instituto politÉcnico nacionaltesis.ipn.mx/jspui/bitstream/123456789/6066/1/esime-forensia.pdf ·...
TRANSCRIPT

INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA MECÁNICA Y
ELÉCTRICA UNIDAD CULHUACAN
SEMINARIO DE TITULACIÓN “SEGURIDAD DE LA INFORMACIÓN”
TESINA “ESQUEMA DE FORENSIA EN RED”
QUE PRESENTAN PARA OBTENER EL TÍTULO DE INGENIERÍO EN INFORMÁTICA
CANIZAL ZÚÑIGA JOSÉ CARLOS
LICENCIADO EN CIENCIAS DE LA INFORMÁTICA
DE LA CRUZ SAMAYOA ALVARO HUMBERTO
DIONICIO NIÑO CARLOS ALEJANDRO ROMERO MARTÍNEZ JUAN ANTONIO
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
FUENTES JIMENEZ DAVID
Asesores: DR. GABRIEL SANCHEZ PÉREZ
M. EN C. MARCOS ARTURO ROSALES GARCÍA
VIGENCIA: DES/ESIME-CUL/23/08
México, D.F., Junio 2009



AGRADECIMIENTOS A NUESTROS PADRES Y COMPAÑEROS: Por el apoyo que nos proporcionaron en todo momento, desde los mejores hasta nuestros peores momentos ya que, gracias a ustedes hemos tenido la oportunidad de estudiar y llegar a ser profesionistas. AL INSTITUTO POLITÉCNICO NACIONAL: Por ser la institución que por cortos pero valiosos años nos mostró cómo la ética, moral, y el profesionalismo son virtudes invaluables, y que se demuestran día con día.

ÍNDICE GENERAL PRELIMINARES Pág. INTRODUCCIÓN I OBJETIVO II ALCANCE III ESQUEMA IV CAPÍTULO I. ATAQUES EN RED 1
1.1 Clasificación de los ataques en la red 2 1.1.1 Clasificación por Lista de Términos 2 1.1.2 Clasificación por Lista de Categorías 2 1.1.3 Clasificación por Resultado de Categorías 3 1.1.4 Listas Empíricas 3 1.1.5 Clasificación de Ataques Basados en la Acción 3
1.2 Taxonomía de los Incidentes 4 1.2.1 Eventos 4 1.2.2 Acciones 5 1.2.3 Objetivos 6 1.2.4 Ataques 7 1.2.5 Herramientas 8 1.2.6 Vulnerabilidad 8 1.2.7 Resultado No Autorizado 9 1.2.8 Incidentes 9 1.2.9 Los Atacantes y sus Propósitos 10
CAPÍTULO II. INFORMATICA FORENSE 11
2.1 Objetivos de la Forensia 12 2.2 Tipos de Forensia Informática 13
2.2.1 Forensia Basada en Host 13 2.2.2 Forensia Basada en Red 14
2.3 Análisis Forense 14 2.4 Evidencia Digital 15
2.4.1 Clasificación de la Evidencia Digital 16 2.4.2 Criterios de Admisibilidad 16
2.5 Procedimiento Forense Computacional 17 2.6 Documentos de Informática Forense 19
2.6.1 RFC 3227 20 2.6.2 Guía de la IOCE 20 2.6.3 Investigación de la escena del crimen electrónico 20

2.6.4 Exámen forense de evidencia digital 20 2.6.5 Computación Forense: Mejores prácticas 20 2.6.6 Guía de buenas prácticas para evidencia basadas en
computadoras 21
2.6.7 Guía para el manejo de evidencia en IT 21 CAPÍTULO III. PROTOCOLOS DE RED Y SU MONITOREO 25
3.1 Tipos de Protocolos 25 3.2 Protocolo TCP/IP 31
3.2.1 Protocolo IP 32 3.2.2 Protocolo TCP 35
3.3 SMNP 39
3.3.1 MIB 40 3.3.2 RMON 41
3.4 Esquema típico de monitoreo 42 3.4.1 Monitoreo Activo 44 3.4.2 Monitoreo Pasivo 44 3.4.3 Elementos de Interconectividad 44 3.4.4 Controles de Seguridad en Red 48
3.5 Monitoreo de una red TCP/IP 52 CAPÍTULO IV. CASO PRÁCTICO 56
4.1 Wireshark/Tshark 56 4.1.1 Simulando un DoS en Windows 57 4.1.2 Tshark 63
4.2 Tcpdump 66 4.3 Elección de Herramienta 68
CONCLUSIONES 69 REFERENCIAS BIBLIOGRÁFICAS 70 GLOSARIO 71

ÍNDICE DE FIGURAS
Figura Nombre Página
Figura 1.1 Espectro de las actividades en una red 5 Figura 1.2 Ataques basados en la experiencia 7 Figura 1.3 Diagrama general de los incidentes de seguridad 9 Figura 2.1 Cuadro comparativo de documentos de Informática
Forense
22 Figura 3.1 Representación del modelo OSI 27 Figura 3.2 Arquitectura del protocolo TCP/IP 32 Figura 3.3 Datagrama IP 33 Figura 3.4 Segmento TCP 37 Figura 4.1 Uso de Windows según Xitimonitor durante enero
de 2007
56 Figura 4.2 Comparativo de los sistemas operativos y su uso en
la red según Xitimonitor
57 Figura 4.3 Esquema básico de conectividad entre dos equipos 58 Figura 4.4 Elementos por defecto en Wireshark 59 Figura 4.5 Gráfica de entrada/salida 60 Figura 4.6 Un ping por tiempo indefinido 61 Figura 4.7 Demostración de ICMP iniciado por ping 61 Figura 4.8 Tráfico de red cuando inicia el ping 62 Figura 4.9 Tráfico cuando el ping finalizo 62
Figura 4.10 Tshark a la espera de tráfico ICMP 64 Figura 4.11 Tshark Capturando y registrando el trafico ICMP 65 Figura 4.12 Paquetes ICMP capturados por Tshark 65 Figura 4.13 Tcpdump escuchando los paquetes icmp a través
de la interfaz eth0 67
Figura 4.14 Tcpdump resumen de paquetes capturados 67 Figura 4.15 Archivo donde se registro el tráfico del protocolo
icmp 68

I
INTRODUCCIÓN
Hoy día un aspecto clave para el éxito de las empresas es la seguridad de la información que genera, procurando mantener la confidencialidad, disponibilidad e integridad de la misma, de igual manera la necesidad de compartir información a través de la red corporativa hacen que esta deba tener un nivel de seguridad alto ya que los ataques dirigidos a protocolos, sistemas operativos y dispositivos de red están incrementándose a causa de la aparición de nuevas y más complejas herramientas que automatizan los ataques y aprovechan con mayor eficiencia las vulnerabilidades existentes en la organización, por lo cual surge la necesidad de plantear políticas y un esquema de seguridad. A pesar de todas estas medidas muchas veces un mal diseño del esquema de seguridad o imposición de criterios económicos por sobre los de seguridad de la empresa dan lugar a que se susciten ataques, y por ende perdidas para la empresa Lo que sucede actualmente en las pequeñas y medianas empresas (PyMe) nacionales es que no cuentan con un sistema de respuesta a incidentes ni mucho menos con alguno de forensia y, una vez sufrido algún tipo de ataque, éstas empresas se preocupan más por recuperar la información y que no afecte este evento en sus operaciones diarias. La ciencia forense aplicada a la informática se encuentra en pleno auge y actualmente existen diferente metodologías dependiendo el enfoque que se tome, pero básicamente se trata de localizar y/o generar la evidencia a priori (forensia en red) antes de que se presente un ataque para después poder analizar la secuencia de eventos que dieron lugar al ataque aplicando metodologías reproducibles y estandarizadas, de tal manera que tengan validez y puedan ser presentados como pruebas fehacientes. La presente tesina pretende mostrar al lector un esquema de forensia causal, es decir, se centra en conocer los hechos únicamente, utilizando una combinación de las distintas metodologías existentes, además de justificarse en base a datos estadísticos de los distintos ataques en red arrojados por instituciones normativas sobre la forensia y seguridad informática.

II
OBJETIVO Proponer herramientas de monitoreo para obtener evidencia y así tener elementos para aplicar forensia en una red TCP/IP.

III
ALCANCE La presente investigación se centra en establecer los procesos de monitoreo para obtener evidencia digital, y así contar con elementos para aplicar forensia en una red TCP/IP.

IV
ESQUEMA Un esquema de forensia en red es una serie de elementos teóricos que pretende dar una visión de lo que puede ser puesto a prueba en la realidad, en el presente documento se muestran los fundamentos teóricos de una red LAN y cómo funcionan en un caso práctico. Es importante diferenciar tres conceptos básicos modelo, esquema y arquitectura, para conocer por que se presenta un esquema de forensia y no un modelo o una arquitectura.
Modelo: Es el resultado del proceso de generar una representación abstracta,
conceptual, grafica o visual para analizar, describir, explicar, simular y predecir
fenómenos o procesos.
Esquema: Es un sistema de ideas, un conjunto organizado de conceptos
universales que permiten una aproximación a un objeto particular. Se trata de
un paquete teórico abierto que puede ser puesto a prueba en la vida cotidiana.
Arquitectura: La arquitectura es el diseño conceptual y la estructura
operacional fundamental de un sistema.
Como se muestra un modelo pretende simular un fenómeno o proceso, en este documento no se pretende simular procesos de forensia, ni hacer un diseño conceptual como lo indica la Arquitectura. Se muestra una serie de fundamentos teóricos aplicables a casos reales.

1
CAPÍTULO I. ATAQUES EN LA RED
En la actualidad el activo más importante de una empresa, institución pública, o de un individuo es la información. La información que una empresa posee es de vital importancia para llevara a cabo sus operaciones, es lo que le permite tomar decisiones, que hacer, como hacerlo y para qué hacerlo. No se puede imaginar a un banco sin la información de estados financieros, o a una empresa de publicidad sin la cartera de clientes. La información que es relevante para una empresa puede no serlo para otra. Más importante aún, la información que posee una empresa puede colocarle en una posición más adelantada que la de la competencia, aquí es donde inician muchos de los problemas de seguridad de la información, robo y venta de la información confidencial de los clientes, vender secretos industriales a la competencia, son algunos ejemplos. Para las empresas o instituciones que ofrecen servicios, los mas importante es la calidad del mismo, si los servicios que ofrecen son de calidad, difícilmente un cliente va requerir nuevamente de sus servicios. ¿Qué pasa si la competencia evita que la empresa ofrezca un servicio de calidad, o en el extremo, evita que la empresa ofrezca el servicio?, con seguridad la empresa perderá gran cantidad de clientes; ¿quién gana?: la competencia. Hasta este momento no se ha hablado de procesos automatizados de información, son casos generales de problemas con el manejo de la información y los servicios en las empresas. Como se sabe en la actualidad, la mayoría de las empresas utilizan algún medio informático -entendiendo como medio informático a herramientas como computadoras, lectores, escáneres, redes de computadoras- para el manejo de su información o para la administración de sus servicios. En este punto es donde entra la seguridad en las redes y los equipos de cómputo. Cuando ocurre un incidente de seguridad se dice que el sistema sufrió uno o varios ataques. Un ataque en la red se puede definir como una parte de una serie de pasos intencionados para intentar obtener un resultado no autorizado [1].
Pero para llevar a cabo un ataque en la red es necesario que exista una vulnerabilidad, es decir, una debilidad en la red que puede ser explotada. Por lo tanto se puede definir un ataque en la red como:

2
“El intento intencionado de obtener un resultado no autorizado en la red aprovechando una vulnerabilidad existente”.
1.1 Clasificación de los Ataques en la Red Existen diversos autores que clasifican a los ataque en la red de diversas maneras de acuerdo a la perspectiva que tiene cada uno de dichos ataques.
1.1.1 Clasificación por Lista de Términos
Esta clasificación no es satisfactoria ya que los términos no forzosamente independientes; por ejemplo, en la lista se puede encontrar el término virus y bomba lógica, pero un virus puede contener una bomba lógica. Y el problema fundamental con esta clasificación es que la lista puede llegar a ser muy grande y en consecuencia difícil de aplicar, además del problema que implicaría la correcta comprensión y aplicación de cada uno de los términos.
1.1.2 Clasificación por Lista de Categorías
Ésta es una variante de la clasificación por lista de términos, esta clasificación la presenta Cheswick en su texto firewalls [2], aquí se presenta una
clasificación de ataques en siete categorías: Robo de contraseñas: se refiere a cualquier método para robar la contraseña de un usuario.
Ingeniería social: Técnicas para que los propios usuarios proporcionen la
información confidencial de sus cuentas.
Puertas traseras: Aprovecharse de hoyos de seguridad para poder
realizar los ataques.
Errores de autenticación: Utilizar métodos para vencer los mecanismos
de autenticación.
Errores de protocolo: Cuando los protocolos por si mismos contienen
errores ya que fueron mal diseñados o implementados.
Fuga de información: Cuando información de los administradores de la
red se hace pública y es utilizada para ataques.
Negación de servicio: evitar que los usuarios utilicen los servicios
disponibles.

3
Esta clasificación es una mejora respecto a la lista de términos, por que presenta una estructura, pero presenta los mismos problemas que la lista de términos.
1.1.3 Clasificación por Resultado de Categorías
Russell y Gangemi [3] utilizan una clasificación que agrupa la lista de términos en categorías que describen el resultado del ataque: Confidencialidad: Como resultado del ataque la información fue vista por persona no autorizado para ello. Integridad y autenticidad: Como resultado del ataque ya no se puede confiar en la que la información sea correcta y que provenga de donde dice venir. Disponibilidad: Que la información o los servicios puedan ser utilizados en cualquier momento que se requiera. El problema de esta clasificación radica en que proporciona información muy limitada de los ataques, y gran parte de ellos cae en una sola categoría.
1.1.4 Listas Empíricas
Neumann y Parker [4] clasifican los ataques de acuerdo a los datos empíricos que se han obtenido de los mismos.
Robo de información desde un lugar externo (de manera remota).
Abuso de los recursos.
Registro de las transmisiones en la red.
Instalación de programas maliciosos.
Salto de métodos de autenticación.
Abuso de autoridad suplantando identidad.
Mala administración intencional.
Abuso Indirecto: utilizar otros sistemas para crear programas maliciosos.
El problema de estas categorías es que un ataque generalmente puede ser clasificado en más de una categoría, además de no existir un conector lógico entre las diversas categorías.
1.1.5 Clasificación de Ataques Basados en la Acción
Stallings [5] presenta un modelo basado en la acción el cual se enfoca en la
información en tránsito.

4
Interrupción: La información no está disponible o es destruida antes de
llegar a su destino.
Intercepción: La información es tomada por una entidad no autorizada y
evita que llegue a su destino.
Modificación: La información es alterada.
Fabricación: La información es creada por una entidad no autorizada y es
insertada en el sistema.
Esta clasificación es muy simple y tiene una utilidad muy limitada.
1.2 Taxonomía de los Incidentes
1.2.1 Eventos
En general una computadora o una red genera una innumerable cantidad de eventos. Un evento es un cambio discreto en el estado de un sistema o dispositivo (según el IEEE96:373), desde el punto de vista de seguridad en redes, los cambios de estado generados por un evento son el resultado de acciones realizadas contra un objetivo en especifico. Dado lo anterior se puede decir que: “Un evento de seguridad en la red es una acción dirigida a un objetivo especifico con el fin de cambiar el estado de dicho objeto”. Es importante resaltar diversos aspectos de la definición anterior: inicialmente si ocurre un evento de seguridad contra un objetivo en específico con el propósito de cambiar su estado (y si hasta este momento el cambio de estado no ha tenido éxito), se puede afirmar que ha ocurrido un evento de seguridad, más sin embargo el cambio de estado pudo o no haber sucedido. Otra parte importante es que el evento de seguridad no discrimina entre acciones autorizadas y las no autorizadas, esto es, si se están registrando los eventos que suceden en la red, se registran ambos. Para tener más clara la definición de evento es importante dejar en claro a que se refieren los términos acción y objetivo:
Acción: Una acción se define como una serie de pasos para obtener un
resultado.
Objetivo: Se refiere una entidad lógica en la red (cuentas de usuario,
procesos, información, datos, servicios) o a entidades físicas de la red (computadoras, redes, intranet) del cual se quiere obtener un resultado.

5
1.2.2 Acciones.
Las acciones en la figura 1.1 representan un espectro de las actividades que pueden llegar a suceder en una red. El evento inicia con una acción que se ejecuta sobre un blanco del ataque, existen diversas acciones así como diversos blancos del ataque, los cuales se detallan a continuación.
Figura 1.1 Espectro de las actividades en una red
Existen dos acciones para obtener información del objetivo, nombradas en ingles probe (sondeo) y scan (exploración). Probe es utilizado para conocer las características especificas del objetivo, mientras que scan es utilizado para verificar en un rango de objetivos cuales cumplen con características particulares. Ambos pueden ser utilizados de manera combinada para reunir mayor información. Otra acción es la nombrada en ingles flood (inundación) en esta acción no se trata de obtener información acerca del objetivo si no saturar o sobrecargar la capacidad del objetivo, accediendo a el de manera repetida. Autentificación es una acción tomada apara asumir una identidad, la autentificación generalmente requiere de un nombre de usuario y una contraseña, y no solo es utilizada para acceder a una cuenta si no también a procesos u objetos.

