jhu mt class: probability and language models
TRANSCRIPT

Homework 1
•Already posted at http://mt-class.org/jhu
•Implementation due February 17 at 6pm.
•Writeup due February 18 in class.
•You must turn in: results, code, and writeup.

Probability and Language

Goal
•Write down a model over sentence pairs.
•Learn an instance of the model from data.
•Use it to predict translations of new sentences.

Why probability?
•Formalizes...
•the concept of models
•the concept of data
•the concept of learning
•the concept of inference (prediction)
•Derive logical conclusions in the face of ambiguity.

Basic Concepts•Sample space S: set of all possible outcomes.
•Event space F: any subset of the sample space.
•Random variable: function from S to a set of disjoint events in S.
•Probability measure P: a function from events to positive real numbers satisfying these axioms:
1.
2.
3.
∀E ∈ F, P (E) ≥ 0
P (S) = 1
∀E1, ..., Ek :k�
i=1
Ei = ∅ ⇒ P (E1 ∪ ... ∪ Ek) =k�
i=1
Pi

Writing a model
•There are many, many ways to specify a model.
•We will focus mostly on categorical distributions: measures over a finite set of discrete outcomes.
•Implementation: write down a table from outcomes to numbers.

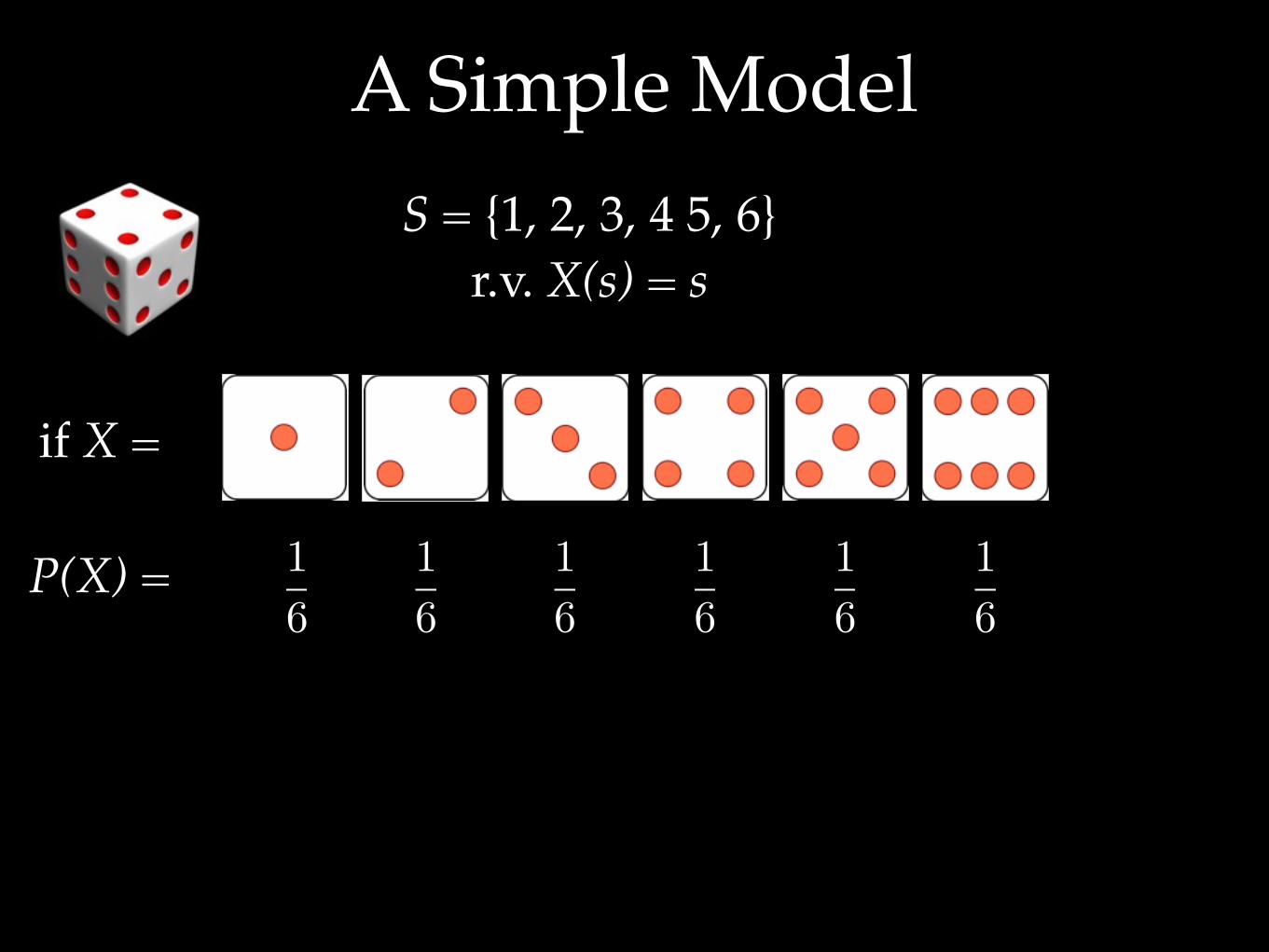
A Simple ModelS = {1, 2, 3, 4 5, 6}
r.v. X(s) = s
P(X) =
if X =

