.Sampling should be considered when too muchdata is likely to be generated. Building properlyinstrumented sampling strategies requires expertiseand experience.
Supervision
Data collectors require constant supervision. Forsingle subject experiments it will only be necessaryto check that all the equipment is being operated(audio and video recorders), that the time scheduleis being followed, and the requisite questions areasked and the answers recorded. For larger

267Chapter 10
experiments where the subjects are interactingwith each other and with the scenario, checks needto be made to establish that the observations areproducing the required data. Refresher trainingmay be required on the fly or during off-hours forobservers/collectors who have forgotten thedefinit ions of some of the measures or theimportance of collecting certain data. Data sheetsmust be checked for completeness and forconfidence that the correct data are beingcaptured. Data collectors also need to beapprised (in a way that does not alert the subjects)when events are likely to affect their stations.Quite likely, daily or shift meetings will be necessaryto keep all the observers/controllers in the loopand the data quality high. This can be difficult toaccomplish during 24 hour per day operations, butthe price of ignoring the need for team building andtimely interaction can be very high.
Data Collection
Automated Collection
With the increasing use of automated systems,much of the data can be collected directly from thesystem via screen captures, e-mail archiving,requests for information, snapshots of databases,etc. This data must be checked at regular intervalsto ensure that the agreed upon data is providedin the proper format. The intervals will be based onthe volume of data expected with shorter intervalsfor higher volumes of data so as not to overwhelmthe checking process. Also, care must be taken

268 Code of Best Practice for Experimentation
when creating such a system so that the volumeof data does not overload the analysts. Datacollected in this manner needs to be carefullyselected and archived so that the analysts canreadily manipulate it without having to first sortthrough a mass of raw data. Surveys can also beself-administered in this manner. The subjects caninput their own answers into a database forlater analysis.
Quality Control
This is perhaps the most important and mostoverlooked part of data collection. It is tempting tofeel that once the data collectors have been trainedand briefed, the data collection will be automaticand the next event will be analysis. This couldn’tbe further from the truth. Automated collectionsystems and instrumentation can fail, humansbring their own backgrounds and foibles to theprogram and, regardless of training, some will tryto collect what they feel is interesting rather thanwhat they are assigned to collect. To ensure thesuccess of the experiment, it is imperative thatdata collectors be supervised and a quality controlmechanism is in place to ensure that the necessarydata is being collected. Those responsible forquality control must ensure that all members ofthe team, including observers/controllers, areneutral observers and do not influence subjects’answers and/or comments. For example, theymust not provide hints to subjects who appearpuzzled by a question, or suggest that they considersomething that has obviously been overlooked

269Chapter 10
in their analysis. Maintaining the integrity of thedata is one of the most important elements of thequality control process.
Incidents will occur where failure to provide certaininformation could cause the experiment to godrastically awry. To account for those instances,procedures should be established for the observers/controllers to get advice from the senior member ofthe observation team who, in turn, should conferwith the experiment director and senior controller.On the other hand, the observers need to be alertfor qualitative data that can shed light on a situation.The fact that an error of omission has occurredmay be very important to understanding subjectbehavior and decisionmaking, so those casesshould be recorded and reported. Another situationthat arises is when a supervisor or other trustedagent alerts observers to an event that requiresobservation. This must be done discreetly. If itis not, the fact that the observer is being alertedwill also be an alert for the subject(s).
Management of Anomalies
At the most general level, all experiments aresubject to anomalies – system crashes or failures,humans who drop out, and compromises of thescenario. The experimentation team, knowing thatanomalies threaten the experiment, must makeevery effort to detect and record them, correctingthem when possible and excluding the impacteddata or subjects when necessary.

270 Code of Best Practice for Experimentation
Loss of Subjects
In spite of all the planning and preparation,situations arise that cause subjects to drop out ofthe experiment. There are ways to overcome this,but the development of a contingency plan isrequired. One way to overcome this is to scheduleenough observers and trials that the loss of twoor three subjects won’t affect the statistical validityof the experiment. This will generally only workwhen the experiment deals with individual subjects.Another method is to train and have replacementsready to join the effort while in progress. This ismore typical when experiment trials employ teamsof subjects. A last resort is to have time built in forrefresher training and use this time to train newsubjects, but even this requires having a pool ofsubjects on standby. Sometimes, particularly ifsomeone is lost well into the experiment after teamdynamics are well-established, teams are simplyasked to carry on short-handed. However, thoseteams will be working short-handed, which mayimpact their performance, so statistical tests ofperformance before and after the reduction in teamsize will be needed.
Loss of Observers/Controllers
Observers/controllers can also drop out of theexperiment for various reasons. The ideal situationwould be to have additional trained observers/controllers in a standby position. These would likelybe drawn from an organization located near theexperiment venue, so that they could go abouttheir daily routine while on standby. Failing that, a

271Chapter 10
supervisor may be able to fill in, or observers canbe transferred from less important stations to themore essential ones. This technique minimizes theimpact of the loss. The importance of the data, thenature of the observation, and the resourcesavailable will dictate the nature of the contingencyplan.
System Problems and Failures
The best way to mitigate against a system failurethat destroys the experiment is to avoid single pointsof failure (one element that, if it fails, bringseverything to a halt). This is generally achievedthrough redundancy. Failures can be avoidedthrough a thorough, comprehensive test programthat exercises al l the elements prior to theexperiment. A common problem that arises duringtesting is that the system is not as fully stressedduring testing as it will be during the experiment.This leads to unexpected system crashes. Thenumber of operational stations during the testperiod must equal the number of stations to beused during the experiment.
Data Contamination
Subjects in an experiment are often highly motivatedto perform well. No matter how often they are toldthat they are not being evaluated, they still strive toexcel. In some past experiments subjects have beenable to learn about the scenario or get help frommembers of the experimentation team. In extremecases, one or more of the subjects has deliberatelysought to undermine the experiment. (There is an

272 Code of Best Practice for Experimentation
apocryphal story of a bored and frustrated youngtrooper in a field experiment deliberately inflictingfriendly casualties.) As a consequence of any or allof these types of action, some parts of the data maybe contaminated and lack the objectivity needed foranalysis. If this occurs, the bad data will have to beexcluded from the analysis.
Data Capture and Archiving
Data Preservation
In order for an experiment to contr ibute toknowledge generation, it must be replicable. Thismeans, among other things, that the data must bepreserved in their original form. The data shouldbe copied before they are manipulated. Too manythings can happen to alter the data once workbegins. Data can lose its original format, be parsed,and be improperly categorized. In addition toarchiving the data in their original form, a recordmust be kept of al l the steps involved inmanipulation of the data. This allows other analyststo reconstruct the analysis. For the sake of ensuringthat data are saved, the prudent team savesthem in more than one location and on more thanone medium.
Privacy protection is also an important aspect. Thedata must be kept separate from the identities ofthe subjects. Care must be taken so that it isnot possible to link the subjects with performanceor data.

273Chapter 10
Data Reduction
Data reduction is an important function thatfrequently gets short-changed in practice. It is onething to collect the data; it is another to convertthem to a form that can be used by analysts.Generally, those most well-suited to perform datareduction are the data collectors. They are familiarwith the data and their notations. Data reductionshould occur as soon after the data collection aspractical, preferably in the days immediatelyfollowing the experiment. This has the benefit ofperforming the data reduction while experimentevents are still fresh in the minds of the datacollectors. It also has the added benefit of havingall the collectors together so that they can workas a team. This is especially valuable whenlooking at data across nodes. Unfortunately, insome recent experiments data collectors were froma variety of organizations and on temporary dutyfor only the training and game days, with notime provided for data reduction. This practiceinvites difficulties and reflects a failure to developa proper experimentation plan and/or allocateresources appropriately.
The participants in the data reduction processinclude all of the data collectors, data collectionsupervisors, and analysts. It is important thatanalysts participate because they will be able toguide the data collectors if they have a problemdeciding how to code certain events, and they willbetter understand the data and its origins.

274 Code of Best Practice for Experimentation
It is also important for the analysts to be presentin the data reduction effort for cases wherejudgement is required in making coding decisions.Inter-coder reliability is vital. The analysts, becausethey see all the data, can spot where coders arediffering in how they code the data and resolve thesedifferences on the spot.
In many instances, the venue and systems used forthe experiment is immediately used for otherpurposes. It is therefore imperative that data andother experiment artifacts (scenarios, eventinjections, survey forms, interview schedules, etc.)be archived immediately after the completion ofthe experiment to prevent it from being lostwhen the supporting systems are reconfigured forthe next event.
In-Process and Quick LookReporting
It has become common practice in trainingexercises to provide immediate feedback in theform of results while an exercise is sti l l inprocess, as well as “quick look” reports all butimmediately on completion of the formal exercise.While this makes perfect sense in a trainingenvironment, where prompt and authoritativefeedback is one of the best ways to teach, it isnot the proper approach to experimentation. It isimperative that this training tradition does notcarry over to experimentation. Experimenters,sponsors of experiments, and decisionmakersneed to realize that considerable analysis is

275Chapter 10
often required to ascertain the results of anexperiment. Instant feedback can (1) be misleadingand (2) lead people to believe that they do not needto execute the data analysis plan.
Having said this, some data from experiments canbe captured and presented quickly (in near realtime). This is particularly true of data that evaluatessystems – measuring load, throughput, frequencyof use, etc. However, even this data is incompletewhen first captured. The patterns in it must be readat the first order and in isolation from otherinformation. Furthermore, this data is often not atthe heart of the experimental hypothesis.
Having this system data quickly available is requiredso that i t can be used to drive models andsimulations in the post-experiment phase. Justbecause it is available does not mean one shouldshare it. Sharing it without putting it into context(by complete analysis) can result in false andunwarranted conclusions being reached. Onlywhen the analysis is completed can issues such aslimits and interactive effects be studied.
It needs to be understood that much of themost valuable data collected cannot be extractedquickly. For example, the quali ty of sharedawareness can only be assessed after what isknown by individuals (not systems) is comparedwith ground truth. Similarly, shared awarenessmust wait until individual perceptions of theoperating environment are compared with oneanother. Even simple system characteristics,such as the difference between information

276 Code of Best Practice for Experimentation
available in different command centers, cannot beexamined unti l comparat ive analyses haveoccurred.
Strong reliance on immediate reporting andpreliminary analysis also tends to drive outgood findings and analysis. If decisionmakers’attention focuses on immediate results, those tendto stick – to become the primary learning fromthe experiment. Later results, particularly if theydiffer or show that alternative interpretations aremore consistent with the data, have a tendencyto be ignored. Cases have been reported wheremid-level managers hesitated to put moreconsidered analytic results forward because theywere inconsistent with the initial reports.
The proper uses of in-progress and quick lookreports are to spot trends and develop insights(hypotheses that might be checked later when betterdata and more time for analysis are available). Ifshared, they should not be briefed as conclusive orimplying causality, and their preliminary natureshould be emphasized. From the perspective of theexperimentation team, the entire subject ofexperimentation products and scheduling is one inwhich both expectations and interpretations willneed to be actively managed.
Example Experiment:Self-Synchronization
The illustrative self-synchronization experimentinvolved virtually every form of challenge anexperimentation team can encounter. Their pretest

277Chapter 10
was chaotic. They lost a trained observer at thelast minute. The host institution failed to renewthe license for their scenario driver, which camedue between the pretest and the experiment. Oneof the subjects was called away on emergencyleave. Moreover, their collaboration tool crashedduring the second day of the experiment. However,because the experiment plan was robust andwell-thought out, the experiment was still able toaccomplish its objectives.
Here is how the events unfolded. First, the pretesttraining proved inadequate for both the observersand the subjects. Extra time had to be devoted toobserving, classifying, and coding behaviors,particularly collaboration behaviors. The plannedsubject training in the use of collaboration toolsand search tools failed to reach the level ofproficiency specified for about 40 percent of thepretest subjects. Those with the greatest difficultywere found to be those with the least computerexpertise and experience. Finally, subjects showeda clear tendency to impute today’s characteristicsto the sensors and communications systemsavailable during the game.
The interval between the pretest and the experimentwas busy. First, revised training was developed forobservers and tested on a small new group, whowere set up as a backup team for the experimentitself. Second, a qualification test for basic computerskills was developed to screen out subjects whowould have difficulty mastering the systems theywould need to employ during the experiment. Inaddition, the data analysis plan was adjusted to

278 Code of Best Practice for Experimentation
include statistical controls based on subjectproficiency test results. Finally, the training forsubjects was altered to stress the differencebetween the capabilities available during thegame and those available today. These adjustmentsalso caused the addition of one-half day to thetraining schedule.
As the start of the experiment approached, oneof the experienced observers became ill. Theexistence of the standby observer team was,therefore val idated as the best qual i f iedreplacement was moved into an active role. Asthe systems were being put into place for theexperiment and tested, the scenario dr iver(commercial game) failed. A quick check foundthat the host institution had forgotten to renewthe license for the system. An emergency purchaseorder was generated and the problem waspromptly resolved.
The experiment started well. However, at the endof the first training day, one of the subjects wascalled home on emergency leave. She was replacedby her commander, who had to be given specialtraining during off-duty hours to be ready for thestart of the experiment runs. Data for her team wastagged to permit later analysis in order todetermine whether her absence made a difference.
Finally, the collaboration tool, which was beingused more heavily than expected and for functionsnot foreseen in the experiment plan, crashed onthe second day of the experiment. Players wereinformed that a cyber-attack had taken out the

279Chapter 10
system and play continued. Data from the periodimpacted were also tagged. The technical supportteam determined that more server capacity wasneeded. The system came back up after 6 hoursand performed well from then on.
Among the lessons learned from our illustrationexperiments is the fact that things will not all goexactly as planned. Stuff happens. Subjects dropout immediately before and during experiments,observers get sick or are called away, systemsfail, and scenarios bog down. Controllers need tobe alert for problems. Solutions will often needto be conceived on the fly. Solutions and problemsneed to be thoroughly documented so that theanalysis can take them into account.
1Given that transformational experiments are designed to testlimits, it is difficult if not impossible to predict how subjects willuse the systems.

281
CHAPTER 11
Products
G ood experimentation requires gooddocumentation in order to provide a record of
what went into its planning and what resultedfrom its execution. First and foremost, gooddocumentation provides the basis for understandingexperimentation results and judging theirimplications for transformation policy andinvestment decisions, without which they wouldhave limited veracity and value to the DoD.Secondly, products that document and explain whatwent on before, during, and after an experimentcarefully preserve a record of the scientific researchaccomplished. Finally, these products provide anarchival basis for extending and integrating theexperimentation results into the larger body ofknowledge. This chapter takes a closer look at thevarious types of documentation required byexperimentation, what information and knowledgethey contain, and what purpose they are intendedto serve. Additionally, we reflect upon a numberof “best practice” principles that should be keptin mind when developing these variousdocumentation products.

282 Code of Best Practice for Experimentation
Types of DocumentationProducts and Their Use
Experiments are documented in a variety of ways,with each product serving the needs of a specificaudience. Illustrated in Figure 11-1 are the principalproducts of interest in a typical experiment,although other types of reports, papers, briefings,or other products could be generated to meet therequirements of a specific experiment. As suggestedfrom this figure, good documentation is requiredthroughout the life cycle of the experiment, frompre-experiment planning to dissemination andarchiving of results. Following this practice avoidsa common misperception (carried over fromexercise tradition) that the only documentation ofsignificance is the so-called “quick look” briefingoften provided to senior officials immediatelyfollowing the completion of the event.
Management Plan
The management plan for the experiment,developed at the beginning of the pre-experimentation phase, provides the overallguidance for the experiment and specifies howthe experiment will be planned and executed. Inaddition, this plan relates the experiment to thevarious external constituencies by articulatingthe various sponsor issues and stakeholderinterests. Finally, the management plan providesthe basis for securing support for the experimentfrom various part ic ipat ing mil i tary units,organizations, and other resources.
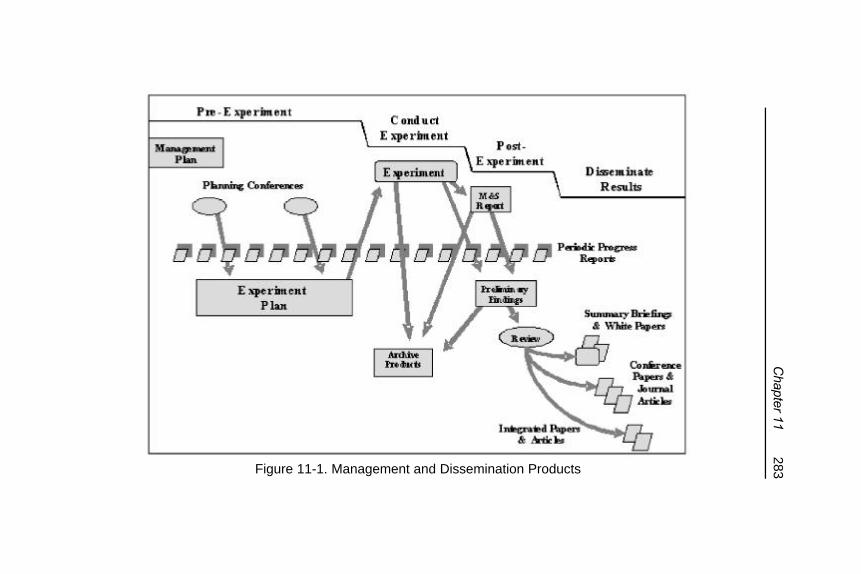
283C
hapter 11
Figure 11-1. Management and Dissemination Products

284 Code of Best Practice for Experimentation
Experiment Plan
A common mindset and practice of the past hasbeen to treat the experiment plan as a looselyorganized set of information papers or briefingslides that are circulated largely to inform seniorofficials about the purposes of the experiment, orto address specific aspects of the experiment (e.g.,data collection plan). Very rarely are all of thevarious planning details brought together in acentrally maintained, integrated, and cohesivedocument. Such a sloppy and informal practiceoften leads to a fragmented understanding of howthe experiment will come together to addresscritical questions, or how the various elementsand participants will be synchronized. To avoidsuch problems, it is necessary to think of theexperiment plan as being a living coordinationdocument that communicates a consistent,comprehensive, and cohesive understanding of allof the planning details to every participant,supporter, and consumer of the experiment. Anexperiment plan is more than just a set ofbulleted briefing slides. Like a military operationsplan, it is the formal glue that holds the broad(and often diverse) experimentation communitytogether and focuses them on a common set ofobjectives and intent.
Developed in accordance with the managementplan, the experiment plan serves as the principalcontrol vehicle for refining and documenting agreeddetails of the experiment. Maintained by theexperiment manager, the experiment plan is aliving document that is subject to revision and

285Chapter 11
refinement throughout the course of the pre-experimentation phase. Documented within theexperiment plan are the specific elements of theexperiment outlined in Chapter 5, including acareful record of how each element is revised orrefined during the pre-experiment phase. Forexample, these elements should address:
• Experimentation hypotheses and researchquestions;
• Experimentation treatments, baselineconditions, and controls;
• Experimentation subjects (including selectionand training requirements);
• Experimentation scenarios;
• Definition of measures and data collection plan;
• Facility and other resource/asset requirements;
• Experimentation schedule (including pretestand rehearsal events); and
• Contingency options.
Because experimentation serves a broad set ofconstituencies, it is important that the experimentplan reflects multiple disciplines and perspectives,rather than being dominated by a single view. Properscope and balance are crucial and reflect the critical,integrative role played by the experiment planfor achieving and maintaining synchronizationamong the various participants. Good experimentsand productive learning do not just happen byaccident or wishful thinking. Rather, they are the

286 Code of Best Practice for Experimentation
products of various professional communitiescoming together via conscious and comprehensiveplanning that is articulated and coordinated via agood Experiment Plan. To quote the South Africanprofessional golfer, Gary Player, “The harder youwork, the luckier you get.” A good experimentplan effectively communicates the product of thishard work.
Planning Conferences
To achieve this level of articulation and coordination,i t is often necessary to hold one or moreplanning conferences for a specific experiment.Planning conferences represent a major elementin the planning of large and comprehensiveexperiments. However, they also constitute partof the documentat ion process since theirdeliberations and findings ultimately feed backinto the experiment plan. They become necessarybecause of the sheer complexity of negotiating andcoordinating the myriad of details involved in asuccessful experiment. Planning conferencesbring together the key participants, peer reviewers,and supporting organizations at critical juncturesin the planning process in order to (1) focusattention on major “show stoppers,” (2) identify thestrategy and means for overcoming each obstacleto conducting the experiment, and (3) documentthe inter-organizat ional agreements andcommitments that produce a successful experiment.The timing and frequency of planning conferencesdepend upon the specific scope and complexity ofthe experiment. Planning conferences can be

287Chapter 11
convened to address major, emerging issues, or beset on a prescribed schedule (e.g., Joint ForcesCommand experiments typically include an initialplanning conference, a mid-term planningconference, and a final product conference).
Periodic Progress Reports
Periodic progress reports, typically issued by theexperiment manager on a regular basis to thesponsors, stakeholders, supporting organizations,and key participants, serve as a vehicle thatfocuses attention on coordination andsynchronization issues between major planningconferences. Like these conferences, progressreports provide a vehicle for obtaining anddocumenting organizational commitment andsupport for the experimentation, although the issuesaddressed might be of a lesser scope andsignificance. Responses to each progress report arecirculated for coordination and then reflected asrevisions to the experiment plan. In this manner,progress reports can remain focused on coordinationand synchronization issues, while the l ivingexperiment plan continues to serve as the principalarchive of agreements and commitments.
As shown in Figure 11-1, it is important thatprogress reports are issued throughout the entirelife cycle of an experiment. A past weakness ofsome military experiments has been the tendencyof participating organizations to quickly lose interestonce an experiment has been executed, thusmaking it difficult to maintain access to keypersonnel who can make valuable contributions

288 Code of Best Practice for Experimentation
during the post-experiment analysis anddocumentation phases. In response, the experimentmanager should consider using the progressreports as a vehicle for maintaining the necessaryaccess and commitment needed to properlycomplete the experimentation life cycle.
Modeling and Simulation Report(When Appropriate)
As discussed in Chapter 5, many good experimentswill seek to explore and extend the empiricalfindings through an adjunct modeling and simulationeffort. This work, often undertaken during theanalysis phase of the experiment, can serve toexamine a broader range of conditions and variablesthan could be feasibly addressed in the actualexperiment. Since these results form an equallyimportant part of the analysis, they require properintegration and documentation with other aspectsof the experimentation. Depending upon the levelof modeling and simulation work undertaken, theresults can either be documented in a separatereport (as shown in Figure 11-1) or directlyincorporated into the report of the main analysisof the experiment. When such modeling andsimulation are performed as a major study by aseparate organization, it is appropriate that aseparate report be developed in order for theaddit ional assumptions and other analyticalconsiderations to be uniquely recognized and fullydocumented. At the end of the day, however,the modeling and simulation results need to befolded back into the main experimentation analysis.