6
Existen dos formas de realizar una autentificación no autorizada: la primera consiste en obtener credenciales validas para la autentificación, es decir, utilizar herramientas para obtener el nombre usuario y contraseña de algún usuario y autentificarte con sus credenciales. La segunda es aprovechar vulnerabilidades en el proceso de autentificación para con ello saltarla, esto es, no autentificarte si no saltar el proceso de autentificación. A esta acción se le llama en ingles bypass (salto). El llamado Spoofin (engaño) es una acción en donde una entidad se hace pasar por otra, para manipular la comunicación que existe en la red. Existen otras acciones que se encuentran asociadas con la información y datos que se pueden encontrar en los equipos de cómputo o las redes estas acciones son: la lectura, copiado, modificación, robo y borrado de datos.
1.2.3 Objetivos
Los objetivos se pueden clasificar en siete categorías, las tres primeras lógicas (cuentas, procesos y datos) y las cuatro restantes físicas (componentes, computadoras, redes e intranet). Objetivos Lógicos:
Cuentas: Un usuario utiliza los servicios e información de una red
mediante información que contiene su nombre de cuenta, contraseña y
privilegios.
Procesos: Programas en ejecución, así como datos del programa y la
memoria y la información necesaria para ejecutar un programa.
Datos: Representa hechos, conceptos o instrucciones de una manera
apropiada para la comunicación, interpretación o proceso por los
humanos. Pueden ser datos almacenados en memoria volátil o no volátil.
Objetivos Físicos:
Componentes: Cualquier elemento que conforma una computadora o red.
Computadoras: Dispositivo que consiste en uno o más componentes
asociados, como unidades de procesamiento, periféricos, unidad
aritmética lógica, puede encontrarse sola o interconectada con otras
computadoras.
Red: Grupo de computadoras interconectadas o interrelacionadas.
Internet: Red que interconecta redes del todo el mundo.

7
1.2.4 Ataques
Algunas veces cuando sucede un evento en un red es parte de varios pasos para lograr un resultado no autorizado en la red. Este evento es considerado parte de un ataque, un ataque se conforma de distintos elementos. Un ataque sucede cuando un atacante hace uso de una herramienta para explotar una o varias vulnerabilidades en la red atacando a un objetivo y así tratar lograr un resultado no autorizado, el ataque puede o no tener éxito. En la figura 1.2 se presenta una matriz de posibles ataques basados en la experiencia.
Figura 1.2 Ataques basados en la experiencia
En las dos primeras etapas del ataque, la herramienta y la vulnerabilidad son usadas para generar un evento en la red, el final lógico de tener éxito el ataque es el resultado no autorizado. La diferencia entre resultado autorizado y uno no autorizado es:
Autorizado: Es aprobado por el administrador de la red.
No Autorizado: No es aprobado por el administrador de la red.

8
1.2.5 Herramientas
Una herramienta desde el punto de vista del atacante, es un medio para explotar una vulnerabilidad en la red. Las herramientas las se pueden clasificar en:
Ataque físico: Dañar o robar físicamente computadoras o componentes
de la red.
Intercambio de información: Obtener información de otros atacantes o
de las personas que serán atacadas, a esto se le llama ingeniería social.
Comandos del usuario: Explotar una vulnerabilidad ingresando
comandos a un proceso, utilizando de manera directa la interfaz del
usuario.
Programa: Explotar una vulnerabilidad ingresando comandos en un
proceso a través de la ejecución de un archivo de comandos (script) o de
un programa.
Agente Autónomo: Explotar una vulnerabilidad utilizando un programa o
fragmento de programa, que opera de manera independiente del usuario.
Kit de herramientas: Paquete de software que contiene programas, o
agentes autónomos para explotar vulnerabilidades.
Herramienta distribuida: Herramienta que puede ser ubicada en varios
equipos para coordinarlos de manera anónima y preparar un ataque de
manera simultánea.
Llave de datos: Permite monitorear la radiación electromagnética que
emana de una computadora o red, utilizando un dispositivo externo.
1.2.6 Vulnerabilidad
Una vulnerabilidad es una debilidad en el sistema que permite una acción no autorizada. Esta definición permite categorizar a las vulnerabilidades en tres tipos:
Vulnerabilidad en el diseño: Viene desde el diseño o especificaciones
del hardware o software, por lo cual al implementarlo de manera correcta
el diseño como resultado se obtiene una vulnerabilidad.
Vulnerabilidad de implementación: Es el resultado de un error durante
la implementación de un diseño correcto.
Vulnerabilidad de configuración: Es el resultado de un error en la
configuración del sistema.

9
1.2.7 Resultado No Autorizado
Un evento no autorizado es una consecuencia (no aprobada por el administrador) de un evento, si un ataque tiene éxito el resultado no autorizado puede ser:
Acceso incrementado: Un aumento no autorizado de los privilegios de un
usuario en la red.
Exposición de información: Diseminación de la información a cualquiera
que no esté autorizado a acceder a esa información.
Corrupción de la información: Alteración no autorizada de los datos.
Negación de servicio: Degradación o bloqueo intencional de los recursos
de la red.
Robo de servicios: Uso no autorizado de los recursos de la red.
1.2.8 Incidentes
Un incidente en la red es un grupo de ataques que puede ser distinguido de otros ataques por su carácter propio de los atacantes, ataques, objetivos, sitios y tiempo. Un incidente está formado de tres partes principales, los atacantes, los ataques y los objetivos, como se muestra en la figura 1.3.
Figura 1.3 Diagrama general de los incidentes de seguridad

10
1.2.9 Los Atacantes Y Sus Propositos
Hay personas que atacan redes y equipos de cómputo y lo hacen de diversas formas y por diversas razones, pero se puede tener una categoría de atacantes así como del objeto de su ataque. Atacantes: Individuo o grupo de individuos que intenta uno o más ataques con un propósito determinado. De acuerdo al propósito que persiguen los atacantes se pueden clasificar en 6 categorías.
Hackers: Atacan redes y computadoras por reto, status o la emoción de
obtener el acceso.
Espías: Buscan información para obtener una ganancia política.
Terroristas: Buscan que a través de sus ataques se genere miedo para
obtener una ganancia política.
Ladrón corporativo: Empleados que atacan a la competencia para
obtener ganancia financiera.
Criminales profesionales: Buscan obtener ganancia financiera personal.
Vándalos: Buscan simplemente causar daño.
Fisgones: Atacan equipos y redes por la emoción de obtener información
sensible. Como se puede ver la taxonomía de los incidentes permite tener detalle del ataque. Las clasificaciones anteriores no son específicas y un ataque puede caer en más de una clasificación. La taxonomía del incidente no solo se centra en el ataque si no que vas mucho más atrás para poder clasificarlo iniciando por el atacante, ¿quién es?, y finalizando por ¿Cuál es su objetivo? Para clasificar el ataque con la taxonomía del incidente se debe de conocer quién es el atacante, qué herramienta utilizo, cual es la vulnerabilidad que exploto y que acción realizo, cual fue el blanco de su ataque, que resultado pretendía obtener u obtuvo y con qué objetivo. Es por ello que para clasificar un ataque se recomienda utiliza la taxonomía del incidente, la desventaja es que requiere mucho mas recolección de información, no solo basta saber que ocurrió un ataque y cuál fue el blanco.

11
CAPÍTULO II. INFORMÁTICA FORENSE La informática forense está adquiriendo una gran importancia dentro del área de la información electrónica, esto debido al aumento del valor de la información y/o al uso que se le da a ésta, al desarrollo de nuevos espacios donde es usada un ejemplo es el Internet, y al extenso uso de computadores por parte de las compañías de negocios tradicionales como los bancos. Es por esto que cuando se realiza un crimen, muchas veces la información queda almacenada en forma digital. Sin embargo, existe un gran problema, debido a que las computadoras guardan la información de información forma tal que no puede ser recolectada o usada como prueba utilizando medios comunes, se deben utilizar mecanismos diferentes a los tradicionales. Es de aquí que surge el estudio de la informática forense como una ciencia relativamente nueva la cual aplicando procedimientos estrictos y rigurosos puede ayudar a resolver grandes crímenes apoyándose en el método científico, aplicado a la recolección, análisis y validación de todo tipo de pruebas digitales. La proliferación de redes y sistemas informáticos ha llevado a la sociedad a vivir en un mundo en el cual se trabaja y se vive globalmente conectado, se pueden mantener conversaciones, intercambiar correo o realizar transacciones monetarias con personas que se encuentran en cualquier parte del mundo de forma rápida y eficiente. Sin embargo, la facilidad de acceso a Internet y el desarrollo del mercado que está relacionado con los dispositivos que permiten acceder a las nuevas comunicaciones han cambiado no solo la forma en la que se pasa el tiempo libre y la forma en la que se llevan a cabo los negocios sino también la forma en la que los delincuentes comenten sus crímenes. La utilización de computadoras y redes para preparar ataques violentos, los delitos relacionados con la posesión o distribución de pornografía infantil, la falsificación y fraude de datos bancarios muestran un panorama complejo, en el cual los profesionales de las tecnologías de información y los profesionales de la defensa de la ley deben cooperar y trabajar juntos en la detección y procesamiento de las personas que utilizan las nuevas tecnologías para dañar individuos, organizaciones, empresas o sociedad en general. Estas computadoras y redes suelen ser las herramientas para cometer un crimen, ser las víctimas del crimen o ser utilizadas para propósitos incidentales relacionados con el crimen. El Análisis Forense comprende el proceso de extracción,

12
conservación, identificación, documentación, interpretación y presentación de las evidencias digitales de forma que sean legalmente aceptadas en cualquier proceso legal, proporcionando las técnicas y principios que facilitan la investigación del delito. Según el FBI, la informática (o computación) forense es la ciencia de adquirir, preservar, obtener y presentar datos que han sido procesados electrónicamente y guardados en un medio computacional. [6]
Disciplina de las ciencias forenses, que considerando las tareas propias asociadas con la evidencia, procura descubrir e interpretar la información en los medios informáticos para establecer los hechos y formular las hipótesis relacionadas con el caso. [7] La informática forense consiste en un proceso de investigación de los sistemas de información para detectar toda evidencia que pueda ser presentada como medio de prueba fehaciente para la resolución de un litigo dentro de un procedimiento judicial. Su implementación debe llevarse a cabo considerando lo dispuesto por la normativa legal aplicable, a efectos de no vulnerar los derechos de protección de datos y de intimidad de terceros. [8]
Del análisis anterior y tratando de encontrar una definición clara para el lector la informática forense se define como: Es el proceso de investigación que consiste en una identificación, preservación, análisis y presentación de evidencias digitales en una forma que sea legalmente aceptable en cualquier proceso judicial o administrativo.
2.1 Objetivos de la Forensia
El objetivo de una investigación forense tras un ataque son en general las siguientes:
Reconocimiento de los métodos o los puntos débiles que posibilitaron la
agresión
Determinación de los daños ocasionados
Identificación del autor
Aseguramiento de las evidencias
De la formulación de estos objetivos se derivan las siguientes cuestiones: ¿Cómo puede verificarse el ataque? ¿Cómo debe asegurarse el sistema comprometido y su entorno? ¿Cuales métodos deben emplearse para la captura de evidencias? ¿En qué secuencia deben preservarse las evidencias? ¿Dónde deben buscarse puntos de referencia y como pueden ser encontrados?

13
¿Cómo puede analizarse lo desconocido?
2.2 Tipos de Forensia Informática
Cuando alguien habla de forensia informática generalmente piensa en forensia en host, su pensamiento se centra en recuperación de datos de discos duros, reconstrucción de dispositivos dañados, obtener información de discos borrados y formateados. Pocos saben que existe también la forensia en la red, que se apoya en el registro de eventos ocurridos en la red, para su análisis y establecer evidencias de donde surgió el ataque, de donde viene cierta información y hacia dónde va. En este documento se enfocará hacia la forensia en red, como obtener esos datos que dado un ataque, posteriormente servirán como evidencia para llegar al origen del mismo.
2.2.1 Forensia Basada en Host
La forensia en host es la recolección de elementos que se encuentran en un equipo de cómputo y que puedan ser usados como evidencia de algún evento que se presume se realizo en dicho equipo. La forensia en host puede usarse tanto para determinar si dicho equipos fue víctima de algún ataque, o por el contrario si se realizaron actividades ilícitas desde ahí. Para aplicar forensia en host principalmente se analizan los medios de almacenamiento, en los cuales se puede encontrar las evidencias que se buscan, se debe analizar los procesos que se han ejecutado desde ese equipo, memoria cache, información de medios extraíbles. Generalmente un usuario sin conocimientos de computo podría pensar que al eliminar los archivos del equipo ya no existe evidencia que lo incrimine, pero no es así, precisamente la forensia en el host busca las huellas que han quedado de dichos archivos hasta obtener una evidencia solida de lo que ahí paso. La forensia en host va de la mano con la forensia en red, sin embargo el host pudo nunca haber estado conectado a una red y aún así se puede obtener evidencia de hechos ilícitos cometidos en ese equipo. Otro aspecto importante de la forensia en host es que si el dispositivo del cual se pretende obtener evidencia se encuentra dañado tanto físicamente como lógicamente, la forensia puede reconstruirlo y así obtener la información digital integra del dispositivo.

14
2.2.2 Forensia Basada en Red
La forensia en la red es la captura, almacenamiento y análisis de eventos en la red para poder encontrar el origen de ataques de seguridad u otros incidentes en la red. La forensia en redes es más compleja que la forensia en host, debido a la gran cantidad de elementos que involucra una red, ya que es necesario entender y comprender el funcionamiento de cada uno de los elementos, cómo funcionan los protocolos, como se encuentran configurados los equipos y la infraestructura de la red. A diferencia de la forensia en host, la forensia en red implica tener la capacidad de relacionar eventos de dispositivos particulares. Se contemplan dos tipos de forensia en la red: El primero de ellos se basa en que todos los paquetes pasan a través de un punto en el cual se captura y registra todo el tráfico para posteriormente ser analizado. Lo que requiere tener suficiente espacio de almacenamiento para registrar todo el tráfico. El segundo está basando en detener el paquete, analizarlo y si es necesario registrarlo. Requiere menos espacio de almacenamiento pero más capacidad de procesamiento para atender a todo el tráfico de entrada. Para poder aplicar forensia en la red es necesario conocer la arquitectura de la misma y es muy importante es conocer exactamente cuál es el tráfico que se desea registrar, para ello es necesario hacer un análisis y conocer en donde se encuentra el tráfico de interés; para así, en base a esta premisa poder registrar dicho tráfico. Para poder hacer forensia en la red de una manera efectiva es necesario tener un registro completo del tráfico en la red, entre mas trafico se tenga registrado el análisis forense será más efectivo.
2.3 Análisis Forense
El Análisis Forense comprende el proceso de extracción, conservación, identificación, documentación, interpretación y presentación de las evidencias digitales de forma que sean legalmente aceptadas en cualquier proceso legal. Proporciona las técnicas y principios que facilitan la investigación del delito y su metodología básica consiste en:
1. Adquirir las evidencias sin alterar ni dañar el original. La forma ideal de
examinar un sistema consiste en detenerlo y examinar una copia de los datos
originales, es importante tener en cuenta que no se puede examinar un sistema
presuntamente comprometido utilizando las herramientas que se encuentran en
dicho sistema pues estas pueden estar afectadas. La cadena de custodia

15
documenta el proceso completo de las evidencias durante la vida del caso,
quién la recogió y donde, quien y como la almacenó, quién la procesó… etc.
Cada evidencia deberá ser identificada y etiquetada a ser posible en presencia
de testigos, con el número del caso, una breve descripción, la firma y la fecha
en que fue recogida.
2. Comprobar (Autenticar) que las evidencias recogidas y que van a ser la base de
la investigación son idénticas a las abandonadas por el delincuente en la
escena del crimen. Las técnicas y herramientas de control de integridad que
mediante la utilización de una función hash generan una huella electrónica
digital de un fichero o un disco completo constituyen una ayuda básica.
3. Analizar los datos sin modificarlos. En este punto, es crucial proteger las evidencias físicas originales trabajando con copias idénticas de forma que en caso de error se pueda recuperar la imagen original y continuar con el análisis de forma correcta. Se recomienda la realización de dos copias de los discos originales. Estas copias deben ser clones realizados bit a bit del dispositivo original, los backups normales no copian ficheros que han sido borrados ni determinadas partes de los discos que pueden contener pistas importantes para el desarrollo de la investigación.
2.4 Evidencia Digital A diferencia de la documentación en papel, la evidencia digital es frágil y una copia de un documento almacenado en un archivo es idéntica al original. Otro aspecto único de la evidencia digital es el potencial de realizar copias no autorizadas de archivos, sin dejar rastro de que se realizó una copia. Debe tenerse en cuenta que los datos digitales adquiridos de copias no se deben alterar de los originales, porque esto invalidaría la evidencia; por esto los investigadores deben revisar con frecuencia que sus copias sean exactas a las del dispositivo del sospechoso, para esto se utilizan varias tecnologías, como por ejemplo checksums o hash MD5 solo por citar algunas. Las características propias de la evidencia digital son las siguientes: La evidencia de Digital puede ser duplicada de forma exacta y se puede sacar una copia para ser examinada como si fuera la original. Esto se hace comúnmente para no manejar los originales y evitar el riesgo de dañarlos. Actualmente, con las herramientas existentes, es muy fácil comparar la evidencia digital con su original, y determinar si la evidencia digital ha sido alterada.

