inteligencia artificial básica. mauricio paletta
TRANSCRIPT

DEDICATORIA
AGRADECIMIENTO
CONTENIDO
PRÓLOGO
CAPÍTULO 1Introducción a la Inteligencia Artificial
CAPÍTULO 2Los Sistemas basados en Conocimiento
CAPÍTULO 3La Adquisición y representación del Conocimiento
CAPÍTULO 4La simulación basada en Conocimiento
CAPÍTULO 5El Procesamiento del Lenguaje Natural
CAPÍTULO 6Las Redes Neurales Artificiales
CAPÍTULO 7Los Algoritmos Genéticos
CAPÍTULO 8Lenguaje de Programación para la Inteligencia Artificial
BIBLIOGRAFÍA

Inteligencia ArtificialBásica
Mauricio PalettaUniversidad Nacional Experiemental de Guayana

Inteligencia ArtificialBásica
Mauricio PalettaUniversidad Nacional Experiemental de Guayana

UNIVERSIDAD NACIONAL EXPERIMENTAL DE GUAYANAVICERRECTORADO ACADÉMICODEPARTAMENTO DE CIENCIA Y TECNOLOGíA_______________________________________________
©Inteligencia Artificial Básica_______________________________________________
©EditorFondo Editorial UNEGhttp://fondoeditorial.uneg.edu.ve
Cuidado de la edición Ing. Ana María Contreras Diseño, diagramación y montaje TSU. Emerson Guerrero Ibáñez
Diseño de portadaTSU. Emerson Guerrero Ibáñez
Coordinación editorialIng. Ana María Contreras
Reproducción DigitalCopiados Unidos, c.a.
Tiraje 100 ejemplares
Primera ediciónAño 2010
Hecho el Depósito de LeyDepósito LegalLF93320100011996ISBN978-980-6864-24-5
Todos los títulos publicados bajo el sello Fondo Editorial UNEG son arbitrados entre pares bajo el sistema doble ciego. Reservados todos los derechos.
El contenido de esta obra está protegido por la ley que establece penas de prisión y/o multa además de las correspondientes indemnizaciones por daños y perjuicios para quienes reproduzcan, plagien, distribuyan o comuniquen públicamente en todo una obra literaria, artística o científica, o su transformación, interpretación o ejecución artística fijada en cualquier tipo de soporte o comunicado a través de cualquier medio sin la respectiva autorización.

Índice
Dedicatoria
A la princesa de mi hogar, mi hija Andrea Fabianna que aún le falta mucho por recorrer en la vida; a mi esposa por su comprensión y
afecto; a mi madre por todo lo que me ha dado; a mi padre que ya no está con nosotros y a mis estudiantes que fueron mi principal
motivación e inspiración para realizar este libro.

Índice
Agradecimientos
Mi primera experiencia en el campo de la Inteligencia A rtificial la viví durante mi estadía laboral en la División de Proyectos
Especiales de la empresa Venezolana de Aluminio, C.A. (Venalum). Quiero agradecer a todos mis compañeros de trabajo que en esa oportunidad me brindaron apoyo y me ayudaron con sus
sugerencias, especialmente a los ingenieros Carlos Abaffy, Alberto Alarcón, Irene Torres y José Ramírez.
Deseo agradecer a todos aquellos estudiantes y colegas de la Universidad Nacional Experimental de Guayana que me ayudaron a recopilar y resumir todo el material que utilicé para realizar este libro, producto principalmente de las cátedras de Inteligencia Artificial que
dicto en esta magna casa de estudios.
Deseo agradecer también a todas aquellas personas por sus valiosas observaciones que resultaron de la revisión de este material,
principalmente al Dr. Daniel Bermúdez y al Dr. José Tarazona.
Un agradecimiento muy especial al Dr. Daniel Bermúdez por ser mi maestro en la laboriosa carrera académica de docente y motivarme
continuamente a realizar obras y proyectos como éste.

Índice
Dedictoria ................................................................................................................................Agradecimientos .....................................................................................................................Contenido ...............................................................................................................................Índice de Figuras ...................................................................................................................Índice de Tablas .....................................................................................................................Prólogo ....................................................................................................................................
CAPÍTULO 1. Introducción a la Inteligencia Artificial1.1. Conceptos básicos ……………………..................................................……………..1.2. Algo de historia ..........………………………….......................................…………….1.3. Técnicas de resolución de problemas …...........................................……………… 1.4. Agentes …………………………………….................................................…………. 1.5. Búsqueda y teoría de juegos ……..…………........…...................................………. 1.6. Resumen del Capítulo ………...…………….........…..................................…………
CAPÍTULO 2. Los Sistemas Basados en Conocimiento2.1. Conceptos básicos ……………........………………......................................……….2.2. La arquitectura interna ………………...……............................................…………..2.3. Una metodología de desarrollo …….....................................................…………….2.4. El manejo de incertidumbre ……………….………............................................…...2.5. Integración con sistemas de control …….........…………...................................…... 2.6. Ejemplos y aplicaciones ………………….............................................……………. 2.7. Resumen del Capítulo …………………...........…….....................................……….
CAPÍTULO 3. La Adquisición y Representación del Conocimiento3.1. El proceso de adquisición ………………….…............................................……….. 3.2. Técnicas de adquisición del conocimiento ……...........................................……….3.3. Técnicas para la documentación del conocimiento ..........................................…… 3.4. Esquemas de representación del conocimiento y sus mecanismos de inferencia ………....………………....……….........................................…………3.5. Resumen del Capítulo ……..…………………….........….....................................…. 3.6. Ejercicios …………………....……….……...............................................…………...
56791112
141621262938
41434655626674
778089
95105105
Contenido

Índice
CAPÍTULO 4. La Simulación Basada en Conocimiento4.1. La simulación tradicional ……………....….........….....................................…………4.2. Integrar IA y simulación …….........……….....……..….......................................……4.3. La Simulación Basada en Conocimiento ……..................................……..........……4.4. Resumen del Capítulo ……………………….................................................……….
CAPÍTULO 5. El Procesamiento de Lenguaje Natural5.1. Lenguaje natural y lenguaje formal …………............................................………….5.2. Procesamiento del lenguaje ………………….............................................…………5.3. La arquitectura básica del procesador ………............................................…………5.4. Aplicaciones …………………...………………................................................………5.5. Resumen del Capítulo ………………….................................................…………….
CAPÍTULO 6. Las Redes Neurales Artificiales6.1. El sistema neural humano ………………..............................................……………..6.2. Algo de historia ………………...…………..............................................…...………..6.3. El modelo neural artificial …………………..............................................…………...6.4. Clasificación ………………………………...............................................……………6.5. Los modelos conexionistas ……………….............................................…………….6.6. Ejemplos y aplicaciones ………………….............................................……………..6.7. Resumen del Capítulo …………………….................................................………….
CAPÍTULO 7.Los Algoritmos Genéticos7.1. Introducción ………….....…….…………….................................................…………7.2. Implementación ………………..……….…...............................................…………...7.3. Aplicaciones ………………………………...............................................……………7.4. Resumen del capítulo ……………………..............................................…………….
CAPÍTULO 8. Lenguajes de programación para la Inteligencia Artificial8.1. Prolog ………………...……..…………...............................................……………….8.2. Lisp …………………………………….................................................……………….8.3. OPS-5 …………………………………................................................……………….8.4. Resumen del capítulo …………………..............................................……………….8.5. Ejercicios ………………………………................................................………………
Bibliografía ………………..……………...…….................….............................………………Indice ……...………………..…………..………...............................................…………....….
108109110116
118120128129131
133144146153160178187
190191198206
209223248270270
277280

Índice
Figura 1.1 Evolución de los Sistemas Basados en Conocimiento …...............……….. Figura 1.2 Evolución de los Sistemas Inteligentes de Tutoría …….............….....…….. Figura 1.3 Evolución de la Robótica …….............………………………………….......... Figura 1.4 Evolución del Procesamiento de Lenguaje Natural …….........…………...... Figura 1.5 Un agente en interacción con el ambiente ………………….….................… Figura 1.6 Estado inicial y final del problema de rompecabezas de 8 piezas .............. Figura 1.7 Estado inicial y final del problema de las 8 reinas ……………...............….. Figura 1.8 Arbol de búsqueda para un caso del problema de los cubos …..............… Figura 1.9 Parte del árbol que representa el juego tres en línea ................................... Figura 2.1 Características de un área de aplicación …………...........……….........…… Figura 2.2 Automatización del conocimiento ………….………..............…........………. Figura 2.3 Arquitectura interna de un SBC ………….………..............…....................… Figura 2.4 Esquema metodológico en espiral ………....…...............………..............…. Figura 2.5 Esquema metodológico ………….………....……..........……….........……… Figura 2.6 Actividades de la identificación del problema ………….................……….... Figura 2.7 Actividades de la conceptualización …………...........……….........………… Figura 2.8 Actividades de la formalización ………….………..……........…..........……... Figura 2.9 Actividades de la construcción del prototipo …………..................……….… Figura 2.10 Actividades de la prueba y redefinición ………….…..........…….......………. Figura 2.11 Arquitectura general de un SBC-TR …………..........…….….….......………. Figura 2.12 Arquitectura de un sistema Blackboard ………….…..........…….......………. Figura 2.13 Areas y tipos de aplicación en función de la cantidad de sistemas .............. Figura 3.1 Secuencias de preguntas para una entrevista ……………..…..........……... Figura 3.2 Formas de trabajo con múltiples expertos …………………...............….….. Figura 3.3 Ejemplo de conocimiento representado en redes semánticas …...........….. Figura 3.4 Ejemplo de conocimiento representado en lógica de predicados de primer orden ……………………………………………..........……..........…… Figura 3.5 Ejemplo de conocimiento representado en reglas de producción ...........… Figura 3.6 Ejemplo de errores en la representación del conocimiento usando reglas de producción ……………………………..........………………........… Figura 3.7 Ejemplo de conocimiento representado en encuadres ……............………. igura 4.1 Ejemplo de Modelado Cualitativo ………………………..........….........……. Figura 4.2 Sistema secuencial integrado ………………...........…………….......………. Figura 4.3 Sistema paralelo integrado …………..........…………………….........……… Figura 4.4 Interfaz inteligente para simulación ……..................................…………......Figura 4.5 Arquitectura generalizada de un SSBC …....................................................Figura 5.1 Pasos que se dan cuando un orador comunica a un oyente la oración “el animal está muerto” ………………......………….........................
Índice de Figuras21222525263031313741434446464948515354636472848797
9899
100102111112113113114
119

Índice
Figura 5.2 Organización del proceso de interpretación semántica ……............……… Figura 5.3 Proceso de interpretación del discurso ………………………...............…… Figura 5.4 Arquitectura básica de un procesador de lenguaje natural …..…..........….. Figura 6.1 La neurona y sus partes ………………………………………................…... Figura 6.2 Sinapsis química ……………………………………........…….…..........……. Figura 6.3 Tipos de sinapsis ……………………………………........……...........……… Figura 6.4 Primer modelo de neurona artificial …………………...............…..………… Figura 6.5 Modelo genérico de neurona artificial ………………......……..........………. Figura 6.6 Funciones de activación discretas ………………………...............………… Figura 6.7 Funciones sigmoide y sigmoide desplazada ……………...…..........………. Figura 6.8 Función gaussiana ……………………………………………..........….......… Figura 6.9 Modelo genérico de RNA (propagación hacia adelante) …..........…...……. Figura 6.10 Modelo genérico de RNA (propagación hacia atrás) ………..............…….. Figura 6.11 Esquemas de funcionamiento de las RNAs …………………............…..…. Figura 6.12 Ejemplo de la separación lineal de un problema y un problema que no es linealmente separable …………………………………................……. Figura 6.13 Ejemplo de la curva del error en función de los pesos de las conexiones ……………………………………………………....................….. Figura 6.14 Ejemplo de una red hiperesférica de dos entradas ………...…..........…….. Figura 6.15 Ejemplo de una red simple de aprendizaje competitivo ……..............…….. Figura 6.16 Un caso particular del problema del agente viajero ……………...............… Figura 6.17 Estado estable de la red Hopfield en el problema del agente viajero para 5 ciudades …………………………………..………...............… Figura 6.18 Ejemplo de simulación de control de nivel en un tanque …….............……. Figura 6.19 Topología de la red Backpropagation para representar el problema del tanque ………………………………………………………..................…. Figura 6.20 Forma general de onda de una señal de electrocardiograma ..................... Figura 7.1 Ejemplo de una rueda de la ruleta ……………………………...............…… Figura 7.2 Juego de los seis peones …………………………………..........…….....….. Figura 7.3 Ejemplo de un grafo para mostrar el problema de coloración ..…..........…. Figura 8.1 Problema de las torres de hanoi ……………………..........………….....…... Figura 8.2 Representación del tablero para el juego tres en línea ………............……. Figura 8.3 Una solución al problema de las ocho reinas en el tablero de Ajedrez ………………………………………………………..........…..........… Figura 8.4 Tipos de dato en Lisp …………………………………..........…….........……. Figura 8.5 CONS es el inverso de CAR + CDR …………………..........…….......…….. Figura 8.6 Diagrama de bloques de la lista (A B C) ……………..........……......………. Figura 8.7 Diagrama de bloques de la lista (A B.C) ……………..........……......………. Figura 8.8 Diagrama de bloques de la definición de la función factorial ….............….. Figura 8.9 El valor del símbolo X se cambia de (A B C) a (D E F) ….......................….Figura 8.10 Ejemplo de un árbol binario …………………………………..................…… Figura 8.11 Ciclo de reconocimiento-acción ……………………......................................
124127129135137138144148150150151152153158
161
168175177180
181182
183186195202226220221
222226231242242243244247253

Índice
Índice de Tablas
1419-203347-4848-49546068-7281
85118159-160180
198-201217-218228231-232234261264-265266
Tabla 1.1 Definición de IA dada por varios autores ………........……........……….. Tabla 1.2 Historia de los acontecimientos en IA ….………………............……….. Tabla 1.3 Comparación de las estrategias de búsqueda a ciegas .….…..…......... Tabla 2.1 Cuestionario para la evaluación de proyectos ….……….......…...…….. Tabla 2.2 Análisis de resultados ….………………………………..........…....…….. Tabla 2.3 Participantes y productos de los segmentos metodológicos ….........…. Tabla 2.4 Escala de certeza usada por ADS ….………………………....….......…. Tabla 2.5 Ejemplos de SBCs ….……………………………………....……..........… Tabla 3.1 Comparación de las técnicas de adquisición ….………….............……. Tabla 3.2 Ejemplo de una entrevista entre un ingeniero de conocimiento y un experto ………………………………………………....……...........….. Tabla 5.1 Diferencias entre lenguaje formal y lenguaje natural ….…............……. Tabla 6.1 Modelos de RNA y su clasificación ….…………………..…..............….. Tabla 6.2 Aplicaciones de algunos modelos de RNA ….………….............……… Tabla 7.1 Ejemplos de aplicaciones y trabajos de investigación en algoritmos genéticos ….………………………………..……..............….. Tabla 8.1 Cláusulas predefinidas de Prolog estándar ….……….…....….......……. Tabla 8.2 Los predicados más importantes de Lisp ….……….……...…........…… Tabla 8.3 Algunas primitivas de Lisp para el manejo de listas …………............… Tabla 8.4 Algunas primitivas de Lisp para controlar el flujo de ejecución ............. Tabla 8.5 Predicados de OPS-5 …………………………………………............….. Tabla 8.6 Acciones de OPS-5 ………………………………………...…….........…. Tabla 8.7 Funciones de OPS-5 ……………………………………...……........……

Mauricio Paletta
12Índice
Desde que me inicié, varios años, en el campo de la investigación y enseñanza de la Inteli-gencia Artificial, no he podido salir de allí. No se si es por lo tanto que me ha llamado la atención o por lo realista de sus aplicaciones y la forma como resuelve problemas. Lo que sí está claro es que durante este tiempo he tenido la oportunidad de acumular gran cantidad de conocimientos producto de la experiencia que he ganado gracias a la realización de proyectos, a la instrucción de cursos y a la enseñanza de cátedras universitarias.
Pero lo que para mi ha sido más placentero es haber iniciado la enseñanza de la Inteligencia Artificial en la Universidad Nacional Experimental de Guayana y poner al alcance de los estudi-antes de Ingeniería en Informática estos conocimientos.
Este libro representa el compendio de una gran cantidad de material bibliográfico que se fue gestando gracias a las cátedras dictadas. Está orientado hacia todos aquellos estudiantes y pro-fesionales que desean incursionar en el mundo de la Inteligencia Artificial. Es un texto de ense-ñanza básica que facilita la apertura de las puertas hacia este mundo y no se requiere ningún conocimiento previo para su lectura.
El libro está estructurado de forma tal que cada capítulo se concentra en alguna de las partes fundamentales de la Inteligencia Artificial. Se empieza con una introducción en el capítulo 1 donde se abarcan los conceptos más importantes y una breve reseña histórica. Posteriormente se van desarrollando las técnicas de resolución de problemas más importantes: los Sistemas Basados en Conocimiento en los capítulos 2 y 3; la Simulación Basada en Conocimiento en el capítulo 4; el Procesamiento de Lenguaje Natural en el capítulo 5; las Redes Neurales Artificiales en el capítulo 6 y los Algoritmos Genéticos en el capítulo 7.
También he querido incorporar el material básico necesario para la comprensión y uso de tres lenguajes de programación muy importantes dentro del contexto de la Inteligencia Artificial, como lo son Prolog, Lisp y OPS-5. Esto se encuentra en el capítulo 8, último de este libro.
Mauricio Paletta
Prológo

CapítuloIntroducción a la Inteligencia Artificial
En este capítulo se presenta la Inteligencia Artificial (IA) bajo un entorno introductorio,
mostrando principalmente los conceptos básicos, un poco de su historia y las técnicas de resolución
de problemas más importantes.
1

Mauricio Paletta
14Índice
1.1. Conceptos básicos
Cada vez que me ha tocado definir la Inteligencia Artificial (IA) hago uso de los dos términos que se utilizan en el concepto y digo que IA es hacer artificial la inteligencia. Si bien esta defini-ción no llega al nivel de detalle adecuado, no está del todo errada ya que el objetivo de la IA es precisamente ese. Lo que sí debe quedar claro es que para entender lo que IA es, hay que saber qué es inteligencia y qué es hacer algo artificial.
Muchos autores han escrito varias definiciones sobre IA y todas ellas conllevan a la realización de elementos no naturales que tengan que ver con la inteligencia humana. La diferencia en estas definiciones está en la parte de la inteligencia humana que se quiere hacer artificial. Los autores Russell y Norving1 dividen las definiciones dadas a la IA (ver tabla 1.1) en cuatro categorías:
Actuar como los humanos. En este esquema se dice que algo tiene comportamiento in-1. teligente cuando es capaz de desarrollar tareas cognitivas que están al mismo nivel que los humanos2 .
Pensar como los humanos. Para saber si algo piensa como un humano, es importante 2. primero saber cómo los humanos pueden pensar. Este es el principio de los modelos cogni-tivos y su ciencia implícita.
Actuar racionalmente. Comprende el estudio de los agentes racionales, es decir, entes 3. capaces de percibir su ambiente y actuar sobre él en respuesta de lo percibido.
Pensar racionalmente. Basado en las leyes del pensamiento a la que se incluye el razo-4. namiento lógico y que datan desde la Grecia antigua3.
Tabla 1.1Definición de AI dad por varios autores
1 Artificial Intelligence: A modern approach; Stuart Russell and Peter Norving; Prentice Hall, 1995 (ISBN: 0-13-103805-2)2 El primero que propuso esta idea fue Alan Turing en 1950 el cual desarrolló un proceso para proveer una definición operativa de inteligen-cia. Este proceso se conoce con el nombre de Prueba de Turing y consiste en que un humano interrogue a una computadora (o cualquier otro elemento artificial) a través de una vía oculta (el humano ni sabe ni puede ver a quién está interrogando) y se pasa la prueba si el interrogador humano no es capaz de saber si el que está del otro lado es una máquina u otro humano.3 El filósofo griego Aristóteles fue uno de los primeros que intentó entender y explicar el proceso de razonamiento.
Pensar como los humanos
“El nuevo esfuerzo excitante de hacer computadoras pensantes (máquinas con mentes) en todo sentido”Haugeland, 1985.
“La automatización de actividades que asociamos con el pensamiento humano tales como la toma de decisión, la resolución de problemas, el apren-dizaje…”Bellman, 1978.
Actuar como los humanos
“El arte de crear máquinas que ejecutan funciones que requieren inteligencia…”Kurzweil, 1990
“El estudio de cómo hacer computación que hagan cosas en la forma y momento mejores que las personas” Rich & Knight, 1991.
Pensar racionalmente
“El estudio de las facultades mentales a través del uso de modelos computacionales”Charniak & McDermott, 1985.
“El estudio de la computación que hace posible la percep-ción, el razonamiento y la actuación”Winston, 1992.
Actuar racionalmente
Un campo de estudio que busca explicar y emular el comportamiento inteligente en términos de procesos computacionales”Schalkoff, 1990
“La rama de la ciencia de la computación que se encarga de la automatización del comportamiento inteligente”Luger & Stubblefield, 1993.

Inteligencia Artificial Básica
15Índice
Pensando en una generalización de las cuatro categorías anteriores y tomando un poco de cada una de estas definiciones, he formulado mi definición de IA como sigue:
Es la ciencia de emular procesos propios de la inteligencia humana tales como la per-cepción, el razonamiento y el aprendizaje, haciendo uso de modelos no naturales.
Lo primero que resalta en esta definición es ver a la IA como una ciencia, ya que ha demos-trado ser y es una doctrina de trabajo e investigación. Una de las palabras que mejor se asocian al concepto de IA es “emular”, que quiere decir copiar o imitar de forma tal de llegar a ser igual o mejor que la fuente. De hecho, la IA es posible gracias a que existe la inteligencia natural. Es importante estar claro que la IA no busca innovar o descubrir nuevos comportamientos sino hacer que los comportamientos propios naturales o humanos se puedan imitar de forma aceptable4 .
En lo que va del capítulo ha aparecido varias veces el concepto de inteligencia, humana por supuesto y no se ha presentado una definición. La mayoría de las veces la inteligencia se con-funde con otro concepto importante que es el de conocimiento. En realidad tienen mucho que ver el uno con el otro, pero ambos deben ser claramente diferenciados.
Se puede definir la inteligencia como la habilidad para manejar el conocimiento que se dispone para la toma de una decisión para la rápida solución de un problema.
Como se puede ver en esta definición, la inteligencia no es el conocimiento que se tiene, sino la habilidad para manejarlo. Cuando se comparan dos personas por su inteligencia, es decir, se dice que una persona es más inteligente que otra, no se quiere aludir a que una persona tiene más conocimiento que la otra sino que ha usado su conocimiento de una forma más hábil. Este comportamiento lo podemos ver por ejemplo, cuando dos alumnos que han sido alimentados con el mismo conocimiento y durante una prueba, uno de ellos termina exitosamente mucho antes que el otro que pudiera hasta incluso no terminar en el tiempo previsto. De hecho, es muy común en el ámbito académico la frase ¡…si es inteligente!.
Esto quiere decir que el principal objetivo de la IA no es buscar emular el conocimiento natural de alguien sino los procesos que permiten que el manejo de este conocimiento sea efectivo y efi-ciente. De hecho, los tres procesos más importantes de la inteligencia humana son la percepción, el razonamiento y el aprendizaje.
La percepción le permite al ser humano interactuar con el medio ambiente que lo rodea; el razonamiento es la búsqueda de una respuesta hacia las necesidades percibidas y el aprendi-zaje es la forma en la cual se puede reforzar o aumentar lo que se sabe (conocimiento) sobre el
4 Cuando me ha tocado dictar una cátedra de IA en la universidad, le digo a mis alumnos en son de broma, que los que trabajamos en IA somos unos “copiones” o “emuladores”.

Mauricio Paletta
16Índice
ambiente o la forma en la cual se puede actuar sobre él. Estas son las tres funciones básicas de un autómata racional.
El conocimiento es uno de los cuatro tipos de información5 que almacena todo lo que un ente sabe sobre su ambiente.
Para concluir con la definición de IA, un modelo no natural o artificial es aquél que es realizado por la mano del hombre mediante elementos mecánicos, electrónicos, eléctricos, etc., siendo el más importantes los medios computacionales.
Dado la gran cantidad de tópicos involucrados en la IA se pueden identificar otras ciencias en la cual ésta se fundamenta: la filosofía (desde el 428 a.C.), la matemática (desde el 800), la psicología (desde el 1879), la ingeniería de la computación (desde el 1940) y la lingüística (desde el 1957).
1.2. Algo de historia
Para hablar de historia de la IA hay que hablar de una etapa de prehistoria en la cual el hombre hacía IA sin que ésta existiera formalmente y una etapa que va desde su nacimiento formal hasta el desarrollo actual.
La prehistoria de la IA abarca desde los primeros tiempos de nuestra civilización hasta me-diados del siglo veinte. Los hechos más importantes a considerar en este período son aquellos que están relacionados con la construcción de autómatas6. Ya en la Grecia antigua encontramos obras donde se hace mención a autómatas . Por otro lado, la tradición judía creó el mito del “golem”, una figura hecha de arcilla a la que un rabino podía dar vida propia, convirtiéndola en criado.
Durante el siglo XVIII empezaron a aparecer mecanismos como los de Jacques de Vaucan-son, como por ejemplo el flautista que movía los dedos (1737) y el pato que era capaz de nadar, batir alas, comer y hasta expulsar excrementos simulados (1738).
En 1912 Torres Quevedo construyó un autómata para jugar el final de ajedrez de rey y torre contra rey. El escritor Capek, en su obra RUR (1920) presenta unos seres creados para realizar las tareas que el hombre no quiere hacer, que acaban siendo más poderosos que éste poniendo en peligro su existencia.
5 Los otros tres tipos de información son los datos, el texto y las imágenes. La informática o manejo artificial de la información ofrece herramien-tas automatizadas para el procesamiento de cada uno de ellos.6 Iliada, canto XVIII, V. 368-384 y 410-423; “…veinte trípodes que tenían ruedas de oro para que de propio impulso pudieran entrar donde los dioses se reunían y volver a casa…”; “…dos estatuas de oro semejantes a vivientes jóvenes, pues tenían inteligencia, voz y fuerza…”.

Inteligencia Artificial Básica
17Índice
Con la aparición de la computación y junto a la idea que se tenía de los autómatas, se dieron los primeros pasos para la formalización del razonamiento y las máquinas que estaban a punto de surgir tras la segunda guerra mundial7.
El último concepto importante a mencionar en esta etapa de prehistoria es el de cibernética y con él todos aquellos procesos propios que le son característicos, entre los cuales destacan la realimentación, el control y la autoorganización.
La gestación de la IA se da entre 1943 y 1956. El trabajo de Warren McCulloch y Walter Pitts8 en 1943 es el que generalmente se reconoce como el primero de IA realizado. En este trabajo se define el primer modelo de neurona artificial, que luego sirvió de base para la realización de otros trabajos como el de Donald Hebb9 en 1949 y los de Marvin Minsky y Dean Edmonds en 1951.
Fue en el año de 1956 cuando aparece por primera vez el nombre de Inteligencia Artificial, ya que ese fue el nombre que se le dió al grupo de investigación que para la fecha contaba con actividades en teoría de autómatas, redes neurales artificiales y el estudio de la inteligencia. Este pequeño grupo de personas10 se reunió gracias a la realización de la conferencia de Darmouth con el patrocinio de la Fundación Rockefeller. Uno de los temas que más se discutió en esta conferencia fue el trabajo sobre la lógica teórica, considerado como el primer programa de IA y usado para resolver problemas de búsqueda heurística.
Entre los años de 1952 y 1969 es cuando se puede apreciar el primer entusiasmo sobre IA y hay grandes expectativas por sus resultados. Hacia 1961 Allen Newell y Herbert Simon terminan (su comienzo se remonta desde 1957) su trabajo referido a la resolución de problemas genera-les (GPS). En este trabajo se imitan los protocolos humanos para resolver problemas aplicando técnicas de resolución codificada. En 1956 Arthur Samuel desarrolló un programa que estaba capacitado para aprender el juego de damas. Este programa fue mostrado en televisión causan-do gran impresión para la fecha. El investigador John MacCarthy del MIT diseñó en 1958 uno de los lenguajes de programación más importantes de IA. El objetivo de este lenguaje, llamado Lisp, es usar conocimiento para buscar solución a los problemas haciendo uso de la representación simbólica. Herbert Gelernter desarrolló en 1959 un programa para probar teoremas de geome-tría elemental y Slage comenzó la automatización de la integración simbólica con su programa “Saint” (llamado más tarde “Macsyma”).
Durante los años que pasaron entre 1966 y 1974 se desarrollaron varios trabajos que le dieron a la IA una dosis de realidad. Entre los más importantes destaca ELIZA 11, desarrollado en 1965 7 No es extraño que la aparición de las primeras máquinas electrónicas de cómputo fuera seguida inmediatamente por los intentos de aplicarlas a lo que hoy llamamos IA.8 A logical calculus of the ideas imminent in nervious activity. Trabajo de mucha importancia histórica en el área de las redes neurales artificiales.9 The organization of behavior. Con este trabajo se inician los procesos de investigación en el campo del aprendizaje automático. Como producto de este trabajo se tiene la muy conocida regla de aprendizaje de Hebb.10 Los nombre que más destacan por su importancia en la investigación de IA para la fecha son: John McCarthy, Marvin Minsky, Claude Shan-non, Nathaniel Rochester, Trenchard More, Arthur Samuel, Ray Solomonoff y Oliver Selfridge.11 Fue creado como un programa de psicología que simula las respuestas de un terapista en diálogo interactivo con un paciente. ELIZA causó

Mauricio Paletta
18Índice
por Weizenbaum. Se trata de un programa para el estudio de la comunicación hombre-máquina mediante el lenguaje natural interactivo. Otro de los trabajos importantes durante este período fue la definición del modelo neural conocido como “propagación hacia atrás” (backpropagation) desarrollado por Bryson y Ho en 1969.
A partir de 1969 se produjo la institucionalización de la comunidad científica que trabajaba en IA; tuvo lugar el primer congreso internacional de IA. En 1970 apareció el primer número de la revista Inteligencia Artificial, una importante fuente de publicación de los trabajos de investigación más destacados del área.
Los sistemas basados en conocimiento ganaron mucha fuerza entre los años 1969 y 1979. A este respecto se tienen los proyectos “Dendral”12 , “Mycin”13 y “Prospector”14 como los más im-portantes. Otro desarrollo importante en este período fue la concepción de los marcos (“frames”) como esquema de representación del conocimiento (M. Minsky - 1975). Entre 1971 y 1976 la Agencia de Investigación de Proyectos Avanzados para la Defensa de los Estados Unidos (DAR-PA) financió las investigaciones relacionadas con la capacidad de comprensión del lenguaje y el desarrollo de la teoría de la visión y del hardware para el procesamiento de imágenes.
Alain Colmerauer define, en 1975, el lenguaje de programación Prolog que representa uno de los lenguajes más importantes dentro de la investigación de IA ya que libera al programador de la necesidad de especificar los procedimientos de resolución de problemas. La aparición de lenguajes declarativos como éste fue un paso importante para la IA.
Para los años que van desde el 1980 hasta el 1988 se reconoce el ingreso definitivo de la IA en la industria. La prueba más significativa de esto es la puesta en operación comercial del XCON, un sistema capaz de almacenar y manejar el conocimiento necesario para la configuración de equipos DEC a gusto del cliente, desarrollado por J. McDermott en 1981. En ese mismo año se publica el primer volumen del Handbook de IA elaborado por A. Barr. Otro aspecto relevante en este período fue el llamado Proyecto de la Quinta Generación de Computadoras anunciado por los japoneses15.
gran impresión ya que las personas que mantenían un diálogo con el programa creían que hablaban con un psicólogo humano.12 Para la predicción de fórmulas estructurales en complejos orgánicos a partir de mediciones con espectrógrafos de masas, espectros de resonan-cia nuclear y análisis químico. Desarrollado en 1969 por Ed Feigenbaum, Bruce Buchanan y Joshua Lederberg.13 Para el diagnóstico y determinación de terapia en enfermedades infecciosas. Desarrollado en 1971 por Ed Feigenbaum, Bruce Buchanan y el Dr. Edward Shortliffe.14 Para la búsqueda de yacimientos de minerales y petróleo. Desarrollado por R. O. Duda y su grupo en 1979.15 Mediante la unión de la industria y gobierno japoneses se concibió el Instituto para la Nueva Generación de Tecnología de Computadoras (ICOT) dedicado a la investigación en las áreas de hardware, software y aplicaciones, con el fin de formular una teoría unificada para todo el campo de representación y procesamiento de la información. El grupo de hardware se concentra en una arquitectura caracterizada por la inferencia secuencial, inferencia en paralelo y el desarrollo de máquinas para base de datos afines. La investigación en el área de software está en la búsqueda de un lenguaje que sea el núcleo del proyecto (incluyendo sistema operativo, procesamiento de lenguaje natural y representación del conocimiento). El último grupo combina los resultados de los dos primeros en la labor sobre sistemas de gestión de bases de datos afines y sistemas basados en conocimiento. El mayor logro obtenido en los primeros cuatro años del proyecto fue una máquina basada en conocimiento llamada Delta (comprende un sistema de inferencia, un sistema de conocimiento, un sistema de software y un sistema para el desarrollo de prototipos de software).
Inteligencia Artificial Básica
19Índice
En la actualidad se aprecia un auge importante en el área de las redes neurales artificiales gracias a la gran cantidad de aplicaciones y trabajos de investigación realizados16 . Entre los tra-bajos más importantes que destacan en estos últimos años está “SOAR”, el mejor ejemplo de IA conocido de arquitectura completa para un agente17 . Las actividades recientes de investigación en IA se están integrando con otros temas de interés en la automatización computarizada, como lo son la orientación a objetos, la realidad virtual, el avance en la interfaz gráfica y los multime-dios. Algunos autores identifican esta fusión de conceptos como Computación Emergente.
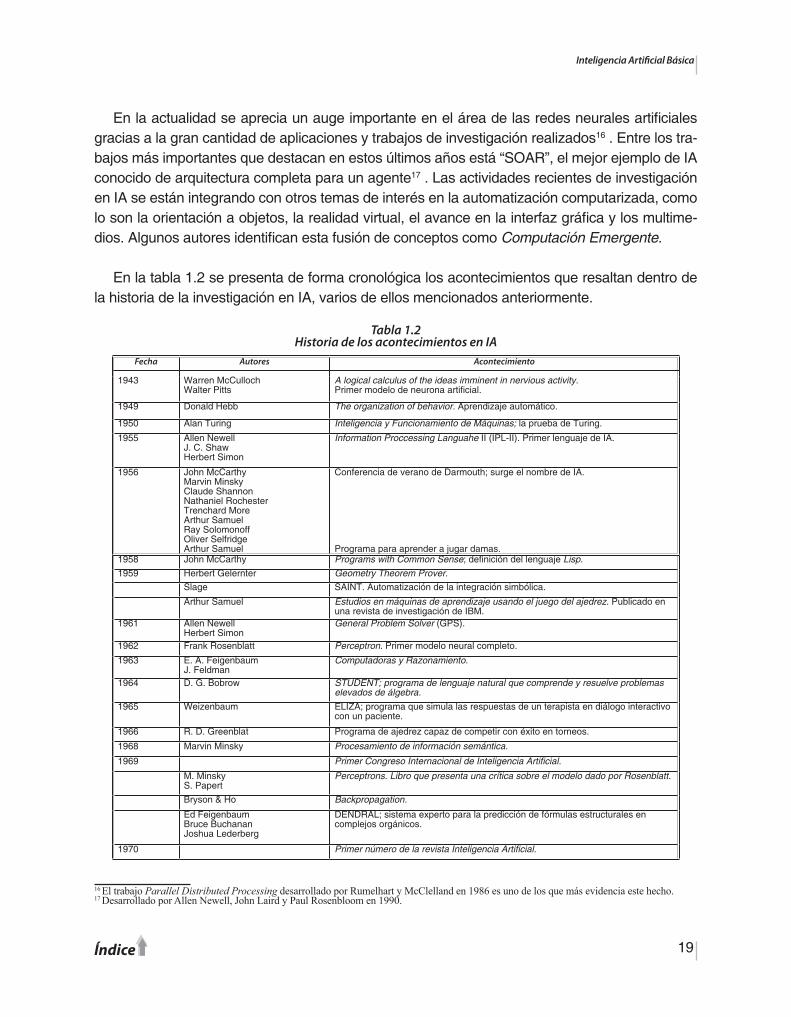
En la tabla 1.2 se presenta de forma cronológica los acontecimientos que resaltan dentro de la historia de la investigación en IA, varios de ellos mencionados anteriormente.
Tabla 1.2Historia de los acontecimientos en IA
16 El trabajo Parallel Distributed Processing desarrollado por Rumelhart y McClelland en 1986 es uno de los que más evidencia este hecho.17 Desarrollado por Allen Newell, John Laird y Paul Rosenbloom en 1990.
Fecha Autores Acontecimiento1958 John McCarthy Programs with Common Sense; definición del lenguaje Lisp.1959 Herbert Gelernter Geometry Theorem Prover.
Slage SAINT. Automatización de la integración simbólica.
Arthur Samuel Estudios en máquinas de aprendizaje usando el juego del ajedrez. Publicado en una revista de investigación de IBM.
1961 Allen NewellHerbert Simon
General Problem Solver (GPS).
1962 Frank Rosenblatt Perceptron. Primer modelo neural completo.
1963 E. A. FeigenbaumJ. Feldman
Computadoras y Razonamiento.
1964 D. G. Bobrow STUDENT; programa de lenguaje natural que comprende y resuelve problemas elevados de álgebra.
1965 Weizenbaum ELIZA; programa que simula las respuestas de un terapista en diálogo interactivo con un paciente.
1966 R. D. Greenblat Programa de ajedrez capaz de competir con éxito en torneos.
1968 Marvin Minsky Procesamiento de información semántica.
1969 Primer Congreso Internacional de Inteligencia Artificial.
M. MinskyS. Papert
Perceptrons. Libro que presenta una crítica sobre el modelo dado por Rosenblatt.
Bryson & Ho Backpropagation.
Ed FeigenbaumBruce BuchananJoshua Lederberg
DENDRAL; sistema experto para la predicción de fórmulas estructurales en complejos orgánicos.
1970 Primer número de la revista Inteligencia Artificial.
Fecha Autores Acontecimiento
1943 Warren McCulloch Walter Pitts
A logical calculus of the ideas imminent in nervious activity. Primer modelo de neurona artificial.
1949 Donald Hebb The organization of behavior. Aprendizaje automático.
1950 Alan Turing Inteligencia y Funcionamiento de Máquinas; la prueba de Turing.
1955 Allen NewellJ. C. ShawHerbert Simon
Information Proccessing Languahe II (IPL-II). Primer lenguaje de IA.
1956 John McCarthyMarvin MinskyClaude ShannonNathaniel RochesterTrenchard MoreArthur SamuelRay SolomonoffOliver SelfridgeArthur Samuel
Conferencia de verano de Darmouth; surge el nombre de IA.
Programa para aprender a jugar damas.

Mauricio Paletta
20Índice
Fecha Autores Acontecimiento
R. O. DudaP. E. Hart
Clasificación de modelos y análisis de escenas.
1975 Marvin Minsky Frames; esquema de representación del conocimiento.DARPA Programa de Comprensión de Imagen.
La Psicología de la visión con computadoras.
R. C. SchankR. Abelson
SAM; uso de la escritura en las representaciones de dependencia conceptual.
D. G. BobrowA. Collins
Representación e Inteligencia.
Alain Colmerauer Definición del lenguaje Prolog.
1976 D. B. Lenat AM; programa de aprendizaje que define y evalúa conceptos matemáticos con teoría de conjuntos y números.
R. Davis TEIRESIAS; usa metaniveles de conocimiento para entrar y actualizar bases de conocimiento usadas en sistemas expertos.
1979 R. O. Duda y grupo PROSPECTOR; sistema experto para la búsqueda de yacimientos de minerales y petróleo
1980 J. McDermott XCON; sistema experto para la configuración de equipos DEC.
1981 Proyecto de la Quinta Generación de Computadoras; anunciado por los japone-ses.
A. Barr Publicación del primer volumen del Handbook de IA.
1984 Conferencia Internacional sobre la Quinta Generación.
1986 Rumelhart & McClelland Parallel Distributed Proccessing.
1987 David Chapman Planificación usando estructuras simples.
Berliner HITECH; primer programa computarizado en derrotar a un maestro en ajedrez (Arnold Denker).
1988 Judea Pearl Razonamiento probabilístico en sistemas inteligentes.
1990 Allen NewellJohn LairdPaul Rosenbloom
SOAR; arquitectura completa para agente.
1992 Schwuttke MARVEL; sistema experto tiempo-real que monitorea los datos transmitidos por una nave espacial.
1993 Pomerleau Sistema robótico para conducir un vehículo con capacidad de aprendizaje.
1994 Zue PEGASUS; sistema de reservaciones de vuelos aéreos con interacción telefónica con los clientes.
Tabla 1.2 (Continuación)Historia de los acontecimientos en IA
Terry Winograd SHRDLU; parte de un proyecto de comprensión del lenguaje natural capaz de comprender y ejecutar correctamente órdenes dadas en inglés sobre un dominio específico.
P. H. Winston Descripciones de ejemplos de aprendizaje estructural; se describe el programa ARCHES que aprende de ejemplos.
1971 Ed FeigenbaumBruce BuchananEdward Shortliffe
MYCIN; sistema experto para el diagnóstico y determinación de terapia en enfer-medades infecciosas.
N. NilssonR. Fikes
STRIPS; planifica proyectos mediante la secuencia de operadores.
1972 SRI Internacional SHAKEY; robot móvil capaz de recibir instrucciones y planear acciones inteligen-tes para realizar tareas.
1973 William Woods LUNAR; sistema de recuperación de la información para un sistema gramatical de lenguaje natural. Usado por el Apolo 11 para evaluar los materiales traídos de la Luna.
J. D. MyersH. E. Pople
INTERNIST; sistema para el diagnóstico de las enfermedades humanas.
SUMEXAIM (Proyecto Experimental de IA en Medicina con Computadoras de la Universidad Médica de Stanford).
R. C. Schank Dependencia conceptual: una teoría para la comprensión del lenguaje conceptual.
R. C. SchankK. M. Colby
Modelos de razonamiento y lenguaje con computadoras.
Fecha Autores Acontecimiento

Inteligencia Artificial Básica
21Índice
1.3. Técnicas de resolución de problemas
La IA brinda un amplio conjunto de técnicas para la resolución de una gran variedad de pro-blemas. Desde el punto de vista de lo que se pretende emular, hay dos corrientes claramente identificadas:
Emulación estructural. Busca el logro de un resultado copiando la estructura del cerebro • humano.Emulación funcional. Busca el logro de un resultado emulando las características funcionales • del cerebro humano.
En los siguientes párrafos se presenta una breve definición de las técnicas más importantes de la IA, muchas de ellas desarrolladas en capítulos posteriores de este libro.
Sistemas Basados en Conocimiento. Son sistemas capaces de resolver o asistir en la re-solución de problemas que requieren de experiencia o inteligencia humana. Pertenecen al grupo de trabajo de la emulación funcional. En la figura 1.1 se muestra la evolución de estos sistemas los cuales seran desarrollados en detalle en el capítulo 2.
Figura 1.1Evolución de los Sistemas Basados en Conocimiento
Sistemas Inteligentes de Tutoría. Son sistemas que modelan el comportamiento de instruc-tores y participantes en un proceso de aprendizaje. Representan casos particulares de Sistemas Basados en Conocimiento, donde el conocimiento es suministrado por los instructores en función de lo que se enseña y a quien se enseña. Por supuesto, al igual que en el caso de los Sistemas Basados en Conocimiento, se orientan hacia la emulación estructural. La figura 1.2 muestra la evolución de estos sistemas.
Sistemas de procesamiento por lotes
Sistemas en línea
Sistemas de información gerencial
Sistemas de soporte de decisiones
Sistemas basados en conocimiento

Mauricio Paletta
22Índice
Figura 1.2Evolución de los Sistemas Inteligentes de Tutoría
En este tipo de sistemas se desarrollan ambientes interactivos con un énfasis en el aprendiza-je y el uso de elementos de multimedia (manejo de sonido, procesamiento de imágenes, etc.).
Los Sistemas de Tutoría se basan en el principio de “aprender haciendo” y le permiten al alumno no sólo nuevas formas de abordar el proceso de aprendizaje sino también explorar nuevo conocimiento de carácter más general que el ligado a un dominio específico. Hay cuatro esque-mas para realizar la enseñanza:
La pizarra electrónica. El papel del sistema es llevar registro de una forma estructurada, de 1. todas las actividades que el alumno va realizando para atacar un problema. Permite realzar el proceso de resolución con el objetivo de reflexionar sobre el conocimiento estratégico agregando una nueva perspectiva al aprendizaje.
En este esquema de trabajo, el alumno selecciona las reglas a aplicar de un menú de opcio-nes que se le ofrece y en pasos sucesivos. Un área de la pizarra llamada espacio de búsqueda refleja todo el proceso de exploración hasta llegar a la solución (se representa mediante una estructura de árbol). Otra zona de la pizarra llamada traza muestra el camino junto con las reglas aplicadas para llegar al resultado.
La idea fundamental de la pizarra electrónica es destacar la importancia del proceso para encontrar la solución. En todo momento el alumno puede reflexionar sobre su actividad, observar el camino que sigue, intentar compararlo con otras actividades, etc. Se trata, por lo tanto, de fo-mentar no sólo el aprender a resolver problemas en un dominio concreto sino mejorar al mismo tiempo la forma de aprender a partir del estudio crítico del espacio de búsqueda desarrollado, razonar el por qué se ha aplicado una cierta regla siguiendo un camino determinado, etc.
Las bases de conocimiento. El alumno describe en forma de reglas cómo resolver pro-2. blemas; el sistema permite comprobar mediante simulación si estas reglas expresan o no
Entrenamiento basadoen computadores
Instrucción basada encomputadores
Sistemas Inteligentesde Tutoría

Inteligencia Artificial Básica
23Índice
el comportamiento deseado. El objetivo principal es estimular la capacidad de plantear hipótesis, analizar datos, experimentar y aprender de los errores haciendo énfasis en el conocimiento estratégico.
La máquina diagnosticadora. Es una variante de la pizarra electrónica en la cual se le 3. agrega al sistema la capacidad de detección de errores concluyendo sobre las causas conceptuales que los originan. Este razonamiento es fundamental para realizar luego una corrección eficaz.
Se basa en la hipótesis del error estructural, que establece que una vez que se diagnostica el error, el sistema es capaz de predecir el comportamiento del alumno frente a un nuevo pro-blema. Este entorno ha sido utilizado para desarrollar la capacidad de análisis y las técnicas de diagnóstico de los estudiantes. Se trata en definitiva de dar un papel positivo al error, como punto principal de reflexión para mejorar el proceso de aprendizaje.
La asistencia inteligente4. 18. Los sistemas se estructuran en torno a un tutor automático que realizan las actividades de seguimiento, diagnóstico de errores, reparación y exposición de conceptos, que conforman el papel del profesor en una sesión de enseñanza perso-nalizada. El conocimiento y las diversas funciones del sistema se distribuyen en cuatro módulos:
Un experto capaz de resolver problemas en el dominio que se desea enseñar. Comprende la • representación del conocimiento sobre el dominio ya que para enseñar es necesario conocer a fondo el tema objeto de aprendizaje.
Un modelo del alumno que refleja su estado de aprendizaje. La tarea de enseñar requiere un • análisis continuo de la actividad del estudiante, en particular de la evaluación de sus respues-tas. El tutor no sólo debe detectar los errores, sino también establecer un diagnóstico que le permita tomar una iniciativa adecuada para corregirlos. La base de un buen diagnóstico es conocer lo que el estudiante sabe, por eso es que el tutor debe construir a lo largo de su interacción con el alumno un modelo del conocimiento que éste va adquiriendo en el proceso de aprendizaje19.
Un tutor conocedor de estrategias de enseñanza, diagnóstico y explicación. El experto es la • herramienta que el tutor usa para enseñar pero además hay un conocimiento pedagógico que es necesario incorporar para organizar el proceso de aprendizaje. Este conocimiento de-termina la forma en la cual se debe enseñar una determinada materia. El modelo pedagógico
18 Sistemas Inteligentes de Enseñanza Asistida (ICAI).19 Se presentan tres modelos: el modelo overlay ve al estudiante como un miniexperto en el sentido que su conocimiento es un subconjunto del conocimiento del tutor, que va creciendo a lo largo del aprendizaje; el modelo diferencial pone el énfasis en el análisis comparativo entre los resultados del experto y los obtenidos por el alumno; el modelo de grafo genético considera que es importante no sólo representar la situación final de cada sesión, sino que es también fundamental conocer cómo se han adquirido.

Mauricio Paletta
24Índice
se formaliza mediante los procedimientos de discurso para determinar la forma de explica-ción y por medio de las reglas de enseñanza para estimar el interés de un tema, seleccionar un procedimiento de discurso y mantener el modelo del alumno.
Una interfaz tutor-alumno que gestione el diálogo, preferiblemente en lenguaje natural.•
Robótica. Rama que se ocupa de la creación de máquinas que automatizan tareas principal-mente mecánicas que requieren de capacidad humana. Se orienta hacia la emulación estructu-ral. El término robot designa una importante variedad de ingenios provistos de capacidades muy diferentes y dirigidos a campos diversos de aplicación20.
Es importante mencionar que todos los sentidos corporales (gusto, olfato, tacto, vista y audi-ción) se pueden automatizar hoy en día. Es decir, actualmente es posible tener un ente artificial capaz de reconocer olores, sabores y texturas, que puede entender lo que oye y que puede reconocer lo que ve. El problema está en el dominio de elementos que puede reconocer en un momento dado, es decir, hacer que el comportamiento de los robots sea más inteligente.
Uno de los objetivos de investigación en esta área es el de poder modificar los planes de ac-ción en tiempo real o durante el trabajo e incorporar una reacción apropiada según el resultado. Esta estrategia de crear un plan con sentido a partir de capacidades elementales se puede usar también para crear planes nuevos. Por otro lado, se requiere atender también otras capacidades para lograr que un robot no sea monótono en su actividad. Para poder convertir éstas y otras capacidades más avanzadas en realidad, se están usando técnicas como las siguientes:
Solución de problemas en espacios tridimensionales y de geometría de objetos.• Optimización de procesos de movimiento y coordinación.• Tratamiento de señales sensoriales (datos visuales, electrónicas, etc.).• Sistemas de planificación que coordinan informaciones espaciales, temporales y sensoria • les, para realizar la tarea de forma óptima o para coordinar varios robots en una producción en serie.
Son muchas las áreas de aplicación de la robótica pero las más importantes son en la indus-tria, en los procesos de manufactura y en la investigación y exploración espacial21. La figura 1.3 muestra como ha evolucionado esta ciencia en el tiempo.
Desde el punto de vista industrial, los robots se pueden dividir en dos grandes familias: los móviles y los poliarticulados. Los robots móviles pueden ser rodantes y multípodos (locomoción basada en dispositivos que se asemejan a patas o piernas de animales). Los robots poliarticu-
20 La palabra robot procede del eslavo antiguo “robota”, que en checo significa esclavitud o servidumbre.21 Hoy en día hay proyectos de biología, genética, etc. orientados hacia la robótica. En una conferencia nacional americana de IA (AAAI) en la que tuve la oportunidad de asistir, se presentó un proyecto que trataba sobre un micro-robot-biológico que al inyectarse en las venas, era capaz de reconocer componentes de grasa adheridos en las mismas y devorarlos con el objetivo de reducir el riesgo de infarto.

Inteligencia Artificial Básica
25Índice
lados o también llamados robots industriales son aquellos que se reconocen por tener un brazo mecánico poliarticulado.
Figura 1.3Evolución de la Robótica
Según el nivel de complejidad de su sistema de control, el robot puede ser manipulador se-cuencial (sus movimientos están definidos en forma discreta), reproductor (mediante una técnica de guiado, se les enseña unos movimientos que se repiten invariablemente tantas veces como se les solicite), de control numérico (permiten la realización de trayectorias continuas, definidas por guiado o mediante un programa en lenguaje simbólico) e inteligente (tienen capacidades de percepción evolucionada de su entorno y la generación automática de planes de acción, apren-dizaje a partir de la propia experiencia, toma de decisiones, etc.).
Procesamiento de Lenguaje Natural. Son interfaces que permiten al usuario comunicarse con una máquina haciendo uso de su lenguaje habitual. Se orientan a la emulación funcional y su evolución se muestra en la figura 1.4. En sistemas de este tipo parte de la información a procesar está codificada en lenguaje natural y se aplican algoritmos para el análisis sintáctico, semántico y pragmático de la información y para la generación en lenguaje natural. Dentro de los campos de investigación más importantes de esta área están la comprensión de textos, la traducción auto-mática y la generación de resúmenes. El capítulo 5 desarrolla este tema en detalle.
Figura 1.4Evolución del Procesamiento de Lenguaje Natural
Robots mecánicos
Robots con componentes electrónicos
Robots programables
Robots de propósito múltiple
Robots inteligentes
Procesamiento poranálisis sintáctico
Procesamiento poranálisis semántico
comprensión dellenguaje

Mauricio Paletta
26Índice
Sistemas Neurales o Conexionistas. Esquemas de procesamiento paralelo distribuido que tratan de emular la forma en la cual las neuronas cerebrales se organizan para realizar su proce-samiento. Es evidente su influencia en el grupo de trabajo de la emulación estructural. Se estudia en el capítulo 6.
Algoritmos Genéticos. Sistemas inspirados en la evolución natural derivada de la genética, que simula la evolución de una población de cromosomas hasta llegar a un óptimo global me-diante operaciones locales de reproducción, modificación y selección. Se orientan en la emula-ción estructural y se estudian en detalle en el capítulo 7.
1.4. Agentes
Cualquier cosa que puede percibir su ambiente a través de sensores y actuar sobre el am-biente mediante elementos ejecutores se denomina un agente (figura 1.5). Cuando un agente tiene autonomía y es capaz de tomar decisiones sobre su forma de actuar para realizar las cosas bien, se dice que es un agente racional. Para reconocer que un ente es racional, hay que tomar en cuenta cuatro factores:
• Una medida que defina el grado en el cual el ente es exitoso en su forma de actuar,• Mantener registro de todo lo que el ente percibe,• Todo lo que el ente conoce sobre el ambiente y• El conjunto de acciones que el ente es capaz de ejecutar.
Figura 1.5Un agente en interacción con el ambiente
Esto nos lleva a la definición de un agente racional ideal:
“Para cada posible secuencia que se percibe, un agente racional ideal debe de ejecutar la acción que maximiza su medida de éxito, basado en la evidencia que se da con lo per-cibido y en el conocimiento que el agente tiene”.

Inteligencia Artificial Básica
27Índice
El ambiente lo constituyen todos los elementos externos al agente. Presenta las siguientes propiedades:
Si es o no accesible. Se dice que un ambiente es accesible si los sensores del agente son • capaces de percibir todos los aspectos que son relevantes para tomar una acción. El aje-drez, por ejemplo, representa un ambiente accesible ya que el jugador tiene toda la informa-ción necesaria a la vista para decidir el juego; el póker por el contrario, es un ambiente no accesible.
Si es o no determinístico. Un ambiente es determinístico si el estado siguiente es determina-• do completamente por las acciones seleccionadas y ejecutadas por el agente sobre el estado actual. Por ejemplo, un sistema de diagnóstico médico es no determinístico mientras que un sistema de análisis de imágenes si lo es.
Si es o no episódico. Un episodio consiste en la percepción-actuación de un agente. Si la • experiencia del agente se divide en episodios, se dice que el ambiente en el cual él actúa es episódico. Las acciones que se toman sobre un episodio no dependen de aquellas que se tomaron en los episodios anteriores. Como ejemplo se pueden citar un robot manipulador secuencial para un ambiente episódico y el control de una refinería como no episódico.
Si es estático o dinámico. Si el ambiente puede cambiar mientras el agente está deliberando, • se dice que el ambiente es dinámico. Un taxista, por ejemplo, se desenvuelve sobre un am-biente dinámico mientras que un jugador de ajedrez en un ambiente estático.
Si es discreto o continuo. Si hay un número limitado de percepciones distintas claramente • definidas, el ambiente es discreto. Un profesor interactivo de idiomas es discreto mientras que el control de una refinería es contínuo.
Dado que el comportamiento de un agente depende de la forma en la cual éste actúa en fun-ción de lo que percibe, se tiene la posibilidad de mantener una tabla que contenga las relaciones entre todas las acciones que se pueden hacer con respecto a todo lo que se puede percibir. A esta tabla se le llama un mapa de las secuencias de percepción a las acciones. Hay que conside-rar que para algunos agentes, esta información puede ser muy extensa y hasta infinita. Si sólo se requiere un mapa para definir a un agente, un mapa ideal define un agente ideal: “Al especificar las acciones que un agente debe ejecutar en respuesta de alguna percepción particular, se tiene un diseño para un agente ideal”.
Un ejemplo de mapas son las tablas de comportamiento de cualquier función. Todas las po-sibles combinaciones de valores de los parámetros de entrada de la función, determinan las

Mauricio Paletta
28Índice
secuencias que el agente percibe. Lo que retorna la función para cada secuencia de valores de entrada, es la respuesta del agente asociada a esa percepción.
Una forma de reducir el tamaño de los mapas es limitando el ambiente de percepción del agente. Los agentes deben resolver una variedad limitada de tareas en una variedad limitada de ambientes.
Uno de los aspectos importantes que hay que tomar en cuenta en la definición del agente ra-cional ideal es la parte que maneja el conocimiento. Si el agente es capaz de tomar las acciones en función de su conocimiento, en lugar de poner atención a lo que percibe, se dice que el agente tiene autonomía. Para que un agente sea autónomo, su comportamiento debe ser determinado por su propia experiencia.
Uno de los principales objetivos que busca la IA es diseñar el programa para los agentes, es decir, una función que implemente la transición del agente entre la percepción y la acción. Una consideración especial se debe tomar en cuenta con respecto a la arquitectura computacional en la cual se va a ejecutar el programa del agente, sobre todo en lo concerniente a los elementos de percepción y actuación. Una relación entre los agentes, sus programas y la arquitectura donde estos corren, se puede ver como:
agente = programa + arquitectura
Desde un punto de vista muy general, el algoritmo de la función que permite a un agente reci-bir lo que percibe y retornar una acción adecuada correspondiente, se ve como sigue (la memoria es la información que el agente tiene sobre el estado actual del ambiente):
- Cambiar la memoria en función de lo que se percibe. - Escoger la mejor acción en función del estado actual de la memoria. - Cambiar la memoria en función de la acción seleccionada. - Retornar la acción seleccionada.
Nótese que en este algoritmo, la parte más importante es la selección de la acción en función de lo que se conoce. Esto se traduce en un proceso de búsqueda sobre un espacio de posibles soluciones.
Algunas veces, conocer el estado actual del ambiente no es suficiente para decidir lo que hay que hacer, sobre todo en aquellos casos en los cuales el ambiente es continuo y no determinís-tico. Para estos casos, el agente requiere de información referida al objetivo que se persigue y

Inteligencia Artificial Básica
29Índice
en el cual se describen las situaciones deseables (por ejemplo, para que un taxista pueda tomar una decisión correcta, depende del lugar al cual el taxi tenga que ir y esto depende del destino del pasajero). Agentes de este tipo se pueden llamar “agentes basados en objetivos” y aunque parecen ser menos eficientes, son más flexibles.
Por otro lado, el objetivo por sí solo no es suficiente para demostrar un comportamiento de alta calidad (aunque el taxista sabe cual es su destino, hay muchas acciones que se pueden tomar para satisfacer este objetivo, algunas más rápidas, económicas, seguras que otras). Se debe hacer una comparación de los diferentes estados para medir el comportamiento más adecuado. Esto es lo que se conoce como la utilidad del agente. La utilidad es una función que relacio-na cada estado con un número real que describe su grado de adecuación. Una especificación completa de la función de utilidad permite llegar a decisiones racionales en aquellos casos en los cuales el objetivo no es suficiente, ya sea porque éste no sea único o porque haya conflictos entre ellos.
1.5. Búsqueda y teoría de juegos
El principio básico de resolución de problemas de IA se refiere al logro de un objetivo, en fun-ción de la información que se tiene disponible. Para satisfacer este objetivo, es necesario evaluar varias opciones y tomar la decisión de cuál realizar primero. Este proceso de evaluación y deci-sión sobre el espacio finito de posibles soluciones se conoce como búsqueda. Esta es la razón por la cual es importante para la IA, el estudio de algoritmos eficientes y efectivos de búsqueda.
Un algoritmo de búsqueda recibe las especificaciones de un problema como entrada y retorna una secuencia de acciones como solución. El algoritmo no solo debe garantizar una solución, sino debe poder dar la mejor respuesta en el menor tiempo posible. Se desea que un algoritmo o estrategia de búsqueda sea:
• Completo: cuando el algoritmo garantiza encontrar una solución.• Optimo en tiempo: cuánto se tarda en llegar a una solución.• Optimo en espacio: cuánta memoria se requiere para realizar la búsqueda.• Optimo en respuesta: si es capaz de obtener la mejor solución entre varias.
Para garantizar éxito en los procesos de búsqueda, es importante plantear correctamente el objetivo. El planteamiento del objetivo depende de la adecuada definición del problema. Un problema se puede definir como el conjunto de información que un agente usa para tomar la decisión de lo que tiene que hacer. La definición de un problema depende de la identificación de los siguientes componentes:

Mauricio Paletta
30Índice
el estado inicial del problema desde el punto de vista del agente;• el conjunto de operadores o acciones disponibles por el agente para actuar sobre el • problema;la prueba que permite al agente determinar que ha alcanzado una solución del objetivo; y • la función de costo que el agente puede aplicar para evaluar las opciones.•
Un estado del problema viene dado por la situación actual en la que se encuentra el elemento que representa al problema. Generar estados nuevos aplicando los operadores sobre el estado actual es lo que se conoce como “expandir el estado”. La selección de cuál estado expandir pri-mero es determinado por la estrategia de búsqueda.
Por ejemplo, en el problema del rompecabezas de 8 piezas que se muestra en la figura 1.6, el estado inicial es la localización inicial de las 8 piezas y del blanco (parte “a” de la figura); los ope-radores se refieren a movimientos de izquierda, derecha, hacia arriba o hacia abajo en dirección a la ubicación del blanco; y la prueba del objetivo se da cuando el estado del juego coincide con el objetivo final (parte “b” de la figura). Por ahora se asume que la función de costo establece que todos los movimientos cuestan lo mismo (1 por ejemplo).
Figura 1.6Estado inicial (a) y final (b) del problema de rompecabezas de 8 piezas
En el problema clásico de colocación de 8 reinas en un tablero de ajedrez, el estado inicial viene dado por el tablero vacío y las ocho reinas esperando ser colocadas (figura 1.7 a); el único operador posible es ubicar una reina en el tablero de forma tal que no esté al alcance de las ya colocadas; la prueba del objetivo viene dada cuando las 8 reinas están en el tablero ubicadas correctamente (figura 1.7 b) y la función de costo es nula ya que todas las soluciones son igual-mente válidas.
La estructura más adecuada para representar este tipo de problemas es el árbol22 . El estado inicial del problema es la raíz del árbol; los estados terminales son las hojas o terminaciones del árbol. Cada nodo na del árbol representa el estado del problema en un momento dado; puede 22 Un árbol es un grafo conexo y sin ciclos. Un grafo es un conjunto de nodos o vértices, alguno de los cuales están conectados por aristas.

Inteligencia Artificial Básica
31Índice
tener un nodo np (nodo padre) en el nivel superior que está conectado con na y que representa el nodo que fue expandido para llegar a na y, puede tener varios nodos nhi (nodos hijos) en el nivel inferior que representan los nodos que resultan después de expandir na.
Figura 1.7Estado inicial (a) y final (b) del problema de las 8 reinas
La figura 1.8 muestra el árbol que representa el problema de llevar unos cubos organizados de la forma como se indica en la raíz, a la nueva organización expresada en el terminal indicado.
Figura 1.8Arbol de búsqueda para un caso del problema de los cubos
Siendo un árbol la estructura para representar el problema, los algoritmos de búsqueda se convierten entonces en estrategias de búsqueda en árboles. El algoritmo general de este tipo de estrategia es como sigue:

Mauricio Paletta
32Índice
Inicializar el árbol usando el estado inicial del problema.• Repetir• Si no hay más nodos para expandir, entonces• retornar que la búsqueda no tuvo éxito.• Según la estrategia, seleccionar un nodo para su expansión.• Si el nodo seleccionado es un estado terminal o cumple con el objetivo, entonces• retornar la solución correspondiente.• sinoexpandir el nodo y agregar los nodos resultantes al árbol de búsqueda.•
Como se puede ver, el objetivo de la estrategia de búsqueda en árboles es ir seleccionando los nodos adecuados para su expansión. Expandir un nodo significa bajar de nivel en el árbol. Si se comienza desde el nodo raíz que está en la cima del árbol y se quiere llagar a un nodo terminal se está haciendo un recorrido del árbol. La idea en definitiva es entonces, encontrar en el árbol el camino más adecuado desde la raíz hasta un terminal (desde el inicio del problema hasta el objetivo).
Las técnicas de búsqueda en árboles se dividen en dos grupos. La búsqueda sin información o búsqueda a ciegas se refiere a aquellas estrategias que no tienen información sobre el número de pasos o el costo del camino entre el estado actual y el objetivo. La búsqueda con información o búsqueda heurística son estrategias que sí usan estas consideraciones.
Las estrategias de búsqueda a ciegas se diferencian por el orden en el cual son expandidos los nodos. Las más importantes son las siguientes:
Primero en amplitud (breadth-first). Primero se expande el nodo raíz, luego se expanden • todos los nodos generados por el raíz y así sucesivamente. La idea es expandir primero los nodos padres antes de sus hijos. Siempre se garantiza una solución, si existe al menos una, pero ésta puede no ser la mejor ya que se da siempre la primera que se consigue. Dadas las características de la estrategia, hay que preocuparse más por los requerimientos de memoria que por el tiempo de ejecución.
Costo uniforme (uniform cost). Es una variante del caso anterior en la cual se expande pri-• mero el nodo que sea menos costoso de expandir antes que los demás. La idea viene ya que primero en amplitud garantiza llegar al objetivo cuyo camino es el más corto, pero no necesariamente el menos costoso. El costo viene dado por la aplicación de las acciones para ejecutar la expansión. Esta estrategia garantiza la expansión más económica.

Inteligencia Artificial Básica
33Índice
Primero en profundidad (depth-first): Se expande siempre uno de los nodos del nivel más • profundo del árbol, siguiendo un orden definido (izquierda, derecha, etc.). Esta estrategia presenta un costo modesto de memoria ya que sólo requiere almacenar un camino simple desde la raíz del árbol. En aquellos problemas que tienen muchas soluciones, esta estrategia puede ser más rápida que primero en amplitud. Uno de los problemas de primero en profun-didad es tratar con árboles muy profundos que hacen que el algoritmo se pierda o caiga en lazos infinitos.
Profundidad limitada (depth-limited). Es una variante del caso anterior en el cual se define • un límite de que tan profundo puede llegar el algoritmo en el árbol. El objetivo es adaptar la estrategia de primero en profundidad para árboles muy profundos. Si el límite es igual a la profundidad del estado final más bajo entonces se minimiza el costo en tiempo y espacio. Uno de los problemas de esta estrategia es seleccionar adecuadamente el límite.
Profundidad iterativa (iterative deepening). Trata de escoger el mejor límite de profundidad • de entre todos los límites posibles. Combina los beneficios de primero en amplitud y primero en profundidad, es decir, es óptimo y completo al igual que primero en amplitud y modesto en el uso de espacio al igual que primero en profundidad. El orden en el cual se expanden los estados es similar a la forma en la cual lo hace primero en profundidad con la diferencia de que algunos estados se expanden muchas veces.
Bidireccional (bidirectional). La idea es realizar una búsqueda simultánea hacia adelante • partiendo del estado inicial y hacia atrás partiendo del objetivo y detenerse cuando los dos procesos se interceptan en la mitad. Es ideal para aquellos problemas cuyo árbol sea bien distribuido entre todas sus ramas.
La tabla 1.3 muestra una comparación de las estrategias en función del tiempo de ejecución, el espacio de memoria que ocupan y si son o no óptimos y completos. b es el factor de ramifica-ción del árbol, d es la profundidad de la solución, m es la profundidad máxima y l es el límite de la profundidad23.
Tabla 1.3Comparación de las estrategias de búsqueda a ciegas
23 Artificial Intelligence: A Modern Approach; Stuart Russel & Peter Norving; Prentice-Nall, Inc., 1995; sección 3.5; pág. 81.
Criterio Primero en amplitud
Costo uniforme Primero en pro-fundidad
Profundidad limitada
Profundidad iterativa
Bidireccio-nal
Tiempo bd bd bm bl bd b(d / 2)
Espacio bd bd b * m b * l b * d b(d / 2)
¿Optimo? Si Si No No Si Si
¿Completo? Si Si No Si l Si Si

Mauricio Paletta
34Índice
En muchos problemas es importante llegar a la solución a través del camino que resulte me-nos costoso o también llamado camino óptimo. Una forma de reducir el costo de la búsqueda es usar información que ayuda a decidir la transición más adecuada para cada paso. Información de este tipo recibe el nombre de información heurística y la búsqueda que hace uso de esta in-formación se llama pues, búsqueda heurística24.
La búsqueda heurística es también llamada una búsqueda con conocimiento. El costo de expandir un nodo puede ser estimado pero no puede ser determinado con exactitud. La función que permite calcular este costo se denomina función heurística y se denota h(n) para el nodo n. Por ejemplo, para el problema del rompecabezas de 8 piezas (figura1.6), dos posibles funciones heurísticas son:
h1: número de piezas colocadas en mala posición, (h1(0) = 7).
h2: suma de las distancias de las piezas a sus posiciones finales, (h2(0) = 2 + 2 + 2 + 2 + 1 + 0 + 2 + 1 = 12).
Alguna de las estrategias de búsqueda heurísticas son las siguientes:
El mejor primero (best-first). El nodo que mejor se acerca al objetivo (que sea menos costoso) • es el que se expande primero. Por supuesto, el costo estimado para alcanzar el objetivo se minimiza.
Control irrevocable. Se basa en el criterio de que se tiene la suficiente información o conoci-• miento local del problema para poder elegir la mejor acción aplicable al estado actual. Esta estrategia también es aplicable cuando se sabe el hecho de que al decidir sobre una acción equivocada no impedirá la subsiguiente aplicación de una acción correcta. El único efecto negativo de las equivocaciones es el de alargar los tiempos de búsqueda.
Retroceso en camino único. Es la estrategia más sencilla de implementar y la que requiere • menos memoria ya que sólo se guarda el camino de búsqueda en proceso de expansión. En cada ciclo se considera la posibilidad de volver atrás y escoger un estado de dicho camino distinto del actual. Esta estrategia es parecida a la de primero en profundidad con la diferen-cia que se le han agregado restricciones al algoritmo25.
24 Heurística viene de la palabra griega “heuriskein” que significa encontrar o descubrir. De esta palabra nace la expresión “heureka” que da a entender “lo encontré”.25 Una de las implementaciones conocidas de estrategia de retroceso en camino único es “backtracking”, usado por el lenguaje de programación Prolog como máquina de búsqueda.

