introducción a los sistemas de información geográfica y...
TRANSCRIPT

0
Introducción a los
Sistemas de Información
Geográfica y al software
ArcGIS
ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA
INFORMACIÓN GEOGRÁFICA UNIVERSIDAD NACIONAL DEL NORDESTE

1
Introducción a los Sistemas de Información Geográfica
y al software ArcGIS
Autores:
Javier Gutiérrez Puebla
Michael Gould
Juan Carlos García Palomares
Eduardo Rodríguez Núñez
José Carpio Pinedo
Jaime Díaz Pacheco
Gustavo Romanillos Arroyo
Miguel Vía García
ESRI, a partir de fuentes oficiales
Madrid, diciembre de 2013
Departamento de Geografía Humana
Facultad de Geografía e Historia
Universidad Complutense de Madrid

1
Índice de contenidos
1. Introducción ....................................................................................¡Error! Marcador no definido.
2. ¿Qué son los Sistemas de Información Geográfica? ...................................................................... 5
2.1. ¿Qué son los Sistemas de Información Geográfica? ............................................................ 5
2.2. Cuestiones a las que puede responder un SIG ....................................................................... 6
3. Los datos geográficos ................................................................................................................................ 9
7.1 Las tres componentes de los datos geográficos ........................................................................... 9
7.1.1 La componente espacial ............................................................................................... 9
7.1.2 La componente temática ........................................................................................... 10
7.1.3 La componente temporal ........................................................................................... 11
7.2 ¿Cómo representamos la realidad en un mapa? ........................................................................ 11
7.2.1 Conceptos básicos ............................................................................................... 11
7.2.2 ¿Qué es el Datum? .............................................................................................. 12
7.2.3 Sistema de Referencia y Datum .......................................................................... 13
7.2.4 Sistemas de Coordenadas ................................................................................... 13
7.2.5 ¿Qué es la Proyección UTM? ............................................................................... 14
4. Modelos y estructuras de datos........................................................................................................... 16
4.1 Modelos de datos .................................................................................................................................... 16
4.2 El modelo ráster ...................................................................................................................................... 20
4.3 El modelo vectorial ................................................................................................................................ 23
4.3.1 El modelo de datos: la representación de las entidades por medio de puntos, líneas
y polígonos .......................................................................................................................... 23
4.3.2 Estructuras de datos en el modelo vectorial .............................................................. 24
4.4 Modelos clásicos de bases de datos ................................................................................................ 25
5. Introducción al software ArcGIS ......................................................................................................... 27
5.1 Introducción los productos de ArcGIS ........................................................................................... 27
ArcGIS .................................................................................................................................. 27
ArcGIS Desktop .................................................................................................................... 27
5.2 Introducción al interfaz de ArcMap ................................................................................................ 30
Marco de datos ................................................................................................................... 30
Tabla de contenido .............................................................................................................. 31
Diseños de página ............................................................................................................... 31
Ventana Catálogo ................................................................................................................ 32

2
6. Producción de mapas. Salida gráfica y web. ................................................................................... 34
Proceso para trabajar con un diseño .................................................................................. 34
Preguntas a considerar al crear el diseño ........................................................................... 35
Crear un diseño de mapa .................................................................................................... 35
Configurar el tamaño de página de la composición de mapa ............................................. 36
Flechas de norte .................................................................................................................. 40
Barras de escala ................................................................................................................... 40
Texto de escala .................................................................................................................... 40
Leyendas .............................................................................................................................. 40
Transparencia en leyendas .................................................................................................. 41
Marcos ................................................................................................................................. 42
Convertir elementos de mapa en gráficos .......................................................................... 42
Impresión del mapa o exportación a otros formatos ......................................................... 43
7. Análisis Ráster ............................................................................................................................................ 47
7.1. Introducción ...................................................................................................................................... 47
7.2. Visualización ...................................................................................................................................... 49
7.3. Operaciones Locales ....................................................................................................................... 50
7.3.1 Reclasificación ............................................................................................................ 50
7.3.2 Superposición de mapas ............................................................................................ 51
7.4. Operaciones de vecindad inmediata ........................................................................................ 53
7.4.1 Pendientes y orientaciones ........................................................................................ 53
7.4.2 Análisis de las cuencas de drenaje ............................................................................. 54
7.4.3 Distancias euclidianas ................................................................................................ 55
7.4.4 Superficies de fricción ................................................................................................ 57
7.4.5 Análisis de intervisibilidad .......................................................................................... 58
7.4.6 Estadísticas de zonas .................................................................................................. 59
8. Análisis Vectorial ....................................................................................................................................... 60
8.1 Presentación de la información ........................................................................................................ 60
8.2 Operaciones con capas ......................................................................................................................... 62
8.3 Unión de objetos por atributos ........................................................................................................ 65
8.4 Mediciones espaciales sobre objetos .............................................................................................. 66
A) Mediciones sobre líneas ................................................................................................. 66
B) Mediciones sobre polígonos ........................................................................................... 66
8.5 Consultas a la Base de Datos .............................................................................................................. 67

3
8.5.1 Consultas por atributos .............................................................................................. 67
8.5.2 Consultas espaciales ................................................................................................... 68
8.6 Medición de distancias y Análisis de Proximidad ..................................................................... 69
8.6.1 Medición de distancias entre objetos ........................................................................ 69
8.6.2 Análisis de proximidad ............................................................................................... 70
8.6.3 Generación de polígonos de Thiessen ....................................................................... 71
8.6 Superposición de mapas ..................................................................................................................... 72
9. Análisis de Redes ....................................................................................................................................... 73
9.1 Introducción al análisis de redes ..................................................................................................... 73
9.2 Análisis de caminos mínimos ............................................................................................................ 77
9.3 Análisis de las áreas de influencia de los centros de servicio .............................................. 79
Anexo 1.................................................................................................................................................................... 81
Aplicación de metodologías Multicriterio para la asignación de Usos del Suelo. .................... 81
1. Introducción ........................................................................................................................................... 82
2. Análisis de localizaciones óptimas mediante análisis multicriterio booleano ........... 84
3. Análisis de localizaciones óptimas mediante la combinación lineal ponderada ....... 85
4. Consideraciones finales ..................................................................................................................... 88
5. Bibliografía citada ................................................................................................................................ 90
Anexo 2.................................................................................................................................................................... 96
Metodología para el análisis de la vulnerabilidad en redes de transporte público. El caso de
la red de metro de Madrid ............................................................................................................................... 96
Anexo 3................................................................................................................................................................. 107
Análisis conjunto de entorno urbano y transporte público: los puntos de intermodalidad
de la ciudad de Madrid. ................................................................................................................................. 107
1. Introducción ........................................................................................................................................ 108
2. Selección de variables significativas: ‘indicadores’. ............................................................ 109
a. Demanda y población cubierta de un punto de transporte...................................... 109
b. Integración de la movilidad. ...................................................................................... 110
c. Usos del suelo y entorno urbano. ............................................................................. 113
d. Integración urbana. ................................................................................................... 115
3. Herramienta para la comprensión conjunta y el diagnóstico. ........................................ 116
4. Herramienta para la planificación de un nuevo punto intermodal a la escala ciudad.
118
5. Conclusiones. ....................................................................................................................................... 120
6. Referencias. .......................................................................................................................................... 121
Anexo 4................................................................................................................................................................. 122

4
Propuesta metodológica para la generación de corredores de mínimo impacto ambiental
de carreteras: Integración del paisaje. El caso de la autopista radial 5. Comunidad de
Madrid .................................................................................................................................................................. 122

5
1. ¿Qué son los Sistemas de Información Geográfica?
1.1. ¿Qué son los Sistemas de Información Geográfica?
Los Sistemas de Información Geográfica (SIG) son una tecnología que forma parte
del ámbito más extenso de los Sistemas de Información. El contexto general en el que surgen
es el de la "sociedad de la información", en la que resulta esencial la disponibilidad rápida de
información, para resolver problemas y contestar a las preguntas de modo inmediato.
Los SIG permiten gestionar y analizar la información espacial, por lo que han venido
a constituirse en la alta tecnología de los geógrafos y otros profesionales que trabajan sobre
el territorio. Se trata de sofisticadas herramientas multipropósito con aplicaciones en
campos tan dispares como la planificación urbana, la gestión catastral, la ordenación del
territorio, el medio ambiente, la planificación del transporte, el mantenimiento y la gestión
de redes públicas, el análisis de mercados, etc.
El término de Sistemas de Información Geográfica (SIG) hoy está ampliamente
difundido, especialmente entre los profesionales que trabajan en la planificación o en la
resolución de problemas socioeconómicos y ambientales.
Los SIG se encuadran dentro de la familia de los Sistemas de Información, que tan
amplia aceptación han tenido en las últimas décadas. Los Sistemas de Información
computerizados no son más que programas o conjuntos de programas diseñados para
representar y gestionar grandes volúmenes de datos sobre ciertos aspectos del mundo real.
Operaciones que antes se desarrollaban manualmente, de forma tediosa y con numerosos
errores, hoy son llevadas a cabo automáticamente mediante tales sistemas. Por otro lado,
estos sistemas se orientan frecuentemente a facilitar información para la toma de decisiones:
se trata de un conjunto de procesos informáticos que permiten producir, a partir de datos no
tratados, información útil en la toma de decisiones.
Un SIG es un "Sistema de Información diseñado para trabajar con datos
georreferenciados mediante coordenadas espaciales o geográficas", es decir, con
información geográfica. De hecho la Geografía constituye el elemento clave para estructurar
la información dentro de un SIG y para realizar operaciones de análisis. El National Center
for Geographic Information and Analysis (NCGIA), de los Estados Unidos, amplía la definición
anterior cuando dice que un SIG es "un sistema de hardware, software y procedimientos
diseñado para realizar la captura, almacenamiento, manipulación, análisis, modelización y
presentación de datos referenciados espacialmente para la resolución de problemas
complejos de planificación y gestión".
Desde hace mucho tiempo los geógrafos y otros científicos de la tierra estamos
acostumbrados a estructurar la información en mapas temáticos, según sean los aspectos del
espacio que nos interese estudiar. De la misma forma un SIG descompone la realidad en
distintos temas, es decir, en distintas capas o estratos de información de la zona que se desea
estudiar: el relieve, la litología, los suelos, los ríos, los asentamientos, las carreteras, los
límites administrativos... El analista puede trabajar sobre cualquiera de esas capas según las
necesidades del momento. Pero la gran ventaja de los SIG es que pueden relacionar las
distintas capas entre sí, lo que concede a estos sistemas unas sorprendentes capacidades de
análisis. Los mapas almacenados en el ordenador pueden ser objeto de peticiones muy
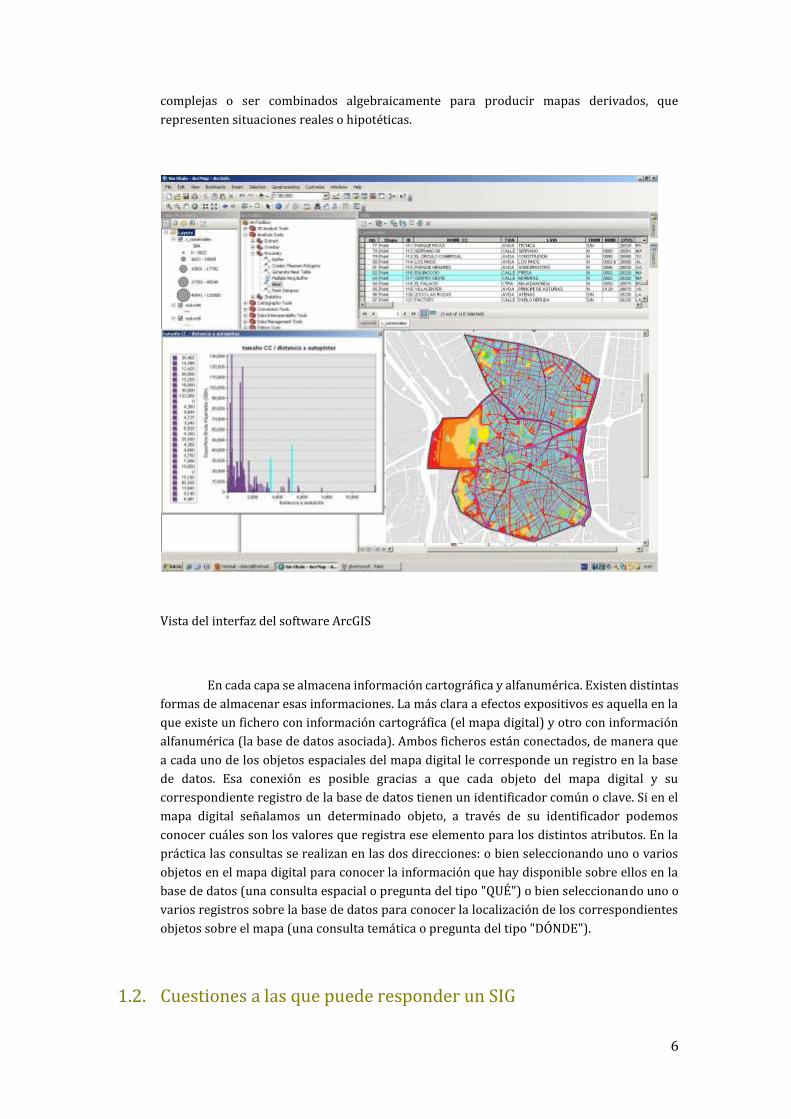
6
complejas o ser combinados algebraicamente para producir mapas derivados, que
representen situaciones reales o hipotéticas.
Vista del interfaz del software ArcGIS
En cada capa se almacena información cartográfica y alfanumérica. Existen distintas
formas de almacenar esas informaciones. La más clara a efectos expositivos es aquella en la
que existe un fichero con información cartográfica (el mapa digital) y otro con información
alfanumérica (la base de datos asociada). Ambos ficheros están conectados, de manera que
a cada uno de los objetos espaciales del mapa digital le corresponde un registro en la base
de datos. Esa conexión es posible gracias a que cada objeto del mapa digital y su
correspondiente registro de la base de datos tienen un identificador común o clave. Si en el
mapa digital señalamos un determinado objeto, a través de su identificador podemos
conocer cuáles son los valores que registra ese elemento para los distintos atributos. En la
práctica las consultas se realizan en las dos direcciones: o bien seleccionando uno o varios
objetos en el mapa digital para conocer la información que hay disponible sobre ellos en la
base de datos (una consulta espacial o pregunta del tipo "QUÉ") o bien seleccionando uno o
varios registros sobre la base de datos para conocer la localización de los correspondientes
objetos sobre el mapa (una consulta temática o pregunta del tipo "DÓNDE").
1.2. Cuestiones a las que puede responder un SIG

7
Rhind (1990) distingue seis grandes tipos de cuestiones a las que un SIG puede
responder (cuadro 1.2):
1. Localización.- Apuntando con el cursor sobre la pantalla se puede obtener
información sobre lo que hay en un lugar determinado (por ejemplo, cuánta
población escolar habita en una sección censal). Se trata simplemente realizar una
consulta en la que es necesario relacionar la información cartográfica con la base de
datos de atributos.
2. Condición.- A partir de unas condiciones previamente especificadas, el sistema debe
indicar dónde se cumplen o no esas condiciones (por ejemplo, indicar dónde
encontramos un lago para pescar situado a menos de 50 kilómetros de nuestra casa
y rodeado de bosques).
3. Tendencias.- En esta pregunta lo fundamental es la comparación entre situaciones
temporales distintas, si bien para ello se pueden incluir condiciones (por ejemplo,
cuántas hectáreas de naranjos se encuentran a menos de 200 metros de una
carretera, en una fecha dada y veinte años después). Ello supone trabajar con varios
mapas de la misma zona referidos a fechas distintas.
4. Rutas.- El sistema puede calcular el camino óptimo (el más corto, más barato o más
rápido) entre dos puntos a través de una red (por ejemplo, entre el lugar donde se
ha producido una catástrofe y el hospital más próximo).
5. Pautas.- Ciertas regularidades espaciales pueden ser detectadas con la ayuda de un
SIG (por ejemplo, qué patrones de distribución espacial presentan los casos de
cáncer en torno a una central nuclear en la que se ha producido un accidente).
6. Modelos.- Se pueden generar modelos para simular el efecto que producirían
posibles fenómenos o actuaciones en el mundo real (por ejemplo, que sucedería si
se construyera un nuevo tramo de autopista o si se produjera un aumento de dos
metros en el nivel de las aguas del mar).
Cuadro 1.2: Cuestiones básicas que pueden ser investigadas con un SIG (Rhind, 1990)
1 LOCALIZACIÓN ¿Qué hay en ...?
2 CONDICIÓN ¿Dónde sucede que ...?
3 TENDENCIAS ¿Qué ha cambiado ...?
4 RUTAS ¿Cuál es el camino óptimo ...?
5 PAUTAS ¿Qué pautas existen ...?
6 MODELOS ¿Qué ocurriría si ...?

8
Estas cuestiones son de interés primordial en las actividades de planificación. Dado
que los SIG trabajan con datos sobre el mundo real, es posible implementar modelos que
permitan predecir cuáles serán las tendencias futuras o qué efectos se producirán en caso
de que cambie alguno de los elementos del sistema territorial. En este sentido, Burrough
(1986) señala que si se utiliza un SIG del modo en que un piloto utiliza un simulador de vuelo,
es posible que los planificadores y políticos puedan explorar los posibles escenarios y
obtener una idea de las consecuencias de una actuación antes de que se hayan cometido
errores irreversibles.
Maguire (1991) pone en relación el esquema de cuestiones básicas de Rhind con las
fases de evolución de los SIG que distinguen Crain y MacDonald (1984) (figura 1.7). Estos
autores sugieren que cada fase en la evolución de los SIG está caracterizada por un tipo de
aplicación. Distinguen tres fases: la de inventario, la de análisis y la de gestión. En los SIG
menos maduros predominan las aplicaciones para la elaboración de inventarios, que
después van cediendo terreno al análisis y más tarde ambas dejan espacio a la gestión. Hoy
en día la mayor parte de los SIG se encuentran en el estadio de las aplicaciones tipo
inventario, algunos han pasado al del análisis y muy pocos son utilizados en la gestión.
La primera fase de la evolución de los SIG está caracterizada por las aplicaciones
relacionadas con los grandes inventarios de datos, como los inventarios forestales y de redes
públicas, o el catastro. En esta fase los sistemas son utilizados fundamentalmente para
realizar consultas, dentro de las cuestiones 1 y 2 (localización y condición) que plantea
Rhind.
En una segunda fase los Sistemas de Información Geográfica son capaces de resolver
cuestiones más complejas, que exigen relacionar distintas capas de información y utilizar
técnicas estadísticas y de análisis espacial. La determinación de localizaciones óptimas, por
ejemplo, para un vertedero de residuos sólidos o de un nuevo punto de atención al público,
exige un tratamiento complejo de la información en cuestiones relativas a condiciones y
tendencias (cuestiones 2 y 3 de Rhind).
En la tercera fase de evolución de los SIG surge una orientación hacia la gestión y la
decisión, es decir, un acercamiento hacia lo que se conoce como Sistemas de Apoyo a la
Decisión (SAD) (ver Densham, 1991, Guariso y Werthner, 1989, y Fedra y Reitsma, 1990). Se
pone un énfasis especial en el análisis espacial sofisticado y en la modelización. Se pueden
resolver problemas del tipo de dónde se debe construir un nuevo hospital o cuál es la ruta
óptima para un reparto de mercancías. Las cuestiones 4, 5 y 6 del esquema de Rhind (rutas,
pautas y modelos) son características de esta tercera fase.

9
2. Los datos geográficos
Si, de acuerdo con lo visto en el capítulo anterior, los SIG se distinguen de otros
Sistemas de Información por el hecho de trabajar con "información geográfica", parece
necesario tratar con un cierto detalle sobre la naturaleza los datos geográficos. En realidad
un SIG es mucho más que un software específico. El uso efectivo de esta tecnología alcanza
otras muchas cuestiones, algunas de las cuales tienen muy poco que ver con la informática,
pero son tan importantes como ésta para el usuario; muchas de esas cuestiones están
relacionadas con el conocimiento de la naturaleza de los datos geográficos (Goodchild, Rhind
y Maguire, 1991). De hecho la información geográfica tiene características únicas, y su
recolección, compilación y análisis presenta problemas únicos: la realidad representada por
la información geográfica es frecuentemente continua y siempre infinitamente compleja, por
lo que tiene que ser "discretizada", abstraída, generalizada o interpretada para su posterior
tratamiento y análisis (Kemp, Goodchild y Dodson, 1992).
En este contexto conviene recordar que la Geografía se ocupa de describir y explicar
las distribuciones espaciales, es decir, la frecuencia con que algo ocurre sobre el espacio, y
que esa descripción y explicación se realiza a partir de los datos geográficos (Martin, 1991).
Conocer la naturaleza de los datos geográficos supone una cuestión previa al manejo de
cualquier sistema.
7.1 Las tres componentes de los datos geográficos
7.1.1 La componente espacial
La componente espacial hace referencia tanto a la localización geográfica y a las
propiedades espaciales de los objetos, como a las relaciones espaciales que existen entre
ellos.
A) La localización geográfica
La localización geográfica o posición de los objetos en el espacio se expresa
mediante un sistema de coordenadas, que debe ser el mismo para las distintas capas o
estratos de información con los que se representa el área de estudio. En los casos en que ello
sea conveniente, el SIG puede realizar las transformaciones necesarias para pasar de un
sistema de coordenadas a otro.
B) Las propiedades espaciales
Los objetos con que se representa la realidad tienen ciertas propiedades espaciales
de acuerdo con su naturaleza. Así, entre las propiedades espaciales de las líneas figuran la
longitud, la forma, la pendiente y la orientación. En el caso de los polígonos se pueden
identificar la superficie, el perímetro, la forma, la pendiente y la orientación. En el caso de los
SIG raster, en los que normalmente todos los objetos (las celdas) son de igual tamaño y
forma, se constituyen conjuntos de celdas (que habitualmente reciben el nombre de zonas)

10
que pueden ser tratados como si fueran polígonos a efectos del análisis de sus propiedades
espaciales.
C) Las relaciones espaciales
Los objetos espaciales mantienen ciertas relaciones entre sí basadas en el espacio.
Se trata de un número elevado de relaciones (como conectividad, contigüidad, proximidad,
etc.) por lo que no es posible que todas ellas sean almacenadas en un Sistema de Información
Geográfica. Algunas están explícitamente definidas en un SIG, otras son calculadas cuando
son requeridas o sencillamente no están disponibles (Aronoff, 1989).
Así, por ejemplo, numerosos SIG almacenan explícitamente la relación topológica de
contigüidad entre dos polígonos, pero en cambio la relación de proximidad (cerca/lejos)
entre dos objetos puede ser calculada en el momento requerido a través de la geometría, de
la localización de ambos objetos, de acuerdo con lo que entienda el usuario por los términos
cerca/lejos. Así, serán objetos próximos a un objeto dado todos aquellos que se encuentren
a menos de una determinada distancia con respecto a ese objeto, previamente especificada
por el usuario.
7.1.2 La componente temática
De acuerdo con lo indicado anteriormente, los objetos con los que representamos la
variación que se produce en el mundo real poseen unas determinadas características que se
conocen como atributos (o variables). Así, cada objeto registra un determinado valor para
cada uno de los atributos considerados. Pero estos valores no presentan unas pautas de
variación más o menos aleatorias, sino que es posible encontrar ciertas regularidades en su
variación tanto sobre el espacio como sobre el tiempo:
Autocorrelación espacial
Los valores temáticos tienden a ser más parecidos entre objetos próximos en el espacio que
entre objetos situados lejos los unos de los otros. Este principio general, conocido como
autocorrelación espacial, es básico en Geografía y en los Sistemas de Información Geográfica,
ya que implica la existencia de un cierto orden en el espacio. Como señaló Humboldt en
alusión a los fenómenos naturales, lejos de producirse cambios bruscos (a saltos) en el
espacio, en la realidad tienden a producirse gradaciones más o menos suaves. Este principio
parece cumplirse no sólo en las variables de tipo físico, sino también en las de tipo humano.
El relieve terrestre, las precipitaciones y las temperaturas, por un lado, y las densidades de
población y las disparidades de renta, por otro, constituyen buenos ejemplos al respecto: si
tomamos un determinado punto del mapa como referencia, observaremos que los valores
temáticos de la variable considerada tienden a modificarse gradualmente a medida que nos
alejamos de él.
Autocorrelación temporal.
Pero los valores temáticos no sólo cambian en el plano del espacio, sino también en el eje
del tiempo. Y, al igual que ocurre sobre el espacio, los cambios que se producen en el eje del
tiempo tienden a ser graduales. Este principio es conocido en las Ciencias Sociales como
autocorrelación temporal, y hace alusión a que los datos próximos en el tiempo tienden a ser
más parecidos entre sí que los más lejanos. Aplicando esta idea a una secuencia de mapas de

11
densidades de población de una determinada zona, resultará que los cambios que se
producen entre dos fechas próximas serán pequeños, pero irán aumentando a medida que
aumente el intervalo de tiempo comprendido entre las fechas de los dos mapas. Dicho de
otra forma: las distribuciones espaciales se modifican paulatinamente a lo largo del tiempo,
de manera que cabe esperar cambios tanto mayores cuanto mayor sea el tiempo
transcurrido. Así, el mapa de densidades de población de España de 1991 presenta las
mismas pautas generales que el de 1981, pero es radicalmente distinto al de hace 200 años.
7.1.3 La componente temporal
El tiempo juega un papel fundamental en la Geografía. El mundo real sólo puede ser
explicado a partir de procesos espacio-temporales. Los geógrafos clásicos franceses se
referían a esta cuestión cuando afirmaban que la Historia explica el presente. Hartshorne
(1939) se mostraba en esa misma línea cuando indicaba que la interpretación de las
configuraciones geográficas presentes requiere cierto conocimiento de su desarrollo
histórico y proponía como forma de captar los procesos el proyectar sucesivas imágenes de
la geografía histórica de una misma región: "un intento de desarrollar una imagen en
movimiento produciría una variación continua tanto en el tiempo como en el espacio que
reflejaría, en efecto, la realidad en toda su complejidad".
7.2 ¿Cómo representamos la realidad en un mapa?
Para trabajar con la información ráster y los distintos sistemas de referencia hay que tener
claro una serie de conceptos para no utilizar información geográfica de forma incorrecta o
errónea, y de esta forma se evitarán problemas en la georreferenciación y errores en la
utilización de las distintas bases de referencia.
En este documento se exponen los conceptos básicos que definen la Geodesia como ciencia
que tiene como objeto la determinación de la forma y dimensiones de la figura de la Tierra,
el posicionamiento de puntos sobre la superficie física terrestre y el estudio del campo de la
gravedad externo del planeta (Benaviedez, 2005). Ésta nos permitirá trabajar sobre distintos
sistemas de referencia con diferentes herramientas, fundamentalmente los sistemas de
información geográfica.
7.2.1 Conceptos básicos
Superficie de la Tierra: Es la real, la que forman los mares y los océanos.
Geoide: Superficie equipotencial del campo de gravedad terrestre que resulta de
prolongar el nivel medio del mar por debajo de los continentes. No es posible
ajustarlo a una expresión matemática.
Elipsoide: Superficie matemática que más se aproxima al geoide. Los parámetros
que definen un elipsoide son los semiejes (a y b) y el aplanamiento (α).

12
Ondulación o altura del Geoide (N): Distancia entre la superficie del elipsoide
de referencia y el geoide, medida a lo largo de la normal al elipsoide.
Representación conceptual de la Superficie real de la tierra
Esquema explicativo de los Conceptos
7.2.2 ¿Qué es el Datum?
Un Datum es un modelo matemático que se ajusta a una parte o la totalidad del geoide,
proporcionando todos los parámetros de referencia para establecer los puntos de la
superficie de la tierra sobre un elipsoide.
Cada Datum está compuesto por:

13
Un elipsoide, definido por sus parámetros (semieje mayor, semieje menor y
achatamiento)
Un punto llamado punto fundamental en el que el geoide y el elipsoide coinciden.
Definido el Datum, ya se puede elaborar la cartografía de cada lugar.
7.2.3 Sistema de Referencia y Datum
La posición de un punto se expresa con un sistema de coordenadas en relación a un sistema
de referencia geodésico. En la norma ISO 19111 se define un Sistema de Referencia de
Coordenadas como un sistema de coordenadas que está referido a la Tierra a través de un
Datum geodésico.
Los sistemas de referencia geográficos pueden ser:
Absolutos o Globales: basados en coordenadas esféricas o geográficas, que requieren
tener una representación de la superficie terrestre. Son sistemas globales, que se pueden
aplicar a cualquier punto del globo.
Relativos o Locales: basados en coordenadas polares, que indican dirección, ángulo y
distancia a un punto fijo de inicio. Son sistemas locales, aplicables a cualquier punto del
globo.
Uno de los Sistemas de Referencia más utilizados es el World Geodetic System 1984
(WGS1984). Sistema Geodésico Mundial de 1984 desarrollado por la NIMA (National
Imagery and Mapping Agency ) de los EE.UU. La exactitud de este sistema es del orden del
metro y a él están referidas las efemérides radiotransmitidas por los satélites GPS. El Datum
del WGS1984está definido por:
Elipsoide , World Geodetic System 1984
Origen, centro de masas de la tierra o geocentro.
7.2.4 Sistemas de Coordenadas
Los Sistemas de Coordenadas permiten establecer de forma unívoca la posición que ocupa
cada objeto en la superficie terrestre.
Se basan en una serie de puntos cuya posición absoluta es conocida, a partir de los cuales se
establece la posición de los demás mediante indicaciones de dirección y distancia
La georreferenciación es el uso de coordenadas de mapa para asignar una ubicación espacial
a entidades cartográficas. Todos los elementos de una capa de mapa tienen una ubicación
geográfica y una extensión específicas que permiten situarlos en la superficie de la Tierra o
cerca de ella.
La correcta descripción de la ubicación y la forma de entidades requiere un marco para
definir ubicaciones del mundo real. Un sistema de coordenadas de latitud-longitud global es
uno de esos marcos. Otro marco es un sistema de coordenadas cartesianas o planas que

14
surge a partir del marco global. Así pues, existen dos formas de representar la superficie
terrestre, por medio de coordenadas geográficas o coordenadas planas.
Coordenadas Geográficas: Dividen la tierra en una serie de anillos imaginarios, paralelos
al ecuador (paralelos) y una serie de círculos perpendiculares a los mismos que
convergen en los polos (meridianos) .
Longitud (λ): Es el ángulo formado por el meridiano que pasa por el punto y un
meridiano que se toma como origen. El meridiano que se toma como origen es el
meridiano de Greenwich.
Latitud (φ): Es el ángulo que forma la vertical (que es perpendicular a la superficie
terrestre en ese punto) del punto con el ecuador.
Coordenadas Proyectadas Planas: Dividen son aquellas que provienen de proyectar las
coordenadas geográficas sobre un plano, para esto es necesario aplicar una serie de
transformaciones matemáticas denominadas proyecciones cartográficas. En cualquier caso,
las coordenadas proyectadas se pueden definir en 2D (x,y) o 3D (x,y,z), donde las mediciones
x,y representan la ubicación en la superficie de la Tierra y z representaría la altura por
encima o por debajo del nivel del mar.
Esquemas de los tres Sistemas de Coordenadas proyectadas: Cónico, Cilíndrico y Plano.
7.2.5 ¿Qué es la Proyección UTM?

