introduccion a las redes neuronales...
TRANSCRIPT

Introduccion a las Redes Neuronales AplicadasCURSO DE EXPERTOS DE U.C.M. (2012)
Juan Miguel Marın Diazaraque
Universidad Carlos III de Madrid

CURSO DE EXPERTOS U.C.M. (2012)
INDICE:
Redes Neuronales en Economıa y Marketing.
Redes Neuronales de Tipo Biologico.
Redes Neuronales Artificiales Aplicadas.
Tipos y estructuras de Redes Neuronales Artificiales
Modelos de Regresion y Redes Neuronales.
El Perceptron Multicapa.
Redes Neuronales como generalizacion de las tecnicas de Analisis Discriminan-te.
SOM.
Aplicaciones.
J. Miguel Marın (U. Carlos III) 2

CURSO DE EXPERTOS U.C.M. (2012)
Redes Neuronales en Economıa y Marketing
Negocios y Finanzas
Las redes neuronales se aplican en analisis financiero para la asignacion de re-cursos y scheduling. Se aplican en Data Mining, esto es, recuperacion de datosy busqueda de patrones a partir de grandes bases de datos. Pero casi todo eltrabajo hecho en este area es para la empresa privada y grandes companıas.
Marketing
En la aplicacion Airline Marketing Tactician (AMT ) se aplican redes neuronalesque incluyen diversos sistemas expertos. Se utiliza una red neuronal que usael algoritmo de back-propagation para asesorar en el control de asignacion deplazas de vuelos. Se usa como un sistema de control de ofertas y reservas envuelos.
J. Miguel Marın (U. Carlos III) 3

CURSO DE EXPERTOS U.C.M. (2012)
Evaluacion de Creditos
Ejemplo: La empresa HNC de R. Hecht-Nielsen, ha desarrollado aplicaciones deredes neuronales para calcular el ranking de creditos (Credit Scoring). El sistemaHNC se aplica tambien para calcular el riesgo hipotecario. La empresa Nestoraplica redes neuronales para aplicar seguros de manera automatica en la conce-sion de prestamos hipotecarios con un 84 % de exito aproximadamente.
J. Miguel Marın (U. Carlos III) 4
CURSO DE EXPERTOS U.C.M. (2012)
IntroduccionLas Redes Neuronales (ANN: Artificial Neural Networks) surgieron originalmente
como una simulacion abstracta de los sistemas nerviosos biologicos, constituidospor un conjunto de unidades llamadas neuronas conectadas unas con otras.
El primer modelo de red neuronal fue propuesto en 1943 por McCulloch y Pittsen terminos de un modelo computacional de actividad nerviosa. Este modelo era unmodelo binario, donde cada neurona tenıa un escalon o umbral prefijado, y sirvio debase para los modelos posteriores.
J. Miguel Marın (U. Carlos III) 5
CURSO DE EXPERTOS U.C.M. (2012)
Una primera clasificacion de los modelos de ANN es:
1. Modelos inspirados en la Biologıa: Estos comprenden las redes que tratan desimular los sistemas neuronales biologicos, ası como ciertas funciones como lasauditivas o de vision.
2. Modelos artificiales aplicados: Estos modelos no tienen por que guardar similitudestricta con los sistemas biologicos. Su organizacion (arquitectura) esta bastanteligada a las necesidades de las aplicaciones para las que son disenados.
J. Miguel Marın (U. Carlos III) 6

CURSO DE EXPERTOS U.C.M. (2012)
Ideas sobre Redes Neuronales de tipo biologicoSe estima que el cerebro humano contiene mas de cien mil millones (1011) de
neuronas y 1014 sinapsis (conexiones) en el sistema nervioso. Los estudios realiza-dos sobre la anatomıa del cerebro humano concluyen que hay, en general, mas de1000 sinapsis por termino medio a la entrada y a la salida de cada neurona.
Aunque el tiempo de conmutacion de las neuronas biologicas (unos pocos mili-segundos) es casi un millon de veces mayor que en las actuales componentes delas computadoras, las neuronas naturales tienen una conectividad miles de vecessuperior a la de las neuronas artificiales.
El objetivo principal de las redes neuronales de tipo biologico es desarrollar ope-raciones de sıntesis y procesamiento de informacion, relacionadas con los sistemasbiologicos.
J. Miguel Marın (U. Carlos III) 7

CURSO DE EXPERTOS U.C.M. (2012)
Figura 1: Esquema de una neurona biologica
Las neuronas y las conexiones entre ellas (sinapsis) constituyen la clave para elprocesado de la informacion.
La mayor parte de las neuronas poseen una estructura de arbol, llamada dendri-tas, que reciben las senales de entrada procedentes de otras neuronas a traves delas sinapsis.
J. Miguel Marın (U. Carlos III) 8
CURSO DE EXPERTOS U.C.M. (2012)
Una neurona consta de tres partes:
1. El cuerpo de la neurona,
2. Las dendritas, que reciben las entradas,
3. El axon, que lleva la salida de la neurona a las dendritas de otras neuronas.
La forma completa en la que dos neuronas se relacionan no se conoce comple-tamente, y depende ademas del tipo particular de cada neurona. En general, unaneurona envıa su salida a otras por su axon, y este lleva la informacion por mediode diferencias de potencial electrico.
J. Miguel Marın (U. Carlos III) 9

CURSO DE EXPERTOS U.C.M. (2012)
Figura 2: Funcionamiento de una neurona
J. Miguel Marın (U. Carlos III) 10
CURSO DE EXPERTOS U.C.M. (2012)
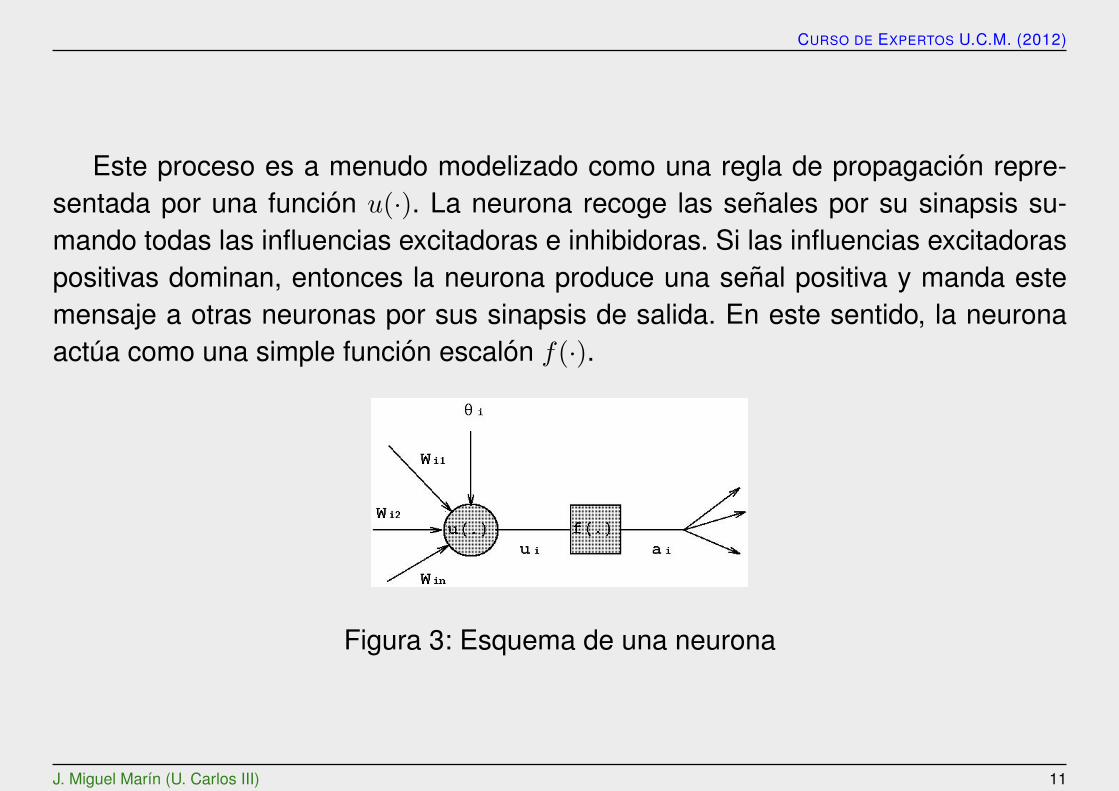
Este proceso es a menudo modelizado como una regla de propagacion repre-sentada por una funcion u(·). La neurona recoge las senales por su sinapsis su-mando todas las influencias excitadoras e inhibidoras. Si las influencias excitadoraspositivas dominan, entonces la neurona produce una senal positiva y manda estemensaje a otras neuronas por sus sinapsis de salida. En este sentido, la neuronaactua como una simple funcion escalon f(·).
Figura 3: Esquema de una neurona
J. Miguel Marın (U. Carlos III) 11

CURSO DE EXPERTOS U.C.M. (2012)
Redes Neuronales Artificiales (ANN)Las ANN aplicadas estan, en general, inspiradas en las redes neuronales biologi-
cas, aunque poseen otras funcionalidades y estructuras de conexion distintas a lasvistas desde la perspectiva biologica. Las caracterısticas principales de las ANN sonlas siguientes:
1. Auto-Organizacion y Adaptabilidad : utilizan algoritmos de aprendizaje adaptati-vo y auto-organizacion, por lo que ofrecen mejores posibilidades de procesadorobusto y adaptativo.
2. Procesado no Lineal : aumenta la capacidad de la red para aproximar funciones,clasificar patrones y aumenta su inmunidad frente al ruido.
3. Procesado Paralelo: normalmente se usa un gran numero de nodos de procesa-do, con alto nivel de interconectividad.
J. Miguel Marın (U. Carlos III) 12
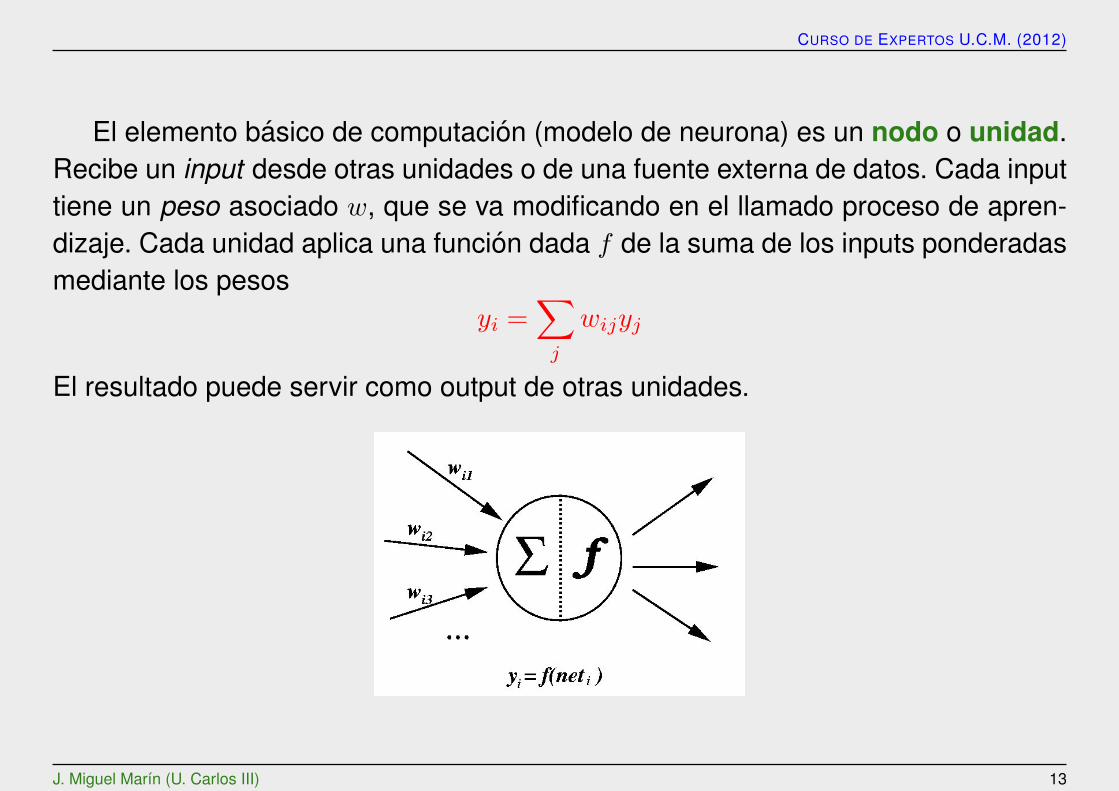
CURSO DE EXPERTOS U.C.M. (2012)
El elemento basico de computacion (modelo de neurona) es un nodo o unidad.Recibe un input desde otras unidades o de una fuente externa de datos. Cada inputtiene un peso asociado w, que se va modificando en el llamado proceso de apren-dizaje. Cada unidad aplica una funcion dada f de la suma de los inputs ponderadasmediante los pesos
yi =∑j
wijyj
El resultado puede servir como output de otras unidades.
J. Miguel Marın (U. Carlos III) 13

