interval statistics: the cinderella of statistical...
TRANSCRIPT

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
Interval Statistics:the "Cinderella" of Statistical Linguistics
Francis E. KNOWLES
Many scholars in the field of literary and linguistic statistics are amenableto the idea of using statistical methods for the purposes of making theiranalyses less vulnerable on grounds of subjectivity. In mûst cases, however,such investigators turu-by defanlt, it would seem-to what Herdan calledlIstatistics of the mass", thereby ignorillg what he called, by way of contrast)"statisties of the Hne". If the former approach provides information of aglobal nature about textual entities of interest, then the latter technique yieldsvaluable information about the location of such entilies: it then becomespossible to analyse in a quantitative way important textual features snch as"bunching" and other types of patteruing. This paper comments on methodsof this sort, paying particular attention to the calculus developed by Levin. Apotelltial enhancement is put forward for the purposes of discussion which maybe able to take into account the linguistically important variable of sentencelength in calculations of distributional evenness.
For linguistic and literary scholars of a statistical turu of mind-and forsimilarly inclined observers-it is greatly encouraging to see at the present timea number of trends firmly establishing themselves in research methodology: onesuch welcome evolution has been the advent of corpus linguistics with its effortsto create corpora of considerable size which may he used either as statisticalpopulations in their own right or, preferably, as samples of linguistic behaviourof a more general nature, capable of beiug studied in and related to that widercontext.
The analogy of the corpus as a sample and of the world of text, actual andpotential, as a population is very attractive and needs no protagonists in thepresent company. The increasingly recognised importance of the methodologiesdeveloped within text linguistics serves merely to underline the realism andobjectivity of growing numbers of linguistic and literary researchers. Il is a pity,

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
242 FRANCIS E. KNOWLES
in passing, that suelt wisdom emanating from the very core of the linguistic andliterary paradigm has not been perceived as such by many of those who workon one partieular and important periphery of language-based studies, namelyArtificial Intelligence (AI)-and this in spite of the corporate expertise in suchmatters possessed by their close "neighboursH
1 information seientists who sharemany of their concerns.
Be all that as it may, it is-for us-much more interesting to note and taspeculate on the evolution and sophistication of quantitative techniques withinthe central areas oflinguistic and literary studies. It is, 1submit,uatural enoughat this stage of development that emphasis is still largely being placed oncorporate statistics rather than on the linear studies which deserve much moreattention and offer exceedingly good prospects for research. This "statisticsof the line" does not at all seek to oust traditional statistical analyses ofchiefly-Iexical phenomena: the aim is rather to complement such methodsand to develop ideas and tools suitable for and worthy of text linguisties itself.
It is always salntary to recall the etymologieal meauing of text: Latintextu8 (from texo, texere, texui, textum) , that is, "something woven", andpresurnably woven with care and attentioll, and even affection. It is up tolinguists and literary scholars to study these textual Hfabries" in an effort todescribe the subtlety of their weave and pattern. It is not suflicient merely tonote the size, weight and general texture of literary fabrics. 1 willnot labour thepoint~I have no need to, as sorne of the world's foremost experts in statisticallinguistics are here present, having devoted major efforts to investigating themany and often tiny but precious threads making up these skeins. 1 amsure, in fact, that we wonld all commend "statistics of the line" not just tothose of our colleagues already knowledgeable and entlmsiastic abont "statisticsof the mass" but also to those more generally searching for reliable, robnstquantitative methods of enquiry in the field of language and literatnre. Thesearch for many entities of linguistic interest mnst proceed along this path:features such as the intrieate patterns and rhythms of various sorts wmch makenp all proper text-be it belletristic or pnrely functional writing-can only besurely detected, indentified and categorised thus.
1 would now like to tnrn to one such qnantitative method relating tointerval statistics, proposed exactly twenty years ago by Yu.!. Levin in anarticle entit1ed (in English translation) "On the quantitative characteristicsof symbol distributions in text"; this article appeared in Russian in thepages of the prestigions and authoritative Soviet linguistics journal "VoprosyJazykoznanija" .
ln what follows 1 adhere closely to Levin's own exposition. His concernwas to develop a robust quantitative measure for the sequentiality of a chosen

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
INTERVAL STATISTICS 243
symbol in text, the symbol being at the choiee of the investigator and rangingfrom phonemes upwards, through morphemes or lexical units, to syntacticconstructions, verse forms etc. His particular aim was to establish a calculusfor defining the compactness or, conversely, diffuseness of a chosen element asit makes its disparate entrées into a textual environment.
Levin's predse argument (somewhat abbreviated here) runs thus. Let thefeature of interest be called a and all other features be called f3. A sequenceis therefore going to consist of n instances of lX and m of f3. The a's areassigned numbers which increment for each new token and a coded sequencetherefore takes shape thus:
The distance between ai and aH1 is the Humber of intervening f3 's. Itfollows that the distance values di range from 1 to n - 1 and may, individually,assume a value between 0 and m. There is a "spedal" distance value dn wWchis the sum of the number of f3 's before a, and after an' In other words, thetext loops round on itself to form a ring. The sum of all the distance valuesequals m, natural1y. A maximally compact sequence is a sequence where allthe distance values for aIl the f3 's except one of them are zero. Conversely,a maximally diffuse (or minimally compact) distribution would occur whend, = d2 = d3 = ... = dn (= m/n). If the quotient min does not yield aninteger a total1y even distribution is, of course, impossible.