15
La proyección Universal Transverse de Mercator es un sistema de coordenadas
rectangulares, planas, desarrollado por el Ejército de los Estados Unidos y es adoptado por
la mayoría de los países del mundo.
Características:
El Sistema de Coordenadas UTM secciona el globo terráqueo en divisiones
denominadas ZONAS o HUSOS, que miden 6° de ancho; son proyectadas desde el
centro de la Tierra; 60 zonas cubren la tierra y van de los 84° Norte a los 80° Sur. El
origen de este sistema se encuentra en el meridiano 180° Oeste.
Las distancias, se miden en metros.
Este tipo de proyección es muy útil para cartografía de pequeñas áreas o de áreas
que cubran poca Longitud, dado que la distorsión de la proyección aumenta en
función de la distancia al meridiano tangente.
Las coordenadas UTM (X, Y) son similares a un sistema cartesiano común, por lo
que son ortogonales, formando una cuadrícula perfecta.
En el Sistema UTM, una posición es descrita por 3 elementos:
1. La zona a la que pertenece. (Huso).
2. La coordenada en el eje de las X
3. La coordenada en el eje de las Y
Figura: Esquema de la Proyección UTM

16
3. Modelos y estructuras de datos
El mundo real es enormemente rico y variado. Cada investigador se propone un
objetivo en su estudio, que sólo puede ser alcanzado mediante una simplificación de la
realidad, mediante un modelo. En esa tarea es necesario ser selectivos: no se puede ni se
debe representar toda la realidad en toda su complejidad, sino que hay que aislar aquellos
elementos y relaciones del mundo real que son útiles para los propósitos del estudio que se
aborda. Un modelo más complicado (con más elementos y relaciones) no es necesariamente
mejor, pero indudablemente supone un aumento del coste del estudio.
En el mundo de los Sistemas de Información Geográfica existen dos aproximaciones
básicas a la cuestión de cómo modelizar el espacio, de las que resultan dos modelos de datos:
vectorial y raster. Las páginas que siguen a continuación se dedican a analizar estos modelos
y algunas de sus formas de implementación en el ordenador (1).
4.1 Modelos de datos
La base de datos espacial de un SIG no es más que un modelo del mundo real, una
representación digital en base a objetos discretos. Una base de datos espacial es, en
definitiva, una colección de datos referenciados en el espacio que actúa como un modelo de
la realidad (NCGIA, 1990). Las reglas según las cuales se modeliza el mundo real por medio
de objetos discretos constituyen el modelo de datos.
Aunque a veces se utilizan como sinónimos, conviene establecer una diferenciación
entre los términos modelo de datos (la conceptualización del espacio) y estructura de datos
(la implementación de esa conceptualización en el ordenador). Más concretamente Laurini
y Thomson (1992) señalan que el primero se refiere al conjunto de herramientas
conceptuales para la organización de los datos e incluye cuestiones relacionadas con los
mosaicos (teselaciones) del modelo raster y las polilíneas del modelo vectorial; el segundo,
en cambio, hace referencia a la descripción práctica más detallada y concreta de los
fenómenos espaciales e incluye cuestiones como el almacenamiento de los datos geográficos
mediante procedimientos como la codificación en grupos de longitud variable en el modelo
raster o las listas de las coordenadas de los polígonos en el modelo vectorial (ver los
siguientes apartados). Por otro lado, algunos autores utilizan el término de estructuras de
datos de alto nivel para referirse a los modelos de datos y el de estructuras de datos de bajo
nivel para referirse a lo que habitualmente se conoce como estructuras de datos (Egenhofer
y Herring, 1991).
Pero ¿cómo modelizar el espacio? Aquí aparece de nuevo la cuestión de cómo
individualizar las unidades de observación, si atendiendo a las propiedades (aproximación
vectorial) o la localización (aproximación raster) (ver figura 2.3 y apartado 2.2.2):

17
1- El modelo vectorial
Las propiedades constituyen el criterio de diferenciación de los individuos geográficos que
existen en el mundo real: las entidades. Esas entidades son representadas por medio de
objetos en la base de datos. Así, por ejemplo, un lago (la entidad) puede representarse en un
SIG mediante un polígono (el objeto). Habitualmente se utiliza el término de entidad para
hacer referencia a elementos que no pueden ser subdivididos en unidades menores del
mismo tipo (una ciudad no puede ser subdividida en ciudades menores, sino en barrios o
distritos), mientras que el término de objeto se reserva a la representación digital de ese
fenómeno (Laurini y Thomson, 1992). Las entidades no tienen por qué ser elementos visibles
en el espacio (una división administrativa, como por ejemplo, una sección censal, es también
una entidad del mundo real). La forma de representar las entidades varía en función de la
escala. Así, por ejemplo, en un mapa de una ciudad un equipamiento educativo puede
representarse mediante un punto a escala 1:50.000 o mediante un polígono a escala 1:2.000.
Aquellos elementos similares que son almacenados en la base de datos (como las ciudades o
las secciones censales) constituyen tipos de entidades. Estos no deben ser confundidos con
los tipos de objetos espaciales (puntos, líneas y polígonos) con los que se representan esos
tipos de entidades (figura 3.1).
2- El modelo raster
En este caso los individuos geográficos se diferencian en función de un criterio locacional.
El espacio es compartimentado en porciones de igual tamaño y forma mediante la
superposición de una retícula regular y a continuación se registran las propiedades de esas
porciones de espacio, habitualmente en capas distintas. La retícula suele ser de objetos
cuadrados o rectangulares, de manera que cada uno de esos objetos (celdas) representa una
pequeña porción del espacio. Así pues, el modelo raster propone una aproximación basada
en objetos elementales (celdas), que pueden agruparse para constituir objetos complejos
que representan elementos del mundo real. En una capa en la que se representa el uso del
suelo, un lago, por ejemplo, puede representarse mediante un grupo de celdas colindantes
que tienen un mismo valor temático. Así, en el modelo raster no quedan registrados de forma
explícita los límites entre los elementos geográficos (como ocurre en el vectorial), aunque
éstos se puedan inferir aproximadamente a partir de los valores que toman las celdas.
Figura: Esquema de los modelos de datos Raster y Vectorial

18
Comparación entre los modelos de datos raster y vectorial (según Aronoff, 1989).
MODELO RASTER
Ventajas
1. Es una estructura de datos simple.
2. Las operaciones de superposición de mapas se implementan de forma más rápida
y eficiente.
3. Cuando la variación espacial de los datos es muy alta el formato raster es una
forma más eficiente de representación.
4. El formato raster es requerido para un eficiente tratamiento y realce de las
imágenes digitales.
Desventajas
1. La estructura de datos raster es menos compacta. Las técnicas de compresión de
datos pueden superar frecuentemente este problema.
2. Ciertas relaciones topológicas son más difíciles de representar.
3. La salida de gráficos resulta menos estética, ya que los límites entre zonas tienden
a presentar la apariencia de bloques en comparación con las líneas suavizadas de los
mapas dibujados a mano. Esto puede solucionarse utilizando un número muy
elevado de celdas más pequeñas, pero entonces pueden resultar ficheros
inaceptablemente grandes.
MODELO VECTORIAL
Ventajas
1. Genera una estructura de datos más compacta que el modelo raster.
2. Genera una codificación eficiente de la topología y, consecuentemente, una
implementación más eficiente de las operaciones que requieren información
topológica, como el análisis de redes.
3. El modelo vectorial es más adecuado para generar salidas gráficas que se
aproximan mucho a los mapas dibujados a mano.
Desventajas
1. Es una estructura de datos más compleja que el modelo raster.
2. Las operaciones de superposición de mapas son más difíciles de implementar.
3. Resulta poco eficiente cuando la variación espacial de los datos es muy alta.

19
4. El tratamiento y realce de las imágenes digitales no puede ser realizado de manera
eficiente en el formato vectorial.

20
4.2 El modelo ráster
El modelo raster centra su interés más en las propiedades del espacio que en la
representación precisa de los elementos que lo conforman. Para ello compartimenta el
espacio en una serie de elementos discretos por medio de una retícula regular.
Habitualmente se trata de una retícula rectangular compuesta por celdas cuadradas, si bien
algunos sistemas utilizan otras figuras geométricas como los triángulos o los hexágonos.
Cada una de esas celdas se considera como indivisible y es identificable por su número de
fila y columna (figura 3.2). Conviene señalar que se emplea indistintamente el nombre de
celda o de pixel (abreviatura de la expresión inglesa picture element, es decir, elemento de
dibujo). En cuanto a la información temática, a cada celda le corresponde normalmente un
único valor relativo a la variable que se está representando (altitud, uso del suelo, materiales
geológicos...).
El conjunto de la retícula sería comparable a un mosaico, en el que cada celda
equivaldría a una tesela. Dado que todas las celdas son iguales, se dice que el modelo raster
se basa en teselaciones regulares, frente a lo que ocurre en las capas de polígonos en el
modelo vectorial (teselaciones irregulares). Por el hecho de basarse en una teselación, el
modelo raster cubre todo el espacio, sin dejar huecos, lo que no ocurre necesariamente en el
modelo vectorial.
Figura:
Esquema de representación

21
La representación de los elementos del mundo real se realiza de la siguiente forma:
un elemento puntual se representa mediante una celda, un elemento lineal mediante una
secuencia de celdas alineadas y un elemento poligonal mediante una agrupación de celdas
contiguas. Uno de los mayores inconvenientes que se asocian al modelo de raster es la falta
de exactitud a la hora de localizar los elementos. Mediante este tipo de representación se
indica que un elemento puntual (por ejemplo, un manantial) está localizado en alguna parte
dentro de la celda correspondiente o que un elemento lineal (por ejemplo, un arroyo)
atraviesa una celda por algún lugar, pero no conocemos exactamente por dónde. En
consecuencia tampoco se conoce con exactitud cuál es la forma y el tamaño de los elementos
poligonales, si bien ambas características se pueden inferir aproximadamente a partir de la
configuración que presentan las celdas.
Para aumentar la exactitud posicional se debe incrementar el nivel de resolución, es decir,
trabajar con celdas que representan superficies más pequeñas en el mundo real.
Teóricamente estas celdas podrían ser tan pequeñas como se deseara hasta llegar a la misma
exactitud que presentan las coordenadas X e Y en un sistema vectorial, pero se producirían
unas necesidades en el almacenamiento y proceso de datos que no pueden ser cubiertas con
los ordenadores más modernos (Berry, 1993). En consecuencia en teoría no es un problema
de exactitud posicional, sino de resolución. Para ilustrar esta idea podemos remitirnos al
siguiente ejemplo: si tenemos una imagen de satélite con una resolución de
aproximadamente 30 por 30 metros, no podremos distinguir dos casas en una urbanización,
lo que no quiere decir que el modelo raster sea poco exacto, sino que la resolución de la
imagen es baja.
Figura: Esquema de la importancia de la escala en los modelos Raster
El formato raster permite representar no sólo elementos del mundo real, sino
también variables que presentan una variación continua sobre el espacio (es decir,
superficies). El ejemplo más típico es el del mapa de altitudes. A cada celda se le asigna un
valor, de forma que se puede conocer fielmente cómo varía la altitud por toda el área que
cubre un mapa. Se pueden representar de esta forma superficies tridimensionales, ya que a
las dos coordenadas de localización (X e Y) se añade una tercera (Z) para representar el valor

22
de la variable, en este caso la altitud. Es lo que se conoce como un modelo digital del terreno
(MDT), aplicable no sólo a la variable altitud, sino a cualquier otra variable que presente una
variación continua sobre el espacio (presión atmosférica, precipitaciones, coste de
transporte, etc.)
Figura: Ejemplo de un Modelo Digital del Terreno (MDT)
Un conjunto de celdas y sus valores asociados (relativos a una determinada
variable) constituye una capa o estrato de información. Dado que en cada celda se registra
un único valor, si se quiere almacenar información -sobre una misma zona- relativa a
distintas variables, se han de incluir tantas capas como variables se consideren (por ejemplo,
altitud, litología, pendiente, precipitación, uso del suelo...). En principio todas esas capas
deben basarse en la misma retícula para facilitar las comparaciones entre capas celda a
celda: así se podrá conocer los valores que una misma celda toma para cada una de las
variables (capas) consideradas (4). En realidad cada capa está constituida por un conjunto
de valores que conforman una matriz y, como las unidades de soporte de información son
las mismas en las distintas capas, se pueden realizar multitud de operaciones para relacionar
unas capas con otras, lo que se conoce como álgebra de mapas.

23
4.3 El modelo vectorial
4.3.1 El modelo de datos: la representación de las entidades por medio de puntos,
líneas y polígonos
En el modelo vectorial el foco de interés se sitúa en las entidades, en su
posicionamiento sobre el espacio. De hecho los elementos del mundo real (especialmente los
artificiales) son representados en este modelo con mucha mayor nitidez que en el modelo
ráster, en el que el uso de las celdas suelen suponer una pérdida de precisión en los
contornos (cuando la resolución no es lo suficientemente alta). Para modelizar las entidades
del mundo real se utilizan tres tipos de objetos espaciales: puntos, líneas y polígonos (figuras
3.1 y 3.4). Los objetos no son más que representaciones digitales de las entidades. La
diferenciación entre estos tipos de objetos es puramente topológica:
a) Los puntos son objetos espaciales de 0 dimensiones: tienen una localización en el
espacio, pero no tienen ni longitud de anchura. Se puede representar mediante puntos
cualquier elemento cuyas dimensiones sean despreciables desde una perspectiva
cartográfica: manantiales, pozos, semáforos, bocas de riego, etc.
b) Las líneas son objetos espaciales de 1 dimensión, ya que tienen longitud, pero no
anchura. Las líneas están definidas mediante una sucesión de puntos. Habitualmente se
representan mediante líneas elementos que se integran en redes, ya sean naturales (como
las redes hidrográficas) o artificiales (como las redes de carreteras).
c) Los polígonos son objetos espaciales de 2 dimensiones, ya que tienen longitud y
anchura. Se representan mediante una sucesión de líneas que cierran (un anillo). Las
parcelas del catastro o las secciones censales son buenos ejemplos de elementos que se
representan como polígonos en las bases de datos.
La escala del mapa resulta fundamental en algunos casos a la hora de elegir un tipo
de objeto para representar una entidad. Así, por ejemplo, una ciudad puede ser representada
mediante un punto si se trabaja a escala 1:10.000.000, mediante un polígono si la escala es
1:200.000 o mediante un conjunto de polígonos si la escala es 1:25.000.
Es cierto que la mayor parte de las entidades espaciales tienen tres dimensiones.
Pero sólo algunas de esas dimensiones pueden ser relevantes desde el punto de vista de su
representación en un SIG. En este sentido se habla de entidades puntuales, lineales y
poligonales. Así, por ejemplo, en un tramo de carretera se podría medir su anchura y el

24
espesor del pavimento, pero lo más importante es su longitud a efectos de representación y
análisis en un SIG (NCGIA, 1990). Las otras dimensiones (espesor del pavimento y anchura
de la vía) pueden ser almacenadas como atributo en la base de datos (y ello es importante
desde el punto de vista de su representación cartográfica), pero no son propiedades
geométricas de las líneas. Sólo en el momento de dibujar la línea podría ser necesario
conocer la anchura de la carretera y el espesor del pavimento, que son atributos -como
también lo son la intensidad media de tráfico, la velocidad media, etc.- y no propiedades
geométricas del objeto línea. Conviene recordar aquí la diferenciación que se estableció
anteriormente entre las propiedades espaciales de las entidades del mundo real y las de los
objetos que utilizamos para su representación cartográfica.
Figura: Esquema de la importancia de la escala en los modelos Vectoriales
4.3.2 Estructuras de datos en el modelo vectorial
Estructura de datos topológica
En el modelo vectorial es importante establecer una diferenciación entre
estructuras de datos cartográficas y topológicas. En las primeras se registra únicamente la
geometría, es decir, las coordenadas, mientras que en las segundas se registran también
relaciones topológicas. Se dice que una estructura de datos es topológica cuando almacena
una o más de las siguientes relaciones (NCGIA, 1990):
Conectividad de los arcos en las intersecciones
Existencia de conjuntos ordenados de arcos formando los límites de los polígonos
Relaciones de contigüidad entre polígonos
Estructura de datos cartográfica

25
Si ninguna de estas relaciones está presente, entonces la estructura es cartográfica. En
cualquier caso, es posible convertir una estructura de datos cartográfica en topológica
mediante el cálculo y almacenamiento de esas relaciones en un proceso que se denomina
"construcción de topología". El sistema debe ser capaz de determinar dónde se produce la
intersección de dos líneas, para marcar allí los nodos correspondientes y a partir de éstos
identificar los arcos. En base a arcos y nodos ya es posible registrar relaciones topológicas.
4.4 Modelos clásicos de bases de datos
1- El modelo jerárquico
Este modelo es el más limitado de los tres y está prácticamente en desuso hoy en día. Los
objetos se organizan en una estructura arborescente. Las relaciones de los objetos son, pues,
jerárquicas, es decir, que cada objeto se relaciona con otros que se sitúan por encima o por
debajo de él en la jerarquía, pero no a su mismo nivel. Más concretamente es posible sólo
una relación con un elemento de un nivel superior (padre) y una o más relaciones con
elementos de un nivel inferior (hijos). El nivel jerárquico más elevado está compuesto por
un único elemento (raíz). En consecuencia, este modelo soporta bien las relaciones uno-a-
uno y también las relaciones uno-a-muchos (como en el ejemplo del catastro cuando una
persona es propietaria de muchas parcelas distintas), pero no soporta bien las relaciones
muchos-a-muchos, ya que su estructura lógica permite que cada hijo tenga un solo padre.
En resumen, el modelo jerárquico se adecúa bien a las estructuras
jerárquicas, es fácilmente comprensible y ofrece una gran sencillez en las tareas de
actualización. Sus principales desventajas son la rigidez con que contempla las relaciones
(sólo jerárquicas y siempre con la limitación de una relación con un único elemento del nivel
superior) y las dificultades que existen en la búsqueda de información cuando es necesario
atravesar varios niveles jerárquicos en esa operación.
2- El modelo de red.
Este modelo supera alguna de las rigideces del modelo jerárquico. Cada objeto puede tener
relaciones con varios de niveles superiores (padres) y no es necesario que exista una raíz
única, por lo que el modelo de red soporta las relaciones muchos-a-muchos. Un ejemplo
típico de este tipo de relaciones se da en el catastro de la propiedad, donde una parcela puede
tener varios propietarios y un propietario puede tener varias parcelas. Así, en el modelo de
red no es necesario recorrer varios niveles jerárquicos al realizar búsquedas, por lo que
resulta mucho más eficaz. Por otro lado, las redundancias tienden a ser menores que en el
modelo jerárquico, a la vez que se ofrece un modelo más complejo del mundo real.
3- El modelo relacional
Los datos se almacenan en tablas, en las que las filas corresponden a los distintos objetos y
las columnas a los atributos de esos objetos. Para que ningún objeto esté repetido existe una
columna que recibe el nombre de clave primaria o identificador. Las búsquedas se pueden
realizar sobre una tabla en base a cualquiera de los atributos o sobre varias tablas utilizando
atributos comunes (ver texto). Las principales ventajas del modelo relacional son su mayor
flexibilidad frente a los otros modelos (en el sentido de que el usuario puede crear nuevas

26
relaciones entre objetos en tiempo real), la simplicidad de la organización de los datos y la
minimización de los niveles de redundancia. En contrapartida su principal desventaja estriba
en que el tiempo de respuesta y el consumo de recursos tienden a ser mayor cuando es
necesario relacionar varias tablas entre sí.
Figura: Esquema de los modelos clásicos de bases de datos

27
4. Introducción al software ArcGIS
5.1 Introducción los productos de ArcGIS
ArcGIS
ArcGIS es un Sistema de Información Geográfica que permite recopilar, organizar,
administrar, analizar, compartir y distribuir información geográfica. Como la plataforma
líder mundial para crear y utilizar sistemas de información geográfica (SIG), ArcGIS es
utilizada por personas de todo el mundo para poner el conocimiento geográfico al servicio
de los sectores del gobierno, la empresa, la ciencia, la educación y los medios. ArcGIS permite
publicar la información geográfica para que esté accesible para cualquier usuario. El sistema
está disponible en cualquier lugar a través de navegadores Web, dispositivos móviles como
smartphones y equipos de escritorio.
Hoy en día ArcGIS es una plataforma para trabajar con distintos dispositivos, desde
ordenadores personales, dispositivos móviles o desde la propia web.
ArcGIS Desktop
ArcGIS Desktop es el producto principal que utilizan los profesionales SIG para compilar,
usar y administrar la información geográfica. Incluye aplicaciones SIG profesionales y
completas que admiten diversas tareas SIG, incluidas la representación cartográfica, la
compilación de datos, el análisis, la administración de geodatabase y el uso compartido de
información geográfica.

28
ArcGIS Desktop es la plataforma que los profesionales SIG utilizan para administrar sus
flujos de trabajo y proyectos SIG, y para crear datos, mapas, modelos y aplicaciones. Es el
punto de partida y la base de la implementación de SIG en organizaciones y en la Web.
ArcGIS Desktop consta de un conjunto de aplicaciones: ArcMap, ArcCatalog, ArcGlobe,
ArcScene, ArcToolbox y ModelBuilder. Con estas aplicaciones e interfaces, puede realizar
cualquier tarea de SIG, simple o avanzada.
En ArcGIS Desktop, estas aplicaciones se utilizan para crear y trabajar con varios tipos de
información geográfica. Por ejemplo, puede crear documentos de mapa en la aplicación
ArcMap, documentos de globo terráqueo en la aplicación ArcGlobe y modelos de
geoprocesamiento en la aplicación ModelBuilder, para trabajar con todos ellos.
Al utilizar ArcGIS Desktop, trabajará con varios elementos de información SIG, por ejemplo:
Documentos de mapa, documentos de globo terráqueo y capas
Geodatabases
Cajas de herramientas de geoprocesamiento
Otros archivos de datos, como imágenes
ArcMap es la aplicación principal que se utiliza en ArcGIS for Desktop para la representación
cartográfica, edición, análisis y administración de datos. ArcMap se utiliza para el trabajo de
representación cartográfica y visualización 2D.
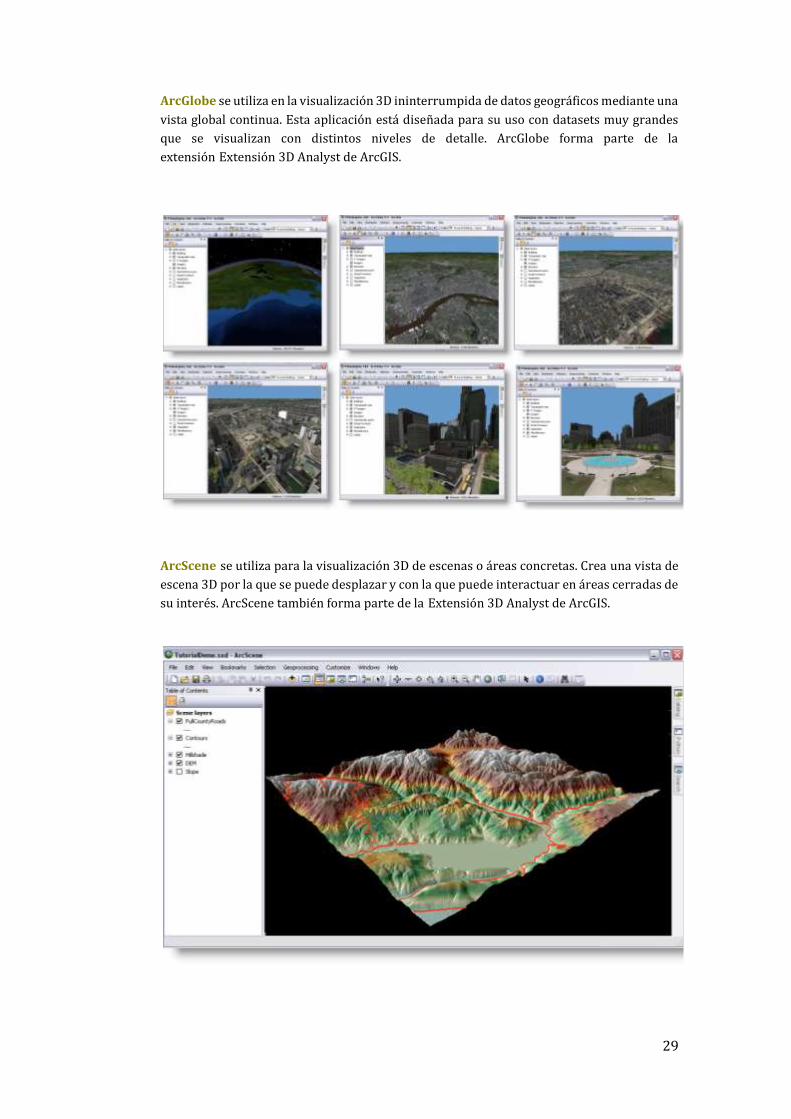
29
ArcGlobe se utiliza en la visualización 3D ininterrumpida de datos geográficos mediante una
vista global continua. Esta aplicación está diseñada para su uso con datasets muy grandes
que se visualizan con distintos niveles de detalle. ArcGlobe forma parte de la
extensión Extensión 3D Analyst de ArcGIS.
ArcScene se utiliza para la visualización 3D de escenas o áreas concretas. Crea una vista de
escena 3D por la que se puede desplazar y con la que puede interactuar en áreas cerradas de
su interés. ArcScene también forma parte de la Extensión 3D Analyst de ArcGIS.

30
5.2 Introducción al interfaz de ArcMap
ArcMap muestra el contenido del mapa en dos vistas posibles:
1. Vista de datos
2. Vista de composición de mapa
Cada vista le permite obtener una perspectiva del mapa y modo de interactuar con el mismo
específicos.
En vista de datos de ArcMap, el mapa es el marco de datos. En vista de datos, el marco de
datos activo se presenta como una ventana geográfica en la que las capas de mapa se
muestran y utilizan. En un marco de datos, se trabaja con información del SIG que se presenta
a través de las capas de mapa mediante coordenadas geográficas (mundo real). Se trata, por
lo general, de mediciones del terreno en unidades como pies, metros o medidas de latitud-
longitud (como grados decimales). La vista de datos oculta todos los elementos de mapa en
el diseño, como títulos, flechas de norte y barras de escala y le permite centrarse en los datos
en un marco de datos único, por ejemplo, edición o análisis
La interfaz de ArcMap se compone principalmente de las siguientes partes:
Marco de datos
El marco de datos muestra una serie de capas dibujada en un orden determinado para una
extensión de mapa y proyección de mapa determinadas. En la tabla de contenido del lado
izquierdo de la ventana de mapa se muestra la lista de capas del marco de datos.

31
Tabla de contenido
En la tabla de contenido se enumeran todas las
capas del mapa y se muestra lo que representan
las entidades de cada capa. La casilla de
verificación que hay al lado de cada capa indica
si su visualización está activada o desactivada
actualmente. El orden de capas en la tabla de
contenido especifica su orden de dibujo en el
marco de datos de abajo a arriba.
La tabla de contenido del mapa le ayuda a
administrar el orden de visualización de las
capas del mapa y la asignación de símbolos.
También le ayuda a establecer la visualización y
otras propiedades de cada capa del mapa.
Diseños de página
Un diseño es una colección de elementos de mapa colocados y organizados en una página.
Son elementos de mapa habituales uno o varios marcos de datos (cada uno con un conjunto
ordenado de capas de mapa), una barra de escala, la flecha de norte, el título del mapa, texto
descriptivo y una leyenda de los símbolos.

32
Ventana Catálogo
ArcMap, ArcGlobe y ArcScene contienen una ventana Catálogo que se utiliza para organizar
y administrar diversos tipos de información geográfica en colecciones lógicas, por ejemplo,
los datos, mapas y resultados de los proyectos de SIG con los que trabaja en ArcGIS.
La ventana Catálogo proporciona una vista de árbol de las carpetas de archivos y las
geodatabases. Las carpetas de archivos se utilizan para organizar los documentos y archivos
de ArcGIS. Las geodatabases se utilizan para organizar los dataset SIG.

33

34
5. Producción de mapas. Salida gráfica y web.
Un diseño de página (a menudo conocido simplemente como un diseño) es una colección de
elementos de mapa dispuestos y organizados en una página, diseñados para la impresión del
mapa. Elementos de mapa habituales que se disponen en el diseño con uno o varios marcos
de datos (cada uno con un conjunto ordenado de capas de mapa), una barra de escala, la
flecha de norte, el título del mapa, texto descriptivo y una leyenda de los símbolos.
En la vista de composición se agregan al mapa marcos, retículas y otro elementos de acabado
final. Lo que ve en el diseño es lo que obtiene al imprimir o exportar el mapa al mismo tamaño
de página.
En este tema se describen algunas de los conceptos y tareas clave para trabajar con diseños
en ArcMap.
Proceso para trabajar con un diseño
El primer paso en ArcMap es cambiar la vista del mapa a diseño, ya sea seleccionando Vista
de composición de mapa en el menú Vista o haciendo clic en el botón Vista de
composición de mapa en la esquina inferior izquierda de la visualización del mapa.

35
Cuando esté trabajando en la vista de diseño, puede configurar las dimensiones de la página
y empezar a agregar elementos de mapa. Utilice el menú Insertar para seleccionar
elementos de mapa para agregarlos al diseño.
Cuando agregue elementos de mapa, puede editar sus propiedades, tamaño, aspecto, etc. y
organizarlos en la página con otros elementos de mapa. Cuando haya finalizado este trabajo
en el diseño, puede imprimir el mapa o crear otros tipos de formatos de salida: archivos PDF,
archivos PostScript o archivos de Illustrator.
Preguntas a considerar al crear el diseño
He aquí algunas consideraciones de diseño para trabajar con diseños de mapa:
¿El mapa será independiente o formará parte de una serie de mapas que comparten un
diseño similar? Si el mapa tiene varias páginas, debería considerar utilizar páginas
controladas por datos.
¿Qué tamaño tendrá el mapa impreso? Utilice esto para establecer el tamaño de página del
diseño. Encontrará más información al respecto en la sección Establecer el tamaño de página
del diseño de mapa, a continuación.
¿Cómo se orientará la página? Puede utilizar el cuadro de diálogo Configuración de Página e
Impresión para orientar la página en vertical o en horizontal.
¿Cuántos marcos de datos tendrá el mapa?
¿Tendrá el mapa otros elementos tales como título, flecha de norte y leyenda?
¿Contendrá el mapa gráficos o informes para complementar la vista geográfica de los datos?
¿Cómo se indicará la escala en el mapa?
¿Cómo se organizarán los elementos del mapa en la página?
En las siguientes secciones se tratan estos temas con más detalle.
Crear un diseño de mapa
A continuación se indican los pasos generales para diseñar un mapa en ArcMap:
Antes de empezar en ArcMap, es buena idea diseñar la disposición de los elementos en la
página del mapa y planear el diseño.
Empiece por establecer el tamaño de página del diseño y sus dimensiones. Vea Establecer el
tamaño de página del diseño de mapa, a continuación.
Cree, edite y simbolice los datos como resulte adecuado en los marcos de datos.
En la vista de diseño, haga clic en el menú Insertar para agregar elementos al diseño. Si tiene
más de un marco de datos en el mapa, los elementos que inserte estarán relacionados con el
marco de datos activo (para activar un marco de datos, haga clic con el botón derecho en su
nombre y elija Activar).