A Simple ModelS = {1, 2, 3, 4 5, 6}
r.v. X(s) = s
P(X) =
if X =
A Simple Model
16
16
16
16
16
16
S = {1, 2, 3, 4 5, 6}r.v. X(s) = s
P(X) =
if X =

A Simple Model
16
16
16
16
16
16
Axioms satisfied.
S = {1, 2, 3, 4 5, 6}r.v. X(s) = s
P(X) =
if X =

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
X, Y
S = {1, 2, 3, 4 5, 6}2
r.v. X(x,y) = x, Y(x,y) = y

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
X, Y
A measure over multiple events is a joint probability.

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(X = 1, Y = 1) =136

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(1, 1) =136

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
A probability distribution over a subset of variables is a marginal probability.

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(Y = 1) =�
x∈X
p(X = x, Y = 1) =16Axiom 3

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
p(X = 1) =�
y∈Y
p(X = 1, Y = y) =16

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
The probability of a r.v. when the when the values of the other r.v.’s are known is its conditional probability.

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
P (Y = 1|X = 1) =P (X = 1, Y = 1)�
y∈Y P (X = 1, Y = y)=
16

Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
joint marginal
P (Y = 1|X = 1) =P (X = 1, Y = 1)�
y∈Y P (X = 1, Y = y)=
16
Probabilistic Primer136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
