introduction à elasticsearch
TRANSCRIPT

Introduction à ElasticSearch(Première partie : Administration)
Fadel ChafaiTechnical Team Lead at Capgemini
Agenda
Elasticsearch ?Lucene ?Concepts de base :
- Near real time (NRT)- Cluster - Node ( Roles ) - Shards & Replicas- Installation & Configuration- Index , Type , Document - Routing & Alias- Plugins
Ressources

Elasticsearch
ElasticSearch est un moteur de recherche NoSQL très puissant basé sur Lucene
(un projet de Apache Software Foundation). ElasticSearch a été développé en
Java et est distribué de façon open source sous licence Apache 2.0. Il fournit un
moteur de recherche "full-text" disponible avec une API RESTFul et dont les
entités sont sauvegardées sous forme de documents JSON. Il a été conçu dans
l'optique d'être évolutif, avec un système de clustering, de loadbalancing et est
capable de reconstruire les données perdues dû à, par exemple, un node
défectueux.


Lucene
ElasticSearch est basé sur l’excellente librairie Apache Lucene. Cette librairie existe depuis de nombreuses années et est au cœur de nombreux moteurs de recherche open source (le plus connu étant Apache SolR). Elle fournit toutes les classes Java nécessaires à l’indexation de documents et à l’exécution des requêtes de recherches.
ElasticSearch facilite l’utilisation de Lucene en intégrant la librairie dans une application Java modulaire, facilement configurable et capable de fonctionner en cluster.
Zend_Search_Lucene

Concepts de base : Near real time (NRT)
Elasticsearch est une plate forme de recherche (NTR : Near réal time) temps quasi réel, ce que cela
signifie est qu'il y a une légère latence (normalement une seconde) à partir du moment où vous indexez
un document jusqu'à ce que le document devient consultable.

Concepts de base : Cluster
Un cluster ElasticSearch est composé de plusieurs nœuds
qui communiquent entre eux. Chaque nœud (node en
anglais) correspond à une instance d’ElasticSearch en
cours d’exécution, et peut être ajouté ou retiré du cluster
même lorsque ce dernier est en train de fonctionner.

Concepts de base : Cluster (2)
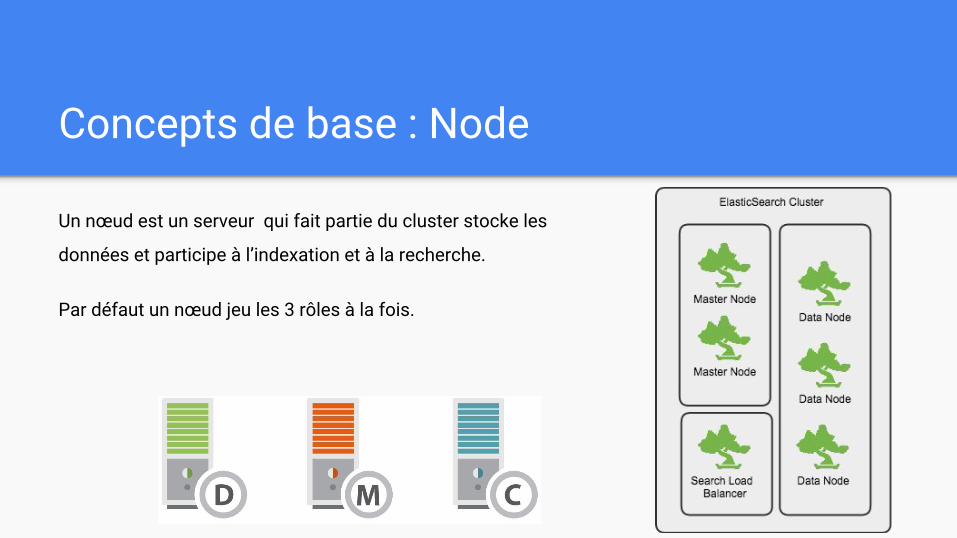
Concepts de base : Node
Un nœud est un serveur qui fait partie du cluster stocke les
données et participe à l’indexation et à la recherche.
Par défaut un nœud jeu les 3 rôles à la fois.
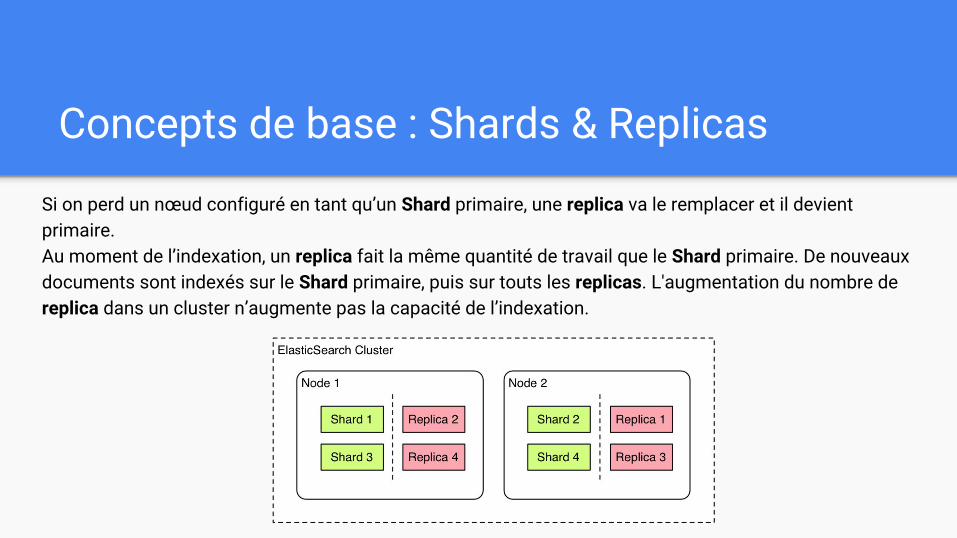
Concepts de base : Shards & Replicas
Si on perd un nœud configuré en tant qu’un Shard primaire, une replica va le remplacer et il devient primaire. Au moment de l’indexation, un replica fait la même quantité de travail que le Shard primaire. De nouveaux documents sont indexés sur le Shard primaire, puis sur touts les replicas. L'augmentation du nombre de replica dans un cluster n’augmente pas la capacité de l’indexation.

