information retrieval and social media
TRANSCRIPT

Information Retrieval and Social Media
Prof.dr.ir. Arjen P. de Vries
[email protected] for the User-Centred Social Media Summer School
Duisburg, September 19, 2017

Social MediaNoun
social media (uncountable)
Interactive forms of media that allow users to interact with and publish to
each other, generally by means of the Internet.
The early 21st century saw a huge increase in social media thanks to the widespread availability of the
Internet.

Social Media
“Social bookmarking” sites “User generated content”
- Images (flickr) and videos (youtube, vimeo), but also blogs, Wikipedia, etc. Social network services
- Twitter, facebook, instagram, snapchat




Not just one beast!
User contributed content
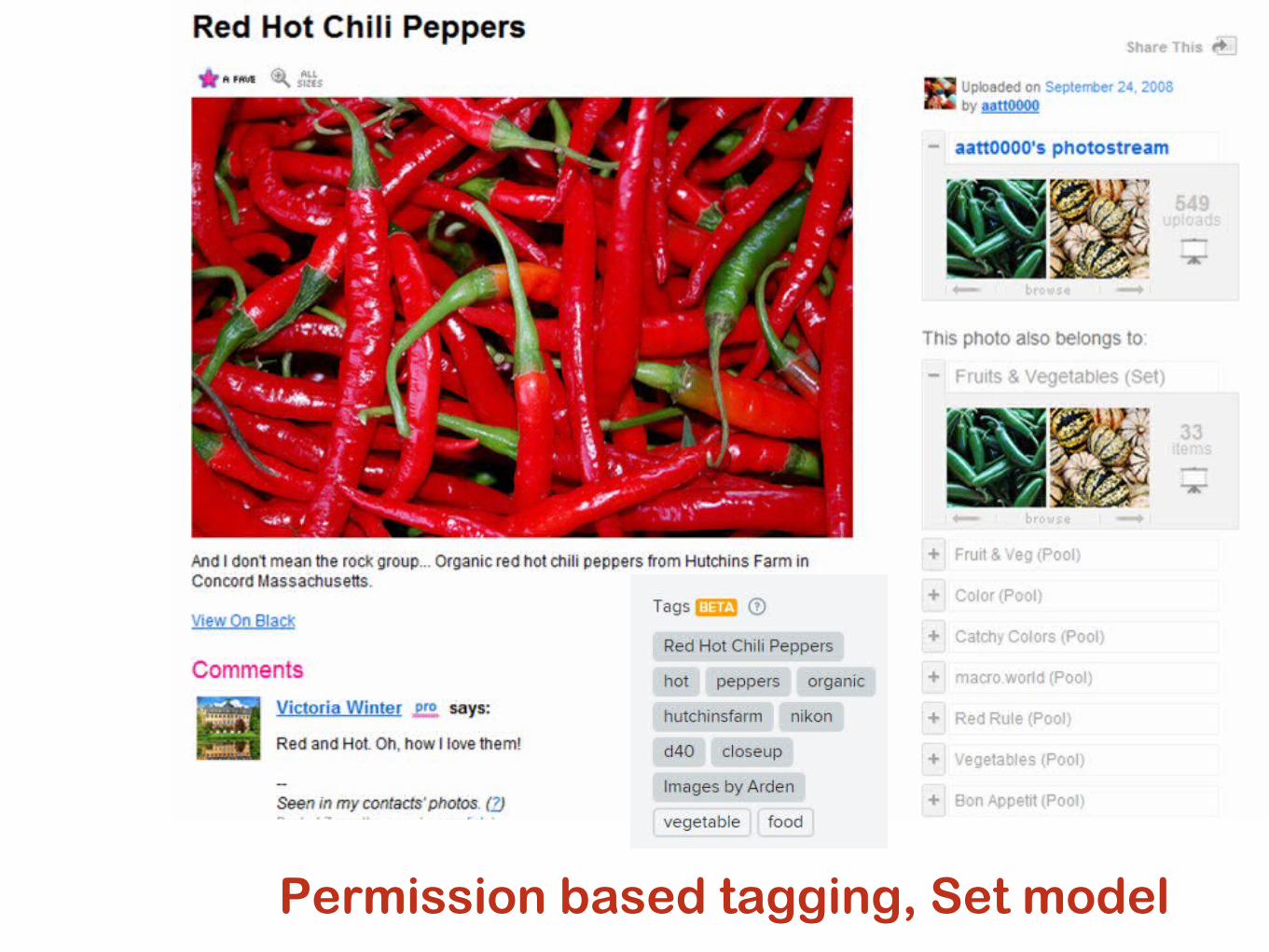
Permission based tagging, Set model
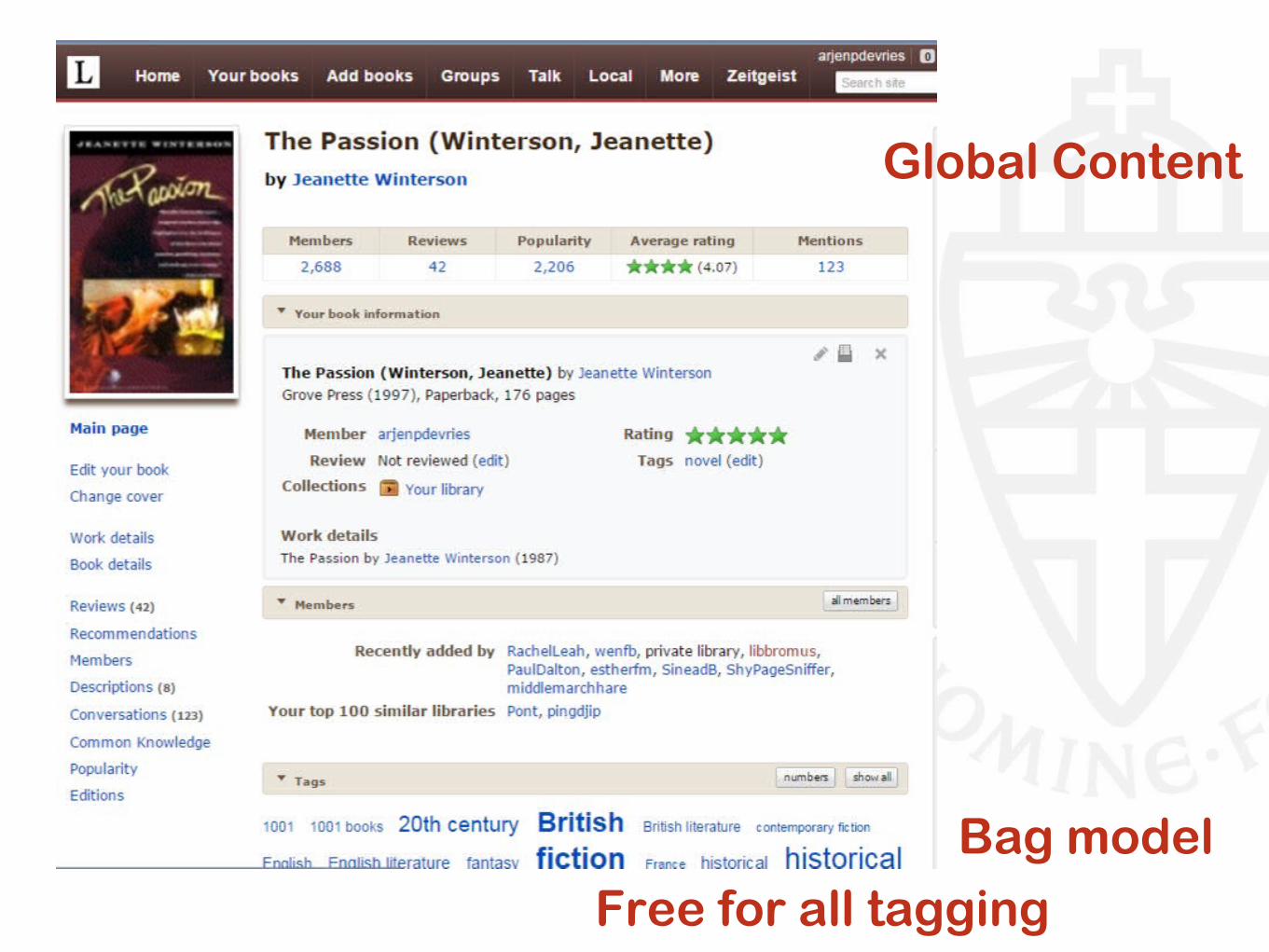
Bag model
Global Content
Free for all tagging