Inteligencia Artificial Básica
35Índice
Las estrategias de búsqueda heurística son la base para la implementación de los motores de inferencia propios de los Sistemas de Producción y Sistemas Basados en Conocimiento. Estos temas se tratarán en capítulos posteriores de este libro.
Teoría de Juegos. Los juegos ocupan un role importante en las facultades intelectuales de los hombres y representan una de las áreas más antiguas de la IA. Lo que hace que los juegos sean realmente diferentes es que usualmente son muy duros de resolver y utilizan un lenguaje que involucra la lógica de las relaciones estratégicas. La finalidad de la teoría de juegos es inves-tigar de qué modo los individuos se deben relacionar cuando sus intereses entran en conflicto. Fue creada por Von Neumann y Morgenstern en su libro “The Theory of Games and Economic Behavior”, publicado en 1944.
Un juego se desarrolla cada vez que dos o más individuos se relacionan entre sí. Por ejemplo, conducir un vehículo en una calle urbana y transitada, pujar en una subasta, negociar un contrato colectivo, etc. Desde un punto de vista matemático, la definición formal de un juego es bastante simple, pero no es tan simple entender lo que la definición formal significa.
Desde el punto de vista en la cual se maneja la información disponible, los juegos pueden ser de información perfecta e imperfecta. Tres en línea y el ajedrez son dos ejemplos de juegos de información perfecta porque cada vez que le toca el turno a un jugador, éste sabe todo lo que tiene que saber sobre lo que ha ocurrido hasta ahora en el juego. El póquer, por el contrario, es un juego de información imperfecta ya que cuando hay que decidirse por una apuesta no se sabe las manos del resto de los jugadores, aunque a cualquiera le gustaría saberlo.
Por otro lado, un juego puede depender o no del azar para realizar las jugadas. El parchís es un juego con jugadas de azar ya que lo que un jugador puede hacer cuando le toca jugar depen-de del lanzamiento de un dado.
Un juego se puede definir como un tipo de problema de búsqueda con los siguientes componentes:
El estado inicial que incluye las posiciones de comienzo sobre el entorno donde se va a de-• sarrollar el juego y una indicación de los movimientos posibles.Un conjunto de operadores que definen los movimientos legales.• Una prueba final que determina cuando el juego finalizó, es decir, que se ha llegado a alguno • de sus estados terminales.Una función de utilidad que retorna un valor numérico e indica el resultado del juego.•
El objetivo de un juego es llegar a un estado terminal y la estrategia es llegar a este estado antes que cualquier otro. Las reglas deben decirnos quién puede hacer qué, cuándo lo puede hacer y cuánto gana cada uno cuando el juega ha terminado. La estructura más adecuada que se usa para representar esta información es el árbol.

Mauricio Paletta
36Índice
La primera jugada o estado inicial del juego se identifica en el nodo raíz del árbol. Una partida consiste de una cadena conexa de aristas que empiezan en la raíz del árbol y terminan, si el juego es finito, en un nodo terminal. Los nodos terminales del árbol corresponden a los posibles resultados del juego.
Los nodos del árbol deben representar cada una de las posibles jugadas durante el juego. Los segmentos o arcos que salen de un nodo representan las posibles acciones a realizar sobre la jugada indicada en ese nodo que permiten llegar hasta el otro nodo del árbol conectado con tal arista. A cada nodo no terminal se le debe asignar el nombre o identificación del jugador de forma tal de saber quién eligió la jugada. En los juegos que contienen jugadas de azar, estas situacio-nes se tratan asignando jugadas a un jugador mítico llamado “azar”. Cada acción en una jugada de “azar” se marca con la probabilidad con la que será elegida.
La función de evaluación retorna un estimado de la utilidad del juego esperado sobre una posición o nodo dado. El desempeño de un programa de juego es extremadamente dependiente de la calidad de su función de evaluación.
A todos los nodos terminales se le debe colocar una marca que indique las consecuencias que tiene para cada jugador, que el juego termine con el resultado correspondiente a ese nodo terminal.
La figura 1.9 muestra una parte del árbol que representa el juego de tres en línea. A pesar de lo simple que es el juego, su árbol es muy grande para mostrarlo completo. Nótese que sólo se muestran tres nodos terminales. Las letras G, P y E en los nodos terminales indican que el jugador I gana, pierde o empata respectivamente (por razones obvias no se indica lo que ocurre con el jugador II).
Una posible función de evaluación f sobre un nodo p es la expresión que determina el número de filas, columnas y diagonales libres dejadas por el jugador I menos el número de filas, colum-nas y diagonales libres dejadas por el jugador II. A medida que f(p) sea mayor será una “buena jugada” para I y “mala jugada” para II. Por ejemplo, si p es el nodo más a la izquierda del tercer nivel del árbol de la figura 1.9, f(p) = 5 - 4 = 1.
Uno de los aspectos más importantes que trata la teoría de juegos es el estudio de las estra-tegias. Una estrategia pura es un plan que especifica las acciones a tomar para cada uno de los nodos en los que el jugador debe tomar una decisión, si el nodo es alcanzado. Cuando se tienen varias estrategias puras y el jugador debe seleccionar aleatoriamente alguna de ellas, se dice que la estrategia es mixta. Si todos los jugadores de un juego seleccionan una estrategia pura y se mantienen fieles a ella, entonces el desarrollo del juego sin jugadas de azar queda totalmente determinado. La definición de una estrategia en juegos con información incompleta tiene que ser

Inteligencia Artificial Básica
37Índice
modificada y sólo se requiere especificar las acciones a tomar para cada conjunto de información sobre el que correspondería a un jugador optar por una opción en el supuesto de que alcanzara este conjunto de información.
Figura 1.9Parte del árbol que representa el juego tres en línea
Uno de los métodos que plantea la teoría de juegos como estrategia para llegar al resultado deseado, es el que se conoce con el nombre de “inducción hacia atrás” y que fue dado por Zer-melo en 1912 (también se le llama algoritmo de Zermelo) el cual lo utilizó para analizar el ajedrez. Este método plantea empezar por el final del juego (desde un nodo terminal del árbol) y marchar hacia atrás hasta su principio (raíz del árbol). Esta misma idea es lo que esencialmente se hace en la investigación operativa con el nombre de “programación dinámica”.
Muchas de las cosas que se han planteado hasta aquí se refiere a juegos estrictamente com-petitivos, es decir en aquellos en los cuales lo que es bueno para un jugador es malo para los demás. Pero la teoría de juegos también estudia los juegos en equipo en donde los intereses de los jugadores coinciden y por ende, lo que es bueno para un jugador también es bueno para los demás. Los juegos en equipo de información perfecta se pueden analizar como juegos de un

Mauricio Paletta
38Índice
solo jugador y por ende no son muy interesantes, pero cuando la información es imperfecta, los juegos en equipo pueden ser realmente muy interesantes. Por ejemplo, su estudio nos puede enseñar cosas acerca de las maneras óptimas de comunicar la información dentro de organiza-ciones cuyos miembros comparten un mismo objetivo.
1.6. Resumen del capítulo
Inteligencia Artificial (IA) es la ciencia que busca emular procesos que son propios de la inte-ligencia humana haciendo uso de modelos no naturales o artificiales. Los principales procesos a emular son la percepción, el razonamiento y el aprendizaje. La inteligencia es la habilidad de manejar el conocimiento que se tiene para la toma de decisiones en la rápida solución de pro-blemas. El conocimiento es uno de los cuatro tipos de información que almacena todo lo que un ente sabe sobre su ambiente.
La historia de la IA se resume en dos etapas: una prehistoria en la cual se hacía IA sin que ésta existiera formalmente y una etapa que va desde su nacimiento formal hasta el desarrollo actual.
Las técnicas de resolución de problemas de la IA se agrupan en dos corrientes: la emulación estructural que busca el logro de un resultado copiando la estructura del cerebro humano y, la emulación funcional que busca el logro de un resultado emulando las características funcionales del cerebro. Los Sistemas Basados en Conocimiento son sistemas capaces de resolver o asistir en la resolución de problemas que requieren de experiencia o inteligencia humana. Los Sistemas Inteligentes de Tutoría son sistemas que modelan el comportamiento de instructores y partici-pantes en un proceso de aprendizaje. La Robótica se ocupa de la creación de máquinas que automatizan tareas principalmente mecánicas que requieren de capacidad humana. El Procesa-miento de Lenguaje Natural representa interfaces que permiten al usuario comunicarse con una máquina haciendo uso de su lenguaje habitual. Los Sistemas Neuronales son esquemas de pro-cesamiento paralelo distribuido que tratan de emular la forma en la cual las neuronas cerebrales se organizan para realizar su procesamiento. Los Algoritmos Genéticos son sistemas inspirados en la evolución natural derivada de la genética.
Un agente es cualquier cosa que puede percibir su ambiente a través sensores y actuar sobre él mediante elementos ejecutores. Un agente racional tiene autonomía y es capaz de tomar deci-siones sobre su forma de actuar. Un agente racional ideal debe ejecutar la acción que maximiza su medida de éxito, basado en la evidencia y el conocimiento que se tiene.
El principio básico de resolución de problemas de IA se refiere a un proceso de evaluación y decisión sobre un espacio finito de posibles soluciones o búsqueda. Las técnicas de búsqueda

Inteligencia Artificial Básica
39Índice
sobre árboles se dividen en dos grupos: la búsqueda sin información o a ciegas y la búsqueda con información o heurística. Algunas de las estrategias de búsqueda a ciegas son: primero en amplitud, costo uniforme, primero en profundidad, profundidad limitada, profundidad iterativa y bidireccional. Algunas de las estrategias de búsqueda heurística son: el mejor primero, control irrevocable y retroceso en camino único.
Los juegos ocupan un role importante en las facultades intelectuales de los hombres y repre-sentan una de las áreas más antiguas de la IA. Usualmente son muy duros de resolver y utilizan un lenguaje que involucra la lógica de las relaciones estratégicas. La finalidad de la teoría de juegos es investigar de qué modo los individuos se deben relacionar cuando sus intereses entran en conflicto.

CapítuloLos Sistemas Basados en Conocimiento
Este capítulo se dedica al estudio de los Sistemas Basados en Conocimiento (SBC) desde
sus conceptos hasta el uso de técnicas avanzadas como el manejo de incertidumbre y la integración
con control.
2

Inteligencia Artificial Básica
41Índice
2.1. Conceptos básicos
Un Sistema Basado en Conocimiento (SBC) se puede definir como una técnica de resolución de problemas de la IA que:
Incorpora conocimiento estructurado sobre un dominio específico (conocimiento).• Busca resolver efectiva y eficientemente un conjunto de problemas específicos en ese domi-• nio (funcionalidad).Provee un conjunto de interfaces para diversos tipos de usuarios (presentación).•
La base de este concepto se dio como resultado de la convergencia de líneas clásicas en el desarrollo de IA, la heurística y la deducción automática. Las heurísticas son reglas no determi-nísticas para hacer conjeturas acertadas que normalmente proporcionan resultados acertados1 y la deducción automática se basa en la mecanización de las teorías de interpretación de fórmulas lógicas. Durante los primeros años de la década de los setenta se plantean los sistemas de re-glas de producción como paradigma general para la resolución de problemas2. Los elementos de este tipo de sistemas se plasman posteriormente en el lenguaje OPS3.
La figura 2.1 muestra la situación básica que se debe presentar en un área de aplicación para incorporar un SBC. En primer lugar debe existir una fuente de conocimiento, que no sólo sabe operar sobre el área, sino que además enriquece su conocimiento aprendiendo sobre el compor-tamiento de la misma. La fuente de conocimiento es utilizada por un conjunto de usuarios que trabajan sobre el área de aplicación. Estos usuarios acuden a la fuente de conocimiento para re-solver ciertos problemas que ellos no están capacitados para solucionar. Problemas como estos son los que precisamente comprueban la existencia de alguien o algo que posee conocimiento para buscar una solución.
Figura 2.1Características de un área de aplicación
1 Estos resultados pueden no ser garantizados. Anteriormente a un sistema basado en heurísticas se le daba la concepción de un “sistema inteli-gente”.2 En el trabajo Human problem solving realizado por Newell y Simon.3 Operating Production Systems fue la base para los lenguajes OPS-83 y OPS-5, este último se detalla en el capítulo 5 de este libro.

Mauricio Paletta
42Índice
La necesidad de usar la fuente de conocimiento para resolver problemas se da por la falta de algoritmos o de teorías completas o lo complicado de las mismas para llegar a la solución. La fuente de conocimiento encuentra con frecuencia una solución al problema, gracias a la infor-mación que tiene sobre el dominio de la aplicación y, la mayoría de las veces, a su experiencia. Cuando se ha observado durante largo tiempo que este conocimiento que se usa para resolver problemas es válido y haya una cantidad potencial de usuarios entonces se puede pensar en la factibilidad de hacer un SBC.
En definitiva, el objetivo que se persigue es emular la fuente de conocimiento. Esto se puede ver en la figura 2.1 si se reemplaza la fuente de conocimiento por una herramienta automatiza-da o SBC. Aunque se habla de reemplazo, lo que se quiere al final no es substituir la fuente de conocimiento, sino descargar su trabajo rutinario y por ende, solucionar los problemas de una forma más rápida4.
A medida que el número de fuentes de conocimiento sea pequeño y que el número de usua-rios sea grande, tenemos una situación de embudo para buscar respuestas a problemas, que puede demorar su atención o apresurar la deducción y que conlleva a graves problemas en el área de aplicación. Cuando la labor de la fuente de conocimiento no está tan sobrecargada se pueden reducir las decisiones erróneas y se aceleran los procesos de toma de decisión. Hay que recordar que existe la posibilidad de tener copias del SBC.
Nótese la importancia que tienen los usuarios dentro de este contexto. No tiene sentido pen-sar en realizar un SBC si no existen usuarios. En un área de aplicación donde no hay usuarios y por ende el trabajo es realizado por la misma fuente de conocimiento no se justifica realizar un SBC a menos que las actividades concernientes para la realización del trabajo sean automatiza-das también.
Todo lo que posee conocimiento puede ser una fuente de conocimiento, un humano, un ma-terial bibliográfico, una base de datos, etc. Una de las fuentes de conocimiento más comunes y de más fácil adquisición son los expertos:
Una persona X es un experto en el área Y, si X ha acumulado, consciente o incons-cientemente a través de su experiencia, un conjunto de heurísticas que permiten que se observen comportamientos exitosos en la solución de problemas en el área Y.
Cuando la fuente de conocimiento en un SBC está constituida principalmente por la experien-cia de un experto, se dice que el SBC es un Sistema Experto.
4 Es muy importante tener claro este punto. La mayoría de las veces, cuando el conocimiento viene de un humano, éste tiene la concepción de que el SBC va a sustituirlo de sus actividades cotidianas. La idea no es quitar uno y poner otro sino agregar más para agilizar el tráfico de la actividad “resolver problemas” .

Inteligencia Artificial Básica
43Índice
La automatización del conocimiento, es decir, el proceso mediante el cual se lleva el conoci-miento de una fuente de conocimiento a la computadora, se logra mediante la ejecución de dos actividades (figura 2.2):
La adquisición del conocimiento. El conocimiento de la fuente de conocimiento es extraído y • documentado (se lleva a un formato predeterminado).La representación del conocimiento. El conocimiento documentado se expresa mediante • un esquema establecido por la herramienta de software usada, para formar una base de conocimiento.
Figura 2.2Automatización del conocimiento
El desarrollo de un SBC es guiado principalmente por un equipo formado por tres componen-tes básicos:
La fuente de conocimiento que suministra el conocimiento.• El • ingeniero de conocimiento que automatiza el manejo del conocimiento5.El usuario que determina las necesidades de operación del sistema.•
2.2. La arquitectura interna
Un SBC tiene dos componentes básicos que siempre deben existir: la base de conocimiento y el motor de inferencia. La base de conocimiento son los hechos, hipótesis, creencias y heurís-ticas que bajo una representación específica contiene el dominio del conocimiento; soporta la función de almacenamiento de la información de un SBC. Dado que el conocimiento se almacena haciendo uso de un esquema de representación formal y específico y dada su importancia en el sistema, el acceso a este conocimiento tiene que ser controlado. Este es el trabajo del motor o máquina de inferencia.
5 Las funciones que realiza el ingeniero de conocimiento se presentan en el capítulo 3 donde se estudia en detalle los procesos de adquisición y representación del conocimiento.

Mauricio Paletta
44Índice
Según la definición de SBC dada anteriormente, la base de conocimiento y el motor de infe-rencia satisfacen los dos primeros criterios referidos por esta definición: conocimiento y funciona-lidad respectivamente. Si bien la presentación no se requiere para que el SBC sea operativo, es recomendable la incorporación de elementos de interfaz para que junto al motor de inferencia y a la base de conocimiento conformen la arquitectura básica del SBC.
La inferencia es una línea de razonamiento. Corresponde a un proceso de búsqueda de la solución según un conjunto de evidencias dadas. Esa búsqueda se realiza por supuesto, en la base de conocimiento. La máquina de inferencia es entonces, el proceso que permite emular el razonamiento humano, haciendo uso del conocimiento representado en la base de conocimiento que emula las características de almacenamiento del conocimiento en el cerebro.
Todo motor de inferencia presenta dos componentes:
Un • mecanismo de control para buscar y encontrar una solución a un problema dado.La • estrategia de control o conjunto de condiciones impuestas al mecanismo de control para optimizar la búsqueda.
La figura 2.3 contiene la arquitectura completa de un SBC. Nótese que en la parte central están los componentes básicos formando la línea vertebral del sistema. Nótese también que el único que puede acceder a la base de conocimiento es el motor de inferencia.
Figura 2.3Arquitectura interna de un SBC

Inteligencia Artificial Básica
45Índice
El sistema de explicación permite conocer cada uno de los pasos que se siguieron para obte-ner la solución propuesta. Una de las características propias de un SBC es que puede explicar la forma en la cuál llegó a la conclusión. Esto es posible gracias a que los esquemas de repre-sentación del conocimiento permiten formar trazas en la línea de razonamiento. La explicación se da simplemente mostrando estas trazas al usuario de una forma que éste las entienda y en respuesta a preguntas del tipo “¿por qué …?” y “¿cómo …?”. Por esta razón este módulo se integra con los componentes de interfaz.
Otra forma en la cual el SBC se “presenta” al usuario es haciendo uso de una interfaz de lenguaje natural, sobre todo en sistemas expertos. Está claro que la forma en la cual el usuario interactúa con un experto es a través del lenguaje. Por lo tanto, lo más aceptado por el usuario es una esquema de comunicación con el SBC que no se aleje de la forma como éste lo hace con la fuente de conocimiento6.
Uno de los procesos humanos más importantes que la IA busca emular es el aprendizaje. Aunque los SBC no aprenden por definición, es posible añadir esta función incorporando un mó-dulo de “adquisición automática del conocimiento”. Este módulo tiene integración con la fuente de conocimiento que no sólo suministra el conocimiento nuevo sino que además permite validar o corregir el existente7.
Otro componente importante para el aprendizaje son las estrategias a seguir para realizar esta función. Estas estrategias determinan la forma en la cual el conocimiento nuevo se tiene que incorporar a la base de conocimiento sin causar impacto al usuario. Parte de este impacto es prevenir la posible ocurrencia de errores en el conocimiento como las inconsistencias y re-dundancias que degradan los tiempos de búsqueda y por ende de respuesta. Este cambio en el SBC es totalmente transparente al usuario y para realizar la actividad no se requiere sacar de operación al sistema.
En la figura 2.3 se aprecia la posibilidad de integrar el SBC con otros sistemas, específicamen-te en aquellos casos en los cuales la base de datos es fuente de conocimiento para el problema tratado por el SBC. En este caso, el módulo de adquisición del conocimiento debe suministrar procesos de adquisición automática de conocimiento a partir de bases de datos8.
6 El procesamiento de lenguaje natural es otra de las técnicas de resolución de problemas importante de la IA. Este tema se desarrolla en detalle en el capítulo 6 de este libro.7 Hay que tener presente que el conocimiento no es finito. Una vez que se haya concebido una base de conocimiento con el conocimiento sobre el dominio del problema existente hasta el momento, pueden ocurrir problemas en la cual la fuente de conocimiento no sabe actuar y mucho menos el SBC. Es ideal entonces un proceso de adquisición que le permita a la base de conocimiento del SBC crecer. Por esta razón se dice que el desarrollo de un SBC es incremental que el producto no deja de ser nunca un prototipo.8 Muchos investigadores han realizado trabajos en esta área. La mayoría de los casos se hace uso de algoritmos de entropía que analizan la repetición de ocurrencias dentro de la data. Existe una gran variedad de aplicaciones que usan las bases de datos para obtener conocimiento, sobre toda en aquellas grandes empresas donde se maneja un gran volumen de datos (la información del personal y las finanzas por ejemplo).

Mauricio Paletta
46Índice
2.3. Una metodología de desarrollo
Por definición, el desarrollo de SBCs es incremental. Se orienta a la definición y progresiva refinación de prototipos, que pasan de ser elementos de demostración a constituirse en módulos operativos. El planteamiento metodológico más adecuado para cubrir estas necesidades de de-sarrollo es aquél que une las ventajas de los esquemas en espiral y el de prototipos rápidos9. La figura 2.4 presenta un diagrama genérico sobre este planteamiento.
Figura 2.4Esquema metodológico en espiral
La metodología que aquí se expone es iterativa, usando un enfoque de seis segmentos, tal como se muestra en la figura 2.5. Se parte de la realización de un estudio de factibilidad del pro-yecto (E), para luego entrar en un ciclo que parte de una identificación del problema (I), en la cual se definen el alcance y objetivos del sistema. Luego se pasa a una conceptualización (C) pro-funda del dominio del problema, a la formalización (F) del sistema y la construcción del prototipo (P) que refleje la solución buscada, el cual es revisado exhaustivamente mediante una prueba y redefinición (R).
Figura 2.5Esquema metodológico
9 Información detallada de estos esquemas metodológicos se puede consultar en textos de Ingeniería de Software.

Inteligencia Artificial Básica
47Índice
Existen ciclos externos e internos de iteración. Los ciclos internos se realizan dentro de cada segmento hasta obtener los productos específicos de cada uno de ellos. Los ciclos externos se realizan entre los diferentes segmentos y su objetivo es refinar los prototipos10. Cada prototipo prueba el concepto desarrollado y justifica la ejecución del resto de los ciclos hasta la total inte-gración del sistema al ambiente final de ejecución.
Estudio de Factibilidad. La identificación de problemas adecuados para ser solucionados mediante SBCs es una labor delicada. Los problemas seleccionados deben ser lo suficiente-mente valiosos para justificar el uso de estas técnicas y además se debe haber descartado una solución mediante métodos tradicionales.
Para la evaluación potencial del desarrollo de un SBC se deben tomar en cuenta cuatro pun-tos básicos:
La justificación económica,1. El nivel de experiencia en el problema,2. Las características del problema y3. Las características políticas y organizacionales.4.
La tabla 2.1 muestra un cuestionario que puede ser utilizado para la evaluación de proyectos potenciales y servir de base para realizar el informe de factibilidad. La tabla 2.2 analiza los re-sultados que se pueden derivar de este cuestionario en función de tres posibles conclusiones sobre cada uno de los ítems.
Tabla 2.1Cuestionario para la evaluación de proyectos
10 La experiencia ha demostrado que la duración de los ciclos externos se incremente a medida que se avance en el desarrollo del prototipo, par-tiendo de un ciclo rápido para la producción del primer prototipo. Este esquema de trabajo se conoce con el nombre de Prototipos Rápidos.
A. Justificación
¿ Existe la necesidad de difundir el conocimiento de una o más personas talentosas o entrenadas especialmente ?1. ¿ La experiencia se puede perder si no es capturada ?2. ¿ La captura del conocimiento representa ahorros o ingresos significativos ?3. ¿ Existe la necesidad de aumentar la eficiencia en la toma de decisiones mediante una mayor consistencia y celeri-4. dad ?¿ Es costoso entrenar a personas para manejar el problema ?5. ¿ La automatización del manejo del conocimiento puede ayudar a futuros desarrollos ?6.
B. Experiencia
¿ Existen fuentes de conocimiento disponibles en el área del problema ?1. ¿ La experiencia a usar es precisa y correcta ?2. ¿ Existen pocas personas claves con conocimiento especializado y experiencia empleando demasiado tiempo ayu-3. dando a otros ?¿ Las fuentes de conocimiento son capaces de explicar su metodología con claridad ?4. ¿ En el caso de que las fuentes de conocimiento sean expertos, poseen éstos el tiempo suficiente para dedicarle al 5. proyecto ?¿ Si existen varios expertos, existe una máxima autoridad en el área ?6.

Mauricio Paletta
48Índice
Tabla 2.1 (Continuación)Cuestionario para la evaluación de proyectos
La realización de cuestionarios que permitan determinar la factibilidad de un posible proyecto se deben enfocar en las siguientes características básicas:
1) Posibilidad del desarrollo:La actividad no requiere sentido común.• Existe al menos una fuente de conocimiento.• La actividad no es muy difícil.• La actividad es entendida.•
2) Apropiado el desarrollo:La actividad requiere manipulación simbólica.• La actividad requiere soluciones heurísticas.• La actividad tiene un valor práctico y no es muy fácil.• La actividad es de un tamaño manejable.•
3) Justificación del desarrollo:La solución tiene un gran beneficio.• Se está perdiendo el conocimiento.• El conocimiento es escaso.• Se requiere el conocimiento en muchos sitios (posiblemente hostiles).•
Tabla 2.2Análisis de resultados
C. Problema
¿ La resolución del problema requiere principalmente razonamiento basado en experiencia ?1. ¿ Para llegar a una solución del problema no es necesario un razonamiento guiado por sentido común ?2. ¿ El problema requiere poco tiempo de la fuente de conocimiento para solucionarlo y explicarlo (menos de dos horas) 3. ?¿ Los usuarios necesitan evaluar todas las posibilidades antes de resolver el problema ?4.
D. Organización
¿ Existe compromiso gerencial para el desarrollo del proyecto ?1. ¿ Los usuarios están comprometidos a usar el sistema ?2. ¿ La introducción de una herramienta automatizada causará repercusiones políticas y de control derivadas de su uso, 3. contenido o recomendaciones ?¿ El proyecto va a manejar una necesidad del negocio importante y real ?4.
A. Justificación
Bueno Una excelente oportunidad para un SBC.Regular Puede ser una buena oportunidad si el costo no es muy alto.Malo No es justificable el desarrollo.
B. Experiencia
Bueno La experiencia es la adecuada para el proyecto.Regular La experiencia existente puede no ser la más adecuada.Malo No existe suficiente experiencia.
C. Problema
Bueno El problema puede ser soportado por un SBC.Regular Algunos aspectos del problema pueden ser difíciles.Malo El problema puede ser difícil de soportar con un SBC.

Inteligencia Artificial Básica
49Índice
Tabla 2.2 (Continuación)Análisis de resultados
El producto que se debe realizar y entregar en este segmento es un documento que resuma el estudio de factibilidad del proyecto, basado en los cuatro ítems anteriores.
Identificación del problema. El principal objetivo de este segmento es identificar las fuentes de conocimiento que se van a usar, las cuales deben satisfacer con las siguientes características:
tener conocimiento que sea reconocido por los demás,• tener disponibilidad de tiempo o ser accesible para el desarrollo y• tener un conocimiento práctico del problema.•
El número de fuentes de conocimiento debe ser el mínimo necesario para cubrir el dominio del problema y se debe realizar una selección adecuada de los mismos para tener éxito en el futuro desarrollo11.
El otro objetivo de este segmento es preparar al ingeniero de conocimiento para el proceso de adquisición. Para ello, éste se familiariza con el área del problema y le va a permitir manejar de forma aceptable todos los conceptos implícitos en el dominio del problema. Una forma de hacer esto es realizar un documento de definición del problema que explica detalladamente la situación actual y aquella que se plantea con la incorporación del sistema. Este documento es otro de los productos de este segmento.
Figura 2.6Actividades de la identificación del problema
11 En el caso de que la fuente de conocimiento esté constituida por expertos, es recomendable que no se identifiquen más de dos, sobre todo en estos primeros pasos ya que se puede derivar en largas discusiones entre ellos que dilatan considerablemente el desarrollo.
D. Organización
Bueno La organización soportará el proyecto.Regular El éxito total puede ser difícil.Malo Los obstáculos organizativos impedirán el éxito del proyecto.

Mauricio Paletta
50Índice
La figura 2.6 muestra las etapas o tareas de este segmento. En esta se puede ver que luego de haber realizado la identificación de las fuentes de conocimiento, se pueden realizar en pa-ralelo las actividades que conllevan a la realización del informe de definición del problema y la identificación de los casos de estudio, ambos mediante la conducción de sesiones y la revisión de la documentación existente sobre el dominio del problema. Los casos de estudio permiten di-vidir el problema en partes claramente separables con el fin de pensar en un futuro desarrollo por módulos o la posibilidad de fraccionar la base de conocimiento en partes. Su objetivo principal es enumerar las situaciones problema y establecer una guía para el proceso de adquisición.
Conceptualización. Este segmento tiene dos objetivos, iniciar el proceso de adquisición del conocimiento y desarrollar el prototipo de demostración, tal como se puede ver en la figura 2.7. Durante el proceso de adquisición, el conocimiento debe documentarse haciendo uso de formas o técnicas apropiadas para plasmar el contenido de la base de conocimiento12.
Figura 2.7Actividades de la conceptualización
El prototipo de demostración consiste en una implementación funcional que permita simular la forma en la cual el prototipo puede interactuar con su entorno . La lógica involucrada en este prototipo es mínima y consiste principalmente en mapas de pantalla y reportes. Este segmento fi-naliza con la validación de este prototipo que debe ser completamente aceptado por los usuarios y entes involucrados antes de poder iniciar el siguiente segmento.
Formalización. La adquisición del conocimiento continúa en este segmento haciendo uso del prototipo de demostración. Pero el objetivo principal de este segmento es formalizar o definir las estructuras apropiadas para automatizar el conocimiento, basándose en las características propias del problema tales como su metodología de resolución, los mecanismos de recolección de evidencia y las estructuras del conocimiento. Ver figura 2.8.12 En el capítulo 3 referido a la adquisición y representación del conocimiento se presentan alguna de las técnicas más importantes para la docu-mentación del conocimiento.

Inteligencia Artificial Básica
51Índice
A pesar de que este segmento puede ser extremadamente breve y directo, sobre todo en aquellos casos en los cuales no es posible realizar una selección entre varias herramientas, su existencia es imprescindible para poder anticipar las consideraciones que se deben tomar en cuenta antes de iniciar la construcción del prototipo.
Una de las consideraciones que se tienen que tomar en cuenta para seleccionar una herra-mienta adecuada para el problema, es la facilidad de interfaz que éstas posean en función de las necesidades planteadas. La idea es condicionar lo menos posible la implementación del prototipo a las posibles limitaciones técnicas que pueda tener la herramienta que se utilice. Fruto de este segmento es la definición precisa de:
formatos de representación del conocimiento,• mecanismos de inferencia• métodos de explicación, diálogo e interfaz y• arquitectura técnica general.•
Existen varias alternativas para automatizar el conocimiento. El principal factor a considerar es la naturalidad con que el esquema a seleccionar es capaz de representar las estructuras del co-nocimiento y las ventajas de manipulación que se brinden. En la actualidad es común encontrar representaciones estructuradas que permiten dividir el conocimiento en porciones representati-vas de las situaciones encontradas en la realidad. De estos métodos, el paradigma de abstrac-ción de objetos es el más usado por su versatilidad, alto nivel de abstracción y expresividad13.
Figura 2.8Actividades de la formalización
Seleccionar un único mecanismo de inferencia para todo el sistema es difícil, si consideramos que en la realidad los humanos hacen uso de varios métodos, algunos de ellos no conocidos aún o difícilmente representables (como por ejemplo el sentido común). Por otra parte, durante los
13 En este campo se centran las herramientas Orientadas a Objetos. Algunas de las más importantes son Nexpert Object, Level-5 Object, ADS, KEE, Goldworks II, etc.

Mauricio Paletta
52Índice
procesos heurísticos se realizan cómputos y recuperaciones de información muy determinísticos o algoritmos, que no deben de ser forzados hacia métodos heurísticos sino ser invocados en el momento adecuado. El mecanismo de inferencia que se vaya a usar debe permitir estas llama-das a métodos externos asociadas a condiciones que se vayan presentando.
A pesar de que los métodos de explicación, diálogo e interfaz son procesos que se definen en detalle en la construcción del prototipo, están estrechamente asociados con los mecanismos de inferencia y la representación del conocimiento usados. Los métodos de explicación son muy im-portantes en aquellos sistemas que interactúan con humanos con el fin de justificar conclusiones alcanzadas o explicar los métodos utilizados14.
Los esquemas de diálogo tienen que poder simular en secuencia, contenido y formato las interacciones entre los usuarios y las fuentes de conocimiento para la resolución de problemas que estos últimos realizan sobre los primeros. El usuario debe sentir que está realmente interac-tuando con una fuente de conocimiento y no verse forzado a preprocesar sus dudas o problemas a fin de adecuarse al sistema. Es recomendable que los esquemas de diálogo tengan facilidades gráficas a fin de resumir información textual y guiar al usuario a una resolución más rápida del problema.
En muchos casos es necesario tomar en cuenta la interfaz o integración del SBC con otros sistemas u aplicaciones existentes, ya que esto puede aumentar la utilidad, actualización y efica-cia del SBC. Es común encontrar facilidades de acceso a bases de datos y procesos externos en casi todas las herramientas para la construcción de SBCs, más aún con los desarrollos recientes de estándares en el manejo de los datos y la tecnología de los sistemas abiertos. La arquitectura técnica general no es más que una definición de las herramientas técnicas en la cual se debe construir o se basa cada elemento del sistema y las interrelaciones entre cada una de ellas15.
Para la conducción de este segmento es conveniente realizar pruebas de implementación en las herramientas potenciales. No debemos olvidar que el objetivo no es construir aún el prototi-po de prueba sino probar que las estructuras que estamos definiendo sean adecuadas para el problema.
Construcción del prototipo. El prototipo de demostración realizado en el segmento de con-ceptualización dista mucho de lo que puede definirse como el producto de desarrollo, carece de los elementos fundamentales (las interfaces y los procesos de adquisición de datos) que son definidos en este segmento y concretados en un prototipo de prueba.
14 Esta característica es altamente necesaria en sistemas con fines tutoriales o didácticos.15 A pesar de las bondades de los productos disponibles, la mayoría de las veces se cuenta con una herramienta para el desarrollo del prototipo y otras para el desarrollo de las interfaces necesarias.

Inteligencia Artificial Básica
53Índice
Figura 2.9Actividades de la construcción del prototipo
El desarrollo de un SBC tiene dos líneas paralelas de trabajo, una para el manejo del cono-cimiento y otra para las actividades que conciernen a la interfaz. El manejo del conocimiento comprende la realización de los proceso de adquisición y representación del conocimiento para obtener como producto final la base de conocimiento del sistema. El desarrollo de la interfaz nos lleva a la obtención de las facilidades gráficas o el procesamiento de lenguaje natural para usar el sistema. La combinación de los productos obtenidos en ambas líneas de desarrollo conforma el prototipo de prueba.
La figura 2.9 muestra las actividades genéricas que se siguen en este segmento. El prototipo de prueba debe ser validado y aprobado antes de que se pueda pasar al segmento siguiente o prueba del prototipo.
Prueba y redefinición. La prueba del prototipo en el ambiente del problema es parte de la adquisición del conocimiento. El conocimiento no es estático y debe refinarse y ajustarse conti-nuamente. La única documentación imprescindible para el inicio de la prueba es un manual de inducción en el sistema y su operación, que sirve para entrenar al personal usuario. Es evidente que la mayoría de las observaciones identificadas durante la prueba no podrán ser implementa-das de inmediato, por lo tanto es fundamental una buena documentación de estas observaciones para su implementación en los ciclos futuros del prototipo. Las actividades de este segmento se aprecian en la figura 2.10.
Luego de que el prototipo demuestre ser consistente en sus respuestas, se puede pensar en convertirlo al ambiente definitivo de operación o prototipo operativo. Antes de finalizar la integra-

Mauricio Paletta
54Índice
ción del sistema, se tiene que concluir el proceso de documentación, que consiste principalmente en la elaboración de los manuales del sistema y del usuario.
Figura 2.10Actividades de la prueba y redefinición
Una parte importante del desarrollo es la evaluación exhaustiva de la efectividad del sistema y sus beneficios, los cuales deben ser cuantificados a fin de consolidar la tecnología.
Tabla 2.3Participantes y productos de los segmentos metodológicos
La tabla 2.3 hace una síntesis de los segmentos que forman parte del esquema metodológico mostrando los productos y participantes de cada uno de ellos.
Seg. Participantes ProductosE Ingeniero del conocimiento
UsuarioEstudio de factibilidad
I Ingeniero del conocimientoUsuarioFuente del conocimiento
Fuentes de conocimiento identificadasDefinición del problemaCasos de estudio
C Ingeniero del conocimientoUsuarioFuente del conocimientoProgramador del conocimiento
Documentación del conocimientoPrototipo de demostración
Seg. Participantes Productos
F Ingeniero del conocimientoFuente del conocimiento
Base de conocimiento inicialMétodos de control e interfaz
P Ingeniero del conocimientoUsuarioFuente del conocimientoProgramador del conocimiento
Prototipo de prueba
R Ingeniero del conocimientoUsuarioFuente del conocimientoProgramador del conocimiento
Manuales del sistemaPrototipo operativoEvaluación de desempeño

Inteligencia Artificial Básica
55Índice
2.4. El manejo de incertidumbre
La incertidumbre en el conocimiento se refiere a la falta de conocimiento sobre el dominio de la aplicación para poder resolver problemas específicos. Esta falta de conocimiento se puede identificar mediante cuatro factores:
Cuando el conocimiento es incierto. En este caso, cierto conjunto de evidencias implicará • probablemente una determinada conclusión.Cuando hay datos inciertos. Se intenta deducir una causa específica a partir de un efecto • observado.Cuando la información es incompleta. Tomar decisiones teniendo lo que se tiene.• Cuando se usa el azar. El dominio tiene propiedades estocásticas.•
Hay varias técnicas que se pueden usar para manejar la incertidumbre en el conocimiento pero las más importantes y que más se usan son los factores de certeza y la lógica difusa.
Factores de certeza. Fueron desarrollados en 1984 durante la elaboración del proyecto My-cin16. Son valores numéricos que expresan el grado en el cual una conclusión dada es aceptada, según un conjunto de evidencias que la sustentan.
Los factores de certeza (FC) se definen en un intervalo cerrado donde el valor mínimo repre-senta el total de no creencia (las evidencias no aportan nada a la conclusión) y el valor máximo es el total de creencia de la conclusión17.
Por ejemplo, en la siguiente regla de producción:
SI la lámpara está conectada, la toma tiene corriente, el interruptor está encendidoENT el bombillo está defectuoso (0.8)
se expresa que las tres evidencias que se presentan: “la lámpara está conectada”, “la toma tiene corriente” y “el interruptor está encendido”, permiten que la conclusión “el bombillo está de-fectuoso” tenga un factor de certeza alto de 0.8 (haciendo uso del intervalo [-1, +1]). De la regla se deduce que estas evidencias no son suficientes para poder afirmar que esa conclusión es siem-pre verdad, de hecho, el 0.2 de certeza restante debe estar asociado a otra u otras conclusiones como por ejemplo “el interruptor está defectuoso”.
16 Sistema para el diagnóstico y terapia de enfermedades infecciosas bacterianas. Para mayor información, consultar la siguiente referencia: Rule-based Expert Systems: The Mycin experiments of the Stanford heuristic programming project; Bruce G. Buchanan y Edward H. Shortliffe; Addison-Wesley; 1984.17 La mayoría de las veces se usa el intervalo [-1, +1] ya que facilita los cálculos de actualización de certeza.

Mauricio Paletta
56Índice
Una conclusión puede aparecer repetida en más de una regla dentro de la base de conoci-miento, en ese caso las reglas se deben estructurar de forma tal que o bien se aumente la creen-cia en la conclusión o se incremente la no creencia de la misma. Para cada regla, la conclusión tiene un factor de certeza componente que se expresa como FCcomp(c,e) y que determina la credibilidad de la conclusión c dado solamente la evidencia e representada en las condiciones de la regla. El factor de certeza componente se calcula haciendo uso de la siguiente ecuación:
donde:
c es la conclusión,e es la evidencia,FCcomp(c,e) es el factor de certeza de c dado e,MCcomp(c,e) es la medida de creencia componente o número que indica el grado en el cual
la conclusión c se incrementa o puede aumentar por la presencia de la evidencia e yMDcomp(c,e) es la medida de no creencia componente o número que indica el grado con el
cual se aumenta la no creencia de la conclusión c dada la evidencia e
Tanto la medida de creencia como la medida de no creencia son valores positivos que se de-finen en el intervalo que va desde 0 hasta el máximo valor permitido de certeza (+1 en el caso de usar el intervalo [-1, +1] como referencia). Obviamente, cuando se tiene creencia sobre una con-clusión con una evidencia específica, no se puede tener no creencia sobre la misma conclusión con la misma evidencia y viceversa. Se tienen entonces las siguientes consideraciones:
Si MCcomp(c,e) > 0 entonces MDcomp(c,e) = 0 y FCcomp(c,e) = MCcomp(c,e).Si MDcomp(c,e) > 0 entonces MCcomp(c,e) = 0 y FCcomp(c,e) = -MDcomp(c,e).
El factor de certeza acumulado de una conclusión es la certeza desde un punto de vista glo-bal, tomando en cuenta las certezas componentes de cada una de las reglas donde aparece la conclusión. Viene expresado mediante la siguiente expresión:
donde:
c es la conclusión,ec es toda la evidencia relativa a c,ef es toda la evidencia a favor de c,ea es toda la evidencia en contra de c,
FCcomp c e MCcomp c e MDcomp c e( , ) ( , ) ( , )= −
FC c e MC c e MD c ec f a( , ) ( , ) ( , )= −

Inteligencia Artificial Básica
57Índice
FC(c,ec) es el factor de certeza acumulado de c dado ec,MC(c,ef) es la medida de creencia acumulada de c dado ef yMD(c,ea) es la medida de no creencia acumulada de c dado ea
Cuando se tienen dos fuentes de evidencia s1 y s2 sobre una misma conclusión c en dos reglas distintas de la base de conocimiento, se hace uso de las siguientes expresiones para el cálculo de las medida de creencia y no creencia acumulada:
Mientras haya más evidencia que crea en una conclusión, la medida de creencia debe aumen-tar. Lo mismo ocurre para la medida de no creencia y el inverso ocurre para los casos contradic-torios. Por ejemplo, supongamos que las conclusiones c1, c2 y c3 tienen los valores de certeza 0.8, -0.2 y 0.5 respectivamente y se tiene una nueva evidencia con los valores de certeza -0.5, -0.2 y -0.3 respectivos. El factor de certeza acumulado de c1 disminuye a 0.7 ya que no aumentó su creencia; el de c2 aumenta su no creencia a -0.36 y el de c3 aumenta su creencia a 0.65.
Ejercicio: Encontrar el factor de certeza acumulado de la conclusión c dado los siguien-tes factores componentes: FCcomp(c,e1) = 0.6, FCcomp(c,e2) = 0.2, FCcomp(c,e3) = -0.3 y FCcomp(c,e4) = 0.9.
1.
2.
3.
4.
5.
Algunas veces es necesario combinar conclusiones de forma tal de formar conjunciones o disyunciones de dos o más conclusiones dada una misma evidencia. Para estos casos hay que aplicar las siguientes expresiones:
MC c s sMD c s s
MC c s MC c s MC c s MD c s s( , )( , )
( , ) ( , ) ( ( , )) ( , )1 21 2
1 2 1 1 2
1 01 0 y
, y , y =
=+ ∗ − >
MD c s sMC c s s
MD c s MD c s MD c s MC c s s( , )( , )
( , ) ( , ) ( ( , )) ( , )1 21 2
1 2 1 1 2
1 01 0 y
, y , y =
=+ ∗ − >
MC c e MD c e( , ) . ( , )1 10 6 0= = MC c e e MD c e e( , ) . . ( , )1 2 1 20 6 0 2 0 y (1- 0.6) = 0.68 y = + ∗ =
MC c e e e MD c e e e( , ) ( , ) .1 2 3 1 2 30 0 3 y y .68 y y = =MC c e e e e MD c e e e e( , ) . . ( , ) .1 2 3 4 1 2 3 40 68 0 9 0 3 y y y (1- 0.68) = 0.96 y y y = + ∗ =FC c e e e e( , ) . .1 2 3 4 0 3 0 66 y y y 0.96 -= =

Mauricio Paletta
58Índice
Ejercicio: Dada las siguientes conclusiones: c1: el problema requiere solución inmediata, c2: existe un problema en el sistema eléctrico, c3: existe un corto circuito y c4: existe una falla en la computadora de control de flujo y, sabiendo que MC(c1,e) = 0.9, MC(c2,e) = 0.7, MC(c3,e) = 0.6 y MC(c4,e) = 0.3, hallar la medida de creencia de que exista un problema en el sistema eléctrico que requiera atención inmediata y que sea un corto circuito o una falla en la computadora de control de flujo.
1.
2.
3.
4.
5.
Un último caso ocurre cuando existe incertidumbre en las condiciones de una regla. Esto se puede dar ya sea porque la evidencia representa las conclusiones de una prueba que tuvo resultados o porque la evidencia es una conclusión que resultó de una ejecución previa y por ende se está realizando un proceso de encadenamiento. En este caso, se tienen que aplicar las siguientes expresiones:
donde:
MC’(c,s) es la creencia en c dada la completa confianza en s yMD’(c,s) es la no creencia en c dada la completa confianza en s
Ejercicio: Supongamos que se tiene una base de conocimiento con las siguientes 4 reglas de producción y se desea ejecutar un proceso de inferencia conociendo que las siguientes eviden-
MC c c e MC c e MC c eMD c c e MD c e MD c e
MC c c e MC c e MC c eMD c c e MD c e MD c e
( , ) min( ( , ), ( , ))( , ) max( ( , ), ( , ))
( , ) max( ( , ), ( , ))( , ) min( ( , ), ( , ))
1 2 1 2
1 2 1 2
1 2 1 2
1 2 1 2
y y
o o
==
==
MC c c c c e MC c e MC c e MC c c e( , ) min( ( , ), ( , ), ( , ))1 2 3 4 1 2 3 4 y y ( o ) o =
MC c c c c e MC c e MC c e( , ) min( . , . ,max( ( , ), ( , ))1 2 3 4 3 40 9 0 7 y y ( o ) =
MC c c c c e( , ) min( . , . ,max( . , . ))1 2 3 4 0 9 0 7 0 6 0 3 y y ( o ) =MC c c c c e( , ) min( . , . , . )1 2 3 4 0 9 0 7 0 6 y y ( o ) =
MC c c c c e( , ) .1 2 3 4 0 6 y y ( o ) =
MC c s MC c s FC s eMD c s MD c s FC s e
( , ) ( , ) max( , ( , ))( , ) ( , ) max( , ( , ))
'
'
= ∗
= ∗
00

Inteligencia Artificial Básica
59Índice
cias son verdad: e1: se ha reportado una falla del sistema, e2: el CPU no responde, e3: el voltaje en el CPU es de 3.8 V y e4: la fuente de la falla es el tablero:
R1: SI e1: el sistema falla, e3: el tablero reporta bajo voltaje ENT s1: el problema es la fuente de energía (0.7)
R2: SI s1: el problema es la fuente de energía en el tablero, s2: el puerto del CPU está cerrado, s3: el voltaje del CPU es menor que 4.5 V ENT c: el problema es una falla en la fuente de energía (0.9)
R3: SI e2: el CPU no responde, e1: hay una falla en el sistema ENT s2: el puerto del CPU está cerrado (0.4)
R4: SI e1: hay una falla en el sistema, e4: la fuente de la falla es el tablero ENT s1: el problema es la fuente de energía (0.6)
hallar la certeza con la cual se puede concluir que la fuente de energía del CPU ha fallado (FC(c, s1 y s2 y s3)). (Para simplificar, hacemos e = e1 y e2 y e3 y e4).
1. , por R1 y R4
2. , por R3
3. , ya que según e3 el voltaje del CPU es 3.8 V y por ende menor que 4.5 V.
4. , por R2
5.
6.
7.
8.
Algunas implementaciones hacen uso de una escala de conversión para poder llevar el valor numérico a una palabra o término que sea mejor comprendido por un usuario a la hora de leer una respuesta. La tabla 2.4 muestra un ejemplo de la escala que usa el producto ADS18.
18 ADS (Aion Development System) de Aion Corporation
MC c s s s MC c s s s s s s( , ) ( , )'1 2 3 1 2 3 1 2 3 y y y y max(0, FC( y y ,e))= ∗
FC s e( , ) . . ( . ) .1 0 7 0 6 1 0 7 0 78= + ∗ − = FC s e( , ) .2 0 4=FC s e( , )3 1=
MC c s s s s s s( , ) .1 2 3 1 2 30 9 y y max(0, min(FC( ,e), FC( ,e), FC( ,e)))= ∗
MC c s s s( , ) .1 2 3 0 9 y y max(0, min(0.78,0.4,1))= ∗MC c s s s( , ) .1 2 3 0 9 y y max(0, 0.4) = 0.36= ∗FC c s s s( , )1 2 3 y y 0.36 - 0 = 0.36=

Mauricio Paletta
60Índice
Tabla 2.4Escala de certeza usada por ADS
Lógica difusa. Fue iniciada en 1965 por Lofti A. Zadech de la universidad de California en Berkley, en un trabajo de investigación donde establece las bases iniciales de la teoría de conjun-tos difusos combinando lógica multivaluada19, la teoría de probabilidades y la IA.
El fundamento de este trabajo es el hecho de que la gente puede basar sus decisiones sobre información imprecisa, no numérica. La lógica difusa se focaliza principalmente sobre el lenguaje natural donde es normal el razonamiento aproximado con proposiciones imprecisas. Como parte de su trabajo, Zadech introduce el concepto de variables lingüísticas, es decir, una variable cuyos posibles valores son palabras o términos y no números, como por ejemplo: alto, medio, mas o menos, alrededor, etc.
La lógica difusa ha experimentado un gran desarrollo teórico y se aplica en diversos campos entre los cuales destaca el control automático, por lo que se ha convertido en una de las teorías actuales más exitosas en lo que concierne a la automatización de sistemas de control.
Los conjuntos difusos están constituidos por colecciones de objetos para los cuales las transi-ciones de pertenecer a no pertenecer a los mismos no es abrupta sino gradual. Estos se caracte-rizan por tener definida una función de pertenencia que determina el grado de membrecía de un elemento al conjunto, expresado como un número real en el intervalo [0,1]. Veamos el entorno teórico y la definición matemática de los conjuntos difusos:
Si U es un universo de discurso y es la función de membrecía que define el conjunto difuso A en U, este puede ser representado de la siguiente forma:
19 La lógica multivaluada es una extensión de la lógica trivaluada (verdadero, falso e indeterminado).
1.0 Absolutamente cierto0.8 Casi cierto0.6 Probablemente cierto0.3 Hay una pequeña evidencia de si0.20-0.2
No se sabe
-0.3 Hay una pequeña evidencia de no-0.6 Probablemente falso-0.8 Casi falso
-1.0 Absolutamente falso
µA
{ }[ ]
A = u u / u U
U 0,1A
A
( , ( ))
:
µ
µ
∈
→

Inteligencia Artificial Básica
61Índice
El soporte de un conjunto difuso A es el conjunto de elementos u en U tal que . Un elemento u en U tal que es denominado punto de “crossover” y se llama “singleton” al conjunto difuso cuyo único elemento u en U tenga .
Ya que los conjuntos difusos están regidos por la definición de conjunto, se pueden aplicar las operaciones de unión, intersección y complemento. En estos casos se requiere de expresiones para obtener las funciones de membrecía resultantes. Si A y B son dos conjuntos difusos con funciones de membrecía y respectivamente, se tiene que:
Cuando una regla de producción tiene más de una premisa, el grado de pertenencia del con-secuente o conclusión es el valor mínimo de los grados de pertenencia respectivos de las pre-misas (se aplica una operación de intersección). Cuando hay más de una regla que concluye lo mismo, las premisas se unen y por lo tanto el grado de membrecía de la conclusión viene dado por el valor máximo de los grados de pertenencia de las premisas.
La inferencia sobre una base de conocimiento que hace uso de la lógica difusa para el manejo de incertidumbre, está basada en la regla modus ponens generalizado. Se trata de una inferencia directa en la cual no existe un encadenamiento de reglas.
Ejercicio: Se tiene un valor d=1.0 que es grande con un grado de 0.3 y medio con un grado de 0.7 y otro valor e=-0.6 que es pequeño con un grado de 1.0 y se aplican las siguientes reglas de producción:
R1: SI d es medio, e es pequeño ENT u es negativo
R2: SI d es grande, e es pequeño ENT u es cero
¿ qué se puede decir sobre la conclusión u?
, por R11. , por R22.
µA u( ) .= 05µA u( ) = 1
µ µ µ
µ µ µ
µ µ
A B A B
A B A B
A A
u u uu u u
u u
( ) max( ( ), ( ))( ) min( ( ), ( ))
( ) ( )
=
=
= −¬ 1
µA µB
µ µ µn m p( ) min( ( ), ( . )) min( . , ) .u d e= = = − = =1 0 6 0 7 1 0 7µ µ µc g p( ) min( ( ), ( . )) min( . , ) .u d e= = = − = =1 0 6 0 31 0 3

Mauricio Paletta
62Índice
Como se mencionó anteriormente, la aplicación más importante de la lógica difusa está en la automatización de controladores ya que se aproxima mucho a lo que el humano hace realmen-te20. Por ejemplo en la casa, para controlar la máquina lavadora se hace uso de dos variables lingüísticas, una para medir la temperatura del agua con los valores {caliente, tibia, fría} y otra para el nivel del agua con los valores {alto, medio, bajo}. De hecho, cuando se va a controlar la lavadora no se dice “lavar a 75 grados con 40 litros” sino “lavar con temperatura caliente y nivel alto”.
2.5. Integración con sistemas de control
El desarrollo de SBCs para la automatización de procesos de control es uno de los frentes que está presentando un crecimiento acelerado dentro de esta técnica de resolución de problemas de la IA. Comúnmente a este tipo de sistema se les llama sistemas basados en conocimiento tiempo real (SBC-TR).
Los SBC-TR deben mantenerse a un tiempo con la data recibida para dar una respuesta antes de que el proceso cambie de estado21. Esta respuesta puede ser tanto una señal a un efector como un mensaje a un operador.
Se distinguen dos vertientes principales. Los sistemas en tiempo real estricto en los cuales es vital que la respuesta se produzca en un lapso de tiempo al cabo del cual la misma ya no tendría ninguna validez y los sistemas en tiempo real flexible donde el tiempo también tiene un carácter determinante, pero aún después de haber pasado este tiempo, la respuesta sigue teniendo algún valor.
Un SBC-TR debe satisfacer un conjunto de requisitos para poder exhibir un comportamiento verdadero de tiempo real, en particular los siguientes:
Ser capaz de suministrar un número de decisiones en un tiempo configurable por el • problema.Trabajar con data altamente cambiante cuyos valores caducan en lapsos de tiempo • preestablecidos.Considerar la ejecución de operaciones específicas en intervalos fijos o acciones que se • ejecutan repetidamente de la misma forma cada vez.Estar capacitado para manejar volúmenes considerables de data.•
20 Los japoneses son los que más han aplicado esta técnica para el control de procesos. Algunos ejemplos son el sistema de enfoque automático de cámaras de video (Sanyo, Fisher y Canon); el sistema de control de aire acondicionado (Mitsubishi); las máquinas lavadoras, aspiradoras y calentadores de agua (Matsushita); el tren subterráneo de Sendai (Hitachi); el sistema de transmisión automática para automóbiles (Subaru).21 Tiempo real no necesariamente quiere decir rápido. La rapidez depende del intervalo de tiempo en el cual el proceso tiene una transición de estados. En algunos procesos lentos esta transición puede llegar a ser de hasta 30 minutos.

Inteligencia Artificial Básica
63Índice
Ser capaz de evaluar la data histórica con el fin de considerar tendencias que pueden for-• talecer los argumentos a favor de algunas decisiones.
Es necesario tener la capacidad de seleccionar sólo las porciones de información que aplican a un caso en cuestión y dejar de lado aquellas que no califican, sin perder el alerta general. Esta propiedad se conoce con el nombre de focalización. El carácter muchas veces aleatorio en que ocurren los eventos que el sistema debe atender obliga a que éste deba considerar la ocurrencia asíncrona de operaciones, incluso concurrentes.
Para poder satisfacer todos estos requisitos, un SBC-TR debe presentar las siguientes características:
Alto rendimiento dado en velocidad de ejecución, capacidad de respuesta, esquema de 1. asignación de prioridades en el tiempo y adaptividad a cambios.
Tiempos de respuesta garantizados dentro del lapso de validez establecido.2. Mejor respuesta disponible en el tiempo dado.3. Manejo de eventos asíncronos o imprevistos.4. Incorporación del tiempo dentro del razonamiento.5. Flexibilidad para la reasignación de recursos y el cambio en las prioridades.6. Funcionamiento con data incorrecta e incompleta.7. Vigencia de las conclusiones en el tiempo.8.
La principal preocupación de los SBC-TR se centra en la garantía de los tiempos de respues-ta. La mayor parte del trabajo se enfoca al planteamiento de arquitecturas que soporten estos requerimientos. Estas arquitecturas pueden ser débil o fuertemente acopladas desde el punto de vista de acoplamiento o comunicación entre la máquina de adquisición de datos ligada al proceso y la máquina de inferencia ligada a la base de conocimiento. Ver figura 2.11.
Figura 2.11Arquitectura general de un SBC-TR

Mauricio Paletta
64Índice
Hay cuatro arquitecturas posibles:
Software puro: se usa un sistema operativo concurrente con el proceso de adquisición y el 1. proceso basado en conocimiento.Software ayudado por un material de hardware: La máquina de adquisición y la máquina 2. de inferencia están conectadas mediante un canal de comunicación.Material controlado por hardware: La máquina de adquisición y la máquina de inferencia 3. están conectadas mediante de una red en “bus”.Electrónica rápida: Se tiene una máquina vectorial de adquisición e inferencia.4.
Una de las estrategias más adoptadas es la que se conoce con el nombre de blackboard (pi-zarrón). La idea es que el “pizarrón” sirva como mecanismo de comunicación entre los distintos elementos que intervienen en el proceso, informando y actualizando continuamente el estado de las operaciones para que de manera flexible, se tenga un manejo de recursos, reasignación de prioridades, cambio de tareas, etc.
Como se ve en la figura 2.12, existe un “manejador de agenda” que administra todas las po-sibles tareas a ser ejecutadas, colocándolas y retirándolas de cierta forma en la agenda según el caso. Se encuentra un programador que selecciona de la agenda la siguiente operación a ejecutar según el plan de control y la coloca dentro del “pizarrón”.
Figura 2.12Arquitectura de un sistema Blackboard

Inteligencia Artificial Básica
65Índice
El “ejecutor” toma el paso siguiente, lo ejecuta y lo registra como evento en la historia. Para cerrar el ciclo, el “manejador de agenda” observa la historia de eventos para actualizar la agenda según corresponda. La “interfaz de comunicación” establece el puente con los demás compo-nentes del sistema.
Sin embargo, independientemente de la arquitectura que se utilice, hay muchos factores que degradan el tiempo de respuesta del controlador como por ejemplo el número de reglas y el tipo de acciones incluidas en la tarea. Para tratar inconvenientes como estos, han surgido algunos planteamientos como los siguientes:
Compilación total o parcial de la base de conocimiento. Principalmente aquellos casos que 1. permiten mejorar la ejecución de los pasos que tienen el mayor consumo de tiempo, que no incurran en elevados requerimientos de memoria y que no pierdan el carácter dinámico propio y adecuado de las operaciones dentro del proceso de ejecución.Eliminación de patrones iguales a tiempo de ejecución.2. Distribución entre recursos. Considerando esquemas de procesamiento distribuidos o 3. paralelos.Restricción de la data. Razonar con parte representativa de la data de entrada y no con la 4. totalidad de la misma.Focalización de atención. Condicionar la activación de grupos de reglas o porciones del 5. sistema en relación a objetos o situaciones específicas. Dividir la base de conocimiento.Activación de operaciones a intervalos. Fijar una cierta frecuencia para la ejecución de 6. operaciones. Una frecuencia muy baja puede desconocer cambios en la data y una fre-cuencia alta puede ocasionar observaciones innecesarias a la data. Se puede considerar la definición dinámica de la frecuencia determinada principalmente por el comportamiento de la data.Hardware de propósito especial.7.
Junto a estos planteamientos que ayudan a obtener un alto rendimiento, se proponen una serie de métodos para la restricción del razonamiento en el tiempo, con el fin de llegar a un com-promiso entre la calidad y la oportunidad de la respuesta:
Esquema de asignación de prioridades: Obliga a reformular el plan de tareas a ejecutar 1. basado en las metas y disponibilidad de recursos.Profundización progresiva: Se ejecuta el proceso durante un cierto tiempo preestablecido 2. con la garantía de tener siempre una respuesta que se determina por niveles y se toma la respuesta del nivel de profundidad inmediatamente anterior al del momento de vencimiento del tiempo.