Installation
sudo apt-get update
Installation Java :sudo apt-get install openjdk-7-jrejava -version
Telechargement et installation d’Elasticsearch :wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.debsudo dpkg -i elasticsearch-1.7.2.deb
# Installation : /usr/share/elasticsearch/# config : /etc/elasticsearch# Script : /etc/init.d/elasticsearch
Auto start :sudo update-rc.d elasticsearch defaults
https://www.digitalocean.com/community/tutorials/how-to-install-and-configure-elasticsearch-on-ubuntu-14-04
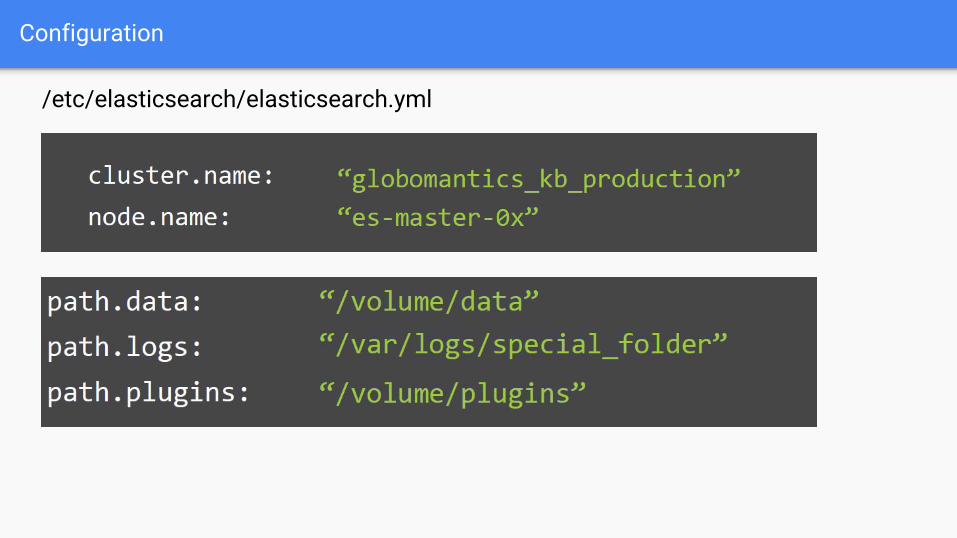
Configuration
/etc/elasticsearch/elasticsearch.yml
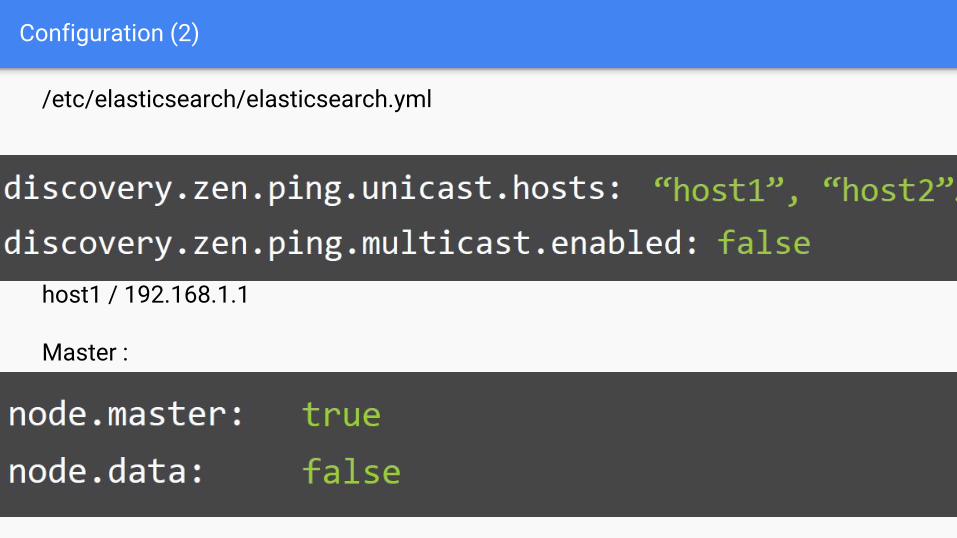
Configuration (2)
/etc/elasticsearch/elasticsearch.yml
host1 / 192.168.1.1
Master :
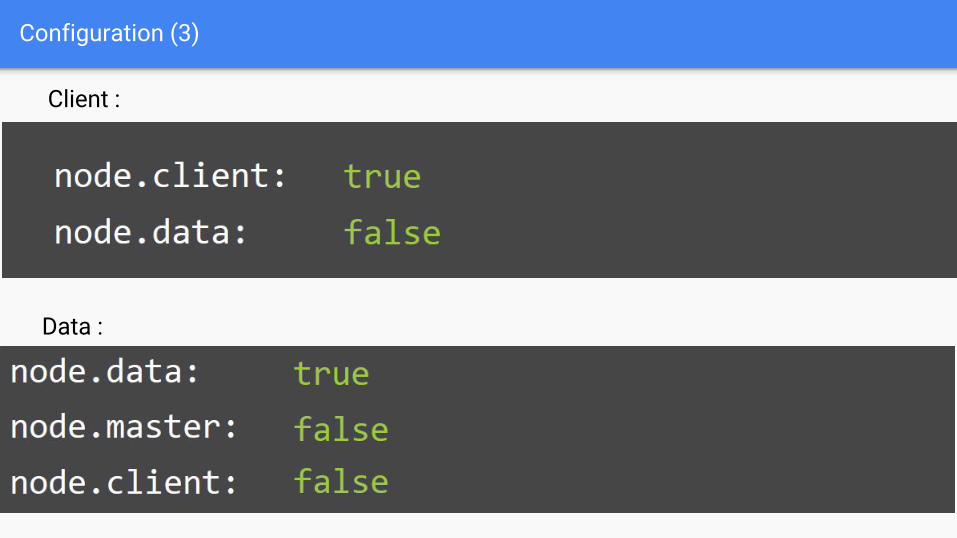
Configuration (3)
Client :
Data :
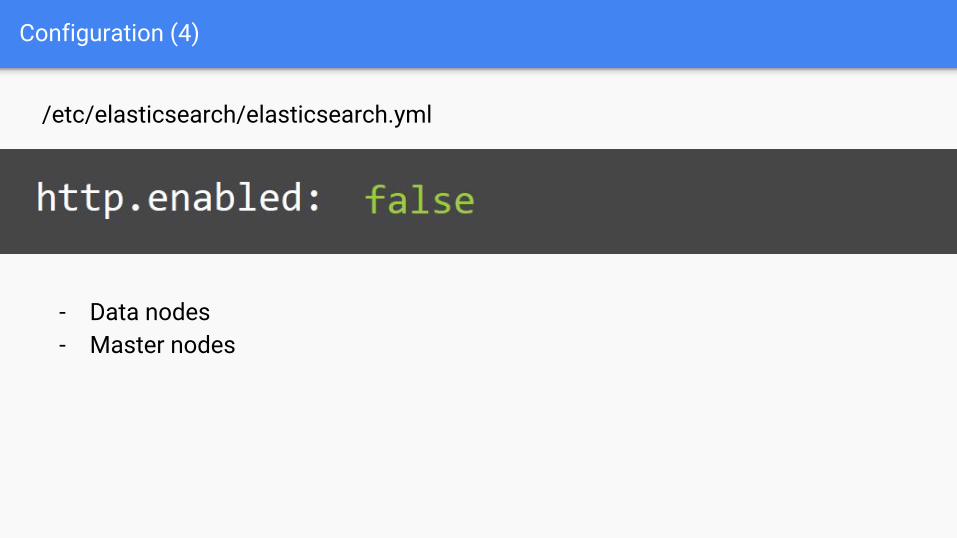
Configuration (4)
/etc/elasticsearch/elasticsearch.yml
- Data nodes- Master nodes