Social Media to help improve IR (1)

‘Co-creation’ Social Media:
- Consumer becomes a co-creator- Many ‘data consumption’ traces in social media are public

Richer information representations

Richer information representations User profiles
- User name, full name, description, image, homepage url, etc. Connections between users
- Networks of friends, followers, etc Comments/reactions Endorsing and sharing
E.g., Twitter Bio
- Often includes a geo-location of the profile Friends Followers Lists
- Groups followed Twitter accounts; lists can be followed Hashtags Mentions

User Demographics Gender from Tweet author’s first name Geographic location from profile
Diaz, Gamon, Hofman, Kiciman, Rothschild. Online and Social Media as an Imperfect Continuous Panel Survey. In PLOS ONE, 2016

Detailed User Characteristics…
de Volkskrant, March 13, 2013
Michal Kosinski, David Stillwell, and Thore Graepel. Private traits and
attributes are predictable from digital records of human behavior. PNAS
2013.
Youyou, W., Kosinski, M. & Stillwell, D. (2015) Computer-based personality judgments are more accurate than
those made by humans. PNAS 2015.

… in Search Age and Gender, and perhaps also political and religious
views Maps both Page Likes from myPersonality dataset and
search results on a common space of ODP categories Learning approach to overcome the difference in
distribution between myPersonality data and Search data- E.g., their FB dataset has 63% female, vs. only 47% in Bing
Bi, Kosinski, Shokouhi, Graepel. Inferring the Demographics of Search Users. WWW 2013

Many Opportunities for IR Expand content representation Reduce the vocabulary gap(s) between creators of
content (the indexers) and consumers of content (the users)
More diverse views on the same content