Mauricio Paletta
66Índice
Lógica de precisión variable: Se maneja el compromiso entre la precisión de la respuesta y 3. el costo de derivarla de acuerdo a la especificidad de la conclusión y a la certeza con que se toma la decisión.Técnicas analíticas de decisión: Se manejan una serie de compromisos propios del análisis 4. de decisiones, como por ejemplo la prontitud contra la precisión o la transparencia contra lo óptimo de la inferencia. Aplicación de algoritmos especiales: Se buscan algoritmos apropiados para la resolución 5. de problemas de búsqueda o recorrido.
2.6. Ejemplos y aplicaciones
Son muchas los tipos de aplicación que se pueden realizar con un SBC, pero en síntesis se pueden enumerar los cinco siguientes:
Interpretación: Dado un conjunto de datos de entrada, se quiere encontrar el significado 1. de los mismos. Se necesita habilidad para el manejo de datos inciertos, incompletos e inexactos y la posible aparición de contradicciones. El análisis o llegar a una conclusión y la síntesis son los dos casos en las cuales se aplica la interpretación de los datos.Diagnóstico: Dado un conjunto de datos o síntomas observables, se quiere identificar las 2. causas internas que pueden provocar un problema. Se necesita habilidad para el manejo de nuevas manifestaciones, datos incompletos, contradicciones e incertidumbre. Los casos posibles son la selección o escogencia de una entre varias respuestas y la construcción de una única respuesta.Reparación / Corrección: Consiste en suministrar las acciones necesarias para resolver un 3. problema previamente diagnosticado. Es importante el manejo de criterios de optimización (tiempo, costo, etc.), el manejo de prioridades y planificación. Hay que tener cuidado con los efectos secundarios que se pueden dar por las respuestas ofrecidas.Control: Repetición de tareas anteriores con el fin de guiar un proceso. Dependiendo de la 4. forma en la cual el sistema está interactuando con el proceso, el control puede ser de lazo abierto o cerrado. Dependiendo del tiempo en el cual se tiene que dar una respuesta, el control puede ser de tiempo diferido o tiempo real.Simulación: Dado un conjunto de entradas, se quiere crear modelos basados en hechos, 5. observaciones e interpretaciones en función de las salidas con miras de estudiar el com-portamiento de un sistema.
Desde el punto de vista de importancia según la cantidad de manifestaciones exitosas exis-tentes, las áreas de aplicación de los SBCs son las siguientes:

Inteligencia Artificial Básica
67Índice
1. Medicina: . diagnóstico y tratamiento de enfermedades, . enseñanza de la medicina, . monitorización de procesos, . interpretación de pruebas e imágenes, . radiología.2. Finanzas y gestión: . análisis de mercado, . análisis de riesgo y tasación de seguros, . aplicación de impuestos y tasas, . asesoría jurídica y fiscal, . concesión de créditos y préstamos, . gestión del personal, . planes de inversión, . supervisión de estados financieros, . verificación de firmas.3. Industria: . control de procesos, . control de calidad, . configuración de equipos, . diagnóstico y tratamiento de fallas, . enseñanza / entrenamiento.4. Electrónica, informática y telecomunicaciones: . diseño de circuitos, . diagnóstico y reparación de fallas, . configuración de equipos y sistemas, . control de redes de comunicación.5. Militar: . guiado automático de vehículos y proyectiles, . planificación estratégica, . reconocimiento automático de blancos y valoración de los mismos, . reconocimiento de planes del enemigo, . interpretación de señales, . estrategia para la conversación de desarme, . diagnóstico y tratamiento de fallas en armamento y equipo militar.6. Educación: . diagnosticar causas de los problemas de aprendizaje, . recomendar tratamientos o estrategias de aprendizaje.7. Otros: . exploración espacial (aeronáutica),

Mauricio Paletta
68Índice
. simulación o planes de cultivo (agricultura), . interpretación de leyes (derecho), . diagnóstico de suelos y explotación de minerales (geología), . estudio y análisis de muestras (arqueología), . descomposición y análisis de elementos (química), . control de rutas (transporte), . estudio de mercado (ventas).
La tabla 2.5 presenta ejemplos de los SBCs más importantes hasta la fecha. Su dimensión demuestra lo importante de esta técnica para la resolución de problemas en muchas áreas de aplicación22. Las dos últimas columnas indican los tipos y las áreas de aplicación respectivamen-te, según las anteriores
Tabla 2.5Ejemplos de SBCs
22 Nebendahl, Dieter; Sistemas Expertos; Siemens S.A. & Marcombo, S.A.; 1988; anexo A.2; p. A-7:A-23.
Nombre Autor AsuntoAQ /ADVISE /PLANT-ds /PLANT-dc /BABY
Univ. de Illinois Diagnóstico de enfermedades de las plantas. 2 1
ARS MIT Análisis de circuitos eléctricos. 1 4ATC Univ. de Carnegie-Mellon Control del tráfico aéreo. 4 3
ATTENDING Univ. de Yale Determinación de anestesia preoperatoria. 2 1BACON /GLAUBER /DALTON
Univ. de Carnegie-Mellon Rastreo de regularidades en bases de datos para la creación de hipótesis.
1 6
BIRTHDEFECTSDIAGNOSIS
MIT / Tufts England Medical Center
Investigación y diagnóstico de enfermedades congénitas. 3 1
CAA Univ. de Toronto Reconocimiento de arritmias cardíacas y anomalías en ECG. 2 1CADHELP Univ. de Conneticut Creación de textos aclarativos inteligentes para sistemas gráficos
CAD.1 6
CALLISTO DEC Gestión de métodos auxiliares para diseñadores de chips. 2 2
Nombre Autor AsuntoAALPS Ejército USA Optimización de carga en aviones. 2 5AARON Univ. de California Creación de gráficos abstractos. 5 6ABEL MIT Diagnósticos de disfunciones metabólicas y disfunciones del nivel
de bases ácidas.2 1
ACE Bell Lab. Mantenimiento y búsqueda de fallas en líneas telefónicas. 3 4ACT Univ. de Carnegie-Mellon Modelado de fenómenos mentales humanos. 5 1ADA*TUTOR
Computer Thought Co. Instrucción computarizada para el aprendizaje de ADA. 1 6
ADS IBM Apoyo automatizado para la programación de aplicaciones médicas.
5 6
AIRPLAN Univ. de Carnegie-Mellon Planificación de aterrizaje y despegue de aviones en portaavio-nes.
4 5
AI-SPEAR DEC Diagnóstico de fallas en unidades de cintas magnéticas. 2 3ALVEN Univ. de Toronto Determinación del rendimiento del corazón humano. 1 1AM / EURISKO Univ. de Stanford Generación de nuevos conceptos e hipótesis. 1 6APE Univ. de Bonn Desarrollo de métodos para la codificación del conocimiento en
programas de gran alcance.1 6
APEX First Financial Planning Systems
Apoyo para asesores financieros. 1 2
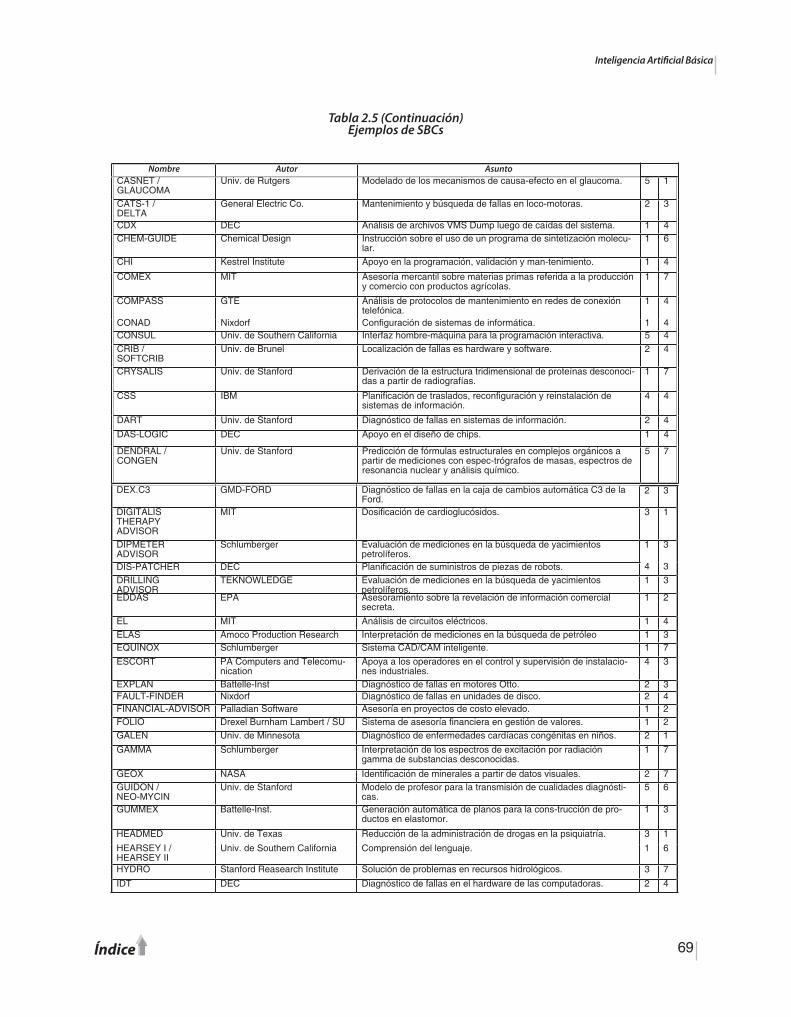
Inteligencia Artificial Básica
69Índice
Nombre Autor AsuntoDEX.C3 GMD-FORD Diagnóstico de fallas en la caja de cambios automática C3 de la
Ford.2 3
DIGITALISTHERAPYADVISOR
MIT Dosificación de cardioglucósidos. 3 1
DIPMETERADVISOR
Schlumberger Evaluación de mediciones en la búsqueda de yacimientos petrolíferos.
1 3
DIS-PATCHER DEC Planificación de suministros de piezas de robots. 4 3DRILLINGADVISOR
TEKNOWLEDGE Evaluación de mediciones en la búsqueda de yacimientos petrolíferos.
1 3
EDDAS EPA Asesoramiento sobre la revelación de información comercial secreta.
1 2
EL MIT Análisis de circuitos eléctricos. 1 4ELAS Amoco Production Research Interpretación de mediciones en la búsqueda de petróleo 1 3EQUINOX Schlumberger Sistema CAD/CAM inteligente. 1 7ESCORT PA Computers and Telecomu-
nicationApoya a los operadores en el control y supervisión de instalacio-nes industriales.
4 3
EXPLAN Battelle-Inst Diagnóstico de fallas en motores Otto. 2 3FAULT-FINDER Nixdorf Diagnóstico de fallas en unidades de disco. 2 4FINANCIAL-ADVISOR Palladian Software Asesoría en proyectos de costo elevado. 1 2FOLIO Drexel Burnham Lambert / SU Sistema de asesoría financiera en gestión de valores. 1 2GALEN Univ. de Minnesota Diagnóstico de enfermedades cardíacas congénitas en niños. 2 1GAMMA Schlumberger Interpretación de los espectros de excitación por radiación
gamma de substancias desconocidas.1 7
GEOX NASA Identificación de minerales a partir de datos visuales. 2 7GUIDON /NEO-MYCIN
Univ. de Stanford Modelo de profesor para la transmisión de cualidades diagnósti-cas.
5 6
GUMMEX Battelle-Inst. Generación automática de planos para la cons-trucción de pro-ductos en elastomor.
1 3
HEADMED Univ. de Texas Reducción de la administración de drogas en la psiquiatría. 3 1
HEARSEY I /HEARSEY II
Univ. de Southern California Comprensión del lenguaje. 1 6
HYDRO Stanford Reasearch Institute Solución de problemas en recursos hidrológicos. 3 7IDT DEC Diagnóstico de fallas en el hardware de las computadoras. 2 4
Tabla 2.5 (Continuación)Ejemplos de SBCs
CASNET /GLAUCOMA
Univ. de Rutgers Modelado de los mecanismos de causa-efecto en el glaucoma. 5 1
CATS-1 /DELTA
General Electric Co. Mantenimiento y búsqueda de fallas en loco-motoras. 2 3
CDX DEC Análisis de archivos VMS Dump luego de caídas del sistema. 1 4CHEM-GUIDE Chemical Design Instrucción sobre el uso de un programa de sintetización molecu-
lar.1 6
CHI Kestrel Institute Apoyo en la programación, validación y man-tenimiento. 1 4
COMEX MIT Asesoría mercantil sobre materias primas referida a la producción y comercio con productos agrícolas.
1 7
COMPASS GTE Análisis de protocolos de mantenimiento en redes de conexión telefónica.
1 4
CONAD Nixdorf Configuración de sistemas de informática. 1 4CONSUL Univ. de Southern California Interfaz hombre-máquina para la programación interactiva. 5 4CRIB /SOFTCRIB
Univ. de Brunel Localización de fallas es hardware y software. 2 4
CRYSALIS Univ. de Stanford Derivación de la estructura tridimensional de proteínas desconoci-das a partir de radiografías.
1 7
CSS IBM Planificación de traslados, reconfiguración y reinstalación de sistemas de información.
4 4
DART Univ. de Stanford Diagnóstico de fallas en sistemas de información. 2 4DAS-LOGIC DEC Apoyo en el diseño de chips. 1 4
DENDRAL /CONGEN
Univ. de Stanford Predicción de fórmulas estructurales en complejos orgánicos a partir de mediciones con espec-trógrafos de masas, espectros de resonancia nuclear y análisis químico.
5 7
Nombre Autor Asunto

Mauricio Paletta
70Índice
Nombre Autor AsuntoONCOCIN Univ. de Stanford Apoyo en el tratamiento terapéutico de enfermos de cáncer. 3 1PALLADIO Univ. de Stanford /
Xerox PARCCreación de chips VSLI 5 4
PECOS Univ. de Stanford Implementación de algoritmos abstractos. 1 4PHI-NIX Schlumberger Sistema automático de programación para prototipos rápidos de
software de exploración petrolífera.5 3
PHOTO-LITHO-GRAPHY ADVISOR
Hewlett-Packard Diagnóstico de fallas en la producción de chips. 2 4
PICON Lisp Machines Inc. Sistema en tiempo real para el control de procesos. 4 3PIES Fairchild Diagnóstico de fallas en la producción de chips. 2 4
PIP MIT Modelado de procesos clínicos de decisión en anámnesis y diagnósticos.
2 1
PLAN-POWER Applied Expert Systems Asesoramiento de bancos, seguros y empresas inversoras. 5 2
Nombre Autor AsuntoINFOMART ADVISOR Infomart Asesoría en la compra de computadoras. 2 4IPT Hewlett Packard Diagnóstico para periféricos. 2 4ISA DEC Planificación de producción y suministro. 4 3ISAAK Univ. de Texas Solución de problemas físicos. 1 7ITINERARY PLAN-NER
Expert-Systems International Planificación de viajes. 5 7
KLAUS Artificial Intelligence Center, Menlo Park
Adquisición de conocimiento por enseñanza oral. 1 6
KNOBS /SNUKA
MITRE Corp. Realización de batallas aéreas tácticas para combatir objetos enemigos volantes.
5 5
KNOESPHERE ATARI Enciclopedia de memoria electrónica con inclu-sión de medios audiovisuales.
1 6
LDS RAND Corp. Determinación de reclamaciones por daños y perjuicios por derechos de garantía.
3 7
LEGOL London School of Economics Transformación de nuevas disposiciones fiscales en normas algorítmicas.
1 7
LIBRA Univ. de Carnegie-Mellon Análisis de efectividad de programas. 1 4LINKMAN Blue-Circle-Technical Control y automatización de procesos de pro-ducción. 4 3LOPS Univ. de Munich Síntesis automática de programas. 1 4
MACSYMA MIT Manipulación de fórmulas. 1 6MDX Univ. de Ohio Diagnóstico de enfermedades hepáticas 2 1MENTOR Honeywell Mantenimiento de instalaciones de refrigeración y ventilación en
edificios.3 3
MICRO-FAST 2 LEE Micromatics Generación automática de software de fun-cionamiento correcto. 1 4MICRO-SYNTHESE Escuela Nacional Superior de
Química de ParísGenera árboles de síntesis de moléculas orgánicas. 1 7
MOLGEN Univ. de Stanford Planificación de experimentos genéticos. 4 7MYCIN Univ. de Stanford Diagnóstico y determinación de terapia en enfer-medades infec-
ciosas.3 1
NAVEX NASA Control del sistema de navegación de la lanzadera espacial. 4 7NDS SMART Systems Technology Localización de fallas en redes de comunicación. 4 4NEXPERTS Composition Systems Inc. Creación del layout de páginas para periódicos. 1 7NTC DEC Análisis de fallas en redes Ethernet y DECnet. 3 4NUCLEAR POWER PLANT CONSUL-TANT
Instituto de Tecnología de Georgia
Control y entrenamiento de operador para reactores. 1 6
NUDGE MIT Asistente en la planificación de horarios para reuniones de conv-ersación o asesoramiento.
1 2
ODYSSEY Xerox PARC Planificación de viajes y configuración de interfaces. 5 2
Nombre Autor Asunto
Tabla 2.5 (Continuación)Ejemplos de SBCs
IMS Univ. de Carnegie-Mellon Automatización de la producción industrial (simulación). 5 3
IN-ATE U.S. Naval Research Lab. Búsqueda de fallas en circuitos eléctricos. 2 4INTERNIST /CADUCEUS
Univ. de Pittsburg Diagnósticos en procesos pluripatológicos. 2 1
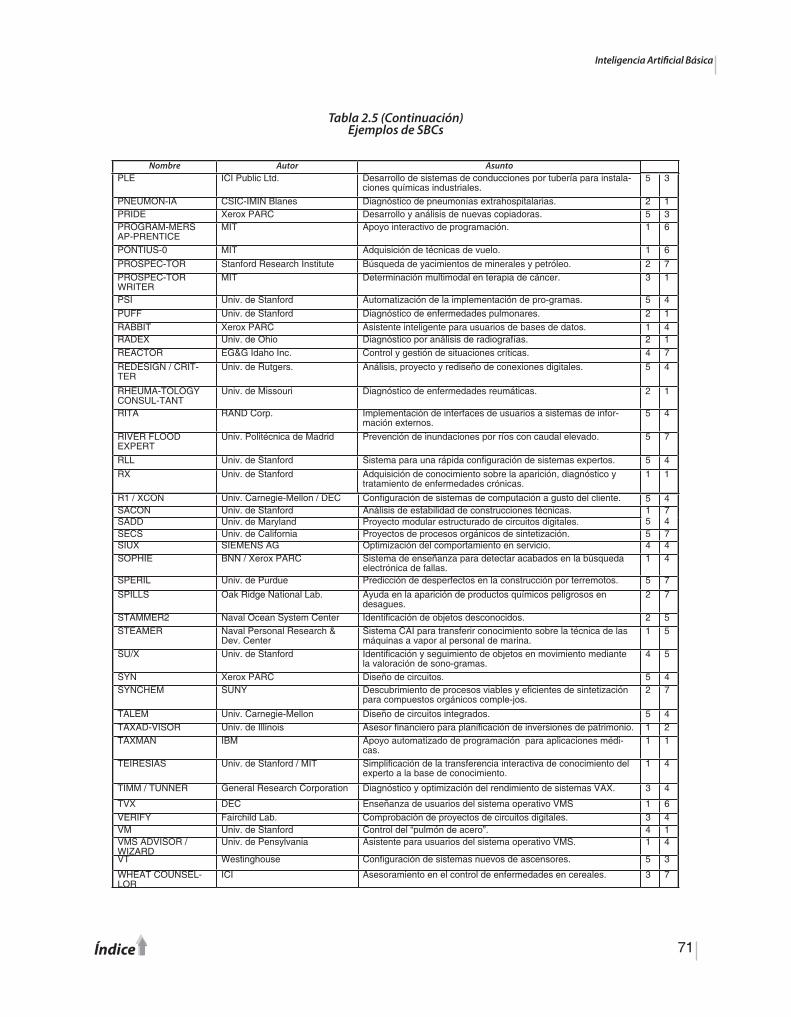
Inteligencia Artificial Básica
71Índice
Nombre Autor AsuntoR1 / XCON Univ. Carnegie-Mellon / DEC Configuración de sistemas de computación a gusto del cliente. 5 4SACON Univ. de Stanford Análisis de estabilidad de construcciones técnicas. 1 7SADD Univ. de Maryland Proyecto modular estructurado de circuitos digitales. 5 4SECS Univ. de California Proyectos de procesos orgánicos de sintetización. 5 7SIUX SIEMENS AG Optimización del comportamiento en servicio. 4 4SOPHIE BNN / Xerox PARC Sistema de enseñanza para detectar acabados en la búsqueda
electrónica de fallas.1 4
SPERIL Univ. de Purdue Predicción de desperfectos en la construcción por terremotos. 5 7SPILLS Oak Ridge National Lab. Ayuda en la aparición de productos químicos peligrosos en
desagues.2 7
STAMMER2 Naval Ocean System Center Identificación de objetos desconocidos. 2 5STEAMER Naval Personal Research &
Dev. CenterSistema CAI para transferir conocimiento sobre la técnica de las máquinas a vapor al personal de marina.
1 5
SU/X Univ. de Stanford Identificación y seguimiento de objetos en movimiento mediante la valoración de sono-gramas.
4 5
SYN Xerox PARC Diseño de circuitos. 5 4SYNCHEM SUNY Descubrimiento de procesos viables y eficientes de sintetización
para compuestos orgánicos comple-jos.2 7
TALEM Univ. Carnegie-Mellon Diseño de circuitos integrados. 5 4TAXAD-VISOR Univ. de Illinois Asesor financiero para planificación de inversiones de patrimonio. 1 2TAXMAN IBM Apoyo automatizado de programación para aplicaciones médi-
cas.1 1
TEIRESIAS Univ. de Stanford / MIT Simplificación de la transferencia interactiva de conocimiento del experto a la base de conocimiento.
1 4
TIMM / TUNNER General Research Corporation Diagnóstico y optimización del rendimiento de sistemas VAX. 3 4
TVX DEC Enseñanza de usuarios del sistema operativo VMS 1 6VERIFY Fairchild Lab. Comprobación de proyectos de circuitos digitales. 3 4VM Univ. de Stanford Control del “pulmón de acero”. 4 1VMS ADVISOR / WIZARD
Univ. de Pensylvania Asistente para usuarios del sistema operativo VMS. 1 4
VT Westinghouse Configuración de sistemas nuevos de ascensores. 5 3
WHEAT COUNSEL-LOR
ICI Asesoramiento en el control de enfermedades en cereales. 3 7
Tabla 2.5 (Continuación)Ejemplos de SBCs
PLE ICI Public Ltd. Desarrollo de sistemas de conducciones por tubería para instala-ciones químicas industriales.
5 3
PNEUMON-IA CSIC-IMIN Blanes Diagnóstico de pneumonías extrahospitalarias. 2 1PRIDE Xerox PARC Desarrollo y análisis de nuevas copiadoras. 5 3PROGRAM-MERS AP-PRENTICE
MIT Apoyo interactivo de programación. 1 6
PONTIUS-0 MIT Adquisición de técnicas de vuelo. 1 6PROSPEC-TOR Stanford Research Institute Búsqueda de yacimientos de minerales y petróleo. 2 7PROSPEC-TOR WRITER
MIT Determinación multimodal en terapia de cáncer. 3 1
PSI Univ. de Stanford Automatización de la implementación de pro-gramas. 5 4PUFF Univ. de Stanford Diagnóstico de enfermedades pulmonares. 2 1RABBIT Xerox PARC Asistente inteligente para usuarios de bases de datos. 1 4RADEX Univ. de Ohio Diagnóstico por análisis de radiografías. 2 1REACTOR EG&G Idaho Inc. Control y gestión de situaciones críticas. 4 7REDESIGN / CRIT-TER
Univ. de Rutgers. Análisis, proyecto y rediseño de conexiones digitales. 5 4
RHEUMA-TOLOGY CONSUL-TANT
Univ. de Missouri Diagnóstico de enfermedades reumáticas. 2 1
RITA RAND Corp. Implementación de interfaces de usuarios a sistemas de infor-mación externos.
5 4
RIVER FLOOD EXPERT
Univ. Politécnica de Madrid Prevención de inundaciones por ríos con caudal elevado. 5 7
RLL Univ. de Stanford Sistema para una rápida configuración de sistemas expertos. 5 4RX Univ. de Stanford Adquisición de conocimiento sobre la aparición, diagnóstico y
tratamiento de enfermedades crónicas.1 1
Nombre Autor Asunto

Mauricio Paletta
72Índice
Nombre Autor AsuntoXPRT-SYSTEM MIT Apoyo en la implementación de sistemas expertos. 1 4
XSEL / XCITE / XCALIBUR
Univ. Carnegie-Mellon / DEC Configuración específica para el cliente de sistemas de com-putación VAX.
5 4
YES / VMS IBM Control del sistema operativo VMS. 4 4
Tabla 2.5 (Continuación)Ejemplos de SBCs
Es un resultado interesante analizar estadísticamente los ejemplos presentados en la tabla 2.5. De este análisis se llega a que el tipo de aplicación más común es la interpretación de resul-tados (1) y el área más abordada es la de electrónica, informática y telecomunicaciones (4). Los resultados se muestran gráficamente en la figura 2.13.
Figura 2.13Areas y tipos de aplicación en función de la cantidad de sistemas
ELIZA. Programa escrito a finales de los años sesenta por el profesor Joseph Weizenbaum del MIT. Fue diseñado como una ayuda al análisis del lenguaje y su nombre se debe a la mu-chacha que aparece en la obra de G. B. Shaw “Pigmalión”, que comenzó como una vendedora callejera de flores y su vida se transformó cuando un profesor de dicción le enseñó a hablar correctamente.
El programa puede aprender a conversar acerca de cualquier tema, comenzando por respon-der una serie de frases escogidas al azar, para luego continuar usando palabras usadas por el usuario. Las respuestas son examinadas para buscar frases o palabras claves. ELIZA sirvió de base para la realización de programas que incluyen un mecanismo de diálogo o conversación acerca de cualquier tema.
El objetivo que Weizenbaum buscaba al escribir el programa era demostrar la dificultad que existe al tratar de comunicarse en lenguaje natural con una computadora. Se sorprendió de que

Inteligencia Artificial Básica
73Índice
el programa fuese considerado como un paso hacia una prueba general de que era posible la comprensión del lenguaje natural por parte de una máquina y por el hecho de que personas in-teligentes estuvieran dispuestas a establecer una relación tan personal con la computadora, que las llevara hasta el extremo de confiar en ella y de tratarla como un sabio y comprensivo doctor.
MYCIN. Este es un sistema experto que fue publicado en 1976 por E. Shortcliffe y que está ca-pacitado para diagnosticar enfermedades infecciosas, en particular aquellas infecciones que se originan en la sangre. Es usado por médicos para obtener ayuda de sus diagnósticos y además, el mismo sistema se actualiza con el conocimiento proporcionado por los especialistas.
El programa puede producir un resultado basándose en las manifestaciones del usuario, los hechos almacenados en la base de datos y las reglas que posee. Puede asignar una probabi-lidad en la escala comprendida entre 0.0 y 1.0 según considere la verosimilitud de sus conclu-siones (manejo de incertidumbre en el conocimiento). Puede proporcionar una explicación del razonamiento que lo llevó a una conclusión determinada.
Uno de los aspectos más resaltantes del trabajo realizado en MYCIN fue la elaboración de su propio motor o máquina de inferencia al cual se le dio el nombre de EMYCIN. Esta misma má-quina de inferencia fue utilizada para la creación de otros sistemas expertos tales como MARC (para el análisis de elementos finitos en la Fuerza Aérea de los Estados Unidos), GUIDON (para dictar clases particulares acerca de cualquier tema).
DENDRAL. Es un sistema experto para realizar análisis químicos y se ha aplicado con éxito en muchos lugares del mundo. Soluciona un problema de ingeniería química en tres fases. En primer lugar se infiere cualquier posible restricción sobre la solución; luego permite a los usuarios agregar cualquier otra posible restricción y por último, genera y comprueba una lista de posibles soluciones.
XCON. Este sistema experto permite llegar a configuraciones de redes de computadoras VAX, según los deseos individuales de los clientes. Fue elaborado por la Digital Equipment Corporation (DEC) ya que la cantidad de productos que se ofrecían en el mercado era muy amplia y la com-pleta y correcta configuración de estos equipos resultaba ser un problema de gran complejidad. El sistema se desarrolló en el lenguaje de programación OPS-5.
El sistema fue capaz de comprobar y completar los pedidos entrantes de una forma mucho más rápida y mejor que las personas que en ese momento estaban encargadas de hacerlo.
Aplicaciones en Venezuela. En Venezuela, el desarrollo de Sistemas Basados en Conoci-miento se ve principalmente en el campo de la investigación orientada a la industria petrolera. La mayoría de estos sistemas que nacen en un área de investigación, pasan a un área operativa.

Mauricio Paletta
74Índice
Básicamente, su enfoque está en el diagnóstico de fallas de equipos usados para la perforación y almacenamiento de petróleo.
Otra área importante a mencionar es la que se refiere a la financiera, específicamente a la ban-ca. Se identifican aquí, sistemas para la toma de decisiones sobre la aceptación y otorgamiento de créditos, interpretación y análisis financieros, etc. Otro caso se refiere al monitoreo de tran-sacciones de la banca electrónica (cajeros automáticos y puntos de venta). Un ejemplo de este último caso es SBCO, un Sistema Basado en Conocimiento para la Operación de transacciones de una red de más de 800 cajeros y 1500 puntos de venta de uno de los bancos más importantes del país. Este sistema es capaz de detectar un problema en el dispositivo (ya sea mecánico, de comunicación o de configuración) y enviar de forma automática, al personal encargado de darle solución al problema, un diagnóstico y recomendaciones sobre la corrección de la falla.
2.7. Resumen del capítulo
Un Sistema Basado en Conocimiento (SBC) incorpora conocimiento estructurado sobre un dominio específico, busca resolver efectiva y eficientemente un conjunto de problemas específi-cos en ese dominio y provee un conjunto de interfaces para diversos tipos de usuarios.
Un experto es aquella persona que ha acumulado en el tiempo un conjunto de heurísticas que permiten que se observen comportamientos exitosos en la solución de problemas. Cuando la fuente de conocimiento de un SBC está constituída principalmente por la experiencia de un experto, se tiene un Sistema Experto.
Llevar el conocimiento de una fuente de conocimiento a una computadora implica la realiza-ción de dos procesos: la adquisición y la representación del conocomiento.
El desarrollo de un SBC es guiado por un equipo formado por tres componentes: la fuente de conocimiento, el ingeniero de conocimiento y el usuario.
La arquitectura básica de un SBC está formada por una base de conocimiento que almacena el conocimiento sobre el dominio del problema y el motor de inferencia que contiene los meca-nismos de control y estrategias de búsqueda para realizar el razonamiento sobre el conocimiento almacenado. Una arquitectura completa plantea la incorporación de mecanismos de aprendizaje automático, sistemas de explicación y módulos de interfaz gráfica y de procesamiento de lengua-je natural.
El desarrollo de un SBC es incremental y se orienta a la definición y progresiva refinación de prototipos, que pasan de ser elementos de demostración a módulos operativos. Una metodología

Inteligencia Artificial Básica
75Índice
propuesta plantea un esquema de cinco segmentos: la identificación del problema, la conceptua-lización, la formalización, la construcción del prototipo y la prueba y redefinición.
La incertidumbre en el conocimiento se refiere a la falta de conocimiento sobre el dominio de la aplicación para resolver problemas específicos. Dos técnicas para manejar la incertidumbre del conocimiento en un SBC son: los factores de certeza y la lógica difusa. Los factores de certeza son números que indican el grado en el cual una conclusión es aceptada. La lógica difusa es un tipo de razonamiento basado en conjuntos difusos.
Uno de los frentes que está presentando un crecimiento acelerado dentro de los desarrollos de SBCs es su integración a los sistemas de control. Para este tipo de sistemas es importante tomar en cuenta varias consideraciones y hay arquitecturas especializadas para su buen desem-peño. Un ejemplo de estas arquitecturas es el esquema de pizarrón (blackboard).
Los ejemplos más comunes de SBCs se refieren a aplicaciones de interpretación de resulta-dos en las áreas de electrónica, informática y telecomunicaciones. En Venezuela, el desarrollo de estos sistemas se ve principalmente en el campo de la investigación orientada a la industria petrolera.

CapítuloLa Adquisición y Representación del Conocimiento
En este capítulo se estudian los dos procesos más importantes del manejo de conocimiento:
la Adquisición y la Representación del Conocimiento. Se presentan técnicas y ejemplos.
3

Inteligencia Artificial Básica
77Índice
3.1. El proceso de adquisición
Antes de presentar el objetivo del proceso de adquisición del conocimiento, es importante tener claro sobre lo que es el conocimiento. El conocimiento es un tipo de información que ha sido interpretada, categorizada, aplicada y revisada. Puede ser ejemplificado por los conceptos, restricciones, métodos heurísticos y principios que gobiernan un dominio específico. Más espe-cíficamente, el conocimiento consiste en:
Descripciones simbólicas de las definiciones,1. Descripciones simbólicas de las relaciones y2. Procedimientos para manipular ambos tipos de descripciones.3.
Comúnmente, el proceso de adquisición del conocimiento es referido como el más importante y problemático aspecto en el desarrollo de un SBC. De la adecuada ejecución de este proceso dependerá en gran medida la calidad del sistema en su versión final. Se le da también el nombre de extracción o elicitación1 del conocimiento. Se puede definir como:
La transferencia y transformación del conocimiento para la solución de problemas, desde la fuente de conocimiento hacia un esquema codificado del mismo.
Esta idea no es nueva, ya que es la misma que utilizan por ejemplo, los reporteros o escritores para realizar su trabajo. Como se puede interpretar de la definición anterior, el objetivo de este proceso es obtener toda la información necesaria para implementar un SBC. En el desarrollo de un SBC, la adquisición es un proceso de distintas fases que ameritan la consideración de las formas más adecuadas de ejecución de cada una de ellas. Como proceso puede tener una duración altamente variable.
Dada la importancia de los resultados que se obtienen durante el proceso de adquisición, es importante tomar en cuenta una serie de limitaciones que pueden afectar el correcto desenvolvi-miento de esta actividad:
La gran dependencia de la organización hacia la fuente de conocimiento, lo hace • indispensable.La dificultad para que la fuente de conocimiento explique su proceso de razonamiento.• Las diferencias culturales y de vocabulario entre la fuente de conocimiento y el que realiza la • adquisición.La renuencia de la fuente de conocimiento a participar en el desarrollo.•
1 Del verbo latín “elicio” que significa evocar, hacer salir o descubrir.

Mauricio Paletta
78Índice
El encargado de realizar el proceso de adquisición en el desarrollo de un SBC es el Inge-niero de Conocimiento. La ingeniería del conocimiento tiene su equivalencia en la recopilación, modelaje, codificación, prueba y revisión del conocimiento. La meta es capturar e incorporar conocimiento fundamental del dominio de una fuente de conocimiento, así como sus procesos de predicción y control. Para definir ingeniero del conocimiento voy a usar la idea que aplicó el profesor Jorge Baralt2, haciendo uso de una definición genérica de ingeniería:
“Ingeniería X esla conceptualización,el diseño,la construcción,la instalación,la supervisión de la operación,el mantenimiento,la evaluación,la adaptación yel mejoramiento
de sistemas basados en X”
para completar la definición, basta reemplazar X por la palabra conocimiento. Las actividades de la ingeniería del conocimiento se resumen en:
Revisión de la información obtenida.• Familiarización con el dominio.• Esfuerzos de análisis y diseño.• Traducción del conocimiento a código y su posterior prueba y depuración.• Interacción con un equipo multidisciplinario de trabajo.•
Desde un punto de vista más detallado, las funciones del ingeniero del conocimiento son:
adquirir conocimiento,• sugerir una estructura modular para la aplicación,• sugerir los mecanismos de • representación del conocimiento más adecuados yllevar un registro preciso que permita hacer seguimiento al conocimiento.•
Para poder realizar estas actividades con éxito, el ingeniero de conocimiento debe poseer las siguientes habilidades:
2 Para la fecha en que fue escrito este libro el Dr. Baralt se desempeñaba como profesor, investigador de la Universidad Simón Bolívar y uno de las personalidades más destacadas en el campo de la IA en Venezuela.

Inteligencia Artificial Básica
79Índice
analizar y conceptualizar el dominio (sus conceptos e interrelaciones),• aprender rápido,• comunicar efectivamente• dominar técnicas de adquisición y documentación del conocimiento• tener experiencia en la elaboración de bases de conocimiento• ser organizado y metódico y• poseer conocimiento en áreas diversas.•
El proceso de adquisición se realiza en dos fases. La adquisición del conocimiento para la creación de una base de conocimiento y la adquisición del conocimiento para la refinación de una base de conocimiento existente.
Desde el punto de vista del objetivo que se busca, el conocimiento puede ser conceptual y operativo. El conocimiento conceptual o declarativo lo forman todos los conceptos, objetos, tér-minos y en definitiva, cualquier otra cosa que el ingeniero de conocimiento tenga que conocer acerca del dominio del problema. Este conocimiento es lo primero que se tiene que adquirir y de su resultado depende la forma en la cual el ingeniero de conocimiento se prepara para realizar el resto del proceso de adquisición. El proceso de adquisición del conocimiento conceptual es algu-nas veces llamado Conceptualización del Dominio. El conocimiento operativo es propiamente el que determina la forma como se resuelven los problemas.
La eficiencia en el proceso de adquisición viene dada por la cantidad de conocimiento que se obtiene por unidad de tiempo. La cantidad de conocimiento se puede medir por el número de piezas de código que resulta de la transferencia o documentación. Las siguientes, son posibles causas que bajan la eficiencia en el proceso:
1. La falta de manejo y organización:Incapacidad del módulo de explicación.• Redundancia en el conocimiento.• Aumento en el costo y tiempo de desarrollo.• Dificultad en definir el alcance de la adquisición.• Nivel errado de abstracción del conocimiento adquirido.• Falta de una documentación apropiada.• Consumo de tiempo del ingeniero de conocimiento en otras actividades.• Enfadar a la fuente de conocimiento.•
2. La falta de entrenamiento del ingeniero del conocimiento.3. Errores en el traslado del conocimiento de la sesión al código:
Análisis incorrecto de los resultados de la sesión.• Mala escogencia de la técnica adecuada.•

Mauricio Paletta
80Índice
3.2. Técnicas de adquisición del conocimiento
La adquisición del conocimiento se puede realizar a través de tres formas:
Mediante entrevistas. A través de sesiones en las cuales se realizan un conjunto de pre-1. guntas en relación a hechos y procedimientos. Puede ser tedioso tanto para la fuente de conocimiento como para el ingeniero de conocimiento. Se requiere de mucha habilidad de este último en aspectos tales como comunicación, conceptualización y percepción. La fuente de conocimiento no sólo debe demostrar que tiene conocimiento sino además debe poder expresarlo. Requiere de poco equipo y es altamente flexible y portátil. Aprendiendo de lo que se dice en recuentos, relatos o referencias. La idea es establecer 2. y conducir diálogos entre las partes. Es útil para atacar problemas o casos específicos. La fuente de conocimiento debe expresar y refinar su propio conocimiento y de la habilidad con la cual éste lo haga, depende el éxito de la adquisición.Por observación. También conocido como inducción, el objetivo es presentar escenarios 3. o casos de estudio sobre el dominio de aplicación. Le permite a la fuente de conocimiento concentrarse en la formulación de ejemplos que permiten expresar su conocimiento (es útil para aquellos casos en la cual la fuente de conocimiento tenga dificultades de expresión).
Independientemente de la forma como se haga la adquisición, es recomendable tomar en cuenta las siguientes facilidades y equipos para la correcta realización del proceso:
Sesiones de no más de tres personas.• Mesa con superficie para escribir cómodamente o el uso de pizarras.• Libre de distracciones o ruido que pueda perturbar la sesión.• Medios audiovisuales como por ejemplo, grabadoras (solicitar aceptación primero con la • fuente de conocimiento).Colocar los equipos de video en lugares apropiados, si es el caso.• Uso de modelos o simuladores.• Salas confortables (tener una ventana con vista agradable, por ejemplo).•
El uso de equipos de video tienen la ventaja de que el ingeniero de conocimiento se ocupa de la forma en la cual se realiza la sesión y no del contenido de la misma. Por otro lado, no hay distracciones para escribir, no es posible que se pierda información y ésta se puede luego com-partir con los demás ingenieros de conocimiento del grupo de trabajo, si los hay. Pero no todo es bueno al usar estos equipos, ya que pueden provocar distracción en la fuente de conocimiento, requiere de una orientación y la sesión puede requerir más tiempo.

Inteligencia Artificial Básica
81Índice
El uso de pizarras o transparencias permiten la realización de diagramas, gráficos, etc., que facilitan el entendimiento de lo que se está expresando. Si es posible, se recomienda que los mecanismos que se usen no se pierdan al finalizar la sesión.
Hay un conjunto de técnicas que combinan las formas en las cuales se realiza la adquisi-ción del conocimiento y las facilidades y equipos descritos. Algunas de estas técnicas son las siguientes:
Tareas análogas: Consiste en el análisis de las tareas que son usuales a la fuente de cono-• cimiento y la revisión de bibliografía.Entrevistas estructuradas y no estructuradas: Cuando la entrevista tiene una preparación pre-• via a la sesión se dice que es estructurada. Por el contrario, cuando no se lleva nada prepa-rado y la sesión se realiza con preguntas que surjan de acuerdo al curso de la conversación, la entrevista es no estructurada.Tareas con información limitada: Son tareas familiares a la fuente de conocimiento pero sin • proporcionar información que normalmente está disponible o recursos auxiliares.Tareas con restricciones en el proceso: La idea es forzar situaciones en las cuales se presen-• tan ciertas restricciones. Se simulan tareas familiares tomando data archivada y produciendo cortes arbitrarios al proceso de la tarea. Se trabaja mediante escenarios cada uno de los cua-les representa la revisión de diversas variantes de un mismo caso con la óptica de similitudes o diferencias.Casos de excepción: Son tareas familiares pero considerando data representativa de un caso • -excepcional. Abordan características no usuales o familiares, por lo que representan un reto para la fuente de conocimiento. Requieren de métodos especiales por lo esporádico de su ocurrencia. En caso de que no se cuente con el ingeniero de conocimiento, se debe hallar el medio de preservar la situación para su análisis posterior.
Para la creación de la base de conocimiento se recomienda el uso del análisis de tareas aná-logas y las entrevistas no estructuradas. Para la refinación posterior de la base de conocimiento, son adecuadas las entrevistas tanto estructuradas como no estructuradas, las tareas familiares con información restringida y las tareas familiares con restricciones en el proceso. La tabla 3.1 presenta una comparación de los métodos expuestos.
Tabla 3.1Comparación de las técnicas de adquisición
Técnica Ventaja DesventajaTareas análogas Confortable para la fuente de cono-cimiento. Alto consumo de tiempo.Entrevistas Pueden generar mucha información. Alto consumo de tiempo.Información limitada Permite direccionar conocimiento de subdom-
inios.Poco confortable para la fuente de conocimien-to y reticencia a emitir juicios.
Proceso con restricciones Permite direccionar conocimiento de subdominios y de estrategia de la fuente de conocimiento.
Poco confortable para la fuente de conocimien-to y reticencia a emitir juicios.
Casos de excepción Descubre información de razonamien-to refinado. No se puede predecir su ocurrencia.

Mauricio Paletta
82Índice
La tarea de decidir cuál es la mejor técnica para ser aplicada sobre una situación específica está asignada al ingeniero de conocimiento. Para ello, se toman en cuenta variables como el tamaño y los objetivos del sistema, la fase de la adquisición, la disponibilidad de la fuente de co-nocimiento y el número y experiencia del ingeniero de conocimiento3. Los siguientes criterios son útiles para realizar una selección:
Duración de la actividad: total de tiempo a invertirse en la preparación, ejecución y análisis • de la tarea.Flexibilidad de la actividad: adaptación de la actividad a diferentes instrucciones, recursos, • fuentes de conocimiento.Simplicidad de la tarea: brevedad para especificar lo que se espera de la fuente de conoci-• miento y el orden.Simplicidad de materiales: cantidad y complejidad de los materiales y recursos en general, • requeridos para la actividad.Artificialidad de la actividad: variación entre la tarea familiar verdadera y la actividad.• Formato de los datos: similitud entre el formato de los resultados y el formato requerido para • la documentación del conocimiento.Validez de los datos: cantidad y valor de la evidencia que aportan los datos al conocimiento y • a las estrategias de razonamiento.Eficiencia del método: cantidad de información por minuto que proporciona el método de • acuerdo con cada caso.
Entrevistas. Dado que la forma más frecuente de realizar el proceso de adquisición es a través de entrevistas, es interesante analizar esta técnica en detalle. Aunque es la técnica más común, hay que tomar en cuenta que puede no ser la más correcta para un caso particular o puede también ser aplicada erróneamente.
Ya se mencionó con anterioridad que la entrevista puede ser estructurada y no estructurada. La entrevista no estructurada es el método central de adquisición, en ella aparecen un conjunto de preguntas espontáneas. La entrevista estructurada fuerza a una comunicación organizada y orientada, requiere de planificación y estudio de material previos.
Es recomendable que una entrevista no sea muy extensa (aproximadamente 1 hora) y se debe tener siempre a mano los materiales necesarios de forma tal de aprovechar el valioso tiem-po de la fuente de conocimiento. Es sumamente importante evitar las distracciones y mantener en lo posible el contacto visual. Lo más difícil de la entrevista es comenzar.
Las preguntas que aparecen en una entrevista pueden ser abiertas o cerradas. Las preguntas abiertas son aquellas que implican respuestas libres. Son apropiadas para reconocer el alcance 3 La experiencia sugiere que lo más recomendable es la combinación de diversas técnicas de adquisición.

Inteligencia Artificial Básica
83Índice
de la fuente de conocimiento en el dominio, su calidad de respuesta y lo que él considera impor-tante. Son ideales para la identificación de palabras claves, conceptos y referencias, necesario para la conceptualización del dominio. Consumen mucho tiempo y pueden ocasionar problemas a la hora de su codificación. “Discute”, “interpreta”, “explica”, “evalúa” y “compara” son algunas palabras claves que se pueden usar para formular preguntas abiertas. Algunos ejemplos de pre-guntas abiertas son:
¿ Cómo trabaja el sistema ?¿ Qué necesitas saber antes de tomar una decisión ?¿ Por qué escogiste esta opción ?¿ Cuál es tu opinión sobre … ?
Las preguntas cerradas son aquellas cuya respuesta limita el tipo, nivel y cantidad de infor-mación. Permiten detallar puntos específicos y tener un control más efectivo del progreso de la sesión, es decir, se aprovecha mejor el tiempo. Las palabras claves pueden ser: “qué”, “cuándo”, “dónde”, “quién”, “nombre”. Algunos ejemplos son:
¿ Cuántas horas demoraste en la cabina ?¿ Cuál de estas inversiones consideras la más fuerte?¿ Esto causa que la presión del aceite baje o suba ?¿ Es 225 grados el límite ?
Por otro lado, desde el punto de vista del orden en la cual se realiza la pregunta, éstas pueden ser primarias y secundarias. Las preguntas primarias son aquellas que se utilizan para abrir una sesión y permiten introducir un tópico. Las preguntas secundarias buscan más información sobre las preguntas primarias.
Se dice que una entrevista sigue una secuencia embudo cuando se abre con una pregunta abierta, se continúa con preguntas abiertas y cerradas secundarias y se termina con una pre-gunta cerrada. Este tipo de entrevista es más efectiva. Por otro lado, se presenta una secuencia embudo invertido cuando la sesión se abre con una pregunta cerrada, se continúa con preguntas abiertas y cerradas secundarias y se termina con una pregunta abierta. La ventaja de este tipo de entrevista es que permite refrescar la memoria de la fuente de conocimiento. La figura 3.1 detalla gráficamente los dos tipos de secuencia mencionados.

Mauricio Paletta
84Índice
Figura 3.1Secuencias de preguntas para una entrevista
Lo más importante que tiene que tener en cuenta el ingeniero de conocimiento a la hora de realizar una entrevista, es la forma como se comunica con la fuente de conocimiento. Algunas recomendaciones que se pueden seguir al respecto son las siguientes:
Parafrasear o hacer explicaciones. Ejemplos:• ¿ Creo que lo que me quieres decir es … ?¿ Me corriges si estoy equivocado, pero … ?¿ En otras palabras, … ?Clarificar. Ejemplos:• No entiendo, …Podrías explicármelo.Podrías repetir …Puedes darme un ejemplo.Sumarizar. Ejemplos:• En resumen, lo que has dicho …Creo que hemos concluido que …Trato de confianza. Ejemplos:• Te ves frustrado sobre …Te ves como si te pusieron obligado …Siento que estás disconforme con …
Por otro lado, algunas recomendaciones con respecto al vocabulario son las siguientes:
Evitar el uso de palabras con múltiples significados (ejemplo: papa).• Evitar el uso de palabras vagas (ejemplos: rápido, caliente, etc.).• Controlar el uso de palabras que expresan duda (ejemplos: casi, a lo mejor, etc.)• Eliminar inclinaciones en la pregunta (ejemplos: yo creo, mi opinión es, etc.).•

Inteligencia Artificial Básica
85Índice
La tabla 3.2 presenta el ejemplo de una sesión entre un ingeniero de conocimiento (IC) y un experto (E) sobre un dominio particular. Nótese cómo el ingeniero de conocimiento formula sus preguntas para obtener la información del experto.
Tabla 3.2Ejemplo de una entrevista entre un ingeniero de conocimiento y un experto
Adquisición de conocimiento con más de una fuente de conocimiento. Hay situaciones que, debido a las características del problema que se está tratando, amerita la participación de más de una fuente de conocimiento para su desarrollo. En aquellos casos donde estas fuentes de conocimiento son expertos y por ende el ingeniero de conocimiento tiene que interactuar con más de un experto, el proceso de adquisición llega a ser más complicado y amerita de la aplica-ción de otras técnicas especiales.
Trabajar con más de un experto no implica necesariamente que el SBC final va a contener más conocimiento o va a estar capacitado a resolver más problemas. Es importante estar claro de cuándo se necesita realmente múltiples expertos. En aquellos casos donde el dominio de la aplicación es muy restringido y hay muchos expertos, es necesario que se realice un proceso de selección y se utilice un sólo experto en el desarrollo.
Si el dominio es muy grande que amerita una subdivisión del conocimiento entre múltiples especialistas, o cuando se identifica que el conocimiento de los expertos llega a ser incompleto e inconsistente, entonces debemos usar todos los expertos cuyo conocimiento cubra en su tota-lidad el alcance del sistema final.
Ahora bien, cuando se trata del primer caso en el cual el dominio es muy grande y donde cada experto es utilizado para una de las partes en las cuales se dividió este dominio, se realiza con cada uno de ellos un proceso individual de adquisición aplicando las técnicas y demás sugeren-cias mencionadas con anterioridad. Por ejemplo, un experto especialista en eléctrica nos va a
IC Dados los síntomas, ¿ cuál es tu sospecha sobre la causa del problema ?E Probablemente está obstruida la inyección de combustible.IC Dijiste “probablemente”. ¿ Podría haber otra posible causa ?E Es posible que requiera un ajuste en los tiempos o puede necesitar un trabajo en las válvulas.IC Sería útil si pudieras ordenar estas posibles causas en orden de frecuencia de ocurrencia.E Cierto, creo que puedo hacerlo.IC ¿ Crees que el problema se debe más a la inyección de gasolina que a las otras causas ?E Claro, porque es la más común.IC ¿ Cuáles son los indicadores que aseguran lo que afirmas ?E Bueno, no tengo duda al respecto y yo conozco que esto pasa así.IC ¿ Podrías estimar un porcentaje que pueda describir que estos síntomas originan este problema ?E Si, es el caso más frecuente.IC Algo así como un 75 % u 85 %.E Yo diría un 80 %, pero eso depende del modelo del carro.IC Así que el modelo del carro es una variable importante.

Mauricio Paletta
86Índice
permitir extraer conocimiento para diagnosticar problemas en sistemas eléctricos, el conocimien-to de otro especialista en hidráulica nos va a permitir diagnosticar problemas en sistemas hidráu-licos. La unión de ambos dominios se convierte en un sistema para el diagnóstico de sistemas electrico-hidráulicos.
Los problemas serios vienen cuando múltiples expertos son usados para adquirir el conoci-miento sobre un mismo dominio y empiezan a surgir contradicciones entre los mismos. En estos casos hay que aplicar técnicas especiales para el trato con múltiples expertos y la resolución de conflictos. En general son cuatro los principales problemas que acontecen:
La diferencia de niveles (rango, situación, cultura, etc.) que existe entre los expertos.• Los conflictos personales e internos que puede haber entre los expertos.• Violar la confidencialidad (los expertos no quieren compartir el conocimiento entre ellos).• El conflicto de las opiniones sobre situaciones específicas (a veces se generan conflictos tan • sólo por querer llevar la contraria al otro).
Hay cuatro formas en las cuales se puede hacer adquisición con múltiples expertos:
Individualmente. El ingeniero de conocimiento trabaja con cada experto por separado y 1. en sesiones independientes. La ventaja de hacer esto es que se libera al ingeniero de co-nocimiento de la difícil labor de organizar y controlar un grupo de trabajo. El problema de trabajar de esta forma es que se tiene mucha más información que analizar (ya que hay más sesiones) e implica una posible solución de los conflictos que con seguridad van a aparecer. La parte a de la figura 3.2 ilustra esta situación.Como experto primario y secundario. Con miras de solucionar los conflictos que se gene-2. ran al realizar la adquisición mediante la forma anterior, en esta nueva forma de trabajo, la idea es identificar a uno de los expertos (que va a ser el primario) como el responsable de validar la información obtenida del resto (serían los secundarios) y por ende, tomar la deci-sión para resolver los conflictos en el caso de respuestas contradictorias sobre un mismo punto. El problema de esta forma de trabajo es que el ingeniero de conocimiento tiene que decidir quién es el experto primario, labor que resulta compleja la mayoría de las veces. (Ver figura 3.2 b).En grupos pequeños. Trabajar de esta forma le permite al ingeniero de conocimiento ob-3. servar esquemas alternos de solución para los problemas y los puntos claves que surgen durante las discusiones entre los expertos. Sin embargo, se necesita de mucha planifica-ción y habilidad de dominio de grupo por parte del ingeniero de conocimiento. (Ver figura 3.2 c)Como un panel. La intención de realizar un panel de trabajo con todos los expertos involu-4. crados en el desarrollo, es para concluir objetivos específicos y verificar o validar la infor-mación que el ingeniero de conocimiento ya tiene como resultado de sesiones anteriores

Inteligencia Artificial Básica
87Índice
de adquisición (figura 3.2 d). La desventaja de hacer un panel es que requiere de mucho tiempo y de mucho esfuerzo de planificación. Además, la difícil necesidad de contar con el tiempo de todos los expertos en un mismo momento.
Las consultas individuales aseguran la privacia y el respeto individual de cada experto. Una recomendación que se puede seguir es informar o presentar a los expertos la información adqui-rida con el resto. Esto es de mucha ayuda para la validación del conocimiento adquirido. Para ello hay que preservar la confidencialidad de los expertos.
Para realizar las consultas en grupo es importante seleccionar adecuadamente el equipo de trabajo. Si son amigables, cooperativos, etc. y tratar en lo posible de minimizar las diferencias que puedan existir. En estos casos, el ingeniero de conocimiento debe funcionar como líder o mediador de la sesión, ya que e el que las coordina y facilita las discusiones. Al concluir la sesión es recomendable sumarizar la misma.
Figura 3.2Formas de trabajo con múltiples expertos
Las técnicas de adquisición para tratar con múltiples expertos tienen que ver principalmente con dos cosas: resolver conflictos y el trabajo en grupo. Entre las más importantes se encuentran las siguientes técnicas:
Método de Delphi• 4: Se solicita la opinión de varios expertos sobre un problema específico. Las opiniones se clasifican y se le devuelven a cada experto solicitándole que ratifiquen o modifiquen su opinión inicial. El proceso se repite hasta llegar a una situación estable.
4 Linstone y Turoff, 1975.

Mauricio Paletta
88Índice
Tormenta de ideas• 5: Se presenta un problema al grupo y éstos proponen diferentes solucio-nes sin importar que sean inapropiadas. El ingeniero de conocimiento invita a los expertos a plantear sus ideas tan rápido como ellos puedan, ofreciéndole un turno a cada uno de ellos (si alguno de los expertos no tiene una contribución, puede pasar su turno). Es ideal para estimular el razonamiento y generar ideas de forma que no se den sólo las soluciones ordinarias.Consenso en toma de decisión: Se enfoca en encontrar la mejor solución a un problema. • Una forma de hacerlo es mediante la identificación de las ventajas y desventajas de cada respuesta para luego asignarle un peso o medida a la misma. La mejor respuesta será la que tiene mayor peso. Otra forma de llegar al consenso es mediante una votación entre los expertos sobre todos los planteamientos. La solución que alcance el mayor número de votos será considerada la mejor.Grupo nominal• 6: Es un procedimiento que reduce los efectos negativos que puede traer la interacción cara a cara entre los miembros del grupo. La idea es que el conjunto de exper-tos llegue a ser un grupo “nominal”, es decir, los miembros están juntos pero se les permite funcionar independientemente y hasta de forma anónima si lo desean. Por experiencia, esta técnica aumenta la creatividad de los expertos y la calidad de las soluciones.
Automatización del proceso de adquisición. Existen herramientas computacionales cuyo objetivo es automatizar el proceso de adquisición del conocimiento, con miras de ayudar al inge-niero de conocimiento en la realización de esta labor o servir como parte del sistema final, para incorporarle facilidades de aprendizaje o alimentación de conocimiento nuevo.
Herramientas de este tipo son implementaciones basadas en hallar el reverso de diagramas de influencia. El objetivo principal es la determinación de la relación causal “hipótesis implica ac-ciones” (causa-efecto) e inversión del esquema con la correspondiente herencia de influencias.
Se pueden identificar dos grupos de herramientas:
Sistemas basados en inducción. Como ejemplo se tienen los sistemas que extraen reglas de • producción a partir de bases de datos con la aplicación de algoritmos sobre los campos de las mismas. Por lo general tienen un basamento estadístico, lo cual no necesariamente modela la experiencia. Una herramienta de este tipo es “INDUCE”, que automatiza el algoritmo ID3 y permite extraer reglas a partir de una base de datos mediante la repetición del método de escoger el atributo de menor entropía y ramificar las restantes con respecto a él.Sistemas interactivos. La fuente de conocimiento puede interactuar directamente con ellos • sin la intervención del ingeniero de conocimiento, siendo guiado a través de una sesión en la que se toman diversos aspectos. Explotan exhaustivamente el conocimiento de un dominio o las técnicas de adquisición y en realidad no siempre los casos son tan “completos”. Como
5 En inglés “brainstorming”, ideada por Osborn en 19536 Huseman, 1973.

Inteligencia Artificial Básica
89Índice
ejemplo se puede citar a “MOLE”, un paquete que diferencia las fases de creación y refina-ción de la base de conocimiento y toma consideraciones sobre la indeterminación y exclusi-vidad en las asociaciones de los dos eventos manejados: síntomas e hipótesis.
Otros ejemplos son los siguientes:
TEIRESIAS: Creada para MYCIN; usa encadenamiento hacia atrás para adquirir, refinar y añadir nuevo conocimiento.
ETS (“Expertise Transfer System”): Usado para generar varios prototipos de sistemas exper-tos; realiza entrevistas automáticas con el experto y extrae vocabulario, conclusiones, etc.
BDM-KAT: Conjunto de herramientas que ayudan al ingeniero de conocimiento para trabajar con el experto; consiste de tres modos: clarificación, predicción y diagnosis.
KNACK: Permite evaluar diseños de sistemas electromecánicos.MORE: Para la realización de sistemas de diagnóstico de fallas en discos, problemas de redes
y problemas en circuitos; realiza entrevistas e identifica áreas críticas.KRITON: Usa tres métodos para hacer la adquisición: entrevistas, el análisis de textos y el
análisis de protocolos; permite adquirir tanto conocimiento conceptual como operativo.TDE (“Test Development Environment”): Se basa en la representación de la causa-efecto de
los problemas funcionales o fallas; es útil para sistemas de diagnóstico de falla en la industria.
3.3. Técnicas para la documentación del conocimiento
El conocimiento documentado es el producto que resulta luego de finalizar el proceso de ad-quisición y consiste en codificar el conocimiento adquirido. El proceso de codificación se realiza haciendo uso de un esquema formal previamente definido por el ingeniero de conocimiento.
Es importante documentar el conocimiento para que pueda ser fácilmente revisado y verifica-do por la fuente de conocimiento y luego ser llevado sin mucho esfuerzo a su representación final en la computadora. Por lo tanto, el esquema o formato de documentación debe ser muy practico y de fácil lectura y comprensión.
Por otro lado, la documentación del conocimiento ayuda al ingeniero de conocimiento en la localización de posibles errores que se pueden presentar debido a la gran cantidad de informa-ción que se tiene a lo largo de todo el proceso. Estos errores se presentan en el conocimiento operativo y se pueden dar de tres formas:
Redundancia: Es la duplicidad de código y ocurre cuando a partir de las mismas evidencias • se llega al mismo resultado.

Mauricio Paletta
90Índice
Inconsistencia: Es la contradicción en el código y ocurre cuando a partir de las mismas evi-• dencias se llega a resultados totalmente contrarios.Ciclos: Ocurre cuando a partir de un conjunto de evidencias se llega a concluir exactamente • lo que ya se sabe, representado en las evidencias.
Existe una gran cantidad de formas de documentar el conocimiento. En este libro solo voy a tratar dos esquemas:
tablas de decisión y• reglas de implicación.•
Tablas de decisión. Son tablas que separan la parte causal de las acciones mediante una línea horizontal. Las causas están una por cada fila en la parte superior y las acciones quedan una por cada fila en la parte inferior. Las columnas sucesivas de la tabla establecen las relaciones causa-efecto entre la parte superior y la inferior.
El formato de las tablas de decisión es como se muestra a continuación. Dentro de las casillas que están en el mismo nivel que las condiciones se coloca el valor de la condición asociado a cada una de las relaciones en la cual esta condición interviene. Por ejemplo, si la condición es una comparación, los posibles valores pueden ser ´S´ y ´N´ para representar Si (verdadero) y No (falso) respectivamente. Es posible colocar como condición una variable y el valor en la casilla construye la condición estableciendo la relación de igualdad entre la variable y el valor.
En las casillas asociadas a las acciones, simplemente se debe colocar una marca que indica que esa acción está implícita en la relación que se está definiendo.
Las tablas de decisión se pueden hacer de forma tal de agrupar el conocimiento en pequeños dominios o casos. Esto es importante para evitar que las tablas sean de un tamaño difícil de ma-nejar y leer. Para hacer esto, basta colocar el nombre de una tabla como acción. La ejecución de
Relaciones
Nombre R1 … Rp
C1
… … Condiciones
Cn
A1
… … Acciones
Am

Inteligencia Artificial Básica
91Índice
esta acción consiste en saltar de la tabla actual hacia la tabla identificada con el nombre expre-sado en la acción y continuar con el razonamiento.
Reglas de implicación. Son relaciones que separan la parte causal de las acciones mediante un operador de implicación. Las causas se encuentran lado izquierdo y están separadas por una coma (´,´) y las acciones se ubican del lado derecho de la implicación y también están separadas por una coma (´,´). La coma representa una operación de conjunción. El formato es como sigue:
Ejemplo1. Se usan las variables A, B, C, F, M y R y se debe añadir F2 a M si A es mayor que B; en caso contrario se comparan A y C. Si A es mayor que C se añade a M F3; si A es más pequeño que B y C, añadir 1 a R.
La tabla de decisión que resulta luego de adquirir y documentar el conocimiento queda como sigue:
Las reglas de implicación son:
Nótese que el número de columnas o relaciones en la tabla de decisión es exactamente igual al número de reglas de implicación.
Ejemplo2. Algunos militares son muy sensibles sobre sus rangos y la forma como dirigirse a ellos. Por lo tanto, es importante aprender a identificar los rangos de un militar mediante las insignias de su vestimenta. Si el uniforme tiene el rango identificado en el hombro, se trata de un oficial y se debe dirigir a él como “señor” además de su rango. Si el uniforme tiene el rango identi-ficado en la manga en forma de rayas, se trata de un recluta. Aquellos que llevan dos o más rayas en la manga son referidos como suboficiales y el número de rayas indica su rango. Cuando el uniforme lleva un águila en la manga (con o sin rayas), se trata de un especialista. Cada insignia denota un grado diferente. El único uniforme que no lleva ningún grado es el que usa el soldado raso. Cuando hay una raya en la manga, se trata de un soldado raso de primera clase; con dos
Ri: C1, …, Cn A1, …, Am
Ejemplo1 R1 R2 R3A > B S N NA > C --- S NAñadir F2 a M XAñadir F3 a M XAñadir 1 a R X
R1: A > B Añadir F2 a MR2: A <= B, A > C Añadir F3 a MR3: A <= B, A <= C Añadir F a M

Mauricio Paletta
92Índice
rayas es un cabo; con tres rayas es un sargento; con cuatro rayas es un sargento de estado. El sargento de primera clase usa cinco rayas y el sargento maestro seis. El rango más alto de los reclutas es el sargento mayor con siete rayas en la manga. A los especialistas se les aplica un esquema similar. El águila que ellos llevan en la manga puede contener también pequeñas rayas que identifican su rango. El águila sola denota especialista IV; con una raya simple, especialista V; especialista VI con dos rayas; especialista VII, tres rayas; cuatro rayas para el especialista VIII y por último, el especialista IX con cinco rayas. Un oficial que lleva una barra de oro es un teniente segundo; con una barra de plata es un teniente primero. Con dos barras de plata es un capitán. Un mayor lleva una hoja de roble de oro; la de plata la lleva un teniente coronel. El coronel tiene un águila de plata y sobre su rango hay cinco grados de general diferenciados por el número de estrellas de oro que llevan: general brigadier con una; general mayor con dos; general teniente con tres; general raso con cuatro y cinco para el general de la armada.
Ejemplo2 R1 R2rango en el hombro S N“señor” XOFICIAL XRECLUTA X
RECLUTA R1 R2 R3 R4 R5 R6 R7 R8 R9número de rayas 0 1 2 3 4 5 6 7 ---tiene un águila --- --- --- --- --- --- --- --- S“soldado raso” X“soldado raso de primera clase” X“cabo” X “sargento” X“sargento de estado” X“sargento de primera clase” X“sargento maestro” X“sargento mayor” XESPECIALISTA X
ESPECIALISTA R1 R2 R3 R4 R5 R6número de rayas en águila 0 1 2 3 4 5“especialista IV” X“especialista V” X“especialista VI” X “especialista VII” X“especialista VIII” X“especialista IX” X
Inteligencia Artificial Básica
93Índice
OFICIAL R1 R2 R3 R4 R5 R6 R7número de barras de oro 1 0 0 0 0 0 0número de barras de plata 0 1 2 0 0 0 0hoja de roble de oro N N N S N N Nhoja de roble de plata N N N N S N Náguila de plata N N N N N S Nnúmero de estrellas de oro > 0 N N N N N N S“teniente segundo” X“teniente primero” X“capitán” X “mayor” X“teniente coronel” X“coronel” X“general” XGENERAL X
GENERAL R1 R2 R3 R4 R5número de estrellas de oro 1 2 3 4 5“brigadier” X“mayor” X“teniente” X “ ” X“de la armada” X
R1: rango en el hombro, número de barras de oro = 1,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,no número de estrellas de oro > 0
“señor”,“teniente segundo”
R2: rango en el hombro,número de barras de oro = 0,número de barras de plata = 1,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,no número de estrellas de oro > 0
“señor”,“teniente primero”
R3: rango en el hombro,número de barras de oro = 0,número de barras de plata = 2,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,no número de estrellas de oro > 0
“señor”,“capitán”

Mauricio Paletta
94Índice
R4: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,hoja de roble de oro,no hoja de roble de plata,no águila de plata,no número de estrellas de oro > 0
“señor”,“mayor”
R5: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,hoja de roble de plata,no águila de plata,no número de estrellas de oro > 0
“señor”,“teniente coronel”
R6: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,águila de plata,no número de estrellas de oro > 0
“señor”,“coronel”
R7: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,número de estrellas de oro = 1
“señor”,“general”,“brigadier”
R8: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,número de estrellas de oro = 2
“señor”,“general”,“mayor”
R9: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,número de estrellas de oro = 3
“señor”,“general”,“teniente”
R10: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,número de estrellas de oro = 4
“señor”,“general”,“ ”
R11: rango en el hombro,número de barras de oro = 0,número de barras de plata = 0,no hoja de roble de oro,no hoja de roble de plata,no águila de plata,número de estrellas de oro = 5
“señor”,“general”,“de la armada”

Inteligencia Artificial Básica
95Índice
3.4. Esquemas de representación del conocimiento y sus mecanismos de inferencia
La representación del conocimiento es el proceso mediante el cual se expresa el conocimiento en la computadora haciendo uso de un esquema formal simbólico. El poder de un SBC radica en los esquemas seguidos para la representación del conocimiento y el motor de inferencia que actúa sobre éste.
La evolución en las técnicas y herramientas de representación del conocimiento ha estado orientada hacia un aumento en el nivel de abstracción para reflejar la realidad con un menor es-fuerzo e inversión de tiempo. Se pueden identificar tres generaciones:
R12: no rango en el hombro,número de rayas = 0
“soldado raso”
R13: no rango en el hombro,número de rayas = 1
“soldado raso de primera clase”
R14: no rango en el hombro,número de rayas = 2
“cabo”
R15: no rango en el hombro,número de rayas = 3
“sargento”
R16: no rango en el hombro,número de rayas = 4
“sargento de estado”
R17: no rango en el hombro,número de rayas = 5
“sargento de primera clase”
R18: no rango en el hombro,número de rayas = 6
“sargento maestro”
R19: no rango en el hombro,número de rayas = 7
“sargento mayor”
R20: no rango en el hombro,tiene un águila,número de rayas en águila = 0
“especialista IV”
R21: no rango en el hombro,tiene un águila,número de rayas en águila = 1
“especialista V”
R22: no rango en el hombro,tiene un águila,número de rayas en águila = 2
“especialista VI”
R23: no rango en el hombro,tiene un águila,número de rayas en águila = 3
“especialista VII”
R24: no rango en el hombro,tiene un águila,número de rayas en águila = 4
“especialista VIII”
R25: no rango en el hombro,tiene un águila,número de rayas en águila = 5
“especialista IX”

Mauricio Paletta
96Índice
El desarrollo de lenguajes de manipulación simbólica.• El desarrollo de herramientas ambientes de investigación.• El desarrollo de herramientas comerciales.•
De la representación del conocimiento se quiere poder expresivo o facilidad de su descripción (mientras más simbólico es el lenguaje, más potente su expresividad) y eficacia o facilidad de razonar (mientras más simbólico menos eficaz). Cada esquema de representación debe definir la estructura empleada para describir los elementos (sintaxis del lenguaje) y el proceso interpre-tativo o regla de inferencia que se requiere (semántica). Las características básicas que se desea cumpla un esquema de representación son:
Suficiencia representacional: abarcar todos los tipos de conocimiento existentes en el domi-• nio del problema.Suficiencia inferencial: capacidad de derivar nuevas estructuras a partir de las ya existentes • para lograr todas las respuestas necesarias.Eficiencia inferencial: capacidad de aprovechar el nuevo conocimiento incorporado para ob-• tener la respuesta más idónea.Eficiencia adquisicional: capacidad para incorporar nuevo conocimiento con facilidad.•
Una de las funciones del ingeniero de conocimiento es sugerir el esquema de representación más adecuado para el desarrollo de un SBC específico. Algunos de los criterios que este puede tomar en cuenta para hacer esta evaluación son los siguientes:
Transparencia: facilidad para identificar el conocimiento almacenado.• Claridad: facilidad para representar el conocimiento directamente de la adquisición.• Naturalidad: facilidad para representar el conocimiento en su forma original.• Eficiencia: facilidad de acceder a conocimientos específicos durante la ejecución.• Adecuación: usar una misma estructura para representar todos los conocimientos • requeridos.Modularidad: permitir el almacenaje independiente de fragmentos de conocimiento.•
Redes semánticas7. Son grafos dirigidos usados para representar gráficamente las relacio-nes entre los elementos de un dominio. Los nodos del grafo son los conceptos, objetos o ele-mentos que resultan de la adquisición y los arcos representan las relaciones entre dos elementos estableciendo la afirmación de un objeto con respecto al otro.
Dos de las relaciones más importantes que se expresan en una red semántica son “es-un” y “parte-de”. La primera establece una relación de generalización y el objetivo es asociar un ele-mento con otro de mayor jerarquía y un conjunto de propiedades en común. La relación “parte-de”
7 Quillian y Collins, 1968.

Inteligencia Artificial Básica
97Índice
es una agregación que liga un objeto a sus componentes8. La figura 3.3 presenta dos ejemplos diferentes de redes semánticas.
Los elementos relacionados en una red semántica satisfacen el concepto de herencia de propiedades, que establece que cualquier propiedad verdadera para una clase de elementos, es cierta para cualquier ejemplo de la clase.
Las redes semánticas tienen como ventaja su potencial a la hora de definir relaciones y son capaces de representar cualquier tipo de conocimiento. Además, ofrece una buena visión gene-ral sobre las relaciones y dependencias de un área de conocimiento y es muy apropiada para la estructuración y verificación del conocimiento. Pero su gran flexibilidad las hace ineficientes en la búsqueda de objetivos, tarea que no es tan fácil en la mayoría de los casos. Por otro lado, son poco flexibles para las modificaciones y su lectura se hace muy complicada cuando las bases de datos son muy grandes.
Figura 3.3Ejemplo de conocimiento representado en redes semánticas
En lo que respecta a la inferencia, esta se realiza por seguimiento de los enlaces o por acción de la herencia representada en la red. El razonamiento es muy directo y su implementación se realiza haciendo uso de algoritmos de búsqueda en grafos.
Lógica. Es el esquema más antiguo de representación. Se basa en la definición del qué de los objetos y su comportamiento. Encuentra su base en el cálculo de predicados que describe el conocimiento en forma de enunciados (predicados).
Los predicados son relaciones que se forman entre los símbolos del dominio; su valor es ver-dadero si los elementos están relacionados de una forma específica y falso en caso contrario. El 8 Haciendo una analogía con la orientación a objetos, “es-un” es similar al concepto de herencia y “parte-de” al concepto de instancia de objeto.

Mauricio Paletta
98Índice
cálculo de predicados es un lenguaje formal con sintaxis y gramática propias, capaz de valorar enunciados lógicos y extraer conclusiones para la creación de nuevos enunciados. Ver los ejem-plos de la figura 3.4.
Figura 3.4Ejemplo de conocimiento representado en lógica de predicados de primer orden
Mediante este esquema de representación se facilita la inferencia como descripción formal. La regla de inferencia es deducir la verdad de una conclusión de la veracidad de ciertas proposicio-nes. Es fácil de razonar ya que el razonamiento es un proceso lógico.
El predicado se escribe de forma tal que se separa el lado que se quiere afirmar (izquierdo), del lado que hay que probar (derecho), mediante un signo de implicación (implicación inversa). En otras palabras, para poder afirmar que lo que está del lado izquierdo es verdadero, hay que probar primero lo que está en el lado derecho. El número de elementos que se encuentran del lado izquierdo determinan el orden del cálculo de predicados. La lógica de predicados de primer orden es el sistema de lógica formal que más se emplea9.
Para definir un esquema de representación basado en la lógica, hay que plantear un alfabeto (sintaxis del lenguaje) para expresar los predicados, variables, constantes, funciones, conjuncio-nes, cuantificadores y delimitadores y, las reglas de inferencia a aplicar sobre el conocimiento para probar los enunciados.
Reglas de producción10. Es la forma más común de representar el conocimiento que se ideó para replicar una forma natural del comportamiento humano como lo es la heurística. Es la representación clásica del conocimiento causa-efecto bajo el esquema “si …, entonces …”. Los 9 El ejemplo más aceptado de representación de conocimiento en lógica de predicados de primer orden, es el lenguaje de programación Prolog (ver capítulo 5 de este libro).10 Post, 1943.

Inteligencia Artificial Básica
99Índice
SBCs cuyo conocimiento se representa mediante reglas de producción se denominan Sistemas de Producción11.
Una regla es una pieza de código sencilla, inteligible e inflexible formada por dos componen-tes, una parte izquierda y una parte derecha. La parte izquierda (LHS - “Left Hand Side”), llamada también el condicional o antecedente de la regla, contiene las premisas que justifican su existen-cia. La parte derecha (RHS - “Right Hand Side”) o consecuente, contiene el conjunto de acciones que representan la forma de actuar en respuesta a las premisas del antecedente. (Ver ejemplos en la figura 3.5 a).
La inferencia se establece cuando la regla de producción ejecuta sus acciones si el antece-dente es satisfecho (esto se conoce comúnmente como disparar la regla).
Aunque cada regla es independiente de las demás, es posible establecer una relación entre dos reglas cuando el consecuente de una de ellas satisface una parte del antecedente de la otra. A este tipo de relación se le da el nombre de cadena. Cuando las reglas de una base de conoci-miento se relacionan formando una serie de cadenas, se dice que hay un encadenamiento y su representación gráfica se denomina árbol de razonamiento (figura 3.5 b).
Una de las ventajas de las reglas de producción es su carácter declarativo e independencia que le permite explicar por ella misma todo el conocimiento que quiere representar. Además de su sencillez, son fácilmente agrupables en módulos lo que permite fraccionar la base de conoci-miento en subdominios con mucha facilidad.
Figura 3.5Ejemplo de conocimiento representado en reglas de producción
11 Uno de los lenguajes de programación más conocidos para desarrollar sistemas de producción es OPS-5. En el capítulo 5 de este libro se puede encontrar más detalles sobre este lenguaje y la teoría general de los sistemas de producción.

Mauricio Paletta
100Índice
Pero no todo es bueno en las reglas de producción ya que, gracias a su independencia, es di-fícil establecer relaciones y es muy fácil producir errores, como por ejemplo la inconsistencia que se muestra en la parte a de la figura 3.6, la redundancia (figura 3.6 b) y el ciclo (figura 3.6 c).
Figura 3.6Ejemplo de errores en la representación del conocimiento usando reglas de producción
Tres son los métodos de inferencia característicos de un SBC basado en reglas de produc-ción: el ensayo y error, el encadenamiento hacia adelante y el encadenamiento hacia atrás.
Ensayo y error es un algoritmo fácil de implementar. La idea es que dado una premisa, se prueba cada una de las reglas hasta encontrar alguna que se dispare. Es muy costoso en tiem-po ya que en el peor de los casos hay que recorrer toda la base de conocimiento. Por otro lado, dado que se realiza una búsqueda secuencial, la respuesta obtenida puede no ser la mejor. El algoritmo es como sigue:
-Dado una o varias premisas.-Mientras haya reglas hacer -Tomar una regla y probarla. -Si la regla se satisface con las premisas dadas entonces, -disparar la regla y retornar éxito.-Retornar que no hubo éxito en la búsqueda.
El encadenamiento hacia adelante consiste en buscar conclusiones definitivas de acuerdo a un conjunto de condiciones. La idea es seguir el árbol de razonamiento de izquierda a derecha hasta llegar a alguna de las terminaciones del mismo. En el algoritmo se identifican tres fases:
Decisión Obtener el conjunto de reglas que satisfacen las condiciones.1. Acción Ejecutar las acciones de las reglas identificadas en 1.2. Repetición Realizar 1 y 2 mientras el conjunto obtenido en 1 no sea vacío.3.
Para implementar el algoritmo hay que usar conocimientos previos de recorrido en grafos y árboles con criterios de nodos visitados. El algoritmo es como sigue:

Inteligencia Artificial Básica
101Índice
-Dado una o varias premisas.-Mientras haya reglas sin marcar hacer -Tomar una regla sin marcar y probarla -Si la regla se satisface con las premisas dadas entonces -disparar la regla y agregar a la evidencia las acciones ejecutadas, -marcar la regla.-Retornar como respuesta las acciones que se obtuvieron en la iteración final.
El encadenamiento hacia atrás por el contrario, consiste en buscar posibles condiciones de una conclusión dada. Esta vez, la idea es seguir el árbol de razonamiento de derecha a izquierda hasta llegar a alguna de las raíces del mismo. Las fases del algoritmo son:
Decisión Obtener el conjunto de reglas cuya conclusión sea la meta deseada.1. Acción Reemplazar la meta buscada por las condiciones de las reglas identificadas en2. Repetición Realizar 1 y 2 mientras el conjunto obtenido en 1 no sea vacío.3.
El algoritmo es como sigue:
-Dado una meta.-Mientras haya reglas sin marcar hacer -Tomar una regla sin marcar. -Si el consecuente de la regla actúa sobre la meta dada entonces -colocar todo el antecedente de la regla como meta a buscar, -marcar la regla.-Retornar como respuesta la evidencia que se obtuvo en la iteración final.
Encuadres12. Visión enfocada a objetos con uso natural de sus propiedades, instancias, he-rencia, clases y otros elementos propios de este paradigma. Surge como un intento de combinar las virtudes de las redes semánticas y las reglas de producción. “Un encuadre (“frame”) es una estructura de datos que sirve para representar una situación estereotipada, como estar en algún tipo especial de salón o ir a la fiesta de cumpleaños de un niño. Añadido a cada encuadre hay va-rios tipos de información. Parte de esta información hace referencia a cómo utilizar el encuadre; otra se refiere a lo que uno puede esperar que suceda en segundo lugar. Y otra a su vez indica qué hacer si tales esperanzas no son confirmadas” (M. Minsky).
12 M. Minsky, 1975.