The degree of compactness needs to be evaluated by a function ij\ wmchmust conform to the fol1owing cWef requirements:1. q, has a single minimum when aIl the distance values are identical;
2. q, achieves its maximum when, as stated above, aU distance values arezero, except for one;
3. ij\ is symmetrie with respect to any pair of variables-Olùy the intervallengths, not their locations, are considered important. This condition isnecessary enough but it is weaker than it might be hoped: ironically, thewhole question at issue here is that of location within a linear framework.However, in terms of Levin 's calculus the strings:
aaf3f3af3af3af3f3f3af3af3af3af3aaf3f3af3f3f3f3af3aaf3af3f3f3af3af3
aIl possess the same degree of compactness.
Il is furthermore desirable to obtain a function wmch varies from 0 (totaldiffuseness) to 1 (total compactness).

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
244 FRANCIS E. KNOWLES
The quest for a satisfactory funetion responding ta the above requirementscan he seell ta reduce ta a statement of the farm
~ = 1 - Im;nfmax - fmin
Expressing his formulation less crypticallYI Levin advances as a measureof compaetness the expression
~h = 'Eh(d;) - nh(';;)h(m) - nh( ';;)
wherem
nh(-) = Im!n , h(m) = Ima,n
and h is a transformation fuuction yet ta he chosen.
Levin concludes that there are two suitable transformations:
h = ",log", and h = "'" (a> 1)
and final1y-after further proofs-arrives at the fol1owing propositions:
L=I_'E-ô;logô; (where ô;=d;)logn m
andn'Ed~-m2
Q = m2(~ -1)
The former expression is, it will he seeu, Shanuon's redundancy for thedistribution of the 0: 's. The latter expression is the standardised variance ofthe distance values representing the intervallength between two successive 0: 's.
Given,,2 = 'E(d; - db., )2
nand
hence,,2
F=-2(Jmax
Which of these two measures is to be preferred? Mathematicaliy, theybehave ,differently with respect to transformation and linguistical1y, differentInterpretations suggest themselves. Levin himself points out that L is muchhandier to deal with: given n = 50, Q is halved if text length is doubled butin order to halve L text length would need to be multiplied fiftyfold! The Qvalues quoted later are very smali by reason of the very large m values. For

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
a~a~a~a~a~a~a~a~a~a~a~a~
aa~~aa~~aa~~aa~~aa~~aa~~
aaa~~~aaa~~~aaa~~~aaa~~~
aaaa~~~~aaaa~~~~aaaa~~~~
aaaaaa~~~~~~aaaaaa~~~~~~
aaaaaaaaaaaa~~~~~~~~~~~~
INTERVAL STATISTICS
the moment, sorne brief illustrative calculations show the fol1owing:L Q
0.00 0.000.28 0.090.44 0.180.56 0.270.72 6.451.00 1.00
245
Taking one of the examples used earlier: 0i10i2{3{30i3{3cq{30i5{3{3{30i6{3 theactual calculations proceed thus:
n=6 and m=8
f 6 -log6 6(-log6) Ed, =0 0.000 0.000 0.000 0.000d, =2 0.250 1.386 0.347 0.347d3 = 1 0.125 2.079 0.260 0.607d, = 1 0.125 2.079 0.260 0.867d, =3 0.376 0.981 0.368 1.234d, = 1 0.125 2.079 0.260 1.494--
1.494
L = 1- 1.494 = 1- 0.834 = 0.166,log6
Q = (6)(16) - 64 = ~ = 0.100.(64)(5) 320
Levin addresses two other vital questions: the first is the calculation of atheoretical random distribution for both Land Q.
The formulae given are as follows, respeetively:
L(n) = 1 - 0.5772 - 1/2n ,logn
1Q(n) = -.
n+1If the experimental values of L or Q are higher or lower than the theoret
ical values for Land Q then this hints at a greater degree of "organisation" inthe sample: either c1ustering-plus-rarefaction or, conversely, outright evenness.
The other important issue raised is the question of comparing resultsfrom different texts: experiments on individual texts give individual readingsonly, 80 if interest is focused on general feature behaviour then other readingsmust be takeu and processed by orthodox statistical methods. It is importantto appreciate that the procedures used for calculating Land Q values aredeterministic, not stochastic. They become stochastic only when dilferent textsamples are analysed-thus opening the door for the traditioual statistical

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
246 FRANCIS E. KNOWLES
"gamell j theu, howerver1 there is the notorious problem of comparing likewith like. In such cases one text may be taken as the benchmark and othertexts normalised and then calibrated against that (arbitrary?) benchmark,symbolised by index 1 . The Land Q values of the benchmark text are usedto modify the Land Q values of ail the other texts being investigated; themodification equatiolls are, respectively:
lognjLmod = Lj *-
lognland
Those interested in ruller details of this must consult Leviu's article. Thequestion of hypothesis testing of Land Q values is also problematical: if theexperiment is snch that a distribution of Land Q values emerges, well andgood. Sorne writers state that the X2 test may be applied in many cases butcautions opinion would cali for much more experimelltatioll before this canbe properly asserted. The standard literature on information theory measuressuch as entropy offers no real enlightenment on the hypothesis of actual valueswit1ùn the standard statistical paradigm.
l should now like ta raise sorne linguistic questions relating ta the procedures described above. One obvions difficnlty in using the Levin calcnlusHstraight-ofP' is this fact that, in certain applications, the characteristic of sentence length may he said ta illtervene. :More gelleral1y, punctuation marks may"prevenf' twa Cl' 'g fram being in true juxtaposition-after aH, the purposeof punctuation marks is to juncture discourse! Is it hence necessary to ponder the feasibility and suitability of compounding two distance distributions:the one of real interest and the constant underlying one stemming from punctuation? In otIler words) shouJd sentence terminators-and potelltial1y, otherdiscourse-structuring marks-be allocated express statns as units co-equal withor analogous to words? 1 am interested in discussion on tWs point.