LibraryThing Items People Tags Ratings
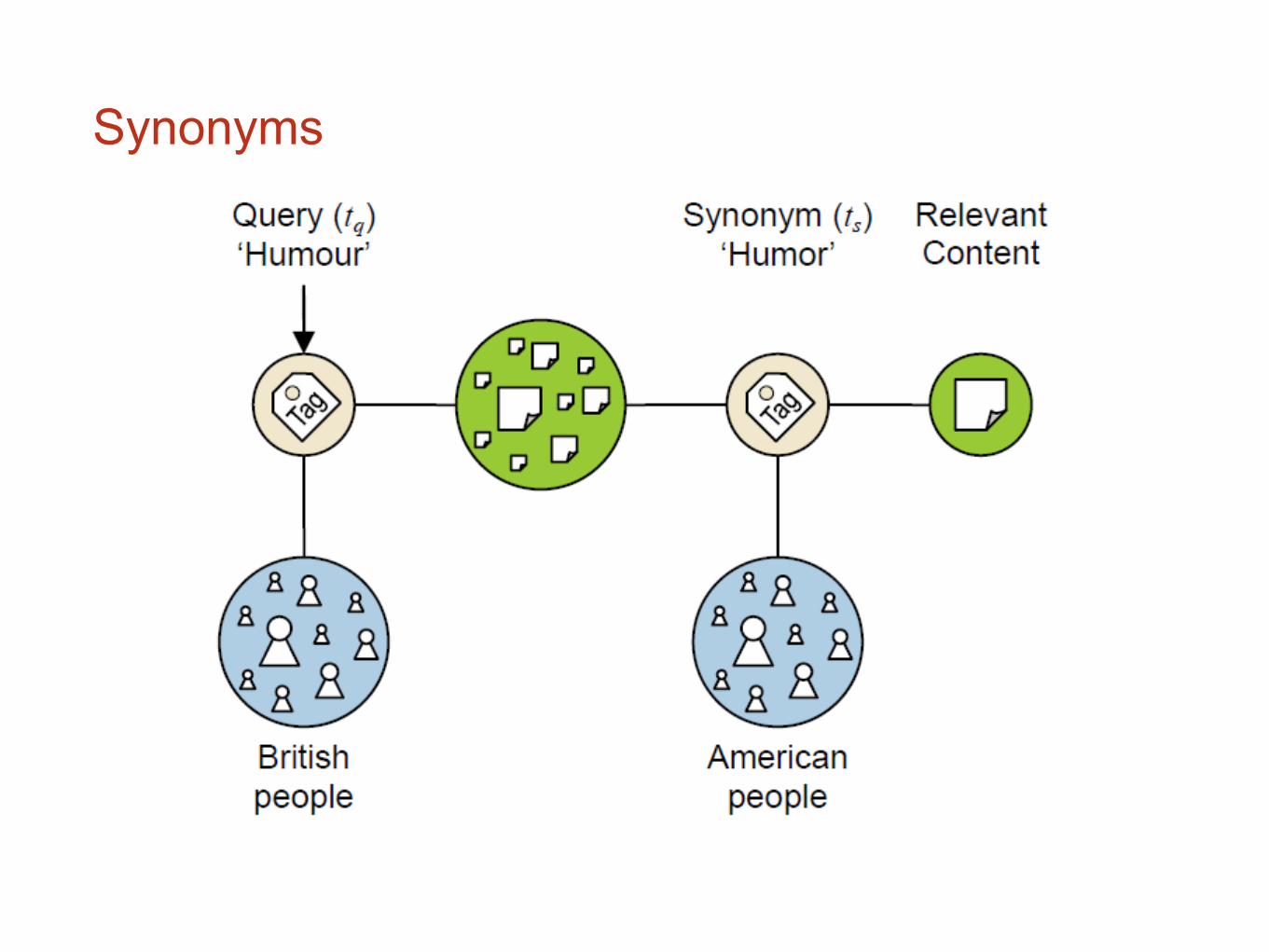
Synonyms
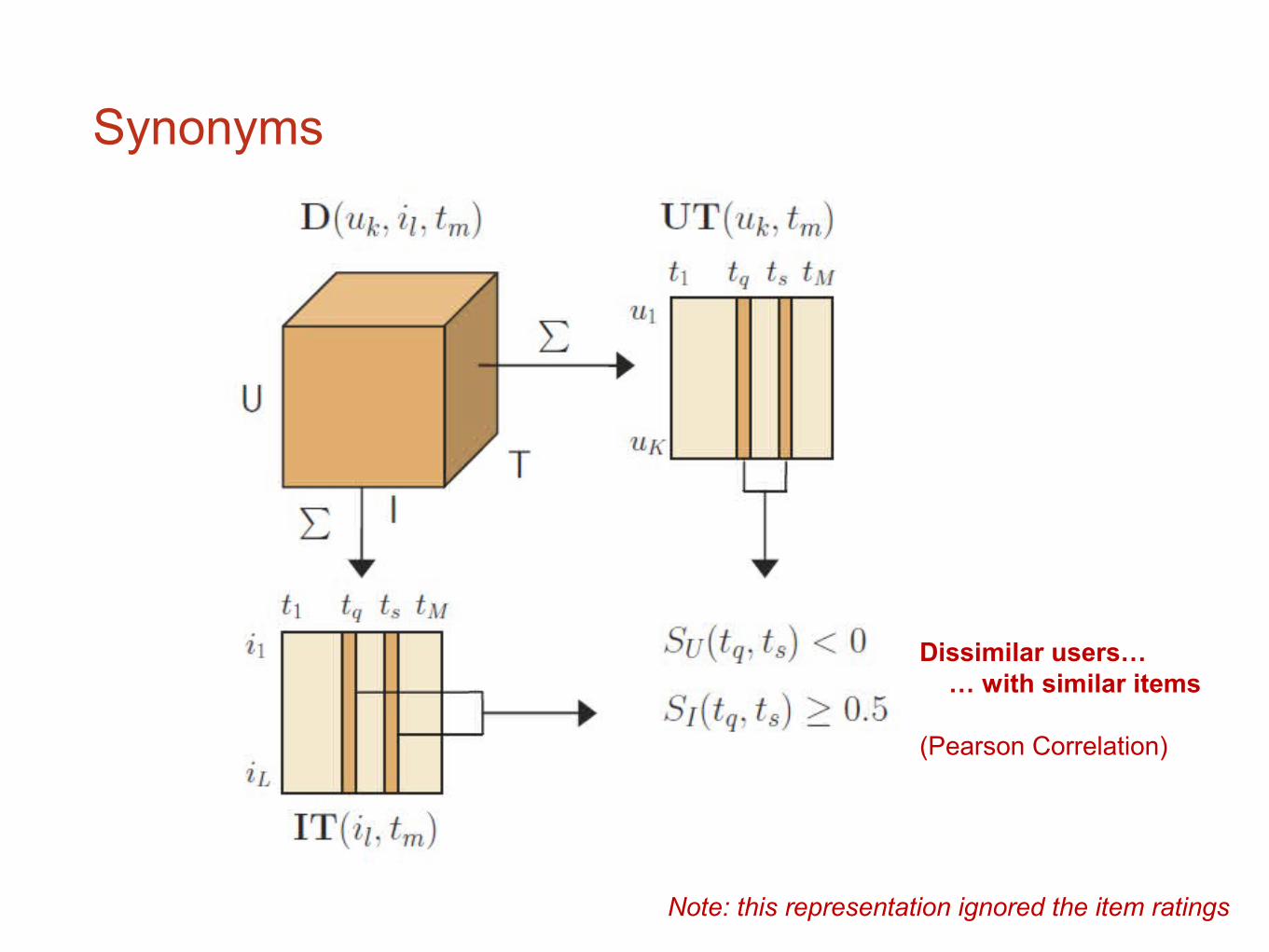
