introducing amazon aurora
TRANSCRIPT

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
February 22, 2016
Introducing Amazon Aurora
Sailesh Krishnamurthy ([email protected]) Amazon Aurora Engineering

Overview
What did we do, Why did we do it, How did we do it

MySQL-compatible relational database
Performance and availability of commercial databases
Simplicity and cost-effectiveness of
open source databases
What is Amazon Aurora?

How do you design for the Cloud?
The Old Way Share scarce system resources
The New Way Exploit abundant system resources .

Reimagining the Relational Database
What if you were inventing the database today?
You wouldn’t design it the way we did in 1970. At least not entirely. You’d build something that can scale out, that is self-healing, and that leverages existing AWS services.

SQL
Transactions
Caching
Logging
SQL
Transactions
Caching
Logging
Storage
Application
SQL
Transactions
Caching
Logging
Application
Even when you scale it out, you’re still replicating the same stack
SQL
Transactions
Caching
Logging
SQL
Transactions
Caching
Logging
Application
Storage Storage
SQL
Transactions
Caching
Logging
Application
Storage Storage
Current DB Architectures are Monolithic

This is a problem. For cost. For flexibility. And for availability.

Aurora Architecture
A Microservice approach for the cloud

Microservice Architecture
Moved the logging and storage layer into a multi-tenant, scale-out database-optimized storage service Integrated with other AWS services like Amazon EC2, Amazon VPC, Amazon DynamoDB, Amazon SWF, and Amazon Route 53 for control plane operations Integrated with Amazon S3 for continuous backup with 99.999999999% durability
Control Plane Data Plane
Amazon DynamoDB
Amazon SWF
Amazon Route 53
Logging + Storage
SQL
Transactions
Caching
Amazon S3
for a DB

Aurora Storage
Highly available by default • 6-way replication across 3 AZs • 4 of 6 write quorum
• Automatic fallback to 3 of 4 if an Availability Zone (AZ) is unavailable
• 3 of 6 read quorum
SSD, scale-out, multi-tenant storage • Seamless storage scalability • Up to 64 TB database size • Only pay for what you use
Log-structured storage • Many small segments, each with their own redo logs • Redo logs used to generate data pages on demand • Eliminates chatter between database and storage
SQL
Transactions
AZ 1 AZ 2 AZ 3
Caching
Amazon S3

Performance
How did we make this fly ?

Do fewer IOs
Minimize network packets
Cache prior results
Offload the database engine
DO LESS WORK
Process asynchronously
Reduce latency path
Use lock-free data structures
Batch operations together
BE MORE EFFICIENT
How did we make this fast ?
DATABASES ARE ALL ABOUT I/O
NETWORK-ATTACHED STORAGE IS ALL ABOUT PACKETS/SECOND
HIGH-THROUGHPUT PROCESSING DOES NOT ALLOW CONTEXT SWITCHES

IO Traffic in RDS MySQL
BINLOG DATA DOUBLE-WRITE LOG FRM FILES
T Y P E O F W R I T E
MYSQL WITH STANDBY
EBS mirror EBS mirror
AZ 1 AZ 2
Amazon S3
EBS Amazon Elastic
Block Store (EBS)
Primary Instance
Standby Instance
1
2
3
4
5
Issue write to EBS – EBS issues to mirror, ack when both done Stage write to standby instance using DRBD Issue write to EBS on standby instance
IO FLOW
Steps 1, 3, 5 are sequential and synchronous This amplifies both latency and jitter Many types of writes for each user operation Have to write data blocks twice to avoid torn writes
OBSERVATIONS
780K transactions 7,388K I/Os per million txns (excludes mirroring, standby) Average 7.4 I/Os per transaction
PERFORMANCE
30 minute SysBench writeonly workload, 100GB dataset, RDS SingleAZ, 30K PIOPS