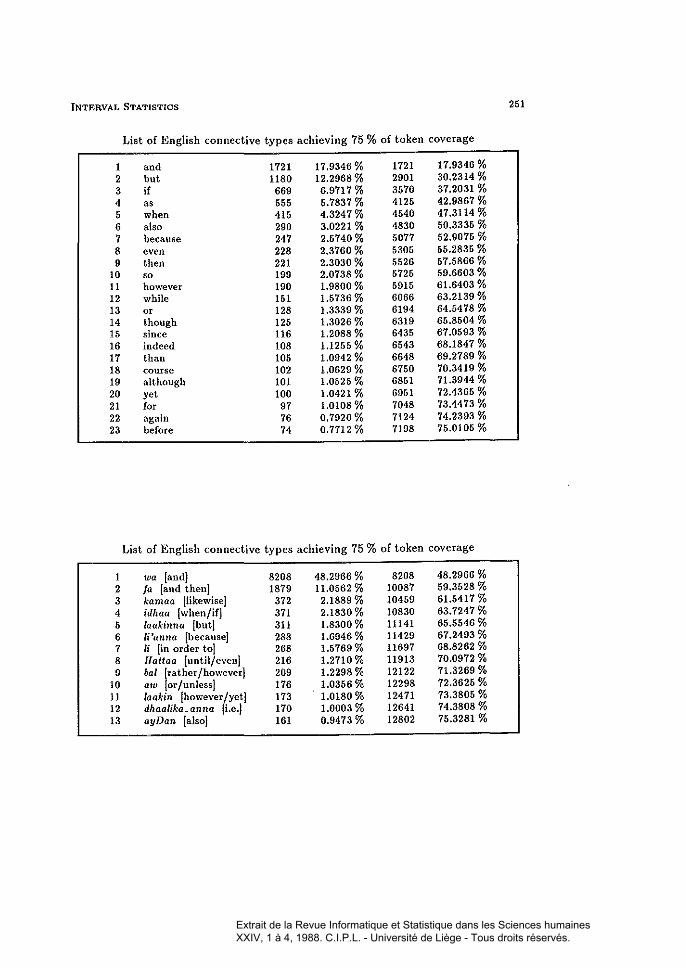
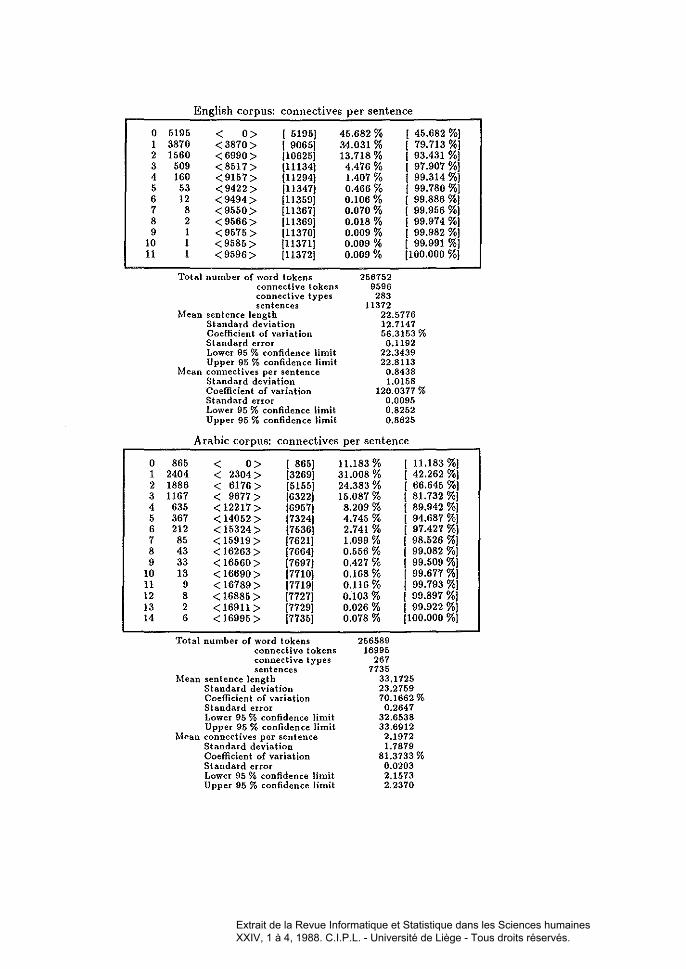
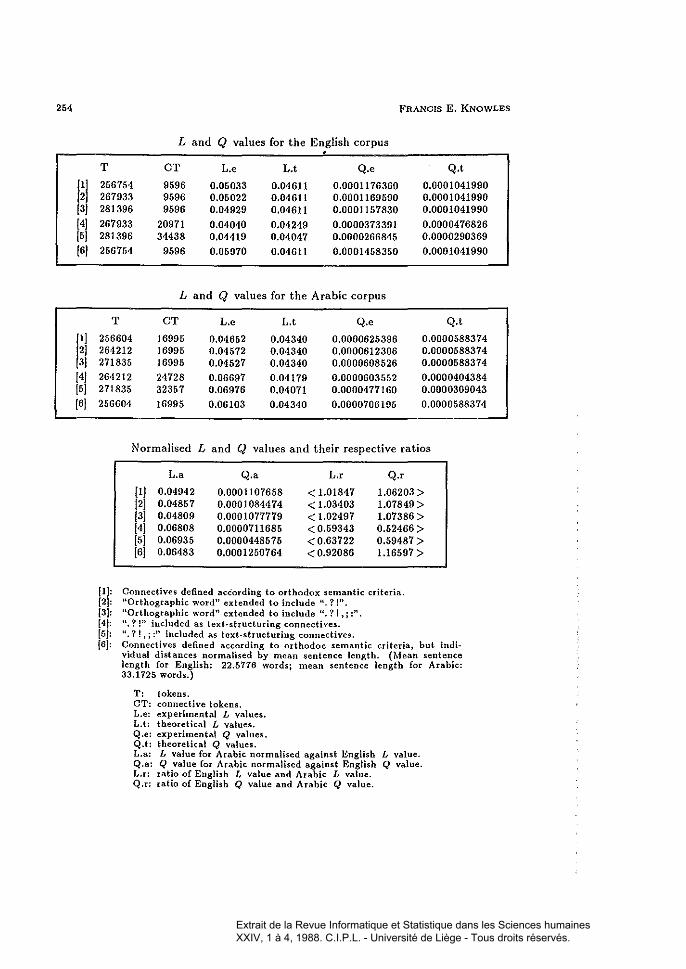
By way of example, 1 quote from some research 1 have been doing withMr. AI-Jubouri) a doctoral student, who is investigating-in both quantitativeand qualitative terms-the behaviour of certain cohesive devices (i.e. sentenceconnectives) in a contrastive corpus of Ellglish and Arabie text, llumbering overquarter of a million tokens in each language. It is important to have an evennessmeasure of such cohesive tokens, if at ail possible. Taking as an example theEnglish corpus (a stratified corpus of English journalistic text, by the way) therewere 256,754 word tokens in the corpus, of wlùch 9,596 sentence connectives,separately tagged and accounting for almost 4 %of the text tokens, representedthe featnres of interest. On tiùs basis Land Q values were computed as0.05033 and 0.0001176360, respectively. The theoretical Land Q vaines tnrnout to be 0.04611 and 0.0001041990, respectively. On this basis the corpus

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
INTERvAL STATISTICS 247
appears to be "organised" in the direction of a slight degree of clusteringplus-rarefaction, when compared with the random configuration representedby the theoretical values. The corresponding figures for the Arabie corpus(equivalent to its English counterpart in both typological and structural terms)are: 256,604 tokens, including 16,995 sentence connectives; the experimentalLand Q values are 0.04652 and 0.0000625396, as against theoretical LandQ values of 0.04340 and 0.0000588374. The same finding as above appears tobe indicated. However, we know that sentence length is-as