Synonyms
Dissimilar users… … with similar items
(Pearson Correlation)
Note: this representation ignored the item ratings
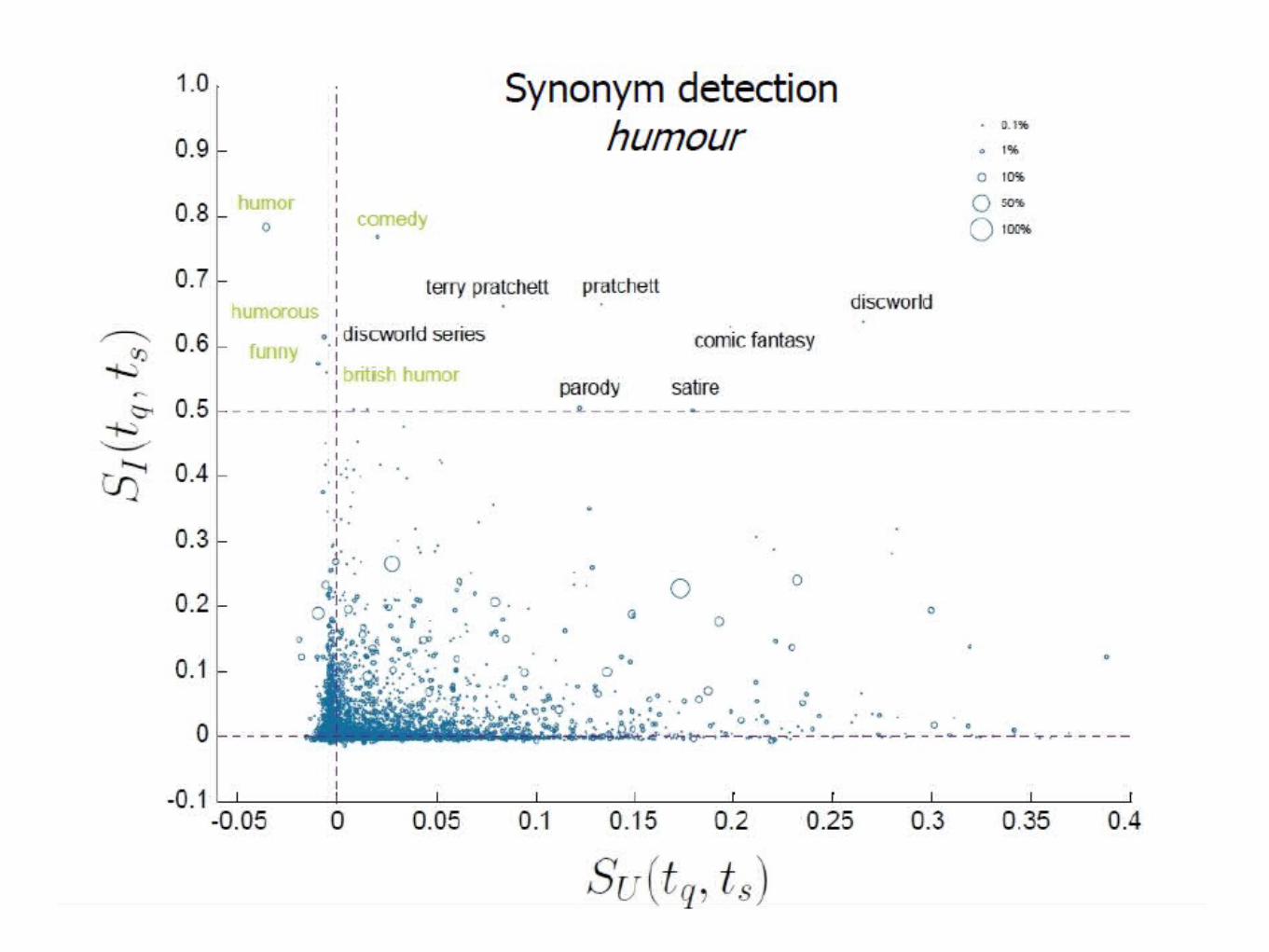
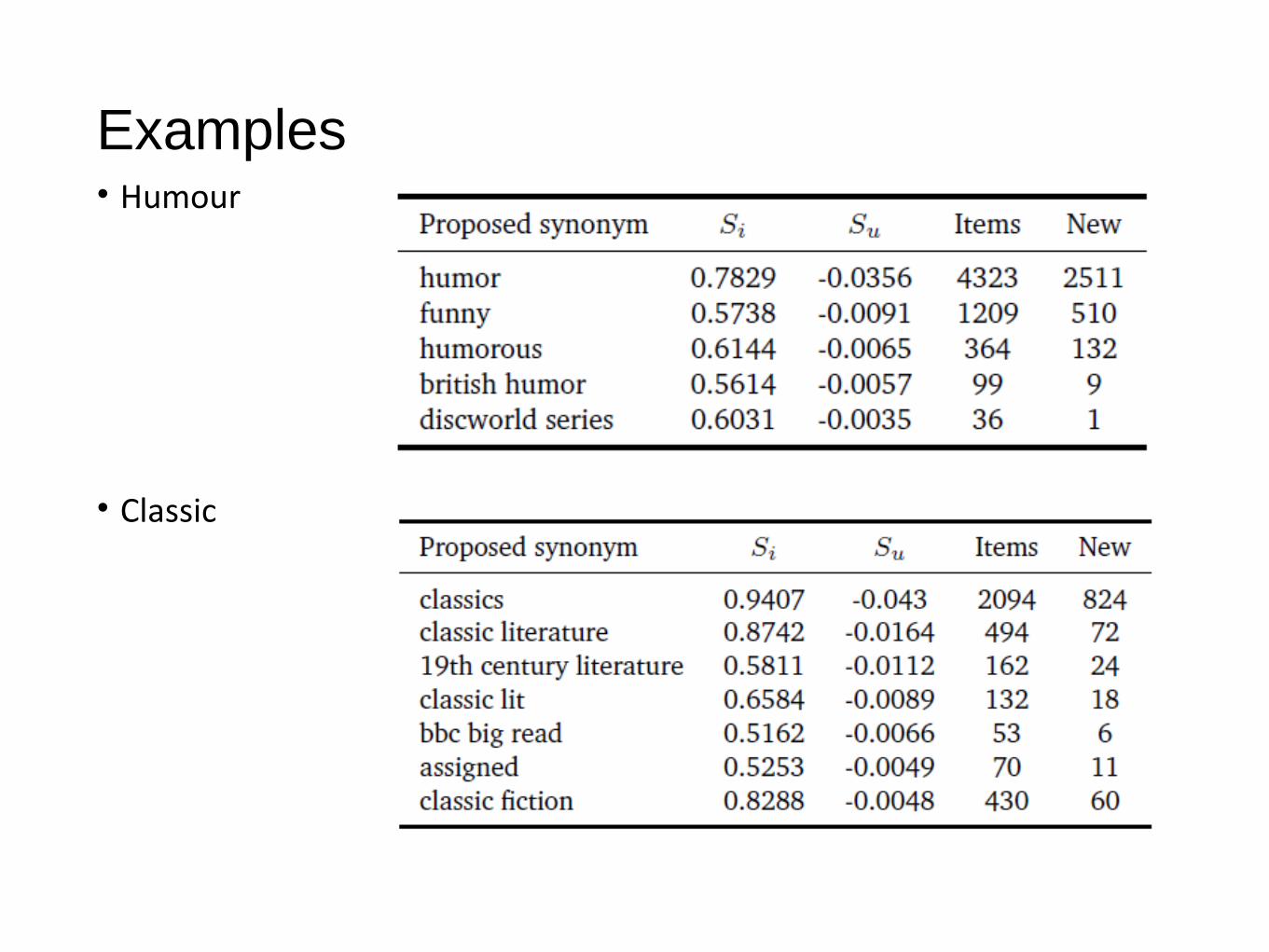
Examples• Humour
• Classic