CURSO DE EXPERTOS U.C.M. (2012)
Las caracterısticas de las ANN juegan un importante papel, por ejemplo, en elprocesado de senales e imagenes. Se usan arquitecturas que comprenden elemen-tos de procesado adaptativo paralelo, combinados con estructuras de interconexio-nes jerarquicas.
Hay dos fases en la modelizacion con redes neuronales:
Fase de entrenamiento: se usa un conjunto de datos o patrones de entrena-miento para determinar los pesos (parametros) que definen el modelo de redneuronal. Se calculan de manera iterativa, de acuerdo con los valores de losvalores de entrenamiento, con el objeto de minimizar el error cometido entre lasalida obtenida por la red neuronal y la salida deseada.
J. Miguel Marın (U. Carlos III) 14

CURSO DE EXPERTOS U.C.M. (2012)
Fase de Prueba: en la fase anterior, el modelo puede que se ajuste demasiadoa las particularidades presentes en los patrones de entrenamiento, perdiendo suhabilidad de generalizar su aprendizaje a casos nuevos (sobreajuste).
Para evitar el problema del sobreajuste, es aconsejable utilizar un segundo grupode datos diferentes a los de entrenamiento, el grupo de validacion, que permitacontrolar el proceso de aprendizaje.
Normalmente, los pesos optimos se obtienen optimizando (minimizando) algunafuncion de energıa.
Por ejemplo, un criterio muy utilizado en el llamado entrenamiento supervisado,que consiste en minimizar el error cuadratico medio entre el valor de salida y el valorreal esperado.
J. Miguel Marın (U. Carlos III) 15
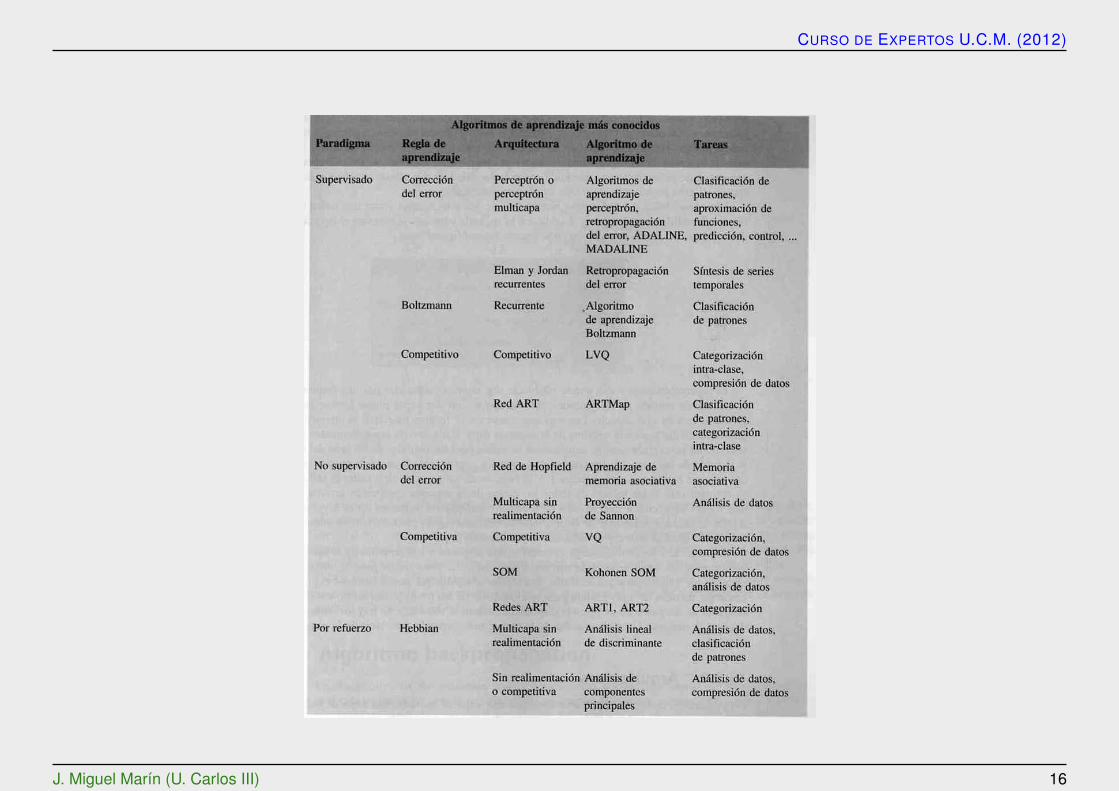
CURSO DE EXPERTOS U.C.M. (2012)
J. Miguel Marın (U. Carlos III) 16

CURSO DE EXPERTOS U.C.M. (2012)
Redes Neuronales Supervisadas y No SupervisadasLas redes neuronales se clasifican comunmente en terminos de sus correspon-
dientes algoritmos o metodos de entrenamiento: redes de pesos fijos, redes no su-pervisadas, y redes de entrenamiento supervisado. Para las redes de pesos fijos noexiste ningun tipo de entrenamiento.
Reglas de entrenamiento Supervisado
Las redes neuronales de entrenamiento supervisado son las mas populares. Losdatos para el entrenamiento estan constituidos por varios pares de patrones deentrenamiento de entrada y de salida. El hecho de conocer la salida implica que elentrenamiento se beneficia de la supervision de un maestro. Dado un nuevo patronde entrenamiento, en la etapa (m + 1)-esima, los pesos se adaptan de la siguienteforma:
wm+1ij = wm
ij + ∆wmij
J. Miguel Marın (U. Carlos III) 17

CURSO DE EXPERTOS U.C.M. (2012)
Se puede ver un diagrama esquematico de un sistema de entrenamiento super-visado en la siguiente figura:
J. Miguel Marın (U. Carlos III) 18
CURSO DE EXPERTOS U.C.M. (2012)
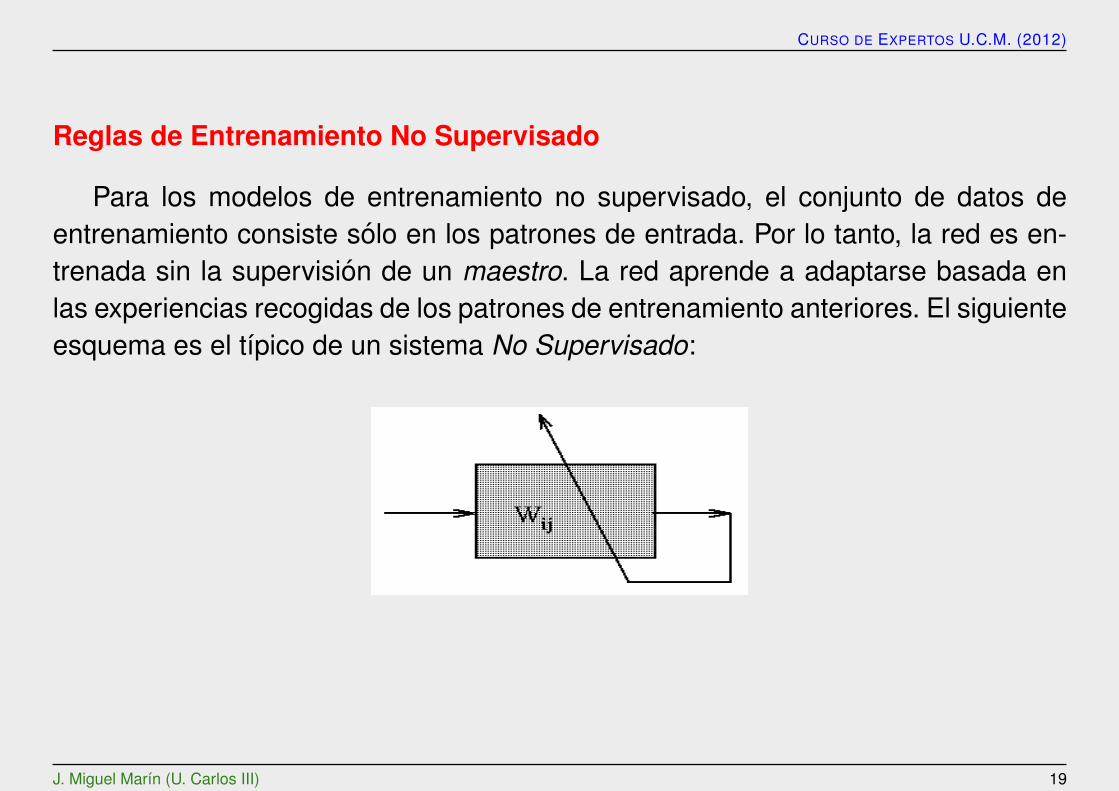
Reglas de Entrenamiento No Supervisado
Para los modelos de entrenamiento no supervisado, el conjunto de datos deentrenamiento consiste solo en los patrones de entrada. Por lo tanto, la red es en-trenada sin la supervision de un maestro. La red aprende a adaptarse basada enlas experiencias recogidas de los patrones de entrenamiento anteriores. El siguienteesquema es el tıpico de un sistema No Supervisado:
J. Miguel Marın (U. Carlos III) 19

CURSO DE EXPERTOS U.C.M. (2012)
Por ejemplo, se aplican la Regla de Aprendizaje de Hebb y la Regla de Aprendi-zaje Competitivo. Ası, en el primer caso se refuerza el peso que conecta dos nodosque se excitan simultaneamente.
En el aprendizaje competitivo, si un patron nuevo pertenece a una clase ya pre-sente, entonces la inclusion de este nuevo patron a esta clase matiza la represen-tacion de la misma. Si el nuevo patron no pertenece a ninguna de las clases ante-riores, entonces la estructura y los pesos de la red neuronal seran ajustados paragenerar una nueva clase.
J. Miguel Marın (U. Carlos III) 20

CURSO DE EXPERTOS U.C.M. (2012)
Funciones de Base y de Activacion
Una red neuronal tıpica se puede caracterizar por la funcion base y la funcionde activacion.
Cada nodo (unidad de proceso), produce un valor yj en su salida. Este valor sepropaga a traves de la red mediante conexiones unidireccionales hacia otros nodosde la red. Asociada a cada conexion hay un peso {wij}, que determina el efecto delnodo j-esimo sobre el siguiente nodo i-esimo.
Las entradas al nodo i-esimo que provienen de otros nodos se suman junto conel valor umbral θi (que hace el papel del termino independiente de la regresion), yse aplica la funcion base f , obteniendo el valor ui.
Finalmente se obtiene el valor yi aplicando la funcion de activacion sobre ui.
J. Miguel Marın (U. Carlos III) 21

CURSO DE EXPERTOS U.C.M. (2012)
Tipos de Funcion Base
La funcion base tiene dos formas tıpicas:
Funcion lineal de tipo hiperplano: El valor de red es una combinacion lineal delas entradas,
ui (w, x) =
n∑j=1
wijxj
Funcion radial de tipo hiperesferico: es una funcion base no lineal. El valor obte-nido representa la distancia a un determinado patron de referencia,
ui (w, x) =
√√√√ n∑j=1
(xj − wij)2
J. Miguel Marın (U. Carlos III) 22

