introduction to gpu computing - hpc@lr€¦ · introduction to heterogeneous/hybrid computing...
TRANSCRIPT

INTRODUCTION TO
HETEROGENEOUS/HYBRID COMPUTING
François Courteille |Senior Solutions Architect, NVIDIA |[email protected]

2
Agenda:
1 Introduction : Heterogeneous Computing & GPUs
2 CPU versus GPU architecture
3 Accelerated computing roadmap 2015
AGENDA

3
Introduction : Heterogeneous Computing & GPUs

4
RACING TOWARD EXASCALE

ACCELERATORS SURGE IN WORLD’S TOP SUPERCOMPUTERS
100
100+ accelerated systems now on Top500 list
75
1/3 of total FLOPS powered by accelerators
NVIDIA Tesla GPUs sweep 23 of 24 new accelerated supercomputers
50
Tesla supercomputers growing at 50% CAGR over past five years
25
0 2013 2014 2015
Top500: # of Accelerated Supercomputers

NEXT-GEN SUPERCOMPUTERS ARE GPU-ACCELERATED
SUMMIT
SIERRA
U.S. Dept. of Energy Pre-Exascale Supercomputers
for Science
NOAA New Supercomputer for Next-Gen
Weather Forecasting
IBM Watson Breakthrough Natural Language
Processing for Cognitive Computing

7
WHAT IS HETEROGENEOUS COMPUTING?
Application Execution
+
GPU CPU
High Data Parallelism High Serial
Performance

The World Leader in Visual Computing
PC DATA CENTER MOBILE
ENTERPRISE VIRTUALIZATION
AUTONOMOUS MACHINES
HPC & CLOUD SERVICE PROVIDERS GAMING DESIGN

RIVA 128 3M xtors
GeForce 256 23M xtors
GeForce FX 250M xtors
GeForce 8800 681M xtors
GeForce 3 60M xtors
“Kepler” 7B xtors
1995 2000 2001 2006 2012
Fixed function Programmable shaders CUDA
2003
Evolution of GPUs

Performance Lead Continues to Grow
0
500
1000
1500
2000
2500
3000
3500
2008 2009 2010 2011 2012 2013 2014
Peak Double Precision FLOPS
NVIDIA GPU x86 CPU
M2090
M1060
K20
K80
Westmere Sandy Bridge
Haswell
GFLOPS
0
100
200
300
400
500
600
2008 2009 2010 2011 2012 2013 2014
Peak Memory Bandwidth
NVIDIA GPU x86 CPU
GB/s
K20
K80
Westmere Sandy Bridge
Haswell
Ivy Bridge
K40
Ivy Bridge
K40
M2090
M1060

GPU CPU
Add GPUs: Accelerate Applications
GPU Motivation: Peak Flops & Memory BW

GPUs Enable Faster Deployment of Improved Algorithms
CAZ WEM (VTI)
KPrSTM
KPrSDM Gaussian Beam
Wave Equation
Reverse Time Migration
Elastic Waveform Inversion
Shot WEM (TTI)
Schedule pull-in
due to GPUs
Wave Equation
Reverse Time Migration
Elastic Waveform Inversion
GPUs CPUs

ACCELERATING
discoveries
USING A SUPERCOMPUTER POWERED BY 3,000 TESLA
PROCESSORS, UNIVERSITY OF ILLINOIS SCIENTISTS
PERFORMED THE FIRST ALL-ATOM SIMULATION OF THE
HIV VIRUS AND DISCOVERED THE CHEMICAL STRUCTURE
OF ITS CAPSID — “THE PERFECT TARGET FOR FIGHTING
THE INFECTION.”
WITHOUT GPU, THE SUPERCOMPUTER WOULD NEED TO
BE 5X LARGER FOR SIMILAR PERFORMANCE.

ACCELERATING INSIGHTS
GOOGLE DATACENTER
1,000 CPU Servers 2,000 CPUs • 16,000 cores
600 kWatts
$5,000,000
STANFORD AI LAB
3 GPU-Accelerated Servers 12 GPUs • 18,432 cores
4 kWatts
$33,000
Now You Can Build Google’s
$1M Artificial Brain on the Cheap
“ “
Deep learning with COTS HPC systems, A. Coates, B. Huval, T. Wang, D. Wu, A. Ng, B. Catanzaro ICML 2013

Enough to power all of San Francisco
120 petaflops | 376 megawatts
Power is the Problem

Green500
Rank MFLOPS/W Site
1 4,389.82 GSIC Center, Tokyo Tech
2 3,631.70 Cambridge University
3 3,517.84 University of Tsukuba
4 3,459.46 SURFsara
5 3,185.91 Swiss National Supercomputing
(CSCS)
6 3,131.06 ROMEO HPC Center
7 3,019.72 CSIRO
8 2,951.95 GSIC Center, Tokyo Tech
9 2,813.14 Eni
10 2,629.10 (Financial Institution)
16 2,495.12 Mississippi State (top non-
NVIDIA)
59 1,226.60 ICHEC (top X86 cluster)
Top500
Rank TFLOPS/s Site
1 33,862.7 National Super Computer Centre
Guangzhou
2 17,590.0 Oak Ridge National Lab
3 17,173.2 DOE, United States
4 10,510.0 RIKEN Advanced Institute for
Computational Science
5 8,586.6 Argonne National Lab
6 6,271.0 Swiss National Supercomputing
Centre (CSCS)
7 5,168.1 University of Texas
8 5,008.9 Forschungszentrum Juelich
9 4,293.3 DOE, United States
10 3,143.5 Government
CSCS Piz Daint Top 10 in Top500 and Green500
#1 USA
#1 Europe
Piz Daint: 5,272 nodes with 1 x Xeon E5-2670 (SB) CPU,
1 x NVIDIA K20X GPU, Cray XC30 at 2.0 MW

CUDA: World’s Most Pervasive Parallel
Programming Model
700+ University Courses
In 62 Countries 14,000 Institutions with CUDA Developers
2,000,000 CUDA Downloads
487,000,000 CUDA GPUs Shipped

370 GPU-Accelerated Applications
www.nvidia.com/appscatalog

70% OF TOP HPC APPS ACCELERATED
Quantum Espresso BLAST
= Not supported
TOP 25 APPS IN SURVEY
GROMACS LAMMPS
SIMULIA Abaqus NWChem
NAMD LS-DYNA
AMBER Schrodinger
ANSYS Mechanical
Exelis IDL Gaussian
MSC NASTRAN GAMESS
ANSYS Fluent ANSYS CFX
WRF Star-CD
VASP CCSM
OpenFOAM COMSOL
CHARMM Star-CCM+
= All popular functions accelerated
= Some popular functions accelerated
= In development
INTERSECT360 SURVEY OF TOP APPS
Top 10 HPC Apps Top 50 HPC Apps 90% 70%
Accelerated Accelerated
Intersect360, Nov 2015 “HPC Application Support for GPU Computing”

CORAL: Built for Grand Scientific Challenges
Fusion Energy Role of material disorder, statistics, and fluctuations in nanoscale materials and systems.
Combustion Combustion simulations to enable the next gen diesel/bio- fuels to burn more efficiently
Climate Change Study climate change adaptation and mitigation scenarios; realistically represent detailed features
Nuclear Energy Unprecedented high-fidelity radiation transport calculations for nuclear energy applications
Biofuels Search for renewable and more efficient energy sources
Astrophysics Radiation transport – critical to astrophysics, laser fusion, atmospheric dynamics, and medical imaging

21
CPU versus GPU architecture

Low Latency or High Throughput? CPU
Optimised for low-latency
access to cached data sets
Control logic for out-of-order
and speculative execution
10’s of threads
GPU
Optimised for data-parallel,
throughput computation
Architecture tolerant of
memory latency
Massive fine grain threaded
parallelism
More transistors dedicated to
computation
10000’s of threads
Cache
ALU Control
ALU
ALU
ALU
DRAM
DRAM

GPU Architecture:
Two Main Components Global memory
Analogous to RAM in a CPU server
Accessible by both GPU and CPU
Currently up to 12 GB per GPU
Bandwidth currently up to ~288 GB/s (Tesla products)
ECC on/off (Quadro and Tesla products)
Streaming Multiprocessors (SMs)
Perform the actual computations
Each SM has its own:
Control units, registers, execution pipelines, caches
DR
AM
I/F
G
iga T
hre
ad
H
OS
T I
/F
DR
AM
I/F
DR
AM
I/F
DR
AM
I/F
DR
AM
I/F
DR
AM
I/F
L2

GPU Architecture
GPU L2
GPU DRAM
SM-0 SM-1 SM-N
SYSTEM
MEMORY

GPU Memory Hierarchy
L2
Global Memory
Registers
L1
SM-N
SMEM
Registers
L1
SM-0
SMEM
Registers
L1
SM-1
SMEM
~ 150 GB/S
~ 1 TB/S

Scientific Computing Challenge: Memory
Bandwidth
DR
AM
I/F
H
OS
T I
/F
Gig
a
Th
read
D
RA
M I
/F D
RA
M I/F
D
RA
M I/F
D
RA
M I/F
D
RA
M I/F
L2
NVIDIA
GPU
PCI-Express
6.4 GB/s
GPU Memory
177 GB/s
L2 Cache
280 GB/s
Register
10.8 TB/s
NVIDIA Technology Solves Memory Bandwidth Challenges
Shared Memory
1.3 TB/s

Kepler GK110 Block Diagram
Architecture
7.1B Transistors
15 SMX units
> 1 TFLOP FP64
1.5 MB L2 Cache
384-bit GDDR5

SM SM
SM
GPU SM Architecture
Functional Units = CUDA cores
192 SP FP operations/clock
64 DP FP operations/clock
Register file (256KB)
Shared memory (16-48KB)
L1 cache (16-48KB)
Read-only cache (48KB)
Constant cache (8KB)
Kepler SM
SM
Register
File
L1 Cache
Shared
Memory
Read-only
Cache
Constant
Cache
Functional
Units
Shared
Memory

SIMT Execution Model
Thread: sequential execution unit
All threads execute same sequential program
Threads execute in parallel
Thread Block: a group of threads
Threads within a block can cooperate
Light-weight synchronization
Data exchange
Grid: a collection of thread blocks
Thread blocks do not synchronize with each other
Communication between blocks is expensive
Thread
Thread Block
Grid

SIMT Execution Model Software Hardware
Threads are executed by CUDA Cores
Thread
CUDA
Core
Thread Block Multiprocessor
Thread blocks are executed on multiprocessors
Thread blocks do not migrate
Several concurrent thread blocks can reside on one
multiprocessor - limited by multiprocessor resources
(shared memory and register file)
Grid
A kernel is launched as a grid of thread blocks
Device

SIMT Execution Model
Threads are organized into groups of 32 threads called “warps”
All threads within a warp execute the same instruction simultaneously

Simple Processing Flow
1. Copy input data from CPU memory/NIC to
GPU memory
PCI Bus

Simple Processing Flow
1. Copy input data from CPU memory/NIC to
GPU memory
2. Load GPU program and execute
PCI Bus

Simple Processing Flow
1. Copy input data from CPU memory/NIC to
GPU memory
2. Load GPU program and execute
3. Copy results from GPU memory to CPU
memory/NIC
PCI Bus

Accelerator Fundamentals
We must expose enough parallelism to saturate the device
Accelerator threads are slower than CPU threads
Accelerators have orders of magnitude more threads
t0 t1 t2 t3
t4 t5 t6 t7
t8 t9 t10 t11
t12 t13 t14 t15
t0 t0 t0 t0
t1 t1 t1 t1
t2 t2 t2 t2
t3 t3 t3 t3
Fine-grained parallelism is good Coarse-grained parallelism is bad

Best Practices
Minimize data transfers between CPU and GPU
Optimize Data Locality: GPU
System Memory
GPU Memory

Best Practices
Minimize redundant accesses to L2 and DRAM
Store intermediate results in registers instead of global memory
Use shared memory for data frequently used within a thread block
Use const __restrict__ to take advantage of read-only cache
Optimize Data Locality: SM
SM
L2
Cache
GPU
DRAM

3 Ways to Accelerate Applications
Applications
Libraries
Easy to use
Most Performance
Programming
Languages
Most Performance
Most Flexibility
Easy to use
Portable code
Compiler
Directives

Resources
CUDA resource center:
http://docs.nvidia.com/cuda
GTC on-demand and webinars:
http://on-demand-gtc.gputechconf.com
http://www.gputechconf.com/gtc-webinars
Parallel Forall Blog:
http://devblogs.nvidia.com/parallelforall
Self-paced labs:
http://nvlabs.qwiklab.com
Learn more about GPUs

40
Accelerated COMPUTING Roadmap
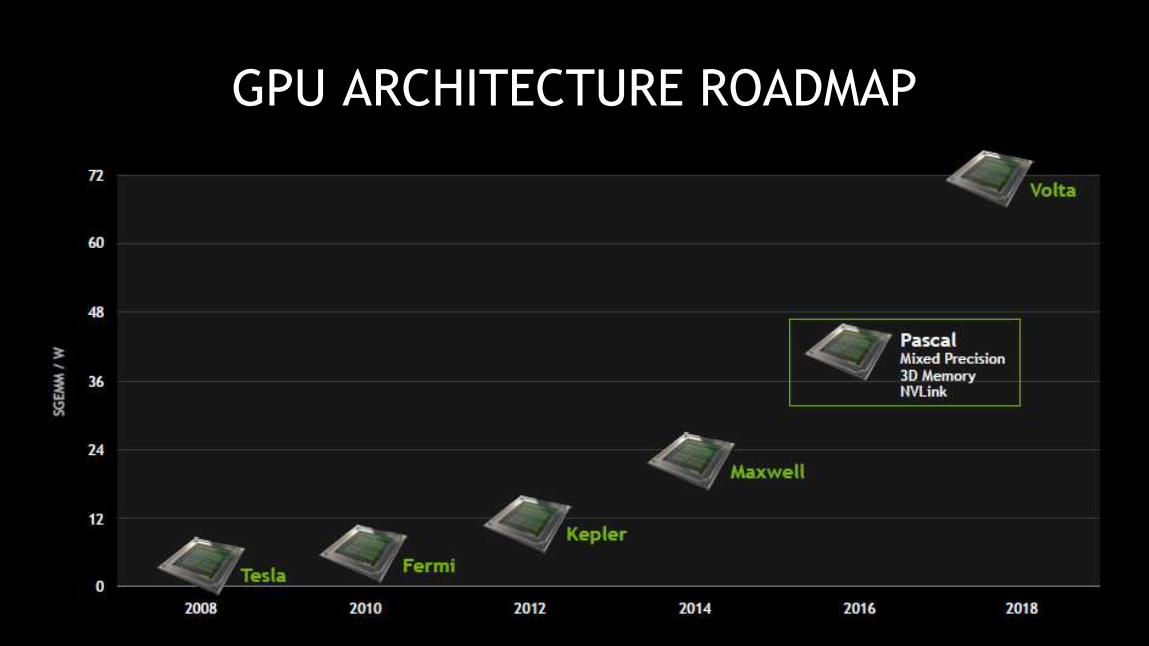
41
GPU ARCHITECTURE ROADMAP

TESLA ACCELERATES DISCOVERY AND INSIGHT
SIMULATION MACHINE LEARNING VISUALIZATION
TESLA ACCELERATED COMPUTING

A NEW PLATFORM FOR NEW WORKLOADS
MEDIA PROCESSING
MACHINE LEARNING
VIDEO TRANSCODING
DATA ANALYTICS
http://blogs.parc.com/blog/2015/11/the-new-kid-on-the-block-gpu-accelerated-big-data-analytics/

44
TESLA ACCELERATOR LINE-UP FOR 2015
K40
K10
K20X
K20
K80
K40
Best in Class Performance
Mid-Range
Seismic, Data Analytics, HPC Labs, Defense
Multi-GPU Accelerated Apps
Single and Double Precision Workloads
Higher Ed, Data Analytics, HPC Labs, Defense
Double Precision Workloads
2015

45
TESLA K40
TESLA KEPLER GPU PRODUCT FAMILY TESLA K80
24 GB 480 GB/sec 12 GB 288 GB/sec

5x Faster AMBER Performance
Dual CPU Server
TESLA K80 Simulation Time from to 1 Week
World’s Fastest Accelerator Tesla K80 Server
for HPC 0 5 10 15
# of Days
20 25 30
AMBER Benchmark: PME-JAC-NVE Simulation for 1 microsecond CPU: E5-2698v3 @ 2.3GHz. 64GB System Memory, CentOS 6.2
CUDA Cores
Peak DP
Peak DP w/ Boost
GDDR5 Memory
Bandwidth
Power
2496
1.9 TFLOPS
2.9 TFLOPS
24 GB
480 GB/s
300 W
1 Month
to 1 We

TESLA K80 BOOSTS DATA CENTER THROUGHPUT
CPU: Dual E5-2698 [email protected] 3.6GHz, 64GB System Memory, CentOS 6.2 GPU: Single Tesla K80, Boost enabled
TESLA K80: 5X FASTER 1/3 OF NODES ACCELERATED, 2X SYSTEM THROUGHPUT
Speed-up vs Dual CPU CPU-only System Accelerated System 15x
K80 CPU
10x
5x
0x QMCPACK LAMMPS CHROMA NAMD AMBER 100 Jobs Per Day 220 Jobs Per Day

QUESTIONS ?