IR to help improve Social Media

LibraryThing – beyond terms
Items People Tags Ratings
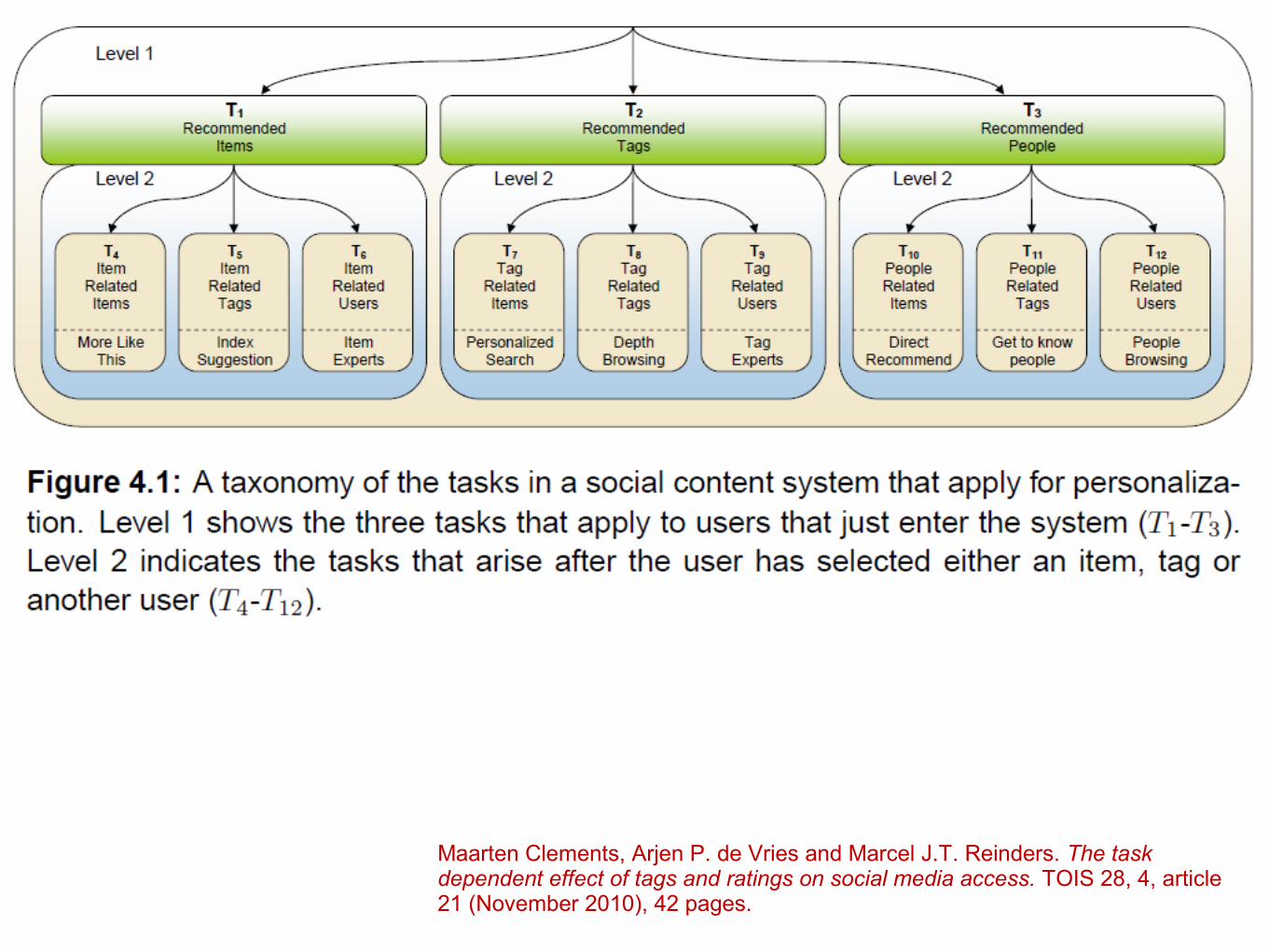
Maarten Clements, Arjen P. de Vries and Marcel J.T. Reinders. The task dependent effect of tags and ratings on social media access. TOIS 28, 4, article 21 (November 2010), 42 pages.

