information retrieval - did.mat.uni-bayreuth.de · 19. februar 2003 © prof. dr. andreas henrich,...
TRANSCRIPT

19. Februar 2003 © Prof. Dr. Andreas Henrich, Universität Bayreuth 1
Information Retrievaloder: wie Suchmaschinen funktionieren
Prof. Dr. Andreas HenrichAngewandte Informatik ISoftwaretechnik und InformationssystemeFakultät für Mathematik und PhysikUniversität Bayreuth

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 2
Funktionalität von Suchmaschinen
Suche
Katalog
…

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 3
Was steckt dahinter? Hier werden Informationen zu den bekannten Dokumenten verwaltet, um eine schnelle Suche zu ermöglichen.
Durchsuchen des Netzes nach Dokumenten und Eintragen der Indexdaten in den Index.
Portalseite zur Suchmaschine.
Bearbeitung der Anfragen auf Basis des Index.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 4
Was hat Information Retrieval damit zu tun?
Information Retrieval (IR) betrachtet Informationssysteme in Bezug auf ihre Rolle im Prozess des Wissenstransfers vom menschlichen Wissensproduzenten zum Informations-Nachfragenden.
Idee
Dokument
Dokumenten-Pool
Features derDokumente
Ähnlichkeits-suche
Ergebnis-liste
Anfrage als Repräsentation des Informationsbedürfnisses
Dokumente
Informations-bedürfnis
Anfrage
Idee
Dokument
…
Im Falle einer Suchmaschine das WWW.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 5
Gliederung
Modelle des Information Retrieval
Boolesches Retrieval
Vektorraummodell
Qualitätskriterien für IR-Modelle
Übertragung auf andere Medien
Crawling
Wie wird „gecrawlt“?
Probleme des Crawling
Ganz andere Ansätze
der Markt regelt fast alles!

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 6
Modelle des Information Retrieval
Aspekte:Repräsentation des Informationswunsches
Repräsentation der Dokumente
Matching
Implementierung

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 7
Das Boolesche IR-Modell
„Wirtschaft und Gesellschaft befinden sich derzeit im
größten Umbruch seit der Industrialisierung. …“
{Wirtschaft, Gesellschaft,Umbruch, Industrialisierung,
…}

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 8
Implementierung: Invertierte Listen
Grundidee:Die normale Darstellung ist:
Das Dokument wird mit allen in ihm vorkommenden Wörtern gemeinsam abgespeichert.
Die Suche geht aber nicht von den Dokumenten, sondern von den Wörtern aus!
Also invertiert man die Verwaltung:
Man speichert zu jedem Wort alle Dokumente ab, die dieses Wort enthalten.
Dazu wird zu jedem Wort eine Liste der Dokumente verwaltet, die dieses Wort enthalten:
die invertierte Liste

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 9
Beispiel: Invertierte Listen

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 10
Bearbeitung von Anfragen
Motorrad AND Qualität:paralleles Durchlaufen der zugehörigen Listen
Übernahme der Dokumentreferenzen, die in beiden Listen vorhanden sind in die Ergebnisliste
durch Sortierung der Listen hohe Effizienz

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 11
Nachteile des Booleschen Retrieval
keine Rückführung der Wörter auf eine Grundform
keine Gewichtung der Wörter
nach dem Ort des Vorkommens
nach der Häufigkeit des Vorkommens
keine Zerlegung von Mehrwortgruppen
relativ aufwendige Formulierung der Anfrage
kaum vorhersehbare Ergebnisgröße
kein Ranking der Dokumente

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 12
Das Vektorraummodell nach Salton
„Wirtschaft und Gesellschaft befinden sich derzeit im
größten Umbruch seit der Industrialisierung. …“

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 13
Gewinnung eines Beschreibungsvektors für Text
1. Stoppworteliminierung:entferne Wörter, die allein keine Bedeutung tragen und in fast allen Texten vorkommen (und, oder, der, die, …)
2. Stammformreduktion:Rückführen aller auftretenden Wortformen auf den Wortstamm (Kaisern → Kaiser, …)
3. Synonym-/Homonymbehandlung:Ersetze Synonyme ggf. durch eine Vorzugsbenennung
4. Mehrwortgruppenbetrachtung:Zerlege Mehrwortgruppen und/oder fasse Wörter zu Mehrwortgruppen zusammen
5. Bildung eines Vektors:die einzelnen Komponenten stehen für die Vorkommenshäufigkeiten der einzelnen Begriffe (z.B. 1 = Frankreich, 2 = Napoleon, …)
„Dies ist ein Text über Frankreich und Napoleon. Er handelt von Revolutionen, Kaisern, Kriegen und auch von Waterloo. Er bezieht sich auf Frankreich und Europa …“
1
0
1
0
0
1
2
M