always-a majorvariable, characterised by its own distribution [see Appendices). If the sentenceterminators ".?!" are admitted to the status of ,8 -symbols then the LandQ values change to 0.05022 and 0.0001169590 for English, and to 0.04572 and0.0000612306 for Arabie, respectively. If other major punctuation marks suchas the comma, colon and semi-colon are given the same status the figures moveto 0.04929 and 0.0001157380 for English, and to 0.04527 and 0.0000608526 forArabie. There is a movement in the direction of diffuseness in these figures: thisis clear immediately on inspection [see the appropriate table in the Appendices].Taking the English corpus as the benchmark and calibrating the Arabie corpusagainst it produces an interesting set of figures, quoted in the Appendices (seebelow for further discussion).
One linguistic consideration whieh may weil obtrude at this point is theview that sentence terminators may weil themselves be regarded as cohesivedevices and should therefore rate as a-symbols. Il is not really possible togo into the full linguistic and tactical ramifications of such a suggestion herebut Mr. Al-Jubouri and 1 are considering this point very carefully. If thesuggestion is adopted for the purposes of experimentation then for English theLand Q values become 0.04040 aud 0.0000373391, and for Arabie 0.06697and 0.0000603552. Admitting the chief intrasentential punctuation marks tothe scheme moves the figures to 0.04419 and 0.0000266845 for English andto 0.06976 and 0.0000477160 for Arabie. The crux may be that the use ofsentence terminators in any text is mandatory, whereas the incorporation oflexical cohesive devices in text is optional-although always helpful.