Configuration (5)
JVM HEAP :
- Valeur par défaut : 1G - Data nodes : = 64G/2 = 32G Heap
- 32 pour le HEAP- Le reste pour Lucene
- une valeur > 32G pour le HEAP est sans effet vu la conf de la JVM
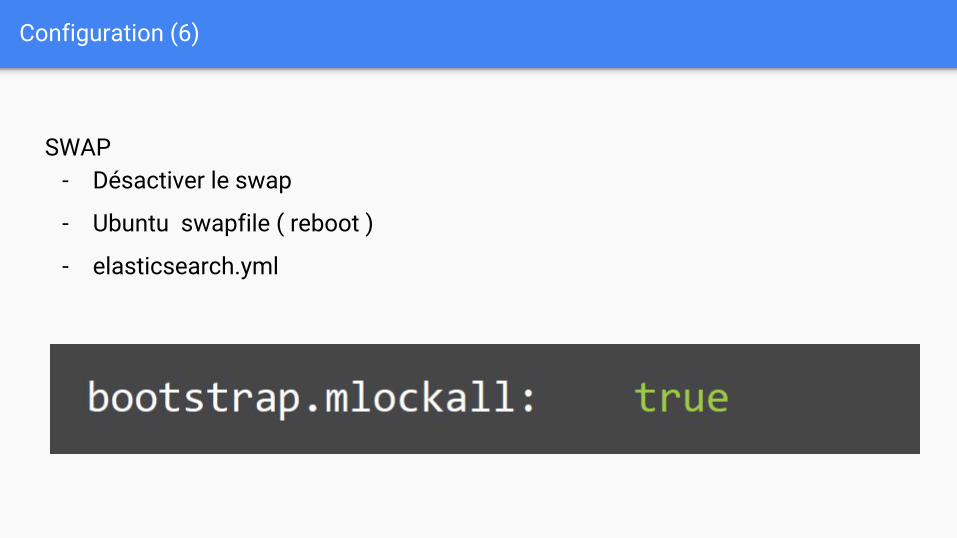
Configuration (6)
SWAP- Désactiver le swap
- Ubuntu swapfile ( reboot )
- elasticsearch.yml
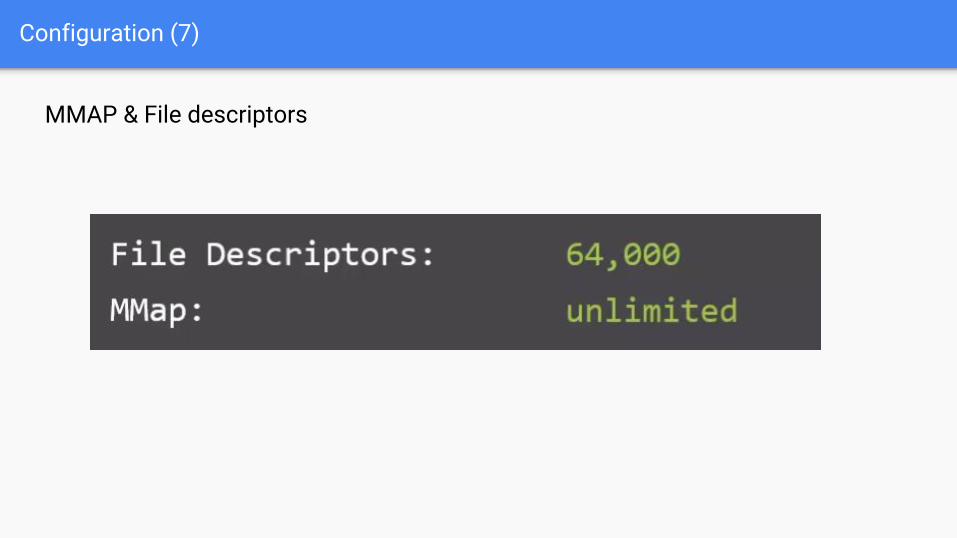
Configuration (7)
MMAP & File descriptors