CURSO DE EXPERTOS U.C.M. (2012)
Funcion de Activacion
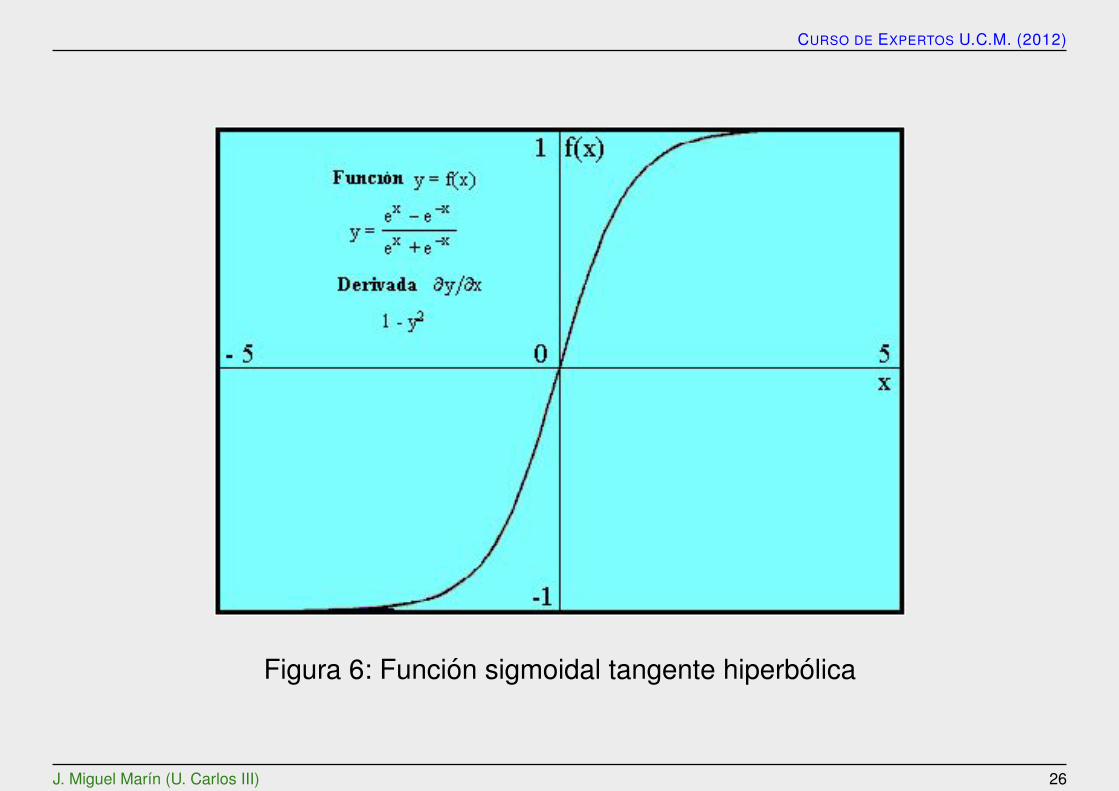
El valor de red, expresado por la funcion de base, u(w, x), se transforma median-te una funcion de activacion no lineal. Las funciones de activacion mas comunes sonla funcion logıstica y la funcion tangente hiperbolica:
Funcion logıstica
f(x) =1
1 + e−x
Funcion tangente hiperbolica
f(x) =ex − e−x
ex + e−x
J. Miguel Marın (U. Carlos III) 23
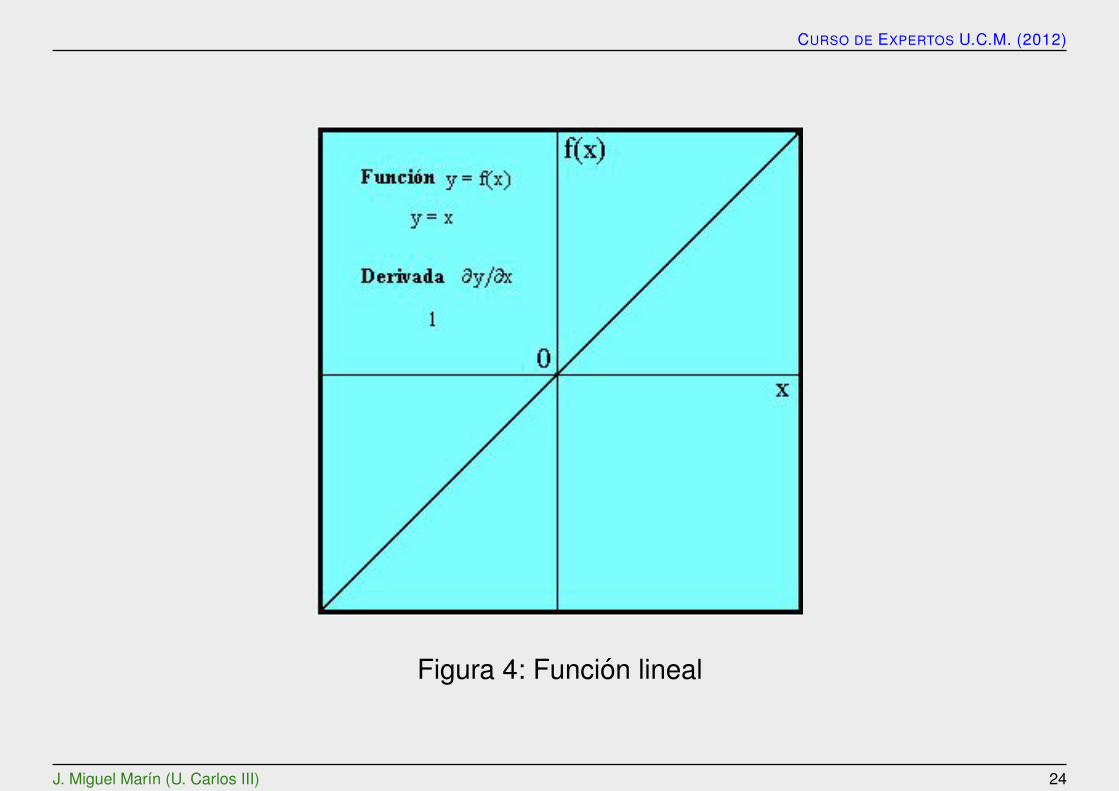
CURSO DE EXPERTOS U.C.M. (2012)
Figura 4: Funcion lineal
J. Miguel Marın (U. Carlos III) 24

CURSO DE EXPERTOS U.C.M. (2012)
Figura 5: Funcion sigmoidal logıstica
J. Miguel Marın (U. Carlos III) 25
CURSO DE EXPERTOS U.C.M. (2012)
Figura 6: Funcion sigmoidal tangente hiperbolica
J. Miguel Marın (U. Carlos III) 26
CURSO DE EXPERTOS U.C.M. (2012)
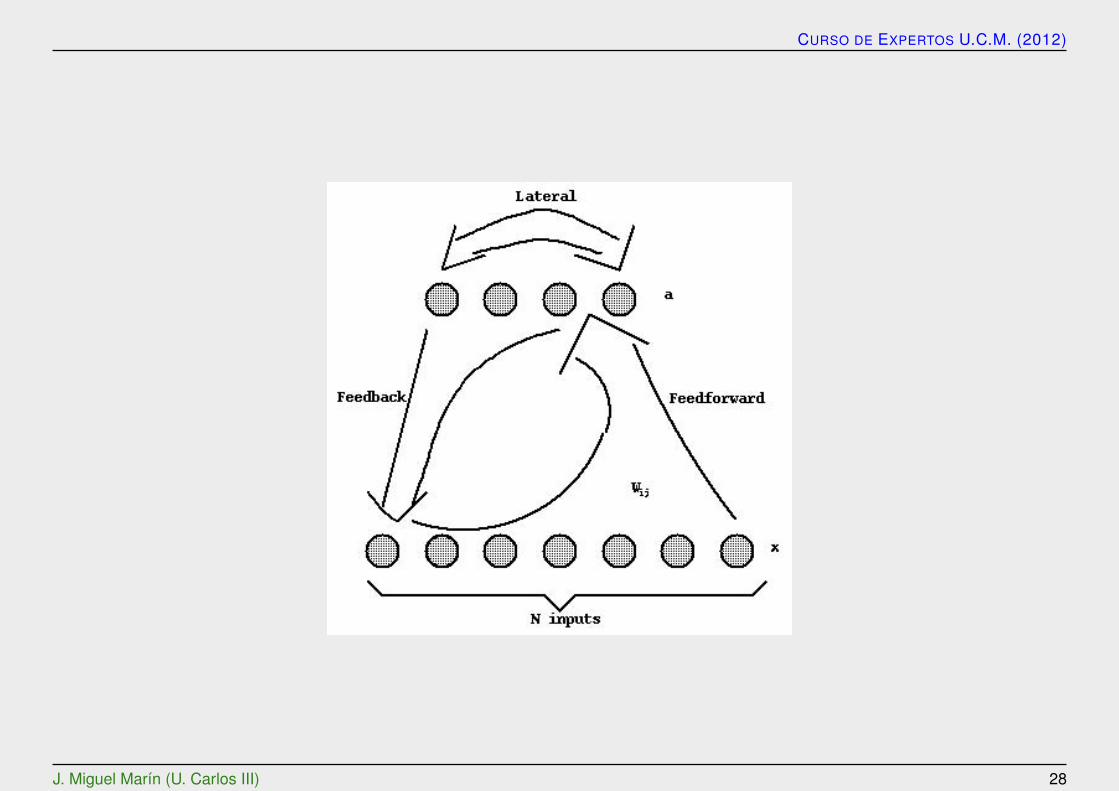
Estructuras de conexion de atras hacia delante
Una red neuronal se determina por las neuronas y la matriz de pesos.
Se pueden definir tres tipos de capas de neuronas:
la capa de entrada,
la capa oculta y
la capa de salida.
Entre dos capas de neuronas existe una red de pesos de conexion, que puedeser de los siguientes tipos:
hacia delante, hacia atras, lateral y de retardo:
J. Miguel Marın (U. Carlos III) 27
CURSO DE EXPERTOS U.C.M. (2012)
J. Miguel Marın (U. Carlos III) 28
CURSO DE EXPERTOS U.C.M. (2012)
1. Conexiones hacia delante: los valores de las neuronas de una capa inferior sonpropagados hacia las neuronas de la capa superior por medio de las redes deconexiones hacia adelante.
2. Conexiones hacia atras: estas conexiones llevan los valores de las neuronas deuna capa superior a otras de la capa inferior.
3. Conexiones laterales: Un ejemplo tıpico de este tipo es el circuito “el ganadortoma todo” (winner-takes-all), que cumple un papel importante en la eleccion delganador: a la neurona de salida que da el valor mas alto se le asigna el valor total(por ejemplo, 1), mientras que a todas las demas se le da un valor de 0
4. Conexiones con retardo: los elementos de retardo se incorporan en las conexio-nes para implementar modelos dinamicos y temporales, es decir, modelos queprecisan de memoria.
J. Miguel Marın (U. Carlos III) 29

CURSO DE EXPERTOS U.C.M. (2012)
Las conexiones pueden ser total o parcialmente interconectadas, como se mues-tra la siguiente figura:
Tambien es posible que las redes sean de una capa con el modelo de pesoshacia atras o bien el modelo multicapa hacia adelante. Es posible ası mismo, elconectar varias redes de una sola capa para dar lugar a redes mas grandes.
J. Miguel Marın (U. Carlos III) 30
CURSO DE EXPERTOS U.C.M. (2012)
Tamano de las Redes Neuronales
En una red multicapa de propagacion hacia delante, puede haber una o mascapas ocultas entre las capas de entrada y salida. El tamano de las redes dependedel numero de capas y del numero de neuronas ocultas por capa.
El numero de unidades ocultas esta directamente relacionado con las capaci-dades de la red. Para que el comportamiento de la red sea correcto, se tiene quedeterminar apropiadamente el numero de neuronas de la capa oculta.
J. Miguel Marın (U. Carlos III) 31