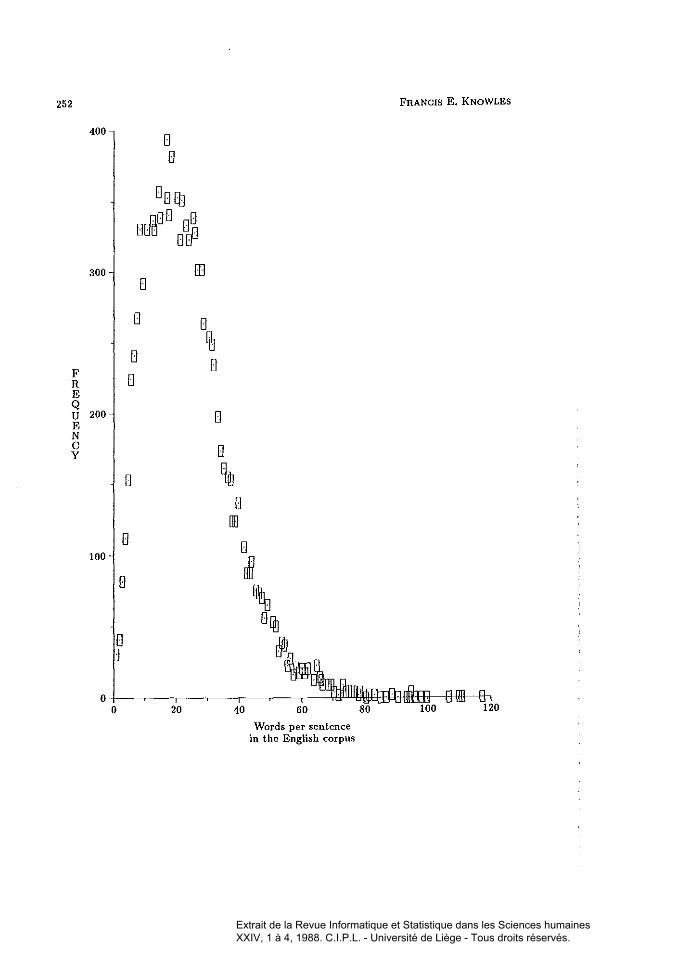
On the more general point, a more expert way of doing the situationjustiee must surely be to elaborate a suitable composition function for thecombined compactness of cohesive devices and sentence length. Deriving sucha function would be a laborious business and one is tempted to think of waysto obviate the necessity of doing that. One intuitive idea is that ail distancedata should be standardised according to sentence length. Mean sentencelength in the English corpus is known: it is 22.5776, derived from a totalof 10,717 sentences and showing a standard deviation of 12.7147. Fitting themean value into the computer program permits the distance values of each

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
248 FRANCIS E. KNOWLES
sentence ta he "stretched)) or "squeezed", as appropriate, before the distancevalues are passed to the compactness algorithm. The new Land Q valuesyielded after this transformation are 0.05970 and 0.000145835, respectively.The corresponding figures for the Arabie corpus, with its mean sentence lengthof 33.1725 and standard deviation of 23.2759, are 0.06103 and 0.0000706195.These llmassaged)l values are intuitively more satisfying, given the importanceof cohesive devices in text: we do kllOW that the rnean Humber of sentenceconnectives per sentence in the English corpus is 0.8438 with a standarddeviation of 1.0158. In Arabic the situation shows a mean number of sentenceconnectives as 2.1972, with a standard deviation of 1.7879. These last Land Q values, inc1uding the normalised Arabic values, certaiuly indicate aconsiderable degree of diffuseness, or~perhaps, better~evenlless and this doesappear, prima jade, to he a well-founded and useflù quantitative measureof the phenomenon we are studying. Using the ratios of the English andthe normalised Arabie Land Q values leads to the view that it is anextraordinarily difficult task to truly discriminate between the corpora inIllauy cases: the ratios tUTn out to hover around unity. This is where weneed a delicate hypothesis testing procedure. The two cases where the ratiosare distant from unity (where either sentence terminators or ail the chiefpunctuation marks are granted the status of "connective") can be attributed toa very well-known phenomenoll: the waywardness of Arabic-speaking writersand editors when it cornes to punctuation.
Of course, a lot more work still needs doing on the whole business ofmeasuring compactness and diffuseness, not least on the choice of the bestsignificallce test for inter-sample comparison and for inferential statementsabout the underlying populations.
Finally, ju~t a quick word about the computer programming strategy forthis projeet. 1 programmed the software in SPITBOL, runulng on a VAX 8650mainframe. SPITBOL was chosen because of its excellent pattern-matchingfeatures; it was, however, llecessary for me to write my own fUllction forcomputing logarithms; SPITBOL's overall performance is really excellent butlibrary functions are sparse! The application has to be run as a two-pass system:the first pass "rotates" the text, as mentioned above, and produces the œand f3 COUllts, plus-if necessary-mean sentence length. The second passcalculates the distances, as appropriate, and computes the Land Q indices.The core section of this esselltial1y very simple second program is shown in theAppendices.
We hope-but it still remains to be seen in the light of further experimentation by others, as weil as ourselves, and in the light of satisfaetory solutionsto some remaining linguistic cruees-that the strategy described in this paper

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
INTERVAL STATISTICS 249
will evolve into a robust and rellable technique which expert statisticians willbe able to give their blessing to. Anything which helps the Cinderella of intervalstatistics to get to the Bali on time will be we!come!
Appendices.
A sample from the English corpus.
The bill Aalso broadly adopts most of the Royal Commission's proposais, Abutthere are a number of significant departures.
On detention in the police station, the Commission proposed that there shouldsbe no absolute time lirnit Aprovided_that detention without charge had been approvedby a magistrate's court for successive 24-hour periods. The bill, Ahowever, sets anoverall Jimit of 96 hours.
The Commission said that Awhen the police applied to the magistrates forpermission to detain a suspect without charge for more than 24 hours he shouldhave the right to be present and to be legally represented. The bill gives the suspectthis right only after 48 hours.