Concepts de base : Index , Type , Document
Index (JSON + Metadata) = SQL Data base

Concepts de base : Index , Type , Document (2)

Concepts de base : Index , Type , Document(3)
Création d’un document :
curl -XPOST http://es.dev:9200/articles/article -d “{
"article_name":"TITANIUM DIOXIDE, ZINC OXIDE",
"article_text":"Trimalleolar fracture,closed",
"article_date":"2015-05-31T21:14:42Z"
}"
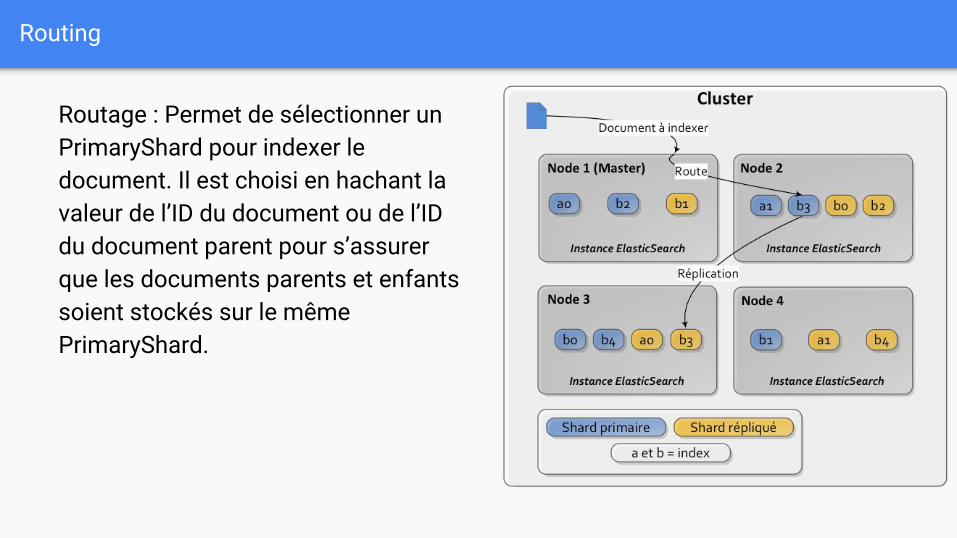
Routing
Routage : Permet de sélectionner un PrimaryShard pour indexer le document. Il est choisi en hachant la valeur de l’ID du document ou de l’ID du document parent pour s’assurer que les documents parents et enfants soient stockés sur le même PrimaryShard.
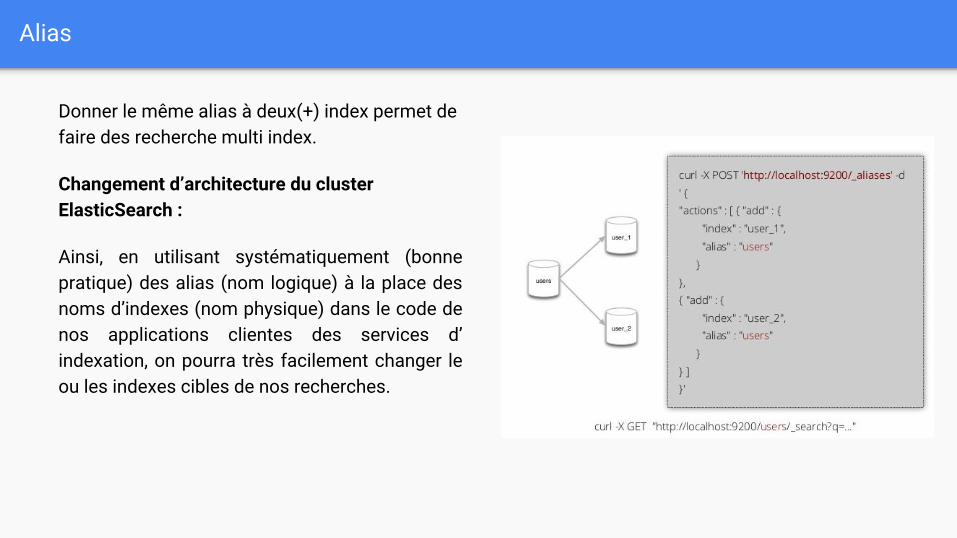
Alias
Donner le même alias à deux(+) index permet de faire des recherche multi index.
Changement d’architecture du cluster ElasticSearch :
Ainsi, en utilisant systématiquement (bonne pratique) des alias (nom logique) à la place des noms d’indexes (nom physique) dans le code de nos applications clientes des services d’indexation, on pourra très facilement changer le ou les indexes cibles de nos recherches.