IO Traffic in Aurora (Database)
AZ 1 AZ 3
Primary Instance
Amazon S3
AZ 2
Replica Instance
AMAZON AURORA
ASYNC 4/6 QUORUM
DISTRIBUTED WRITES
BINLOG DATA DOUBLE-WRITE LOG FRM FILES
T Y P E O F W R I T E S
30 minute SysBench writeonly workload, 100GB dataset
IO FLOW
Only write redo log records; all steps asynchronous No data block writes (checkpoint, cache replacement) 6X more log writes, but 9X less network traffic Tolerant of network and storage outlier latency
OBSERVATIONS
27,378K transactions 35X MORE 950K I/Os per 1M txns (6X amplification) 7.7X LESS
PERFORMANCE
Boxcar redo log records – fully ordered by LSN Shuffle to appropriate segments – partially ordered Boxcar to storage nodes and issue writes

IO Traffic in Aurora (Storage Node)
LOG RECORDS
Primary Instance
INCOMING QUEUE
STORAGE NODE
S3 BACKUP
1
2
3
4
5
6
7
8 UPDATE QUEUE
ACK
HOT LOG
DATA BLOCKS
POINT IN TIME SNAPSHOT
GC
SCRUB COALESCE
SORT GROUP
PEER TO PEER GOSSIP Peer Storage Nodes
All steps are asynchronous Only steps 1 and 2 are in foreground latency path Input queue is 46X less than MySQL (unamplified, per node) Favor latency-sensitive operations Use disk space to buffer against spikes in activity
OBSERVATIONS
IO FLOW
① Receive record and add to in-memory queue ② Persist record and ACK ③ Organize records and identify gaps in log ④ Gossip with peers to fill in holes ⑤ Coalesce log records into new data block versions ⑥ Periodically stage log and new block versions to S3 ⑦ Periodically garbage collect old versions ⑧ Periodically validate CRC codes on blocks
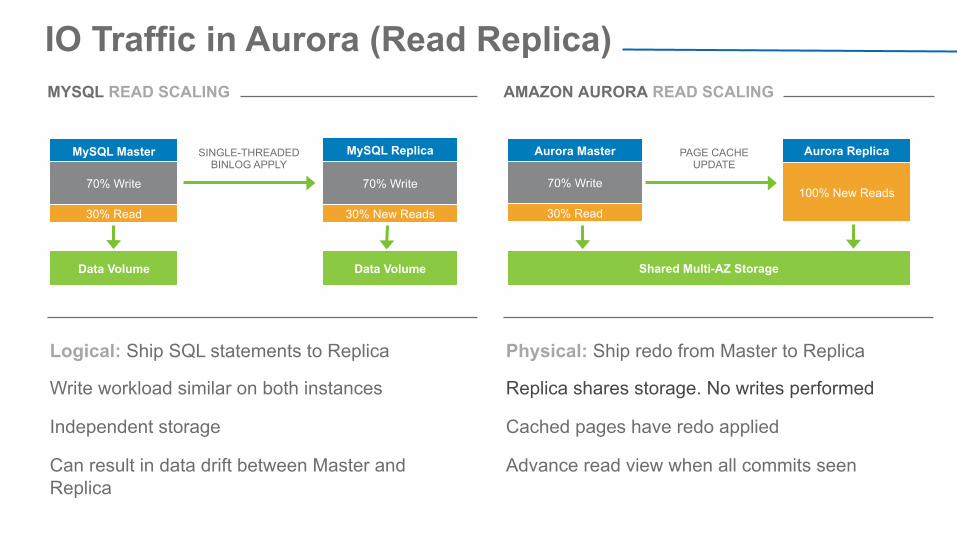
IO Traffic in Aurora (Read Replica)
PAGE CACHE UPDATE
Aurora Master
30% Read
70% Write
Aurora Replica
100% New Reads
Shared Multi-AZ Storage
MySQL Master
30% Read
70% Write
MySQL Replica
30% New Reads
70% Write
SINGLE-THREADED BINLOG APPLY
Data Volume Data Volume
Logical: Ship SQL statements to Replica
Write workload similar on both instances
Independent storage
Can result in data drift between Master and Replica
Physical: Ship redo from Master to Replica
Replica shares storage. No writes performed
Cached pages have redo applied
Advance read view when all commits seen
MYSQL READ SCALING AMAZON AURORA READ SCALING