16
La evidencia de Digital es muy difícil de eliminar. Aún cuando un registro es borrado del disco duro de la computadora, y éste ha sido formateado, es posible recuperarlo.
2.4.1 Clasificación de la Evidencia Digital
La evidencia digital se puede clasificar en tres tipos principales:
Registros generados por computador: Estos registros son aquellos, que
como dice su nombre, son generados como efecto de la programación de un computador. Los registros generados por las computadoras son inalterables por una persona. Estos registros son llamados registros de eventos de seguridad (logs) y sirven como prueba tras demostrar el correcto y adecuado funcionamiento del sistema o computador que generó el registro. Registros no generados sino simplemente almacenados por o en computadoras: Estos registros son aquellos generados por una persona, y
que son almacenados en la computadora, por ejemplo, un documento realizado con un procesador de palabras. En estos registros es importante lograr demostrar la identidad del generador, y probar hechos o afirmaciones contenidas en la evidencia misma. Para lo anterior se debe demostrar sucesos que muestren que las afirmaciones humanas contenidas en la evidencia son reales. Registros híbridos: Que incluyen tanto registros generados por la
computadora, como almacenados en los mismos: Los registros híbridos son aquellos que combinan afirmaciones humanas y logs. Para que estos registros sirvan como prueba deben cumplir los dos requisitos anteriores.
2.4.2 Criterios de Admisibilidad
En legislaciones modernas existen cuatro criterios que se deben tener en cuenta para analizar al momento de decidir sobre la admisibilidad de la evidencia: la autenticidad, la confiabilidad, la completitud o suficiencia, y el apego y respeto por las leyes y reglas del poder judicial.
Autenticidad: Una evidencia digital será autentica siempre y cuando se cumplan dos elementos:
El primero, demostrar que dicha evidencia ha sido generada y
registrada en el lugar de los hechos
La segunda, la evidencia digital debe mostrar que los medios originales
no han sido modificados, es decir, que los registros corresponden
efectivamente a la realidad y que son un fiel reflejo de la misma.

17
A diferencia de los medios no digitales, en los digitales se presenta gran volatilidad y alta capacidad de manipulación. Por esta razón es importante aclarar que es indispensable verificar la autenticidad de las pruebas presentadas en medios digitales contrarios a los no digitales. Para asegurar el cumplimiento de la autenticidad se requiere que una arquitectura exhiba mecanismos que certifiquen la integridad de los archivos y el control de cambios de los mismos. Confiabilidad: Se dice que los registros de eventos de seguridad son
confiables si provienen de fuentes que son “creíbles y verificables”. Para probar esto, se debe contar con una arquitectura de computación en correcto funcionamiento, la cual demuestre que los logs que genera tiene una forma confiable de ser identificados, recolectados, almacenados y verificados. Una prueba digital es confiable si el “sistema que lo produjo no ha sido violado y estaba en correcto funcionamiento al momento de recibir, almacenar o generar la prueba”. La arquitectura de computación del sistema logrará tener un funcionamiento correcto siempre que tenga algún mecanismo de sincronización del registro de las acciones de los usuarios del sistema y que a posea con un registro centralizado e íntegro de los mismos registros. Suficiencia o completitud de las pruebas: Para que una prueba esté
considerada dentro del criterio de la suficiencia debe estar completa. Para asegurar esto es necesario “contar con mecanismos que proporcionen integridad, sincronización y centralización” para lograr tener una vista completa de la situación. Para lograr lo anterior es necesario hacer una verdadera correlación de eventos, la cual puede ser manual o sistematizada. Apogeo y respeto por las leyes y reglas del poder judicial: Este criterio se refiere a que la evidencia digital debe cumplir con los códigos de procedimientos y disposiciones legales del ordenamiento del país.
2.5 Procedimiento Forense Computacional El procedimiento forense computacional debe de cumplir con los siguientes puntos:
1. Esterilidad de los medios de informáticos de trabajo. Los medios informáticos
utilizados por los profesionales en esta área, deben estar certificados de tal
manera, que éstos no hayan sido expuestos a variaciones magnéticas, ópticas
(láser) o similares, para evitar que las copias de la evidencia que se ubiquen
en ellos puedan estar contaminadas.

18
2. La esterilidad de los medios es una condición fundamental para el inicio de
cualquier procedimiento forense en informática.
3. Verificación de las copias en medios informáticos. Las copias efectuadas en
los medios previamente esterilizados, deben ser idénticas al original del cual
fueron tomadas. La verificación de éstas debe estar asistida por métodos y
procedimientos matemáticos que establezcan la completitud de la información
traspasada a la copia. Para esto, se sugiere utilizar algoritmos y técnicas de
control basadas en firma digitales que puedan comprobar que la información
inicialmente tomada corresponde a la que se ubica en el medio de copia.
Adicionalmente, es preciso que el software u aplicación soporte de esta
operación haya sido previamente probado y analizado por la comunidad
científica, para que conociendo su tasa de efectividad, sea validado en un
procedimiento ante una diligencia legal.
4. Documentación de los procedimientos, herramientas y resultados sobre los
medios informáticos analizados: el investigador debe ser el custodio de su
propio proceso, por tanto cada uno de los pasos realizados, las herramientas
utilizadas (sus versiones, licencias y limitaciones), los resultados obtenidos del
análisis de los datos, deben estar claramente documentados, de tal manera,
que cualquier persona externa pueda validar y revisar los mismos. Ante una
confrontación sobre la idoneidad del proceso, el tener documentado y validado
cada uno de sus procesos ofrece una importante tranquilidad al investigador,
pues siendo rigurosos en la aplicación del método científico es posible que un
tercero reproduzca sus resultados utilizando la misma evidencia.
5. Mantenimiento de la cadena de custodia de las evidencias digitales. Este
punto es complemento del anterior. La custodia de todos los elementos
allegados al caso y en poder del investigador, debe responder a una diligencia
y formalidad especiales para documentar cada uno de los eventos que se han
realizado con la evidencia en su poder. Quién la entregó, cuándo, en qué
estado, cómo se ha transportado, quién ha tenido acceso a ella, cómo se ha
efectuado su custodia, entre otras, son las preguntas que deben estar
claramente resueltas para poder dar cuenta de la adecuada administración de
las pruebas a su cargo.
6. Informe y presentación de resultados de los análisis de los medios
informáticos. Este elemento es tan importante como los anteriores, pues una
inadecuada presentación de los resultados puede llevar a falsas expectativas
o interpretación de los hechos que ponga en entredicho la idoneidad del

19
investigador. Por tanto, la claridad, el uso de un lenguaje amable y sin
tecnicismos, una redacción impecable sin juicios de valor y una ilustración
pedagógica de los hechos y los resultados, son elementos críticos a la hora de
defender un informe de las investigaciones.
7. Generalmente existen dos tipos de informes, los técnicos con los detalles de la
inspección realizada y el ejecutivo para la gerencia y sus dependencias.
8. Administración del caso realizado. Los investigadores forenses en informática
deben prepararse para declarar ante un jurado o juicio, por tanto, es probable
que en el curso de la investigación o del caso, lo puedan llamar a declarar en
ese instante o mucho tiempo después. Por tanto, el mantener un sistema
automatizado de documentación de expedientes de los casos, con una
adecuada cuota de seguridad y control, es labor necesaria y suficiente para
salvaguardar los resultados de las investigaciones y el debido cuidado,
diligencia y previsibilidad del profesional que ha participado en el caso.
9. Auditoria de los procedimientos realizados en la investigación. Finalmente y no menos importante, es recomendable que el profesional investigador mantenga un ejercicio de autoevaluación de sus procedimientos, para contar con la evidencia de una buena práctica de investigaciones forenses, de tal manera que el ciclo de calidad: PHVA - Planear, Hacer, Verificar y Actuar, sea una constante que permita incrementar la actual confiabilidad de sus procedimientos y cuestionar sus prácticas y técnicas actuales para el mejoramiento de su ejercicio profesional y la práctica de la disciplina.
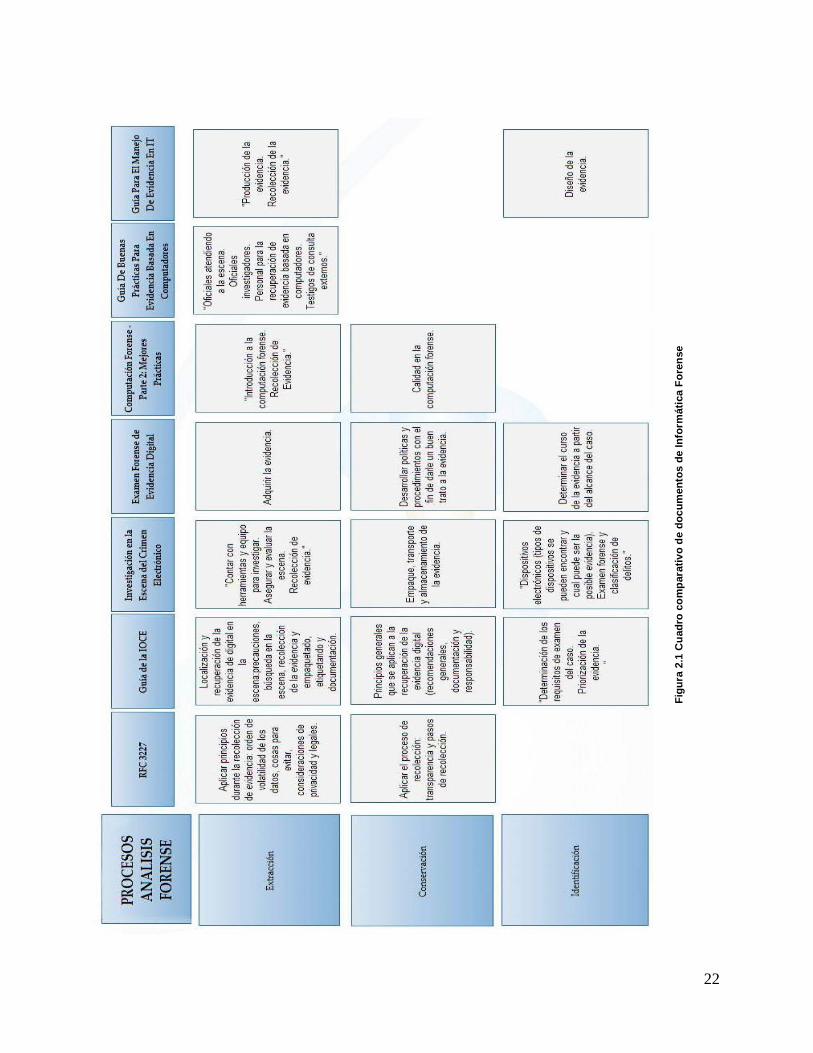
2.6 Documentos de Informática Forense. La tendencia es alinearse a las tendencias que proponen algunos documentos para construir una estrategia de seguridad exitosa. Las exigencias cada día son mayores para los responsables de la seguridad informática de las compañías. Y es que hoy, ya no basta con mantener una estrategia reactiva de protección: los tiempos demandan proactividad, alineación con el negocio. Cumplir con todo esto suena difícil; sin embargo, los encargados de seguridad tienen a su disposición para enfrentar dichas demandas las mejores prácticas que se sugieren en el desarrollo de la informática forense. Cuáles de esas mejores prácticas implementar dependerá de las necesidades de cada organización, a continuación se hace mención de las mejores prácticas recomendadas actualmente para un manejo más integral, estratégico y proactivo de la seguridad.

20
2.6.1 RFC 3227
El “RFC 3227: Guía Para Recolectar y Archivar Evidencia” (Guidelines for Evidence Collection and Archiving), escrito en febrero de 2002 por Dominique Brezinski y Tom Killalea, ingenieros del Network Working Group. Es un documento que provee una guía de alto nivel para recolectar y archivar datos relacionados con intrusiones. Muestra las mejores prácticas para determinar la volatilidad de los datos, decidir que recolectar, desarrollar la recolección y determinar cómo almacenar y documentar los datos. También explica algunos conceptos relacionados a la parte legal.
2.6.2 Guía de la IOCE
La IOCE, publico “Guía para las mejores prácticas en el examen forense de tecnología digital” (Guidelines for the best practices in the forensic examination of digital technology). El documento provee una serie de estándares, principios de calidad y aproximaciones para la detección prevención, recuperación, examinación y uso de la evidencia digital para fines forenses. Cubre los sistemas, procedimientos, personal, equipo y requerimientos de comodidad que se necesitan para todo el proceso forense de evidencia digital, desde examinar la escena del crimen hasta la presentación en la corte.
2.6.3 Investigación de la Escena del Crimen Electrónico
El Departamento de Justicia de los Estados Unidos de América (DoJ EEUU), publico “Investigación En La Escena Del Crimen Electrónico” (Electronic Crime Scene Investigation: A Guide for First Responders). Esta guía se enfoca más que todo en identificación y recolección de evidencia.
2.6.4 Exámen Forense de Evidencia Digital
Otra guía del DoJ EEUU, es “Examen Forense de Evidencia Digital” (Forensic Examination of Digital Evidence: A Guide for Law Enforcement). Esta guía está pensada para ser usada en el momento de examinar la evidencia digital.
2.6.5 Computación Forense – Parte 2: Mejores Prácticas
El ISFS, Information Security and Forensic Society (Sociedad de Seguridad Informática y Forense) creada en Hong Kong, publico “Computación Forense - Parte 2: Mejores Practicas” (Computer Forensics – Part 2: Best Practices). Esta guía cubre los procedimientos y otros requerimientos necesarios involucrados en el proceso forense de evidencia digital, desde el examen de la escena del crimen hasta la presentación de los reportes en la corte.

21
2.6.6 Guía de Buenas Prácticas para Evidencia Basada en Computadoras
La ACPO, Association of Chief Police Officers (Asociación de Jefes de Policía), del Reino Unido mediante su departamento de crimen por computador, publico “Guía de Buenas Prácticas para Evidencia basada en Computadores” (Good Practice Guide For Computer Based Evidence) .
2.6.7 Guía Para el Manejo de Evidencia en IT
Standards Australia (Estándares de Australia) publico “Guía Para El Manejo de Evidencia En IT” (HB171:2003 Handbook Guidelines for themanagement of IT evidence) [HBIT03]. Esta guía no está disponible para su libre distribución, por esto para su investigación se consultaron los artículos “Buenas Prácticas En La Administración De La Evidencia Digital” [BueAdm06] y “New Guidelines to Combat ECrime”.
La figura número 2.1 muestra el comparativo entre las mejores prácticas aplicadas a la metodología de análisis forense.
22
Figura 2.1 Cuadro comparativo de documentos de Inforática Forense
Fig
ura
2.1
Cu
ad
ro c
om
para
tiv
o d
e d
oc
um
en
tos
de
In
form
áti
ca
Fo
ren
se

23
Fig
ura
2.1
Cu
ad
ro c
om
para
tiv
o d
e d
oc
um
en
tos
de
In
form
áti
ca
Fo
ren
se

24
La metodología de análisis forense varía ligeramente si se aplicara forensia en host o en red, ya que el análisis en red requiere de mayor conocimiento de los protocolos y un esquema de monitoreo que filtre gran parte del tráfico; de esta parte se desprende que la mayor cantidad de evidencia útil para una investigación en red dependerá de la robustez del esquema de monitoreo que se adopte y de la habilidad, conocimiento y experiencia del analista, existen dos enfoques dentro de la forensia uno de los cuales se enfoca a encontrar al atacante y el otro se enfoca a los hechos y circunstancias que dieron lugar al ataque, este último parece ser el más acertado cuando se trabaja con evidencia digital y sobretodo en un ambiente tan complejo como lo es una red, dada la gran cantidad de posibles atacantes que existen . En lo referente a las recomendaciones internacionales que se tratan en el capítulo se puede decir que la guía de primeras respuestas publicada por el departamento de defensa de los Estados Unidos cubre una gran cantidad de aspectos, ya que tipifica el tipo de análisis en base a ambientes en los cuales propone una descripción, usos principales de los elementos que lo componen y la evidencia potencial que generan estos, otra parte significativa es que hace mención a la evidencia convencional, es decir no solo se basa en el sistema electrónico objeto del ataque o causante del mismo, sino también en meros aspectos físicos como lo son las huellas dactilares latentes en la escena, haciendo hincapié en que estas se deben recolectar al final de la recolección electrónica dado que los elementos químicos utilizados para obtención de evidencia convencional pueden dañar los elementos electromagnéticos del sistema. En general todas las recomendaciones aquí presentadas hacen énfasis en que la investigación forense debe realizarse con apego a las leyes estatales y federales que aplican en cada país y menciona la responsabilidad civil que genera dicha investigación para el analista forense. La documentación de la escena es otro aspecto importante del que se habla, reportando detalladamente los estados de los componentes electrónicos, su ubicación y conexiones, de igual manera la cadena de custodia debe asegurar que ninguna información ha sido agregada o alterada, que las copias con las que se trabaja están completas y todos los dispositivos con evidencia potencial han sido asegurados. Las metodologías propuestas pueden variar ya que todas las escenas del crimen son únicas pero siempre aplicará el mismo procedimiento forense.