289Chapter 11
Preliminary Findings Report
A frequently noted weakness of many pastmilitary experiments is the tendency to maintainthe findings and interpretations in a “close hold”manner until the publication of a final “approved”report . Such a pract ice ref lects a lack ofappreciation for the true nature of experimentation(i.e., what constitutes success or failure) and afear that the experiment might cast specificprograms or other initiatives in a negative light.However, this practice represents a disserviceto the scientific validity and operational relevanceof the experimentation. Good experimentationalways (subject to security restrictions) allows forproper review and critique of the findings by both(1) participating subjects, observers, controllers,analysts, and support team members and (2)external sponsors, stakeholders, and peerreviewers. This review serves two re latedpurposes. First, the review provides an opportunityfor the empirical findings to be rigorously reviewedand interpreted by mult iple discipl ines andperspectives. The synthesis of these multipleperspectives is crucial for developing a deepunderstanding of the issues and complexitysurrounding the development of mission capabilitypackages. Second, this review strengthens andvalidates the analytic “audit trail” that relatesthe limited context of the experimentation to thebroader questions associated with transformationpolicy and investment decisions.
As noted in the following section of this chapter,the content and format of the final report needs to

290 Code of Best Practice for Experimentation
be tailored to the specific needs and interests ofthe different audiences served by the experiment(e.g., senior defense officials, members of thedefense research and development community,and military historians and futurists). Accordingly,the preliminary findings report should address thesebroad sets of interests and allow the variousconstituencies to gain an initial understanding ofwhat the experiment produced. In doing so,however, it is important that care is taken indistinguishing findings from interpretations.
Reporting Findings
Findings are simply the reported outcomes of theexperiment, usually a combination of quantitativeor statistical comparisons of the various casesor treatments examined in the experiment,supplemented or ampli f ied by qual i tat iveobservations and assessments gleaned fromsubject matter expert observers. In addition,findings generally include (or specifically reference)the basic observations and data collected inthe experiment along with the important artifacts(scenarios, constraints, probes, training, etc.)associated with the experiment. Findings arereported in a concise and carefully documentedmanner since they are intended to convey anobjective impression of what transpired in theexperiment, and provide a basis for the variousconstituencies to contextually judge the outcome ofthe experiment.
Likewise, findings typically serve to focus attentionon important or significant outcome differences

291Chapter 11
found among the cases or treatments addressedin the experiment. In some cases, depending uponthe nature of the questions or hypotheses beingaddressed, i t is also important to highl ightsituations in which no differences were found.Focusing on outcome differences (or the lack ofdifferences) gets to the heart of why experimentsare conducted in the first place. To merely say thata new doctrinal concept, new piece of technology,or new organizational structure produced a goodwarfighting outcome is not sufficient since itholds little meaning for any audience. Rather,the key findings of the experiment should centeron how this outcome compared to that of a baselinecase or some other meaningful conditions. Failureto emphasize comparative findings has oftenbeen the most frequently observed weakness ofpast military experiments.
Reporting Interpretations
By contrast, interpretations reflect the applicationof experienced judgment to the experiment findings.Interpretations are subjective in nature and involvedrawing inferences and/or implications from theobjectively reported findings. Hence, care shouldbe taken to distinguish findings from interpretationsin the reporting of an experiment. Like findings,interpretations occupy an important (but different)place in the reports of the experiment since theyallow the various constituencies the opportunity toview the outcome of the experiment from differentpoints of view. Thus, interpretations serve alegitimate role in the experiment reports, provided

292 Code of Best Practice for Experimentation
that they are clearly distinguished from objectivefindings and that they are properly attributed to aparticular point of view.
Dissemination of the PreliminaryFindings Report
The prel iminary f indings report should becirculated for comment by appropriate audiences,usually within a reasonably short period of timeafter the initial analysis phase (including themodeling and simulation work) has been completed.At the same time, the experiment manager mustensure that this review is completed in an orderlyand timely manner (perhaps a few weeks) andthat it does not extend into an unending debateamong different perspectives and interests. Toaccomplish this, the experiment manager needsto have the strong support of sponsors andstakeholders, who have agreed beforehand on aset of review and publication schedules.
Final Products for External Audiences
Since transformation experiments are of interestto a broad audience, it is only natural that theirfindings and interpretations be documented in avariety of tailored products. One such productincludes summary briefings and white papers thatfocus on the implications of experimentationfindings for transformation policy and investmentdecisions. Typically, these briefings and papers areaimed at senior defense officials and are gearedto highl ight the operat ional aspects of theexperimentation and to interpret/summarize the

293Chapter 11
f indings in the terms of mi l i tary capabi l i tyimprovements, operat ional concepts, andassociated operational risks. At the same time,these documents illustrate the interdependentnature of the elements making up a missioncapability package. Finally, these documents tendto be written in a concise manner that immediatelydraws attent ion to the major insights andconclusions drawn from the experiment.
In contrast to this set of “executive level” products,a set of products needs to be developed for theresearch and development community. Theseinclude technical conference papers and refereedjournal articles that are aimed more at the researchand development community. Here, these paperswill typically focus on specific theoretical orproposit ional issues of interest to speci f icprofessional forums such as the Institute ofElectrical and Electronics Engineers (IEEE), theAmerican Institute of Aeronautics and Astronautics(AIAA), the American Psychological Society (APS),the Human Factors Society (HFS), and the MilitaryOperations Research Society (MORS). The venuefor presenting such papers includes any numberof workshops, symposia, conferences, andprofessional journals sponsored by theseorganizations. As opposed to the summary natureof the executive level papers and briefings aimedat senior defense officials, these more academicproducts will often describe selected aspects of theexperimentation in extensive academic detail.Additionally, these technical products will oftenfocus greater emphasis on placing and interpretingthe detailed findings of the experiment within the

294 Code of Best Practice for Experimentation
context of the existing research literature. Finally,these products will focus more on how the availableempirical evidence has led to the support andrefinement of specific bodies of theory (e.g., networkcentric operations, sensemaking, collaboration).
Finally, a third set of products includes integratedpapers and articles that place the set of experimentfindings in an overall defense transformationframework. Such products tend to combine anoperational and force development focus witha r igorous analyt ic presentation in order toexamine the broader impl icat ions of theexperimentation for the professional militaryaudience. Here, a likely venue of publicationwill include senior service school journals, militarytrade and association magazines, the annualCommand and Control Research and TechnologySymposium (CCRTS), the biannual InternationalCommand and Control Research and TechnologySymposium (ICCRTS), NATO or coalition workinggroups, and other national and internationalmilitary forums that can expose these results toa broad mil i tary audience. Accordingly, theintegrated papers and articles should appeal to abroad readership and be organized along the majorthemes of defense transformation.
Archiving the Experiment forFuture Investigations
Experiments seldom have more than limitedrelevance or utility in isolation, hence their findingsand interpretations should usually be placed in

295Chapter 11
a broader context. In Chapter 4, the concept ofthe experimentation campaign was introducedalong with a discussion of how knowledge andunderstanding are often developed through acumulative series of individual experiments.However, it would be a mistake to interpret anexperimentation campaign as only being a set ofindividual experiments strung together. Rather,an experimentation campaign can be characterizedas a well-designed sequence of investigationsthat successively builds knowledge within anorganized framework of questions, hypotheses,performance and outcome measures, andassociated empirical evidence. Even if a specificexperiment has not been anticipated to form partof a larger campaign, it is often instructive anduseful to compare and integrate future findingswith those obtained in a previous experiment.Given this broader context, consideration must begiven to preserving the methodology and originalempirical evidence in a form that makes it availableto future studies and experimentation.
The requirement to careful ly archive eachexperiment is different from the management anddissemination purposes discussed earlier in thischapter. In one sense, archival documentation isaimed more toward an internal, practit ioneraudience within the operations research, analysis,and experimentation communities rather than atan external, consumer audience. Secondly, thebody of empirical evidence from each experimentis archived so that it can be made available toothers for subsequent analysis and integration withother experimentation efforts. Finally, the archival

296 Code of Best Practice for Experimentation
documentation contributes to the refinement ofexperimentation methodology, measurement andassessment instruments, and modeling andsimulation techniques - all interests of an internal,practitioner community.
As shown in Figure 11-2, a variety of archivingproducts should be developed from both theplanning and execution of the experiment. Eachtype of product reflects a specific content and servesa specific purpose.
Original Data Records, Transcripts, andOther Artifacts
Data records, interview transcripts, and otherartifacts of the experiment (e.g., scenario materials,injections/probes, background books, trainingmaterials) should be collected immediately afterexecution of the experiment and preserved in theiroriginal form. This can include a variety of bothelectronic and hand-written materials such asaudio/video tape recordings, telemetry fi les,computer modeling output, voice and digitalmessage traffic, SME observer and assessmentforms, interview notes, and survey forms. In somecases, preservation of this material might bebased upon legal requirements (e.g., Use of HumanSubject requirements); however, the main purposeof preserving the original material is to make itavailable to future studies for refined analysis andsynthesis. Experience with past experimentationhas demonstrated that, with the passage of time,new questions will arise or new perspectives willbe developed that can shed new light on existing

297C
hapter 11
Figure 11-2. Archival Products

298 Code of Best Practice for Experimentation
data. Making these data available to future studiesand experimentation offers the opportunity forrefining the interpretation of data or makingcomparative assessments, a hallmark of scientificexperimentation.
In preserving original records, transcripts, and otherartifacts, consideration should be given to selectingan appropriate repository organization. Thisorganization should provide a mechanism forboth (1) promoting awareness of the material acrossthe DoD research community and (2) providingappropriate access to the material. The length oftime for maintaining the material will dependupon the nature and significance of the experiment,possibly lasting years, or even decades as in thecase of “classic” or “seminal” experiments.
Data Dictionary/Glossary of Terms, Constructs,and Acronyms
Perhaps the most frustrating aspect of comparingresearch findings across different experiments isthe frequent lack of consistency regarding thedefinition of key terms, constructs, and acronyms.This is particularly true when one moves beyondthe engineering terminology associated with thephysical domain and into the more subjectiveterminology associated with the information andcognitive domains. Without consistency of meaning,the comparison and integration of findings acrossexperiments becomes problematic at best. Thus,a fundamental requirement for experimentationcampaigns (and a good principle to follow ingeneral) is proper documentation of the terms,

299Chapter 11
constructs, and acronyms to be used in theexperiments. Specifically, for the information andcognitive domains, the documentation shouldinclude accepted operational definitions of eachterm/construct/measure, accompanied by whatevercontextual information is required to ensureconsistent interpretation in future research.
As noted earlier, the consumer of data dictionariesand glossaries is primarily the internal, practitioneraudience within the DoD and international researchand development communities. Thus, disseminationof this information can be both internal to theServices or Joint commands, and via the CCRPwebsite, MORS, and various NATO or coalitionworking groups. Ultimately, much of this materialcan be incorporated into future Codes of BestPractice or propositional inventories maintained bythe practitioner community.
Methodology / Metric Dictionary
Considerable time, effort, and creativity often gointo the development of measurement andassessment instruments that can accuratelyilluminate the structures, processes, and functioningof a military operation. As with key terms andconstructs, however, it is important to achieveconsistency across different experiments. Thus, animportant product of any experiment is the properdocumentation of how these various instrumentswere developed and employed. This consistencyprovides the basis for both (1) comparing empiricalevidence across different experiments within acampaign and (2) extending and refining the

300 Code of Best Practice for Experimentation
measurement and assessment instruments withinthe practitioner community. While this task isrelat ively straightforward for engineeringmethodologies applied to the physical domain,greater challenges exist within the informationand cognitive domains. Within these domains, itis important to document the accepted dimensionaldefinitions and metric scales employed as partof each instrument, accompanied by whatevercontextual information is required to ensureconsistent interpretation and use in future research.
As with key terms and constructs, the consumerof measurement/metric dictionaries is primarilythe internal, practitioner audience within the DoDand international research and developmentcommunities. Thus, the dissemination of thisinformation can be both internal to the Services orJoint commands, and via the CCRTS and ICCRTSconferences, MORS workshops and symposiums,and various NATO or coalition working groups.Ult imately, much of this material can beincorporated into future Codes of Best Practicemaintained by the practitioner community.
Key Considerations: Productsand Their Dissemination
Experimentation provides essential support forinforming and supporting defense transformation. Forthis to occur, however, it is important that theexperimentation products that are disseminated foreach of the different audiences give properconsideration to several issues:

301Chapter 11
• What are the different questions beingaddressed at each stage in the transformationprocess?
• What are the relevant perspectives of themultiple sponsors and stakeholders?
• What types of evidence should be consideredand how should this evidence be forged into acohesive story that supports transformationpolicy and investment decisions?
• What type of audience is being informed by aparticular dissemination product?
Product Focus Depends Upon the Type ofExperiment
As noted in Chapter 1, experiments of variouskinds have begun to proliferate throughout theDoD as part of the general interest in defensetransformation. In Chapter 2, these experimentswere further broken down into three categoriesor uses: discovery experiments, hypothesistest ing exper iments, and demonst ra t ionexperiments. Accordingly, what is documented willdepend, in some degree, upon the purpose of theexperiment and the level of maturity reflected inthe experiment. Discovery experiments focus onnovel systems, concepts , organizat iona lstructures, technologies, and other elements in asetting where they can be explored, observed, andcataloged. Quite often, a major emphasis in theirdocumentation will be the important constructsand re la t ionsh ips d iscovered dur ing theexperiment. Here, it is important that the products

302 Code of Best Practice for Experimentation
identify the potential military benefits suggestedby the exper iment , to document emergingconcepts of employment, and to begin articulatinghypotheses for future experimentation. At thisstage of experimentation, decisionmakers relyupon experimentation products to weed out ideasthat will not work, refine the ideas that seempromising, and lay out a framework for furtherresearch and development. While results at thisstage of experimentation are often tentative,documentation can support future research anddevelopment investment decisions by addressingthe following questions:
• What new performance variables orrelationships have been introduced or stronglyaffected by the systems, concepts, processes,and structures?
• What new constructs have emerged that requiremore careful observation and measurement infuture experiments?
• What are the important contextual features andboundary conditions that enable or prevent thesystems, concepts, processes, and structuresfrom making an operational contribution?
By contrast, hypothesis testing experiments reflecta more classic approach to experimentation, whichseeks to examine carefully constructed comparisonsamong alternative cases (including a baseline case)under carefully constructed conditions in order toprovide supportive evidence for carefully articulatedpropositions. Thus, a major emphasis in theirproducts is the r igorous documentat ion of

303Chapter 11
experiment assumptions and controls, the empiricaldata and their analysis, and the level of evidencesupporting each hypothesis. At this stage ofexperimentation, decisionmakers look to theexperimentation products to validate specifictransformation init iat ives by addressing thefollowing questions:
• Do the comparative findings make a militarydifference (operational significance)?
• Are the comparative findings reliable, given theexperimentation sample size (statisticalsignificance)?
• To what extent can the findings be generalized toreal-world military operational conditions(experimental controls)?
Final ly, demonstration experiments offer anopportunity to demonstrate the efficacy of a newsystem, concept, process, or structure undercarefully orchestrated conditions. Additionally,demonstration experiments often afford theopportunity to examine the combined effect oftwo or more such initiatives, thus balancingdecisionmaker attention across several elementsthat comprise a mission capability package. Incontrast to the first two types of experiments,demonstrat ion experiments are not aboutdocumenting new knowledge. Rather, the purposeof the documentation is to communicate thedemonstrated capability to those decisionmakersunfamil iar with i t . Good documentation cansupport critical transformation investment and

304 Code of Best Practice for Experimentation
fielding decisions by refining the answers to thefollowing questions:
• What is the critical range of conditions overwhich the demonstrated capability can beexpected to exist?
• What is the complete set of initiatives that mustbe pursued in order to produce a robust missioncapability package?
Reporting Implications for Mission CapabilityPackages
It is clear from Chapter 2 that the objectives ofexperimentat ion are to develop and ref ineinnovative concepts of operation in the form ofmission capability packages. To accomplish thisobject ive, experimentat ion must consider abroad range of perspectives that includes (butis not limited to) the various DOTMLPF elements.A weakness of many past military experimentshas been a preoccupation with technology at theexpense of adequately documenting other aspectsof the operation. If experimentation is to truly supportthe development of mission capability packages,then i t is important that the documentat ioncaptures multiple perspectives on what is beingaddressed and discovered, rather than narrowlyfocusing only on materiel technology issues.Beyond the more famil iar (and more easi lymeasured) aspects of technology performance,such perspectives can include:

305Chapter 11
• Doctrinal lessons learned (e.g., the validation ofnew theories of warfare or new principles ofoperation);
• Personnel performance and trainingeffectiveness (e.g., the adaptability of leadersand soldiers/airmen/seamen to newtechnologies, tactics, and procedures); and
• Organizational dynamics and performance(e.g., the ability of new organizationalstructures to support new forms of leadershipand collaboration).
The broad nature of the issues involved indefense transformation requires the use of amult idiscipl inary team for developing theexperimentation products. Such a team not onlyreflects expertise from each of the DOTMLPFcommunities, but is also (as a whole) sensitive tothe various challenges associated with buildingintegrated mission capability packages. Expertisefrom each community is required in order toarticulate each perspective in an appropriate andinsightful manner. Overall perspective is requiredin order to balance the presentation of the issuesin the various experimentation products.
Document All of the Evidence
While it is true that all experimentation, by definition,produces empirical evidence, it is not true thatall empirical evidence comes in the singular formof precise engineering metrics (e.g., geographiccoverage, bandwidth, kills/engagement). Just asgood documentat ion considers mult iple

306 Code of Best Practice for Experimentation
perspectives on an experiment, so too will thatsame documentat ion seek to organize andsynthesize multiple classes of evidence. Here, thethree classes of evidence are:
• Quantified, objective measures of engineeringperformance;
• Calibrated, observable measures of behavioraland organizational performance; and
• Subject matter expert judgment of outcome.
Each of these classes of evidence correspondsto different types of capability and performanceissues being addressed in the experiment. Eachclass of evidence provides a critical ingredient inthe final story being written about the experiment.
Quantified, objective measures of engineeringperformance are considered the “gold standard” ofscientific experimentation because they allowoutcomes and findings to be documented in adefined, reliable, and replicable manner. Withoutsuch a documentation standard, a comparison offindings from one treatment or case to anotherbecomes problematic, thus negating much of thevalue and purpose of experimentation in the defensetransformation process.
In the case of behavioral and organizationalperformance, however, much of what transpires inan experiment cannot be directly observed ormeasured in an engineering sense. Hence, otherapproaches must be taken to documenting thisaspect of an experiment. Unfortunately, too often inthe past, such dimensions and variables have

307Chapter 11
been rout inely ignored because they wereconsidered too hard to document. By contrast,however, the social sciences provide a varietyof well-accepted methods for observing anddocumenting behavioral and organizat ionalperformance in a structured manner. In mostcases, it is simply a matter of expending the timeand resources necessary to properly understandand apply these methods. However, this investmentin time and energy will yield appropriate dividends.Capturing this type of evidence in an experimentis critical because much of the success in exploitingnew military technologies will be dependent uponhow human operators and decisionmakers reactand interact (both individually and collectively)with these technologies. Ignoring this class ofevidence results in telling only half of the story ofthe experiment.
The third class of evidence, subject matter expertopinion, is valuable because of the experiencedinsights that it typically brings to an experiment.However, the documentation of such evidencemust recognize the scientific l imitations andbiases of such evidence. Subject matter experts,despite their experience, suffer from the samejudgmental biases as other human beings, hencetheir contributions cannot be substituted forsound statistical analysis of more objective,structured, and quantified measures. Here, over-reliance on this class of evidence in documentingthe findings of an experiment can be problematic.
There have been several weaknesses that havebeen often observed in past military experiments.

308 Code of Best Practice for Experimentation
There has been a tendency to document only whatcan be easily measured and quantified (i.e., focusexperimentation reports and other products only onmeasures of engineering performance). Withoutplacing this information in the context of otherclasses of empirical evidence, these results aremisleading, they can miss the “big picture,” andthey are often irrelevant to the questions posedby senior decisionmakers. In cases that go beyondtechnical data, there has been a tendency to collectand document only SME opinion, usually in the formof summary judgments by senior “gray beards”selected because of their interest in a particulartransformation initiative. While this approachattempts to focus on the “big picture” findings ofan experiment, it suffers from a lack of scientificrigor and precision insight. Documentation thatreflects only SME judgment not only runs the risk ofbeing self-serving and biased, but also discreditsthe entire notion of scientific experimentation.
By contrast, good experimentation (as anticipatedand documented in the experiment plan) seeksto exploit the strengths of each of these threeclasses of evidence and to present a balancedpicture of this evidence to decisionmakers.Recognizing that di f ferent aspects of theexperiment are best captured by different classesof empirical evidence, the experimentation teammust work to integrate and document multiplethreads of analysis into a cohesive story, a storythat relates the various findings and insights ofthe experimentation to potential transformationinvestment decisions. As noted earl ier, this

309Chapter 11
challenge will require a multi-disciplinary teamthat can perform several critical functions:
• Select and combine the appropriate classes ofevidence for illuminating and supporting eachmajor insight or finding;
• Seek, where possible, to cross-validate oneclass of evidence with other classes ofevidence addressing the sameexperimentation issue;
• Compare these insights and findings with bothoperational experience and the broader bodyof research literature;
• Communicate across functional or DOTMLPFcommunity boundaries to relate the differentinsights and findings within the context of anintegrated mission capability package; and
• Weave the various insights and findings intosupportable arguments that address specifictransformation investment decisions.
Tailoring Products to Various Audiences
Dissemination products serve different audiences,hence they must be individually tailored to theinterests of these audiences. As noted earlier in thischapter, these audiences include:
• Senior defense officials concerned withimmediate transformation policy andinvestment decisions and their associatedrisks and opportunities;

310 Code of Best Practice for Experimentation
• Members of the defense research anddevelopment community concerned with thetheoretical and technical issues beingexplored in a given experiment; and
• Military historians, futurists, and conceptualthinkers concerned with placing theexperimentation results in a broader contextof defense transformation.
Given the different needs and interests of thesethree different audiences, it is unlikely that asingle report, paper, or briefing would serve toeffect ively communicate the f indings andinterpretations of a given experiment. Accordingly,the dissemination products aimed at each typeof audience must be consciously focused andwritten in a manner that is best understood byeach recipient.
Decision papers, summary reports, and briefingsaimed at senior defense officials must be writtenin a manner and tone that relates experimentdetails to real-world, operational issues andconsiderations. These dissemination productsfocus attent ion on the key impl icat ions fortransformation policy and investment decisions. Aspart of this focus, products must carefully distinguishfindings from interpretations and address theoperational “So what?” questions, rather thanmerely reciting experiment outcomes. Additionally,they should carefully outline the limitations ofthe experiment so that decisionmakers understandthe key risks and uncertainties still surrounding aparticular policy or investment issue. In this manner,

311Chapter 11
the products serve to justify the investment inthe experiment and help to articulate the roleand utility of experimentation in the defensetransformation process.
By contrast, scientific papers, reports, and briefingsaimed at members of the defense research anddevelopment community are written with a moretechnical tone and often with a specific technicalfocus. These dissemination products will focusattention on the key theoretical, technical, andpropositional issues addressed in the experiment.As part of this focus, these products placeexperiment outcomes in the context of existingtechnical knowledge by addressing andemphasizing the scient i f ic and engineering“Why?” questions. Additionally, they serve tohighlight the relationships that exist among keymateriel, behavioral, process, and organizationalvariables. Their purpose is to inform research anddevelopment personnel in a scient i f ical lyrigorous manner so that the experimentationresults can contribute to a larger body of scientificand engineering knowledge. In this manner,the products serve to establish the scientificcredibility of experimentation in the defensetransformation process.
Finally, white papers, articles, and books aimed ata broad audience of military historians, futurists, andconceptual thinkers tend to reflect an integratedperspective on both operational and technicalissues. These dissemination products place theexperiment outcomes in the context of broadtransformational themes (e.g., Network Centric

312 Code of Best Practice for Experimentation
Warfare, Information Age warfare, effects-basedoperations, and asymmetric warfare). Here, thefocus might be placed on interpreting the experimentoutcomes in the light of historical military casestudies, projecting their implications for futureoperational scenarios, or integrating these findingswith other studies and experiments to developbroader doctrinal and force structure conclusions.The critical question often addressed in thistype of paper or article is “Where do we go fromhere?” As such, these dissemination products areoften used to stimulate new conceptual thinking andto motivate the undertaking of new areas ofresearch. In this manner, the products serve toguide and extend the transformation process withinthe DoD.
Tying it all Together:Documenting ExperimentationCampaigns
As noted earlier in Chapter 4, experimentationcampaigns represent a systematic approach tosuccessively refining knowledge and understandingin a specific transformation area. The value of anexperimentation campaign exceeds that of acollection of individual experiments preciselybecause of the integrated and cohesive learningthat takes place over an orchestrated set ofexperiments. But for this broader learning to takeplace, the synthesis of findings and interpretationsfrom across several related experiments must beaccomplished in a scientific or professional manner.