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 14
Bestimmung der Vektorkomponenten:Die tf⋅idf-Formel nach Salton
t = Anzahl der Terme im Vokabular
N = Anzahl der Dokumente in der Kollektion
nk = Anzahl der Dokumente, die Term k enthalten
tfdk = Vorkommenshäufigkeit von Term k in Dokument D
∑=
⋅
⋅=
t
i idi
kdk
dk
n
Ntf
n
Ntf
w
1
2
log
logBerücksichtigung der
Trennschärfe des Begriffs (idf)
Berücksichtigung der Vorkommenshäufigkeit
Normierung, um den Einfluss der Dokumentlänge
zu eliminieren
Gewicht des Terms kfür Dokument D

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 15
Anfragevektor und Ähnlichkeitsbestimmung
Bestimmung des Anfragevektors:
Im Prinzip analog zu tf⋅idf-Formel aber mit Mindestgewicht für in der Anfrage auftretende Terme
ohne Normierung für Anfragelänge
Ähnlichkeitsbestimmung z.B. über das Skalarprodukt:
=
>⋅
⋅
+=
≤≤
0falls0
0fallslogmax
5,05,0
1
qk
qkk
tiqi
qk
qk
tf
tfn
N
tf
tf
w
dk
t
kqk wwDQsimilarity ∑
=
⋅=1
),(

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 16
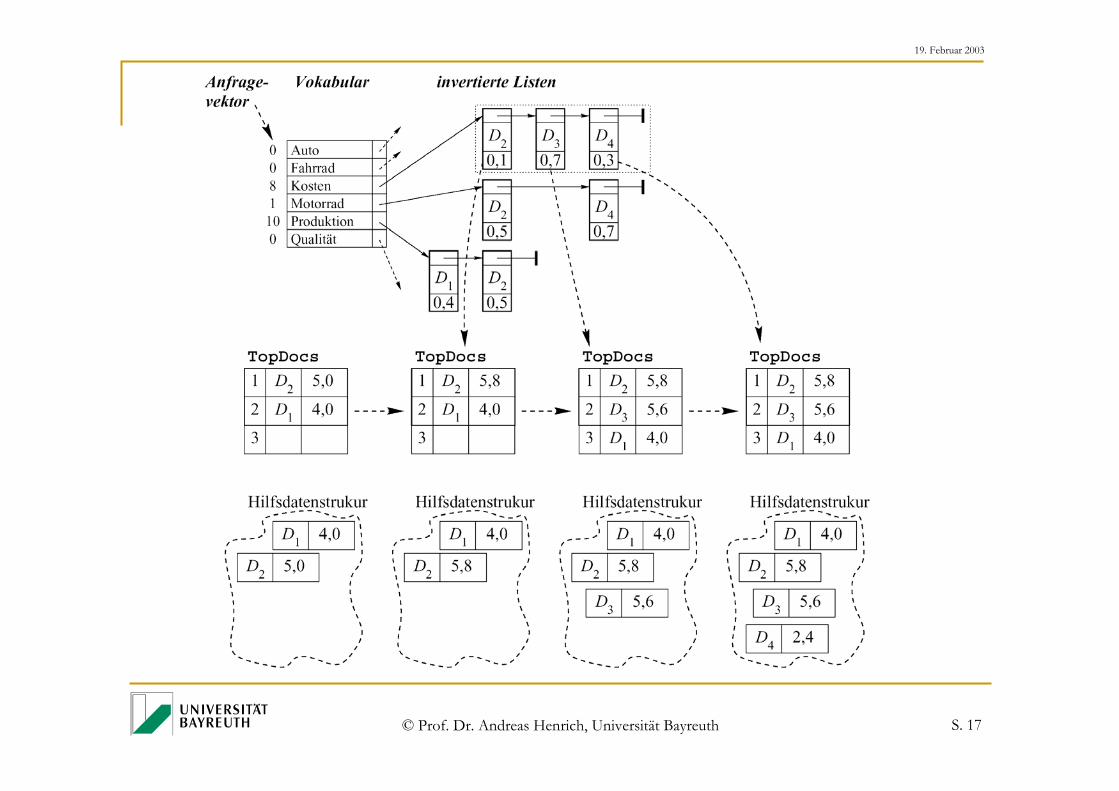
Gesucht sind die γ = 2 am besten zur Anfrage passenden Dokumente
Anfragebearbeitung:
Durchlaufe die Listen, die im Anfragevektor ein Gewicht ≠ 0 haben.
Berechne dabei für die auftretenden Dokumente schrittweise das Skalarprodukt.
Implementierung
19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 17