25
CAPÍTULO III. PROTOCOLOS DE RED Y SU MONITOREO
Un protocolo es un conjunto de reglas (semánticas, sintácticas y de temporización) que gobiernan la comunicación entre entidades de una misma capa. Es decir, en el protocolo de la capa N, una entidad intercambia información con su homóloga en la máquina destino, de cara a proporcionar los servicios asignados a esa capa. Para ello, hará uso de los servicios que proporciona la capa anterior. Un protocolo se define como el conjunto de normas que regulan la comunicación (establecimiento, mantenimiento y finalización) entre los distintos componentes de una red informática. Existen dos tipos de protocolos: protocolos de bajo nivel y protocolos de red.
3.1 Tipos de Protocolos Los pasos del protocolo se tienen que llevar a cabo en un orden apropiado y que sea el mismo en cada una de los equipos de la red. En el equipo origen, estos pasos se tienen que llevar a cabo de arriba hacia abajo. En el equipo de destino, estos pasos se tienen que llevar a cabo de abajo hacia arriba.
El equipo Origen Los protocolos en el equipo origen:
1. Se dividen en secciones más pequeñas, denominadas paquetes, que puede manipular el protocolo.
2. Se añade a los paquetes información sobre la dirección, de forma que el equipo de destino pueda determinar si los datos le pertenecen.
3. Prepara los datos para la transmisión a través de la NIC y enviarlos a través del cable de la red.

26
El equipo de Destino Los protocolos en el equipo de destino constan de la misma serie de pasos, pero en sentido inverso.
1. Toma los paquetes de datos del cable. 2. Introduce los paquetes de datos en el equipo a través de la NIC. 3. Extrae de los paquetes de datos toda la información transmitida eliminando la
información añadida por el equipo origen. 4. Copia los datos de los paquetes en un búfer para reorganizarlos. 5. Pasa los datos reorganizados a la aplicación en una forma utilizable. 6. Los equipos origen y destino necesitan realizar cada paso de la misma forma
para que los datos tengan la misma estructura al recibirse que cuando se enviaron.
7. Por ejemplo, dos protocolos diferentes podrían dividir datos en paquetes y añadirles cierta información sobre secuenciación, temporización y comprobación de errores, pero cada uno de forma diferente. Por tanto, un equipo que utilice uno de estos protocolos no se podrá comunicar correctamente con otro equipo que esté utilizando el otro protocolo.
Protocolos Encaminables
Hasta mediados de los ochenta, la mayoría de las redes de área local (LAN) estaban aisladas. Una LAN servía a un departamento o a una compañía y rara vez se conectaba a entornos más grandes. Sin embargo, a medida que maduraba la tecnología LAN, y la comunicación de los datos necesitaba la expansión de los negocios, las LAN evolucionaron, haciéndose componentes de redes de comunicaciones más grandes en las que las LAN podían hablar entre sí. Los datos se envían de una LAN a otra a lo largo de varios caminos disponibles, es decir, se encaminan. A los protocolos que permiten la comunicación LAN a LAN se les conoce como protocolos encaminables. Debido a que los protocolos encaminables se pueden utilizar para unir varias LAN y crear entornos de red de área extensa, han tomado gran importancia. Protocolos en una Arquitectura Multinivel
En una red, tienen que trabajar juntos varios protocolos. Al trabajar juntos, aseguran que los datos se preparan correctamente, se transfieran al destino correspondiente y se reciban de forma apropiada. El trabajo de los distintos protocolos tiene que estar coordinado de forma que no se produzcan conflictos o se realicen tareas incompletas. Los resultados de esta coordinación se conocen como trabajo en niveles.

27
Jerarquías de Protocolos
Una jerarquía de protocolos es una combinación de protocolos. Cada nivel de la jerarquía especifica un protocolo diferente para la gestión de una función o de un subsistema del proceso de comunicación. Cada nivel tiene su propio conjunto de reglas. Los protocolos definen las reglas para cada nivel en el modelo OSI:
Figura 3.1 Representación del modelo OSI
Los niveles inferiores en el modelo OSI especifican cómo pueden conectar los fabricantes sus productos a los productos de otros fabricantes, por ejemplo, utilizando NIC de varios fabricantes en la misma LAN. Cuando utilicen los mismos protocolos, pueden enviar y recibir datos entre sí. Los niveles superiores especifican las reglas para dirigir las sesiones de comunicación (el tiempo en el que dos equipos mantienen una conexión) y la interpretación de aplicaciones. A medida que aumenta el nivel de la jerarquía, aumenta la sofisticación de las tareas asociadas a los protocolos.
El proceso de Ligadura
El proceso de ligadura (binding process), el proceso con el que se conectan los protocolos entre sí y con la NIC, permite una gran flexibilidad a la hora de configurar una red. Se pueden mezclar y combinar los protocolos y las NIC según

28
las necesidades. Por ejemplo, se pueden ligar dos jerarquías de protocolos a una NIC, como Intercambio de paquetes entre redes e Intercambio de paquetes en secuencia (IPX/SPX). Si hay más de una NIC en el equipo, cada jerarquía de protocolos puede estar en una NIC o en ambas. El orden de ligadura determina la secuencia en la que el sistema operativo ejecuta el protocolo. Cuando se ligan varios protocolos a una NIC, el orden de ligadura es la secuencia en que se utilizarán los protocolos para intentar una comunicación correcta. Normalmente, el proceso de ligadura se inicia cuando se instala o se inicia el sistema operativo o el protocolo. Por ejemplo, si el primer protocolo ligado es TCP/IP, el sistema operativo de red intentará la conexión con TCP/IP antes de utilizar otro protocolo. Si falla esta conexión, el equipo tratará de realizar una conexión utilizando el siguiente protocolo en el orden de ligadura. El proceso de ligadura consiste en asociar más de una jerarquía de protocolos a la NIC. Las jerarquías de protocolos tienen que estar ligadas o asociadas con los componentes en un orden para que los datos puedan moverse adecuadamente por la jerarquía durante la ejecución. Por ejemplo, se puede ligar TCP/IP al nivel de sesión del Sistema básico de entrada/salida en red (NetBIOS), así como al controlador de la NIC. El controlador de la NIC también está ligado a la NIC. Jerarquías Estándar
La industria informática ha diseñado varios tipos de protocolos como modelos estándar de protocolo. Los fabricantes de hardware y software pueden desarrollar sus productos para ajustarse a cada una de las combinaciones de estos protocolos.
Los modelos más importantes incluyen:
La familia de protocolos ISO/OSI.
La arquitectura de sistemas en red de IBM (SNA).
Digital DECnet.
Novell NetWare.
Apple Talk de Apple.
El conjunto de protocolos de Internet, TCP/IP.
Los protocolos existen en cada nivel de estas jerarquías, realizando las
tareas especificadas por el nivel. Sin embargo, las tareas de comunicación
que tienen que realizar las redes se agrupan en un tipo de protocolo entre
tres. Cada tipo está compuesto por uno o más niveles del modelo OSI.
Antes del modelo de referencia OSI se escribieron muchos protocolos. Por
tanto, no es extraño encontrar jerarquías de protocolos que no se
correspondan directamente con el modelo OSI.

29
Protocolos de red
Los protocolos de red proporcionan lo que se denominan «servicios de
enlace». Estos protocolos gestionan información sobre direccionamiento y
encaminamiento, comprobación de errores y peticiones de retransmisión. Los
protocolos de red también definen reglas para la comunicación en un entorno
de red particular como es Ethernet o Token Ring.
IP: El protocolo de TCP/IP para el encaminamiento de paquetes.
IPX: El protocolo de Novell para el encaminamiento de paquetes.
NWLink: La implementación de Microsoft del protocolo IPX/SPX.
NetBEUI: Un protocolo de transporte que proporciona servicios de transporte
de datos para sesiones y aplicaciones NetBIOS.
DDP (Protocolo de entrega de datagramas): Un protocolo de Apple Talk para
el transporte de datos.
Protocolos de Aplicación
Los protocolos de aplicación trabajan en el nivel superior del modelo de referencia OSI. Proporcionan interacción entre aplicaciones e intercambio de datos.
APPC (Comunicación avanzada entre programas): Protocolo SNA Trabajo en
Grupo de IBM, mayormente utilizado en equipos AS/400. APPC se define
como un protocolo de aplicación porque trabaja en el nivel de presentación
del modelo OSI. Sin embargo, también se considera un protocolo de
transporte porque APPC utiliza el protocolo LU 6.2 que trabaja en los niveles
de transporte y de sesión del modelo OSI.
FTAM (Acceso y gestión de la transferencia de archivos): Un protocolo OSI
de acceso a archivos
X.400: Un protocolo CCITT para las transmisiones internacionales de correo
electrónico.
X.500: Un protocolo CCITT para servicios de archivos y directorio entre
sistemas.
SMTP (Protocolo básico para la transferencia de correo): Un protocolo para
las transferencias de correo electrónico.
FTP (Protocolo de transferencia de archivos): Un protocolo para la
transferencia de archivos en Internet.
SNMP (Protocolo básico de gestión de red): Un protocolo para el control de
redes y componentes.
Telnet: Un protocolo para la conexión a máquinas remotas y procesar los
datos localmente.
SMBs (Bloques de mensajes del servidor) de Microsoft y clientes o
redirectores: Un protocolo cliente/servidor de respuesta a peticiones.

30
NCP (Protocolo básico de NetWare) y clientes o redirectores: Un conjunto de
protocolos de servicio.
AppleTalk y AppleShare: Conjunto de protocolos de red de Apple.
AFP (Protocolo de archivos AppleTalk): Protocolo de Apple para el acceso a
archivos remotos.
DAP (Protocolo de acceso a datos): Un protocolo de DECnet para el acceso
a archivos.
Protocolos de transporte.
Los protocolos de transporte facilitan las sesiones de comunicación entre
equipos y aseguran que los datos se pueden mover con seguridad entre
equipos.
TCP: El protocolo de TCP/IP para la entrega garantizada de datos en forma
de paquetes secuenciados.
SPX: Parte del conjunto de protocolos IPX/SPX de Novell para datos en
forma de paquetes secuenciados.
NWLink: La implementación de Microsoft del protocolo IPX/SPX.
NetBEUI (Interfaz de usuario ampliada NetBIOS): Establece sesiones de
comunicación entre equipos (NetBIOS) y proporciona los servicios de
transporte de datos subyacentes (NetBEUI).
ATP (Protocolo de transacciones Apple Talk) y NBP (Protocolo de asignación
de nombres): Protocolos de Apple de sesión de comunicación y de transporte
de datos.
Estándares de protocolo
El modelo OSI se utiliza para definir los protocolos que se tienen que utilizar
en cada nivel. Los productos de distintos fabricantes que se ajustan a este
modelo se pueden comunicar entre sí.
La ISO, el Instituto de ingenieros eléctricos y electrónicos (IEEE), ANSI
(Instituto de estandarización nacional americano), CCITT (Comité consultivo
internacional de telegrafía y telefonía), ahora llamado ITU (Unión
internacional de telecomunicaciones) y otros organismos de estandarización
han desarrollado protocolos que se correspondan con algunos de los niveles
del modelo OSI.
Los protocolos de IEEE a nivel físico son:
802.3 (Ethernet). Es una red lógica en bus que puede transmitir datos a 10
Mbps. Los datos se transmiten en la red a todos los equipos. Sólo los
equipos que tenían que recibir los datos informan de la transmisión. El
protocolo de acceso de múltiple con detección de portadora con detección de
colisiones (CSMA/CD) regula el tráfico de la red permitiendo la transmisión
sólo cuando la red esté despejada y no haya otro equipo transmitiendo.

31
802.4 (paso de testigo). Es una red en bus que utiliza un esquema de paso
de testigo. Cada equipo recibe todos los datos, pero sólo los equipos en los
que coincida la dirección responderán. Un testigo que viaja por la red
determina quién es el equipo que tiene que informar.
802.5 (Token Ring). Es un anillo lógico que transmite a 4 ó a 16 Mbps.
Aunque se le llama en anillo, está montada como una estrella ya que cada
equipo está conectado a un hub. Realmente, el anillo está dentro del hub. Un
token a través del anillo determina qué equipo puede enviar datos.
El IEEE definió estos protocolos para facilitar la comunicación en el subnivel de Control de acceso al medio (MAC). Un controlador MAC está situado en el subnivel de Control de acceso al medio; este controlador de dispositivo es conocido como controlador de la NIC. Proporciona acceso a bajo nivel a los adaptadores de red para proporcionar soporte en la transmisión de datos y algunas funciones básicas de control del adaptador. Un protocolo MAC determina qué equipo puede utilizar el cable de red cuando varios equipos intenten utilizarlo simultáneamente. CSMA/CD, el protocolo 802.3, permite a los equipos transmitir datos cuando no hay otro equipo transmitiendo. Si dos máquinas transmiten simultáneamente se produce una colisión. El protocolo detecta la colisión y detiene toda transmisión hasta que se libera el cable. Entonces, cada equipo puede volver a tratar de transmitir después de esperar un período de tiempo aleatorio.
3.2 El Protocolo TCP/IP TCP establece un circuito de comunicaciones administrado, full-duplex y punto a punto para ser usado por protocolos de aplicación. Cada vez que se necesita enviar datos entre dos aplicaciones basadas en TCP, se establece un circuito virtual entre los dos proveedores de TCP, y se realiza un intercambio de datos de aplicaciones altamente controlado. Una vez que todos los datos han sido exitosamente enviados y recibidos, la conexión finaliza. TCP/IP no es un único protocolo, sino que es en realidad lo que se conoce con este nombre es un conjunto de protocolos que cubren los distintos niveles del modelo OSI. Los dos protocolos más importantes son el TCP (Transmission Control Protocol) y el IP (Internet Protocol), que son los que dan nombre al conjunto. La arquitectura del TCP/IP consta de cinco niveles o capas en las que se agrupan los protocolos, y que se relacionan con los niveles OSI de la siguiente manera y se muestran en la figura 3.2:

32
Aplicación: Se corresponde con los niveles OSI de aplicación, presentación y
sesión. Aquí se incluyen protocolos destinados a proporcionar servicios, tales
como correo electrónico (SMTP), transferencia de ficheros (FTP), conexión
remota (TELNET) y otros más recientes como el protocolo HTTP (Hypertext
Transfer Protocol).
Transporte: Coincide con el nivel de transporte del modelo OSI. Los
protocolos de este nivel, tales como TCP y UDP, se encargan de manejar los
datos y proporcionar la fiabilidad necesaria en el transporte de los mismos.
Internet: Es el nivel de red del modelo OSI. Incluye al protocolo IP, que se
encarga de enviar los paquetes de información a sus destinos
correspondientes. Es utilizado con esta finalidad por los protocolos del nivel de
transporte.
Físico: Análogo al nivel físico del OSI.
Figura 3.2 Arquitectura protocolo TCP/IP
3.2.1 Protocolo IP
El protocolo IP es parte de la capa de Internet del conjunto de protocolos TCP/IP. Es uno de los protocolos de Internet más importantes ya que permite el desarrollo y transporte de datagramas de IP (paquetes de datos), aunque sin garantizar su "entrega". En realidad, el protocolo IP procesa datagramas de IP de manera independiente al definir su representación, ruta y envío. El protocolo IP determina el destinatario del mensaje mediante 3 campos:
El campo de dirección IP: Dirección del equipo.
El campo de máscara de subred: Una máscara de subred le permite al
protocolo IP establecer la parte de la dirección IP que se relaciona con la
red;

33
El campo de pasarela predeterminada: Le permite al protocolo de
Internet saber a qué equipo enviar un datagrama, si el equipo de destino
no se encuentra en la red de área local.
Datagrama
Los datos circulan en Internet en forma de datagramas (también conocidos como paquetes). Los datagramas son datos encapsulados, es decir, datos a los que se les agrega un encabezado que contiene información sobre su transporte (como la dirección IP de destino) la figura 3.3 muestra la estructura de un datagrama IP.
Figura 3.3 Datagrama IP
Los routers analizan (y eventualmente modifican) los datos contenidos en un datagrama para que puedan transitar como se muestra en la figura 3.3. A continuación se indican los significados de los diferentes campos:
Versión (4 bits): Es la versión del protocolo IP que se está utilizando
(actualmente se utiliza la versión 4 IPv4) para verificar la validez del
datagrama. Está codificado en 4 bits.
Longitud del encabezado o IHL por Internet Header Length
(Longitud del encabezado de Internet) (4 bits): Es la cantidad de
palabras de 32 bits que componen el encabezado (Importante: el valor
mínimo es 5). Este campo está codificado en 4 bits.
Tipo de servicio (8 bits): Indica la forma en la que se debe procesar el
datagrama.