36
Al agregar elementos de mapa (por ejemplo, una
barra de escala), el mapa refleja las actualizaciones.
Puede seleccionar, recolocar y modificar elementos
del mapa. Haga clic con el botón derecho en un
elemento seleccionado para acceder a su menú de
acceso directo y establecer opciones adicionales.
Agregue otro texto o gráficos, tales como notas,
bordes y marcos, utilizando la barra de
herramientas Dibujar. Puede utilizar guías,
cuadrículas y reglas como ayuda para colocar con
precisión los elementos en la página.
Vea Información general sobre el trabajo con
gráficos para obtener más información.
Imprimir o publicar el mapa. Puede leer más sobre
la impresión en Acerca de la impresión de mapas y
sobre la exportación de mapas en Exportar el mapa.
Configurar el tamaño de página de la composición de mapa
Dado que una composición es el orden de elementos de mapa de varios tipos en una página
para impresión, uno de los pasos iniciales obvios en la construcción de la composición es
establecer el tamaño de página deseado con el cuadro de diálogo Configuración de Página e
Impresión. De manera predeterminada, cuando crea un mapa nuevo en ArcMap y elijeMapa
en blanco, las dimensiones de la composición de página se establecen al tamaño de página
predeterminado de la impresora.
Pasos para configurar el tamaño de la composición de página
Haga clic en Archivo > Configuración de Página e Impresión en el menú principal para abrir
el cuadro de diálogoConfiguración de Página e Impresión.
Puede establecer el tamaño de página de composición como se muestra aquí.

37
De manera predeterminada, el tamaño de página de su composición para un mapa en blanco
se establecerá al tamaño de papel de la impresora (por ejemplo, 8,5 por 11 pulgadas).
Nota:
Es posible que desee cambiar a una impresora de formato grande (graficador) de su
organización. Utilice la lista desplegableNombre para establecer la impresora actual.
Para establecer su propio tamaño de página, desmarque la casilla de verificación Utilice las
propiedades de papeles para impresora para establecer el tamaño de página de su
configuración. Si desmarca esta opción, puede elegir cualquiera de las dimensiones de página
que desee, pero el nombre de la impresora no se guardará en el documento de mapa (.mxd).
Configure el tamaño de página ingresando las dimensiones que prefiere en las
cajas Ancho y Altura.

38
O bien, puede seleccionar un tamaño de página estándar de la lista desplegable Tamaños
estándar, como por ejemplo ANSI C, Architectural D, o ISO A2.
Una vez que cambió el tamaño de página de la composición, deberá cambiar el tamaño de
todos los elementos del mapa y reposicionarlos para que se ajusten a las nuevas dimensiones
de la página. Es necesario hacer esto incluso si está trabajando con un mapa completamente
nuevo y todavía no ha agregado elementos o capas de mapa.
El Tamaño Página de Mapa está vinculado al Tamaño del papel de la impresora actual
siempre que la casilla de verificación Utilice las Propiedades de Papeles para Impresoraesté
seleccionada. De manera predeterminada, esta opción está seleccionada para los mapas
nuevos que se crearon con la opción Mapa en blanco en los cuadros de diálogoNuevo
documento o ArcMap: Introducción . En los ejemplos a continuación, la configuración de la
impresora Tamaño del papel utilizado como la opción predeterminada para ArcMap es de
8,5 x 11 pulgadas. Sin embargo, el Tamaño Página de Mapa se ha desvinculado del tamaño
original de 8,5 x 11 y se ha configurado a una página más grande de 22 x 34. El marco de
datos iniciales se ubicó en la composición basándose en el tamaño de página original, más
pequeño. Entonces, después de cambiar el Tamaño Página de Mapa, deberá utilizar la vista
de composición en ArcMap para volver a ordenar la composición. Reposicione el marco de
datos y los elementos de composición de manera que funcionen bien con el nuevo tamaño
de página.

39
Algunos elementos de mapa están relacionados con los datos de marcos de datos. Las flechas
de norte, barras de escala, texto de escala y leyendas son ejemplos de tales elementos.
Obtenga información sobre otros elementos de mapa, tales como títulos; elementos gráficos,
imágenes y bordes interiores; informes y gráficos.
Cada elemento de mapa tiene un nombre que se utiliza para identificar el elemento. Por
ejemplo, cuando el diseño está en modo de borrador, cada elemento se dibuja como un marco
vacío que contiene el nombre del elemento. De forma predeterminada, el nombre se basa en
el tipo de elemento, tal como Línea de la escala o Flecha de norte, pero puede cambiarlo por
un nombre único o más descriptivo en la ficha Tamaño y Posición del cuadro de
diálogo Propiedades del elemento. El nombre del elemento también es muy importante para
las secuencias de comandos de automatización de mapas que utilizan el
módulo arcpy.mapping. Las secuencias de comandos de automatización de mapas utilizan
los nombres de los elementos para identificar qué elementos modificará la secuencia de
comandos.
La propiedad de nombre de un marco de datos siempre es igual a lo que se muestra en la
tabla de contenido. En consecuencia, al actualizar el nombre dentro del cuadro de
diálogoPropiedades del Marco de datos también se actualizará el nombre en la tabla de
contenido.
Los elementos de mapa no siempre tienen el tamaño que se desea cuando se agregan a un
mapa. Puede cambiar el tamaño de los elementos de mapa seleccionándolos y arrastrando
los controladores de selección. Al arrastrar un controlador alejándolo de un elemento, el
elemento se amplía, mientras que al arrastrar un controlador acercándolo a un elemento, el
elemento se reduce. Solo se puede cambiar el tamaño, la posición y el marco de un elemento
una vez colocado en el mapa. Si hace clic en Propiedades mientras está dentro del cuadro de

40
diálogo de configuración inicial de una barra de escala, por ejemplo, no verá la ficha Tamaño
y Posición ni la ficha Marco.
Flechas de norte
Las flechas de norte indican la orientación del mapa. Un elemento de flecha de norte
mantiene una conexión con un marco de datos. Cuando se gire ese marco de datos, el
elemento de flecha de norte girará con él.
Barras de escala
Las barras de escala proporcionan una indicación visual del tamaño de las entidades y las
distancias entre las entidades en el mapa. Una barra de escala es una línea o una barra
dividida en partes y etiquetada con su longitud sobre el terreno, normalmente en múltiplos
de las unidades del mapa, tales como decenas de kilómetros o centenares de millas. Si se
amplía o se reduce el mapa, la barra de escala continúa siendo correcta.
Al agregar una barra de escala a un mapa, es posible que el número y el tamaño de las
divisiones no sean exactamente los que se desean. Por ejemplo, quizá desee mostrar cuatro
divisiones en lugar de tres o mostrar 100 metros por división en lugar de 200. También es
posible que desee desear cambiar las unidades que muestra la barra de escala o ajustar cómo
se representan esas unidades. Puede ajustar muchas características de una barra de escala
en el cuadro de diálogo Scale Bar Properties.
Al agregar una barra de escala a un mapa, es posible que las etiquetas de número y las marcas
no sean exactamente las que se desean. Por ejemplo, quizá desee etiquetar los extremos de
la barra de escala pero no las divisiones, o marcas mayores en las divisiones principales de
la barra que en las secundarias.
De forma predeterminada, la etiqueta de las unidades de una barra de escala es igual que las
unidades de la barra de escala. En ocasiones, quizá desee cambiar la etiqueta de la barra de
escala, por ejemplo, de Kilómetros a km. Solo tiene que escribir la nueva etiqueta de la barra
de escala en el cuadro de texto Etiqueta.
Texto de escala
También puede representar la escala del mapa con texto de escala. El texto de escala indica
la escala del mapa y las entidades del mapa. El texto de escala indica al lector de un mapa
cuántas unidades de terreno representa una unidad del mapa: por ejemplo, un centímetro
es igual a 100.000 metros.
El texto de escala también puede ser una proporción absoluta independiente de las unidades,
tal como 1:24.000. Esto significa una unidad en el mapa es igual a 24.000 de las mismas
unidades sobre el terreno. La ventaja del texto de escala absoluto es que los lectores del mapa
pueden interpretarlo con cualquier unidad que deseen.
Una desventaja del texto de escala es que si se duplica una copia impresa del mapa en otra
escala (si se amplía o se reduce), el texto de la escala será erróneo. Las barras de escala no
padecen esta limitación. Muchos mapas tienen tanto texto de escala como una barra de z
Leyendas

41
Una leyenda indica al lector del mapa el significado de los símbolos utilizados para
representar las entidades en el mapa. Las leyendas constan de ejemplos de los símbolos del
mapa con etiquetas que contienen texto explicativo. Cuando se utiliza un único símbolo para
las entidades de una capa, la capa se etiqueta con el nombre de la capa en la leyenda. Cuando
se utilizan varios símbolos para representar las entidades en una única capa, el campo
utilizado para clasificar las entidades se convierte en un encabezado en la leyenda y cada
categoría se etiqueta con su valor.
Las leyendas tienen superficies que muestran ejemplos de los símbolos del mapa. De forma
predeterminada, las superficies de la leyenda son puntos, líneas rectas o rectángulos que
coinciden con los símbolos del mapa. Puede personalizar las superficies de la leyenda, por
ejemplo, de modo que las áreas se representen con superficies de otra forma o que los ríos
se dibujen con una línea ondulada en lugar de una línea recta.
Para obtener más información, vea trabajar con formas de superficie de leyenda.
Cuando hay más de un marco de datos, al insertar una leyenda se agrega una leyenda para el
marco de datos seleccionado. Cada leyenda corresponde a un único marco de datos, aunque
es posible disponer varias leyendas juntas como una leyenda única para un mapa complejo.
Puede cambiar el símbolo de texto utilizado por varios elementos de leyenda utilizando la
ficha Elementos del cuadro de diálogo Propiedades de leyenda. Puede cambiar el símbolo de
texto de todos los elementos de la leyenda o solo los seleccionados en la lista. Una lista
desplegable permite elegir las partes de los elementos de la leyenda a los que se desea aplicar
el símbolo de texto. Si desea que la descripción esté en más de una línea, inserte un salto de
línea presionando CTRL+ENTRAR mientras se encuentra en la Descripción del cuadro de
diálogo Leyenda.
Puede editar el texto de las etiquetas que aparecen en la leyenda cambiando el texto en la
tabla de contenido de ArcMap o en la ficha Simbología del cuadro de diálogo Propiedades de
capa. El texto de la leyenda se puede formatear con etiquetas de formato de texto de ESRI.
Si desea que aparezca en la leyenda una descripción adicional de las capas de símbolo único,
elija un estilo de elemento de leyenda que incluya una descripción. Para agregar una
descripción, haga clic con el botón derecho en la capa a la que desee agregar el texto
descriptivo en la tabla de contenido, haga clic en Propiedades y, a continuación, haga clic en
la ficha Simbología en el cuadro de diálogo Propiedades de capa. Si está utilizando el método
de Símbolo único, haga clic en el botón Descripción. Si está utilizando un método de dibujo
diferente de Gráficos, haga clic con el botón derecho en un símbolo tras haber especificado
sus opciones de simbología y haga clic en Editar descripción. El texto que escriba aparecerá
junto a ese símbolo en la leyenda; el texto no aparecerá en la tabla de contenido.
Para obtener más información, vea trabajar con leyendas.
Transparencia en leyendas
Si tiene capas con transparencia en el mapa, ArcMap simulará los colores transparentes en
la leyenda. Cuando las capas de un marco de datos se hacen transparentes, la tabla de

42
contenido y las leyendas de la vista de composición utilizan automáticamente colores más
claros para reflejar la transparencia.
La opción para simular la transparencia en las leyendas se establece en la ficha General del
cuadro de diálogo Propiedades del marco de datos. Cuando esta opción está activada, una
capa dibujada con polígonos sólidos de color rojo brillante aparecerá en la leyenda con un
color rojo claro o rosa, dependiendo del porcentaje de transparencia aplicado a la capa. Sin
embargo, con la opción de simulación de transparencia desactivada, la leyenda continuará
mostrando el símbolo del polígono en rojo, aunque los polígonos no aparezcan en rojo en el
mapa porque la capa es transparente.
De forma predeterminada, esta configuración está desactivada (no marcada) en los mapas
creados con versiones de ArcGIS anteriores a la 9.3, pero puede activarla si lo desea. Esta
configuración se activa automáticamente en los nuevos marcos de datos que se crean en
documentos de mapa existentes.
Además, puede convertir la leyenda en gráficos y especificar manualmente los colores de las
superficies de leyenda. Con la herramienta Identificador de colores, puede obtener el valor
RGB exacto de un píxel y utilizar ese color para la superficie de leyenda.
Marcos
Ciertos elementos de mapa, entre ellos las barras de escala, el texto de escala, las flechas de
norte, las leyendas y los marcos de datos, pueden tener marcos. Los marcos permiten
elegir Borde, Fondo y Sombra para el elemento. Puede utilizar marcos para separar
elementos de mapa de otros elementos o del fondo del mapa. También puede utilizar los
marcos para vincular visualmente elementos de mapa a otras partes del mapa utilizando
marcos similares para los elementos relacionados.
Convertir elementos de mapa en gráficos
Quizá desee convertir un elemento de mapa, tal como una leyenda, en gráficos si desea un
control más preciso sobre cada elemento que compone el elemento de mapa.
Es importante tener en cuenta que una vez convertido un elemento de mapa en un gráfico,
dejará de estar conectado a los datos originales y no responderá a los cambios realizados en
el mapa. Por ejemplo, con un elemento de leyenda, si decide agregar otra capa al mapa una
vez convertida la leyenda en un gráfico, la leyenda no se actualizará automáticamente.
Tendrá que eliminarla y reconstruirla de nuevo utilizando el Asistente de leyenda. Por
consiguiente, es una buena idea no convertir los elementos en gráficos hasta haber finalizado
la simbología y las capas del mapa.
La siguiente imagen muestra una leyenda convertida en un gráfico.

43
Puede desagrupar más los gráficos de leyenda para poder editar los elementos individuales
(las superficies, el texto, etc.) que componen la leyenda.
Impresión del mapa o exportación a otros formatos
A menudo, la impresión de mapas puede ser más compleja que la simple impresión de
documentos de procesamiento de texto o de presentaciones de PowerPoint. Los archivos de
mapa pueden tener tamaños muy grandes y consumir temporalmente grandes espacios del
espacio del disco mientras se realiza la impresión. Además, las dimensiones de la página de
la composición de mapa pueden exceder el tamaño del papel de impresora. Este tema cubre
una serie de consideraciones y opciones disponibles para imprimir mapas en ArcGIS.
Configurar la impresión de mapa para graficadores (impresora de formato grande)
Es probable que su organización SIG tenga impresoras para tamaños de páginas más grandes
que las impresoras de oficina de formato pequeño. Un importante paso inicial será realizar
una referencia a la impresora de formato grande en ArcGIS. Para cambiar la impresora, abra
el cuadro de diálogo Configuración de Página e Impresión y use la lista
desplegableNombre para establecer la impresora actual.
Configurar el tamaño de página de la composición de mapa
Dado que una composición es el orden de elementos de mapa de varios tipos en una página
para impresión, uno de los pasos iniciales obvios en la construcción de la composición es
establecer el tamaño de página deseado con el cuadro de diálogo Configuración de
Página e Impresión. De manera predeterminada, cuando crea un mapa nuevo en ArcMap
y elijeMapa en blanco, las dimensiones de la composición de página se establecen al
tamaño de página predeterminado de la impresora.
Pasos para configurar el tamaño de la composición de página
Haga clic en Archivo > Configuración de Página e Impresión en el menú principal
para abrir el cuadro de diálogoConfiguración de Página e Impresión.
Puede establecer el tamaño de página de composición como se muestra aquí.

44
De manera predeterminada, el tamaño de página de su composición para un mapa en blanco
se establecerá al tamaño de papel de la impresora (por ejemplo, 8,5 por 11 pulgadas).
Nota:
Es posible que desee cambiar a una impresora de formato grande (graficador) de su
organización. Utilice la lista desplegableNombre para establecer la impresora actual.
Para establecer su propio tamaño de página, desmarque la casilla de verificación Utilice las
propiedades de papeles para impresora para establecer el tamaño de página de su
configuración. Si desmarca esta opción, puede elegir cualquiera de las dimensiones de página
que desee, pero el nombre de la impresora no se guardará en el documento de mapa (.mxd).
Configure el tamaño de página ingresando las dimensiones que prefiere en las
cajas Ancho y Altura.

45
O bien, puede seleccionar un tamaño de página estándar de la lista desplegable Tamaños
estándar, como por ejemplo ANSI C, Architectural D, o ISO A2.
Una vez que cambió el tamaño de página de la composición, deberá cambiar el tamaño de
todos los elementos del mapa y reposicionarlos para que se ajusten a las nuevas dimensiones
de la página. Es necesario hacer esto incluso si está trabajando con un mapa completamente
nuevo y todavía no ha agregado elementos o capas de mapa.
El Tamaño Página de Mapa está vinculado al Tamaño del papel de la impresora
actual siempre que la casilla de verificación Utilice las Propiedades de Papeles para
Impresoraesté seleccionada. De manera predeterminada, esta opción está seleccionada
para los mapas nuevos que se crearon con la opción Mapa en blanco en los cuadros de
diálogoNuevo documento o ArcMap: Introducción . En los ejemplos a continuación,
la configuración de la impresora Tamaño del papel utilizado como la opción
predeterminada para ArcMap es de 8,5 x 11 pulgadas. Sin embargo, el Tamaño Página de
Mapa se ha desvinculado del tamaño original de 8,5 x 11 y se ha configurado a una página
más grande de 22 x 34. El marco de datos iniciales se ubicó en la composición basándose en
el tamaño de página original, más pequeño. Entonces, después de cambiar el Tamaño
Página de Mapa, deberá utilizar la vista de composición en ArcMap para volver a ordenar
la composición. Reposicione el marco de datos y los elementos de composición de manera
que funcionen bien con el nuevo tamaño de página.

46

47
6. Análisis Ráster
6.1. Introducción
En los SIG ráster se compartimenta el espacio en una serie de elementos discretos
por medio de una retícula regular. Habitualmente se trata de una retícula rectangular
compuesta por celdas cuadradas, si bien algunos sistemas utilizan otras figuras geométricas
como los triángulos o los hexágonos. Cada una de esas celdas se considera como indivisible
y es identificable por su número de fila y columna. Conviene señalar que se emplea
indistintamente el nombre de celda o de pixel (abreviatura de la expresión inglesa picture
element, es decir, elemento de dibujo). En cuanto a la información temática, a cada celda le
corresponde un único valor relativo a la variable que se está representando (altitud, uso del
suelo, materiales geológicos...).
El conjunto de la retícula sería comparable a un mosaico, en el que cada celda
equivaldría a una tesela. Dado que todas las celdas son iguales, se dice que el modelo raster
se basa en teselaciones regulares, frente a lo que ocurre en las capas de polígonos en el
modelo vectorial (teselaciones irregulares). Por el hecho de basarse en una teselación, el
modelo raster cubre todo el espacio, sin dejar huecos, lo que no ocurre necesariamente en el
modelo vectorial.
Algunos conceptos básicos:
Término Descripción
Ráster
Un modelo de datos espaciales que define el espacio como un conjunto de
celdas del mismo tamaño, ordenadas en filas y columnas y compuestas
por bandas únicas o múltiples (capas). Cada celda contiene un valor de
atributo. A diferencia de una estructura de vector, que guarda
explícitamente las coordenadas, las coordenadas ráster se guardan
intrínsecamente en el orden de la matriz. Los grupos de celdas que
comparten el mismo valor representan el mismo tipo de entidad
geográfica.

48
Celda
Una celda es la unidad de información más pequeña en datos ráster. Cada celda
representa el valor numérico de alguna medida en la ubicación del área de
unidad correspondiente en la tierra.
Las celdas normalmente tienen forma cuadrada. El área que cada celda
representa depende de la resolución del ráster. Las celdas ráster de alta-
resolución (en gran escala) representarían áreas pequeñas, medidas en
unidades tan pequeñas como metros cuadrados. Las celdas en un ráster de
resolución más baja (pequeña escala) representan el valor uniforme de un área
más grande, como hectáreas o kilómetros cuadrados.
Imagen
Un dataset de ráster generado al digitalizar una superficie con un dispositivo
óptico o electrónico. Entre los ejemplos comunes se incluyen documentos
digitalizados, datos de detección remota (por ejemplo, imágenes de satélite) y
fotografías aéreas. Una imagen se almacena como un dataset de ráster de
valores binarios o enteros que representa la intensidad de luz reflejada, calor u
otro intervalo de valores en el espectro electromagnético.
Píxel
La unidad más pequeña de información en una imagen o mapa de ráster,
normalmente cuadrados o rectangular. El término píxel se utiliza a menudo
como sinónimos de celda.
Análisis
basado en
celda
En el análisis basado en celdas, cada ubicación es un valor en un dataset
ráster y las distintas herramientas generan un ráster de salida basado en
la aplicación de algunas reglas matemáticas, espaciales o algorítmicas a
los valores de celda de entrada.
Análisis
espacial
El proceso de examen de las ubicaciones, los atributos y las relaciones de
las entidades en los datos espaciales por medio de la superposición y otras
técnicas analíticas para tratar una duda o ganar en conocimiento práctico.
El análisis espacial extrae o crea nueva información a partir de los datos
espaciales.
Modelado
espacial
Una metodología o conjunto de procedimientos analíticos usados para
derivar información acerca de las relaciones espaciales entre fenómenos
geográficos.
Clasificación
de imágenes
El proceso de ordenar u organizar los píxeles de una imagen en clases o
clústeres. Dependiendo de la interacción entre el analista y el equipo, existen
dos tipos de clasificación de imágenes: clasificación supervisada y clasificación
sin supervisión.
Clasificación
supervisada
Un enfoque de clasificación de imágenes basado en los ejemplos de formación
recopilados por el analista. Los ejemplos de formación "enseñan" al software
cómo clasificar el resto de los píxeles de la imagen.
Clasificación
sin
supervisión
Un enfoque de clasificación de imágenes que ordena los píxeles de la imagen en
clústeres sin la intervención del analista. El proceso se basa únicamente en la
distribución de valores de píxeles en un espacio de atributos multidimensional.

49
Clase Un grupo de píxeles de una imagen que representa el mismo objeto en la
superficie de la tierra.
Clúster
Un grupo de píxeles que se puede distinguir en un espacio de atributos
multidimensional. Un clúster es similar a una clase solo que el objeto de base
que representa es desconocido cuando se realiza el análisis de clustering.
6.2. Visualización
En un SIG raster convencional a cada celda le corresponde un valor único en cada
capa. Si, para la visualización de los datos, se asigna un color a cada uno de esos valores, cada
celda aparecerá representada mediante ese color, conformándose un mapa raster
característico. El aspecto del mapa resultante depende del número de celdas: si es lo
suficientemente alto puede no llegar a percibirse que se trata de una imagen raster, pero el
mapa tarda más tiempo en desplegarse sobre la pantalla y, sobre todo, se hace un uso más
intensivo de los recursos del ordenador al efectuar cualquier operación.
Cuando la variable representada es cualitativa, el número de clases que puede tomar
la variable suele ser relativamente reducido y los valores con que se codifican esas clases son
números enteros. Entonces a cada uno de esos valores se le asigna un determinado color. Esa
asignación se hace de acuerdo con una paleta de color, en la que simplemente se indica el
color que corresponde a cada número. Por ejemplo, las celdas que registren el valor 1 se
representan en rojo; en azul las que tienen el 2, y así sucesivamente. Por supuesto siempre
debe haber una leyenda que explique a qué clase corresponde cada color, así como un título
indicativo del contenido del mapa.
Cuando la variable es cuantitativa puede tomar un número elevadísimo de valores.
En tales casos se deben agrupar los valores en intervalos. Esta operación de agrupación de
valores en intervalos se puede hacer de forma automática cuando se requiere visualizar el
mapa o previamente mediante los procedimientos de agrupación (reclasificación). De esta
forma, a cada intervalo le corresponderá un color de acuerdo con la paleta elegida.
La elección de una paleta de color adecuada a cada variable es esencial a la hora de
visualizar mapas. Si la variable es cualitativa, los colores de la paleta simplemente deben
reflejar los convencionalismos cartográficos: en el caso del uso del suelo, las láminas de agua
se representan en azul, los bosques en verde, los cultivos en tonos pardos, etc. Pero si la
variable es cuantitativa, debe existir una gradación progresiva en las tonalidades del color
que indique de forma expresiva si nos encontramos ante valores altos o bajos. Los colores
que figuren en los extremos pueden responder también a convencionalismos. Así, por
ejemplo, en un mapa de temperaturas se puede emplear una rampa de color que vaya desde
el rojo (para las zonas más cálidas) hasta el azul (para las más frías).

50
6.3. Operaciones Locales
Algunas de las operaciones que realizan los SIG raster no tienen en cuenta la relación
de cada celda con las demás, sino que cada celda se considera aisladamente. Se trata de
obtener un nuevo mapa en el que el valor de cada celda depende de los datos asociados a esa
celda. En este sentido se pueden diferenciar dos posibilidades:
1- Que las operaciones para generar los nuevos valores se basen en los valores
existentes en una sola capa (operaciones de recodificación o reclasificación).
2- Que dichas operaciones se basen en los valores existentes en varias capas, que
son combinados celda a celda (operaciones de superposición de mapas).
En la práctica es muy frecuente que ambas operaciones (reclasificación y
superposición) se ejecuten sucesivamente, ya que uno de los tipos de superposición (la
superposición lógica) exige partir de mapas binarios, que se obtienen previamente mediante
operaciones de reclasificación.
7.3.1 Reclasificación
Se trata de una operación local a partir de una capa o mapa fuente. Por lo tanto, a
partir del valor de cada celda en el mapa fuente se obtiene el valor que corresponde a esa
misma celda en el mapa resultante. Antes de recodificar una variable debe considerarse su
naturaleza, ya que algunas operaciones de reclasificación pueden no tener sentido ante
determinados tipos de variables. Existen básicamente los siguientes tipos de reclasificación:
A) En variables cualitativas
1- Recodificación de clases.- Consiste en recodificar las clases del mapa fuente una
por una. Así, por ejemplo, en un mapa de usos del suelo de una región pueden
existen 70 clases y, sin embargo, en la hoja con la que nosotros trabajamos sólo
aparecen 5: las clases 23, 35, 50, 54 y 59. Para generar cartografía puede tener
sentido recodificar esas clases con las nuevas etiquetas de 1, 2, 3, 4 y 5.
2- Agregación de clases.- La agregación de clases es una operación importante
desde el punto de vista de lo que se conoce como generalización cartográfica. Se
trata de agrupar las clases del mapa fuente y asignar nuevos códigos a las clases
resultantes.
B) En variables cuantitativas
1- Agrupación de los valores en intervalos.- Consiste en agrupar los valores de una
variable cuantitativa de acuerdo con unos intervalos previamente definidos por
el usuario o calculados automáticamente por el sistema.
2- Operaciones matemáticas.- Los valores del mapa final se obtienen a partir de los
valores del mapa original, mediante una ecuación que puede incluir cualquier

51
función matemática (suma, resta, multiplicación, división, potencias, raíces,
etc.) o trigonométrica.
7.3.2 Superposición de mapas
Se trata de una operación local a partir de dos o más mapas fuente: el valor de cada
celda en el mapa final depende de los valores de esa misma celda en los mapas fuente.
Los valores de los mapas fuente se pueden combinar por medio de operaciones
aritméticas o utilizando condiciones lógicas, lo que da lugar a la diferenciación de dos tipos
de superposición de mapas:
A) Superposición lógica
Se trata de encontrar las áreas donde se cumplen unas determinadas condiciones
lógicas. Pongamos un ejemplo. En una determinada zona, un constructor puede tener interés
en identificar áreas aptas, desde el punto de vista físico, para la edificación de viviendas, para
lo contempla dos condiciones: que el terreno sea lo suficientemente resistente y que la
pendiente no sea excesiva. Se considera que de las litologías existentes en la zona (arcillas,
calizas, margas y yesos) son adecuadas para la construcción las tres primeras; en cuanto a
las pendientes, se consideran aptas aquellas que no superan el 10%. Mediante la
superposición de ambos mapas el sistema debe ser capaz de determinar dónde se cumplen
ambas condiciones.
Como se trata de una operación de superposición lógica, los mapas fuente deben ser
binarios.
En la superposición lógica se utilizan las operaciones de lógica booleana: el Y (AND)
lógico y el O (OR) lógico.
1- Y lógico.- Se trata de identificar las áreas en las que se cumplen ambas
condiciones (la primera Y la segunda). En tal caso la operación de superposición
se lleva a cabo multiplicando los valores de las dos capas celda a celda. El
resultado es un mapa en el que muestran el valor 1 las celdas donde se cumplen
las dos condiciones y el valor 0 las celdas donde no se cumple ninguna de las
dos o sólo se cumple una.
2- O lógico.- Se trata de identificar las áreas donde se cumple una de las dos
condiciones (la primera O la segunda). Cuando de lo que se trata es de conocer
las celdas donde se cumplen alguna de las dos condiciones (la primera O la
segunda), la superposición se lleva a cabo sumando los valores de las dos capas,
celda a celda. El mapa resultante muestra el valor 2 donde se cumplen ambas
condiciones, el 1 donde sólo se cumple una de ellas y el 0 donde no se cumple
ninguna. Si de lo que se trata es de conseguir un mapa binario, dado que tanto
en el valor 1 como en el 2 se cumplen alguna de las dos condiciones, sería

52
necesario reclasificar los valores: el 1 y el 2 se codifican como 1 (se cumple
alguna de las dos condiciones) y el 0 se mantiene como 0 (no se cumple ninguna
de las dos).
B) Superposición aritmética
En este caso se trata de combinar dos o más capas, celda a celda, mediante una
ecuación matemática. En estas ecuaciones puede incluirse cualquier tipo de operación
matemática: suma, resta, multiplicación, división, raíces, potencias, funciones
trigonométricas...
En ArcGIS, la herramienta Calculadora ráster ejecuta las expresiones del Álgebra de mapas.
La herramienta tiene una interfaz de calculadora fácil de utilizar desde la cual se crean la
mayoría de declaraciones del Álgebra de mapas simplemente al hacer clic en los botones. La
Calculadora ráster se puede utilizar como una herramienta independiente, pero también en
ModelBuilder. Como resultado, la herramienta permite integrar la potencia del Álgebra de
mapas en el ModelBuilder.
C) Combinación de celdas
Se trata de cruzar los valores de dos capas para obtener las correspondientes
combinaciones (equivalentes a tabulaciones cruzadas en estadística). Si, por ejemplo, una
capa contiene los valores del 1 al 3 (intervalos de pendiente: débil, media y fuerte) y otra los
valores del 1 al 2 (cultivos y bosques), se obtendrán todos los cruces: 1-1 (pendiente débil
sobre cultivos), 1-2 (pendiente débil sobre bosque), 2-1 (pendiente media sobre cultivos), 2-
2 pendiente media sobre bosque), etc.