CURSO DE EXPERTOS U.C.M. (2012)
Metodos de Regresion y Redes NeuronalesLos modelos de regresion estudian la relacion entre una serie de variables, de-
nominadas independientes xi, y otras variables dependientes o respuesta que sedenotan como y. El objetivo es predecir los valores de y en funcion de los valoresde xi.
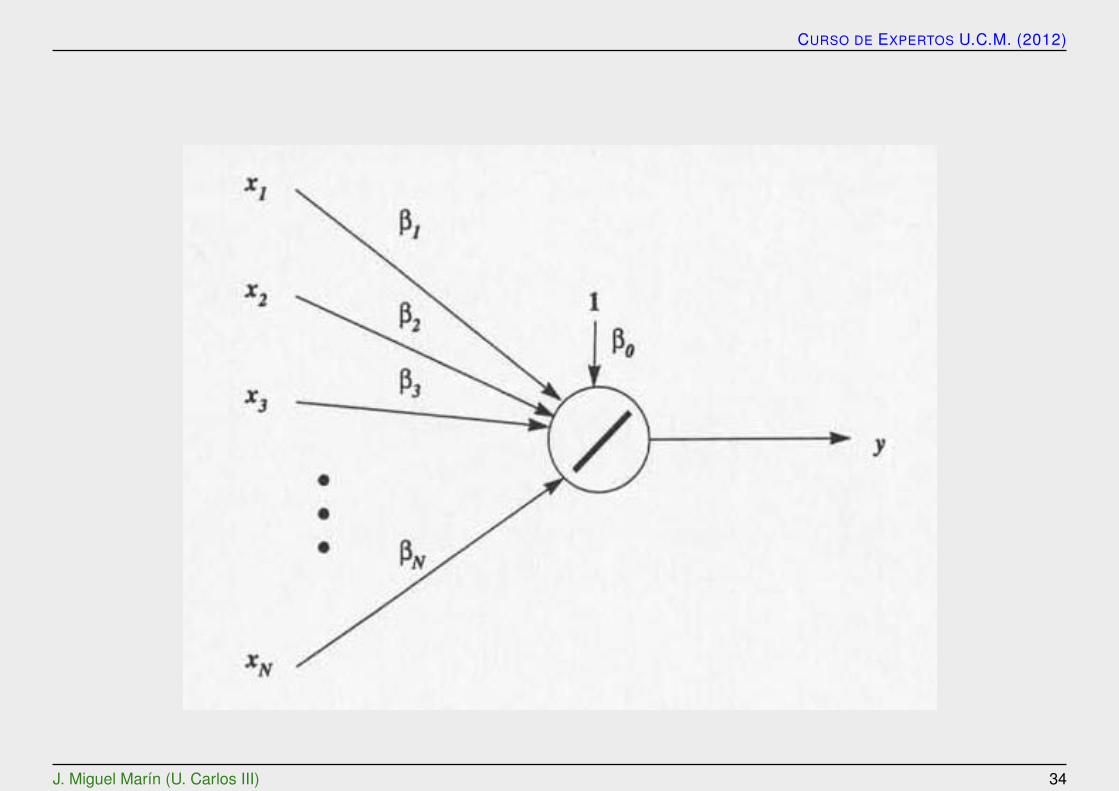
El modelo basico se puede expresar como
η =N∑i=0
βixi
donde
E(y) = µ
µ = h(η)
J. Miguel Marın (U. Carlos III) 32
CURSO DE EXPERTOS U.C.M. (2012)
En estas expresiones h(·) es la funcion que liga los componentes, βi son loscoeficientes, N es el numero de variables independientes y β0 es la pendiente.
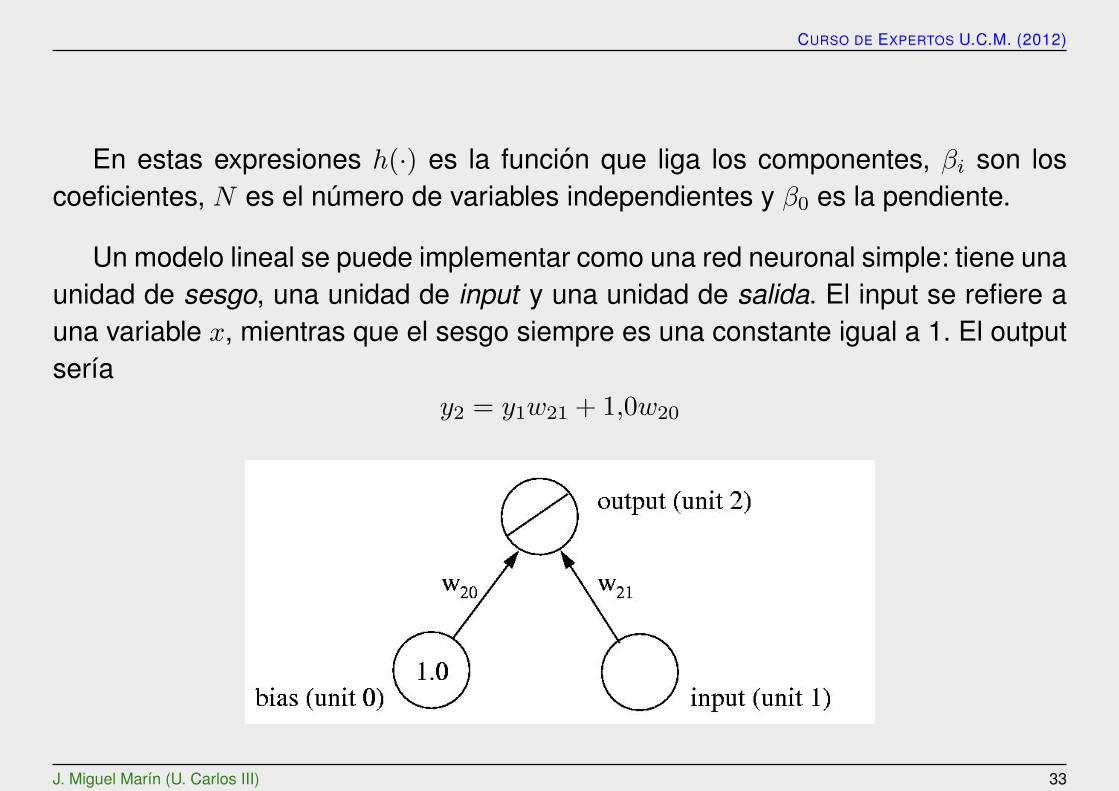
Un modelo lineal se puede implementar como una red neuronal simple: tiene unaunidad de sesgo, una unidad de input y una unidad de salida. El input se refiere auna variable x, mientras que el sesgo siempre es una constante igual a 1. El outputserıa
y2 = y1w21 + 1,0w20
J. Miguel Marın (U. Carlos III) 33
CURSO DE EXPERTOS U.C.M. (2012)
J. Miguel Marın (U. Carlos III) 34

CURSO DE EXPERTOS U.C.M. (2012)
El modelo tiene tres componentes:
1. Un componente aleatorio de la variable respuesta y con media µ y varianza σ2.
2. Un componente que relaciona las variables independientes xi con una funcionlineal η =
∑Ni=0 βixi.
3. Una funcion que relaciona la media con el predictor lineal η = h−1(µ).
El modelo lineal generalizado se reduce al modelo de regresion lineal multiplesi se considera que el componente aleatorio se distribuye como una normal y lafuncion h(·) se asume que es la identidad:
yp = β0 +
N∑i=1
βixpi + εp
J. Miguel Marın (U. Carlos III) 35

CURSO DE EXPERTOS U.C.M. (2012)
donde εp ∼ N(0, σ2).
El objetivo es encontrar los coeficientes βi que minimizan la suma de cuadradosde los errores
∆ =
n∑p=1
(yp −
N∑i=0
βixpi
)2
.
Este problema es equivalente al recogido por una red neuronal con una solacapa, donde los parametros βi equivalen a los pesos de la misma y la funcion deactivacion es la identidad.
J. Miguel Marın (U. Carlos III) 36

CURSO DE EXPERTOS U.C.M. (2012)
El Perceptron MulticapaEl Perceptron Multicapa es capaz de actuar como un aproximador universal de
funciones. Esta propiedad convierte a las redes perceptron multicapa en herramien-tas de proposito general, flexibles y no lineales.
Rumelhart et al. (1986) formalizaron un metodo para que una red del tipo per-ceptron multicapa aprendiera la asociacion que existe entre un conjunto de patronesde entrada y sus salidas correspondientes: metodo backpropagation error (propa-gacion del error hacia atras).
Una red con backpropagation, conteniendo al menos una capa oculta con sufi-cientes unidades no lineales, puede aproximar cualquier tipo de funcion o relacioncontinua entre un grupo de variables de entrada y salida.
Esta red tiene la capacidad de generalizacion: facilidad de dar estimaciones co-rrectas de observaciones que no han sido incluidas en la fase de entrenamiento.
J. Miguel Marın (U. Carlos III) 37

CURSO DE EXPERTOS U.C.M. (2012)
Arquitectura
Un perceptron multicapa esta compuesto por una capa de entrada, una capa desalida y una o mas capas ocultas; aunque se ha demostrado que para la mayorıade problemas bastara con una sola capa oculta. En la figura siguiente se puedeobservar un perceptron tıpico formado por una capa de entrada, una capa oculta yuna de salida.
J. Miguel Marın (U. Carlos III) 38

CURSO DE EXPERTOS U.C.M. (2012)
Figura 7: Perceptron multicapa
J. Miguel Marın (U. Carlos III) 39

CURSO DE EXPERTOS U.C.M. (2012)
Las conexiones entre neuronas son siempre hacia delante: las conexiones vandesde las neuronas de una determinada capa hacia las neuronas de la siguiente ca-pa; no hay conexiones laterales ni conexiones hacia atras. Por tanto, la informacionsiempre se transmite desde la capa de entrada hacia la capa de salida.
Como notacion se denomina wji al peso de conexion entre la neurona de entradai y la neurona oculta j, y vkj al peso de conexion entre la neurona oculta j y laneurona de salida k.
J. Miguel Marın (U. Carlos III) 40

CURSO DE EXPERTOS U.C.M. (2012)
Algoritmo backpropagation
Se considera una etapa de funcionamiento donde se presenta un patron de en-trada y este se transmite a traves de las sucesivas capas de neuronas hasta obteneruna salida. Despues, hay una etapa de entrenamiento o aprendizaje donde se mo-difican los pesos de la red de manera que coincida la salida objetivo con la salidaobtenida por la red.
J. Miguel Marın (U. Carlos III) 41

CURSO DE EXPERTOS U.C.M. (2012)
Etapa de funcionamiento
Cuando se presenta un patron p de entrada Xp: xp1, . . . , xpi , . . . , x
pN , este se trans-
mite a traves de los pesos wji desde la capa de entrada hacia la capa oculta. Lasneuronas de esta capa intermedia transforman las senales recibidas mediante laaplicacion de una funcion de activacion proporcionando, de este modo, un valor desalida. Este se transmite a traves de los pesos vkj hacia la capa de salida, dondeaplicando la misma operacion que en el caso anterior, las neuronas de esta ultimacapa proporcionan la salida de la red.
J. Miguel Marın (U. Carlos III) 42

CURSO DE EXPERTOS U.C.M. (2012)
Este proceso se resume en lo siguiente:
La entrada total, θpj , que recibe una neurona oculta j es:
θpj =
N∑i=1
wjixpi + λj
donde λj es un peso asociado a una neurona ficticia con valor de salida igual a 1que hace el papel de termino independiente o intercept.
El valor de salida de la neurona oculta j, ypj , se obtiene aplicando una funcion deactivacion f(·) sobre su entrada neta:
ypj = f(θpj)
J. Miguel Marın (U. Carlos III) 43

CURSO DE EXPERTOS U.C.M. (2012)
De igual forma, la entrada neta que recibe una neurona de salida k, θpk, es:
θpk =
H∑j=1
vkjypj + λk
Por ultimo, el valor de salida de la neurona de salida k, ypk, es:
ypk = f (θpk)
J. Miguel Marın (U. Carlos III) 44

CURSO DE EXPERTOS U.C.M. (2012)
Etapa de aprendizaje
En la etapa de aprendizaje, el objetivo es hacer mınimo el error entre la salida ob-tenida por la red y la salida optima ante la presentacion de un conjunto de patrones,denominado grupo de entrenamiento.
Ası, el aprendizaje en las redes backpropagation es de tipo supervisado.
La funcion de error que se pretende minimizar para cada patron p viene dadapor:
Ep =1
2
M∑k=1
(dpk − ypk)2
donde dpk es la salida deseada para la neurona de salida k ante la presentacion delpatron p.
J. Miguel Marın (U. Carlos III) 45