34
Longitud total (16 bits): Indica el tamaño total del datagrama en bytes.
El tamaño de este campo es de 2 bytes, por lo tanto el tamaño total del
datagrama no puede exceder los 65536 bytes. Si se le utiliza junto al
tamaño del encabezado, este campo permite determinar dónde se
encuentran los datos.
Identificación, indicadores y margen del fragmento: son campos
que permiten la fragmentación de datagramas. Esto se explica a
continuación.
TTL o Tiempo de vida (8 bits): Este campo especifica el número
máximo de routers por los que puede pasar un datagrama. Por lo tanto,
este campo disminuye con cada paso por un router y cuando alcanza el
valor crítico de 0, el router destruye el datagrama. Esto evita que la red
se sobrecargue de datagramas perdidos.
Protocolo (8 bits): Este campo, en notación decimal, permite saber de
qué protocolo proviene el datagrama.
o ICMP 1
o IGMP: 2
o TCP: 6
o UDP: 17
Suma de comprobación del encabezado (16 bits): Este campo
contiene un valor codificado en 16 bits que permite controlar la
integridad del encabezado para establecer si se ha modificado durante
la transmisión. La suma de comprobación es la suma de todas las
palabras de 16 bits del encabezado (se excluye el campo suma de
comprobación). Esto se realiza de tal modo que cuando se suman los
campos de encabezado (suma de comprobación inclusive), se obtenga
un número con todos los bits en 1.
Dirección IP de origen (32 bits): Este campo representa la dirección
IP del equipo remitente y permite que el destinatario responda.
Dirección IP de destino (32 bits): dirección IP del destinatario del
mensaje.
Fragmentación de Datagramas de IP
El tamaño máximo de un datagrama varía según el tipo de red y se denomina MTU (Unidad de transmisión máxima). El datagrama se fragmentará si es más grande que la MTU de la red. La fragmentación del datagrama se lleva a cabo a nivel de router, es decir, durante la transición de una red con una MTU grande a una red con una MTU más pequeña. Si el datagrama es demasiado grande para pasar por la red, el router lo fragmentará, es decir, lo dividirá en fragmentos más

35
pequeños que la MTU de la red, de manera tal que el tamaño del fragmento sea un múltiplo de 8 bytes. El router enviará estos fragmentos de manera independiente y los volverá a encapsular (agregar un encabezado a cada fragmento) para tener en cuenta el nuevo tamaño del fragmento. Además, el router agrega información para que el equipo receptor pueda rearmar los fragmentos en el orden correcto. Sin embargo, no hay nada que indique que los fragmentos llegarán en el orden correcto, ya que se enrutan de manera independiente. Para tener en cuenta la fragmentación, cada datagrama cuenta con diversos campos que permiten su rearmado:
Campo Margen del fragmento (13 bits): Campo que brinda la posición
del comienzo del fragmento en el datagrama inicial. La unidad de
medida para este campo es 8 bytes (el primer fragmento tiene un valor
cero);
Campo Identificación (16 bits): Número asignado a cada fragmento
para permitir el rearmado;
Campo Longitud total (16 bits): Esto se vuelve a calcular para cada
fragmento;
Campo Indicador (3 bits): Está compuesto de tres bits
El primero no se utiliza. El segundo (denominado DF: No fragmentar) indica si se puede fragmentar el datagrama o no. Si el datagrama tiene este bit en uno y el router no puede enrutarlo sin fragmentarlo, el datagrama se rechaza con un mensaje de error. El tercero (denominado MF: Más fragmentos) indica si el datagrama es un fragmento de datos (1). Si el indicador se encuentra en cero, esto indica que el fragmento es el último (entonces el router ya debe contar con todos los fragmentos anteriores) o que el datagrama no se ha fragmentado.
Enrutamiento IP
El enrutamiento IP es una parte integral de la capa de Internet del conjunto TCP/IP. El enrutamiento consiste en asegurar el enrutamiento de un datagrama de IP a través de la red por la ruta más corta. A esta función la llevan a cabo los equipos denominados routers, es decir, equipos que conectan al menos dos redes.
3.2.3 Protocolo TCP
El servicio que da TCP está orientado a conexión. Esto significa que se

36
requiere:
Establecer la conexión
Mantener la conexión
Liberar la conexión
Los servicios orientados a la conexión garantizan que los datos lleguen en la secuencia correcta, y que la conexión es confiable. Es necesario que TCP sea orientado a la conexión dado que IP (con el que trabaja estrechamente) no es un protocolo confiable. TCP otorga 5 servicios clave a las capas superiores:
Circuitos virtuales
Administración de I/O de aplicaciones
Administración de I/O de red
Control de flujo
Confiabilidad
Métodos de Control de Flujo
El sistema emisor ajusta la tasa de transmisión a la que enviará los datos al sistema receptor. La variación de esta tasa está ligada, entre otras cosas, al espacio en buffer del sistema receptor y a las características de manejo de paquetes en la red. Es por eso que TCP incorpora varios mecanismos de control de flujo, permitiéndole al sistema reaccionar fácilmente ante la necesidad de estos cambios.
Esquema de otorgamiento de créditos.
Ventana deslizante: Cuando un emisor manda un segmento, inicia un
reloj. El destino responde con un segmento que contiene un acuse de recibo (acknowledgment flag) con un número de acuse igual al próximo número de secuencia que espera. Si el reloj termina antes de que llegue el acuse, el emisor manda el segmento de nuevo.
Sistema de créditos: Además de advertirle al emisor el tamaño de la
ventana, el receptor otorga “créditos” al emisor para indicarle cuántos
segmentos puede enviarle antes de que los acuses de recibo de los
segmentos enviados anteriormente lleguen nuevamente al emisor. Esto
le permite a un endpoint enviar datos aunque los datos precedentes no
hayan sido todavía acusados (“acknowledged”), confiando que llegará
su acuse antes del tiempo límite establecido.

37
Métodos de Control de Errores
TCP usa el método de retransmisión para controlar errores, íntimamente ligado a la ventana deslizante, en la figura 3.4 se muestra como está constituido un segmento TCP y los elementos que lo componen se describen a continuación:
Figura 3.4 Segmento Tcp
Checksums: Sumas de comprobación.
Números de secuencia
Acknowlegments: Acuses de recibo correcto.
Timers: Relojes.
Puerto de origen (16 bits): Identifica el puerto a través del que se
envía.
Puerto destino (16 bits): Identifica el puerto del receptor.
Número de secuencia (32 bits): Sirve para comprobar que ningún
segmento se ha perdido, y que llegan en el orden correcto. Su
significado varía dependiendo del valor de SYN.
Si el flag SYN está activo (1): Entonces este campo indica el número
inicial de secuencia (con lo cual el número de secuencia del primer byte
de datos será este número de secuencia más uno).
Si el flag SYN no está activo (0): Entonces este campo indica el
número de secuencia del primer byte de datos.
Número de acuse de recibo (ACK) (32 bits): Si el flag ACK está
puesto a activo, entonces en este campo contiene el número de
secuencia del siguiente byte que el receptor espera recibir.
Longitud de la cabecera TCP (4 bits): Especifica el tamaño de la
cabecera TCP en palabras de 32-bits. El tamaño mínimo es de 5
palabras, y el máximo es de 15 palabras (lo cual equivale a un tamaño
mínimo de 20 bytes y a un máximo de 60 bytes). En inglés el campo se
denomina “Data offset”, que literalmente sería algo así como

38
“desplazamiento hasta los datos”, ya que indica cuántos bytes hay entre
el inicio del paquete TCP y el inicio de los datos.
Reservado (4 bits): Bits reservados para uso futuro, deberían ser
puestos a cero.
Bits de control (flags) (8 bits): Son 8 flags o banderas. Cada una
indica “activa” con un 1 o “inactiva” con un 0.
CWR o “Congestion Window Reduced” (1 bit): Este flag se activa (se
pone a 1) por parte del emisor para indicar que ha recibido un paquete
TCP con el flag ECE activado. Se utiliza para el control de la congestión
en la red.
ECE o “ECN-Echo” (1 bit): Indica que el receptor puede realizar
notificaciones ECN. La activación de este flag se realiza durante la
negociación en tres pasos para el establecimiento de la conexión.
URG o “urgent” (1 bit): Si está activo significa que el campo “Urgente”
es significativo, si no, el valor de este campo es ignorado.
ACK o “acknowledge”: 1 bit, Si está activo entonces el campo con el
número de acuse de recibo es válido, si no, es ignorado.
PSH o “push” (1 bit): Activa/desactiva la función que hace que los
datos de ese segmento y los datos que hayan sido almacenados
anteriormente en el buffer del receptor deben ser transferidos a la
aplicación receptora lo antes posible.
RST o “reset” (1 bit): Si llega a 1, termina la conexión sin esperar
respuesta.
SYN o “synchronize” (1 bit): Activa/desactiva la sincronización de los
números de secuencia.
FIN (1 bit): Si se activa es porque no hay más datos a enviar por parte
del emisor, esto es, el paquete que lo lleva activo es el último de una
conexión.
Ventana (16 bits): Es el tamaño de la ventana de recepción, que
especifica el número de bytes que el receptor está actualmente
esperando recibir.
Suma de verificación (checksum) (16 bits): Es una suma de
verificación utilizada para comprobar si hay errores tanto en la cabecera
como en los datos.
Puntero urgente (16 bits): Si el flag URG está activado, entonces este
campo indica el desplazamiento respecto al número de secuencia que
indica el último byte de datos marcados como “urgentes”.
Opciones (número de bits variable): La longitud total del campo de
opciones ha de ser múltiplo de una palabra de 32 bits (si es menor, se

39
ha de rellenar al múltiplo más cercano), y el campo que indica la
longitud de la cabecera ha de estar ajustado de forma adecuada.
Datos (número de bits variable): No forma parte de la cabecera, es la
carga (payload), la parte con los datos del paquete TCP. Pueden ser datos de cualquier protocolo de nivel superior en el nivel de aplicación; los protocolos más comunes para los que se usan los datos de un paquete TCP son HTTP, telnet, SSH, FTP, etcétera.
3.3 SNMP SNMP es un conjunto de aplicaciones de gestión de red que emplea los servicios ofrecidos por TCP/IP y que se ha convertido en un estándar. Las primeras versiones de SNMP fueron desarrolladas en los ochentas. SNMP funciona enviando mensajes, llamados unidades de datos de protocolo (PDU) hacia diferentes partes de la red y cada uno de los elementos de la red guarda información acerca de si mismos en las llamadas Bases de administración de Información (MIB) y regresan la información a las peticiones de SNMP. Para el protocolo SNMP la red constituye un conjunto de elementos básicos, ubicados en los equipos de gestión de red y gestores (elementos pasivos ubicados en los nodos-host, routers, módems, multiplexores, etc.), siendo los gestores los que envían información a los equipos de gestión, información relacionada con los elementos gestionados ya sea por iniciativa propia o al pedir una respuesta, ser interrogados, apoyándose en los parámetros contenidos en sus Bases de Administración de Información (MIB). La Arquitectura de Administración de Red se compone de cuatro componentes principales:
Estación de administración: Es la interface del administrador de red en el
sistema. Contiene el software de gestión, y mantiene una MIB.
Agente de administración del dispositivo administrado: Es el proceso de
los dispositivos que están siendo monitorizados. Puentes, routers, hubs, and
switches
Base de información de administración (MIB): Una base de datos relacional
(organizada por objetos (o variables) y sus atributos (o valores)) que contiene
información del estado y es actualizada por los agentes.
Protocolo de administración: El método de comunicación entre los
dispositivos administrados y los servidores. SNMP facilita la comunicación entre la estación administradora y el agente de un dispositivo de red (o nodo

40
administrado), permitiendo que los agentes transmitan datos estadísticos (variables) a través de la red a la estación de administración.
Uno de los principales inconvenientes es el exceso de tráfico que genera, lo que lo puede hacer incompatible para entornos amplios de red, por el contrario de CMIS/CMIP (Common Managment Information Service/Protocol) del modelo OSI que ofrece un mejor rendimiento y seguridad, estando orientado a la administración de sistemas extendidos. La versión 2 de SNMP aporta una serie de mejoras frente a la original, que, fundamentalmente, se manifiesta en tres áreas particulares de seguridad (las cuales son la autentificación, la privacidad y el control de accesos), transferencia de datos y comunicaciones de administrador a administrador. Los cinco tipos de mensajes SNMP intercambiados entre los Agentes y los Administradores, son:
Get Request: Una petición del Administrador al Agente para que envíe los
valores contenidos en el MIB (base de datos).
Get Next Request: Una petición del Administrador al Agente para que envíe los
valores contenidos en el MIB referente al objeto siguiente al especificado anteriormente.
Get Response: La respuesta del Agente a la petición de información lanzada
por el Administrador.
Set Request: Una petición del Administrador al Agente para que cambie el
valor contenido en el MIB referente a un determinado objeto.
Trap: Un mensaje espontáneo enviado por el Agente al Administrador, al
detectar una condición predeterminada, como es la conexión/desconexión de una estación o una alarma.
El protocolo de gestión SNMP facilita, pues, de una manera simple y flexible el intercambio de información en forma estructurada y efectiva, proporcionando significantes beneficios para la gestión de redes multivendedor, aunque necesita de otras aplicaciones en el NMS que complementen sus funciones y que los dispositivos tengan un software Agente funcionando en todo momento y dediquen recursos a su ejecución y recogida de datos.
3.3.1 MIB.
A través del MIB se tiene acceso a la información para la gestión, contenida en la memoria interna del dispositivo en cuestión. MIB es una base de datos completa y bien definida, con una estructura en árbol, adecuada para manejar diversos grupos de objetos (información sobre variables/valores que se pueden adoptar), con identificadores exclusivos para cada objeto.

41
Los 8 grupos de objetos habitualmente manejados por MIB, que definen un total de 114 objetos (recientemente, con la introducción de MIB-II se definen hasta un total de 185 objetos), son:
Sistema: Incluye la identidad del vendedor y el tiempo desde la última
reinicialización del sistema de gestión.
Interfaces: Un único o múltiples interfaces, local o remoto, etc.
ATT (Address Translation Table): Contiene la dirección de la red y las
equivalencias con las direcciones físicas.
IP (Internet Protocol): Proporciona las tablas de rutas, y mantiene estadísticas sobre los datagramas IP recibidos.
ICMP (Internet Communication Management Protocol): Cuenta el número de mensajes ICMP recibidos y los errores.
TCP (Transmission Control Protocol): Facilita información acerca de las conexiones TCP, retransmisiones, etc.
UDP (User Datagram Protocol): Cuenta el número de datagramas UDP, enviados, recibidos y entregados.
EGP (Exterior Gateway Protocol): Recoge información sobre el número de mensajes EGP recibidos, generados, etc.
3.3.2 RMON
RMON define las funciones de supervisión de la red y las interfaces de comunicaciones entre la plataforma de gestión SNMP, los monitores remotos y los Agentes de supervisión que incorporan los dispositivos inteligentes. Alarmas: Informa de cambios en las características de la red, basado en valores umbrales para cualquier variable MIB de interés. Permite que los usuarios configuren una alarma para cualquier Objeto gestionado.
Estadísticas: Mantiene utilización de bajo nivel y estadísticas de error.
Historias: Analiza la tendencia, según instrucciones de los usuarios,
basándose en la información que mantiene el grupo de estadísticas.
Filtros: Incluye una memoria para paquetes entrantes y un número
cualquiera de filtros definidos por el usuario, para la captura selectiva de
información; incluye las operaciones lógicas AND, OR y NOT.
Ordenadores: Una tabla estadística basada en las direcciones MAC, que
incluye información sobre los datos transmitidos y recibidos en cada
ordenador.
Los N principales: Contiene solamente estadísticas ordenadas de los "N"
ordenadores definidos por el usuario, con lo que se evita recibir
información que no es de utilidad.

42
Matriz de tráfico: Proporciona información de errores y utilización de la red,
en forma de una matriz basada en pares de direcciones, para
correlacionar las conversaciones en los nodos más activos.
Captura de paquetes: Permite definir buffers para la captura de paquetes
que cumplen las condiciones de filtrado.
Sucesos: Registra tres tipos de sucesos basados en los umbrales definidos por el usuario: ascendente, descendente y acoplamiento de paquetes, pudiendo generar interrupciones para cada uno de ellos.
3.4 Esquema Típico de Monitoreo En lo referente a la disponibilidad de la información y de forma precisa a la disponibilidad de la red es fundamental asegurar su buen funcionamiento y eficiencia a través de políticas, dispositivos y mecanismos de seguridad que reduzcan el riesgo ya sea de un acceso no autorizado, una interrupción del servicio, robo o alteración de la información, etc. El diseñador de la red debe prever el tráfico que se manejara dentro de la misma para considerar el ancho de banda como una métrica para el diseño, así como el crecimiento a futuro y el impacto que esto causara al esquema de seguridad que se adopte, dada la importancia de la red y los servicios que esta ofrece surge la necesidad de contar con un esquema capaz de notificar de manera oportuna las irregularidades ocurridos en la red y de mostrar su comportamiento mediante la recolección de trafico para poder analizar comportamientos sospechosos. El monitoreo se emplea para identificar situaciones anómalas del tráfico de paquetes que circulan por la red que se pueden derivar por problemas de eficiencia, diseño o seguridad de la red, ésta investigación se centra en este ultimo y el uso indebido que se hace de los recursos de la red. El monitoreo de una red corporativa es una función crítica de las tecnologías de información que puede salvar dinero en el desempeño de una red, ya que básicamente su función es la de monitorear una red interna en busca de problemas. Puede ayudar a resolver desde velocidades de transferencias lentas, hasta inclusive el porqué un servidor ha caído. Los sistemas de monitoreo de red (NMS por sus siglas en inglés “Network Monitoring Systems”), son bastante diferentes a los IDS‟s e IPS‟s. Éstos últimos detectan intrusiones y previenen actividades con dolo de usuarios no autorizados. El monitoreo de la red puede ser logrado usando distintos tipos de software o un híbrido de solución que implica una combinación de hardware con software. En teoría cualquier tipo de red puede ser monitoreada, no importa si es una red