Mauricio Paletta
102Índice
Un encuadre permite entonces, describir un concepto u objeto según un formato o modelo (plantilla). Esta plantilla consiste en una serie de ranuras (llamadas “slots”) cada una de las cua-les representa una propiedad o atributo del objeto o elemento representado en el encuadre. Una ranura puede ser una fórmula, un proceso, la referencia a otro encuadre o alguna característica propia del objeto lo que le da mucha flexible al esquema de representación. En un mismo en-cuadre se integra tanto el conocimiento conceptual como el operativo y es posible representar objetos complejos.
Los valores de una ranura son heredables, de forma tal que no hace falta sino modificar el valor jerárquicamente superior en la ranura y todas las instancias de los niveles inferiores del en-cuadre obtienen el nuevo valor. A cada ranura se le pueden asociar una serie de procedimientos para que se ejecuten automáticamente cuando, por ejemplo, se necesite, sea agregado, sea removido, etc. (Ver figura 3.7 para ejemplo).
Figura 3.7Ejemplo de conocimiento representado en encuadres
La inferencia se establece mediante las relaciones que existen entre los objetos (igual que en la red semántica), incluyendo la herencia y el proceso de instanciación. Los hechos se infieren relativamente rápido y se permite razonar con conocimiento incompleto.

Inteligencia Artificial Básica
103Índice
El aspecto más negativo que tiene este esquema de representación es la necesidad de rea-lizar un diseño preciso previo a su uso, cosa que, la mayoría de las veces, no es fácil ni directo luego de haber terminado el proceso de adquisición. Por otro lado, algunas veces puede ser difícil aplicar algunos tipos de razonamiento.
Orientación a objetos. Para la representación del conocimiento conceptual. Consiste en la definición de clases como un conjunto de atributos. Cada clase representa un concepto del do-minio. La herencia de clases representa la herencia de atributos. En el momento de la ejecución (proceso de inferencia) se crea el objeto como una instancia de la clase.
El término “orientación a objetos”13 significa que el problema se organiza como un conjunto de objetos discretos cada uno de los cuales incorpora su estructura de datos y su comportamiento. Es una nueva forma de pensar basado en los conceptos del mundo real.
Ejemplo. “Los naturalistas estudian las especies en peligro. Una de las especies que está en peligro es un ave llamado colibrí. Un caso particular es Y, un colibrí que vive en el nido N1 hecho de ramas secas, de un tamaño aproximado de 10 cm. y que está en el árbol A17, un araguaney ubicado en el jardín J de la casa C del señor X.
Una red semántica que representa este conocimiento es como sigue:
Algunos de los predicados de la lógica primer orden asociados a la red semántica anterior son como sigue:
13 La Orientación a Objetos está dominando actualmente muchas áreas de la informática, entre las cuales destacan los lenguajes de programación como C++, Java y Smalltalk, la interfaz gráfica y los sistemas operativos y las bases de datos. Muchos productos de software son Orientados a Objetos debido a la reducción de la complejidad y la facilidad de implementación.

Mauricio Paletta
104Índice
Dos de las reglas de producción correspondientes son:
Por último, ejemplos de algunos encuadres son como sigue:
Un ejercicio interesante es llevar el conocimiento de un esquema de representación a otro. Nótese en los casos anteriores las formas diferentes como se expresa la misma información y los aspectos importantes de cada esquema.

Inteligencia Artificial Básica
105Índice
3.5. Resumen del capítulo
La adquisición del conocimiento es la transferencia y transformación del conocimiento para la solución de problemas, desde la fuente de conocimiento hacia un esquema codificado del mis-mo. El ingeniero del conocimiento es el encargado de realizar este proceso. Se puede realizar a través de tres formas: mediante entrevistas, aprendiendo de lo que se dice y por observación. Algunas técnicas para realizar este proceso son: tareas análogas, entrevistas estructuradas y no estructuradas, tareas con información limitada, tareas con restricciones en el proceso y casos de excepción.
La técnica de adquisición más común es la entrevista. Las preguntas abiertas son aquellas que implican respuestas libres; las preguntas cerradas son aquellas cuya respuesta limita el tipo, nivel y cantidad de información. Las preguntas primarias se usan para abrir una sesión y las pre-guntas secundarias buscan más información sobre las primarias.
Si el dominio es muy grande o se identifica que el conocimiento de los expertos llega a ser incompleto e inconsistente, hay que hacer adquisición sobre más de un experto. Est amerita la aplicación de técnicas especiales: método de Delphi, tormenta de ideas, consenso en toma de decisión y grupo nominal. Hay cuatro formas de trabajar con múltiples expertos: individualmente, como experto primario y secundario, en grupos pequeños y como un panel.
La documentación del conocimiento consiste en codificar el conocimiento adquirido para fa-cilitar su verificación y posterior representación. Dos técnicas para hacer esto son: las tablas de decisión y las reglas de implicación.
La representación del conocimiento es el proceso mediante el cual se expresa el conocimiento en la computadora haciendo uso de un esquema formal simbólico. Los mecanismos de inferencia están íntimamente relacionados con el esquema de representación. Algunos de los esquemas de representación del conocimiento son: las redes semánticas, la lógica de predicados de primer orden, las reglas de producción, los encuadres y la orientación a objetos.
El esquema de representación más utilizado es el de reglas de producción y sus mecanismos de inferencia asociados son: ensayo y error, encadenamiento hacia adelante y encadenamiento hacia atrás.
3.6. Ejercicios
Para cada uno de los siguientes casos, realizar la documentación del conocimiento hacien-1. do uso de tablas de decisión y reglas de implicación.

Mauricio Paletta
106Índice
a) En una cierta agencia del gobierno, los visitantes son bienvenidos para ver las computa-doras mientras están en operación y no estén procesando material clasificado y cuando haya un guía disponible. Sin embargo, si alguna de estas condiciones no se da, no se les permite a los visitantes ver las computadoras a menos que no estén en operación.b) Una compañía necesita contratar los servicios de un grupo de secretarias que puedan tomar dictado de por lo menos 90 palabras por minuto y mecanografiar un mínimo de 50 palabras por minuto. También se quiere contratar un grupo de mecanógrafas que puedan escribir un mínimo de 50 palabras por minuto. Por último, se requiere de los servicios de una recepcionista que debe ser capaz de teclear un mínimo de 50 palabras por minuto y tomar dictado de a lo sumo 90 palabras por minuto y aunque la edad o raza no es importante, se desea que sea atractiva. Los flojos no son requeridos.c) Una firma que vende productos de limpieza usa el siguiente criterio para decidir el despa-cho de una orden: Si la orden es de no más de una docena de barriles y el departamento de crédito la ha aprobado y la cantidad en existencia es mayor o igual que la requerida, la orden se despacha. Si la cantidad en existencia no es suficiente, la orden se congela y se hace el pedido de los productos necesarios para cubrir las necesidades. Si la orden es de más de una docena de barriles se rechaza. Si el departamento de crédito no ha aprobado la orden y se trata de más de un barril, reducir la cantidad de barriles a la mitad y volver a entregar la orden al departamento de crédito.d) Si un carro necesita ser auxiliado para encender (usando cables o empujado), pero el motor no da revolución al intentar encenderlo, hay que revisar el voltaje de la batería, que debe estar entre 12 y 14.5 voltios. Si el voltaje es menor que 12 voltios indica una descar-ga de batería, pero hay que ver si se produce por alguna de las siguientes condiciones: si cuando el carro está en marcha disminuyen las luces o se va el sonido de la radio, significa que se descarga en marcha y se puede afirmar que es un problema de alternador; en caso contrario se produce cuando el carro está apagado y por ende se puede hablar de un robo de corriente. Si al auxiliar el carro da revolución y éste es de encendido electrónico, hay que ver si se apaga cuando está en marcha. Si es así, se trata del módulo de encendido electrónico o de la unidad magnética, en cuyo caso se deben revisar ambos; en caso contrario, se deben revisar la bobina y el rotor del distribuidor. Si el carro no enciende bajo ninguna circunstancia, se debe revisar la batería; si está seca y el tiempo de uso es mayor de 2 años hay que cam-biarla; sino, si al revisar el voltaje se tiene que el mismo es mayor que 14.5 voltios, estamos es presencia de un problema con el regulador; si el voltaje es normal se trata de una batería defectuosa; si el nivel de agua de la batería es normal, el carro no presenta ningún problema electromecánico.
Para cada uno de los casos anteriores, representar el conocimiento haciendo uso de los 2. siguientes esquemas: redes semánticas, lógica de predicados, reglas de producción y encuadres.

CapítuloLa Simulación Basada en Conocimiento
La Simulación Basada en Conocimiento es una de las respuestas de la IA para sustituir las técnicas
de simulación tradicional. Se estudian en este capítulo el por qué esta técnica ayuda a solventar los problemas de la simulación tradicional y cómo
se fundamenta.
4

Mauricio Paletta
108Índice
4.1. La simulación tradicional
La simulación ha resultado ser una herramienta poderosa para el estudio del comportamiento de sistemas del mundo real que son difíciles de representar matemáticamente. Representa el proceso de predecir el estado futuro de un sistema a través del estudio de un modelo ideal del mismo. Cuando hablamos de modelo nos referimos a una representación abstracta de la estruc-tura y función del sistema que debe ser flexible y extensible. Flexible en el sentido de que permite resolver diferentes tipos de situaciones que se presentan en el problema y extensible en el senti-do de que puede soportar cambios y modificaciones en el dominio del problema.
La simulación es uno de los principales métodos para predecir el comportamiento de sistemas complejos. Permite tomar decisiones sobre posibles acciones con base en predicciones. El mo-delo o comportamiento del sistema es usualmente representado por ecuaciones o distribución de probabilidades.
Desde el punto de vista en la cual se maneja el tiempo, se pueden identificar dos tipos princi-pales de simulación:
Simulación continua: Se da en aquellos sistemas que experimentan cambios uniformes de • sus características en el tiempo y su comportamiento es descrito mediante ecuaciones dife-renciales que expresan la forma en la cual las variables cambian en el tiempo.Simulación discreta: Predice el comportamiento de aquellos sistemas que están basados en • eventos. El sistema se observa solamente en puntos seleccionados del tiempo que coincide con eventos que pueden efectuar cambios en el sistema.
A veces el estudio de los sistemas continuos se simplifica considerando que los cambios ocu-rren como una serie de pasos discretos. Por ejemplo, los modelos de los sistemas económicos no siguen el flujo de dinero y bienes en forma continua sino que consideran los cambios a inter-valos regulares. Por otro lado, la descripción de los sistemas discretos se simplifica considerando que los cambios ocurren continuamente. Por ejemplo, se puede describir la producción de una fábrica como una variable continua, ignorando los cambios discretos que ocurren conforme se terminan los productos.
La tarea de obtener el modelo de un sistema comprende dos actividades: determinar la es-tructura, que fija la frontera e identifica las entidades, atributos y actividades del sistema y, pro-porcionar los datos que suministran los valores de los atributos que pueden tener y definen las relaciones involucradas en las tareas.
Desde el punto de vista de la forma en la cual se representan los atributos de las entidades del sistema, los modelos pueden ser físicos o matemáticos. En los modelos físicos, las actividades

Inteligencia Artificial Básica
109Índice
del sistema se reflejan en las leyes físicas que fundamentan el modelo. En los modelos matemá-ticos las actividades se describen mediante funciones matemáticas que interrelacionan con las variables que representan a las entidades y atributos del sistema.
Es difícil suministrar reglas para la construcción de modelos, pero si se pueden presentar al-gunos principios que pueden ayudar en esta tarea:
La descripción del sistema se debe organizar en una serie de bloques o subsistemas • (modulación).El modelo sólo debe incluir los aspectos relevantes del sistema en los objetivos del estudio • (relevancia).Se debe tener en cuenta la exactitud de la información recabada (exactitud).• Se debe considerar el grado con el cual se pueden agrupar las distintas entidades individua-• les en entidades mayores (agregación).
A pesar de las grandes ventajas que presenta la simulación, la industria ha avanzado muy lentamente en aceptarla como medio para analizar problemas de decisión compleja, ya que se presentan varios inconvenientes:
La complejidad de los lenguajes de simulación.1. La complejidad y la gran cantidad de tiempo que se requiere para la construcción de los 2. modelos.Sólo nos permite representar situaciones analíticas.3. El poco poder de expresividad que tiene. Se puede predecir la ocurrencia de los eventos 4. pero no se puede indicar como solucionarlos.No proporciona explicación o interpretación de la salida producida. Sólo se producen resul-5. tados numéricos y se deja la interpretación al usuario.El modelo se comporta como una caja negra.6. Se pueden hacer predicciones con el modelo, pero no se puede indicar cuál es la mejor 7. solución al problema.
4.2. Integrar IA y simulación
Durante varios estudios realizados entre los que se destacan los trabajos de Ramana Reddy, Tuncer Oren y otros, se encontraron varias áreas de influencia entre la IA y la simulación, más específicamente en lo referido a los SBCs. De hecho, un SBC y un sistema de simulación se ase-mejan en que ambos representan conocimiento y experticia acerca de un sistema y su comporta-miento en un dominio específico y ambos pueden manejar incertidumbre en el conocimiento.

Mauricio Paletta
110Índice
Otros factores como la existencia de herramientas de soporte inteligente para la simulación, el uso de técnicas de representación de conocimiento para modelar sistemas reales y la combina-ción de ambas, hacen ver que la simulación no está del todo aislada de la IA.
Hay un conjunto de factores que justifican la necesidad de integración entre la simulación y los SBCs:
Las limitaciones presentadas por los modelos de simulación se pueden resolver estudiando • estos mecanismos de integración.Los usuarios demandan modelos más realistas y poderosos.• Se necesitan las facilidades de expresión y justificación de resultados en los modelos.• Es indispensable ampliar el campo de acción de la simulación.•
4.3. La Simulación Basada en Conocimiento
La técnica que integra las características de un SBC para realizar los objetivos de un sistema de simulación es conocida como Simulación Basada en Conocimiento. Son sistemas de simula-ción que incluyen conocimiento sobre las estructuras y características de un sistema físico y que se manipula usando motores de simulación integrados a motores de inferencia.
Hay cuatro conceptos básicos a saber en el entorno de los Sistemas de Simulación Basados en Conocimiento (SSBC):
- el razonamiento cualitativo,- el modelado cualitativo,- la simulación cualitativa y- el razonamiento basado en modelos.
Razonamiento cualitativo. Enfoque de análisis de problemas que permite el estudio de sis-temas mediante el conocimiento general de los objetos en el ambiente estudiado y su comporta-miento y relaciones con una situación dada. Este enfoque se centra en tres puntos:
Causalidad: es el conjunto de elementos que permiten representar la propagación de la 1. información del sistema a través de las entidades para alcanzar el propósito final.Estructura: se asocia a las partes o entidades que forman el sistema.2. Función: se refiere al papel que cada entidad juega en el sistema.3.
Modelado cualitativo. Representa una abstracción del sistema que se quiere modelar y constituye una técnica basada en las descripciones de la estructura del dominio del problema. A

Inteligencia Artificial Básica
111Índice
partir de estas descripciones se define el modelo. Este estilo de modelado es más flexible para abstraer un sistema de la vida real ya que se utilizan al mínimo las ecuaciones diferenciales y derivadas que describen el sistema. Hace más fácil el arte de modelar.
Para la construcción de este modelo se realizan tres pasos. Primero se definen las entidades principales, luego se definen los atributos y funciones que caracterizan a cada entidad y por últi-mo, se definen las relaciones que permiten las conexiones entre estas entidades. La represen-tación del modelo se realiza mediante un grafo dirigido. Los nodos son bloques que identifican las entidades con sus atributos y funciones y los arcos representan las relaciones entre estas entidades. La figura 4.1 presenta un ejemplo genérico de esta situación.
Figura 4.1Ejemplo de Modelado Cualitativo
Para controlar el flujo en la red o grafo y conectar una entidad con otra, es necesario in-cluir en el modelo restricciones en las relaciones. Estas restricciones pueden ser cualitativas y cuantitativas.
Las restricciones cualitativas controlan el flujo en la red. Contienen todas las alternativas po-sibles y hace que se representen las relaciones de dependencia entre una entidad y otra. Por ejemplo: “cuando el freno electromagnético está funcionando el motor no puede funcionar”.
Las restricciones cuantitativas actúan sobre las variables exógenas del modelo definiendo el intervalo de valores para cada variable en su entorno de operación. Por ejemplo: “la cantidad de productos aleados en una colada es mayor que 0 y menor o igual que X”.
Nótese que en las restricciones se hace uso del conocimiento del dominio del problema. Es decir, este tipo de modelo contienen tanto conocimiento heurístico como conocimiento teórico.

Mauricio Paletta
112Índice
Simulación cualitativa. Es una técnica de simulación donde el sistema es representado por abstracciones cualitativas de las ecuaciones del sistema. Representa una simplificación del com-portamiento del sistema.
Razonamiento basado en modelos. En este caso, el conocimiento del sistema está conteni-do en un modelo y no en un conjunto de reglas. El modelo puede tratar con situaciones nuevas, es decir, no se restringe a un conocimiento ya conocido. Gracias a esta características, este tipo de modelado es muy usado en sistemas de diagnósticos.
Clasificación. Los SSBC son clasificados por la forma en la cual la información es transferida entre la componente numérica y la componente basada en conocimiento. Se definen cuatro tipos de sistemas:
Secuenciales integrados: La información fluye en un sólo sentido y se puede dar ya sea 1. por un SBC que genera resultados que son usados por la simulación (figura 4.2.a) o por una simulación que genera resultados que son usados por el SBC (figura 4.2.b). En estos sistemas los componentes se ejecutan uno después de otro en secuencia y de allí su nom-bre. Uno de las aplicaciones más comunes de este tipo de sistemas son las selecciones de candidatos óptimos. En este caso, el SBC genera escenarios para lograr un conjunto de metas y el simulador predice el resultado de la implantación de cada una de estas metas.
Figura 4.2Sistema secuencial integrado
Paralelos integrados: Consiste de un SBC y una componente de simulación numérica. 2. Cada una de estas componentes funciona como una entidad independiente y las dos se transfieren el control a medida que necesitan procesar conocimiento o hacer cálculos nu-méricos (ver figura 4.3).

Inteligencia Artificial Básica
113Índice
Figura 4.3Sistema paralelo integrado
Interfaz inteligente para simulación: En este caso, el SBC es elaborado de forma tal de 3. ayudar al usuario en la construcción dinámica del modelo de simulación. No exige que los usuarios tengan conocimiento de programación y de herramientas de simulación. Aquí la componente de simulación deja de ser una caja negra. La figura 4.4 muestra un diagrama de la forma como puede ser este tipo de sistema. Se puede ver que el sistema se basa en la especificación de componentes y procesos donde resaltan tres componentes principa-les: un diálogo para permitir al usuario describir el modelo; una base de datos de hechos y relaciones acerca del dominio y, una base de conocimiento que revisa la consistencia del modelo. El resultado es un modelo de simulación que puede ser empleado independiente-mente de la base de conocimiento. Una vez que se genera el modelo de simulación, éste puede ser cambiado por el sistema o directamente en el código del programa.
Figura 4.4Interfaz inteligente para simulación

Mauricio Paletta
114Índice
Totalmente manejado por conocimiento: Todo el sistema se maneja por conocimiento y por 4. ende la componente numérica del modelo es insignificante. El flujo del modelo es decidido totalmente por el conocimiento del sistema. Su uso depende exclusivamente del dominio del sistema a modelar.
Arquitectura. La figura 4.5 muestra la arquitectura completa generalizada de un SSBC. Se puede ver la existencia de cuatro módulos: interfaz, modelo, simulación y análisis de datos. El módulo de interfaz se encarga de la comunicación entre el usuario y el SBC. Este debe poseer una gran facilidad para el manejo directo de objetos gráficos; debe tener capacidad de presentar los resultados en forma gráfica y texto para facilitar la comprensión de los mismos.
El módulo modelo se encarga de la construcción y almacenamiento de los modelos de simu-lación. Mantiene contacto con el “banco de clases” (conjunto de definiciones abstractas) para realizar las instancias de cada entidad principal. Está formado por tres componentes:
Banco de entidades: representa todas las entidades principales que forman el sistema, 1. cada una de ellas con su representación interna, la respuesta a los mensajes del medio ambiente y la relación con otras entidades.Banco de modelos: son todos los modelos que estudian aspectos específicos del sistema. 2. Cada modelo puede ser utilizado para realizar corridas con datos particulares o como base para la construcción de un nuevo modelo. Para cada modelo se almacena la información referente a su uso, metas, etc.Banco de conocimiento: también llamado base de conocimiento, permite verificar la consis-3. tencia del modelo construido, asistir a los usuarios novatos en la construcción del modelo y ayudar en la selección del mejor modelo según las metas y los aspectos que se deseen estudiar. Es usado para la representación interna de los objetos complejos del modelo.
Figura 4.5Arquitectura generalizada de un SSBC

Inteligencia Artificial Básica
115Índice
El módulo simulación se encarga de ejecutar la corrida del modelo. Genera una lista de los eventos que se tienen que ejecutar, para lo cual se dispone de un mecanismo que controla la generación y secuencia de ejecución de cada evento. Este mecanismo decide cuándo debe eje-cutarse el próximo evento y qué funciones serán ejecutadas en cada evento. Es deseable que este módulo tenga capacidades gráficas para mostrar los cambios generados en el modelo en cada evento. Contiene además, mecanismos de inferencia con estrategias de encadenamiento hacia atrás, que le permiten indicar las condiciones iniciales para alcanzar una meta dada.
El módulo análisis de datos analiza los datos que resultan de la simulación. Decide si se lo-graron satisfacer las metas propuestas haciendo uso de una base de conocimiento que relaciona los datos obtenidos con las metas. Otro aspecto importante que se atribuye a este módulo es la de tener la capacidad de sugerir cambios que se pueden hacer al modelo para conseguir las metas esperadas. Otra base de conocimiento se usa para explicar e interpretar los resultados de la simulación que son enviados al módulo de interfaz para ser presentados al usuario.
Características ideales. Hay una serie de características deseables para que un SSBC sea exitoso:
El SSBC debe aceptar una descripción de las entidades que conforman el sistema y cons-1. truir el modelo en función de éstas. El conjunto de entidades con sus atributos y funciones se almacenan en un banco de clases. Para construir el modelo se forman instancias de cada entidad principal según las descripciones que el usuario suministra, que luego son relacionadas entre sí respetando las restricciones introducidas en la representación de la entidad.Para ejecutar la simulación se deben introducir una serie de metas en forma de restric-2. ciones o especificaciones a las cuales se les mide su grado de satisfacción, de acuerdo a los resultados obtenidos por la simulación. Cuando se termina de ejecutar un escenario, la base de conocimiento del sistema sugiere cambios que se le pueden realizar al modelo para ejecutar el escenario siguiente. Este proceso continúa hasta que las metas introduci-das se hayan cumplido.Capacidad de explicación del por qué de la escogencia de uno o varios escenarios para 3. cumplir las metas.Capacidad de interpretar los resultados obtenidos y dar recomendaciones sobre las ac-4. ciones a tomar. Esta es una de las características que más a gustado a nivel gerencial y aumenta la aceptación de los SSBC.Capacidad gráfica de explicar lo ocurrido durante el proceso de simulación, manteniendo al 5. usuario informado en todo momento sobre el comportamiento del sistema.

Mauricio Paletta
116Índice
4.4. Resumen del capítulo
La simulación es uno de los principales métodos para predecir el comportamiento de sistemas complejos. A pesar de sus grandes ventajas, la industria ha avanzado muy lentamente en acep-tarla ya que presenta varios inconvenientes. Para solventar estos inconvenientes se justifica la necesidad de integración entre la simulación y técnicas propias de la IA, en particular los SBC. Esta integración se conoce con el nombre de Simulación Basada en Conocimiento. Son sistemas de simulación que incluyen conocimiento sobre las estructuras y características de un sistema físico y que se manipula usando motores de simulación integrados a motores de inferencia.
Hay cuatro conceptos básicos asociados a la Simulación Basada en Conocimiento: el razo-namiento cualitativo, el modelado cualitativo, la simulación cualitativa y el razonamiento basado en modelos.
Los Sistemas de Simulación Basados en Conocimiento se clasifican según la forma en la cual la información es transferida entre la componente numérica y la componente basada en cono-cimiento: secuenciales integrados, paralelos integrados, interfaz inteligente para simulación y totalmente manejado por conocimiento.
La arquitectura generalizada de este tipo de sistemas contempla cuatro módulos: interfaz, modelo, simulación y análisis de datos. El módulo modelo comprende un banco de entidades, un banco de modelos y un banco de conocimiento.

CapítuloEl Procesamiento de Lenguaje Natural
Este capítulo describe en detalle una de las técnicas de resolución de problemas de la IA conocida con el
nombre de Procesamiento de Lenguaje Natural. Bási-camente se tratan dos aspectos: ¿qué se necesita saber para poder comunicar en lenguaje natural? y ¿cómo se pueden diseñar y construir sistemas que
conversen en lenguaje natural?
5

Mauricio Paletta
118Índice
5.1. Lenguaje natural y lenguaje formal
Entre los temas que los investigadores de IA trabajan, se encuentra la necesidad de hacer que un elemento artificial y un ente natural intercambien información voluntariamente o, lo que es lo mismo, se comuniquen. Para comunicarse, los humanos han desarrollado un sistema complejo y estructurado de signos llamado lenguaje.
El Procesamiento de Lenguaje Natural es el intento de realizar programas que emulen la forma en la cual los humanos se comunican a través del lenguaje. Los lenguajes artificiales (aquellos que son inventados y definidos en forma rígida), como por ejemplo los lenguajes de programación, se denominan lenguajes formales. La tabla 5.1 presenta las diferencias entre el lenguaje formal y el lenguaje natural.
Tabla 5.1Diferencias entre lenguaje formal y lenguaje natural
Un episodio típico de comunicación en el cual un orador X desea hacer llegar la frase F a un oyente Y haciendo uso de un conjunto de palabras P, se define mediante siete pasos:
Intención X desea que Y tenga creencia en F (por lo general X cree en F).1. Generación X escoge las palabras P que expresan el significado de F.2. Síntesis X expresa las palabras P (usualmente seleccionadas para Y).3. Percepción Y percibe P’ (lo ideal es que P’ = P; pero puede ocurrir error de 4. percepción).Análisis Y infiere que P’ puede significar F5. i, …., Fn (palabras y frases pueden tener muchos significados).Desambigüedad Y infiere que X intenta expresar F6. i (lo ideal es que Fi = F; pero puede ocurrir error de interpretación). Incorporación Y decide creer en F7. i (o lo rechaza si esto está fuera de la línea de creencia de Y).
Formal NaturalCreado Capacidad cognoscitiva innata y en evolución.Los símbolos generalmente tienen una sola interpretación
Existe ambigüedad: palabras tienen múltiples interpretaciones (Ejemplo: banco, sobre, etc.).
Dependencia limitada, relaciones especifica-das explícitamente (funciones, por ejemplo).
Casi todas las interpretaciones de expresiones dependen del contexto. Relaciones especifica-das implícitamente.
Interpretación literal solamente. La interpretación depende de la intención aso-ciada al discurso.

Inteligencia Artificial Básica
119Índice
Los tres primeros pasos son realizados por el orador y los cuatro últimos por el oyente. La “Intención” implica razonamiento sobre las creencias y objetivos del oyente; en la “Generación”, el orador usa su conocimiento sobre el lenguaje para decidir lo que tiene que decir; la “Síntesis” implica la definición y uso de procesos de salida de información (sonido, pantalla, papel, etc.); la “Percepción” implica la definición y uso de procesos de entrada de información (reconocimiento de caracteres a través de la visión o del sonido); el “Análisis” involucra la interpretación sintáctica y semántica de lo percibido; en la “Desambigüedad” se selecciona la mejor interpretación que resulta del análisis y por último, con la “Incorporación” se alimenta el conocimiento del oyente a su conveniencia.
La figura 5.1 muestra un esquema de los sietes pasos que se deben dar para que un orador le comunique a un oyente la oración “el animal está muerto”.
Figura 5.1Pasos que se dan cuando un orador comunica a un oyente la oración “el animal está muerto”
Quizás el paso más difícil en la comunicación es el análisis de lo percibido. La primera parte del análisis en la interpretación sintáctica o descomposición de la oración en sus partes. Una forma de ver el resultado del análisis sintáctico es mediante un árbol, como el que se muestra en el ejemplo de la figura 5.11. En estos árboles, los nodos internos representan frases, los enlaces son aplicaciones de las reglas gramaticales y en las hojas están las palabras.
1 Este proceso de descomposición de la oración en partes se llama comúnmente “parsing”, palabra que viene de la frase latina “pars orationis” y que significa partes de la oración. El árbol que resulta de hacer un “parsing” se denomina “árbol de parse”.

Mauricio Paletta
120Índice
La otra parte del análisis es la interpretación semántica, proceso de extraer el significado de una expresión hablada en cualquier lenguaje. Nótese que en el ejemplo de la figura 5.1, hay dos interpretaciones semánticas de lo percibido (no vivo y cansado). En este caso cuando hay más de una interpretación semántica de la oración, se dice que hay ambigüedad. Una de las maneras con las cuales se puede tratar con la ambigüedad, es mirando la situación actual o el contexto donde aparece la oración. La interpretación pragmática es la parte de la interpretación semántica que aprovecha la situación actual.
Desde un punto de vista externo, una oración se puede considerar como una secuencia de caracteres. Pero, cuando hablamos de comprensión, no sólo se refiere a un procesamiento de caracteres. Lo que interesa es entender el contenido y la primera dificultad para esto es saber exactamente lo que significa comprender.
Se puede afirmar que comprender conlleva a asimilar la información recibida, es decir, conec-tarla con el conocimiento que ya se tiene y esto implica un proceso de razonamiento. Por lo tanto, si el razonamiento es fundamental en el proceso de comprensión y la inferencia es una forma de hacer artificial el razonamiento, se puede concluir que un sistema de procesamiento de lenguaje natural tiene que ser capaz de producir inferencias. La comprensión se puede definir como el proceso de traducción de las oraciones a un formalismo que describa su significado y pueda ser manipulado automáticamente.
5.2. Procesamiento del lenguaje
Realizar procesamiento de lenguaje formal es usar programas como compiladores o interpre-tadores que contienen analizadores sintácticos y semánticos basados en la “Teoría de Parsig”2.
El objetivo del procesamiento del lenguaje natural es construir sistemas automatizados capa-ces de interpretar y generar información en lenguaje natural. Su base teórica está en entender las estructuras y procesos asociados a la interpretación del lenguaje.
Se pueden distinguir cuatro procesos sobre el lenguaje:
morfológico,1. sintáctico,2. semántico y3. pragmático4.
2 Este es el fundamento de la teoría general sobre los lenguajes de programación.

Inteligencia Artificial Básica
121Índice
Análisis morfológico. El análisis morfológico o léxico consiste en transformar la secuencia de caracteres de entrada en una secuencia de unidades significativas. El conocimiento necesario para realizar este proceso se distribuye entre un diccionario, unas reglas morfológicas y la forma de aplicar estas reglas.
El diccionario está normalmente formado por raíces, formas compuestas y excepciones que facilitan la búsqueda de palabras como los verbos conjugados. Todas las palabras que pueden tener significados diferentes tienen entradas diferentes en el diccionario, para que el analizador léxico ofrezca todas las soluciones posibles.
Las reglas morfológicas permiten construir las diversas variaciones que experimenta una pa-labra a partir de su raíz. Reducen o evitan las oraciones con estructuras sin sentido. El procedi-miento de análisis especifica cómo aplicar las reglas para reconocer en la oración las unidades lexicales definidas en los diccionarios.
El análisis morfológico es capaz de decir si una oración está formada correctamente o tiene estructura. Por ejemplo la oración
“verdes tienen orejas largas”
no está estructurada de forma correcta ya que una oración no puede empezar con un adje-tivo. Pero, las oraciones pueden ser morfológicamente correctas (estar formadas por palabras válidas en el diccionario y ubicadas correctamente) y carecer de estructura (sin sentido), como los siguientes ejemplos:
“Los aviones supersónicos tienen orejas largas”
“Los conejos supersónicos tienen orejas largas”
Análisis Sintáctico. En el análisis sintáctico se identifica la forma en que las unidades defini-das en el análisis léxico forman oraciones de acuerdo a las reglas del lenguaje. La sintaxis per-mite el reconocimiento de la estructura de las oraciones. La forma de representar la información sintáctica es haciendo uso de un conjunto explícito de reglas llamado la gramática del lenguaje.
Hay dos tareas que realiza el proceso de análisis sintáctico. Por un lado se reconoce si una oración es o no correcta según la gramática; en segundo lugar, se genera una representación de la oración que refleja su estructura sintáctica. Por ejemplo, la oración “la mujer incauta presenció la escena” se puede representar sintácticamente mediante la pequeña gramática siguiente del lenguaje español:

Mauricio Paletta
122Índice
Oración Frase_Sustantiva Frase_Verbal
Frase_Verbal verbo Frase_Sustantiva
verbo
Frase_Sustantiva artículo sustantivo adjetivo
artículo sustantivo
sustantivo
Gramáticas como la anterior se denominan de libre contexto ya que no se toma en cuenta el contexto que rodea la formación de la oración. Una variante son las gramáticas aumentadas que contienen algunas reglas adicionales sobre la validez de las frases (por ejemplo, la regla “Ora-ción Frase_sustantiva Frase_verbal” es válida sólo si el número y la persona correspondien-te a la Frase_Sustantiva concuerda con el verbo del predicado).
El análisis sintáctico debe tener presente los siguientes factores:
Las palabras pueden ser ambiguas. Por ejemplo, la palabra “junta” en las oraciones “él junta • las palabras” y “la junta comenzó tarde”.Las oraciones pueden ser estructuralmente ambiguas. Por ejemplo, en la oración “María • ve a José con el telescopio en la montaña”, ¿quién está en la montaña? y ¿quién tiene el telescopio?La estructura puede ser flexible en algunos lenguajes (el español es muy flexible). Por ejem-• plo, las siguientes cuatro oraciones expresan lo mismo: ¿ve María a José en la montaña?; ¿María ve a José en la montaña?; ¿ve María en la montaña a José? y ¿María ve en la mon-taña a José?.
La ambigüedad se da por haber más de una interpretación con la gramática. Es decir, se sigue más de un camino válido con una misma oración. Esto no es culpa del analizador sintáctico ya que en el lenguaje natural la ambigüedad es muy frecuente.
Un analizador sintáctico puede tomar en cuanta las siguientes estrategias para su operación:
Flexibilidad: aceptar frases aunque sean gramaticalmente incorrectas.• Análisis con vuelta atrás o en paralelo: explorar las diferentes alternativas a cada momento.• Análisis descendente: análisis de las reglas a la oración.• Análisis ascendente: análisis de las palabras al símbolo inicial de la gramática.• Análisis secuencial: análisis de la oración en dirección izquierda-derecha, a la inversa o avan-• zando a partir de una determinada palabra.

Inteligencia Artificial Básica
123Índice
Las gramáticas permiten expresar el problema del análisis en términos de la lógica. Por esa razón es que se utiliza mucho Prolog como lenguaje de programación para la implementación de este tipo de procesos.
El proceso sintáctico tiene que manejar dos problemas básicos. Por un lado debe tratar con palabras desconocidas y por otro, el tener que interpretar oraciones parciales.
Análisis Semántico. Proceso mediante el cual se asocian las expresiones lingüísticas a los conceptos manejados en nuestra visión del mundo. Tiene como objetivo extraer el significado literal (contenido preposicional) de la frase y representarlo adecuadamente. Por ejemplo, cuando se habla de “ratón”, se refiere al “mundo animal” o al “mundo de la computación”.
Hay diferentes propuestas en cuanto a la forma de llevar a cabo el análisis semántico y el tipo de representación que se tiene que hacer del significado. Por un lado se destaca el papel fundamental que juega el razonamiento de sentido común en el proceso de comprensión y que ponen su énfasis en esquemas de estructuración y organización del conocimiento necesario para realizar inferencias (entre las cuales destacan las redes semánticas y los encuadres).3
Por otro lado se considera que la representación del significado se debe hacer en términos de la lógica, de forma que los procesos de razonamiento se traten con mecanismos generales de deducción automática.
Mediante las restricciones semánticas, el significado de las palabras restringe el tipo de frases en las cuales pueden aparecer con sentido lógico. Por ejemplo, relaciones causales en las accio-nes de “comer”. Distintos niveles conceptuales del significado de las palabras son especificados mediante la jerarquía semántica. Ejemplo: “Juan está comiendo pan”.
Hay dos esquemas de trabajo en la cual se puede realizar u organizar el proceso de interpre-tación semántica, en relación al análisis sintáctico. En el primero de ellos, llamado entrelazado (figura 5.2.a), el análisis semántico se realiza luego de finalizar el análisis sintáctico. El otro caso (figura 5.2.b), llamado post-proceso ambos análisis se realizan simultáneamente para llegar a la representación final.
3 En este caso la implementación se da mediante programas llamados intérpretes que son capaces de manejar la representación escogida. Cada lenguaje de representación define las formas específicas de tratamiento e inferencia sobre los objetos que se pueden generar.

Mauricio Paletta
124Índice
Figura 5.2Organización del proceso de interpretación semántica
En el campo de la semántica hay muchos problemas entre los que destacan el tratamiento del tiempo, las modalidades, los indefinidos y cuantificativos, los nombres que designan cosas contínuas, los comparativos y superlativos, etc. Algunas sugerencias para tratar estos problemas son las siguientes:
Ver el alcance de los operadores:• “Juan conoce al profesor de cada alumno”• “Todos los países están gobernados por un capital”• Ver las referencias (principalmente pronombres):• “Gisela llegó tarde y su esposo se preocupó”• Cuidado con el significado de palabras identificados por el contexto:• “Encontré el reloj y la mica estaba rota”•
Análisis Pragmático. Este último paso del procesamiento del lenguaje natural es, finalmente, el que resuelve todas las referencias relativas al contexto, así como el que produce la interpreta-ción del significado literal en término del conocimiento sobre el dominio y las intenciones de los oradores. También se le llama análisis del discurso ya que la información existente en oraciones anteriores definen un contexto para la interpretación de oraciones posteriores.
El objetivo es categorizar el conocimiento para automatizar el proceso. Es necesario que las frases se relacionen con el texto o diálogo donde se produce con el fin de resolver pronombres, elipsis, frases incompletas, etc. Por ejemplo, de los siguientes diálogos:

Inteligencia Artificial Básica
125Índice
“¿Dónde está el pan?” “¿Dónde está el pan?”
“En la dispensa” “En la dispensa”
“Tráelo” “Ciérrala”
se puede afirmar que:
“El pan” designa a un objeto concreto, al igual que “la dispensa”.1. “En la dispensa” es una frase incompleta ligada a la anterior: “el pan está en la dispensa”.2. En el diálogo de la izquierda “…lo” se refiere al pan, mientras que en el diálogo de la dere 3. cha se refiere a la dispensa.
Para encontrar el referente de este pronombre es necesario determinar de entre todos los objetos que aparecen en el diálogo, cuáles son los posibles referentes y elegir uno de ellos. La propuesta más interesante para hacer la búsqueda de los posibles referentes es el mecanismo de foco de atención sugerido por B. Grosz. La idea es mantener un contexto donde estén de forma explícita los posibles candidatos para cada momento del diálogo. Un conjunto de reglas determina cómo actualizar el contexto en cada momento del diálogo.
La selección del mejor candidato del foco es de nuevo un proceso de razonamiento guiado por conocimiento. El dominio de este conocimiento determina el alcance de interpretación y com-prensión del discurso del procesador de lenguaje natural. Una de las teorías para expresar este conocimiento y organizar las inferencias en situaciones conocidas es la de los scripts, propuesta por Schanck.4
Los scripts permiten almacenar la estructura básica de un episodio de un tipo determinado, a la vez que proveen la capacidad de predecir actividades que no han sido referidas específica-mente y organizar las acciones que se han sucedido. Por ejemplo, para el concepto “operación”, se tiene el siguiente script:
Script: Operación
Lugar: Hospital
Elementos: Pabellón, anestesia, equipo quirúrgico, etc.
Condiciones de comienzo: Resultados:
Paciente está enfermo Paciente está operado
Paciente requiere operación Paciente sanará
Las elipsis se dan cuando en un diálogo el uso de un nombre o concepto contiene el foco de la intención del mensaje. Por ejemplo, en el siguiente diálogo:4 Basado en una generalización de la teoría de scripts, se construyó el sistema FRUMP, con 48 scripts y un vocabulario de 1.000 palabras. Al estar conectado a un teletipo durante un día de pruebas, FRUMP arrojó los siguientes resultados: de 368 textos producidos por el terminal, 121 eran noticias susceptibles de ser procesadas, sólo había esqueletos (unidad de abstracción por encima del script formado por una agrupación estructurada de scripts) para 39, de las cuáles 11 fueron interpretadas correctamente (30 % de éxito).

Mauricio Paletta
126Índice
“¿Cuál es la presión del paciente?”
“¿La temperatura?”
la segunda pregunta es igual a la primera cambiando el concepto al cual se está haciendo referencia. Algunas sugerencias para resolver elipsis son:
Mantener un registro de la información presente en las oraciones anteriores.• Analizar las nuevas oraciones haciendo unificación sintáctica y unificación de categorización • semántica.
Las anáforas, en cambio, son referencias mediante pronombres. Por ejemplo:
“Carlos fue operado por un equipo excelente de cirujanos. Estos tuvieron una reunión previa a la operación”.
Algunas sugerencias para resolver elipsis son:
Mantener una lista de todos los objetos mencionados.• Buscar un objeto en la lista que coincida en número, persona, género y tipo semántico.•
Otra forma de hacer referencias es a través de las definiciones de los conceptos del texto. Un caso de este tipo también se encuentra en el ejemplo anterior:
“Carlos fue operado por un equipo excelente de cirujanos. Estos tuvieron una reunión previa a la operación”.
Una sugerencia para resolver este tipo de referencias es aumentar la lista de los objetos mencionados con los posibles componentes, el role que desempeñan estos componentes y sus características asociadas.5
Uno de los fundamentos para la representación del conocimiento y la inferencia de la com-prensión del discurso es la Teoría de Dependencia Conceptual que establece que la acción en la oración no es representada por el verbo sino por la interrelación de un conjunto de Acciones Primarias cada una de las cuales está implícita en el significado del verbo. Por ejemplo, a partir de la oración “el asistente le dio la tijera al cirujano”, se puede inferir lo siguiente:
El cirujano tiene la tijera.1. El asistente no tiene la tijera.2. Ambos se encontraban a una distancia próxima.3. El asistente hizo un movimiento para pasar la tijera.4. El cirujano hizo un movimiento para recibir la tijera.5.
5 Esto está muy ligado al diseño orientado a objetos y al esquema de representación del conocimiento basado en encuadres.

Inteligencia Artificial Básica
127Índice
Una cosa importante que tiene que estar claro es que cuando se usa lenguaje natural, una gran cantidad de información no se dice explícitamente pero se puede inferir a partir de lo dicho.
El discurso es la unidad natural del lenguaje y no las oraciones aisladas. Un discurso coheren-te tiene estructura y por ende, no está formado por una secuencia de oraciones tomadas al azar. Una comunicación fluida en lenguaje natural requiere la habilidad de determinar el propósito de los interlocutores.
El reconocimiento de la estructura del discurso es de suma importancia para determinar el significado y/o propósito del mismo. Para entender el discurso es necesario reconocer su es-tructura y para generar un discurso coherente se requiere seguir una estructura específica. El sentido común, el conocimiento del dominio y la capacidad de razonamiento son necesarios para entender el discurso; sin embargo, no son suficientes. La figura 5.3 muestra los pasos a seguir para realizar el proceso de interpretación del discurso.
Figura 5.3Proceso de interpretación del discurso
El tratamiento adecuado del contexto requiere de la coordinación de múltiples fuentes de conocimiento y la habilidad de “enfocar” la atención sólo en información relevante. Los puntos claves de la pragmática (uso del lenguaje en relación al contexto) se refieren a cómo inferir co-nexiones entre las oraciones y cómo reconocer la intención de los interlocutores. Para realizar el proceso de interpretación pragmática se requiere el siguiente conocimiento:
Conocimiento general de actividades comunes y situaciones (scripts y encuadres).• Conocimiento general de resolución de problemas.• Conocimiento específico acerca de la creencia e intención de los interlocutores.• Conocimiento específico de la situación•
Hay dos técnicas que son las más importantes para modelar el contenido del discurso:

Mauricio Paletta
128Índice
“Script Matching”. Se realiza un modelo en el cual se describen de forma coherente las ac-• ciones involucradas en una situación determinada. La idea es asociar el discurso a un script. Presenta dos dificultades. Por un lado hay que identificar el script apropiado, tarea que puede no ser fácil y, por otro lado, la poca capacidad para el manejo de situaciones complejas.Reconocimiento del plan de discurso. El plan de discurso es constituido a partir de las ac-• ciones observadas y la situación actual. Es más flexible que la anterior pero, es limitado al dominio de situaciones que involucren la ejecución de acciones.
5.3. La arquitectura básica del procesador
La información que se necesita manejar para realizar el procesamiento de lenguaje natural se resume en los siguientes conceptos:
Léxico• . Información sobre las palabras: morfología, categoría semántica y significados en términos del dominio del modelo.Gramática• . Forma en que las palabras se combinan para formar expresiones válidas en el lenguaje: Reglas sintácticas.Reglas semánticas• . Asocian a la estructura sintáctica una representación lógica formal del significado expresado.Reglas del discurso• . Determinan el efecto del contexto en la interpretación.Reglas para el reconocimiento de la intención• . Determinan la conexión entre lo dicho y la intención implícita asociada.
La figura 5.4 muestra cómo esta información es usada por los diferentes procesos de análisis para conformar la arquitectura básica del procesador de lenguaje natural.

Inteligencia Artificial Básica
129Índice
Figura 5.4Arquitectura básica de un procesador de lenguaje natural
5.4. Aplicaciones
Las motivaciones prácticas más resaltantes de hacer procesamiento de lenguaje natural son:
Desarrollar nuevos esquemas de interfaz hombre-máquina.• Disminuir la diferencia entre los conceptos que manipulan los hombres y la forma en que • éstos se codifican en una computadora.Procesar grandes volúmenes de texto.•
Las aplicaciones de lenguaje natural se pueden dividir en aquellas que son basadas en diálo-gos y aquellas que no lo son. Las aplicaciones basadas en diálogos en estos momentos constitu-yen el principal campo de utilización del lenguaje natural debido a las siguientes razones:
El auge que han tenido en los últimos años las aplicaciones de tipo interactivo.1. La ampliación de usuarios potenciales de un sistema y la necesidad de acercar el lenguaje 2. de comunicación al lenguaje usado por estos usuarios.

Mauricio Paletta
130Índice
La ventaja que para un sistema de tratamiento del lenguaje natural supone poder co-3. municarse con el usuario para requerir confirmación ante una decisión insegura, solicitar información adicional, etc. La ventaja que para el sistema supone la fragmentación del texto en unidades pequeñas.4.
Las principales aplicaciones basadas en diálogo son las interfaces hombre-máquina y los sistemas de acceso a bases de datos en lenguaje natural. Es importante resaltar que el uso de diálogos en lenguaje natural es una solución muy útil para resolver el problema de comunicación pero, no siempre es la mejor solución.
De entre los sistemas de acceso a bases de datos, los más importantes a considerar son los llamados sistemas transportables cuyo objetivo es funcionar, mediante un módulo de adquisición o aprendizaje, en entornos diferentes: cambio de la estructura de los datos, cambio en la semán-tica de los datos y cambio en la aplicación. Las características que poseen estos sistemas son:
La información está claramente dividida entre las partes dependientes y las independien-1. tes de la base de datos y del dominio. La parte dependiente es lo más pequeña posible, siendo normalmente la sintaxis más 2. independiente del dominio que la semántica. Los mecanismos lingüísticos son inalterables, de forma que el proceso de adquisición del 3. nuevo dominio se realiza mediante un diálogo con un experto en la nueva base de datos y no con un lingüista. La representación del conocimiento en la parte dependiente de la base de datos es lo su-4. ficientemente general que permite su aplicación a cualquier base de datos. El sistema de representación de la información del dominio permite la descripción de cual-5. quier dominio semántico.
Los sistemas no basados en diálogo son aquellos en los cuales el diálogo no es fundamental o es inexistente. Por lo general son sistemas de tratamiento masivo de información y sus aplica-ciones más relevantes son los sistemas de traducción automática y los sistemas de tratamiento de la información textual.
Es común, en todos los sistemas de traducción, la separación clara de algoritmos por una par-te y gramáticas y diccionarios por otra. Todos los sistemas admiten la necesidad de una o varias teorías lingüísticas sobre las que apoyarse. Existen sistemas que realizan la traducción directa desde el lenguaje fuente al objeto. Otros, en cambio, utilizan un paso intermedio en la traducción (puede ser un sistema de representación del significado independiente del lenguaje superficial).
Los sistemas de tratamiento de la información textual están conformados por aplicaciones de edición y corrección de textos, sistemas de indiciación y sistemas de documentación. Entre los

Inteligencia Artificial Básica
131Índice
problemas que se tienen en los sistemas de edición y corrección de textos está la partición de una palabra entre dos líneas por una posición correcta y el de la corrección de palabras.
La indiciación de información textual mediante palabras clave es una aplicación muy exten-dida: bibliotecología, bases de datos de información, etc. El proceso tiene dos fases separadas: la incorporación de un texto a la base de datos, con la consiguiente selección y almacenamiento de las palabras clave o descriptores y el acceso posterior, mediante esos descriptores a la infor-mación almacenada. En la mayoría de los casos el proceso de selección de los descriptores es manual (su estructura se reduce a una simple lista asociada al documento indiciado).
La primera característica de los sistemas de documentación con soporte de lenguaje natural es la de tener como estrada documentos altamente estructurados. La segunda característica es la de tener un dominio semántico estrecho y definido (palabras muy denotativas, poca ambigüe-dad, definición clara de clases léxicas de tipo semántico, etc.).
5.5. Resumen del capítulo
El Procesamiento de Lenguaje Natural es el intento de realizar programas que emulen la forma en la cual los humanos se comunican a través del lenguaje. Un episodio típico de comu-nicación se define mediante siete pasos: intención, generación, síntesis, percepción, análisis, desambiguedad e incorporación.
El paso más difícil en la comunicación es el análisis de lo percibido que comprende dos partes: la interpretación sintáctica y la interpretación semántica.
El objetivo del procesamiento del lenguaje natural es construir sistemas automatizados capa-ces de interpretar y generar información en lenguaje natural. Su base teórica está en entender las estructuras y procesos asociados a la interpretación del lenguaje. Se pueden distinguir cuatro procesos sobre el lenguaje: morfológico, sintáctico, semántico y pragmático.
La información que se necesita manejar para realizar el procesamiento de lenguaje natural se resume en los siguientes conceptos: el léxico, la gramática, las reglas semánticas, las reglas del discurso y las reglas para el reconocimiento de la intención.

CapítuloLas Redes Neurales Artificiales
La Neurocomputación o Conexionismo o Redes Neuronales o simplemente Redes Neurales
Artificiales (RNA) son algunos de los nombres que se le ha dado a la técnica de resolución de
problemas de la IA que busca emular la forma como el sistema neural humano trabaja. Esta importante técnica de mucho auge en la actualidad se estudia
con detalle en este capítulo.
6

Inteligencia Artificial Básica
133Índice
6.1. El sistema neural humano
La inquietud de si se puede algún día desarrollar mejores y más eficientes herramientas artifi-ciales empleando circuitos inspirados en la estructura del cerebro, ha sido propuesta por investi-gadores un par de veces al año durante las últimas tres décadas. La respuesta sigue siendo “tal vez… pero no pronto,” a pesar que desde comienzos de siglo la comprensión de los procesos neurales y sus principios ha ido aumentando en forma exponencial1.
Como resultado de estas investigaciones, surge una imagen de la organización y estructura del cerebro que difiere marcadamente de aquella que se tenía por cierta hasta hace unos años. Los modelos primitivos del cerebro de finales del siglo pasado, asumían que éste era una red de neuronas interconectadas al azar. Los modelos siguientes admitían que efectivamente había algún tipo de orden, pero que éste era superficial y poco relevante para el funcionamiento del tejido. Si bien se reconocía la existencia de áreas cerebrales con funciones particulares, pocos aceptaban que los patrones de interconexión neuronal eran críticos para el desarrollo de dichas funciones (se tendía a creer que éstas eran fruto de la compleja actividad de neuronas específi-cas, actividad cuyo origen y propósito no eran del todo comprendidas).
En los modelos actuales es ampliamente aceptado que las neuronas, lejos de estar interco-nectadas al azar, están organizadas en patrones altamente regulares y se encuentran agrupadas en claras divisiones funcionales. Aunque, en un examen microscópico, la distribución de las neu-ronas recuerda mucho la disposición aleatoria de las ramas y raíces de los árboles en una selva (de ahí el origen de la teoría de las conexiones al azar), ese desorden es tan sólo aparente. Las interconexiones neurales siguen con frecuencia “mapas” precisos y regulares que se extienden desde los órganos de los sentidos hasta las regiones de procesamiento sensorial situadas en la corteza o en los núcleos subcorticales, así como desde los centros motores del cerebro o de la médula espinal hacia las diversas partes del cuerpo. De hecho, durante el desarrollo del cerebro, las neuronas de un área determinada localizan y establecen contactos específicos con neuronas situadas en otras áreas, a veces bastante retiradas.
Recientemente, tanto neurofisiólogos como investigadores en el área de las RNAs han pres-tado gran atención a esta propiedad del tejido neural de organizarse en “mapas topológicos” que preservan alguna propiedad importante de los estímulos recibidos. Es muy posible que la auto-organización sea la clave para lograr una de las metas de la IA que se ha denominado “procesa-miento inteligente de la información”. Lo importante a averiguar es identificar las propiedades de las neuronas que dan origen a la auto-organización del tejido neural.
1 La información acumulada acerca de la anatomía, fisiología y funcionamiento del tejido neural ha crecido grandemente gracias a novedosas técnicas de investigación y análisis entre las cuales se cuentan la tomografía por emisión de positrones, la radiohemodinamia cortical por in-fusión de xenón, la tomografía por resonancia magnética nuclear y la inmunofluorescencia, por mencionar algunas. Con excepción de la última, que puede trazar las conexiones de una población de neuronas, estas técnicas son no invasoras y permiten el examen dinámico de un cerebro vivo mientras se le somete a estímulos sensoriales cuidadosamente controlados por el experimentador.

Mauricio Paletta
134Índice
Las Neuronas. Aunque todos los cerebros de una especie animal son fundamentalmente iguales, su estructura varía ligeramente de un individuo a otro. Así mismo, aunque todas las neuronas son fundamentalmente iguales, su estructura varía de un ejemplar a otro. En el cerebro humano, por ejemplo, hay más de 10.000.000.000 de neuronas, tantas como árboles individua-les hay en una gran selva como la del Amazonas, con tantos tipos y tamaños distintos como especies diferentes de plantas hay en un pequeño bosque. No hay dos neuronas exactamente iguales, así como no hay dos árboles idénticos, aunque sean de la misma especie.
Las neuronas son células altamente especializadas que toman su forma y estructura precisa del medio ambiente que las rodea. Es decir, de la composición química del medio fisiológico que las alimenta, de las hormonas que las afectan y de los campos eléctricos y gradientes químicos que experimentaron durante su crecimiento y maduración. En particular, las neuronas son fuerte-mente afectadas por la naturaleza y distribución en el tiempo de los potenciales eléctricos y neu-rotransmisores producidos en su cercanía como resultado de la actividad de otras neuronas.
Desde el punto de vista de su función, las neuronas se clasifican en cuatro grandes grupos: sensoriales, motoras, de comunicación e interneuronas. Los dos primeros grupos se especiali-zan en transmitir señales entre regiones distantes del cuerpo (por ejemplo, desde los órganos de los sentidos hacia el cerebro o desde éste hacia los músculos). Las neuronas de comunicación conectan entre sí áreas del cerebro que pueden incluso estar separadas por decenas de centí-metros, pero no abandonan jamás la circunscripción del tejido. Las interneuronas son neuronas de comunicación que limitan su alcance a unas pocas décimas de milímetro a su alrededor, en-trando en contacto tan sólo con sus vecinas inmediatas.
A pesar de las marcadas diferencias morfológicas existentes entre los diversos tipos de neu-ronas, todas estas células están compuestas por un cuerpo celular o soma, las dendritas con sus importantísimas “espículas sinápticas”, el axón con un recubrimiento opcional o “vaina de mieli-na” y las ramificaciones terminales. La figura 6.1 muestra la forma más natural de una neurona e identifica cada una de sus partes.
El soma constituye la parte central y más voluminosa de la neurona. Su forma es variada (en algunas células es esférico, piramidal o de estrella en otras) pero frecuentemente es irregular. Dentro del soma y generalmente en el centro, se halla el núcleo, que dirige las funciones me-tabólicas de la célula con su información genética. Suspendida en el citoplasma del soma se encuentra la maquinaria metabólica necesaria tanto para la supervivencia de la célula como para producir y mantener la actividad de los mecanismos propios de la neurona.

Inteligencia Artificial Básica
135Índice
Figura 6.1La neurona y sus partes
Las dendritas son estructuras filamentosas que se desprenden del soma de manera similar a como las ramas o raíces de los árboles se desprenden del tronco. Su única función es la de hacer contacto (sinapsis) con otras neuronas, por lo que su superficie se halla profusamente recubierta por regiones o “espículas sinápticas”2.
El axón es un largo tubo que se desprende del soma. Su propósito es el de transportar las señales eléctricas producidas por la neurona desde el soma, donde se originan, hasta los bo-tones terminales del axón, donde se transmiten a otras neuronas o células efectoras (como las musculares). Algunas neuronas envían largos axones a lugares distantes del cerebro o de la médula espinal (los axones de las neuronas motoras llegan a abandonar el cerebro, terminando con células musculares y glandulares situadas en regiones periféricas del cuerpo). La mayoría de las neuronas, sin embargo, tan sólo proyectan axones a sus vecinas más cercanas.
El potencial de membrana. Todas las células están rodeadas por una membrana aislante compuesta fundamentalmente por ciertos tipos de grasas. Las neuronas no son excepción y tam-bién poseen esta membrana. En este caso, en lugar de ser una envoltura pasiva, la membrana celular es un órgano activo que da a la célula nerviosa sus propiedades particulares.
En las neuronas, la membrana celular crea un potencial eléctrico a través de sí misma al “bombear” iones de sodio hacia la parte exterior de la célula, a la vez que admite iones de potasio hacia el interior. La membrana es bastante impermeable al sodio, por lo que gran parte del mis-
2 Cuando se examina microscópicamente una sección de tejido neural, la extensa ramificación dendrítica da al corte el aspecto de un bosque densamente poblado, por ello frecuentemente se habla de las “ramificaciones dendríticas” o del “árbol dendrítico”.

Mauricio Paletta
136Índice
mo permanece fuera. Por el contrario, es relativamente permeable al potasio, por lo que buena parte de éste se difunde nuevamente al exterior. Como consecuencia de este flujo de iones se establece una diferencia de potencial eléctrico a través de la membrana, haciendo al interior de la neurona unos 70 milivolts más negativo que el exterior. A este gradiente eléctrico se le denomina potencial de membrana. En efecto, la neurona aprovecha la acción del bombeo sodio-potasio para convertirse así misma en una pequeña pero eficiente batería eléctrica.
Este bombeo iónico lo realizan varios cientos de millones de complejos proteínicos activos denominados “canales iónicos” que se hallan dispersos a lo largo de la membrana. Cada ca-nal es específico al paso de un determinado ión, sea sodio, potasio, calcio o cloro. Igualmente, cada canal bombea iones ya sea hacia el interior de la célula o hacia el exterior, pero no en ambas direcciones a la vez (aunque existen “compuertas” que permiten el flujo iónico en ambas direcciones).
Dependiendo de la presencia de un estímulo apropiado, los canales pueden abrirse o cerrar-se al paso de los iones. En función de esto, se clasifican en canales excitables por estímulos externos (neurotransmisores, hormonas, luz, presión, etc.) y canales excitables por estímulos internos (presencia de un potencial eléctrico o la concentración de ión calcio en el interior de la neurona).
La actividad de los canales iónicos siempre afecta el potencial eléctrico de la membrana. Los canales electrosensibles, aquellos excitables por un potencial eléctrico, interactuan entre sí, a la vez que son afectados indirectamente por los demás tipos de canales. De igual forma, los canales excitados por la concentración del ión de calcio son afectados por aquellos canales que transportan calcio a través de la membrana. El efecto de estas complejas interacciones entre los canales es el de producir el potencial de reposo de la neurona (de unos 70 milivolts).
En la mayoría de las neuronas el potencial de reposo es estable, se necesita de algún estímulo externo para cambiarlo. Hay algunas neuronas donde la interacción de los canales iónicos causa que el potencial de reposo sea inestable y oscile continuamente a una frecuencia determinada. A estas neuronas, denominadas “pacemakers” o “generadores de ritmo,” se debe la mayoría de los movimientos rítmicos de los animales, desde el latido cardíaco y la respiración, hasta los mo-vimientos básicos de caminar, la masticación y los movimientos digestivos.En todas las neuronas (estables o inestables), el potencial de membrana es afectado profundamente por la composición química del medio en que se encuentra la célula. Este es el origen de los efectos del alcohol y de muchos otros neurotóxicos. En particular, la presencia de substancias neurotransmisoras afecta a ciertos canales iónicos denominados “canales neurosensibles”, abriéndolos o cerrándolos.
La Sinapsis. Son las regiones en las cuales ocurre la transmisión del impulso nervioso de una neurona a otra. Toda sinapsis consiste en el acercamiento de las membranas de dos neu-

Inteligencia Artificial Básica
137Índice
ronas, denominadas “pre-sináptica” y “post-sináptica” de acuerdo con aquella que origina y con aquella donde va dirigido el impulso nervioso. Las señales siempre fluyen desde la membrana pre-sináptica, localizada en los botones terminales del axón, hacia la membrana post-sináptica, localizada en las dendritas.
Hay dos tipos principales de sinapsis; la sinapsis química, en la cual el impulso nervioso causa que la membrana pre-sináptica libere neurotransmisores que afectan a los canales neurosensi-bles de la membrana post-sináptica y, la sinapsis eléctrica, en la cual el potencial eléctrico pre-sente en la membrana pre-sináptica actúa directamente sobre los canales electrosensibles de la membrana post-sináptica. La sinapsis química es la más conocida y se muestra en la figura 6.2.
Figura 6.2Sinapsis química
Cuando un impulso nervioso llega a los botones terminales de un axón, causa que éstos li-beren pequeños paquetes o vesículas que contienen neurotransmisores. Dichas substancias se difunden rápidamente a través de la región intersináptica (espacio angosto entre las membranas pre-sináptica y post-sináptica). La presencia del neurotransmisor causa la apertura o el cierre de los canales neurosensibles localizados en la membrana post-sináptica, creando una corriente iónica a lo largo de la dendrita. Cada sinapsis crea su propia corriente iónica, que es recogida por las dendritas y conducida hasta el soma.
La apertura o cierre de los canales post-sinápticos ante la llegada del neurotransmisor, afecta al aumento o disminución de la corriente iónica y se dice en este caso que su contribución es positiva, o negativa respectivamente. A los incrementos positivos o decrementos negativos de corriente iónica se les denomina excitación puesto que tienden a aumentar la actividad de la

Mauricio Paletta
138Índice
neurona. Los incrementos negativos o decrementos positivos se denominan inhibición porque tienden a reducir dicha actividad.
Así como cada tipo de neurona produce un neurotransmisor determinado, también cada tipo de neurona posee una combinación determinada de canales neurosensibles en sus sinapsis. Como consecuencia, un neurotransmisor excitará a ciertos tipos de neuronas e inhibirá a otros y, puesto que cada neurona produce un solo tipo de neurotransmisor, se puede decir que algunas neuronas son excitatorias mientras que otras son inhibitorias (siempre con respecto a otra neuro-na). En función de esto, es común hablar de dos tipos de sinapsis: excitatorias e inhibitorias. Una neurona puede tener ambas clases de sinapsis. Otra forma de clasificar las sinapsis es viendo el punto en el cual la neurona transmisora hace el contacto sináptico con la neurona receptora, ya sea en la espícula, dendrita o soma de esta última. Así, se habla de tres tipos de sinapsis (figura 6.3): espicular, dendrítica y somática.
Figura 6.3Tipos de sinapsis
No todas las sinapsis poseen la misma sensibilidad a un neurotransmisor dado. Algunas pue-den ser más sensibles que otras, dependiendo de la cantidad de canales neurosensibles presen-tes en la membrana post-sináptica. Si se tienen dos impulsos neurales de idéntica intensidad, es decir, a igual concentración de neurotransmisor, una sinapsis con mayor cantidad de canales neurosensibles producirá una corriente iónica mayor que otra con menor cantidad. De esta ma-nera, una sinapsis puede acentuar o atenuar un impulso nervioso.
Uno de los descubrimientos neurobiológicos más importantes de los últimos años fue el haber determinado que la cantidad de canales neurosensibles en la membrana post-sináptica no es fija, sino que varía de acuerdo con la actividad de la sinapsis y de la neurona receptora. Este meca-nismo de cambio sináptico provee la base biológica del aprendizaje y del conocimiento.

Inteligencia Artificial Básica
139Índice
Es importante tener claro que el flujo de información a través de la sinapsis es estrictamente unidireccional, fluyendo siempre desde el botón terminal de la neurona transmisora hasta la den-drita, soma o espícula de la neurona receptora. No hay forma conocida por medio de la cual la neurona receptora pueda afectar a la transmisora, a menos de que el axón de la segunda haga sinapsis con la primera. Esta clase de conexiones mutuas, para sorpresa de muchos, son bas-tante frecuentes en el sistema nervioso.
Las corrientes iónicas provenientes de las dendritas son integradas por el soma, el cual “suma” las contribuciones excitatorias y “resta” las inhibitorias (aunque estas sumas y restas no son pro-piamente algebraicas ni lineales). El resultado de esta integración es el cambio del potencial de membrana en el soma y la consiguiente apertura o cierre de los canales electrosensibles que se hallan en él. Si las contribuciones excitatorias prevalecen, los canales de sodio comenzarán a bombear dicho ión positivo al interior de la célula, neutralizando parcial o totalmente el potencial negativo de reposo de la neurona. A este fenómeno se le denomina despolarización. Por el con-trario, si prevalecen las contribuciones inhibitorias, se abrirán otros canales, esta vez permeables al potasio, causando que este ión positivo se difunda rápidamente al exterior de la célula y au-mente el potencial negativo de reposo. A este fenómeno se le denomina hiperpolarización3.
El potencial de membrana en el punto donde el axón se une al soma representa el resultado del cómputo realizado por la neurona. Por medio de este potencial la neurona determina la exis-tencia de algún evento o la presencia de algún patrón o relación entre sus estímulos. Para que sea útil, este resultado debe ser comunicado a otras neuronas y finalmente, a células efectoras que hagan reaccionar el organismo.
La transmisión de las señales neurales no es un problema simple, ya que el potencial en el soma es muy pequeño (menos de un décimo de voltios) y las distancias a recorrer pueden ser bastante grandes. El axón, encargado de transmitir el potencial de membrana, es mucho más largo que ancho, por lo que su resistencia eléctrica es muy elevada (de no existir algún meca-nismo de amplificación, la señal producida por la neurona se disiparía completamente a pocos milímetros de su origen). Para solventar este problema, los axones emplean un mecanismo es-pecial para codificar el potencial de membrana del soma en impulsos discretos que pueden ser transmitidos a grandes distancias.
Los canales iónicos localizados en la membrana del tubo axonal son fuertemente electrosen-sibles y tienen la propiedad de producir una dramática y rápida inversión del potencial de mem-brana del axón. Si el potencial en el soma asciende por encima de unos 50 milivoltios negativos
3 Al combinar los efectos de atenuación y acentuación de sus sinapsis tanto excitatorias como inhibitorias, la neurona es capaz de computar di-versas funciones en las que combina las intensidades relativas de los diversos impulsos nerviosos a los cuales está sometida. Es factible imaginar neuronas que se activan cuando un determinado número de sus sinapsis están excitadas, o neuronas que se activan sólo cuando ciertas sinapsis están excitadas y otras no están inhibidas. La función que representa el potencial de membrana de una neurona es muy compleja. En muchos casos el potencial depende en forma no lineal de la intensidad de las diversas sinapsis y pueden también depender del instante relativo de llegada de las señales.