53
6.4. Operaciones de vecindad inmediata
Son operaciones en las que el valor de una celda en un nuevo mapa está en función
de los valores de las celdas situadas en su vecindad inmediata, es decir, las celdas contiguas
a ella, ya sea a través de un lado o a través de un vértice común.
7.4.1 Pendientes y orientaciones
A partir de una capa en la que se registra la altitud de cada celda (un modelo digital
del terreno ráster) es posible calcular automáticamente el valor de las pendientes y su
orientación. Se trata de una operación de vecindad inmediata: se trabaja con ventanas de 3
x 3 celdas de manera que el valor de la celda central de la ventana se obtiene a partir del
cálculo del valor de las pendientes existentes entre esa celda y las celdas vecinas. El valor y
la orientación de las pendientes son variables utilizadas en multitud de aplicaciones (pautas
de distribución de la vegetación, modelos de erosión, delimitación de cuencas hidrográficas,
capacidad de acogida de nuevos usos, etc.). Por otro lado, la orientación de las pendientes
permite conocer la dirección del flujo del agua sobre la superficie de la tierra y, en
consecuencia, delimitar cuencas de drenaje.
Pendientes.- Existen distintas soluciones para generar un mapa de pendientes a
partir de un mapa de altitudes en un SIG raster. La más sencilla y usual es la siguiente: se
calcula el valor de las pendientes existentes entre la celda central y sus ocho celdas vecinas,
y se toma el mayor de esos ocho valores (o la media aritmética de los ocho). Para este cálculo
es necesario conocer no sólo la diferencia altitudinal entre las celdas, sino también la
distancia en la horizontal. La distancia en la horizontal se mide sobre el centro de las celdas
y varía según se trate de celdas contiguas por sus lados o por sus vértices. En el primer caso
la distancia coincide con la resolución: si la resolución es de 100 x 100 metros, la distancia
entre las celdas contiguas por sus lados será lógicamente de 100 metros. En el segundo caso
la distancia es aproximadamente 1,4 veces mayor que en el primero: en consecuencia, con
esa resolución de 100 x 100 metros, la distancia entre celdas contiguas por sus vértices será
de 140 metros. Si se quiere calcular el valor de la pendiente en tantos por ciento, se utiliza
una sencilla regla de tres, para expresar la diferencia altitudinal como porcentaje de la
distancia en la horizontal. En el caso de que se quiera medir la pendiente en grados se utiliza
un sencillo cálculo trigonométrico.
Orientación.- El concepto de orientación de las pendientes se refiere al punto
cardinal hacia el que éstas están inclinadas y, en consecuencia, hacia dónde vierten las aguas
de lluvia. De ahí que la delimitación de cuencas de drenaje se efectúe a partir de mapas de
orientación de las pendientes. La orientación de las pendientes se obtiene mediante cálculos
trigonométricos. El resultado es un valor en grados que expresa el ángulo formado entre el
punto cardinal hacia el que está orientada la pendiente y el norte. Así, por ejemplo, una
pendiente orientada hacia el este tendrá un valor de 90 grados, de 180 si está orientada hacia
el sur, etc. También puede expresarse de forma cualitativa por aproximación al punto
cardinal al que esté más próximo su valor en grados (noreste, suroeste, etc.).

54
Cálculo de Pendientes (Slope) Cálculo de Orientaciones del terreno (Aspect)
Sombreado del relieve. Esta es una técnica cartográfica clásica, según la cual se
supone que existe un foco luminoso, generalmente en el noroeste y con un ángulo de 45
grados sobre la horizontal, que ilumina la superficie representada en el mapa produciendo
un efecto de sombreado: las celdas, de acuerdo con su pendientes y orientación, reciben los
rayos de luz con mayor o menor intensidad o incluso quedarán en sombra. El resultado es
un nuevo mapa cuyos valores expresan distintas intensidades de iluminación.
Sombreado del relieve (Hillshade)
7.4.2 Análisis de las cuencas de drenaje
Sobre el mapa de orientación de las pendientes se puede determinar hacia qué celda de las
ocho vecinas vierte el agua de lluvia que cae sobre una celda dada. Si la orientación de la
pendiente en esa celda es la sur, el agua de escorrentía de esa celda se dirigirá hacia la celda
vecina del sur. En el caso de que la orientación se exprese en grados, el flujo se producirá
hacia la celda que se encuentre en el punto cardinal cuyo valor se aproxime más al valor de
la orientación de la pendiente. Así, por ejemplo, si el valor de la orientación es de 85 grados,
el valor del punto cardinal más próximo es el del este (90 grados), por lo que se asume que
el agua fluirá hacia la celda contigua en dirección este. Esta operación debe realizarse para
cada celda, de manera que finalmente se pueda conocer la dirección del flujo en todas las
celdas del mapa. Una vez finalizado este proceso, el SIG puede determinar qué celdas vierten
el agua de escorrentía hacia una celda o celdas dadas y delimitar cuencas de drenaje.

55
También se puede calcular el flujo acumulado sobre una celda dada en función de la cantidad
de agua que aportan las celdas que directa o indirectamente vierten sobre ella.
Representación de las cuencas hidrológicas:
Representación de cuenca hidrológica y sistema de cuencas hidrológicas
7.4.3 Distancias euclidianas
En un sistema raster se pueden generar distintos tipos de mapas basados en las
distancias entre celdas. Los resultados dependen del concepto de distancia con que se
trabaje. En ocasiones es suficiente con utilizar simplemente la distancia euclidiana, es decir,
en línea recta.
Mapas de distancias euclidianas
En un mapa raster es posible, en base a la resolución, medir la distancia
euclidiana entre una celda (o zona) dada y cada una de las celdas restantes. El resultado es
un mapa de distancias, en el que en cada celda se almacena el valor de distancia hasta la celda
o zona dada.
Supongamos que la resolución es de 30 x 30 metros. La medición de las
distancias en el caso de celdas que se encuentran en la misma fila o columna es directa: habrá
que multiplicar el número de filas o columnas de diferencia por la resolución. Así, si nos
mantenemos en la primera fila, la primera celda se encuentra a 30 metros de distancia con
respecto a la segunda, a 60 metros con respecto a la tercera y así sucesivamente. En el caso
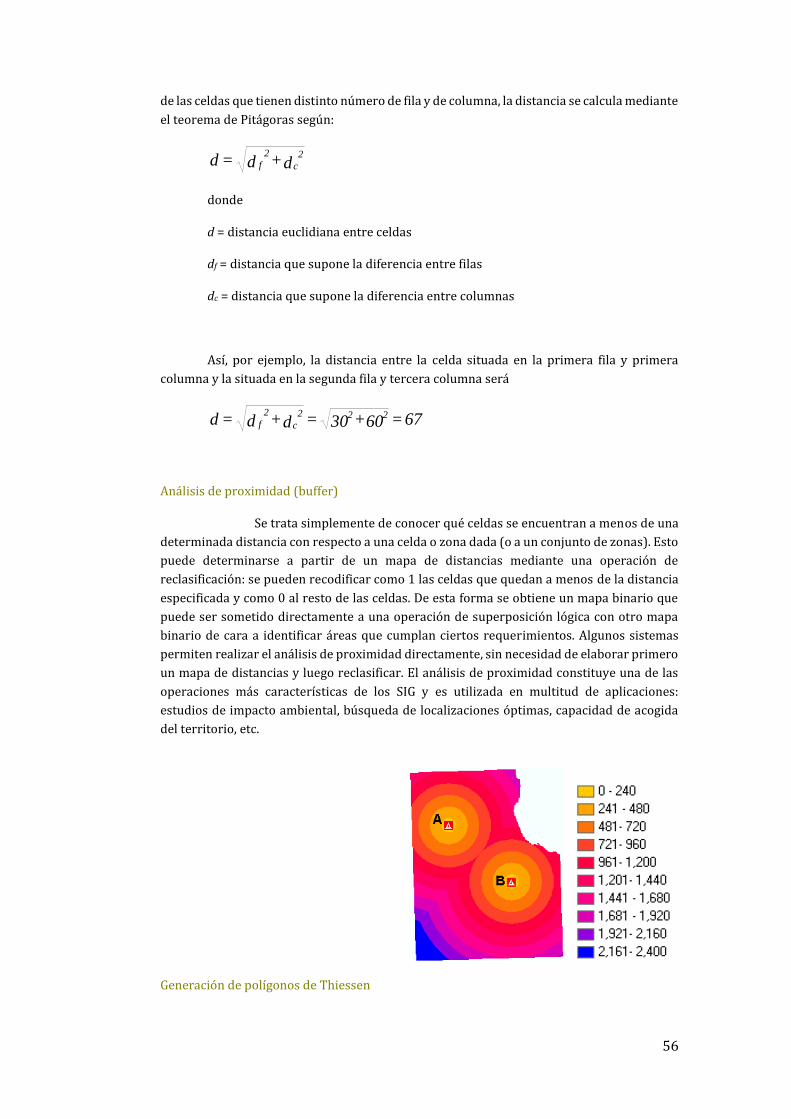
56
de las celdas que tienen distinto número de fila y de columna, la distancia se calcula mediante
el teorema de Pitágoras según:
d+d=d c
2f
2
donde
d = distancia euclidiana entre celdas
df = distancia que supone la diferencia entre filas
dc = distancia que supone la diferencia entre columnas
Así, por ejemplo, la distancia entre la celda situada en la primera fila y primera
columna y la situada en la segunda fila y tercera columna será
67=60+30=d+d=d 22c
2f
2
Análisis de proximidad (buffer)
Se trata simplemente de conocer qué celdas se encuentran a menos de una
determinada distancia con respecto a una celda o zona dada (o a un conjunto de zonas). Esto
puede determinarse a partir de un mapa de distancias mediante una operación de
reclasificación: se pueden recodificar como 1 las celdas que quedan a menos de la distancia
especificada y como 0 al resto de las celdas. De esta forma se obtiene un mapa binario que
puede ser sometido directamente a una operación de superposición lógica con otro mapa
binario de cara a identificar áreas que cumplan ciertos requerimientos. Algunos sistemas
permiten realizar el análisis de proximidad directamente, sin necesidad de elaborar primero
un mapa de distancias y luego reclasificar. El análisis de proximidad constituye una de las
operaciones más características de los SIG y es utilizada en multitud de aplicaciones:
estudios de impacto ambiental, búsqueda de localizaciones óptimas, capacidad de acogida
del territorio, etc.
Generación de polígonos de Thiessen

57
Los polígonos de Thiessen se generan a partir de un conjunto de puntos
previamente definidos (en su caso representados mediante celdas), de forma que cada celda
queda asignada al punto más próximo a ella. Lógicamente resultan tantos polígonos (zonas)
como puntos se hayan fijado previamente. El resultado final es una división del espacio en
polígonos que recibe el nombre de teselación Voronoi, en la que los límites entre los
polígonos son equidistantes con respecto a los puntos vecinos. Cada uno de esos polígonos
es realmente una zona, que se puede reconocer por el hecho de que sus celdas presentan un
mismo valor.
Los polígonos de Thiessen tienen una amplia aplicación en estudios sobre
áreas de influencia de centros de servicio (oficinas administrativas, bancos, bibliotecas,
estaciones de metro, etc.), especialmente cuando se consideran movimientos peatonales. El
polígono generado a partir de un determinado centro englobaría todas aquellas
localizaciones (celdas) para las que ese centro es el más próximo. Si se dispone de la
distribución de la población en otra capa, se puede calcular cuál es la demanda potencial de
cada centro.
Figura: Poligonos de Thiessen
También se puede recurrir a una teselación Voronoi cuando se trabaja con datos
muestrales y se desconoce cuál es el valor de la variable en cuestión en un punto diferente al
muestral. Por ejemplo, si se han tomado un conjunto de muestras para medir el Ph del suelo,
el valor de cada punto muestral se asigna a todas las celdas del polígono, es decir, el pH de
cualquier celda del polígono se considera igual al del correspondiente punto muestral.
7.4.4 Superficies de fricción
Hasta aquí se ha tratado exclusivamente de distancias euclidianas. Pero en multitud
de ocasiones esta medida de la distancia resulta poco realista, ya que el espacio no es
isotrópico. Por el contrario, el efecto de fricción de la distancia (o si se prefiere, la resistencia
al desplazamiento por el espacio) varía en función de distintos criterios, como el tipo de
relieve, la existencia de láminas de agua, etc. Estas características pueden ser tenidas en
cuenta en el cálculo de los mapas de costes y en los análisis de proximidad. Para ello se debe
especificar en una nueva capa cuál es el coste (el efecto de fricción) asociado a cada celda. Si
existe un área que no puede ser atravesada por constituir una barrera absoluta al
movimiento, a las celdas correspondientes a ese área se les debe asignar un coste de

58
transporte tan elevado que en la práctica se comporten como si se tratara de barreras
absolutas.
Mapas de costes y análisis de proximidad
En este caso se utiliza como distancia base no la euclidiana, sino la que resulta de
atravesar sucesivamente celdas contiguas: si el movimiento se produce por los lados, la
distancia equivale a la resolución; si se produce por los vértices, equivale a la resolución
multiplicada por 1,4. Para tener en cuenta las características del territorio, cada paso de
una celda a otra se pondera en función del valor que tienen las celdas en la superficie de
fricción. De esta forma, se produce una distorsión en las aureolas que se generan al
calcular los costes con respecto a una celda o punto dado y al hacer un análisis de
proximidad sobre esos datos.
Cálculo de caminos mínimos
Sobre los datos de la superficie de fricción también es posible calcular el camino
mínimo entre dos celdas o grupos de celdas. El sistema es capaz de encontrar la ruta
óptima de forma que se minimicen los costes mediante un procedimiento semejante al
que se ha indicado para la generación de los mapas de costes, pero en este caso el
resultado es un conjunto de celdas alineadas que marcan el camino óptimo y que se
diferencian de las demás mediante un código (por ejemplo, el 1). Esta funcionalidad es
extraordinariamente útil para el trazado de infraestructuras lineales. Así, por ejemplo,
el SIG puede determinar cuál es el trazado óptimo de una carretera teniendo en cuenta
criterios como el uso del suelo, las pendientes, la excavabilidad de las rocas, etc. De esta
forma se puede elegir un trazado que, siendo respetuoso con el medio ambiente,
minimice los costes de expropiación y de construcción.
Raster representando costes de viaje
acumulado
7.4.5 Análisis de intervisibilidad

59
A partir de un mapa de elevaciones del terreno es posible determinar qué celdas son
visibles y no visibles desde una determinada celda (punto) o grupo de celdas (o puntos). El
resultado es un mapa en el que se diferencian las primeras de las segundas mediante un
determinado código (por ejemplo, 1 para las áreas visibles y 0 para las no visibles), de forma
que se delimitan cuencas visuales de forma automática. Para ello el sistema traza líneas de
visión en todas direcciones, de forma que puede determinar si dos celdas son visibles entre
sí o si por el contrario existe algún obstáculo entre ellas que impide la intervisibilidad.
Esta funcionalidad es de gran interés en la búsqueda de localizaciones óptimas en
las que la variable visibilidad sea decisiva: en unos casos se deben buscar puntos visibles
desde amplias zonas circundantes (torretas de incendios, emisoras de radio); en otros se
trata exactamente de lo contrario, es decir, de ocultar instalaciones ya sea porque produzcan
un impacto visual negativo sobre el paisaje (una fábrica de cemento) o por necesidades
estratégicas en el campo militar. Por otro lado, la delimitación de cuencas visuales constituye
un elemento esencial en los modelos de difusión de las ondas sonoras.
7.4.6 Estadísticas de zonas
Se trata simplemente de efectuar cálculos sobre una capa en función de las zonas (celdas con
un mismo valor) de otra capa. Lógicamente la primera es cuantitativa (como la altitud) y la
segunda cualitativa (como uso del suelo). Así, por ejemplo, se le puede pedir al sistema que
calcule la altitud media según usos del suelo.

60
7. Análisis Vectorial
8.1 Presentación de la información
En diferentes ocasiones el usuario de un SIG necesita presentar la información, ya
sea simplemente la información que se ha cargado en el sistema o los resultados de un
análisis previamente efectuado. En un sistema vectorial la presentación de los datos se puede
realizar de distintas formas:
- En unos casos puede interesar exclusivamente presentar la geometría y la
topología de los objetos almacenados en la base de datos, es decir, centrarse en la
componente espacial de los datos (por ejemplo, mostrar un mapa de carreteras con los arcos
que representan sus distintos tramos y los nodos que representan las intersecciones).
- En otros casos el usuario requiere del sistema que presente exclusivamente
información temática (por ejemplo, un listado y un histograma con las intensidades medias
diarias de los distintos tramos).
- Finalmente, en otros casos, el usuario desea una presentación de información
espacial y temática de forma simultánea (por ejemplo, un mapa en el que se representan las
intensidades medias de los distintos tramos por medio de líneas de diferente grosor).
Evidentemente la forma más característica de presentación de la información en un
SIG es esta última, ya que supone la combinación de las componentes temática y espacial.
Pero en la corrección de errores de digitalización es muy habitual trabajar con mapas que
muestran exclusivamente la geometría de los objetos; asimismo, en la corrección de errores
de la componente temática es muy frecuente utilizar listados.
Los sistemas vectoriales tienen una serie de utilidades que permiten confeccionar
mapas de alta calidad: paletas de color y de tramas, símbolos, posibilidad de representación
de una o más variables al mismo tiempo, escala gráfica, tipos de letras distintos para los
títulos y la leyenda, etc. Los mapas pueden ser presentados en la pantalla o impresos en papel
mediante periféricos de distintos tipos (ver anexo 2).
A) Mapas de puntos
Cuando los objetos espaciales de una capa son puntos, sus atributos se
pueden representar de distinta forma. Si la variable es cualitativa, se suelen utilizar signos
distintos para señalar la presencia de distintos tipos de entidades (por ejemplo, tipos de
comercios) o un mismo signo con distintos colores.
En el caso de las variables cuantitativas, se suelen producir mapas en los que los objetos
puntuales se representan mediante círculos proporcionales: el tamaño del círculo es
proporcional al valor que registra el objeto puntual en la variable en cuestión.
Evidentemente se pueden combinar en un mismo mapa criterios cualitativos y cuantitativos

61
(colores para indicar los tipos de comercios y círculos proporcionales para señalar el número
de sus empleados).
B) Mapas de líneas
Los objetos lineales se representan en mapas de líneas de distintos colores
o anchura. La primera solución se suele utilizar en el caso de variables cualitativas (por
ejemplo, tipos de carretera) y la segunda en el caso de las variables cuantitativas (por
ejemplo, intensidades medias de tráfico). Nada obsta para que ambas técnicas de
representación gráfica (colores y anchura de las líneas) se utilicen para representar una sola
variable o dos variables al mismo tiempo. Así, por ejemplo, el tipo de carretera (que es
realmente una variable semicuantitativa, ya que implica una jerarquización) se puede
representar mediante la combinación de líneas de distinto ancho y color.
Un caso especial lo constituyen los mapas de isolíneas. Estos se obtienen a
partir de mapas de puntos, mediante procedimientos de interpolación que se llevan a cabo
de forma automática en el SIG. La estructura de datos TIN resulta muy adecuada para este
fin (ver subapartado 3.3.2). Así, por ejemplo, en algunos sistemas a partir de una capa de
puntos con sus respectivas altitudes se puede generar automáticamente una estructura TIN
y producir después un mapa de curvas de nivel por medio de la interpolación de los valores
contenidos en los nodos de los triángulos. Los puntos en el mapa original pueden estar
distribuidos regular o irregularmente. Conviene señalar que existen distintas funciones de
interpolación, que resultan más o menos adecuadas al tipo de variable que se representa. Las
más comunes se basan en el cálculo de la media de los valores de los puntos vecinos o en
medias ponderadas donde los pesos son inversamente proporcionales a la distancia
(Aronoff, 1989).
C) Mapas de polígonos
En los mapas de polígonos se suelen utilizar colores o tramas, pudiendo
combinarse ambas técnicas en un mismo mapa. En la elección del color (y de las tramas) son
aplicables los mismos criterios que ya se expresaron para la presentación de los mapas
raster (apartado 4.2.1).
D) Mapas de superficies y generación de perfiles
Un caso especial lo constituyen los mapas tridimensionales generados a
partir de estructuras como la TIN. El efecto es semejante al que se consigue con los mapas
raster en tres dimensiones, sólo que con la estructura TIN se puede conseguir un modelo
más preciso de la realidad al basarse en una red de triangulación irregular. La representación
de otra variable (como el uso del suelo) por medio de colores sobre un mapa tridimensional
produce un efecto de gran expresividad. Al igual que en el modelo raster, también es posible
generar perfiles topográficos a partir de la definición de una línea de corte sobre un modelo
digital del terreno.

62
E) Tablas y resúmenes numéricos
La base de datos alfanumérica puede ser tratada con un sistema gestor de
bases de datos para obtener tablas y estadísticas básicas (valor máximo, mínimo, media,
desviación típica, etc.) o para seleccionar valores en función de ciertas condiciones lógicas.
En general las operaciones de análisis estadístico que se pueden realizar en un SIG son muy
elementales, pero siempre existe la posibilidad de exportar los datos sobre atributos a un
paquete de análisis estadístico (como BMDP, SPSS, SAS, Statgraphics, etc.).
8.2 Operaciones con capas
Podemos distinguir entre:
Operaciones para «preparar las capas»:
• Merge (fusión)
• Dissolve
• Clip (recortar) / Split
Operaciones de superposición:
• Erase / Update
• Identity / Interset / Unión
• Symmetrical Deifference
Merge
Para capas contiguas, normalmente hojas en una serie de mapas, permite fusionarlas en una
única capa.

63
Dissolve
Se funcionan figuras que comparten un mismo atributo, combinando elementos adyacentes
de acuerdo a un campo de la tabla de atributos, es decir los disuelve en una sola área. Trabaja
con polígonos y línea. Es ideal para trabajar en elaboración de mapas temáticos con la
finalidad de reducir categorías
Clip
Se limita la información de una capa a un área especifico, de acurdo a un molde, se trabaja
con líneas, puntos y polígono.
Multipart to singlepart
Individualiza los elementos presentes en el archivo. Se usa para puntos, líneas o polígonos.

64
Unión
Combina la geometría y los datos de todas las capas y la convierte en una sola capa. Se usa
solo para polígonos.
Erase
Una capa le borra su área a otra, se utiliza para polígonos.
Intersect
Se cruzan dos capas generando sólo las áreas comunes.

65
Identidy
Se cruzan dos capas y las proporciones comunes en la capa de entrada adquieren los
atributos de la capa que se sobrepone.
8.3 Unión de objetos por atributos
Las operaciones de reclasificación, disolución y fusión se utilizan de forma sucesiva
para agregar objetos poligonales a partir de un atributo determinado. El resultado final es
un mapa más general que el anterior, tanto en lo que se refiere a la información cartográfica
(menor número de objetos) como al atributo temático considerado (menor número de
valores posibles).
- La operación de reclasificación supone la agregación de clases (en el caso de las
variables cualitativas) o la agrupación de valores en intervalos (en el caso de las
cuantitativas). Esta operación se puede llevar a cabo sobre un atributo o una combinación
de atributos de la base de datos.
- La operación de disolución consiste en eliminar los arcos que separan polígonos
con el mismo valor en la variable reclasificada
- Finalmente, la operación de fusión consiste en especificar la secuencia de arcos que
forman cada uno de los nuevos polígonos (reconstruir la topología) y asignar identificadores
a esos nuevos objetos.
Ambas funciones de generalización presentan un grado de complejidad muy
distinto. La generalización líneas sólo conlleva una modificación de la geometría de los
objetos. Pero la unión de objetos, que se basa en la relación topológica de contigüidad
(disolución), implica también la reconstrucción de la topología (fusión), lo que puede llevar
un cierto tiempo si la base de datos con que se trabaja contiene un elevado número de
objetos.

66
8.4 Mediciones espaciales sobre objetos
Los objetos lineales y poligonales poseen ciertas propiedades espaciales que pueden
ser medidas (apartado 2.1.2). Entre las propiedades de las líneas figuran la longitud y la
sinuosidad, y entre las propiedades de los polígonos el área y el perímetro. Otras mediciones
que se pueden realizar sobre los objetos no se refieren a sus propiedades, como ocurre con
el centroide del polígono.
A) Mediciones sobre líneas
- Longitud
Una línea está compuesta por uno o varios segmentos rectos (figura 5.4). A partir de
las coordenadas de los puntos que marcan la localización de los segmentos se puede calcular
fácilmente la longitud de éstos recurriendo al teorema de Pitágoras (ver apartado 4.5.1). En
consecuencia la longitud total de una línea será igual a la suma de las longitudes de los
segmentos que la componen. En las capas de líneas normalmente este dato es calculado
automáticamente por el sistema y almacenado como atributo espacial en la base de datos.
- Sinuosidad
Otra magnitud interesante en relación a las líneas es la distancia que separa a sus
puntos extremos. Ésta puede calcularse fácilmente por medio del teorema de Pitágoras, una
vez identificados sus puntos extremos. El cociente entre la longitud de la línea y la distancia
entre sus extremos es una medida habitual de sinuosidad. El valor más bajo posible (igual a
1) se obtendrá cuando ambos valores coincidan, es decir, cuando la línea esté compuesta por
un sólo segmento; a medida que aumente el valor de dicho cociente mayor será la sinuosidad
de la línea.
B) Mediciones sobre polígonos
Perímetro y área
Dado que un polígono está enmarcado por una sucesión de líneas, su perímetro será
igual a la suma de las longitudes de esas líneas.
El cálculo del área es más complicado, dado que habitualmente no se trabaja con
polígonos regulares. Se puede llevar a cabo mediante un conocido algoritmo que se basa en
la descomposición del polígono en trapezoides (NCGIA, 1990 y Bosque, 1992). En numerosos
sistemas ambas magnitudes (perímetro y área) son calculadas automáticamente y
almacenadas en la base de datos como atributo espacial de los objetos poligonales.
Centroides

67
El centroide de un polígono es su punto central. Este puede ser calculado
fácilmente hallando las medias de las coordenadas X e Y de los distintos vértices del polígono
(figura 5.7). Pero éste método puede plantear problemas en polígonos cuyos vértices se
encuentran muy irregularmente repartidos. En algunas ocasiones este problema puede ser
solucionado con la operación de simplificación de líneas, ya que muchos de esos vértices
podrían ser redundantes; pero en otras ello es simplemente un reflejo de la realidad, es decir,
el contorno es más irregular en unas partes del polígono que en otras. En tal caso existen
otras soluciones más complejas que pueden encontrarse en NCGIA (1990) y Bosque (1992).
8.5 Consultas a la Base de Datos
Un SIG puede ser utilizado como herramienta de análisis, pero también simplemente
como instrumento de consulta. En multitud de aplicaciones, especialmente en las de tipo
inventario, las consultas a la base de datos constituyen una operación de una importancia
capital. Piénsese en un SIG municipal, en el que constantemente se está requiriendo del
sistema información relacionada con la gestión urbanística (uso del suelo, edificabilidad,
impuestos municipales, etc.), o en un inventario de carreteras, donde se consultan cuestiones
relacionadas con su mantenimiento (año de asfaltado, señalización, estado de las
estructuras, etc.).
Las consultas a la base de datos se pueden hacer en dos direcciones: desde la base
de datos de atributos o desde el mapa digital.
8.5.1 Consultas por atributos
En la base de datos se seleccionan los objetos espaciales que cumplen una o varias
condiciones fijadas por el usuario y esos objetos pueden ser visualizados en la pantalla.
Generalmente lo que se quiere es conocer DÓNDE se localizan esos objetos. Por ejemplo, si
tenemos una capa con polígonos, se le puede pedir al sistema que seleccione aquellos
polígonos cuyo uso del suelo sea "industrial". Si la información sobre el uso del suelo está
contenida en la variable "USO" y el código asignado al suelo industrial es el 8, habrá que
pedirle al sistema que seleccione aquéllos objetos en los que se cumpla la condición "USO =
8".
En la búsqueda por atributos se pueden utilizar operadores de distinto tipo:
- Relacionales: <, >, <=, >=
- Aritméticos: =, -, *, /
- Booleanos: AND, OR, NOT
Estos operadores se pueden combinar para realizar selecciones más complejas. Así,
en el ejemplo anterior, se le puede pedir al sistema que seleccione las parcelas de uso
industrial con una superficie superior a los 1.000 metros cuadrados (figura 5.8). Se trata de

68
dos condiciones, una referente a la variable "USO" en la que se utiliza un operador aritmético
(USO = 8) y otra referente a la variable "AREA" en la que se utiliza un operador relacional
(AREA > 1000). Ambas condiciones quedan enlazadas por el operador booleano AND, lo que
significa que sólo se seleccionan los registros que cumplan ambas condiciones (USO = 8 AND
AREA > 1000). Una vez realizada la selección se le puede pedir al sistema que presente en
un mapa los objetos seleccionados (figura 5.8). En este caso las dos variables se encuentran
en la misma tabla, pero no hay inconveniente en hacer operaciones de consulta a través de
varias tablas, relacionándolas a través de un campo común (RELATE) (ver subapartado
3.3.3).
Figura: Consulta por atributos.
8.5.2 Consultas espaciales
En este caso se seleccionan ciertos objetos sobre el mapa y los correspondientes
registros quedan asimismo seleccionados en la base de datos (figura 5.9). Generalmente lo
que se quiere conocer es QUÉ hay en las localizaciones seleccionadas. Esta operación se
realiza sobre un mapa que se visualiza en la pantalla. Existen distintas posibilidades de
selección, como las siguientes:
- Marcando con el ratón el objeto o los objetos deseados.
- Dibujando un círculo con el ratón para que el sistema seleccione los objetos tocados
por el círculo o contenidos dentro del mismo. Para dibujar el círculo el usuario fija un punto
sobre el mapa y a partir de él marca un radio de una determinada longitud (por ejemplo, 15
kilómetros).