136136136136136136
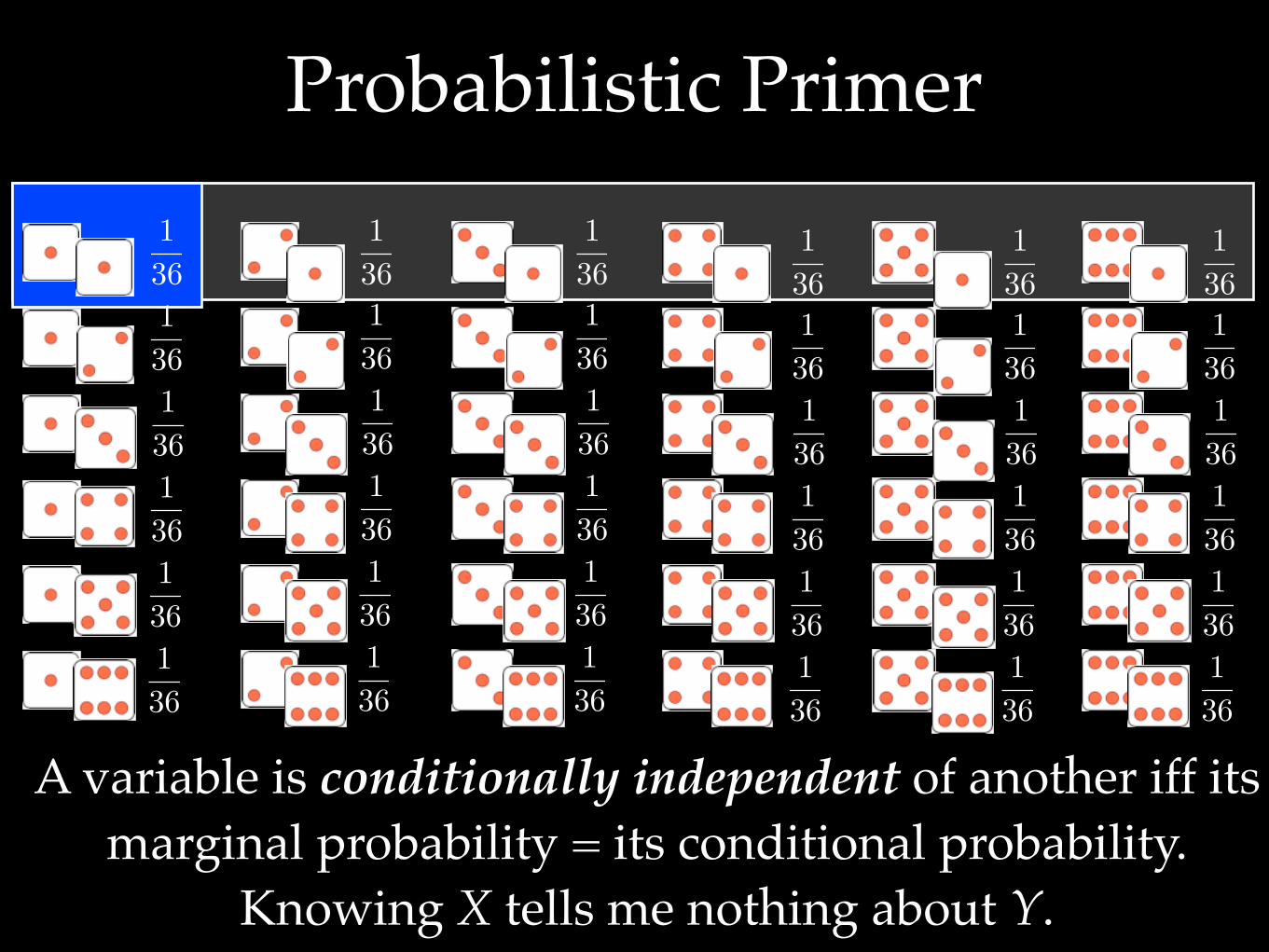
A variable is conditionally independent of another iff its marginal probability = its conditional probability.
Knowing X tells me nothing about Y.

Practical benefit of independence
16
16
16
16
16
16
P(X) =
if X =
16
16
16
16
16
16
P(Y) =
if Y =
P(X,Y) = P(X)P(Y)Far fewer parameters!

Probabilistic Primer
Under this distribution, temperature and weather r.v.’s are not conditionally independent!
70°F60°F50°F40°F30°F20°F
70°F60°F50°F40°F30°F20°F
000
.003.01.03
.2.25.2
.147.09.07
p(snow| 20°F) = .30 p(snow) = .043

Probabilistic Primer
p(A, B) = p(A) · p(B|A)
Chain rule:

Probabilistic Primer
p(A, B) = p(A) · p(B|A)

Probabilistic Primer
p(A, B) = p(A) · p(B|A) = p(B) · p(A|B)

Probabilistic Primer
p(A) · p(B|A) = p(B) · p(A|B)

Probabilistic Primer
p(B|A) =p(B) · p(A|B)
p(A)

Probabilistic Primer
p(B|A) =p(B) · p(A|B)
p(A)Bayes’ Rule

Probabilistic Primer
p(B|A) =p(B) · p(A|B)
p(A)Bayes’ Rule
prior likelihoodposterior
evidence

...But the probability that an event has happened is the same as the probability I
have to guess right if I guess it has happened. Wherefore the following
proposition is evident: If there be two subsequent events, the probability of the 2d b/N and the probability both together P/N, and it being 1st discovered that the
2d event has also happened, the probability I am right is P/b.
Thomas Bayes