CURSO DE EXPERTOS U.C.M. (2012)
A partir de esta expresion se puede obtener una medida general del error totalmediante:
E =
P∑p=1
Ep
La base del algoritmo backpropagation para la modificacion de los pesos es latecnica conocida como gradiente decreciente.
J. Miguel Marın (U. Carlos III) 46
CURSO DE EXPERTOS U.C.M. (2012)
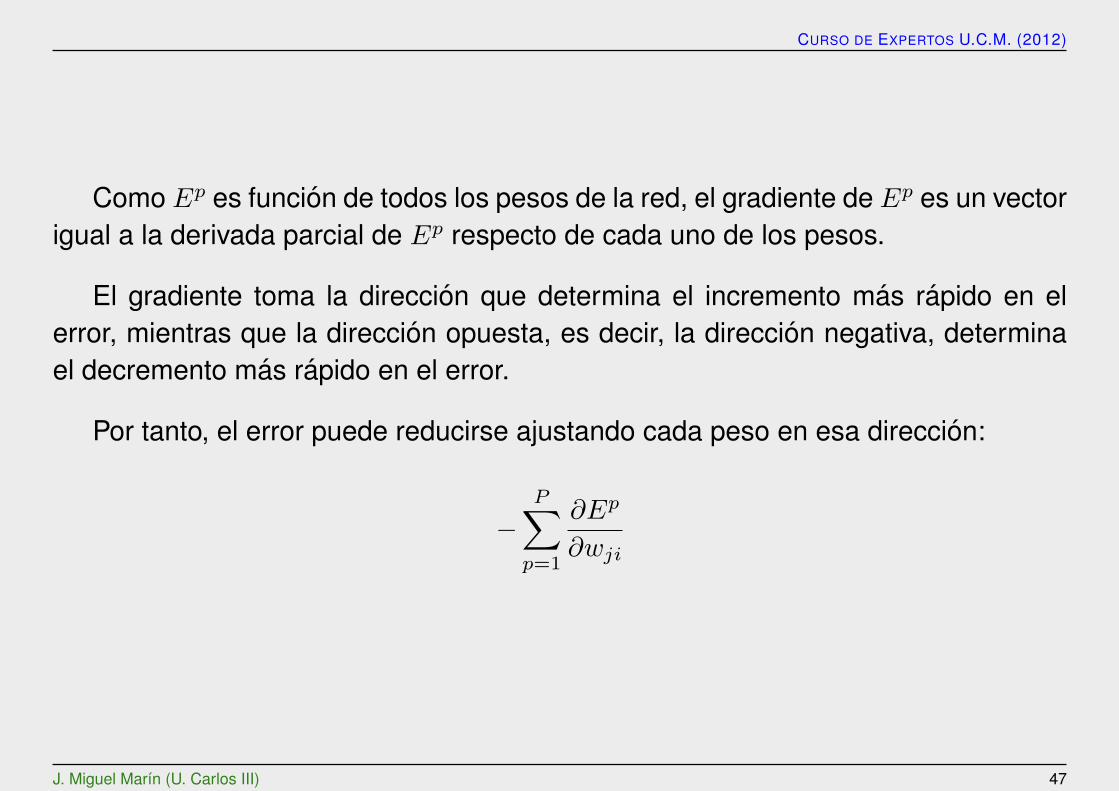
Como Ep es funcion de todos los pesos de la red, el gradiente de Ep es un vectorigual a la derivada parcial de Ep respecto de cada uno de los pesos.
El gradiente toma la direccion que determina el incremento mas rapido en elerror, mientras que la direccion opuesta, es decir, la direccion negativa, determinael decremento mas rapido en el error.
Por tanto, el error puede reducirse ajustando cada peso en esa direccion:
−P∑
p=1
∂Ep
∂wji
J. Miguel Marın (U. Carlos III) 47

CURSO DE EXPERTOS U.C.M. (2012)
Un peligro que puede surgir al utilizar el metodo del gradiente decreciente es queel aprendizaje converja a un mınimo local. Sin embargo, el problema potencial delos mınimos locales se da en raras ocasiones en datos reales.
A nivel practico, la forma de modificar los pesos de forma iterativa consiste enaplicar la regla de la cadena a la expresion del gradiente y anadir una tasa dada deaprendizaje η. Ası, en una neurona de salida se tendrıa:
∆vkj (n+ 1) = −η∂Ep
∂vkj= η
P∑p=1
δpkypj
dondeδpk = (dpk − y
pk) f ′ (θpk)
y n indica la iteracion.
J. Miguel Marın (U. Carlos III) 48

CURSO DE EXPERTOS U.C.M. (2012)
En una neurona oculta:
∆wji (n+ 1) = η
P∑p=1
δpjxpi
donde
δpj = f(θpj) M∑k=1
δpkvkj
Se puede observar que el error o valor δ asociado a una neurona oculta j, vienedeterminado por la suma de los errores que se cometen en las k neuronas de salidaque reciben como entrada la salida de esa neurona oculta j. De ahı que el algoritmotambien se denomine propagacion del error hacia atras.
J. Miguel Marın (U. Carlos III) 49

CURSO DE EXPERTOS U.C.M. (2012)
Para la modificacion de los pesos, la actualizacion se realiza despues de ha-ber presentado todos los patrones de entrenamiento. Este es el modo habitual deproceder y se denomina aprendizaje por lotes o modo batch.
Otra modalidad denominada aprendizaje en serie o modo on line consiste enactualizar los pesos tras la presentacion de cada patron de entrenamiento que hade hacerse en orden aleatorio.
Para acelerar el proceso de convergencia de los pesos, Rumelhart et al. (1986)sugirieron anadir un termino α, denominado momento, que tiene en cuenta la direc-cion del incremento tomada en la iteracion anterior:
∆vkj (n+ 1) = η
P∑p=1
δpkypj
+ α∆vkj (n)
J. Miguel Marın (U. Carlos III) 50
CURSO DE EXPERTOS U.C.M. (2012)
Fases en la aplicacion de un perceptron multicapa
Una red del tipo perceptron multicapa intenta resolver dos tipos de problemas:
– Problemas de prediccion, que consisten en la estimacion de una variable continuade salida, a partir de la presentacion de un conjunto de variables predictoras deentrada (discretas y/o continuas).
– Problemas de clasificacion, que consisten en la asignacion de la categorıa depertenencia de un determinado patron a partir de un conjunto de variables pre-dictoras de entrada (discretas y/o continuas).
J. Miguel Marın (U. Carlos III) 51

CURSO DE EXPERTOS U.C.M. (2012)
Seleccion de las variables relevantes y preprocesamiento de los datos
Para obtener una buena aproximacion, se deben elegir cuidadosamente las va-riables a emplear: se trata de incluir en el modelo las variables predictoras querealmente predigan la variable dependiente o de salida, pero que a su vez no ten-gan relaciones entre sı, ya que esto puede provocar un sobreajuste innecesario enel modelo.
Las variables deben seguir una distribucion normal o uniforme, y el rango deposibles valores debe ser aproximadamente el mismo y acotado dentro del intervalode trabajo de la funcion de activacion empleada en las capas ocultas y de salida dela red neuronal.
Ası, las variables de entrada y salida suelen acotarse en valores comprendidosentre 0 y 1 o entre −1 y 1.
J. Miguel Marın (U. Carlos III) 52

CURSO DE EXPERTOS U.C.M. (2012)
Si la variable es discreta, se utiliza la codificacion dummy.
Por ejemplo, la variable sexo podrıa codificarse como: 0 = hombre, 1 = mujer;estando representada por una unica neurona.
La variable nivel social podrıa codificarse como: 100 = bajo, 010 = medio, 001 =
alto; estando representada por tres neuronas.
Por su parte, si la variable es de naturaleza continua, esta se representa median-te una sola neurona, como, por ejemplo, la renta de una persona.
J. Miguel Marın (U. Carlos III) 53

CURSO DE EXPERTOS U.C.M. (2012)
Entrenamiento de la red neuronal
Eleccion de los pesos iniciales
Se hace una asignacion de pesos pequenos generados de forma aleatoria en unrango de valores entre −0,5 y 0,5 o algo similar.
Arquitectura de la red
Respecto a la arquitectura de la red, se sabe que para la mayorıa de problemaspracticos bastara con utilizar una sola capa oculta.
J. Miguel Marın (U. Carlos III) 54
CURSO DE EXPERTOS U.C.M. (2012)
El numero de neuronas de la capa de entrada esta determinado por el numerode variables predictoras.
Ası, en los ejemplos anteriores, la variable sexo estarıa representada por unaneurona que recibirıa los valores 0 o 1. La variable estatus social estarıa repre-sentada por tres neuronas. La variable renta de una persona estarıa representadapor una neurona que recibirıa un valor previamente acotado, por ejemplo, a valoresentre 0 y 1.
El numero de neuronas de la capa de salida esta determinado segun el mismoesquema que en el caso anterior.
J. Miguel Marın (U. Carlos III) 55

CURSO DE EXPERTOS U.C.M. (2012)
Cuando intentamos discriminar entre dos categorıas, bastara con utilizar unaunica neurona.
Ppor ejemplo, salida 1 para la categorıa A, salida 0 para la categorıa B.
Si estamos ante un problema de estimacion de una variable continua, tendremosuna unica neurona que dara como salida el valor de la variable a estimar.
El numero de neuronas ocultas determina la capacidad de aprendizaje de lared neuronal. Para evitar el sobreajuste, se debe usar el mınimo numero de neu-ronas ocultas con las cuales la red funcione de forma adecuada. Esto se consigueevaluando el rendimiento de diferentes arquitecturas en funcion de los resultadosobtenidos con el grupo de validacion.
J. Miguel Marın (U. Carlos III) 56
CURSO DE EXPERTOS U.C.M. (2012)
Tasa de aprendizaje y factor momento
El valor de la tasa de aprendizaje (η) controla el tamano del cambio de los pe-sos en cada iteracion. Se deben evitar dos extremos: un ritmo de aprendizaje de-masiado pequeno puede ocasionar una disminucion importante en la velocidad deconvergencia y la posibilidad de acabar atrapado en un mınimo local; en cambio,un ritmo de aprendizaje demasiado grande puede conducir a inestabilidades en lafuncion de error, lo cual evitara que se produzca la convergencia debido a que sedaran saltos en torno al mınimo sin alcanzarlo.
Por tanto, se recomienda elegir un ritmo de aprendizaje lo mas grande posible sinque provoque grandes oscilaciones. En general, el valor de la tasa de aprendizajesuele estar comprendida entre 0.05 y 0.5.
El factor momento (α) acelera la convergencia de los pesos. Se suele tomar unvalor proximo a 1 (por ejemplo, 0.9).
J. Miguel Marın (U. Carlos III) 57

CURSO DE EXPERTOS U.C.M. (2012)
Funcion de activacion de las neuronas ocultas y de salida
Se unan dos funciones basicas: la funcion lineal (o identidad) y funciones sig-moidales (como la funcion logıstica o la funcion tangente hiperbolica).
En general, se utiliza una funcion sigmoidal como funcion de activacion en lasneuronas de la capa oculta.
La eleccion de la funcion de activacion en las neuronas de la capa de salidadependera del tipo de tarea que se considera.
En tareas de clasificacion, se toma la funcion de activacion sigmoidal.
En cambio, en tareas de prediccion o aproximacion de una funcion, general-mente se toma la funcion de activacion lineal.
J. Miguel Marın (U. Carlos III) 58

CURSO DE EXPERTOS U.C.M. (2012)
Evaluacion del rendimiento del modelo
Una vez seleccionado el modelo de red que ha obtenido el mejor resultado conel conjunto de validacion, se debe evaluar la capacidad de generalizacion de la redcon otro grupo de datos independiente, o conjunto de datos de test.
Se utiliza la media cuadratica del error para evaluar el modelo:
MCerror =
P∑p=1
M∑k=1
(dpk − ypk)
2
P ·M
En problemas de clasificacion de patrones es mejor usar el porcentaje de cla-sificaciones correctas e incorrectas. Se puede construir una tabla de confusion ycalcular diferentes ındices de asociacion y acuerdo entre el criterio y la decisiontomada por la red neuronal.
J. Miguel Marın (U. Carlos III) 59
CURSO DE EXPERTOS U.C.M. (2012)
Interpretacion de los pesos obtenidos
Se trata de interpretar los pesos de la red neuronal. El metodo mas popular esel analisis de sensibilidad.
El analisis de sensibilidad esta basado en la medicion del efecto que se observaen una salida yk debido al cambio que se produce en una entrada xi. Cuanto mayorefecto se observe sobre la salida, mayor sensibilidad se puede deducir que presentarespecto a la entrada.
Un metodo comun consiste en fijar el valor de todas las variables de entrada asu valor medio e ir variando el valor de una de ellas a lo largo de todo su rango,registrando el valor de salida de la red.
J. Miguel Marın (U. Carlos III) 60