69
- Pidiendo al sistema que seleccione los polígonos contiguos a un polígono
previamente seleccionado, etc.
8.6 Medición de distancias y Análisis de Proximidad
8.6.1 Medición de distancias entre objetos
Dado que en un SIG vectorial los objetos espaciales están localizados mediante
coordenadas, no presenta ninguna dificultad especial el medir la distancia que les separa en
línea recta (distancia euclidiana) recurriendo al teorema de Pitágoras (ver apartado 4.5.1).
El caso más sencillo sería la medición de la distancia entre dos puntos, pero también se puede
calcular la distancia entre cualquier par de objetos, independientemente de que sean puntos,
líneas o polígonos. El sistema puede responder a preguntas del tipo de cuál es la carretera
más cercana al lugar donde se ha producido un accidente de aviación (distancia entre punto
y línea) o cuál es el núcleo habitado más próximo al área en la que está ardiendo el bosque
(distancia entre polígono y polígono). Cuando en el cálculo de las distancias al menos uno de
los objetos es línea o polígono, se suele calcular la distancia "más corta" entre el par de
objetos, como en los dos ejemplos anteriores. Si se trata, más concretamente, de la distancia
entre dos polígonos, en algunas aplicaciones puede tener más sentido calcular la distancia
entre sus centroides (ver apartado 5.2.4), en tanto que estos representan la "localización
media" de los polígonos.

70
8.6.2 Análisis de proximidad
La medición de distancias en línea recta se utiliza en los análisis de proximidad
(buffer), una de las operaciones más características de los Sistemas de Información
Geográfica. Como ya se vió en el capítulo dedicado al modelo raster (apartado 4.5.1), se trata
de delimitar el área que queda a menos de una determinada distancia de un objeto o grupo
de objetos. Si en el mundo raster las distancias se medían con respecto a una celda o un grupo
de celdas, en el mundo vectorial se miden con respecto a objetos puntuales, lineales o
poligonales. El resultado es la creación de nuevos objetos poligonales que rodean a los
objetos sobre los que se realiza el análisis (figura 5.10).
Figura 5.10.- Análisis de proximidad sobre punto, línea y polígono.
A diferencia de lo que ocurre en el mundo raster, en el modelo vectorial el análisis
de proximidad sólo se puede realizar sobre distancias euclidianas (no sobre superficies de
fricción). Pero en cambio los atributos de los objetos sirven para efectuar selecciones y para
fijar el ancho de la zona de proximidad. Así, por ejemplo, sobre una capa de carreteras se le
puede pedir al sistema que efectúe un análisis de proximidad sólo sobre las que tienen el
código 1 (autopistas) en la variable "tipo". Pero también es posible fijar una distancia distinta
para cada tipo de carretera: por ejemplo, de 300 m para las de tipo 1 (autopistas), 200 m
para las de tipo 2 (carreteras nacionales) y 100 metros para las de tipo 3 (otras carreteras).
Cuando los objetos sobre los que se realiza el análisis de proximidad están muy
juntos o la distancia elegida es muy grande, las zonas de proximidad de los distintos objetos
pueden solaparse. En tal caso es muy útil recurrir a la operación de unión de objetos por
atributos . Supongamos que queremos calcular la superficie de una ciudad que queda servida
por la red de metro, entendiendo como tal el espacio que queda a menos de 1.000 m de una
estación. Si existen ocho estaciones, tras el análisis de proximidad podríamos tener ocho
círculos superpuestos, de manera que algunos lugares se encuentran servidos por más de
una estación. Como esos círculos son objetos poligonales, el sistema calcula
automáticamente su superficie. Sin embargo, la suma de la superficie de esos ocho nuevos
polígonos no es igual al área servida por la red de metro, debido al solapamiento de los
círculos. En tal caso se pueden unir esos objetos (mediante la operación de disolución y
fusión) para obtener un nuevo objeto poligonal cuya superficie es el área servida por la red
de metro.
Los resultados de los análisis de proximidad pueden ser sometidos a nuevos análisis.
Entonces es cuando queda patente la potencia de los SIG. En el ejemplo anterior puede tener
algún interés conocer cuál es la superficie servida por la red de metro (de acuerdo con los

71
criterios especificados anteriormente), pero resulta mucho más relevante calcular cuánta
población queda dentro de esas áreas de influencia marcadas en el análisis de proximidad.
Ello podría averiguarse por medio de una superposición de la capa que contiene las zonas de
proximidad con otra en la que se registre la población residente en las distintas secciones
censales (ver apartado 5.5).
El análisis de proximidad es más lento en el modelo vectorial que en el raster. El
sistema no sólo tiene que dibujar las áreas que quedan a menos de una cierta distancia de un
determinado conjunto de objetos, sino además construir la topología de los nuevos objetos,
calcular si existen intersecciones entre esos nuevos objetos, disolverlos y fundirlos (en caso
de que efectivamente haya solapamientos) y, finalmente, volver a construir la topología de
los objetos resultantes.
8.6.3 Generación de polígonos de Thiessen
Como ya se indicó en el capítulo dedicado al modelo raster (apartado 4.5.1), se trata
de generar polígonos a partir de un conjunto de puntos, de tal forma que los lados de los
polígonos sean equidistantes con respecto a los puntos vecinos. Pero el procedimiento de
obtención de los polígonos es muy distinto en el modelo vectorial. Aunque el problema que
se plantea es la minimización de distancias euclidianas con respecto a los puntos originales,
la solución en el modelo vectorial no se alcanza por cálculos de distancias, sino mediante un
procedimiento geométrico:
- En primer lugar se debe generar una triangulación Delaunay a partir del conjunto
de puntos. Una triangulación de un conjunto de puntos es una triangulación Delaunay sólo
si la circunferencia circunscrita a cada triángulo no contiene ningún punto en su interior
(Weibel y Heller, 1991) (figura 5.12 A y B).
- Los centros de las circunferencias circunscritas a los triángulos de Delaunay
constituyen los vértices de los polígonos de Thiessen; los segmentos que unen esos vértices,
trazados perpendicularmente a los lados de los triángulos, constituyen los lados de dichos
polígonos (figura 5.12 C y D).
Algunas de las aplicaciones de la generación de los polígonos de Thiessen fueron ya
expuestas en el apartado 4.5.1. Más información sobre este tipo de teselación puede
encontrarse en Okabe, Boots y Sugira (1992).
Figura: Generación de polígonos de Thiessen a partir de una triangulación Delaunay.

72
8.6 Superposición de mapas
Como ya se señaló en el caso del modelo raster, en la superposición de mapas se
parte de dos mapas fuente que se combinan para obtener un mapa final. Pero en el mundo
vectorial las capas pueden ser de tres tipos (puntos, líneas y polígonos), de lo que resultan
distintos tipos de superposición. Los más habituales son los de punto en polígono, línea en
polígono y polígono en polígono. El resultado de esta operación es una nueva capa del mismo
tipo que la primera de las capas fuente, con modificaciones que afectan tanto a los objetos
espaciales (excepto en la superposición punto en polígono) como a sus atributos. La
superposición de capas en el modelo vectorial es una operación muy compleja, ya que se
debe calcular la geometría y construir la topología de los objetos de la capa resultante.
Tipo de pozo Perforado
Propiet. parcela Smith
Tipo de suelo Arenoso

73
8. Análisis de Redes
9.1 Introducción al análisis de redes
Una red está formada por un conjunto de arcos interconectados, a través de los
cuales es posible el movimiento de recursos de acuerdo con ciertas restricciones. Existen
redes de muy diversos tipos: de transporte, hidrográficas, telefónicas, eléctricas, de
abastecimiento de agua, de alcantarillado, etc. Pues bien, en un SIG vectorial se puede
representar una red y simular el movimiento de recursos sobre la misma. Dado que existen
redes de muy distintos tipos, las posibilidades de implementación de modelos de análisis de
redes son muy variadas. Así, por ejemplo, se puede implementar un modelo hidrológico que
simule el comportamiento de la corriente de un río o un modelo que calcule las pérdidas que
se producen a lo largo de una línea de transmisión eléctrica en función de la distancia.
Conceptos básicos:
Término Descripción
Red de
transporte
Las redes de transporte (como redes de ferrocarril, peatones y calles)
permiten viajar en los bordes en ambas direcciones. El agente en la red, por
ejemplo, un camionero que viaja por carreteras, suele tener libertad para
decidir la dirección de la travesía así como el destino.
Nota:
En ArcGIS, las redes de transporte se modelan mejor mediante datasets de
red.
Precaución:
Si desea modelar una red fluvial o una red de servicios, tal como tuberías o
líneas de conducción, debe utilizar redes geométricas en lugar de datasets de
red.
Entidades de
origen
Las entidades de origen son las entidades de puntos y líneas utilizadas para
crear un dataset de red. Pueden verse como la red física, que no tiene
topología incrustada dentro de las entidades. El dataset de red se puede ver
como la red lógica, que incrusta relaciones topológicas necesarias para
realizar los análisis de red.
Dataset de red
El dataset de red es una colección de elementos de red interconectados (ejes,
cruces y giros) que modelan flujo no dirigido. Su aplicación más común es el
modelado de redes de carreteras.
Cualquier análisis de red en ArcGIS Network Analyst requiere un dataset de
red, que es una red lógica. Quizá se pregunte por qué es necesario un dataset
de red si ya tiene una clase de entidad de línea que se parece a una red. La
razón es que las entidades de línea no saben inherentemente a qué están
conectadas, pero los elementos de red sí lo saben. Cuando se realiza un

74
análisis de red, el solucionador necesita digitalizar rápidamente una multitud
de elementos de red para deducir qué rutas de acceso puede tomar para
alcanzar un destino. Si tuviera que hacer referencia a entidades de línea
simples, necesitaría realizar operaciones espaciales que exigen mucho tiempo
para cada línea que inspeccionara; el proceso sería demasiado lento. Además,
la configuración de esquemas de conectividad complejos sería difícil, si no
imposible, de definir solo con entidades de línea. Como alternativa, cuando el
solucionador digitaliza un dataset de red, los elementos pueden proporcionar
la información precisa sin reducir tanto la velocidad del solucionador.
Los términos red y dataset de red se utilizan a menudo de manera
intercambiable en los documentos de ayuda de Network Analyst.
Elementos de
red
Los dataset de red se componen de ejes, cruces y giros; estos componentes se
conocen genéricamente como elementos de red.
Atributos de
red
Los atributos de red contienen información sobre el dataset de red. Hay
cuatro tipos:
Coste: penaliza el recorrido sobre un elemento. Se requiere al menos un
atributo de coste.
Descriptor: contiene información general; se utiliza a menudo para almacenar
valores a los que hacen referencia otros atributos de red para calcular sus
valores.
Jerarquía: estratifica una red principalmente con el propósito de resolver los
análisis de red más rápidamente.
Restricción: prohíbe ciertos movimientos en elementos de red. Las calles de
un solo sentido y los giros ilegales se modelan mediante atributos de
restricción de red.
Coste de la red
o impedancia
El coste de la red y la impedancia hacen referencia al mismo concepto.
Siempre que un agente atraviesa un elemento de red, se le carga alguna
cantidad, que es el coste de la red. Por ejemplo, una ruta de acceso de una
ciudad a otra podría tener un "coste" de red de 45 millas.
El coste de la red puede ser cualquier cosa que elija pero, normalmente, es la
distancia o el tiempo de viaje. Para poder utilizarlo en un análisis de red, un
dataset de red debe tener al menos un atributo de coste, porque los análisis de
red siempre optimizan algún coste. Por ejemplo, un análisis de ruta busca la
ruta de menor coste entre dos o más puntos. En algunos casos, se requiere
incluso más de un atributo de coste.
Evaluadores
Después de agregar un atributo de red a un dataset de red, es necesario
calcular los valores de los atributos. Los evaluadores sirven para esta función.
Hay muchos evaluadores para cada atributo de red. Un atributo de red tiene
un evaluador único para cada elemento de red (cruces, ejes y giros) y cada una
de sus clases de entidad de origen. Además, hay dos evaluadores para cada
clase de entidad de origen de eje: uno para el lado de origen a destino de los

75
bordes, y otro para el lado de destino a origen. Por ejemplo, si se agrega un
atributo de coste a un dataset de red creado a partir de una clase de entidad
de calles y una clase de entidad de giros, puede haber un evaluador que
calcule los valores de atributo de coste para cada uno de los siguientes
elementos:
Cruces del sistema
Giros
El lado de origen a destino de las calles
El lado de destino a origen de las calles
Si se agregarán más entidades de origen a la red, serían necesarios más
evaluadores para calcular los costes para sus elementos de red
correspondientes.
Hay varios tipos de evaluador, tales como evaluadores constantes que asignan
un valor único a todos los elementos de los evaluadores de campo y grupo que
puedan extraer valores de entidades de origen y asignarlos a sus elementos de
red correspondientes.
Capa de red Cuando un dataset de red se representa en ArcMap como una capa, se
denomina una capa de dataset de red o, más sencillamente, una capa de red.
Capa de
análisis de red
Las capas de análisis de red, o capas de análisis para abreviar, se pueden ver
como un marco para configurar y resolver un problema de red.
Por ejemplo, se crea una capa de análisis de ruta cuando se decide resolver un
problema de ruta (ruta de menor coste) en ArcMap. Se asocia
automáticamente al dataset de red activo. Además, la capa de análisis tiene
propiedades que permiten definir mejor el problema, tales como una
propiedad que permite especificar si las paradas se deben secuenciar de
manera óptima o realizarse en el orden en que aparecen en la lista.
Las capas de análisis de red también contienen un conjunto de clases de
análisis de red predefinidas para el tipo de problema de red: las capas de
análisis de ruta contienen clases de análisis de red para paradas, rutas y
diversas barreras; las capas de análisis de origen-destino contienen orígenes,
destinos, líneas y barreras. Las clases de análisis, a su vez, contienen los datos
de entrada proporcionados y los datos de salida que proporciona la operación
de resolución.
Clase de
análisis de red
Las clases de análisis de red son clases de entidad y tablas. Las entidades y
registros que contienen sirven como datos de entrada y salida para las capas
de análisis de red; por ejemplo, en una capa de análisis de ruta, las paradas y
barreras proporcionadas y las entidades de ruta resultantes se almacenan en
clases de análisis de red.

76
Las clases de entidad del análisis de red se muestran en la tabla de contenido
de ArcMap como subcapas. No se mantienen en disco; en su lugar, se
almacenan en memoria y se guardan en el documento de mapa.
Objetos de
análisis de red
Este es un término genérico para los registros y entidades almacenados en
una clase de análisis de red. Si los datos son una entidad y se encuentran en
una red, se puede utilizar el término ubicación de red, más preciso, en su
lugar.
Ubicaciones de
red Una ubicación de red puede hacer referencia a un objeto de anál
Figuras: Red y Atributos de arco de red
Figuras: Impedancias de arco de red

77
Las funcionalidades más populares dentro del análisis de redes son el cálculo de
caminos mínimos (routing) y el análisis de áreas de influencia de centros de servicio
(allocate).
9.2 Análisis de caminos mínimos
Algunos SIG comerciales de propósito general permiten calcular el camino mínimo
(óptimo) entre dos nodos cualesquiera dentro de una red. No se trata necesariamente del
camino más corto, sino del camino de menor impedancia. La impedancia no es más que una
medida de la resistencia al desplazamiento, que puede ser expresada de distintas formas
(distancia, tiempo, coste, etc.). De acuerdo con lo anterior el camino mínimo entre dos puntos
podrá ser distinto según sea la variable que se tome como impedancia: el camino más corto
entre dos puntos opuestos de una ciudad atravesará el centro, pero el camino mínimo en
tiempo posiblemente siga alguna vía rápida de circunvalación, para evitar la congestión de
las calles más céntricas. El cálculo de caminos mínimos es muy importante en multitud de
aplicaciones: distribución de mercancías, rutas de ambulancias y otros vehículos de
emergencia, rutas de transporte escolar, etc.
En una red de transporte la impedancia se utiliza para reflejar las condiciones en
que se produce la circulación. Puede ir asociada a los arcos y a los nodos:
a) Impedancias de arco.- Es la resistencia a recorrer un arco desde uno de sus
extremos hasta el otro. En los viajes peatonales puede ser razonable utilizar la longitud de
los arcos como medida de la impedancia (cuesta más recorrer un arco cuanto más largo sea);
pero en los viajes mecanizados la variable fundamental suele ser el tiempo (las condiciones
de circulación pueden provocar que un arco más largo puede recorrerse en menos tiempo
que otro más corto). El usuario debe indicar al sistema qué variable de las contenidas en la
base de datos de atributos tomará como impedancia de arco en los análisis que quiera llevar
a cabo.

78
Las impedancias de arco pueden ser direccionales. De esta forma es posible
tener en cuenta las condiciones del tráfico según el sentido de circulación. Si las velocidades
de circulación son distintas en un sentido y en otro, el tiempo de recorrido del arco será
también distinto. También puede ocurrir que una calle sólo pueda recorrerse en un sentido
de circulación, por ser prohibida en el contrario. Todas esas circunstancias deben quedar
registradas en la base de datos, debiendo reservarse dos campos para la impedancia, uno
para cada sentido de circulación.
b) Impedancias de nodo.- Las impedancias de nodo se utilizan generalmente para
simular las circunstancias que afectan a los giros en las intersecciones. Ante un semáforo, un
giro a la derecha puede llevar menos tiempo que continuar recto y sobre todo que girar a la
izquierda. Esa mayor o menor dificultad para efectuar movimientos en las intersecciones
puede simularse mediante las impedancias de nodo. Así, por ejemplo, el giro a la derecha
puede penalizarse con una impedancia de 20 segundos, el continuar recto con 40 segundos
y el giro a la izquierda con 60 segundos. En el caso del ferrocarril las impedancias de nodo
podrían representar el tiempo que está detenido el tren en cada las estación o el que emplea
el usuario en los trasbordos. En última instancia, la impedancia total entre dos nodos de la
red será igual a la suma de las impedancias de arco y de nodo por el camino mínimo.
Para realizar un análisis de caminos mínimos se le debe indicar al sistema cuál es la
variable de impedancia de arco que se quiere utilizar, si se van a utilizar impedancias de
nodo y cuáles son los puntos de origen y de destino de la ruta, ya sea especificando los
números de esos nodos, sus direcciones o marcándolos directamente sobre la pantalla. El
SIG dibuja sobre la pantalla el camino mínimo e indica cuál es la impedancia total de esa ruta.
Algunos sistemas pueden facilitar asimismo un listado con la relación de las calles que se
atraviesan y los correspondientes giros entre unas y otras.
Figuras: Cálculo de camino mínimo Sin barreras y Con barreras
Otra interesante opción es la de efectuar paradas intermedias entre los puntos de
origen y de destino. En esas paradas se recogen o se dejan viajeros o mercancías, de manera

79
que el sistema no sólo debe trazar el camino óptimo entre paradas, sino también calcular
cuál es la carga (número de pasajeros o mercancías) que se están transportando en cada
momento a lo largo de la ruta. Algunos sistemas no sólo calculan el camino óptimo entre
paradas, sino que además señalan el orden en que éstas deben ser realizadas de forma que
se minimice el movimiento a lo largo de toda la ruta (lo que se conoce como el problema del
viajante de comercio).
Por otro lado, el cálculo de caminos mínimos resulta de gran interés para la
implementación en un SIG de modelos gravitatorios realistas. Estos modelos, que se basan
en la vieja fórmula newtoniana de la gravitación universal, requieren el cálculo de la
distancia entre pares de objetos. Mediante el cálculo de caminos mínimos esa distancia
puede medirse de forma precisa a través de la red que realmente canaliza los movimientos,
en lugar de utilizar distancias euclidianas.
Figuras: Cálculo de camino mínimo con paradas de orden prefijado y con orden optimizado
9.3 Análisis de las áreas de influencia de los centros de servicio
El área de influencia de los centros de servicio puede calcularse sobre distancias
euclidianas mediante la construcción de polígonos de Thiessen. Pero aquí también resulta
mucho más realista medir las distancias a través de la red que realmente canaliza los
movimientos y utilizando las impedancias que resulten más adecuadas. En definitiva se trata
de determinar desde qué arcos de la red se puede alcanzar en un determinado tiempo un
punto dado en el que se encuentra situado un centro de servicios.
El acceso a un colegio electoral se realiza habitualmente a pie, por lo que pueden utilizarse
impedancias en tiempo que reflejen la velocidad de estos desplazamientos a través del viario
de la ciudad. Pero el acceso a un hipermercado en la periferia de una ciudad se efectúa

80
habitualmente en transporte privado, por lo que resulta más realista trabajar con los tiempos
de recorrido sobre la red de transporte privado (calles y carreteras): un lugar más lejano,
pero bien comunicado con el hipermercado por autopista, puede quedar a menos tiempo que
otro más cercano pero fuera de los principales corredores de transporte. Esto significa que
las áreas de influencia de los centros de servicio pueden quedar distorsionadas en función
de las impedancias que presentan los arcos que componen la red, alargándose en el sentido
de las vías más rápidas. Pero las distorsiones también pueden deberse a la competencia entre
varios centros de servicio del mismo tipo, de manera que sus áreas de influencia tienden a
ser más reducidas en las direcciones en las que se produce esa competencia y más amplias
en el resto de las direcciones.
Figura Análisis de áreas de influencia de los centros de servicio. A) Un solo centro. B)
Competencia entre varios centros con límites de tiempo o distancia.

81
Anexo 1.
Aplicación de metodologías Multicriterio para la
asignación de Usos del Suelo.
Javier Gutiérrez Puebla
Departamento de Geografía Humana
Universidad Complutense de Madrid
Miguel Vía García
Centro de Investigaciones Ambientales “Fernando González Bernáldez”
Comunidad de Madrid

82
1. Introducción
Se presenta aquí un ejemplo de aplicación de metodologías multicriterio para
la búsqueda de localizaciones óptimas de actividades humanas sostenibles en un
espacio natural protegido: el Parque Natural de Sanabria 1. Se trata de un espacio de
montaña de gran valor paisajísico, en el que la vegetación se escalona en pisos, desde
el rebollar hasta el matorral de alta montaña. Aparecen también, aunque con menor
frecuencia, bosques o bosquetes de castaños, tejos y abedules. Pero lo más
destacado desde el punto de vista natural es sin duda el complejo lacustre, cuyo
máximo exponente es el lago de Sanabria, que alcanza un carácter simbólico y es
lugar de visita obligada para los que acuden a conocer el parque. Se trata de un lago
de origen glaciar de importantes dimensiones (tres kilómetros de largo por uno de
ancho), en el que de forma natural se represa el río Tera. Existen, además, en zonas
más elevadas, un considerable número lagunas también de origen glaciar, de gran
valor ecológico. La mayor parte de ellas tienen un difícil acceso, lo que ha favorecido
su preservación.
La ganadería y los aprovechamientos forestales, junto con la
agricultura en pequeñas parcelas, todavía hoy ocupan a una parte apreciable de la
población. Este sector cuenta con graves problemas estructurales. La población
activa dedicada a la agricultura y la ganadería está muy envejecida y el fenómeno de
abandono de tierras (de labor o de pastos) es ostensible, en un medio poco
favorecido para la agricultura y con pastos para la ganadería de menor calidad que
los de Galicia y las comunidades del Cantábrico.
Pero se han dado algunos pasos orientados a valorizar los productos locales
(como el habón, la ternera sanabresa o la miel de brezo) que pueden hacer más
rentables las producciones invocando a la calidad y mejorando los canales de
comercialización. En cuanto a la explotación forestal, junto con el aprovechamiento
1 Esta aplicación fue desarrollada en el marco del proyecto SIGMA (Sistema de
Información y Gestión Medioambiental de Sanabria y Carballeda), realizado por un
equipo de investigadores del Departamento de Geografía Humana de la Universidad
Complutense (Javier Gutiérrez Puebla, José Carpio y Miguel Vía) por encargo de
ADISAC (Asociación para el Desarrollo Integrado de Sanabria y Carballeda), entidad
gestora del PRODER de la comarca (Carpio, Gutiérrrez Puebla y Vía, 2001).

83
de los bosques autóctonos hay que destacar los ingresos derivados de la explotación
de los pinares de repoblaciones forestales.
Como en otras muchas áreas rurales, en la comarca de Sanabria-Carballeda a
lo largo de los últimos tiempos se ha producido una importante expansión del sector
servicios y también un considerable auge de la construcción. Se trata tanto de
servicios a la población local (escuelas, centros de salud, administración pública,
entidades financieras) como de servicios orientados a los turistas y visitantes del
parque. Y en cuanto a la construcción, el sector se ha revitalizado por el dinamismo
del turismo, que ha promovido una importante actividad en la restauración de
viviendas (construcciones tradicionales en piedra y madera de gran belleza), unas
para ser utilizadas como segundas residencias y otras con destino a ser ocupadas
por los turistas que visitan la zona (casas rurales, pequeños hoteles rurales). La
industria tiene un papel prácticamente simbólico en la comarca.
La valorización de los productos locales constituye un campo de acción clave
en la estrategia de desarrollo sostenible de la comarca. En los últimos años desde
ADISAC (la asociación que gestiona el PRODER de la comarca) se ha impulsado la
comercialización de un producto local (el habón, un tipo de alubia de gran calidad),
con resultados muy positivos. Tras un primer impulso de ADISAC para mejorar la
comercialización del habón (en pequeños saquitos, con el nombre del productor),
ahora los productores se han asociado y el habón de Sanabria se vende como
producto típico a un precio relativamente alto en numerosas tiendas y mercadillos
de la comarca. La nueva demanda generada y el precio de venta han producido un
cambio de coyuntura, de forma que lo que era un cultivo en recesión hoy ofrece
perspectivas francamente positivas.
En este contexto se ha planteado la necesidad de identificar áreas aptas para
la expansión de este cultivo local, tanto en el interior del parque como en su entorno,
lo que se ha llevado a cabo mediante la aplicación de metodologías multicriterio en
el entorno de los Sistemas de Información Geográfica. Para ello se ha partido de la
capas de información contenidas en el SIGMA (Sistema de Información de la
comarca), que han sido oportunamente tratadas y combinadas hasta alcanzar los
resultados finales. Las operaciones de análisis se realizaron en formato ráster con el
software Arc/View 3.2 (ESRI) e Idrisi32 (Universidad Clark).

84
2. Análisis de localizaciones óptimas mediante análisis
multicriterio booleano
El procedimiento más sencillo de análisis multicriterio en el contexto de los
Sistemas de Información Geográfica es la intersección booleana. Se trata de
establecer una condición para cada una de las capas de información y
posteriormente superponer todas esas capas para comprobar dónde se cumplen
todas las condiciones. El procedimiento de análisis en formato ráster consiste en
asignar el valor 1 a las celdillas que cumplen la condición especificada y el 0 a las
que no la cumplen. Ésta operación se realiza capa por capa y, una vez que todas las
capas han sido convertidas a este formato binario de unos y ceros, se procede a
multiplicarlas entre sí, celda a celda. Lógicamente sólo las celdas que tienen valor 1
en todas las capas reciben ese mismo valor en la capa final (cumplen todas las
condiciones); el resto de las celdas reciben el valor 0 (no cumplen todas las
condiciones) (Figura 1). En la práctica este método supone que todos los criterios
son considerados como restricciones y el resultado es su intersección.
<Figura 1>
En el caso de la identificación de localizaciones óptimas para la expansión del
cultivo del habón en el Parque Natural de Sanabria se fijaron criterios tanto de tipo
técnico como ambiental. Tras consultar a los productores y técnicos locales, se
estableció que los terrenos elegidos debían reunir las siguientes condiciones: llanos
(para facilitar la práctica de la agricultura sin recurrir al aterrazamiento), próximos
a los cursos fluviales (ya que se trata de un cultivo de regadío), situados a una altitud
moderada (por razones térmicas) y con orientación sur (para aumentar la
insolación). Además, por ser un cultivo intensivo, los terrenos debían ser fácilmente
accesibles desde los núcleos de población o desde las carreteras. Finalmente,
también se tuvo en cuenta el uso del suelo preexistente: por razones ambientales,
serían aptas las áreas ocupadas por otros cultivos, por pastizales o por matorral,
pero no las que están cubiertas por bosques.
De forma más concreta estos criterios quedaron formulados de la siguiente
forma:
- Pendiente: inferior al 5%. - Orientación: sur-suroeste (entre 135 y 270 grados acimutales).

85
- Altitud: menos de 1.200 metros. - Distancia a los cursos fluviales: menor de 200 metros. - Accesibilidad: distancia a los núcleos de población inferior a 1.500 metros o
distancia a las carreteras inferior a 500 metros. - Uso del suelo actual: cultivos, pastizales o matorral.
En el Sistema de Información Geográfica se disponía ya de algunas de las variables
requeridas, como la altitud o el uso del suelo. El resto de las variables (pendientes,
orientaciones, distancias a los ríos, carreteras y núcleos de población) fueron obtenidas
mediante las funcionalidades del propio sistema. Posteriormente se llevaron a cabo
reclasificaciones para obtener mapas binarios de unos y ceros, expresivos de dónde se
cumple cada una de las condiciones (Mapas 1-6 de la Figura 2). Al multiplicar estos
mapas binarios entre sí resultaron las zonas óptimas para el cultivo del habón de acuerdo
con el conjunto de los criterios especificados (Mapa 7 de la Figura 2).
<Figura 2>
3. Análisis de localizaciones óptimas mediante la combinación
lineal ponderada
La combinación lineal ponderada es una técnica que considera tanto factores
ponderales como restricciones. La combinación de los factores se realiza a través de una
suma lineal ponderada, multiplicando cada factor por su peso y, posteriormente, sumando
los resultados (Figura 3). Por otro lado, las restricciones se tratan en la forma indicada
más arriba para la intersección booleana (Figura 1), es decir, tras generar mapas binarios
de unos (no hay restricción) y ceros (sí hay restricción), uno por cada restricción, éstos se
multiplican entre sí, definiendo así las áreas de exclusión. Finalmente se multiplica el
resultado de la suma lineal ponderada de los factores por el resultado de la intersección
booleana de las restricciones, de forma que si ésta última registra un valor igual a 1 (no
hay restricciones) se mantiene el valor de la suma lineal y si registra un valor igual a 0
(hay alguna restricción) el resultado final es también 0 (áreas de exclusión). Este proceso,
que caracteriza a la combinación lineal ponderada, nos permite disponer de un mapa final
que discrimina las zonas más favorables para el cultivo del habón de las zonas menos
aptas, de una forma más precisa y menos rígida que al utilizar el método de intersección
booleana.
<Figura 3>
Un primer paso al aplicar esta metodología consiste en convertir las variables en
factores (es decir, transformarlas a una escala de medida homogénea) y en restricciones
(capas binarias en las que el 0 significa la presencia de una restricción y el 1 su ausencia).
Hay que tener en cuenta que de una misma variable se puede derivar un factor y una
restricción. Así, por ejemplo, puede haber pendientes más o menos favorables para el
cultivo dentro de un determinado rango de valores (factor), pero por encima de un cierto
umbral se puede determinar la imposibilidad técnica de cultivar (restricción).