313Chapter 11
The synthesis of findings and interpretationsfrom any set of studies or experiments is alwaysenabled through careful documentation. In thecase of exper imentat ion campaigns, thedocumentation serves to weave the individualfindings and interpretations into a cohesive storythat addresses one or more transformationthemes. As in the case of a single experiment,the products of an experimentation campaignshould be tailored to specific audiences: seniordefense of f ic ia ls; members of the defenseresearch and development community; and thosewith a broader historical, futurist, or conceptualfocus. Thus, the focus and tone of each productshould be carefully matched to the interests andneeds of the intended audience.
Regardless of the audience, however, the principalchallenge in the documentation of experimentationcampaigns is to present the set of findings andinterpretations in a consistent and purposefulmanner. This places an additional burden on boththe managers of individual experiments and thoseresponsible for the broader experimentationcampaigns. Such a challenge underscores the needto carefully document each individual experimentsince the authors of the campaign papers, reports,and other products will draw heavily on theseprevious documents for their raw material. Ifcritical assumptions, conditions, and limitationshave not been accurately captured in these previousdocuments, then the l ikel ihood for somemisinterpretation and inappropriate conclusionsremains high. By contrast, the development ofcampaign dissemination products should follow

314 Code of Best Practice for Experimentation
accepted scientific practices of carefully citing thespecific document references of each finding orinterpretation. Only by careful documentation andthorough and complete citation is it possible totranslate the long-term investment in anexperimentation campaign into useful guidancefor defense transformation.
Conclusion
Good documentation of experiments goes wellbeyond the creation of a few action officer briefingslides, a set of press releases, or a “quick look”briefing, an approach taken all too often in the past.Experiments need to be carefully documentedthroughout their life cycle by means of a specificset of management, dissemination, and archivalproducts. The specific focus and tone of theseproducts must be matched to their particularaudiences. This reflects both good practice andcommon sense since each type of audience willbe looking at the experiment to provide answersto a different set of questions. In addition, theseproducts will also be shaped by the degree ofmaturity reflected in an experiment (i.e., discovery,hypothesis testing, and demonstration) since,again, different questions are posed at each stage.
Likewise, the documentation of experiments mustreflect a broad set of perspectives, rather thanbeing held captive by a particular set of technologyinterests. This is true for two related reasons. First,the successful planning and execution of a goodexperiment requires the support and synchronized

315Chapter 11
part ic ipat ion of a diverse set of DOTMLPFcommunities. Secondly, the experiment shouldserve to shed light on a broad set of transformationissues typically associated with developing missioncapability packages.
Finally, there is a degree of both science and artreflected in the good documentation of experiments.First, experiments should be documented in ascientific manner, following the accepted practicesof the engineering and research professions.Careful, professional documentation preservesan objective record of what the experimentproduced and provides a solid foundation fordrawing a range of operational, scientific, andinvestment/policy inferences from the empiricalevidence obtained in the experiment. At the sametime, good documentation reflects the art ofskillful communication. Since the purpose ofexperimentation is discovery and learning, thisevidence must be assembled and communicated ina way that highlights the comparative findings anddifferences revealed by the experiment. Only in thismanner does the experiment contribute in ameaningful way to the support of transformationinvestment and policy decisions, the maturation oftechnology, and the refinement of warfighting theory.Both science and art are essential ingredients togood documentat ion and must be properlyconsidered for the DoD to obtain appropriate returnon investment in the experiment.

317
CHAPTER 12
Model-BasedExperiments
Overview
Models and simulations have a role, albeit adifferent one, in support of all three uses of
experiments: discovery, hypothesis testing, anddemonstration. As a well-crafted experimentationcampaign matures, the roles and characteristicsof the models and simulations in use coevolve withchanges in the operational concepts and technologies.
This chapter describes a special k ind ofexperimentation, a model-based experiment, inwhich models, most likely in the form of simulations(executable models), substitute for human subjectsand military hardware in the experimentationprocess and are the sources of the data. The sameprinciples, articulated in Chapters 4 and 5, applyto model-based experiments just as they applyto empirically-based experimentation. Model-basedexperiments still require extensive pre-experimenteffort, must be supported by a multidisciplinaryteam, and must adhere to the scientific method.

318 Code of Best Practice for Experimentation
There are many situations in which model-basedexperimentation is the preferred method forgenerating experimentation “data.” In fact, there aretimes when they are the only mechanism forachieving the desired insights. Given that thetransformation of the DoD focuses on the future, atime for which empirical data is hard to find, model-based experimentation can be expected to be usefulin exploring the possibilities. The DoD’s strategyfor transformation involves the coevolution of missioncapability packages. The MCP concept recognizesthe need for systematic and simultaneous change inhow the military functions along multiple dimensions-change needed to leverage Information Agetechnologies. At an overview level, three types ofthings are changing:
• People - this includes the numbers, skills, andways in which they are organized foroperations;
• Process - how members of the militaryorganization, coalition, or interagency teamaccomplish their responsibilities; and
• Infrastructure - the systems, federations ofsystems, technologies, and other materialresources that are applied in support of militaryoperations.
Models can represent elements of a system andexplore how they interact. This can be helpful insearching for two kinds of insights. First, there maybe insights about the binding constraints on theperformance of the system(s) or federation ofsystems. For example, one might observe that

319Chapter 12
increasing communications bandwidth betweenHQ’s A and B did not improve B’s situationawareness. A simulation might demonstrate thatthe binding constraint on B’s performance is a limitedability to process (fuse) the data that they are alreadyreceiving. Therefore, additional communicationscapacity could in fact prove to be of limited value.
Second, there may be insights related touncertainties that could affect force performance.For example, consider a si tuat ion where asignificant number of chemical attacks are perceivedby troops in an area of operations. The reportingassociated with these types of events place largedemands on the command and control systems.These demands might inhibit other types ofcommunications and information related to otheraspects of the situation. This interference with otherinformation f lows could have unantic ipatedconsequences on operations (e.g., ATO processes,maneuver control). A simulation experiment wouldbe a very efficient way of exploring the robustnessof a command and control system when subjectedto extreme circumstances, and for exploringcommand and control logic that might increase therobustness of a given command and control systemunder extreme conditions.
Model-based experimentation has its most obviousutility in support of discovery and hypothesis testingexperiments. Some specific reasons for choosing amodel-based experiment include:
• Efficiently (both in terms of cost and time)exploring a set of scenarios, operational

320 Code of Best Practice for Experimentation
concepts, and technologies for combinationsof circumstances that appear to be fruitfulopportunities for further exploration usinghuman subjects and hardware (discovery);
• Supplementing other experiments withsimulation experiments that evaluate theconcepts and technologies under a broaderset of conditions. This data can then help tomore completely inform additionalexperimentation, acquisition, doctrine, andforce structure decisions (discovery andhypothesis testing);
• Extension, or evaluating the results of a testedconcept in a different context. An examplewould be to use the data from a JTF HQcommand and control experiment as input to aconstructive combat simulation that assessesthe operational contribution of the HQ’sperformance improvement, or placing limitedexperiment results into an entire missioncapability package and simulating overallforce performance (discovery and hypothesistesting);
• Decomposing an entire MCP that was tested ina live experiment, and exploring changes inspecific components (discovery andhypothesis testing);
• Exploring the potential utility of technologiesthat may not yet exist. An example being theuse of small agile robots as an integral part ofurban combat operations (discovery);

321Chapter 12
• Efficiently evaluating the suitability of proposedmetrics (dependent variables) that are beingconsidered for application in an experiment orexperimentation campaign (discovery andhypothesis testing); and
• Inexpensively replicating a concept and set oftechnologies that were demonstrated in andACTD for explanatory purposes(demonstration).
There are two major benefits to be gained fromproperly crafted model-based experimentation. First,the rules of logic that apply to modeling andquantification bring discipline to thinking that isoften necessary to address complex problemseffectively. A related benefit of good modeling is thatit reduces a situation of interest to its essentialelements, focusing the experimentation team onthe important issues. Second, insight into verycomplex issues and systems requires iterationbetween analysis and synthesis. Scientists, analysts,subject matter experts, and decisionmakers mustbe able to understand how a system decomposesinto its component parts, and how it behaves in itstotality. Good modeling supports both of theserequirements efficiently.
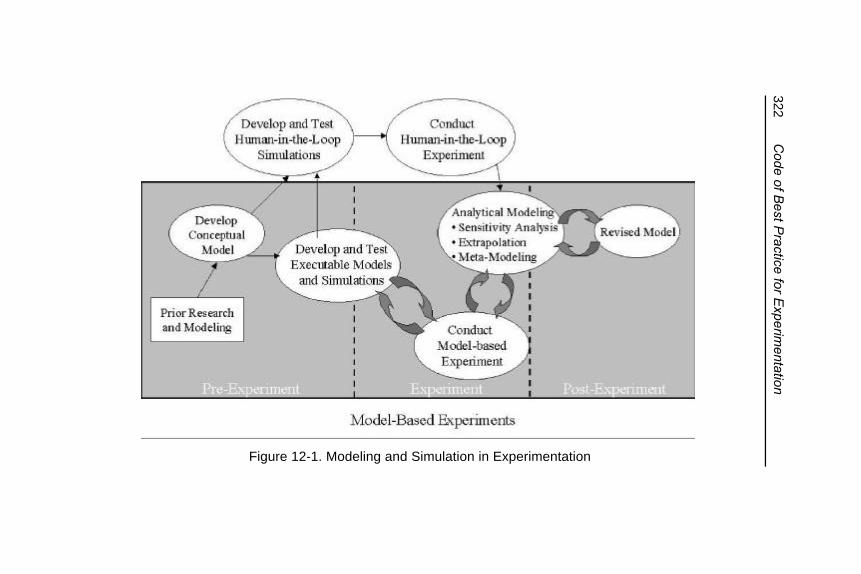
322C
ode of Best P
ractice for Experim
entation
Figure 12-1. Modeling and Simulation in Experimentation

323Chapter 12
The Anatomy of a Model-BasedExperiment
The principles that should be considered forsuccessfully conducting a model-based experimentare the same as those identified in Chapter 5. Figure12-1 highlights the subset of the modeling discussedin Chapter 5 with which we are concerned.
There are differences in specific requirements formodel-based experimentation that in some waysmake model-based experiments easier. But there arealso differences that make them much morechallenging. Perhaps the biggest pitfall in model-based experimentation is the failure to recognizethe importance of the subtleties in modeling. Thissection attempts to highlight some of the subtletiesthat should be considered. The sequencing of thisdiscussion maps to the stages of the experimentationprocess identified earlier.
Pre-Experiment Phase
The basic principles in Chapter 5, highlighting theneed for detailed preparation, also apply to model-based experimentation. A point to emphasize formodel-based experiments is that the essentialactivity in the pre-experiment phase is to identifythe goals of the experiment. Depending on the typeof experiment, these goals could be stated as apriori hypotheses (hypothesis testing experiment),or as desired improvements in Information Agecommand and control, like a continuously adaptiveAir Tasking Order (discovery experiment). The

324 Code of Best Practice for Experimentation
expression of these goals provides the foundationfor all subsequent activities. They support theselection of relevant measures and metrics, help toidentify the necessary skills in the team, and willhelp to bound the types of existing models and toolsthat are applicable to the experiment.
Developing, tailoring, and employing models andsimulations should be done by multidisciplinaryteams. The team should consist of experts as wellas stakeholders in the experiment (Figure 12-2). Thisoften requires special attention in model-basedexperiments because many of the issues that mightcause a concept to fail in a full experiment will onlybecome evident in a model-based experiment if theyare represented in the model. An example might becommunications representation. In an experiment, ifthere is no connectivity, then the players in theexperiment are unable to share information, andthe need for communications and a communicationsexpert are obvious. On the model side, manysimulations embed assumptions regardingcommunications capacity, or informationdissemination delays (and concepts). Obtainingreasonable behavior of a model along this dimensionwill require coordination between communicationsspecialists (or technologists for advanced concepts)and modelers. Otherwise, a model may haveembedded (implicit) assumptions or gaps in logic thatare essential considerations for evaluating theexperimental tool or concept.

325Chapter 12
Figure 12-2. Multidisciplinary Modeling Team
There are some analogies that can be drawn betweenmodeling terminology and experimentationterminology that can help clarify our thinking inrelation to formulation of an experiment. Specifically:
• Independent variables in experiments areequivalent to the subset of the model’s inputdata. Those that we choose to vary are calledcontrollable variables. Those that will not bevaried are called uncontrollable variables. Ineffect, the controllable variables equal thetreatments in an experiment.
• Dependent variables (experimentation data) inexperiments are equivalent to the output dataor target variables in models. In both cases,these should be clearly defined metrics that areselected for their relevance to the goals of the

326 Code of Best Practice for Experimentation
experiment. The NATO Code of Best Practicesfor C2 Assessment1 provides an excellentsupporting discussion on metrics.
• Intervening variables in experiments areequivalent to the remaining data, algorithms,and logic in a model that either providescontext for the model, or describe somerelevant cause-and-effect relationship amongindependent and dependent variables.
Identifying what we already know is an essentialpart of the pre-experiment phase. The principlesconcerning the identification of relevant operationalknowledge, organizational knowledge, insight intorelated experiments, and operational environmentsremain important in model-based experimentation.There are also additional dimensions that should beconsidered when thinking this special case through:
• What tools exist that could potentially describeboth the baseline and treatments of interest ofthe experiment? One of the fundamentalprinciples of experimentation is that one mustform a baseline and systematically introducechange. This implies that we can describe thebaseline and its behavior. In DoD architectureterms, the baseline is analogous to the “As Is”architecture, and the treatments are potential“To Be” architectures.2
• Are there any complete models developed thatrepresent the phenomenon of interest?
• What are the model’s assumptions (explicitand implicit)?

327Chapter 12
• Given the assumptions, what is the validextensibility of the model? In experimentation,we are extrapolating off of existing knowledge.We need to ensure that the model does notmisrepresent the concepts of interest.
Usually, an initial conceptual model supportingan experiment consists of a collection of logical andgraphical representations of baseline systems andprocesses, and the changes to the systems andprocesses that form the “treatment(s) in theexperiment. There are two models of interest inmodel-based experimentation. The first model isa description of the baseline systems and processesagainst which the changes will be evaluated. Thesecond is the experimentation conceptual model.It is this model that identifies the components ofthe MCP that are to be represented and evaluatedduring the experiment.
For transformation-related modeling, it is importantto explicitly consider variables in the physical,information, and cognitive domains (Figure 12-3).Alberts et al3 discuss in detail these domains andtheir inter-relationships. How these domains and theactivities within them are represented in the modelsor simulations should be determined as part of thepre-experiment process. The NCW Value Chain(Figure 2-1) describes the role of information inachieving desired effects in an operational context.
During the pre-experiment phase, it is important toidentify existing models of the baseline system.Some of them may even be formally validatedsimulations of the system. These sources should
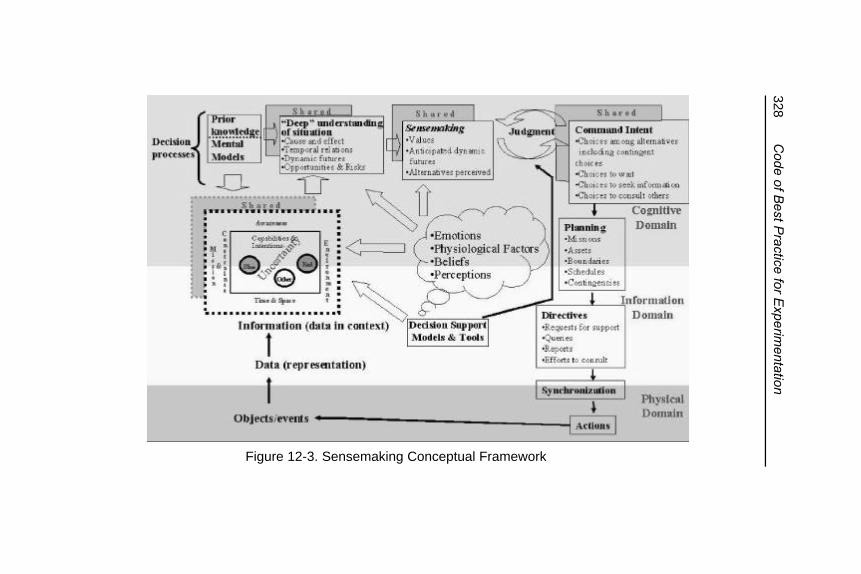
328C
ode of Best P
ractice for Experim
entation
Figure 12-3. Sensemaking Conceptual Framework

329Chapter 12
be vetted for relevant concepts to be included inconceptual models, as well as potential applicationin the experiment.
Executable Models(Simulations)
A simulation is simply an executable model. Theselection or development of the simulation(s)intended to support a transformation-relatedexperiment is one of the most important activitiesin the pre-experiment phase. The artificial worldbeing simulated consists of only those components(or abstracts thereof) of the real world and thoseinteractions among those components that arerepresented in data or in algorithms. There is bydefinition a loss of information when one reducesthe real world to a model. A good model will includeboth the essent ial elements and adequaterepresentations of the real world and real worldbehavior or effects. At an overview level, whenthinking about applying constructive simulation toolsto experimentation, interactions in the physicaland information domains have high potential forachieving insight into cause and effect relationships.Normally, the mapping between the components ofinterest in the MCP and the simulation components(algorithm and data) is possible. Cognitive domain-related issues can be explored in simulations.However, the exploration of cognitive cause andeffect relationships (to generate experimentationdata) is often not suited to constructive computersimulation because of the “soft” and complex

330 Code of Best Practice for Experimentation
characteristics of human cognitive processes, likesensemaking.
For transformation-related experimentation, thereare some important features to look for in asimulation tool. First, information needs to betreated as a commodity in the simulation. It isimportant that it be a commodity that can moveamong simulation entities in either a push or a pullfashion. That is, the command and controlalgorithms in the simulation cannot assume thatperfect information exists in the abstract, and then“reduce performance” based on a simple multiplier.For many transformation-related experiments, thispractice reduces to the propagation of an assertionthrough the simulation. This practice could lead toa misleading conclusion. Network Centric Warfareseeks to reduce and manage uncertainty forcommanders and staffs. It does not assert thatuncertainty can be el iminated. 4 Therefore,simulations need to address explicitly essentialuncertainties. Most important among these are (a)uncertain enemy behaviors (and goals), (b) errorsin key sensor systems (false positive and negative),(c) potential errors in the sensemaking process,and (d) potential information infrastructure lossesand fai lures. Third, command and controlrepresentations (and representations of informationflows) cannot be assumed to be hierarchical, orcentrally located. NCW principles seek to recognizeand support evaluation of the necessarily distributeddecisionmaking that wi l l exist in the futureoperational environment. Finally, the resolution ofthe simulation should be consistent with theresolution of the components of the MCP that are

331Chapter 12
the independent variables in the experiment. In theextreme, if one is considering experimentingwith the structure of a Standing Joint ForceHeadquarters, a constructive simulation thatexplicitly models sensor-to-shooter kill chains isprobably inappropriate.
Given the above principles, many exist ing,“validated” simulations can not effectively supporttransformation experimentation. Some rules ofthumb for selecting or developing useful simulationtools are:
• Do not limit the search to formally validatedmodels. These models may in fact not be validfor transformation concepts;
• Seek to use stochastic models as a default. The“second moment” or variability of outcomes isusually where the catastrophic failures andexceptional opportunities are found.Deterministic models assume those conditionsaway; and
• Ground the simulation in sound conceptualmodels of the baseline and modified MCP orMCP component and its behaviors.
Conduct of the Experiment
Let us assume we have selected or developed asimulation to support a modeling experiment, andthat we are now ready to use the executable modelor simulation to generate the data we need to“collect.” We must now carefully consider the designof the experiment (what data is to be collected

332 Code of Best Practice for Experimentation
under what “circumstances.” This design must beconsistent with the stated hypotheses or discoveryobjectives. The best information for achieving thisconsistency is found in the mission capabilitypackage and the supporting conceptual models.Complex MCPs in which multiple hypotheses arebeing tested need to be treated differently fromsmall, focused discovery experiments.
All experiments should be supported by asystematic exploration of the space of interest. Thisis sometimes referred to as the design matrix. Thedetails of these designs should be groundedsomewhere in the rich academic literature thatdescribes specific techniques.5 6 For the purposes ofthis discussion, there are two top-level designconcepts with which we should be familiar. The firstare designs that capture first order effects. Thesedesigns are the simplest and are intended to capturemajor, direct changes that are attributable to theindependent variables. Normally, these types ofdesigns are applicable to limited objective anddiscovery experiments. An example would be a“Plackert-Berman Design,” which was applied insupport of Army equipment modernization simulationexperiments in the 1990s.7 This type of designrequires fewer runs of the supporting simulation, andthe output can be efficiently used in traditionalstatistical inference approaches. The disadvantagesare that the insights are limited to these first ordereffects. Most MCPs and most operationalphenomenology are highly interdependent andnonlinear. There are many experimentationtechniques that support the exploration of thesecomplex situations. These should be selected for

