is 4800 empirical research methods for information science class notes february 15, 2012 instructor:...
TRANSCRIPT

IS 4800 Empirical Research Methods for Information Science
Class Notes February 15, 2012
Instructor: Prof. Carole Hafner, 446 [email protected] Tel: 617-373-5116
Course Web site: www.ccs.neu.edu/course/is4800sp12/

Outline
■ Review/finish reliability and validity techniques for composite measures
■ Sampling and volunteer bias

3
Validating a Composite Measure

4
What is a validated measure?
■ Has reliability
■ Has validity
■ For psychological measures, these are collectively referred to as a measure’s “psychometrics”.

5
Measure Reliability
■ A reliable measure produces similar results when repeated measurements are made under identical conditions
■ Reliability can be established in several ways• Test-retest reliability: Administer the same
test twice• Parallel-forms reliability: Alternate forms of
the same test used• Split-half reliability: Parallel forms are
included on one test and later separated for comparison

6
Reliability
■ For surveys, this also encompasses internal consistency: ■ Do all of the questions address the same
underlying construct of interest?■ That is, do scores covary?■ A standard measure is Cronbach’s alpha
• 0 = no correlation• 1 = scores always covary in the same way• 0.7 used as conventional threshold

Correlation coefficient■ A measure of association between two numeric
variables X and Y (Pearson’s R)
■ When will R be positive ?■ When Xi and Yi are both larger than the mean
■ When Xi and Yi are both smaller than the mean
■ Represents a general tendency for X and Y to vary in the same way
■ Normalized to range from -1 to +1

Interpreting the correlation coefficient
■ -1.0 to -0.7 strong negative association.
■ -0.7 to -0.3 weak negative association.
■ -0.3 to +0.3 little or no association.
■ +0.3 to +0.7 weak positive association.
■ +0.7 to +1.0 strong positive association.

Cronback’s Alpha
■ A test for composite measure reliability
■ K = the number of test items
■ r is the mean of K(K-1) non-redundant correlation coefficients
■ Can take on negative numbers but they are not meaningful
■ Therefore considered to run from 0 to 1

10
Increasing the Reliability of a Questionnaire
■ Check to be sure the items on your questionnaire are clearly written and appropriate for those who will complete your questionnaire
■ Increase the number of items on your questionnaire
■ Standardize the conditions under which the test is administered (e.g., timing procedures, lighting, ventilation, instructions)
■ Make sure you score your questionnaire carefully, eliminating scoring errors

11
Measure Validity
– A valid measure measures what you intend it to measure
– Very important when using psychological tests (e.g., intelligence, aptitude, (un)favorable attitude)
– Validity can be established in a variety of ways• Face validity: Is a measure clearly related to the
construct. Least powerful method.• Content validity: How adequately does a
measure sample the full range of behavior it is intended to measure?

12
■ The degree to which a measure corresponds to what happens in the real world.
■ Example:■ Assessing productivity/day in the lab vs.■ Assessing productivity/day in the office
Ecological Validity

13
• Criterion-related validity: How adequately does a test score match some criterion score? Takes two forms
–Concurrent validity: Does test score correlate highly with score from a measure with known validity?
–Predictive validity: Does test predict behavior known to be associated with the behavior being measured?
Measure Validity

14
• Construct validity: Do the results of a test correlate with what is theoretically known about the construct being evaluated?
– Convergent validity (subtype): measures of constructs that should be related to each other are related. (conservative, religious ??)
– Discriminant validity (subtype): measures of constructs that should not be related are not
Measure Validity

15
Example
Seniority
MonitorSize Productivity
■ Assume we have good evidence for this model of the world..
■ We now propose a new measure for Productivity■ What would be evidence for convergent validity?■ What would be evidence for discriminant validity?

16
More Concerns with Measures
■ Sensitivity■ Is a dependent measure sensitive enough to detect behavior
change?
■ An insensitive measure will not detect subtle behaviors
■ Range Effects■ Occur when a dependent measure has an upper or lower limit
• Ceiling effect: When a dependent measure has an upper limit
• Floor effect: When a dependent measure has a lower limit.