Mauricio Paletta
140Índice
(20 milivoltios por encima del potencial de reposo), los canales iónicos localizados en la mem-brana axonal adyacente al soma se abren rápidamente, permitiendo el paso de iones de sodio positivo, que inmediatamente penetran al interior del axón y causan una repentina inversión de su potencial hasta alcanzar unos 50 milivoltios positivos. Este fenómeno es momentáneo ya que luego de un breve retardo de unos 0.5 milisegundos, los canales iónicos que transportan potasio se cierran repentinamente. De esta forma el axón recobra, e incluso excede, su potencial negati-vo de reposo. Esta secuencia de eventos, con una duración total aproximada de un milisegundo, constituye el potencial de acción.
El potencial de acción se propaga a lo largo del axón como una llama a lo largo de una mecha, a medida que cada segmento del axón sufre una inversión de potencial, el siguiente segmento se dispara e invierte el suyo. De esta manera, el potencial de acción se transmite sin pérdida de intensidad, independientemente de la longitud del axón o de la cantidad de veces que éste se ramifica.
Luego de haber producido un potencial de acción, el segmento de membrana axonal entra en un “período refractario” durante el cual es incapaz de dispararse, sin importar cuan grande sea la despolarización en la membrana. La duración de este período es de varios milisegundos y varía de acuerdo a la intensidad de la despolarización y a las condiciones químicas tanto internas a la neurona como de su medio ambiente. Durante este intervalo, el sodio que había entrado durante la inversión de potencial es lentamente bombeado fuera del axón, a la vez que el potasio es ad-mitido nuevamente hasta restaurar el segmento a su condición original de excitabilidad.
La existencia del período refractario causa que el potencial de acción se propague desde el comienzo del axón hasta sus botones terminales y no de regreso. Es fácil ver que las secciones de axón que acaban de dispararse han entrado en su fase refractaria y son por lo tanto incapaces de dispararse nuevamente, sólo pueden activarse las secciones que se hallan más adelante del “frente de propagación” del potencial de acción.
Aunque la frecuencia de los potenciales de acción crece a medida que el potencial del soma crece, este crecimiento no es ilimitado (la frecuencia máxima es de unos 500 ciclos por segundo y está dictada por la duración mínima del período refractario). El axón simplemente no puede dispararse más rápido. Sin embargo, no parece haber una frecuencia mínima (exceptuando la frecuencia de 0 ciclos por segundo producida por una neurona totalmente inhibida).
La principal función del axón es entonces, la de codificar el potencial de membrana del soma en una secuencia de impulsos y transmitirlos a sus botones terminales, donde afectan a otras neuronas o células efectoras. El potencial de membrana, que es un valor continuamente variable, queda transformado en impulsos con una frecuencia determinada (cada uno de los cuales es un valor discreto de amplitud constante).

Inteligencia Artificial Básica
141Índice
En los vertebrados, los axones que se extienden a lo largo de distancias mayores de un mi-límetro se hallan recubiertos por una capa aislante llamada vaina de mielina y compuesta por la membrana de un tipo especial de célula denominada célula de Schwann, la cual se enrolla repetidas veces alrededor de cada segmento de axón. La función de la vaina de mielina es la de aumentar la velocidad y eficiencia con la cual el axón transmite sus potenciales de acción. Cada décima de milímetro aproximadamente, la vaina de mielina es interrumpida por los nodos de Ranvier, regiones en las cuales el axón queda al descubierto. La corriente iónica necesaria para generar los potenciales de acción no puede penetrar la mielina, por lo que los iones se ven obligados a fluir alrededor de ella (los potenciales de acción saltan de nodo en nodo, aumentando su velocidad de propagación desde unos 30 metros por segundo en un axón normal hasta más de 300 metros por segundo en uno con mielina)4.
Otro efecto de la mielina es el de disminuir la cantidad de energía empleada por el axón en producir cada potencial de acción. Esto es debido a que las corrientes iónicas necesarias para sustentar los potenciales de acción tan sólo deben fluir a lo largo de una muy pequeña fracción de la superficie axonal, en vez de a lo largo de toda ella. Este ahorro energético puede ser importante.
Los axones de las neuronas con mielina componen la materia blanca del cerebro y médula espinal (miles de millones de axones envueltos en mielina y agrupados en haces como si fueran alambres en un cable telefónico). Se le conoce como materia blanca porque al preservar sec-ciones de cerebro en formaldehido, la capa de mielina de los axones se ve más blanca que las regiones circundantes que contienen los cuerpos celulares y las dendritas (materia gris).
Cuando los potenciales de acción alcanzan los botones terminales del axón, cada uno de ellos causa la liberación de una cantidad fija de neurotransmisores en el espacio intersináptico. En este espacio se encuentran enzimas que constantemente destruyen el neurotransmisor a medida que se libera, evitando su acumulación (ciertas drogas estimulantes bloquean este proceso, causan-do una excitación artificial). La interacción de los mecanismos de liberación y destrucción causa que la concentración instantánea de neurotransmisores en la sinapsis sea proporcional a la fre-cuencia de llegada de los potenciales de acción (a mayor frecuencia, mayor concentración).
La función de transferencia que rige la relación causa-efecto desde el soma hasta la sinapsis, es creciente y aproximadamente lineal, muy similar a la curva matemática denominada sigmoi-de5. Los potenciales de acción son tan sólo un medio de codificación empleado por las neuronas para transmitir con eficiencia y precisión un potencial de membrana particularmente débil a lo largo de distancias considerables.
4 Este aumento de velocidad es crítico para el buen funcionamiento de los largos axones de las neuronas sensoriales y motoras que se hallan en gran parte del cuerpo. Las terribles consecuencias de la poliomielitis justamente derivan en la destrucción viral de la vaina de mielina en las neuronas periféricas.5 Antiguamente se pensaba que esta función era regida por la ley binaria de “todo o nada”, es decir, que una neurona o transmite una señal o no la transmite.

Mauricio Paletta
142Índice
El tejido neural. A grandes rasgos, el sistema nervioso de un mamífero se puede dividir en tres partes en las cuales se cuentan cerca de un centenar de zonas o áreas funcionales anatómi-camente distintas, conectadas entre sí en forma compleja pero regular:
El sistema nervioso periférico, que incluye el sistema espinal.• El sistema subcortical, en el cual se hallan la mayoría de los sistemas autónomos de pre-• procesamiento sensorial y de control motor básico.La corteza cerebral. •
El sistema nervioso periférico consta de dos grandes partes: el sistema neurovegetativo y el sistema espinal. El sistema neurovegetativo está constituido por numerosas neuronas periféricas y “pacemakers” o generadores de ritmo, distribuido
s principalmente a lo largo del tórax y del abdomen en agrupaciones denominadas “ganglios” y “plexos”, cada uno de los cuales controla uno o más órganos internos en forma semiautomática e involuntaria. La actividad de este sistema es indispensable para la “homeostasis” del organis-mo (mantenimiento, regulación y coordinación de los procesos vitales y del equilibrio químico interno). El sistema espinal está contenido casi por completo dentro del canal óseo de la espina dorsal. Tiene tres funciones:
Servir de conducto transmisor para las señales del sistema nervioso central hacia los múscu-• los voluntarios y desde éstos, los tendones, las articulaciones y la piel hacia el cerebro.Regular el funcionamiento del sistema músculo-esqueletal por medio de reflejos autónomos.• Coordinar grupos de músculos para lograr movimientos simétricos y balanceados (como por • ejemplo los movimientos opuestos de brazos y piernas al caminar).
El sistema nervioso periférico consta de dos grandes partes: el sistema neurovegetativo y el sistema espinal. El sistema neurovegetativo está constituido por numerosas neuronas periféricas y “pacemakers”, distribuidas principalmente a lo largo del tórax y del abdomen en agrupaciones denominadas “ganglios” y “plexos”, cada uno de los cuales controla uno o más órganos internos en forma semiautomática e involuntaria. La actividad de este sistema es indispensable para la “homeostasis” del organismo (mantenimiento, regulación y coordinación de los procesos vitales y del equilibrio químico interno). El sistema espinal está contenido casi por completo dentro del canal óseo de la espina dorsal. Tiene tres funciones:
Servir de conducto transmisor para las señales del sistema nervioso central hacia los múscu-• los voluntarios y desde éstos, los tendones, las articulaciones y la piel hacia el cerebro.Regular el funcionamiento del sistema músculo-esqueletal por medio de reflejos autónomos.• Coordinar grupos de músculos para lograr movimientos simétricos y balanceados (como por • ejemplo los movimientos opuestos de brazos y piernas al caminar).

Inteligencia Artificial Básica
143Índice
El sistema subcortical está constituido por un gran número de núcleos, agrupaciones bien definidas de neuronas con funciones específicas e interconexiones muy precisas. Estos núcleos, a veces denominados núcleos ancestrales, son capaces de producir por sí solos conductas com-plejas, entre las cuales se hallan las actividades básicas de todo vertebrado (la locomoción, la alimentación y los diversos aspectos de la reproducción).
La corteza cerebral fue la última parte del sistema nervioso en evolucionar. En el hombre alcanza su máximo desarrollo. Está constituida por una delgada capa de neuronas que, en for-ma de dos hemisferios, cubre completamente los núcleos subcorticales y establece extensivas conexiones con ellos en ambas direcciones. Su función es la de interpretar detalladamente las sensaciones, iniciar los complejos y coordinados movimientos voluntarios e integrar sus propias capacidades de conducta (que en el hombre incluyen el lenguaje y el razonamiento) con las ca-pacidades básicas de los núcleos ancestrales.
La plasticidad neural. Durante los últimos 25 años, gran cantidad de estudios han demostra-do sin lugar a dudas que una actividad anormal en una región del cerebro produce con certeza un desarrollo anormal del “cableado neural” en regiones conectadas a ella. Por ejemplo, un des-balance durante la infancia en el uso de uno de los ojos, causa una deficiencia permanente en la percepción a través de ese ojo.
A raíz de estos descubrimientos, muchos investigadores comenzaron a sospechar que la ex-periencia y en particular el normal flujo de potenciales de acción a través de los circuitos neurales, ayuda a refinar detalles tales como el número, la distribución y la eficiencia de la sinapsis. Investi-gaciones posteriores revelaron que la actividad neural no sólo afecta el desarrollo sináptico, sino que los potenciales de acción son esenciales para el desarrollo mismo de las células nerviosas. Si se evita que una neurona produzca potenciales de acción, los botones terminales del axón degeneran y dejan de ser capaces de transmitir el impulso nervioso.
En algunos sistemas cerebrales es deseable la ausencia de esta plasticidad neural. Por ejem-
plo, un sistema sensorial una vez maduro, debería ser capaz de responder en forma consistente a estímulos dados (para ello es necesario que su “cableado” permanezca esencialmente inalte-rable). De hecho, muchos circuitos neurales (fundamentalmente los situados en los núcleos sub-corticales), una vez establecidos durante la gestación, permanecen plásticos durante un breve tiempo luego del nacimiento, período durante el cual su “cableado” se refina en base a la expe-riencia sensorial. Al finalizar ese usualmente corto “período crítico”, dichos circuitos esencialmen-te pierden su capacidad para cambiar. Por otra parte, la capacidad de alterar constantemente el cableado neural es presumiblemente esencial para ciertas otras partes del cerebro. Los sistemas encargados de aprender y de categorizar, han de permanecer plásticos indefinidamente, de lo contrario les sería imposible almacenar nueva información o crear nuevas categorías.

Mauricio Paletta
144Índice
6.2. Algo de historia
No fue sino en el año de 1943 cuando se inician los intentos de usar los conceptos relativos al sistema neural humano, como base para la investigación de campos de solución de problemas. En este año, McCulloch y Pitts escriben un trabajo titulado “A logical calculus of the ideas immi-nent in nervious activity” cuyo principal aporte fue describir el primer modelo teórico de neurona artificial. En este modelo, la neurona artificial se ve como un elemento lógico binario que opera en tiempo discreto.
La ley que describe el comportamiento de este primer modelo de neurona artificial es como sigue: en cada instante de tiempo t, la neurona puede disparar o no un potencial de acción dependiendo si la suma algebraica de la actividad sináptica generada por las conexiones que recibe, supera o no un umbral determinado. La figura 6.4 muestra el modelo; la neurona recibe n entradas “x1, …, xn” y produce la salida “y”; cada entrada o conexión “xi” tiene un peso “wi” asociado que indica la fuerza excitatoria (si el peso es positivo) o inhibitoria (si el peso es negati-vo) con la cual la entrada afecta a la neurona; la salida “y” viene dada por la siguiente expresión ( representa el umbral):
Haciendo una analogía de la neurona natural (figura 6.1) y la neurona artificial de la figura 6.4 se aprecia que las entradas emulan la actividad presináptica que ocurre en las dendritas; el cuer-po de la neurona con la sumatoria de los pesos de las conexiones por las entradas representa el soma en estado de potencial en acción y, la salida “y” emula al axón con su futura propagación por las ramificaciones terminales.
Figura 6.4Primer modelo de neurona artificial
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ

Inteligencia Artificial Básica
145Índice
A finales de esa misma década de los años cuarenta, Donald Hebb desarrolla un trabajo titu-lado “The organization of behavior” en el cual, usando como base el modelo de neurona artificial presentado por McCulloch y Pitts, describe una forma en la cual los pesos de las conexiones pue-den irse ajustando para alcanzar resultados de salida deseados. Este resultado le dio al modelo habilidades de aprendizaje y la expresión que Hebb obtuvo y que hoy en día se sigue utilizando en algunos modelos neurales, se conoce con el nombre de regla de aprendizaje de Hebb y es la siguiente:
Como se puede notar, la regla de aprendizaje de Hebb establece que la variación del peso en un instante t, viene dado por el producto de la entrada correspondiente a la conexión y la salida de la neurona, ambos en ese instante t. El símbolo representa un factor o constante de apren-dizaje (generalmente pequeña) con la cual se puede variar la rapidez de cambio del peso.
En el año de 1950 varios investigadores aportan trabajos en el área de aprendizaje, específi-camente en técnicas de reforzamiento y no fue sino en 1951 cuando Marvin Misnky desarrolla la primera implementación artificial de algo basado en el sistema neural humano. Se trató de una máquina con 40 unidades interconectadas constituyéndose en el primer sistema de aprendizaje en una red, basado en reforzamiento.
A mediados de la década de los cincuenta, existía disertación entre los conceptos de seriali-zación, programación y generalización, propios de lo que en ese momento se asociaba a los de-sarrollos de software (para ese entonces estaba naciendo el lenguaje de programación Fortran), contra los conceptos de paralelismo, aprendizaje y especificación que se estaban dando a raíz de los trabajos asociados a la emulación de las neuronas y su entorno.
En 1957 Frank Rosenblatt publica su trabajo “Principles of Neurodynamics” en el cual desarro-lla y describe el primer modelo de interconexión de neuronas artificiales, llamado Perceptrón. En este trabajo, Rosenblatt hace una variación de la regla de aprendizaje de Hebb, al incluir un nue-vo concepto llamado salida deseada (o “target”). La idea es que se calcule un error o diferencia entre la salida generada por la neurona y la salida que se desea obtener y usar este factor para ser multiplicado por la entrada para obtener la variación del peso. La expresión es como sigue:
Bernard Widrow y Marcial Hoff desarrollaron en 1959, el modelo Adaline (adaptative linear elements), cuya importancia está en el hecho de haber sido la primera RNA aplicada a un pro-
w w w w x y
i i i
i
( ) ( ) ( )( ) ( ( ) ( ))
t t tt t ti
+ = += ⋅
1 ∆∆ α
w w w w x y
i i i
i
( ) ( ) ( )( ) ( ( ) ( ))
t t tt t ti
+ = += ⋅
1 ∆∆ α
[ ]w w w
w x z yi i i
i
( ) ( ) ( )
( ) ( ) ( ( ) ( ))
t t t
t t t ti
+ = +
= ⋅ −
1 ∆
∆ α

Mauricio Paletta
146Índice
blema real6. Su única diferencia con el Perceptrón es que el Adaline permite entradas y salidas de números reales.
Desde finales de la década de los cincuenta y durante un largo período de veinte años se vive una época de oscurantismo en el campo de investigación de las RNAs. Esto debido a la gran cantidad de críticas que aparecieron para ese entonces, motivadas principalmente por las pocas implementaciones o desarrollos que pudieran probar lo exitoso de los modelos7. Una de las críti-cas más notorias fue la realizada por Marvin Minsky y Seymour Papert cuando en su libro “Per-ceptrons”, presentan varias e importantes limitaciones del modelo desarrollado por Rosenblatt y su incapacidad para resolver muchos problemas interesantes.
No fue sino hasta 1982 cuando esta teoría de las RNAs toma interés nuevamente. En este año acontecen varios eventos simultáneamente donde destacan el desarrollo del modelo de John Hopfield que lleva su nombre y la realización de la conferencia “US-Japan Joint Conference on Cooperative / Competitive Neural Networks”.
Desde mediados de los años ochenta hasta la actualidad, se cuenta con una gran cantidad de trabajos de investigación, se han diseñado numerosos modelos neurales, se han estado apli-cando exitosamente muchas RNAs en una gran variedad de campos y se están realizando varias asociaciones y conferencias nacionales e internacionales en todo el mundo8.
6.3. El modelo neural artificial
Una RNA es una interconexión de neuronas artificiales, basado en abstracciones de las neu-ronas naturales como procesadores elementales, conectados entre sí mediante lazos electró-nicos o lógicos que simulan conexiones sinápticas9. Al desarrollo de elementos computaciones asociado al concepto de RNA se le da el nombre de Neurocomputación y se puede definir como sigue:
Computación en redes paralelas de procesadores, las cuales almacenan su conoci-miento en la fortaleza de sus conexiones.
En una definición dada por Hecht y Niesen se ve a la RNA como “…un sistema de compu-tación hecho por un gran número de elementos simples, elementos de proceso muy interco-
6 La ADALINE se usó exitosamente como un filtro adaptativo para la eliminación de ecos en las líneas telefónicas. Su uso comercial se extendió durante varias décadas.7 Quizás, una de las razones que pueda justificar este hecho es el poco potencial que en ese momento se tenía en lo que respecta a lenguajes de programación y herramientas para el desarrollo de software.8 Destacan la reunión anual de “Neural Networks for Computing” del instituto americano de física; la “International Neural Network Soci-ety” (INNS); la “International Joint Conference on Neural Networks” (IJCNN); la “International Conference on Artificial Neural Networks” (ICANN) y la reunión annual de la “Neural Information Processing Systems” (NIPS).9 No intentan duplicar la operación del cerebro humano. Se inspiran en el conocimiento que existe sobre cómo éste funciona y acerca de su estructura.

Inteligencia Artificial Básica
147Índice
nectados, los cuales procesan información por medio de su estado dinámico como respuesta a entradas externas”. Kohonen define las RNAs como “…redes interconectadas masivamente en paralelo de elementos simples (usualmente adaptativos) y con organización jerárquica, las cua-les intentan interactuar con los objetos del mundo real del mismo modo que lo hace el sistema nervioso biológico”.
Una RNA presenta las siguientes características generales:
Aprendizaje adaptativo: Capacidad de aprender basado en un entrenamiento o experiencia • previa.Autoorganización: Almacenar el conocimiento aprendido creando su propia organización.• Tolerancia a fallos: Aprendizaje con ruido; la respuesta no depende de toda la red.• Operación en tiempo real: Aprovechar el paralelismo para buscar rapidez de actuación.• Fácil inserción dentro de la tecnología existente: De una forma rápida y económica se puede • obtener una RNA entrenada para casos específicos.
Las características más importantes se concentran en el aprendizaje y la autoorganización. Mientras el aprendizaje permite que la RNA se adapte a un problema específico, la autoorgani-zación permite que esta adaptación sea posible. Ambas cualidades provocan la capacidad de la red de responder apropiadamente cuando se le presentan situaciones a las que no había sido ex-puesta con anterioridad y tratar de dar una respuesta en función del conocimiento que tiene alma-cenado de lo que si fue presentado. Esta facultad se conoce con el nombre de generalización.
El modelo genérico de la neurona artificial no difiere mucho del modelo presentado por Mc-Culloch y Pitts (figura 6.4). Además de la función de umbral que determina si la actividad de la neurona es lo suficientemente grande para propagar la salida (también se le dice “disparar” la neurona), se definen otras dos funciones: la función sumatoria que calcula la suma algebraica de la actividad de la neurona (sumatoria del producto de las entradas por los pesos de las conexio-nes correspondientes) y la función de activación que calcula la salida de la neurona. La figura 6.5 muestra el modelo genérico de la neurona artificial.

Mauricio Paletta
148Índice
Figura 6.5Modelo genérico de neurona artificial
Los elementos que forman el modelo son los siguientes:
( x1 … xn ) vector de entradas (del exterior o proveniente de la salida de otra neurona). y salida (hacia el exterior o hacia la entrada de otra neurona).( w1 … wn ) vector de pesos de las conexiones. función sumatoria, también llamado NET, calcula el valor o estado de activación
o simplemente activación asociado a la neurona. función umbral o simplemente umbral, determina si el estado de activación es lo
suficientemente fuerte para que la neurona genere una señal de salida. función de activación o propagación, transforma el estado actual de activación en
una señal de salida.
Se satisfacen las siguientes expresiones:
Por lo general, la función de activación no está centrada en el origen del eje que forma con NET, ya que el umbral provoca un desplazamiento de la misma. Por esta razón y para mayor comodidad a la hora de su manejo y representación, la expresión se suele escribir de la siguiente forma:
Hay que hacer notar que tanto la función de activación como el umbral permanecen invaria-bles en una neurona una vez que estos se hayan definido. Si se mantiene fijo el vector de valores de entrada ( x1 … xn ), lo único que está cambiando en la unidad de procesamiento es el vector de pesos de las conexiones ( w1 … wn ) y por ende el resultado de su activación o NET. Por esta
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
y( ) = NET -t + ƒ1 ( )θ
NET x w y = NET)n
= ƒ=∑ i ii 1
(
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θy = NET -ƒ( )θ
y( ) = NET -t + ƒ1 ( )θ

Inteligencia Artificial Básica
149Índice
razón es que se dice que los pesos almacenan el conocimiento de cada neurona (y de la RNA en general) y que el proceso de aprendizaje los ajusta para que las salidas obtenidas correspondan o sean las adecuadas para un problema específico. Dado que el proceso de aprendizaje se rea-liza en varias iteraciones y que el vector de pesos está cambiando desde un conjunto de valores iniciales (por lo general aleatorio) hasta su correspondiente conjunto de valores definitivo, se tiene un valor de activación de la neurona en cada instante t:
La salida o valor de activación de una neurona puede ser continua o discreta, la mayoría de las veces definido entre un mínimo y un máximo. Las salidas discretas están asociadas a un conjunto finito de posibles valores (el ejemplo más común son los valores binarios representado por los símbolos “1” y “0” y los llamados valores bipolares: “+1” y “-1”). Las salidas continuas son números reales que por lo general están definidos en los intervalos [0, 1] o [-1, +1].
Para definir la función de activación de la neurona es necesario, por supuesto, considerar
como es el tipo de salida (discreta o continua). En el caso de las salidas discretas, las funciones de activación más usadas son la función escalón (o Heaviside) que puede ser tanto en el interva-lo [1, 0] (binaria) como en el intervalo [+1, -1] (bipolar), la función identidad (o lineal) y una función mixta (tanto lineal como escalón), cuyas expresiones son las siguientes, respectivamente:
La figura 6.6 muestra gráficamente las funciones de escalón en el intervalo [+1, -1] (parte a), identidad (parte b) y mixta (parte c). La función de escalón en el intervalo [1, 0] es similar a la que se muestra en la figura con la diferencia que tiene su cota inferior en 0. Nótese que la función mixta está definida haciendo uso de un par de constantes b y B.
y( ) = NET -t + ƒ1 ( )θ
yNET
y NETNET
yNET
y NETNET
y NET
yNET b +
NET b + NET < B +NET
( ),( ),,
( ),
( ),,
( )
( ),
,,
t t t t
t
tb
B B
+ =>
=<
+ =+ >
=− <
+ = −
+ =≤
− <≥
11
01
1
1
1
1
θθ
θ
θθθ
θ
θθ θ θ

Mauricio Paletta
150Índice
Figura 6.6Funciones de activación discretas
Cualquier función definida en un intervalo de posibles valores de entrada, con sus límites su-perior e inferior y que describa un incremento o curva continua, puede ser usada como función de activación para salidas continuas. Una de las funciones que tiene estas características y la que más se utiliza para servir como función de activación continua es la sigmoide, ya sea en su versión original o desplazada (bipolar):
Figura 6.7Funciones sigmoide (a) y sigmoide desplazada (b)
La figura 6.7 muestra la forma de la sigmoide (parte a) y la sigmoide desplazada (parte b).
Otras funciones de activación continuas importantes son la tangente hiperbólica (y su versión desplazada) y la función gaussiana. Esta última representada gráficamente en la figura 6.8.
y yNET- )
NET- )
NET- )( ) ( )(
(
(te
tee
+ =+
+ =−+−
−
−11
11
11θ
θ
θ

Inteligencia Artificial Básica
151Índice
Figura 6.8Función gaussiana
Una RNA se establece cuando se interconectan neuronas artificiales de una forma organi-zada. La RNA está organizada por capas cada una de las cuales está formada por un número finito de neuronas artificiales. En su forma más genérica y tal como se muestra en la figura 6.9, se distinguen tres capas de neuronas:
Capa de entrada: Conjunto de neuronas cuya función es recibir, desde el exterior, la infor-1. mación relativa al problema que se está tratando de resolver y propagar esta información a la capa siguiente. Las neuronas artificiales pertenecientes a esta capa se denominan neuronas de entrada y cada una de ellas tiene asociada una característica o elemento que describe el problema representado. El número de neuronas de entrada viene dado por la cantidad de características que se identifican para describir los estados de un problema específico.Capa escondida: Número finito de capas o niveles cada una de las cuales tiene cual-2. quier número finito de neuronas artificiales. Las neuronas que pertenecen a esta capa se denominan neuronas escondidas ya que esconden el conocimiento representado por las conexiones existentes. Las entradas y salidas de estas neuronas están dentro del sistema (no hay comunicación con el exterior). Capa de salida: Conjunto de neuronas cuya función es calcular y almacenar el resultado 3. del procesamiento de la RNA correspondiente a una entrada específica y enviar el resulta-do fuera del sistema. Las neuronas se denominan neuronas de salida y su cantidad depen-de del tipo de respuesta que debe emitir la RNA en relación a un problema determinado.
Se dice que una RNA es totalmente conectada cuando todas las salidas de las neuronas de una capa o nivel llegan como entradas a todas las unidades del nivel inmediatamente siguiente. En caso contrario, la RNA es parcialmente conectada.
e(( )NET- )θ µ
σ
− 2
22

Mauricio Paletta
152Índice
El proceso de recibir una entrada a través de las neuronas de entrada, propagar esta in-formación por todas las capas escondidas y generar una salida en las neuronas de salida, se denomina propagación (o ejecución) de la RNA. Cuando ninguna salida de las neuronas de una capa regresa como entrada a ese mismo nivel o alguna de las capas anteriores, se dice que la RNA describe un proceso de propagación hacia adelante (figura 6.9). En caso contrario, la RNA describe un proceso de propagación hacia atrás (figura 6.10)10.
Figura 6.9Modelo genérico de RNA (propagación hacia adelante)
El proceso de propagación de una RNA es muy simple: Siguiendo la organización de la red (desde la capa de entrada hasta la capa de salida y una capa a la vez), cada neurona recibe un vector de entrada, obtiene su activación, calcula su salida y propaga esta salida hacia la capa siguiente. El proceso se inicia con el vector de entrada representativo del problema que se pre-senta a las neuronas de entrada (un componente del vector por neurona) y termina con la infor-mación de salida producido por las neuronas de salida.
Por supuesto, propagar o ejecutar una RNA sin antes ajustar los pesos de las conexiones (entrenar) no garantiza en absoluto que los resultados obtenidos sean los deseados. En otras
10 Estos diagramas no son estándares. Algunos autores describen la propagación de abajo hacia arriba. Otros, no toman en cuenta la capa de entrada, debido a la casi nula participación de estas neuronas en el proceso. También puede variar la forma de representar los enlaces hacia atrás.
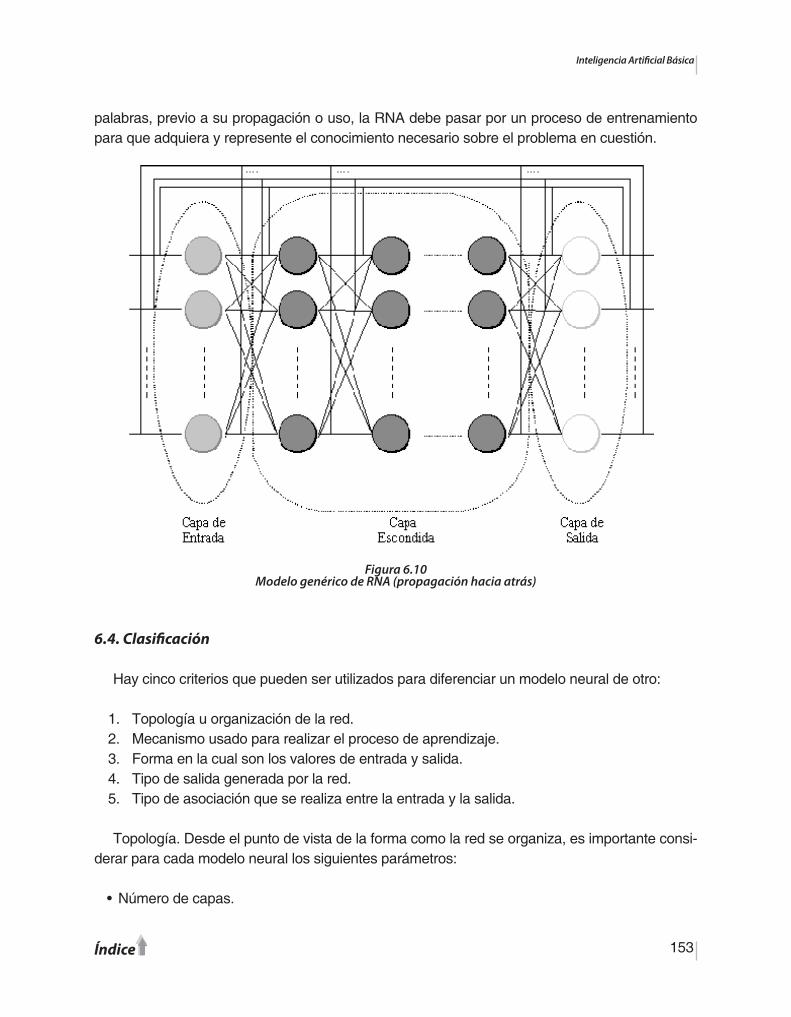
Inteligencia Artificial Básica
153Índice
palabras, previo a su propagación o uso, la RNA debe pasar por un proceso de entrenamiento para que adquiera y represente el conocimiento necesario sobre el problema en cuestión.
Figura 6.10Modelo genérico de RNA (propagación hacia atrás)
6.4. Clasificación
Hay cinco criterios que pueden ser utilizados para diferenciar un modelo neural de otro:
Topología u organización de la red.1. Mecanismo usado para realizar el proceso de aprendizaje.2. Forma en la cual son los valores de entrada y salida.3. Tipo de salida generada por la red.4. Tipo de asociación que se realiza entre la entrada y la salida.5.
Topología. Desde el punto de vista de la forma como la red se organiza, es importante consi-derar para cada modelo neural los siguientes parámetros:
Número de capas.•

Mauricio Paletta
154Índice
Número de neuronas por cada capa.• Grado de conectividad de la red: total o parcial.• Tipo de conexiones entre las neuronas: hacia adelante, hacia atrás, recurrentes, • autorecurrentes.
En esta clasificación se distinguen dos tipos de RNAs:
Redes monocapa: Son aquellas que tienen una sola capa de neuronas para el proceso de • propagación (sin contar la capa de entrada cuya función es simplemente propagar la entrada y no hay un cálculo de salida implícito en sus neuronas). Aquí podemos encontrar redes que tienen su capa de salida y no tienen capas escondidas o aquellas que tienen una capa de neuronas escondidas y no tienen una capa de salida como tal. Este tipo de redes se utilizan típicamente en tareas relacionadas con la autoasociación (manejo de entrada incompleta o con ruido).Redes multicapa: Aquellas redes en la cual intervienen más de una capa en el proceso de • propagación. Mirando el tipo de conexión entre las neuronas de capas distintas se pueden distinguir redes multicapa con conexiones hacia adelante (en inglés “feddforward”) y con co-nexiones hacia adelante y hacia atrás (en inglés “feddforward / feddback”).
El ejemplo más conocido de RNA monocapa es Hopfield. En cuando a las redes multicapa con conexión hacia adelante se distinguen Perceptrón, Adaline y Backpropagation11. Las redes multicapa con conexiones hacia adelante y hacia atrás suelen ser de dos capas y son particular-mente adecuadas para realizar una asociación entre el vector de entrada que se le presenta a la primera capa y el vector de salida generado en la segunda capa. Esta idea se conoce con el nombre de heteroasociación. Otras redes de este tipo hacen que la información de ambas capas interactúen entre sí hasta alcanzar un estado estable. A esta forma de funcionar se le denomina resonancia. Los ejemplos más conocidos de este tipo de redes multicapa son BAM12 (“Bidirectio-nal Associative Memory”), ART13 (“Adaptive Resonance Theory”) y Neocognitrón14.
Mecanismo de aprendizaje. El aprendizaje es el proceso mediante el cual una RNA modifica sus pesos en respuesta a un conjunto de entradas. La ley que domina la forma en la cual se debe realizar este proceso se llama regla de aprendizaje. Desde el punto de vista en la cual se definen estas reglas, el entrenamiento de una RNA puede ser:
Supervisado: El aprendizaje es controlado pon un agente externo (o supervisor) que indica la • respuesta correcta que debe generar la RNA a una entrada dada. Las reglas de aprendizaje hacen uso de la repuesta actual y la respuesta deseada para calcular la variación que se
11 Ideado por Rumelhart, Hinton y Williams.12 Desarrollada por Kosko en 1988.13 Desarrollada por Grossberg, Carpenter y otros colaboradores.14 Fukushima, 1983.

Inteligencia Artificial Básica
155Índice
tiene que hacer sobre los pesos de las conexiones (por ejemplo, la regla de aprendizaje dada por Rosenblatt en el Perceptrón). Hay cuatro formas de realizar entrenamiento supervisado:
Aprendizaje por corrección de error. Los pesos se ajustan en función de la diferencia entre 1. la salida actual y la salida deseada que equivale al error cometido en la respuesta. Por ejemplo, en la regla de aprendizaje del Perceptrón:
si la salida deseada z(t) es mayor que la salida actual y(t), el error cometido es positivo (la salida actual no alcanzó el valor de la salida deseada) y la variación de peso wi(t) debe ser un factor positivo que permita aumentar la actividad de la neurona para producir una salida mayor. En el otro caso, si z(t) es menor que y(t), el error cometido es negativo (la salida actual superó el valor de la salida deseada) y wi(t) debe ser un factor negativo que permita disminuir la actividad de la neurona para producir una salida menor.
La regla de aprendizaje del Perceptrón considera solo los errores individuales de cada en-trada, no tomando en cuenta la magnitud del error global cometido en todo el proceso de en-trenamiento. Esta mejora la toma en cuenta la regla delta usada por primera vez en el modelo Adaline. La idea que originó esta regla es muy ingeniosa y bastante simple. Se trata de obtener una expresión para calcular el error global de todo el proceso de aprendizaje y buscar los pesos que minimizan esta función (por derivación simple). Las expresiones que conforman regla delta son las siguientes:
donde P es el número de vectores de entrada dados en el entrenamiento y N el número de neuronas de salida. El cálculo de la derivada del error depende, por supuesto, de la función de activación que se use para obtener la salida de la neurona15.
Aprendizaje por reforzamiento. La salida deseada no se indica con exactitud y la función 2. del supervisor es indicar mediante una señal de refuerzo (+1 cuando hay éxito y –1 cuando hay fracaso) si la salida actual se ajusta a la salida deseada.
15 Una variante o modificación de la regla delta es la regla delta generalizada o algoritmo de retropropagación del error, para ser aplicada a redes multicapa con conexión hacia adelante.
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
ErrorP
t t
tError
jk
j
N
k
P
jiji
= −
=
==∑∑1
22
11( ( ) ( ))
( )
z y
ww
jk
∆ α∂∂

Mauricio Paletta
156Índice
El ajuste de pesos se realiza mediante un mecanismo de probabilidades. Como ejemplo de reglas de aprendizaje de este tipo se pueden citar los algoritmos “Linear Reward-Penalty”16 y “Adaptive Heuristic Critic”17.
Aprendizaje estocástico. Se basa en realizar cambios aleatorios a los pesos de las co-3. nexiones y evaluar su efecto partiendo de la meta deseada y utilizando distribuciones de probabilidad. El estudio de este tipo de redes se suele asociar a algunos conceptos ma-nejados en termodinámica. La idea es que la RNA se asocia a un sólido con cierto estado energético que va a representar su grado de estabilidad. El aprendizaje consiste en hacer un cambio aleatorio de los pesos y determinar la energía de la red. El cambio se acepta si la energía disminuye después del mismo sino, se acepta en función de una distribución de probabilidades determinada.
El procedimiento de usar ruido para evitar caer en mínimos locales se denomina temple simu-lado. Hacer aprendizaje estocástico es combinar temple simulado con asignación probabilística. La idea general es hacer ver a la RNA como un sólido con una temperatura inicial alta (ruido) y que se va enfriando gradualmente hasta alcanzar el equilibrio térmico o mínima energía (mínimo global).
Las redes más conocidas que hacen uso de este tipo de aprendizaje son la Máquina de Bol-tzmann18 y la Máquina de Cauchy19.
Aprendizaje hiperesférico. En los modelos hiperesféricos las neuronas artificiales se ven 4. como esferas en un hiperespacio N-dimensional, donde N es el tamaño del vector de en-trada. El entrenamiento de estas redes se realiza ajustando el radio de la esfera de forma tal de cubrir pedazos adecuados del hiperespacio. La ubicación de la esfera en el hiperes-pacio se realiza mediante el cálculo de distancias euclidianas.
No supervisado: También llamado entrenamiento autosupervisado, se caracteriza por no re-• querir de influencia externa para realizar el proceso. Se distinguen dos tipos:
Aprendizaje hebbiano. Como su nombre lo indica, está basado en la regla de aprendizaje 1. de Hebb20:
16 Presentado por Narendra y Thathacher en 1974 y posteriormente mejorado por Barto y Anandan en 1985 quienes desarrollaron el algoritmo “Associative Reward-Penalty”.17 Introducido por Barto, Sutton y Anderson en 1983.18 Ideada por Hinton, Ackley y Sejnowsky en 1984.19 Desarrollada por Szu en 1986.20 “Cuando un axón de una celda A está suficientemente cerca como para conseguir excitar una celda B y repetida o persistentemente toma parte en su activación, algún proceso de crecimiento o cambio metabólico tiene lugar en una o ambas celdas, de tal forma que la eficiencia de A, cuando la celda a activar es B, aumenta”. Desarrollada por Hecht-Nielsen en 1987.
∆w y yij i jt t t( ) ( ) ( )= ⋅

Inteligencia Artificial Básica
157Índice
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
El ajuste de los pesos viene dado en función de los valores de activación (+1 ó –1) de las neuronas conectadas. Si las dos unidades son activas (+1) o inactivas (-1) se produce un refor-zamiento en la conexión ( wij(t) positivo). Pero si alguna de las neuronas es activa y la otra es inactiva, se produce un debilitamiento de la conexión ( wij(t) negativo).
Se han desarrollado muchas variantes del aprendizaje hebbiano entre los cuales se pueden mencionar el aprendizaje hebbiano diferencial (usa la correlación de las derivadas en el tiempo de las funciones de activación) y el aprendizaje hebbiano difuso (la información con la cual la red aprende está representada en conjuntos difusos).
Como ejemplo de redes que usan este tipo de aprendizaje se puede citar a Hopfield, BAM y Counterpropagation.
Aprendizaje competitivo. La idea es que las neuronas de cada capa de la RNA compiten 2. entre sí para obtener una sola ganadora del grupo. La neurona ganadora se activa (alcanza su máximo valor de respuesta) y las perdedoras se anulan (forzadas a mínimos valores de respuestas). Entre las neuronas de una capa hay conexiones recurrentes de autoexcita-ción y conexiones de inhibición (signo negativo) por parte de las neuronas vecinas.
El objetivo de este tipo de redes es agrupar conjuntos de entradas con características simila-res. Todos aquellos vectores de entrada que sean similares, pertenecen a la misma categoría y grupo y por ende deben activar la misma neurona. Las clases o categorías son definidas por la misma red.
El ajuste de los pesos se realiza solo en las neuronas ganadoras, redistribuyendo el valor de su activación entre sus conexiones. Se resta una porción a los pesos de todas las conexiones que llegan a la neurona ganadora y se reparte esta cantidad por igual entre todas las conexiones que vienen de las unidades activas.
Una RNA que hace uso de este tipo de aprendizaje fue la desarrollada por Kohonen que lleva su nombre. Otro ejemplo es Counterpropagation que combina el aprendizaje hebbiano con el aprendizaje competitivo.
Valores de entrada y salida. Los valores con los cuales se representa la entrada y la salida de una RNA pueden ser de naturaleza analógica o continua (valores reales) y de valores discre-tos o representados por un alfabeto finito de símbolos. En función de esto se pueden distinguir tres tipos de red:
Entrada y salida discretas (redes discretas).• Entrada y salida continuas (redes continuas).• Entrada discreta y salida continua / entrada continua y salida discreta (redes híbridas).•

Mauricio Paletta
158Índice
Tipo de salida. Al mirar la forma en la cual una RNA obtiene y da el resultado de la propaga-ción, se distinguen dos esquemas de funcionamiento (figura 6.11):
Clasificador. Cada neurona de salida representa una • clase o posible salida de la red. Hay tantas neuronas de salida como clases del problema que se está representando. Con estas redes son típicas las aplicaciones relativas al reconocimiento de patrones o problemas de clasificación o categorización. Counterpropagation es un ejemplo de este tipo de RNA.
Asociador. Cada neurona de salida representa una componente del vector solución al cual de • le da el nombre de vector asociado. Las aplicaciones típicas son aquellas relativas al proce-samiento de patrones. Se pueden citar como ejemplo las redes Backpropagation y BAM.
Hay que notar que el reconocimiento de patrones es un caso particular de procesamiento. De hecho, con una RNA que funciona bajo el esquema de asociador, es posible realizar tareas de clasificación (basta generar como salida un vector donde sólo una componente es no nula y ésta es la que determina la categoría o clase resultante).
Figura 6.11Esquemas de funcionamiento de las RNAs
Por ejemplo, supongamos que se quiere representar en una RNA una compuerta XOR. Como se trata de un operador binario, se debe tener un vector de entrada de dos componentes, es de-cir, dos neuronas para la capa de entrada. Si se usa una red como clasificador, se deben definir dos neuronas de salida, una para cada clase o tipo de respuesta (“0” y “1”). Pero si se usa una red como asociador, basta con una sola neurona de salida cuyo valor es en sí la respuesta al problema.
Tipo de asociación. Una RNA se puede ver como un tipo de memoria que es capaz de alma-cenar, a través de los valores que adquieren los pesos de las conexiones, el conocimiento que se le ha dado durante el entrenamiento. Producto de este conocimiento, la red es capaz de asociar a cada entrada presentada una salida adecuada correspondiente. Desde el punto de vista en la cual se realiza esta asociación, se puede hablar de dos tipos de redes:

Inteligencia Artificial Básica
159Índice
Modelo Topología Aprendizaje Entrada y Salida Tipo de Salida AsociaciónAGc 1 capa – auto-recur-
rentes Hebbiano o competitivo Continua Asociador Auto
ARPd 2 capas – hacia adelante
Reforzamiento es-tocástico
Híbrida Asociador Hetero
Back-propagation N capas – hacia adelante
Corrección de error Continua Asociador Hetero
BAM 2 capas – hacia adel-ante y hacia atrás
Hebbiano Discreta Asociador Hetero
Cognitrón N capas – hacia adel-ante y hacia atrás
Competitivo Discreta Clasificador Hetero
Counter-propaga-tion
3 capas – hacia adelante
Competitivo y correc-ción de error
Continua Clasificador Hetero
FAMe 2 capas – hacia adel-ante y hacia atrás
Hebbiano difuso Continua Asociador Hetero
Heteroasociativas. La RNA aprende al recibir un par de vectores (la entrada y su salida aso-• ciada) como información. Son redes que deben tener por lo menos dos capas, una para rete-ner la información de entrada y otra para mantener la salida asociada. Hay redes heteroaso-ciativas con aprendizaje supervisado como el Perceptrón y Backpropagation y hay también redes heteroasociativas con aprendizaje no supervisado como ART y BAM.
Autoasociativas. La RNA aprende un conjunto de vectores de entrada de tal forma que cuan-• do se realiza la propagación o ejecución, hay una autocorrelación, respondiendo con el vector que más se aproxima al aprendido. Estas redes son capaces de manejar vectores de entrada que se presentan incompletos o distorsionados. Basta una sola capa para implementar este tipo de red que puede hacer las funciones tanto de entrada como de salida. El ejemplo más significativo es Hopfield.
En la tabla 6.1 se presentan los modelos de RNA más importantes y se incluye su clasificación según los criterios antes presentados.
Tabla 6.1Modelos de RNA y su clasificación
Modelo Topología Aprendizaje Entrada y Salida Tipo de Salida Asociación
ABAMa 2 capas – hacia adel-ante y hacia atrás
Hebbiano diferencial Continua Asociador Hetero
Adaline 2 capas – hacia adelante
Corrección de error Híbrida Asociador Hetero
AHCb 3 capas – hacia adelante
Reforzamiento por ajuste temporal
Híbrida Asociador Hetero
ART1 2 capas – hacia adel-ante y hacia atrás
Competitivo (reso-nancia)
Discreta Asociador Hetero
ART2 2 capas – hacia adel-ante y hacia atrás
Competitivo (reso-nancia)
Continua Asociador Hetero
a “Adaptive Bidirectional Associative Memory”, Kosko, 1987.b “Adaptive Heuristic Critic”, Barto, 1983.c “Aditive Grossberg”, Grossberg, 1968.d “Associative Reward Penalty”, Barto, 1985.e “Fuzzy Associative Memory”, Kosko, 1987.f “Linear Associative Memory”, Anderson, 1968.

Mauricio Paletta
160Índice
Modelo Topología Aprendizaje Entrada y Salida Tipo de Salida AsociaciónRCEj 2 capas – hacia
adelanteHiperesférico Continua Clasificador Hetero
RBFk 3 capas – hacia adelante
Hiperesférico y correc-ción de error
Continua Asociador Hetero
TAMl 2 capas – hacia adel-ante y hacia atrás
Hebbiano Discretas Asociador Hetero
Tabla 6.1 (Continuación)Modelos de RNA y su clasificación
6.5. Los modelos conexionistas
Un modelo conexionista o neuronal es aquél que permite representar problemas mediante una RNA. Para definir un modelo se tienen que identificar y desarrollar los siguientes elementos:
Clasificación según su topología, mecanismo de aprendizaje, valores de entrada y salida, tipo • de salida y tipo de asociación.Descripción de los parámetros involucrados: constante de aprendizaje, función de evalua-• ción, umbral, inicialización de conexiones o radios, etc.Algoritmo de propagación o ejecución.• Algoritmo de entrenamiento.•
Perceptrón. Este modelo tiene dos capas: la capa de entrada con N neuronas y la capa de salida con una sola neurona. Las entradas son continuas mientras que la salida es discreta bipo-
Hopfield Continuo 1 capa – laterales Hebbiano Continua Asociador AutoHopfield Discreto 1 capa – laterales Hebbiano Discreta Asociador AutoLAMf 2 capas – hacia
adelanteHebbiano Continua Asociador Hetero
LMg 1 capa Hebbiano Discretas Asociador AutoLRPh 2 capas – hacia
adelanteReforzamiento es-tocástico
Híbridas Asociador Auto
LVQi 2 capas – hacia adelan-te, auto-recurrentes
Competitivo Continua Clasificador Hetero
Madaline N capas – hacia adelante
Corrección de error Continua Asociador Hetero
Máquina de Boltzmann
1 capa – conexio-nes laterales / 3 capas – hacia adelante
Estocástico (tem-ple simulado), Hebbiano, corre-cción de error
Discreta Asociador Hetero
Máquina de Cauchy
1 capa – conexio-nes laterales / 3 capas – hacia adelante
Estocástico (tem-ple simulado)
Híbrida Asociador Hetero
Perceptrón 2 capas – hacia adelante
Corrección de error Híbrida Asociador Hetero
Modelo Topología Aprendizaje Entrada y Salida Tipo de Salida Asociación
g “Learning Matrix”, Steinbuch, 1961.h “Linear Reward Penalty”, Barto, 1985.i “Learning Vector Quantizer”, Kohonen, 1981.j “Restricted Coulomb Energy”,k “Radial Based Functions”,l“Temporal Associative Memory”, Amari, 1972.

Inteligencia Artificial Básica
161Índice
lar utilizando una función de activación lineal del tipo escalón. El entrenamiento es supervisado por corrección de error y se usa la regla de aprendizaje de Rosenblatt.
La idea básica de este modelo es que los problemas se pueden representar de forma tal de establecer una separación lineal entre las dos posibles respuestas. La cantidad de elementos definidos en el vector de entrada determina la dimensión del espacio. Por ejemplo, para un vector de dos entradas, se obtiene la expresión de una recta:
Lo que implica que el modelo es capaz de separar con una recta en un espacio bidimensional, dos respuestas distintas (figura 6.12 a). Esto solo es posible si el problema es linealmente sepa-rable. Precisamente esta fue una de las grandes críticas que Minsky y Paper hicieron sobre el Perceptrón, ya que el modelo no era capaz de representar problemas tan simples como el XOR (figura 6.12 b).
Figura 6.12Ejemplo de la separación lineal de un problema (a) y un problema
que no es linealmente separable (b)
Pero, si bien el XOR no es linealmente separable para un espacio de dos dimensiones, ha-ciendo un pequeño truco es posible lograr que un Perceptrón simple represente este problema. El truco es muy simple, basta preprocesar las entradas antes de ser presentadas a la red. En el caso del problema del XOR, con solo agregar otra entrada al vector que represente el produc-to de las dos entradas originales se logra la separación lineal, esta vez en un espacio de tres dimensiones. Hay muchos métodos para realizar el preprocesamiento de la entrada, este caso particular se conoce como preprocesamiento polinómico.
Esta idea de preprocesamiento de las entradas originales lo que hace es agregar redundancia a la data y es muy común hacerlo en la mayoría de los modelos o paradigmas neurales. Al agre-gar redundancia a la data se aumenta la capacidad de representación del problema21.21 Esta idea no está muy lejos de lo que ocurre realmente en el sistema neural natural, ya que está comprobado que el procesamiento neural es eminentemente redundante.
y w x xw
wx
w2= ƒ − ⇒ =−
+=∑( )i ii
N
θθ
1
1
21
2

Mauricio Paletta
162Índice
Cuando se quiere tener más de una salida, basta colocar en paralelo la cantidad de percep-trones que hagan falta. Cada una de estas unidades actúa independiente de la otra. Se dice que es un procesamiento paralelo porque en la propagación, todos los perceptrones reciben y procesan el mismo vector de entrada a la vez. Con las salidas de todos los perceptrones se cons-truye un vector. Cada perceptrón es autónomo, se entrena por separado y representa su propio espacio del problema.
Algunas implementaciones del Perceptrón y de muchos otros modelos, agregan una entrada adicional a la red cuyo valor se mantiene constante igual a 1 (x0 = 1) o también –1 (x0 = -1). La razón de esto no es la de tener otra entrada (ya que por su valor no tiene efecto en el cálculo de NET) pero sí, tener otro peso de conexión (w0) que sustituye o representa el componente umbral o desplazamiento de la función de activación22.
Dado que hay una sola capa de neuronas de activación y una sola neurona en esta capa, el algoritmo de propagación es muy simple:
- Dado un vector de entrada (x0 x1 … xn).- Calcular la activación NET de la neurona de salida.- Obtener la salida y = (NET).
El algoritmo de entrenamiento es también sencillo:
- Dado un vector de entrada (x0 x1 … xn) y una salida deseada z.- Calcular la activación NET de la neurona de salida.- Obtener la salida y = (NET).- Para todos los pesos de las conexiones (w0 w1 … wn), hacer - wi wi + (z - y)
Nótese que en el algoritmo de entrenamiento hay una propagación (ejecución) de la RNA. Esto se ve con mucha frecuencia en casi todos los modelos, específicamente en aquellos cuyo entrenamiento es supervisado por corrección de error. Esto es aceptable si se entiende que para poder entrenar es necesario saber antes la salida de la red a una entrada específica. De forma tal que el algoritmo se puede escribir de la forma siguiente:
22 En algunas bibliografías a este elemento se le da el nombre de “bias”. Es independiente al número de neuronas de entrada que se definen en el problema.
y( ) = NET -t + ƒ1 ( )θ
y( ) = NET -t + ƒ1 ( )θ
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('

Inteligencia Artificial Básica
163Índice
- Dado un vector de entrada (x1 x2 … xn) y una salida deseada z.- Propagar la red.- Para todos los pesos de las conexiones (w1 w2 … wn), hacer - wi wi + (z - y) xi
Por otro lado, hay dos maneras de realizar el entrenamiento para un conjunto finito de vecto-res de entrada:
Entrenamiento uno a uno (también llamado patrón a patrón): El ajuste de pesos se realiza por • cada vector de entrada que se presenta.Entrenamiento por lotes: Para todos los vectores de entrada, las variaciones de los pesos se • van acumulando y se aplica al final del lote.
El algoritmo anterior describe el entrenamiento uno a uno. El algoritmo que realiza el entrena-miento por lotes se ve como sigue:
- Hacer wi 0 (1 i n).- Para todos los vectores de entrada - Tomar un vector (x1 x2 … xn) y su salida deseada z correspondiente. - Propagar la red. - Para todos los pesos de las conexiones (w1 w2 … wn), hacer - wi wi + (z - y) xi
- Para todos los pesos de las conexiones (w1 w2 … wn), hacer - wi wi + wi
En respuesta a la deficiencia de representación que el Perceptrón tiene sobre algunos proble-mas, manteniendo el vector de entrada original (XOR, por ejemplo), se tomó la idea de seguir ha-ciendo separación lineal a medida que el espacio se vaya dividiendo (se obtiene una representa-ción del XOR si se trazan dos rectas en lugar de una). Esto se logra si a la salida de un perceptrón simple se coloca otro perceptrón y así sucesivamente. De esta concepción nace el Perceptrón multicapa, una RNA multicapa de propagación hacia adelante. Las regiones o espacios que se pueden formar con perceptrones multicapa son realmente complejas de analizar. Gracias a esta complejidad es que no se han podido definir algoritmos adecuados de entrenamiento para este modelo.
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
yNET
yNETNET
yNET
yNETNET
yNET
yNETb+
NETb+NET<B+NET
(),(),,
(),
(),,
()
(),
,,
tttt
t
tb
BB
+=>
=<
+=+>
=−<
+=−
+=≤−<
≥
11
01
1
1
1
1
θθ
θ
θθθ
θ
θθθθ
yNET
yNETNET
yNET
yNETNET
yNET
yNETb+
NETb+NET<B+NET
(),(),,
(),
(),,
()
(),
,,
tttt
t
tb
BB
+=>
=<
+=+>
=−<
+=−
+=≤−<
≥
11
01
1
1
1
1
θθ
θ
θθθ
θ
θθθθ
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α [ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('

Mauricio Paletta
164Índice
Adaline. La topología y demás características de este modelo son iguales a las del Percep-trón, con la única diferencia que la salida de activación de la neurona es continua produciendo, por ende, una salida continua.
Para el entrenamiento se usa la regla de aprendizaje delta cuyo objetivo es minimizar la ex-presión del error que es una función de los cuadrados mínimos:
por lo tanto, el ajuste de los pesos viene dado por la siguiente expresión:
que para el caso de que la función de activación sea la sigmoide, corresponde a lo siguiente:
Otra función que se usa con mucha frecuencia en el Adaline es la tangente hiperbólica. El algoritmo de propagación es idéntico al del Perceptrón y el algoritmo de entrenamiento difiere en la aplicación de la regla de aprendizaje, como se puede ver en las expresiones anteriores:
- Dado un vector de entrada (x1 x2 … xn) y una salida deseada z.- Propagar la red.- Para todos los pesos de las conexiones (w1 w2 … wn), hacer - wi wi + xi
Dado que se tiene una expresión continua del error, una forma adecuada de detener el entre-namiento es si el error cuadrado medio alcanza una cota aceptable.
En este modelo es necesario considerar varios aspectos prácticos como el número de vec-tores de entrada para el entrenamiento, la salida deseada de cada uno de estos vectores, los valores iniciales de los pesos de las conexiones, cuándo se debe finalizar el entrenamiento y,
< >= −∑ε12
2( )( ) ( )z yik
ik
ik
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
ƒ =+ +
= ƒ − ƒ
⇒= − ƒ ƒ − ƒ
−
−
−' ( ( (
( ( ( (
NET) NET)( NET))
w NET)) NET)( NET))x
NET
NET
NET
11 1
1
1
ee
e
yij i∆ α
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('

Inteligencia Artificial Básica
165Índice
quizás el más importante, cuál debe ser el valor apropiado de la constante de aprendizaje (por lo general un número pequeño, entre 0.01 y 0.25). No hay respuestas concretas sobre todas estas inquietudes, dependen directamente del problema y el logro de resultados adecuados dependen de la aplicación de varias pruebas de ensayo y error.
Lo que si se puede afirmar sin equivocación es que los vectores de entrada para el entrena-miento de la red tienen que ser linealmente independientes y esto se logra sólo si el número de vectores es menor o igual que la dimensión N que los define (número de componentes o neuro-nas de entrada). Por lo tanto, sólo es posible representar N asociaciones como máximo.
Hay una versión lineal del Adeline que permite a través del método de la pseudo-inversa, llegar a una expresión determinista para obtener los pesos de las conexiones. En este método se define una matriz Q de pxp elementos (donde p es el número de vectores de entrenamiento) como la matriz de superposición de los vectores de entrada, que se obtiene mediante la siguiente expresión (N es la dimensión del vector):
Se puede demostrar que la matriz de pesos se calcula como:
Se llama método de la pseudo-inversa porque Q no es una matriz cuadrada y funciona como tal. También se le llama método de la proyección.
Al igual que el Perceptrón, también hay una versión multicapa del Adaline. Este nuevo modelo recibe el nombre de Madaline (múltiples Adaline).
Backpropagation. Se trata de uno de los modelos de RNA más utilizados para implementar una gran variedad de problemas. Es una red multicapa de propagación hacia adelante hete-roasociativa con aprendizaje supervisado por corrección de error basado en una generalización de la regla delta. Su nombre se debe a la idea de que el error es propagado hacia atrás una vez que se calcula haciendo la propagación hacia adelante.
Una característica importante del algoritmo de propagación hacia atrás es que logra una re-presentación interna del conocimiento que es capaz de organizar las capas escondidas de la red, de forma tal de conseguir cualquier correspondencia entre la entrada y la salida dadas en el
QN
x xuv ku
kv
k= ∑1 ( ) ( )
wN
y (Q ) x-1ij i
uuv j
v
u v= ∑1 ( ) ( )
,

Mauricio Paletta
166Índice
entrenamiento. Luego de que la red está entrenada, tiene la facilidad de dar salidas satisfactorias a entradas que no ha visto en el entrenamiento, gracias a su capacidad de generalización.
El entrenamiento se realiza en dos fases:
Dado un vector de entrada con el vector de salida deseada asociado, se propaga la red 1. desde la capa de entrada hasta la capa de salida y obtener un vector de salida actual. Con los vectores de salida deseada y actual se calcula un error para cada neurona de salida.
Los errores calculados se transmiten hacia atrás, partiendo de la capa de salida hasta 2. llegar a la capa de entrada. En el camino cada conexión recibe el porcentaje de error aproxi-mado a la participación de la neurona en la salida original.
Este proceso se repite varias veces de forma tal que cada vez que se presenta el mismo vector de entrada, el error disminuye (la salida está más cercana a la deseada). La cantidad de veces que hay que repetir el ciclo de entrenamiento (llamado algunas veces época), es un tema que muchos investigadores han trabajado para lograr resultados que lleven a reducir el tiempo de entrenamiento y buscar que la RNA converja más rápidamente23.
El modelo utiliza una función de activación continua no decreciente y derivable, siendo la sig-moide la más usada. También se tiene una función o superficie de error asociado y la idea básica es buscar el estado estable de mínimo error a través del camino descendente de su superficie.
Para un par de unidades Ui y Ui unidas por una conexión cuyo peso es w si yi es la salida de la unidad Ui, el ajuste del peso wij para el vector de entrada viene dado por la expresión:
si Uj es una neurona de salida (por lo tanto se conoce la salida deseada asociada). Para las neuronas Uj escondidas, el error que se produce está en función del error que se comete en las neuronas que reciben como entrada la salida de dicha neurona (procedimiento de propagación del error hacia atrás) y el ajuste del peso se calcula mediante la siguiente expresión:
para todas las unidades Uk que están conectadas a la salida de Uj. De esta manera, el error cometido en una neurona escondida es equivalente a la suma de los errores producidos en las neuronas que están conectadas a la salida de ésta.
23 Normalmente, una red Backpropagation requiere entre 300 y 600 épocas de entrenamiento. El tiempo de ejecución de este proceso puede durar varias horas y depende de la cantidad de capas y neuronas de la red.
∆w y z y NET)ij pj pi pj pj pj= = − ⋅ ƒαε ε; ( ) ('
∆w y w NET)ij pj pi pj pk kjk
= = ⋅ ƒ∑αε ε ε; ( ) ('

Inteligencia Artificial Básica
167Índice
Debido a la gran cantidad de veces que hay que repetir el entrenamiento sobre un mismo conjunto de vectores de entrada, hay algunas sugerencias y variantes que se pueden aplicar para llegar a la convergencia más en menos tiempo. Una forma de modificar el tiempo de entre-namiento es cambiando el valor de la constante de aprendizaje (debe ser un número pequeño entre 0.05 y 0.25). A medida que esta constante crezca, mayor es la modificación que se le hace al peso y por lo tanto, más rápido se logra el aprendizaje. Pero, si se colocan valores muy gran-des, se pueden producir oscilaciones que impiden llegar al mínimo global de la curva del error. Una idea que permite que no ocurran este tipo de oscilaciones y se acelere el aprendizaje, es agregar a la expresión de ajuste de los pesos, un término que determina, en el instante t+1, el efecto del cambio de los pesos en el instante t. Este término se denomina momento y es una constante (aproximadamente entre 0.6 y 0.9) que modifica la expresión del ajuste de pesos de la siguiente forma:
Al usar el momento, se consigue la convergencia del entrenamiento de la RNA en menor número de épocas ya que si en los tiempos t y t+1 los incrementos de un peso son positivos, el descenso por la superficie del error en t+1 es mayor. Por el contrario, si en t el incremento es po-sitivo y en t+1 es negativo, el paso que se da en t+1 es más pequeño, lo que significa que se ha pasado por un mínimo y que los pasos deben ser menores para poder alcanzar este mínimo.
El algoritmo de propagación de la red es como sigue:
- Dado un vector de entrada (x1 … xn).- Para todas las capas escondidas y la capa de salida - Para todas las neuronas de cada capa - Calcular la activación NET de la neurona. - Obtener la salida y = (NET).
Mientras que el algoritmo de entrenamiento es como sigue:
w w y w w w y w
ji ji pj pj ji ji
ji pj pj ji
t t t tt t
( ) ( ) ( ( ) ( )( ) ( )+ = + + − − ⇒
+ = +
1 11
αε β
αε β∆∆
w w y w w w y w
ji ji pj pj ji ji
ji pj pj ji
t t t tt t
( ) ( ) ( ( ) ( )( ) ( )+ = + + − − ⇒
+ = +
1 11
αε β
αε β∆∆
y( ) = NET -t + ƒ1 ( )θ

Mauricio Paletta
168Índice
- Hacer wij 0 (una para cada conexión en la red).- Dado un vector de entrada (x1 … xn) y su vector de salida deseada asociado (z1 … zn).- Propagar la red.- Para todas las neuronas de la capa de salida - (z - y). ’(NET) - Para todas las conexiones que vienen hacia la neurona - wij . .y + . wij
- wij wij + wij
- Para todas las capas escondidas desde la última hasta la primera - Para todas las neuronas de cada capa - Para todas las conexiones que vienen hacia la neurona - k wk. ’(NET) - wij . .y + . wij - wij wij + wij
La función de error a lo largo del proceso de aprendizaje, describe una curva en la que se pueden hallar varios mínimos locales y un mínimo global y hasta puntos estacionarios (la figura 6.13 muestra un ejemplo). Lo ideal es encontrar el mínimo global pero, como se está usando un algoritmo de descenso de gradiente, existe la posibilidad de caer en un mínimo local o en algún punto estacionario. Este es uno de los graves problemas que presenta este algoritmo de entrenamiento. Sin embargo, para muchos problemas, no es estrictamente necesario alcanzar el mínimo global ya que se puede llegar hasta una situación en la cual las salidas de la red son aceptables.
Figura 6.13Ejemplo de la curva del error en función de los pesos de las conexiones
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('w
Ny (Q ) x-1
ij iu
uv jv
u v= ∑1 ( ) ( )
,
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('y( ) = NET -t + ƒ1 ( )θ[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
w w y w w w y w
ji ji pj pj ji ji
ji pj pj ji
t t t tt t
( ) ( ) ( ( ) ( )( ) ( )+ = + + − − ⇒
+ = +
1 11
αε β
αε β∆∆
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
y( ) = NET -t + ƒ1 ( )θ
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
w w y w w w y w
ji ji pj pj ji ji
ji pj pj ji
t t t tt t
( ) ( ) ( ( ) ( )( ) ( )+ = + + − − ⇒
+ = +
1 11
αε β
αε β∆∆
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α
[ ] w x z yi∆ ( ) ( ) ( ( ) ( ))t t t ti= ⋅ −α

Inteligencia Artificial Básica
169Índice
Es importante que el descenso en la curva del error se haga con incrementos o saltos peque-ños ya que si se aplican saltos muy grandes se corre el riesgo de pasar por encima del mínimo. Aunque se tarda más en llegar con incrementos pequeños, es más seguro de que se va a alcan-zar el mínimo.
En lo que respecta al número de capas y el número de neuronas que debe haber por cada capa, no hay una regla que indique la mejor topología para un problema específico. Se recomien-da que por lo menos haya una capa de neuronas escondidas y que ésta tenga por lo menos una cantidad de neuronas equivalente al mínimo entre las capas de entrada y de salida. El ensayo y error va a determinar la mejor estructura para una aplicación determinada. Lo que si hay que tener claro es que el tiempo de entrenamiento se degrada a medida que las capas crezcan en neuronas o la RNA crezca en capas.
Hopfield. Es una red monocapa de N neuronas autoasociativa con dos versiones: el modelo discreto (de entrada y salida discretas, ya sea binarias o bipolares) y el modelo continuo (entra-das y salidas continuas). En el modelo discreto se usa una función de activación lineal del tipo escalón y en el modelo continuo se usa una función de tipo sigmoidal.
Cada una de las neuronas de la red se conecta con el resto (conexiones laterales) y los pesos de las conexiones entre pares de neuronas son simétricos(wij = wji).
En la versión discreta, el umbral que se utiliza en la función escalón es igual a la suma de los pesos de las conexiones de cada neurona con el resto. Para la versión continua, si se usan valo-res de entrada en el rango [-1, +1] se aplica como función de activación la tangente hiperbólica y, si los valores de entrada están en el rango [0, 1], se usa la función sigmoide. En ambas funciones continuas se usa un parámetro que determina la pendiente de la función:
La red Hopfield se comporta como una memoria, capaz de almacenar (recordar) varios vec-tores de entrada que se le han dado durante el entrenamiento. Durante la etapa de ejecución, si se le presenta a la red alguno de los vectores que se le dio durante el entrenamiento, ésta evolu-ciona hasta estabilizarse (llegar a un estado estable) y se da como salida el mismo vector que se dio como entrada. Pero, si el vector de entrada no coincide con ninguno de los que fueron dados durante el entrenamiento (ya sea porque la información está incompleta o distorsionada), la red evoluciona generando como salida el vector que más se aproxima al dado.
El vector de entrada tiene tantas componentes como neuronas hay en la red. Cada neurona recibe una componente del vector y como cada neurona está conectada con el resto, la activa-
∆ww
x y NET)) NET) xi iijij
= − = = − ƒ ƒα∂ε∂
αε α ( ( ('
ƒ − = − ƒ − =+ − −( ) tgh( ( )) ( ) ( )NET NET NET NETθ α θ θ α θ
11 e
ƒ − = − ƒ − =+ − −( ) tgh( ( )) ( ) ( )NET NET NET NETθ α θ θ α θ
11 e

Mauricio Paletta
170Índice
ción de la misma va a ser igual a la suma del resto de las entradas multiplicadas por las conexio-nes respectivas. Con esta activación se calcula la salida de la neurona aplicando la función de activación correspondiente y el proceso se repite hasta que se llegue a un estado estable. La red se estabiliza cuando todas las neuronas dejan de cambiar de valor. La salida de las neuronas en el momento de llegar al estado estable forman el vector de salida de la RNA. El algoritmo es como sigue:
- Dado un vector de entrada (x1 … xn).- Mientras no se alcance un estado estable (comparar salidas con la iteración anterior) - Para todas las neuronas de la red - Calcular la activación NET de la neurona. - Obtener la salida y = (NET).
El aprendizaje en este modelo es no supervisado del tipo hebbiano. En el caso del modelo discreto y suponiendo que hay P vectores de entrada del tipo (p1 … pn), se tienen las siguientes expresiones para obtener el peso de las conexiones, tanto para el caso bipolar como para el binario:
Dado que los pesos de las conexiones se pueden expresar como una matriz W de dimensión NxN, que además es una matriz simétrica con la diagonal principal nula, la regla de aprendizaje también se puede expresar haciendo uso de notación matricial:
siendo PkT la transpuesta del vector Pk e I la matriz identidad de NxN.
El algoritmo de aprendizaje de este modelo se reduce tan sólo a la obtención de la matriz de peso W en función del conjunto de vectores de entrada que se desea almacenar.
Para demostrar que la red siempre llega a un estado estable, Hopfield formuló una función de energía que describe el comportamiento del modelo. Para las versiones discreta y continua, estas funciones son como sigue:
y( ) = NET -t + ƒ1 ( )θ
w wij ik
jk
k
P
ij ik
jk
k
P
p p p p= = − −= =∑ ∑( ) ( ) ( ) ( )( )( )
1 12 1 2 1
W I]= −=∑[P Pk
Tk
k
P
1

Inteligencia Artificial Básica
171Índice
E
E
ij i j i ii
N
ji j
N
i
N
ij i j
y
i
N
ji j
N
i
N i
= − +
= − + −
==≠
=
==≠
=
∑∑∑
∫∑∑∑
12
12
11
111
0111
w y y y
w y yy
ds
θ
ln
Uno de los inconvenientes más importantes que tiene el modelo de Hopfield es la fuerte li-mitación que hay sobre el número de vectores de entrada dados en el entrenamiento. Algunos estudios han demostrado que el límite viene dado por el valor (N / 4lnN) para N neuronas de entrada.
Modelos estocásticos. Son redes cuyas funciones de activación son no determinísticas de la forma probabilística y cuyos mecanismo de aprendizaje se basan en la idea de seleccionar valo-res aleatorios para los pesos de las conexiones y comprobar su efecto en la salida de la RNA.
Al igual que en otros mecanismos de aprendizaje, en este caso también se busca minimizar la función de error o energía asociada y para resolver el problema de los mínimos locales, se hace uso de los conceptos de termodinámica de la mecánica estadística. La idea general es ver a la red como un cuerpo compuesto de un gran número de partículas elementales (átomos, molécu-las, etc.) con estado energético estocástico individual, de forma tal que la adopción de un estado de alta o baja energía de cada elemento depende de una distribución de probabilidad específica. La combinación de estas energías individuales, junto al grado de desorden que hay en ellas (en-tropía) y la temperatura del material, producen la energía libre global del sistema, que siempre está en equilibrio, buscando un estado de mínima energía.
Cada una de las neuronas de la RNA está asociada a una de las partículas individuales y la función de energía de la red tiene relación directa con la energía global del material. Para simular la búsqueda del estado de mínima energía se usa un algoritmo llamado temple simulado. Se par-te de una alta temperatura inicial y gran desorden interno y se simula un enfriamiento progresivo hasta encontrar un estado estable (mínimo global de la función de energía).
Los modelos neuronales estocásticos más conocidos son las Máquinas de Boltzmann, que deben su nombre al físico austríaco L. Boltzmann, quien formuló funciones termodinámicas para determinar la probabilidad de que una partícula elemental alcance su estado de alta y baja ener-gía. Son tres topologías diferentes que usan el algoritmo de temple simulado para la propagación y entrenamiento de la red. Los modelos son los siguientes:
La red de terminación (“Boltzmann Completion Network”): su topología es similar a una red • Hopfield, con una capa de neuronas donde N de ellas son visibles (entrada y salida) y P son escondidas.