333Chapter 12
their fit with the situation the researcher encounters.Factors such as the number of control lableindependent variables, suspected complexity of thedependencies, and computational capacity shouldbe considered.
A technique that is rapidly emerging as an effectiveapproach for addressing complex decisions andoutcome spaces is exploratory modeling.8 9 Thesetechniques support the conduct of experiments thatsearch large combinations of independent andintervening variables and then present the outputdata in a manner that assists human insight. In fact,this is a technique that might be employed to effectivelysimulate stochastic modeling using deterministicsimulations and large numbers of different inputvariables.
Post-Experiment Phase
One of the advantages of model-based experimentsis that they are potentially more flexible thanexperiments involving human subjects (particularlylarge military organizations). So, activities normallyassociated with the post-experiment phase of anexperiment can and should stimulate rapid iterationand evolution of the model, the experiment’s design,and expectations. It is this phase of the experimentthat should, in most circumstances, be led by skilledanalysts. Skilled, energetic inquiry into modelbehavior and experiment data provided to theremaining members of the experimentation team willcontribute to higher-quality results. These resultscould confirm or refute a priori hypotheses, generate

334 Code of Best Practice for Experimentation
new hypotheses, or cause refinement of the modelto support more refined exploration of the hypothesesof interest.
Analysis
In practice, the analysis is iterative with multiple entrypoints. Figure 12-4 describes this cyclic process interms of the types of reasoning that should be appliedto systematically explore the experiment’s results,and its implications with respect to the hypothesesof interest.
Figure 12-4. Analysis of Model-Based Experiment Results
We will begin discussion with deduction. This isactually accomplished during the pre-experiment andexperiment phases when we fully specify the model.Models, including simulations, are deductive tools

335Chapter 12
because all possible behaviors are specified by theinput data, including the algorithms. Historically,modeling and simulation were largely limited tosupporting deductive approaches to analyticalthinking. Emerging computational power, simulationtechniques, and inductive tools and techniquesprovide a previously unachievable foundation foranalysis. It is the combination of these capabilitiesthat enables this more robust approach to be applied.
The generation of model output centers on theconduct of the experiment, or the execution of theexperiment design. The objective of this stage, asdescribed earlier, is the production of data about thedependent variables.
Model-based experiments, using the techniquesdescribed above, will generate significant amountsof data. This data is explored using inductivetechniques that generate a fully specified model fromthe inputs. Examples of such approaches areBayesian Networks, Neural Networks, and DataMining. These techniques effectively generate a“meta-model” that describes the relationship betweenthe dependent and independent variables implied bythe model.
There are a number of possible conclusions that canbe drawn from the “meta-model.” It could conclusivelyconfirm the hypothesis, in which case the resultscould then be used to support more robustexperimentation. However, the hypothesis could alsobe seemingly disproved. The experimentation teamin this case could traverse one of two paths. First, itcould conclude that the model did not adequately

336 Code of Best Practice for Experimentation
represent the real world and modify the model usingthe insights that were developed as a result of theexperiment. Another possibility is that the insightsresulted in the formulation of a new set of hypotheses.That is, a form of abduction occurs and the model ismodif ied to support exploration of the newhypotheses. In both of the cases that result in modelmodification, the process proceeds back to the pre-experiment phase and structured explorationcontinues.
Counterintuitive Model Results
Sometimes when analyzing the results of a model,counterintuit ive results are encountered. Intransformation-focused modeling experiments, it islikely that this will occur relatively more frequentlythan in traditional analyses using models. Moreover,model-based experimentation best demonstrates itsvalue during the exploration and resolution ofcounterintuitive results. Achieving those insightsrequires the ski l l ful part icipation of themultidisciplinary team.
When a ful ly-specif ied model generatescounterintuitive results, there are three possiblecauses. First, the model is wrong. It is incorrectlyrepresenting some important element of the realworld, and that error is skewing the model’s results.These errors should be corrected, and theexperiment redone. The second possibility is thatthe model is correct, as far as it goes, but it isinsufficient in its representation of the real world.That is, there is some essential element of the real

337Chapter 12
world system that is missing from the model. Thisdeficiency has situational-dependent responses. Ifit is possible, the model should be extended toinclude the omitted features and the experimentshould be redone. If it is not possible to addressthe deficiency within the context of the existingmodel, then the team should either develop aseparate model-based experiment that focuses onthe deficient area, or the experiment’s report shouldcontain caveats that describe the deficiency and itsimplications. This documentation can serve toprevent inappropriate conclusions and to help focusfuture experimentation on the exploration of theissue. The final possibility for a counterintuitiveresult is that the model is providing an unexpectedinsight. These potential insights are the mostvaluable contr ibut ions of model-basedexperimentation. It is these insights that providenew directions for transformation conceptdevelopment and planning.
Issues in Model-BasedExperimentation
Model Validity
DoD Instruction 5000.61 lays out policies andprocedures for validating models and simulations.In the case of transformation experimentation,following the letter of this policy can, in fact, becounterproductive. Under the policy, componentshave the final authority for validating representationof their forces and capabilities.10 This means that onlyface validity (credibility to expert audiences) is sound

338 Code of Best Practice for Experimentation
and that it is valued over construct validity (correctidentification of the factors at work and theirrelationships) and empirical validity (the ability of amodel to make correct predictions). By definition,exploring transformation involves changing the wayforces, headquarters, and support functions areorganized and interact. Representations of theseexperimental concepts in models, althoughsubstantively appropriate, may not be consistent withthe traditional component view of modeling.Moreover, the administrative timelines and expensesassociated with meeting the VV&A requirements areinconsistent with the concept of rapid iterationthrough discovery types of experiments.
Thinking about validity effectively in the context oftransformation experimentation mandates a return tofirst principles in modeling. One way of organizingvalidity-related thinking is to recognize three kinds ofmodel validity: technical, operational (tactical), anddynamic.11
Technical validity has four primary components:
• Model validity - refers to the model’scorrespondence to the real world (fidelity, or inthe language above, this includes some aspectsof construct validity);
• Data validity - refers to the validity of both rawand structured data. Raw data validity refers tothe capacity to capture the phenomenon beingmodeled correctly or the accuracy, impartiality,and the ability to generalize. Structured datavalidity deals with abstract data, such asaggregated units;

339Chapter 12
• Logical validity - refers to the way in which modelbehaviors and results are considered. Forexample, consider two replications of astochastic simulation. In one replication, anaircraft carrier is sunk, and in the other itsupports the mission at full capacity. But,analysis of half an aircraft carrier is notreasonable. This also refers to the absence ofrelevant variables. For example, a model of anetwork-centric concept that assumes perfectcommunications and perfect sensor performance(again, in the language above, this includessome aspects of construct validity); and
• Predictive validity - do the model’s results makereasonable predictions of outcome conditions?This is very difficult to confirm for models andsimulations of future concepts and technologies.However, the issue should be raised. If a modelis generating counter-intuitive predictions or itsresults appear inconsistent, the modeler willwant to investigate the causal mechanisms withthe model.
No model meets all of the criteria for technical validity.Therefore, the next step in validation is to assessthe importance of the divergence, or evaluate theoperational validity of the model. This process shouldhave support and input from all segments of themultidisciplinary team supporting the experiment. Inoperational validation, the team should explore theoutputs of the model and trace the relationships inthe model from that output back to the changes ininputs that caused the change. Additionally,operationally-oriented team members should be

340 Code of Best Practice for Experimentation
assessing operational reasonableness (face validity)of the force behaviors implied by the modeling.
Dynamic validation explores the limiting conditionsunder which the model is valid. There are twofacets that should be considered. The first is withrespect to the insight it provides into the behaviorof a force or concept. That is, experiments shouldnot draw conclusions lightly about the performanceof some platform or small unit doctrine changesfrom a simulation whose entity resolution is at thelevel of flight groups and battalions. Second,experimentation teams need to explore andunderstand the limiting conditions of the decisionsthat the model should reasonably support.
As a matter of practice, the key validation attributesand conditions should be identified as part of theearly pre-experiment planning. The team shouldidentify necessary and sufficient conditions that themodel must meet to be considered valid for achievingthe experiment’s objective. The conditions should bepresented to leaders as potential sources of risk tothe experiment and be revisited periodically as theexperiment planning progresses.
Uncertainty
The best practices described above present sometechniques to address issues of uncertainty. Explicitconsideration of uncertainty is absolutely essentialin experimentation, especially transformation-focused experimentation. The systematic explorationof issues of uncertainty is a necessary componentof transformation risk management. Model-based

341Chapter 12
experiments are a potentially high payoff approachto exploring uncertainty because of their efficiencyand flexibility. Unfortunately, it is also often amongthe first things to “go overboard” as the experimentplanning process reacts to schedule pressures.
Peer Review
The purpose of transformation-relatedexperimentation is to generate new knowledge.Academia has a long-standing tradit ion ofsystematic peer review as professional researchersassert they have “created” new knowledge. Model-based experimentation especially requires this typeof peer review because these assertions will bemade, either for decisionmaking or for furtherexploration, without the benefit of real world contact.
Unfortunately, many model-based experiments (andstudies) have been completed without the benefit ofconstructive peer review. This often results in twounfavorable conditions. First, there are logicalmistakes in the model (it is invalid) that underminethe model’s results. Second, the supportedcommunity does not trust the model, which couldundermine the experiment’s results, even if they aretechnically credible.
Leaders of model-based experimentation teamsshould explicitly plan for external peer reviewthroughout the experiment. Ideally, this processshould remain informal and flexible. This will keepmodel-based experiments resource efficient.

342 Code of Best Practice for Experimentation
Conclusion
Model-based experimentation is a necessarycomponent of an experimentation campaign,particularly in the context of transformationexperimentation. If carefully integrated into theexperimentation campaign and effectively executed,it will make significant contributions in both theefficiency and effectiveness of the DoD’stransformation programs.
1The NATO COBP for Command and Control Assessment.Washington, DC: CCRP. 1998.2C4ISR Architecture Framework Version 2.0. Washington, DC:The Architecture Working Group and the Office of the Secretaryof Defense. 1997.3Alberts, David S., John Garstka, Richard Hayes, and DavidSignori. Understanding Information Age Warfare. Washington,DC: CCRP. 2001.4Understanding Information Age Warfare. p160.5Recommended reading: McBurney, D.H. Research Methods.Pacific Grove, CA: Brooks/Cole. 1994.6Recommended reading: Vadum, Arlene and Neil Rankin.Psychological Research Methods for Discovery and Validation.Boston: McGraw Hill Higher Education. 1997.7Loerch, Andrew, Robert Koury, and Daniel Maxwell. ValueAdded Analysis for Army Equipment Modernization. New York,NY: John Wiley & Sons, Inc. 1999.8Bankes, Steve. “Exploratory Modeling for Policy Analysis.”Operations Research. Linthicum, MD: INFORMS. 1993.9Bankes, Steve, Robert Lempert, and Steven Popper.“Computer-Assisted Reasoning.” CSE in Industry. St Louis, MO:American Institute of Physics. 2001.10DoD Instruction No. 5000.61. Subject: DoD Modeling andSimulation (M&S) Verification, Validation, and Accreditation(VV&A). October 5, 2001.11Schellenberger, Robert E. “Criteria for Assessing Model Validityfor Managerial Purposes.” Decision Sciences Journal. Atlanta,GA: Decision Sciences Institute. 1974. No. 5. pp644-653.

343
CHAPTER 13
Adventures inExperimentation:
CommonProblems and
PotentialDisasters
Purpose
Transformation has become a major thrust for DoDleadership. As a result, more and more
organizations have undertaken campaigns ofexperimentation to discover, explore, refine, anddemonstrate innovative concepts and applicationsof technology. While these efforts are clearly well-intended, and many have produced valuable insightsand knowledge, not all of these efforts have beenfully thought through. As a consequence, manyexperiments have been less productive than they

344 Code of Best Practice for Experimentation
could have been. Similarly, because of a failure toeven think about, much less manage, linkages amongindividual experiments, many past campaigns ofexperimentation have contributed far less to the bodyof knowledge than they might have.
This chapter identifies and illustrates the types ofproblems experienced within the past several years.Looked at with perfect hindsight, some of theseerrors appear to defy common sense and logic.However, every type of mistake described here hashappened to at least two different experimentationteams working within the DoD. Because the purposeof this Code of Best Practice, and this chapter, is toinform and teach, no individuals, teams,organizations, or agencies are identified by nameand some effort has been made to mask the identityof the specific experiments from which these lessonshave been drawn.
Many of the issues raised here have also beenreviewed in earlier sections of the Code where theactions necessary to avoid these mistakes werediscussed as being a part of best practice. Thissection of the Code approaches these issues fromthe opposite perspective, treating them as errors anddiscussing the problems that result. We hope thatthis may help experimentation teams and theirsponsors see the importance of thoughtful planning,careful implementation, and specific attention to theissues raised here.
Problems experienced in the pre-experiment phaseoften prove the most serious because they aredifficult and expensive to fix later on and may, indeed,

345Chapter 13
prove impossible to overcome. Unfortunately, theyhave also proven to be quite common, particularlyas DoD organizations, with limited experience andmuch to learn, have begun to experiment.
Flawed ExperimentationEnvironment
One of the most common problems is the effort to“piggyback” transformational experiments ontotraining exercises. As noted earlier, training exercisesalways take place in the context of immediate needsand current doctrine, organization, and training.Moreover, the bulk of the funding in these exercisescomes from the training budget. For both of thesereasons, experimentation objectives have beensubordinated to training objectives. Consequently,genuinely transformational MCPs can almost neverbe introduced into these venues. At best, specificlimited innovations (hardware, software, etc.) areintroduced piecemeal. This is no more productivethan introducing military forces into a battlepiecemeal. Their full potential is simply not going tobe realized.
Another common problem is introducing multipleexperiments into a single venue, such that theyactually interfere with one another. Because modernmilitary operations are complex and interrelated,conducting several experiments in the same venue(for example an ACTD or a JWID) opens thepossibility that two or more of the experimentsactually confound one another. In some cases, thishas occurred because one experiment’s independent

346 Code of Best Practice for Experimentation
variable was the dependent variable in another.However, the first variable was being consciouslymanipulated, which rendered the second experimentmoot. More commonly, intervening variablesimportant to one experiment (and thereforecontrolled) are being treated as factors in anotherexperiment, again undercutting the secondexperiment. Multi-experiment venues need carefuland detailed experimentation plans as well ascontinuous opportunities for interaction between thevarious participants.
On a similar note, partial implementation ofdevelopmental technology can have a sudden,disruptive effect on experimentation when not all ofthe essential supporting functions have beenincluded. Of particular concern in some pastexperiments has been the lack of adequate logisticsand infrastructure support for newly developedsystems. By their very nature, advanced technologyexperiments involve the application of systems thathave not gone through a full development cycle.Hence, the ability or inability to support such systemsin an experiment can be problematic and disruptiveto experimentation events. In other cases, thepresence of technical support personnel, sometimesin very large numbers, can introduce artificialities.One of the best strategies for anticipating andminimizing such disruptions is the inclusion ofrehearsal events in the experiment schedule.
Advocacy experiments designed to showcase orbuild an unambiguous body of evidence to supporta particular initiative fly in the face of goodexperimentation practice and waste precious

347Chapter 13
resources needed for genuine experimentation. Thisoccurs when an organization seeks to prove thevalue of their concept or system enabler, rather thangenuinely researching alternatives. It is oftencharacterized by unrealistic assumptions, scriptingred so that the blue approach will be optimized,collecting narrow data on easily controlled topicsor other artificialities designed to ensure that theresults are consistent with organizational goalsrather than knowledge gain.
The failure to allow intelligent red in dynamicexperiments is a similar error. Many of the mosteffective U.S. and coalition courses of action involvetargeting red’s decisionmaking and C4ISR systems– delaying decisions, overloading the systems, ormanipulating those systems. However, if the redmoves are pre-scripted or significantly constrained,then there is no impact on red C2, regardless of howwell the blue approach functions. Moreover, theabsence of an intelligent red force means that theU.S. force and C2 systems are not being challengedto be agile.
Reliance on a single scenario rather than capability-based analysis is another problem sometimesencountered. Choosing a single scenario meansoptimizing blue’s approach during the experiment.This fails to acknowledge the fact that the U.S. andits coalition partners are facing an increasinglydiverse set of threats and should be relying oncapability-based analysis to ensure our futuresystems are robust and adaptable to the range ofpossible threats. Moreover, when scenarios are anessential part of an experiment, then a set of

348 Code of Best Practice for Experimentation
scenarios that represents the range of interesting andimportant challenges is the correct approach. Theselection of only a single problem or class ofproblems is incorrect.
Failure to select appropriate subjects can limit thevalue of an experiment. Most DoD experimentsassume that the subjects are competent at theirmilitary specialties. However, experiments havebeen held in which the subjects were partly drawnfrom groups who lacked the experience and trainingrequired to perform the key tasks effectively. Whenthis occurs, performance is more closely associatedwith subject capability than with the innovationsbeing assessed. The result is an experiment thatdoes not contribute to increased knowledge orunderstanding.
An earlier discussion stressed the problemsassociated with failure to train subjects adequately.When this happens, performance improves overtime as the subjects improve their skills withexperience, and thus the data tend to understatethe value of the intervention. In essence, part ofthe experiment is spent training the subjects.Because most experiments train on a schedule anddo not give the subjects proficiency tests to see howwell they have mastered the interventions beingstudied, the experimentation team can only makeinformed guesses about the potential value of theintervention. If proficiency tests are introduced, dataanalysis can be done that controls for differencesin the initial skills of the subjects. If pre- and post-experiment proficiency tests are used, even richeranalyses are possible.

349Chapter 13
Lack of Adequate Resources
For a variety of reasons, several DoD organizationsthat “recognized” the importance of performingexperiments have not given them adequate resourcesor priority, or devoted adequate time to the pre-experiment phase. This is a serious problem and hasgreatly impacted the value of a number of importantefforts. This low priority for resources, planning, andtime can result in late creation of the experimentationteam, insufficient organization during the pre-experiment phase, failure to identify and organizeadequate expertise, failure to have a pool ofappropriate subjects, failure to provide adequatetraining materials or training time for experimentparticipants, failure to provide an appropriate varietyof rich scenarios or drivers for experimentation, andfailure to provide enough resources for qualityanalysis. All other things being equal, mostorganizations would benefit from only a few well-crafted and properly supported experiments than withmore that are inadequately resourced.
All too often, the experimentation teams are toonarrow, lacking the skills and experience necessaryfor success. First, they often leave out the range ofrelevant disciplines necessary to understand thesubstantive problems under study, includingexperience and expertise in research design as wellas the “soft” disciplines of psychology, anthropology,sociology, organization theory, and political science.Second, teams often fail to include the interagency,coalition, and international communities that createthe setting for most military operations today.Excluding either expertise or substantive context

350 Code of Best Practice for Experimentation
under the assertion that these complicating factorswill be addressed later, after mastering the coreengineering and military problems under study, is aweak argument. Transformation needs to occur inrealistic contexts, not artificially constrained ones.Moreover, human behavior is one of the very realobstacles to success, so it needs to be embracedas a crucial element of the problem.
Flawed Formulation
As the DoD has worked to learn how to experiment,some teams have generated sets of hypotheses thatwill not contribute to knowledge maturation. Theseare often long, clumsy structures that essentiallyargue “IF we do lots of things correctly, THEN wewill perform successfully.” These formalisms areinadequate to guide research, even discoveryexperiments. They need to be replaced by the simpleIF, THEN, CONDITION form introduced earlier in thisCode. Formulations also need to be supported by aset of null hypotheses that will guide analysis andpermit genuine gains in knowledge.
Another form of weak experiment formulation is thecreation of models so simple that obviously relevantvariables are simply ignored. When the underlyingmodel is “under-specified,” the results will be artificialand wil l lack the robustness needed fortransformation. The simplest and most common formof this error occurs when the differences betweenhuman subjects or teams of subjects are ignored.Experimentation designs that assume all subjectsand teams are identical often fail to generate useful

351Chapter 13
products because their results actually depend onthe humans involved. Similarly, failures to instrumentin order to record changes in work processes orinformal group structures have led to missedopportunit ies to gain important knowledge.Simulation experiments in which perfect informationis assumed also fall into this class of error.
Some recent experiments have not manipulated theindependent variable adequately, thus failing toprovide the basis for establishing causality. Withoutvariabi l i ty in the independent variable, i t isimpossible to show correlation or causality. One ofthe major reasons for developing a model of thephenomenon under study before each experimentis to ensure that the “ interesting” region isunderstood for the variables of interest. If the rangeof values the independent variables will take is leftto chance, or worse yet, if it is designed as a verynarrow range, then the likelihood that major effectsare observed in the dependent variables of interestdeclines rapidly. This can reduce the quality andimportance of experimentation results dramatically.
Failure to control for human subjects can also createproblems in experiments. One recent experiment thatused small groups as surrogates for commandcenters had the unfortunate experience of havinggroup leaders with radically different interpersonalstyles. As a result, the differences in performancewere clearly associated with those differences andcould not be linked to the innovations under study.Another experiment had serious problems becausethere was a clear difference in the expertise andknowledge of its teams. Fortunately, this experiment

352 Code of Best Practice for Experimentation
was using a “Latin Squares” design in which eachteam had equal exposure to each treatment orintervention, so the very obvious difference betweenteams did not adversely impact the results.
Failure to control for organizational change can alsobe a problem. Most DoD experiments assumeconsistent work processes and organizationalstructures. However, human subjects are remarkablyadaptive. More than once they have decided to altertheir functional organization in the middle of anexercise. Sometimes they do so in the middle of asingle trial. Unless the experimentation team isprepared to capture those changes and to includethem as intervening variables in its analyses, theexperiment may well miss important findings.
Experiments often lack a baseline or comparativestructure. The lack of a baseline or comparisonbetween two meaningfully different alternativesviolates a fundamental principle of experimentation.This error has often occurred in transformationexperiments involving the introduction of advancedinformation system technology into command andcontrol operations. The absence of a meaningfulbaseline (in this case, the absence of this technology)or comparison between alternative approachesmakes it impossible to measure the value-addedassociated with the new technology. As a result,sponsors and stakeholders are left with onlyanecdotal evidence that the new technologyrepresents a worthwhile return on investment.
Perhaps among the most frustrating problemsencountered are experiments that consciously

353Chapter 13
implement only part of a mission capability package.The rationale given is almost always the same – anopportunity existed to try something new, but notenough time or money was available to include theother elements believed necessary to create a realcapability. The consequences of these decisions areeasy to foresee. At best, the impact of the isolatedelement will be badly understated. At worst, thisisolated element will perform worse than the currentor baseline system or approach. Both the greaterfamiliarity with existing tools and approaches andthe fact that new tools and technologies implydifferent work processes, organizational structures,and training mean that thrusting a partial changeinto an existing system is a very weak approach totransformational experimentation.
Failure to develop an explicit model of the problemand processes under study also makes it verydifficult to run a successful experiment or campaignof experimentation. The approach that, “we’ll try itand see what happens,” almost invariably meansthat the experimentation team wil l have anincomplete or erroneous data collection plan. As aresult, they will have a very difficult time generatingmeaningful empirical findings. Even discoveryexperiments should be supported by a simple modelof what the team believes is important and thedynamics they expect to observe. For example, thehumans in C2 systems are often very creative inadapting their work processes and even structuresas they gain experience with a set of tools orproblems. Failure to be ready to capture anddocument those changes, which are often crucialintervening variables, may mean those changes are

354 Code of Best Practice for Experimentation
missed. At a minimum, it will mean that the sametopics will have to be reexamined in anotherexperiment.
Flawed Project Plan
All too often, DoD experimentation is started from anarrow base, or even as though no one else hasthought about the subject under analysis. This isenormously wasteful of both time and energy. Allexperimentation efforts should organize a team toidentify the leading researchers and practitioners inany field where research is contemplated. (This is apractice that DARPA, among other research andacademic institutions, regularly employs.) This, anda rich review of existing work, are important ways toidentify crucial issues, work only on innovations thatcan matter, and save resources by building onexisting knowledge.
As noted earlier, experiment design is a difficult,complex, and dynamic field. While the basicprinciples are clear, the specific techniquesavailable, and the types of analyses and modelingappropriate to assess experiments are not easy tomaster. Failure to expose the detailed researchdesign to peer review has often resulted in less thanoptimum use of resources and knowledge gain fromDoD experiments. This does not imply that researchdesigns should be circulated widely l ikeexperimental findings. It does mean that seekingconstructive criticism from a few trusted peersoutside the experimentation team will often pay offhandsomely.

