infinite-horizon discounted markov decision processes · vector notation for markov decision...
TRANSCRIPT

Infinite-Horizon DiscountedMarkov Decision Processes
Dan ZhangLeeds School of Business
University of Colorado at Boulder
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 1

Outline
The expected total discounted reward
Policy evaluation
Optimality equations
Value iteration
Policy iteration
Linear Programming
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 2

Expected Total Reward Criterion
Let π = (d1, d2, . . . ) ∈ ΠHR
Starting at a state s, using policy π leads to a sequence ofstate-action pairs {Xt ,Yt}. The sequence of rewards is givenby {Rt ≡ rt(Xt ,Yt) : t = 1, 2, . . . }.Let λ ∈ [0, 1) be the discount factor
The expected total rewards from policy π starting in state s isgiven by
vπλ (s) ≡ limN→∞
Eπs
[N∑t=1
λt−1r(Xt ,Yt)
].
The limit above exists when r(·) is bounded; i.e.,sups∈S,a∈As
|r(s, a)| = M <∞.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 3

Expected Total Reward Criterion
Under suitable conditions (such as the boundedness of r(·)),we have
vπλ (s) ≡ limN→∞
Eπs
[N∑t=1
λt−1r(Xt ,Yt)
]= Eπs
[ ∞∑t=1
λt−1r(Xt ,Yt)
].
Let
vπ(s) ≡ Eπs
[ ∞∑t=1
r(Xt ,Yt)
].
We have vπ(s) = limλ↑1 vπλ (s) whenever vπ(s) exists.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 4

Optimality Criteria
A policy π is discount optimal for λ ∈ [0, 1) if
vπ∗
λ (s) ≥ vπλ (s), ∀s ∈ S , π ∈ ΠHR .
The value of a discounted MDP is defined by
v∗λ(s) ≡ supπ∈ΠHR
vπλ (s), ∀s ∈ S .
Let π∗ be a discount optimal policy. Then vπ∗
λ (s) = v∗λ(s) forall s ∈ S .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 5

Vector Notation for Markov Decision Processes
Let V denote the set of bounded real valued functions on Swith componentwise partial order and norm||v || ≡ sups∈S |v(s)|.
The corresponding matrix norm is given by
||H|| ≡ sups∈S
∑j∈S|H(j |s)|,
where H(j |s) denotes the (s, j)-th component of H.
Let e ∈ V denote the function with all components equal to1; that is, e(s) = 1 for all s ∈ S .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 6

Vector Notation for Markov Decision Processes
For d ∈ DMD , let
rd(s) ≡ r(s, d(s)) and pd(j |s) ≡ p(j |s, d(s)).
Similarly, for d ∈ DMR , let
rd(s) ≡∑a∈As
qd(s)(a)r(s, a), pd(j |s) ≡∑a∈As
qd(s)(a)p(j |s, a).
Let rd denote the |S |-vector, with the s-th component rd(s)and Pd the |S | × |S | matrix with (s, j)-th entry pd(j |s). Werefer to rd as the reward vector and Pd as the transitionprobability matrix.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 7

Vector Notation for Markov Decision Processes
π = (d1, d2, . . . ) ∈ ΠMR . The (s, j) component of the t-steptransition probability matrix Pt
π(j |s) satisfies
Ptπ(j |s) = [Pd1 . . .Pdt−1Pdt ](j |s) = Pπ(Xt+1 = j |X1 = s).
For v ∈ V ,
Eπs [v(Xt)] =∑j∈S
Pt−1π (j |s)v(j).
We also have
vπλ =∞∑t=1
λt−1Pt−1π rdt .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 8

Assumptions
Stationary rewards and transition probabilities: r(s, a) andp(j |s, a) do not vary with time
Bounded rewards: |r(s, a)| ≤ M <∞
Discounting: λ ∈ [0, 1).
Discrete state space: S is finite or countable
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 9
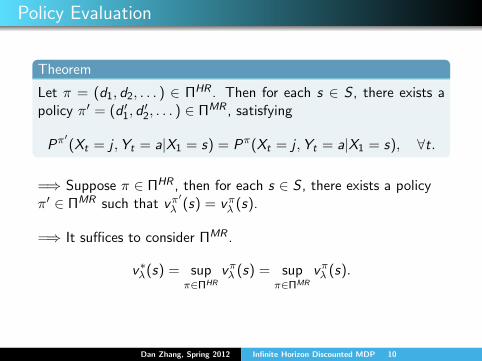
Policy Evaluation
Theorem
Let π = (d1, d2, . . . ) ∈ ΠHR . Then for each s ∈ S , there exists apolicy π′ = (d ′1, d
′2, . . . ) ∈ ΠMR , satisfying
Pπ′(Xt = j ,Yt = a|X1 = s) = Pπ(Xt = j ,Yt = a|X1 = s), ∀t.
=⇒ Suppose π ∈ ΠHR , then for each s ∈ S , there exists a policyπ′ ∈ ΠMR such that vπ
′λ (s) = vπλ (s).
=⇒ It suffices to consider ΠMR .
v∗λ(s) = supπ∈ΠHR
vπλ (s) = supπ∈ΠMR
vπλ (s).
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 10