...But the probability that an event has happened is the same as the probability I
have to guess right if I guess it has happened. Wherefore the following
proposition is evident: If there be two subsequent events, the probability of the 2d b/N and the probability both together P/N, and it being 1st discovered that the
2d event has also happened, the probability I am right is P/b.
Thomas Bayes
(image by Chris Dyer)

Bayes’ Rulep(English)

configuration
Bayes’ Rulep(English)

configuration
Bayes’ Rulep(English)
p(image|English)

configuration
Bayes’ Rulep(English)
p(image|English)

Bayes’ Rule
p(DNA)

Bayes’ Rule
p(DNA)

Bayes’ Rule
p(DNA) p(mutation|DNA)

Bayes’ Rule
p(DNA) p(mutation|DNA)

Bayes’ Rulep(English)

However, the sky remained clear under the strong north wind .
Bayes’ Rulep(English)

However, the sky remained clear under the strong north wind .
Bayes’ Rulep(English)
p(Chinese|English)

However, the sky remained clear under the strong north wind .
Bayes’ Rulep(English)
虽然 北 风 呼啸 , 但 天空 依然 十分 清澈 。
p(Chinese|English)

When I look at an article in Russian, I say: “This
is really written in English, but it has been coded in some strange symbols. I will now proceed to decode.”
Warren Weaver (1949)


Claude Shannon
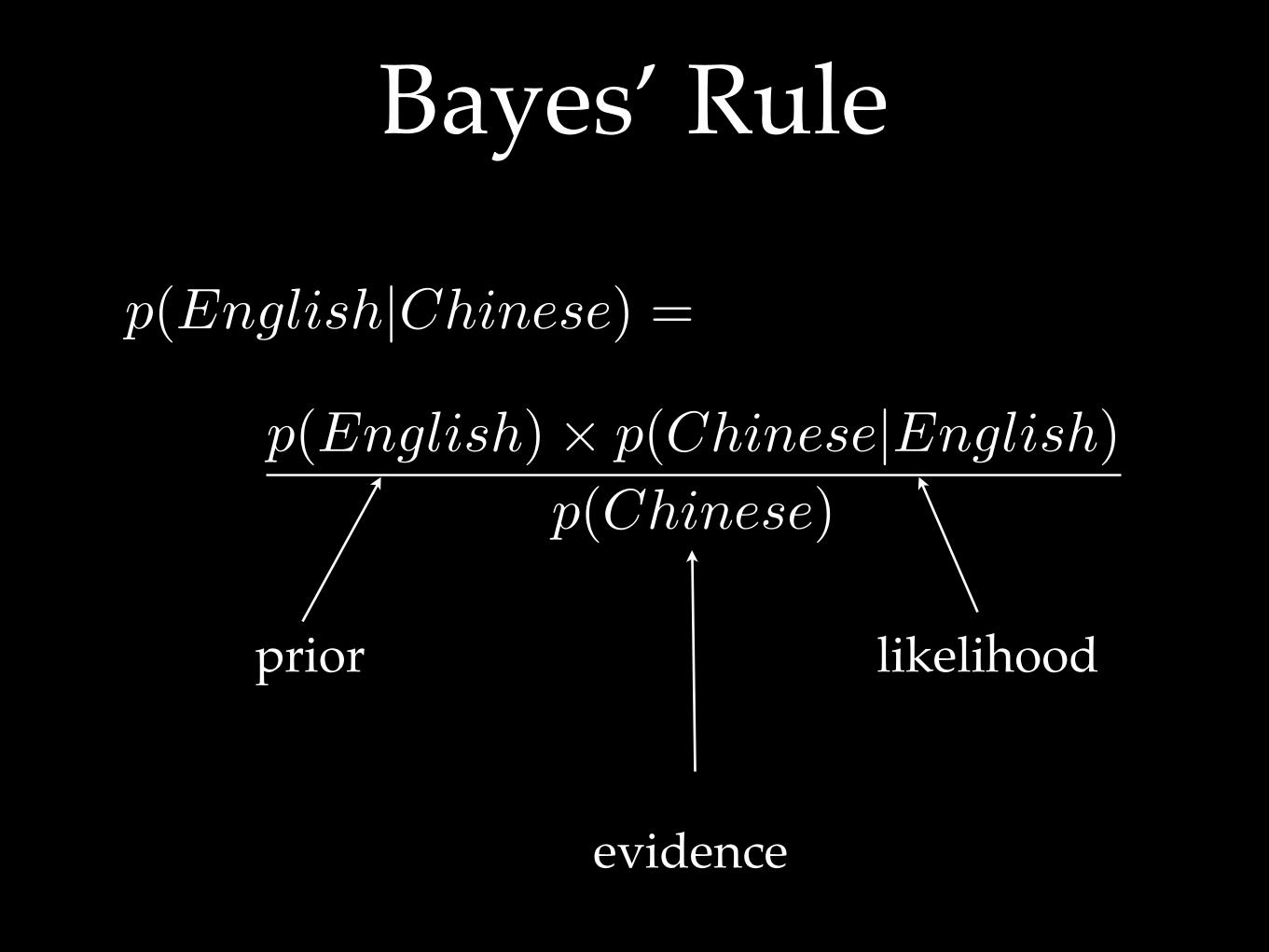
p(English|Chinese) =
p(English) ! p(Chinese|English)
p(Chinese)
likelihoodprior
evidence
Bayes’ Rule