17
Example
■ You want to assess the effect of TV viewing on whether people like large computer monitors or not (yes/no).
■ You run an experiment in which participants are randomized to watch either 2 hrs or 0 hrs of TV per day for a week, then answer your question.
■ What’s going on?
Participant Condition LikesLargeMonitors1 TV Yes2 No TV Yes3 TV Yes4 No TV Yes
18
Developing a New Measure
■ Say you decide you need a new survey measure, “attitude towards large computer monitors” (ATLCM)■ I like big monitors.■ Big monitors make me nervous.■ I prefer small monitors, even if they cost more.■ 7-pt Likert scales
■ How would you validate this measure?

19
Example
■ You want to assess the effect of TV viewing on attitude towards large computer monitors (ATLCM).
■ You run an experiment in which participants are randomized to watch either 2 hrs or 0 hrs of TV per day for a week, then fill out the ATLCM.
■ What’s going on?
Participant Condition ATLCM1 TV 7.02 No TV 6.73 TV 6.94 No TV 7.0

20
Validation - Summary■ Reliability
■ Test-retest/parallel forms/split-half■ Internal consistency
■ Validity■ Face■ Content■ Criterion-related
• Concurrent• Predictive
■ Construct• Convergent• Discriminant

21
Sampling
■ Sometimes you really can measure the entire population (e.g., workgroup, company), but this is rare…
■ “Convenience sample”■ Cases are selected only on the basis of feasibility
or ease of data collection.

22
Acquiring A Survey Sample
■ You should obtain a representative sample■ The sample closely matches the characteristics of the
population
■ A biased sample occurs when your sample characteristics don’t match population characteristics■ Biased samples often produce misleading or inaccurate
results
■ Usually stem from inadequate sampling procedures
■ Convenience samples are not representative – they are subject to “volunteer bias” !!

Volunteer Bias
How can it affect external validity?
Characteristics of volunteers?
How do you address volunteer bias?

Characteristics of Individuals Who Volunteer for Research
Maximum Confidence1. tend to be more highly educated than nonvolunteers
2. tend to come from a higher social class than nonvolunteers
3. are of a higher intelligence in general, but not when volunteers for atypical research (such as hypnosis, sex research)
4. have a higher need for approval than nonvolunteers
5. are more social than nonvolunteers

Considerable Confidence
1. Volunteers are more “arousal seeking” than nonvolunteers (especially when the research involves stress)
2. Individuals who volunteer for sex research are more unconventional than nonvolunteers
3. Females are more likely to volunteer than males, except when the research involves physical or emotional stress
4. Volunteers are less authoritarian than nonvolunteers
5. Jews are more likely to volunteer than Protestants; however, Protestants are more likely to volunteer than Catholics
6. Volunteers have a tendency to be less conforming than nonvolunteers, except when the volunteers are female and the research is clinically oriented
Source: Adapted from Rosenthal & Rosnow, 1975.

Remedies for Volunteer Bias
Make your appeal very interesting Make your appeal as nonthreatening as possible Explicitly state the theoretical and practical
importance of your research Explicitly state why the target population is relevant to
your research Offer a small reward for participation

Have a high-status person make the appeal for participants
Avoid research that is physically or psychologically stressful
Have someone known to participants make the appeal
Use public or private commitment to volunteering when appropriate
Remedies for Volunteer Bias (cont.)