43
inalámbrica o alámbrica, una red de área local corporativa, una red privada virtual o inclusive una red de área extensa. Se pueden monitorear dispositivos en distintos sistemas operativos con una variedad enorme de funciones; desde dispositivos BlackBerry o celulares, hasta servidores, ruteadores o switches y estos sistemas pueden ayudar a identificar actividades específicas y métricas de rendimiento. El decidir específicamente qué es lo que se va a someter a un monitoreo es tan importante como decidir el tipo de topología que se usa en la red. Por supuesto que el monitoreo de la red difiere de empresa a empresa: una empresa pequeña puede que lo haga solamente cuando se encuentre con síntomas preocupantes; mientras que una empresa grande lo haga las veinticuatro horas al día, todos los días.
Métricas
El monitoreo de la red no es de utilidad a menos de que se trate de rastrear los indicios adecuados. Las áreas que usualmente se examinan son el uso del ancho de banda, así como el rendimiento tanto de las aplicaciones como de los servidores. Monitorear el tráfico es una tarea fundamental, sobre la cual las tareas de mantenimiento y desarrollo están basadas; y usualmente se centra en el soporte a usuarios internos y usuarios finales. Algunos sistemas de monitoreo de redes vienen con la pre configuración de „descubrimiento automático‟, la cual es la habilidad de guardar dispositivos así como van siendo añadidos, o hay algún tipo de cambio de configuración, como por ejemplo en:
La dirección IP
Servicios
Tipos de dispositivos (switches, ruteadores, entre otros)
Direcciones físicas
Así también hay algunos puntos estratégicos que pueden ser monitoreados, y algunos de los cuales son:
Conformidad en la aplicación y uso de políticas internas
Ahorro en costos potencial al encontrar recursos redundantes como por ejemplo sesiones de correo perdidas
Ayudar a determinar la productividad de un empleado
Encontrar equipo sobrecargado antes de que pueda tirar una red
Identificar el retraso en la transferencia de la señal
Encontrar tráfico anormal interno que pudiera ser un indicio de una amenaza de seguridad
Mientras que el sistema de monitoreo de red mapeará la topología de la red, por ejemplo, les corresponde a los gerentes examinar y decidir el destino de cada pieza de la topología. Un monitoreo comprensivo podría ayudar a solucionar

44
preguntas tales como la capacidad de los servidores, los dispositivos remotos que están siendo usados, los sistemas operativos y las aplicaciones que están corriendo en cada servidor ( y si son necesarias), entre otras.
3.4.1 Monitoreo Activo
Este se utiliza para medir el rendimiento de la red inyectando paquetes de prueba a diferentes servicios o aplicaciones para medir el tiempo de respuesta. Se debe contar con un conocimiento detallado de los protocolos y el tipo de tráfico de la red para en un determinado momento detectar posibles ataques a dispositivos específicos.
3.4.2 Monitoreo Pasivo
Se basa en la obtención de datos en base a la recolección y análisis del tráfico que circula por la red. Consiste en guardar las cabeceras de los paquetes que circulan por la red y almacenarlos en forma de texto. Cabe mencionar que las cabeceras almacenadas logran ocupar una cantidad considerable de espacio de almacenamiento en disco, provocando la inminente necesidad de llevar a cabo una selección de la información. El proceso consecuente a la obtención de datos es identificado como filtrado de los datos y se refiere a la selección de la información que será manipulada dentro de la parte de análisis. A partir del momento en que los datos se obtienen del monitoreo son sometidos a dos códigos que se encargan de la selección de la información y del mapeo de las direcciones IP, el cual se lleva a cabo mediante la asignación de un número único para cada IP localizada dentro de los archivos, de tal manera que una IP posea el mismo número de mapeo sin importar que esté presente en más de una ocasión dentro del archivo.
3.4.3 Dispositivos de Interconectividad
Enlazar LANs requiere de equipos que realicen ese propósito. Estos dispositivos están diseñados para sobrellevar los obstáculos para la interconexión sin interrumpir el funcionamiento de las redes. A estos dispositivos que realizan esa tarea se les llama equipos de Interconectividad.
Dispositivos de la Capa de Enlace. Los bridges y switches de la Capa 2 son dispositivos que funcionan en la capa de enlace de datos de la pila del protocolo. La conmutación de la Capa 2 se basa en el puenteado por hardware. En un switch, el reenvío de tramas se controla por medio de un hardware

45
especial llamado circuitos integrados específicos de aplicaciones (ASIC). La tecnología ASIC permite que un chip de silicio pueda ser programado para realizar una función específica durante el proceso de fabricación del mismo, ya que esta tecnología permite que las funciones puedan llevarse a cabo a una velocidad mucho mayor que si el chip estuviese programado por software. Debido a la tecnología ASIC, los switches proporcionan escalabilidad a velocidades de gigabits con una latencia baja. Cuando un bridge o switch recibe una trama, utiliza la información del enlace de datos para procesar dicha trama. En un entorno de bridges transparente, el bridge procesa la trama determinada si ésta necesita ser copiada en otros segmentos conectados. Un bridge transparente detecta todas las tramas que cruzan un segmento y visualiza cada trama y el campo de dirección de origen para determinar en qué segmento reside el puesto de origen. El bridge transparente guarda esta información en memoria en lo que se conoce como tabla de envío. La tabla de envío contiene un listado de todos los puestos finales (desde los cuales el bridge puede detectar una trama en un periodo de tiempo determinado) y el segmento en el que éste reside. Cuando un bridge detecta una trama en la red, examina la dirección de destino y la compara con la tabla de envío para determinar si ha de filtrar, inundar o copiar la trama en otro segmento. Este proceso de decisión tiene lugar como se indica a continuación:
Si el dispositivo de destino está en el mismo segmento que la trama, el bridge bloquea el paso de la trama a otro segmento. Este proceso se conoce como filtrado.
Si el dispositivo de destino se encuentra en un segmento diferente, el bridge envía la trama al segmento apropiado.
Si la dirección de destino es desconocida para el bridge, éste envía la trama a todos los segmentos excepto a aquel de donde se ha recibido la información. Este proceso se denomina inundación. Debido a que el bridge aprende todos los puestos finales a partir de las direcciones de origen, nunca aprenderá la dirección de difusión. Por tanto, todas las difusiones serán inundadas a todos los segmentos del bridge o switch. En consecuencia, todos los segmentos de un entorno basado en bridge o switches se consideran residentes en el mismo dominio de difusión.
Una red puenteada/conmutada proporciona una excelente administración del tráfico. La finalidad del dispositivo de Capa 2 es reducir las colisiones al asignar a cada segmento su propio dominio de colisión. Cuando hay dos o más paquetes que necesitan entrar en un segmento, quedan almacenados en memoria hasta que el segmento esté disponible.

46
Las redes punteadas/conmutadas poseen las siguientes características:
Cada segmento posee su propio dominio de colisión.
Todos los dispositivos conectados al mismo bridge o switch forman parte del mismo dominio de difusión.
Todos los segmentos deben utilizar la misma implementación al nivel de la capa de enlace de datos como, por ejemplo, Ethernet o Token Ring. Si un puesto final concreto necesita comunicarse con otro puesto final a través de un medio diferente, se hace necesaria la presencia de algún dispositivo, como puede ser un router o un bridge de traducción, que haga posible al diálogo entre los diferentes tipos de medios.
En un entorno conmutado, puede haber un dispositivo por segmento, y todos los dispositivos pueden enviar tramas al mismo tiempo, permitiendo de este modo que se comparta la ruta primaria. Dispositivo Capa de Red.
Los routers operan en la capa de red registrando y grabando las diferentes redes y eligiendo la mejor ruta para las mismas. Los routers colocan esta información en una tabla de enrutamiento, que incluye los siguientes elementos:
Dirección de red: Representa redes conocidas por el router. La
dirección de red es específica del protocolo. Si un router soporta varios
protocolos, tendrá una tabla por cada uno de ellos.
Interfaz: Se refiere a la interfaz usada por el router para llegar a una
red dada. Ésta es la interfaz que será usada para enviar los paquetes
destinados a la red que figura en la lista.
Métrica: Se refiere al coste o distancia para llegar a la red de destino.
Se trata de un valor que facilita el router la elección de la mejor ruta
para alcanzar una red dada. Esta métrica cambia en función de la forma
en que el router elige las rutas. Entre las métricas más habituales
figuran el número de redes que han de ser cruzadas para llegar al
destino(conocido también como saltos), el tiempo que se tarda en
atravesar todas las interfaces hasta una red dada(conocido también
como retraso), o un valor asociado con la velocidad de un
enlace(conocido también como ancho de banda).
Debido a que los routers funcionan en la capa de red del modelo OSI, se utilizan para separar segmentos en dominios de colisión y de difusión únicos. Cada segmento se conoce como una red y debe estar identificado por una dirección de red para que pueda ser alcanzado por un puesto final. Además

47
de identificar cada segmento como una red, cada puesto de la red debe ser identificado también de forma unívoca mediante direcciones lógicas. Esta estructura de direccionamiento permite una configuración jerárquica de la red, ya que está definida por la red en la que se encuentra, así como por un identificador de host. Para que los routers puedan operar en una red, es necesario que cada tarjeta esté configurada en la red única que ésta representa. El router debe tener también una dirección de host en esa red. El router utiliza la información de configuración de la tarjeta para determinar la parte de la dirección correspondiente a la red, a fin de construir una tabla de enrutamiento. Además de identificar redes y proporcionar conectividad, los routers deben proporcionar estas otras funciones:
Los routers no envían difusiones de Capa 2 ni tramas de multidifusión.
Los routers intentan determinar la ruta más óptima a través de una red
enrutada basándose en algoritmos de enrutamiento.
Los routers separan las tramas de Capa 2 y envían paquetes basados
en direcciones de destino Capa 3.
Los routers asignan una dirección lógica de Capa 3 individual a cada
dispositivo de red; por tanto, los routers pueden limitar o asegurar el
tráfico de la red basándose en atributos identificables con cada
paquete. Estas opciones, controladas por medio de listas de acceso,
pueden ser aplicadas para incluir o sacar paquetes.
Los routers pueden ser configurados para realizar funciones tanto de
puenteado como de enrutamiento.
Los routers proporcionan conectividad entre diferentes LAN virtuales (VLAN) en entornos conmutados.
Los routers pueden ser usados para desplegar parámetros de calidad de servicio para tipos específicos de tráfico de red.
Además de las ventajas que aporta su uso en un campus, los routers pueden utilizarse también para conectar ubicaciones remotas con la oficina principal por medio de servicios WAN. Los routers soportan una gran variedad de estándares de conectividad al nivel de la capa física, lo cual ofrece la posibilidad de construir WAN. Además, pueden proporcionar controles de acceso y seguridad, que son elementos necesarios cuando se conectan ubicaciones remotas.

48
3.4.4 Controles de Seguridad en Red
Firewalls
Los firewalls son dispositivos o sistemas que controlan el flujo del tráfico entre redes empleando diferentes perfiles de seguridad. Independientemente de la arquitectura del firewall y de las capas del modelo OSI que cubra, pueden tener servicios adicionales, como pueden ser Traducción de dirección de red (NAT), Protocolo de configuración dinámica de host (DHCP) y funciones de cifrado como Redes virtuales privadas (VPNs) y filtrado de contenidos. Firewalls de Filtrado de Paquetes Es el más básico, son esencialmente dispositivos de ruteo que incluyen la funcionalidad de control de acceso para sistemas de direcciones y sesiones de comunicación. La función de control de acceso esta dada por directivas denominadas reglas. Este tipo de firewalls opera en la capa 3 del modelo OSI. La funcionalidad de control de acceso se basa en información contenida en el paquete.
Dirección origen del paquete: Dirección de computadora o dispositivo
de red que origino el paquete, es decir, una dirección IP.
Dirección de destino del paquete: Dirección de computadora o
dispositivo de red a la cual se trata de acceder.
Tipo de tráfico: Esto es, el protocolo específico de red usado para
comunicarse entre el destino y el origen (a menudo “Ethernet” en capa 2 e “IP” en capa 3.
Características de sesiones de comunicación en la capa 4: Como lo
son los puertos de origen y destino de las sesiones.
Interfáz del router: Algunas veces el firewall muestra información
perteneciente a cuál interfaz del router es de donde proviene el paquete y que interfaz es el destino del mismo.
Firewalls de filtrado son comúnmente usados dentro de infraestructuras de red TCP/IP, aunque también pueden ser usados en cualquier infraestructura de red basada en capa 3. Firewalls y routers de filtrado basan su operación en ciertas características del tráfico, como si el protocolo de los paquetes de capa 3 pudo ser ICMP que usualmente los atacantes usan este protocolo para hacer ataques de inundación. Los firewalls de filtrado tienen la capacidad de bloquear algunos ataques que se basan en debilidades de TCP/IP. Los firewalls de filtrado están diseñados para un ambiente donde los

49
paquetes provienen de un red externa, filtrando únicamente protocolos, puertos origen y destino así como direcciones de red basadas en alguna relación de confianza, por tanto se necesitan otro tipo de firewalls que hagan un análisis en capas superiores para atender vulnerabilidades de aplicación. Firewalls de Inspección de Estado Este tipo de firewalls incorporan la funcionalidad de la capa 4 del modelo OSI. Cuando TCP crea una sesión con un host remoto, un puerto es creado en el sistema origen con el propósito de recibir tráfico en el destino. De acuerdo a las especificaciones de TCP, el puerto origen tiene que ser un número mayor que 1023 y menor que 16384 y el puerto destino tiene que ser un número menor, es decir menos que 1024. Abrir todos los puertos para una comunicación interna provoca un gran riesgo de que un intruso no autorizado utilice varias técnicas de penetración. Este tipo de firewalls solo es útil con el protocolo TCP/IP. Firewalls de Aplicación
Combinan capas inferiores de control de acceso con capas superiores de funcionalidad, no requieren la ruta de la capa 3 entre las interfaces internas y externas del firewall; el software realiza la ruta. Todos los paquetes de red que atraviesan el firewall deben hacerlo en base al control de software. Cada proxy se refiere a un agente, trabaja directamente con las reglas de control de acceso del firewall para determinar si la pieza de tráfico debe ser permitida. Adicionalmente cada agente tiene la habilidad de requerir autentificación a cada usuario de red, por ejemplo:
ID de usuario y contraseña
Un token de autentificación
Autenticación de dirección origen
Biometría La ventaja de este tipo de firewalls es que tiene la capacidad de examinar el paquete completo en vez de solo las direcciones y los puertos. Por ejemplo pueden guardar comandos específicos de aplicaciones dentro del tráfico de la red. Otra ventaja es que pueden autenticar usuarios directamente, y son menos vulnerables ante los ataques de spoofing.

50
Servidores Dedicados
El principio operativo básico de un servidor proxy se trata de un servidor que actúa como "representante" de una aplicación efectuando solicitudes en Internet en su lugar. De esta manera, cuando un usuario se conecta a Internet con una aplicación del cliente configurada para utilizar un servidor proxy, la aplicación primero se conectará con el servidor proxy y le dará la solicitud. El servidor proxy se conecta entonces al servidor al que la aplicación del cliente desea conectarse y le envía la solicitud. Después, el servidor le envía la respuesta al proxy, el cual a su vez la envía la aplicación del cliente. La finalidad más habitual es permitir el acceso a Internet a todos los equipos de una organización cuando sólo se puede disponer de un único equipo conectado, esto es, una única dirección IP. O bien; la función más habitual en Internet, es mantener el anonimato de la dirección IP real. Es altamente recomendado, para evitar escaneos de usuarios malintencionados; que podrían llegar a comprometer la seguridad. Por otra parte, al utilizar un servidor proxy, las conexiones pueden rastrearse al crear registros de actividad (logs) para guardar sistemáticamente las peticiones de los usuarios cuando solicitan conexiones a Internet. Gracias a esto, las conexiones de Internet pueden filtrarse al analizar tanto las solicitudes del cliente como las respuestas del servidor. El filtrado que se realiza comparando la solicitud del cliente con una lista de solicitudes autorizadas se denomina lista blanca; y el filtrado que se realiza con una lista de sitios prohibidos se denomina lista negra. Finalmente, el análisis de las respuestas del servidor que cumplen con una lista de criterios (como palabras clave) se denomina filtrado de contenido. IDPS La detección de intrusos es el proceso de monitoreo de eventos que ocurren en una computadora o en una red, analizándolos en busca de señales de posibles incidentes, los cuales son violaciones o ataques en contra de las políticas de seguridad o prácticas de seguridad. Un sistema de detección y prevención de intrusos se centra en identificar posibles incidentes, guardar información acerca de los mismos, tratar de detenerlos y reportarlos a los administradores de seguridad. Muchos IDPSs también pueden responder a un ataque detectado tratando de prevenir que sea exitoso usando diferentes técnicas tratando de detener los ataques cambiando el ambiente de seguridad, por ejemplo, reconfigurando firewalls o cambiando el contenido del ataque. Un sistema de detección de intrusos (IDS) es software que automatiza el proceso de detección de intrusos; un sistema de prevención de intrusos (IPS)

51
es un software que tiene toda la capacidad de un IDS y también trata de detener los posibles incidentes. Si el IDPS previno el ataque exitosamente, los administradores deben ser notificados del ataque. Es particularmente importante si el objetivo es una vulnerabilidad bien conocida que el atacante puede explotar. Los atacantes pueden usar diferentes tipos de ataques para explotar la misma vulnerabilidad que los IDPS pueden no reconocer. Las tecnologías IPS se diferencian de los IDS por una característica, los IPSs responden a los ataques detectados y usan varias técnicas de respuesta, que se pueden dividir en los siguientes grupos: IPS detienen el ataque por sí mismo: Esto lo hace de tres formas:
Termina la conexión o sesión de usuario que está siendo usado para
el ataque.
Bloquea el acceso al objetivo (o posibles objetivos), como la cuenta de
usuario, dirección ip, u otro atributo del atacante.
Bloquea todos los accesos al host objetivo, servicio, aplicación u otro
recurso.
El IPS cambia el ambiente de seguridad ya que puede cambiar la configuración de otros controles de seguridad para romper el ataque. Ejemplos comunes son reconfiguración de un dispositivo de red (firewall, router, switch) para bloquear el acceso al atacante y alterando por ejemplo un firewall basado en host para bloquear ataques entrantes e inclusive algunos IPS pueden incluso aplicar parches a una vulnerabilidad detectada en un host. Cambian el contenido de los ataques. Algunas tecnologías de IPS pueden remover o reemplazar las porciones maliciosas de un ataque para iniciarlo. Un ejemplo de esto es un IPS que remueve un archivo infectado de correo y entonces permite que el correo desinfectado llegue a su destino. Otro ejemplo más complejo es cuando actúa como un proxy y normaliza las peticiones, lo cual significa que el proxy reempaqueta el contenido de las peticiones y descarda la información de cabecera. Las metodologías de detección son las siguientes:
Detección basada en firmas: Es el proceso de comparar firmas
observadas en eventos para identificar posibles incidentes. Ejemplos de firmas son las siguientes: o Una sesión telnet con usuario “root”, la cual es una violación
contra las políticas de seguridad. o Un correo electrónico con título o datos adjuntos cuyo nombre sea
sospechoso, podría ser una forma de malware.