Mauricio Paletta
172Índice
La red entrada-salida (“Boltzmann Input-Output Network”): hay tres capas de neuronas: una • de entrada, una de salida y otra escondida. Hay conexión hacia adelante entre la capa de entrada y las otras dos capas, conexiones laterales entre las neuronas escondidas y entre las neuronas de salida y conexiones hacia adelante y hacia atrás entre las neuronas escondidas y las neuronas de salida.La red de conexiones hacia adelante (“Boltzmann Feedforward Network): red de tres capas • como la anterior pero con conexiones hacia adelante entre ellas. El funcionamiento de esta red es similar a un Perceptrón multicapa.
En los tres modelos, las salidas de las neuronas son discretas binarias y se obtiene mediante una función estocástica de la activación de la neurona que determina la probabilidad de activa-ción de la unidad. Se usan expresiones como las siguientes:
donde es un factor de ganancia que establece la forma de la pendiente de la función de pro-babilidad y cuyo valor es equivalente a 1/T, siendo T la temperatura a la que se mantiene la red (temple simulado).
Dado que se tiene un comportamiento probabilístico, la salida de la red casi nunca va a ser igual para un mismo vector de entrada. Para evitar esto, la salida se calcula luego de obtener un valor aleatorio entre 0 y 1 que funcione como umbral:
Es estos modelos es muy importante la elección de un plan de templado o enfriamiento (tem-peratura inicial y decrementos sucesivos), para evitar caer en mínimos locales y alcanzar el mínimo global de energía. Normalmente se utiliza una disminución logarítmica de la temperatura para hacer la simulación. Para iniciar la simulación, antes se deben inicializar las salidas de las neuronas. Las neuronas escondidas y las neuronas de salida (modelo entrada-salida) se iniciali-zan con valores aleatorios entre 0 y 1. Las neuronas visibles se inicializan con los valores de los componentes del vector de entrada. Algunas expresiones que permiten calcular el cambio de la temperatura en el tiempo son las siguientes:
Pe
P P( ) ( ) ( )y y yNET= =+
= = − =−11
10 1 12β
w w y w w w y w
ji ji pj pj ji ji
ji pj pj ji
t t t tt t
( ) ( ) ( ( ) ( )( ) ( )+ = + + − − ⇒
+ = +
1 11
αε β
αε β∆∆
y y y=
= ≥= <
1 10 1, ( ), ( )
PP
θθ
T t
T t tT t t tT t t tT t t
T tT
tT t
Tt
a
a b
b c
c
( )
,,,,
( )ln
( )=
≤ <≤ <≤ <≥
=+
=+
0
1
2
3
0 0
0
1 1

Inteligencia Artificial Básica
173Índice
El algoritmo genérico de propagación o funcionamiento de estas redes es como sigue:
- T(0) T0 (temperatura inicial alta).- t 0- Inicializar las salidas de todas las neuronas.- Mientras t < tiempo de simulación - Mientras no se alcance el número de neuronas escondidas + salida de la red - Seleccionar aleatoriamente una neurona (se puede repetir la elección). - Calcular la activación NET de la neurona. - Obtener P(y = 1). - Obtener un número aleatorio entre 0 y 1. - Calcular la salida y. - t t + 1 - Actualizar T(t)
Un criterio que se puede usar para saber cuántas iteraciones de tiempo (tiempo de simula-ción) hay que repetir el proceso, consiste en suponer que el sistema alcanza el equilibrio cuando no hay variación de la energía (error) en la red a causa de ninguna de sus neuronas en dos o más iteraciones consecutivas. Este incremento de energía coincide con el valor de activación de la neurona NET.
Con respecto al entrenamiento, la idea es hacer cambios aleatorios en los pesos de las co-nexiones y comprobar su efecto sobre la función de energía o error de la red. Sólo se aceptan aquellos cambios que suponen una disminución de este error o en función de una distribución de probabilidades específica. Según el modelo, se aplica una regla de aprendizaje no supervisa-do que es una versión estocástica del aprendizaje hebbiano (red de terminación) y una versión estocástica de la regla de aprendizaje supervisado del Perceptrón (entrada-salida y conexiones hacia adelante).
Para el modelo monocapa, se siguen las siguientes expresiones para el ajuste de los pesos:
donde es una constante de proporcionalidad y es la probabilidad de que las unidades i y j estén activas al mismo tiempo cuando a la red se le presentan los K vectores de entrada. Para cada vector de entrada, la red debe evolucionar un cierto número de iteraciones (tiempo de si-mulación) hasta que se alcanza el equilibrio térmico. La diferencia entre p+ y p- es que la primera se calcula bloqueando las salidas de las neuronas visibles forzando a que éstas permanezcan
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
∆w =1K
y y i(k)
j(k)
k=1
K
ij ij ij ijp p p= −+ − ∑η( )
∆w =1K
y y i(k)
j(k)
k=1
K
ij ij ij ijp p p= −+ − ∑η( )

Mauricio Paletta
174Índice
invariables durante todas las iteraciones sobre un mismo vector de entrada. En el otro caso se permite la variación de los valores en el proceso.
La idea básica del aprendizaje es que las probabilidades p+ y p- deben llegar a ser iguales, en cuyo caso no habrá variación de los pesos, cuyos valores deben alcanzar una situación de esta-bilidad en donde las salidas de las neuronas visibles coincidan con el vector de entrada (memoria autoasociativa).
El algoritmo general para este modelo de redes es como sigue:
El algoritmo de entrenamiento del modelo de entrada-salida con conexiones hacia adelante y hacia atrás es similar al anterior. La única diferencia es, como las neuronas visibles son tanto de entrada como de salida, a las neuronas de entrada se le asignan los valores del vector de entre-namiento y estos se mantienen sin variar durante todo el proceso, mientras que los valores de las neuronas de salida son los que quedan fijos y cambian para el cálculo de las probabilidades p+ y p-.
En lo que respecta al modelo de conexiones hacia adelante, se usa una versión estocástica de la regla usada en el Perceptrón. La función de activación de las neuronas es de tipo escalón binaria. La versión estocástica de la regla establece la realización de modificaciones aleatorias en los pesos de las conexiones y comprobar su efecto en el error (diferencia entre la salida deseada y la salida actual). Si el error disminuye o si aumenta de acuerdo a una distribución de probabili-dad (para escapar de los mínimos locales), los cambios en los pesos son aceptados. El algoritmo es como sigue:
- Inicialización aleatoria de todos los pesos con valores entre –1 y 1.- t 1.- Desde k 1 hasta K (todos los vectores de entrada) - Asignar a la salida de las neuronas de entrada el vector de entrada Ek
- Propagar la entrada para obtener una salida. - Calcular el error cometido Error1. - Para todos los pesos de las conexiones de la red - Hacer un cambio leve temporal de sus valores (pueden ser aleatorios). - Propagar de nuevo la entrada para obtener una otra salida. - Calcular un segundo error Error2. - Si Error2 - Error1 < 0 - Aceptar el cambio en los pesos - Si Error2 - Error1 > 0 - Calcular la probabilidad de modificación del error x (derivada de la función de distribución de probabilidad).

Inteligencia Artificial Básica
175Índice
- Generar un número aleatorio entre 0 y 1. - Si p > - Aceptar el cambio en los pesos- t t + 1- Actualizar T(t)
Otro modelo estocástico muy conocido es la Máquina de Cauchy cuya topología y funcio-namiento es similar a la Máquina de Boltzmann con la única diferencia relativa a la función de probabilidad la cual sigue una distribución de Cauchy:
Modelos hiperesféricos. En estas redes hay una concepción diferente sobre lo que repre-senta una unidad o neurona. Para estos modelos una neurona artificial se ve como una esfera en un hiperespacio N-dimensional donde N (dimensión del espacio) viene dado por el número de elementos del vector de entrada. Cada una de estas unidades o esferas tiene un radio máximo inicial que determina el tamaño de la esfera en el momento de su creación. El punto central de la esfera, llamado prototipo, corresponde a un vector de entrada dado en el entrenamiento.
Cada esfera representa una salida, clase o categoría específica. Cada clase puede estar representada por más de una esfera. El objetivo de este tipo de redes es hacer que un conjunto finito de esferas asociadas a una misma salida, “rellenen” una región que equivale al espacio de solución ocupado por esa salida específica. La figura 6.14 presenta un ejemplo de cómo un conjunto de esferas para un espacio de dos dimensiones, definen dos regiones diferentes “A” (esferas grises) y “B” (esferas blancas).
Figura 6.14Ejemplo de una red hiperesférica de dos entradas
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
PT
( )y +1
arctanNET
= =
1
12 π

Mauricio Paletta
176Índice
La ejecución o propagación de estas redes se basa en una idea muy simple. Basta conseguir la esfera que encierre un punto indicado en el vector de entrada. Mientras más grande es una esfera (radio) más puntos encierra y por ende tiene mayor poder de generalización.
El problema empieza a aparecer cuando dos esferas que representan salidas diferentes se entrecruzan o sobrelapan, en este caso se dice que hay un “conflicto” entre ellas. Por esta razón durante el aprendizaje, no sólo se crean esferas sino que los radios de las mismas se reducen de forma tal de evitar el sobrelapamiento. Dado que estas redes son de aprendizaje supervisado, cuando en el entrenamiento un punto (patrón) está encerrado en más de una esfera de clases diferentes, todas aquellas esferas que no pertenecen a la clase deseada se reducen hasta que el punto queda fuera de las mismas o hasta llegar al radio mínimo permitido.
Si durante la ejecución se presenta un punto que no es encerrado por ninguna esfera, se tiene una respuesta “no identificada”. Una estrategia para evitar este tipo de situaciones se conoce como “el vecino más cercano” y consiste en dar como respuesta la clase representada por la esfera que está más cerca del punto. Si por el contrario, el punto está encerrado por más de una esfera de clases diferentes, se tiene una respuesta “incierta”. Para evitar este caso se pueden usar las siguientes dos estrategias:
La mejor respuesta corresponde a la clase representada por la mayor cantidad de esferas • que encierra al punto.La mejor respuesta corresponde a la clase representada por la esfera cuyo centro (prototipo) • esté más próximo al punto.
Aprendizaje Competitivo. Este es uno de los tipos de aprendizaje que se usan en redes de entrenamiento no supervisado. La idea principal es que sólo una unidad de salida (o una por gru-po) se puede activar a la vez. Las unidades de salida “compiten” para ver quién de ellas es la que se va a activar y la que resulte vencedora recibe el nombre de “ganadora”. La neurona ganadora es usualmente aquella que tiene la mayor activación.
El objetivo principal de este tipo de redes es agrupar o categorizar la data de entrada. Las en-tradas similares se deben clasificar en una misma categoría y por ende deben activar la misma neurona de salida. La RNA tiene que identificar por sí misma a las clases mediante la correlación de la data de entrada.
En la red de aprendizaje competitivo más simple, hay una capa de neuronas de entrada que están totalmente conectadas con las neuronas de salida. Estas conexiones son excitatorias (wij 0).Las neuronas de la capa de salida están totalmente conectadas entre ellas.
La figura 6.15 muestra un ejemplo de la arquitectura de una red con 5 neuronas de entrada y 3 de salida.
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ

Inteligencia Artificial Básica
177Índice
Figura 6.15Ejemplo de una red simple de aprendizaje competitivo
Uno de los problemas con este tipo de redes es escoger adecuadamente el vector de pesos de forma tal que la neurona ganadora no sea siempre la misma. Se comienza con una inicializa-ción aleatoria de valores pequeños, tomando en cuenta el hecho de que no se formen simetrías en el vector. Los vectores de entrada para el entrenamiento se presentan en un orden aleatorio para evitar que hayan agrupaciones de patrones que tiendan a una misma neurona ganadora.
El aprendizaje es bastante sencillo. Para cada vector de entrada (x1 … xn), se encuentra una neurona ganadora i (aquella cuya activación sea mayor) y sólo se modifican los pesos asociados a la neurona ganadora, haciendo uso de alguna regla de aprendizaje competitiva. A continuación se presentan las tres reglas más comunes: la primera es la más simple de todas ya que la varia-ción del peso sólo está influenciado por la componente del vector de entrada correspondiente; la segunda regla toma en cuenta la normalización del vector de entrada y la tercera y última, lla-mada “regla de aprendizaje competitiva estándar”, mueve directamente el peso hacia la entrada (sin normalizar)24:
24 Esta última regla de aprendizaje fue propuesta por Oja y es la que mejores resultados arroja. La idea es aproximar el vector de entrada lo más posible al peso que es visto como un prototipo o centro de un cluster que agrupa todos los vectores de entrada similares.
( )
∆
∆
∆
w x
wx
xw
w x w
ij j
ijj
jj
ij
ij j ij
=
= −
= −
∑
η
η
η

Mauricio Paletta
178Índice
Una de las desventajas de aplicar las reglas de aprendizaje anteriores es que al siempre ac-tuar sobre la unidad de proceso ganadora, se puede llegar con mucha facilidad a tener neuronas que nunca van a ganar (“unidades muertas”). Teuvo Kohonen propuso una regla de aprendizaje que toma en cuenta no sólo la unidad ganadora sino también el conjunto de sus vecinas más próximas. Esta regla que lleva su nombre, es parecida a la regla de Oja, con la diferencia que se le agrega un término llamado función de vecindad. La regla de Kohonen y dos formas de calcular la función de vecindad tienen las siguientes expresiones:
donde i* es la unidad ganadora, ri es el prototipo de la unidad i y (t) es un parámetro de ancho que se decrementa con el tiempo.
6.6. Ejemplos y aplicaciones
Uno de los nombres con el que mejor se conoce al vector de entrada para una RNA es patrón y por esa razón se dice que las RNAs permiten hacer procesamiento de patrones. A raíz de esto, no es erróneo afirmar que cualquier problema que pueda ser descrito en un número finito y sig-nificativo de patrones, es apto para ser representado por una RNA.
Se pueden identificar cuatro grandes grupos de aplicaciones en donde las RNAs han demos-trado ser exitosas:
Reconocimiento de patrones. Es una de las aplicaciones más comunes. El patrón o vector 1. de entrada está formado por un conjunto de rasgos característicos asociados a lo que se debe reconocer, como por ejemplo: altura, ancho, color, dimensión, cantidad, etc. La salida está asociada al conjunto de clases o categorías que hay que identificar, por eso es que las redes que trabajan bajo el esquema de clasificador, son las que mejor se comportan para implementar este tipo de problemas. Las redes son entrenadas para que aprendan a reco-nocer todas las clases del problema y durante la ejecución, es posible presentar patrones incompletos o distorsionados.
Por lo general, para este tipo de problemas se pueden identificar tres tipos de salida:
( )( )
( )( )
( )
∆
Λ
Λ
w x w
en caso contrario
ij j ij
r r
t
i i
i i
i i e
i ir r t
i i
= −
=
=− ≤
−−
ηΛ
σ
σ
,
,
,, ( )
,
*
*( )
*
*
*
2
2
1
0
( )( )
( )( )
( )
∆
Λ
Λ
w x w
en caso contrario
ij j ij
r r
t
i i
i i
i i e
i ir r t
i i
= −
=
=− ≤
−−
ηΛ
σ
σ
,
,
,, ( )
,
*
*( )
*
*
*
2
2
1
0

Inteligencia Artificial Básica
179Índice
Identificado / reconocido: una sola de las clases está asociada al patrón de entrada.• Incierto: más de una clase está asociada al patrón de entrada.• No identificado: ninguna clase de las aprendidas se asocia al patrón de entrada.•
Lo más difícil e importante en la implementación de problemas de este tipo es la tarea que con-lleva a la extracción de características del problema cuyo resultado conlleva a la definición de la capa de entrada de la RNA. Es importante tener presente que mientras menos características se definan menos neuronas de entrada tendrá la red (más rápido la propagación) pero la cantidad de características debe ser suficiente para identificar y diferenciar todas las clases que se quieren aprender a reconocer.
De entre los ejemplos más importantes que se pueden mencionar, están el reconocimiento de alfabetos (caracteres, dígitos, direcciones postales, códigos, etc.) y el reconocimiento de figuras en dos y tres dimensiones (geométricas, objetos, etc.).
Visión. Es un caso particular de reconocimiento donde el patrón está formado por la infor-2. mación necesaria para describir una imagen. Por lo general los patrones son vectores muy grandes y están formados por valores binarios (imágenes en blanco y negro). En estas aplicaciones están centrados muchos trabajos de investigación de IA en visión artificial. Es muy frecuente usar modelos cuya función no es generalizar sino más bien recordar o aso-ciar una entrada dada en la ejecución a alguno de los patrones dados en el entrenamiento (modelos del tipo memoria).
Señales. Es otro caso particular de reconocimiento donde el patrón está formado por la 3. información necesaria para describir una señal. Algunas características que se toman en la extracción son la frecuencia y amplitud de la señal, el número de crestas, la mayor y menor amplitud, etc. Aplicaciones importantes de este tipo son, por ejemplo, el reconocimiento del habla, la interpretación de electrocardiogramas, la interpretación de sismógrafos, etc.
Otro uso importante que se les da a las RNAs en esta área son el filtraje o eliminación de ruido en señales generadas por canales de transmisión de voz, data, etc.
Control. Es una de las áreas que más se le ha dado énfasis en los últimos años. El pa-4. trón está formado por la información que describe el estado del elemento que se desea controlar. La salida representa el conjunto de acciones a tomar sobre el elemento cuando está en el estado correspondiente. Las redes que mejor se comportan para implementar problemas de control son las heteroasociativas con aprendizaje supervisado por corrección de error y que funcionan como asociador. Son innumerables la cantidad de aplicaciones que se pueden mencionar como ejemplo, pero para la IA, una de las áreas que más ha explotado es el control de robots.

Mauricio Paletta
180Índice
La tabla 6.2 muestra las aplicaciones más comunes sobre alguno de los modelos más importantes.
Tabla 6.2Aplicaciones de algunos modelos de RNA
Problema del agente viajero. Se tienen N ciudades conectadas entre sí y con una distancia específica entre ellas. Se quiere que el agente viajero visite todas las ciudades, pasando por ellas una sola vez y haciendo el menor recorrido posible (reduciendo la distancia total del recorrido).
En este ejemplo se van a considerar 5 ciudades (12 caminos posibles) cuyas distancias están reflejadas en el grafo de la figura 6.16. En la figura también aparece una representación matricial de las distancias entre las ciudades.
Figura 6.16Un caso particular del problema del agente viajero
Para representar este problema se va a usar una RNA Hopfield continua de NxN neuronas (25 en este caso). La activación de cada neurona (salida igual a 1) indica el orden de la ciudad representada por esa neurona en el recorrido del viajero. Hay que imaginarse la organización de
Modelo AplicacionesAdaline Filtrado de señales, ecualizador adaptativo y modemos.ART Reconocimiento de patrones (radar, sonar, etc.)Backpropagation Control, predicción, síntesis de voz desde texto y reconocimiento de
patrones.BAM Memoria heteroasociativa de acceso por contenido.Cognitrón Reconocimiento de caracteres manuscritos.Counter-propagation Interpretación de imágenes y reconocimiento del habla.Hopfield Reconstrucción de patrones y optimización.Máquina de Boltzmann Reconocimiento de patrones (imágenes, sonar y radar) y optimi-
zación.Máquina de Cauchy Reconocimiento de patrones (imágenes, sonar y radar) y optimi-
zación.Perceptrón Reconocimiento de caracteres impresos.RCE Reconocimiento de patrones.RBF Control y reconocimiento de patrones.

Inteligencia Artificial Básica
181Índice
las neuronas como si estuvieran en una matriz cuadrada de tal forma que cada fila se asocia con una ciudad del recorrido y las columnas con la posición de cada ciudad dentro de la ruta. Esto quiere decir que si la unidad Uij está activa, la ciudad i será la parada número j de la ruta. Una ciudad sólo puede aparecer en una parada de la ruta por lo tanto hay que evitar que se activen dos neuronas de la misma fila.
Para dar con la solución del problema, es necesario buscar una expresión de la función obje-tivo que se está tratando de minimizar:
donde: i y k representan ciudades (filas de la matriz de neuronas) j y l representan paradas en la ruta (columnas de la matriz de neuronas) dij es la distancia entre las ciudades i y j A, B, C y D son constantes que sirven para cuantificar la importancia relativa de cada término de la función.
El primer término representa la restricción de que una ciudad i sólo puede aparecer en una parada de la ruta; el segundo término representa la restricción de que una parada l de la ruta sólo puede corresponder a una ciudad; la tercera componente obliga a que haya exactamente N ciudades en la ruta y el último término recoge la condición de que la distancia total del recorrido sea mínima.
Figura 6.17Estado estable de la red Hopfield en el problema del agente viajero para 5 ciudades
ƒ = + + − +
+
≠ ≠
≠
+ −
∑∑∑ ∑∑∑∑∑
∑∑∑
A B C
Dd
ij illl j
jiij kj ij
jikk i
ji
ijkk i
ij kj ij kjji
2 2 2
2
2
1 1
y y y y y N
y y y y
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
=1
N
( )
( )

Mauricio Paletta
182Índice
La función objetivo se relaciona con la expresión general de energía de la red Hopfield:
para dar lugar a la siguiente expresión, que se llega buscando que sean equivalentes los va-lores de los pesos de las conexiones entre dos neuronas, una en la fila i, columna j y otra en la fila k, columna l:
Al implementar una red Hopfield continua cuyos pesos y umbrales se calculen de la forma an-terior, se va a llegar a una situación de estabilidad en la que sólo habrá N neuronas activas (1 por cada fila y columna) mostrando el camino óptimo del agente viajero (figura 6.17). Para encontrar los valores adecuados de las constantes A, B, C y D hay que realizar pruebas de ensayo y error, empezando con valores pequeños e ir subiendo progresivamente.
Control de nivel en un tanque. Supongamos que se tiene un tanque que recibe un flujo variable de líquido (agua, por ejemplo) y cuya salida es controlada por una válvula que se puede abrir o cerrar según 10 posiciones. Si el tanque tiene un nivel inicial cualquiera (medido en por-centaje), la idea es realizar un control sobre la válvula de forma tal de mantener un nivel mínimo de líquido en el tanque. La figura 6.18 ilustra la situación a simular.
Los estados de este problema (situación en un momento dado) están descritos por la siguien-te información:
El flujo de entrada del líquido que se puede medir en porcentaje.• El nivel del tanque.• El flujo de salida del líquido que viene dado por la posición de la válvula.•
Figura 6.18Ejemplo de simulación de control de nivel en un tanque
E ij kl ji kllk
ij ijjiji
= − +∑∑ ∑∑∑∑12 1111
w y y y=1
N
=1
N
=
N
=
N
=
N
=
N
, θ
w ij kl ik jl jl ik ik j l j lA B C Dd, , ,( ) ( ) ( )= − − − − − − ++ −δ δ δ δ δ δ1 1 1 1

Inteligencia Artificial Básica
183Índice
Quiere decir entonces que para representar este problema en una RNA es necesario definir tres neuronas de entrada, ya que el patrón o vector de entrada está formado por estas tres com-ponentes de información.
Por otro lado, la salida de red debe establecer una acción de control sobre la válvula. Lo más simple es tener una red de salida continua (Backpropagation por ejemplo) con una neurona de salida que indique la posición en la que debe estar la válvula en función del estado representado por el vector de entrada. Dado que la salida de una red Backpropagation viene dada con un valor en el intervalo [0, 1], se puede multiplicar por 10 para tener un valor entre 0 y 10, válido para la válvula.
Con un vector de entrada de tres componentes (x1 x2 x3) y un vector de salida asociado con una componente (y1), lo único que hay que definir para completar la topología de la red Backpro-pagation es determinar el número de capas escondidas y el número de neuronas por cada capa. Dado que el problema tiene una sola salida, con una sola capa escondida es suficiente y ésta no debería ser de más de tres neuronas (número de entradas). La figura 6.19 muestra un ejemplo de la topología de la red que se puede usar para representar este problema.
Figura 6.19Topología de la red Backpropagation para representar el problema del tanque
Para el entrenamiento se deben usar patrones significativos que describan los casos típicos del problema. Por ejemplo, se puede manejar un flujo de entrada de 0, 25, 50 y 100 por ciento, combinado con un nivel del tanque de 0, 25, 50 y 100 por ciento y una posición de la válvula de 0, 5 y 10. La información que se tiene que presentar para hacer el aprendizaje debe tener la siguiente forma:
x1 x2 x3 y1

Mauricio Paletta
184Índice
lo que implica que con un flujo de entrada por ciento, teniendo un nivel de por ciento y estan-do la válvula en una posición, hay que mover la válvula a una nueva posición y1. Nótese que los patrones para el aprendizaje se pueden definir para mantener cualquier nivel mínimo que se quiera en el tanque (no es lo mismo enseñar a la red a mantener un 75 % de nivel mínimo, que mantener un 25 %). Los siguientes son algunos ejemplos de patrones que se pueden usar para entrenar una RNA de este tipo para mantener un 50 % de nivel mínimo:
100 25 5 1100 75 5 10 50 50 10 10
Otra forma de representar este problema es usando una RNA que trabaje bajo un esquema de clasificador como por ejemplo la red hiperesférica RCE. A diferencia del caso anterior, hay que definir un conjunto de clases o salidas que determinen acciones sobre la válvula. Por ejemplo, se tienen las cinco clases siguientes:
Abrir una• Abrir toda• Cerrar una• Cerrar toda• Dejar igual•
Esto cambia la topología de la red, ya que ahora se tienen 5 neuronas en la capa de salida. Un ejemplo de un conjunto de patrones a presentar en el aprendizaje es como sigue:
100 25 5 Cerrar toda100 75 5 Abrir toda 50 50 10 Dejar igual
Aplicación de síntomas y diagnósticos. En este ejemplo se va a considerar el problema de diagnosticar la razón por la cual un automóvil no arranca, en función de los siguientes síntomas:
S1: No hace nada (no pasa nada al girar el encendido).• S2: Hace clic (se oyen fuertes chasquidos al girar el encendido).• S3: Molinillo (se oye un ruido parecido a un molinillo al girar el encendido).• S4: Arranque (el motor gira pero no es capaz de funcionar).• S5: Sin chispa (se detectan que no saltan chispas del cable de una bujía).• S6: Cable caliente (se detecta que el cable que va de la batería a la bobina está caliente).• S7: Sin gasolina (se detecta que no sale gasolina de la manguera de inyección al • carburador).

Inteligencia Artificial Básica
185Índice
Por otro lado, las posibles causas, de acuerdo a los síntomas anteriores, son las siguientes:
C1: Batería descargada.• C2: Falla en la bobina.• C3: Falla en el motor de arranque.• C4: Falla en los cables de encendido.• C5: Rotor o tapa del distribuidor corroídos.• C6: Falla en la bomba de gasolina.•
El conocimiento está representado por las siguientes reglas de correlación:
S1, S2 C1S2, S6 C2S2, S3, S6 C3S3, S4, S5 C4S3, S4, S5 C5S3, S4, S7 C6
Para representar el problema se va a usar el modelo de Máquina de Boltzmann del tipo entra-da-salida. Las neuronas de entrada representan los síntomas (7 en total) y las unidades de salida van a ser las conclusiones o diagnósticos (6). Para determinar el número adecuado de neuronas escondidas es necesario realizar pruebas de ensayo y error. Un buen comienzo es usar el doble de neuronas de entradas (14 en este caso).
Los valores de las entradas y las salidas son discretos binarios. El valor 1 indica que el sín-toma o la conclusión están presentes, mientras que un 0 indica su ausencia. Los vectores a ser usados para el entrenamiento son los siguientes:
0 1 0 0 0 0 0 1 0 0 0 0 01 0 0 0 0 0 0 1 0 0 0 0 00 1 0 0 0 1 0 0 1 0 0 0 00 1 1 0 0 1 0 0 0 1 0 0 00 0 1 1 1 0 0 0 0 0 1 1 00 0 1 1 0 0 1 0 0 0 0 0 1
Este mismo tipo de problema también se puede representar con otro modelo del tipo memoria heteroasociativa como por ejemplo una red BAM.

Mauricio Paletta
186Índice
Interpretación de electrocardiogramas. Este es un problema típico de reconocimiento de patrones cuyo objetivo es leer la salida impresa por un electrocardiograma y clasificar la misma de entre un grupo de 7 posibles categorías:
Normales.• Con hipertrofia ventricular izquierda.• Con hipertrofia ventricular derecha.• Con hipertrofia bi-ventricular.• Infarto de miocardio anterior.• Infarto de miocardio inferior.• Infarto de miocardio combinado.•
El paso más difícil es la extracción de características para lo cual, se toman en cuenta pará-metros característicos de la forma de onda de la señal en diferentes derivaciones (figura 6.20). En total resultan 39 características, algunas de las cuales son las siguientes:
Amplitud del segmento QRS.• Duración del segmento QRS.• Elevación o depresión del segmento ST.• Area bajo el segmento QRS.• Area bajo las ondas T.• Sexo del paciente.• Edad del paciente.•
Figura 6.20Forma general de onda de una señal de electrocardiograma

Inteligencia Artificial Básica
187Índice
Los modelos cuya forma natural de funcionar es bajo el esquema de clasificador son los que mejor se comportan para este tipo de problemas. Por ejemplo, una red RCE con 39 neuronas de entrada y 7 neuronas de salida. Para entrenar se deben seleccionar unos electrocardiogramas significativos para cada uno de los casos. Si se toman unos cinco por cada caso, la red estará completamente entrenada con 35 patrones.
6.7. Resumen del capítulo
Las neuronas son células altamente especializadas que toman su forma y estructura precisa del medio ambiente que las rodea. Están compuestas por un cuerpo celular o soma, las dendritas con sus espículas sinápticas, el axón con un recubrimiento opcional o vaina de mielina y las rami-ficaciones terminales. La membrana celular de las neuronas crea un potencial eléctrico a través de sí misma al bombear iones de sodio hacia la parte exterior de la célula, a la vez que admite iones de potasio hacia el interior. A este gradiente eléctrico se le llama potencial de membrana. La región donde ocurre la transmisión del impulso nervioso de una neurona a otra se denomina sinapsis.
La historia de la neurocomputación comienza en el año 1943 con el trabajo de McCulloch y Pitts cuyo principal aporte fue describir el primer modelo teórico de neurona artificial. A finales de esa misma década, Donald Hebb formula una ley de aprendizaje para el modelo de neurona artificial antes propuesto. En 1957 Frank Rosenblatt desarrolla y describe el primer modelo de interconexión de neuronas artificiales conocido como el Perceptrón.
Una red de neuronas artificiales es una interconexión de unidades basado en abstracciones de las neuronas naturales como procesadores elementales, conectados entre sí mediante lazos electrónicos o lógicos que simulan conexiones sinápticas. Entre las características más importan-tes se cuenta: aprendizaje adaptativo, autoorganización, tolerancia a fallos, operación en tiempo real y fácil inserción dentro de la tecnología existente.
En el modelo genérico de la neurona artificial se definen tres funciones: la función sumatoria que calcula la activación de la unidad (suma de las entradas por los pesos de las conexiones); la función umbral que determina si la activación de la unidad es lo suficientemente fuerte para generar la señal de salida y, la función de propagación que transforma la activación en la señal de salida de la unidad.
Una red de unidades está organizada en capas entre las cuales se identifica una capa de neuronas de entrada que reciben los estímulos de entrada, una capa de neuronas de salida que producen las señales de salida y una serie de capas de neuronas escondidas que almacenan y representan el conocimiento del problema.

Mauricio Paletta
188Índice
Según su topología, las redes pueden ser monocapa y multicapa; de acuerdo al mecanismo de aprendizaje se tienen redes supervisadas y no supervisadas; con respecto a los valores de entrada y salida las hay de entrada y salida discretas, de entrada y salida continuas y las híbridas; desde el punto de vista de la salida de la red, se cuenta con clasificadoras y asociadoras; con respecto al tipo de asociación se tienen redes heteroasociativas y autoasociativas.
Se pueden identificar cuatro grupos de aplicaciones con redes de neuronas artificiales: reco-nocimiento de patrones, visión, señales y control.

CapítuloLos Algoritmos Genéticos
Se presenta en este capítulo una de las técnicas de resolución de problemas más jóvenes de
la IA y que han resultado ser una herramienta excelente para los procesos de optimización.
7

Mauricio Paletta
190Índice
7.1. Introducción
La idea de los algoritmos genéticos viene de John Holland quien, a comienzos de los años 70, se le ocurrió incorporar en un algoritmo alguno de los procesos observados en la evolución natu-ral que se deriva de la genética. Tanto Holland como sus colegas y estudiantes de la universidad de Michigan han estado trabajando específicamente en dos puntos de investigación:
Abstraer y explicar en detalle el proceso adaptativo de los sistemas naturales.1. Diseñar elementos de software que implementen los principales mecanismos de estos 2. sistemas.
Hasta la fecha no se conoce todo sobre el mecanismo de la evolución genética, pero si se saben muchas de sus características que son importantes conocer para entender los algoritmos genéticos:
La evolución toma lugar en los cromosomas, dispositivos orgánicos para codificar la es-1. tructura de los seres vivos. Cada cromosoma está formado por un conjunto de genes, la mínima unidad en la teoría genética.Un ser vivo es creado principalmente mediante un proceso de decodificación de 2. cromosomas.El proceso de reproducción es el punto en el cual toma lugar la evolución.3. Las mutaciones pueden causar que los cromosomas de los hijos biológicos sean diferentes 4. a los de sus padres.El proceso de recombinación puede crear cromosomas en los hijos muy diferentes a los 5. de sus padres.La evolución biológica no tiene memoria. La información está en la población actual del 6. cromosoma.
El punto central de investigación en los algoritmos genéticos está en la búsqueda de un equi-librio entre la eficiencia y la eficacia necesaria para sobrevivir en ambientes diferentes. A este característica se le denomina robustez y su implicación sobre la elaboración de software son muchas, empezando por la reducción o eliminación de los costos de rediseño.
Una de las principales ventajas que se gana por tener un software robusto está en la calidad de las respuestas obtenidas, que se logra deduciendo lo mejor una vez que se conoce lo que es bueno y malo. Aquellos procesos que siguen este esquema de resolución alcanzan la opti-mización. Los algoritmos genéticos son excelentes implementaciones para la optimización de procesos. Son diferentes a otros procedimientos de búsqueda y optimización normal en cuatro aspectos:

Inteligencia Artificial Básica
191Índice
Trabajan con una codificación del conjunto de parámetros y no con los parámetros mismos.• La búsqueda se realiza sobre una población de puntos y no sobre un sólo punto.• Usan como fuente de información una función de costo o evaluación del objetivo.• Usan reglas de transición probabilística y no reglas determinísticas.•
7.2. Implementación
La estructura elemental que representa la información necesaria para dar una solución al problema se denomina cromosoma. El objetivo del algoritmo es encontrar buenos cromosomas manipulando el material de los cromosomas actuales. Un gen es la mínima unidad de informa-ción en la cual está formado cada cromosoma.
Además de la forma de codificar soluciones del problema en estructuras elementales o cro-mosomas, para representar un problema también se necesita definir una función de evaluación que retorne una medida de que tan bueno es un cromosoma en el contexto del problema. Esta función juega el mismo papel que el ambiente lo hace en la evolución natural. Al valor que retorna la función de evaluación se le llama aptitud del cromosoma (en inglés “fitness”). Por esta razón es que a la función de evaluación también se le llama función de aptitud.
Tanto la definición del cromosoma como la de la función de evaluación dependen del proble-ma que se quiere representar. Por ejemplo, en los trabajos iniciales de Holland, el cromosoma estaba representado por un tren de bits; cada bit o conjunto de bits representa un gen. Por ejem-plo, supongamos que se quiere representar un problema simple, cuyo espacio de solución viene dado por un valor que está en el intervalo [1, 31]; al llevar tales valores a su representación binaria se llega a los trenes de bits 00001 y 11111 respectivamente; es decir, el espacio de soluciones se puede representar mediante un cromosoma definido por 5 genes, cada uno de los cuales es 1 bit1.
En sus trabajos, Holland define un alfabeto formado por tres elementos y no dos para repre-sentar trenes de bits. El tercer elemento es un símbolo que representa “cualquier valor”. La idea de hacer esto es fijar valores de genes en el cromosoma de forma tal que no sean alterados por los operadores genéticos. Holland llamó a estas estructuras “schema” y una de sus conclusiones en la investigación es que los algoritmos genéticos manipulan “schemata” cuando ellos corren. Por ejemplo, si se usa el símbolo ‘*’ para representar el valor “cualquiera”, se tiene el alfabeto de tres símbolos {0, 1, *} para representar las cadenas de bits. En este caso, el “schema” *0000 uni-fica con los trenes {00000, 10000}. En otro ejemplo, el “schema” *111* describe un subconjunto con cuatro miembros {01110, 01111, 11110, 11111}. ‘*’ es un metasímbolo que se usa sólo como un mecanismo de notación y no tiene repercusiones operativas sobre el algoritmo genético. 1 El tren de bits es, por lo general, la estructura más usada para definir los cromosomas son. Un gen puede ser cualquier número de bits, lo sufi-ciente para representar un valor o estado en la solución del problema.

Mauricio Paletta
192Índice
A diferencia de otros métodos de optimización que trabajan con un espacio de decisión de un sólo punto a la vez y usan un algoritmo de pasos sucesivos, los algoritmos genéticos trabajan con una población de puntos o cromosomas por cada iteración del proceso. Esto da una visión de procesamiento en paralelo y reduce la probabilidad de llegar a resultados que no son realmente óptimos.
Otro aspecto interesante a mencionar sobre los algoritmos genéticos es que estos no requie-ren de ninguna otra información adicional para trabajar adecuadamente. Tan sólo se requiere de la definición de una función de evaluación que mida lo bueno o no de cada cromosoma, aunque en muchos casos, llegar a una definición adecuada de esta función no es una tarea simple y rápida.
Una última característica que hay que mencionar de los algoritmos genéticos es que su base principal está en la selección aleatoria, como una herramienta para guiar la búsqueda hacia el espacio de soluciones o población actual.
En una forma muy genérica, el algoritmo genético se puede escribir como sigue:
- Inicializar una población de cromosomas.- Evaluar cada cromosoma en la población.- Mientras no se alcance el número de generaciones deseado - Aplicar mutación y recombinación para crear nuevos cromosomas usando los cromoso mas actuales. - Borrar miembros de la población para darle espacio a los cromosomas nuevos. - Evaluar los cromosomas nuevos e insertar los mejores en la población.- Tomar el mejor cromosoma.
Para la operación del algoritmo y tal como se puede apreciar, se necesitan los siguientes re-querimientos que se deben definir previo a la ejecución:
Una estrategia de inicialización que generalmente es aleatoria.1. Determinar el tamaño de la población o número de cromosomas existente en cada iteración 2. del algoritmo. Este valor permanece constante a lo largo de todo el proceso evolutivo.Determinar el número máximo de generaciones a realizar o cantidad de iteraciones del 3. proceso evolutivo.Una estrategia para decidir cuáles cromosomas deben ser eliminados de la población ac-4. tual para incorporar los nuevos cromosomas generados (hay que recordar que el tamaño

Inteligencia Artificial Básica
193Índice
de la población no cambia). Generalmente se escogen los peores cromosomas de la po-blación actual. En los trabajos iniciales de Holland, toda la población es sustituida.Una estrategia para aplicar los operadores genéticos que permiten crear nuevos cromo-5. somas a partir de la población actual. Se debe decidir sobre qué cromosomas se van a realizar las operaciones.
Los operadores genéticos son los responsables de combinar o modificar los miembros de una población para producir la nueva población de la siguiente generación. Algunos de los operado-res genéticos más utilizados son los siguientes:
Cruzamiento uniforme: se seleccionan aleatoriamente genes de ambos padres y se constru-• yen los hijos.Cruzamiento promedio: sumar o restar los genes de los padres pesados por factores • apropiados.Mutación: sustituye uno o más genes seleccionados aleatoriamente por un valor aleatorio en • un intervalo permitido.Serpenteo: modificar uno o más genes seleccionados aleatoriamente, añadiendo o sustra-• yendo una cantidad aleatoria.Inversión: el hijo es igual al inverso de un cromosoma padre.•
En trabajos recientes de investigación sobre algoritmos genéticos se han estudiado y definido otros operadores genéticos y sus comportamientos sobre diferentes problemas. Sólo para citar algunos nombres de estos operadores, se pueden mencionar los siguientes: “dominancia”, “di-ploide”, “segregación”, “translocación”, “duplicación”, etc.
La forma de implementar estos mecanismos de reproducción y cruzamiento es bastante sim-ple. Las únicas operaciones involucradas son la generación de números aleatorios, la copia de estructuras y la modificación de partes de la estructura. El siguiente es un ejemplo de la aplica-ción de cruzamiento uniforme suponiendo que cada cromosoma se define mediante un tren de 5 bits:
Se seleccionan los padres [0 1 1 0 1] y [1 1 0 0 0].1. Se genera un número aleatorio 2. k entre 1 y el número de genes – 1 (en este caso 4); supon-gamos que el número obtenido es 3.Se crean dos cromosomas nuevos intercambiando los genes de los padres que se en-3. cuentran a partir de la posición k + 1 (4); dando como resultado los hijos [0 1 1 0 0] y [1 1 0 0 1].Síntesis: 0 1 1 0 1 0 1 1 0 04.
1 1 0 0 0 1 1 0 0 1

Mauricio Paletta
194Índice
Una de las estrategias más usadas para hacer la selección de los cromosomas padres que van a ser utilizados para crear los hijos de la nueva generación, es la llamada rueda de la ruleta o “roulette wheel”. El objetivo es elegir un cromosoma de forma aleatoria con una probabilidad proporcional al valor de su aptitud. Nótese que la aptitud del cromosoma es un valor asociado que determina su grado de participación en el proceso. Lo que se quiere es que mientras mayor es la aptitud de un cromosoma, mayor es la probabilidad de que este cromosoma sea seleccio-nado como padre para producir la próxima generación, sin quitarle la oportunidad al resto de la población. Se llama rueda de la ruleta porque cada cromosoma tiene un pedazo de la rueda (el tamaño del pedazo es proporcional a la aptitud).
El algoritmo de la rueda de la ruleta es como sigue:
- Obtener la aptitud-total de todos los miembros de la población siguiendo la siguienteexpresión: aptitud-totali = aptitud-totalI-1 + aptitudi
- Generar una valor aleatorio n entre 0 y el valor de aptitud-total del último cromosoma (mayor de todos).- Seleccionar el primer cromosoma que satisfaga aptitud-total n.
Evidentemente el éxito del algoritmo depende de los valores de aptitud calculados sobre cada uno de los cromosomas. Generalmente este valor está asociado a la evaluación del cromosoma sobre cada iteración del proceso evolutivo. El siguiente ejemplo muestra una aplicación del algo-ritmo de la rueda de la fortuna:
En función de los valores de aptitud y aptitud-total para una población de 10 cromosomas que aparecen en la siguiente tabla (la figura 7.1 muestra el estado de la rueda para estos valores de aptitud):
se seleccionan los cromosomas que aparecen en esta otra tabla, suponiendo la generación de números aleatorios indicados:
yw x
w x
n
n=≥
<
∑
∑
1
0
,
,
i ii
i ii
θ
θ
Cromosoma 1 2 3 4 5 6 7 8 9 10aptitud 8 2 17 7 2 12 11 7 3 7aptitud-total 8 10 27 34 36 48 59 66 69 76
Aleatorio 23 49 76 13 1 27 57Cromosoma seleccionado 3 7 10 3 1 3 7

Inteligencia Artificial Básica
195Índice
Nótese que el cromosoma con mayor aptitud (número 3) es el que más ha sido seleccionado en este muestreo. Esto es razonable viendo el tamaño del pedazo de la rueda que le toca a este cromosoma con respecto al resto (figura 7.1).
Figura 7.1Ejemplo de una rueda de la ruleta
Lo importante de aplicar el algoritmo de la rueda de la ruleta es que se evita que los mejores cromosomas siempre sean seleccionados para crear la nueva generación. Tienen más probabili-dad de ser seleccionados pero hay garantía de que se le está dando una oportunidad a los peo-res cromosomas de la población, que pueden llegar a ser los mejores a futuro. Evitar que haya una tendencia siempre hacia los mismos cromosomas impide caer en óptimos locales antes de llegar a un óptimo global de la solución.
Una generalización de las estructuras y definiciones que se requieren para implementar un algoritmo genético se ve como sigue:
Constantes: Tamaño-Población : entero positivo. Tamaño-Cromosoma : entero positivo.
Tipos: Gen : Según el espacio de soluciones del problema. Cromosoma : Arreglo [1 .. Tamaño-Cromosoma] de Gen. Individuo : { Cromosoma, Aptitud }. Población : Arreglo [1 .. Tamaño-Población] de Individuo.

Mauricio Paletta
196Índice
Como se puede apreciar, una “Población” está formada por un conjunto finito de “Individuos”, cada uno de los cuales se presenta como un par formado por un “Cromosoma” y su correspon-diente valor de “Aptitud”. Un “Cromosoma” es un conjunto finito de “Genes” cuya representación depende del problema y cuya mínima expresión es un bit.
Se deben definir el siguiente conjunto de operaciones o funciones:
Población • Inicializar-Población(Población):Dada una población, asignar valores iniciales a sus individuos y retornar la población modificada.Población • Evaluar-Población(Población):Dada una población, aplicar la función de evaluación sobre cada individuo, actualizar las aptitudes de los cromosomas y ordenar la población en orden decreciente en función de su evaluación (primero va el mejor y en último va el peor). Se retorna la población ordenada2.Operadores • Seleccionar-Operador-Genético( ):Determinar cuáles operadores genéticos (reproducción, cruzamiento y mutación) serán usa-dos para generar la nueva población.Padres • Seleccionar-Padres(Población, Operadores):En función de una población y los operadores genéticos a aplicar, se determina cuáles serán los cromosomas a los cuales se les aplicará los operadores genéticos para generar la nueva población. La cantidad y calidad de padres a seleccionar depende de los operadores.Hijos • Aplicar-Operador-Genético(Población, Operadores, Padres):A la población se aplican los operadores sobre los cromosomas padres dados y se genera un número definido de cromosomas hijos de la nueva generación.Población • Reemplazar-Cromosomas(Población, Hijos):
De una población original se seleccionan un número definido de cromosomas para ser elimi-nados de la población. Los cromosomas eliminados son reemplazados por los cromosomas hijos dados y se construye y retorna una nueva población.
En función de las estructuras y definiciones presentadas anteriormente y escrito de una forma más detallada, el algoritmo genético se ve como sigue:
2 No es una imposición del algoritmo genético el tener la población ordenada de acuerdo a la aptitud de los cromosomas, aunque es conveniente para agilizar la búsqueda de los mejores y peores de la población.

Inteligencia Artificial Básica
197Índice
Constantes: Tamaño-Población : entero positivo. Tamaño-Cromosoma : entero positivo. Número-Hijos-Crear : entero positivo. Náximo-Generaciones : entero positivo.Tipos: Gen : Según el espacio de soluciones del problema. Cromosoma : Arreglo [1 .. Tamaño-Cromosoma] de Gen. Individuo : { Cromosoma, Aptitud }. Población : Arreglo [1 .. Tamaño-Población] de Individuo.
Variables: P : Población. Generación : entero positivo. Operadores : entero positivo. Padres : Arreglo [1 .. Número-Hijos-Crear] de Individuo. Hijos : Arreglo [1 .. Número-Hijos-Crear] de Individuo.
Generación 0. P Inicializar-Población(P). P Evaluar-Población(P). Mientras (Generación Náximo-Generaciones) o (P[1] no es satisfactorio) hacer Operadores Seleccionar-Operador-Genético( ). Padres Seleccionar-Padres(P, Operadores). Hijos Aplicar-Operador-Genético(P, Operadores, Padres). P Reemplazar-Cromosomas(P, Hijos). Generación Generación + 1. P Evaluar-Población(P). Retornar P[1].
En resumen, para poder resolver un problema haciendo uso de un algoritmo genético se ne-cesitan los siguientes elementos:
Representación de la solución del problema en una estructura: cromosoma.• Función de evaluación.• Estrategia de inicialización.• Tamaño de la población.• Número máximo de generaciones.• Estrategia de eliminación.• Estrategia de reproducción, cruzamiento y mutación.•

Mauricio Paletta
198Índice
Año Descripción Investigadores
1967 Simulación de la evolución de poblaciones de organis-mos de una célula.
Rosenberg.
Quizás, uno de los puntos más complicados a la hora de representar y resolver un problema con algoritmos genéticos, es definir la función de evaluación o de costo sobre cada una de las soluciones posibles. No hay criterios generalizados sobre como hacer esta tarea ya que hay una dependencia estrictamente directa con el problema y su espacio de solución. El siguiente ejem-plo muestra la función de evaluación que utiliza el algoritmo GA 1-1 escrito por John Grefenstette y cuyo cromosoma está definido por una estructura de 44 bits:
0.- Se tiene el cromosoma
P: 00001010000110000000011000101010001110111011
1.- Se divide en dos partes:
0000101000011000000001 / 1000101010001110111011
2.- Se lleva cada una de las partes a base 10 para obtener:
X1 = 165377 Y1 = 2270139
3.- Se multiplican por 0.00004768372718899898 para obtener:
X2 = 7.885791751335085 Y2 = 108.24868875710696
4.- Se le resta 100 para obtener:
X3 = -92.11420824866494 Y3 = 8.248688757106959
5.- Se llega al resultado f(P) = 0.5050708 aplicando la expresión:
7.3. Aplicaciones
La tabla 7.1 muestra ejemplos de varias aplicaciones y trabajos de investigación hacien-do uso de la técnica de algoritmos genéticos3. Luego se presentan algunos ejemplos de implementación.
Tabla 7.1Ejemplos de aplicaciones y trabajos de investigación en algoritmos genéticos
3 Tomada del libro de David E. Goldberg, Genetic Algorithms in Search, Optimization, and Machine Learning; páginas 126-129.
0505
10 0 00132
32 2
32
32 2.
(sen ) .( . . ( ))
−+ −
+ ⋅ +X Y
X Y
Año Descripción Investigadores1962 Sistemas adaptativos. Holland.
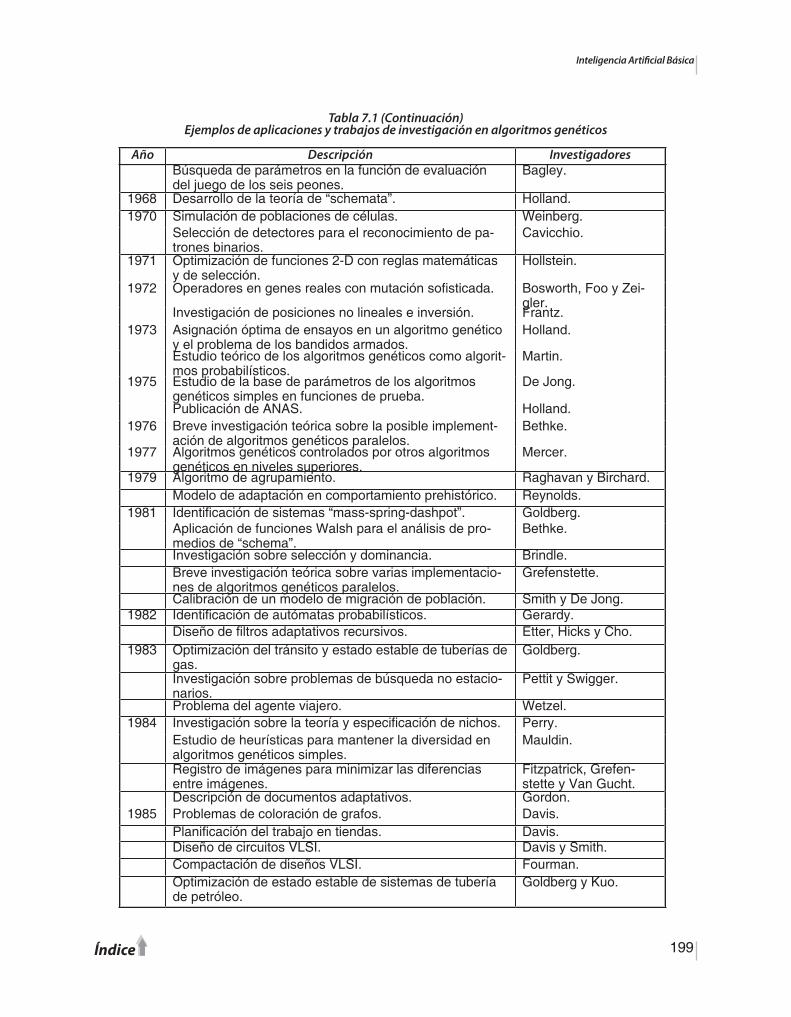
Inteligencia Artificial Básica
199Índice
Año Descripción Investigadores
Tabla 7.1 (Continuación)Ejemplos de aplicaciones y trabajos de investigación en algoritmos genéticos
Búsqueda de parámetros en la función de evaluación del juego de los seis peones.
Bagley.
1968 Desarrollo de la teoría de “schemata”. Holland.1970 Simulación de poblaciones de células. Weinberg.
Selección de detectores para el reconocimiento de pa-trones binarios.
Cavicchio.
1971 Optimización de funciones 2-D con reglas matemáticas y de selección.
Hollstein.
1972 Operadores en genes reales con mutación sofisticada. Bosworth, Foo y Zei-gler.
Investigación de posiciones no lineales e inversión. Frantz.1973 Asignación óptima de ensayos en un algoritmo genético
y el problema de los bandidos armados.Holland.
Estudio teórico de los algoritmos genéticos como algorit-mos probabilísticos.
Martin.
1975 Estudio de la base de parámetros de los algoritmos genéticos simples en funciones de prueba.
De Jong.
Publicación de ANAS. Holland.1976 Breve investigación teórica sobre la posible implement-
ación de algoritmos genéticos paralelos.Bethke.
1977 Algoritmos genéticos controlados por otros algoritmos genéticos en niveles superiores.
Mercer.
1979 Algoritmo de agrupamiento. Raghavan y Birchard.Modelo de adaptación en comportamiento prehistórico. Reynolds.
1981 Identificación de sistemas “mass-spring-dashpot”. Goldberg.Aplicación de funciones Walsh para el análisis de pro-medios de “schema”.
Bethke.
Investigación sobre selección y dominancia. Brindle.Breve investigación teórica sobre varias implementacio-nes de algoritmos genéticos paralelos.
Grefenstette.
Calibración de un modelo de migración de población. Smith y De Jong.1982 Identificación de autómatas probabilísticos. Gerardy.
Diseño de filtros adaptativos recursivos. Etter, Hicks y Cho.1983 Optimización del tránsito y estado estable de tuberías de
gas.Goldberg.
Investigación sobre problemas de búsqueda no estacio-narios.
Pettit y Swigger.
Problema del agente viajero. Wetzel.1984 Investigación sobre la teoría y especificación de nichos. Perry.
Estudio de heurísticas para mantener la diversidad en algoritmos genéticos simples.
Mauldin.
Registro de imágenes para minimizar las diferencias entre imágenes.
Fitzpatrick, Grefen-stette y Van Gucht.
Descripción de documentos adaptativos. Gordon.1985 Problemas de coloración de grafos. Davis.
Planificación del trabajo en tiendas. Davis.Diseño de circuitos VLSI. Davis y Smith.Compactación de diseños VLSI. Fourman.Optimización de estado estable de sistemas de tubería de petróleo.
Goldberg y Kuo.

Mauricio Paletta
200Índice
Tabla 7.1 (Continuación)Ejemplos de aplicaciones y trabajos de investigación en algoritmos genéticos
Año Descripción InvestigadoresSimulación de algoritmos genéticos diploides con subpo-blaciones explícitas y migración.
Grosso.
Funciones de evaluación para juegos. Rendell.Ensayo del procedimiento de selección de las pruebas de De Jong.
Baker.
Sugerencia de resultados parciales, compartición y re-stricciones matemáticas.
Booker.
Problema del agente viajero usando cruzamiento parcial y análisis de “o-schema”.
Goldberg y Lingle.
Prueba de algoritmos genéticos simples con funciones que tienen ruido.
Grefenstette y Fitzpat-rick.
Problema del agente viajero. Brady.Optimización de múltiples objetivos usando algoritmos genéticos con subpoblacines.
Schaffer.
Algoritmos conexionistas con algoritmos genéticos para la obtención de propiedades.
Ackley.
Problema del agente viajero usando operadores gené-ticos con conocimiento.
Grefenstette y grupo.
Selección de detectores para saber la clasificación de imágenes.
Englander.
Búsqueda de detectores de características en imágenes. Gillies.
Resolución de ecuaciones no lineales. Shaefer.Simulación de la evolución de las normas del comporta-miento.
Axelrod.
Una solución al problema del dilema de la iteración de los prisioneros.
Axelrod.
1986 Diseño de teclados. Glover.Optimización de estructuras de aviones. Goldberg y Samtani.Optimización del peso de estructura en el aterrizaje de aeronaves.
Minga.
Maximizar el contenido de los “schema” para un tamaño estimado de población óptimo.
Goldberg.
El problema de la mochila ciega. Goldberg y Smith.Algoritmos genéticos controlados por otros algoritmos genéticos en niveles superiores.
Grefenstette.
1987 Reducción de errores estocásticos en procedimientos de selección.
Baker.
Análisis extendido de reproducción y cruzamiento en algoritmos genéticos de l-bits.
Bridges y Goldberg.
Algoritmos genéticos adaptados a estructuras que re-sponden a disponibilidad de comida temporal y parcial.
Sannier y Goodman.
Agrupamiento de documentos. Raghavan y Agarwal.Optimización de los enlaces en redes de comunicación. Davis y Ritter.Planificación de aulas mediante anillos simulados. Davis y Ritter.El problema del engaño mínimo usando reproducción y cruzamiento.
Goldberg.
Inducción de especies y nichos usando funciones com-partidas.
Goldberg y Richard-son.
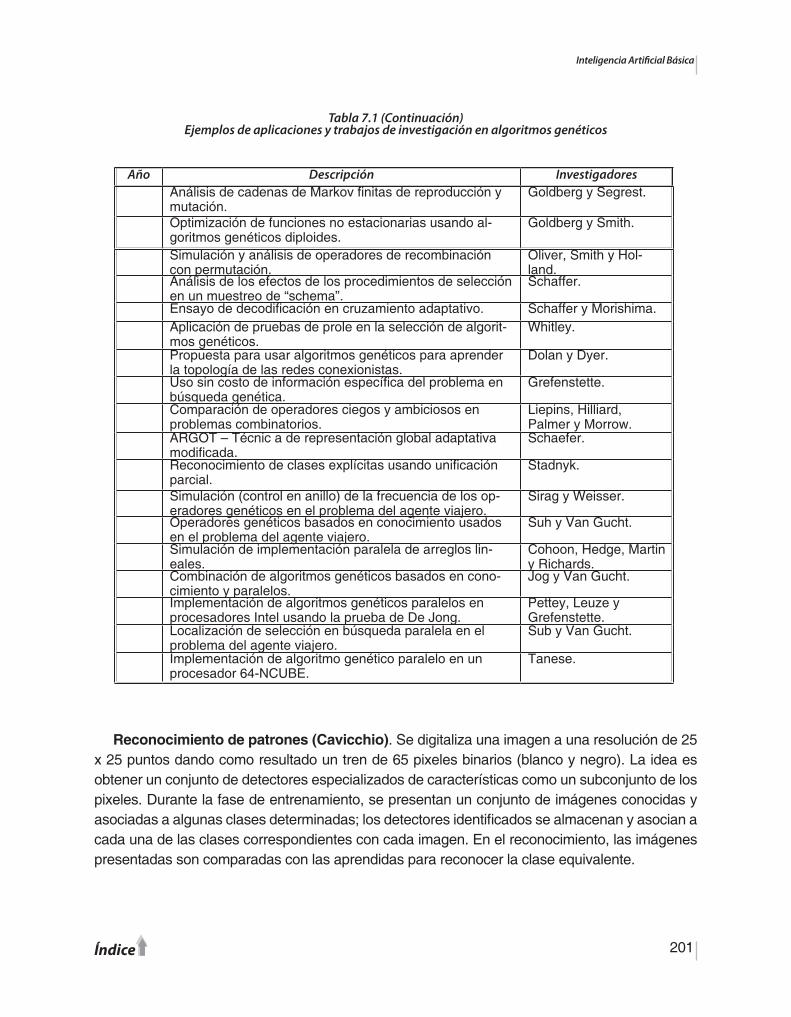
Inteligencia Artificial Básica
201Índice
Año Descripción InvestigadoresSimulación y análisis de operadores de recombinación con permutación.
Oliver, Smith y Hol-land.
Análisis de los efectos de los procedimientos de selección en un muestreo de “schema”.
Schaffer.
Ensayo de decodificación en cruzamiento adaptativo. Schaffer y Morishima.Aplicación de pruebas de prole en la selección de algorit-mos genéticos.
Whitley.
Propuesta para usar algoritmos genéticos para aprender la topología de las redes conexionistas.
Dolan y Dyer.
Uso sin costo de información específica del problema en búsqueda genética.
Grefenstette.
Comparación de operadores ciegos y ambiciosos en problemas combinatorios.
Liepins, Hilliard, Palmer y Morrow.
ARGOT – Técnic a de representación global adaptativa modificada.
Schaefer.
Reconocimiento de clases explícitas usando unificación parcial.
Stadnyk.
Simulación (control en anillo) de la frecuencia de los op-eradores genéticos en el problema del agente viajero.
Sirag y Weisser.
Operadores genéticos basados en conocimiento usados en el problema del agente viajero.
Suh y Van Gucht.
Simulación de implementación paralela de arreglos lin-eales.
Cohoon, Hedge, Martin y Richards.
Combinación de algoritmos genéticos basados en cono-cimiento y paralelos.
Jog y Van Gucht.
Implementación de algoritmos genéticos paralelos en procesadores Intel usando la prueba de De Jong.
Pettey, Leuze y Grefenstette.
Localización de selección en búsqueda paralela en el problema del agente viajero.
Sub y Van Gucht.
Implementación de algoritmo genético paralelo en un procesador 64-NCUBE.
Tanese.
Tabla 7.1 (Continuación)Ejemplos de aplicaciones y trabajos de investigación en algoritmos genéticos
Reconocimiento de patrones (Cavicchio). Se digitaliza una imagen a una resolución de 25 x 25 puntos dando como resultado un tren de 65 pixeles binarios (blanco y negro). La idea es obtener un conjunto de detectores especializados de características como un subconjunto de los pixeles. Durante la fase de entrenamiento, se presentan un conjunto de imágenes conocidas y asociadas a algunas clases determinadas; los detectores identificados se almacenan y asocian a cada una de las clases correspondientes con cada imagen. En el reconocimiento, las imágenes presentadas son comparadas con las aprendidas para reconocer la clase equivalente.
Análisis de cadenas de Markov finitas de reproducción y mutación.
Goldberg y Segrest.
Optimización de funciones no estacionarias usando al-goritmos genéticos diploides.
Goldberg y Smith.
Año Descripción Investigadores

Mauricio Paletta
202Índice
Para hacer esto, se permite un promedio de 110 detectores por diseño (entre 2 y seis pixeles por detector). Los cromosomas se representan mediante grupos alternos de números positivos y negativos separando cada detector. Por ejemplo, el cromosoma
+5 +372 +9 –518 –213 –35 –76 +44 +348 …
especifica los pixeles 5, 372 y 9 para el primer detector; 518, 213, 35 y 76 para el segundo detector y así sucesivamente.
En el algoritmo genético se usaron los operadores de reproducción y cruzamiento y se inven-taron tres operadores de mutación: cambiar un simple pixel de un detector, cambiar todos los pixeles de un detector y cambiar los pixeles asociados entre los detectores adyacentes. También se usó la inversión, el cruzamiento en dos puntos y la duplicación de cromosomas. Una de las innovaciones realizadas fue lo llamado preselección cuya idea es reemplazar a uno de los padres en el proceso evolutivo.
Problema de los seis peones (Bagley). Se trata de un juego que se desenvuelve en un ta-blero de 3 x 3 con tres peones para cada oponente (con las mismas características del ajedrez), tal como se ve en la figura 7.2. El objetivo del juego es alcanzar el lado opuesto. Bagley escribió algoritmos genéticos para buscar el conjunto adecuado de parámetros para las funciones de evaluación del juego y los comparó con algoritmos de correlación. Los resultados encontrados demostraron que para aplicar los algoritmos de correlación era necesario una buena unificación entre la no linealidad del juego y del algoritmo, mientras que el algoritmo genético no era sensible a la no linealidad del juego. Se usó un alfabeto no binario para representar los cromosomas y se idearon operadores de reproducción, cruzamiento y mutación.
Figura 7.2Juego de los seis peones

Inteligencia Artificial Básica
203Índice
Optimización de funciones (De Jong). Este estudio considera los algoritmos genéticos para la optimización de funciones, específicamente en aquellas aplicaciones que se refieren al diseño de estructuras de datos, diseño de algoritmos y el control adaptativo de los sistemas operativos.. El trabajo de De Jong consistió en construir un ambiente de prueba de cinco problemas en la minimización de funciones. Se incluyeron funciones continuas y discontinuas, convexas y no convexas, unimodales y multimodales, cuadráticas y no cuadráticas, de baja y alta dimensión y determinísticas y estocásticas. Las funciones son las siguientes:
De Jong también definió en su trabajo una medida del desempeño de una estrategia s en un ambiente e, mediante la siguiente expresión:
siendo fe(t) el valor de la función objetivo para el ambiente e en el tiempo t.
Se utilizó el algoritmo de selección de la “rueda de la fortuna” y los operadores genéticos cru-zamiento simple y mutación simple. Todos los operadores se aplicaron a poblaciones sucesivas de trenes de bits codificados como mapas. En los trabajos experimentales se usó una población de 50 individuos, una probabilidad de cruzamiento de 1.0 y una probabilidad de mutación entre 0.1 y 0.54.
Optimización de sistemas de tubería (Goldberg). Este problema es gobernado por ecua-ciones no lineales de transición de estado que indican las bajas presiones a través de las tuberías 4 Para mayor información sobre los trabajos de De Jong, consultar el libro de David Goldberg en las páginas 106-120.
f x x12
1
5
( ) = ∑
f x x22100( ) (= - x) + (1- x)2 2
f x x31
5
( ) entero( )= ∑
para − ≤ ≤512 512. .x
para − ≤ ≤2 048 2 048. .x
para − ≤ ≤512 512. .x
para − ≤ ≤128 128. .xf x ix44
1
30
0 1( ) Gauss( , )= ∑ +
f xj x aij
i
j5
6
1
21
25
0 0021
( ) .( )
= ++ −
=
= ∑∑ para − ≤ ≤65536 65536. .x
x sT
f te e
T
( ) ( )= ∑11

Mauricio Paletta
204Índice
y las altas presiones en los compresores. El objetivo es minimizar el poder de consumo sujeto a las presiones máxima y mínima. La ecuación que rige el poder de consumo de un compresor viene dado por la siguiente expresión:
donde A, B y C son constantes asociadas al compresor correspondiente, Q es la rata de flujo estándar, PD es la presión de descarga y PS es la presión de succión. El criterio de optimización es entonces satisfacer la siguiente expresión:
para todos los compresores del sistema.
En un sistema de 10 compresores y 10 tramos de tubería colocados en serie, se definió un algoritmo genético para una población de 50 individuos con una probabilidad de cruzamiento de 1.0 y una probabilidad de mutación de 0.001. El proceso de selección se realizó usando sustitu-ción estocástica sin remanentes.
Las variables que representan los compresores fueron codificadas con un mapa de cuatro bits. La función de evaluación toma en cuenta el tiempo que alcanza el fluido desde la entrada hasta la salida de la tubería. Se asumió una variación de flujo lineal.
Optimización de estructuras (Goldberg y Samtani). El objetivo en este problema es mini-mizar el peso de la estructura con miras de maximizar y minimizar la resistencia en cada punto. Se usa una matriz estándar de la estructura para analizar el diseño generado por el algoritmo genético. Con respecto a los operadores, se hace uso del algoritmo de selección de la “rueda de la fortuna”, cruzamiento simple y mutación. La función de evaluación es una función externa cuadrática. Los cromosomas están formados por grupos de cuatro bits, cada uno de los cuales define un área de la estructura desde un mínimo de 0.1 pulgadas cuadradas hasta un máximo de 10 pulgadas cuadradas.
Registro de imágenes en medicina (Fitzpatrick, Grefenstette y Van Gucht). Se usó un algoritmo genético para registrar imágenes que son parte de un sistema DAS (“Digital Subtraction Angiography”). En DAS, un doctor examina el interior de una arteria comparando dos imágenes de rayos x, una tomada antes de la inyección de tinta en la arteria y otra tomada después. Las dos imágenes son digitalizadas y el análisis de los pixeles detecta las diferencias entre ambas. Movimientos leves del paciente causan que las imágenes no estén alineadas correctamente lo que provoca ruido en el análisis de comparación.
[ ]HP Q A PD PS Bi i i i i
Ci
i= −( / )
min HPii∑

Inteligencia Artificial Básica
205Índice
En este trabajo, la imagen previa a la inyección fue transformada en un mapa de la siguiente forma (x´(x, y) = a0 + a1x + a2y + a3xy y y´(x, y) = b0 + b1x + b2y + b3xy). Se usó un algoritmo ge-nético para buscar los coeficientes que minimizaran las diferencias entre ambas imágenes. Las coordenadas x / y de cada una de las cuatro esquinas de la imagen se codificaron en un subcon-junto de 8 bits del tren, dispuestos linealmente en grupos de –8 y +8 pixeles. Este tren de 64 bits se usó en un algoritmo genético simple para buscar transformaciones adecuadas.
Una consideración importante de este trabajo fue el costo computacional involucrado en la función de evaluación, ya que la imagen se representaba en una matriz de 100 x 100 puntos, lo que involucraba un análisis sobre 10.000 puntos.
El problema de la coloración de grafos (Davis). Se tienen n colores y se debe asignar un color a cualquiera de los nodos del grafo, de forma tal que dos nodos adyacentes no tengan el mismo color y satisfacer una restricción que establece que el óptimo es la mayor cantidad que se logra al sumar los pesos asociados a los nodos coloreados. Por ejemplo, si se tiene un grafo como el de la figura 7.3, una representación del cromosoma indicando los nodos y manteniendo un orden descendente en función de los pesos es “( 9 7 8 4 2 6 5 1 3 )”. Para n = 1 (un color), la mejor solución es “( 9´ 7 8 4´ 2´ 6 5 1 3 )” ya que se logra un óptimo de 15 + 9 + 8 = 32 como suma total de pesos. Para n = 2, la solución es “( 9´ 7´´ 8 4´ 2´ 6´´ 5´´ 1 3 )”.
En este problema se usó el concepto de permutación como el resultado de intercambiar el orden de los individuos en una población. Esto con miras de representar en el cromosoma un orden de los nodos del grafo.
El problema del agente viajero (Davis). Se tiene un grafo cuyos nodos representan ciuda-des y los arcos indican los caminos y distancias entre las ciudades. El objetivo es encontrar el ca-mino más corto (menor recorrido) que se logra al visitar todas las ciudades pasando tan solo una vez por cada una de ellas. La clave para dar una solución de este problema usando algoritmos genéticos está en obtener una representación adecuada del cromosoma que informe todo lo que ocurre en un momento dado. La representación es muy simple, basta colocar los identificadores de los nodos secuencialmente para indicar la ruta. Así por ejemplo, si se tienen seis ciudades identificadas desde A hasta F, el cromosoma “[B D C A E F]” representa el recorrido “BD – DC – CA – AE – EF – FB”. Nótese que la ruta BD es equivalente a DB, ya que lo que importa es la distancia y no la dirección.