Aln_the_firsLinstance, the police would have to make their case after 24 hoursto a magistrate Aand Aon_thaLoccasion the suspect would have the right only to putwritten submissions.
The bill varies the Royal Commission's recommendations to extend police powerof arrest. The Commission proposed that an officier should he able to arrest someonefor an offence not serious enough to he arrestable Aif he saw the person commiting itAand he refused to give his name and address.
The bill goes further by including any case Awhere the policeman believes anarrest necessary to prevent loss of or damage to property, an affront to public decensy,Aor an obstruction of the highway. AOn_the_otller_hand it does not extend arrestableoffences, Aas recommended by the Commission, to aH offences bearing a sentence ofimprisonment.
The same sample from the English corpus with connectives removed.
The bill < > broadly adopts most of the Royal Commission's proposais, < >there are a number of significant departures.
On detention in the police station, the Commission proposed that. there shouldsbe no absolute time limit < > detention without charge had been approved by amagistrate's court for successive 24-hour periods. The bill, <>, sets an overaHlimitof 96 hours.
The Commission said that < > the police applied to the magistrates forpermission to detain a suspect without charge for more than 24 hours he shouldhave the right to be present and to be legally represented. The bill gives the suspectthis right only after 48 hours.

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
250 FRANCIS E. KNOWLES
< > 1 the police would have to make their case aCter 24 hours to a magistrate< > < > the suspect would have the right anly to put written submissions.
The bill varies the Royal Commission's recommendations to extend police powerof arrest. The Commission proposed that an officier should he able to arrest gamcanefor an affence not sedous enough to he arrestable <> he saw the person commitingit < > he refused to give his name and address.
The bill goes further by including any case < > the policeman believes an arrestnecessary to prevent 108s of or damage to property, an affront to public decensy, <>an obstruction of the highway. < > it does not extend arrestable offences, < >recommended by the Commission, to aIl offences bearing a sentence of imprisonment.
The Sallie s8mple frOID the Engllsh corpus with only connectives retained.
--- ---- Aalso ------- ------ ---- -- --- ----- ------------ ---------,-but ----- --- - ------ -- ----------- ----------.
-- --------- -- --- ------ -------, --- ---------- -------- ---- ------------ -- -- -------- ---- ----- Aprovided_that --------- ------- ------ --
----, Aho\'1ever, ---- -- ------- ----- -- --------,
--- ---------- ---- ---- A\vhen --- ------ ------- -- --- ----------- ---
Aln_the_firsLinstance, --- ------ ----- ---- -- ---- ----- ---- ----- ------- -- - ---------- Aand Aon_thaLoccasion --- ------- ----- ---- --- -----
------ ------- --- -- ------- --- ------- ------ -- -- ---------- -~ -- ------ ------ --------- -- Aand -- ------- -- ---- --- ---- --- -------.
--- ---- ---- ------- -- --------- --- ---- A\vhere --- --------- --------,
--- -------, Aor -- ----------- -- --- -------, AOn_the_other_hand -- ---- ---______ - , Aas , _
Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
INTERVAL STATISTICS
List of English connective types achieving 75 % of token coverage
251
1 and 1721 17.9346 % 1721 17.9346 %2 bul 1180 12.2988 % 2901 30.2314 %3 if 669 6.9717% 3570 37.2031 %4 as 555 5.7837 % 4125 42.9867 %5 when 415 4.3247 % 4540 47.3114 %6 also 290 3.0221 % 4830 50.3335 %7 because 247 2.5740 % 5077 52.9075 %8 even 228 2.3780 % 5305 55.2835 %9 then 221 2.3030 % 5526 57.5866 %
10 50 199 2.0738 % 5725 59.6603 %11 however 190 1.9800 % 5915 61.6403 %12 while 151 1.5736 % 6066 63.2139 %13 0< 128 1.3339 % 6194 64.5478 %14 though 125 1.3026 % 6319 65.8504 %15 since 116 1.2088 % 6435 67.0593 %16 indeed 108 1.1255 % 6543 68.1847 %17 than 105 1.0942 % 6648 69.2789 %18 course 102 1.0629 % 6750 70.3419 %19 although 101 1.0525 % 6851 71.3944 %20 yel 100 1.0421 % 6951 72.4365 %21 for 97 1.0108 % 7048 73.4473 %22 again 76 0.7920 % 7124 74.2393 %23 before 74 0.7712% 7198 75.0105 %
List of English connective types achieving 75 % of token coverage
1 wa [and) 8208 48.2966 % 8208 48.2966 %2 fa land thenJ 1879 11.0562 % 10087 59.3528 %3 kamaa [likewise} 372 2.1889 % 10459 61.5417 %4 idhaa Iwhen/if) 371 2.1830 % 10830 63.7247 %5 laakinna [butl 311 1.8300 % 11141 65.5546 %6 li'anna [becauseJ 288 1.6946 % 11429 67.2493 %7 li lin order toi 268 1.5769 % 11697 68.8262 %8 Hattaa [untilJevenJ 216 1.2710 % 11913 70.0972 %9 bal [ratherJhoweverJ 209 1.2298 % 12122 71.3269 %
