jist2015-computing the semantic similarity of resources in dbpedia for recommendation purposes
TRANSCRIPT

Computing the Semantic Similarity of Resources
in DBpedia for Recommendation Purposes
Guangyuan Piao, Safina showkat Ara, John G. Breslin Insight Centre for Data Analytics @NUI Galway, Ireland
Unit for Social Software
The 5th Joint International Semantic Technology Conference Yichang, China, 12/11/2015

Contents
• Introduction
• Related Work
• Resim (Resource similarity) Measure
• Evaluation Setup and Results
• Study of Linked Data Sparsity Problem
• Conclusions
2

• Linked Data (especially DBpedia) has been used for various applications including recommendations:
• LOD-enabled Recommender Systems Challenge (ESWC’14, 15)
• User Modeling for Personalization in Online Social Networks
• Use entities/resources in a Knowledge Graph (e.g., DBpedia, Freebase) to represent user interests
• measuring the semantic similarity between resources is important
3
Introduction

• Linked Data for Recommendation Purposes (single domain)
4
Introduction
dbpedia:Cheryl_Cole
• measure the semantic similarity in the context of DBpedia
• recommend similar items based on what you like in a single domain (e.g., music, movie)
Who is the most similar artist to Cheryl Cole?

• Linked Data for Recommendation Purposes (social domain)
5
Introduction
dbpedia:Cheryl_Cole
• user interests can be any topical resources in DBpedia
• can we reuse the similarity measures that were designed for recommendations in single domain?
dbpedia:SIOC
dbpedia:Linked_data
wi1:preference
What news the user will be interested in?
1. http://smiy.sourceforge.net/wi/spec/weightedinterests.html

6
Related Work
• LDSD (Linked Data Semantic Distance) – Passant, 2010 • evaluated on music artist recommendations • widely used and has comparative performance with supervised learning
approaches
• Shakti – Leah, 2012 • similarity was measured based on proximity: two entities are more
similar if they have more number of paths (penalty for longer paths)
• some problems need to be addressed: • not suitable for measuring the similarity between general resources • fundamental axioms are violated • performance over each other is unproven
• supervised learning approaches (Di Noia etc.)

sim(ra, ra) = sim(rb, rb), for all resources ra and rb
7
Fundamental Axioms
equal self-similarity
sim(ra, rb) = sim(rb, ra), for all resources ra and rb
symmetry
sim(ra, ra) > sim(ra, rb), for all resources ra ≠ rb
minimality
• http://www.scholarpedia.org/article/Similarity_measures

8
The goal of the paper
propose a semantic similarity measure - Resim on top of a revised LDSD to
satisfy fundamental axioms
be able to measure the semantic similarity between general resources
provide a comparative study
study Linked Data sparsity problem

9
Linked Data Semantic Distance (LDSD) List_of_The_Tonight_Show_with_Jay_Leno
_episodes_(2013–14)
Category:21st-century_American_singers
Ariana_Grande
Selena_Gomez
musicalguests musicalguests
subject
subject
associatedMusicArtist
influences
Cd(influences, Ariana_Grande, Selena_Gomez) = 1
Cii(musicalguests, Ariana_Grande, Selena Gomez) = 1

10
Resim (Resource similarity) Measure - 1
sim(ra, ra) = sim(rb, rb), for all resources ra and rb
equal self-similarity
sim(ra, ra) > sim(ra, rb), for all resources ra ≠ rb
minimality
✔
✔
• to satisfy “equal self-similarity” and “minimality” axioms

11
Resim (Resource similarity) Measure - 2
sim(ra, rb) = sim(rb, ra), for all resources ra and rb
symmetry
✔
• to satisfy “symmetry” axiom

• incorporating property similarity
• from the definition of an ontology, the properties of each concept describe various features and attributes of the concept.
• Thus, property similarity is important when there is no similarity can be indicated using LDSD’
• property similarity measure
• based on the number of shared incoming/outgoing properties
• Csip: shared incoming properties, Cip: # of incoming properties
12
Resim (Resource similarity) Measure - 3