355Chapter 13
Failure to develop explicit data collection plans anddata analysis plans leads to serious difficulties.Remarkable as it sounds, one of the most visibleexperiments conducted in the last decade had noformal data analysis plan. The assumption was that“everything” should be captured and the analystscould then figure out what to analyze later. Notsurprisingly, serious problems occurred because theyhad to try to create information relevant to a numberof issues that emerged as crucial but had not beenforeseen, and the process of analysis took anextremely long time. Another program, in a differentagency, proceeded on the assumption that theywould recognize what was important and thereforecreated no data collection plan. They have had greatdifficulty generating credible results and gettingresources to continue their efforts.
Failure to hold a rehearsal is one of the most seriouserrors an experimentation team can make. Despitea wealth of experience demonstrat ing thatrehearsals and pretests surface problems, thushelping to avoid practical problems that are difficultto foresee when planning in the abstract, someexperimentation teams have found that they lackthe time or resources for a proper rehearsal. Whenthat occurs, the first several trials of the experimentessentially become the rehearsal. This can meanthat important objectives are not achieved, andalmost always means that the data from those firstseveral trials will have to be thrown out.
Due in no small measure to the press of events anda legitimate desire to use data from an experimentto support decisions (particularly resource allocation

356 Code of Best Practice for Experimentation
decisions) experimentation results have beenrushed. So-called “quick look” reports and “initialassessments” are scheduled days, or even hours,after the end of the experimental trials. This is anappropriate approach when conducting trainingexercises, but far from useful in experimentationwhere detailed data analysis is often needed to findwhat was learned. It is important to note that theempir ical data sometimes contradict theimpressions of human observers and controllers.When these early evaluat ion sessions arescheduled, the most readily available data drive thesenior leadership’s understanding of what waslearned. Hence, data generated automatically andsurvey data from subjects and observers, which canbe gathered and processed quickly, predominate.Serious analyses, often involving comparisons ofdata and information collected in different locationsat different times as well as the careful review ofthe data and searches for anomalies and alternativeexplanations, typically require weeks and can takemonths for complex experiments. Moreover, theseserious analyses often contradict or condition thedata readily available and the opinions of theparticipants in the experiment. However, the “rushto judgement” has often already occurred, renderingthese r icher f indings and their strongerinterpretation moot.
Failure to control visitor access would seem to be anobvious problem, but remains a factor in too manyDoD experiments . Mil i tary organizations arehierarchies and prominent efforts at transformationactivities are often visited by sponsors and seniorofficials who are trying to understand what is going

357Chapter 13
on and provide support. However, the presence ofsenior officers or experts will alter the behavior ofsubjects. Sometimes they become distracted,sometimes they work extra hard and become hyper-vigilant, and sometimes they become nervous.Remarkably, some experimentation teams do notplan for visitor control. One recent experiment wasconducted in spaces that had to be transited by thoseworking on an adjacent project. Others have beeninterrupted by senior officers who wanted to talk withsome of the subjects while the experiment was inprogress. Still others have invited senior visitors totake a seat and participate in the experiment itself.All these experiments were impacted and, therefore,less useful than they might have been.
Last minute set-up and equipment problems tend tooccur as a consequence of not planning ahead.Almost all experimentation involves federations ofsystems. Even when the IT being used is from asingle system, new linkages must be establishedbetween the simulation driver and that system,between the system and the automated datacollection efforts, and to support experimentationadministration. Failure to allow appropriate lead timefor bringing these systems online or resources tomaintain them and respond rapidly when problemsare encountered can disrupt the schedule forexperimentation and may corrupt some of the databeing collected.
Failure to debrief all participants is a puzzling error.Those involved in an experiment all see the eventsfrom different perspectives. All of them should bedebriefed so that their insights are available to

358 Code of Best Practice for Experimentation
support understanding of the findings and alsobecause many of the less central participants willknow about glitches and anomalies that may not beimmediately visible to the senior members of theexperimentation team.
Measurement/AnalysisProblems
Failure to instrument properly so that the neededdata can be collected is all too common. This usuallyis a consequence of waiting too late to develop thedata collection plan and therefore being unable toinstrument the computer systems being used or toarrange for proper recording of crucial aspects ofthe experiment. Failure to instrument properlyalmost always means failure to capture dataproperly and reliance on indirect indicators orhuman observers, reducing the validity of what islearned. This also stems from failure to use a model.
Reliance on “happiness tests” for assessment ofobjective issues is all too common. Military utility isimportant and the comments and insights ofexperienced personnel, subjects, observers, andcontrollers are all valuable to the experimentationteam. However, there is a rich literature thatdemonstrates that people of all types, despite theirbest efforts, tend to see what they expect to see.Moreover, several DoD experiments have shownthat the opinions of experimentation participantsabout their performance using specific innovationsand their performance measured objectively arevery different. Experimentation teams that seek to

359Chapter 13
avoid the hard work of identifying objectivemeasures by relying on simple surveys are verylikely to generate flawed results.
Too often, experimental data collection focuses onlyon what can be easily recorded and measured,rather than on metrics for critical indicators ofperformance and effectiveness. This type of erroris most often observed in experiments involving theintroduction of advanced information technologyinto command and control. For example,considerable effort will be focused on measuringthe flow of message traffic among command andcontrol nodes, or on electronically capturing thestatus of specific situation displays during anexperiment. Yet, at the same time, little or noattention will be given to the information content ofmessage traffic or situation displays, the relativesignificance of this information in the context of theoperat ional scenario, or the impact of thisinformation on the sensemaking and decisionprocesses of a command group. As a result,analysts are left with little empirical basis to judgewhether or not the increased distribution ofinformation actually had a positive effect oncommand and control performance.
Inadequate access for observers has also been aproblem in some experiments. Those experimentsthat depend on human observers always face atradeoff between keeping them from impacting thedata and allowing them access. However, a fewexperiments have actual ly been run on thecontradictory assumptions that human observersare needed to track the behavior of subjects, but

360 Code of Best Practice for Experimentation
should not have access to decisionmaking or otherkey activities. In fact, while the presence ofobservers will impact behavior somewhat, thatimpact can be minimized by (a) having them presental l the t ime, including subject t raining andrehearsals, so they “fade into the woodwork,” and(b) being certain that the participants and observersunderstand that they are recording what happensin order to assess the innovation and its impact,but not to evaluate the subjects.
Confusing measures of performance with measuresof effectiveness is not a “fatal” error, but it doesimpact the interpretation of findings. Measures ofperformance deal with whether systems work.Measures of effectiveness deal with whether itmatters whether the systems work. To take a simpleexample, precision munitions designed to hit targetswith very small aim points have “performed well” ifthey hit those targets. If, however, the weapons carryonly a small warhead and therefore do not damagethe targets significantly, they have not beeneffective. The value chain discussed in the sectionon measures of merit should enable experimentationteams to select the appropriate sets of metrics foreach experiment. When possible, these should notbe limited to measures of performance, but alsoinclude appropriate measures of effectiveness(force effectiveness, mission accomplishment,policy effectiveness, etc.).
Failure to capture anomalous events and timeperiods can also limit the value of experimentationdata. No experiment goes perfectly. Systems beingused by the participants break down, subjects

361Chapter 13
become ill and must be replaced by others with lessexperience on a team, errors are made bycontrollers, and so forth. As a consequence, someperiods of time of performance by subjects will beimpacted by factors outside the design. When thisoccurs, the experimentation team must record theanomaly and make sure that the data from theimpacted subjects, teams, or time periods areanalyzed to determine whether it is different onvariables that matter. If it is, it must be excludedfrom the main analysis, though it may be examinedto see if any useful insights can be inferred fromhow the anomalous data differ from the main case.
Failure to properly select and train observers andcontrollers or to maintain quality control on theiractivities during the experiment will result in poor orirrelevant data. While subject training has been awidely reported issue in DoD experiments, a numberof problems have also arisen with observers andcontrollers. First, these people need substantiveknowledge – they need to understand what the areobserving as well as the setting in which they areobserving it. Hence, the use of academics orgraduate students will require training about theexperiment setting as well as the substance of thework being performed. People with prior militaryexperience are preferred because they require lessintroduction. Even so, their experience may well beout of date or drawn from a different perspective thanthat in use during the experiment, so some “refresher”training is wise. Observers and controllers shouldalso be given training that describes their roles andthe behaviors expected from them. Experimentationis an effort to duplicate some aspects of reality, so

362 Code of Best Practice for Experimentation
those involved in conducting experiments need tobe as unobtrusive as possible. Remarkably, somecontrollers schooled in training exercises have beenfound to try to teach the participants and improvetheir performance, while other observers have “lenta hand” when the subjects were busy.
Failure to perform inter-coder reliability tests, whenhuman observers and judges must code data,results in data that lacks reliability and credibility.Developing coding rules and maintaining them overtime and across several people responsible forconverting raw observations into data is verydifficult. Social scientists have developed processesover decades of effort to help ensure the datagenerated are both valid and reliable. Teams thathurry and fail to spend the time and effort to test forinter-coder reliability both after training and duringthe data coding process itself are vulnerable to bothhigh error rates and “coder drift” as the rules changewith coder experience and the types of casesencountered.
Post-Experiment Problems
Data from transformational experimentation arevaluable not only to the team that collects andanalyzes them, but also for the larger DoDcommunity. First, they are an essential part of thepeer review and broad discussion necessary for richknowledge. Second, they can be of great value forresearch on related topics. However, all too oftenexperimentation data are not available beyond theteam that collects and analyzes them. This occurs

363Chapter 13
at times because of classification, though that israre and should not prevent circulation to otherswith legitimate need to know and appropriateclearances. It also occurs in an effort to avoidembarrassing the individuals or organizationsparticipating in the experiment. However, data canbe masked. All too often, holding experimentationdata closely for no obvious good reason calls thecredibility of the work into question. In every case,failure to keep and circulate detailed results anddata slows the effort to acquire better knowledge.
Failure to retain experimentation materials is arelated, but less obvious, problem. Experiments,even very simple ones, require a lot of work, muchof it in creating the setting and infrastructurenecessary for success. Scenarios and vignettesdesigned to focus experimentation, sets of “injects”intended to manipulate independent variables andcreate experimentation data, data structures usedto drive simulations, linkages between disparatesystems to make them function coherently,measurement tools, training materials, video andaudio tapes that have already been mined for thedata needed in a single experiment, and a host ofother experimentation artifacts are potentiallyvaluable to others developing experimentation plansor seeking to replicate important aspects of theexperiment. All too often, these artifacts arediscarded, disassembled, or not documented, whichmeans they are lost at the end of the experiment.

364 Code of Best Practice for Experimentation
Issues in Campaigns
Organizations charged with transformationalexperimentation, whether at the DoD level, withinCINCdoms, within Services, or in separateagencies, are very busy and under great pressureto move ahead rapidly. Unfortunately, this hastranslated, in some cases, into unrealistic scheduleswhere events start occurring so rapidly that they canneither be managed properly nor used to buildcoherent knowledge. While the transformationalexperimentation agenda is large, progress requireswell-conceived, well-executed and tightly linkedcampaigns of experimentation. Even if they needto be tightly scheduled, failure to provide theresources to fully understand and exploit eachexperiment and to create schedules that permit theaccumulation of knowledge over time are seriouserrors.
Campaigns of experimentation are, by definition, setsof linked experiments. However, beyond a commonname, some campaigns have not truly linked theirexperiments together. That is, they have no realknowledge gain purpose, variables are defineddifferently, and the outputs from early experimentsare not used as inputs to the later experiments. Theseefforts represent major missed opportunities forimproved knowledge.
Unless a model and explicit knowledge repositoryare created, many of the benefits of experimentationcampaigns are lost. Good campaigns capture andreuse knowledge, sets of scenarios, experimentalinjectures, measurement schemes, analyses plans,

365Chapter 13
data, and working models. Enormous waste and lossof knowledge occur when these factors are ignored.
Rather than seeking to accumulate understandingand knowledge, some experimentation campaignshave sought to create “bake-offs” between competinghypotheses, approaches, or technologies. Thisattitude fails to appreciate the likelihood that differentapproaches and technologies offered within theprofessional community are more likely to be usefulunder different circumstances or integrated into asingle, coherent approach than they are to be“superior” or “inferior” to one another. Hence, bothexploratory and hypothesis testing experiments needto be thought of as crucibles, within which usefulknowledge and innovations are tested andtransformational knowledge built, rather than asprocesses of serial elimination.
Conclusions
Perhaps the strongest indication that DoDexperimentation remains immature is the inability torecognize the value of permitting “failure.” Failure iseither (A) a failure to support the hypothesis or novelideas, or (B) a failure to run a good experiment.Currently, many in DoD will not accept a failure ofType A, but often accept a failure of Type B. This isexactly wrong and a sign that these individuals andorganizations do not understand experimentation.This attitude arises from the mindset necessary formilitary success. However, in many cases, the mostsuccessful experiments are those that show whatcannot work, the circumstances under which a new

366 Code of Best Practice for Experimentation
system or approach is inappropriate, or how someinnovation can be thwarted by simple counter-measures. Learning is every bit as much aboutunderstanding what is not true as it is about graspingnew insights and knowledge. A real life, positiveexample of the value of being open to “failure” isJFCOM’s concept of Rapid Decisive Operations.After several years of concept development, anumber of workshops and seminars to flesh out theconcept, and a few experiments to learn how it mightbe implemented, MG Cash, Director ofExperimentation at J-9, was able to tell a workshopthat “the word rapid may not be right.” Hisorganization was not so invested in the concept thatthey could not learn from their efforts and changethe concept while still experimenting with it. This typeof knowledge gain is essential if DoD is to besuccessful in transformational experimentation.
The thrust of this chapter is that there are a greatmany problems and pitfalls for those seeking toconduct transformational experiments. The goodnews is that they can be avoided with foresight andplanning. This Code of Best Practice is offered asboth an introduction to experimentation for thoseunfamiliar with that process or with that process inthe DoD context and also a source of guidelinesintended to ensure success.

367
APPENDIX A
MeasuringPerformance
andEffectiveness in
the CognitiveDomain
Introduction
M ilitary experimentation in the past has focusedpredominantly around the assessment of
technology, using tradit ional measurementapproaches from the engineering sciences. Yet, theemergence of concepts such as Network CentricWarfare, Information Age warfare, and effects-based operat ions have placed increasingimportance on how well this technology performswithin a more complex socio-cognitive setting.Evidence from the past few years suggests thatthese traditional measurement approaches haveyielded little more than anecdotal insight into how

368 Code of Best Practice for Experimentation
technology and human performance combine ineither productive or unproductive ways. Such data,while interesting, does not provide DoD with thequantitative foundation for assessing the return-on-investment of various transformation initiatives. Asa result, experimenters have begun to search formore appropriate (and quantitative) methods of datacollection that can be usefully applied to addressingperformance in the cognitive domain.
To this end, it is useful to address the state-of-practicefor quantifying performance in the social sciences.Such methods have matured over the past severaldecades to provide socio-cognitive research with thesame types of statistical analysis and modeling toolsused in the physical sciences.
Behavioral Observation andAssessment Scales
Given the “hidden” nature of mental processes,performance in the cognitive domain must beinferred indirectly through behavioral observationor structured interviews. As compared withlaboratory experimentation, conducting militaryexperimentation in a real-world setting presents amore complex measurement chal lenge. Inlaboratory experimentation, cognitive performanceis often reduced to a set of objective measures bylimiting the experimental task to a fairly elementarylevel (e.g., memorize a string of random numbers).In military experimentation, however, participantsengage in a variety of extremely complex cognitivetasks for which there are no straightforward

369Appendix A
object ive performance measures. Hence,measurement of cognitive performance in a real-world setting must be built upon an operationaldefinition of the task process and task outcome.
Responding to this challenge, psychologistsconcluded decades ago that structured methodsmust be developed for reliably observing differentaspects of task behavior and output that wererelevant to real-world task performance. Suchmethods should be capable of assessing bothacceptable and unacceptable performance in a waythat was amenable to statistical analysis andmodel ing. Final ly, i t was recognized thatassessment of cognitive task performance is bestaccomplished by having subject matter expertsjudge the performance. Unfortunately, subject matterexperts are not always readily available to theexperimentation team. Additionally, different subjectmatter experts might not agree on which aspects ofperformance to focus on or what constitutes differentlevels of performance. In response to this challenge,a number of behavioral observation methods weredeveloped – initially for use in investigating humanerror in aircraft accidents, later refined for use injob performance evaluations, and finally broadenedto address a variety of dimensions of performanceinvolving humans, technology, and organizations.These methods were designed to capture expertjudgments of task performance in the form of astandardized set of quantitative measures.
Two such methods, Behavior Observation Scalesand Behavioral-Anchored Rating Scales, arerelevant to military experimentation. These methods

370 Code of Best Practice for Experimentation
can be used as direct observation tools during anexperiment, or applied via structured interviews afteran experiment to quantify important dimensions ofperformance in the cognitive domain. BehaviorObservation Scales (BOS) are simply a checklist ofcritical (and observable) behaviors that correlatewith acceptable task performance. They can beemployed during an experiment to provide aquantitative estimate of how many times acceptabletask performance occurred in a particular setting.However, a more useful tool is represented in theBehavioral-Anchored Rating Scale (BARS). Here,the experimenter can use a BARS to assess thedegree to which some task dimension is performed–typically on a 3, 5, or 7-point scale that extendsfrom unacceptable performance, through minimallyacceptable performance, to outstandingperformance. At each point along the scale, thelevels of performance are “anchored” by detaileddescriptions of what type of behaviors might be seenby an observer in a real-world task setting.Compared to the BOS, a well-developed BARSprovides more utility for conducting an in-depthanalysis of cognitive performance observed duringan experiment.
To illustrate these methods further, the followingdiscussion outlines the manner in which a BARSinstrument is developed for use in an experiment.Similar concepts apply to the simpler BOSinstrument. The procedure for developing BARS isstraightforward; however, it includes a number ofessential steps:

371Appendix A
• Identify a set of critical incidents that exemplifya range of performance in the task area ofinterest. In this step, the experimenter obtainsnarrative descriptions of incidents thatcharacterize examples of unacceptable,minimally satisfactory, good, and excellent taskperformance. These narrative descriptionsshould pertain to observable aspects of thetask performance (e.g., behaviors and output)and should be specific enough to uniquelycharacterize the level of performance. That is,the descriptions should be sufficiently specificto allow different observers to agree on thelevel of performance witnessed.
• Cluster the critical events into meaningfuldimensions. In this step, the experimenterdefines one or more dimensions of taskperformance that allow the critical incidents tobe commonly grouped. This step relies uponjudgment informed by a review of relevantresearch literature.
• Develop a brief, but precise definition of eachtask dimension. In this step, the experimenter isconstructing a framework for observation,assessment, and data collection. As part of thisframework, these definitions help to orient thefocus of subject matter expert data collectorsduring the experiment. It is useful for this stepto involve some level of review by subjectmatter experts (e.g., experienced commandersand staff officers) so that good agreement isachieved on defining each relevant taskdimension.

372 Code of Best Practice for Experimentation
• Develop the behaviorally anchored rating scalefor each task dimension. In this step, theexperimenter typically defines a 3, 5, or 7 pointordinal scale that represents a ranked ratingscale for the task dimension. At each pointalong the scale, example behaviors drawn fromthe set of critical incidents are used to constructa brief narrative anchor for that level ofperformance. By providing a narrativedescription that uniquely identifies each level ofperformance, the scale anchors serve tocalibrate the observation and judgment of thesubject matter expert data collectors. As withthe previous step, this step should involvesome level of review by subject matter experts.
• Train the experiment observers and datacollectors in the use of the anchored ratingscales. In this final step, the experimenterconducts training and rehearsal to ensure theconsistency of observations and ratings amongdifferent data collectors. As part of this step, itis often necessary to “recalibrate” the datacollectors mid-way through an experiment. Thisrecalibration is needed because repeatedobservations of task performance cansometimes produce a downward bias in theratings as data collectors become moresensitized and focused on task error.
Critical Event Framework
While BARS instruments are useful for assessingcertain types of observable task performance, their

373Appendix A
utility is limited for assessing outcome measures inthe cognitive domain. The difficulty arises becauseinternal cognitive functions such as perception,pattern recognit ion, sensemaking, anddecisionmaking are not avai lable for directobservation. At the same time, these internalprocesses are occurring almost continuouslythroughout many experiments. Thus, a strategy isrequired for capturing the most significant aspectsof cognitive activity during an experiment. Onemethod for organizing the collection of cognitiveperformance metrics involves the development of acritical event framework. Based on theories drawnfrom the scientific literature, this framework is anartifact of the experiment and most likely does notexist in the real world. Similar in purpose to BARS,it serves to focus the attention of data collectors onrelevant events within the experiment. However, inthis case, the critical incidents are often obtainedthrough post-experiment interviews with theparticipants rather than being observed in real-timeduring the experiment.
To illustrate this method, consider an experiment inwhich new technology and procedures are beingassessed for improving the collaboration within acommand center. Here, the need arises for ameasurement framework for assessing the level andquality of collaboration observed during theexperiment. Construction of this framework focuseson how certain critical decisions were formulatedand made during the course of the operation.Accordingly, one way of defining each “decisionevent” might be to break it into three basic steps:

374 Code of Best Practice for Experimentation
• Framing the decision (identifying what problemor anomaly is being addressed by the decision,what constraints and givens are applicable, andwhich variables are considered relevant);
• Identifying alternative responses; and
• Evaluating the alternative response.
Next, the experimenter develops a rating scale fordescribing the level of staff collaboration thatsupported the commander in each of these steps.Here, two BARS instruments might be developed toprovide an ordinal scale assessment – one pertainingto the level of participation (e.g., none, one advisor,many advisors) and another pertaining to the qualityof interaction (e.g., low—concurrence only,moderate—solicited options, high—debatedoptions).
Finally, the experimenter defines how the BARS willbe used in the experiment. One option here mightbe to conduct a post-experiment interview with thecommander and his principal staff advisors toidentify the top three to five decisions that shapedthe course of the operation. Then, for each decision“event,” the experimenter would have theparticipants assess the level of collaboration usingthe BARS instrument.