10 aw lorJunlessJ 176 1.0356 % 12298 72.3625 %11 laaMn [howeverJyetJ 173 1.0180 % 12471 73.3805 %12 dhaalika_anna {Le.j 170 1.0003 % 12641 74.3808 %13 ayDan lalsol 161 0.9473 % 12802 75.3281 %
Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
252 FRANCIS E. KNOWLES
40000
Omod800 0
o rw0
300 œ0
0 0
0%0F
R 0EQu 200 0ENC 0y
0 \
o100
o
o
o..j-~-~~~-~~---\1CjlJllJ J\!jQ:l=j;HOOffi--tHlll--tJ-,o 20 40 60 80 100 120
'\Tords per sentencein the Engllsh corpus
Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
English corpus: connectives per sentence
0 5195 < 0> ( 5195) 45.682 % ( 45.682 %)1 3870 <3870> 1 9065) 34.031 % [ 79.713 %)2 1560 <6990> 110625) 13.718 % ( 93.431 %]3 509 <8517> 111134) 4.476 % ( 97.907 %]4 160 <9157> 111294) 1.407 % ( 99.314 %)5 53 <9422> (11347) 0.466 % 1 99.780 %)6 12 <9494> (11359) 0.106 % 1 99.886 %17 8 <9550> [113671 0.070 % 1 99.956 %18 2 <9566> (113691 0.018 % 1 99.974 %19 1 <9575 > (113701 0.009 % ( 99.982 %1
10 1 < 9585 > 111371) 0.009 % [ 99.991 %)11 1 <9596> 111372) 0.009 % (100.000 %]
Total number of word tokensconnective tokensconnective typessentences
Mean sentence lengthStandard deviationCoefficient of variationStandard errorLower 95 % confidence limitUpper 95 % confidence limit
Mean connectives per sentenceStandard deviationCoefficient of variationStandard errorLower 95 % confidence limitUpper 95 % confidence Iimit
2567529596283
1137222.577612.714756.3153 %0.1192
22.343922.8113
0.84381.0158
120.0377 %0.00950.82520.8625
Arabie corpus' connectives per sentence
0 865 < 0> [ 865) 11.183 % 1 11.183 %11 2404 < 2304> (32691 31.008 % 1 42.262 %12 1886 < 6176 > 151551 24.383 % 1 66.645 %13 1167 < 9677> 16322) 15.087 % 1 81.732 %)4 635 <12217> 169571 8.209 % 1 89.942 %)5 367 < 14052 > 17324] 4.746 % ( 94.687 %)6 212 < 15324 > 17536) 2.741 % [ 97.427 %)7 85 < 15919 > (7621) 1.099 % [ 98.526 %)8 43 < 16263 > [7664] 0.556 % ( 99.082 %19 33 < 16560 > (7697) 0.427 % ( 99.509 %1
10 13 < 16690 > (7710) 0.168 % 1 99.677 %111 9 < 16789 > (77191 0.116 % 1 99.793 %)12 8 < 16885 > 177271 0.103 % 1 99.897 %)13 2 < 16911 > 177291 0.026 % [ 99.922 %)14 6 < 16995 > 17735] 0.078 % (100.000 %1
Total number of word tokensconnective tokensconnective typessentences
Mean sentence lengthStandard deviationCoefficient of variationStandard errorLower 95 % confidence IimitUpper 95 % confidence !imit
Mean connectives per sentenceStandard deviationCoefficient of variationStandard errorLower 95 % confidence limitUpper 95 % confidence limit
25658916995
2677735
33.172523.275970.1662 %
0.264732.653833.69122.19721.7879
81.3733 %0.02032.15732.2370
Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
264 FRANCIS E. KNOWLES
Land Q values for the English corpus.T OT L.e L.t Q.e Q.t
(li 266764 9696 0.06033 0.04611 0.0001176360 0.0001041990[2( 267933 9696 0.06022 0.04611 0.0001169690 0.0001041990131 281396 9696 0.04929 0.04611 0.0001167830 0.0001041990
[41 267933 20971 0.04040 0.04249 0.0000373391 0.0000476826[6( 281396 34438 0.04419 0.04047 0.0000266846 0.0000290369
16( 266764 9696 0.06970 0.04611 0.0001468360 0.0001041990
Land Q values for the Arabie corpus
T OT L.e L.t Q.e Q.t
(li 266604 16996 0.04662 0.04340 0.0000626396 0.0000688374[2( 264212 16996 0.04672 0.04340 0.0000612306 0.000068837413( 271836 16996 0.04627 0.04340 0.0000608626 0.0000688374
(41 264212 24728 0.06697 0.04179 0.0000603552 0.0000404384[61 271836 32367 0.06976 0.04071 0.0000477160 0.0000309043
16( 266604 16996 0.06103 0.04340 0.0000706196 0.0000688374
Normalised Land Q values and their respective ratios
L.a Q.a L.r Q..
(II 0.04942 0.0001107668 < 1.01847 1.06203 >[21 0.04867 0.0001084474 < 1.03403 1.07849 >13( 0.04809 0.0001077779 < 1.02497 1.07386 >14( 0.06808 0.0000711686 <0.69343 0.62466 >[61 0.06936 0.0000448676 < 0.63722 0.69487 >[6 0.06483 0.0001260764 < 0.92086 1.16697 >
(1J: Connectives defined according to orthodox semantic criteria.{2]: "Orthographie ward" extended to include ".? 1".13]: "Orthographie ward" extended to inclucle Cl.? 1,;:".(41: H,?!" inclucled as text-structuring connectives.(5J: Ll.?!,;:" included as text·structuring connectives.{6]: Connectives de6.ned accorcling to orthodoc semantic criteria, but indi
vidual distances normalised by mean sentence lengtb. (Mean sentencelength for Englisb: 22.5116 worcls; mean sentence length for Arabie:33.1725 words.)