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 18
Wann kann man aufhören?
1. Idee:
Wir hören dann auf weitere Listen zu betrachten, wenn sich die Platzierungen in TopDocs nicht mehr ändern können!
2. Idee:
Wir hören schon auf, wenn sich kein weiteres Element unter die γgesuchten mischen kann!
3. Idee:
Wir hören bereits auf, wenn wir n < γ Dokumente sicher erkannt haben!
Frage:
Welche Variante ist besser?

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 19
Qualitätskriterien für IR-Systeme
Welche Aspekte sind von Bedeutung für die Beurteilung eines IR-Systems?
durch Korrektheit abgedeckt
sehr wichtigErgebnisqualität
unabdingbar???Korrektheit
wichtigwichtigSpeicherplatzbedarf
wichtigwichtigLaufzeitverhalten
DatenbanksystemeIR-Systeme

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 20
Evaluierung von IR-Systemen
Wie kann man die Qualität des Ergebnisses messen?
Annahme:Für eine gegebene Anfrage kann für jedes Objekt eindeutig entschieden werden ob es relevant oder nicht relevant ist.
Qualität des ErgebnissesWie vollständig ist das Ergebnis?
Enthält das Ergebnis nur relevante Einträge?
insgesamt) Dokumente (relevante#
Ergebnis) im Dokumente (relevante#Recall =
insgesamt) Ergebnis im (Dokumente#
Ergebnis) im Dokumente (relevante#Precision =

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 21
Werden wir schlechter, wenn wir ungenauer arbeiten?
Experimentelle Ergebnisse von Buckley & Lewit für die INSPEC-Kollektion
Qualitätsmaß: Recall nach γ = 10 Dokumenten

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 22
Kollektionvon Bildern
Extraktioncharakteristischer Eigenschaften(Features)
Feature-vektoren
Anfragebild Anfragezkizze
…
Anfrage-vektor
Feature-Extraktion
Ähnlichkeits-suche
Anfrageergebnis (Rangordnung)
7
6
12
28
0
15
Übertragung des Verfahrens auf Bilder

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 23
Gewinnung eines Beschreibungsvektors für Bilder
Eigenschaften:Farbe
Textur
Form
255 0
255
255
Aufteilung desRGB-Farbraums
Anzahl
Topf
Farbhistogramm
1 2 3 4 5 6
1 2 3 4 5 6
zählen der Pixel mit einem Farbwert im jeweiligen Teilbereich

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 24
Übertragung auf strukturierte MM-Dokumente
Struktur
Medienobjekte
Segmentierung

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 25
Ein BeispieldokumentThesis : document
Einleitung : chunk
In dieser Arbeit …
Hauptteil : chunk Schluss : chunk
HT1 : chunk HT2 : chunkFerner …
In Zukunft …
Wir sehen …
Außer …
Hier …
Am Ende …