CURSO DE EXPERTOS U.C.M. (2012)
Redes Neuronales como generalizacion de las tecnicas deAnalisis Discriminante
En este apartado se trata la vision de las redes neuronales en terminos de unageneralizacion de las funciones lineales empleadas en Analisis Discriminante.
En este se clasifica un objeto como resultado de una aplicacion lineal, cuyosparametros se estiman a partir de un proceso de optimizacion.
Se puede generalizar el concepto anterior, considerando diferentes formas de lafuncion discriminante φ. De modo especıfico, se considera una funcion de la forma
gj(x) =
m∑i=1
wjiφi (x;µi) + wj0,
j = 1, . . . , C;
J. Miguel Marın (U. Carlos III) 61

CURSO DE EXPERTOS U.C.M. (2012)
donde hay m funciones base, φi, cada una de las cuales tiene una serie de parame-tros, y se utiliza la siguiente regla discriminante, dado un nuevo elemento x:
Asignar x a la clase ωi si gi(x) = maxjgj(x),
esto es, x se asigna a la clase cuya funcion discriminante alcanza mayor valor.
La ecuacion anterior generaliza el Analisis Discriminante lineal, usando funcio-nes no lineales φi.
J. Miguel Marın (U. Carlos III) 62

CURSO DE EXPERTOS U.C.M. (2012)
Si,
φi (x;µi) ≡ (x)i, esto es, una funcion lineal discriminante m = p, donde p es ladimension de x.
φi (x;µi) ≡ φi(x)i esto es, una funcion generalizada discriminante que puede serno lineal.
J. Miguel Marın (U. Carlos III) 63

CURSO DE EXPERTOS U.C.M. (2012)
Se puede interpretar como una transformacion de los datos x ∈ Rp a RC me-diante un espacio intermediario Rm determinado por las funciones φi.
Ejemplo: La llamada funcion de base radial (RBF) se puede describir como unacombinacion lineal de funciones de base no lineales radialmente simetricas
gj(x) =
m∑i=1
wjiφi (|x− µi|) + wj0
donde j = 1, . . . n. Los parametros wji son los pesos; wj0 se denomina el sesgo y alos vectores µi se les denomina los centros.
J. Miguel Marın (U. Carlos III) 64

CURSO DE EXPERTOS U.C.M. (2012)
Los mapas auto-organizados de Kohonen (SOM)En 1982 T. Kohonen presento un modelo de red denominado mapas auto-
organizados o SOM (Self-Organizing Maps), basado en ciertas evidencias descu-biertas a nivel cerebral. Este tipo de red posee un aprendizaje no supervisado com-petitivo.
No existe ningun maestro externo que indique si la red neuronal esta operandocorrecta o incorrectamente, porque no se dispone de ninguna salida objetivo haciala cual la red neuronal deba tender.
La red auto-organizada debe descubrir rasgos comunes, regularidades, correla-ciones o categorıas en los datos de entrada, e incorporarlos a su estructura internade conexiones. Se dice, por tanto, que las neuronas deben auto-organizarse en fun-cion de los estımulos (datos) procedentes del exterior.
J. Miguel Marın (U. Carlos III) 65

CURSO DE EXPERTOS U.C.M. (2012)
En el aprendizaje competitivo las neuronas compiten unas con otras con el finde llevar a cabo una tarea dada. Se pretende que cuando se presente a la red unpatron de entrada, solo una de las neuronas de salida (o un grupo de vecinas) seactive.
Por tanto, las neuronas compiten por activarse, quedando finalmente una comoneurona vencedora y anuladas el resto, que son forzadas a sus valores de respuestamınimos.
El objetivo de este aprendizaje es categorizar (clusterizar ) los datos que se intro-ducen en la red. Se clasifican valores similares en la misma categorıa y, por tanto,deben activar la misma neurona de salida.
Las clases o categorıas deben ser creadas por la propia red, puesto que se tratade un aprendizaje no supervisado, a traves de las correlaciones entre los datos deentrada.
J. Miguel Marın (U. Carlos III) 66
CURSO DE EXPERTOS U.C.M. (2012)
Fundamentos biologicos
Se ha observado que en el cortex de los animales superiores aparecen zonasdonde las neuronas detectoras de rasgos se encuentran topologicamente ordena-das; de forma que las informaciones captadas del entorno a traves de los organossensoriales, se representan internamente en forma de mapas bidimensionales.
Aunque en gran medida esta organizacion neuronal esta predeterminada geneti-camente, es probable que parte de ella se origine mediante el aprendizaje. Estosugiere, por tanto, que el cerebro podrıa poseer la capacidad inherente de formarmapas topologicos de las informaciones recibidas del exterior.
J. Miguel Marın (U. Carlos III) 67

CURSO DE EXPERTOS U.C.M. (2012)
Tambien se ha observado que la influencia que una neurona ejerce sobre lasdemas es funcion de la distancia entre ellas, siendo muy pequena cuando estanmuy alejadas.
En determinados primates se producen interacciones laterales de tipo excitatorioentre neuronas proximas en un radio de 50 a 100 micras, de tipo inhibitorio en unacorona circular de 150 a 400 micras de anchura alrededor del cırculo anterior, y detipo excitatorio muy debil desde ese punto hasta una distancia de varios centımetros.
J. Miguel Marın (U. Carlos III) 68
CURSO DE EXPERTOS U.C.M. (2012)
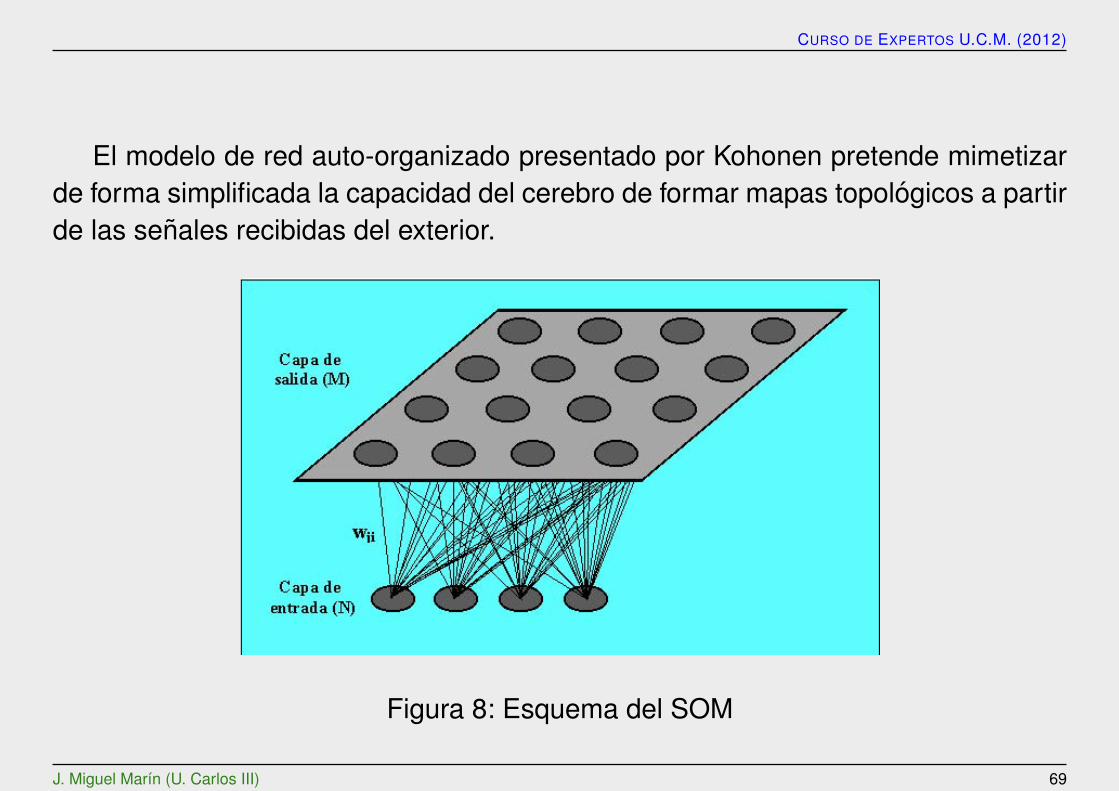
El modelo de red auto-organizado presentado por Kohonen pretende mimetizarde forma simplificada la capacidad del cerebro de formar mapas topologicos a partirde las senales recibidas del exterior.
Figura 8: Esquema del SOM
J. Miguel Marın (U. Carlos III) 69

CURSO DE EXPERTOS U.C.M. (2012)
Ideas intuitivas sobre el algoritmo del SOM
En multidimensional scaling (MDS) o escalamiento multidimensional se parte dedistancias entre pares de observaciones en un espacio de altas dimensiones (conmuchas variables).
Se puede tener un conjunto de verdaderas distancias o simplemente una seriede medidas de similitud. Estas ultimas no tiene por que ser simetricas ni cumplirla llamada desigualdad triangular.
La idea basica es proyectar los puntos en en un mapa bidimensional donde lospuntos mantienen las mismas distancias relativas que en el espacio original dealta dimension.
El SOM es en realidad un tipo de algoritmo para clasificacion (cluster).
J. Miguel Marın (U. Carlos III) 70

CURSO DE EXPERTOS U.C.M. (2012)
En el algoritmo de las k-medias cada observacion se asigna al cluster cuyo cen-troide o representante mj este mas proximo.
El SOM es muy parecido, salvo que en este caso se asocia una cierta estructurao topologıa a los representantes mj.
Se elige un gran numero de clusters y se colocan en forma de una red bidimensio-nal. La idea es que los representantes (o pesos, segun la notacion de Kohonen)esten correlacionados espacialmente, de modo que los puntos mas proximos enla rejilla sean mas parecidos entre sı que los que esten muy separados.
Este proceso es conceptualmente similar al MDS que transforma observacionessimilares en puntos cercanos del espacio bidimensional.
J. Miguel Marın (U. Carlos III) 71

CURSO DE EXPERTOS U.C.M. (2012)
Si se discretiza el espacio bidimensional dividiendolo, por ejemplo, en una rejillade componentes rectangulares se puede definir una aplicacion desde el espaciode alta dimensiones original sobre dicho espacio bidimensional.
Ademas, se puede tomar la media de los elementos que se encuentran en cadaelemento de la rejilla para definir representantes de las clases de la rejilla. Losrepresentantes que estan en clases proximas se parecen entre sı.
El espıritu del SOM es, ası, proporcionar una version discreta de MDS.
Kohonen afirma: I just wanted an algorithm that would effectively map similarpatterns (pattern vectors close to each other in the input signal space) onto con-tiguous locations in the output space. (Kohonen, 1995, p. VI.)
J. Miguel Marın (U. Carlos III) 72
CURSO DE EXPERTOS U.C.M. (2012)
Metodologıa del algoritmo del SOM
El SOM define una proyeccion desde un espacio de datos en alta dimension a unmapa bidimensional de neuronas. Cada neurona i del mapa se asocia con un vectorn-dimensional de referencia: ml = (ml1,ml2, . . . ,mln)
′ donde n denota la dimensionde los vectores de entrada.
Los vectores de de referencia forman el llamado codebook. Las neuronas delmapa se conectan con las neuronas adyacentes mediante una relacion de vecindad,que produce la topologıa o estructura del mapa. Las topologıas mas frecuentes sonla rectangular y la hexagonal.
J. Miguel Marın (U. Carlos III) 73

CURSO DE EXPERTOS U.C.M. (2012)
Las neuronas adyacentes pertenecen a una vecindad Ni de la neurona i. Latopologıa y el numero de neuronas permanece fijo desde el principio. El numerode neuronas determina la suavidad de la proyeccion, lo cual influye en el ajuste ycapacidad de generalizacion del SOM.
Durante la fase de entrenamiento, el SOM forma una red elastica que se pliegadentro de la nube de datos originales. El algoritmo controla la red de modo que tien-de a aproximar la densidad de los datos. Los vectores de referencia del codebookse acercan a las areas donde la densidad de datos es alta.
Eventualmente unos pocos vectores el codebook estaran en areas donde existebaja densidad de datos.
J. Miguel Marın (U. Carlos III) 74

CURSO DE EXPERTOS U.C.M. (2012)
El proceso de aprendizaje del SOM es el siguiente:
Paso 1. Un vector x es seleccionado al azar del conjunto de datos y se calcula sudistancia (similitud) a los vectores del codebook, usando, por ejemplo, la distanciaeuclıdea:
‖x−mc‖ = mıni{‖x−mi‖}
Paso 2. Una vez que se ha encontrado el vector mas proximo o BMU (best mat-ching unit) el resto de vectores del codebook es actualizado. El BMU y sus vecinos(en sentido topologico) se mueven cerca del vector x en el espacio de datos. Lamagnitud de dicha atraccion esta regida por la tasa de aprendizaje.
Mientras se va produciendo el proceso de actualizacion y nuevos vectores seasignan al mapa, la tasa de aprendizaje decrece gradualmente hacia cero. Juntocon ella tambien decrece el radio de vecindad tambien.
J. Miguel Marın (U. Carlos III) 75

