information retrieval basic document scoring. similarity between binary vectors document is binary...
TRANSCRIPT

Information Retrieval
Basic Document Scoring

Similarity between binary vectors
Document is binary vector X,Y in {0,1}v
Score: overlap measure
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
YX What’s wrong ?

Normalization
Dice coefficient (wrt avg #terms):
Jaccard coefficient (wrt possible terms):
Cosine measure:
Cos-measure less insensitive to doc’s sizes
YXYX /
YXYX /
|)||/(|2 YXYX
OK, triangular
NO, triangular

What’s wrong in doc-similarity ?
Overlap matching doesn’t consider: Term frequency in a document
Talks more of t ? Then t should be weighted more.
Term scarcity in collection of commoner than baby bed
Length of documents score should be normalized

A famous “weight”: tf x idf
)/log(,, tdtdt nntfw
where nt = #docs containing term t n = #docs in the indexed collection
log
Frequency of term t in doc d = #occt / |d|
nnidf
tf
t
t
t,d
0:)log1(?0 ,, dtdt tftf
Sometimes we smooth the absolute term frequency:
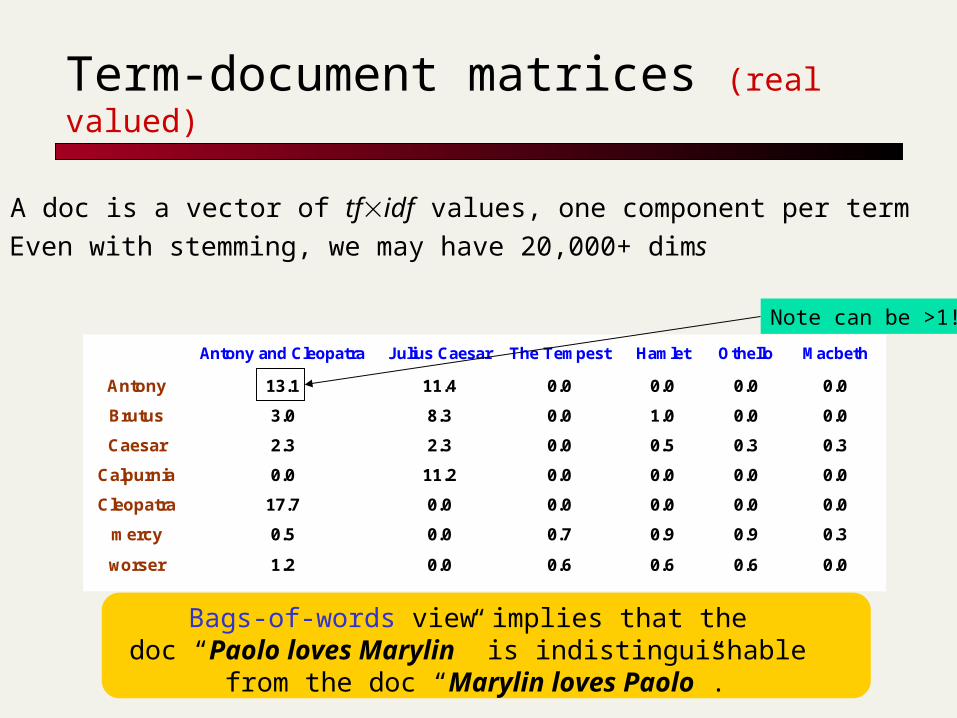
Term-document matrices (real valued)
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 13.1 11.4 0.0 0.0 0.0 0.0
Brutus 3.0 8.3 0.0 1.0 0.0 0.0
Caesar 2.3 2.3 0.0 0.5 0.3 0.3
Calpurnia 0.0 11.2 0.0 0.0 0.0 0.0
Cleopatra 17.7 0.0 0.0 0.0 0.0 0.0
mercy 0.5 0.0 0.7 0.9 0.9 0.3
worser 1.2 0.0 0.6 0.6 0.6 0.0
Note can be >1!
Bags-of-words view implies that the doc “Paolo loves Marylin” is indistinguishable
from the doc “Marylin loves Paolo”.
A doc is a vector of tfidf values, one component per term Even with stemming, we may have 20,000+ dims

A graphical example
Postulate: Documents that are “close together” in the vector space talk about the same things.Euclidean distance sensible to vector length !!
t1
d2
d1
d3
d4
d5
t3
t2
φ
Euclidean distance
vsCosine similarity
(no triangular inequality)

Doc-Doc similarity
If normalized, cosine of angle between doc-vectors sim = cosine Euclidean dist.
Vt ktVt jt
Vt ktjt
kj
kjkj
ww
ww
dd
ddddsim
2,
2,
,,),(
dot product
Recall that ||u - v||2 = ||u||2 + ||v||2 - 2 u •
v

Query-Doc similarity
We choose the dot product as measure of proximity between document and query (seen as a short doc)
Note: 0 if orthogonal (no words in common)
||,,
d
wwdq t dtqt
)/log(,, tdtdt nntfw
MG-book proposes adifferent weighting scheme
)/log(, tqt nnw

MG book
dtdt tfw ,, log1
)1log(,t
tqt n
nidfw
||
)log1(
||),( ,,,
d
idftf
d
wwdqsim tdttt dtqt
•|d| may be precomputed, |q| may be considered as a constant; •Hence, normalization does not depend on the query

Vector spaces and other operators
Vector space OK for bag-of-words queries
Clean metaphor for similar-document
queries Not a good combination with operators:
Boolean, wild-card, positional, proximity
First generation of search engines Invented before “spamming” web search

Relevance Feedback: Rocchio
User sends his/her query Q Search engine returns its best results User marks some results as relevant and resubmits
query plus marked results (repeat the query !!) Search engine exploit this refined knowledge of the
user need to return more relevant results.