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 26
Anfragebearbeitung/Optimierung
chunk
textimage
image segment
ranking withrespect to
colorsimilarity(e.g. fromLSDh-tree)
combine streams(e.g. with Quick
Combine)
combinestreams (e.g.with QuickCombine)
transfer rankingwith RSV-Transfer
rankingaccording to theVSM (e.g. frominverted files)
transfer rankingwith RSV-Transfer
ranking withrespect to
shapesimilarity(e.g. fromLSDh-tree)
ranking withrespect to
texturesimilarity(e.g. fromLSDh-tree)
Image
ImageSegment1
ImageSegment3
ImageSegment2
Chunk
Text2Text1
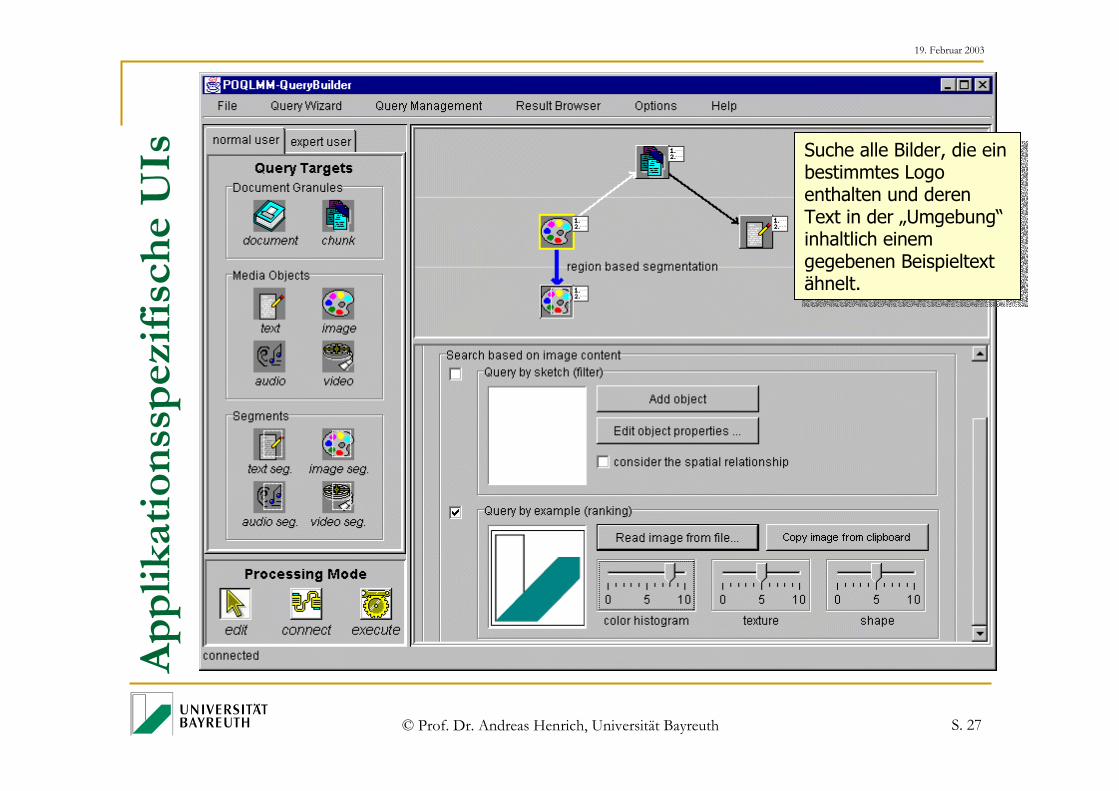
Anfrage: Suche alle Bilder, dieein bestimmtes Logo enthalten und deren Text in der „Umgebung“ inhaltlich einem gegebenen Beispieltext ähnelt.
Anfrage: Suche alle Bilder, dieein bestimmtes Logo enthalten und deren Text in der „Umgebung“ inhaltlich einem gegebenen Beispieltext ähnelt. Maximumsemantik
∅-Semantik
1.
2.
6.
5.
3.
4.
19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 27
Appl
ikat
ions
spez
ifisc
heU
Is Suche alle Bilder, die ein bestimmtes Logo enthalten und deren Text in der „Umgebung“ inhaltlich einem gegebenen Beispieltext ähnelt.
Suche alle Bilder, die ein bestimmtes Logo enthalten und deren Text in der „Umgebung“ inhaltlich einem gegebenen Beispieltext ähnelt.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 28
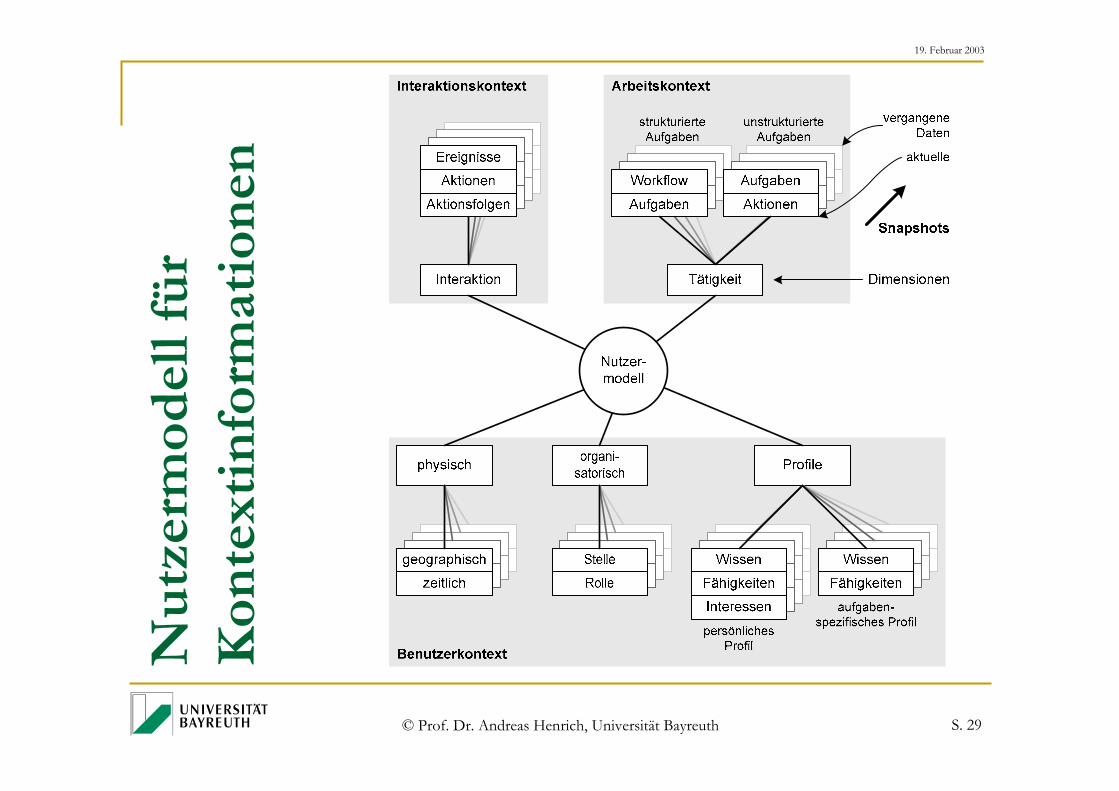
Kontextunterstütztes Information Retrieval
Idee:Eine weitere Quelle zur Konkretisierung des Informationswunschesnutzen!
Rückgriff auf Wissen über den Kontext des Benutzers
Dieses Wissen wird verwendet, um eine gezieltereAnfragerepräsentationabzuleiten.
Kontext des Benutzers
Anfrage als Repräsentation des
Informationsbedürfnisses
Informations-bedürfnis
Anfrage
19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 29
Nut
zerm
odel
l für
K
onte
xtin
form
atio
nen