375Appendix A
The Role of StatisticalInference in Measuring andModeling CognitivePerformance
As noted earlier in this chapter, the goal of militaryexperimentation and modeling is to develop anunderstanding of how specific transformationinitiatives relate to improvements in performance andeffectiveness. Thus, the analytic purpose of metricsand data collection is to support the process ofidentifying relationships among specific input andoutput variables. In the case of many processes inthe physical and information domains, theserelationships are largely deterministic in nature.Assuming our measurements to be accurate, wewould expect to observe precisely the sameexperimental relationship on one day as we wouldon another. If the results vary, we look for additionalvariables or factors that explain the difference andthen add these to our model. Scientists do not likeunexplained variability, and this approach has workedwell in many areas of research – up to a point!
Two problems arise, however, as experimentsaddress processes with greater complexity. First, wemight not be able to conceive of enough variablefactors to explain all of the variability in the processwe are observing. Second, we cannot be sure thatour existing metrics accurately reflect thephenomenon that we intended to measure. Thus,despite the best intentions of the research, we areleft with a certain percentage of the process variabilitythat we cannot yet explain. So how does one draw

376 Code of Best Practice for Experimentation
conclusions about what was found or not found in aparticular experiment? This is the basic challengefacing those who desire to experimentally measureand then model performance in the cognitive domain.
One approach taken by operations researchanalysts in dealing with this problem has been totraditionally assume away the relevance of cognitiveprocesses and variables. Hence, early combatsimulation models often ignored command andcontrol issues or accounted for them by means ofsimplified mathematical constructs (e.g., Petri nets).As the field of artificial intelligence matured, thesemathematical constructs were replaced by predicatecalculus (“if then”) rule sets in an attempt to modelthe cognitive logic inherent in certain militarydecision processes. The problem with thisapproach, however, is that the size of these rulesets grew tremendously (e.g., over 20,000 rules todescribe a battalion headquarters) but still did notadequately “explain” output variability. In othercases, analysts simply defined cognitive processesas a stochastic “black box.” Random numbergenerators were used to select outcomes from arange of possibi l i t ies so that the internalmechanisms of these processes could be ignored.At the end of the day, however, modelers can onlymodel what can be discovered empirically throughexperimentation or real-world experience. Thisbrings the discussion back to the question of howto approach the measurement and modeling ofcognitive performance.
Over the years, the goal of many social scientists(those dealing with social quantification) has been

377Appendix A
similar to that of operations research analysts: themeasurement and modeling of complex phenomena.The traditional tool for doing this has been statisticalinferential methods of analysis. The use of suchmethods allows the researcher to do three things:
• Estimate the strength of relationship that existsamong a set of process variables/factors andthe performance/effectiveness outcomes of theexperiment. Applied to transformationexperiments, this estimate can provide insightas to whether or not specific transformationinitiatives have produced a practicalimprovement in some military task or function.At the same time, statistical modelers can linkvarious estimates of this type together to form acausal path model that predicts how theseimprovements translate upwards to higherlevels of force effectiveness and policyeffectiveness;
• Describe the level of statistical confidence onehas in estimating these relationships from thelimited amount of data collected during anexperiment. This level of statistical confidencecan be used as an indicator of whetheradditional experimental trials are needed toassure decisionmakers that the estimatedimprovement is real; and
• Characterize the degree to which variability inthe outcome measure(s) has been “explained”by the different process variables and factors.This characterization provides the experimenterwith insight regarding which variables or factors

378 Code of Best Practice for Experimentation
were the most influential in producing theimprovement – a particularly useful piece ofinformation when multiple transformationchanges are being investigated simultaneously.Conversely, the amount of outcome variabilitynot explained by the experiment is a usefulindicator of the degree to which vonClausewitz’s “fog and friction of warfare” arestill operating.
While a number of simple, nonparametric analysismethods (e.g., Mann-Whitney U Test, Sign Test, andChi-Square Test) exist for analyzing data, mostcurrently accepted methods of statistical analysis areall based upon an underlying mathematical equationcalled the General Linear Model (GLM). The generalform of this model is
youtcome
= β1x
1 + β
2x
2 + β
3x
3 + … + βιxi
+… + βnx
n
where,
youtcome
= the level of predicted performanceoutcome,
xi = the level of the ith predictor variable or factor,
βi = the estimated linear weight of the ith predictorvariable, or factor derived from the experimentaldata, and
n = number of predictor variables or factorsconsidered.
The GLM provides the experimenter with a methodfor predicting the level of system performance orforce effectiveness (y
outcome) that results from

379Appendix A
combining specific levels or values of each of the npredictor variables or factors. These predictorvariables/factors can represent either process inputs(e.g., presence of a new information display) orintermediate process variables (e.g., level ofcollaboration achieved). Obviously, increasing thetypes of measures collected during an experimentincreases the number of terms in this equation and(potentially) improves the quality of prediction.
The model is called “linear” because this estimate isproduced by constructing a “best fit” n-dimensionalline through a scatter plot of the empirical datacollected for each of the variables or factors duringeach experimental trial. The term “best fit” impliesthat this n-dimensional line is adjusted until itminimizes the squared sum of error between eachestimated outcome point and the outcome actuallyobserved in a given trial. The resulting n-dimensionalline is described by the various estimated β
icoefficients that essentially represent the scalingfactors for each input variable or factor. Theestimated β
i coefficients are normalized so that they
can be compared in relative size to provide anindication of which variables and factors impactgreatest on outcome.
A number of different manifestations of the GLM havebeen traditionally used in scientific research.Historically, a special case of the General LinearModel – called Analysis of Variance (ANOVA) - hasenjoyed popular use in experimental research.Typically, ANOVA is used as a statistical test todetermine if a single input factor – say, comparisonof a new information display against a baseline

380 Code of Best Practice for Experimentation
condit ion – produces a rel iable change inperformance outcome between two groups of trials.As part of this method, the experimental differencesfound over each group of trials are used to constructan F-value that can be related to different levels ofstatistical significance (expressed in terms of theprobability that the observed difference in outcomecould have been produced by chance). The desireof the experimenter is to achieve an F-value thatreflects less than an β=0.05 probability of chanceoccurrence (Note: in some instances researchersdemand a more stringent value of β=0.01). Variationsof the ANOVA test have been developed bystatisticians to account for pre-existing conditions(Analysis of Covariance, ANCOVA), multiple inputfactors (Multiple Analysis of Variance, MANOVA), anda combination of multiple input factors andpreexisting condit ions (Mult iple Analysis ofCovariance, MANCOVA).
ANOVA-type methods have been traditionally usedby researchers to justify the academic publicationof their experiment findings. However, limitationsof these methods are an issue for mil i taryexperimentation. First, these methods apply onlywhen the input variables and factors arerepresented as discrete cases, not continuousvariables. Second, these methods tel l theexperimenter only if statistical significance wasachieved or not, and do not provide any sort ofindicator of the strength of the relationship found.Thus, this method ignores the fact that anexperimental finding may be statistically significant(and, hence, publishable in a scientific sense), butnot reflect a real practical finding. Finally, as more

381Appendix A
factors and levels of each factor are considered inan experiment, ANOVA methods can become quiteexhausting to employ.
Given the demand for a better analytic tool, interesthas grown during the past several decades in a moregeneralized type of statistical analysis, MultivariateRegression / Correlation Analysis (MRC). This moregeneral form of analysis offers several advantagesover the ANOVA methods used in academicresearch. First, the MRC methodology can acceptcontinuous variables and factors as input, thuspermitting more detailed types of measurements infield experiments. Past studies have shown that theresults of multivariate regression/correlation analysisgenerally hold up even when the predictor variablesdo not exactly meet the rigorous definition of aninterval scale or ratio scale variable. Second, theexperimenter can employ transformed variables toreflect non-linear relationships (e.g., logarithmicscaling) and “dummy coded” variables to reflectdiscrete cases or options. This extends multivariateregression/correlation analysis to address morecomplex relationships among the experimentationvariables.
The GLM also provides experimenters with a visiblemeasure of modeling progress. As with the morerestricted ANOVA methods, the GLM allows one toestimate the statistical significance of the model –that is, compute the likelihood that the experimentmodeling results were produced by random chance.In addition to yielding a prediction model of the formy
outcome= Σβ
ix
i, the GLM also provides a measure
called the total correlation coefficient, [0<R<1], that

382 Code of Best Practice for Experimentation
reflects the degree of variability of youtcom
that hasbeen accounted for in the prediction equation. Inpractical terms, R2 provides a direct estimate of thepercentage of outcome variability “explained” by theset of n predictor variables or factors considered inthe model. For example, an MRC prediction modelyielding a value of R=0.75 would imply that themodel has accounted for (0.75)2 = 56.25% of theoutcome variability observed in an experiment. Thismight suggest that the researchers should eithersearch for additional explanatory measures and/orconduct additional experiments to raise the level ofprediction. In this manner, experimentation can usethe R2 metric as a measure of campaign progressor modeling success.
Sometimes the experimenter will collect measuresthat are themselves correlated. For example, if onemeasured both the quality of situation awareness andsituation understanding in a given experiment, theywould expect to find that these two measures arecorrelated with one another. If they were to then useboth measures as predictors of decision quality, theywould find that their predictive contributions overlapsomewhat. To address this issue, analysts typicallyemploy the MRC modeling approach in a hierarchicalfashion – adding various sets of predictor variablesand factors to see which combination yields the bestprediction equation. At the same time, this procedureallows the analyst to ignore other, redundantvariables or irrelevant variables that do notsignificantly add to the prediction.
Other forms of the MRC model have been developedby statisticians to provide the experimenter with

383Appendix A
addit ional tools for exploring and modelingrelationships. Among these are the following:
Canonical Correlation This method allows theexperimenter to construct a model with multiple typesof outcome measures. Canonical correlation isconceptually similar to MRC, except that it examinesthe prediction of m outcome measures instead of asingle outcome measure. Hence, the procedureinvolves the estimation of two sets of β coefficients,one set for the predictor variables and factors and asecond set for the outcome measures. Canonicalcorrelation provides the experimenter with a morepowerful tool for predicting operational performanceand effectiveness in more complex types ofoperations –e.g., effects-based operations.
Factor Analysis This method al lows theexperimenter to explore sets of measures collectedduring an experiment and to statistically reducethem into a smaller set of composite measures.Using other considerations and backgroundinformation, the experimenter can then developinterpretations of each composite variable todevelop a deeper understanding of the basicfunctions or constructs operating within an overallsocio-technical process. Such analyses assist thisstage of experimentat ion by helping theexperimenter to develop more abstract and simplerexplanations of how the various transformationvariables and factors are combining and interactingto produce improved performance or effectiveness.
Causal Path Analysis Causal path analysis is astraightforward extension of MRC in which the

384 Code of Best Practice for Experimentation
experimenter is interested in constructing a morecomplex, multi-level process model. As discussed inthe last section of this chapter, causal path analysisprovides a technique for combining data from a seriesof experiments, with each experiment addressing adifferent portion of the overall process
Specialized Analysis Models Other specializedmodels exist for specific types of statistical modelinginquiries. For example, discriminant analysis,logistics regression, and probit analysis reflectdifferent methods for classifying outputs. Techniquessuch as multidimensional scaling offer a method foridentifying important underlying dimensions in an n-dimensional data space. Methods such as Kaplan-Meier survival analysis provide a method ofpredicting time-to-onset of specific outcomes.
In short, there exists a wide range of statisticalinference methods for translating experimental datainto empirical prediction models. Commerciallypackaged models such as SPSS (social sciences),BMDP (biomedical sciences), Genstat (agriculture),and Systat (psychology) offer a basic set of linearmodeling procedures that are based on community-accepted criteria for achieving goodness-of-fit in themodeling process. As such, these packages offermilitary experimentation with a robust set of toolsquite adequate for investigating f irst-orderrelationships. Through the use of transformationfunctions, these same models can be used to identifya wide range of nonlinear relationships underlyingexperimental data structures.

385Appendix A
Their ease of use, however, is offset somewhat bytheir limited ability to address more complexmodeling issues, such as non-normal distributions,heteroscedasticity, statistical bootstrapping, andcross-val idat ion. Accordingly, stat ist ic iansinterested in more sophisticated types of analysisare more apt to use general purpose modeling toolssuch as GLM for data exploration and statisticalmodeling. At the end of the day, however, themodeling of cognitive processes comes down towhat level of empirical evidence decisionmakers arecomfortable with in making program and policydecisions. At one extreme, the academic practiceof publ ishing research with relat ively lowpredictabi l i ty (e.g., R2 = 0.4) is clearly notacceptable for mil i tary experimentation andmodeling. At the other extreme, expecting empiricalmodeling to achieve nearly perfect predictability(e.g., R2 = 0.9) is unrealistic given the complexityof human behavior at the individual andorganizational levels. In the end, the decision restsupon two interrelated sets of questions – one setthat addresses practical significance and the otherset that addresses statistical significance:
• What is the estimated magnitude of theperformance/effectiveness increase, and is thesize of this increase of practical significance tothe military?
• Do we sufficiently understand what influencesperformance/effectiveness, and has theexperimental research accounted for asufficient number of variables and factors?

386 Code of Best Practice for Experimentation
Answering these questions requires a combinationof good science and good judgment. At some point,the marginal return of conducting additionalexperiments or modeling investigations is not worththe added time and cost. In some cases, time andattention are better spent addressing new questionsand challenges rather than refining ourunderstanding of old ones. But, ultimately, this is adecision that is collectively made by the sponsorsand stakeholders within the experimentationcommunity.

387
APPENDIX B
MeasurementHierarchy
Introduction
M ilitary transformation experimentation shouldbe built upon a multilevel foundation of metrics
that (1) acknowledges the contributions of bothtechnical and human performance and (2) tracesthese contributions up through various casualpathways as they contribute to mission and policyeffectiveness. One such hierarchy that has recentlyemerged from work within NATO researchcommunity and the DoD Command and ControlResearch Program is shown in Figure B-1. Thisf igure depicts nine specif ic levels at whichmeasurements can be taken to provide insightregarding the impact of specific transformationinitiatives.
As one moves from the rudimentary level of technicalperformance to the higher level of policyeffectiveness, it is clear that different types of metricsare required and that different approaches must betaken to observing and measuring outcome in anexperiment or analysis. Generally speaking, thesedifferences can be addressed in terms of:

388 Code of Best Practice for Experimentation
Figure B-1. Hierarchy of Experimentation Metrics
• The context or focus of observation andmeasurement in the experiment;
• The types of influencing factors or variablesthat must be controlled or accounted for;
• The basic dimensions by which performance oreffectiveness are assessed;
• The timescale or event focus for conducting theobservation and assessment;
• The degree of observational transparency thatdictates the level of probing and reasonedjudgment required for making the assessment;and

389Appendix B
• The types of observation and assessmentapproaches that can be employed eitherbefore, during, or after the experiment.
The following sections summarize and compare theeach level of measurement in terms of these sixissues.
Real-Time Information andKnowledge
At this level, metrics address the collection, storage,movement, and interpretation of reports and sensordata received from the battlespace. Data istransformed into information by placing it in ameaningful operational context. Information istransformed into knowledge by drawing from itrelevant conclusions concerning current events,activities, and entities within the existing battlespace.These processes occur at every level within thecommand hierarchy (e.g., tactical, operational,strategic); however, metrics will typically correspondto that level of command and control of interest inthe specific experiment. Figure B-2 summarizes themeasurement issues for this level.
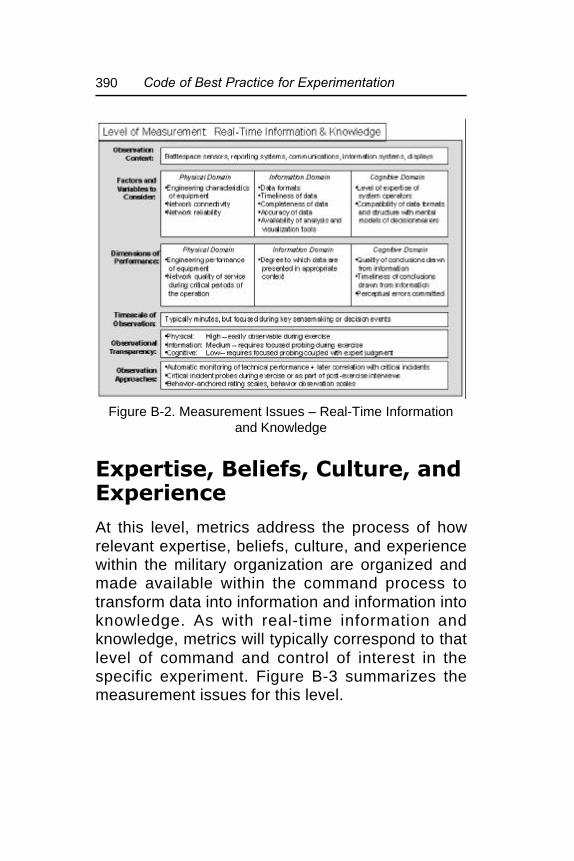
390 Code of Best Practice for Experimentation
Figure B-2. Measurement Issues – Real-Time Informationand Knowledge
Expertise, Beliefs, Culture, andExperience
At this level, metrics address the process of howrelevant expertise, beliefs, culture, and experiencewithin the military organization are organized andmade available within the command process totransform data into information and information intoknowledge. As with real-time information andknowledge, metrics will typically correspond to thatlevel of command and control of interest in thespecific experiment. Figure B-3 summarizes themeasurement issues for this level.

391Appendix B
Figure B-3. Measurement Issues – Expertise, Beliefs, Culture,and Experience
Individual Awareness andUnderstanding
At this level, metrics address the process of individualsensemaking – the integration of relevant militaryexperience and expertise with real-time battlespaceknowledge to generate individual awareness andunderstanding. Awareness can be defined asknowledge that is overlaid with a set of values,objectives, and cultural norms that are unique to theindividual, to a community of expertise within thecommand process (e.g., intelligence, logistics, airsupport), or to an individual command (in the caseof joint/coalition operations). Understanding movesbeyond awareness by requiring a sufficient level ofknowledge to (1) draw inferences about possible
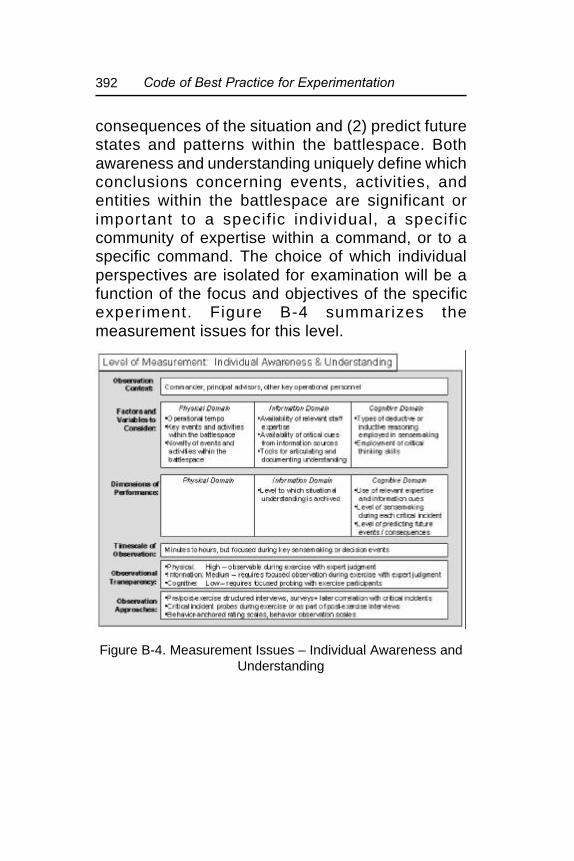
392 Code of Best Practice for Experimentation
consequences of the situation and (2) predict futurestates and patterns within the battlespace. Bothawareness and understanding uniquely define whichconclusions concerning events, activities, andentities within the battlespace are significant orimportant to a specific individual, a specificcommunity of expertise within a command, or to aspecific command. The choice of which individualperspectives are isolated for examination will be afunction of the focus and objectives of the specificexperiment. Figure B-4 summarizes themeasurement issues for this level.
Figure B-4. Measurement Issues – Individual Awareness andUnderstanding

393Appendix B
Collaboration
At this level, metrics address the process structuresand mechanisms required to integrate differentbodies of knowledge and different perspectives intoa relevant common operating picture. These differentbodies of knowledge and perspective can exist withina command headquarters or across componentcommands within a joint or coalit ion force.Collaboration serves to both (1) reconcile differentgoals/objectives of the participants and (2) enhanceproblem-solving capability by bringing to bearmultiple perspectives and knowledge sources.Collaboration can take many different forms and beinfluenced through a number of dimensions, includingmedia, time, continuity, breadth, content richness,domain structure, participant roles, and linkagesacross which it takes place. Collaboration isnecessary because rarely will any single individualor community of expertise be capable of dealing withthe complexity of military operations. Figure B-5summarizes the measurement issues for this level.

394 Code of Best Practice for Experimentation
Figure B-5. Measurement Issues – Collaboration
Shared Awareness andUnderstanding
At this level, metrics address the degree to whichthe relevant bodies of knowledge and perspectiveshave been usefully integrated and focused on acommon problem or task faced by the organizationas a whole. In this regard, shared awareness andunderstanding are the result of sensemakingextended to the organization level. As the nature ofproblems and tasks vary over time in a militaryoperation, so will the focus and scope of sharedawareness and understanding. Contrary to popularbelief, shared awareness and understanding isproblem/task-specific and does not imply a universalsharing of all knowledge or experience. Figure B-6summarizes the measurement issues for this level.