• w1 = 1 and w2 = 2 for the experiment
13
Resim (Resource similarity) Measure
final equation for Resim

14
Evaluation Setup and Results
1. similarity measures evaluated on axioms
2. evaluation on calculating similarities for general resources
Axiom LDSDsim Shakti Resim
equal self-similarity ✔
symmetry ✔ ✔
minimality ✔ ✔
(1) extract word pairs from WordSim353 dataset
sim(Wa, Wb) > sim(Wa, Wc)
the difference is higher than 2
(2) retrieve the corresponding DBpedia resources
construct a test pair as sim(ra, rb) > sim(ra, rc)
15
Evaluation Setup and Results
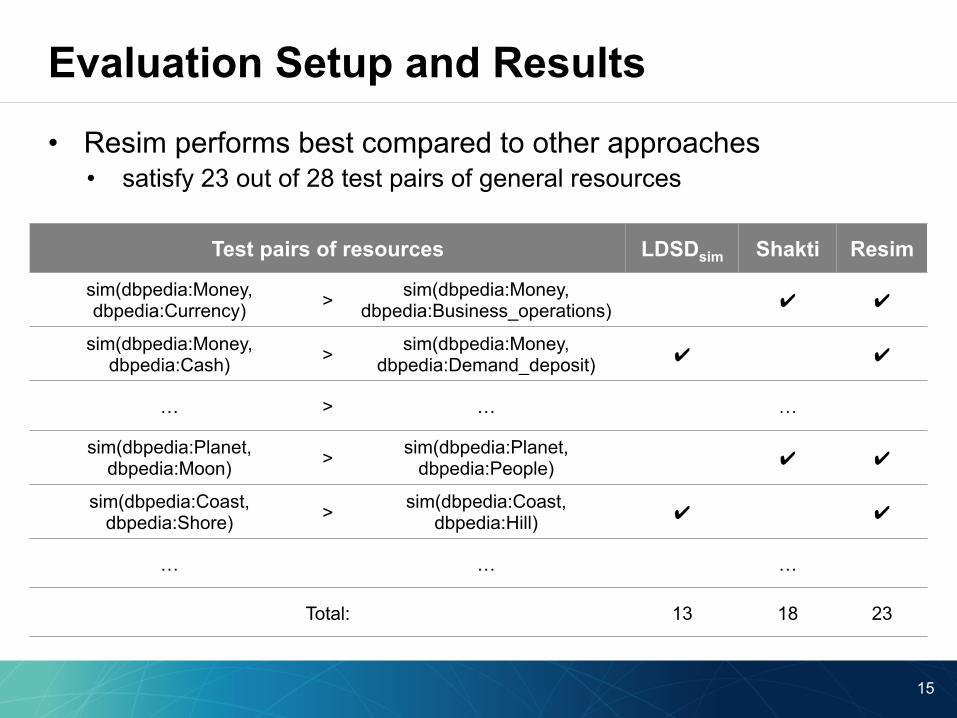
• Resim performs best compared to other approaches • satisfy 23 out of 28 test pairs of general resources
Test pairs of resources LDSDsim Shakti Resim
sim(dbpedia:Money, dbpedia:Currency) > sim(dbpedia:Money,
dbpedia:Business_operations) ✔ ✔
sim(dbpedia:Money, dbpedia:Cash) > sim(dbpedia:Money,
dbpedia:Demand_deposit) ✔ ✔
… > … …
sim(dbpedia:Planet, dbpedia:Moon) > sim(dbpedia:Planet,
dbpedia:People) ✔ ✔
sim(dbpedia:Coast, dbpedia:Shore) > sim(dbpedia:Coast,
dbpedia:Hill) ✔ ✔
… … …
Total: 13 18 23