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 30
Gen
eris
cher
Arch
itekt
urra
hmen
organisatorisch Profile Tätigkeit
Interaktion
schrittweise Erhöhung der semantischen Ebene
automatische Generierung und Präzisierung von Anfragen

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 31
Techniken des Crawling

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 32
Crawling: Breiten- und Tiefensuche
Soll das Internet durchsucht werden, werden dazu Links verfolgt:
Tiefensuche
Jeder besuchte Knoten wird auf Links zu weiteren Knoten untersucht.
Wird ein Link gefunden, so wird dieser auf einem Stapel abgelegt.
Ist der Knoten vollständig analysiert, so wird der oberste auf dem Stapel liegende Link vom Stapel entfernt und als nächstes analysiert.
Breitensuche
Neu gefundene Links werden am Ende einer Warteschlange eingereiht.
Ist ein Knoten vollständig analysiert, wird vom Kopf der Warteschlange die Adresse des nächsten zu besuchenden Knoten genommen.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 33
Breiten- und Tiefensuche
Breitensuche:Der Baum wird ebenenweise durchsucht.
Tiefensuche:An einer Stelle wird zunächst in die Tiefe gesucht.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 34
Was ist ein Crawler, Spider oder Robot?
Der Name Crawler steht für das „Kriechen“ durch das Web.
Crawler verwenden bei ihrer Suche durch das Netz fast immer das Konzept der Breitensuche.
Auf diese Weise werden Dokumente in der Reihenfolge indexiert, in der sie per Hyperlink entdeckt wurden.
Der vom Crawler verursachte Traffic wird relativ gleichmäßig auf verschiedene WWW-Server verteilt.
Crawler verursachen nach Schätzungen etwa 5-15% des gesamten Datenverkehrs im Internet!