Search with Random Walk
Present nodes according to estimated probability that a random walk that starts from (task dependent) starting nodes, would end at this node
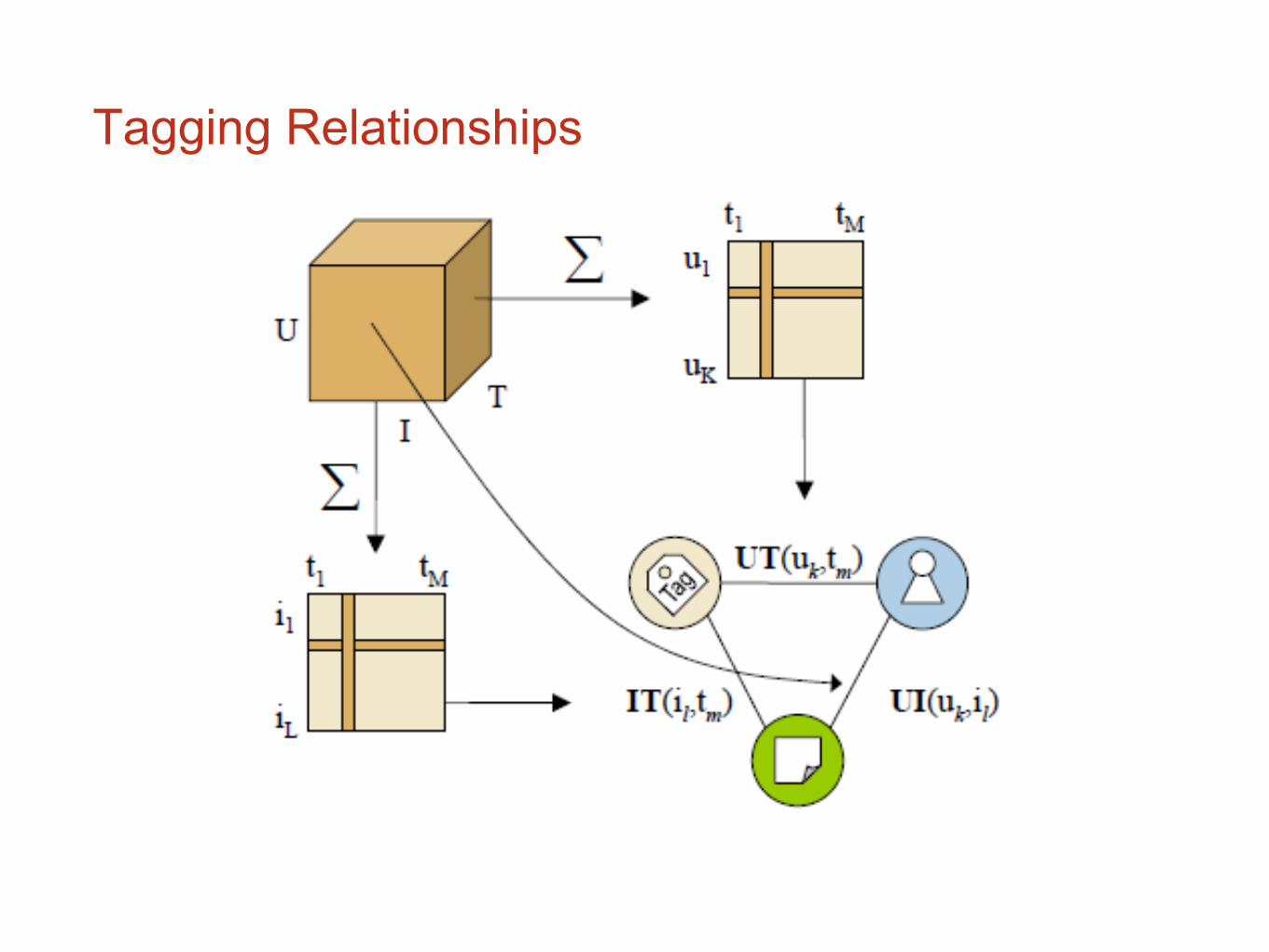
Tagging Relationships

Note: this representation used the item ratings in the user – item transitions

An item recommendation walk

Personalized Search
Assume a user who types a single tag as query

A soft clustering effect smoothly relates similar concepts before converging to the background probability
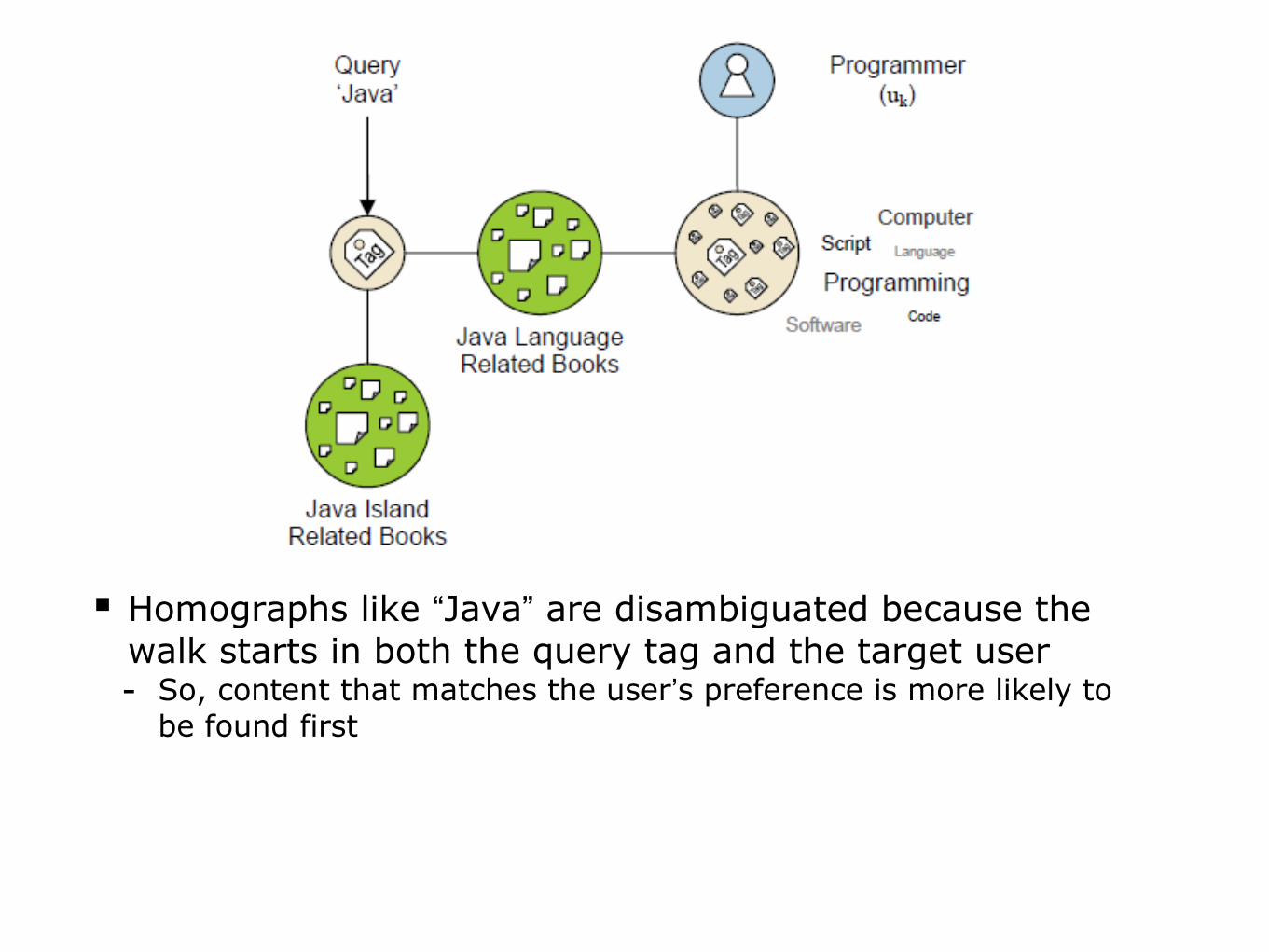
Homographs like “Java” are disambiguated because the walk starts in both the query tag and the target user- So, content that matches the user’s preference is more likely to
be found first