86
La conversión de variables en factores se puede llevar a cabo a través de distintas
funciones de transformación. La más simple (y la que se ha utilizado aquí) es la
transformación lineal que se realiza según
cvv
vvf i
i
)(
)(
minmax
min
donde
fi es el valor de la celda i en el factor considerado,
vi es el valor de la celda i en la variable,
vmax y vmin son los valores máximo y mínimo de la variable y
c es el coeficiente de normalización utilizado (en nuestro caso 255)
En este proyecto se consideraron seis factores (pendiente, altitud, orientación,
proximidad a los ríos, distancia a los núcleos de población y distancia a las carreteras) y
siete restricciones (pendiente excesiva, altitud excesiva, orientación desfavorable, lejanía
con respecto a los ríos, inaccesibilidad con respecto a los núcleos de población,
inaccesibilidad con respecto a las carreteras y uso del suelo inadecuado), construidos de
la siguiente forma:
- Pendientes.- Se utiliza para establecer el límite de pendiente apropiada para el
cultivo del habón la clasificación agrológica de pendientes desarrollada por López
Cadenas y Blanco Criado (CEOTMA, 1991), que define como límite para suelos
agrícolas una pendiente del 12%. Para generar el factor se reclasifica el mapa de
pendientes dando un valor de 12 a todas aquellas pendientes iguales o superiores
al 12% y dejando su valor original al resto. Posteriormente se normaliza el mapa
resultado de la reclasificación y se invierte el orden de aptitud, ya que las
pendientes más bajas deben tener los valores más altos de aptitud. Para la
normalización se realiza un ajuste de tipo lineal en 256 categorías (de 0 a 255) en
la forma indicada más arriba, de forma que el valor 255 se corresponde a los
terrenos con una pendiente igual o supuerior al 12% y el 0 a los de una pendiente
igual a 0%. Para invertir el orden o dirección de los valores, a un mapa con un
valor de 255 en todos los píxeles se le resta el mapa resultado de la normalización,
de forma que en el mapa final el valor 255 corresponda a las celdas de un 0% de
pendiente (máxima aptitud) y el 0 a las de pendiente igual o superior a 12%
(mínima aptitud) (Mapa 1 de la Figura 5). A partir de la variable pendiente
también se construye una restricción, reclasificando como 0 las pendientes iguales
o superiores al 12% y como 1 las inferiores a ese valor.
- Orientaciones sur-suroeste.- Según los expertos de la zona, la orientación sur-
suroeste es la más apropiada en la zona para el cultivo del habón. Para generar
este factor, se han realizado una serie de operaciones de reclasificación sobre el
mapa general de orientaciones, debido a que nos encontramos ante una variable
que está definida por valores de tipo angular. Se ha establecido como la
orientación más apta la sur-suroeste (202,5º) disminuyendo la aptitud según nos
alejemos de esta orientación. Como límite de aptitud se ha tomado un ángulo de
67,5º tanto en dirección Este como Oeste. Se obtiene un mapa después de esas

87
operaciones en donde 202,5º se corresponde con un valor de 67,5 (normalizado
255) disminuyendo hasta 0 según nos movamos hacia el ángulo 135º o el 270º
(Figura 4). El resto de las orientaciones se reclasifican con un valor de 0 (y con
esos valores se construye la correspondiente restricción). Posteriormente se
normalizan los valores como en el factor anterior, no siendo en este caso necesario
la inversión en el orden de los valores ya que los más altos se encuentran en los
202,5 grados, es decir, en la orientación más apta (Mapa 2 de la Figura 5).
<Figura 4>
- Altitud.- Para la obtención de este factor se reclasifican como 1.200 todas las
altitudes iguales o superiores a los 1.200 metros, se normalizan los valores con un
ajuste de tipo lineal y se procede también –como en el caso de las pendientes- a
invertir el orden de los valores, ya que son las zonas más bajas las más aptas, es
decir, aquéllas que deben tener los valores de aptitud más elevados (Mapa 3 de la
Figura 5). Se considera como restricción una altitud superior a los 1.200 metros,
operando de forma análoga a la restricción anterior para construir un mapa binario
de ceros y unos.
- Proximidad a los ríos.- Para este factor, al igual que todos los factores de tipo
proximidad, precisa de la elaboración en un primer momento de un mapa que mida
la distancia euclidiana, en línea recta, entre cada celda y la más próxima de una
serie de elementos de referencia, en este caso los ríos. También es necesaria la
normalización e inversión de la dirección de los valores, ya que las zonas más
próximas son las más aptas para el cultivo del habón (Mapa 4 de la Figura 5). El
límite de distancia de los 200 metros marca el comienzo de la correspondiente
restricción.
- Proximidad a los núcleos de población.- El proceso es similar al factor anterior:
es también necesaria la inversión en la dirección de los valores, ya que las celdas
con menor valor de distancia son las zonas más aptas. Se considera como límite
de distancia los 1.500 metros (Mapa 5 de la Figura5). Valores superiores a esos
límites suponen una restricción en cuanto a inaccesibilidad.
- Proximidad a las carreteras.- Este factor se construyó de forma similar al caso
anterior, sólo que considerando un límite de distancia de 500 metros (Mapa 6 de
la Figura 5), a partir del cual se consideraba la correpondiente restricción por
inaccesibilidad desde las carreteras.
- Usos del suelo.- El uso del suelo se considera sólo como una restricción. Matorral,
pastos y cultivos son usos apropiados (unos), mientras que los bosques y el suelo
urbano constituyen restricciones (ceros). La capa correspondiente a esta
restricción ya fue creada al realizar la intersección booleana (Mapa 6 de la Figura
2).
A continuación se establecieron las ponderaciones de los factores, de forma que
pesen más en el modelo aquéllos que se considera que tienen una mayor importancia.
Para fijar los pesos se recurrió a la opinión de expertos de la comarca, encargados de la
gestión territorial y del desarrollo rural, a los que se pidió que establecieran una serie de
comparaciones entre pares de factores, para la aplicar con esas matrices el procedimiento

88
conocido como Proceso Jerárquico Analítico (Saaty, 1980; Eastman y otros 1993). El
resultado de este proceso se muestra en la Tabla 1.
Tabla 1: Pesos de los factores
Factores Pesos
Altitud 0,27
Proximidad a los núcleos de población 0,22
Orientación de la pendiente 0,19
Distancia a los ríos 0,16
Proximidad a las carreteras 0,14
Pendiente 0,03
Construidos los criterios y definidos los pesos de los factores, se combinaron
factores y restricciones mediante el método anteriormente descrito (combinación lineal
ponderada). El resultado final es un mapa de aptitud, cuyos valores oscilan entre 241
(próximo al máximo teórico de 255) y 0 (presencia de alguna restricción) (Mapa 7 de la
Figura 5). A diferencia del mapa elaborado con el método de intersección booleana, donde
se expresaba sólamente si los terrenos eran aptos (unos) o no aptos (ceros), ahora los
terrenos seleccionados se discriminan de forma detallada en función de su mayor o menor
aptitud para el cultivo del habón.
<Figura 5>
4. Consideraciones finales
El análisis multicriterio en el entorno de los Sistemas de Información Geográfica
permite resolver cuestiones relativamente complejas en la planificación de espacios
naturales protegidos, como se ha puesto de manifiesto aquí con un ejemplo sobre la
localización óptima de un cultivo tradicional. Mediante la combinación de capas de
información, y estableciendo previamente unos criterios, se pueden seleccionar los
terrenos de mayor aptitud para la implantación de actividades humanas sostenibles o
aquéllos en los que, por su alta calidad ambiental, deben primar los criterios de estricta
conservación.
Por razones de espacio sólo se han utilizado dos métodos multicriterio, la
intersección booleana y la combinación lineal ponderada, llegándose lógicamente a
resultados distintos. El método de la intersección booleana es considerablemente más
rígido y en la práctica supone trabajar sólamente con restricciones (y no con factores).
Supone un mínimo riesgo de equivocarse al aplicar la regla de decisón, ya que es un
método no compensatorio: sólo son seleccionados los terrenos que cumplen todas las
condiciones establecidas. Tiene el inconveniente de que no discrimina entre las celdas
seleccionadas (ni en cada criterio ni en el conjunto de los criterios). Si se fijan 200 metros
como límite de distancia a los ríos, se consideran igualmente aptos los terrenos situados
junto al río que los que están a casi 200 metros; igualmente el resultado final no ofrece

89
ninguna información acerca de qué terrenos, de entre los seleccionados, son más o menos
aptos 2.
Por su parte, la combinación lineal ponderada es un método que se caracteriza por
la existencia de compensación entre factores: valores bajos en un factor pueden ser
compensados con valores altos en otros factores. Los pesos de los factores son muy
importantes aquí, al determinar cómo los factores se compensarán entre sí. Sin embargo,
el carácter compensatorio del método supone la aceptación de un cierto nivel de riesgo,
ya que en la práctica se podrían seleccionar terrenos no aptos, una vez que se ha superado
un determinado umbral en alguno de los factores (por ejemplo, pendientes excesivas).
Este riesgo puede ser controlado combinando los factores con restricciones y
estableciendo el rango de los valores de aptitud de los factores siempre en relación a las
restricciones (dicho rango debe extenderse sólo hasta que se alcanza el umbral en el que
comienza a actuar la restricción). Así, por ejemplo, si no se contempla la posibilidad de
aterrazar los terrrenos, tiene sentido valorar las pendientes en el rango de valores
compendido entre 0% y 12%, pero no entre 0 y el valor de máxima pendiente de la zona
de estudio.
El procedimiento de la combinación lineal ponderada es algo más complejo, pero
tiene la ventaja de que ofrece unos resultados más ricos que los aportados por la
intersección booleana. En los mapas adjuntos puede observarse cómo la combinación
lineal ponderada permite conocer el diferente grado de aptitud de los terrenos
seleccionados.
Frente a lo que se suele pensar habitualmente, la aplicación de metodologías
multicriterio en el entorno de los Sistemas de Información Geográfica para la
resolución de problemas territoriales no es necesariamente un proceso de arriba a
abajo, en el que unos técnicos venidos de fuera aportan sus soluciones. Este ejemplo
sobre la localización óptima de un cultivo tradicional pone de manifiesto que la
participación de los agentes locales no sólo es posible, sino también deseable. Éstos
pueden participar en el proceso estableciendo los criterios y los pesos de los
factores, de forma que el analista que trabaja con el Sistema de Información
Geográfica se limita a aplicar los conocimientos y la experiencia que poseen esos
2 El límite fijado para la pendiente (5%) en la intersección booleana no es
propiamente una restricción técnica (en cuyo caso estaría en torno al 12%, como se
ha señalado anteriormente), sino más bien un valor que busca la identificación de
los mejores terrenos. Es decir, desde el punto de vista de la pendiente no se han
buscado los terrenos donde es posible el cultivo del habón, sino los terrenos más
aptos. En cambio, en la combinación lineal ponderada se ha optado por utilizar el
límite del 12%, que supone efectivamente una restricción técnica.

90
actores. Por otro lado, también es importante resaltar que el proceso es sumamente
transparente (ya que se pueden visualizar los mapas de los criterios y la
combinación de éstos en un mapa final) y que se puede aplicar de forma interactiva
(resultados inadecuados pueden ser corregidos modificando las restricciones, los
valores de los factores o los pesos y volviendo a realizar los cálculos).
5. Bibliografía citada
Carpio, J., Gutiérrez Puebla, J. y Vía, M. (2001): “Innovación, nuevas tecnologías y
desarrollo local: aplicaciones de los SIG a la gestión integral del medio ambiente y los
montes”. Cuenca, Coloquio Hispano-Francés de Geografía Rural: las relaciones entre las
comunidades agrícolas y el monte.
Saaty, T. (1980): The analytical hierarchy process. Nueva York, McGraw Hill.

91
Figura 1: Análisis multicriterio: intersección booleana
1 0 0 1 1 0 1 0 0
0 1 1 * 1 0 1 = 1 0 1 1 0 0 1 0 1 1 0 0
Ejemplo: 1ª Celda : 1 * 1 = 1 2ª Celda : 0 * 1 = 0
Capa 1 Capa 2 Capa final

92
Figura 2: Zona de expansión del cultivo del habón según la intersección booleana
1 2
3 4
5 6
1. Pendiente < 5% 2. Orientación Suroeste. 3. Altitud < 1200m. 4. Ríos < 200m. 5. Núcleos < 1500m y Carreteras <
500m. 6. Uso del suelo apto
7

93

94
Figura 3: Valoración de las orientaciones de las pendientes
Figura 4: Análisis multicriterio: suma lineal ponderada
2 2 3 3 3 2 2,25 2,25 2,75
2 1 1 1 3 1 = 1,75 1.5 1 1 2 2 2 3 1 1,25 2,25 1,75
Pesos: 0.75 + 0.25 = 1
Ejemplo: 1ª Celda : 2 * 0.75 + 3 * 0.25 = 1.5 + 0.75 = 2.25
Factor 1 Factor 2 Mapa final

95
Figura 5: Zona de expansión del cultivo del habón según la combinación lineal
ponderada.
1. Bajas pendientes 2. Orientación Suroeste. 3. Altitud baja. 4. Proximidad a red
fluvial. 5. Proximidad a núcleos. 6. Proximidad a
carreteras.
1 2
3 4
5 6
7

96
Anexo 2.
Metodología para el análisis de la vulnerabilidad en
redes de transporte público. El caso de la red de metro
de Madrid
JUAN CARLOS GARCÍA PALOMARES
Departamento de Geografía Humana. Universidad Complutense de Madrid
EDUARDO RODRÍGUEZ NÚÑEZ
Departamento de Geografía Humana. Universidad Complutense de Madrid
JAVIER GUTIÉRREZ PUEBLA
Departamento de Geografía Humana. Universidad Complutense de Madrid

97
METODOLOGÍA PARA EL ANÁLISIS DE LA VULNERABILIDAD
EN REDES DE TRANSPORTE PÚBLICO:
EL CASO DE LA RED DE METRO DE MADRID
JUAN CARLOS GARCÍA PALOMARES
Departamento de Geografía Humana. Universidad Complutense de Madrid
EDUARDO RODRÍGUEZ NÚÑEZ
Departamento de Geografía Humana. Universidad Complutense de Madrid
JAVIER GUTIÉRREZ PUEBLA
Departamento de Geografía Humana. Universidad Complutense de Madrid
RESUMEN
El objetivo de esta comunicación es desarrollar una metodología para medir la
vulnerabilidad en una red de transporte público. Se usa la red de Metro de Madrid y se
analizan las consecuencias de la caída de cada uno de los tramos de la red sobre los
tiempos de los viajes o el número de viajes sin servicio. La metodología propuesta permite
conocer la criticidad de cada arco y la vulnerabilidad de las estaciones. Es posible además
obtener las peores situaciones en una caída sucesiva de tramos (simulando un ataque
coordinado sobre la red).
MEASURING THE VULNERABILITY OF PUBLIC TRANSPORT
NETWORKS: THE CASE OF THE MADRID METRO NETWORK
ABSTRACT
The aim of this paper is to develop a methodology for measuring public transport network
vulnerability, taking the Madrid Metro system as an example. The consequences of
disruption for riding times or the number of missed trips are analysed for each of the
network links. Using each link criticality, vulnerability of stations is calculated. The
proposed methodology also makes it possible to obtain a worst-case scenario for the
successive disruption of links by simulating a targeted attack.
1. INTRODUCCIÓN
Las redes de transporte público son un elemento fundamental en la movilidad de
los espacios urbanos. Cualquier tipo de incidencia en ellas afecta al funcionamiento diario
de la propia ciudad, en especial cuando se trata de los modos ferroviarios, por la cantidad
de viajeros que transportan y por su mayor vulnerabilidad. Fallos en los trenes, caídas de
la tensión eléctrica, obras, o sucesos como suicidios, manifestaciones o huelgas alteran
con frecuencia el servicio, afectando a múltiples usuarios. Otros acontecimientos más
graves, como ataques terroristas, afectan de forma sustancial a las redes durante largo
tiempo. Los ataques terroristas sobre el metro y los autobuses de Londres o los trenes de
cercanías de Madrid, por ejemplo, produjeron una tremenda perturbación en la vida sus
residentes.
En este contexto cobran cada vez más importancia los estudios de vulnerabilidad
de las redes, considerando la vulnerabilidad como la susceptibilidad a que determinados
incidentes en la red puedan causar reducciones en los niveles de servicio y las condiciones
de accesibilidad (BERDICA, 2002). Se dice que un nodo de la red (paradas o estaciones)

98
es vulnerable cuando la pérdida o degradación de un determinado número de arcos
produce una merma significativa de su accesibilidad (TAYLOR et. al., 2006).
Junto a la vulnerabilidad es importante conocer la criticidad. Los elementos críticos
de una red son los que más afectan a su vulnerabilidad: cuanto más crítico es un
componente, mayores son los efectos de su pérdida sobre el conjunto de la red (TAYLOR
et. al., 2006; JENELIUS et al., 2006; RODRÍGUEZ y GUTIÉRREZ, 2012). El nivel de
criticidad de un elemento de la red depende del papel que juegue en su estructura y de los
flujos que circulen por ella. Conocer los puntos débiles de una red y las rutas alternativas
es importante a la hora de mitigar la vulnerabilidad de la red (CHEN et al., 2007) o, por
ejemplo, dar prioridad tras una catástrofe a la reconstrucción de unos tramos sobre otros
(SOHN, 2006; BONO y GUTIÉRREZ, 2011).
En líneas generales, los trabajos sobre vulnerabilidad de redes de transporte pueden
diferenciarse según se trate de redes de carreteras (más frecuentes) o de transporte público
(menos habituales). Para el análisis se utilizan dos grandes tipos de indicadores. Desde
las ciencias físicas y matemáticas aparecen estudios que aplican indicadores de teoría de
grafos y redes complejas. Mientras, desde los estudios del transporte y el territorio lo
habitual es medir la vulnerabilidad a partir de indicadores de accesibilidad. Finalmente,
además del tipo de red al que se aplican o de los indicadores utilizados, los trabajos de
vulnerabilidad de redes pueden diferenciarse en función del enfoque que adoptan, ya se
trate de evaluación de escenarios específicos, identificación de los peores escenarios o
evaluación de escenarios de estrategias de ataques coordinados.
El objetivo de esta comunicación es presentar una metodología que permita medir
la vulnerabilidad y la criticidad en una red de transporte público. A diferencia de la mayor
parte de estudios sobre vulnerabilidad de redes de transporte público, que trabajan con
indicadores de teoría de grafos (ver por ejemplo el aplicado a Madrid de MOURONTE Y
BENITO, 2012), aquí se analizan los incrementos en los tiempos de viaje debido a la
necesidad de utilizar rutas alternativas a la óptima.
Para ello se toma como caso de estudio la red de Metro de Madrid. El área
metropolitana de Madrid es un buen ejemplo de la importancia del sistema de transporte
público en la movilidad y, dentro de ella, el Metro es el modo más importante. Según el
Consocio Regional de Transportes de Madrid, en 2010 el Metro transporta 630 millones
de viajes de los 1.488 millones que se realizaban en transporte público en Madrid.
Para la red de Metro de Madrid se mide la criticidad de cada tramo de la red y de
las líneas fundamentales para el sistema. A partir de la criticidad se calcula la
vulnerabilidad de las estaciones. Finalmente, se obtienen las peores situaciones en una
caída sucesiva de tramos, simulando un ataque coordinado sobre la red. En todos los casos
es posible conocer las consecuencias de esas situaciones sobre la distribución de los
flujos. Este análisis se hace usando un Sistema de Información Geográfica (SIG).
2. EL CASO DE ESTUDIO: LA RED DE METRO DE MADRID
La red de Metro de Madrid utilizada, en función de la información disponible de
los flujos de viajes, es del año 2007 y estaba formada por 12 líneas y 239 estaciones. Un
elemento fundamental para reducir la vulnerabilidad es la conexión de varias líneas en
una misma estación. En este caso existían 27 estaciones con conexión entre 2 líneas, 10
con conexión entre tres líneas y en 1 (Avenida de América) convergen 4 líneas. La red
presenta una estructura compleja y evolucionada, como corresponde a una de las más
largas y densas del mundo (Figura 1).

99
Figura 1: Red de Metro de Madrid
En 2007, tomando un día entre semana del mes de Octubre, se realizaban en el
Metro de Madrid casi 2.500.000 viajes diarios. La línea 10 y la circular 6 eran las que
más viajes canalizaban, con 367 y 353 mil respectivamente, seguidas de otras líneas
radiales como la 1, 3 y 5. Eran también las líneas 6 y 10 las que tenían un mayor número
medio de viajes por tramo. El máximo se localizaba en la línea 10, con tramos en el centro
de la ciudad por los que pasaban más de 250 mil viajes. Mientras, las líneas periféricas
llevaban un número mucho menor de viajeros (Figura 2).
Figura 2: Distribución de los flujos por la red
3. FUENTES
Para el análisis de la vulnerabilidad de la red de Metro de Madrid se ha contado con
la siguiente información cartográfica y estadística, toda ella facilitada por el Consorcio
de Transportes de Madrid:

100
- Red de Metro de Madrid. Incluye las estaciones y los tramos (arcos) de las líneas
referidas al año 2007. Como decíamos, se compone de 239 estaciones y 12
líneas, con 268 arcos que unen las estaciones entre ellas. Cada uno de los arcos
contiene el tiempo de recorrido, su longitud y la información de la línea a la que
pertenece. Se han incluido además 60 pasillos, que permiten simular los
transbordos dentro de las estaciones con más de un línea, con un tiempo de
penalización por transbordo.
- Matriz de viajes entre estaciones en 2007. Proporciona el total de viajes que se
realizan entre cada par de estaciones. Esta información permite conocer la
distribución de los flujos en la red (Figura 2).
4. METODOLOGÍA
La metodología seguida para estimar la vulnerabilidad de la red ha sido evaluar la
variación de la accesibilidad, midiéndola antes y después de una alteración hipotética de
cada uno de los arcos individuales de la red (SOHN, 2006). Al analizar el papel de cada
uno de los arcos en el funcionamiento de la red, estamos utilizando una metodología
calificada como “full scan approach” (JENELIUS et al., 2006). Un arco será o no
importante para el correcto funcionamiento de la red si al dejar de ser operativo tiene un
efecto notable sobre el rendimiento global del sistema (JENELIUS, 2009).
El corte de cada arco puede tener dos tipos de consecuencias. En unos casos, cuando
no existe otra alternativa para el viaje, la caída de un arco deja descolgadas de la red a
una estación o grupo de estaciones. En esta situación la criticidad de los arcos puede
medirse en relación al total de viajes que quedan sin poder alcanzar su estación de destino
(demanda no satisfecha). En otros casos, cuando existe otra alternativa, la caída del arco
produce un incremento en los tiempos de viaje debido a la necesidad de utilizar rutas
alternativas a la óptima. Obviamente, ese impacto es mayor cuando afecta a arcos
atravesados por muchos viajes que cuando lo hace sobre un arco poco utilizado.
Para el análisis de los impactos en los tiempos se ha usado como indicador el tiempo
medio de viaje de cada estación con el resto de estaciones de la red3, ponderadas por el
total de viajes entre las mismas. Se ha calculado según �̅�𝑖 =∑ 𝑇𝑖𝑗𝐹𝑖𝑗
𝐹𝑖 , siendo, T̅i el tiempo
medio para la estación i; Tijel tiempo de viaje entre la estación i y j; Fijel número de viajes
entre la estación i y j; y 𝐹𝑖 el total de viajes generados desde la estación i. A partir de los
tiempos medios de cada estación se calculan las estadísticas básicas de los tiempos en el
conjunto de estaciones de la red.
Para conocer el impacto que tiene la caída de cada arco de la red se calculan los
tiempos medios sin ese arco y se comparan la media de tiempos de las estaciones en la
situación inicial y en la situación sin dicho arco, según 𝐼𝑎 = �̅�0 − �̅�𝑎, donde Iaes la pérdida
de tiempo por el corte del arco a; T̅0 el tiempo medio de las estaciones en una situación
normal; y T̅a el tiempo medio de las estaciones en la situación sin el arco a. El proceso se
repite para cada arco. Los resultados a nivel de arcos son cartografiados y su análisis
puede realizarse también según líneas y tipos de líneas (que por razones de espacio no se
presenta aquí).
3 En este caso, con el fin de tener situaciones comparables se trabaja con las estaciones que tienen alternativas de viajes
a cada corte de tramos, tanto en el escenario inicial con en el escenario de cada corte.

101
Con este análisis se obtiene la criticidad (importancia) de cada arco. Esto permite
hacer un ranking de los arcos más críticos. A la vez, podemos medir la vulnerabilidad de
las estaciones. En aquellas estaciones que se encuentran con un arco sin otra alternativa
para el viaje, la vulnerabilidad se ha medido como el número de arcos hasta encontrar una
estación con dos o más alternativas de viaje. En las estaciones que tienen varias
alternativas, se han calculado las pérdidas medias de tiempos de los cortes de cada uno
de los arcos.
Finalmente, se identifican los escenarios más críticos en una secuencia sucesiva
de caída de arcos. La metodología usada es similar a la planteada por MATISZIW y
MURRAY (2009). Lo que se hace es identificar el arco que tiene el mayor impacto en los
tiempos y, a partir de esa situación, recalcular nuevamente las pérdidas que produce la
caída del resto de los arcos sobre una situación de partida en la que se ha eliminado ese
arco. Este proceso se repite el número de veces como escenarios críticos se quieran
identificar. En esta comunicación se han identificado los 5 arcos más críticos. Para cada
uno de esos escenarios se recalcula la distribución de los flujos en la red. Esto permite
identificar los arcos que absorben los desvíos de viajes.
5. RESULTADOS
5.1 Arcos sin otras opciones para los desplazamientos: demanda no satisfecha
La Figura 3 muestra los arcos sin otras opciones de desplazamiento según el total
de viajes que quedarían sin poder realizarse. Se trata de arcos que unen espacios
periféricos con el centro y con el resto de la red Metro. Los más críticos se localizan en
las líneas 1 (116.000 viajes colgados), la 9 (104.000) y la 10 (100.000). Se trata de arcos
que conectan líneas largas (dejan muchas estaciones desconectadas) y de espacios
residenciales densos del sur de la ciudad. En el caso de los arcos del sur de la línea 10, su
caída deja sin conexión con el resto de la red a la línea suburbana 12. En otros casos, la
caída afecta a elementos importantes en la cuidad, como la caída de los arcos de la línea
8, que dejarían sin servicio al aeropuerto de Barajas o al recinto Ferial IFEMA.
Como es lógico, las estaciones más vulnerables se localizan en las terminales de las
líneas de los conjuntos de arcos que quedan desconectados. En la figura 3 se muestra el
número de arcos que dejarían descolgadas a esas estaciones terminales. En este caso, las
más vulnerables se localizan en las estaciones de líneas radiales que alcanzan municipios
del este metropolitano (estación de Henares, línea 7), del sureste (Arganda del Rey, línea
9) o del sur metropolitano (Valdecarros, línea 1), que tienen que recorrer hasta 12 arcos
para alcanzar un arco con alternativas para continuar el viaje.
5.2 Arcos con otras opciones en los desplazamientos: pérdidas de tiempos
Para el análisis de los impactos en los tiempos se trabaja con los arcos y estaciones
para los que existe una alternativa de viaje. La media de las estaciones en los tiempos
ponderados en la situación normal es de 30,4 minutos. La media de las pérdidas por la
caída de cada uno de los arcos es de 0,5 minutos, lo que supone un 1.7%. Podemos decir
que la vulnerabilidad de la red de Metro de Madrid es baja. Sin embargo, el nivel de
criticidad de algunos arcos es más llamativo. El arco que produce las mayores pérdidas
de tiempos lo hace en 2,2 minutos, una pérdida del 7,2%. Dado que estas pérdidas se
refieren al total de relaciones entre estaciones, y muchas de ellas no usan ese arco, esta
pérdida es muy importante.

102
Figura 3: Viajes sin servir en los arcos sin otra opción de desplazamiento
La figura 4 muestra la distribución de las pérdidas porcentuales en los tiempos por
la caída de cada arco. La situación más crítica aparece en la unión de la línea 10 con la 6
(entre las estaciones de Casa de Campo-Príncipe Pío), donde la reducción de los tiempos
es del 7% (zona 1, figura 4). Estos arcos conectan los grandes municipios suburbanos del
sur, servidos por la línea 12, y las áreas densamente pobladas del suroeste del municipio
con el centro de la ciudad. Por ellos pasan alrededor de 160.000 viajes diarios, que con
su caída tienen que desviarse por la línea 5, lo que supone un recorrido extra de al menos
15 estaciones. Por detrás se sitúan los arcos de la línea 6 entre Pacífico-Sainz de Baranda
(zona 2), con impactos por encima del 5%. La caída de estos arcos afecta a unos 190.000
viajes entre el sur y el este de la ciudad, que con la caída de estos arcos tienen que entrar
hasta el centro de la ciudad (estación de Sol) y salir nuevamente al este. Otras dos zonas
críticas a reseñar se sitúan en dos zonas de la red muy diferentes, con pérdidas por encima
del 4%. En el centro de la ciudad los arcos de la línea 1, que conectan la estación de
ferrocarril de Atocha con Sol (el centro de la red) (zona 3) y en la periferia, los arcos que
conectan la línea circular suburbana 12 con la línea 10, que le dan acceso al resto de la
red (zona 4).
La Figura 5 muestra la vulnerabilidad a nivel de estación (media de la caída
porcentual en los tiempos como consecuencia de los cortes de todos los arcos). La pérdida
media de las estaciones es de 0,6 minutos, con un máximo de 2 minutos. Esto supone
pérdidas porcentuales de un 2% de media y un máximo del 7%. Las estaciones más
vulnerables se localizan en el sur de la ciudad, donde las alternativas de viaje son menores
y suponen un rodeo mayor. Es especialmente vulnerable la línea suburbana 12, con
pérdidas superiores al 5% en todas las estaciones, que tienen además unos tiempos de
viaje elevados. Junto a ellas, las estaciones del suroeste de la ciudad, en las líneas 10, 5 y
6 tienen pérdidas de tiempos elevadas. En todos los casos se ven afectadas por los altos
impactos de los cortes de la línea 10 en su acceso a sur a la ciudad.