T: tokens.CT: connective tokens.L.e: experimental L values.L.t: theoretieal L values.Q.e: experimental Q values.Q.t: theoretical Q values.L.a: L value for Arabie normalised against English L value.Q.a: Q value for Arabie normalised against English Q value.L.r: ratio of English L value and Arabie L value.Q.r: ratio of English Q value and Arabie Q value.

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
INTERVAL STATISTICS
Excerpt from compactness program
255
text
vord
*****••."Y·S
codaend
uppers : JABCDEFGHIJKLMNOPQRSTUVWXYZ'lovers = Jabcdefghijklmnopqrstuvwxyz'numbers : '1234667890'extras : "J_/[]_C Alialphabetics = uppers lovers numbers extrasspecials = null ô* INSERT special character here, if neededalphabetics : differ(alphabetics.null) alphabetics specialspickpat = break(alphabetics) span(alphabetics) tokenmean_sentence_length = read_datatext_length : read_dataalphas : read_databetas = text_Iength - alphasdistance_array = array(alphas,O)sentence: next_sentence() :f(coda)current_length : sentence_length(sentence)sentence pickpat: :f(text)token break(JAJ) :s(yes)special form of next statement for massaging distancesdistance = distance +
(mean_sentence_length / current_length) :(word)distance: distance + 1 :(vord)distance_array<index> = distance + 1 :(word)delta distance / betasl_cum = gt(distance,O) l_cum + (delta * abs(ln(delta»)q_cum : q_cum + distance ** 2distance = 0index : index + 1ident(end_of_file,null) :s(vord)1 : 1 - (l_cum / ln(betas»output : ilL = " format Cl,l, 6)betas2 : betas ** 2q : «alphas *q_cum) - betas2) / (betas2 * (alphas - 1»output = "Q "format(q,I,10) :(end)end_of_file = 'true J :(yes)

Extrait de la Revue Informatique et Statistique dans les Sciences humaines XXIV, 1 à 4, 1988. C.I.P.L. - Université de Liège - Tous droits réservés.
256 FRANCIS E. KNOWLES
References.
ALTMANN, G. (1980). Statîstik für Linguiste», Brockmeyer, Bochum.
ALTMANN, G. and LEHFELDT, W. (1980). Einfiihrung in die quantitative Phonologie,Brockmeyer, Bochum.
BEKTAEV, KB. (1978). CTaTucTuK<rU"<ilopMau.uoHHaja Tl-mOnOI'uja TjYPKcKoroTeKeTa lin Russian: Stati-stical and information-theoretic typology of Turkic texi],Nauka, Alma-Ata.
BRAINERD, B. (1974). Weighing evidence in language and literature: a stati.sticalapproach, Toronto D.P., Toronto.
GOLOVIN, B.N. (1970). Ja3hlK " CT8THCTHKa [in Russian: Language and stati.stics],ProsveScenie, Moscow.
GRÛTJAHN, R. (1979). Linguistische und staiistische Methoden in Metrik undTextwissenschaft, Brockmeyer, Bochum.
HERDAN, G. (1964). Quantitative linguistics, Butterworth, London.
HERDAN, G. (1966). The advanced theory of language as choice and chance, Springer,Berlin.
HORBATJUK, N.S. and PEREBYJNIS, V.S. (1968). TIpo MeTOAbi CTaTHCTbIIJ,HoTbInOnOX»IJ,HOXO AOCnHA3eHl-ba {in Ukrainian: On statistical and typologicalresearch methodsj in MeToAbI CTpYKTYPHOXO AocnHA.3eHlba MOBbI, NaukovaDumka, Kiev.
KULLBACK, S. (1968). Information theory and statistics, Dover, New York.
KULLBACK, S. (1976). Statistical methods in cryptanalysis, Aegean Park Press,Laguna Hills CA, U.S.A.
MEYER-EpPLER, W. (1969). Grundlagen und Anwendungen der Informationstheorie,Springer, Berlin.
MORTON, A.Q. (1978). Literary detection, Bowker, London.
MULLER, Ch. (1973). Initiation aux méthodes de la statistique linguistique, Hachette,Paris.
MULLER, Ch. (1977). Principes et méthodes de statistique lexicale, Hachette, Paris.
PIOTROVSKIJ, R.G. et al. (1977). MaTeMaTHlJ,eCKaja nHHI'BHCTHKa {in Russian:Mathematicallinguistics], Vyssaja Skola, Moscow.
REEDS, J. (1977). Entropy calculations and particular methods of cryptanalysis inCryptologia, Vol. l, N° 3.
SAMBOR, J. (1972). Slowa i liczby - zagadnienia it:zykoznawsta statystycznego [inPolish: Words and numbers ~ problems of statistical linguistics], Ossolineum,Wroclaw.
L.G. VEDENINA, L.O. and SOR, E.N. (1973). HeKoTopble npHeMbI CTHRHCTHlJ,eCKOI'OHccneAoBaHHja TeKCTa [in Russian: Methods for stylistic text researchj, Nauka,Moscow.
WOODS, A. et al. (1986). Statistics in language studiesJ Cambridge U.P., CambridgeMA.