28
■ Simple Random Sampling■ Randomly select a sample from the population
■ Random digit dialing is a variant used with telephone surveys
■ Reduces systematic bias, but does not guarantee a representative sample
• Some segments of the population may be over- or underrepresented
Scientific Sampling Techniques

29
Scientific Sampling Techniques
■ Systematic Sampling■ Every kth element is sampled after a randomly
selected starting point• Sample every fifth name in the telephone book after
a random page and starting point selected, for example
■ Empirically equivalent to random sampling (usually)
• May still result in a non-representative sample
■ Easier than random sampling

30
■ Stratified Sampling■ Used to obtain a representative sample
■ Population is divided into (demographic) strata• Focus also on variables that are related to other variables of interest in your
study (e.g., relationship between age and computer literacy)
■ A random sample of a fixed size is drawn from each stratum
■ May still lead to over- or underrepresentation of certain segments of the population
■ Proportionate Sampling■ Same as stratified sampling except that the proportions of different
groups in the population are reflected in the samples from the strata
Scientific Sampling Techniques

31
Sampling Example:
■ You want to conduct a survey of job satisfaction of all employees but can only afford to contact 100 of them.
■ Personnel breakdown:■ 50% Engineering■ 25% Sales & Marketing■ 15% Admin■ 10% Management
■ Examples of■ Stratified sampling?■ Proportionate sampling?

32
■ Cluster Sampling■ Used when populations are very large■ The unit of sampling is a group (e.g., a class in a
school) rather than individuals■ Groups are randomly sampled from the population
(e.g., ten classes from a particular school)
Sampling Techniques

33
■ Multistage Sampling■ Variant of cluster sampling
■ First, identify large clusters (e.g., school districts) and randomly sample from that population
■ Second, sample individuals from randomly selected clusters
■ Can be used along with stratified sampling to ensure a representative sample
Scientific Sampling Techniques

Sampling and Statistics
■ If you select a random sample, the mean of that sample will (in general) not be exactly the same as the population mean. However, it represents an estimate of the population mean
■ If you take two samples, one of males and one of females, and compute the two sample means (let’s say, of hourly pay), the difference between these is an estimate of the difference between the population means.
■ This is the basis of inferential statistics based on samples

Sampling and Statistics (cont.)
■ If larger the sample, the better estimate (more likely it is close to the population mean)
■ The variance/SD of the sample means is related to the variance/SD of the population. However, it is likely to be LESS (!) than the population variance.

June 9, 2008 3636
Inference with a Single Observation
• Each observation Xi in a random sample is a representative of unobserved variables in population
• How different would this observation be if we took a different random sample?
Population
Observation Xi
Parameter:
Sampling Inference
?

June 9, 2008 37
Normal Distribution• The normal distribution is a model for our overall
population• Can calculate the probability of getting observations
greater than or less than any value
• Usually don’t have a single observation, but instead the mean of a set of observations

June 9, 2008 38
Inference with Sample Mean
• Sample mean is our estimate of population mean
• How much would the sample mean change if we took a different sample?
• Key to this question: Sampling Distribution of x
Population
Sample
Parameter:
Statistic: x
Sampling Inference
Estimation
?

June 9, 2008 39
Sampling Distribution of Sample Mean
• Distribution of values taken by statistic in all possible samples of size n from the same population
• Model assumption: our observations xi are sampled from a population with mean and variance 2
Population
UnknownParameter:
Sample 1 of size n xSample 2 of size n xSample 3 of size n xSample 4 of size n xSample 5 of size n xSample 6 of size n xSample 7 of size n xSample 8 of size n x .
. .
Distributionof thesevalues?

June 9, 2008 40
Mean of Sample Mean
• First, we examine the center of the sampling distribution of the sample mean.
• Center of the sampling distribution of the sample mean is the unknown population mean:
mean( X ) = μ
• Over repeated samples, the sample mean will, on average, be equal to the population mean
– no guarantees for any one sample!