Asynchronous group commit acks
Read
Write
Commit
Read
Read
T1
Commit (T1)
Commit (T2)
Commit (T3)
LSN 10
LSN 12
LSN 22
LSN 50
LSN 30
LSN 34
LSN 41
LSN 47
LSN 20
LSN 49
Commit (T4)
Commit (T5)
Commit (T6)
Commit (T7)
Commit (T8)
LSN GROWTH Durable LSN at head-node
COMMIT QUEUE Pending commits in LSN order
TIME
GROUP COMMIT
TRANSACTIONS
Read
Write
Commit
Read
Read
T1
Read
Write
Commit
Read
Read
Tn
TRADITIONAL APPROACH AMAZON AURORA Maintain a buffer of log records to write out to disk
Issue write when buffer full or time out waiting for writes
First writer has latency penalty when write rate is low
Request I/O with first write, fill buffer till write picked up
Individual write durable when 4 of 6 storage nodes ACK
Advance DB Durable point up to earliest pending ACK

Re-entrant connections multiplexed to active threads
Kernel-space epoll() inserts into latch-free event queue
Dynamically size threads pool
Gracefully handles 5000+ concurrent client sessions on r3.8xl
Standard MySQL – one thread per connection
Doesn’t scale with connection count
MySQL EE – connections assigned to thread group
Requires careful stall threshold tuning
CLI
EN
T C
ON
NE
CTI
ON
CLI
EN
T C
ON
NE
CTI
ON
LATCH FREE TASK QUEUE
epol
l()
MYSQL THREAD MODEL AURORA THREAD MODEL
Adaptive thread pool

Improvements over the past few months
Write batch size tuning Asynchronous send for read/write I/Os Purge thread performance Bulk insert performance
BATCH OPERATIONS
Failover time reductions Malloc reduction System call reductions Undo slot caching patterns Cooperative log apply
OTHER Binlog and distributed transactions Lock compression Read-ahead
CUSTOMER FEEDBACK
Hot row contention Dictionary statistics Mini-transaction commit code path Query cache read/write conflicts Dictionary system mutex
LOCK CONTENTION

Availability
Performance only matters if your database is up

Aurora Storage Availability
Quorum system for read/write; latency tolerant Peer to peer gossip replication to fill in holes Continuous backup to S3 (designed for 11 9s durability) Continuous scrubbing of data blocks Continuous monitoring of nodes and disks for repair 10GB segments as unit of repair or hotspot rebalance to quickly rebalance load Quorum membership changes do not stall writes
AZ 1 AZ 2 AZ 3
Amazon S3

Traditional databases Have to replay logs since the last checkpoint Typically 5 minutes between checkpoints Single-threaded in MySQL; requires a large number of disk accesses
Amazon Aurora Underlying storage replays redo records on demand as part of a disk read Parallel, distributed, asynchronous No replay for startup
Checkpointed Data Redo Log
Crash at T0 requires a re-application of the SQL in the redo log since last checkpoint
T0 T0
Crash at T0 will result in redo logs being applied to each segment on demand, in parallel, asynchronously
Instant crash recovery

Survivable caches
We moved the cache out of the database process Cache remains warm in the event of a database restart Lets you resume fully loaded operations much faster Instant crash recovery + survivable cache = quick and easy recovery from DB failures
SQL Transactions
Caching
SQL
Transactions
Caching
SQL Transactions
Caching
Caching process is outside the DB process and remains warm across a database restart

Faster, more predictable failover
App Running Failure Detection DNS Propagation
Recovery Recovery
DB Failure
MYSQL
App Running
Failure Detection DNS Propagation
Recovery
DB Failure
AURORA WITH MARIADB DRIVER
1 5 - 2 0 s e c
3 - 2 0 s e c

ALTER SYSTEM CRASH [{INSTANCE | DISPATCHER | NODE}]
ALTER SYSTEM SIMULATE percent_failure DISK failure_type IN
[DISK index | NODE index] FOR INTERVAL interval
ALTER SYSTEM SIMULATE percent_failure NETWORK failure_type
[TO {ALL | read_replica | availability_zone}] FOR INTERVAL interval
Simulate failures using SQL
To cause the failure of a component at the database node:
To simulate the failure of disks:
To simulate the failure of networking:

Usability
Focus on the application and not managing the system

Simplify Database Management
Create a database in minutes Automated patching Push-button scale compute Continuous backups to Amazon S3 Automatic failure detection and failover
Amazon RDS

Simplify Storage Management
Read replicas are available as failover targets—no data loss Instantly create user snapshots—no performance impact Continuous, incremental backups to Amazon S3 Automatic storage scaling up to 64 TB—no performance or availability impact Automatic restriping, mirror repair, hot spot management, encryption

Simplify Data Security
Encryption to secure data at rest • AES-256; hardware accelerated • All blocks on disk and in Amazon S3 are encrypted • Key management via AWS KMS
SSL to secure data in transit
Network isolation via Amazon VPC by default
No direct access to nodes
Supports industry standard security and data protection certifications
Storage
SQL
Transactions
Caching
Amazon S3
Application

Benchmarks
Enough already, show me the data

4 client machines with 1,000 connections each
WRITE PERFORMANCE READ PERFORMANCE
Single cl ient machine with 1,600 connections
MySQL SysBench
R3.8XL with 32 cores and 244 GB RAM
SQL Benchmark Results

Reproducing these results
h t t p s : / / d 0 . a w s s t a t i c . c o m / p r o d u c t - m a r k e t i n g / A u r o r a / R D S _ A u r o r a _ P e r f o r m a n c e _ A s s e s s m e n t _ B e n c h m a r k i n g _ v 1 - 2 . p d f
AMAZON AURORA
R3.8XLARGE
R3.8XLARGE
R3.8XLARGE
R3.8XLARGE
R3.8XLARGE
• Create an Amazon VPC (or use an existing one).
• Create four EC2 R3.8XL client instances to run the SysBench client. All four should be in the same AZ.
• Enable enhanced networking on your clients
• Tune your Linux settings (see whitepaper)
• Install Sysbench version 0.5
• Launch a r3.8xlarge Amazon Aurora DB Instance in the same VPC and AZ as your clients
• Start your benchmark!
1
2
3
4
5
6
7

Beyond benchmarks
If only real world applications saw benchmark performance POSSIBLE DISTORTIONS
Real world requests contend with each other Real world metadata rarely fits in data dictionary cache Real world data rarely fits in buffer cache Real world production databases need to run HA

Scaling Table Count
Tables Amazon Aurora
MySQL I2.8XL
local SSD
MySQL I2.8XL
RAM disk
RDS MySQL
30K IOPS (single AZ)
10 60,000 18,000 22,000 25,000
100 66,000 19,000 24,000 23,000
1,000 64,000 7,000 18,000 8,000
10,000 54,000 4,000 8,000 5,000
SysBench write-only workload 1,000 connections Default settings
11x U P TO
FA S T E R

Scaling Data Set Size
DB Size Amazon Aurora RDS MySQL
30K IOPS (single AZ)
1GB 107,000 8,400
10GB 107,000 2,400
100GB 101,000 1,500
1TB 26,000 1,200
67x U P TO
FA S T E R
SYSBENCH WRITE-ONLY
DB Size Amazon Aurora RDS MySQL
30K IOPS (single AZ)
80GB 12,582 585
800GB 9,406 69
CLOUDHARMONY TPC-C
136x U P TO
FA S T E R

Scaling User Connections
SysBench OLTP Workload 250 tables
Connections Amazon Aurora RDS MySQL
30K IOPS (single AZ)
50 40,000 10,000
500 71,000 21,000
5,000 110,000 13,000
8x U P TO
FA S T E R

Running with Read Replicas
Updates per second Amazon Aurora
RDS MySQL 30K IOPS (single AZ)
1,000 2.62 ms 0 s
2,000 3.42 ms 1 s
5,000 3.94 ms 60 s
10,000 5.38 ms 300 s
SysBench Writeonly Workload 250 tables
500x U P TO
L O W E R L A G
Getting Started aws.amazon.com/rds/aurora aws.amazon.com/rds/aurora/getting-started
Contact me for Aurora credits on AWS

Thank you! P.S. We’re hiring ! Email me at: [email protected] aws.amazon.com/rds/aurora