103
Figura 4: Impacto medio de cada corte de arcos sobre el escenario sin cambios
Figura 5: Vulnerabilidad de las estaciones
5.3 Secuencias de caídas más críticas en ataques coordinados
La figura 6 reproduce la secuencia de peores escenarios ante una caída sucesiva de
arcos en la red. Esta situación podría darse en un ataque terrorista, en un boicot en una
situación por de huelga, o en cualquier otro tipo de ataque coordinado sobre la red. Como
vimos antes, la peor situación con la caída de un único arco se produce en el arco Lago-
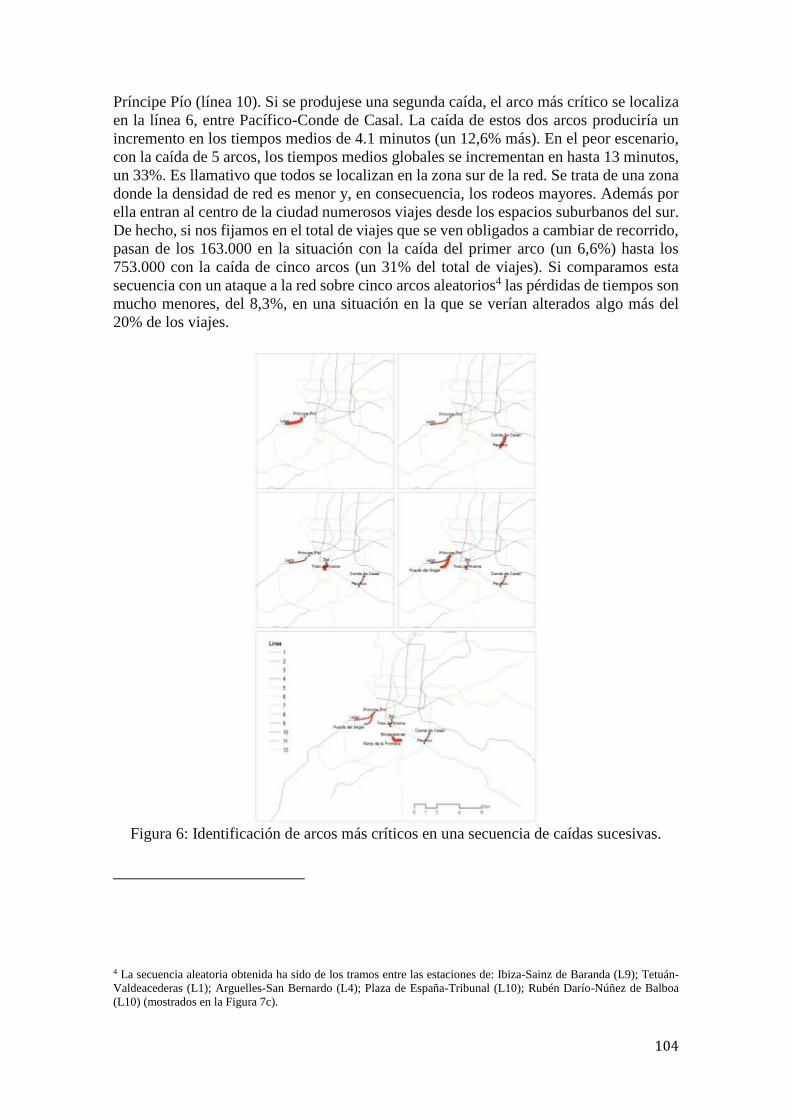
104
Príncipe Pío (línea 10). Si se produjese una segunda caída, el arco más crítico se localiza
en la línea 6, entre Pacífico-Conde de Casal. La caída de estos dos arcos produciría un
incremento en los tiempos medios de 4.1 minutos (un 12,6% más). En el peor escenario,
con la caída de 5 arcos, los tiempos medios globales se incrementan en hasta 13 minutos,
un 33%. Es llamativo que todos se localizan en la zona sur de la red. Se trata de una zona
donde la densidad de red es menor y, en consecuencia, los rodeos mayores. Además por
ella entran al centro de la ciudad numerosos viajes desde los espacios suburbanos del sur.
De hecho, si nos fijamos en el total de viajes que se ven obligados a cambiar de recorrido,
pasan de los 163.000 en la situación con la caída del primer arco (un 6,6%) hasta los
753.000 con la caída de cinco arcos (un 31% del total de viajes). Si comparamos esta
secuencia con un ataque a la red sobre cinco arcos aleatorios4 las pérdidas de tiempos son
mucho menores, del 8,3%, en una situación en la que se verían alterados algo más del
20% de los viajes.
Figura 6: Identificación de arcos más críticos en una secuencia de caídas sucesivas.
4 La secuencia aleatoria obtenida ha sido de los tramos entre las estaciones de: Ibiza-Sainz de Baranda (L9); Tetuán-
Valdeacederas (L1); Arguelles-San Bernardo (L4); Plaza de España-Tribunal (L10); Rubén Darío-Núñez de Balboa
(L10) (mostrados en la Figura 7c).

105
5.4 Redistribución de los flujos en la red
La figura 7 muestra la redistribución de los flujos en el caso de producirse las
situaciones con la caída del arco más crítico (Lago-Príncipe Pio), en el caso de un ataque
coordinado sobre los 5 arcos del escenario más crítico y de un ataque sobre 5 arcos
aleatorios. Se han redistribuido todos los viajes con el fin de conocer qué arcos serían los
más afectados por los desvíos de viajes a otras líneas. Con la caída del arco Lago-Príncipe
Pio, los flujos de entrada al centro de la ciudad pasan en su mayor parte a la línea 5 y a la
circular 6, que sirve como redistribuidor para conectar nuevamente con la línea 10 y en
menor medida con las líneas 3 y 1 (Figura 7a). Como consecuencia, los arcos de la línea
5 multiplican por 4 sus flujos actuales y los de la línea 6 los duplican. Al contrario, se
produce una caída de los viajes en los arcos centrales de la línea 10 del 10%-20% de los
viajes. En las dos situaciones con 5 cortes las redistribuciones son más complejas (Figuras
7b y 7c), pero en ambos casos la línea 6 cobra un papel clave en la redistribución de los
flujos. En el primer caso, los arcos del sur de la línea 6 redistribuirían los viajes de entrada
a la ciudad de las líneas 1, 3 y 10, que usarían la línea 6 para alcanzar la línea 5 y acceder
por esta al centro de la ciudad. Los arcos de la línea 6 y de la 5 verían multiplicada su
demanda por más de 10, lo que produciría su saturación. Con 5 cortes aleatorios, son los
arcos del NW y NE de la línea 6 los que reciben un mayor número de viajes, duplicando
su demanda.
Figura 7: Redistribución de los flujos en tres situaciones críticas
6. CONSIDERACIONES FINALES
En esta comunicación hemos presentado una metodología para analizar el grado de
vulnerabilidad en una red de transporte público, automatizada dentro de un SIG. Los
resultados muestran que el impacto que tiene el corte de cada arco es diferente en función
de su posición en la red y del total de viajes que canaliza. La caída de arcos para los que
no existe alternativa de viaje supone dejar sin posibilidad de servicio a los viajes que lo
atraviesan, que se verían obligados a usar otra red de transporte. Estas situaciones se
producen en las líneas radiales de acceso a la ciudad. En el caso de los arcos para los que
sí existe otra alternativa de viaje, los más críticos son aquellos que canalizan un flujo
importante de viajes, en espacios donde la densidad de la red es menor y, en consecuencia,
las alternativas para esos viajes son escasas y suponen rodeos importantes (es el caso de
algunos arcos de las líneas radiales del sur de Madrid). Las estaciones más vulnerables
son aquellas que se sitúan en los entornos de los arcos más críticos.
Un elemento que no se ha considerado son las características de la población
afectada por la caída de los arcos. Es evidente que la situación de vulnerabilidad será
mayor en las estaciones localizadas en entornos residenciales más pobres de la ciudad,
donde la población es más dependiente del transporte público. De hecho, en Madrid, los

106
arcos más críticos y las estaciones más vulnerables se localizan en la zona sur, que es la
de sectores residenciales más pobres de la ciudad. Tener en cuenta las características de
la población afectada permite relacionar vulnerabilidad de redes y vulnerabilidad social.
El tratamiento de las alternativas de viajes y la consideración de otras redes de
transporte público como alternativa es otro de los pasos necesarios para mejorar este
análisis. Al funcionar el transporte público como una red multimodal, muchas de las
incidencias en la red de Metro son resueltas buscando una alternativa a través de otras
redes. En Madrid, las redes de autobuses urbanos e interurbanos son muy densas, e incluso
el tren de cercanías supone una alternativa de viaje.
Conocer la información de criticidad y de vulnerabilidad es importante para mitigar
los efectos de incidencias sobre la red. Esta información es también de gran ayuda en la
planificación de nuevas líneas o ampliaciones de la red, de manera que su ampliación se
haga considerando no solo la eficiencia y la equidad en el servicio sino también una
reducción de la vulnerabilidad y de los elementos críticos.
7. BIBLIOGRAFÍA
BERDICA, K. (2002): «An introduction to road vulnerability: what has been done,
is done and should be done». Transport Policy, n. 9, p. 117-127
BONO, F. y GUTIÉRREZ, E. (2011): «A network-based analysis of the impact of
structural damage on urban accessibility following a disaster: the case of the seismically
damaged Port Au Prince and Carrefour urban road networks». Journal of Transport
Geography, n. 19, p. 1443–1455
CHEN, A., YANG, C., KONGSOMSAKSAKUL, S. y LEE, M. (2007): «Network-
based Accessibility Measures for Vulnerability Analysis of Degradable Transportation
Networks». Networks and Spatial Economics, v. 7, n. 3, p. 241-256
JENELIUS, E. (2009): «Network structure and travel patterns: Explaining the
geographical disparities of road network vulnerability. Journal of Transport Geography,
n. 17(3), p. 234-244.
JENELIUS, E., PETERSEN, T. y MATTSSON, L.G. (2006): «Importance and
exposure in road network vulnerability analysis», Transportation Research A, n. 40, p.
537-560
MATISZIW, T.C., MURRAY, A.T., GRUBESIC, T.H. (2009): «Exploring the
vulnerability of network infrastructure to disruption». The Annals of Regional Science n.
43(2), 307–321.
MOURONTE, M. y BENITO, R. Mª. (2012): «Structural properties of urban bus
and subway networks of Madrid». Networks and Heterogeneous Media, n. 7, p.415- 428
RODRÍGUEZ, E. y GUTIÉRREZ, J. (2012): «Análisis de vulnerabilidad de redes
de carreteras mediante indicadores de accesibilidad y SIG: Intensidad y polarización de
los efectos del cierre de tramos en la red de carreteras de Mallorca», GeoFocus, n.12, p.
374-394
SOHN, J., (2006): «Evaluating the significance of highway network links under the
flood damage: accessibility approach». Transportation Research A, n. 40, p. 491-506.
TAYLOR, M. A. P., SEKHAR, S. V. C. y D’ESTE, G. M. (2006): «Application of
Accessibility Based Methods for Vulnerability Analysis of Strategic Road Networks».
Networks & Spatial Economics, n. 6, p. 267–291

107
Anexo 3.
Análisis conjunto de entorno urbano y transporte
público: los puntos de intermodalidad de la ciudad de
Madrid.
José Carpio Pinedo
Departamento de Urbanística y Ordenación del Territorio
Universidad Politécnica de Madrid

108
1. Introducción
Se presenta aquí un ejemplo del uso de los Sistemas de Información
Geográfica como software idóneo y necesario para la integración de una gran
diversidad de capas de información, capaz además de generar nuevos datos fruto
del análisis de las anteriores. Supone por tanto una base imprescindible en la
elaboración de herramientas como las que se presentan.
El Consorcio Regional de Transportes de Madrid, por medio del Área de
Intercambiadores, participa desde 2012 en el proyecto I+D+i de la Comisión
Europea ‘NODES’: ‘New Tools for Design and operation of urban transport
interchanges’ (7º Programa Marco). Dentro de éste, el equipo del CRTM lidera el
tema “Estrategias para la planificación integrada de los usos del suelo y la
infraestructura de transporte urbano”.
En una primera etapa, el enfoque es global a nivel ciudad/área metropolitana,
donde el objetivo es proponer herramientas de apoyo al planificador de cara a
provocar las sinergias convenientes entre los entornos urbanos y la red de
transporte público. Este objetivo se enmarca en un nuevo contexto de
reivindicación de la multi- e intermodalidad, como única estrategia viable en las
políticas de movilidad sostenible, ante la heterogeneidad y dispersión de los
crecimientos urbanos contemporáneos (Ascher, 2001).
Se presenta en primer lugar una selección de variables significativas o
‘indicadores’ que suponen un marco de comprensión conjunta de las
características, dinámicas e interacciones entre los entornos urbanos y el sistema de
transporte multimodal (cap.2).
Para este primer acercamiento a la cuestión a nivel metropolitano, una
primera herramienta es precisamente un marco para la comprensión conjunta
y diagnóstico general. Éste permite igualmente detectar entornos urbanos o
puntos de la red de transporte de intervención prioritaria (cap.3).
Una segunda herramienta acompaña al planificador en el proceso de
proyecto de un nuevo punto de la red de transporte, evaluando las diferentes
alternativas o escenarios posibles con el fin de seleccionar el idóneo entre ellos. A
una escala metropolitana esto afecta a la elección de la localización en la ciudad, el
o los modos de transporte adecuados y sus conexiones a la red existente (cap. 4).

109
2. Selección de variables significativas: ‘indicadores’.
¿Cómo caracterizar los distintos entornos en cuanto a sus características
urbanísticas y del servicio prestado por la red de transporte público?
Los indicadores se han seleccionado para, por una parte, ser capaces de
describir suficientemente los aspectos relevantes para la planificación. Por otra
parte, se ha tenido en cuenta que todos los indicadores sean de práctica habitual en
la planificación (de cara a incrementar su comprensibilidad, pero especialmente su
disponibilidad). En los casos en que, de cara a una mayor innovación, los indicadores
propuestos no sean de práctica habitual, éstos son calculables “fácilmente” por
medio de software, una única capa de información normalmente disponible y, por
tanto, sin basarse en trabajo de campo.
Se emplea una clasificación en cuatro grupos de indicadores:
a. Demanda y población cubierta de un punto de transporte.
Demanda (total y por cada modo).
La demanda, como número de viajeros, indica la utilidad y uso de una parada,
estación o intercambiador de transporte.
Para el planificador, este indicador se vincula directamente con el tamaño, diseño,
equipamiento e inversión necesaria y maximizar este valor (dentro de las
previsiones) es un objetivo prioritario. Por ello, conviene encontrar las variables
capaces de explicar la demanda que se está produciendo en los puntos de la red
existente, de cara a pronosticarla en nuevas intervenciones mediante un modelo
multivariable.
Estas medidas se recogen por las empresas gestoras de la red de transporte, con
medios muy distintos (conteo visual, mecánico, digital).

110
Figura 1: Representación de la variedad de demanda total (diámetro) y por modos
(colores) en puntos de intermodalidad de la ciudad de Madrid.
Población cubierta.
La población cubierta por cada punto de la red, independientemente del uso real de
la infraestructura que dicha población realice, representa la demanda potencial y la
capacidad de servicio, entendida esta última además como un deber de la
Administración en la línea del ‘derecho a la movilidad’.
Estas medidas pueden calcularse de forma precisa y sencilla con el manejo de
Sistemas de Información Geográfica.
b. Integración de la movilidad.
El proyecto ‘NODES’ se plantea para una planificación genérica pero
consciente de unos entornos urbanos donde se solapan distintos modos de
transporte y donde la intermodalidad es por tanto fundamental para entender la
utilidad de la red de transporte público.
Múltiples estudios han explorado las relaciones entre entorno urbano y redes
de transporte, pero muchos estudian el impacto de un solo tipo de red y modo, o la
introducción de una nueva línea. Son menos frecuentes, aunque empiezan a
proliferar, aquellos que estudian el sistema de transporte público en su conjunto y
de forma integrada. Hemos seleccionado algunas variables propuestas en uno de
estos últimos (Curtis, 2011).

111
Interesa aquí determinar mediante valores sintéticos la dotación de
transporte público en su conjunto pero aplicado a localizaciones específicas: el
entorno urbano de un punto, estación o intercambiador.
Con este fin, se recurre a los siguientes tres indicadores, que caracterizan el
papel de cada punto en el conjunto de la red, desde un punto de vista estratégico.
Igualmente sirven para valorar la “utilidad” de cada punto de la red en comparación
con los otros, por lo que se puede interpretar también en términos de “atractivo”.
Closeness centrality – Accesibilidad en tiempo de viaje.
La accesibilidad o centralidad de tipo ‘closeness’ es una medida de red que refleja el
“tiempo medio necesario para alcanzar todos los otros puntos”. Se trata por tanto de
una “centralidad” en el sentido tradicional, pero valorando la reducción de tiempos
aportada por la red de transporte. De esta forma, se identifican los entornos más y
menos accesibles desde el conjunto del territorio y se relaciona con el potencial del
entorno como origen y como destino.
Straightness centrality – Accesibilidad en nº de trasbordos.
La accesibilidad o centralidad de tipo ‘straightness’ (‘degree centrality’ en Curtis,
2011) es una medida de red que refleja el “número medio de trasbordos necesario
para alcanzar todos los otros puntos”. Se trata por tanto de una “centralidad”
asociada al número de rupturas del viaje, las cuales han resultado en todo estudio
de la intermodalidad los factores principales de disuasión para el uso del transporte
público.
Se asocia a una “facilidad física” del viaje, pero también psicológica, tocando incluso
aspectos económicos en el caso de no existir integración tarifaria entre modos.
Igualmente, sirve para, junto con la variable anterior, identificar los entornos más y
menos accesibles desde el conjunto del territorio, asó como con el potencial del
entorno como origen y como destino.

112
Figura 2: Representación de la accesibilidad en nº de trasbordos (‘straightness
centrality’) en la ciudad de Madrid.
Las dos variables anteriores reflejan la utilidad del punto de transporte para dos
viajeros de tipo extremo: 1) aquel que prioriza la reducción del tiempo de
desplazamiento, no importándole las inconveniencias físicas de posibles
trasbordos; frente a 2) el viajero que prioriza la simplicidad y comodidad del viaje,
carente de trasbordos, pasando a un segundo plano la reducción del tiempo de viaje.
Estas dos variables permiten, mediante un modelo bi-variable abarcar todo el
abanico de preferencias y, por tanto, estudiar el conjunto de viajeros.
Betweenness centrality – Accesibilidad de paso.
La accesibilidad o centralidad de tipo ‘betweenness’, o de paso, es un indicador del
flujo potencial de viajeros, al medir la probabilidad de un punto de situarse dentro
del recorrido entre otros dos puntos cualesquiera de la red.
Tiene consecuencias importantes al valorar el punto de transporte no por su
potencial como origen o destino, sino por su flujo. Éste se relaciona mejor con
importantes aspectos de la planificación, como el dimensionado o la asociación de
ciertos usos, como el comercial.
Los tres indicadores proponen de esta forma la caracterización de los puntos de la
red de transporte en relación a tres aspectos relevantes de las dinámicas de
desplazamiento. Conjuntamente permiten valorar el papel estratégico o la jerarquía

113
de un punto dentro del conjunto, así como estudiar el potencial de un entorno
urbano para acoger o atraer ciertos usos.
Pueden calcularse con herramientas específicas de análisis de redes en SIG o
mediante software para la modelización del transporte, precisando en cada caso
únicamente de una capa de información: la propia red modelizada.
c. Usos del suelo y entorno urbano.
Describir el entorno urbano de un punto de transporte es fundamental para
comprender la utilidad de dicha infraestructura (Cervero & Kockelman, 1997;
Ewing & Cervero, 2001), ya que es el entorno urbano el que acoge los posibles
orígenes o destinos que producen y justifican el desplazamiento. Éstos son diversos
y pueden ser residencias, puestos de empleo, servicios, comercios, etc.
Igualmente, la configuración y características del entorno explica, de acuerdo al
estado del arte, la realización del desplazamiento peatonal entre el punto de
origen/destino y el punto de transporte en condiciones de seguridad, comodidad e
incluso atractivo.
Se caracteriza el entorno urbano de cada punto de intermodalidad mediante una
serie de indicadores que sintetizan la presencia de usos y la morfo-tipología del
entorno:
Usos del suelo.
Los usos principales, a nivel de planeamiento general y parcial, explican grosso
modo la posible generación y atracción de viajes, así como el carácter de los
entornos urbanos y se relacionan igualmente con la experiencia subjetiva de las
condiciones de comodidad, seguridad y atractivo.
Su cálculo es generalizable mediante el uso de Sistemas de Información Geográfica.

114
Figura 3: Captura de los principales usos del suelo a 500 metros de desplazamiento
peatonal desde el punto de intermodalidad a través de la red de viario.
Morfo-tipología: edificabilidad, ocupación y densidad de viario.
La edificabilidad o densidad construida, junto con el índice de ocupación del suelo y
la densidad de viario sirven para describir el entorno urbano en términos de
“intensidad” y “percepción”, lo cual se relaciona con la calidad percibida, la vitalidad
urbana o la seguridad natural, entre otros.
A nivel económico, la edificabilidad tiene además una relación directa con los
beneficios y plusvalías derivadas de la urbanización.
La ocupación se relaciona con la calidad de los espacios libres, así como para la
percepción y orientación en éstos.
La densidad de viario tiene una relación evidente con la facilidad de movimiento en
un entorno, reduciendo los índices de rodeo, pero además, incrementa los frentes
de fachada, que son el soporte de usos como el comercial, incrementando la
intensidad de las actividades en el entorno.
Población y actividades económicas.
Como se ha explicado, la población y el empleo constituyen las dos principales
variables explicativas de la generación y atracción de viajes en un entorno.

115
d. Integración urbana.
Los planificadores del transporte siempre reclaman la importancia de localizar los
puntos estratégicos de la red de transporte en lugares igualmente estratégicos de la
ciudad, pero ¿qué significa esto? Desde los años 80, se ha querido entender la
jerarquía de espacios urbanos aplicando la teoría y análisis de redes, con el fin de
explicar patrones de las dinámicas tanto sociales como económicas.
La teoría y metodología Space Syntax (Hillier y Hanson, 1984; Hillier, 2007)
investiga las relaciones entre la estructura espacial de la trama urbana y los
fenómenos sociales, económicos y ambientales.
Según esta teoría, los usos del suelo buscan de forma natural su lugar óptimo en la
ciudad, y no al revés. Así, mediante el único input de la red de espacios urbanos, ha
demostrado su potencial para explicar diversas variables como la densidad, la
mezcla de usos, el comercio, el crecimiento urbano o el índice de delincuencia. Por
estos motivos, Space Syntax se constituye en una herramienta fundamental para la
planificación y diseño de los espacios urbanos.
Integración global.
La accesibilidad o integración urbana global explica la estructura general del
conjunto de la ciudad, lo cual resulta fundamental para la localización óptima de una
infraestructura de transporte del mismo rango.

116
Figura 4: Mapa de integración global en la ciudad de Madrid. Gradiente entre los
espacios más integrados (rojo) y menos (azul).
Integración local.
La accesibilidad o integración urbana local explica la capacidad de los peatones para
orientarse en el espacio público (‘wayfinding’). Es fundamental para asegurar un
acceso fácil a la infraestructura de transporte desde el entorno. Por tanto, sirve para
encontrar el lugar óptimo de la infraestructura en un entorno concreto, planificar en
qué punto han de situarse los accesos, etc.
3. Herramienta para la comprensión conjunta y el diagnóstico.
La primera herramienta trata de explotar al máximo la capacidad explicativa
de las variables previamente descritas. Se propone una matriz de correlaciones bi-
variadas donde se cruzan todas las variables entre sí, permitiendo encontrar las
relaciones e interacciones que se producen entre ellas.
Cabe apuntar a ciertas precauciones que este método implica, como la posible
conveniencia de normalizar algunas de las variables, la identificación de ‘outliers’ en
cada cruce o la existencia de ‘terceros factores’ explicativos. Éstas y otras cautelas
han de estudiarse en la literatura específicamente estadística.
El marco sirve para la comprensión conjunta de los fenómenos que se están
produciendo, permitiendo valorar grandes decisiones o líneas estratégicas de
conjunto con una visión rica, rigurosa y cuantitativa, pero sintética.

117
Varios software de análisis de datos permite sombrear rápidamente
relaciones en función de su coeficiente de correlación, dando pie a sacar
conclusiones de conjunto visualmente.
Esta herramienta se plantea como un útil más para el planificador, pero no le
sustituye. Entender las relaciones que se producen no significa que éstas sean algo
a proteger o potenciar. Cada relación (o ausencia de ella) debe considerarse de
forma aislada, en base a principios de tipo ciudadano, social, medioambiental,
económico, etc. y, de esta forma, valorar si la situación es satisfactoria o debe ser
corregida y en qué grado.
Precisamente, para este último fin, cada cruce de correlaciones permite
obtener una nube de puntos donde identificar los puntos que más se alejen de la
situación deseada y, por tanto, supongan puntos de intervención prioritaria.

118
4. Herramienta para la planificación de un nuevo punto intermodal
a la escala ciudad.
Con la aplicación para el caso de la ciudad de Madrid de la herramienta
anteriormente descrita, se obtuvieron importantes conclusiones que dieron lugar a
priorizar ciertos indicadores frente a otros de cara a la elaboración de una
herramienta para acompañar el proceso de planificación de un nuevo punto
intermodal a la escala ciudad.
Se propone así una herramienta más sencilla y reducida. No todas las
variables seleccionadas (cap.2) presentan una incidencia igual de relevante al
estudiar las interacciones entorno urbano-transporte a una escala metropolitana o
de conjunto de ciudad. A esta escala, las variables de red, tanto de accesibilidad en
la red de transporte público como en la trama urbana, resultan de mayor
importancia a la hora de comprender el conjunto y la incidencia sobre la demanda
del transporte. Muchas otras variables recibirán una mayor atención a una escala
más próxima, de entorno urbano, en lo que se centra la siguiente fase del proyecto
NODES.
A una escala ciudad, se considera primordial la la elección de la localización
en la ciudad, el o los modos de transporte adecuados y sus conexiones a la red
existente. Sin embargo, estas posibilidades no son infinitas, sino que la inversión en
un punto de transporte viene normalmente condicionada por factores de naturaleza
diversa como:
a) La existencia previa (incluso histórica) de un punto, estación o
intercambiador, que requiere una mejora, ampliación o incorporación de
nuevos modos o conexiones.
b) La disponibilidad y precio del suelo urbano.
c) Políticas urbanas amplias, como las de regeneración, que incorporan la
movilidad como una línea de trabajo más, pero no la única.

119
Muchas de las actuaciones en infraestructura del transporte en Europa
pueden explicarse en base a este tipo de factores, que no pueden sistematizarse.
Sin embargo, estas razones van a limitar las posibles localizaciones a un
número reducido de puntos y, en cada uno de ellos, las posibles conexiones y modos
de transporte serán igualmente limitados.
Estas combinaciones posibles quedan resumidas en lo que llamamos
‘escenarios’, los cuales sí pueden ser evaluados con criterios homogéneos.
Estas alternativas de proyecto se han de evaluar teniendo en cuenta una serie
de variables relevantes a nivel global:
‘Closeness’ del nuevo punto.
El impacto del nuevo punto en el valor de ‘closeness’ en el resto de puntos
(media de variaciones).
‘Straightness’ del nuevo punto.
El impacto del nuevo punto en el valor de ‘straightness’ en el resto de
puntos (media de variaciones).
Integración urbana – local (Space Syntax).
Finalmente se distingue si la nueva infraestructura se plantea como un punto
de gran relevancia para el transporte metropolitano, para lo cual hay que añadir dos
exigencias:
Integración urbana – global (Space Syntax).
Consideración en conjunto de ‘Betweenness’: flujos que se reconducen
por el nuevo punto, así como su impacto en el flujo de los puntos ya
existentes.

120
Una vez más, la herramienta propuesta no sustituye al planificador en la toma
de decisiones. De hecho, tal y como está diseñada, distintos escenarios pueden
obtener los mejores valores en distintas variables, lo cual deja al planificador la
decisión final en base a sus prioridades.
5. Conclusiones.
A pesar de la complejidad implícita en el estudio de las dinámicas e interacciones
urbanas y en particular con el sistema de transporte, es posible plantear
herramientas lo suficientemente ricas pero igualmente sencillas para enriquecer y
guiar el proceso de planificación conjunta urbanística y de transporte.
Igualmente es posible plantear herramientas que hagan aportaciones
significativas a una escala global metropolitana o ciudad, pero no por ello sustituir
al planificador en la toma de decisiones, por lo que se habla de ‘metodología abierta’.
Por otra parte, la metodología abierta afecta a la posibilidad de ser adaptada y
aceptar modificaciones parciales para el estudio de ámbitos concretos,
otras/nuevas variables, etc.
Aunque en este documento se trate sólo la escala global, las variables
seleccionadas permiten considerar las relaciones entorno urbano-transporte
público de manera transversal multi-escalar, suponiendo un marco de análisis
coherente para plantear también herramientas a escalas más próximas.

121
6. Referencias.
Ascher, F. (2001). Les nouveaux principes de l'urbanisme. La fin des villes n'est pas
à l'ordre du jour. Paris: Éditions de l’Aube.
Cervero, R., & Kockelman, K. (1997). “Travel demand and the 3Ds: density, diversity,
and design.” Transportation Research Part D: Transport and Environment, 2(3),
199-219.
Ewing, R., & Cervero, R. (2001). “Travel and the built environment: a synthesis.”
Transportation Research Record: Journal of the Transportation Research Board,
1780(1), 87-114.
Curtis, C. (2011). “Integrating Land Use with Public Transport: The use of a
discursive accessibility tool to inform metropolitan spatial planning in Perth”
Transport Reviews, vol.31, no. 2.
Hillier, B., & Hanson, J. (1984). The social logic of space. Cambridge: Cambridge
University Press.
Hillier, B. (2007). Space is the machine: a configurational theory of architecture.
Cambridge: Cambridge University Press.