CURSO DE EXPERTOS U.C.M. (2012)
La regla de actualizacion para el vector de referencia dado i es la siguiente:
mi (t+ 1) =
{mi (t) + α(t) (x(t)−mi(t)) i ∈ Nc(t)mi (t) i /∈ Nc(t)
Los pasos 1 y 2 se van repitiendo hasta que el entrenamiento termina. El numerode pasos de entrenamiento se debe fijar antes a priori, para calcular la tasa deconvergencia de la funcion de vecindad y de la tasa de aprendizaje.
Una vez terminado el entrenamiento, el mapa ha de ordenarse en sentido to-pologico: n vectores topologicamente proximos se aplican en n neuronas adyacen-tes o incluso en la misma neurona.
J. Miguel Marın (U. Carlos III) 76

CURSO DE EXPERTOS U.C.M. (2012)
Medidas de calidad del mapa y precision del mapa
Una vez que se ha entrenado el mapa, es importante saber si se ha adaptadoadecuadamente a los datos de entrenamiento. Como medidas de calidad de losmapas se considera la precision de la proyeccion y la preservacion de la topologıa.
La medida de precision de la proyeccion describe como se adaptan o respon-den las neuronas a los datos. Habitualmente, el numero de datos es mayor que elnumero de neuronas y el error de precision es siempre diferente de 0.
J. Miguel Marın (U. Carlos III) 77

CURSO DE EXPERTOS U.C.M. (2012)
Para calcular la precision de la proyeccion se usa el error medio de cuantificacionsobre el conjunto completo de datos:
εq =1
N
N∑i=1
‖xi −mc‖
La medida de preservacion de la topologıa describe la manera en la que el SOMpreserva la topologıa del conjunto de datos. Esta medida considera la estructura delmapa. En un mapa que este retorcido de manera extrana, el error topografico esgrande incluso si el error de precision es pequeno.
J. Miguel Marın (U. Carlos III) 78

CURSO DE EXPERTOS U.C.M. (2012)
Una manera simple de calcular el error topografico es:
εt =1
N
N∑k=1
u (xk)
donde u (xk) es igual a 1 si el primer y segundo BMUs de xk no estan proximos eluno al otro. De otro modo, u (xk) es igual a 0.
J. Miguel Marın (U. Carlos III) 79

CURSO DE EXPERTOS U.C.M. (2012)
Visualizacion del SOM
El SOM es facil de visualizar y, ademas, en los ultimos anos se han desarrolladodiferentes tecnicas de visualizacion, tanto para los vectores de referencia como paralos histogramas de datos.
La proyeccion de Sammon representa el SOM de la manera grafica que se mues-tra en la figura 9.
La proyeccion de Sammon trata de encontrar una proyeccion no lineal optimapara los datos en alta dimension, de manera que los vectores que se proyectanen la superficie bidimensional, conservan la misma distancia euclıdea relativa entreellos que la que tenıan en alta dimension.
J. Miguel Marın (U. Carlos III) 80
CURSO DE EXPERTOS U.C.M. (2012)
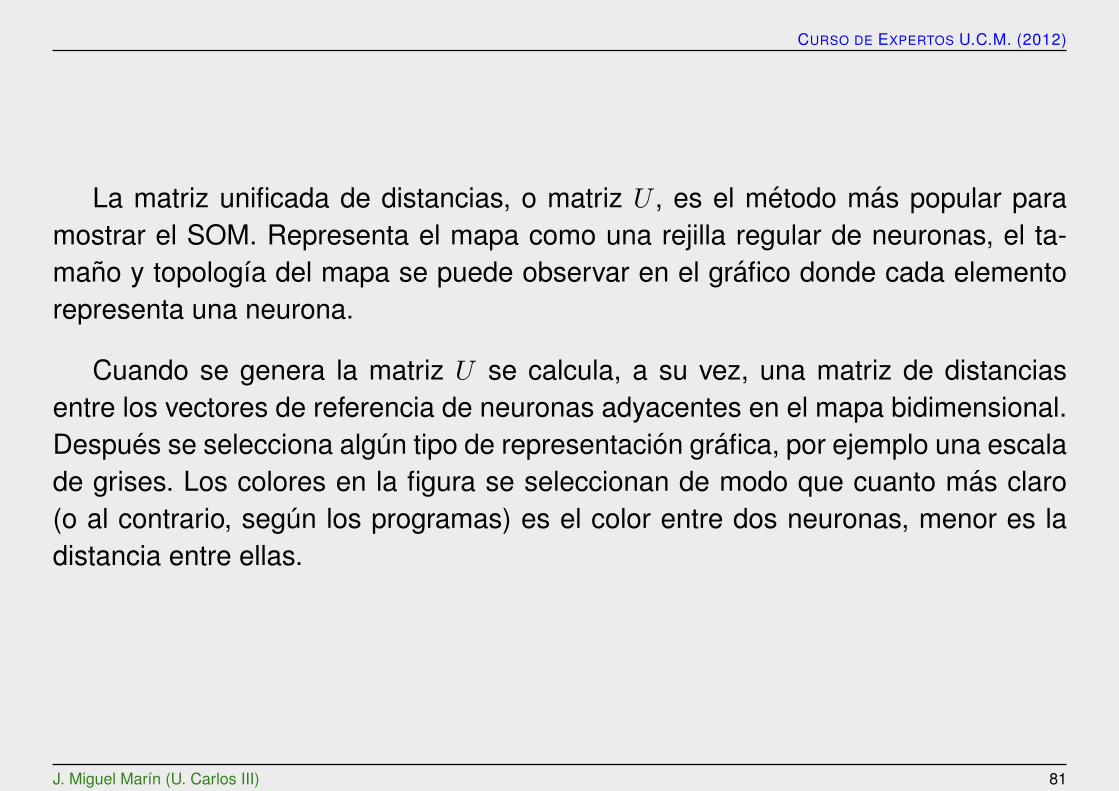
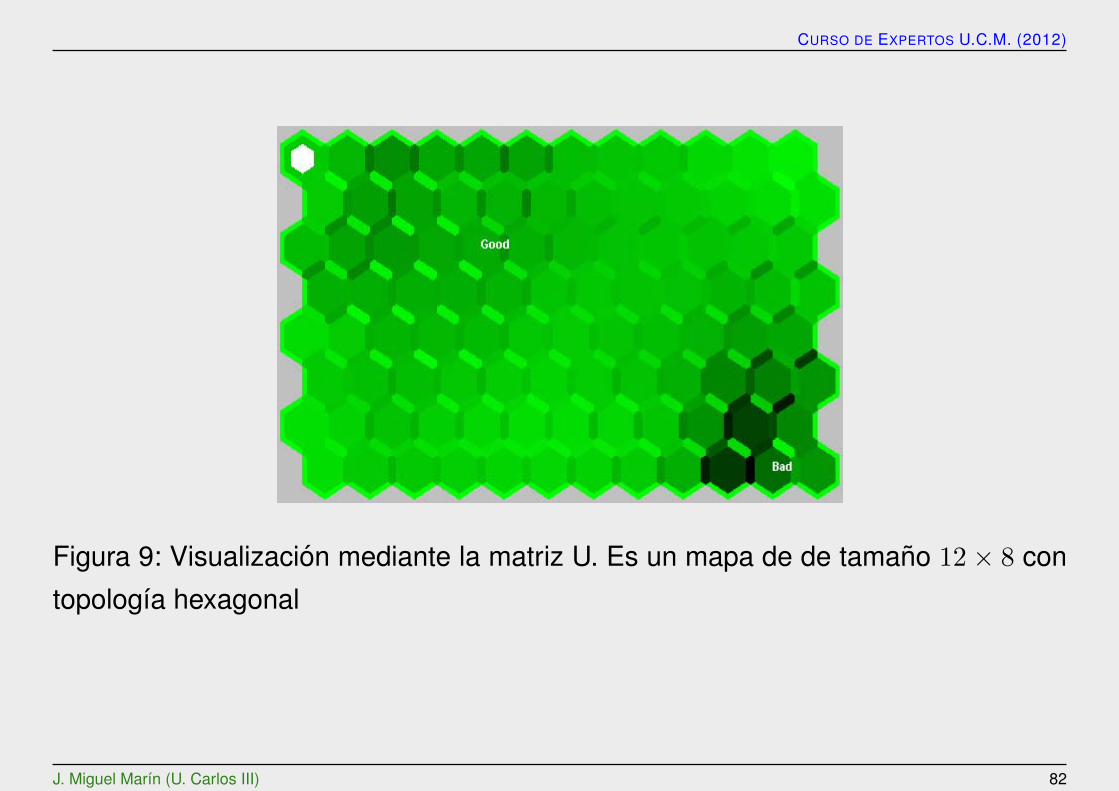
La matriz unificada de distancias, o matriz U , es el metodo mas popular paramostrar el SOM. Representa el mapa como una rejilla regular de neuronas, el ta-mano y topologıa del mapa se puede observar en el grafico donde cada elementorepresenta una neurona.
Cuando se genera la matriz U se calcula, a su vez, una matriz de distanciasentre los vectores de referencia de neuronas adyacentes en el mapa bidimensional.Despues se selecciona algun tipo de representacion grafica, por ejemplo una escalade grises. Los colores en la figura se seleccionan de modo que cuanto mas claro(o al contrario, segun los programas) es el color entre dos neuronas, menor es ladistancia entre ellas.
J. Miguel Marın (U. Carlos III) 81
CURSO DE EXPERTOS U.C.M. (2012)
Figura 9: Visualizacion mediante la matriz U. Es un mapa de de tamano 12 × 8 con
topologıa hexagonal
J. Miguel Marın (U. Carlos III) 82

CURSO DE EXPERTOS U.C.M. (2012)
Visualizacion de histogramas de datos
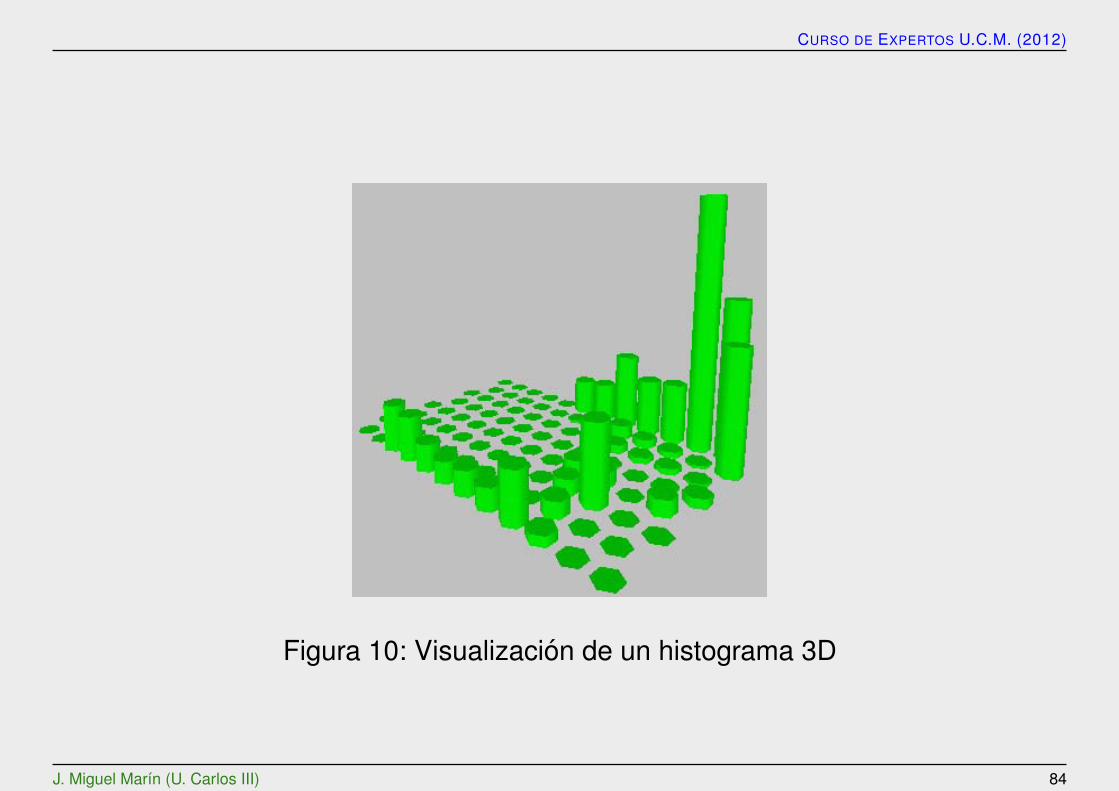
Se trata de mostrar como los vectores de datos son clasificados por el SOM.El histograma de datos muestran cuantos vectores pertenecen a un cluster definidopor cada neurona. El histograma se genera usando un SOM entrenado y el conjuntode datos.
J. Miguel Marın (U. Carlos III) 83
CURSO DE EXPERTOS U.C.M. (2012)
Figura 10: Visualizacion de un histograma 3D
J. Miguel Marın (U. Carlos III) 84