52
o Un log de sistema con un código de status de valor 645 lo cual indica que el host auditado ha sido deshabilitado.
Detección basada en anomalías: Es el proceso de comparar
definiciones de que actividad es considerada normal contra los eventos observados e identificados con desviaciones significativas, este tipo de IDPS cuenta con perfiles que representan el comportamiento normal como usuarios, host, conexiones de red o aplicaciones. Los perfiles se desarrollan para monitorear características de la actividad típica en un periodo de tiempo. Por ejemplo, un perfil de red debe mostrar la actividad web en promedio para observar el consumo de banda durante las horas de trabajo en un día normal. Los perfiles se pueden desarrollar para varios atributos, tales como el número de correos enviados por un usuario, el número de intentos fallidos para acceder a un host y el nivel de procesamiento usado por un host en un periodo de tiempo.
Análisis de estado de protocolos: Se crean perfiles que determinan el
correcto e incorrecto funcionamiento de los protocolos que se utilizan en la red
Si se cuenta con un IDPS basado en firmas, se deberá guardar en un log las comparaciones que concuerden con la lista de firmas predefinidas para hacer su detección, dado que no hace inferencia sobre comparaciones que no concuerdan con su lista pero que son concurrentes en su contenido, se recomienda que se utilicen adicionalmente otro tipo de detector de intrusos. Si se cuenta con un IDPS basado en anomalías se debe ser cuidadoso en la creación de perfiles y analizar en qué casos se utilizaran valores absolutos y en cuales otros valores porcentuales como parámetros para cierto comportamiento, para evitar que se den falsos positivos, en este caso se guardarán los registros de actividad sospechosa que comprometan enlaces que el administrador considere prioritarios. Si se cuenta con un IDPS basado en el análisis de estado de protocolo y si se considera necesario el nivel de detalle del tráfico, se deben establecer perfiles para sesiones TCP cuando se hagan peticiones a la DMZ, los perfiles se basaran en el análisis de actividades sospechosas, es decir, por ejemplo, cuando se realicen modificaciones a las secciones del paquete o datagrama que el administrador considere que deben ser inalterables en base a estándares del software, para el establecimiento de las comunicaciones. Este IDPS deberá guardar aquellas peticiones de establecimiento de sesión cuando esta no concuerde con el perfil predefinido de cada protocolo que previamente se ha filtrado en un firewall.

53
3.5 Monitoreo de una Red TCP/IP El sistema de administración de red se basa en dos elementos principales: el administrador y los agentes. El supervisor es el terminal que le permite al administrador de red realizar solicitudes de administración, mientras que los agentes son entidades que se encuentran al nivel de cada interfaz (ellos conectan a la red los dispositivos administrados y permiten recopilar información sobre los diferentes objetos). Los conmutadores, concentradores (hubs), routers y servidores son ejemplos de hardware que contienen objetos administrados. Estos objetos administrados pueden ser información de hardware, parámetros de configuración, estadísticas de rendimiento y demás elementos que estén directamente relacionados con el comportamiento en progreso del hardware en cuestión. Estos elementos se encuentran clasificados en algo similar a una base de datos denominada MIB ("Base de datos de información de administración"). SNMP permite el diálogo entre el supervisor y los agentes para recolectar los objetos requeridos en la MIB. La arquitectura de administración de la red propuesta por el protocolo SNMP se basa en tres elementos principales:
Los dispositivos administrados son los elementos de red (puentes, concentradores, routers o servidores) que contienen "objetos administrados" que pueden ser información de hardware, elementos de configuración o información estadística.
Los agentes, es decir, una aplicación de administración de red que se encuentra en un periférico y que es responsable de la transmisión de datos de administración local desde el periférico en formato SNMP.
El sistema de administración de red (NMS), esto es, un terminal a través del cual los administradores pueden llevar a cabo tareas de administración.
Las principales tareas de un administrador de red son asegurarse que todos los dispositivos que conforman su red como switches, routers, servidores, etc., estén funcionando correctamente y de manera óptima, en este objetivo SNMP (Simple Network Management Protocol) o protocolo de administración de redes, puede ser muy útil. Éste fue introducido en 1988 por la necesidad de un protocolo para manejar la cantidad creciente de dispositivos IP. SNMP provee un conjunto de operaciones sencillas para manejar dispositivos remotamente y frecuentemente; es asociado a la administración de Routers y puede ser usado para administrar cualquier tipo de dispositivo que lo soporte como sistemas UNIX, sistemas Windows, impresoras, UPS hasta aires acondicionados, entre otros.
Administradores y Agentes.
En el mundo de SNMP existen dos tipos de entidades, los administradores y los

54
agentes. Un administrador es un servidor que ejecuta un programa que realiza tareas de administración en una red, usualmente se refieren como Estaciones de Administración de redes (NMS). Por otro lado, un agente es un programa ejecutado en un dispositivo con soporte SNMP, sea mediante un proceso demonio o incorporado en el Sistema Operativo, provee información de administración al NMS sobre varios aspectos operacionales del dispositivo. Un ejemplo de algunos dispositivos son switches, routers, servidores, UPS, entre otros. El acto de envío de un mensaje por parte de un NMS a un agente se denomina “polling” que consiste en consultar al agente algún tipo de información. En este sentido, el mensaje enviado por un agente a un NMS se denomina “trap”, este consiste en una interrupción relacionada a algún problema ocurrido en el dispositivo agente, es decir, es una manera alertar al NMS que algún problema ha ocurrido.
SNMP es protocolo que funciona en la capa de aplicación que usa UDP como protocolo de transporte para transmitir datos entre agentes y administradores (NMS), fue elegido sobre TCP ya que no establece conexiones y, el envío y recepción de paquetes produce poco tráfico y por esto no hay mucha congestión en la red. La desventaja de usar UDP es que es desconfiable ya que no hay conocimiento de datagramas perdidos en esta capa, por lo tanto, queda para la aplicación determinar si se perdieron datagramas y si se proceda a la retransmisión si es necesario.
Para consultas por parte del NMS al agente no es desventaja la desconfianza de UDP, sin embargo, para las interrupciones que envía un agente al NMS si es preocupante que no llegue el datagrama ya que el NMS nunca se enteraría que el agente le ha enviado un mensaje sobre un problema y el agente no sabría que tiene que reenviar la interrupción, esto lo tiene que controlar la aplicación SNMP. Además, usar TCP es mala idea ya que tampoco este protocolo es infalible y SNMP está diseñado para trabajar en redes con fallas y si la red nunca falla entonces no hay necesidad de monitorearla. Cuando una red está fallando, no es buena idea usar un protocolo que congestione la red de paquetes por retransmisiones. SNMP usa el puerto UDP 161 para enviar y recibir peticiones de consulta de información en los agentes y el puerto UDP 162 para recibir interrupciones de dispositivos que administra.
Estructura de la Información Administrada (SMI) y MIBS
La estructura de la información administrada (SMI) consiste en una manera de definir objetos administrados por los agentes y su comportamiento. Un agente posee una lista de objetos que rastrea. Un objeto, por ejemplo, consiste en el estatus operacional de una interfaz de router. Esta lista define colectivamente la información que el NMS puede usar para determinar el estado del dispositivo donde reside el agente. Por otra parte, la Base de Administración de Información (MIB) es una base de datos de objetos que el agente revisa. Cualquier información de estatus o estadística puede ser accesada por el NMS si es definida en la MIB. SMI provee una manera de definir un objeto administrado, mientras que la MIB es la definición usando sintaxis SMI de los propios objetos. MIB define un nombre

55
textual para el objeto y explica su significado. Un agente puede implementar muchas MIBs, pero todos los agentes implementan uno en particular llamado MIB-II (RFC 1213). Este estándar define variables para cosas como estadísticas de la interfaces así como cuestiones concernientes al sistema. El objetivo principal de MIB-II es proveer información general a TCP/IP. Además los distribuidores de dispositivos con soporte SNMP en ocasiones pueden definir nuevas variables MIB ajustadas al dispositivo en particular. La manera de representar los objetos que son administrados es a través de tres atributos: Nombre, es el identificador del objeto (OID), define únicamente a un objeto, puede aparecer en forma numérica y canónica. Los objetos que administra SNMP de ciertos dispositivos son organizados en una jerarquía de árbol. El ID de un objeto está compuesto de una serie de enteros separados por puntos donde cada punto representa bajar un nivel en el árbol, de forma equivalente, la forma canónica en lugar de enteros son cadenas, cada uno representa un nodo. Así que es equivalente usar cualquiera de las dos notaciones. Esta representación numérica es la manera como se identifica el objeto en el agente, la representación canónica facilita no tener que recordar los números. Dentro de las redes de comunicaciones las convenciones que dictaminan la forma en que se establece, mantiene y finaliza una comunicación entre elementos de red se le denomina protocolo. Existen dos modelos de referencia en los cuales se basan la mayor parte de los protocolos existentes, uno es el modelo OSI y el otro es TCP/IP. Cada protocolo tiene una función diferente y realiza tareas específicas. Alguno solo trabajan en cierto niveles de OSI, los protocolos pueden trabajar juntos en una jerarquía de protocolos. La comunicación mediante protocolos se lleva a cabo mediante una comunicación entre capas, la cuales proporcionan información útil a la capa consecutiva, esto es del lado del origen, una vez en el destino la interpretación del protocolo se llevan en sentido inverso. Existe el denominado proceso de ligadura “binding process” que describe como los protocolos se comunican con la NIC, esto brinda flexibilidad al momento de ligar las jerarquías de protocolos, el orden elegido determina la secuencia en la que el sistema operativo ejecuta el protocolo. TCP/IP es conocido como la familia de protocolos de internet que gracias a que es un protocolo estándar para la interoperabilidad entre diferentes equipos se ha popularizado, además de que proporciona servicios de red encaminable permite acceder a internet. Las ventajas de TCP/IP se basa en que es un protocolo abierto por lo cual presenta pocos problemas de compatibilidad al no estar regulado por alguna compañía.

56
CAPÍTULO IV. CASO PRÁCTICO A continuación se analizarán dos herramientas que sirven para hacer el monitoreo de la red: Wireshark (Tshark), y TCPDUMP. Wireshark, es un analizador de protocolos utilizado para realizar análisis y solucionar problemas en redes de comunicaciones para desarrollo de software y protocolos, y como una herramienta didáctica para educación. Cuenta con todas las características estándar de un analizador de protocolos, por lo que es considerado popularmente como un sniffer (esto es debido a que con esta herramienta se puede capturar todos los protocolos que el cliente así lo desee).
4.1 Wireshark/Tshark Wireshark es una herramienta multiplataforma ya que corre en sistemas operativos tipo Unix (incluyendo Linux, Solaris, FreeBSD, NetBSD, OpenBSD, Mac OS X, Microsoft Windows, U3 y en Portable Apps); así en el sistema operativo Windows. ¿Por qué elegir Wireshark?: Una de las principales razones por las cuales la herramienta fue elegida para la demostración de un esquema de monitoreo, es debido a que puede ejecutarse sobre el sistema operativo Windows, ya que como se muestra en la página de Xitimonitor [12], el sistema operativo Windows es el que más se ha usado, y continúa siendo mucho mayor el número de usuarios que lo utilizan a comparación de Mac OS o Linux, tal y como se muestra la figura 4.1
Figura 4.1 Uso de Windows según Xitimonitor durante enero de 2007

57
Los primeros indicios del uso de Windows Vista fueron mostrados en enero de 2007, y en la figura 4.2 se muestra un comparativo entre las distintas versiones de sistemas operativos usados con mayor frecuencia en la red con usuarios con necesidades básicas.
Figura 4.2 Comparativo de los sistemas operativos y su uso en la red según Xitimonitor
Otra de las razones por las cuales Wireshark ha sido elegido es debido a su gran capacidad de monitorear protocolos, ya que dentro de esta variedad se encuentran algunos de los más comunes usados por TCP/IP tales como ARP, ICMP (que posteriormente se usará en el caso práctico de este documento), IP, IPX, STP, TCP, UDP, HTTP; solo por mencionar a algunos de los más representativos.
4.1.1 Simulando un DoS En Windows.
Un DoS en informática es un ataque de denegación de servicio y puede ser perpetrado en un número muy variado de formas; algunas de ellas consisten en:
Consumo de recursos computacionales, tales como ancho de banda, espacio de disco, o tiempo de procesador.
Alteración de información de configuración, tales como información de rutas de encaminamiento.
Alteración de información de estado, tales como interrupción de sesiones TCP (TCP reset).

58
Este documento se enfocará a demostrar cómo mediante un PING usando dos máquinas se puede alterar el tráfico en la red, así como el consumo de recursos (ancho de banda); y por último y no menos importante: demostrar los protocolos que intervienen en este “ataque” y el momento en el que se disparan al hacerlo. Este esquema será como el propuesto en la figura 4.3.
Figura 4.3 Esquema básico de conectividad entre dos equipos
Los pasos a seguir durante este proceso se agrupan de la siguiente manera:
Consiguiendo Información Básica
Los primeros pasos a seguir para preparar el establecimiento del monitoreo a seguir en el equipo A; será conseguir la dirección IP de éste, así como de la máquina a la cual se hará el PING. Esto se hace abriendo una consola de MS-DOS en el sistema operativo Windows que se use para la prueba (en este caso en específico se hará con Windows XP Professional). Posteriormente en ambos equipos se introducirá una sentencia del tipo “ipconfig/all”; y se mostrará un resultado en el cual se obtienen datos importantes para la identificación de ambos equipos durante el incidente. Algunos de los datos que se podrán obtener son:
Dirección física (MAC Address)
Nombre del host
Dirección IP
Máscara de Subred
Puertas de enlace
En cuanto al caso práctico el equipo A posee la dirección IP: 192.168.1.68, y el equipo B posee la dirección IP: 192.168.1.66.
Preparando Wireshark
En paralelo al obtener las direcciones IP de ambos equipos, se deberá instalar Wireshark (que como se mencionó anteriormente, es de distribución

59
gratuita). Una vez instalado, se procede a iniciar una captura de todos los protocolos que fluyen a través de la tarjeta de red del equipo A. Esto se hace yendo al menú Captura (Capture), y posteriormente seleccionar Interfaces (Interfaces…). Se mostrará un cuadro de dialogo en el que se aprecian las distintas tarjetas de red con que el equipo cuenta, para así posteriormente poder seleccionar la tarjeta con la IP deseada, y dar clic en Iniciar (start). Una vez hecho el inicio de la captura se mostrarán por defecto los protocolos activos, las direcciones IP de origen y destino, la hora en que el protocolo fue activado; del estado actual de la red. La interfaz en Windows se muestra como en la figura 4.4
Figura 4.4 Elementos por defecto en Wireshark
Haciendo el PING.
Al hacer un ping a otra máquina, dos protocolos intervienen en esta acción directamente: el IP y el ICMP. Éste último pertenece al conjunto de protocolos IP y sus mensajes son construidos a nivel de capa de red (tomando como referencia el modelo OSI) [13].
Teniendo en cuenta esto, si se hace un ping al equipo B mientras se tiene un analizador de protocolos de red activo en el equipo A, la herramienta de monitoreo deberá de ser capaz de identificar que:

60
Ha habido una solicitud de ICMP, lo cual conlleva que se haga una petición (o request en inglés), y que en base a este se envíen paquetes de datos mediante el protocolo IP; y que
El tráfico de la red se ha incrementado, debido a que se ha encendido una bandera del protocolo ICMP.
Si el ping hecho al equipo B es por tiempo indefinido, podrá tener un histórico del momento en que se inició el incidente, así como si aún sigue éste activo.
Hasta el momento la comunicación entre el equipo A y el equipo B se ha mantenido de una manera estable y con un flujo no muy alto de datos en la red; esto es comprobable mediante una de las características que ofrece Wireshark: gráficas de entrada y salida (IO graphs). Un poco más adelante en este documento se mostrará el uso de este tipo de gráficas, pero por el momento se puede comentar que al ingresar a esta característica, se muestra una serie de filtros y colores, así como una gráfica lineal cuyos ejes se basan en el tiempo (de monitoreo), y en los paquetes enviados tal y como se muestra en la figura 4.5 Ahora bien, se procederá a ejecutar un ping desde el equipo A y hacia el equipo B con el comando puesto de esta manera “ping 192.168.1.66 –t –l 65500”. En dicha sentencia los parámetros propuestos corresponden a lo siguiente: -t : Indica que se hará un ping a un equipo por tiempo indefinido. -l : Indica el tamaño del buffer. .
Figura 4.5 Gráfica de entrada/salida
Lo cual para fines prácticos indica que se hará un ping al equipo 192.168.1.66 con 65500 octetos de información por tiempo indefinido. Esto provocará que el tráfico se dispare como se muestra en la figura 4.6; en