Information Retrieval
Efficient cosine computation

Find k top documents for Q
IR solves the k-nearest neighbor problem for each query
For short queries: standard indexes are optimized
For long queries or doc-sim: we have high-dimensional spaces Locality-sensitive hashing…

Encoding document frequencies
#docs(t) useful to compute IDF term freq useful to compute tft,d
Unary code is very effective for tft,d
abacus 8aargh 12
acacia 35
1,2 7,3 83,1 87,2 …
1,1 5,1 13,1 17,1 …
7,1 8,2 40,1 97,3 …
IDF ? TF ?

Computing a single cosine
Accumulate component-wise sum
Three problems: #sums per doc = #vocabulary terms #sim-computations = #documents #accumulators = #documents
Vt dt
wqtwdqsim,,)( ,

Two tricks
Sum only for terms in Q [wt,q ≠ 0]
Compute Sim only for docs in IL [wt,d ≠ 0] On the query aargh abacus would only do
accumulators 1,5,7,13,17,….,83,87,…
abacus 8aargh 12
acacia 35
1,2 7,3 83,1 87,2 …
1,1 5,1 13,1 17,1 …
7,1 8,2 40,1 97,3 …
We could restrict to docs in the intersection!!
Vt dt
wqtwdqsim,,)( ,

Advanced #1: Approximate rank-search
Preprocess: Assign to each term, its m best documents (according to the TF-IDF).
Lots of preprocessing Result: “preferred list” of answers for each term
Search: For a q-term query, take the union of their q preferred
lists – call this set S, where |S| mq. Compute cosines from the query to only the docs in S,
and choose the top k.
Need to pick m>k to work well empirically.

Advanced #2: Clustering
Query
LeaderFollower

Advanced #2: Clustering
Recall that docs ~ T-dim vector Pre-processing phase on n docs:
pick L docs at random: call these leaders For each other doc, pre-compute nearest leader
Docs attached to a leader: its followers; Likely: each leader has ~ n/L followers.
Process a query as follows: Given query Q, find its nearest leader. Seek k nearest docs from among its followers.

Advanced #3: pruning
Classic approach: scan docs and compute their sim(d,q).
Accumulator approach: all sim(d,q) are computed in parallel. Build an accumulator array containing all sim(d,q), d,q.
Exploit IL so that t in Q: d in ILt, compute TF-IDFt,d and sum it to sim(d,q)
We RE-structure the computation: Terms of Q are considered for decreasing IDF (i.e. smaller ILs first)
Documents in IL lists are ordered by decreasing TF This way, when a term is picked and its IL is scanned, the TF-IDF are computed
by decreasing value, so that we can apply some pruning
Vt
tIdfdtTfdqsim
,)( ,

Advanced #4: Not only term weights
Current search engines use various measures for estimating the relevance of a page wrt a query
Relevance(Q,d) = h(d, t1, t2,…,tq)
PageRank [Google] is one of these methods and denotes the relevance taking into account the hyperlinks in the Web graph (more later)Google tf-idf PLUS PageRank (PLUS other weights)
Google toolbar suggests that PageRank is
crucial

Advanced #4: Fancy-hits heuristic Preprocess:
Fancy_hits(t) = its m docs with highest tf-idf weight Sort IL(t) by decreasing PR weight
Idea: a document that scores high should be in FH or the front of IL
Search for a t-term query: First FH: Take the common docs of their FH
compute the score of these docs and keep the top-k docs.
Then IL: scan ILs and check the common docs of ILs FHs Compute the score of these docs and possibly insert them
into the current top-k. Stop when m docs have been checked or the PR score goes
below some threshold.

Advanced #5: high-dim space
Binary vectors are easier to manage: Map unit vector u to {0,1}
r is drawn from the unit sphere. The h is locality sensitive:
Map u to h1(u), h2(u), ..., hk(u)Repeat g times, to control error.
If A & B sets

Information Retrieval
Recommendation Systems

Recommendations
We have a list of restaurants with and ratings for some
Which restaurant(s) should I recommend to Dave?
Brahma Bull Spaghetti House Mango Il Fornaio Zao Ming's Ramona's Straits Homma'sAlice Yes No Yes NoBob Yes No No
Cindy Yes No NoDave No No Yes Yes YesEstie No Yes Yes YesFred No No

Basic Algorithm
Recommend the most popular restaurants say # positive votes minus # negative votes
What if Dave does not like Spaghetti?
Brahma Bull Spaghetti House Mango Il Fornaio Zao Ming's Ramona's Straits Homma'sAlice 1 -1 1 -1Bob 1 -1 -1
Cindy 1 -1 -1Dave -1 -1 1 1 1Estie -1 1 1 1Fred -1 -1

Smart Algorithm
Basic idea: find the person “most similar” to Dave according to cosine-similarity (i.e. Estie), and then recommend something this person likes.
Perhaps recommend Straits Cafe to Dave
Brahma Bull Spaghetti House Mango Il Fornaio Zao Ming's Ramona's Straits Homma'sAlice 1 -1 1 -1Bob 1 -1 -1
Cindy 1 -1 -1Dave -1 -1 1 1 1Estie -1 1 1 1Fred -1 -1
Do you want to rely on one person’s opinions?