Snapshotting Elasticsearch Indexes
ElasticSearch a sa fonction de sauvegarde propre connu comme Snapshotting. Il est un moyen très efficace de sauvegarder tout ou une partie des indices dans un cluster.
ElasticSearch prend en charge plusieurs stratégies de sauvegarde out-of-the-box. Vous pouvez envoyer des instantanés directement à un système de fichiers partagé ou d'un stockage en réseau, Amazon S3, ou même le service de cloud Azure de Microsoft.
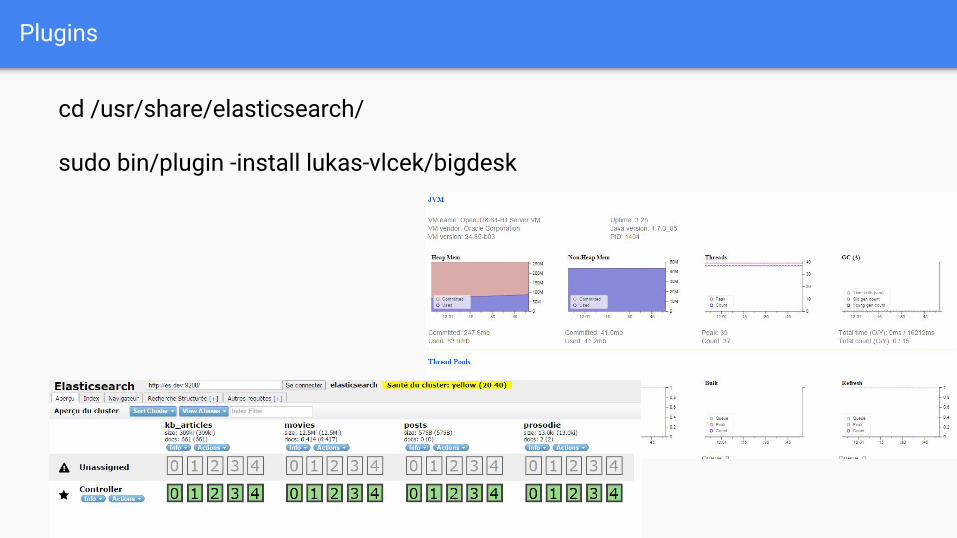
Plugins
cd /usr/share/elasticsearch/
sudo bin/plugin -install lukas-vlcek/bigdesk

Ressources
Docs :
https://www.elastic.co/
https://www.elastic.co/guide/en/elasticsearch/guide/current/administration.html
Plugins :
https://mobz.github.io/elasticsearch-head/
http://www.elastichq.org/
E-Book :
https://www.safaribooksonline.com/library/view/mastering-elasticsearch/9781783281435/
