introduccion a apache spark
TRANSCRIPT


Co-founder & CTO, Socialmetrix Lic. Ciencias Computación MBA Marketing Servicios @arjones [email protected] Brasileño, en ARG desde 2008
Gustavo Arjones

Qué es Apache Spark?

Qué es Spark? Apache Spark™ is a fast and general engine for large-scale data processing. • Procesamiento In-memory (preferencialmente)
• Framework de Procesamiento Unificado
• Para Ingenieros & Data Scientists
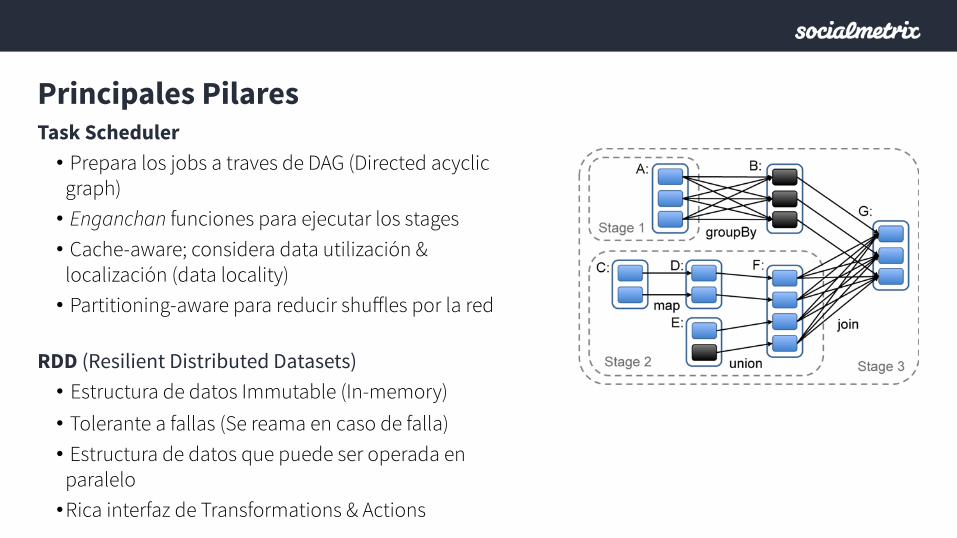
Principales Pilares Task Scheduler • Prepara los jobs a traves de DAG (Directed acyclic
graph) • Enganchan funciones para ejecutar los stages • Cache-aware; considera data utilización &
localización (data locality) • Partitioning-aware para reducir shuffles por la red
RDD (Resilient Distributed Datasets) • Estructura de datos Immutable (In-memory) • Tolerante a fallas (Se reama en caso de falla) • Estructura de datos que puede ser operada en
paralelo • Rica interfaz de Transformations & Actions

Porqué me gusta?

Viene de buen “origen” BDAS, the Berkeley Data Analytics Stack (AMPLAB)
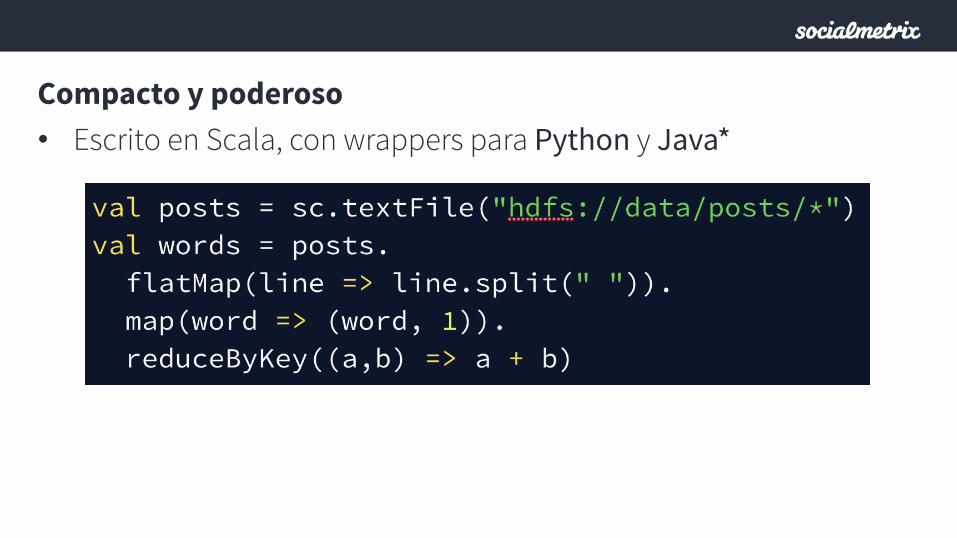
Compacto y poderoso • Escrito en Scala, con wrappers para Python y Java*

API muy expresiva
Ver: https://spark.apache.org/docs/latest/api/scala/#org.apache.spark.rdd.RDD