Mauricio Paletta
206Índice
Figura 7.3Ejemplo de un grafo para mostrar el problema de coloración
En este problema la función de evaluación viene dada por la suma de las distancias de todas las rutas del recorrido y el objetivo es minimizar esta cantidad. Para implementar el algoritmo, Da-vis definió un operador genético llamado recombinación que produce un cromosoma hijo como resultado de la recombinación de las rutas de dos cromosomas padres5.
7.4. Resumen del capítulo
La idea de los algoritmos genéticos consiste en incorporar en un algoritmo alguno de los procesos observados en la evolución natural que se deriva de la genética. El punto central en la investigación de estos algoritmos está en la búsqueda de un equilibrio entre la eficiencia y la eficacia necesaria para sobrevivir en ambientes diferentes (robustez). Los algoritmos genéticos son excelentes implementaciones para procesos de optimización.
La estructura elemental que representa la información necesaria para dar una solución al problema se denomina cromosoma. Cada cromosoma está formado por un conjunto de genes, la mínima unidad de información en la implementación. Para la representación de un problema, también se requiere definir una función de evaluación o aptitud que mide lo bueno que un cromo-soma es para el contexto del problema.
Los algoritmos genéticos trabajan con un espacio de decisión de un sólo punto a la vez y una población de cromosomas por cada iteración del proceso. Esto da una visión de procesamiento en paralelo y reduce la posibilidad de llegar a resultados que no son óptimos. La base principal de los algoritmos genéticos está en la selección aleatoria. El algoritmo de selección más utiliza-5 Para mayor información sobre este trabajo, consultar el libro Handbook of Genetic Algorithms de Lawrence Davis en las páginas 350-357.

Inteligencia Artificial Básica
207Índice
do es el llamado rueda de la ruleta, que le da mayor oportunidad a los mejores individuos de la población.
Los operadores genéticos son los encargados de combinar o modificar los miembros de una población para producir la nueva población de la siguiente generación. Los operadores más utili-zados son los de cruce y los de mutación.
Para poder resolver un problema haciendo uso de un algoritmo genético se debe definir lo si-guiente: una representación de la solución del problema en una estructura (cromosoma); una fun-ción de evaluación; una estrategia de inicialización; el tamaño de la población; el número máximo de generaciones; una estrategia de sustitución o eliminación; una estrategia de reproducción

CapítuloLenguajes de Programación para la
Inteligencia Artificial
Se presenta aquí un capítulo dedicado a tres lenguajes de programación que tienen mucha importancia para
la IA. Prolog es un lenguaje basado en lógica, Lisp está basado en el manejo simbólico y OPS-5 tiene su basamento en las reglas de producción. Se presentan
ejemplos y ejercicios.
8

Inteligencia Artificial Básica
209Índice
8.1. Prolog
Prolog (Programación en lógica) fue concebido en la Universidad de Marsella en 1972 por Alain Colmerauer, el cual estaba investigando una detección eficiente de errores sintácticos en un programa mediante una sola pasada. Su concepción se fundamenta en el principio de reso-lución automática1, específicamente en la teoría matemática básica de relaciones. La primera implementación se realizó en la Universidad de Edimburgo en 1975, en una plataforma DEC-10 y gracias al interés mostrado por la Digital Equipment Company.
Desde un punto de vista conceptual, Prolog se ve como un lenguaje de programación decla-rativa. El programador especifica lo que necesita (la declaración) en lugar de indicar la forma de obtener lo que quiere (el procedimiento). Por esta razón se dice que Prolog es el lenguaje del “qué” y no del “cómo”.
La forma de “programar declaraciones” se realiza mediante la descripción de objetos del do-minio y las relaciones o reglas que vinculan estos objetos. Para escribir estas relaciones se usa un subconjunto de lógica formal denominado “lógica de cláusulas de Horn”.
Las cláusulas de Horn son aquellas que tienen a lo sumo un consecuente, que puede ser explicado o demostrado por la existencia o no de 1 o más antecedentes. La lógica se presenta en forma de predicados que aparecen en tres tipos distintos: como hechos, como reglas y como objetivos o preguntas. El conjunto de predicados que se formulan como hechos y reglas se deno-mina base de reglas, base de datos o, más apropiadamente, base de conocimiento. Una cláusula en Prolog llamada también estructura, tiene la siguiente forma:
[nombre]([parámetro-1], …, [parámetro-n])
El “nombre” de la cláusula o estructura, también llamado cabecera o “functor” es un conjunto de caracteres que comienza con una letra en minúscula. El conjunto de parámetros o cuerpo de la cláusula pueden ser una o más constantes o variables.
Los predicados en Prolog se escriben haciendo uso del estilo de “implicación inversa”. A dife-rencia de las reglas de producción, el consecuente se escribe del lado izquierdo y los anteceden-tes del lado derecho. La interpretación del predicado (regla) establece que para determinar que lo que está en la izquierda es cierto (consecuente) es necesario probar primero lo que está en la derecha (antecedentes). La sintaxis para escribir un predicado en Prolog es como sigue:
1 Robinson, 1965.

Mauricio Paletta
210Índice
[cláusula-consecuente] :- [cláusula-antecedente-1],…[cláusula-antecedente-n] .
Los antecedentes se separan con una coma (´,´) para representar una operación lógica de conjunción que establece que todos los antecedentes tienen que ser satisfechos para probar el consecuente. El predicado finaliza con un punto (´.´) y representa el final del razonamiento. Si se llega al punto el objetivo o consecuente se terminó de probar alcanzando una respuesta afirma-tiva o verdadera.
Los hechos son predicados que tienen un consecuente sin antecedentes, Esto quiere decir que no se necesita nada para probar el consecuente que se da por cierto. Se escriben colo-cando el punto luego del símbolo de implicación (´:-´) o simplemente después de la cláusula consecuente:
[cláusula-consecuente] :- .[cláusula-consecuente].
El ambiente de operación de Prolog es interpretado. La forma de interacción con el usuario es mediante el uso del indicador (´?-‘) que sugiere la necesidad de introducir una pregunta, objetivo o necesidad que el usuario desea probar en función de los hechos y reglas que están en la base de conocimiento actual. Un objetivo se escribe mediante la conjunción de una o más cláusulas. Una vez que el motor de inferencia de Prolog llegue a un resultado, lo expresa mediante una de las dos posibles respuestas lógicas (SI / NO).
Un programa Prolog está formado por un conjunto de hechos y reglas y su finalidad es probar una serie de objetivos a partir de los hechos mediante el uso de las reglas. Hace uso del esquema de representación de lógica de predicados de primer orden e implemen-ta el backtracking como algoritmo de búsqueda para el mecanismo de inferencia.
Por ejemplo:
trabaja(gladys, ventas). Es un hecho que establece la relación “Gladys trabaja en Ventas”.
trabaja(X, Y) :- jefe(X, Y). Es una regla que indica “si X es el jefe en Y entonces X trabaja en Y”.
?- jefe(X, producción). Es un objetivo que no sólo quiere probar que existe alguien (X) que es el jefe en producción, sino también averiguar quién es X.

Inteligencia Artificial Básica
211Índice
Del ejemplo anterior se pueden extraer las siguientes características de Prolog:
Las constantes pueden ser de dos tipos: átomos y enteros. Los átomos o cadenas de carac-• teres siempre empiezan con letra minúscula (“gladys”, “ventas” y “producción” en el ejemplo). Los enteros son un conjunto de dígitos.Las variables son todas aquellas cadenas de caracteres que comienzan con una letra en • mayúscula (“X” y “Y” en el ejemplo). Una variable puede ser instanciada o no instanciada. El mecanismo de instanciación es la unión de una variable no instanciada a un valor (constante o estructura). La variable instanciada se comporta luego como una constante. El alcance de la variable es el predicado donde se presenta la misma.Dos predicados pueden tener la misma cláusula consecuente (“trabaja(…)” en el ejemplo). • De esta forma se representa una disyunción o dos posibles caminos para demostrar el mismo consecuente. El orden de colocación de estos predicados determina el orden de evaluación o prueba del objetivo.
Estructuras. Las estructuras permiten representar elementos de información para el proceso del programa. Están formadas por una cabecera o functor y un cuerpo y se pueden representar como árboles donde la raíz es la cabecera y las ramas cada uno de los elementos del cuerpo. Hay dos tipos: las cláusulas y las listas.
Las cláusulas se definen exactamente igual que las que se usan para formar los predicados. La cabecera es el nombre de la cláusula y el cuerpo viene dado por los parámetros. Supongamos por ejemplo, que se desea representar un árbol binario, el nombre de la cláusula es el nombre de la estructura y se tienen tres argumentos, uno para representar la información del nodo y los otros dos para representar la rama izquierda y derecha de cada árbol:
arbol(INF, arbol(INF1, SUB_IZQ1, SUB_DER1), SUB_DER)
tiene la siguiente representación como árbol:
Las listas son cláusulas particulares cuya cabecera es el punto (´.´) y dos argumentos: el pri-mer elemento o cabeza de la lista y el resto de los elementos de la lista. Por ejemplo, la lista o conjunto de elementos {A, B, C, D} se representa mediante una estructura de la forma:

Mauricio Paletta
212Índice
.(a, .(b, .(c, .(d, []))))
y su representación como árbol es
Debido a la frecuencia de uso de este tipo de estructura, Prolog provee una notación más sencilla para las mismas que consiste en encerrar los elementos entre corchetes (´[´, ́ ]´). Es decir que el ejemplo anterior queda de la forma:
[a, b, c, d]
Además, se puede usar el operador ´|´ para tomar cada una de las componentes de la lista es decir que si:
[a, b, c, d] = [C | R]
entonces:
C = a y R = [b, c, d]
Para representar una lista vacía basta colocar los corchetes sin elementos ([ ]). Si se quiere hacer referencia a un elemento pero no se necesita su instancia, basta con colocar el carácter ́ _´ en la posición que ocupa este elemento. Por ejemplo:
[_, B, C, D] - indica que la lista tiene cuatro elementos pero no me interesa el primero [_ | T] - sólo la lista menos su primer elemento [H | _] - sólo el primer elemento de la lista [_, _ | T] - sólo la lista que resulta luego de extraer los dos primeros elementos
La unificación es el mecanismo mediante el cual se verifica una estructura. La comprobación de una estructura se da cuando puede ser unificada con un hecho o cuando se puede verificar con la cabecera de una regla y las estructuras del cuerpo de dicha regla se pueden verificar. Las reglas para decidir cuándo dos términos unifican son las siguientes:

Inteligencia Artificial Básica
213Índice
Una constante sólo unifica con si misma.• Una variable instanciada unifica con el objeto asociado.• Una variable no instanciada unifica con cualquier objeto.• Una estructura unifica con otra si tienen la misma cabecera, igual número de parámetros y • todos los parámetros unifican entre si.
Recursión. En Prolog no hay instrucciones de control que permitan representar ciclos dentro de las reglas. La forma de desarrollar códigos repetitivos es mediante la recursión, que se da cuando el antecedente de una regla hace referencia a la misma cláusula que define el conse-cuente de la misma regla. La recursividad representa el mecanismo más importante en el desa-rrollo del programa y es la más apropiada para procesar estructuras de datos como las listas, que son recursivas por definición2.
Analicemos el siguiente ejemplo que permite calcular la suma de los N primeros términos de una serie:
suma_serie(1, 1).suma_serie(S, N) :- N > 0, X = N - 1, suma_serie(P, X), S = N + P.
la cláusula “suma_serie(S, N)” representa la relación “S es la suma de los N primeros términos de la serie”, o lo que es lo mismo, Sn = 1 + 2 + … + N o, utilizando mejor una definición recursiva, Sn = 1 + Sn-1. Nótese que se está usando la definición recursiva del problema para implementar la solución. Para verificar la cláusula “suma_serie(…)” se tiene que verificar a sí misma hasta que N sea igual a 1. Nótese que la variable inicial N se decrementa en 1 y la nueva variable X que recibe el nuevo valor se usa para formar el nuevo objetivo a verificar. El hecho “suma_serie (1, 1)” permite detener el proceso de verificación recursiva al dar por cierto que si N es igual a 1, la suma de los términos es 1.
Para tener éxito en la elaboración de un programa Prolog es conveniente realizar una definición recursiva del problema que se quiere implementar.
Estrategia de búsqueda. Cada uno de los predicados que forman un programa Prolog se puede representar mediante un árbol Y/O. La raíz del árbol es la cláusula consecuente del pre-dicado. Las ramas (hijos) agrupadas por un arco establecen que las cláusulas asociadas a ellas están unidas mediante una relación conjuntiva (Y) y todas se deben verificar para lograr la veri-2 La definición recursiva de una lista la hace ver como una estructura de dos componentes: la cabeza (el primer elemento) y el cuerpo (la lista con el resto de los elementos). Nótese que el cuerpo es otra lista, es decir se está colocando en la definición lo que se quiere definir (definición recursiva).

Mauricio Paletta
214Índice
ficación del nodo inmediatamente superior (padre). Las ramas no agrupadas establecen que las cláusulas asociadas a ellas están unidas mediante una relación disyuntiva (O) y alguna de ellas se debe verificar para lograr la verificación del nodo padre.
La estrategia de búsqueda que Prolog utiliza una vez que se da un objetivo es un encadena-miento regresivo al árbol Y/O. El proceso de verificación se realiza de derecha a izquierda (estra-tegia primero en profundidad). Si la verificación de alguna de las cláusulas falla en el camino, se regresa al nodo inmediatamente superior que permite continuar el camino (backtracking).
En Prolog es importante el orden de definición de los predicados, ya que para satisfa-cer un objetivo se hace una búsqueda secuencial de arriba hacia abajo hasta encontrar una cláusula que unifique con el objetivo.
Existe un predicado predefinido llamado “cut” y representado con el carácter ´!´ que permite detener el mecanismo de “backtracking” (trazado hacia atrás). Es decir, una vez que se pasa por él no hay vuelta atrás. El “cut” evita que se haga “backtracking” sobre los predicados que se encuentran a su izquierda en el árbol Y/O.
Sea el siguiente programa en Prolog:
trabaja(gladys, ventas).
trabaja(pedro, producción).
trabaja(rosa, producción).
trabaja(carlos, administración).
jefe(maría, ventas).
jefe(juan, producción).
presidente(luis).
departamento(producción).
departamento(ventas).
departamento(administración).
igual(X, X).
trabaja(X, Y) :- jefe(X, Y).
supervisor(X, Y) :- departamento(Z),
jefe(X, Z),
trabaja(Y, Z),
not(igual(X, Y)).
supervisor(X, Y) :- presidente(X),
gerente(Y).
gerente(X) :- departamento(Z),

Inteligencia Artificial Básica
215Índice
jefe(X, Z).
superior(X, Y) :- supervisor(X, Y).
superior(X, Y) :- superior(X, Z),
supervisor(Z, Y).
los siguientes son ejemplos de la verificación de objetivos:
?- trabaja(pedro, producción).
si
?- trabaja(pedro, D).
D = producción
si
?- trabaja(P, producción).
P = pedro
P = rosa
si
?- jefe(P, D).
P = ana D = administración
P = maría D = ventas
P = juan D = producción
?- supervisor(ana, pedro).
no
?- supervisor(maría, gladys).
si
?- supervisor(luis, P).
P = juan
P = maría
P = ana
P = pedro
P = rosa
P = gladys
P = carlos
si

Mauricio Paletta
216Índice
el siguiente es el árbol Y/O que se forma para el objetivo indicado:?- gerente(X).
el siguiente ejemplo muestra la traza de ejecución de un objetivo dado:
?- supervisor(X, gladys).
departamento(Z), jefe(X, Z), trabaja(gladys, Z), not(igual(X, gladys))1.
éxito - Z = producción
jefe(X, producción), trabaja(gladys, producción), not(igual(X, gladys))2.
éxito - X = juan
trabaja(gladys, producción), not(igual(juan, gladys))3.
falla - no existe ese hecho - se aplica backtracking
jefe(X, producción), trabaja(gladys, producción), not(igual(X, gladys))4.
falla - no hay otro X que no sea juan - se aplica backtracking
departamento(Z), jefe(X, Z), trabaja(gladys, Z), not(igual(X, gladys))5.
éxito - Z = ventas
jefe(X, ventas), trabaja(gladys, ventas), not(igual(X, gladys))6.
éxito - X = maría
trabaja(gladys, ventas), not(igual(maría, gladys))7.
éxito
not(igual(maría, gladys))8.
éxito
X = maría
si
Cláusulas predefinidas. La tabla 8.1 contiene la lista de las cláusulas más importantes que están predefinidas en la versión estándar de Prolog. En el grupo destacan aquellas que permiten evaluar expresiones y las que permiten manejar archivos. En este último caso se usa el criterio del archivo por defecto, es decir, un archivo para capturar todas las entradas en un momento

Inteligencia Artificial Básica
217Índice
dado (el teclado inicialmente) y un archivo para emitir todas las salidas en un momento dado (el monitor inicialmente).
Tabla 8.1Cláusulas predefinidas de Prolog estándar
Predicado Descripción! Se le da el nombre de “cut” y una vez que se pasa por él no hay posibili-
dad de retroceder.true El objetivo siempre se satisface.fail El objetivo siempre falla.consult(A) Trae al área de trabajo los predicados almacenados en el archivo A.var(X) Se satisface si X es una variable no instanciada.nonvar(X) Se satisface si X no es una variable instanciada.atom(X) Se satisface si X es un átomo o símbolo.integer(X) Se satisface si X es un entero.atomic(X) Se satisface si X es un átomo o un entero.listing(A) Muestra todas las cláusulas cuyo nombre sea dado por el átomo A.clause(X, Y) Se satisface si en la base de datos existe al menos una cláusula cuya
cabeza y cuerpo coinciden con X y Y respectivamente.asserta(C) Agregar la cláusula C al comienzo de la base de conocimiento.assertz(C) Agregar la cláusula C al final de la base de conocimiento.retract(C) Remover la cláusula C de la base de conocimiento.retractall(A) Remover de la base de conocimiento todas las cláusulas que tengan como
nombre el átomo A.functor(T, F, N) Se satisface cuando existe una estructura T cuyo functor sea F y tiene N
parámetros.C = ..L Permite construir una lista L cuyo primer elemento es el functor de la cláu-
sula C y el resto de los elementos son los parámetros de X.name(A, L) Permite construir una lista L con los caracteres que forman el átomo A.call(C) Se satisface si la cláusula C se satisface.not(C) Se satisface si la cláusula C falla.X = Y Se satisface si existe una igualdad de unificación entre X y Y. Si X es una
variable no instanciada y Y es una variable instanciada, el predicado se satisface y la variable X se instancia con el valor de Y. Si Y es no instan-ciada el predicado falla.
X \= Y Es el opuesto del caso anterior. Se satisface si X = Y falla.X == Y Similar al caso X = Y con la diferencia de que si X y Y son variables no
instanciadas, el predicado se satisface.X \== Y Es el opuesto del caso anterior. Se satisface si X == Y falla.get0(X) Se satisface si X puede ser instanciada con el carácter siguiente de la
entrada por defecto.get(X) Se satisface si X puede ser instanciada con el siguiente carácter im-
primible de la entrada por defecto.skip(X) Lee y salta caracteres de la entrada por defecto hasta que se obtenga un
carácter que coincida con X, en el cual el predicado se satisface, o hasta que se terminen los caracteres, en el cual el predicado falla.
read(X) Se lee el próximo término de la entrada por defecto y se unifica con X. Un término se reconoce porque finaliza con un punto (´.´).
put(X) Escribe el entero X como caracter en la salida por defecto.

Mauricio Paletta
218Índice
Predicado Descripciónseeing(A) Se satisface si el nombre de la entrada por defecto unifica con A.seen Cierra la entrada por defecto actual y la asocia al teclado.tell(A) Abre el archivo A para ser considerado como salida por defecto. El archivo no
debe haber sido abierto con anterioridad.
telling(A) Se satisface si el nombre de la salida por defecto unifica con A.told Cierra la salida por defecto actual y la asocia al video.X is Y Se resuelve la expresión representada por Y y su valor es instanciado en X si
ésta es una variable no instanciada. Si X tiene un valor instanciado, éste se compara con el valor calculado en Y y su igualdad determina si se satisface o no el predicado.
Tabla 8.1 (Continuación)Cláusulas predefinidas de Prolog estándar
Ejemplos. A continuación se presentan varios ejemplos de predicados completos escritos en Prolog para realizar funciones de diversa índole:
a) Calcular el factorial de un número. Se hace uso de la definición recursiva de factorial donde N! = N * (N-1)!. Nótese la importancia del orden de colocación de las cláusulas para poder dete-ner la recursión.
factorial(1, 1) :- !.
factorial(N, R) :- X = N - 1,
factorial(X, RP),
R = N * RP.
b) Mostrar el contenido de una lista. Nótese el recorrido de la lista tomando siempre el primer elemento o cabeza y aplicando recursión con el resto o cuerpo. La definición recursiva del pro-blema nos dice que para mostrar una lista, mostramos su primer elemento y luego mostramos el resto (otra lista). El problema y por ende la recursión termina cuando la lista que se quiere mostrar está vacía.
mostrar_lista([ ]).
mostrar_lista([H | T ]) :- write(H),
nl Escribe un salto de línea en la salida por defecto.tab(X) Escribe X espacios en blanco en la salida por defecto.write(X) Escribe el término X en la salida por defecto.display(X) Igual que el caso anterior pero ignorando las operaciones implícitas.display(X) Igual que el caso anterior pero ignorando las operaciones implícitas.see(A) Abre el archivo A para ser considerado como entrada por defecto. El ar-
chivo no debe haber sido abierto con anterioridad.
Predicado Descripción

Inteligencia Artificial Básica
219Índice
nl,
mostrar_lista(T).
c) Buscar un elemento en una lista. En este caso, la definición recursiva nos dice que un ele-mento está en la lista si él es el primero ó está en el resto de la lista. Hay que notar que cuando se llega a una lista vacía es necesario obligar a que la cláusula falle (de allí el uso de “fail”), ya que la búsqueda no tuvo éxito. Por otro lado, nótese el uso del “cut” (´!´) que impide que el “backtrac-king” intente verificar en las cláusulas siguientes y detiene el proceso de verificación.
buscar_lista(_, [ ]) :- !, fail.
buscar_lista(H, [H | _ ]).
buscar_lista(H, [_ | T ]) :- buscar_lista(H, T).
d) Descomponer una lista en otras dos según los menores y mayores a un número dado. Lo importante que se puede ver en este ejemplo es la forma como se utiliza el proceso de instancia-ción de las variables para construir las listas.
split(M, [H | T], [H | L1], L2) :- H <= M,
split(M, T, L1, L2).
split(M, [H | T], L1, [H | L2]) :- split(M, T, L1, L2).
split(_, [ ], [ ], [ ]).
?- split(40, [30, 50, 20, 25, 65, 95], L1, L2).
L1 = [30, 20, 25]
L2 = [50, 65, 95]
e) Agregar una lista dentro de otra. Nótese la importancia del mecanismo de instanciación de las variables.
agrega([ ], L, L).
agrega([N | L1], L2, [N | L3]) :- agrega(L1, L2, L3).
f) Torres de hanoi. Es un juego que se desarrolla con tres pilas (identificadas normalmente como A, B y C) y N discos (identificados por números) que varían en tamaño de forma tal que el disco 1 es el más pequeño y el disco N el más grande (ver figura 8.1). Los discos tienen un hoyo en el centro que permite que sean insertados en alguna de las pilas. Inicialmente todos los discos están en la pila que está más a la izquierda (A). El objetivo del juego es mover todos los discos hacia la pila de la derecha (C) usando la pila del centro (B) de forma temporal. Dado que A, B y C son pilas, sólo el disco que está en el tope es el que se puede mover en cada paso y nunca un disco mayor puede ser colocado sobre uno menor. Aunque a simple vista la implementación se ve complicada, basta con definir el problema recursivamente para facilitar las cosas. El problema

Mauricio Paletta
220Índice
consiste en pasar N discos de A a C usando B. La definición recursiva plantea los siguientes pasos:
Pasar N-1 discos de A a B usando C. 1. Pasar el disco N de A a C.2. Pasar N-1 discos de B a C usando A.3.
Figura 8.1Problema de las torres de hanoi
Nótese que después del tercer paso el estado del juego queda similar a como empezó pero con menos discos en A y más discos en C.
mover(0, _, _, _) :- !.
mover(N, A, C, B) :- M is N - 1, mover(M, A, B, C), informar(A, C),
mover(M, B, C, A).
informar(X, Y) :- write([mover, disco, de, X, a, Y]), nl.
hanoi(N) :- mover(N, a, c, b).
Juego de tres en línea. Se tiene un tablero representado por una matriz de 3x3 celdas (re-presentado por una lista de 9 elementos) en la que dos jugadores pueden colocar sus marcas (identificadas con los átomos ‘x´ y ́ o´). El primer jugador que puede colocar sus marcas de forma tal que quede una línea de tres marcas consecutivas vence (ver la figura 8.2). El programa está hecho de forma tal que juegue la computadora con un usuario, el usuario comienza siempre y su marca es ´o´.

Inteligencia Artificial Básica
221Índice
Figura 8.2Representación del tablero para el juego tres en línea
Los hechos que aparecen a continuación representan una línea o victoria en el juego según la representación anterior del tablero:
linea([1, 2, 3]).
linea([4, 5, 6]).
linea([7, 8, 9]).
linea([1, 4, 7]).
linea([2, 5, 8]).
linea([3, 6, 9]).
linea([1, 5, 9]).
linea([3, 5, 7]).
amenaza([X, Y, Z], B, X, T) :- atom(T), vacio(X, B), hay(Y, B, T), hay(Z, B, T).
amenaza([X, Y, Z], B, Y, T) :- atom(T), vacio(Y, B), hay(X, B, T), hay(Z, B, T).
amenaza([X, Y, Z], B, Z, T) :- atom(T), vacio(Z, B), hay(X, B, T), hay(Y, B, T).
vacio(X, B) :- elemento(X, B, Val), var(Val).
elemento(1, [H | _], H).
elemento(N, [_ | T], Val) :- X = N - 1, elemento(X, T, Val).
buscar_movimiento(B, T, X) :- linea(L), amenaza(L, B, X, T).
jugar(X, B, T) :- integer(X), vacio(X, B), asigna(X, T, B).
asigna(1, T, [T | _]).
asigna(N, T, [_ | R]) :- X = N - 1, asigna(X, T, R).

Mauricio Paletta
222Índice
juega_tu(B, T, F) :- write(“Tu juego: “), get(X), integer(X), vacio(X, B),
asigna(X, T, B), !, buscar_movimiento(B, T, X), F is fin.
juega_tu(_, _, F) :- F is no.
juego_yo(B, T, F) :- buscar_movimiento(B, T, X), asigna(X, T, B), F is fin.
juego_yo(B, T, F) :- aleatorio(Y, B), asigna(Y, T, B), F is no.
aleatorio(Z, B) :- random(Z), vacio(Z, B).
mostrar(B) :- mlinea(1, B).
mlinea(_, [ ]).
mlinea(N, [H | T]) :- N < 3, write(H), write(“|”), X = N + 1, mlinea(X, T).
mlinea(3, [H | [ ]]) :- write(H), nl.
mlinea(3, [H | T]) :- write(H), nl, write(“---------“),nl, mlinea(1, T).
juego(B) :- juega_tu(B, o, F), mostrar(B), !, F = fin, write(“Tu ganas”).
juego(B) :- juego_yo(B, x, F), mostrar(B), !, F = fin, write(“Yo gano”).
juego(B) :- juego(B).
tres_linea :- B = [_, _, _, _, _, _, _, _, _], mostrar(B), !, juego(B).
h) Colocar ocho reinas en un tablero de ajedrez. El juego de ajedrez se realiza sobre un ta-blero de 8x8 celdas y la reina se puede desplazar en cualquiera de las 8 direcciones posibles partiendo de cada celda. El problema consiste en ir colocando las reinas una a la vez de forma tal que ninguna se pueda “comer” o entre dentro del alcance de la otras. La figura 8.3 muestra una de las soluciones del problema (son 8 soluciones). Para la solución de este problema se hace uso de la estructura “reina(F, C)” que indica que la reina de la fila F está en la columna C.
Figura 8.3Una solución al problema de las 8 reinas en el tablero de ajedrez

Inteligencia Artificial Básica
223Índice
Nótese la creación y eliminación dinámica de cláusulas en la base de conocimiento haciendo uso de “asserta” y
“retract”.
colocar_reina(_, 9).
colocar_reina(Y, X) :- not(columna(X)), not(diagonal_1(Y, X)), not(diagonal_2(Y, X)),
asserta(reina(Y, X)), YN = Y + 1, colocar_reina(1, YN).
colocar_reina(Y, X) :- C = X + 1, C <= 8, !, colocar_reina(1, C).
colocar_reina(_, _) :- reina(Y, X), retract(reina(Y, X)), Z = X + 1,
Z <= 8, !, colocar_reina(Y, Z).
colocar_reina(_, _) :- reina(Y, X), retract(reina(Y, X)), Z = X + 1, colocar_reina(Y, Z).
columna(X) :- reina(_, X).
diagonal_1(1, X) :- !, reina(1, X).
diagonal_1(Y, 1) :- !, reina(Y, 1).
diagonal_1(Y, X) :- YA = Y - 1, XA = X - 1, diagonal_1(YA, XA).
diagonal_2(1, X) :- !, reina(1, X).
diagonal_2(Y, 8) :- !, reina(Y, 8).
diagonal_2(Y, X) :- YA = Y - 1, XA = X + 1, diagonal_2(YA, XA).
mostrar_posiciones :- mostrar_reina(1).
mostrar_reina(9).
mostrar_reina(Y) :- reina(Y, X), write([Y, “ – “, X]), nl, Z = Y + 1, mostrar_reina(Z).
reinas :- colocar_reina(1, 1), mostrar_posiciones.
8.2. Lisp
Lisp es un lenguaje de programación que toma su nombre de procesamiento de listas (“List Processing” en inglés). Fue creado por John McCarthy del MIT a comienzos de los años 60. Hasta alrededor de mediados de los 80, existían muchas versiones diferentes de Lisp sin que ninguna de ellas fuera el dominante. Por fortuna, un grupo selecto de especialistas en lenguajes de programación y representantes de varias instituciones destacadas, diseñaron la versión Com-mon Lisp (de seudónimo CLISP) como una acertada combinación de todo lo que existía para la fecha. CLISP se ha convertido en un estándar comercial, ampliamente respaldado por los princi-pales fabricantes de computadoras3.
3 Recientemente, Common Lisp ha sido enriquecido con la incorporación de elementos que le han dado la capacidad de lenguaje orientado a objetos. Esta versión de Common Lisp Orientado-Objetos se denomina CLOS (“Common Lisp Object System”).

Mauricio Paletta
224Índice
Sabemos que en una computadora todo se maneja mediante cadenas de dígitos binarios o bits, pero poco tiempo después de que las computadoras fueron inventadas, los investigadores se dieron cuenta que éstas podían procesar información simbólica de la misma forma como lo ha-cían con los números binarios. Este descubrimiento no es nuevo si pensamos, por ejemplo, que la aritmética usa símbolos para representar ideas, de forma tal que el procesamiento simbólico está relacionado en forma pareja con la aritmética.
Los lenguajes de programación convencionales son simbólicos. Por ejemplo, la sentencia
A = función1(B) + función2(C)
es una representación simbólica de la secuencia de operaciones aritméticas requeridas para computar la “función1” de B, la “función2” de C, sumar los resultados y almacenar la suma en A. La computadora no es capaz de entender una instrucción simbólica como ““función2(B)”, así que los símbolos deben ser traducidos en la secuencia adecuada de números que permiten a las instrucciones llevar a cabo los cálculos. Los programas que hacen el trabajo de traducir las re-presentaciones simbólicas de cálculos (que la gente entiende) a los números que son entendidos por la computadora son llamados “compiladores”.
Lisp es un lenguaje eminentemente simbólico. Fue inventado para llevar a cabo relaciones entre diferentes tipos de información. La información es representada por símbolos que forman ideas, de la forma como el símbolo “perro” expresa la idea de un animal doméstico que es “el mejor amigo del hombre”. La programación en términos de relaciones entre símbolos es llamada programación simbólica4.
Una de las cosas que más llama la atención de Lisp es que es capaz de expresar información que es difícil de hacer en otros lenguajes. Puramente por accidente, Lisp tendió a ser comercial-mente útil así como es académicamente interesante.
“Esta es la principal razón que motiva a los ingenieros a conocer sobre Lisp. Mientras más trucos tengamos en nuestras cajas de herramientas, más fácil es ejecutar hazañas estupendas. El noventa por ciento de los ingenieros está conociendo dónde están las rocas planas, así que podemos caminar sobre el agua con comandos. Lisp es justamente otra roca plana, pero bonito, grande y redondo5.”
Otras de las razones que justifican aprender sobre Lisp son las siguientes:
4 Escribir programas simbólicos más grandes, mejores y algunas veces más inteligentes ha sido la clave de los esfuerzos de investigación para entender el pensamiento humano.5 Taylor, William A.; What Every Engineer Should Know About AI; pág. 73.

Inteligencia Artificial Básica
225Índice
Actualmente es el lenguaje de programación más usado en la investigación de IA. Muchas • personas han trabajado en programas Lisp para tratar de explicar cómo trabaja el cere-bro. Las áreas de trabajo más importantes han sido el razonamiento con sentido común, el aprendizaje, las interfaces en lenguaje natural y la educación y los sistemas de apoyo inteligentes.Ofrece mejores herramientas de desarrollo de software que muchos otros lenguajes. Las • ideas implícitas en estas herramientas reducen el costo de desarrollo.Fue diseñado para crecer según las diferentes direcciones que la investigación tome. La ex-• tensibilidad le ha permitido a Lisp adaptarse a nuevas teorías de como se pueden escribir los programas sin cambiar el lenguaje de alguna forma fundamental.Es una herramienta soberbia para escribir nuevos lenguajes de programación. • Se basa en la teoría de la función recursiva lo que hace que algunos problemas sean mucho • más fáciles de resolver en Lisp que en otros lenguajes.
Tipos de datos. Lisp es un lenguaje tan simple que tiene solamente dos tipos de datos bá-sicos: los átomos, que son cadenas de caracteres limitadas por espacios (“José”, “padre-de” y “3.14159” por ejemplo) y las listas que contienen átomos encerrados por paréntesis (por ejemplo, si A es un átomo, (A) es una lista que contiene el átomo A y la lista (A B C D) tiene cuatro ele-mentos: los átomos A, B, C y D). En conjunto, los átomos y las listas se denominan expresiones simbólicas. En Lisp no se hace discriminación entre el uso de minúsculas y mayúsculas.
Los átomos son similares a las variables de otros lenguajes en el sentido que a los átomos de Lisp se les pueden asignar valores. Este valor puede ser un número, un texto o también una lista. Los átomos numéricos pueden ser enteros, reales o de punto flotante; los átomos no numéricos se denominan símbolos.
Las listas son estructuras recursivas en el sentido de que una lista puede ser colocada dentro de otra. Por ejemplo, la lista ((A B) C) tiene dos elementos. El primer elemento es la lista (A B) y el segundo elemento es el átomo C. Usando procesos recursivos se pueden construir listas real-mente complicadas. Un ejemplo para hacer listas complejas de una lista simple es haciendo uso de la siguiente regla recursiva: “hacer una lista de dos elementos donde, tanto el primero como el segundo son copias de la lista original”.
Al aplicar esta regla a la lista (A B) se produce la nueva lista de dos elementos ((A B) (A B)); aplicando la regla de nuevo se tiene (((A B) (A B)) ((A B) (A B))), otra lista de dos elementos; el siguiente paso da ((((A B) (A B)) ((A B) (A B))) (((A B) (A B)) ((A B) (A B)))). Meterse con estas monstruosidades para revisar el balanceo de paréntesis es una tarea que sólo le puede gustar a una computadora6.6 En realidad el problema de los paréntesis desaparece cuando se aprende a usar un editor para programas en Lisp que arregla las cosas de una forma apropiada para la fácil lectura. Los ambientes de programación Lisp fueron los pioneros en ser ambientes verdaderamente amigables para los programadores.

Mauricio Paletta
226Índice
Cuando una lista no tiene elementos se dice que está vacía y se puede representar, ya sea utilizando la palabra reservada “NIL” (o “nil”) o también, mediante una pareja de paréntesis “( )” sin encerrar ningún elemento.
La figura 8.4 muestra en definitiva los tipos de dato usados en Lisp para escribir expresiones. El átomo es el elemento indivisible y la lista es la agrupación de átomos.
Figura 8.4Tipos de dato en Lisp
Hay dos formas para que la máquina Lisp se de cuenta que ha llegado a la finalización o último elemento de una lista en el momento de su procesamiento. La primera y más común de ellas es colocando como último elemento el átomo “nil”. A este tipo de listas se les llama “terminadas en nil” y por razones de comodidad, el “nil” no se escribe en la expresión. Así por ejemplo, la lista (A B C) es “terminada en nil” y la máquina Lisp sabe que el átomo C es el último ya que en la repre-sentación interna de la lista, hay un “nil” al lado de C. Hay que notar que la lista de tres elementos (A B C) no es equivalente a la lista de cuatro elementos (A B C NIL).
Las otras listas que no satisfacen este esquema de representación son las “no terminadas en nil” y la manera de reconocer el último elemento de la lista es anteponiendo a éste un punto ´.´. Por ejemplo, la lista (A B . C) es “no terminada en nil” y se sabe que C es el último elemento ya que es el que está después del punto. Cuando el último elemento de este tipo de listas es otra lista, se simplifica la expresión eliminando el punto y descomponiendo la lista interna colocando todos sus elementos como elementos de la lista principal. Veamos esto con algunos ejemplos:
(A B C . ( )) es equivalente a (A B C)
(A B . (C)) es equivalente a (A B C)
(A . (B C)) es equivalente a (A B C)
(A . (B . C)) es equivalente a (A B . C)

Inteligencia Artificial Básica
227Índice
Tanto las listas “terminadas en nil” como las “no terminadas en nil” tienen esquemas deferen-tes de representación interna. Estas diferencias se podrán apreciar mejor cuando más adelante se toque lo relacionado con este tópico.
Funciones. Una función en Lisp es una lista, escrita de forma tal que su primer elemento representa el nombre del procedimiento o función o la operación que se desea ejecutar. El resto de los elementos de la lista son los argumentos o parámetros con los cuales se quiere aplicar la función u operación. Esta forma de escribir expresiones se denomina notación prefija o en pre-orden (la operación primero) y su uso facilita la uniformidad porque el nombre siempre está en el mismo lugar sin importar la cantidad de argumentos. El formato es el siguiente:
( [nombre-función / operación] [argumento-1] … [argumento-n] )
Las funciones u operaciones predefinidas por el lenguaje se denominan primitivas. Por su-puesto, un programador puede definir sus propias funciones y lo hace mediante una primitiva que se denomina “defun” (“definir función”) y que tiene como argumentos el nombre de la función, la lista de parámetros y el cuerpo o expresión. Un programa en Lisp es un conjunto de funciones que trabajan juntas para lograr objetivos específicos. La sintaxis para la primitiva “defun” es como sigue:
( defun [nombre-función-definir] ( [parámetro-1] … [parámetro-n] )[cuerpo-función])
El ambiente de operación de Lisp es interpretado. Por lo general se usa como indicador el caracter ´>´ que representa una máquina de evaluación de expresiones (también es muy común ver el indicador ´*´). Las siguientes son expresiones Lisp válidas haciendo uso de primitivas y la respuesta que retorna la máquina Lisp luego de la evaluación:
> (+ 2 1.4)
3.4
> (* (+ 5 2) (+ 2 3))
35
> (max (+ 4 2) (* 2 1) 3 2)
6
> (* (max 3 4 5) (min 3 4 5))
15

Mauricio Paletta
228Índice
El siguiente ejemplo muestra la definición de una función muy simple y un par de llamadas a la misma:
> (defun plusp (x) (> x 0))
> (plusp 5)
t
> (plusp -8)
nil
Una función que retorna un valor lógico (verdadero o falso) se denomina predicado. El valor falso se indica con “NIL” (o “nil”), cualquier cosa diferente de NIL es verdadero y se expresa me-diante el átomo “T” (o “t”). La tabla 8.2 contiene algunos de los predicados más importantes de Lisp.
Tabla 8.2Los predicados más importantes de Lisp
Se pueden escribir expresiones lógicas mediante la combinación de predicados y haciendo uso de las operaciones de conjunción, disyunción y negación “and”, “or” y “not” respectivamente. A continuación unos ejemplos:
Nombre Propósitoequal Si el valor de los argumentos es la misma expresión.eql Si el valor de los argumentos es el mismo símbolo o número.eq Si el valor de los argumentos es el mismo símbolo.= Si el valor de los argumentos es el mismo número.atom Si el valor del argumento es un átomo.numberp Si el valor del argumento es un número.symbolp Si el valor del argumento es un símbolo.listp Si el valor del argumento es una lista.null Si el argumento es una lista vacía.endp Si el argumento, que debe ser una lista, es una lista vacía.zerop Si el valor del argumento es cero.plusp Si el valor del argumento es un número positivo.minusp Si el valor del argumento es un número negativo.evenp Si el valor del argumento es un número par.oddp Si el valor del argumento es un número impar.> Si el valor de los argumentos está en orden descendente.< Si el valor de los argumentos está en orden ascendente.

Inteligencia Artificial Básica
229Índice
> (numberp 4)
t
> (evenp (* 9 7 5 3 1))
nil
> (atom ( ))
nil
> (and (> 4 2 1) (plusp 3 4 5))
t
Para Lisp todas las expresiones deben ser evaluadas y los resultados ser usados para la eva-luación de otras expresiones, si es el caso. Algunas veces se hace necesario que no se evalúe una expresión sino que su lista se utilice tal como se expresa. En este caso, Lisp necesita ayuda para saber lo que debe o no evaluar. Cuando la expresión está precedida por un apóstrofo (’), se le está informando a la máquina Lisp que la lista que está representando a esa expresión debe ser utilizada tal como está y no debe ser evaluada. Este concepto u operación recibe el nombre de quote y el apóstrofo es un refinamiento sintáctico o forma rápida de escribir la primitiva “quote”. Veamos unos ejemplos:
> (listp (+ 2 3))
nil
> (listp ’(+ 2 3))
t
> (listp (quote (+ 2 3)))
t
> (equal ’(A B C) (quote (A B C)))
t
Por otro lado, la evaluación de un átomo da como resultado el mismo valor expresado en el átomo y al evaluar una variable se retorna el valor actual de la misma. En Lisp, las variables no requieren de una declaración (aunque en CLisp se cuenta con primitivas predefinidas para la de-claración de variables). Por ejemplo, si X es una variable que tiene en un momento dado el valor (A B C), la expresión (listp X) retorna verdadero mientras que (listp ’X) retorna falso.
Las primitivas SETQ y PSETQ7 se usan para asignar o inicializar un conjunto de variables. Los argumentos son las parejas variable-valor correspondientes. La diferencia entre SETQ y PSETQ es que en esta última las asignaciones se realizan simultáneamente. Por ejemplo:
7 SETQ viene de las palabras inglesas “set quote” que quiere decir establecer una data. La P en PSETQ viene de la palabra inglesa “parallel” o paralelo.

Mauricio Paletta
230Índice
> (setq x 3)
3
> (setq y 5 z 7)
7 - retorna el último valor
> (+ x y z)
15 - el valor de las variables prevalece
> (setq x (+ y z))
12
> x
12 - la evaluación de una variable es su valor
> (setq p 2 q 3)
3
> (psetq p q q p)
2 - asignación paralela, intercambio de valores entre p y q
> p
3
> q
2
> (setq p q q p)
2 - asignación secuencial, nótese la diferencia con respecto a psetq
> p
2
> q
2
Operaciones sobre listas. Hay tres operaciones básicas que en Lisp se aplican sobre listas:
CAR retorna el primer elemento de una lista.• CDR retorna toda la lista excepto su primer elemento.• CONS toma dos átomos o listas y los combina en una lista mayor.•
Al evaluar el CAR de la lista (A B C) se retorna el átomo A, que es el primer elemento de la lis-ta. El CDR de (A B C) es la lista (B C), que es la lista original menos el primer elemento. El CONS del átomo A y de la lista (B C) es la lista (A B C). Por lo tanto, CONS reversa el efecto de CAR y CDR ya que al pasarle como argumento los retornos de CAR y CDR se obtiene la lista original de éstos (la figura 8.5 ilustra esta situación). El estándar CLisp define las operaciones “First” y “Rest” que hacen lo mismo que CAR y CDR respectivamente8.
8 Los nombres CAR y CDR se deben al segundo sistema Lisp que fue escrito para una computadora IBM 709 del MIT. CAR y CDR fueron los nombres de dos instrucciones importantes del 709: “los contenidos del registro de dirección” y “los contenidos del registro de decremento”.

Inteligencia Artificial Básica
231Índice
Otra facilidad de Lisp es el uso de las funciones CxxR, CxxxR y CxxxxR donde x puede ser una A en representación de CAR o una D en representación de CDR y que constituyen una facilidad para escribir expresiones que combinan un conjunto de operaciones CAR y CDR simul-táneas (desde dos hasta cuatro operaciones de CAR o CDR continuas).
Figura 8.5CONS es el inverso de CAR + CDR
Al igual que CONS, la primitiva LIST también se usa para construir una lista, con la diferencia que LIST construye una lista colocando como elementos cada uno de sus argumentos. Al evaluar LIST sobre los parámetros A y (B C), da como resultado la lista de dos elementos (A (B C)). Nótese la diferencia con respecto a lo que resulta al evaluar CONS.
La primitiva APPEND también es muy utilizada y su finalidad es agregar elementos al final de una lista válida que debe ser dada como primer argumento. En la tabla 8.3 se pueden ver, ade-más de CAR, CDR, CONS, LIST y APPEND, otras primitivas para el manejo de listas.
Tabla 8.3Algunas primitivas de Lisp para el manejo de listas
Nombre Propósitocar / first Retorna el primer elemento de la lista.cdr / rest Retorna la lista sin el primer elemento.caar / cadr / cdar / cddr / caaar / caadr / cadar / caddr / cdaar / cdadr / cddar / cdddr / caaaar / caaadr / caadar / caaddr / cadaar / cadadr / caddr / cdaaar / cdaadr / cda-dar / cdaddr / cddaar / cddadr / cdddar / cddddr
Combinación de car y cdr en el mismo sentido en que apa-rezca una ´a´ o una ´d´ respectivamente.
cons Dado dos argumentos, retorna una nueva lista “no terminada en nil”.
list Retorna una lista “terminada en nil” cuyos elementos son los argumentos dados.

Mauricio Paletta
232Índice
Nombre Propósito
Tabla 8.3 (Continuación)Algunas primitivas de Lisp para el manejo de listas
En los siguientes ejemplos supongamos que la variable X vale ((A 1) (B 2) (C 3)):
> (caddr X)
(C 3)
> (car (cadr X))
B
> (equal (car (cadr X)) (first (cadr X)))
t
> (equal (cdr X) (rest X))
t
> (cadr (cadr X))
2
> (length X)
3
> (length (car X))
2
> (cons ’(Z 4) X)
((Z 4) . ((A 1) (B 2) (C 3))) ((Z 4) (A 1) (B 2) (C 3))
> (cons ’(W 5) (cons ’(Z 4) X))
((W 5) (Z 4) (A 1) (B 2) (C 3))
> (cons (caddr X) (cons (cadr X) (cons (car X) nil)))
((C 3) (B 2) (A 1))
> (list 0 0 7)
(0 0 7)
append Dado una lista y otros argumentos, modifica y retorna la misma lista colocando los argumentos al final y en el mismo orden.
Nombre Propósitolength Retorna el número de elementos de la lista.nth Retorna el n-ésimo elemento de la lista.nthcdr Retorna la lista original menos los n primeros elementos.second / third / … / tenth Retorna el segundo / tercero / … / décimo elemento de la
lista.last Retorna el último elemento de la lista.reverse Retorna la lista original invertida.member Determina si un elemento es miembro de una lista.

Inteligencia Artificial Básica
233Índice
> (list 1 (quote +) 2 (quote =) 3)
(1 + 2 = 3)
> (list ’+ (list ’* 2 ’3) 5)
(+ (* 2 3) 5)
> (list (car X) (cadr X) (caddr X))
((A 1) (B 2) (C 3))
> (append ’(a b c) ’(d e f) ’( ) ’(g))
(a b c d e f g)
> (append ’(a b c) ’d)
(a b c . d)
> (setq x ’feos)
perros
> (setq x (list ’perros x))
(perros feos)
> (setq x (list 3 x))
(3 (perros feos))
Nótese las diferencias entre CONS, LIST y APPEND en el siguiente ejemplo:
> (cons ’(1 2) ’(3 4))
((1 2) 3 4)
> (list ’(1 2) ’(3 4))
((1 2) (3 4))
> (append ’(1 2) ’(3 4))
(1 2 3 4)
Se define y usa una función que construye y retorna una lista:
> (defun mi-funcion (x y)
(list (< x y) (<= x y) (= x y) (>= x y) (> x y))
)
> (mi-funcion 1 2)
(t t nil nil nil)
> (mi-funcion 2 2)
(nil t t t nil)
> (mi-funcion 3 2)
(nil nil nil t t)
Estructuras de control. El elemento más poderoso con el que cuenta Lisp para escribir las funciones es la recursión. Esta se da cuando al definir una función, se escribe una expresión cuya

Mauricio Paletta
234Índice
lista tiene como primer elemento el mismo nombre de la función que se quiere definir (algo muy parecido a lo que ocurre en Prolog con las cláusulas recursivas). Vea el siguiente ejemplo que calcula el n-ésimo término de la secuencia de Fibonacci:
(defun fib (n)
(if (< n 2) 1 (+ (fib (- n 1)) (fib (- n 2))))
)
Pero a diferencia de Prolog, esta no es la única herramienta que tiene Lisp para controlar el flujo de los programas, ya que se ofrece una amplia gama de primitivas que permiten entre otras cosas, condicionar secuencias de acción, controlar ciclos, ejecutar acciones en paralelo. La tabla 8.4 presenta las más importantes (expi son expresiones).
Tabla 8.4Algunas primitivas de Lisp para controlar el flujo de ejecución
(cond (exp11 exp12 … exp1m) (exp21 exp22 … exp2n) … (expq1 expq2 … expqp))
Condicional múltiple. Dependiendo de la veracidad de las condi-ciones expresadas en exp11, ... expq1, se ejecutan las expresio-nes correspondientes. La primera evaluación que sea verdadera domina el flujo de ejecución y se retorna lo que resulta de evaluar la última expresión de la línea precedida por la condición.
(return exp) Detiene la secuencia de ejecución y retorna el valor que resulta al evaluar la expresión.
(loop exp1 exp2 … expn) Las expresiones se ejecutan continuamente hasta que se detenga la primitiva RETURN.
Sintaxis Propósito(let* ((var1 val1) … (varm valm)) exp1 exp2 … expn)
Una variante del caso anterior en el cual las operaciones de asig-nación se hacen en forma secuencial..
(dotimes (con sup res) exp1 exp2 … expn)
Iteración controlada con un contador. El contador con varía desde 0 hasta p-1 siendo p el resultado de evaluar la expresión sup. Luego de las p iteraciones de exp1… expn, la expresión res se evalúa para obtener el resultado.
(dolist (ele lis res) exp1 exp2 … expn)
Es similar a DOTIMES excepto que los elementos de una lista lis se asignan al parámetro ele uno después de otro y se itera hasta que se terminen de recorrer todos los elementos de la lista.
Sintaxis Propósito(if exp1 exp2 exp3) Si exp1 es verdadera se ejecuta exp2 sino, se ejecuta exp3.
(when exp1 exp2 … expn) Si exp1 es verdadera se ejecutan exp2 … expn.
(unless exp1 exp2 … expn)
Si exp1 es falsa se ejecutan exp2 … expn.

Inteligencia Artificial Básica
235Índice
En el siguiente ejemplo se pueden apreciar varias maneras de escribir una función que calcula la suma de los elementos de una lista:
(defun suma-lista (x) - usando recursión
(if (null x) 0 (+ (suma-lista (cdr x)) (car x)))
)
(defun suma-lista (x) - usando LET y LOOP
(let ((sum 0))
(loop (when (null x) (return sum))
(setq sum (+ (car x) sum))
(setq x (cdr x))))
)
(defun suma-lista (x) - usando nuevamente LET y LOOP con operaciones para
el uso de la pila
(let ((sum 0))
(loop (when (null x) (return sum))
(incf sum (car x))
(pop x ))))
)
(defun suma-lista (x) - usando LET y DOLIST
(let ((sum 0))
(dolist (n x sum)
(incf sum n)))
)
(defun suma-lista (x) - usando DO*
(do* ((sum 0 (+ sum (car y)))
(y x (cdr y)))
(endp y) sum))
)
En este caso se define una función que determina el número de elementos de una lista:
(defun mi-length (x)
(let ((n 0))
(loop (when (null x) (return n))
(incf n)
(pop x)))

Mauricio Paletta
236Índice
Nótese la diferencia entre LET y LET*9 en el siguiente ejemplo:
> (setq x ’exterior)
exterior
> (let ((x ’interior) (y x)) - la primera x es local a LET y su alcance termina cuando
se cierra la
(list x y) - expresión iniciada por LET; la ejecución en paralelo
hace que el valor
) - de la segunda x esté asociado a la variable global.
(interior exterior)
> (let* ((x ’interior) (y x))
(list x y)
)
(interior interior)
Generalmente, en la mayoría de los lenguajes de programación las funciones retornan un valor. En Lisp hay varias primitivas que permiten el retorno de más de un valor para la definición de funciones. La más importante de ellas es VALUES cuyos argumentos son cada uno de los retornos. Su uso se puede ver en el siguiente ejemplo que es una función para obtener las raíces de un polinomio de segundo grado:
(defun polinomio-grado-2 (a b c)
(let ((x (sqrt (- (* b b) (* 4 a c)))))
(if (zerop x)
(/ (- b) (* 2 a))
(values (/ (+ (-b) x (* 2 a)) (/ (- (-b) x (* 2 a)))))
)
En Lisp hay una manera de escribir un procedimiento o función sin necesidad de definirlo me-diante un nombre. Esta tipo de procesos se denominan expresiones lambda. La primitiva con la cual se escribe la expresión es LAMBDA y además acepta parámetros. Ejemplos:
> ((lambda (a b) (list a b)) 1 2)
(1 2)
> ((lambda (a b &optional (c 30)) (list a b c)) 1 2)
(1 2 30)
> ((lambda (a b &optional (c 30)) (list a b c)) 1 2 3)
(1 2 3)
> ((lambda (a b &optional (c (- a b)) d) (list a b c d)) 1 2 3)9 Es muy común ver en Lisp parejas de primitivas cuyos nombres se diferencian por un ‘*’. Otros ejemplos son PROG y PROG*, DO y DO*, LIST y LIST*.

Inteligencia Artificial Básica
237Índice
(1 2 3 nil)
> ((lambda (a b &optional (c (- a b)) d) (list a b c d)) 1 2 3 4)
(1 2 3 4)
> ((lambda (a b &optional (c 30) &rest d) (list a b c d)) 1 2)
(1 2 30 nil)
> ((lambda (a b &optional (c 30) &rest d) (list a b c d)) 1 2 3)
(1 2 3 nil)
> ((lambda (a b &optional (c 30) &rest d) (list a b c d)) 1 2 3 4)
(1 2 3 (4))
> ((lambda (a b &optional (c 30) &rest d) (list a b c d)) 1 2 3 4 5)
(1 2 3 (4 5))
Uno de los aspectos importantes de las expresiones lambda es que se pueden asignar a símbolos y luego usar la
primitiva FUNCALL para su ejecución. Por ejemplo:
> setq x 1)
1
> (let ((x 100))
(setq f #’(lambda ( ) (incf x)))
(setq g ’(lambda ( ) (incf x)))
(lambda ( ) (incf x))
> (funcall f)
101
> (funcall g)
2
> (funcall f)
102
> x
2
Estructuras de datos. Uno de los conceptos más importantes de Lisp asociado a la repre-sentación del conocimiento es el de lista de propiedades. Una propiedad es una característica asociada a algún elemento y una colección de nombres de propiedades y sus valores asociados a ese elemento forman una lista de propiedades. Haciendo uso de este concepto, con Lisp es posible representar conocimiento basado en el esquema de encuadres.
Las listas de propiedades no son más que listas de pares de elementos donde el primero de la pareja es el nombre de la propiedad y el segundo su valor. Esta lista está asociada a un símbolo

Mauricio Paletta
238Índice
que representa el concepto u objeto descrito con las propiedades de la lista. La primitiva GET recupera o lee el valor de una propiedad asociada a un símbolo, mediante la siguiente sintaxis:
(get [símbolo] [nombre-propiedad])
Para incorporar una nueva propiedad (agregar un nuevo elemento a la lista) o modificar el valor de una propiedad ya existente asociada a un símbolo, se usa la primitiva SETF10 mediante la siguiente sintaxis:
(setf (get [símbolo] [nombre-propiedad]) [valor-propiedad])
Nótese que el primer argumento de SETF es la misma expresión que se usa para leer el valor de la propiedad y que SETF tiene un doble papel cuando es usado con propiedades: como fun-ción de construcción (primera vez) y como función de modificación (otras veces).
Para eliminar una propiedad de la lista se puede hacer utilizando SETF y colocando el valor NIL. Pero la forma más elegante de hacer esto es usando la primitiva REMPROP con la siguiente sintaxis:
(remprop [símbolo] [nombre-propiedad])
Supongamos por ejemplo que queremos un símbolo llamado “bolsa” al cual se le asigna la propiedad “contenido”. Veamos:
> (setf (get ’bolsa ’contenido) ’(pan mantequilla))
(pan mantequilla) - se crea la propiedad
> (get ’bolsa ’contenido)
(pan mantequilla) - se lee el valor de la propiedad
> (setf (get ’bolsa ’contenido) ’(pan mermelada))
(pan mermelada) - se modifica el valor de la propiedad
> (remprop ’bolsa ’contenido)
t - se elimina la propiedad
> (get ’bolsa ’contenido)
nil - se lee el valor de una propiedad inexistente
Para construir un arreglo en Lisp, hay que indicar la cantidad de dimensiones y el tamaño de cada una de ellas. Esto se hace usando la primitiva MAKE-ARRAY; su argumento es una lista 10 SETF viene de las palabras inglesas “set field” que quiere decir establecer un campo.

Inteligencia Artificial Básica
239Índice
cuya longitud determina el número de dimensiones y sus elementos especifican el tamaño de la dimensión correspondiente a su posición. Cuando se quiere un vector o arreglo de una sola dimensión, el argumento puede ser un átomo entero en lugar de una lista.
Para usar un arreglo, luego de su creación, se requiere saber cómo se usan las primitivas de lectura y escritura correspondientes. Para acceder a un dato en el arreglo se usa la primitiva AREF11 al cual, además del arreglo, se le da como argumento un entero que indica el lugar o posición que nos interesa. Para almacenar datos en un arreglo, de la misma forma como ocurre con las listas de propiedades, se emplea una combinación de SETF y AREF. La sintaxis para la lectura y escritura es como sigue:
(aref [arreglo] [ind0] … [indn])(setf (aref [arreglo] [ind0] … [indn]) [valor])
Ejemplos:
> (setf cajones (make-array ’(4)))
t - se crea el vector cajones de 4 elementos en el rango 0 a 3
> (setf cajones (make-array 4))
t - equivalente al anterior
> (setf cajones (make-array 4 :initial-element ’v))
#(v v v v) - los elementos del vector son inicializados a un valor en la creación
> (setf tablero (make-array ’(8 8)))
t - se crea matriz tablero de 8x8 elementos
> (setf tablero (make-array ’(8 8) :initial-contents
’((1 2 3 4 5 6 7 8)
(2 3 4 5 6 7 8 1)
(3 4 5 6 7 8 1 2)
(4 5 6 7 8 1 2 3)
(5 6 7 8 1 2 3 4)
(6 7 8 1 2 3 4 5)
(7 8 1 2 3 4 5 6)
(8 1 2 3 4 5 6 7))))
#2A ’((1 2 3 4 5 6 7 8) - los elementos de la matriz son inicializados en la creación
(2 3 4 5 6 7 8 1)
(3 4 5 6 7 8 1 2)
(4 5 6 7 8 1 2 3)
11 AREF viene de las palabras inglesas “array reference” que quiere decir referencia a arreglo.

Mauricio Paletta
240Índice
(5 6 7 8 1 2 3 4)
(6 7 8 1 2 3 4 5)
(7 8 1 2 3 4 5 6)
(8 1 2 3 4 5 6 7))
> (aref tablero 0 3)
4 - obtiene valor almacenado en la posición [0, 3] de tablero
> (setf (aref cajones 0) ’clavos)
t - almacena una expresión en la posición 0 del vector cajones
Otra de las estructuras de datos que se pueden definir en Lisp son los registros o conjunto de campos de cualquier tipo. La forma de hacer esto es especificar los nombres de los campos y sus valores por defecto.
La primitiva que se usa para crear nuevas estructuras o registros es DEFSTRUCT y su sin-taxis es como sigue:
(defstruct [nombre]([nombre-campo1] [valor-defecto-campo1])…([nombre-campon] [valor-defecto-campon])
Una de las cosas que DEFSTRUCT hace es crear un procedimiento que construya instancias de la estructura definida. El nombre de este procedimiento es una combinación de “MAKE-” con el nombre de la estructura. Así por ejemplo, si se define una estructura de nombre “persona”, para crear instancias de esta estructura se usa un procedimiento de nombre”make-persona”.
Para poder leer los campos del registro, DEFSTRUCT también crea procedimientos de lectura de estos campos, cuyos nombres son una combinación del nombre de la estructura y el nombre del campo. De esta forma, si la estructura “persona” tiene un campo llamado “sexo”, la forma de obtener el valor de este campo es mediante el procedimiento “persona-campo”.
Para modificar el valor de los campos existentes, nuevamente se usa SETF en combinación con la forma como se lee el campo. Por último, DEFSTRUCT también crea un predicado para determinar si un objeto es o no una instancia de la estructura. En este caso, el nombre del predi-cado se forma combinando el nombre de la estructura y “-P” (“persona-p” si la estructura se llama persona). Veamos los ejemplos:

Inteligencia Artificial Básica
241Índice
> (defstruct persona
(sexo nil)
(personalidad ’agradable))
t - se define la estructura persona con los campos sexo y personalidad
> (setf persona-1 (make-persona))
t - se crea la ocurrencia persona-1 con los valores por defecto
> (setf persona-2 (make-persona :sexo ’femenino))
t - se crea la ocurrencia persona-2 cambiando el valor del campo sexo
> (persona-sexo persona-2)
femenino - se lee el valor del campo sexo de la instancia persona-2 de persona
> (persona-personalidad persona-2)
agradable - se lee el valor del campo personalidad de persona-2
> (setf (persona-sexo persona-1) ’femenino))
femenino - se modifica el valor del campo sexo de persona-1
> (persona-p persona-1)
t - indica que persona-1 es una instancia de persona
Una variante importante de la definición de estructuras es la incorporación de conceptos de orientación a objetos, tales como la definición de clases, herencias, métodos, etc12.
Representación y manejo interno. El manejo automático de memoria es una de las carac-terísticas más útiles de Lisp. Muchos lenguajes permiten el manejo manual de la memoria en el cual los programas piden más memoria cuando la necesitan y luego la retornan cuando la termi-naron de usar (la memoria es asignada desde un conjunto disponible y regresa al inventario de memoria libre cuando el programa la retorna)13.
Lisp asume la carga del manejo de memoria. Cuando un programa necesita memoria, ésta se asigna automáticamente sin que el programa tenga que pedirlo y cuando el programa deja de usar parte de la memoria, ésta es reclamada automáticamente. Esta facilidad del manejo de memoria, guarda el camino de los retornos de las funciones en los programas que hacen las llamadas y maneja la memoria que se usa para almacenar la data (cuando funciones recursivas se llaman a sí mismas, la computadora debe diferenciar los diferentes conjuntos de direcciones de retorno y parámetros).
En los lenguajes de programación convencional, las variables son asignadas por el compila-dor o ensamblador a direcciones de memoria fijas. La data en Lisp no se puede almacenar en localidades fijas de memoria ya que la memoria que se usa para almacenar un valor cambia con frecuencia. Un ejemplo de esto ocurre cuando los números son muy grandes para una palabra, 12 Para mayor información ver CLOS (Common Lisp Object System).13 Forzar a los usuarios a escribir programas que manejen la memoria ocasiona una gran cantidad de errores. Si un programa retorna una memoria que no está realmente libre, tarde o temprano esta memoria será entregada a otro programa para su uso. En este caso, dos programas diferentes intentarán almacenar información en las mismas palabras de memoria. El caos resultante es similar a unos cables telefónicos cruzados.

Mauricio Paletta
242Índice
en cuyo caso se asigna otra palabra de memoria para agrandar el espacio de representación. Otro caso son las listas que necesitan más memoria a medida que se agreguen elementos y me-nos cuando los elementos son eliminados (ya que no se puede saber por adelantado la cantidad de memoria que necesita una lista, la asignación de memoria de las listas se tiene que cambiar mientras el programa corre)14.
La forma de almacenar una lista en memoria es enlazar los elementos usando bloques de memoria de tamaño fijo llamados celdas-cons. Cada celda-cons contiene dos apuntadores, uno apunta a la dirección de memoria de la palabra que contiene el car de la lista y el otro apunta a la dirección del cdr. La figura 8.6 muestra el diagrama de bloques de como la lista (A B C) se almacena en memoria. Cada rectángulo o bloque representa una celda-cons y la flecha que sale de cada mitad del rectángulo muestra lo que el apuntador de esa palabra apunta.
Figura 8.6Diagrama de bloques de la lista (A B C)
El primer apuntador de la primera celda-cons en la lista apunta a A, así que A es el car de la lista; el segundo apuntador de la misma celda apunta a otra celda-cons, que es la primera celda de la sublista (B C), así que (B C) es el cdr de la lista (A B C). Nótese que el segundo apuntador de la última celda-cons no apunta a nada, indicando esto que se trata de la terminación de la lista o “NIL” (recuerde que (A B C) es una lista terminada en nil).
El diagrama de bloques para la lista no terminada en nil (A B . C), es ligeramente diferente a la anterior y se muestra en la figura 8.7. Nótese que su única diferencia está en la terminación y que ocupa una celda-cons menos que el caso anterior (ya que no se representa el nil).
Figura 8.7Diagrama de bloques de la lista (A B . C)
14 Si los programadores se tuvieran que preocupar de la asignación de memoria en lugar de realizar los cómputos correctamente, escribir grandes programas sería una tarea muy costosa en esfuerzo y tiempo.

Inteligencia Artificial Básica
243Índice
Por supuesto que toda expresión simbólica o lista en Lisp tiene su diagrama de bloques, in-dependientemente de que tan compleja sea la expresión. La figura 8.8 presenta el diagrama de bloques de la expresión que define una función para el cálculo del factorial de un número dado.
Conocer la dirección de memoria de la primera celda-cons de una lista es todo lo que hace falta para encontrar cualquier elemento o procesar la lista y esta dirección está almacenada en una tabla, junto con el nombre de cada símbolo (cada entrada de la tabla de símbolos almacena el nombre del símbolo y un apuntador a su valor). Este procesamiento de información en Lisp requiere usualmente secuencias largas de llamadas de CAR y CDR para obtener la data ade-cuada. Estas operaciones fundamentales de Lisp manipulan los apuntadores en lugar de hacer aritmética15.
Cuando se necesita agregar un elemento a una lista, automáticamente se localiza una nueva celda-cons en la memoria libre para albergar los apuntadores del car y cdr de la nueva lista. En los lenguajes convencionales es relativamente raro que se de la asignación de memoria y la memoria es asignada y reclamada en bloques grandes (de unas 4.096 palabras cada uno). Lisp asigna memoria siempre que cualquier programa lo necesite y la memoria es asignada y recla-mada en término de bloques de dos palabras16.
Figura 8.8Diagrama de bloques de la definición de la función factorial
15 Si un sistema Lisp está corriendo en una computadora donde el procesamiento de apuntadores es lento, la ejecución de la máquina evaluadora de Lisp corre lentamente.16 Se toma mayor poder de procesamiento trabajar con incrementos de memoria de dos bloques que en bloques de 4.096 palabras. Lisp usa más capacidad computacional para el manejo de memoria que cualquier otro lenguaje.