p(English|Chinese) =
p(English) ! p(Chinese|English)
p(Chinese)
channel modelsignal model
normalization (ensures we’re working with valid probabilities).
Noisy Channel

p(English|Chinese) =
p(English) ! p(Chinese|English)
p(Chinese)
translation modellanguage model
normalization (ensures we’re working with valid probabilities).
Machine Translation

English
p(Chinese|English)

English
p(Chinese|English)
! p(English)

English
p(Chinese|English)
! p(English)
∼ p(English|Chinese)

p(English|Chinese) =
p(English) ! p(Chinese|English)
p(Chinese)
translation modellanguage model
evidence
Machine Translation

p(English|Chinese) !
p(English) ! p(Chinese|English)
Machine Translation
Questions our model must answer:

p(English|Chinese) !
p(English) ! p(Chinese|English)
Machine Translation
What is the probability of an English sentence?
Questions our model must answer:

p(English|Chinese) !
p(English) ! p(Chinese|English)
Machine Translation
What is the probability of an English sentence?
What is the probability of a Chinese sentence, given a particular English sentence?
Questions our model must answer:

Language Models
Our language model must assign a probability to every possible English sentence.

Language Models
Our language model must assign a probability to every possible English sentence.
Q: What should this model look like?

Language Models
Our language model must assign a probability to every possible English sentence.
Q: What should this model look like?
A: What is the dumbest thing you can think of?

Language Models
Assign every English sentence a non-zeroprobability.

Language Models
Assign every English sentence a non-zeroprobability.
Problem: there are an infinite number of sentences.

Language Models
Assign every English sentence a non-zeroprobability.
Problem: there are an infinite number of sentences.✘

Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)

Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)
= p(X0) p(X1|X0) .... p(Xk|X0...Xk-1) ....by chain rule:

Language Models
S = V*V = set of all English words
Define an infinite set of events:Xi(s) = ith word in s if len(s)≥i, ε otherwise.
Must define: p(X0...X∞)
= p(X0) p(X1|X0) .... p(Xk|X0...Xk-1) ....by chain rule:
= p(X0) p(X1|X0) .... p(Xk|Xk-1) ....assume conditional independence:

Language Models
Key idea: since the language model is a joint model over all words in a sentence, makewords depend on n previous words in the
sentence.

p(However|START )
Language Models

p(However|START )
Language Models
A number between 0 and 1.

p(However|START )
Language Models
A number between 0 and 1.�
x
p(x|START ) = 1

However
p(However|START )
Language Models

However ,
p(, |However)
Language Models

However , the
p(the|, )
Language Models

However , the sky
p(sky|the)
Language Models

However , the sky remained
Language Models
p(remained|sky)