122
Anexo 4
Propuesta metodológica para la generación de
corredores de mínimo impacto ambiental de
carreteras: Integración del paisaje. El caso de la
autopista radial 5. Comunidad de Madrid
Miguel Vía García
Centro de Investigaciones Ambientales “Fernando González Bernáldez”
Comunidad de Madrid
Javier Gutiérrez Puebla
Departamento de Geografía Humana
Universidad Complutense de Madrid

123
TÍTULO: PROPUESTA METODOLÓGICA PARA LA GENERACIÓN DE
CORREDORES DE MÍNIMO IMPACTO AMBIENTAL DE CARRETERAS:
INTEGRACIÓN DEL PAISAJE. EL CASO DE LA AUTOPISTA RADIAL 5.
COMUNIDAD DE MADRID.
AUTORES:
AUTOR 1: Miguel Vía García
CARGO/DEPARTAMENTO :
Técnico Superior - Investigador
EMPRESA/ORGANISMO :
Centro de Investigaciones Ambientales de la Comunidad de Madrid “Fernando
González Bernáldez” - DG. de Medio Natural. Consejería de Medio Ambiente y
Ordenación del Territorio de la Comunidad de Madrid
DIRECCIÓN DE EMPRESA/ORGANISMO :
C/ San Sebastián, 71 (esq. C/ Almendro)
CIF EMPRESA/ORGANISMO: S-7800001-E
C.P/ POBLACIÓN Y PROVINCIA:
28791 – Soto del Real (Madrid)
TLF/FAX/ E-MAIL:
Tf: 918478911 / 918477265 Fax: 918480013 E-mail: [email protected]
AUTOR 2: Javier Gutiérrez Puebla
CARGO/DEPARTAMENTO:
Catedrático de Geografía Humana. Facultad de Geografía e Historia
EMPRESA/ORGANISMO:
Universidad Complutense de Madrid
DIRECCIÓN DE EMPRESA/ORGANISMO:
C/Profesor Aranguren, s/n
CIF EMPRESA/ORGANISMO: Q28/18014/I
C.P/ POBLACIÓN Y PROVINCIA:
28040 Madrid
TLF/FAX/ E-MAIL:
Tf. 91 3945949 Fax: 91 3945960 E-mail: [email protected]

124
PROPUESTA METODOLÓGICA PARA LA GENERACIÓN DE CORREDORES DE
MÍNIMO IMPACTO AMBIENTAL DE CARRETERAS: INTEGRACIÓN DEL PAISAJE. EL
CASO DE LA AUTOPISTA RADIAL 5. COMUNIDAD DE MADRID.
AUTORES:
Miguel Vía García. Centro de Investigaciones Ambientales de la Comunidad de
Madrid “Fernando González Bernáldez”
Javier Gutiérrez Puebla. Departamento de Geografía Humana. Universidad
Complutense de Madrid
PALABRAS CLAVE:
SIG, Evaluación Multicriterio, Carreteras, Impacto Ambiental, Corredores y
Paisaje.
Este trabajo se enmarca en un proyecto de investigación más amplio (TRA2005-
06619/MODAL) denominado “Evaluación de los efectos de las vías de alta capacidad
sobre el territorio, la socioeconomía y la movilidad: el caso de Madrid”
RESUMEN
Ante la necesidad de desarrollar nuevas tecnologías y herramientas que nos
faciliten la toma de decisiones a la hora de afrontar problemas territoriales
complejos, la integración de metodologías de Evaluación Multicriterio (EMC) en
los Sistemas de Información Geográfica (SIG), suponen una herramienta de alto
potencial. En este trabajo se realiza un análisis comparativo de la eficacia de
diferentes metodologías de EMC a la hora de generar corredores de mínimo
impacto ambiental de infraestructuras lineales. A su vez, se propone una
sistemática de trabajo operativa para este tipo de estudios. La integración del
paisaje en el procedimiento metodológico, se ha considerado un elemento clave
en la valoración ambiental y en el correcto diseño de los corredores. La Autopista
de la región de Madrid denominada “Radial 5” se toma como caso de estudio.
PRESENTACIÓN

125
En el momento actual, los modelos de desarrollo sostenible son el objetivo de la mayor
parte de las políticas de ordenación del territorio. Debido a la complejidad de
interrelaciones que se producen en el territorio y que caracterizan al medio ambiente,
se considera necesario abordar trabajos de investigación dirigidos a mejorar las políticas
ambientales y de ordenación del territorio. En este sentido, la minimización de los
impactos negativos que ocasionan las acciones del hombre, es una de las labores
fundamentales que se debe perseguir.
Para solucionar este tipo de problemáticas, las nuevas Tecnologías de Información
Geográficas (TIG) aplicadas al medio ambiente, nos permiten resolver estos problemas
con una mayor fiabilidad. La integración de metodologías de evaluación multicriterio
(EMC) en los Sistemas de Información Geográfica (SIG) suponen una herramienta de
gran utilidad en la toma de decisiones, y más aún, a la hora de afrontar una problemática
de índole espacial tan compleja.
En este trabajo, a partir de un análisis metodológico comparativo, se propone un
procedimiento para poder planificar y diseñar de forma eficaz corredores de
transporte de mínimo impacto ambiental. La Autopista “Radial 5”, localizada al
suroeste de la región de Madrid, se toma como caso de estudio.
En este esquema general de trabajo, la integración del paisaje en el procedimiento
metodológico, se considera un elemento clave en la valoración ambiental y en el
correcto diseño de los corredores. Debido a la diversidad de variables que se
tienen en cuenta en esta metodología, muchas de ellas, componentes básicos en
los análisis clásicos del paisaje (vegetación, relieve, usos del suelo, etc.), se ha
considerado que las características visuales del paisaje suministran una
información de gran utilidad, aportando un valor añadido al procedimiento de
generación de corredores de mínimo impacto ambiental. Son las variables
vinculadas a la calidad y fragilidad visual las utilizadas para el análisis del paisaje
en este trabajo.
OBJETIVOS Y PROBLEMÁTICA DE TRABAJO
Una Ordenación del Territorio eficiente, permitirá a priori reducir un gran número de
impactos que a posteriori serían de difícil minimización. El correcto diseño de las
infraestructuras lineales es fundamental en la minimización del impacto que ocasionan.
Una vez queda demostrada la teórica necesidad real que tiene la construcción de una
infraestructura de estas características, habida cuenta del servicio público que presta,
se precisa afrontar el cómo acomodarla de una forma eficiente en el territorio. Este tipo

126
de proyectos deben ajustarse a una serie de objetivos, entre los que está la aptitud
ambiental, junto a otros requisitos, como son: la aptitud o viabilidad técnica, la eficiencia
del proyecto respecto a sus objetivos y la aptitud económica. En muchos casos, la
aptitud ambiental se encuentra excesivamente supeditada al cumplimiento de los otros
tres requisitos, siendo necesario por ello, metodologías que compatibilicen todos los
criterios sin minusvalorar a ninguno.
Desde un punto de vista operativo y de fundamento geográfico, en el caso de las
infraestructuras lineales, se intenta diseñar corredores aptos ambientalmente (Figura 1),
para posteriormente, el equipo técnico de ingenieros se encargue de diseñar desde un
punto de vista técnico y económico, el trazado concreto más apto dentro de ese
corredor. Esta sistemática de trabajo permite introducir la aptitud ambiental desde un
primer momento en el diseño de la infraestructura, consideración que tradicionalmente
quedaba en un segundo plano.
Figura 1. Corredor y trazados de aptitud ambiental.
Ante esta problemática general, los principales objetivos de este trabajo se
podrían resumir en:
Realizar una propuesta metodológica y una sistemática de trabajo útil para
la generación de corredores de mínimo impacto ambiental.
Realizar un análisis comparativo de diferentes metodologías de EMC
implementadas en los SIG, aplicado a un caso concreto (La autopista
Radial 5)
Plantear posibles líneas de investigación y de desarrollo metodológico
para este tipo de trabajos.

127
Se podrían mencionar otra serie de objetivos de segundo nivel, entre los que
destacaría, debido a la especial atención que se le presta en este trabajo, la
incorporación adecuada de los modelos de valoración del paisaje en el
procedimiento metodológico general.
ÁMBITO DE ESTUDIO
El ámbito de estudio seleccionado para el desarrollo de este trabajo es el suroeste de
la región de Madrid (Figura 2), por la que discurre la actual autovía A5, y de forma
paralela, la autopista de peaje Radial 5.
Es importante para este trabajo desde un punto de vista metodológico la correcta
definición de un ámbito de estudio amplio y adecuado para el tipo de proyecto a estudiar,
así como para poder evaluar correctamente los impactos que provoca sobre el medio.
Esto es debido a que según el factor o variable ambiental analizado, el impacto que
ejerce la infraestructura puede ser mayor o menor espacialmente. Por ejemplo, no se
ocasiona un impacto de igual extensión sobre la vegetación, que sobre el paisaje.
Figura 2. Ámbito de estudio.
DESARROLLO METODOLÓGICO
Definidos los objetivos y el ámbito de estudio, se realizó un inventario territorial de toda
la información cartográfica disponible. Esta es una de las fases más importantes para el
éxito de cualquier trabajo de estas características. El inventario es el que nos posibilita
la predicción de la evolución y desarrollo de los factores ambientales en los horizontes

128
temporales en los que se quiere determinar los impactos ambientales (Mendoza, L.E.,
2000)
Una vez identificadas las acciones que conlleva la construcción de una autopista en sus
diferentes fases (construcción, explotación y abandono), se identifican las alteraciones
que estas acciones generan sobre el medio. Estas alteraciones nos permiten
seleccionar los indicadores de impacto principales, los cuales se agrupan por factores
ambientales, generando para cada factor a través de una integración multicriterio simple,
un indicador sintético de valoración.
Estos indicadores sintéticos conforman los factores del modelo, los cuales precisan de
ponderación, y que junto a las restricciones, conforman los criterios que los alimentan.
Posteriormente, se aplican las diferentes metodologías de EMC, generando diferentes
mapas de impacto, que se corresponden con la superficie de fricción necesaria para la
obtención de los corredores de mínimo impacto ambiental.
Tras un análisis comparativo de las diferentes metodologías, se realiza una propuesta
metodológica concreta para este tipo de estudios. Esta sistemática de trabajo (Figura 3)
se considera un resultado metodológico más que aporta este estudio, que busca hacer
operativo de una forma relativamente sencilla un trabajo espacial complejo, en el que
intervienen un alto número de variables y consideraciones.

129
Figura 3. Metodología general de trabajo.
CRITERIOS DEL MODELO: VALORACIÓN DEL IMPACTO
La evaluación de impactos ambientales de un proyecto consiste en la identificación y
valoración de impactos individuales y su posterior agregación (Otero, I. 1999). En este
proyecto, se ha intentado superar esta fase de gran importancia en los Estudios de
Impacto Ambiental, realizando una identificación de los indicadores que aportan una
mayor información sobre el impacto que conlleva la construcción de la autopista sobre
los distintos factores del medio que se ven afectados. Esta selección ha estado muy
condicionada por el nivel de detalle, la información disponible y el objetivo metodológico
del proyecto.
Se ha optado por seleccionar los indicadores de impacto más representativos de cada
factor ambiental, para así, realizar con posterioridad una primera agregación de
indicadores a través de una integración multicriterio simple (Suma lineal Ponderada),
obteniendo un indicador sintético de impacto para cada factor ambiental.
Estos indicadores sintéticos una vez normalizados, son los factores finales que
alimentan las diferentes metodologías de EMC, y que junto a las restricciones, nos

130
permiten obtener lo que se ha denominado mapas de impacto finales. En este trabajo,
la única restricción que se utiliza es el suelo urbano.
A continuación se presentan, en función del factor ambiental, los indicadores de impacto
utilizados, con los respectivos pesos aplicados en su integración (Figura 4).
Figura 4. Indicadores de impacto.
A modo de ejemplo, se muestra a continuación la cartografía de los indicadores
utilizados para generar el indicador sintético de impacto del factor ambiental Hidrología
(Figura 5).

131
Figura 5. Hidrología: Indicador Sintético de Impacto.
INTEGRACIÓN DE MODELOS DE VALORACIÓN DEL PAISAJE
La integración del paisaje en este tipo de estudios se considera una cuestión clave
en la valoración ambiental y en el correcto diseño de los corredores de mínimo
impacto. El paisaje es tratado como un indicador sintético de impacto y se integra
en el desarrollo metodológico general junto a los demás indicadores sintéticos.
Se incorpora en la integración multicriterio como un criterio más del modelo, junto
al peso relativo que le otorga el panel de expertos consultado.
Debido a la diversidad de variables que se introducen en esta metodología,
muchas de ellas, componentes básicos en los análisis clásicos del paisaje
(vegetación, relieve, usos del suelo, etc.), se ha considerado que las
características visuales del paisaje son las que nos aportan un valor añadido al
procedimiento de generación de corredores de mínimo impacto ambiental. Las
variables utilizadas para el análisis del paisaje en este trabajo son las vinculadas
a la calidad y fundamentalmente a la fragilidad visual.
Existe una diferencia esencial entre estos dos conceptos; así, mientras la calidad
visual de un paisaje es una cualidad intrínseca del territorio que se analiza, la
fragilidad depende del tipo de actividad que se pretende desarrollar (Montoya, R.,

132
2002). Por ello, y desde un punto de vista operativo, utilizamos en este estudio la
fragilidad visual, dirigiendo su valoración de forma concreta al impacto que
genera una autopista sobre el paisaje visual.
A su vez, muchos de los componentes que forman parte de la calidad visual de un
paisaje ya han sido incorporados al modelo en la valoración de otros indicadores
sintéticos, como por ejemplo, la valoración de la vegetación, del relieve, etc.
El concepto de Fragilidad Visual, también designado como vulnerabilidad, puede
definirse como “la susceptibilidad de un territorio al cambio cuando se desarrolla
un uso sobre el mismo” (Cifuentes, P. 1979), Para la valoración de la fragilidad
visual se siguió la siguiente metodología (Montoya, R. y Padilla, J., 2001): Se
realizó una primera integración de variables para obtener un mapa de fragilidad
visual intrínseca. Las variables utilizadas fueron: la capacidad de la vegetación
para ocultar una actividad; la pendiente y la fisiografía entendidas como la
posición en el territorio de la actividad, existiendo zonas más visibles que otras;
La forma y tamaño de la cuenca visual y por último, la compacidad de las unidades
de paisaje, es decir, en función de la complejidad morfológica de la cuenca visual
las actividades se ocultarán mejor o peor.
En una segunda integración se incorpora a la fragilidad visual intrínseca la
consideración de la distribución de los observadores potenciales en el territorio
(mapa de distancias a carreteras y zonas habitadas), obteniendo así, el mapa final
de Fragilidad Visual (Figura 6).
Figura 6. Mapa de impacto del Paisaje. Fragilidad visual.

133
NORMALIZACIÓN DE VARIABLES
Una vez obtenidos los indicadores sintéticos de cada factor, es necesario estandarizar
las variables en una misma escala para hacerlos comparables, debido a que el rango
de valores finales de cada indicador sintético es diferente. Realizada la normalización,
estos indicadores se convierten en los criterios finales de los modelos. Se ha realizado
un ajuste de tipo lineal, de forma similar a lo realizado con los indicadores de impacto
iniciales, utilizando de rango de estandarización 50 categorías. La fórmula del ajuste de
tipo lineal es la siguiente (Eastman, J. 1999):
cvvvvf ii )()( minmaxmax
donde: es el valor del factor normalizado es el valor origen del factor es el valor máximo
es el valor mínimo es el rango de estandarización
La normalización o estandarización de las variables es un paso de gran importancia
tanto para el desarrollo metodológico de los modelos multicriterio, como para una
correcta valoración en cada indicador del impacto. Siguiendo un criterio de operatividad,
esta cuestión no ha sido objeto de estudio en este trabajo, utilizando un ajuste similar
para todas las variables o indicadores. A estas funciones de correlación entre la
intensidad de la acción y el impacto se las denomina funciones de transformación o
funciones de valor. Estas funciones determinan la relación entre los valores que pueden
tomar un indicador de impacto y la calidad del factor ambiental en estudio. (Mendoza,
L.E. 2000). En muchos casos esta correlación no es lineal, debiendo ajustar de forma
específica para cada factor o indicador una función determinada.
ASIGNACIÓN DE PESOS
Desde un punto de vista operativo en este trabajo se ha utilizado un método sencillo
para la asignación de pesos, denominado “rating”. Este método precisa de la valoración
de los diferentes factores de forma individual en relación a una escala establecida (en
nuestro caso de 0 a 10). El panel de expertos debe indicar en que punto de esa escala
se encuentra ese criterio, sabiendo que 0 significa que ese criterio puede ser ignorado
del análisis y 10 que ese criterio tiene el máximo valor en el análisis (Malczewsky, J.
1999). Se realizó una consulta a 5 expertos y una vez establecieron los pesos se realizó
la media y se obtuvo el peso final para cada factor (Figura 7).
if iv maxvminv
c

134
Figura 7. Tabla de ponderación de factores.
Existen otros métodos más complejos y precisos, pero que requieren un mayor trabajo
por parte del panel de expertos, como es el caso de las jerarquías analíticas o
comparación por pares (Saaty, T.L., 1977), que consiste en la elaboración de una matriz
en los que se especifica la importancia relativa de cada factor respecto a los demás.
SIG – EMC: MAPAS DE IMPACTO AMBIENTAL
Una vez se dispone de los criterios y los pesos, se han aplicado los modelos de EMC,
obteniendo con ello, los mapas finales de impacto (Figuras 8 y 9). Estos mapas
suministran una información sintética de todas las variables utilizadas, permitiéndonos
así, evaluar el impacto ambiental que en cada punto del territorio ocasionaría la
construcción de la autopista.
En nuestro caso concreto, nos encontramos ante un problema cuyo objetivo es la
minimización del impacto que ocasionaría la construcción de esta infraestructura, por lo
tanto, ante un problema de objetivo único. Existen muchas otras situaciones en las que
el objetivo ante un problema de localización espacial es múltiple, optando en ese caso
por la utilización de metodologías de evaluación multiobjetivo, entre las que se
encuentran como más conocidas y utilizadas, la extensión jerárquica, cuando los
objetivos son complementarios y cuando están en conflicto, la solución priorizada y
solución compromiso (Barredo, JI. 1996). Se han escogido para realizar los análisis dos
metodologías diferentes, una de ellas de tipo compensatorio y otra no compensatoria.
Las técnicas de tipo compensatorio, asumen compensación entre los diferentes
criterios, permitiendo compensar un valor alto en un criterio con un valor bajo en otro,
como es el caso de la técnica que aquí se utiliza denominada suma lineal ponderada
(SLP). Es una técnica de tipo aditiva (Janckowski, P. 1995) en la que el valor de impacto,
se obtiene para cada alternativa, según:

135
jii rwxa
donde: a es el valor de impacto; ix es el valor de la celda i en el factor i ; iw es el peso del factor i ;
jr son las restricciones
En la SLP los criterios pueden incluir tantos factores ponderados como restricciones. El
procedimiento comienza multiplicando cada factor, ya normalizado, por su peso
correspondiente y, posteriormente, suma los resultados. Éstos serán multiplicados por
el producto de las restricciones, definiendo las áreas excluidas del análisis. Los pesos
de los factores son muy importantes en el método, porque determinan como los factores
individuales se compensan entre sí. A mayor peso del factor, mayor influencia tendrá
este factor en el mapa de impacto final. Se caracteriza por ser un método con una
compensación total y por un nivel de riesgo medio, es decir, a medio camino entre la
minimización (operación “Y”) y la maximización (operación “O”) de las áreas
consideradas adecuadas en el resultado final. (Eastman, J. 1999). El procedimiento se
ha realizado en ArcView GIS 3.2 utilizando la calculadora de mapas. El software IDRISI,
lleva implementado este algoritmo en el módulo de evaluación multicriterio “MCE”.
En las técnicas de tipo no compensatorio, en general, no se produce compensación
entre criterios, obteniendo el resultado final a partir de la relevancia de un criterio frente
a los demás, partiendo de un punto de vista que defina tal criterio. Estas técnicas
demandan un proceso cognitivo menor del centro decisor, ya que, por lo general,
precisan de una jerarquización ordinal de los criterios basada en las prioridades del
centro decisor (Barredo, 1996). En la metodología utilizada en este trabajo, denominada
medias ponderadas ordenadas (MPO) no se cumplen al detalle esas características
generales de los modelos no compensatorios, obligando al centro decisor a un mayor
trabajo. Se incluye dentro de las técnicas de superposición o agregación borrosa
(Malczewski, J. 1999).
La compensación se puede producir con mayor o menor intensidad en función de que
el centro decisor seleccione unos determinados pesos de ordenes. En este método
intervienen junto a los pesos de los factores, un orden de los pesos. Los pesos
ordenados son un conjunto de pesos asignados no a los factores en sí, sino a la posición
en el rango ordenado de los valores del factor para una localización (píxel) dada. En
nuestro caso, el criterio con la puntuación de impacto más alta, una vez aplicados los
pesos del factor, será el primer peso ordenado, el factor con la siguiente valoración de

136
impacto más alta tendrá el segundo peso ordenado y así sucesivamente. El sesgo
relativo, tanto hacia el mínimo como hacia el máximo de los pesos ordenados, controla
el nivel del riesgo. Si se da el mismo peso a todos los órdenes, la MPO funciona como
una SLP, ya que no importa que un criterio tenga un valor más alto que otro.
En esta metodología el valor de impacto se obtendría según:
donde: a es el valor de impacto; ix es el valor de la celda i en el factor i ; w es el peso de los
factores; iw es el peso del factor i ; o es el peso de los ordenes; io es el peso ordenado del factor i en la
celda i ; jr son las restricciones
El funcionamiento del algoritmo se basa en la SLP, sólo modificado por la influencia del
peso de los órdenes. Para cada celda o alternativa, los pesos de los factores se ven
matizados por el orden de los mismos en esa localización. Se multiplica el peso del
factor por el peso del orden correspondiente a ese factor en esa celda, dividiéndolo para
normalizar los valores, por la suma de los productos de los pesos de cada celda.
Para este proyecto se han seleccionado unos pesos de órdenes que suponen una
importante reducción de la compensación. Permite reducir el riesgo al establecer para
cada alternativa o píxel un orden de importancia de cada criterio. Los pesos de ordenes
utilizados para los 9 casos son los siguientes: [1- 0.400; 2- 0.300; 3- 0.150; 4- 0.070; 5-
0.040; 6-0.020; 7- 0.010; 8- 0.007; 9-0.003 (SUMA=1.000)]
Con este procedimiento, se está dando más peso en el resultado final de cada
alternativa a los factores con los valores más altos de impacto en ese píxel, sin dejar de
tener en cuenta los pesos que el panel de expertos otorgó a cada factor en general. El
modelo se ha realizado con el software IDRISI 32, a través del módulo de evaluación
multicriterio “MCE”.
j
i
iii r
ow
owxa

137
Figura 8. Mapa final de impacto generado con la metodología EMC de la SLP.
Figura 9. Mapa final de impacto generado con la metodología EMC de las MPO.
CORREDORES Y TMIA.
El espacio no es isotrópico, las distancias o resistencia para el desplazamiento por el
espacio, en el mundo real, no suelen ser en línea recta (Gutiérrez, J y Gould, M 1994).
En este caso concreto, nos interesa disponer de una cartografía que refleje el coste de
fricción ambiental asociado a cada celda en relación a la construcción de una autopista.
Estos mapas o superficies de fricción, son los mapas de impacto generados a partir de

138
los modelos multicriterio. Los valores de cada píxel en ese mapa informan sobre el coste
ambiental que supone que el trazado de la autopista discurra sobre él.
Para generar los corredores de mínimo impacto ambiental se precisa de un mapa de
origen del corredor, un mapa del destino y el mapa de fricción. Se crea a partir de ellos
un mapa de distancias desde el origen y otro desde el destino, usando en ambos casos,
el mapa de superficie de fricción como base. Para este proyecto, las únicas barreras
que se han utilizado ha sido la restricción de los mapas de impacto, es decir, el suelo
urbano.
Una vez se dispone de los dos mapas de distancias o costes, se realiza una suma entre
ellos, obteniendo un mapa en el que los valores más bajos representan el corredor de
mínimo impacto ambiental. Según se elija el rango o intervalo de valores mínimo para
considerarlo corredor, este será más o menos amplio.
El sistema es capaz de calcular los trazados concretos de mínimo impacto ambiental
(TMIA), usándolos en nuestro caso para el análisis comparativo de los resultados.
RESULTADOS Y PROPUESTAS METODOLÓGICAS
A continuación, se muestran los corredores generados a partir de las dos metodologías
utilizadas (Figuras 10 y 11) para nuestro caso de estudio.
Figura 10. Corredor de mínimo impacto ambiental generado con la metodología EMC de la SLP.

139
Figura 11. Corredor de mínimo impacto ambiental generado con la metodología EMC de las MPO.
En el caso del trazado generado con la metodología MPO, este tiene un impacto global
más alto, debido a ser más largo, pero en cambio, su impacto medio es más bajo, ya
que con el uso de esa metodología, el trazado evita cruzar los píxeles que tienen un
valor muy alto en cualquiera de sus criterios, al dar un mayor peso en cada píxel a los
criterios con valores de impacto más altos. Esta metodología demuestra su carácter
menos compensatorio, ya que por las celdas en las que tienen un valor muy alto alguno
de los criterios, tiende a evitarlas, realizando por tanto un trazado más largo.
En cambio, el trazado SLP, al ser más compensatorio, es capaz de discurrir por zonas
en las que existen factores con un impacto ambiental muy alto, ya que si en otros
factores estos valores son bajos, se compensan, lo que conlleva que sus trazados sean
más cortos (impacto global más bajo) pero con un impacto medio más alto.
Una conclusión importante a la luz de estos resultados, es si realmente nuestras
metodologías están valorando suficiente la relación impacto global (distancia) e impacto
medio, es decir, en que punto está el equilibrio o la relación que define la opción entre
seguir un camino más corto con más impacto o pasar por uno más largo de menor
impacto. Una correcta valoración de los factores del modelo, a través de unas funciones
de transformación eficaces, evitaría que ese desequilibrio fuese importante.
Se ha realizado también un análisis comparativo a través del impacto que producen los
distintos trazados sobre los factores del medio afectados (Figura 13).

140
Figura 13. Valores de impacto de los trazados de mínimo impacto ambiental sobre los factores
El trazado generado a partir de la metodología MPO es el que genera un menor impacto
medio en un mayor número de factores, caracterizándose además estos factores, por
ser los de mayor peso. La metodología de las MPO, al no ser tan compensatoria, ya que
pondera con un mayor peso los valores más altos en los criterios de cada píxel, provoca
que en el mapa de impacto final las celdas con valores altos aunque sea sólo en un
criterio o factor, mantengan un valor final alto. El que además, los factores de menor
impacto medio son los que tienen un peso alto, indica que el trazado MPO evita pasar
fundamentalmente por aquellos píxeles en los que los valores de los factores más altos
corresponden a factores asignados con un peso alto por el panel de expertos, ya que al
combinarse el peso alto de los ordenes con el alto peso del factor, las celdas al
incrementarse el valor de ponderación, obtienen un valor muy alto.
Una vez analizados los resultados obtenidos, se ha comprobado las diferencias
metodológicas principales entre los dos modelos. La MPO es la menos compensatoria,
debido a que son los valores más altos los que entran en juego en el resultado final,
viéndose imposibilitados los valores más bajos a compensar a los más altos, debido a
que presentan un peso muy bajo en los ordenes.
En el mundo real, la mayor calidad ambiental de un espacio, no sólo se mide por ser un
espacio de alto valor en todas sus variables ambientales. Cuando en un espacio de baja
calidad ambiental, existe una variable con un valor muy alto, es decir, una singularidad,
esta no debe compensarse con los valores bajos de los demás factores del medio. A
modo de ejemplo, el impacto ambiental es muy alto cuando una autopista va a pasar
por una zona de nidificación de aves esteparias protegidas, como por ejemplo de la
Avutarda. A pesar de que el lugar de nidificación sea una superficie de cultivo de secano
en las proximidades de una zona industrial, es decir, una zona con baja calidad de
vegetación, de aire, ruido etc. no debe compensar el valor alto de calidad en fauna,
convirtiendo a ese espacio en un lugar de escasa calidad ambiental, y por lo tanto, apto
para la construcción de una autopista.

141
No sólo por los resultados positivos de impacto medio, sino también, por el
procedimiento aritmético-estadístico que realiza, la metodología de evaluación
multicriterio menos compensatoria, denominada Medias Ponderadas Ordenadas, se
propone como metodología más apropiada para este tipo de estudios. Se considera que
es la metodología que salvaguarda de una forma más eficiente los valores ambientales
de cada territorio. Con la aplicación de esta metodología, se valora de forma prioritaria
en cada lugar concreto de ese territorio, aquellos factores ambientales con un valor de
calidad más alto. Por lo tanto, gracias a esta metodología propuesta, de carácter
claramente menos compensatoria, las singularidades concretas de cada espacio son
tenidas en cuenta.
Otro resultado importante de este trabajo es el diseño de una sistemática de trabajo, en
la que se definen una serie de fases previas a la aplicación de los modelos multicriterio
en el SIG, que son consideradas de gran utilidad y eficacia en la valoración. Destacan
entre ellas: la creación de indicadores sintéticos de valoración, la normalización de
variables a partir de la aplicación de correctas funciones de transformación y el
procedimiento de ponderación de factores.
CONCLUSIONES
A la hora de afrontar un trabajo de estas características se deben de tener en cuenta un
gran número de consideraciones previas para obtener un resultado acorde con la
realidad. La correcta selección y valoración de los criterios a introducir en los modelos,
la ponderación de los mismos a través de una correcta consulta a expertos, así como
una selección apropiada de la metodología de EMC a utilizar en función de nuestro
objetivo, nos evitará obtener unos resultados mediocres. Es por lo tanto, la selección de
la metodología de EMC, un elemento clave a definir claramente en la fase previa del
trabajo, ya que por la elección de una u otra metodología, utilizando los mismos pesos
y criterios el resultado puede ser muy distinto. A su vez, una sistemática de trabajo como
la planteada aquí, permite dar operatividad a un problema espacial tan complejo, o por
lo menos acercarnos a los pasos a dar para obtener un resultado final, que permita
tomar decisiones sobre la adecuación de la localización de una infraestructura lineal.
La generación de trazados y corredores de mínimo impacto ambiental a través
de los SIG y el uso de estas metodologías de EMC, queda comprobado que son una
herramienta de alto potencial a la hora de diseñar corredores reales para cualquier tipo
de infraestructura lineal. Disponer de estos corredores, permiten minimizar en gran

142
medida el impacto ambiental que pueden llegar a generar, introduciendo la
consideración ambiental desde un primer momento del diseño de la infraestructura.
REFERENCIAS BIBLIOGRÁFICAS
BARREDO, J.I.: “Sistemas de Información Geográfica y Evaluación multicriterio en la
Ordenación del Territorio” Ed. Ra-ma. Madrid, 1996
CIFUENTES, P.: “La Calidad Visual de Unidades Territoriales. Aplicación al Valle del
Río Tiétar” Tesis Doctoral. E.T.S. de Ing. de Montes. Universidad Politécnica, Madrid,
1979.
CONESA FDEZ-VÍTORA, V.: “Guía metodológica para la Evaluación del Impacto
Ambiental” 3ª Edición. Ed. Mundi-prensa. Madrid, 1997
EASTMAN, J.: “Guide to GIS and Image processing. Idrisi 32”. Clarck Labs.
Worcester, MA. 1999.
GUTIÉRREZ PUEBLA J Y GOULD M.: “SIG: Sistemas de Información Geográfica”. Ed.
Síntesis. Madrid, 1994.
JANKOWSKI, P.: “Integrating geographical information systems and multiple criteria
decision-making methods”. International journal of Geographical Information systems, 9
(3): 251-273. 1995
MALCZEWSKI, J.: “GIS and multicriteria decision análisis”. Jhon Wiley and Sons. Inc.
New York, 1999
MENDOZA, L.E.: “Evaluación del impacto ambiental de proyectos de infraestructura
viaria: Funciones de transformación”. Tesis Doctoral. ETSI de Caminos, Canales y
Puertos. UPM. Madrid, 2000
MONTOYA, R. y PADILLA J.: “Utilización de un SIG para la valoración de la calidad y
fragilidad visual del paisaje”. Actas del XVII Congreso de Geógrafos Españoles. AGE.
pp. 181-184. Oviedo, 2001.
MOPU.: “Guías metodológicas para la elaboración de estudios de impacto ambiental. 1.
Carreteras y ferrocarriles”. Serie Monografías. Madrid, 1989
OTERO PASTOR, I.: “Localización e impacto de las estructuras lineales”. Planificación
Territorial. Estudio de casosFundación Conde del Valle del Salazar. ETSIM. pp. 227-
266. Madrid, 1993
OTERO PASTOR, I. (coord..) “Impacto Ambiental de Carreteras. Evaluación y
Restauración”. Asoc. Española de la Carretera. Comunidad de Madrid. Madrid, 1999.

143
SAATY, T.L.: “A Scaling Method for Priorities in Hierarchical Structures”. Journal of
Mathematical Psychology, 15, pp 234-281. 1977