CURSO DE EXPERTOS U.C.M. (2012)
AplicacionesCon el fin de llegar al entendimiento global de las redes neuronales, se suele
adoptar la perspectiva top-down que empieza por la aplicacion, despues se pasa alalgoritmo y de aquı a la arquitectura:
J. Miguel Marın (U. Carlos III) 85

CURSO DE EXPERTOS U.C.M. (2012)
Las principales aplicaciones son el procesado de senales y el reconocimiento depatrones. Ası, la ventaja de las redes neuronales reside en el procesado paralelo,adaptativo y no lineal. Las redes neuronales se han aplicado con exito en la visionartificial, el procesado de senales e imagenes, reconocimiento de voz y de carac-teres, sistemas expertos, analisis de imagenes medicas, control remoto, control derobots e inspeccion industrial.
Las aplicaciones mas importantes de las redes neuronales son las de asociacion,clasificacion, generalizacion y optimizacion.
J. Miguel Marın (U. Carlos III) 86

CURSO DE EXPERTOS U.C.M. (2012)
Asociacion y Clasificacion
En esta aplicacion, los patrones de entrada estaticos o senales temporales de-ben ser clasificadas o reconocidas. Idealmente, un clasificador deberıa ser entre-nado para que cuando se le presente una version ligeramente distorsionada delpatron, pueda ser reconocida correctamente sin problemas. De la misma forma, lared deberıa presentar cierta inmunidad contra el ruido, esto es, deberıa ser capazde recuperar una senal limpia de ambientes o canales ruidosos.
J. Miguel Marın (U. Carlos III) 87
CURSO DE EXPERTOS U.C.M. (2012)
Asociacion. De especial interes son las dos clases de asociacion autoasociaciony heteroasociacion.
El problema de la autoasociacion es recuperar un patron enteramente, dada unainformacion parcial del patron deseado. La heteroasociacion consiste en recupe-rar un conjunto de patrones B, dado un patron de ese conjunto. Los pesos en lasredes asociativas se basan en la regla de Hebb: cuando una neurona participaconstantemente en activar una neurona de salida, la influencia de la neurona deentrada es aumentada.
Normalmente, la autocorrelacion del conjunto de patrones almacenado determi-na los pesos en las redes autoasociativas. Por otro lado, la correlacion cruzadade muchas parejas de patrones se usa para determinar los pesos de la red deheteroasociacion.
J. Miguel Marın (U. Carlos III) 88
CURSO DE EXPERTOS U.C.M. (2012)
Clasificacion. En muchas aplicaciones de clasificacion, por ejemplo en recono-cimiento de voz, los datos de entrenamiento consisten en pares de patrones deentrada y salida. En este caso, es conveniente adoptar las redes supervisadas,como las redes de retropropagacion. Este tipo de redes son apropiadas para lasaplicaciones que tienen una gran cantidad de clases con lımites de separacioncomplejos.
J. Miguel Marın (U. Carlos III) 89
CURSO DE EXPERTOS U.C.M. (2012)
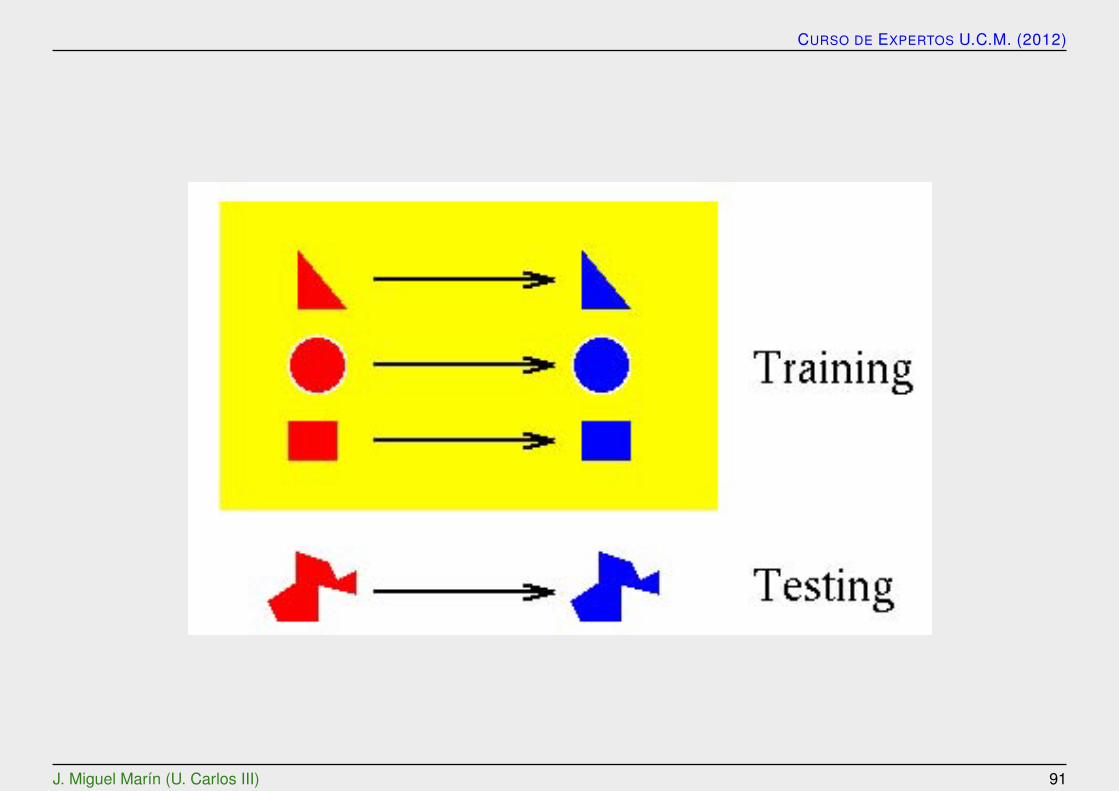
Generalizacion
Se puede extender a un problema de interpolacion. El sistema es entrenado porun gran conjunto de muestras de entrenamiento basados en un procedimiento deaprendizaje supervisado.
Una red se considera que esta entrenada con exito si puede aproximar los va-lores de los patrones de entrenamiento y puede dar interpolaciones suaves para elespacio de datos donde no ha sido entrenada.
El objetivo de la generalizacion es dar una respuesta correcta para un estımu-lo de entrada que no ha sido considerado previamente. Esto hace que el sistemafuncione eficazmente en todo el espacio, incluso cuando ha sido entrenado por unconjunto limitado de ejemplos. Por ejemplo, en la siguiente figura:
J. Miguel Marın (U. Carlos III) 90
CURSO DE EXPERTOS U.C.M. (2012)
J. Miguel Marın (U. Carlos III) 91
CURSO DE EXPERTOS U.C.M. (2012)
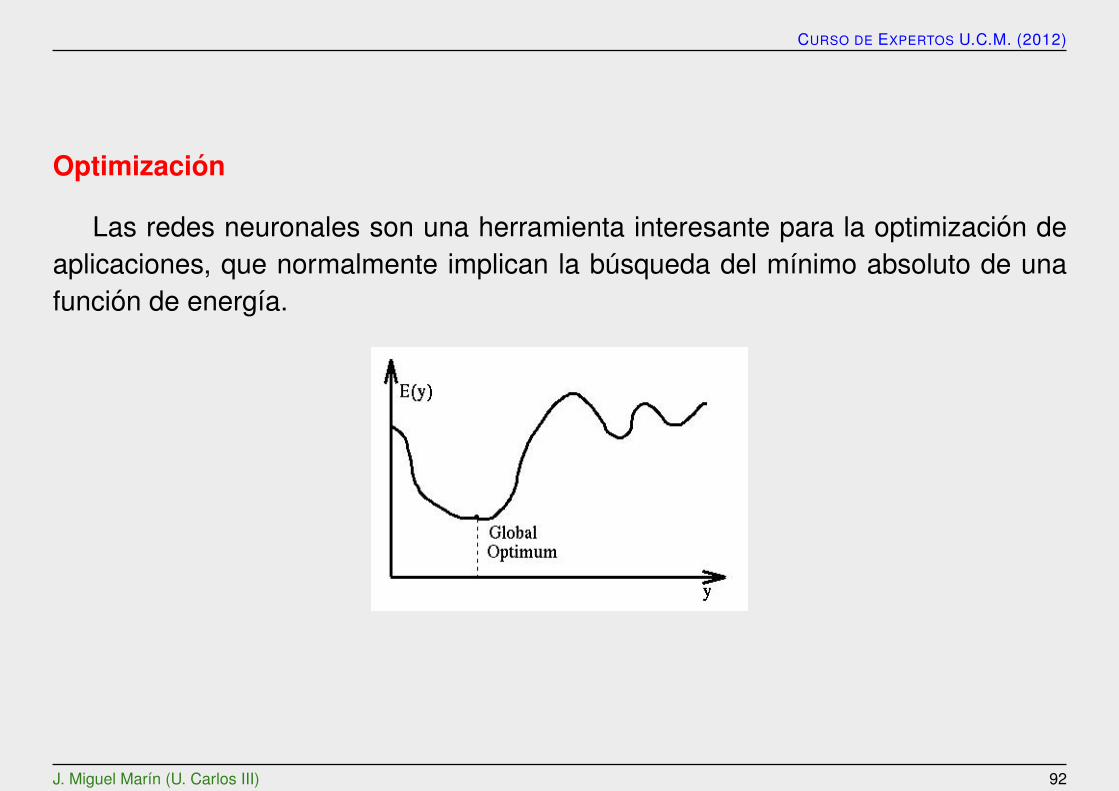
Optimizacion
Las redes neuronales son una herramienta interesante para la optimizacion deaplicaciones, que normalmente implican la busqueda del mınimo absoluto de unafuncion de energıa.
J. Miguel Marın (U. Carlos III) 92

CURSO DE EXPERTOS U.C.M. (2012)
Una vez que se define la funcion de energıa, se determinan los pesos sinapticos.Para algunas aplicaciones, la funcion de energıa es facilmente deducible. En otras,sin embargo, esta funcion de energıa se obtiene a partir de ciertos criterios de costey limitaciones especiales. El mayor problema asociado al problema de optimizaciones la alta posibilidad de converger hacia un mınimo local, en vez de hacia el mınimoabsoluto. Para evitar este problema se utilizan procedimientos estocasticos.
J. Miguel Marın (U. Carlos III) 93

CURSO DE EXPERTOS U.C.M. (2012)
Paginas sobre Redes Neuronales
Tutoriales sobre Redes Neuronales en Castellano
http://www.bibliopsiquis.com/psicologiacom/vol6num1/3301/
http://www.bibliopsiquis.com/psicologiacom/vol5num2/2833/
An Introduction to Neural Networks
http://www.cs.stir.ac.uk/~lss/NNIntro/InvSlides.html
CS-449: Neural Networks
http://www.willamette.edu/%7Egorr/classes/cs449/intro.html
J. Miguel Marın (U. Carlos III) 94
CURSO DE EXPERTOS U.C.M. (2012)
Neural Computing Publications Worldwide
http://www.ewh.ieee.org/tc/nnc/research/nnpubs.html
Tutor in Neural Nets
http://www.doc.ic.ac.uk/~nd/
surprise 96/journal/vol4/cs11/report.html
Toolbox Neural Nets de MatLab
http://www.mathworks.com/access/helpdesk/help/toolbox/nnet/
Stuttgart Neural Network Simulator
http://www-ra.informatik.uni-tuebingen.de/SNNS/
J. Miguel Marın (U. Carlos III) 95