61
dicha imagen se muestra que la fuente 192.168.1.68 ha enviado la petición al destino 192.168.1.66, la hora en que cada uno de los pings ha sido enviado, y que para cada una de estas peticiones se ha mandado una respuesta como se muestra en la figura 4.6. Esto es comprobable haciendo un filtro con el protocolo ICMP y dando clic en aplicar (apply) como se muestra en la figura 4.7.
Figura 4.6 Un ping por tiempo indefinido
Todo este proceso ha sido capturado gracias a Wireshark en el ambiente controlado antes mencionado, y puede ser guardado como un archivo con extensión “*.pcap” (entre algunas otras extensiones).
Figura 4.7 Demostración de ICMP iniciado por ping
Viendo los Reportes.
En Wireshark se pueden ver los reportes de manera activa y de manera pasiva: al hacer mención de la manera activa se hace referencia a que cuando se está haciendo la captura, se puede ingresar al menú de estadísticas y activar la que se requiera analizar en ese momento; mientras

62
que en el modo pasivo se pueden abrir archivos existentes grabados en una sesión anterior y se puede reconstruir el escenario. Esto se puede demostrar (como ya se había mencionado con anterioridad), mediante las gráficas que se manejan en la aplicación y que hacen el monitoreo segundo a segundo o bien, mostrar un histórico de tráfico en la red. Para fines de demostrar el ping, se tomarán como muestra las imágenes 4.8 y 4.9. En la primera de ellas se muestra cómo el tráfico en la red se dispara a partir del ping hecho después del punto de control a las 22:07:24; con todas las implicaciones que esto conlleva.
Figura 4.8 Tráfico de red cuando inicia el ping
Así también en la figura 4.9 se muestra cómo una vez terminado el ping después del punto de control a las 22:09:04, la red ha vuelvo a su estado de tráfico normal.
Figura 4.9 Tráfico cuando el ping finalizó

63
Con esto queda comprobado que Wireshark es una herramienta que sirve para detectar el tráfico en la red, por medio de los protocolos que intervienen en éste, con la premisa de que se guarda todo el tráfico que viaja por la red.
4.1.2 Tshark.
Tshark es un analizador de protocolo de red. Permite capturar paquetes de datos de una red activa, o leer paquetes de una captura previamente guardada, así como imprimir de manera cifrada esos paquetes a un formato estándar o guardarlos en un archivo. Tshark es capaz de detectar, leer y escribir los mismos archivos que son soportados por Wireshark, utiliza la librería libcap que es la que proporciona las funciones para la captura de a nivel de usuario, se utiliza para monitorear redes de bajo nivel. Se pueden especificar opciones de filtrado de captura o lectura, en donde se debe expresar como un argumento sencillo o puede ser especificado por línea de comandos después de la opción argumentos, en tal caso todos los argumentos después del filtro son tratados como la expresión de filtrado. Los filtros de captura solo son soportados cuando se realiza una captura en tiempo real, filtros de lectura están diseñados para soportar captura en tiempo real o lectura de un archivo. Dentro de las opciones de Tshark se pueden establecer criterios para que se finalice la escritura de datos en un archivo, también dado que Tshark utiliza una serie de archivos donde almacena varios archivos de captura, al momento de llenarse uno Tshark escribe en el siguiente. Cuando se especifica la opción de guardar la captura en un archivo se procede a guardar en el buffer en forma de anillo, es decir, una vez llenos los archivos se procede a sobrescribir sobre el primero. El filtrado se puede hacer de protocolos y de los campos que originalmente se muestran, también es modificable el formato de salida de los ficheros. A pesar de utilizar una interfaz de comando de línea Tshark ofrece la opción de estadísticos, en el cual se deberán habilitar los filtros para poder tener consultas precisas.
Monitoreo con Tshark.
Tshark no cuenta con una interfaz gráfica por lo que se ejecuta desde línea de comandos. El escenario de este caso es una maquina virtual de VMware y sobre la cual corre BackTrack. Las tarjetas de red ya se encuentran configuradas para establecer comunicación entre ellos. De ahora en adelante al equipo con BackTrack se le llamara Equipo A y al equipo con Windows Vista se le llamara Equipo B.

64
El Equipo B tiene instalado WireShark, pero Tshark se utiliza desde línea de comandos, por tanto se debe tener el conocimiento de donde se encuentra el archivo ejecutable tshark.exe, abrir el interprete de línea de comandos y se ubica la carpeta donde vive tshark.exe; en este caso C:\Program Files\WireShark\. Una vez que en esta carpeta se ejecuta Tshark especificando qué protocolo se desea registrar y en que archivo se va a guardar el tráfico filtrado.
Figura 4.10 Tshark a la espera de tráfico ICMP
Se ejecuta el comando Tshark icmp –w icmpTraffic En la figura 4.10 se muestra como Tshark está a la espera de paquetes del protocolo ICMP. Ahora desde el Equipo A se comienza a enviar paquetes ICMP, se abre una terminal en el Equipo B y se ejecuta el siguiente comando: #ping 192.168.2.24 –l 65500 Donde: 192.168.2.24: Es la dirección IP del Equipo B –l: Es el tamaño del paquete 65500 Kb.
Ahora el Equipo A esta enviando paquetes del protocolo ICMP con un tamaño de 65500 Kb al Equipo B y el Equipo B comenzó a registrar el tráfico en la red, esto es comprobable en la figura 4.1.

65
Figura 4.11 Tshark Capturando y registrando el trafico ICMP
Para ver el tráfico registrado en el archivo icmpTraffic se introduce el comando: tshark –r icmpTraffic En la figura 4.12 se muestra el registro de los paquetes como se puede ver existen los paquetes ICMP que son peticiones y los paquetes ICMP que son respuestas, es decir el Equipo A envía una petición al equipo B, dirección origen 192.168.2.25 y dirección destino 192.168.2.24, y el equipo B envía una respuesta dirección origen 192.168.2.24 y dirección destino 192.168.2.25
Figura 4.12 Paquetes ICMP capturados por Tshark

66
4.2 Tcpdump Tcpdump es una herramienta utilizada para analizar el tráfico de la red, Permite al usuario capturar y mostrar a tiempo real los paquetes transmitidos en la red. Tcpdump se ejecuta sobre la mayoría de sistemas UNIX. No cuenta con una interfaz gráfica por lo que se ejecuta desde línea de comandos. Además puede registrar el tráfico de la red mediante la librería pcap. El usuario puede aplicar varios filtros para que sea más depurada la salida. Un filtro es una expresión que va detrás de las opciones y que permite seleccionar los paquetes que se están buscando. En ausencia de ésta, el tcpdump volcará todo el tráfico que vea el adaptador de red seleccionado. Tcpdump es utilizado:
Para depurar aplicaciones que utilizan la red para comunicar.
Para depurar la red misma.
Para capturar y leer datos enviados por otros usuarios u ordenadores. Algunos protocolos como telnet y HTTP no cifran los datos que envían en la red. Un usuario que tiene el control de un router a través del cual circula tráfico no cifrado puede usar tcpdump para conseguir contraseñas u otras informaciones.
Monitoreo con Tcpdump.
En este caso práctico se utiliza la distribución de BackTrack 3 en la cual ya viene incluido tcpdump. BackTrack se está ejecutando desde una maquina virtual de VMware que corre sobre Windows Vista. Para este caso práctico ya se encuentran configuradas las tarjetas de red de BackTrack y de Windows Vista para establecer una comunicación entre ellas. De ahora en adelante al equipo con BackTrack se le llamara Equipo A y al equipo con Windows Vista se le llamara Equipo B. Desde el equipo B se hará una serie de pings por tiempo indefinido y con un tamaño de 65500 bytes con el objetivo de generar tráfico en la red. Este caso se centra en un ambiente controlado, donde se tiene acceso a ambos equipos. Inicialmente se obtienen las direcciones IP de los equipos. En el Equipo A se abre una terminal y se introduce el comando ifconfig, inet addres es la dirección IP del Equipo A: 192.168.2.25. En el equipo B se abre una ventana de línea de comandos y se introduce el comando ipconfig, la dirección IPv4 del equipo B es: 192.168.2.24. En el equipo A se inicia tcpdump con parámetros que ayudaran al monitoreo, ya

67
que el ping utiliza el protocolo ICMP, se filtrará dicho monitoreo para que solo registre paquetes del protocolo ICMP y que lo guarde en un archivo de nombre icmpTraffic, para poder posteriormente acceder a él. Para iniciar el monitoreo en la terminal del Equipo A se introduce el comando:
#tcpdump proto \\icmp –w /traffic/icmpTraffic Donde: proto: Especifica el protocolo a monitorear, que es ICMP. -w: Especifica que el trafico se guardara en un archivo ubicado en /traffic y su
nombre es icmpTraffic. Tcpdump estará a la espera de paquetes ICMP y los guardara en el archivo icmpTraffic. Desde la maquina B se ejecuta el comando: ping 192.168.2.25 –t –l 65500
Donde 192.168.2.25 es la dirección IP del Equipo A que obtuvo previamente, –t especifica que el ping se realizara por tiempo indefinido y –l 65500 el tamaño del paquete en bytes. En el Equipo A tcpdump esta capturando todo el tráfico de paquetes ICMP del Equipo B, en la figura 4.13 se muestra como tcpdump mediante la interfaz eth0 esta capturado los paquetes ICMP.
Figura 4.13 Tcpdump escuchando los paquetes icmp a través de la intrefaz eth0
Se detiene Tcpdump con las teclas crtl+c y aparece el resumen de paquetes capturados, como se muestra en la figura 4.14
Figura 4.14 Tcpdump resumen de paquetes capturados

68
Se capturaron 13169 paquetes de los cuales 14130 son del protocolo ICMP, que son los que interesan. Ya que el tráfico ICMP se guardo en el archivo /Traffic/icmpTraffic el tráfico se puede visualizar con el comando: #tcpdump –r /Traffic/icmpTraffic
Figura 4.15 Archivo donde se registro el tráfico del protocolo icmp
En la figura 4.15 se muestra el contenido del archivo donde se guardo el registro del tráfico ICMP. El resultado muestra la hora en que se recibió el paquete, la IP origen (Equipo B: 192.168.2.24) y la IP destino (Equipo A: 192.168.2.25) y el protocolo del paquete (icmp).
4.3 Elección de Herramienta Como se observo con las tres herramientas que se utilizaron (Wireshark, Tshark y Tcpdump) se puede capturar y registrar el tráfico de la red pero se elige una herramienta Tshark por las siguientes razones:
Es libre.
Existen versiones para Windows y para sistemas UNIX.
Permite hacer filtrado de paquetes.
Permite registrar el tráfico de la red en Archivos.
Consume menos memoria ya que no utiliza interfaz gráfica. Tshark se eligió sobre Wireshark principalmente por la interfaz gráfica, a pesar de que una interfaz gráfica es mucho más amigable y fácil de usar consume mas recursos del equipo que lo ejecuta, Tshark requiere más conocimientos para ejecutar los comandos, pero permite muchas más opciones de filtrado. Respecto a Tcpdump, la principal diferencia por la que se elije Tshark sobre Tcpdump es que Tcpdump no se ejecuta sobre sistemas Windows y Tshark sí lo hace.

69
CONCLUSIONES. Al finalizar esta investigación se puede concluir que se cumplió el objetivo de proponer herramientas que permiten monitorear una red. Se probaron tres herramientas de software libre que permiten monitorear y almacenar el tráfico de una red, y hacerlo tan especifico como los requerimientos del monitoreo lo necesiten. En cuanto a la metodología de investigación se puede concluir que debido a que en la actualidad en México no existe una documentación formal para análisis forense, es decir, solo existen recomendaciones de organismos internacionales la recopilación de información fue extensa y hubo que hacer un análisis detallado, para limitar lo que aplicaba para esta investigación. La principal problemática que se presento fue que la mayoría de la documentación habla sobre la Forensia en host y no en red, es por ello que hubo que hacer una análisis de que aplicaba para esta investigación y qué no, debido a que es un tema de investigación muy extenso se delimitó a una parte del monitoreo la cual es la captura de tráfico mediante herramientas de monitoreo. Para trabajos futuros se pretende tomar el trabajo actual y complementarlo con otras herramientas como firewalls e IDS para así tener un esquema de monitoreo completo. Con los conocimientos adquiridos actualmente, que es capturar el tráfico que circula en una red TCP/IP se podrá aplicar forensia sobre los paquetes capturados.

70
REFERENCIAS BIBLIOGRAFICAS
[1] Howard John D., Longstaff Thomas A. “A common language for
computer security incidents”. Págs. 6-11, 15-25.
[2] Bill Cheswick, Firewalls and Internet Security. Págs 159-166.
[3] Russell/Gangemi. Computer Security Basics, Págs 9, 10.
[4] Peter G. Neumann y Donn Parker, “A Summary of Computer Misuse
Techniques. Págs. 33-35.
[5] William Stallings. “Cryptography and Network Security”, Tercera Edición.
Pág. 7.
[6] Michael G. Noblett. (2000) Recovering and Examining Computer
Forensic Evidence. Disponible en:
http://www.fbi.gov/hq/lab/fsc/backissu/oct2000/computer.htm
[7] Cano Martines Jeimy José. Introducción a la informática forense.
Revista ACIS Junio de 2006 Disponible en:
http://www.acis.org.co/fileadmin/Revista_96/dos.pdf
[8] http://www.inteco.es/wikiAction/Seguridad/Observatorio/area_juridica/Es
nciclopedia_Juridica/Articulos_1/inf_forense.
[9] Canelada Oset Juan Manuel. “Curso de Verano 2004: ANÁLISIS
FORENSE DE SISTEMAS LINUX”, Pág. 3.
[10] Encyclopedia online Wikipedia: www.wikipedia.org.
[11] Tanenbaum, Andrew: Computer networks. Prentice Hall, 1996.
[12] Página de referencia,
http://www.xitimonitor.com/en-us/technicals/operating-systems-
february-2007/index-1-2-3-73.html?xtor=11
[13] Enciclopedia en línea Wikipedia, http://es.wikipedia.org/wiki/ICMP

71
GLOSARIO
Arquitectura de red: Es la forma en que una red se define por su topología, el
método de acceso a la red y los protocolos de comunicación de ésta.
Dato: Unidad básica de información, la cual por sí sola no representa utilidad o
sentido sino hasta que es interpretada.
Dirección IP: Un número que identifica de manera lógica a un dispositivo
(usualmente computadoras) dentro de una red que utilice el protocolo IP. Este número puede ser estático o dinámico.
Evidencia: En su sentido más amplio, la evidencia incluye a cualquier cosa que
es usada para determinar o demostrar la veracidad de una afirmación.
Firewall: Es un elemento de hardware o software que se utiliza en una red de
computadoras para controlar las comunicaciones, permitiéndolas o prohibiéndolas según las políticas de red que haya definido la organización responsable de la red.
Forensia: Se refiere a la aplicación de un amplio espectro de diversas ciencias
para responder preguntas de interés usualmente con el fin de ayudar al sistema legal. Abarca las metodologías teóricas o científicas aceptadas; así como las normas bajo las cuales los hechos (o resultados) son asociados con un acontecimiento, artefacto o evidencia mediante una ley existente.
Host (servidor): es una computadora que pertenece a una red; y a su vez
provee de servicios a otros equipos denominados clientes.
IDS. “Intrusion Detection System”: Sistema que trabaja junto con el firewall para ayudar a eliminar las amenazas de un atacante que trata de conseguir el acceso a una red. El IDS incluye el uso de logs, así como bloquear y enviar un mensaje de alerta al administrador de la red en caso de que se detecte tráfico sospechoso o malicioso.
IPS. “Intrusion Prevention System”: Sistema de prevención de intrusos:
ejerce el control de acceso en una red informática para proteger a los sistemas computacionales de ataques y abusos (establece políticas de seguridad para proteger el equipo o la red de un ataque).
IP. Internet Protocol (protocolo de internet): Es un protocolo no orientado a
conexión que usan dispositivos origen y destino para comunicar datos a través de una red de paquetes. Los datos son enviados por bloques de información conocidos como paquetes.
Información: Es un conjunto de datos, y que en su conjunto constituye un
mensaje sobre un determinado tema dentro de un contexto.
Informática. Es la disciplina que se encarga del tratamiento automático de la información mediante métodos, procesos, técnicas, desarrollo; así como su implementación.
Log: Se refiere al registro de eventos que sucedieron en un tiempo y lugar en

72
específico: es usado para averiguar quién, qué, cuándo, dónde, y por qué ocurrió un evento.
Memoria Caché: Es un sistema de almacenamiento de alta velocidad, puede
estar incluido en la memoria principal o ser una memoria independiente.
Paquete de red: Segmentos de información que son enviados mediante una
red; son conformados por una cabecera (que va de acuerdo al protocolo de nivel de red), así como por los datos.
Red: Es un conjunto de computadoras y dispositivos conectados entre sí. La red les permite a estos elementos la comunicación entre ellos así como compartir recursos e información
Tráfico de datos: Se refiere al ancho de banda que los usuarios de una red
consumen por el uso de la misma.
IEEE: Corresponde a las siglas de “Institute of Electrical and Electronics
Engineers”, el Instituto de Ingenieros Eléctricos y Electrónicos.
NIC. “Network Interface Card”, Tarjeta de Red: es un dispositivo que permite
compartir recursos entre dos o más equipos.