June 9, 2008 41
Variance of Sample Mean• Next, we examine the spread of the sampling distribution
of the sample mean
• The variance of the sampling distribution of the sample mean is
variance( X ) = 2/n
• As sample size increases, variance of the sample mean decreases! • Averaging over many observations is more accurate than just
looking at one or two observations

June 9, 2008 42
• Comparing the sampling distribution of the sample mean when n = 1 vs. n = 10
June 9, 2008 43
Law of Large Numbers
• Remember the Law of Large Numbers:• If one draws independent samples from a population
with mean μ, then as the sample size (n) increases, the sample mean x gets closer and closer to the population mean μ
• This is easier to see now since we know that
mean(x) = μ
variance(x) = 2/n 0 as n gets large

June 9, 2008 44
Example• Population: seasonal home-run totals for 7032
baseball players from 1901 to 1996• Take different samples from this population and
compare the sample mean we get each time
• In real life, we can’t do this because we don’t usually have the entire population!
Sample Size Mean Variance
100 samples of size n = 1 3.69 46.8
100 samples of size n = 10 4.43 4.43
100 samples of size n = 100 4.42 0.43
100 samples of size n = 1000 4.42 0.06
Population Parameter = 4.42

June 9, 2008 45
Distribution of Sample Mean
• We now know the center and spread of the sampling distribution for the sample mean.
• What about the shape of the distribution?
• If our data x1,x2,…, xn follow a Normal distribution, then the sample mean x will also follow a Normal distribution!

June 9, 2008 46
Example
• Mortality in US cities (deaths/100,000 people)
• This variable seems to approximately follow a Normal distribution, so the sample mean will also approximately follow a Normal distribution

June 9, 2008 47
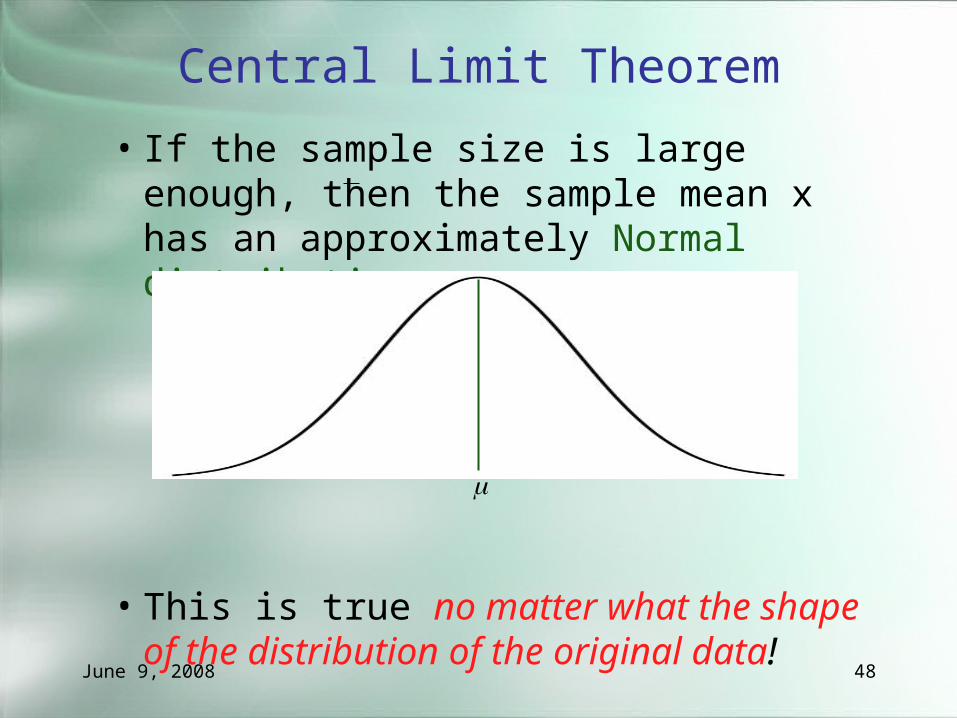
Central Limit Theorem
• What if the original data doesn’t follow a Normal distribution?
• HR/Season for sample of baseball players
• If the sample is large enough, it doesn’t matter!
June 9, 2008 48
Central Limit Theorem
• If the sample size is large enough, then the sample mean x has an approximately Normal distribution
• This is true no matter what the shape of the distribution of the original data!

June 9, 2008 49
Example: Home Runs per Season
• Take many different samples from the seasonal HR totals for a population of 7032 players
• Calculate sample mean for each sample
n = 1
n = 10
n = 100