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 35
Funktionsweise von CrawlernIn (un)regelmäßigen Abständen wird ein Crawler angehalten.
Der erstellte Index wird zur Suchmaschine kopiert und aktualisiert den vorhandenen Index.
Ab diesem Zeitpunkt können Nutzer auf dem neuen Index suchen.
Danach setzt der Crawler seine „Reise“ durch das WWW fort.
Betreiber können ihre Website bei einem Crawler anmelden und den Crawler dadurch zum Indexieren auffordern.
Folgen: Website wird indexiert, bevor der Crawler sie über Hyperlinks erreicht.
Auch Websites, auf die nicht verwiesen wird, können indexiert werden.
Die Liste der neu angemeldeten Websites wird üblicherweise an den Crawler übertragen, wenn dieser angehalten wurde.
⇒ Es dauert einige Tage/Wochen/Monate, bis ein Crawler eine neue Website besucht.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 36
robots.txt – der Robots Exclusion Standard
Robots besuchen standardmäßig alle über Hyperlinks erreichbaren Dokumente einer Website.
Aus verschiedenen Gründen kann dies unerwünscht sein:
Man möchte den von Crawlern verursachten Traffic auf der eigenen Website u.U. minimieren (Kosten für Bandbreite).
Es sollen vor allen Dingen die Einstiegsseiten der Website indexiert werden, damit Nutzer auch auf diesen Seiten einsteigen und nicht tief unten in der Hierarchie.
Manche Bereiche einer Website werden zwar nicht als geheim eingestuft, dennoch möchte man nicht, dass sie per Suchmaschine zu finden sind.
⇒ Robots Exclusion Standard

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 37
robots.txt
Durch eine Datei robots.txt im Hauptverzeichnis des WWW-Servers können die Crawler beeinflusst werden.
Alle Crawler sollen von bestimmten Bereichen der Websiteausgeschlossen werden:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /private/
Ein einzelner Crawler soll ausgeschlossen werden:
User-agent: BadBotDisallow: /

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 38
Robots Exclusion Standard
Alternativ können diese Angaben auch als <meta>-Tag im Headereines HTML-Dokuments enthalten sein.
Zur Zeit implementieren allerdings noch nicht alle Crawler dieseFunktionalität.
<html><head><title>Lehrstuhl für Angewandte Informatik I</title><META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
</head><body><p>Herzlich willkommen auf den Seiten des Lehrstuhlsfü Angewandte Informatik I an der UniversitätBayreuth.
</body></html>

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 39
Indexierung verschiedener Dokumenttypen
Um neben HTML-Seiten auch PDF-, PS-, … -Dateienindexieren zu können braucht man entsprechende Parser
Diese existieren heute in großer Zahl und sind z.T. sogar frei verfügbar

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 40
Priorisierung wichtiger Websites
Einige Websites sind für die Nutzer besonders interessant.
z.B. Online-Magazine, Zeitungen, …
Diese Websites werden üblicherweise häufig aktualisiert.
Der Crawler überprüft in bestimmten Intervallen, ob sich ein Dokument geändert hat.
Falls ja, wird das Besuchsintervall für dieses Dokument verringert.
Falls nein, wird das Intervall belassen oder sogar erhöht.
Folge: Der Index ist auch für Seiten, die sich häufig ändern, aktuell.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 41
Probleme von Crawlern
Frames:Eine indexierte Seite kann nur in einem Rahmen sinnvoll dargestellt werden.
Lösung: Ein JavaScript, das erkennt, wenn die Seite nicht im Rahmen dargestellt wird und diesen nachlädt.
JavaScript:Mit JavaScripts lassen sich z.B. Links zu vorangehenden und nachfolgenden Dokumenten erzeugen.
Die so erzeugten Links werden aber erst durch die JavaScript-Laufzeit-Umgebung im Browser des Clients in das Dokument geschrieben.
Lösung: Man sollte zusätzlich eine „Sitemap“ anlegen.
Imagemaps:Auch hier hilft eine zusätzliche „Sitemap“.

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 42
Es war einmal: offenes Bezahlen pro Click

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 43

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 44

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 45
Aber:

19. Februar 2003
© Prof. Dr. Andreas Henrich, Universität Bayreuth S. 46
Wie geht es weiter?
Semantic Web?
Thematisch fokussierte Suchmaschinen
Metasuchmaschinen
Aber:durch personalisierte Angebote
durch dynamisch erzeugte Webseiten
wird den Suchmaschinen das Leben schwer gemacht