Policy Evaluation
Let π = (d1, d2, . . . ) ∈ ΠMR . Then
vπλ (s) = Eπs
[ ∞∑t=1
λt−1r(Xt ,Yt)
].
In vector notation, we have
vπλ =∞∑t=1
λt−1Pt−1π rdt
= rd1 + λP1πrd2 + λ2P2
πrd3 + . . .
= rd1 + λPd1rd2 + λ2Pd1Pd2rd3 + . . .
= rd1 + λPd1 (rd2 + λPd2rd3 + . . . )
= rd1 + λPd1vπ′λ ,
where π′ = (d2, d3, . . . ).
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 11

Policy Evaluation
When π is stationary, π = (d , d , . . . ) ≡ d∞ and π′ = π.
It follows that vd∞
λ satisfies
vd∞
λ = rd1 + λPdvd∞λ ≡ Ldv
d∞λ ,
where Ld : V → V is a linear transformation.
Theorem
Suppose λ ∈ [0, 1). Then for any stationary policy d∞ with d ∈DMR , vd
∞λ is a solution in V of
v = rd + λPdv .
Furthermore, vd∞
λ may be written as
vd∞
λ = (I − λPd)−1rd .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 12

Optimality Equations
For any fixed n, the finite horizon optimality equation is givenby
vn(s) = supa∈As
r(s, a) +∑j∈S
λP(j |s, a)vn+1(j)
.Taking limits on both sides leads to
v(s) = supa∈As
r(s, a) +∑j∈S
λP(j |s, a)v(j)
.The equations above for all s ∈ S are the optimality equations.
For v ∈ V , let
Lv ≡ supd∈DMD
[rd + λPdv ],
Lv ≡ maxd∈DMD
[rd + λPdv ].
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 13

Optimality Equations
Proposition
For all v ∈ V and λ ∈ [0, 1),
supd∈DMD
[rd + λPdv ] = supd∈DMR
[rd + λPdv ].
Replacing DMD with D, the optimality equation can bewritten as
v = Lv .
In case supremum can be attained above for all v ∈ V ,
v = Lv .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 14

Solutions of the Optimality Equations
Theorem
Suppose v ∈ V .
(i) If v ≥ Lv , then v ≥ v∗λ ;
(ii) If v ≤ Lv , then v ≤ v∗λ ;
(iii) If v = Lv , then v is the only element of V with this propertyand v = v∗λ .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 15

Solutions of the Optimality Equations
Let U be a Banach space (complete normed linear space).
Special case: space of bounded measurable real-valuedfunctions
An operator T : U → U is a contraction mapping if thereexists a λ ∈ [0, 1) such that ||Tv − Tu|| ≤ λ||v − u|| for all uand v in U.
Theorem [Banach Fixed-Point Theorem]
Suppose U is a Banach space and T : U → U is a contractionmapping. Then
(i) There exists a unique v∗ in U such that Tv∗ = v∗;
(ii) For arbitrary v0 ∈ U, the sequence {vn} defined byvn+1 = Tvn = T n+1v0 converges to v∗.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 16

Solutions of the Optimality Equations
Proposition
Suppose λ ∈ [0, 1). Then L and L are contraction mappings on V .
Theorem
Suppose λ ∈ [0, 1), S is finite or countable, and r(s, a) is bounded.The following results hold.
(i) There exits a v∗ ∈ V satisfying Lv∗ = v∗ (Lv = v∗).Furthermore, v∗ is the only element of V with this propertyand equals v∗λ ;
(ii) For each d ∈ DMR , there exists a unique v ∈ V satisfyingLdv = v . Furthermore, v = vd
∞λ .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 17

Existence of Stationary Optimal Policies
A decision rule is d∗ is conserving if
d∗ ∈ argmaxd∈D
{rd + λPdv∗λ}.
Theorem
Suppose there exists a conserving decision rule or an optimal policy,then there exists a deterministic stationary policy which is optimal.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 18

Value Iteration
1 Select v0 ∈ V , specify ε > 0, and set n = 0.2 For each s ∈ S , compute vn+1(s) by
vn+1(s) = maxa∈As
r(s, a) +∑j∈S
λp(j |s, a)vn(j)
.3 If
||vn+1 − vn|| < ε(1− λ)
2λ,
go to step 4. Otherwise, increment n by 1 and return to step2.
4 For each s ∈ S , choose
dε(s) ∈ argmaxa∈As
r(s, a) +∑j∈S
λp(j |s, a)vn+1(j)
and stop.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 19

Policy Iteration
1 Set n = 0 and select an arbitrary decision rule d0 ∈ D.
2 (Policy evaluation) Obtain vn by solving
(I − λPdn)v = rdn .
3 (Policy improvement) Choose dn+1 satisfy
dn+1 ∈ argmaxd∈D
[rd + λPdvn].
Setting dn+1 = dn if possible.
4 If dn+1 = dn, stop and set d∗ = dn. Otherwise increment n by1 and return to step 2.
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 20

Linear Programming
Let α(s) be positive scalars such that∑
s∈S α(s) = 1.
Primal linear program is given by
minv
∑j∈S
α(j)v(j)
v(s)−∑j∈S
λP(j |s, a)v(j) ≥ r(s, a), ∀s ∈ S , a ∈ As .
Dual linear program is given by
maxx
∑s∈S
∑a∈As
r(s, a)x(s, a)
∑a∈Aj
x(j , a)−∑s∈S
∑a∈As
λp(j |s, a)x(s, a) = α(j), ∀j ∈ S ,
x(s, a) ≥ 0, ∀s ∈ S , a ∈ As .
Dan Zhang, Spring 2012 Infinite Horizon Discounted MDP 21