Evaluation Setup and Results
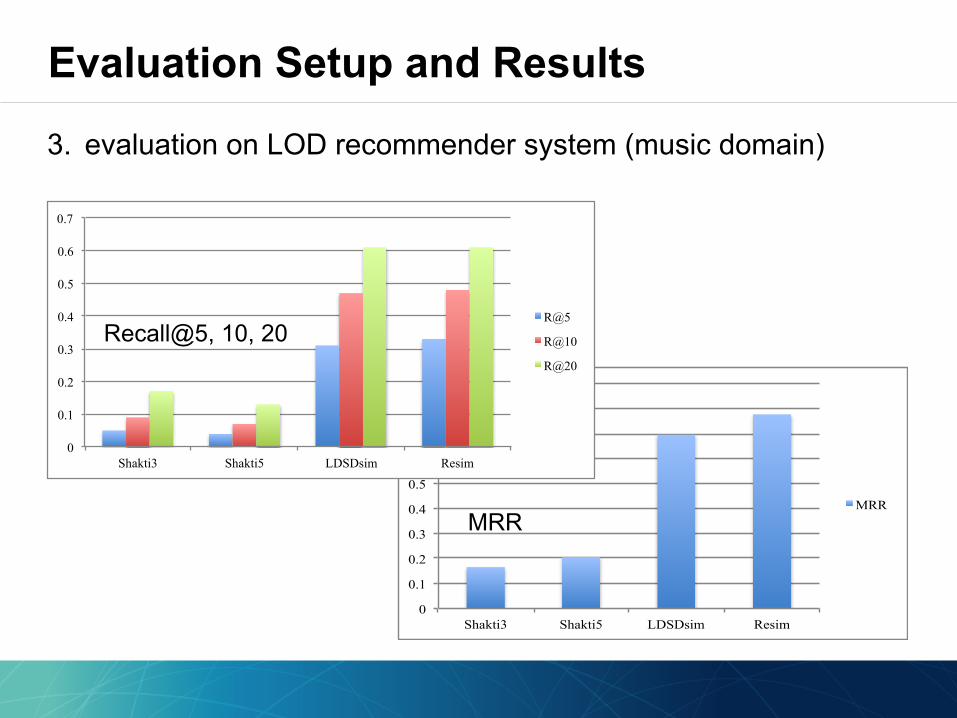
• 10 similar music artists from Last.fm for given artist
golden truth
• 200 randomly selected music artists from 75,682 resources in DBpedia of type dbpedia-owl:MusicArtist or dbpedia-owl:Band
candidate list
• Recall and Mean Reciprocal Rank (MRR)
evaluation methods
3. evaluation on LOD recommender system (music domain)
Evaluation Setup and Results
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Shakti3 Shakti5 LDSDsim Resim
MRR
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Shakti3 Shakti5 LDSDsim Resim
R@5
R@10
R@20
Recall@5, 10, 20
MRR
3. evaluation on LOD recommender system (music domain)

18
Study of Linked Data Sparsity Problem
• Linked Data Sparsity Problem: • the performance of the recommender system based on similarity
measures of resources decreases when resources lack information (i.e., when they have a lesser number of incoming/outgoing relationships to other resources).
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
R@5 R@10 R@20
Random
Popular
The average performance of recommendations
on popular music artists
The average performance of recommendations
on random music artists

19
Study of Linked Data Sparsity Problem
1XPEHU�ORJ��RI�LQFRPLQJ�RXWJRLQJ�OLQNV��������������������
5#���RI�UHFRP
PHQGHU�V\VWHP
����
���
���
���
���
���
3DJH��
H0 : The number(log) of incoming/outgoing links for resources has no relationship to the performance of a recommender system. • in other words, the performance of the recommender system
decreases for the resources with sparsity.
Pearson’s correlation of 0.798 thus, we reject H0

20
Conclusions
• Results show that our proposed similarity measure:
• satisfy the fundamental axioms
• outperforms baselines for measuring the semantic similarity between general resources
• outperforms Sharkti on single-domain recommendations
• Linked Data sparsity problem for LOD recommender system
• on one hand, utilizing Linked Data to build a recommender system can mitigate the traditional sparsity problem of collaborative recommender systems, but on the other hand, the system can also have a Linked Data sparsity problem for resources in the Linked Data set that the recommender system has adopted

• extend the current similarity measure (with longer paths)
• investigate different normalization strategies
• apply it to social recommendations (e.g., news recommendations in Twitter)
21
Future Work