Expert Finding on Twitter Empirical evidence demonstrates that a mix of tweet text,
friends, followers and lists is most effective to infer expertise
Expertise ground truth taken from Quora, where (many) users list their expertise and their social media accounts
Xu, Zhou and Lawless. Inferring your expertise from Twitter: combining multiple types of user activity. WI ‘2017

Multiple Social Networks
Accounts linked via services like about.me and Quora Users explicitly list their multiple accounts in one profile
Missing data addressed via non-negative matrix factorization (NMF)- E.g., 57% list school in FB, 81% in LinkedIn
Applied to various prediction tasks, e.g.,topics users are interesting in

Social Media to help improve IR (2)

Relevant for Search… (1/4) Wikipedia contains semantically very rich annotations:
- Wikipedia Categories, Lists- Times (1930, 1931, 1932, etc. etc.)- Disambiguation pages- Edit historyEtc.
Note: DBPedia is “just” Wikipedia

Relevant for Search… (2/4) “Twanchor text”
- Tweets citing online media can be used as additional resources describing the content, just like anchor text

Relevant for Search… (3/4) Geotags / POIs
- Recommend geo-locations to people- Recommend people to geo-locations- Predict a user’s whereabouts (or “trails”)

Relevant for Search… (4/4) Timestamps
- Helps reveal trends, e.g., which documents went viral?- Allows to search “in the past”

Searching the Social Web Do not improve Web search with social annotations, but
improve search in Social
Builds on the observation in prior work (Goel et al., 2016) that virality is really different from popularity- The most viral content is often distinct from the most popular
content being shared online- Can we surface that content more easily?
Alonso, Kandylas, Tremblay, Hofman, Sen. What’s Happening and What Happened: Searching theSocial Web. WebSci ‘17.


Pipeline Content selection:
- Select tweets that contain links and satisfy simple user, content and time range criteria
User selection: - Extract and normalize links and select those that have been
shared by a minimum number of trusted users Link selection:
- Clean-up links, compute link virality and popularity, cluster similar links, and apply heuristic criteria to select good quality links
Annotations: - Generate metadata for the selected links from the associated
tweets


Collecting Data

API BluesBit.ly API used in my own research:
/v3/link/contentdeprecated Note: This endpoint was deprecated on 10/15/2014.

API Blues The combination of rate limits and Terms of Service of
most social media platforms complicates our life
Not even to mention volume- TREC Microblog collection of 2013 “Tweets2013” consists of
107 GB compressed (for only 2 months of data!)
Did I mention ToS?- Mandatory continual processing of deletions…

Good News for Twitter The Internet Archive distributes two collections from 2013
that can be used as drop-in replacement for evaluation purposes
Deletions seem to affect non-relevant documents more than relevant documents
Sequira and Lin. Finally, a Downloadable Test Collection of Tweets. SIGIR 2017.

Social Media as Panel Survey Online population is a non-representative sample of the
off-line world Demographic skew and user participation is non-
stationary and difficult to predict over time- E.g., women are underrepresented in the raw volume of tweets,
but tweet more often about politics than men- Half of the activity on a specific debate came from individuals
who had not previously posted about the election
Diaz, Gamon, Hofman, Kiciman, Rothschild. Online and Social Media as an Imperfect Continuous Panel Survey. In PLOS ONE, 2016

Fred Morstatter, Jürgen Pfeffer, Huan Liu and Kathleen M. Carley. Is the Sample Good Enough? Comparing Data from Twitter’s
Streaming API with Twitter’s Firehose.ICWSM 2013
API Blues

Take home message(s)

Take home message(s)• Social media give access to a rich resource of context
- Including time & location!

Take home message(s)• Social media give access to a rich resource of context
- Including time & location!
• The academic’s alternative to click data?

Take home message(s)• Social media give access to a rich resource of context
- Including time & location!
• The academic’s alternative to click data?
• A big open research question:
Can one theory (about matching users and content) address the
complete spectrum of IR tasks that arise in social media?