Mauricio Paletta
244Índice
Si X es un símbolo cuya dirección apunta a la lista (A B C) y un programa cambia su valor a la lista (D E F), Lisp automáticamente asigna tres celdas-cons para almacenar la estructura de infor-mación y memoria para almacenar los elementos D, E y F. La figura 8.9 ilustra este cambio.
Figura 8.9El valor del símbolo X se cambia de (A B C) a (D E F)
El valor de X ahora apunta a la lista (D E F) en lugar de la lista (A B C). La memoria que al-macena (A B C) ya no está en uso porque no es más apuntada por el valor de X (en general, al cambiar el valor de una variable se asignan nuevas celdas-cons y las celdas originales dejan de ser apuntadas). Estas celdas-cons que ya no son apuntadas pueden ser recicladas o reutiliza-das. Al proceso de reciclaje de las celdas-cons se le denomina recolección de desperdicio y su principio es simple: El recolector de desperdicio busca en la memoria celdas-cons que ya no son apuntadas ni por otra celda ni por el valor de un símbolo y las marca como libres.
Uno de los métodos más simples para implementar un recolector de desperdicio es el que se conoce con el nombre de “marcar y barrer”. El recolector marca primero todas las celdas que ya no son apuntadas; luego sigue todos los apuntadores de los valores de todos los símbolos de la tabla, le coloca una bandera a todas las celdas-cons que se están apuntando; luego se realiza una ultima pasada a través de la memoria, reciclando todas las celdas que están todavía marca-das como “no apuntadas”17.
Otra técnica de recolección de desperdicios es la llamada “contador de referencia”. Cuando se va a asignar un apuntador a una celda-cons, un contador que nos dice cuántos apuntadores están dirigidos a esa celda, se incrementa en uno. Cuando un apuntador se cambia de forma tal que ya no apunta más a una celda, el contador correspondiente se decrementa en uno. Si el contador de referencia de una celda-cons llega a cero, no hay más apuntadores a esa celda y éste es reciclado inmediatamente18.
17 Una de las dificultades de este método ocurre si el programa Lisp se detiene mientras el recolector de desperdicios revisa la memoria. Si la máquina Lisp está en un proceso de producción continua, el resultado es desastroso.18 El recolector de desperdicio impone una carga tan pesada en el hardware de la computadora que amerita un esfuerzo para evitarlo. Es posible escribir programas Lisp de forma tal de no generar celdas-cons en exceso. A este estilo de programación se le llama “Lisp de pocos desperdicios” y permite que Lisp corra programas en computadoras convencionales sin tener que pagar una pena de bajo desempeño por el uso del recolector de desperdicios. Escribir programas Lisp libres de desperdicio es una tarea bastante compleja.

Inteligencia Artificial Básica
245Índice
Otra de las potencialidades de Lisp es la posibilidad de asignar a un mismo símbolo datos de tipos diferentes en forma dinámica. Lisp usa bits de etiquetas para registrar el tipo de información al cual apunta un apuntador. Cuando a X se le asigna el valor (A B C), el apuntador de X tiene la dirección de comienzo de la lista e incluye también bits de etiquetas que indican que el valor de X es una lista. Si posteriormente el programa le asigna a X un 2, el apuntador es cambiado a apuntar a 2 y los bits de etiqueta son cambiados para indicar que el valor es un entero de una palabra simple. Si luego los cálculos hacen que el valor de X se incremente de forma tal que no quepa en una palabra, una palabra extra es asignada y los bits de etiqueta son cambiados para indicar que X es un número que ocupa más de una palabra19.
Ejemplos. A continuación aparecen varios ejemplos de funciones completas escritas en Lisp:
a) Determinar si todos los elementos de una lista son átomos. Nótese la llamada recursiva de la función que se está definiendo.
(defun todos-atomos (L)
(cond ((null L) t)
((atom (car L)) (todos-atomos (cdr L)))
(t nil))
)
b) Determinar si un elemento es miembro de una lista.
(defun miembro (a L)
(cond ((null L) nil)
(t (or (eq (car L) a) (miembro a (cdr L)))))
)
c) Retornar las coordenadas polares asociadas a un par dado. Nótese el uso de la primitiva VALUES para hacer
que la función retorne más de un valor .
(defun polar (x y)
(values (sqrt (+ (* x x) (* y y)))
(atan y x))
)
d) Suma de vectores. Nótese la forma como se construye la lista con la primitiva CONS, que luego se da como
respuesta.
(defun vec+ (vec1 vec2)
(cond ((null vec1) vec2)
((null vec2) vec1)
(t (cons (+ (car vec1) (car vec2)) (vec+ (cdr vec1) (cdr vec2)))))
)
19 Algunas máquinas Lisp incorporan bits extras en cada palabra para manejar las etiquetas.

Mauricio Paletta
246Índice
e) Invertir una lista. En este caso se muestra que no sólo recursivamente se hacen las cosas en Lisp. La primera parte de la primitiva DO es una lista de parámetros con valores iniciales (si alguno de los parámetros ya tenía un valor antes de entrar al DO, este se restituye a la salida); la segunda parte del DO establece cuándo se termina el ciclo y lo que se debe retornar.
(defun invertir (L)
(do ((x L (cdr x))
(y ´( ) (cons (car x) y)))
(endp x) y))
)
f) Predicado para determinar si una cadena de caracteres es o no un palíndromo20. Nótese el manejo de las cade-
nas de caracteres y la forma como se puede configurar el uso de los parámetros.
(defun palindromop (string &opcional (start 0) (end (length string)))
(dotimes (k (floor (- end start) 2) t)
(unless (char-equal (char string (+ start k))
(char string (- end k 1)))
(return nil)))
)
g) Problema de las torres de hanoi (ver ejercicio f de Prolog y figura 8.1). Nótese la forma como se construyen formatos de salida usando la primitiva FORMAT.
(defun hanoi (n)
(hanoi-aux n ’a ’c ’b)
)
(defun hanoi-aux (n desde hacia libre)
(when (> n 0)
(hanoi-aux (1- n) desde libre hacia)
(mover-disco n desde hacia)
(hanoi-aux (1- n) libre hacia desde))
)
(defun mover-disco (disco desde hacia)
(format t “~&Mover disco ~A desde ~A hacia ~A.” disco desde hacia)
)
h) Problema de las ocho reinas en un tablero de ajedrez. Para la solución se construyen tres listas, “columna”, “izquierda” y “derecha” en las cuales se va guardando información relativa a las reinas que se van colocando con respecto a la columna del tablero y las diagonales izquierda y derecha respectivamente. La diagonal izquierda guarda la suma entre la fila y la columna, valor que se repite si se sigue la diagonal y que permite saber si ya hay en el tablero alguna reina en esa misma dirección. La diagonal derecha en cambio, guarda el valor de la fila menos la columna y sigue la misma idea. (Ver ejercicio h de Prolog y figura 8.3).
(proclaim ´(special *n*))20 Cuando un escrito se lee igual tanto de izquierda a derecha como de derecha a izquierda, se dice que es un palíndromo (por ejemplo “ANA”, “RAPAR”, etc.).

Inteligencia Artificial Básica
247Índice
(defun reina (*n*)
(reina1 0 0 nil nil nil)
)
(defun reina1 (i j columna izquierda derecha)
(cond ((= i *n*) columna)
((= j *n*) nil)
((or (member j columna) (member (+ i j) izquierda) (member (-i j) derecha))
(reina1 i (1+ j) columna izquierda derecha))
((reina1 (1+ i) 0 (cons j columna) (cons (+ i j) izquierda) (cons (- i j) derecha)))
)
i) Búsqueda en árboles binarios ordenados. Un árbol binario como el que se muestra en la figura 8.10 (el hijo izquierdo menor que el padre y el hijo derecho mayor que el padre) se puede representar en Lisp mediante una lista como sigue: (8 (5 (2 nil (3 nil nil)) (7 nil nil)) (15 (10 (9 nil nil) (13 nil nil)) nil))). Se quiere definir una función que indique si un elemento dado está en un árbol binario representado de la forma anterior.
Figura 8.10Ejemplo de un árbol binario
(defun b-arbol-binario (n arbol)
(cond ((null arbol) nil)
((= n (car arbol)) t)
((< n (car arbol)) (b-arbol-binario n (cadr arbol)))
(t (b-arbol-binario n (caddr arbol)))))
j) Multiplicación de matrices. La primitiva ARRAY-DIMENSIONS retorna una lista con las di-mensiones de los arreglos.
(defun multiplicar-matrices (A B)
(let* ((p (car (array-dimensions A)))
(q (cadr (array-dimensions A)))
(r (cadr (array-dimensions B)))
(c (make-array (list p r))))

Mauricio Paletta
248Índice
(dotimes (i p c)
(dotimes (j r)
(let ((s 0))
(dotimes (k q)
(incf s (* (aref a i k) (aref b k j))))
(setf (aref c i j) s))))))
8.3. OPS-5
El Official Production System 5 (Sistema de Producción Oficial versión 5), es un lenguaje para la programación de sistemas basados en reglas de producción bajo un mecanismo de inferencia de encadenamiento hacia adelante. Fue usado por la Digital Equipment Corporation (DEC) para el desarrollo de sus sistemas expertos comerciales.
La primera versión del lenguaje llamada simplemente OPS, fue creado por C. L. Forgy de la Universidad de Carnegie Mellon en la mitad de la década de los setenta. Tanto la primera imple-mentación como OPS-5 son ambientes interpretados y fueron realizados en plataformas LISP.
Todo el funcionamiento de OPS-5 se basa en los fundamentos principales de la teoría de los sistemas de producción. El programa consiste de un conjunto de unidades básicas llamadas producciones o reglas.
La sintaxis del lenguaje es muy sencilla, existen pocos comandos e instrucciones y su léxico cuenta con un pequeño conjunto de caracteres. Es un lenguaje de programación que no se debe usar cuando el problema a resolver se divide en muchos contextos o cuando sean problemas cuyas soluciones dependan de cálculos muy complejos.
La memoria de trabajo. En OPS-5 al igual que todo lenguaje de programación existe un área de datos para representar la información del dominio del problema. En todos los ambientes de sistemas de producción esta área recibe el nombre de memoria de trabajo y constituye el conjun-to de objetos que permiten almacenar y representar la información referida al problema tratado. Tales objetos reciben el nombre de elementos y son entidades que se agrupan de acuerdo a un conjunto de atributos mediante una definición abstracta que llamamos clase.
La unidad de datos recibe el nombre de átomo. Se pueden manejar tres tipos de átomos:
Simbólico: cadena de hasta un máximo de 256 caracteres.1. Entero: valores numéricos enteros que están definidos en el rango comprendido entre 2. -229 y 228.Punto flotante: valores numéricos reales que están definidos en el rango comprendido en-3. tre 0.29E-38 y 1.7E38.

Inteligencia Artificial Básica
249Índice
Por ejemplo:
Primer-Apellido; |Primer Apellido| son átomos simbólicos
45; 876765564; 1; -800 son átomos enteros
0.009; -1.00; .35e10 son átomos punto flotante
Como se puede ver en el ejemplo anterior, la forma de encerrar un átomo simbólico o definir una cadena de caracteres constante es haciendo uso de la barra vertical ( | ) como delimitador, tanto para abrir como para cerrar la cadena.
Una clase es una entidad abstracta que se identifica en el dominio del problema y está forma-da por un identificador (nombre de la clase) y un conjunto de campos o atributos. Un elemento de la memoria de trabajo u objeto que corresponde a una clase previamente definida, está formado por el identificador de la clase y el conjunto de átomos o valores asociados a los campos que conforman la misma. Si se tiene por ejemplo la siguiente clase:
Computadora - CPU; RAM; DD
donde, “Computadora” representa el identificador y “CPU”, “RAM” y “DD” son sus atributos, entonces
Computadora - |486 DX2 66|; 16; 840
es un elemento válido de la memoria de trabajo creado a partir de la definición de esa clase con “|486 DX2 66|” el átomo simbólico asociado al campo “CPU” y 16 y 840 los átomos enteros asociados a los campos “RAM” y “DD” respectivamente.
Los campos para la definición de una clase reciben el nombre de atributos y se distinguen dos tipos de ellos:
Escalares: toman sólo el valor de un átomo.1. Vectores: toman el valor de hasta un máximo de 127 átomos que pueden ser de diferente 2. tipo.
Para definir los atributos de una clase no es necesario indicar su tipo, más aún, éstos pueden cambiar dinámicamente. En realidad el tipo del atributo viene dado por el valor del átomo que se le asigne al objeto en un momento dado. Por ejemplo, cuando a un atributo se le asigna el valor 3 pasa a ser un atributo de tipo entero, si posteriormente se le asigna el valor 3. su tipo cambia de entero a punto flotante.

Mauricio Paletta
250Índice
Como restricciones del lenguaje, sólo es posible definir un máximo de 255 atributos escalares y un sólo atributo vector por clase.
Al momento de crear o modificar la información de el elemento de una clase, no es necesario darle valor a todos los atributos de la misma. Los atributos a los que no se les asigna ningún átomo en el momento de la creación toman automáticamente un valor nulo, que se representa mediante la constante “NIL”. En el caso de una modificación, los atributos quedan con el mismo valor que tenían antes de la operación.
La memoria de trabajo varía dinámicamente a lo largo de la ejecución de un programa. Es decir, el ingreso, modificación y eliminación de elementos en la memoria de trabajo se realiza por medio de acciones contenidas en las producciones o reglas.
Cada elemento de la memoria de trabajo tiene asociado un valor numérico entero que indica que tan reciente es la actualización del elemento. Este valor recibe el nombre de “time-tag” y no es más que un consecutivo numérico usado por el motor de inferencia para aplicar estrategias para la solución de conflictos. La asignación de este valor se realiza en forma automática y por cada elemento que se crea o modifica se le asigna el valor actual más uno. La idea es asociar al elemento con el valor más grande la propiedad de ser el más reciente en la memoria de trabajo. En la eliminación del objeto, desaparece tanto el elemento como su “time-tag” (no vuelve a apa-recer en la ejecución del programa) y el valor inmediatamente anterior pasa a ser el mayor.
No existen limitaciones sobre la cantidad de elementos que puede haber en la memoria de trabajo en un momento dado, depende de la capacidad de memoria que tiene el hardware que se esté usando. El programador debe administrar bien el uso de esta área de trabajo. La creación y sobre todo eliminación de los elementos depende de la programación de las producciones.
Las producciones. Están constituidas por las reglas de producción que representan el cono-cimiento del dominio del problema. El conjunto de condiciones está unido mediante la operación lógica de conjunción. Es decir, todas las condiciones de una producción deben ser ciertas en un momento dado para afirmar que la LHS de la producción está satisfecha. Así mismo, todas las acciones de la RHS de la producción están sujetas a la misma probabilidad de ejecución, todas se ejecutan al mismo tiempo.
Las condiciones de una producción se escriben de forma tal de intentar unificar elementos de la memoria de trabajo. El proceso de unificación se da si ocurren las siguientes reglas:
Si la condición especifica el nombre de una clase, el sistema compara el primer átomo del 1. elemento con ese nombre y deben ser iguales.

Inteligencia Artificial Básica
251Índice
Si la condición especifica un atributo escalar y un valor, el sistema busca el nombre de ese 2. atributo en la clase dada por la primera regla y compara el valor del atributo con el valor del componente de la condición siguiendo las cuatro últimas reglas.Si la condición especifica un atributo vector y un valor (conjunto de átomos), el sistema 3. busca el atributo en la clase dada por la primera regla y compara uno a uno, en orden, los átomos del valor del componente de la condición con los átomos del valor del atributo del elemento siguiendo las cuatro últimas reglas.Dos átomos simbólicos unifican si están compuestos de la misma secuencia de 4. caracteres. Dos átomos numéricos (entero o punto flotante) unifican si la diferencia entre ambos es 5. cero y son del mismo tipo.Un átomo unifica con cualquier variable no instanciada y la variable se instancia con el valor 6. del átomo.Un átomo unifica con una variable instanciada si el valor del átomo y el valor de la variable 7. unifican siguiendo las reglas cuatro y cinco.
Nótese que la quinta regla indica que un átomo entero y un átomo punto flotante nunca unifi-can aunque tengan el mismo valor.
Cuando se escriben condiciones de forma tal de buscar unificación entre la condición y un ele-mento de la memoria de trabajo se dice que la condición es positiva. Es posible escribir una con-dición que se quiera no tenga unificación con ningún elemento, en este caso se define lo que se denomina una condición negativa. Nótese que la condición negativa no es equivalente al negado de la condición positiva, ya que la condición negativa se satisface cuando no hay elementos en la memoria de trabajo que unifiquen lo descrito mientras que el negado de una condición positiva se satisface cuando existe un elemento que unifique con la negación de lo descrito. Una producción puede tener un máximo de 64 condiciones positivas y cualquier número de condiciones negati-vas. Es obligatorio que la primera condición sea positiva.
Los valores especificados en los componentes de una condición que se relacionan con el atributo de alguna clase pueden ser átomos, variables o llamadas a funciones. La comparación entre el componente y el valor se realiza mediante operadores de relación que reciben el nombre de predicados. Los predicados permiten hacer comparaciones de igualdad, desigualdad, mayor que, menor que, mayor o igual que, menor o igual que y mismo tipo.
El ciclo de reconocimiento-acción. Es el motor de inferencia con el cual trabajan todos los sistemas de producción. Consiste en la repetición continua de un proceso formado por tres pa-sos, tal como se ve en la figura 8.11:
Seleccionar todas aquellas producciones cuyas condiciones se han satisfecho, de acuerdo 1. a los elementos que se encuentran actualmente en la memoria de trabajo.

Mauricio Paletta
252Índice
Escoger una sola producción del conjunto obtenido en 1, haciendo uso de una serie de 2. reglas y estrategias predefinidas.Ejecutar las acciones de la producción obtenida en 2.3.
Todas las producciones son candidatas a ser seleccionadas en cualquier momento. Nótese que si la estrategia a seguir no considera descartar del conjunto las producciones escogidas en la iteración anterior, es posible disparar constantemente la misma producción y caer con facilidad en un ciclo infinito.
El proceso puede terminar por alguna de las siguientes razones:
El conjunto de producciones satisfechas es nulo.• Fue forzado por una acción de alguna de las producciones.•
El conjunto conflicto. Este es el nombre que se le da al conjunto de producciones que ha sido seleccionado en el paso 1 del ciclo de reconocimiento-acción. Cuando más de una produc-ción satisface sus condiciones en una iteración del ciclo de reconocimiento-acción y dado que sólo una de ellas debe dispararse, entonces se dice que estas producciones entran en conflicto. Cuando el conjunto está vacío el motor de inferencia detiene su proceso repetitivo. Si hay una sola producción en el conjunto no hay conflicto y por ende se salta del paso 1 al paso 3 del pro-ceso directamente.
La forma en la cual los sistemas de producción resuelven los conflictos entre las producciones cambia entre una implementación y otra. En cada una de ellas se ofrece una gama de estrategias y reglas con las cuales el programador puede configurar sus programas. Parte del éxito en la cual los programas escritos en OPS-5 funcionen está en la forma en la cual se escoge la estrategia para resolver los conflictos.

Inteligencia Artificial Básica
253Índice
Figura 8.11Ciclo de reconocimiento-acción
Reglas y estrategias para la solución de conflictos. En cada iteración del ciclo de reconoci-miento-acción y una vez obtenido el conjunto conflicto, es necesario seleccionar una producción de dicho conjunto y ejecutar sus acciones correspondientes. Esta situación se conoce como un conflicto. Cada implementación de arquitecturas para el desarrollo de sistemas de producción tiene su propio conjunto de reglas y estrategias para resolver conflictos.
En OPS-5, la solución de conflictos depende de tres reglas fundamentales y el uso de estas reglas está basado en los principios de dos estrategias. Las reglas son las siguientes:
Refraction1. Se debe seleccionar una y sólo una instancia. Evita que un pro- grama caiga en ciclo infinito a causa de la misma producción, eliminando la instancia seleccionada del conjunto.Recency2. Selecciona la instancia cuyo LHS hace referencia con el elemen- to más reciente de la memoria de trabajo (tenga el “time-tag” mayor).Specificity3. Selecciona la producción cuyo LHS sea el más específico (deter- minado por el número de condicionales que tengan los elementos

Mauricio Paletta
254Índice
condición). Los ítems de una condición que son considerados condi- cionales son los siguientes:
- el nombre de una clase; - una disyunción; - el valor de una constante precedida por algún predicado (excepto cuan
do es una disyunción) y, - la ocurrencia de una variable (excepto cuando es la primera).
Las dos estrategias que usan las reglas anteriores son las siguientes:
Lexicographic-Sort1. (LEX): Debe ser usada en aquellos programas que no dependen del orden en el cual son seleccionadas sus producciones. El algoritmo usado por esta estrate-gia es el siguiente:
- Aplica Refraction (regla 1) para remover del conjunto conflicto las instancias que el sistema seleccionó en la iteración anterior del ciclo.- Ordena el resto de las instancias aplicando Recency (regla 2) y se seleccionan las de mayor valor.- Si hay más de una instancia seleccionada entonces - Ordena las instancias de acuerdo a lo específico de las mismas, aplicando Specificity (regla 3). - Si más de una instancia tienen el mayor valor de especificidad entonces - se selecciona una instancia aleatoriamente.sino - se selecciona la instancia que tenga la mayor especificidad.sino - se selecciona la instancia que hace referencia al elemento más reciente.
Means-Ends-Analysis (MEA): Esta estrategia se basa en considerar el primer elemento 2. condición de la producción como el más importante. Coloca la más alta prioridad a la pro-ducción cuyo primer elemento condición unifica con el elemento más reciente de la me-moria de trabajo. Esta estrategia debe ser usada por aquellos programas que requieren la división de tareas y cuya solución depende del agrupamiento de producciones. El algoritmo usado es el siguiente:

Inteligencia Artificial Básica
255Índice
- Aplica Refraction (regla 1) para remover del conjunto conflicto las instancias que el sistema seleccionó en la iteración anterior del ciclo.- Aplica Recency (regla 2) para seleccionar las instancias donde la primera condición haga referencia al elemento más reciente de la memoria de trabajo.- Si hay más de una instancia seleccionada entonces - Ordena las instancias aplicando Recency (regla 2) para todas las condiciones(no sólo la primera) y selecciona las de mayor valor. - Si hay más de una instancia seleccionada entonces - Ordena las instancias de acuerdo a lo específico de las mismasaplicando Specificity (regla 3). - Si más de una instancia tienen el mayor valor de especificidad entonces - se selecciona una instancia aleatoriamente.sino - se selecciona la instancia que tenga mayor especificidad.sino - se selecciona la instancia que haga referencia al elemento más reciente.sino - se selecciona la instancia cuya primera condición haga referencia al elemento más reciente de la memoria de trabajo.
Cuando el problema a resolver se tiene que descomponer en procesos que deben ejecutarse en forma secuencial, es recomendable seleccionar la estrategia MEA. Para tal fin, todas las pro-ducciones del programa deben tener el mismo elemento condición (referencia a la misma clase) como primer elemento de la LHS.
Cuando se usa la estrategia MEA y el problema a resolver se divide en contextos de ejecu-ción, el orden en el cual uno desea se seleccionen y ejecuten las producciones, depende del orden en el cual se ingresan a la memoria de trabajo los elementos de la clase escogida para ser los primeros elementos condición de la LHS de las producciones.
Sintaxis del lenguaje. Un programa en OPS-5 consiste de una parte de declaraciones que describen los objetos o clases manejados por el programa clases y una parte de producciones que contiene las reglas con las cuales se maneja la data y se obtienen los resultados. La parte de declaraciones debe preceder a la sección de producciones.
Toda instrucción del lenguaje, ya sea una declaración o una producción, va encerrada entre paréntesis { “(“, “)” }, tomando una semejanza con el lenguaje de programación Lisp21.
21 Esto se justifica ya que OPS-5 fue realizado en Lisp.

Mauricio Paletta
256Índice
Un identificador puede tener cualquier número del siguiente conjunto de caracteres { “A”, ..., “Z”, “a”, ..., “z”, “0”, ..., “9”, “:”, “-” }. El único identificador que no se puede usar es la palabra reser-vada “NIL” que representa el átomo nulo y es usado para inicializar cualquier atributo o variable. De hecho, este es el valor por defecto que toman las variables y atributos si no se les ha asignado algún valor.
Las variables se diferencian porque van encerradas entre corchetes angulados { “<“, “>“ }. El alcance de una variable está delimitado dentro de una producción, desde el momento en que aparece por primera vez hasta que finaliza el código de la producción. No hay limitación sobre la cantidad de variables a usar en una producción. La interpretación de la variable guarda cierta similitud con lo que se hace en el lenguaje de programación Prolog:
Si la variable no ha sido instanciada (aparece por primera vez), toma el valor o se instancia 1. con el valor al cual se está relacionando.Si ya ha sido instanciada se usa el valor actual.2.
Para hacer referencia al atributo de una clase basta anteponer al identificador del atributo el caracter “ˆ”. En el caso de los atributos vectores, además de referenciar el atributo, para realizar el acceso a los componentes del vector se encierra entre paréntesis { “(“, “)” } las relaciones empezando con el índice del componente, siguiendo con la operación y terminando con el valor a comparar.
Es posible escribir líneas de comentarios en un programa, para ello se debe iniciar la línea con el caracter “;”.
Ejemplos:; Lo siguiente es un identificador válido
Regla:01:Sistema-Reduccion
; Lo siguiente es una variable
<var-aux>
; En el siguiente ejemplo se desea comprobar si para un elemento de la clase Linea,
; el atributo escalar Celda es 51 y los componentes 3, 9 y 10 del atributo vector
; Anodos son S, S y N respectivamente
Linea
ˆCelda 51
ˆAnodos ( 3 S 9 S 10 N )
Declaraciones. Hay sólo tres entidades que se deben declarar: las clases, los atributos vec-tores y las funciones externas.

Inteligencia Artificial Básica
257Índice
Para declarar una clase basta asociar a un nombre el conjunto de identificadores de los atri-butos que le pertenecen. Esto se realiza con la instrucción LITERALIZE y haciendo uso del siguiente formato:
( LITERALIZE [nombre-clase] [atributo-1] [atributo-2] ... [atributo-n])
El nombre de la clase debe ser único en el programa (no puede haber clases con el mismo nombre); dos atributos no pueden llamarse igual dentro una misma clase pero si pueden tener el mismo nombre en clases diferentes.
El orden con el cual se definen los atributos de una clase no es importante ya que no se tiene que respetar cuando se haga referencia a ellos en las condiciones de una producción. Para eso basta con indicar el identificador que lo reconoce.
En caso de que no se quiera hacer referencia a un atributo mediante su identificador, se le puede asociar al atributo un número de acuerdo a la posición que ocupa dentro de la clase y hacer referencia a través de ese número, tomando en cuenta que el número 1 es siempre el que está asociado al nombre de la clase. Este valor numérico recibe el nombre de entero designador y su uso dentro de un programa se debe especificar mediante la instrucción LITERAL:
( LITERAL [atributo-1] = p1 [atributo-2] = p2 ... [atributo-n] = pn)
Solamente puede haber una instrucción LITERAL en un programa y no está asociada a nin-guna clase particular sino a todas en conjunto, por lo tanto, cuando haya un atributo con nombre repetido en clases diferentes, el efecto de LITERAL está asociado al primero que se consiga de acuerdo a una búsqueda secuencial. Cualquier atributo válido (previamente declarado) puede ser indicado en esta instrucción; puede usarse cualquier número excepto el 1 y pueden haber números repetidos. Si dos atributos de una misma clase tienen el mismo entero designador, éste estará asociado al primero que se haya definido.

Mauricio Paletta
258Índice
No es recomendable hacer uso de la instrucción LITERAL ya que puede originar confusiones difíciles de detectar y complica la labor de mantenimiento del programa.
Cuando uno de los atributos de una clase es de tipo vector es necesario declararlo como tal. Para tal fin se utiliza la instrucción VECTOR-ATTRIBUTE cuyo formato es el siguiente:
( VECTOR-ATTRIBUTE[atributo-vector-1][atributo-vector-2]...[atributo-vector-n])
Esta instrucción declarativa debe aparecer luego de las declaraciones de las clases que con-tienen los atributos correspondientes. Nótese que si hay N atributos vectores debe haber por lo menos N clases diferentes.
Ejemplo:
; Declaración de una clase que representa los empleados de una empresa
;
( LITERALIZE Empleado
Nombre
Edad
Codigo-Cargo
Lista-Sueldos
)
; Declaración de una clase que representa las unidades organizativas de la empresa
;
( LITERALIZE Cargo
Codigo-Cargo
Descripcion
)
; Atributo de la clase “Empleado” declarado como un vector
;
( VECTOR-ATTRIBUTE Lista-Sueldos )
En OPS-5 hay dos tipos de funciones que pueden ser incorporadas en un programa, las predefinidas por el lenguaje y las que son codificadas en otros lenguajes (C, Pascal, etc.). Estas

Inteligencia Artificial Básica
259Índice
últimas se denominan funciones externas, sus códigos son enlazados por el objeto escrito en OPS-5 y deben ser declaradas en el programa haciendo uso de la instrucción EXTERNAL, ha-ciendo uso del siguiente formato:
( EXTERNAL( [nombre-función-1] [tipo-retorna] ( [tipo-parámetro-11] ) ( [tipo-parámetro-12] ) ... ( [tipo-parámetro-1p] ) )( [nombre-función-2] [tipo-retorna] ( [tipo-parámetro-21] ) ( [tipo-parámetro-22] ) ... ( [tipo-parámetro-2q] ) )...( [nombre-función-n] [tipo-retorna] ( [tipo-parámetro-n1] ) ( [tipo-parámetro-n2] ) ... ( [tipo-parámetro-nr] ) ))
Los nombres de funciones deben ser identificadores válidos en el lenguaje donde éstas se van a definir. Los tipos de retorno identifican el tipo de átomo que puede retornar la función; es opcional y puede ser uno de los siguientes valores:
SYMBOLIC-ATOM Cadena de caracteres o átomo simbólico válido para OPS-5.• FLOAT-ATOM Atomos punto flotante válidos para OPS-5.• INTEGER-ATOM Atomos enteros válidos para OPS-5.• NUMERIC-ATOM Valores numéricos que no son ni entero ni punto flotante.• ANY-ATOM Cualquier otra cosa.•
Por último, los tipos de los parámetros representan los tipos de átomos que identifican cada uno de los parámetros (si hay) pasados en la llamada de la función. Se indica un valor como el caso del retorno y si el parámetro es pasado por valor o por referencia. Esto se indica acompa-ñando al tipo de átomo la expresión BY VALUE o BY REFERENCE, dependiendo del caso.

Mauricio Paletta
260Índice
Supongamos por ejemplo una función externa que calcula el factor de certeza de una entidad; esta función debe recibir como parámetros los valores del factor actual y el factor de la nueva ocurrencia de la entidad y retorna la nueva certeza del elemento. La forma de declarar esta fun-ción para ser usada en un programa OPS-5 es como sigue:
( EXTERNAL
( CalculoCerteza FLOAT-ATOM ( FLOAT-ATOM BY VALUE )
( FLOAT-ATOM BY VALUE )
)
)
Producciones. El formato general para definir una producción es como sigue:
( P [nombre-producción] ( [condición-1] ) [-] ( [condición-2] ) ... [-] ( [condición-n] )--> ( [acción-1] ) ( [acción-2] ) ... ( [acción-m] ))
Como puede verse, la producción así como también cada una de sus condiciones y accio-nes debe ir encerrada en paréntesis. El nombre que identifica la producción debe ser único en el programa (no puede ser la palabra reservada “NIL”). No hay limitaciones sobre el número de producciones que se pueden definir en un programa.
Condiciones. La condición de una producción es el intento de unificación de algún elemento de la memoria de trabajo. La unificación se da cuando ambos elementos están compuestos de la misma secuencia de caracteres.
Cuando existe unificación entre un símbolo de un elemento de la memoria de trabajo y una condición, esta última recibe el nombre de condición positiva. Es posible indicar la posibilidad de que no exista ningún elemento de la memoria de trabajo que unifique con la condición, en este caso se debe colocar una condición negativa y para ello basta anteponer a la condición el caracter ´-´.

Inteligencia Artificial Básica
261Índice
Una producción puede tener un máximo de 64 condiciones positivas y cualquier cantidad de condiciones negativas. Es obligatorio que la primera condición sea siempre positiva.
Hay que hacer notar que una condición negativa no es equivalente a un negado lógico ya que la negación de una condición no implica necesariamente la no existencia de elementos en la memoria de trabajo.
A continuación se presenta un ejemplo de cada tipo de condición:
; La siguiente es una condición positiva
;
( Empleado ; nombre de la clase
ˆNombre <Nombre> ; atributo instanciado por una variable
ˆEdad 35 ; atributo comparado por un átomo entero
)
; La siguiente es una condición negativa
;
- ( Empleado ; nombre de la clase
ˆNombre <Nombre> ; atributo comparado con la variable instanciada en la
; condición anterior
ˆEdad 35 ; atributo comparado por un átomo entero
)
Los valores especificados en los componentes de un elemento condición que se relacionan con algún atributo de una clase pueden ser átomos, variables o llamadas a funciones. Entre ambos componentes debe haber un operador de relación que por defecto (cuando no aparece, como en los ejemplos anteriores) es la igualdad. Los operadores de relación se denominan pre-dicados y son los que se indican en la tabla 8.5.
Tabla 8.5Predicados de OPS-5

Mauricio Paletta
262Índice
Cualquiera sea el predicado, lo primero que se compara es la igualdad de los tipos de los componentes relacionados. Cuando se quiere relacionar un atributo con más de un valor, basta encerrar las relaciones entre llaves ( ´{´ y ´}´ ); de esta forma se realiza una conjunción de rela-ciones dentro de una misma condición. Por otro lado, si se quiere relacionar un atributo con un conjunto de átomos (relación de pertenencia), basta encerrar los átomos entre dos corchetes angulados (´<<´ y ´>>´); de esta forma se realiza una disyunción de relaciones sobre una misma condición. Por ejemplo:
ˆCelda << 325 326 327 >> ; disyunción: Celda = 325 o Celda = 326 o
; Celda = 327
ˆTemperatura { >= 120 <= 130 } ; conjunción: Temperatura >= 120 y
; Temperatura <= 130
Para poder usar un símbolo, operador, variable o llamada de función como una constante o átomo dentro de un elemento condición, basta anteceder al átomo el operador unario ´//´. Por ejemplo:
//<Número> ; es un átomo simbólico y no una variable
//( SUBSTR <Ele-Var> 2 INF ) ; es un átomo simbólico y no una llamada a la
; función SUBSTR
Los cambios en la memoria de trabajo, ya sea por la modificación, creación o eliminación de sus elementos debe hacerse en las acciones de una producción. En el caso de la modificación y eliminación de elementos, las acciones pertinentes requieren obligatoriamente una variable como parámetro que esté asociada al elemento de la memoria de trabajo que se va a alterar. La instanciación de esta variable debe hacerse en una condición de la misma producción que realiza la acción de cambio. Estas variables reciben el nombre de elementos variables.
Los elementos variables se asocian a una condición para instanciar en ella el elemento de la memoria de trabajo que unifica con la condición expresada. Un elemento condición que tenga un elemento variable va encerrada entre llaves ( ´{´ y ‘}’ ) y la variable precede a la condición. Por ejemplo:
; El siguiente es un ejemplo de la definición del elemento variable “<Un-Empleado>”;
; el objetivo es instanciar en la variable el elemento “Empleado” de la memoria de
; trabajo cuyo atributo “Nombre” unifique con el átomo simbólico “Pedro Jose
; Hernandez” y el atributo “Edad” unifique con el átomo entero “35”
;
{ <Un-Empleado> ( Empleado
ˆNombre | Pedro Jose Hernandez |
ˆEdad 35 ) }

Inteligencia Artificial Básica
263Índice
Además del concepto de elemento variable, se puede hacer referencia a una condición de la producción mediante el valor de la posición que ocupa esa condición dentro de la regla. Este valor recibe el nombre de elemento designador. Su uso trae complicaciones a la hora de hacer mantenimiento del programa. Cuando una acción o función usa un elemento designador, éste hace referencia al elemento de la memoria de trabajo que unifica con el elemento condición indi-cado por ese número.
Acciones. La parte derecha de una producción de OPS-5 está formada por una secuencia de acciones, cada una de las cuales se compone por una estructura que contiene el nombre o iden-tificador de la acción seguido por los argumentos o parámetros necesarios para su ejecución.
OPS-5 tiene un total de 12 acciones predefinidas que permiten, entre otras cosas, alterar la memoria de trabajo, detener la ejecución, relacionar variables, realizar operaciones de entrada y salida, crear producciones dinámicamente y transferir el control a rutinas externas.
En lo que respecta a las operaciones de entrada y salida, OPS-5 funciona bajo la filosofía de un dispositivo por defecto. Es decir, existe un dispositivo de salida por defecto (inicialmente asociado a la pantalla) y un dispositivo de entrada por defecto (inicialmente asociado al teclado) al cual van a ir dirigidas o de la cual provienen todas las acciones de salida o entrada respectivamente.
Siguiendo un orden alfabético, la tabla 8.6 contiene las 12 acciones que son permitidas en OPS-5. Se incluye una pequeña descripción sobre la función de la operación y los formatos respectivos.

Mauricio Paletta
264Índice
Tabla 8.6Acciones de OPS-5
Tabla 8.6 (Continuación)Acciones de OPS-5
( BUILD [nombre-producción] ( [condición-1] ) [-] ( [condición-2] ) ... [-] ( [condición-n] ) --> ( [acción-1] ) ( [acción-2] ) ... ( [acción-m] ) )
CALL Transfiere el control a una rutina externa previamente declarada.
( CALL [nombre-función] [parámetro-1] ... [parámetro-n] )
CBIND Representa el operador de asignación para los elementos variables que pudo haber sido instanciado con anterioridad.
( CBIND [elemento-variable] [valor] )
CLOSEFILE Cerrar un archivo previamente abierto.
( CLOSEFILE [nombre-lógico] )
DEFAULT Determina la fuente en la cual se harán las operaciones de entrada (“ACCEPT”) o las de salida (“WRITE”). Inicialmente la entrada y salida por defecto están asocia-das al teclado y pantalla respectivamente.
( DEFAULT [nombre-lógico] ACCEPT )( DEFAULT [nombre-lógico] WRITE )( DEFAULT NIL ACCEPT )( DEFAULT NIL WRITE )
HALT Permite detener la ejecución del ciclo de reconocimiento y acción.
BIND Representa el operador de asignación y es usado para cambiar el valor o instan-ciar variables; la variable pudo haber sido instanciada con anterioridad.
( BIND [variable] [valor] )
BUILD Creación dinámica de producciones.

Inteligencia Artificial Básica
265Índice
Tabla 8.6 (Continuación)Acciones de OPS-5
Funciones. OPS-5 tiene un conjunto de 9 funciones22 predefinidas que permiten entre otras cosas calcular expresiones aritméticas simples y leer valores de dispositivos de entrada. Todas 22 La diferencia entre una función y una acción es que la primera retorna un átomo. Por otro lado, las funciones se pueden usar tanto en una
( MAKE [nombre-clase] ˆ [atributo-1] [valor-1] ˆ [atributo-2] [valor-2] ... ˆ [atributo-n] [valor-n])
MODIFY Para cambiar los valores de los atributos de alguno de los elementos existentes en la memoria de trabajo; la modificación es posible ya que un elemento variable fue instanciado en alguna de las condiciones de la producción; basta con indicar sólo los atributos que van a ser modificados.
( MODIFY [elemento-variable] ˆ [atributo-1] [valor-1] ˆ [atributo-2] [valor-2] ... ˆ [atributo-n] [valor-n])
OPENFILE Permite abrir un archivo tanto para lectura como para escritura; no hay limitaciones sobre la cantidad de archivos abiertos al mismo tiempo. Para iniciar la lectura en un archivo de entrada o escribir sobre un archivo de salida es necesario cambiar la entrada y salida por defecto (acción “DEFAULT”) y asociarla al archivo correspon-diente.
( OPENFILE [nombre-lógico] [nombre-físico] IN )( OPENFILE [nombre-lógico] [nombre-físico] OUT )
REMOVE Permite eliminar o remover un elemento existente de la memoria de trabajo; requi-ere de la instancia previa de un elemento variable en alguna de las condiciones de la producción.
( REMOVE [elemento-variable] )
WRITE Mediante esta acción es posible escribir cualquier tipo de información al dispositivo de salida por defecto (la pantalla si no se indica lo contrario).
( WRITE [inf-1] [inf-2] ... [inf-n] )
( HALT )
MAKE Permite crear un elemento en la memoria de trabajo; se debe indicar el nombre de la clase al cual va a pertenecer el elemento a ser creado y el conjunto de atribu-tos que van a recibir un valor inicial en la creación (es válido no indicar ningún atributo).

Mauricio Paletta
266Índice
las funciones pueden ser usadas para escribir condiciones y para escribir acciones. Se presentan en orden alfabético en la tabla 8.7.
Tabla 8.7Funciones de OPS-5
condición como en una acción de la primitiva.
ACCEPT Leer un átomo de la entrada por defecto (sea archivo o teclado) y retornar el valor leído.
( ACCEPT )
ACCEPTLINE Para leer un átomo de la entrada por defecto actual con salto de línea incluido. Retorna el valor leído.
( ACCEPTLINE )
COMPUTE Evaluar expresiones aritméticas y retornar el valor calculado; los operadores válidos son: + (adición), - (sustracción), * (multiplicación), / (división), // (división entera) y \\ (módulo).
( COMPUTE [expresión] )
CRLF Escribe un fin de línea; debe ser un parámetro de la acción WRITE.
( CRLF )
GETATOM Permite crear y retornar un nuevo átomo simbólico con el valor NIL.
( GETATOM )
LITVAL Dado el identificador de un atributo, retorna el valor numérico de la posición que ocupa dicho atributo en la clase respectiva.
( LITVAL [atributo] )
RJUST Dado un valor entero, causa a la acción WRITE, justificar a la derecha la salida indicada en un rango especificado por ese valor.
( RJUST [valor] )
SUBSTR Retorna el conjunto de componentes de un elemento desde uno inicial hasta uno final. Requiere de un elemento variable para operar. Es útil para trabajar con atributos vector. El átomo INF se utiliza para indicar el último componente del elemento. Un componente se puede especificar colocando el nombre del atributo o bien el número que corre-sponde a la posición que ocupa dicho componente dentro del elemento. Tanto [compo-nente-inicial] como [componente-final] pueden ser el átomo INF, un entero designador o el nombre de un atributo.
( SUBSTR [elemento-variable] [componente-inicial] [componente-final] )
TABTO Dado un valor entero, coloca el cursor en el lugar indicado por ese valor (columna); debe ser un parámetro de la acción WRITE.
( TABTO [valor] )

Inteligencia Artificial Básica
267Índice
Funciones externas. Para definir y usar rutinas externas, existe un API de funciones (bibliote-ca de funciones) necesarias para establecer la comunicación entre el módulo externo y el módulo OPS-5. Hay una biblioteca de funciones por cada uno de los lenguajes de programación que se vayan a usar para desarrollar la rutina externa y su uso depende de la gramática del lenguaje.
Instrucciones de control. Junto a las declaraciones y producciones existen dos instrucciones que pueden ejecutarse al mismo nivel que éstas y permiten realizar acciones sobre el control de ejecución del programa. La primera de ellas, llamada STARTUP, permite realizar una serie de acciones antes de iniciar la ejecución del ciclo de reconocimiento-acción, sólo se ejecuta una vez y siempre de primero. Entre las acciones más importantes que deben estar en esta instrucción, está la de crear al menos un elemento de la memoria de trabajo (hay que recordar que la memo-ria de trabajo no puede estar vacía antes de iniciar el ciclo) y configurar ciertos parámetros para el ambiente de ejecución (estrategia, traza, etc.). El formato es como sigue:
( STARTUP ( [acción-1] ) ( [acción-2] ) ... ( [acción-n] ) )
La segunda instrucción de control se denomina CATCH y constituye una lista de acciones que se ejecutan después de realizar un número específico de ciclos de reconocimieno-acción. El número de ciclos a ejecutar y el nombre del CATCH se indican mediante la instrucción AFTER (puede ser incluida como una acción en STARTUP). Dado que los CATCH se identifican con un nombre se pueden definir varios en un programa. Son útiles por ejemplo para visualizar el estado de la memoria de trabajo cada cierto tiempo. El formato de las instrucciones es como sigue:
( AFTER [número-ciclos] [nombre-Catch] )( CATCH [nombre-Catch] ( [acción-1] ) ( [acción-2] ) ... ( [acción-n] ) )
Las acciones que se pueden colocar en STARTUP y CATCH son las mismas que aparecen en la tabla 8.6 y que se pueden ejecutar en el ambiente interactivo de OPS-5.
Ejemplo. Un granjero, una cabra, un lobo y un repollo llegan juntos a un río que deben atra-vesar. Hay un bote pero sólo cabe en él, el granjero y alguno de los otros tres integrantes. El granjero tiene que imaginarse la secuencia de travesías por el río de forma tal de no dejar solo al lobo con la cabra o la cabra con el repollo en ninguno de los dos lados ya que en ambos casos, el primero se comería al segundo. Nótese la forma en la cual se inicializa el programa con la ins-trucción “STARTUP” y la forma como se controla la secuencia de ejecución de las producciones mediante la parte condicional.
(LITERALIZE Personaje
ˆQuien
ˆPosicion

Mauricio Paletta
268Índice
)
(STARTUP
(MAKE Personaje ˆQuien granjero ˆPosicion este_lado)
(MAKE Personaje ˆQuien cabra ˆPosicion este_lado)
(MAKE Personaje ˆQuien lobo ˆPosicion este_lado)
(MAKE Personaje ˆQuien repollo ˆPosicion este_lado)
(STRATEGY MEA)
)
(P inicio_llevar_cabra
{ <granjero> (Personaje ˆQuien granjero ˆPosicion este_lado) }
{ <cabra> (Personaje ˆQuien cabra ˆPosicion este_lado) }
(Personaje ˆQuien lobo ˆPosicion este_lado)
(Personaje ˆQuien repollo ˆPosicion este_lado)
(WRITE 1 |llevar la cabra al otro lado| nl)
(MODIFY <granjero> ˆPosicion otro_lado)
(MODIFY <cabra> ˆPosicion otro_lado)
)
(P regresa_granjero_despues_llevar_cabra
{ <granjero> (Personaje ˆQuien granjero ˆPosicion otro_lado) }
(Personaje ˆQuien cabra ˆPosicion otro_lado)
(Personaje ˆQuien lobo ˆPosicion este_lado)
(Personaje ˆQuien repollo ˆPosicion este_lado)
(WRITE 2 |regresar a este lado| nl)
(MODIFY <granjero> ˆPosicion este_lado)
)
(P llevar_lobo
{ <granjero> (Personaje ˆQuien granjero ˆPosicion este_lado) }
{ <lobo> (Personaje ˆQuien lobo ˆPosicion este_lado) }
(Personaje ˆQuien cabra ˆPosicion otro_lado)
(Personaje ˆQuien repollo ˆPosicion este_lado)
(WRITE 3 |llevar el lobo al otro lado| nl)
(MODIFY <granjero> ˆPosicion otro_lado)
(MODIFY <lobo> ˆPosicion otro_lado)

Inteligencia Artificial Básica
269Índice
)
(P regresar_cabra
{ <granjero> (Personaje ˆQuien granjero ˆPosicion otro_lado) }
{ <cabra> (Personaje ˆQuien cabra ˆPosicion otro_lado) }
(Personaje ˆQuien lobo ˆPosicion otro_lado)
(Personaje ˆQuien repollo ˆPosicion este_lado)
(WRITE 4 |regresar la cabra de este lado| nl)
(MODIFY <granjero> ˆPosicion este_lado)
(MODIFY <cabra> ˆPosicion este_lado)
)
(P llevar_repollo
{ <granjero> (Personaje ˆQuien granjero ˆPosicion este_lado) }
{ <repollo> (Personaje ˆQuien repollo ˆPosicion este_lado) }
(Personaje ˆQuien lobo ˆPosicion otro_lado)
(Personaje ˆQuien cabra ˆPosicion este_lado)
(WRITE 5 |llevar el repollo del otro lado| nl)
(MODIFY <granjero> ˆPosicion otro_lado)
(MODIFY <repollo> ˆPosicion otro_lado)
)
(P regresa_granjero_despues_llevar_repollo
{ <granjero> (Personaje ˆQuien granjero ˆPosicion otro_lado) }
(Personaje ˆQuien cabra ˆPosicion este_lado)
(Personaje ˆQuien lobo ˆPosicion otro_lado)
(Personaje ˆQuien repollo ˆPosicion otro_lado)
(WRITE 6 |regresar a este lado| nl)
(MODIFY <granjero> ˆPosicion este_lado)
)
(P final_llevar_cabra
{ <granjero> (Personaje ˆQuien granjero ˆPosicion este_lado) }
{ <cabra> (Personaje ˆQuien cabra ˆPosicion este_lado) }
(Personaje ˆQuien lobo ˆPosicion otro_lado)
(Personaje ˆQuien repollo ˆPosicion otro_lado)

Mauricio Paletta
270Índice
(WRITE 7 |llevar la cabra al otro lado| nl)
(MODIFY <granjero> ˆPosicion otro_lado)
(MODIFY <cabra> ˆPosicion otro_lado)
)
8.4. Resumen del capítulo
Prolog es un lenguaje de programación basado en la lógica de predicados de primer orden. Un programa está formado por un conjunto de hechos y reglas y su finalidad es probar una serie de objetivos a partir de los hechos mediante el uso de las reglas. El mecanismo de control más importante para escribir los programas es la recursión. La estrategia de búsqueda que usa el mecanismo de inferencia es “backtracking”.
Lisp es un lenguaje de programación de procesamiento simbólico (programación en términos de relaciones entre símbolos). Tanto los programas como la información se representa mediante una lista que se define por un conjunto de elementos encerrados entre paréntesis.
El lenguaje de programación OPS-5 permite crear bases de conocimiento representadas me-diante reglas de producción. Los conceptos a dominar son el de memoria de trabajo, el ciclo de reconocimiento y acción, la producción y el conjunto conflicto. Un conflicto se da cuando más de una producción satisface sus condiciones en una iteración del ciclo. Para resolver el conflicto se hace uso de tres reglas (refraction, recency y specificity) y dos estrategias (lexicographic-sort y means-ends-analysis). El lenguaje presenta doce acciones y nueve funciones.
8.5. Ejercicios
Dadas las siguientes cláusulas Prolog:1.
basicpart(rim).basicpart(rearframe).basicpart(gears).basicpart(nut).basicpart(spoke).basicpart(handles).basicpart(bolt).basicpart(fork).assembly(bike, [quant(wheel, 2), quant(frame, 1)].assembly(whell, [quant(spoke, 20), quant(rim, 1), quant(hub, 1)]).assembly(frame, [quant(rearframe, 1), quant(frontframe, 1)]).

Inteligencia Artificial Básica
271Índice
assembly(frontframe, [quant(fork, 1)]).assembly(hub, [quant(gears, 1)]).assembly(axle, [quant(bolt, 1), quant(nut, 2)]).
partlist(T) :- partsof(1, T, P), collect(P, Q), printpartlist(Q).
partsof(N, X, P) :- assembly(X, S), partsoflist(N, S, P).partsof(N, X, [quant(X, N)]) :- basicpart(X).
partsoflist(_, [ ], [ ]).partsoflist(N, [quant(X, Num) | L], T) :- M is N * Num, partsof(N, X, Xparts), partsoflist(M, L, Restparts), append(Xparts, Restparts, T).
collect([ ], [ ]).collect([quant(X, N) | R1], [quant(X, Ntotal) | R2) :- collectrest(X, N, R1, O, Ntotal), collect(O, R2).
collectrest(_, N, [ ], [ ], N).collectrest(X, N, [quent(X, Num) | Rest], Others, Ntotal) :- !, M is N + Num, collectrest(X, M, Rest, Others, Ntotal).collectrest(X, N, [Other | Rest], [Other | Others], Ntotal) :- collectrest(X, N, Rest, Others, Ntotal).
printpartlist([ ]).printpartlist([quant(X, N) | R]) :- tab(4), wite(N), put(9), write(X), nl, printpartlist(R).
append([ ], L, L).append([X | L1], L2, [X | L3]) :- append(L1, L2, L3).
Resolver los siguientes objetivos:a) ?- partlist(bike).b) ?- partlist(car).

Mauricio Paletta
272Índice
c) ?- partlist(X).
Dada la siguiente representación de números enteros positivos, implementar las operacio-2. nes de suma, resta y multiplicación en Prolog.
0 -> 0 1 -> s(0) 2 -> s(s(0)) ...
Mediante la cláusula de Prolog “arco(g, d)” que significa que existe un arco o vértice desde 3. el nodo “g” al nodo “d”, es posible tener una representación de grafos dirigidos. Se desea que, haciendo uso de esta representación, se escriba el camino entre dos nodos dados.
Realizar cláusulas de Prolog para calcular la derivada de una expresión dada. Las ecuacio-4. nes para el cálculo son las siguientes:
Ejemplo: ?- d(x+1, x, X). Si X = 1+0 ?- d(x*x-2, x, X). Si X = x*1+1*x-0
Realizar un predicado de Prolog para aplanar una lista dada. Por ejemplo:5.
?- aplanar([a, [b, c], [[d], [ ], e]], S).SiS = [a, b, c, d, e]
Realizar un predicado de Prolog para calcular el intervalo de días entre dos fechas dadas. 6. Por ejemplo:
?- dias(3-marzo-1995, 7-abril-1995, D).SiD = 35
Realizar un predicado de Prolog para determinar si un átomo es o no un palíndromo.7.

Inteligencia Artificial Básica
273Índice
Representación y manipulación en Prolog de conjuntos con las siguientes operaciones: 8. pertenencia, subconjunto, disjuntos (ningún elemento de un conjunto está en el otro), inter-sección y unión.
Buscando en un laberinto. Es una noche oscura y tormentosa; mientras manejas en una 9. vía solitaria, tu vehículo se daña y se detiene frente a un gran palacio. Vas a la puerta, ves que está abierta y comienzas a buscar un teléfono. ¿ Cómo realizar la búsqueda en el pala-cio sin perderte y saber que has entrado a todos los cuartos ? Más aún, ¿ cuál es el camino más corto hacia el teléfono ? Es por estas emergencias que se han definido los métodos de resolución de laberintos. A continuación se define uno de esos métodos o algoritmos.
Es necesario mantener una lista de los cuartos visitados de forma tal de no ir caminando en círculos y visitar el mismo cuarto siempre. Basta con revisar la lista antes de entrar a un cuarto determinado; si está, busco otro cuarto, sino, escribo el número en la lista y entro al cuarto. Una mejora de este método es escribir la lista en orden.
El mapa del palacio se puede representar por la cláusula Prolog “puerta(A, B)” que indica que existe una puerta entre los cuartos A y B. Asumir que existe la cláusula “telefono(A)” que indica que el cuarto A tiene teléfono. Se desea que escriba un programa en Prolog para buscar el te-léfono en el palacio haciendo uso del método antes expuesto y una vez encontrado, escribir el camino de regreso hacia la primera puerta o puerta principal (suponer que el exterior es el cuarto identificado con el átomo “a” o el número “1”).
Una expresión preposicional puede ser escrita con los siguientes operadores: “implies”, 10. “and”, “or” y “not”, por ejemplo: “p implies (q and not r)”. Se tiene la cláusula Prolog “valor(V, T)” que indica el valor T (“true”, “false”) de la variable V en un momento dado (si no existe para alguna variable se asume un valor de falso). Realizar un programa en Prolog que resuelva la expresión preposicional y obtenga los valores de las variables implicadas y otro predicado que convierta una expresión dada en otra que haga uso de los operadores “nand” y “nor” que equivalen a las siguientes expresiones “not (a and b)” y “not (a or b)” respectivamente.

Mauricio Paletta
274Índice
Ejemplo: valor(q, true) valor(r, false) ... ?- resuelve(“p implies (q and not r)”). Si ** Se debe crear la cláusula “valor(p, true)”
?- convierte(“p implies not (q and r) and w”, Exp). Si Exp = p implies q nand r and w
Un sistema de producción es una secuencia de reglas de la forma “Si situación entonces 11. acción”. Escribir un programa en Prolog para interpretar un conjunto de reglas de produc-ción. Por ejemplo, si se tiene el siguiente conocimiento:
Si una planta tiene un tallo cuadrado, licencias emparejadas, dos flores encapuchadas y la fruta consiste de cuatro pequeñas nueces adjuntas al cáliz, entonces pertenece a la familia de las Lablatae.
y si el programa pregunta: “¿ Tiene la flor un tallo cuadrado ?” y se responde “no”, entonces se descarta la posibilidad de que la flor pertenezca a la familia Lablatae.
Dada la siguiente función definida en Lisp, se pide:12. a. Realizar la representación en diagrama de bloques.b. Indicar qué hace la función mostrando un ejemplo.
(defun taller ( O L )( cond ( null L ) ‘( ) )( ( eq ( car L ) O ) ( cdr L ) )( t ( cons ( car L ) ( taller O ( cdr L ) ) ) )
Escribir la expresión simbólica equivalente a la siguiente representación en diagrama de 13. bloques.

Inteligencia Artificial Básica
275Índice
Definir el conjunto de funciones Lisp necesarias para obtener la derivada de una expresión 14. con respecto al átomo x. La expresión se recibe en una lista como un parámetro repre-sentada en notación estándar y cada operador está con sus operandos en una lista. Por ejemplo, para representar la expresión 3 + x + 6 se tiene la lista ((3 + x)+ 6).
Ejemplo:Entrada Salida0x 1( 3 * x ) ( ( 0 * x ) + ( 3 * 1 ) )( x ^ 2 ) ( 2 * ( x ^ 1 ) )( ln x ) ( 1 / x )
Una regla de producción se puede representar en Lisp como un símbolo con dos propieda-15. des: la lista de condiciones y la lista de acciones, de la siguiente forma:
( REGLA1 ( CONDICIONES ( <COND1> ... <CONDn> ) )( ACCIONES ( <ACC1> ... <ACCm> ) ) )

Mauricio Paletta
276Índice
Cada condición <CONDi> y cada acción <ACCj> pueden ser una expresión simbólica cual-quiera. Además, una representación de símbolo puede ser usada para guardar en una conclu-sión, el valor y el factor de certeza asociado, de la siguiente forma:
( CONCLUSION ( VALOR <Valor> ) ( CERTEZA <FC> ) )
Se desea que defina expresiones LISP para:
a) Actualizar el factor de certeza asociado a la conclusión haciendo uso del siguiente algoritmo (usado por ADS):
Si (exisFC >= 0) y (nuevoFC >= 0)actualFC = exisFC + nuevoFC * (1 - exisFC)sinoSi ((exisFC >= 0) y (nuevoFC < 0) o(exisFC < 0) y (nuevoFC >= 0))actualFC = (exisFC + nuevoFC) / (1 - min(abs(exisFC), abs(nuevoFC)))sinoactualFC = exisFC + nuevoFC * (1 + exisFC)
b) Dado un símbolo que representa una regla, escribir la misma en el formato tradicional. Por ejemplo:
Si el símbolo que contiene la siguiente información:( REGLA1 ( CONDICIONES ( ( >= T 0 ) ( MOTOR_OK ) )( ACCIONES ( C1 0.6 ) (C2 -0.2 ) ) )
La salida debe ser:REGLA1:SI T >= 0 y MOTOR_OKENTC1(0.6), C2(-0.2)
Realizar versiones Lisp de los ejercicios 2 hasta el 9.16.
Realizar programas OPS-5 para representar el conocimiento expresado en los ejercicios 17. que se encuentran en el capítulo 3.

Inteligencia Artificial Básica
277Índice
Bibliografía
Abaffy, C.; Simulación Basada en Conocimiento; Tutorial de la III Conferencia Nacional sobre Inteligencia Artificial y Sistemas Expertos; noviembre de 1990.
Abbott, R.; Knowledge Abstraction; CACM,; vol. 30; Nº 8, 1987.
Barr, A. F.; The handbook of Artificial Intelligence; Vol. 1, 2 y 3; Addison-Wesley Publishing Company, Inc.; 1981.
Binmore, K.; Teoría de Juegos; McGraw-Hill; 1994.
Bobrow, D.; Expert Systems: Perils and Promises; CACM; vol. 29; Nº 9, 1986.
Buchanan, B. G. y Shortliffe, E. H.; Rule-Based Expert Systems: The MYCIN experiments of the Stanford heuristic programming project; Addison-Wesley Publishing Company, Inc.; 1984.
Charniak, E. M.; Introduction to Artificial Intelligence; Addison-Wesley Publishing Company, Inc.; 1984.
Davis, L.; Handbook of Genetic Algorithms; Van Mostrand Reinhold; 1991.
Goldberg, D. E.; Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley Publishing Company, Inc.; 1989.
Gordon, G.; Simulación de sistemas; Prentice-Hall, Inc.; 1990.
Grabowski, M. y Wallace, A. W.; Knowledge Acquisition using Prototyping: an empirical investigation.
Hertz, J.; Krogh, A. y Palmer, G.; Introduction to the theory of Neural Computation; Addison Wesley; 1991.
Kohonen, T.; Self-Organization and Associative Memory; Springer-Verlag Berlin Heidelberg; 1990.
Lugi; Knowledge based support for rapid software prototyping; IEEE Expert; Winter 1988;

Mauricio Paletta
278Índice
Madni, A.; The role of human factors in Expert Systems Design and Acceptance; Human Fac-tors Journal; Agosto 1988.
MacDougall, M. H.; Simulating Computer Systems: Techniques and Tools; MIT Press Series in Computer Systems; 1987.
McAllister, J.; Inteligencia Artificial y Prolog en Microordenadores; Marcombo S.A.; 1991.
McGraw, L. K. y Harbison-Briggs, K.; Knowledge Acquisition: Principles and Guidelines; Pren-tice-Hall; 1989.
Mendoza, J.; Procesamiento de Lenguaje Natural; Tutorial de la III Conferencia Nacional de Inteligencia Artificial y Sistemas Expertos; noviembre de 1990.
Michalewicz, Z.; Genetic Algorithms + Data Structures = Evolution Programs; Springer-Verlag Berlin Heidelberg; 1994.
Minsky, M.; A framework for representing knowlegde readings in Cognitive Science; Morgan Kauffman; 1989.
Müller, B. y Reinhardt, J.; Neural Networks: An introduction; Springer-Verlag Berlin Heidelberg; 1990.
Nebendahl, D.; Sistemas Expertos; Siemens, S.A. & Marcombo, S.A.; 1988.
Poblet, J. M. y varios autores; Inteligencia Artificial: conceptos, técnicas y aplicaciones; Serie: Mundo Electrónico; Marcombo, S.A.
Pressman, R. S.; Ingeniería del Software; McGraw-Hill; 1993.
Rolston, D. W.; Principios de Inteligencia Artificial y Sistemas Expertos; McGraw-Hill Interame-ricana, S.A.; 1990.
Round, A.; Knowledge-Based Simulation; The Hadnbook of Artificial Intelligence; vol. IV; 1989.
Rumbaugh, J.; Blaha, M.; Premerlani, W.; Eddy, F. y Lorensen, W.; Object-Oriented Modeling and Design; Prentice-Hall; 1991.
Sanchez, J. P.; Sistemas Expertos: Una metodología de programación; Macrobit Corporation; 1990.
Taylor, W. A.; What Every Eengineer Should Know About AI; The MIT Press; 1988.

Inteligencia Artificial Básica
279Índice
Torres, I. y Zambrano, A.; Arquitecturas en Tiempo Real para Sistemas Expertos; Tutorial de la III Conferencia Nacional de Inteligencia Artificial y Sistemas Expertos; noviembre de 1990.
Zambrano, A.; Meier, A. y Mauro, L.; Redes Neurales y Control de Procesos; Tutorial de IN-FORVEN; septiembre de 1990.
Weitzel, J. K.; Developping Knowledge-Based Systems: reorganizing the systems develom-pent life cycle; CACM; vol. 32; #4.
Winston, P. H. y Horn, B. K. P.; Lisp; Addison-Wesley Iberoamericana, S.A.; 1991.
Yuasa, T.; Common Lisp Drill; Academic Press, Inc.; 1987.

Mauricio Paletta
280Índice
Índice
A _____________________________
Abelson R., 8Activación de la neurona, 122Adaline, 120, 127, 128, 132, 136-137Adquisición del conoci-miento, 27, 34, 59Adquisición del conoci-miento con múltiples exper-tos, 66-69Agentes, 13-15Algoritmos Genéticos, 13, 159-160Anáforas, 104Análisis morfológico, 100Análisis pragmático, 102Análisis semántico, 101-102Análisis sintáctico, 100-101Aprendizaje, 128Aprendizaje estocástico, 129Aprendizaje hebbiano, 129Aprendizaje hiperesférico, 129Aprendizaje competitivo, 130, 148-149Aprendizaje por corrección de error, 128Aprendizaje por reforza-miento, 128Aptitud, 160ART, 127, 131Asociador, 130-131Autoasociativa, 131Axón, 110
B _____________________________
Backpropagation, 127, 131, 132, 138-140
Backtracking, 20, 177BAM, 127, 130, 131, 132Barr A., 8Base de conocimiento, 28Bobrow D. G., 8Buchanan B., 7Búsqueda:definición, 15criterios, 16estrategias, 18-20
C _______________________________
Cadena, 78CAR, 202CDR, 202Celda-cons, 202Célula de Schwann, 116Chapman D., 8Ciclo de reconocimiento-acción, 210Clase, 130
Clasificador, 130Colby K. M., 7Colmerauer A., 5, 8Collins A., 8Computación Emergente, 6Conjunto conflicto, 210Conocimiento, 3Counterpropagation, 130, 132Cromosoma, 160Crossover, 43Cruzamiento, 162

Inteligencia Artificial Básica
281Índice
D _______________________________
Davis R., 8Deducción automática, 25Dendral, 5, 50, 56Dendritas, 110Discurso, 104Documentación del conoci-miento, 70-75Duda R. O., 8
E ________________________________
Edmonds D., 4Elipsis, 103ELIZA, 5, 55Encadenamiento hacia ade-lante, 79Encadenamiento hacia atrás, 80Encuadres, 80-81Ensayo y error, 79Entrevista, 64-66Emulación estructural, 8Emulación funcional, 8Espículas sinápticas, 110Experto, 27
F ________________________________
Factor de certeza, 38Factor de certeza compo-nente, 39Feldman J., 7Feigenbaum E., 7Función de activación, 122Función de evaluación, 160Función gaussiana, 124
G _______________________________
Gen, 160Generalización, 122
GPS, 5Gramática, 106H _______________________________
Hart P. E., 8Hebb D., 4, 6, 119, 120, 129Herbert S., 4, 6, 7Heteroasociación, 127, 131Heurística, 25Hiperpolarización, 115Hoff M., 120Holland J., 159Hopfield, 127, 130, 131, 132, 140-142
I ________________________________
IA (Inteligencia Artificial):definición, 2historia, 3-8técnicas, 8-13Incertidumbre, 38Ingeniero de conocimien-to, 27, 37, 60Inteligencia, 1, 3Interpretación pragmáctica, 99Interpretación semántica, 99Interpretación sintáctica, 99
K ________________________________
Kohonen T., 149
L ________________________________
Laird J., 8Lenat D. B., 8Lenguaje formal, 97Léxico, 106

Mauricio Paletta
282Índice
Lisp, 5, 187-188Lógica de predicados de primer orden, 77-78Lógica difusa, 42-44M _______________________________
MACSYMA, 52Máquina de Boltzmann, 129, 133, 143Máquina de Cauchy, 129, 133Modelos estocásticos, 142-146Modelos hiperesféricos, 146-148McCarthy J., 5, 6, 7McCulloch W., 4, 6, 119McDermott J., 8Medida de creencia, 39Medida de no creencia, 39Memoria de trabajo, 207Minsky M., 4, 5, 6, 7, 8, 121Modelado cualitativo, 89More T., 6Motor de inferencia, 28Mutación, 162MYCIN, 5, 52, 55-56Myers J. D., 7
N _______________________________
Neocognitrón, 127Neurona, 110Neurona de entrada, 125Neurona de salida, 125Neurona escondida, 125Neurotransmisores, 110Newell A., 4, 6, 8Nilsson N., 7Nodos de Ronvier, 116
O _______________________________
Oja, 149
Operadores genéticos, 162OPS, 25OPS-5, 207Orientación a Objetos, 81P _______________________________
_
Papert S., 7, 121Pearl J., 8Perceptrón, 120, 127, 128, 131, 133-136Pitts W., 4, 6, 119Pizarra electrónica, 10Plasticidad neural, 118-119Pople H. E., 7Potencial de acción, 115Potencial de membrana, 111-112Potencial de reposo, 112Procesamiento del Lenguaje Natural, 12, 97-99Producciones, 209, 217Prolog, 5, 175-177Propagación, 126Prototipo, 147PROSPECTOR, 5, 53
R ________________________________
RNA (Red de Neuronas Artificiales), 121-123Razonamiento basado en modelos, 90Razonamiento cualitativo, 89Reconocimiento del plan de discurso, 105Redes monocapa, 127Redes multicapa, 127Redes semánticas, 76-77Regla de aprendizaje, 128Reglas de implicación, 71Reglas de producción, 78-80Reglas del discurso, 106

Inteligencia Artificial Básica
283Índice
Reglas para el reconoci-miento de la intención, 106Reglas semánticas, 106Representación del conoci-miento, 27Robótica, 11-12Rochester N., 6Rosenblatt F., 120Rosenbloom P., 8Rueda de la ruleta, 162-163Rumelhart, 8
S ________________________________
Samuel A., 5, 6, 7SBC (Sistemas Basados en Conocimiento), 9arquitectura interna, 27definición, 25metodología, 29tiempo real, 44Script, 103Script Matching, 105Selfridge O., 6Shank R. C., 7, 8Shannon C., 6Shortliffe E., 7Secuencia embudo, 65Secuencia embudo inverti-do, 65Sigmoide, 124Simulación, 87-88Simulación cualitativa, 90Sinapsis, 111, 112-114Singleton, 43Sistemas de Producción, 78Sistema Experto, 27Sistema Blackboard, 46Sistemas Conexionistas, 12Sistemas Inteligentes de Tutoría, 9-11Sistemas transportables, 107
SSBC (Sistemas de Simulación Basada en Conocimiento), 89-92Sistemas Neurales, 12SOAR, 6Solomonoff R., 6Soma, 110
T ________________________________
Tablas de decisión, 70Técnicas de adquisición del conocimiento, 61-66Temple simulado, 129Teoría de Dependencia Conceptual, 104Tejido neural, 117-118
Teoría de Juegos, 20-23Turing A., 6
V ________________________________
Vaina de mielina, 110-111, 116Vector asociado, 130Vesículas, 113
W _______________________________
Weizenbaum, 5, 7Widrow B., 120Winston P. H., 7Woods W., 7
X ________________________________
XCON, 5, 53, 56

Índice
Este Libro, Inteligencia Artificial Básica del profesor Mauricio Paletta, es una obra editada en Venezuela en junio del 2010. Su elaboración y re-producción en soporte digital se realizó en el Fondo Editorial de la Uni-versidad Nacional Experimental de Guayana. En su preparación para visualización electrónica, se utilizaron las fuentes tipográficas Helvética Regular (11 pt.) y Myriad Pro (10 pty12 pt.).