395Appendix B
Figure B-6. Measurement Issues – Shared Awareness andUnderstanding
Decisionmaking
At this level, metrics address the process oftranslating understanding into action – all within theframework of the mission/task goals and objectivesarticulated in command intent. While the generaldimensions of quality and timeliness apply todecisionmaking, there exist other importantcharacterist ics that can be measured in anexperiment. For example, decisions can be arrivedat through a number of different socio-cognitivestrategies, depending upon (1) time available, (2)the degree of situation recognition that derives frompast experience, and (3) the nature of situationalignorance (e.g., too much/little information, toomany/few explanatory frameworks). Thus, it is
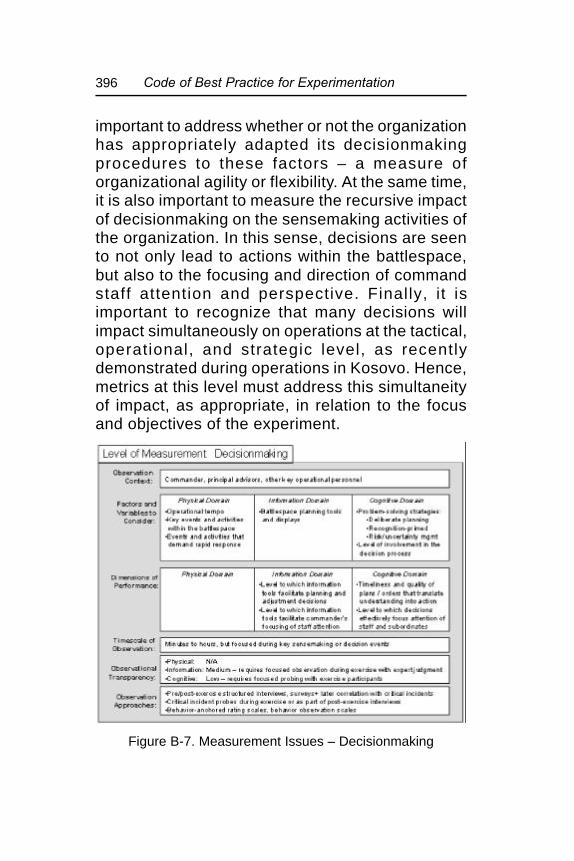
396 Code of Best Practice for Experimentation
important to address whether or not the organizationhas appropriately adapted its decisionmakingprocedures to these factors – a measure oforganizational agility or flexibility. At the same time,it is also important to measure the recursive impactof decisionmaking on the sensemaking activities ofthe organization. In this sense, decisions are seento not only lead to actions within the battlespace,but also to the focusing and direction of commandstaff attention and perspective. Finally, it isimportant to recognize that many decisions willimpact simultaneously on operations at the tactical,operational, and strategic level, as recentlydemonstrated during operations in Kosovo. Hence,metrics at this level must address this simultaneityof impact, as appropriate, in relation to the focusand objectives of the experiment.
Figure B-7. Measurement Issues – Decisionmaking

397Appendix B
Force Element Synchronization
At this level, metrics address the degree to whichspecific military functions and elements (e.g.,reconnaissance and surveillance, informationoperations, maneuver/assault, logistics, civil affairs)are coordinated to achieve the desired operationaleffects with maximum economy of force. Because thefocus at this level is on operational effects (e.g.,combat force attrition, infrastructure damage, areadenial, point target destruction, information denial,civilian population management, humanitarian relief),it is important that the metrics accurately reflect theconsequences of each effect in the physical,information, and cognitive domains of interest.Synchronization is a multi-dimensional phenomenon.Hence, metrics at this level must addresssynchronization from a variety of perspectives suchas (1) coordination/harmonization of componentgoals and subtasks, (2) coordination of schedules/timing, (3) geographic coordination, and (4)coordination of contingency actions taken inresponse to emergent situations. Synchronizationalso assesses the level of military force maturity byilluminating the degree to which joint operations haveevolved from the strategy of simple deconfliction offorce elements to the strategy of creating synergisticeffects among force elements. Figure B-8summarizes the measurement issues for this level.

398 Code of Best Practice for Experimentation
Figure B-8. Measurement Issues – Force ElementSynchronization
Military Task / MissionEffectiveness
At this level, metrics address the degree to whichthe operational effects combine within a militarycampaign to achieve the desired end-state or impacton the adversary’s will and capabilities. Thus,success at this level of measurement is highlyscenario-dependent and is influenced not only byU.S. force capabilities, but also by the capabilitiesof the adversary, the presence of third-partyinterests, the geographic region of operation, andthe stated goals and objectives of the military taskor mission. In addition, the relative contribution ofdifferent weapons systems, command and controlsystems, doctrine, training, leadership and other
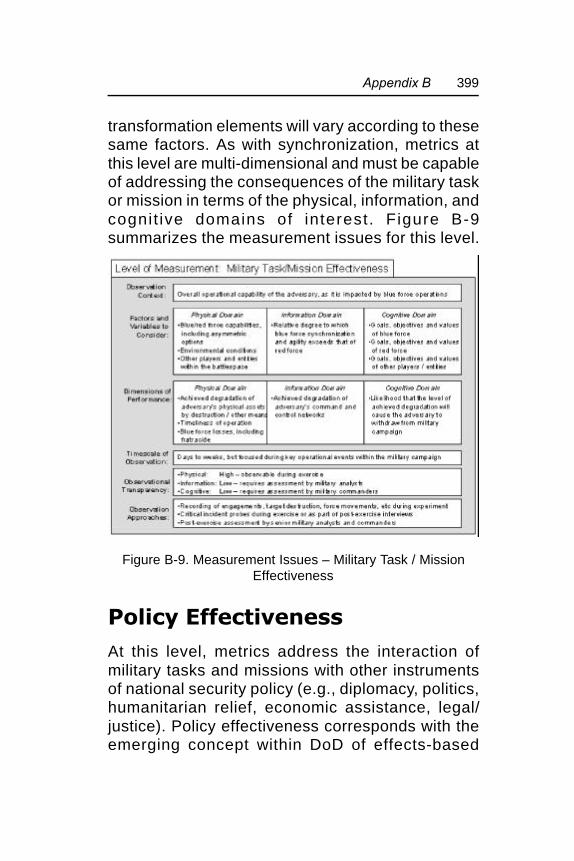
399Appendix B
transformation elements will vary according to thesesame factors. As with synchronization, metrics atthis level are multi-dimensional and must be capableof addressing the consequences of the military taskor mission in terms of the physical, information, andcognit ive domains of interest. Figure B-9summarizes the measurement issues for this level.
Figure B-9. Measurement Issues – Military Task / MissionEffectiveness
Policy Effectiveness
At this level, metrics address the interaction ofmilitary tasks and missions with other instrumentsof national security policy (e.g., diplomacy, politics,humanitarian relief, economic assistance, legal/justice). Policy effectiveness corresponds with theemerging concept within DoD of effects-based

400 Code of Best Practice for Experimentation
operations – as characterized within recent counter-terrorist operations against al-Qaida and otherinternat ional terror ist groups. This level ofmeasurement represents a potentially complexchallenge because of the often subtle manner inwhich these instruments combine to producecoercion and influence against an adversary. Thus,metrics must be capable of reflecting the degree ofdeconfliction, cooperation, or synergy present whenmilitary operations are combined with otherinstruments to achieve specific policy goals. At thesame time, metrics at this level must reflect anumber of real-world considerations that impingeupon the military operations –e.g., the presence,contributions, and conflicting goals of coalitionpartners, private-voluntary relief organizations, non-governmental organizations, and transnationalorganizations in the battlespace. Figure B-10summarizes the measurement issues at this level.
Figure B-10. Measurement Issues – Policy Effectiveness

401
APPENDIX C
Overview ofModels andSimulations
Introduction
A model is defined to be a physical, mathematical,or otherwise logical representation of a system,
entity, phenomenon, or process.1 Conceptually,military experiments use models of postulated futuremilitary situations to support the full range ofexperimentat ion types, including discovery,hypothesis testing, and demonstration experiments.Simulations are defined as the process of designinga model of a real-world system and conductingexperiments with this model for the purpose eitherof understanding the system or of evaluating variousstrategies (within the limits imposed by a criterionor set of criteria) for the operation of the system.2
In considering modeling and simulation (M&S) “BestPractices” to support experimentation, users shouldalways bear in mind that “all models are wrong.Some are useful.”3 The discussion in this chapter isintended to help members of multidisciplinary

402 Code of Best Practice for Experimentation
experimentation teams better understand models,and guide them through the process of selecting,applying, or possibly developing models andsimulations to support the experimentation process.The overall goal is to increase the likelihood ofhaving “useful” models.
Models can be as simple as conceptual flow chartsof decision processes, or as complex as large force-on-force combat simulations executing manythousands of lines of software code. Models at bothends of this spectrum can and should be usedthroughout the experimentation process. Anemerging concept in the DoD experimentation,testing, and acquisition communities that reinforcesthis point is called the model-experimentation-modelparadigm.
In order to use models successfully inexperimentation, model(s) should meet three basictests:
• Models must be clearly defined. Theexperimenter must be able to determine what is(and is not) being described in the model(s)quickly and unambiguously.
• The contents of models must be logicallyconsistent. The logic, algorithms, and data thatdescribe the phenomenology of interest mustbe compatible. If this is not true, the “answer”the model and accompanying analysis generatecould be incorrect or misleading. Seeminglysimple inconsistencies can potentially havecatastrophic consequences, especially inwarfare.

403Appendix C
• Models must be transparent. When models areapplied and begin generating results,transparency allows team members to betterinterpret model behavior, identify cause andeffect relationships, and obtain insights. This isespecially important in C2 experimentationbecause emerging network-centric doctrine andenabling technologies may result in somecounterintuitive outcomes that will requireexploration.
Overview of Models andSimulations
The different professional disciplines that areinvolved in modeling and simulation have subtle butfundamental differences in the meaning of field-specific terms. There is no “right” answer in relationto these differences. It is important, however, thatthose involved in a particular experimentation effortreach a clear and common understanding of termsand the implications of those terms.
Types of Models
There are many taxonomies in different professionalcommunities categorizing different types of models.This discussion addresses predominantly descriptivemodels, and draws a distinction between static anddynamic models. Descriptive models focus onproviding insight into how a system is, or how itbehaves. Static models emphasize the logical,physical, or conceptual layout of a system. Thesemodels focus on the system’s components, their

404 Code of Best Practice for Experimentation
relationships, and their interactions. Examples ofrelevant static models are:
• Static Conceptual models - IDEF XX, and theDoD Architecture Framework; and
• Dynamic models (simulations) - which introducethe notion of time, and explore the behavior ofthe system as the components interact.(Examples include colored petri nets,executable architectures, systems dynamicsmodels, and combat simulations.)
Models and simulat ions are ideal izedrepresentations of systems (or networks ofsystems). Good models capture the essentialproperties and facilitate insight into the system. Animportant consideration in developing models ofcomplex systems is the identification of what arethe “essential properties” of the system. These willbe situation dependent, and should be carefullyaligned with the goals of the experiment.
Static Models
Descriptive static models describe how an entity orsystem is designed, or is expected to behave. Onebroadly applied static model is the DoD ArchitectureFramework. The products in the DoD ArchitectureFramework are an excellent example of how differentcommunities involved in experimentation havediffering views of “essential properties.” Theoperational, system, technical, and architecturalviews of a modeled military system all providedifferent views of the same thing. As a matter ofpractice, it is essential that the different views be

405Appendix C
consistent, balanced, and appropriately resolved tosupport an experiment.
A conceptual flow chart is another specific exampleof a simple static model. These models can be usedquickly and easily to depict important physical andinformational relationships that might exist in thesystem. Figure C-1 is an example of a conceptualflow chart that shows the l inkage models ofinformation value in a command and controlsystem. These models are most useful early in theexperimentation process to support early conceptdevelopment, and to communicate complexconcepts to stakeholders that may not be familiarwith overall concepts. Their strength is theirsimplicity. They are domain independent, can bedeveloped with minimal resources, and arestraightforward to understand. The weakness ofconceptual f low models is in thei r l imi tedextensibility. As concepts and the supportingmodels become more complex, these types ofmodels can become unwieldy and confusing.
IDEF type modeling is a logical extension of simpleconceptual models, and a possible next step oncethe limits of a simple model are reached. IDEFdiagrams have syntactical and structural rules thatallow the models to represent more complex systemsclearly than straight graphical models.
A supplemental feature of IDEF models is an abilityto be constructed hierarchically. A single node cancontain another network that describes the processin more detail. IDEF models are best suited to refining
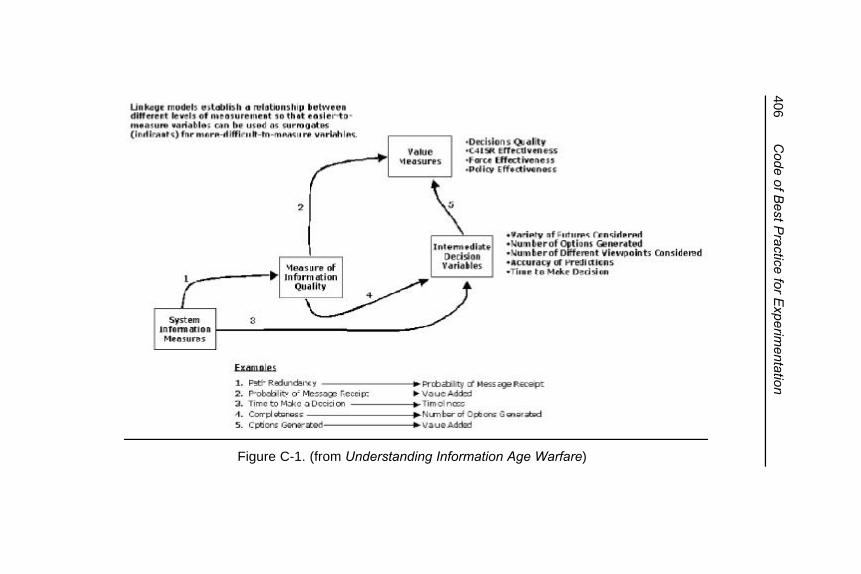
406C
ode of Best P
ractice for Experim
entation
Figure C-1. (from Understanding Information Age Warfare)

407Appendix C
operational concepts early in the discovery phase ofexperimentation.
Dynamic Models (Simulations)
Dynamic models, or simulations, are logical ormathematical abstractions of a “real” system thatdescribe, explain, and potentially predict how “real”systems will behave over time. Within the context ofexperimentation, it is useful to think about threecategories of simulations:
• Live simulation - These use human role playersinteracting with actual or postulated C2systems within some artificial scenario. FieldExercises are an example of a live simulation.
• Virtual simulations - Sometimes referred to as“human-in-the-loop,” these simulations provideautomated players and forces that interact withlive subjects. The JTASC Confederation is anexample of a virtual simulation.
• Constructive simulations - These are closedform simulations designed to run a scenario orset of scenarios end-to-end without humanintervention. JWARS, ITHINK, and executableprocess models are examples of constructivesimulations.
Constructive Combat Simulations
Most “standard” constructive combat models in theDoD were designed and developed during the ColdWar. They are attrition-based, usually have onlylimited ability to realistically represent maneuver,

408 Code of Best Practice for Experimentation
and only rarely consider information flows in relationto command and control. Because of this, thesemodels have very limited utility in support ofexperimentation (and analysis) in support oftransformation. These simulations can be usedeffectively to provide context for some experiments.For example, a simulation describing strategic flowcould give first order estimates on force arrivals insupport of a game.
There are some ongoing large constructivesimulation development efforts that hold somepromise for experimentation. JWARS representsexplicitly the operation of key sensor systems, flowof information, and operational command andcontrol. The algorithms provided for use in thesimulation have been (or are in the process of being)validated by the services. That said, it is a complextool that is still immature, and has limited scenariodata. JWARS would be an appropriate tool tosupport large-scale wargames, and to providecontext for more localized experiments. It is tooresource-intensive for early discovery experiments,and focused hypothesis testing.
Executable Architectures (Process Models)
A quickly emerging and maturing class of simulationdevelopment environments are called processmodeling tools. These tools allow one to rapidlyprototype a model of a C2 concept, and then toexecute simulations of how that operational conceptmight behave. Commercially available tools such asG-2 / rethink, Extend, and Bona Parte are already inuse throughout the M&S and experimental

409Appendix C
communities. The advantages of these tools are thatthey allow rapid prototyping, and are resourceefficient compared to live or virtual simulationtechniques. These tools are very appropriate insupport of discovery and early hypothesis testingtypes of experiments. The graphical features allowdomain experts to work more directly in the modeldevelopment and analysis process. A disadvantageis that the models produced are often “one of.”Therefore, their quality control can vary greatly, andcan be problematic to V&V in accordance with theDoD instructions.
Agent-Oriented Modeling
Agent-Oriented Modeling is an increasinglypopular subtype of the constructive simulationtechnique that allows for entities to act (andinteract) as “independent actors” in a simulatedenvironment. The description and representationof the C2 process through agent modeling andprogramming techniques is a dist inguishingfeature. Modeling of the C2 process as a group ofagents, based on artificial intelligence concepts,favors the modeling of the cognitive nature ofcommand tasks. Agents can be implemented, inan object-oriented environment, as either objects(e.g. , actor or “applet” type of agents) oraggregates of objects (coarse-grain agents). Suchagents interact wi th each other through amessaging infrastructure. The term agent-orientedmodeling is used as a way of capturing this idea.
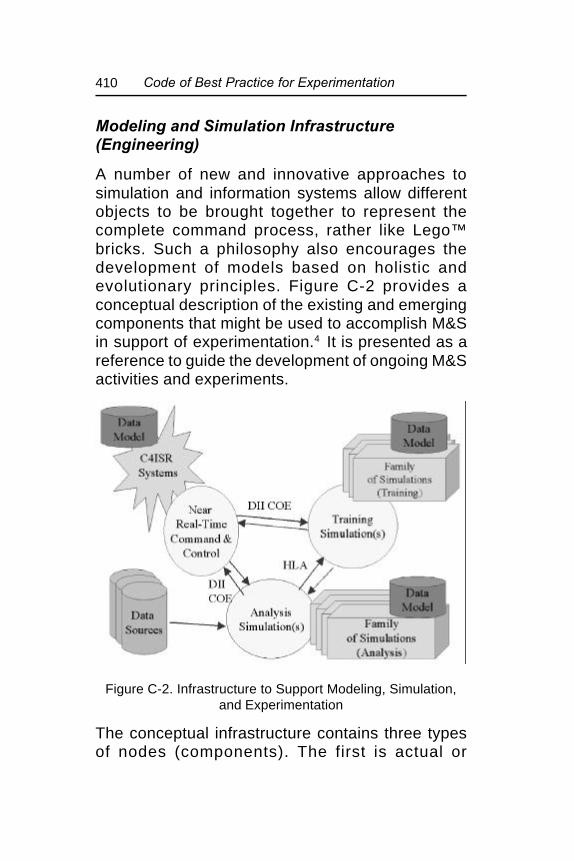
410 Code of Best Practice for Experimentation
Modeling and Simulation Infrastructure(Engineering)
A number of new and innovative approaches tosimulation and information systems allow differentobjects to be brought together to represent thecomplete command process, rather like Lego™bricks. Such a philosophy also encourages thedevelopment of models based on holistic andevolutionary principles. Figure C-2 provides aconceptual description of the existing and emergingcomponents that might be used to accomplish M&Sin support of experimentation.4 It is presented as areference to guide the development of ongoing M&Sactivities and experiments.
Figure C-2. Infrastructure to Support Modeling, Simulation,and Experimentation
The conceptual infrastructure contains three typesof nodes (components). The first is actual or

411Appendix C
postulated command and control systems. Theseallow domain experts to serve as subjects andbehave as realist ical ly as possible underexperimental conditions. The second node consistsof high-resolution virtual simulations and moretraditional training simulations. These simulations,such as the JTASC training confederation (JFAST)or the emerging JSIMS simulations, often providethe context that stimulates the C2 systems andadjudicates interactions among entities. Finally, theinfrastructure contains constructive, or analysis,simulations. The data repositories indicate that allof these tools should be populated with consistentdata (See Chapter 9).
There are two specific types of links identified toconnect the components. The first, the DII COE,provide a set of standards that facilitate meaningfulcommunication between the different types ofapplications identified in the nodes. Similarly, theHLA provides a conduit and set of standards thatfacilitates communications between simulations.
Model “Translators”
Recent advances in the state-of-the-art of modelingand s imulat ion support systems that havetremendous potential to support experimentationare model translators. There are commercial andGOTS tools emerging that allow analysts andengineers to develop different, but consistent,views of the same system. The use of translatorscan facilitate consistent views between static anddynamic models of systems.5

412 Code of Best Practice for Experimentation
Linking of Performance Models to EffectivenessModels
One approach to using the infrastructure describedis to create a structured hierarchy of models andan audit trail from C2 systems, processes, andorganizations to battle outcome. The objective isto create supporting performance level models ofpart icu lar aspects of the process (e.g. ,communications, logistics) which can be examinedat the performance level. These supporting modelscreate inputs to higher level force-on-force models.This ensures that the combat models themselvesdo not become overly complex.
Figure C-3. Model Hierarchy
For example, a detailed model of the intelligencesystem can be very complex, if we wish to take intoaccount the flow of intelligence requirements,taskings, collection processes, fusion processes,and intelligence products. In order to analyze the

413Appendix C
impact of intelligence, it is important to have all ofthis detail, but it does not necessarily have to berepresented explicit ly in the main model. Asupporting model that captures all of this detail canbe created in order to produce outputs at themeasures of effectiveness level, such as speed andquality of intelligence. These can then form inputsto the main simulation model. The main model thentakes these into account in producing its ownoutputs. These will now be at the measures of forceeffectiveness level. Examples include friendlycasualty levels, adversary attrition, and time toachieve military objectives.
C2 Modeling Guidelines
A general set of C2 modeling guidelines based ona set of requirements should be reviewed by theexperimentation team and may be a good candidatefor peer review. The primary objective of theseguidelines is to relate C2 processes and systemsto battle outcome. In order to do this, a model mustbe capable of explicitly representing the collection,processing, dissemination, and presentation ofinformation. These capabilities, therefore, lead tothe set of C2 modeling guidelines described below.It should be noted that these requirements are notyet fully satisfied by any existing model.
These guidelines should be considered part of themodel selection and development processes for aspecific problem. The experimentation team shouldbe conscious about an explicit or implicitimplementation of the consideration points. The C2

414 Code of Best Practice for Experimentation
modeling guidelines, as presented in the NATOCOBP for C2 Assessment, include:
• Representation of information as a commodity.This consideration is the most critical anddifficult to implement, but is the foundation forthe other guidelines, as well as for the modelitself. Information should be considered as aresource that can be collected, processed, anddisseminated. It includes information aboutboth adversary and friendly forces, as well asenvironmental information such as weather andterrain. Information should posses dynamicattributes such as accuracy, relevance,timeliness, completeness, and precision. Thesevalues should affect other activities within themodel, to include, when appropriate, combatfunctions;
• Representation of the realistic flow ofinformation in the battlespace. Information hasa specific source, and that source is usually notthe end user of the information. A requirementexists, therefore, to move information from oneplace to another. Communications systems ofall forms exist to accomplish this movement.These systems can be analog or digital.Information can be lost and/or degraded as itflows around the battlespace. The modelshould represent the communications systemsand account for these degradation factors as itrepresents information flow;
• Representation of the collection of informationfrom multiple sources and tasking of

415Appendix C
information collection assets. This guidelineapplies equally to adversary and friendlyinformation. For the collection of adversaryinformation, the model should represent a fullsuite of sensors and information collectionsystems, and the ability of these systems to betasked to collect specific information. For thecollection of friendly information, thisconsideration is just as critical. Knowledge ofone’s own capability in combat, as well as thatof the adversary, is essential for effectivedecisionmaking;
• Representation of the processing ofinformation. Information is rarely valuable inoriginal form and must be processed in someway. Typical processing requirements includefiltering, correlation, aggregation,disaggregation, and fusion of information.These processes can be accomplished byeither manual or automated means. The ability,or inability, to properly process information canhave a direct bearing on combat outcome;
• Representation of C2 systems as entities on thebattlefield. C2 systems perform informationcollection, processing, dissemination, andpresentation functions. They should beexplicitly represented as entities that can betargeted, degraded, and/or destroyed by eitherphysical or non-physical means. Additionally,the model should account for continuity ofoperations of critical functions during periods ofsystem failure or degradation;