• Aprender, prototipado rápido • Análisis interactivo sobre los datos
Consola interactiva
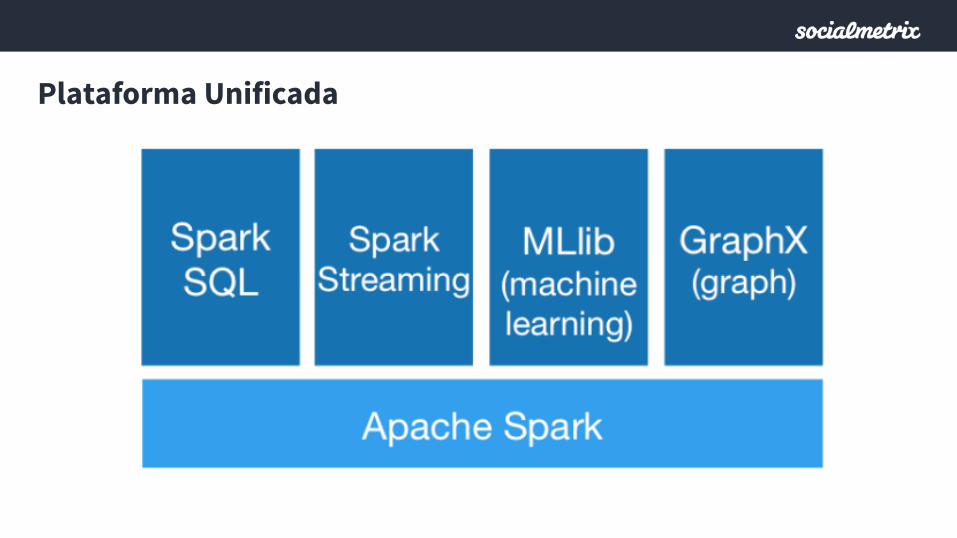
Plataforma Unificada

Plataforma Unificada
• No es necesario copiar datos/ETL entre sistemas
• Varios tipos de procesamientos en el mismo código (claridad)
• Reutilización de código (Batch & Realtime)
• Un único sistema para aprender
• Un único sistema para mantener
Big Deal para Arquitectura Lambda

Plataforma Unificada (lines of code)
0 20000 40000 60000 80000
100000 120000 140000
Hadoop MapReduce
Storm (Streaming)
Impala (SQL) Giraph (Graph)
Spark
non-test, non-example source lines
GraphX
Streaming SparkSQL

Spark UI

Código Testeable! • El contexto puede crear RDD

Proyecto muy activo (y ganando tracción)
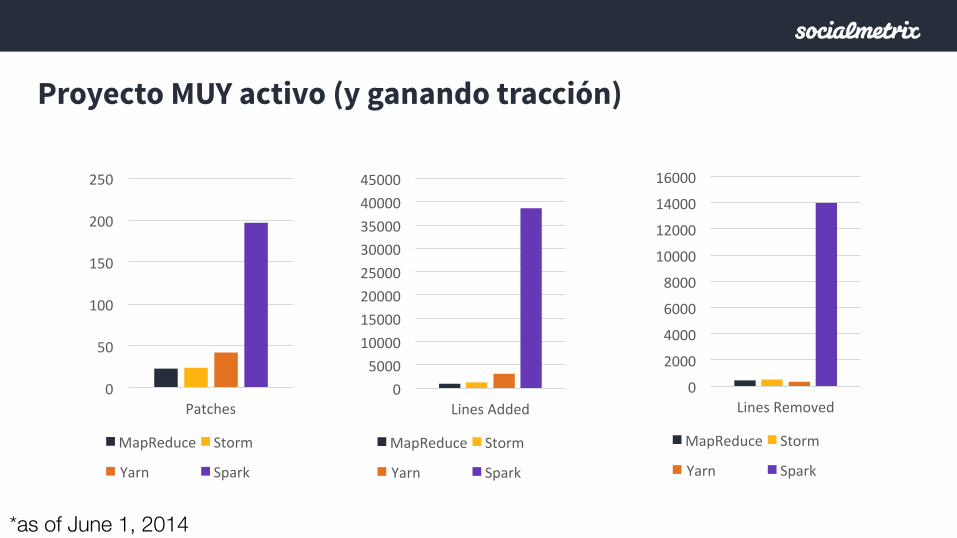
Proyecto MUY activo (y ganando tracción)
*as of June 1, 2014
0
50
100
150
200
250
Patches
MapReduce Storm
Yarn Spark
0 5000
10000 15000 20000 25000 30000 35000 40000 45000
Lines Added
MapReduce Storm
Yarn Spark
0
2000
4000
6000
8000
10000
12000
14000
16000
Lines Removed
MapReduce Storm
Yarn Spark

Y más … • Esfuerzo para estandarización de la plataforma
• Certificación para Distros & Apps gratis
• Material de training gratis
• Databricks levantó $47M
• Databricks Cloud???

Y Hadoop?

Modelo Map-Reduce
iter. 1 iter. 2 . . .
Input
HDFS read
HDFS write
HDFS read
HDFS write
Input
query 1
query 2
query 3
result 1
result 2
result 3
. . .
HDFS read
Lento porque necesita replicación, serialización y I/O

iter. 1 iter. 2 . . .
Input
Distributed memory
Input
query 1
query 2
query 3
. . .
one-time processing
10-100× más rápido
Spark (in-memory + DAG execution engine)

Spark y Hadoop pueden ser amigos • YARN / Mesos • Acceso HDFS / S3 • Usando Input/Output formats
de Hadoop

DEMO http://bit.ly/NardozSparkDemo

Donde aprender más?

Mucha documentación disponible https://spark.apache.org/documentation.html http://spark-summit.org/2014/training http://shop.oreilly.com/product/0636920028512.do http://arjon.es/tag/spark/