However , the sky remained clear
Language Models
p(clear|remained)

However , the sky remained clear ... wind .
Language Models
p(STOP |.)...

p(English) =
length(English)!
i=1
p(wordi|wordi!1)
Language Models

p(English) =
length(English)!
i=1
p(wordi|wordi!1)
Language Models
Note: the prior probability that word0=START is 1.

p(English) =
length(English)!
i=1
p(wordi|wordi!1)
Language Models
Note: the prior probability that word0=START is 1.
This model explains every word in the English sentence.

p(English) =
length(English)!
i=1
p(wordi|wordi!1)
Language Models
Note: the prior probability that word0=START is 1.
This model explains every word in the English sentence.But it makes very strong conditional independence
assumptions!

Question: where do these numbers come from?
Language Models
p(clear|remained)p(sky|the)
p(remained|sky)

This is just a model that we can train on data.
Language Models
... in the night sky as it orbits earth ...... said that the sky would fall if ...
... falling dollar , sky high interest rates ...However , the sky remained clear ...
p(remained|sky) = ???


p(heads)

p(heads) 1− p(heads)



p(heads) ?

p(data) = p(heads)7 ! p(tails)3

p(data) = p(heads)7 ! [1 " p(heads)]3

0 1
p(heads)
p(data)

0 1.7
p(heads)
p(data)

0 1.7
p(heads)
p(data)
can be derived analytically using Lagrange multipliers


• Optimization

p(remained|sky)
# of times I saw “sky remained”# of times I saw “sky”
=
Language Models

Language ModelsThis is a pretty old trick.

Language ModelsThis is a pretty old trick.
http://twitter.com/markov_bible

Language ModelsThis is a pretty old trick.
http://twitter.com/markov_bibleJesus shall raise up children unto the way of the spices.
And some of them that do evil.

Language ModelsThis is a pretty old trick.
http://twitter.com/markov_bible
But be careful! What if we haven’t seen someword sequences?
Jesus shall raise up children unto the way of the spices.And some of them that do evil.

Language ModelsThis is a pretty old trick.
http://twitter.com/markov_bible
But be careful! What if we haven’t seen someword sequences?
Engineering approach: smoothing.
Jesus shall raise up children unto the way of the spices.And some of them that do evil.

Language Models
•The language model does not depend in any way on parallel data.
•How much English data should we train it on?

Language Models39
Monolingual data
Sources of monolingual data:
LDC Gigaword corpora: Chinese, Arabic, English (~1 billion words)
News corpora
The Web (>> 200 billion words)
Standard use of monolingual data:
Train trigram language model: p(wn|wn-2,wn-1)
Smoothing methods: linear interpolation, Kneser-Ney, …
How much data is needed?
Answer: MORE
40
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system (NIST test data)
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M 150M
AE BLEU[%]

Language Models41
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M 150M 300M
AE BLEU[%]
42
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M 150M 300M 600M
AE BLEU[%]

Language Models43
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
AE BLEU[%]
44
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
2.5B
AE BLEU[%]

Language Models45
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
2.5B 5B
AE BLEU[%]
46
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
2.5B 5B 10
B
AE BLEU[%]

Language Models47
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
2.5B 5B 10
B18
B
AE BLEU[%]
48
More data is better data…
Impact on size of language model training data (in words) on quality of
Arabic-English statistical machine translation system
47.5
48.5
49.5
50.5
51.5
52.5
53.5
75M
150M
300M
600M
1.2B
2.5B 5B10
B18
B
+web
lm
AE BLEU[%]
+weblm =
LM trained on
219B words of
web data

Language Models
•There’s no data like more data.
•Language models serve a similar function in speech recognition, optical character recognition, and other probabilistic models of text data.
•Tuesday: translation models.
p(English|Chinese) !
p(English) ! p(Chinese|English)

Remember•Write down a model over sentence pairs.
•Learn an instance of the model from data.
•Use it to predict translations of new sentences.
• Optimization