416 Code of Best Practice for Experimentation
• Representation of unit perceptions built,updated, and validated from the informationavailable to the unit from its informationsystems. This is a critical requirement. Eachunit should have its own perceptions, gainingknowledge from superior, subordinate, oradjacent units only when appropriate;
• Representation of the commander’s decisionsbased on his unit’s perception of the battlefield.Each unit should act based on what it perceivesthe situation to be, not based on ground truthavailable within the model. When a unit takesaction based on inaccurate perceptions, itshould suffer the appropriate consequences;and
• Representation of IO for combatants. Withinformation so critical to combat outcome, themodel should be able to represent thedeliberate attack and protection of information,information systems, and decisions. Thisapplies to all sides represented in the model.
Issues in C2 Modeling
This section addresses the core problem of analyzingthe effectiveness of C2-related systems, and what itis that sets it apart from other types of operationalanalysis. The problem lies in making a properlyquantified linkage between C2 measures of policyeffectiveness, such as communication system delays,C2 measures of effectiveness, such as planning time,and their impact on higher level measeures of forceeffectiveness, such as friendly casualties, attrition

417Appendix C
effects, and time to achieve military objectives, whichcapture the emergent effects on battle outcome.These higher level MoFE are required in order to beable to trade off investment in C2 systems againstinvestment in combat systems such as tanks oraircraft. At present, there is no routine way of makingthis linkage. Hence, all analyses of C2 systemsdemand a high level of creative problem structuringand approach to overcome this challenge.
Other modeling issues that have proved importantto C2 analysis are:
• Representation of human behavior: rule-based,algorithmic, or “human-in-the-loop;”
• Homogeneous models versus hierarchies/federations;
• Stochastic versus deterministic models;
• Adversarial representation;
• Verification, Validation, and Accreditation(VV&A); and
• The conduct of sensitivity analysis.
Representation of Human Behavior: Rule-Based, Algorithmic, or “Human-in-the-Loop”
In developing models that represent C2 processes,most approaches (until recently) have been foundedon the artificial intelligence (AI) methods of expertsystems. These represent the commander’sdecisionmaking process (at any given level ofcommand) by a set of interacting decision rules. The

418 Code of Best Practice for Experimentation
advantage of such an approach is that it is based onsound artificial intelligence principles. However, inpractice it leads to models that are large, complex,and slow running. The decision rules themselves are,in many cases, very scenario dependent and, asnoted earlier, human factors and organizationalexpertise may be needed on a project team to treatthese issues correctly.
These factors were not a problem during the ColdWar. There was sufficient time to complete extendedanalyses, and only one key scenario dominated.However, in the post-Cold War environment, suchcertainties have evaporated. Indeed, uncertainty isnow an even more key driver in analyses. There isan increasing requirement to consider largenumbers of scenarios and to perform a wide rangeof sensitivity analyses. This has led to a requirementfor ‘lightweight,’ fast running models, that can easilyrepresent a wide range of scenarios, yet still havea representation of C2 which is ‘good enough.’ Someauthors have begun to explore advanced algorithmictools based on mathematics such as catastrophetheory and complexity theory. This is discussedbelow under new methods.
Many analyses employ human-in-the-looptechniques in order to ensure realistic performanceor to check assumptions and parameters. However,human-in-the-loop techniques are expensive andrequire the inclusion of soft factors and theirattendant Measures of Merit. The introduction ofhuman factors also raises the level of uncertaintyas these factors are difficult to integrate and arenot necessarily well understood in the C2 specific

419Appendix C
context. The increased cost, complexity, anduncertainty of human-in-the-loop requires analyststo use these techniques for small portions of theoverall problem structure, rather than as the primaryanalytical method. However, much transformationalexperimentation will require human-in-the-loopsimulations, whether live or virtual.
Homogeneous Models Versus Hierarchies/Federations
In order to establish the audit trail referred to earlier(tying individual C2 systems, processes, andorganisations to battle outcomes), all the detailedprocesses involved, such as the transmission ofcommunications across the battlefield and theimpact of logistics on decisionmaking, should berepresented explicitly in a simulation. In thisexample, the question then arises as to whether allthe transmission media (radio, satellites, etc.), withtheir capacities, security level, communicationsprotocols, etc., should be represented in the mainmodel explicitly, or whether this aspect should besplit out as a supporting model of the overallprocess. Similarly, the detailed logistics modelingrequired to establish constraints on decisionmakingcould be undertaken as part of the main model or ina specialized supporting model. These supportingmodels could be run off-line, providing sets of inputdata to the main model (giving rise to a modelhierarchy) or they could be run in real t imeinteraction with the main model (giving rise to amodel federation). In the off-line mode, the mainmodel would generate demands on the

420 Code of Best Practice for Experimentation
communications and logistics systems. Thesupporting models would check whether thesedemands could be satisfied. If not, communicationdelays and logistics constraints in the main modelwould be increased, and the main model rerun. Thiswould have to be done a number of times to bringthe main and supporting models into balance.However, such an approach can generate valuableanalytical insights. The high rate of services thatmay be required to support the main model caninvolve a long analysis process. This methodbecomes critical with a large assortment of C2parameters or a long scenario period. Sensitivityanalysis requirements may also contribute to therequirements for implementation of this approach.
Figure C-4. Illustrative Model Linkage
Figure C-4 shows the main model producing (inaddition to its MoFE) a set of dynamic demands on

421Appendix C
communications (such as communications systemscapacity as a function of time) and logistics (demandsfor transport and key consumables) processes in orderto achieve the assessed levels of MoFE. These arethen fed back into detailed models of thecommunications and logistics infrastructure. Thosesupporting models can then match the dynamicdemand placed on the communications and logisticsinfrastructure to the available capacity. If there is amismatch, the assumptions in the main model areadjusted iteratively to bring the two models intobalance. This approach is more flexible and reactivefor a large set of C2 assessments. Nevertheless, themain disadvantage arises from the complexity of thearchitecture itself (number of linked sub-processes,failure of the sub-model, etc.).
A similar approach can be applied to concepts ofoperation. In some models, it is possible to describea concept of operations as a sequence of standardmissions (e.g. attack, defend, move). Thesemissions can then be analyzed to determine thedemand that they place on the support inginfrastructures. Then, as before, this can be testedoffline to see if the infrastructure can cope. Again,this would have to be iterated a number of times,but leads to an ability to relate the infrastructurecapacity to its ability to support a defined conceptof operations (and hence battle outcome). Inaddition to the use of such hierarchies of supportingmodels in an off-line mode, it is possible to createreal-time federations of such models to represent,inter alia, combined or joint operations.

422 Code of Best Practice for Experimentation
Stochastic Versus Deterministic Models
The ideas of chaos theory show that structuralvariance (or ‘deterministic chaos’) can occur whensets of decision rules interact in the simulation of adynamic process. Small changes in initial conditionscan lead to very different trajectories of systemevolution. Any simulation model of combat, with arepresentation of C2, has to confront this kind ofproblem. The merits of a deterministic approach arereduction of run times and the creation of a single‘thread’ connecting the input data and the results,making analysis of the model output potentiallyeasier. However, the representation of the C2process (whether using decision rules or not) givesrise to a number of alternative decision options at agiven moment, and can thus potentially give rise tosuch ‘deterministic chaos’. If such effects are likelyto arise, one solution is to use stochastic modeling.The use of stochastic sampling in the model,together with multiple replications of the model,gives rise to a distribution of outcomes which is muchmore resistant to such chaotic effects.
Representing Adversary Forces
Historically, adversary capabilities and behaviorswere often fully scripted or heavily constrained. Thiswas more appropriate in Cold War contexts than itis today. However, it was never ideal for C2 analysisbecause the dynamic interaction between friendlyand adversary forces is a critical element of C2representation. Today, much more robust adversarycapabi l i t ies are employed and indeed are

423Appendix C
necessary. Analysts must consider not only a rangeof scenarios, but also the range of possibleadversary actions and reactions.
Verification, Validation, and Accreditation(VV&A)
VV&A has traditionally been a challenge for modeldevelopment efforts, but is particularly challengingfor C2 modeling. This is due to the variabilityinherent in most C2 processes, especially those thatinvolve the human aspects of informationprocessing and decisionmaking.
1“A Glossary of Modeling and Simulation Terms for DistributedInteractive Simulation (DIS).” August, 1995.2Robert E. Shannon. Systems Simulation the Arts and Science.Prentice-Hall, 1975.3George E.P. Box. “Robustness is the Strategy of Scientific ModelBuilding.” Robustness in Statistics. eds., R.L. Launer and G.N.Wilkinson, 1979, Academic Press, p. 202.)4”Evolving the Practice of Military Operations Analysis.” DoDApplying Knowledge Management, MORS Symposium. March2000.5”Executable Architecture for the First Digitized Division.” PaulC. Barr, Alan R. Bernstein, Michael Hamrick, David Nicholson,Thomas Pawlowski III, and Steven Ring.

425
APPENDIX D
SurveySituation Awareness Questions
Part 1 (Unprompted)
Summarize your assessment of the situation.
Part 2 (Prompted)
1. What is the friendly mission?
2. What are the friendly opportunities?
3. What are the risks to friendly forces?
4. What are the adversary’s vulnerabilities?
5. What are the adversary’s intentions?
6. What are the adversary’s defensivecapabilities?
7. What are the adversary’s offensive capabilities?
8. If you are unsure of adversary’s intentions, whatare the different possibilities?
9. What are the important environmental factors inthis situation?

Note: There were other questions on the survey form,but the above were the questions used for determiningthe situation awareness scores.

427
Acronyms
AACTD - Advanced Concept TechnologyDemonstrations
AIAA - American Institute of Aeronautics andAstronautics
AIDS - Acquired Immune Deficiency Syndrome
APS - American Psychological Society
ATD - Advanced Technology Demonstration
ATO - Air Tasking Order
CC2 - Command and Control
C4ISR - Command, Control, Communications,Computers, Intelligence, Surveillance, Reconnaissnce
CCRTS - Command and Control Research andTechnology Symposium
CINC - Commander in Chief
COBP - Code of Best Practice
CPOF - Command Post of the Future
CPX - Command Post Exercises

428 Code of Best Practice for Experimentation
DDARPA - Defense Advanced Research ProjectsAgency
DM - Dominant Maneuver
DoD - Department of Defense
DOTMLPF - Doctrine, Organization, Training,Material, Leadership, Personnel, and Facilities
DTIC - Defense Technical Information Center
EEBO - Effects-Based Operations
ESC - Electronic Systems Center
ETO - Effects Tasking Orders
FFTX - Field Training Exercise
GGPS - Global Positioning System
HHEAT - Headquarters Effectiveness Assessment Tool
HFS - Human Factors Society
HQ - Headquarters

429Acronyms
IICCRTS - International Command and ControlResearch and Technology Symposium
IDEF-0 - a formal process modeling language, whereactivity boxes are named as verbs or verb phrases,and are connected via arrows, named as nouns ornoun phrases, which define inputs (from the left),controls (from the top), outputs (to the right), ormechanisms (from the bottom). Each activity has adefinition, keywords, and can be quantified by time,cost, frequency, etc.
IEEE - Institute of Electrical and Electronics Engineers
IQ - intelligence quotients
JJEFX - Joint Expeditionary Force Exercise
JFCOM - Joint Forces Command
JROC - Joint Requirements Oversight Council
JTF - Joint Task Force
JV - Joint Vision
JWID - Joint Warrior Interoperability Demonstration
LLOEs - Limited Objective Experiments

430 Code of Best Practice for Experimentation
MMCP - Mission Capability Packages
MOCE - Measures of C2 Effectiveness
MOFE - Measures of Force Effectiveness
MOP - Measures of Performance
MOPE - Measures of Policy Effectiveness
MORS - Military Operations Research Society
M&S - Modeling and Simulation
NNATO - North Atlantic Treaty Organization
NCW - Network Centric Warfare
NGO - Non-Governmental Organization
OONA - Operational Net Assessments
OOB - Order of Battle
RRDO - Rapid Decisive Operations
RPV - Remotely Piloted Vehicles
SSME - Subject Matter Experts

431Acronyms
STOW - Synthetic Theater of War
TTD - Technology Demonstration
VVIPs - Very Important Persons
VV&A - Verification, Validation & Accreditation

433
BibliographyAlberts, David S., John J. Garstka, and Frederick P.
Stein. Network Centric Warfare: Developingand Leveraging Information Superiority. SecondEdition. Washington, DC: CCRP. 1999.
Alberts, David S. and Richard E. Hayes. CommandArrangements for Peace Operations .Washington, DC: NDU Press. 1995.
Alberts, David S. John J. Gartska, Richard E. Hayes,and David A. Signori. UnderstandingInformation Age Warfare. Washington, DC:CCRP. 2001.
Bankes, Steve. “Exploratory Modeling for PolicyAnalysis.” Operations Research. Linthicum,MD: INFORMS. 1993.
Bankes, Steve, Robert Lempert, and Steven Popper.“Computer-Assisted Reasoning.” CSE inIndustry. St Louis, MO: American Institute ofPhysics. 2001.
C4ISR Architecture Framework Version 2.0 .Washington, DC: The Architecture WorkingGroup and the Office of the Secretary ofDefense. 1997.
DoD Instruction No. 5000.61. Subject: DoD Modelingand Simulation (M&S) Verification, Validation,and Accreditation (VV&A). October 5, 2001.

434 Code of Best Practice for Experimentation
Headquarters Effectiveness Assessment Tool “HEAT”User’s Manual. McLean, VA: Defense Systems,Inc. 1984.
Loerch, Andrew, Robert Koury, and Daniel Maxwell.Value Added Analysis for Army EquipmentModernization. New York, NY: John Wiley &Sons, Inc. 1999.
Ludwig Mies van der Rohe. The New York Times.August 19, 1969.
McBurney, D.H. Research Methods. Pacific Grove,CA: Brooks/Cole. 1994.
NATO COBP for Command and Control Assessment.Washington, DC: CCRP. 1998.
Network Centric Warfare Department of DefenseReport to Congress. July 2001.
Schellenberger, Robert E. “Criteria for AssessingModel Validity for Managerial Purposes.”Decision Sciences Journal. Atlanta, GA:Decision Sciences Institute. 1974. No. 5.pp644-653.
Vadum, Arlene and Neil Rankin. PsychologicalResearch Methods for Discovery andValidation. Boston: McGraw Hill HigherEducation. 1997.

435
About theEditors
Dr. Alberts is currently the Director, Research andStrategic Planning, OASD (C3I). Prior to this he wasthe Director, Advanced Concepts, Technologies, andInformation Strategies (ACTIS), Deputy Director of theInstitute for National Strategic Studies, and theexecutive agent for DoD’s Command and ControlResearch Program. This included responsibility for theCenter for Advanced Concepts and Technology (ACT)and the School of Information Warfare and Strategy(SIWS) at the National Defense University. He has morethan 25 years of experience developing and introducingleading-edge technology into private and public sectororganizations. This extensive applied experience isaugmented by a distinguished academic career incomputer science, operations research, andGovernment service in senior policy and managementpositions. Dr. Alberts’ experience includes serving as aCEO for a high-technology firm specializing in the designand development of large, state-of-the-art computersystems (including expert, investigative, intelligence,information, and command and control systems) in bothGovernment and industry. He has also led organizationsengaged in research and analysis of command andcontrol system performance and related contributionsto operational missions. Dr. Alberts has had policyresponsibility for corporate computer andtelecommunications capabilities, facilities, andexperimental laboratories. His responsibilities have also

436 Code of Best Practice for Experimentation
included management of research aimed at enhancingthe usefulness of systems, extending their productive life,and the development of improved methods for evaluatingthe contributions that systems make to organizationalfunctions. Dr. Alberts frequently contributes to Governmenttask forces and workshops on systems acquisition,command and control, and systems evaluation.
As President and founder of Evidence BasedResearch, Inc., Dr. Hayes specializes in multidisciplinaryanalyses of command and control, intelligence, andnational security issues; the identification ofopportunities to improve support to decisionmakers inthe defense and intelligence communities; the designand development of systems to provide that support;and the criticism, test, and evaluation of systems andprocedures that provide such support. His areas ofexpertise include crisis management; political-militaryissues; research methods; experimental design;simulation and modeling; test and evaluation; militarycommand, control, communication, and intelligence(C3I); and decision-aiding systems. Since coming toWashington in 1974, Dr. Hayes has established himselfas a leader in bringing the systematic use of evidenceand the knowledge base of the social sciences into playin support of decisionmakers in the national securitycommunity, domestic agencies, and major corporations.He has initiated several programs of research and linesof business that achieved national attention and manyothers that directly influenced policy development in clientorganizations.
1994 - Present
For further information on CCRP, please visit our Web site at
www.dodccrp.org
Title Author(s) Year
INFORMATION AGE TRANSFORMATION SERIES
Information Age Transformation Alberts 2002
Code of Best Practice for Experimentation Alberts & Hayes, eds. 2002
The Big Issue Potts 2002
COMMAND AND CONTROL
Coalition Command and Control Maurer 1994
Command, Control, and the Common Defense Allard 1996
Command and Control in Peace Operations Alberts & Hayes 1995
Command Arrangements for Peace Operations Alberts & Hayes 1995
Complexity, Global Politics, and National Security Alberts & Czerwinski 1997
Coping with the Bounds Czerwinski 1998
INFORMATION TECHNOLOGIES AND INFORMATION WARFARE
Behind the Wizard's Curtain Krygiel 1999
Defending Cyberspace and Other Metaphors Libicki 1997
Defensive Information Warfare Alberts 1996
Dominant Battlespace Knowledge Johnson & Libicki 1996
From Network-Centric to Effects-Based Operations Smith 2002
Information Age Anthology Vol. I Alberts & Papp 1997
Information Age Anthology Vol. II Alberts & Papp 2000
Information Age Anthology Vol. III Alberts & Papp 2001
Understanding Information Age Warfare Alberts, Garstka, Hayes, & Signori 2001
Information Warfare and International Law Greenberg, Goodman, & Soo Hoo 1998
The Mesh and the Net Libicki 1994
Network Centric Warfare Alberts, Garstka, & Stein 1999
Standards: The Rough Road to the Common Byte Libicki 1995
The Unintended Consequences of Information Age Technologies Alberts 1996
What Is Information Warfare? Libicki 1995
OPERATIONS OTHER THAN WAR
Confrontation Analysis: How to Win Operations Other Than War Howard 1999
Doing Windows B. Hayes & Sands 1999
Humanitarian Assistance and Disaster Relief in the Next Century Sovereign 1998
Information Campaigns for Peace Operations Avruch, Narel, & Siegel 2000
Interagency and Political-Military Dimensions of Peace Operations: Haiti Daly Hayes & Wheatley, eds. 1996
Lessons from Bosnia: The IFOR Experience Wentz, ed. 1998
Lessons from Kosovo: The KFOR Experience Wentz, ed. 2002
NGOs and the Military in the Interagency Process Davidson, Landon, & Daly Hayes 1996
Operations Other Than War Alberts & Hayes 1995
Shock and Awe: Achieving Rapid Dominance Ullman & Wade 1996
Target Bosnia: Integrating Information Activities in Peace Operations Siegel 1998
A f
ax c
over
she
et h
as b
een
prov
ided
for
you
r co
nven
ienc
e on
the
rev
erse
sid
e of
thi
s fo
rm.
Order Form
AL
LO
W 4
TO
6 W
EE
KS
FO
R D
EL
IVE
RY
Order # _____CCRP Use Only
Title Name e-mailCompanyAddressCity State Zip Country
Quantity Titles in Stock CCRPUse Only
Behind the Wizard's Curtain 95015
The Big Issue
Code of Best Practice for Experimentation
Command Arrangements for Peace Operations 95743
Command, Control, and the Common Defense D4699
Complexity, Global Politics, and National Security D4946
Confrontation Analysis 723-125
Doing Windows D4698
Dominant Battlespace Knowledge 95743D
Humanitarian Assistance and Disaster Relief in the Next Century D6192
Information Age Anthology Vol. I FY0103
Information Age Anthology Vol. II D9727
Information Age Anthology Vol. III FY0102
Information Age Transformation
Information Campaigns for Peace Operations 518-843
Interagency and Political-Military Dimensions of Peace Operations: Haiti 95743C
Lessons from Kosovo: The KFOR Experience
The Mesh and the Net 93339A
Network Centric Warfare 518-270
Standards: The Rough Road to the Common Byte 93339B
Understanding Information Age Warfare D5297
2000 CCRTS CD-ROM CD00
4th Int'l CCRTS CD-ROM CD4I
5th Int'l CCRTS CD-ROM CD5I
6th Int'l CCRTS CD-ROM CD6I
2002 CCRTS CD-ROM CD02
7th Int'l CCRTS CD-ROM CD7I

02
FAX COVER SHEET
To:Fax:E-mail:
From:Telephone:Fax:E-mail:Date:Pages:
Publications Coordinator(703) [email protected]
CCRP publications are available at no cost throughDoD. Complete the order form on the reverse sideand fax the sheets or mail to c/o address below.
c/o EBR, Inc. tt 1595 Spring Hill RD tt Suite 250 tt Vienna, VA 22182-2216
Additional Information:

CCRP/COBP FeedbackThank you for your interest in the Code of Best Practice (COBP) forExperimentation. If you are a potential user of this document, thenyou are invited to contribute to a review being carried out to test itseffectiveness (principally in format, but views on content are alsowelcome).
Please spend an appropriate amount of time reading the documentand then complete this short questionnaire. Return to the CCRPusing the fax cover sheet provided on the reverse side of thisquestionnaire. Alternatively, you may log on to www.dodccrp.organd fill out an electronic version of this form.
1. What three features of best practice stick in your mind most?
_____________________________________________________________________________________
_____________________________________________________________________________________
_____________________________________________________________________________________
2. Are there any points which you found new or unexpected?
_____________________________________________________________________________________
3. Are there any points which did not appear in this Code thatyou think should be included?
_____________________________________________________________________________________
4. Did you find the Code easy to read and understand?Yes ___ No ___ If no, please state why?
_____________________________________________________________________________________
5. Did you find the Code…Too wordy? ___ About right? ___ Too terse? ___
6. Is the layout…Very clear? ___ Clear? ___ Unclear? ___ Very unclear? ___
If unclear or very unclear, please state why?
_____________________________________________________________________________________
7. Do you accept all of the guidance contained in the Code? Yes ___ No ___ If No, what do you disagree with? _____________________________________________________________________________________
_____________________________________________________________________________________
8. Do you have any other comments or suggestions?
_____________________________________________________________________________________
_____________________________________________________________________________________
_____________________________________________________________________________________
A f
ax c
over
she
et h
as b
een
prov
ided
for
you
r co
nven
ienc
e on
the
rev
erse
sid
e of
thi
s fo
rm.

02
FAX COVER SHEET
To:Fax:E-mail:
From:Telephone:Fax:E-mail:Date:Pages:
COBP Experimentation Editors(703) [email protected]
c/o EBR, Inc. tt 1595 Spring Hill RD tt Suite 250 tt Vienna, VA 22182-2216
Additional Information: