introduction to ncbi & ensembl tools including blast and database searching incorporating...
TRANSCRIPT

Introduction to NCBI & Ensembl tools including BLAST and database
searching
Incorporating Bioinformatics into the High School Biology Curriculum
Fran Lewitter, Ph.D.Director, Bioinformatics & Research ComputingWhitehead Institute for Biomedical ResearchLewitter AT wi.mit.eduhttp://jura.wi.mit.edu/bio

Lewitter-Whitehead Institute – August 15, 2012
What I hope you’ll learn
• What do we learn from database searching and sequence alignments
• What tools are available at NCBI• What tools are available through
Ensembl2

First some background info
Lewitter-Whitehead Institute – August 15, 2012 3

4Lewitter-Whitehead Institute – August 15, 2012

Lewitter-Whitehead Institute – August 15, 2012
Doolittle RF, Hunkapiller MW, Hood LE, Devare SG, Robbins KC, Aaronson SA, Antoniades
HN. Science 221:275-277, 1983.
Simian sarcoma virus onc gene, v-sis, is derived from the gene (or genes) encoding a platelet-derived
growth factor.
5

Lewitter-Whitehead Institute – August 15, 2012
Why do alignments
• Use sequence similarity to infer homology and/or structural similarity between 2 or more genes/proteins
• Identify more conserved regions of a protein, potentially identifying regions of most functional importance
• Compare and contrast homologs (perhaps into groups) based on shared positions or regions
• Infer evolutionary distance from sequence dissimilarity
6

Lewitter-Whitehead Institute – August 15, 2012
Evolutionary Basis of Sequence Alignment
• Similarity - observable quantity, such as percent identity
• Homology - conclusion drawn from data that two genes share a common evolutionary history; no metric is associated with this– Paralog – genes related by duplication– Ortholog – genes related by speciation
7

Lewitter-Whitehead Institute – August 15, 2012
Local vs Global Alignment
From Mount, Bioinformatics, 2004, pg 71
GLOBAL
LOCAL
8

Nucleotide vs Protein
• If comparing protein coding genes, use protein sequences because of less noise
• If protein sequences are very similar, it might be more instructive to use DNA sequences
Lewitter-Whitehead Institute – August 15, 2012 9

Lewitter-Whitehead Institute – August 15, 2012
Example of simple scoring system for nucleic acids
• Match = +1 (ex. A-A, T-T, C-C, G-G)• Mismatch = -1 (ex. A-T, A-C, etc)• Gap opening = - 5• Gap extension = -2
T C A G A C G A G T GT C G G A - - G C T G
+1 +1 -1 +1 +1 -5 -2 -1 -1 +1 +1 = -4
10
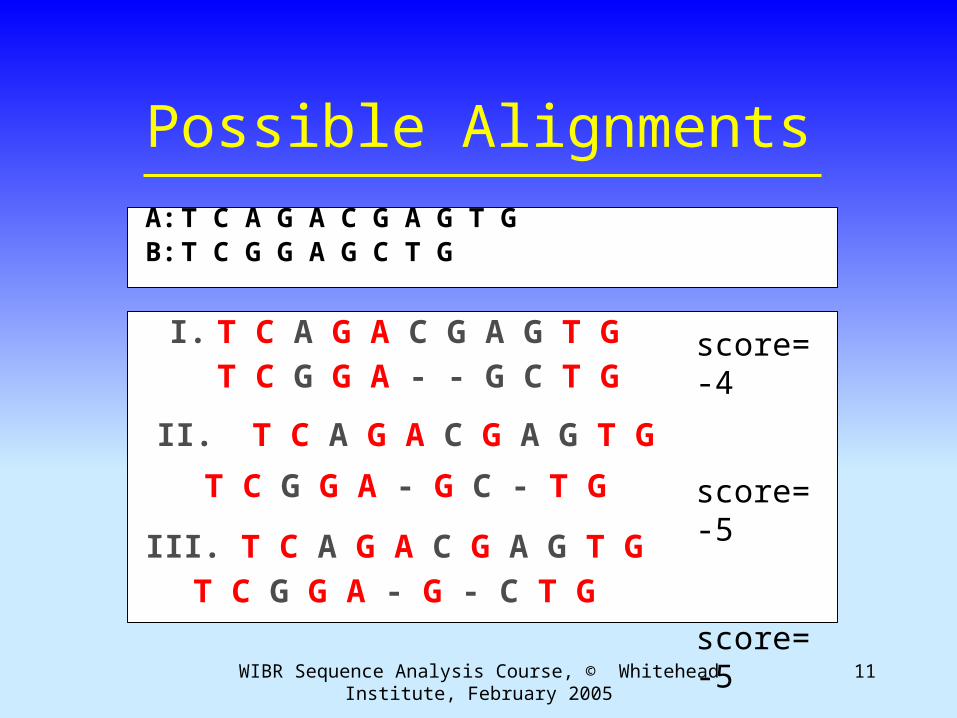
11WIBR Sequence Analysis Course, © Whitehead Institute, February 2005
Possible AlignmentsA:T C A G A C G A G T GB:T C G G A G C T G
I. T C A G A C G A G T GT C G G A - - G C T G
II. T C A G A C G A G T G
T C G G A - G C - T G
III. T C A G A C G A G T GT C G G A - G - C T G
score=-4
score=-5
score=-5

Lewitter-Whitehead Institute – August 15, 2012
Scoring for Protein Alignments - Amino Acid
Substitution Matrices
• PAM - point accepted mutation based on global alignment [evolutionary model]
• BLOSUM - block substitutions based on local alignments [similarity among conserved sequences]
12

Lewitter-Whitehead Institute – August 15, 2012
AA Scoring Matrices
• PAM - point accepted mutation based on global alignment [evolutionary model]
• BLOSUM - block substitutions based on local alignments [similarity among conserved sequences]
Log-odds= pair in homologous proteins
pair in unrelated proteins by chance
Log-odds= obs freq of aa substitutions
freq expected by chance
13

Lewitter-Whitehead Institute – August 15, 2012
Substitution Matrices
BLOSUM 30
BLOSUM 62
BLOSUM 80
% identity
PAM 250 (80)
PAM 120 (66)
PAM 90 (50)
% change
Increasing
similarity
14

Lewitter-Whitehead Institute – August 15, 2012
Scoring for BLAST AlignmentsScore = 94.0 bits (230), Expect = 6e-19Identities = 45/101 (44%), Positives = 54/101 (52%), Gaps = 7/101 (6%)
Query: 204 YTGPFCDV----DTKASCYDGRGLSYRGLARTTLSGAPCQPWASEATYRNVTAEQ---AR 256 Y+ FC + + CY G G +YRG T SGA C PW S V Q A+Sbjct: 198 YSSEFCSTPACSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQ 257
Query: 257 NWGLGGHAFCRNPDNDIRPWCFVLNRDRLSWEYCDLAQCQT 297 GLG H +CRNPD D +PWC VL RL+WEYCD+ C TSbjct: 258 ALGLGKHNYCRNPDGDAKPWCHVLKNRRLTWEYCDVPSCST 298
Position 1: Y - Y = 7Position 2: T - S = 1Position 3: G - S = 0Position 4: P - E = -1 . . .Position 9: - - P = -11Position 10: - - A = -1
. . . Sum 230
Based on BLOSUM62
15

Lewitter-Whitehead Institute – August 15, 2012
Statistical Significance
• Raw Scores - score of an alignment equal to the sum of substitution and gap scores.
• Bit scores - scaled version of an alignment’s raw score that accounts for the statistical properties of the scoring system used.
• E-value - expected number of distinct alignments that would achieve a given score by chance. Lower E-value => more significant.
16

Lewitter-Whitehead Institute – August 15, 2012
A formulaE = Kmn e-lS
This is the Expected number of high-scoring segment pairs (HSPs) with score at least S
for sequences of length m and n.
This is the E value for the score S.
The parameters K and l can be thought of simply as natural scales for the search space size and the scoring system respectively.
17

What’s significant?
• High confidence - >40% identity for long alignments (Rost, 1999 found that sequence alignments unambiguously distinguish between protein pairs of similar and non-similar structure when the pairwise sequence identity >40%)
• “Twilight zone” – blurry - 20-35% identity• “Midnight zone” - <20% identity
Lewitter-Whitehead Institute – August 15, 2012 18

Tools of Interest
• NCBI (US) - http://www.ncbi.nlm.nih.gov/– BLAST– Entrez
• EBI/EMBL/WTSI (Europe)– Ensembl (http://www.ensembl.org/)
Lewitter-Whitehead Institute – August 15, 2012 19

Lewitter-Whitehead Institute – August 15, 2012
NCBI Home Page
20

Lewitter-Whitehead Institute – August 15, 2012
Ensembl Home Page
21

Hands-On
• Entrez – finding sequences• BLAST – look for similar sequences• Ensembl – finding sequences
Lewitter-Whitehead Institute – August 15, 2012 22

How is BLAST used @ WIBR?
• Looking for homologs• Identifying domains in proteins• Peptide identification• Genome annotation
Lewitter-Whitehead Institute – August 15, 2012 23

Lewitter-Whitehead Institute – August 15, 2012
Remember
1. Don’t be afraid to look at help pages for each website• Click, click, click
2. Any analysis tool will give you results
3. Interpret results you find
24

Lewitter-Whitehead Institute – August 15, 2012
Sequence of Note
1 GCGTTGCTGG CGTTTTTCCA TAGGCTCCGC
31 CCCCCTGACG AGCATCACAA AAATCGACGC
61 GGTGGCGAAA CCCGACAGGA CTATAAAGAT
…………..
1371 GTAAAGTCTG GAAACGCGGA AGTCAGCGCC
“Here you see the actual structure of a small fragment of dinosaur DNA,” Wu said. “Notice the sequence is made up of four compounds - adenine, guanine, thymine and cytosine. This amount of DNA probably contains instructions to make a single protein - say, a hormone or an enzyme. The full DNA molecule contains three billion of these bases. If we looked at a screen like this once a second, for eight hours a day, it’d still take more than two years to look at the entire DNA strand. It’s that big.” (page 103)
(Published in 1990)
Biotechniques, 1992
25

Lewitter-Whitehead Institute – August 15, 2012
DinoDNA "Dinosaur DNA" from Crichton's THE LOST WORLD p. 135
GAATTCCGGAAGCGAGCAAGAGATAAGTCCTGGCATCAGATACAGTTGGAGATAAGGACGACGTGTGGCAGCTCCCGCAGAGGATTCACTGGAAGTGCATTACCTATCCCATGGGAGCCATGGAGTTCGTGGCGCTGGGGGGGCCGGATGCGGGCTCCCCCACTCCGTTCCCTGATGAAGCCGGAGCCTTCCTGGGGCTGGGGGGGGGCGAGAGGACGGAGGCGGGGGGGCTGCTGGCCTCCTACCCCCCCTCAGGCCGCGTGTCCCTGGTGCCGTGGCAGACACGGGTACTTTGGGGACCCCCCAGTGGGTGCCGCCCGCCACCCAAATGGAGCCCCCCCACTACCTGGAGCTGCTGCAACCCCCCCGGGGCAGCCCCCCCCATCCCTCCTCCGGGCCCCTACTGCCACTCAGCAGCGCCTGCGGCCTCTACTACAAAC……
Published in 199526

Lewitter-Whitehead Institute – August 15, 2012
>Erythroid transcription factor (NF-E1 DNA-binding protein)
Query: 121 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLG 300 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLGSbjct: 1 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLG 60
Query: 301 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECVMARKNCGAT 480 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECV NCGATSbjct: 61 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECV----NCGAT 116
Query: 481 ATPLWRRDGTGHYLCNWASACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCSHERENCQT 660 ATPLWRRDGTGHYLCN ACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCS NCQTSbjct: 117 ATPLWRRDGTGHYLCN---ACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCS----NCQT 169
Query: 661 STTTLWRRSPMGDPVCNNIHACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPG 840 STTTLWRRSPMGDPVCN ACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPG Sbjct: 170 STTTLWRRSPMGDPVCN---ACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPG 226
Query: 841 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGF 1020 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGF Sbjct: 227 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGF 286
Query: 1021 FGGGAGGYTAPPGLSPQI 1074 FGGGAGGYTAPPGLSPQISbjct: 287 FGGGAGGYTAPPGLSPQI 304
27

Lewitter-Whitehead Institute – August 15, 2012
>Erythroid transcription factor (NF-E1 DNA-binding protein)
Query: 121 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLG 300 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLGSbjct: 1 MEFVALGGPDAGSPTPFPDEAGAFLGLGGGERTEAGGLLASYPPSGRVSLVPWADTGTLG 60
Query: 301 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECVMARKNCGAT 480 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECV NCGATSbjct: 61 TPQWVPPATQMEPPHYLELLQPPRGSPPHPSSGPLLPLSSGPPPCEARECV----NCGAT 116
Query: 481 ATPLWRRDGTGHYLCNWASACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCSHERENCQT 660 ATPLWRRDGTGHYLCN ACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCS NCQTSbjct: 117 ATPLWRRDGTGHYLCN---ACGLYHRLNGQNRPLIRPKKRLLVSKRAGTVCS----NCQT 169
Query: 661 STTTLWRRSPMGDPVCNNIHACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPG 840 STTTLWRRSPMGDPVCN ACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPGSbjct: 170 STTTLWRRSPMGDPVCN---ACGLYYKLHQVNRPLTMRKDGIQTRNRKVSSKGKKRRPPG 226
Query: 841 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGF 1020 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGFSbjct: 227 GGNPSATAGGGAPMGGGGDPSMPPPPPPPAAAPPQSDALYALGPVVLSGHFLPFGNSGGF 286
Query: 1021 FGGGAGGYTAPPGLSPQI 1074 FGGGAGGYTAPPGLSPQISbjct: 287 FGGGAGGYTAPPGLSPQI 304
28